Область техники
Изобретение относится к реализации функций обработки изображений, связанных с нахождением границ объектов, удалением объектов из изображения, вставкой объектов в изображение, созданием новых изображений из комбинации уже существующих.
Описание известного уровня техники
Уровень техники раскрывает следующие методы неконтролируемой и слабо контролируемой сегментации объектов. В работе [18] авторы предлагают метод, основанный на GAN [30], для создания масок сегментации объектов из ограничивающих рамок. Их обучающий конвейер включает в себя получение двух вырезок одного и того же изображения: одной вырезки с объектом и одной без объекта. Обнаружение объектов осуществляется с помощью Faster R-CNN [19]. Затем GAN обучают создавать маску сегментации для слияния этих двух вырезок и получения правдоподобного изображения. Авторы используют комбинацию состязательной потери, потери наличия (которая проверяет наличие объекта на изображении) и потери вырезки (которая проверяет, чтобы после вырезки объекта не осталось ни одной его части). Эксперименты проводились только с некоторыми классами из набора данных Cityscapes [5] и со всеми классами из набора данных MS COCO [14]. Авторы сообщают, что их метод позволяет достичь более высоких средних значений коэффициента Жаккара, чем классический алгоритм GrabCut [21] и недавний Simple-Does-It [12]. Такой подход требует предварительно обученной Faster R-CNN и специальной политики для выбора патчей переднего плана и фона. В нем также имеются проблемы с правильностью сегментирования некоторых классов объектов (например, воздушный змей, жираф и т.д.). Кроме того, этот метод хорошо работает только с изображениями, имеющими низкое разрешение (28×28).
В работе [23] авторы предлагают среду без аннотаций для изучения сети сегментации для однородных объектов. Они используют адаптивный процесс генерации синтетических данных для создания обучающего набора данных.
Хотя проблема неконтролируемой сегментации изображений традиционно решается кластеризацией суперпикселей, в последнее время для ее решения стали применять глубокое обучение [9]. В последней работе авторы предлагают максимизировать информацию между двумя кластеризованными векторами, полученными полносверточной сетью из соседних патчей одного и того же изображения. Подобный метод был предложен в [24], хотя он ограничен потерями реконструкции. Авторы описывают W-Net (автокодер с кодером и декодером U-Netlike), который пытается кластеризовать пиксели на внутреннем слое, а затем реконструировать изображение из кластеров пикселей. В результате их сегментации классы объектов не известны.
Визуальное обоснование. Методы визуального обоснования нацелены на неконтролируемое или слабо контролируемое сопоставление произвольных текстовых запросов и областей изображений. Обычно контроль принимает форму пар (изображение; надпись). Эффективность модели обычно измеряется мерой Жаккара относительно истинных меток. Наиболее популярными наборами данных являются Visual Genome [13], Flickr30k [17], Refer-It-Game [11] и MS COCO [14]. Общий подход к обоснованию заключается в прогнозировании, соответствуют ли данная надпись и изображение друг другу. Отрицательные выборки получаются при независимом перемещении подписей и изображений. Внимание к тексту/изображению является основной особенностью большинства моделей визуального обоснования [28]. Очевидно, что использование более детального контроля (например, аннотации на уровне области, а не изображения) позволяет получить более высокие оценки [29].
Создание тримэпа. Создание тримэпа - это задача сегментации изображения на три класса: передний план, фон и неизвестный (прозрачный передний план). В большинстве алгоритмов для предложения тримэпа требуется участие человека, однако недавно были предложены суперпиксельный и кластерный подходы для автоматического создания тримэпа [7]. Но в этом методе необходимо выполнить несколько этапов оптимизации для каждого изображения. Для создания маски альфа-матирования данного изображения и тримэпа используется глубокое обучение [26]. Известна также работа по матированию видео и замене фона в видео [8]. В ней используется покадровая суперпиксельная сегментация, а затем оптимизируется энергия в условном случайном поле моделей гауссовой смеси для покадрового разделения переднего плана и фона.
Генеративно-состязательные сети. В последние годы по всей видимости наиболее часто используемым подходом для обучения генеративной модели являются генеративно-состязательные сети, GAN [6]. Несмотря на их мощность, эти сети подвержены нестабильности процесса обучения и эффективности на изображениях с более высоким разрешением. В методе, предложенном не так недавно, CycleGAN [30] обучает две GAN вместе, чтобы установить двунаправленное преобразование между двумя доменами. Этот метод обеспечивает более высокую стабильность и согласованность. В нем, напротив, требуется, чтобы набор данных визуализировал своего рода обратимую операцию. Было опубликовано множество модификаций и приложений для CycleGAN, включая семантическое управление изображениями [22], доменную адаптацию [2], неконтролируемое преобразование изображений в изображения [15], многодоменное преобразование [3] и многие другие. Существует также проблема возможной неоднозначности такого преобразования между доменами. BicycleGAN [31] и дополненный CycleGAN [1] решают эту проблему вводом требования, чтобы преобразование сохраняло скрытые представления.
В данной работе авторы берут за основу идеи Cut&Paste [18] и CycleGAN [6] и предлагают новую архитектуру и конвейер, который решает другую проблему (замену фона) и позволяет получить лучшие результаты при неконтролируемой сегментации объектов, подрисовке и смешивании изображений.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В настоящем изобретении представлен новый подход к визуальному восприятию посредством одновременного обучения сегментированию масок объектов и удалению объектов из фона (т.е. вырезке и вставке).
Предложена вычислительная система для выполнения автоматической обработки изображений, содержащая: первую нейронную сеть для формирования грубого изображения z путем сегментации объекта O из исходного изображения x, содержащего объект O и фон Bx с помощью маски сегментации, и вырезки с помощью данной маски сегментированного объекта O из изображения x и вставки его в изображение y, содержащее только фон By; вторую нейронную сеть для создания улучшенной версии изображения 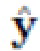 с вставленным сегментированным объектом O путем улучшения грубого изображения z на основе исходных изображений x и y и маски m; третью нейронную сеть для восстановления изображения только фона
с вставленным сегментированным объектом O путем улучшения грубого изображения z на основе исходных изображений x и y и маски m; третью нейронную сеть для восстановления изображения только фона 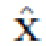 без удаленного сегментированного объекта O путем подрисовки изображения, полученного путем обнуления пикселей изображения x с использованием маски m; причем первая, вторая и третья нейронные сети объединены в общую архитектуру нейронной сети для последовательного выполнения сегментации, улучшения и подрисовки и одновременного обучения; при этом общая архитектура нейронной сети принимает изображения и выдает обработанные изображения одинаковых размеров. При этом первая, вторая и третья нейронные сети являются генераторами, которые создают изображения и и конвертируют их. Система дополнительно содержит две нейронные сети, сконфигурированные как дискриминаторы, которые оценивают правдоподобие изображений. При этом первый дискриминатор является дискриминатором фона, который пытается провести различие между эталонным реальным изображением фона и подрисованным изображением фона; второй дискриминатор является дискриминатором объекта, который пытается провести различие между эталонным реальным изображением объекта O и улучшенным изображением объекта O. При этом первая и вторая нейронные сети составляют сеть замены. При этом сеть замены выполнена с возможностью непрерывного обучения с функциями потерь для создания улучшенной версии изображения с вставленным сегментированным объектом О. При этом одна из функций потерь является функцией реконструкции объекта для обеспечения согласованности и стабильности обучения и реализуется как средняя абсолютная разница между изображением х и изображением . При этом одна из функций потерь является состязательной функцией объекта для повышения правдоподобия изображения и реализуется с помощью выделенной сети дискриминатора. При этом одна из функций потерь является функцией согласованности маски для придания первой сети инвариантности относительно фона, и реализуется как среднее абсолютное расстояние между маской, извлеченной из изображения x, и маской, извлеченной из изображения . Одна из функций потерь является это функцией улучшения идентичности объекта, которая вынуждает вторую сеть создавать изображения более близкие к реальным изображениям и представляет собой среднее абсолютное расстояние между Genh(x) и самим х. При этом одна из функций потерь представляет собой функцию идентичности фона для обеспечения того, чтобы общая архитектура не делала ничего с изображением, которое не содержит объектов. При этом одна из функций потерь представляет собой общую функцию потерь, которая является линейной комбинацией функции реконструкции объекта, состязательной функции объекта, функции согласованности маски, функции улучшения идентичности объекта, функции идентичности фона. При этом маска сегментации прогнозируется первой сетью с учетом изображения x.
