ПЕРЕКРЕСТНАЯ ССЫЛКА
[01] Отсутствует
ОБЛАСТЬ ТЕХНИКИ
[02] Настоящая технология относится к исполняемым на компьютере способам и системам для поиска в инвертированном индексе, обладающем множеством списков словопозиций.
УРОВЕНЬ ТЕХНИКИ
[03] На сегодняшний день большие центры обработки данных располагают коллекциями данных, содержащими миллиарды элементов данных. В подобных больших коллекциях элементов данных поиск конкретных элементов, которые удовлетворяют условиям какого-либо поиска, является задачей, которая требует значительных затрат вычислительных мощностей и занимает существенное количество времени.
Поисковые системы - Общее Описание
[04] Обычно при создании систем эффективного управления коллекциями данных, элементы данных индексируются в соответствии с некоторыми или всеми возможными поисковыми терминами, которые могут содержаться в поисковых запросах. Таким образом, системой обычно создается "инвертированный индекс" набора данных, он размещен на системе и обновляется ею. Инвертированный индекс будет содержать большое число "списков словопозиций", которые будут просмотрены в момент выполнения поискового запроса. Каждый список словопозиций соответствует потенциальному поисковому термину и содержит "словопозиций", которые ссылаются на элементы данных в коллекции данных, включающие поисковый термин (или иным образом удовлетворяющие другим условиям, которые выражены в поисковом термине). Например, если элементы данных являются текстовыми документами, что часто является справедливым для поисковых систем в Интернете (или "Вебе"), то поисковые термины являются индивидуальными словами (и/или их наиболее частыми сочетаниями), и инвертированный индекс содержит один список словопозиций для каждого слова, которое было обнаружено по меньшей мере в одном из документов.
[05] Поисковые запросы, особенно те, которые были созданы пользователями, обычно представляют собой список из одного или нескольких слов, которые являются "поисковыми терминами" поискового запроса. Каждый такой поисковый запрос может быть запросом поисковой системе найти каждый элемент данных в коллекции данных, который содержит все поисковый термины, указанные в поисковом запросе. Обработка поискового запроса будет включать в себя поиск в одном или нескольких списках словопозиций инвертированного индекса. Как было указано выше, обычно каждому поисковому термину в поисковом запросе соответствует список словопозиций. Проводится поиск по спискам словопозиций, поскольку их удобно хранить и обрабатывать в быстродействующем запоминающем устройстве, в отличие от самих элементов данных (элементы данных обычно хранятся в запоминающем устройстве более медленного действия). В общем случае это позволяет выполнять поисковые запросы с куда большей скоростью.
QIR & QSR
[06] Обычно, каждый элемент данных в наборе данных является пронумерованным. Вместо того, чтобы быть упорядоченными в хронологическом, географическом или алфавитном порядке в наборе данных, элементы данных обычно упорядочиваются (и, соответственно, нумеруются) в пределах набора данных в порядке убывания того, что известно в данной области техники как "релевантность, не зависящая от запроса" (QIR) (англ. "query-independent relevance"). Релевантность, не зависящая от запроса (QIR) является системно-вычисляемым эвристическим параметром, который определяется тем, что элементы данных с наиболее высоким показателем релевантности, не зависящей от запроса (QIR), статистически с большей вероятностью будут считаться релевантными для инициатора поиска. Элементы данных в коллекции данных будут упорядочены таким образом, что элементы с более высокой релевантностью, не зависящей от запроса (QIR), будут находиться в начале поиска. Следовательно, они появятся в начале (или близко к нему) списка результатов поиска (который обычно расположен на нескольких страницах, и результаты из начала списка результатов поиска отображены на первой странице). Таким образом, каждый список словопозиций в инвертированном индексе будет содержать словопозиций, список ссылок на элементы данных, содержащий термин, с которым связан этот список словопозиций, причем словопозиций упорядочены в порядке убывания релевантности, не зависящей от запроса (QIR). (Это очень распространено в отношении веб-поисковых систем.)
[07] Тем не менее, должно быть очевидно, что эвристический параметр релевантности, не зависящей от запроса (QIR), может не предоставлять оптимального порядка результатов поиска в отношении данного конкретного запроса, например, в случае, если элемент данных, который в общем случае релевантен для многих поисках (т.е. обладать высокой релевантностью, не зависящей от запроса (QIR)), не является релевантным в данном конкретном запросе. Кроме того, релевантность данного конкретного элемента данных будет варьироваться от поиска к поиску. По этой причине, обычные поисковые системы реализуют различные способы фильтрации, ранжирования и/или переупорядочивания результатов поиска, чтобы они были представлены в порядке, который будет релевантным конкретному поисковому запросу, который получает эти результаты поиска. В данной области техники это известно как "релевантность, зависящая от запроса" (QSR) (англ. "query-specific relevance"). Обычно при определении релевантности, зависящей от запроса (QSR), в расчет принимаются многие параметры. Эти параметры включают в себя: различные характеристики поискового запроса; инициатора поиска; элементов данных, которые необходимо ранжировать; данные, которые были собраны в (или, в более общем случае, некоторые "знания", которые были получены из) предыдущих похожих поисках.
[08] Таким образом, общий процесс выполнения поискового запроса может быть условно разделен на две большие стадии: Первую стадию, в которой все результаты поиска собираются на основе (частично) их релевантности, не зависящей от запроса (QIR), агрегируются и упорядочиваются в порядке убывания релевантности, не зависящей от запроса (QIR); и вторую стадию, в которой по меньшей мере некоторые результаты поиска переупорядочиваются в соответствии с их релевантностью, зависящей от запроса (QSR). Далее создается новый список, упорядоченный в соответствии с релевантностью, зависящей от запроса (QSR), и этот список предоставляется инициатору поиска. Список результатов поиска обычно предоставляется по частям, начиная с части, которая содержит результаты поиска с наиболее высокой релевантностью, зависящей от запроса (QSR).
[09] Обычно, на первой стадии сбор результатов поиска останавливается после получения некоторого заранее определенного максимального числа результатов или по достижении некоторого заранее определенного минимума значения релевантности, не зависящей от запроса (QIR). В данной области техники это известно как "усечение"; и оно возникает в случаях, когда удовлетворяется условие усечения, и с большой вероятностью релевантные элементы данных уже были обнаружены.
[10] Обычно, на второй стадии, создается укороченный список (который является подмножеством результатов поиска после первой стадии), упорядоченный в соответствии с релевантностью, зависящей от запроса (QSR). Это происходит по той причине, что обычная система веб-поиска при проведении поиска по свой коллекции данных (которая содержит несколько миллиардов элементов данных) на предмет элементов данных, который удовлетворяют данному поисковому запросу, может запросто создавать список из десятков и тысяч результатов поиска (а в некоторых случаях и более). Очевидно, инициатору поиска не следует предоставлять такое количество результатов поиска. Следовательно, крайне важно сокращать число результатов поиска, которые будут фактически предоставляться инициатору запроса, до нескольких десятков, которые потенциально будут обладать наиболее высокой релевантностью для инициатора поиска.
Правило Кворума
[11] Обычные системы веб-поиска сталкиваются с проблемой того, что поисковые запросы от человека могут быть выражены неточно или не самым лучшим образом. Например, поисковый запрос может содержать поисковый термин Т (например, "perambulator" (рус. «детская коляска")), который относится к "тематике" поиска (например, "baby carriages" (рус. «детские коляски")) инициатор поиска ищет информацию о детских колясках), вместо более частого выражения "strollers" (рус. «детская коляска"). Поскольку выражение "perambulator" (рус. «детская коляска") встречается куда реже в ежедневном использовании, чем выражение "strollers" (рус. «детская коляска"), многие элементы данных, которые фактически были бы релевантными результатами поиска (в отношении тематики поиска), не будут обнаружены в конкретном поиске, который требует наличия слова "perambulator" (рус. «детская коляска"), чтобы их признали результатами поиска, поскольку они содержат выражение "stroller" (рус. «детская коляска") вместо поискового термина "perambulator" (рус. «детская коляска"). Таким образом, на первой стадии (например, сбор результатов поиска) многие элементы данных, являющиеся релевантными по тематике поиска, даже не будут включены в список результатов поиска, поскольку они не содержат термин Т.
[12] Для того, чтобы справиться с этой проблемой (и по другим причинам, которые не относятся к настоящей теме), обычные поисковые системы часто выполнены с возможностью искать не только элементы данных, которые включают вхождения каждого из поисковых терминов из поискового запроса, но и дополнительные элементы данных, в которых отсутствует один или несколько поисковых терминов (например, менее значительные поисковые термины), но, тем не менее, содержатся все остальные поисковые термины (например, более значительные поисковые термины). В данной области техники это известно как "правило кворума".
[13] В очень обобщенной форме правило кворума состоит из эвристического назначения различных весовых коэффициентов каждому из индивидуальных поисковых терминов T1, Т2, … Тn в поисковом запросе, и установление пороговой "величины кворума", которая ниже, чем общий весовой коэффициент всех поисковых терминов (т.е. сумма индивидуальных весовых коэффициентов каждого из поисковых терминов). Элементы данных, которые позволяют достичь весового коэффициента поискового кворума, считаются фактическими результатами поиска, несмотря на тот факт, что в них может отсутствовать один или несколько (например, менее важные) поисковых терминов (в данном примере "менее важные" поисковые термины это те термины, которые имеют наименьшие весовые коэффициенты). (Весовой коэффициент поискового кворума любого конкретного элемента данных в отношении любого конкретного поиска является суммой весовых коэффициентов поисковых терминов, которые фактически находятся в этом элементе данных).
[14] Например, очень простая форма применения правила кворума может быть использована для целей иллюстрации следующим образом: Поисковые термины поискового запроса могут быть разделены на незначительные поисковые термины (например, слова, которые редко используются в американском английском, слова, которые крайне часто используются в американском английском, предлоги, союзы, артикли, вспомогательные глаголы, и так далее) и значительные поисковые термины (например, поисковые термины, отличные от незначительных поисковых терминов). Общее число значительных поисковых терминов в поисковом запросе может далее быть представлено переменной К, и каждому из значительных поисковых терминов может быть назначен эквивалентный весовой коэффициент 1/К. Пороговое значение кворума может быть установлено как 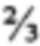 . Таким образом, любой элемент данных, чей весовой коэффициент по отношению к конкретному поисковому запросу составляет по меньшей мере , будет считаться результатом поиска для этого поискового запроса; и любой элемент данных, чей весовой коэффициент составляет менее , не будет считаться результатом поиска для этого поискового запроса. (Таким образом, по отношению к вышепредставленному примеру, элемент данных может считаться результатом поиска по отношению к поиску, содержащему поисковый термин "perambulator" (рус. "детская коляска") (слово, которое редко используется в американском английском), если он содержит все поисковые термины поискового запроса, даже если в нем отсутствует слово "perambulator" (рус. «детская коляска").)
. Таким образом, любой элемент данных, чей весовой коэффициент по отношению к конкретному поисковому запросу составляет по меньшей мере , будет считаться результатом поиска для этого поискового запроса; и любой элемент данных, чей весовой коэффициент составляет менее , не будет считаться результатом поиска для этого поискового запроса. (Таким образом, по отношению к вышепредставленному примеру, элемент данных может считаться результатом поиска по отношению к поиску, содержащему поисковый термин "perambulator" (рус. "детская коляска") (слово, которое редко используется в американском английском), если он содержит все поисковые термины поискового запроса, даже если в нем отсутствует слово "perambulator" (рус. «детская коляска").)
[15] Применение правила кворума на первой стадии поиска (т.е. стадии поиска результатов в коллекции данных), в общем случае увеличивает общее число полученных результатов поиска (в сравнении с тем случаем, когда результатами поиска считаются только те элементы данных, которые включают в себя все поисковые термины), поскольку в этом случае не все поисковые термины должны присутствовать в элементе данных, чтобы он считался результатом поиска. Таким образом, применение правила кворума на первой стадии поиска делает вторую стадию поискового процесса (ранжирование с помощью релевантности, зависящей от запроса (QSR)) еще более значимой, но одновременно и усложняет ее выполнение, поскольку количество элементов данных значительно больше того, которое было бы в случае, если бы правило кворума не применялось. Для решения этой проблемы, обычные поисковые системе применяют алгоритмы ранжирования на основе принципов машинного обучения, используя не только информацию, которая может быть получена из поискового запроса и одновременно использована, но также используя информацию, собранную в предыдущих поисковых запросах.
Данные о переходах по щелчку
[16] В связи с этим, одним из важнейших типов информации, которую можно получить из предыдущих поисковых запросов, являются данные о "переходах по щелчку". В конце выполнения любого поискового запроса инициатору поиска обычно предоставляется страница результатов поиска (SERP), на которой показана часть результатов поиска. На странице результатов поиска (SERP) каждый элемент данных, который является результатом поиска, обладает заголовком, гиперссылкой на местоположение элемента данных в сети Интернет и "сниппетом" (короткой выдержкой из тела элемента данных, которая обычно содержит некоторые или все поисковые термины из поискового запроса). Информация, показанная на странице результатов поиска (SERP), может быть использована инициатором поиска при выборе элементов данных, которые наиболее интересны ему для дальнейшего изучения. Обычно инициатор поиска выбирает только несколько элементов данных путем клика на гиперссылки, чтобы открыть их для дальнейшего чтения. Таким образом, многие другие элементы данных остаются без внимания. Несмотря на то, что не каждый из элементов данных, на которые кликнул ("перешел по щелчку") инициатор поиска, будет сочтен им как интересный элемент данных, эти элементы данных, на которые был осуществлен "переход по щелчку", тем не менее, могут быть сочтены в целом как обладающие большим интересом для инициатора поиска, чем тем данные, на которые подобный переход осуществлен не был. Такие элементы данных, на которые был осуществлен переход по щелчку, соответственно могут считаться обладающими более высокой релевантностью, зависящей от запроса (QSR), по отношению к поисковому запросу, чем тем, на которые подобный переход осуществлен не был.
[17] Подобные данные о "переходах по щелчку" обычно хранятся в базе(ах) данных поисковой системы. Эта информация может быть очень полезной для будущих похожих поисковых запросов, поскольку может быть использована далее для улучшения ранжирования результатов поиска на основании релевантности, зависящей от запроса (QSR) (для будущих поисковых запросов с теми же или почти теми же поисковыми терминами). При ранжировании результатов поиска подобного будущего запроса, данные о переходах по щелчкам из предыдущих похожих запросов могут быть использованы для назначения элементам данным, на которые был осуществлен переход по щелчку, более высокой релевантности, зависящей от запроса (QSR). Таким образом, подобные элементы данных могут быть отображены инициатору текущего поиска перед другими элементами данных, которые были найдены в результате стадии сбора (первой стадии) текущего поискового запроса, но по которым не был осуществлен переход по щелчку в прошлом в отношении аналогичных поисковых запросов.
Поисковые Системы - Типы серверов и Функциональности
[18] Для того, чтобы обеспечить наилучшее понимание обычных поисковых систем, обратимся к Фиг. 1, на которой представлен следующий пример: Обычная поисковая Интернет-система 10, включающая в себя четыре разных типа серверов (или групп серверов), показанная на Фиг. 1, т.е. сервер 12 "поискового робота", "сервер 14 "индексирования", сервер 16 "поиска" и сервер 18 "запросов", каждый из которых будет отдельно описан ниже.
