Область техники, к которой относится изобретение
[01] Настоящее техническое решение относится к области поисковых систем в целом и в частности к способу и устройству для создания аннотированного поискового индекса.
Уровень техники
[02] Интернет предоставляет доступ к широкому спектру ресурсов, например видеофайлам, файлам изображений, аудиофайлам или веб-страницам, содержащим контент по специфическим тематикам, к выдержкам из книг и новостным статьям. Поисковая система в ответ на получение поискового запроса может выбрать один или несколько ресурсов. Поисковый запрос представляет собой данные, которые пользователь отправляет (или инициирует, сознательно или неосознанно, их передачу или получение) поисковой системе для осуществления поиска с целью удовлетворения своих информационных потребностей. Поисковые запросы почти всегда содержат данные в виде текста - например, один или несколько терминов поискового запроса, - а также другую информацию. Для предоставления результатов поиска, связанных с выбранными ресурсами, поисковая система выбирает и оценивает ресурсы на основе их соответствия поисковому запросу и относительной важности по сравнению с другими ресурсами. Поисковые результаты обычно ранжируются по порядку в соответствии с оценками и выводятся в соответствии с этим порядком.
[03] Современные большие центры обработки данных обрабатывают наборы данных, содержащих миллиарды элементов данных. В таких больших наборах поиск конкретных элементов, которые отвечают условиям данного поискового запроса, является задачей, которая требует значительных вычислительных ресурсов. Эта задача также требует значительного количества времени, даже при обработке на наиболее мощных многопроцессорных компьютерных системах. Во многих приложениях время ответа на поисковый запрос является решающим, либо из-за конкретных технических требований, либо из-за ожиданий пользователей. Чтобы уменьшить время выполнения поискового запроса, используются различные общеизвестные способы.
[04] Обычно при формировании системы управления набором данных с возможностью поиска элементы данных индексируются в соответствии с некоторыми или всеми возможными поисковыми терминами, которые могут содержаться в поисковых запросах. Системой создается (а также сохраняется и обновляется) "инвертированный индекс" набора данных для использования при выполнении поисковых запросов. Инвертированный индекс состоит из ряда "списков словопозиций". Каждый список словопозиций соответствует поисковому термину и содержит ссылки на элементы данных, содержащие данный поисковый термин (или иным образом удовлетворяющие некоторым иным условиям, которые выражаются поисковым термином). Например, если элементы данных являются текстовыми документами, что часто встречается в работе поисковых интернет-систем, то поисковые термины являются индивидуальными словами (и/или некоторыми наиболее часто используемыми их комбинациями), а инвертированные индексы содержат один список словопозиций для каждого слова, которое встретилось по меньшей мере в одном документе. В другом примере набор данных является базой данных, содержащей одну или несколько очень длинных таблиц. Элементы данных являются индивидуальными записями (т.е. строками в таблице) с рядом характеристик, представленных определенными значениями в подходящих столбцах таблицы. Поисковые термины являются конкретными значениями характеристик или иными условиями или характеристиками. Список словопозиций для поискового термина является списком ссылок (индексов, порядковых номеров) на записи, которые удовлетворяют поисковому термину.
[05] Чтобы сократить время, требуемое на выполнение поискового запроса, инвертированный индекс обычно сохраняется в устройстве быстродействующей памяти (например, в ОЗУ) одной или нескольких компьютерных систем, в то время как сами элементы данных сохраняются на большем, но функционирующем медленнее носителе (например, на магнитных или лазерных дисках или иных сходных устройствах большой емкости). Таким образом обработка поискового запроса будет включать в себя поиск в одном или нескольких списках словопозиций инвертированных индексов в устройстве быстродействующей памяти, а не поиск самих элементов данных (в устройстве медленнодействующей памяти). В общем случае это позволяет осуществлять поисковые запросы с гораздо более высокой скоростью.
[06] Учитывая объем информации в Интернете и бессистемность распределения разнообразных ресурсов, пользователю не всегда просто сформулировать поисковый запрос, который легко и быстро приведет к получению нужной информации. Кроме того, во многих случаях интересующий пользователя ресурс не связан напрямую с поисковыми терминами в поисковом запросе или с предложениями поисковых запросов. Страница с высокой релевантностью может быть не включена в списки словопозиций для поискового запроса и таким образом может не быть найдена с помощью обычного инвертированного индекса. Например, документ с высокой релевантностью может быть веб-ресурсом, содержащим только графики-изображения, которые не включают в себя никаких текстовых символов или ссылок на поисковый запрос (например URL, заголовок и т.д.).
[07] Существует необходимость в улучшении существующих поисковых систем для предоставления более полных поисковых результатов и еще более удовлетворительного поискового взаимодействия пользователям.
[08] В публикации патентной заявки США No. US 20070038608 раскрыта компьютерная поисковая система для улучшения ранжирования веб-страниц и их представления на основе дополнительной информации, относящейся к содержимому извлеченного документа. Дополнительная информация напрямую относится к содержимому извлеченных веб-страниц, но не присутствует на извлеченных веб-страницах и/или в структуре ссылки. Новая поисковая система ищет обычный набор веб-страниц, а также базы данных, содержащие публикации и семантические веб-данные, которые предоставляют указанную выше дополнительную информацию. Информация, относящаяся к концепту, затем используется при определении итогового ранжирования страниц, что приводит к более релевантному и объективному ранжированию страниц.
[09] В публикации патентной заявки США No. US 20130132381 раскрыта система разметки элементов с помощью фраз-описаний. Может быть определено множество фраз-описаний, связанных с первым доменом на основе анализа первого множества документов для определения совместной встречаемости фраз-описаний с одной или несколькими метками имени, связанными с первым доменом. Может быть получена запись, связанная с первым доменом. Анализ второго множества документов может быть инициирован для идентификации совместной встречаемости упоминаний полученного элемента и одного или нескольких множеств фраз-описаний и контекстов, связанных с каждым из совместной встречаемости упоминаний и фраз-описаний в каждом из второго множества документов. На основе анализа идентифицированных контекстов может быть определена связь через метку-описание между полученным элементом и одной из фраз-описаний.
[10] Патент США No. US 8095538 раскрывает систему и способ аннотированного индекса. В данном патенте описан способ программирования компьютерной системы для извлечения информации в структуре аннотации, обладающей видом инвертированного списка, включая сбор группы документов и сохранение их в цифровом формате, определение группы аннотаций, ссылающихся на группу документов и формирование индекса фрагмента информации с помощью группировки группы аннотаций с помощью уникального идентификатора аннотаций. Способ также включает в себя формирование словаря фрагментов информации, который для каждого уникального идентификатора аннотаций указывает соответствующее положение в индексе фрагментов информации для группы аннотаций, которая имеет этот уникальный идентификатор аннотаций.
Раскрытие изобретения
[11] Задачей предлагаемого изобретения является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники.
[12] Первым объектом настоящего технического решения является способ создания аннотированного поискового индекса (поискового индекса с примечаниями). Способ может выполняться на сервере. Способ включает в себя: извлечение части поисковой сессии из истории для первого поискового запроса, причем эта часть включает в себя первый ресурс и второй ресурс, которые релевантны первому поисковому запросу, первый ресурс включает в себя по меньшей мере некоторые из поисковых терминов первого поискового запроса и был проиндексирован по включенным в него поисковым терминам в первом поисковом индексе, а второй ресурс не включает в себя ни одного поискового термина первого поискового запроса, и он не был проиндексирован по поисковым терминам в первом поисковом индексе; создание параметра связи для второго ресурса, причем параметр связи основан на первом параметре истории и втором параметре истории; и, в ответ на то, что параметр связи для второго ресурса превышает заранее определенный порог, связывание второго ресурса с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами, что создает аннотированный поисковый индекс для этих поисковых терминов.
[13] Первый параметр истории является числом переходов между первым ресурсом и вторым ресурсом в поисковой сессии из истории. Второй параметр истории является временем, проведенным предыдущим пользователем во взаимодействии со вторым ресурсом в поисковой сессии из истории.
[14] В некоторых вариантах осуществления настоящего технического решения параметр связи находится выше предварительно определенного порога, когда первый параметр истории является одним из следующего: 1, 2 или 3 перехода, а второй параметр истории составляет по меньшей мере 30 секунд. В других вариантах осуществления настоящего технического решения параметр связи находится выше предварительно определенного порога, когда первый параметр истории является одним из следующего: 1 или 2 перехода, а второй параметр истории составляет по меньшей мере 30 секунд. Число переходов между первым поисковым запросом и первым ресурсом обычно равно 1, но в некоторых вариантах осуществления настоящего технического решения оно может быть более 1.
[15] В некоторых вариантах осуществления настоящего технического решения аннотированный поисковой индекс создается путем связывания второго ресурса с первым ресурсом и включенными в него поисковыми терминами. В альтернативных вариантах осуществления настоящего технического решения аннотированный поисковой индекс создается связыванием второго ресурса с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами.
[16] В некоторых вариантах осуществления настоящего технического решения первый и второй ресурс независимо являются одним или несколькими пунктами из списка: документ, изображение, аудиофайл, веб-страница, твит (запись в Твиттере), ссылка, заголовок документа и фрагмент документа.
