Изобретение относится к области обработки цифровых данных с помощью электрических устройств, в частности к техническим решениям, предназначенным для обнаружения и исправления ошибок данных на носителях информации с помощью избыточности в представлении данных.
С целью обеспечения достаточности раскрытия изобретения и обеспечения возможности проведения информационного поиска в отношении заявляемого технического решения ниже приведен перечень терминов, используемых в описании заявляемого изобретения.
Асинхронные действия - действия, выполнение которых не требует остановки основного процесса (выполняемые в неблокирующем режиме), что позволяет основному потоку программы продолжить обработку данных. Асинхронные действия обеспечивают возможность параллельного выполнения двух и более ветвей процесса.
Блок данных - последовательность символов фиксированной длины, используемая для представления данных или самостоятельно передаваемая в сети, представляющая собой несколько последовательных логических записей, объединенных в одну физическую запись на диске.
Восстановление данных - процесс восстановления утраченных данных, хранившихся на вышедшем из строя диске, с помощью данных, сохранившихся на других дисках массива.
Диск - запоминающее устройство, предназначенное для хранения информации (данных), например, твердотельный накопитель, жесткий диск HDD, ленточный накопитель, оптический накопитель или любое другое запоминающее устройство, известное специалистам в данной области. Для чтения информации с диска и записи информации на диск используется дисковод. Диск и дисковод, как правило, объединены в единое дисковое устройство хранения данных.
Дисковый массив (Disk Array) - устройство хранения данных, состоящее из нескольких физических дисковых устройств хранения данных, виртуально объединенных в единый логический модуль и определяемых операционной системой ЭВМ как единый накопитель.
Доступность (Availability) - характеристика системы хранения данных, отражающая вероятность того, что данные из системы будут доступны по запросу пользователя. Высокая доступность достигается, в частности, за счет кодирования, когда часть дискового пространства системы отводится не под пользовательские данные, а для хранения контрольных сумм. В случае отказа дисков системы утраченные данные могут быть восстановлены с помощью этих контрольных сумм - тем самым обеспечивается доступность данных.
RAID (Redundant Array of Independent Disks) - Избыточный Массив Независимых Дисков - технология виртуализации данных для объединения нескольких физических дисковых устройств в логический модуль, в котором один или несколько физических дисковых устройств используются для хранения избыточной информации - копии данных или контрольной суммы данных, позволяющей восстановить данные при выходе из строя одного или большего количества дисков. RAID массивы предназначены для повышения отказоустойчивости, производительности и общего объема дисковых систем хранения данных.
Группы Дисков или Дисковые Пакеты (Drive Groups or Drive Packs) - группа дисков (обычно одной модели), которые логически привязаны друг другу и адресуются как единое устройство. В некоторых случаях такая группа может называться «дисковым пакетом», когда речь идет только о физических устройствах.
Контроллер группы дисков (RAID-контроллер) - это аппаратное устройство или программное обеспечение, используемое для управления жесткими дисками ( HDD ) или твердотельными дисками ( SSD ) в компьютере или массиве хранения, чтобы они работали как логическая единица . RAID-контроллер обеспечивает определенную степень защиты хранимых данных, а также может помочь повысить производительность вычислений за счет ускорения доступа к хранимым данным.
Кэш (Cache) - внутренняя оперативная память ЭВМ или контроллера, позволяющая ускорять чтение данных с устройства хранения данных и запись данных на это устройство.
Кэширование (Caching) - сохранение данных в предопределенной области диска или оперативной памяти (кэша). Кэширование позволяет получить быстрый доступ к недавно прочитанным/записанным данным и используется для ускорения операций чтения/записи RAID систем, дисков, компьютеров и серверов, или других периферийных устройств.
Кэш со Сквозной Записью (Write Through Cache) - стратегия кэширования, при которой данные записываются в кэш и на диск прежде, чем состояние завершения будет возвращено ведущей операционной системе RAID. Эта стратегия кэширования считается наиболее безопасной для хранения данных, так как в случае применения такой стратегии минимизируется вероятность потери данных в случае сбоя питания. Вместе с тем, запись через кэш приводит к некоторому снижению производительности системы.
Кэш с Отложенной Записью (Write-Back Cache) - стратегия кэширования, при которой сигнал завершения операции записи посылается ведущей операционной системе RAID, как только кэш принимает данные, которые должны быть записаны. На целевой диск эти данные запишутся только через некоторое время. Такая стратегия практически не снижает производительность системы, однако существует угроза потери данных в случае сбоя питания. Для защиты от потери данных в результате сбоя питания или аварийного отказа системы при применении такой стратегии кеширования рекомендуется использовать альтернативный источник питания микросхем кэша.
Локальные группы реконструкции - LRG (Local Reconstruction Groups) - комбинации (наборы) блоков данных, входящих в полосу, в количестве, не превышающем количество блоков данных в полосе. Локальные группы реконструкции также могут быть названы сокращенно «локальные группы».
Отказ (сбой) (Failure) - утрата работоспособности физического накопителя, обнаруживаемое физическое изменение в оборудовании массива, восстанавливаемое путем замены диска.
Отказоустойчивость (Fault tolerance / failure tolerance) - способность системы хранения данных продолжать выполнять свои функции даже тогда, когда один из ее физических дисков вышел из строя. Как правило, для того чтобы компьютерная система была отказоустойчива, необходима избыточность в дисководах, источниках питания, адаптерах, контроллерах и соединительных кабелях
Избыточность (Redundancy) - характеристика информации, обеспечивающая повышение вероятности безошибочного считывания или передачи данных за счет их повтора. Для повышения надежности системы хранения данных на физическом уровне избыточность достигается за счет включения в систему хранения данных дополнительных однотипных компонентов, в дополнение к компонентам минимально необходимым для работы системы хранения данных. Дополнительные данные могут быть как полной копией фактических данных, так и избранными фрагментами данных, которые позволяют обнаруживать ошибки и восстанавливать потерянные или поврежденные данные до определенного уровня.
Паритет (Parity) - это тип дополнительных данных, которые рассчитываются и хранятся вместе или отдельно от данных, которые пользователь хочет записать на массив жестких дисков. Эти дополнительные данные могут использоваться для проверки целостности сохраненных данных, а также для вычисления любых «недостающих» данных, если некоторые из данных не могут быть прочитаны, например, при выходе из строя диска. Также для обозначения паритета могут быть использованы термины «информация о четности» (четность) и «контрольная сумма».
Режим восстановления (Rebuild) - процесс восстановления данных и контрольных сумм, утраченных в результате выхода из строя одного или нескольких физических дисков массива на диски горячего резерва, в результате исполнения которого резервный диск получает восстановленные данные, утраченные при выходе из строя диска.
Режим деградирования (Degraded) - режим работы системы хранения данных, в который система хранения данных переходит, когда один или несколько физических дисков массива утратили работоспособность, в результате исполнения которого происходит восстановление утраченных данных и обеспечивается возможность передачи их хосту в ответ на запрос чтения данных.
Обнаружение неисправности дисков (Disk Failure Detection) - функция контроллера RAID, за счет которой контроллер может автоматически обнаруживать повреждения дисков. Процесс контроля основывается, среди прочего, на анализе времени выполнения команд, посланных дисков. Если диск в течение определенного времени не подтверждает выполнение команды, контроллер осуществляет «сброс» диска и посылает команду повторно. Если команда снова не выполняется за заданное время, диск может быть отключен контроллером и его состояние фиксируется, как "dead" ("мертвый"). Многие RAID контроллеры также контролируют ошибки четности шины и другие потенциальные проблемы.
Горячий резерв (Hot Spare) - функция резервной замены дисков в RAID, необходимая для обеспечения безостановочного обслуживания RAID с высокой степенью отказоустойчивости. В случае выхода из строя одного или нескольких дисков восстанавливающая операция будет выполнена RAID контроллером автоматически. Физический диск может также быть помечен как резервный диск (Hot Spare), при помощи соответствующей утилиты RAID контроллера. Возможность обеспечения замены дисков без остановки работы массива - одна из ключевых задач, выполняемых контроллером группы дисков.
Чтение-Модификация-Запись (Read-Modify-Write (RCW) (чтение - реконструкция - запись ) - в известных способах для обновления данных четности при записи частичной полосы используются два альтернативных метода: RMW («чтение - изменение - запись») и RCW («чтение - реконструкция - запись»).
Полоса (Stripe) - данные записываются на диски по полосам (stripe), каждая полоса состоит из блоков (block), каждый блок помещается на отдельный диск в массиве. Число дисков в массиве называется шириной полосы (stripe width). Каждая полоса содержит либо набор данных, либо данные либо их контрольные суммы, которые вычисляются на основе данных каждой такой полосы. Глубиной или шириной полосы (Stripe width/depth) называется объем данных, содержащийся в каждой полосе.
Глубина очереди - количество одновременных запросов на чтение или запись.
Хост - любое устройство, предоставляющее сервис формата «клиент-сервер» в режиме сервера по каким-либо интерфейсам и уникально определённое на этих интерфейсах. Хостом может выступать любой компьютер, сервер, подключенный к локальной или глобальной сети.
Уровень техники
С развитием компьютерных технологий стали появляться системы и способы хранения данных, обеспечивающие возможность восстановления информации после сбоя дисков без потери данных и восстановления системы хранения данных до состояния, в котором система находилась до отказа одного или нескольких элементов системы. Наравне с отказоустойчивостью системы хранения данных важным параметром эффективности систем хранения данных стала производительность операций чтения и записи, выполняемых по пользовательским запросам одновременно с операцией восстановления данных. Производительность системы хранения данных во время ее восстановления после сбоя дисков имеет решающее значение для приложений, которые требуют как высокой производительности ввода-вывода, так и высокой надежности данных.
С целью создания отказоустойчивой и производительной системы хранения данных были разработаны технологии RAID - избыточные массивы независимых дисков. При этом в зависимости от задач пользователя RAID может быть структурирован несколькими известными способами для достижения различных комбинаций свойств системы хранения данных.
Традиционно различные конфигурации RAID называются уровнями RAID. Например, одной из конфигураций RAID является RAID level 1, который создает полную копию данных на дополнительном устройстве хранения. Преимущество RAID 1 заключается в том, что помимо доступа к данным, хранящимся на исходном устройстве, система RAID 1 дает параллельный доступ к полной копии данных на устройстве для хранения копий данных, за счет чего чтение данных происходит относительно быстро. RAID 1 также обеспечивает резервную копию данных для обеспечения возможности восстановления данных в случае выхода из строя устройства хранения. Недостатком RAID 1 является то, что запись происходит относительно медленно, поскольку все данные, хранимые в системе хранения данных, должны быть записаны дважды: на устройство для хранения данных и на устройство для хранения копии данных.
Другой известной конфигурацией RAID является RAID level 0. При использовании такой конфигурации данные равномерно распределяются по дискам массива, физические диски объединяются в один логический диск, который может быть размечен на несколько логических разделов. Распределенные операции чтения и записи позволяют значительно увеличить скорость работы, поскольку несколько дисков одновременно читают/записывают свою порцию данных, следовательно, при использовании RAID 0 достигается максимальная производительность. Однако, такая конфигурация снижает надежность хранения данных, поскольку при отказе одного из дисков массив обычно разрушается и восстановить данные практически невозможно.
Следующей известной конфигурацией RAID массивов является RAID 5 - RAID пятого уровня. RAID 5 включает чередование N сегментов данных между N устройствами хранения и хранение сегмента данных четности (контрольных сумм) на N+1 устройстве хранения. RAID 5 обеспечивает отказоустойчивость, поскольку RAID может выдержать один отказ устройства хранения. Например, если устройство хранения данных выходит из строя, пропущенный сегмент данных полосы может быть восстановлен с использованием других доступных сегментов данных и сегмента данных четности, рассчитанного специально для полосы. RAID 5 также обычно использует меньше места для хранения, чем RAID 1, поскольку каждое устройство хранения из набора устройств хранения RAID не требуется для хранения полной копии данных, а только сегмент данных полосы или сегмент данных четности. RAID 5, как и RAID 0, относительно быстр для записи данных, но относительно медленен для чтения данных. Однако запись данных для RAID 5 происходит медленнее, чем для RAID 0, поскольку сегмент данных четности в RAID 5 должен быть вычислен для каждой полосы из N сегментов данных полосы.
Также известной конфигурацией RAID является RAID level 6, который использует двойную распределенную четность (контрольные суммы. Каждый сегмент данных четности для полосы вычисляется отдельно. За счет этого при условии обеспечения минимально допустимой избыточности хранения данных, система хранения данных RAID level 6 позволяет восстановить данные в случае выхода из строя до двух дисков массива. Утраченные по причине отказа дисков данные могут быть восстановлены с использованием оставшихся доступных сегментов данных и/или сегментов данных четности. RAID 6 имеет те же преимущества и недостатки производительности, что и RAID 5.