[19] Сервер 12 "поискового робота" реализован как обычный поисковый интернет-робот, чьей задачей является поиск и сбор копий веб-страниц из всемирной паутины (показана как "Веб" 28 на Фиг. 1), а также сохранение этих страниц в виде "элементов данных" в базе 20 данных "элементов данных". Для каждого элемента данных сервер 12 поискового робота определяет и сохраняет в базе 20 данных элементов данных значение "релевантности, не зависящей от запроса" (QIR). (В некоторых системах эта функциональность может выполняться отдельным сервером, независимым от сервера 12 поискового робота.)
[20] Сервер 14 индексирования представляет собой обычный сервер индексирования, который нумерует и перенумеровывает элементы данных в базе 20 данных элементов данных. (Соответственно, сервер 14 индексирования получает значение
релевантности, не зависящей от запроса (QIR) для каждого элемента данных от сервера 12 поискового робота.) Сервер 14 индексирования также создает и поддерживает работу инвертированного индекса в элементах данных в базе 22 данных "инвертированного индекса". Таким образом, сервер 14 индексации отвечает за фактический просмотр каждого элемента данных и определение того, какие ключевые слова содержатся в элементе данных, и добавление словопозиций к соответствующему списку словопозиций в отношении этого элемента данных.
[21] Сервер 16 поиска представляет собой обычный сервер поиска, который получает поисковые запросы от сервера 18 запросов (см. ниже), выполняет поиск по инвертированному индексу, хранящемуся в базе 22 данных инвертированного индекса в отношении подобных поисковых запросов, и составляет список результатов поиска в порядке релевантности, не зависящей от запроса (QIR).
[22] Сервер 18 запросов представляет собой обычный сервер запросов, который получает и проводит синтаксический анализ поисковых запросов от инициаторов поиска (представленных компьютером 26); и для каждого полученного поискового запроса, сервер 18 запросов инициирует выполнение поиска сервером 16 поиска. Сервер 18 запросов получает в отношении поиска "список результатов поиска" в порядке релевантности, не зависящей от запроса (QIR), от сервера 16 поиска. Сервер 18 запросов определяет по меньшей мере для некоторых элементов данных в списке результатов поиска релевантность, зависящую от запроса (QSR), и сервер 18 запросов создает в отношении поиска список результатов поиска в порядке релевантности, зависящей от запроса (QSR). Сервер 18 запросов извлекает "заголовок" и зависящий от запроса "сниппет" из базы 20 данных элементов данных (не показана на чертежах) для каждого элемента данных в списке результатов поиска. Сервер 18 запросов предоставляет инициатору 26 поиска части списка результатов поиска в порядке релевантности, зависящей от запроса (QSR), вместе с заголовками и сниппетами. (Каждая из вышеупомянутых функциональностей сервера 18 запросов является обычной и хорошо известной в данной области техники.) Также в данной области техники известно, что сервер 18 запросов далее записывает действия инициатора поиска, являющиеся "переходами по щелчкам" на некоторые элементы данных, показанные ему в виде части результатов поиска, и сохраняет соответствующие данные в отношении переходов по щелчку "в базе 24 данных запросов". Сервер 18 запросов также ищет информацию о предыдущих запросах в базе 24 данных запросов при подготовке результатов поиска по текущему запросу и определяет порядок релевантности, зависящей от запроса (QSR), по меньшей мере некоторых результатов поиска в виде функции информации, найденной в базе 24 данных запросов, до предоставления результатов поиска инициатору поиска.
Поисковые Системы - Операции сервера
[23] С учетом описания общих функций каждого из серверов 12, 14, 16 и 18, будут описаны некоторые конкретные операции серверов 12, 14, 16 и 18. В связи с этим, сервер 12 поискового робота реализует поискового робота, который (постоянно или периодически - в зависимости от обстоятельств) исследует Всемирную паутину и ищет новые (или недавно обновленные) веб-страницы (показано на канале 30 передачи данных). Для каждого подобной найденной веб-страницы создается элемент данных в базе 20 данных элементов данных (показана на канале 30 передачи данных). В обычной поисковой интернет-системе, каждый элемент данных в базе 20 данных элементов данных включает в себя локальную копию соответствующей веб-страницы в сети Интернет, гиперссылку на оригинальную веб-страницу в сети Интернет (также называемую веб-адресом), и набор признаков элемента данных, которые назначаются элементу данных в момент его обработки поисковой системой 10. Некоторые из признаков элемента данных будут описаны здесь, но те признаки, которые не будут упомянуты в настоящем описании, также могут быть определены и использованы различными обычными поисковыми системами.
[24] В отношении к каждому новому элементу данных, выполняется первая операция - определение значения релевантности, не зависящей от запроса (QIR), элемента данных. Значения релевантности, не зависящей от запроса (QIR), используются для упорядочивания элементов данных, и обычно они являются числовой (хотя это не является обязательно) характеристикой элемента данных. Значение релевантности, не зависящей от запроса (QIR), определяется поисковой системой 10 с помощью многих различных признаков самого элемента данных (включая, среди прочего, заголовок, дату создания, местонахождение оригинальной веб-страницы и так далее), и с помощью количества и качества ссылок на этот элемент данных на других вебстраницах, а также, скорее всего, с помощью некоторых данных "об истории", которые были "выучены" системой 10 из элементов данных, которые были ранее введены в систему, из предыдущих выполненных поисковых запросов и другой традиционно используемой информации. В этом отношении, существует несколько хорошо известных в данной области техники, практичных и удобных способов определения значения релевантности, не зависящей от запроса (QIR). В большинстве обычных Интернет-систем определение значения релевантности, не зависящей от запроса (QIR) для каждого нового элемента данных выполняется сервером 12 поискового робота; тем не менее, в некоторых других, оно выполняется другим сервером, например, сервером 14 индексирования или специальным сервером релевантности, не зависящей от запроса (QIR).
[25] Каждый элемент данных, который хранится в базе 20 данных элементов данных известен системе 12 под уникальным назначаемым системой идентификатором, который обычно представляет собой порядковое число. Обычно вся коллекция элементов данных, которая управляется поисковой Интернет-системой, является слишком большой для того, чтобы содержаться на одном сервере базы данных, и, следовательно, ее обычно разделяют на несколько "шардов" базы данных. В таком случае, каждый шард обычно обладает собственной схемой нумерации элементов данных и собственной логикой выполнения поиска в своей части базы данных документов. При выполнении поискового запроса частичные списки результатов поиска от каждого шарда, после создания, объединяются в один общий список в порядке релевантности, не зависящей от запроса (QIR), который далее упорядочивается по релевантности, зависящей от запроса (QSR).
[26] Элементы данных пронумерованы системой 10 в порядке убывания их релевантности, не зависящей от запроса (QIR), а не в порядке получения их сервером 12 поискового робота. Элементы данных с одинаковой релевантностью, не зависящей от запроса (QIR), могут быть пронумерованы в любом порядке, например, в обратном хронологическом порядке (наиболее поздно полученные элементы данных обладают меньшим номером, чтобы они обнаруживались раньше, чем более старые). Следовательно, новый полученный элемент данных D обладает более низкой релевантностью, не зависящей от запроса (QIR), чем существующий элемент данных (например #999), но более высокой или одинаковой релевантностью, не зависящей от запроса (QIR), по сравнению со следующим элементом данных (#1000), тогда элемент D будет назначен #1000, а более старый #1000 становится #1001 и так далее. Следовательно, и номера элементов данных и содержимое инвертированного индекса (см. ниже) являются постоянными и периодически обновляются. Обычно нумерация (или перенумерация) элемента данных выполняется сервером 120 индексирования, но это не является обязательным.
[27] После того, как элемент данных (например, D) был получен сервером 12 поискового робота, сохранен в базе 20 данных элементов данных, ему было присвоено значение релевантности, не зависящей от запроса (QIR), и номер элемента данных (например, #1000), он передается серверу 14 индексации (канал 34 передачи данных на Фиг. 1) для дальнейшей обработки (двусторонний канал 36 передачи данных). Сервер 14 индексации управляет базой 22 данных (двусторонний канал 36 передачи данных), которая обычно содержит инвертированный индекс коллекции элементов данных, которая содержится в базе 20 данных элементов данных.
Словопозиций и Списки словопозиций
[28] Как было описано выше, инвертированный индекс обычно включает в себя ряд списков словопозиций. Сервер 14 индексации изучает новый элемент данных #1000, определяет в нем различные "поисковые термины", и для каждого поискового термина, который был найден в элементе данных, создает новую запись (т.е. "словопозицию") в соответствующем списке словопозиций.
[29] Словопозиция в списке словопозиций обычно включает в себя номер элемента данных (или другую информацию, которая является достаточной для определения номера элемента данных) и, опционально, некоторую дополнительную информацию. Каждый список словопозиций соответствует поисковому термину и включает в себя серию словопозиций, каждая из которых ссылается на те элементы данных в базе 20 данных элементов данных, которые содержат по меньшей мере одно вхождение этого поискового термина.
[30] Дополнительные данные также могут содержаться в словопозиций; например, число вхождений данного поискового термина в конкретном элементе данных; появляется ли этот поисковый термин в заголовке элемента данных и так далее. Эта дополнительная информация может зависеть от поисковой системы.
[31] Поисковые термины обычно, но не всегда, являются словами или другими строками символов. Системы веб-поиска общего назначения обычно имеют дело с практически каждым словом из огромного числа различных языков, а также с названиями, числами, символами и так далее. Также сюда можно включить "слова", обладающие часто встречающимися орфографическими ошибками. В настоящем описании любой поисковый термин может упоминаться как "слово" или "термин". Для каждого поискового термина, который был встречен по меньшей мере в одном элементе данных, сервер 14 индексации обновляет соответствующий список словопозиций или создает новый, если термин встретился впервые. Следовательно, общее число списков словопозиций может достигать нескольких миллионов. Длина конкретного списка словопозиций зависит от того, как часто используется соответствующее слово во множестве элементов данных (т.е. в сети Интернет). Очень часто используемое слово может обладать списком словопозиций длиной в миллиард записей (и даже более - без ограничений). (На практике, когда база 20 данных элементов данных делится на несколько "шардов", на каждом шарде размещается собственный инвертированный индекс 22, что существенно снижает длину списков словопозиций в каждом шарде.)
[32] В каждом списке словопозиций, словопозиций элементов данных располагаются в порядке возрастания номеров их элементов данных, т.е. в порядке убывания их релевантности, не зависящей от запроса (QIR). Следовательно, процесс индексации нового элемента данных D не ограничивается добавлением номера элемента данных D, например #1000, в список словопозиций каждого слова Тi, которое встречается в D. При назначении для D уже существующего номера #1000, каждая существующая словопозиция в каждом списке словопозиций, для элемента данных с числом равным или выше #1000, должна быть обновлена (в данном примере, увеличена на 1). В действительности обычные поисковые системы обычно выполняют эту операцию обновления периодически для серии элементов данных, которые были получены с момента предыдущего раза, когда обновлялась база 22 данных инвертированного индекса.
Обычное выполнение Поисковых запросов
[33] Элементы данных, хранящиеся в базе 20 данных элементов данных, и индексированные в базе 22 данных инвертированного индекса, могут быть использованы для поиска. Опять же, со ссылкой на Фиг. 1, поисковые запросы были введены пользователями-людьми ("инициаторами поиска", которые коллективно представлены на Фиг. 1 изображением персонального компьютера 26), и получены сервером 18 запросов (канал 50 передачи данных на Фиг. 1). Сервер 18 запросов проводит синтаксический анализ каждого полученного поискового запроса на предмет наличия различных поисковых терминов (анализ может опционально включать в себя отбрасывание вспомогательных слов, таких как предлоги и союзы, которые не будут использоваться при поиске из-за их слишком частого употребления), и может выполнять некоторые другие обычные действия. Например, поисковый запрос Q1, полученный в момент времени t0, может содержать четыре поисковых термина T1, Т2, Т3, Т4. На Фиг. 2 это представлено как Q1[T1,T2,T3,T4].
[34] Далее запрос Q1 передается через сервер 18 запросов серверу 16 поиска (канал 44 передачи данных). Последний фактически управляет базой 22 данных инвертированного индекса, в котором содержится множество списков словопозиций. В данном примере, процесс поиска, или выполнения поискового запроса, состоит из нахождения номеров элементов данных из всех элементов данных, которые содержат вхождения каждого поискового термина, указанного в поисковом запросе (как было описано выше в упрощенной форме поискового процесса; в дальнейшем примере ниже будет представлено правило кворума). Обычно это осуществляется путем параллельного изучения каждого из списков словопозиций, соответствующего поисковым терминам запроса, начиная с начала каждого списка словопозиций. В настоящем примере, списки словопозиций P1, Р2, Р3, Р4 соответствуют поисковым терминам T1, Т2, Т3, Т4 соответственно (как показано в верхней части на Фиг. 2). (В общем случае, список словопозиций, соответствующий термину Тn, в этом описании отмечен как Рn). Элемент данных, чей номер встречается в каждом списке словопозиций, релевантном поисковому запросу, считается результатом поиска (иногда также упоминаемом как "хит"), и будет помещен в список результатов поиска как следующий элемент списка результатов поиска (т.е. после "хитов", которые уже были помещены в список результатов). Таким образом, список результатов поиска по поисковому запросу составлен в порядке возрастания номеров их элементов данных, и, соответственно, в порядке убывания их релевантности, не зависящей от запроса (QIR).
[35] Это процедура нахождения дальнейших результатов поиска останавливается либо по достижении конца одного из списков словопозиций, либо при выполнении "условия усечения" (как было упомянуто ранее). В различных обычных примерах, условие усечения может, например, определяться сервером 18 запросов на основе каждого запроса и предоставляться вместе с каждым запросом Q сервером 18 запросов серверу 16 поиска; альтернативно, условие усечения может быть фиксированным по отношению к системе и быть одинаковым для всех запросов. В обоих случаях, условие усечения может быть выражено, например, в виде максимального числа элементов данных в списке результатов поиска или в виде минимального значения релевантности, не зависящей от запроса (QIR), для элемента данных, который будет включен в список результатов поиска, или в любой другой подходящей форме. В любом случае, условия усечения применяется для "выбора" лучших результатов с учетом их релевантности, не зависящей от запроса (QIR).
[36] Список результатов поиска, подготовленный сервером 16 поиска для данного запроса, например, запроса Q1, далее передается обратно сервером 16 поиска серверу 18 запросов (канал 42 передачи данных). (В нижеследующем описании Фиг. 2 и 3 список результатов поиска для запроса Qm отмечен как "R(Qm)". В условиях двухстадийного выполнения запроса, которое было описано выше, первая стадия - сбор результатов поиска - завершена, а вторая стадия - ранжирования и переупорядочивания результатов поиска - начинается. В связи с этим, сервер 18 запроса, до предоставления результатов инициатору поиска, изменяет их порядок на наиболее подходящий для данного конкретного запроса, помещая на самые верхние позиции списка те результаты поиска (элементы данных), которые обладают наиболее высокой релевантностью, зависящей от запроса (QSR), для данного конкретного запроса. Это ранжирование на основе релевантности, зависящей от запроса (QSR), и переупорядочивание первоначального списка результатов поиска в порядке релевантности, не зависящей от запроса (QIR), вероятно является наиболее сложной операцией, которую выполняет система веб-поиска, и, при этом, наиболее важной для конечного пользователя (например, инициатора поиска).
