ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее техническое решение относится к области вычислительной техники, а именно к способу и системе классификации и фильтрации запрещенного контента в сети.
УРОВЕНЬ ТЕХНИКИ
[0002] Правительства многих стран в настоящее время вводят законодательное регулирование содержания запрещенного веб контента в сети. К такому контенту могут относиться любое наполнение веб ресурса, запрещенное государством для просмотра и ознакомления, например, текст, изображения, видео и др.
[0003] Контроль запрещенного контента является сложной задачей, так как скорость прироста, обновления и распространения информации в сети слишком велика.
[0004] Современные подходы к решению этой проблемы основаны на автоматической фильтрации запрещенного контента на основе баз данных, содержащих списки URL веб-сайтов, распознавании запрещенных ключевых слов, а также иных видов классификации.
[0005] Однако, описанные выше способы не дают надлежащего качества, так как списки составляются вручную и не дают возможности учитывать вновь появившиеся ресурсы, к тому же ключевые слова не способны полностью отражать сущность контента и дают достаточно грубую оценку, а также стоит учитывать, что возможна ложная блокировка ресурсов из-за использования слов в "переносном" значении.
[0006] Таким образом, одной из актуальных задач на данный момент является усовершенствование известных способов фильтрации запрещенного контента в сети.
[0007] Из уровня техники известно решение US 2019/0052694 A1 (DIRK et al., Automatic Genre Classification Determination of Web Content to which the Web Content Belongs Together with a Corresponding Genre Probability, опубл. 14.02.2019. кл. G06N 99/00), в котором описан способ, в котором реализован процесс обучения и процесс классификации для автоматического определения жанра контента сети, причем: процесс обучения для каждого из, по меньшей мере, одного типа жанра содержит этапы: извлечения набора типов признаков, включающих в себя жанровые и не жанровые признаки, из собранных учебных материалов первого типа и учебных материалов второго типа соответственно, причем жанровые признаки и не-жанровые признаки представлены токенами, состоящими из символьных строк фиксированной длины, извлеченных из строк содержимого первого и второго типов учебных материалов; и сохранения каждого токена в базе данных соответствующих признаков вместе с первым целочисленным количеством, представляющим частоту появления токена в первом типе учебного материала, и вторым целым числом, представляющим частоту появления токена во втором типе учебного материала; и процесс классификации, в котором процесс классификации содержит этапы: предоставления веб-контента; извлечение токенов фиксированной длины для каждого типа объектов из набора типов объектов из различных текстовых и структурных элементов веб-содержимого; вычисляют для каждого типа признаков из набора типов признаков соответствующую вероятность признака того, что веб-контент принадлежит соответствующему конкретному обученному жанру веб-контента, путем объединения вероятностей характеристик жанра и не-жанровых характеристик; объединение вероятностей признаков с общей вероятностью жанра, что веб-контент принадлежит к определенному обученному жанру веб-контента; и вывода результата классификации жанра, содержащего, по меньшей мере, один конкретный обученный жанр веб-контента, к которому относится веб-контент, с соответствующей вероятностью жанра.
[0008] Также из уровня техники известно решение US 2014/0358929 A1 (BAILEY et al., METHODS, APPARATUS AND SOFTWARE FOR ANALYZING THE CONTENT, опубликовано 04.12.2014, кл. G06F 17/30), в котором описана возможность классификации наборов входящих сообщений, полученных от кластеризатора, применяя к ним набор правил классификации, чтобы определить темы, к которым относятся различные текстовые сообщения. Так, в данном документе правила в основном имеют следующий формат: «Если А найден в наборе сообщений, то набор сообщений относится к теме В с вероятностью (или релевантностью) Z%». Полученная коллекция организована в форме «классов» и «экземпляров» данных о классах и таблицах перекрестных ссылок, которые связывают классы друг с другом.
[0009] Кроме того, из уровня техники также известно решение US 2015/0156183 A1 (BEYER et al., SYSTEM AND METHOD FOR FILTERING NETWORK COMMUNICATIONS, опубл. 04.01.2015, кл. H04L 29/06) в котором описано обнаружение типа контента, а именно при обнаружении типа содержимого фильтр проверяет тип содержимого. Так, определение типа контента может использоваться для правильной маршрутизации контента, входящего или исходящего из / в WEB, к конкретным цепочкам фильтрации в соответствии с категорией обрабатываемого материала. Поскольку они являются несколькими способами установки типа контента, фильтр сначала проверяет заголовок content type. Если он не установлен, фильтр просматривает значение mime-type в заголовке. Если фильтр все еще не знает, каков тип содержимого файла, обрабатываемого в данный момент, он может посмотреть расширение файла. После этого, если все проверки не пройдены, фильтр обрабатывает его как стандартную страницу html / text. Далее возможно обнаружение изображения / анализ файла изображения: для этого используют модуль IMDetect, который фильтрует насильственные изображения и порнографические изображения на основе подписи изображения, которая представляет собой сборник характеристик изображения, который позволяет сопоставлять изображения в различных масштабах и разрешениях (сторонний модуль). Если изображение найдено - оно блокируется и заменяется блокирующим изображением. Содержимое также может быть проверено внутри на наличие вирусов.
[0010] При рассмотрении различных методов фильтрации контента в том числе, рассмотренных ранее, выявлено, что они основаны на наборах терминах или подписях, характеризующих набор данных в классе. Как уже было описано выше такой подход сталкивается с проблемой неоднозначности терминов (синонимия, полисемия, омонимия), затрудняющих сопоставление терминов в процессе содержательной фильтрации. Для преодоления подобных семантических проблем, в уровне техники, например, предложены методы, основанные на лингвистической онтологии, в качестве которой используется WordNet. Основным недостатком такого подхода является трудоемкость построения лингвистической онтологии для разных языковых групп и предметных областей.
[0011] Настоящие изобретение создано для решения части выявленных при анализе выше проблем предшествующего уровня техники и создании улучшенного комплексного метода распознавания, классификации и фильтрации запрещенного контента.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0012] Задача предполагаемого изобретения заключается в разработке системы и способа классификации и фильтрации запрещенного контента в сети.