RAID массивы разных уровней могут быть скомбинированы между собой, образуя основной RAID и вложенный RAID. Вложенный RAID может быть использован для повышения отказоустойчивости там, где требуется высокая надежность. Например, два набора устройств хранения данных, каждый из которых настроен как RAID 5, могут быть зеркально отражены в конфигурации RAID 1. Полученную конфигурацию можно назвать RAID 51. Если для каждого зеркального набора используется RAID 6, то конфигурация может называться RAID 60. Вложенные конфигурации RAID обычно имеют те же проблемы с производительностью, что и базовые группы RAID.
В ходе патентного поиска были обнаружены документы, определяющие уровень техники и не считающиеся особо релевантным по отношению к заявленному изобретению, а именно:
«Снижение избыточности четности в системе хранения» (патент US10810083B1, приоритет от 21.12.2018, Патентообладатель: Pure Storage Inc.)
«Система дискового массива и способ управления» (патент US8464094B2, приоритет от 21.09.2005, патентообладатель: Hitachi Ltd);
«Управление хранением данных в массиве запоминающих устройств» (патент US9378093B2, приоритет 25.04.2013, патентообладатель: GlobalFoundries Inc);
«Устройство RAID, устройство управления и способ управления» (WO2009157086 , приоритет 27.06.2008, Патентообладатель: Fujitsu Limited);
«Адаптер хранилища RAID, система и метод создания контрольного значения» (патент CN101042633, приоритет 13.03.2007, Патентообладатель: IBM);
«Устройство управления областью хранения и способ управления областью хранения» (патент US20100169575A1, приоритет: 25.12.2008, патентообладатель: Fujitsu Ltd);
«Метод построения высокопроизводительных отказоустойчивых систем хранения данных на основе распределенных файловых систем и технологии NVMe over Fabrics», ( патент на изобретение РФ №2716040 приоритет 22.06.2018, патентообладатель: Общество с ограниченной ответственностью "РСК Лабс" (ООО "РСК Лабс").
Вышеуказанные технические решения, как и заявляемое изобретение, в той или иной мере предназначены для создания отказоустойчивой и производительной системы хранения данных RAID, однако устройство систем и способов вышеуказанных технических решений существенно отличается от предлагаемого в настоящем изобретении.
В качестве прототипа заявляемого изобретения можно рассматривать техническое решение, раскрытое в публикации US7506187B2 «METHODS, APPARATUS AND CONTROLLERS FOR A RAID STORAGE SYSTEM» («Способ, устройства и контроллеры для системы хранения RAID») (Правообладатель: International Business Machines Corporation, Armonk, NY (US), патент US 7,506,187 B2, приоритет 30.08. 2004).
Техническое решение, представленное в публикации US7506187B2, описывает систему хранения данных RAID, где в одной системе одновременно используются RAID массивы разных уровней. При этом в первом массиве RAID одного уровня осуществляется хранение первой копии данных, соответствующем уровню RAID, обеспечивающему избыточность (например, RAID-5), а хранение второй копии данных осуществляется во втором массиве RAID другого уровня, например, RAID-0. Данные считываются из двух RAID-массивов параллельно для повышения производительности чтения. Контроллер реагирует на отказ диска и в случае недоступности данных в одном массиве производит извлечение данных из другого массива. Избыточность в первом массиве RAID также позволяет контроллеру восстанавливать данные после выхода из строя одного диска за счет данных, хранимых на других дисках первого массива.
Формула вышеуказанного изобретения предлагает использовать для хранения основной копии данных массив RAID, обеспечивающий избыточность. В таком случае, общая система хранения данных, выполненная в соответствии с формулой вышеуказанного изобретения на двух массивах разных уровней, будет обладать теми же недостатками, которые присущи известным уровням RAID. Основным недостатком технического решения, представленного в публикации US7506187B2, является то, что данная система имеет ограничения отказоустойчивости. Так, подобная система при реализации минимально допустимой избыточности данных в системе обеспечит восстановление данных только в том случае, если из строя выйдет не более двух дисков массива.
Предлагаемый в заявляемом изобретении способ хранения данных существенно отличается от технического решения, предложенного в прототипе. В прототипе в двух RAID массивах разных уровней хранятся копии данных. Заявленный способ предполагает хранение данных в массиве дисков без использования структуры RAID массивов известных уровней. В частности, система для исполнения заявляемого способа представляет собой единый массив, внутри которого используются две логические группы дисков, в первой из которых хранятся исходные данные, а в другой хранятся контрольные суммы исходных данных. Реализация заявляемого способа позволяет на логическом и аппаратном уровне функционально распределить асинхронно выполняемые задачи по разным группам дисков, управляемых самостоятельными контроллерами. Так, в частности, функции чтения и записи, как ключевые, реализуются в первой группе дисков, управляемой соответствующим контроллером первой группы дисков, тогда как вспомогательные функции, обеспечивающие отказоустойчивость системы хранения данных, а именно расчет паритета (контрольных сумм), его хранение, и восстановление данных исполняются за счет использования второй группы дисков, управляемой контроллером второй группы дисков.
Техническая задача, для решения которой предназначено настоящее изобретение, заключается в снижении вероятности безвозвратной потери данных в системе хранения данных при отказе одного или нескольких дисков, входящих в состав дискового массива, с сохранением производительности чтения и записи данных пользователем.
Технический результат настоящего изобретения заключается в повышении отказоустойчивости системы хранения данных с минимизацией влияния процессов, обеспечивающих отказоустойчивость системы, на производительность процессов чтения и записи данных пользователем.
Заявленный технический результат достигается при использовании заявляемого технического решения в системе хранения данных за счет распределения предлагаемым способом процессов чтения и записи блоков данных, расчетов и записи контрольных сумм на две логические группы дисков, управляемых самостоятельными контроллерами, взаимодействующими между собой, с последующим восстановлением данных в случае отказа одного или нескольких дисков.
Раскрытие изобретения
Для решения поставленной задачи и достижения вышеуказанного технического результата предлагается способ хранения данных в избыточном массиве независимых дисков.
Система хранения данных для реализации настоящего способа представляет собой избыточный массив независимых дисков, который состоит из двух логических групп дисков, которые управляются соответственно контроллером первой группы дисков и контроллером второй группы дисков.
Изобретение раскрывается и поясняется на следующих чертежах:
Фиг. 1 - Общая схема организации системы хранения данных для реализации настоящего способа
Фиг. 2 - Работа системы хранения данных в режиме восстановления утраченного диска
Фиг. 2а - Работа системы хранения данных в режиме восстановления утраченного диска с одновременным исполнением запроса хоста на чтение утраченных данных (режим деградирования)
Фиг. 3 - Примеры создания локальных групп, с расчетом для них контрольных сумм, и размещение контрольных сумм на дисках второй группы дисков
Фиг. 4 - Вариант восстановления блоков данных в системе хранения данных с двойной избыточностью в случае выхода из строя всех дисков первой группы
Фиг. 5 - Вариант восстановления данных в системе хранения данных с двойной избыточностью в случае выхода из строя любых трех дисков
Фиг. 6 - Вариант восстановления данных в системе хранения данных с показателем избыточности 2,5 в случае выхода из строя любых четырех дисков
Фиг. 7 - Вариант восстановления данных в системе хранения данных с показателем избыточности 3 в случае выхода из строя любых пяти дисков
Фиг. 8 - Порядок осуществления частичной записи полосы на уровне блоков
Фиг. 9 - Общая логика исполнения заявляемого способа хранения данных
Фиг. 10 - Порядок осуществления записи при условии доступности всех дисков системы хранения данных
Фиг. 11 - Порядок записи новых данных в режиме деградирования при выходе из строя одного или нескольких дисков первой группы
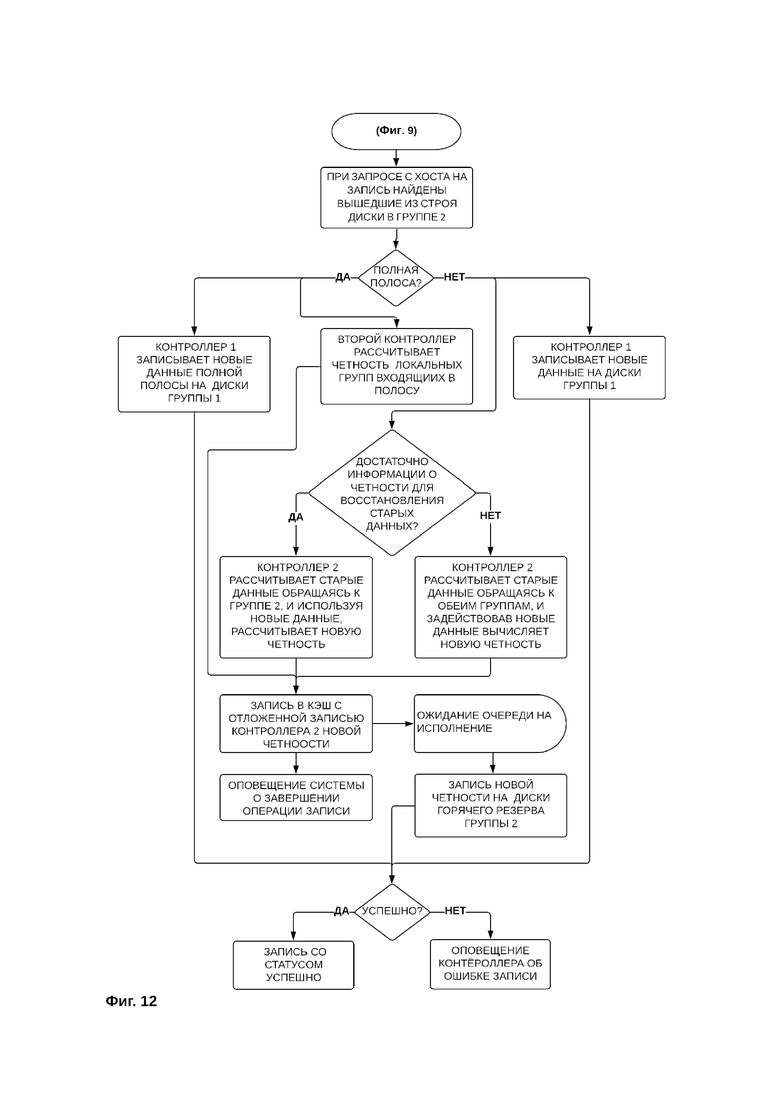
Фиг. 12 - Порядок записи новых данных в случае обнаружения выхода из строя дисков во второй группе дисков.