[37] Для того, чтобы определить лучшее ранжирование на основе релевантности, зависящей от запроса (QSR), для данного конкретного запроса, в расчет берется информация одновременно из многих различных источников. Часть информации, используемая для получения релевантности, зависящей от запроса (QSR), элемента данных, может быть найдена в самом элементе данных; например, общее число вхождений в элемент данных каждого поискового термина из данного поискового запроса; вхождения двух или более поисковых терминов, находящиеся вблизи друг от друга (например, в одной фразе), или, даже лучше, следующие друг за другом в том же порядке, что и в поисковом запросе; поисковые термины, находящиеся в заголовке документа, и так далее. Тем не менее, все эти ограничивающие объем технологии критерии, не обязательно отражают степень "удовлетворенности пользователя" данным элементом данных в контексте данного конкретного запроса.
[38] Следовательно, некоторые системы веб-поиска могут использовать информацию из истории, собранную из большого количества ранее выполненных поисковых запросов, и хранящуюся в базе данных. Эта "база данных запросов" показана на Фиг. 1 под номером 24, и к ней имеет доступ сервер 18 запросов по двустороннему каналу 46 передачи данных. Как известно в данной области техники, из каждого запроса можно извлечь, сохранить и обработать различную информацию, которую далее можно использовать для улучшения ранжирования на основе релевантности, зависящей от запроса (QSR), результатов следующего запроса. В контексте настоящего примера, только данные о "переходах по клику" считаются релевантными, как было вкратце упомянуто выше. В связи с этим, пользователь U1, который ввел поисковый запрос, например, Q1[T1,T2,T3,T4], получает от сервера 18 запросов список результатов поиска, который был найден для запроса сервером 16 поиска, и далее ранжирован сервером 18 запросов (как было описано выше). Во многих случаях, список очень длинный, и он передается пользователю по частям (или "страницам"), в каждой из которых, например, по 20 записей. Каждая запись является "кликабельной" в том смысле, что при нажатии пользователем на нее мышкой или другим указывающим устройством, открывается элемент данных, например, в другом окне или в другой вкладке браузерного приложения на компьютере пользователя. Для пользователя является преимуществом возможность быстрого просмотра каждого результата поиска до его открытия, и ему(ей) не приходится тратить своей время на открытие каждого элемента данных в попытке найти нужный. Поэтому сервер 18 запросов обычно предоставляет пользователю "сниппет", короткую выдержку (или несколько еще более коротких фрагментов, собранных вместе) из элемента данных, в которых встречаются запрошенные поисковые термины в достаточно понятном контексте. После просмотра сниппета (а также другой предоставляемой информации) пользователь может решить, открывать ему элемент данных (путем "перехода по щелчку") или нет.
Пример традиционного использования данных о Переходах по щелчку
[39] При открытии элемента данных, пользователь может посмотреть его более внимательно и решить, заинтересован(а) ли он(а) в нем или нет. Поскольку поисковая система не может "знать", является ли элемент данных интересным для пользователя, поисковая система может записать только факт того, что пользователь перешел по щелчку к данному элементу данных, который был на странице результатов поиска. Это происходит по той причине, что страница результатов поиска, обычно предоставляемая пользователю поисковой системой в веб-приложении, как правило, запрограммирована таким образом, что каждый "переход по щелчку" на странице сначала передается обратно поисковой системе (в настоящем примере, серверу 18 запросов системы 10). Сервер 18 запросов далее перенаправляет пользователя к вебстранице запрашиваемого элемента данных (или, альтернативно, показывает ему(ей) копию элемента данных, сохраненную в базе 20 данных элементов данных). В этом случае, сервер 18 запросов способен записать все переходы по щелчку, выполненные пользователями на страницах результатов поиска, которые были предоставлены им.
[40] Статически подтверждено, что среди результатов поиска по запросу, которые были показаны инициатору поиска, те, к которым был осуществлен переход по щелчку, являются в среднем наиболее интересными, чем те, к которым подобный переход осуществлен не был. Кроме того, последний элемент данных, к которому был осуществлен переход по щелчку, в списке, то есть, тот, после которого пользователь перестал далее просматривать список и не перешел по щелчку ни на какие другие элементы, считается в среднем еще более интересным пользователю, чем все документы, к которым ранее был осуществлен переход по щелчку. Эти статистические предположения и "история переходов по щелчку" используются для наилучшего ранжирования списка результатов поиска для каждого последующего запроса, путем использования "истории переходов по щелчку" из предыдущих поисковых запросов.
[41] На Фиг. 2 представлена база 18 данных запросов, которая хранит данные о переходах по щелчку от прошлых запросов в форме записей <Dk; Qm[T1,T2,T3, …Tn]>, которые указывают на документ Dk, на который был осуществлен переход по щелчку инициатором поиска Qm[T1, Т2, Т3, … Тn], когда он(а) просматривал(а) результаты поиска для того запроса. Опционально, как известно в данной области техники, также могут быть записаны (и использованы в какой-то момент далее) данные, относящиеся к инициатору поиска (например, IP-адрес), время выполнения запроса; и так далее. Вышепредставленная коллекция записей представляет собой базу данных, которая может быть сортирована по переходам по щелчку на документы или по некоторым или всем поисковым поисковым терминам, использованным в запросах, или любым другим способом.
[42] На Фиг. 2, например, пользователь U1 вводит запрос Q1[T1,T2,T3,T4], который выполняется сервером 16 поиска путем просмотра списков словопозиций P1, Р2, Р3, Р4 для поисковых терминов T1, Т2, Т3, Т4 (соответственно) поискового запроса Q1. Например, элемент D1 данных (конкретнее, словопозиция (т.е. ссылка) для D1) находится в каждом из этих списков словопозиций; следовательно, элемент D1 включен в список R(Q1) результатов поиска для запроса Q1. Список результатов поиска, после ранжирования на основе релевантности, зависящей от запроса (QSR), предоставляется пользователю U1. Пользователь U1 переходит по щелчку к записи, соответствующей элементу D1 данных в списке, предполагая, что он может быть в нем заинтересован. (Факт того, что был осуществлен переход по щелчку, схематически указан на Фиг. 2 и Фиг. 3 символом звездочки "*".) Эта информация хранится в базе 24 данных запросов в виде записи <D1; Q1[T1, Т2, Т3, Т4]>.
[43] В более поздний момент времени, путем сравнения запросов с "почти такими же" поисковыми запросами и/или с "в основном такими же" списками результатов поиска, особенно, с теми, в которых "в основном такие же" подмножества результатов, по которым был осуществлен "переход по щелчку", система 10 (а именно - сервер 18 запросов) может устанавливать некоторую "степень похожести" среди предыдущих запросов, а также между следующим запросом Q2, и некоторым из предыдущих запросов, например, Q0. Поскольку то, как это конкретно происходит, является сложным и хорошо известным процессом, детали его не будут представлены здесь; для настоящих целей важно понимать, как информация от предыдущих запросов, похожих на текущий запрос Q2, обычно используется для помощи поисковой системе в предоставлении наиболее подходящих результатов инициатору текущего поиска.
[44] С этой целью, если текущий запрос, например, Q2, считается похожим на некоторый предыдущий запрос, например, Q1, и если среди результатов поиска для Q2 есть элемент данных D1, для которого существует запись <D1; Q1[…]> в базе 24 данных запросов, означающая, что документ D1 был среди результатов для Q1 и, более того, что по нему был осуществлен переход по щелчку предыдущим инициатором поиска Q1, то элемент данных D1 считается обладающим более высокой релевантностью, зависящей от запроса (QSR), для Q2, чем другие результаты для Q2 с теми же или аналогичными характеристиками. Другими словами, представленный выше критерий "осуществлен переход по щелчку в одном или нескольких похожих запросах", хоть и не является решающим, тем не менее, используется как один из критериев, который повышает релевантность, зависящую от запроса (QSR), для Q2, и, следовательно, продвигает D1 выше в упорядоченном списке результатов поиска для Q2. Таким образом, D1 будет показан инициатору поиска в списке результатов поиска ранее (т.е. на более высокой позиции в списке), чем он был бы показан в том случае, если бы ранее по нему не был осуществлен переход по щелчку.
[45] Это иллюстративно показано на Фиг. 2 Пользователь U2 (который может являться тем же пользователем, что и U1 или же другим пользователем) вводит поисковый запрос Q2[T1,Т2,Т4,Т5], который отличается от ранее введенного запроса Q1[T1,T2,T3,T4], который включал поисковый термин Т3, но в котором отсутствует другой поисковый термин Т5. Опять же, сервер 16 поиска просматривает списки словопозиций, соответствующие поисковым терминам, в этот раз это списки словопозиций P1, Р2, Р4, Р5, соответствующие поисковым терминам T1, Т2, Т4, Т5 запроса Q2. (На Фиг. 2 это показано во втором изображении базы 22 данных индексирования, обозначенной цифрой 22(2).) Например, тот же самый элемент D1 данных снова находится в каждом из этих списков словопозиций; следовательно, элемент D1 включен в список R(Q2) результатов поиска для запроса Q2. Тем не менее, на этот раз список R(Q2) результатов поиска содержит слишком много других документов с предположительно более высокой релевантностью для пользователя U2, чтобы документ D1 был ему показан. Это схематично представлено на Фиг. 2 путем помещения D1 на более низкую позицию в списке R(Q2).
[46] В соответствии с обычным использованием данных о переходах по щелчку, тем не менее, сервер 18 запросов (не показан на Фиг. 2) до представления списка R(Q2) результатов поиска пользователю U2, проверяет базу 24 данных запросов и обнаруживает там (среди, предположительно, другой информации) ранее сохраненную запись <D1;Q1[T1,T2,T3,T4]>, которая показывает, что на документ D1 был осуществлен переход по щелчку в одном из предыдущих запросов, а именно в запросе Q1[Т1,Т2,Т3,Т4], который отличается от текущего запроса Q2[T1,T2,T4,T5] только одним из четырех своих поисковых терминов. Факт перехода по щелчку добавляет некоторое дополнительное значение документу D1, и сервер 18 запросов повышает позицию документа D1 в списке R(Q2), что показано пунктирной дугой на Фиг. 2, так что документ D1 теперь будет представлен пользователю U2.
Пример традиционного использования Правила Кворума
[47] Прежде чем продолжить, полезно будет иметь представление о другом понятии, которое используется в данной области техники (и был кратко представлен выше): кворум в многокритериальном поиске данных. В общем случае, поиска на основе кворума означает, что при выполнении поиска по многокритериальному запросу, результатами поиска являются не только те элементы данных, которые удовлетворяют всем критериям поискового запроса, но и другие элементы данных, которые возможно удовлетворяют только одному критерию в соответствии с "правилом кворума".
[48] Правило кворума обычно выражено в терминах минимального значения wq суммы "весовых коэффициентов" всех поисковых критериев, которые удовлетворяются для данного элемента данных или, конкретнее, из всех поисковых терминов в запросе, которые содержатся в элементе данных. Итак, для запроса Qm[T1,T2, … Тn] с n терминов, соответствующие весовые коэффициенты терминов будут установлены как w1, w2, … wn, а затем величина wq будет зафиксирована на некотором значении ниже суммы w1+w2+ … +wn, так что некоторые из элементов данных, которые не содержат все поисковые термины T1, Т2, … Тn, будут, тем не менее, считаться результатами поиска, если сумма весовых коэффициентов всех терминов, которые содержит такой элемент данных, не опускается ниже значения wq кворума.
[49] Более конкретно,
- пусть occ(T,D) - булева функция, указывающая на наличие термина Т в элементе D данных, которая равна 1, если Т встречается хотя бы один раз в D, и равна 0 в противном случае;
- пусть w(T,Q) - весовой коэффициент термина Т в запросе Q, который содержит этот термин; и
- пусть w(D, Q) - весовая функция документа D для запроса Q[T1, Т2, … Тn], определяемая как:
w(D,Q)=w(T1,Q)⋅occ(T1,D)+w(T2,Q)⋅occ(T2,D)+ … +w(Tn,Q)⋅occ(Tn,D).
- Тогда условие кворума означает, что для значения wq кворума, каждый документ D, для которого w(D,Q)≥wq, считается результатом поиска для Q.
[50] Как было описано выше, наиболее простая форма правила кворума соответствует случаю, когда все поисковые термины в запросе обладают одинаковым весовым коэффициентом, и правило кворума устанавливается таким образом, что позволяет некоторой доле терминов отсутствовать в документе. Например, все термины в запросе Q с числом терминов n, могут быть определены как имеющие одинаковый весовой коэффициент 1 (таким образом их общий весовой коэффициент равен n), и значение wq кворума устанавливается на 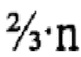 . Другая форма функционально того же правила кворума, может состоять из назначения для запроса Q[T1,T2, … Тn] с любым числом n поисковых терминов w(T1,Q)=w(T2,Q)= … =w(Tn,Q)=1/n (таким образом, что общий весовой коэффициент равен 1), и установление
. Другая форма функционально того же правила кворума, может состоять из назначения для запроса Q[T1,T2, … Тn] с любым числом n поисковых терминов w(T1,Q)=w(T2,Q)= … =w(Tn,Q)=1/n (таким образом, что общий весовой коэффициент равен 1), и установление 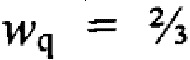 . В последующих примерах в основном будет использована эта простая форма правила кворума.
. В последующих примерах в основном будет использована эта простая форма правила кворума.
Пример
[51] Как было вкратце описано выше, в контексте веб-поиска, необходимость в определении и применении правила кворума возникает по причине того, что пользователи часто выражают свои поисковые запросы в таком виде, что некоторые поисковые термины, несмотря на их соответствие "тематике" данного поискового запроса, фактически не появляются в текстовом виде в некоторых элементах данных, которые могут потенциально быть интересными этим пользователям. Эта идея снова показана ниже, но на этот раз в более подробном примере.
[52] Предположим, что поисковый запрос имеет следующий вид: "hybrid cars fuel consumption" (рус. "расход топлива гибридным автомобилем"), и отмечен как Q3['hybrid', 'cars', 'fuel', 'consumption'] или просто Q3. Предположим, что пользователь хочет сравнить гибридные автомобили по степени потребления топлива. Тем не менее, многие веб-страницы, которые могут быть потенциально интересными пользователю, не содержат слова "consumption" (рус. «расход") в текстовом виде. Вместо этого они могут содержать выражение "miles per gallon" (рус. "миль на галлон"), аббревиатуру "mpg", такие качественные понятия, как "economy" (рус. «экономичный") или "efficiency" (рус. «эффективный"), или многие другие понятия. Следовательно, поисковый термин "consumption" (рус. «расход"), если считать его наличие необходимым, не позволит всем подобные веб-страницам появиться в списке результатов поиска для запроса Q3. В соответствии с вышеописанным простейшим правилом кворума (в котором у всех поисковых терминов одинаковые весовые коэффициенты и значение кворума равно 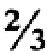 ), однако, предполагая, что в представленном выше запросе тот же весовой коэффициент
), однако, предполагая, что в представленном выше запросе тот же весовой коэффициент 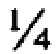 назначен для каждого из четырех поисковых терминов, каждый элемент данных, включающий только 3 из 4 поисковых терминов (включая те, которые не включают в себя термин "consumption" (рус. "расход") - но включают три других термина) будут обладать общим весовым коэффициентом
назначен для каждого из четырех поисковых терминов, каждый элемент данных, включающий только 3 из 4 поисковых терминов (включая те, которые не включают в себя термин "consumption" (рус. "расход") - но включают три других термина) будут обладать общим весовым коэффициентом 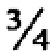 . Поскольку выше, чем значение кворума , такие документы будут включены в список результатов поиска.
