ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к способу и устройству для кодирования множественных аудиосигналов, и к способу и устройству для декодирования смеси множественных аудиосигналов с улучшенным выделением множественных аудиосигналов.
УРОВЕНЬ ТЕХНИКИ
Задача разделения аудиоисточников состоит в оценивании отдельных источников (например, речи, музыкальных инструментов, шума, и т.д.) на основании их смесей. В контексте звука, смесь означает запись множественных источников единственным микрофоном или множественными микрофонами. Информированное разделение (выделение) источников (informed source separation - ISS) для аудиосигналов может рассматриваться в виде задачи извлечения отдельных аудиоисточников из смеси источников, если некоторая информация об источниках является доступной. ISS относится также к сжатию аудиообъектов (источников) [6], т.е. к кодированию многоисточниковых аудиосигналов, если смесь этих источников является известной как на стадии кодирования, так и на стадии декодирования. Обе эти задачи являются взаимосвязанными. Они являются важными для разнообразных применений.
Известные решения (например, [3], [4], [5], [20], [21]) основаны на предположении того, что первоисточники являются доступными во время стадии кодирования. Дополнительную информацию вычисляют и передают вместе со смесью, и их обрабатывают на стадии декодирования для восстановления источников.
Например, в документе [21], в частности, раскрыто композиционное моделирование для разложения амплитудной спектрограммы на ее атомные единицы (называемые атомами), в виде разложения неотрицательной матрицы. Спектральные векторы могут быть, таким образом, получены на основании комбинации векторов активации и матрицы, состоящей из атомов. В качестве конкретной реализации, словарные обучающие технологии, используемые в области разреженных представлений и сжимающего восприятия, используются для поиска словарей, имеющих разреженные представления. Это обеспечивает модель, которой можно воспользоваться на стороне декодирования.
Хотя известно несколько способов ISS, во всех этих подходах стадия кодирования является более сложной и вычислительно более затратной, чем стадия декодирования. Таким образом, эти подходы не являются предпочтительными в случаях, когда платформа, выполняющая кодирование, не может обрабатывать вычислительную сложность, требуемую кодером. Наконец, известные сложные кодеры являются непригодными к использованию для оперативного кодирования, т.е. для постепенного кодирования сигнала по мере того, как он поступает, что является очень важным для некоторых применений.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Ввиду вышеупомянутого, весьма желательно иметь полностью автоматическое и эффективное решение для обеих задач ISS. Конкретно, было бы желательным решение, в котором кодер требует значительно меньшей обработки, чем декодер.
Настоящее изобретение обеспечивает простую схему кодирования, которая смещает большую часть нагрузки по обработке со стороны кодера на сторону декодера. Предлагаемый простой путь для генерирования дополнительной информации обеспечивает не только кодирование с низкой сложностью, но и эффективное восстановление в декодере. Наконец, в отличие от некоторых существующих эффективных способов, которые нуждаются в том, чтобы во время кодирования был известен полный сигнал (что называется пакетным кодированием), предлагаемая схема кодирования обеспечивает оперативное кодирование, т.е. сигнал кодируется постепенно по мере того, как он поступает.
Кодер отбирает случайные образцы из аудиоисточников со случайной структурой. В одном варианте осуществления, случайная структура является псевдослучайной структурой. Отобранные значения квантуются предопределенным квантователем, и результирующие квантованные образцы сцепляются и сжимаются без потерь энтропийным кодером для генерирования дополнительной информации. Смесь может быть также создана на стороне кодирования, или она может быть получена другими путями и уже является доступной на стороне декодирования.
Декодер сначала восстанавливает квантованные образцы на основании дополнительной информации, и затем вероятностно оценивает наиболее вероятные источники в смеси, зная квантованные образцы и смесь.
В одном варианте осуществления, принципы настоящего раскрытия относятся к способу для кодирования множественных аудиосигналов, раскрытому в пункте 1 формулы изобретения. В одном варианте осуществления, принципы настоящего раскрытия относятся к способу для декодирования смеси множественных аудиосигналов, раскрытому в пункте 3 формулы изобретения.
В одном варианте осуществления, принципы настоящего раскрытия относятся к кодирующему устройству, которое содержит множество отдельных аппаратных компонентов, по одному для каждого этапа способа кодирования, описанного ниже. В одном варианте осуществления, принципы настоящего раскрытия относятся к декодирующему устройству, которое содержит множество отдельных аппаратных компонентов, по одному для каждого этапа способа декодирования, описанного ниже.
В одном варианте осуществления, принципы настоящего раскрытия относятся к машиночитаемому носителю, имеющему исполняемые команды для предписания компьютеру выполнять способ кодирования, содержащий этапы, описанные ниже. В одном варианте осуществления, принципы настоящего раскрытия относятся к машиночитаемому носителю, имеющему исполняемые команды для предписания компьютеру выполнять способ декодирования, содержащий этапы, описанные ниже.
В одном варианте осуществления, принципы настоящего раскрытия относятся к кодирующему устройству для разделения аудиоисточников, содержащему по меньшей мере один аппаратный компонент, например, аппаратный процессор, и энергонезависимый, материальный, машиночитаемый носитель данных, материально реализующий по меньшей мере один программный компонент, и, при исполнении на упомянутом по меньшей мере одном аппаратном процессоре, программный компонент предписывает выполнение этапов способа кодирования, описанного ниже. В одном варианте осуществления, принципы настоящего раскрытия относятся к кодирующему устройству для разделения аудиоисточников, содержащему по меньшей мере один аппаратный компонент, например, аппаратный процессор, и энергонезависимый, материальный, машиночитаемый носитель данных, материально реализующий по меньшей мере один программный компонент, и, при исполнении на упомянутом по меньшей мере одном аппаратном процессоре, программный компонент предписывает выполнение этапов способа декодирования, описанного ниже.
В отличие от существующих решений, кодирование основано на случайном отборе образцов аудиосигналов временной области, вместо привлечения моделей и/или вычислений с использованием преобразования Фурье. Это может потенциально обеспечить очень быстрый процесс кодирования, который может требовать только достаточно ограниченной обработки в конкретных реализациях. Несмотря на этот неожиданный случайный отбор образцов временной области, обеспечивается возможность восстановления аудиосигналов на основании их смеси на стороне декодирования.
