Область техники, к которой относится изобретение
[0001] Настоящее изобретение обеспечивает системы и способы получения параметрического бинаурального выходного сигнала улучшенной формы, дополнительно используя слежение за движением головы.
Литература
[0002] Gundry, K., ʺA New Matrix Decoder for Surround Sound,ʺ AES 19th International Conf., Schloss Elmau, Germany, 2001.
[0003] Vinton, M., McGrath, D., Robinson, C., Brown, P., ʺNext generation surround decoding and up-mixing for consumer and professional applicationsʺ, AES 57th International Conf, Hollywood, CA, USA, 2015.
[0004] Wightman, F. L., and Kistler, D. J. (1989). ʺHeadphone simulation of free-field listening. I. Stimulus synthesis,ʺ J. Acoust. Soc. Am. 85, 858-867.
[0005] ISO/IEC 14496-3:2009 - Information technology -- Coding of audio-visual objects -- Part 3: Audio, 2009.
[0006] Mania, Katerina, et al. "Perceptual sensitivity to head tracking latency in virtual environments with varying degrees of scene complexity." Proceedings of the 1st Symposium on Applied perception in graphics and visualization. ACM, 2004.
[0007] Allison, R. S., Harris, L. R., Jenkin, M., Jasiobedzka, U., & Zacher, J. E. (2001, March). Tolerance of temporal delay in virtual environments. In Virtual Reality, 2001. Proceedings. IEEE (pp. 247-254). IEEE.
[0008] Van de Par, Steven, and Armin Kohlrausch. "Sensitivity to auditory-visual asynchrony and to jitter in auditory-visual timing." Electronic Imaging. International Society for Optics and Photonics, 2000.
Уровень техники изобретения
[0009] Любое обсуждение уровня техники изобретения на протяжении всего описания никоим образом не должно рассматриваться как признание, что такой уровень техники широко известен или является частью обычных общих знаний в данной области.
[0010] Создание контента, кодирование, распространение и воспроизведение аудиоконтента традиционно основывается на канале. То есть, одна конкретная целевая система воспроизведения предполагается для контента, проходящего по всей экосистеме контента. Примерами таких целевых систем воспроизведения являются моно-, стереосистемы, системы 5.1, 7.1, 7.1.4 и т.п.
[0011] Если контент должен воспроизводиться не на той системе, для которой он предназначен, может быть применено понижающее микширование или повышающее микширование. Например, контент 5.1 может воспроизводиться через систему стереовоспроизведения, используя определенные известные уравнения понижающего микширования. Другим примером является воспроизведение стереоконтента на установке громкоговорителей 7.1, которая может содержать так называемый процесс повышающего микширования, который может или не может управляться информацией, присутствующей в стереосигнале, такой, которая используется так называемыми матричными кодерами, такими как Dolby Pro Logic. Чтобы управлять процессом повышающего микширования, информация об исходном состоянии сигналов перед понижающим микшированием может быть сообщена неявно, вводя в уравнения понижающего микширования специальные фазовые соотношения, или, говоря иначе, применяя уравнения понижающего микширования с комплексными значениями. Известным примером такого способа понижающего микширования, использующего коэффициенты понижающего микширования с комплексными значениями для контента с громкоговорителями, расположенными в двух измерениях, является LtRt (Vinton и др., 2015).
[0012] Полученный в результате (стерео) сигнал с пониженным микшированием может быть воспроизведен через систему стереофонических громкоговорителей или может микшироваться вверх для установок с громкоговорителями звукового окружения и/или верхними фронтальными громкоговорителями. Целевое местоположение сигнала может быть получено посредством повышающего микширования из межканальных фазовых соотношений. Например, в стереопредставлении LtRt, сигнал, не совпадающий по фазе (например, имеющий нормированный коэффициент взаимной корреляции, близкий к -1, для формы межканального сигнала), должен, в идеале, воспроизводиться одним или более громкоговорителями с эффектом окружающего звука, тогда как положительный коэффициент корреляции (близкий к +1) указывает, что сигнал должен воспроизводиться фронтальными громкоговорителями, расположенными перед слушателем.
[0013] Было разработано множество алгоритмов и стратегий повышающего микширования, которые различаются своими стратегиями воссоздания многоканального сигнала из стерео даун-микса. Что касается относительно простых повышающих микшеров, то нормированный коэффициент взаимной корреляции стереосигналов отслеживается как функция времени, тогда как сигнал(-ы) на фронтальные или тыловые громкоговорители регулируется в зависимости от значения нормированного коэффициента взаимной корреляции. Этот подход хорошо работает для относительно простого контента, в котором в одно и то же время присутствует только один объект прослушивания. Более совершенные повышающие микшеры основываются на статистической информации, которую получают из конкретных частотных областей для управления сигнальным потоком от стереовхода к мультиканальным выходам (Gundry 2001, Vinton и др., 2015). Конкретно, модель сигнала, основанная на регулируемом или доминантном компоненте и остаточном (диффузном) стереосигнале, может использоваться в индивидуальных временных/частотных элементах разбиения. Помимо оценки доминантного компонента и остаточных сигналов, также оценивается угол направления (по азимуту, возможно, возрастающий с углом места) и в дальнейшем сигнал доминантной компоненты регулируется для одного или более громкоговорителей, чтобы во время воспроизведения реконструировать (оценочное) положение.
[0014] Использование матричных кодеров и декодеров/повышающих микшеров не ограничивается контентом, основанным на каналах. Последние разработки в аудиоиндустрии основаны на аудиообъектах, а не на каналах, где один или более объектов состоят из аудиосигнала и ассоциированных метаданных, указывающих, помимо прочего, его целевое местоположение как функцию времени. Как отмечено у Vinton и др., 2015, для такого аудиоконтента, основанного на объектах, могут также использоваться матричные кодеры. В такой системе сигналы от объектов подвергаются понижающему микшированию в представление стереосигнала с помощью коэффициентов понижающего микширования, зависящих от позиционных метаданных объекта.
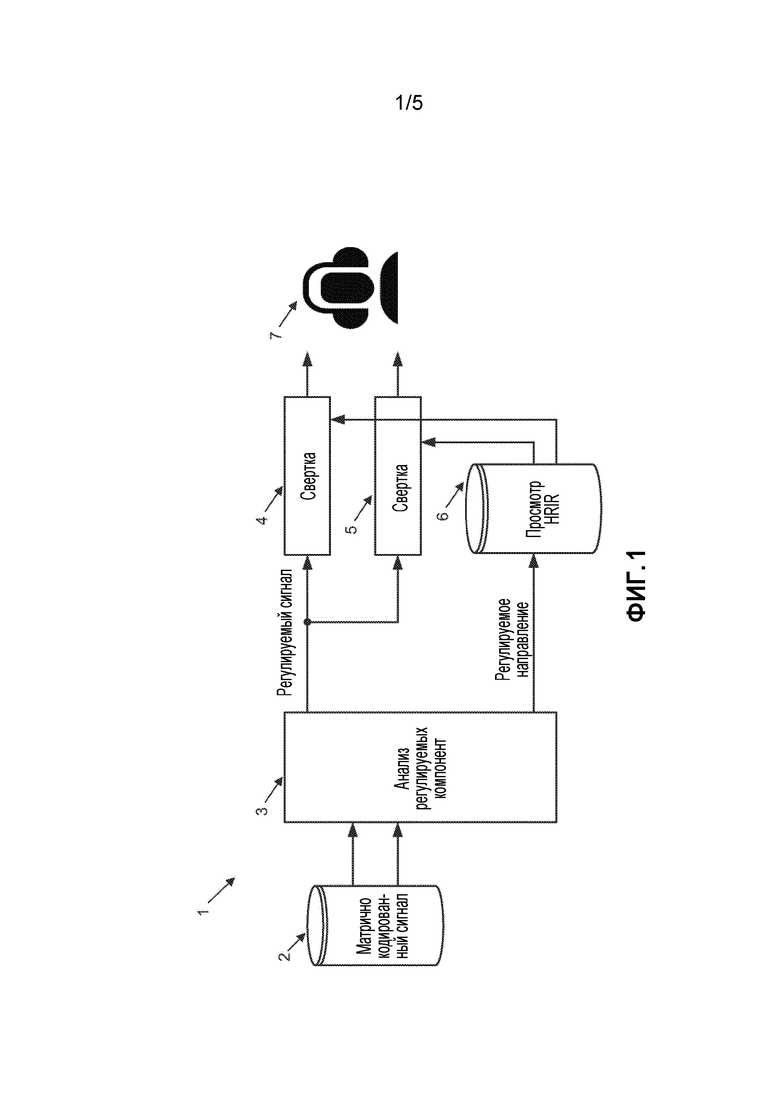
[0015] Повышающее микширование и воспроизведение матрично кодированного контента не обязательно ограничиваются воспроизведением через громкоговорители. Представление регулируемого или доминантного компонента, состоящего из доминантного компонентного сигнала и (целевого) местоположения, обеспечивает возможность воспроизведения через наушники посредством свертки с импульсными реакциями, связанными с головой, (HRIR) (Wightman и др., 1989). Упрощенная схема системы 1, реализующей этот способ, показана на фиг. 1. Входной сигнал 2 в формате кодированной матрицы сначала анализируется 3, чтобы определить направление и величину доминантной компоненты. Доминантный компонентный сигнал свертывается 4, 5 посредством пары HRIR, полученной из справочной информации 6 на основе направления доминантной компоненты, чтобы вычислить выходной сигнал для воспроизведения 7 через наушники, так чтобы воспроизводимый сигнал воспринимался как приходящий с направления, которое было определено на этапе 3 анализа доминантной компоненты. Эта схема может быть применена для широкополосных сигналов, а также для индивидуальных поддиапазонов, и может быть усовершенствована различными способами с помощью специализированной обработки остаточного (или диффузного) сигналов.
