Изобретение относится к области цифровой обработки сигналов (ЦОС), а именно к реконфигурируемым вычислителям быстрого преобразования Фурье (БПФ) сверхбольшой длины преобразования, и может применяться для цифровой обработки сигналов во всех областях современной техники.
Быстрое преобразование Фурье (БПФ) является алгоритмом быстрого вычисления дискретного преобразования Фурье (ДПФ) и применяется как для программной, так и для аппаратной реализации ввиду гораздо меньшего количества умножителей и сумматоров по сравнению с ДПФ. Преобразование Фурье, как одно из главных преобразований в ЦОС, используется практически во всех областях современной техники. Многие цифровые стандарты связи, телевидения, измерительная аппаратура и т.д. подразумевают использование БПФ.
Хорошо известны две схемы вычисления БПФ: с прореживанием по частоте и с прореживанием по времени. По количеству математических операций (количеству аппаратных умножителей и сумматоров при аппаратной реализации) обе схемы одинаковы. Отличие в различном порядке либо входных (временных) отсчетов, либо выходных (частотных) отсчетов. Существует прямой порядок и порядок с инверсией адресов. БПФ вычисляют конвейерно по стадиям. Основным вычислительным узлом схемы БПФ является операция «бабочка», включающая в себя два комплексного умножения и суммирования. Также устройство БПФ включает в себя блоки памяти и схему коммутации между ячейками блоков памяти различных стадий. Существует большое количество схем коммутации с оптимизацией по объему памяти, аппаратным затратам, быстродействию. Слабым местом в схеме коммутации является доступ к памяти ввиду того, что операция «бабочка» подразумевает считывание значений из разных адресов памяти, и после вычисления результата запись его в разные адреса. Адреса зависят от выбранной схемы коммутации и стадии вычисления БПФ. В классической схеме коммутации считывание значений и запись результатов осуществляют по-разному от стадии к стадии, что накладывает большие аппаратные затраты на вычисление адресов. К тому же из однопортовой памяти, как правило, нельзя считать одновременно из двух адресов в один такт работы, что делает невозможным применять один блок памяти для одной операции «бабочка».
Наиболее близкой к заявленному изобретению является унифицированная реконфигурируемая схема коммутации быстрого преобразования Фурье, описанная в патенте RU2700194, которая содержит унифицированную схему коммутации узлов «бабочка» в разных стадиях конвейера. Данная схема выбрана в качестве прототипа заявленного изобретения.
Недостатком схемы прототипа является его дороговизна и низкое быстродействие, вследствие отсутствия возможности бесконфликтного доступа к памяти для последовательного вычисления БПФ с целью оптимизации использования аппаратных ресурсов, в том числе памяти.
Техническим результатом изобретения является создание реконфигурируемого вычислителя быстрого преобразования Фурье (БПФ) сверхбольшой длины преобразования с бесконфликтным линейным доступом к памяти с меньшей стоимостью изготовления и увеличенным быстродействием, вследствие оптимизации использования аппаратных ресурсов, в том числе памяти, за счет применения унифицированной (единой) схемы коммутации значения из памяти для базовых узлов вычислений операции «бабочка» для всех стадий конвейера.
Поставленный технический результат достигнут путем создания реконфигурируемого вычислителя быстрого преобразования Фурье сверхбольшой длины преобразования для 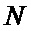
В предпочтительном варианте осуществления вычислителя вычислительный узел «бабочка» является типовым и состоит из двух сумматоров и комплексного умножителя, при этом первый вход А узла «бабочка» соединен с первыми входами двух сумматоров, выход первого сумматора является первым выходом Y узла «бабочка», а второй В вход узла «бабочка» соединен с вторым входом первого сумматора, а также с входом умножителя на -1, выход которого соединен с вторым входом второго сумматора, выход которого соединен в входом комплексного умножителя, выход которого является вторым выходом Z узла «бабочка».
Для лучшего понимания заявленного изобретения далее приводится его подробное описание с соответствующими графическими материалами.
Фиг. 1. Схема вычисления БПФ с прореживанием по частоте, известная из уровня техники.
Фиг. 2. Схема базовой операции «бабочка», известная из уровня техники: А-структурная схема; Б-функциональная.
Фиг. 3. Унифицированная схема коммутации БПФ с прореживанием по частоте (при N=8), выполненная согласно изобретению.
