ОБЛАСТЬ ТЕХНИКИ
[01] Настоящая технология относится к системе умного персонального помощника и, конкретнее, к способам и электронным устройствам для определения намерения, связанного с произнесенным высказыванием пользователя.
УРОВЕНЬ ТЕХНИКИ
[02] Электронные устройства, такие как смартфоны и планшеты, способны получать доступ к огромному и различному числу приложений и сервисов для обработки и/или доступа к различным типам информации. Тем не менее, новые пользователи и/или пользователи с нарушениями и/или пользователи, ведущие автомобиль, могут не быть способны эффективно взаимодействовать с подобными устройствами, в основном из-за множества функций, предоставляемых этими устройствами, или невозможности использования человеко-машинного интерфейса, предоставляемого подобными устройствами (например, клавиатурой). Например, пользователь, который ведет автомобиль, или пользователь, который плохо видит, может не быть способен использовать сенсорную клавиатуру, связанную с некоторыми из этих устройств.
[03] Были разработаны системы умного личного помощника (IPA) для выполнения функций в ответ на пользовательские запросы. Подобные системы IP А могут быть использованы, например, для извлечения информации и навигации, а также просто для "разговора". Обычная система IPA, например, Siri®, может получать произнесенное высказывание пользователя в форме цифрового аудиосигнала от устройства и выполнять большое количество различных задач для пользователя. Например, пользователь может связываться с Siri® путем произнесения высказываний (через голосовой интерфейс Siri®) с вопросом, например, о текущей погоде, о ближайшем торговом центре и так далее. Пользователь также может выполнять различные приложения, установленные на электронном устройстве. Как упоминалось ранее, пользователь может даже хотеть простого и естественного "разговора" с системой IPA без какого-либо дополнительного запроса в систему.
[04] Обычные системы IPA в основном сфокусированы на извлечении текстовых данных из цифрового аудиосигнала и на анализе этих текстовых данных для предоставления логической информации в ответ. Тем не менее, в некоторых случаях, два произнесенных высказывания могут обладать идентичным по тексту представлением, связанным с различными намерениями. Например, два произнесенных высказывания могу обладать идентичным по тексту представлением "Today is beautiful" ("Сегодня отличный день"), несмотря на то, что первое произнесенное высказывание может быть утверждением, а второе произнесенное высказывание может быть вопросом. В результате, различные информация может представляться пользователям, которые ввели их соответствующие произнесенные пользовательские высказывания. Например, пользователю в ответ на первое произнесенное высказывание может предоставляться "Indeed" ("Действительно"), в то время как второму пользователю в ответ на второе произнесенное высказывание может предоставляться информация о текущей погоде. По этой причине, предоставление зависящей от намерения информации может представлять собой сложную задачу.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[05] Разработчики настоящей технологии обратили внимание на некоторые технические недостатки, связанные с существующими системами IPA. Обычные системы IPA сфокусированы на предоставлении логичных ответов на произнесенные пользователем высказывания. Тем не менее, следует отметить, что высказывания могут быть связаны с "намерениями", т.е. введены с учетом "намерения" пользователя, и зависят от намерения данного высказывания, логические ответы на них могут быть различными. Например, два пользовательских высказывания могут быть идентичным по тексту, но могут быть связаны с различными намерениями пользователя и, следовательно, может быть уместно предоставлять два различных зависящих от намерения ответа на два пользовательских высказывания.
[06] Задачей предлагаемой технологии является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники. Разработчики настоящей технологии приняли предлагают систему, которая учитывает акустические характеристики произнесенного пользователем высказывания для определения зависящих от намерения ответов, предоставляемых пользователем. Разработчики осознают, что намерения являются, в некоторым смысле, "спрятанными" в акустических характеристиках и, следовательно, их анализ и обработка могут предоставлять информацию, указывающую на конкретное намерение данного произнесенного пользовательского намерения.
[07] Подразумевается, что система, которая предполагается разработчиками настоящей технологии, позволяет анализировать произнесенные высказывания для определения намерений, связанных с ними. Предполагаемая система выполнена с возможностью учитывать не только акустические характеристики произнесенного высказывания пользователя, но и текстовое представление произнесенного высказывания пользователя для определения намерения произнесенного высказывания пользователя.
[08] В некоторых вариантах осуществления настоящей технологии, после того как произнесенное высказывание пользователя было получено системой в форме цифрового аудиосигнала, системы выполнена с возможностью определять акустические характеристики, связанные с каждым словом, которое было "произнесено" пользователем. Также система выполнена с возможностью определять акустические характеристики, связанные с паузами между "произнесенными" словами, и использовать их в сочетании с акустическими характеристиками и текстовыми характеристиками каждого слова для определения намерения произнесенного пользователем высказывания.
[09] Первым объектом настоящей технологии является способ определения намерения, связанного с произнесенным пользователем высказыванием, где произнесенное пользователем высказывание улавливается в форме звукового аудиосигнала, и где способ выполняется на сервере. Способ включает в себя выполнение сервером анализа речи-в-текст цифрового аудиосигнала для определения по меньшей мере одного речевого элемента из произнесенного пользователем высказывания, причем каждый речевой элемент обладает текстовыми данными, представляющими собой слово или паузу, и причем каждый речевой элемент обладает соответствующим сегментом цифрового аудиосигнала. Способ включает в себя, для каждого речевого элемента, создание соответствующего вектора текстовых характеристик путем (i) определения сервером на основе соответствующих текстовых данных, текстовых характеристик соответствующего речевого элемента и (ii) создания сервером на основе соответствующих текстовых характеристик, соответствующего вектора текстовых характеристик. Способ включает в себя, для каждого речевого элемента, создание соответствующего вектора акустических характеристик путем (i) определения сервером на основе соответствующего сегмента цифрового аудиосигнала соответствующих акустических характеристик соответствующего сегмента цифрового аудиосигнала и (ii) создания сервером на основе соответствующих акустических характеристик, соответствующего вектора акустических характеристик. Способ включает в себя, для каждого речевого элемента, создание сервером соответствующего расширенного вектора характеристик путем объединения соответствующего вектора акустических характеристик и соответствующего вектора текстовых характеристик. Способ включает в себя использование сервером нейронной сети (NN), выполненной для определения намерения произнесенного пользователем высказывания путем ввода в NN расширенного вектора характеристик, причем NN была обучена для оценки вероятности того, что намерение относится к данному типу.
[10] В некоторых вариантах осуществления способа, нейронная сеть (NN) является рекуррентной нейронной сетью (RNN).
[11] В некоторых вариантах осуществления способа, выполнение анализа речи-в-текст включает в себя определение (i) текстовых данных каждого речевого элемента и (ii) временного интервала соответствующего сегмента цифрового аудиосигнала каждого речевого элемента.
[12] В некоторых вариантах осуществления способа, создание соответствующего вектора текстовых характеристик выполняется с помощью процесса внедрения слов, выполняемого сервером.
[13] В некоторых вариантах осуществления способа, вектор текстовых характеристик данного речевого элемента, являющийся паузой, является вектором с нулевыми значениями.
[14] В некоторых вариантах осуществления способа, акустические характеристики являются по меньшей мере некоторыми из: уровень громкости, уровень энергии, уровень высоты, гармония и темп.
[15] В некоторых вариантах осуществления способа, определение соответствующих акустических характеристик соответствующего сегмента цифрового аудиосигнала включает в себя определение сервером соответствующих акустических характеристик каждого подсегмента соответствующего сегмента цифрового аудиосигнала путем применения скользящего окна. Также, создание соответствующего вектора акустических характеристик включает в себя (i) создание сервером соответствующих промежуточных векторов акустических характеристик для каждого подсегмента на основе соответствующих акустических характеристик и (ii) создание сервером, на основе соответствующих промежуточных векторов акустических характеристик, причем соответствующий вектор акустических характеристик предназначен для соответствующего сегмента цифрового аудиосигнала.
[16] В некоторых вариантах осуществления способа каждый подсегмент обладает заранее определенной продолжительностью во времени.
[17] В некоторых вариантах осуществления способа, по меньшей мере два подсегмента частично перекрываются.
[18] В некоторых вариантах осуществления способа скользящее окно скользит с временным шагом заранее определенной продолжительности во времени.
[19] В некоторых вариантах осуществления способа создание соответствующего вектора акустических характеристик для соответствующего сегмента цифрового аудиосигнала, которое основано на соответствующих промежуточных векторах акустических характеристик, включает в себя использование сервером основанной на статистике комбинации соответствующих промежуточных векторов акустических характеристик.
[20] В некоторых вариантах осуществления способа сочетание соответствующего вектора акустических характеристик и соответствующего вектора текстовых характеристик включает в себя конкатенацию сервером соответствующего вектора акустических характеристик и соответствующего вектора текстовых характеристик.
[21] В некоторых вариантах осуществления способа, данный тип представляет собой одно из следующего: вопрос открытого типа, вопрос закрытого типа, утверждение и восклицание.
[22] В некоторых вариантах осуществления способа получение сервером дополнительных данных, созданных NN для каждого введенного расширенного вектора характеристик, связанного с данным словом. В ответ на определение того, что намерение относится к данному типу, способ включает в себя выполнение сервером дополнительного MLA для определения целевого слова среди по меньшей мере одного слова путем ввода в дополнительный ML А дополнительных данных. Целевое слово указывает на контекст произнесенного пользователем высказывания.
[23] Вторым объектом настоящей технологии является сервер для определения намерения, связанного с произнесенным пользователем высказыванием, где произнесенное пользователем высказывание улавливается в форме звукового аудиосигнала. Сервер выполнен с возможностью осуществлять выполнение анализа речи-в-текст цифрового аудиосигнала для определения по меньшей мере одного речевого элемента из произнесенного пользователем высказывания, причем каждый речевой элемент обладает текстовыми данными, представляющими собой слово или паузу, и причем каждый речевой элемент обладает соответствующим сегментом цифрового аудиосигнала. Сервер выполнен с возможностью осуществлять, для каждого речевого элемента, создание соответствующего вектора текстовых характеристик путем (i) определения сервером на основе соответствующих текстовых данных, текстовых характеристик соответствующего речевого элемента и (ii) создания сервером на основе соответствующих текстовых характеристик, соответствующего вектора текстовых характеристик. Сервер выполнен с возможностью осуществлять, для каждого речевого элемента, создание соответствующего вектора акустических характеристик путем (i) определения сервером на основе соответствующего сегмента цифрового аудиосигнала соответствующих акустических характеристик соответствующего сегмента цифрового аудиосигнала и (ii) создания сервером на основе соответствующих акустических характеристик, соответствующего вектора акустических характеристик. Сервер выполнен с возможностью осуществлять, для каждого речевого элемента, создание соответствующего расширенного вектора характеристик путем объединения соответствующего вектора акустических характеристик и соответствующего вектора текстовых характеристик. Сервер выполнен с возможностью осуществлять использование нейронной сети (NN), выполненной для определения намерения произнесенного пользователем высказывания путем ввода в NN расширенного вектора характеристик, причем NN была обучена для оценки вероятности того, что намерение относится к данному типу.
[24] В некоторых вариантах осуществления сервера, нейронная сеть (NN) является рекуррентной нейронной сетью (RNN).
[25] В некоторых вариантах осуществления сервера, сервер, который выполнен с возможностью осуществлять выполнение анализа речи-в-текст, представляет собой сервер, который выполнен с возможностью осуществлять определение текстовых данных каждого речевого элемента и временного интервала соответствующего сегмента цифрового аудиосигнала каждого речевого элемента.
[26] В некоторых вариантах осуществления сервера, сервер, который выполнен с возможностью осуществлять определение соответствующих акустических характеристик соответствующего сегмента цифрового аудиосигнала, представляет собой сервер, который выполнен с возможностью осуществлять определение соответствующих акустических характеристик каждого подсегмента соответствующего сегмента цифрового аудиосигнала путем применения скользящего окна. Сервер, который выполнен с возможностью осуществлять создание соответствующего вектора акустических характеристик, представляет собой сервер, который выполнен с возможностью осуществлять (i) создание соответствующих промежуточных векторов акустических характеристик для каждого подсегмента на основе соответствующих акустических характеристик и (ii) создание, на основе соответствующих промежуточных векторов акустических характеристик, соответствующего вектора акустических характеристик для соответствующего сегмента цифрового аудиосигнала.
[27] В некоторых вариантах осуществления сервера, данный тип представляет собой одно из следующего: вопрос открытого типа, вопрос закрытого типа, утверждение и восклицание.
[28] В некоторых вариантах осуществления сервер выполнен с возможностью осуществлять получение дополнительных данных, созданных NN для каждого введенного расширенного вектора характеристик, связанного с данным словом. В ответ на определение того, что намерение относится к данному типу, сервер выполнен с возможностью осуществлять исполнение дополнительного MLA для определения целевого слова среди по меньшей мере одного слова путем ввода в дополнительный MLA дополнительных данных. Целевое слово указывает на контекст произнесенного пользователем высказывания.
[29] В контексте настоящего описания "сервер" подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данной технологии. В контексте настоящей технологии использование выражения "сервер" не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение "по меньшей мере один сервер".
[30] В контексте настоящего описания "устройство" подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как устройство в настоящем контексте, может вести себя как сервер по отношению к другим устройствам. Использование выражения «клиентское устройство» не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного способа.
[31] В контексте настоящего описания, "база данных" подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. В контексте настоящего описания слова "первый", "второй", "третий" и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными.
[32] В контексте настоящего описания "информация" включает в себя информацию любую информацию, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы, списки слов и т.д.
[33] В контексте настоящего описания "компонент" подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[34] В контексте настоящего описания "используемый компьютером носитель компьютерной информации" подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[35] В контексте настоящего описания слова "первый", "второй", "третий" и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[36] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[37] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[38] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[39] На Фиг. 1 представлена система, подходящая для реализации неограничивающих вариантов осуществления настоящей технологии;
[40] На Фиг. 2 представлена схематическая иллюстрация входных и выходных потоков по меньшей мере некоторых исполняемых на компьютере процедур, которые осуществляются сервером, показанном на Фиг. 1, в соответствии с некоторыми вариантами осуществления настоящей технологии;
[41] На Фиг. 3 представлена схематическая иллюстрация анализа речи-в-текст для определения речевых элементов произнесенного пользователем высказывания в соответствии с некоторыми вариантами осуществления настоящей технологии;
[42] На Фиг. 4 представлена схематическая иллюстрация процедуры создания вектора текстовых характеристик в соответствии с некоторыми вариантами осуществления настоящей технологии;
[43] На Фиг. 5 представлена схематическая иллюстрация процедуры создания промежуточного вектора акустических характеристик в соответствии с некоторыми вариантами осуществления настоящей технологии;
[44] На Фиг. 6 представлена схематическая иллюстрация процедуры статистической агрегации для создания векторов акустических характеристик в соответствии с некоторыми вариантами осуществления настоящей технологии;
[45] На Фиг. 7 представлена схематическая иллюстрация процедуры создания расширенного вектора характеристик в соответствии с некоторыми вариантами осуществления настоящей технологии;
[46] На Фиг. 8 представлена схематическая иллюстрация процедуры определения намерения в соответствии с некоторыми вариантами осуществления настоящей технологии; и
[47] На Фиг. 9 представлена схематическая блок-схема способа определения намерения, связанного с произнесенным пользователем высказыванием в соответствии с некоторыми вариантами осуществления настоящей технологии.
ОСУЩЕСТВЛЕНИЕ
[48] На Фиг. 1 представлена принципиальная схема системы 100, с возможностью реализации вариантом осуществления настоящей технологии, не ограничивающих ее объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание иллюстративных вариантов осуществления настоящего технического решения. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии.
[49] Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящей технологии. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящей технологии, и в подобных случаях представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[50] В общем случае, система 100 выполнена с возможностью определить намерения, связанные с произнесенными пользователем высказываниями. Например, произнесенное пользователем высказывание 150 пользователя 102 может улавливаться электронным устройством 104 (или просто "устройством 104"), которое, в ответ, выполнено с возможностью предоставлять зависящую от намерения информацию пользователю 102 на основе связанного намерения, в некоторых случаях, в форме "созданного машиной высказывания". Таким образом, можно утверждать, что это приводит к некоторому "зависящему от намерения обмену информацией" между пользователем 102 и устройством 104, например, зависящему от намерения разговору человека и машины, где зависящий от намерения разговор человека и машины состоит из (i) произнесенного пользователем высказывания 150, связанного с намерением, определенным системой 100, и (ii) созданного машиной высказывания, указывающего на зависящую от намерения информацию, которая конкретна для намерения, связанного с произнесенным пользователем высказыванием 150.
[51] В общем случае, данное произнесенное пользователем высказыванием может быть связано с данным типом намерения, которое существенно в определении зависящей от намерения информации, предназначенной для предоставления. Например, различные типы намерения могут быть связаны с данным произнесенным пользователем высказыванием, например: вопрос открытого типа, вопрос закрытого типа, утверждение, восклицание и так далее. Следует иметь в виду, что тип намерения может изменяться в зависимости, среди прочего, от информации, которую желает получить данный пользователь.
[52] Без ограничений какой-либо конкретной теорией, информация, указывающая на намерение, может быть, по меньшей мере частично "спрятана" в акустических характеристиках произнесенных пользователем высказываний.
[53] Например, предположим, что произнесенное пользователем высказывание 150 пользователя 102: "Sounds good" ("Звучит неплохо"). В данном случае, когда это слышит человек (например, пользователь 102), человек может определить, что связанное намерение более вероятно является утверждением, поскольку пользователь 102, по-видимому, утверждает, что ему/ей что-то нравится. Другими словами, человек может определить, на основе акустических характеристик произнесенного пользователем высказывания 150, что пользователь 102 подтверждает свое одобрение и просто "общается", а не задает вопрос, и не ожидает получить информацию, отвечающую на него.
[54] Как уже упоминалось ранее, следует иметь в виду, что различная зависящая от намерения информация может предоставляться для данного произнесенного пользователем высказывания, и, среди прочего, она будет зависеть от типа намерения, связанного с данным произнесенным пользователем высказыванием.
[55] Например, предположим, что произнесенное пользователем высказывание 150 пользователя 102: "Is today a beautiful day" ("Сегодня хороший день"). В данном случае, когда это слышит человек, он может сначала определить, что соответствующим намерением, скорее всего, является некий вопрос, а не утверждение. Другими словами, человек может определить, на основе акустических характеристик произнесенного пользователем высказывания 150, что пользователь 102 задает некий вопрос, и ожидает получить информацию, отвечающую на этот вопрос.
