ОБЛАСТЬ ТЕХНИКИ
Настоящее техническое решение относится к области вычислительной техники, в частности, к способу подбора слов для создания мнемотехнических словарей.
УРОВЕНЬ ТЕХНИКИ
Для запоминания незнакомых слов существует ряд способов и методик.
Например, известно интервальное запоминание, которое основано на том, что если повторять изучаемый материал в определенные промежутки времени, то можно добиться его запоминания.
Идея состоит в том, что интервальные повторения можно использовать для улучшения процесса обучения, и впервые была предложена в книге «Психология обучения» (англ. Psychology of Study), написанной профессором Алеком Мейсом в 1932 году. В 1939-м метод был протестировал на студентах в Айове. Исследование проводилось на более чем 3600 студентах и была доказана его эффективность. Примерно в то же время Пол Пимслер стал первопроходцем в практическом применении теории интервальных повторений для обучения языков.
А в 1973-м Себастьян Лейтнер придумал «Систему Лейтнера», универсальную систему обучения, основанную на карточках. На сегодняшний день, этот метод используется в мобильных приложениях Aword; Lingvaleo; Memrise и др. Он не упрощает задачу по запоминанию незнакомых слов настолько, чтобы уйти от утомительной зубрежки. А также не гарантирует сохранение информации на долгий срок.
Также известно решение - кривая забывания или кривая Эббингауза, которая была получена вследствие экспериментального изучения памяти немецким психологом Германом Эббингаузом в 1885 году.
В ходе опытов было установлено, что после первого безошибочного повторения серии незнакомых символов/сочетания букв, забывание идет вначале очень быстро. Уже в течение первого часа забывается до 60 % всей полученной информации, через 10 часов после заучивания в памяти остается 35 % от изученного. Далее процесс забывания идет медленно, и через 6 дней в памяти остается около 20 % от общего числа первоначально выученных слогов, столько же остается в памяти и через месяц. Выводы, которые можно сделать на основании данной кривой в том, что для эффективного запоминания необходимо повторение заученного материала. Повторение с определенным промежутками времени по Эббингаузу растягивается на два месяца, что является крупным недостатком данной методики.
В использовании мнемотехники (мнемоники) особенно преуспели чемпионы по запоминанию рекордного объема незнакомых слов. Один из них Самвел Гарибян, дважды рекордсмен Книги рекордов Гиннеса. Метод описан в книге, Самвел Гарибян «Английский без английского» издания: 2008 ISBN: 978-5-903455-10-2. В книге использована мнемотехника (мнемоника) но в очень громоздком и не системном варианте. В описываемых мнемотехнических образах нет алгоритма повторения иностранных слов и мнемов. Не понятно, какое слово является переводом, какое запоминаемым словом, а какое слово осуществляет роль фонетической кальки, запоминаемого слова. В связи с чем, сложно использовать этот метод масштабно и предлагать, как четкую, методику для обучения.
Известен способ запоминания слов по системе «Джордано» (см. http://mnemotexnika.narod.ru/avtor.htm). Запоминание слов по системе «Джордано» основано на мыслительных операциях со зрительными образами в воображении. Автором этого способа предложено самостоятельное кодирование элементов информации в зрительные образы. Создание, соединение и удержание образов в воображении - это активный мыслительный процесс, зачастую переходящий в глубокую медитацию. Для того чтобы человек с обычными способностями смог запоминать слова по данной системе, то есть чтобы система «заработала», нужно для начала увлечься системой, затем в процессе длительных тренировок «разогнать свой мозг» для представления красочных ярких образов предметов явлений, подбора к ним удачных ассоциаций, завязку в логическую связь и удержания этой конструкции в своей памяти для определенного количества повторений. Такая работа со своим воображением не каждому под силу и зависит от степени тренированности отдельного человека, так как поддержание внимания на выполнении этих упражнений требует длительного количества времени, определенного напряжения и затрат умственной энергии. Отсутствие у некоторых людей способностей к художественному, творческому воображению также затрудняет или делает вовсе невозможным использование этого способа.
Из уровня техники известно решение, описывающее способ обучения для формирования навыка ускоренного запоминания иностранных слов и слов родного языка (RU 2383932 C2, опубл. 10.03.2010). При формировании базиса каждое подлежащее запоминанию слово изображают на отдельном бумажном носителе в последовательности, включающей перевод этого слова на родной язык - смысл, само слово, слово или сочетание слов родного языка, имеющих сходство в произношении со словом, подлежащим запоминанию, образ, выполненный преимущественно в виде рисунка, ее композиционно и ассоциативно объединяющего перевод на родной язык слова, подлежащего запоминанию, и слово или сочетание слов родного языка, имеющих с ним сходство в произношении. В процессе изучения осуществляют выделение при написании наиболее трудного для запоминания изучаемого материала на рисунке ярким цветом с одновременным многократным произношением вслух подлежащего запоминанию слова. Повторение подлежащего запоминанию слова осуществляют многократно путем чередования его прочтения, восстановления из памяти соответствующего ему рисунка и воспроизведения на его основе произношения и перевода с прочтением его перевода, восстановлением из памяти соответствующего ему рисунка и воспроизведением на его основе самого подлежащего запоминанию слова, его произношения и правописания.
