Область техники, к которой относится изобретение
[1] Настоящая технология относится в целом к поисковым системам и алгоритмам машинного обучения и, в частности, к способу и системе для повторного обучения алгоритма машинного обучения.
Уровень техники
[2] Алгоритмы машинного обучения (MLA, Machine Learning Algorithm) используются для удовлетворения разнообразных потребностей в компьютерных технологиях. Обычно алгоритмы MLA используются для формирования прогноза, связанного с взаимодействием пользователя и компьютерного устройства. В качестве примера одной из сфер, где требуется такой прогноз, можно привести взаимодействие пользователя с контентом, доступным в сети Интернет.
[3] Объем информации, доступной на различных интернет-ресурсах, в течение двух последних лет растет экспоненциально. Для помощи типичному пользователю в поиске необходимой информации было разработано несколько решений. Одним из примеров таких решений является поисковая система. В качестве примера можно привести поисковые системы GOOGLE™, YANDEX™, YAHOO!™ и т.д. Пользователь может получать доступ к интерфейсу поисковой системы и отправлять поисковый запрос, связанный с информацией, которую требуется найти в сети Интернет. В ответ на поисковый запрос поисковая система выдает ранжированный список результатов поиска. Ранжированный список результатов поиска формируется на основе различных алгоритмов ранжирования, применяемых конкретной поисковой системой, используемой пользователем для поиска. Общая цель таких алгоритмов ранжирования заключается в представлении наиболее релевантных результатов поиска в верхней части ранжированного списка, тогда как менее релевантные результаты поиска могут располагаться в ранжированном списке на менее заметных местах (наименее релевантные результаты поиска находятся в нижней части ранжированного списка).
[4] Поисковые системы обычно обеспечивают хороший инструментарий для обработки поискового запроса, когда пользователь заранее знает, что требуется найти. Иными словами, если пользователь заинтересован в получении информации о наиболее популярных местах в Италии (т.е. известна тема поиска), он может отправить поисковый запрос: «Наиболее популярные места в Италии?». В ответ поисковая система выдает ранжированный список интернет-ресурсов, потенциально релевантных поисковому запросу. Пользователь может просмотреть ранжированный список результатов поиска, чтобы получить требуемую информацию, касающуюся мест для посещения в Италии. Если пользователь по какой-либо причине не удовлетворен полученными результатами поиска, он может выполнить повторный поиск, например, с более точным поисковым запросом, таким как «Наиболее популярные места в Италии летом?», «Наиболее популярные места на юге Италии?», «Наиболее популярные места для романтического отпуска в Италии?».
[5] В одном примере поисковой системы для формирования ранжированных результатов поиска используется алгоритм MLA. Например, алгоритм MLA может быть использован для классификации запросов, документов, например, веб-страниц, изображений, видеоматериалов, сообщений электронной почты, а также для классификации пользователей на основе их прошлого взаимодействия с сервисами, связанными с поисковой системой.
[6] В патентной заявке US20090287655A1 «Image search engine employing user suitability feedback» (RPX Corp., опубликована 19 ноября 2009 г.) описана интернет-инфраструктура, обеспечивающая поддержку поиска изображений путем сравнения образца для поиска и/или строки для поиска с множеством изображений, размещенных на интернет-серверах. Сервер поиска изображений обеспечивает предоставление страниц результатов поиска клиентскому устройству на основе строки для поиска или образца для поиска и содержит изображения с множества интернет-серверов для веб-хостинга. Сервер поиска изображений предоставляет страницу результатов поиска, содержащую изображения, в ответ на получение от веб-браузера строки для поиска и/или образца для поиска. Изображения для страницы результатов поиска выбираются на основе: (а) совпадения слов, т.е. путем выбора изображений, названия которых соответствуют строке для поиска, и (б) соответствия изображений, т.е. путем выбора изображений, характеристики которых соответствуют характеристикам образца для поиска. Выбор изображений для страницы результатов также выполняется на основе популярности и может оптимизироваться с учетом информации обратной связи или предпочтений пользователя.
[7] В патентной заявке US20060184577A1 «Methods and apparatuses to determine adult images by query association» (IAC Search and Media Inc., опубликована 17 августа 206 г.) описаны различные способы и устройства для обнаружения контента для взрослых. В одном варианте осуществления изобретения способ предусматривает обнаружение изобразительного контента для взрослых с использованием сопоставления отслеженного ранее запроса с запросом пользователя на поиск изображения. Набор изображений, выдаваемых в ответ на запрос пользователя в поисковой системе, основан на том, классифицировано ли одно или несколько изображений в этом наборе как изобразительный контент для взрослых.
[8] В патентной заявке US20090274364A1 «Apparatus and methods for detecting adult videos» (Oath Inc., опубликована 5 ноября 2009 г.) описаны устройства и способы для определения целевой аудитории видеоматериала: взрослые или дети. В некоторых вариантах осуществления изобретения система обучения может использоваться для формирования одной или нескольких моделей для обнаружения видеоматериала для взрослых. Модель формируется на основе большого набора видеоматериалов, которые были определены как предназначенные для взрослых или для детей. Дальнейшее обнаружение видеоматериала для взрослых основано на этой модели обнаружения видеоматериала для взрослых. Эта модель обнаружения видеоматериала для взрослых может быть применена для выбранных ключевых кадров неизвестного видеоматериала. В некоторых вариантах осуществления изобретения эти ключевые кадры могут быть выбраны из числа кадров неизвестного видеоматериала. В общем случае каждый ключевой кадр может соответствовать кадру, содержащему ключевые части, которые могут быть релевантными для обнаружения порнографических или предназначенных для взрослых аспектов неизвестного видеоматериала. Например, ключевые кадры могут содержать движущиеся объекты, кожу, людей и т.д. В других вариантах осуществления изобретения видеоматериал не разделяется на ключевые кадры и все кадры анализируются системой обучения с целью формирования модели, а также системой обнаружения видеоматериала для взрослых на основе такой модели.
Раскрытие изобретения
[9] Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений. Варианты осуществления настоящей технологии способны обеспечить и/или расширить арсенал подходов и/или способов достижения целей в настоящей технологии.
[10] Разработчики настоящей технологии обнаружили по меньшей мере одну техническую проблему, связанную с известными решениями.
[11] Варианты осуществления настоящей технологии разработаны на основе понимания разработчиками того, что эффективность алгоритма машинного обучения (например, точность формируемых прогнозов и т.п.) зависит от качества и количества обучающих объектов, предоставленных на этапе обучения алгоритма машинного обучения. Разработчики также обнаружили, что в некоторых случаях получение большого количества качественных обучающих объектов может требовать значительных затрат времени и средств.
[12] Алгоритм машинного обучения может неверно формировать прогнозы, например, вследствие неверной классификации объекта, в частности, если объект содержит общие для различных классов признаки и если алгоритм машинного обучения никогда не обучался на таких объектах. Обычно возникновение подобных ситуаций может создавать проблемы, например, когда от результата классификации зависит распределение вычислительных и/или финансовых ресурсов, выполненной алгоритмом машинного обучения, или когда пользователям предоставляется контент, который должен быть однозначно исключен, например, когда детям встречаются шокирующие или иные неприемлемые изображения во время работы веб-браузера в режиме родительского контроля.
[13] Разработчики настоящей технологии также обнаружили, что операторам поисковых систем, таких как Google™, Yandex™, Bing™, Yahoo™ и т.д., доступно большое количество данных о действиях пользователей с результатами поиска, полученными в ответ на пользовательские поисковые запросы. Разработчики также обнаружили, что данные о действиях пользователей могут эффективно использоваться для понимания поведения пользователей и определения предпочтений пользователей поисковой системы.
[14] Разработчики также обнаружили, что социальные сети, такие как Facebook™, VKontakte™, Twitter™ и т.д., предоставляющие пользователям возможность общения, могут в некоторых случаях иметь прикладные программные интерфейсы (API, Application Programing Interface) или другие средства, позволяющие третьим сторонам анализировать информацию, отправляемую пользователями в социальных сетях (если пользователи выразили согласие и выполнили соответствующие настройки), которая также может быть использована для понимания поведения пользователей и для определения предпочтений пользователей социальных сетей.
[15] Разработчики установили, что пользователи могут отправлять в социальных сетях контент, такой как тексты, гиперссылки или изображения, который может быть связан с документами в поисковой системе или ссылаться на них. Разработчики предположили, что такие элементы контента иногда могут приводить к изменениям поведения пользователя и пользовательского трафика в социальной сети, а также в поисковой системе, поскольку эти элементы контента могут ссылаться на неверно классифицированные поисковой системой документы, которые пользователи могли определить как юмористические или шокирующие и решили разместить в социальной сети. Разработчики настоящей технологии обнаружили, что такие ситуации могут быть использованы для автоматического поиска неверно классифицированных алгоритмом MLA документов, которые, в свою очередь, могут быть использованы для повторного обучения алгоритма MLA с целью повышения его четкости и точности.
[16] Варианты осуществления настоящей технологии относятся к способу и системе для повторного обучения алгоритма машинного обучения. Технический результат настоящего изобретения заключается в реализации назначения расширенного арсенала технических средств для повторного обучения алгоритма машинного обучения.
[17] В соответствии с первым аспектом настоящей технологии реализован способ повторного обучения алгоритма MLA, обученного классифицировать документы на основе их признаков. Алгоритм MLA выполняется на сервере и способ также выполняется сервером. Способ включает в себя обращение сервера через сеть связи к ресурсу, содержащему множество элементов контента, каждый из которых был отправлен этому ресурсу по меньшей мере одним пользователем. Способ включает в себя идентификацию сервером на основе первого набора признаков по меньшей мере одного элемента контента из множества элементов контента, связанных с документом, представленным сервером поисковой системы в качестве результата поиска в ответ на поисковый запрос. Сервер на основе набора признаков документа анализирует по меньшей мере один элемент контента из множества элементов контента, чтобы определить, был ли этот документ неверно классифицирован алгоритмом MLA в ответ на поисковый запрос. Если определено, что документ был классифицирован неверно, то сервер на основе такого документа формирует обучающий объект, включая присвоение документу метки в виде указания на неверную классификацию. Затем алгоритм MLA повторно обучается на основе обучающего объекта.
[18] В некоторых вариантах осуществления способа сервер связан с базой данных. Способ перед обращением к ресурсу дополнительно включает в себя получение сервером из базы данных множества ранее отправленных серверу множеством пользователей поисковых запросов, каждый из которых связан с набором документов, представленных в качестве результатов поиска соответствующим пользователям из множества пользователей. Способ включает в себя получение сервером из базы данных для каждого поискового запроса из множества поисковых запросов информации о трафике, включая количество отправок, и определение сервером поискового запроса на основе количества отправок.
[19] В некоторых вариантах осуществления способа информация о трафике содержит источник трафика. Определение поискового запроса дополнительно включает в себя определение ресурса на основе источника трафика.
[20] В некоторых вариантах осуществления способа определение ресурса дополнительно основано на том, что этот ресурс соответствует источнику из заранее заданного списка источников трафика.
[21] В некоторых вариантах осуществления способа определение поискового запроса на основе количества отправок дополнительно основано на превышении количеством отправок заранее заданного порога в течение заранее заданного периода времени.
[22] В некоторых вариантах осуществления способа сервер связан с базой данных. Способ перед обращением к ресурсу дополнительно включает в себя получение сервером из базы данных множества ранее отправленных серверу множеством пользователей поисковых запросов, каждый из которых связан с набором документов, представленных в качестве результатов поиска соответствующим пользователям из множества пользователей. Способ включает в себя получение сервером из базы данных для каждого поискового запроса из множества поисковых запросов информации о трафике, включая количество отправок и источник трафика. Способ включает в себя определение сервером ресурса, связанного с по меньшей мере одним запросом, на основе количества отправок и источника трафика.
[23] В некоторых вариантах осуществления способа первый набор признаков содержит указание на поисковый запрос и указание на по меньшей мере один документ из набора документов, представленных в качестве результатов поиска для этого поискового запроса.
[24] В некоторых вариантах осуществления способа первый набор признаков дополнительно содержит заранее заданный список слов.
[25] В некоторых вариантах осуществления способа документ представляет собой изображение, а набор признаков документа представляет собой набор признаков изображения.
[26] В некоторых вариантах осуществления способа неверная классификация документа указывает на то, что результат поиска не отвечает условиям поискового запроса.
[27] В некоторых вариантах осуществления способа неверная классификация документа указывает на то, что результат поиска не подходит для поискового запроса.
[28] В некоторых вариантах осуществления способа неверная классификация документа указывает на то, что результат поиска не соответствует режиму работы веб-браузера, используемого пользователем, отправившим поисковый запрос.
[29] В некоторых вариантах осуществления способа алгоритм MLA представляет собой бинарный классификатор.
[30] В некоторых вариантах осуществления способа ресурс представляет собой социальную сеть.
[31] В соответствии с другим аспектом настоящей технологии реализован соединенный с сетью связи сервер для повторного обучения алгоритма MLA, обученного классифицировать документы на основе их признаков. Сервер содержит процессор и машиночитаемый физический носитель информации, содержащий команды. Процессор при выполнении команд способен обращаться через сеть связи к ресурсу, содержащему множество элементов контента, каждый из которых был отправлен этому ресурсу по меньшей мере одним пользователем. Процессор способен идентифицировать на основе первого набора признаков по меньшей мере один элемент контента из множества элементов контента, связанных с документом, представленным сервером поисковой системы в качестве результата поиска в ответ на поисковый запрос. Процессор способен на основе набора признаков документа проанализировать по меньшей мере один элемент контента из множества элементов контента, чтобы определить, был ли этот документ неверно классифицирован алгоритмом MLA в ответ на поисковый запрос. Если определено, что документ был классифицирован неверно, процессор на основе этого документа способен сформировать обучающий объект, включая присвоение документу метки в виде указания на неверную классификацию, и повторно обучить алгоритм MLA на основе этого обучающего объекта.