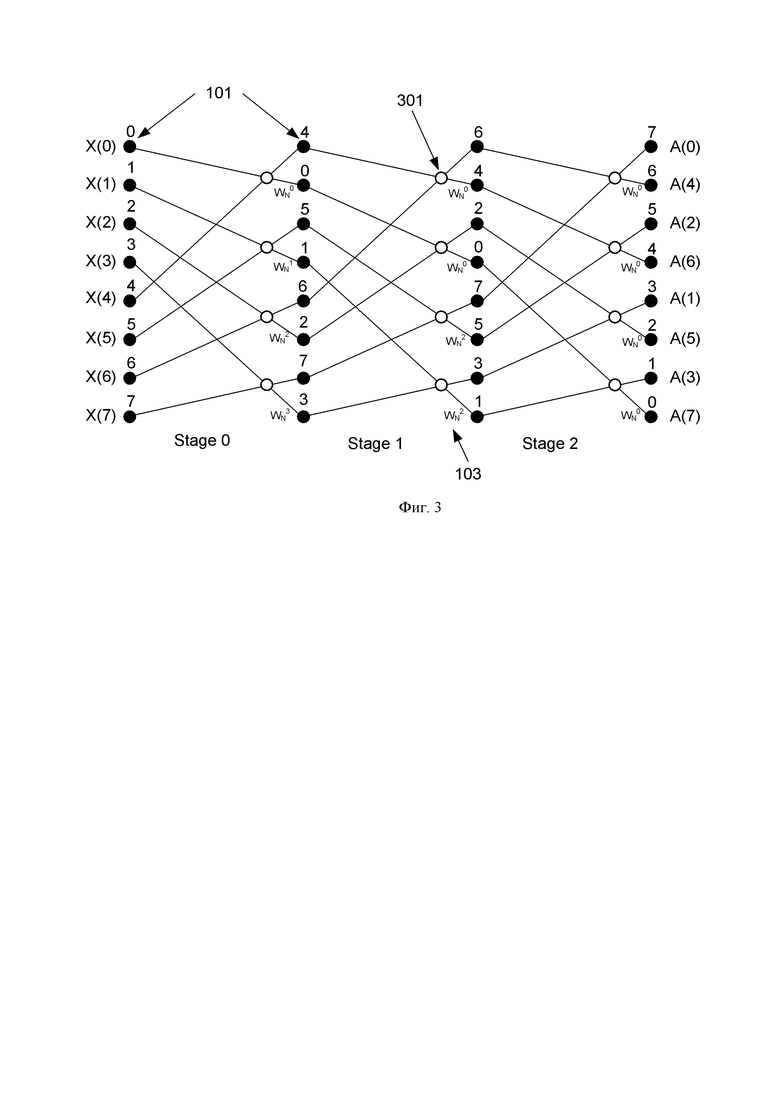
Фиг. 4. Схема вычисления БПФ с прореживанием по частоте (при N=16), известная из уровня техники.
Фиг. 5. Унифицированная схема коммутации БПФ с прореживанием по частоте (при N=16), выполненная согласно изобретению.
Фиг. 6. Схема организация памяти для бесконфликтного доступа при вычислении БПФ с прореживанием по частоте (при N=16), выполненная согласно изобретению.
Фиг. 7. Схема реконфигурируемого вычислителя БПФ сверхбольшой длины преобразования, выполненная согласно изобретению.
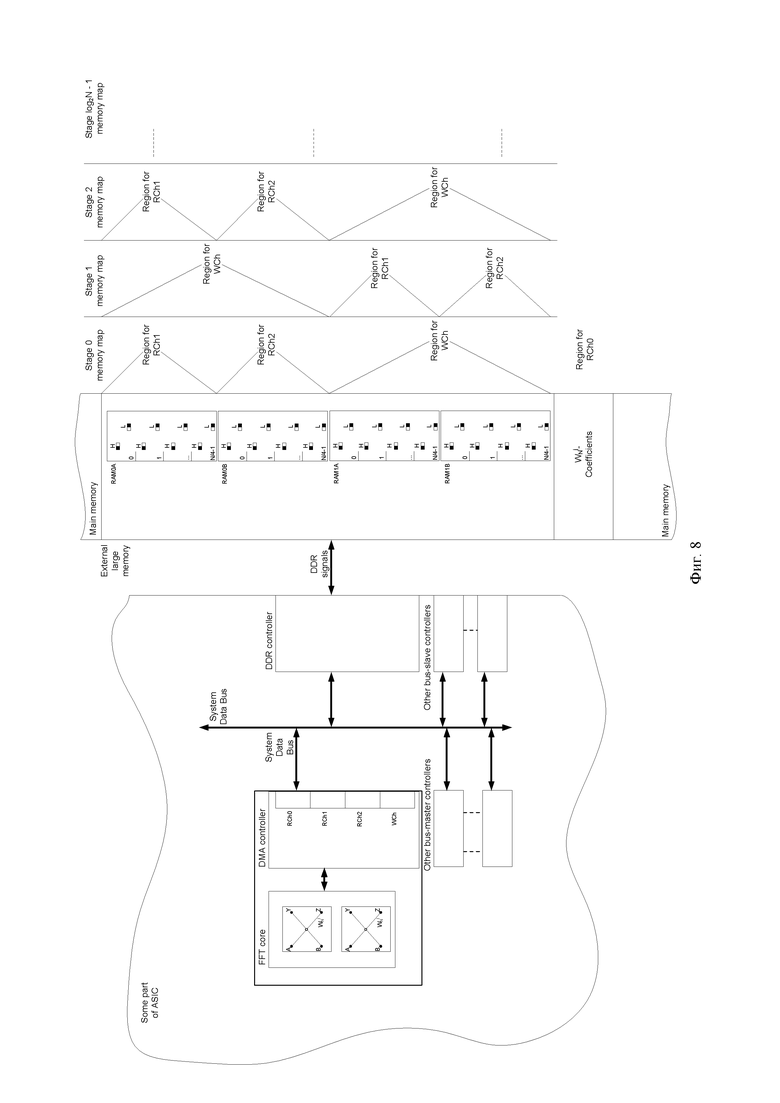
Фиг. 8. Схема системы с использованием внешней DDR памяти, выполненная согласно изобретению.