[56] Тем не менее, дополнительно, произнесенное пользователем высказывание 150 "Is today a beautiful day" может быть связано с различными типами вопросов (например, открытый, закрытый) и, следовательно, в ответ может предоставляться различная зависящая от намерения информация.
[57] С одной стороны, когда это слышит человек, он может далее определить, на основе акустических характеристик произнесенного пользователем высказывания 150, что оно является вопросом закрытого типа, т.е. является ли сегодняшний день хорошим или нет. В результате, человек далее может определить, на основе намерения типа "закрытый вопрос", связанного с произнесенным пользователем высказыванием 150, что предоставляемая зависящая от намерения информация представляет собой "да/нет" или любой другой бинарный тип ответа.
[58] С другой стороны, когда это слышит человек, он может альтернативно определить, на основе акустических характеристик произнесенного пользователем высказывания 150, что оно является вопросом открытого типа, т.е. какая сегодня в целом погода. В результате, человек альтернативно может определить, на основе намерения типа вопрос открытого типа, связанного с произнесенным пользователем высказыванием 150, что предоставляемая зависящая от намерения информация представляет собой текущую погоду.
[59] В самом деле, когда данное высказывание слышит человек, определение типа намерения, связанного с данным произнесенным пользователем высказыванием, выполняется легко и, следовательно, информация, которая зависит от этого типа намерения, может предоставляться с большей простотой. В общем случае, возможности человеческого мозга идеально подходят для задач подобного типа, где произнесенное пользователем высказывание улавливается нейронными рецепторами уха и переводится в акустическую информацию, которая далее анализируется нейронами и синапсами, формируя вычислительные элементы мозга для определения типа намерения данного произнесенного пользователем высказывания. Другими словами, для человека естественно определять тип намерения, связанный с данным произнесенным пользователем высказыванием и, следовательно, люди прекрасно адаптированы для предоставления зависящей от намерения информации в ответ на них.
[60] Когда же произнесенное пользователем высказывание улавливает компьютерная система, это совсем другая ситуация. Обычные компьютерные системы являются не настолько эффективными и умелыми как люди для определения типа намерения, связанного с данным произнесенным пользователем высказываний и, следовательно, предоставление зависящей от намерения информации компьютерными системами в ответ на данное произнесенное пользователем высказыванием является сложной задачей.
[61] В некоторых вариантах осуществления настоящей технологии, как упоминалось заранее, подразумевается, что система 100 может быть выполнена с возможностью определять намерение, связанное с данным произнесенным пользователем высказыванием, и предоставлять в ответ зависящую от намерения информацию. Далее будут описаны различные компоненты системы 100 и то, как эти компоненты могут быть выполнены с возможностью определения намерения и предоставления зависящей от намерения информации.
Пользовательское устройство
[62] Как было упомянуто ранее, система 100 включает в себя устройство 104. Варианты осуществления устройства 104 конкретно не ограничены, но в качестве примера устройства 104 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (смартфон, мобильный телефон, планшет, умный динамик и т.п.), а также сетевое оборудование (маршрутизаторы, коммутаторы или шлюзы). Таким образом, устройство 104 может иногда упоминаться как "электронное устройство", "устройство конечного пользователя", "клиентское электронное устройство" или просто "устройство". Следует отметить, что тот факт, что устройство 104 связано с пользователем 102, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, быть зарегистрированным, или чего-либо подобного.
[63] Подразумевается, что устройство 104 включает в себя аппаратное и/или прикладное программное обеспечение и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для того, чтобы (i) обнаружить или уловить произнесенное пользовательское высказывание 150 и (ii) предоставить или воспроизвести созданное машиной высказывание (например, в ответ на уловленное произнесенное пользователем высказыванием 150). Например, устройство 104 может включать в себя один или несколько микрофонов для обнаружения или улавливания произнесенного пользователем указания 150 и один или несколько динамиков для предоставления или воспроизведения созданного машиной высказывания, указывающего на зависящую от намерения информацию.
[64] Естественно, подразумевается, что устройство 104 выполнено с возможностью создавать цифровой аудиосигнал 155, представляющий собой произнесенное пользователем высказыванием 150, при его обнаружении или улавливании. В общем случае, данный цифровой аудиосигнал представлен звуковыми волнами, которые были обнаружены/уловлены и/или записаны и преобразованы в цифровую форму. В результате, устройство 104 может передавать произнесенное пользователем высказывание 150 в форме цифрового аудиосигнала 155 другой компьютерной системе из системы 100. Например, устройство 104 может быть выполнено с возможностью создавать пакет 160 данных, содержащий информацию, указывающую на цифровой аудиосигнал 155, и может передавать пакет 160 данных другим компьютерным системам из системы 100.
[65] В некоторых вариантах осуществления технологи, устройство 104 также включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для использования приложения умного личного помощника (IPA). В общем случае, целью приложения IPA, также известного как "чатбот", является возможность (i) позволить пользователю 102 "общаться" с устройством 104 с помощью речи, например, произнесенного пользователем высказывания 150 и, в ответ, (ii) предоставлять пользователю 102 информацию с помощью созданной машиной речи, например, созданного машиной высказывания.
[66] Следует отметить, что в некоторых вариантах осуществления настоящей технологии, устройство 104 может также быть выполнено с возможностью выполнять по меньшей мере некоторые функции, процедуры и другие вычислительные процессы сервера 106 системы 100. По меньшей мере некоторые функции, процедуры или другие вычислительные процессы сервера 106, которые могут выполняться устройством 104, будут очевидны из нижеследующего описания.
Сеть передачи данных;
[67] В примерном варианте системы 100, устройство 104 коммуникативно соединено с сетью 110 передачи данных для доступа и передачи пакетов данных (например, пакет 160 данных) серверу 106 или от сервера 106 и/или другим веб-ресурсам (не показано). В некоторых вариантах осуществления настоящего технического решения, не ограничивающих ее объем, сеть 110 передачи данных может представлять собой Интернет. В других неограничивающих вариантах осуществления настоящей технологии, сеть ПО передачи данных может быть реализована иначе - в виде глобальной сети связи, локальной сети связи, частной сети связи и т.п.Реализация линии передачи данных (отдельно не пронумерована) между устройством 104 и сетью 110 передачи данных будет зависеть среди прочего от того, как именно реализовано устройство 104.
[68] В качестве примера, но не ограничения, в данных вариантах осуществления настоящей технологии в случаях, когда устройство 104 представляет собой беспроводное устройство связи (например, смартфон), линия передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных 3G, линия передачи данных 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где устройство 104 представляет собой портативный компьютер, линия связи может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п) так и проводной (соединение на основе сети Ethernet).
Сервер
[69] Как уже ранее упоминалось, система 100 также включает в себя сервер 106, который может быть реализован как обычный сервер. В примере варианта осуществления настоящей технологии, сервер 106 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 106 может представлять собой любое другое подходящее аппаратное, прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, сервер 106 является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность сервера 106 может быть разделена, и может выполняться с помощью нескольких серверов.
[70] В общем случае, сервер 106 выполнен с возможностью осуществлять:
 получение данных, связанных с произнесенным пользователем высказыванием 150, например, информацию, которая указывает на цифровой аудиосигнал 155;
получение данных, связанных с произнесенным пользователем высказыванием 150, например, информацию, которая указывает на цифровой аудиосигнал 155;
определение разговорных элементов произнесенного пользователем высказывания 150 на основе полученных данных;
создание, для каждого речевого элемента, соответствующего расширенного вектора характеристик, указывающего на (i) текстовые характеристики и (ii) акустические характеристики соответствующего речевого элемента; и
определение намерения произнесенного пользователем высказывания 150 на основе расширенных векторов характеристик, связанных с речевыми элементами.
[71] С этой целью, сервер 106 размещает сервис 108 IPA, связанный с приложением 104 IPA устройства 104. Следует иметь в виду, что в некоторых вариантах осуществления настоящей технологии, сервер 106 может быть выполнен с возможностью выполнять дополнительные функции, процедуры или вычислительные процессы к тем, которые были перечислены выше и не являются исчерпывающими для простоты понимания, не выходя за пределы настоящей технологии.
[72] Сервис 108 IPA выполнен с возможностью выполнять множество исполняемых на компьютере процедур, например: анализ 300 речи-в-текст, процедуру 400 создания вектора текстовых характеристик, процедуру 500 создания вектора акустических характеристик, процедуру 700 создания расширенного вектора характеристик и процедуру 800 определения намерения. То, как именно сервис 108 IPA может выполнять множество исполняемых на компьютере процедур на основе цифрового аудиосигнала 155 будет описано далее со ссылкой на Фиг. 2-8.
[73] Тем не менее, следует отметить, что сервис 108 IP А реализует различные компоненты, например, один или несколько алгоритмом машинного (MLA) для выполнения по меньшей мере некоторых из множества исполняемых на компьютере процедур.
Алгоритмы машинного обучения (MLA)
[74] В общем случае, MLA могут обучаться и делать прогнозы на основе данных. MLA обычно используются сначала для создания модели на основе обучающих данных для дальнейших прогнозов данных или решений, выраженных в качестве выходных данных, вместо следования статичным машиночитаемым инструкциям. ML А обычно используются при анализе речи-в-текст, процедурах встраивания и так далее.
[75] Следует иметь в виду, что различные типы MLA обладают различными структурами или топологиями, и могут быть использованы для различных задач. Один конкретный тип ML А включает в себя нейронные сети (NN).
[76] В общем случае, данная нейронная сеть содержит взаимосвязанную группу искусственных "нейронов", которая обрабатывает информацию с использованием коннекционистского подхода к вычислению. Нейронные сети используются для моделирования сложных взаимосвязей между входными и выходными данными (без фактических знаний об этих взаимосвязях) или для поиска паттернов в данных. Нейронные сети сначала описываются в фазе обучения, в которой они предоставляются с известным набором "входных данных" и информацией для адаптации нейронной сети для создания подходящих выходных данных (для данной ситуации, для которой происходит моделирование). Во время фазы обучения, данная нейронная сеть адаптируется под изучаемую ситуацию и изменяет свою структуру таким образом, что данная нейронная сеть будет способна предоставлять подходящие прогнозированные выходные данные для данных входных данных с учетом новой ситуации (на основе того, что было выучено). Таким образом, вместо попыток определения сложных статистических механизмов или математических алгоритмов для данной ситуации; данная нейронная сеть пытается предоставить "интуитивный" ответ на основе "ощущения" для ситуации. Данная нейронная сеть, таким образом, представляет собой что-то наподобие "черного ящика", который может использоваться в ситуации, когда само содержимое "ящика" не является существенным; но важно, что "ящик" предоставляет логичные ответы на данные входные данные.
[77] Нейронные сети часто используются во многих подобных ситуациях, где важны только выходные данные, основывающиеся на данных входных данных, но то как именно были получены эти выходные данные значительно менее важно или неважно вовсе. Например, нейронные сети часто используются для оптимизации распределения веб-трафика между серверами и обработкой данных, включая, фильтрацию, кластеризацию, разделение сигналов, сжатие, создание векторов и так далее.
[78] Следует иметь в виду, что нейронные сети могут быть разделены на различные классы, и один из этих классов включает в себя рекуррентные сети (RNN). Эти конкретные NN адаптированы для использования их "внутренних состояний" (сохраненной памяти) для обработки последовательностей входных данных. Это делает рекуррентные сети подходящими таких задач как, например, распознавание несегментированного почерка и речи. Эти внутренние состояния рекуррентных сетей контролируются и упоминаются как "гейтовые" состояния или "гейтовая" память.
[79] Также следует отметить, что сами RNN могут быть разделены на различные подклассы RNN. Например, RNN, включающие в себя сети с долговременной и кратковременной памятью (LSTM) и управляемые рекуррентные блоки (GRU), двусторонние RNN (BRNN) и так далее.
[80] Сети LSTM являются системами глубинного обучения, которые могут изучать задачи, требующие, в некотором смысле, "воспоминаний" о событиях, которые произошли ранее за очень короткие и дискретные временные шаги. Топологии сетей LSTM могут варьироваться на основе конкретных задач, которые они "обучаются" выполнять. Например, сети LSTM могут обучаться выполнять задачи, в которых между событиями появляются достаточно долгие задержки, или где события появляются вместе как с низкой, так и с высокой частотой. RNN, которые обладают конкретными выборочными механизмами, упоминаются как GRU. В отличие от сетей LSTM, в GRU отсутствует "выходная выборочность" и, следовательно, они обладают меньшим числом параметров, чем сети LSTM. BRNN могут обладать "скрытыми слоями" нейронов, которые соединены в различных направлениях, что позволяет использовать информацию из прошлых и из будущих состояний.
[81] Суммируя, использование данного алгоритма машинного обучения сервисом 108 IPA может быть в широком смысле разделено на две фазы - фазу обучения и фазу использования. Сначала данный MLA обучается в фазе обучения. Далее, после того как данная MLA знает, какие данные ожидаются в виде входных данных и какие данные предоставлять в виде выходных данных, данный MLA фактически работает, используя рабочие данные в фазе использования.
[82] В некоторых вариантах осуществления настоящей технологии, подразумевается, что данный MLА, который реализован сервисом 108 IPА, может сам включать в себя различные MLA. Например, данный MLA, реализованный сервисом 108 IPA, может включать в себя 850 и множество MLA 852, как показано на Фиг. 1. Естественно, вариант осуществления RNN 850 и множество MLА 852 могут в широком смысле быть категоризованы в обучающие фазы RNN 850 для каждого из множества 852 и в фазы использования RNN 850 для каждого из множества 852.
[83] В результате, RNN 850 и каждый из множества MLA 852 может быть адаптирован (обучен) для соответствующей исполняемой на компьютере процедуры сервиса 108 IP А. Например, фаза использования RNN 850 может соответствовать выполнению процедуры 800 определения намерения сервиса 108 IPA. В другом примере, фазы использования множества MLA 852 соответствуют выполнению по меньшей мере некоторых других из множества исполняемых на компьютере процедур сервиса 108 IPA. То как RNN 850 обучается и используется для выполнения процедуры 800 определения намерения сервиса 108 IPA и то как множество MLA 852 обучается и используется для выполнения по меньшей мере некоторых других из множества исполняемых на компьютере процедур сервиса 108 IPA, будет более подробно описано далее.
[84] Следует отметить, что несмотря на то, что некоторые описанные здесь варианты осуществления настоящей технологии с использованием RNN 850 для выполнения процедуры 800 определения намерения, другие NN с другими архитектурами могут использоваться в других вариантах осуществления настоящей технологии, например, NN с архитектурой Transformer, не выходя за пределы настоящей технологии.
База данных обработки
[85] Возвращаясь к Фиг. 1, сервер 106 также коммуникативно соединен с базой 124 данных обработки. В представленной иллюстрации, база 124 данных обработки представлена как единый физический элемент. Но это не является обязательным для каждого варианта осуществления настоящей технологии. Таким образом, база 124 данных обработки может быть реализована как множество отдельных баз данных. Опционально, база 124 данных обработки может быть разделена на несколько распределенных баз данных.
[86] База 124 данных обработки выполнена с возможностью сохранять информацию, извлеченную или иным образом определенную или созданную сервером 106 во время обработки. В общем случае, база 124 данных обработки может получать данные с сервера 106, которые были извлечены или иным образом определены или созданы сервером 106 во время обработки для временного и/или постоянного хранения, и могут предоставлять сохраненные данные серверу 106 для их использования.
[87] Подразумевается, что база 124 данных обработки может также хранить обучающие данные для обучения RNN 850 и по меньшей мере некоторые из множества ML А 852. Например, обучающие данные могут содержать коллекцию предыдущих цифровых аудиосигналов, представляющий предыдущие произнесенные пользователем высказывания. Например, база 124 данных обработки может хранить большое число предыдущих цифровых аудиосигналов, например, 10000, 100000, 1000000 и так далее. То как цифровые аудиосигналы собирались и сохранялись в базу 124 данных обработки, никак конкретно не ограничено. Тем не менее, просто в качестве примера, предыдущие цифровые аудиосигналы могут записываться людьми-асессорами или внешними сотрудниками.
[88] Тем не менее, в дополнение к сбору предыдущих цифровых аудиосигналов, обучающие данные, хранящиеся в базе 124 данных обработки, могут далее включать в себя оцененные людьми данные, которые связаны с предыдущими цифровыми аудиосигналами. Оцененные людьми данные могут содержать информацию, указывающую на (i) оцененные людьми речевые элементы для соответствующих цифровых аудиосигналов и (ii) оцененные людьми намерения, связанные с соответствующими предыдущими произнесенными пользователями высказываниями, записанными в форме соответствующих предыдущих цифровых аудиосигналов.
[89] В общем случае, данный речевой элемент данного произнесенного пользователем высказывания может быть связан с (i) данным словом, которое было "произнесено" как часть данного произнесенного пользователем высказывания или (ii) данной паузой между "произнесенными" словами.
[90] Например, данный человек-асессор может прослушать данное произнесенное пользователем высказывание, воспроизведенное на основе соответствующего предыдущего цифрового аудиосигнала. Предположим, что данный человек-асессор слышит "What is Kombucha" ("Что такое комбуча"). В этом случае, человек-асессор может идентифицировать пять различным речевых элементов, представляющих собой (i) слово "What", (ii) слово "is", (iii) слово "Kombucha", (iv) паузу между словами "What" и "is" и (v) паузу между словами "is" и "Kombucha". Следует иметь в виду, что речевые элементы, связанные со словами, могут быть идентифицированы человеком-асессором путем прослушивания данного произнесенного пользователем высказывания, а речевые элементы, связанные с паузами, могут быть идентифицированы или логически выведены человеком-асессором как интервалы между словами.
[91] В результате, данный человек-асессор может (i) идентифицировать сегменты соответствующего предыдущего цифрового аудиосигнала, который соответствует словам, "произнесенным" как часть данного предыдущего произнесенного пользователем высказывания и (ii) предоставлять текстовые данные, представляющие эти слова. Аналогичным образом, сегменты соответствующего предыдущего цифрового аудиосигнала, которые соответствуют паузам, могут быть идентифицированы или логически выведены как сегменты из соответствующего предыдущего цифрового аудиосигнала, которые расположены между (например, ограничены) сегментами соответствующего предыдущего цифрового аудиосигнала, который соответствует словам.