[32] В некоторых вариантах осуществления сервер связан с базой данных. Процессор перед обращением к ресурсу дополнительно способен получать из базы данных множество ранее отправленных серверу множеством пользователей поисковых запросов, каждый из которых связан с набором документов, представленных в качестве результатов поиска соответствующим пользователям из множества пользователей. Процессор способен получать из базы данных для каждого поискового запроса из множества поисковых запросов информацию о трафике, включая количество отправок, и определять поисковый запрос на основе количества отправок.
[33] В некоторых вариантах осуществления сервера информация о трафике дополнительно содержит источник трафика, а определение поискового запроса дополнительно включает в себя определение ресурса на основе источника трафика.
[34] В некоторых вариантах осуществления сервера определение ресурса дополнительно основано на том, что этот ресурс соответствует источнику из заранее заданного списка источников трафика.
[35] В некоторых вариантах осуществления сервера определение поискового запроса на основе количества отправок дополнительно основано на превышении количеством отправок заранее заданного порога в течение заранее заданного периода времени.
[36] В некоторых вариантах осуществления сервер связан с базой данных. Процессор перед обращением к ресурсу дополнительно способен получать из базы данных множество ранее отправленных серверу множеством пользователей поисковых запросов, каждый из которых связан с набором документов, представленных в качестве результатов поиска соответствующим пользователям из множества пользователей. Процессор способен получать из базы данных для каждого поискового запроса из множества поисковых запросов информацию о трафике, включая количество отправок и источник трафика. Процессор способен определять ресурс, связанный с по меньшей мере одним запросом, на основе количества отправок и источника трафика.
[37] В некоторых вариантах осуществления сервера первый набор признаков содержит указание на поисковый запрос и указание на по меньшей мере один документ из набора документов, представленных в качестве результатов поиска для поискового запроса.
[38] В некоторых вариантах осуществления сервера первый набор признаков дополнительно содержит заранее заданный список слов.
[39] В некоторых вариантах осуществления сервера документ представляет собой изображение, а набор признаков документа представляет собой набор признаков изображения.
[40] В некоторых вариантах осуществления сервера неверная классификация документа указывает на то, что результат поиска не отвечает условиям поискового запроса.
[41] В некоторых вариантах осуществления сервера неверная классификация документа указывает на то, что результат поиска не подходит для поискового запроса.
[42] В некоторых вариантах осуществления сервера неверная классификация документа указывает на то, что результат поиска не соответствует режиму работы веб-браузера, используемого пользователем, отправившим поисковый запрос.
[43] В некоторых вариантах осуществления сервера алгоритм MLA представляет собой бинарный классификатор.
[44] В некоторых вариантах осуществления сервера ресурс представляет собой социальную сеть.
[45] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от электронных устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая определенная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[46] В контексте настоящего описания термин «электронное устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры электронных устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как электронное устройство, также может функционировать как сервер в отношении других электронных устройств. Использование выражения «электронное устройство» не исключает использования нескольких электронных устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов либо шагов любого описанного здесь способа.
[47] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерного оборудования для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в том же оборудовании, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельном оборудовании, таком как специализированный сервер или множество серверов.
[48] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), тексты (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы и т.д., но не ограничивается ими.
[49] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая ОЗУ, ПЗУ, диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[50] В контексте настоящего описания, если явно не указано другое, в качестве указания на информационный элемент может выступать сам информационный элемент, а также указатель, ссылка, гиперссылка или другое косвенное средство, с помощью которого получатель данных может найти место в сети, памяти, базе данных или на другом машиночитаемом носителе информации, откуда можно извлечь этот информационный элемент . Например, указание на документ может включать в себя сам документ (т.е. его содержимое) или это указание может представлять собой уникальный дескриптор документа, указывающий на файл в определенной файловой системе, или какие-либо другие средства для указания получателю данных места в сети, адреса памяти, таблицы в базе данных или другого места, где можно получить доступ к файлу. Специалисту в данной области должно быть очевидно, что степень точности, требуемая для такого указания, зависит от объема предварительных пояснений относительно интерпретации информации, которой обмениваются отправитель и получатель данных. Например, если перед началом обмена данными между отправителем и получателем установлено, что указатель на информационный элемент представляет собой ключ базы данных для этого элемента в определенной таблице заранее заданной базы данных, содержащей этот информационный элемент, то для эффективной передачи информационного элемента получателю достаточно оправить ключ базы данных, даже если сам информационный элемент не передается между отправителем и получателем данных.
[51] В контексте настоящего описания числительные «первый» «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях – различные программные и/или аппаратные средства.
[52] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[53] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[54] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[55] На фиг. 1 представлена схема системы, реализованной согласно вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[56] На фиг. 2 и 3 представлена схема процедуры мониторинга, реализованной согласно вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[57] На фиг. 4 представлена схема процедуры определения неверной классификации документов, соответствующей вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[58] На фиг. 5 представлена схема процедуры повторного обучения, реализованной согласно вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[59] На фиг. 6 приведена блок-схема способа определения поискового запроса, связанного с потенциально неверно классифицированным документом, выполняемого в представленной на фиг. 1 системе в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[60] На фиг. 7 приведена блок-схема способа повторного обучения алгоритма MLA, выполняемого в представленной на фиг. 1 системе в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
Осуществление изобретения
[61] Представленные в данном описании примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но реализуют принципы настоящей технологии в пределах ее существа и объема.
[62] Кроме того, чтобы способствовать лучшему пониманию, последующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалистам в данной области должно быть понятно, что различные варианты осуществления данной технологии могут быть значительно сложнее.
[63] В некоторых случаях также приводятся полезные примеры модификаций настоящей технологии. Они способствуют пониманию, но также не определяют объем или границы настоящей технологии. Представленный перечень модификаций не является исчерпывающим и специалист в данной области способен разработать другие модификации в пределах объема настоящей технологии. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии.
[64] Более того, описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры, предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть очевидно, что любые описанные структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих принципы настоящей технологии. Также должно быть очевидно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены на машиночитаемом физическом носителе информации и выполняться компьютером или процессором, независимо от того, показан явно такой компьютер или процессор либо нет.
[65] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как «процессор» или «графический процессор», могут быть реализованы с использованием специализированных аппаратных средств, а также с использованием аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, эти функции могут выполняться одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может подразумевать, помимо прочего, аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и энергонезависимое ЗУ. Также могут подразумеваться другие аппаратные средства, общего назначения и/или заказные.
[66] Программные модули или просто модули, реализация которых предполагается в виде программных средств, могут быть представлены здесь как любое сочетание элементов блок-схемы или других элементов, указывающих на выполнение шагов процесса и/или содержащих текстовое описание. Такие модули могут выполняться аппаратными средствами, показанными явно или подразумеваемыми.
[67] Учитывая вышеизложенные принципы, далее рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
[68] Система
[69] На фиг. 1 представлена система 100, реализованная согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии. Система 100 содержит множество 102 клиентских устройств, включая первое клиентское устройство 104, второе клиентское устройство 106, третье клиентское устройство 108 и четвертое клиентское устройство 110, соединенные с сетью 112 связи линиями 114 связи (только одна из них обозначена на фиг. 1). Система 100 также содержит сервер 120 поисковой системы, сервер 130 отслеживания, сервер 140 социальной сети и обучающий сервер 150, соединенные с сетью 112 связи линиями 114 связи.
[70] Множество клиентских устройств
[71] В качестве примера, первое клиентское устройство 104 может быть реализовано в виде смартфона, второе клиентское устройство 106 может быть реализовано в виде ноутбука, третье клиентское устройство 108 может быть реализовано в виде смартфона, а четвертое клиентское устройство 110 может быть реализовано в виде планшета. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 112 связи может использоваться сеть Интернет. В других вариантах осуществления настоящей технологии сеть 112 связи может быть реализована иначе, например, в виде произвольной глобальной сети связи, локальной сети связи, частной сети связи и т.д.
[72] На реализацию линии 114 связи не накладывается каких-либо особых ограничений, она зависит от реализации первого клиентского устройства 104, второго клиентского устройства 106, третьего клиентского устройства 108 и четвертого клиентского устройства 110. Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где первое клиентское устройство 104, второе клиентское устройство 106, третье клиентское устройство 108 или четвертое клиентское устройство 110 реализовано в виде беспроводного устройства связи (такого как смартфон), линия 114 связи может быть реализована в виде беспроводной линии связи (такой как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где первое клиентское устройство 104, второе клиентское устройство 106, третье клиентское устройство 108 или четвертое клиентское устройство 110 реализовано в виде ноутбука, смартфона или планшетного компьютера, линия 114 связи может быть беспроводной (такой как Wireless Fidelity или кратко WiFi®, Bluetooth® и т.п.) или проводной (такой как соединение на основе Ethernet).
[73] В общем случае каждое устройство из множества 102 клиентских устройств связано с соответствующим пользователем из множества пользователей (не показаны).
[74] Очевидно, что варианты реализации множества 102 клиентских устройств, содержащего первое клиентское устройство 104, второе клиентское устройство 106, третье клиентское устройство 108 и четвертое клиентское устройство 110, а также линии 114 связи и сети 112 связи, приведены лишь для иллюстрации. Специалистам в данной области должны быть очевидными и другие конкретные детали реализации первого клиентского устройства 104, второго клиентского устройства 106, третьего клиентского устройства 108, четвертого клиентского устройства 110, лини 114 связи и сети 112 связи. Представленные выше примеры никак не ограничивают объем настоящей технологии.
[75] Несмотря на то, что только четыре клиентских устройства 104, 106, 108 и 110 показаны на фиг. 1, предполагается, что к системе 100 может быть подключено любое количество клиентских устройств из множества 102 клиентских устройств. Также предполагается, что в некоторых вариантах осуществления изобретения множество 102 клиентских устройств, подключенных к системе 100, может содержать десятки или сотни тысяч клиентских устройств.
[76] Сервер поисковой системы
[77] К сети 112 связи также подключен вышеупомянутый сервер 120 поисковой системы. Сервер 120 поисковой системы может быть реализован в виде традиционного компьютерного сервера. В примере осуществления настоящей технологии сервер 120 поисковой системы может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Сервер 120 поисковой системы может быть реализован с применением любых других подходящих аппаратных средств и/или программного обеспечения, и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 120 поисковой системы представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 120 поисковой системы могут быть распределены между несколькими серверами. В некоторых вариантах осуществления настоящей технологии сервер 120 поисковой системы управляется и/или администрируется оператором поисковой системы. В качестве альтернативы, сервер 120 поисковой системы может управляться и/или администрироваться поставщиком услуг.
[78] Сервер 120 поисковой системы предоставляет множеству пользователей (не показаны) доступ к поисковой системе 126, которая доступна пользователям с использованием клиентских устройств из множества 102 клиентских устройств. Доступ к поисковой системе 126 может осуществляться путем ввода универсального адреса ресурса (URL, Uniform Resource Locator) в браузерном приложении (не показано) в клиентском устройстве или путем использования автономного программного обеспечения (такого как мобильное приложение).
[79] Сервер 120 поисковой системы поддерживает базу 122 данных журнала поиска, содержащую индекс 124.
[80] В общем случае сервер 120 поисковой системы предназначен для выполнения следующих действий: (а) обнаружение и индексация документов, доступных в сети Интернет; (б) выполнение поисков в ответ на пользовательский поисковый запрос; (в) анализ документов и ранжирование документов в ответ на поисковый запрос; (г) группировка документов и формирование страницы результатов поисковой системы (SERP, Search Engine Result Page) для вывода в клиентское устройство (такое как первое клиентское устройство 104, второе клиентское устройство 106, третье клиентское устройство 108 или четвертое клиентское устройство 110), использованное для отправки поискового запроса, в результате выполнения которого сформирована страница SERP.
[81] На способ выполнения сервером 120 поисковой системы обнаружения и индексации документов, поисков, анализа и ранжирования документов не накладывается каких-либо особых ограничений. Специалистам в данной области известен ряд способов и средств реализации сервера 120 поисковой системы, поэтому различные структурные компоненты сервера 120 поисковой системы описаны лишь в общем виде.
[82] Сервер 120 поисковой системы способен выполнять процедуру обнаружения документов (не показана), обычно используемую сервером 120 поисковой системы для обнаружения документов, доступных через сеть 112 связи. Например, сервер 120 поисковой системы способен выполнять приложение обходчика, которое посещает сетевые ресурсы, доступные через сеть 112 связи, и загружает их для дальнейшей обработки.
[83] На характер документов, к которым сервер 120 поисковой системы способен обращаться и загружать их, не накладывается каких-либо особых ограничений. Например, описанные здесь документы могут представлять веб-страницы, изображения, документы в формате PDF, документы Word™, документы PowerPoint™, доступные через сеть 112 связи.
[84] Сервер 120 поисковой системы также может быть способным выполнять процедуру индексации (не показана), обычно используемую сервером 120 поисковой системы для построения и/или поддержания структур индексации, используемых поисковой системой для выполнения поисков. Например, сервер 120 поисковой системы способен создавать и/или поддерживать инвертированный индекс, который называется индексом 124.