Рассмотрим более подробно функционирование заявленного реконфигурируемого вычислителя быстрого преобразования Фурье (БПФ) сверхбольшой длины преобразования (Фиг. 1 - 8).
БПФ основано на дискретном преобразовании Фурье, согласно которому:

где 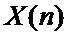
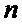
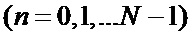
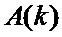

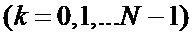
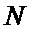

Традиционная известная из уровня техники схема вычисления БПФ с прореживанием по частоте показана на Фиг. 1. Входные отсчеты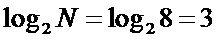
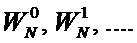

где 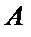
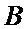
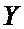

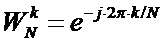
Схема коммутации, представленная на Фиг. 1, на каждой стадии различна, поэтому для каждой стадии необходим свой неунифицированный дешифратор адреса. Для лучшего понимания черные кружки обозначены цифрами, это вклад каждого первоначального отсчета
Унифицированная схема коммутации БПФ, применяемая в заявленном устройстве, представлена на Фиг. 3. Узел операции «бабочка» (301) схематично стал несимметричен, при этом работа узла по-прежнему эквивалентна схеме на Фиг. 2-Б и выражению (2). Видно, что схема коммутации на каждой стадии (Stage0, Stage1, Stage2) остается одинаковой. Вклад (номер над черными кружками) первоначального отсчета
Аналогичным образом можно построить схему для любого количества отсчетов N. На Фиг. 4 представлена традиционная схема вычисления БПФ с прореживанием по частоте (N=16), а на Фиг. 5 ее аналог - унифицированная схема коммутации БПФ с прореживанием по частоте (N=16). Исходя из заявленной унифицированной схемы коммутации (N=8,16) и выражения (2) для общего случая (любого N) справедливо итеративное выражение:
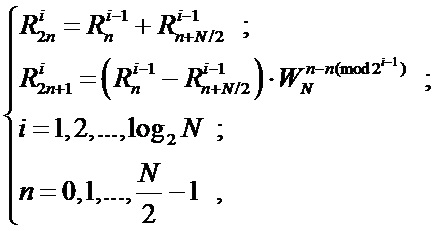
где 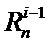
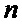
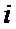
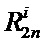
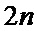
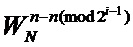
Зачастую требуется меньшее количество отсчетов для преобразования БПФ, а именно 
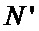
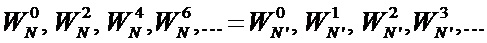
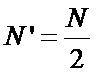
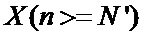
С целью уменьшения аппаратных затрат используют вариант выполнения заявленного изобретения с последовательным вычислением БПФ, требующий один узел «бабочка» и два массива памяти объема
На Фиг. 6 представлена организация памяти для бесконфликтного доступа с линейной адресацией. Два массива памяти разбиты пополам, таким образом, что за один такт вычитывают два значения из двух разных памятей для одной операции «бабочка», а результат записывают в третью (или четвертую) память по одному адресу, в старшую (прямоугольник с закрашенной левой частью) и младшую часть слова (прямоугольник с закрашенной правой частью). При использовании одного узла «бабочка» такая организация памяти позволяет осуществлять доступ к памяти без конфликта по чтению и записи в один такт, при этом адресация линейная, то есть с инкрементацией адреса плюс один. Линейная адресация существенно упрощает узел генерации адресов, что в свою очередь увеличивает быстродействие данного устройства при аппаратной реализации.