Недостатком известного способа является низкая скорость и прочность запоминания неизвестных слов и, как следствие, низкая эффективность их запоминания.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технической проблемой, на решение которой направлено заявленное техническое решение, является создание компьютерно-реализуемого способа подбора слов для создания мнемотехнических словарей, который охарактеризован в независимом пункте формулы. Дополнительные варианты реализации настоящего изобретения представлены в зависимых пунктах изобретения.
Технический результат заключается в повышении эффективности обучения языку, упрощение процесса запоминания и ускорение процесса изучения новых слов, которые может запомнить конкретный человек в процессе создания мнемотехнического словаря.
В предпочтительном варианте реализации заявлен компьютерно-реализуемый способ, заключающийся в выполнении этапов, на которых с помощью вычислительного устройства:
задается слово на иностранном языке;
бот обращается к словарю иностранных слов и находит это слово с соответствующей ему транскрипцией;
на основе данного соответствия формируется словарная пара, после чего бот автоматически подбирает в составленной заранее таблице звуков соответствующие звуковые сочетания;
по звуковым сочетаниям бот подбирает релевантные по звучанию слова в словарях русского языка;
слова ранжируются по степени релевантности от наиболее релевантных к менее релевантным;
из наиболее релевантного слова формируется мнемотехническая фраза и картинка ассоциация;
из словарных пар и соответствующих им мнемотехнических фраз формируется мнемотехнический словарь;
словарные пары словаря с соответствующие им мнемотехнические фразы объединяют в блоки-истории с сюжетной линией.
В частном варианте мнемотехническая фраза состоит из первого слова перевода, а второгофонетически созвучного слова на знакомом для обучаемого языке - мнема.
В другом частном варианте во время подбора звуковых сочетаний учитывается фонетическое ударение и редукция гласных звуков.
В другом частном варианте дополнительно к блоку-истории добавляют звуковое сопровождение.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
Фиг. 1 представляет собой блок-схему последовательности операций способа согласно изобретению;
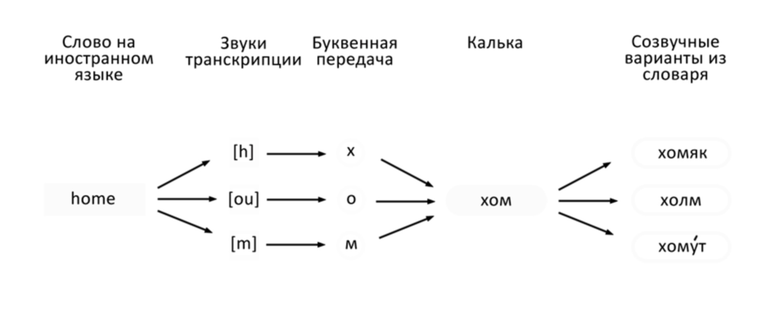
Фиг. 2 иллюстрирует блок-схему выполнения алгоритма на примере конкретного слова;
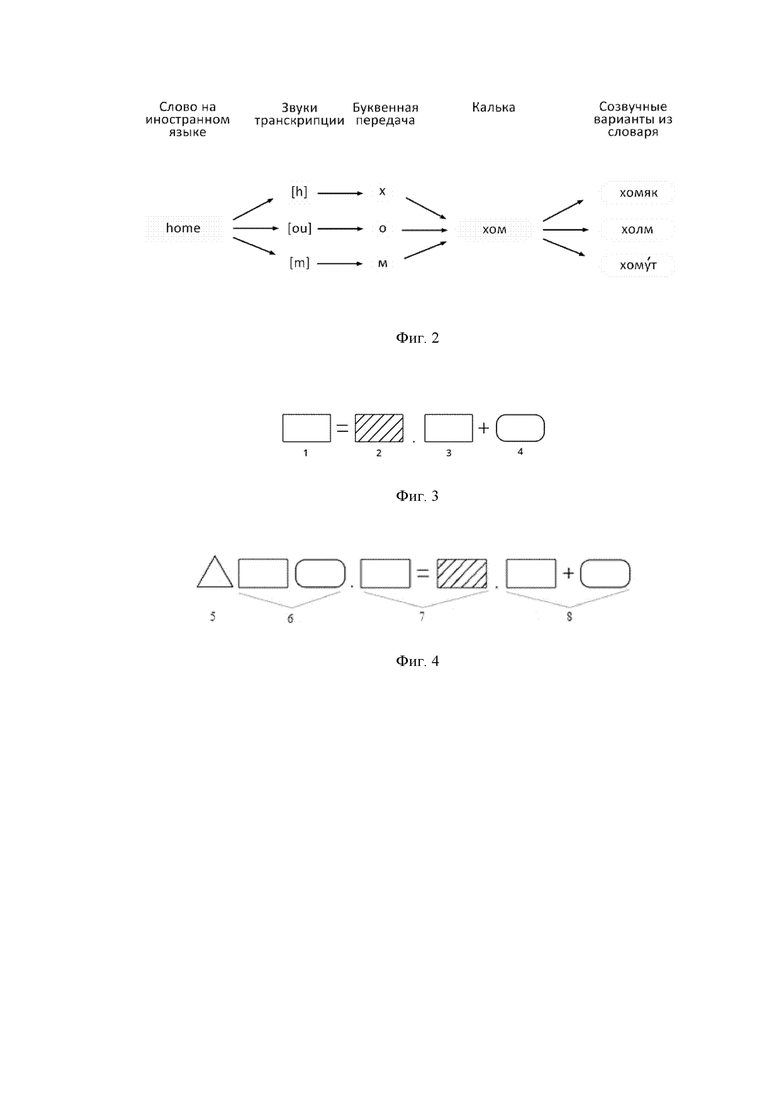
Фиг. 3 иллюстрирует пример пары словарной пары и мнемотехнической фразы;
Фиг. 4 иллюстрирует схему одного из предложений блок-истории;
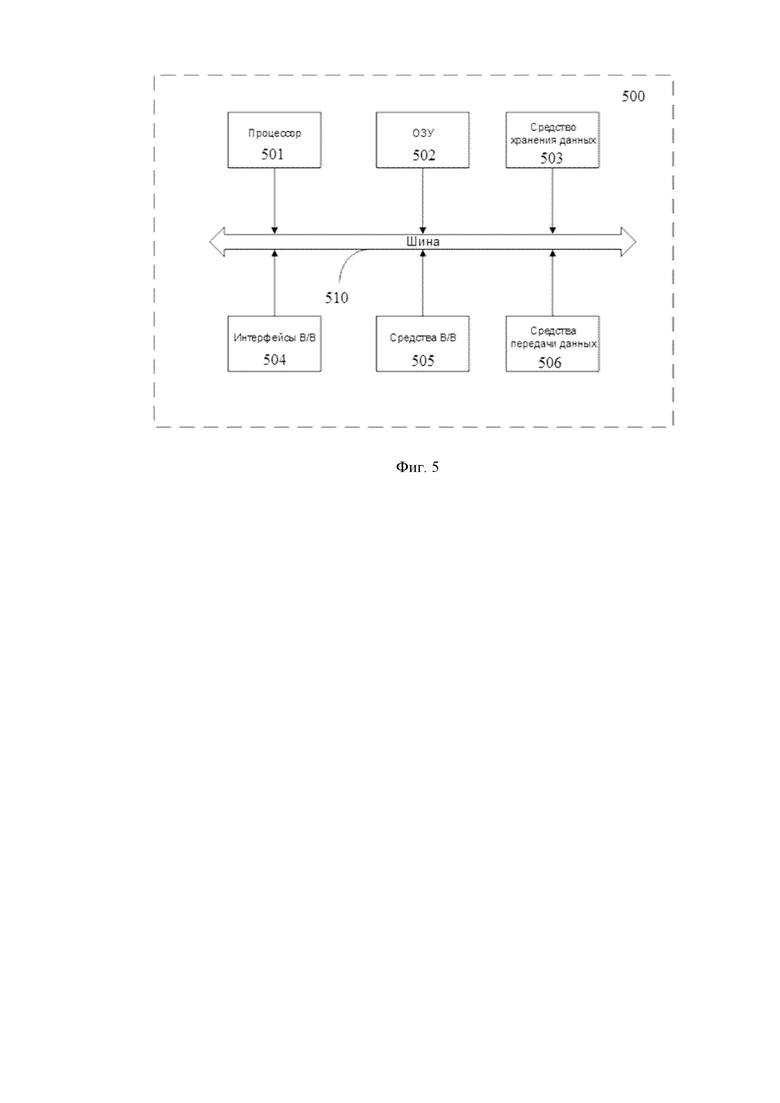
Фиг. 5 иллюстрирует пример общей схемы компьютерного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Настоящее изобретение направлено на обеспечение компьютерно-реализуемого способа подбора слов для создания мнемотехнических словарей.
