Изобретение относится к области информационных технологий и вычислительной техники и может быть использовано для сбора и обработки данных при формировании рейтинга публичных компаний по экологическим, социальным и управленческим критериям (ESG (Environmental, Social and Governance) для повышения в долгосрочной перспективе безопасности жизнедеятельности человека.
ESG-рейтинг – это независимая оценка компании, показывающая качество ее управления вопросами охраны окружающей среды и социальной сферы (включая управление персоналом, работу с клиентами, воздействия на сообщества и др.) Как правило, оцениваются ESG-риски бизнеса (нефинансовые риски), которые могут нанести ущерб развитию организации в долгосрочной перспективе. При этом анализируются сферы, где компания имеет наибольшее воздействие на экономику, экологию и общество (ESG-рейтинги и как они работают. URL: https://www.pwc.com/kz/en/assets/esg-rating/esg-rating.pdf. Дата обращения: 02.10.2023).
Различных ESG-рейтингов уже более пятисот, они отличаются по подходам к оценке и методологиям.
Например, инвестиционная компания Research Affiliates (США) делит агентства на три группы:
1. Провайдеры данных – организации, специализирующиеся на сборе ESG-показателей компаний. Они не имеют как таковой методологии оценки ESG-профиля и работают с общедоступными данными о компаниях (примерами являются Bloomberg, Refinitiv).
2. Комплексный ESG-рейтинг – агентства, имеющие собственную методологию комплексной оценки компании по экологическим, социальным и управленческим показателям. Оценка включает в себя анализ как общедоступных данных, так и данных, напрямую предоставленных компаниями по запросу. Среди агентств, присваивающих такие ESG-рейтинги, можно выделить традиционные рейтинговые агентства, которые ранее работали с кредитными рейтингами (например, S&P Global и Moody’s), и «новые» агентства, которые специализируются именно на устойчивом развитии (MSCI, Sustainalytics, RepRisk, и др.).
3. Специализированные рейтинги - это агентства, которые оценивают лишь отдельные темы устойчивого развития, и не претендуют на оценку комплексного профиля ESG. К примеру, CDP (Carbon Disclosure Project) специализируется на экологических темах, таких как изменение климата, защита лесов и водных ресурсов (Li F., Polychronopoulos A. What a difference an ESG ratings provider makes //Research affiliates. January 2020. URL: https://www.researchaffiliates.com/publications/articles/what-a-difference-an-esg-ratings-provider-makes. Дата обращения: 02.10.2023).
С развитием технологий обработки данных стал прослеживаться тренд на расширение их применения и среди рейтинговых агентств, присваивающих ESG-Рейтинги. Некоторые агентства, стремясь улучшить качество собираемых данных и охват, начинают внедрять технологии искусственного интеллекта (AI), машинного обучения (ML) и др. Одним из таких агентств является RepRisk, который использует AI и ML для анализа данных. MSCI и Sustainalytics также используют AI и другие технологии для обеспечения точности и анализа данных, и для мониторинга новостей и других источников в больших массивах информации. Более того, Moody’s разработал уникальную модель прогнозирования ESG оценки - ESG Score Predictor, который использует машинное обучение и базу данных тысяч компаний для расчета ESG оценки и получения прогнозируемых показателей для любой фирмы, для которой известны размер, местоположение и отрасль (ESG-рейтинги и как они работают. URL: https://www.pwc.com/kz/en/assets/esg-rating/esg-rating.pdf. Дата обращения: 02.10.2023).
Согласно анализу известных ESG-рейтингов, проведенному авторами работы (Berg F., Koelbel J. F., Rigobon R. Aggregate confusion: The divergence of ESG ratings //Review of Finance. – 2022. – Т. 26. – №. 6. – С. 1315-1344.), недостатком применяемых в настоящее время систем формирования ESG-рейтинга компаний состоит в разнице в охвате, в способе измерения и в весах для используемых в системе индикаторов. Разница в способе измерения вносит наибольший вклад в расхождения (около 56%), и представляет ситуацию, когда рейтинговые агентства измеряют один и тот же фактор, используя разные индикаторы (трудовая практика фирмы может оцениваться на основе текучести кадров или количества судебных дел, связанных с трудовыми отношениями). Вторая важная причина расхождений – разница в охвате (38%), связана с тем, что рейтинги основаны на разных наборах факторов, где одно агентство включает определенный индикатор в расчет, а другое – нет. Разница в весах (вклад в различия на уровне 6%) возникает из-за того, что рейтинги по-разному оценивают важность тех или иных ESG факторов (ESG-рейтинги и как они работают. URL: https://www.pwc.com/kz/en/assets/esg-rating/esg-rating.pdf. Дата обращения: 02.10.2023).
Заявляемое изобретение позволяет сформировать рейтинг публичных компаний по экологическим, социальным и управленческим критериям (ESG-рейтинг), избегая приведенных выше недостатков.