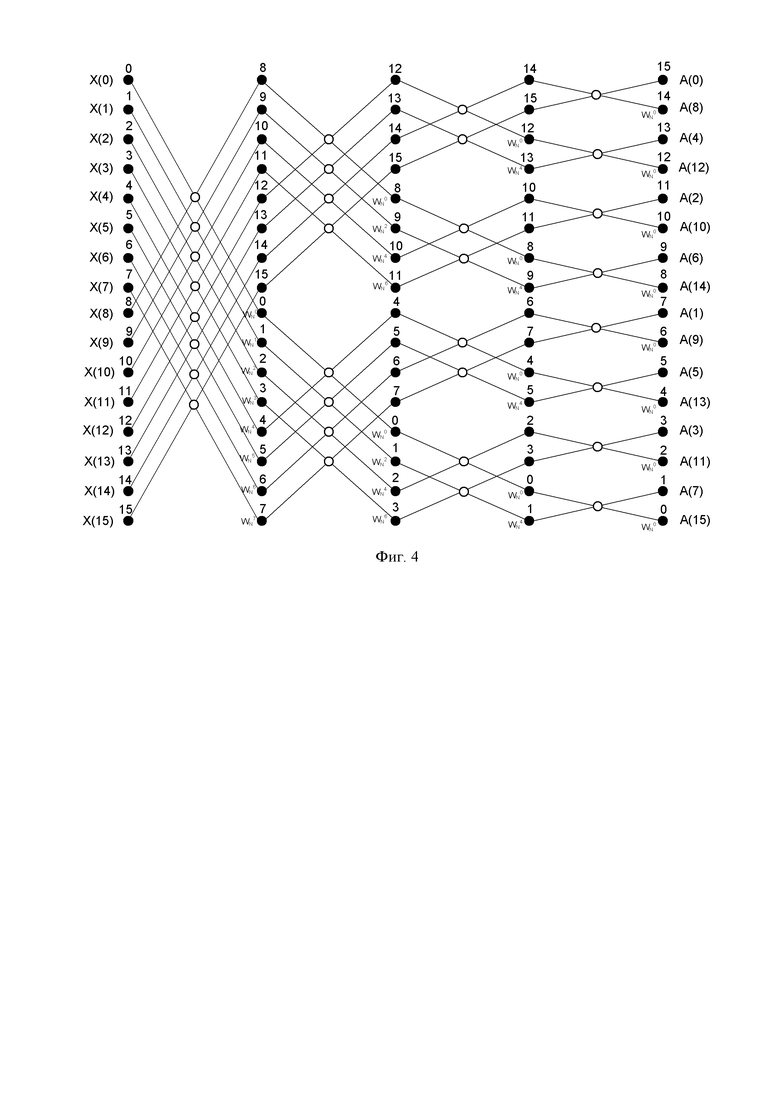
На Фиг. 7 представлена схема заявленного реконфигурируемого вычислителя БПФ сверхбольшой длины преобразования. Реконфигурируемый вычислитель быстрого преобразования Фурье сверхбольшой длины преобразования для входных отсчетов, содержит два вычислительных узла «бабочка» (700, 701), четыре буфера FIFO (702, 705, 709, 710) и контроллер прямого доступа к памяти DMA (703), который соединен с сиcтемной шиной (704) и шиной управления Control Bus. Выход Rdata0 данных нулевого канала контроллера DMA (703) соединен с входом данных коэффициентов буфера коэффициентов RfifoCoef (702), старшая часть Coef1 выходной шины которого соединена с входом умножителя первого узла «бабочка» BFly1 (701), а младшая часть Coef0 выходной шины соединена с входом умножителя нулевого узла «бабочка» BFly0 (700). Вход WE разрешения записи буфера коэффициентов RfifoCoef (702) соединен с выходом WE0 нулевого канала контроллера DMA (703). Вход Full0 нулевого канала контроллера DMA (703) соединен с выходом заполненности FullCoef буфера коэффициентов RfifoCoef (702). Вход разрешения чтения RE буфера коэффициентов RfifoCoef (702) соединен и выполнен с возможностью приема сигнала разрешения En с инверсного выхода элемента НЕ-ИЛИ (711). Нулевой вход элемента НЕ-ИЛИ (711) соединен с выходом опустошения EmptyCoef буфера коэффициентов RfifoCoef (702). Третий вход элемента НЕ-ИЛИ (711) соединен с выходом заполненности FullW буфера записи данных Wfifo (705). Первый и второй входы элемента НЕ-ИЛИ (711) соединены c выходами опустошения EmptyDown и EmptyUp буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA. Инверсный выход логического элемента НЕ-ИЛИ (711) соединен с входом логического элемента И (706) и с входом WE разрешения записи буфера записи данных Wfifo (705), а также с входами RE разрешения чтения буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA. Входы WE разрешения записи буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA соединены с выходами WE1 и WE2 разрешения записи каналов чтения контроллера DMA (703). Входы Full1 и Full2 заполненности буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA соединены с выходами FullDown и FullUp заполненности буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA. Входные шины данных чтения Rdata_Down и Rdata_Up буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA соединены с выходами данных чтения Rdata1 и Rdata2 каналов чтения контроллера DMA (703). Старшие половины разрядов RdataH выходных шин данных Rdata_Up и Rdata_Down буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA соединены с входами A и B нулевого узла «бабочка» BFly0 (700). Младшие половины разрядов RdataL выходных шин Rdata_Up и Rdata_Down буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA соединены с входами A и B первого узла «бабочка» BFly1 (701). Выходы Y и Z нулевого узла «бабочка» BFly0 (700) объединены в общую шину и соединены с нулевым входом мультиплексора (708), первый вход которого соединен с объединенной шиной выходов Y и Z первого узла «бабочка» BFly1 (701). Выходная шина данных мультиплексора (708) соединена с входом данных буфера записи данных Wfifo (705). Выходная шина данных буфера записи данных Wfifo (705) соединена с входом Wdata канала записи контроллера DMA (703). Вход Empty контроллера DMA (703) соединен с выходом EmptyW буфера разрешения записи Wfifo (705), а выход RE разрешения записи с входом RE буфера разрешения записи Wfifo (705). Выход элемента И-НЕ (706) соединен с входом элемента задержки D (707), выход которого соединен с инверсным входом элемента И-НЕ (706) и с входом селектора мультиплексора (708).
