ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к кодированию или декодированию блоков заданной компоненты видео, в частности, интра-предсказанию (intra prediction) таких блоков компоненты или получению выборок таких блоков. Изобретение находит применение в получении блоков компоненты, обычно блоков компоненты хромы, видеоданных из выборок другой компоненты, обычно выборок люмы.
УРОВЕНЬ ТЕХНИКИ
Предсказательное кодирование видеоданных базируется на делении кадров на блоки пикселей. Для каждого блока пикселей, в доступных данных производится поиск блок предсказателя. Блоком предсказателя может быть блок в опорном кадре, отличном от текущего в интер-режимах кодирования, или сформированный из соседних пикселей в текущем кадре в интра-режимах кодирования. В разных режимах кодирования блок предсказателя определяется по-разному. Результатом кодирования является сигнализация блока предсказателя и остаточного блока, представляющего собой разность между блоком, подлежащим кодированию, и блоком предсказателя.
Что касается интра-режимов кодирования, обычно предусмотрены различные режимы, например, режим постоянного тока (DC), плоскостной режим и угловые режимы. В каждом из них выборки блока предсказываются с использованием ранее декодированных граничных выборок из пространственно соседствующих блоков.
Кодирование может осуществляться для каждой компоненты, образующей пиксели видеоданных. Хотя представление RGB (красный-зеленый-синий) общеизвестно, для кодирования предпочтительно используемый представление YUV, чтобы снизить межканальную избыточность. Согласно этим режимам кодирования, блок пикселей можно рассматривать как состоящий из нескольких, обычно трех, блоков компонентов. Блок пикселей RGB состоит из блока R-компоненты, содержащего значения R-компоненты пикселей блока, блока G-компоненты, содержащего значения G-компоненты этих пикселей, блока B-компонента, содержащего значения B-компоненты этих пикселей. Аналогично, блок пикселей YUV состоит из блока Y компоненты (люмы), блока U-компоненты (хромы) и V-компоненты блока (также хромы). Другим примером является YCbCr, где Cb и Cr также известны как компоненты хромы. Однако локально все еще наблюдается интеркомпонентная (также известная как межкомпонентная) корреляция.
Для повышения эффективности сжатия, в уровне техники известно использование межкомпонентного предсказания (CCP). CCP в основном применяется для предсказания от люмы к хроме. Это означает, что выборки люмы уже закодированы и реконструируются из кодированных данных (на декодере), и что хрома предсказывается из люмы. Однако CCP можно использовать для предсказания от хромы к хроме или, в более общем случае, для предсказания от первой компоненты ко второй компоненте (в том числе RGB).
Межкомпонентное предсказание может применяться непосредственно к блоку пикселей хромы или может применяться к остаточному блоку хромы (то есть к разности между блоком хромы и предсказателем блока хромы).
В режиме линейной модели (LM) линейная модель используется для предсказания хрома из люмы как интра-режим предсказания хромы, на основе одного или двух параметров, наклона (α) и смещения (β), подлежащих определению. Таким образом, интра-предсказатель хромы выводится из реконструированных выборок люмы текущего блока люмы с использованием линейной модели с параметрами.
Линейность, т.е. параметры α и β, выводится из реконструированных каузальных выборок, в частности, из соседствующего набора выборок хромы, содержащего реконструированные выборки хромы, соседствующие с текущим блоком хромы для предсказания и из соседствующего набора выборок люмы, содержащего выборки люмы, соседствующие с текущим блоком люмы.
В частности, для блока хромы N×N, N соседей над строкой и N соседей слева от столбца используются для формирования соседствующего набора выборок хромы для вывода.
Соседствующий набор выборок люмы также выполнен из N соседствующих выборок непосредственно над соответствующим блоком люмы и N соседствующих выборок слева от блока люмы.
Известно уменьшение размера видеоданных для кодирования без значительного ухудшения визуальной рендеризации, путем понижающей дискретизации компонентов хромы. Известные режимы понижающей дискретизации обозначаются 4:1:1, 4:2:2, 4:2:0.
В ситуации, когда данные хромы видео дискретизируются с понижением, блок люмы, соответствующий блоку хромы N×N, больше, чем N×N. В этом случае, соседствующий набор выборок люмы дискретизируется с понижением для согласования разрешения хромы. Интра-предсказатель хромы для предсказания выборок хромы в текущем блоке хромы N×N нужно формировать с использованием линейной модели, выведенной с одним или более параметрами α и β, и реконструированных выборок люмы текущего блока люмы, которые заранее дискретизируются с понижением для согласования разрешения хромы. Понижающая дискретизация реконструированных выборок люмы до разрешения хромы позволяет извлекать такое же количество выборок, сколько выборок хромы нужно для формирования набора выборок люмы и интра-предсказателя хромы.
Таким образом, интра-предсказатель хромы вычитается из текущего блока хромы для получения остаточного блока хромы, который кодируется на кодере. Напротив, на декодере, интра-предсказатель хромы прибавляется к принятому остаточному блоку хромы для извлечения блока хромы, что также известно как реконструкция декодированного блока. При этом также можно обрезать результаты сложения, выходящие за пределы диапазона выборки.
Иногда остаточный блок хромы бывает пренебрежимо мал и поэтому не учитывается при кодировании. В этом случае вышеупомянутый интра-предсказатель хромы используется как сам блок хромы. В результате, вышеупомянутый режим LM позволяет получать выборку для текущего блока заданной компоненты из связанной (т.е. совмещенной или соответствующей) реконструированной выборки блока другой компоненты в одном и том же кадре с использованием линейной модели с одним или более параметрами. Выборка получается с использованием выведенной линейной модели с одним или более параметрами и связанных реконструированных выборок в блоке другой компоненты. При необходимости, блок другой компоненты выполнен из выборок, дискретизированных с понижением, для согласования с разрешением блока текущей компоненты. Хотя блок текущей компоненты обычно является блоком хромы, и блок другой компоненты - блоком люмы, это не всегда может быть так. Для ясности и простоты, приведенные здесь примеры сосредоточены на предсказании блока хромы из блока люмы, очевидно, что описанный механизм может применять для предсказания любой компоненты из другой компоненты.
Уже известна объединенная исследовательская модель (JEM) объединенной исследовательской команды видео (JVET), которая добавляет шесть межкомпонентных (от люмы к хроме) режимов линейной модели к традиционным режимам интра-предсказания. Все эти режимы состязаются друг с другом в предсказании или формировании блоков хромы, выбор обычно делается на основании критерия скорости-искажения на стороне кодера.
Шесть межкомпонентных (от люмы к хроме) режимов линейной модели отличаются друг от друга схемами понижающей дискретизации, используемыми для понижающей дискретизации реконструированных выборок люмы и/или наборами выборок, из которых выводятся параметры α и β.
Например, наборы выборок могут быть выполнены из двух линий (т.е. строк и столбцов) выборок, соседствующих с текущим блоком люмы или хромы, причем эти линии параллельны и непосредственно соседствуют с каждой из верхней и/или левой границ текущего блока люмы или хромы при разрешении хромы. Такой иллюстративный набор выборок описан в публикации US 9736487.
Другие иллюстративные наборы выборок также раскрыты в публикациях US 9288500 и US 9462273.
Схемы понижающей дискретизации, используемые в JEM, включают в себя фильтр 6-го порядка (6-tap filter), определяющий дискретизированную с понижением реконструированную выборку люмы из шести реконструированных выборок люмы, а также три фильтра 2-го порядка, которые выбирают либо верхнюю правую и нижнюю правую выборки из шести реконструированных выборок люмы, либо нижнюю и нижнюю правую выборки, либо верхнюю и верхнюю правую выборки, и фильтр 4-го порядка, который выбирает верхнюю, верхнюю правую, нижнюю и нижнюю правую выборки из шести реконструированных выборок люмы.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
JEM сложна в отношении обработки. Например, она требует сложного вывода параметров линейной модели для вычисления выборок блока предсказателя хромы.
Настоящее изобретение призвано решать один или более из вышеупомянутых вопросов. Оно предусматривает улучшенный способ получения выборки хромы для текущего блока хромы, возможно, посредством интра-предсказания хромы.
Согласно первому аспекту настоящего изобретения, предусмотрен способ по п. 1.
Согласно другому аспекту настоящего изобретения, предусмотрено устройство для кодирования изображений по п. 29.
Согласно другому аспекту настоящего изобретения, предусмотрено устройство для декодирования изображений по п. 30.
Согласно другому аспекту настоящего изобретения, предусмотрены компьютерный программный продукт, компьютерно-считываемый носитель или компьютерная программа по пп. 31-33.
Дополнительные аспекты изобретения обеспечены в зависимых пунктах формулы изобретения.
Согласно еще одному аспекту, предусмотрен способ вывода линейной модели для получения значения выборки первой компоненты из связанного реконструированного значения выборки второй компоненты, причем способ содержит: взятие двух наборов из двух или более наборов, каждого набора, содержащего значение выборки первой компоненты и значение выборки второй компоненты, из реконструированных значений выборки первой компоненты и второй компоненты; и вывод линейной модели на основании отношения изменений значений выборки первой компоненты и значений выборки второй компоненты между двумя наборами, благодаря чему, значения выборки первой компоненты из двух наборов получаются из значений выборки второй компоненты соответствующих наборов с использованием выведенной линейной модели.
Следует понимать, что значение выборки первой компоненты и связанное реконструированное значение выборки второй компоненты связаны друг с другом заранее заданным соотношением.
Соответственно, заранее заданное соотношение состоит в том, что они совмещены друг с другом или соответствуют друг другу. Это соотношение совмещения или соответствия, может задаваться для каждого значения выборки по отдельности, или между блоком/группы значений выборки первой компоненты и блоком/группой значений выборки второй компоненты.
Соответственно, заранее заданное соотношение состоит в том, что они связаны с по меньшей мере одним пикселем текущего блока пикселей, подлежащего обработке, например они являются совмещенными, или соответствующими, значениями выборки по меньшей мере одного пикселя, подлежащего обработке. Это соотношение совмещения или соответствия может задаваться для каждого значения выборки по отдельности, или между блоком/группой значений выборки и блоком/группой пикселей.
Также понятно, что процесс понижающей дискретизации или повышающей дискретизации может применяться к блоку значений выборки первой компоненты или значений выборки второй компоненты, благодаря чему, заранее заданное соотношение между блоками, или с по меньшей мере одним пикселем текущего блока пикселей, можно устанавливать после понижающей дискретизации /повышающей дискретизации.
Соответственно, значение выборки первой компоненты и связанное значение выборки второй компоненты связаны с блоками пикселей одного и того же изображения, или кадра, подлежащего обработке. Следует понимать, что здесь набор, содержащий значение выборки первой компоненты и значение выборки второй компоненты является набор значений выборки компонента, содержащий значение выборки первой компоненты и значение выборки второй компоненты. Поэтому набор представляет собой n-кортеж, элементами которого являются значение выборки первой компоненты и значение выборки второй компоненты. Соответственно, набор представляет собой 2-кортеж. Альтернативно, набор представляет собой n-кортеж, имеющий более двух элементов (n элементов).
Соответственно, реконструированные значения выборки первой компоненты и второй компоненты связаны с одним или более блоков, соседствующих текущему блоку, подлежащему обработке. Соответственно, один или более блоков, соседствующих с текущим блоком, располагаются выше или слева текущего блока.
Соответственно, два взятых набора являются наборами, содержащими наименьшее значение выборки второй компоненты и наибольшее значение выборки второй компоненты из значений выборки второй компоненты в двух или более наборах. Соответственно, два взятых набора являются наборами, содержащими наименьшее значение выборки первой компоненты и наибольшее значение выборки первой компоненты из значений выборки первой компоненты в двух или более наборах.
Соответственно, взятие двух наборов содержит: определение первой группы наборов, содержащих наименьшее значение выборки второй компоненты и наибольшее значение выборки второй компоненты из значений выборки второй компоненты в двух или более наборах; определение второй группы наборов, содержащих наименьшее значение выборки первой компоненты и наибольшее значение выборки первой компоненты из значений выборки первой компоненты в двух или более наборах; и выбор двух наборов из наборов первой группы и второй группы.
Соответственно, выбор двух наборов из наборов первой группы и второй группы содержит: выбор первой группы, если разность между наименьшим значением выборки второй компоненты и наибольшим значением выборки второй компоненты больше, чем разность между наименьшим значением выборки первой компоненты и наибольшим значением выборки первой компоненты; и выбор второй группы в противном случае.
Соответственно, выбор двух наборов из наборов первой группы и второй группы содержит: определение позиций значений выборки наборов первой группы и второй группы; и выбор двух наборов на основании определенных позиций значений выборки. Соответственно, позиции значений выборки определяются для реконструированных значений выборки второй компоненты в отношении блока реконструированных значений выборки второй компоненты, который связан с блоком значений выборки первой компоненты, подлежащим обработке. Соответственно, позиции значений выборки определяются для реконструированных значений выборки первой компоненты в отношении блока реконструированных значений выборки первой компоненты подлежащий обработке. Соответственно, позиции значений выборки определяются на основании связанных/совмещенных/соответствующих позиций, заданных в отношении блока пикселей, подлежащих обработке.
Соответственно, выбор двух наборов на основании определенных позиций значений выборки содержит выбор набора, содержащего значение выборки в заранее определенной позиции, соседствующей блоку, подлежащему обработке. Соответственно, выбор двух наборов на основании определенных позиций значений выборки содержит: определение, содержит ли любой из наборов первой группы и второй группы значение выборки в заранее определенной позиции; и выбор набора, содержащего значение выборки в заранее определенной позиции в качестве одного из двух наборов. Соответственно, выбор двух наборов на основании определенных позиций значений выборки содержит: если набор, содержащий значение выборки в заранее определенной позиции, недоступен, определение, содержит ли какой-либо из наборов первой группы и второй группы значение выборки в другой заранее определенной позиции; и выбор набора, содержащего значение выборки в другой заранее определенной позиции в качестве одного из двух наборов. Соответственно, заранее определенная позиция или другая заранее определенная позиция является левой нижней или правой верхней позицией из позиций, соседствующей с текущим блоком, подлежащим обработке.
Соответственно, выбор двух наборов из первой группы и второй группы наборов содержит сравнение расстояния между двумя наборами из первой группы и второй группы наборов, где расстояния задаются в пространстве значений выборки первой и второй компоненты, которая задается элементами наборов, благодаря чему, каждый набор из двух или более наборов соответствует позиции в упомянутом пространстве.
Соответственно, выбор двух наборов содержит: определение, больше ли расстояние между наборами в первой группе, чем расстояние между наборами во второй группе; и выбор первой группы, если расстояние между наборами в первой группе больше, чем расстояние между наборами во второй группе, и выбор второй группы в противном случае. Соответственно, выбор двух наборов содержит выбор двух наборов с наибольшим расстоянием между ними из первой группы и второй группы наборов.
Соответственно, выбор двух наборов содержит: определение, имеют ли соответствующие элементы наборов в первой группе одинаковые или разные значения; и выбор первой группы, если соответствующие элементы не имеют одинаковые значения или имеют разные значения, и выбор второй группы, если соответствующие элементы имеют одни и те же значения или не имеют разные значения. Соответственно, соответствующие элементы наборов являются одним или обоими из значений выборки первой компоненты и значений выборки второй компоненты.
Соответственно, выбор двух наборов содержит: определение, имеют ли соответствующие элементы наборов во второй группе одинаковые или разные значения; и выбор второй группы, если соответствующие элементы не имеют одинаковые значения или имеют разные значения, и выбор первой группы, если соответствующие элементы имеют одни и те же значения или не имеют разные значения.
Соответственно, выбор двух наборов содержит: получение отношения изменений значений выборки первой компоненты и значений выборки второй компоненты между наборами первой группы; определение, больше ли полученное отношение, равно или меньше, чем заранее заданное значение; и выбор первой группы, если полученное отношение больше, равно или меньше, чем заранее заданное значение, и выбор второй группы в противном случае. Соответственно, выбор двух наборов содержит: получение отношения изменений значений выборки первой компоненты и значений выборки второй компоненты между наборами второй группы; определение, больше ли полученное отношение, равно или меньше, чем заранее заданное значение; и выбор второй группы, если полученное отношение больше, равно или меньше, чем заранее заданное значение, и выбор первой группы в противном случае.
Соответственно, взятые два набора являются наборами, содержащими значения выборки второй компоненты из одного или более блоков, соседствующих с блоком значений выборки второй компоненты, который связан с текущим блоком, подлежащим обработке, и взятие двух наборов содержит выбор двух наборов на основании их значений выборки второй компоненты. Соответственно, взятые два набора являются наборами, содержащими два наиболее часто возникающие значения выборки второй компоненты из реконструированных значений выборки блока соответствующих значений выборки второй компоненты.
Соответственно, реконструированные значения выборки второй компоненты делятся на по меньшей мере две группы, и, для каждой группы, берутся два набора, и линейная модель выводится на основании взятых двух наборов. Соответственно, если два набора, взятые для группы, имеют отношение изменений значений выборки первой компоненты и значений выборки второй компоненты между наборами меньшее или равное заранее заданному значению, линейная модель для этой группы выводится на основании двух наборов, взятые для другой группы. Соответственно, если два набора, взятые для группы, имеют отношение изменений значений выборки первой компоненты и значений выборки второй компоненты между наборами меньшее или равное заранее заданному значению, линейная модель для этой группы выводится на основании двух взятых наборов, если все реконструированные значения выборки второй компоненты принадлежат одной группе.
Согласно еще одному аспекту, предусмотрен способ кодирования или декодирования одного или более изображений в битовый поток или из битового потока, причем способ содержит этап, на котором выводят линейную модель для получения значения выборки первой компоненты из связанного реконструированного значения выборки второй компоненты согласно способу первого аспекта настоящего изобретения.
Соответственно, способ дополнительно содержит выбор одного из множества режимов вывода линейной модели для получения значения выборки первой компоненты для текущего блока изображения, подлежащего обработке, где множество режимов вывода линейной модели содержит первый режим, в котором используется единая линейная модель, и второй режим, в котором используется более одной линейной модели, и выведенная линейная модель пригодна в выбранном режиме вывода линейной модели. Соответственно, выведенная линейная модель используется только в первом режиме. Альтернативно, выведенная линейная модель используется только во втором режиме.
Согласно еще одному аспекту, предусмотрено устройство для вывода линейной модели для получения значения выборки первой компоненты из связанного реконструированного значения выборки второй компоненты, причем устройство выполнено с возможностью осуществления способа первого аспекта настоящего изобретения.
Согласно еще одному аспекту, предусмотрено устройство для кодирования или декодирования одного или более изображений в битовый поток или из битового потока, причем устройство выполнено с возможностью осуществления способа второго аспекта настоящего изобретения.