Технической задачей заявляемого изобретения является создание унифицированной системы формирования ESG-рейтинга компаний, целью которой является получение нефинансовой информации о наиболее безопасных и устойчивых в долгосрочной перспективе компаниях-партнерах во всех направлениях устойчивого развития: экологической, социальной и корпоративной ответственности.
Технический результат заключается в повышении объективности ESG-рейтинга компаний и, как следствие, в долгосрочной перспективе – повышении уровня безопасности жизнедеятельности человека.
Сущность предлагаемого изобретения состоит в следующем.
Предлагается система обработки текстов для формирования ESG-рейтинга, содержащая по меньшей мере один web-сервер, модуль хранения данных, вычислительный модуль, терминал пользователя, шину данных, при этом web-сервер является источником данных, при этом терминал пользователя имеет выход в глобальную сеть Интернет и соединяется через сеть Интернет с входом-выходом по меньшей мере одного web-сервера, при этом терминал пользователя соединен через шину данных с входом- выходом модуля хранения данных и вычислительным модулем, при этом модуль хранения данных соединен с шиной данных и выполнен с возможностью приема сигналов управления с терминала пользователя, приема и отправки потока данных через шину данных на терминал пользователя и на вычислительный модуль, при этом вычислительный модуль соединен с шиной данных и выполнен с возможностью приема сигналов управления с терминала пользователя, приема и отправки потока данных через шину данных на терминал пользователя и на модуль хранения, при этом вычислительный модуль состоит из операционных блоков, соединенных друг с другом через входы-выходы и подключающихся в двух режимах: в режиме настройки подключаются последовательно: блок формирования топиков, блок формирования словарей, блок формирования обучающей выборки, блок формирования матрицы признаков, блок формирования эталонной выборки и обучения модели рейтингования, при этом в блоке формирования топиков формируется перечень тем и подтем, отношение к которым необходимо оценить, при этом в блоке формирования словарей формируется множество ключевых слов - словарей, характерных для каждого из топиков, при этом в блоке формирования обучающей выборки производится разбивка текста на блоки размером не менее 2000 символов и разметка абзацев для обучающей выборки, при этом более мелкие части текста исключают из рассмотрения, при этом в блоке формирования матрицы признаков производится обучение матрицы признаков и определение числа слов из словаря, при котором топики будут определяться наилучшим образом, в режиме рейтингования подключаются последовательно: блок подготовки данных, блок предобработки данных, блок оценки топиков, блок рейтингования, блок вывода результатов, при этом в блоке подготовки данных формируются перечень источников данных и перечень текстовых материалов, характеризующих оцениваемые компании, при этом в блоке предобработки данных производится разбивка текстов на блоки размером не менее 2000 символов, при это более мелкие части текста исключают из рассмотрения, при этом в блоке оценки топиков отобранные блоки текста для каждой компании оцениваются на их соответствие топикам и формируются промежуточные данные для оценки текстов, на основании которых формируется ESG-рейтинг.
Пользователь системы может самостоятельно определять множество используемых данных для настройки системы и составления рейтинга и управляет режимами работы вычислительного модуля с терминала пользователя.
Проведенный заявителем анализ уровня техники, включающий поиск по патентам и научно-техническим источникам информации и выявление источников, содержащих сведения об аналогах заявленного изобретения, позволил установить, что заявитель не обнаружил аналог, характеризующийся признаками, тождественными всем существенным признакам заявленного изобретения.
Следовательно, заявленное изобретение соответствует условию «новизна».
Заявляемое изобретение иллюстрируется чертежами, где:
- на фиг. 1 изображена структурная схема взаимодействия технических устройств системы;
- на фиг. 2 изображена структурная схема системы повышения безопасности жизнедеятельности человека за счет формирования esg-рейтинга компаний;
- на фиг. 3 дан пример графического определения величины граничного условия.
Заявленное изобретение реализуется следующим образом.