Вычислительные узлы «бабочка» (700, 701) являются типовыми и состоят из двух сумматоров и комплексного умножителя. Первый вход А узла «бабочка» соединен с первыми входами двух сумматоров, выход первого сумматора является первым выходом Y узла «бабочка». Второй В вход узла «бабочка» соединен с вторым входом первого сумматора, а также с входом умножителя на -1, выход которого соединен с вторым входом второго сумматора, выход которого соединен в входом комплексного умножителя, выход которого является вторым выходом Z узла «бабочка».
Так как считывание отсчетов для одной операции «бабочка» происходит с двух ячеек, хранящих четыре значения, то можно использовать еще одну операцию «бабочка», для того, чтобы не считывать значения с одной ячейки дважды. При этом запись результатов операции «бабочка» выполняют последовательно, сначала по всему одному диапазону памяти, затем по всему другому. Такая организация памяти, позволяет выполнять БПФ сколь угодно большой длины преобразования, если использовать внешнюю память, например, DDR, а доступ к ней осуществлять при помощи контроллера DMA (703).
Поворотные множители вычисляются в процессе преобразования или хранят во внешней памяти предварительно подсчитанными. После настройки всех каналов DMA и записи входных отсчетов в нужный диапазон внешней памяти начинают преобразование. С помощью контроллера DMA (703) по двум каналам чтения данных считывают по системной шине значения из внешней памяти в буфер коэффициентов RfifoCoef (702), параллельно считывают необходимый поворотный множитель. При наличии данных в буфере коэффициентов RfifoCoef (702), выполняют две операции «бабочка» параллельно, результат которых записывают в буфер разрешения записи Wfifo (705), содержащий данные на запись в память, и далее по каналу записи с помощью контроллера DMA (703) записывают по системной шине данные в следующий диапазон памяти. Описанную выше итерацию повторяют для всех отсчетов и всех стадий преобразования, по мере выполнения всех заданий с помощью контроллера DMA (703) формируют прерывание об окончании преобразования, при этом задают следующее преобразование. Буферы FIFO (702, 705, 709, 710) необходимы для согласования и оптимального использования пропускной способности системной шины с возможностью пачкового доступа к данным. Реконфигурируемость вычислителя под различную длину преобразования обеспечиваются изменением настроечных регистров DMA: N-длина преобразования (диапазонов памятей), BASE_DATA – начальный базовый адрес данных, BASE_W – базовый адрес поворотных подсчитанных множителей, Stages – количество стадий преобразования.