[92] Следовательно, каждый оцененный человеком речевой элемент данного предыдущего цифрового аудиосигнала связан с (i) либо со словом, либо с паузой в соответствующем произнесенным пользователем высказыванием и (ii) соответствующим сегментом данного предыдущего цифрового аудиосигнала. Дополнительно, если данный оцененный человеком речевой элемент связан с данным словом, оцененный человеком речевой элемент также связан с текстовыми данными, представляющими это данное слово.
[93] Подразумевается, что оцененные человеком речевые элементы могут храниться в базе 124 данных обработки, связанной с соответствующим предыдущим цифровым аудиосигналом. Также подразумевается, что речевые элементы могут храниться в упорядоченном виде или, другими словами, с указанием на позиции их соответствующих сегментов предыдущего цифрового сигнала в предыдущем цифровом аудиосигнале (например, в том порядке, в котором они появлялись в предыдущем произнесенным пользователем высказывании).
[94] Как уже ранее упоминалось, в дополнении к оцененным пользователям речевым элементам, оцененные людьми данные могут также включать в себя информацию, указывающую на оцененные человеком намерения, связанные с соответствующими произнесенными пользователем высказываниями, записанными в форме соответствующих предыдущих цифровых аудиосигналов. Как уже упоминалось ранее, данный человек-асессор (т.е. человек) очень эффективно и умело определяет намерения, связанные с произнесенными пользователем высказываниями и, следовательно, может идентифицировать данное оцененное человеком намерение, связанное с данным произнесенным пользователем высказыванием. Например, человек-асессор может идентифицировать, что намерение, связанное с данным предыдущим произнесенным пользователем высказыванием представляет собой один из заранее определенного списка возможных типов намерения, включающего в себя: вопрос открытого типа, вопрос закрытого типа, утверждение и восклицание. Подразумевается, что заранее определенный список возможных типов намерения, из которых человек-асессор может выбирать данный тип намерения, предназначенный для связывания с данным предыдущим произнесенным пользователем высказыванием, может представлять собой другие типы намерения, отличные от представленного выше неисчерпывающего списка.
[95] Альтернативно, от людей-асессоров может потребоваться записывать соответствующее предыдущее произнесенное пользователем высказывание с конкретным заранее предписанным намерением, например, записать соответствующее предыдущее произнесенное пользователем высказывание как вопрос, записать соответствующее предыдущее произнесенное пользователем высказывание как утверждение и т.д.
[96] То как именно вместе выполняются исполняемые на компьютере процедуры сервера 106 для определения намерения произнесенного пользователем высказывания 150, будет более подробно описано далее со ссылкой на Фиг. 2.
[97] На Фиг. 2 представлена схематическая иллюстрация 200, описывающая обработку цифрового аудиосигнала сервисом 108 IPA сервера 106. Конкретнее, на иллюстрации 200 представлены входные и выходные данные различных исполняемых на компьютере процедур сервиса 108 IPA для определения намерения произнесенного пользователем высказывания 150 пользователя 102.
[98] Предполагается, что цифровой аудиосигнал 155 (представляющий произнесенное пользователем высказывание 150) был получен сервером 106. Например, как упоминалось ранее, цифровой аудиосигнал 155 мог быть получен через пакет 160 данных, передаваемый устройством 104 через сеть ПО передачи данных. В некоторых вариантах осуществления настоящей технологии, сервер 106 может также сохранять данные/информацию, указывающую на цифровой аудиосигнал 155 в базе 124 данных обработки.
[99] Когда сервер 106 получает информацию, указывающую на цифровой аудиосигнал 155, сервер 106 может быть выполнен с возможностью выполнять анализ 300 речи-в-текст для цифрового аудиосигнала 155, тем самым создавая выходные данные 202 анализа 300 речи-в-текст. В общем случае, сервер 106 может выполнять анализ 300 речи-в-текст для цифрового аудиосигнала 155 для определения речевых элементов произнесенного пользователем высказывания 150.
[100] Как упоминалось ранее, данный речевой элемент произнесенного пользователем высказывания 150 может быть связан с (i) данным словом, которое "произнес" пользователь 102 как часть произнесенного пользователем высказывания 150 или (ii) данной паузой между "произнесенными" словами, которая является частью произнесенного пользователем высказывания 150. Другими словами, анализ 300 речи-в-текст цифрового аудиосигнала 155 может определять:
 текстовое представление "произнесенных(ого)" слов(а) в произнесенном пользователем высказывании 150; и
текстовое представление "произнесенных(ого)" слов(а) в произнесенном пользователем высказывании 150; и
сегменты цифрового аудиосигнала 155, которые соответствуют (i) "произнесенному(ым)" слову(ам) и (ii) паузе между "произнесенными" словами в произнесенном пользователе высказывании 150.
[101] Подразумевается, что сервер 106 может выполнять множество ML А 852 для осуществления анализа 300 речи-в-текст. Например, сервер 106 может выполнять алгоритм автоматического распознавания речи (ASR) для осуществления анализа 300 речи-в-текст.
[102] Алгоритм ASR может быть обучен во время фазы обучения, на основе (i) предыдущих аудиосигналов и (ii) соответствующих оцененных человеком речевых элементов, хранящихся в базе 124 данных обработки. Например, как часть одной итерации обучения алгоритма ASR, данный предыдущий цифровой аудиосигнал может быть входными данными, а выходные данные обучения могут создаваться "необученным" алгоритмом ASR. Выходные данные могут далее сравниваться с соответствующими оцененными людьми речевыми элементами для уточнения алгоритма ASR для выходных данных речевых элементов, которые максимально аналогичны соответствующим оцененным людьми речевым элементам.
[103] То, как именно сервер 106 выполняет анализ 300 речи-в-текст для цифрового аудиосигнала 155 для создания выходных данных 202 речи-в-текст (например, речевые элементы произнесенного пользователем высказывания 150), будет более подробно описано далее со ссылкой на Фиг. 3. Тем не менее, подразумевается, что в некоторых вариантах осуществления настоящей технологии, анализ 300 речи-в-текст может выполняться для цифрового аудиосигнала с помощью устройства 104, и выходные данные 202 речи-в-текст могут передаваться серверу 106 по сети 110 передачи данных с помощью пакета 160 данных или с помощью дополнительных пакетов данных.
[104] Сервер 106 также выполнен с возможностью выполнять процедуру 400 создания вектора текстовых характеристик для выходных данных 202 речи-в-текст, тем самым создавая выходные данные 204 вектора текстовых характеристик для процедуры 400 создания вектора текстовых характеристик. В общем случае, сервер 106 может выполнять процедуру 400 создания вектора текстовых характеристик для выходных данных 202 речи-в-текст для (i) определения текстовых характеристик каждого речевого элемента произнесенного пользователем высказывания 150 и (ii) создания соответствующего вектора текстовых характеристик для каждого речевого элемента на основе соответствующих текстовых характеристик.
[105] Подразумевается, что сервер 106 может выполнять множество MLA 852 для осуществления процедуры 400 создания вектора текстовых характеристик. Например, что сервер 106 может выполнять алгоритм встраивания слов для осуществления процедуры 400 создания вектора текстовых характеристик. В общем случае, встраивание слов относится к процессу моделирования языка и методам обучения текстовым характеристикам при обработке естественного языка (NLP). Можно сказать, что как часть встраивания слов, текстовые данные, представляющие слова, сопоставляются с соответствующими векторами текстовых характеристик, которые указывают на соответствующие текстовые характеристики соответствующих слов.
[106] Подразумевается, что текстовые данные, представляющие паузы, либо отсутствуют, либо учитываются сервером 106 как нули. В результате, можно сказать, что выполнение процедуры 400 создание вектора текстовых характеристик для данного речевого элемента, связанного с паузой, может приводить к созданию соответствующего вектора текстовых характеристик, который представляет собой ноль.
[107] Альтернативно, вместо создания соответствующего вектора текстовых характеристик, представляющего собой ноль, для каждого речевого элемента, связанного с паузой, подразумевается, что сервер 106, при определении того, что данный речевой элемент связан с паузой, может извлекать, для связывания с данным речевым элементом, заранее определенный/заранее созданный нулевой вектор из базы 124 данных обработки. Другими словами, векторы текстовых характеристик для речевых элементов, связанных с паузами, нет необходимости создавать как таковые во время процедуры 400 создания вектора текстовых характеристик, но могут альтернативно ранее сохраняться в базе 124 данных обработки и извлекаться при определении того, что данный речевой элемент связан с паузой.
[108] Следует отметить, что несмотря на то, что процедура 400 создания вектора текстовых характеристик описана здесь как выполняемая данным MLA из множества MLA 852, подразумевается, что сервер 106 может использовать соответствующую NN, которая была обучена выполнять встраивание слов, вместо использования данного MLA из множества ML А 852, в некоторых вариантах осуществления настоящей технологии и не выходя за пределы настоящей технологии. В этих вариантах осуществления настоящей технологии, данный MLA из множества MLA 852 может быть опущен из архитектуры системы.
[109] То как именно сервер 106 выполняет процедуру 400 создания вектора текстовых характеристик для создания выходных данных 204 вектора текстовых характеристик (например, соответствующие векторы текстовых характеристик речевых элементов из произнесенного пользователем высказывания 150), будет более подробно описано далее со ссылкой на Фиг. 4. Тем не менее, подразумевается, что в некоторых вариантах осуществления настоящей технологии, процедура 400 создания вектора текстовых характеристик может выполняться устройством 104 и выходные данные 204 вектора текстовых характеристик может передаваться серверу 106 по сети 110 передачи данных с помощью пакета 160 данных или с помощью дополнительных пакетов данных.
[110] Сервер 106 далее выполнен с возможностью осуществлять процедуру 500 создания вектора акустических характеристик на основе (i) информации, указывающей на цифровой аудиосигнал 155 и (ii) выходных данных 202 речи-в-текст. Подразумевается, что в некоторых вариантах осуществления настоящей технологии, процедура 500 создания вектора акустических характеристик включает в себя (i) процедуру 550 создания промежуточного вектора акустических характеристик и (ii) процедуру 600 статистической агрегации.
[111] Конкретнее, сервер 106 может выполнять процедуру 550 создания промежуточного вектора акустических характеристик на цифровом аудиосигнале 155, тем самым создавая промежуточные выходные данные 206. В общем случае, сервер 106 может выполнять процедуру 550 создания промежуточного вектора акустических для выходных данных 155 речи-в-текст для (i) определения текстовых характеристик каждого речевого элемента произнесенного пользователем высказывания 155 и (ii) создания соответствующего промежуточного вектора акустических характеристик для каждого подсегмента цифрового аудиосигнала 155 на основе соответствующих акустических характеристик.
[112] Подразумевается, что акустические характеристики могут указывать на: уровень громкость, уровень высоты тона, уровень энергии, гармоничность (например, автокорреляция высоты тона), темп (например, число фонем за единицу времени), спектральные характеристики и так далее. Подразумевается, что по меньшей мере некоторые из вышепредставленного неисчерпывающего списка акустических характеристик могут извлекаться с помощью алгоритмов обработки сигнала.
[113] Как будет описано далее со ссылкой на Фиг. 5, подразумевается, что созданные подсегменты цифрового аудиосигнала 155 для каждого соответствующего промежуточного вектора акустических характеристик, короче по продолжительности, чем сегменты цифрового аудиосигнала 155, соответствующие соответствующим речевым элементам. Другими словами, данное подмножество подсегментов цифрового аудиосигнала 155, для которого создаются промежуточные векторы акустических характеристик, может быть связано с временными интервалами, которые попадают во временной интервал единый сегмент цифрового аудиосигнала 155, соответствующий данному речевому элементу.
[114] То как именно сервер 106 выполняет процедуру 550 создания промежуточного вектора акустических характеристик для создания промежуточных выходных данных 206 (например, промежуточные векторы акустических характеристик подсегментов цифрового аудиосигнала), будет более подробно описано далее со ссылкой на Фиг. 5. Тем не менее, подразумевается, что в некоторых вариантах осуществления настоящей технологии, процедура 550 создания промежуточного вектора акустических характеристик может выполняться устройством 104, и промежуточные выходные данные 206 может передаваться серверу 106 по сети 110 передачи данных с помощью пакета 160 данных или с помощью дополнительных пакетов данных.
[115] Сервер 106 также выполнен с возможностью выполнять процедуру 400 статистической агрегации на основе (i) выходных данных 202 речи-в-текст и (ii) промежуточных выходных данных 206, тем самым создавая выходные данные 208 вектора акустических характеристик для процедуры 500 создания вектора акустических характеристик. В общем случае, сервер 106 может выполнять процедуру 600 статистической агрегации для создания соответствующего вектора акустических характеристик для каждого речевого элемента произнесенного пользователем высказывания 150 на основе промежуточных векторов акустических характеристик, связанных с подсегментами цифрового аудиосигнала 155. Например, данный вектор акустических характеристик может быть создан для данного речевого элемента на основе промежуточных векторов акустических характеристик, связанных с подсегментами, которые соответствуют сегменту цифрового аудиосигнала 155 данного речевого элемента, как было упомянуто ранее.
[116] То как именно сервер 106 выполняет процедуру 600 статистической агрегации для создания выходных данных 208 вектора акустических характеристик (например, векторы акустических характеристик речевых элементов из произнесенного пользователем высказывания 150), будет более подробно описано далее со ссылкой на Фиг. 6. Тем не менее, подразумевается, что в некоторых вариантах осуществления настоящей технологии, процедура 600 статистической агрегации может выполняться устройством 104 и выходные данные 208 вектора акустических характеристик могут передаваться серверу 106 по сети 110 передачи данных с помощью пакета 160 данных или с помощью дополнительных пакетов данных.
[117] Сервер 106 также выполнен с возможностью выполнять процедуру 700 создания расширенного вектора на основе (i) выходных данных 204 вектора текстовых характеристик (например, векторов текстовых характеристик соответствующих речевых элементов произнесенного пользователем высказывания 150) и (ii) выходных данных 208 вектора акустических характеристик (например, векторов акустических характеристик соответствующих речевых элементов произнесенного пользователем высказывания 150), тем самым создавая выходные данные 210 расширенного вектора характеристик. В общем случае, сервер 106 может создавать расширенный вектор характеристик для каждого речевого элемента путем сочетания информации о (i) соответствующем векторе текстовых характеристик и (ii) соответствующем векторе акустических характеристик.
[118] То как именно сервер 106 выполняет процедуру 700 создания расширенного вектора характеристик для создания выходных данных 210 расширенного вектора характеристик (например, соответствующие расширенные векторы характеристик речевых элементов из произнесенного пользователем высказывания 150), будет более подробно описано далее со ссылкой на Фиг. 7. Тем не менее, подразумевается, что в некоторых вариантах осуществления настоящей технологии, процедура 700 создания расширенного вектора характеристик может выполняться устройством 104 и выходные данные 210 расширенного вектора характеристик могут передаваться серверу 106 по сети 110 передачи данных с помощью пакета 160 данных или с помощью дополнительных пакетов данных.
[119] Сервер 106 может также быть выполнен с возможностью выполнять процедуру 800 определения намерения выходных данных 210 расширенного вектора характеристик из процедуры 700 создания расширенного вектора характеристик для создания выходных данных 212, которые представляют вероятность того, что намерение произнесенного пользователем 150 высказывания относится к данному типу.
[120] Как уже упоминалось ранее, сервер 106 может использовать RNN 850 для осуществления процедуры 800 определения намерения. Как упоминалось ранее, для использования RNN 850 во время ее фазы использования, RNN 850 должна быть заранее обучена во время фазы обучения.
[121] RNN 850 была обучена во время фазы обучения на основе (i) предыдущих расширенных векторов характеристик, связанных с речевыми элементами предыдущих произнесенных пользователем высказываний, связанных с предыдущими цифровыми аудиосигналами и (ii) оцененных человеком намерений предыдущих произнесенных пользователем высказываний. Предыдущие расширенные векторы характеристик были созданы на основе соответствующих оцененных людьми речевых элементом аналогично тому, как были созданы расширенные векторы характеристик, связанные с речевыми элементами произнесенного пользователем высказывания 150.
[122] Например, как часть одной итерации обучения RNN 850, предыдущие расширенные векторы характеристик, связанные с данным предыдущим произнесенным пользователем высказыванием, могут быть входными данными, а выходные данные обучения могут создаваться "необученной" RNN 850. Эти выходные данные обучения могут далее сравниваться с оцененным человеком намерением данного предыдущего произнесенного пользователем высказывания для настройки RNN 850 для вывода высокой вероятности того, что данное предыдущее произнесенное пользователем высказывание связано с соответствующим оцененным человеком намерением.
[123] RNN 850 может быть обучена оценивать вероятность того, что намерение данного произнесенного пользователем высказывания относится к данному типу. Предположим, что данный тип представляет собой открытый вопрос, даже если в других вариантах осуществления настоящей технологии подразумевается, что данный тип может представлять собой другой тип намерения. Например, во время обучения RNN 850, если оцененное человеком намерение данного предыдущего произнесенного пользователем высказывания представляет собой вопрос открытого типа, обучающий набор, связанный с данным предыдущим произнесенным пользователем высказыванием, может быть отмечен как положительный пример для RNN 850. В другом примере, во время обучения RNN 850, если оцененное человеком намерение данного предыдущего произнесенного пользователем высказывания представляет собой вопрос любого другого типа, отличного от данного (т.е. любого другого, отличного от открытого типа), обучающий набор, связанный с данным предыдущим произнесенным пользователем высказыванием, может быть отмечен как отрицательный пример для RNN 850. В результате, во время фазы использования RNN 850 может использоваться для оценки вероятности того, что данное (используемое) произнесенное пользователем высказывание относится к данному типу (например, вопрос открытого типа).
[124] То как именно сервер 106 выполняет процедуру 800 определения намерения (например, фаза использования RNN 850) для создания выходных данных 212, будет описано подробнее далее со ссылкой на Фиг. 8.
