Изобретение относится к компьютерным устройствам массовой памяти, и, в частности, к их архитектуре.
В данной заявке используется следующая терминология
Узел системы хранения данных (узел) - компьютерный сервер на основе архитектуры х86 или иной, предназначенный в первую очередь для решения задач хранения данных. Может иметь в своем составе один или несколько SSD, подключенных по интерфейсу NVMe.
Вычислительный узел - компьютерный сервер на основе архитектуры х86 или иной, предназначенный в первую очередь для решения вычислительных задач. Может иметь в своем составе один или несколько SSD, подключенных по интерфейсу NVMe.
Кластер - совокупность узлов, объединенных в общую высокоскоростную сеть (интерконнект), поддерживающую технологию NVMeoF.
Target, в терминах NVMeoF - программное или программно-аппаратное решение, позволяющее узлу предоставлять доступ к NVMe дискам для других узлов.
Host, в терминах NVMeoF - программное или программно-аппаратное решение, позволяющее узлу получать доступ к удаленным NVMe дискам.
NVMeoF - технология, позволяющая подключать к компьютерным серверам (Host) NVMe диски, расположенные на других серверах (Target). При подключении на Host создается блочное устройство, представляющее удаленный NVMe диск, обращение к этому устройству аналогично обращению к удаленному диску.
Распределенная файловая система (РФС) - программный комплекс, предназначенный для решения задач хранения данных. РФС содержит в своем составе один или несколько Object Storage System (OSS), содержащих непосредственно данные, совокупность OSS составляет общее пространство данных. OSS работают параллельно, доступ к OSS также осуществляется параллельно, для функционирования РФС необходима одновременная и бесперебойная работа всех OSS в ее составе.
RAID или RAID массив - совокупность из нескольких блочных устройств хранения (SSD, HDD), объединенных в единое логическое блочное устройство таким образом, что выход из строя одного или нескольких блочных устройств в составе RAID не вызывает выхода из строя самого массива, и не приводит к потере данных. Существует несколько разновидностей RAID массивов, отличающихся способом организации данных, степенью их избыточности и соответственно, отказоустойчивостью.
Введение
Современные большие компьютерные кластеры, особенно кластеры, предназначенные для массовых параллельных вычислений (High Performance Computing, НРС) характеризуются очень высокими требованиями к входящим в их состав системам хранения данных. Во многих случаях общая производительность кластера, даже при решении вычислительных задач, ограничивается именно производительностью системы хранения данных. Требования к пропускной способности системы хранения данных могут достигать десятков, или даже сотен ГБ/с, как за запись, так и на чтение, при выполнении сотен тысяч или даже миллионов операций ввода/вывода в секунду. Общая емкость дискового пространства системы хранения современных кластеров может достигать десятков Петабайт.
Системы хранения данных, которые могут соответствовать столь высоким требованиям, строятся на основе распределенных файловых систем (РФС), которые позволяют распараллеливать нагрузку при обращении к данным на множество отдельных серверов системы хранения данных, то есть, используют принцип параллелизма. Такие системы распределяют данные между набором отдельных хранилищ (Object Storage Service, OSS, в общепринятой терминологии), и предоставляют клиентам РФС возможность параллельного обращения к OSS. Современные РФС, такие как Lustre, характеризуются хорошей линейной масштабируемостью, то есть производительность и емкость РФС может быть увеличена почти без ограничений путем добавления в нее новых OSS.
Для доступа к РФС в кластерах используются высокопроизводительные локальные сети (Interconnect), в том числе с реализацией функциональности прямого доступа к удаленной памяти RDMA. Примерами такого интерконнекта могут служить технологии Ethernet от 10 Gb/s и выше, Intel Omni-Path, Mellanox Infiniband, при этом обеспечивается пропускная способность до 200 Gb/s на порт и выше. Intel Omni-Path и Mellanox Infiniband также характеризуются очень низкими задержками при передаче данных, поэтому они широко применяются для построения вычислительных кластеров (НРС). И клиенты, и OSS распределенной файловой системы объединяются при помощи подобных высокопроизводительных сетей, что позволяет осуществлять доступ к данным с максимальной производительностью и минимальными задержками.
Уровень техники
Известен способ и устройство распределенной виртуальной системы хранения для серверов, использующее распределение данных по NVMe устройствам в том числе и по технологии NVMe over Fabrics (SHAREABLE VIRTUAL NON-VOLATLE STORAGE DEVICE FOR A SERVER, US патент US 20130198450 A1, 2013 г.).
Недостатком описанного способа и устройства является отсутствие описанных способов обеспечения отказоустойчивости при отказе одного или нескольких узлов, предоставляющих доступ к данным.
Известен способ и устройство доступа к множественным устройствам хранения информации с множества серверов без использования удаленного прямого доступа к памяти (RDMA), использующее аналогичное распределение данных по удаленным NVMe устройствам для обеспечения отказоустойчивости при отказе NVMe дисков. (SHAREABLE VIRTUAL NON-VOLATLE STORAGE DEVICE FOR A SERVER, US патент US 20150248366 A1, 2015 г.).
Недостатком описанного способа и устройства является необходимость использования отдельной локальной сети SAN для обеспечения доступа к данным, что снижает производительность, а также увеличивает стоимость и сложность конструкции.
Наиболее близким решением к заявляемому является способ и устройство система хранения и передачи данных, использующее подключение устройств NVMe клиентских вычислительных узлов для использования их в составе системы хранения данных. (LARGE-SCALE DATA STORAGE AND DELIVERY SYSTEM, US патент US 20150222705 A1, 2015 г.).
Недостатком описанного способа и устройства является необходимость разработки и использования специального оборудования, что увеличивает сложность и стоимость конструкции. Также не предусмотрены средства обеспечения отказоустойчивости при отказе одного или нескольких узлов, предоставляющих доступ к данным.
Технический результат заявляемого изобретения заключается в упрощении конструкции системы хранения данных, повышении производительности и отказоустойчивости системы.
Указанный технический результат достигается тем, метод построения высокопроизводительной отказоустойчивой системы хранения данных на основе распределенной файловой системы и технологии NVMe over Fabrics в гиперконвергентных инфраструктурах (системах) заключается в построении системы включающей: вычислительные узлы серверной фермы (серверы), имеющие в своем составе стандартные компоненты, такие как CPU, оперативную память, полнодуплексную сеть передачи данных с поддержкой технологии RDMA, подсистемы питания, охлаждения, управления, устройства хранения данных в виде SSD накопителей, подключенных к вычислительным узлам серверной фермы (серверам) по протоколу NVMe и полнодуплексную сеть передачи данных с поддержкой технологии RDMA. Где вычислительные узлы серверной фермы (серверы), SSD накопители и полнодуплексная сеть передачи данных с поддержкой технологии RDMA объединены в гиперконвергентную инфраструктуру с помощью программных средств, а управление ими происходит через общую консоль администрирования. При этом используются устройства хранения данных, предоставляемых технологией NVMe over Fabrics со всей гиперконвергентной инфраструктуры, объединенные сетью передачи данных с поддержкой технологии RDMA; все компоненты сети дублируются; в качестве узлов, предоставляющих доступ ко всей гиперконвергентной инфраструктуре по технологии NMVe over Fabrics, выступают все серверы гиперконвергентной инфраструктуры, а также специализированные полки с NVMe дисками. Часть узлов, содержащих NVMe устройства хранения данных, используемых в системе хранения данных, получают роль Target, и предоставляют удаленный доступ к устройствам хранения данных в своем составе, а остальные узлы, содержащие NVMe устройства хранения данных, используемые в системе хранения данных получают роль Host, к ним подключаются удаленные устройства хранения данных, которые в свою очередь собираются в программные RAID массивы с определенным уровня избыточности данных, эти RAID массивы выступают в роли дискового пространства для данных (OSS), распределенной файловой системы (РФС), также запускаемых на узлах системы хранения, где один RAID массив подключается к одному OSS, работающему на том же узле хранения данных, при этом все устройства хранения данных, включенные в один RAID массив, должны физически располагаться на разных Target, то есть на разных серверах, для каждого активного RAID массива должна существовать как минимум одна неактивная копия, располагающаяся на другом узле хранения данных, для каждого активного OSS должна существовать как минимум одна неактивная копия, располагающаяся на другом узле хранения данных.