Пример построения системы с использованием внешней DDR памяти и с применением заявленного реконфигурируемого вычислителя быстрого преобразования Фурье (БПФ) сверхбольшой длины преобразования представлен на Фиг. 8.
Вариант выполнения заявленной унифицированной схемы коммутации БПФ с прореживанием по частоте (для N=16), представленный на Фиг. 5, может применяться для различных целей:
• с целью уменьшения аппаратных затрат - последовательная схема, итерационная, требующая один узел «бабочка» и два массива памяти объема
• с целью максимизации производительности - полностью параллельная схема, конвейерная, требующая 
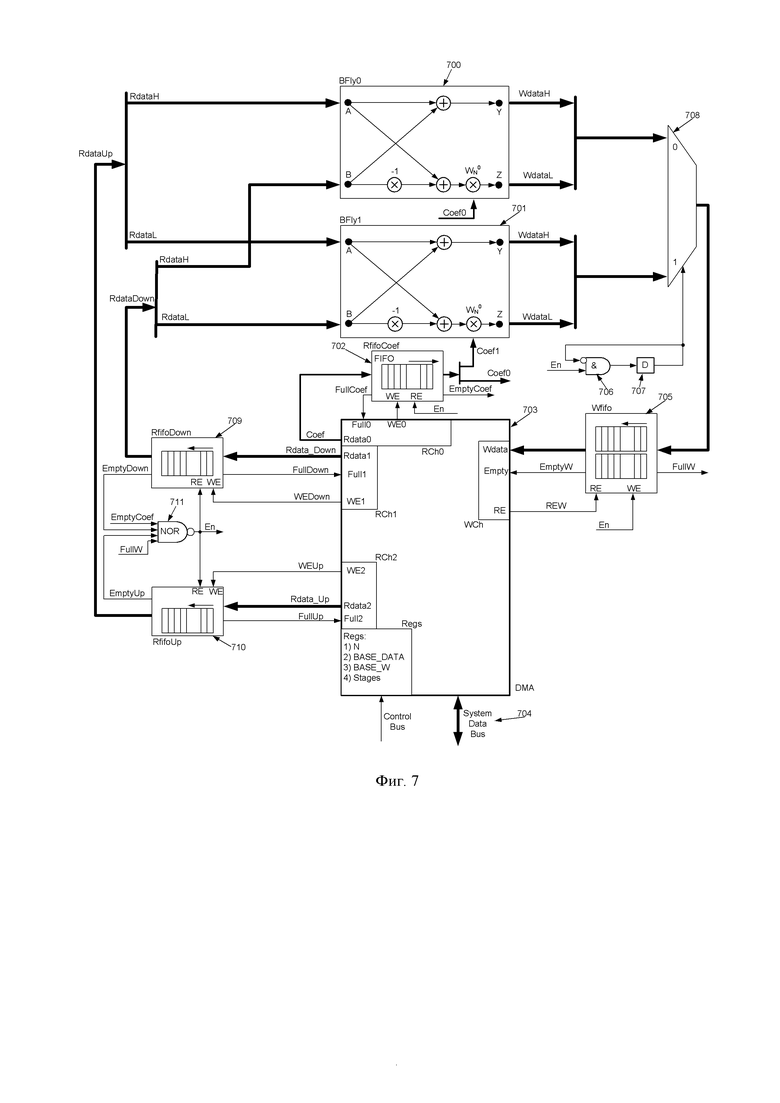
• для целевых задач – последовательно параллельная схема, итерационная, требующая несколько узлов «бабочка» не более 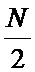
Заявленное изобретение представляет собой вычислитель БПФ с прореживанием по частоте и оптимизацией аппаратных затрат на схему коммутации. Вычислитель обеспечивает последовательное вычисление БПФ, с бесконфликтным доступом к памяти с линейной адресацией.
Заявленный вычислитель БПФ выполнен на основе унифицированной (единой) схемы коммутации значения из памяти для базовых узлов вычислений операции «бабочка» для всех стадий конвейера. Ввиду того, что схема коммутации едина, она позволяет построить вычислитель, оптимизированный по используемым ресурсам, в том числе по ресурсам памяти, быстродействию и т.д. Например, в случае жестких требований по аппаратным затратам, заявленный вычислитель позволяет использовать контроллер прямого доступа к памяти (DMA).
При этом, благодаря использованию единой схемы коммутации и бесконфликтного линейного доступа к памяти в заявленном вычислителе может быть использован контроллер DMA общего назначения, а именно с каналами чтения и записи с системной шины. Ввиду наличия доступа контроллера DMA к системной шине, возможно использование контроллера внешней памяти, например, DDR сколь угодно большого размера, требуемого для хранения входных, выходных, промежуточных значений и поворачивающих множителей.
Преимуществом заявленного изобретения является возможность выполнять преобразования практически неограниченной длины, с аппаратными затратами лишь на два узла «бабочка» и на согласующие буферы FIFO. Благодаря применяемой в заявленном изобретении схеме вычисления БПФ, доступ к памяти является линейным, что крайне важно для достижения максимальной производительности DDR памяти. Ввиду наличия пакетного режима обмена данными на системной шине и возможности линейного доступа к памяти быстродействие заявленного вычислителя соразмерно скорости поступления необработанных данных, что крайне важно для решения задач потоковой обработки.