. Поскольку выше, чем значение кворума , такие документы будут включены в список результатов поиска.
[53] Инициатор запроса Q3, например, U3, при просмотре списка результатов поиска и чтении заголовков и сниппетов индивидуальных результатов, скорее всего, не обратит внимания на элементы данных, в которых речь идет не о "hybrid" (рус. "гибридный") автомобилях, а только об обычных (такие документы могли быть включены в список результатов поиска по тому причине, что, несмотря на отсутствие термина "hybrid" (рус. «гибридный"), они содержали три остальных поисковых термина запроса Q3). А элемент данных "hybrid car ratings fuel efficiency" (рус. «эффективность расхода топлива гибридных автомобилей") (несмотря на то, что он не включает в себя термин "consumption" (рус. «расход")), например, элемент данных D2, может привлечь интерес пользователя. Когда далее происходит нажатие на гиперссылку для открытия элемента данных D2, этот "переход по щелчку" будет зафиксирован и записан сервером 18 запросов. Запись перехода по щелчку, скорее всего, будет сохранена в базе 24 данных запросов для дальнейшего использования для улучшения ранжирования на основе релевантности, зависящей от запроса (QSR), результатов поиска будущих запросов.
[54] Этот пример будет использован далее в настоящем описании как вариант осуществления настоящей технологии.
[55] Несмотря на то, что с помощью описанных процедур, обычные поисковые системы предоставляют инициаторам запроса релевантные результаты поиска, всегда остаются возможности для улучшения технологий поисковой системы в этой области.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[56] Задачей предлагаемой технологии является предоставление пользователю поисковой системы, улучшенной по меньшей мере в одном аспекте по сравнению по меньшей мере с некоторыми из обычных поисковых систем.
[57] Для этого предполагается, что есть потенциальные возможности использования данных о переходах по щелчку (кроме обычных, которые были описаны выше), которые не были реализованы в обычных поисковых системах. Конкретно, как было описано выше, данные о переходах по щелчку на данный момент момент учитываются на второй стадии поиска (на этапе ранжирования результатов поиска на основе релевантности, зависящей от запроса (QSR)). Данные о переходах по щелчку на текущий момент не используются на первой стадии поиска (сбор результатов поиска). Без установки ограничений какой-либо конкретной теорией, одной из причин, по которой это никогда не делалось ранее, является тот факт, что в условиях очень жестких требований ко времени, за которое поисковая система должна выдавать результаты поиска, просматривались только списки словопозиций, и никакая другая информация не учитывалась.
[58] Предполагается, тем не менее, что в некоторых случаях, из-за того, что данные о переходах по щелчку не были использованы на первой стадии поиска, элементы данные, которые потенциально могли быть релевантными (на основе данных о переходах по щелчку и, таким образом, истории о предыдущих поисковых запросах), не были включены в результаты поиска, поскольку такие элементы данных не были собраны на первой стадии поиска. (Использование данных о переходах по щелчку на второй стадии не исправляет эту проблему, данные о переходах по щелчку на этой стадии используются только для ранжирования результатов поиска, которые были собраны на первой стадии, и не добавляют другие несобранные элементы данных в результаты поиска.)
[59] Для иллюстрации используется следующий пример: Первый поисковый запрос Q3 обладает поисковыми терминами [Т1, T2, Т3, Т4], каждый из которых является "важным термином". Проводится поиск в отношении Q3, в котором используется простое правило кворума, описанное выше, в нем каждый поисковый термин обладает одинаковым весовым коэффициентом (каждый термин, соответственно, обладает весовым коэффициентом 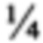 ), а значение кворума равно
), а значение кворума равно 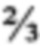 . Документ D2, содержащий термины T1, Т2, и Т3, но не термин Т4, добавляется как поисковый результат (поскольку весовой коэффициент D2 (
. Документ D2, содержащий термины T1, Т2, и Т3, но не термин Т4, добавляется как поисковый результат (поскольку весовой коэффициент D2 (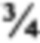 ) выше значения кворума (
) выше значения кворума (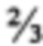 )). На документ D2 был осуществлен переход по щелчку инициатором поиска.
)). На документ D2 был осуществлен переход по щелчку инициатором поиска.
[60] Второй, более поздний поисковый запрос Q4 обладает поисковыми терминами [T1, Т2, Т4, Т5], которые отличаются от Q3 тем, что в Q4 содержится Т5 вместо Т3. Каждый из поисковых терминов Q4 является важным термином. Как было описано выше, документ D2 содержит термины [Т1, Т2, Т3]. Он не содержит термин Т4; он также не содержит термин Т5. Таким образом, в обычной поисковой системе документ D2 не будет включен в результаты поиска, проведенного в отношении Q4, поскольку документ D2 содержит только T1 и Т2, его весовой коэффициент будет составлять 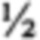 , что ниже чем значение кворума . Документ D2 просто не будет собран как результат поиска на первой стадии процесса поиска и не будет показан пользователю в списке результатов поиска никогда.
, что ниже чем значение кворума . Документ D2 просто не будет собран как результат поиска на первой стадии процесса поиска и не будет показан пользователю в списке результатов поиска никогда.
[61] Тем не менее, возможно, что документ D2 был бы хорошим кандидатом на результат поиска по отношению к Q4, поскольку по нему ранее был осуществлен переход по щелчку в отношении Q3, который отличается от Q4 только одним термином (Т5 вместо Т3). Тем не менее, как было описано выше, с этой проблемой обычные поисковые системы не справляются. Целью настоящей технологии является устранение, по меньшей мере, частичное, подобной ситуации.
[62] Таким образом, одним объектом настоящей технологии является исполняемый на компьютере способ поиска в инвертированном индексе, обладающем множеством списков словопозиций, способ включает в себя:
- получение от первого клиентского устройства по меньшей мере одним сервером первого поискового запроса, по которому будет проведен поиск, причем первый поисковый запрос включает в себя первое множество поисковых терминов;
- осуществление по меньшей мере одним сервером первого поиска первого множества списков словопозиций для получения первых результатов поиска, причем каждый из первого множества списков словопозиций связан с одним из первого множества поисковых терминов, и каждый из первого множества списков словопозиций включает в себя множество словопозиций первого типа, причем словопозиция первого типа является ссылкой на элемент данных, который фактически содержит поисковый термин, с которым связан этот список словопозиций, и первые результаты поиска включают в себя первое множество элементов результата, первые результаты поиска включают в себя элемент результата, в котором отсутствует один из первого множества поисковых терминов;
- передачу по меньшей мере одним сервером первому клиентскому устройству по меньшей мере части первых результатов поиска, включая элемент результата, в котором отсутствует один из первого множества поисковых терминов;
- получение от первого клиентского устройства по меньшей мере одним сервером указания на первый выбранный пользователем элемент результата, причем первый выбранный пользователем элемент результата является элементом результата, в котором отсутствует один из первого множества поисковых терминов;
- осуществление по меньшей мере одним сервером, вставки в список словопозиций, связанный с отсутствующим термином из первого множества поисковых терминов в первом выбранном пользователем элементе результата, словопозиций второго типа, причем словопозиция второго типа является ссылкой на выбранный пользователем элемент результата, в котором отсутствует этот поисковый термин.
[63] В некоторых вариантах осуществления технологии исполняемый на компьютере способ дополнительно включает в себя:
- получение от второго клиентского устройства по меньшей мере одним сервером второго поискового запроса, по которому будет проведет поиск, второй поисковый запрос включает в себя второе множество поисковых терминов, и один из второго множества поисковых терминов является отсутствующим термином в первом множестве поисковых терминов в первом выбранном пользователем элементе результата из первого множества элементов результата; и
- осуществление по меньшей мере одним сервером, второго поиска второго множества списков словопозиций для получения вторых результатов поиска, каждый из второго множества списков словопозиций связан с одним из второго множества поисковых терминов, один из второго множества списков словопозиций является списком словопозиций, связанным с отсутствующим термином из первого множества поисковых терминов в первом выбранном пользователем элементе результата из первого множества элементов результата, и включение в себя словопозицию второго типа, и второй поиск включает в себя учет словопозиций второго типа.
[64] В некоторых вариантах осуществления технологии, в результате учета словопозиций второго типа, результаты второго поиска будут включать в себя первый выбранный пользователем элемент результата из первых результатов поиска.
[65] В некоторых вариантах осуществления технологии, осуществление второго поиска включает в себя назначение каждому элементу данных весового коэффициента, который учитывается во втором поиске; и каждый элемент данных включается во вторые результаты поиска только если весовой коэффициент элемента не находится ниже границы весового коэффициента элемента.
[66] В некоторых вариантах осуществления технологии, каждому из второго множества поисковых терминов назначается весовой коэффициент поискового параметра; и в котором определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму весовых коэффициентов поисковых терминов, обладающих одной из: словопозицией первого типа и словопозицией второго типа из списка словопозиций, связанных с одним из второго множества поисковых терминов.
[67] В некоторых вариантах осуществления технологии, определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму множества слагаемых, слагаемые относятся к словопозициям первого типа, которые являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающих одной из: словопозицией первого типа в отношении элемента данных в одном из второго множества списков словопозиций, связанного с этим одним из второго множества поисковых терминов, помноженного на понижающий коэффициент первого типа в отношении этого слагаемого, причем слагаемые, относящиеся к словопозиций второго типа являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающего одной из словопозиций второго типа, относящейся к элементу данных в одном из второго множества списков словопозиций, связанных с одним из второго множества поисковых терминов.
[68] В некоторых вариантах осуществления технологии, определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму множества слагаемых, слагаемые относятся к словопозициям первого типа, которые являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающих одной из: словопозицией первого типа в отношении элемента данных в одном из второго множества списков словопозиций, связанного с этим одним из второго множества поисковых терминов, причем слагаемые, относящиеся к словопозиций второго типа являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающего одной из словопозиций второго типа, относящейся к элементу данных в одном из второго множества списков словопозиций, связанных с одним из второго множества поисковых терминов, помноженном на понижающий коэффициент второго типа в отношении этого слагаемого.
[69] В некоторых вариантах осуществления технологии, определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму множества слагаемых, слагаемые относятся к словопозициям первого типа, которые являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающих одной из: словопозицией первого типа в отношении элемента данных в одном из второго множества списков словопозиций, связанного с этим одним из второго множества поисковых терминов, помноженном на понижающий коэффициент первого типа для этого слагаемого, причем слагаемые, относящиеся к словопозиций второго типа являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающего одной из словопозиций второго типа, относящейся к элементу данных в одном из второго множества списков словопозиций, связанных с одним из второго множества поисковых терминов, помноженном на понижающий коэффициент второго типа в отношении этого слагаемого.
[70] В некоторых вариантах осуществления технологии, понижающий коэффициент второго типа в отношении этого слагаемого представляет собой функцию от числа раз, когда на этот элемент данных был осуществлен переход по щелчку в результатах поиска предыдущих поисковых запросов, включая поисковый термин, с которым связан этот один из второго множества списков словопозиций.
[71] В некоторых вариантах осуществления технологии, понижающий коэффициент первого типа в отношении этого слагаемого представляет собой функцию от числа раз, когда элемент данных содержал поисковый термин, с которым связан этот один из второго множества списков словопозиций.
[72] В некоторых вариантах осуществления технологии, элемент данных включен во вторые результаты поиска только если значение отношения словопозиций второго типа к словопозициями первого типа не превышает порогового значения.
[73] В некоторых вариантах осуществления технологии исполняемый на компьютере способ дополнительно включает в себя:
- передачу по меньшей мере одним сервером второму клиентскому устройству по меньшей мере части вторых результатов поиска, включая первый выбранных пользователем элемент результата;
- получение от второго клиентского устройства по меньшей мере одним сервером указания на второй выбранный пользователем элемент результата, причем второй выбранный пользователем элемент результата является первым выбранным пользователем элементом результата;
- осуществление по меньшей мере одним сервером, изменения списка словопозиций, связанного с отсутствующим одним из множества поисковых терминов словопозиций второго типа первого выбранного пользователя элемента результата; для принятия во внимание первого выбранного пользователем элемента результата, который также является вторым выбранным пользователем элементом результата.
[74] Другим объектом настоящей технологии является система, содержащая по меньшей мере один сервер, и по меньшей мере одни сервер обладает по меньшей мере одним компьютерным процессором, и постоянным компьютерным носителем информации, хранящим программные инструкции, которые при выполнении по меньшей мере одним компьютерным процессором осуществляют:
- получение от первого клиентского устройства по меньшей мере одним сервером первого поискового запроса, по которому будет проведен поиск, причем первый поисковый запрос включает в себя первое множество поисковых терминов;
- осуществление по меньшей мере одним сервером первого поиска первого множества списков словопозиций для получения первых результатов поиска, причем каждый из первого множества списков словопозиций связан с одним из первого множества поисковых терминов, и каждый из первого множества списков словопозиций включает в себя множество словопозиций первого типа, причем словопозиция первого типа является ссылкой на элемент данных, который фактически содержит поисковый термин, с которым связан этот список словопозиций, и первые результаты поиска включают в себя первое множество элементов результата, первые результаты поиска включают в себя элемент результата, в котором отсутствует один из первого множества поисковых терминов;
- передачу по меньшей мере одним сервером первому клиентскому устройству по меньшей мере части первых результатов поиска, включая элемент результата, в котором отсутствует один из первого множества поисковых терминов;
- получение от первого клиентского устройства по меньшей мере одним сервером указания на первый выбранный пользователем элемент результата, причем первый выбранный пользователем элемент результата является элементом результата, в котором отсутствует один из первого множества поисковых терминов;
- осуществление по меньшей мере одним сервером, вставки в список словопозиций, связанный с отсутствующим термином из первого множества поисковых терминов в первом выбранном пользователем элементе результата, словопозиций второго типа, причем словопозиция второго типа является ссылкой на выбранный пользователем элемент результата, в котором отсутствует этот поисковый термин.
[75] В некоторых вариантах осуществления, в которой постоянный носитель компьютерной информации дополнительно хранит программные инструкции, при выполнении которых по меньшей мере одним компьютерным процессором осуществляется:
- получение от второго клиентского устройства по меньшей мере одним сервером второго поискового запроса, по которому будет проведет поиск, второй поисковый запрос включает в себя второе множество поисковых терминов, и один из второго множества поисковых терминов является отсутствующим термином в первом множестве поисковых терминов в первом выбранном пользователем элементе результата из первого множества элементов результата; и
- осуществление по меньшей мере одним сервером, второго поиска второго множества списков словопозиций для получения вторых результатов поиска, каждый из второго множества списков словопозиций связан с одним из второго множества поисковых терминов, один из второго множества списков словопозиций является списком словопозиций, связанным с отсутствующим термином из первого множества поисковых терминов в первом выбранном пользователем элементе результата из первого множества элементов результата, и включение в себя словопозиций второго типа второго поиска, и второй поиск включает в себя учет словопозиций второго типа.