[125] Следует отметить, что схематическая иллюстрация 200, которая представляет обработку цифрового аудиосигнала 155 сервисом 108 IPА является представление фактической обработки цифрового 155 аудиосигнала сервисом 108 и представлено только для целей упрощения. Тем не менее, подразумевается, что обработка цифрового аудиосигнала 155 сервисом 108 IPА может включать в себя дополнительные функции, процедуры или дополнительные вычислительные процессы к тем, которые показаны в схематической иллюстрации 200, как будет понятно из нижеследующего описания, не выходя за границы настоящей технологии.
[126] Анализ 300 речи-в-текст, процедура 400 создания вектора текстовых характеристик, процедура 500 создания вектора акустических характеристик, процедура 700 создания расширенного вектора характеристик и процедура 800 определения намерений будут описаны далее со ссылкой на Фиг. 3-8.
[127] Со ссылкой на Фиг. 3, анализ 300 речи-в-текст, который выполняется сервером 106, будет описан далее подробно. Как упоминалось ранее, сервер 106 может выполнять анализ 300 речи-в-текст для цифрового аудиосигнала 155 для определения речевых элементов произнесенного пользователем высказывания 150.
[128] Предположим, что во время выполнения анализа 300 речи-в-тест, сервер 106 определяет наличие трех слов в цифровом аудиосигнале 155 на основе сегментов 308, 310 и 312 цифрового аудиосигнала 155. Другими словами, сервер 106 может определять текстовые данные 302, 304 и 306, представляющие каждое из трех слов, являющихся "Is", "Kombucha" и "Effervescent" соответственно, и связанные с сегментами 308, 310 и 312 цифрового аудиосигнала 155.
[129] Следует отметить, что сервер 106 может определять временные интервалы для каждого из сегментов 308, 310 и 312 цифрового аудиосигнала 155. Например, сервер 106 может определять, что сегмент 308 связан с временным интервалом, определенным как находящийся между t1 и t2. В другом примере, сервер 106 может определять, что сегмент 310 связан с временным интервалом, определенным как находящийся между t3 и t4. В еще одном примере, сервер 106 может определять, что сегмент 312 связан с временным интервалом, определенным как находящийся между t5 и t6. Подразумевается, что сервер 106 может связывать временными интервалами сегментов 308, 310 и 312 соответственно с текстовыми данными 302, 304 и 306.
[130] Дополнительно, сервер 106 может определять наличие двух пауз в произнесенном пользователем высказывании 150 на основе цифрового аудиосигнала 155. В одном варианте осуществления технологии, сервер 106 может определять наличие двух пауз в цифровом аудиосигнале 155 на основе сегментов 314 и 316 цифрового аудиосигнала 155. Альтернативно, в другом варианте осуществления технологии, сервер 106, который определяет наличие двух пауз в цифровом аудиосигнале 155, может включать в себя или логически выводить наличие двух пауз на основе сегментов 308, 310 и 312 цифрового аудиосигнала 155. В самом деле, сервер 106 может логически выводить, что сегменты цифрового аудиосигнала 155, которые (i) являются комплиментарными для сегментов 308, 310 и 312 и (ii) ограничены двумя из сегментов 308, 310 и 312 цифрового аудиосигнал 155, являются сегментами цифрового аудиосигнала 155, связанного с паузами.
[131] В любом случае, подразумевается, что сервер 106 может идентифицировать, определять или иначе выводить логически наличие двух пауз, которые представляют собой первую паузу между словами "Is" и "Kombucha", и вторую паузу между словами "Kombucha" и "Effervescent".
[132] Естественно, сервер 106 может связывать сегменты 314 и 316 с соответствующими первой и второй паузами. Дополнительно, сервер 106 может связывать временной интервал, определенный между t2 и t3 с первой паузой, и временной интервал, определенный между t4 и t5 со второй паузой.
[133] В некоторых вариантах осуществления настоящей технологии, сервер 106 может определять текстовые данные 318, представляющие собой первую паузу и текстовые данные 320, представляющие собой вторую паузу. Естественно, текстовые данные 318 и 320 могут представлять собой пространство или другой маркер, указывающий на паузу. В другом варианте осуществления технологии, текстовые данные 318 и 320 могут представлять собой нулевое значение или любой символ, представляющий собой нулевое значение.
[134] В других вариантах осуществления настоящей технологии, сервер 106 может быть совсем не выполнен с возможностью определять текстовые данные, предназначенные для связывания с паузам. В самом деле, сервер 106 может маркировать или иначе идентифицировать соответствующие сегменты 314 и 316 как связанные с паузами, без явного определения каких-либо текстовых данных, связанных с ними.
[135] В результате выполнения анализа 300 речи-в-текст, сервер 106 определяет выходные данные 202 речи-в-текст, включающие в себя множество речевых элементов 350. Конкретнее, продолжая с этим примером, множество речевых элементов 350 включает в себя:
 первый речевой элемент 352, обладающий (i) текстовыми данными 302, представляющими собой слово "Is" и (ii) соответствующим сегментом 308 цифрового аудиосигнала 155, связанного с временным интервалом, определенным как находящийся между t1 и t2;
первый речевой элемент 352, обладающий (i) текстовыми данными 302, представляющими собой слово "Is" и (ii) соответствующим сегментом 308 цифрового аудиосигнала 155, связанного с временным интервалом, определенным как находящийся между t1 и t2;
второй речевой элемент 354, обладающий (i) текстовыми данными 318, представляющими собой первую паузу и (ii) соответствующим сегментом 314 цифрового аудиосигнала 155, связанного с временным интервалом, определенным как находящийся между t2 и t3;
третий речевой элемент 356, обладающий (i) текстовыми данными 304, представляющими собой слово "Kombucha" и (ii) соответствующим сегментом 310 цифрового аудиосигнала 155, связанного с временным интервалом, определенным как находящийся между t3 и t4;
четвертый речевой элемент 358, обладающий (i) текстовыми данными 320, представляющими собой вторую паузу и (ii) соответствующим сегментом 316 цифрового аудиосигнала 155, связанного с временным интервалом, определенным как находящийся между t4 и t5; и
пятый речевой элемент 360, обладающий (i) текстовыми данными 306, представляющими собой слово "Effervescent" и (ii) соответствующим сегментом 312 цифрового аудиосигнала 155, связанного с временным интервалом, определенным как находящийся между t5 и t6.
[136] Следует иметь в виду, что в некоторых вариантах осуществления настоящей технологии второй и четвертый речевой элемент 354 и 358 могут не обладать никакими текстовыми данными как таковыми, и, вместе этого, обладать маркером или идентификатором определенного типа, который маркирует или идентифицирует соответствующие сегменты 314 и 316 как связанные с первой или второй паузой соответственно.
[137] Подразумевается, что временные интервалы соответствующих сегментов 308, 314, 310, 316 и 312 могут указывать на временной порядок речевых элементов по мере того как они появляются в произнесенном пользователем высказывании 150. Другими словами, временные интервалы соответствующих сегментов 308, 314, 310, 316 и 312 могут указывать на следующий временной порядок речевых элементов: первый речевой элемент 312 встречается первым, далее встречается второй речевой элемент 354, третий речевой элемент 356, далее четвертый речевой элемент 358 и пятый речевой элемент 360 встречается последним в произнесенном пользователем высказывании 150.
[138] В общем случае, можно сказать, что анализ 300 речи-в-текст при выполнении сервером 106 на цифровом аудиосигнале 155 позволяет определить различные сегменты цифрового аудиосигнала 155, например, сегменты 308, 314, 310, 316 и 312 и их связи с (i) соответствующими временными интервалами и (ii) соответствующими текстовыми данными, связанными со словами или паузами, как описано выше со ссылкой на Фиг. 3.
[139] Подразумевается, что сервер 106 может быть выполнен с возможностью сохранять множество речевых элементов 350 в связи с цифровым аудиосигналом 155 в базе 124 данных обработки для будущего использования.
[140] Как уже ранее упоминалось, сервер 106 выполнен с возможностью выполнять процедуру 400 создания вектора текстовых характеристик (см. Фиг. 2) и процедуру 500 создания вектора акустических характеристик (см. Фиг. 2). То, как именно сервер 106 выполнен с возможностью выполнять процедуру 400 создания вектора текстовых характеристик и процедуру 500 создания вектора акустических характеристик, будет описано далее.
[141] На Фиг. 4 представлена процедуры 400 создания вектора текстовых характеристик, которая выполняется сервером 106 на выходных данных 202 речи-в-текст. Как уже ранее упоминалось, сервер 160 может выполнять алгоритм 402 встраивания слов для создания множества векторов 404 текстовых характеристик. Подразумевается, что алгоритм 402 встраивания слов может выполняться сервером 106, который использует данный из множества MLA 852, или альтернативно соответствующую NN, которая была обучена выполнять встраивание слов, не выходя за границы настоящей технологии.
[142] Сервер 106 выполнен с возможностью предоставлять текстовые данные 302, 318, 304, 320 и 306, представляющие собой слова и паузы произнесенного пользователем высказывания 150, в виде входных данных для алгоритма 402 встраивания слов. Для каждых текстовых данных 302, 318, 304, 320 и 306, алгоритм 402 встраивания слов выполнен с возможностью (i) определять текстовые характеристики каждого соответствующего из множества речевых элементов 350 и (ii) создавать соответствующий вектор текстовых характеристик для каждого из множества речевых элементов 350.
[143] Конкретнее, путем выполнения процедуры 400 создания вектора текстовых характеристик, сервер 106 выполнен с возможностью создавать:
 на основе текстовых данных 302, первый вектор 406 текстовых характеристик, связанный с первым речевым элементом 352;
на основе текстовых данных 302, первый вектор 406 текстовых характеристик, связанный с первым речевым элементом 352;
на основе текстовых данных 318, второй вектор 408 текстовых характеристик, связанный со вторым речевым элементом 354;
на основе текстовых данных 304, третий вектор 410 текстовых характеристик, связанный с третьим речевым элементом 356;
на основе текстовых данных 320, четвертый вектор 412 текстовых характеристик, связанный с четвертым речевым элементом 358; и
на основе текстовых данных 306, пятый вектор 414 текстовых характеристик, связанный с пятым речевым элементом 360.
[144] Подразумевается, что в некоторых вариантах осуществления настоящей технологии, второй и четвертый вектор 408 и 412 текстовых характеристик могут представлять собой нулевые векторы. Другими словами, второй и четвертый вектор 408 и 412 текстовых характеристик могу обладать тем же количеством измерений, что и первый, третий и пятый вектор 406, 410 и 414 текстовых характеристик с нулевыми значениями.
[145] В других вариантах осуществления настоящей технологии, подразумевается, что сервер 106 может быть выполнен с возможностью создавать векторы текстовых характеристик только для тех речевых элементов, которые связаны со словами. Другими словами, сервер 106 может быть выполнен с возможностью создавать только первый, третий и пятый вектор 406, 410 и 414 текстовых характеристик и автоматически назначает нулевые векторы для векторов текстовых характеристик для речевых элементов, связанных с паузами. Это означает, что в некоторых вариантах осуществления настоящей технологии, где сервер 106 выполнен без возможности создавать текстовые данные 318 и 320, представляющие собой паузы, сервер 106 может автоматически назначать нулевые векторы для векторов текстовых характеристик для второго и четвертого речевого элемента 354 и 358 на основе маркера или любого другого типа указания на то, что второй и четвертый речевые элементы 354 и 358 связаны с паузами.
[146] В результате выполнения процедуры 400 создания вектора текстовых характеристик, сервер 106 создает выходные данные 204 вектора текстовых характеристик, который включает в себя множество векторов 404 текстовых характеристик, соответственно связанных со множеством речевых элементов 350. Подразумевается, что сервер 105 может быть выполнен с возможностью сохранять множество векторов 404 текстовых характеристик (например, первый, второй, третий, четвертый и пятый векторы 406, 408, 410, 412 и 414 текстовых характеристик), связанные с соответствующими из множества речевых элементов 350 в базе 124 данных обработки для дальнейшего использования.
[147] Сервер 106 также выполнен с возможностью выполнять процедуру 500 создания вектора акустических характеристик. Как уже ранее упоминалось, процедура 500 создания вектора акустических характеристик может включать в себя (i) процедуру 550 создания промежуточного вектора акустических характеристик и (ii) процедуру 600 статистической агрегации, которая будет далее описана более подробно со ссылками на Фиг. 5 и 6.
[148] На Фиг. 5 представлена процедура 550 создания промежуточного вектора акустических характеристик, выполняемая сервером 106 на цифровом аудиосигнале 155. Во время процедуры 550 создания промежуточного вектора акустических характеристик, цифровой аудиосигнал 115 может быть сегментирован с помощью метода скользящего окна, применяемого к нему сервером 106, который "скользит" с временным шагом 554 вдоль цифрового аудиосигнала 155 в направлении стрелки 553. Скользящее окно 552 может представлять собой заранее определенное время, например, 25 миллисекунд; а временная отметка 554, в соответствии с которой скользящее окно 552 скользит заранее определенное время, например, 10 миллисекунд.
[149] Скользящее окно 552 сегментирует цифровой аудиосигнал 155 на множество подсегментов, которое включает в себя, среди прочего, первый сегмент 556, второй подсегмент 558 и третий подсегмент 560. Следует иметь в виду, что скользящее окно 552 сегментирует цифровой аудиосигнал 155 на больше число подсегментов, и только три подсегмента показаны на Фиг. 5 для целей упрощения. Подразумевается, что число подсегментов цифрового аудиосигнал 155 может варьироваться в зависимости от, среди прочего, заранее определенного времени скользящего окна 552 и временной отметки 554.
[150] Естественно, каждый подсегмент обладает продолжительностью, которая равна заранее определенному времени скользящего окна 552. Другими словами:
(i) первый сегмент 556 связан с временным интервалом, определенным как находящийся между t01 и t02,
(ii) второй сегмент 558 связан с временным интервалом, определенным как находящийся между t03 и t04, и
(iii) третий сегмент 560 связан с временным интервалом, определенным как находящийся между t05 и t06,
и где временные интервалы каждого из первого, второго и третьего подсегментов 556, 558 и 560 равны заранее определенной продолжительностью скользящего окна 552.
[151] Подразумевается, что заранее определенная продолжительность скользящего окна 552 и заранее определенная продолжительность временной отметки 554 может варьироваться в зависимости, среди прочего, от различных вариантов осуществления настоящей технологи, и, следовательно, продолжительность (т.е. широта временных интервалов) подсегментов цифрового аудиосигнала 155, будет также зависеть, среди прочего, от различных вариантах осуществления технологии.
[152] Тем не менее, следует отметить, что в данном варианте осуществления технологии, все подсегменты цифрового аудиосигнала 155 (например, первый подсегмент 556, второй подсегмент 558 и третий подсегмент 560) обладают идентичной продолжительностью, а сегменты 308, 310, 312, 312 и 316 (см. Фиг. 3), соответствующие речевым элементам произнесенного пользователем высказывания 150, могут обладать различным временем. В самом деле, несмотря на то, что в различных вариантах осуществления настоящей технологии заранее определенная продолжительность скользящего окна 552 может отличаться, в данном варианте осуществления настоящей технологии все подсегменты в этом данном варианте осуществления настоящей технологии будут обладать той же продолжительностью, которая идентична заранее определенной продолжительности скользящего окна 552 в данном варианте осуществления технологии. Тем не менее, сегменты, соответствующие речевым элементам, могут обладать разными продолжительностями, которое не зависит от конкретного варианта осуществления настоящей технологии как таковое, но скорее от того как быстро или как медленно пользователь 102 "произнес" соответствующие слова произнесенного пользователем высказывания 150 и насколько долгими или короткими были паузы между "произнесенными" словами.
[153] Также следует отметить, что заранее определенная продолжительность скользящего окна 552 предпочтительно по меньшей мере равно заранее определенной продолжительности временного шага 554. Это позволяет избежать "потери" акустической информации о некоторых частях цифрового аудиосигнала 155.
[154] Например, если заранее определенная продолжительность временной отметки 554 превышает заранее определенная продолжительность скользящего окна 552, некоторые части цифрового аудиосигнала 155 (в данном случае, некоторые части являются исключенными частями между подсегментами, которые обладают продолжительностью, равной разнице между (i) заранее определенной продолжительностью временной отметки 554 и (ii) заранее определенной продолжительностью скользящего окна 552) не будут включены в какой-либо подсегмент цифрового аудиосигнала 155.
[155] Следовательно, можно сказать, что заранее определенная продолжительность скользящего окна 552 может представлять собой любое из:
(i) равно заранее определенной продолжительности временного шага 544; или
(ii) превышает заранее определенная продолжительность временного шага 554.
[156] С одной стороны, если заранее определенную продолжительность скользящего окна 552 равно заранее определенной продолжительности временного шага 554, подсегменты цифрового аудиосигнала 155 будут дополняющими (например, не перекрываться).
[157] С другой стороны, как показано на Фиг. 5, если заранее определенная продолжительность скользящего окна 552 превышает заранее определенную продолжительность временного шага 554, подсегменты цифрового аудиосигнала 155 будут частично перекрываться. Например, второй подсегмент 558 частично перекрывается первым подсегментом 556, а третий подсегмент частично перекрывается вторым подсегментом 558.
[158] Подразумевается, что обладание частично перекрывающимися сегментами цифрового аудиосигнала 155 содержит конкретный технический эффект, который приводит к избеганию "потери" акустической информации о некоторых частях цифрового аудиосигнала 155 и, как будет описано далее, к включению акустической информации о некоторых частях цифрового аудиосигнала 155 в два последовательных промежуточных вектора акустических характеристик.
[159] Во время процедуры 550 создания вектора акустических характеристик, сервер 106 выполнен с возможностью определять соответствующие акустические характеристики каждого из множества подсегментов цифрового аудиосигнала 155 и создавать соответствующие промежуточные векторы акустических характеристик для каждого из множества подсегментов цифрового аудиосигнала 155 на основе соответствующих акустических характеристик. Как ранее упоминалось, сервер 106 может быть выполнен с возможностью определять акустические характеристики, которые указывают на по меньшей мере некоторое из: уровень громкость, уровень высоты тона, уровень энергии, гармоничность (например, автокорреляция высоты тона), темп (например, число фонем за единицу времени), спектральные характеристики и так далее.