Кроме того система хранения может иметь некоторое количество запасных (spare) NVMe устройства хранения данных, подключенных к тем или иным серверам в роли Target, и не включенных ни в один из RAID массивов..
Настоящее изобретение поясняется следующими чертежами.
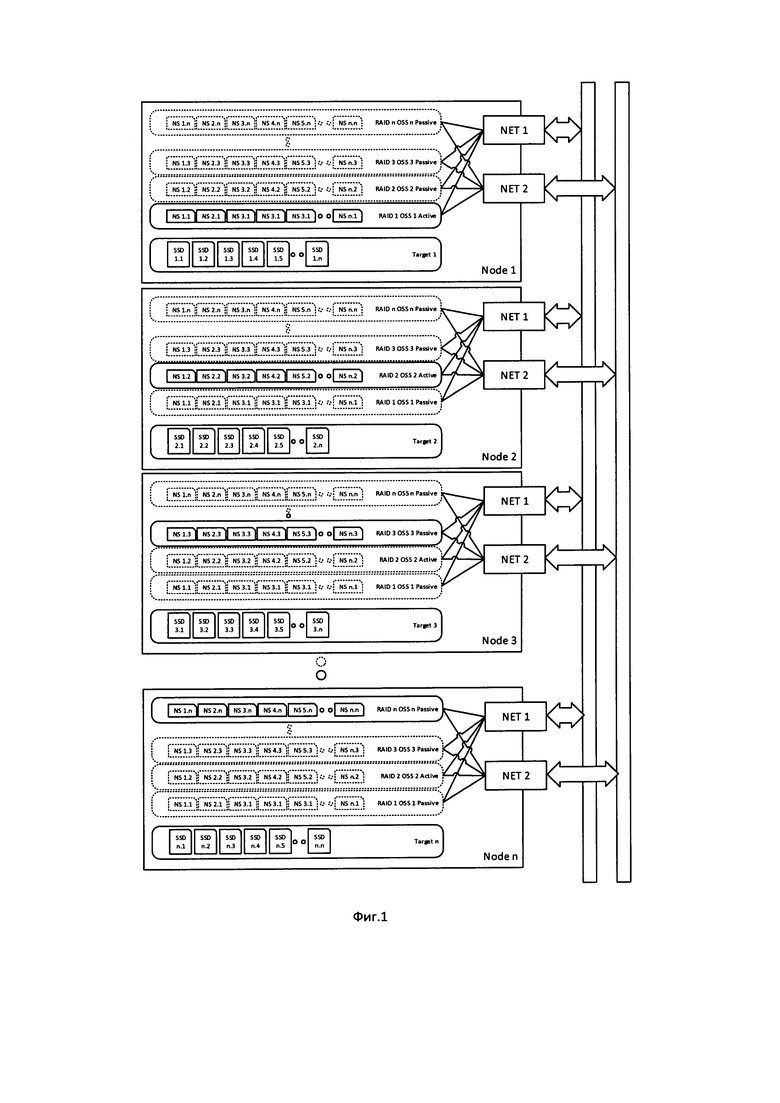
Фиг. 1 - Конфигурация системы хранения при использовании в качестве Target узлов системы хранения n с m устройствами хранения данных,
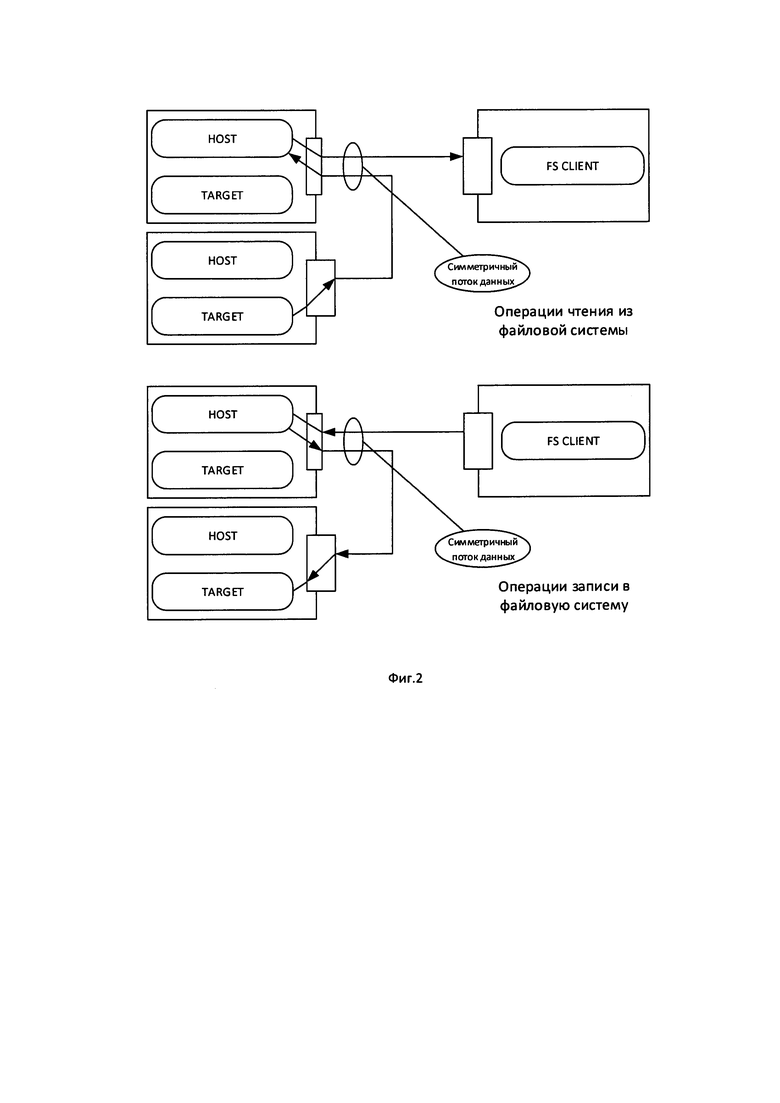
Фиг. 2 - Метод повышения утилизации пропускной способности сети,
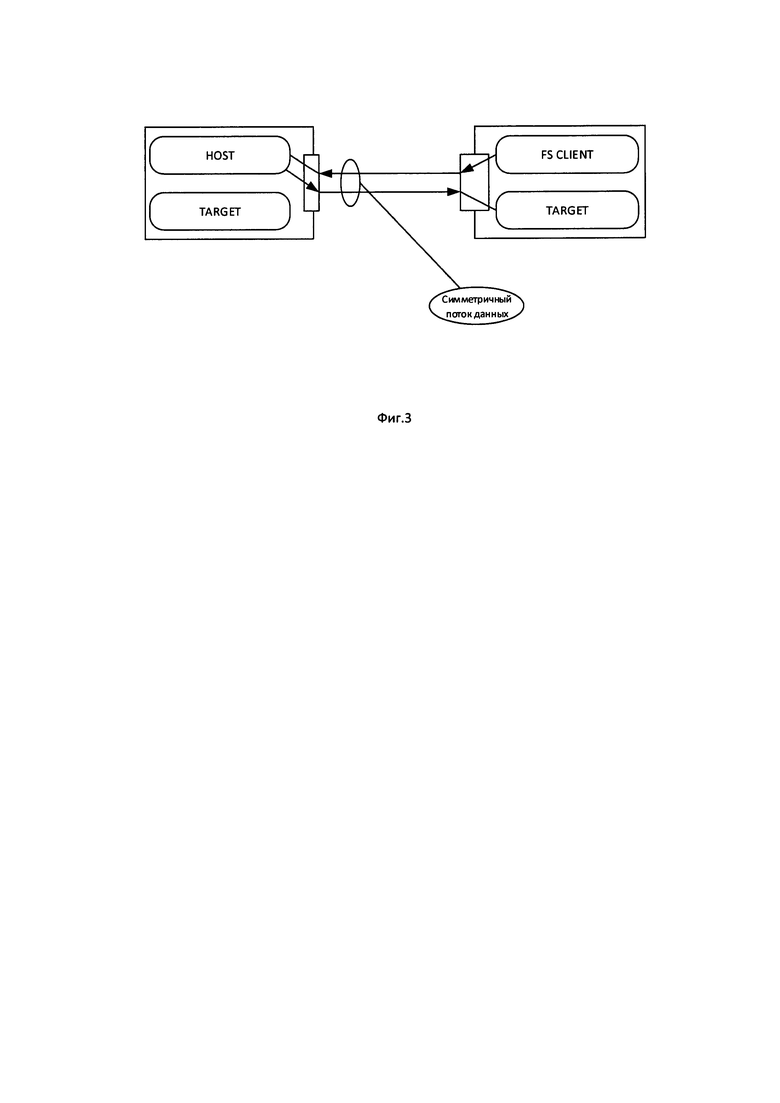
Фиг. 3 - Использование оборудования с совмещением ролей Target и Host и/или Target и клиент файловой системы,
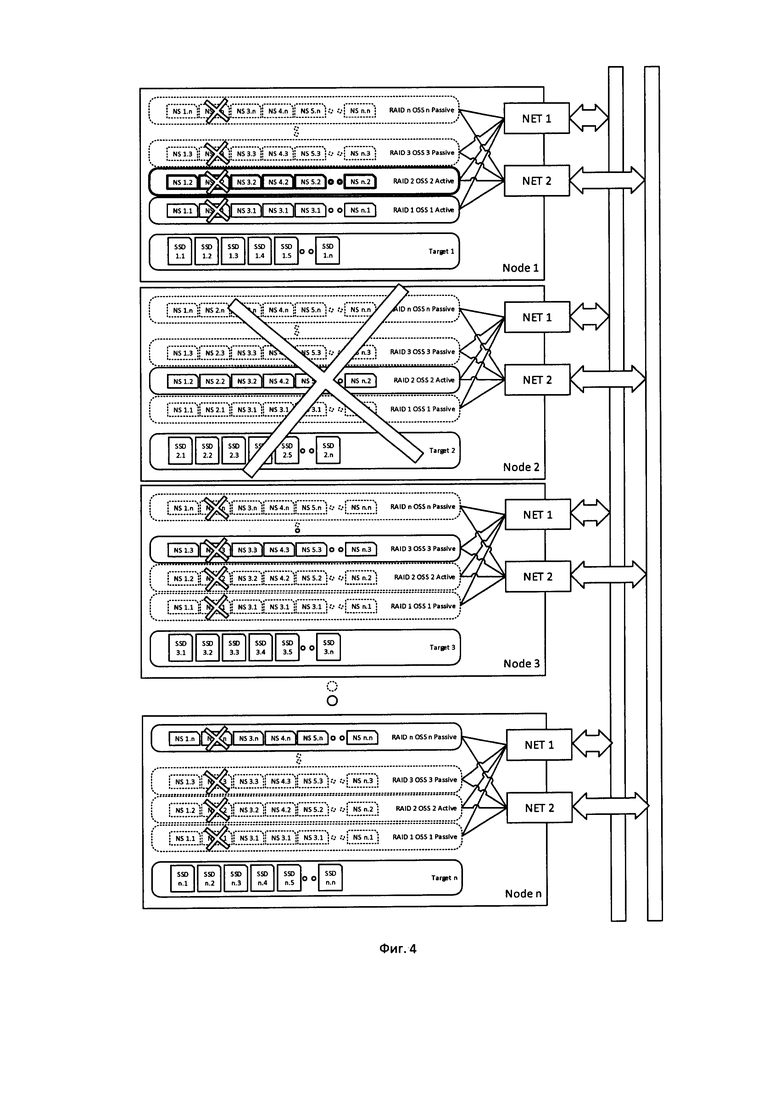
Фиг. 4 - Конфигурация системы хранения при выходе из строя узла системы хранения, или при потере связи с ним,
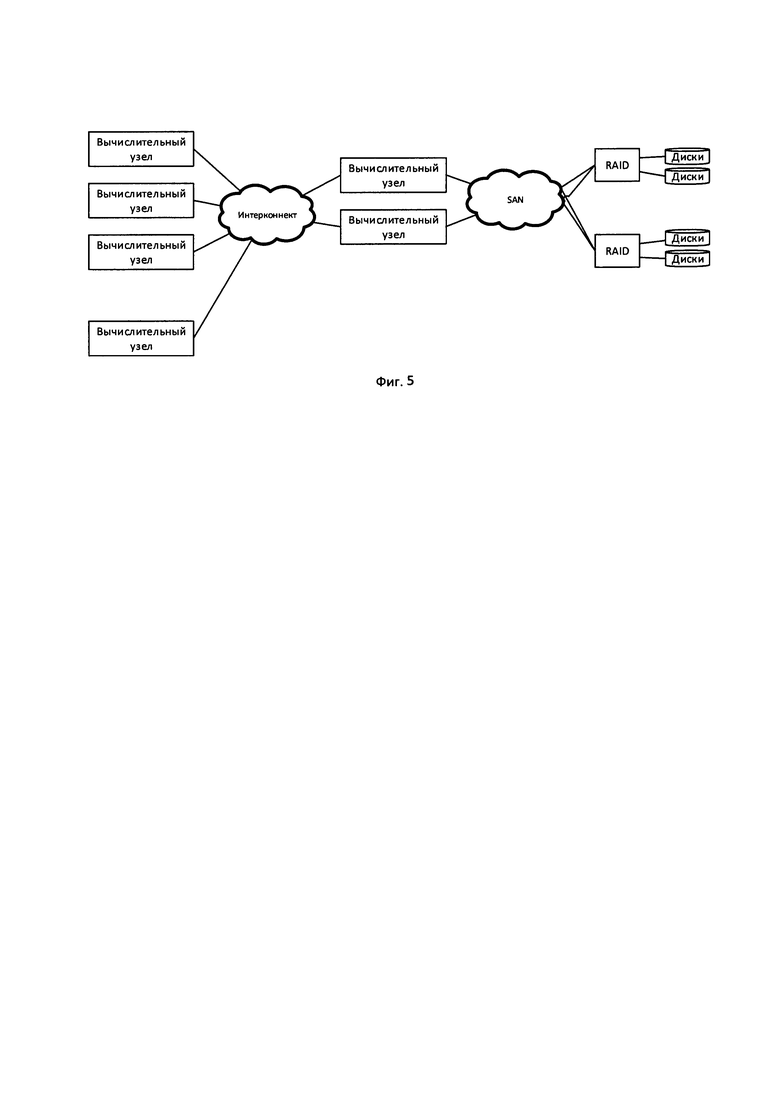
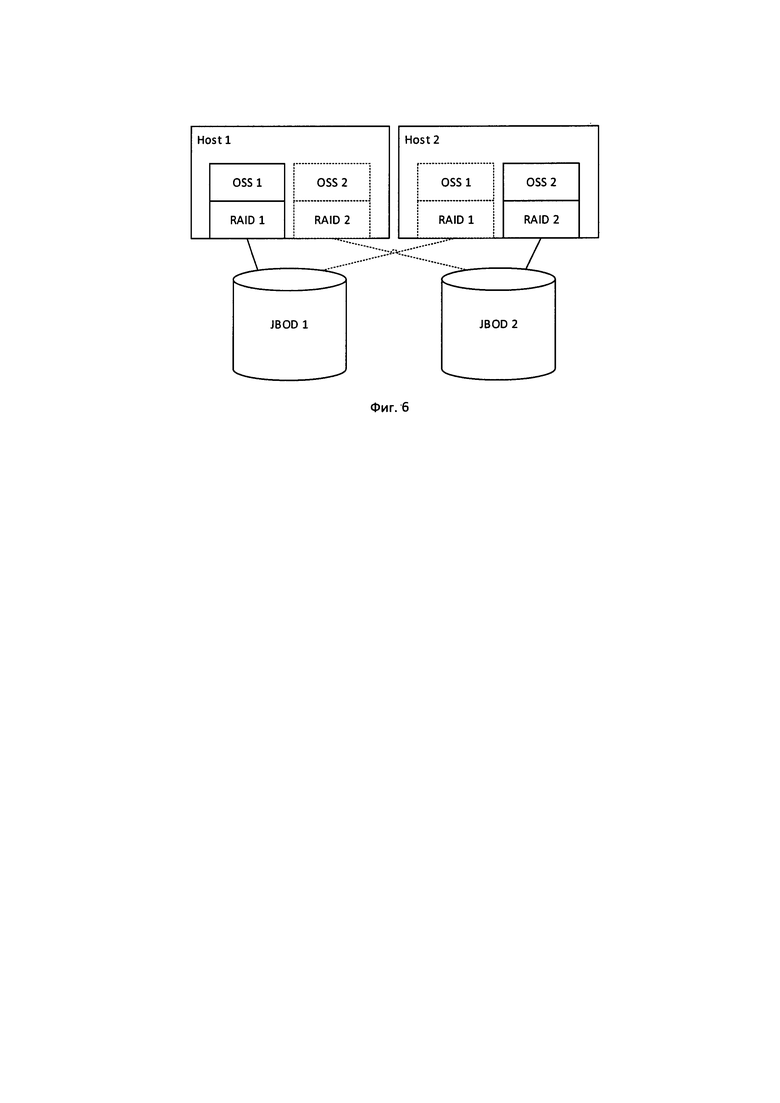
Фиг. 5-6 - Конфигурации известных систем хранения.
Предпосылки изобретения
Как правило, пропускная способность одного OSS ограничивается общей пропускной способностью сетевых каналов, подключенных к серверу OSS. Емкость дискового пространства OSS определяется общей емкостью дисковых накопителей, которые к нему подключены.
Особенностью высокопроизводительных РФС типа Lustre см. фиг. 5 (наиболее распространенная высокопроизводительная РФС) является то, что, как правило, они не имеют встроенных средств обеспечения отказоустойчивости и сохранения целостности данных в случае отказов дисковых накопителей или самих серверов. Отказ одного OSS или потеря данных в одном OSS как правило делает недоступными все данные РФС, поскольку данные равномерно распределяются между OSS таким образом, что даже один файл может находиться сразу на нескольких (или даже всех OSS). При этом для больших кластеров перерывы в работе системы хранения данных очень нежелательны или недопустимы, а также недопустима потеря данных. Таким образом, задача обеспечения отказоустойчивости становится принципиально важной при построении систем хранения, и она решается внешними по отношению к РФС средствами.