Дополнительные цели, признаки и преимущества принципов настоящего раскрытия станут понятными после рассмотрения нижеследующего описания и прилагаемой формулы изобретения, приведенных в сочетании с сопутствующими чертежами.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Иллюстративные варианты осуществления описаны со ссылкой на сопутствующие чертежи, в которых
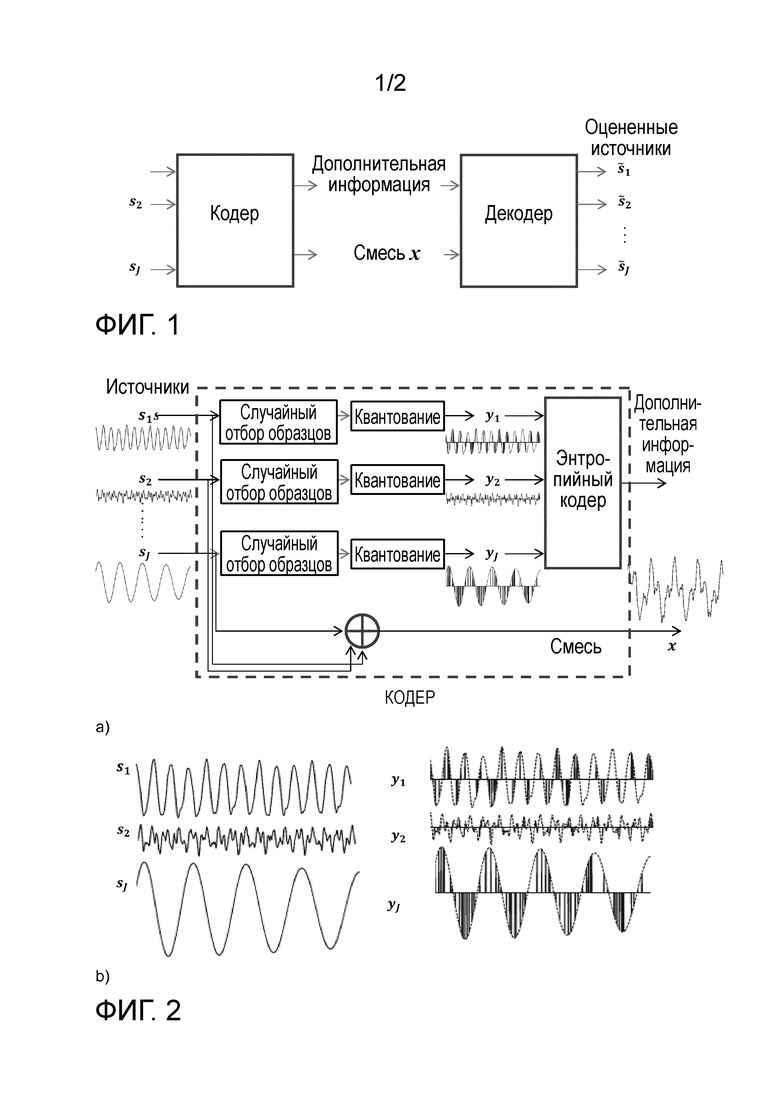
Фиг. 1 показывает структуру системы передачи и/или хранения, содержащей кодер и декодер;
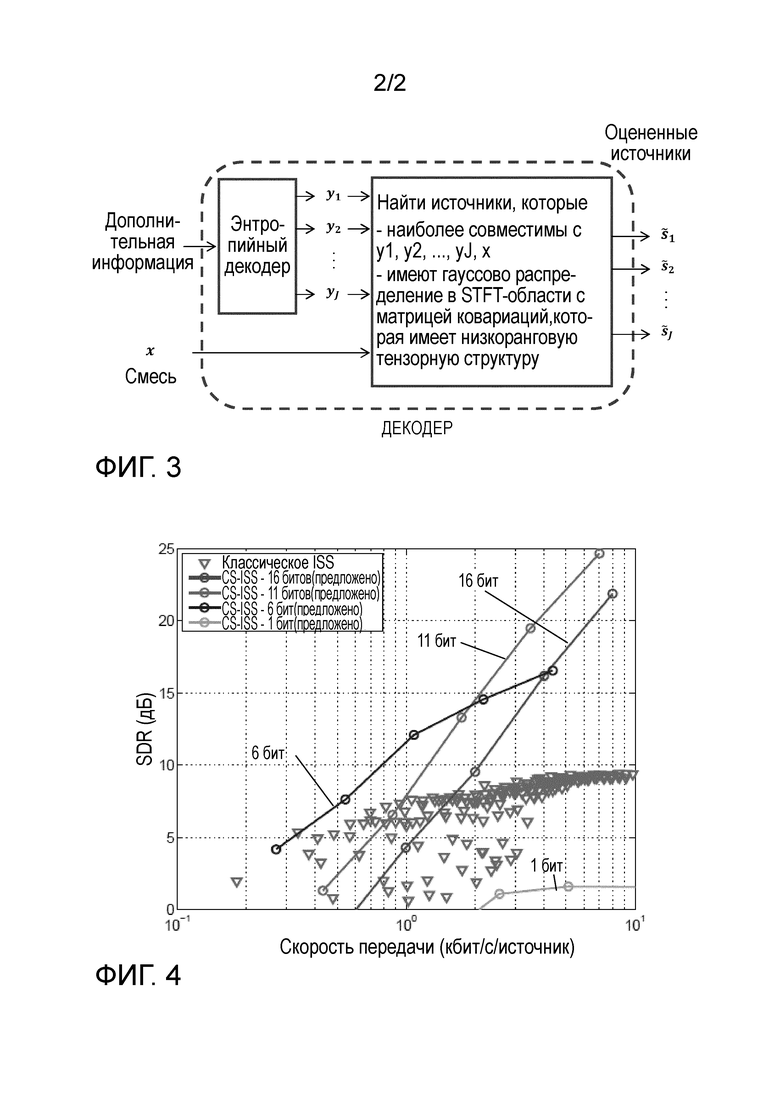
Фиг. 2 показывает упрощенную структуру иллюстративного кодера;
Фиг. 3 показывает упрощенную структуру иллюстративного декодера; и
Фиг. 4 показывает сравнение характеристик CS-ISS и классической ISS.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Фиг. 1 показывает структуру системы передачи и/или хранения, содержащей кодер и декодер. Первоисточники 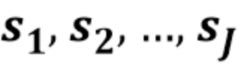 звука вводятся в кодер, который обеспечивает смесь х и дополнительную информацию. Декодер использует смесь х и дополнительную информацию для восстановления звука, причем предполагается, что некоторая информация была потеряна: таким образом, декодер должен оценить источники звука и обеспечивает оцененные источники
звука вводятся в кодер, который обеспечивает смесь х и дополнительную информацию. Декодер использует смесь х и дополнительную информацию для восстановления звука, причем предполагается, что некоторая информация была потеряна: таким образом, декодер должен оценить источники звука и обеспечивает оцененные источники 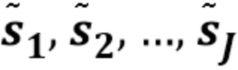 звука.
звука.
Предполагается, что первоисточники являются доступными в кодере, и обрабатываются кодером для генерирования дополнительной информации. Смесь может быть также сгенерирована кодером, или она может быть получена другими средствами и является доступной в декодере. Например, для известной аудиодорожки, доступной в Интернете, дополнительная информация, генерируемая на основании отдельных источников, может быть сохранена, например, авторами аудиодорожки или другими лицами. Одной задачей, описываемой здесь, является наличие одноканальных аудиоисточников, записанных единственными микрофонами, которые суммируются вместе для образования смеси. Другие конфигурации, например, многоканальный звук или записи с использованием множественных микрофонов, могут быть легко обработаны посредством прямого расширения описываемых способов.
Одна техническая задача, которая рассматривается здесь в пределах описанной выше системы, состоит в следующем: при наличии кодера для генерирования дополнительной информации, спроектировать декодер, который может оценить источники , которые являются как можно более близкими к первоисточникам . Декодер должен эффективно использовать дополнительную информацию и известную смесь х для минимизации необходимого размера дополнительной информации для данного качества оцененных источников. Предполагается, что декодер знает как смесь, так и то, как она образована с использованием источников.
Таким образом, настоящее изобретение содержит две части: кодер и декодер.
Фиг. 2 а) показывает упрощенную структуру иллюстративного кодера. Кодер спроектирован таким образом, чтобы он был вычислительно простым. Он отбирает случайные образцы из аудиоисточников. В одном варианте осуществления, он использует предопределенную псевдослучайную структуру. В другом варианте осуществления, он использует любую случайную структуру. Отобранные значения квантуются (предопределенным) квантователем, и результирующие квантованные образцы 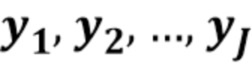 сцепляются и сжимаются без потерь энтропийным кодером (например, кодером Хаффмана или арифметическим кодером) для генерирования дополнительной информации. Также, создают смесь, если она еще не является доступной на стороне декодирования.
сцепляются и сжимаются без потерь энтропийным кодером (например, кодером Хаффмана или арифметическим кодером) для генерирования дополнительной информации. Также, создают смесь, если она еще не является доступной на стороне декодирования.
Фиг. 2 b) показывает увеличенные иллюстративные сигналы в кодере. Сигнал х смеси получают посредством наложения или микширования сигналов разных источников. Из каждого из сигналов источников также случайно отбирают образцы в блоках отбора образцов, и образцы квантуют в одном или нескольких квантователях (в этом варианте осуществления, имеется один квантователь для каждого сигнала) для получения квантованных образцов . Квантованные образцы кодируют для использования в качестве дополнительной информации. Следует отметить, что в других вариантах осуществления порядок следования отбора образцов и квантования может быть изменен.
Фиг. 3 показывает упрощенную структуру иллюстративного декодера. Декодер сначала восстанавливает квантованные образцы на основании дополнительной информации. Затем он вероятностно оценивает наиболее вероятные источники , зная наблюдаемые образцы и смесь х, и используя известные структуры и корреляции между источниками.
Возможные реализации кодера являются очень простыми. Одна возможная реализация декодера функционирует на основе следующих двух предположений:
(1) Источники имеют совместное гауссово распределение в области краткосрочного преобразования Фурье (Short-Time Fourier Transform - STFT) с размером F окна и числом N окон.
