ОБЛАСТЬ ТЕХНИКИ
Заявленное изобретение относится к компьютерно-реализованным способам и системам для оценки эмоций и, более конкретно, к способам распознавания речевых эмоций при помощи 3D сверточной нейронной сети.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Распознавание речевых эмоций является сложной темой в области распознавания образов и обработки речевых сигналов и в последние десятилетия вызывает большой исследовательский интерес. Цель распознавания эмоций по речи - классифицировать основные эмоции, включая грусть, радость, страх, гнев, отвращение, удивление, скуку и нейтральные эмоции. Речевые сигналы могут быть использованы в различных приложениях для взаимодействия человека с компьютером. Обычно для распознавания речевых эмоций используется 2D-модель сверточной нейронной сети.
Подобные подходы известны из уровня техники, например система и способ автоматизированной оценки намерений и эмоций пользователей диалоговой системы (см. RU2762702C2, опубл. 22.12.2021), при которых выполняют обработку входных текстовых данных, при которой осуществляется очистка, нормализация и токенизация данных; формируют по меньшей мере один вектор предложения на основании получаемых токенов данных; осуществляют анализ тональности, при котором определяют тип предложения на основании упомянутых векторов предложений с помощью их обработки моделью машинного обучения, при этом тип предложения представляет собой: негативный, позитивный, нейтральный или разговорный; выполняют извлечение диалоговых актов, при котором определяют общее намерение в поступающих предложениях с помощью обработки упомянутого вектора предложения моделью машинного обучения; выполняют обработку упомянутых токенов предложений, полученных по итогу анализа тональности и диалоговых актов, на предмет выявления по меньшей мере одного из: субъект, объект, действие или их сочетания в каждом предложении и определяют конкретное намерение и/или причину, а также эмоции объекта и субъекта на основании обработки упомянутых токенов предложения.
Также из уровня техники известен способ и система анализа голосовых вызовов на предмет выявления и предотвращения социальной инженерии (см. RU2744012, опубл. 02.03.2021), выполняемого с помощью процессора и содержащего этапы, на которых: получают входящий аудиопоток, поступающий от вызывающей стороны; осуществляют обработку входящего аудиопотока с помощью по меньшей мере одной модели машинного обучения, в ходе которой: преобразовывают входящий аудиопоток в векторную форму; выполняют сравнение векторной формы аудиопотока с ранее сохраненными векторами, характеризующими мошенническую активность; осуществляют транскрибирование аудиопотока для анализа диалога вызывающей стороны на по меньшей мере семантический состав информации и паттерн ведения диалога; осуществляют классификацию входящего аудиопотока на основании выполненной обработки.
Указанные подходы основаны на 2D-модели сверточной нейронной сети, и поэтому имеют низкую эффективность.
Из уровня техники также известны устройство, способ и компьютерная программа оценки эмоций (см. JP2022072619A, опубл. 17.05.2022) Устройство оценки эмоций включает в себя: многоголовочный GAT 66, который обновляет соответствующие признаки множества видов модальностей посредством релевантности, присутствующей между признаками, полученными для множества видов модальностей; и полностью подключенный уровень, который оценивает эмоцию человека, используя обновленные признаки множества видов модальностей. Многоголовочный GAT 66 включает в себя блоки обновления, которые вычисляют корреляции, присутствующие между признаками, полученными для множества видов модальностей в качестве внимания между узлами в графовой нейронной сети, которая имеет признаки в качестве узлов и имеет ребра, соединяющие соответствующие узлы, и обновляет характеристику рассматриваемого узла, используя внимание от каждого из соседних узлов, которые являются смежными с узлом среди внимания.
Указанный в ближайшем аналоге подход сложен и имеет большие энергетические потери, что снижает его эффективность.
КРАТКОЕ ИЗЛОЖЕНИЕ ИЗОБРЕТЕНИЯ
Данное изобретение направлено на решение технической проблемы, связанной с созданием способа распознавания речевых эмоций, при помощи 3D сверточной нейронной сети повышенной эффективности.
Техническим результатом изобретения является повышение эффективности распознавания речевых эмоций при помощи 3D сверточной нейронной сети.