[0016] Использование матричных кодеров в большой степени пригодно для распределения и воспроизведения на AV-приемниках, но может быть проблематичным для мобильных применений, требующих низких скоростей передачи данных и низкого потребления энергии.
[0017] Независимо от того, используется ли контент, основанный на каналах или на объектах, матричные кодеры и декодеры полагаются на достаточно точные межканальные фазовые соотношения сигналов, которые распространяются с матричного кодера на декодер. Другими словами, формат распределения должен в значительной степени сохранять форму сигнала. Такая зависимость от сохранения формы сигнала может создавать проблемы в условиях ограниченного битрейта, когда аудиокодеки используют параметрические способы, а не инструменты кодирования формы сигнала, чтобы получить лучшее качество звука. Примеры таких параметрических инструментов, которые общеизвестны как не сохраняющие форму сигнала, часто упоминаются как спектральная репликация диапазона, параметрическое стереокодирование, пространственное аудиокодирование и т. п., как они используются в аудиокодеках MPEG 4 (14496-3:2009 ISO/IEC).
[0018] Как коротко описано в предыдущем разделе, повышающее микширование состоит из анализа и регулирования (или свертки HRIR) сигналов. Для устройств, питаемых от сети, таких как AV-приемники, это обычно не вызывает проблем, но для устройств, работающих от батареи, таких как мобильные телефоны и планшеты, вычислительная сложность и соответствующие требования к памяти, связанные с этими процессами, часто являются нежелательными из-за их отрицательно влияния на время работы от батареи.
[0019] Вышеупомянутый анализ обычно также вводит дополнительную аудиозадержку. Такая аудиозадержка нежелательна, потому что (1) она требует видеозадержку для поддержания синхронизации движения губ с фонограммой, для которой необходим значительный объем памяти и вычислительной мощности, и (2) такая задержка может вызвать асинхронность/задержку между движениями головы и рендерингом аудио в случае слежения за движением головы.
[0020] Матрично кодированный даун-микс также может не звучать оптимально на стереофонических громкоговорителях или наушниках из-за потенциального присутствия сильно несовпадающих по фазе сигнальных компонент.
Сущность изобретения
[0021] Задача изобретения состоит в обеспечении улучшенной формы параметрического бинаурального выходного сигнала.
[0022] В соответствии с первым аспектом настоящего изобретения, обеспечивается способ кодирования входного аудиосигнала, основывающегося на канале или объекте, для воспроизведения, причем упомянутый способ включает в себя этапы, на которых: (a) первоначально проводят рендеринг входного аудиосигнала, основывающегося на канале или объекте, в начальное выходное представление (например, начальную выходную презентацию); (b) определяют оценку доминантного аудиокомпонента из входного аудиосигнала, основывающегося на канале или объекте, и определяют последовательность весовых коэффициентов доминантного аудиокомпонента для отображения начального выходного представления в доминантный аудиокомпонент; (c) определяют оценку направления и положения доминантного аудиокомпонента; и (d) кодируют начальное выходное представление, весовые коэффициенты доминантного аудиокомпонента, направление или положение доминантного аудиокомпонента как кодированный сигнал для воспроизведения. Обеспечивая последовательность весовых коэффициентов доминантного аудиокомпонента для отображения начального выходного представления в доминантный аудиокомпонент можно позволить использовать весовые коэффициенты доминантного аудиокомпонента и начальное выходное представление для определения оценки доминантного компонента.
[0023] В некоторых вариантах осуществления способ дополнительно включает в себя определение оценки остаточного микса, являющегося начальным выходным представлением за вычетом рендеринга доминантного аудиокомпонента или его оценки. Способ может также включать в себя генерацию безэхового бинаурального микса входного аудиосигнала, основывающегося на канале или объекте, и определение оценки остаточного микса, причем оценка остаточного микса может быть безэховым бинауральным миксом за вычетом рендеринга доминантного аудиокомпонента или его оценки. Дополнительно, способ может включать в себя определение последовательности остаточных матричных коэффициентов для отображения начального выходного представления в оценку остаточного микса.
[0024] Начальное выходное представление может содержать представление посредством громкоговорителя или наушников. Входной аудиосигнал, основывающийся на канале или объекте, может быть разбит на элементы разбиения по времени и по частоте и этап кодирования может повторяться для последовательности временных этапов и последовательности диапазонов частот. Начальное выходное представление может содержать микс стереогромкоговорителей.
[0025] В соответствии с дополнительным аспектом настоящего изобретения, обеспечивается способ декодирования кодированного аудиосигнала, причем кодированный аудиосигнал включает в себя: первое (например, начальное) выходное представление (например, первую/начальную выходную презентацию); направление доминантного аудиокомпонента и весовые коэффициенты доминантного аудиокомпонента; причем способ содержит этапы, на которых: (a) используют весовые коэффициенты доминантного аудиокомпонента и начальное выходное представление для определения оценочного доминантного компонента; (b) проводят рендеринг оценочного доминантного компонента с помощью бинаурализации в пространственном местоположении относительно целевого слушателя в соответствии с направлением доминантного аудиокомпонента, чтобы сформировать отрендеренный бинаурализированный оценочный доминантный компонент; (c) реконструируют оценку остаточного компонента из первого (например, начального) выходного представления; и (d) объединяют отрендеренный бинаурализированный оценочный доминантный компонент и оценку остаточного компонента, чтобы сформировать выходной пространственно ориентированный кодированный аудиосигнал.
[0026] Кодированный аудиосигнал дополнительно может включать в себя последовательность остаточных матричных коэффициентов, представляющих остаточный аудиосигнал, и этап (c) дополнительно может содержать этап (c1), на котором применяют остаточные матричные коэффициенты к первому (например, начальному) выходному представлению, чтобы реконструировать оценку остаточного компонента.
[0027] В некоторых вариантах осуществления оценка остаточного компонента может быть реконструирована вычитанием отрендеренного бинаурализированного оценочного доминантного компонента из первого (например, начального) выходного представления. Этап (b) может включать в себя начальный поворот оценочного доминантного компонента в соответствии с входным сигналом слежения за движением головы, указывающим ориентацию головы целевого слушателя.
[0028] В соответствии с дополнительным аспектом настоящего изобретения, обеспечивается способ декодирования и воспроизведения аудиопотока для слушателя, использующего наушники, причем упомянутый способ содержит этапы, на которых: (a) принимают поток данных, содержащий первую аудиопрезентацию и дополнительные данные аудиопреобразования; (b) принимают данные ориентации головы, представляющие ориентацию слушателя; (c) создают один или более вспомогательных сигналов, основываясь на первой аудиопрезентации и принятых данных преобразования; (d) создают вторую аудиопрезентацию, состоящую из объединения первой аудиопрезентации и вспомогательного сигнала(ов), в которой один или более вспомогательных сигналов были модифицированы в ответ на данные ориентации головы; и (e) выводят вторую аудиопрезентацию в качестве выходного аудиопотока.
[0029] Некоторые варианты осуществления могут дополнительно включать в себя модификацию вспомогательных сигналов, которая состоит из моделирования акустического пути прохождения от положения источника звука до ушей слушателя. Данные преобразования могут состоять из коэффициентов матрицирования и по меньшей мере одного из положения источника звука и направления источника звука. Процесс преобразования может применяться как функция времени или частоты. Вспомогательные сигналы могут представлять по меньшей мере один доминантный компонент. Положение или направление источника звука может быть принято как часть данных преобразования и может поворачиваться в ответ на данные ориентации головы. В некоторых вариантах осуществления максимальная величина поворота ограничивается значением меньше 360 градусов по азимуту или углу места. Вторичная презентация может быть получена из первой презентации путем матрицирования в области преобразования или набора фильтров. Данные преобразования дополнительно могут содержать дополнительные коэффициенты матрицирования и этап (d) дополнительно может содержать модификацию первого аудиопредставления в качестве реакции на дополнительные коэффициенты матрицирования перед объединением первого аудиопредставления и вспомогательного аудиосигнала(ов).