(2) Дисперсионный тензор 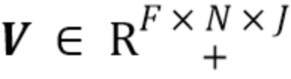 гауссова распределения имеет низкоранговое неотрицательное тензорное разложение (Non-Negative Tensor Decomposition - NTF) ранга K, так что
гауссова распределения имеет низкоранговое неотрицательное тензорное разложение (Non-Negative Tensor Decomposition - NTF) ранга K, так что
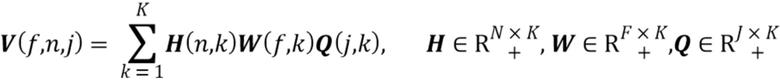
Исходя из этих двух предположений, функционирование декодера может быть обобщено с помощью следующих этапов:
1. Инициализировать матрицы  со случайными неотрицательными значениями и вычислить дисперсионный тензор
со случайными неотрицательными значениями и вычислить дисперсионный тензор 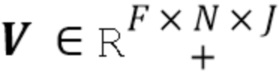 следующим образом:
следующим образом:
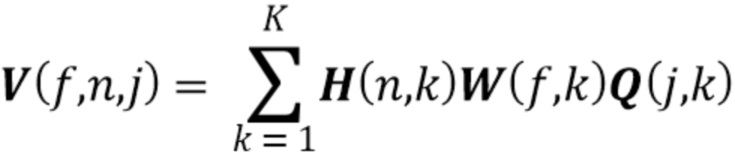
2. Пока не будет достигнута сходимость или максимальное число итераций, повторять:
2.1 Вычислить условные математические ожидания спектров мощности источников следующим образом:
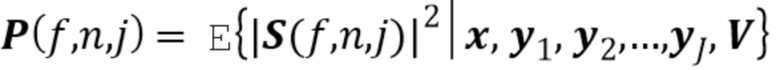
где 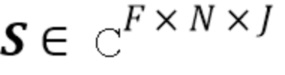 является матрицей комплексных STFT-коэффициентов источников. Дополнительные подробности в отношении вычисления условных математических ожиданий приведены ниже.
является матрицей комплексных STFT-коэффициентов источников. Дополнительные подробности в отношении вычисления условных математических ожиданий приведены ниже.
2.2 Повторно оценить параметры NTF-модели с использованием правил мультипликативного обновления (multiplicative update - MU), минимизирующих IS-расходимость [15] между трехвалентным тензором оцененных спектров 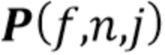 мощности источников и трехвалентным тензором приближения
мощности источников и трехвалентным тензором приближения 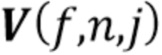 NTF-модели следующим образом:
NTF-модели следующим образом:
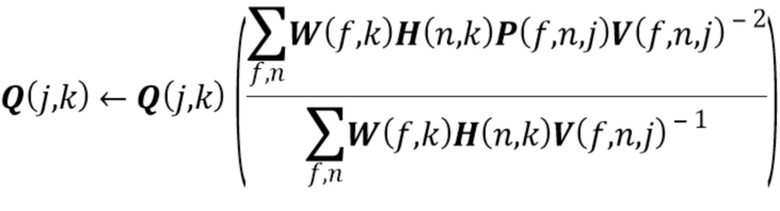
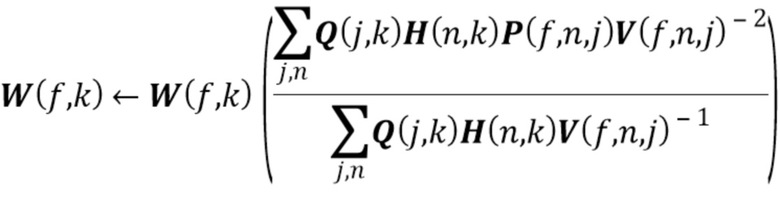
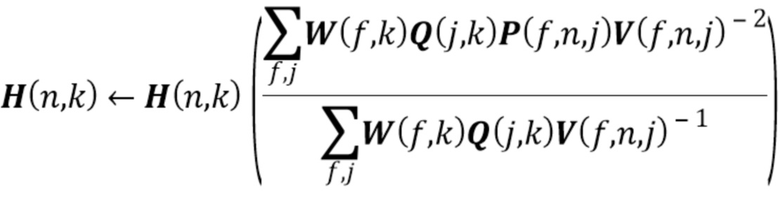
Эти обновления могут быть итерационно повторены много раз.
3. Вычислить матрицу STFT-коэффициентов 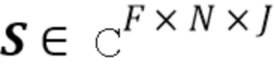 как апостериорное среднее следующим образом:
как апостериорное среднее следующим образом:
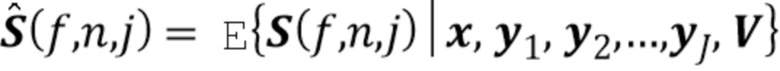
и преобразовать обратно во временную область для восстановления оцененных источников . Дополнительные подробности в отношении вычисления апостериорного среднего приведены ниже.
Нижеследующее описывает некоторые математические основы вышеупомянутых вычислений.
Тензор является структурой данных, которая может рассматриваться в качестве более многомерной матрицы. Матрица является двумерной, тогда как тензор может быть N-мерным. В данном случае, V является трехмерным тензором (подобно кубу). Он представляет матрицу ковариаций совместного гауссова распределения источников.
Матрица может быть представлена в виде суммы нескольких матриц с рангом, равным 1, каждая из которых образована посредством умножения двух векторов, в низкоранговой модели. В данном случае, тензор подобным образом представляют в виде суммы К тензоров ранга, равного одному, причем тензор ранга, равного одному, образован посредством умножения трех векторов, например, hi, qi и wi. Эти векторы соединяют для образования матриц H, Q и W. Существует К наборов векторов для К тензоров ранга, равного одному. По существу, тензор представлен К компонентами, и матрицы H, Q и W представляют, как компоненты распределены по разным кадрам, разным частотам STFT и разным источникам, соответственно.
Подобно низкоранговой модели в матрицах, К поддерживают малым, поскольку малое К лучше определяет характеристики данных, таких как аудиоданные, например, музыка. Следовательно, можно предположить неизвестные характеристики сигнала с использованием информации о том, что V должен быть тензором низкого ранга. Это уменьшает число неизвестных и определяет взаимосвязь между разными частями данных.
Этапы описанного выше итерационного алгоритма могут быть описаны следующим образом.
Сначала, инициализировать матрицы H, Q и W и, таким образом, V.
Зная V, узнают распределение вероятностей сигнала. Затем, если рассмотреть наблюдаемую часть сигналов (сигналы наблюдаются только частично), можно оценить STFT-коэффициенты 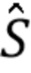 , например, посредством винеровской фильтрации. Это является апостериорным средним сигнала. Дополнительно, также вычисляют апостериорную ковариацию сигнала, которая будет использоваться ниже. Этот этап выполняют независимо для каждого окна сигнала, и он является параллелизуемым. Этот этап называют этапом математического ожидания или Е-этапом.
, например, посредством винеровской фильтрации. Это является апостериорным средним сигнала. Дополнительно, также вычисляют апостериорную ковариацию сигнала, которая будет использоваться ниже. Этот этап выполняют независимо для каждого окна сигнала, и он является параллелизуемым. Этот этап называют этапом математического ожидания или Е-этапом.
После вычисления апостериорного среднего и ковариации, их используют для вычисления апостериорных спектров p мощности. Это необходимо для обновления более ранних параметров модели, т.е. H, Q и W. Может оказаться предпочтительным повторение этого этапа более одного раза для достижения лучшей оценки (например, 2-10 раз). Это называют этапом максимизации или М-этапом.
После обновления параметров H, Q и W модели, все этапы (из оценивания STFT-коэффициентов ), могут повторяться до тех пор, пока не будет достигнута некоторая сходимость, в одном варианте осуществления. После достижения этой сходимости, в одном варианте осуществления, апостериорное среднее STFT-коэффициентов преобразуют во временную область для получения аудиосигнала в качестве конечного результата.
Одно преимущество настоящего изобретения состоит в том, что оно обеспечивает улучшенное восстановление множественных аудиосигналов источников из их смеси. Это обеспечивает возможность эффективного хранения и передачи многоисточниковых аудиозаписей, не требующих мощных устройств. Мобильные телефоны или планшеты могут быть легко использованы для сжатия информации в отношении множественных источников аудиодорожки без большого разряда заряда аккумуляторной батареи или использования процессора.
Дополнительное преимущество состоит в том, что вычислительные ресурсы для кодирования и декодирования источников используются более эффективно, поскольку сжатая информация в отношении отдельных источников декодируется только тогда, когда она является необходимой. В некоторых применениях, таких как создание музыки, информацию в отношении отдельных источников всегда кодируют и сохраняют, однако она не всегда необходима и доступна впоследствии. Таким образом, в отличие от дорогостоящего кодера, который выполняет обработку с высокой сложностью в отношении каждого кодированного аудиопотока, система с кодером с низкой сложностью и декодером с высокой сложностью имеет преимущество в использовании вычислительной мощности только для тех аудиопотоков, для которых отдельные источники фактически потребуются позже.
Третье преимущество, обеспечиваемое настоящим изобретением, состоит в адаптируемости к новым и лучшим способам декодирования. Когда открывают новый и улучшенный способ использования корреляций в данных, может быть разработан новый способ для декодирования (лучший способ для оценки , зная 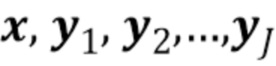 ), и можно декодировать более ранние кодированные битовые потоки с лучшим качеством, без необходимости повторного кодирования источников. Тогда как в традиционных теориях кодирования-декодирования, когда улучшенный способ использования корреляций в данных приводит к новому способу кодирования, необходимо декодировать и повторно кодировать источники для использования преимуществ нового подхода. Кроме того, процесс повторного кодирования уже закодированного битового потока, как известно, вводит дополнительные ошибки в отношении первоисточников.