[0013] Техническим результатом заявленной группы изобретений является повышение точности классификации и фильтрации запрещенного контента в сети.
[0014] Данный технический результат достигается за счет предложенного способа классификации и фильтрации контента в сети, выполняющегося на вычислительном устройстве, содержащем по меньшей мере процессор и память, которая при этом содержит инструкции для выполнения:
[0015] подготовительного этапа, на котором:
[0016] формируют подборку HTML документов, причем подборка сформирована таким образом, что каждый из входящих в нее документов может относиться к разным классам контента;
[0017] преобразуют полученные на предыдущем этапе данные из HTML документа в текст;
[0018] формируют матрицу токенов для обучения ансамбля классификаторов;
[0019] на основе полученной матрицы токенов создают ансамбль классификаторов, содержащий по меньшей мере четыре классификатора,
[0020] причем для каждого классификатора заранее определен решающий приоритет;
рабочий этап, на котором:
[0021] получают URL и скачивают относящийся к нему HTML документ;
[0022] переводят HTML документ в текст;
[0023] формируют вектор токенов для ансамбля классификаторов;
[0024] запускают ансамбль классификаторов, обученный на подготовительном этапе;
[0025] выводят результат анализа, содержащий результат классификации контента, содержащегося в принятом документе;
[0026] производят фильтрацию контента на основе полученного класса.
[0027] Дополнительно в одном частном варианте заявленного изобретения при формировании матрицы токенов извлекают информацию из по меньшей мере четырех интересующих полей полученного HTML документа.
[0028] Дополнительно в одном частном варианте заявленного изобретения к извлекаемым из HTML документа полям по меньшей мере относятся: 'text', 'title', 'meta', 'url'.
[0029] Дополнительно в одном частном варианте заявленного изобретения при формировании матрицы токенов создают по меньшей мере четыре параллельные цепочки обработки документов, причем обработка включает по меньшей мере процесс токенизации и нахождения чистых токенов, причем под чистыми токенами понимаются те, которые характерны для определенного класса контента.
[0030] Дополнительно в одном частном варианте заявленного изобретения процесс токенизации включает в себя по меньшей мере одно из: исключение пунктуации из текста документа; преобразование всех букв в нижний регистр; преобразование слов к первоначальной форме; символьную и статистическую обработку естественного языка; морфологический анализ.
[0031] Дополнительно в одном частном варианте заявленного изобретения в конце каждой цепочки обработки создают словарь, состоящий из чистых токенов.
[0032] Дополнительно в одном частном варианте заявленного изобретения получившиеся цепочки словарей чистых токенов объединяют в общий словарь.
[0033] Дополнительно в одном частном варианте заявленного изобретения вычисляют значимые признаки, содержащиеся в общем словаре чистых токенов и получают матрицу для обучения, причем каждая строка матрицы - id документа в обучающей выборке, столбец матрицы - чистый токен, найденный в данном наборе документов, в ячейке матрицы - вес токена.
[0034] Дополнительно в одном частном варианте заявленного изобретения вес токена отражает значимость токена для данного документа, являющегося частью коллекции документов.
[0035] Дополнительно в одном частном варианте заявленного изобретения при составлении матрицы токенов учитывается параметр стоп-слов (stop words), содержащий массив слов, которые не желательно учитывать при классификации.
[0036] Дополнительно в одном частном варианте заявленного изобретения HTML документ может быть отнесен к по меньшей мере одному из классов: бизнес и промышленность (business and industry), карьера и образование (career and education), искусство и развлечение (arts and entertainment), наука (science), компьютеры и электроника (computer and electronics), шоппинг (shopping), рекомендации (reference), люди и общество (people and society), интернет и телекоммуникации (internet and telecom), спорт (sports), финансы (finance), контент для взрослых (adult), авто и другие транспортные средства (autos and vehicles), книги и литература (books and literature), здоровье (health), игры (games), закон и право (law and government), путешествия (travel), новости (news and media), дом и сад (home and garden), еда и напитки (food and drink), азартные игры (gambling), отдых и развлечения (recreation and hobbies), красота и фитнесс (beauty and fitness), животные (pets and animals).
[0037] Данный технический результат также достигается за счет предложенной системы классификации и фильтрации контента в сети по меньшей мере содержит:
[0038] модуль ввода, выполненный с возможностью принимать данные URL для классификации и фильтрации и скачивать относящийся к нему HTML документ;
[0039] вычислительное устройство, выполненное с возможностью осуществления способа классификации и фильтрации контента в сети
[0040] модуль вывода.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0041] Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
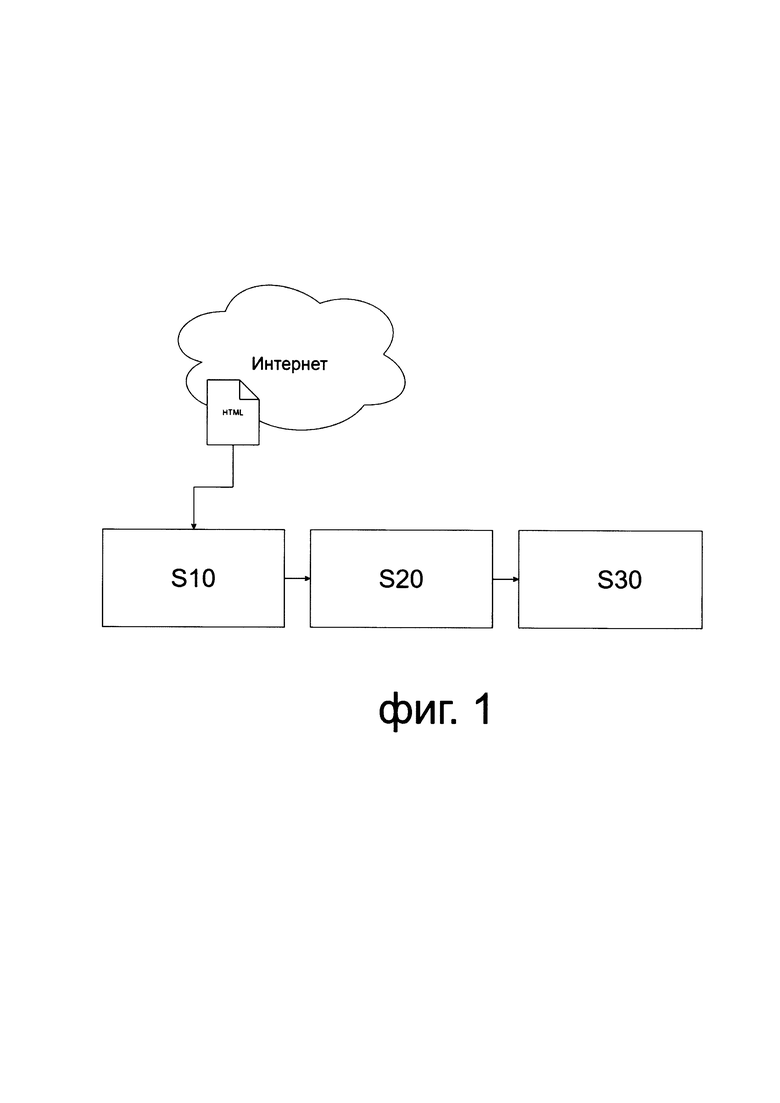
[0042] Фиг. 1 иллюстрирует примерный вариант реализации системы классификации и фильтрации контента в сети.