Технический результат достигается посредством способа распознавания речевых эмоций при помощи трехмерной (3D) сверточной нейронной сети, реализуемого с помощью компьютера и включающего два основных этапа, на первом этапе предоставляются трехмерные тензоры с использованием реконструированного фазового пространства входных речевых сигналов, а на втором этапе с использованием 3D сверточной нейронной сети, обученной на основе трехмерных тензоров и соответствующих им меткам эмоций, выполняют предсказание эмоций, содержащихся во входных речевых сигналах, при этом используют реконструированное фазовое пространство следующим образом: одномерный сигнал отображается в трехмерном пространстве, а затем трехмерный тензор извлекается для применения в качестве входных данных 3D сверточной нейронной сети.
В частном варианте выполнения трехмерный тензор представляет собой трехмерную гистограмму точек в пространстве, которая является представлением соответствующего речевого сигнала.
В частном варианте выполнения сверточная нейронная сеть использует 3D-фильтры для анализа входных данных, которые относятся к извлечению признаков, при этом в процессе обучения присваиваются веса выходным данным фильтров для выделения или игнорирования информативных или избыточных функций, соответственно, эти веса вычисляют путем минимизации функции потерь, пытающейся связать входные данные с выходными целевыми классами.
В частном варианте выполнения речевые сигналы распознают по полу и затем подвергают независимой обработке, соответствующей полу
КРАТКОЕ ОПИСАНИЕ РИСУНКОВ
Сущность изобретения поясняется рисунками, на которых:
Рис.1 - принципиальная схема предлагаемого способа;
Рис.2 - схема предлагаемого способа распознавания речевой эмоции на основе средней взаимной информации по наборам данных;
Рис.3 - схема трехмерной архитектуры CNN;
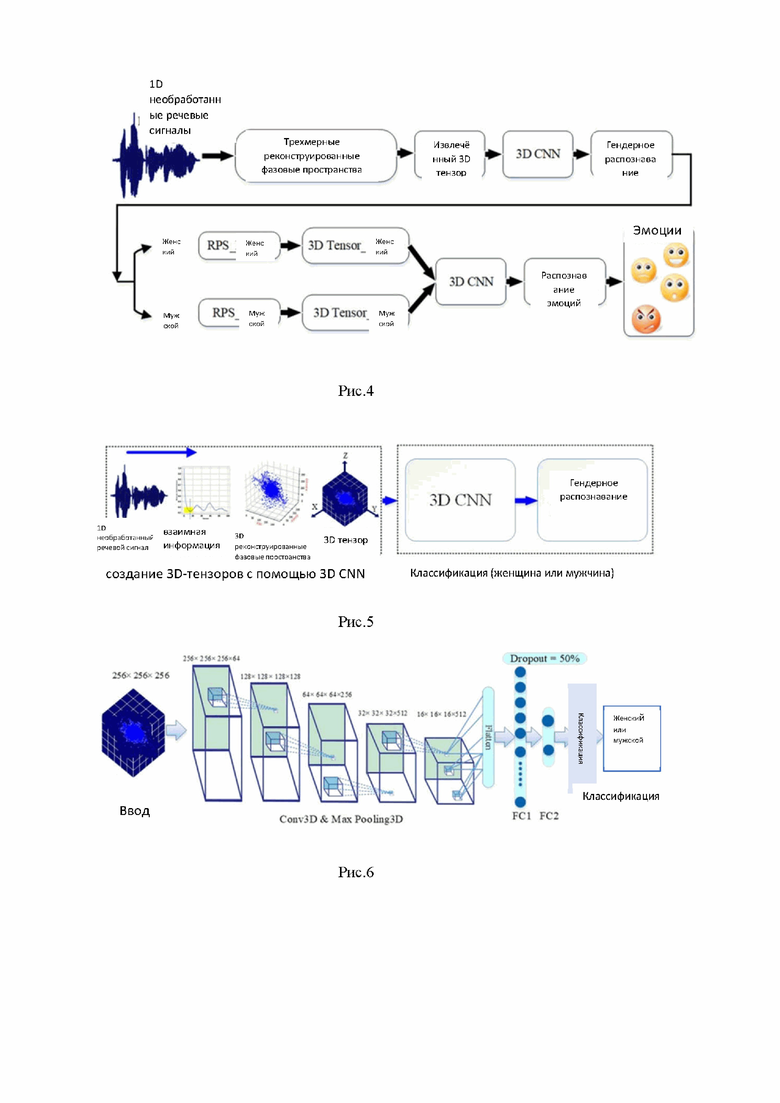
Рис.4 - принципиальная схема предлагаемого способа с учетом признания пола;
Рис.5 - схема предлагаемого способа распознавания пола на основе средней взаимной информации по наборам данных;
Рис.6 - предлагаемая архитектура 3D CNN для распознавания пола.