[76] В некоторых вариантах осуществления технологии, в результате учета словопозиций второго типа, результаты второго поиска будут включать в себя первый выбранный пользователем элемент результата из первых результатов поиска.
[77] В некоторых вариантах осуществления технологии, осуществление второго поиска включает в себя назначение каждому элементу данных весового коэффициента, который учитывается во втором поиске; и каждый элемент данных включается во вторые результаты поиска только если весовой коэффициент элемента не находится ниже границы весового коэффициента элемента.
[78] В некоторых вариантах осуществления технологии, каждому из второго множества поисковых терминов назначается весовой коэффициент поискового параметра; и в котором определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму весовых коэффициентов поисковых терминов, обладающих одной из: словопозицией первого типа и словопозицией второго типа из списка словопозиций, связанных с одним из второго множества поисковых терминов.
[79] В некоторых вариантах осуществления технологии, определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму множества слагаемых, слагаемые относятся к словопозициям первого типа, которые являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающих одной из: словопозицией первого типа в отношении элемента данных в одном из второго множества списков словопозиций, связанного с этим одним из второго множества поисковых терминов, помноженного на понижающий коэффициент первого типа в отношении этого слагаемого, причем слагаемые, относящиеся к словопозиций второго типа являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающего одной из словопозиций второго типа, относящейся к элементу данных в одном из второго множества списков словопозиций, связанных с одним из второго множества поисковых терминов.
[80] В некоторых вариантах осуществления технологии, определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму множества слагаемых, слагаемые относятся к словопозициям первого типа, которые являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающих одной из: словопозицией первого типа в отношении элемента данных в одном из второго множества списков словопозиций, связанного с этим одним из второго множества поисковых терминов, причем слагаемые, относящиеся к словопозиций второго типа являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающего одной из словопозиций второго типа, относящейся к элементу данных в одном из второго множества списков словопозиций, связанных с одним из второго множества поисковых терминов, помноженном на понижающий коэффициент второго типа в отношении этого слагаемого.
[81] В некоторых вариантах осуществления технологии, определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму множества слагаемых, слагаемые относятся к словопозициям первого типа, которые являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающих одной из: словопозицией первого типа в отношении элемента данных в одном из второго множества списков словопозиций, связанного с этим одним из второго множества поисковых терминов, помноженном на понижающий коэффициент первого типа для этого слагаемого, причем слагаемые, относящиеся к словопозиций второго типа являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающего одной из словопозиций второго типа, относящейся к элементу данных в одном из второго множества списков словопозиций, связанных с одним из второго множества поисковых терминов, помноженном на понижающий коэффициент второго типа в отношении этого слагаемого.
[82] В некоторых вариантах осуществления технологии, понижающий коэффициент второго типа в отношении этого слагаемого представляет собой функцию от числа раз, когда на этот элемент данных был осуществлен переход по щелчку в результатах поиска предыдущих поисковых запроса, включая поисковый термин, с которым связан этот один из второго множества списков словопозиций.
[83] В некоторых вариантах осуществления технологии, понижающий коэффициент первого типа в отношении этого слагаемого представляет собой функцию от числа раз, когда элемент данных содержал поисковый термин, с которым связан этот один из второго множества списков словопозиций.
[84] В некоторых вариантах осуществления технологии, элемент данных включен во вторые результаты поиска только если значение отношения словопозиций второго типа к словопозициями первого типа не превышает порогового значения.
[85] В некоторых вариантах осуществления, в которой постоянный носитель компьютерной информации дополнительно хранит программные инструкции, при выполнении которых по меньшей мере одним компьютерным процессором осуществляется:
- передача по меньшей мере одним сервером второму клиентскому устройству по меньшей мере части вторых результатов поиска, включая первый выбранных пользователем элемент результата;
- получение от второго клиентского устройства по меньшей мере одним сервером указания на второй выбранный пользователем элемент результата, причем второй выбранный пользователем элемент результата является первым выбранным пользователем элементом результата;
- осуществление по меньшей мере одним сервером, изменения списка словопозиций, связанного с отсутствующим одним из множества поисковых терминов словопозиций второго типа первого выбранного пользователя элемента результата; для принятия во внимание первого выбранного пользователем элемента результата, который также является вторым выбранным пользователем элементом результата.
[86] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данной технологии. В контексте настоящей технологии использование выражения «сервер» не означает, что каждая задача (например, полученные инструкции или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может являться одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
[87] В контексте настоящего описания «клиентское устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами клиентских устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как клиентское устройство в настоящем контексте, может вести себя как сервер по отношению к другим клиентским устройствам. Использование выражения «клиентское устройство» не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного метода.
[88] В контексте настоящего описания термин «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, которое выполняет процесс, который сохраняет или использует информацию, хранящуюся в базе данных, или же она может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
[89] В контексте настоящего описания термин «информация» включает в себя информацию любую информацию, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
[90] В контексте настоящего описания термин «компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[91] В контексте настоящего описания «используемый компьютером носитель компьютерной информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[92] В контексте настоящего описания слова «первый», «второй», «третий» и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной связи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый сервер" и "третий сервер " не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[93] Каждый вариант осуществления настоящей технологии включает по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[94] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы технологии.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[95] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[96] На Фиг. 1 представлено схематичное изображение, показывающее (i) некоторые из различных аппаратных и программных компонентов поисковой интернет-системы, которая является вариантом осуществления настоящей технологии, и (ii) некоторые из взаимодействий и передача данных между этими компонентами.
[97] На Фиг. 2 схематически показан известный уровень техники, использующий информацию о переходах по щелчку.
[98] На Фиг. 3 представлен пример использования информации о переходах по щелчку для обогащения инвертированного индекса в соответствии с вариантом осуществления настоящей технологии.
[99] На Фиг. 4 представлена общая блок-схема выполнения запроса и обогащения инвертированного индекса в соответствии с вариантом осуществления настоящей технологии.
[100] На Фиг. 5 является продолжением блок-схемы, показанной на Фиг. 4, в которой представлено использование обогащенного инвертированного индекса при выполнении следующего запроса, в соответствии с вариантом осуществления настоящей технологии.
ОСУЩЕСТВЛЕНИЕ ТЕХНОЛОГИИ
[101] На Фиг. 1 показано изображение поисковой интернет-системы 10, включающей в себя различные сетевые компьютерные системы и компоненты, связанные друг с другом в сети передачи данных. Важно иметь в виду, что поисковая интернет-система 10 является только одним из вариантов осуществления настоящей технологии. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. Некоторые полезные примеры модификаций поисковой интернет-системы 10 (или ее компонентов) также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящей технологии. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что поисковая интернет-система предоставляет собой достаточно простой вариант осуществления настоящей технологии, который представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью. Поисковая интернет-система 10 использует обычное серверное оборудование в данном варианте осуществления.
[102] В представленном выше примере поисковый запрос Q3,: "hybrid cars fuel consumption" (рус. «расход топлива гибридным автомобилем") отмечен как Q3['hybrid', 'cars', 'fuel', 'consumption'] будет снова использован для иллюстрации варианта осуществления настоящей технологии. В связи с этим предположим, что пользователь хочет сравнить гибридные автомобили по степени потребления топлива. Тем не менее, многие веб-страницы, которые могут быть потенциально интересными пользователю, не содержат слова "consumption" (рус. «расход") в текстовом виде. Вместо этого они могут содержать выражение "miles per gallon" (рус. «миль на галлон"), "liters per 100 kilometers" (рус. «литров на 100 километров"), аббревиатуру "mpg", аббревиатуру "1/100km", такие качественные понятия, как "economy" (рус. «экономичный") или "efficiency" (рус. «эффективный"), или многие другие понятия. Следовательно, поисковый термин "consumption" (рус. «расход"), если считать его наличие необходимым, будет блокировать все подобные веб-страницы от появления в списке результатов поиска для запроса Q3. В соответствии с вышеописанным простейшим правилом кворума (в котором у всех терминов одинаковые весовые коэффициенты и значение кворума равно 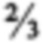 ), однако, предполагая, что в представленном выше запросе тот же весовой коэффициент
), однако, предполагая, что в представленном выше запросе тот же весовой коэффициент 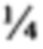 назначен для каждого из четыре поисковых терминов, каждый элемент данных, включающий только 3 из 4 поисковых терминов (включая те, которые не включают в себя термин "consumption" (рус. «расход") - но включают три других термина) будут обладать общим весовым коэффициентом
назначен для каждого из четыре поисковых терминов, каждый элемент данных, включающий только 3 из 4 поисковых терминов (включая те, которые не включают в себя термин "consumption" (рус. «расход") - но включают три других термина) будут обладать общим весовым коэффициентом 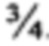 . Поскольку выше, чем значение кворума , такие документы будут включены в список результатов поиска.
. Поскольку выше, чем значение кворума , такие документы будут включены в список результатов поиска.
[103] На Фиг. 3 схематически показан представленный выше пример, в котором поисковые термины запроса Q3 отмечены как T1 для 'hybrid', Т2 для 'cars', Т3 для 'fuel', Т4 для 'consumption', и им соответствуют списки словопозиций P1, Р2, Р3, Р4. Элемент данных D2, находящийся в первых трех списках словопозиций, но не в четвертом (который не включает в себя слово 'consumption'), тем не менее, будет включен в список R(Q3) результатов поиска по запросу Q3, применяя простое правило кворума.
[104] Инициатор запроса Q3, например, U3, при просмотре списка результатов поиска и чтении заголовков и сниппетов индивидуальных результатов, скорее всего, не обратит внимания на элементы данных, в которых речь идет не о "hybrid" (рус. «гибридный") автомобилях, а только об обычных (такие документы могли быть включены в список результатов поиска по тому причине, что, несмотря на отсутствие термина "hybrid" (рус. «гибридный"), они содержали три остальных поисковых термина запроса Q3). А элемент данных "hybrid car ratings fuel efficiency" (рус. «эффективность расхода топлива гибридных автомобилей") (несмотря на то, что он не включает в себя термин "consumption" (рус. «расход")), например, элемент данных D2, может привлечь интерес пользователя. Когда далее происходит нажатие на гиперссылку для открытия элемента данных D2, этот "переход по щелчку" будет зафиксирован и записан сервером 18 запросов. Обычно, запись перехода по щелчку, скорее всего, будет сохранена в базе 24 данных запросов для дальнейшего использования для улучшения ранжирования на основе релевантности, зависящей от запроса (QSR), результатов поиска будущих запросов. В этом варианте осуществления настоящей технологии, это не изменится.
[105] Тем не менее, в соответствии с настоящей технологией, в различных вариантах ее осуществления, вне зависимости от любых данных о переходах по щелчку, который были записаны в базе 24 данных запросов (что является распространенным случаем в настоящей области техники), сервер 18 запросов (после перехвата запроса на переход по щелчку от пользователя U3 для элемента D2 данных) передает серверу 16 индекса (через канал 52 передачи данных) запрос на создание новой словопозиций для элемента D2 данных в списке Р4 словопозиций для термина "consumption" (рус. «расход"). (Список Р4 словопозиций в текущий момент не содержит какой-либо "стандартной словопозиций" для D2, поскольку D2 не содержит в текстовом виде вхождений термина "consumption". Эта "специальная" словопозиция Р4 может предполагать следующее: "Элемент D2 данных считается неявно включающим термин 'consumption', поскольку на D2 был совершен переход по щелчку в последнем запросе, содержащем этот поисковый термин". "Специальные" словопозиций такого рода будут далее упоминаться как "словопозиций переходов по щелчку", и словопозиций переходов по щелчку документа D в списке словопозиций термина Т будут иногда отмечены как "CTP(T,D)", в отличие от стандартных словопозиций, которые отмечены как "SP(T,D)" - На Фиг. 1 показано эта дополнительное действие сервера 14 индексации на канале 54 передачи данных).
[106] В этом варианте осуществления технологии сервер 16 индексации далее создает словопозицию переходов по щелчку по запросу сервера 18 запросов в списке Р4 словопозиций в базе 22 данных инвертированного индекса, если таковая отсутствует там в текущий момент. Если словопозиция перехода по щелчку уже имеется в списке Р4 словопозиций в базе 22 данных инвертированного индекса, то в этом варианте осуществления технологии сервер 16 индексации не совершает никаких дополнительных действий в этой связи. В других вариантах осуществления (некоторые из которые будут подробнее описаны далее), если словопозиция перехода по щелчку в отношении документа D2 уже имеется в списке Р4 словопозиций, сервер 16 индексации обновляет некоторую информацию, которая относится к истории переходов по щелчкам D2 в такой словопозиций перехода по щелчку (например, число раз, соответствующее количеству переходов по щелчку).
[107] Создание словопозиций перехода по щелчку для документа D2 в списке Р4 словопозиций символически представлена на Фиг. 3 в виде ячейки с пунктирными границами, в которой курсивом указано "D2*", она находится в рамках списка Р4 словопозиций на втором изображении базы 22 данных инвертированного индекса, обозначенной 22(2) в середине Фиг. 3.
[108] Для того, чтобы сервер 18 запросов "узнал", что в данных D2 (на которые был осуществлен переход по щелчку) отсутствует термин "consumption" (рус. «расход), но содержатся остальные поисковые термины из запроса Q3, сервер 18 запросов получит информацию от сервера 16 поиска, которая в некоторых вариантах осуществления технологии будет добавлена в список результатов поиска. (Например, каждый номер элемента данных в списке результатов поиска для поискового запроса, который обладает различными поисковыми терминами, может быть дополнен растровым изображением, которое указывает на отсутствие или наличие поисковых терминов в этих элементах данных в порядке поисковых терминов в запросе.)
[109] Альтернативно, в других вариантах осуществления технологии, запроса создать словопозицию перехода по щелчку может быть передан сервером 18 запроса серверу 16 индексации для каждого элемента D данных, на которые был осуществлен переход по щелчку, вместе со списком поисковых терминов поискового запроса, к которым относится этот переход по щелчку. В таких случаях, сервер 14 индексации при обновлении инвертированного индекса 22 может проверить наличие элемента D данных в каждом из списков словопозиций для этих терминов, и создать словопозицию перехода по щелчку для D в тех списках словопозиций для термина(ов), в которых D отсутствует.
[110] Эта последовательность действий показана на Фиг. 4, которая представляет собой обычную блок-схему получения нового поискового запроса сервером 18 запросов, выполнения поиска сервером 16 поиска, предоставление инициатору запроса списка результатов поиска, записи сервером 18 запросов переходов по щелчку инициатором поиска, передачи данных о переходах по щелчку серверу 14 индексации и соответствующего обновления инвертированного индекса сервером 14 индексации. Такое обновление инвертированного индекса может быть далее упомянуто как "обогащение".