Для обеспечения бесперебойной работы РФС необходимо обеспечить два условия:
• Обеспечить бесперебойную работу дисковых массивов, которые используются OSS непосредственно для хранения данных.
• Обеспечить устойчивость РФС к отказу самого OSS или сервера, на котором он выполняется.
Для выполнения первого условия для непосредственного хранения данных используются избыточные массивы дисков (RAID), которые устойчивы к отказам отдельных накопителей. Все диски, подключенные к одному серверу OSS, объединяются в один или несколько RAID массивов, и таким образом для OSS обеспечивается непрерывное и отказоустойчивое пространство данных см. фиг. 6.
Для обеспечения устойчивости к отказам самих OSS используется методика дублирования. Стандартный подход выглядит следующим образом. Аппаратная часть системы хранения строится из модулей, каждый из которых содержит два специализированных сервера, подключенных к общему массиву двухпортовых дисков, разделенному на два одинаковых RAID массива, при этом каждый диск подключается к обоим хостам. Каждый из этих серверов (хостов) обеспечивает работу одного из двух OSS в активном режиме, при этом OSS подключен к одному из двух RAID массивов с использованием двухпортового подключения. Также на каждом из хостов имеется неактивная копия OSS и RAID массива парного хоста, при этом диски активного RAID массива одного хоста являются дисками неактивного RAID массива другого хоста, и наоборот.
В стандартном режиме такая конфигурация работает независимо, т.е. каждый OSS принимает соединения от клиентов через сетевые каналы хоста, и обращается к дискам своего RAID массива для непосредственного доступа к данным. Неактивные копии не принимают участия в работе.
В случае отказа одного из хостов (программного, аппаратного, или отказа канала связи) управляющая система приводит в действие неактивные копии RAID и OSS на парном хосте, которые вступают в работу немедленно, и замещают отказавший OSS. Так как копия RAID подключена к тем же дискам, что и отказавший RAID, OSS получает доступ к тем же данным и в том же состоянии, в котором они были на момент отказа, потери данных и заметного перерыва в обслуживании при этом не происходит.