Краткое описание чертежей
[0030] Теперь только для примера будут описаны варианты осуществления изобретения со ссылкой на сопроводительные чертежи, на которых:
[0031] Фиг. 1 схематично иллюстрирует декодер наушников для матрично кодированного контента;
[0032] Фиг. 2 схематично иллюстрирует кодер, соответствующий варианту осуществления;
[0033] Фиг. 3 представляет собой блок-схему декодера;
[0034] Фиг. 4 представляет собой подробную визуализацию кодера; и
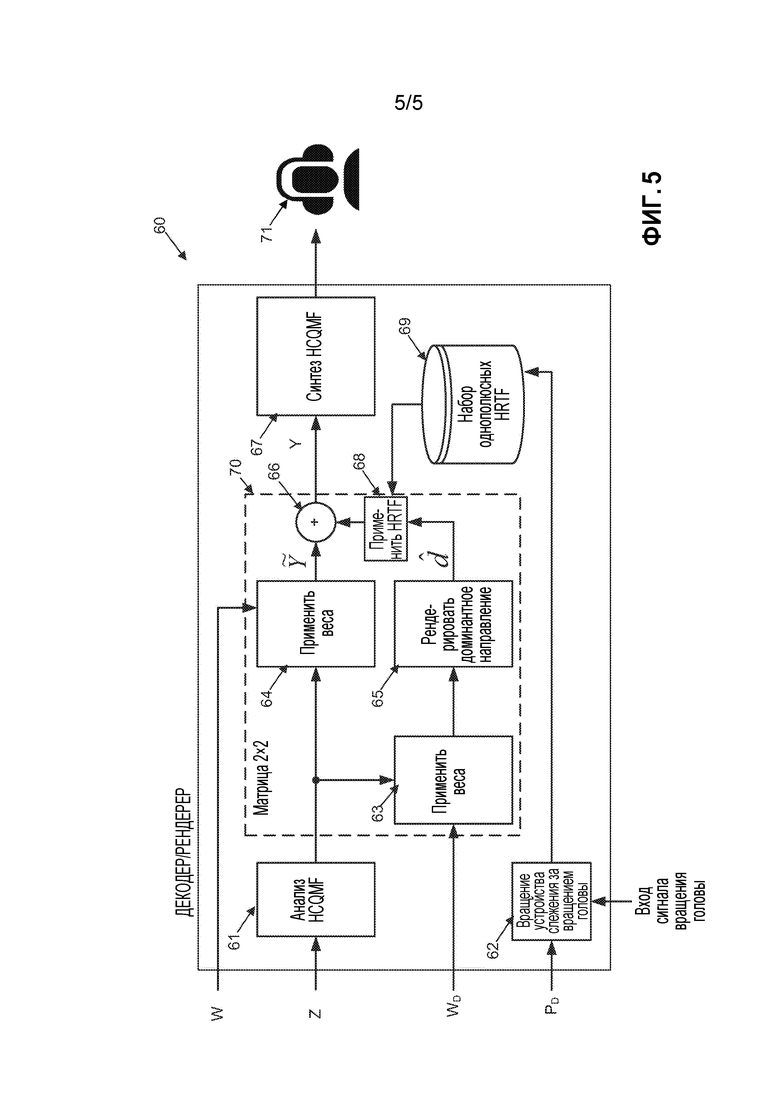
[0035] Фиг. 5 более подробно иллюстрирует одну из форм декодера.
Осуществление изобретения
[0036] Варианты осуществления показывают систему и способ представления аудиоконтента, основывающегося на канале или объекте, который (1) совместим со стереовоспроизведением, (2) позволяет бинауральное воспроизведение, включающее в себя слежение за движением головы, (3) обладает небольшой сложностью декодера, и (4) не опирается, но, тем не менее, совместим с матричным кодированием.
[0037] Это достигается путем объединения выполняемого на стороне кодера анализа одного или более доминантных компонент (или доминантного объекта или их сочетания), включающего в себя веса для предсказания этих доминантных компонент из даун-микса, в комбинации с дополнительными параметрами, которые минимизируют ошибку между бинауральным рендерингом, основанным на одних только регулируемых или доминантных компонентах, и желаемого бинаурального представления полного контента.
[0038] В варианте осуществления анализ доминантного компонента (или многочисленных доминантных компонент) обеспечивается в кодере, а не в декодере/рендерере. Аудиопоток затем нарастает с помощью метаданных, указывающих направление доминантного компонента, и информации о том, как доминантный компонент(-ы) может быть получен из сопутствующего сигнала даун-микса.
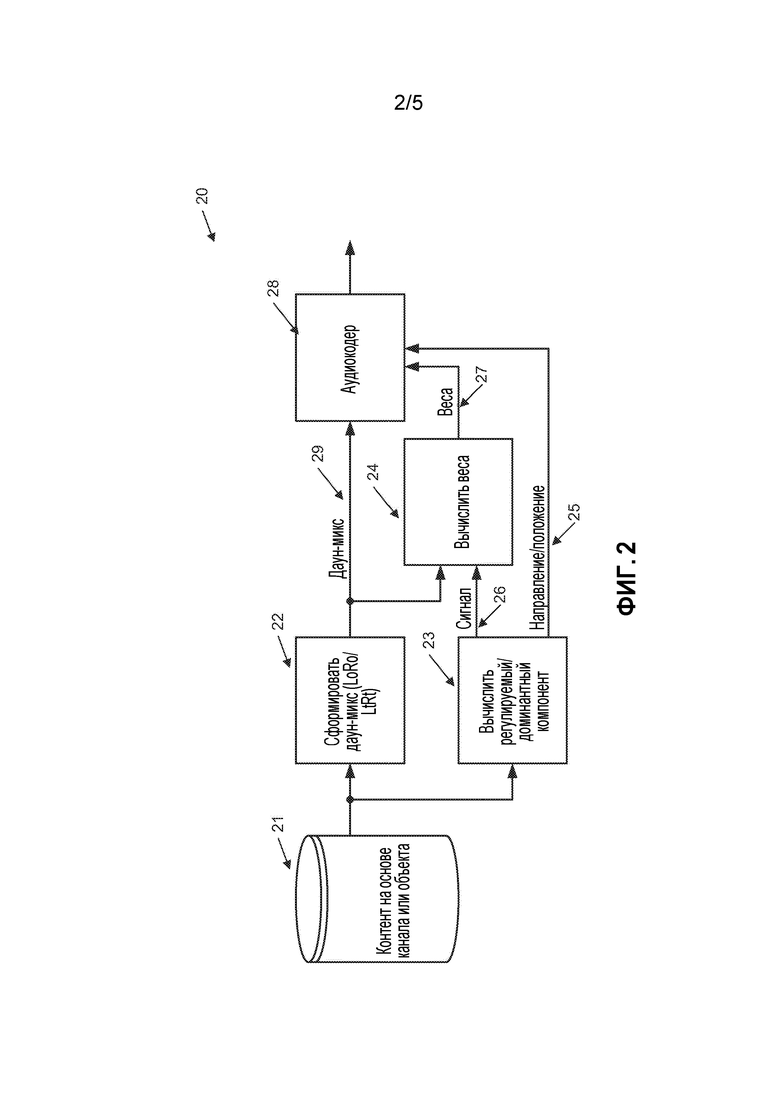
[0039] На фиг. 2 показана одна форма кодера 20 предпочтительного варианта осуществления. Контент 21, основанный на объекте или канале, подвергается анализу 23, чтобы определить доминантный компонент(-ы). Этот анализ может иметь место как функция времени и частоты (предполагается, что аудиоконтент разбивается на временные элементы и частотные подэлементы). Результатом этого процесса является доминантный компонентный сигнал 26 (или многочисленные доминантные компонентные сигналы) и ассоциированная информация 25 о положении(ях) или о направлении(ях). Далее делают оценку 24 и выводят 27 веса, чтобы позволить реконструкцию доминантного компонентного сигнала(ов) из переданного даун-микса. Этот генератор 22 даун-микса не обязательно должен твердо следовать правилам даун-микса LtRt, а может быть стандартным даун-миксом ITU (LoRo), использующим неотрицательные, с действительными значениями коэффициенты даун-микса. Наконец, выходной сигнал 29 даун-микса, веса 27 и позиционные данные 25 упаковывают аудиокодером 28 и готовят к распространению.