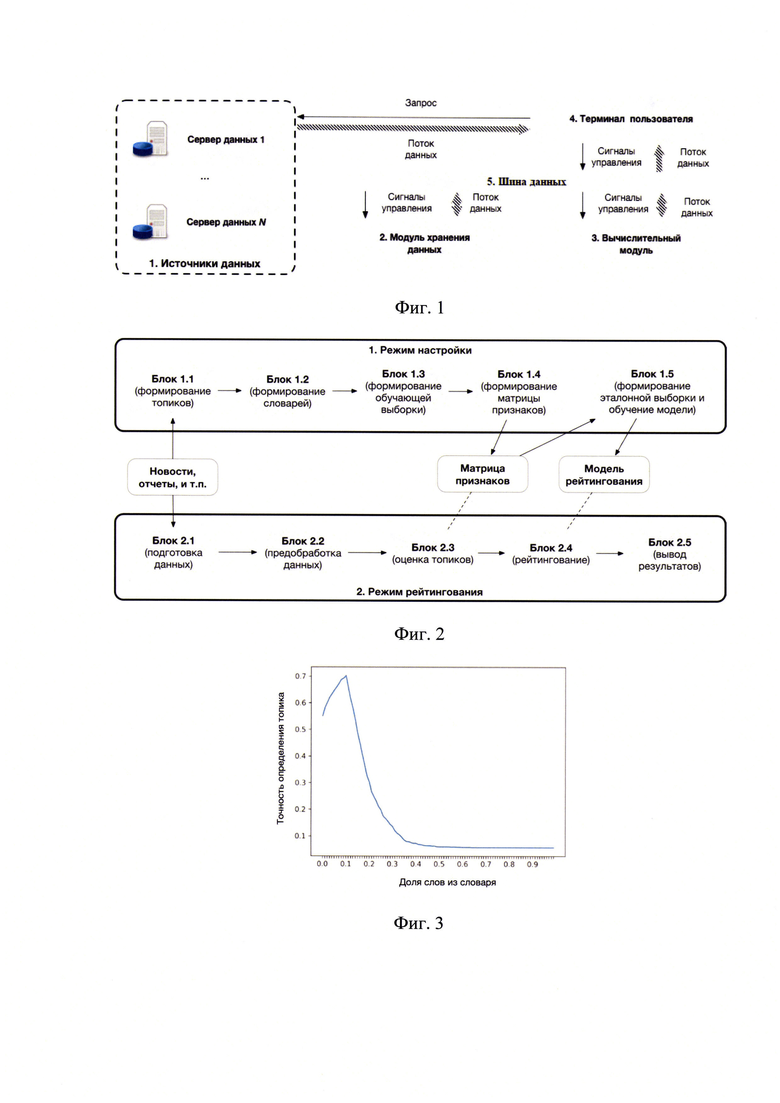
Предлагается система обработки текстов для формирования ESG-рейтинга, содержащая по меньшей мере один web-сервер (1), а также модуль хранения данных (2), вычислительный модуль (2), терминал пользователя (4), шину данных (5) (фиг. 1).
Взаимодействие всех технических устройств системы, приводящее к заявленному техническому результату, реализуется следующим образом.
По меньшей мере один web-сервер является источником данных (1), при этом терминал пользователя (4) имеет выход в глобальную сеть Интернет и соединяется через сеть Интернет с входом-выходом по меньшей мере одного web-сервера (1).
Терминал пользователя (4) соединен через шину данных с входом-выходом модуля хранения данных и вычислительным модулем (3).
Модуль хранения данных (2) соединен с шиной данных (5) и выполнен с возможностью приема сигналов управления с терминала пользователя (4), приема и отправки потока данных через шину данных (5) на терминал пользователя (4) и на вычислительный модуль (3).
Вычислительный модуль (3) соединен с шиной данных (5) и выполнен с возможностью приема сигналов управления с терминала пользователя (4), приема и отправки потока данных через шину данных (5) на терминал пользователя (4) и на модуль хранения (2).
Вычислительный модуль состоит из операционных блоков, соединенных друг с другом через входы-выходы и подключающихся в двух режимах – настройки и рейтингования.
Последовательность работы операционных блоков системы в режиме настройки 1 и режиме рейтингования 2 отображена на структурной схеме системы повышения безопасности жизнедеятельности человека за счет формирования ESG-рейтинга компаний на фиг. 2.
В режиме настройки 1 подключаются последовательно: блок формирования топиков (Блок 1.1), блок формирования словарей (Блок 1.2), блок формирования обучающей выборки (Блок 1.3), блок формирования матрицы признаков (Блок 1.4), блок формирования эталонной выборки и обучения модели рейтингования (Блок 1.5).
В блоке формирования топиков (Блок 1.1) формируется перечень тем и подтем, отношение к которым необходимо оценить.
В блоке формирования словарей (Блок 1.2) формируется множество ключевых слов – словарей, характерных для каждого из топиков.
В блоке формирования обучающей выборки (Блок 1.3) производится разбивка текста на блоки размером не менее 2000 символов и разметка абзацев для обучающей выборки, при этом более мелкие части текста исключают из рассмотрения. Обучающая выборка – это выборка, состоящая из частей текста, размеченных по принадлежности к топикам вручную и являющаяся эталоном для составления матрицы признаков.
В блоке формирования (Блок 1.4) матрицы признаков производится обучение матрицы признаков и определение числа слов из словаря, при котором топики будут определяться наилучшим образом.
Режим настройки системы необходим для дальнейшей работы системы в режиме рейтингования, так как при этом формируется эталонная выборка и производится обучение модели рейтингования (Блок 1.5), используемая в режиме рейтингования для формирования ESG-рейтинга компаний.