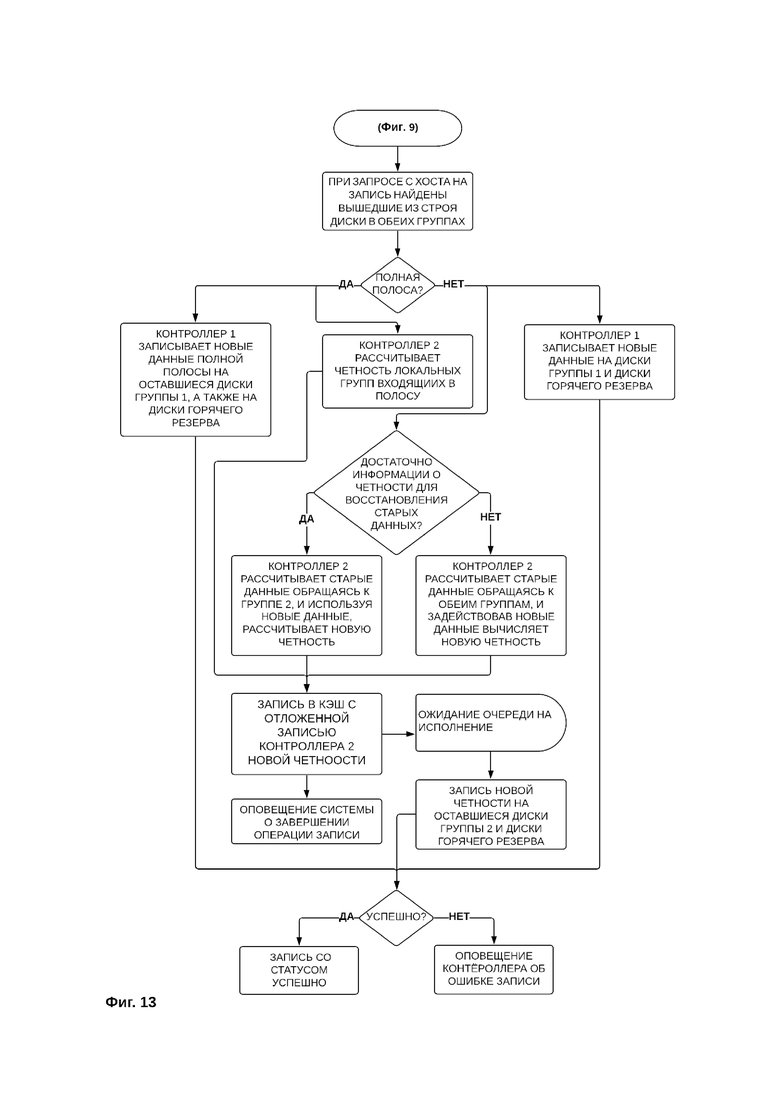
Фиг. 13 - Порядок записи новых данных при обнаружении выхода из строя дисков в обеих группах дисков
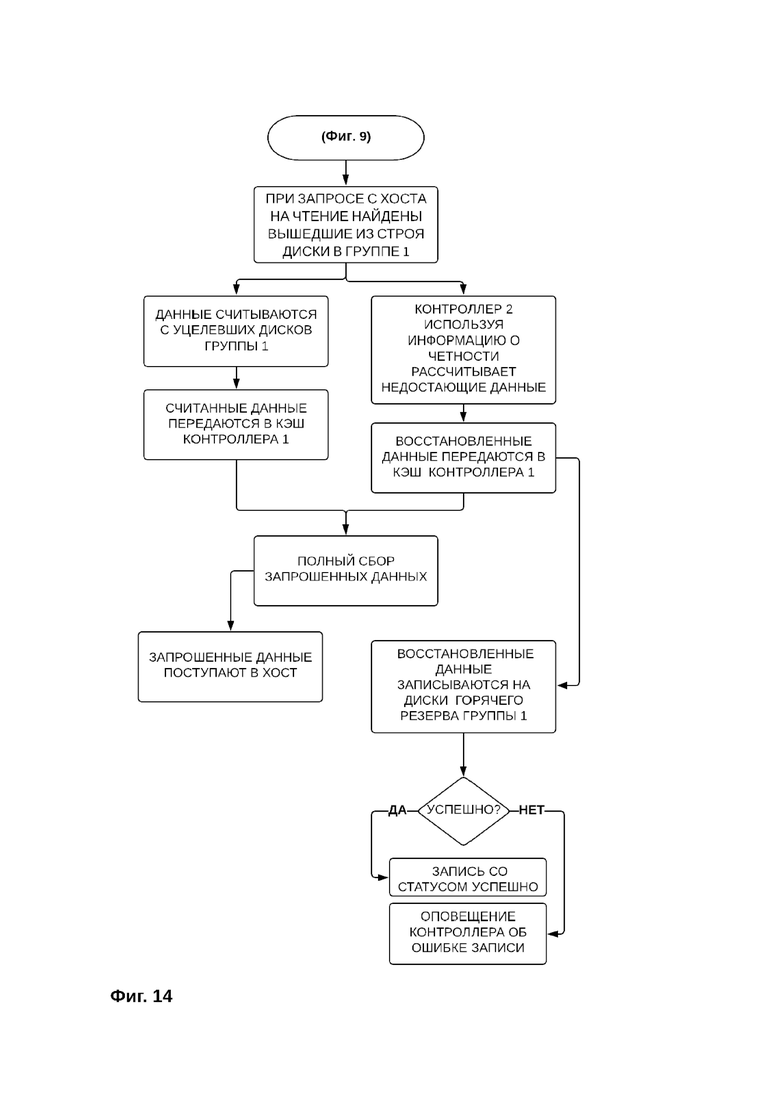
Фиг. 14 - Порядок чтения данных при обнаружении выхода из строя одного или нескольких дисков первой группы дисков
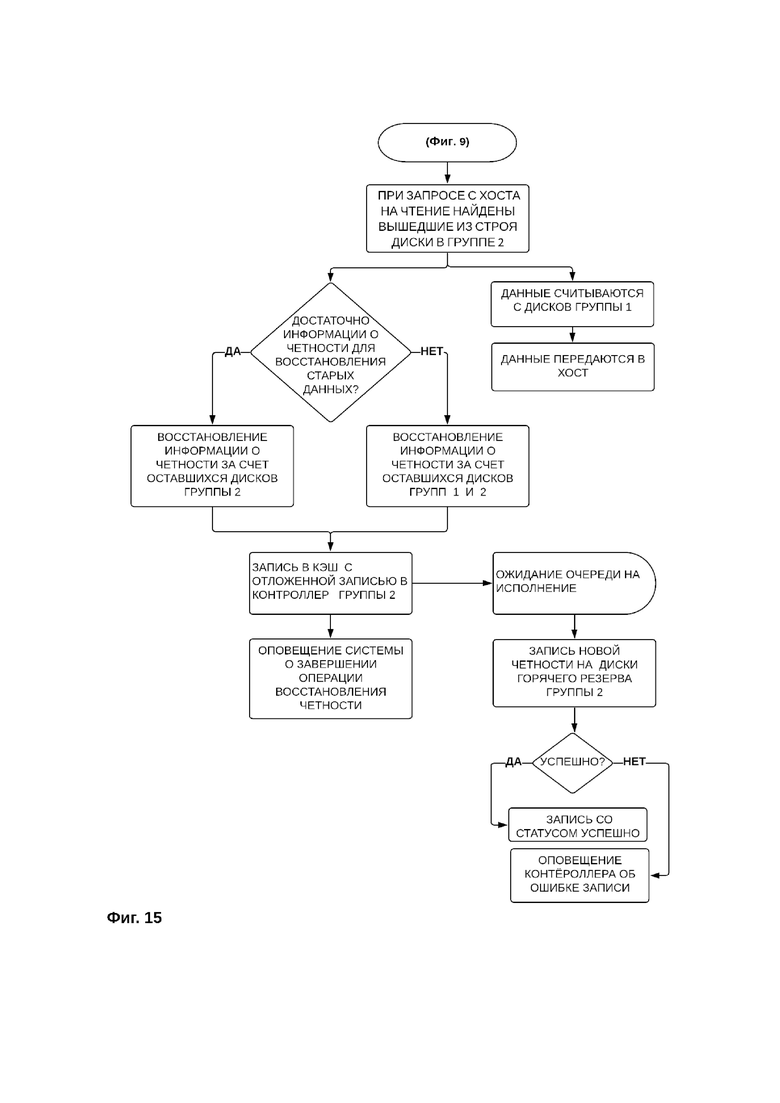
Фиг. 15 - Порядок чтения данных при обнаружении выхода из строя одного или нескольких дисков второй группы дисков
Фиг. 16 - Порядок чтения данных при обнаружении выхода из строя дисков обеих групп дисков
Фиг. 17 - Порядок чтения данных в исходном отказоустойчивом состоянии системы
Фиг. 18 - Порядок осуществления частичной записи полосы
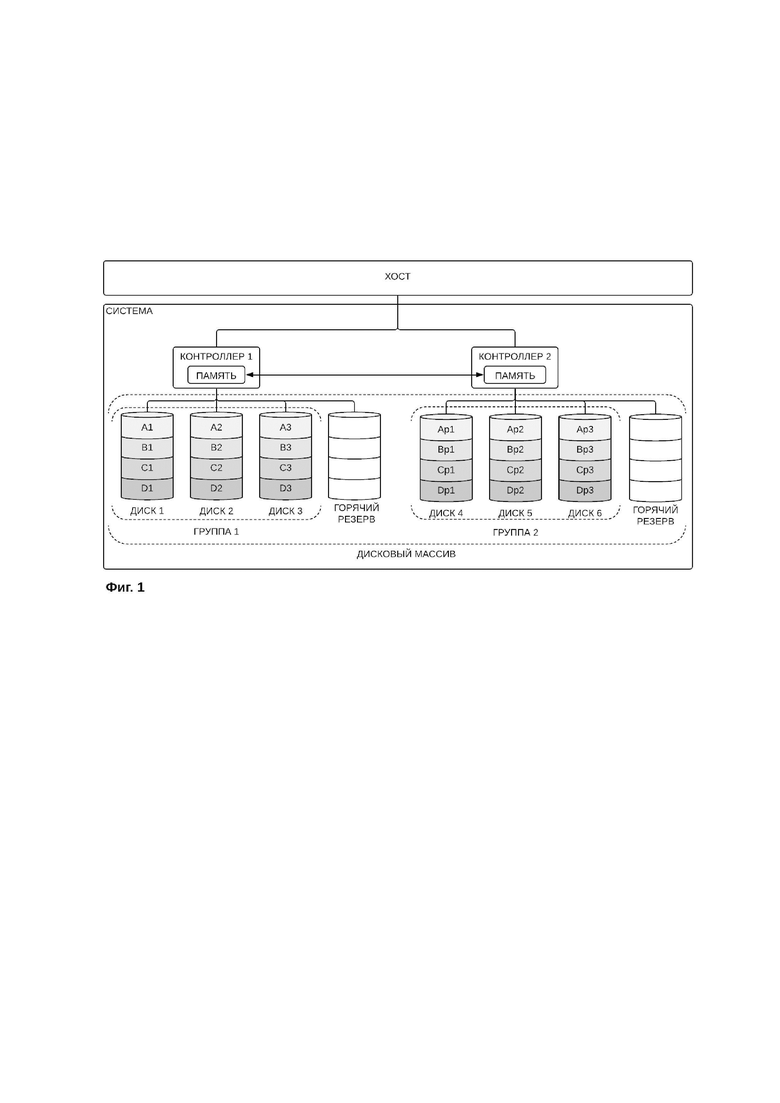
Система хранения данных для реализации настоящего способа изображена на фиг. 1, где изображена система хранения данных (система), контроллеры первой и второй группы с кэш-памятью (контроллер 1 и контроллер 2), а также группы дисков (группа 1 и группа 2). На диски первой группы полными полосами А, В, С и D записаны блоки данных (А1…A3, B1…B3, C1…C3, D1…D3). На диски второй группы записаны контрольные суммы комбинаций локальных групп блоков данных (Аp1…Ap3, Bp1…Bp3, Cp1…Cp3, Dp1…Dp3). Каждая группа дисков может включать также резервные диски (диски горячего резерва).
Контроллеры выполнены с возможностью обмена данными с внешним хостом для получения команд записи и чтения данных. Для снижения вероятности потери данных при отказе одного из контроллеров, контроллеры выполнены с возможностью обмена данными между собой. Обмен данными между контроллерами используется для проверки данных, синхронизируемых между кэшами (памятью) двух контроллеров в процессе текущей операции записи или чтения. Также обмен данными между контроллерами используется для проверки данных, накопленных в кэшах контроллеров на момент выполнения операции.
В случае отказа одного из контроллеров, оставшийся в рабочем состоянии контроллер получает сигнал об отказе другого контроллера. После получения сигнала об отказе контроллера оставшийся в рабочем состоянии контроллер уведомляет администратора системы хранения данных об отказе контроллера и переходит в режим исполнения функций обоих контроллеров на то время, пока отказавший контроллер не будет приведен в рабочее состояние или заменен пользователем на исправный.
Первая группа дисков используется для хранения блоков данных. Контроллер первой группы дисков осуществляет запись и чтение блоков данных на диски первой группы дисков. Блоки данных записываются на диски первой группы посредством выполнения неизбыточного чередования записи данных по дискам с использованием кэша со сквозной записью.
Вторая группа дисков используется для хранения контрольных сумм, рассчитанных контроллером второй группы дисков. Контрольные суммы записываются на диски второй группы дисков контроллером второй группы диском с применением кэша с отложенной записью. В случае выхода из строя одного или несколько дисков в системе хранения данных, контрольные суммы, хранящиеся на дисках второй группы дисков, используются для восстановления утраченных данных и/или утраченных контрольных сумм.
Запись новых блоков данных осуществляется на диски первой группы дисков через кэш контроллера первой группы со сквозной записью. Контрольные суммы новых блоков данных рассчитываются контроллером второй группы дисков и записываются в кэш с отложенной записью контроллера второй группы дисков, после чего записываются из кэша контроллера второй группы дисков на диски второй группы дисков.
Контрольные суммы рассчитываются для локальных групп блоков данных, состоящих из различных комбинаций блоков данных входящих в полосу, и хранятся на дисках второй группы дисков. В локальной группе может быть два и более неповторяющихся блока данных, при этом количество блоков данных не должно превышать количество блоков в полосе.