без удаленного сегментированного объекта O путем подрисовки изображения, полученного путем обнуления пикселей изображения x с использованием маски m; причем первая, вторая и третья нейронные сети объединены в общую архитектуру нейронной сети для последовательного выполнения сегментации, улучшения и подрисовки и одновременного обучения; при этом общая архитектура нейронной сети принимает изображения и выдает обработанные изображения одинаковых размеров. При этом первая, вторая и третья нейронные сети являются генераторами, которые создают изображения и и конвертируют их. Система дополнительно содержит две нейронные сети, сконфигурированные как дискриминаторы, которые оценивают правдоподобие изображений. При этом первый дискриминатор является дискриминатором фона, который пытается провести различие между эталонным реальным изображением фона и подрисованным изображением фона; второй дискриминатор является дискриминатором объекта, который пытается провести различие между эталонным реальным изображением объекта O и улучшенным изображением объекта O. При этом первая и вторая нейронные сети составляют сеть замены. При этом сеть замены выполнена с возможностью непрерывного обучения с функциями потерь для создания улучшенной версии изображения с вставленным сегментированным объектом О. При этом одна из функций потерь является функцией реконструкции объекта для обеспечения согласованности и стабильности обучения и реализуется как средняя абсолютная разница между изображением х и изображением . При этом одна из функций потерь является состязательной функцией объекта для повышения правдоподобия изображения и реализуется с помощью выделенной сети дискриминатора. При этом одна из функций потерь является функцией согласованности маски для придания первой сети инвариантности относительно фона, и реализуется как среднее абсолютное расстояние между маской, извлеченной из изображения x, и маской, извлеченной из изображения . Одна из функций потерь является это функцией улучшения идентичности объекта, которая вынуждает вторую сеть создавать изображения более близкие к реальным изображениям и представляет собой среднее абсолютное расстояние между Genh(x) и самим х. При этом одна из функций потерь представляет собой функцию идентичности фона для обеспечения того, чтобы общая архитектура не делала ничего с изображением, которое не содержит объектов. При этом одна из функций потерь представляет собой общую функцию потерь, которая является линейной комбинацией функции реконструкции объекта, состязательной функции объекта, функции согласованности маски, функции улучшения идентичности объекта, функции идентичности фона. При этом маска сегментации прогнозируется первой сетью с учетом изображения x.
Предложен способ автоматической обработки согласно которому: используют первую нейронную сеть для формирования грубого изображения z путем сегментации объекта O из исходного изображения x, содержащего объект O и фон Bx, с помощью маски сегментации, и вырезают с помощью данной маски сегментированный объект O из изображения x и вставляют его в изображение y, содержащее только фон By; используют вторую нейронную сеть для построения улучшенной версии изображения с вставленным сегментированным объектом O, посредством улучшения грубого изображения z на основе исходных изображений x и у и маски m; используют третью нейронную сеть для восстановления изображения только фона без удаленного сегментированного объекта O путем подрисовки изображения, полученного путем обнуления пикселей изображения x с использованием маски m; выводят изображения и одинакового размера. При этом первая, вторая и третья нейронные сети являются генераторами, которые создают изображения и и конвертируют их. Способ дополнительно содержит две нейронные сети, сконфигурированные как дискриминаторы, которые оценивают достоверность изображений. При этом первый дискриминатор является дискриминатором фона, который пытается провести различие между эталонным реальным изображением фона и подрисованным изображением фона; второй дискриминатор является дискриминатором объекта, который пытается провести различие между эталонным реальным изображением объекта O и улучшенным изображением объекта O. При этом первая и вторая нейронные сети составляют сеть замены. При этом сеть замены выполнена с возможностью непрерывного обучения с функциями потерь для создания улучшенной версии изображения с вставленным сегментированным объектом О. При этом одна из функций потерь является функцией реконструкции объекта для обеспечения согласованности и стабильности обучения и реализуется как средняя абсолютная разница между изображением х и изображением . При этом одна из функций потерь является состязательной функцией объекта для повышения правдоподобия изображения и реализуется с помощью выделенной сети дискриминатора. При этом одна из функций потерь является функцией согласованности маски для придания первой сети инвариантности относительно фона и реализуется как среднее абсолютное расстояние между маской, извлеченной из изображения x, и маской, извлеченной из изображения . При этом одна из функций потерь является функцией улучшения идентичности объекта для улучшения второй сети для получения изображений более близких к реальным изображениям, и представляет собой среднее абсолютное расстояние между Genh(x) и самим х. При этом одна из функций потерь представляет собой функцию идентичности фона для обеспечения того, чтобы общая архитектура не делала ничего с изображением, которое не содержит объектов. При этом одна из функций потерь представляет собой общую функцию потерь, которая является линейной комбинацией функции реконструкции объекта, состязательной функции объекта, функции согласованности маски, функции улучшения идентичности объекта, функции идентичности фона. При этом маска сегментации прогнозируется первой сетью с учетом изображения x.
Описание чертежей
Представленные выше и/или другие аспекты станут более очевидными из описания примерных вариантов осуществления со ссылками на прилагаемые чертежи, на которых:
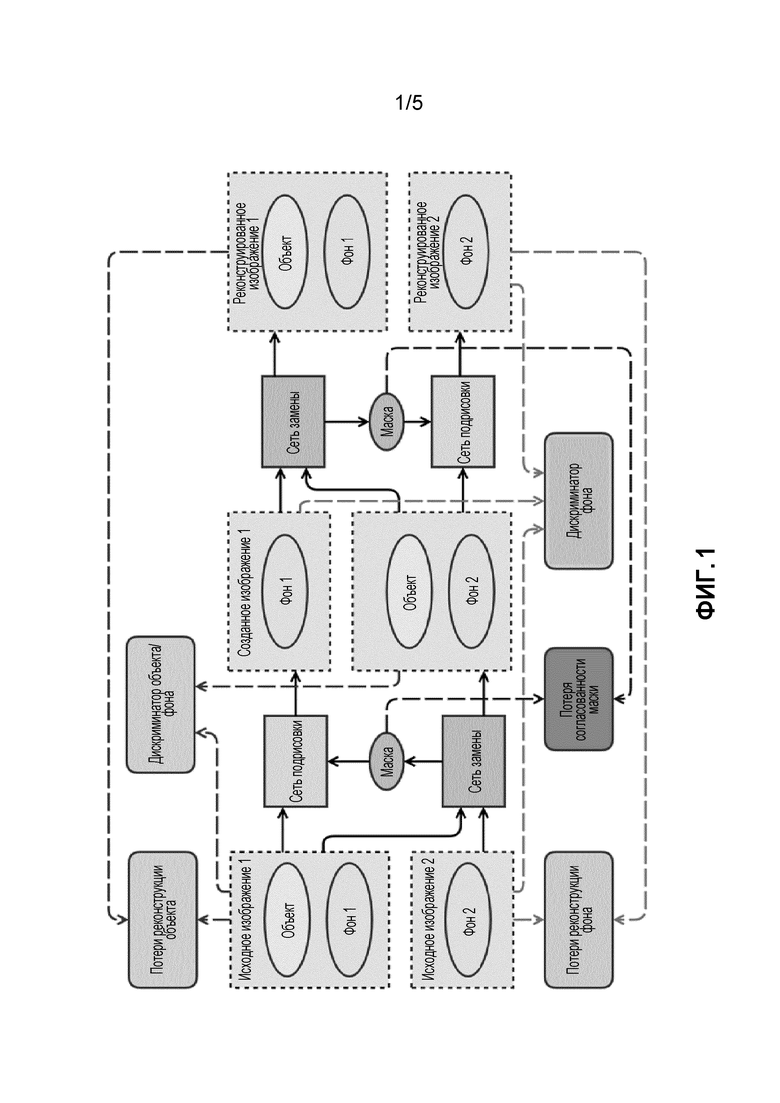
Фиг.1 изображает архитектуру нейронной сети, схему подготовки данных и установку ее параметров. Высокоуровневый общий вид конвейера SEIGAN (Segment-Enhance-Inpainting) для совместной сегментации и подрисовки: операция замены выполняется дважды и оптимизируется для воспроизведения исходных изображений. Эллипсы обозначают объекты и данные; сплошные прямоугольники - нейронные сети; скругленные прямоугольники - функции потерь; сплошные линии - потоки данных, а пунктирные линии показывают поток значений к функциям потерь.
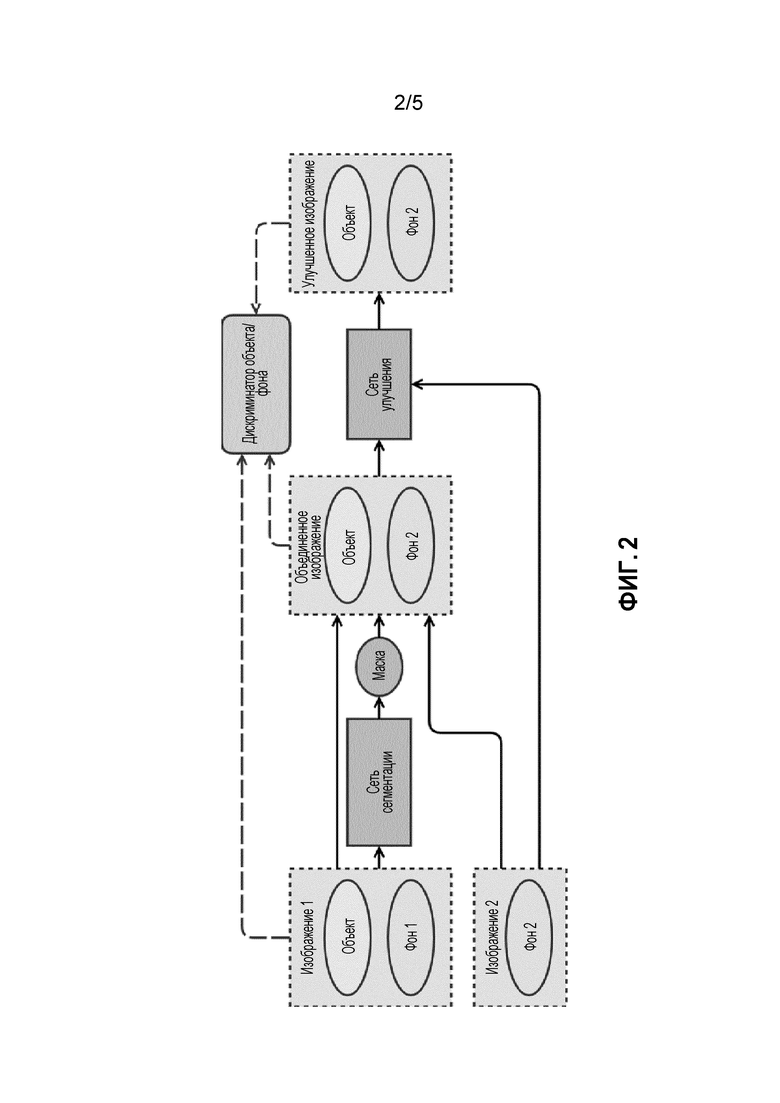
Фиг. 2 - архитектура сети замены (из фиг. 1), которая вырезает объект из одного изображения и вставляет его в другое.
