ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к системе и способу для подготовки сетевого трафика для анализа и, в частности, к такой системе и способу для подготовки сетевых потоков для анализа.
УРОВЕНЬ ТЕХНИКИ
Сетевой трафик подлежит анализу по множеству причин.
«Определение несанкционированного доступа на основе потока» (автор Рик Хофстед, ISBN: 978-90-365-4066-7; 2016, далее по тексту «диссертация») описывает один из способов анализа сетевого трафика, который отличается от пакетного анализа. Диссертация описывает пакетный анализ сети и некоторые приложения для определения несанкционированного доступа к вычислительным устройствам, подключенным к сети. Потоковый анализ сети включает подготовку и экспорт потоков в качестве информации, относящейся к поведению сети, в форме записей экспорта потоков.
Для функционирования процесса осуществляют анализ пакетов для извлечения информации, которая является подходящей для экспорта в качестве экспортного потока. В составе экспортного потока имеются данные из множества пакетов. Экспорт выполняется в соответствии с протоколом экспортного потока, в том числе, но без ограничения, IPFIX или Netflow. Хотя оба протокола являются пригодными, IPFIX был разработан для поддержки экспорта потока от устройств или сетевых датчиков, предназначенных для направления пакетов. Однако ни один из протоколов не предусматривает необходимость того, чтобы единственное устройство осуществляло захват и анализ пакетов для получения экспортного потока.
Например, в случае IPFIX информация о потоке экспортируется в виде информационных элементов или IE. Формат, который могут принимать разные IE, и тип содержимой информации относится к стандартам, поддерживаемым IANA. Ниже приведена таблица некоторых примеров допустимых элементов экспорта потока (IE или полей). Таблица 1 показывает неограничивающий пример приемлемых элементов IANA потока.
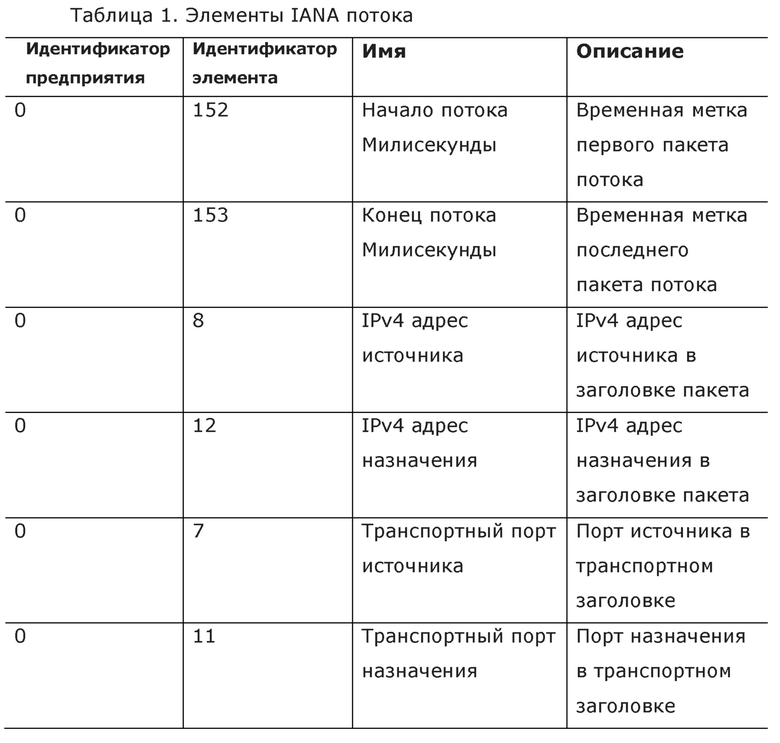
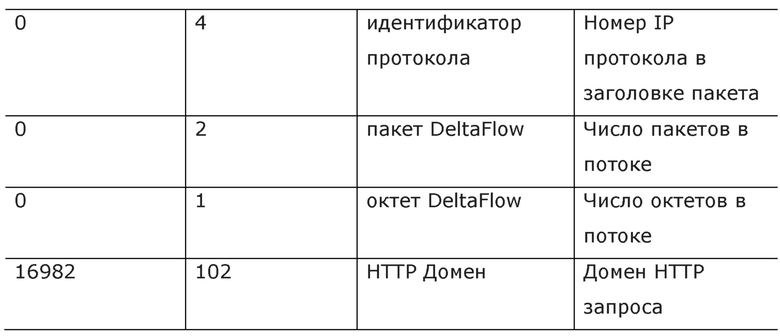
Поток может быть при необходимости определен как «набор IP-пакетов, проходящих точку наблюдения в сети в течение конкретного интервала времени, так что все пакеты, принадлежащие конкретному потоку, имеют набор общих свойств», в соответствии с экспортными протоколами IPFIX или Netflow. Данные экспортные протоколы определяют эти общие свойства следующим образом: поля заголовка пакета, такие как IP-адреса и номера портов источника и назначения, интерпретируемая информация, основанная на содержимом пакета, и метаданные. Как только поток завершен, поток экспортируется.
При необходимости общие свойства могут быть сохранены в качестве строк в типичной базе данных с одним столбцом на свойство. При необходимости анализ пакетов может быть выполнен так, как описано в отношении вышеупомянутой диссертации.
КРАТКОЕ РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к системе и способу для подготовки сетевых потоков для анализа путем разбиения таких потоков на множество элементов, которые затем тегируются. При необходимости, тегированные элементы могут содержать комбинацию любого типа элемента в соответствии с любым типом стандарта сетевого потока, в том числе, но без ограничения, стандарта IPFIX или Netflow, или могут быть, при необходимости, получены из таких элементов, например, необязательно, с добавлением внешней (непотоковой) информации или путем выполнения некоторого типа вычисления на стандартном(ых) элементе(ах) сетевого потока.
Тегированный элемент, который получен от одного или более стандартных элементов сетевого потока, например, в соответствии с информацией, внешней по отношению к сетевому потоку, или путем выполнения некоторого типа вычисления на стандартном(ых) элементе(ах) сетевого потока, определен в данном документе как простой тегированный элемент. Тегированный элемент получают из стандартного(ых) элемента(ов) сетевого потока, но сам по себе не является отдельным стандартным элементом сетевого потока.
Неограничивающим примером такого простого тегированного элемента является тегированный элемент геолокации, который получен от IP-адреса экспортируемого сетевого потока и таблицы соответствия. Таблица соответствия соотносит IP-адрес с геолокацией и не считается стандартным элементом сетевого потока. Другим неограничивающим примером простого тегированного элемента является промежуток времени или длительность, которые, при необходимости, могут быть рассчитаны из стандартных элементов времени начала потока и времени окончания потока сети. Другим неограничивающим примером простого тегированного элемента является вычисление частоты трафика от определенного IP-адреса. Еще одним неограничивающим примером такого тегированного элемента является коэффициент трафика, который, при необходимости, выводят из объема данных, отправляемых и получаемых с конкретного IP-адреса или конкретного порта с конкретным IP-адресом. Еще одним неограничивающим примером такого тегированного элемента является элемент порта/1Р-адреса, который, при необходимости, выводят из комбинации IP-адреса источника и порта назначения сетевого потока.
При необходимости, тегированный элемент определяют из одного или более обработанных стандартных элементов сетевого потока (то есть из одного или более простых тегированных элементов) и он обозначается в данном документе термином составной тегированный элемент. Составной элемент, при необходимости, может содержать комбинацию множества простых тегированных элементов. Дополнительно или в качестве альтернативы, составной элемент, при необходимости, может быть выведен из простого тегированного элемента с добавлением информации, внешней по отношению к сетевому потоку, путем выполнения некоторого типа вычисления для простого тегированного элемента или путем объединения стандартного элемента сетевого потока с простым тегированным элементом (при необходимости, дополнительно включая некоторые виды вычисления или информацию, внешнюю по отношению к сетевому потоку).
Неограничивающий пример такого составного тегированного элемента, при необходимости, может быть выведен из комбинации вышеописанного простого тегированного элемента с интервалом или продолжительностью с добавлением другого простого тегированного элемента, относящегося к геолокации. Другой неограничивающий пример такого составного тегированного элемента, при необходимости, может быть выведен путем подсчета объема трафика (либо по частоте, байтам или их комбинации) для конкретной геолокации. Тегированные элементы, при необходимости, могут быть также использованы в качестве строительных блоков для создания более сложных тегированных элементов, которые также обозначены в данном документе термином составные элементы. Например, ранее описанное соотношение трафика, при необходимости, может быть проанализировано для того чтобы определить, какая часть принадлежит конкретному порту или отправляется на конкретный порт по IP-адресу назначения. Такой анализ, при необходимости, может быть выполнен путем объединения множества составных тегированных элементов или составного тегированного элемента с простым тегированным элементом. Таким образом, тегированные элементы могут быть использованы очень гибкими способами и, при необходимости, могут быть скомбинированы для создания новых таких тегированных элементов.
В соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения, способ анализа сетевых потоков включает прием сетевого потока, анализ сетевого потока и запись тегированных элементов по столбцам. При необходимости, анализ сетевого потока осуществляют построчно. Это повышает эффективность процесса. Предпочтительно, способ включает анализ сетевого потока для того чтобы сначала определить более простые тегированные элементы перед определением составных тегированных элементов. Предпочтительно, способ настраивают так, что процесс тегирования, которому необходим конкретный тегированный элемент, выполняют после того, как был определен конкретный тегированный элемент. При необходимости, данную настройку выполняют путем соотнесения каждого типа тегированных элементов (простых, составных или сложных) со столбцом записи таких тегированных элементов для сетевого потока. Простые тегированные элементы, предпочтительно, соотносят со столбцами, которые должны быть записаны первыми, тогда как составные тегированные элементы, предпочтительно, должны быть соотнесены только со столбцами, которые по меньшей мере записаны после тех столбцов, которые содержат простые элементы, от которых зависят составные тегированные элементы. Составные тегированные элементы, которые сами по себе по меньшей мере требуют одного составного тегированного элемента, предпочтительно, соотносят со столбцами, которые по меньшей мере записаны после тех столбцов, которые содержат требуемый(е) составной(ые) тегированный(ые) элемент(ы) и т.д.
Если иное не определено, все технические и научные термины, используемые в настоящем документе, имеют одинаковое значение, что будет главным образом ясно специалисту в области техники, к которой относится настоящее изобретение. Материалы, способы и примеры, предоставленные в настоящем документе, являются только иллюстративными и не предназначены для ограничения.
Реализация способа и системы по настоящему изобретению включает в себя выполнение или решение определенных выбранных задач или этапов вручную, автоматически или с использованием их комбинации. Более того, в соответствии с фактическим техническим оснащением и оборудованием предпочтительных вариантов реализации способа и системы в соответствии с изобретением, несколько выбранных этапов могут быть реализованы посредством аппаратного обеспечения или программного обеспечения в любой операционной системе любого встроенного программного обеспечения или их комбинации. Например, в качестве аппаратного обеспечения, выбранные этапы изобретения могут быть реализованы в виде интегральной микросхемы или электронной схемы. В качестве программного обеспечения, выбранные этапы изобретения могут быть реализованы в виде множества программных инструкций, приводимые в действие компьютером с использованием любой подходящей операционной системы. В любом случае, выбранные этапы способа и системы в соответствии с изобретением, могут быть описаны как выполняемые процессором для обработки данных, таким как вычислительная платформа для приведения в действие множества инструкций.
Несмотря на то, что настоящее изобретение описано в отношении «компьютера» в «компьютерной сети», следует отметить, что, при необходимости, любое устройство с процессором для обработки данных и способностью выполнять одну или несколько инструкций может быть описано как компьютер или как вычислительное устройство, в том числе, но без ограничения, персональный компьютер (ПК) любого типа, сервер, сотовый телефон, IP-телефон, смартфон, КПК (карманный персональный компьютер), тонкий клиент, устройство мобильной связи, интеллектуальные часы, шлем виртуальной реальности или другие носимые устройства, выполненные с возможностью внешней связи, виртуальный или облачный процессор или пейджер. Любые два или более таких устройств, находящихся в системе передачи данных друг с другом, при необходимости, могут содержать «компьютерную сеть».
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Изобретение описано в данном документе только в качестве примера со ссылкой на прилагаемые чертежи. Далее, с конкретной ссылкой на подробные чертежи, следует подчеркнуть, что показанные подробные сведения приведены только в качестве примера и в целях иллюстративного описания только предпочтительных вариантов реализации настоящего изобретения, и представлены для обеспечения того, что считается наиболее полезным и понятным описанием принципов и концептуальных аспектов изобретения. В связи с этим, не предпринимаются попытки показать структурные детали изобретения более подробно, чем это необходимо для фундаментального понимания изобретения, описание, взятое с чертежами, делает очевидным для специалистов в данной области техники то, каким образом различные формы изобретения могут быть воплощены на практике.
На фиг. 1 в качестве примера показана неограничивающая иллюстративная система для сбора и анализа потоков в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения.
На фиг. 2 в качестве примера показана неограничивающая иллюстративная система для сбора и подготовки потоков, в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения.
На фиг. 3 в качестве примера показан неограничивающий иллюстративный способ экспорта, сбора и анализа потока, в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения.
На фиг. 4 в качестве примера показан неограничивающий иллюстративный подробный способ анализа потока, в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения.
На фиг. 5 в качестве примера показан неограничивающий иллюстративный подробный способ предварительной обработки потоковых данных, в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения.
На фиг. 6 в качестве примера показан неограничивающий иллюстративный подробный способ обработки потоковых данных, в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения.
На фиг. 7 в качестве примера показан неограничивающий иллюстративный подробный способ тегирования элементов потока, в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
В соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения, представлены система и способ подготовки сетевых потоков для анализа посредством тегирования. Не требуется предварительных сведений о потоках для осуществления успешного тегирования, равно как не требуется какого-либо суждения о значении или ролей потоков. Вместо этого, тегирование обеспечивает устойчивый, воспроизводимый и эффективный способ быстрого разбиения сетевых потоков на полезную информацию.
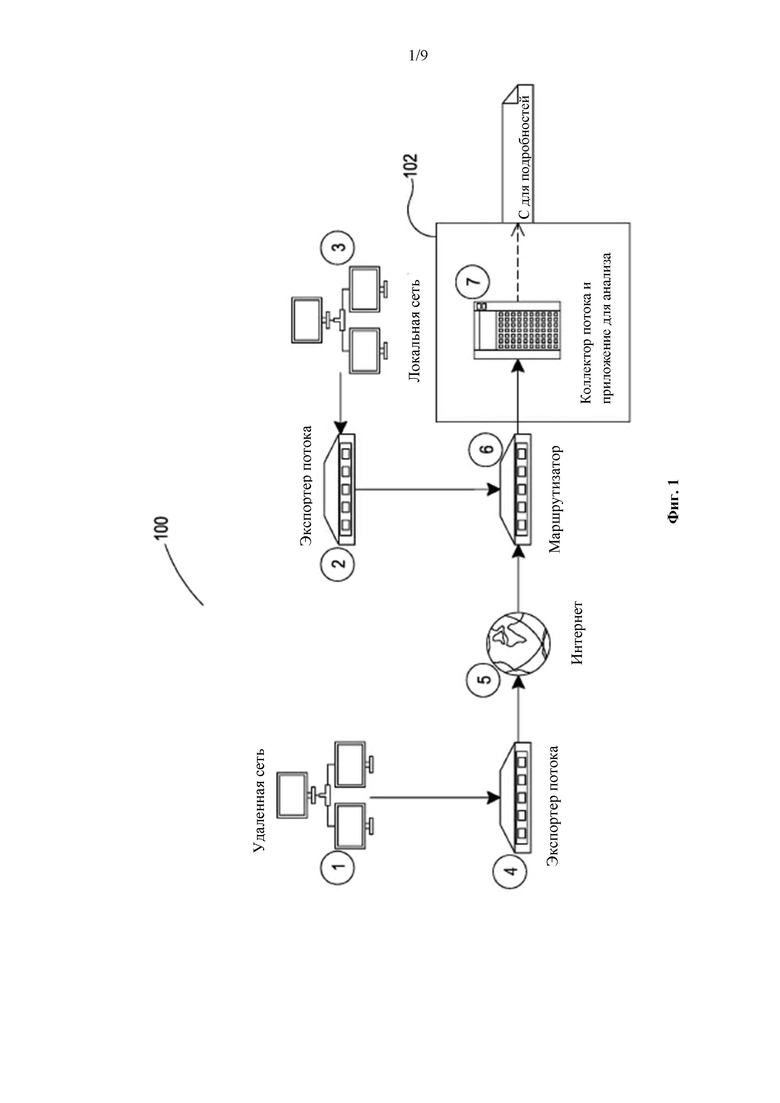
Обращаясь теперь к чертежам, на фиг. 1 в качестве примера показана неограничивающая иллюстративная система для сбора и анализа потоков, в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения. Как показано на фиг. 1, представлена система 100, которая имеет в наличии одну или более сетей, посредством которых осуществляется сбор потоковых данных. Как было описано ранее, потоковые данные относятся к данным о потоке пакетов посредством сети или множества сетей. Как показано, представлена удаленная сеть 1, которая может быть дополнительно подключена к приспособлению, известному как экспортер 4 потока. Экспортер 4 потока может быть, при необходимости, выделенным приспособлением или устройством. В качестве альтернативы, экспортер 4 потока может быть сервером или другим вычислительным устройством, которое имеет другие функции помимо экспорта потока.