[0043] Фиг. 2 иллюстрирует примерную блок-схему последовательности операций способа классификации и фильтрации контента в сети.
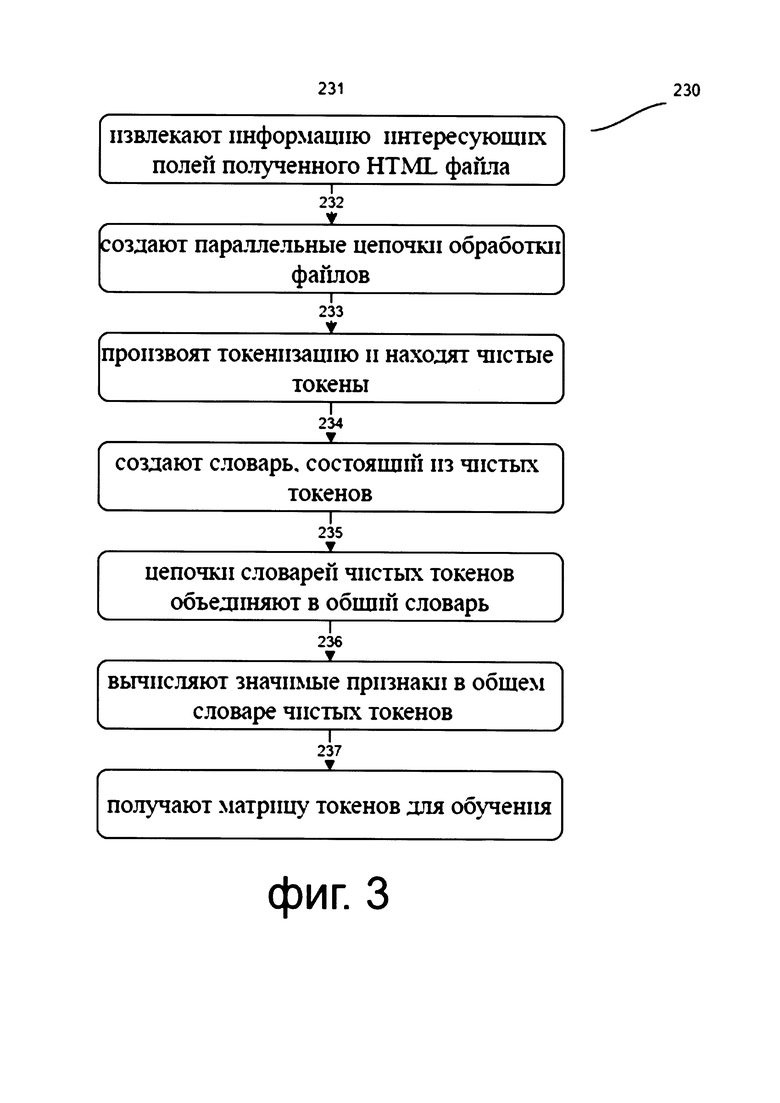
[0044] Фиг. 3 иллюстрирует примерную блок-схему последовательности этапа формирования матрицы токенов для обучения.