Фиг. 3 - примеры изображений и масок, сгенерированных предложенной моделью.
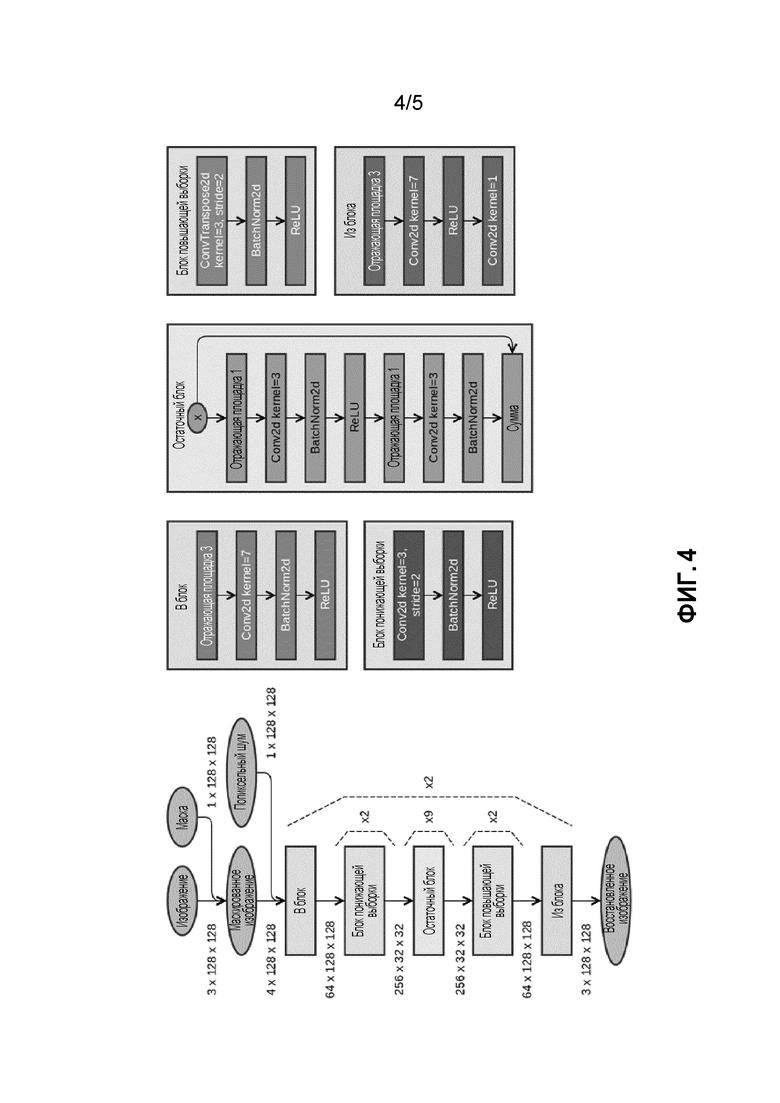
Фиг. 4 - архитектура остаточной сети, используемой для сетей подрисовки и/или сегментации.
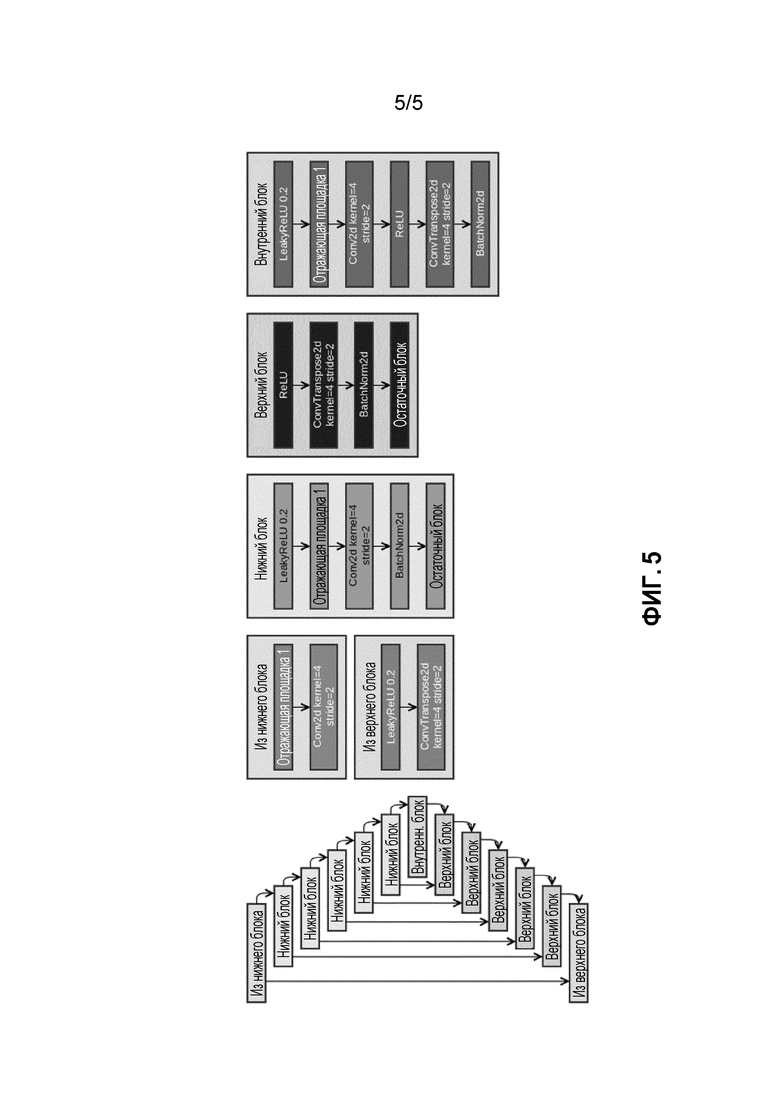
Фиг. 5 - архитектура U-Network, используемая для сетей сегментации и уточнения.
Подробное описание
Предлагаемое изобретение может быть полезным аппаратным средством, содержащим программные продукты и устройства, которые выполняют автоматическую или автоматизированную обработку изображений, включающим в себя:
- графический редактор;
- креативные приложения для создания графического контента;
- аппаратные системы (носимые устройства, смартфоны, роботы), для которых желательно найти объекты на изображениях;
- моделирование дополненной реальности (виртуальная/дополненная реальность);
- подготовку данных для настройки методов машинного обучения (в любой отрасли).
Ниже поясняются символы, используемые в материалах заявки.
О - объект, показанный на изображении.
Bx - фон, показанный на изображении x.
By - фон, показанный на изображении y.
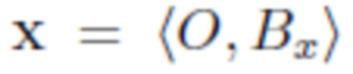 - изображение, содержащее объект O и фон Bx.
- изображение, содержащее объект O и фон Bx.
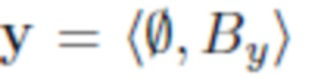 - изображение, содержащее только фон By (без объекта на переднем плане).
- изображение, содержащее только фон By (без объекта на переднем плане).
X - набор всех изображений x.
Y - набор всех изображений y.
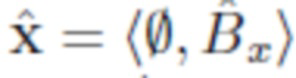 - изображение x с удаленным объектом O (изображение содержит только фон Bx).
- изображение x с удаленным объектом O (изображение содержит только фон Bx).
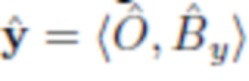 - изображение y со вставленным объектом O.
- изображение y со вставленным объектом O.
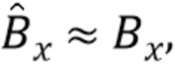
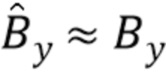 и
и 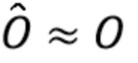 - преобразованные (приближенные) варианты фонов Bx и By и объекта O.
- преобразованные (приближенные) варианты фонов Bx и By и объекта O.
 - маска сегментации для изображения х.
- маска сегментации для изображения х.
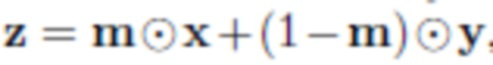 - грубое изображение, построенное путем смешивания изображений x и y с маской смешивания m.
- грубое изображение, построенное путем смешивания изображений x и y с маской смешивания m.
Gseg, Ginp, Genh - нейронные сети, используемые в качестве генераторов для сегментации, подрисовки и улучшения.
Dbg, Dobj - нейронные сети, используемые в качестве дискриминаторов (Dbg отсортировывает изображения с реальным фоном от изображений с нарисованным фоном, Dobj отсортировывает изображения с реальными объектами от изображений со вставленными объектами).
Gram(i) - матрица Грама, построенная из трехмерного тензора, представляющего признаки пикселей изображения.
VGG(i) - функция для вычисления трехмерного тензора, который представляет признаки пикселей изображения.
 - критерии оптимизации, используемые для настройки параметров нейронных сетей.
- критерии оптимизации, используемые для настройки параметров нейронных сетей.
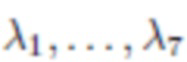 - неотрицательные реальные коэффициенты, используемые для уравновешивания важности различных критериев оптимизации.