В режиме рейтингования подключаются последовательно: блок подготовки данных (Блок 2.1), блок предобработки данных (Блок 2.2), блок оценки топиков (Блок 2.3), блок рейтингования (Блок 2.4), блок вывода результатов (Блок 2.5).
В блоке подготовки данных (Блок 2.1) формируются перечень источников данных и перечень текстовых материалов, характеризующих оцениваемые компании.
В блоке предобработки данных (Блок 2.2) производится разбивка текстов на блоки размером не менее 2000 символов, при это более мелкие части текста исключают из рассмотрения.
В блоке оценки топиков (Блок 2.3) отобранные блоки текста для каждой компании оцениваются на их соответствие топикам и формируются промежуточные данные для оценки текстов.
В блоке рейтингования с использованием разработанной в режиме настройки модели рейтингования формируется ESG-рейтинг компаний (Блок 2.4).
В блоке вывода результатов (Блок 2.5) производится запись результатов в структурированный файл (первая строка – наименование колонок, а затем построчно для каждой организации значения, разделенные разделительным символом (запятая, точка с запятой, табуляция и т.п.)).
Пользователь системы может самостоятельно определять множество используемых данных для настройки системы и составления рейтинга и управляет режимами работы вычислительного модуля с терминала пользователя (4).
Ниже реализация изобретения иллюстрируется примером.
Пример. К сотрудникам департамента менеджмента Санкт-Петербургской школы экономики и менеджмента НИУ ВШЭ в г. Санкт-Петербурге обратились представители российской сети продовольственных магазинов с просьбой определить поставщика бутилированной питьевой воды для продажи потребителю через розничную сеть, так как проведенный ими анализ бутилированной питьевой воды вызвал сомнения в качестве поставляемой воды и надежности компаний-поставщиков.
При проведении экспертизы бутилированной питьевой воды в некоторых случаях были обнаружены несоответствия качества воды норме по остаточному количеству хлора, количеству консервантов, фталатов, тяжелых металлов.
Проблема заключается в том, что розничная сеть не может проводить регулярные проверки всех поставляемых партий бутилированной питьевой воды и необходимо отслеживать вероятность получения некачественного продукта заблаговременно через оценку фундаментальных рисков отдельных поставщиков.
Такую оценку можно провести, если обработать всю открытую доступную информацию о данном поставщике (веб-сайты, отчетность, новости и т. д.).
Ввиду очень большого объема информации о нескольких сотнях поставщиков бутилированной питьевой воды данную задачу можно выполнить за счет формирования объективного ESG-рейтинга компаний, который может быть получен при реализации заявленного изобретения.
Источниками данных (1) являются web-серверы 1-N, подключённые к сети Интернет. Собранные, обработанные и расчетные данные (новости, отчеты, и т. п.; матрица признаков; модель рейтингования) накапливаются в модуле хранения данных (2). Операционные блоки (Блоки 1.1-1.5, 2.1-2.5) реализуются и выполняются в вычислительном модуле (3). Пользователь системы может самостоятельно определять множество используемых данных для настройки системы и составления рейтинга и управляет режимами работы вычислительного модуля с терминала пользователя (4).
Вначале в режиме настройки (1) вычислительного модуля создавали инструмент измерения – операционные блоки настройки (Блоки 1.1-1.5).
В Блоке 1.1 производили формирование перечня топиков – тем и подтем, отношение к которым необходимо будет в дальнейшем оценить. Для оценки ситуации, рассмотренной ранее, были сформированы следующие топики (таблица 1).
Таблица 1 – Структура топиков E, S, G
6 топиков
8 топиков
12 топиков
• вода (99 слов)
• климат (99 слов)
• отходы (99 слов)
• социально-культурное воздействие (49 слов)
• экологический менеджмент (49 слов)
• энергия (649 слов)
• дивиденды и акционеры (599 слов)
• инновации (149 слов)
• лидерство (749 слов)
• отчетность и прозрачность (1051 слово)
• предотвращение коррупции (100 слов)
• управление рисками (300 слов)
• эффективность и производительность (601 слово)
• безопасность продукта (50 слов)
• благотворительность (299 слов)
• инвестиции и капитальные вложения (702 слова)
• налоги (99 слов)
• обучение и развитие (575 слов)
• оплата труда (200 слов)
• отношения потребителями (150 слов)
• отношения с работниками (101 слово)
• охрана здоровья (50 слов)
• профсоюзы и коллективные договоры (152 слова)
• трудовые отношения (700 слов)
В Блоке 1.2 производили формирование множества ключевых слов (словарей), характерных для каждого из топиков (количество объема словаря для каждого топика указано в таблице 1 в скобках). Пример словаря для топика «Вода» на русском языке приведен в таблице 2.