[17] В варианте осуществления настоящего технического решения первый поисковый индекс является инвертированным индексом; первый ресурс и включенные в него поисковые термины связаны друг с другом в списке (списках) словопозиций в инвертированном индексе; и ссылка на второй ресурс вставлена в подходящий список (списки) словопозиций в инвертированном индексе, что создает аннотированный поисковой индекс. В альтернативном варианте осуществления настоящего технического решения второй ресурс связан с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами во втором поисковом индексе, причем созданный аннотированный поисковый индекс включает в себя второй поисковый индекс и отличается от первого поискового индекса. Второй поисковый индекс может быть, например, трех- или четырехмерным массивом данных (т.е. с 3 или 4 уровнями данных). 3 или 4 измерения включают один или несколько пунктов из списка: docID (ID документа), breakID (ID разрыва), regionID (ID области) и sourceID (ID источника).
[18] Другим объектом настоящего технического решения является система создания аннотированного поискового индекса, причем система включает в себя сервер. Сервер включает в себя интерфейс передачи данных для передачи данных по сети передачи данных поисковому кластеру, у которого есть доступ к базе данных, память и процессор, функционально соединенный с интерфейсом передачи данных и памятью, причем процессор выполнен с возможностью сохранять объекты в памяти. Процессор дополнительно выполнен с возможностью осуществлять: извлечение части поисковой сессии из истории для первого поискового запроса, причем эта часть включает в себя первый ресурс и второй ресурс, которые релевантны первому поисковому запросу, первый ресурс включает в себя по меньшей мере некоторые из поисковых терминов первого поискового запроса и был проиндексирован по включенным в него поисковым терминам в первом поисковом индексе, а на втором ресурсе нет ни одного поискового термина из первого поискового запроса, и он не был проиндексирован по поисковым терминам в первом поисковом индексе; создание параметра связи для второго ресурса, причем параметр связи основан на первом параметре истории и втором параметре истории; и в ответ на то, что параметр связи для второго ресурса превышает заранее определенный порог, связывание второго ресурса с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами, что создает аннотированный поисковый индекс для этих поисковых терминов.
[19] В некоторых вариантах осуществления настоящего технического решения процессор выполнен с возможностью связывать второй ресурс с первым ресурсом и включенными в него поисковыми терминами для создания аннотированного поискового индекса. В других вариантах осуществления настоящего технического решения процессор выполнен с возможностью связывать второй ресурс с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами для создания аннотированного поискового индекса.
[20] В одном варианте осуществления настоящего технического решения первый поисковый индекс является инвертированным индексом; первый ресурс и включенные в него поисковые термины связаны друг с другом в списке (списках) словопозиций в инвертированном индексе; и процессор выполнен с возможностью вставлять ссылку на второй ресурс в подходящий список (списки) словопозиций в инвертированном индексе, что создает аннотированный поисковой индекс. В другом варианте осуществления настоящего технического решения процессор выполнен с возможностью связывать второй ресурс с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами во втором поисковом индексе, причем созданный аннотированный поисковый индекс включает в себя второй поисковый индекс и отличается от первого поискового индекса. Второй поисковый индекс может быть, например, трех- или четырехмерным массивом данных, причем 3 или 4 измерения содержат один или несколько пунктов из списка: docID (ID документа), breakID (ID разрыва), regionID (ID области) и sourceID (ID источника).
[21] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для настоящего технического решения. В контексте настоящего технического решения использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы, извлечение поисковых сессий из истории) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «сервер».
[22] В контексте настоящего описания «клиентское устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами клиентских устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как клиентское устройство в настоящем контексте, может вести себя как сервер по отношению к другим клиентским устройствам. Использование выражения «клиентское устройство» не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного способа.
[23] В контексте настоящего описания «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, выполняющем процесс, который сохраняет или использует информацию, хранящуюся в базе данных, или же она может находиться на отдельном оборудовании, например выделенном сервере или множестве серверов.
[24] В контексте настоящего описания «информация» включает в себя информацию любого рода или типа, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
[25] В контексте настоящего описания «компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[26] В контексте настоящего описания «используемый компьютером носитель компьютерной информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[27] В контексте настоящего описания, как было описано ранее, "список словопозиций" для данного поискового термина - это обычно список ссылок на элементы данных в наборе данных, который включает в себя этот поисковый термин. В этом случае понятно, что чем более общим является поисковый термин, тем большим будет число ссылок в списке словопозиций. Для широко распространенных поисковых терминов, например, артикля "the" в английском языке, список словопозиций будет включать в себя ссылки на каждый элемент данных в наборе данных. Почти для всех других поисковых терминов такого не происходит, однако, будут существовать разрывы между элементами данных в наборе данных, содержащими данный поисковый термин, причем эти разрывы образованы элементами данных, которые не содержат этот термин. Так, например, принимая, что ссылки в списке словопозиций указывали на номера документов, соответствующие разрывы в номерах документов будут присутствовать в списке словопозиций.
[28] Список словопозиций для данного общего поискового термина (т.е. поисковый термин, который можно обнаружить в относительно большом числе документов, но не во всех) будет содержать ссылки в форме номеров документов, на те документы, в которых этот поисковый термин появляется. Ссылки в списках словопозиций сами по себе пронумерованы по порядку, но при отсутствии поискового термина в документах образуются разрывы между номерами документов из-за пропущенных документов. Длина списка словопозиций может быть различной в зависимости от числа элементов данных в наборе данных, которые включают в себя поисковый термин. Длина списка словопозиций может быть нулевой, при отсутствии в наборе данных документов, в которых встречается поисковый термин из запроса.
[29] В контексте настоящего описания, как было описано выше, "инвертированный индекс" содержит ряд списков словопозиций.
[30] В некоторых вариантах осуществления настоящего технического решения каждый из множества списков словопозиций соответствует множеству ссылок поисковых терминов на множество индексированных элементов, причем проиндексированные элементы последовательно пронумерованы. Как было описано выше, такую схему используют поисковые интернет-системы, причем проиндексированные элементы последовательно пронумерованы номерами документов.
[31] В некоторых вариантах осуществления настоящего технического решения каждый из множества списков словопозиций соответствует множеству ссылок поисковых терминов на множество индексированных элементов, причем проиндексированные элементы сгруппированы в порядке понижения их релевантности, не зависящей от запроса. Эту схему обычно используют поисковые интернет-системы, в которых элементы данных не вносятся в набор данных бессистемно. Обычно элементы в наборе данных расположены в порядке понижения их релевантности, не зависящей от запроса. Таким образом, элементы данных, вероятность которых оказаться частью поисковых результатов любого данного поискового запроса статистически выше, будут расположены таким образом, чтобы их можно было найти в начале поиска. Поэтому более вероятно, что они будут найдены быстрее, чем данные в наборе данных, которые были введены бессистемно.
[32] В контексте настоящего описания слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной связи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[33] Каждый вариант осуществления настоящего технического решения преследует по меньшей мере одну из вышеупомянутых целей. Следует иметь в виду, что некоторые объекты настоящего технического решения, полученные в результате попыток достичь вышеупомянутой цели, могут удовлетворять и другим целям, отдельно не указанным здесь.
[34] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящего технического решения станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
Краткое описание чертежей
[35] Для лучшего понимания настоящего изобретения, а также других его вариантов осуществления и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[36] На Фиг. 1 представлена принципиальная схема системы, реализованной в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
[37] На Фиг. 2 представлена поисковая сессия из истории в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
[38] На Фиг. 3 представлена принципиальная схема, изображающая аннотированный поисковый индекс, содержащий четырехмерный набор данных в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
[39] На Фиг. 4 представлена блок-схема способа, выполняемого в рамках системы, изображенной на Фиг. 1, и выполненного в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем.
Осуществление изобретения
[40] На Фиг. 1 представлена принципиальная схема системы 100, выполненной в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание показательных вариантов осуществления настоящего технического решения. Таким образом, все последующее описание представлено только как описание показательного примера настоящего технического решения. Это описание не предназначено для определения объема или установления границ настоящего технического решения. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящего технического решения. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящего технического решения. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящего технического решения, и в подобных случаях он представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящего технического решения будут обладать гораздо большей сложностью.
[41] В общем случае система 100 выполнена с возможностью получать поисковые запросы и проводить поиски (например, обычные и вертикальные поиски) в ответ на эти запросы, а также создавать аннотированные поисковые индексы в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем. Поэтому любой вариант системы, выполненный с возможностью обрабатывать поисковые запросы пользователя и создавать аннотированные поисковые индексы, может быть адаптирован специалистом к выполнению вариантов осуществления настоящего технического решения после того, как специалистом было прочитано настоящее описание.
[42] Система 100 включает в себя электронное устройство 102. Электронное устройство 102 обычно связано с пользователем (не показан) и, таким образом, иногда может упоминаться как «клиентское устройство». Следует отметить, что тот факт, что электронное устройство 102 связано с пользователем, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, регистрации, или чего-либо подобного.
[43] Варианты электронного устройства 102 конкретно не ограничены, но в качестве примера электронного устройства 102 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (смартфоны, мобильные телефоны, планшеты и т.п.), а также сетевое оборудование (маршрутизаторы, коммутаторы или шлюзы). Электронное устройство 102 включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для использования поискового приложения 104. В общем случае, целью поискового приложения 104 является предоставление возможности пользователю (не показан) выполнять поиск, например, сетевой поиск с помощью поисковой системы.