Как было описано ранее, экспорт потока необязательно и предпочтительно предполагает сбор пакетных данных, а затем организацию пакетных данных в поток экспорта, который затем экспортируется. При необходимости, экспорт потока происходит в соответствии с одним или более различными протоколами, в том числе, но без ограничения, IPFIX и/или NetFlow. Протокол IPFIX в настоящее время известен как RFC 7011, а протокол NetFlow известен как RFC 3954. Потоковые данные представляют собой сводку метаданных, которую экспортер 2 потока подготавливает с использованием одного из данных протоколов экспорта потока. Потоковые данные, предпочтительно, организует таким образом, что не все пакетные данные необходимы, например, при необходимости, потоковые данные могут быть получены только на основе пакетных заголовков или на основе других пакетных форм поведения измеримых количеством пакетных характеристик или анализа.
Экспортер 4 потока, а также экспортер 2 потока, при необходимости, могут подготовить такие данные и отправить их приложению 7 для сбора и анализа потока, которое необязательно и предпочтительно управляется вычислительным устройством 102. Теперь, в зависимости от относительного местоположения вычислительного устройства 102, при необходимости, могут быть созданы связи между вычислительным устройством 102, удаленной сетью 1 и, при необходимости, например, локальной сетью 3. Данные соединения, при необходимости, могут быть созданы посредством любой сети, в том числе, но без ограничения, сети Интернет 5.
В примере, показанном в данном документе для системы 100, экспортер 4 потока связывается с маршрутизатором 6 посредством сети Интернет 5. Экспортер 2 потока принимает потоки и обрабатывает содержащиеся в них данные из локальной сети 3. Экспортер 2 потока и экспортер 4 потока, в конечном итоге, связываются посредством вычислительного устройства 102 посредством маршрутизатора 6, несмотря на то, что, при необходимости, может быть использовано любое сетевое приспособление любого типа для соединения данных различных потоков из данных разных сетей, при необходимости, включая любой тип связи посредством Интернет 5.
Приложение 7 для сбора и анализа потока, как показано, затем собирает потоки и, при необходимости, может выполнять некоторый тип анализа. Это описано более подробно на схеме С.
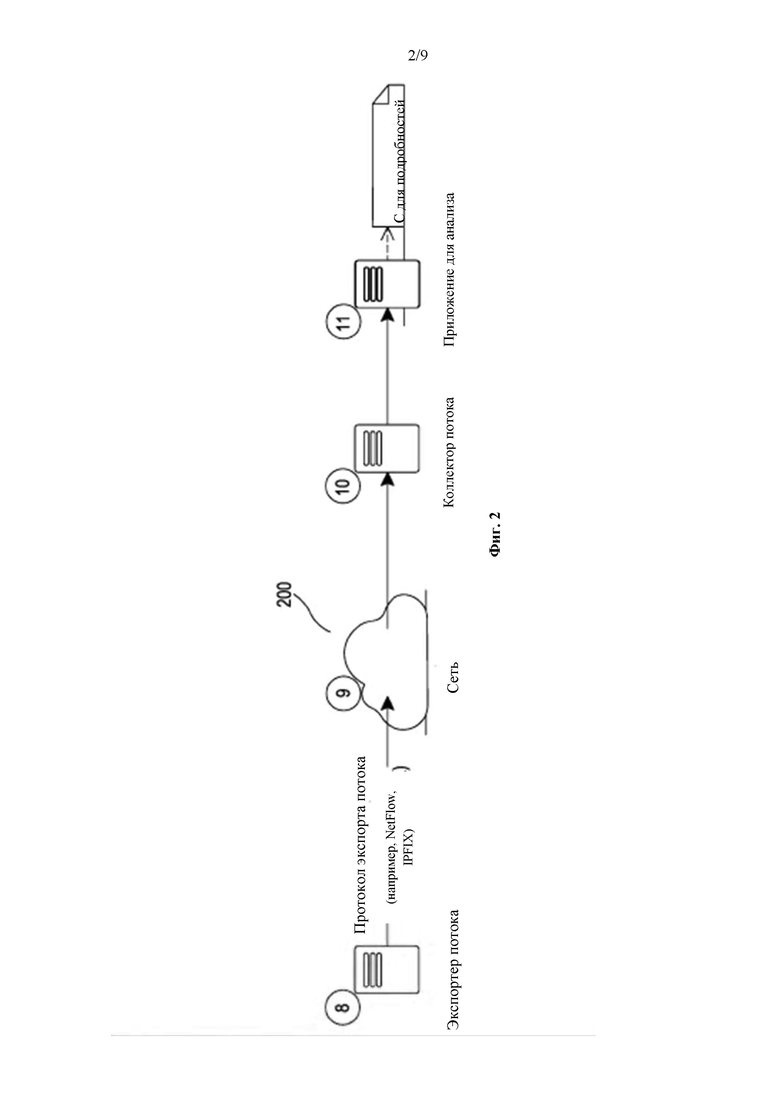
На фиг. 2 в качестве примера показана неограничивающая иллюстративная система для сбора и подготовки потоков, в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения, включая представленную в качестве примера систему 200, которая предоставляет дополнительные подробности в отношении анализа и подготовки потоков. На данной диаграмме некоторые вычислительные устройства были исключены для простоты объяснения, однако следует отметить, что, при необходимости, каждое из экспортера 8 потока, сборщика 10 потока и приложения 11 для анализа, при необходимости, может быть реализовано как сетевое устройство или приспособление, и/или как сервер, эксплуатирующий любой тип программного обеспечения, даже несмотря на то, что такие устройства, при необходимости, могут быть показаны в данном случае для простоты объяснения.
Итак, экспортер 8 потока вновь подготавливает потоки и экспортирует их, в соответствии с протоколом экспортера потоков, который также может, при необходимости, представлять собой NetFlow, IPFIX или любой другой подходящий протокол экспорта потоков. Затем потоки экспортируются посредством сети 9, которая может представлять собой, например, сеть Интернет, на сборщик 10 потока.
Сборщик 10 потока, при необходимости, может собирать потоки от множества экспортеров 8 потока, которые не показаны, и затем отправлять собранные потоки на приложение 11 для анализа.
Сборщик 10 потока, при необходимости, может или не может постоянно находиться в той же базовой компьютерной системе, что и один или более экспортеров 8 потока. Таким образом, в данном случае, например, сборщик 10 потока, при необходимости, может находиться в другой базовой компьютерной системе и/или в другой сети, в отличие от экспортера 8 потока. Сборщик 10 потока, при необходимости, может эксплуатироваться в той же базовой компьютерной системе или даже на том же вычислительном устройстве, что и приложение 11 для анализа, или может, при необходимости, эксплуатироваться в другой базовой компьютерной системе и/или эксплуатироваться на другом вычислительном устройстве, в отличие от приложения 11 для анализа. И вновь, дополнительные детали показаны на схеме С относительно процесса анализа сбора потоков.
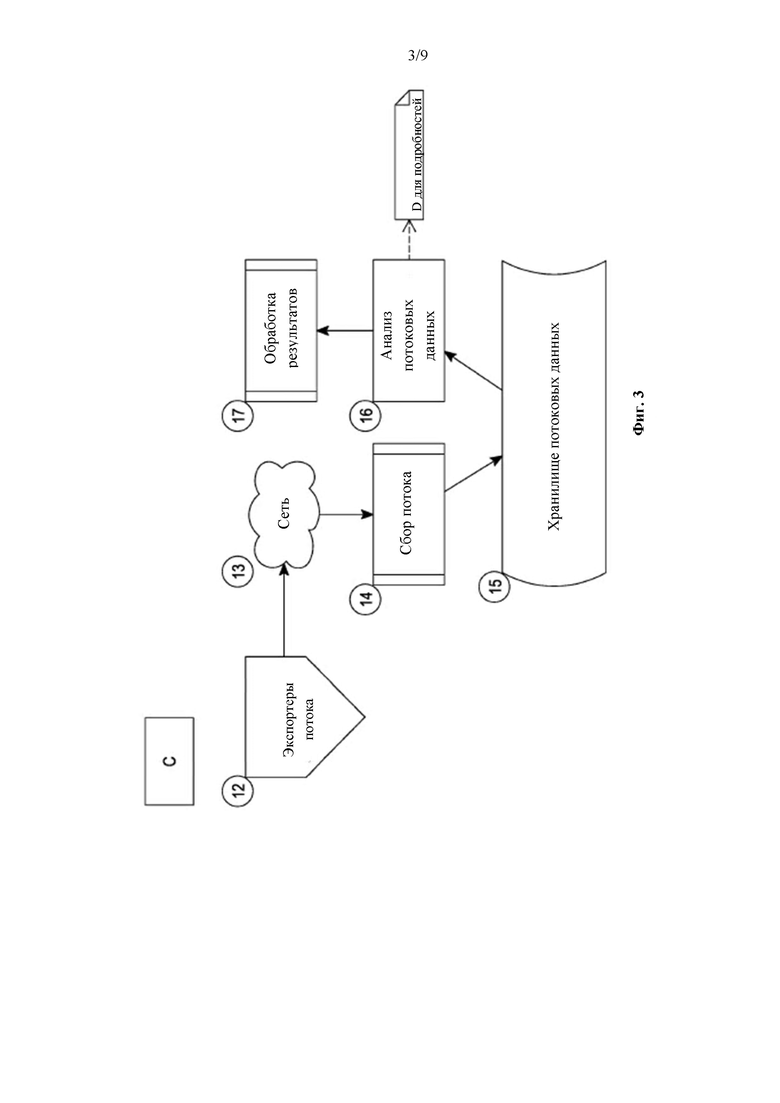
Далее, фиг. 3 относится к схеме С, которая показывает необязательный процесс для экспорта, сбора и анализа потока, в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения. Как показано, предпочтительно, чтобы множество экспортеров 12 потока осуществляло экспорт потоков посредством сети 13 в коллектор 14 потока. Согласно вышеуказанному описанию в отношении предыдущих схем, при необходимости, каждый из показанных здесь компонентов может быть реализован как отдельное сетевое приспособление или устройство, или, при необходимости, может быть реализован как часть сервера или группы серверов, при необходимости, как встроенное программное обеспечение или как программное обеспечение. Несмотря на то, что такие вычислительные устройства не показаны, предполагается, что они являются неотъемлемой частью схемы и фактически могут быть легко добавлены и понятны специалисту в данной области техники.
