Предлагаемое изобретение относится к вычислительной технике и, в частности, к области параллельных вычислений в средах функционального программирования и может быть использовано для решения задач интеллектуального анализа данных.
Реализация параллельного выполнения вычислений, в общем случае, является сложной задачей. В большинстве случаев распараллеливание для выполнения задач осуществляется применительно к конкретному приложению и конкретной задаче. Такой подход является весьма трудоемким и, при этом, может быть малоэффективным по причине ошибок, которые может допустить разработчик при его осуществлении.
Особенно это характерно для задач интеллектуального анализа данных (ИАД). Такой вид анализа данных обычно предполагает обработку больших объемов цифровых данных, полученных после преобразования входных сигналов, что, соответственно, требует использования значительных вычислительных ресурсов для обеспечения приемлемого времени выполнения ИАД. Поэтому актуальным направлением в разработке и реализации ИАД является ориентация на выполнение анализа в распределенной вычислительной среде, которое должно поддерживаться методами реализации ИАД с целью его распараллеливания.
Известен способ выполнения обработки данных в среде распределенной и параллельной обработки (патент США №9612883, приоритет от 06.12.2013), который также иногда называют MapReduce.
Способ включает (в совокупности соединенных между собой вычислительных подсистем, каждая из которых имеет один или несколько процессоров и память):
- выполнение множества рабочих процессов;
- выполнение не зависящего от приложения контрольного процесса для:
- определения для входных файлов множества задач обработки данных, включая множество данных, специфицирующих задачи отображения из входных файлов, которые будут обработаны для получения промежуточных значений данных, и множества задач сокращения, определяющих промежуточные значения данных, которые будут переработаны в финальные выходные данные;
- присвоение задачам обработки данных статуса незанятых в рабочих процессах, а именно использование совокупности не зависящих от приложения функций отображения, выполняемых первым подмножеством из множества рабочих процессов, чтобы считывать части входных файлов, содержащих данные, и сформировать промежуточные значения данных посредством применения, по крайней мере, одной, определенной пользователем, специализированной приложением операции отображения к данным;
- сохранение промежуточных значений данных в совокупности промежуточных структур данных, распределенных среди множества соединенных между собой вычислительных подсистем;
- использование совокупности не зависящих от приложения функций сокращения, отличных от совокупности не зависящих от приложения функций отображения, чтобы сформировать финальные выходные данные посредством применения, по крайней мере, одной, определенной пользователем, специализированной приложением операции сокращения с промежуточными значениями данных, причем совокупность не зависящих от приложения функций сокращения выполняется вторым подмножеством из множества рабочих процессов.
При этом совокупность не зависящих от приложения функций отображения и совокупность не зависящих от приложения функций сокращения независимы от специализированных приложением операторов и операций, включая, по крайней мере, одну определенную пользователем, специализированную приложением операцию отображения и, по крайней мере, одну, определенную пользователем, специализированную приложением операцию сокращения.
Способ может также включать применение операции разделения, по крайней мере, к подмножеству промежуточных значений данных, причем для каждого соответствующего промежуточного значения данных, по крайней мере, в подмножестве промежуточных значений данных, операция разделения определяет соответствующую промежуточную структуру данных множества промежуточных структур данных, в которых сохраняются соответствующее промежуточное значение данных.
Способ может также предусматривать, что соответствующая специализированная приложением операция отображения включает специализированную приложением операцию объединения для объединения начальных значений, сформированных посредством выполнения соответствующей специализированной приложением операцией отображения, так чтобы сформировать промежуточные значения данных.
В ходе применения способа количество задач отображения превышает значение множества процессов, которым контролирующий процесс может назначить задачи отображения, а контролирующий процесс поддерживает информацию о состоянии относительно задач отображения, ждущих назначения в рабочий процесс.
Основным недостатком известного способа является то, что он подходит только для некоторых задач ИАД. При этом существуют методы ИАД, например, Apriori, PageRank и др., для которых известный способ не походит, так как используемые ими функции не обладают списочным гомоморфизмом (Gorlatch S. Extracting and Implementing List Homomorphisms in Parallel Program Development // Science of Computer Programming, 1999, v. 33, pp. 1-27; Dean J., Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters // In Proceedings of the USENIX Symposium on Operating SystemsDesign & Implementation (OSDI), 2004, pp. 137-147; Harmelen R, Kotoulas S., Oren E., Urbani J. Scalable Distributed Reasoning using Map Reduce // Proceedings of the International Semantic Web Conference, 2009, v. 5823, pp. 293-309).
Функциями не обладающими списочным гомоморфизмом являются функции, которые дают разные результаты, в случае, если применять их к полному набору данных, по сравнению со случаем, если применять функцию к частям входных данных с последующим объединением результатов. Если разделить входные данные ИАД, не обладающего списочным гомоморфизмом, на части, и далее применить функцию отдельно к полученным частям, а после получения результатов для отдельных частей входных данных объединить полученные результаты, то финальные результаты будут некорректными (Gibbons J. The Third Homomorphism Theorem // Journal of Functional Programming, 1996, v. 6, pp. 657-665).