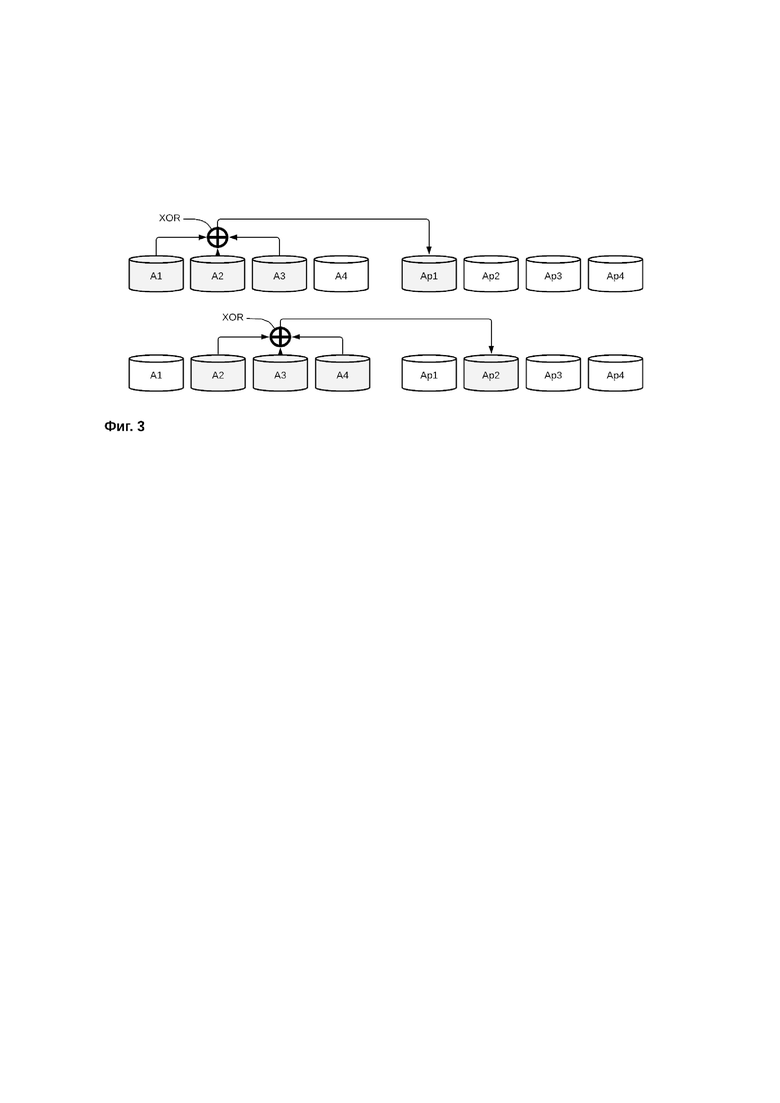
Контрольные суммы могут быть рассчитаны различными способами. Например, контрольные суммы могут быть рассчитаны как XOR блоков данных, входящих в локальную группу. Пример создания локальных групп и расчет их контрольных сумм приведен на фиг. 3, где изображены блоки данных А1, А2, А3, А4, записанные на диски первой группы дисков, также изображены контрольные суммы Аp1, Аp2, Аp3, Аp4, записанные на диски второй группы дисков, причем скомбинирована локальная группа А1, А2, А3 и ее контрольная сумма рассчитана как А1 XOR A2 XOR A3 = Ap1 , и также скомбинирована локальная группа А2, А3, А4 и ее контрольная сумма рассчитана как А2 XOR A3 XOR A4 = Ap2.
XOR - булева функция «исключающего или», а также логическая и битовая операция, в случае двух переменных результат выполнения операции истинен тогда и только тогда, когда один из аргументов истинен, а другой - ложен. XOR обладает особенностью, которая дает возможность заменить любой операнд результатом, и, применив алгоритм XOR, получить в результате недостающий операнд. Например, если у нас в массиве есть три диска A, B, C, то мы выполняем операцию:
A XOR B = C
В случае если диск А выйдет из строя, мы можем восстановить хранившиеся на нем утраченные данные проведя операцию XOR между C и B:
A= C XOR B .
Данный порядок восстановления утраченных данных с помощью заранее вычисленных контрольных сумм применим вне зависимости от количества операндов, например, при наличии пяти дисков, можно рассчитать:
A XOR B XOR C XOR D = E.
Если выходит из строя диск С, тогда возможно восстановить утраченные данные этого диска, выполнив операцию XOR по формуле
C= A XOR B XOR E XOR D .
Полученные контрольные суммы (информация о четности) распределяются по дискам второй группы дисков в количестве, необходимом для полного восстановления утраченных данных в случае отказа, в зависимости от установленных параметров отказоустойчивости, одного или нескольких дисков, преимущественно за счет блоков информации о четности.
Диски горячего резерва задействуются в том случае, если диски первой или второй группы выходят из строя. После обнаружения выхода из строя дисков, система осуществляет восстановление утраченных данных, хранившихся на вышедших из строя дисках, после чего записывает восстановленные данные на резервные диски, таким образом резервные диски заменяют в системе хранения данных вышедшие из строя диски.
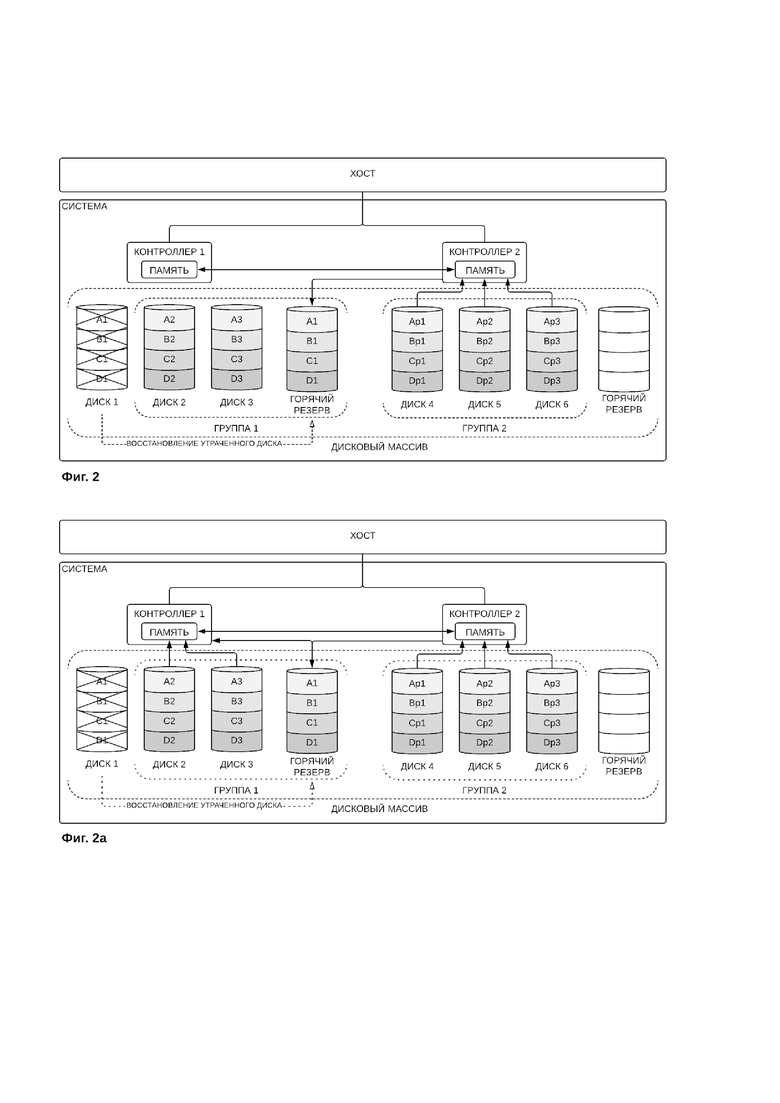
На фиг. 2 изображена работа системы хранения данных в режиме восстановления утраченного диска. Так, на фиг. 2.а изображена система хранения данных (система), контроллеры первой и второй группы с кэш-памятью (контроллер 1 и контроллер 2), а также дисковый массив, состоящий из логический групп дисков (группа 1 и группа 2). На диски первой группы полными полосами А, В, С и D записаны блоки данных (А1…A3, B1…B3, C1…C3, D1…D3). На диски второй группы записаны контрольные суммы комбинаций локальных групп блоков данных (Аp1…Ap3, Bp1…Bp3, Cp1…Cp3, Dp1…Dp3). При этом диск 1 помечен как вышедший из строя, соответственно контроллер второй группы дисков восстанавливает утраченные данные диска 1, после чего осуществляется запись восстановленных данных на резервный диск первой группы. Таким образом, данные утраченного диска полностью восстанавливаются на резервном диске.
На фиг. 2а изображена работа системы хранения данных в режиме восстановления утраченного диска, когда с хоста поступает запрос на чтение данных. Также, как в случае, приведенном на фиг.2 изображена система хранения данных (система), контроллеры первой и второй группы с кэш-памятью (контроллер 1 и контроллер 2), а также дисковый массив, состоящий из логических групп дисков (группа 1 и группа 2). На диски первой группы полными полосами А, В, С и D записаны блоки данных (А1…A3, B1…B3, C1…C3, D1…D3). На диски второй группы записаны контрольные суммы комбинаций локальных групп блоков данных (Аp1…Ap3, Bp1…Bp3, Cp1…Cp3, Dp1…Dp3). При этом диск 1 помечен как вышедший из строя, соответственно контроллер второй группы дисков восстанавливает утраченные данные диска 1 и записывает их на резервный диск первой группы. При этом запрос на чтение выполняется за счет считывания запрошенных хостом данных с сохранившихся дисков первой группы, и восстановленных вторым контроллером, используя контрольные суммы данных утраченного диска первой группы. Таким образом, достигается возможность обработки запроса хоста на чтение данных при потере одного из дисков одновременно с выполнением процесса восстановления утраченного диска.
Заявляемый способ с использованием вышеуказанного порядка расчета и размещения контрольных сумм (также известных как данные паритета или данные четности) позволяет в большинстве случаев не задействовать диски с блоками данных в процессе восстановления утраченных данных, в отличие от известных RAID систем, где для процесса восстановления утраченных данных обращение к блокам данных наряду с обращениями к блокам контрольных сумм является необходимым условием восстановления данных, в результате которого неизбежно снижается производительность системы.
Блоки данных могут быть сгруппированы в локальные группы путем различных комбинаций данных между собой. Количество локальных групп и, как следствие, количество контрольных сумм, рассчитанных для этих групп, влияет на избыточность системы хранения данных.
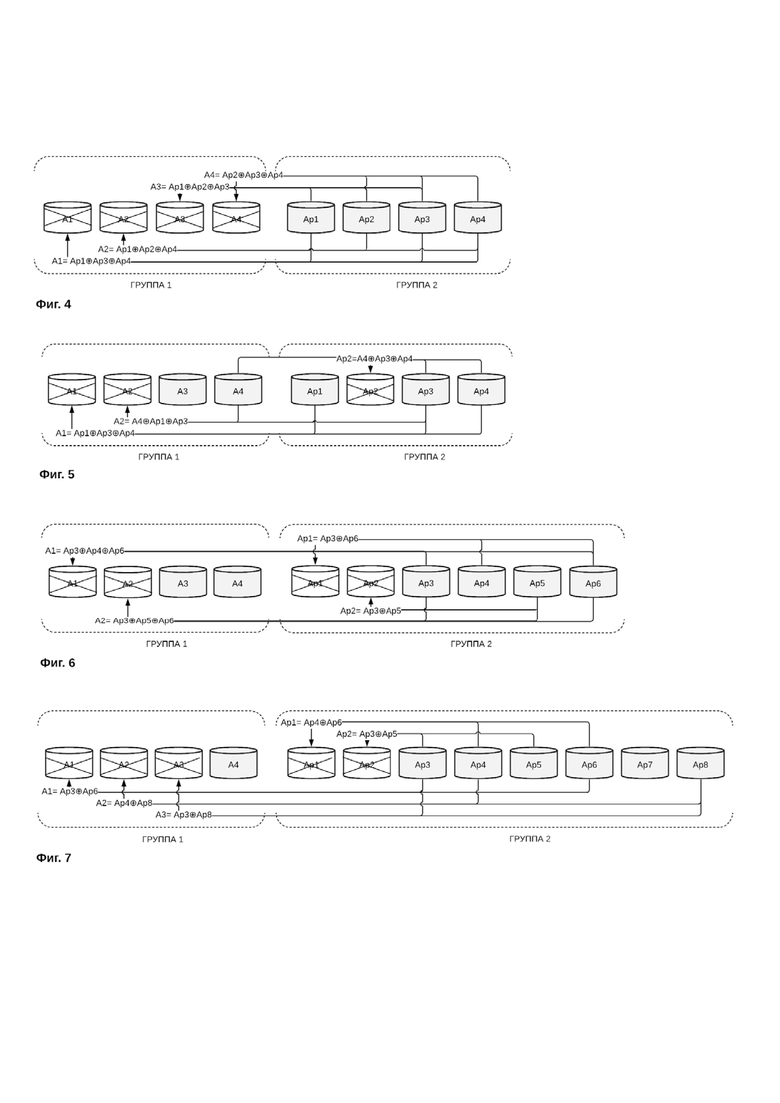
При увеличении количества контрольных сумм (увеличении избыточности), вследствие использования большего количества комбинаций локальных групп, увеличивается количество возможных вариантов восстановления утраченных данных (Фиг. 4-7).