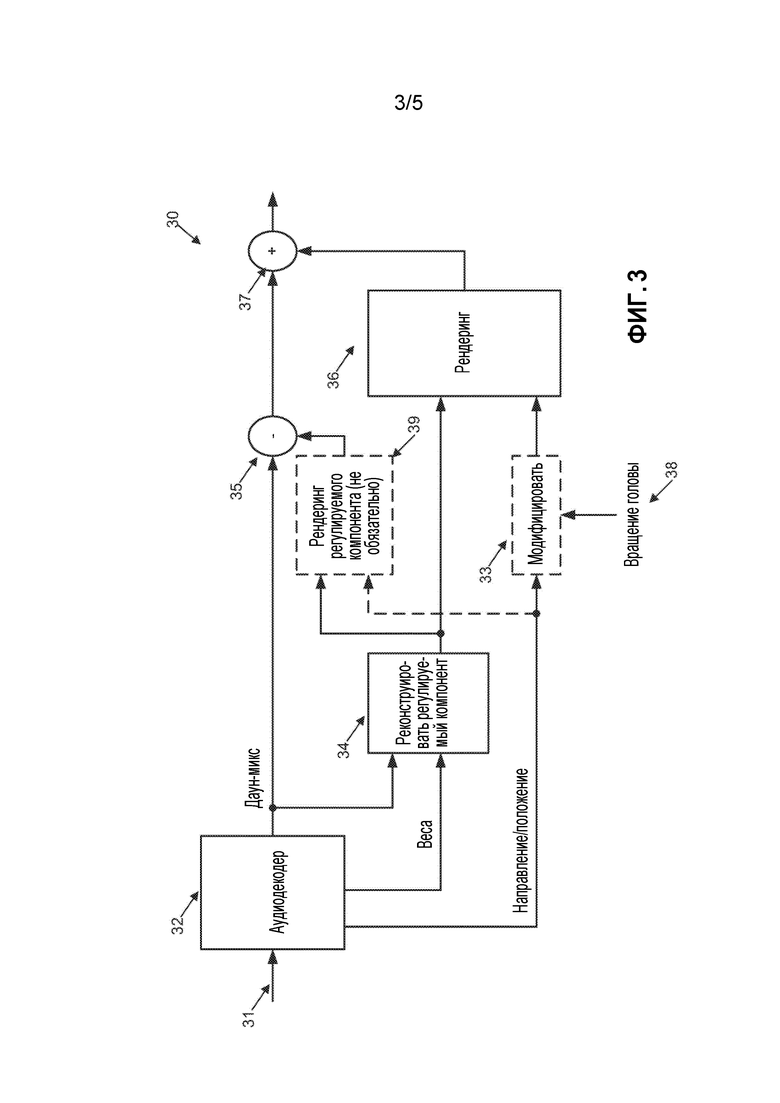
[0040] На фиг. 3 показан соответствующий декодер 30 из предпочтительного варианта осуществления. Аудиодекодер реконструирует сигнал даун-микса. Сигнал вводят 31 и распаковывают посредством аудиодекодера 32 в сигнал даун-микса, веса и направление доминантных компонент. Далее, веса оценочных доминантных компонентов используют для реконструкции 34 регулируемых компонент, которые рендерируются 36, используя позиционные данные или данные о направлении. Позиционные данные, как вариант, могут модифицироваться 33 в зависимости от поворота головы или информации 38 преобразования. Дополнительно, реконструированный доминантный компонент(-ы) может вычитаться 35 из даун-микса. Как вариант, имеет место вычитание доминантного компонента(ов) в пределах пути прохождения даун-микса, но, альтернативно, вычитание может также происходить в кодере, как описано ниже.
[0041] Чтобы улучшить удаление или отмену реконструированного доминантного компонента в вычитающем устройстве 35, выходной сигнал доминантного компонента может сначала быть рендерирован, используя перед вычитанием переданные позиционные данные или данные направления. Этот необязательный этап 39 рендеринга показан на фиг. 3.
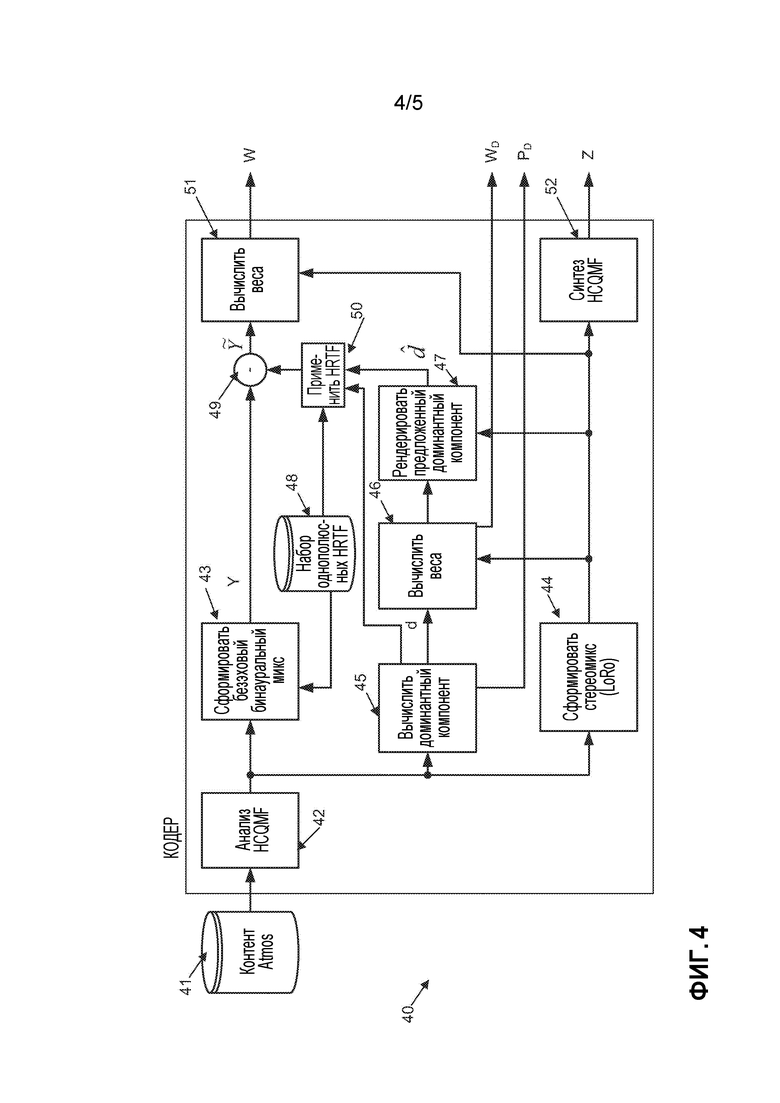
[0042] Возвращаясь теперь обратно, чтобы сначала описать кодер более подробно, на фиг. 4 представлена одна из форм кодера 40 для обработки аудиоконтента, основанного на объекте (например, система Dolby Atmos). Аудиообъекты первоначально хранятся в качестве объектов 41 Atmos и первоначально делятся на временные и частотные элементы, используя набор 42 гибридных зеркальных квадратурных фильтров с комплексными значениями (hybrid complex-valued quadrature mirror filter, HCQMF). Входные сигналы объектов могут быть обозначены как 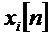 , когда мы опускаем соответствующие временные и частотные индексы; соответствующее положение в пределах текущего кадра задается единичным вектором
, когда мы опускаем соответствующие временные и частотные индексы; соответствующее положение в пределах текущего кадра задается единичным вектором 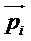 , и индекс i относится к номеру объекта, а индекс n относится ко времени (например, индекс выборки поддиапазона). Входные сигналы объекта являются примером входного аудиосигнала, основывающегося на канале или объекте.
, и индекс i относится к номеру объекта, а индекс n относится ко времени (например, индекс выборки поддиапазона). Входные сигналы объекта являются примером входного аудиосигнала, основывающегося на канале или объекте.