Известен способ распараллеливания программ в среде логического программирования в вычислительной системе (патент РФ №2691860, приоритет от 25.06.2018), позволяющий распараллеливать в среде логического программирования программы, реализующие функции, не обладающие списочным гомоморфизмом, а также уменьшающий вероятность ошибок пользователя.
Способ распараллеливания программ в среде логического программирования в вычислительной системе, включающей совокупность соединенных между собой систем, каждая из которых имеет один или несколько процессоров и память, причем каждая система содержит установленное на каждую систему и сконфигурированное программное обеспечение, выполненное с возможностью:
- передачи данных из множества рабочих процессов в главный рабочий процесс,
- приема данных в главном рабочем процессе из множества рабочих процессов,
- определения номера рабочего процесса в системе,
- выполнения множества рабочих процессов, в том числе главного рабочего процесса,
- передачи рабочих процессов в системы для выполнения множества рабочих процессов, в том числе и главного рабочего процесса
- считывания из входных файлов или баз данных множества входных данных, специфицирующих задачу,
- хранения фактов в базе знаний,
- осуществления процесса логического вывода; заключающийся в том, что пользователи:
- получают входные данные и приложение для их обработки;
- формируют предикаты, при удовлетворении которых, в процессе логического вывода входные данные из файлов или баз данных преобразуются в факты базы знаний;
- осуществляют декомпозицию метода анализа на отдельные шаги, которые представляют собой предикаты, являющимися левой частью логического правила, реализующего метод;
- формируют предикат для разбиения входных данных на части для работы одного из множества рабочих процессов;
- формируют предикат для объединения результатов работы множества рабочих процессов в единую промежуточную модель знаний в виде фактов базы знаний;
- формируют предикат приема данных главного рабочего процесса, выполненный с возможностью принимать данные из множества рабочих процессов;
- формируют предикат главного рабочего процесса, являющийся правой частью правила, при этом левая часть состоит из предикатов:
- передачи данных во множество рабочих процессов,
- приема данных в главном рабочем процессе,
- записи полученных фактов в базу знаний главного рабочего процесса,
- объединения результатов работы множества рабочих процессов в единую промежуточную модель знаний;
- формируют предикаты рабочих процессов, при этом данные предикаты являются правой частью правил, при этом левая часть состоит из предикатов:
- преобразования входных данных из файлов или баз данных в факты базы знаний,
- разбиения входных данных на части для работы одного из множества рабочих процессов,
- приема данных главного рабочего процесса из множества рабочих процессов для получения промежуточной модели знаний,
- записи полученных фактов в базу знаний набора операций, выполняемых на множестве рабочих процессов,
- обособленных предикатов, реализующих шаг метода,
- передачи результатов удовлетворения процессом логического вывода обособленных предикатов в главный рабочий процесс;
- запускают на выполнение множество рабочих процессов и главный рабочий процесс, с помощью чего выполняют следующие действия:
- в процессе логического вывода последовательно удовлетворяют, предикаты, представляющие шаги приложения, начиная с первого, на множестве рабочих процессов, причем на каждом шаге:
• разбивают данные на части для работы одного из множества рабочих процессов,
• преобразуют входные данные из файлов или баз данных в факты базы знаний,
• в процессе логического вызова удовлетворяют предикат, представляющий шаг метода,
• передают после удовлетворения предиката, представляющего шаг метода, сформированные в базе знаний факты из множества рабочих процессов в главный рабочий процесс,
• принимают данные из множества рабочих процессов в главном рабочем процессе,
• помещают полученные факты в базу знаний главного рабочего процесса,
• объединяют с помощью предиката объединения результаты работы множества рабочих процессов в единую промежуточную модель знаний и таким образом формируют в базе знаний главного рабочего процесса единую промежуточную модель знаний,
• далее данная промежуточная модель в виде фактов используется на следующем шаге в процессе логического вывода в вычислительной системе;
- после удовлетворения в процессе логического вывода всех предикатов, представляющих шаги метода, объединяют полученные на последнем шаге результаты работы множества рабочих процессов;
- получают финальную выходную модель знаний в виде фактов в базе знаний главного рабочего процесса.
Способ подразумевает использование языка и среды логического программирования.
Известный способ относится к вычислительной технике и, в частности, к области параллельных вычислений и может быть использован для решения задач интеллектуального анализа данных в средах логического программирования.
Описанный известный способ принят за прототип.
Однако, известный способ имеет недостатки. Способ подходит к операциям, реализованным в средах логического программирования, но отсутствует возможность его применения к операциям, реализованным в средах функционального программирования.