Возможные варианты (примеры) восстановления данных приведены на фиг. 4-7.
На фиг.4 изображен вариант восстановления блоков данных в системе хранения данных с двойной избыточностью в случае выхода из строя всех дисков первой группы. На фиг. 4 блоки А1,А2, А3, А4 показывают вышедшие из строя диски первой группы, блоки Ap1, Ap2, Ap3, Ap4 показывают диски второй группы дисков, хранящие контрольные суммы локальных групп блоков данных первой группы дисков. При этом расчет контрольных сумм осуществлялся по следующим правилам (здесь и далее символ ⊕ означает применение описанной ранее функции XOR):
Ap1=A1⊕A2⊕A3;
Ap2=A2⊕A3⊕A4;
Ap3=A3⊕A4⊕A1;
Ap4=A4⊕A1⊕A2
Следовательно, на фиг.4 указана логика восстановления дисков первой группы дисков:
A1=Ap1⊕Ap3⊕Ap4;
A2=Ap1⊕Ap2⊕Ap4;
A3=Ap1⊕Ap2⊕Ap3;
A4=Ap2⊕Ap3⊕Ap4
На фиг.5 изображен вариант восстановления данных в системе хранения данных с двойной избыточностью в случае выхода из строя любых трех дисков. На фиг. 5 блоки А1,А2, А3, А4 показывают диски первой группы, причем диски А1 и А2 вышли из строя, блоки Ap1, Ap2, Ap3, Ap4 показывают диски второй группы дисков, хранящие контрольные суммы утраченных блоков данных первой группы дисков, причем диск Аp2 вышел из строя. При этом расчет контрольных сумм осуществлялся по следующим правилам :
Ap1=A1⊕A2⊕A3;
Ap2=A2⊕A3⊕A4;
Ap3=A3⊕A4⊕A1;
Ap4=A4⊕A1⊕A2;
Следовательно, на фиг.5 указана логика расчета восстановления данных вышедших из строя дисков:
A1=Ap1⊕Ap3⊕Ap4
A2=A4⊕Ap1⊕Ap3
Ap2=A4⊕Ap3⊕Ap4
На фиг.6 изображен вариант восстановления данных в системе хранения данных с показателем избыточности 2,5 в случае выхода из строя любых четырех дисков, причем для восстановления блоков данных используются только контрольные суммы, записанные на дисках второй группы и не используются работающие диски первой группы. На фиг. 6 блоки А1,А2, А3, А4 показывают диски первой группы, причем диски А1 и А2 вышли из строя, блоки Ap1, Ap2, Ap3, Ap4, Ap5, Ap6 показывают диски второй группы дисков, хранящие контрольные суммы утраченных блоков данных первой группы дисков, причем диски Ap1 и Аp2 вышли из строя. При этом расчет контрольных сумм осуществлялся по следующим правилам:
Ap1=A1⊕A2⊕A3;
Ap2=A2⊕A3⊕A4;
Ap3=A3⊕A4⊕A1;
Ap4=A4⊕A1⊕A2;
Ap5=A1⊕A2;
Ap6=A3⊕A4
Следовательно, на фиг.6 указана логика расчета восстановления данных вышедших из строя дисков:
A1=Ap3⊕Ap4⊕Ap6
A2=Ap3⊕Ap5⊕Ap6
Ap1=Ap3⊕Ap6
Ap2=Ap3⊕Ap5
На фиг.7 изображен вариант восстановления данных в системе хранения данных с показателем избыточности 3 в случае выхода из строя любых пяти дисков, причем для восстановления данных используются только контрольные суммы, записанные на дисках второй группы и не используются работающие диски первой группы. На фиг. 7 блоки А1,А2, А3, А4 показывают диски первой группы, причем диски А1, А2 и А3 вышли из строя, блоки Ap1, Ap2, Ap3, Ap4, Ap5, Ap6, Ap7, Ap8 показывают диски второй группы дисков, хранящие контрольные суммы утраченных блоков данных первой группы дисков, причем диски Ap1 и Аp2 вышли из строя. При этом расчет контрольных сумм осуществлялся по следующим правилам:
Ap1=A1⊕A2⊕A3;
Ap2=A2⊕A3⊕A4;
Ap3=A3⊕A4⊕A1;
Ap4=A4⊕A1⊕A2;
Ap5=A1⊕A2;
Ap6=A3⊕A4;
Ap7=A2⊕A3;
Ap8=Ap1⊕Ap4
Следовательно, на фиг.7 указана логика расчета восстановления данных вышедших из строя дисков:
A1=Ap3⊕Ap6
A2=Ap4⊕Ap8
A3=Ap3⊕Ap8
Ap1=Ap4⊕Ap6
Ap2=Ap3⊕Ap5
Вышеуказанные примеры, показанные на фиг. 4-7, показывают пример восстановления данных в случае реализации системы хранения данных с определенным количеством дисков. Данные примеры не должны трактоваться как единственно возможный вариант реализации системы хранения данных для исполнения заявляемого способа. Заявляемый способ может быть реализован в системах хранения данных с количеством диском больше трех.
При увеличении избыточности увеличивается максимально допустимое количество дисков, которые система хранения данных может потерять, сохраняя возможность восстановления данных, хранившихся на вышедших из строя дисках, в большинстве случаев позволяя полностью исключить участие первой группы дисков из процесса восстановления.
При расчете контрольных сумм как XOR блоков данных, из которых состоит локальная группа, избыточность можно рассчитать по следующей формуле: R= (2X+2) / N,
(где R- размер избыточности, Х- допустимое количества дисков, которые система может потерять, сохраняя возможность восстановления данных, N- кол-во дисков в первой группе).
Таким образом, при реализации заявляемого изобретения, избыточность системы хранения данных является регулируемым параметром. Показатель избыточности системы хранения данных может быть установлен, в зависимости от требуемого уровня отказоустойчивости, администратором системы при определении количества дисков, которые система может потерять, сохраняя возможность восстановления данных.
Так, например, при необходимости увеличения отказоустойчивости системы хранения данных в условиях отсутствия ограничений количества дисков в составе системы, пользователь может задать параметр повышенной избыточности, соответственно, для хранения избыточных данных понадобятся дополнительные диски, но при этом сама система будет обладать более высокой отказоустойчивостью по сравнению с реализацией системы в условиях ограниченного количества дисков, когда администратор устанавливает низкий показатель избыточности, чтобы уменьшить количество дисков в составе системы хранения данных.
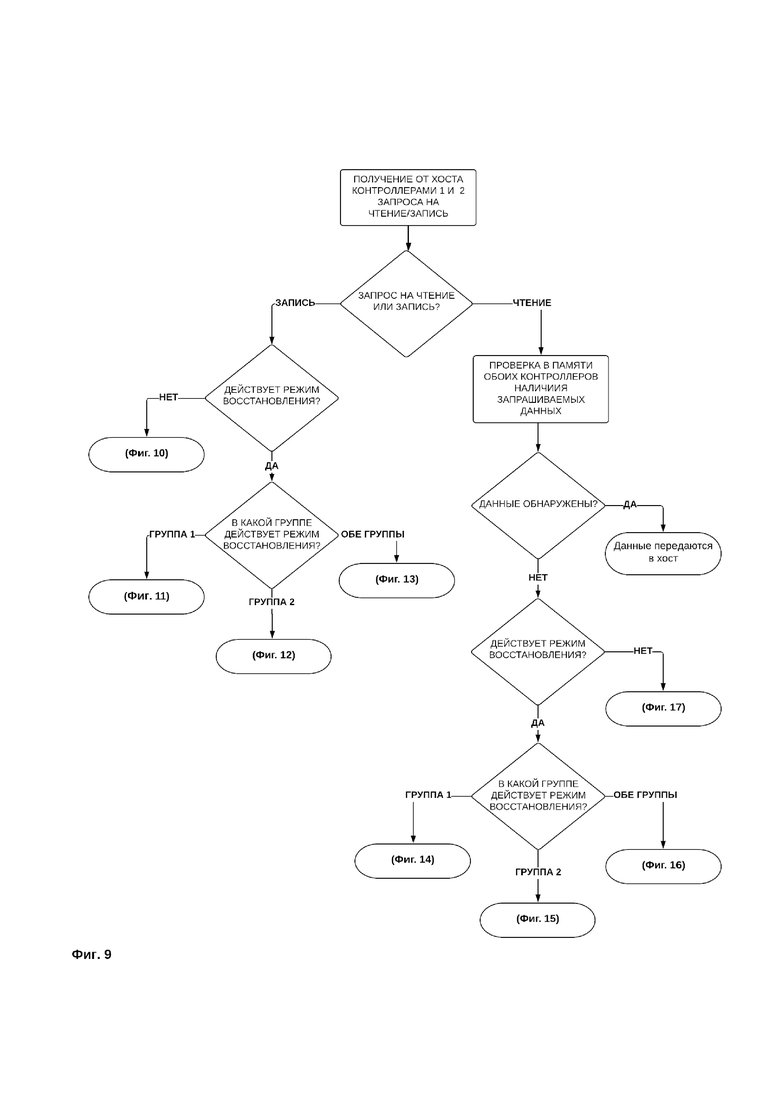
Общая логика исполнения заявляемого способа хранения данных приведена на фиг. 9.
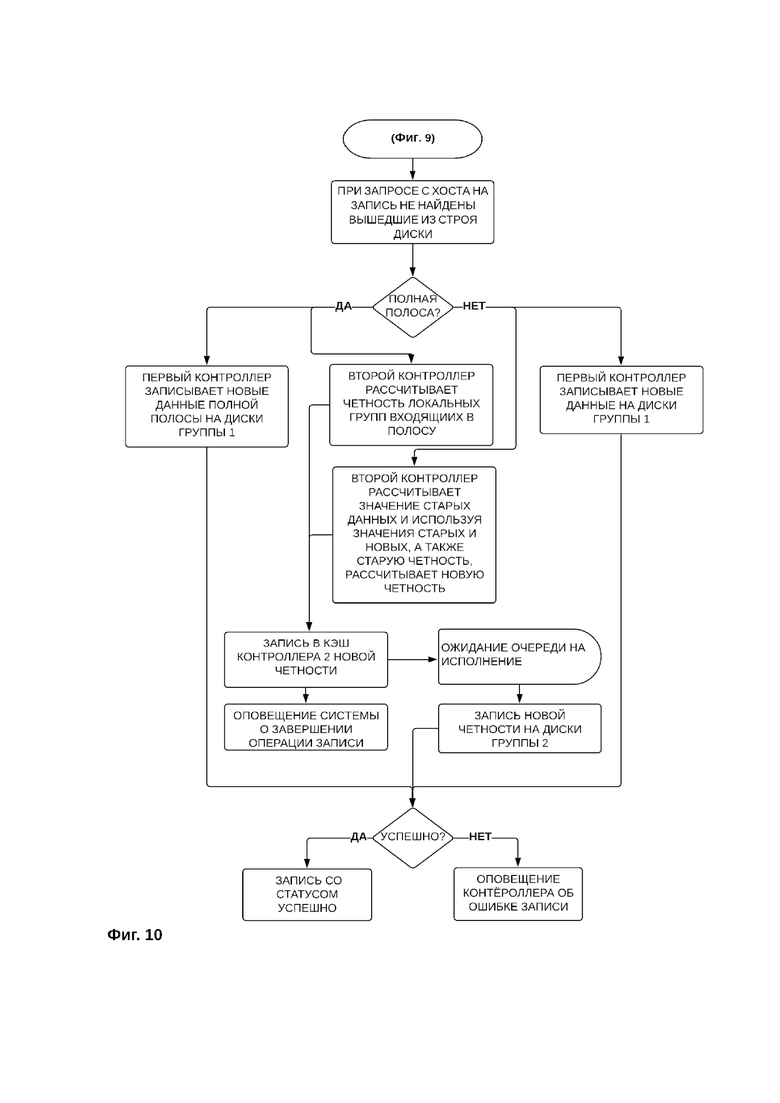
В том случае, если система хранения данных в момент поступления запроса на запись не осуществляет восстановление утраченных данных, запись осуществляется следующим образом (фиг. 10).