Согласно еще одному аспекту, предусмотрен способ получения значения выборки первой компоненты из связанного реконструированного значения выборки второй компоненты, причем способ содержит: выбор одного режима линейной модели из множества режимов линейной модели для получения значения выборки первой компоненты; и получение значения выборки первой компоненты с использованием выбранного режима линейной модели, причем по меньшей мере один из множества режимов линейной модели использует линейную модель, выведенную с использованием способа вывода согласно первому аспекту настоящего изобретения. Соответственно, множество режимов линейной модели содержит первый режим, в котором используется единая линейная модель, и второй режим, в котором используется более одной линейной модели. Соответственно, только первый режим использует способ вывода согласно первому аспекту настоящего изобретения. Альтернативно, только второй режим использует способ вывода согласно первому аспекту настоящего изобретения.
Согласно еще одному аспекту, предусмотрено устройство для получения значения выборки первой компоненты из связанного реконструированного значения выборки второй компоненты, причем устройство выполнено с возможностью осуществления способа пятого аспекта настоящего изобретения.
Согласно еще одному аспекту, предусмотрен способ кодирования одного или более изображений в битовый поток, причем способ содержит получение значения выборки первой компоненты из связанного реконструированного значения выборки второй компоненты согласно пятому аспекту настоящего изобретения. Соответственно, способ дополнительно содержит обеспечение, в битовом потоке, информации, указывающей выбор режима линейной модели, полезной для получения выборки первой компоненты.
Согласно еще одному дополнительному аспекту, предусмотрен способ декодирования одного или более изображений из битового потока, причем способ содержит получение значения выборки первой компоненты из связанного реконструированного значения выборки второй компоненты согласно пятому аспекту настоящего изобретения. Соответственно, способ дополнительно содержит получение, из битового потока, информации, указывающей выбор режима линейной модели, полезной для получения выборки первой компоненты, и выбор одного режима линейной модели из множества режимов линейной модели осуществляется на основании полученной информации.
Согласно еще одному аспекту, предусмотрено устройство для кодирования одно или более изображений в битовый поток, причем устройство выполнено с возможностью осуществления описанного здесь способа.
Согласно еще одному аспекту, предусмотрено компьютерная программа, которая, при исполнении, предписывает осуществлять описанный здесь способ и (нетранзиторный) компьютерно-считываемый носитель, где хранятся инструкции для реализации описанного здесь способа.
Согласно настоящему изобретению предусмотрено устройство, способ, компьютерная программа (продукт), и компьютерно-считываемый носитель данных, как изложено в нижеследующей формуле изобретения. Другие признаки вариантов осуществления изобретения заданы в нижеследующей формуле изобретения и нижеследующем описании. Некоторые из этих признаков объяснены ниже со ссылкой на способ, хотя они могут быть преобразованы в системные признаки, относящиеся к устройству.
Способы согласно изобретению могут быть по меньшей мере частично компьютерно реализованными. Соответственно, настоящее изобретение может принимать форму полностью аппаратного варианта осуществления, полностью программного варианта осуществления (включающего в себя, программно-аппаратное обеспечение, резидентные программы, микрокод и т.д.) или вариант осуществления, объединяющий в себе программный и аппаратный аспекты, которые можно в целом именовать здесь “процессором и памятью”, "схемой", "модулем" или "системой". Кроме того, настоящее изобретение может принимать форму компьютерного программного продукта, воплощенного в любом материальном носителе выражения, имеющего пригодный для компьютера программный код, воплощенный в носителе.
Поскольку настоящее изобретение можно реализовать программными средствами, настоящее изобретение может быть воплощено в виде компьютерно-считываемого кода для подачи на программируемое устройство по любой подходящей среде переноса. Материальная среда переноса может содержать среду хранения, например, жесткий диск, привод магнитной ленты или твердотельное запоминающее устройство и пр. Переходная среда переноса может включать в себя сигнал, например, электрический сигнал, электронный сигнал, оптический сигнал, акустический сигнал, магнитный сигнал или электромагнитный сигнал, например, микроволновой или радиосигнал.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления изобретения будут описаны ниже, исключительно в порядке примера, со ссылкой на следующие чертежи, в которых:
фиг. 1 - функциональная блок-схема видеокодера;
фиг. 2 - функциональная блок-схема видеодекодера, соответствующая функциональной блок-схеме видеокодера, проиллюстрированной на фиг. 1;
фиг. 3 - примеры схемы дискретизации YUV для дискретизации 4:2:0;
фиг. 4 - блок-схема последовательности операций, демонстрирующая способ формировании предсказателя блока в режиме LM, осуществляемый на кодере или декодере;
фиг. 5 - схема блока хромы и связанного или совмещенного блока люмы, с понижающей дискретизацией выборок люмы, и соседствующих выборок хромы и люмы, согласно уровню техники;
фиг. 6 - иллюстративные наборы выборок для вывода параметра LM согласно уровню техники;
фиг. 7 - некоторые фильтры понижающей дискретизации, известные в уровне техники;
фиг. 8 - иллюстративное кодирование флагов сигнализации для сигнализации режимов LM;
фиг. 9 - точки соседних выборок люмы и хромы и прямая линия, представляющая параметры линейной модели, полученные в одном варианте осуществления изобретения;
фиг. 10 - основные этапы процесса упрощенного вывода LM в одном варианте осуществления изобретения;
фиг. 11 - несколько точек соседних выборок люмы и хромы и отрезки, используемые для определения двух наилучших точек в некоторых вариантах осуществления изобретения;
фиг. 12 - основные этапы процесса вывода MMLM в одном варианте осуществления изобретения; и
фиг. 13 - блок-схема вычислительного устройства для реализации одного или более вариантов осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
Фиг. 1 демонстрирует архитектуру видеокодера. В видеокодере исходная последовательность 101 делится на блоки пикселей 102, именуемые блоками кодирования или единицами кодирование для HEVC. Затем режим кодирования применяется к каждому блоку. Для кодирования видеосигнала обычно используется два семейства режимов кодирования: режимы кодирования на основе пространственного предсказания или “интра-режимы” 103 и режимы кодирования на основании временного предсказания или “интер-режимы” на основе оценки 104 движения и компенсации 105 движения.
Блок интра кодирования в общем случае предсказывается из закодированных пикселей на своей каузальной границе в процессе, именуемом интра-предсказанием. Таким образом, предсказатель для каждого пикселя блока интра кодирования формирует блок предсказателя. В зависимости от того, какие пиксели используются для предсказания блока интра кодирования, предлагаются различные интра-режимы: например, режим DC, плоскостной режим и угловые режимы.
Хотя на фиг. 1 приведено общее описание архитектуры видеокодера, следует отметить, что пиксель соответствует здесь элементу изображения, который обычно состоит из нескольких компонент, например, красной компоненты, зеленый компоненты и синей компоненты. Выборка изображения является элементом изображения, который содержит одну-единственную компоненту.
Временное предсказание прежде всего состоит в нахождении в предыдущем или будущем кадре, именуемом опорным кадром 116, опорной области, ближайшей к блоку кодирования на этапе 104 оценки движения. Эта опорная область образует блок предсказателя. Затем этот блок кодирования предсказывается с использованием блока предсказателя для вычисления остатка или остаточного блока на этапе 105 компенсации движения.
В обоих случаях, пространственного и временного предсказания, остаток или остаточный блок вычисляется путем вычитания полученного блока предсказателя из блока кодирования.
В интра-предсказании кодируется режим предсказания.
Во временном предсказании кодируются индекс, указывающий используемый опорный кадр, и вектор движения указывающий опорную область в опорном кадре. Однако для дополнительного снижения потери битовой скорости, связанной с кодированием вектора движения, вектор движения кодируется не напрямую. Действительно, исходя из однородности движения, особенно полезно кодировать вектор движения разностью между этим вектором движения и вектором движения (или предсказателем вектора движения) в его окружении. Например, в стандарте кодирования H.264/AVC векторы движения кодируются относительно медианного вектора, вычисленного из векторов движения, связанных с тремя блоками, находящимися выше и левее текущего блока. Только разность, также именуемая остаточным вектором движения, вычисленная между медианным вектором и вектором движения текущего блока, кодируется в битовом потоке. Эта обработка модулем “предсказание и кодирование движения” 117. Значение каждого закодированного вектора сохраняется в поле 118 векторов движения. Соседствующие векторы движения, используемые для предсказания, извлекаются из поля 118 векторов движения.
В стандарте HEVC используются три разных интер-режима: режим Inter, режим Merge b режим Merge Skip, которые в основном отличаются друг от друга сигнализацией информации движения (т.е. вектора движения и связанного опорного кадра посредством его так называемого индекса опорного кадра) в битовом потоке 110. Для простоты, вектор движения и информация движения в дальнейшем объединены. Что касается предсказания вектора движения, HEVC обеспечивает несколько кандидатов в предсказатели вектора движения, которые оцениваются в ходе состязания за скорость-искажение для нахождения наилучшего предсказателя вектора движения или наилучшей информации движения, соответственно, для режима Inter или Merge. Индекс, соответствующий наилучшим предсказателям или наилучшему кандидату в качестве информации движения, вставляется в битовый поток 110. Благодаря этой сигнализации, декодер может выводить один и тот же набор предсказателей или кандидатов и использовать наилучший из них согласно декодированному индексу.
Конструкция вывода предсказателей вектора движения и кандидатов способствует достижению максимальной эффективности кодирования без большого влияния на сложность. В HEVC предлагаются два способа вывода вектора движения: один для режима Inter (известный как усовершенствованное предсказание вектора движения (AMVP)) и один для режимов Merge (известный как процесс вывода Merge).
Затем в модуле 106 выбирается режим кодирования, оптимизирующий критерий скорости-искажения для рассматриваемого в данный момент блока кодирования. Для дополнительного снижения избыточности в полученных остаточных данных к остаточному блоку в модуле 107 применяется преобразование, обычно DCT, и квантование применяется к полученным коэффициентам в модуле 108. Затем квантованный блок коэффициентов подвергается энтропийному кодированию в модуле 109, и результат вставляется в битовый поток 110.
Затем кодер осуществляет декодирование каждого из закодированных блоков кадра для оценки будущего движения в модулях 111-116. Эти этапы позволяют кодеру и декодеру иметь одни и те же опорные кадры 116. Для реконструкции кодированного кадра, каждый из квантованных и преобразованных остаточных блоков подвергается обратному квантованию в модуле 111 и обратному преобразованию в модуле 112 для обеспечения соответствующего “реконструированного” остаточного блока в пиксельной области. В силу потерь при квантовании, этот “реконструированный” остаточный блок отличается от исходного остаточного блока, полученного на этапе 106.
Затем, согласно режиму кодирования, выбранному на этапе 106 (интер или интра), этот “реконструированный” остаточный блок добавляется к блоку 114 интер-предсказателя или к блоку 113 интра-предсказателя, для получения “заранее реконструированного” блока (блока кодирования).
Затем “заранее реконструированные” блоки фильтруются в модуле 115 посредством пост-фильтрации одного или нескольких видов для получения “реконструированных” блоков (блоков кодирования). Одни и те же пост-фильтры встроены в кодер (в контуре декодирования) и в декодер для однотипного использования для получения в точности одинаковых опорных кадров на сторонах кодера и декодера. Эта пост-фильтрация осуществляется с целью удаления артефактов сжатия.
Фиг. 2 демонстрирует архитектура видеодекодера, соответствующую архитектуре видеокодера, проиллюстрированной на фиг. 1.
Сначала видеопоток 201 подвергается энтропийному декодированию в модуле 202. Затем каждый полученный остаточный блок (блок кодирования) подвергается обратному квантованию в модуле 203 и обратному преобразованию в модуле 204 для получения “реконструированного” остаточного блока. Это аналогично началу контура декодирования на стороне кодера.
Затем, согласно режиму декодирования, указанному в битовом потоке 201 (либо декодированию типа "интра", либо декодированию типа "интер"), строится блок предсказателя.
В случае интра-режима, блок интра-предсказателя определяется 205 на основании интра-режима предсказания, указанного в битовом потоке 201.
В случае режима Inter, информация движения извлекается из битового потока в ходе энтропийного декодирования 202. Информация движения состоит, например в HEVC и JVET, из индекса опорного кадра и остатка вектора движения.
Предсказатель вектора движения получается таким же образом, как на кодере (из соседствующих блоков) с использованием уже вычисленных векторов движения, хранящихся в данных 211 поля векторов движения. Он, таким образом, добавляется 210 к извлеченному блоку остатка вектора движения для получения вектора движения. Этот вектор движения прибавляется к данным 211 поля векторов движения для использования для предсказания затем декодированных векторов движения.
Вектор движения также используется для определения положения опорной области в опорном кадре 206, который является блоком интер-предсказателя.
Затем “реконструированный” остаточный блок, полученный на этапе 204, прибавляется к блоку 206 интер-предсказателя или к блоку 205 интра-предсказателя, для получения “заранее реконструированного” блока (блока кодирования) таким же образом, как контур декодирования кодера.
Затем этот “заранее реконструированный” блок подвергается пост-фильтрации в модуле 207, как и на стороне кодера (сигнализация пост-фильтрации для использования может извлекаться из битового потока 201).
Таким образом, получается “реконструированный” блок (блок кодирования), который формирует видео 209 со снятым сжатием в качестве выходного сигнала декодера.
Вышеописанный процесс кодирования/декодирования может применяться к монохромным кадрам. Однако наиболее распространенными кадрами являются цветные кадры, в общем случае, состоящие из трех массивов выборок цвета, причем каждый массив соответствует “цветовой компоненте”, например, R (красной), G (зеленой) и B (синей). Пиксель изображения содержит три совмещенные/соответствующие выборки, по одной для каждой компоненты.
Компоненты R, G, B обычно хорошо коррелируют между собой. Таким образом, при сжатии изображения и видео обычно осуществляется декорреляция цветовых компонент до обработки кадров, путем преобразования их в другое цветовое пространство. Наиболее распространенным форматом является YUV (YCbCr), где Y - компонента люмы (или яркости), и U (Cb) и V (Cr) - компоненты хромы (или цветности).
Для уменьшения объема данных для обработки, некоторые цветовые компоненты цветных кадров можно дискретизировать с понижением, что приводит к разным отношениям дискретизации для трех цветовых компонент. Схема понижающей дискретизации обычно выражается как трехчастное отношение J:a:b, которое описывает количество выборок люмы и хромы в концептуальном участке высотой 2 пикселя. ‘J’ задает ссылку на горизонтальную дискретизацию концептуального участка (т.е. ширину в пикселях), обычно 4. ‘a’ задает количество выборок хромы (Cr, Cb) в первой строке из J пикселей, тогда как ‘b’ задает количество (дополнительных) выборок хромы (Cr, Cb) во второй строке из J пикселей.
Схемы понижающая дискретизация позволяют сократить количество выборок хромы по сравнению с количеством выборок люмы.
Формат 4:4:4 YUV или RGB не обеспечивает понижающую дискретизацию и соответствует кадру, не дискретизированному с понижением, где кадры люмы и хромы имеют одинаковый размер W×H.
Формат 4:0:0 YUV или RGB имеет одну-единственную цветовую компоненту и поэтому соответствует монохромному кадру.
Ниже представлены иллюстративные форматы дискретизации.
Формат 4:2:0 YUV имеет вдвое меньше выборок хромы, чем выборок люмы в первой строке, и вовсе не имеет выборок хромы во второй строке. Таким образом, два кадра хромы имеют ширину W/2 пикселей и высоту H/2 пикселей, где кадр люмы имеет размеры W×H.
Формат 4:2:2 YUV имеет вдвое меньше выборок хромы в первой строке и вдвое меньше выборок хромы во второй строке, чем выборок люмы. Таким образом, два кадра хромы имеют ширину W/2 пикселей и высоту H пикселей, где кадр люмы имеет размеры W×H.
Формат 4:1:1 YUV имеет на 75% меньше выборок хромы в первой строке и на 75% меньше выборок хромы во второй строке, чем выборок люмы. Таким образом два кадра хромы имеют ширину W/4 пикселей и высоту H пикселей, где кадр люмы имеет размеры W×H.
В случае дискретизации с понижением, позиции выборок хромы в кадрах сдвинуты по сравнению с позициями выборок люмы.
Фиг. 3 демонстрирует иллюстративное позиционирование выборок хромы (треугольнички) относительно выборок люмы (кружки) для кадра 4:2:0 YUV.
Процесс кодирования, представленный на фиг. 1, может применяться к каждой цветовой компоненте входного кадра.
В силу корреляций между цветовыми компонентами (между RGB или оставшихся корреляций между YUV несмотря на преобразование RGB в YUV), способы межкомпонентного предсказания (CCP) разработаны для использования этих (оставшихся) корреляций для повышения эффективности кодирования.
Способы CCP могут применяться на разных стадиях процесса кодирования или декодирования, в частности либо на первой стадии предсказания (для предсказания текущей цветовой компоненты), либо на второй стадии предсказания (для предсказания компоненты текущего остаточного блока).
Один известный способ CCP предусматривает режим LM, также именуемый CCLM (межкомпонентное предсказание линейной модели). Он используется для предсказания обеих компонент хромы Cb и Cr (или U и V) из люмы Y, в частности из реконструированной люмы (на стороне кодера или на стороне декодера). Для каждой компоненты формируется один предсказатель. Способ действует на уровне блоков (хромы и люмы), например, на уровне CTU (единиц дерева кодирования), CU (единиц кодирования), уровне PU (единиц предсказания), уровне суб-PU или TU (единиц преобразования).
Фиг. 4 демонстрирует в порядке примера, в виде блок-схемы последовательности операций, способ формировании предсказателя блока в режиме LM, осуществляемый на кодере (используемом ниже в качестве эталона) или декодере.
В нижеследующем описании, иллюстративной первой компонентой является хрома, тогда как иллюстративной второй компонентой является люма.
Предполагая, что текущий блок 502 хромы (фиг. 5A) для кодирования или декодирования и связанный с ним или соответствующий ему (т.е. “совмещенный”) блок 505 люмы (т.е., например, одного и того же CU) находятся в одном и том же кадре, кодер (или декодер) принимает, на этапе 401, соседствующий набор выборок люмы RecL, содержащий выборки 503 люмы, соседствующие с текущим блоком люмы, и принимает соседствующий набор выборок хромы RecC, содержащий выборки 501 хромы, соседствующие с текущим блоком хромы, обозначенным 402. Следует отметить, что для некоторых форматов дискретизации хромы и фазы хромы, выборки 504 и 503 люмы непосредственно не соседствуют с блоком 505 люмы, как указано на фиг. 5A. Например на фиг. 5A, для получения левого столбца RecL' (503) требуется только второй влево столбец, а не непосредственно левый столбец. Таким же образом, для верхней строки 504 вторая вверх строка также рассматривается для понижающей дискретизации выборки люмы, как указано на фиг. 5A.