Таким образом, возвращаясь к фиг. 3, сбор потоков осуществляется посредством коллектора потока или точки 14 сбора потока и, необязательно и предпочтительно, потоки размещаются в хранилище 15 потоковых данных. Хранилище 15 потоковых данных может быть временным или постоянным типом хранилища данных. Компонент 16 анализа потоковых данных затем необязательно и предпочтительно извлекает потоки из хранилища 15 потоковых данных для выполнения некоторого типа анализа. Результаты анализа, при необходимости, могут быть обработаны компонентом 17 для обработки результатов.
Хранилище 15 потоковых данных может быть дополнительно реализовано в соответствии с любым типом запоминающего устройства, в том числе, но без ограничения, как жесткий диск, хранилище SAN, диск ОЗУ, структура памяти любого типа, очередь и т.д. Результаты анализа 16 потоковых данных, которые отправлены компоненту 17 обработки результатов, при необходимости, могут содержать, в том числе, но без ограничения, предупреждения, отправляемые при ненормальном поведении, обновления сетевой маршрутизации, создание или обновления сетевой модели, низкий прогноз и т.д. Однако анализ 16 потоковых данных, при необходимости, может быть независим от значения анализа, вследствие чего, например, анализ 16 потоковых данных, при необходимости, может не определять, указывает ли конкретный поток на несанкционированный доступ к какой-либо части компьютерной системы, наличие (или отсутствие) вредоносных программ и тому подобное. При необходимости, анализ 16 потоковых данных не отправляет все результаты на компонент 17 для обработки результатов, а скорее выбирает те результаты, которые являются наиболее информативными и/или представляют какой-либо тип изменения состояния сети, модели сети или системы и/или которые могут представлять какой-либо тип предупреждения, при необходимости, установленный в соответствии с заданными правилами, которые могут указывать на результат, который должен быть более подробно изучен компонентом 17 для обработки результатов.
Компонент 17 для обработки результатов, при необходимости, может содержать, без ограничения, одно или более приложений для обнаружения вредоносных программ, приложений для обнаружения несанкционированного доступа или приложений для обнаружения отклонений от нормального состояния, или любого типа обнаружения несанкционированного доступа, при котором работа компьютерной системы была поставлена под угрозу каким-либо образом.
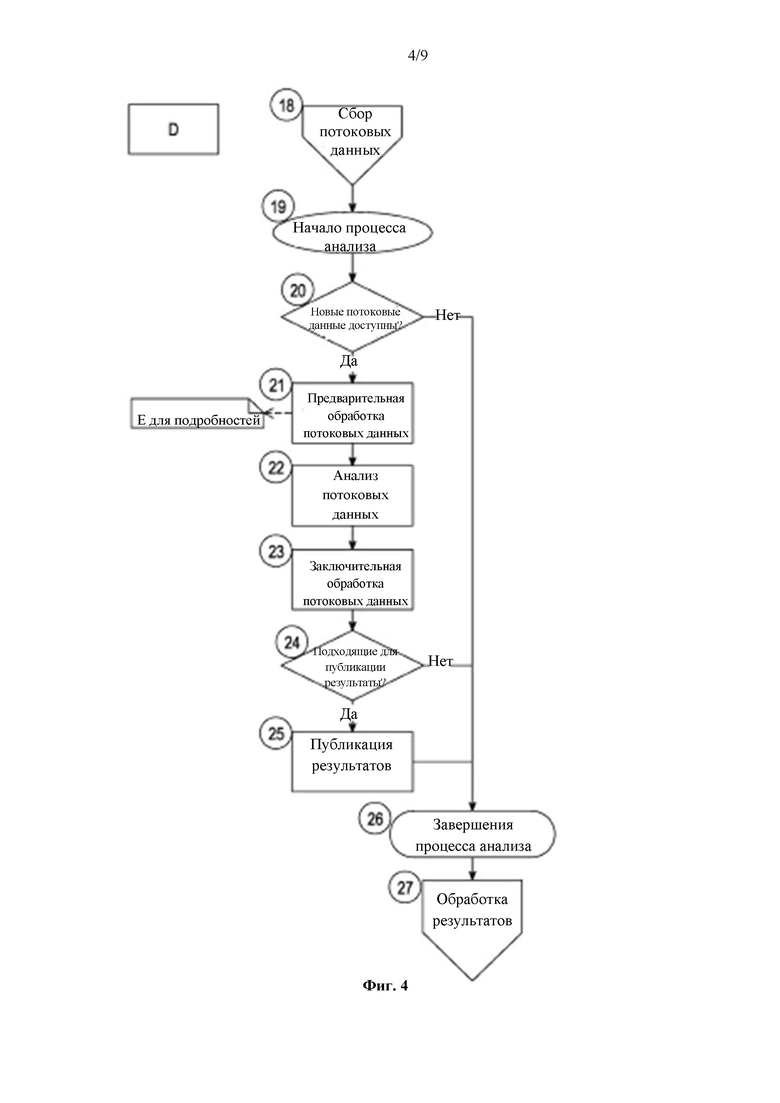
Фиг. 4, также обозначенная как D, которая называется стадией «D» на фиг. 3, предоставляет более подробную информацию относительно анализа 16 потоковых данных. Фиг. 4 относится к примеру подробного способа анализа данных. Как показано, вновь предусмотрен сбор потоковых данных или коллектор 18, который собирает данные. При необходимости, в данном случае это может быть функциональный компонент, представляющий сбор потоковых данных от множества компонентов, и, при необходимости, с предварительной обработкой или без предварительной обработки.
На стадии 19 начинается процесс анализа, который, например, может дополнительно включать некоторый тип предварительной обработки или сбора данных. На этапе 20 осуществляется определение того, доступны ли новые потоковые данные. Если новые потоковые данные недоступны, то процесс, предпочтительно, переходит непосредственно к стадии 26, на которой процесс анализа завершается, и любые ненормальные или другие важные результаты отправляются на стадию 27 обработки результатов, который был описан ранее. Необязательно и предпочтительно, содержатся только те результаты, которые обозначены термином важные, ненормальные, представляющие изменения или которые, при необходимости, могут быть активированы в соответствии с одним или более правилами.
Однако если новые потоковые данные доступны на стадии 20, то процесс переходит к стадии 21 с предварительной обработкой потоковых данных. Данная стадия предварительной обработки описана более подробно со ссылкой на чертеж Е. Стадия предварительной обработки, предпочтительно, добавляет больше метаданных в форме столбцов потоковых данных к потоковым данным. Предварительная обработка и тегирование являются важными для настоящего изобретения по меньшей мере в некоторых вариантах реализации, поскольку оно относится к способу, в котором исследуемые данные могут быть предварительно проанализированы или предварительно обработаны таким образом, чтобы уменьшить количество требуемых вычислительных ресурсов, и/или распределить эти вычислительные ресурсы таким образом, который может быть более простым в реализации и по меньшей мере более гибким, и позволяет различным приспособлениям и/или вычислительным устройствам или компонентам в пределах системы реализовывать разные аспекты способа обработки, и/или любого типа анализа.