При поступлении от хоста запроса на осуществление записи новых данных производится проверка на предмет наличия в системе хранения данных вышедших из строя дисков. В том случае если вышедшие из строя диски в системе хранения данных не обнаружены, новые данные записываются в кэш контроллера первой группы дисков, и на диски первой группы дисков.
Запись новых данных на диски первой группы дисков может осуществляется путем записи полной полосы или частичной записи полосы.
Если поступает запрос на запись полной полосы, первый контроллер записывает новые данные полной полосы на диски первой группы дисков, а второй контроллер рассчитывает четность (контрольные суммы) локальных групп, скомбинированных из блоков данных, входящих в полосу, записывает в кэш второго контроллера новую четность (контрольные суммы) и оповещает систему хранения данных о завершении записи контрольных сумм в кэш контроллера второй группы. Затем после ожидания очереди на исполнение записи новой четности осуществляется запись новой четности на диски второй группы. В том случае, если запись новых блоков данных на диски первой группы дисков и запись новых контрольных сумм на диски второй группы дисков осуществлена успешно, контроллеры оповещают систему хранения данных об успешной записи. Если в процессе записи произошел сбой, контроллер, в работе группы дисков которого произошел сбой, передает данные о сбое на хост.
Если новых данных в кэше контроллера первой группы недостаточно для формирования полной полосы, осуществляется запись новых данных на диски первой группы дисков в порядке частичной записи полосы.
Для записи частичной полосы первый контроллер записывает новые данные на диски первой группы дисков, а второй контроллер асинхронно рассчитывает новую четность из ранее записанных данных (старых данных) и новых данных, а также ранее записанной (старой) четности, после чего контроллер второй группы записывает в кэш второго контроллера новую четность (контрольные суммы) и оповещает систему хранения данных о завершении записи контрольных сумм в кэш контроллера второй группы. Затем после ожидания очереди на исполнение осуществляется запись новой четности на диски второй группы. В том случае, если запись новых блоков данных на диски первой группы дисков и запись новых контрольных сумм на диски второй группы дисков осуществлена успешно, контроллеры оповещают систему хранения данных об успешной записи. Если в процессе записи произошел сбой, то контроллер, в работе группы дисков которого произошел сбой, передает данные о сбое на хост.
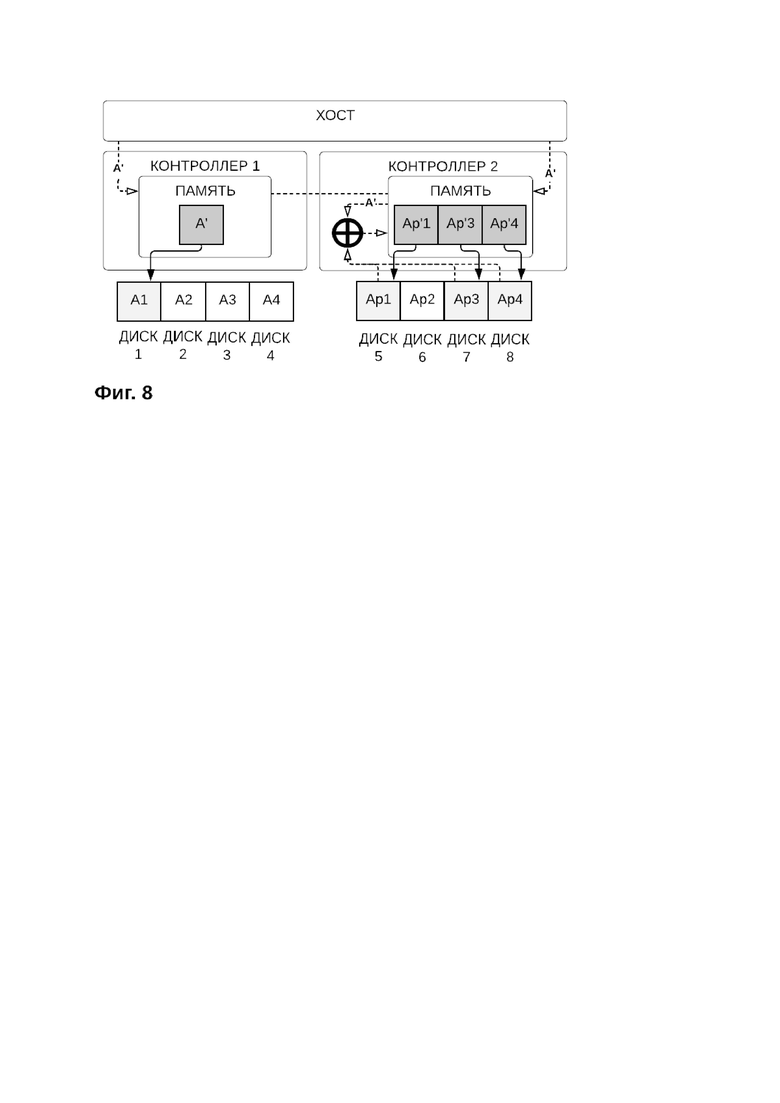
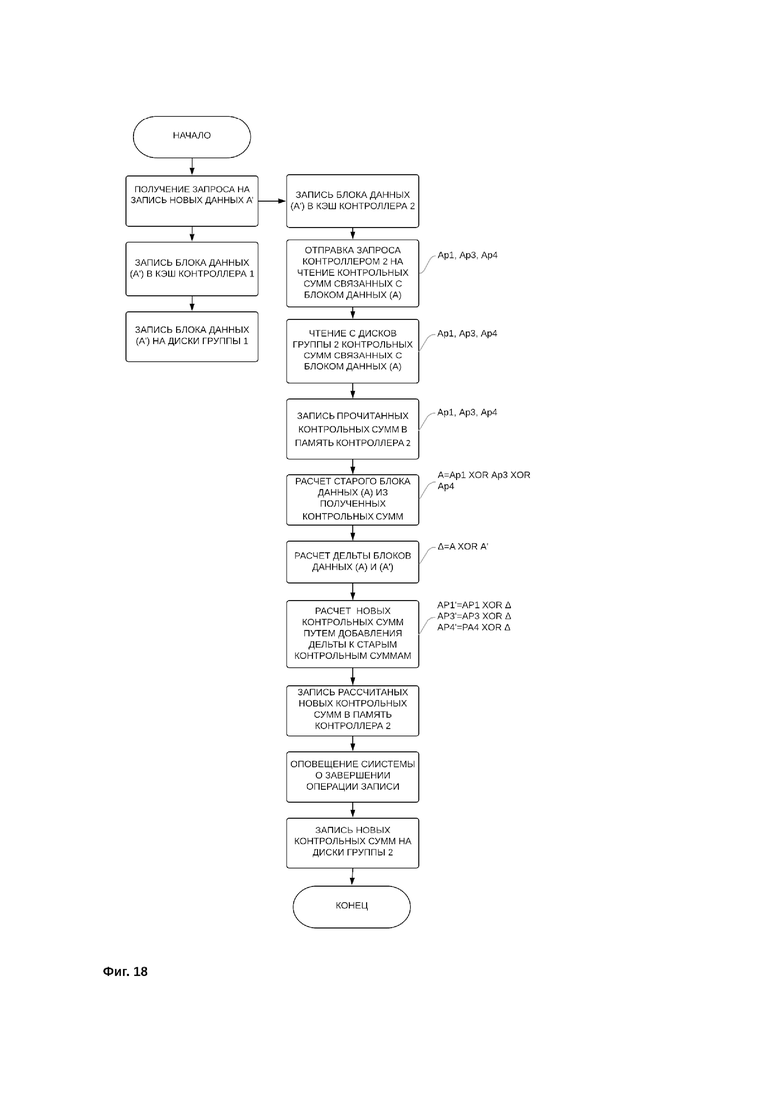
Порядок осуществления частичной записи полосы более подробно раскрыт на фиг. 8 и фиг. 18, где:
А - старые данные находящиеся на дисках на момент поступления запроса на запись новых данных
А’ - новые данные, на запись которых пришел запрос
А1, А2, А3, А4 - блоки данных, ранее записанные на диски первой группы дисков
Ap’1, Ap’3, Ap’4 - новые контрольные суммы, рассчитанные с учетом новых данных, на запись которых пришел запрос
Аp1, Аp2, Аp3, Аp4 - контрольные суммы, ранее записанные на диски второй группы дисков
Диск 1-4 - диски первой группы дисков
Диски 5-8 - диски второй группы дисков
Порядок осуществления частичной записи полосы производится следующим образом:
Получение запроса на запись новых данных A’
Запись новых данных A’ в кэш контроллера первой группы дисков и кэш контроллера второй группы дисков
Запись новых данных A’ на диски первой группы дисков
Отправка запроса контроллером второй группы дисков на чтение связанных с блоком данных (A) контрольных сумм (Ap1, Ap3, Ap4)
Чтение с дисков второй группы контрольных сумм связанных с блоком данных (A)
Запись прочитанных контрольных сумм в кэш-память контроллера второй группы дисков
Расчет старого блока данных (А) из полученных контрольных сумм(A=Ap1⊕Ap3⊕Ap4)
Расчет дельты блоков данных (А) и (А') (△= A⊕A’)
Расчет новых контрольных сумм путем добавления дельты к старым контрольным суммам: Ap1’=△⊕Ap; Ap3’=△⊕Ap3; Ap’4= △⊕Ap4
Запись новых контрольных сумм Ap’1, Ap’3, Ap’4 в кэш с отложенной записью контроллера второй группы
Оповещение системы о завершении операции записи
Запись новых контрольных сумм Ap’1, Ap’3, Ap’4 из кэша контроллера второй группы на диски второй группы дисков
Подтверждение записи новых данных в систему хранения данных происходит на этапе записи новых контрольных сумм в кэш контроллера второй группы дисков. Запись новых контрольных сумм из кэша контроллера второй группы дисков на диски второй группы дисков или резервные диски может быть отложена в зависимости от глубины очереди.
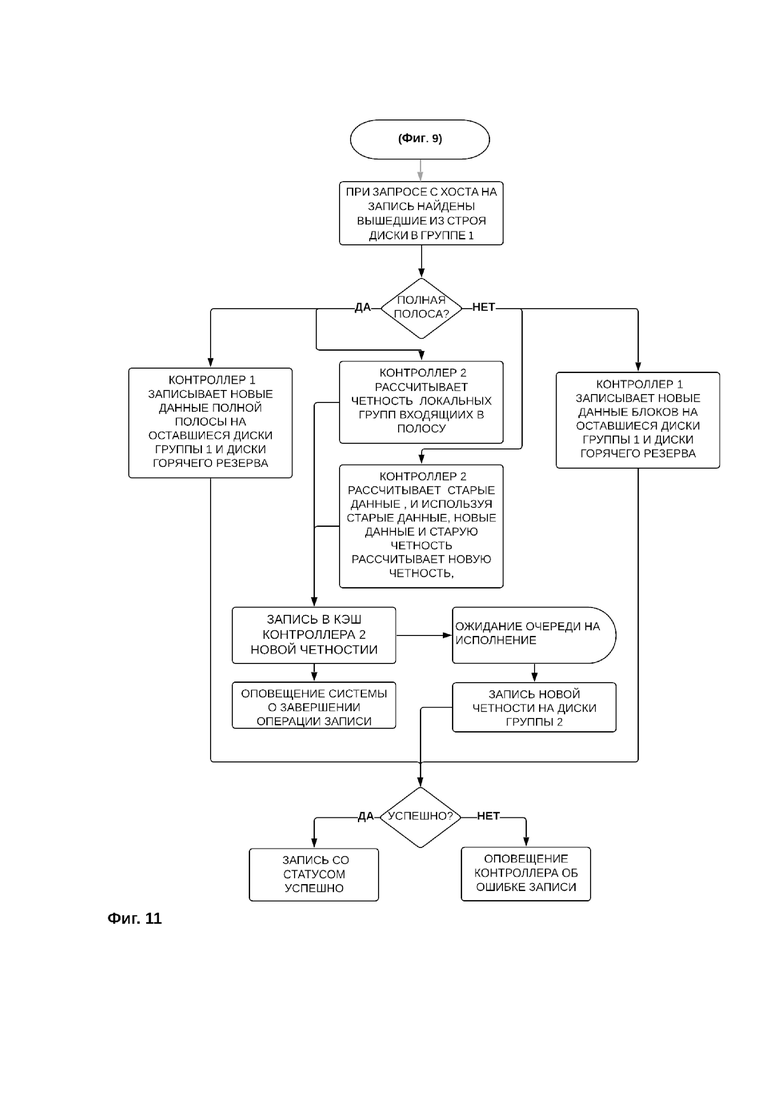
В том случае, если при поступлении от хоста запроса на осуществление записи новых данных в системе хранения данных обнаруживаются вышедшие из строя диски в первой группе дисков, то запись новых данных происходит в режиме деградирования в следующем порядке (фиг. 11).