Задачей, на решение которой направлено заявляемое изобретение, является задача интеллектуального анализа данных в распределенной вычислительной среде. В результате решения указанной задачи возникает техническое решение, характеризующееся:
1) появлением возможности распараллеливания нового класса набора операций, в частности набора операций, реализованных в средах функционального программирования,
2) снижением вероятности ошибки пользователя посредством использования среды функционального программирования, а, следовательно, повышением качества реализации распараллеливания.
Для этого предлагается способ распараллеливания ИАД в вычислительной среде, включающей совокупность соединенных между собой подсистем, каждая из которых имеет один или несколько процессоров и память, причем каждая подсистема содержит установленное на каждую подсистему и сконфигурированное программное обеспечение, выполненное с возможностью:
- передачи данных из множества рабочих процессов в главный рабочий процесс,
- приема данных в главном рабочем процессе из множества рабочих процессов,
- определения номера рабочего процесса в подсистеме,
- выполнения множества рабочих процессов, в том числе главного рабочего процесса (при этом, в ходе выполнения процессов выполняются наборы операций, созданные в среде функционального программирования),
- передачи рабочих процессов в подсистемы для выполнения множества рабочих процессов, в том числе и главного рабочего процесса,
- считывания из входных файлов или баз данных множества входных данных, специфицирующих задачу,
- сохранения промежуточных и финальных значений данных. Применение способа заключается в том, что пользователи:
- получают входные данные и приложение для их обработки,
- в среде функционального программирования формируют библиотечные функции, реализующие циклы по спискам атрибутов и спискам векторов
- в среде функционального программирования формируют функции отображения, преобразующие входные данные из файлов или баз данных в набор списочных структур данных, содержащих списки атрибутов и списки векторов;
- осуществляют декомпозицию приложения в последовательность обособленных функций, реализующих шаги приложения и представляющих собой функции без последействия
- в среде функционального программирования формируют функцию разбиения входных данных на части для работы одного из множества рабочих процессов;
- в среде функционального программирования формируют функцию объединения результатов работы множества рабочих процессов в единую промежуточную модель знаний в виде набора списочных структур данных;
- в среде функционального программирования формируют функцию для формирования финальной выходной модели знаний из промежуточной модели знаний, полученной на последнем этапе;
- в среде функционального программирования формируют функцию приема данных главного рабочего процесса, выполненную с возможностью принимать данные из множества рабочих процессов;
- в среде функционального программирования формируют функцию главного рабочего процесса, выполненную с возможностью запускать выполнение
- функции разбиения входных данных на части;
- обособленных функций на множестве рабочих процессов;
- функции объединения;
- функции приема данных главного рабочего процесса;
- в среде функционального программирования формируют функцию рабочих процессов, выполненную с возможностью запускать выполнение
- обособленные функции в данном рабочем процессе,
- функции передачи результатов работы обособленных функций в главный рабочий процесс;
- запускают выполнение функции главного рабочего процесса, с помощью которой выполняют следующие действия:
- преобразуют с помощью функции отображения входные данные из файлов или баз данных в набор списочных структур данных, содержащих списки атрибутов и списки векторов;
- передают входные данные и входную модель знаний на первом шаге в первую обособленную функцию, реализующую шаг приложения;
- выполняют последовательность обособленных функций, реализующих шаги приложения, начиная с первой, на множестве рабочих процессов, причем на каждом шаге
• выполняют заданные преобразования в обособленной функции;
• передают после завершения работы обособленной функции промежуточные структуры данных из множества рабочих процессов в главный рабочий процесс;
• принимают данные из множества рабочих процессов в главном рабочем процессе;
• объединяют с помощью функций объединения результаты работы множества рабочих процессов в единую промежуточную модель знаний;
• передают исходные структуры данных и единую промежуточную модель знаний в следующую обособленную функцию;
- после окончания работы всех обособленных функций формируют из полученной на последнем шаге единой промежуточной модели знаний финальную выходную модель знаний;
- получают финальную выходную модель знаний.
Предлагаемый способ подразумевает подход к распараллеливанию ИАД на функциональных языках программирования. Способ подразумевает использование функциональных языков программирования. Использование функциональных языков программирования снижает вероятность ошибки пользователя, по сравнению с реализацией на императивных языках. Это достигается, в том числе, благодаря отсутствию при функциональном подходе потенциальных ошибок, связанных с переменными и присваиванием им новых значений. При этом наборы операций на функциональных языках являются менее эффективными по критерию быстродействия (Себеста Роберт У. Основные концепции языков программирования, 5-е изд.: М.: Изд. дом «Вильяме», 2001 г., 672 с.).
Способ предполагает разделение набора операций на функциональных языках, реализующих ИАД, на отдельные шаги, которые представляют собой обособленные функции без последействия, каждая из которых может выполняться в параллельном режиме. Выполнение в параллельном режиме каждой отдельной обособленной функции, а не всего метода сразу, позволяет, в отличие от MapReduce, применять данный способ для распараллеливания функций, которые не обладают списочным гомоморфизмом.