[160] Это означает, что сервер 106 может быть выполнен с возможностью:
 на основе акустических характеристик первого подсегмента 556 цифрового аудиосигнала 155, создавать первый промежуточный вектор 580 акустических характеристик, связанный с временным интервалом первого подсегмента 556;
на основе акустических характеристик первого подсегмента 556 цифрового аудиосигнала 155, создавать первый промежуточный вектор 580 акустических характеристик, связанный с временным интервалом первого подсегмента 556;
на основе акустических характеристик второго подсегмента 558 цифрового аудиосигнала 155, создавать второй промежуточный вектор 582 акустических характеристик, связанный с временным интервалом второго подсегмента 558; и
на основе акустических характеристик третьего подсегмента 560 цифрового аудиосигнала 155, создавать третий промежуточный вектор 584 акустических характеристик, связанный с временным интервалом третьего подсегмента 560.
[161] Следует отметить, что поскольку в этом случае подсегменты цифрового аудиосигнала 155 частично перекрываются, информация, которая указывает на акустические характеристики перекрывающихся частей цифрового аудиосигнала 155, может быть включена или иным образом "содержаться" в более чем одном промежуточном векторе акустических характеристик. Например, информация, указывающая на акустические характеристики второй части 564, может быть включена или иным образом "содержаться" в первом промежуточном векторе 580 акустических характеристик и втором промежуточном векторе 582 акустических характеристик. В другом примере, информация, указывающая на акустические характеристики четвертой части 568, может быть включена или иным образом "содержаться" во втором промежуточном векторе 582 акустических характеристик и третьем промежуточном векторе 584 акустических характеристик.
[162] В результате процедуры 550 создания промежуточного вектора акустических характеристик, сервер 106 определяет промежуточные выходные данные 206, включающие в себя (i) множество промежуточных векторов 590 акустических характеристик, соответственно связанных со множеством подсегментов цифрового аудиосигнала и (ii) временные интервалы соответствующих из множества подсегментов цифрового аудиосигнала 155. Подразумевается, что сервер 106 может быть выполнен с возможностью сохранять промежуточные выходные данные 206 в базе 124 данных обработки для будущего использования.
[163] На Фиг. 6 представлена процедура 600 статистической агрегации, выполняемая сервером 106. Сервер 106 может быть выполнен с возможностью идентифицировать, какие подмножества промежуточных векторов акустических характеристик, связанных с соответствующими временными интервалами, которые попадают в соответствующие временные интервалы каждого из множества речевых элементов 350.
[164] Например, на основе выходных данных 202 речи-в-текст и промежуточных выходных данных 206, сервер 106 может определять, что промежуточные векторы акустических характеристик в первом подмножестве промежуточных векторов 602 акустических характеристик связаны с соответствующими временными интервалами (соответствующие подсегменты цифрового аудиосигнала 155), которые попадают во временной интервал, определенный между t0 и t1 первого речевого элемента 352 (соответствующий сегмент 308 цифрового аудиосигнала 155).
[165] Таким образом, можно сказать, что сервер 106 может связывать первое подмножество промежуточных векторов 602 акустических характеристик с первым речевым элементом 352, поскольку все временные интервалы подсегментов, соответственно связанные с первым подсегментом промежуточных векторов 602 акустических характеристик, попадают во временной интервал сегмента 308, соответствующего первому речевому элементу 352. Аналогичным образом, сервер 106 может быть выполнен с возможностью связывать:
 второе подмножество промежуточных векторов 604 акустических характеристик со вторым речевым элементом 354;
второе подмножество промежуточных векторов 604 акустических характеристик со вторым речевым элементом 354;
третье подмножество промежуточных векторов 606 акустических характеристик с третьим речевым элементом 356;
четвертое подмножество промежуточных векторов 608 акустических характеристик с четвертым речевым элементом 358; и
пятое подмножество промежуточных векторов 610 акустических характеристик с пятым речевым элементом 360.
[166] Подразумевается, что первое, второе, третье, четвертое и пятое подмножества промежуточных векторов 602, 604, 606, 608 и 610 могут не содержать идентичные номера промежуточных векторов акустических характеристик. В самом деле, поскольку (i) существует соответствующий вектор акустических характеристик для каждого подсегмента цифрового аудиосигнала 155, (ii) все подсегменты цифрового аудиосигнала 155 обладают идентичной продолжительностью и (iii) сегменты цифрового аудиосигнала 155, которые соответствуют речевым элементам, могут обладать различной продолжительностью в зависимости от того, как быстро речевой элемент был "произнесен" пользователем 102, различное число промежуточных векторов акустических характеристик может быть связано с двумя данными сегментами цифрового аудиосигнала 155, связанного с соответствующими речевыми элементами.
[167] Сервер 106 может далее выполнять процедуру 600 статистической агрегации для создания для каждого подмножества промежуточных векторов акустических характеристик соответствующий вектор акустических характеристик. Другими словами, путем выполнения процедуры 600 статистической агрегации, сервер 106 выполнен с возможностью создавать:
первый вектор 622 акустических характеристик на основе первого подмножества промежуточных векторов 602 акустических характеристик для первого речевого элемента 352;
второй вектор 624 акустических характеристик на основе второго подмножества промежуточных векторов 604 акустических характеристик для второго речевого элемента 354;
третий вектор 626 акустических характеристик на основе третьего подмножества промежуточных векторов 606 акустических характеристик для третьего речевого элемента 356;
четвертый вектор 628 акустических характеристик на основе четвертого подмножества промежуточных векторов 608 акустических характеристик для четвертого речевого элемента 358; и
пятый вектор 630 акустических характеристик на основе пятого подмножества промежуточных векторов 610 акустических характеристик для пятого речевого элемента 360.
[168] Подразумевается, что выполнение процедуры 600 статистической агрегации сервером 106 может включать в себя создание данного вектора акустических характеристик как основанной на статистике комбинации соответствующего подмножества промежуточных векторов акустических характеристик. Например, процедура 600 статистической агрегации может учитывать по меньшей мере некоторые из следующих статистик: статистики экстремума (минимум и максимум), диапазон значений, центроиды, стандартные отклонения, дисперсии, асимметрия, эксцесс, процентили, число пересечений с нулевым значением, статистика пиков, средняя статистика, полиномиальные регрессии разных порядков и тому подобное.
[169] В результате процедуры 600 статистической агрегации, сервер 106 определяет выходные данные 208 вектора акустических характеристик, который включает в себя множество векторов 640 акустических характеристик, соответственно связанных со множеством речевых элементов 350. Подразумевается, что сервер 106 может быть выполнен с возможностью сохранять выходные данные 208 вектора акустических характеристик в связи со множеством речевых элементов 350 в базе 124 данных обработки для будущего использования.
[170] На Фиг. 7 представлена процедура 700 создания расширенного вектора характеристик, выполняемая сервером 106. Сервер 106 выполнен с возможностью осуществлять процедуру 700 создания расширенного вектора характеристик на основе (i) выходных данных 204 вектора текстовых характеристик и (ii) выходных данных 208 вектора акустических характеристик. Сервер 106 выполнен с возможностью комбинировать, для каждого речевого элемента во множестве речевых элементов 350, (i) соответствующий вектор текстовых характеристик из множества векторов 404 текстовых характеристик с (ii) соответствующим вектором акустических характеристик из множества векторов 640 акустических характеристик. Например, сервер 106 может быть выполнен с возможностью конкатенировать, для данного речевого элемента, соответствующий вектор текстовых характеристик и соответствующий вектор акустических характеристик для создания соответствующего расширенного вектора.
[171] Таким образом, сервер 106 может быть выполнен с возможностью создавать:
 первый расширенный вектор 702 для первого речевого элемента 352 путем комбинирования первого вектора 406 текстовых характеристик и первого вектора акустических характеристик 622;
первый расширенный вектор 702 для первого речевого элемента 352 путем комбинирования первого вектора 406 текстовых характеристик и первого вектора акустических характеристик 622;
второй расширенный вектор 704 для второго речевого элемента 354 путем комбинирования второго вектора 408 текстовых характеристик и второго вектора акустических характеристик 624;
третий расширенный вектор 706 для третьего речевого элемента 356 путем комбинирования третьего вектора 410 текстовых характеристик и третьего вектора акустических характеристик 626;
четвертый расширенный вектор 708 для четвертого речевого элемента 358 путем комбинирования четвертого вектора 412 текстовых характеристик и четвертого вектора акустических характеристик 628; и
пятый расширенный вектор 710 для пятого речевого элемента 360 путем комбинирования пятого вектора 414 текстовых характеристик и пятого вектора акустических характеристик 630.
[172] Подразумевается, что данный из множества расширенных векторов 720 характеристик включает в себя информацию, указывающую на текстовые характеристики и акустические характеристики соответствующего речевого элемента из множества речевых элементов 350.
[173] В результате выполнения процедуры 700 создания расширенного вектора характеристик, сервер 106 определяет выходные данные 210 расширенного вектора характеристик, который включает в себя множество расширенных векторов 720 характеристик, соответственно связанных со множеством речевых элементов 350. Подразумевается, что сервер 106 может быть выполнен с возможностью сохранять выходные данные 208 расширенного вектора характеристик в связи со множеством речевых элементов 350 в базе 124 данных обработки для будущего использования.
[174] На Фиг. 8 представлена процедура 800 определения намерения, выполняемая сервером 106. Конкретнее, процедура 800 определения намерения соответствует фазе использования RNN 850, как ранее описывалось, причем RNN 850 получает в качестве входных данных множество расширенных векторов 720 характеристик выходных данных 210 расширенного вектора характеристик.
[175] Следует отметить, что множество расширенных векторов 720 характеристик вводятся в RNN 850 в соответствии с временным порядком, в котором соответственно связанные речевые элементы появляются в произнесенном пользователем высказывании. Альтернативно, подразумевается, что в некоторых вариантах осуществления настоящей технологии, данные, указывающие на временной порядок соответствующих связанных речевых элементов (например, данные, указывающие на соответствующие позиции произнесенного пользователем высказывания 150), могут быть включены в соответствующие расширенные векторы характеристик или иным образом логически выводиться с помощью RNN 850 из соответствующих расширенных векторов характеристик.
[176] В некоторых вариантах осуществления настоящей технологии, подразумевается, что RNN 850 может выполняться как "механизм внимания". То, как реализуется этот "механизм внимания", может быть реализовано с помощью RNN 850, описано в опубликованной статье, озаглавленной "Neural Machine Translation by Jointly Learning to Align and Translate" (англ. "Нейронный машинный перевод с помощью совместного обучения связыванию и переводу"), опубликованной в качестве доклада на "International Conference on Learning Representations" (англ. "Международная конференция по представлениям обучения") в 2015 году, в соавторстве с Бахданау Д., Чо К. и Бенгио Ю., содержание которого включено в настоящее описание в полном объеме посредством ссылке. В общем случае, RNN 850, которая реализует этот механизм внимания, в некотором смысле "решает", какому из речевых элементов следует уделять больше внимания во время создания выходных данных 212. В самом деле, RNN 850, реализуя механизм внимания, может определить, что некоторые речевые элементы более важны, чем другие, и, следовательно, обладают более высоким влиянием во время создания выходных данных 212.
[177] В результате, RNN 850 выполнен с возможностью создавать выходные данные 212. Выходные данные 212 указывают на вероятность того, что намерение произнесенного пользователем высказывания 150 будет связано с данным типом намерения, для которого была обучена RNN 850. Например, если RNN 850 была обучена для оценки вероятности того, что данное произнесенное пользователем высказывание будет связано с намерением типа "открытый вопрос", выходные данные 212 указывают на вероятность того, что намерение произнесенного пользователем высказывания 150 будет связано с типом "открытый вопрос".
[178] В некоторых вариантах осуществления настоящей технологии, сервер 106 может сравнивать выходные данные 212 с заранее определенным порогом. Если выходные данные 212 превышают заранее определенный порог, сервер 106 может определить, что произнесенное пользователем высказывание 150 связано с намерением данного типа (например, открытый вопрос). Если выходные данные 212 ниже заранее определенного порога, сервер 106 может определить, что произнесенное пользователем высказывание 150 не связано с намерением данного типа.
[179] Предположим, что сервер 106 сравнивает выходные данные 212 с предопределенным порогом и что выходные данные 212 выше предопределенного порога. Таким образом, сервер 106 может определить, что произнесенное пользователем высказывание 150 связано с намерением типа "открытый вопрос".
[180] В ответ на определение того, что произнесенное пользователем высказывание 150 связано с намерением типа "открытый вопрос", сервер 106 может быть выполнен с возможностью создавать зависящий от намерения ответ (информацию, который будет предоставлен пользователю 102. Например, вместо того, чтобы создавать ответ, например "Yes" ("Да"), то сервер 106 может создавать, в ответ на определение того, что произнесенное пользователем высказывание 150 связано с намерением типа "открытый вопрос", зависящий от намерения ответ, такой как "Kombucha refers to a variety of fermented, and indeed, lightly effervescent, sweetened black or green tea drinks.. It is produced by fermenting tea using a symbiotic culture of bacteria and yeast which gives it effervescency". ("Комбучей называют большой ряд ферментированых, слабогазированных, сладких напитков на основе черного или зеленого чая. Он производится путем ферментации чая с использованием симбиотической культуры бактерий и дрожжей, что придает ему газированность".
[181] В некоторых вариантах осуществления данной технологии сервер 106 может быть выполнен с возможностью, в дополнение к определению типа намерения данного произнесенного пользователем высказывания, определять "контекст" данного произнесенного пользователем высказывания. Например, предположим, что цифровой аудиосигнал 155, при обработке с помощью анализа 300 речи-в-текст сервера 106, представляет собой следующее "Can I go to an event downtown" ("Я могу пойти на мероприятие в центр города"). В результате, как это было описано выше, сервер 106 может быть выполнен с возможностью создавать соответствующие расширенные векторы характеристик для каждого из следующих речевых элементов: речевой элемент, связанный со словом "Can" ("Могу"), речевой элемент, связанный со словом "I" ("Я"), речевой элемент, связанный со словом "go" ("Пойти"), речевой элемент, связанный со словом "to" ("на"), речевой элемент, связанный со словом "an" (артикль), речевой элемент, связанный со словом "event" ("мероприятие"), речевой элемент, связанный со словом "downtown" ("центр города"), речевой элемент, связанный с паузой между "Can" и "I", речевой элемент, связанный с паузой между "I" и "go", речевой элемент, связанный с паузой между "go" и "to", речевой элемент, связанный с паузой между "to" и "an", речевой элемент, связанный с паузой между "an" и "event" и речевой элемент, связанный с паузой между "event" и "downtown".
[182] Сервер 106 может также быть выполнен для использования RNN 850 с целью определения намерения произнесенного пользователем высказывания 150. Предполагается, что сервер 106 определяет, что произнесенное пользователем высказывание 150 "Can I go to an event downtown" связано с данным намерением, которое относится к типу "открытый вопрос", аналогично тому как было описано выше. В результате сервер 106 не может создать ответ "Yes", и вместо этого выполнен с возможностью создавать данный зависящий от намерения ответ.
[183] Однако, следует иметь в виду, что, когда произнесенное пользователем высказывание 150 "Can I go to an event downtown" произносится с намерением типа "открытый вопрос", оно также может быть произнесено пользователем 102 в различных контекстах. В этом случае контекст произнесенного пользователем высказывания 150 может быть либо, например, (i) связан с выбором данного мероприятия среди всех мероприятий в центре города, либо (ii) связан с маршрутом или каким-либо другим типом информации о поездке для того, чтобы добраться до данного мероприятия, происходящего в центре города. Действительно, когда человек слышит высказывание пользователя 150 "Can I go to an event downtown", он может определить, что пользователь 102 "акцентирует" или "выделяет" одно из (i) слов "event" или (ii) слово "downtown". В результате, зависящая от намерения информация, которая должна предоставляться пользователю 102 сервером 106 может зависеть не только от данного типа намерения произнесенного пользователем высказывания 150, а также, в некотором смысле, от данного слова, выступающего в качестве "контекстного якоря" для произнесенного пользователем высказывания 150.
[184] Сервер 106 может быть настроен для использования дополнительного MLА для определения того, какой речевой элемент связан с данным словом, служащим как контекстный якорь (т.е. целевым словом) для соответствующего данного произнесенного пользователем высказывания.
[185] Без ограничения какой-либо конкретной теорией, разработчики настоящей технологии эмпирически определили, что выходные данные "входного гейта" RNN 850 указывают на отношения между данными словами и контекстами произносимых пользователем высказываний. Другими словами, когда в RNN 850 вводятся расширенные векторы характеристик речевых элементов данного произнесенного пользователем высказывания, сервер 106 может получать от RNN 860 данный вектор входного гейта для каждого расширенного вектора характеристик и, таким образом, связываться с соответствующим речевым элементом. Дополнительный MLA обучается предсказывать, какое слово служит контекстным якорем (т.е. целевым словом) в соответствующем произнесенном пользователем высказывании на основе этих векторов входного гейта. Далее будет описано то, как дополнительный MLA обучается и используется для прогнозов того, какое слово в соответствующем произнесенном пользователем высказывании является целевым словом
[186] Во время обучающей итерации дополнительного MLA, в дополнительный MLA может вводиться обучающий набор. Обучающий набор может быть создан частично человеком-асессором и частично с помощью RNN 850. Например, для данного предыдущего цифрового аудиосигнала, хранящегося в базе 124 данных обработки, сервер 106 может создавать множество расширенных векторов характеристик, аналогично тому, что было описано выше. Кроме того, человек-асессор может пометить данное слово, связанное с данным речевым элементом предыдущего цифрового аудиосигнала, как контекстный якорь (т.е. обучающее целевое слово) для соответствующего предыдущего произнесенного пользователем высказывания. Кроме того, в RNN 850 может быть введено множество расширенных векторов характеристик, из которых сервер 106 получает соответствующие обучающие векторы входных гейтов для каждого речевого элемента (или для речевых элементов, связанных только со словами) из обучающего цифрового аудиосигнала.
[187] В итоге, обучающий набор состоит из (i) множества векторов входного гейта и (ii) метки, показывающей, какой из множества векторов входного гейта связан со словом, служащим контекстным якорем (т.е. обучающим целевым словом) для предыдущего произнесенного пользователем высказывания.
[188] Когда обучающий набор вводится в дополнительный MLA, дополнительный MLА в некотором смысле "обучается" тому, что среди всех обучающих векторов входного гейта для предыдущего произнесенного пользователем высказывания, обучающий вектор входного гейта, связанный с целевым словом, является "желаемый" вектором. Таким образом, во время использования вспомогательный MLA может быть введен со множеством используемых входных векторов ворот и может выводить в ответ значения, указывающие на вероятность того, что каждая соответствующая речевая единица (или речевые единицы, связанные только со словами) будет связана с целевым словом используемого разговорного пользовательского высказывания.