[44] Реализация поискового приложения 104 никак конкретно не ограничена. Одним из примеров выполнения поискового приложения 104 является доступ пользователем на веб-сайт, соответствующий поисковой системе, для получения доступа к поисковому приложению 104. Например, поисковое приложение может быть вызвано путем ввода URL, связанного с поисковой системой Яндекс (Yandex™): www.yandex.ru. Важно иметь в виду, что поисковое приложение 104 может быть вызвано с помощью любой другой коммерчески доступной или собственной поисковой системы.
[45] В других вариантах осуществления настоящего технического решения, не ограничивающих его объем, поисковое приложение 104 может представлять собой браузерное приложение на портативном устройстве (например, беспроводном устройстве связи). Для тех случаев (но не только), когда электронное устройство 102 является портативным устройством, таким как, например, Samsung™ Galaxy™ Sill, электронное устройство может использовать приложение Яндекс-браузер. Важно иметь в виду, что любое другое коммерчески доступное или собственное браузерное приложение может быть использовано для реализации вариантов осуществления настоящего технического решения, не ограничивающих его объем.
[46] В общем случае, поисковое приложение 104 включает в себя интерфейс 106 поисковых запросов и интерфейс результатов 108 поиска. Основной задачей интерфейса 106 поисковых запросов является предоставление возможности пользователю (не показан) вводить свой запрос или «поисковый запрос». Основной задачей интерфейса 108 результатов поиска является предоставление результатов поиска, отвечающих пользовательскому поисковому запросу 210, который был введен в интерфейс 106 поисковых запросов.
[47] К сети передачи данных также присоединен сервер 116. Сервер 116 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения сервер 116 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 116 может представлять собой любое другое подходящее аппаратное, и/или прикладное программное, и/или системное программное обеспечение. В представленном варианте осуществления настоящего технического решения, не ограничивающем его объем, сервер 116 является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих его объем, функциональность сервера 116 может быть разделена и может выполняться с помощью нескольких серверов.
[48] Электронное устройство 102 выполнено с возможностью обмениваться данными с сервером 116 через линию 112 передачи данных. В общем случае линия 112 передачи данных предоставляет электронному устройству 102 выполнять доступ к серверу 116 через сеть передачи данных (не показана). В некоторых вариантах осуществления настоящего технического решения, не ограничивающих его объем, сеть передачи данных (не показана) может представлять собой Интернет. В других вариантах осуществления настоящего технического решения сеть передачи данных (не показана) может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
[49] Реализация линии 112 передачи данных не ограничена и будет зависеть от того, какое электронное устройство 102 используется. В качестве примера, но не ограничения, в данных вариантах осуществления настоящего технического решения в случаях, когда электронное устройство 102 представляет собой беспроводное устройство связи (например, смартфон), линия 112 передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных 3G, линия передачи данных 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где электронное устройство 102 представляет собой портативный компьютер, линия передачи данных может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п), так и проводной (соединение на основе сети Ethernet).
[50] Сервер 116 соединен функционально (или иным образом имеет доступ) с поисковым кластером 118. В соответствии с этими вариантами осуществления настоящего технического решения поисковый кластер 118 выполняет общий и/или вертикальный поиск в ответ на поисковый запрос пользователя, введенный с помощью интерфейса 106 поисковых запросов, и выводит результаты поиска для представления их пользователю с помощью интерфейса результатов поиска 108. В рамках этих вариантов осуществления настоящего технического решения, не ограничивающих его объем, поисковый кластер 118 включает в себя или имеет доступ к базе данных 122. Как известно специалистам в данной области техники, база данных 122 хранит информацию, связанную со множеством ресурсов, потенциально доступных через сеть передачи данных (например, эти ресурсы доступны по интернету). База данных 122 также сохраняет информацию и данные, например характеристики поисковых историй в отношении конкретного поискового запроса 210 (например, поисковых сессий из истории), инвертированному индексу и т.д. Процесс заполнения и ведения базы данных 122 общеизвестен как "сбор данных" ("кроулинг" от англ. "crawling").
[51] Осуществление базы данных 122 никак конкретно не ограничено. Следует понимать, что может быть использовано любое подходящее для хранения данных оборудование. В некоторых вариантах осуществления настоящего технического решения база данных 122 может быть физически совмещена с поисковым кластером 118, т.е. нет необходимости в том, чтобы они являлись отдельными частями аппаратного оборудования, как это изображено, хотя они могут являться отдельными частями аппаратного оборудования. В представленном варианте осуществления настоящего технического решения, не ограничивающем его объем, база данных 122 является одиночной базой данных. В альтернативных неограничивающих вариантах осуществления настоящего технического решения база данных 122 может быть разделена на одну или несколько отдельных баз данных (не изображены). Эти отдельные базы данных могут являться частями той же самой физической базы данных или могут быть реализованы как самостоятельные физические единицы. Например, одна база данных в, допустим, базе данных 122 может хранить инвертированный индекс, а другая база данных в базе данных 122 может хранить доступные ресурсы, а еще одна база данных в базе данных 122 может хранить характеристики поисковых историй, относящихся к конкретным поисковым запросам (т.е. поисковым сессиям в истории). Излишне упоминать, что вышеприведенный пример является только иллюстрацией, и возможны другие дополнительные возможности для реализации вариантов осуществления настоящего технического решения.
[52] Важно иметь в виду, что для упрощения нижеследующего описания конфигурация поискового кластера 118 и базы данных 122 была сильно упрощена. Считается, что специалисты в данной области техники смогут понять подробности реализации поискового кластера 118 и его компонентов и базы данных 122.
[53] В общем случае поисковый запрос 210 может быть рассмотрен как серии одного или нескольких поисковых терминов, а поисковые термины этих запросов могут быть представлены как Т1, Т2, … Tn. Таким образом поисковый запрос 210 может пониматься как запрос поисковому приложению 104 определить каждый документ в наборе данных (не изображен), сохраненный в базе данных 122, содержащей каждый поисковый термин T1, T2, … Τn (логический эквивалент "и" между поисковыми терминами; т.е. в каждом документе, найденном в поиске, должно встречаться по меньшей мере один раз слово Ti, для каждого i от 1 до n. Это простейшая форма выполнения поискового запроса 210.
[54] В этих вариантах осуществления настоящего технического решения сервер 116 выполнен с возможностью выполнять доступ к поисковому кластеру 118 (чтобы осуществлять обычный веб-поиск и/или вертикальный поиск, например, в ответ на поисковый запрос 210). В рамках варианта осуществления настоящего технического решения, изображенного на Фиг. 1, сервер 116 выполнен с возможностью: (i) проводить поиски (с помощью доступа к поисковому кластеру 118); (ii) проводить анализ результатов поиска и ранжирование результатов поиска; (iii) группировать результаты и компилировать страницы результатов поиска (SERP) для вывода на электронное устройство 102 в ответ на поисковый запрос 210 (не изображен).
[55] В соответствии с неограничивающими вариантами осуществления настоящего технического решения сервер 116 дополнительно выполнен с возможностью создавать аннотированный поисковый индекс с помощью: извлечения части поисковой сессии 200 (Фиг. 2) из истории для поискового запроса 210 (поисковая сессия 200 из истории хранится, например, в базе данных 122); создания параметра связи для связанного документа 280, идентифицированного в поисковой сессии 200 из истории, но не имеющего ни одного из терминов поискового запроса 210; и в ответ на то, что параметр связи превышает ранее определенный порог, связывания связанного документа 280 с поисковым запросом 210 или первым ресурсом 220 для создания аннотированного поискового индекса 300 (Фиг. 3) (который может быть сохранен, например, в базе данных 122). Аннотированный поисковый индекс 300 затем становится доступен для использования при проведении будущих поисков пользователей при поиске результатов для поискового запроса 210 в контексте системы 100, как описано выше.
[56] Как известно специалистам в данной области техники, индексирование используется для увеличения эффективности поиска для больших наборов данных. Таким образом, одна из областей техники, в которой настоящее техническое решение будет применимо, является областью поисковых приложений, которые используют, например, поисковые интернет-системы, как описано выше, хотя настоящее техническое решение может быть использовано и в других областях (например, в отношении больших баз данных). Варианты осуществления настоящего технического решения, описанные здесь, упоминают поисковые интернет-системы, поскольку они являются хорошим примером для иллюстрации и понимания, но важно помнить, что настоящее техническое решение не ограничивается поисковыми интернет-системами.
[57] Поисковая интернет-система будет, как правило, обладать доступом (через поисковое приложение 104 и сервер 116) к набору данных в базе данных 122, включая, среди прочего, очень большое число веб-страниц из интернета, которые, наряду со связанными с ними гиперссылками, могут упоминаться как "документы". Обычно набор данных содержит в себе другие ресурсы, доступные в Интернете, а не только документы; для простоты понимания в описанных здесь примерах фигурируют только документы, но следует понимать, что настоящее техническое решение применяет все типы ресурсов в наборе данных. Неограничивающие примеры других типов ресурсов включают в себя изображения, аудио-файлы, веб-страницы, ссылки, заголовки документов и фрагменты документов.