[111] Далее пользователь U4 вводит новый запрос Q4 (причем это может быть тот же пользователь, что и U3 или другой), в момент времени не ранее, чем список словопозиций для термина "consumption" (рус. «расход) будет эффективно обновлен словопозицией перехода по щелчку для D2 как было описано выше. Новый запрос Q4 - "hybrid car consumption comparison" (рус. «сравнение расхода гибридных автомобилей"). Как и в случае с запросом Q3 ("hybrid cars fuel consumption"), запрос Q4 обладает четырьмя терминами с весовыми коэффициентами . Три из этих терминов совпадают с Q3, а именно "hybrid" (рус. «гибридный"), "cars" (рус. «автомобили") и "consumption" (рус. «расход"), а четвертый отличается: "fuel" (рус. «топливо") в Q3, и "comparison" (рус. «сравнение") в Q4. Элемент D2 данных, как обсуждалось выше, содержит оба термина "hybrid" и "cars", но не содержит термин "consumption". Для целей настоящего примера предполагается, что D2 также не содержит термин "comparison".
[112] Тем не менее, очевидно, что элемент D2 данных может быть интересен инициатору поискового запроса Q4, поскольку в D2 содержится информация о гибридных автомобилях и о топливе (и, следовательно, косвенно - о потреблении), и, вероятно, содержится сравнение гибридных автомобилей по уровню их расхода топлива. В известном уровне техники элемент D2 данных не будет собран сервером 16 поиска как поисковый результат в отношении Q4, поскольку в текстовом виде он содержит только два из четырех поисковых терминов запроса (т.е. "hybrid" и "cars"), и, следовательно, обладает весовым коэффициентом 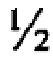 , который находится ниже значения кворума .
, который находится ниже значения кворума .
[113] В вариантах осуществления настоящей технологии, тем не менее, элемент D2 данных будет считаться сервером 17 поиска (неявно) содержащим третий из поисковых терминов (т.е. "consumption"), и, следовательно, он будет обладать общим весовым коэффициентом 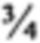 , что выше значения кворума
, что выше значения кворума 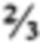 . D2 будет включен в список результатов поиска для Q4.
. D2 будет включен в список результатов поиска для Q4.
[114] Вышепредставленный аспект настоящей технологии схематически показан в нижней части Фиг. 3. В Q4 поисковый термин "comparison" (рус. «сравнение") отмечен как Т5, и его список словопозиций отмечен как Р5. Элемент D2 данных, который находится в списках словопозиций трех из четырех поисковых терминов запроса Q4 (в одном из них, а именно в Р4, с помощью словопозиций перехода по щелчку, которая показана пунктирной ячейкой на Фиг. 3), будет выбран и показан пользователю U4. Также, на Фиг. 5 (являющейся продолжением Фиг. 4) представлена блок-схема этих поздних этапов общей процедуры поиска, которая завершается отображением пользователю элемента данных, такого как D2 или похожих элементов.
[115] Выше представлено описание очень простого варианта осуществления настоящей технологии; но возможны и более сложные варианты осуществления технологии. В связи с этим, продолжая с предыдущим примером, если на элемент D2 данных будет снова осуществлен переход по щелчку (на этот раз пользователем U4, инициатором поиска по запросу Q4), то сервер 18 запроса запишет этот переход по ссылке и передаст серверу 14 индексирования запроса создать вторую словопозицию перехода по ссылке в D2, на этот раз в списке Р5 словопозиций для термина "comparison" (рус. «сравнение").
[116] Теперь, предположим, что после того, как вторая словопозиция перехода по щелчку для D2 была добавлена в список Р5 словопозиций, сервер 18 запросов получает третий запрос Q5 "electric cars consumption comparison" (рус. «сравнение расхода электрических автомобилей) (от пользователя U4 или от другого пользователя). Для настоящих целей предположим, что элемент D2 данных не содержит термин "electric" (рус. «электрический"); то есть он имеет отношение только к гибридным автомобилям. Тем не менее, в вариантах осуществления настоящей технологии описанных выше, элемент D2 данных будет выбран сервером 16 поиска как один из результатов поиска в отношении Q5, поскольку он неявно содержит термин "cars" и также "неявно" содержит термины "consumption" и "comparison" (с помощью двух ранее добавленных словопозиций переходов по щелчку). Таким образом, общий весовой коэффициент D2 в отношении Q5 будет составлять 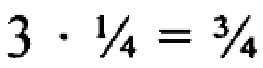 , что превосходит значение кворума . В связи с этим, тем не менее, элементы данных, которые обладают меньшей релевантностью, могут возникнуть в списке результатов поиска для Q5, благодаря высокой доле "неявно содержащихся" поисковых терминов (по сравнению с их "явно содержащимися" поисковыми терминами).
, что превосходит значение кворума . В связи с этим, тем не менее, элементы данных, которые обладают меньшей релевантностью, могут возникнуть в списке результатов поиска для Q5, благодаря высокой доле "неявно содержащихся" поисковых терминов (по сравнению с их "явно содержащимися" поисковыми терминами).
[117] Чтобы уменьшить эту потенциальную проблемы, в других вариантах осуществления настоящей технологии, каждая словопозиция и каждом списке словопозиций инвертированного индекса 22 включает в себя дополнительную информацию, которая будет использована сервером 16 поиска для того, чтобы отличать стандартные словопозиций и словопозиций переходов по щелчку. В простейшей форме такая информация может представлять собой однобитный флажок, обладающий значением (например) "0" для словопозиций перехода по щелчку и значением "1" для стандартной словопозиций. Альтернативно, если инвертированный индекс 22 выполнен в том виде, где каждая словопозиция для элемента D данных в списке словопозиций для термина Т содержит счетчик числа вхождений Т в D, например, нулевое значение на счетчике может быть использовано для указания на словопозицию перехода по щелчку, вместо отдельного однобитного флажка, как описано выше.
[118] Таким образом, сервер 14 индексирования для каждого запроса на создание словопозиций перехода по щелчку, который был получен от запроса, сервер 18 создает словопозицию перехода по щелчку, которая несет в себе указание на неявную природу "перехода по щелчку". Это указание (может представлять собой один из вышеописанных вариантов или какой-либо другой) позволяет серверу 16 обращаться со словопозициями перехода по щелчку способом, который отличается обращения со стандартными словопозициями. Здесь также возможны различные варианты, два из которых описаны далее.
[119] В соответствии с первым вариантом, правило кворума дополнено требованием учитывать не более какого-то конкретного числа или процентной доли словопозиций переходов по щелчку (среди общего числа словопозиций, найденных для элемента данных) при определении общего "весового коэффициента" документа в поиске для данного поискового термина. Например, может быть применено правило не учитывать более одной словопозиций перехода по щелчку на каждые три из четырех словопозиций, или не учитывать более двух словпозиций перехода по щелчку из каждых пяти словопозиций, и так далее. Таким образом, например, могут быть созданы допустимые или недопустимые соотношения для словопозиций перехода по щелчку; например, соотношения 0:3 или 1:3 являются допустимыми, а соотношения 2:3 или 3:3 недопустимыми. Следовательно, в предыдущем примере элемент D2 данных все еще будет считаться результатом поиска для запроса Q4 (одна словопозиция перехода по щелчку и две обычных словопозиций, допустимое соотношение словопозиций перехода по щелчку 1:3), но не для запроса Q5 (две словопозиций перехода по щелчку и одна обычная словопозиция, недопустимое соотношение словопозиций перехода по щелчку 2:3).
[120] Второй вариант состоит в применении понижающего коэффициента в отношении словопозиций перехода по щелчку в определении общего весового коэффициента. Например, каждая словопозиция перехода по щелчку может быть снижена на коэффициент , по отношению к стандартным словопозициям, для которых нет понижающего коэффициента. В этом случае, в предыдущем примере элемент D2 данных в отношении запроса Q4, считая понижающий коэффициент равным для словопозиций перехода по щелчку, общий весовой коэффициент элемента D2 данных будет составлять 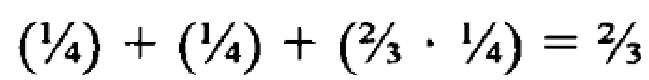 ; таким образом, значение кворума будет достигнуто. Но в отношении запроса Q5 общий весовой коэффициент для D2 будет составлять
; таким образом, значение кворума будет достигнуто. Но в отношении запроса Q5 общий весовой коэффициент для D2 будет составлять 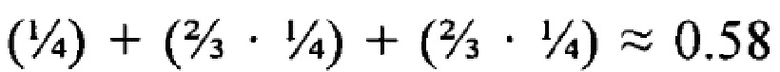 ; таким образом, значение кворума (0.66) не будет достигнуто.
; таким образом, значение кворума (0.66) не будет достигнуто.
[121] Понижающий коэффициент не обязательно будет постоянной, как в предыдущем примере. В других вариантах осуществления технологии он может быть переменной. Например, пусть noc(T,D) - счетчик, учитывающий общее число раз, когда на документ D были осуществлены переходы по щелчку в результатах поиска различных запросов, которые включают термин Т, не встречающийся в D. Значение этого счетчика со временем будет только расти. Может быть сделано предположение (которое было статистически подтверждено), что, чем выше значение noc(T,D), тем выше уверенность в том, что Т в действительности "неявно присутствует" в D.
[122] В одном варианте осуществления технологии, понижающий коэффициент будет возрастать вместе со значением noc(T,D), хотя он никогда не будет выше 1 (или тогда он уже не будет понижающим коэффициентом). Таким образом, в одном варианте осуществления технологии, понижающий коэффициент может быть определен как следующая функция:
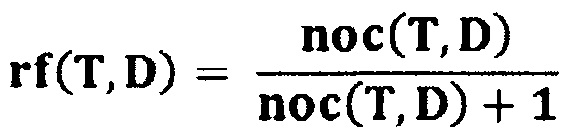
[123] С этой целью, до появления каких-либо встречающихся релевантных переходов по щелчку rf(T,D) будет обладать изначальным значением, равным нулю (0) (поскольку noc(T,D)=0), и для первого перехода по щелчку noc(T,D)=1, и rf(T,D) станет равно . rf(T,D) возрастет до , когда (T,D)=2, до , когда noc(T,D)=3, и так далее. Понижающий коэффициент определен в данном случае только как пример; любая другая монотонно возрастающая функция от числа переходов по щелчку может быть использована (возможно с немного улучшенными или ухудшенными результатами в контексте релевантности финальных результатов поиска для пользователя).
[124] Используя счетчик числа предыдущих переходов по щелчку (например, счетчик пос, который был описан выше) в отношении примеров поисковых запросов Q3, Q4 и Q5 (в которых значение кворума составляет ), будут получены следующие результаты: Элемент D2 данных будет считаться результатом поиска для запроса Q4, если было по меньшей мере два предыдущих перехода по щелчку на D2 в поисковых запросах, содержащих термин "consumption" (рус. «расход") (Например, запрос Q3 и некоторый прошлый запрос Q0 ("fuel consumption levels of hybrid cars"), который также содержал элемент D2 данных как результат поиска, на который тогда был осуществлен переход по ссылке инициатором поиска по запросу Q0.)
[125] В этом случае, если было два предыдущих перехода по щелчку на D2 (для неявных вхождений термина "consumption"), понижающий коэффициент rf("consumption", D2) будет составлять . Таким образом, общий весовой коэффициент D2 в отношении Q4 будет равным 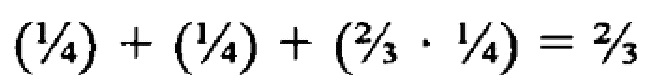 , как и в оригинальном примере. Тем не менее, если был только один переход по щелчку, общий весовой коэффициент D2 в отношении Q4 будет равен только
, как и в оригинальном примере. Тем не менее, если был только один переход по щелчку, общий весовой коэффициент D2 в отношении Q4 будет равен только 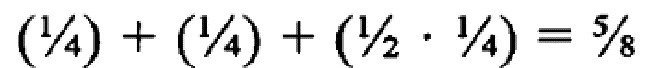 , который будет ниже, чем значение кворума .
, который будет ниже, чем значение кворума .
[126] Для того, чтобы использовать вышеописанный счетчик переходов по щелчку noc(T,D) сервером 16 поиска при выполнении поисковых запросов, включающих термин Т, счетчик должен храниться и поддерживаться сервером 18 запросов или сервером 14 индексации. В одном варианте осуществления настоящей технологии, счетчик переходов по щелчку noc(T,D) хранится в (или в пределах) словопозиций D в списке словопозиций для Т. Например, в некоторых обычных поисковых системах, сервер 14 индексации может хранить в каждой стандартной словопозиций (SP(T,D)) элемента D данных в списке словопозиций для Т, в дополнение к номеру элемента D данных общее число вхождений Т в D (или некоторая другая функция числа вхождений Т в D, и их конкретное распределение, например их наличие в "заголовке" документа). Для словопозиций (CTP(T,D)) перехода по щелчку в простых вариантах осуществления настоящей технологии, это поле данных словопозиций не будет использовано. В других вариантах осуществления настоящей технологии, сервер 14 индексации будет хранить в этом поле данных число предыдущих щелчков на D, инициированных "неявными вхождениями" Т в D. В таких вариантах осуществления технологии тип каждой словопозиций (стандартной или перехода по щелчку) определен однобитным флажком, как в одном из более ранних вариантов осуществления технологии, который был описан выше.
[127] Как конкретно эта информация, хранящаяся в / размещенная сервером 14 индексации может быть использована сервером 16 поиска, будет описано далее в связи с другим вариантом осуществления настоящей технологии. Как было описано выше, в отношении любого элемента D данных, в котором не встречается термин Т, понижающий коэффициент rf(T,D) может быть определен так, как это изложено выше. При определении подобным образом, rf(T,D) является монотонной возрастающей функцией с нижней границей 0 и верхней границей 1. В контексте описания этого варианта осуществления технологии rf(T,D) будет назван rfi(T,D) (для понижающего коэффициента в отношении неявных вхождений термина Т в элемент D данных. (Значение noc(T,D) обычно будет определено в словопозиций для D в списке словопозиций для термина Т - или некотором другом подходящем счетчике, хранящемся в словопозиций CTP(Т,D)).
[128] В любом элементе D данных, в котором термин Т встречается, функция noo(T,D) может быть определена как число явных вхождений термина Т в элементе D данных. (Значение noo(T,D) обычно будет определено в словопозиций для D в списке словопозиций для термина Т - или некотором другом подходящем счетчике, хранящемся в словопозиций SP(Т,D)) Таким образом, понижающий коэффициент в отношении явных вхождений rfe(T,D) может быть определен аналогичным образом:
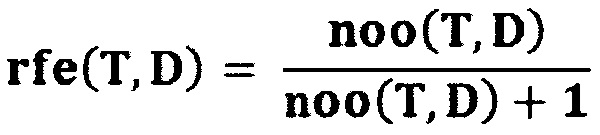
[129] При определении подобным образом, rfe является монотонной возрастающей функцией с нижней границей 0 и верхней границей 1.
[130] Функция imp(T,D) может быть определена, как показано, для каждого элемента D данных и каждого поискового термина Т, и "важность" термина Т в отношении:
IMP(T,D)=rfe(T,D)+rfi(T,D).