ИАД на входе принимает набор входных данных, а результатом его работы является финальная выходная модель знаний. Таким образом, ИАД задает функцию, так как получает на вход набор входных данных и выдает результат анализа к входным данным в виде финальной выходной модели знаний. Следовательно, ИАД можно представить в виде функции, которой в качестве аргумента передается набор входных данных, а возвращаемым значением является построенная финальная выходная модель знаний.
В ходе работы функции ИАД анализируют набор данных и строят промежуточную модель знаний на каждом шаге. Построенная промежуточная модель знаний передается на следующий этап. Таким образом, каждый шаг ИАД должен принимать набор данных и промежуточную модель знаний в качестве входных аргументов. Результатом работы шага является новая промежуточная модель знаний.
Таким образом, ИАД можно представить в виде последовательности вызовов функций без последействия, представляющих шаг анализа. Далее такие функции будут называться обособленными функциями, имеющие вид
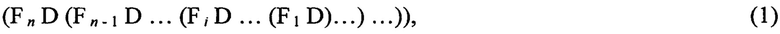
где Fi - обособленная функция, реализующая i-й шаг ИАД, принимает на вход набор входных данных D для ИАД и промежуточную модель знаний.
Чистой функцией называется детерминированная функция без последействия. Детерминированной функцией называется функция, результат которой зависит только от входных параметров. Функцией без последействия называется функция, которая не изменяет состояния процесса, т.е. не изменяет переменные и другие области памяти, значения которых могут обрабатываться после завершения выполнения функции.
При этом обособленная функция F1, реализующая 1-й шаг ИАД, принимает набор данных и пустую модель знаний в качестве входных аргументов.
Результатом работы функции является промежуточная модель знаний, которая используется на следующем шаге, а результатом работы функции Fn является финальная выходная модель знаний.
При этом при реализации ИАД одна и та же обособленная функция или группа обособленных функций может вызываться рекурсивно до достижения определенного условия, в зависимости от метода анализа.
Ниже приведен пример определения обособленной функции, которая принимает на вход набор входных данных ИАД и промежуточную модель знаний. Здесь и далее для примеров будет использоваться нотация языка функционального программирования Common Lisp [статья по адресу: http://www.lispworks. com/documentation/HyperSpec/Front/Contents.htm]:
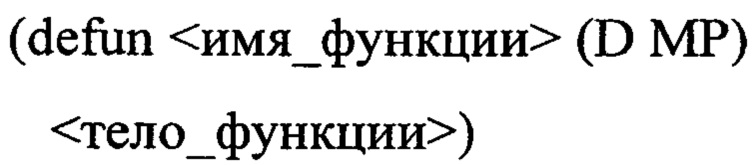
В примере выше <имя_функции> - это имя обособленной функции, D и MP - соответственно, набор входных данных и промежуточная модель знаний. В языке Common Lisp в определении функции отсутствуют возвращаемые результаты, при этом возвращаемые результаты определяются телом функции. В примере <тело_функции> - реализация тела функции, которое формирует промежуточную модель знаний.
Использование функционального подхода, и, соответственно, чистых функций позволяет обеспечить отсутствие потенциальных ошибок, связанных с переменными и присваиванием им новых значений. На результат работы функций влияют только входные параметры, что исключает появление ошибок, которые трудно обнаружить. Подобные ошибки могут быть связанны, например, с присваиваниями значений одной и той же переменной в различных участках кода.
Кроме того, повышается удобство тестирования и отладки набора операций. На результат работы функций влияют только входные параметры, поэтому для тестирования функций достаточно проверить значения функций при различных входных параметрах.
Набор входных данных ИАД нужно представить в виде списочных структур данных функционального языка программирования: списка атрибутов и списка векторов. На языке Common Lisp набор входных данных можно представить в виде структуры, содержащей список атрибутов (attributes_list), список векторов (vectors_list) и список всех возможных классов целевого атрибута (class_list):
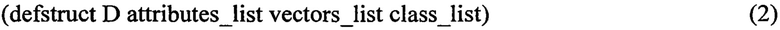
Список из K атрибутов attributes list можно определить следующим образом
(defparameter attributes_list (list attr0, …, attrK)),
где attr<i> - список возможных значений i-го атрибута.
Ниже приведен пример для атрибута 0, который может иметь пять значений:
(defparameter attr0 (list 0.5 3.0 4.5 5.4 2.5))
Список из L векторов можно определить следующим образом
(defparameter vectors_list (list vector0, vector 1, …, vectorL))
где vector <i> - список конкретных значений каждого атрибута и значения целевого атрибута.