В заявленном решении осуществлена возможность создания мнемотехнических словарей, используя которые с помощью методологического алгоритма повторения/чередования иностранных слов (незнакомых терминов) и мнемов, объединенных в блоки-истории, решается задача запоминания большого объема незнакомых иностранных слов и терминов в максимально короткие сроки. Также данная методология позволяет сохранять эти слова в памяти максимально долго.
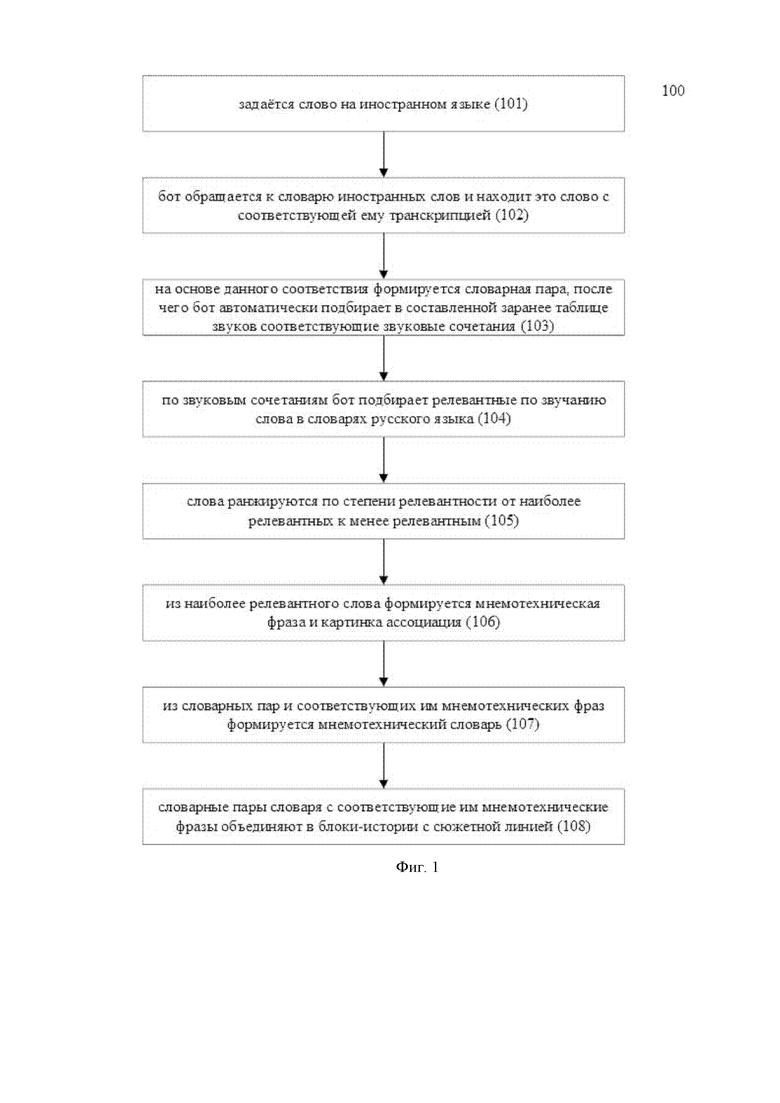
Как представлено на Фиг. 1, заявленный компьютерно-реализуемый способ подбора слов для создания мнемотехнических словарей (100) реализован с помощью вычислительного устройства и следующим образом:
На этапе (101) задается слово на иностранном языке.
Далее на этапе (102) бот обращается к словарю иностранных слов и находит это слово с соответствующей ему транскрипцией.
На этапе (103) на основе данного соответствия формируется словарная пара, после чего бот автоматически подбирает в составленной заранее таблице звуков соответствующие звуковые сочетания.
На этапе (104) по звуковым сочетаниям бот подбирает релевантные по звучанию слова в словарях русского языка.
На этапе (105) слова ранжируются по степени релевантности от наиболее релевантных к менее релевантным, а на этапе (106) из наиболее релевантного слова формируется мнемотехническая фраза и картинка ассоциация.
При этом, на этапе (107) из словарных пар и соответствующих им мнемотехнических фраз формируется мнемотехнический словарь.
После чего, на этапе (108) словарные пары словаря с соответствующие им мнемотехнические фразы объединяют в блоки-истории с сюжетной линией.