Эти чертежи не охватывают и, кроме того, не ограничивают весь объем вариантов реализации данного технического решения, а представляют собой только иллюстративный материал частного случая его реализации.
ВАРИАНТ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Заявленный способ распознавания речевых эмоций при помощи 3D сверточной нейронной сети осуществляется следующим образом.
Представленный способ состоит из двух основных этапов. В на первом этапе выполняется предварительная обработка входных речевых сигналов, при которой трехмерные тензоры предоставляются с использованием реконструированного фазового пространства входных речевых сигналов, а на втором этапе - 3D CNN на стадии обучения обучается на основе трехмерных тензоров, предоставленных на первом этапе, и соответствующих им меткам эмоций, а затем на стадии эксплуатации, будучи обученной, выполняет предсказание эмоций, содержащихся в анализируемом входном речевом сигнале. Речевой сигнал имеет нелинейное и хаотическое поведение, поэтому корреляция параметров эмоциональной речи в одномерном пространстве невозможна. Реконструкция сигнала в фазовом пространстве - подходящий способ для изучения сигналов в более высоких измерениях. Чтобы применить совместимые входные данные для 3D CNN сети и изучить взаимосвязь между эмоциональными параметрами, речевые сигналы моделируются и анализируются в трехмерном пространстве. На рис. 1 представлена схема предлагаемого способа распознавания речевых эмоций. Как показано, используя реконструированное фазовое пространство, одномерный сигнал отображается в трехмерное пространство, а затем трехмерный тензор извлекается для применения в качестве входных данных трехмерной CNN.
При реконструкции фазового пространства преобразуется одномерный сигнал, известный как вектор, в d-мерный сигнал, который называется тензором. Для реконструкции фазового пространства системы, выходной сигнал системы принимается как временной ряд Sn, n = 1, 2, 3, …, N. Уравнение (1) показывает строку-вектор, являющейся единственной точкой в реконструированном фазовом пространстве.
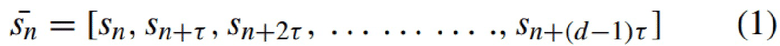 ,
,
где τ обозначает временную задержку, а d указывает размерность.
Все возможные точки системы в реконструированном фазовом пространстве определяются следующей матрицей траекторий:
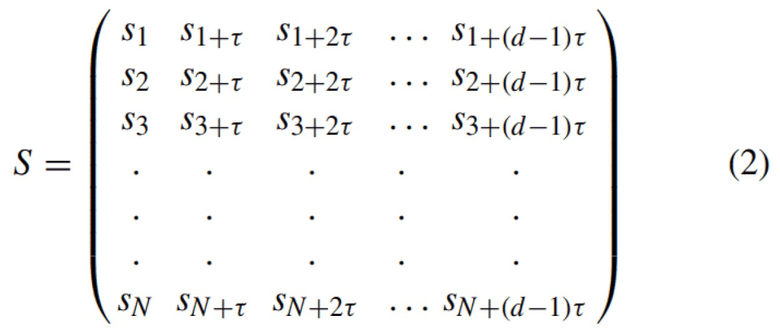
Каждый вектор-строка Sn представляет речевой элемент и его взаимосвязь с образцами с задержкой τ. Основные методы определяют оптимальную временную задержку τ и размерность d на основе взаимной информации и ложных ближайших соседей соответственно. Поскольку входные данные должны быть совместимы с 3D CNN, для установки d = 3 выбирается метод ложных ближайших соседей. Чтобы вычислить подходящее значение τ, используется функция взаимной информации. Функция взаимной информации между двумя сигналами получается из следующего уравнения:
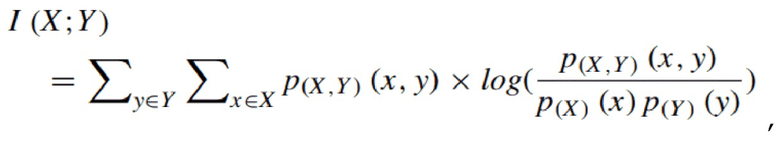
где р(Х,У) - совместная функция распределения вероятностей,
а p(X) и p(Y) - отдельные функции распределения вероятностей.