[58] Документы обычно вносятся в набор данных посредством выполнения фонового процесса индексирования веб-страниц, который в общем случае упоминается в этой области техники как "поисковый робот" (англ. "crawler"). Общее число документов в наборе данных для индексации и документов, сочтенных доступными для поиска, может обычно находиться в диапазоне от 10 до 100 миллиардов, в зависимости от различных факторов, например языкового объема набора данных (т.е. содержания в наборе данных документов на одном языке или на нескольких). В неограничивающем варианте осуществления настоящего технического решения, изображенном на Фиг. 1, как часть поискового кластера 118 может быть реализован поисковый веб-робот, который направляет результаты своей работы в базу данных 122. Обычно поисковый веб-робот осуществляет систематический автоматический просмотр сети для нахождения новых или недавно обновленных веб-страниц.
[59] Процесс индексирования документа обычно состоит из определения того, какие слова (на любом языке), какие веб-адреса (гиперссылки, также упоминающиеся здесь как "ссылки"), и/или какие иные конкретные термины, которые сочтены потенциальными поисковыми терминами, появляются в документе. В некоторых случаях некоторые фразы (например, последовательности слов) могут также быть рассмотрены как поисковые термины, и в этом случае эти фразы будут сами по себе становиться частью процесса индексирования. В некоторых процессах индексирования документов поисковый термин будет включать в себя различные лексические представления, например, различные грамматические формы одного слова-основы. Что будет использовано как поисковый термин, а что – нет, обычно определяется конкретными поисковыми политиками данной поисковой машины. Публичные общие сервисы поисковых интернет-систем обычно рассматривают каждое слово на любом языке как корректный поисковый термин.
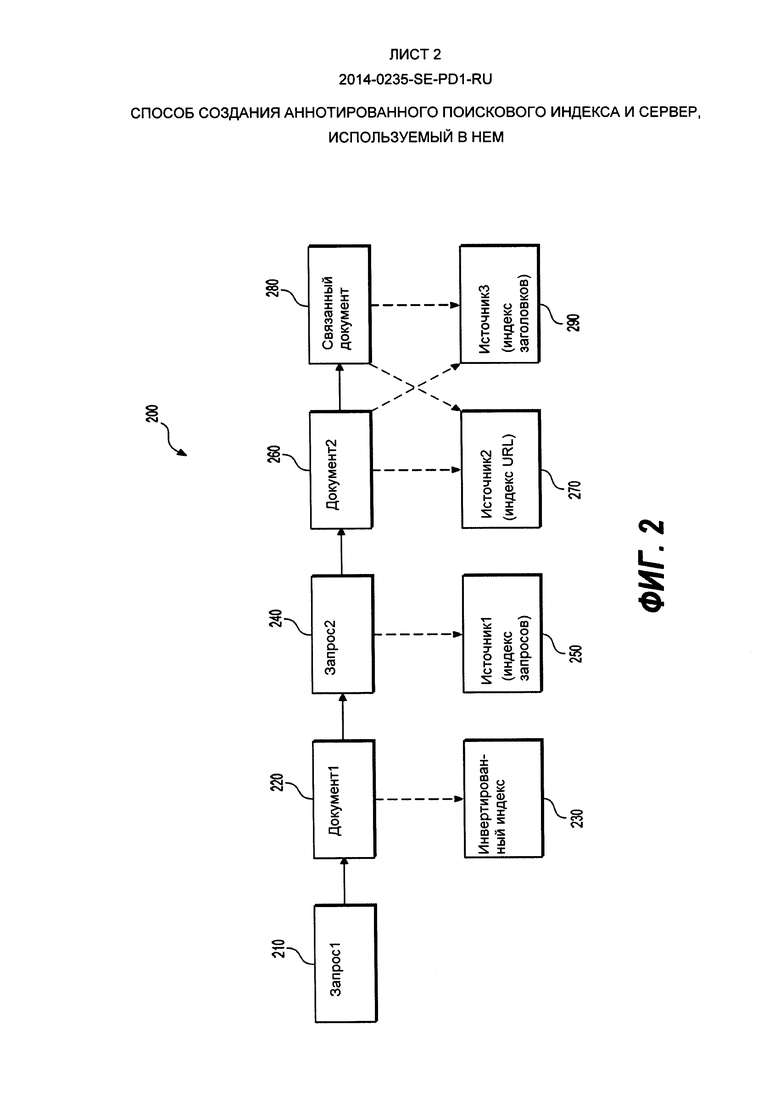
[60] Для любого данного поискового термина (например, слова, гиперссылки, конкретного термина или фразы) процесс индексирования документов создает и поддерживает список ссылок на документы, в которых содержится данный поисковый термин - список словопозиций этого поискового термина. Таким образом список словопозиций поискового термина набора данных содержит ссылки на каждый документ в наборе данных, в котором этот поисковый термин встречается по меньшей мере один раз. Ссылка на документ (в общем случае называемая "словопозицией" - от этого термина произошел термин "список словопозиций") может быть, например, номером этого документа. Каждый список словопозиций сформирован по возрастанию номеров документов, на которые даны ссылки. В качестве примера список словопозиций для данного термина в данном наборе данных может начинаться с документа номер 5 и включать в себя, по порядку, номера документов 7, 8, 40, 41, 64 и так далее. Список не будет включать в себя любой не упомянутый номер меньше 64 (поскольку в этом примере поисковый термин не появляется в таких документах с такими номерами). Таким образом, такой список словопозиций может быть представлен как {5, 7, 8, 40, 41, 64, …}.
[61] Относительно выполнения поискового запроса пример запроса Q={T1, Т2, Т3} понимается как "найти все документы, в которых встречается каждый поисковый термин (обычно слово) T1, Т2 и Т3". Следует также понимать, что списки словопозиций, которые соответствуют этим поисковым терминам, будут отмечены как Р1, Р2 и Р3 соответственно. Это конкретный случай более общего поискового запроса Q={T1, Т2, … Tn} с n поисковых терминов. Этот конкретный случай рассматривается только с целью иллюстрации и упрощения.
[62] Процедура выполнения поискового запроса является итерационным процессом, который создаст новый список словопозиций R, содержащий найденные результаты поиска, т.е. номера документов этих документов (в возрастающем порядке), которые удовлетворяют всем поисковым критериям запроса Q (в котором, например, возникает каждый из поисковых терминов прошлого примера Т1, Т2, Т3).
[63] Общеизвестны многие системы индексирования документов, предполагается, что специалисты в данной области техники могут понять детали вариантов осуществления настоящего технического решения для создания и поддержки системы индексирования документов.
[64] Для простой иллюстрации и в качестве помощи для понимания на Фиг. 2 показана принципиальная схема поисковой сессии 200 из истории для первого поискового запроса ("запрос1") (210). В поисковой сессии 200 из истории первый документ ("документ1") 220 был извлечен и отображен в интерфейсе 108 поисковых результатов после введения запроса1 210 в интерфейс 106 поисковых запросов по словопозиций документ1 220 в запросе1 210 в инвертированном индексе 230. После перехода на документ1 220 пользователь переформулировал запрос1 210 как запрос2 240. В ответ на запрос2 240 был извлечен и отображен в интерфейсе 108 поисковых результатов второй документ ("документ2") 260. От док2 260 пользователь перешел на связанный с ним документ ("связанный документ") 280.
[65] Таким образом в варианте осуществления настоящего технического решения, изображенном на Фиг. 2, число переходов между документом1 220 и связанным документом 280 равно трем. Следует понимать, что поисковая сессия 200 из истории показана исключительно с иллюстративными целями и возможны многие другие варианты и перестановки.
[66] В поисковой сессии 200 из истории, хотя связанный документ 280 не включает в себя ни одного поискового термина из запроса1 210 и хотя переход на связанный документ 280 был выполнен после выполнения запроса2 240, связанный документ 280, тем не менее, является релевантным по отношению к исходному поисковому запросу (запрос1 210). Следовательно, желательно в этом примере создать аннотированный поисковый индекс 300, в котором связанный документ 280 связан с одним или несколькими запросом1 210 и документом1 220 для увеличения полноты будущих поисков.
[67] В некоторых неограничивающих вариантах осуществления настоящего технического решения аннотированный поисковый индекс 300 создается занесением ссылки на связанный документ 280 в подходящий список (списки) словопозиций для включенного в него (них) поискового термина(ов) (причем эти списки словопозиций уже включают в себя документ1 220 в инвертированном индексе 230. В таких вариантах осуществления настоящего технического решения аннотированный поисковый индекс 300 может быть рассмотрен как расширение исходного инвертированного индекса 230.