), и можно декодировать более ранние кодированные битовые потоки с лучшим качеством, без необходимости повторного кодирования источников. Тогда как в традиционных теориях кодирования-декодирования, когда улучшенный способ использования корреляций в данных приводит к новому способу кодирования, необходимо декодировать и повторно кодировать источники для использования преимуществ нового подхода. Кроме того, процесс повторного кодирования уже закодированного битового потока, как известно, вводит дополнительные ошибки в отношении первоисточников.
Четвертым преимуществом настоящего изобретения является возможность кодирования источников в оперативном режиме, т.е. источники кодируются по мере того, как они поступают к кодеру, и доступность полного потока не является необходимой для кодирования.
Пятое преимущество настоящего изобретения состоит в том, что пропуски в сигналах отдельных аудиоисточников могут быть восстановлены, что известно как звуковое окрашивание. Таким образом, настоящее изобретение обеспечивает возможность совместного звукового окрашивания и разделения источников, как описано ниже.
На подход, раскрытый здесь, повлияли теория распределенного кодирования [9] источников и, конкретно, теория распределенного кодирования [10] видео, где цель также состоит в смещении сложности от кодера к декодеру. Этот подход основан на принципах [11-13] сжимающего восприятия/ отбора образцов, поскольку источники проецируются на линейное подпространство, измеряемое случайно выбранным подмножеством векторов базиса, который является некогерентным [13] с базисом, где источники звука являются разреженными. Раскрытый подход может называться основанным на сжимающем отборе образцов ISS (CS-ISS).
Более конкретно, предлагается кодировать источники посредством простого случайного выбора подмножества временных образцов источников, после чего следует однородное квантование и энтропийный кодер. В одном варианте осуществления, это является единственной дополнительной информацией, передаваемой к декодеру.
Следует отметить, что преимущество отбора образцов во временной области является двойным. Во-первых, он является более быстрым, чем отбор образцов в любой преобразованной области. Во-вторых, временной базис является достаточно некогерентным с кадром краткосрочного преобразования Фурье (Short-Time Fourier Transform - STFT), где аудиосигналы являются разреженными, и он является даже более некогерентным с низкоранговым NTF- представлением STFT-коэффициентов. В теории сжимающего восприятия показано, что некогерентность области измерения и предшествующей информационной области является существенной для восстановления источников [13].
Для восстановления источников в декодере на основании квантованных образцов источников и смеси, предлагается использовать основанный на моделях подход, который согласуется с основанным на моделях сжимающем восприятии [14]. В частности, в одном варианте осуществления, используется модель неотрицательного тензорного разложения (nonnegative tensor factorization - NTF) Itakura-Saito (IS) спектрограмм источников, как в [4,5]. Благодаря ее гауссовой вероятностной формулировке [15], эта модель может быть оценена в смысле наибольшего правдоподобия (maximum-likelihood - ML) на основании смеси и переданного квантованного участка образцов источников. Для оценивания модели, может быть использован новый обобщенный алгоритм [16] максимизации математического ожидания (generalized expectation-maximization - GEM) на основе правил [15] мультипликативного обновления (multiplicative update - MU). Зная оцененную модель и все другие наблюдения, источники могут быть оценены посредством винеровской фильтрации [17].
ОБЗОР ИНФРАСТРУКТУРЫ CS-ISS
Общая структура предлагаемого CS-ISS-кодера/ декодера показана на фиг. 2, как уже объяснено выше. Кодер случайным образом производит подвыборку образцов из источников с необходимой скоростью, с использованием предопределенной структуры рандомизации, и квантует эти образцы. Квантованные образцы затем упорядочивают в единственный поток, подлежащий сжатию энтропийным кодером для образования конечного кодированного битового потока. Случайная структура отбора образцов (или затравка, которая генерирует случайную структуру), известна как кодеру, так и декодеру, и, следовательно, не должна передаваться, в одном варианте осуществления. В другом варианте осуществления, случайная структура отбора образцов или затравка, которая генерирует случайную структуру, передается к декодеру. Также предполагается, что аудиосмесь должен узнать декодер. Декодер выполняет энтропийное декодирование для извлечения квантованных образцов источников, после чего следует CS-ISS-декодирование, как будет подробно обсуждаться ниже.
Предлагаемая CS-ISS-инфраструктура имеет несколько преимуществ по сравнению с традиционными ISS, которые могут быть обобщены следующим образом:
Первое преимущество состоит в том, что простой декодер на фиг. 2 может быть использован для кодирования с низкой сложностью, необходимого, например, в маломощных устройствах. Схема кодирования с низкой сложностью является также предпочтительной для применений, где кодирование используется часто, но только некоторые кодированные потоки должны быть декодированы. Примером такого применения является создание музыки в студии, где источники каждого создаваемого музыкального произведения сохраняются для будущего использования, но требуются редко. Следовательно, с использованием CS-ISS возможна значительная экономия в отношении вычислительной мощности и времени обработки.
Второе преимущество состоит в том, что выполнение отбора образцов во временной области (а не в преобразованной области) обеспечивает не только простую схему отбора образцов, но и возможность выполнения кодирования в оперативном режиме, при необходимости, что не всегда прямо реализуется в других способах [4,5]. Кроме того, независимая схема кодирования обеспечивает возможность кодирования источников распределенным образом без снижения эффективности декодирования.
Третье преимущество состоит в том, что этап кодирования выполняется без каких-либо предположений в отношении этапа декодирования. Таким образом, можно использовать декодеры, отличные от декодера, предлагаемого в этом варианте осуществления. Это обеспечивает значительное преимущество перед классическим ISS [2-5] в том смысле, что когда будет спроектирован лучше выполняющий свою функцию декодер, кодированные источники смогут прямо получить выгоду от улучшенного декодирования, без необходимости повторного кодирования. Это стало возможным посредством случайного отбора образцов, используемого в кодере. Теория сжимающего восприятия показывает, что схема случайного отбора образцов обеспечивает некогерентность с большим числом областей, так что становится возможным проектировать эффективные декодеры, основанные на разной предшествующей информации в отношении данных.
CS-ISS-ДЕКОДЕР
Обозначим несущее множество случайных образцов как Ωʺ, тогда из источника 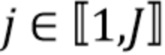 отбирают образцы в индексированные моменты времени
отбирают образцы в индексированные моменты времени 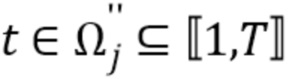 . После стадии энтропийного декодирования, CS-ISS-декодер имеет подмножество квантованных образцов источников
. После стадии энтропийного декодирования, CS-ISS-декодер имеет подмножество квантованных образцов источников 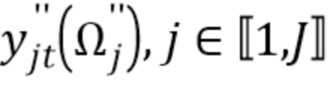 , где квантованные образцы определяются как
, где квантованные образцы определяются как
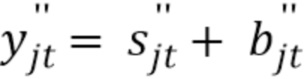 (1)
(1)
где 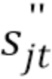 указывает на истинный сигнал источника, а
указывает на истинный сигнал источника, а 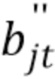 является шумом квантования.
является шумом квантования.
Следует отметить, что здесь сигналы временной области представляют буквами с двумя штрихами, например, xʺ, в то время как кадровые или оконные сигналы временной области обозначают буквами с одним штрихом, например, x', и комплексные коэффициенты краткосрочного преобразования Фурье (STFT) обозначают буквами без штрихов, например, x.
Смесь, как предполагается, является суммой первоисточников, так что
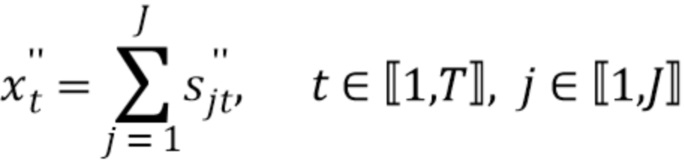 (2)
(2)
Предполагается, что смесь является известной в декодере. Следует отметить, что смесь, как предполагается здесь, является свободной от шумов и неквантованной. Однако раскрытый алгоритм может быть также легко расширен для включения шума в смесь.