В заявленном решении применятся бот, который использует специализированный алгоритм, способный автоматически подбирать схожие по звучанию слова из разных языков.
Кроме того, в заявленном решении применяется рекомендательный алгоритм, осуществляющий релевантную выборку по заданным критериям оптимальности. В результате чего получают список схожих по звучанию слов релевантных запоминаемому иностранному слову. Из этого списка остается только подобрать наиболее логически и эмоционально подходящий вариант для составления мнемотехнической фразы. Слова предлагаются по степени убывания релевантности, выборка осуществляется следующим образом:
1 шаг - задается слово на иностранном, например, на английском языке.
2 шаг - бот обращается к словарю иностранных, в данном примере английских слов, где берется это слово с соответствующей ему транскрипцией.
3 шаг - на основе данного соответствия формируется словарная пара, после чего бот автоматически подбирает в составленной заранее таблице звуков соответствующие звуковые сочетания. В заявленном решении это фонемы английского языка и их буквенная передача посредством русского алфавита (см. таблица 1). При этом, во время подбора звуковых сочетаний учитывается фонетическое ударение и редукция гласных звуков.
вариант
передачи
вариант
передачи
4 шаг - далее бот обращается к словарям русского языка и подбирает наиболее подходящие по звучанию слова согласно заданному критерию оптимальности. Слова ранжируются по степени релевантности от наиболее релевантных к менее релевантным.
5 шаг - из наиболее релевантного слова формируется мнемотехническая фраза и картинка ассоциация. При этом, мнемотехническая фраза состоит из первого слова перевода, а второго фонетически созвучного слова на знакомом для обучаемого языке - мнема.
6 шаг - из словарных пар и соответствующих им мнемотехнических фраз формируется мнемотехнический словарь.
7 шаг - словарные пары словаря с соответствующие им мнемотехнические фразы объединяют в блоки-истории с сюжетной линией. Дополнительно к блоку-истории добавляют звуковое сопровождение.
Методика обучения с помощью алгоритма повторения иностранных слов и мнемов, объединенных в пакеты-истории, решает задачу быстрого запоминания больших объемов незнакомых иностранных слов/терминов.
Так как, согласно методике слова выстроены в определенной последовательности, обучаемый всегда понимает, что есть «словарная пара», а что «мнемотехническая фраза». Причем в мнемотехнической фразе первое слово - всегда перевод, а второе - мнем.
Так, например, Словарная пара: блестящий - brilliant;
Мнемотехническая фраза: блестящий (слово-перевод) бриллиант (мнем).
Под «мнемом» следует понимать слово на знакомом для обучаемого языке, схожее фонетически с запоминаемым словом и связанного с ним логически. Причем логика этой связи должна быть визуализируема, что ведет к привязке к визуальному образу и моментальному запоминанию (якорению в памяти через визуальный образ/картинку).
Эти словарные пары и мнемотехнические фразы объединяются в блоки-истории с сюжетной линией. Таким образом возникает эффект, когда обучаемый вспоминает сюжет и визуальные образы, которые содержат в себе незнакомые слова и их перевод. Так срабатывает механизм якорения в памяти слов через визуальное восприятие, наиболее свойственное для человеческой памяти. Вспоминая слова в будущем, обучаемый всегда может использовать сюжет и образы по принципу «где-то я уже это видел». При запоминании больших объемов эта визуализация всплывает в памяти моментально и при использовании слов на практике уже незаметна и фактически исчезает. Слова при этом остаются в долгосрочной памяти обучаемого.
В заявленном решении методика повторения слов в определенном порядке в словарных парах и мнемотехнических фразах, позволяет проходить этот путь быстро, удобно и максимально эффективно. Это делает возможным сходу якорить в памяти большой объем запоминаемых слов.
На фиг. 3 представлен пример словарной пары и мнемотехнической фразы, где под позициями 1, 3 представлено - слово-перевод, под позицией 2 - запоминаемое слово на иностранном языке, под позицией 4 - мнем - понятное слово/словосочетание, фонетически созвучное запоминаемому слову.
На фиг. 4 представлена схема одного из предложений блок-истории, где под позицией 5 представлена - сюжетная связка, под позицией 6 - мнемотехническая фраза в контексте, под позицией 7 - словарная пара, а под позицией 8 - мнемотехническая фраза.
Разберем подробно сам процесс составления мнема (ассоциативного ключа памяти) для определенных словарных пар в частности, и на его основе мнемотехнических словарей для любых языковых пар в целом:
1. Словарные пары и мнемотехнические фразы.
Словарная пара = слово-перевод + запоминаемое слово, записанное на оригинальном алфавите, проаудированное и записанное на понятной обучаемому транскрипции. К ней составляется мнемотехническая фраза, где всегда на первом месте стоит слово-перевод, а далее фонетически созвучные слова - фонетическая калька на знакомом для обучаемого языке.