[68] В некоторых вариантах осуществления настоящего технического решения создаются дополнительные индексы, относящиеся к поисковой сессии 200 из истории. Например, в варианте осуществления настоящего технического решения, показанном на Фиг. 2, создаются индекс 250 запросов ("источник 1"); индекс 270 URL ("источник 2"); и индекс 290 заголовков ("источник 3"). В общем случае аннотации того же типа (например, запросы, документы и их части) могут быть собраны в источники и сведены в аннотированный поисковой индекс. В качестве примера, может быть создано следующее (без ограничений): источник Википедии, содержащий заголовки статей Википедии, изображенные на Фиг. 2 в виде индекса 290 заголовков; индекс ссылок, содержащий URL на определенные веб-ресурсы, изображенные на Фиг. 2 как индекс 270 URL; и источник связанных запросов, изображенный на Фиг. 2 как индекс 250 запросов. В некоторых вариантах осуществления настоящего технического решения такие источники являются аннотациями в аннотированном поисковом индексе, таком как аннотированный поисковый индекс 300 (описан далее).
[69] В альтернативных вариантах осуществления настоящего технического решения аннотированный поисковый индекс 300 создается как второй поисковый индекс, в котором связанный документ 280 связан с одним или несколькими запрсом1 210 и документом1 220 в массиве данных. Второй поисковый индекс может быть, например, отдельной базой данных или индексом, содержащим множество уровней данных или ссылок на связанный документ 280, например трех- или четырехмерный массив данных. Для простоты иллюстрации и как помощь для понимания пример такого аннотированного поискового индекса 300, содержащий четырехмерный массив 305 данных (также упоминаемый как "массив данных 4D"), показан на Фиг. 3, которая изображает принципиальную схему аннотированных поисковых индексов 300, содержащих массив 305 данных 4D.
[70] Массив 305 данных 4D содержит 4 уровня данных: первый уровень 310, состоящий из документов, содержащих построчное сравнение запроса или части запроса (docID); второй слой 320, содержащий строки (например, описания, фразы) документов (breakID); третий слой 330, содержащий области, в которых находились пользователи, когда вводили свои запросы (regionID); и четвертый слой 340, содержащий источники аннотаций определенного типа (sourceID). Во время обработки запроса запрос1 210 и связанный документ1 220 сначала определяются в стандартном инвертированном индексе 230, а также извлекаются идентификаторы doclDI и breaklDI для документа1 220, что схематично показано в ячейках 310 и 320 соответственно на Фиг. 3. Эти идентификаторы приведут к извлечению regionID для документ1 220, схематично изображенного в ячейке 330. В соответствии с идентификаторами docID, breakID и regionID извлекаются источники аннотаций (sourceIDs) и сохраняются как аннотации (схематично показано в ячейке 340).
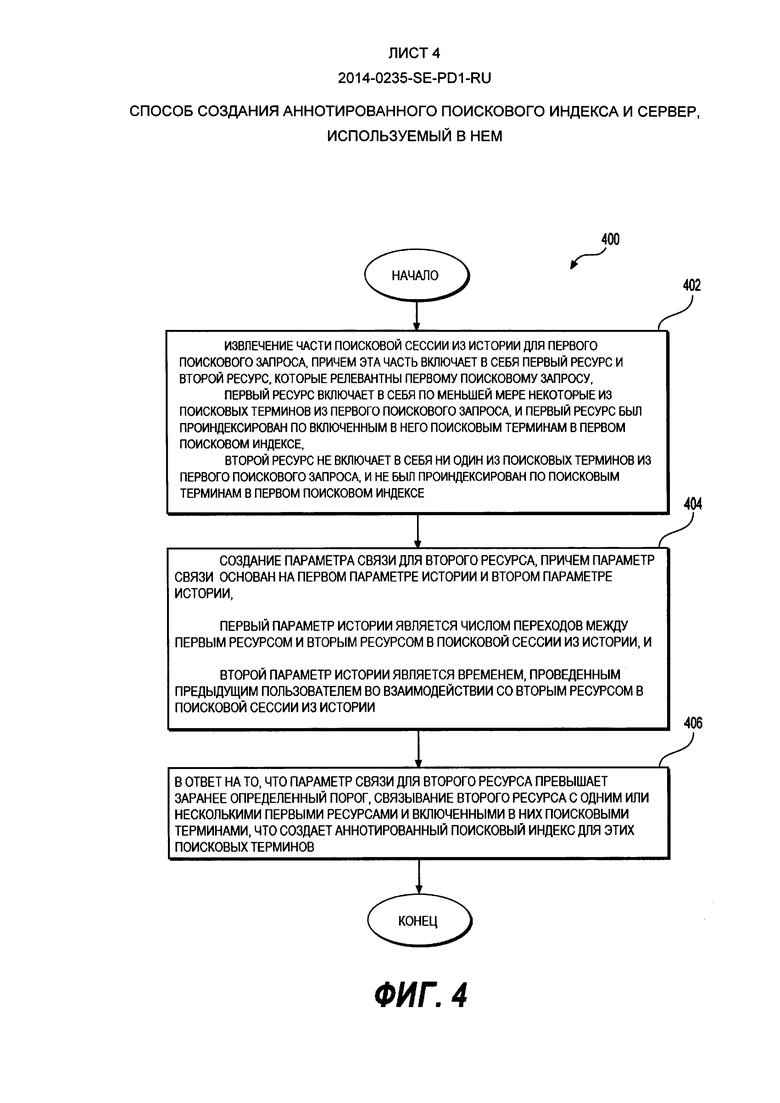
[71] Всего массив 305 данных 4D содержит 4 уровня данных. В неограничивающем варианте осуществления настоящего технического решения, показанном на Фиг. 3, эти четыре уровня следующие: 1) уровень 1 - docID - например, идентификатор документа, который может быть строкой, совпадающей с запросом или его частью (310); 2) уровень 2 - break ID - строки (например, описания, фразы) документов (320); 3) уровень 3 - regionID - области, в которых находились пользователи, когда вводили свои запросы (330); и 4) уровень 4 - sourceID - данные из аннотированного источника (например, заголовок, URL, ссылка и т.д.) (340).
[72] Следует понимать, что на конкретный ресурс может быть приведена ссылка или же он может быть идентифицирован многими иными путями в аннотированном поисковом индексе 300. Способ аннотации никак конкретно не ограничен. В качестве примера, ресурс, например, связанный документ 280, может быть аннотирован с использованием одного или нескольких пунктов из следующего списка (без ограничений): 1) запрос пользователя или часть запроса (например, после получения ответа на запрос1 210, пользователь перешел на связанный документ 280; этот запрос или его ключевые слова могут быть использованы как аннотация к любым иным запросам); 2) текст ссылки на связанный документ 280, который может быть связан со связанным документом 280. Ссылка может содержать в себе, например, ключевые слова, синонимы, URL, аналогичные словам запроса1 210, метку и так далее; 3) текст, расположенный перед и/или после ссылки, причем ссылка связана со связанным документом 280; 4) заголовок описания сайта в каталоге веб-ресурсов или индекс запросов и так далее; 6) твит, например, текст твита, имеющий отношение к связанному документу 280. Может быть использовано множество других ссылок и идентификаторов. Следует понимать, что каждая ссылка и идентификатор вносят сигнал, который позволяет найти связанный документ 280 в ответ на запрос1 210.
[73] Хотя вариант осуществления настоящего технического решения, показанный на Фиг. 3, изображает массив 305 данных 4D, следует понимать, что настоящее техническое решение не ограничивается аннотированными поисковыми индексами, содержащими массив данных 4D. Например, в одном варианте осуществления настоящего технического решения, как было упомянуто выше, аннотированный поисковый индекс может содержать расширение существующего инвертированного индекса, например, где инвертированный индекс 230 аннотирован с помощью введения ссылок на связанный документ 280 в соответствующий список (списки) словопозиций. В некоторых неограничивающих вариантах осуществления настоящего технического решения инвертированный индекс 230 является индексом ссылок. Индекс ссылок основан не на содержимом документов, а на тексте ссылок на документы. В случае присутствия поискового термина в тексте ссылок на документ, этот документ будет помещен в список словопозиций для этого поискового термина. Обычно, каждая запись в индексе ссылок содержит данные о веб-странице, на которую дана ссылка, например язык, географическая область, владелец ссылок на источник, дата создания, другие ссылки и так далее. В альтернативных неограничивающих вариантах осуществления настоящего технического решения аннотированный поисковый индекс может содержать двухмерный (массив данных 2D) или трехмерный (массив данных 3D) массив данных. Известны и другие варианты осуществления настоящего технического решения, которые входят в его объем.
[74] На Фиг. 4 представлена принципиальная схема способа 400, выполненного в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем. Способ 400 может выполняться на сервере 116.
[75] Этап 402 - извлечение части поисковой сессии из истории для первого поискового запроса, причем эта часть включает в себя первый ресурс и второй ресурс, которые релевантны первому поисковому запросу
[76] Способ 400 начинается на этапе 402, на котором сервер 116 извлекает часть поисковой сессии 200 из истории для первого поискового запроса ("запрос1") 210. Часть поисковой сессии 200 из истории включает в себя первый ресурс ("документ1") 220 и второй ресурс ("связанный документ") 280, которые релевантны запросу1 210.
[77] Первый ресурс ("документ1 ") 220 включает в себя по меньшей мере некоторые из поисковых терминов из запроса1 210, и первый ресурс был проиндексирован по включенным в него поисковым терминам в первом поисковом индексе. В некоторых вариантах осуществления настоящего технического решения первый поисковый индекс является инвертированным индексом 230. Инвертированный индекс 230 никак конкретно не ограничен. Например, он может быть инвертированным индексом уровня записи (содержащим список ссылок на документы для каждого поискового термина), уровня слова (дополнительно содержащим позиции каждого слова в документе), индексом ссылок (содержащим список ссылок на ссылки, содержащие каждый поисковый термин) и так далее.