Запись новых данных на диски первой группы дисков при условии обнаружения выхода из строя одного или нескольких дисков первой группы дисков может осуществляется путем записи полной полосы или частичной записи полосы.
Если поступает запрос на запись полной полосы, первый контроллер записывает новые данные полной полосы на оставшиеся диски первой группы дисков и диски горячего резерва, а второй контроллер асинхронно рассчитывает четность (контрольные суммы) локальных групп, скомбинированных из блоков данных, входящих в полосу, записывает в кэш второго контроллера новую четность (контрольные суммы) и оповещает систему хранения данных о завершении записи контрольных сумм в кэш контроллера второй группы. Затем после ожидания очереди на исполнение записи новой четности осуществляется запись новой четности на диски второй группы. В том случае, если запись новых блоков данных на диски первой группы дисков и запись новых контрольных сумм на диски второй группы дисков осуществлена успешно, контроллеры оповещают систему хранения данных об успешной записи. Если в процессе записи произошел сбой, контроллер, в работе группы дисков которого произошел сбой, передает данные о сбое на хост.
Если поступает запрос на частичную запись, осуществляется запись новых данных на диски первой группы дисков в порядке частичной записи полосы.
Для записи частичной полосы первый контроллер записывает новые данные на диски первой группы дисков и диски горячего резерва, а второй контроллер асинхронно рассчитывает новую четность ранее записанных данных (старых данных) и новых данных из значений старых и новых данных, после чего контроллер второй группы записывает в кэш второго контроллера новую четность (контрольные суммы) и оповещает систему хранения данных о завершении записи контрольных сумм в кэш контроллера второй группы. Затем после ожидания очереди на исполнение осуществляется запись новой четности на диски второй группы. В том случае, если запись новых блоков данных на диски первой группы дисков и запись новых контрольных сумм на диски второй группы дисков осуществлена успешно, контроллеры оповещают систему хранения данных об успешной записи. Если в процессе записи произошел сбой, то контроллер, в работе группы дисков которого произошел сбой, передает данные о сбое на хост.
Фиг. 12 иллюстрирует порядок записи новых данных в случае обнаружения выхода из строя дисков во второй группе дисков.
Если поступает запрос на запись полной полосы, первый контроллер записывает новые данные полной полосы на диски первой группы дисков, а второй контроллер асинхронно рассчитывает четность (контрольные суммы) локальных групп, скомбинированных из блоков данных, входящих в полосу, записывает в кэш второго контроллера новую четность (контрольные суммы) и оповещает систему хранения данных о завершении записи контрольных сумм в кэш контроллера второй группы. Затем после ожидания очереди на исполнение записи новой четности осуществляется запись новой четности на оставшиеся диски, и диски горячего резерва второй группы дисков. В том случае, если запись новых блоков данных на диски первой группы дисков и запись новых контрольных сумм на оставшиеся диски, и диски горячего резерва второй группы дисков осуществлена успешно, контроллеры оповещают систему хранения данных об успешной записи. Если в процессе записи произошел сбой, контроллер, в работе группы дисков которого произошел сбой, передает данные о сбое на хост.
Если новых данных в кэше контроллера первой группы недостаточно для формирования полной полосы, осуществляется запись новых данных на диски первой группы дисков в порядке частичной записи полосы.
Для записи частичной полосы первый контроллер записывает новые данные на диски первой группы дисков, а второй контроллер асинхронно проверяет достаточно ли ранее записанной информации о четности для восстановления старых данных контрольных сумм.
Если существующей информации достаточно, то контроллер второй группы дисков восстанавливает утраченные контрольные суммы и с учетом новых данных рассчитывает новую четность. Если существующей информации не достаточно для восстановления утраченных данных четности, то контроллер второй группы дисков обращается к дискам обеих групп и восстанавливает утраченные данные о четности с использованием блоков данных первой группы дисков и сохранившихся контрольных сумм, после чего с учетом новых данных рассчитывает новую четность (контрольные суммы).
Затем контроллер второй группы дисков записывает в кэш второго контроллера новую четность (контрольные суммы) и оповещает систему хранения данных о завершении записи контрольных сумм в кэш контроллера второй группы. Затем после ожидания очереди на исполнение осуществляется запись новой четности на оставшиеся диски, и диски горячего резерва второй группы. В том случае, если запись новых блоков данных на диски первой группы дисков и запись новых контрольных сумм на диски второй группы дисков осуществлена успешно, контроллеры оповещают систему хранения данных об успешной записи. Если в процессе записи произошел сбой, то контроллер, в работе группы дисков которого произошел сбой, передает данные о сбое на хост.
Фиг. 13 иллюстрирует порядок записи новых данных при обнаружении выхода из строя дисков в обеих группах дисков. В таком случае запись новых данных осуществляется в том же порядке, что и при записи новых данных в случае обнаружения выхода из строя дисков во второй группе дисков (фиг.12) с тем отличием, что в случае записи полной полосы новые данные полной полосы записываются на оставшиеся диски первой группы и диски горячего резерва первой группы дисков, и при частичной записи полосы новые данные также записываются на диски первой группы и диски горячего резерва первой группы дисков.
В том случае, если система хранения данных в момент поступления запроса на осуществление частичной записи полосы новых блоков данных исполняет процесс восстановления данных, то запись новых данных может также осуществляться через ожидание полной полосы в следующем порядке.
Новые данные, по мере поступления запросов на запись, записываются на диски первой группы дисков и в кэш контроллера второй группы дисков. По мере ожидания того, как новые данные составят полосу, вторая группа дисков, включая контроллер второй группы дисков может осуществлять асинхронный процесс, например чтение контрольных сумм для параллельного осуществления режима восстановления.
После того, как новые данные составили полосу, второй контроллер асинхронно рассчитывает четность (контрольные суммы) локальных групп, скомбинированных из блоков данных, входящих в полосу, и записываются в кэш контроллера второй группы дисков. Далее, контрольные суммы данной полосы записываются из кэша контроллера второй группы дисков на оставшиеся диски, и диски горячего резерва второй группы.
Чтение данных осуществляется следующим образом.
После получения запроса на чтение контроллеры первой и второй группы проверяют кэш-память контроллеров, чтобы определить, находятся ли запрошенные данные в кэше контроллеров. Если данные найдены в кэше, контроллеры передают запрошенные данные устройству пользователя (фиг. 9).
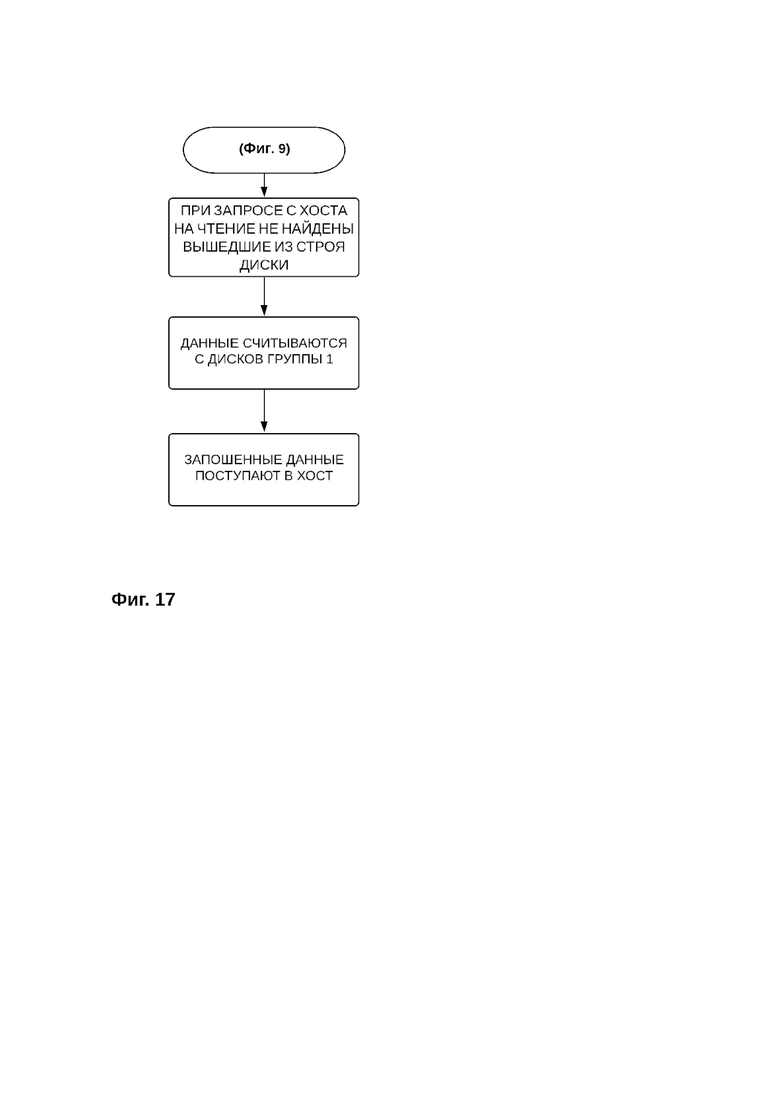
Если запрошенные данные не были обнаружены в кэше и при этом все диски системы хранения данных работают исправно, то чтение данных осуществляется только с дисков первой группы дисков (фиг. 17).
Если запрошенные данные не были обнаружены в кэше и при этом система хранения данных осуществляет восстановление данных в момент поступления запроса на чтение, чтение данных производится в следующем порядке.
При выходе из строя одного или нескольких дисков первой группы дисков (фиг. 14) запрашиваемые пользователем данные считываются с уцелевших дисков первой группы дисков и записываются в кэш контроллера первой группы дисков. Недостающие данные асинхронно восстанавливаются из блоков контрольных сумм, хранящихся на дисках второй группы дисков, и также записываются в кэш контроллера первой группы дисков, формируя таким образом полный пакет запрошенных данных. В результате данные в полном запрошенном объеме поступают на хост, а восстановленные данные записываются на резервные диски, назначенные вместо вышедших из строя дисков первой группы. Таким образом, для восстановления данных не задействуется первая группа дисков, что позволяет обслуживать пользовательские запросы на чтение блоков данных без потери производительности системы хранения данных.
Если из строя выходит один или несколько дисков второй группы дисков (фиг. 15), запрашиваемые на чтение данные считываются с дисков первой группы и передаются на хост, а утраченные блоки контрольных сумм, в первую очередь, восстанавливаются за счет сохранившихся блоков контрольных сумм, и только в случае нехватки оставшихся контрольных сумм для восстановления, производится обращение к блокам данных на дисках первой группы дисков. После, восстановленные контрольные суммы записываются в кэш второго контроллера и затем записываются на резервные диски второй группы дисков. Такая организация процесса чтения данных в режиме восстановления системы позволяет сохранить доступность данных, сохраняя достаточную производительность.
