ОБЛАСТЬ ТЕХНИКИ
[001] Настоящая технология относится к получению информации в целом и конкретно к способу и системе для обновления базы данных поискового индекса сервера поисковой системы.
УРОВЕНЬ ТЕХНИКИ
[002] Различные глобальные или локальные сети связи (интернет, всемирная паутина, локальные сети и подобные им) предлагают пользователю большой объем информации. Информация включает в себя контекстуальные разделы, такие как, среди прочего, новости и текущие события, карты, информация о компаниях, финансовая информация и ресурсы, информация о трафике, игры и информация развлекательного характера. Пользователи используют множество клиентских устройств (настольный компьютер, портативный компьютер, ноутбук, смартфон, планшеты и подобные им) для получения доступа к богатому информационному контенту (например, изображениям, аудио- и видеофайлам, анимированным изображениям и прочему мультимедийному контенту подобных сетей).
[003] В общем случае, пользователь может получить доступ к ресурсу сети передачи данных двумя основными способами. Данный пользователь может получить доступ к конкретному ресурсу напрямую, введя адрес ресурса (обычно URL или Единый указатель ресурса, или же выбрав ссылку в электронном сообщении или на другом веб-ресурсе. В противном случае пользователь может выполнить поиск желаемого ресурса с помощью поисковой системы. Последнее особенно подходит для тех случаев, когда пользователю известна интересующая его тематика, но неизвестен конкретный адрес интересующего ресурса.
[004] Коротко говоря, поисковая система обычно работает в трех фазах: просмотр поисковым роботом, индексирование и поиск. Во время фазы просмотра поисковым роботом, поисковая система выполняет множество веб-просмотров, также известных как "пауки", которые являются компьютерными программами, которые "ползают" и просматривают Всемирную Сеть (Сеть) и скачивают копии цифровых документов, например, веб-страницы, которые хранятся в устройстве хранения. Во время фазы индексирования, хранящиеся цифровые документы обрабатываются для извлечения информации, и извлеченная информация используется для создания поискового индекса. Поисковый индекс сохраняет обработанную информацию в подходящий формат, позволяющий быстро ее извлекать. Обычно цифровые документы "индексируются" в соответствии с некоторыми или всеми возможными поисковыми терминами, содержащимися в цифровом документе, которые могут потенциально совпадать с одним или несколькими будущими поисковыми запросами. Так называемый инвертированный индекс коллекции данных поддерживается и обновляется системой, и используется при выполнении данного поискового запроса. Инвертированный индекс включает в себя множество "списков словопозиций", причем каждый список словопозиций соответствует поисковому термину и содержит ссылки на элементы данных, которые содержат этот поисковый термин.
[005] Во время фазы поиска пользователь обычно вводит и подтверждает ввода поискового запроса в поле в поисковой системе, которая получает цифровые документы, релевантные к поисковым терминам, включенным в поисковый запрос, из поискового индекса, и алгоритм машинного обучения обычно ранжирует цифровые документы на основе их вычисленной релевантности терминам поискового запроса. Ранжированные цифровые документы далее предоставляются пользователю на страницах результатов поиска.
[006] Американская патентная заявка №2009/0193406 А1, опубликованная 30 июля 2009 под авторством Джеймса Чарльза Уильямса, и озаглавленная "Bulk Search Index Updates" ("Массовые обновления поискового индекса") описывает выполнение массовых обновлений поискового индекса для хранилища информации. В некоторых вариантах осуществления технологии, выполняется дозированный набор запросов на обновление, и идентифицируется набор документов, предназначенных для обновления, на основе набора запросов. В некоторых вариантах осуществления технологии, используемый способ массового обновления выбирается на основе оценки затрат на выполнение массового обновления. В некоторых вариантах осуществления технологии, способ массового обновления, который основан на обновлении только индексов документов, предназначенных для обновления, может использоваться вместо способа массового обновления, которое предполагает повторную индексацию полного набора документов в хранилище.
[007] Американская патентная заявка №9,430,543 В2, выданная 30 августа 2016 компании Walmart и озаглавленная "Incrementally updating a large key-value store" ("Постепенное обновление большого хранилища ключевых значений") описывает способы, системы и компьютерные программные продукты для постепенного обновления большого хранилища ключевых значений, которое может включать в себя выполняемый компьютером способ обновления главной базы данных, содержащей обновление обновленного набора наиболее старых записей в главной базе данных, объединение аварийного набора записей в аварийной базе данных в главную базу данных и удаление аварийного набора записей из аварийной базы данных. В некоторых вариантах осуществления технологии, исполняемый на компьютере способ может далее включать в себя объединение измененного набора записей в измененной базе данных в главную базу данных и удаление измененного набора записей из измененной базы данных. Также предлагаются другие варианты осуществления связанных способов и систем.
[008] Американская патентная заявка №2003/101183 А1, опубликованная 29 мая 2003 года, принадлежащая компаниям QUIG Inc. и Kanisa Inc., и озаглавленная "Information retrieval index allowing updating while in use" ("Индекс извлечения информации, позволяющий обновление во время использования") описывает обратный индекс, полезный для идентификации документов при поиске для извлечения информации, который используется одновременно для индексации во время обновления с помощью новых документов. Прерывание при использовании индекса сохраняется на приемлемом уровне путем разбиения индекса и обновления только одиночных секций индекса в данный момент времени, и далее - путем дальнейшего разделения индекса на высокоскоростную дополнительную часть, которая может быть скорректирована одновременно в режиме реального времени, и периодически объединяться с более крупной основной долей. Эти две структуры объединяются во время чтения после краткой блокировки с перемещением указателя.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[009] Задачей предлагаемой технологии является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники.
[0010] Число страниц в Сети экспоненциально растет, и на данный момент считается, что в Сети доступно более десятков триллионов документов. В общем случае, только сегмент доступных документов в Сети, индексируется поисковыми системами в поисковый индекс, поскольку большинство документов находятся в "Глубокой Сети" и/или не индексируются по различным причинам. Тем не менее, поисковые веб-роботы просматривают и сохраняют миллиарды документов, причем только доля сохраненных документов обрабатывается и индексируется, поскольку обработка и индексирование документов для создания поискового индекса является затратной задачей по вычислительным ресурсам из-за, среди прочего, компромисса между постоянным ростом числа документов в Сети и вычислительной емкостью, необходимой для обработки и хранения документов дата-центрами поисковых систем.
[0011] Далее, поисковый индекс должен обновляться часто для добавления новых документов, которые могут быть релевантны для пользователей поисковой системы, для удаления документов, которые могут быть устаревшими, не представляемыми часто или вовсе в ответ на введенные пользователями запросы, и/или могут отсутствовать какие-либо взаимодействия с пользователями, из-за низкой релевантности их запросам.
[0012] Разработчики настоящей технологии предположили, что существующие на данном уровне техники подходы к обновлению поискового индекса могут сложными и ресурсозатратными, поскольку одна или несколько копий поискового индекса должны храниться и использоваться для предоставления пользователям поисковых результатов в ответ на запросы в реальном времени, в то время как другая "обновленная" копия поискового индекса также должна храниться в то время как она обновляется, что требует поддержки по меньшей мере двух копий поискового индекса, пока одна активно используется, что требует вычислительных и емкостных ресурсов.
[0013] Таким образом, варианты осуществления настоящей технологии направлены на способ и систему для обновления базы данных поискового индекса.
[0014] Подразумевается, что система предполагаемая разработчиками настоящей технологии может позволить управлять ограниченным объемом вычислительной мощности и памятью, которая может выделяться для управления и обновления поискового индекса путем разделения поискового индекса на доли или "части", и путем выборочного обновления документов в долях на основе различных критериев, например, размера "активных" документов в части, размера документов, предназначенных для добавления и удаления, доступного пространства для хранения и прочее.
[0015] Первым объектом настоящей технологии является исполняемый на компьютере способ динамического обновления поискового индекса сервера, причем поисковый индекс разделен на множество частей, каждая из которых включает в себя соответствующую долю из множества документов, причем способ выполняется на сервере и включает в себя: получение сервером запроса на обновление набора документов в поисковом индексе, причем запрос на обновление набора документов включает в себя удаление первого подмножества документов; вычисление сервером, для каждой части из набора из множества частей, где каждая часть включает в себя по меньшей мере один документ из первого подмножества документов: соответствующего обновленного активного размера соответствующего набора активных документов из соответствующей доли из множества документов в данной части, причем соответствующий набор активных документов не включает в себя по меньшей мере один документ из первого подмножества документов, предназначенных для удаления, соответствующего обновленного общего размера соответствующей доли из множества документов в данной части, причем соответствующая доля из множества документов не включает в себя по меньшей мере один документ из первого подмножества документов, предназначенных для удаления, и соответствующего соотношения соответствующего обновленного активного размера к соответствующему обновленному общему размеру; создание копии сервером, на основе соответствующего отношения, подмножества частей из набора частей для получения подмножества частей-кандидатов; обновление сервером по меньшей мере доли из набора документов в наборе частей-кандидатов; замещение сервером подмножества частей подмножеством частей-кандидатов.
[0016] В некоторых вариантах осуществления способа, запрос на обновление набора документов в поисковом индексе далее включает в себя: добавление второго подмножества документов ко множеству документов во множестве частей.
[0017] В некоторых вариантах осуществления способа, обновление по меньшей мере доли набора документов в подмножестве частей включает в себя: удаление сервером из подмножества частей-кандидатов первого подмножества документов на удаление; и распределение сервером второго подмножества документов в подмножестве частей-кандидатов.
[0018] В некоторых вариантах осуществления способа, способ дополнительно включает в себя, до этапа распределения второго подмножества документов в подмножестве частей-кандидатов: добавление сервером оставшихся документов в подмножестве частей-кандидатов во второе подмножество документов.
[0019] В некоторых вариантах осуществления способа, подмножество частей-кандидатов включает в себя заранее определенное количество частей, обладающих соответствующим наименьшим соотношением.
[0020] В некоторых вариантах осуществления способа, каждый соответствующий документ из множества документов поискового индекса обладает: соответствующим размером; местоположением в соответствующей части; и идентификатором соответствующей части.
[0021] В некоторых вариантах осуществления способа, распределение второго подмножества документов в подмножестве частей-кандидатов включает в себя, для данного документа во втором подмножестве документов: обновление сервером идентификатора соответствующей части данного документа; и обновление сервером местоположения данного документа в соответствующей части.
[0022] В некоторых вариантах осуществления способа, набор документов для обновления связан с размером обновления; и размер обновления меньше заранее определенного порогового размера обновления.
[0023] В некоторых вариантах осуществления способа, каждая данная часть из множества частей включает в себя: соответствующий набор активных документов обладает соответствующим активным размером; соответствующий набор неактивных документов обладает соответствующим неактивным размером; и соответствующая доля из множества документов обладает соответствующим общим размером.
[0024] В некоторых вариантах осуществления способа, способ дополнительно включает в себя, до этапа вычисления: определение сервером того, находится ли размер обновления выше заранее определенного порогового размера обновления; и в ответ на то, что размер обновления выше заранее определенного порогового размера обновления: разделение сервером набора документов для обновления на по меньшей мере два подмножества документов таким образом, что каждое из по меньшей мере двух подмножеств находится ниже заранее определенного порогового размера изменения; и выполнение сервером вычисления, создания копии и обновления для каждого из по меньшей мере двух подмножеств.
[0025] В некоторых вариантах осуществления способа, вычисление, создание и обновление выполняются оффлайн.
[0026] В некоторых вариантах осуществления способа, сервер является сервером поисковой системы; и каждый соответствующий набор неактивных документов во множестве частей поискового индекса включает в себя по меньшей мере одно из: документы, с которыми не было пользовательских взаимодействий в ответ на любой запрос в течение заранее определенного периода времени, и документы, которые не были представлены в ответ на любой запрос в течение заранее определенного периода времени
[0027] В некоторых вариантах осуществления способа, сервер соединен с устройством хранения, включающим первую долю и вторую долю; поисковый индекс хранится в первой доле; подмножество частей-кандидатов хранится во второй доле; и ограничение по размеру первой части ниже ограничения по размеру второй доли.
[0028] Вторым объектом настоящей технологии является система динамического обновления поискового индекса, причем поисковый индекс разделен на множество частей, каждая из которых включает в себя соответствующую долю из множества документов, причем система включает в себя: процессор, постоянный машиночитаемый носитель, включающий в себя инструкции, при выполнении которых процессор настраивается на возможность осуществлять: получение запроса на обновление набора документов в поисковом индексе, причем запрос на обновление набора документов включает в себя удаление первого подмножества документов; вычисление, для каждой части из набора из множества частей, где каждая часть включает в себя по меньшей мере один документ из первого подмножества документов: соответствующий обновленный активный размер соответствующего набора активных документов из соответствующей доли из множества документов в данной части, причем соответствующий набор активных документов не включает в себя по меньшей мере один документ из первого подмножества документов, предназначенных для удаления, соответствующий обновленный общий размер соответствующей доли из множества документов в данной части, причем соответствующая доля из множества документов не включает в себя по меньшей мере один документ из первого подмножества документов, предназначенных для удаления, и соответствующее соотношение соответствующего обновленного активного размера к соответствующему обновленному общему размеру; создание копии, на основе соответствующего отношения, подмножества частей из набора частей для получения подмножества частей-кандидатов; обновление по меньшей мере доли из набора документов в наборе частей-кандидатов; замещение подмножества частей подмножеством частей-кандидатов.