Таблица 2 – Пример словаря для топика «Вода» на русском языке
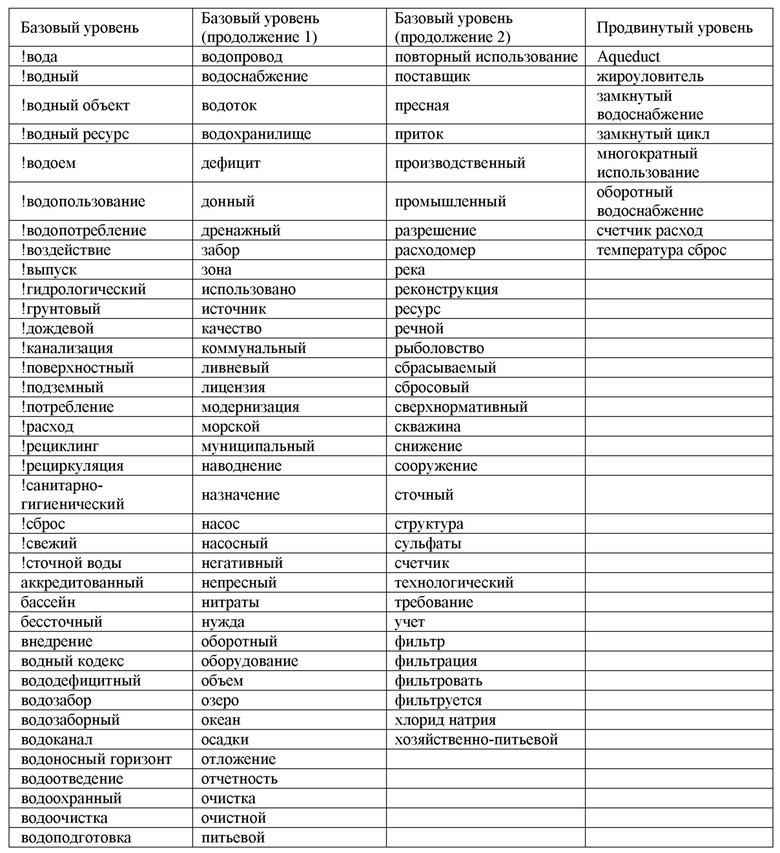
В Блоке 1.3 формировали из выбранного перечня данных текстовые материалы для последующего определения топиков и их оценки. Производили разбивку текста на блоки по абзацам/параграфам размером не менее 2000 символов. Более мелкие части текста исключали из рассмотрения. Производили разметку абзацев для обучающей выборки (таблица 3).
Таблица 3 – Разметка абзацев для обучающей выборки
В Блоке 1.4 производили обучение матрицы признаков и определение числа слов из словаря, при котором топики будут определяться наилучшим образом.
Процесс обучения состоял из 5 шагов:
Шаг 1. Построение матрицы, заполненной нулями, в которой по строкам расположены топики, а по столбцам все уникальные слова из словарей топиков.
Шаг 2. Соотнесение каждого топика с вектором «правильных» ответов, в котором единицы ставятся в местах присутствия слова из словаря соответствующего топика.
Шаг 3. Проверка принадлежности всех размеченных топиков, которая производится путем вычисления значения численной оценки принадлежности к топику (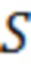 ) как скалярное произведение для каждого блока текста и двух множеств ключевых слов (словарей), характерных для каждого из топиков: 1) множества общей лексики топика, 2) множества специальной лексики топика (уравнение 1):
) как скалярное произведение для каждого блока текста и двух множеств ключевых слов (словарей), характерных для каждого из топиков: 1) множества общей лексики топика, 2) множества специальной лексики топика (уравнение 1):
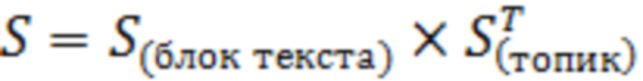 (1)
(1)
где  – вектор размерности
– вектор размерности 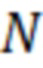 заполненный нулями или единицами (0, если соответствующего слова в тексте нет, 1, если слово присутствует в проверяемой части текста), – число уникальных слов в словаре для всех топиков,
заполненный нулями или единицами (0, если соответствующего слова в тексте нет, 1, если слово присутствует в проверяемой части текста), – число уникальных слов в словаре для всех топиков,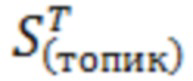 – вектор матрицы признаков, соответствующий проверяемому топику.
– вектор матрицы признаков, соответствующий проверяемому топику.
Части текста присваивается то значение топика, для которого будет максимально значение S, и S будет больше граничного  . Если значение для топика, который был идентифицирован как
. Если значение для топика, который был идентифицирован как  , то присваивается значение «без топика» (остается неразмеченным).
, то присваивается значение «без топика» (остается неразмеченным).
Шаг 4. Прибавление вектора правильных ответов к строке соответствующего класса с каждым вектором правильных ответов, а из остальных – вычитание.