Первый минимум функции взаимной информации является оптимальным. Вычисление параметра τ для каждого речевого образца занимает много времени и имеет высокую вычислительную сложность, поэтому в качестве оптимальной временной задержки рассматривается первый минимум функции взаимной информации. Кроме зависимости τ, основанной на временной задержке, частота дискретизации речевых сигналов является еще одним параметром, влияющим на вычисления τ. Найдя подходящие значения τ и d, можно смоделировать реконструированное фазовое пространство. Задание оптимального значения τ очень важно для анализа реконструированного фазового пространства. В конкретном примере первый минимум средней функции взаимной информации в качестве оптимальных временных задержек в наборах данных EMO-DB и eNTERFACE05 расположены на τ = 17 и τ = 31, соответственно. Каждый образец речи в них имеет разное первое минимальное значение функции взаимной информации.
Процедура создания 3D тензоров из 1D необработанных речевых сигналов должна быть совместима с 3D CNN для распознавания речевых эмоций, как показано на рисунке 2. Как показано на этом рисунке, соответствующие значения временных задержек были установлены на τ = 17 для набора данных EMO-DB и τ = 31 для набора данных eNTERFACE05.
Реконструированное фазовое пространство речевого сигнала представлено в многомерном пространстве. Поскольку целью является создание совместимых входных данных для 3D CNN с использованием речевых образцов, формируют трехмерное реконструированное фазовое пространство каждого речевого сигнала, которое затем преобразуется в трехмерный тензор. При этом каждая ось трехмерного пространства разбивается на 256 сегментов. Следовательно, пространство преобразуется в сетку 256 × 256 × 256. Следовательно, трехмерная матрица рассматривается как трехмерный тензор. Другими словами, выходной трехмерный тензор представляет собой трехмерную гистограмму точек в пространстве. Таким образом, каждый трехмерный тензор можно рассматривать как представление соответствующего речевого сигнала, помеченного соответствующей эмоцией в наборе данных. Далее этот трехмерный тензор будет применяться к 3D CNN для обучения, тестирования и эксплуатации. Число 256 устанавливается произвольно, так как его можно сопоставить с размером входа сети через процедуру изменения размера. Однако предпочтительнее выбирать значение, равное размеру входа сети, чтобы избежать дополнительных вычислений.
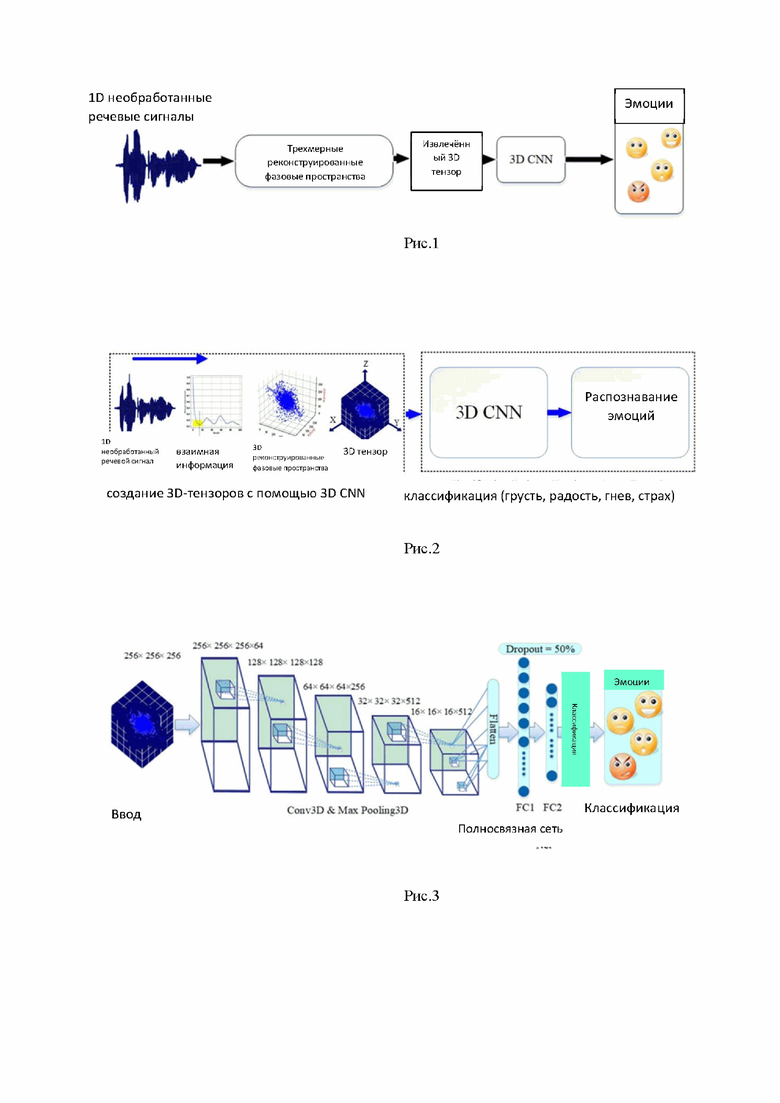
Структура предлагаемой трехмерной модели CNN отображается на Рис. 3. Эта модель основана на архитектуре VGG16, которая является наиболее успешной в классификации двумерных изображений. В настоящем изобретении аналогичная архитектура предложена в трехмерном виде.