[0029] В некоторых вариантах осуществления системы, запрос на обновление набора документов в поисковом индексе далее включает в себя: добавление второго подмножества документов ко множеству документов во множестве частей.
[0030] В некоторых вариантах осуществления системы, для обновления по меньшей мере доли набора документов в подмножестве частей, процессор выполнен с возможностью осуществлять: удаление из подмножества частей-кандидатов первого подмножества документов на удаление; и распределение второго подмножества документов в подмножестве частей-кандидатов.
[0031] В некоторых вариантах осуществления системы, процессор дополнительно выполнен с возможностью осуществлять, до этапа распределения второго подмножества документов в подмножестве частей-кандидатов: добавление оставшихся документов в подмножестве частей-кандидатов во второе подмножество документов.
[0032] В некоторых вариантах осуществления системы, подмножество частей-кандидатов включает в себя заранее определенное количество частей, обладающих соответствующим наименьшим соотношением.
[0033] В некоторых вариантах осуществления системы, каждый соответствующий документ из множества документов поискового индекса обладает: соответствующим размером; местоположением в соответствующей части; и идентификатором соответствующей части.
[0034] В некоторых вариантах осуществления системы, для распределения второго подмножества документов в подмножестве частей-кандидатов, процессор выполнен с возможностью осуществлять, для данного документа во втором подмножестве документов: обновление идентификатора соответствующей данному документу части; и обновление местоположения данного документа в соответствующей части.
[0035] В некоторых вариантах осуществления системы, набор документов для обновления связан с размером обновления; и размер обновления меньше заранее определенного порогового размера обновления.
[0036] В некоторых вариантах осуществления системы, каждая данная часть из множества частей включает в себя: соответствующий набор активных документов обладает соответствующим активным размером; соответствующий набор неактивных документов обладает соответствующим неактивным размером; и соответствующая доля из множества документов обладает соответствующим общим размером.
[0037] В некоторых вариантах осуществления системы, система далее выполнена с возможностью осуществлять, до этапа вычисления: определение того, находится ли размер обновления выше заранее определенного порогового размера обновления; и в ответ на то, что размер обновления выше заранее определенного порогового размера обновления: разделение набора документов для обновления на по меньшей мере два подмножества документов таким образом, что каждое из по меньшей мере двух подмножеств находится ниже заранее определенного порогового размера изменения; и выполнение вычисления, создания копии и обновления для каждого из по меньшей мере двух подмножеств.
[0038] В некоторых вариантах осуществления системы, вычисление, создание и обновление выполняются оффлайн.
[0039] В некоторых вариантах осуществления системы, сервер является сервером поисковой системы; и каждый соответствующий набор неактивных документов во множестве частей поискового индекса включает в себя по меньшей мере одно из: документы, с которыми не было пользовательских взаимодействий в ответ на любой запрос в течение заранее определенного периода времени, и документы, которые не были представлены в ответ на любой запрос в течение заранее определенного периода времени
[0040] В некоторых вариантах осуществления системы, система соединена с устройством хранения, включающим первую долю и вторую долю, поисковый индекс хранится в первой доле, подмножество частей-кандидатов хранится во второй доле, и ограничение по размеру первой части ниже ограничения по размеру второй доли.
[0041] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данной технологии. В контексте настоящей технологии использование выражения "сервер" не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение "по меньшей мере один сервер".
[0042] В контексте настоящего описания «клиентское устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами электронных устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как электронное устройство в настоящем контексте, может вести себя как сервер по отношению к другим электронным устройствам. Использование выражения "электронное устройство" не исключает возможности использования множества электронных устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного метода.
[0043] В контексте настоящего описания "база данных" подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, которое выполняет процесс, который сохраняет или использует информацию, хранящуюся в базе данных, или же она может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
[0044] В контексте настоящего описания, термин "информация" включает в себя любую информацию, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
[0045] В контексте настоящего описания «используемый компьютером носитель компьютерной информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[0046] В контексте настоящего описания, если четко не указано иное, "указание" информационного элемента может представлять собой сам информационный элемент или указатель, отсылку, ссылку или другой косвенный способ, позволяющий получателю указания найти сеть, память, базу данных или другой машиночитаемый носитель, из которого может быть извлечен информационный элемент. Например, указание на документ может включать в себя сам документ (т.е. его содержимое), или же оно может являться уникальным дескриптором документа, идентифицирующим файл по отношению к конкретной файловой системе, или каким-то другими средствами передавать получателю указание на сетевую папку, адрес памяти, таблицу в базе данных или другое место, в котором можно получить доступ к файлу. Как будет понятно специалистам в данной области техники, степень точности, необходимая для такого указания, зависит от степени первичного понимания того, как должна быть интерпретирована информация, которой обмениваются получатель и отправитель указателя. Например, если до установления связи между отправителем и получателем понятно, что признак информационного элемента принимает вид ключа базы данных для записи в конкретной таблице заранее установленной базы данных, содержащей информационный элемент, то передача ключа базы данных - это все, что необходимо для эффективной передачи информационного элемента получателю, несмотря на то, что сам по себе информационный элемент не передавался между отправителем и получателем указания.
[0047] В контексте настоящего описания слова "первый", "второй", "третий" и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[0048] В контексте настоящего описания выражение "множество результатов поиска" подразумевает под собой набор из более чем одного результата поиска, причем результаты общего (например, сетевого) поиска и/или результаты вертикального поиска собраны вместе в наборе результатов поиска или на странице результатов поиска. Например, результаты вертикального поиска могут быть интегрированы с результатами общего (например, сетевого) поиска на странице результатов поиска, или наоборот, т.е. результаты общего поиска могут быть интегрированы с результатами вертикального поиска на странице результатов поиска. Таким образом, в некоторых вариантах осуществления настоящей технологии результаты общего поиска и результаты вертикального поиска могут быть агрегированы и ранжированы относительно друг друга. В альтернативных вариантах осуществления технологии множество результатов поиска может включать в себя только результаты общего поиска или результаты только вертикального поиска, например, результаты поиска из конкретного интересующего вертикального домена.
[0049] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[0050] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0051] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[0052] На Фиг. 1 представлена схема системы, выполненной в соответствии с неограничивающими вариантами осуществления настоящего технического решения.
[0053] На Фиг. 2 представлена принципиальная схема структуры поискового индекса, выполняемого системой, показанной на Фиг. 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[0054] На Фиг. 3 представлена принципиальная схема процесса обновления поискового индекса, показанного на Фиг. 2, причем процесс обновления выполняется системой, показанной на Фиг. 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[0055] На Фиг. 4 представлена принципиальная схема другого этапа процесса обновления, показанного на Фиг. 3, причем процесс обновления выполняется системой, показанной на Фиг. 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[0056] На Фиг. 5 представлена принципиальная схема другого этапа процесса обновления, показанного на Фиг. 3, причем процесс обновления выполняется системой, показанной на Фиг. 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[0057] На Фиг. 6 представлена блок-схема способа обновления поискового индекса, показанного на Фиг. 2, причем способ выполняется системой, показанной на Фиг. 1, в соответствии с неограничивающими вариантами осуществления настоящей технологии.
ОСУЩЕСТВЛЕНИЕ
[0058] Все примеры и используемые здесь условные конструкции предназначены, главным образом, для того, чтобы помочь читателю понять принципы настоящей технологии, а не для установления границ ее объема. Следует также отметить, что специалисты в данной области техники могут разработать различные схемы, отдельно не описанные и не показанные здесь, но которые, тем не менее, воплощают собой принципы настоящей технологии и находятся в границах ее объема.
[0059] Кроме того, для ясности в понимании, следующее описание касается достаточно упрощенных вариантов осуществления настоящей технологии. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[0060] Некоторые полезные примеры модификаций настоящей технологии также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающего списка, и специалисты в данной области техники могут создавать другие модификации, остающиеся в границах объема настоящей технологии. Кроме того, те случаи, где не были представлены примеры модификаций, не должны интерпретироваться как то, что никакие модификации невозможны, и/или что то, что было описано, является единственным вариантом осуществления этого элемента настоящей технологии.
[0061] Более того, все заявленные здесь принципы, аспекты и варианты осуществления настоящей технологии, равно как и конкретные их примеры, предназначены для обозначения их структурных и функциональных основ, вне зависимости от того, известны ли они на данный момент или будут разработаны в будущем. Таким образом, например, специалистами в данной области техники будет очевидно, что представленные здесь блок-схемы представляют собой концептуальные иллюстративные схемы, отражающие принципы настоящей технологии. Аналогично, любые блок-схемы, диаграммы, псевдокоды и т.п.представляют собой различные процессы, которые могут быть представлены на машиночитаемом носителе и, таким образом, могут использоваться компьютером или процессором, вне зависимости от того, показан ли подобный компьютер или процессор явно, или нет.
[0062] Функции различных элементов, показанных на чертежах, включая функциональный блок, обозначенный как "процессор" или "графический процессор", могут быть обеспечены с помощью специализированного аппаратного обеспечения или же аппаратного обеспечения, способного использовать подходящее программное обеспечение. Когда речь идет о процессоре, функции могут обеспечиваться одним специализированным процессором, одним общим процессором или множеством индивидуальных процессоров, причем некоторые из них могут являться общими. В некоторых вариантах осуществления настоящей технологии, процессор может являться универсальным процессором, например, центральным процессором (CPU) или специализированным для конкретной цели процессором, например, графическим процессором (GPU). Более того, использование термина «процессор» или «контроллер» не должно подразумевать исключительно аппаратное обеспечение, способное поддерживать работу программного обеспечения, и может включать в себя, без установления ограничений, цифровой сигнальный процессор (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянное запоминающее устройство (ПЗУ) для хранения программного обеспечения, оперативное запоминающее устройство (ОЗУ) и энергонезависимое запоминающее устройство. Также в это может быть включено другое аппаратное обеспечение, обычное и/или специальное.
[0063] Программные модули или простые модули, представляющие собой программное обеспечение, могут быть использованы здесь в комбинации с элементами блок-схемы или другими элементами, которые указывают на выполнение этапов процесса и/или текстовое описание. Подобные модели могут быть выполнены на аппаратном обеспечении, показанном напрямую или косвенно.
[0064] С учетом этих примечаний, далее будут рассмотрены некоторые не ограничивающие варианты осуществления аспектов настоящей технологии.
[0065] На Фиг. 1 представлена система 100, реализованная в соответствии с неограничивающими вариантами осуществления настоящей технологии. Система 100 включает в себя первое клиентское устройство 102, второе клиентское устройство 104, третье клиентское устройство 106 и четвертое клиентское устройство 108, соединенные с сетью 110 передачи данных через соответствующую линию 115 передачи данных (пронумеровано только на Фиг. 1) Система 100 включает в себя сервер 120 индексации, сервер 140 поисковой системы и сервер 160 отслеживания, соединенные с сетью 110 передачи данных с помощью их соответствующей линии 115 передачи данных (только одна из них пронумерована на Фиг. 1). В некоторых вариантах осуществления настоящей технологии, сервер 140 индексации, сервер 250 поисковой системы и сервер 160 отслеживания могут быть выполнены как единый сервер.
[0066] Только в качестве примера, первое клиентское устройство 102 может быть выполнено как смартфон, второе клиентское устройство 104 может быть выполнено как ноутбук, третье клиентское устройство 106 может быть выполнено как смартфон и четвертое клиентское устройство 108 может быть выполнено как планшет. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих ее объем, сеть 110 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящей технологии сеть 110 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
[0067] То, как именно реализована данная линия 115 передачи данных, никак конкретно не ограничено, и будет зависеть только от того, как именно реализовано соответствующее одно из: первое клиентское устройство 102, второе клиентское устройство 104, третье клиентское устройство 106 и четвертое клиентское устройство 108. В качестве примера, но не ограничения, в данных вариантах осуществления настоящей технологии в случаях, когда по меньшей мере одно из первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106 и четвертого клиентского устройства 108, реализовано как беспроводное устройство связи (например, смартфон), соответствующая одна из: линия 115 передачи данных может представлять собой беспроводную сеть передачи данных (например, среди прочего, линию передачи данных 3G, линию передачи данных 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где по меньшей мере одно из первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106 и четвертого клиентского устройства 108 реализованы соответственно как портативный компьютер, смартфон, планшет, соответствующая линия 115 передачи данных может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.) так и проводной (соединение на основе сети Ethernet).
[0068] Важно иметь в виду, что варианты осуществления воплощения первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106, четвертого клиентского устройства 108, линии 115 передачи данных и сети 110 передачи данных представлены исключительно в иллюстрационных целях. Таким образом, специалисты в данной области техники смогут понять подробности других конкретных вариантов осуществления первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106, четвертого клиентского устройства 108 и линии 115 передачи данных и сети 110 передачи данных. То есть, представленные здесь примеры не ограничивают объем настоящей технологии.