[85] На реализацию индекса 124 в настоящей технологии не накладывается каких-либо особых ограничений. Например, индекс 124 может содержать несколько списков вхождений (posting list), каждый из которых связан с соответствующим использованным для поиска термином. Вхождение в списке вхождений включает в себя данные определенного вида, указывающие на документ, содержащий использованный для поиска термин, связанный с этим списком вхождений, а в некоторых случаях и некоторые дополнительные данные (например, место вхождения использованного для поиска термина в документе, количество вхождений в документе и т.п.). Вкратце, каждый список вхождений соответствует использованному для поиска термину и содержит ряд вхождений в каждый обнаруженный документ, содержащий по меньшей мере одно вхождение этого использованного для поиска термина (или его части).
[86] Следует отметить, что в состав вхождения также могут быть включены дополнительные данные, такие как признаки проиндексированных документов, например, количество вхождений использованного для поиска термина в документе, указание на появление поискового термина в заголовке документа и т.д. Разумеется, что эти дополнительные данные могут отличаться в зависимости от конкретной поисковой системы, а также в зависимости от различных вариантов осуществления настоящей технологии.
[87] Доступные для поиска термины обычно, но не обязательно, представляют собой слова или другие строки символов, изображения и т.п. Поисковая система обычно может обрабатывать практически каждое слово на нескольких языках, а также имена собственные, числа, символы и т.д. Очень часто используемому слову может соответствовать список вхождений, содержащий миллиард вхождений (или даже больше).
[88] Сервер 120 поисковой системы также может быть способным выполнять процедуру выдачи запросов (не показана), обычно используемую сервером 120 поисковой системы для идентификации документов, которые могут содержать некоторую часть запроса, отправленного поисковой системе. Например, когда запрос (например, текущий запрос пользователя первого клиентского устройства 104) принят сервером 120 поисковой системы, сервер 120 поисковой системы может разделить этот запрос на множество используемых для поиска терминов. Затем сервер 120 поисковой системы может обратиться к индексу 124 и определить списки вхождений, связанные с по меньшей мере одним термином из множества используемых для поиска терминов. В результате сервер 120 поисковой системы может обратиться к по меньшей мере некоторым вхождениям из определенных таким образом списков вхождений и идентифицировать по меньшей мере некоторые документы, которые могут содержать по меньшей мере некоторые термины из множества используемых для поиска терминов из запроса.
[89] Сервер 120 поисковой системы способен выполнять ранжирование идентифицированных документов из индекса 124, содержащих по меньшей мере некоторые термины из множества используемых для поиска терминов из запроса.
[90] В качестве примера, не имеющего ограничительного характера, некоторые известные способы ранжирования результатов поиска по степени соответствия сделанному пользователем поисковому запросу основаны на некоторых или на всех следующих критериях: (а) популярность данного поискового запроса или соответствующего ответа при выполнении поисков; (б) количество результатов; (в) наличие в запросе определяющих терминов (таких как «изображения», «фильмы», «погода» и т.п.); (г) частота использования другими пользователями данного поискового запроса с определяющими терминами; (д) частота выбора другими пользователями, выполняющими аналогичный поиск, определенного ресурса или определенных результатов вертикального поиска, представленных с использованием страницы SERP. Сервер 120 поисковой системы может рассчитывать и назначать коэффициент релевантности (основанный на различных представленных выше критериях) для каждого результата поиска, полученного по сделанному пользователем поисковому запросу, а также формировать страницу SERP, где результаты поиска ранжированы согласно их коэффициентам релевантности. Предполагается, что ранжирование документов в качестве результатов поиска может выполняться за несколько шагов.
[91] В представленных здесь вариантах осуществления изобретения сервер 120 поисковой системы выполняет множество алгоритмов 128 MLA, которые совместно называются алгоритмом 128 MLA. В не имеющем ограничительного характера примере алгоритм 128 MLA может использоваться для ранжирования документов в ответ на запрос, для классификации запросов и для классификации документов.
[92] В другом не имеющем ограничительного характера примере алгоритм 128 MLA может быть обучен классификации документов на основе их признаков, как содержащих или не содержащих контент, требующий особого обращения.
[93] В некоторых вариантах осуществления настоящей технологии сервер 120 поисковой системы может выполнять ранжирование для поисков нескольких видов, включая общий поиск и вертикальный поиск, но не ограничиваясь ими.
[94] Сервер отслеживания
[95] К сети 112 связи также подключен вышеупомянутый сервер 130 отслеживания. Сервер 130 отслеживания может быть реализован как традиционный компьютерный сервер. В примере осуществления настоящей технологии сервер 130 отслеживания может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 130 отслеживания может быть реализован с использованием любых других подходящих аппаратных средств и/или прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 130 отслеживания представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 130 отслеживания могут быть распределены между несколькими серверами. В других вариантах осуществления изобретения функции сервера 130 отслеживания могут полностью или частично выполняться сервером 120 поисковой системы. В некоторых вариантах осуществления настоящей технологии сервер 130 отслеживания управляется и/или администрируется оператором поисковой системы. В качестве альтернативы, сервер 130 отслеживания может управляться и/или администрироваться другим поставщиком услуг.
[96] В общем случае сервер 130 отслеживания способен отслеживать взаимодействие пользователя с поисковой системой 126. Это взаимодействие может представлять собой запросы в виде поисковых запросов, отправленных поисковой системе 126, и результаты поиска, предоставленные сервером 120 поисковой системы в ответ на эти запросы (например, сделанные пользователями первого клиентского устройства 104, второго клиентского устройства 106, третьего клиентского устройства 108 или четвертого клиентского устройства 110). Сервер 130 отслеживания может отслеживать действия пользователей (например, фиксировать данные о выборе пользователями), когда пользователи выполняют общие веб-поиски и вертикальные веб-поиски в поисковой системе 126, и сохранять эти действия пользователей в базе 132 данных отслеживания.
[97] Сервер 130 отслеживания также может быть способным автоматически определять параметры действий пользователей на основе отслеженных действий пользователей с результатами поиска. В не имеющем ограничительного характера примере сервер 130 отслеживания может рассчитывать коэффициент «кликов» (CTR, Click-Through Rate) на основе количества «кликов» на элементе и количества показов элемента на странице SERP через заранее заданные интервалы времени или после получения соответствующего указания.
[98] Не имеющие ограничительного характера примеры отслеживаемых сервером 130 отслеживания действий пользователей включают в себя:
- успех/неудача: был документ выбран в ответ на поисковый запрос или нет;
- просмотры: количество показов документа;
- время пребывания: время, затраченное пользователем на документ перед возвратом на страницу SERP;
- длинный/короткий клик: было действие пользователя с документом длинным или коротким по сравнению с действием пользователя с другими документами на странице SERP.
[99] Разумеется, что представленный выше список не является исчерпывающим и он может включать в себя другие виды действий пользователей без выхода за границы настоящей технологии. В некоторых вариантах осуществления изобретения сервер 130 отслеживания может объединять данные о действиях пользователей (которые в не имеющем ограничительного характера примере могут включать в себя действия пользователей в течение каждого часа) и формировать параметры действий пользователей для сохранения в базе 132 данных отслеживания в подходящем для реализации настоящей технологии формате (которые в не имеющем ограничительного характера примере могут представлять собой параметры действий пользователей, включая количество действий пользователей в течение каждого часа для заранее заданного периода времени длительностью 3 месяца). В других вариантах осуществления изобретения сервер 130 отслеживания может сохранять данные о действиях пользователей в необработанном виде в базе 132 данных отслеживания так, чтобы они могли извлекаться и объединяться сервером 120 поисковой системы и/или сервером 150 обучения и/или другим сервером (не показан) в формате, подходящем для реализации настоящей технологии.
[100] Сервер 130 отслеживания обычно поддерживает вышеупомянутую базу 132 данных отслеживания, содержащую журнал 136 запросов и журнал 138 действий пользователей.
[101] Журнал 136 запросов предназначен для регистрации поисков, выполненных с использованием сервера 120 поисковой системы. В частности, в журнале 136 запросов хранятся термины поисковых запросов (т.е. слова для поиска) и результаты поиска (или указания на них). Следует отметить, что журнал 136 запросов может поддерживаться в обезличенной форме, когда для поисковых запросов невозможно определить пользователей, отправивших эти поисковые запросы.
[102] В частности, журнал 136 запросов может содержать список запросов с терминами, с информацией о документах, указанных сервером 120 поисковой системы в списке в ответ на запрос, и с отметкой времени, а также может содержать список пользователей, идентифицируемых с использованием анонимных идентификаторов (или вообще без идентификаторов), и документы, выбранные ими после отправки запроса. В некоторых вариантах осуществления изобретения журнал 136 запросов может обновляться при каждом выполнении нового поиска на сервере 120 поисковой системы. В других вариантах осуществления изобретения журнал 136 запросов может обновляться через заранее заданные интервалы времени. В некоторых вариантах осуществления изобретения может существовать множество копий журнала 136 запросов, каждая из которых соответствует журналу 136 запросов в разные моменты времени.
[103] Журнал 138 действий пользователей может быть связан с журналом 136 запросов и содержать действия пользователей, отслеженные сервером 130 отслеживания после того, как пользователь отправил запрос и выбрал один или несколько документов на странице SERP на сервере 120 поисковой системы. В не имеющем ограничительного характера примере журнал 138 действий пользователей может содержать ссылку на документ, который может быть идентифицирован с использованием идентификационного номера или URL-адреса, список запросов, каждый из которых был использован для доступа к этому документу, и действия пользователей, связанные с документом для этого запроса из списка запросов (если осуществлялись действия с документом), что более подробно описано ниже. Множество действий пользователей в общем случае может отслеживаться и объединяться сервером 130 отслеживания и, в некоторых вариантах осуществления изобретения, оно может включаться в список для каждого отдельного пользователя.
[104] В некоторых вариантах осуществления изобретения сервер 130 отслеживания может отправлять отслеженные запросы, результат поиска и действия пользователей серверу 120 поисковой системы, который может сохранять отслеженные запросы, действия пользователей и соответствующие результаты поиска в базе 122 данных журнала поиска. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 130 отслеживания и сервера 120 поисковой системы могут быть реализованы в одном сервере.
[105] Сервер социальной сети
[106] К сети 112 связи также подключен вышеупомянутый сервер 140 социальной сети. Сервер 140 социальной сети может быть реализован в виде традиционного компьютерного сервера. В примере осуществления настоящей технологии сервер 140 социальной сети может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 140 социальной сети может быть реализован с использованием любых других подходящих аппаратных средств и/или прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 140 социальной сети представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 140 социальной сети могут быть распределены между несколькими серверами.
[107] В общем случае сервер 140 социальной сети способен поддерживать социальную сеть 146, которая, среди прочего, включает в себя множество 148 элементов контента, отправленных пользователями из множества пользователей (не показаны) с использованием по меньшей мере части множества 102 клиентских устройств.
[108] На характер и вид каждого элемента из множества 148 элементов контента не накладывается каких-либо ограничений. Они могут включать в себя тексты, изображения, видеоматериалы, игры, цифровые файлы или их сочетание. В некоторых вариантах осуществления изобретения социальная сеть 146 может представлять собой тематическую социальную сеть, т.е. предназначенную для обсуждения конкретной темы или события, или она может быть разделена на несколько тематических социальных сетей.
[109] Сервер 140 социальной сети может поддерживать базу 142 данных социальной сети для хранения, среди прочего, множества 148 элементов контента, профилей пользователей, цифровых файлов и/или другой информации, связанной с социальной сетью 146.
[110] Сервер 140 социальной сети может предоставлять интерфейс API для получения пользователями данных из социальной сети 146. В общем случае интерфейс API позволяет разработчикам направлять в социальную сеть 146 запросы относительно элементов контента, пользователей, каналов, демографических данных и т.п.
[1111] Сервер обучения
[112] К сети 112 связи также подключен вышеупомянутый сервер 150 обучения. Сервер 150 обучения может быть реализован как традиционный компьютерный сервер. В примере осуществления настоящей технологии сервер 150 обучения может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 150 обучения может быть реализован с использованием любых других подходящих аппаратных средств и/или прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 150 обучения представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 150 обучения могут быть распределены между несколькими серверами. В контексте настоящей технологии описанные здесь способы и система могут быть частично реализованы на сервере 150 обучения. В некоторых вариантах осуществления настоящей технологии сервер 150 обучения управляется и/или администрируется оператором поисковой системы. В качестве альтернативы, сервер 150 обучения может управляться и/или администрироваться поставщиком других услуг.
[113] В общем случае сервер 150 обучения способен обучать множество алгоритмов MLA (включая алгоритм 128 MLA), используемых сервером 120 поисковой системы, сервером 130 отслеживания и/или другими серверами (не показаны), связанными с оператором поисковой системы.
[114] Сервер 150 обучения может, например, обучать один или несколько алгоритмов MLA, связанных с поставщиком услуг поисковой системы, для оптимизации общих и вертикальных веб-поисков, предоставления рекомендаций, прогнозирования итогов, классификации запросов, документов и пользователей и для других вариантов применения. Обучение и оптимизация алгоритмов MLA могут выполняться через заранее заданные интервалы времени или когда поставщик услуг поисковой системы сочтет это необходимым.