[0043] Безэховый, поддиапазонный, бинауральный микс Y ( ) создают 43, используя скаляры с комплексными значениями
) создают 43, используя скаляры с комплексными значениями  (например, однополюсные HRTF 48), которые представляют презентацию поддиапазона для HRIR, соответствующих положению :
(например, однополюсные HRTF 48), которые представляют презентацию поддиапазона для HRIR, соответствующих положению :
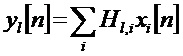

[0044] Альтернативно, бинауральный микс Y () может быть создан посредством свертки, используя связанные с головой импульсные реакции (HRIR). Дополнительно, стерео даун-микс 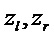 (как пример, реализующий начальное выходное представление) создают 44, используя коэффициенты
(как пример, реализующий начальное выходное представление) создают 44, используя коэффициенты 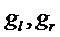 усиления амплитудного панорамирования:
усиления амплитудного панорамирования:
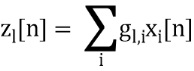

[0045] Вектор направления доминантного компонента 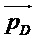 (в качестве примера реализующий направление или положение доминантного аудиокомпонента) может оцениваться путем вычисления доминантного компонента 45, первоначально вычисляя взвешенную сумму единичных векторов направления для каждого объекта:
(в качестве примера реализующий направление или положение доминантного аудиокомпонента) может оцениваться путем вычисления доминантного компонента 45, первоначально вычисляя взвешенную сумму единичных векторов направления для каждого объекта:
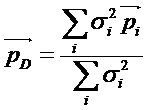
где 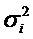 - энергия сигнала :
- энергия сигнала :
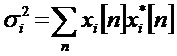
и (.)* - комплексный оператор свертки.
[0046] Доминантный/регулирующий сигнал d[n] (в качестве примера реализующий доминантный аудиокомпонент) далее задается следующим образом:
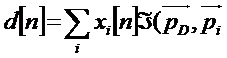
[0047] где 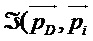 - функция, выполняющая усиление, которое уменьшается с увеличением расстояния между единичными векторами
- функция, выполняющая усиление, которое уменьшается с увеличением расстояния между единичными векторами  . Например, чтобы создать виртуальный микрофон с помощью модели направленности, основанной на сферических гармониках высшего порядка, одна из реализаций должна соответствовать следующему:
. Например, чтобы создать виртуальный микрофон с помощью модели направленности, основанной на сферических гармониках высшего порядка, одна из реализаций должна соответствовать следующему:
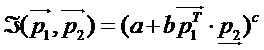
где 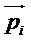 - единичный вектор направления в двух- или трехмерной системе координат,(.) - оператор скалярного произведения двух векторов, и a, b, c - примерные параметры (например a=b=0,5; c=1).
- единичный вектор направления в двух- или трехмерной системе координат,(.) - оператор скалярного произведения двух векторов, и a, b, c - примерные параметры (например a=b=0,5; c=1).
[0048] Веса или коэффициенты предсказания wl,d, wr,d вычисляются 46 и используются для вычисления 47 оценочного регулируемого сигнала  :
:
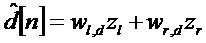
где веса wl,d, wr,d минимизируют среднеквадратичную ошибку между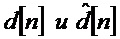 , заданными сигналами даун-микса. Веса wl,d, wr,d являются примером весовых коэффициентов доминантного аудиокомпонента для отображения начального выходного представления (например,) в доминантный аудиокомпонент (например,
, заданными сигналами даун-микса. Веса wl,d, wr,d являются примером весовых коэффициентов доминантного аудиокомпонента для отображения начального выходного представления (например,) в доминантный аудиокомпонент (например, ). Известный способ получения этих весов заключается в применении устройства прогнозирования минимальной среднеквадратичной ошибки (MMSE):
). Известный способ получения этих весов заключается в применении устройства прогнозирования минимальной среднеквадратичной ошибки (MMSE):
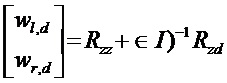
где Rab - матрица ковариации между сигналами для сигналов a и сигналов b, и ∈ - параметр регуляризации.
[0049] Мы можем затем вычесть 49 отрендеренную оценку доминантного компонентного сигнала из безэхового бинаурального микса  , чтобы создать остаточный бинауральный микс
, чтобы создать остаточный бинауральный микс  , используя HRTF (HRIR)
, используя HRTF (HRIR)  50, связанный с направлением/положением
50, связанный с направлением/положением 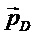 доминантного компонентного сигнала
доминантного компонентного сигнала  :
:
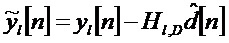

[0050] Наконец, оценивают 51 другой набор коэффициентов предсказания или весов wi,j, которые позволяют реконструкцию остаточного бинаурального микса из стереомикса  ,используя оценочные минимальные среднеквадратичные ошибки:
,используя оценочные минимальные среднеквадратичные ошибки:
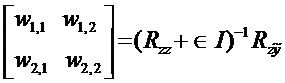
где Rab - матрица ковариации между сигналами для презентации а и презентации b, и ∈ - параметр регуляризации. Коэффициенты прогнозирования или веса wi,j являются примером остаточных матричных коэффициентов для отображения начального выходного представления (например,  ) в оценочный остаточный бинауральный микс . Приведенное выше выражение может быть подвергнуто дополнительным ограничениям уровня, чтобы преодолеть любые потери прогнозирования. Кодер выводит следующую информацию:
) в оценочный остаточный бинауральный микс . Приведенное выше выражение может быть подвергнуто дополнительным ограничениям уровня, чтобы преодолеть любые потери прогнозирования. Кодер выводит следующую информацию:
[0051] Стереомикс (в качестве примера реализации начального выходного представления);
[0052] Коэффициентами для оценки доминантного компонента wl,d, wr,d (в качестве примера реализующего весовые коэффициенты доминантного аудиокомпонента) являются;
[0053] положение или направление доминантного компонента ;
[0054] и, дополнительно, остаточные веса wi,j (в качестве примера реализации остаточных матричных коэффициентов).
[0055] Хотя представленное выше описание относится к рендерингу, основанному на одном единственном доминантном компоненте, в некоторых вариантах осуществления кодер может быть выполнен с возможностью обнаружения многочисленных доминантных компонент, определения весов и направлений для каждого из многочисленных доминантных компонентов, рендеринга и вычитания каждого из многочисленных доминантных компонент из безэхового бинаурального микса Y, и затем определения остаточных весов после того, как каждый из многочисленных доминантных компонент был вычтен из безэхового бинаурального микса Y.
Декодер/рендерер
[0056] На фиг. 5 более подробно показана одна из форм декодера/рендерера 60. Декодер/рендерер 60 применяет процесс, направленный на реконструкцию бинаурального микса для вывода слушателю 71 из распакованной входной информации zl, zr; wl,d, wr,d; , wi,j. Здесь стерео микс zl, zr является примером первой аудиопрезентации и коэффициенты или веса предсказания wi,j и/или направление/положение доминантного компонентного сигнала 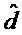 являются примерами дополнительных данных аудиопреобразования.
являются примерами дополнительных данных аудиопреобразования.
[0057] Первоначально, стереодаун-микс разбивается на временные/частотные элементы, используя соответствующий набор фильтров или преобразование 61, такое как аналитическая группа HCQMF 61. Другие преобразования, такие как дискретное преобразование Фурье, (модифицированное) косинусное или синусное преобразование, набор фильтров во временной области или вейвлет-преобразование также могут быть применимы в равной степени. В дальнейшем, оценочный доминантный компонентный сигнал вычисляется 63, используя веса wl,d, wr,d коэффициентов предсказания:
=wl,dzl+wr,dzr
Оценочный доминантный компонентный сигнал является примером вспомогательного сигнала. Следовательно, можно сказать, что этот этап соответствует созданию одного или более вспомогательных сигналов, основанных на упомянутой первой аудиопрезентации и принятых данных преобразования.
[0058] Этот доминантный компонентный сигнал в дальнейшем рендерируется 65 и модифицируется 68 с помощью HRTF 69, основанных на переданных данных положения/направления , возможно, модифицированных (повернутых) на основе информации, полученной из устройства 62 слежения за головой. Наконец, общий приглушенный бинауральный выходной сигнал состоит из отрендеренного доминантного компонентного сигнала, суммированного 66 с реконструированными остатками , основанными на весах wij коэффициентов предсказания:
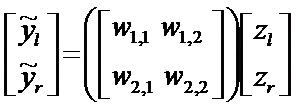
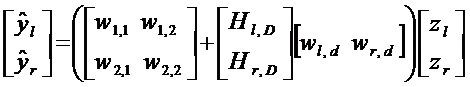
Полный приглушенный бинауральный выходной сигнал является примером второй аудиопрезентации. Следовательно, этот этап, можно сказать, должен соответствовать созданию второй аудиопрезентации, состоящей из сочетания упомянутой первой аудиопрезентации и упомянутого вспомогательного сигнала(ов), в которой один или более из упомянутых вспомогательных сигналов были модифицированы в ответ на упомянутые данные ориентации головы.
[0059] Дополнительно следует заметить, что если принята информация о более чем одном доминантном сигнале, каждый доминантный сигнал может быть рендерирован и добавлен к реконструированному остаточному сигналу.