[0069] Несмотря на то, что представлены только первое клиентское устройство 102, второе клиентское устройство 104, третье клиентское устройство 106 и четвертое клиентское устройство 108, подразумевается, что любое число клиентских устройств может быть соединено с системой 100. Далее подразумевается, что в некоторых вариантах осуществления технологии, число клиентских устройств, которые включены в систему 100, может достигать десятков или сотен тысяч.
[0070] Сервер Индексации
[0071] С сетью 110 передачи данных также соединен вышеупомянутый сервер 120 индексации. Сервер 120 индексации может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящей технологии сортировочный сервер 120 индексации представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 120 индексации может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, сервер 120 индексации является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность сервера 120 индексации может быть разделена, и может выполняться с помощью нескольких серверов. В других вариантах осуществления технологии, функции сервера 120 индексации могут быть реализованы полностью или частично сервером 140 поисковой системы. В некоторых вариантах осуществления настоящей технологии, сервер 120 индексации находится под контролем и/или управлением оператора поисковой системы. Как вариант, сервер 120 индексации может находиться под контролем и/или управлением другого поставщика сервиса.
[0072] В общем случае, целью сервера 120 индексации является (i) просмотр Сети и извлечение документов, например, множества документов 117; (ii) обработка множества документов 117; и (iii) индексация по меньшей мере доли обработанного множества документов 117 в базе 136 данных поискового индекса сервера 140 поисковой системы; и (iv) обновление базы 146 данных поискового индекса сервера 140 поисковой системы.
[0073] Сервер 120 индексации выполняет множество поисковых роботов 112, анализатор 130, первый алгоритм 132 машинного обучения, и соединен с базой 136 данных поискового робота и базой 138 данных предварительной индексации.
[0074] Множество документов 117 может быть расположено на различных компьютерных системах, доступных, например, через сеть 110 передачи данных. Природа множества документов 117 никак конкретно не ограничена. В контексте настоящей технологии, множество документов 117 может также упоминаться как "множество веб-страниц", "веб-страницы", "веб-документы" или просто "документы". Тем не менее, подразумевается, что данный один из множества документов 117 может представлять собой любую форму структурированной цифровой информации, которая может извлекаться или быть доступной с помощью соответствующего URL, не выходя за пределы настоящей технологии.
[0075] В широком смысле, данный один из множества документов 117 может содержать одно или несколько предложений. Данный один из множества документов 117 может представлять собой, например, веб-страниц, содержащую текст и/или изображения (например, опубликованная новостная статья, связанная с какими-то экстренными новостями). Другой данный из множества документов 117 может представлять собой, в качестве другого примера, цифровую версию книги (например, цифровую версию книги «Гордость и Предубеждение» Джейн Остин). Другой данный из множества документов 117, может, например, представлять собой статью в Википедии™, которая время от времени может обновляться.
[0076] Подразумевается, что по меньшей мере некоторые из множества документов 117 могли быть созданы (или обновлены) недавно или иным образом могли стать доступными в 110 передачи данных. В самом деле, большое число веб-страниц создается или иным образом становится доступным в сети 110 передачи данных каждый день и, таким образом, может быть необходимо индексировать по меньшей мере некоторые из этих веб-страниц, чтобы предоставлять их содержимое пользователям данной поисковой системы.
[0077] Следует отметить, что по меньшей мере некоторые из множества документов 117 могут быть "свежими" веб-страницами, например, веб-страницами, у которых самое свежее содержимое, которое достаточно часто обновляется (например, погода), при этом по меньшей мере некоторые другие из множества документов 117 могут быть "неподвижными" веб-страницами, например, веб-страницы, которые обладают "неподвижным" содержимым, которое с меньшей вероятностью будет обновляться или будет обновляться с менее частыми интервалами (например, статья в Википедии о конституции Канады). С одной стороны, для пользователей данной поисковой системы польза свежего содержимого обычно (i) максимальна в момент времени, близкий к моменту его создания, и (ii) снижается после некоторого времени. С другой стороны, польза неподвижного содержимого для пользователей данной поисковой системы обычно (i) меньше в момент времени, близкий к моменту его создания, чем польза свежего содержимого в момент времени, близкий к моменту его создания, но (ii) достаточно постоянна во времени.
[0078] Подразумевается, что по меньшей мере некоторые из множества документов 117 могут быть ранее индексированы, поскольку по меньшей мере некоторые другие из множества документов 117 могли не быть ранее индексированы. Например, множество документов 117 может включать в себя "новые" веб-страницы, которые не были ранее индексированы. В другом примере, множество документов 117 может включать в себя "старые" веб-страницы, которые были ранее индексированы. В еще одном другом примере, множество документов 117 может включать в себя "обновленные" веб-страницы, которые, в некотором смысле, являются "обновленными" версиями старых веб-страниц, где содержимое обновленной версии веб-страницы отличается от содержимого старой версии веб-страницы, которая была ранее индексирована.
[0079] Множество поисковых роботов 112 включает в себя главных поисковых роботов 124 и срочных поисковых роботов 126. Главные поисковые роботы выполнены с возможностью просматривать множество документов 117 в Сети, начиная со списка URL, предназначенных для посещения (не показано), где гиперссылки на документы также идентифицируются и добавляются в список, предназначенный для посещения. Срочные поисковые роботы 126 выполнены с возможностью выполнять срочную индексацию "свежих" документов (которые могут быть включены во множество документов 117), которые появились в Сети прямо перед процедурой просмотра, таким образом свежие документы также доступны для индексации. Главные поисковые роботы 124 и срочные поисковые роботы 126 также включают в себя соответствующие планировщики (не показано), которые создают расписания и порядки документов для просмотра в Сети. Множество поисковых роботов 122, включая главные поисковые роботы 124 и срочные поисковые роботы 126, в общем случае скачивают множество документов 117 и сохраняют множество документов 117 в базе 136 данных поисковых роботов для их дальнейшей обработки, как будет описано более подробно далее.
[0080] Анализатор 130 в общем случае выполнен с возможностью анализировать (парсить) множество документов 117, хранящихся в базе 136 данных поискового робота, и извлекать информацию из них, например, среди прочего, термины индексации и гиперссылки. Анализатор 130 в общем случае убирает язык разметки из просмотренных документов, таким образом, чтобы текстовую информацию можно было извлечь и далее проанализировать или использовать напрямую для индексации. Анализатор 130 может далее извлекать множество факторов из документов, например, факторы используемые для ранжирования (факторы ранжирования), факторы URL, факторы кликов, факторы документы и так далее. В некоторых вариантах осуществления настоящей технологии, анализатор 130 может сохранять информацию как векторы факторов в базе 138 данных предварительной индексации. В других вариантах осуществления технологии, сервер 120 индексации может использовать устройство извлечения факторов (не показано) для извлечения факторов из множества документов 117 из базы 136 данных поискового робота.
[0081] Первый алгоритм 132 машинного обучения выполнен с возможностью выбирать по меньшей мере долю из множества документов 117 для включения в базу 146 данных поискового индекса сервера 140 поисковой системы на основе векторов факторов множества документов 117, в также другую информацию, связанную со множеством документов 117, причем векторы факторов хранятся в базе 138 данных предварительной индексации.
[0082] Сервер 120 индексации выполнен с возможностью обновлять базу 146 данных поискового индекса при получении указания на обновления или через предварительно определенные интервалы времени. То как именно сервер 120 индексации обновляет базу 146 данных поискового индекса, будет описано далее более подробно.
[0083] Сервер поисковой системы
[0084] С сетью 110 передачи данных также соединен вышеупомянутый сервер 140 поисковой системы. Сервер 140 поисковой системы может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения, сервер 140 поисковой системы может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 140 поисковой системы может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящего технического решения, не ограничивающем его объем, сервер 140 поисковой системы является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих ее объем, функциональность сервера 140 хостинга содержимого может быть разделена, и может выполняться с помощью нескольких серверов. В некоторых вариантах осуществления настоящей технологии, сервер 140 поисковой системы находится под контролем и/или управлением поставщика поисковой систем, такого, например, как оператор поисковой системы Yandex. Как вариант, сервер 140 поисковой системы может находиться под контролем и/или управлением поставщика сервиса.
[0085] В общем случае задачей сервера 140 поисковой системы осуществляет (i) проведение поиска; (ii) проведение анализа результатов поиска и ранжирование результатов поиска в ответ на поисковый запрос; (iv) группировку результатов и компиляцию страницы результатов поиска (SERP) для вывода на электронное устройство (например, первое клиентское устройство 102, второе клиентское устройство 104, третье клиентское устройство 106 и четвертое клиентское устройство 108), причем электронное устройство использовалось для ввода поискового запроса, который привел к SERP.
[0086] Конфигурация сервера 140 поисковой системы для выполнения поиска конкретно ничем не ограничена. Специалистам в данной области техники будут понятны некоторые способы и средства для выполнения поиска с помощью сервера 140 поисковой системы и, соответственно, некоторые структурные компоненты сервера 140 поисковой системы будут описаны только на поверхностном уровне. Сервер 140 поисковой системы может содержать базу 146 данных поискового индекса.
[0087] Сервер 140 поисковой системы настроен на выполнение общих доменных поисков, как известно в данной области техники. Например, общий доменный поиск не ограничивается поиском конкретной категории результатов, а способен предоставить все результаты, которые наилучшим образом подходят к поисковому запросу. Такой общий (независимый от категории) поиск с помощью сервера 140 поисковой системы может возвращать результаты поиска, которые включают в себя неспецифичный для категорий цифровой контент, а также специфичный для категорий цифровой контент, например, изображение, видео, новости, товары, блоги, книги, места, дискуссии, рецепты, билеты, биографическую информацию, патенты, акции, расписания и так далее, а также другой цифровой контент, который тесно связан и адресован конкретному типу цифрового контента. Например, общий доменный поиск может быть WWW-поиском. Поиск, произведенный в общем домене, создает «результат общего поиска». Такие результаты общего поиска также упоминаются здесь как «сетевые результаты». Обычно сетевой результат включает в себя ссылку на веб-сайт и фрагмент информации (сниппет), который дает краткое описание содержимого вебсайта. Пользователь может выбрать ссылку на веб-сайт, включенную в состав сетевого результата, для перехода на веб-страницу, относящуюся к поисковому запросу пользователя. Термины «результат общего поиска» и «элемент результата общего поиска» используются здесь взаимозаменяемо, как и «результат поиска» и «элемент результата поиска».
[0088] Сервер 140 поисковой системы также выполнен с возможностью осуществлять вертикальные доменные поиски. Например, "вертикальный домен" может представлять собой информационный домен, включающий в себя специализированный контент, например, контент одного типа (например, типа медиа, жанра контента, актуальности и т.д.) Вертикальный домен, таким образом, включает в себя конкретную подгруппу данных, например, конкретную подгруппу сетевых данных. Например, вертикальный домен может включать в себя конкретную информацию, такую как изображения, видео, новости, товары, блоги, книги, места, обсуждения, рецепты, билеты, биографическую информацию, патенты, акции, расписания и так далее. Поиск, осуществленный в вертикальном домене, создает "результат вертикального поиска" или "элемент результата вертикального поиска". Такие результаты вертикального поиска также упоминаются здесь как «вертикали» и «вертикальные результаты». Термины «результат вертикального поиска» и «элемент результата вертикального поиска» используются здесь взаимозаменяемо.
[0089] Сервер 140 поисковой системы выполнен с возможностью создавать ранжированный список результатов поиска, включая, результаты из общего доменного поиска и вертикального доменного поиска. Сервер поисковой системы может выполнять один или несколько алгоритмов 142 машинного обучения для ранжирования документов для создания ранжированного списка поисковых результатов.
[0090] Множество алгоритмов для ранжирования поисковых результатов известно и может быть использовано сервером 140 поисковой системы.
[0091] В качестве примера, а не ограничения, один или несколько алгоритмов 142 машинного обучения могут ранжировать документы в соответствии с их релевантностью для введенного пользователем поискового запроса на основе всех или некоторых из следующих критериев: (i) популярность данного поискового запроса в поисках; (ii) число выведенных результатов; (iii) включает ли в себя поисковый запрос какие-либо ключевые термины (например, «изображения», «видео», «погода» или т.п.), (iv) насколько часто конкретный поисковый запрос включает в себя ключевые термины при вводе его другими пользователями; (v) насколько часто другие пользователи при выполнении аналогичного поиска выбирали конкретный ресурс или конкретные результаты вертикального поиска, когда результаты были представлены на SERP. Север 140 поисковой системы может вычислять и назначать оценку релевантности (на основе другого представленного выше критерия) для каждого поискового результата, полученного в ответ на введенный пользователем поисковый запрос, и создавать SERP, причем поисковые результаты ранжированы в соответствии с их соответствующими оценками релевантности.
[0092] Сервер 140 поисковой системы обычно содержит вышеупомянутую базу 146 данных поискового индекса.