Были проведены эксперименты, чтобы проверить, можно ли улучшить производительность классификации путем упрощения модели, удалив часть слоев, или путем добавления новых слоев. Для этого был добавлен сверточный слой перед первым слоем предлагаемой модели. Это привело к снижению общей скорости классификации. Далее был добавлен сверточный слой в конце модели, непосредственно перед слоем сглаживания. Это также привело к падению скорости. В других экспериментах, имеющиеся у модели VGG16 первый и последний сверточные слои, наоборот, были удалены. Эти эксперименты также привели к снижению общей производительности классификации. Следовательно, предлагаемая структура модели наиболее эффективна, когда задана аналогично архитектуре VGG16.
Трехмерная CNN обучается на трехмерных тензорах, полученных из реконструированного представления речевых сигналов в фазовом пространстве. В отличие от классических систем распознавания образов, CNN объединяет этапы выделения и классификации признаков в сквозную модель, которая выполняет обе задачи. Следовательно, 3D CNN можно рассматривать как модель, которая может изучать признаки трехмерных тензоров (которые представляют собой новое представление входных речевых сигналов), связанных с метками целевых эмоций. Как показано на рисунке 3, 3D CNN использует 3D-фильтры для анализа входных данных, которые относятся к извлечению признаков. Затем присваиваются веса выходным данным фильтров для выделения или игнорирования информативных или избыточных функций, соответственно. Эти веса вычисляются в процессе обучения путем минимизации функции потерь, пытающейся связать входные данные с выходными целевыми классами.
Вход предлагаемой сети представляет собой трехмерный тензор с размером 256 × 256 × 256. Меньшая размерность входных данных может снизить разрешение и, следовательно, привести к потере полезной информации, большая размерность может усложнить вычисления. 3D CNN состоит из трех типов слоев, в том числе свертки, пулинга (подвыборки) и полносвязных слоев, где каждый слой выполняет свою конкретную задачу. Предлагаемая 3D архитектура CNN состоит из пяти сверточных слоев с 64, 128, 256, 512 и 512 3D-фильтрами. Размер ядра сверточных слоев 3 × 3 × 3 с шагом 1. Имеется слой max-pooling (подвыборки по максимальному значению) с размером ядра 2×2×2 и размером шага 2 после каждого сверточного слоя. Этот слой max-pooling отвечает не только за выборку, но и уменьшает размеры элементов. Наконец, дальше располагаются слой выравнивания и два полносвязных слоя. Слой выравнивания преобразует трехмерный тензор в вектор. Первый полносвязный слой (FC1) состоит из 1000 нейронов, а последний полносвязный слой (FC2) - это слой классификатора с количеством нейронов, соответствующим числу эмоций. Число эмоций в конкретном примере в наборах данных EMO-DB и eNTERFACE05 составляет 7 и 6, соответственно. В качестве функции активации в первом полносвязном и в сверточных слоях может использоваться, например, ReLU или другая подходящая функция. В последнем полносвязном слое (классификаторе) может использоваться, например, функция активации softmax.
Из-за ключевой роли τ в реконструированных фазовых пространствах и анализа методом функции взаимной информации, для получения более высокой точности способа предлагается проводить вычисления τ на основе распознавания пола. С этой целью речевые сигналы от мужчин и женщин моделируются независимо в каждом наборе данных. Результаты показывают, что существует значительная разница между средним значением τ для мужчин и женщин в EMO-DB и наборах данных eNTERFACE05. На рис. 4 представлена структурная схематическая диаграмма для распознавания речевых эмоций на основе распознавания пола. Как показано на рис.4, в предложенный способ было добавлено распознавание пола. Для этого предлагаемая трехмерная сверточная нейронная сеть должна классифицировать входные речевые сигналы на основе пола на две категории: женскую и мужскую. Затем реконструированные фазовые пространства и трехмерные тензоры могут быть извлечены из речевых сигналов мужчин и женщин по отдельности.