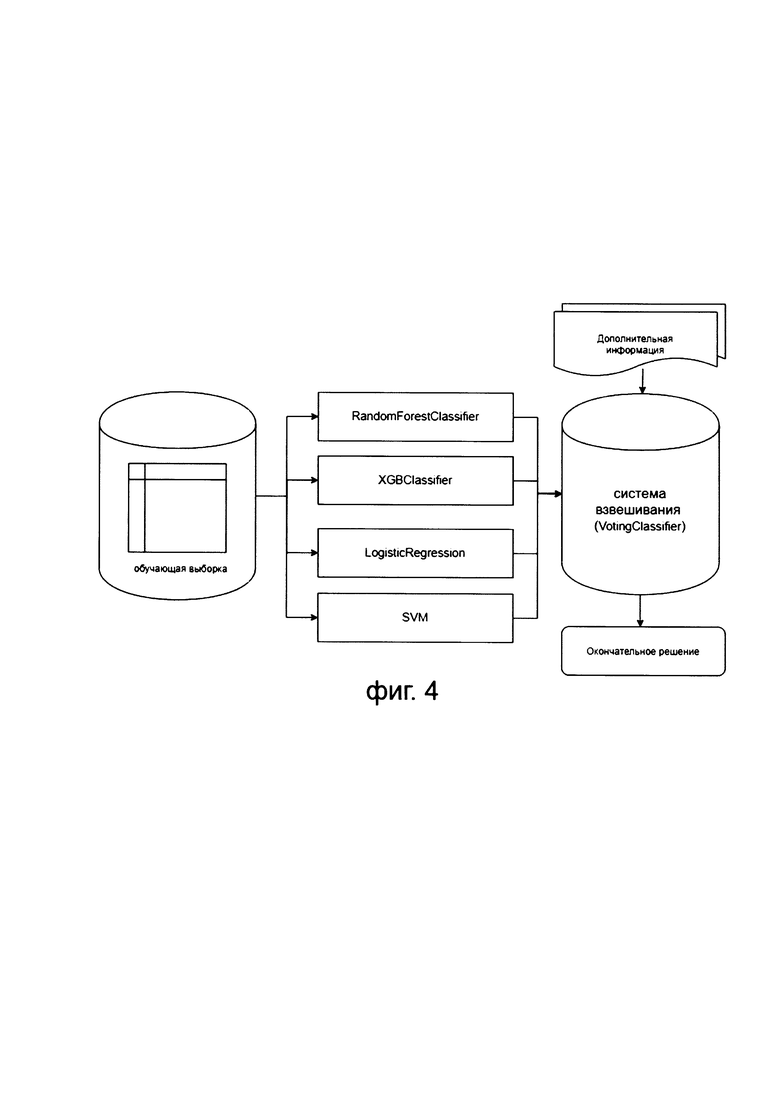
[0045] Фиг. 4 иллюстрирует предпочтительный вариант реализации ансамбля классификаторов
[0046] Фиг. 5 иллюстрирует выбор категорий, которые предположительно могут содержать нежелательный контент
[0047] Фиг. 6 иллюстрирует пример общей схемы вычислительного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0048] Следующее далее подробное описание представлено, чтобы дать возможность любому специалисту в данной области для осуществления и использования настоящего изобретения. Для целей описания, конкретные детали приводятся, чтобы дать глубокое понимание настоящего изобретения. Однако специалисту в данной области будет ясно, что эти конкретные детали не являются необходимыми для осуществления настоящего изобретения. Описания конкретных применений приводятся только как репрезентативные примеры. Различные модификации предпочтительных вариантов осуществления будут очевидны специалистам в данной области, и общие принципы, определенные в настоящем документе, могут применяться к другим вариантам осуществления и применениям без отклонения от рамок настоящего изобретения.
[0049] Описанное в данном документе решение, как предполагается, не является ограниченным указанными вариантами осуществления, но должно соответствовать самым широким возможным рамкам, совместимым с принципами и признаками, описанными в настоящем документе.
[0050] Настоящее изобретение направлено на обеспечение компьютерно-реализуемого способа и системы классификации и фильтрации контента в сети.
[0051] На фиг. 1 представлен один из возможных вариантов осуществления системы классификации и фильтрации контента в сети (100).
[0052] Так, модуль сбора и хранения данных (S10) может принимать URL адрес интересующего веб ресурса в сети Интернет и скачивать HTML документ, находящиеся по данному адресу.
[0053] Дополнительно описанный модуль S10 может сохранять полученный HTML документ, соответствующий введенному в систему URL адресу, во внутренней базе данных системы (100).
[0054] Далее принятая и сохраненная посредством модуля S10 информация передается в вычислительное устройство, выполненное с возможностью осуществления способа классификации и фильтрации контента в сети S20, где обрабатывается и передается в модуль вывода S30.
[0055] Стоит отметить, что модуль вывода S30 выполнен с возможностью вывода аналитического отчета по полученному модулем S10 URL адресу.
[0056] Как представлено на фиг. 2 способ классификации и фильтрации контента в сети выполняется на вычислительном устройстве, которое имеет по меньшей мере процессор и память, которая содержит инструкции, а также состоит из подготовительного этапа 200 и рабочего этапа 250.
[0057] Соответственно, на этапе 210 формируют подборку HTML документов, причем подборка сформирована таким образом, что каждый из входящих в нее документов может относиться к разным классам контента.
[0058] Причем сформированная подборка может быть отнесена к одному из двадцати пяти заранее определенных классов, к которым по меньшей мере относятся: бизнес и промышленность (business and industry), карьера и образование (career and education), искусство и развлечение (arts and entertainment), наука (science), компьютеры и электроника (computer and electronics), шоппинг (shopping), рекомендации (reference), люди и общество (people and society), интернет и телекоммуникации (internet and telecom), спорт (sports), финансы (finance), контент для взрослых (adult), авто и другие транспортные средства (autos and vehicles), книги и литература (books and literature), здоровье (health), игры (games), закон и право (law and government), путешествия (travel), новости (news and media), дом и сад (home and garden), еда и напитки (food and drink), азартные игры (gambling), отдых и развлечения (recreation and hobbies), красота и фитнесс (beauty and fitness), животные (pets and animals).
[0059] Кроме того, стоит отметить, что данная подборка документов может быть сформирована заранее и сохранена во внутренней или внешней базе данных системы или может получена из внешних баз данных.
[0060] Кроме того стоит отметить, что дополнительно данная подборка может быть сформирована посредством использования сканера веб ресурсов, который сканирует совокупность HTML страниц в сети, и который способен извлекать необходимые признаки из исследуемой страницы.
[0061] После выполнения этапа 210 способ переходит к этапу 220, на котором посредством использования метода <html2text> преобразуют полученные на предыдущем этапе данные из каждого HTML документа в текст.
[0062] После выполнения преобразований, выполненных на 210-220 способ, переходит к этапу формирования матрицы токенов для обучения ансамбля классификаторов 230, который более подробно раскрыт на фиг. 3.
[0063] Более подробно на этапе 231 извлекают из каждого документа подборки, переведенного в текстовый вид, информацию по меньшей мере по четырем интересующим полям, а именно: 'text' - вся информация из тела html, 'title' - информация взятая из полей <title>…</title>, 'meta' - информация из полей <meta…>, 'url' - url страницы.
[0064] Далее способ переходит к этапу 232, на котором создают по меньшей мере четыре параллельные цепочки обработки информации, извлеченной на предыдущем этапе из HTML-документов.
[0065] Например в первую цепочку обработки собирают все поля <text>, извлеченные из сформированной на этапе 210 подборки HTML документов, во вторую все поля <title>, в третью - <meta>, в четвертую - <url>.
[0066] Стоит отметить, что дальнейшая обработка по меньшей мере четырех цепочек обработки информации может выполняться параллельно, однако, обработка каждой цепочки выполняется по собственной методике.