[78] Второй ресурс ("связанный документ") 280 не содержит поисковых терминов из запроса1 210 и не был проиндексирован по поисковым терминам из запроса1 в первом поисковом индексе, например, инвертированном индексе 230. Таким образом, связанный документ 280 может не иметь очевидной связи с запросом1 210, не имея, например, ни одного поискового термина из запроса1 210. Поэтому связанный документ 280 не был извлечен и отображен в интерфейсе 108 поисковых результатов в ответ на запрос1 210 в поисковой сессии 200 из истории. Тем не менее поисковая сессия 200 из истории указывает, что связанный документ 280 релевантен запросу1 210 (релевантность определяется на основе параметра связи для связанного документа 280, как описано ниже).
[79] В некоторых вариантах осуществления настоящего технического решения первый ресурс и второй ресурс являются документами (например, документ1 220 и связанный документ 280 соответственно). Однако тип ресурса ничем конкретно не ограничен. В одном неограничивающем примере первый и второй ресурс независимо могут быть документом, изображением, аудиофайлом, веб-страницей, твитом (записью в Твиттере), ссылкой, заголовком документа или фрагментом документа. Следует понимать, что первый ресурс и второй ресурс могут быть ресурсами одного типа или могут быть ресурсами разных типов. Например, первый ресурс и второй ресурс могут оба быть документами. Или же первый ресурс может быть документом, а второй ресурс может быть изображением. Возможно множество других вариантов, которые входят в объем настоящего технического решения.
[80] Этап 404 - создание параметра связи для второго ресурса, причем параметр связи основан на первом параметре истории и втором параметре истории.
[81] При продолжении способа на этапе 404 создается параметр связи для второго ресурса ("связанный документ") 280. Параметр связи основан на первом параметре истории и втором параметре истории.
[82] Первый параметр истории является числом переходов между первым ресурсом ("документ1") 220 и вторым ресурсом ("связанный документ") 280 в поисковой сессии 200 из истории. В варианте осуществления настоящего технического решения, показанном на Фиг. 2, первый параметр истории равен 3, поскольку было три перехода между документом1 220 и связанным документом 280 (первый переход от документа1 220 к запросу2 240; второй переход от запроса2 240 к документу2 260; и третий переход от документа2 260 к связанному документу 280. Следует отметить, что один переход от запроса1 210 на документ1 220, причем запрос1 210 и документ1 220 проиндексированы вместе в списке словопозиций в инвертированном индексе 230. Следует понимать, что первый параметр истории не ограничивается значением 3 и может принимать различные значения в зависимости от многих факторов, например конкретный поисковый запрос, конкретная поисковая сессия из истории, релевантность ресурса поисковому запросу и так далее. В некоторых вариантах осуществления настоящего технического решения первый параметр истории равен 1. В некоторых вариантах осуществления настоящего технического решения первый параметр истории равен 2. В некоторых вариантах осуществления настоящего технического решения первый параметр истории равен 3. В некоторых вариантах осуществления настоящего технического решения первый параметр истории равен либо 1, либо 2, либо 3.
[83] Второй параметр истории является временем, проведенным предыдущим пользователем во взаимодействии со вторым ресурсом ("связанный документ") 280 в поисковой сессии из истории. Количество времени, которое пользователь провел, взаимодействуя со связанным документом 280, дает одну меру релевантности связанного документа 280. В общем случае, чем дольше пользователь взаимодействовал со связанным документом 280, тем больше релевантность связанного документа 280.
[84] Этап 406 - в ответ на то, что параметр связи для второго ресурса превышает заранее определенный порог, связывание второго ресурса с одним или несколькими первыми ресурсами и включенными в них поисковыми терминами, что создает аннотированный поисковый индекс для этих поисковых терминов.
[85] Способ 400 продолжается на этапе 406, на котором аннотированный поисковый индекс 300 создается в ответ на то, что параметр связи для связанного документа 280 превышает заранее определенный порог. В некоторых вариантах осуществления настоящего технического решения параметр связи находится выше предварительно определенного порога, когда в поисковой сессии 200 из истории первый параметр истории является одним из следующего: 1, 2 или 3 перехода, а второй параметр истории составляет по меньшей мере 30 секунд. В других вариантах осуществления настоящего технического решения параметр связи находится выше предварительно определенного порога, когда в поисковой сессии 200 из истории первый параметр истории является одним из следующего: 1 или 2 перехода, а второй параметр истории составляет по меньшей мере 30 секунд. В некоторых вариантах осуществления настоящего технического решения в поисковой сессии 200 из истории число переходов между запросом1 210 и документом1 220 равно единице. Однако следует понимать, что в альтернативных вариантах осуществления настоящего технического решения число переходов между запросом1 210 и документом1 220 может быть больше единицы, т.е. два или три, в частности, если присутствуют другие указатели высокой релевантности связанного документа 280 (например, второй параметр истории значительно превышает 30 секунд, или первый параметр истории равен одному, указывая на тесную связь между связанным документом 280 и документом 1 220).
[86] В ответ на то, что параметр связи для связанного документа 280 превышает заранее определенный порог, связанный документ 280 связывается с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами, что создает аннотированный поисковый индекс 300 для этих включенных в них поисковых терминов. В некоторых вариантах осуществления настоящего технического решения связанный документ 280 связан с включенными в него поисковыми терминами (например - аннотирован в них). В некоторых вариантах осуществления настоящего технического решения связанный документ 280 связан с документом1 220 (например - аннотирован в нем). В некоторых вариантах осуществления настоящего технического решения связанный документ 280 связан и с включенными в него поисковыми терминами и с документом1 220 (например - аннотирован в них) в аннотированном поисковом индексе 300.
[87] Как было упомянуто выше, способ связывания связанного документа 280 с одним или несколькими документами1 220 и включенными в него или них поисковыми терминами никак конкретно не ограничен. Например, в некоторых вариантах осуществления настоящего технического решения первый поисковый индекс является инвертированным индексом 230, а документ1 220 и включенные в него поисковые термины связаны вместе в списке (списках) словопозиций в инвертированном индексе 230. Аннотированный поисковый индекс 300 может быть создан с помощью внесения ссылок на связанный документ 280 в подходящий список (списки) словопозиций в инвертированном индексе 230. В альтернативных вариантах осуществления настоящего технического решения аннотированный поисковый индекс 300 создается с помощью связывания связанного документа 280 с одним или несколькими документами1 220 и включенными в них поисковыми терминами во втором поисковом индексе, например, массиве 305 данных 4D.
[88] Ссылка или информация для идентификации, которые используются для аннотирования конкретного ресурса, например, связанного документа 280, также никак конкретно не ограничены. Как было упомянуто выше, в некоторых вариантах осуществления настоящего технического решения ссылка или информация для идентификации является одним или несколькими пунктами из списка: docID, breakID, regionID и source ID, например URL, ссылки, заголовки документов и т.д.
[89] Следует понимать, что процедура, описанная выше, является просто иллюстративным вариантом осуществления настоящего технического решения. Она не предназначена для определения или установления объема настоящего технического решения.
[90] Некоторые технические эффекты не ограничивающих вариантов осуществления настоящего технического решения могут включать в себя предоставление более полных результатов поиска пользователю в ответ на введение пользователем поискового запроса. Ресурсы, которые интересны пользователю, но неочевидно связаны с поисковым запросом, могут быть извлечены и отображены на странице результатов поиска SERP. Такие ресурсы могут включать в себя, например, документы, которые не содержат поисковые термины из поискового запроса, например, изображения-схемы, не включающие в себя текстовых символов, которые могли бы быть признаками релевантности поисковому запросу. Предоставление таких ресурсов может позволить пользователю более эффективно находить информацию, которую он(а) искал(а) и погрузиться в интересующий предмет более глубоко. Способность пользователя более эффективно находить информацию приводит к снижению использования траффика. Также, при том, что электронное устройство 102 выполнено как беспроводное устройство передачи данных, способность пользователя более эффективно находить информацию приведет к экономии заряда аккумулятора электронного устройства 102. Что также может предоставить пользователю более привлекательный или интересный поисковый интерфейс или страницу результатов поиска. Важно иметь в виду, что варианты осуществления настоящего технического решения могут быть реализованы с проявлением и других технических результатов.
[91] Модификации и улучшения вышеописанных вариантов осуществления настоящего технического решения будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы изобретения.
[92] Соответственно, варианты осуществления настоящего технического решения, описанные выше, могут быть кратко изложены в перечисленных ниже пунктах формулы изобретения.