Как показано на рис. 5, трехмерный тензор, созданный из одномерного необработанного речевого сигнала, был применен к 3D CNN для классификации мужских и женских сигналов. На этом этапе оптимальные временные задержки представлены на τ = 17 для набора данных EMO-DB и τ = 15 для набора данных eNTERFACE05 аналогично тому, как выше в настоящем документе это делалось без учета пола.
Блок-схема предлагаемой трехмерной модели CNN для распознавания пола показана на рис. 6. Параметры 3D CNN такие же, как описано на рис. 2. Первый полностью связный слой (FC1) состоит из 1000 нейронов, а последний полносвязный слой (FC2) - это слой классификатора с 2 нейронами, соответствующими женскому или мужскому полу.
Для разработки и оценки предлагаемой трехмерной модели CNN используется аппаратное обеспечение рабочей станции с процессором Intel Core i7-7500U с графическим процессором NVIDIA GeForce GTX 960M (4 ГБ) и оперативной памятью DDR4 объемом 16 ГБ. Python использовался для всех реализаций, которые проводились на платформе Spyder в среде Anaconda. Библиотека Skedm применялась для создания реконструкции фазового пространства. Библиотека Keras, работающая поверх платформы TensorFlow, использовалась для разработки 3D-модели CNN. CUDA Toolkit v8 и cuDNN v6 использовались для выполнения GPU в рамках TensorFlow. Метод отсева со скоростью 0,5 был принят для полносвязных слоев. Этот метод позволяет избежать риска переобучения, временно удаляя нейроны из каждого слоя. Тесты выполняются на наборах данных EMO-DB и eNTERFACE05 на основе архитектуры 3D CNN с использованием стратегии перекрестной проверки, называемой независимой от говорящего. В стратегии, не зависящей от говорящего, тестовые прогоны выполняются с применением схем «выход одного говорящего» (LOSO) и «выход группы одного говорящего» (LOSGO). Когда в наборе данных несколько человек, выбирается метод LOSO, а если в наборе данных много людей, выбирается метод LOSGO. Таким образом, схема LOSO применяется для EMO-DB, а схема LOSGO используется для eNTERFACE05.
Заявленное изобретение предлагает использовать 3D CNN для распознавания речевых эмоций. Предлагаемая 3D CNN напрямую использует сгенерированные трехмерные тензоры из реконструированного фазового пространства речевых сигналов. Результаты на наборах данных EMO-DB и eNTERFACE05 показывают, что предлагаемые трехмерные тензоры содержат существенные эмоциональные сигналы говорящих и, следовательно, 3D CNN может с повышенной вычислительной эффективностью и точностью классифицировать соответствующие эмоции. Использование техники распознавания пола для предложенных 3D CNN позволяет дополнительно улучшить показатели точности.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОБРАБОТКИ ДВУХМЕРНОГО ИЗОБРАЖЕНИЯ И РЕАЛИЗУЮЩЕЕ ЕГО ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ПОЛЬЗОВАТЕЛЯ | 2018 |
|
RU2703327C1 |
| Способ и электронное устройство для обнаружения трехмерных объектов с помощью нейронных сетей | 2021 |
|
RU2776814C1 |
| Способ автоматической классификации рентгеновских изображений с использованием масок прозрачности | 2019 |
|
RU2716914C1 |
| СИСТЕМА СЖАТИЯ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ НА ОСНОВЕ ИТЕРАТИВНОГО ПРИМЕНЕНИЯ ТЕНЗОРНЫХ АППРОКСИМАЦИЙ | 2019 |
|
RU2734579C1 |
| ВИЗУАЛИЗАЦИЯ РЕКОНСТРУКЦИИ 3D-СЦЕНЫ С ИСПОЛЬЗОВАНИЕМ СЕМАНТИЧЕСКОЙ РЕГУЛЯРИЗАЦИИ НОРМАЛЕЙ TSDF ПРИ ОБУЧЕНИИ НЕЙРОННОЙ СЕТИ | 2023 |
|
RU2825722C1 |