[115] В контексте не имеющих ограничительного характера вариантов осуществления настоящей технологии сервер 150 обучения способен: (а) контролировать поисковые запросы, которые были отправлены поисковой системе 126 с использованием по меньшей мере части множества 102 клиентских устройств и которые связаны с документами, предоставленными в ответ на эти запросы; (б) контролировать элементы контента, отправленные в социальную сеть 146 с использованием по меньшей мере части множества 102 клиентских устройств; (в) определять, что один или несколько документов, связанных с элементом контента в социальной сети 146 и предоставленных поисковой системой 126 в ответ на поисковый запрос, были неверно классифицированы алгоритмом 128 MLA, выполняемым сервером 120 поисковой системы; (г) формировать набор обучающих объектов на основе неверно классифицированных документов; (д) повторно обучать алгоритм 128 MLA на основе этого набора обучающих объектов. Далее более подробно описано выполнение сервером 150 обучения этих действий.
[116] Сервер 150 обучения может поддерживать базу 152 данных обучения для хранения обучающих объектов (не показаны) и/или других данных, которые могут быть использованы сервером 120 поисковой системы, сервером 130 отслеживания и/или другими серверами (не показаны), связанными с оператором поисковой системы.
[117] На фиг. 2 и 3 представлена схема процедуры 200 мониторинга, соответствующей не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[118] Процедура мониторинга
[119] Процедура 200 мониторинга выполняется сервером 150 обучения.
[120] В некоторых вариантах осуществления настоящей технологии процедура 200 мониторинга может выполняться сервером 130 отслеживания и/или сервером 150 обучения. В других вариантах осуществления настоящей технологии процедура 200 мониторинга может выполняться бóльшим количеством серверов (не показаны).
[121] Процедура 200 мониторинга включает в себя процедуру 210 мониторинга поисковой системы и процедуру 250 мониторинга социальной сети.
[122] В общем случае процедура 200 мониторинга предназначена для отслеживания действий пользователей, осуществляемых множеством пользователей (не показаны) в поисковой системе 126, путем выполнения процедуры 210 мониторинга поисковой системы и отслеживания контента, размещаемого множеством пользователей (не показаны) в социальной сети 146, с целью обнаружения документов, упоминаемых в социальной сети 146 и индексируемых поисковой системой 126, которые потенциально могли быть неверно классифицированы алгоритмом 128 MLA. Таким образом, можно сказать, что сигналы из социальной сети 146 и из поисковой системы 126 рассматриваются совместно и используются для обнаружения потенциально неверно классифицированных документов.
[123] Документ может быть неверно классифицирован алгоритмом 128 MLA по различным причинам, например, из-за неоднозначности признаков документа, характеристики которых могут соответствовать нескольким классам, или из-за того, что алгоритм MLA никогда не обрабатывал подобные признаки документа во время обучения. Неверная классификация документа алгоритмом 128 MLA в поисковой системе 126 может указывать на то, что документ в качестве результата поиска не отвечает условиям поискового запроса, или на то, что документ не подходит для поискового запроса. Неверная классификация документа алгоритмом 128 MLA может указывать на то, что документ не соответствует режиму работы веб-браузера, используемого пользователем, отправившим поисковый запрос, например, веб-браузера, работающего в режиме родительского контроля для ограничения доступа к контенту, требующему особого обращения.
[124] Как описано выше, процедура 200 мониторинга включает в себя процедуру 210 мониторинга поисковой системы и процедуру 250 мониторинга социальной сети.
[125] Процедура мониторинга поисковой системы
[126] Процедура 210 мониторинга поисковой системы обычно выполняется сервером 150 обучения. Процедура 210 мониторинга поисковой системы может выполняться в автономном режиме путем доступа к отслеженной информации в базе 132 данных отслеживания. Предполагается, что в других вариантах осуществления настоящей технологии процедура 210 мониторинга поисковой системы может выполняться сервером 130 отслеживания. Следует отметить, что процедура 210 мониторинга поисковой системы также может выполняться распределенным образом или частично сервером 120 поисковой системы и/или сервером 130 отслеживания и/или сервером 150 обучения и/или другими серверами (не показаны).
[127] Процедура 210 мониторинга поисковой системы предназначена для мониторинга действий пользователей, осуществляемых по меньшей мере частью пользователей с использованием множества 102 клиентских устройств в поисковой системе 126, с целью обнаружения «флуктуаций» в действиях пользователей.
[128] В контексте процедуры 210 мониторинга поисковой системы «флуктуации» в действиях пользователей соответствуют любым беспорядочным изменениям значений данных для действий пользователей. Следует отметить, что «регулярные» и «беспорядочные» изменения числовых значений для действий пользователя могут быть определены на основе статистического анализа прошлых действий пользователей и/или могут быть определены операторами в рамках настоящей технологии. В некоторых вариантах осуществления настоящей технологии флуктуации могут быть определены на основе заранее заданного порога, который может быть абсолютным или относительным. Кроме того, флуктуации могут быть определены на основе заранее заданного порога в течение заранее заданного периода времени. Также могут учитываться такие факторы, как позиция документа, наличие относящихся к запросу новостных сообщений, дата модификации и т.д.
[129] Не имеющие ограничительного характера примеры беспорядочных действий пользователей включают в себя внезапное увеличение количества отправок некоторого запроса, например, увеличение на 20% отправок некоторого запроса в течение часа; увеличение количества переходов пользователей к документу, предоставленному в ответ на другой запрос, например, когда документ, ранг которого в ответе на поисковый запрос соответствует 30-й позиции, выбирается чаще, чем документ, ранг которого в ответе на поисковый запрос соответствует 1-й позиции, что может рассматриваться как необычная ситуация для этого запроса.
[130] Процедура 210 мониторинга поисковой системы получает из журнала 136 запросов множество 212 запросов, в котором каждый запрос 214 связан с набором 216 документов, представленных в качестве результатов поиска на странице SERP сервера 120 поисковой системы для части множества пользователей (не показаны). В некоторых вариантах осуществления настоящей технологии набор 216 документов может представлять собой указание на каждый документ, предоставленный в качестве результата поиска в ответ на запрос 214.
[131] Процедура 210 мониторинга поисковой системы получает из журнала 136 запросов и из журнала 138 действий пользователей информацию 220 о трафике для каждого запроса 214 из множества 212 запросов.
[132] В общем случае информация 220 о трафике включает в себя данные 222 о действиях пользователей, относящиеся к запросу 214.
[133] В некоторых вариантах осуществления настоящей технологии данные 222 о действиях пользователей для каждого запроса 214 включают в себя данные о действиях пользователей с одним или несколькими документами 218 из набора 216 документов. В не имеющем ограничительного характера примере данные 222 о действиях пользователей могут включать в себя количество «кликов», коэффициент «кликов» и время пребывания.
[134] В некоторых вариантах осуществления настоящей технологии информация 220 о трафике дополнительно содержит источник 224 трафика.
[135] Источник 224 трафика может представлять собой URL-адрес предыдущего ресурса, к которому обращался пользователь из множества пользователей (не показаны) перед вводом запроса из множества 212 запросов в поисковой системе 126. В не имеющем ограничительного характера примере источник 224 трафика может представлять собой элемент контента, размещенный пользователем в социальной сети 146. В некоторых вариантах осуществления настоящей технологии пользователь может обратиться к поисковой системе 126 после открытия браузерного приложения (не показано) и источник 224 трафика может представлять собой пустое значение. В некоторых вариантах осуществления настоящей технологии источник 224 трафика может включать в себя указание на программное обеспечение, такое как мобильное приложение. Например, пользователь может обратиться к поисковой системе 126 через мобильное приложение, связанное с социальной сетью 146.
[136] В некоторых вариантах осуществления настоящей технологии, когда данные о действиях пользователей не объединены в журнале 136 запросов и/или в журнале 138 действий пользователей, т.е. когда данные о действиях пользователей представлены в необработанном виде, процедура 210 мониторинга поисковой системы может на основе информации 220 о трафике определять для каждого запроса 214 из множества 212 запросов один или несколько параметров действий пользователей.
[137] В не имеющем ограничительного характера примере, когда журнал 136 запросов для каждого идентификатора пользователя содержит отправленный запрос, документы, представленные в качестве результатов поиска в ответ на этот запрос, и отметку времени, процедура 210 мониторинга поисковой системы получает все экземпляры запроса для конкретного периода времени, например, одной недели, и определяет параметр действий пользователей, указывающий на количество отправок для каждого часа в течение одной недели.
[138] Фильтрация множества запросов
[139] Процедура 210 мониторинга поисковой системы фильтрует множество 212 запросов на основе информации 220 о трафике с целью определения набора 240 запросов, содержащего по меньшей мере один запрос 214 из множества 212 запросов. По меньшей мере один запрос 214 из набора 240 запросов связан с набором 216 документов, содержащим потенциально неверно классифицированный документ.
[140] Процедура 210 мониторинга поисковой системы фильтрует множество 212 запросов на основе источника 224 трафика. В общем случае фильтрация множества 212 запросов на основе источника 224 трафика предназначена для выбора запросов и/или документов, предоставленных в ответ на запросы и поступивших из источника трафика, который может быть источником флуктуаций в действиях пользователей в поисковой системе 126. Предполагается, что источник 224 трафика может представлять собой социальную сеть 146. В некоторых вариантах осуществления настоящей технологии процедура 210 мониторинга поисковой системы может быть выполнена для идентификации источников трафика, таких как социальная сеть 146, которые могут быть источниками флуктуаций в действиях пользователей в поисковой системе и могут указывать на неверно классифицированные документы в поисковой системе 126.
[141] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии процедура 210 мониторинга поисковой системы фильтрует множество 212 запросов на основе того, что источник 224 трафика является источником из заранее заданного списка 228 источников трафика. Заранее заданный список 228 источников трафика может быть определен операторами согласно настоящей технологии и может включать в себя социальные сети, персональные блоги и ресурсы других видов.
[142] В не имеющем ограничительного характера примере заранее заданный список 228 источников трафика может включать в себя социальные сети, такие как Facebook™, VKontakte™, Twitter™, Reddit™, Instagram™, Pinterest™, YouTube™, платформы для ведения персональных блогов, такие как WordPress™, Tumblr™, Medium™, и платформы для обмена сообщениями, такие как Viber™ и WhatsApp™.
[143] Процедура 210 мониторинга поисковой системы фильтрует множество 212 запросов на основе параметров 230 действий пользователей. В некоторых вариантах осуществления настоящей технологии процедура 210 мониторинга поисковой системы фильтрует множество 212 запросов на основе параметров 230 действий пользователей, превышающих заранее заданный порог 236. Заранее заданный порог 236 может быть определен в виде заранее заданного периода времени.
[144] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии параметр 230 действий пользователей может представлять собой количество отправок поискового запроса. Предполагается, что заранее заданный порог 236 и/или заранее заданный период времени может быть определен на основе источника 224 трафика.
[145] В других не имеющих ограничительного характера вариантах осуществления настоящей технологии процедура 210 мониторинга поисковой системы может сортировать множество 212 запросов на основе параметров 230 действий пользователей и выбирать заранее заданное количество запросов с наибольшими параметрами 230 действий пользователей. В не имеющем ограничительного характера примере процедура 210 мониторинга поисковой системы может сортировать множество 212 запросов на основе количества отправок в поисковой системе 126 и выбирать 10 запросов с наибольшим количеством отправок для включения в состав набора 240 запросов.
[146] Кроме того, в некоторых вариантах осуществления настоящей технологии процедура 210 мониторинга поисковой системы фильтрует множество 212 запросов на основе параметра действий пользователей (не показан), связанного с документом из набора 216 документов. Процедура 210 мониторинга поисковой системы фильтрует множество 212 запросов на основе того, что параметр действий пользователей (не показан), связанный с документом 218 из набора 216 документов, предоставленного в ответ на запрос из множества 212 запросов, превышает заранее заданный порог.
[147] Предполагается, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии фильтрация множества 212 запросов может быть выполнена во время получения множества 212 запросов из журнала 136 запросов, т.е. путем указания таких условий, как получение только запросов из источника 224 трафика из заранее заданного списка 228 источников трафика, получение только запросов с количеством отправок свыше заранее заданного порога и т.д.
[148] Процедура 210 мониторинга поисковой системы выдает набор 240 запросов, содержащий по меньшей мере один запрос 242, связанный с набором 244 (нет на чертежах) документов, представленных в качестве результатов поиска в ответ на запрос 242. Набор 240 запросов содержит запросы, связанные с флуктуациями в действиях пользователей, которые могут указывать на то, что запрос 242 связан с потенциально неверно классифицированным документом (не показан) в наборе 216 документов.
[149] Набор признаков контента
[150] Процедура 210 мониторинга поисковой системы извлекает набор 245 признаков контента для набора 240 запросов. Извлеченный набор 245 признаков контента позволяет во время выполнения процедуры 250 мониторинга социальной сети идентифицировать документы, потенциально неверно классифицированные алгоритмом 128 MLA поисковой системы 126.
[151] В общем случае набор 245 признаков контента указывает на контент запроса 214, связанный с потенциально неверно классифицированным документом.
[152] В качестве не имеющего ограничительного характера примера, набор 245 признаков контента может содержать запрос 214 и его варианты, а также запросы, которые могли быть определены как подобные запросу 214, например, путем определения параметра сходства на основе сходства результатов поиска или семантического сходства, как описано в заявке на патент Российской Федерации № 2018122689 «Способ и система для ранжирования результатов поиска с использованием алгоритма машинного обучения» (подана 21 июня 2018 г.), содержание которой полностью включено в настоящий документ посредством ссылки, и поэтому более подробно не обсуждается.
[153] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии набор 245 признаков контента содержит указание на по меньшей мере один документ из набора 216 документов, связанных с запросом 214. В не имеющем ограничительного характера примере указание на по меньшей мере один документ 218 может представлять собой заголовок документа или его варианты либо по меньшей мере часть контента документа 218.