[189] Возвращаясь к примеру с разговорного высказывания пользователей 150 "Can I go to an event downtown", сервер 106 может получать множество векторов входного гейта фазы использования (например, вспомогательные данные для каждого речевого элемента), созданных RNN 850 для речевых элементов, связанных с соответствующими словами "Can", "I", "go", "to", "an", "event" и "downtown". Сервер 106 далее настроен для ввода множества векторов входного гейта фазы использования (например, вспомогательных данных для каждого речевого элемента) в дополнительный MLA, для оценки которых одно из слов "Can", "I", "go", "to", "an", "event" и "downtown" выступает как контекстный якорь для произнесенного пользователем высказывания 150 (для определения того, какое из этих слов является целевым).
[190] Предположим, что сервер 106, который использует дополнительный ML А, определяет, что слово "downtown" связано среди слов "Can", "I", "go", "to", "an", "event" и "downtown" с наибольшей вероятностью того, что оно выступает в качестве контекстного якоря для произнесенного пользователем высказывания 150. Это означает, что сервер 106 может определить, что целевое слово - "downtown".
[191] В результате, сервер 106 может создать зависящий от намерения ответ, который не только конкретен для данного намерения произнесенного пользователем высказывания 150 (например, вопрос открытого типа), но также и связан с контекстным якорем "downtown". Таким образом, сервер 106 может создавать зависящий от намерения ответ, представляющий информацию, связанную с маршрутом пользователю 102 для прибытия в центр города из его/ее текущего местоположения, например, вместо того, чтобы перечислять возможные события, происходящие в центре города. Другими словами, сервер 106 может быть выполнен с возможностью осуществлять "тонкую настройку" (т.е. увеличивать релевантность) зависящего от намерения ответа на основе "слова-якоря".
[192] На Фиг. 9 представлена блок-схема способа 1000 определения намерения произнесенного пользователем высказывания 150 в соответствии с некоторыми вариантами осуществления настоящей технологии. Несмотря на то, что способ 1000 будет описан как выполняемый сервером 106, следует отметить, что устройство 104 может быть выполнено с возможностью выполнять по меньшей мере некоторые этапы способа 1000 аналогично тому, как сервер 106 выполнен с возможностью выполнять по меньшей мере некоторые этапы способа 1000, не выходя за пределы настоящей технологии.
ЭТАП 1002: выполнение анализа преобразования речи-в-текст цифрового сигнала
[193] Способ 1000 начинается на этапе 1002, где сервер 106 выполнен с возможностью выполнять анализ 300 речи-в-текст цифрового аудиосигнала 155, как показано на Фиг. 3. Конкретнее, выполнение анализа 300 речи-в-текст цифрового аудиосигнала 155 приводит к определению по меньшей мере одного речевого элемента, связанного с цифровым аудиосигналом 155.
[194] Например, в сценарии, показанном на Фиг. 3, выполнение анализа 300 речи-в-текст цифрового аудиосигнала 155 приводит к определению множества речевых элементов 350. Каждый из множества речевых элементов 350 соответственно связан с одним из (i) словом или (ii) паузой. Например, первый, третий и пятый речевые элементы 352, 356 и 360 связаны с соответствующие словами, которые были "произнесены" как часть произнесенного пользователем высказывания 150, а второй и четвертый речевые элементы 354 и 358 связаны с соответствующими паузами, которые присутствуют между "произнесенными" словами в произнесенном пользователем высказывании 150.
[195] В некоторых вариантах осуществления настоящей технологии подразумевается, что выполнение анализа 300 речи-в-текст может включать в себя определение текстовых данных для каждого речевого элемента. В самом деле, каждый речевой элемент обладает соответствующими текстовыми данными, представляющими собой соответствующее слово или паузу. Например, первый речевой элемент 352 обладает текстовыми данными 302, представляющими соответствующее слово "Is". Аналогично, третий речевой элемент 356 обладает текстовыми данными 304, представляющими соответствующее слово "Kombucha", а пятый речевой элемент 460 обладает текстовыми данными 306, представляющими соответствующее слово "Effervescent". В другом примере, второй речевой элемент 354 обладает текстовыми данными 318, представляющими первую паузу, а четвертый речевой элемент 358 обладает текстовыми данными 318, представляющими вторую паузу.
[196] Подразумевается, текстовые данные 318 и 320 могут представлять собой пространство или другой маркер, указывающий на паузу. Альтернативно, текстовые данные 318 и 320 могут представлять собой нулевое значение или любой символ, представляющий собой нулевое значение. Опционально, второй и четвертый речевые элементы 354 и 358 могут не требовать текстовых данных, представляющих соответствующую паузу, а вместо этого обладают некоторым типом информации, которая указывает на то, что второй и четвертый речевые элементы 354 и 358 связаны с соответствующими паузами в произнесенном пользователем высказывании 150.
[197] Следует иметь в виду, что каждый из множества речевых элементов 350 также обладает соответствующим сегментом цифрового аудиосигнала 155. Например, первый речевой элемент 352 обладает соответствующим сегментом 308 цифрового аудиосигнала 155, который обладает соответствующим временным интервалом, определенным между t1 и t2. Подразумевается, что выполнение анализа 300 речи-в-текст может включать в себя определение временного интервала соответствующего сегмента цифрового аудиосигнала 155, связанного с каждым соответствующим речевым элементом из множества речевых элементов.
[198] Как показано на Фиг. 2, выходные данные 202 речи-в-текст, включающие в себя множества речевых элементов 350, могут использоваться сервером 106 для выполнения процедуры создания 400 вектора текстовых характеристик и процедуры создания 500 вектора акустических характеристик. Подразумевается, что сервер 106 может сохранять выходные данные 202 речи-в-текст в связи с цифровым аудиосигналом 155 для будущего использования.
[199] Подразумевается, что после того как выходные данные 202 речи-в-текст создаются анализом 300 речи-в-текст, выполняемым сервером 106, процедура создания 400 вектора текстовых характеристик и процедура создания 500 вектора акустических характеристик могут выполняться сервером 106.
[200] Следует иметь в виду, что этапы 1004, 1006 и 1008, описанные далее, могут выполняться сервером 106 для каждого из множества речевых элементов 350 в различном порядке. Например, этапы 1004, 1006 и 1008 могут выполняться для первого данного из множества речевых элементов 350 и далее для второго данного из множества речевых элементов 350 и так далее. В другом примере, этап 1004 может выполняться для каждого из множества речевых элементов 350, далее этап 1006 может выполняться для каждого из множества речевых элементов 350 и далее этап 1008 может выполняться для каждого из множества речевых элементов 350.
[201] Другими словами, подразумевается, что в некоторых вариантах осуществления настоящей технологии, этапы 1004, 1006 и 1008 могут выполняться сервером 106 для любого данного речевого элемента независимо от любого другого речевого элемента.
ЭТАП 1004: создание соответствующего вектора текстовых характеристик для каждого речевого элемента
[202] Способ 1000 продолжается на этапе 1004, где сервер 106 создает для каждого из множества речевых элементов 350 соответствующий вектор текстовых характеристик, как показано на Фиг. 4, со ссылкой на процедуру 400 создания вектора текстовых характеристик.
[203] Создание данного вектора текстовых характеристик выполняется сервером 106 путем (i) определения текстовых характеристик соответствующего речевого элемента на основе текстовых данных, связанных с соответствующим речевым элементом и (ii) создания данного вектора текстовых характеристик на основе соответствующих текстовых характеристик.
[204] Подразумевается, что создание множества векторов 404 текстовых характеристик может выполняться с помощью процесса внедрения слов, выполняемого сервером 106. Например, сервер 160 может выполнять алгоритм 402 встраивания слов для создания множества векторов 404 текстовых характеристик. В одном варианте осуществления настоящей технологии, алгоритм 402 встраивания слов может выполняться сервером 106, который использует данный один из множества MLА 852. В другом варианте осуществления настоящей технологии, алгоритм 402 встраивания слов может выполняться сервером 106, который использует соответствующую NN, которая была обучена выполнять встраивание слов, не выходя за границы настоящей технологии.
[205] Также подразумевается, что когда данный речевой элемент связан с паузой, соответствующий вектор текстовых характеристик может представлять собой нулевой вектор. Например, второй и четвертый векторы 408 и 412 текстовых характеристик из множества векторов 404 текстовых характеристик, могут быть нулевыми векторами. Другими словами, второй и четвертый вектор 408 и 412 текстовых характеристик могу обладать тем же количеством измерений, что и первый, третий и пятый вектор 406, 410 и 414 текстовых характеристик с нулевыми значениями.
[206] В других вариантах осуществления настоящей технологии, сервер 106 может быть выполнен с возможностью создавать векторы текстовых характеристик только для тех речевых элементов, которые связаны со словами. Другими словами, сервер 106 может быть выполнен с возможностью создавать только первый, третий и пятый вектор 406, 410 и 414 текстовых характеристик и автоматически назначает нулевые векторы для векторов текстовых характеристик для речевых элементов, связанных с паузами. Подразумевается, что заранее определенные / заранее созданные нулевые вектора могут храниться в базе 124 данных обработки, и могут быть получены сервером 106 при определении того, что данный речевой элемент связан с паузой.
[207] Также подразумевается, что сервер 106 может быть выполнен с возможностью сохранять выходные данные 204 вектора текстовых характеристик, содержащие множество векторов 404 текстовых характеристик, соответственно связанных со множеством речевых элементов 350 в базе 124 данных обработки.
ЭТАП 1006: создание соответствующего вектора акустических характеристик для каждого речевого элемента
[208] Способ 1000 продолжается на этапе 1006, где сервер 106 создает для каждого из множества речевых элементов 350 соответствующий вектор акустических характеристик путем выполнения процедуры 500 создания вектора акустических характеристик. Создание данного вектора акустических характеристик выполняется сервером 106 путем (i) определения акустических характеристик соответствующего сегмента цифрового аудиосигнала 155 на основе соответствующего сегмента цифрового аудиосигнала 155 и (ii) создания данного вектора акустических характеристик на основе соответствующих акустических характеристик.
[209] В некоторых вариантах осуществления настоящей технологии подразумевается, что акустические характеристики могут включать в себя по меньшей мере некоторые из: уровень громкость, уровень высоты тона, уровень энергии, гармоничность (например, автокорреляция высоты тона), темп (например, число фонем за единицу времени), спектральные характеристики и так далее.
[210] В некоторых вариантах осуществления настоящей технологии подразумевается, что процедура 500 создания вектора акустических характеристик может включать в себя (i) процедуру 550 создания промежуточного вектора акустических характеристик, как показано на Фиг. 5, и (ii) процедуру 600 статистической агрегации, как показано на Фиг. 6.
[211] На Фиг. 5, выполнение процедуры 550 создания промежуточного вектора акустических характеристик сервером 106 может включать в себя сегментирование цифрового аудиосигнала 155 на соответствующие подсегменты цифрового аудиосигнала 155. Например, цифровой аудиосигнал 115 может быть сегментирован с помощью метода скользящего окна, применяемого к нему сервером 106, который "скользит" с временным шагом 554 вдоль цифрового аудиосигнала 155 в направлении стрелки 553.
[212] Подразумевается, что скользящее окно 552 может обладать заранее определенной продолжительностью. Временной шаг 554, в соответствии с которым перемещается скользящее окно 552, может обладать другой продолжительностью.
[213] Следует отметить, что временной интервал каждого подсегмента (например, заранее определенная продолжительность скользящего окна 5532) короче, чем временные интервалы сегментов цифрового аудиосигнала, соответствующего связанным речевым элементам.
[214] Подразумевается, что, если заранее определенная продолжительность временного шага 554 равна заранее определенной продолжительности скользящего окна 552, подсегменты цифрового аудиосигнала 155 будут дополняющими и не будут перекрываться.
[215] С другой стороны подразумевается, что если заранее определенная продолжительность временного шага 554 выше заранее определенной продолжительности скользящего окна 552, соответствующие подсегменты цифрового аудиосигнала 155 будут перекрываться, как показано на Фиг. 5.
[216] Например, вторая часть 564 является частью первого подсегмента 556, который перекрывается вторым подсегментом 558. Таким образом, можно сказать, что первый подсегмент 556 и второй подсегмент 558 являются двумя подсегментами цифрового аудиосигнала 155, которые частично перекрываются.
[217] В некоторых вариантах осуществления настоящей технологии, сервер 106 может быть выполнен с возможностью создавать множество промежуточных векторов 590 акустических характеристик, связанных с соответствующими подсегментами цифрового аудиосигнала 155 на основе акустических характеристик соответствующих подсегментов.
[218] В других вариантах осуществления настоящей технологии, сервер 106 может быть выполнен с возможностью создавать данный вектор акустических характеристик для данного цифрового аудиосигнала, соответствующего данному речевому элементу, на основе соответствующих промежуточных векторов акустических характеристик.
[219] Например, со ссылкой на Фиг. 6, сервер 106 может определять, что промежуточные векторы акустических характеристик в первом подмножестве промежуточных векторов 602 акустических характеристик связаны с соответствующими временными интервалами (соответствующие подсегменты цифрового аудиосигнала 155), которые попадают во временной интервал, определенный между t0 и t1 первого речевого элемента 352 (соответствующий сегмент 308 цифрового аудиосигнала 155).
[220] Таким образом, можно сказать, что сервер 106 может связывать первое подмножество промежуточных векторов 602 акустических характеристик с первым речевым элементом 352, поскольку все временные интервалы подсегментов, соответственно связанные с первым подсегментом промежуточных векторов 602 акустических характеристик, попадают во временной интервал сегмента 308, соответствующего первому речевому элементу 352.
[221] После того как были определены промежуточные векторы акустических характеристик данного соответствующего сегмента цифрового аудиосигнала 155 как было описано выше, сервер 106 может быть выполнен с возможностью создавать соответствующий вектор акустических характеристик для речевого элемента данного соответствующего сегмента цифрового аудиосигнала 155. Например, сервер 106 может создавать первый вектор 622 акустических характеристик для первого речевого элемента 352 на основе первого подмножества промежуточных векторов 602 акустических характеристик, поскольку каждый из первого подмножества промежуточных векторов 602 акустических характеристик связан с соответствующим сегментом 308 цифрового аудио сигнала 155.
[222] Как уже упоминалось ранее, сервер 106 может выполнять процедуру 600 статистической агрегации для каждого подмножества промежуточных векторов акустических характеристик для создания соответствующего вектора акустических характеристик для каждого речевого элемента. Предполагается, что сервер 106, выполняющий процедуру 600 статистической агрегации, может включать в себя выполнение основанной на статистике комбинации соответствующих подмножеств промежуточных векторов акустических характеристик.
[223] Также подразумевается, что процедура 600 статистической агрегации, в некоторых вариантах осуществления настоящей технологии, может учитывать по меньшей мере некоторые из следующих статистик: статистики экстремума (минимум и максимум), диапазон значений, центроиды, стандартные отклонения, дисперсии, асимметрия, эксцесс, процентили, число пересечений с нулевым значением, статистика пиков, средняя статистика, полиномиальные регрессии разных порядков и тому подобное.
[224] В некоторых вариантах осуществления настоящей технологии подразумевается, что в результате шага 1006 сервер 106 может создавать множество векторов 640 акустических характеристик, соответственно связанных со множеством речевых элементов 350. Подразумевается, что сервер 106 может также сохранять множество векторов 640 акустических характеристик в сочетании с соответствующими из множества речевых элементов 350 в базе 124 данных обработки.
ЭТАП 1008: создание соответствующего расширенного вектора характеристик для каждого речевого элемента
[225] Способ 1000 далее продолжается на этапе 1008, где сервер 106 создает соответствующий расширенный вектор характеристик для каждого речевого элемента путем сочетания соответствующего вектора текстовых характеристик, созданного на этапе 1004, и вектора акустических характеристик, созданного на этапе 1006.
[226] В некоторых вариантах осуществления настоящей технологии, сервер 106, который осуществляет сочетание соответствующего вектора акустических характеристик и соответствующего вектора текстовых характеристик, включает в себя конкатенацию сервером соответствующего вектора акустических характеристик и соответствующего вектора текстовых характеристик, тем самым создавая соответствующий расширенный вектор характеристик.
[227] На Фиг. 7 представлена процедура 700 создания расширенного вектора характеристик, выполняемая сервером 106. Сервер 106 может осуществлять процедуру 700 создания расширенного вектора характеристик на основе (i) выходных данных 204 вектора текстовых характеристик и (ii) выходных данных 208 вектора акустических характеристик. Подразумевается, что данный из множества расширенных векторов 720 характеристик включает в себя информацию, указывающую на текстовые характеристики и акустические характеристики соответствующего речевого элемента из множества речевых элементов 350.
[228] Подразумевается, что сервер 106 может быть выполнен с возможностью сохранять расширенные векторы 720 характеристик в связи с цифровым аудиосигналом 350 в базе 124 данных обработки для будущего использования.
ЭТАП 1010: выполнение RNN для определения намерения произнесенного пользователем высказывания
[229] Способ 1000 завершается на этапе 1010, где сервер 106 использует RNN 850 (или другой возможный тип NN), выполненную с возможностью определять намерение произнесенного пользователем высказывания 150 путем ввода в RNN 850 множества расширенных векторов 720 характеристик.
[230] В результате, RNN 850 выполнена с возможностью создавать выходные данные 212, которые указывают на вероятность того, что намерение произнесенного пользователем высказывания 150 будет связано с данным типом намерения, для которого была обучена RNN 850. Например, если RNN 850 была обучена для оценки вероятности того, что данное произнесенное пользователем высказывание будет связано с намерением типа "открытый вопрос", выходные данные 212 указывают на вероятность того, что намерение произнесенного пользователем высказывания 150 будет связано с типом "открытый вопрос".
[231] В некоторых вариантах осуществления настоящей технологии, сервер 106 может сравнивать выходные данные 212 с заранее определенным порогом. Если выходные данные 212 превышают заранее определенный порог, сервер 106 может определить, что произнесенное пользователем высказывание 150 связано с намерением данного типа (например, открытый вопрос). Если выходные данные 212 ниже заранее определенного порога, сервер 106 может определить, что произнесенное пользователем высказывание 150 не связано с намерением данного типа.