Значение i-го атрибута располагается на i-м месте в списке. Если значение целевого атрибута неизвестно, то в языке Common Lisp оно может быть задано символом nil. Значение целевого атрибута можно расположить в конце списка. Ниже приведен пример для вектора 0, в котором первые четыре значения соответствуют значениям атрибутов, а последнее значение соответствует значению целевого атрибута:
(defparameter vector0 (list 1.5 4.0 4.2 5.5 8.5))
Структура промежуточной и финальной выходной модели знаний зависит от метода анализа и функции, реализующей ИАД. Промежуточную и финальную выходную модель знаний удобно представлять в виде списочных структур данных. Например, распространенной среди методов ИАД является модель знаний в виде деревьев решений. Для деревьев решений узлы дерева и соответствующие им множества, можно представить в виде списков. В общем виде промежуточную модель знаний можно представить в виде структуры, содержащей список параметров текущего шага step_list и списка правил rules_list:

Список параметров текущего шага step_list может содержать, например, список атрибутов, которые еще не использовались для построения модели знаний, и, следовательно, должны быть обработаны на следующих шагах. Список правил rules_list представляет собой часть сформированной на данный момент финальной выходной модели знаний.
Предложенный подход предполагает введение библиотечных функций циклов по векторам и атрибутам, так как в ИАД данные циклы являются достаточно частой операцией. Следует отметить, что при функциональном подходе для организации повторений допустима только рекурсия. Использование указанных библиотечных функций должно обеспечить однотипность реализации и снизить вероятность ошибки при реализации циклов, так как функционал для циклов по векторам или атрибутам реализуется один раз, а далее должен использоваться в качестве шаблона.
Приложения ИАД в основном характеризуются параллелизмом данных. В этом случае требуется добавление функционала разбиения данных и объединения результатов, полученных в разных рабочих процессах. Выполнение в параллельном режиме каждой отдельной обособленной функции, а не всего анализа сразу, позволяет, в отличие от MapReduce, применять данный способ для распараллеливания функций, которые не обладают списочным гомоморфизмом.
Для параллельного выполнения приложения целесообразно добавление функций, которые позволит распараллеливать приложение для системы MPI (Message Passing Interface; статья по адресу: http://parallel.ru/tech/tech_dev/mpi.html). При этом правильно сконфигурированная MPI система, установленная на совокупность соединенных между собой подсистем, каждая из которых имеет один или несколько процессоров и память, обладает возможностью:
- передачи данных из множества рабочих процессов в главный рабочий процесс,
- приема данных в главном рабочем процессе из множества рабочих процессов,
- определения номера рабочего процесса в подсистеме,
- выполнения множества рабочих процессов, в том числе главного рабочего процесса, при этом, в ходе выполнения процессов выполняются наборы операций, созданные в среде функционального программирования
- передачи рабочих процессов в подсистемы для выполнения множества рабочих процессов, в том числе и главного рабочего процесса
В число функций, которые нужно реализовать для параллельного выполнения приложения входят:
- функция разбиения входных данных на части для работы одного из множества рабочих процессов;
- функция объединения результатов работы множества рабочих процессов в единую промежуточную модель знаний в виде набора списочных структур данных;
- функция для формирования финальной выходной модели знаний из промежуточной модели знаний, полученной на последнем этапе;
- функция приема данных главного рабочего процесса, выполненная с возможностью принимать данные из множества рабочих процессов;
- функция рабочего процесса, выполненная с возможностью запускать выполнение:
- обособленные функции в данном рабочем процессе,
- функцию передачи результатов работы обособленных функций в главный рабочий процесс;
- функция главного рабочего процесса, выполненная с возможностью запускать выполнение:
- функции разбиения входных данных на части,
- функции объединения,
- функции приема данных главного рабочего процесса.
Входные данные из файлов или баз данных (БД) должны быть считаны главным рабочим процессом в набор списочных структур данных, содержащих списки атрибутов и списки векторов. Функционалом для считывания из входных файлов или БД множества входных данных, специфицирующих задачу, должна обладать сконфигурированная MPI система. Так как главный рабочий процесс может быть запущен на любой машине, входящей в систему, то доступ к файлам или БД должен быть у любой машины в системе.
С целью упрощения реализации для некоторых случаев каждый рабочий процесс может считать самостоятельно входные данные из файлов или БД. При этом рабочий процесс может считать не все данные, а только ту часть данных, которая предназначена ему для обработки. Диапазон данных для обработки рабочий процесс может получить от главного рабочего процесса, а также может вычислить его с помощью функции разбиения входных данных на части, в зависимости от удобства реализации.
При запуске рабочего процесса в системе ему присваивается порядковый номер. Каждый рабочий процесс имеет свой порядковый номер. Каждый процесс может отличить является ли он главным или рабочим процессом по порядковому номеру, порядковый номер главного процесса должен быть изначально задан и соответствующим образом интерпретироваться. На одной машине, входящей в совокупность соединенных между собою подсистем, может быть запущено несколько рабочих процессов, в зависимости от числа процессорных ядер на машине.
Реализация предложенного способа может быть осуществлена в вычислительной среде, работающей, например, под управлением операционной системы Linux, с установленной на ней средой функционального программирования.