[131] Таким образом, imp(T,D)=0 для элемента D данных, который не содержит явно поисковый термин Т, и на который не был осуществлен переход по щелчку в прошлом запросе, содержащем Т. Функция imp(T,D) является монотонной возрастающей функцией с нижним пределом 0 и верхним пределом 1.
[132] Обратимся к формуле для определения кворума, которая была описана в части "Уровень Техники". Для простоты формула будет представлена ниже:
w(D,Q)=w(T1,Q)⋅occ(T1,D)+w(T2,Q)⋅occ(T2,D)+ … +w(Tn,Q)⋅occ(Tn,D)
где w(D,Q) - функция для определения весового коэффициента элемента D данных в отношении запроса Q[T1,T2, … Тn]; каждый w(Ti,Q) является весовым коэффициентом для термина Ti в отношении запроса Q; и occ(Ti,D) - является простой булевой функцией, указывающей на "наличие" термина Т в элементе D данных. occ(Ti,D)=0, если термин Т не встречается в элементе D данных, и occ(Ti,D)=1, если термин Т встречается в элементе D данных.
[133] В соответствии с этим вариантом осуществления настоящей технологии, вышеупомянутая формула может быть изменена с учетом эффекта от словопозиций перехода по щелчку и числа переходов по щелчку, путем замены occ(Ti,D) на определенную выше функцию imp(T,D). Измененная формула будет выглядеть следующим образом:
w(D,Q)=w(T1,Q)⋅imp(T1,D)+w(T2,Q)⋅imp(T2,D)+ … +w(Tn,Q)⋅imp(Tn,D)
[134] В этой измененной формуле каждый термин w(Ti,Q)⋅imp(Ti,D) является продуктом двух значений. Первое значение - весовой коэффициент термина Т; в отношении поискового запроса Q и, следовательно, оно показывает важность термина Т; в отношении поискового запроса Q. Второе значение - значение функции imp(T,D), оно показывает важность термина Ti в отношении элемента D данных.
[135] С учетом того, что пороговое значение кворума wq, то каждый элемент D данных с общим весовым коэффициентом, который равен или превышает пороговое значение кворума (т.е. w(D,Q)≥wq), будет сочтен сервером 16 поиска результатом поиска для поискового запроса Q.
[136] Последнее важное замечание касается времени выполнения сервером 14 индексирования обновлений инвертированного индекса 22, которые запрашиваются сервером 18 запросов (как было описано выше). Как было упомянуто выше, обычные обновления для добавления новых документов в инвертированный индекс 22 обычно не выполняются по одному, а группируются в серии, которые будут периодически обрабатываться все вместе. Это происходит по той причине, что обработка каждого нового элемента D данных включает в себя не только создание другой словопозиций в списке словопозиций каждого термина Т, встречающегося в D, но и обновление номеров элементов данных всех документов с меньшей релевантностью, не зависящей от запроса (QIR), чем у D (и, соответственно, обладающих номером элемента данных ниже, чем D), и эту процедуру необходимо выполнить во всем инвертированном индексе 22. Группирование таких операций обновления для нескольких новых элементов данных в серии помогает существенно сократить общее время обновления, что важно, поскольку за это время инвертированный индекс 22 или, по меньшей мере, одна из его копий недоступна для поисковых операций.
[137] В отличие от этой достаточно "трудной" обработки новых элементов данных сервером 14 индексирования, обработка новых запросов перехода по ссылке от сервера 18 запросов, переданных серверу 14 индексирования в соответствии с настоящей технологией требует меньшей вычислительной мощности и времени, поскольку не требует перенумерации какого-либо элемента данных. Тем не менее, поскольку списки словопозиций обычно хранятся в закодированной форме в порядке убывания количества занимаемого ими объема, добавление новой словопозиций в середине списка словопозиций может быть выполнено только путем последовательного декодирования и перекодирования нескольких последовательных сегментов из этого списка словопозиций. Эта требующая времени операция также делает список словопозиций временно недоступным для поисковых операций.
[138] По этому причине, по меньшей мере в некоторых вариантах осуществления настоящей технологии, операции обновления инвертированного индекса 22 в отношении новых созданных данных переходе по щелчку, выполняются не по одной, а также в сгруппированных сериях. Выполнение запросов на обновление серии переходов по щелчку выполняется предпочтительно сервером 14 индексирования в тот же момент времени, что он выполняет обработку серии новых документов. В этом случае, общее время обработки будет ниже, чем если бы обе серии обрабатывались по отдельности.
[139] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
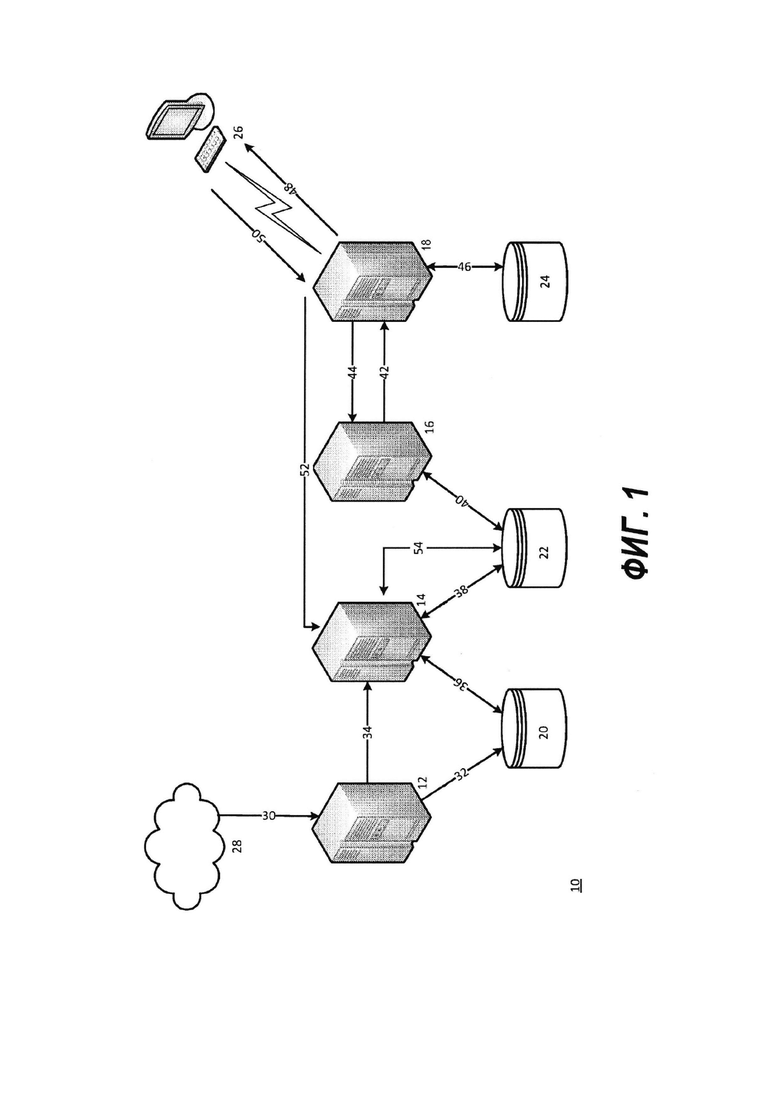
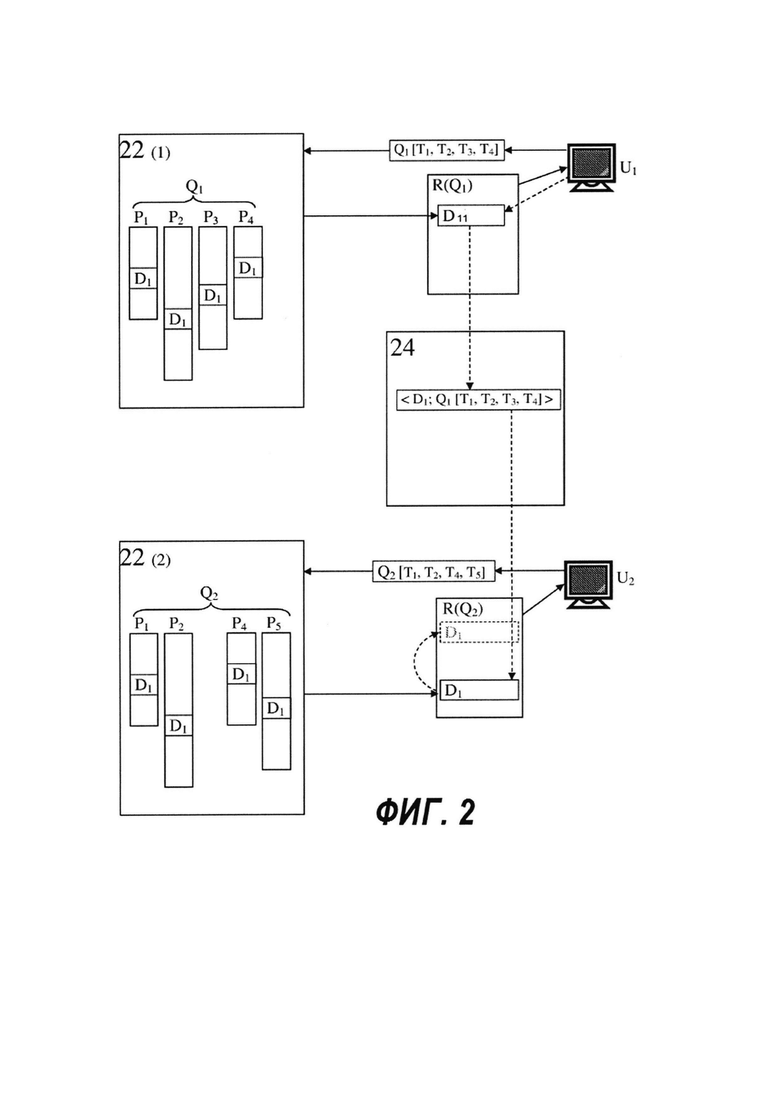
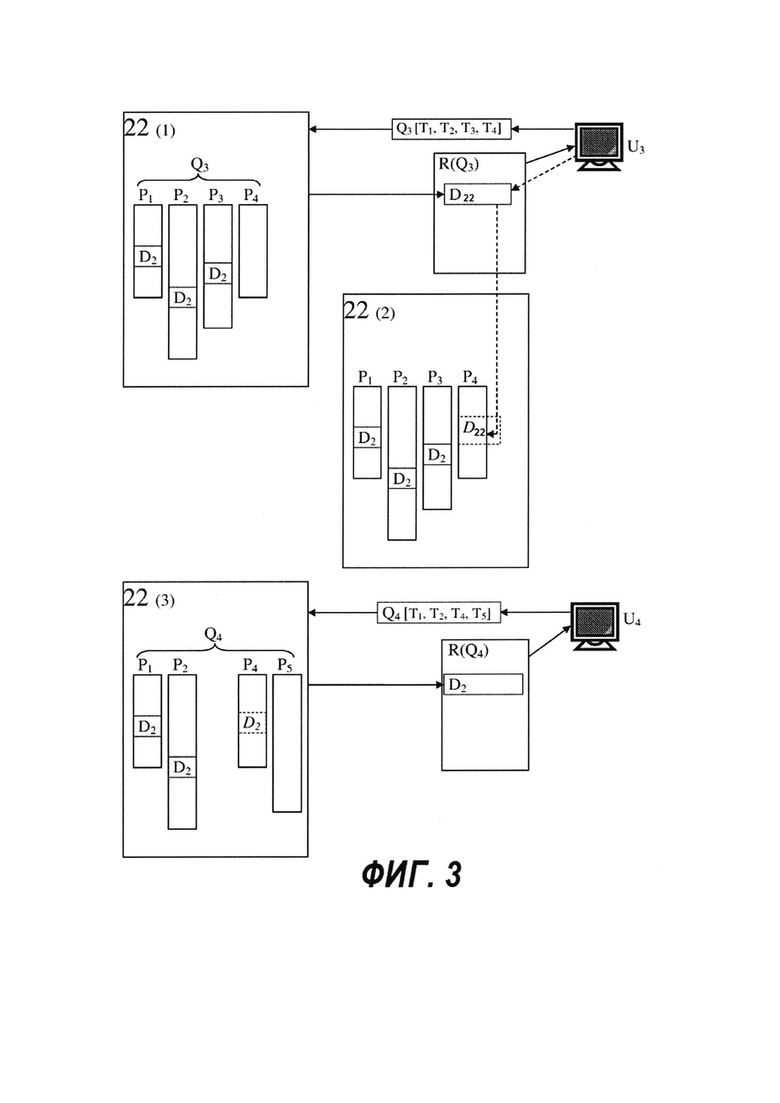
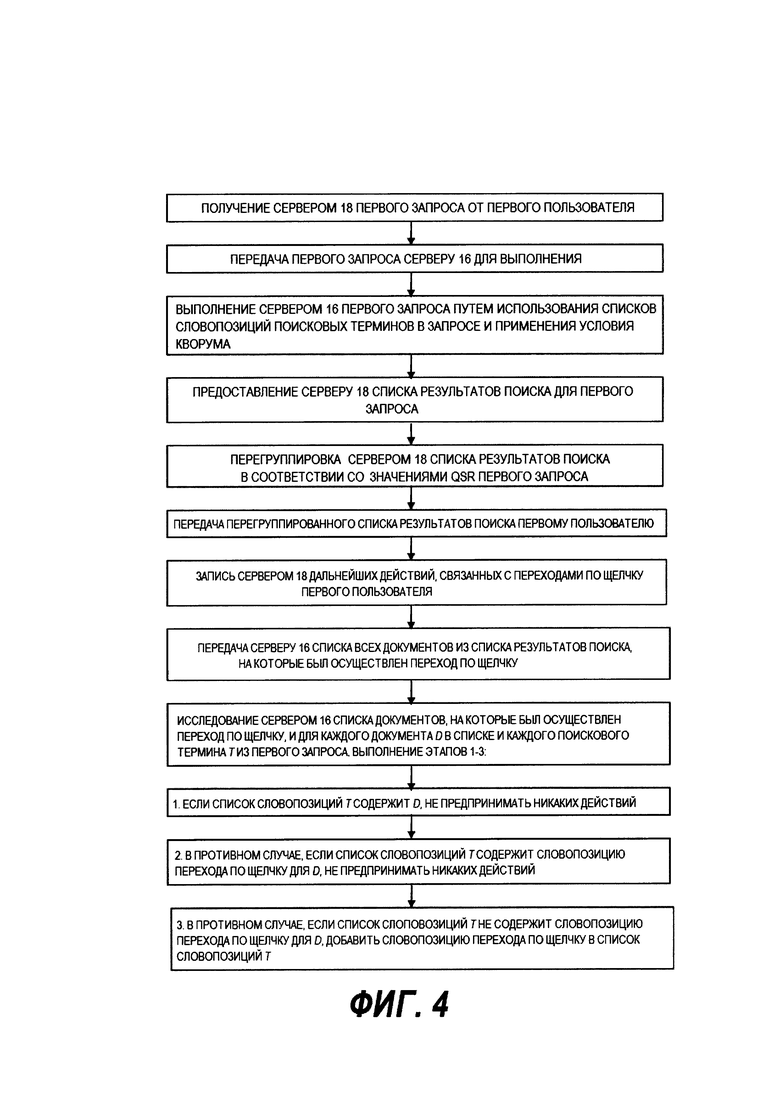

Изобретение относится к средствам поиска в инвертированном индексе. Технический результат заключается в расширении арсенала средств. Способ поиска в инвертированном индексе, обладающем множеством списков словопозиций, включающий в себя получение поискового запроса, включающего поисковые термины, осуществление поиска списков словопозиций, причем списки словопозиций связаны с поисковыми терминами, включают в себя множество словопозиций первого типа, который является ссылкой на элемент данных, который фактически содержит поисковый термин, с которым связан этот список словопозиций, и результаты поиска включают в себя элементы результата, в которых отсутствует один из поисковых терминов, передачу первых результатов поиска, получение указания на выбранный пользователем элемент результата, который является элементом результата, в котором отсутствует один из поисковых терминов, осуществление вставки в список словопозиций, связанный с отсутствующим термином в выбранном пользователем элементе результата, словопозиций второго типа, которая является ссылкой на выбранный пользователем элемент результата, в котором отсутствует этот поисковый термин. 2 н. и 16 з.п. ф-лы, 5 ил.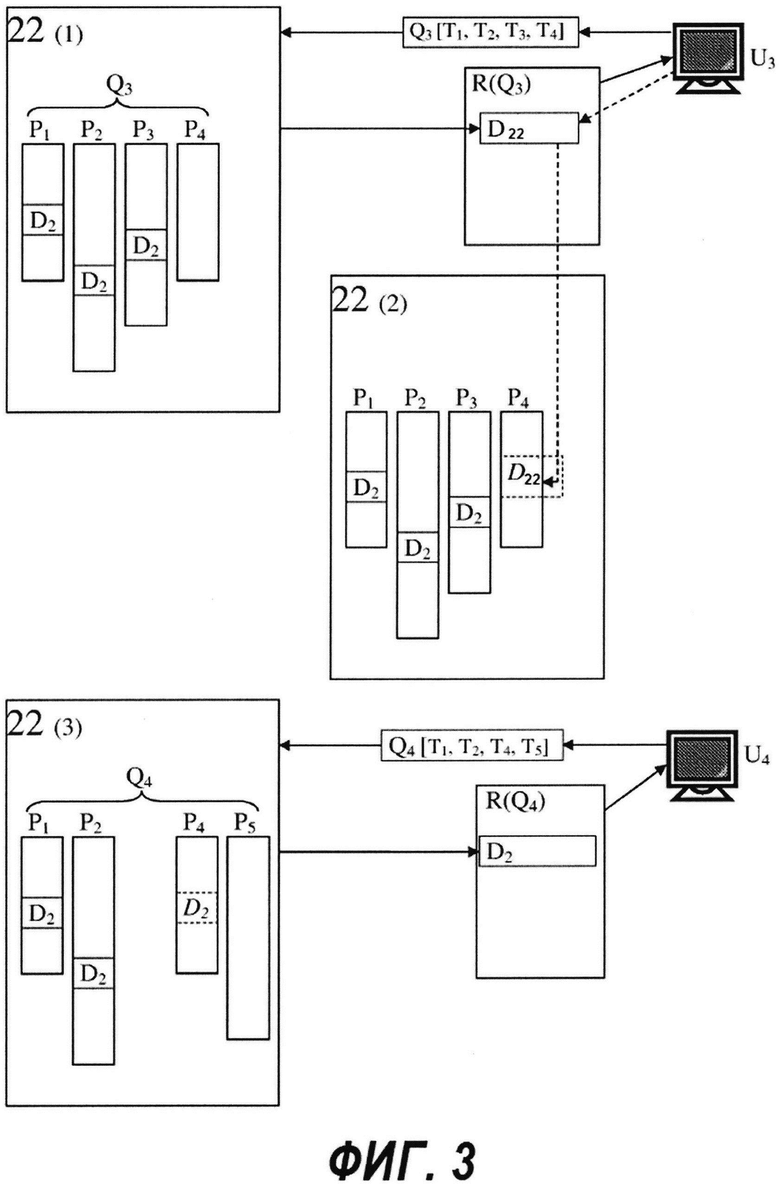
1. Исполняемый на компьютере способ поиска в инвертированном индексе, обладающем множеством списков словопозиций, включающий:
получение от первого клиентского устройства по меньшей мере одним сервером первого поискового запроса для проведения поиска, причем первый поисковый запрос включает в себя первое множество поисковых терминов;
осуществление по меньшей мере одним сервером первого поиска первого множества списков словопозиций для получения первых результатов поиска, причем каждый из первого множества списков словопозиций связан с одним из первого множества поисковых терминов, и каждый из первого множества списков словопозиций включает в себя множество словопозиций первого типа, причем словопозиция первого типа является ссылкой на элемент данных, который фактически содержит поисковый термин, с которым связан этот список словопозиций, и первые результаты поиска включают в себя первое множество элементов результата, первые результаты поиска включают в себя элемент результата, в котором отсутствует один из первого множества поисковых терминов;
передачу по меньшей мере одним сервером первому клиентскому устройству по меньшей мере части первых результатов поиска, включая элемент результата, в котором отсутствует один из первого множества поисковых терминов;
получение от первого клиентского устройства по меньшей мере одним сервером указания на первый выбранный пользователем элемент результата, причем первый выбранный пользователем элемент результата является элементом результата, в котором отсутствует один из первого множества поисковых терминов;
осуществление по меньшей мере одним сервером вставки в список словопозиций, связанный с отсутствующим термином из первого множества поисковых терминов в первом выбранном пользователем элементе результата, словопозиций второго типа, причем словопозиция второго типа является ссылкой на первый выбранный пользователем элемент результата, в котором отсутствует этот поисковый термин.
2. Способ по п. 1, в котором дополнительно выполняют:
получение от второго клиентского устройства по меньшей мере одним сервером второго поискового запроса для проведения поиска, второй поисковый запрос включает в себя второе множество поисковых терминов, и один из второго множества поисковых терминов является отсутствующим термином в первом множестве поисковых терминов в первом выбранном пользователем элементе результата из первого множества элементов результата; и
осуществление по меньшей мере одним сервером второго поиска второго множества списков словопозиций для получения вторых результатов поиска, каждый из второго множества списков словопозиций связан с одним из второго множества поисковых терминов, один из второго множества списков словопозиций является списком словопозиций, связанным с отсутствующим термином из первого множества поисковых терминов в первом выбранном пользователем элементе результата из первого множества элементов результата, и включение в себя словопозиций второго типа, и второй поиск включает в себя учет словопозиций второго типа.
3. Способ по п. 2, в котором в результате учета словопозиций второго типа результаты второго поиска будут включать в себя первый выбранный пользователем элемент результата из первых результатов поиска.
4. Способ по любому из пп. 2, 3, в котором при осуществлении второго поиска выполняют назначение каждому элементу данных весового коэффициента, который учитывается во втором поиске, и каждый элемент данных включается во вторые результаты поиска, только если весовой коэффициент элемента не находится ниже границы весового коэффициента элемента.
5. Способ по п. 4, в котором каждому из второго множества поисковых терминов назначают весовой коэффициент поискового термина и в котором определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму весовых коэффициентов поисковых терминов, обладающих одной из: словопозицией первого типа и словопозицией второго типа относительно этого элемента данных в одном из второго множества списков словопозиций, связанных с одним из второго множества поисковых терминов.