[154] Кроме того, набор 245 признаков контента может содержать множество заранее заданных слов, связанных с флуктуацией в действиях пользователей из набора 240 запросов. В не имеющем ограничительного характера примере множество заранее заданных слов может содержать такие слова, как: wow, funny, unbelievable, fail, failure, ridiculous, stupid, название поисковой системы 126 либо любое другое слово или фразу, которая может быть связана с вирусным контентом.
[155] Процедура 210 мониторинга поисковой системы выдает набор 245 признаков контента. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии набор 245 признаков контента может храниться в базе 152 данных обучения.
[156] Процедура мониторинга социальной сети
[157] Процедура 250 мониторинга социальной сети выполняется сервером 130 отслеживания.
[158] Процедура 250 мониторинга социальной сети выполняется после выполнения процедуры 210 мониторинга поисковой системы. Предполагается, что в других не имеющих ограничительного характера вариантах осуществления настоящей технологии процедура 250 мониторинга социальной сети может выполняться перед выполнением процедуры 210 мониторинга поисковой системы или одновременно с процедурой 210 мониторинга поисковой системы, т.е. с целью определить, имеют ли документы, связанные с элементами контента, флуктуации в действиях пользователей на сервере 120 поисковой системы. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии процедура 250 мониторинга социальной сети может выполняться параллельно или последовательно для множества социальных сетей (не показаны).
[159] В общем случае процедура 250 мониторинга социальной сети предназначена для обнаружения в социальной сети 146 документов, потенциально неверно классифицированных алгоритмом 128 MLA в поисковой системе 126. Для достижения этой цели процедура 250 мониторинга социальной сети обращается к ресурсу, связанному с социальной сетью 146, для отслеживания информации или получает информацию с использованием интерфейса API, предоставленного социальной сетью 146.
[160] Процедура 250 мониторинга социальной сети получает по меньшей мере часть множества 148 элементов контента социальной сети 146.
[161] Как описано выше, социальная сеть 146 содержит множество 148 элементов контента, отправленных пользователями социальной сети 146 с использованием их клиентских устройств, таких как множество 102 клиентских устройств. Каждый элемент 252 контента из множества 148 элементов контента может содержать документы, такие как тексты, изображения, музыка, видеоматериалы, гиперссылки, цифровые файлы или их сочетание. Очевидно, что термин «документ» в данном контексте относится к любому цифровому файлу, который может иметь ссылку на сервере 120 поисковой системы и который может быть классифицирован алгоритмом 128 MLA.
[162] Предполагается, что в некоторых вариантах осуществления настоящей технологии элемент 252 контента из множества 148 элементов контента может содержать метаданные 258, описывающие контент или тему элемента 252 контента. Например, метаданные 258 могут представлять собой один или несколько тегов метаданных, которые могут быть определены создателем или потребителем элемента 252 контента либо могут быть автоматически сформированы в социальной сети 146. В не имеющем ограничительного характера примере теги метаданных для элемента контента, содержащего изображение, могут включать в себя хэштеги, такие как #image, #funny, #2019, #fail, #StupidAI.
[163] Процедура 250 мониторинга социальной сети на основе набора 245 признаков контента анализирует по меньшей мере часть множества 148 элементов контента в социальной сети 146, чтобы идентифицировать набор 260 идентифицированных элементов контента, который может включать в себя потенциально неверно классифицированные документы.
[164] В других не имеющих ограничительного характера вариантах осуществления настоящей технологии процедура 250 мониторинга социальной сети может анализировать часть множества 148 элементов контента, соответствующую элементам контента, отправленным в социальную сеть 146 в течение заранее заданного периода времени. Дополнительно или в качестве альтернативы, процедура 250 мониторинга социальной сети может анализировать часть множества 148 элементов контента, соответствующих набору условий (не показаны). Например, этот набор условий может содержать такие условия, как конкретный период времени, конкретный вид контента, конкретная демографическая группа, конкретные метаданные и конкретные пользователи, дискуссионные группы или компании. В не имеющем ограничительного характера примере набор условий может задавать получение всех элементов контента, содержащих текст на английском языке, по меньшей мере один тег метаданных и по меньшей мере одно изображение. В некоторых вариантах осуществления настоящей технологии набор условий может быть включен в состав набора 245 признаков контента.
[165] Предполагается, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии набор условий может содержать заранее заданные пороги в зависимости от источника 224 трафика. В не имеющем ограничительного характера примере набор условий может содержать пороги на основе количества случаем «репостинга» элемента 252 контента, количества «лайков», полученных для этого элемента контента, количества полученных для него комментариев и т.п. Очевидно, что набор условий может быть определен во время выполнения процедуры 210 мониторинга поисковой системы и/или процедуры 250 мониторинга социальной сети.
[166] Процедура 250 мониторинга социальной сети в каждом определенном элементе 262 контента из набора 260 идентифицированных элементов контента идентифицирует по меньшей мере часть потенциально неверно классифицированных документов 282. Следует отметить, что идентифицированный элемент 262 контента может содержать несколько неверно классифицированных документов, например, когда пользователь публикует фотоальбом, содержащий множество фотографий, представляющих собой потенциально неверно классифицированные документы. Кроме того, идентифицированный элемент 262 контента может содержать лишь часть потенциально неверно классифицированного документа 282, например, часть текста или изображения, на которую возможна ссылка в поисковой системе 126. Процедура 250 мониторинга социальной сети формирует набор 280 потенциально неверно классифицированных документов.
[167] В не имеющем ограничительного характера примере, если элемент контента содержит текст и изображение, представляющее собой снимок экрана со страницей SERP, отображающий лишь часть документа, например, другого изображения, потенциально неверно классифицированного алгоритмом 128 MLA, процедура 250 мониторинга социальной сети может извлечь этот снимок экрана и/или часть другого изображения, потенциально неверно классифицированного алгоритмом 128 MLA. Часть по меньшей мере одного потенциально неверно классифицированного документа 282 может быть идентифицирована и извлечена алгоритмом MLA (не показан), обученным для выполнения этой задачи. Например, алгоритм MLA может быть обучен распознавать документ и название поисковой системы 126 на снимке экрана браузерного приложения.
[168] В общем случае каждый потенциально неверно классифицированный документ 282 связан с информацией 284 о документе. Информация 284 о документе включает в себя указание на идентифицированный элемент 262 контента, из которого она была извлечена (не показано), а также признаки из набора 245 признаков контента, которые были использованы для определения идентифицированного элемента 262 контента из множества 148 элементов контента, такие как запрос, использованный для доступа к потенциально неверно классифицированному документу 282 в поисковой системе 126.
[169] На фиг. 4 представлена схема соответствующей не имеющим ограничительного характера вариантам осуществления настоящей технологии процедуры 300 определения неверной классификации документов.
[170] Процедура 300 определения неверной классификации документов по меньшей мере частично выполняется сервером 150 обучения. В некоторых вариантах осуществления настоящей технологии сервер 150 обучения может обращаться к алгоритму MLA (не показан) для выполнения по меньшей мере части процедуры 300 определения неверной классификации документов.
[171] В общем случае процедура 300 определения неверной классификации документов предназначена для определения неверной классификации алгоритмом 128 MLA документов из набора 280 потенциально неверно классифицированных документов, идентифицированного во время выполнения процедуры 250 мониторинга социальной сети. Для достижения этой цели процедура 300 определения неверной классификации документов способна: (а) идентифицировать в базе 122 данных журнала поиска каждый потенциально неверно классифицированный документ 282 из набора 280 потенциально неверно классифицированных документов; (б) получать набор 302 признаков документа для каждого потенциально неверно классифицированного документа 282 из набора 280 потенциально неверно классифицированных документов; (в) анализировать каждый потенциально неверно классифицированный документ 282 из набора 280 потенциально неверно классифицированных документов на основе набора 302 признаков документа с целью определения их неверной классификации и получения подмножества 320 неверно классифицированных документов.
[172] Процедура 300 определения неверной классификации документов идентифицирует потенциально неверно классифицированный документ 282 в индексе 124 на основе информации 284 о документе для каждого потенциально неверно классифицированного документа 282 из набора 280 потенциально неверно классифицированных документов.
[173] Процедура 300 определения неверной классификации документов получает для потенциально неверно классифицированного документа 282 набор 302 признаков документа, который был использован алгоритмом 128 MLA для классификации потенциально неверно классифицированного документа 282.
[174] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии процедура 300 определения неверной классификации документов получает набор 302 признаков документа для потенциально неверно классифицированного документа 282 из базы данных, например, из базы 122 данных журнала поиска. В частности, в других не имеющих ограничительного характера вариантах осуществления настоящей технологии, когда набор 302 признаков документа не был сохранен, процедура 300 определения неверной классификации документов может извлечь набор 302 признаков документа для потенциально неверно классифицированного документа 282. Процедура 300 определения неверной классификации документов может обращаться к алгоритму 128 MLA для извлечения набора 302 признаков документа.
[175] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии процедура 300 определения неверной классификации документов может получать из базы данных, например, из базы 152 данных обучения, или путем выполнения алгоритма 128 MLA значение вероятности, связанное с классификацией каждого потенциально неверно классифицированного документа 282. В не имеющем ограничительного характера примере один или несколько документов из набора 280 потенциально неверно классифицированных документов могут быть связаны с меньшими вероятностями того, что они принадлежат к классу, выбранному в результате неверной классификации.
[176] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии набор 280 потенциально неверно классифицированных документов может быть отправлен одному или нескольким экспертам с тем, чтобы неверно классифицированные документы из набора 280 потенциально неверно классифицированных документов могли быть проанализированы одним или несколькими экспертами с целью определения ошибочности их классификации и определения верного класса, к которому они должны принадлежать. Дополнительно или в качестве альтернативы, набор 280 потенциально неверно классифицированных документов может быть проанализирован другим алгоритмом MLA, который мог быть обучен иным образом для выполнения той же задачи.
[177] Процедура 300 определения неверной классификации документов определяет подмножество 320 неверно классифицированных документов из набора 280 потенциально неверно классифицированных документов. Подмножество 320 неверно классифицированных документов содержит по меньшей мере один неверно классифицированный документ 322 (нет на чертежах).
[178] В некоторых вариантах осуществления настоящей технологии каждый неверно классифицированный документ 322 из подмножества 320 неверно классифицированных документов может содержать набор 302 признаков документа.
[179] Процедура 300 определения неверной классификации документов формирует набор 330 обучающих объектов, при этом каждый обучающий объект 332 включает в себя метку 334 исправленного класса. Процедура 300 определения неверной классификации документов сохраняет набор 330 обучающих объектов в базе 152 данных обучения.
[180] На фиг. 5 представлена схема соответствующей не имеющим ограничительного характера вариантам осуществления настоящей технологии процедуры 400 (нет на чертежах) повторного обучения.
[181] Процедура повторного обучения
[182] Процедура 400 повторного обучения выполняется сервером 150 обучения.
[183] В общем случае процедура 400 повторного обучения предназначена для повторного обучения алгоритма 128 MLA для классификации объектов, подобных набору 330 обучающих объектов, которые для алгоритма 128 MLA представляют собой неоднозначные объекты с точки зрения их признаков. Процедура 400 повторного обучения может выполняться через заранее заданные интервалы времени. Дополнительно или в качестве альтернативы, процедура 400 повторного обучения может выполняться, только когда количество обучающих объектов в наборе 330 обучающих объектов превышает заранее заданное количество.
[184] Процедура 400 повторного обучения повторно обучает алгоритм 128 MLA по меньшей мере на первой части набора 330 обучающих объектов и на первоначальных обучающих объектах, которые были использованы для обучения алгоритма 128 MLA. Процедура 400 повторного обучения повторно обучает алгоритм 128 MLA на основе того же набора признаков документа или на основе новых признаков документа (которые по меньшей мере частично могут быть определены операторами в рамках настоящей технологии или определены алгоритмом 128 MLA).
[185] Затем процедура 400 повторного обучения проверяет повторно обученный алгоритм 428 MLA на второй части набора 330 обучающих объектов.
[186] На фиг. 6 приведена блок-схема способа 500 определения поискового запроса, связанного с потенциально неверно классифицированным документом, выполняемого в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[187] Способ 500 выполняется сервером 150 обучения. Сервер 150 обучения содержит процессор и машиночитаемый физический носитель информации, содержащий команды. Процессор при выполнении команд способен выполнять способ 500.
[188] Способ 500 начинается с шага 502.
[189] Шаг 502: получение множества ранее отправленных серверу поисковых запросов, каждый из которых связан с набором документов, представленных в качестве результатов поиска пользователям из множества пользователей.
[190] На шаге 502 сервер 150 обучения путем выполнения процедуры 510 мониторинга поисковой системы получает множество 212 запросов, ранее отправленных поисковой системе 126 сервера 120 поисковой системы, при этом каждый запрос 214 связан с набором 216 документов, представленных в качестве результатов поиска на клиентских устройствах из множества 102 клиентских устройств соответствующим пользователям из множества пользователей.
[191] В некоторых вариантах осуществления настоящей технологии наборы 216 документов содержат изображения.
[191] Способ 500 продолжается на шаге 504.
[192] Шаг 504: получение для каждого поискового запроса из множества поисковых запросов информации о трафике, включая количество отправок.