[0093] Задачей базы 146 данных поискового индекса является индексирование документов (или указание на документы), такие как, без установления ограничений, веб-страницы, изображения, PDF, документы Word™, документы PowerPoint™, которые были просмотрены, в качестве неограничивающего примера, выбраны первым алгоритмом 132 машинного обучения. В некоторых вариантах осуществления настоящей технологии, базы 146 данных поискового индекса ведется в форме списков словопозиций. Таким образом, когда пользователь одного из первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106 и четвертого клиентского устройства 108 вводит поисковый запрос и выполняет поиск на сервере 140 поисковой системы, сервер 140 поисковой системы анализирует базу 146 данных поискового индекса и извлекает документы, которые содержат термины запроса, и ранжирует их в соответствии с алгоритмом ранжирования.
[0094] Сервер отслеживания
[0095] С сетью 110 передачи данных также соединен вышеупомянутый сервер 160 отслеживания. Сервер 160 отслеживания может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящей технологии, сервер 160 отслеживания может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 160 отслеживания может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, сервер 160 отслеживания является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих его объем, функциональность сервера 160 отслеживания может быть разделена и может выполняться с помощью нескольких серверов. В других вариантах осуществления технологии, функции сервера 160 отслеживания могут быть реализованы полностью или частично сервером 140 поисковой системы. В некоторых вариантах осуществления настоящей технологии, сервер 160 отслеживания находится под контролем и/или управлением оператора поисковой системы. Как вариант, обучающий сервер 160 может находиться под контролем и/или управлением другого поставщика сервиса.
[0096] В общем случае, целью сервера 160 отслеживания является отслеживание пользовательских взаимодействий с сервером 140 поисковой системы сервера 140 поисковой системы, например, на пользовательские запросы и термины, введенные пользователями, и документы, к которым далее был получен доступ пользователями (например, первого клиентского устройства 102, второго клиентского устройства 104, третьего клиентского устройства 106 и четвертого клиентского устройства 108). Сервер 160 отслеживания может отслеживать пользовательские взаимодействия (например, или данные о кликах), когда пользователи выполняют общие доменные поиски и вертикальные доменные поиски на сервере 140 поисковой системы.
[0097] Неограничивающие примеры пользовательских взаимодействий, которые отслеживаются или вычисляются сервером 160 отслеживания, включают в себя:
 Loss/Win: был ли совершен клик по документу в ответ на поисковый запрос или нет.
Loss/Win: был ли совершен клик по документу в ответ на поисковый запрос или нет.
 Время пребывания: время, которое пользователь проводит на документе до возвращения на SERP,
Время пребывания: время, которое пользователь проводит на документе до возвращения на SERP,
 Длинное/короткое нажатие: было ли пользовательское взаимодействие с документом длинным или коротким по сравнению с пользовательским взаимодействием с другими документами на SERP.
Длинное/короткое нажатие: было ли пользовательское взаимодействие с документом длинным или коротким по сравнению с пользовательским взаимодействием с другими документами на SERP.
 Показатель кликабельности (CTR): Число кликов на элемент, деленное на число раз, когда элемент был показан (показы).
Показатель кликабельности (CTR): Число кликов на элемент, деленное на число раз, когда элемент был показан (показы).
[0098] Естественно, вышепредставленный список не является исчерпывающим и может включать в себя другие типы параметров пользовательского взаимодействия, не выходя за границы настоящей технологии.
[0099] Сервер 160 отслеживания могут сохранять отслеживаемые пользовательские взаимодействия в базе 162 данных отслеживания. В представленном варианте осуществления технологии, база 162 данных отслеживания включает в себя журнал 164 поисковых запросов и журнал 166 пользовательских взаимодействий.
[00100] Целью журнала 164 поисковых запросов является ведение журнала поисков, введенных в сервер 140 поисковой системы. Конкретнее, журнал 164 поисковых запросов может содержать список запросов, каждый соответствующий запрос из списка обладает соответствующими поисковыми терминами, связанные документы были перечислены сервером 140 поисковой системы в ответ на соответствующий поисковый запрос, число введений соответствующего запроса в течение периода времени (упоминается далее как частоты предыдущего использования), и может также содержать список пользователей (или группу пользователей), идентифицированных с помощью анонимного ID (или совсем без ID), и соответствующие документы, на которые они нажали после ввода соответствующего поискового запроса. В некоторых вариантах осуществления технологии, журнал 164 поисковых запросов может обновляться каждый раз, когда выполняется новый запрос на сервере 140 поисковой системы. В других вариантах осуществления технологии, журнал 164 поисковых запросов может обновляться в заранее определенные моменты. В некоторых вариантах осуществления технологии, может быть множество копий журнала 164 поисковых запросов, и каждая соответствует журналу 164 поисковых запросов в различные моменты времени.
[00101] Способ, в соответствии с которым создается журнал 166 пользовательских взаимодействий, никак конкретно не ограничен. Журнал 166 пользовательских взаимодействий может быть связан с журналом 164 поисковых запросов, и может составлять список параметров пользовательских взаимодействий, которые отслеживались сервером 160 отслеживания после того как пользователь ввел поисковый запрос и кликнул на один или несколько документов на странице результатов поиска на сервере 140 поисковой системы. В качестве неограничивающего примера, журнал 166 пользовательских взаимодействий может содержать: (i) ссылку на соответствующий документ или указание на него, который может быть идентифицирован, в качестве неограничивающего примера, с помощью ID или URL; (ii) соответствующий список запросов, где каждый соответствующий запрос из списка соответствующих запросов связан с соответствующим документов, и где каждый из соответствующих запросов был использован одним или несколькими пользователями для доступа к соответствующему документу; и (iii) соответствующее множество параметров пользовательских взаимодействий для каждого запроса (если с документом было взаимодействие), которые указывают на пользовательские взаимодействия с соответствующим документом пользователями, которые ввели соответствующий запрос из списка запросов. Журнал 166 пользовательских взаимодействий может далее включать в себя соответствующие временные отметки, связанные с соответствующими пользовательскими взаимодействиями, и другие статистические данные. В некоторых вариантах осуществления настоящей технологии, журнал 164 поисковых запросов и журнал 166 пользовательских взаимодействий могут быть реализованы как единый журнал.
[00102] В общем случае, данные из базы 162 данных отслеживания (включая данные из журнала 166 пользовательских взаимодействий) могут быть получены по меньшей мере одним из сервера 230 поисковой системы, сервера 140 отслеживания одновременно (т.е. в заранее определенные временные интервалы) или не одновременно (например, при получении указания).
[00103] В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность сервера 160 отслеживания и сервера 140 поисковой системы может быть разделена, и может выполняться с помощью одного сервера.
[00104] Целью журнала 164 поисковых запросов является ведение журнала поисков, введенных в сервер 140 поисковой системы. Конкретнее, журнал 164 поисковых запросов может содержать список запросов, каждый соответствующий запрос из списка обладает соответствующими поисковыми терминами, связанные документы были перечислены сервером 140 поисковой системы в ответ на соответствующий поисковый запрос, число введений соответствующего запроса в течение периода времени (упоминается далее как частоты предыдущего использования), и может также содержать список пользователей (или группу пользователей), идентифицированных с помощью анонимного ID (или совсем без ID), и соответствующие документы, на которые они нажали после ввода соответствующего поискового запроса. В некоторых вариантах осуществления технологии, журнал 164 поисковых запросов может обновляться каждый раз, когда выполняется новый запрос на сервере 140 поисковой системы. В других вариантах осуществления технологии, журнал 164 поисковых запросов может обновляться в заранее определенные моменты. В некоторых вариантах осуществления технологии, может быть множество копий журнала 164 поисковых запросов, и каждая соответствует журналу 164 поисковых запросов в различные моменты времени.
[00105] На Фиг. 2 представлена принципиальная схема структуры базы 146 данных поискового индекса, которая представлена в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00106] База 146 данных поискового индекса включает в себя главную долю 210 и долю 280 обновления. В общем случае, база 146 данных поискового индекса обладает ограничением 205 по размеру, который представляет собой доступное пространство на носителе сервера 120 индексации.
[00107] Главная доля 210 базы 146 данных поискового индекса хранит множество проиндексированных документов 250. Главная доля 210 является "активной" версией базы 146 данных поискового индекса, и главная доля 210 используется сервером 140 поисковой системы, включая один или несколько алгоритмов 142 машинного обучения, для извлечения документов из множества проиндексированных документов 250, предназначенных для представления поисковых результатов пользователям в ответ на запросы в режиме реального времени. Главная доля 210 базы 146 данных поискового индекса обладает ограничением 212 по главному размеру. Естественно, ограничение 212 по главному размеру ниже ограничения 205 по размеру базы 146 данных поискового индекса.
[00108] Доля 280 обновления базы 146 данных поискового индекса выполнена с возможностью быть использованной для обновления документов, например, множества проиндексированных документов 250, включенных в главную долю 210 базы 146 данных поискового индекса. В контексте настоящего описания, "обновление" документа в главной доле 210 базы 146 данных поискового индекса может включать в себя: удаление данного проиндексированного документа 260 из множества проиндексированных документов 250, добавление нового документа ко множеству проиндексированных документов 250 и модификацию данного проиндексированного документа 250 во множестве проиндексированных документов 250.
[00109] Доля 280 обновления может быть "временным" хранилищем, которое используется для обновления документов в главной доли 210 базы 146 данных поискового индекса. Доля 280 обновления обладает ограничением 282 по размеру обновления, который равен у, причем ограничение 282 по размеру обновления ниже ограничения 212 главного размера. В качестве неограничивающего примера, ограничение 282 по размеру обновления может составлять 20% от ограничения 212 главного размера или любое другое подходящее количество, выбранное оператором базы 146 данных поискового индекса. То как именно определяется ограничение 282 у размера обновления, будет описано далее более подробно.
[00110] В некоторых вариантах осуществления настоящей технологии, доля 280 обновления может находиться в энергозависимой памяти сервера 120 индексации. То как именно используется доля 280 обновления для обновления документов в главной доли 210, будет более подробно описано далее.
[00111] Для целей упрощения настоящего описания, следует предполагать, что в среднем число документов из множества проиндексированных документов 250 в главной доле 210 базы 146 данных поискового индекса, является постоянным, т.е. число документов во множестве проиндексированных документов 250, после добавления новых документов и удаления документов, остается примерно тем же самым. Другими словами, число документов из множества проиндексированных документов 250 является постоянным благодаря ограничению 205 по размеру базы 146 данных поискового индекса сервера 120 индексации. Тем не менее, как будет понятно специалистам в данной области техники, дополнительное пространство для хранения может добавляться периодически серверу 120 индексации, и, следовательно, ограничение 205 размера базы 146 данных поискового индекса может увеличиться, и число документов из множества проиндексированных документов 250 также может увеличиться.
[00112] Главная доля 210 разделена на множество долей или частей 220, причем множество частей 220, включая заранее определенное число частей 221, может быть выражено как п. То, как именно определяется заранее определенное число частей 221 из множества частей 220, будет описано более подробно далее.
[00113] Как было упомянуто ранее, главная доля 210 базы 146 данных поискового индекса включает в себя множество проиндексированных документов 250, причем множество проиндексированных документов 250 было разделено среди множества частей 220. данная часть 222 из множества частей 220 включает в себя соответствующую долю проиндексированных документов 252 из множества проиндексированных документов 250. Данная часть 222 обладает соответствующим общим размером 254, который является суммой индивидуального размера проиндексированных документов в соответствующей доле проиндексированных документов 250.
[00114] Соответствующий общий размер 254 данной части 222 может быть выражен как:

[00115] где s - соответствующий общий размер 254, и i - идентификатор 224 данной части 222.
[00116] В общем случае, данный проиндексированный документ 260 в соответствующей части проиндексированных документов 252 данной части 222 обладает:
 соответствующим идентификатором 262 документа;
соответствующим идентификатором 262 документа;
 соответствующим размером 264;
соответствующим размером 264;
 идентификатор 224 части данной части 222;
идентификатор 224 части данной части 222;
 соответствующим местоположением 266 в данной части 222; и
соответствующим местоположением 266 в данной части 222; и
 соответствующей информацией 268 документа.
соответствующей информацией 268 документа.
[00117] Соответствующая информация 268 документа включает в себя, без установки ограничений:
 дату создания данного проиндексированного документа 260,
дату создания данного проиндексированного документа 260,
 дату модификации данного проиндексированного документа 260,
дату модификации данного проиндексированного документа 260,
 дату извлечения данного проиндексированного документа 260 (т.е. когда данный проиндексированный документ 260 был в последний раз представлен как поисковый результат в ответ на запрос на сервере 140 поисковой системы),
дату извлечения данного проиндексированного документа 260 (т.е. когда данный проиндексированный документ 260 был в последний раз представлен как поисковый результат в ответ на запрос на сервере 140 поисковой системы),
 пользовательские взаимодействия с данным проиндексированным документов 260 (например, число кликов, рейтинг CTR, и т.д.),
пользовательские взаимодействия с данным проиндексированным документов 260 (например, число кликов, рейтинг CTR, и т.д.),
 тип данного проиндексированного документа 260 (например, новостную статью, запись из энциклопедии, и так далее),
тип данного проиндексированного документа 260 (например, новостную статью, запись из энциклопедии, и так далее),
 термины индекса данного проиндексированного документа 260,
термины индекса данного проиндексированного документа 260,
 факторы ранжирования данного проиндексированного документа 260,
факторы ранжирования данного проиндексированного документа 260,
 и так далее.