Когда используется формат дискретизации хромы (например, 4:2:0, 4:2:2 и т.д.), соседствующий набор выборок люмы дискретизируется с понижением на этапе 403 в RecL' 404 для согласования разрешения хромы (т.е. разрешения выборки соответствующего кадра/блока хрома). Таким образом, RecL' содержит реконструированные выборки 504 люмы, соседствующие с текущим блоком люмы, которые дискретизируются с понижением. Благодаря понижающей дискретизации, RecL' и RecC содержат такое же количество N2 выборок (блок 502 хромы имеет размер N×N). Тем не менее, в уровне техники существуют конкретные выборки более низкого разрешения границы люмы, где для получения RecL' требуется меньше выборок. Кроме того, даже если RecL и RecC имеют одинаковое разрешение, RecL' можно рассматривать как обесшумленный вариант RecL, благодаря использованию низкочастотного сверточного фильтра.
В примере, показанном на фиг. 5A, соседствующие наборы выборок люмы и хромы образованы из дискретизированных с понижением верхней и левой соседствующих выборок люмы и из верхней и левой соседствующих выборок хромы, соответственно. Точнее говоря, каждый из двух наборов выборок образован первой линией, непосредственно соседствующей с левой границей и первой линией, непосредственно соседствующей с верхней границей соответствующего блока люмы или хромы. В силу понижающей дискретизации (4:2:0 на фиг. 5A), единая линия соседствующих выборок люмы RecL' получается из двух линий не дискретизированных с понижением реконструированных выборок люмы RecL (левой или верхней).
В US 9,565,428 предлагается использовать понижающую дискретизацию, в которой выбирается единственная выборка, только для верхней строки (т.е. соседствующий с верхней границей блока люмы) но не для самого блока люмы (как описано ниже со ссылкой на этап 408). Предложенная понижающая дискретизация проиллюстрирована на фиг. 6A. Этот подход мотивирован уменьшением линейного буфера верхней строки.
Линейная модель, которая задается одним или двумя параметрами (наклоном α и смещением β), выводится из RecL' (при наличии, в противном случае RecL) и RecC. На этом этапе 405 получаются параметры 406.
Параметры LM α и β получаются методом наименьших средних квадратов с использованием следующего уравнению:
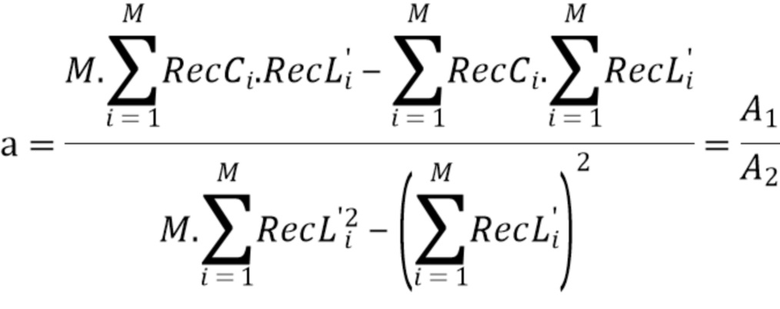
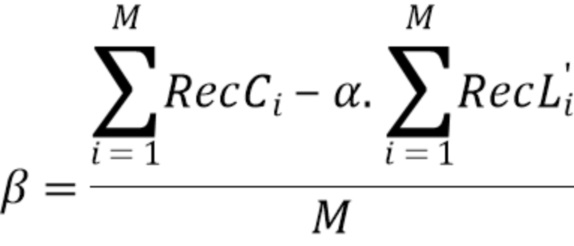
где M - значение, которое зависит от размера рассматриваемого блока. В общем случае квадратных блоков, как показано на фиг. 5A и 5B, M=2N. Однако CCP на основе LM может применяться к блоку любой формы, где M, является, например, суммой высоты H блока и ширины W блока (для блока прямоугольной формы).
Следует отметить, что значение M, используемое в качестве весового коэффициента в этом уравнении, можно регулировать во избежание вычислительных перегрузок на кодере и декодере. Точнее говоря, при использовании арифметики с 32-битовой или 64-битовой архитектурой со знаком, некоторые вычислительные операции иногда могут приводить к переполнению и, таким образом, вызывать нестандартное поведение (что строго запрещено в любом межплатформенном стандарте). Чтобы справиться с этой ситуацией, можно оценивать максимальный возможный модуль, заданный для входных значений RecL' и RecC, и M (и, в свою очередь, вышеупомянутые суммы) можно соответственно масштабировать, чтобы гарантировать отсутствие переполнения.
Параметры обычно выводятся из наборов выборок RecL’ и RecC, показанных на фиг. 5A.
Были предложены вариации наборов выборок.
Например, в US 9,288,500 предлагаются три состязающихся набора выборок, включающие в себя первый набор выборок, образованный внешней линией, соседствующей с верхней границей, и внешней линией, соседствующей с левой границей, второй набор выборок, образованный только внешней линией, соседствующей с верхней границей, и третий набор выборок, образованный только внешней линией, соседствующей с левой границей. Эти три набора выборок показаны на фиг. 6B только для блока хромы (и поэтому могут быть преобразованы в блок люмы).
Согласно US 9,462,273 второй и третий наборы выборок распространяются на дополнительные выборки, проходящие по внешним линиям (обычно удваивая их длину). Удлиненные наборы выборок показаны на фиг. 6C только для блока хромы. В этом документе также предусмотрено уменьшение количества доступных режимов LM для снижения затрат на сигнализацию для сигнализации режима LM, используемого в битовом потоке. Уменьшение может быть контекстуальным, например, основываться на интра-режиме, выбранном для связанного блока люмы.
В US 9,736,487 предлагаются три состязающихся набора выборок, аналогичные предложенным в US 9,288,500, но образованные, каждый раз, двумя линиями за пределами соседствующих выборок, параллельными и непосредственно соседствующими с рассматриваемыми границами. Эти наборы выборок показаны на фиг. 6D только для блока хромы.
Также US 9,153,040 и документы того же семейства патентов предлагают дополнительные наборы выборок, образованные одной линией для каждой границы, с меньшим числом выборок для каждой линии, чем предыдущие наборы.
Возвращаясь к процессу, показанному на фиг. 4, с использованием линейной модели с одним или более выведенными параметрами 406, интра-предсказатель 413 хромы для блока 502 хромы, таким образом, может получаться из реконструированных выборок 407 люмы текущего блока люмы, представленного позицией 505. Опять же, если используется формат дискретизации хромы (например, 4:2:0, 4:2:2 и т.д.), реконструированные выборки люмы дискретизируются с понижением на этапе 408 в L' 409 для согласования разрешения хромы (т.е. разрешения выборки соответствующего кадра/блока хрома).
Может использоваться такая же понижающая дискретизация, как на этапе 403, или другая по причине линейного буфера. Например, фильтр 6-го порядка может использоваться для обеспечения дискретизированного с понижением значения в качестве взвешенной суммы верхней левой, верхней, верхней правой, нижней левой, нижней и нижней правой выборок, окружающей позицию понижающей дискретизации. Когда не достает некоторых окружающих выборок, вместо фильтра 6-го порядка используется лишь фильтр 2-го порядка.
В результате применения к реконструированным выборкам люмы L, получается выходной сигнал L' иллюстративного фильтра 6-го порядка следующим образом:
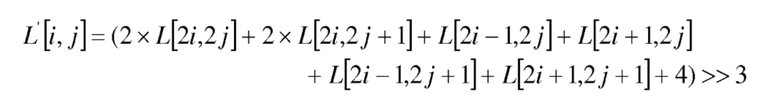
где (i, j) - координаты выборки в дискретизированном с понижением блоке, и >> - операция битового сдвига вправо.
Также адаптивная понижающая дискретизация люмы может использоваться, как описано в US 2017/0244975. Только содержимое блока люмы используется для определения, какой фильтр понижающей дискретизации используется для каждой реконструированной выборки люмы блока люмы. Доступен фильтр 1-го порядка. Этот подход позволяет избежать распространения края в дискретизированном с понижением блоке люмы.
Благодаря этапу 408 понижающей дискретизации, блоки L' и C (набор выборок хромы в блоке 502 хромы) содержат такое же количество N2 выборок (блок 502 хромы имеет размер N×N).
Затем, каждая выборка интра-предсказателя 413 хромы PredC вычисляется с использованием контура 410-411-412 согласно формуле
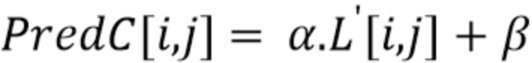
где (i, j) - координаты всех выборок в блоках хромы и люмы.
Во избежание операций деления и операций умножения, вычисления можно реализовать с использованием менее сложных способов на основе поисковых таблиц и операции сдвига. Например, вывод 411 фактического интра-предсказателя хромы может осуществляться следующим образом:
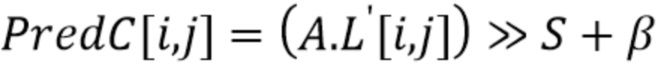
где S - целое число, и A выводится из A1 и A2 (введенных выше при вычислении α и β) с использованием вышеупомянутой поисковой таблицы. Оно фактически соответствует перемасштабированному значению α. Операция (x >> S) соответствует операции битового сдвига вправо, эквивалентной делению целого числа x (с усечением) на 2S.
Когда все выборки дискретизированного с понижением блока люмы разложены (412), интра-предсказатель 413 хромы доступен для вычитания из блока 502 хромы (для получения остаточного блока хромы) на стороне кодера или для суммирования с остаточным блоком хромы (для получения реконструированного блока хромы) на стороне декодера.
Заметим, что остаточный блок хромы незначителен и поэтому отбрасывается, и в этом случае полученный интра-предсказатель 413 хромы непосредственно соответствует предсказанным выборкам хромы (образующим блок 502 хромы).
Обе группы стандартизации ITU-T VCEG (Q6/16) и ISO/IEC MPEG (JTC 1/SC 29/WG 11), которые установили стандарт HEVC, изучают будущие технологии кодирования видеосигнала для преемника HEVC в совместной работе, известной как объединенная исследовательская команда видео (JVET). Объединенная исследовательская модель (JEM) содержит инструменты HEVC и новые добавленные инструменты, выбранный этой группой JVET. В частности, это справочное программное обеспечение содержит некоторые инструменты CCP, как описано в документе JVET-G1001.
В JEM, всего 11 интра-режимов разрешено для кодирования хромы. Эти режимы включают в себя пять традиционных интра-режимов и шесть межкомпонентных режимов LM для предсказания Cb из Y (сигнализированного в битовом потоке 110, 201) и один межкомпонентный режим LM для предсказания Cr из Cb.
Одним из шести режимов LM Y в Cb CC является вышеописанный CCLM, в котором каждый из соседствующих наборов выборок люмы и хромы RecL' и RecC образован первой линией, непосредственно соседствующей с левой границей, и первой линией, непосредственно соседствующей с верхней границей соответствующего блока люмы или хромы, как показано на фиг. 5A.
Пять других режимов LM Y в Cb CC основаны на конкретном выводе, известном как множественная модель (MM). Эти режимы обозначены MMLM.
По сравнению с CCLM, режимы MMLM используют две линейные модели. Соседствующие реконструированные выборки люмы из набора RecL' и соседствующие выборки хромы из набора RecC классифицируются на две группы, причем каждая группа используется для вывода параметров α и β одной линейной модели, что приводит к двум наборам параметров линейной модели (α1,β1) и (α2,β2).
Например, порог может вычисляться как среднее значение соседствующих реконструированных выборок люмы, образующих RecL'. Затем соседствующая выборка люмы с RecL'[i, j] ≤ порог причисляется к группе 1; тогда как соседствующая выборка люмы с RecL'[i, j] > порог причисляется к группе 2.
Затем интра-предсказатель хромы (или предсказанные выборки хромы для текущего блока 602 хромы) получается согласно следующим формулам:
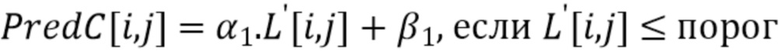
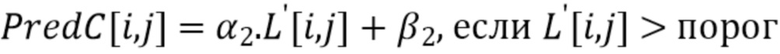
Кроме того, по сравнению с CCLM, режимы MMLM используют соседствующие наборы выборок люмы и хромы RecL’ и RecC, каждый из которых выполнен из двух линий за пределами соседствующих выборок, параллельными и непосредственно соседствующими с левой и верхней границами рассматриваемого блока. На фиг. 5B показан пример, демонстрирующий формат дискретизации 4:2:0, для которого две линии соседствующих выборок люмы получаются (с использованием понижающей дискретизации) из четырех линий, не дискретизированных с понижением реконструированных выборок люмы.
Пять режимов MMLM отличаются друг от друга пятью разными фильтрами понижающей дискретизации для понижающей дискретизации реконструированных выборок люмы для согласования разрешения хромы (для получения RecL' и/или L').
Первый режим MMLM опирается на тот же фильтр 6-го порядка, который используется в CCLM (см. 6 черных точек, обозначенных 701 на фиг. 7). Режимы MMLM со второго по четвертый опираются нафильтры 2-го порядка, которые, соответственно, обеспечивают дискретизированное с понижением значение в качестве взвешенной суммы:
- верхней правой и нижней правой выборок из шести выборок (используемых фильтром 6-го порядка, окружающих позицию понижающей дискретизации (см. фильтр 1, 702 на фиг. 7):
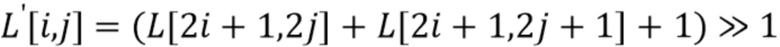 (то же самое применяется с RecL),
(то же самое применяется с RecL),
- нижней и нижней правой выборок из шести выборок (используемых фильтром 6-го порядка, окружающих позицию понижающей дискретизации (см. фильтр 2, 703 на фиг. 7):
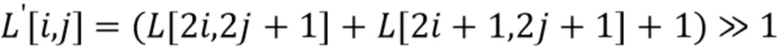 , и
, и
- верхней и верхней правой выборок из шести выборок (используемых фильтром 6-го порядка, окружающих позицию понижающей дискретизации (см. фильтр 4, 705 на фиг. 7):
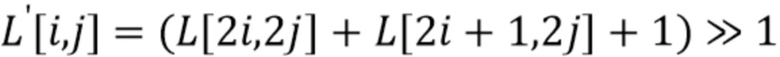 .
.
Пятый режим MMLM опирается на фильтр 4-го порядка, который обеспечивает дискретизированное с понижением значение в качестве взвешенной суммы верхней, верхней правой, нижней и нижней правой выборок из шести выборок (используемых фильтром 6-го порядка, окружающих позицию понижающей дискретизации (см. фильтр 3, 704 на фиг. 7):
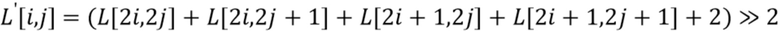 .
.
Как указано выше, режим CCLM или MMLM должен сигнализироваться в битовом потоке 110 или 201. Фиг. 8 демонстрирует иллюстративную сигнализацию режима LM для JEM. Первый двоичный флаг указывает, предсказывается ли текущий блок с использованием режима LM или других интра-режимах, включающих в себя так называемые режимы DM. В случае режима LM необходимо сигнализировать шесть возможных режимов LM. Первый режим MMLM (с использованием фильтра 6-го порядка сигнализируется с одним вторым двоичным флагом, заданным равным 1. Этот второй двоичный флаг задается равным 0 для оставшихся режимов, и в этом случае третий двоичный флаг задается равным 1 для сигнализации режима CCLM и задается равным 0 для оставшихся режимов MMLM. Затем два дополнительных двоичных флагов используются для сигнализации одного из четырех оставшихся режимов MMLM.
Для каждой компоненты хромы сигнализируется один режим.
Введенный выше режим CCLM Cb в Cr используется в режимах DM и применяется на уровне остатка. Действительно, режим DM использует для хромы интра-режим, который использовался люмой в заранее определенном положении. Традиционно, режим кодирования наподобие HEVC использует один-единственный режим DM, совмещенный с верхним левым углом CU. Не углубляясь в детали и для ясности, JVET обеспечивает несколько таких положений. Затем этот режим используется для определения способа предсказания, таким образом создавая обычное интра-предсказание для компоненты хромы, которая, при вычитании из опорных/исходных данных, дает вышеупомянутые остаточные данные. Предсказание для остатка Cr получается из остатка Cb (ниже ResidualCb) согласно следующей формуле:
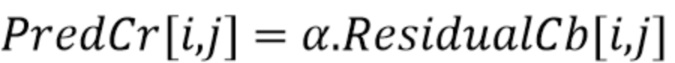
где 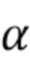 выводится аналогичным образом, как в предсказании CCLM от люмы к хроме. Единственное отличие состоит в добавлении стоимости регрессии относительно значения α по умолчанию в функции ошибок, благодаря чему, выведенный масштабный коэффициент смещается к значению, принятому по умолчанию равным -0,5, следующим образом:
выводится аналогичным образом, как в предсказании CCLM от люмы к хроме. Единственное отличие состоит в добавлении стоимости регрессии относительно значения α по умолчанию в функции ошибок, благодаря чему, выведенный масштабный коэффициент смещается к значению, принятому по умолчанию равным -0,5, следующим образом:
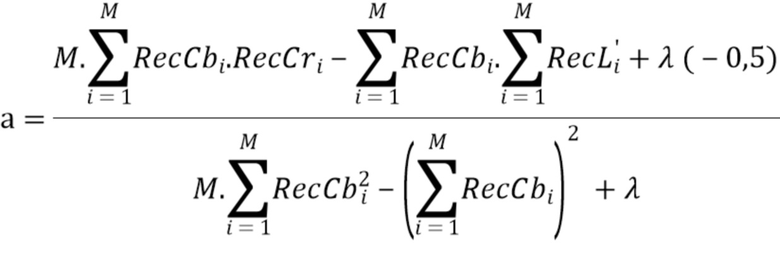
где 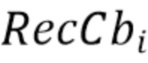 представляет значения соседствующих реконструированных выборок Cb,
представляет значения соседствующих реконструированных выборок Cb, 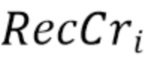 представляет соседствующие реконструированные выборки Cr, и
представляет соседствующие реконструированные выборки Cr, и
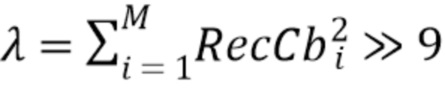 .
.
Известные режимы LM демонстрируют большую вычислительную сложность, в частности, при выводе параметра линейной модели методом наименьших квадратов.