Для вычисления STFT-коэффициентов, смесь и источники сначала преобразуют в оконную временную область с длиной М окна и N окнами всего. Результирующие коэффициенты, обозначаемые 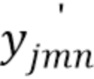 ,
, 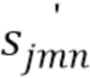 и
и 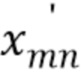 , представляют квантованные источники, первоисточники и смесь в оконной временной области, соответственно, для j=1,…,J, n=1,…,N и m=1,…,M (только для m в соответствующем подмножестве
, представляют квантованные источники, первоисточники и смесь в оконной временной области, соответственно, для j=1,…,J, n=1,…,N и m=1,…,M (только для m в соответствующем подмножестве 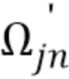 в случае квантованных образцов источников). STFT-коэффициенты источников, sjfn, и смеси, xfn, вычисляют посредством применения унитарного преобразования
в случае квантованных образцов источников). STFT-коэффициенты источников, sjfn, и смеси, xfn, вычисляют посредством применения унитарного преобразования 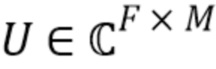 , (F=M) Фурье к каждому окну соответствующих элементов оконной временной области. Например, [x1n,…, xFn]T=
, (F=M) Фурье к каждому окну соответствующих элементов оконной временной области. Например, [x1n,…, xFn]T=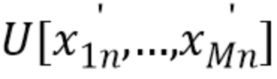 Т.
Т.
Источники моделируют в STFT-область с нормальным распределением 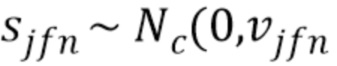 , причем дисперсионный тензор V=[
, причем дисперсионный тензор V=[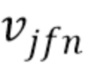 ]j,f,n имеет следующую низкоранговую NTF-структуру [18]:
]j,f,n имеет следующую низкоранговую NTF-структуру [18]:
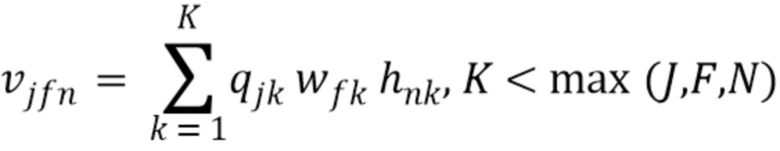 (3)
(3)
Эта модель параметризуется посредством 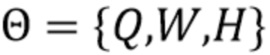 , где
, где 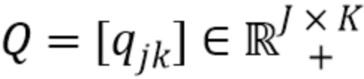 ,
, 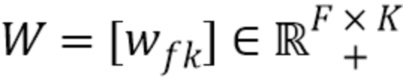 и
и 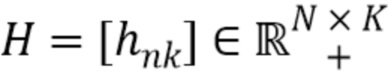 .
.
Согласно одному варианту осуществления принципов настоящего раскрытия, сигналы источников восстанавливают с использованием обобщенного алгоритма максимизации математических ожиданий, который кратко описан в Алгоритме 1. Этот алгоритм оценивает источники и статистику источников на основании наблюдений с использованием данной модели Θ посредством винеровской фильтрации на этапе вычисления математических ожиданий, и затем обновляет модель с использованием апостериорной статистики источников на этапе максимизации. Подробности в отношении каждого этапа алгоритма приведены ниже.
2: Инициализировать неотрицательные 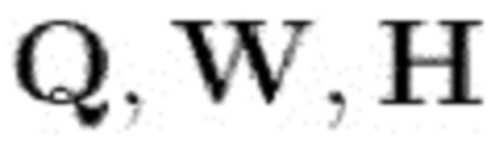 случайным образом
случайным образом
3: повторять
4: Оценить 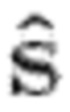 (источники) и
(источники) и 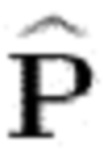 (апостериорные спектры мощности), зная
(апостериорные спектры мощности), зная 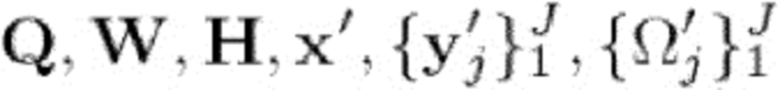 - Е-этап, см. раздел 3.1
- Е-этап, см. раздел 3.1
5: Обновить , зная - М-этап, см. раздел 3.2
6: пока не будут удовлетворены критерии сходимости
7: закончить процедуру
ОЦЕНИВАНИЕ ИСТОЧНИКОВ
Поскольку все базовые распределения являются гауссовыми, и все соотношения между источниками и наблюдениями являются линейными, источники могут быть оценены в смысле минимальной среднеквадратической ошибки (minimum mean square error - MMSE) посредством винеровского фильтра [17], зная дисперсионный тензор V, определяемый в (3) параметрами Q,W,H модели.
Пусть наблюдаемый вектор данных для n-го кадра 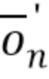 определен как
определен как
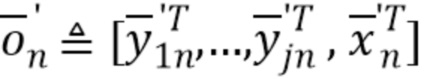 T, где
T, где 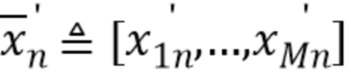 T и
T и 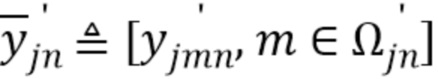 T.
T.
Зная соответствующие наблюдаемые данные и Θ NTF-модели, апостериорное распределение каждого кадра sjn источника может быть записано как 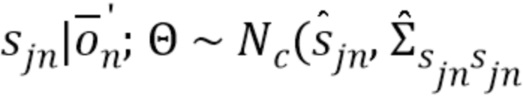 , где
, где 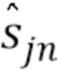 и
и 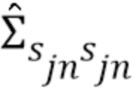 являются, соответственно, апостериорным средним и апостериорной матрицей ковариаций. Каждый из них может быть вычислен посредством винеровской фильтрации в виде
являются, соответственно, апостериорным средним и апостериорной матрицей ковариаций. Каждый из них может быть вычислен посредством винеровской фильтрации в виде
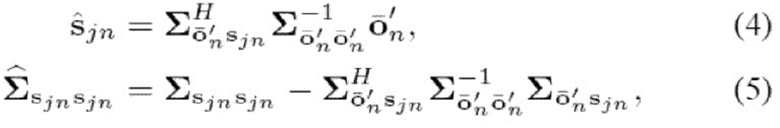
зная определения
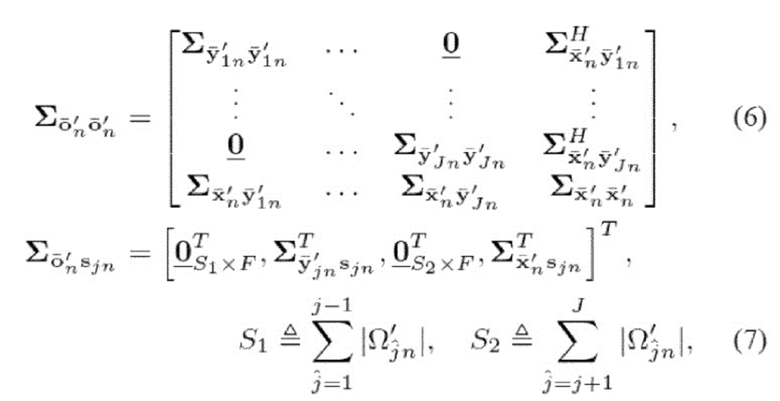
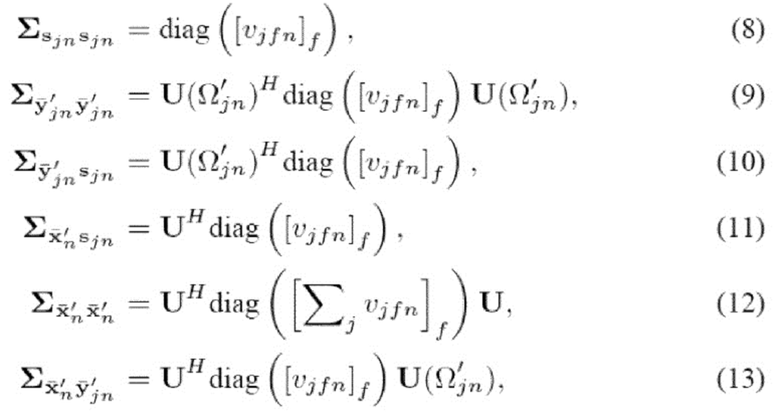
где U() является матрицей  столбцов из U с индексом в . Таким образом, апостериорные спектры
столбцов из U с индексом в . Таким образом, апостериорные спектры  мощности, которые будут использоваться для обновления NTF-модели, как описано ниже, могут быть вычислены в виде
мощности, которые будут использоваться для обновления NTF-модели, как описано ниже, могут быть вычислены в виде
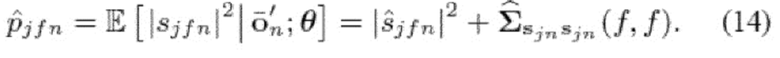
ОБНОВЛЕНИЕ МОДЕЛИ
Параметры NTF-модели могут повторно оцениваться с использованием правил мультипликативного обновления (MU), минимизирующих IS-расходимость [15] между трехвалентным тензором оцененных спектров 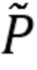 мощности источников и трехвалентным тензором приближения V NTF-модели, определяемого в виде
мощности источников и трехвалентным тензором приближения V NTF-модели, определяемого в виде 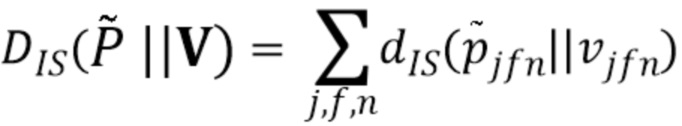 , где
, где 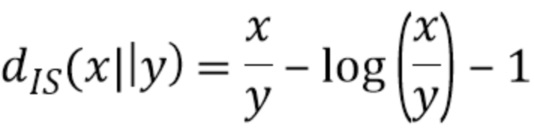 является IS-расходимостью; и
является IS-расходимостью; и 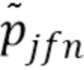 и
и 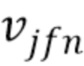 заданы (14) и (3). В результате, Q,W,H могут быть обновлены с использованием правил MU, представленных в [18]. Эти правила MU могут повторяться несколько раз для улучшения оценки модели.