и так далее.
[00118] Соответствующая информация 268 документа может быть получена, по меньшей мере частично, из журнала 164 поисковых запросов, и/или журнала 166 пользовательских взаимодействий через заранее определенные интервалы времени, и храниться в базе 146 данных поискового индекса, или может быть получена как неограничивающий пример при получении запроса на обновление, и может храниться в базе 146 данных поискового индекса.
[00119] Соответственно, сервер 120 индексации может содержать список 215 множества проиндексированных документов 250, причем список 215 включает в себя, для каждого данного проиндексированного документа 260 из множества проиндексированных документов 250, соответствующий идентификатор 262 документа, идентификатор 224 соответствующей части, местоположение 266 соответствующего документа и информацию 268 о соответствующем документе. Другими словами, список 215 может "сопоставлять" каждый данный проиндексированный документ 260 с данной частью 222, и включать всю информацию, связанную с данной часть 222, и данным проиндексированных документов 260.
[00120] Соответствующая доля проиндексированных документов 252 в данной части 222 включает в себя соответствующий набор активных документов 230 и соответствующий набор неактивных документов 240. Каждый данный проиндексированный документ 260 данной части 222 либо является частью набора активных документов 230, либо соответствующего набора неактивных документов 240. Сервер 120 индексации может определять, что данный проиндексированный документ 260 является часть соответствующего набора активных документов 230, или соответствующего набора неактивных документов 240 на основе соответствующей информации 268 о документе.
[00121] В некоторых неограничивающих вариантах осуществления настоящей технологии, сервер 120 индексации может "сканировать" по меньшей мере долю из множества частей 220 для определения, для данной части 222, того, является ли каждый данный проиндексированный документ 260 частью соответствующего набора активных документов 230 или соответствующего набора неактивных документов 240, на основе соответствующей информации 268 о документах. Сервер 120 индексации может сканировать по меньшей мере долю из множества частей 220 через заранее определенные промежутки времени, или при получении указания, например, запроса для обновления одного или нескольких документов во множестве частей 220 из базы 146 данных поискового индекса. Дополнительно или альтернативно, информация о соответствующем наборе активных документов 230 и соответствующем наборе неактивных документов 240 в каждой данной части может содержаться в списке 215. В других неограничивающих вариантах осуществления настоящей технологии, каждая данная часть 222 может содержать информацию о соответствующем наборе активных документов 230 и соответствующий набор неактивных документов 240 в метаполях (не показано) данной части.
[00122] Соответствующий набор активных документов 230 включает в себя документы, которые считаются "полезными" для сервера 140 поисковой системы. Сервер 120 индексации может определять, что документ является полезным для сервера 140 поисковой системы на основе информации 268 о соответствующем документе. В качестве неограничивающего примера, данный проиндексированный документ 260 может находиться в соответствующем наборе активных документов 230, если информация 268 о соответствующем проиндексированном документе 260 удовлетворяет одному или нескольких из следующих условий:
 была недавно проиндексирована сервером 120 индексирования,
была недавно проиндексирована сервером 120 индексирования,
 была недавно модифицирована,
была недавно модифицирована,
 была представлена как поисковый результат в ответ на запроса на сервере 140 поисковой системы во время заранее определенного периода времени,
была представлена как поисковый результат в ответ на запроса на сервере 140 поисковой системы во время заранее определенного периода времени,
 было получено некоторое число пользовательских взаимодействий, находящееся выше заранее определенного порога, при представлении в качестве поискового результата на сервере 140 поисковой системы за заранее определенный период времени.
было получено некоторое число пользовательских взаимодействий, находящееся выше заранее определенного порога, при представлении в качестве поискового результата на сервере 140 поисковой системы за заранее определенный период времени.
[00123] Соответствующий набор активных документов 230 обладает соответствующим активным размером 232, который является суммой соответствующих размеров 264 документов в соответствующем наборе активных документов 230.
[00124] Соответствующий активный размер 232 из соответствующего набора активных документов 230 данной части 222 может быть выражен как:

[00125] где u - соответствующий активный размер 254, и соответствующий набора активных документов 230, и i - идентификатор 224 части для данной части 222.
[00126] Соответствующий набор неактивных документов 240 включает в себя документы, которые считаются неактивными или не полезными для сервера 140 поисковой системы. Сервер 120 индексации может определять, что документ является неактивным и/или не полезным для сервера 140 поисковой системы на основе информации 268 о соответствующем документе. В качестве неограничивающего примера, данный проиндексированный документ 260 может находиться в соответствующем наборе неактивных документов 240, если информация 268 о соответствующем данном проиндексированном документе 260 удовлетворяет одному или нескольких из следующих условий:
 не была недавно обновлена,
не была недавно обновлена,
 не была получена сервером 140 поисковой системы для представления в качестве поискового результата в ответ на запроса за заранее определенный период времени,
не была получена сервером 140 поисковой системы для представления в качестве поискового результата в ответ на запроса за заранее определенный период времени,
 было получено некоторое число пользовательских взаимодействий, например, кликов, находящееся ниже заранее определенного порога, при представлении в качестве поискового результата на сервере 140 поисковой системы за заранее определенный период времени.
было получено некоторое число пользовательских взаимодействий, например, кликов, находящееся ниже заранее определенного порога, при представлении в качестве поискового результата на сервере 140 поисковой системы за заранее определенный период времени.
[00127] Соответствующий набор неактивных документов 240 обладает соответствующим неактивным размером 242, причем соответствующий неактивный размер 242 обладает разницей между общим размером 254 и соответствующим активным размером 232, который может быть выражен как:

[00128] где s - соответствующий активный размер 254, и u - соответствующий активный размер 232, и i - идентификатор 224 части для данной части 222.
[00129] В некоторых вариантах осуществления настоящей технологии, данная часть 222 может обладать только соответствующим набором активных документов 230 или соответствующим набором неактивных документов 240.
[00130] С учетом того, что на Фиг. 2 описано то, как структурирована база 146 данных поискового индекса на множество частей 220, далее рассматриваются Фиг. 2-5, на которых представлены схематические диаграммы процесса 300 обновления базы 146 данных поискового индекса в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00131] В общем случае, запрос 130 на обновление размера документов 320 может быть получен сервером 120 индексации. Запрос 310 может быть получен сервером 140 поисковой системы за заранее определенные интервалы времени. В некоторых вариантах осуществления настоящей технологии, запрос 310 на обновление набора документов 320 может быть получен после завершения процедуры просмотра множеством поисковых роботов 122, причем запрос 310 может включать в себя новые просмотренные документы, например, новые просмотренные документы из множества цифровых документов 117. Другими словами, запрос 310 на обновление набора документов 320 может быть получен после процедуры просмотра, выполняемой множеством поисковых роботов 122, определяет, что некоторые документы были обновлены, удалены или появился новый документ.
[00132] Запрос 310 на обновление набора документов 320 в общем случае включает в себя: удаление первого подмножества документов 330 из базы 146 данных поискового индекса и добавление второго подмножества документов 340 в базу 146 данных поискового индекса. Для целей настоящего описания, документы, предназначенные для модификации (т.е. документы, представленные в базе 146 данных, которые были модифицированы оператором(ами)), включены как в первое подмножество документов 330, так и во второе подмножество документов 340. Другими словами, документы, которые были модифицированы, могут обладать "старой" версией, удаленной из базы 146 данных поискового индекса, и "новой" версией, добавленной в базе 146 данных поискового индекса, и список 215 может обновляться в соответствии с изменениями.
[00133] Несмотря на то, что запрос 310 представлен с первым подмножеством документов 330 для удаления и вторым подмножеством документов 340 для добавления, следует иметь в виду, что запрос 310 может только включать в себя указание на первое подмножество документов 330 и указание на второе подмножество документов 340 в форме списка изменений, и второе подмножество документов 340 для добавление может быть извлечено из базы 138 данных предварительной индексации или другой базы данных (не показано) и добавлено в базу 146 данных поискового индекса в конце процесса 300 обновления.
[00134] Размер 312 запроса 310 для обновления набора документов 320 может быть в общем случае равным или ниже заранее определенного порогового размера 315, который может быть выражен как:

[00135] где Δ - размер 312 запроса 310 на обновление набора документов 320, и х - заранее определенный пороговый размер 315.
[00136] Размер 312 запроса 310 может определяться на основе суммы размеров документов в наборе документов 320. Другими словами, размер 312 запроса может представлять собой сумму размеров документов во втором подмножестве документов 340 (которое может быть добавлено в базу 146 данных поискового индекса), минус сумма размеров документов в первом подмножестве документов 330 (которое будет удалено из базы 146 данных поискового индекса).
[00137] Заранее определенный пороговый размер 315 может быть выражен как процент от ограничения 205 по размеру базы 146 данных поискового индекса. В качестве неограничивающего примера, заранее определенный пороговый размер 315 может составлять 3%. То как именно определяется заранее ограниченный пороговый размер 315 х, будет описано далее более подробно.
[00138] В некоторых вариантах осуществления настоящей технологии, запрос 310 на обновление набора документов 320 может быть выше заранее определенного порогового 315 размера, и сервер 120 индексирования может разделять набор документов 320 на множество подмножества (не показано), таким образом, что каждое подмножество находится ниже заранее определенного порогового размера 315. Сервер 120 индексирования может далее последовательно выполнять обновление для каждого из множества подмножеств.
[00139] Данный документ, предназначенный для удаления 332 в первом подмножестве документов 330, может быть включен в запрос 310 по одной или нескольким из следующих причин:
 соответствующий документ, предназначенный для удаления 332 является частью соответствующего набора неактивных документов 240 и не удовлетворяет заранее определенным условиям, чтобы считаться частью соответствующего набора активных документов 230 (что может быть определено на основе информации 226 о соответствующем документе, связанной с данным проиндексированном документе 260),
соответствующий документ, предназначенный для удаления 332 является частью соответствующего набора неактивных документов 240 и не удовлетворяет заранее определенным условиям, чтобы считаться частью соответствующего набора активных документов 230 (что может быть определено на основе информации 226 о соответствующем документе, связанной с данным проиндексированном документе 260),
 соответствующий документ, предназначенный для удаления 332, является недопустимым,
соответствующий документ, предназначенный для удаления 332, является недопустимым,
 соответствующий документ, предназначенный для удаления 332, был удален из Интернета,
соответствующий документ, предназначенный для удаления 332, был удален из Интернета,
 соответствующий документ, предназначенный для удаления 332, был отмечен как недопустимое содержимое, незаконное содержимое, нарушение авторских прав и так далее.
соответствующий документ, предназначенный для удаления 332, был отмечен как недопустимое содержимое, незаконное содержимое, нарушение авторских прав и так далее.
[00140] Разумеется, вышепредставленный список не является исчерпывающим и может включать в себя другие причины.
[00141] Каждый соответствующий документ, предназначенный для удаления 332 в первом подмножестве документов 330 обладает соответствующим идентификатором 334 документе, соответствующим идентификатором 336 части и соответствующим местоположением 338 части, причем соответствующее местоположение 338 части указывает на местоположение соответствующего документа, предназначенного для удаления 332 в соответствующей части.
[00142] Данный соответствующий документ, предназначенный для добавления 342, включенный во второе подмножество документов 340, может быть включен в запрос 310 по одной или нескольким из следующих причин:
 соответствующий документ, предназначенный для добавления 342, был недавно "просмотрен" или обнаружен множеством поисковых роботов 122 в Сети, и может быть одним из множества документов 117,
соответствующий документ, предназначенный для добавления 342, был недавно "просмотрен" или обнаружен множеством поисковых роботов 122 в Сети, и может быть одним из множества документов 117,
 соответствующий документ, предназначенный для добавления 342, был недавно добавлен (что может включать в себя добавление или удаление информации, содержащей в соответствующем документе, предназначенном для добавления 342),
соответствующий документ, предназначенный для добавления 342, был недавно добавлен (что может включать в себя добавление или удаление информации, содержащей в соответствующем документе, предназначенном для добавления 342),
 соответствующий документ, предназначенный для добавления 342, не был ранее индексирован сервером 120 индексации и/или был определен как "полезный" документ для сервера 140 поисковой системы (например, с помощью алгоритма машинного обучения сервера 120 индексации).
соответствующий документ, предназначенный для добавления 342, не был ранее индексирован сервером 120 индексации и/или был определен как "полезный" документ для сервера 140 поисковой системы (например, с помощью алгоритма машинного обучения сервера 120 индексации).
[00143] Разумеется, вышепредставленный список не является исчерпывающим и может включать в себя другие причины.
[00144] Каждый соответствующий документ, предназначенный для добавления 342, во втором подмножестве документов 340, обладает соответствующим идентификатором 344 документа, и соответствующей информацией 349 о документе.