Настоящее изобретение призвано повышать эффективность кодирования и/или снижать вычислительную сложность.
Изобретение предусматривает замену вывода линейной модели, используемой для вычисления выборок блока предсказателя хромы из выборок блока люмы путем определения параметров линейной модели на основании уравнения прямой линии. Прямая линия задается двумя парами выборок, заданными на основании реконструированных пар выборок в окрестности блока. Сначала определяются две пары выборок, подлежащие использованию. Затем из этих двух пар выборок определяются параметры линейной модели. Благодаря ограничению количества пар выборок, используемых при определении линейной модели, числом 2, можно избежать использования метода наименьших квадратов. Таким образом, предложенный способ менее вычислительно интенсивен, чем известный способ, где используется метод наименьших квадратов.
Фиг. 9 демонстрирует принцип этого способа с учетом минимума и максимума значений выборки люмы в наборе пар выборок в окрестности текущего блока. Все пары выборок изображены на фигуре согласно их значению хромы и их значению люмы. На фигуре идентифицированы две разные точки, а именно точка A и точка B, причем каждая точка соответствует паре выборок. Точка A соответствует паре выборок с наинизшим значением люмы 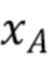 из RecL' и
из RecL' и 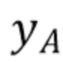 совмещенным с ним значением хромы из RecC. Точка B соответствует паре выборок с наивысшим значением люмы
совмещенным с ним значением хромы из RecC. Точка B соответствует паре выборок с наивысшим значением люмы 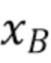 и
и 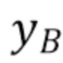 совмещенным с ним значением хромы.
совмещенным с ним значением хромы.
Фиг. 10 демонстрирует блок-схему последовательности операций предложенного способа вывода параметров линейной модели. Эта блок-схема последовательности операций является упрощенным вариантом фиг. 4. Способ базируется на соседних выборках люмы RecL', полученных на этапе 1001, и выборках хромы RecC, полученных на этапе 1002.
На этапе 1003 определяются две точки A и B (1004), соответствующие двум парам выборок. В первом варианте осуществления, эти две точки A и B соответствуют парам выборок, соответственно, с наинизшим и наивысшим значениями выборки люмы и с их соответствующими значениями выборки хромы и .
Затем, на этапе 1005, вычисляется уравнение прямой линии, проходящей через точки A и B согласно следующему уравнению:
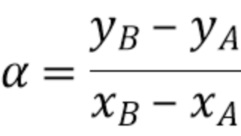
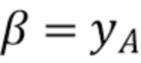 -
- 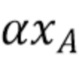
Полученные 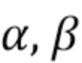 являются параметрами 1006 линейной модели, используемыми для формировании предсказателя хромы.
являются параметрами 1006 линейной модели, используемыми для формировании предсказателя хромы.
Вывод линейной модели на основании алгоритма LMS, используемого в уровне техники, имеет определенную сложность. Согласно этому известному способу, параметр модели вычисляется согласно следующему уравнению:

Анализ этого уравнения в отношении вычислительной сложности дает следующие результаты. Вычисление 
 требует M+1 операций умножения и M операций суммирования, и вычисление
требует M+1 операций умножения и M операций суммирования, и вычисление 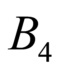 , соответствующего
, соответствующего 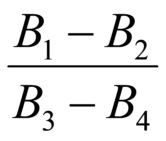
Для вычисления 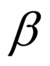
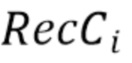 и
и 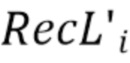 .
.
Таким образом, сложность вывода и 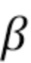 в LMS составляет
в LMS составляет 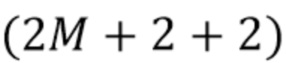 операции умножения,
операции умножения, 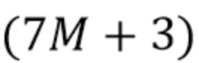 операций суммирования и две операции деления.
операций суммирования и две операции деления.
В сравнении, анализ предложенного способа на основе вычисления уравнения прямой линии с использованием только двух точек дает следующие результаты. Как сообщалось, этап 1005 вывода требует одной-единственной операции умножения, трех операций суммирования и одной операции деления. Это большое уменьшение сложности формирования параметров линейной модели является основным преимуществом предложенного изобретения.
Следует отметить, что поиск минимального и максимального значений сам по себе сложен, что обычно связано с алгоритмом сортировки. Операция не является полностью последовательной: N точек могут сравниваться с N другими точками, формируя N минимумов/максимумов. Затем N/2 минимальных и N/2 максимальных точек могут сравниваться с N/2 другими, заряд снова N/4 и т.д., пока не останется только нужное количество минимальных и максимальных точек. Обычно такой поиск минимума и максимума дает приблизительно 2*N-2 сравнений (N-1 для каждого).
Как описано выше, предсказатель хромы можно вычислять с помощью целочисленного умножения и сдвига вместо умножения с плавающей точкой и деления при вычислении наклона. Это упрощение состоит в замене:
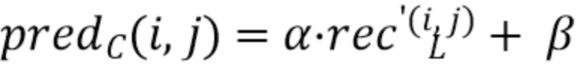
на:
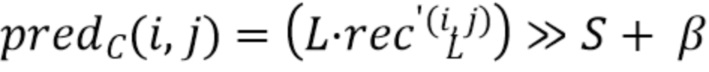
Для использования только целочисленного умножения и сдвига, в одном варианте осуществления уравнение прямой линии получается следующим образом:
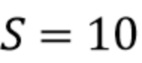
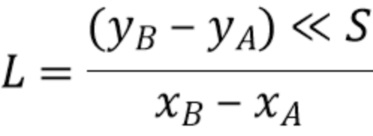
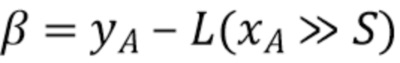
Заметим, что относится к этому уравнению в дальнейшем, если заменить на L и S, в противном случае оно относится к традиционному уравнению - .
Другое преимущество этого вывода состоит в том, что значение 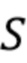 сдвига всегда имеет одно и то же значение. Это особенно интересно для аппаратной реализации, которую можно упростить, пользуясь преимуществом этого свойства.
сдвига всегда имеет одно и то же значение. Это особенно интересно для аппаратной реализации, которую можно упростить, пользуясь преимуществом этого свойства.
В еще одном варианте осуществления, значение S принудительно снижается, поскольку L может быть большим, и требует больше операций умножения. Действительно, умножать 8-битовые значения на 8-битовое значение гораздо проще, чем, например, умножать 8*16. Типичные практические значения L часто бывают эквивалентны множителю размером меньше, чем 8 битов.
Однако предпочтительным вариантом осуществления является реализация, известная как фиксированная точка: для каждого значения D=(xB-xA), возможно квантованного (например, результаты для 2D+0 и 2D+1 сохраняются как единый результат), значение (1<<S)/D сохраняется в таблице. Предпочтительно делать это только для положительных значений, поскольку знак можно легко извлечь. С использованием массива TAB, вычисление L, таким образом, приобретает вид:
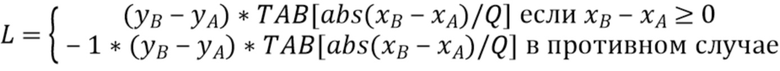
Q управляет квантованием и, таким образом, количеством элементов в таблице. Таким образом, использование Q=1 означает отсутствие квантования. Также заметим, что вместо 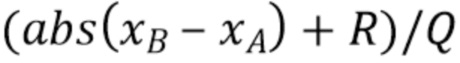 можно использовать поисковый индекс, обычно с R=Q/2, или его разновидностью в виде деления с округлением. Следовательно, Q в идеале является степенью двойки, благодаря чему, деление на Q=2P эквивалентно сдвигу вправо на P.
можно использовать поисковый индекс, обычно с R=Q/2, или его разновидностью в виде деления с округлением. Следовательно, Q в идеале является степенью двойки, благодаря чему, деление на Q=2P эквивалентно сдвигу вправо на P.
Наконец, некоторые значения в этой таблице могут быть не равны 0: низкие значения abs(xB-xA) или abs(yB-yA) часто приводят к очень плохим оценкам L. В таком случае могут использоваться заранее определенные, или явные (например, в заголовке слайса или наборе параметров, например PPS или SPS) значения. Например, для всех значений D ниже 4, массив TAB может содержать значение, принятое по умолчанию, например -(1<<S)/8.
Для 10-битового содержимого и Q=1, в массиве требуется до 2048 записей. Используя симметрию со знаком, как показано выше, это количество можно сократить до 1024. Дополнительное увеличение Q аналогично будет приводить к уменьшению размера TAB.
Если некоторые выборки (RecL или RecC, или обе) являются остаточными выборками (т.е. полученными из разности между двумя блоками, возможно квантованной), что имеет место в JVET с предсказанием из Cb в Cr, то размер (и содержимое) таблицы можно соответственно адаптировать.
В другом предпочтительном варианте осуществления, определение двух параметров α и β прямой линии вычисляется в следующей формуле , что позволяет использовать целочисленную арифметику, которую легко реализовать аппаратными средствами.
Точнее говоря, определение параметров α и β может осуществляться только посредством целочисленных операций умножения и операций битового сдвига над целыми числами. Такие вычисления расходуют меньше аппаратных ресурсов (например, памяти и времени), чем другие типы вычислений, например, арифметика с плавающей точкой.
Для осуществления этой целочисленной арифметики, осуществляются следующие этапы.
Первое промежуточное значение “pshift” определяется с учетом битовой глубины выборок люмы и хромы, подлежащих обработке. Это значение битового сдвига гарантирует указанное максимальное значение знаменателя (именуемое ‘diff’) для α. В настоящем варианте осуществления, максимальное значение ‘diff’ равно 512, что позволяет представлять его в таблице, имеющей 512 записей. Благодаря заданию конкретного максимального значения ‘diff’, общая таблица (или набор таблиц) может использоваться для самых разных битовых глубин, что смягчает требования к полной памяти.
Значение pshift, таким образом, зависит от битовой глубины выборок, например, если выборки кодируются с использованием 10 битов, максимальная разность между максимумом и минимумом равна 1024. Чтобы представить это в таблице из 512 записей, его нужно разделить на 2 или подвергнуть битовому сдвигу на 1 бит, поэтому pshift=1. Соотношение между pshit и bitdepth можно, например, извлечь для следующей таблицы 1, или задать следующим выражением:
pShift = (BitDepth>9) ? BitDepth - 9: 0
Это можно альтернативно представить следующим выражением:
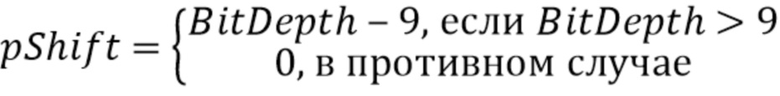
Необязательное значение округления “add” также можно вычислять, чтобы сделать ‘diff’ целым числом, после битового сдвига. Значение ‘add’ связано с pshift следующим выражением:
add=pshift ? 1 << (pshift - 1): 0 .
Это можно альтернативно представить следующим выражением:
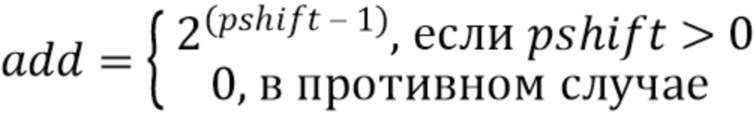
Альтернативно, прямое соотношение между ‘BitDepth’ и ‘add’ может обеспечиваться следующими выражениями:
add = (BitDepth>9) ? 1 << (BitDepth - 10): 0
или:
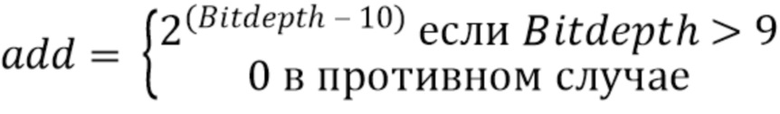
В нижеследующей таблица 1 приведены иллюстративные значения “pshift” и “add”, соответствующие битовой глубине выборок люмы и хромы, подлежащих обработке, в пределах от 8 до 16 битов.
Таблица 1: пример значений “pshift” и “add”
Эта таблица может храниться в памяти во избежание необходимости повторно вычислять ‘pshift’ и ‘add’, что может уменьшать количество операций обработки. Однако в определенных реализациях предпочтительнее уменьшать используемую память, чем количество операций обработки, и в этом случае ‘pshift’ и ‘add’ могут вычисляться каждый раз.
Значение “diff” представляет диапазон между минимальным и максимальным значениями выборок люмы в котором возможна обработка с использованием целочисленной арифметики. Значение ‘diff’ является целым числом, заключенным в определенном диапазоне благодаря использованию ‘pshift’. Это значение “diff” вычисляется по следующей формуле:
diff = (xB - xA+add) >> pshift
Затем вычисляются параметры α и β - напомним, что α и β задают наклон и точку пересечения линейной модели, проходящей через точки A и B:
-
Если значение “diff” равно нулю, то параметры α и β назначаются следующим образом:
α = 0
β = yA (или β = yB )
Выбор использования точки A или B может определяться тем, какая точка в данный момент хранится в памяти, для уменьшения количества операций обработки.
В противном случае, если значение “diff” строго положительно, то значение α определяется согласно следующей формуле
α=(((yB-yA)*Floor(2k/diff)+div+add)>>pshift) (1)
где функция Floor(x) (округление вниз) обеспечивает наибольшее целочисленное значение, меньшее или равное x
и где промежуточный параметр “div” вычисляется следующим образом:
div=((yB-yA)*(Floor((2k*2k)/diff)-Floor(2k/diff)*2k)+2(k-1))>>k (2)
Точность этого деления выражается переменной “k”. Значение k=16 найдено для обеспечения максимальной эффективности кодирования и позволяет точно представлять α и β с использованием целочисленной арифметики. Это дает возможность точно предсказывать выборку хромы при использовании соответствующей выборки люмы.
Как будет более подробно описано ниже, значение k также указывает, сколько памяти требует каждая запись. Значение k=16 позволяет использовать 16-битовый регистр памяти, который может быть представлен 2 байтами для использования при обращении к каждой из записей в таблице.
Параметр β определяется путем применения уравнения прямой линии в одной точке прямой линии, которой может быть либо точка A
β = yA - ((α*xA) >> k),
либо точка B
β = yB - ((α*xB) >> k).
Выбор использования точки A или B может определяться тем, какая точка в данный момент хранится в памяти, для уменьшения количества операций обработки. Альтернативно, это может быть фиксированный выбор - например, заданный в стандарте.
С точки зрения аппаратной реализации, некоторые из члены в формулах (1) и (2) можно заменить таблицами, в которых хранятся заранее вычисленные значения. Основным преимуществом таких таблиц является избавление от вычисления промежуточной функции “Floor” каждый раз, когда осуществляется вывод параметров α и β. Таким образом, множественные операции обработки можно заменить поисковой операцией.
Например, уравнение (1) можно упростить следующим образом для обеспечения уравнения (3) за счет использования таблицы TAB1[diff]:
α = (((yB - yA) * TAB1[diff] + div+add) >> pshift) (3)
где TAB1[diff] = Floor(2k/diff).
Аналогично уравнение (2) можно упростить за счет использования заранее определенных таблиц TAB1[diff] и TAB2[diff] во избежание повторения одних и тех же операций.
div=((yB-yA)*(TAB2[diff]-TAB1[diff]*2k)+2(k-1))>>k (4)
где TAB2[diff] = Floor((2k * 2k) / diff).
Это уравнение (4) можно дополнительно упростить согласно следующему уравнению:
div = ((yB - yA) * (TAB3[diff]) + 2(k-1)) >> k (5)
где
TAB3[diff]=TAB2[diff]-TAB1[diff]*2k=Floor((2k*2k)/diff)-2k*Floor(2k/diff).
TAB1 и TAB3 (и также TAB2) являются таблицами, каждая из которых имеет N записей N=2(BitDepth-pshift), и каждая запись представлена k битами.
Согласно заданию вышеупомянутой целочисленной переменной “diff”, и, например, для значения выборки люмы или хромы, представленного 10 битами, максимальное значение “diff” равно 512 (с использованием вышеприведенной таблицы 1). Это означает, что каждая из таблиц TAB1 и TAB3 (и также TAB2) может быть представлена массивом из 512 записей и каждая запись кодируется “k=16” битами. Переменная “pshift”, заданная в таблице 1, позволяет получать то же количество записей (здесь 512) согласно битовой глубина выборок, подлежащих обработке.
Как упомянуто ранее, эти массивы (TAB1 - TAB3) могут храниться в памяти для уменьшения количества операций, осуществляемых для вывода параметров α и β в уравнениях (1) и (2).
В объеме работ по стандартизации VVC, такой способ может использоваться для реализации деления для извлечения параметров α и β линейной модели для предсказания выборки хромы из выборки люмы, однако неожиданно было обнаружено, что размер таблицы и представление каждой записи можно уменьшить без негативного влияния на эффективность кодирования.
Как рассмотрено выше, полная память, необходимая для хранения каждой таблицы, зависит от значения “pshift”, и количество битов для представления каждой записи может кодироваться за счет использования значения “k”. В рассмотренном выше варианте осуществления используются две таблицы (TAB1 и TAB3), и каждая таблица имеет 512 записей и k=16. Память, необходимая для представления этих двух таблиц TAB1 и TAB3, равна: 2*512*16=16384 битов, которые могут храниться в 2048 байтах.
Теперь рассмотрим модификацию параметров, определяющих требования к памяти (как независимо, так и совместно).
Количество записей в каждой таблице (массиве)
Несмотря на то, что хорошее сжатие достигается за счет использования таблицы, имеющей размер 512 записей, эти таблицы можно рассматривать как весьма большие и желательно уменьшать их размер.
Таблицы 3 и 4 демонстрируют влияние на эффективность кодирования согласно метрикам Бьонтегарда (см., например, Bjontegard. Calculation of average PSNR differences between rd-curves. Doc. VCEG-M33 ITU-T Q6/16, April 2001. 79 Z. Xiong, A. Liveris, and S. Cheng, где поясняется определение этих метрик) путем уменьшения количества записей с 512 до 256 и 128 записей соответственно. Уменьшение размера таблицы осуществляется путем увеличения значения ‘pshift’ на единицу (N=2(BitDepth-pshift)). Соответственно может регулироваться значение ‘add’. Изменение N до 256 или 128 показано в нижеследующей таблице 2:
Таблица 2: пример значений “pshift” и “add” для таблицы из 256 или 128 записей
Эта таблица может быть представлена следующими выражениями:
256 записей
pShift = (BitDepth>8) ? BitDepth - 8: 0
Это можно альтернативно представить следующим выражением:
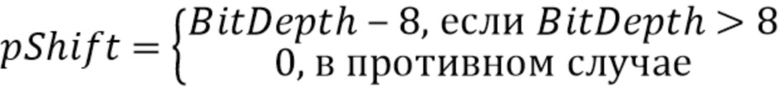
Необязательное значение округления “add” также можно вычислять, чтобы сделать ‘diff’ целым числом, после битового сдвига. Значение ‘add’ связано с pshift следующим выражением:
add=pshift ? 1 << (pshift - 1): 0 .