- неотрицательные реальные коэффициенты, используемые для уравновешивания важности различных критериев оптимизации.
Предлагаемые функции обработки изображений требуют менее детального контроля со стороны человека по сравнению с аналогами, существующими на данный момент.
Предложенное изобретение может быть реализовано в программном обеспечении, которое в свою очередь может работать на любых устройствах, имеющих достаточную вычислительную мощность.
Во всем описании изображения обозначаются как кортежи фона объекта, например, означает, что изображение x содержит объект O и фон Bx, а означает, что изображение y содержит фон By и никаких объектов.
Основную проблему, решаемую в настоящем изобретении, можно сформулировать следующим образом. Имея набор данных изображений фона 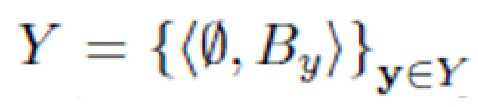 и набор данных объектов на различных фонах
и набор данных объектов на различных фонах 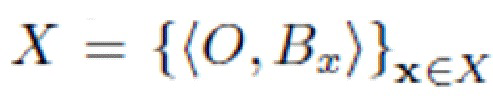 (непарные, т.е. без преобразования между X и Y), обучают модель брать объект из изображения
(непарные, т.е. без преобразования между X и Y), обучают модель брать объект из изображения 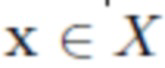 и вставлять его в новый фон, определенный изображением
и вставлять его в новый фон, определенный изображением 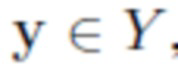 , в то же время удаляя его из исходного фона. Иными словами, задача состоит в том, чтобы преобразовать пару изображений
, в то же время удаляя его из исходного фона. Иными словами, задача состоит в том, чтобы преобразовать пару изображений 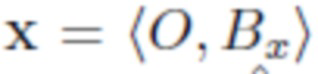 и
и 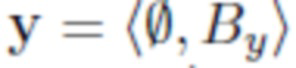 в новую пару и
в новую пару и 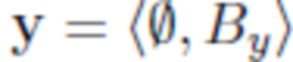 , где
, где 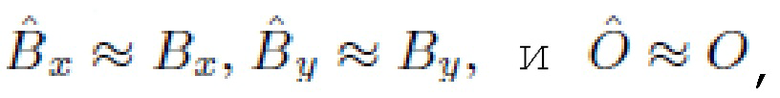
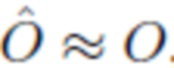 , но объект и оба фона изменяются так, чтобы новые изображения выглядели естественными.
, но объект и оба фона изменяются так, чтобы новые изображения выглядели естественными.
Эту общую задачу можно разбить на три подзадачи:
- Сегментация: сегментируют объект O из исходного изображения 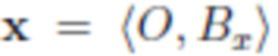 путем прогнозирования сегментации ; с этой маской можно получить грубую смесь, которая просто отсекает сегментированный объект от x и вставляет его в y: , где
путем прогнозирования сегментации ; с этой маской можно получить грубую смесь, которая просто отсекает сегментированный объект от x и вставляет его в y: , где  означает покомпонентное умножение. В процессе обучения параметры нейронной сети корректируются таким образом, что при вводе изображения с объектом эта нейронная сеть дает корректную маску, на которой выбран данный объект. Пользователь не участвует в этом процессе.
означает покомпонентное умножение. В процессе обучения параметры нейронной сети корректируются таким образом, что при вводе изображения с объектом эта нейронная сеть дает корректную маску, на которой выбран данный объект. Пользователь не участвует в этом процессе.
- Улучшение: из исходных изображений x и y, грубого изображения z и маски сегментации m создают улучшенную версию
- Подрисовка: взяв маску сегментации m и изображение 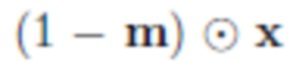 , полученное путем обнуления пикселей x в соответствии с m, восстанавливают изображение только фона
, полученное путем обнуления пикселей x в соответствии с m, восстанавливают изображение только фона 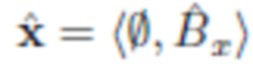 . Вместо удаленного сегментированного объекта O третья нейронная сеть заполняет часть изображения на основании оставшейся части изображения и случайного сигнала. Во время обучения параметры третьей нейронной сети настраиваются таким образом, чтобы на основе этой фрагментарной информации сеть создала правдоподобное заполнение фона. В результате получают два изображения и . Однако основное внимание уделяется изображению , а изображение с пустым фоном является промежуточным результатом этого алгоритма, хотя его также можно использовать.
. Вместо удаленного сегментированного объекта O третья нейронная сеть заполняет часть изображения на основании оставшейся части изображения и случайного сигнала. Во время обучения параметры третьей нейронной сети настраиваются таким образом, чтобы на основе этой фрагментарной информации сеть создала правдоподобное заполнение фона. В результате получают два изображения и . Однако основное внимание уделяется изображению , а изображение с пустым фоном является промежуточным результатом этого алгоритма, хотя его также можно использовать.
Для каждой из этих задач можно построить отдельную нейронную сеть, которая принимает изображение или пару изображений и выдает новое изображение или изображения такого же размера. Однако, основная гипотеза, исследуемая в данной работе, заключается в том, что при отсутствии больших парных и помеченных наборов данных (что является нормальным состоянием дел в большинстве приложений) очень целесообразно обучать все эти нейронные сети вместе.
Поэтому авторы представляют свою архитектуру SEIGAN (Segment-Enhance-Inpaint, сегментация-улучшение-подрисовка), которая объединяет все три компонента в новый и ранее неизученный метод. На фиг. 1 рамка с пунктирным контуром обозначает данные (изображения); эллипсы - объекты, содержащиеся в данных; прямоугольники с острыми углами - подпрограммы, реализующие нейронные сети; прямоугольники со скругленными углами - подпрограммы, управляющие процессом настройки параметров нейронной сети в процессе обучения; линии обозначают потоки данных в процессе обучения (тот факт, что стрелка указывает от одного блока к другому, означает, что результаты первого блока передаются второму в качестве ввода). На фиг. 1 представлен общий поток предложенной архитектуры; модуль "сеть замены" объединяет сегментацию и улучшение. Поскольку вырезка и вставка являются частично обратимой операцией, естественно организовать процесс обучения аналогично CycleGAN [30]: сети замены и подрисовки применяются дважды, чтобы завершить цикл и иметь возможность использовать свойство идемпотентности для функций потерь. Результаты первого приложения обозначены как  и у, а результаты второго приложения, перемещение объекта назад от , как
и у, а результаты второго приложения, перемещение объекта назад от , как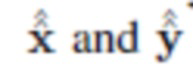 (см. фиг. 1).
(см. фиг. 1).
Архитектура, показанная на фиг. 1, объединяет пять различных нейронных сетей, три из которых используются в качестве генераторов, создающих изображение и преобразующих его, и две - в качестве дискриминаторов, оценивающих достоверность изображения:
Gseg решает задачу сегментации: взяв изображение x, предсказывает Mask(x), маску сегментации объекта на изображении;
Ginp решает задачу подрисовки: взяв m и , предсказывает 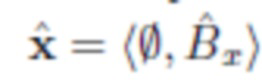 ;
;
Сenh осуществляет улучшение: взяв x, y, и z=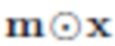 +…., предсказывает
+…., предсказывает 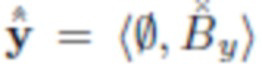 ;
;
Dbg - дискриминатор фона, который пытается осуществить различие между реальным и фиктивным (подрисованным) изображениями только фона: его вывод Dbg(х) должен быть ближе к 1, если x реальное изображение, и ближе к 0, если x фиктивное;
Dobj - дискриминатор объекта, который осуществляет то же самое для изображений объекта на фоне; его вывод Dobj(x) должен быть ближе к 1, если x реальное изображение, и ближе к 0, если x фиктивное.
Генераторы Gseg и Geng образуют так называемую "сеть замены", которая изображена на фиг. 1 в виде одного блока и подробно объясняется на фиг. 2. На этой фигуре изображена архитектура "сети замены" (блок под названием "сеть замены" на фиг. 1) наряду с минимальным набором других компонентов, необходимых для описания того, как используется "сеть замены". Рамки с пунктирным контуром обозначают данные (изображения); эллипсы - объекты, содержащиеся в этих данных; прямоугольники с острыми углами - подпрограммы, реализующие нейронные сети; прямоугольники со скругленными углами - подпрограммы, управляющие процессом настройки параметров нейронной сети в процессе обучения; линии обозначают потоки данных в процессе обучения (тот факт, что стрелка указывает от одного блока к другому, означает, что результаты первого блока передаются во второй как ввод). Сеть сегментации - это нейронная сеть, которая берет изображение и выдает маску сегментации такого же размера. Сеть улучшения берет изображение и выводит его улучшенную версию (т.е. с более реалистичными красками, удаленными артефактами и т.д.) такого же размера.
По сравнению с [18], процесс обучения в SEIGAN оказался более стабильным и способным работать с более высокими разрешениями. Кроме того, предложенная архитектура позволяет решать больше задач одновременно (подрисовка и смешивание), а не только предсказывать маски сегментации. Как обычно в дизайне GAN, уникальной особенностью архитектуры является хорошее сочетание различных функций потерь. В SEIGAN используется комбинация состязательных потерь и потерь реконструкции и регуляризации.