[193] На шаге 504 сервер 150 обучения получает из журнала 136 запросов и из журнала 138 действий пользователей информацию 220 о трафике для каждого запроса 214 из множества 212 запросов. Информация 220 о трафике включает в себя данные 222 о действиях пользователей, относящиеся к запросу 214, например, количество отправок. В некоторых вариантах осуществления настоящей технологии информация 220 о трафике дополнительно содержит источник 224 трафика.
[194] Способ 500 продолжается на шаге 506.
[195] Шаг 506: определение поискового запроса на основе количества отправок.
[196] На шаге 506 сервер 150 обучения фильтрует множество 212 запросов на основе информации 220 о трафике с целью определения набора 240 запросов, содержащего по меньшей мере один запрос, связанный с потенциально неверно классифицированным документом. В некоторых вариантах осуществления настоящей технологии процедура 210 мониторинга поисковой системы с целью определения набора 240 запросов фильтрует множество 212 запросов на основе того, что источник 224 трафика представляет собой источник из заранее заданного списка 228 источников трафика.
[197] В некоторых вариантах осуществления настоящей технологии сервер 150 обучения извлекает для набора 240 запросов набор 245 признаков контента, содержащий указание на каждый запрос из набора 240 запросов. Набор 245 признаков контента может содержать множество заранее заданных слов.
[198] На этом способ 500 завершается.
[199] На фиг. 7 приведена блок-схема способа 600 повторного обучения алгоритма MLA, выполняемого в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[200] Способ 600 выполняется сервером 150 обучения. Сервер 150 обучения содержит процессор и машиночитаемый физический носитель информации, содержащий команды. Процессор при выполнении команд способен выполнять способ 600.
[201] Способ 600 начинается с шага 602.
[202] Шаг 602: обращение к ресурсу, содержащему множество элементов контента, каждый из которых был отправлен этому ресурсу по меньшей мере одним пользователем.
[203] На шаге 602 сервер 150 обучения обращается к ресурсу, связанному с социальной сетью 146, или получает информацию с использованием интерфейса API, предоставленного социальной сетью 146. Социальная сеть 146 содержит множество 148 элементов контента, отправленных пользователями с использованием их клиентских устройств, таких как по меньшей мере часть множества 102 клиентских устройств. Каждый элемент 252 контента из множества 148 элементов контента может содержать документы, такие как тексты, изображения, музыка, видеоматериалы, гиперссылки, цифровые файлы или их сочетание. В некоторых вариантах осуществления настоящей технологии элемент 252 контента из множества 148 элементов контента может содержать метаданные 258, описывающие контент или тему элемента 252 контента.
[204] Сервер 150 обучения получает по меньшей мере часть множества 148 элементов контента социальной сети 146.
[205] Способ 600 продолжается на шаге 604.
[206] Шаг 604: идентификация на основе первого набора признаков по меньшей мере одного элемента контента из множества элементов контента, связанного с документом, представленным сервером поисковой системы в качестве результата поиска в ответ на поисковый запрос.
[207] На шаге 604 сервер 150 обучения на основе набора 245 признаков контента идентифицирует по меньшей мере часть множества 148 элементов контента в социальной сети 146, чтобы идентифицировать набор 260 идентифицированных элементов контента, который может включать в себя потенциально неверно классифицированные документы. Сервер 150 обучения в каждом идентифицированном элементе 262 контента из идентифицированного набора 260 элементов контента идентифицирует по меньшей мере часть потенциально неверно классифицированных документов 282, чтобы сформировать набор 280 потенциально неверно классифицированных документов.
[208] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 150 обучения может анализировать часть множества 148 элементов контента, соответствующую набору условий (не показаны). Например, этот набор условий может содержать такие условия, как конкретный период времени, конкретный вид контента, конкретная демографическая группа, конкретные метаданные и конкретные пользователи, дискуссионные группы или компании.
[209] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии каждый потенциально неверно классифицированный документ 282 связан с информацией 284 о документе. Информация 284 о документе включает в себя указание на идентифицированный элемент 262 контента, из которого она была извлечена (не показано), а также признаки из набора 245 признаков контента, использованные для определения идентифицированного элемента 262 контента из множества 148 элементов контента, такие как запрос, использованный для доступа к потенциально неверно классифицированному документу 282 в поисковой системе 126.
[210] Способ 600 продолжается на шаге 606.
[211] Шаг 606: анализ на основе набора признаков документа по меньшей мере одного элемента контента из множества элементов контента с целью определения того, был ли этот документ неверно классифицирован алгоритмом MLA в ответ на поисковый запрос.
[212] На шаге 606 сервер 150 обучения получает набор 302 признаков документа для потенциально неверно классифицированного документа 282 из базы данных, например, из базы 122 данных журнала поиска. В других вариантах осуществления настоящей технологии, например, если набор 302 признаков документа не был сохранен, сервер 150 обучения может извлечь набор 302 признаков документа для потенциально неверно классифицированного документа 282. Сервер 150 обучения может обращаться к алгоритму 128 MLA для извлечения набора 302 признаков документа. В некоторых вариантах осуществления настоящей технологии документ может представлять собой изображение, а набор признаков документа может представлять собой набор признаков изображения.
[213] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии набор 280 потенциально неверно классифицированных документов может быть отправлен одному или нескольким экспертам с тем, чтобы неверно классифицированные документы из набора 280 потенциально неверно классифицированных документов могли быть проанализированы одним или несколькими экспертами с целью определения ошибочности их классификации и определения класса, к которому они должны принадлежать. Дополнительно или в качестве альтернативы, набор 280 потенциально неверно классифицированных документов может быть проанализирован другим алгоритмом MLA, который мог быть обучен иным образом для выполнения той же задачи.
[214] Процедура 300 определения неверной классификации документов определяет подмножество 320 неверно классифицированных документов из набора 280 потенциально неверно классифицированных документов. Подмножество 320 неверно классифицированных документов содержит по меньшей мере один неверно классифицированный документ 322.
[215] Неверно классифицированный документ из подмножества 320 неверно классифицированных документов может быть неверно классифицирован алгоритмом 128 MLA по различным причинам, например, из-за неоднозначности признаков документа, характеристики которых могут соответствовать нескольким классам, из-за того, что алгоритм MLA никогда не обрабатывал подобные признаки документа во время обучения, и т.д. Неверная классификация документа алгоритмом 128 MLA в поисковой системе 126 может указывать на то, что документ в качестве результата поиска не отвечает условиям поискового запроса, или на то, что документ не подходит для поискового запроса. Неверная классификация документа алгоритмом 128 MLA может указывать на то, что документ не соответствует режиму работы веб-браузера, используемого пользователем, отправившим поисковый запрос, например, веб-браузера, работающего в режиме родительского контроля для ограничения доступа к контенту, требующему особого обращения.