[232] Предположим, что сервер 106 сравнивает выходные данные 212 с предопределенным порогом и что выходные данные 212 выше предопределенного порога. Таким образом, сервер 106 может определить, что произнесенное пользователем высказывание 150 связано с намерением типа "открытый вопрос".
[233] В ответ на определение того, что произнесенное пользователем высказывание 150 связано с намерением типа "открытый вопрос", сервер 106 может быть выполнен с возможностью создавать зависящий от намерения ответ (информацию, который будет предоставлен пользователю 102. Например, вместо того, чтобы создавать ответ, например "Yes" ("Да"), то сервер 106 может создавать, в ответ на определение того, что произнесенное пользователем высказывания 150 связано с намерением типа "открытый вопрос", зависящий от намерения ответ, таких как "Kombucha refers to a variety of fermented, and indeed, lightly effervescent, sweetened black or green tea drinks.. It is produced by fermenting tea using a symbiotic culture of bacteria and yeast which gives it effervescency". ("Комбучей называют большой ряд ферментированых, слабогазированных, сладких напитков на основе черного или зеленого чая. Он производится путем ферментации чая с использованием симбиотической культуры бактерий и дрожжей, что придает ему газированность". В ответ на определение того, что произнесенное пользователем 150 высказывание не связано с намерением, которое относится к типу "открытый вопрос" (т.е. определение приводит к негативному результату), сервер 106 может создавать подходящий зависящий от намерения ответ.
[234] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
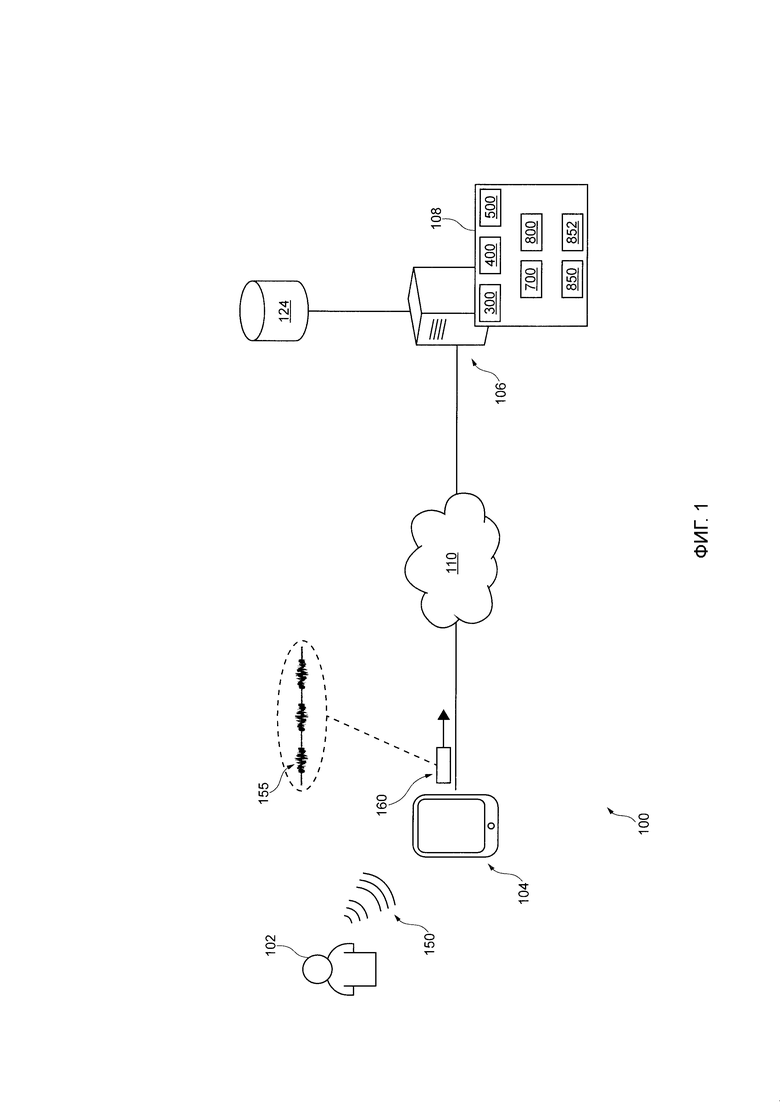
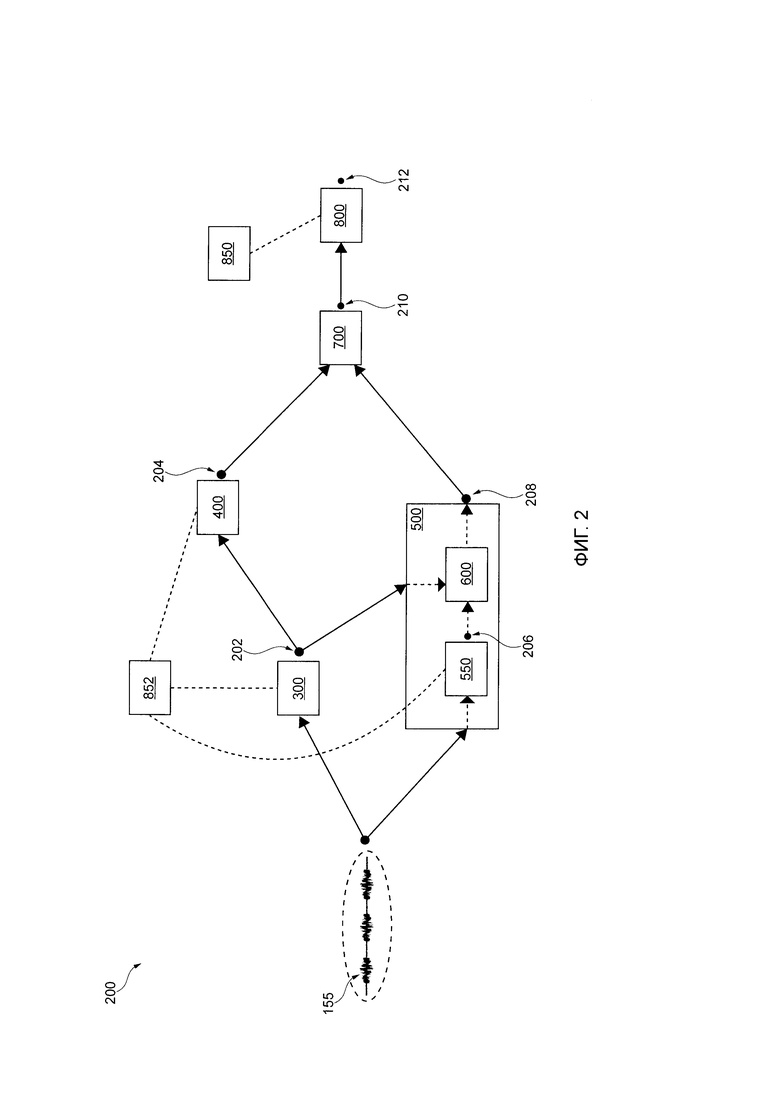
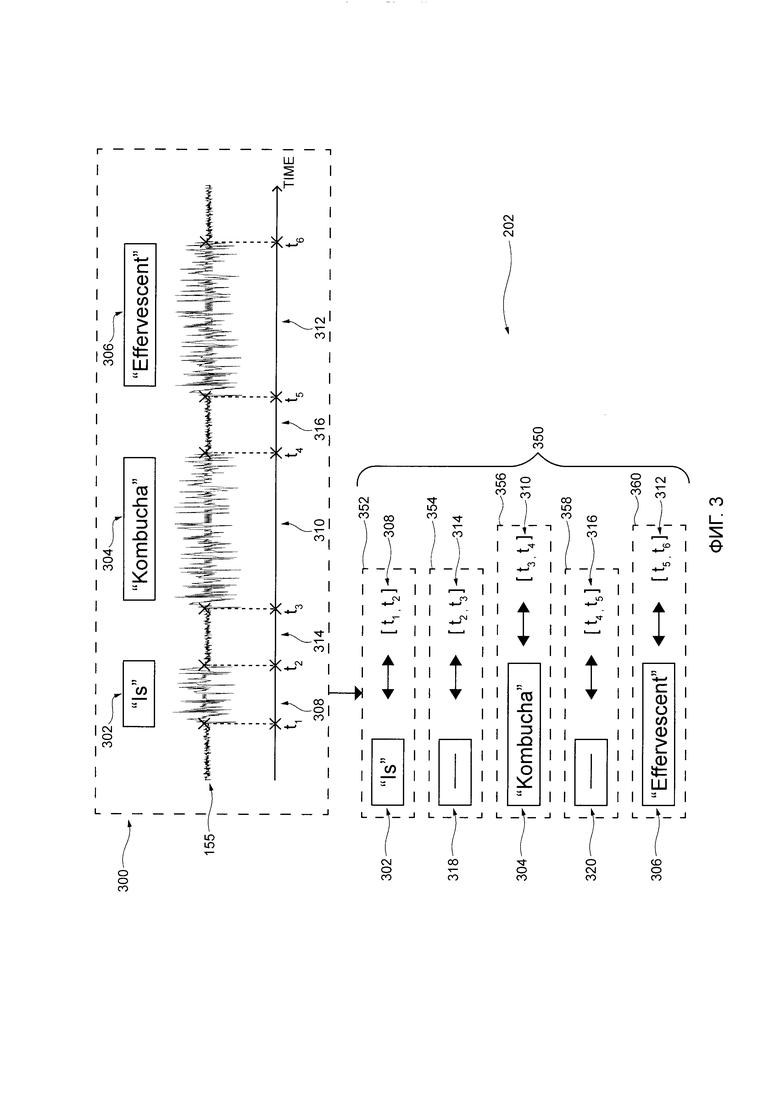
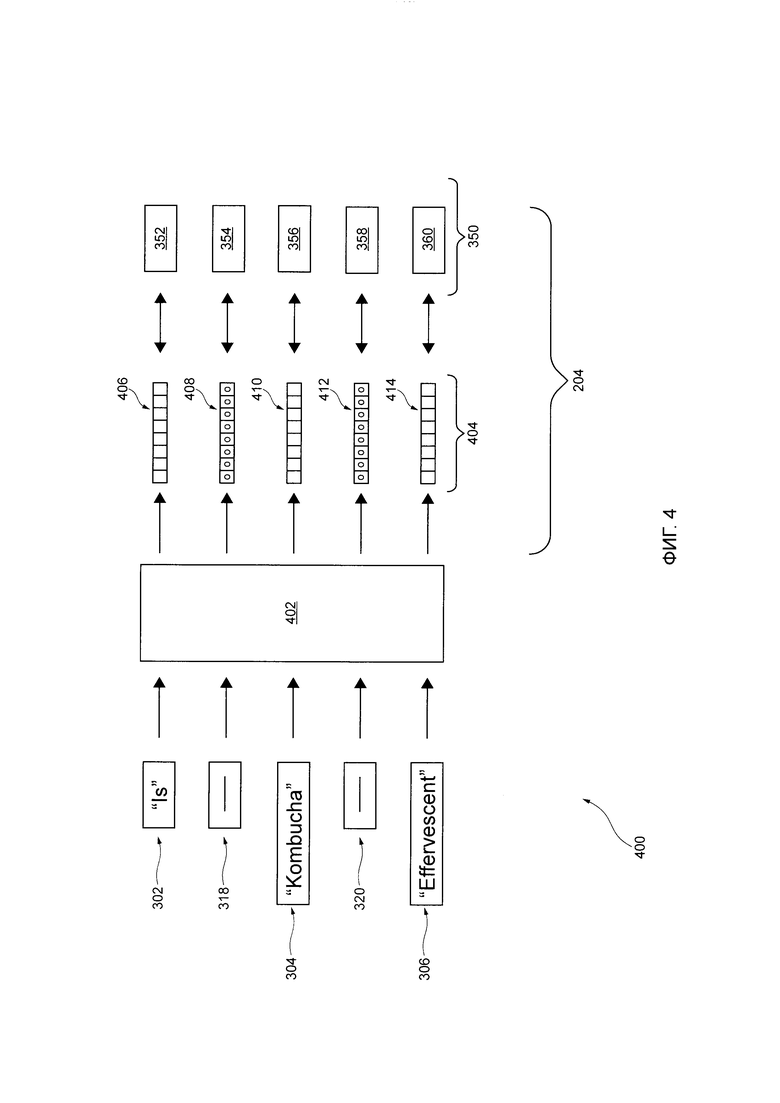
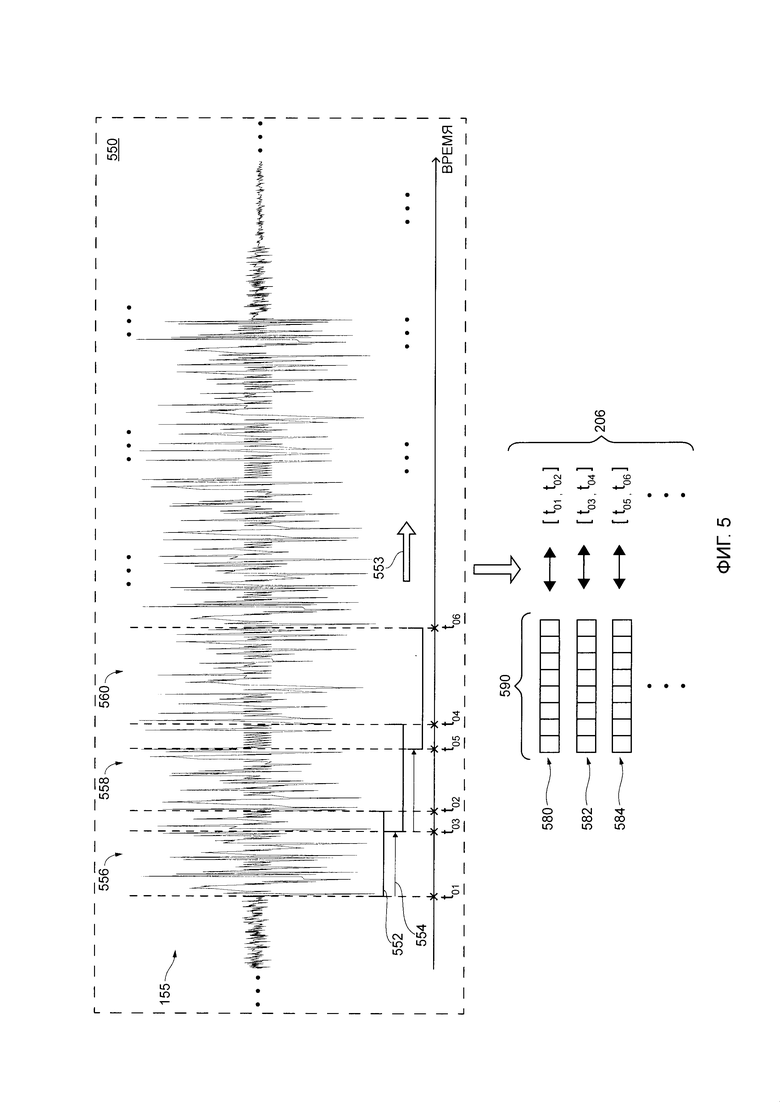
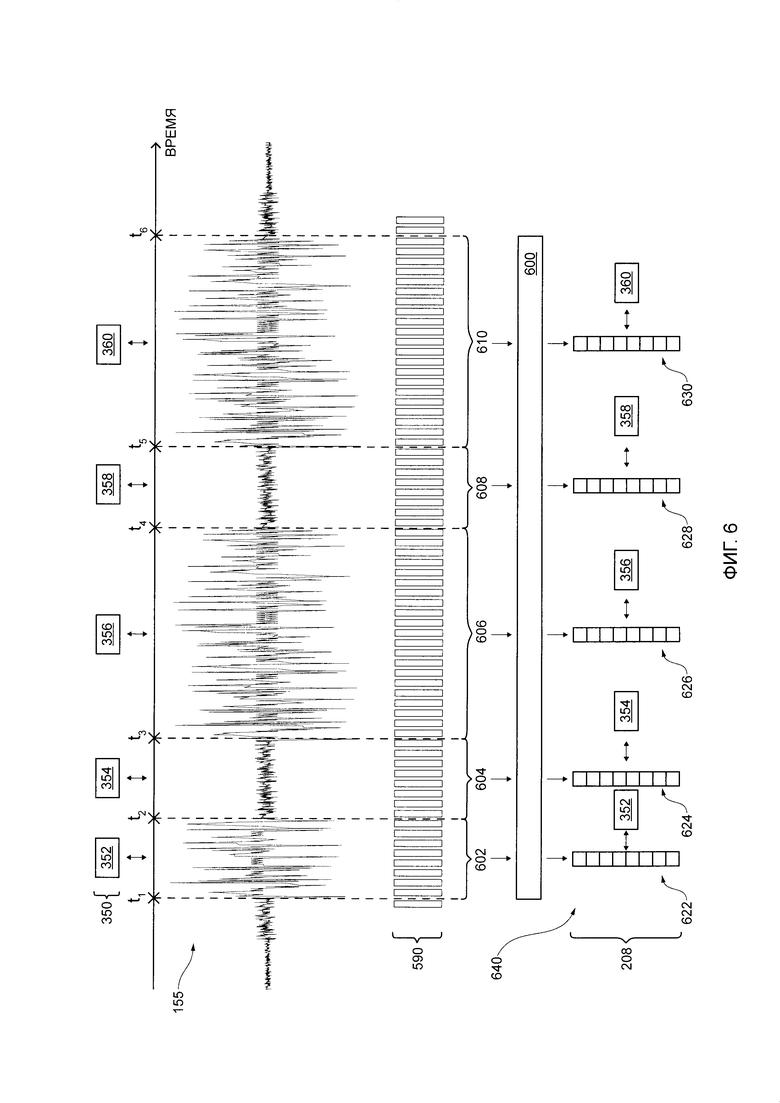
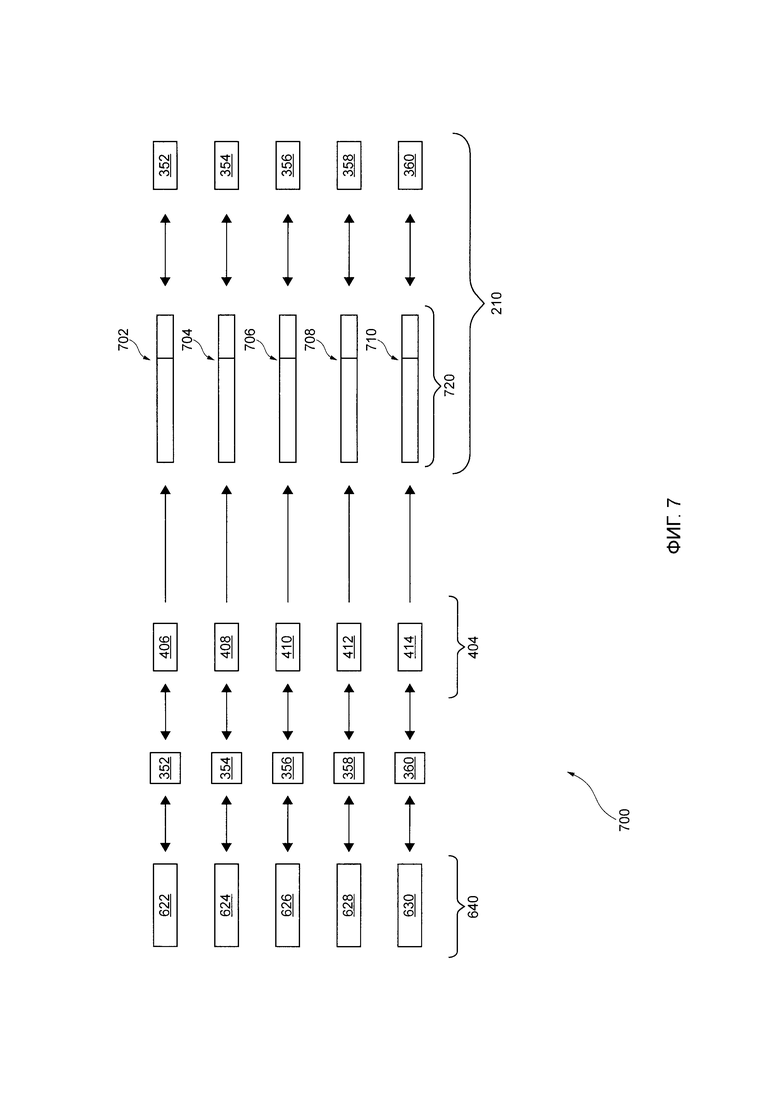
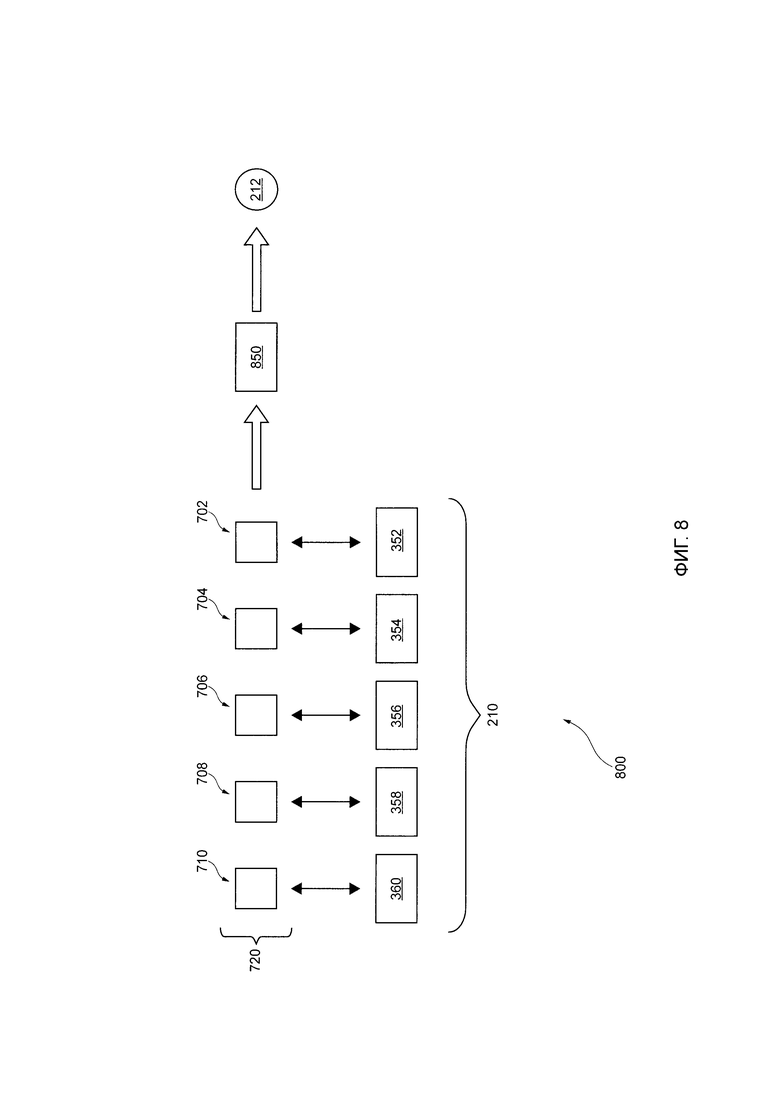
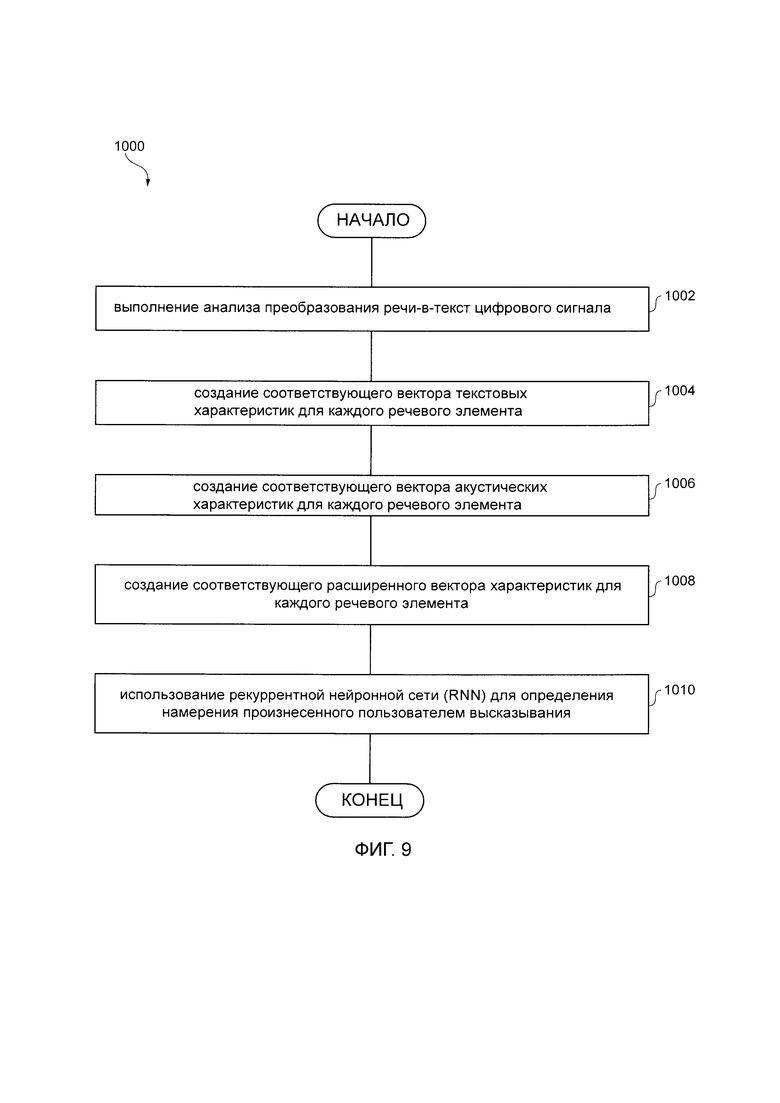
Изобретение относится к средствам для определения намерения, связанного с произнесенным пользователем высказыванием. Технический результат заключается в учете акустических характеристик произнесенного пользователем высказывания для определения намерения, связанного с данным высказыванием. Способ включает в себя определение по меньшей мере одного речевого элемента, причем каждый речевой элемент обладает текстовыми данными, представляющими слово или паузу, и обладает соответствующим сегментом цифрового аудиосигнала. Для каждого речевой элемента способ включает в себя создание соответствующей текстовой характеристики, создание соответствующего вектора акустических характеристик и создание соответствующего расширенного вектора характеристик. Способ также включает в себя использование нейронной сети (NN), выполненной с возможностью определять намерение произнесенного пользователем высказывания путем ввода в NN расширенных векторов характеристик. NN была обучена оценивать вероятность того, что намерение относится к данному типу. 2 н. и 18 з.п. ф-лы, 9 ил.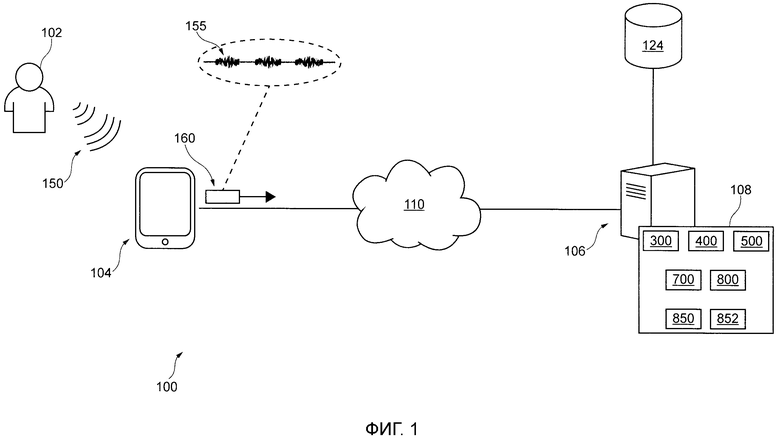
1. Способ определения намерения, связанного с произнесенным пользователем высказыванием, которое улавливается в форме звукового аудиосигнала, причем способ выполняется на сервере и включает в себя:
выполнение сервером анализа преобразования речи-в-текст цифрового сигнала для определения:
по меньшей мере одного речевого элемента произнесенного пользователем высказывания, причем каждый речевой элемент обладает текстовыми данными, представляющими собой одно из: слово и паузу, и каждый речевой элемент обладает соответствующим сегментом цифрового аудиосигнала;
для каждого речевого элемента:
создание соответствующего вектора текстовых характеристик путем:
 определения сервером на основе соответствующих текстовых данных, текстовых характеристик соответствующего речевого элемента;
определения сервером на основе соответствующих текстовых данных, текстовых характеристик соответствующего речевого элемента;
создания сервером на основе соответствующих текстовых характеристик, соответствующего вектора текстовых характеристик;
создание соответствующего вектора акустических характеристик путем:
определения сервером на основе соответствующего сегмента цифрового аудиосигнала соответствующих акустических характеристик соответствующего сегмента цифрового аудиосигнала;
создания сервером на основе соответствующих акустических характеристик, соответствующего вектора акустических характеристик;
создание сервером соответствующего расширенного вектора характеристик путем объединения соответствующего вектора акустических характеристик и соответствующего вектора текстовых характеристик;
использование сервером нейронной сети (NN), выполненной для определения намерения произнесенного пользователем высказывания путем ввода в NN расширенного вектора характеристик, причем NN была обучена для оценки вероятности того, что намерение относится к данному типу.
2. Способ по п. 1, в котором нейронная сеть является рекуррентной нейронной сетью (RNN).
3. Способ по п. 1, в котором выполнение анализа речи-в-текст включает в себя определение:
текстовых данных каждого речевого элемента; и
временного интервала соответствующего сегмента цифрового аудиосигнала каждого речевого элемента.
4. Способ по п. 1, в котором создание соответствующего вектора текстовых характеристик выполняется с помощью процесса внедрения слов, выполняемого сервером.
5. Способ по п. 1, в котором вектор текстовых характеристик данного речевого элемента, являющийся паузой, является вектором с нулевыми значениями.
6. Способ по п. 1, в котором акустические характеристики представляют собой по меньшей мере одно из:
 уровень громкости;
уровень громкости;
уровень энергии;
уровень высоты;
гармонию; и
темп.
7. Способ по п. 1, в котором определение соответствующих акустических характеристик соответствующего сегмента цифрового аудиосигнала включает в себя:
определение сервером соответствующих акустических характеристик каждого подсегмента соответствующего сегмента цифрового аудиосигнала путем применения скользящего окна, и причем
создание соответствующего вектора акустических характеристик включает в себя:
 создание сервером соответствующих промежуточных векторов акустических характеристик для каждого подсегмента на основе соответствующих акустических характеристик; и