[0067] Кроме того, необходимо отметить, что обработка включает по меньшей мере процесс токенизации и нахождения чистых токенов (этап 233), причем под чистыми токенами понимаются те, которые характерны для определенного класса контента.
[0068] Более подробно рассмотрим процесс токенизации (Tokenizer). При выполнении указанного процесса происходит параллельная обработка текста, собранного в каждую из цепочек обработки.
[0069] Таким образом, из обрабатываемого текста по меньшей мере исключается вся пунктуация; все буквы переводятся в нижний регистр; слова преобразуются к первоначальной форме; происходит символьная и статистическая обработка естественного языка; и морфологический анализ.
[0070] Например, при приведении слов к первоначальной форме русскоязычные слова "нем", "него", "его" заменяются словом "он", англоязычные слова "useless", "using", "useful", "used" заменяются словом "use".
[0071] Стоит отметить, что, например, для токенизации текстов, а именно для символьной и статистической обработки естественного языка на различных языках кроме русского (приоритетно на английском, испанском, немецком, французском, итальянском и арабском), используется пакет библиотек (Natural Language Toolkit). Применительно к русскому тексту используется, например, библиотека <pymorphy> для морфологического анализа, которая хорошо работает с русскими словами (например, "люди -> человек", или "гулял -> гулять").
[0072] Также на этапе 233 находят чистые токены, причем под чистыми токенами понимаются те, которые характерны для определенного класса контента.
[0073] Кроме того, стоит отметить, что если процентное содержание слова в документах определенного класса (одного из 25, описанных ранее) больше 30% и при этом в других классах оно содержится менее, чем в 10% документах, то слово принято считать "чистым" токеном.
[0074] Так, например, для класса контента "азартные игры" характерными будут являться чистые токены "покер", "рулетка" и др.
[0075] Далее способ переходит к этапу 234, на котором создают упорядоченный вектор вида <токен>: <количество вхождений в документе>, который является по сути словарем, состоящим из чистых токенов, где каждый элемент определяет количество вхождений токенов указанного типа.
[0076] Получившиеся четыре вектора-словаря, объединяют в один общий словарь токенов (этап 235). Стоит отметить, что словарь представляет собой вектор, в котором в качестве индекса (в словаре будет называться ключ) могут выступать не только числа, но и любые другие типы данных (например, строки или другие вектора, прочие структуры данных).
[0077] Так способ переходит на этап 236, на котором вычисляют значимые признаки в общем словаре токенов.
[0078] Более подробно, применяется векторайзер данных (<TfldTransformer>) на основе алгоритма tf-idf (term frequency-inverse document frequency), показывающего <частотность термина в документе> умноженную на <инверсию частоты, с которой термин встречается в документах коллекции>.
[0079] Применение указанного алгоритма помогает оценить важность термина для какого-либо документа относительно всех остальных документов. Так, если токен встречается в каком-либо документе из подборки часто, при этом встречаясь редко во всех остальных документах - это слово имеет большую значимость для того самого документа.
[0080] Так, значение TF представляет собой частотность токена, которая измеряет, насколько часто токен встречается в документе. То есть,
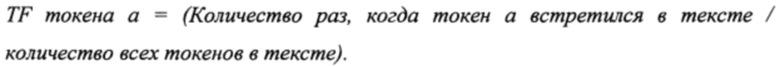
[0081] Так, значение IDF - это инверсия частоты, с которой некоторое слово встречается в документах коллекции. Важность токена она не отражает, причем учет IDF уменьшает вес широко употребительных слов.

[0082] Далее вычисляется TF-IDF токена а=(TF токена а) * (IDF токена а), что означает, что проверяется каждый текст в корпусе текстов, и считается для него TF всех слов, находящихся в нем. Затем для каждого слова считается IDF и умножается на уже посчитанный TF. Полученный словарь (dictionary) добавляется в список, чтобы сохранить такой же порядок текстов, какой был на входе. И возвращается этот список словарей с посчитанными TF-IDF для каждого токена.
[0083] Следовательно векторайзер данных (<TfldTransformer>) преобразует коллекцию необработанных документов в матрицу параметров TF-IDF (этап 237), в которой вычисленные значимые признаки содержатся в общем словаре чистых токенов матрицы для обучения, причем каждая строка матрицы - <id документа в обучающей выборке>, столбец матрицы - <чистый токен, найденный в данном наборе документов>, в ячейке матрицы - <вес токена>, причем под весом токена понимают значимость токена для данного документа.
[0084] Стоит отметить, что для поля 'text' учитываются только слова, для полей 'title' и 'meta' учитываются как просто слова, так и двуграммы слов, для поля 'url' в учет берутся 1,2-граммы символов в URL адресе.
[0085] Кроме того, необходимо дополнительно отметить, что векторайзер данных (<TfldTransformer>) дополнительно учитывает параметр стоп слов (stop_words), который представляет собой массив слов, которые не желательно учитывать при классификации, т.к. они могут находиться во всех исследуемых документах и поэтому "загрязняют" общую картину распределения в документе.
[0086] Например, стоит исключить все междометия, предлоги, союзы и частицы, а также наиболее часто употребляющиеся слова в повседневной речи.
[0087] Способ переходит на этап 240, на котором на основе полученной матрицы токенов создают ансамбль классификаторов, содержащий по меньшей мере четыре классификатора, где для каждого классификатора заранее определен решающий приоритет.
[0088] Более подробно рассмотрим создание ансамбля классификаторов.
[0089] Так, имея готовые матрицы токенов, а по-другому параметров TF-IDF, получившиеся в результате прохождения каждым набором документов через вышеописанные этапы преобразования данных - переходим к классификации.
[0090] Так, на фиг. 4 показан иллюстративный вариант полученного ансамбля классификаторов, где под обучающей выборкой понимаются имеющиеся матрицы токенов для обучения, в ансамбле присутствуют следующие классификаторы: RandomForestClassifier, XGBClassifier, LogisticRegression, SVM; для вынесения общего вердикта используется система взвешивания (VotingClassifier библиотеки <scikit-learn> с параметром voting='soft'), а дополнительной информацией является решающий приоритет, определенный для каждого из классификаторов.