Хотя описанный выше вариант выполнения изобретения был изложен с целью иллюстрации заявленного изобретения, специалистам ясно, что возможны разные модификации, добавления и замены, не выходящие из объема и смысла заявленного изобретения, раскрытого в прилагаемой формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВЫСОКОСКОРОСТНОЕ УСТРОЙСТВО БЫСТРОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ С БЕСКОНФЛИКТНЫМ ЛИНЕЙНЫМ ДОСТУПОМ К ПАМЯТИ | 2020 |
|
RU2717950C1 |
| УНИФИЦИРОВАННАЯ РЕКОНФИГУРИРУЕМАЯ СХЕМА КОММУТАЦИИ БЫСТРОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ И СПОСОБ ЕЁ ФОРМИРОВАНИЯ | 2018 |
|
RU2700194C1 |
| ЯДРО СОПРОЦЕССОРА БЫСТРОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ РЕАЛЬНОГО ВРЕМЕНИ | 2013 |
|
RU2539868C1 |
| Способ организации работы компонентов сетевого оборудования для обработки сетевых пакетов (4 варианта) | 2018 |
|
RU2710302C1 |
| АРИФМЕТИЧЕСКОЕ УСТРОЙСТВО ДЛЯ ВЫПОЛНЕНИЯ ДИСКРЕТНОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ | 1991 |
|
RU2015550C1 |
| Коррелятор вибросейсмических данных | 1989 |
|
SU1665326A1 |
| Устройство для ортогонального преобразования цифровых сигналов по Фурье-Чебышеву | 1983 |
|
SU1136181A1 |
| БОРТОВОЙ СПЕЦВЫЧИСЛИТЕЛЬ | 2013 |
|
RU2522852C1 |
| ПРОЦЕССОР С МАКСИМАЛЬНО ВОЗМОЖНОЙ ПРОИЗВОДИТЕЛЬНОСТЬЮ ДЛЯ БЫСТРОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ | 2005 |
|
RU2290687C1 |
| АРИФМЕТИЧЕСКОЕ УСТРОЙСТВО ДЛЯ ВЫЧИСЛЕНИЯ БЫСТРОГО ПРЕОБРАЗОВАНИЯ ХАРТЛИ-ФУРЬЕ | 1999 |
|
RU2190874C2 |




Изобретение относится к области цифровой обработки сигналов. Техническим результатом изобретения является создание реконфигурируемого вычислителя быстрого преобразования Фурье (БПФ) сверхбольшой длины преобразования с бесконфликтным линейным доступом к памяти с увеличенным быстродействием, вследствие оптимизации использования аппаратных ресурсов, в том числе памяти, за счет применения унифицированной (единой) схемы коммутации значения из памяти для базовых узлов вычислений операции «бабочка» для всех стадий конвейера. Реконфигурируемый вычислитель быстрого преобразования Фурье сверхбольшой длины преобразования для входных отсчетов содержит два вычислительных узла «бабочка», четыре буфера FIFO и контроллер прямого доступа к памяти DMA, который соединен с сиcтемной шиной и шиной управления Control Bus. При этом выход Rdata0 данных нулевого канала контроллера DMA соединен с входом данных коэффициентов буфера коэффициентов RfifoCoef, старшая часть Coef1 выходной шины которого соединена с входом умножителя первого узла «бабочка» BFly1, а младшая часть Coef0 выходной шины соединена с входом умножителя нулевого узла «бабочка» BFly0. 1 з.п. ф-лы, 8 ил.
1. Реконфигурируемый вычислитель быстрого преобразования Фурье сверхбольшой длины преобразования для  входных отсчетов, содержащий два вычислительных узла «бабочка» (700, 701), четыре буфера FIFO (702, 705, 709, 710) и контроллер прямого доступа к памяти DMA (703), который соединен с системной шиной (704) и шиной управления Control Bus, при этом выход Rdata0 данных нулевого канала контроллера DMA (703) соединен с входом данных коэффициентов буфера коэффициентов RfifoCoef (702), старшая часть Coef1 выходной шины которого соединена с входом умножителя первого узла «бабочка» BFly1 (701), а младшая часть Coef0 выходной шины соединена с входом умножителя нулевого узла «бабочка» BFly0 (700), вход WE разрешения записи буфера коэффициентов RfifoCoef (702) соединен с выходом WE0 нулевого канала контроллера DMA (703), вход Full0 которого соединен с выходом заполненности FullCoef буфера коэффициентов RfifoCoef (702), вход разрешения чтения RE которого соединен и выполнен с возможностью приема сигнала разрешения En с инверсного выхода элемента НЕ-ИЛИ (711), нулевой вход которого соединен с выходом опустошения EmptyCoef буфера коэффициентов RfifoCoef (702), третий вход соединен с выходом заполненности FullW буфера записи данных Wfifo (705), а первый и второй входы соединены c выходами опустошения EmptyDown и EmptyUp буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA, при этом инверсный выход логического элемента НЕ-ИЛИ (711) соединен с входом логического элемента И (706) и с входом WE разрешения записи буфера записи данных Wfifo (705), а также с входами RE разрешения чтения буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA, входы WE разрешения записи которых соединены с выходами WE1 и WE2 разрешения записи каналов чтения контроллера DMA (703), а входы Full1 и Full2 заполненности которых соединены с выходами FullDown и FullUp заполненности буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA, входные шины данных чтения Rdata_Down и Rdata_Up которых соединены с выходами данных чтения Rdata1 и Rdata2 каналов чтения контроллера DMA (703), при этом старшие половины разрядов RdataH выходных шин данных Rdata_Up и Rdata_Down буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA соединены с входами A и B нулевого узла «бабочка» BFly0 (700), а младшие половины разрядов RdataL выходных шин Rdata_Up и Rdata_Down буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA соединены с входами A и B первого узла «бабочка» BFly1 (701), при этом выходы Y и Z нулевого узла «бабочка» BFly0 (700) объединены в общую шину и соединены с нулевым входом мультиплексора (708), первый вход которого соединен с объединенной шиной выходов Y и Z первого узла «бабочка» BFly1 (701), при этом выходная шина данных мультиплексора (708) соединена с входом данных буфера записи данных Wfifo (705), выходная шина данных которого соединена с входом Wdata канала записи контроллера DMA (703), вход Empty которого соединен с выходом EmptyW буфера разрешения записи Wfifo (705), а выход RE разрешения записи с входом RE буфера разрешения записи Wfifo (705), при этом выход элемента И-НЕ (706) соединен с входом элемента задержки D (707), выход которого соединен с инверсным входом элемента И-НЕ (706) и с входом селектора мультиплексора (708).