создание сервером соответствующих промежуточных векторов акустических характеристик для каждого подсегмента на основе соответствующих акустических характеристик; и
 создание сервером, на основе соответствующих промежуточных векторов акустических характеристик, соответствующего вектора акустических характеристик для соответствующего сегмента цифрового аудиосигнала.
создание сервером, на основе соответствующих промежуточных векторов акустических характеристик, соответствующего вектора акустических характеристик для соответствующего сегмента цифрового аудиосигнала.
8. Способ п. 7, в котором каждый подсегмент обладает заранее определенной продолжительностью во времени.
9. Способ по п. 7, в котором по меньшей мере два подсегмента частично перекрываются.
10. Способ по п. 7, в котором скользящее окно скользит с временным шагом заранее определенной продолжительности во времени.
11. Способ по п. 7, котором создание соответствующего вектора акустических характеристик для соответствующего сегмента цифрового аудиосигнала, которое основано на соответствующих промежуточных векторах акустических характеристик, включает в себя использование сервером основанной на статистике комбинации соответствующих промежуточных векторов акустических характеристик.
12. Способ по п. 12, в котором сочетание соответствующего вектора акустических характеристик и соответствующего вектора текстовых характеристик включает в себя конкатенацию сервером соответствующего вектора акустических характеристик и соответствующего вектора текстовых характеристик.
13. Способ по п. 1, в котором данный тип представляет собой одно из следующего:
вопрос открытого типа;
вопрос закрытого типа;
утверждение; и
восклицание.
14. Способ по п. 1, дополнительно включающий в себя:
получение сервером дополнительных данных, созданных NN для каждого введенного расширенного вектора характеристик, связанного с данным словом;
в ответ на определение того, что намерение относится к данному типу
выполнение сервером дополнительного MLA для определения целевого слова среди по меньшей мере одного слова путем ввода в дополнительный MLA дополнительных данных, причем целевое слово указывает на контекст произнесенного пользователем высказывания.
15. Сервер для определения намерения, связанного с произнесенным пользователем высказыванием, которое улавливается в форме звукового аудиосигнала, сервер выполнен с возможностью осуществлять:
выполнение анализа преобразования речи-в-текст цифрового сигнала для определения:
по меньшей мере одного речевого элемента произнесенного пользователем высказывания, причем каждый речевой элемент обладает текстовыми данными, представляющими собой одно из: слово и паузу, и каждый речевой элемент обладает соответствующим сегментом цифрового аудиосигнала;
для каждого речевого элемента:
создание соответствующего вектора текстовых характеристик путем:
 определения сервером на основе соответствующих текстовых данных, текстовых характеристик соответствующего речевого элемента;
определения сервером на основе соответствующих текстовых данных, текстовых характеристик соответствующего речевого элемента;
создания сервером на основе соответствующих текстовых характеристик, соответствующего вектора текстовых характеристик;
создание соответствующего вектора акустических характеристик путем:
определения сервером на основе соответствующего сегмента цифрового аудиосигнала соответствующих акустических характеристик соответствующего сегмента цифрового аудиосигнала;
создания сервером на основе соответствующих акустических характеристик, соответствующего вектора акустических характеристик;
создание соответствующего расширенного вектора характеристик путем объединения соответствующего вектора акустических характеристик и соответствующего вектора текстовых характеристик;
использование нейронной сети (NN), выполненной для определения намерения произнесенного пользователем высказывания путем ввода в NN расширенного вектора характеристик, причем NN была обучена для оценки вероятности того, что намерение относится к данному типу.
16. Сервер по п. 15, в котором нейронная сеть является рекуррентной нейронной сетью.
17. Сервер по п. 15, который выполнен с возможностью осуществлять анализ речи-в-текст, представляет собой сервер, который выполнен с возможностью определять:
текстовые данные каждого речевого элемента; и
временной интервал соответствующего сегмента цифрового аудиосигнала каждого речевого элемента.
18. Сервер по п. 1, причем сервер, который выполнен с возможностью определять соответствующие акустические характеристики соответствующего сегмента цифрового аудиосигнала, представляет собой сервер, который выполнен с возможностью осуществлять:
определение соответствующих акустических характеристик каждого подсегмента соответствующего сегмента цифрового аудиосигнала путем применения скользящего окна, и причем
сервер, который выполнен с возможностью создавать соответствующий вектор акустических характеристик, представляет собой сервер, который выполнен с возможностью осуществлять:
создание соответствующих промежуточных векторов акустических характеристик для каждого подсегмента на основе соответствующих акустических характеристик; и
создание, на основе соответствующих промежуточных векторов акустических характеристик, соответствующего вектора акустических характеристик для соответствующего сегмента цифрового аудиосигнала.
19. Сервер по п. 1, в котором данный тип представляет собой одно из следующего:
вопрос открытого типа;
вопрос закрытого типа;
утверждение; и
восклицание.
20. Сервер по п. 15, в котором сервер также выполнен с возможностью осуществлять:
получение дополнительных данных, созданных NN для каждого введенного расширенного вектора характеристик, связанного с данным словом;
в ответ на определение того, что намерение относится к данному типу,
выполнение дополнительного MLA для определения целевого слова среди по меньшей мере одного слова путем ввода в дополнительный MLA дополнительных данных, причем целевое слово указывает на контекст произнесенного пользователем высказывания.
| Способ и система для синтеза речи из текста | 2017 |
|
RU2692051C1 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| ГОЛОСОВАЯ СВЯЗЬ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ МЕЖДУ ЧЕЛОВЕКОМ И УСТРОЙСТВОМ | 2014 |
|
RU2583150C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| US 20170263249 A1, 14.09.2017 | |||
| US 20170263248 A1, 14.09.2017. | |||