[00145] При получении запроса 310, сервер 120 индексации может идентифицировать, на основе по меньшей мере одного из соответствующего идентификатора 334 документа, соответствующего идентификатора 336 части и соответствующего местоположения 338 части каждого соответствующего документа, предназначенного для удаления 332 первого подмножества документов 330, набора частей 360, каждой соответствующей части 362 из набора частей 360, включая по меньшей мере один соответствующий документ, предназначенный для удаления 332.
[00146] Сервер 120 индексации может вычислять, для каждой соответствующей части 362 из множества частей 360, и соответствующий обновленный активный размер 364, соответствующий обновленный общий размер 366 и соответствующее соотношение 368 соответствующего обновленного активного размера 364 и обновленного общего размера 366.
[00147] Соответствующий обновленный активный размер 364 - это размер соответствующего набора активных документов 230 в соответствующей части 362, соответствующий обновленный активный размер 364 не включает в себя размеры документов первого подмножества документов 330, из соответствующей части 362. Полученный обновленный активный размер 364 может быть выражен как:

[00148] где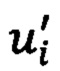 - соответствующий обновленный активный размер 364, ui -соответствующий активный размер 232, и х - заранее определенный пороговый размер 315, и i - идентификатор 224 части для данной части 362.
- соответствующий обновленный активный размер 364, ui -соответствующий активный размер 232, и х - заранее определенный пороговый размер 315, и i - идентификатор 224 части для данной части 362.
[00149] Соответствующий обновленный общий размер 366 - это размер соответствующей доли из множества проиндексированных документов 252 в соответствующей части 362, соответствующий обновленный общий размер 366 не включает в себя документы первого подмножества документов 330, из соответствующей части 362. Полученный обновленный общий размер 366 может быть выражен как:

[00150] где - соответствующий обновленный общий размер 366, si - соответствующий общий размер 254, и х - заранее определенный пороговый размер 315, и i - идентификатор 224 части для данной части 362.
- соответствующий обновленный общий размер 366, si - соответствующий общий размер 254, и х - заранее определенный пороговый размер 315, и i - идентификатор 224 части для данной части 362.
[00151] Сервер 120 индексации может вычислять, для каждой соответствующей части 362 из набора частей 360, соответствующее соотношение 368 соответствующего обновленного активного размера 364 к соответствующему обновленному размеру 366, которое может быть выражено как:

[00152] где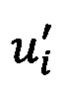 - соответствующий обновленный активный размер 364, и
- соответствующий обновленный активный размер 364, и - соответствующий обновленный общий размер 366.
- соответствующий обновленный общий размер 366.
[00153] Сервер 120 индексации может далее сортировать набор частей 360 на основе соответствующего отношения 368. Сервер 120 индексации может выбирать подмножество частей 370, включая число к частей из набора частей 360 для создания копии в доле 280 обновления базы 146 данных поискового индекса для получения подмножества частей-кандидатов 380. Подмножество частей-кандидатов 380 включает в себя заранее определенное число частей-кандидатов 381, равное к, причем заранее определенное число частей-кандидатов 381 обладает минимальным соответствующим соотношением 368:

[00154] В некоторых вариантах осуществления настоящей технологии, подмножество частей-кандидатов 380 может включать в себя части из набора частей 360, обладающих соответствующим соотношением 368 ниже заранее определенного порога. То, как именно определяется заранее определенное число частей-кандидатов 381 в подмножестве частей-кандидатов 380, будет описано более подробно далее.
[00155] Подмножество частей-кандидатов 380 может сохраняться временно в доле 280 обновления базы 146 данных поискового индекса.
[00156] Сервер 120 индексации может удалять по меньшей мере части первого подмножества документов 330 из подмножества частей-кандидатов 380. Словосочетание "по меньшей мере доля" подмножества документов 330 из подмножества частей-кандидатов 380 предназначено для удаления всех документов, включенных в первое подмножество документов 330, которые также являются частью подмножества частей-кандидатов 380, как некоторых из документов, отмеченных для удаления, в первом подмножестве документов 330, могут быть частями из набора частей 360, которые не включены в подмножестве частей-кандидатов 380.
[00157] Следует отметить, что подмножество частей 370 может не включать в себя все части, обладающие документами, отмеченными для удаления в первом подмножестве документов 330 запроса 310, поскольку части могут обладать соответствующим соотношением 368, который не находится среди к самых низких соответствующих соотношений 360. В некоторых вариантах осуществления настоящей технологии, оставшиеся документы из второго подмножества документов 330 могут добавляться к последующему запросу на обновление набора документов (не показано). В альтернативных варианте осуществления технологии, оставшиеся документы могут быть отмечены как являющиеся неактивными документами (т.е. часть соответствующего набора неактивных документов 240), и могут быть удалено в последующих запросах на обновление набора документов (не показано), когда связанные части выбирают для обновления. Эта информация о документах, предназначенных для удаления, может содержаться в списке 215 множества проиндексированных документов 250 (т.е. для отображения документа, предназначенного для удаления, но еще не удаленного как "неактивный", или просто для удаления его из записей в списке 215).
[00158] Сервер 120 индексации может вычислять соответствующий обновленный активный размер (не показано) для каждой соответствующей части-кандидата 382 подмножества частей-кандидатов 380, соответствующий обновленный активный размер (не показано) является суммой соответствующего набора активных документов (не показано) в соответствующей части-кандидате 382, которая может быть выражена как:

[00159] где u' - соответствующий обновленный активный размер (не показано), и j - идентификатор части соответствующей части-кандидата 382 и к частях подмножества частей-кандидатов 380
[00160] Сервер 120 индексации может добавлять все документы, включенные в подмножество частей-кандидатов 380 во второе подмножество документов 340.
[00161] Сервер индексации может формировать новый запрос 390, причем новый запрос 390 включает в себя второе подмножество документов 340, причем второе подмножество документов 340 включает в себя каждый соответствующий набор активных документов (не показано) из подмножества частей-кандидатов 380. Новый запрос 390 может обладать новым размером 395 запроса, который может быть выражен как:

[00162] где Δ' - новый размер 395 запроса нового запроса 390, Δ - размер 312 запроса 310, u' - соответствующий обновленный активный размер (не показано) соответствующей части-кандидата 382 в подмножестве частей-кандидатов 380, и j - соответствующий идентификатор соответствующей части-кандидата 382 из подмножества частей-кандидатов 380.
[00163] Сервер 120 индексации может распределять второе подмножество документов 340 в подмножестве частей-кандидатов 380. Второе подмножество документов 340 может распределяться в подмножестве частей-кандидатов 380 таким образом, что обновленный общий размер 405 и обновленный активный размер 410 соответствующего обновленного набора активных документов 402 в каждой соответствующей части 382 подмножества частей-кандидатов 380 может быть выражено как:

[00164] где - обновленный активный размер 410 соответствующего обновленного набора активных документов 402 в соответствующей части 382,
- обновленный активный размер 410 соответствующего обновленного набора активных документов 402 в соответствующей части 382, - обновленный общий размер 405, Δ' - размер 395 нового запроса, и k - число частей в подмножества частей-кандидатов 380.
- обновленный общий размер 405, Δ' - размер 395 нового запроса, и k - число частей в подмножества частей-кандидатов 380.
[00165] Подразумевается, что в некоторых неограничивающих вариантах осуществления настоящей технологии, второе подмножество документов 340 распределено таким образом, что каждая соответствующая часть-кандидат 382 из подмножества частей-кандидатов 380 обладает равным обновленным активным размером 410 и равным обновленным общим размером 405. В практическом смысле, это не является обязательным в каждом варианте осуществления настоящей технологии, поскольку документы могут обладать различными размерами и, следовательно, различные техники могут быть использованы для распределения второго подмножества 340 в подмножестве частей-кандидатов 380. В качестве неограничивающего примера, в альтернативных неограничивающих вариантах осуществления настоящей технологии, документы из второго подмножества документов 340 могут распределяться последовательно в каждой части-кандидате 382 до тех пор пока каждая соответствующая часть-кандидат 382 не будет "полной", т.е. пока не будет достигнут лимит каждой соответствующей части-кандидата 382.
[00166] Сервер 120 индексации может замещать подмножество частей 370 в главной доле 210 подмножеством частей-кандидатов 380, причем подмножество частей-кандидатов 380 включает в себя второе подмножество документов 340 из запроса 310.
[00167] Как следует иметь в виду, документы в подмножестве частей-кандидатов 380, которые были частью подмножества частей 370 (т.е. до получения запроса 310), которые были повторно распределены в подмножестве частей-кандидатов 380, могут обладать соответствующим идентификатором 262 документов, и их местоположение 266 обновляется в списке 215 из множества проиндексированных документов 250, содержащихся в сервере 120 индексации. Далее, список 215 множества проиндексированных документов 250 может обновляться, чтобы отобразить добавление новых документов из второго подмножества частей-кандидатов 380.
[00168] Сервер 120 индексации может удалять подмножество частей-кандидатов 380 из доли 280 обновления базы 146 данных поискового индекса.
[00169] В общем случае, заранее определенный пороговый размер 315 х, заранее определенное число частей 221 n, и заранее определенное число частей-кандидатов 381 k могут выбираться таким образом, чтобы процесс 300 обновления базы 146 данных поискового индекса был оптимальным, т.е. есть баланс между ресурсами, необходимыми для хранения базы 146 данных поискового индекса, и обновления базы 146 данных поискового индекса, а также временем вычисления. "Стоимость" обновления может выражаться следующим образом:

[00170] где х - заранее представленный пороговый размер 315, n - заранее определенное число частей 221, k - заранее определенное число частей-кандидатов 381, и y - ограничение 282 по размеру обновления.
[00171] В общем случае, условия, определенные разработчиком(ами) настоящей технологии для заранее определенного числа частей-кандидатов 381, и заранее определенное число частей 331 процесса 300 обновления выражается следующим образом:

[00172] где n - заранее определенное число частей 221, k - заранее определенное число частей-кандидатов 381.
[00173] Таким образом, оптимальный выбор заранее определенного порогового размера 315 х, заранее определенного числа частей 221 n. и заранее определенного числа частей-кандидатов 381 k позволяет сохранить ресурсы и оптимизировать процесс 300 обновления базы 146 данных поискового индекса. В некоторых вариантах осуществления настоящей технологии, алгоритм машинного обучения может быть использован для определения, на основе предыдущих процедур обновления, заранее определенного порогового размера 315 х, заранее определенного числа частей 221 n, и заранее определенного числа частей-кандидатов 381. k
[00174] С учетом того, что на Фиг. 2-5 описано то, как база 146 данных поискового индекса структурирована и обновляется при получении запроса 310 на обновление набора документов 320 в соответствии с неограничивающими вариантами осуществления настоящей технологии, далее будет описан со ссылкой на Фиг. 6, способ 600 динамического обновления базы 146 данных поискового индекса в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[00175] Способ 600 может выполняться сервером 120 индексации. В некоторых вариантах осуществления настоящей технологии, способ 600 может выполняться сервером 120 индексации и сервером 140 поисковой системы. В вариантах осуществления настоящей технологии, где по меньшей мере часть функциональности сервера 120 индексации выполняется сервером 140 поисковой системы, способ 600 может выполняться сервером 140 поисковой системы.
[00176] Способ 600 может начинаться на этапе 602.
[00177] ЭТАП 602: получение запроса на обновление набора документов в поисковом индексе, причем запрос на обновление набора документов включает в себя:
удаление первого подмножества документов, и
добавление второго подмножества документов ко множеству документов во множестве частей.
[00178] На этапе 602, сервер 120 индексации может получать запрос 310 для обновления набора документов 320, причем запрос 310 на обновление набора документов включает в себя: удаление первого подмножества документов 330 из множества частей 220 из базы 146 данных поискового индекса, и добавление второго подмножества документов 340 ко множеству частей 220 базы 146 данных поискового индекса. В некоторых вариантах осуществления технологии, запрос 130 на обновление размера документов 320 может передаваться множеству поисковых роботов 122 после процедуры просмотра.
[00179] Способ 600 далее может перейти к выполнению этапа 604.
[00180] ЭТАП 604: вычисление, для каждой части из набора из множества частей, где каждая часть включает в себя по меньшей мере один документ из первого подмножества документов:
соответствующего обновленного активного размера соответствующего набора активных документов из соответствующей доли из множества документов в данной части, причем соответствующий набор активных документов не включает в себя по меньшей мере один документ из первого подмножества документов, предназначенных для удаления,
соответствующего обновленного общего размера соответствующей доли из множества документов в данной части, причем соответствующая доля из множества документов не включает в себя по меньшей мере один документ из первого подмножества документов, предназначенных для удаления, и
соответствующее соотношение соответствующего обновленного активного размера к соответствующему обновленному общему размеру.