Такие слова - фонетические кальки подбираются автоматически ботом с использованием данных нескольких русских словарей (в т.ч. словарь словоформ, рифм и т.д.) для поиска подходящих звуковых сочетаний и, учитывающее фонетическое ударение, и редукцию гласных звуков.
Это могут быть решения на основе:
1.1. Однослогового звучания.
Например: дом-home [хоум]: дом [хом]*яка
*([]- фонетическая калька, состоящая из схожих по звучанию с запоминаемым словом, знакомых слов или их частей (слогов).
1.2. Многослогового звучания в одном слове.
Например: дядя - uncle [анкл]: дядя-[он-кол]ог
1.3. Многослогового звучания в нескольких словах.
Например: склон-slope [слоуп]: склон, где [сло]н [уп]ал.
2. Подбор схожих по звучанию слов
2.1. К запоминаемому слову подбираются схожие по звучанию слова на знакомом языке. Этот подбор автоматизируется с помощью бота на основе алгоритма подбора слов.
Например: дом-home [хоум]:
1. [хом]*як;
2. [хо]л[м];
3. [хом]ут;
4. [хам]елеон;
5. [хам].
2.2. Из полученного перечня выбираем слова для составления мнемотехнических фраз. Слово-перевод должно быть обязательно первым, а затем фонетически созвучное запоминаемому слово на понятном языке. Важно, чтобы полученное сочетание слов имело смысловую последовательность, которая бы еще и легко визуализировалось.
Например: дом-home [хоум]:
1. дом [хом]яка;
2. дом на [хо]л[м]е;
3. дом с [хом]утом;
4. дом с [хам]елеоном
5. дом, где [хам]ят
2.3. При выборе вариантов сочетания слов надо учитывать ряд приоритетов. Предпочтение следует отдавать слогам в начале слова и находящимся под ударением. Мнем (фонетический паттерн), должен вызывать яркие эмоции, например, быть смешным или необычным.
3. Составление словарей.
Из словарных пар и соответствующих им мнемотехнических фраз формируется мнемотехнический словарь.
Согласно представленному выше алгоритму словарь составляется как последовательность словарных пар, включая кириллическую (или любую другую известную обучаемому) транскрипцию, и соответствующим этим парам мнемам (фонетическим паттернам). Например:
дом-home [хоум]: дом [хом]*яка;
дядя - uncle [анкл]: дядя-[он-кол]ог;
склон-slope [слоуп]: склон, где [сло]н [уп]ал.
4. Составление мнемотехнических новелл.
Словарные пары словаря с соответствующие им мнемотехнические фразы объединяют в блоки-истории с сюжетной линией.
Для того, чтобы с помощью мнемотехнических словарей запоминать большой объем слов за максимально короткий временной промежуток, словарные пары и мнемотехнические фразы объединяются в мнемотехнические новеллы. Здесь они связываются коротким сюжетом в определенном порядке и по определенному мнемотехническому принципу. Должна возникнуть визуализируемая связка, которая позволяет переходить от одного запоминаемого слова к другому в соответствии с указанными выше (пп.1 3) алгоритмами.
Например:
Мышь с малыми усами (мышь - mouse: мышь с малыми усами)
Ела печенье кукушки (печенье - cookie: печенье кукушки)
А рядом шел бой в фате невесты (бой - fighting: бой в фате невесты)
И все вокруг эту прелестную ловили (прелестная - lovely: прелестную ловили)
Потому что у нее был блестящий бриллиант (блестящий - brilliant: блестящий бриллиант)
Спокоен был только дядя-онколог (дядя - uncle: дядя-онколог)
Он в стороне ел ломтик сладкой сливы (ломтик - slice: ломтик сладкой сливы).
В основе решения задачи по быстрому запоминанию большого объема незнакомых/иностранных слов лежит методологический алгоритм повторения/чередования этих слов в словарных парах и мнемотехнических фразах. Существующий с древних времен мнемотехнический метод (мнемоника) запоминания не мог быть использован для решения масштабных задач в связи с отсутствием методики его оптимального применения. В заявленном решили несколько задач для оптимального и масштабного применения мнемотехнического метода (мнемоники) запоминания. На основе современных статистических алгоритмов в заявленном решении применили рекомендательную систему, которая позволила находить необходимые решения по заданным критериям оптимальности. В заявленном решении применение способа автоматического поиска фонетических паттернов в речи позволило активно использовать мнемотехнику для образовательных методик и создать англо-русский мнемотехнический словарь более чем на 4000 слов. Главное же достоинство заявленного решения заключается в создании совершенно новой методики чередования иностранных слов, слов-переводов и слов, обладающих фонетическим сходством с иностранными словами и связанных с ними логически. Для запоминания слов быстро и в больших объемах в заявленном решении их объединили в блоки-истории, связанные сюжетной линией. Это позволило достигнуть максимальной визуализации образов для запоминания. Именно с помощью визуальных образов иностранные слова закрепляются в памяти.