Затем, после завершения предварительной обработки, на стадии 22 осуществляется анализ потоковых данных. После анализа потоковых данных они подвергаются последующей обработке на стадии 23. Если на стадии 24 происходит обнаружение пригодных для публикации результатов, то на стадии 25 осуществляется публикация результатов. В любом случае, при наличии или отсутствии пригодных для публикации результатов, и при наличии пригодных для публикации результатов после публикации, происходит завершение процесса анализа на стадии 26, как было описано ранее.
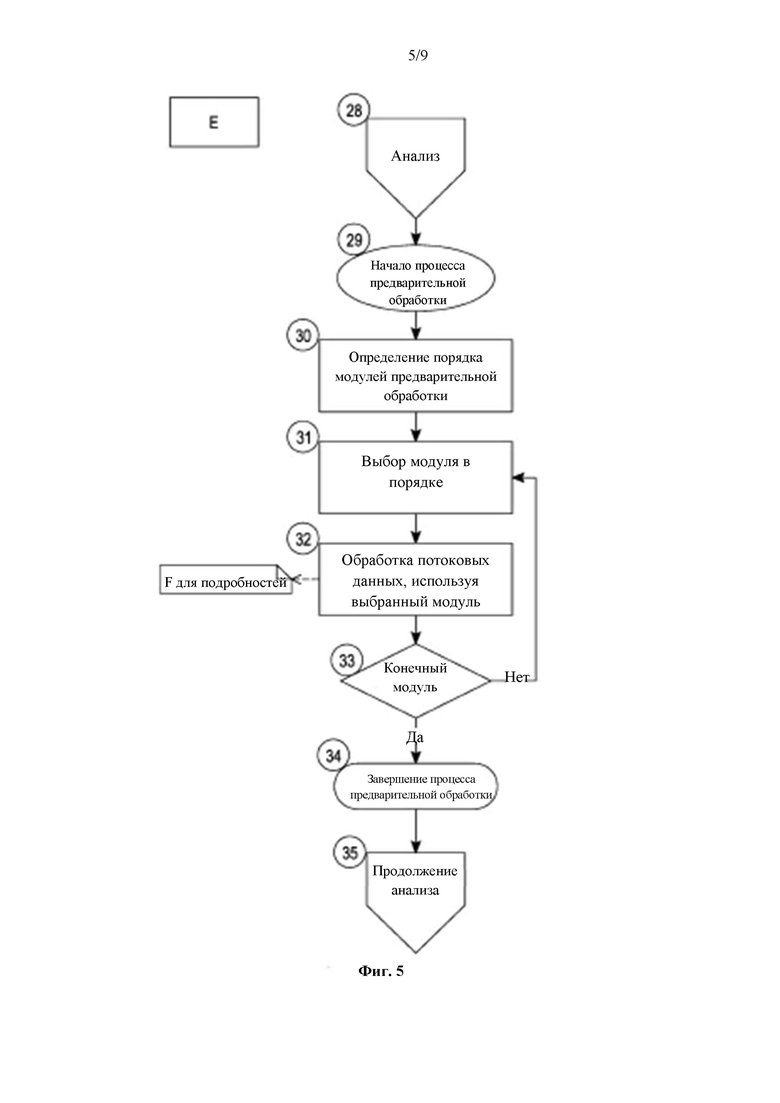
Фиг. 5 относится к чертежу Е, который более подробно описывает предварительную обработку потоковых данных. Таким образом, на фиг. 5, как показано на стадии 28, осуществляется выполнение анализа данных для определения типа полученных данных и подтверждения того, что данные пригодны для обработки. На стадии 29 фактически начинается процесс предварительной обработки. На стадии 30 осуществляется определение порядка модулей предварительной обработки. При необходимости, он может быть определен по меньшей мере частично в соответствии с одной или несколькими характеристиками данных, и/или в соответствии с одним или более правилами, которые могли быть реализованы ранее. При необходимости, данные правила также могут быть активированы одной или более характеристиками данных.
Для предварительной обработки предполагается наличие одного или более модулей, каждый из которых имеет определенную задачу предварительной обработки при анализе потоковых данных. Поскольку модули могут зависеть от наличия определенных тегов, важным является планирование порядка приведения в действие модулей для максимизации объема тегирования, которое может быть выполнено. Такое планирование также предотвращает циклические зависимости в бесконечных циклах. Следовательно, например, если один модуль зависит от результатов другого модуля, то очевидно, что модуль, который зависит от результатов другого модуля, должен быть реализован после модуля, который будет выдавать результаты.
Если планирование является достаточно усовершенствованным и/или если предоставлена достаточная информация, может быть запланировано параллельное исполнение. Планирование, предпочтительно, осуществляется на стадии 30.
На стадии 31 каждый модуль для предварительной обработки, который, предпочтительно, является выделенным модулем для предварительной обработки (выделенным для конкретного простого или составного тегированного элемента), выбирается в определенном порядке. Как было отмечено ранее, определенный порядок, предпочтительно, относится к тому, какая информация требуется каждому модулю. Например, если модуль нуждается только в стандартном элементе сетевого потока, он может, при необходимости, эксплуатироваться первым. Модули, которым требуется уже тегированный элемент, предпочтительно, будут эксплуатироваться позже, после того, как требуемый тегированный элемент будет подготовлен.
Далее на стадии 32 осуществляется предварительная обработка потоковых данных с использованием выбранного модуля. Данный процесс более подробно показан на чертеже F. На стадии 33 осуществляется определение того, был ли фактически реализован каждый модуль для предварительной обработки для предварительной обработки потоковых данных. Если нет, то процесс возвращается на стадию 31. Если да, и все модули были фактически реализованы, то на стадии 34 процесс предварительной обработки завершается, а процесс анализа, предпочтительно, продолжается на стадии 35.
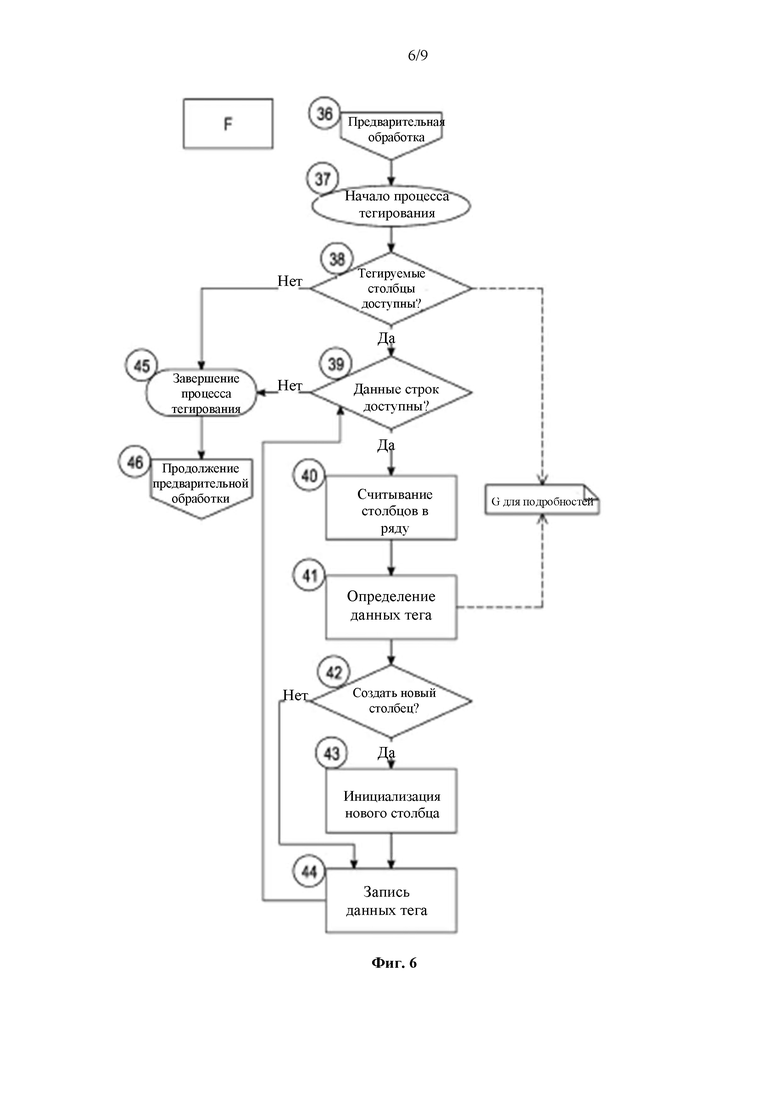
Далее переходя к фиг. 6, на чертеже F более подробно показан способ, который относится к стадии предварительной обработки каждым модулем. Таким образом, как показано, на стадии 36 действия предварительной обработки, затем на этапе 37 начинается приведение в действие модуля в процессе тегирования. Сначала на стадии 38 осуществляется определение того, доступны ли все столбцы, необходимые для данного модуля. Каждому модулю необязательно требуется по меньшей мере один столбец для добавления или обновления метаданных или тегов. В случае отсутствия столбца или в качестве предварительного условия, тег может состоять из метки времени или порядкового номера или чего-либо, что не требует контекста данного конкретного набора потоковых данных.