[00181] На этапе 604, сервер 120 индексации может вычислять, для каждой соответствующей части 362 из набора частей 360, соответствующий обновленный активный размер 364 из соответствующего набора активных документов 230 в соответствующей части 362, причем соответствующий обновленный активный размер 364 не включает в себя документы в первом подмножестве документов 330, которые являются частью соответствующей части 362. Сервер индексации может вычислять, для каждой соответствующей части 362 из набора частей 360, соответствующий обновленный общий размер 366 из соответствующей доли из множества проиндексированных документов 252 в соответствующей части 362, причем соответствующий обновленный общий размер 252 не включает в себя документы в первом подмножестве документов 330, которые являются частью соответствующей части 362. Сервер 120 индексации может вычислять, для каждой соответствующей части 362 из набора частей 360, соответствующее соотношение 368 соответствующего обновленного активного размера 364 к соответствующему обновленному размеру 366.
[00182] Способ 600 далее может перейти к выполнению этапа 606.
[00183] ЭТАП 606: создание копии, на основе соответствующего отношения, подмножества частей из набора частей для получения подмножества частей-кандидатов;
[00184] На этапе 606, сервер 120 индексации может создавать копию подмножества частей 370 в доле 280 обновления базы 146 данных поискового индекса для получения подмножества частей-кандидатов 380. Подмножество частей 370 может быть выбрано из набора частей на основе соответствующего соотношения 368, причем каждая часть в подмножестве частей 370 обладает минимальным соответствующим соотношением 368. Подмножество частей-кандидатов 380 может включать в себя число к заранее определенных частей.
[00185] Способ 600 далее может перейти к выполнению этапа 608.
[00186] ЭТАП 608: обновление сервером по меньшей мере части из набора документов в наборе частей-кандидатов, обновление включает в себя:
удаление сервером из подмножества частей-кандидатов первого подмножества документов на удаление;
добавление сервером оставшихся документов в подмножестве частей-кандидатов во второе подмножество документов.
распределение сервером второго подмножества документов в подмножестве частей-кандидатов.
[00187] На этапе 608, сервер 120 индексации может удалять по меньшей мере части первого подмножества документов 330 из подмножества частей-кандидатов 380. Сервер 120 индексации может далее добавлять все документы, включенные в подмножество частей-кандидатов 380 во второе подмножество документов 340. Сервер 120 индексации может далее распределять второе подмножество документов 340 в подмножестве частей-кандидатов 380. В общем случае, второе подмножество документов 340 может равно распределяться в подмножестве частей-кандидатов 380.
[00188] Способ 600 далее может перейти к выполнению этапа 610.
[00189] ЭТАП 610: замещение сервером подмножества частей подмножеством частей-кандидатов.
[00190] На этапе 610, сервер 120 индексации может замещать подмножество частей 370 подмножеством частей-кандидатов 380, причем подмножество частей-кандидатов 380 включает в себя второе подмножество документов 340.
[00191] Далее способ 600 завершается.
[00192] Способ 600 может повторяться каждый раз, когда сервер 120 индексации получает запрос на обновление набора документов.
[00193] Специалистам в данном области техники будет понятно, что по меньшей мере некоторые варианты осуществления настоящей технологии нацелены на расширение арсенала технический решений, направленных на конкретную техническую проблему, а именно - эффективное обновление поискового индекса с помощью сервера поисковой системы путем разделения поискового индекса на ряд частей, определения числа частей, которые могут быть использованы для обновления поискового индекса, ограничения размера обновлений, а также учета ограничения по размера поискового индекса, что может позволить сэкономить емкостные ресурсы и оптимизировать процесс обновления поискового индекса.
[00194] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом варианте осуществления настоящей технологии. Например, варианты осуществления настоящей технологии могут быть реализованы без проявления некоторых технических результатов, а другие варианты могут быть реализованы с проявлением других технических результатов или вовсе без них.
[00195] Некоторые из этих этапов, а также процессы передачи-получения сигнала являются хорошо известными в данной области техники и поэтому для упрощения были опущены в некоторых частях данного описания. Сигналы могут быть переданы-получены с помощью оптических средств (например, опто-волоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[00196] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ПОВТОРНОГО ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2019 |
|
RU2743932C2 |
| Способ и система для рекомендации свежих саджестов поисковых запросов в поисковой системе | 2018 |
|
RU2692045C1 |
| ИСПОЛНЯЕМЫЙ НА КОМПЬЮТЕРЕ СПОСОБ И СИСТЕМА ДЛЯ ПОИСКА В ИНВЕРТИРОВАННОМ ИНДЕКСЕ, ОБЛАДАЮЩЕМ МНОЖЕСТВОМ СПИСКОВ СЛОВОПОЗИЦИЙ | 2014 |
|
RU2718435C2 |
| ВЫЯВЛЕНИЕ НАВИГАЦИОННЫХ РЕЗУЛЬТАТОВ ПОИСКА | 2014 |
|
RU2680757C2 |
| ВЫЯВЛЕНИЕ НАВИГАЦИОННЫХ РЕЗУЛЬТАТОВ ПОИСКА | 2014 |
|
RU2730278C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СПОСОБ СОЗДАНИЯ АННОТИРОВАННОГО ПОИСКОВОГО ИНДЕКСА И СЕРВЕР, ИСПОЛЬЗУЕМЫЙ В НЕМ | 2015 |
|
RU2606309C2 |
| Способ и система для рекомендации медиаобъектов | 2017 |
|
RU2666336C1 |
| Система и способ формирования обучающего набора для алгоритма машинного обучения | 2018 |
|
RU2744029C1 |
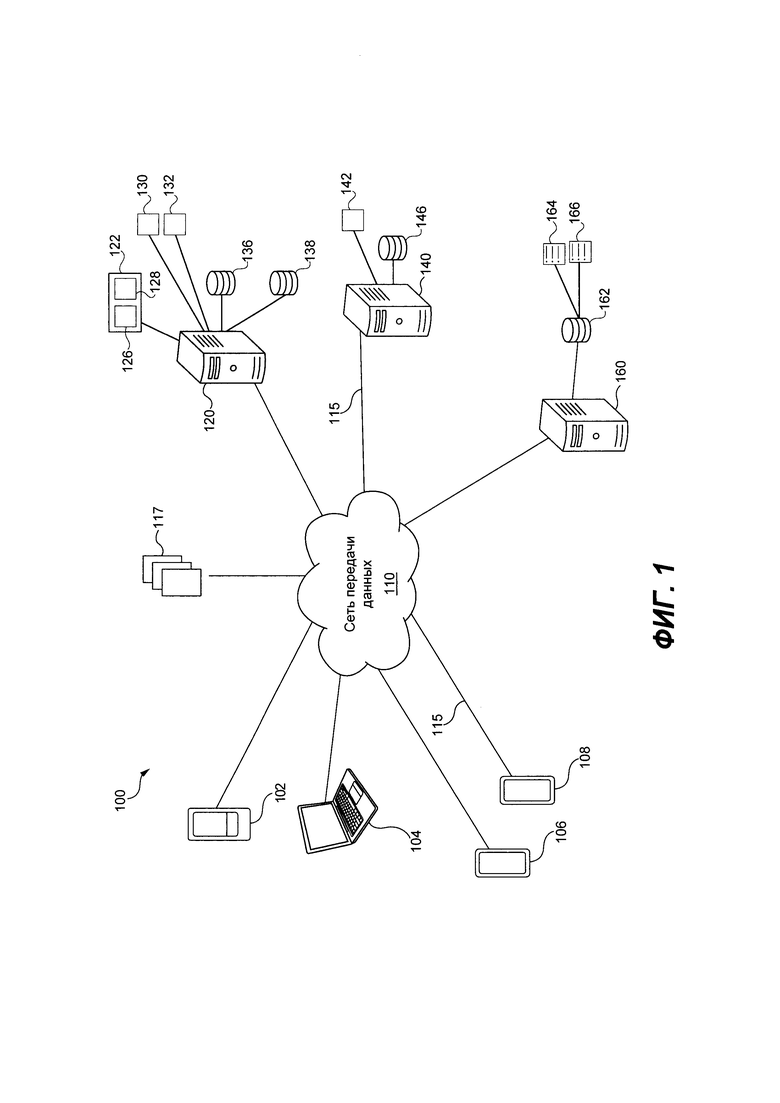


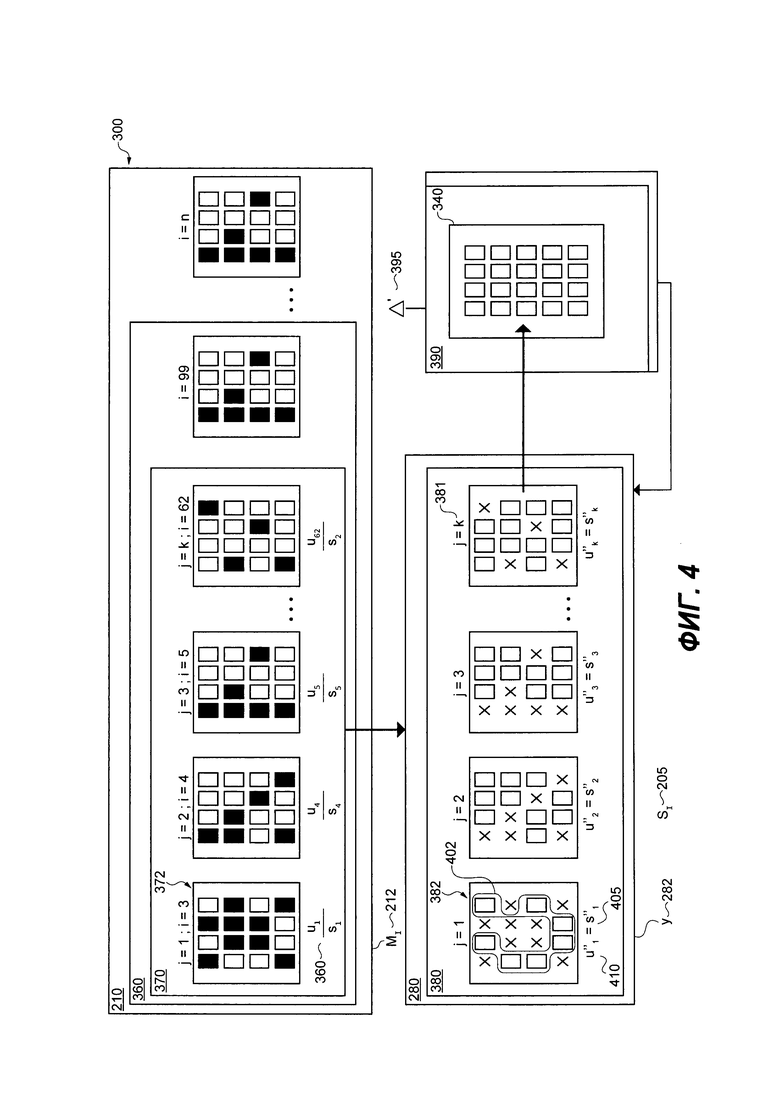
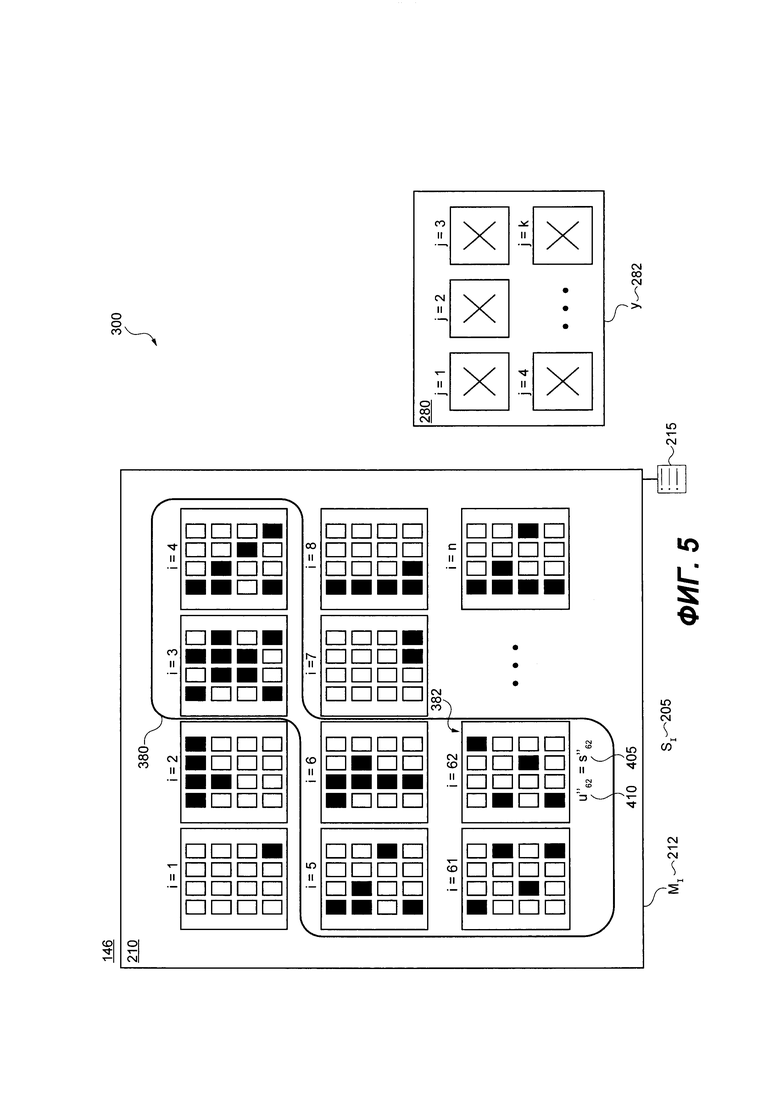
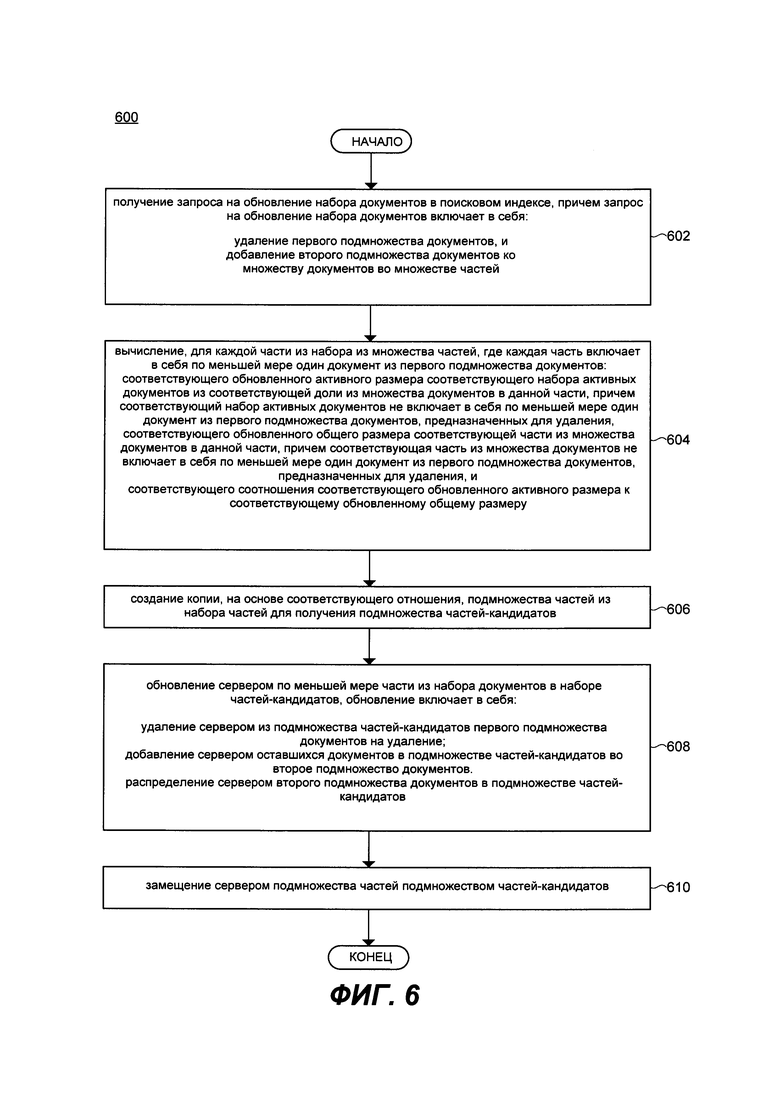
Изобретение относится к вычислительной технике. Технический результат заключается в уменьшении использования вычислительных ресурсов при обновлении базы данных поискового индекса. Способ динамического обновления поискового индекса сервера, разделенного на множество частей, каждая из которых включает в себя долю из множества документов, причем способ включает в себя: получение запроса на обновление набора документов, включая удаление первого подмножества документов, вычисление для каждой данной части из набора из множества частей, причем каждая данная часть включает в себя по меньшей мере один документ из первого подмножества: активного размера набора активных документов, причем набор активных документов не включает в себя по меньшей мере один документ, общего размера, причем общий размер не включает в себя по меньшей мере один документ, и соотношение активного размера к общему, создание копии, на основе отношения, подмножества частей для получения подмножества частей-кандидатов, обновление набора документов в подмножестве частей-кандидатов, замещение подмножества частей подмножеством частей-кандидатов. 2 н. и 24 з.п. ф-лы, 6 ил.
1. Исполняемый на компьютере способ динамического обновления поискового индекса сервера, причем поисковый индекс разделен на множество частей, каждая из которых включает в себя соответствующую долю из множества документов, причем способ выполняется на сервере и включает в себя:
получение сервером запроса на обновление набора документов в поисковом индексе, причем запрос на обновление набора документов включает в себя удаление первого подмножества документов;
вычисление сервером, для каждой части из набора из множества частей, где каждая часть включает в себя по меньшей мере один документ из первого подмножества документов:
соответствующего обновленного активного размера соответствующего набора активных документов из соответствующей доли из множества документов в данной части, причем соответствующий набор активных документов не включает в себя по меньшей мере один документ из первого подмножества документов, предназначенных для удаления,
соответствующего обновленного общего размера соответствующей доли из множества документов в данной части, причем соответствующая доля из множества документов не включает в себя по меньшей мере один документ из первого подмножества документов, предназначенных для удаления, и
соответствующего соотношения соответствующего обновленного активного размера к соответствующему обновленному общему размеру;
создание копии сервером, на основе соответствующего отношения, подмножества частей из набора частей для получения подмножества частей-кандидатов;
обновление сервером по меньшей мере части из набора документов в наборе частей-кандидатов;
замещение сервером подмножества частей подмножеством частей-кандидатов.
2. Способ по п. 1, в котором запрос на обновление набора документов в поисковом индексе далее включает в себя:
добавление второго подмножества документов ко множеству документов во множестве частей.