На Фиг. 5 далее будет представлена общая схема вычислительного устройства (500), обеспечивающего обработку данных, необходимую для реализации способа подбора слов для создания мнемотехнических словарей.
В общем случае устройство (500) содержит такие компоненты, как: один или более процессоров (501), по меньшей мере одну память (502), средство хранения данных (503), интерфейсы ввода/вывода (504), средство В/В (505), средства сетевого взаимодействия (506).
Процессор (501) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (500) или функциональности одного или более его компонентов. Процессор (501) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (502).
Память (502), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (503) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (503) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых файлов с наборами данных пользователей, базы данных, содержащих записи измеренных для каждого пользователя временных интервалов, идентификаторов пользователей и т.п.
Интерфейсы (504) представляют собой стандартные средства для подключения и работы с компьютерным устройством, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
Выбор интерфейсов (504) зависит от конкретного исполнения устройства (500), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук, быть частью банковского терминала, банкомата и т.п.
В качестве средств В/В данных (505) могут использоваться мышь, джойстик, дисплей (сенсорный дисплей), проектор, тачпад, клавиатура, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия (506) выбираются из устройства, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств (N05) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства (500) сопряжены посредством общей шины передачи данных (510).
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ запоминания иностранных слов | 2018 |
|
RU2688292C1 |
| СПОСОБ ФОРМИРОВАНИЯ НАВЫКА ЗАПОМИНАНИЯ СЛОВ | 2007 |
|
RU2383932C2 |
| СПОСОБ ОБУЧЕНИЯ ДЕТЕЙ НАЧАЛАМ ГРАМОТЫ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2009 |
|
RU2404455C1 |
| СПОСОБ ПОСТРОЕНИЯ СЛОВАРЯ ДЛЯ ПЕРЕВОДА С ИНОСТРАННОГО ЯЗЫКА | 1998 |
|
RU2122240C1 |
| СПОСОБ УСКОРЕННОГО ИЗУЧЕНИЯ ИНОСТРАННОГО ЯЗЫКА (ВАРИАНТЫ) | 2008 |
|
RU2393545C2 |
| СПОСОБ ПОСТРОЕНИЯ СЛОВАРЯ ИНОСТРАННОГО ЯЗЫКА | 1999 |
|
RU2165647C2 |
| КРАУД-СОРСНЫЕ СИСТЕМЫ ОБУЧЕНИЯ ЛЕКСИКЕ | 2014 |
|
RU2607416C2 |
| СПОСОБ ЗАПОМИНАНИЯ СЛОВ | 2010 |
|
RU2436169C2 |
| СПОСОБ ОБУЧЕНИЯ ИНОСТРАННОМУ ЯЗЫКУ | 2010 |
|
RU2422911C1 |
| СПОСОБ ОБУЧЕНИЯ АССОЦИАТИВНО-ЭТИМОЛОГИЧЕСКОМУ АНАЛИЗУ ПИСЬМЕННЫХ ТЕКСТОВ НА ИНОСТРАННЫХ ЯЗЫКАХ | 2018 |
|
RU2702148C2 |