[0060] Пока никакое вращение или перемещение головы не применяется, выходные сигналы 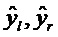 должны быть очень близки (с точки зрения среднеквадратичной ошибки) к опорным бинауральным сигналам
должны быть очень близки (с точки зрения среднеквадратичной ошибки) к опорным бинауральным сигналам 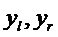 , пока
, пока
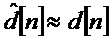
Основные свойства
[0061] Как можно видеть из приведенных выше уравнений, эффективная операция по созданию приглушенного бинаурального представления из стереопредставления состоит из матрицы 2×2 70, в которой матричные коэффициенты зависят от переданной информации wl,d, wr,d; , wi,j и поворота и/или перемещения устройства слежения за головой. Это указывает, что сложность процесса является относительно низкой, поскольку анализ доминантных компонент применяется в кодере вместо декодера.
[0062] Если никакой доминантный компонент не оценен (например,wl,d, wr,d=0), описанное решение эквивалентно параметрическому бинауральному способу.
[0063] В случаях, когда имеется желание исключить определенные объекты из слежения за вращением/перемещением головы, эти объекты могут быть исключены из (1) анализа направления доминантных компонент, и (2) предсказания доминантных компонентных сигналов. В результате эти объекты будут преобразовываться из стерео в бинауральные посредством коэффициентов wi,j и поэтому на них не влияет никакое вращение или перемещение головы.
[0064]При подобном ходе мыслей объекты могут быть установлены в режиме "pass through" (сквозного прохождения), что означает, что в бинауральном представлении они будут подвергнуты амплитудному панорамированию, а не свертке HRIR. Это может быть получено, просто используя коэффициенты усиления амплитудного панорамирования для коэффициентов Hi вместо однополюсных HRTF или любого другого соответствующего бинаурального процесса.
Расширения
[0065] Варианты осуществления не ограничиваются использованием даун-миксов, поскольку также могут использоваться отсчеты других каналов.
[0066] Декодер 60, описанный со ссылкой на фиг. 5, имеет выходной сигнал, состоящий из отрендеренного направления доминантной компоненты плюс входной сигнал, матрицированный посредством матричных коэффициентов wi,j. Последние коэффициенты могут быть получены различными способами, например:
[0067] 1. Коэффициенты wi,j могут быть определены в кодере посредством параметрической реконструкции сигналов . Другими словами, в этой реализации, коэффициенты wi,j направлены на точную реконструкцию бинауральных сигналов 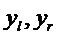 , которые могли бы быть получены при рендеринге первоначальных входных объектов/каналов бинауральным образом; другими словами, коэффициенты wi,j управляются контентом.
, которые могли бы быть получены при рендеринге первоначальных входных объектов/каналов бинауральным образом; другими словами, коэффициенты wi,j управляются контентом.
[0068] 2. Коэффициенты wi,j могут быть переданы от кодера к декодеру, чтобы представить HRTF для определенных пространственных положений, например, с углами +/-45 градусов по азимуту. Другими словами, остаточный сигнал обрабатывается, чтобы моделировать воспроизведение через два виртуальных громкоговорителя в определенных местоположениях. Поскольку эти коэффициенты, представляющие HRTF, передаются от кодера на декодер, местоположения виртуальных громкоговорителей могут изменяться во времени и по частоте. Если этот подход применяется, используя статические виртуальные громкоговорители, чтобы представить остаточный сигнал, коэффициенты wi,j не требуют передачи от кодера к декодеру, и могут вместо этого подключаться проводами в декодере. Вариант такого подхода может состоять из ограниченного набора статических местоположений, которые доступны в декодере, с их соответствующими коэффициентами wi,j, и их выбор, при котором для обработки остаточного сигнала используется статическое местоположение, сообщается от кодера декодеру.
[0069] Сигналы могут подвергаться так называемому повышающему микшированию, реконструируя более 2 сигналов посредством статистического анализа этих сигналов в декодере с последующим бинауральным рендерингом результирующих сигналов повышающего микширования.
[0070] Описанные способы могут быть также применимы в системе, в которой переданный сигнал Z является бинауральным сигналом. В этом конкретном случае декодер 60, показанный на фиг. 5, остается таким, как он есть, в то время как блок, обозначенный как "Generate stereo (LoRo) mix" (сгенерировать стереомикс (LoRo)" 44 и показанный на фиг. 4, должен быть заменен на "Generate anechoic binaural mix" (сгенерировать приглушенный бинауральный микс) 43 (фиг. 4), который является таким же, как и блок, создающий сигнальную пару Y. Дополнительно, в соответствии с требованиями, могут быть сгенерированы и другие формы миксов.
[0071] Этот подход может быть расширен с помощью способов реконструкции одного или более входных сигналов FDN из переданного стереомикса, который состоит из конкретного подмножества объектов или каналов.
[0072] Подход может быть расширен с помощью множественных доминантных компонентов, предсказываемых из переданного стереомикса и рендерируемых на стороне декодера. Не существует никакого принципиального ограничения предсказания только одного доминантного компонента для каждого временного/частотного элемента разбиения. В частности, количество доминантных компонент может различаться в каждом временном/частотном элементе разбиения.
Интерпретация
[0073] В этом описании повсеместно ссылка на "один из вариантов осуществления", "некоторые варианты осуществления" или "вариант осуществления" означает, что конкретный признак, структура или характеристика, описанные в сочетании с вариантом осуществления, вводятся по меньшей мере в один вариант осуществления настоящего изобретения. Таким образом, появление выражений "в одном из вариантов осуществления", "в некоторых вариантах осуществления" или "в варианте осуществления" повсеместно в различных местах настоящего описания не обязательно, поскольку все они относятся к одному и тому же варианту осуществления. Кроме того, конкретные признаки, структуры или характеристики могут объединяться любым приемлемым способом, как должно быть очевидно специалисту в данной области техники, исходя из этого раскрытия, в одном или более вариантах осуществления.
[0074] Использование порядковых числительных "первый", "второй", "третий" и т. д. для описания обычного объекта, как они используются здесь, если не определено иначе, просто указывает, что ссылка делается на различные экземпляры схожих объектов, и не предназначено подразумевать, что объекты, описанные таким образом, должны следовать в приведенной последовательности во времени или в пространстве, по порядку, или любым другим способом.
[0075] В приведенной ниже формуле изобретения и в приведенном здесь описании, любой из терминов "содержащий", "содержащийся" или "который содержит", является открытым термином, который означает включение, по меньшей мере, элементов/признаков, соответствующих термину, но не исключает и других. Таким образом, термин "содержащий", когда используется в формуле изобретения, не должен истолковываться как ограничительный для средств, элементов или этапов, перечисленных здесь далее. Например, объем выражения "устройство, содержащее A и B", не должен ограничиваться устройствами, состоящими только из элементов A и B. Любой из терминов "включающий в себя" или "который включает в себя" или "которые включают", как эти термины используются здесь, также являются открытыми терминами, которые означают включение, по меньшей мере, элементов/признаков, соответствующих термину, но не исключают и других. Таким образом, "включающий в себя" является синонимом и означает "содержащий".
[0076] Термин "примерный", как он используется здесь, применяется в смысле предоставления примеров, а не как указание на качество. То есть, "примерный вариант осуществления" является вариантом осуществления, представляемым в качестве примера, и не является обязательно вариантом осуществления, образцовым по качеству.
[0077] Следует понимать, что в приведенном выше описании примерных вариантов осуществления изобретения, различные признаки изобретения с целью оптимизации раскрытия и оказания помощи в понимании одного или более различных изобретательских подходов иногда группируются вместе в единый вариант осуществления, чертеж или их описание. Этот способ раскрытия, однако, не должен интерпретироваться как отражение намерения, что заявленное изобретение требует большего количества признаков, чем явно приводится в каждом пункте формулы изобретения. Скорее, как это отражает последующая формула изобретения, аспекты изобретения заключаются в менее, чем во всех признаках единого предшествующего раскрытого варианта осуществления. Таким образом, формула изобретения, следующая после раздела "Осуществление изобретения", тем самым явно включается в это "Осуществление изобретения" с каждым пунктом формулы изобретения, являющимся самостоятельным, в качестве отдельного варианта осуществления этого изобретения.
[0078] Дополнительно, хотя некоторые варианты осуществления, описанные здесь, содержат некоторые, но не другие признаки, включенные в другие варианты осуществления, сочетания признаков в различных вариантах осуществления означает, что они находятся в рамках объема изобретения и формируют различные варианты осуществления, как это должны понимать специалисты в данной области техники. Например, в последующей формуле изобретения любой из заявленных вариантов осуществления может использоваться в любом сочетании.