Шаг 5. Проверка правильности разметки и числа проведенных итераций. Если все топики идентифицированы верно или число итераций 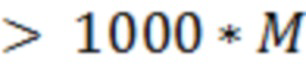 , где
, где 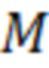 – число идентифицируемых топиков, то система обучена и готова к работе, иначе происходит возвращение к шагу 3.
– число идентифицируемых топиков, то система обучена и готова к работе, иначе происходит возвращение к шагу 3.
Граничное условие для каждого топика выбирали путем максимизации точности определения топика в зависимости от доли слов, которые должны присутствовать в анализируемой части текста из соответствующего топику словаря (фиг. 3). Для примера топика, рассмотренного выше, граничное условие составило 9-10 % слов из топика.
В Блоке 2.5 на основе выделенных топиков и экспертных оценок или рейтинговых оценок за предыдущие периоды формировали TF-IDF матрицу для топиков (таблица 4), которую использовали в качестве эталонной выборки для обучения модели рейтингования.
Таблица 4 – TF-IDF матрица для топиков
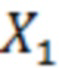
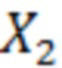
Эталонная выборка – это TF-IDF матрица, составленная на основе группы текстов, используемых для оценки рейтинга компании и дополненная данными рейтинга, которые приняты за истинные значения. В качестве истинных значений могут быть выбраны оценки экспертов или данные другого рейтинга, удовлетворяющие ситуативным требованиям и экспертной проверке.
TF-IDF для топиков – это статистическая мера, используемая для оценки важности топика в контексте документа. Для составления TF-IDF матрицы проводят следующие вычисления:
1) TF (Term Frequency - частота слова) – отношение числа вхождений некоторого слова к общему числу слов документа (уравнение 2).
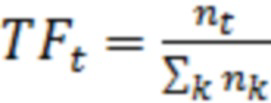 (2)
(2)
где 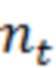 – число вхождений слова
– число вхождений слова 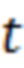 , k – число уникальных слов.
, k – число уникальных слов.
2) IDF (Inverse Document Frequency – обратная частота документа) – инверсия частоты, с которой некоторое слово встречается в документах коллекции. Учёт IDF уменьшает вес широкоупотребительных слов. Для каждого уникального слова в пределах конкретной коллекции документов существует только одно значение IDF (уравнение 3).
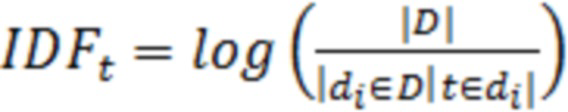 (3)
(3)
где 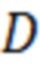 – число документов в коллекции,
– число документов в коллекции, 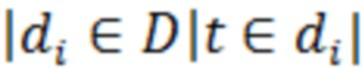 – число документов из коллекции
– число документов из коллекции 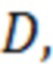 в которых встречается слово .
в которых встречается слово .
В качестве меры частоты использования топика в документе используется произведение (TF*IDF), тогда большой вес в TF-IDF получат топики с высокой частотой использования в пределах конкретного документа и с низкой частотой использования в других документах.
Оценка рейтинга 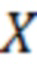 выступает классом, который необходимо научить определять модель классификатора. Значения, которые может принимать
выступает классом, который необходимо научить определять модель классификатора. Значения, которые может принимать 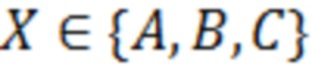 , где
, где 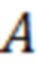 – класс с наилучшей оценкой, а
– класс с наилучшей оценкой, а 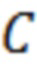 – класс с наихудшей оценкой. Для составления ESG-рейтинга в рассмотренном примере была выбрана модель рейтингования на основе метода опорных векторов.
– класс с наихудшей оценкой. Для составления ESG-рейтинга в рассмотренном примере была выбрана модель рейтингования на основе метода опорных векторов.
Процедуру составления TF-IDF матрицы, её разметки и обучения модели рейтингования необходимо выполнить для каждой составляющей (E, S, G) и всего рейтинга (ESG).
В режиме рейтингования (см. фиг. 2) производили оценку рисков путем составления рейтинга компаний, то есть формировали ESG-рейтинг компаний. Для этого последовательно применяли операционные блоки рейтингования (Блоки 2.1-2.5).
Блок 2.1 включал формирование перечня источников данных и перечня текстовых материалов, характеризующих оцениваемые организации (источники текстов: веб-сайты компаний, ежегодная отчетность компаний, информация о компаниях из социальных сетей и новостных сайтов).
В Блоке 2.2 производили разбивку текстов на блоки по абзацам/параграфам размером не менее 2000 символов. Более мелкие части текста исключали из рассмотрения.