[216] Способ 600 продолжается на шаге 608.
[217] Шаг 608: если определено, что документ был классифицирован неверно:
- формирование на основе этого документа обучающего объекта, включая присвоение документу метки в виде указания на неверную классификацию; и
- повторное обучение алгоритма MLA на основе этого обучающего объекта.
[218] На шаге 608, если определено, что документ был классифицирован неверно, сервер 150 обучения формирует набор 330 обучающих объектов, при этом каждый обучающий объект 332 содержит метку 334 исправленного класса или указание на неверную классификацию.
[219] Сервер 150 обучения повторно обучает алгоритм 128 MLA по меньшей мере на первой части набора 330 обучающих объектов и на первоначальных обучающих объектах, которые были использованы для обучения алгоритма 128 MLA. Процедура 400 повторного обучения повторно обучает алгоритм 128 MLA на основе того же набора признаков документа или на основе новых признаков документа (которые, по меньшей мере частично, могут быть определены операторами в рамках настоящей технологии или определены алгоритмом 128 MLA). Затем процедура 400 повторного обучения проверяет повторно обученный алгоритм 428 MLA на второй части набора 330 обучающих объектов.
[220] Специалистам в данной области техники должно быть очевидно, что по меньшей некоторые варианты осуществления настоящей технологии преследуют цель расширения арсенала технических решений определенной технической задачи, а именно, повышения эффективности выполняемого сервером алгоритма MLA путем использования сигналов из одной или нескольких социальных сетей с целью обнаружения неверно классифицированных документов и формирования набора обучающих объектов для повторного обучения алгоритма MLA. Повышение эффективности выполняемого сервером алгоритма MLA способствует экономии вычислительных ресурсов.
[221] Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте осуществления настоящей технологии. Например, возможны варианты осуществления настоящей технологии, когда пользователь не получает некоторые из этих технических эффектов, или другие варианты осуществления, когда пользователь получает другие технические эффекты либо когда технический эффект отсутствует.
[222] Некоторые из этих шагов и передаваемых или принимаемых сигналов хорошо известны в данной области техники и по этой причине опущены в некоторых частях описания для упрощения. Сигналы могут передаваться или приниматься с использованием оптических средств (таких как волоконно-оптическое соединение), электронных средств (таких как проводное или беспроводное соединение) и механических средств (например, основанных на давлении, температуре или любом другом подходящем физическом параметре).
[223] Для специалиста в данной области могут быть очевидными изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено исключительно в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Система и способ формирования обучающего набора для алгоритма машинного обучения | 2018 |
|
RU2744029C1 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСШИРЕНИЯ ПОИСКОВЫХ ЗАПРОСОВ С ЦЕЛЬЮ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2720905C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ РАНЖИРОВАНИЮ ОБЪЕКТОВ | 2020 |
|
RU2782502C1 |
| СПОСОБ И СИСТЕМА ВЫБОРА ДЛЯ РАНЖИРОВАНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ С ПОМОЩЬЮ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2731658C2 |
| СИСТЕМА И СПОСОБ ФОРМИРОВАНИЯ ОБУЧАЮЩЕГО НАБОРА ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2711125C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ ЭЛЕМЕНТОВ СИСТЕМОЙ РАНЖИРОВАНИЯ | 2020 |
|
RU2781621C2 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ФОРМИРОВАНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ | 2022 |
|
RU2828354C2 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ | 2021 |
|
RU2831678C2 |
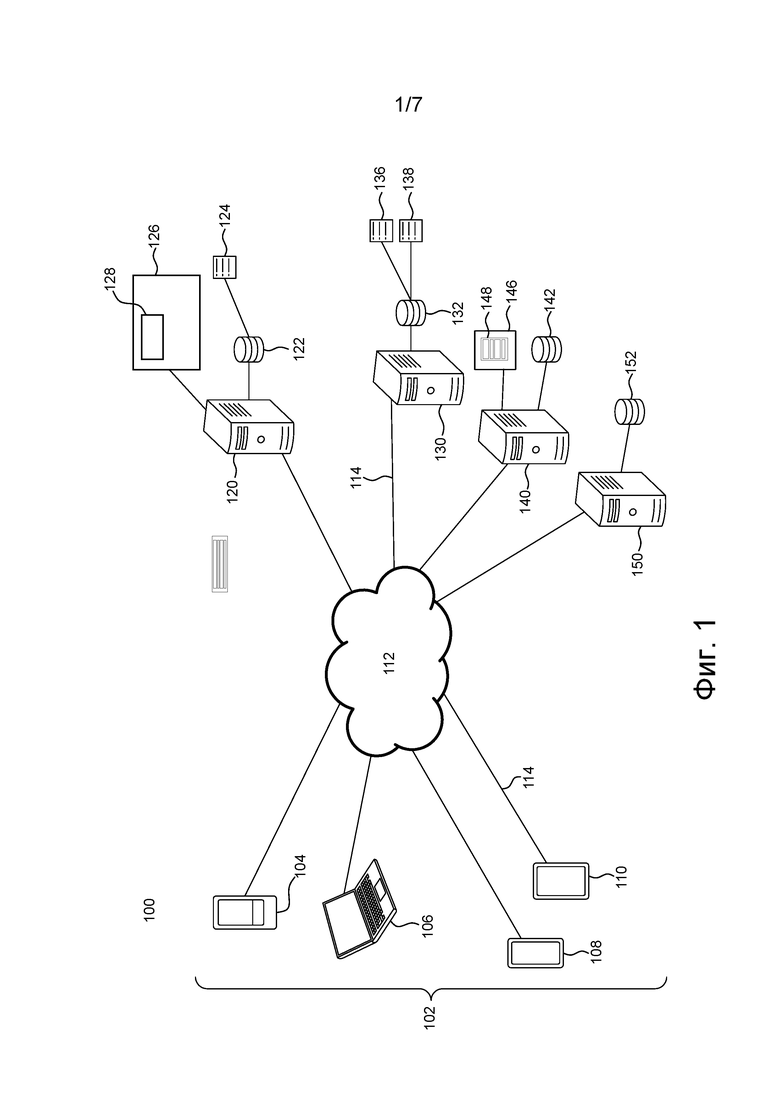
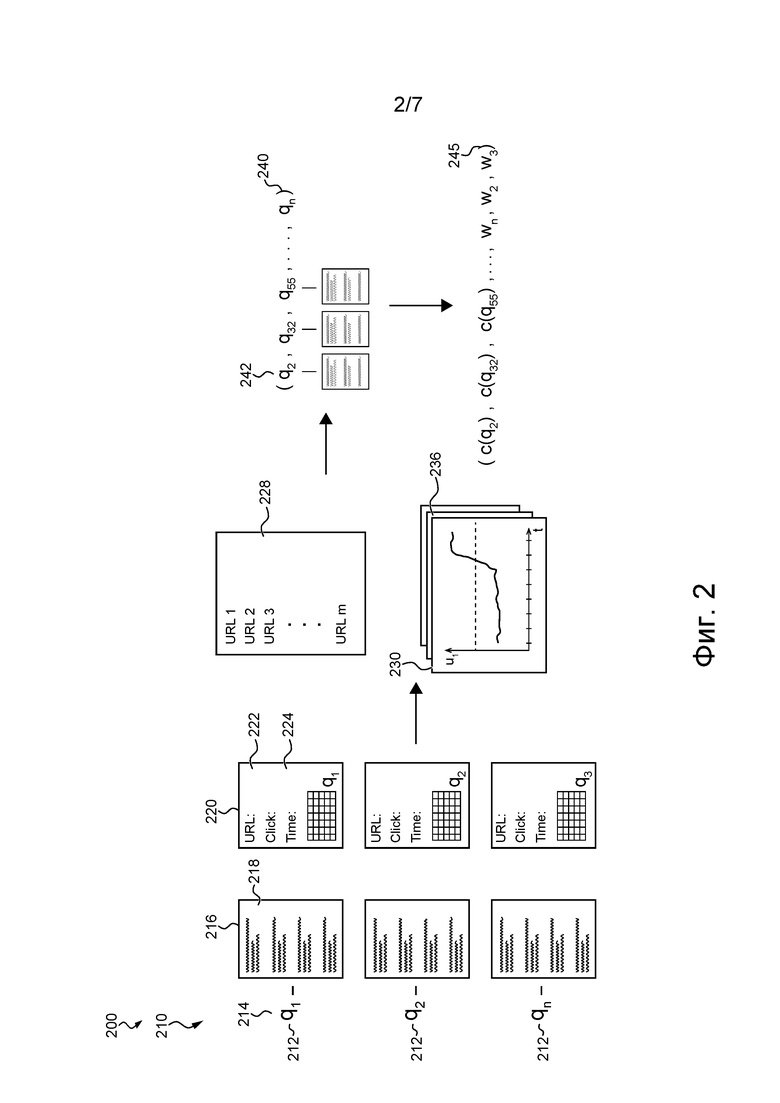
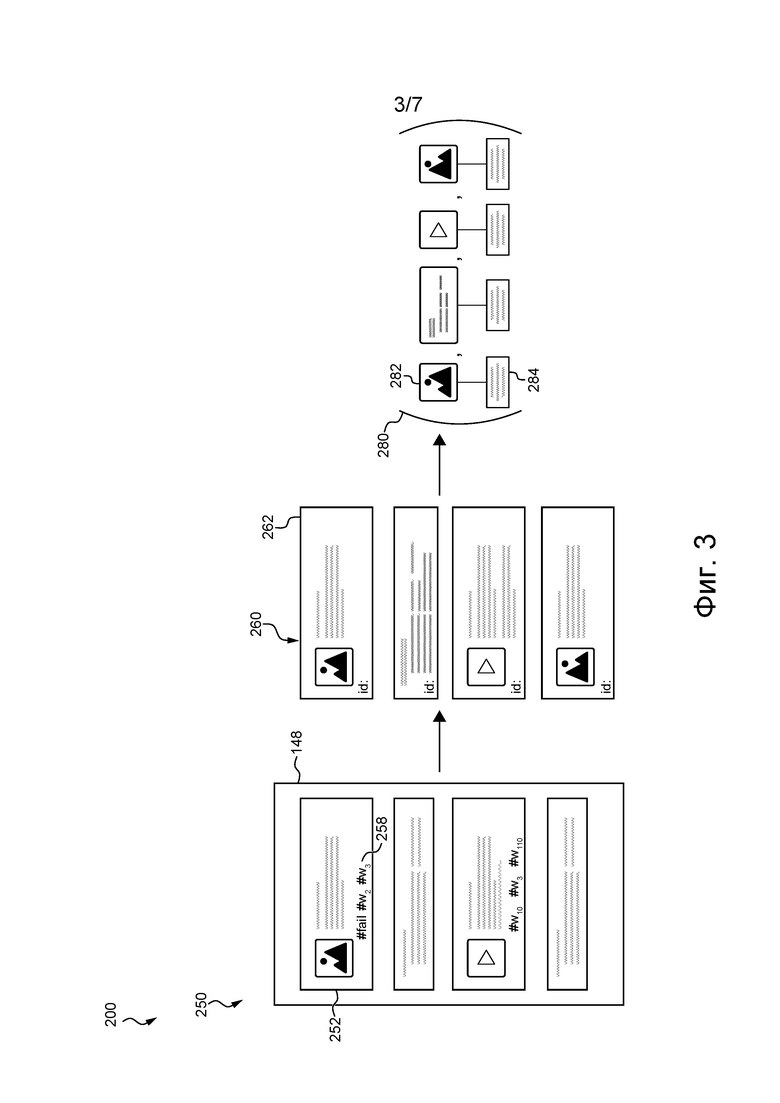
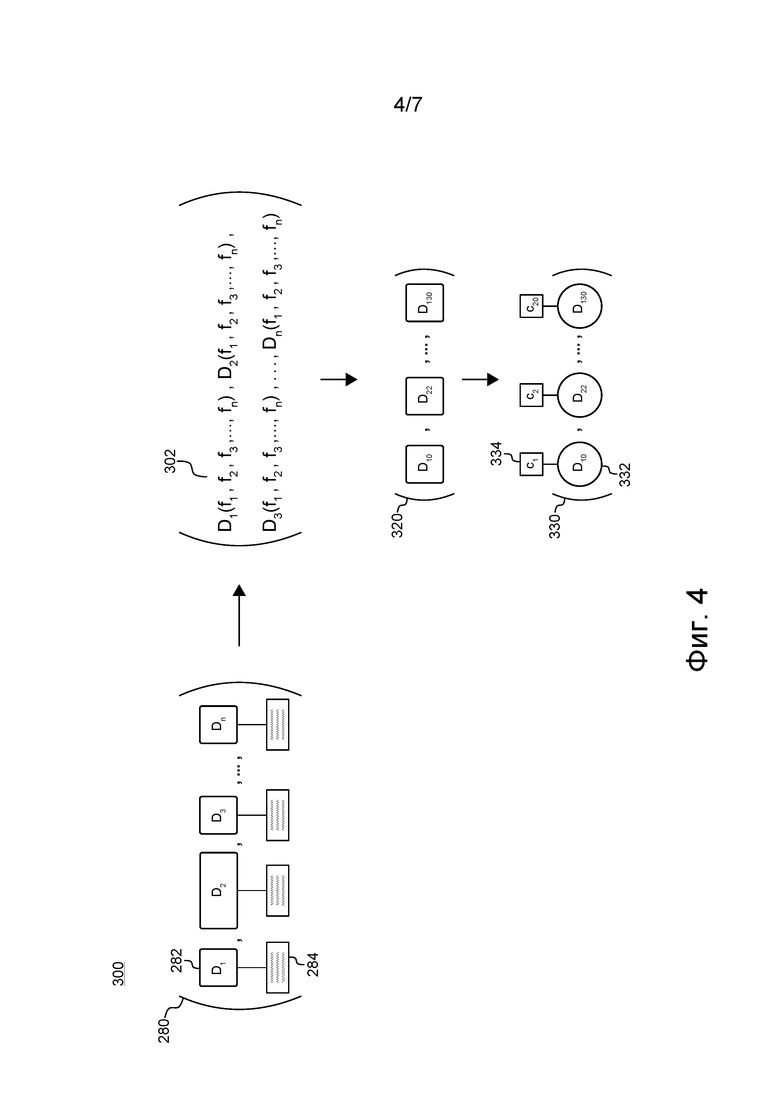
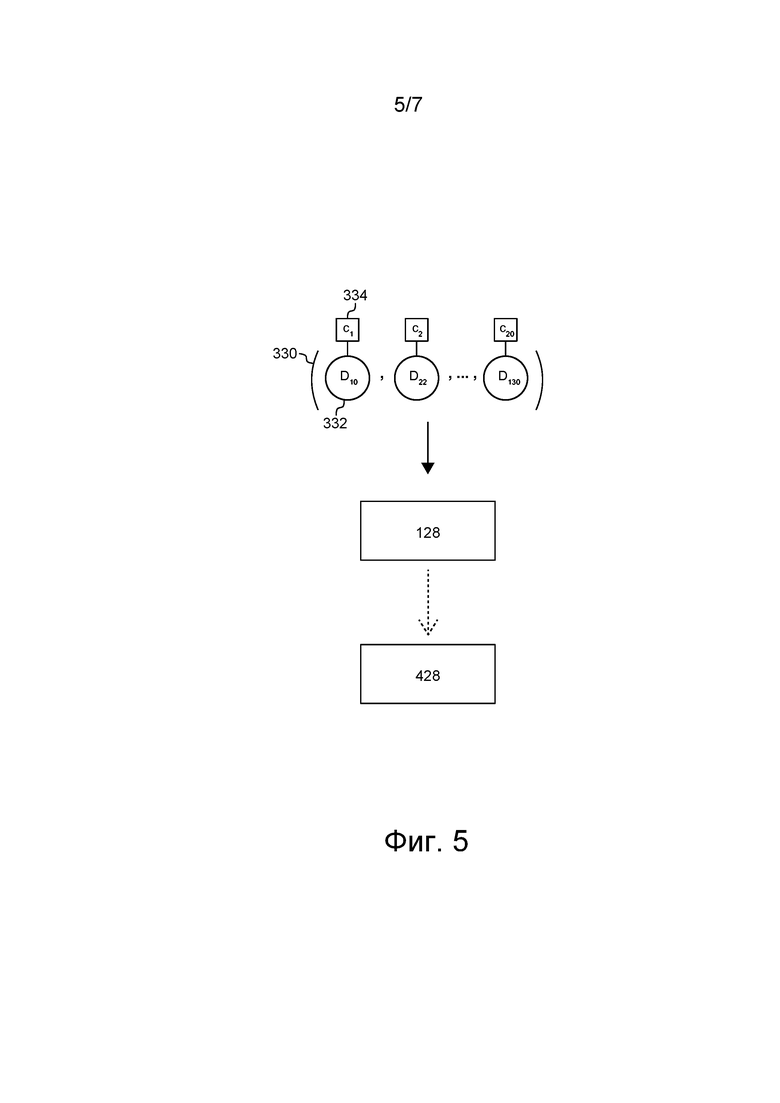
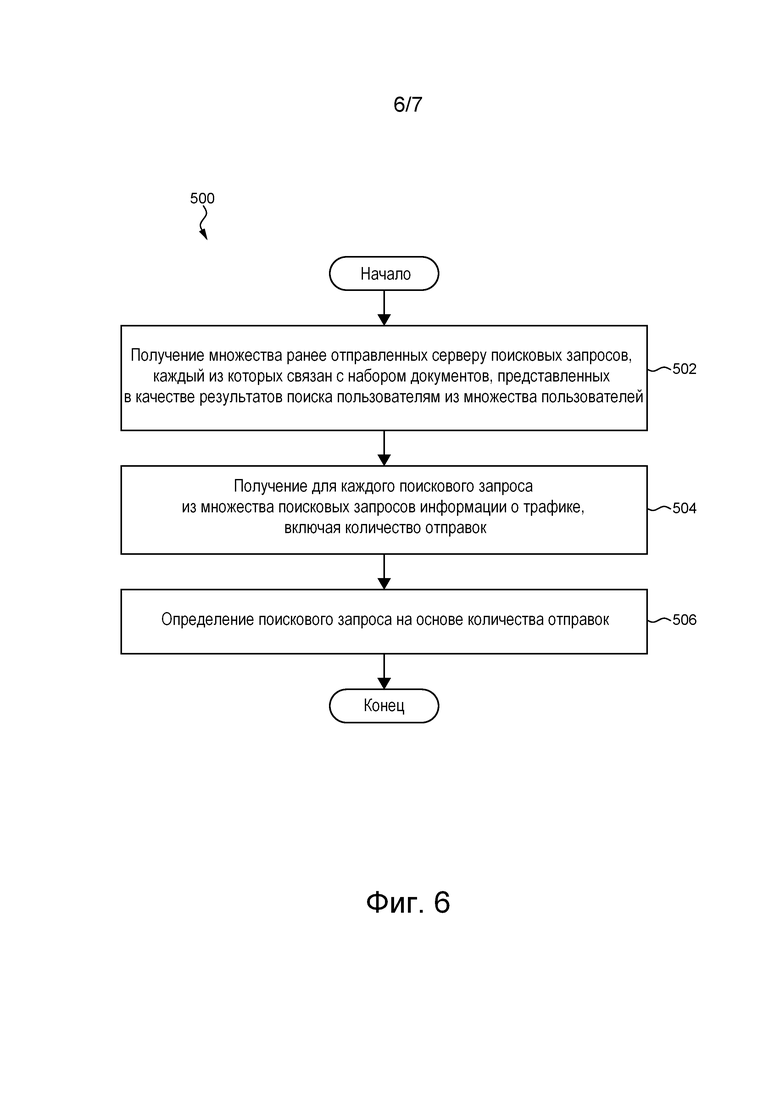
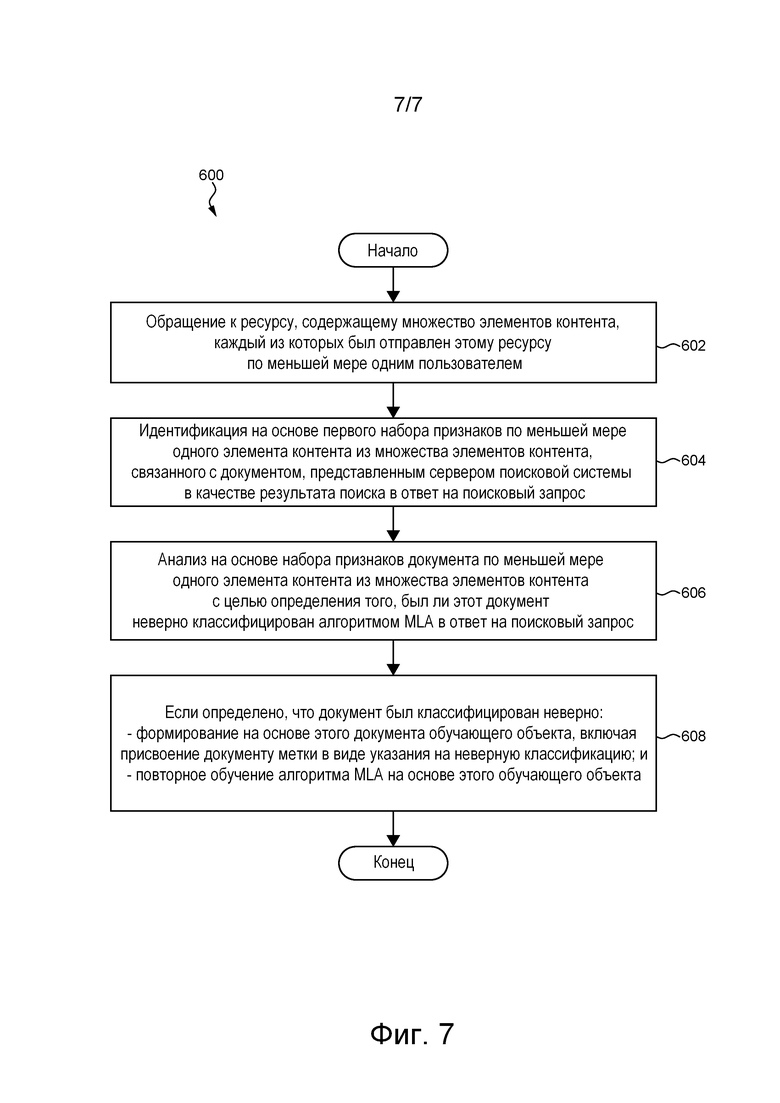
Изобретение относится к способу и серверу повторного обучения алгоритма машинного обучения (MLA). Технический результат заключается в повышении эффективности обучения MLA за счет выполнения повторного обучения. В способе выполняют обращение сервера через сеть связи к ресурсу, содержащему множество элементов контента, каждый из которых был отправлен этому ресурсу по меньшей мере одним пользователем; идентификацию на основе первого набора признаков элемента контента из множества элементов контента, связанных с документом, представленным сервером поисковой системы в качестве результата поиска в ответ на поисковый запрос; анализ на основе набора признаков документа элемента контента с целью определения того, был ли этот документ неверно классифицирован алгоритмом MLA в ответ на поисковый запрос; и если определено, что документ был классифицирован неверно, формирование на основе этого документа обучающего объекта, включая присвоение документу метки в виде указания на неверную классификацию, и повторное обучение алгоритма MLA на основе этого обучающего объекта. 2 н. и 26 з.п. ф-лы, 7 ил.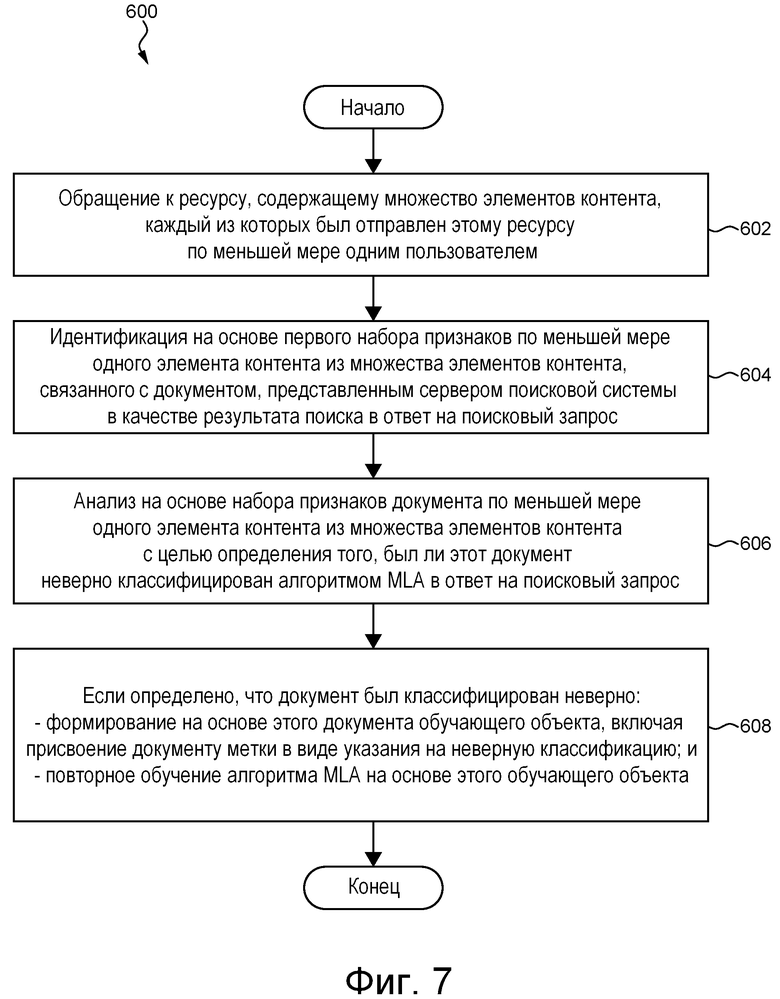
1. Способ повторного обучения алгоритма машинного обучения (MLA), выполняемого на сервере и обученного классифицировать документы на основе их признаков, который выполняется сервером и включает в себя:
- обращение сервера через сеть связи к ресурсу, содержащему множество элементов контента, каждый из которых был отправлен этому ресурсу по меньшей мере одним пользователем;
- идентификацию сервером на основе первого набора признаков по меньшей мере одного элемента контента из множества элементов контента, связанных с документом, представленным сервером поисковой системы в качестве результата поиска в ответ на поисковый запрос;
- анализ сервером на основе набора признаков документа по меньшей мере одного элемента контента из множества элементов контента с целью определения того, был ли этот документ неверно классифицирован алгоритмом MLA в ответ на поисковый запрос; и
- если определено, что документ был классифицирован неверно, формирование сервером на основе этого документа обучающего объекта, включая присвоение документу метки в виде указания на неверную классификацию, и повторное обучение сервером алгоритма MLA на основе этого обучающего объекта.
2. Способ по п. 1, отличающийся тем, что сервер связан с базой данных, а способ перед обращением к ресурсу дополнительно включает в себя:
- получение сервером из базы данных множества ранее отправленных серверу множеством пользователей поисковых запросов, каждый из которых связан с набором документов, представленных в качестве результатов поиска пользователям из множества пользователей;
- получение сервером из базы данных для каждого поискового запроса из множества поисковых запросов информации о трафике, включая количество отправок; и