[0079] Дополнительно, некоторые из вариантов осуществления описываются здесь как способ или сочетание элементов способа, которые могут быть реализованы процессором компьютерной системы или другими средствами выполнения функции. Таким образом, процессор с необходимыми командами для выполнения такого способа или элемента способа образует средство выполнения способа или элемента способа. Дополнительно, описанный здесь элемент варианта осуществления устройства, является примером средства выполнения функции, исполняемой элементом с целью осуществления изобретения.
[0080] В представленном здесь описании изложены многочисленные конкретные подробности. Однако, следует понимать, что варианты осуществления изобретения могут быть осуществлены на практике без этих конкретных подробностей. В других случаях известные способы, структуры и технологии не были показаны подробно, чтобы не мешать понимание настоящего описания.
[0081] Точно также, следует заметить, что термин "связанный", когда используется в формуле изобретения, не должен интерпретироваться как ограничение только прямыми связями. Термины "связанный" и "соединенный", а также их производные могут использоваться. Следует понимать, что эти термины не подразумеваются синонимами друг друга. Таким образом, контекст выражения "Устройство А, связанное с устройством B" не должен ограничиваться устройствами или системами, в которых выход устройства A напрямую соединяется со входом устройства B. Это означает, что существует путь прохождения между выходом устройства A и входом устройства B, который может быть путем прохождения, содержащим другие устройства или средства. "Связанный" может означать, что два или более элементов находятся в прямом физическом или электрическом контакте, или что два или более элементов не находятся в прямом контакте друг с другом но все еще действуют совместно или взаимодействуют с друг другом.
[0082] Таким образом, хотя здесь были описаны варианты осуществления изобретения, специалисты в данной области техники должны признать, в них могут быть сделаны другие и дополнительные модификации, не отступая от сущности изобретения, и подразумевается, что все такие изменения и модификации заявляются как попадающие в рамки объема изобретения. Например, любые формулы, приведенные выше, являются просто репрезентативными для процедур, которые могут использоваться. Функциональные возможности могут добавляться или удаляться из блок-схем, и операции могут чередоваться между функциональными блоками. В способах, описанных в пределах объема настоящего изобретения этапы могут добавляться или удаляться.
[0083] Различные аспекты настоящего изобретения могут быть понятны, исходя из следующих пронумерованных примерных вариантов осуществления (enumerated example embodiment, EEE):
EEE 1. Способ кодирования для воспроизведения входного аудиосигнала, основывающегося на канале или объекте, причем упомянутый способ содержит этапы, на которых:
(a) первоначально рендерируют входной аудиосигнал, основывающийся на канале или объекте, в начальное выходное представление;
(b) определяют оценку доминантного аудиокомпонента из входного аудиосигнала, основывающегося на канале или объекте, и определяют последовательность весовых коэффициентов доминантного аудиокомпонента для отображения начального выходного представления в доминантный аудиокомпонент;
(c) определяют оценку направления или положения доминантного аудиокомпонента; и
(d) кодируют начальное выходное представление, весовые коэффициенты доминантного аудиокомпонента, направление или положение доминантного аудиокомпонента как кодированный сигнал для воспроизведения.
EEE 2. Способ по п. EEE 1, дополнительно содержащий этап, на котором определяют оценку остаточного микса, являющегося начальным выходным представлением, уменьшенной на рендеринг доминантного аудиокомпонента или его оценки.
EEE 3. Способ по п. EEE 1, дополнительно содержащий генерацию безэхового бинаурального микса входного аудиосигнала, основывающегося на канале или объекте, и определение оценки остаточного микса, причем оценка остаточного микса является безэховым бинауральным миксом за вычетом рендеринга доминантного аудиокомпонента или его оценки.
EEE 4. Способ по п. EEE 2 или 3, дополнительно содержащий определение последовательности остаточных матричных коэффициентов для отображения начального выходного представления в оценку остаточного микса.
EEE 5. Способ по любому из предшествующих EEE, в котором упомянутая начальное выходное представление содержит наушники или громкоговоритель.
EEE 6. Способ по любому из предшествующих EEE, в котором упомянутый входной аудиосигнал, основывающийся на канале или объекте, разбивается на элементы по времени и по частоте и упомянутый этап кодирования повторяется в отношении последовательности временных этапов и наборов полос частот.
EEE 7. Способ по любому из предшествующих EEE, в котором упомянутая начальное выходное представление содержит микс стереогромкоговорителей.
EEE 8. Способ декодирования кодированного аудиосигнала, причем кодированный аудиосигнал содержит:
- первое выходное представление;
- весовые коэффициенты доминантного аудиокомпонента и направления доминантных аудиокомпонент;
способ, содержащий этапы, на которых:
(a) используют весовые коэффициенты доминантного аудиокомпонента и начальное выходное представление, чтобы определить оценочный доминантный компонент;
(b) рендерируют оценочный доминантный компонент с бинаурализацией в пространственном местоположении относительно целевого слушателя в соответствии с направлением доминантного аудиокомпонента, чтобы сформировать отрендеренный бинаурализированный оценочный доминантный компонент;
(c) реконструируют оценку остаточного компонента из первого выходного представления; и
(d) объединяют отрендеренный бинаурализированный оценочный доминантный компонент и оценку остаточного компонента для формирования выходного пространственного кодированного аудиосигнала.
EEE 9. Способ по п. EEE 8, в котором упомянутый кодированный аудиосигнал дополнительно содержит последовательность остаточных матричных коэффициентов, представляющих остаточный аудиосигнал, и упомянутый этап (c) дополнительно является этапом, на котором:
(c1) применяют упомянутые остаточные матричные коэффициенты к первому выходному представлению, чтобы реконструировать оценку остаточного компонента.
EEE 10. Способ EEE 8, в котором оценка остаточного компонента реконструируется вычитанием отрендеренного бинаурализированного оценочного доминантного компонента из первого выходного представления.
EEE 11. Способ по EEE 8, в котором упомянутый этап (b) включает в себя начальный поворот оценочного доминантного компонента в соответствии со входным сигналом слежения за движением головы, указывающим ориентацию головы целевого слушателя.
EEE 12. Способ декодирования и воспроизведения аудиопотока для слушателя, использующего наушники, причем упомянутый способ содержит этапы, на которых:
(a) принимают поток данных, содержащий первую аудиопрезентацию и дополнительные аудиоданные преобразования;
(b) принимают данные ориентации головы, представляющие ориентацию слушателя;
(c) создают один или более вспомогательных сигналов, основываясь на упомянутой первой аудиопрезентации и принятых данных преобразования;
(d) создают вторую аудиопрезентацию, состоящую из сочетания первого аудиопредставления и упомянутого вспомогательного сигнала(ов), в которой один или более упомянутых вспомогательных сигналов были модифицированы в ответ на упомянутые данные ориентации головы; и
(e) выводят вторую аудиопрезентацию в качестве выходного аудиопотока.
EEE 13. Способ по п. EEE 12, в котором модификация вспомогательных сигналов состоит из моделирования акустического пути прохождения от положения источника звука до ушей слушателя.
EEE 14. Способ по п. EEE 12 или 13, в котором упомянутые данные преобразования состоят из коэффициентов матрицирования и по меньшей мере одного из следующего: положение источника звука или направление источника звука.
EEE 15. Способ по любому из пп. EEE 12-14, в котором процесс преобразования применяется как функция времени или частоты.
EEE 16. Способ по любому из EEE 12-15, в котором вспомогательные сигналы представляют собой по меньшей мере один доминантный компонент.
EEE 17. Способ по любому из пп. EEE 12-16, в котором положение или направление источника звука, принятое как часть данных преобразования, вращаются ответ на данные ориентации головы.
EEE 18. Способ по п. EEE 17, в котором максимальная величина поворота ограничивается значением менее 360 градусов по азимуту или по углу места.
EEE 19. Способ по любому из пп. EEE 12-18, в котором вторичная презентация получается из первой презентации путем матрицирования в области преобразования или блока фильтров.
EEE 20. Способ по любому из пп. EEE 12-19, в котором данные преобразования дополнительно содержат добавочные коэффициенты матрицирования и этап (d) дополнительно содержит модификацию первого аудиопредставления в ответ на добавочные коэффициенты матрицирования до объединения первой аудиопредставления и вспомогательного аудиосигнала(ов).
EEE 21. Устройство, содержащее одно или более других устройств, выполненное с возможностью осуществления любого из способов по пп. EEE 1-20.
EEE 22. Считываемый компьютером носитель, содержащий программу, состоящую из команд, которые, когда исполняются одним или более процессорами, заставляют одно или более устройств выполнять способ по любому из пп. EEE 1-20.