6. Способ по п. 4, в котором определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму множества слагаемых, слагаемые относятся к словопозициям первого типа, которые являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающих одной из: словопозицией первого типа в отношении элемента данных в одном из второго множества списков словопозиций, связанного с этим одним из второго множества поисковых терминов, помноженного на понижающий коэффициент первого типа в отношении этого слагаемого, причем слагаемые, относящиеся к словопозиции второго типа, являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающего одной из словопозиций второго типа, относящейся к элементу данных в одном из второго множества списков словопозиций, связанных с одним из второго множества поисковых терминов.
7. Способ по п. 4, в котором определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму множества слагаемых, слагаемые относятся к словопозициям первого типа, которые являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающих одной из: словопозицией первого типа в отношении элемента данных в одном из второго множества списков словопозиций, связанного с этим одним из второго множества поисковых терминов, причем слагаемые, относящиеся к словопозиции второго типа, являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающего одной из словопозиций второго типа, относящейся к элементу данных в одном из второго множества списков словопозиций, связанных с одним из второго множества поисковых терминов, помноженного на понижающий коэффициент второго типа в отношении этого слагаемого.
8. Способ по п. 4, в котором определение весового коэффициента каждого элемента данных, который учитывается, включает в себя сумму множества слагаемых, слагаемые относятся к словопозициям первого типа, которые являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающих одной из: словопозицией первого типа в отношении элемента данных в одном из второго множества списков словопозиций, связанного с этим одним из второго множества поисковых терминов, помноженного на понижающий коэффициент первого типа для этого слагаемого, причем слагаемые, относящиеся к словопозиции второго типа, являются весовыми коэффициентами поисковых терминов из второго множества поисковых терминов, обладающего одной из словопозиций второго типа, относящейся к элементу данных в одном из второго множества списков словопозиций, связанных с одним из второго множества поисковых терминов, помноженного на понижающий коэффициент второго типа в отношении этого слагаемого.
9. Способ по любому из пп. 7, 8, в котором понижающий коэффициент второго типа в отношении этого слагаемого представляет собой функцию от числа раз, когда на этот элемент данных был осуществлен переход по щелчку в результатах поиска предыдущих поисковых запросов, включая поисковый термин, с которым связан этот один из второго множества списков словопозиций.
10. Способ по п. 6, в котором понижающий коэффициент первого типа в отношении этого слагаемого представляет собой функцию от числа раз, когда элемент данных содержал поисковый термин, с которым связан этот один из второго множества списков словопозиций.
11. Способ по п. 8, в котором понижающий коэффициент первого типа в отношении этого слагаемого представляет собой функцию от числа раз, когда элемент данных содержал поисковый термин, с которым связан этот один из второго множества списков словопозиций.
12. Способ по п. 9, в котором понижающий коэффициент первого типа в отношении этого слагаемого представляет собой функцию от числа раз, когда элемент данных содержал поисковый термин, с которым связан этот один из второго множества списков словопозиций.
13. Способ по любому из пп. 2, 3, в котором элемент данных включают во вторые результаты поиска, только если значение отношения словопозиций второго типа к словопозициям первого типа не превышает порогового значения.
14. Способ по п. 4, в котором элемент данных включают во вторые результаты поиска, только если значение отношения словопозиций второго типа к словопозициям первого типа не превышает порогового значения.
15. Способ по п. 2, в котором дополнительно выполняют:
передачу по меньшей мере одним сервером второму клиентскому устройству по меньшей мере части вторых результатов поиска, включая первый выбранный пользователем элемент результата;
получение от второго клиентского устройства по меньшей мере одним сервером указания на второй выбранный пользователем элемент результата, причем второй выбранный пользователем элемент результата является первым выбранным пользователем элементом результата;
осуществление по меньшей мере одним сервером изменения списка словопозиций, связанного с отсутствующим одним из множества поисковых терминов словопозиций второго типа первого выбранного пользователем элемента результата; для принятия во внимание первого выбранного пользователем элемента результата, который также является вторым выбранным пользователем элементом результата.
16. Система поиска в инвертированном индексе, содержащая по меньшей мере один сервер, и по меньшей мере один сервер обладает по меньшей мере одним компьютерным процессором и постоянным компьютерным носителем информации, хранящим программные инструкции, при выполнении которых по меньшей мере один компьютерный процессор способен выполнять:
получение от первого клиентского устройства по меньшей мере одним сервером первого поискового запроса для проведения поиска, причем первый поисковый запрос включает в себя первое множество поисковых терминов;
осуществление по меньшей мере одним сервером первого поиска первого множества списков словопозиций для получения первых результатов поиска, причем каждый из первого множества списков словопозиций связан с одним из первого множества поисковых терминов, и каждый из первого множества списков словопозиций включает в себя множество словопозиций первого типа, причем словопозиция первого типа является ссылкой на элемент данных, который фактически содержит поисковый термин, с которым связан этот список словопозиций, и первые результаты поиска включают в себя первое множество элементов результата, первые результаты поиска включают в себя элемент результата, в котором отсутствует один из первого множества поисковых терминов;
передачу по меньшей мере одним сервером первому клиентскому устройству по меньшей мере части первых результатов поиска, включая элемент результата, в котором отсутствует один из первого множества поисковых терминов;
получение от первого клиентского устройства по меньшей мере одним сервером указания на первый выбранный пользователем элемент результата, причем первый выбранный пользователем элемент результата является элементом результата, в котором отсутствует один из первого множества поисковых терминов;
осуществление по меньшей мере одним сервером вставки в список словопозиций, связанный с отсутствующим термином из первого множества поисковых терминов в первом выбранном пользователем элементе результата, словопозиций второго типа, причем словопозиция второго типа является ссылкой на выбранный пользователем элемент результата, в котором отсутствует этот поисковый термин.
17. Система по п. 16, в которой постоянный носитель компьютерной информации дополнительно хранит программные инструкции, при выполнении которых по меньшей мере один компьютерный процессор способен выполнять:
получение от второго клиентского устройства по меньшей мере одним сервером второго поискового запроса для проведения поиска, второй поисковый запрос включает в себя второе множество поисковых терминов, и один из второго множества поисковых терминов является отсутствующим термином в первом множестве поисковых терминов в первом выбранном пользователем элементе результата из первого множества элементов результата; и
осуществление по меньшей мере одним сервером второго поиска второго множества списков словопозиций для получения вторых результатов поиска, каждый из второго множества списков словопозиций связан с одним из второго множества поисковых терминов, один из второго множества списков словопозиций является списком словопозиций, связанным с отсутствующим термином из первого множества поисковых терминов в первом выбранном пользователем элементе результата из первого множества элементов результата, и включение в себя словопозиций второго типа второго поиска, и второй поиск включает в себя учет словопозиций второго типа.
18. Система по п. 17, в которой постоянный носитель компьютерной информации дополнительно хранит программные инструкции, при выполнении которых по меньшей мере один компьютерный процессор способен выполнять:
передачу по меньшей мере одним сервером второму клиентскому устройству по меньшей мере части вторых результатов поиска, включая первый выбранный пользователем элемент результата;
получение от второго клиентского устройства по меньшей мере одним сервером указания на второй выбранный пользователем элемент результата, причем второй выбранный пользователем элемент результата является первым выбранным пользователем элементом результата;
осуществление по меньшей мере одним сервером изменения списка словопозиций, связанного с отсутствующим одним из множества поисковых терминов словопозиций второго типа первого выбранного пользователем элемента результата; для принятия во внимание первого выбранного пользователем элемента результата, который также является вторым выбранным пользователем элементом результата.
| US 20090254523 A1, 08.10.2009 | |||
| RU 2008128332 A, 20.01.2010 | |||
| US 20060161520 A1, 20.07.2006 | |||
| US 20130091166 A1, 11.04.2013 | |||
| СПОСОБ ПОИСКА ИНФОРМАЦИИ В МАССИВЕ ТЕКСТОВ | 2008 |
|
RU2392660C2 |