заданы (14) и (3). В результате, Q,W,H могут быть обновлены с использованием правил MU, представленных в [18]. Эти правила MU могут повторяться несколько раз для улучшения оценки модели.
Дополнительно, в применениях для разделения источников с использованием NTF/NMF-модели часто необходимо иметь некоторую предшествующую информацию об отдельных источниках. Эта информация может быть некоторыми образцами из источников, или знанием о том, в какой момент времени какой источник является «неактивным». Однако, когда такая информация должна быть обеспечена, всегда дело обстоит так, что необходимы алгоритмы для предопределения того, из скольких компонентов состоит каждый источник. Это часто обеспечивают посредством инициализации параметров 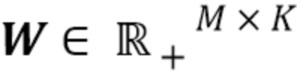 ,
, 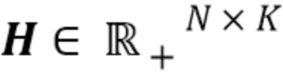 ,
, 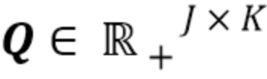 модели таким образом, что некоторые части Q и H устанавливают равными нулю, и каждый компонент присваивают конкретному источнику. В одном варианте осуществления, вычисление модели модифицируют таким образом, что зная общее число компонентов К, каждый источник присваивают компонентам автоматически, а не вручную. Это достигается посредством обеспечения «молчания» источников не посредством параметров модели STFT-области, а посредством образцов временной области (с ограничением на наличие образцов временной области, равных нулю), и посредством смягчения начальных условий в отношении параметров модели таким образом, чтобы они настраивались автоматически. Дополнительная модификация для обеспечения разреженной структуры на распределении компонентов источников (определяемой Q) также возможна посредством небольшой модификации уравнений мультипликативного обновления, приведенных выше. Это приводит к автоматическому присваиванию источников компонентам.
модели таким образом, что некоторые части Q и H устанавливают равными нулю, и каждый компонент присваивают конкретному источнику. В одном варианте осуществления, вычисление модели модифицируют таким образом, что зная общее число компонентов К, каждый источник присваивают компонентам автоматически, а не вручную. Это достигается посредством обеспечения «молчания» источников не посредством параметров модели STFT-области, а посредством образцов временной области (с ограничением на наличие образцов временной области, равных нулю), и посредством смягчения начальных условий в отношении параметров модели таким образом, чтобы они настраивались автоматически. Дополнительная модификация для обеспечения разреженной структуры на распределении компонентов источников (определяемой Q) также возможна посредством небольшой модификации уравнений мультипликативного обновления, приведенных выше. Это приводит к автоматическому присваиванию источников компонентам.
Таким образом, в одном варианте осуществления, матрицы H и Q определяются автоматически, когда присутствует дополнительная информация IS о форме периодов молчания источников. Дополнительная информация IS может включать в себя информацию о том, в какие периоды времени какой источник молчит. При наличии такой конкретной информации, классическим способом использования NMF является инициализация H и Q таким образом, чтобы предопределенные компоненты ki были присвоены каждому источнику. Улучшенное решение устраняет потребность в такой инициализации, и узнает H и Q таким образом, что ki не должны быть известны заранее. Это стало возможным посредством 1) использования образцов временной области в качестве входных данных, так что обработка STFT-области не является обязательной, и 2) ограничения матрицы Q таким образом, чтобы она имела разреженную структуру. Это достигается модификацией уравнений мультипликативного обновления для Q, как описано выше.
РЕЗУЛЬТАТЫ
Для определения характеристики подхода настоящего раскрытия, три источника музыкального сигнала на частоте 16 кГц закодировали и затем декодировали с использованием предлагаемого CS-ISS с разными уровнями квантования (16 битов, 11 битов, 6 битов и 1 бит) и разными скоростями отбора образцов в битах для каждого источника (0,64, 1,28, 2,56, 5,12 и 10,24 кбит/с/источник). В этом примере предполагается, что структура случайного отбора образцов предопределена и известна как во время кодирования, так и во время декодирования. Квантованные образцы усекают и сжимают с использованием арифметического кодера с использованием предположения гауссова распределения с нулевым средним. На стороне декодера, посредством арифметического декодера, источники декодируют на основании квантованных образцов с использованием 50 итераций GEM-алгоритма, причем STFT вычисляют с использованием наполовину перекрывающего синусоидального окна из 1024 образцов (64 мс) с использованием гауссовой оконной функции, и число компонентов является фиксированным и равным K=18, т.е. по 6 компонентов на каждый источник. Качество восстановленных образцов измеряется по отношению сигнал-искажения (signal to distortion ratio - SDR), как описано в [19]. Результирующие скорости кодированной передачи в битах и SDR декодированных сигналов представлены в таблице 1 вместе с процентным отношением кодированных образцов в скобках. Следует отметить, что скорости передачи сжатых данных в таблице 1 отличаются от соответствующих скоростей передачи необработанных данных в битах вследствие переменной характеристики стадии энтропийного кодирования, что является ожидаемым.

11 битов
6 битов
1 бит
Таблица 1: конечные скорости передачи в битах (в кбит/с на каждый источник) после стадии энтропийного кодирования CS-ISS с соответствующим SDR (в дБ) для разных (однородных) уровней квантования и разных скоростей передачи необработанных данных перед энтропийным кодированием. Процентное отношение сохраненных образцов также обеспечено для каждого случая в скобках. Результаты, соответствующие наилучшему компромиссу между скоростью передачи и искажениями приведены полужирным шрифтом.
Характеристика CS-ISS в сравнении с классическим ISS-подходом с более сложным кодером и более простым декодером представлена в [4]. ISS-алгоритм используют с квантованием и кодированием NTF-модели, как в [5], т.е. NTF-коэффициенты однородно квантуют в логарифмической области, размеры шагов квантования разных NTF-матриц вычисляют с использованием уравнений (31)-(33) из [5], и индексы кодируют с использованием арифметического кодера на основе гауссовой модели смеси (Gaussian mixture model - GMM) с двумя состояниями (см. фиг. 5 из [5]). Этот подход оценивается для разных размеров шага квантования и разных чисел NTF-компонентов, т.е. Δ=2-2, 2-1.5, 2-1,…, 24, а K=4, 6,…, 30. Результаты сгенерированы с использованием 250 итераций обновления модели. Характеристики как CS-ISS, так и классического ISS показаны на фиг. 4, причем CS-ISS явно превосходит ISS-подход, даже несмотря на то, что ISS-подход может использовать оптимизированное число компонентов и квантование, в противоположность нашему декодеру, который использует фиксированное число компонентов (кодер является очень простым и не вычисляет это значение). Различие в характеристиках имеет место вследствие высокой эффективности, достигнутой CS-ISS-декодером благодаря некогерентности временной области, в которой случайно отбираются образцы, и низкоранговой NTF-области. Также, ISS-подход не может быть реализован с SDR за пределами 10 дБ, вследствие недостаточной верности передачи в структуре кодера, как объясняется в [5]. Даже несмотря на то, что в этой работе невозможно выполнить сравнение с ISS-алгоритмом, представленным в [5], вследствие временных ограничений, результаты указывают на то, что характеристика скорости передачи относительно искажений демонстрирует похожее поведение. Следует напомнить, что предлагаемый подход отличается своим кодером с низкой сложностью и, следовательно, может быть все же предпочтительным по сравнению с другими ISS-подходами с лучшими характеристиками скорости передачи относительно искажений.