Для реализации способа достаточно реализовать выполнение предложенных операций на языке среды функционального программирования, например, на языке Common Lisp (статья по адресу: http://www.lispworks.com/documentation/HyperSpec/Front/Contents.htm).
Реализовать действия предложенного способа в составе набора опреаций или функции может специалист в области программирования (программист), зная выполняемые действия.
В качестве примера рассмотрим метод С4.5 (Hssina В. et al. A comparative study of decision tree ID3 and C4.5, статья по адресу: http://saiconference.com/Downloads/SpecialIssueNo10/Paper_3-A_comparative_study_of_decision_tree_ID3_and_C4.5.pdf; Деревья решений - C4.5 математический аппарат. Часть 1, статья по адресу: https://basegroup.ru/community/articles/math-c45-part1).
Для реализации использовалась ОС Linux, Steel Bank Common Lisp (SBCL) v1.0.29.11, MPICH (статья по адресу: http://www.mpich.org/downloads/). Анализ базируется на теоретико-информационном подходе и является усовершенствованной версией ID3 (Iterative Dichotomizer). Метод включает четыре основных шага:
- формируется корневой узел дерева, с которым ассоциируется все множество векторов V из набора входных данных D; в (2) множество векторов V задает vectors_list;
- для каждого формируемого узла дерева решений и ассоциированного с ним множества векторов Vi выбирается атрибут А для разбиения;
- если выбранный атрибут А принимает n значений А1, А2 … An, то выбранный атрибут A разбивает множество векторов Vi на подмножества Vi1, Vi2 … Vin, при А равном, соответственно, А1, А2 … An;
- шаги повторяются до тех пор, пока в каждом строящемся узле дерева не окажутся векторы, соответствующие одному классу, либо пустое множество векторов.
На втором шаге для выбора наиболее подходящего атрибута используется следующий критерий:
Gain(A)=Info(Vi)-InfoA(Vi)
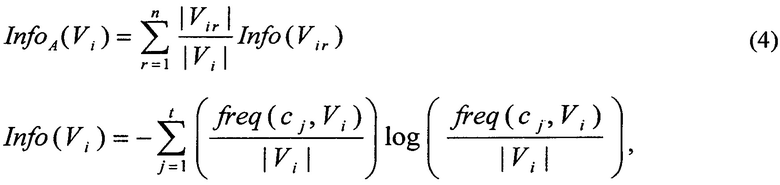
где А - атрибут по которому производится разбиение на текущем шаге;
n - количество значений независимого атрибута А;
t - количество значений зависимого атрибута - классов;
cj - класс, для которого производится вычисление;
freq(cj, Vi) - количество векторов из множества Vi, относящихся к классу cj;
Vir - подмножество данных Vi, у которых атрибут А имеет r-е значение;
Vi - подмножество векторов ассоциированных с текущим узлом дерева.
Здесь и далее для примеров будет использоваться нотация языка функционального программирования Common Lisp (статья по адресу: http://www.lispworks. com/documentation/Hyper Spec/Front/Contents.htm).
C4.5 может быть представлен в виде:
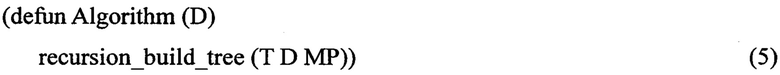
где
recursion_build_tree - рекурсивная функция, которая на последнем шаге возвращает финальную модель знаний в виде дерева решений. Может быть представлена, как композиций обособленных функций (1):


Функция recursion_build_tree на первом шаге строит корневой узел дерева, с которым ассоциируется все множество векторов V из набора входных данных. Выставляет корневой узел в качестве обрабатываемого узла.
Далее построенная промежуточная модель знаний MP передается в качестве параметра функциям из композиции для выполнения шага. После выполнения данные функции возвращают промежуточную модель знаний MP. Из step_list, определенном в (3), функция recursion_build_tree получает список вычисленных критериев (4) для каждого атрибута, выбирает наиболее подходящий атрибут А, добавляет соответствующие значениям атрибута А узлы дерева решений к промежуточной модели MP. Функция recursion_build_tree проверяет, существуют ли узлы дерева решений в промежуточной модели, для которых требуется раскрытие с помощью функции is_finished(D MP). Если существуют, то производится рекурсивный вызов функции recursion_build_tree. Если такие узлы отсутствуют, то функция recursion_build_tree возвращает в качестве результата финальную выходную модель знаний. В качестве дополнительного входного параметра функция имеет флаг is_first_call, сообщающий является ли данный вызов функции первым или рекурсивным.
Функция for_all_attributes_cycle - обособленная функция, которая выполняет итерацию по атрибутам,
Функция calculate_attr_gain - обособленная функция, которая вычисляет Gain (А) из (4) для обрабатываемого атрибута А. Выполняет итерацию по возможным значениям атрибута А для вычисления InfoA(Vi) из (4), а также, выполняет итерацию по всем классам для вычисления Info(Vi) из (4),
Функция build_final_model - функция для формирования финальной выходной модели знаний из промежуточной модели знаний, полученной на последнем этапе.