Если нет доступных тегируемых столбцов, то приведение в действие данного модуля заканчивается на стадии 45, и предварительная обработка продолжается либо с другим модулем, либо приведение в действие продолжается с другой фазой на стадии 46. Если требуемые столбцы доступны, то начинается цикл итерации для каждой строки в данных столбцах. Таким образом, продолжая более подробно, на стадии 38 осуществляется определение того, что тегируемые столбцы доступны, и согласно вышеуказанному, в случае отсутствия доступных тегируемых столбцов, это указывает, что процесс тегирования завершается на стадии 45. Однако это может быть только необязательно процесс для данного конкретного модуля, и в действительности может потребоваться перепланирование конкретного модуля с точки зрения его порядка, для приведения его в действие позже в процессе или, возможно, даже в другом процессе, если в действительности модуль ожидает результатов.
Необязательно и предпочтительно, система является достаточно гибкой, вследствие чего, если было показано, что конкретный модуль приведен в действие не по порядку, модуль, при необходимости, может быть приведен в действие в другой части порядка на более поздней итерации предварительной обработки для того чтобы избежать необходимости перепланирования модулей более одного раза. Безусловно, это не может быть возможно во всех случаях, и в данном случае перепланирование модуля, при необходимости, может происходить для обеспечения уверенности в том, что все модули фактически приведены в действие.
Как только было определено, что тегируемые столбцы доступны, то на стадии 39 осуществляется определение того, доступны ли данные строк. Если данные строк доступны, то на стадии 40, предпочтительно, считываются столбцы в каждой строке. В соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения, способ предварительной обработки функционирует по столбцу, а не по строке, вследствие чего каждая ячейка в каждом столбце полностью считывается перед рассмотрением следующего столбца вместо считывания каждой строки в качестве отдельного объекта. В последнем случае, каждая ячейка и каждая строка будут соответствовать разным столбцам, вследствие чего ячейки из нескольких столбцов считываются построчно, прежде чем будет рассмотрена следующая строка. Однако в данном случае, поскольку ячейки исходят от одного столбца, перед рассмотрением следующего столбца осуществляется рассмотрение ячеек из нескольких строк.
Далее, на стадии 41 осуществляется определение данных тега. Процесс определения данных тега, предпочтительно, описан более подробно со ссылкой на чертеж G. На стадии 42, если необходимо создать новый столбец результатов, он создается и инициализируется на стадии 43.
Данные тега записываются на стадии 44, и затем процесс возвращается обратно на стадию 39, пока столбец не будет полностью завершен. После того, как каждый столбец закончен, процесс тегирования, при необходимости, может быть затем продолжен с другим модулем или, при необходимости, с другим столбцом, пока процесс тегирования не будет завершен, как показано на стадии 45. На стадии 46 процесс предварительной обработки, предпочтительно, имеет свое продолжение со следующим модулем.
Определение значения тега, при необходимости может быть выполнено посредством таблиц соответствия из одного или более столбцов, посредством вычислений или логической индукции/вывода и/или более сложных алгоритмов с использованием различных баз данных. Предпочтительно, процесс тегирования не генерирует каких-либо выводов о значимости в каком-либо контексте значений строки или комбинаций строк. Процесс тегирования, предпочтительно, обрабатывает каждую подходящую строку без исключений, и добавляет тег без обработки целого.
Если данные тега должны быть записаны в новый столбец 42, как было описано ранее, то данный столбец должен быть создан или инициализирован на стадии 43.
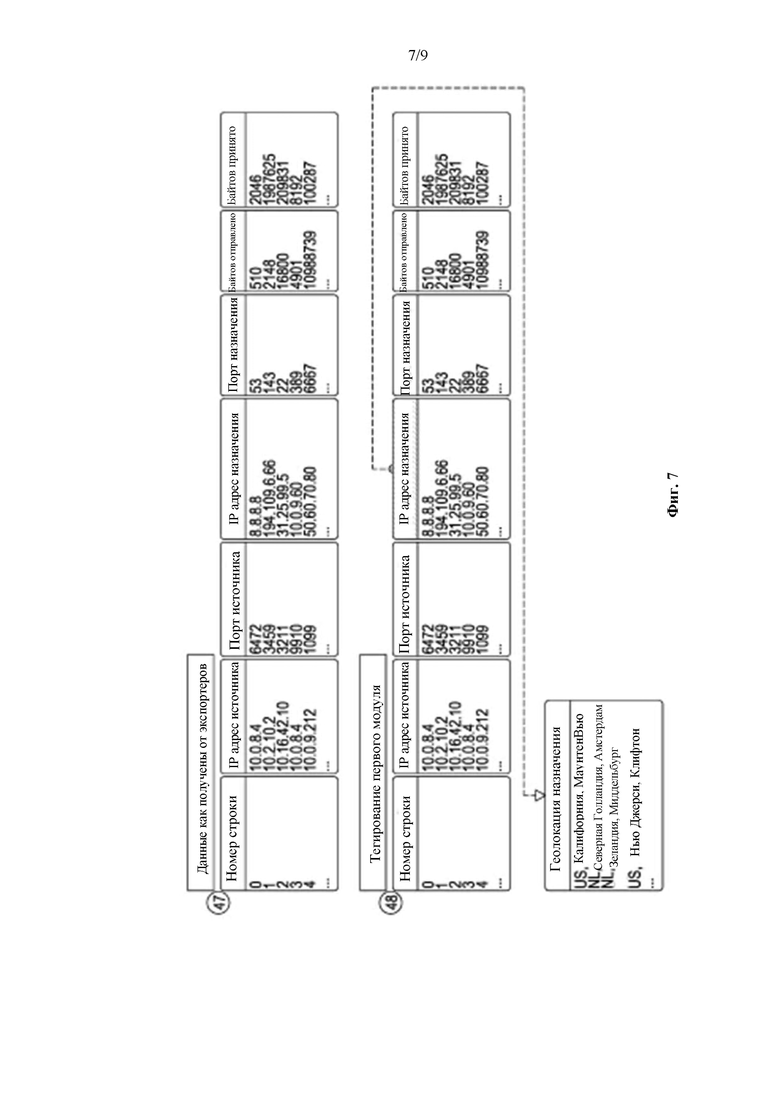
На фиг. 7 в качестве примера показан неограничивающий иллюстративный подробный способ тегирования потоковых элементов, в соответствии с по меньшей мере некоторыми вариантами реализации настоящего изобретения, в отношении неограничивающего примера данных сетевого потока, при обработке для формирования тегированных данных. Данные приведены в качестве неограничивающего иллюстративного примера. Данные принимает коллектор потока, и они сохраняются в промежуточном хранилище в виде столбцов с конкретными типами потоковых метаданных (47). В данном примере приведены некоторые общие, но не ограничивающие примеры атрибутов потоковых данных.
Первый модуль, который начинает тегирование (48), просматривает столбец «IP-адрес назначения» и, путем выполнения поиска в конкретной таблице, определяет зарегистрированное физическое местоположение для данного IP-адреса. Эти данные записываются в новый столбец под названием «Географическое положение назначения», в качестве примера простого тегированного элемента.