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ПРЕОБРАЗОВАНИЯ ТЕКСТА В РЕЧЬ | 2020 |
|
RU2775821C2 |
| Способ обеспечения компьютерного зрения | 2022 |
|
RU2791587C1 |
| СПОСОБ СЕГМЕНТАЦИИ ИЗОБРАЖЕНИЯ С ИСПОЛЬЗОВАНИЕМ НЕЙРОННОЙ СЕТИ | 2017 |
|
RU2720440C1 |
| РЕПРОДУЦИРУЮЩАЯ АУГМЕНТАЦИЯ ДАННЫХ ИЗОБРАЖЕНИЯ | 2018 |
|
RU2716322C2 |
Заявленное изобретение относится к компьютерно-реализованным способам и системам для оценки эмоций и, более конкретно, к способам распознавания речевых эмоций при помощи 3D сверточной нейронной сети. Способ распознавания речевых эмоций при помощи трехмерной (3D) сверточной нейронной сети, реализуемый с помощью компьютера и включающий два основных этапа, на первом этапе предоставляются трехмерные тензоры с использованием реконструированного фазового пространства входных речевых сигналов, а на втором этапе с использованием 3D сверточной нейронной сети, обученной на основе трехмерных тензоров и соответствующих им меткам эмоций, выполняют предсказание эмоций, содержащихся во входных речевых сигналах, при этом используют реконструированное фазовое пространство следующим образом: одномерный сигнал отображается в трехмерном пространстве, а затем трехмерный тензор извлекается для применения в качестве входных данных 3D сверточной нейронной сети. Техническим результатом изобретения является повышение эффективности распознавания речевых эмоций при помощи 3D сверточной нейронной сети. 3 з.п. ф-лы, 6 ил.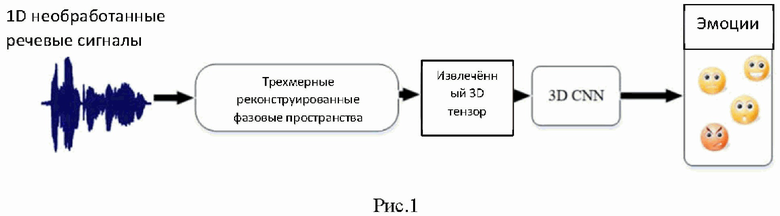
1. Способ распознавания речевых эмоций при помощи трехмерной (3D) сверточной нейронной сети, реализуемый с помощью компьютера и включающий два основных этапа, на первом этапе предоставляются трехмерные тензоры с использованием реконструированного фазового пространства входных речевых сигналов, а на втором этапе с использованием 3D сверточной нейронной сети, обученной на основе трехмерных тензоров и соответствующих им меткам эмоций, выполняют распознавание эмоций, содержащихся во входных речевых сигналах, при этом используют реконструированное фазовое пространство следующим образом: одномерный сигнал отображается в трехмерном пространстве, а затем трехмерный тензор извлекается для применения в качестве входных данных 3D сверточной нейронной сети.
2. Способ распознавания речевых эмоций по п.1, отличающийся тем, что трехмерный тензор представляет собой трехмерную гистограмму точек в пространстве, которая является представлением соответствующего речевого сигнала.
3. Способ распознавания речевых эмоций по п.1, отличающийся тем, что сверточная нейронная сеть использует 3D-фильтры для анализа входных данных, которые относятся к извлечению признаков, при этом в процессе обучения присваиваются веса выходным данным фильтров для выделения или игнорирования информативных или избыточных функций, соответственно, эти веса вычисляют путем минимизации функции потерь, пытающейся связать входные данные с выходными целевыми классами.
4. Способ распознавания речевых эмоций по п.1, отличающийся тем, что речевые сигналы распознают по полу и затем подвергают независимой обработке, соответствующей полу.
| CN 106782602 B, 31.05.2017 | |||
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| РЕЗОНАНСНЫЙ СЕЙСМИЧЕСКИЙ ИСТОЧНИК ВИБРАЦИИ | 1991 |
|
RU2028647C1 |
| Электромагнитный прерыватель | 1924 |
|
SU2023A1 |
| СПОСОБ И ОБОРУДОВАНИЕ РАСПОЗНАВАНИЯ ЭМОЦИЙ В РЕЧИ | 2019 |
|
RU2720359C1 |