Входные данные для С4.5 можно представить в виде таблицы, каждая строка которой содержит значения входных атрибутов и соответствующий им класс целевого атрибута.
Для реализации С4.5 введем следующее представление для входных данных
(defstruct D attributes_list vectors_list class_list),
где attributes_list - список атрибутов;
vectors_list - список векторов;
class_list - список всех возможных классов целевого атрибута. Финальная выходная модель знаний для С4.5 представляется в виде дерева решений. Промежуточная модель знаний для С4.5 представляется в виде неполного дерева решений rules_list в (3). Также промежуточная модель знаний включает список обработанных на данный момент атрибутов, список вычисленных на последнем шаге критериев (4) для атрибутов, обрабатываемый на данном шаге узел дерева решений. Данная часть промежуточной модели обозначена как step_list в (3). Дерево решений можно представить в виде структуры вложенных списков. Первый элемент в списке содержит номер атрибута, которому соответствует данный узел, все следующие элементы являются вложенными списками, причем первым элементом в списках является значение атрибута, а вторым элементом является вложенный список, который аналогичным образом описывает узел, соответствующий данному значению атрибута:

где node_root - корневой узел дерева.
Корневой узел дерева в свою очередь можно представить в виде:
(setf node_root (list attr_N (list attr_N_value_1 node_1) … (list attr_N_value_K node_K)))
где attr_N - номер атрибута, который был выбран для построения корневого узла дерева решений, данный атрибут имеет K значений;
attr_N_value_1 - значения атрибута, соответствующее следующему узлу дерева node_1;
attr_N_value_K - значения атрибута, соответствующее следующему узлу дерева node_K.
Узлы второго яруса дерева решений node_1 … node_K определяются аналогично узлу node_root. Таким же образом определяются узлы всех последующих ярусов дерева решений.
Для параллельного выполнения набора операций в реализацию С4.5 в (5) и (6) требуется добавление функционала разбиения данных и объединения результатов, полученных в разных рабочих процессах.
Рассмотрим вариант набора операций, выполняющего параллельную обработку по атрибутам, реализованного с применением предложенного подхода:

где recursion_build_tree_parall - реализация функции recursion_build_tree для параллельного выполнения анализа с распараллеливанием по атрибутам.
В предложенном подходе функция recursion_build_tree_parall представляет собой функцию главного рабочего процесса.

где
mpi_work_process_funct - функция рабочего процесса. Получает на вход часть входных данных, предназначенную для определенного рабочего процесса. Определяет номер процесса в MPI системе, и если номер процесса не является номером главного процесса, то запускает на выполнение обособленные функции в данном рабочем процессе. В конце своей работы передает результаты работы обособленных функций в главный рабочий процесс;
mpi_divide_attr_parall - функция разбиения входных данных на части для работы одного из множества рабочих процессов. Функция выполняет разделение списка атрибутов на части, предназначенные для каждого рабочего процесса, на основании номера рабочего процесса MPI системе, на котором она в данный момент выполняется и в качестве результат возвращает часть входных данных, которые должны быть в текущем рабочем процессе;
mpi_merge_attr_parall - функция объединения результатов работы множества рабочих процессов в единую промежуточную модели знаний в виде структуры (3).
Если достигнут конец, то функция recursion_build_tree_parall формирует и возвращает в качестве результата финальную выходную модель знаний в виде структуры (7).
Функция рабочего процесса может быть определена в виде:

где for_all_attributes_cycle и for_all_attributes_cycle - рассмотренные ранее обособленные функции.
В примере для упрощения отсутствует функционал для передачи результатов работы обособленных функций в главный рабочий процесс.
Таким образом, рассмотрена реализация распараллеливания по атрибутам набора операций, реализующего С4.5 на основе предложенного подхода в среде функционального программирования.
Если применить концепцию MapReduce без доработок к последовательному варианту (5) С4.5 для распараллеливания по атрибутам, то на фазе Map исходный набор атрибутов будет разбит на N частей, где N это количество рабочих процессов в системе. Каждая из N частей предназначена для обработки одним процессом на фазе Reduce. После завершения фазы Reduce будет получено N деревьев решений, при этом отсутствует возможность получить из этих N деревьев решений финальную выходную модель знаний, так как С4.5 не обладает списочным гомоморфизмом. Отсюда следует, что применение концепции MapReduce к данному анализу требует дополнительных методов. Таким образом, предложенный способ позволяет получить корректный результат в среде функционального программирования, а применение концепции MapReduce к данному анализу напрямую - не позволяет.