3. Способ по п. 2, в котором обновление по меньшей мере доли набора документов в подмножестве частей включает в себя:
удаление сервером из подмножества частей-кандидатов первого подмножества документов на удаление; и
распределение сервером второго подмножества документов в подмножестве частей-кандидатов.
4. Способ по п. 3, в котором способ дополнительно включает в себя, до этапа распределения второго подмножества документов в подмножестве частей-кандидатов:
добавление сервером оставшихся документов в подмножестве частей-кандидатов во второе подмножество документов.
5. Способ по п. 4, в котором
подмножество частей-кандидатов включает в себя заранее определенное количество частей, обладающих соответствующим наименьшим соотношением.
6. Способ по п. 5, в котором каждый соответствующий документ из множества документов поискового индекса обладает:
соответствующим размером;
местоположением в соответствующей части; и
идентификатором соответствующей части.
7. Способ по п. 6, в котором распределение второго подмножества документов в подмножестве частей-кандидатов включает в себя, для данного документа во втором подмножестве документов:
обновление сервером идентификатора соответствующей данному документу части; и
обновление сервером местоположения данного документа в соответствующей части.
8. Способ по п. 7, в котором:
набор документов для обновления связан с размером обновления; и
размер обновления меньше заранее определенного порогового размера обновления.
9. Способ по п. 8, в котором каждая данная часть из множества частей включает в себя:
соответствующий набор активных документов обладающий соответствующим активным размером;
соответствующий набор неактивных документов обладающий соответствующим неактивным размером; и
соответствующую долю из множества документов обладающую соответствующим общим размером.
10. Способ по п. 9, в котором способ дополнительно включает в себя, до этапа вычисления:
определение сервером того, находится ли размер обновления выше заранее определенного порогового размера обновления; и
в ответ на то, что размер обновления выше заранее определенного порогового размера обновления:
разделение сервером набора документов для обновления на по меньшей мере два подмножества документов таким образом, что каждое из по меньшей мере двух подмножеств находится ниже заранее определенного порогового размера изменения; и
выполнение сервером вычисления, создания копии и обновления для каждого из по меньшей мере двух подмножеств.
11. Способ по п. 10, в котором вычисление, создание копии и обновление выполняются оффлайн.
12. Способ по п. 10, в котором:
сервер является сервером поисковой системы; и
каждый соответствующий набор неактивных документов во множестве частей поискового индекса включает в себя по меньшей мере одно из:
документы, с которыми не было пользовательских взаимодействий в ответ на любой запрос в течение заранее определенного периода времени, и
документы, которые не были представлены в ответ на любой запрос в течение заранее определенного периода времени
13. Способ по п. 10, в котором:
сервер соединен с устройством хранения, включающим первую долю и вторую долю;
поисковый индекс хранится в первой доле;
подмножество частей-кандидатов хранится во второй доле; и
ограничение по размеру первой доли ниже ограничения по размеру второй доли.
14. Система для динамического обновления поискового индекса, причем поисковый индекс разделен на множество частей, каждая из которых включает в себя соответствующую долю из множества документов, причем система включает в себя:
процессор;
постоянный машиночитаемый носитель компьютерной информации, содержащий инструкции;
процессор, при выполнении инструкций, настраиваемый на возможность осуществить:
получение запроса на обновление набора документов в поисковом индексе, причем запрос на обновление набора документов включает в себя удаление первого подмножества документов;
вычисление, для каждой части из набора из множества частей, где каждая часть включает в себя по меньшей мере один документ из первого подмножества документов:
соответствующего обновленного активного размера соответствующего набора активных документов из соответствующей доли из множества документов в данной части, причем соответствующий набор активных документов не включает в себя по меньшей мере один документ из первого подмножества документов, предназначенных для удаления,
соответствующего обновленного общего размера соответствующей доли из множества документов в данной части, причем соответствующая доля из множества документов не включает в себя по меньшей мере один документ из первого подмножества документов, предназначенных для удаления, и
соответствующего соотношения соответствующего обновленного активного размера к соответствующему обновленному общему размеру;
создание копии, на основе соответствующего отношения, подмножества частей из набора частей для получения подмножества частей-кандидатов;
обновление по меньшей мере доли из набора документов в наборе частей-кандидатов;
замещение подмножества частей подмножеством частей-кандидатов.
15. Система по п. 14, в которой запрос на обновление набора документов в поисковом индексе далее включает в себя
добавление второго подмножества документов ко множеству документов во множестве частей.
16. Система по п. 15, в которой для обновления по меньшей мере доли набора документов в подмножестве частей процессор выполнен с возможностью осуществлять:
удаление из подмножества частей-кандидатов первого подмножества документов на удаление; и
распределение второго подмножества документов в подмножестве частей-кандидатов.
17. Система по п. 16, в которой процессор выполнен с дополнительной возможностью осуществлять, до этапа распределения второго подмножества документов в подмножестве частей-кандидатов,
добавление оставшихся документов в подмножестве частей-кандидатов во второе подмножество документов.
18. Система по п. 17, в которой:
подмножество частей-кандидатов включает в себя заранее определенное количество частей, обладающих соответствующим наименьшим соотношением.
19. Система по п. 18, в которой каждый соответствующий документ из множества документов поискового индекса обладает:
соответствующим размером;
местоположением в соответствующей части и
идентификатором соответствующей части.
20. Система по п. 19, в которой для распределения второго подмножества документов в подмножестве частей-кандидатов процессор выполнен с дополнительной возможностью осуществлять, для данного документа во втором подмножестве документов:
обновление идентификатора соответствующей данному документу части и обновление местоположения данного документа в соответствующей части.
21. Система по п. 20, в которой:
набор документов для обновления связан с размером обновления и
размер обновления меньше заранее определенного порогового размера обновления.
22. Система по п. 21, в которой каждая данная часть из множества частей включает в себя:
соответствующий набор активных документов обладающий соответствующим активным размером;
соответствующий набор неактивных документов обладающий соответствующим неактивным размером; и
соответствующую долю из множества документов обладающую соответствующим общим размером.
23. Система по п. 22, в которой система далее выполнена с возможностью, до этапа вычисления:
определения того, находится ли размер обновления выше заранее определенного порогового размера обновления; и
в ответ на то, что размер обновления выше заранее определенного порогового размера обновления:
разделения набора документов для обновления на по меньшей мере два подмножества документов таким образом, что каждое из по меньшей мере двух подмножеств находится ниже заранее определенного порогового размера изменения; и
выполнения вычисления, создания копии и обновления для каждого из по меньшей мере двух подмножеств.
24. Система по п. 23, в которой вычисление, создание и обновление выполняются оффлайн.
25. Система по п. 22, в которой:
каждый соответствующий набор неактивных документов во множестве частей поискового индекса включает в себя по меньшей мере одно из:
документы, с которыми не было пользовательских взаимодействий в ответ на любой запрос в течение заранее определенного периода времени, и
документы, которые не были представлены в ответ на любой запрос в течение заранее определенного периода времени
26. Система по п. 22, в которой:
система соединена с устройством хранения, включающим первую долю и вторую долю;
поисковый индекс хранится в первой доле;
подмножество частей-кандидатов хранится во второй доле; и
ограничение по размеру первой доли ниже ограничения по размеру второй доли.
| US 8949247 B2, 03.02.2015 | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| US 7702614 B1, 20.04.2010 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| СПОСОБ И СИСТЕМА ДЛЯ ИНДЕКСИРОВАНИЯ И ПОИСКА В БАЗАХ ДАННЫХ | 2005 |
|
RU2398272C2 |