Это можно альтернативно представить следующим выражением:
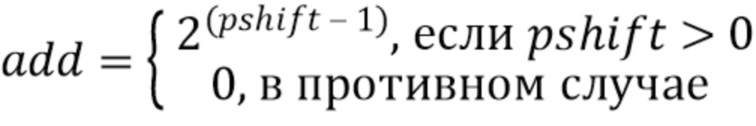
Альтернативно, прямое соотношение между ‘BitDepth’ и ‘add’ может обеспечиваться следующими выражениями:
add = (BitDepth>8) ? 1 << (BitDepth - 9): 0
или:
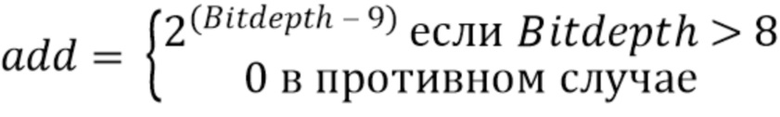
128 записей
pShift = (BitDepth>7) ? BitDepth - 7: 0
Это можно альтернативно представить следующим выражением:
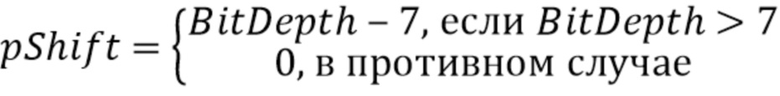
Необязательное значение округления “add” также можно вычислять, чтобы сделать ‘diff’ целым числом, после битового сдвига. Значение ‘add’ связано с pshift следующим выражением:
add=pshift ? 1 << (pshift - 1): 0 .
Это можно альтернативно представить следующим выражением:
Альтернативно, прямое соотношение между ‘BitDepth’ и ‘add’ может обеспечиваться следующими выражениями:
add = (BitDepth>7) ? 1 << (BitDepth - 8): 0
или:
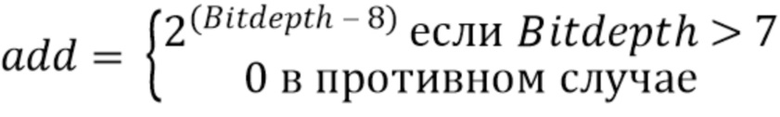
Уменьшение размера таблицы приводит к более грубому представлению разности между максимумом и минимумом значений выборки.
Тест на оценивание эффективности кодирования осуществлялся на наборе видеопоследовательностей используемых комитетом по стандартизации JVET, заданных в документе JVET-L1010. В таблице ниже, отрицательные значения демонстрируют более высокую эффективность кодирования, тогда как положительные значения соответствуют снижению эффективности кодирования.
Таблица 3: производительность сжатия при использовании таблицы размером 256
Как показано в таблице 3, эффективность кодирования, как это ни удивительно, по существу, не подвергается влиянию, несмотря на то, что количество записей в таблицах TAB1 и TAB3 сократилось в 2 раза. Можно видеть, что потери, вносимые модификацией, влияющей на режим CCLM, очень ограничены и меньше, чем 0,2% на каналах хромы (U) и (V), то есть, по существу, пренебрежимо малы (и, наиболее вероятно, представляют шум).
Аналогичный эксперимент был проведен для таблицы размером 128 - сформированной путем увеличения значения pshift на дополнительную 1 (как показано выше в таблице 2).
Таблица 4: производительность сжатия при использовании таблицы размером 128
Как показано в таблице 4, к еще большему удивлению, эффективность кодирования все еще, по существу, не подвергается влиянию, несмотря на то, что количество записей в таблицах TAB1 и TAB3 сократилось в 4 раза. Можно видеть, что потери, вносимые модификацией, влияющей на режим CCLM, очень ограничены и меньше, чем 0,05% на каналах хромы (U) и (V), то есть, по существу, пренебрежимо малы (и, наиболее вероятно, представляют шум).
Однако дальнейшее уменьшение размера таблицы до 64 записей (путем увеличения pshift на дополнительную 1) приводит к большей потере производительности сжатия, что представлено в таблице 5 ниже:
Эти результаты являются частичными, поскольку они не включают в себя класс A2 и, как таковую, графу ‘в целом’.
Представленные выше результаты демонстрируют, что размер таблиц можно уменьшить в 2 или даже 4 раза, без негативного влияния на эффективность режима CCLM, где параметры α и β выводятся с использованием двух точек A и B.
В другом варианте осуществления, количество записей в таблице (т.е. значение pshift) может изменяться в зависимости от битовой глубины (например 128 (или 256) для не более 10 битов и 256 (или 512) для свыше 10 битов). Это можно объяснить тем, что более мощный кодер потребуется для кодирования выборок, представленных (например) 16 битами - и поэтому сложность вычисления с использованием большей таблицы не будет представлять столь большой проблемы. В таком случае, может отдаваться приоритет максимальному увеличению производительности кодирования за счет использования большего количества (например 512 или более) записей.
Количество битов, представляющих каждую запись в таблицах (массивах)
Для дополнительного снижения размера таблицы, каждая запись в таблице также может быть представлена на меньше, чем начальные k=16 битов, которые использует по 2 байта для каждой записи. Уменьшение значения k представляет снижение точности деления, поскольку оно, по существу, соответствует уменьшению модуля для представления α целыми числами. Нижеследующая таблица 6 демонстрируют влияние эффективности кодирования при уменьшении количества битов для представления каждой записи (по сравнению с k=16).
Таблица 6: производительность кодирования при уменьшении значения k.
Вышеприведенная таблица 6 демонстрирует неожиданный результат, состоящий в том, что когда записи представлены 8 битами или меньше, эффективность кодирования, по существу такая же, как при k=16 битов.
Вышеприведенная таблица демонстрирует приемлемые результаты эффективности кодирования получаются для k, которое содержится в интервале от 6 до 8. Аналогичный результат достигается для k в интервале 9-15, но такое представление все же потребует 2 байта, поэтому не будет обеспечивать столь большое преимущество в уменьшении памяти, необходимой для хранения таблицы.
Таблицы 6 демонстрируют, что для k, равного 5 битам или меньше, наблюдается большое ухудшение в силу деления, когда вычисление альфа становится неточным.
Таким образом было неожиданно обнаружено, что наилучший компромисс между производительностью и хранилищем достигается, когда k=8 битов.
По сравнению с k=16 битов, где каждая запись представлена 2 байтами, этот настоящий вариант осуществления может использовать только один байт для представления записи таблицы TAB1 или TAB3. Это уменьшает сложность всех вычислений с участием k, и, таким образом, снижает потребности в обработке.
Значение k=6, 7 или 8 неожиданно обеспечивает производительность кодирования, аналогичную k=16, с более высокими значениями k, обеспечивающими значительно более высокой производительностью кодирования.
Особенно неожиданно, можно уменьшить k на целый байт (8 битов) без сколько бы то ни было заметного уменьшения производительности кодирования.
Кроме того, было обнаружено, что k можно уменьшить вплоть до k=6, и только дальнейшее уменьшение приводиит к заметному снижению производительности кодирования.
При уменьшении k от 16 до 8, полная память, используемая для каждой таблицы уменьшается в 2 раза.
Удивительно, что обычно точность операций с участием битовых сдвигов подвергаются сильному влиянию малых изменений значения параметр битового сдвига, и можно ожидать большого снижения производительности кодирования при снижении значения k даже на малую величину. Однако вышеприведенные результаты неожиданно демонстрируют, что большое изменение значения k (например, от 16 до 6) снижает производительность кодирования лишь на пренебрежимо малую величину (<0,14%).
Выбор k может изменяться в зависимости от битовой глубины (например, 8 для не более 10 битов и 16 для свыше 10 битов). Это можно объяснить тем, что более мощный кодер потребуется для кодирования выборок, представленных (например) 16 битами - и поэтому сложность вычисления с использованием большей таблицы не будет представлять столь большой проблемы. В таком случае, может отдаваться приоритет максимальному увеличению производительности кодирования за счет использования большего количества (например, более 8) битов.
Объединение количества записей и количества битов, представляющих каждую запись
Нижеприведенная таблица 7 демонстрируют результаты для производительности кодирования для изменяющегося k от 8 до 5 при наличии 256 записей в каждой таблице (т.е. объединение двух наборов результатов, представленных в вышеприведенных таблицах 3 и 6) - по сравнению с базовой линией k=16 и 512 записей в каждой таблице.
Таблица 7: производительность кодирования при уменьшении значения k и количества записей от 512 до 256
Вышеупомянутые результаты эффективности кодирования демонстрируют неожиданный результат, состоящий в том, что за счет использования двух таблиц (TAB1 и TAB3), имеющих 256 записей, каждая из которых закодирована с использованием одного байта (т.е. k≤8) можно получить результаты, аналогичные со случаем двух таблиц с 512 записями, представленными 2 байтами. Конкретное преимущество этого варианта осуществления состоит в уменьшении в 4 раза памяти, необходимой для хранения этих таблиц TAB1 и TAB3 без влияния на эффективность результата кодирования. В этом конкретном варианте осуществления, память, необходимая для представления двух таблиц (TAB1 и TAB3), составляет: 2*256*8=4092 бита, которые могут храниться в 512 байтах.
Нижеприведенная таблица 8 демонстрируют результаты для производительности кодирования для изменяющегося k от 8 до 5 при наличии 128 записей в каждой таблице (т.е. объединение двух наборов результатов, представленных в вышеприведенных таблицах 4 и 6) - по сравнению с базовой линией k=16 и 512 записей в каждой таблице.
Таблица 8: производительность кодирования при уменьшении значения k и количества записей от 512 до 128
Вышеупомянутые результаты эффективности кодирования демонстрируют неожиданный результат, состоящий в том, что за счет использования двух таблиц (TAB1 и TAB3), имеющих 128 записей, каждая из которых закодирована с использованием одного байта (т.е. k≤8) можно получить результаты, аналогичные со случаем двух таблиц с 512 записями, представленными 2 байтами. Особенно неожиданно, что в ряде примеров, использование 128 записей фактически повышает производительность кодирования по сравнению с использованием 256 записей. Например, для k=8 (один байт для каждой записи), результаты демонстрируют, что применение таблицы размером 128 приводит к повышенной производительности кодирования по сравнению с таблицей размером 256 записей.
Конкретное преимущество этого варианта осуществления состоит в уменьшении в 8 раз памяти, необходимой для хранения этих таблиц TAB1 и TAB3 без влияния на эффективность результата кодирования. В этом конкретном варианте осуществления, память, необходимая для представления двух таблиц (TAB1 и TAB3), составляет: 2*128*8=2046 битов, которые могут храниться в 256 байты.
Таким образом, режим CCLM может использовать этот способ деления для извлечения параметров α и β, которые можно реализовать посредством целочисленной арифметики для эффективной аппаратной реализации.
В частности, было показано, что объединение уменьшения количество записей в таблице, а также уменьшения размера каждой записи не приводит к дальнейшему снижению производительности (как можно было ожидать), напротив, достигается по существу такая же производительность, при объединении уменьшения количества записей в таблице и уменьшения размера каждой записи по сравнению с независимым уменьшением любого из них.
Для полноты, таблица 9 демонстрируют частичные результаты, когда таблица из N=64 записей используется по сравнению с базовой линией k=16 и N=512. Следует отметить, что потеря производительности значительна для класса A1 (что является основной задачей для VVC) в компонентах U и V:
Таблица 9: частичные результаты производительности кодирования при уменьшении значения k и количества записей от 512 до 64
Представление α
В другом варианте осуществления, значение параметр α изменяется, благодаря чему он может быть представлен “L” битами. Согласно вышеописанному процессу вывода α и β, значение α может достигать 17 битов, когда k равно 8 (и 25 битов, если k=16). Основной целью изменения значения α состоит в ограничении битовой ширины умножения в нижеследующей формуле предсказания:
CC = ((α *Lc) >> k) + β
где Cc - предсказанное значение хромы, соответствующее значению Lc люма, и α и β - параметры наклона (которые могут выводиться, как описано выше).
Если выборки люмы кодируются 10 битами, это означает, что базовый контур предсказания должен быть способен осуществлять умножение до 10 битов на 17 битов, что является вычислительно сложным (и может использовать большие объемы памяти). В этом варианте осуществления, значение α изменяется, благодаря чему умножение не превышает 16 битов. Такое вычисление весьма пригодно для аппаратной реализации - например, 16-битовый процессор может осуществлять вычисление с использованием единого регистра памяти.
С этой целью, α должно быть представлено 6 битами или меньше. Для достижения этого 6-битового представления, диапазон α можно ‘обрезать’, благодаря чему, большие значения помещаются в указанный диапазон.
В другом варианте осуществления, определяется модуль α, благодаря чему он уменьшается, путем его деления на надлежащую величину, и соответствующей регулировки параметра k сдвига. Определение величины регулировки значения (k) сдвига содержит нахождение позиции P “старшего бита” (классическая операция, осуществляемая, например, путем отсчета начальных нулей или взятия двоичного логарифма). В этом случае, если он выше предела L (5 или 6 в предпочтительном варианте осуществления), осуществляются следующие операции:
α = α >> (P-L)
k=k+L - P
т.е. α делится на 2(P-L), и значение k компенсируется противоположной величиной (L-P).
Значение L может зависеть от битовой глубины, но может быть одинаковым для нескольких битовых глубин для упрощения реализаций. Дополнительно, L может учитывать бит знака, т.е. L=5.
Также было установлено, что в большинстве случаев реализации, значение с плавающей точкой α находится в диапазоне [-2,0; 2,0] в режиме CCLM. Использование только 6 битов позволяет, например, представлять 64 значения в интервале [-2,0; 2,0], причем любые вычисленные значения, выходящие за пределы этого диапазона, заменены концевой точкой диапазона.
В любом случае, обрезка α до любого диапазона может осуществляться до уменьшения его модуля. Это гарантирует, что выходящие значения удаляются до осуществления обработки уменьшения модуля.
Фиг. 11 демонстрирует разные способы выбора двух точек (A и B) согласно вариантам осуществления изобретения.
Предложенное упрощение вывода оказывает влияние на эффективность кодирования. Для уменьшения этой потери эффективности кодирования очень важно тщательно выбирать две точки.
В первом варианте осуществления, как описано ранее, выбираются минимум и максимум соседних значений выборки люмы, соответствующие точкам A и B на фиг. 11.
В альтернативном варианте осуществления, двумя выбранными точками являются точки C и D на фиг. 11, которые соответствуют паре выборок люмы и хромы, соответствующих минимуму и максимуму соседних значений выборки хромы. Этот альтернативный вариант осуществления иногда представляет интерес в отношении эффективности кодирования.
В альтернативном варианте осуществления, определяется самый длинный отрезок между отрезками [AB] и [CD], и если отрезок [AB] длиннее, чем отрезок [CD], выбираются точки A и B, в противном случае выбираются точки C и D. Длину каждого отрезка можно вычислять как евклидово расстояние. Можно использовать и другую меру расстояния. Этот вариант осуществления повышает эффективность кодирования по сравнению с первыми двумя. Действительно, когда две выбранные точки далеки друг от друга, в общем случае сформированная линейная модель пригодна. Следовательно, сформированный предсказатель блока хромы пригоден для предсказания текущего блока.
В альтернативном варианте осуществления, самый длинный отрезок из всех возможных отрезков, которые могут формироваться между A, B, C, D, дает две выбранные точки. Это соответствует отрезкам [AB], [CD], [AC], [AD], [CB] и [DB], как указано на фиг. 11. Этот вариант осуществления повышает эффективность кодирования по сравнению с предыдущими ценой более высокой сложности.
В предпочтительном варианте осуществления, точки, представляющие минимум и максимум значений выборки люмы RecL', устанавливаются так, чтобы создавать точки A и B, и если одна компонента точки A равна ее соответствующей компоненте из B ( 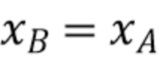 или
или 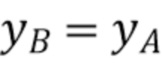 ), выбираются точки, представляющие минимум и максимум значений выборки хромы C и D. Этот вариант осуществления получает максимальную эффективность кодирования, поскольку, если или , то (или
), выбираются точки, представляющие минимум и максимум значений выборки хромы C и D. Этот вариант осуществления получает максимальную эффективность кодирования, поскольку, если или , то (или 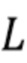 ) соответственно равно бесконечности или равно 0, и, следовательно, блок предсказателя хромы, соответственно, не пригоден или эквивалентен предсказанию DC. Это имеет место постольку, поскольку либо числитель, либо знаменатель дроби, представляющей
) соответственно равно бесконечности или равно 0, и, следовательно, блок предсказателя хромы, соответственно, не пригоден или эквивалентен предсказанию DC. Это имеет место постольку, поскольку либо числитель, либо знаменатель дроби, представляющей 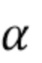 (или L) слишком мал (например, можно проверять следующее условие:
(или L) слишком мал (например, можно проверять следующее условие: 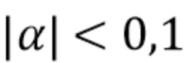 ): любая ошибка в этом (например, в силу квантования) даже на малую величину приводят к очень разным значениям
): любая ошибка в этом (например, в силу квантования) даже на малую величину приводят к очень разным значениям 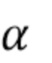 (или L). В оставшейся части документа, случаи, которые, в основном, являются почти горизонтальными или вертикальными наклонами, приводят к тому, что именуется аномальным наклоном, будь то или .
(или L). В оставшейся части документа, случаи, которые, в основном, являются почти горизонтальными или вертикальными наклонами, приводят к тому, что именуется аномальным наклоном, будь то или .
В дополнительном варианте осуществления, несколько пар точек, как все изображенные на фиг. 11, тестируются на “аномалию” . Этот вариант осуществления повышает эффективность кодирования предыдущего, но увеличивает вычислительную сложность.
В одном альтернативном варианте осуществления, вычисляется разность между максимумом и минимумом двух компонент (хромы и люмы). Кроме того, компонента с максимальной разностью выбирается для определения двух точек, задающих линию для вычисления параметров модели. Этот вариант осуществления эффективен, когда две компоненты являются двумя компонентами хромы или двумя компонентами RGB.