[93] ПУНКТ 1. Способ (400) создания аннотированного поискового индекса (300), способ выполняется на сервере (116) и включает в себя:
[94] а) извлечение части поисковой сессии (200) из истории для первого поискового запроса (210), причем эта часть включает в себя первый ресурс (220) и второй ресурс (280), которые релевантны первому поисковому запросу (210),
[95] первый ресурс (220) включает в себя по меньшей мере некоторые из поисковых терминов из первого поискового запроса 210 и был проиндексирован по включенным в него поисковым терминам в первом поисковом индексе (230),
[96] второй ресурс (280) не включает в себя ни одного поискового термина из первого поискового запроса 210 и не был проиндексирован по поисковым терминам в первом поисковом индексе (230);
[97] б) создание параметра связи для второго ресурса (280), причем параметр связи основан на первом параметре истории и втором параметре истории,
[98] первый параметр истории является числом переходов между первым ресурсом (220) и вторым ресурсом (280) в поисковой сессии (200) из истории, и
[99] второй параметр истории является временем, проведенным предыдущим пользователем во взаимодействии со вторым ресурсом (280) в поисковой сессии (200) из истории; и
[100] в) в ответ на то, что параметр связи для второго ресурса (280) превышает заранее определенный порог, связывание второго ресурса (280) с одним или несколькими первыми ресурсами (220) и включенными в него или них поисковыми терминами, что создает аннотированный поисковый индекс (300) для этих поисковых терминов.
[101] ПУНКТ 2. Способ по п. 1, в котором параметр связи находится выше предварительно определенного порога, когда первый параметр истории является одним из следующего: 1, 2 или 3 перехода, а второй параметр истории составляет по меньшей мере 30 секунд.
[102] ПУНКТ 3. Способ по п. 2, в котором параметр связи находится выше предварительно определенного порога, когда первый параметр истории является одним из следующего: 1 или 2 перехода, а второй параметр истории составляет по меньшей мере 30 секунд.
[103] ПУНКТ 4. Способ по п. 2 или 3, в котором число переходов между первым поисковым запросом (210) и первым ресурсом (220) равно одному.
[104] ПУНКТ 5. Способ по любому из пп. 1-4, в котором второй ресурс (280) является одним пунктом из следующего списка: документом, изображением, аудиофайлом, веб-страницей, твитом (записью в Твиттере), ссылкой, заголовком документа или фрагментом документа.
[105] ПУНКТ 6. Способ по любому из пп. 1-5, в котором на этапе в) второй ресурс (280) связан и с первым ресурсом (220) и с включенными в него поисковыми терминами.
[106] ПУНКТ 7. Способ по п. 6, в котором первый поисковый индекс (230) является инвертированным индексом; первый ресурс (220) и включенные в него поисковые термины связаны друг с другом в списке (списках) словопозиций в инвертированном индексе (230); и на этапе в) ссылка на второй ресурс (280) вставлена в подходящий список (списки) словопозиций в инвертированном индексе (230), что создает аннотированный поисковой индекс (300).
[107] ПУНКТ 8. Способ по любому из пп. 1-7, в котором на этапе в) второй ресурс (280) связан с одним или несколькими первыми ресурсами (220) и включенными в него или них поисковыми терминами во втором поисковом индексе, причем созданный аннотированный поисковый индекс (300) включает в себя второй поисковый индекс и отличается от первого поискового индекса (230).
[108] ПУНКТ 9. Способ по п. 8, в котором второй поисковый индекс является трех- или четырехмерным массивом (305) данных.
[109] ПУНКТ 10. Способ по п. 9, в котором 3 или 4 измерения содержат один или более пунктов из списка: docID (310) (ID документа), breakID (320) (ID разрыва), regionID (330) (ID области) и sourceID (340) (ID источника).
[110] ПУНКТ 11. Сервер (116), включающий в себя:
[111] интерфейс передачи данных для передачи данных по сети передачи данных поисковому кластеру (118), который имеет доступ к базе данных (122);
[112] память;
[113] процессор, функционально соединенный с интерфейсом передачи данных и памятью, причем процессор выполнен с возможностью сохранять объекты в памяти; процессор также выполнен с возможностью:
[114] а) извлекать части поисковой сессии (200) из истории для первого поискового запроса (210), причем эта часть включает в себя первый ресурс (220) и второй ресурс (280), которые релевантны первому поисковому запросу (210),
[115] первый ресурс (220) включает в себя по меньшей мере некоторые из поисковых терминов первого поискового запроса 210, и первый ресурс был проиндексирован по включенным в него поисковым терминам в первом поисковом индексе (230),
[116] второй ресурс (280) не включает в себя ни один из поисковых терминов из первого поискового запроса 210, и не был проиндексирован по поисковым терминам в первом поисковом индексе (230);
[117] б) создавать параметр связи для второго ресурса (280), причем параметр связи основан на первом параметре истории и втором параметре истории,
[118] первый параметр истории является числом переходов между первым ресурсом (220) и вторым ресурсом (280) в поисковой сессии (200) из истории, и
[119] второй параметр истории является временем, проведенным предыдущим пользователем во взаимодействии со вторым ресурсом (280) в поисковой сессии (200) из истории; и
[120] в) в ответ на то, что параметр связи для второго ресурса (280) превышает заранее определенный порог, связывать второй ресурс (280) с одним или несколькими первыми ресурсами (220) и включенными в них поисковыми терминами, что создает аннотированный поисковый индекс (300) для этих поисковых терминов.
[121] ПУНКТ 12. Сервер (116) по п. 11, в котором параметр связи находится выше предварительно определенного порога, когда первый параметр истории является одним из следующего: 1, 2 или 3 перехода, а второй параметр истории составляет по меньшей мере 30 секунд.
[122] ПУНКТ 13. Сервер (116) по п. 12, в котором параметр связи находится выше предварительно определенного порога, когда первый параметр истории является одним из следующего: 1 или 2 перехода, а второй параметр истории составляет по меньшей мере 30 секунд.
[123] ПУНКТ 14. Сервер (116) по п. 12 или 13, в котором число переходов между первым поисковым запросом (210) и первым ресурсом (220) равно одному.
[124] ПУНКТ 15. Сервер (116) по любому из пп. 11-14, в котором второй ресурс (280) является одним пунктом из следующего списка: документом, изображением, аудиофайлом, веб-страницей, твитом (записью в Твиттере), ссылкой, заголовком документа или фрагментом документа.
[125] ПУНКТ 16. Сервер (116) по любому из пп. 11-15, в котором процессор выполнен с возможностью связывать второй ресурс (280) с первым ресурсом (220) и с включенными в него поисковыми терминами на этапе в).
[126] ПУНКТ 17. Сервер (116) по п. 16, в котором первый поисковый индекс (230) является инвертированным индексом; первый ресурс (220) и включенные в него поисковые термины связаны друг с другом в списке (списках) словопозиций в инвертированном индексе (230); и в котором процессор выполнен с возможностью вносить ссылку на второй ресурс (280) в подходящий список (списки) словопозиций в инвертированном индексе (230) на этапе в), что создает аннотированный поисковой индекс (300).
[127] ПУНКТ 18. Сервер (116) по любому из пп. 11-17, в котором процессор выполнен с возможностью связывать второй ресурс (280) с одним или несколькими первыми ресурсами (220) и включенными в него или них поисковыми терминами во втором поисковом индексе на этапе в), причем созданный аннотированный поисковый индекс (300) включает в себя второй поисковый индекс и отличается от первого поискового индекса (230).
[128] ПУНКТ 19. Сервер по п. 18, в котором второй поисковый индекс является трех- или четырехмерным массивом (305) данных.
ПУНКТ 20. Сервер по п. 19, в котором 3 или 4 измерения содержат один или более пунктов из списка: docID (310) (ID документа), breakID (320) (ID разрыва), regionID (330) (ID области) и sourceID (340) (ID источника).