Дисковые массивы подключаются к хостам или при помощи внутреннего интерконнекта, такого как SATA, SAS и т.д., или при помощи специализированной локальной сети (SAN), использующей одну из распространенных технологий, таких как Fibre Channel, iSCSI и т.д.
Такая конфигурация обладает следующими особенностями:
• Необходимость использования двухпортовых дисков, и соответствующей аппаратной платформы, поддерживающей применение таких дисков. Такие диски, равно как и платформы, являются узко специализированными, и как правило не применяются за пределами отказоустойчивых систем хранения данных, что определяет их высокую стоимость.
• Так как не выпускается дисков более чем с двумя портами, система в целом может быть только дублированной, более высокой степени отказоустойчивости в рамках стандартной конфигурации невозможно, или крайне сложно. Это означает, что при выходе из строя одного хоста, или при выведении одного хоста на обслуживание, пара теряет отказоустойчивость. С учетом того, что отказ одного OSS как правило означает отказ всей РФС в целом, то отказоустойчивость при входе из строя одного хоста теряет вся система хранения, а не только одна пара хостов.
• Использование специализированных двухпортовых дисков и специализированых аппаратных платформ для них делает наиболее выгодными конфигурации с большими дисковыми массивами, в несколько десятков или даже сотен дисков. В этом случае производительность одного OSS ограничивается в основном пропускной способностью сетевых интерфейсов хоста, поскольку их количество и общая пропускная способность ограничены возможностью ввода-вывода применяемых в хосте CPU.
• При отказе одного из хостов в паре общая производительность пары OSS падает примерно вдвое, поскольку в этом случае два OSS разделяют ресурсы одного хоста (сервера).