[0091] Описанная выше система взвешивания (VotingClassifier) выносит вердикт на основе результата вероятностной классификации (метод <predict_proba>) ансамбля классификаторов. То есть, система взвешивания (VotingClassifier) усредняет значение от каждого классификатора, при этом перед усреднением происходит перемножение вынесенных решений вероятностей (<probability>) на вес соответствующего классификатора.
[0092] Решающий приоритет классификатором определяют следующим образом. Так как классы являются несбалансированными, весом каждого классификатора принято считать F-меру, как наиболее качественного кандидата для оценки классификатора при несбалансированной обучающей выборке. Причем F-мера получается на этапе обучения классификатора при прогоне тестовых данных. Для каждого из классов рассчитывается полнота и точность. Затем результирующая точность классификатора рассчитывается как среднее арифметическое его точности по всем классам. То же самое с полнотой. Затем средние точности и полноты подставляются в формулу F-меры.
[0093] Этап создания и обучения ансамбля классификаторов завершает подготовительный этап 200 и способ переходит к рабочему этапу 250.
[0094] Так, на рабочем этапе получают интересующий URL адрес и скачивают относящийся к нему HTML документ (этап 260), при этом сохраняя данный документ во внутренней базе данных системы.
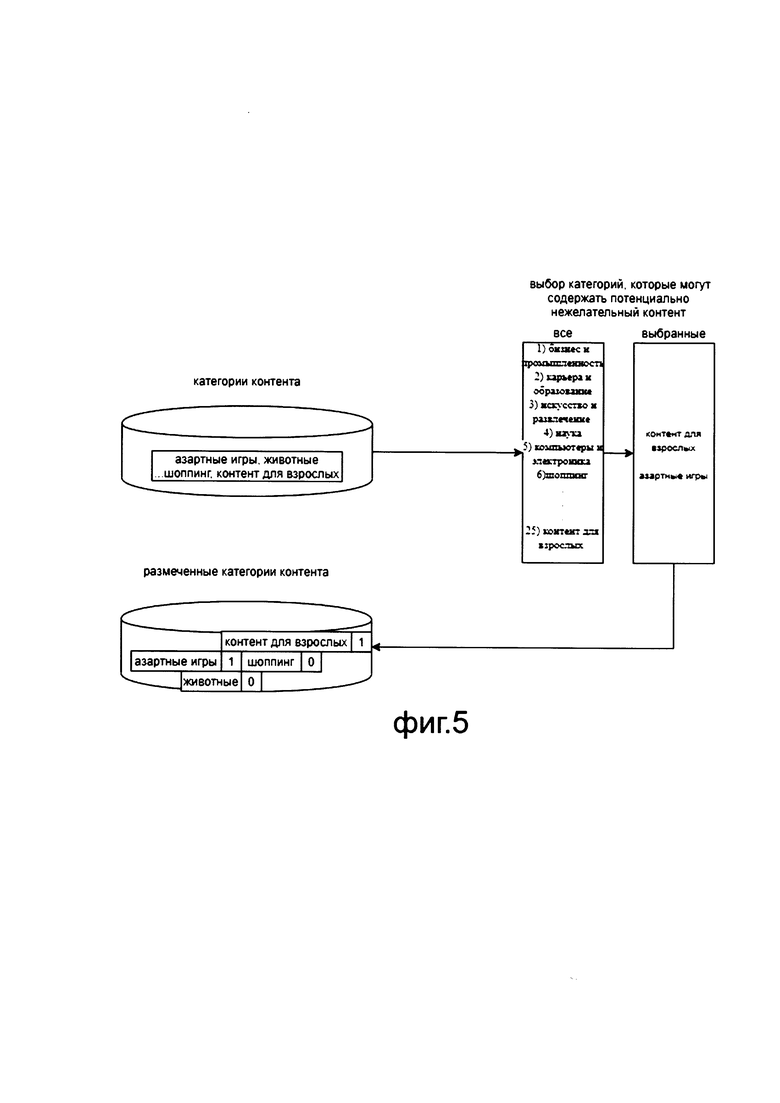
[0095] Далее на этапе 270 применяют метод <html2text> и преобразуют полученный HTML документ в текст.
[0096] При этом на этапе 280 формируют вектор чистых токенов обрабатываемого HTML документа для ансамбля классификаторов и запускают ансамбль классификаторов (этап 290), обученный на подготовительном этапе (этап 240).
[0097] На завершающем этапе выполнения способа 300 выводят результат анализа, содержащий результат классификации контента, содержащегося в принятом документе и производят фильтрацию контента на основе полученного класса.
[0098] Стоит отметить, что фильтрация контента обеспечивается на основе отнесения контента к одному из 25 классов, заложенных изначально.
[0099] Так, фильтрация происходит на основе отнесения контента HTML документа, относящегося к полученному URL адресу, к одному из классов, содержащих потенциально нежелательный контент и учета значения вероятностей вынесенных решений (<probability>), которые превышают заранее заданный порог.
[0100] Так, как показано на фиг. 5, к классам, которые могут содержать потенциально нежелательный контент, например, могут относятся, контент для взрослых (adult), азартные игры (gambling).
[0101] Стоит отметить, что классы, которые могут содержать потенциально нежелательный контент могут изменяться в зависимости от желаний пользователей или настраиваться экспертом, работающим с системой (100).
[0102] Дополнительно фильтрация происходит при учете значения вероятностей вынесенных решений (<probability>), которые превышают заранее заданный порог. Причем указанный порог определяется на основе тестовых выборок заранее и может меняться в зависимости от класса контента.
[0103] Следовательно, например, если способ 200 определил, контент как принадлежащий к классу <контент для взрослых (adult)> и вероятность вынесенного решения (<probability>) превышает заранее заданный порог, ток контенту применяется фильтрация.
[0104] Причем под фильтрацией контента может пониматься по меньшей мере одно из перечисленного:
блокировка введенного URL адреса;
блокировка контента, принадлежащего к введенному URL адресу; применение методов персонализации и др.