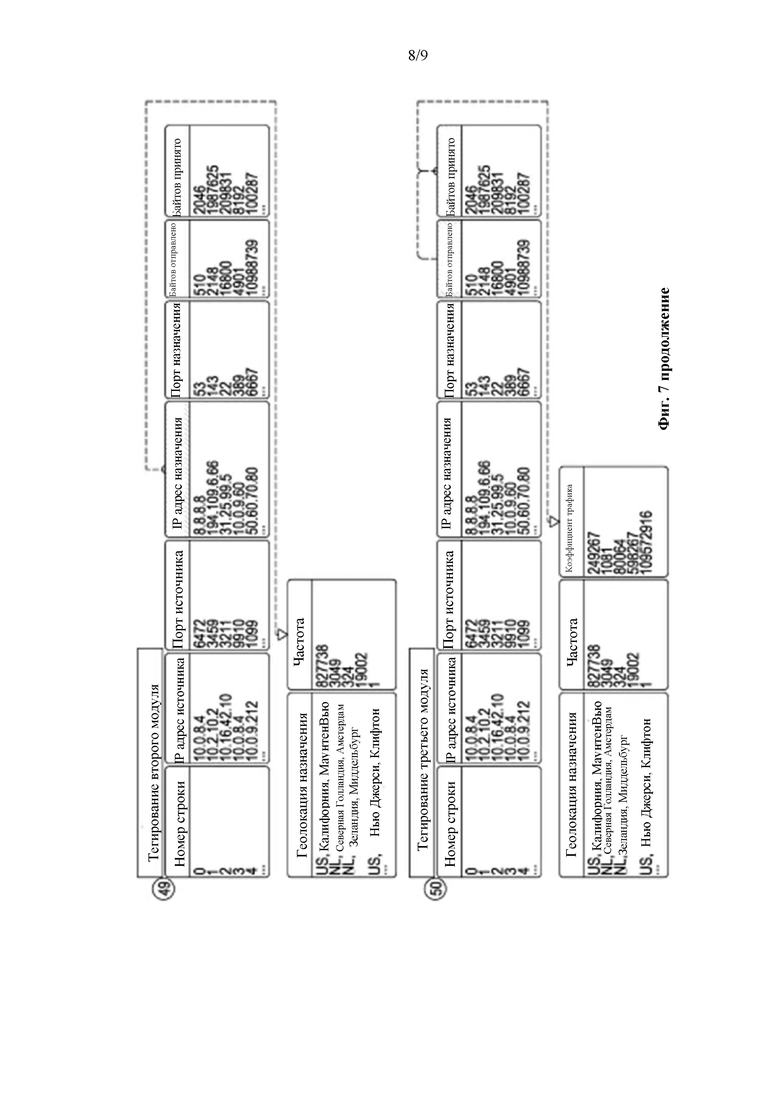
Второй модуль, который начинает тегирование (49), снова использует столбец «IP-адрес назначения», но также использует внутреннюю базу данных, которая отслеживает частоту посещения IP-адреса. Он увеличивает значение во внутренней базе данных, сохраняет это значение в базе данных и записывает данные в новый столбец, называемый «Частота», что является еще одним примером простого тегированного элемента.
Третий модуль (50) использует столбцы «Отправленные байты» и «Принятые байты», а затем, используя формулу (отправлено/получено) × 1000000, рассчитывает коэффициент трафика и помещает это значение в новый столбец «Коэффициент трафика» в качестве другого примера простого тегированного элемента.
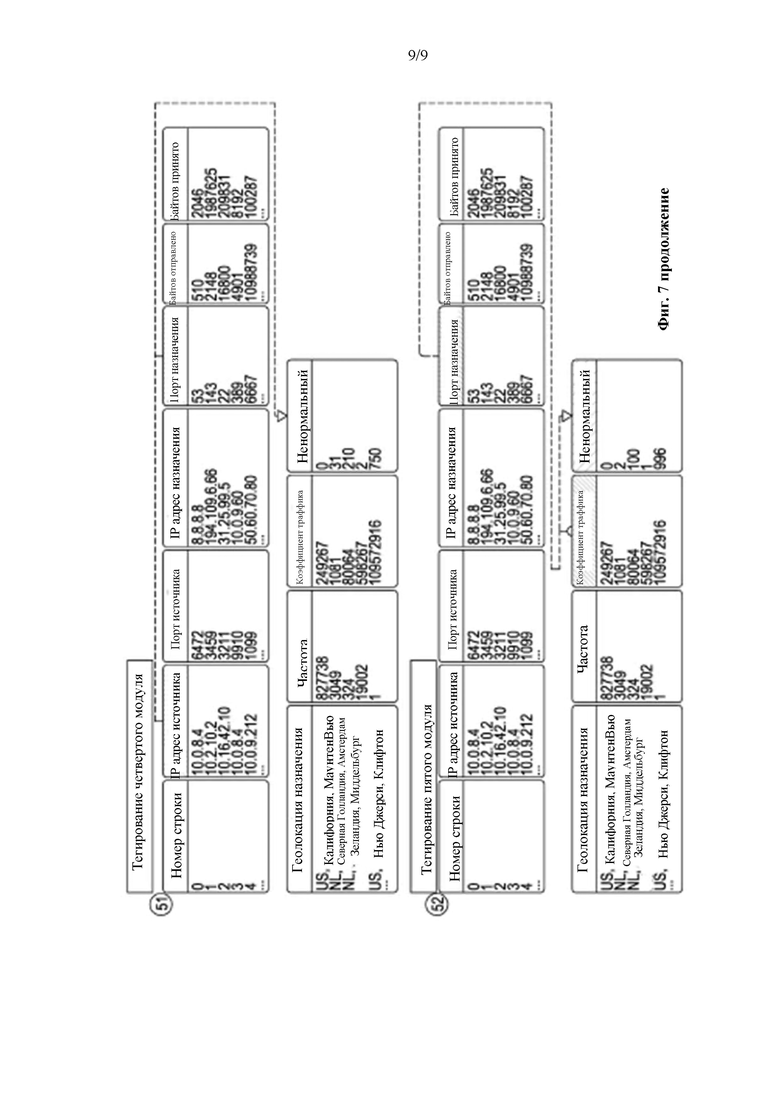
Четвертый модуль (51) использует столбцы «IP-адрес источника» и «Порт назначения» и внутреннюю базу данных для определения того, что эта комбинация является ненормальным, резко отклоняющимся значением от предыдущей активности этого IP-адреса источника. Это измерение записывается в новый столбец «Ненормальный», как пример составного тегированного элемента.
Пятый модуль (52) использует «Порт назначения» и «Коэффициент трафика» для сложения или вычитания значения, уже присутствующего в столбце «Ненормальный». Результат обновляется в существующем столбце «Ненормальный» или, при необходимости, в новом столбце, как пример составного тегированного элемента.
Следует понимать, что некоторые характерные особенности изобретения, которые для наглядности, описаны в контексте отдельных вариантов реализации, также могут быть представлены в комбинации в едином варианте реализации. Наоборот, различные признаки изобретения, которые для краткости описаны в контексте единого варианта реализации, также могут быть представлены отдельно или в любой подходящей подкомбинации.
Несмотря на то, что изобретение было описано в связи с его конкретными вариантами реализации, очевидно то, что многие альтернативы, модификации и варианты будут ясны для специалистов в данной области техники. Соответственно, предполагается, что оно охватывает все такие альтернативы, модификации и варианты, которые находятся в рамках сущности и широкого объема пунктов прилагаемой формулы изобретения. Все публикации, патенты и заявки на выдачу патента, упомянутые и обозначенные в данном описании, включены в настоящее описание посредством ссылки в той же степени, как если бы каждая отдельная публикация была конкретно и индивидуально указана для включения в качестве ссылки. В дополнение, цитирование или идентификация любой ссылки в данной заявке на выдачу патента не должны быть истолкованы как признание того, что данная ссылка доступна в качестве предшествующего уровня техники для настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМЫ И СПОСОБЫ СООБЩЕНИЯ ОБ ИНЦИДЕНТАХ КОМПЬЮТЕРНОЙ БЕЗОПАСНОСТИ | 2019 |
|
RU2757597C1 |
| УПРАВЛЕНИЕ ДАННЫМИ ДЛЯ СОЕДИНЕННЫХ УСТРОЙСТВ | 2014 |
|
RU2670573C2 |
| ПОДДЕРЖКА ТЕГИРОВАННЫХ РЕЗУЛЬТАТОВ ПОИСКА | 2014 |
|
RU2666460C2 |
| СИСТЕМЫ И СПОСОБЫ ИСПОЛЬЗОВАНИЯ СООБЩЕНИЙ DNS ДЛЯ СЕЛЕКТИВНОГО СБОРА КОМПЬЮТЕРНЫХ КРИМИНАЛИСТИЧЕСКИХ ДАННЫХ | 2020 |
|
RU2776349C1 |
| СИСТЕМЫ И СПОСОБЫ АНАЛИЗА СЕТИ И ОБЕСПЕЧЕНИЯ ОТЧЕТОВ | 2015 |
|
RU2677378C2 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ СОЗДАНИЯ И МОДИФИКАЦИИ СПИСКОВ УПРАВЛЕНИЯ ДОСТУПОМ | 2015 |
|
RU2679179C1 |
| БАЗОВЫЕ КОНТРОЛЛЕРЫ ДЛЯ ПРЕОБРАЗОВАНИЯ УНИВЕРСАЛЬНЫХ ПОТОКОВ | 2012 |
|
RU2595540C9 |
| Система и способ защиты от Volume DDoS атак | 2022 |
|
RU2791869C1 |
| ПОИСК ИЗОБРАЖЕНИЙ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2688271C2 |
| СПОСОБ ПЕРЕДАЧИ ЦИФРОВЫХ УСЛУГ ПО СЕТИ И УСТРОЙСТВО, ОСУЩЕСТВЛЯЮЩЕЕ СПОСОБ | 2005 |
|
RU2353069C2 |
Изобретение относится к системе и способу для подготовки сетевого трафика для анализа. Технический результат заключается в обеспечении возможности эффективного и быстрого разбиения сетевых потоков на полезную информацию и её анализа. Указанный результат достигается путем разбиения сетевого потока на множество стандартных элементов сетевого потока, которые затем тегируются. Тегированные элементы содержат составные тегированные элементы, при необходимости могут содержать любой тип элемента в соответствии с любым типом стандарта сетевого потока, в том числе, но без ограничения, стандарта IPFIX или Netflow, или могут быть необязательно выведены из таких элементов. 2 н. и 21 з.п. ф-лы, 7 ил., 1 табл.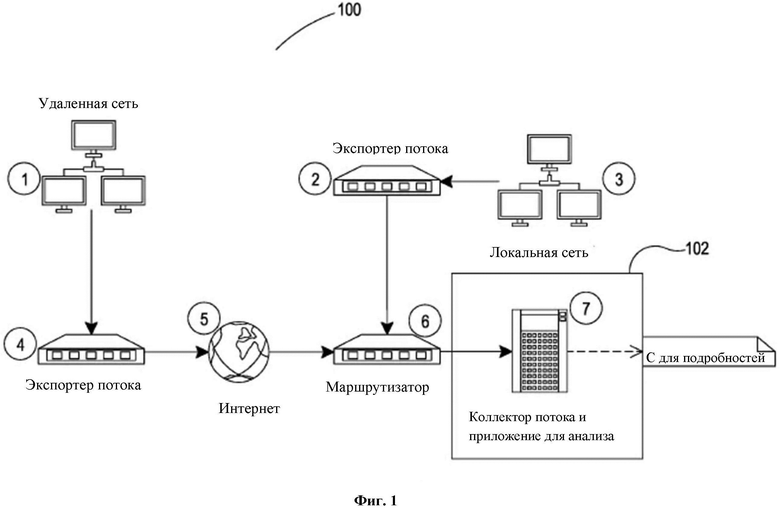
1. Система для анализа компьютерного сетевого потока, содержащая экспортер сетевого потока для подготовки сетевого потока; анализатор сетевого потока для разбиения указанного сетевого потока на множество стандартных элементов сетевого потока в соответствии с одним или более стандартами сетевого потока; и средство тегирования потока для тегирования указанного множества стандартных элементов сетевого потока с формированием тегированных элементов, при этом указанные тегированные элементы содержат составные тегированные элементы, которые выведены по меньшей мере из:
объединенного анализа указанного множества стандартных элементов сетевого потока;
объединенного анализа множества простых тегированных элементов;
объединенного анализа простого тегированного элемента в совокупности с информацией, внешней по отношению к сетевому потоку;
анализа, полученного путем выполнения вычисления над простым тегированным элементом;
или анализа, полученного путем объединения стандартного элемента сетевого потока с простым тегированным элементом;
причем каждый простой тегированный элемент выведен из по меньшей мере одного из указанных стандартных элементов сетевого потока в соответствии с источником информации, внешней по отношению к сетевому потоку, или в соответствии с вычислением, или их комбинацией.
2. Система по п. 1, в которой указанные составные тегированные элементы дополнительно содержат вычисление для составного тегированного элемента, множества составных тегированных элементов или их комбинации.
3. Система по п. 2, в которой указанные тегированные элементы содержат по меньшей мере один простой тегированный элемент и по меньшей мере один составной тегированный элемент, причем указанное средство тегирования потока итеративно тегирует указанное множество стандартных элементов сетевого потока, так что указанный по меньшей мере один составной тегированный элемент определяется после указанного по меньшей мере одного простого тегированного элемента.