Изобретение относится к средствам для кодирования и декодирования аудиосигнала. Технический результат заключается в повышении эффективности кодирования. Выполняют первоначальный рендеринг входного аудиосигнала, основывающегося на канале или объекте, в начальное выходное представление. Определяют оценку доминантного аудиокомпонента из входного аудиосигнала, основывающегося на канале или объекте, и определяют последовательность весовых компонентов доминантного аудиокомпонента для отображения начального выходного представления в доминантный аудиокомпонент. Определяют оценку направления или положения доминантного аудиокомпонента. Кодируют начальное выходное представление, весовые коэффициенты доминантного аудиокомпонента, направление или положение доминантного аудиокомпонента как кодированный сигнал для воспроизведения. 5 н. и 17 з.п. ф-лы, 5 ил.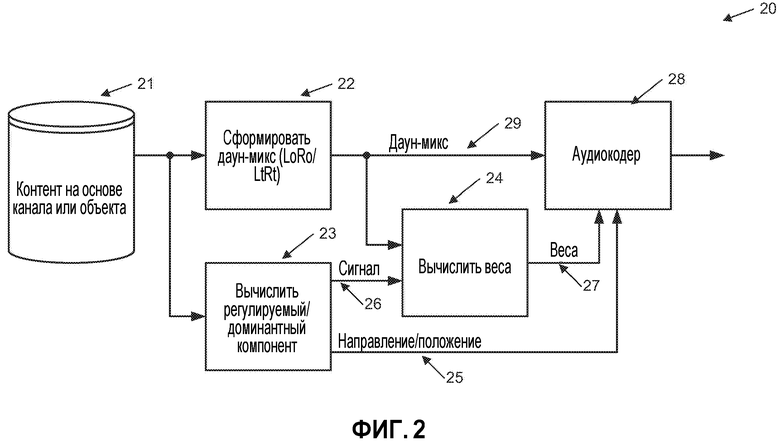
1. Способ кодирования входного аудиосигнала, основывающегося на канале или объекте, для воспроизведения, каковой способ содержит этапы, на которых
(a) выполняют первоначальный рендеринг входного аудиосигнала, основывающегося на канале или объекте, в начальное выходное представление;
(b) определяют оценку доминантного аудиокомпонента из входного аудиосигнала, основывающегося на канале или объекте, и определяют последовательность весовых компонентов доминантного аудиокомпонента для отображения начального выходного представления в доминантный аудиокомпонент, с тем чтобы обеспечить возможность использования весовых коэффициентов доминантного аудиокомпонента и начального выходного представления для определения оценки доминантного компонента;
(c) определяют оценку направления или положения доминантного аудиокомпонента и
(d) кодируют начальное выходное представление, весовые коэффициенты доминантного аудиокомпонента, направление или положение доминантного аудиокомпонента как кодированный сигнал для воспроизведения.
2. Способ по п. 1, дополнительно содержащий этап, на котором определяют оценку остаточного микса, представляющую собой начальное выходное представление за вычетом рендеринга либо доминантного аудиокомпонента, либо его оценки.
3. Способ по п. 1, дополнительно содержащий этап, на котором генерируют безэховый бинауральный микс входного аудиосигнала, основывающегося на канале или объекте, и определяют оценку остаточного микса, причем оценкой остаточного микса является безэховый бинауральный микс за вычетом либо рендеринга доминантного аудиокомпонента, либо его оценки.
4. Способ по п. 2 или 3, дополнительно содержащий этап, на котором определяют последовательность остаточных матричных коэффициентов для отображения начального выходного представления в оценку остаточного микса.
5. Способ по любому из предшествующих пунктов, в котором начальное выходное представление содержит представление посредством наушников или громкоговорителя.
6. Способ по любому из предшествующих пунктов, в котором входной аудиосигнал, основывающийся на канале или объекте, разбивается на элементы разбиения по времени и частоте и упомянутый этап кодирования повторяется в отношении последовательности временных шагов и последовательности полос частот.
7. Способ по любому из предшествующих пунктов, в котором начальное выходное представление содержит микс стереогромкоговорителей.
8. Способ декодирования кодированного аудиосигнала, причем кодированный аудиосигнал включает в себя:
начальное выходное представление;
весовые коэффициенты доминантного аудиокомпонента и направления доминантного аудиокомпонента;
при этом способ содержит этапы, на которых:
(a) используют весовые коэффициенты доминантного аудиокомпонента и начальное выходное представление, чтобы определить оценочный доминантный компонент;
(b) выполняют рендеринг оценочного доминантного компонента с бинаурализацией в пространственном местоположении относительно целевого слушателя в соответствии с направлением доминантного аудиокомпонента, чтобы сформировать отрендеренный бинаурализированный оценочный доминантный компонент;
(c) реконструируют оценку остаточного компонента из начального выходного представления и
(d) объединяют отрендеренный бинаурализированный оценочный доминантный компонент и оценку остаточного компонента для формирования выходного пространственно ориентированного кодированного аудиосигнала.
9. Способ по п. 8, в котором кодированный аудиосигнал дополнительно включает в себя последовательность остаточных матричных коэффициентов, представляющих остаточный аудиосигнал, и этап (c) дополнительно содержит этап, на котором
(c1) применяют упомянутые остаточные матричные коэффициенты к начальному выходному представлению, чтобы реконструировать оценку остаточного компонента.
10. Способ по п. 8, в котором оценка остаточного компонента реконструируется вычитанием отрендеренного бинаурализированного оценочного доминантного компонента из начального выходного представления.
11. Способ по любому из пп. 8-10, в котором этап (b) включает в себя начальный поворот оценочного доминантного компонента в соответствии с входным сигналом слежения за движением головы, указывающим ориентацию головы целевого слушателя.
12. Способ декодирования и воспроизведения аудиопотока для слушателя, использующего наушники, каковой способ содержит этапы, на которых
(a) принимают поток данных, содержащий первую аудиопрезентацию и дополнительные данные аудиопреобразования;
(b) принимают данные ориентации головы, представляющие ориентацию слушателя;
(c) создают один или более вспомогательных сигналов на основе первой аудиопрезентации и принятых данных преобразования;
(d) создают вторую аудиопрезентацию, состоящую из сочетания первой аудиопрезентации и вспомогательного сигнала(ов), где один или более вспомогательных сигналов модифицированы в ответ на данные ориентации головы; и
(e) выводят вторую аудиопрезентацию в качестве выходного аудиопотока.
13. Способ по п. 12, в котором упомянутая модификация вспомогательных сигналов состоит из моделирования акустического пути прохождения от положения источника звука до ушей слушателя.
14. Способ по п. 12 или 13, в котором упомянутые данные преобразования состоят из коэффициентов матрицирования и по меньшей мере одного из положения источника звука и направления источника звука.
15. Способ по любому из пп. 12-14, в котором процесс преобразования применяется как функция времени или частоты.
16. Способ по любому из пп. 12-15, в котором упомянутые вспомогательные сигналы представляют по меньшей мере один доминантный компонент.
17. Способ по любому из пп. 12-16, в котором положение или направление источника звука, принятое как часть данных преобразования, поворачивается в качестве реакции на данные ориентации головы.
18. Способ по п. 17, в котором максимальная величина поворота ограничивается значением менее 360 градусов по азимуту или по углу места.
19. Способ по любому из пп. 12-17, в котором вторичная презентация получается из первой презентации путем матрицирования в области преобразования или блока фильтров.
20. Способ по любому из пп. 12-19, в котором данные преобразования дополнительно содержат добавочные коэффициенты матрицирования и этап (d) дополнительно содержит этап, на котором модифицируют первую аудиопрезентацию в качестве реакции на эти добавочные коэффициенты матрицирования, до объединения первой аудиопрезентации и вспомогательного аудиосигнала(ов).
21. Аппаратура, содержащая одно или более устройств, выполненных с возможностью осуществления способа по любому из пп. 1-20.
22. Машиночитаемый носитель, содержащий программу, состоящую из команд, которые при их исполнении одним или более процессорами предписывают одному или более устройствам выполнять способ по любому из пп. 1-20.
| Волнопродуктор | 1982 |
|
SU1070438A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| СТЕКЛУЕМАЯ СМЕСЬ ДЛЯ ВЫСОКОСОРТНОГО СТЕКЛА | 1995 |
|
RU2137725C1 |
| US 8364497 B2, 29.01.2013 | |||
| УСОВЕРШЕНСТВОВАННЫЙ МЕТОД КОДИРОВАНИЯ И ПАРАМЕТРИЧЕСКОГО ПРЕДСТАВЛЕНИЯ КОДИРОВАНИЯ МНОГОКАНАЛЬНОГО ОБЪЕКТА ПОСЛЕ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ | 2007 |
|
RU2430430C2 |