SSD и NVMe
Появление и распространение высокоскоростных твердотельных накопителей (SSD) привело к тому, что на рынке высокопроизводительных систем хранения данных постепенно происходит переход к конфигурациям All Flash, то есть имеется тенденция к вытеснению обычных шпиндельных дисков твердотельными накопителями. Особенностями SSD являются значительно более высокая пропускная способность (до нескольких Гб/с на один накопитель), а также на порядки большее количество операций ввода-вывода в секунду, по сравнению со шпиндельными накопителями. Высокая пропускная способность SSD приводит к значительно более высоким нагрузкам на сетевые интерфейсы хостов РФС, т.е. для того, чтобы полностью загрузить сетевые интерфейсы, нужно значительно меньшее количество SSD. Ограничения существующих стандартов подключения накопителей, таких как SATA, SCSI, SAS привели к необходимости разработки нового стандарта NVMe, являющегося расширением стандарта РCI-е, т.е. каждый диск подключается как отдельное PCI-е устройство, что избавляет он необходимости установки дополнительных контроллеров, позволяет подключать SSD накопители непосредственно к CPU и существенно сокращает задержки при доступе к данным.
Высокая пропускная способность SSD, и их возможность совершать большое количество операций ввода-вывода в секунду делают наиболее выгодными конфигурации с дисковыми массивами не более 32 твердотельных накопителей, поскольку пропускная способность CPU и сетевых интерфейсов хостов РФС имеют ограничения. Таким образом наращивание емкости РФС выгоднее производить наращиванием количества OSS с небольшими дисковыми массивами, а не увеличением дисковых массивов, как это было при использовании шпиндельных накопителей. Увеличение количества OSS имеет также то преимущество, что при этом почти линейно вырастает общая производительность РФС в целом.
Увеличение количества OSS (и соответственно, хостов) требует снижения цены аппаратной платформы для удержания общей цены системы хранения на приемлемом уровне. Это, в свою очередь, требует максимального отказа от специализированного оборудования и перехода на стандартные аппаратные платформы без снижения уровня производительности и отказоустойчивости.
NVMe over Fabrics
Технология NVMe over Fabrics позволяет подключать удаленные NVMe устройства, как правило SSD, по высокоскоростному интерконнекту (Ethernet, Infiniband, Omni-Path) прозрачным образом, т.е. удаленное NVMe устройство работает аналогично локальному. При этом используются возможности удаленного доступа к памяти (RDMA), что сокращает временные задержки доступа к удаленным устройствам. Использование того же самого типа интерконнекта, который используется в качестве основного в большинстве кластеров, позволяет организовать сеть доступа к дискам без использования специальных SAN сетей.
Особенностью технологии NVMe over Fabrics является то, что удаленное использование накопителей, подключенных к серверу, оказывает минимальное влияние на другие операции, которые этот сервер может выполнять одновременно с предоставлением дисков. Сервер может быть при этом использован для вычислений, использоваться как хост системы хранения данных, и т.д., NVMe over Fabrics создает существенную нагрузку только на сетевые интерфейсы, используемые для удаленного доступа к накопителям.
Одно устройство NMVe может быть подключено по технологии NVMe over Fabrics к нескольким удаленным хостам, и использоваться ими одновременно, полностью аналогично двухпортовым накопителям, но количество хостов может быть произвольным. Арбитраж, обеспечивающий целостность данных в данном случае должен обеспечиваться ПО, работающим с удаленным NVMe устройством, например, по схеме Active-Passive.
Техническая задача
Методика и технология, позволяющая создавать высокопроизводительные, масштабируемые и отказоустойчивые конфигурации систем хранения данных на основе распределенных файловых систем и технологии NVME over Fabrics, при использовании однопортовых NVMe накопителей. Применение данной методики должно обеспечивать следующий результат:
• Возможность построения РФС из большого количества OSS, до нескольких десятков или сотен штук.
• Возможность использования однопортовых накопителей без потери отказоустойчивости системы хранения данных в целом.
• Максимальное использование возможностей SSD накопителей, то есть общая пропускная способность системы хранения данных должна быть сравнима с общей пропускной способностью накопителей, а задержки при работе с данными сравнимы с задержками накопителей.
• Обеспечение пропускной способности для каждого OSS, сравнимой или равной пропускной способности сетевых интерфейсов хоста.
• Предоставление для каждого OSS единого дискового пространства, устойчивого к отказам отдельных накопителей.
• Отсутствие единой точки отказа, то есть конфигурация должна быть устойчива к отказу любого элемента, в том числе накопителя, хоста, сетевых интерфейсов.
Методика также должна обеспечивать масштабируемость близкую к линейной, при увеличении количества или емкости накопителей и увеличении количества OSS.
Описание метода
Для создания конфигурации системы хранения используются узлы системы хранения, имеющие в своем составе стандартные серверные компоненты, такие как CPU, оперативную память, сетевые интерфейсы Ethernet, Omni-Path или Infiniband, подсистемы питания, охлаждения, управления, и т.д. С технической точки зрения такие узлы представляют собой компьютерные серверы достаточной производительности, с подключенными к ним по протоколу NVMe SSD накопителями. Использование специализированных компонентов, таких как двухпортовые диски, не требуется.
В состав системы хранения также входит подсистема управления, представляющая собой набор специализированного ПО, установленного на отказоустойчивом кластере.
Узлы системы хранения, клиентские узлы кластера, а также сервера системы управления объединяются высокоскоростной локальной сетью с поддержкой технологии RDMA. Если необходимо обеспечить полную отказоустойчивость, все компоненты сети дублируются, т.е. каждый узел имеет как минимум 2 сетевых интерфейса, в системе присутствуют как минимум 2 независимых коммутатора, к которым подключается каждый из узлов.
На узлах системы хранения устанавливается набор ПО, обеспечивающий их функционирование как NVMe over Fabrics Target, NVMe over Fabrics Host (Initiator), как OSS выбранной распределенной файловой системы (например, Lustre), а также ПО, необходимое для функционирования программного RAID массива. Также устанавливаются программные агенты системы управления.
В качестве узлов, предоставляющих доступ к NVMe дискам по технологии NMVe over Fabrics также могут выступать клиентские узлы кластера, а также специализированные полки с NVMe дисками. В этом случае на них также устанавливается ПО, необходимое для функционирования в качестве Target NVMeoF, а также агенты системы управления. В этом случае сетевые компоненты клиентских узлов и специализированных полок также могу быть продублированы, если необходимо обеспечить полную отказоустойчиваость.
Все узлы, содержащие NVMe SSD, используемые в системе хранения данных (в том числе клиентские узлы и специализированные полки), получают роль Target, и предоставляют удаленный доступ к SSD в своем составе. Доступ может предоставляться как для всех подключенных NVMe устройств, так и только для некоторых (остальные могут при этом использоваться для других задач, например, для локального хранения данных). Узлы системы хранения получают роль Host, к ним подключаются удаленные диски, которые в свою очередь собираются в программные RAID массивы с определенным уровнем избыточности данных. Эти RAID массивы выступают в роли дискового пространства для OSS РФД, также запускаемых на узлах системы хранения. При этом соблюдаются следующие правила:
1. Один RAID массив подключается к одному OSS, работающему на том же узле хранения данных.
2. Принципиально важно, что все диски, включенные в один RAID массив, должны физически располагаться на разных Target, то есть на разных серверах. Таким образом выход из строя диска или сервера, выполняющего роль Target, не приведет к отказу RAID массива или к потере данных.
3. Для каждого активного RAID массива должна существовать как минимум одна неактивная копия (то есть RAID массив, собранный из тех же дисков), располагающаяся на другом узле хранения данных.
4. Аналогично для каждого активного OSS должна существовать как минимум одна неактивная копия, располагающаяся на другом узле хранения данных.
5. К узлу подключаются те диски, которые входят в состав всех активных и неактивных RAID массивов, копии которых существуют на данном узле.