Выбор двух точек A и B может осуществляться на значениях выборок текущего блока. В одном варианте осуществления, две точки для упрощенного вывода линейной модели устанавливаются на основании значений выборки текущего дискретизированного с понижением блока люмы (505 на фиг. 5). Значения выборок люмы пар выборок в окрестности блока сравниваются со значениями выборки люмы блока люмы. Значение с максимальной частотностью выбирается для создания , и второе значение с максимальной частотностью выбирается для создания . Соответствующие значения хромы 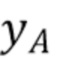 и
и 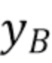 являются средними значениями совмещенных выборок хромы в парах выборок в окрестности блока. Когда (или ) ”аномально” (равно 0 или близко к 0 ()), является одним из значений люмы с меньшим выбором вместо второго после наибольшего выбранного значения. Таким же образом, являются средними значениями совмещенных выборок хромы. Этот вариант осуществления увеличивает эффективность кодирования по сравнению с предыдущим вариантом осуществления ценой наивысшей сложности.
являются средними значениями совмещенных выборок хромы в парах выборок в окрестности блока. Когда (или ) ”аномально” (равно 0 или близко к 0 ()), является одним из значений люмы с меньшим выбором вместо второго после наибольшего выбранного значения. Таким же образом, являются средними значениями совмещенных выборок хромы. Этот вариант осуществления увеличивает эффективность кодирования по сравнению с предыдущим вариантом осуществления ценой наивысшей сложности.
Выбор двух точек A и B может осуществляться в пространственных позициях пар выборок.
В предыдущих вариантах осуществления требуется определять минимальное и максимальное значения люмы (A, B) и/или хромы (C, D) из M пар соседних выборок люмы и хромы. Это можно рассматривать как дополнительную сложность. Таким образом, для некоторых реализаций, предпочтительно получать эти две точки с минимальной сложностью.
В одном варианте осуществления, одна линейная модель формируется с выборками хромы RecC (501 на фиг. 5) и с дискретизированными с понижением выборками люмы границы RecL’ (503). Первой выбранной точкой является нижняя выборка левого столбца, обозначенного 5004, люмы и совмещенная выборка 5001 хромы. Второй выбранной точкой является верхняя правая выборка люмы 5003 и совмещенная выборка хромы 5002. Этот выбор двух точек очень прост, но также менее эффективен, чем предыдущие варианты осуществления, на основании значений.
Дополнительно, если один из верхнего или левого края не существует, например, для блока на границе изображения или слайса или недоступен, например, по причинам сложности или устойчивость к ошибкам, то две выборки (например, имеющие люму 504 или 5003 на доступном краю) выбираются вместо недостающей. Таким образом, можно видеть, что существует несколько условий для выбора выборок.
Опишем дополнительный вариант осуществления, в котором, в отсутствие достаточного количества точек, которые можно выбрать для вычисления наклона, или если они приводят к “аномальному” (или ), то вместо них можно выбрать точку по умолчанию. Этот вариант осуществления также можно применять для режима MMLM с адаптацией. Для создания параметров линейной модели для первой группы, первой точкой является нижняя выборка второго влево столбца (5009) люмы и совмещенная выборка (5005) хромы. Кроме того, второй точкой является верхняя выборка люмы первого влево столбца (5010) и совмещенная выборка (5006) хромы.
Для создания параметров линейной модели для второй группы, первой точкой является левая выборка первой вверх строки (5011) люмы и совмещенная выборка (5007) хромы. Второй точкой является правая выборка люмы второй вверх строки (5012) и совмещенная выборка (5008) хромы.
Этот вариант осуществления упрощает выбор четырех точек для первой и второй группы.
В еще одном варианте осуществления, порогом режима MMLM является значение люмы точек 5010 или 5011, а именно верхней правой точки левой окрестности и нижней левой точки верхней окрестности в примере, или середина между этими точками. Этот дополнительный вариант осуществления упрощает вычисление порога.
В еще одном дополнительном варианте осуществления помимо всех этих вариантов осуществления, связанных с выбором двух точек, процесс понижающей дискретизации люмы запрещен и заменен прореживанием, т.е. для выборок RecL' используется одна из двух выборок люмы. В этом случае, этапы 1001 на фиг. 10 и 1201 на фиг. 12, которые подробно описаны ниже, будут пропущены. Этот вариант осуществления снижает сложность, оказывая незначительное влияние на эффективность кодирования.
Точки A, B, C и D определяются на основании декодированных версий выборок, и поэтому могут не совпадать с исходными значениями выборок. Это может приводить к аномально коротким отрезкам или просто зашумленной оценке, как описано выше при определении “аномального” наклона. A и C являются двумя наинизшими точками, и B и D являются двумя наивысшими, и вместо того, чтобы использовать любые две из них, можно использовать точку E, заданному как средняя между A и C, и точку F, заданную как средняя между B и D, ценой нескольких простых вспомогательных операций:
xE = (xA+xC+1) >> 1 и yE = (yA+yC+1) >> 1
xF = (xB+xD+1) >> 1 и yF = (yB+yD+1) >> 1
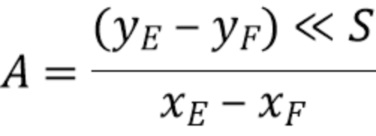
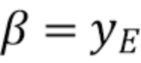 -
- 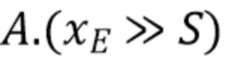
Очевидно, если yE-yF или xE-xF равно 0 или слишком мало (т.е. выведенный наклон “аномален”), то точки A, B, C и D рассматриваются, как обычно для получения лучших параметров.
Отсюда следует, что две точки, используемые при вычислении наклона в модели, могут не быть двумя фактическими точками, образованными значениями RecL' или RecC. Это объясняет использование слова “определить” на этапе 1003 вместо “выбрать”.
В еще одном дополнительном варианте осуществления, для режима MMLM, если параметр (или L) задающий наклон одной группы, является ”аномальным”, то соответствующие параметры LM устанавливаются равными параметрам LM другой группы или еще одной группы при наличии более двух групп параметров LM. Фиг. 12 демонстрирует этот вариант осуществления. После определения (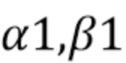 ) и (
) и (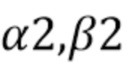 ), задающих две модели для двух групп на этапе 1203,
), задающих две модели для двух групп на этапе 1203, 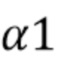 и
и 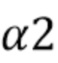 тестируются для проверки, равны ли они 0, на этапах 1204 и 1205. Если да, “аномальный” параметр наклона (или ) устанавливается равным другому параметру наклона , аналогично, соответствующее значение параметра другой группы также используется на этапах 1206 и 1207. Поэтому в этом случае используется один-единственный набор параметров при любом значении из дискретизированных с понижением значений выборки люмы текущего блока, не производится сравнение с порогом, благодаря чему, получается такая же сложность, как в режиме CCLM. Преимущество этого варианта осуществления состоит в повышении эффективности кодирования при малой сложности, поскольку не нужно выводить никакие дополнительные параметры линейной модели.
тестируются для проверки, равны ли они 0, на этапах 1204 и 1205. Если да, “аномальный” параметр наклона (или ) устанавливается равным другому параметру наклона , аналогично, соответствующее значение параметра другой группы также используется на этапах 1206 и 1207. Поэтому в этом случае используется один-единственный набор параметров при любом значении из дискретизированных с понижением значений выборки люмы текущего блока, не производится сравнение с порогом, благодаря чему, получается такая же сложность, как в режиме CCLM. Преимущество этого варианта осуществления состоит в повышении эффективности кодирования при малой сложности, поскольку не нужно выводить никакие дополнительные параметры линейной модели.
В альтернативном варианте осуществления, когда один параметр наклона (или ) “аномален”, один набор линейных параметров повторно выводится с учетом всех начальных выборок MMLM (что соответствует выводу CCLM с двумя верхними строками и двумя соседними столбцами, вместо одной верхней строки и одного соседнего столбца). Этот вариант осуществления дает более высокую эффективность кодирования, чем предыдущий, но более сложен, поскольку требует повторно выводить набор параметров линейной модели.
Упрощенный вывод LM с двумя точками, описанный в этом документе, в общем случае менее эффективен, чем классический вывод LM, если только не заменять все выводы LM, когда состязаются несколько режимов LM.
В одном варианте осуществления, вывод LM с двумя точками используется только для режима CCLM для вывода предсказателя блока хромы. Этот вариант осуществления повышает эффективность кодирования.
В одном варианте осуществления, вывод с двумя точками используется только для режима MMLM, поскольку это наиболее сложный способ предсказания.
В одном варианте осуществления, вывод LM с двумя точками используется для режима CCLM и режима MMLM для вывода предсказателя блока хромы. Этот вариант осуществления имеет примерно такую же эффективность кодирования, как JEM, но снижает сложность худшего случая за счет использования этого упрощенного вывода LM для формировании предсказателей блоков хромы. Действительно, предсказание хромы на основании люмы является режимом, представляющим сложность худшего случая, среди режимов предсказания линейной модели. Оно сложнее, чем предсказание остаточной хромы.
В одном варианте осуществления, вывод LM с двумя точками заменяет все выводы LM (формирование предсказателя блока хромы и предсказание остатка). Этот вариант осуществления снижает эффективность кодирования по сравнению с JEM, но значительно уменьшает сложность. Заметим, что эти два варианта осуществления дают повышение эффективности кодирования при любом способе вывода параметров, используемом на этапе 1203.
В еще одном варианте осуществления, если один или оба параметры (или ) наклона являются “аномальными”, то вместо них на этапах 1206 и/или 1207 используется значение, принятое по умолчанию (например 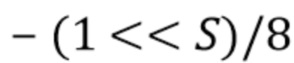 ), и вычисляется соответствующее значение .
), и вычисляется соответствующее значение .
В еще одном дополнительном варианте осуществления, несколько режимов LM состязаются на стороне кодера, и элементы синтаксиса могут сигнализировать выбранный режим LM в битовом потоке на стороне декодера. Эта сигнализация может осуществляться на уровне слайсов (или PPS, или SPS) для указания, какие наборы следует использовать, или по меньшей мере обеспечивать кандидаты для выборка на уровне блоков. По меньшей мере одно из различий между этими состязающимися режимами LM состоит в наборе двух точек, используемом для вывода параметров LM. Набор двух точек и способ формировании этих двух точек задают разные состязающиеся режимы LM. Например, для одного режима LM две точки определяются на основании минимального и максимального значений люмы и для еще одного режима LM две точки выбираются на основании минимального и максимального значений хромы.
Другой вариант осуществления состоит в задании нескольких наборов из возможных положений, как показано на фиг. 5. Хотя четыре такие разные точки могу обеспечивать до двенадцати разных пар, те, которые дают наибольшие значения числителя и знаменателя в уравнении для вычисления параметра наклона (или ), могут быть предпочтительными. Кодер строит список пар и сортирует их согласно некоторому критерию (например, расстоянию в компоненте люмы или декартовому расстояние с использованием обеих компонент люмы и хромы), возможно, удаляя некоторые из них (т.е. если они слишколм близки по наклону), и, таким образом, сосздавая список параметров, который можно выбирать и сигнализировать.
Преимуществом этих вариантов осуществления является повышение эффективности кодирования.
В описании этих вариантов осуществления упоминаются компоненты люмы и хромы, но их можно легко адаптировать к другим компонентам, например, обеим компонентам хромы или компонентам RGB. Согласно варианту осуществления, настоящее изобретение используется в предсказании значения выборки первой компоненты хромы из второй компоненты хромы. В другом варианте осуществления, настоящее изобретение используется в предсказании значения выборки одной компоненты из более чем одного значения выборки более чем одной компоненты. Следует понимать, что в таком случае, линейная модель выводится на основании двух точек /наборов, причем каждая точка/набор, содержит значение выборки одной компоненты и более чем одно значение выборки более чем одной компоненты. Например, если значения выборки двух компонент используются для предсказания значения выборки одной компоненты, каждая точка/набор можно представить позицией в 3-мерном пространстве, и линейная модель базируется на прямой линии, проходящей через две позиции в 3-мерном пространстве, которые соответствуют двум точкам/наборам реконструированных значений выборки.
На фиг. 13 показана блок-схема вычислительного устройства 1300 для реализации одного или более вариантов осуществления изобретения. Вычислительное устройство 1300 может представлять собой, например, микрокомпьютер, рабочую станцию или легкое портативное устройство. Вычислительное устройство 1300 содержит шину связи, подключенную к:
- центральному процессору 1301, например, микропроцессору, обозначенному CPU;
- оперативной памяти 1302, обозначенной RAM, для хранения исполнимого кода способа согласно вариантам осуществления изобретения, а также регистрам, предназначенным для записи переменных и параметров, необходимых для осуществления способа кодирования или декодирования по меньшей мере части изображения согласно вариантам осуществления изобретения, причем их объем памяти можно увеличивать, например, путем подключения необязательной RAM к порту расширения;
- постоянной памяти 1303, обозначенной ROM, для хранения компьютерных программ для реализации вариантов осуществления изобретения;
- сетевому интерфейсу 1304, который обычно подключен к сети связи, по которой передаются или принимаются цифровые данные, подлежащие обработке. Сетевой интерфейс 1304 может быть единым сетевым интерфейсом или состоять из нескольких разных сетевых интерфейсов (например, проводных и беспроводных интерфейсов, или разных видов проводных или беспроводных интерфейсов). Пакеты данных записываются в сетевой интерфейс для передачи или считываются из сетевого интерфейса для приема под управлением прикладной программы, выполняющейся на CPU 1301;
- пользовательскому интерфейсу 1305, который может использоваться для приема вводов от пользователя или для отображения информации пользователю;
- жесткому диску 1306, обозначенному HD, который может обеспечиваться как устройство хранения данных большой емкости;
- модулю 1307 I/O (ввода/вывода), который может использоваться для приема/отправки данных от/на внешние устройства, например, источник видеосигнала или дисплей.
Исполнимый код может храниться либо в постоянной памяти 1303, либо на жестком диске 1306, либо на сменном цифровом носителе, например, диске. Согласно варианту, исполнимый код программ может приниматься посредством сети связи, через сетевой интерфейс 1304, для сохранения в одном из средств хранения устройства 1300 связи, например, жестком диске 1306, до исполнения.
Центральный процессор 1301 предназначен для управления и руководства исполнением инструкций или участков программного кода программы или программ согласно вариантам осуществления изобретения, и эти инструкции сохраняются в одном из вышеупомянутых средств хранения. После включения питания, CPU 1301 способен выполнять инструкции прикладной программы из основной памяти 1302 RAM после загрузки этих инструкций, например, из программной ROM 1303 или жесткого диска (HD) 1306. Такая прикладная программа, исполняемая CPU 1301, предписывает осуществлять этапы способа согласно изобретению.
Любой этап способов согласно изобретению можно реализовать программными средствами, исполняя набор инструкций или программу на программируемой вычислительной машине, например, PC (“персональном компьютере”), DSP (“цифровом сигнальном процессоре”) или микроконтроллере; или иначе реализовать аппаратными средствами в виде машины или специализированного компонента, например, FPGA (“вентильной матрицы, программируемой пользователем”), особенно для выбора минимумов и максимумов, или ASIC (“специализированной интегральной схемы”).
Также следует отметить, что хотя некоторые примеры основаны на HEVC в целях иллюстрации, изобретение не ограничивается HEVC. Например, настоящее изобретение также может использоваться в любом другом процессе предсказания/оценки, где соотношение между значениями выборки двух или более компонент можно оценивать/предсказывать с моделью, где модель является приближенной моделью, определенной на основании по меньшей мере двух наборов значений выборки соответствующей/связанной компоненты, выбранных из всех доступных наборов значений выборки соответствующей/связанной компоненты.
Следует понимать, что каждая точка, соответствующая паре выборок (т.е. набор связанных значений выборки для разных компонент) может храниться и/или обрабатываться в отношении массива. Например, значения выборки каждой компоненты могут храниться в массиве, благодаря чему, каждое значение выборки этой компоненты является ссылочным/доступным/получаемым путем ссылки на элемент этого массива, например, с использованием индекса для этого значения выборки. Альтернативно, массив может использоваться для хранения и обработки каждой пары выборок, причем каждое значение выборки из пар выборок, доступно/получается в качестве элемента массива.
Также понятно, что любой результат вышеописанных сравнения, определения, оценивания, выбора или рассмотрения, например, выбор, сделанный в процессе кодирования, может указываться в или определяться из данных в битовом потоке, например, флага или данных, указывающих результат, благодаря чему, указанный или определенный результат может использоваться при обработке вместо фактического осуществления сравнения, определения, оценивания, выбора или рассмотрения, например в процессе декодирования.
Хотя настоящее изобретение описано выше со ссылкой на конкретные варианты осуществления, настоящее изобретение не ограничивается конкретными вариантами осуществления, и специалист в данной области техники может предложить модификации, которые лежат в объеме настоящего изобретения.
Многие дополнительные модификации и вариации будут очевидны специалист в данной области техники из вышеупомянутых иллюстративных вариантов осуществления, которые заданы исключительно в порядке примера и которые не предназначены для ограничения объема изобретения, который определяется только нижеследующей формулой изобретения. В частности разные признаки из разных вариантов осуществления могут заменять друг друга, когда это целесообразно.
Каждый из вышеописанных вариантов осуществления изобретения можно реализовать по отдельности или в виде комбинации множества вариантов осуществления. Также, признаки из разных вариантов осуществления могут объединяться по мере необходимости или когда объединение элементов или признаков из отдельных вариантов осуществления в единый вариант осуществления целесообразно.
Каждый признак, раскрытый в этой заявке (в том числе в формуле изобретения, реферате и чертежах), можно заменить альтернативными признаками, служащими той же, эквивалентной или аналогичной цели, если в явном виде не указано иное. Таким образом, если в явном виде не указано иное, каждый раскрытый признак является лишь одним примером общей последовательности эквивалентных или аналогичных признаков.
В формуле изобретения, слово “содержащий” не исключает другие элементы или этапы, и употребление единственного числа не исключает множества. Лишь тот факт, что разные признаки упомянуты в отличающихся друг от друга зависимых пунктах формулы изобретения, не указывает, что объединение этих признаков нельзя выгодно использовать.
Следующие пронумерованные выражения также задают некоторые варианты осуществления:
1. Способ вывода линейной модели для получения выборки первой компоненты для блока первой компоненты из связанной реконструированной выборки второй компоненты блока второй компоненты в одном и том же кадре, причем способ содержит этапы, на которых:
определяют две точки, каждая из которых задается двумя переменными, а именно первой переменной, соответствующей значению выборки второй компоненты, и второй переменной, соответствующей значению выборки первой компоненты, на основании реконструированных выборок первой компоненты и второй компоненты;
определяют параметры линейного уравнения, представляющего прямую линию, проходящую через две точки; и
выводят линейную модель, заданную параметрами прямой линии.
2. Способ по п. 1, в котором две точки определяются на основании пар выборок в окрестности блока второй компоненты.
3. Способ по п. 2, в котором две точки определяются на основании значений выборки пар выборок в окрестности блока второй компоненты.