Характеристика CS-ISS в таблице 1 и на фиг. 4 указывает на то, что разные уровни квантования могут быть предпочтительными при разных скоростях передачи. Даже несмотря на то, что ни 16-битовое квантование, ни 1-битовое квантование не кажутся имеющими хорошие характеристики, характеристика указывает на то, что 16-битовое квантование может превосходить другие схемы, когда доступна гораздо более высокая скорость передачи в битах. Подобным образом, более грубое квантование, такое как 1-битовое квантование, может быть предпочтительным при рассмотрении значительно меньших скоростей передачи в битах. Выбор квантования может быть выполнен в кодере с использованием простой справочной таблицы в качестве ссылки. Следует также отметить, что даже несмотря на то, что кодер в CS-ISS является очень простым, предлагаемый декодер имеет значительно большую сложность, обычно большую, чем сложность кодеров традиционных ISS-способов. Однако это можно также преодолеть посредством использования независимости винеровской фильтрации среди кадров в предлагаемом декодере с параллельной обработкой, например, с использованием графических процессоров (graphical processing unit - GPU).
Раскрытое решение обычно приводит к тому факту, что низкоранговая тензорная структура появляется в энергетической спектрограмме восстановленных сигналов.
Следует отметить, что использование глагола «содержать» и его спряжений не исключает наличия элементов или этапов, отличных от элементов или этапов, заявленных в формуле изобретения. Кроме того, использование элемента в единственном числе не исключает наличия множества таких элементов. Несколько «средств» могут быть представлены одним и тем же аппаратным элементом. Дополнительно, настоящее изобретение пребывает во всех до единого новых признаках или комбинациях признаков. При использовании здесь, «цифровой аудиосигнал» или «аудиосигнал» не описывает только математическую абстракцию, а вместо этого означает информацию, реализуемую или носимую физическим носителем, которую может детектировать машина или устройство. Этот термин включает в себя записанные или передаваемые сигналы, и следует понимать, что он включает в себя передачу посредством любой формы кодирования, в том числе импульсно-кодовой модуляции (pulse code modulation - PCM), но не только PCM.
Признаки, где это уместно, могут быть реализованы в аппаратном средстве, программном средстве, или в их комбинации. Соединения, где это применимо, могут быть реализованы в виде беспроводных соединений или проводных, не обязательно прямых или специальных, соединений.
ССЫЛОЧНЫЕ МАТЕРИАЛЫ
[1] E. Vincent, S. Araki, F. J. Theis, G. Nolte, P. Bofill, H. Sawada, A. Ozerov, B. V. Gowreesunker, D. Lutter, and N. Q. K. Duong, ʺThe signal separation evaluation campaign (2007-2010): Achievements and remaining challenges,ʺ Signal Processing, том 92, № 8, стр. 1928-1936, 2012.
[2] M. Parvaix, L. Girin, and J.-M. Brossier, ʺA watermarkingbased method for informed source separation of audio signals with a single sensor,ʺ IEEE Trans. Audio, Speech, Language Process., том 18, № 6, стр. 1464-1475, 2010.
[3] M. Parvaix and L. Girin, ʺInformed source separation of linear instantaneous under-determined audio mixtures by source index embedding,ʺ IEEE Trans. Audio, Speech, Language Process., том 19, № 6, стр. 1721-1733, 2011.
[4] A. Liutkus, J. Pinel, R. Badeau, L. Girin, and G. Richard, ʺInformed source separation through spectrogram coding and data embedding,ʺ Signal Processing, том 92, № 8, стр. 1937- 1949, 2012.
[5] A. Ozerov, A. Liutkus, R. Badeau, and G. Richard, ʺCoding-based informed source separation: Nonnegative tensor factorization approach,ʺ IEEE Transactions on Audio, Speech, and Language Processing, том 21, № 8, стр. 1699-1712, Aug. 2013.
[6] J. Engdegard, B. Resch, C. Falch, O. Hellmuth, J. Hilpert, A. H¨olzer, L. Terentiev, J. Breebaart, J. Koppens, E. Schuijers, and W. Oomen, ʺSpatial audio object coding (SAOC) - The upcoming MPEG standard on parametric object based audio coding,ʺ in 124th Audio Engineering Society Convention (AES 2008), Амстердам, Нидерланды, май 2008.
[7] A. Ozerov, A. Liutkus, R. Badeau, and G. Richard, ʺInformed source separation: source coding meets source separation,ʺ in IEEE Workshop Applications of Signal Processing to Audio and Acoustics (WASPAA'11), New Paltz, Нью-Йорк, США, октябрь 2011, стр. 257-260.
[8] S. Kirbiz, A. Ozerov, A. Liutkus, and L. Girin, ʺPerceptual coding-based informed source separation,ʺ in Proc. 22nd European Signal Processing Conference (EUSIPCO), 2014, стр. 959-963.
[9] Z. Xiong, A. D. Liveris, and S. Cheng, ʺDistributed source coding for sensor networks,ʺ IEEE Signal Processing Magazine, том 21, № 5, стр. 80-94, сентябрь 2004.
[10] B. Girod, A. Aaron, S. Rane, and D. Rebollo-Monedero, ʺDistributed video coding,ʺ Proceedings of the IEEE, том 93, № 1, стр. 71-83, январь 2005.
[11] D. Donoho, ʺCompressed sensing,ʺ IEEE Trans. Inform. Theory, том 52, № 4, стр. 1289-1306, апрель 2006.
[12] R. G. Baraniuk, ʺCompressive sensing,ʺ IEEE Signal Processing Mag., том 24, № 4, стр. 118-120, июль 2007.
[13] E. J. Candes and M. B. Wakin, ʺAn introduction to compressive sampling,ʺ IEEE Signal Processing Magazine, том 25, стр. 21-30, 2008.
[14] R. G. Baraniuk, V. Cevher, M. F. Duarte, and C. Hegde, ʺModel-based compressive sensing,ʺ IEEE Trans. Info. Theory, том 56, № 4, стр. 1982-2001, апрель 2010.
[15] C. Fevotte, N. Bertin, and J.-L. Durrieu, ʺNonnegative matrix factorization with the Itakura-Saito divergence. With application to music analysis,ʺ Neural Computation, том 21, № 3, стр. 793-830, март 2009.
[16] A. P. Dempster, N. M. Laird, and D. B. Rubin., ʺMaximum likelihood from incomplete data via the EM algorithm,ʺ Journal of the Royal Statistical Society. Series B (Methodological), том 39, стр. 1-38, 1977.
[17] S.M. Kay, Fundamentals of Statistical Signal Processing: Estimation Theory. Englewood Cliffs, NJ: Prentice Hall, 1993.
[18] A. Ozerov, C. Fevotte, R. Blouet, and J.-L. Durrieu, ʺMultichannel nonnegative tensor factorization with structured constraints for user-guided audio source separation,ʺ in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP'11), Prague, май 2011, стр. 257-260.
[19] V. Emiya, E. Vincent, N. Harlander, and V. Hohmann, ʺSubjective and objective quality assessment of audio source separation,ʺ IEEE Trans. Audio, Speech, Language Process., том 19, № 7, стр. 2046-2057, 2011.
[20] J. Nikunen, T. Virtanen, and M. Vilermo, ʺMultichannel audio upmixing by time-frequency filtering using non-negative tensor factorizationʺ, J. Audio Eng. Soc., том 60, № 10, стр. 794-806, 2012.