[0105] Кроме того, в дополнительных вариантах реализации контента пользователю может выводиться подробный аналитический отчет о выполненных действиях.
[0106] На Фиг. 6 далее будет представлена общая схема вычислительного устройства (N600), обеспечивающего обработку данных, необходимую для реализации заявленного решения.
[0107] В общем случае устройство (N600) содержит такие компоненты, как: один или более процессоров (N601), по меньшей мере одну память (N602), средство хранения данных (N603), интерфейсы ввода/вывода (N604), средство В/В (N605), средства сетевого взаимодействия (N606).
[0108] Процессор (N601) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (N600) или функциональности одного или более его компонентов. Процессор (N601) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (N0602).
[0109] Память (N0602), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
[0110] Средство хранения данных (N603) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (N603) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых документов с наборами данных пользователей, базы данных, содержащих записи измеренных для каждого пользователя временных интервалов, идентификаторов пользователей и т.п.
[0111] Интерфейсы (N604) представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
[0112] Выбор интерфейсов (N604) зависит от конкретного исполнения устройства (N600), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
[0113] В качестве средств В/В данных (N605) в любом воплощении системы, реализующей описываемый способ, должна использоваться клавиатура. Аппаратное исполнение клавиатуры может быть любым известным: это может быть, как встроенная клавиатура, используемая на ноутбуке или нетбуке, так и обособленное устройство, подключенное к настольному компьютеру, серверу или иному компьютерному устройству. Подключение при этом может быть, как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2 или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
[0114] Средства сетевого взаимодействия (N606) выбираются из устройства, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств (N05505) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
[0115] Компоненты устройства (N600) сопряжены посредством общей шины передачи данных (N610).
[0116] В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации | 2020 |
|
RU2750852C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ И ОЦЕНКИ ЕЕ ПОЛНОТЫ В ЭЛЕКТРОННЫХ ДОКУМЕНТАХ СЕТИ ИНТЕРНЕТ | 2013 |
|
RU2550543C1 |
| СПОСОБ И СИСТЕМА ИЗВЛЕЧЕНИЯ ИМЕНОВАННЫХ СУЩНОСТЕЙ | 2021 |
|
RU2823914C2 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ КОМБИНАЦИИ КЛАССИФИКАТОРОВ, АНАЛИЗИРУЮЩИХ ЛОКАЛЬНЫЕ И НЕЛОКАЛЬНЫЕ ПРИЗНАКИ | 2018 |
|
RU2686000C1 |
| СПОСОБ И СИСТЕМА СТАТИЧЕСКОГО АНАЛИЗА ИСПОЛНЯЕМЫХ ФАЙЛОВ НА ОСНОВЕ ПРЕДИКТИВНЫХ МОДЕЛЕЙ | 2020 |
|
RU2759087C1 |
| Система и способ обнаружения фишинговых веб-страниц | 2024 |
|
RU2836604C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
| СИСТЕМА ОБРАБОТКИ ТЕКСТОВ ДЛЯ ФОРМИРОВАНИЯ ESG-РЕЙТИНГА | 2023 |
|
RU2825081C1 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ИНФОРМАЦИИ, СОСТАВЛЯЮЩЕЙ КОММЕРЧЕСКУЮ ТАЙНУ | 2024 |
|
RU2841161C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ПРОФИЛЯ ПОЛЬЗОВАТЕЛЯ МОБИЛЬНОГО УСТРОЙСТВА НА САМОМ МОБИЛЬНОМ УСТРОЙСТВЕ И СИСТЕМА ДЕМОГРАФИЧЕСКОГО ПРОФИЛИРОВАНИЯ | 2016 |
|
RU2647661C1 |

Изобретение относится к вычислительной технике. Технический результат заключается в повышении точности классификации и фильтрации запрещенного контента в сети. Способ классификации и фильтрации контента в сети, выполняемый на вычислительном устройстве, содержащем по меньшей мере процессор и память, которая при этом содержит инструкции для выполнения подготовительного этапа, на котором формируют подборку HTML документов, причем подборка сформирована таким образом, что каждый из входящих в нее документов может относиться к разным классам контента; преобразуют полученные на предыдущем этапе данные из HTML документа в текст; формируют матрицу токенов для обучения ансамбля классификаторов; на основе полученной матрицы токенов создают ансамбль классификаторов, содержащий по меньшей мере четыре классификатора, причем для каждого классификатора заранее определен решающий приоритет; рабочий этап, на котором получают URL и скачивают относящийся к нему HTML документ; переводят HTML документ в текст; формируют вектор чистых токенов для ансамбля классификаторов; запускают ансамбль классификаторов, обученный на подготовительном этапе; выводят результат анализа, содержащий результат классификации контента, содержащегося в принятом документе; производят фильтрацию контента на основе полученного класса. 2 н. и 10 з.п. ф-лы, 6 ил.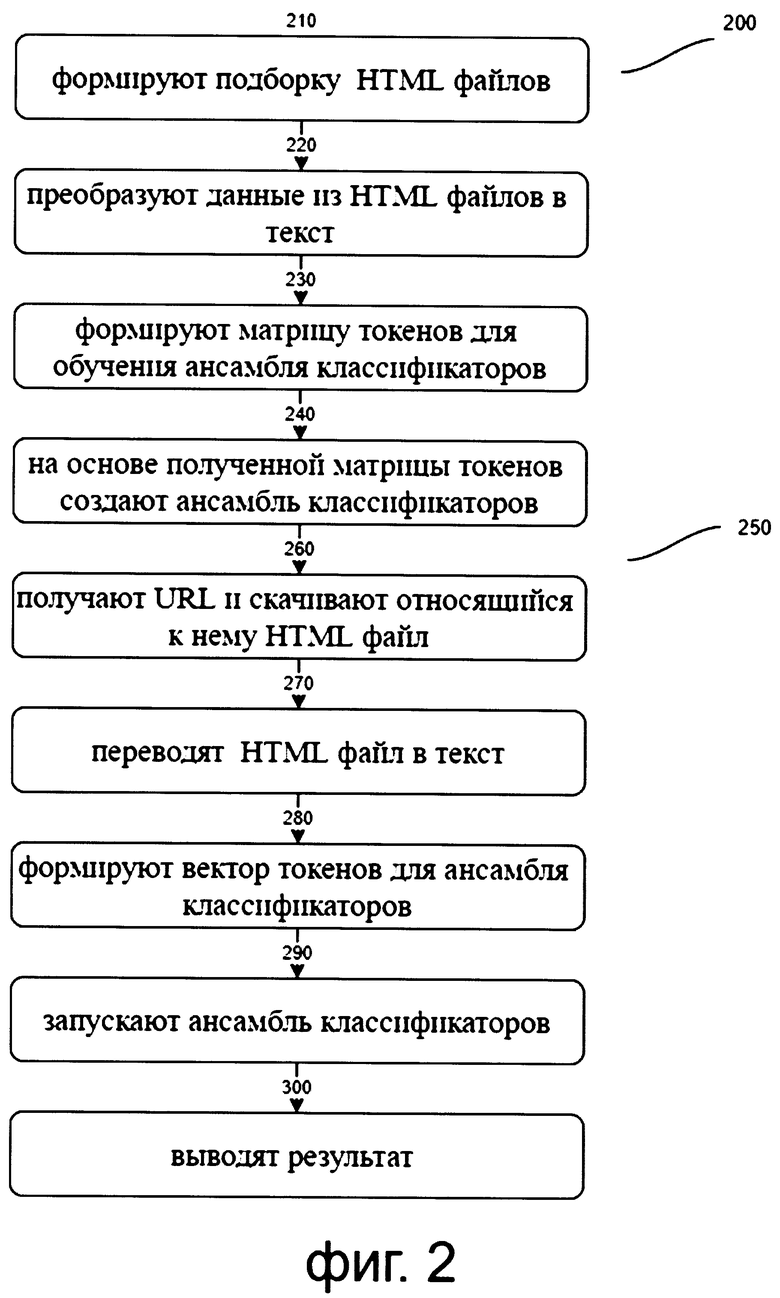