4. Способ по п. 3, в котором две точки соответствуют, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты.
5. Способ по п. 3, в котором две точки соответствуют, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты.
6. Способ по п. 3, содержащий этапы, на которых:
- определяют две первые точки, соответствующие, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты;
- определяют две вторые точки, соответствующие, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты; и
- определяют две точки как две первые точки, если они образуют более длинный отрезок, и определяют две точки, в противном случае, как две вторые точки.
7. Способ по п. 3, содержащий этапы, на которых:
- определяют две первые точки, соответствующие, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты;
- определяют две вторые точки, соответствующие, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты; и
- определяют две точки из двух первых точек и двух вторых точек как две точки, образующие самый длинный отрезок.
8. Способ по п. 3, содержащий этапы, на которых:
- определяют две первые точки, соответствующие, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты;
- определяют две вторые точки, соответствующие, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты; и
- определяют две точки как две первые точки, если все их переменные отличаются, и определяют две точки, в противном случае, как две вторые точки.
9. Способ по п. 3, содержащий этапы, на которых:
- определяют две первые точки, соответствующие, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты;
- определяют две вторые точки, соответствующие, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты; и
- определяют две точки как две первые точки, если параметр наклона прямой линии, заданной этими двумя точками, больше заданного порога, и определяют две точки, в противном случае, как две вторые точки.
10. Способ по п. 3, содержащий этапы, на которых:
- определяют две первые точки, соответствующие, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты;
- определяют две вторые точки, соответствующие, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты; и
- определяют две точки как две первые точки, если разность между наинизшим значением выборки второй компоненты и наивысшим значением выборки второй компоненты больше разности между наинизшим значением выборки первой компоненты и наивысшим значением выборки первой компоненты, и определяют две точки, в противном случае, как две вторые точки.
11. Способ по п. 2, в котором две точки определяются на основании позиции значения выборки второй компоненты пар выборок в окрестности блока второй компоненты.
12. Способ по п. 11, в котором две точки определяются как соответствующие парам выборок в заранее определенной позиции в окрестности блока второй компоненты.
13. Способ по п. 12, дополнительно содержащий этап, на котором определяют по меньшей мере одну из двух точек как соответствующую паре выборок во второй заранее определенной позиции, когда пара выборок в заранее определенной позиции недоступна.
14. Способ по п. 1, в котором две точки определяются на основании пар выборок в окрестности блока второй компоненты и значений выборки блока второй компоненты.
15. Способ по п. 14, в котором:
- первые переменные двух точек определяются как значение выборки, из пар выборок в окрестности блока второй компоненты, с максимальной частотностью в блоке второй компоненты и второй максимальной частотностью в блоке второй компоненты;
- вторые переменные двух точек определяются как соответствующее значение выборки первой компоненты на основании пар выборок в окрестности блока второй компоненты.
16. Способ по любому из пп. 1-15, в котором:
- выборки блока второй компоненты организуются в по меньшей мере две группы; и
- две точки определяются для задания линейной модели для каждой группы выборок блока второй компоненты.
17. Способ по п. 16, в котором, если две точки, определенные для группы, соответствуют параметру наклона, который меньше заранее определенного порога, то они заменяются двумя точками, определенными для другой группы.
18. Способ по п. 16, в котором, если две точки, определенные для группы, соответствуют параметру наклона, который меньше заранее определенного порога, то две новые точки определяются на основании выборок из всех групп, рассматриваемых как единая группа.
19. Способ получения выборки первой компоненты для блока первой компоненты из связанной реконструированной выборки второй компоненты блока второй компоненты в одном и том же кадре, причем способ содержит этапы, на которых:
- задают множество режимов вывода линейной модели, содержащее режимы CCLM, использующие единую линейную модель, и режимы MMLM, использующие несколько линейных моделей; и
- выбирают один из режимов вывода линейной модели для получения выборок первой компоненты для блока первой компоненты,
причем:
- по меньшей мере один из режимов вывода линейной модели использует способ вывода по любому из пп. 1-18.
20. Способ по п. 19, в котором только режимы CCLM используют способ вывода по любому из пп. 1-18.
21. Способ по п. 19, в котором только режимы MMLM используют способ вывода по любому из пп. 1-18.
22. Способ кодирования одного или более изображений в битовый поток, причем способ содержит этап, на котором выводят линейную модель по любому из пп. 1-18.
23. Способ кодирования одного или более изображений в битовый поток, причем способ содержит этап, на котором получают выборку первой компоненты для блока первой компоненты одного или более изображений из связанного блока реконструированных выборок второй компоненты по любому из пп. 19-21.
24. Способ декодирования одного или более изображений из битового потока, причем способ содержит этап, на котором выводят линейную модель по любому из пп. 1-18.
25. Способ декодирования одного или более изображений из битового потока, причем способ содержит этап, на котором получают выборку первой компоненты для блока первой компоненты одного или более изображений из связанного блока реконструированных выборок второй компоненты по любому из пп. 19-21.
26. Устройство для вывода линейной модели для получения выборки первой компоненты для блока первой компоненты из связанной реконструированной выборки второй компоненты блока второй компоненты в одном и том же кадре, причем устройство содержит средство для:
- определения двух точек, каждая из которых задается двумя переменными, а именно первой переменной, соответствующей значению выборки второй компоненты, и второй переменной, соответствующей значению выборки первой компоненты, на основании реконструированных выборок первой компоненты и второй компоненты;
- определения параметров линейного уравнения, представляющего прямую линию, проходящую через две точки; и
- вывода линейной модели, заданной параметрами прямой линии.
27. Устройство по п. 26, в котором две точки определяются на основании пар выборок в окрестности блока второй компоненты.
28. Устройство по п. 27, в котором две точки определяются на основании значений выборки пар выборок в окрестности блока второй компоненты.
29. Устройство по п. 26, в котором две точки соответствуют, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты.
30. Устройство по п. 26, в котором две точки соответствуют, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты.
31. Устройство по п. 26, в котором средство выполнено с возможностью осуществления:
- определения двух первых точек, соответствующих, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты;
- определения двух вторых точек, соответствующих, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты; и
- определения двух точек как двух первых точек, если они образуют более длинный отрезок, и определения двух точек, в противном случае, как двух вторых точек.
32. Устройство по п. 26, в котором средство выполнено с возможностью осуществления:
- определения двух первых точек, соответствующих, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты;
- определения двух вторых точек, соответствующих, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты; и
- определения двух точек из двух первых точек и двух вторых точек как двух точек, образующих самый длинный отрезок.
33. Устройство по п. 26, в котором средство выполнено с возможностью осуществления:
- определения двух первых точек, соответствующих, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты;
- определения двух вторых точек, соответствующих, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты; и
- определения двух точек как двух первых точек, если все их переменные отличаются, и определения двух точек, в противном случае, как двух вторых точек.
34. Устройство по п. 26, в котором средство выполнено с возможностью осуществления:
- определения двух первых точек, соответствующих, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты;
- определения двух вторых точек, соответствующих, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты; и
- определения двух точек как двух первых точек, если параметр наклона прямой линии, заданной этими двумя точками, больше заданного порога, и определения двух точек, в противном случае, как двух вторых точек.
35. Устройство по п. 26, в котором средство выполнено с возможностью осуществления:
- определения двух первых точек, соответствующих, соответственно, парам выборок с наинизшим значением выборки второй компоненты и с наивысшим значением выборки второй компоненты;
- определения двух вторых точек, соответствующих, соответственно, парам выборок с наинизшим значением выборки первой компоненты и с наивысшим значением выборки первой компоненты; и