Целью сети подрисовки Ginp является создание правдоподобного фона 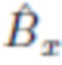 из изображения-источника
из изображения-источника 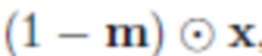 , которое представляет собой исходное изображение x с объектом, удаленным в соответствии с маской сегментации m, полученной путем применения сети сегментации
, которое представляет собой исходное изображение x с объектом, удаленным в соответствии с маской сегментации m, полученной путем применения сети сегментации 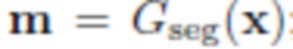 ; на практике пиксели заполняются белым цветом. Параметры сетей подрисовки оптимизируются во время непрерывного обучения в соответствии со следующими функциями потерь (показаны прямоугольниками с закругленными углами на фиг. 1).
; на практике пиксели заполняются белым цветом. Параметры сетей подрисовки оптимизируются во время непрерывного обучения в соответствии со следующими функциями потерь (показаны прямоугольниками с закругленными углами на фиг. 1).
Состязательная потеря фона направлена на улучшение правдоподобия получаемого изображения. Она реализуется специальной сетью- дискриминатором Dbg. Для Dbg используется та же архитектура, что и в исходном CycleGAN [30] за исключением количества слоев; эксперименты показали, что в предложенной схеме лучше работает более глубокий дискриминатор. В качестве функции потерь для Dbg используется состязательная потеря MSE, предложенная в Least Squares GAN (LSGAN) [16], поскольку на практике она гораздо стабильнее, чем другие типы функций потерь GAN:
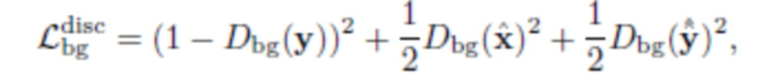
где 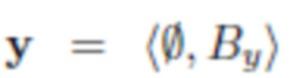 - исходное изображение фона,
- исходное изображение фона,
- изображение фона, полученное из x после первой замены, и - изображение фона, полученное из после второй замены.
Потеря реконструкции фона направлена на сохранение информации об исходном фоне Bx. Она реализуется с использованием потери текстуры [25], средней абсолютной разницы между матрицами Грама карт признаков после первых пяти уровней сетей VGG-16:
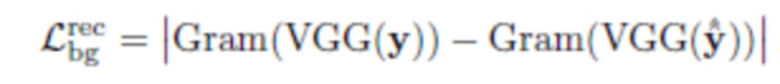
где VGG(y) - матрица признаков предварительно обученной нейронной сети классификации изображений (например, VGG, но не ограничиваясь ею) и 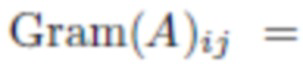
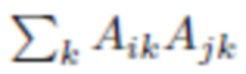 - матрица Грама.
- матрица Грама.
Авторы выбрали функции потерь на основании того, что существует множество возможных правдоподобных реконструкций фона, поэтому функции потерь должны допускать определенную степень свободы, которую не допускает средняя абсолютная ошибка или среднеквадратическая ошибка, но допускает потеря текстуры. В экспериментах авторов оптимизация MAE или MSE обычно приводила к тому, что созданное изображение заполнялось медианными или средними значениями пикселей без каких-либо объектов или текстуры. Следует отметить, что потери реконструкции фона применяются только к у ввиду отсутствия истинного фона для x (см. фиг. 1).
Еще важно отметить, что перед подачей изображения в сеть подрисовки Ginp часть изображения удаляется в соответствии с маской сегментации m, и это делается дифференцируемым образом без применения какого-либо порога к m. Следовательно, градиенты могут распространяться обратно через маску сегментации в сеть сегментации Gseg. Совместное обучение подрисовке и сегментации имеет эффект регуляризации. Во-первых, сеть подрисовки Ginp стремится к максимально точной маске: если она слишком мала, то Ginp придется стереть оставшиеся части объектов, что является проблемой большего порядка, а если она слишком велика, то Ginp будет иметь больше пустой области для подрисовки. Во-вторых, Ginp стремится к тому, чтобы маска сегментации m была высококонтрастной (со значениями, близкими к 0 и 1) даже без применения порога: если большая часть m имеет низкий контраст (близкий к 0,5), то Ginp придется научиться удалять "призрак" объекта (что гораздо сложнее, чем простая подрисовка в пустом пространстве), и, вероятнее всего, дискриминатору Dbg будет гораздо проще решить, что полученная картинка является фиктивной.
На фиг. 3 показан пример потребляемых и получаемых данных согласно предлагаемому способу. Значения изображений, слева направо, сверху вниз:
1) крайнее левое изображение в верхнем ряду - реальное входное изображение с объектом (пример "Исходное изображение 1" на фиг. 1);
2) второе изображение в верхнем ряду - реальное входное изображением без объектов (пример "Исходного изображения 2" на фиг. 1);
3) маска, предсказанная сетью сегментации с учетом изображения 1;
4) реальное входное изображение с объектом (другой пример "исходного изображения 1" на фиг. 1);
5) реальное входное изображение без объектов (еще один пример "исходного изображения 2" на фиг. 1);
6) крайнее левое изображение в нижнем ряду - вывод сети, на которой объект из изображения 1 удален с помощью маски на изображении 3 (пример "Созданного изображения 1" на фиг. 1);
7) вывод сети улучшения с объектом из изображения 1, вставленным в фон из изображения 2 (пример "Созданного изображения 2" на фиг. 1);
8) маска, предсказанная сетью сегментации с учетом изображения 4;
9) вывод сети подрисовки с объектом из изображения 4, удаленным маской на изображении 8 (другой пример "Созданного изображения 1" на фиг. 1);
10) вывод сети улучшения с объектом из изображения 4, вставленным в фон из изображения 5 (другой пример "Созданного изображения 2" на фиг. 1).
Для Ginp используется нейронная сеть, состоящая из двух остаточных, последовательно соединенных блоков (см. фиг. 4). Также выполнялись эксперименты с ShiftNet [27]. На фиг. 4 показана архитектура нейронной сети ResNet, использованной в качестве "сети подрисовки" и "сети сегментации". Эллипсы обозначают данные; прямоугольники - слои нейронных сетей. В левой части данной фигуры показана общая архитектура. В правой части представлено более подробное описание блоков, используемых в левой части. Стрелки обозначают поток данных (то есть вывод одного блока подается как ввод в другой блок). Conv2d обозначает сверточный слой; BatchNorm2d - уровень нормализации пакетов; ReLU - блок линейного выпрямления; ReflectionPad - заполнение пикселей отражением; ConvTranspose2d - слой обратной свертки.
Целью сети замены является создание нового изображения 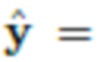
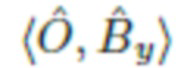 из двух исходных изображений:
из двух исходных изображений: 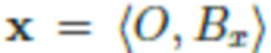 с объектом O и
с объектом O и 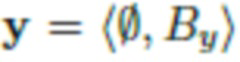 с другим фоном.
с другим фоном.
Сеть замены выполняет две основные операции: сегментацию Gseg и улучшение Genh (см. фиг. 2).
Сеть сегментации Gseg создает приблизительную маску сегментации 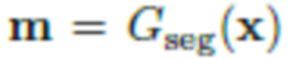 из x. Используя маску m, можно извлечь объект O из исходного изображения x и вставить его в By, чтобы получить "грубую" версию целевого изображения
из x. Используя маску m, можно извлечь объект O из исходного изображения x и вставить его в By, чтобы получить "грубую" версию целевого изображения 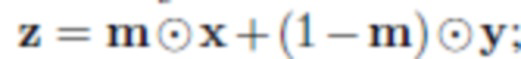 . z не является конечным результатом: ему не хватает сглаживания, коррекции цвета или освещенности и других улучшений. Следует отметить, что в идеальном случае вставка объекта естественным образом может также потребовать более глубокого понимания целевого фона; например, если мы хотим вставить собаку на травяное поле, то, вероятно, потребуется наложить немного фоновой травы перед собакой, прикрыв ее лапы, так как в реальности их не будет видно за травой.
. z не является конечным результатом: ему не хватает сглаживания, коррекции цвета или освещенности и других улучшений. Следует отметить, что в идеальном случае вставка объекта естественным образом может также потребовать более глубокого понимания целевого фона; например, если мы хотим вставить собаку на травяное поле, то, вероятно, потребуется наложить немного фоновой травы перед собакой, прикрыв ее лапы, так как в реальности их не будет видно за травой.
Для решения этой задачи авторы вводят так называемую нейронную сеть улучшения Genh, целью которой является создание "более плавного", более естественного изображения 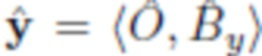 из исходных изображений x и y и маски сегментации m, что приведет к грубому результату
из исходных изображений x и y и маски сегментации m, что приведет к грубому результату 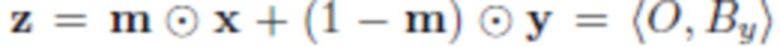 . Были проведены эксперименты с сетью улучшения, реализованной четырьмя различными способами:
. Были проведены эксперименты с сетью улучшения, реализованной четырьмя различными способами:
улучшение по принципу "черного ящика": Genh(x,y,m) выдает окончательное улучшенное изображение;
улучшение маски: Genh(x,y,m) выдает новую маску сегментации m', которая лучше подходит для объекта О и нового фона By вместе взятых;
улучшение цвета:
Genh(х,у,m)
выдает попиксельные множители ϒ для каждого канала, которые следует применить к грубому изображению: 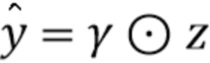 ; веса ϒ регуляризуются для приближения к 1 посредством дополнительной потери MSE;
; веса ϒ регуляризуются для приближения к 1 посредством дополнительной потери MSE;
гибридное улучшение: Genh(x,y,m) выдает новую маску m' и множители ϒ.