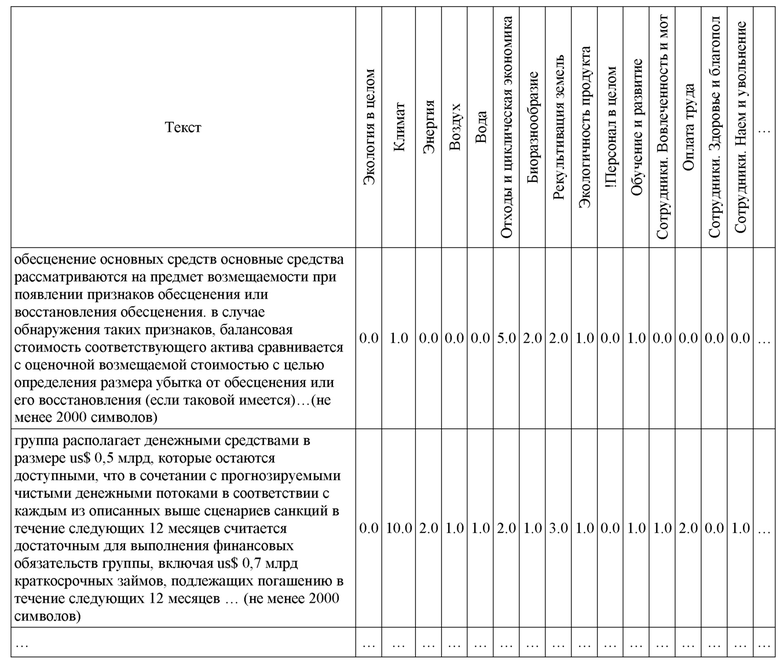
В Блоке 2.3 для отобранных блоков текста для каждой организации производили оценку их соответствия топикам и формировали промежуточные данные для оценки текстов (таблица 5).
Таблица 5 – Предобработка данных и оценка топиков
После этого формировали TF-IDF матрицу для оцениваемых организаций (таблица 6).
Таблица 6 – TF-IDF матрица для оцениваемых организаций
В Блоке 2.4 с использованием разработанной в режиме настройки модели рейтингования формировали рейтинг для организаций-поставщиков (таблица 7).
Таблица 7 – Формирование рейтинга для организаций-поставщиков
В Блоке 2.5 производили запись результатов в структурированный файл (первая строка – наименование колонок, а затем построчно для каждой организации значения, разделенные разделительным символом (запятая, точка с запятой, табуляция и т.п.)).
Полученный ESG-рейтинг выявил топ-3 лучших поставщиков бутилированной питьевой воды (Компании 2, 5, 6), вода которых соответствовала заявленным нормам и в долгосрочной перспективе также будет им соответствовать.
Структурированный файл был выдан представителям российской сети продовольственных магазинов.
В результате выбора ритейлером для продажи качественной бутилированной питьевой воды потребители получили воду, не наносящую вреда здоровью (не содержащую опасных для здоровья компонентов), таким образом достигая заявленного технического результата – формирования объективного ESG-рейтинга компаний и, как следствие, в долгосрочной перспективе – повышения уровня безопасности жизнедеятельности человека.
Следует понимать, что описанный пример реализации изобретения является просто иллюстрацией применения принципов заявленного способа и не ограничивает формулу изобретения, в которой указаны те признаки, которые являются существенными для изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ И ФИЛЬТРАЦИИ ЗАПРЕЩЕННОГО КОНТЕНТА В СЕТИ | 2020 |
|
RU2738335C1 |
| Система и способ определения правила классификации события на терминальном устройстве пользователя | 2020 |
|
RU2772404C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ОТВЕТА НА ПОИСКОВЫЙ ЗАПРОС | 2024 |
|
RU2834217C1 |
| Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации | 2020 |
|
RU2750852C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ ИТЕРАТИВНОЙ КЛАСТЕРИЗАЦИИ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ ПО СЕМАНТИЧЕСКОЙ БЛИЗОСТИ, СПОСОБ ПОИСКА В СОВОКУПНОСТИ КЛАСТЕРИЗОВАННЫХ ПО СЕМАНТИЧЕСКОЙ БЛИЗОСТИ ДОКУМЕНТОВ И МАШИНОЧИТАЕМЫЕ НОСИТЕЛИ | 2014 |
|
RU2556425C1 |
| ИСПОЛЬЗОВАНИЕ АВТОЭНКОДЕРОВ ДЛЯ ОБУЧЕНИЯ КЛАССИФИКАТОРОВ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2017 |
|
RU2678716C1 |
| АВТОМАТИЧЕСКОЕ ОПРЕДЕЛЕНИЕ НАБОРА КАТЕГОРИЙ ДЛЯ КЛАССИФИКАЦИИ ДОКУМЕНТА | 2018 |
|
RU2701995C2 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ЭКСПЛУАТИРУЕМЫХ УЯЗВИМОСТЕЙ В ПРОГРАММНОМ КОДЕ | 2022 |
|
RU2790005C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ ЭЛЕКТРОННОГО КОМПЛЕКТА ДОКУМЕНТОВ | 2019 |
|
RU2702967C1 |
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении точности обработки текстов для формирования ESG-рейтинга. Технический результат достигается за счет системы обработки текстов для формирования ESG-рейтинга, содержащей web-сервер, модуль хранения данных, вычислительный модуль, терминал пользователя, шину данных, при этом вычислительный модуль состоит из операционных блоков, соединенных друг с другом через входы-выходы и подключающихся в двух режимах: в режиме настройки подключаются последовательно: блок формирования топиков, блок формирования словарей, блок формирования обучающей выборки, блок формирования матрицы признаков, блок формирования эталонной выборки и обучения модели рейтингования, в режиме рейтингования подключаются последовательно: блок подготовки данных, блок предобработки данных, блок оценки топиков, блок рейтингования, блок вывода результатов, при этом в блоке подготовки данных формируются перечень источников данных и перечень текстовых материалов, характеризующих оцениваемые компании, при этом в блоке предобработки данных производится разбивка текстов на блоки размером не менее 2000 символов, при этом более мелкие части текста исключают из рассмотрения. 1 з.п. ф-лы, 3 ил., 7 табл.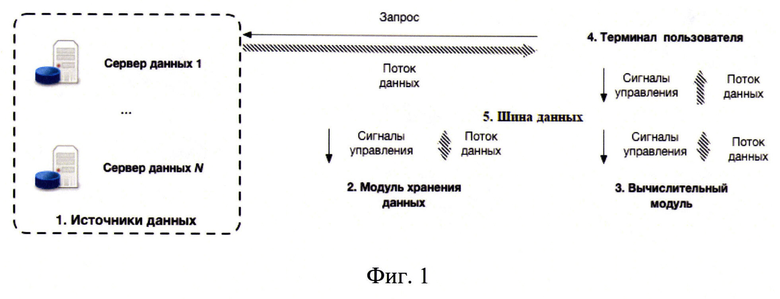