Изобретение относится способу подбора слов для создания мнемотехнических словарей. Технический результат заключается в повышении эффективности обучения языку, упрощении процесса запоминания и ускорении процесса изучения новых слов, которые может запомнить конкретный человек в процессе создания мнемотехнического словаря. Задается слово на иностранном языке. Бот обращается к словарю иностранных слов и находит это слово с соответствующей ему транскрипцией. На основе данного соответствия формируется словарная пара, после чего бот автоматически подбирает в составленной заранее таблице звуков соответствующие звуковые сочетания. По звуковым сочетаниям бот подбирает релевантные по звучанию слова в словарях русского языка. Слова ранжируют по степени релевантности от наиболее релевантных к менее релевантным. Из наиболее релевантного слова формируется мнемотехническая фраза и картинка-ассоциация. Из словарных пар и соответствующих им мнемотехнических фраз формируется мнемотехнический словарь. Словарные пары словаря с соответствующими им мнемотехническими фразами объединяют в блоки-истории с сюжетной линией. 3 з.п. ф-лы, 5 ил.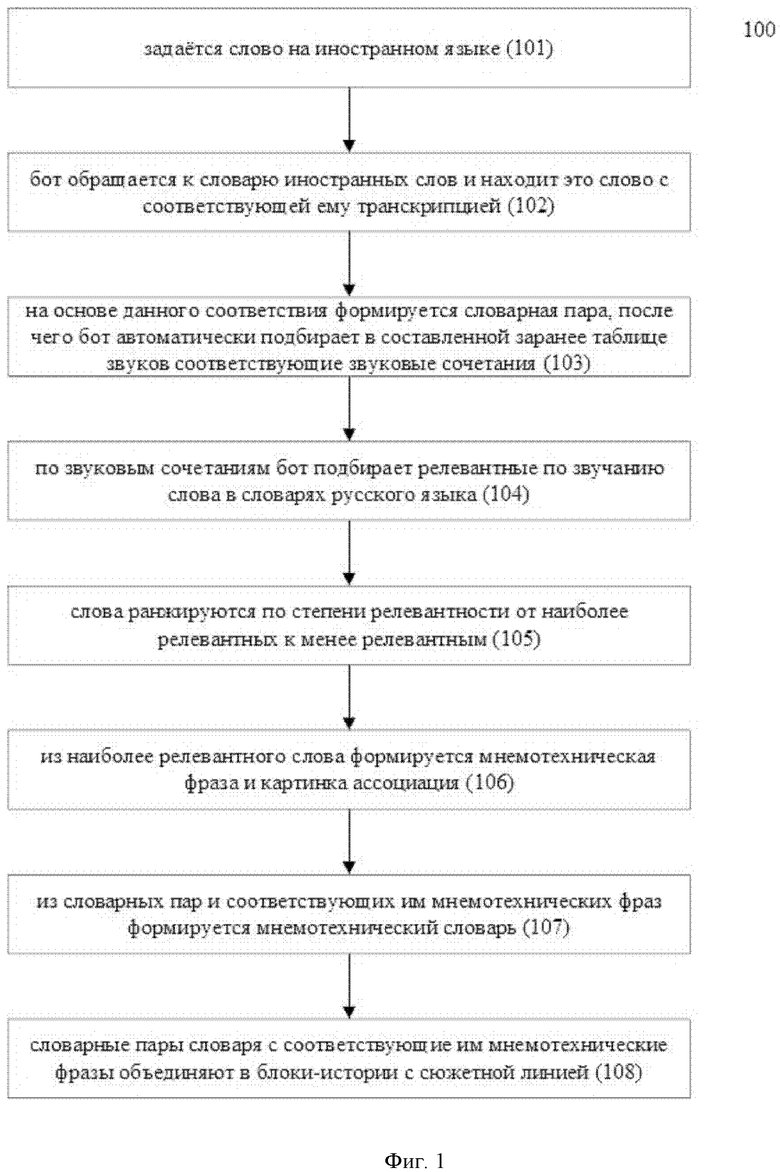
1. Компьютерно-реализуемый способ подбора слов для создания мнемотехнических словарей, заключающийся в выполнении этапов, на которых с помощью вычислительного устройства:
задаётся слово на иностранном языке;
бот обращается к словарю иностранных слов и находит это слово с соответствующей ему транскрипцией;
на основе данного соответствия формируется словарная пара, после чего бот автоматически подбирает в составленной заранее таблице звуков соответствующие звуковые сочетания;
по звуковым сочетаниям бот подбирает релевантные по звучанию слова в словарях русского языка;
слова ранжируются по степени релевантности от наиболее релевантных к менее релевантным;
из наиболее релевантного слова формируется мнемотехническая фраза и картинка ассоциация;
из словарных пар и соответствующих им мнемотехнических фраз формируется мнемотехнический словарь;
словарные пары словаря с соответствующие им мнемотехнические фразы объединяют в блоки-истории с сюжетной линией.
2. Способ по п.1, характеризующийся тем, что мнемотехническая фраза состоит из первого слова перевода, а второго фонетически созвучного слова на знакомом для обучаемого языке - мнема.
3. Способ по п.1, характеризующийся тем, что во время подбора звуковых сочетаний учитывается фонетическое ударение и редукция гласных звуков.
4. Способ по п.1, характеризующийся тем, что дополнительно к блоку-истории добавляют звуковое сопровождение.
| US 5772441, 30.06.1998 | |||
| US 6343935 B1, 05.02.2002 | |||
| US 8386461 B2, 26.02.2013 | |||
| СПОСОБ ФОРМИРОВАНИЯ НАВЫКА ЗАПОМИНАНИЯ СЛОВ | 2007 |
|
RU2383932C2 |