В любом случае, 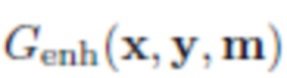 обозначает окончательное улучшенное изображение после того, как все выходы Genh были соответственно применены к z.
обозначает окончательное улучшенное изображение после того, как все выходы Genh были соответственно применены к z.
Сеть замены обучается непрерывно со следующими функциями потерь (показаны закругленными прямоугольниками на фиг. 1).
Потеря реконструкции объекта 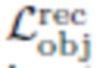 направлена на обеспечение согласованности и стабильности обучения. Она реализуется как средняя абсолютная разница между исходным изображением x=(О,Bx) и
направлена на обеспечение согласованности и стабильности обучения. Она реализуется как средняя абсолютная разница между исходным изображением x=(О,Bx) и
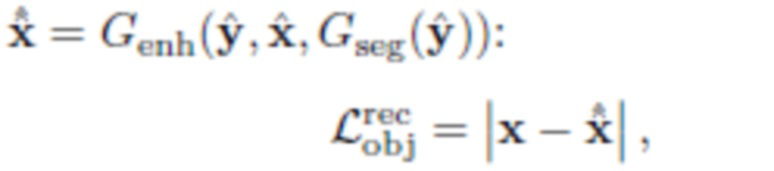
где 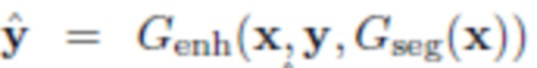 и
и
где 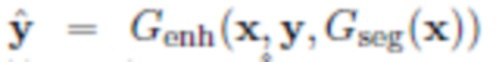 и
и 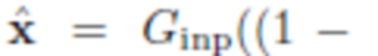
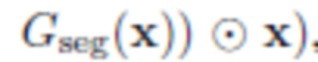 ,
,
т.е. является результатом применения сети замены к x и y дважды.
является результатом применения сети замены к x и y дважды.
Состязательная потеря объекта 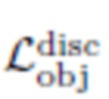 направлена на повышение правдоподобия
направлена на повышение правдоподобия 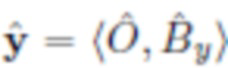 . Она реализуется с помощью специальной сети дискриминатора Dobj. Она также имеет побочный эффект максимизации области, покрытой маской сегментации
. Она реализуется с помощью специальной сети дискриминатора Dobj. Она также имеет побочный эффект максимизации области, покрытой маской сегментации 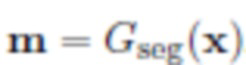 . Авторы применяют эту потерю ко всем изображениям с объектами: реальное изображение x и "фиктивные" изображения
. Авторы применяют эту потерю ко всем изображениям с объектами: реальное изображение x и "фиктивные" изображения  . В этом случае дискриминатор тоже имеет такую же архитектуру, как в CycleGAN [30], за исключением количества слоев, для которого было обнаружено, что лучше работает более глубокий дискриминатор. Здесь снова используется потеря MSK, инспирированная LSGAN [16]:
. В этом случае дискриминатор тоже имеет такую же архитектуру, как в CycleGAN [30], за исключением количества слоев, для которого было обнаружено, что лучше работает более глубокий дискриминатор. Здесь снова используется потеря MSK, инспирированная LSGAN [16]:
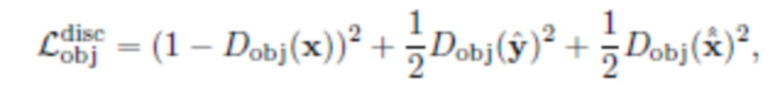
Потеря согласованности маски направлена на то, чтобы сделать сеть сегментации инвариантной относительно фона. Она реализуется как среднее абсолютное расстояние между m=Gseg(x), маской, извлеченной из x=(O,Bx), и m=Gseg(y), маской, извлеченной из 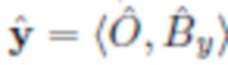 :
:
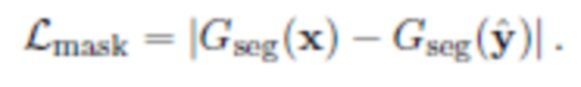
Эта маска представляет собой черно-белое изображение такого же размера, как и изображение, из которого была извлечена данная маска. Белые пиксели на маске соответствуют выбранным областям изображения (в этом случае пиксели, на которых изображен объект), черные пиксели соответствуют фону. Среднее абсолютное расстояние - это модуль разницы значений пикселей, усредненный по всем пикселям. Маска извлекается повторно, чтобы убедиться, что нейронная сеть, извлекающая маску, точно откликается на форму объекта и не откликается на фон позади нее (иными словами, маски для одного и того же объекта должны быть всегда одинаковыми).
И наконец, помимо функций потери, описанных выше, использовалась потеря идентичности, идея которой была выдвинута в CycleGAN [30]. Вводятся два различных случая потери идентичности:
Потеря улучшения идентичности объекта
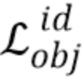 приближает результат сети улучшения Genh на реальных изображениях к идентичности: она представляет собой среднее расстояние между Genh{x) и самим x:
приближает результат сети улучшения Genh на реальных изображениях к идентичности: она представляет собой среднее расстояние между Genh{x) и самим x:
=|Genh(x)-x|;
Потеря идентичности фона
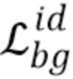 пытается обеспечить, чтобы архитектура вырезки и подрисовки не делала ничего с изображением, не содержащим объектов: для изображения
пытается обеспечить, чтобы архитектура вырезки и подрисовки не делала ничего с изображением, не содержащим объектов: для изображения 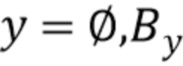 находят маску сегментации Gseg(y), вычитают ее из у для получения (1-Gseg(y))
находят маску сегментации Gseg(y), вычитают ее из у для получения (1-Gseg(y)) y, применяют подрисовку Ginp и затем минимизируют среднее расстояние между исходным у и результатом:
y, применяют подрисовку Ginp и затем минимизируют среднее расстояние между исходным у и результатом:

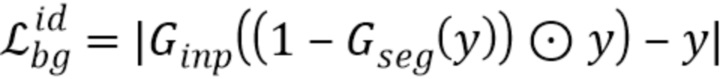
Общая функция потерь SEIGAN представляет собой линейную комбинацию всех описанных выше функций потерь:
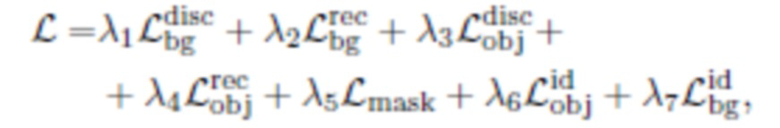
с коэффициентами , выбранными эмпирически.
Во время экспериментов авторы заметили несколько интересных эффектов. Во-первых, перед объединением исходные изображения 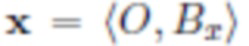 и у =
и у =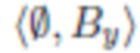 могут иметь различные масштаб и пропорции. Изменение их масштаба для получения одинаковой формы с помощью билинейной интерполяции внесло бы значительные различия в текстуры низкого уровня, которые дискриминатор бы очень легко идентифицировал как фиктивные и тем самым воспрепятствовал конвергенции в GAN.
могут иметь различные масштаб и пропорции. Изменение их масштаба для получения одинаковой формы с помощью билинейной интерполяции внесло бы значительные различия в текстуры низкого уровня, которые дискриминатор бы очень легко идентифицировал как фиктивные и тем самым воспрепятствовал конвергенции в GAN.
Авторы [18] столкнулись с такой же проблемой и решили ее с помощью специальной процедуры, которую они использовали для создания обучающих образцов: они брали патчи переднего плана и фона только с одного и того же изображения, чтобы обеспечить одинаковый масштаб и пропорции, тем самым уменьшая разнообразие и количество изображений, подходящие для обучающего набора. В предложенной схеме эту задачу решает отдельная сеть улучшения, поэтому имеется меньше ограничений при поиске подходящих обучающих данных.
Другим интересным эффектом является низкий контраст в масках сегментации, когда подрисовка оптимизируется относительно потерь реконструкции MAE или MSE. Низкоконтрастная маска (т.е. m со многими значениями около 0,5, а не близко к 0 или 1) позволяет информации об объекте "просачиваться" из исходного изображения и облегчать реконструкцию. Подобный эффект был замечен ранее другими исследователями, и в архитектуре CycleGAN он даже использовался для стеганографии [4]. Авторы сначала решили эту проблему путем преобразования мягкой маски сегментации в жесткую маску просто с помощью применения порога. Позже было обнаружено, что оптимизация подрисовки относительно потери текстуры 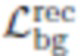 является более элегантным решением, приводящим к лучшим результатам, чем применение порога.
является более элегантным решением, приводящим к лучшим результатам, чем применение порога.
Для сети сегментации Gseg авторы использовали архитектуру из CycleGAN [30], которая сама по себе является адаптацией архитектуры из [10]. Для повышения эффективности слои ConvTranspose были заменены билинейной повышающей выборки. Кроме того, после последнего уровня сети использовалась логистическая сигмоида в качестве функции активации.
Для сети улучшения Genh использовалась архитектура U-net [20], поскольку она способна работать как с изображениями с высоким разрешением, так и вносить небольшие изменения в исходное изображение. Это важно для предложенной схемы ввиду стремления авторов просто "сгладить" границы вставленного изображения в сети улучшения более разумным способом, не внося существенного изменения в содержание изображения.