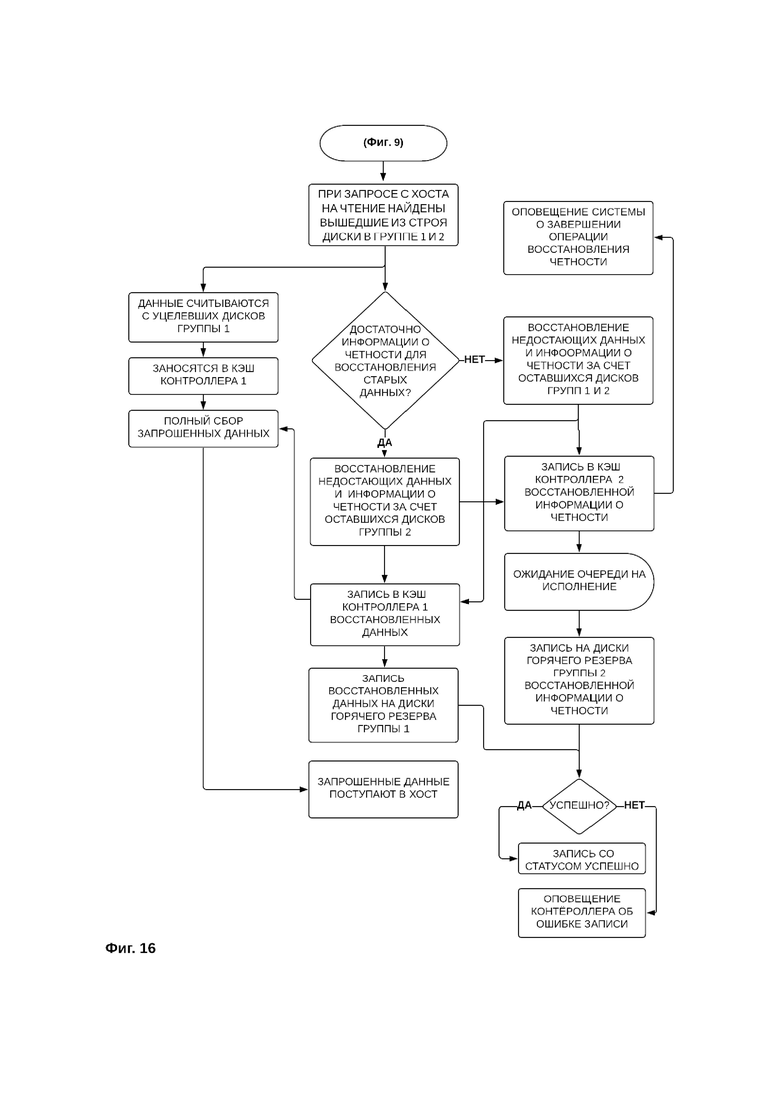
При выходе из строя одного или нескольких дисков обеих групп дисков (фиг. 16) запрашиваемые пользователем данные считываются с уцелевших дисков первой группы дисков и записываются в кэш контроллера первой группы дисков, Недостающие данные, в первую очередь восстанавливаются за счет оставшихся блоков контрольных сумм, хранящихся на дисках второй группы дисков, и, в случае их нехватки, также обращаются к блокам данных хранящихся на дисках первой группы. Далее, восстановленные данные записываются в кэш контроллера первой группы дисков, формируя таким образом полный пакет запрошенных данных, и после чего передаются на устройство пользователя. Следующим этапом восстановленные данные записываются на резервные диски первой группы дисков, а восстановленные контрольные суммы записываются на резервные диски второй группы дисков.
В случае отказа одного или нескольких дисков возврат системы к исходному отказоустойчивому состоянию производится в порядке, раскрытом ранее с иллюстрацией фиг. 2.
С целью минимизировать время, за которое система хранения данных вернется в исходное отказоустойчивое состояние, а также используя возможности предлагаемого решения, а именно осуществления асинхронного выполнения разнонаправленных задач, процесс восстановления данных активизируется с момента ухудшения параметров отказоустойчивости системы одновременно с переходом системы в режим деградирования.
Восстановленные данные необходимые для функционирования системы в режиме деградирования, также записываются на резервные диски, избегая тем самым повторного восстановления данных, в том случае если бы режим восстановления дисков происходил обособленно. В режиме восстановления также допускается выход из строя дисков до количества, предусмотренного установленным показателем избыточности системы. При этом для восстановления данных в приоритетном порядке используются блоки контрольных сумм, и только в случае нехватки этой информации допускается обращения к блокам данных. Таким образом сохраняется возможность обрабатывать запросы на чтение и запись.
Балансировка рабочей нагрузки между процессами чтения-записи и режимом восстановления, равно как характеристики производительности/ надежности, а также очередность выполняемых задач может может задаваться как администратором системы, так и в автоматическом режиме, в зависимости от текущего состояния отказоустойчивости системы(количества вышедших из строя дисков).
Реализация заявляемого способа в системе хранения данных позволяет произвести возврат системы к исходному отказоустойчивому состоянию даже при полном выходе из строя одной из групп дисков.
Также при использовании заявляемого способа достигается дополнительный положительный технический эффект, заключающийся в снижении латентности. Устройства хранения данных, а именно жесткие диски - одна из самых медленных частей компьютерных систем, поэтому для обеспечения высокой производительности всей системы требуется эффективный способ доступа к устройствам хранения. В известных RAID массивах с высокой отказоустойчивостью блоки данных и блоки контрольных сумм чередуются между собой и записываются на один диск. Это приводит к тому, что при последовательном чтении блоков данных необходимо производить перемещение считывающей головки дисковода так, чтобы считывать только блоки данных и не производить считывание блоков контрольных сумм.
При использовании заявляемого способа за счет отсутствия чередования блоков данных и блоков контрольных сумм на одном диске, уменьшается латентность - время позиционирования считывающей головки дисковода над нужным треком диска и время ожидания прихода нужного сектора диска под считывающую головку дисковода, и как следствие повышается скорость последовательного чтения блоков данных. Таким образом, при использовании заявляемого изобретения в системе хранения данных, включающей жесткие диски, исключается время ожидания прохода считывающей головки дисковода для пропуска чтения блоков контрольных сумм.
Пример осуществления изобретения
Приводимый далее пример предназначен исключительно для пояснения сущности изобретения на одном из возможных вариантов исполнения системы хранения данных и не должен быть использован для сужения объема правовой охраны заявляемого изобретения. Заявляемый способ может быть осуществлен, например, в следующей системе хранения данных.
На физическом уровне система хранения данных для реализации заявляемого способа может состоять из следующих компонентов:
Хост-машина, представляющая собой шлюз, обеспечивающий интерфейс доступа к данным (например блочный доступ, файловый доступ). Хост-машина может подключаться к контроллерам через LAN (ethernet cable) или через оптоволоконное соединение (fiber optic cable).
Контроллер дисков первой группы дисков, представляющий собой сервер с установленным на нем модулем ядра Linux и модификации MDADM, обеспечивающий возможность выполнения заявляемого способа
Контроллер дисков второй группы дисков, представляющий собой сервер с установленным на нем модулем ядра Linux и модификации MDADM, обеспечивающий возможность выполнения заявляемого способа.
Дисковый массив JBOD или JBOF, состоящий из HDD и/или SSD дисков, логически разделенных на диски первой группы дисков и диски второй группы дисков, соединенный с контроллером первой группы дисков и контроллером второй группы дисков через высокоскоростные подключения SAS/SATA/miniSAS.
Указанный выше пример конфигурации системы хранения данных является одним из примеров конфигурации системы хранения данных, в которых может быть использовано заявляемое изобретение и достигнут заявляемый технический результат.
Заявляемый способ может быть реализован с разными исполнениями контроллеров групп дисков массива. Так, выделяют следующие виды контроллеров RAID-массива: программные, аппаратные, интегрированные.
В программных контроллерах массива вся нагрузка по управлению массивом ложится на центральный процессор ЭВМ. Системы хранения данных с такими контроллерами являются наименее производительными и отказоустойчивыми.
Программные контроллеры для реализации заявляемого изобретения могут быть реализованы в виде модуля ядра операционной системы Linux (например, Centos7, версии 2.6, на которой был реализован прототип системы хранения данных). При реализации в таком виде, портирование системы на другие дистрибутивы Linux может быть осуществлено путем компиляции модуля ядра и импорта в целевую операционную систему.
Интегрированные контроллеры встраиваются как отдельный чип в материнскую плату ЭВМ, к которой подключена система хранения данных. Интегрированный контроллер выполняет часть задач по управлению, другую часть задач выполняет центральный процессор ЭВМ. Интегрированные контроллеры могут иметь собственную кэш-память. По сравнению с программными, обладают более высокой производительностью и отказоустойчивостью.
Аппаратные контроллеры выполнены в виде плат расширения или отдельных устройств, размещаемых вне сервера (внешние, или мостовые контроллеры). Оснащены собственным процессором, выполняющим все необходимые вычисления, и, как правило, кэш-памятью. Модульные контроллеры могут иметь внешние и внутренние порты, при этом внутренние порты предназначены для подключения накопителей, установленных в сам сервер, а внешние порты используются для подключения внешних дисковых хранилищ.
Реализация заявляемого изобретения возможна с любым видом контроллеров групп дисков. Для достижения максимальных результатов рекомендуется по возможности использовать аппаратные контроллеры групп дисков.
Изобретение относится к системам хранения данных. Техническим результатом является повышение отказоустойчивости системы хранения данных с минимизацией влияния процессов, обеспечивающих отказоустойчивость системы, на производительность процессов чтения и записи данных пользователем. Способ содержит этапы: запись блоков данных в кэш контроллера первой группы дисков, запись блоков данных в составе полосы на диски первой группы дисков, группировку записанных блоков данных в локальные группы, расчет контрольных сумм локальных групп, запись контрольных сумм локальных групп в кэш контроллера второй группы дисков, запись контрольных сумм на диски второй группы дисков, и в случае обнаружения отказа одного или нескольких дисков первой группы осуществляется восстановление утраченных блоков данных из контрольных сумм, записанных на дисках второй группы дисков, и запись восстановленных блоков данных в кэш контроллера первой группы дисков, а в случае обнаружения отказа одного или нескольких дисков второй группы дисков осуществляется восстановление утраченных контрольных сумм из сохранившихся контрольных сумм, записанных на дисках второй группы дисков, и запись восстановленных контрольных сумм в кэш контроллера второй группы дисков. 18 ил.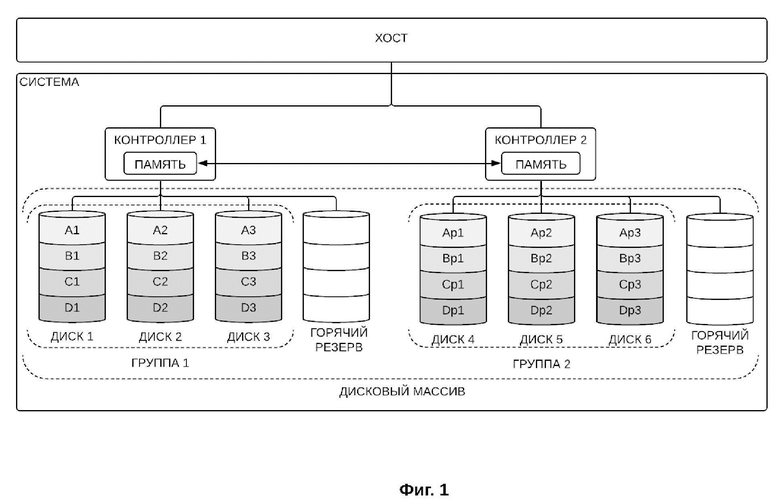
Способ хранения данных в системе хранения данных, содержащей первую группу дисков, управляемую контроллером первой группы дисков, и вторую группу дисков, управляемую контроллером второй группы дисков, причем каждый контроллер выполнен с возможностью обмена данными с хостом и контроллером другой группы дисков, включающий
запись блоков данных в кэш контроллера первой группы дисков;
запись блоков данных в составе полосы на диски первой группы дисков;
комбинация записанных блоков данных в локальные группы;
расчет контрольных сумм локальных групп;
запись контрольных сумм локальных групп в кэш контроллера второй группы дисков;
запись контрольных сумм на диски второй группы дисков;
в случае обнаружения отказа одного или нескольких дисков первой группы осуществляется восстановление утраченных блоков данных из контрольных сумм, записанных на дисках второй группы дисков, и запись восстановленных блоков данных в кэш контроллера первой группы дисков;
в случае обнаружения отказа одного или нескольких дисков второй группы дисков осуществляется восстановление утраченных контрольных сумм из сохранившихся контрольных сумм, записанных на дисках второй группы дисков, и запись восстановленных контрольных сумм в кэш контроллера второй группы дисков.
| US 7506187 B2, 17.03.2009 | |||
| СПОСОБ ОРГАНИЗАЦИИ ХРАНЕНИЯ ДАННЫХ НА БАЗЕ КОДОВ-ПРОИЗВЕДЕНИЙ С ПРОСТОЙ ПРОВЕРКОЙ НА ЧЕТНОСТЬ СО СМЕЩЕНИЕМ | 2018 |
|
RU2699678C2 |
| СПОСОБ КОНТРОЛЯ КОРРЕКТНОСТИ ЗАПИСИ ДАННЫХ В ДВУХКОНТРОЛЛЕРНОЙ СИСТЕМЕ ХРАНЕНИЯ ДАННЫХ НА МАССИВЕ ЭНЕРГОНЕЗАВИСИМЫХ НОСИТЕЛЕЙ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2013 |
|
RU2552151C2 |
| US 9256490 B2, 09.02.2016 | |||
| US 20190163374 A1, 30.05.2019. | |||