- определения двух точек как двух первых точек, если разность между наинизшим значением выборки второй компоненты и наивысшим значением выборки второй компоненты больше разности между наинизшим значением выборки первой компоненты и наивысшим значением выборки первой компоненты, и определения двух точек, в противном случае, как двух вторых точек.
36. Устройство по п. 27, в котором две точки определяются на основании позиции пар выборок в окрестности блока второй компоненты.
37. Устройство по п. 36, в котором две точки определяются как соответствующие парам выборок в заранее определенной позиции в окрестности блока второй компоненты.
38. Устройство по п. 37, дополнительно содержащий этапы, на которых определение по меньшей мере одна из двух точек как соответствующую паре выборок во второй заранее определенной позиции, когда пара выборок в заранее определенной позиции недоступна.
39. Устройство по п. 26, в котором две точки определяются на основании пар выборок в окрестности блока второй компоненты и значений выборки блока второй компоненты.
40. Устройство по п. 39, в котором:
- первые переменные двух точек определяются как значение выборки с максимальной частотностью в блоке второй компоненты и второй максимальной частотностью в блоке второй компоненты;
- вторые переменные двух точек определяются как соответствующее значение выборки первой компоненты на основании пар выборок в окрестности блока второй компоненты.
41. Устройство по любому из пп. 26-40, в котором:
- выборки блока второй компоненты организуются в по меньшей мере две группы; и
- две точки определяются для задания линейной модели для каждой группы выборок блока второй компоненты.
42. Устройство по п. 41, в котором, если две точки, определенные для группы, соответствуют параметру наклона, который меньше заранее определенного порога, то они заменяются двумя точками, определенными для другой группы.
43. Устройство по п. 41, в котором, если две точки, определенные для группы, соответствуют параметру наклона, который меньше заранее определенного порога, то две новые точки определяются на основании выборок из всех групп, рассматриваемых как единая группа.
44. Устройство для получения выборки первой компоненты для блока первой компоненты из связанной реконструированной выборки второй компоненты блока второй компоненты в одном и том же кадре, причем устройство содержит средство для:
- задания множества режимов вывода линейной модели, содержащего режимы CCLM, использующие единую линейную модель, и режимы MMLM, использующие несколько линейных моделей;
- выбора одного из режимов вывода линейной модели для получения выборок первой компоненты для блока первой компоненты;
причем:
- по меньшей мере некоторые из режимов вывода линейной модели используют способ вывода по любому из пп. 1-18.
45. Устройство по п. 44, в котором только режимы CCLM используют способ вывода по любому из пп. 1-18.
46. Устройство по п. 44, в котором только режимы MMLM используют способ вывода по любому из пп. 1-18.
47. Устройство для кодирования изображений, причем устройство содержит средство для вывода линейной модели по любому из пп. 1-18.
48. Устройство для декодирования изображений, причем устройство содержит средство для вывода линейной модели по любому из пп. 1-18.
49. Компьютерный программный продукт для программируемого устройства, причем компьютерный программный продукт содержит последовательность инструкций для реализации способа по любому из пп. 1-25, при загрузке и исполнении программируемым устройством.
50. Компьютерно-считываемый носитель, хранящий программу, которая, при исполнении микропроцессором или компьютерной системой в устройстве, предписывает устройству осуществлять способ по любому из пп. 1-25.
51. Компьютерная программа, которая, при исполнении, предписывает осуществлять способ по любому из пп. 1-25.
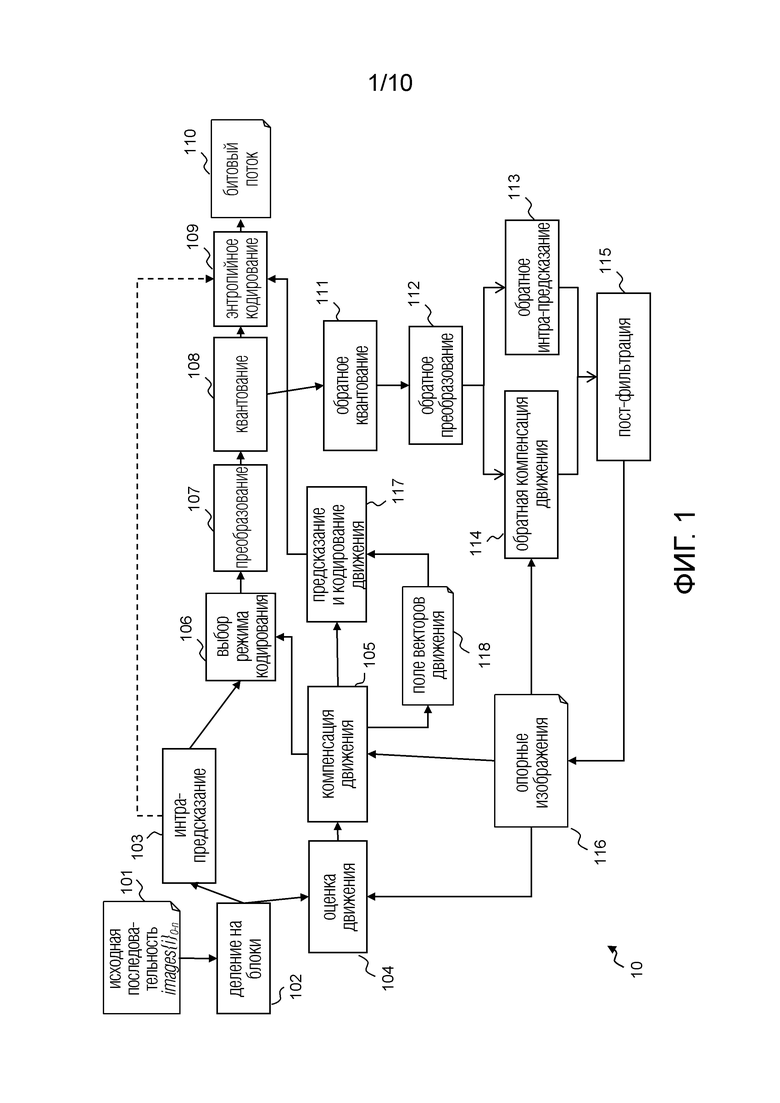
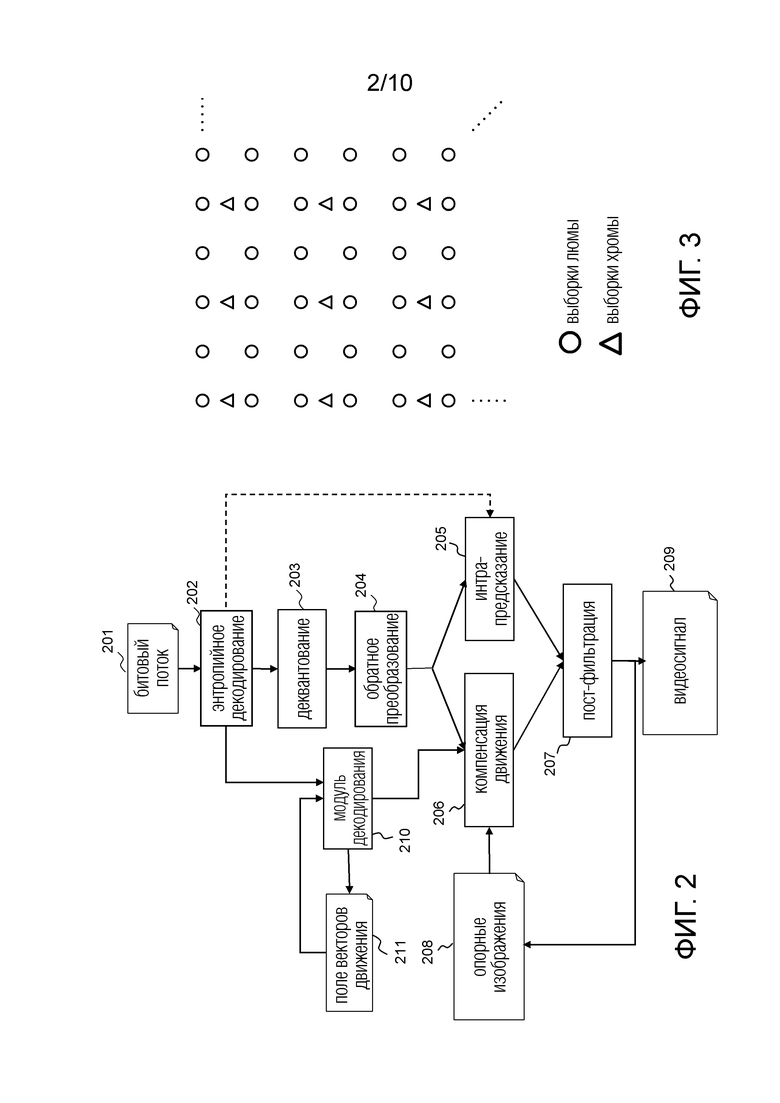
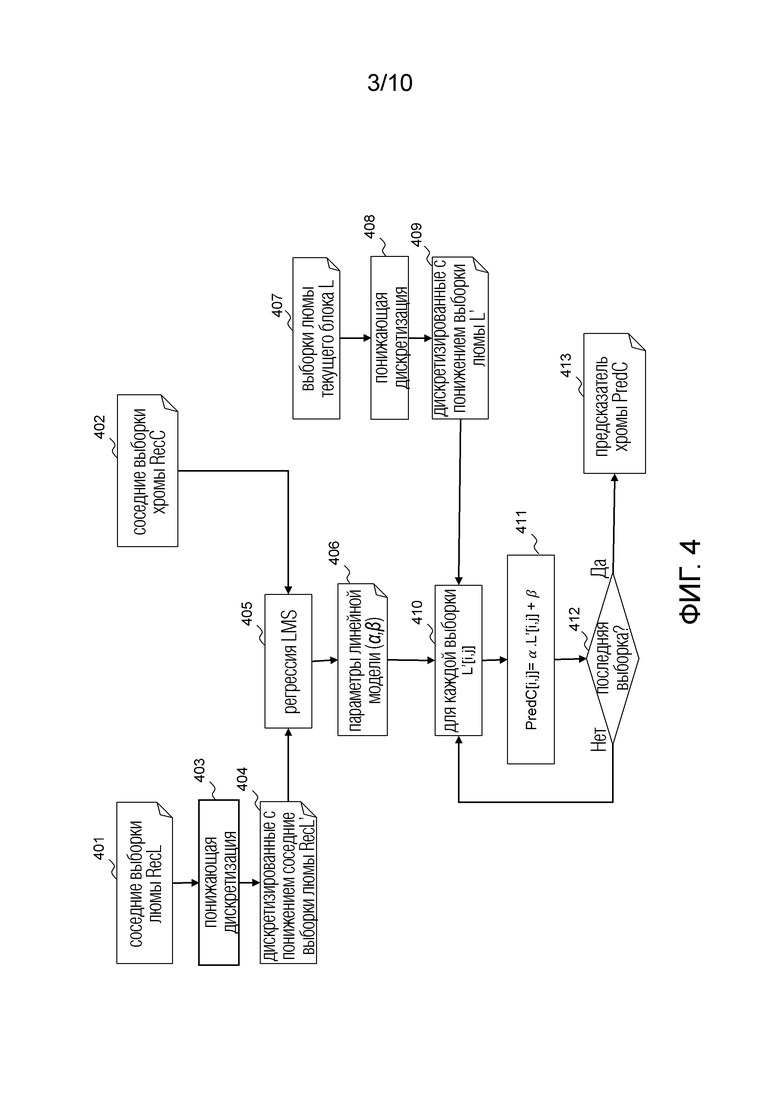
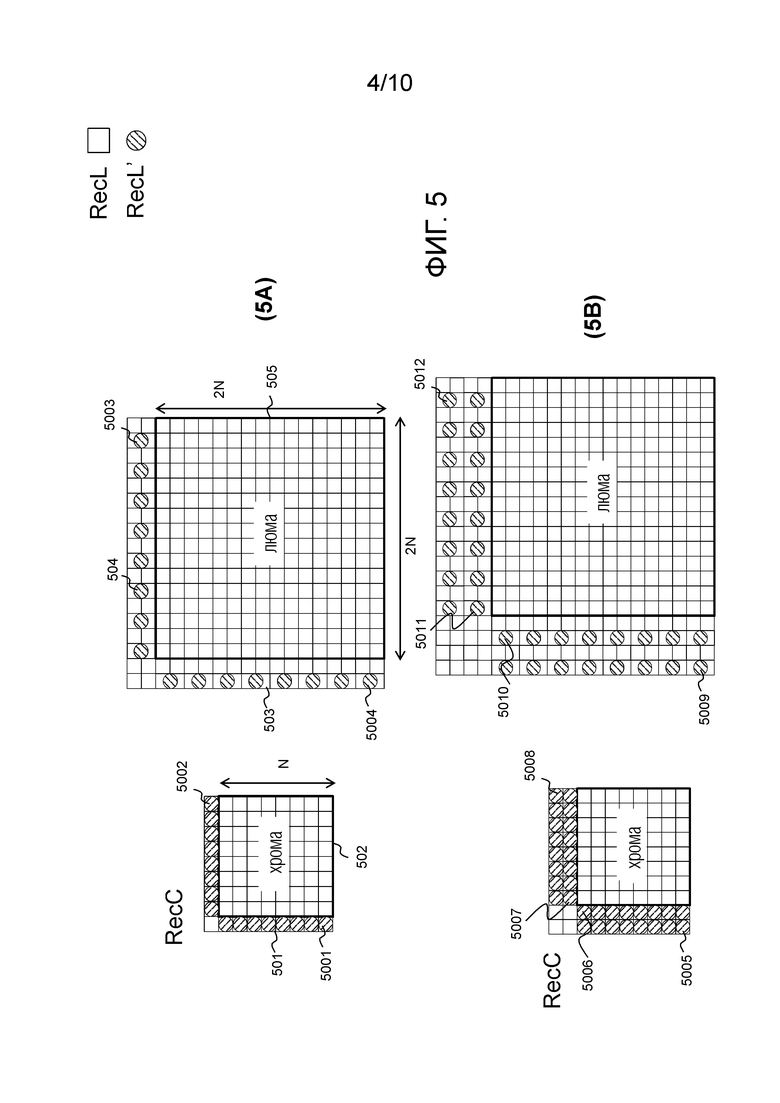
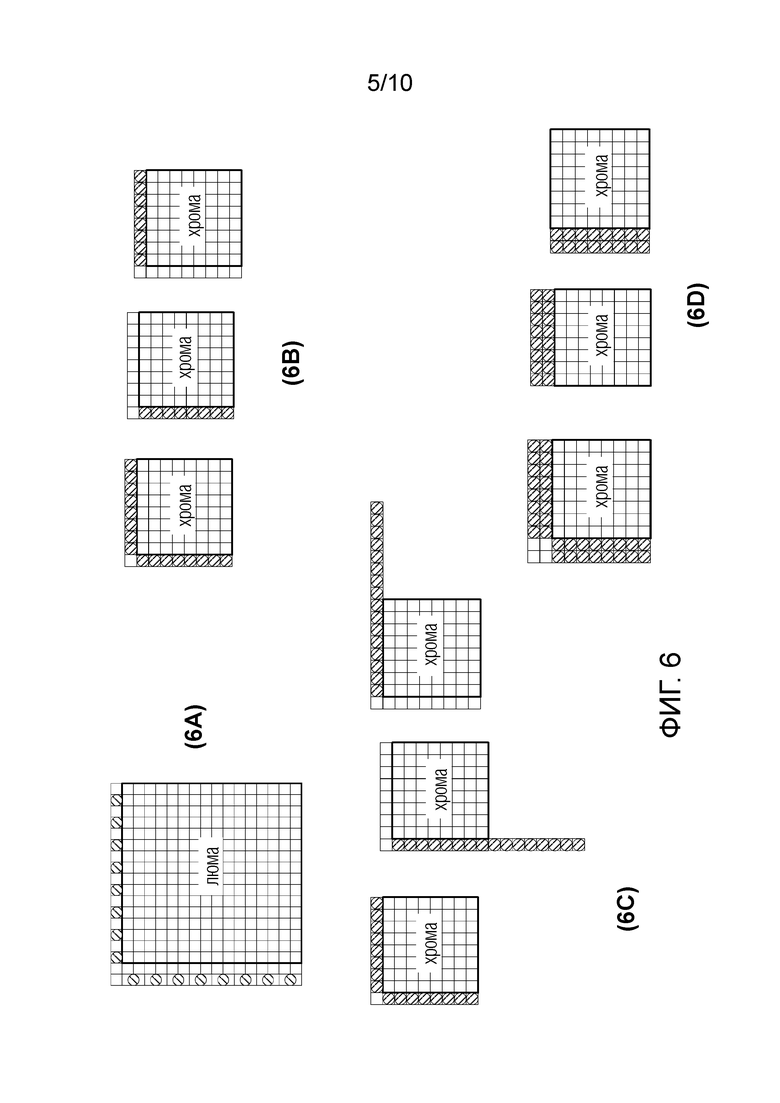
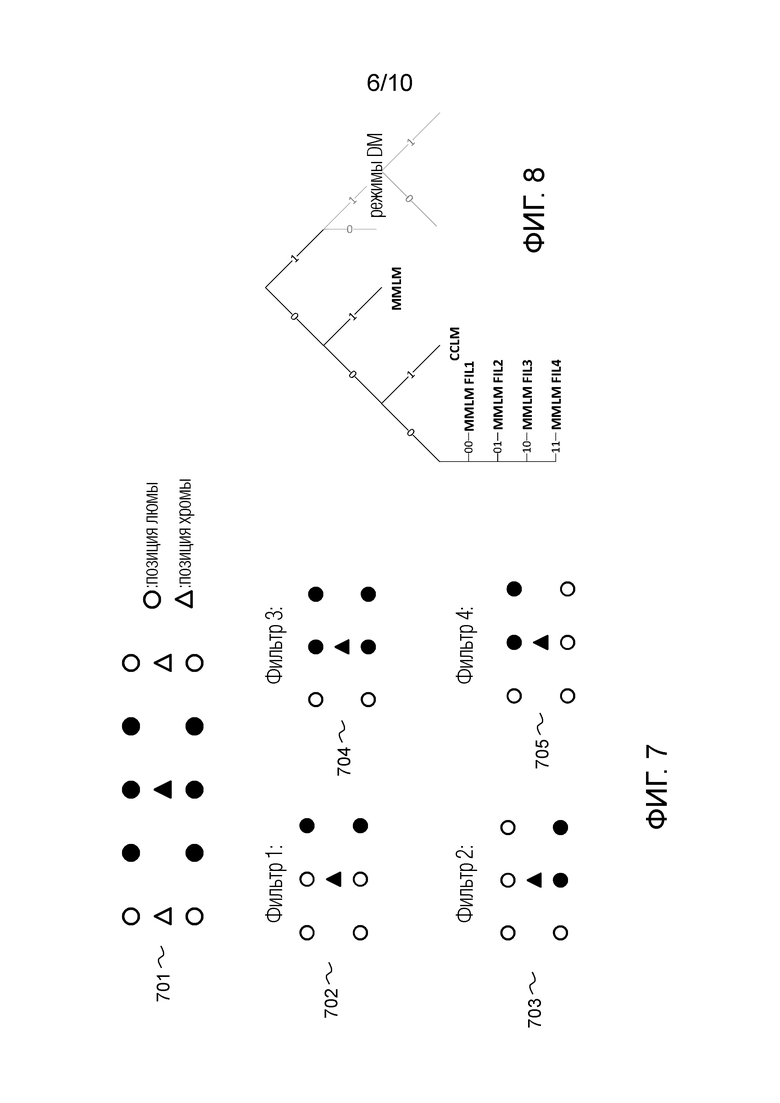
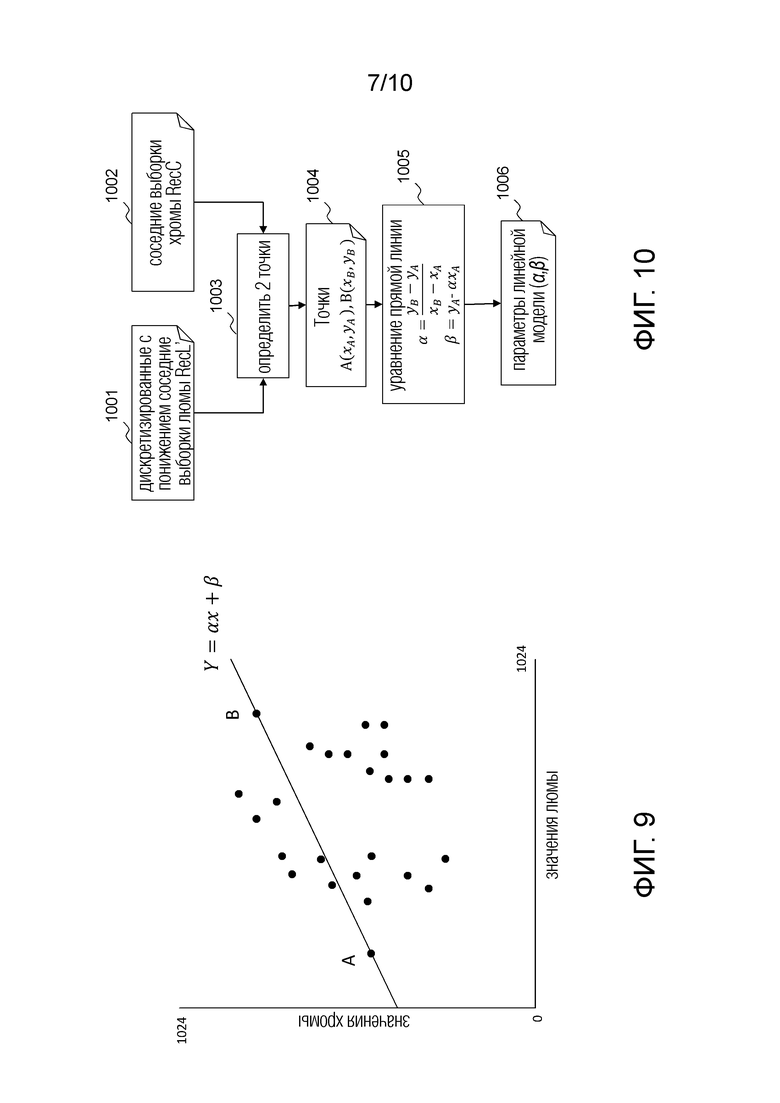
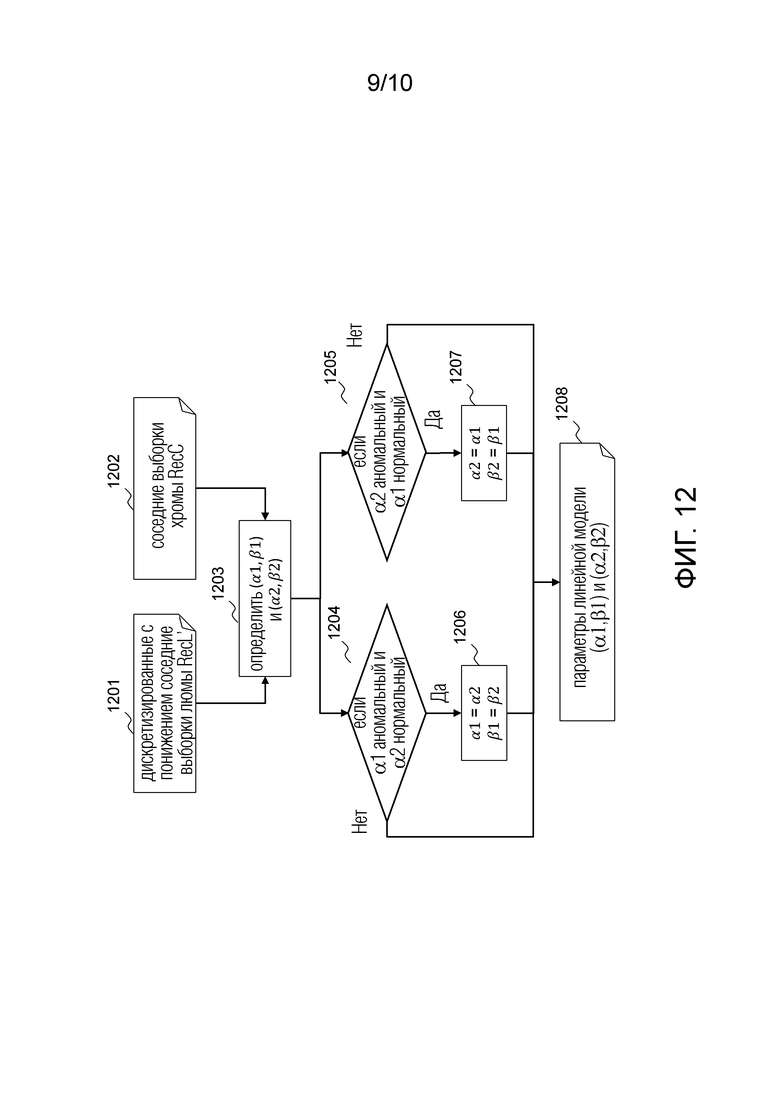
Изобретение относится к кодированию и декодирования видео. Технический результат заключается в повышении эффективности кодирования видео. Определяют две точки прямой линии, причем каждая из двух точек задается двумя переменными, причем первая переменная из двух переменных соответствует выборке яркости и вторая переменная из двух переменных соответствует выборке цветности. Определяют параметры, представляющие прямую линию, проходящую через две точки. Причем для определения по меньшей мере одного из упомянутых параметров используется целочисленная арифметика, использующая по меньшей мере математическую функцию, результат которой ограничивается целым числом. 4 н. и 10 з.п. ф-лы, 13 ил., 9 табл.
1. Способ вывода параметров, представляющих прямую линию, проходящую через две точки, для получения выборки цветности целевого блока из связанной выборки яркости целевого блока, причем способ содержит этапы, на которых:
- определяют две точки прямой линии, причем каждая из двух точек задается двумя переменными, причем первая переменная из двух переменных соответствует выборке яркости и вторая переменная из двух переменных соответствует выборке цветности; и
- определяют параметры, представляющие прямую линию, проходящую через две точки,
причем для определения по меньшей мере одного из упомянутых параметров используется целочисленная арифметика, использующая по меньшей мере математическую функцию, результат которой ограничивается целым числом.
2. Способ по п. 1, в котором параметр в параметрах, соответствующих наклону прямой линии (α), оценивается путем вычисления разности (diff) между выборками цветности двух точек, и величина разности ограничивается путем применения битового сдвига к разности.
3. Способ по п. 2, в котором значение битового сдвига зависит от битовой глубины выборки.
4. Способ по любому из предыдущих пунктов, в котором определение параметра в параметрах, соответствующих наклону прямой линии, содержит определение деления, причем упомянутое определение содержит уменьшение модуля деления путем применения битового сдвига к упомянутому делению.
5. Способ по п. 4, в котором уменьшение модуля содержит этап, на котором ограничивают количество битов, используемое значением деления, одним байтом.
6. Способ по п. 5, в котором количество битов равно 6, 7 или 8.
7. Способ по п. 5 или 6, в котором количество битов зависит от битовой глубины выборки.
8. Способ по любому из предыдущих пунктов, дополнительно содержащий этап, на котором ограничивают размер и/или количество возможных значений параметра в параметрах, соответствующих наклону упомянутой прямой линии.
9. Способ по п. 8, содержащий этап, на котором обрезают значение наклона упомянутой прямой линии до заранее заданного диапазона.
10. Способ по любому из пп. 5–9, в котором ограничение размера и/или количества возможных значений параметра в параметрах, соответствующих наклону упомянутой прямой линии, содержит уменьшение модуля путем ограничения количества битов, используемого значением параметра.
11. Способ по п. 10, в котором количество битов равно 5 или 6.
12. Устройство для кодирования изображений путем вывода параметров, представляющих прямую линию, проходящую через две точки, для получения выборки цветности целевого блока из связанной выборки яркости целевого блока, причем устройство содержит:
- блок вывода для вывода параметров, представляющих прямую линию, проходящую через две точки, для получения выборки цветности целевого блока из связанной выборки яркости целевого блока,
- блок определения для определения двух точек прямой линии, причем каждая из двух точек задается двумя переменными, причем первая переменная из двух переменных соответствует выборке яркости и вторая переменная из двух переменных соответствует выборке цветности; и
- определения параметров, представляющих прямую линию, проходящую через две точки,
причем для определения по меньшей мере одного из упомянутых параметров используется целочисленная арифметика, использующая по меньшей мере математическую функцию, результат которой ограничивается целым числом.
13. Устройство для декодирования изображений путем вывода параметров, представляющих прямую линию, проходящую через две точки, для получения выборки цветности целевого блока из связанной выборки яркости целевого блока, причем устройство содержит:
- блок вывода для вывода параметров, представляющих прямую линию, проходящую через две точки, для получения выборки цветности целевого блока из связанной выборки яркости целевого блока,
- блок определения для определения двух точек прямой линии, причем каждая из двух точек задается двумя переменными, причем первая переменная из двух переменных соответствует выборке яркости и вторая переменная из двух переменных соответствует выборке цветности; и
- определения параметров, представляющих прямую линию, проходящую через две точки,
причем для определения по меньшей мере одного из упомянутых параметров используется целочисленная арифметика, использующая по меньшей мере математическую функцию, результат которой ограничивается целым числом.
14. Компьютерно-считываемый носитель, хранящий программу, которая, при исполнении микропроцессором или компьютерной системой в устройстве, предписывает устройству осуществлять способ по любому из пп. 1-11.
| US 9167269 B2, 20.10.2015 | |||
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| US 9838662 B2, 05.12.2017 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| RU 2016129139 A, 06.02.2018. | |||