входных отсчетов, содержащий два вычислительных узла «бабочка» (700, 701), четыре буфера FIFO (702, 705, 709, 710) и контроллер прямого доступа к памяти DMA (703), который соединен с системной шиной (704) и шиной управления Control Bus, при этом выход Rdata0 данных нулевого канала контроллера DMA (703) соединен с входом данных коэффициентов буфера коэффициентов RfifoCoef (702), старшая часть Coef1 выходной шины которого соединена с входом умножителя первого узла «бабочка» BFly1 (701), а младшая часть Coef0 выходной шины соединена с входом умножителя нулевого узла «бабочка» BFly0 (700), вход WE разрешения записи буфера коэффициентов RfifoCoef (702) соединен с выходом WE0 нулевого канала контроллера DMA (703), вход Full0 которого соединен с выходом заполненности FullCoef буфера коэффициентов RfifoCoef (702), вход разрешения чтения RE которого соединен и выполнен с возможностью приема сигнала разрешения En с инверсного выхода элемента НЕ-ИЛИ (711), нулевой вход которого соединен с выходом опустошения EmptyCoef буфера коэффициентов RfifoCoef (702), третий вход соединен с выходом заполненности FullW буфера записи данных Wfifo (705), а первый и второй входы соединены c выходами опустошения EmptyDown и EmptyUp буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA, при этом инверсный выход логического элемента НЕ-ИЛИ (711) соединен с входом логического элемента И (706) и с входом WE разрешения записи буфера записи данных Wfifo (705), а также с входами RE разрешения чтения буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA, входы WE разрешения записи которых соединены с выходами WE1 и WE2 разрешения записи каналов чтения контроллера DMA (703), а входы Full1 и Full2 заполненности которых соединены с выходами FullDown и FullUp заполненности буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA, входные шины данных чтения Rdata_Down и Rdata_Up которых соединены с выходами данных чтения Rdata1 и Rdata2 каналов чтения контроллера DMA (703), при этом старшие половины разрядов RdataH выходных шин данных Rdata_Up и Rdata_Down буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA соединены с входами A и B нулевого узла «бабочка» BFly0 (700), а младшие половины разрядов RdataL выходных шин Rdata_Up и Rdata_Down буфера RfifoDown (709) чтения данных первого канала DMA и буфера RfifoUp (710) чтения данных второго канала DMA соединены с входами A и B первого узла «бабочка» BFly1 (701), при этом выходы Y и Z нулевого узла «бабочка» BFly0 (700) объединены в общую шину и соединены с нулевым входом мультиплексора (708), первый вход которого соединен с объединенной шиной выходов Y и Z первого узла «бабочка» BFly1 (701), при этом выходная шина данных мультиплексора (708) соединена с входом данных буфера записи данных Wfifo (705), выходная шина данных которого соединена с входом Wdata канала записи контроллера DMA (703), вход Empty которого соединен с выходом EmptyW буфера разрешения записи Wfifo (705), а выход RE разрешения записи с входом RE буфера разрешения записи Wfifo (705), при этом выход элемента И-НЕ (706) соединен с входом элемента задержки D (707), выход которого соединен с инверсным входом элемента И-НЕ (706) и с входом селектора мультиплексора (708).
2. Вычислитель по п. 1, отличающийся тем, что вычислительный узел «бабочка» является типовым и состоит из двух сумматоров и комплексного умножителя, при этом первый вход А узла «бабочка» соединен с первыми входами двух сумматоров, выход первого сумматора является первым выходом Y узла «бабочка», а второй В вход узла «бабочка» соединен с вторым входом первого сумматора, а также с входом умножителя на -1, выход которого соединен с вторым входом второго сумматора, выход которого соединен с входом комплексного умножителя, выход которого является вторым выходом Z узла «бабочка».
| УНИФИЦИРОВАННАЯ РЕКОНФИГУРИРУЕМАЯ СХЕМА КОММУТАЦИИ БЫСТРОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ И СПОСОБ ЕЁ ФОРМИРОВАНИЯ | 2018 |
|
RU2700194C1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| US 9525579 B2, 20.12.2016 | |||
| US 7437395 B2, 14.10.2008 | |||
| АРИФМЕТИЧЕСКОЕ УСТРОЙСТВО ДЛЯ ВЫПОЛНЕНИЯ ДИСКРЕТНОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ | 1991 |
|
RU2015550C1 |
| Арифметическое устройство для процессора быстрого преобразования Фурье | 1989 |
|
SU1631556A1 |
| Устройство для быстрого преобразования Фурье | 1985 |
|
SU1290350A1 |