1. Способ классификации и фильтрации контента в сети, выполняемый на вычислительном устройстве, содержащем по меньшей мере процессор и память, которая при этом содержит инструкции для выполнения:
подготовительного этапа, на котором:
формируют подборку HTML документов, причем подборка сформирована таким образом, что каждый из входящих в нее документов может относиться к разным классам контента;
преобразуют полученные на предыдущем этапе данные из HTML документа в текст;
формируют матрицу токенов для обучения ансамбля классификаторов;
на основе полученной матрицы токенов создают ансамбль классификаторов, содержащий по меньшей мере четыре классификатора,
причем для каждого классификатора заранее определен решающий приоритет;
рабочий этап, на котором:
получают URL и скачивают относящийся к нему HTML документ; переводят HTML документ в текст;
формируют вектор чистых токенов для ансамбля классификаторов;
запускают ансамбль классификаторов, обученный на подготовительном этапе;
выводят результат анализа, содержащий результат классификации контента, содержащегося в принятом документе;
производят фильтрацию контента на основе полученного класса.
2. Способ по п. 1, в котором при формировании матрицы токенов извлекают информацию из по меньшей мере четырех интересующих полей полученного HTML документа.
3. Способ по п. 2, в котором к извлекаемым из HTML документа полям по меньшей мере относятся: 'text', 'title', 'meta', 'url'.
4. Способ по п. 1, в котором при формировании матрицы токенов создают по меньшей мере четыре параллельные цепочки обработки документов,
причем обработка включает по меньшей мере процесс токенизации и нахождения чистых токенов, причем под чистыми токенами понимаются те, которые характерны для определенного класса контента.
5. Способ по п. 4, в котором процесс токенизации включает в себя по меньшей мере одно из:
• исключение пунктуации из текста документа;
• преобразование всех букв в нижний регистр;
• преобразование слов к первоначальной форме;
• символьную и статистическую обработку естественного языка;
• морфологический анализ.
6. Способ по пп. 4, 5, в котором в конце каждой цепочки обработки создают словарь, состоящий из чистых токенов.
7. Способ по пп. 4-6, в котором получившиеся цепочки словарей чистых токенов объединяют в общий словарь.
8. Способ по п. 4-7, в котором вычисляют значимые признаки, содержащиеся в общем словаре чистых токенов и получают матрицу для обучения, причем каждая строка матрицы - id документа в обучающей выборке, столбец матрицы - чистый токен, найденный в данном наборе документов, в ячейке матрицы - вес токена.
9. Способ по п. 8, в котором вес токена отражает значимость токена для данного документа, являющегося частью коллекции документов.
10. Способ по п. 1, в котором при составлении матрицы токенов учитывают параметр стоп-слов (stopwords), содержащий массив слов, которые не желательно учитывать при классификации.
11. Способ по п. 1, в котором HTML документ может быть отнесен к по меньшей мере одному из классов: бизнес и промышленность (business and industry), карьера и образование (career and education), искусство и развлечение (arts and entertainment), наука (science), компьютеры и электроника (computer and electronics), шоппинг (shopping), рекомендации (reference), люди и общество (people and society), интернет и телекоммуникации (internet and telecom), спорт (sports), финансы (finance), контент для взрослых (adult), авто и другие транспортные средства (autos and vehicles), книги и литература (books and literature), здоровье (health), игры (games), закон и право (law and government), путешествия (travel), новости (news and media), дом и сад (home and garden), еда и напитки (food and drink), азартные игры (gambling), отдых и развлечения (recreation and hobbies), красота и фитнесс (beauty and fitness), животные (pets and animals).
12. Система классификации и фильтрации контента в сети по меньшей мере содержит:
• модуль сбора и хранения информации, выполненный с возможностью принимать данные URL для классификации и фильтрации и скачивать относящийся к нему HTML документ;
• вычислительное устройство, выполненное с возможностью осуществления способа классификации и фильтрации контента в сети по пп. 1-11;
• модуль вывода.
| Токарный резец | 1924 |
|
SU2016A1 |
| CN 108304509 A, 20.07.2018 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Балансированный высокочастотный контур | 1941 |
|
SU77465A3 |