Таким образом, в системе хранения создается n Target, причем n не меньше количества дисков в самом большом из создаваемых RAID массивов. При этом в системе хранения существует также m узлов хранения, поддерживающих RAID массивы и OSS. Для обеспечения минимальной отказоустойчивости m не менее 2.
Для обеспечения отказоустойчивости при отказе или выводе на обслуживание какого-либо узла хранения, их количество в системе хранения должно быть не менее трех, то есть m>=3. Для обеспечения отказоустойчивости при выходе из строя или выводе на обслуживание одного из Target, используются RAID массивы уровня не менее RAID6, то есть сохраняющие отказоустойчивость при выходе из строя двух дисков. Таким образом n >=4.
Стандартная конфигурация системы хранения при использовании в качестве Target только узлов системы хранения предполагает, что n = m, и выглядит следующим образом см. фиг. 1:
Узлы системы хранения и подключенные к ним NVMe SSD объединяются в квадратную матрицу размерности n, то есть имеется n узлов (от 1 до n) хранения данных, в составе каждого по n NVMe SSD (от 1 до n). Каждый узел выступает одновременно и в роли Target (то есть предоставляет доступ к своим SSD), и в роли Host (то есть получает доступ к дискам других узлов).
На первый узел подключаются все первые диски всех узлов, включая первый диск первого узла, из них создается RAID 1 и соответствующий ему OSS 1. На второй узел подключаются все вторые диски всех узлов, из них создается RAID 2 и OSS 2. И так далее вплоть до n. Таким образом в системе создается n активных RAID массивов и n соответствующих активных OSS, каждый из которых располагается на своем узле хранения. При этом каждый RAID массив содержит диски со всех узлов, по одному с каждого.
После этого создаются неактивные копии RAID массивов и OSS, при этом каждая копия должна располагаться на своем узле хранения. Копии могут располагаться парами, т.е. каждый узел имеет неактивные копии RAID и OSS с парного ему узла. Также могут быть другие конфигурации, вплоть до полного резервирования, т.е. каждый узел, помимо активного RAID и OSS имеет неактивные копии всех остальных RAID и OSS системы хранения.
Таким образом в полной статической конфигурации система хранения имеет n узлов с n дисками каждый, каждый узел поддерживает n RAID массивов (из которых только один активен), и n OSS (из которых только один активен).
В динамической конфигурации для каждого RAID массива и соответствующего OSS создается по одной неактивной копии, которые располагаются на узлах, выбранных системой управления.
В случае конфигураций, когда n < > m, то есть количество Target не равно количеству Host, конфигурация создается аналогично. На узлах хранения создается m RAID массивов и OSS (размерность и количество дисков в RAID массивах могут быть разными), к ним подключаются диски всех Target, при этом так же соблюдается правило, что все диски одного RAID массива должны располагаться на разных Target. На узлах хранения также создаются неактивные копии RAID массивов и OSS, таким образом, чтобы в любой момент времени существовала как минимум одна неактивная копия OSS и соответствующего RAID массива.
При обычной работе клиенты РФС обращаются по сети к активным OSS, расположенным на узлах системы хранения, которые в свою очередь обращаются к соответствующим RAID массивам. Так как RAID массивы собраны из подключенных по NVMeoF дисков других узлов, данные и нагрузка распределяются по узлам системы хранения и другим узлам, которые выполняют роль Target.
Принципиально важно, что для подключения удаленных клиентов к OSS распределенной файловой системы и для подключения дисков по NVMeoF используется одна и та же высокоскоростная локальная компьютерная сеть (интерконнект).
Производительность такой конфигурации ограничена в первую очередь производительностью сети на одном узле, причем, несмотря на одновременное использование сети и для доступа к РФС для доступа к удаленным дискам, чтение и запись данных можно производить практически на полной скорости сети, поскольку сеть является полнодуплексной. Операции чтения с РФС вызывают нагрузку в основном исходящего канала сети, для чтения с удаленных дисков при этом используется в основном входящий канал. Аналогично операции записи в РФС вызывают нагрузку входящего канала, при этом для записи на удаленные диски используется исходящий канал.
Это позволяет добиться полной утилизации пропускной способности сети, что недостижимо для других конфигураций, в которых для подключения удаленных дисков используется выделенная сеть, будь то специализированная SAN, или обычный высокоскоростной интерконнект, реализующий подключение по NVMeoF. При одной и той же пропускной способности сетевых интерфейсов на узлах хранения, использование общей сети для доступа к данным и для доступа к дискам позволяет достичь на 80% большей пропускной способности файловой системы, чем при использовании выделенной сети доступа к дискам.
При выходе из строя любого из дисков происходит деградация RAID массива (и его копий) в который включен диск. Это не вызывает отказа в обслуживании, и не приводит к потере данных, после замены диска и восстановления RAID (reconcile) система может быть приведена системой управления в исходное состояние. В зависимости от уровня используемых RAID массивов допустим отказ разного количества дисков в одном массиве. Например, для RAID5 это один диск, для RAID6 два диска, могут быть и другие конфигурации массивов, вплоть до полного зеркалирования всех дисков в массиве.
Вышедший из строя диск может быть заменен без вывода из работы Target, в том случае если на данном сервере реализована «горячая» замена дисков (hot-swap). В случае, если «горячая замена» не предусмотрена, диск может быть заменен путем вывода соответствующего сервера на обслуживание, и его отключения для замены дисков. При отказе Target, или при выводе его на обслуживание, произойдет отказ всех дисков, предоставляемых этим Target см. фиг. 4, что в свою очередь вызовет деградацию тех RAID массивов, в которые включены данные диски. Это не вызовет потери данных или отказа в обслуживании файловой системы. После замены дисков Target может быть введен в работу, и система хранения может быть приведена в исходное состояние.
Система хранения может иметь некоторое количество запасных (spare) NVMe накопителей, подключенных к тем или иным Target, и не включенных ни в один из RAID массивов. В случае отказа одного из накопителей, система управления может подключить к соответствующему RAID массиву один из spare дисков, в том случае, если spare накопитель не находится на одном Target с любым из остальных дисков этого массива, за исключением вышедшего из строя. После подключения spare диска система управления проводит процедуру reconcile для данного RAID массива, возвращая его из деградированного в полностью рабочее состояние. Диск, установленный вместо вышедшего из строя, может быть в дальнейшем использован как spare диск.
При выходе из строя узла системы хранения, или при потере связи с ним, происходит следующее см. фиг. 4
1. Отключаются все диски этого узла, а также все RAID массивы и OSS, которые были на нем расположены (включая неактивные копии).
2. Все RAID массивы, которые включают в себя диски этого узла, деградируют, но не перестают работать, и потери данных не происходит.
3. Для активных RAID массивов вышедшего из строя узла, и для соответствующих им OSS системой управления активизируются копии на другом узле хранения, эти копии заменяют собой потерянные OSS и их RAID. Так как RAID массивы копий подключены по NVMeoF к тем же самым дискам на функционирующих узлах, не происходит отказа в обслуживании, или потери данных. Перерыв в работе равен времени обнаружения отказа узла и времени активизации неактивных копий (секунды или менее).
4. В случае динамической конфигурации, система управления создает дополнительные копии отказавшего RAID массива и OSS таким образом, чтобы в системе хранения всегда присутствовала как минимум одна неактивная копия.
5. Из-за потери OSS происходит деградация производительности на 1/n часть, поскольку на одном из узлов хранения начинает работать два активных OSS, разделяющих ресурсы узла, в первую очередь пропускную способность сети.
После восстановления работы узла системы хранения система может быть приведена в исходное состояние без перерыва в работе.
Количество узлов Target, которые могут одновременно выйти из строя без потери работоспособности системы, зависит от уровня применяемых RAID массивов, например, для RAID6 это два узла.