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И ПОИСКОВАЯ СИСТЕМА ПРЕДОСТАВЛЕНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ НА МНОЖЕСТВО КЛИЕНТСКИХ УСТРОЙСТВ | 2015 |
|
RU2632423C2 |
| ИСПОЛНЯЕМЫЙ НА КОМПЬЮТЕРЕ СПОСОБ И СИСТЕМА ДЛЯ ПОИСКА В ИНВЕРТИРОВАННОМ ИНДЕКСЕ, ОБЛАДАЮЩЕМ МНОЖЕСТВОМ СПИСКОВ СЛОВОПОЗИЦИЙ | 2014 |
|
RU2718435C2 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2015 |
|
RU2632148C2 |
| СПОСОБ И СИСТЕМА БАЗЫ ДАННЫХ ДЛЯ ИНДЕКСИРОВАНИЯ ССЫЛОК НА ДОКУМЕНТЫ БАЗЫ ДАННЫХ | 2015 |
|
RU2633178C2 |
| СПОСОБ И СИСТЕМА БАЗЫ ДАННЫХ ДЛЯ НАХОЖДЕНИЯ ДОКУМЕНТОВ | 2014 |
|
RU2679960C2 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБНОВЛЕНИЯ БАЗЫ ДАННЫХ ПОИСКОВОГО ИНДЕКСА | 2018 |
|
RU2733482C2 |
| СПОСОБ И СЕРВЕР ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2718216C2 |
| СПОСОБ (ВАРИАНТЫ) И СИСТЕМА (ВАРИАНТЫ) СОЗДАНИЯ МОДЕЛИ ПРОГНОЗИРОВАНИЯ И ОПРЕДЕЛЕНИЯ ТОЧНОСТИ МОДЕЛИ ПРОГНОЗИРОВАНИЯ | 2015 |
|
RU2632133C2 |
| Способы и серверы для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2775815C2 |


Изобретение относится к способу и серверу для создания аннотированного поискового индекса. Технический результат заключается в повышении полноты поисковых результатов. В способе выполняют извлечение части поисковой сессии из истории для первого поискового запроса, включающей в себя первый и второй ресурс, релевантные первому поисковому запросу, первый ресурс включает в себя некоторые из поисковых терминов из первого поискового запроса, и первый ресурс был проиндексирован по включенным в него поисковым терминам в первом поисковом индексе, второй ресурс не включает в себя ни один из поисковых терминов из первого поискового запроса и не был проиндексирован по поисковым терминам в первом поисковом индексе, создание параметра связи для второго ресурса, причем параметр связи основан на первом параметре истории, являющемся числом переходов между первым ресурсом и вторым ресурсом в поисковой сессии из истории и втором параметре истории, являющемся временем, проведенным предыдущим пользователем во взаимодействии со вторым ресурсом в поисковой сессии из истории, и в ответ на то, что параметр связи для второго ресурса превышает заранее определенный порог, связывание второго ресурса с первым ресурсом и включенными в него поисковыми терминами, что создает аннотированный поисковый индекс для этих поисковых терминов. 2 н. и 12 з.п. ф-лы, 4 ил.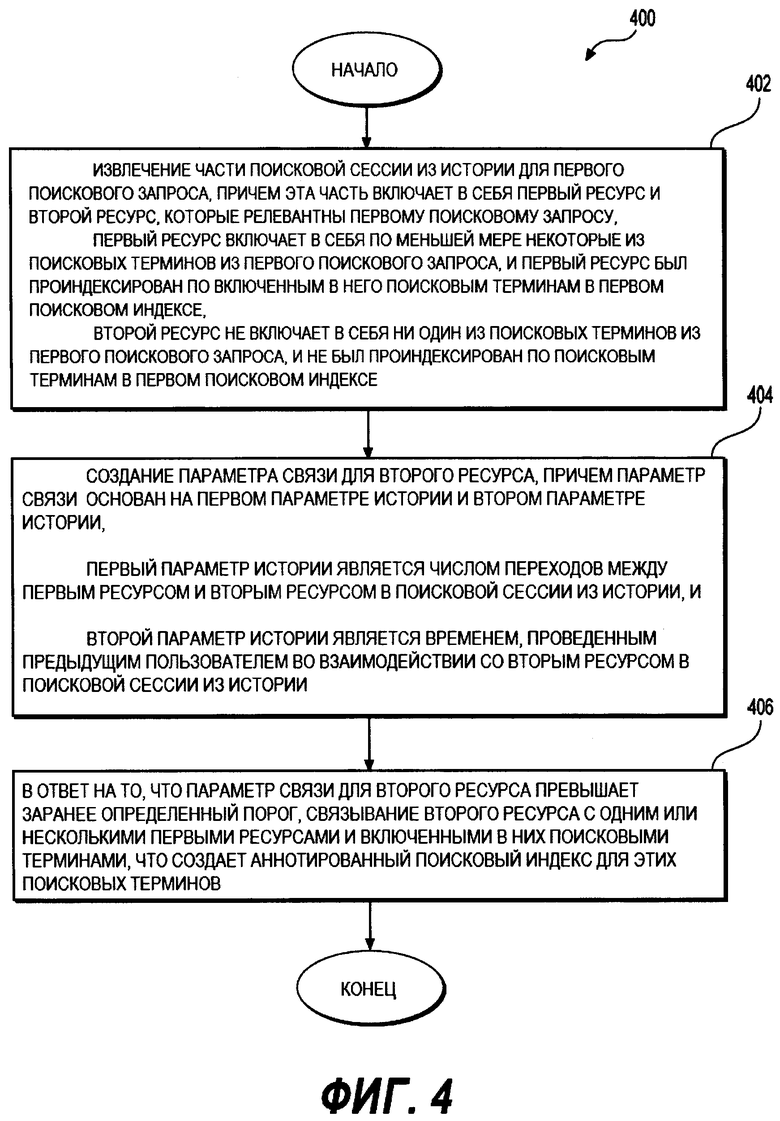
1. Способ создания аннотированного поискового индекса, способ выполняется на сервере и включает в себя:
- извлечение части поисковой сессии из истории для первого поискового запроса, причем эта часть включает в себя первый ресурс и второй ресурс, которые релевантны первому поисковому запросу,
первый ресурс включает в себя по меньшей мере некоторые из поисковых терминов из первого поискового запроса, и первый ресурс был проиндексирован по включенным в него поисковым терминам в первом поисковом индексе,
второй ресурс не включает в себя ни один из поисковых терминов из первого поискового запроса и не был проиндексирован по поисковым терминам в первом поисковом индексе;
- создание параметра связи для второго ресурса, причем параметр связи основан на первом параметре истории и втором параметре истории,
первый параметр истории является числом переходов между первым ресурсом и вторым ресурсом в поисковой сессии из истории, и
второй параметр истории является временем, проведенным предыдущим пользователем во взаимодействии со вторым ресурсом в поисковой сессии из истории; и
- в ответ на то, что параметр связи для второго ресурса превышает заранее определенный порог, связывание второго ресурса с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами, что создает аннотированный поисковый индекс для этих поисковых терминов.
2. Способ по п. 1, в котором параметр связи находится выше предварительно определенного порога, когда первый параметр истории является одним из следующего: 1, или 2, или 3 перехода, а второй параметр истории составляет по меньшей мере 30 секунд.
3. Способ по п. 1, в котором второй ресурс является одним пунктом из следующего списка: документом, изображением, аудиофайлом, веб-страницей, твитом (записью в Твиттере), ссылкой, заголовком документа или фрагментом документа.
4. Способ по п. 1, в котором на этапе связывания второго ресурса с одним или несколькими первыми ресурсами второй ресурс связан и с первым ресурсом, и с включенными в него или них поисковыми терминами.
5. Способ по п. 1, в котором на этапе связывания второго ресурса с одним или несколькими первыми ресурсами второй ресурс связан с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами во втором поисковом индексе, причем созданный аннотированный поисковый индекс включает в себя второй поисковый индекс и отличается от первого поискового индекса.
6. Способ по п. 2, в котором параметр связи находится выше предварительно определенного порога, когда первый параметр истории является одним из следующего: 1 или 2 перехода, а второй параметр истории составляет по меньшей мере 30 секунд.
7. Способ по п. 2, в котором число переходов между первым поисковым запросом и первым ресурсом равно одному.
8. Способ по п. 4, в котором первый поисковый индекс является инвертированным индексом; первый ресурс и включенные в него поисковые термины связаны друг с другом в списке (списках) словопозиций в инвертированном индексе; и на этапе связывания второго ресурса с одним или несколькими первыми ресурсами ссылку на второй ресурс вставляют в подходящий список (списки) словопозиций в инвертированном индексе, что создает аннотированный поисковой индекс.
9. Способ по п. 5, в котором второй поисковый индекс является трех- или четырехмерным массивом данных.
10. Способ по п. 9, в котором 3 или 4 измерения содержат один или более пунктов из списка: ID документа, ID разрыва, ID области и ID источника.
11. Сервер для создания аннотированного поискового индекса включает в себя:
интерфейс передачи данных для передачи данных по сети передачи данных поисковому кластеру, который имеет доступ к базе данных;
память;
процессор, функционально соединенный с интерфейсом передачи данных и памятью, причем процессор выполнен с возможностью сохранять объекты в памяти; процессор дополнительно выполнен с возможностью:
- извлекать части поисковой сессии из истории для первого поискового запроса, причем эта часть включает в себя первый ресурс и второй ресурс, которые релевантны первому поисковому запросу,
- создавать параметр связи для второго ресурса, причем параметр связи основан на первом параметре истории и втором параметре истории,
первый параметр истории является числом переходов между первым ресурсом и вторым ресурсом в поисковой сессии из истории, и
второй параметр истории является временем, проведенным предыдущим пользователем во взаимодействии со вторым ресурсом в поисковой сессии из истории;
и
- в ответ на то, что параметр связи для второго ресурса превышает заранее определенный порог, связывать второй ресурс с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами, что создает аннотированный поисковый индекс для этих поисковых терминов.
12. Сервер по п. 11, в котором процессор выполнен с возможностью связывать второй ресурс с первым ресурсом и с включенными в него поисковыми терминами для создания аннотированного поискового индекса.
13. Сервер по п. 11, в котором процессор выполнен с возможностью связывать второй ресурс с одним или несколькими первыми ресурсами и включенными в него или них поисковыми терминами во втором поисковом индексе, причем созданный аннотированный поисковый индекс включает в себя второй поисковый индекс и отличается от первого поискового индекса.
14. Сервер по п. 12, в котором процессор выполнен с возможностью вносить ссылку на второй ресурс в подходящий список (списки) словопозиций в инвертированном индексе на этапе связывания второго ресурса с одним или несколькими первыми ресурсами, что создает аннотированный поисковой индекс.
| US 8095538 B2, 10.01.2012 | |||
| US 7308643 B1, 11.12.2007 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОГО ПОИСКА ЭЛЕКТРОННЫХ ДОКУМЕНТОВ | 2011 |
|
RU2473119C1 |