На фиг. 5 изображена архитектура нейронной сети U-Net, используемой в качестве "сети подрисовки" и "сети улучшения". Эллипсы обозначают данные; прямоугольники - слои нейронных сетей. В левой части фигуры показана общая архитектура. Правая часть фигуры содержит более подробное описание блоков, используемых в левой части. Стрелки обозначают поток данных (т.е. вывод одного блока подается как ввод в другой блок). Conv2d обозначает сверточный слой; BatchNorm2d - уровень нормализации пакета; ReLU - блок линейного выпрямления; ReflectionPad - заполнение пикселей отражением; ConvTranspose2d - слой обратной свертки.
Подготовка данных
Большая часть экспериментов согласно изобретению выполняется на изображениях, доступных на Flickr по лицензии Creative Commons. Для сборки исходного изображения использовался запрос "собака". Затем использовалась предварительно обученная Faster R-CNN для обнаружения всех объектов (включая собак) и всех областей без объектов. Далее было создано два набора данных 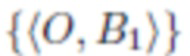 (из областей с собаками) и {(B2)} (из областей без объектов любого класса). После сбора данных была выполнена процедура фильтрации данных, чтобы получить области изображений без посторонних объектов.
(из областей с собаками) и {(B2)} (из областей без объектов любого класса). После сбора данных была выполнена процедура фильтрации данных, чтобы получить области изображений без посторонних объектов.
Процедура фильтрации выполнялась следующим образом. Сначала использовалась Faster R-CNN [19] (предварительно обученная на MS COCO (14]), чтобы обнаружить все объекты на изображении. Затем получали вырезки введенного изображения в соответствии со следующими правилами:
1. После масштабирования размер объекта равен 64×64 и размер конечной вырезки равен 128×128;
2. Объект расположен в центре вырезки;
3. Нет других объектов, которые пересекаются с данной вырезкой;
4. Исходный размер объекта на вырезке превышает 60 (по меньшей стороне) и не превышает 40 процентов от всего исходного изображения (по большей стороне).
Представленные выше примерные варианты осуществления являются примерами и не должны рассматриваться как ограничивающие. Кроме того, описание этих примерных вариантов предназначено для иллюстрации, а не для ограничения объема притязаний, и для специалистов будут очевидны многие альтернативы, модификации и варианты.
ЛИТЕРАТУРА:
[1] J A. Almahairi. S. Rajeswar, A. Sordoni, R Bachman, and A. Courville. Augmented cyclegan: Learning many-to-many mappings from unpaiied data. arXiv preprint arXiv.l802.10151. 2018.
[2] K. Bousmalis. A. Iipan. P. Wohlhait. Y. Bai. M. Kelcey.
M. Kalakrishnan. L Downs. J. I bar/. P. Pastor. K. Konolige. et al. Using simulation and domain adaptation to improve efficiency of deep robotic grasping. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 4243-4250. IEEE, 2018.
[3] Y. Choi. M. Choi. M. Kim. J.-W. Ha. S. Kim. and J. Choo. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. arXiv preprint. 1711, 2017.
[4] C. Chu. A. Zhmoginov. and M. Sandler. Cyclegan: a master of steganography. arXiv preprint arXiv: 1712.02950,2017.
[5] M. Cordts. M. 6mran. S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson. U. Franke. S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016.
[6] I. Goodfellow, J. Pouget-Abadie. M. Miiza, B. Xu, D. Warde-Farley. S. Ozair. A. Courville. and Y. Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672-2680, 2014.
[7] V. Gupta and S. Raman. Automatic trimap generation for image matting. In Signal and Information Processing (ICon-SIP). International Conference on. pages 1-5. IEEE. 2016.
[8] H. Huang. X. Fang. Y. Ye. S. Zhang, and P. L Rosin Prac-tical automatic background substitution for live video. Computational Visual Media, 3(3):273-284.2017.
[9] X. Ji, J. F. Henriques, and A. Vedaldi. Invariant information distillation for unsupervised image segmentation and clustering. arXiv preprint arXiv:1807.06653, 2018.
[10] J. Johnson, A. Alahi, and F. Li. Perceptual losses for real-time style transfer and super-resolution. CoRR, abs/1603.08155, 2016.
[11] S. Kazemzadeh, V. Ordonez, M. Matten, and T. Berg. Referitgame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 conference on empirical methods in natural language processing {EMNLP), pages 787-798,2014.
[12] A. Khoreva, R. Benenson, J. H. Hosang, M. Hein, and B. Schiele. Simple does it: Weakly supervised instance and semantic segmentation. In CVPR, volume 1, page 3,2017.
[13] R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y. Kalantidis, L.-J. Li, D. A. Shamma, M. Bernstein, and L Fei-Fei. Visual genome: Connecting language and vision using crowdsourced dense image annotations. 2016.
[14] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740-755. Springer, 2014.
[15] M.-Y. Liu, T. Breuel, and J. Kautz. Unsupervised image-to image translation networks. In Advances in Neural Information Processing Systems, pages 700-708, 2017.
[16] X. Mao, Q. Li, H. Xie, R. Lau, Z. Wang, and S. P. Smol-
ley. Least squares generative adversarial networks, arxiv preprint. arXiv preprint ArXiv:1611.04076, 2(5), 2016.
[17] B. A. Plummer, L. Wang, С. M. Cervantes, J. С Caicedo, J. Hockenmaier, and S. Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In Proceedings of the IEEE international conference on computer vision, pages 2641-2649, 2015.
[18] T. Remez, J. Huang, and M. Brown. Learning to segment via
cut-and-paste. arXiv preprint arXiv:1803.06414, 2018.
[19] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91-99,2015.
[20] O. Ronneberger, P Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. CoRR, abs/1505.04597,2015.
[21] С. Rother, V. Kolmogorov, and A. Blake. Grabcut: Interactive foreground extraction using iterated graph cuts. In ACM transactions on graphics (TOG), volume 23, pages 309-314. ACM, 2004.
[22] Т.-C. Wang, M.-Y. Liu, J.-Y. Zhu, A. Tao, J. Kautz, and B. Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. arXiv preprint arXiv:1711.11585,2017.
[23] Z. Wu, R. Chang, J. Ma, C. Lu, and C.-K. Tang. Annotation-free and one-shot learning for instance segmentation of homogeneous object clusters. arXiv preprint arXiv:1802.00383, 2018.
[24] X. Xia and B. Kulis. W-net: A deep model for fully unsupervised image segmentation. arXiv preprint arXiv:1711.08506, 2017.
[25] W. Xian, P. Sangkloy, J. Lu, С Fang, F. Yu, and J. Hays. Texturegan: Controlling deep image synthesis with texture patches. CoRR, abs/1706.02823, 2017.
[26] N. Xu, B. L. Price, S. Cohen, and T. S. Huang. Deep image matting. In CVPR, volume 2, page 4, 2017.
[27] Z. Yan, X. Li, M. Li, W. Zuo, and S. Shan. Shift-net: Image inpainting via deep feature rearrangement. arXiv preprint arXiv:1801.09392, 2018.
[28] L. Yu, Z. Lin, X. Shen, J. Yang, X. Lu, M. Bansal, and T. L. Berg. Mattnet: Modular attention network for referring expression comprehension. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[29] Y. Zhang, L. Yuan, Y. Guo, Z. He, I.-A. Huang, and H. Lee. Discriminative bimodal networks for visual localization and detection with natural language queries. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[30] J. Zhu, T. Park, P. Isola, and A. A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. CoRR, abs/1703.10593, 2017.
[31] J.-Y. Zhu, R. Zhang, D. Pathak, T. Darnell, A. A. Efros, O. Wang, and E. Shechtman. Toward multimodal image-to-image translation. In Advances in Neural Information Processing Systems, pages 465-176, 2017.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИНТЕРАКТИВНАЯ СЕГМЕНТАЦИЯ ИЗОБРАЖЕНИЙ | 2023 |
|
RU2833268C1 |
| ОБУЧЕНИЕ GAN (ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ) СОЗДАНИЮ ПОПИКСЕЛЬНОЙ АННОТАЦИИ | 2019 |
|
RU2735148C1 |
| Повторный синтез изображения, использующий прямое деформирование изображения, дискриминаторы пропусков и основанное на координатах реконструирование | 2019 |
|
RU2726160C1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| СПОСОБ ИНТЕРАКТИВНОЙ СЕГМЕНТАЦИИ ОБЪЕКТА НА ИЗОБРАЖЕНИИ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2742701C1 |
| НЕЙРОСЕТЕВОЙ ПЕРЕНОС ВЫРАЖЕНИЯ ЛИЦА И ПОЗЫ ГОЛОВЫ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ ДЕСКРИПТОРОВ ПОЗЫ | 2020 |
|
RU2755396C1 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| Система и способ для получения обработанного выходного изображения, имеющего выбираемый пользователем показатель качества | 2023 |
|
RU2823750C1 |
| СПОСОБ И УСТРОЙСТВО УЛУЧШЕНИЯ РЕЧЕВОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ БЫСТРОЙ СВЕРТКИ ФУРЬЕ | 2022 |
|
RU2795573C1 |

Изобретение относится к области обработки изображений. Техническим результатом является повышение эффективности обработки изображений. Вычислительная система для выполнения автоматической обработки изображений содержит: первую нейронную сеть для формирования грубого изображения z путем сегментации объекта O из исходного изображения x, содержащего объект O и фон Bx, с помощью маски сегментации, и вырезки с помощью данной маски сегментированного объекта O из изображения x и вставки его в изображение y, содержащее только фон By; вторую нейронную сеть для создания улучшенной версии изображения 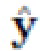 с вставленным сегментированным объектом O путем улучшения грубого изображения z на основе исходных изображений x и y и маски m; третью нейронную сеть для восстановления изображения только фона
с вставленным сегментированным объектом O путем улучшения грубого изображения z на основе исходных изображений x и y и маски m; третью нейронную сеть для восстановления изображения только фона 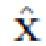 без удаленного сегментированного объекта O путем подрисовки изображения, полученного путем обнуления пикселей изображения x с использованием маски m; причем первая, вторая и третья нейронные сети объединены в общую архитектуру нейронной сети для последовательного выполнения сегментации, улучшения и подрисовки и одновременного обучения; при этом общая архитектура нейронной сети принимает изображения и выдает обработанные изображения одинаковых размеров. 2 н. и 24 з.п. ф-лы, 5 ил.