Для обеспечения отказоустойчивости и увеличения производительности может применяться дублирование (троирование и т.д.) сетевой подсистемы, то есть каждый узел может содержать два или больше сетевых адаптера, в системе может присутствовать два или больше параллельно работающих коммутатора, и т.д.
Система хранения, построенная по данной методике, сохраняет работоспособность при отказе:
• Накопителей, максимальное количество накопителей, которое может выйти из строя без потери работоспособности и потери данных, зависит от уровня применяемых RAID массивов.
• Узлов Target, максимальное количество узлов Target, которое может выйти из строя без потери работоспособности и потери данных, также зависит от уровня применяемых RAID массивов.
• Узлов хранения (Host), система может сохранить работоспособность при выходе из строя всех узлов, кроме одного, при условии, что всегда поддерживается существование неактивных копий всех OSS и RAID массивов.
• Сетевого коммутатора или сетевых адаптеров, при условии, что сеть продублирована.
При симметричной конфигурации, когда n=m, то есть количество Target равно количеству Host (каждый узел совмещает обе роли) и количеству дисков на узле, и использовании RAID6, система хранения может продолжать работу при отказе одного или двух узлов, при условии, что все диски на остальных узлах работоспособны. Уровень отказоустойчивости можно изменять в широких пределах, просто изменяя степень избыточности RAID массивов, что легко делается программным путем. Если используется JBOD без избыточности, отказоустойчивость будет вообще отсутствовать, если используется полное зеркалирование всех дисков в RAID, система будет полностью устойчива к отказу всех узлов, кроме одного (естественно, за счет кратного сокращения доступного дискового пространства). Таким образом, симметричную конфигурацию можно рассматривать одновременно как RAID из дисков, и аналогичный RAID из серверов.
Отказоустойчивость системы можно существенно повысить путем применения spare дисков, причем spare диски даже в симметричной конфигурации могут располагаться на клиентских узлах, в произвольном количестве.
Высокая отказоустойчивость конфигураций систем хранения является одним из основных преимуществ данной методики перед стандартными способами построения систем хранения. Дополнительным фактором является то, что степенью отказоустойчивости можно гибко управлять, применяя программные методы, без переконфигурации аппаратного обеспечения.
Применение RAID массивов уровня 6 и выше позволяет сохранять отказоустойчивость системы хранения в случае вывода на обслуживание одного из узлов с NVMe накопителями. Диски могут быть заменены по необходимости при плановом или внеплановом обслуживании узла. Это позволяет во многих случаях отказаться от использования технологии «горячей» замены дисков, что дает возможность применения более компактных и высокоплотных аппаратных платформ, в первую очередь с жидкостным охлаждением. Что в свою очередь позволяет применять данную методику для построения высокоскоростных систем хранения данных в составе современных суперкомпьютеров, характеризующихся высокой плотностью и как правило жидкостным охлаждением.
Вторым существенным преимуществом данной методики является то, что несмотря на высокую степень отказоустойчивости, все оборудование в составе системы хранения используется всегда, и на полной доступной скорости. В первую очередь это касается сетевой подсистемы, степень утилизации которой в системах, построенных по данной методике, очень высока, и примерно вдвое превышает степень утилизации сети в системах, построенных на основе выделенной SAN. Так как пропускная способность сетевой подсистемы как правило является фактором, ограничивающим общую пропускную способность высокопроизводительных систем хранения, данная методика позволяет существенно увеличить общую производительность системы хранения по сравнению с системами на основе выделенной SAN см Фиг. 2
Высокая степень утилизации пропускной способности сети достигается за счет совмещения ролей Target и Host, для узлов системы хранения, а также за счет совмещения ролей Target и клиент файловой системы для клиентских узлов. Совмещение ролей генерирует встречные потоки данных примерно одинаковой величины, что позволяет полностью использовать возможности полнодуплексных локальных сетей. В связи с этим не рекомендуется использовать оборудование без совмещения ролей, т.е. узлов, работающих только в режиме Host и специализированных полок дисков, которые могут работать только в режиме Target. Также для увеличения общей производительности системы хранения рекомендуется использовать NVMe диски клиентских узлов в составе системы хранения, в качестве основных или spare дисков см. Фиг. 3.
Методика не предполагает использования специализированного оборудования со встроенными средствами дублирования, такого как двухпортовые диски. Это позволяет использовать стандартные аппаратные платформы, увеличить доступность компонентов, а также облегчает применение в высокоплотных конфигурациях и в кластерах с жидкостным охлаждением.
Преимущества по сравнению с существующими методами
• Данный метод описывает построение полностью программно-определяемой системы хранения данных, то есть конфигурация системы может быть гибко изменена и перенастроена без изменения в аппаратной конфигурации.
• В качестве Target могут также выступать не только узлы системы хранения, но и вычислительные узлы, т.е. система хранения при необходимости может включать в себя NVMe диски со всего кластера. Работа Target на вычислительном узле оказывает минимальное влияние на его производительность при решении вычислительных задач. Это позволяет увеличить емкость и производительность системы хранения, задействовав те ресурсы кластера, которые обычно остаются неиспользованными.
• Данный метод позволят добиться практически линейного и неограниченного масштабирования системы хранения, путем добавления дополнительных узлов хранения и дисков. Такое масштабирование может производиться в том числе и без прерывания работы системы хранения.
• Для построения системы хранения могут использоваться сервера (узлы) без внутренних средств резервирования, поскольку система устойчива к выходу узлов из строя.
• При выходе из строя одного из узлов не происходит заметной деградации производительности системы хранения.
• Если используется RAID6, при выходе из строя одного из узлов система сохраняет отказоустойчивость.
• Могут применяться узлы без «горячей замены» дисков. Замена дисков может производиться путем полного выключения узла.
• Узлы можно выводить на обслуживание по одному без существенной потери производительности и при сохранении отказоустойчивости.
• Нет отдельной локальной сети SAN, производительность интерконнекта утилизируется полностью.
• Аппаратная реализация проще, чем при стандартных подходах, и не требует использования специального оборудования.
• При использовании RAID массивов с большой избыточностью может достигаться очень большой уровень резервирования (за счет потери доступного дискового пространства), вплоть до устойчивости к отказу всех узлов хранения, кроме одного.
• Уровень резервирования может гибко варьироваться на одной и той же аппаратной платформе, за счет полной программной определяемости системы хранения.
• Данный метод полностью пригоден для построения систем хранения «по запросу».