Изобретение относится к вычислительной технике и области параллельных вычислений в средах функционального программирования. Техническим результатом является обеспечение возможности параллельного выполнения анализа данных, в частности наборов операций, реализованных в средах функционального программирования, и снижение вероятности ошибки пользователя посредством использования среды функционального программирования. Для этого предлагается способ распараллеливания интеллектуального анализа данных в вычислительной среде, включающей совокупность соединенных между собой подсистем. Каждая подсистема содержит установленное и сконфигурированное программное обеспечение в среде функционального программирования, осуществляющее декомпозицию приложения в последовательность обособленных функций, реализующих шаги приложения и представляющих собой функции без последействия. Для параллельной обработки на вычислительной технике в средах функционального программирования входные данные из файлов или баз данных преобразуются в набор списочных структур данных, содержащих списки атрибутов и списки векторов. Модель знаний, строящаяся в результате обработки данных, также представляется в виде набора списочных структур данных.
Способ распараллеливания интеллектуального анализа данных в вычислительной среде, включающей совокупность соединенных между собой подсистем, каждая из которых имеет один или несколько процессоров и память, причем каждая подсистема содержит установленное и сконфигурированное программное обеспечение, выполненное с возможностью:
- передачи данных из множества рабочих процессов в главный рабочий процесс;
- приема данных в главном рабочем процессе из множества рабочих процессов;
- определения номера рабочего процесса в подсистеме;
- выполнения множества рабочих процессов, в том числе главного рабочего процесса, при этом в ходе выполнения процессов выполняются наборы операций, созданные в среде функционального программирования;
- передачи рабочих процессов в подсистемы для выполнения множества рабочих процессов, в том числе и главного рабочего процесса;
- считывания из входных файлов или баз данных множества входных данных, специфицирующих задачу;
- сохранения промежуточных и финальных значений данных,
заключающийся в том, что для каждой подсистемы:
- в среде функционального программирования формируют библиотечные функции, реализующие циклы по спискам атрибутов и спискам векторов;
- в среде функционального программирования формируют функции отображения, преобразующие входные данные из файлов или баз данных в набор списочных структур данных, содержащих списки атрибутов и списки векторов;
- осуществляют декомпозицию функции в последовательность обособленных функций, реализующих шаги анализа и представляющих собой функции без последействия;
- в среде функционального программирования формируют функцию разбиения входных данных на части для работы одного из множества рабочих процессов;
- в среде функционального программирования формируют функцию объединения результатов работы множества рабочих процессов в единую промежуточную модель знаний в виде набора списочных структур данных;
- в среде функционального программирования формируют функцию для формирования финальной выходной модели знаний из промежуточной модели знаний, полученной на последнем этапе;
- в среде функционального программирования формируют функцию приема данных главного рабочего процесса, выполненную с возможностью принимать данные из множества рабочих процессов;
- в среде функционального программирования формируют функцию главного рабочего процесса, выполненную с возможностью запускать выполнение:
- функции разбиения входных данных на части,
- обособленные функции на множестве рабочих процессов,
- функции объединения,
- функции приема данных главного рабочего процесса;
- в среде функционального программирования формируют функцию рабочих процессов, выполненную с возможностью запускать выполнение:
- обособленные функции в данном рабочем процессе,
- функции передачи результатов работы обособленных функций в главный рабочий процесс;
- запускают выполнение функции главного рабочего процесса, с помощью которой выполняют следующие действия:
- преобразуют с помощью функции отображения входные данные из файлов или баз данных в набор списочных структур данных, содержащих списки атрибутов и списки векторов,
- передают входные данные и входную модель знаний на первом шаге в первую обособленную функцию, реализующую шаг приложения,
- выполняют последовательность обособленных функций, реализующих шаги приложения, начиная с первой, на множестве рабочих процессов, причем на каждом шаге:
- выполняют заданные преобразования в обособленной функции,
- передают после завершения работы обособленной функции промежуточные структуры данных из множества рабочих процессов в главный рабочий процесс,
- принимают данные из множества рабочих процессов в главном рабочем процессе,
- объединяют с помощью функций объединения результаты работы множества рабочих процессов в единую промежуточную модель знаний,
- передают исходные структуры данных и единую промежуточную модель знаний в следующую обособленную функцию,
- после окончания работы всех обособленных функций формируют из полученной на последнем шаге единой промежуточной модели знаний финальную выходную модель знаний;
- получают финальную выходную модель знаний.
| СПОСОБ АВТОМАТИЧЕСКОГО РАСПАРАЛЛЕЛИВАНИЯ ПРОГРАММ | 2009 |
|
RU2411569C2 |
| РОТОРНЫЙ АВТОМАТ ПИТАНИЯ | 0 |
|
SU270453A1 |
| Способ распараллеливания программ в среде логического программирования в вычислительной системе | 2018 |
|
RU2691860C1 |
| Устройство для измерения пульсаций скорости потока жидкости | 1979 |
|
SU775699A1 |
| US 9489233 B1, 08.10.2016. | |||