без удаленного сегментированного объекта O путем подрисовки изображения, полученного путем обнуления пикселей изображения x с использованием маски m; причем первая, вторая и третья нейронные сети объединены в общую архитектуру нейронной сети для последовательного выполнения сегментации, улучшения и подрисовки и одновременного обучения; при этом общая архитектура нейронной сети принимает изображения и выдает обработанные изображения одинаковых размеров. 2 н. и 24 з.п. ф-лы, 5 ил.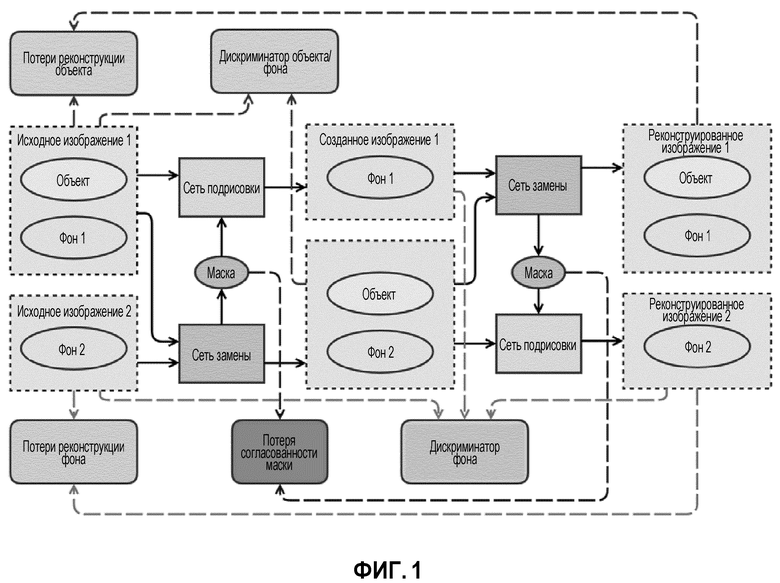
1. Вычислительная система для выполнения автоматической обработки изображений, содержащая:
первую нейронную сеть
для формирования грубого изображения z путем сегментации объекта O из исходного изображения x, содержащего объект O и фон Bx, с помощью маски сегментации, и вырезки с помощью данной маски сегментированного объекта O из изображения x и вставки его в изображение y, содержащее только фон By;
вторую нейронную сеть
для создания улучшенной версии изображения 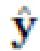 с вставленным сегментированным объектом O путем улучшения грубого изображения z на основе исходных изображений x и y и маски m;
с вставленным сегментированным объектом O путем улучшения грубого изображения z на основе исходных изображений x и y и маски m;
третью нейронную сеть
для восстановления изображения только фона 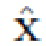 без удаленного сегментированного объекта O путем подрисовки изображения, полученного путем обнуления пикселей изображения x с использованием маски m;
без удаленного сегментированного объекта O путем подрисовки изображения, полученного путем обнуления пикселей изображения x с использованием маски m;
причем первая, вторая и третья нейронные сети объединены в общую архитектуру нейронной сети для последовательного выполнения сегментации, улучшения и подрисовки и одновременного обучения, при этом общая архитектура нейронной сети принимает изображения и выдает обработанные изображения одинаковых размеров.
2. Система по п. 1, в которой первая, вторая и третья нейронные сети являются генераторами, которые создают изображения и и конвертируют их.
3. Система по п. 2, дополнительно содержащая две нейронные сети, сконфигурированные как дискриминаторы, которые оценивают достоверность изображений.
4. Система по п. 3, в которой первый дискриминатор является дискриминатором фона, который пытается провести различие между эталонным реальным изображением фона и подрисованным изображением фона; второй дискриминатор является дискриминатором объекта, который пытается провести различие между эталонным реальным изображением объекта O и улучшенным изображением объекта O.
5. Система по любому из пп. 2-4, в которой первая и вторая нейронные сети составляют сеть замены.
6. Система по п. 5, в которой сеть замены выполнена с возможностью непрерывного обучения с функциями потерь для создания улучшенной версии изображения с вставленным сегментированным объектом О.
7. Система по п. 6, в которой одна из функций потерь является функцией реконструкции объекта для обеспечения согласованности и стабильности обучения и реализуется как средняя абсолютная разница между изображением х и изображением .
8. Система по п. 6, в которой одна из функций потерь является состязательной функцией объекта для повышения правдоподобия изображения и реализуется с помощью выделенной сети дискриминатора.
9. Система по п. 6, в которой одна из функций потерь является функцией согласованности маски для придания первой сети инвариантности относительно фона и реализуется как среднее абсолютное расстояние между маской, извлеченной из изображения x, и маской, извлеченной из изображения .
10. Система по п. 6, в которой одна из функций потерь является функцией улучшения идентичности объекта, которая вынуждает вторую сеть создавать изображения, более близкие к реальным изображениям, и представляет собой среднее абсолютное расстояние между Genh(x) и самим х.
11. Система по п. 6, в которой одна из функций потерь представляет собой функцию идентичности фона для обеспечения того, чтобы общая архитектура не делала ничего с изображением, которое не содержит объектов.
12. Система по п. 6, в которой одна из функций потерь представляет собой общую функцию потерь, которая является линейной комбинацией функции реконструкции объекта, состязательной функции объекта, функции согласованности маски, функции улучшения идентичности объекта, функции идентичности фона.
13. Система по п. 1, в которой маска сегментации прогнозируется первой сетью с учетом изображения x.
14. Способ автоматической обработки изображений, заключающийся в том, что,
используя первую нейронную сеть,
- формируют грубое изображение z путем сегментации объекта O из исходного изображения x, содержащего объект O и фон Bx, с помощью маски сегментации, и, используя маску, вырезают сегментированный объект O из изображения x и вставляют его в изображение y, содержащее только фон By;
используя вторую нейронную сеть,
- создают улучшенную версию изображения с вставленным сегментированным объектом O посредством улучшения грубого изображения z на основе исходных изображений x и у и маски m;
используя третью нейронную сеть,
- восстанавливают изображение только фона без удаленного сегментированного объекта O путем подрисовки изображения, полученного путем обнуления пикселей изображения x с использованием маски m;
выводят изображения и одинакового размера.
15. Способ по п. 14, в котором первая, вторая и третья нейронные сети являются генераторами, которые создают изображения и и конвертируют их.
16. Способ по п. 15, дополнительно содержащий две нейронные сети, сконфигурированные как дискриминаторы, которые оценивают достоверность изображений.
17. Способ по п. 16, в котором первый дискриминатор является дискриминатором фона, который пытается провести различие между эталонным реальным изображением фона и подрисованным изображением фона; второй дискриминатор является дискриминатором объекта, который пытается провести различие между эталонным реальным изображением объекта O и улучшенным изображением объекта O.
18. Способ по любому из пп. 15-17, в котором первая и вторая нейронные сети составляют сеть замены.
19. Способ по п. 18, в котором сеть замены выполнена с возможностью непрерывного обучения с функциями потерь для создания улучшенной версии изображения с вставленным сегментированным объектом О.
20. Способ по п. 19, в котором одна из функций потерь является функцией реконструкции объекта для обеспечения согласованности и стабильности обучения и реализуется как средняя абсолютная разница между изображением х и изображением .
21. Способ по п. 19, в котором одна из функций потерь является состязательной функцией объекта для повышения правдоподобия изображения и реализуется с помощью выделенной сети дискриминатора.
22. Способ по п. 19, в котором одна из функций потерь является функцией согласованности маски для придания первой сети инвариантности относительно фона и реализуется как среднее абсолютное расстояние между маской, извлеченной из изображения x, и маской, извлеченной из изображения .
23. Способ по п. 19, в котором одна из функций потерь является функцией улучшения идентичности объекта для улучшения второй сети для получения изображений, более близких к реальным изображениям, и представляет собой среднее абсолютное расстояние между Genh(x) и самим х.
24. Способ по п. 19, в котором одна из функций потерь представляет собой функцию идентичности фона для обеспечения того, чтобы общая архитектура не делала ничего с изображением, которое не содержит объектов.
25. Способ по п. 19, в котором одна из функций потерь представляет собой общую функцию потерь, которая является линейной комбинацией функции реконструкции объекта, состязательной функции объекта, функции согласованности маски, функции улучшения идентичности объекта, функции идентичности фона.
26. Способ по п. 14, в котором маска сегментации прогнозируется первой сетью с учетом изображения x.
| US 7720283 B2, 18.05.2010 | |||
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| УСТРОЙСТВО БЕСШОВНОГО ОБЪЕДИНЕНИЯ ИЗОБРАЖЕНИЙ В ЕДИНУЮ КОМПОЗИЦИЮ С АВТОМАТИЧЕСКОЙ РЕГУЛИРОВКОЙ КОНТРАСТНОСТИ И ГРАДИЕНТОМ | 2014 |
|
RU2580473C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБРАБОТКИ ИЗОБРАЖЕНИЯ | 2014 |
|
RU2583725C1 |