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ хранения данных в избыточном массиве независимых дисков с повышенной отказоустойчивостью | 2020 |
|
RU2750645C1 |
| Интегрированный программно-аппаратный комплекс | 2016 |
|
RU2646312C1 |
| СПОСОБ И СИСТЕМА РАСПРЕДЕЛЕННОГО ХРАНЕНИЯ ВОССТАНАВЛИВАЕМЫХ ДАННЫХ С ОБЕСПЕЧЕНИЕМ ЦЕЛОСТНОСТИ И КОНФИДЕНЦИАЛЬНОСТИ ИНФОРМАЦИИ | 2021 |
|
RU2777270C1 |
| МНОГОПРОТОКОЛЬНОЕ УСТРОЙСТВО ХРАНЕНИЯ ДАННЫХ, РЕАЛИЗУЮЩЕЕ ИНТЕГРИРОВАННУЮ ПОДДЕРЖКУ ФАЙЛОВЫХ И БЛОЧНЫХ ПРОТОКОЛОВ ДОСТУПА | 2003 |
|
RU2302034C9 |
| Способ, устройство, сетевое устройство, носитель информации для передачи данных | 2021 |
|
RU2834599C1 |
| СПОСОБ КОДИРОВАНИЯ ДАННЫХ И СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2819584C1 |
| СПОСОБ И СИСТЕМА УПРАВЛЕНИЯ МЕТАДАННЫМИ В ВЫСОКОНАГРУЖЕННЫХ ОБЛАЧНЫХ СРЕДАХ | 2024 |
|
RU2829567C1 |
| АППАРАТНО-ВЫЧИСЛИТЕЛЬНЫЙ КОМПЛЕКС С ПОВЫШЕННЫМИ НАДЕЖНОСТЬЮ И БЕЗОПАСНОСТЬЮ В СРЕДЕ ОБЛАЧНЫХ ВЫЧИСЛЕНИЙ | 2013 |
|
RU2557476C2 |
| СИСТЕМА ОТКАЗОУСТОЙЧИВОГО ТРАНСКОДИРОВАНИЯ И ВЫДАЧИ ПРЯМЫХ ПОТОКОВ В ФОРМАТЕ HLS | 2020 |
|
RU2759595C1 |
| СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2824327C1 |
Изобретение относится к системам хранения данных. Технический результат заключается в расширении арсенала средств. Способ построения высокопроизводительных отказоустойчивых систем хранения на основе распределенных файловых систем, который определяет способ распределения NVMe дисков и OSS файловой системы по группе серверов для достижения избыточности и обеспечения отказоустойчивости. Используется общая локальная сеть как для доступа к данным файловой системы, так и для доступа к дискам NVMe over Fabrics, без выделенной сети SAN. 1 з.п. ф-лы, 6 ил.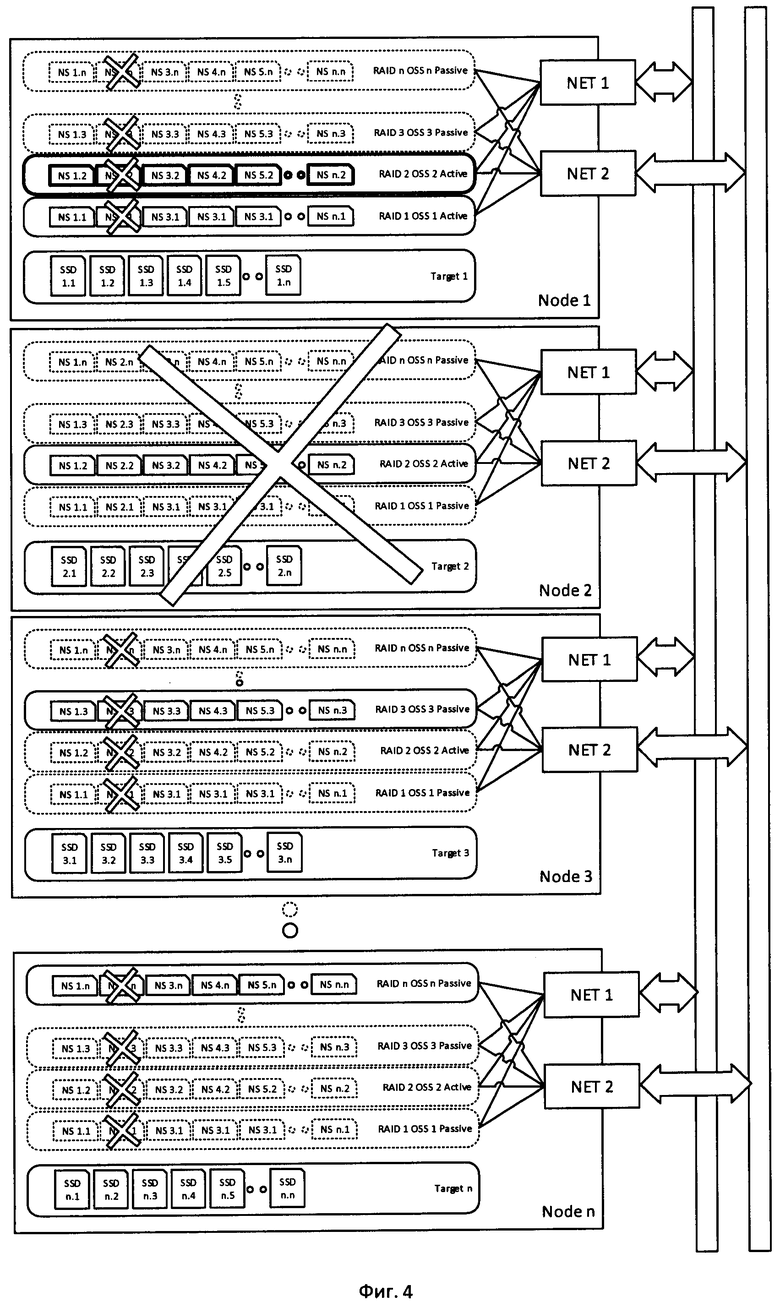
1. Способ построения высокопроизводительной отказоустойчивой системы хранения данных на основе распределенной файловой системы и технологии NVMe over Fabrics в гиперконвергентных инфраструктурах-системах, заключающийся в построении системы, включающей: вычислительные узлы серверной фермы-серверы, имеющие в своем составе стандартные компоненты, такие как CPU, оперативную память, полнодуплексную сеть передачи данных с поддержкой технологии RDMA, подсистемы питания, охлаждения, управления, устройства хранения данных в виде SSD накопителей, подключенных к вычислительным узлам серверной фермы-серверам по протоколу NVMe, и полнодуплексную сеть передачи данных с поддержкой технологии RDMA, при этом вычислительные узлы серверной фермы-серверы, SSD накопители и полнодуплексная сеть передачи данных с поддержкой технологии RDMA объединены в гиперконвергентную инфраструктуру с помощью программных средств, а управление ими происходит через общую консоль администрирования, отличающийся тем, что используются устройства хранения данных, предоставляемых технологией NVMe over Fabrics со всей гиперконвергентной инфраструктуры, объединенные сетью передачи данных с поддержкой технологии RDMA, все компоненты сети дублируются,
в качестве узлов, предоставляющих доступ ко всей гиперконвергентной инфраструктуре по технологии NMVe over Fabrics, выступают все серверы гиперконвергентной инфраструктуры, а также специализированные полки с NVMe дисками,
часть узлов, содержащих NVMe устройства хранения данных, используемых в системе хранения данных, получают роль Target и предоставляют удаленный доступ к устройствам хранения данных в своем составе, а остальные узлы, содержащие NVMe устройства хранения данных, используемые в системе хранения данных, получают роль Host, к ним подключаются удаленные устройства хранения данных, которые в свою очередь собираются в программные RAID массивы с определенным уровнем избыточности данных, эти RAID массивы выступают в роли дискового пространства для данных (OSS), распределенной файловой системы (РФС), также запускаемых на узлах системы хранения, где один RAID массив подключается к одному OSS, работающему на том же узле хранения данных,
при этом все устройства хранения данных, включенные в один RAID массив, располагают на разных Target, то есть на разных серверах, для каждого активного RAID массива существует как минимум одна неактивная копия, располагающаяся на другом узле хранения данных, для каждого активного OSS существует как минимум одна неактивная копия, располагающаяся на другом узле хранения данных.
2. Способ по п. 1, отличающийся тем, что система хранения имеет некоторое количество запасных-spare NVMe устройства хранения данных, подключенных к тем или иным серверам в роли Target и не включенных ни в один из RAID массивов.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| КРУПНОМАСШТАБНАЯ СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2012 |
|
RU2595493C2 |
| СПОСОБ УПРАВЛЕНИЯ РАСПРЕДЕЛЕННОЙ СИСТЕМОЙ ХРАНЕНИЯ | 2006 |
|
RU2411685C2 |