1. Система обработки текстов для формирования ESG-рейтинга, содержащая
по меньшей мере один web-сервер,
модуль хранения данных,
вычислительный модуль,
терминал пользователя,
шину данных,
при этом web-сервер является источником данных,
при этом терминал пользователя имеет выход в глобальную сеть Интернет и соединяется через сеть Интернет с входом-выходом по меньшей мере одного web-сервера,
при этом терминал пользователя соединен через шину данных с входом-выходом модуля хранения данных и вычислительным модулем,
при этом модуль хранения данных соединен с шиной данных и выполнен с возможностью приема сигналов управления с терминала пользователя, приема и отправки потока данных через шину данных на терминал пользователя и на вычислительный модуль,
при этом вычислительный модуль соединен с шиной данных и выполнен с возможностью приема сигналов управления с терминала пользователя, приема и отправки потока данных через шину данных на терминал пользователя и на модуль хранения,
при этом вычислительный модуль состоит из операционных блоков, соединенных друг с другом через входы-выходы и подключающихся в двух режимах:
в режиме настройки подключаются последовательно: блок формирования топиков, блок формирования словарей, блок формирования обучающей выборки, блок формирования матрицы признаков, блок формирования эталонной выборки и обучения модели рейтингования,
при этом в блоке формирования топиков формируется перечень тем и подтем, отношение к которым необходимо оценить,
при этом в блоке формирования словарей формируется множество ключевых слов - словарей, характерных для каждого из топиков,
при этом в блоке формирования обучающей выборки производится разбивка текста на блоки размером не менее 2000 символов и разметка абзацев для обучающей выборки, при этом более мелкие части текста исключают из рассмотрения,
при этом в блоке формирования матрицы признаков производится обучение матрицы признаков и определение числа слов из словаря, при котором топики будут определяться наилучшим образом,
в режиме рейтингования подключаются последовательно: блок подготовки данных, блок предобработки данных, блок оценки топиков, блок рейтингования, блок вывода результатов,
при этом в блоке подготовки данных формируются перечень источников данных и перечень текстовых материалов, характеризующих оцениваемые компании,
при этом в блоке предобработки данных производится разбивка текстов на блоки размером не менее 2000 символов, при этом более мелкие части текста исключают из рассмотрения,
при этом в блоке оценки топиков отобранные блоки текста для каждой компании оцениваются на их соответствие топикам и формируются промежуточные данные для оценки текстов, на основании которых формируется ESG-рейтинг.
2. Система по п. 1, отличающаяся тем, что пользователь системы самостоятельно определяет множество используемых данных для настройки системы и составления рейтинга и управляет режимами работы вычислительного модуля с терминала пользователя.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ СМЫСЛОВЫХ БЛОКОВ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ МИКРОМОДЕЛЕЙ НА БАЗЕ ОНТОЛОГИИ | 2017 |
|
RU2662688C1 |
| СПОСОБ АНАЛИЗА ТЕКСТА | 2008 |
|
RU2392666C1 |