- определение сервером поискового запроса на основе количества отправок.
3. Способ по п. 2, отличающийся тем, что информация о трафике дополнительно содержит источник трафика, а определение поискового запроса дополнительно включает в себя определение ресурса на основе источника трафика.
4. Способ по п. 3, отличающийся тем, что определение ресурса дополнительно основано на том, что ресурс соответствует источнику из заранее заданного списка источников трафика.
5. Способ по п. 4, отличающийся тем, что определение поискового запроса на основе количества отправок дополнительно основано на превышении количеством отправок заранее заданного порога в течение заранее заданного периода времени.
6. Способ по п. 1, отличающийся тем, что сервер связан с базой данных, а способ перед обращением к ресурсу дополнительно включает в себя:
- получение сервером из базы данных множества ранее отправленных серверу множеством пользователей поисковых запросов, каждый из которых связан с набором документов, представленных в качестве результатов поиска пользователям из множества пользователей;
- получение сервером из базы данных для каждого поискового запроса из множества поисковых запросов информации о трафике, включая количество отправок и источник трафика; и
- определение сервером ресурса, связанного с по меньшей мере одним запросом, на основе количества отправок и источника трафика.
7. Способ по п. 6, отличающийся тем, что первый набор признаков содержит указание на поисковый запрос и указание на по меньшей мере один документ из набора документов, представленных в качестве результатов поиска для этого поискового запроса.
8. Способ по п. 7, отличающийся тем, что первый набор признаков дополнительно содержит заранее заданный список слов.
9. Способ по п. 8, отличающийся тем, что документ представляет собой изображение, а набор признаков документа представляет собой набор признаков изображения.
10. Способ по п. 1, отличающийся тем, что неверная классификация документа указывает на то, что результат поиска не отвечает условиям поискового запроса.
11. Способ по п. 1, отличающийся тем, что неверная классификация документа указывает на то, что результат поиска не подходит для поискового запроса.
12. Способ по п. 1, отличающийся тем, что неверная классификация документа указывает на то, что результат поиска не соответствует режиму работы веб-браузера, используемого пользователем, отправившим поисковый запрос.
13. Способ по п. 1, отличающийся тем, что алгоритм MLА представляет собой бинарный классификатор.
14. Способ по п. 1, отличающийся тем, что ресурс представляет собой социальную сеть.
15. Сервер для повторного обучения алгоритма MLА, обученного классифицировать документы на основе их признаков, который связан с сетью связи и содержит процессор и машиночитаемый физический носитель информации, содержащий команды, при этом процессор способен при выполнении команд:
- обращаться через сеть связи к ресурсу, содержащему множество элементов контента, каждый из которых был отправлен этому ресурсу по меньшей мере одним пользователем;
- идентифицировать на основе первого набора признаков по меньшей мере один элемент контента из множества элементов контента, связанных с документом, представленным сервером поисковой системы в качестве результата поиска в ответ на поисковый запрос;
- анализировать на основе набора признаков документа по меньшей мере один элемент контента из множества элементов контента с целью определения того, был ли этот документ неверно классифицирован алгоритмом MLA в ответ на поисковый запрос; и
- если определено, что документ был классифицирован неверно, формировать на основе этого документа обучающий объект, включая присвоение документу метки в виде указания на неверную классификацию, и повторно обучать алгоритм MLA на основе этого обучающего объекта.
16. Сервер по п. 15, отличающийся тем, что сервер связан с базой данных, а процессор дополнительно способен перед обращением к ресурсу:
- получать из базы данных множество ранее отправленных серверу множеством пользователей поисковых запросов, каждый из которых связан с набором документов, представленных в качестве результатов поиска пользователям из множества пользователей;
- получать из базы данных для каждого поискового запроса из множества поисковых запросов информацию о трафике, включая количество отправок; и
- определять поисковый запрос на основе количества отправок.
17. Сервер по п. 16, отличающийся тем, что информация о трафике дополнительно содержит источник трафика, а определение поискового запроса дополнительно включает в себя определение ресурса на основе источника трафика.
18. Сервер по п. 17, отличающийся тем, что определение ресурса дополнительно основано на том, что ресурс соответствует источнику из заранее заданного списка источников трафика.
19. Сервер по п. 18, отличающийся тем, что определение поискового запроса на основе количества отправок дополнительно основано на превышении количеством отправок заранее заданного порога в течение заранее заданного периода времени.
20. Сервер по п. 15, отличающийся тем, что сервер связан с базой данных, а процессор дополнительно способен перед обращением к ресурсу:
- получать из базы данных множество ранее отправленных серверу множеством пользователей поисковых запросов, каждый из которых связан с набором документов, представленных в качестве результатов поиска пользователям из множества пользователей;
- получать из базы данных для каждого поискового запроса из множества поисковых запросов информацию о трафике, включая количество отправок и источник трафика; и
- определять ресурс, связанный с по меньшей мере одним запросом, на основе количества отправок и источника трафика.
21. Сервер по п. 20, отличающийся тем, что первый набор признаков содержит указание на поисковый запрос и указание на по меньшей мере один документ из набора документов, представленных в качестве результатов поиска для поискового запроса.
22. Сервер по п. 21 отличающийся тем, что первый набор признаков дополнительно содержит заранее заданный список слов.
23. Сервер по п. 22, отличающийся тем, что документ представляет собой изображение, а набор признаков документа представляет собой набор признаков изображения.
24. Сервер по п. 15, отличающийся тем, что неверная классификация документа указывает на то, что результат поиска не отвечает условиям поискового запроса.
25. Сервер по п. 15, отличающийся тем, что неверная классификация документа указывает на то, что результат поиска не подходит для поискового запроса.
26. Сервер по п. 15, отличающийся тем, что неверная классификация документа указывает на то, что результат поиска не соответствует режиму работы веб-браузера, используемого пользователем, отправившим поисковый запрос.
27. Сервер по п. 15, отличающийся тем, что алгоритм MLA представляет собой бинарный классификатор.
28. Сервер по п. 15, отличающийся тем, что ресурс представляет собой социальную сеть.
| RU 2016138553 A, 30.03.2018 | |||
| СПОСОБ И СИСТЕМА ВЫБОРА ПОТЕНЦИАЛЬНО ОШИБОЧНО РАНЖИРОВАННЫХ ДОКУМЕНТОВ С ПОМОЩЬЮ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2664481C1 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ МНОЖЕСТВА ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2017 |
|
RU2677380C2 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 10063434 B1, 28.08.2018 | |||
| US 9324022 B2, 26.04.2016 | |||
| Токарный резец | 1924 |
|
SU2016A1 |