4. Система по п. 2, в которой указанный простой тегированный элемент выбран из группы, состоящей из коэффициента трафика, выведенного на основе количества отправленных и полученных данных, конкретного IP-адреса или конкретного порта конкретного IP-адреса; и порта/IР-адреса элемента, выведенного из IP-адреса источника и порта назначения сетевого потока.
5. Система по п. 1, в которой обеспечена возможность определения указанного стандартного элемента сетевого потока в соответствии с одним или обоими из таких стандартов, как стандарты IPFIX или Netflow.
6. Система по п. 1, в которой указанный источник информации, внешней по отношению к сетевому потоку, содержит справочную таблицу для соотнесения значения тегированного элемента со значением внешней информации.
7. Система по п. 6, в которой указанная справочная таблица содержит информацию о геолокации, а указанный тегированный элемент содержит IP-адрес.
8. Система по п. 2, в которой обеспечена возможность осуществления указанного тегирования в итеративном порядке, определенном в соответствии с указанными типами тегированных элементов.
9. Система по п. 1, в которой сетевой поток содержит множество пакетов, имеющих общий набор свойств, а указанный анализатор сетевого потока определяет указанные стандартные элементы сетевого потока на основании указанного общего набора свойств, организованного в виде множества столбцов, каждое свойство в столбце, причем указанное средство тегирования сетевого потока тегирует указанное множество элементов в итеративном порядке, определенном в соответствии с указанными типами тегированных элементов.
10. Система по п. 9, в которой указанное множество свойств пакетов выбрано из группы, состоящей из элемента поля заголовка пакета, измеренного свойства указанного множества пакетов, информации, интерпретированной на основе содержимого пакета, и метаданных.
11. Система по п. 1, в которой указанное средство тегирования содержит множество модулей тегирования, которые выполняются в соответствии с указанными типами тегированных элементов.
12. Система по п. 11, в которой указанное средство тегирования определяет, что необходимо перепланирование по меньшей мере одного из указанного множества модулей тегирования для выполнения в соответствии с указанным типом тегированных элементов, так что в соответствии с указанным перепланированием по меньшей мере один из указанного множества модулей тегирования выполняют после по меньшей мере одного другого из указанного множества модулей тегирования.
13. Система по п. 1, в которой указанная сеть содержит локальную сеть.
14. Система по п. 1, в которой указанные тегированные элементы указывают на изменение статуса указанной сети.
15. Система по п. 1, содержащая хранилище потоковых данных, связанное с указанным анализатором сетевого потока, для хранения указанного сетевого потока.
16. Система по п. 1, в которой указанное средство тегирования содержит множество модулей тегирования, а указанные тегированные элементы выведены из указанного множества стандартных элементов потока указанным множеством модулей тегирования.
17. Система по п. 16, в которой каждый из множества модулей тегирования выполняет соответствующую задачу тегирования для указанного множества стандартных элементов потока с выведением указанных тегированных элементов.
18. Система по п. 17, в которой планирование указанного множества модулей тегирования для выполнения соответствующей задачи тегирования основано на указанных типах тегированных элементов.
19. Система по п. 1, в которой указанные тегированные элементы содержат простые тегированные элементы, которые выведены из по меньшей мере одного из указанных стандартных элементов сетевого потока на основании вычисления.
20. Способ анализа сетевого потока, содержащего множество пакетов, имеющих общий набор свойств, причем способ выполняют вычислительным устройством, при этом способ включает:
a) прием сетевого потока, причем указанный сетевой поток содержит множество пакетных свойств, организованных в столбцы, каждое свойство в столбце;
b) анализ сетевого потока для разбиения сетевого потока на множество стандартных элементов сетевого потока в соответствии с одним или более стандартами сетевого потока;
c) тегирование указанного множества стандартных элементов сетевого потока в соответствии с источником информации, внешним по отношению к указанному сетевому потоку, или в соответствии с вычислением, или их комбинацией для выведения по меньшей мере одного простого тегированного элемента;
d) комбинирование указанного по меньшей мере одного простого тегированного элемента с информацией, внешней по отношению к указанной сети, путем выполнения вычисления для указанного простого тегированного элемента, или путем комбинирования стандартного элемента сетевого потока с простым тегированным элементом с выведением таким образом по меньшей мере одного составного тегированного элемента; и
с) соотнесение тегированных элементов по столбцам, причем столбец, с которым соотнесен указанный по меньшей мере один составной тегированный элемент, записывают после столбца, с которым соотнесен соответствующий по меньшей мере один простой элемент.
21. Способ по п. 20, в котором указанный анализ сетевого потока включает определение более простых тегированных элементов перед определением составных тегированных элементов.
22. Способ по п. 21, в котором указанный анализ сетевого потока дополнительно включает соотнесение каждого типа тегированного элемента со столбцом записи тегированных элементов для сетевого потока и определение порядка указанных столбцов в соответствии с типом тегированного элемента.
23. Способ по п. 20, в котором указанное множество пакетных свойств выбрано из группы, состоящей из элемента поля заголовка пакета, измеренного свойства указанного множества пакетов, информации, интерпретированной на основе содержимого пакета, и метаданных.
| US 20090168648 A1, 02.07.2009 | |||
| US 8125920 B2, 28.02.2012 | |||
| US 8879415 B2, 04.11.2014 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ ФОРМИРОВАНИЯ ПРОТОКОЛА ЕДИНОЙ ПЕРЕДАЧИ РАЗНОРОДНЫХ ТИПОВ ДАННЫХ | 2012 |
|
RU2483463C1 |