[21] T. Virtanen, J. F. Gemmeke, B. Raj, and P. Smaragdis, ʺCompositional models for audio processingʺ, IEEE Signal Processing Magazine, стр. 125-144, 2015
Изобретение относится к средствам для кодирования и декодирования множественных аудиосигналов. Технический результат заключается в повышении эффективности кодирования и декодирования смеси аудиосигналов с улучшением их разделения. Принимают или извлекают из запоминающего устройства или любого источника данных смесь упомянутых множественных аудиосигналов. Генерируют множественные оцененные аудиосигналы, которые аппроксимируют упомянутые множественные аудиосигналы, исходя из дополнительной информации, связанной с упомянутой смесью множественных аудиосигналов. Декодируют и демультиплексируют дополнительную информацию, содержащую случайно отобранные квантованные образцы временной области каждого из множественных аудиосигналов. Генерируют упомянутые множественные оцененные аудиосигналы с использованием упомянутых квантованных образцов каждого из множественных аудиосигналов. 6 н. и 9 з.п. ф-лы, 4 ил.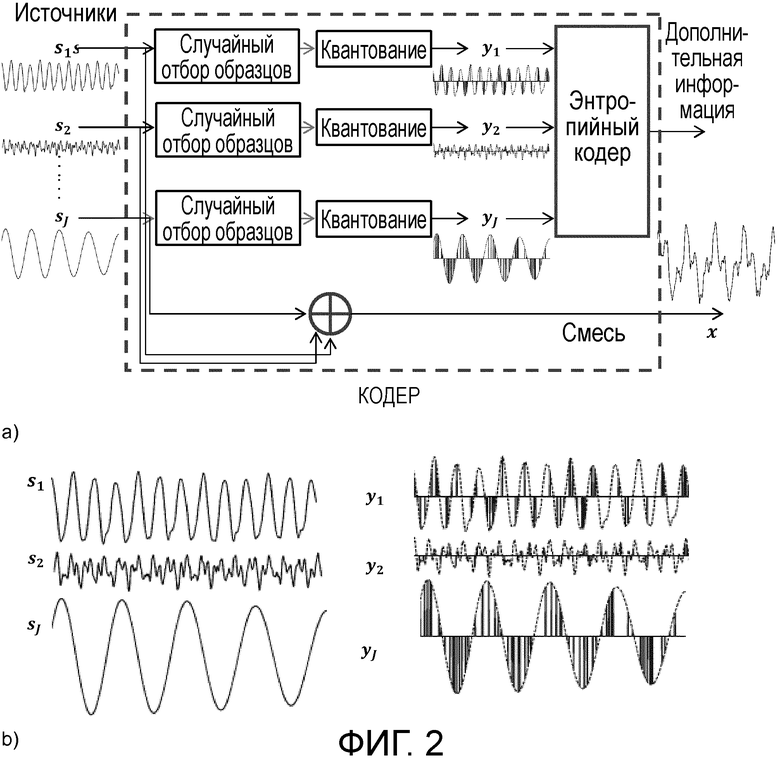
1. Способ для кодирования множественных аудиосигналов (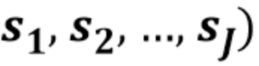 временной области в качестве дополнительной информации, которая может быть использована для декодирования и выделения множественных аудиосигналов временной области из смеси (x) упомянутых множественных аудиосигналов временной области, отличающийся тем, что упомянутый способ содержит этапы, на которых
временной области в качестве дополнительной информации, которая может быть использована для декодирования и выделения множественных аудиосигналов временной области из смеси (x) упомянутых множественных аудиосигналов временной области, отличающийся тем, что упомянутый способ содержит этапы, на которых
- случайно отбирают и квантуют образцы каждого из множественных аудиосигналов временной области; и
- кодируют отобранные и квантованные образцы множественных аудиосигналов временной области в качестве упомянутой дополнительной информации.
2. Способ по п. 1, в котором на этапе случайного отбора образцов используют предопределенную псевдослучайную структуру.
3. Способ по п. 1 или 2, в котором смесь множественных аудиосигналов временной области кодируют постепенно по мере того, как она поступает.
4. Способ по одному из пп. 1-3, дополнительно содержащий этапы, на которых определяют, в какие периоды времени какой источник молчит, и кодируют определенную информацию в упомянутой дополнительной информации.
5. Способ для декодирования смеси (x) множественных аудиосигналов (, содержащий этапы, на которых
- принимают или извлекают, из запоминающего устройства или любого источника данных, смесь упомянутых множественных аудиосигналов; и
- генерируют множественные оцененные аудиосигналы (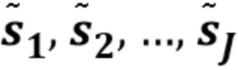 ), которые аппроксимируют упомянутые множественные аудиосигналы, исходя из дополнительной информации, связанной с упомянутой смесью множественных аудиосигналов,
), которые аппроксимируют упомянутые множественные аудиосигналы, исходя из дополнительной информации, связанной с упомянутой смесью множественных аудиосигналов,
отличающийся тем, что упомянутый способ содержит этапы, на которых:
- декодируют и демультиплексируют дополнительную информацию, содержащую случайно отобранные квантованные образцы временной области каждого из множественных аудиосигналов;
- генерируют упомянутые множественные оцененные аудиосигналы с использованием упомянутых квантованных образцов каждого из множественных аудиосигналов.
6. Способ по п. 5, в котором этап генерирования множественных оцененных аудиосигналов содержит этапы, на которых
- вычисляют дисперсионный тензор V из случайных неотрицательных значений;
- вычисляют условные математические ожидания спектров мощности источников квантованных образцов множественных аудиосигналов, причем получают оцененные спектры 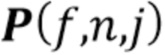 мощности источников и причем используют дисперсионный тензор V и комплексные коэффициенты краткосрочного преобразования Фурье (Short-Time Fourier Transform - STFT) множественных аудиосигналов;
мощности источников и причем используют дисперсионный тензор V и комплексные коэффициенты краткосрочного преобразования Фурье (Short-Time Fourier Transform - STFT) множественных аудиосигналов;
- итерационно повторно вычисляют дисперсионный тензор V из оцененных спектров мощности источников;
- вычисляют матрицу STFT-коэффициентов 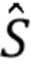 из результирующего дисперсионного тензора V; и
из результирующего дисперсионного тензора V; и
- преобразуют матрицу STFT-коэффициентов во временную область, причем получают множественные оцененные аудиосигналы.
7. Способ по п. 5 или 6, дополнительно содержащий этап, на котором осуществляют звуковое окрашивание для по меньшей мере одного из множественных аудиосигналов.
8. Способ по одному из пп. 5-7, в котором упомянутая дополнительная информация дополнительно содержит информацию, определяющую, в какие периоды времени какой аудиоисточник молчит, дополнительно содержащий этап, на котором автоматически определяют матрицы H и Q, которые задают дисперсионный тензор V.
9. Устройство для кодирования множественных аудиосигналов (в качестве дополнительной информации, которая может быть использована для декодирования и выделения множественных аудиосигналов временной области из смеси (x) упомянутых множественных аудиосигналов, содержащее
по меньшей мере один процессор, выполненный с возможностью предписания устройству выполнить способ для кодирования множественных аудиосигналов временной области, отличающееся тем, что упомянутый по меньшей мере один процессор выполнен с возможностью предписывать устройству выполнить этапы, на которых
- случайно отбирают и квантуют образцы каждого из множественных аудиосигналов временной области; и
- кодируют отобранные и квантованные образцы множественных аудиосигналов временной области в качестве упомянутой дополнительной информации.
10. Устройство по п. 9, в котором случайный отбор образцов использует предопределенную псевдослучайную структуру.
11. Устройство для декодирования смеси (x) множественных аудиосигналов (, содержащее
по меньшей мере один процессор, выполненный с возможностью предписания устройству выполнить способ для декодирования смеси множественных аудиосигналов, который содержит этапы, на которых
- принимают или извлекают из запоминающего устройства или любого источника данных смесь упомянутых множественных аудиосигналов; и
- генерируют множественные оцененные аудиосигналы (), которые аппроксимируют упомянутые множественные аудиосигналы, исходя из дополнительной информации, связанной с упомянутой смесью множественных аудиосигналов;
отличающееся тем, что упомянутый по меньшей мере один процессор выполнен с возможностью выполнения этапов, на которых
- декодируют и демультиплексируют дополнительную информацию, содержащую случайно отобранные квантованные образцы временной области каждого из множественных аудиосигналов;
- генерируют упомянутые множественные оцененные аудиосигналы с использованием упомянутых квантованных образцов каждого из множественных аудиосигналов.
12. Устройство по п. 11, в котором этап генерирования множественных оцененных аудиосигналов содержит этапы, на которых
- вычисляют дисперсионный тензор V из случайных неотрицательных значений;
- вычисляют условные математические ожидания спектров мощности источников квантованных образцов множественных аудиосигналов, причем получают оцененные спектры мощности источников и причем используют дисперсионный тензор V и комплексные коэффициенты краткосрочного преобразования Фурье (Short-Time Fourier Transform - STFT) множественных аудиосигналов;
- итерационно повторно вычисляют дисперсионный тензор V из оцененных спектров мощности источников;
- вычисляют матрицу STFT-коэффициентов из результирующего дисперсионного тензора V; и
- преобразуют матрицу STFT-коэффициентов во временную область, причем получают множественные оцененные аудиосигналы.
13. Устройство по п. 11 или 12, в котором упомянутый по меньшей мере один процессор дополнительно выполнен с возможностью звукового окрашивания для по меньшей мере одного из множественных аудиосигналов временной области.
14. Машиночитаемый носитель данных, хранящий компьютерную программу, содержащую программный код, выполненный с возможностью выполнения способа по любому из пп. 1-4 при его исполнении процессором.
15. Машиночитаемый носитель данных, хранящий компьютерную программу, содержащую программный код, выполненный с возможностью выполнения способа по любому из пп. 5-8 при его исполнении процессором.
| OZEROV ALEXEY et al | |||
| "Coding-based informed source separation: nonnegative tensor factorization approach" | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6975254 B1, 13.12.2005 | |||
| US 8489403 B1, 16.07.2013 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |

