ОБЛАСТЬ ТЕХНИКИ
[0001] Реализация сущности изобретения, относящегося в общем к компьютерным системам, а конкретнее к системам и способам эффективной идентификации записей базы данных в документах с использованием алгоритмов поиска с помощью форм слов применительно к большим данным (big data).
УРОВЕНЬ ТЕХНИКИ
[0002] Обнаружение различных полей и значений (вхождений в данные) этих полей в различных документах, включая неструктурированные цифровые документы, является важной задачей обработки, хранения и связывания информации. Традиционные способы выявления полей могут включать использование большого количества настраиваемых вручную эвристик, сравнение по словам, поиск с участием человека и другие операции, которые неэффективны или требуют большого количества вычислений.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] Реализация настоящего изобретения описывает механизмы эффективной идентификации элементов данных в документах. Способ выявления целевой записи в документе согласно настоящему изобретению включает идентификацию схемы маппинга (mapping), в которой слова представляются посредством формы слов, при этом одна и та же форма слова может соответствовать различным словам; определение базы данных, содержащей множество записей базы данных, и множества наборов форм слов в базе данных, где каждый набор форм слов в базе данных из множества таких наборов соответствует одному или более словам соответствующей записи в базе данных; формирование множества гипотез, включающих: первую гипотезу, проекционно ассоциирующую с целевой записью (i) первый набор слов в документе и (ii) соответствующий первый набор форм слов; и вторую гипотезу, проекционно ассоциирующую с целевой записью (i) второй набор слов в документе и (ii) соответствующий второй набор форм слов; исключение второй гипотезы на основе несоответствия между вторым набором форм слов и каждым из множества наборов форм слов в базе данных; и определение первого набора слов в документе в качестве целевой записи посредством подтверждения первой гипотезы.
[0004] Энергонезависимый машиночитаемый носитель информации согласно описанию изобретения содержит инструкции, которые при поступлении в устройство обработки данных позволяют ему выполнять: определение схемы маппинга, в которой слова представлены посредством форм слов, при этом одна и та же форма слова может соответствовать различным словам; определение базы данных, содержащей множество записей базы данных, и множества наборов форм слов в базе данных, где каждый набор форм слов в базе данных из множества таких наборов соответствует одному или более словам соответствующей записи в базе данных; формирование множества гипотез, включающих: первую гипотезу, проекционно ассоциирующую с целевой записью (i) первый набор слов в документе и (ii) соответствующий первый набор форм слов; и вторую гипотезу, проекционно ассоциирующую с целевой записью (i) второй набор слов в документе и (ii) соответствующий второй набор форм слов; исключение второй гипотезы на основе несоответствия между вторым набором форм слов и каждым из множества наборов форм слов в базе данных; и определение первого набора слов документа в качестве целевой записи посредством подтверждения первой гипотезы.
[0005] Система выявления целевой записи в документе согласно настоящему изобретению содержит память и устройство обработки данных, функционально связанное с памятью, причем устройство обработки используется для: определения схемы маппинга, в которой слова представлены посредством форм слов, при этом одна и та же форма слова может соответствовать различным словам; определения базы данных, содержащей множество записей базы данных, и множества наборов форм слов в базе данных, где каждый набор форм слов в базе данных из множества таких наборов соответствует одному или более словам соответствующей записи в базе данных; формирования множества гипотез, включающих: первую гипотезу, проекционно ассоциирующую с целевой записью (i) первый набор слов в документе и (ii) соответствующий первый набор форм слов; и вторую гипотезу, проекционно ассоциирующую с целевой записью (i) второй набор слов в документе и (ii) соответствующий второй набор форм слов; исключения второй гипотезы на основе несоответствия между вторым набором форм слов и каждым из множества наборов форм слов в базе данных; и определения первого набора слов документа в качестве целевой записи посредством подтверждения первой гипотезы.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Изобретение может быть более полно изучено благодаря детальному описанию, данному ниже, и благодаря прилагающимся иллюстрациям, показывающим различные варианты применения изобретения. Изображения, тем не менее, не должны восприниматься как единственно возможные варианты применения изобретения, а приведены лишь для объяснения и понимания.
[0007] На ФИГ. 1 представлена блок-схема примерной компьютерной системы, в которой может применяться настоящее изобретение.
[0008] На ФИГ. 2A приведена упрощенная схема, иллюстрирующая пример функционирования ядра обработки запросов, выполняющего поиск одной или нескольких целевых элементов с использованием форм слов в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0009] На ФИГ. 2B приведена упрощенная схема, иллюстрирующая фильтрацию гипотез, выдвинутых ядром обработки запросов с использованием форм слов в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0010] На ФИГ. 2C приведена упрощенная схема, иллюстрирующая другой вариант фильтрации гипотез, выдвинутых ядром обработки запросов с использованием форм слов, в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0011] На ФИГ. 3 приведена упрощенная схема, иллюстрирующая пример выполнения поиска с использованием форм слов с применением обученного классификатора, в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0012] На ФИГ. 4 приведена другая упрощенная схема, иллюстрирующая пример выполнения поиска с использованием форм слов, который задействует переобучение классификатора, в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0013] На ФИГ. 5 представлена блок-схема, иллюстрирующая один из примеров способа идентификации целевого входа в документе с выполнением поиска с использованием форм слов в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0014] На ФИГ. 6 представлена блок-схема, иллюстрирующая один из примеров способа исключения или подтверждения гипотезы, которая ассоциирует выбранный набор слов документа с целевым входом в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0015] На ФИГ. 7 представлена блок-схема, иллюстрирующая один из примеров способа с использованием обученного классификатора при поиске с использованием форм слов в документах в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0016] На ФИГ. 8 представлена блок-схема компьютерной системы в соответствии с некоторыми вариантами реализации настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0017] Ниже описываются реализации изобретения для обнаружения полей и значений этих полей в цифровых документах с помощью поиска с использованием форм слов. Документ (например, счет, invoice) может содержать несколько полей: наименование и адрес покупателя, информацию о банковском счете покупателя, список приобретаемых товаров, адрес доставки, ожидаемую дату доставки и др. Некоторые из полей могут быть заполнены информацией, которая соответствует значению соответствующих полей. Некоторые значения могут храниться в базе данных, например, после занесения в ходе предыдущих транзакций с покупателем, или быть доступны из других источников, таких как государственные или коммерческие справочники. Например, наименование, адрес и финансовая информация покупателя могут храниться в базе данных. База данных может собираться в течение нескольких лет и содержать множество записей так, что каждая запись соответствует определенной части информации о конкретном поставщике, клиенте, заказчике, провайдере, партнере, транспортном агенте и т.д. Даже если база данных может быть структурирована (например, каталогизирована) по различным категориям записей, идентификация полей (и соответствующих значений) в документе на основе сравнения с записями в базе данных, тем не менее, может составлять проблему, поскольку поля в документе могут быть не идентифицированы. Например, документ может быть не структурирован, написан нестандартно, может быть напечатан в новой форме, в которой поля расположены в неожиданных местах, и т.д. Один из традиционных подходов к идентификации полей и значений основан на формировании множества гипотез и проверке этих гипотез на различных записях базы данных. Например, для идентификации адреса поставщика, напечатанного или написанного где-то внутри документа, можно выдвигать различные гипотезы, например, последовательные 4, 5 и т.д. слов, слова, расположенные в пределах 2-х, 3-х и т.д. строк, и т.п. В документах с сотнями слов можно сформировать десятки тысяч гипотез и более. Каждую из этих гипотез можно проверить по различным записям в базе данных, это может стать обескураживающей задачей для больших баз данных, которые могут содержать десятки миллионов (или более) записей.
[0018] Нюансы и варианты реализации настоящего изобретения предназначены для решения указанных выше и других проблем технологии работы с big data путем предоставления эффективного механизма формирования и проверки гипотез для идентификации полей и соответствующих значений идентифицированных полей в доступном для поиска, но неструктурированном документе. В некоторых вариантах реализации для повышения скорости и эффективности поиск может включать формы слов, которые несут сокращенную информацию по сравнению с действительными словами. Например, слово может отображаться на форму слова, которая может сохранять некоторую информацию о структуре слова, но не о действительных символах слова. Например, слова «Street» и «Account» могут быть переведены в соответствующие формы слов «Xxxxxx» и «Xxxxxxx», которые сохраняют информацию о длине слов, но не о конкретных буквах. Поиск, производимый в соответствии с некоторыми реализациями настоящего изобретения, может начинаться со сравнения (как часть проверки гипотезы) форм слов, соответствующих словам документа, которые соответствуют словам в записях базы данных. В результате несоответствие между «Street» и «Account» может быть обнаружено даже на уровне формы слова, и большое количество гипотез можно будет быстро отбросить, исходя из формы слов, а не настоящих слов.
[0019] Поскольку формы слов содержат сокращенное количество информации о словах, которым соответствуют формы слов, данная форма слов может отображать множество различных слов, то есть Xxxxxxx может быть формой слова не только для «Account», но и для «Banking», «Routing», «License» и других различных слов. Таким образом, после того, как множество исходных гипотез будут отброшены исходя из несоответствия формы слов, оставшиеся гипотезы можно будет проверить на действительных словах. В этом примере для простоты демонстрации используется один уровень форм слов. В некоторых вариантах реализации можно развернуть иерархическое дерево форм слов. Например, формы слов «Xxxxxx» и «Xxxxxxx» могут быть формами слов промежуточного уровня для слов «Street» и «Account», а еще более упрощенные формы слов «Xx» могут использоваться для обоих слов на следующем (втором) уровне форм слов (на котором последовательность строчных букв отображается в один символ «x»). Хотя слова «Street» и «Account» имеют одинаковую форму второго уровня «Xx» и поэтому не различаются на втором уровне форм слов, эти два слова могут быть отделены от слов, состоящих только из строчных букв «license» или «number» (форма слова «x») или слов с символами пунктуации, таких как «non-negotiable» (форма слова «x-x») и т.д. Со схемой отображения, включающей несколько уровней форм слов, сформированные гипотезы могут проверяться с использованием иерархической процедуры, которая выполняется в направлении, обратном формированию форм слов. Сначала отбрасываются гипотезы, дающие несоответствие на самом высоком уровне форм слов. Затем оставшиеся гипотезы могут проверяться или отбрасываться на следующем самом высоком уровне форм слов и т.д. В конце концов, оставшиеся гипотезы могут быть проверены на уровне действительных слов, к этому моменту может остаться лишь небольшая доля гипотез.
[0020] В некоторых вариантах реализации отсутствует полное совпадение всех оставшихся гипотез. Например, часть значения поля может отсутствовать (например, составитель /автор документа может забыть напечатать или может пропускать/сокращать некоторые слова), значение поля может быть частично нечитаемым (например, помятый, поврежденный или частично неразборчивый документ) и т.д. В таких случаях варианты реализации, изложенные в настоящем документе, позволяют обрабатывающему устройству выполнять поиск с использованием обученного классификатора. Этот классификатор может быть особым образом обучен на документах определенного типа (например, счетах). Этот классификатор может быть в состоянии идентифицировать на основе частичного совпадения имеющихся слов правильную (целевую) запись базы данных. В некоторых вариантах реализации может определяться более одной записи базы данных и их соответствующие уровни уверенности, а финальный выбор может осуществлять пользователь.
[0021] В контексте данного документа «неструктурированный документ» (также именуемый здесь просто «документ») может означать любой документ, изображение или иное цифровое представление, которое доступно вычислительной системе, выполняющей идентификацию данных. Изображение может быть отсканированным, сфотографированным или являться любым другим представлением документа, которое может быть переведено в формат, доступный компьютеру. Например, «неструктурированный документ» может относиться к файлу, состоящему из одного или более цифровых элементов содержимого, которые могут визуально отображаться для обеспечения визуальной представления документа (например, на экране или в печатной форме). В соответствии с различными вариантами реализациями настоящего изобретения, документ может соответствовать любому подходящему формату электронного файла, например, PDF, DOC, ODT, JPEG и так далее. Хотя документ может быть представлен в формате электронного (то есть цифрового) файла, необязательно, чтобы документ был структурирован в электронной форме и чтобы вид документа - расположение различных текстовых полей, таблиц, параграфов и т.д. - был определен в электронном файле. (Это, например, возможно в том случае, если документ был изначально выпущен в электронном виде - электронный счет или другие аналогичные электронные документы - с уже указанным расположением полей и таблиц.)
[0022] «Документ» может представлять собой финансовый документ, юридический документ или любой другой документ, например, документ, полученный путем заполнения полей любыми буквенно-цифровыми символами (например, буквами, словами, числами) или изображениями. «Документ» может быть напечатан, набран на компьютере или написан от руки (например, путем заполнения стандартной формы). «Документ» может представлять форму, содержащую различные поля, которые могут быть указаны с помощью прямоугольников, подчеркивания, теней, ячеек таблицы, строк, столбцов, графических элементов или могут не иметь специальной индикации. Например, документ может содержать водительские права или идентификационный номер автомобиля, впечатанный в письмо как часть текста. В контексте данного документа термин «поле» может относиться к любой части документа, определяемой задачами и/или структурой документа, например, форма заявления на выдачу паспорта может содержать поля «Имя», «Фамилия», «Дата рождения» или любые другие поля, которые заявитель заполняет буквенно-цифровыми данными (словами и числами). Аналогично некоторые документы могут содержать стандартное содержимое (например, обусловленное законодательством или существующими практиками делового оборота), но гибким, зависящим от поставщика распределением этого содержимого внутри документа - заявок на ипотеку/кредит, контрактов на приобретение недвижимости, смет на кредит, контрактов страхования, полицейских отчетов, заказов на покупку, счетов и т.д. Кроме того, «поле» может также относиться к любому блоку информации (адрес, количество приобретаемых товаров, дата истечения срока годности кредитной карты и т.д.), который предоставляется в документе свободной формы, таком как деловое письмо, памятная записка и т.д. Актуальный экземпляр данных внутри определенного поля обозначается в данном документе как значение поля. Например, «432 5th Street, Bloomingdale, West Virginia, USA» является примером значения поля «Адрес». Документы могут содержать поля, встречающиеся один раз или повторяющиеся многократно в одной форме (например, номер документа, дата, общая сумма заявки и т.д.), или поля, которые могут иметь несколько значений (например, множество номеров заказов, дат, адресов доставки, типов поставляемых товаров и т.д.).
[0023] В некоторых вариантах реализации технологии, описанные в этом документе, позволяют производить автоматическое детектирование полей и записей в документе с использованием искусственного интеллекта, такого как нейронные сети или другие системы машинного обучения. Нейронная сеть может включать множество нейронов, которые связаны с обучаемыми весами и смещениями. Нейроны могут быть организованы в слои. Нейронная сеть может быть обучена на обучающем наборе документов, которые включают известные поля и записи. Обучающий документ может быть создан (например, клиентом или разработчиком), например, путем идентификации в документе записи (например «дата истечения срока действия карты 09.12.2022»), присутствующей в базе данных.
[0024] На ФИГ. 1 представлена блок-схема примерной компьютерной системы 100, в которой может применяться настоящее изобретение. Как показано, система 100 может содержать сервер обработки очередей (QPS) 110, хранилище данных 130 и обучающий сервер 150, соединенный с сетью 140. Сеть 140 может быть общедоступной сетью (например, Интернет), частной сетью (например, локальной вычислительной сетью (ЛВС) или глобальной вычислительной сетью (ГВС)) или их комбинацией.
[0025] Вычислительная система 100 может быть настольным компьютером, ноутбуком, смартфоном, планшетом, сервером, сканером или любым подходящим вычислительным устройством, способным выполнять описанные в данном документе способы. В некоторых вариантах реализации QPS 110 может включать одно или более обрабатывающих устройств 802 с ФИГ. 8.
[0026] Документ 102 может быть получен QPS 110. Документ 102 может включать любой подходящий текст, изображения, может относиться к любому подходящему типу, например, коммерческим заявкам или государственным заявлениям, контрактам, научным статьям, памятным запискам, медицинским документам, удостоверениям государственного образца, газетным статьям, визитным карточкам, письмам или документам любого другого типа. В некоторых вариантах реализации тип документа 102 может определяться пользователем (например, путем обращения пользователя к QPS 110, локально или удаленно). В некоторых вариантах реализации тип документа 102 может быть неизвестен. В некоторых вариантах реализации документ 102 может быть получен в составе набора (пачки) из множества документов. Документ 102 может быть получен любым подходящим способом. Например, QPS 110 может получить цифровую копию документа 102 после сканирования или фотографирования документа. В некоторых вариантах реализации изобретения пользователь может загрузить документ 102 в QPS 110, например, по сети 140, с локального компьютера пользователя, с удаленного компьютера, доступного пользователю, из службы облачного хранения файлов и т.д. В некоторых вариантах реализации изобретения текст в документе 102 может быть распознан с использованием любых подходящих способов оптического распознавания символов (OCR).
[0027] В некоторых вариантах реализации изобретения QPS 110 может иметь пользовательский интерфейс (UI) 112. Пользовательский интерфейс 112 может позволять пользователю выбирать документ 102, загружать документ 102, выполнять оптическое распознавание символов (OCR) документа 102, сохранять документ 102 и/или результат OCR, возвращать документ из хранилища, выбирать тип поля (например, «имя», «адрес», «адрес доставки» и т.д.) для поискового запроса, инициировать поисковый запрос, просматривать и сохранять результаты поискового запроса и т.д. UI 112 может быть графическим UI, UI на базе командной строки, UI на базе меню, голосовым UI или любым другим подходящим UI или комбинацией UI различных типов. UI может выводиться на экран настольного компьютера, ноутбука, планшета, смартфона, клиентского устройства удаленного сервера, сенсорного экрана и т.д. или любого сочетания названных выше устройств. Пользовательский ввод может быть организован с помощью позиционирующего устройства (мыши, стилуса, пальца и т.д.), клавиатуры, сенсорной панели, сенсорного экрана, микрофона, устройства, отслеживающего движения глаз, устройства дополненной реальности и т.д. или любого сочетания названных выше устройств.
[0028] QPS 110 может включать модуль 114 отображения формы слов (WS). Модуль 114 отображения токенов может быть выполнен с возможностью реализации одной или нескольких схем отображения, которые отображают слова в формы слов, более подробно это будет рассмотрено ниже и проиллюстрировано ФИГ. 2B и 2C. Модуль 114 отображения токенов может преобразовывать как минимум часть слов документа 102 в соответствующие формы слов. В некоторых вариантах реализации изобретения схема отображения может содержать несколько уровней форм слов, так что каждый следующий уровень содержит более компактные формы слов, чем предыдущий. QPS 110 может дополнительно содержать модуль 116 поиска с использованием формы слов для выполнения поисковых запросов с использованием формы слов для слов документа 102 и формы слов для записей в базе данных, более подробно это будет рассмотрено ниже и проиллюстрировано ФИГ. 2A-2C. Модуль 116 поиска с использованием формы слов может формировать многочисленные гипотезы о возможном соответствии одного или более слов документа 102 различным записям базы данных. Модуль 116 поиска с использованием формы слов может использовать формы слов для отбрасывания некоторых (или большинства) сформированных гипотез до проверки оставшихся гипотез с использованием настоящих слов в этих гипотезах.
[0029] В некоторых вариантах реализации изобретения, если возможно точное совпадение (или совпадение с определенным отклонением), модуль 116 поиска с использованием формы слов может быть в состоянии производить поиск и идентифицировать корректные результаты поискового запроса. В некоторых вариантах реализации изобретения, если точное совпадение не встречается или маловероятно, QPS 110 может задействовать обученный классификатор 118 для выбора во множестве неполных совпадений. Классификатор 118 может быть изначально обучен на стороне провайдера (разработчика) и затем дополнительно обучен (переобучен) в системе переобучения 120 на стороне клиента (пользователя). Например, функциональность разметки UI 112 может позволять пользователю выбирать поля в документах, выбранных в качестве документов для обучения, для обучения классификатора 118 для идентификации полей на основе неполного совпадения, более подробно это будет рассмотрено ниже. В ходе разметки пользователь может идентифицировать поля, интересные пользователю (например, исходя из коммерческих или профессиональных интересов пользователя) и помечать эти поля с помощью рамок, указателей, выделения, теней и другими подобными способами. Также пользователь может идентифицировать тип помеченного поля. Классификатор 118 может обучаться по-разному (например, по отдельности) для разных типов документов и может включать разные типы моделей машинного обучения (например, классификаторы дерева решений и/или модели нейронных сетей), такие как модель наименования поставщика, модель адреса доставки, модель банковской информации и т.д., так что каждая модель специализирована на определении полей одного или нескольких типов. Различные модели классификатора 118 могут иметь различную архитектуру (например, различное количество слоев нейронов и различную топологию соединений между нейронами), в результате различного обучения различные параметры (веса, отклонения, функции активации и т.д.) соответствующих нейронных сетей.
[0030] Вычислительная система 100 может содержать хранилище данных 130, в котором хранится множество документов с интересующими пользователя полями, и базу данных 134 со значениями этих полей. База данных 134 может индексироваться по типу полей, например, по адресу поставщика, телефонному номеру, номеру банковского счета, дате регистрации, объему продаж, запасам и т.д. База данных 134 может дополнительно индексироваться по значениям полей, например, наименования могут перечисляться в алфавитном порядке, водительские права могут перечисляться по порядку выдачи, по порядку цифр, по имени владельца, по количеству и типу зафиксированных нарушений правил и т.д. База данных 134 может содержать множество записей, которые собраны из документов 132 или получены из других источников, например, загружены из других баз данных, собраны из каталогов, телефонных справочников, публичных и государственных документов и т.д. После того, как информация из документов 132 перенесена (и возможно проиндексирована) в базу данных 134, некоторые из документов 132 могут быть выброшены, а некоторые из документов могут быть сохранены для обучения классификатора 118, как будет описано ниже.
[0031] Вычислительная система 100 может включать сервер обучения 150 для начального обучения классификатора 118. Обучающий сервер 150 может включать механизм обучения 152. Механизм обучения 152 может конструировать классификатор 118 для идентификации полей в документах. Классификатор 118, как показано на ФИГ. 1, может обучаться с помощью механизма обучения 152 с использованием обучающей выборки данных, которая содержит наборы входных обучающих данных 154 и соответствующие наборы выходных обучающих данных 156 (правильные совпадения для соответствующих наборов входных обучающих данных). В ходе обучения классификатора 118 обучающий механизм 152 может находить в обучающей выборке данных шаблоны, которые отображают каждый набор входных обучающих данных 154 на набор выходных обучающих данных 156.
[0032] Например, обучающий механизм 152 может выбирать (например, случайно) несколько документов 132 в качестве обучающих документов. Обучающие документы могут храниться в хранилище данных 130. Обучающие документы могут быть размечены с идентификацией нужных полей. В некоторых вариантах реализации разметка может производиться человеком-оператором до помещения размеченного документа в хранилище данных 130. Обучающие данные могут находиться в хранилище 130 и могут включать один или более наборов входных обучающих данных 154 и один или более наборов выходных обучающих данных 156. Обучающие данные могут также включать данные отображения 158, которые связывают входные обучающие данные 154 с выходными обучающими данными 156. В некоторых вариантах реализации изобретения отображение данных 158 может включать идентификацию как минимум некоторых полей входных обучающих данных 154 и соответствующих значений идентифицированных полей. Например, обучающий документ может быть использован как набор входных обучающих данных 154 и может содержать поле «Номер водительских прав». Значение этого поля, например, «123-456-7890», может представлять набор выходных обучающих данных 156. Отображение данных 158 может содержать идентификатор обучающего документа, расположение (например, координаты рамки, линии и/или номера столбцов и т.д.) поля «Номер водительских прав» в обучающем документе, идентификатор выходных обучающих данных 156 и др. В некоторых обучающих документах некоторые из значений полей могут быть смазаны и читаться не полностью.
[0033] При обучении классификатора 118 механизм обучения 152 может изменять параметры (например, веса и отклонения), пока классификатор 118 не будет успешно обучен тому, как правильно идентифицировать значение помеченного поля. Затем можно использовать дополнительные обучающие документы, например, с полями, расположенными в разных частях документа, или документы, напечатанные другим шрифтом или написанные от руки разным почерком, и так далее. Обученный классификатор 118 затем может быть использован для создания идентификаторов (предположений) полей/значений в новых документах. Различные модели могут обучаться на различных типах полей. Некоторые из типов моделей могут быть предварительно обучены с помощью механизма обучения 152. Дополнительные типы моделей могут обучаться на стороне клиента с использованием механизма переобучения 120 для специфических полей, которые могут быть интересны конкретному пользователю, на основе предоставленных пользователем обучающих документов.
[0034] Каждая из моделей, обученных как часть классификатора 118, может содержать алгоритмы дерева решений, машины опорных векторов (SVM), глубинные нейронные сети и другие подобные механизмы. Глубинная нейронная сеть может содержать сверточные нейронные сети, рекуррентные нейронные сети (RNN) с одним или более скрытыми слоями, полносвязные нейронные сети, нейронные сети с долгой краткосрочной памятью, машины Больцмана и т.д.
[0035] Хранилище данных 130 может быть устройством постоянного хранения данных, имеющим возможность хранить документы и структуры данных и настроенным на выполнение автоматического распознавания символов в соответствии с реализацией настоящего изобретения. Хранилище данных 130 может быть размещено на одном или более устройствах хранения, таких как основная память, магнитные или оптические диски, ленты или жесткие диски, NAS, SAN и т.д. Хотя хранилище данных 130 изображено отдельно от QPS 110, в некоторых реализациях оно может быть частью QPS 110. В некоторых вариантах реализации изобретения хранилище данных 130 может быть сетевым файловым сервером, в то время как в других вариантах реализации хранилище данных 130 может относиться к другим типам энергонезависимых хранилищ данных, таким как объектно-ориентированная база данных, реляционная база данных и т.д., и находиться на серверной машине или на одной или более различных машин, доступных для QPS 110 и соединенных через сеть 140.
[0036] На ФИГ. 2A приведена упрощенная схема, иллюстрирующая пример функционирования 200 ядра обработки запросов (например, QPS 110 с ФИГ. 1), выполняющего поиск одной или нескольких целевых элементов с использованием формы слов в соответствии с некоторыми вариантами реализации настоящего изобретения. Входные данные поискового запроса могут включать документ 202, который может иметь любой тип из обсуждавшихся выше или любой другой подходящий тип документа. Документ 202 может быть предварительно сохраненным (например, на компьютере пользователя, в облаке и т.д.) документом, вновь созданным или полученным документом. Документ 202 может быть подвергнут оптическому распознаванию символов (OCR) 204 для получения текста OCR документа и в некоторых реализациях изобретения для разбиения текста OCR на множество символов, представляющих различные слова, числа, предложения, рисунки и др. элементы документа. В некоторых вариантах реализации изобретения QPS могут быть переданы несколько документов 202 (например, пачка документов). Исходные данные поискового запроса могут также содержать поля одного или нескольких типов, значения которых содержатся в документе 202 (или стопке документов). Например, поисковый запрос может указывать, что в документе 202 необходимо найти всю информацию о регистрации автомобиля и водительских правах. В другом примере в документе 202 идентифицируется банковская информация, то есть номер банковского счета клиента, код банка, SWIFT, номера БИК и др. Тип идентифицируемой информации может быть определен пользователем, программным обеспечением, которое развернул пользователь, или может быть стандартным типом информации для исходного типа документа 202 в поисковом запросе. Тип документа 202 и/или тип информации, идентифицируемой в документе 202, может приводить к выполнению QPS поиска для определения, насколько база данных, содержащая записи 206 базы данных, соответствует поиску. Например, в связи с получением поискового запроса на адрес поставщика QPS может определить, что поисковый запрос выполняется на базе сведений о поставщиках (например, части базы данных 134 на ФИГ. 1), и что поиск должен быть ограничен адресом (без финансовой информации и сведений о продукте) в этой базе данных. В некоторых вариантах реализации поиск может быть неограниченным, например, выполняться по всем записям 206 базы данных, содержащимся в базе данных 134. Любая взятая запись 206 базы данных может содержать одно или более слов, чисел, фраз, предложений, абзацев, формул, уравнений, логотипов или любых других элементов.
[0037] Идентифицировав соответствующие записи 206 базы данных, QPS может выполнить (или обратиться к ранее выполненным) связям слово - форма слова, также называемым в этом документе для краткости связями формы слов 208, полученными с помощью любых подходящих схем отображения (например, с помощью модуля 114 отображения формы слов с ФИГ. 1). Связи слово - форма слова 208 могут отображать слова (схематично изображенных с затененными рамками) на один или несколько иерархических уровней форм слов (белые рамки). Слово может быть любым набором одного или нескольких буквенно-цифровых символов, включая буквы, значки, глифы, цифры, знаки пунктуации, пробелы и т.д., и использоваться (или иметь возможность использоваться) в любых воспринимаемых человеком или машиночитаемых формах передачи информации. Например, слово «account» воспринимается человеком и несет в себе определенное информационное содержание (несмотря на то, что его точное значение может зависеть от определенного контекста, в котором используется это слово). Аналогично ASCII-кодирование (или любое другое машинное кодирование) слова «account» может быть прочитано компьютером. Форма слова аналогично может быть набором буквенно-цифровых символов, представляющих это слов, возможно, необратимым способом. Другими словами, в то время как отображение Слово → Токен однозначно (так что определенное слово отображается в уникальную форму слова), обратное отображение Токен → Слово может быть неоднозначным (поскольку одна форма слова может представлять множество слов). Например, в схеме отображения, в которой все согласные буквы отображаются символом «x», а все гласные буквы - символом «y», слово «Total» будет отображено в форму слова «Xyxyx,» и слово «Debit» будет отображено в ту же форму. Обратное отображение может быть неуникальным, поскольку «Xyxyx» может быть формой как слова «Total» так и слова «Debit» (и множества других слов, например, «Milan»). Не все связи форм слов являются необратимыми. Отдельное слово может быть достаточно уникальным (например, длинное слово с необычной последовательностью букв), так что соответствующая связь формы лова может быть обратимой. Таким образом, следует понимать, что необратимость трансформации слово - форма слова относится к общему корпусу (словарю) слов (например, слов в базе данных), и общему корпусу соответствующих форм слов, но не должна восприниматься как необходимое условие для каждой отдельной связи формы слов. В результате корпус 210 базы данных форм слов может иметь некоторое количество различных форм слов (значительно меньше для некоторых схем отображения), которые соответствуют небольшому количеству различных слов в записях 206 базы данных.
[0038] Как схематично показано в рамке, обозначающей связи 208 форм слов, для формирования связей форм слов может использоваться более одного уровня форм слов. Например, второй уровень форм слов может опускать разницу между гласными и согласными буквами и может представлять все последовательные символы одного типа единственным символом такого же типа и т.д. Следует понимать, что можно придумать практически бесконечное число различных схем отображения формы слов, в которых на каждом новом уровне формы слов отображают множество форм слов с предыдущего уровня в заданную форму слов нового уровня.
[0039] По принципу создания корпус форм слов содержит сокращенную информацию по сравнению с корпусом слов. В результате предложение, фраза или другой набор слов может не иметь воспринимаемого смысла для человека или машины после замены (отображения) на соответствующие формы слов. Тем не менее полученный набор форм слов по-прежнему несет важную информацию о структуре слов и может использоваться для устранения различных маловероятных ассоциаций (гипотез) на уровне, требующем значительно меньше единиц (форм слов), чем корпус слов (что в результате значительно ускоряет поиск).
[0040] Связь слово - форма слова может аналогично выполняться на корпусе слов документа 202 для получения корпуса 212 форм слов документа. В некоторых вариантах реализации корпус 212 форм слов документа может быть получен в модуле 114 отображения формы слов на ФИГ. 1 после выполнения OCR 204. В некоторых вариантах реализации корпус 210 формы слов базы данных может быть вычислен предварительно и сохранен, например, в том же хранилище данных 130, так что получение форм слов будет проводиться только для нового документа 202.
[0041] Поскольку корпус 210 форм слов базы данных может иметь меньше различных форм слов, чем имеется различных слов в записях 206 базы данных (и аналогично корпус 212 форм слов документа может иметь меньше форм слов, чем слов в документе 202), таблица 214 отображения базы и таблица 216 отображения документа могут использоваться для проведения преобразования форм слов обратно в слова. Например, таблица 214 отображения базы данных может определять для каждой формы слова в корпусе 210 форм слов базы данных, где в записях 206 базы данных находятся слова, отображенные в соответствующие формы слов. Аналогично таблица 216 отображения документа может определять, для каждой формы слова в корпусе 212 форм слов документа, где в документе 202 находятся соответствующие слова. Расположение может определяться через координаты слов, координаты охватывающих рамок, через счетчики строк/символов или любым другим подходящим способом.
[0042] В некоторых вариантах реализации QPS может выполнять поиск целевых элементов базы данных в документе 202 следующим образом. Исходя из сущности целевого элемента (например, адрес, номер водительских прав и т.д.), QPS может определить, что, вероятно, набор слов в документе 202, который соответствует целевому элементу базы данных, имеет N слов. Например, адрес может иметь N=5 слов (номер дому, улица, почтовый индекс, штат/страна), но может иметь и меньше (например, N-1) слов, если некоторые слова пропущены, или больше слов (например, N+1, N+2, и т.д.), если улица или город содержат больше одного слова). Номер счета клиента может иметь N=3 слова, например, «счет номер 987654,» но может иметь N-1 слов, если опущено слово «счета» или N + 1 слов, если добавлено слово «клиента». Исходя из вероятного числа слов (включая допуски на большее и/или меньшее число), QPS может выполнить формирование гипотезы 220, используя различные возможные комбинации слов в документе 202. Например, если вероятное число слов в целевом элементе N и в документе 202 всего M слов, QPS может сформировать M + 1 - N гипотез о том, что N последовательных слов относятся к целевому элементу. Кроме того, QPS может сформировать множество гипотез, в которых N слов распределены по двум или более соседним строкам, которые находятся поблизости друг от друга по вертикали. Дополнительные гипотезы можно сформировать для строк, не являющихся соседними, чтобы учесть ситуацию, когда некоторые из строк содержат подчеркивание, инструкции, напечатанные под строками и др. Дополнительные гипотезы можно сформировать, чтобы учесть ситуацию, когда слова в целевом элементе могут идти вперемешку со словами инструкций, расположенными на одной линии со словами целевого элемента. Можно предполагать множество других ситуаций в зависимости от вероятного вида документа. Еще больше гипотез можно добавить, если порядок слов, в котором слова целевого элемента могут располагаться в документе, может изменяться (например, «Имя, Фамилия» или «Фамилия, Имя»).
[0043] В традиционном поиске большое количество формируемых гипотез H необходимо сравнить с большим количеством записей D базы данных, что даст H*D различных возможных комбинаций. Для документа с тысячами слов могут быть сформированы десятки тысяч (или более) гипотез, которые потребуют сравнения с миллионами записей базы данных. В результате количество возможных сочетаний может составлять миллионы. Для быстрого удаления множества сформированных гипотез QPS может использовать фильтрацию 230 по форме слов с использованием форм слов в обратном иерархическом порядке по сравнению с порядком, в котором формировались связи 208 с формами слов. Конкретнее для каждой из сформированных гипотез слова заменяются на соответствующие формы слов (например, с использованием таблицы 216 отображения документа), после чего сравниваются с формами слов из записей базы данных. Несоответствие между формами слов верхнего уровня (верхняя строка в рамке, отображающая фильтрацию 230 по формам слов) гипотезы и формами слов верхнего уровня из записей базы данных можно использовать для удаления первого набора гипотез. Эти гипотезы имеют наибольшую разницу с целевыми элементами, значительно большую, чтобы пройти несколько уровней форм слов до наиболее базовых характеристик слов. Удалены могут быть те гипотезы, которые имеют несоответствие, превышающее пороговое значение несоответствия (как более подробно описано ниже) со всеми записями базы данных. Кроме того, удалены могут быть те записи базы данных, которые имеют несоответствие, превышающее первое пороговое значение несоответствия со всеми сформированными гипотезами. Таким образом, количество гипотез, так же как количество (вероятно подходящих) записей базы данных может быть значительно уменьшено. Поскольку корпус 210 форм слов базы данных (и корпус 212 формы слов документа) на верхнем уровне форм слов может содержать значительно меньше записей, чем корпус слов базы данных (и корпус слов документа), фильтрацию форм слов верхнего уровня можно выполнить значительно быстрее, чем поиск по целым словам.
[0044] Для оставшихся гипотез можно аналогичным образом отбросить второй набор, исходя из несоответствия между этими гипотезами, которые характеризуются несоответствием между вторым сверху уровнем форм слов гипотез и вторым сверху уровнем формы слов записей базы данных. И снова удалены могут быть те гипотезы, которые имеют несоответствие, превосходящее второе пороговое значение несоответствия со всеми оставшимися записями базы данных. В некоторых вариантах реализации второе пороговое значение несоответствия может быть таким же или иным по сравнению с первым пороговым значением несоответствия, использованным для удаления на верхнем уровне форм слов. Кроме того, удалены могут быть те записи базы данных (из оставшихся), которые имеют несоответствие, большее порогового значения несоответствия со всеми сформированными гипотезами.
[0045] Процесс фильтрации 230 на основании формы слов может быть продолжен до тех пор, пока для удаления гипотез не будут использованы все уровни форм слов. Оставшиеся гипотезы могут после этого проходить проверку 240 гипотез. В ходе проверки формы слов для слов оставшихся гипотез и формы слов из оставшихся записей базы данных могут снова заменяться полными словами (например, с помощью таблицы 214 отображения базы данных и таблицы 216 отображения документа), и для выявления целевых элементов 242 потребуется выполнить гораздо меньшее количество сравнений.
[0046] На ФИГ. 2B приведена упрощенная схема 250, иллюстрирующая фильтрацию гипотез, выдвинутых ядром обработки запросов с использованием формы слов в соответствии с некоторыми вариантами реализации настоящего изобретения. Показана гипотеза 252, сформированная QPS в ходе выполнения поискового запроса для некоторого типа целевого элемента. Исходя из типа целевого элемента, QPS может сформировать одну или несколько фраз (гипотез) из четырех слов. Гипотеза 252 содержит четыре слова «Broker Account Credit 26,144EU». SPS также может выбрать записи базы данных из четырех слов. Показана запись 254 базы данных «Bank Account Number CDL-196-5467». Вместо определения различия между гипотезой 252 и записью 254 базы данных, используя сравнение по словам, QPS может определить различие, используя формы слов соответствующих фраз. Показан не ограничивающий пример схемы отображения слово - форма слова, имеющей два промежуточных уровня форм слов (уровень-1 и уровень-2) и высший уровень формы слов (верхняя строка на диаграмме 250). Как показано направленными вверх стрелками, гипотеза 252 и запись 254 базы данных представлены соответствующими формами слов (например, с помощью модуля 114 отображения формы слов) с использованием все более (на каждом следующем уровне форм слов) компактных форм слов.
[0047] В приведенной схеме примера формы слов промежуточного уровня-1 получаются из слов путем замены каждой буквы на символ «x» («X» в случае заглавных букв), каждой цифры на «0» и каждого знака пунктуации на точку «.». Формы слов промежуточного уровня-2 получаются из форм слов промежуточного уровня-1 путем объединения всех пар повторяющихся символов («x», «0» или «.») в один символ того же типа. Например, четыре повторяющихся символа «xxxx» отображаются в два символа «xx». В случаях с нечетным количеством повторяющихся символов непарный символ считается как полная пара, то есть последовательность «00000» отображается как «000». Формы слов высшего уровня получаются из форм слов промежуточного уровня-2 путем объединения всех повторяющихся символов определенного типа в один символ того же типа (причем «x» и «X» считаются разными символами). В результате гипотеза 252 отображается в форму слов «Xx Xx Xx 0.0X», а запись базы данных 254 имеет форму слов «Xx Xx Xx 0.0», так что они отличаются.
[0048] QPS (то есть развернутый модуль 116 поиска по формам слов) может начать с высшего уровня форм слов и обнаружить разницу между первой формой слов и второй формой слов, как схематично показано белым крестиком на ФИГ. 2B. Исходя из обнаруженного несоответствия, QPS может удалить предполагаемую связь между гипотезой 252 и записью 254 базы данных.
[0049] На ФИГ. 2C приведена упрощенная схема 260, иллюстрирующая другой вариант фильтрации гипотез, выдвинутых ядром обработки запросов с использованием формы слов, в соответствии с некоторыми вариантами реализации настоящего изобретения. Показана та же гипотеза 252 и другая запись 256 базы данных «Vehicle License Number 72-459S», которая представлена с использованием той же схемы отображения. Аналогично примеру на ФИГ. 2B QPS может начать с высшего уровня форм слов и определить, что как гипотеза 252, так и запись 256 базы данных имеют одинаковую форму слов «Xx Xx Xx 0.0», и в соответствии с этим определением перейти к более низким уровням форм слов (что показано направленными вниз стрелками). Затем QPS может определить, что несоответствия между соответствующими формами слов уровня -2 отсутствуют и в итоге обнаружить различие между соответствующими формами слов уровня-1. В частности, несоответствие может быть обнаружено на основе разного количества символов «x» в первом слове и разного количества символов «X» в последнем слове.
[0050] Если гипотеза обнаружила несоответствие с каждой записью базы данных как минимум на одном уровне формы слов, она может быть удалена (например, «Broker Account Credit 26,144EU» или «Vehicle License Number 72-459S») без проведения сравнения с реальными словами. Аналогично, если результаты записи базы данных не соответствуют ни одной сформированной гипотезе, запись базы данных может быть исключена из дальнейшего рассмотрения.
[0051] Каждый уровень форм слов может иметь заранее определенное граничное несоответствие. Наличие некоторой степени отклонения выгодно, поскольку некоторые несоответствия могут быть вызваны опиской, а не разницей содержания. Например, создатель документа мог неправильно напечатать один или несколько символов, в ходе OCR возможно неправильное распознавание одного или нескольких символов, документ или его изображение может быть частично нечитаемым и т.д. Допуск по несоответствию может определяться множеством различных способов. В некоторых вариантах реализации несоответствие может считаться допустимым, если не совпадают или находятся не на своем месте не более определенного количества или определенного процента символов. В некоторых вариантах реализации изобретения различным типам несоответствия могут назначаться свои заранее определенные веса. Например, несоответствие цифры или буквы может считаться с весом 1, а несоответствие в знаках пунктуации (дефис, запятая, двоеточие и т.д.) может считаться с меньшим весом (например, 0,5 или другое значение). Допуск по несоответствию может зависеть от уровня так, что на уровне слов и нижних уровнях форм слов допустимы большие несоответствия, а на верхних уровнях форм слов допустимы меньшие несоответствия. В одном из неограничивающих примеров на уровне слов допускается ошибка 20%, на промежуточном уровне-1 формы слов допускается ошибка 15%, на промежуточном уровне-2 формы слов допускается ошибка 10%, и на высшем уровне формы слов допускается ошибка 5%. Следует понимать, что возможно использование практически неограниченного количества других метрик допуска, которые могут быть осведомлены об определенном типе документа и конкретном контексте, в котором был создан документ (например, сгенерированные компьютером документы могут иметь меньшие допуски, чем документы, напечатанные или написанные человеком), типе целевого элемента и т.д. Например, поисковые запросы для номеров кредитных карт или табличек с регистрационными номерами автомобилей могут иметь нулевой допуск на несоответствия; названия улиц могут иметь более высокие допуски, чем почтовые индексы и т.д.
[0052] Схема отображения форм слов, показанная на ФИГ. 2B-2C, приведена только для иллюстрации. Возможна реализация неограниченного количества схем отображения форм слов с произвольным количеством уровней формы слов. В некоторых вариантах реализации как минимум на одном уровне формы слов может быть использовано кодирование пар байт (BPE), которое заменяет наиболее часто встречающиеся пары символов (то есть байт ASCII) символами замены, этот процесс может итеративно повторяться, пока в слове или сочетании слов не останется повторяющихся пар.
[0053] На ФИГ. 3 приведена упрощенная схема, иллюстрирующая пример 300 выполнения поиска с использованием формы слов с разворачиванием обученного классификатора, в соответствии с некоторыми вариантами реализации настоящего изобретения. В некоторых вариантах реализации точное совпадение гипотез с записями базы данных (или совпадение в рамках заранее определенных допусков) могут быть непрактичны и могут иногда приводить к нулевому результату. Проблема может встречаться при выполнении запросов, относящихся к рукописным, старым, поврежденным, загрязненным документам, документам, подготовленным в нестандартной форме и т. д.
[0054] В таких случаях пользователь может указать проводить поиск как удовлетворительный «неточный» поиск, при котором одна или более гипотез обрабатываются классификатором (например, классификатором 118). Как показано на ФИГ. 3, начальные стадии поиска могут быть выполнены аналогично операциям, изображенным на ФИГ. 2A. Более конкретно, могут быть выполнены связи форм слов 208, формирование гипотез 220 и фильтрация 230 по формам слов сформированных гипотез для получения набора оставшихся гипотез 310. На шаге 315 принятия решения QPS может определять, имеется ли у поиска пометка неточного поиска, что возможно приведет к нулевому результату. Например, пользователь может пометить поиск, установив флажок «неточный поиск». Если QPS обнаружит, что поиск является обычным поиском, QPS может перейти к проверке 240 гипотез и определению целевых элементов 242 в основном так, как описано в связи с ФИГ. 2A. Однако если он определит на шаге 315 принятия решения, что поиск имеет флаг, QPS может перейти к обработке оставшихся гипотез 310 через обученный классификатор.
[0055] Оставшиеся гипотезы 310 сначала могут быть представлены в виде набора векторных эмбеддингов 320. В представлении вставок каждое слово может быть представлено в виде цифровой строки заранее определенной длины L (которая может быть показана в виде вектора в L-мерном пространстве вставок). Векторная вставка может быть получена, например, в нейронной сети, реализующей математическое преобразование символов, например, буквенно-цифровых символов, знаков препинания и т.д. в их числовое представление.
[0056] Векторные эмбеддинги 320 могут генерироваться с использованием любой подходящей модели или комбинации моделей, например, Word2Vec, GloVe, FastText и т.д. В некоторых вариантах реализации может использоваться рекуррентная нейронная сеть (RNN), посимвольная RNN, нейронная сеть долгой краткосрочной памяти (LSTM) или любая другая аналогичная сеть, включая любые их комбинации. Векторные эмбеддинги 320 могут генерироваться так, что векторная вставка двух (или более) слов, имеющих близкое семантическое значение (например, «число» и «количество») могут иметь близкие числовые значения (например, малое эвклидово расстояние в L-мерном пространстве). Аналогично слова, которые более вероятно найти на близком расстоянии друг от друга (например, «сумма» и «заявленная») также могут быть представлены векторными вставками с близкими числовыми значениями. Система (например, нейронная сеть), которая генерирует векторные эмбеддинги 320, может быть предварительно обучена с использованием наборов входных обучающих данных 154 и выходных обучающих данных 156, как описано выше. Документы, используемые на фазе обучения - наборы входных обучающих данных 154 и наборы выходных обучающих данных 156 - могут быть документами того же типа, который инициировал поиск с пометкой. Система, обученная генерировать векторные эмбеддинги 320, может быть в состоянии предсказать, какое слово, вероятно, следует или находится перед данным словом. Например, система, обученная генерировать векторные эмбеддинги 320, может быть в состоянии предсказать, что слово «сумма» находится перед словом «итого» с вероятностью 30% и за ним идет слово «заявленная» с вероятностью 15%.
[0057] В некоторых вариантах реализации векторные эмбеддинги 320 могут генерироваться на основе реальных слов из оставшихся гипотез 310. В других вариантах реализации векторные эмбеддинги могут генерироваться на основе представлений формы слов реальных слов, которые могут быть формами слов верхнего уровня или формами слов любого из промежуточных уровней (например, формами слов промежуточного уровня-1). После того, как каждая из оставшихся гипотез 310 будет представлена как набор векторных вставок для слов из соответствующей гипотезы, гипотеза может быть обработана классификатором 330. Например, гипотеза, содержащая M слов, может быть подана на вход классификатора 330 в виде M векторов. Кроме того, классификатор 330 может получить векторные эмбеддинги оставшихся (после фильтрации с помощью форм слов) записей базы данных. В некоторых вариантах реализации классификатор 330 может также получать формы слов одного или нескольких уровней для оставшихся гипотез (и оставшихся записей базы данных), степень несоответствия (например, количество иначе поставленных или несоответствующих символов) между соответствующими формами слов для слов в гипотезах и слов в оставшихся записях базы данных.
[0058] Классификатор 330 может выдать на выходе одну или более гипотез (из оставшихся гипотез 310), имеющих наибольшую вероятность совпадения с одной или несколькими записями базы данных. Например, классификатор 330 может генерировать, и QPS может вывести для пользователя (например, через интерфейс пользователя) первую гипотезу, включающую 1) слова документа, отмеченные как часть первой гипотезы, 2) запись базы данных, отмеченную классификатором 330 как наиболее вероятное совпадение и 3) вероятность (уровень уверенности) того, что показанные слова документа соответствуют записи в базе данных. Аналогично в таком же формате и, например, в порядке понижения уровня уверенности могут быть выведены вторая, третья и т. д. гипотезы. В некоторых вариантах реализации интерфейс пользователя может дополнительно показывать (или давать пользователю доступ в виде выбираемой ссылки) часть документа с выделенными словами соответствующей гипотезы, так чтобы пользователь мог оценить истинность совпадения, найденного классификатором 330. В некоторых вариантах реализации классификатор 330 может идентифицировать несколько наборов гипотез. Например, классификатор 330 может определить, что документ содержит множественные совпадения с различными записями базы данных, такими как адрес поставщика, банковская информация поставщика, лицензия поставщика на коммерческую деятельность и т.д. Тогда классификатор 330 может подавать на выход набор совпадений (например, в порядке убывания вероятности) для каждой из идентифицированных записей.
[0059] На ФИГ. 4 приведена другая упрощенная схема, иллюстрирующая пример функционирования 400 ядра обработки запросов, выполняющего поиск, который включает повторное обучение классификатора, в соответствии с некоторыми вариантами реализации настоящего изобретения. В реализации, показанной на ФИГ. 4, QPS может сначала выполнить операции 200 с ФИГ. 2A в попытке найти точное совпадение (или совпадение с заранее определенным допуском на ошибки). Если на шаге 405 установлено, что такое совпадение не было найдено, сервер обработки запросов (QPS) может выявить целевые записи 242 и отобразить выявленные записи в соответствии с приведенным выше описанием. Если на шаге 405 установлено, что поиск не дал результатов, QPS может реализовать векторные эмбеддинги 320 и классификатор 330, в соответствии с описанием ФИГ. 3. На другом шаге принятия решений - шаге 415 - QPS может выполнить повторную оценку успешности поиска. Например, если наиболее вероятная гипотеза имеет вероятность (уровень уверенности) того, что была выявлена правильная запись базы данных (или, как вариант, определить с тем же уровнем уверенности, что соответствующие записи в базе данных найдены не были) выше определенного порогового значения (например, 80%, 90%), то QPS может завершить поиск и отобразить результат (или отсутствие результата) пользователю вместе с выявленными целевыми записями 242. Однако, если наиболее вероятная гипотеза имеет вероятность ниже порогового значения (то есть имеется значительная неопределенность касательно существования соответствующей записи в базе данных), QPS может посчитать поиск неуспешным и начать переобучение классификатора. В некоторых вариантах реализации QPS может определить, что поиск выполнен успешно, но пользователь может ознакомиться с результатом поиска и отменить определение за счет вызова процедуры повторного обучения классификатора.
[0060] После вызова процедуры повторного обучения пользователю (или любому иному оператору) может быть предоставлен документ, при этом пользователь может выполнить разметку документа (шаг 420) и определить поля, представляющие интерес для пользователя. После получения размеченного документа механизм повторного обучения 120 может выполнить повторное обучение классификатора 430 с использованием размеченного документа в качестве входных обучающих данных 154 и определенных пользователем полей (и соответствующих значений этих полей) в качестве новых целевых выходных данных 156. Стрелками схематически показано, что при повторном обучении может использоваться не только классификатор повторного обучения 330, но также будет осуществляться переобучение модели, в результате которого создаются векторные эмбеддинги 320. Если при повторном обучении показано, что определенные пользователем поля (и их соответствующие значения) не входят в существующие записи базы данных, в базу данных могут быть введены соответствующие значения. Следовательно, за счет применения операций 400 QPS обеспечивает возможность дообучения системы на стороне пользователя с использованием обучающих документов, представляющих интерес для пользователя.
[0061] На ФИГ. 5-7 представлены блок-схемы, иллюстрирующие примеры способов 500-700 исполнения поисковых запросов с использованием форм слов в соответствии с некоторыми вариантами реализации настоящего изобретения. Каждый из способов 500-700 может быть выполнен путем обработки логики, которая может включать оборудование (например, схемотехника, специализированная логика, программируемая логика, микрокод и так далее), ПО (например, команды, выполняемые на устройстве обработки), встроенное микропрограммное обеспечение или их комбинацию. В одном из вариантов реализации способы 500-700 могут выполняться обрабатывающим устройством (например, обрабатывающим устройством 802 на ФИГ. 8) сервера обработки запросов 110 и/или сервера обучения 150 согласно описанию к ФИГ. 1. В некоторых вариантах реализации способы 500-700 могут выполняться одним потоком обработки. В другом варианте способы 500-700 могут выполняться двумя или более потоками обработки, каждый из которых выполняет одну или несколько отдельных функций, процедур, подпрограмм или операций способа. Например, потоки обработки, реализующие способы 500-700, могут быть синхронизированы (например с помощью семафоров, критических секций и (или) других механизмов синхронизации потоков). В другом варианте реализации потоки обработки, осуществляющие способы 500-700, могут выполняться асинхронно по отношению друг к другу. Следовательно, если на ФИГ. 5-7 и в связанных с ними описаниях операции способов 500-700 перечислены в конкретном порядке, различные варианты реализации способов могут выполнять по меньшей мере некоторые из описанных операций параллельно и (или) в произвольно выбранном порядке. Способы 500-700 могут использоваться для сопоставления информации, содержащейся в исходном документе, с информацией, хранящейся в базе данных, например, в форме записей в базе данных. В различных вариантах реализации документ и база данных могут находиться на компьютере пользователя, на сервере обработки запросов или в облачном хранилище, в том числе в различных сочетаниях указанных мест хранения. В некоторых вариантах реализации способы 500-700 могут выполняться автоматически без ввода данных со стороны пользователя, а результаты выполнения этих способов могут храниться на локальном носителе или в облачном хранилище для последующего доступа и использования.
[0062] На ФИГ. 5 представлена блок-схема, иллюстрирующая один из примеров способа 500 выявления целевой записи в документе с использованием поиска на основе форм слов в соответствии с некоторыми вариантами реализации настоящего изобретения. Термин «целевая запись» распространяется на записи базы данных, относительно которых на момент начала поискового запроса неизвестно, находятся ли они в документе, и присутствие которых может быть установлено в ходе исполнения поискового запроса. В некоторых вариантах реализации тип целевой записи может быть известен, а цель поиска будет заключаться в выявлении всех целевых записей этого типа в документе. В некоторых вариантах реализации неизвестен даже тип целевой записи, при этом цель поиска заключается в выявлении всех записей в базе данных, которые могут присутствовать в документе. Несмотря на то, что на ФИГ. 5 (и аналогично на ФИГ. 6-7) в целях краткости и лаконичности рассматривается только одна целевая запись, следует понимать, что таким же или аналогичным образом может быть выявлено более одной целевой записи (например, и адрес, и банковские реквизиты).
[0063] На шаге 510 устройство обработки, выполняющее способ 500, может выявить схему сопоставления, в которой слова представлены с помощью форм слов, при этом одна и та же форма слова может представлять различные слова. В результате корпус слов (например, словарь документа или базы данных) представляется меньшим корпусом форм слов. Даже несмотря на то, что в силу множественности соответствий между формой слова и словом фраза форм слов, т.е. фраза, в которой каждое слово заменяется соответствующей формой слова, может не содержать такого же количества информации, как исходная фраза, при этом фраза форм слов имеет преимущество, заключающееся в более широких возможностях изменения для эффективной обработки поисковых запросов, поскольку корпус слов обычно больше (в некоторых случаях значительно больше), чем связанный с ним корпус форм слов.
[0064] В некоторых вариантах реализации схема сопоставления может включать один уровень соответствий между словами и формами слов. В других вариантах реализации схема сопоставления может включать два или более уровней промежуточных форм слов. Например, схема сопоставления может включать первый уровень промежуточных форм слов (например, «уровень 1 промежуточных форм слов» на ФИГ. 2B-2C), который может использоваться для представления различных слов с помощью одной промежуточной формы слова, принадлежащей первому уровню. Аналогичным образом схема сопоставления может дополнительно включать дополнительные уровни промежуточных форм слов (например, «уровень 2 промежуточных форм слов» на ФИГ. 2B-2C), которые могут использоваться для представления различных промежуточных форм слов последнего уровня с помощью одной и той же формы слова (например, «уровень формы слова» на ФИГ. 2B-2C). В некоторых вариантах реализации, когда используется только один уровень форм слов, первый уровень промежуточных форм слов может совпадать с последним уровнем промежуточных форм слов. В различных вариантах реализации может использоваться столько уровней промежуточных форм слов, сколько целесообразно и необходимо. Каждый из промежуточных уровней форм слов, например, первый промежуточный уровень форм слов, может назначать различным буквам один и тот же буквенно-цифровой символ (например, «x» на ФИГ. 2B-2C) и назначать различные цифры одному и тому же второму буквенно-цифровому символу (например, «0» на ФИГ. 2B-2C).
[0065] На шаге 520 устройство обработки, выполняющее способ 500, может выявить (i) базу данных, включающую множество записей базы данных, и (ii) множество наборов баз данных форм слов, каждый из которых представляет одно или более слов соответствующей записи в базе данных. Например, каждое слово в записи в базе данных может быть заменено формой слова для образования набора форм слов для записи в базе данных. Используемый в настоящем документе термин «набор форм слов в базе данных» может относиться к формам слов любого уровня, в том числе любого уровня промежуточных форм слов. В некоторых вариантах реализации каждая запись базы данных или по меньшей мере некоторые из записей базы данных хранятся вместе (или совместно) с формами слов каждого уровня (или некоторых уровней) используемой схемы сопоставления. В других вариантах реализации по меньшей мере некоторые формы слов не сохраняются, но формируются в результате обработки поискового запроса.
[0066] На шаге 530 способ 500 может продолжить формирование множества гипотез с помощью устройства обработки, постепенно связывая различные группы (наборы) слов в документе с целевой записью. Множество гипотез может включать первую, вторую, третью и т.д. гипотезу, поочередно связывая с целевой записью (i) первый, второй, третий и т.д. набор слов в документе и (ii) первый, второй, третий и т.д. набор форм слов. В некоторых вариантах реализации любой из наборов слов в документе, в том числе первый, второй, третий и т.д. набор слов, может иметь заданное количество слов, которое зависит от типа целевой записи. Например, в поиске целевой записи типа «водительское удостоверение» каждая из гипотез или некоторые гипотезы могут включать одно слово (номер водительского удостоверения) или два слова (номер водительского удостоверения и штат выдачи). При поиске целевой записи типа «адрес» каждая из гипотез или некоторые гипотезы могут включать четыре или пять слов и так далее.
[0067] В настоящем описании термины «первый», «второй», «третий» и т. д. следует понимать исключительно как идентификаторы, но не как указание порядка, в котором формируются или проверяются различные гипотезы.
[0068] На шаге 540 устройство обработки, выполняющее способ 500, может исключить вторую гипотезу на основе несоответствия между вторым набором форм слов и каждым элементом из множества наборов форм слов в базе данных, например, при определении того, что каждое такое несоответствие превышает пороговое значение. Такое определение может указывать на то, что слова во второй гипотезе в достаточной степени отличаются от слов в каждой из записей в базе данных. Вторая гипотеза может быть исключена на основе несоответствия на конечном уровне формы слова, при этом также дополнительно может быть исключено любое количество гипотез на основе несоответствия на одном из уровней промежуточных форм слов. Например, третью гипотезу можно исключить на основе несоответствия между (i) набором промежуточных форм слов первого уровня, представляющих третий набор слов в документе (слова, отобранные в рамках третьей гипотезы) и (ii) каждым из промежуточных наборов форм слов в базе данных первого уровня, входящих во множество таких наборов, которые представляют соответствующую запись в базе данных. Более конкретно исключение третьей гипотезы может быть осуществлено в результате определения того, что несоответствие между набором промежуточных форм слов первого уровня (которые представляют третий набор слов) и каждым из промежуточных наборов форм слов в базе данных первого уровня во множестве таких наборов превышает пороговое значение. Соответственно, вторая гипотеза и третья гипотеза могут исключаться на основе несоответствия форм слов (а не самих слов), что может занимать гораздо меньше времени, чем исключение гипотез с использованием фактических слов.
[0069] На шаге 550 способ 500 с помощью устройства обработки может продолжить выявление первого набора слов в документе, являющегося целевой записью, за счет подтверждения первой гипотезы. Более конкретно подтверждение первой гипотезы может осуществляться в соответствии с приведенным ниже описанием для способов 600 и 700.
[0070] На ФИГ. 6 представлена блок-схема, иллюстрирующая один из примеров способа 600 исключения или подтверждения гипотезы, которая ассоциирует выбранные наборы слов документа с целевой записью в соответствии с некоторыми вариантами реализации настоящего изобретения. В некоторых вариантах реализации способ 600 может выполняться совместно со способом 500. Например, после выполнения шагов 510-530 способа 500 устройство обработки, выполняющее способ 500, может исключить конкретную гипотезу, называемую в настоящем документе второй гипотезой, за счет выполнения операций на шагах 610-630, которые могут быть выполнены в составе шага 540 способа 500.
[0071] Например, на шаге 610 устройство обработки, выполняющее способ 600, может выявить второй набор форм слов, представляющих слова во второй гипотезе, и может определить множество значений несоответствия (в форме слова) для второй гипотезы, при этом каждое из значений несоответствия характеризует степень схожести между (i) вторым набором форм слов в документе и (ii) каждым элементом множества наборов форм слов в базе данных. На шаге 620 устройство обработки может определить, что каждый элемент множества значений несоответствия находится не ниже порогового значения несоответствия, и на шаге 630 исключить вторую гипотезу. Значения несоответствия, используемые при исключении второй гипотезы, могут отражать то, как много символов расположено в ином порядке в любых двух форм слов или в сравниваемых наборах форм слов, и какое количество символов отсутствует, какое количество символов добавлено и т. д. В некоторых вариантах реализации измененный порядок слов/форм слов может считаться несоответствием, а в других вариантах (например, в зависимости от типа документа и/или целевой записи) порядок слов/форм слов может не считаться несоответствием. В некоторых вариантах реализации измененный порядок считается частичным несоответствием. Разный порядок слов / форм слов в наборе A и наборе B может быть количественно оценен как минимальное количество перестановок, требуемых для изменения слов / форм слов в наборе A для получения слов / форм слов в наборе B.
[0072] Помимо исключения одной или нескольких гипотез на основе несоответствия форм слов, способ 600 может включать подтверждение по меньшей мере одной гипотезы, которая в настоящем документе называется первой гипотезой. В частности, после выполнения шагов 510-530 способа 500 устройство обработки, выполняющее способ 500, на шаге 640 может получить сокращенное множество записей в базе данных на основе несоответствия (формы слова) между каждым из наборов форм слов, связанного с соответствующей гипотезой из множества гипотез, и набором форм слов в базе данных для каждой исключаемой записи в базе данных. На шагах 610-630 исключаются гипотезы, которые не соответствуют (до порогового значения несоответствия) любой из записей в базе данных, а на шаге 640 исключаются записи в базах данных, которые не соответствуют любой из гипотез. Первая гипотеза может входить в гипотезы, которые не исключаются при исполнении шагов 610-630.
[0073] На шаге 650 устройство обработки, выполняющее способ 600, может определить значение несоответствия (слова), характеризующее степень схожести между (i) первым набором слов в документе и (ii) первой записью в базе данных из сокращенного множества записей в базе данных. На шаге 660 способ 600 может с помощью устройства обработки продолжить определение того, что значение несоответствия (для первой гипотезы) ниже порогового значения несоответствия (слова) и подтверждение первой гипотезы на шаге 670 за счет определения первой целевой записи в базе данных в качестве целевой записи. Значения несоответствия форм слов могут использоваться в операциях, выполняемых на шагах 610-620 и 640, а в операциях, выполняемых на шаге 650, могут использоваться значения несоответствия слов, которые могут вычисляться и оцениваться иначе, чем значения несоответствия форм слов.
[0074] В некоторых вариантах реализации пороговое значение несоответствия слова 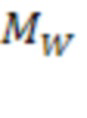 для подтверждения первой гипотезы может быть меньше, чем пороговое значение несоответствия формы слова
для подтверждения первой гипотезы может быть меньше, чем пороговое значение несоответствия формы слова 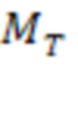 , используемое для исключения гипотез:
, используемое для исключения гипотез: 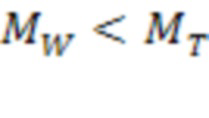 что означает, что если для исключения гипотезы можно ожидать относительно большого порогового значения несоответствия для слова
что означает, что если для исключения гипотезы можно ожидать относительно большого порогового значения несоответствия для слова 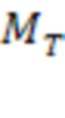 , то для подтверждения гипотезы можно ожидать более низкого порогового значения несоответствия для слова
, то для подтверждения гипотезы можно ожидать более низкого порогового значения несоответствия для слова 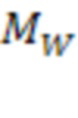 . В некоторых вариантах реализации пороговое значение несоответствия слов может быть фиксированным для различных документов. В некоторых вариантах реализации пороговое значение несоответствия слов может быть динамическим, например, в зависимости от документа. Например, пороговое значение несоответствия слов может быть равно второму минимальному значению несоответствия для документа, что означает, что выбирается гипотеза с минимальным несоответствием (и аналогично максимальным).
. В некоторых вариантах реализации пороговое значение несоответствия слов может быть фиксированным для различных документов. В некоторых вариантах реализации пороговое значение несоответствия слов может быть динамическим, например, в зависимости от документа. Например, пороговое значение несоответствия слов может быть равно второму минимальному значению несоответствия для документа, что означает, что выбирается гипотеза с минимальным несоответствием (и аналогично максимальным).
[0075] На ФИГ. 7 представлена блок-схема, иллюстрирующая один из примеров способа 700 с разворачиванием обученного классификатора при поиске с использованием форм слов в документах в соответствии с некоторыми вариантами реализации настоящего изобретения. В некоторых вариантах реализации способ 700 может выполняться совместно со способом 500. Например, после исполнения шагов 510-540 способа 500 для подтверждения первой гипотезы устройство обработки, выполняющее способ 700, может определить на шаге 710, что каждая гипотеза в подмножестве из множества гипотез характеризуется значением несоответствия между одним или несколькими формами слов, связанными с соответствующей гипотезой и по меньшей мере одним множеством из наборов форм слов в базе данных ниже порогового значения (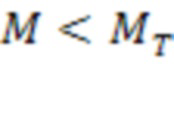 ). В некоторых вариантах реализации подмножество гипотез может включать все гипотезы, которые не исключаются при выполнении операций на шагах 610-630. Это подмножество гипотез может включать первую гипотезу.
). В некоторых вариантах реализации подмножество гипотез может включать все гипотезы, которые не исключаются при выполнении операций на шагах 610-630. Это подмножество гипотез может включать первую гипотезу.
[0076] На шаге 720 устройство обработки, выполняющее способ 700, может получить эмбеддинги слов для одного или более слов по каждой гипотезе из подмножества гипотез. На шаге 730 устройство обработки может выполнить обработку полученных вставок слов с помощью обученного классификатора для подтверждения первой гипотезы и определить первый набор слов в документе как целевую запись. В некоторых вариантах реализации обученный классификатор проходит обучение с использованием множества обучающих документов, при этом каждый обучающий документ из множества обучающих документов имеет признаки одной или нескольких обучающих записей (например, размеченные поля в обучающих документах).
[0077] На ФИГ. 8 изображен пример вычислительной системы 800, которая может выполнять один или более способов, описанных в данном документе. Вычислительная система может подключаться (например, в сети) к другим вычислительным системам с помощью ЛВС, интрасети, экстрасети или Интернета. Вычислительная система может работать в качестве сервера в сетевой среде клиент - сервер. Вычислительная система может быть персональным компьютером (ПК), планшетом, телеприставкой (STB), персональным цифровым помощником (PDA), мобильным телефоном, камерой, видеокамерой или любым устройством, способным выполнять набор команд (последовательных или иных), определяющих действия, которые должны выполняться этим устройством. Кроме того, хотя проиллюстрирована только одна вычислительная система, термин «компьютер» также следует понимать как включающий любую совокупность компьютеров, которые индивидуально или совместно выполняют набор (или несколько наборов) команд для выполнения одного или нескольких из обсуждаемых в данном документе способов.
[0078] Пример вычислительной системы 800 включает в себя устройство обработки 802, основное ЗУ 804 (например, постоянное ЗУ (ПЗУ), флеш-память, динамическое ЗУ с произвольной выборкой (ДЗУПВ), такое как синхронное ДЗУПВ (СДЗУПВ)), статическое ЗУ 806 (например, флеш-память, статическое ЗУ с произвольной выборкой (СЗУВП)) и устройство хранения данных 816, которые связываются друг с другом через шину 808.
[0079] Устройство обработки 802 представляет одно или более устройств обработки общего назначения, таких как микропроцессор, центральный процессор и т. п. В частности, устройство обработки 802 может быть микропроцессором с полным набором команд (CISC), микропроцессором с сокращенным набором команд (RISC), микропроцессором со сверхдлинным командным словом (VLIW) или процессором, реализующим другие наборы команд, или процессорами, реализующими комбинацию наборов команд. Устройство обработки 802 также может быть представлено одним или более устройствами обработки специального назначения, такими как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), цифровой сигнальный процессор (DSP), сетевой процессор и т. п. Устройство обработки 802 создано с возможностью выполнения команд 826 для исполнения модуля 116 поиска с использованием форм слов, обученного классификатора 118 и/или других компонентов и модулей, изображенных на ФИГ. 1, используемых для выполнения описанных в настоящем документе операций и способов, в том числе, помимо прочего, способ 500 выявления целевой записи в документе на основе поиска с использованием форм слов, способ 600 исключения или подтверждения гипотезы, связывающей выбранные наборы слов в документе с целевой записью, и способ 700, реализующий обученный классификатор в поиске в документах с использованием форм слов.
[0080] Вычислительная система 800 может дополнительно включать в себя сетевое интерфейсное устройство 822. Вычислительная система 800 также может включать в себя видеоконтрольное устройство 810 (например, жидкокристаллический дисплей (ЖКД) или электронно-лучевую трубку (ЭЛТ)), буквенно-цифровое устройство ввода 812 (например, клавиатуру), устройство управления курсором 814 (например, мышь) и устройство генерации сигнала 820 (например, динамик). В одном иллюстративном примере видеоконтрольное устройство 810, буквенно-цифровое устройство ввода 812 и устройство управления курсором 814 могут быть объединены в один компонент или устройство (например, сенсорный ЖК-экран).
[0081] Устройство хранения данных 816 включает машиночитаемый носитель данных 824, на котором хранятся команды 826, реализующие одну или более описанных в настоящем документе методологий или функций. Команды 826 могут также находиться полностью или по меньшей мере частично в основном ЗУ 804 и/или в устройстве обработки 802 во время их выполнения вычислительной системой 800, основным ЗУ 804 и устройством обработки 802, также составляющими машиночитаемый носитель. В некоторых вариантах реализации команды 826 могут дополнительно передаваться или приниматься по сети через сетевое интерфейсное устройство 822.
[0082] В то время как машиночитаемый носитель данных 824 показан в иллюстративных примерах как единственный носитель, термин «машиночитаемый носитель данных» следует понимать как включающий один носитель или несколько носителей (например, централизованную или распределенную базу данных и/или связанные кеши и серверы), в которых хранятся один или несколько наборов команд. Термин «машиночитаемый носитель данных» также должен включать любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной и который заставляет машину выполнять одну или несколько методологий настоящего изобретения. Термин «машиночитаемый носитель данных» следует соответственно понимать как включающий твердотельные запоминающие устройства, оптические носители и магнитные носители.
[0083] Хотя операции способов в настоящем документе показаны и описаны в определенном порядке, порядок операций каждого способа может быть изменен так, чтобы определенные операции могли выполняться в обратном порядке, или так, чтобы определенная операция по крайней мере частично могла выполняться одновременно с другими операциями. В некоторых вариантах реализации команды или подоперации отдельных операций могут быть прерывистыми и/или чередующимися.
[0084] Следует понимать, что приведенное выше описание служит для иллюстрации, а не ограничения. Многие другие варианты реализации будут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Следовательно, объем настоящего изобретения должен определяться ссылкой на прилагаемую формулу изобретения вместе с полным объемом эквивалентов, на которые такая формула изобретения имеет право.
[0085] В приведенном выше описании изложены многочисленные подробности. Однако для специалиста в данной области техники будет очевидно, что аспекты настоящего изобретения могут быть реализованы на практике без этих конкретных деталей. В некоторых случаях хорошо известные конструкции и устройства показаны в форме блок-схемы, а не в подробностях, чтобы не затруднять понимание настоящего изобретения.
[0086] Некоторые части подробных описаний выше представлены в терминах алгоритмов и символических представлений операций с битами данных в памяти компьютера. Эти алгоритмические описания и представления являются средствами, используемыми специалистами в области обработки данных, чтобы наиболее эффективно передать суть своей работы другим специалистам в данной области техники. Алгоритм здесь и в целом задуман как самосогласованная последовательность шагов, ведущих к желаемому результату. Эти шаги требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно сохранять, передавать, комбинировать, сравнивать и иным образом использовать. Иногда оказывается удобным, в основном по причинам обычного использования, называть эти сигналы битами, значениями, элементами, знаками, символами, терминами, числами и т. п.
[0087] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и представляют собой просто удобные обозначения, применяемые к этим величинам. Если специально не указано иное, как очевидно из следующего обсуждения, следует понимать, что во всем описании обсуждения с использованием таких терминов, как «получение», «определение», «выбор», «сохранение», «анализ» и т. п., относятся к действию и процессам вычислительной системы или аналогичного электронного вычислительного устройства, которое обрабатывает и преобразует данные, представленные в виде физических (электронных) величин в регистрах и памяти вычислительной системы, в другие данные, аналогично представленные в виде физических величин в памяти или регистрах вычислительной системы или других подобных устройств хранения, передачи или отображения информации.
[0088] Настоящее изобретение также относится к устройству для выполнения операций в данном документе. Это устройство может быть специально сконструировано для требуемых целей или может содержать компьютер общего назначения, выборочно активируемый или реконфигурируемый компьютерной программой, хранящейся в компьютере. Такая вычислительная программа может храниться на машиночитаемом носителе данных, таком как, помимо прочего, диск любого типа, включая дискеты, оптические диски, компакт-диски и магнитооптические диски, постоянные ЗУ (ПЗУ), оперативные ЗУ (ОЗУ), ЭППЗУ, ЭСППЗУ, магнитные или оптические платы или любой тип носителя, подходящий для хранения электронных команд, каждая из которых подключена к системной шине компьютера.
[0089] Алгоритмы и дисплеи, представленные в данном документе, по своей сути не связаны с каким-либо конкретным компьютером или другим устройством. Различные системы общего назначения могут использоваться с программами в соответствии с изложенными идеями, или может оказаться удобным сконструировать более специализированное устройство для выполнения требуемых методических шагов. Требуемая структура для множества этих систем будет отображаться, как указано в описании. Кроме того, варианты реализации настоящего изобретения не описаны посредством ссылки на какой-либо конкретный язык программирования. Будет принято во внимание, что для реализации идей настоящего изобретения, как описано в настоящем документе, можно использовать множество языков программирования.
[0090] Варианты реализации настоящего изобретения могут быть предоставлены в виде компьютерного программного продукта или программного обеспечения, которое может включать в себя машиночитаемый носитель для хранения команд, использующихся для программирования компьютерной системы (или других электронных устройств) с целью выполнения процесса в соответствии с настоящим изобретением. Машиночитаемый носитель включает в себя любой механизм для хранения или передачи информации в форме, читаемой машиной (например, компьютером). Например, машиночитаемый (т. е. считываемый компьютером) носитель включает в себя машиночитаемый (например, компьютером) носитель данных (например, постоянное ЗУ (ПЗУ), оперативное ЗУ (ОЗУ), носители данных на магнитных дисках, оптические носители данных, устройства флеш-памяти и т. д.).
[0091] Слова «пример» или «примерный» используются здесь для обозначения примеров, случаев или иллюстраций. Любой вариант реализации или конструкция, описанные в настоящем документе как «пример», не должны обязательно рассматриваться как предпочтительные или преимущественные по сравнению с другими вариантами реализации или конструкциями. Скорее, использование слов «пример» или «примерный» предназначено для конкретного представления понятий. Используемый в этой заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». То есть если иное не указано или не ясно из контекста, «X включает A или B» означает любую из естественных включающих перестановок. То есть если X включает А, Х включает B или Х включает и А, и В, то высказывание «X включает А или В» является истинным в любом из указанных выше случаев. Кроме того, неопределенные артикли «a» и «an», использованные в англоязычной версии этой заявки и прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Более того, использование терминов «применение», «один вариант применения», «вариант реализации» или «один вариант реализации» не предназначено для обозначения одного и того же применения или реализации, если они не описаны как таковые. Кроме того, используемые здесь термины «первый», «второй», «третий», «четвертый» и т. д. означают метки, позволяющие различать различные элементы, и необязательно могут иметь порядковое значение в соответствии с их числовым обозначением.
[0092] Поскольку многие изменения и модификации изобретения без сомнения будут очевидны для специалиста в данной области после прочтения вышеизложенного описания, следует понимать, что каждое конкретное показанное и описанное посредством иллюстраций применение не должно ни в коем случае считаться ограничением. Следовательно, отсылки к деталям различных применений не должны ограничивать объем запросов, которые сами по себе содержат только те особенности, которые рассматриваются как изобретение.

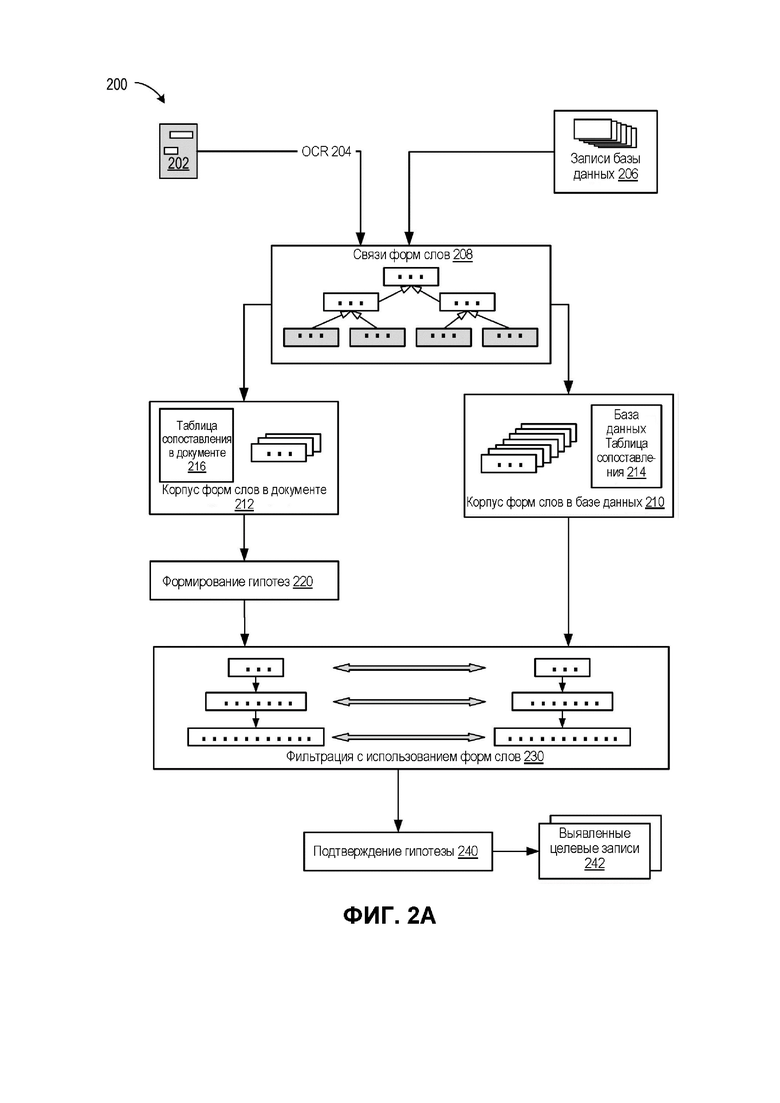

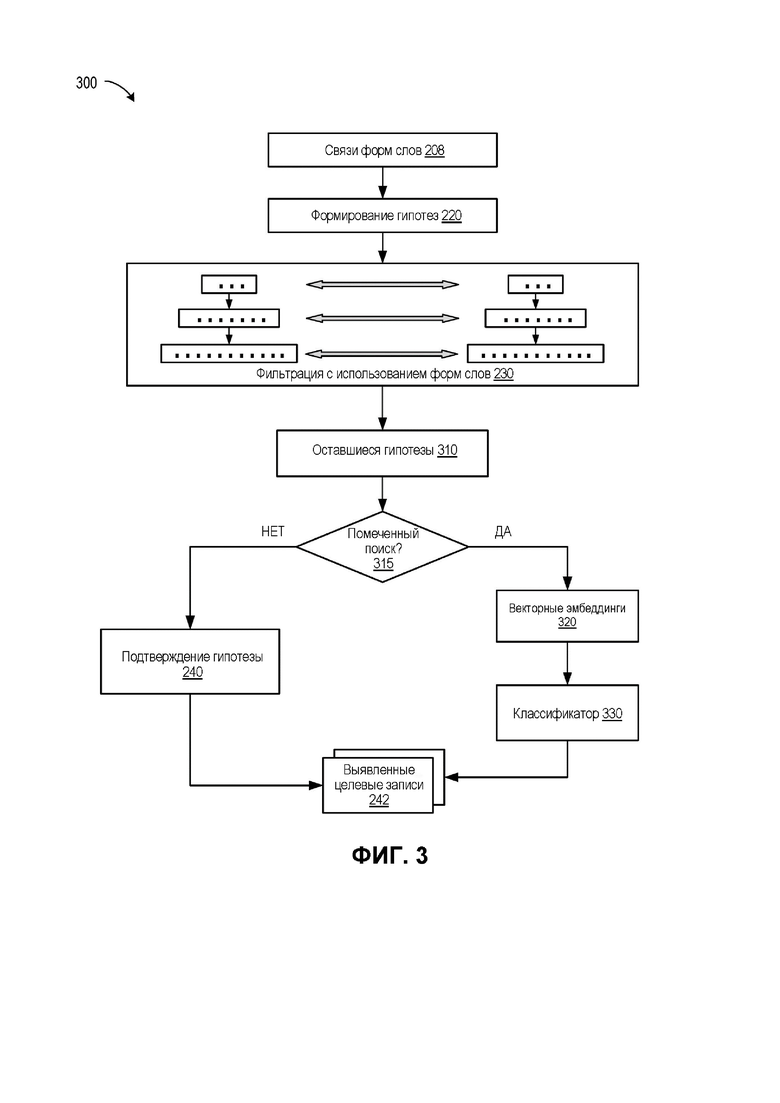
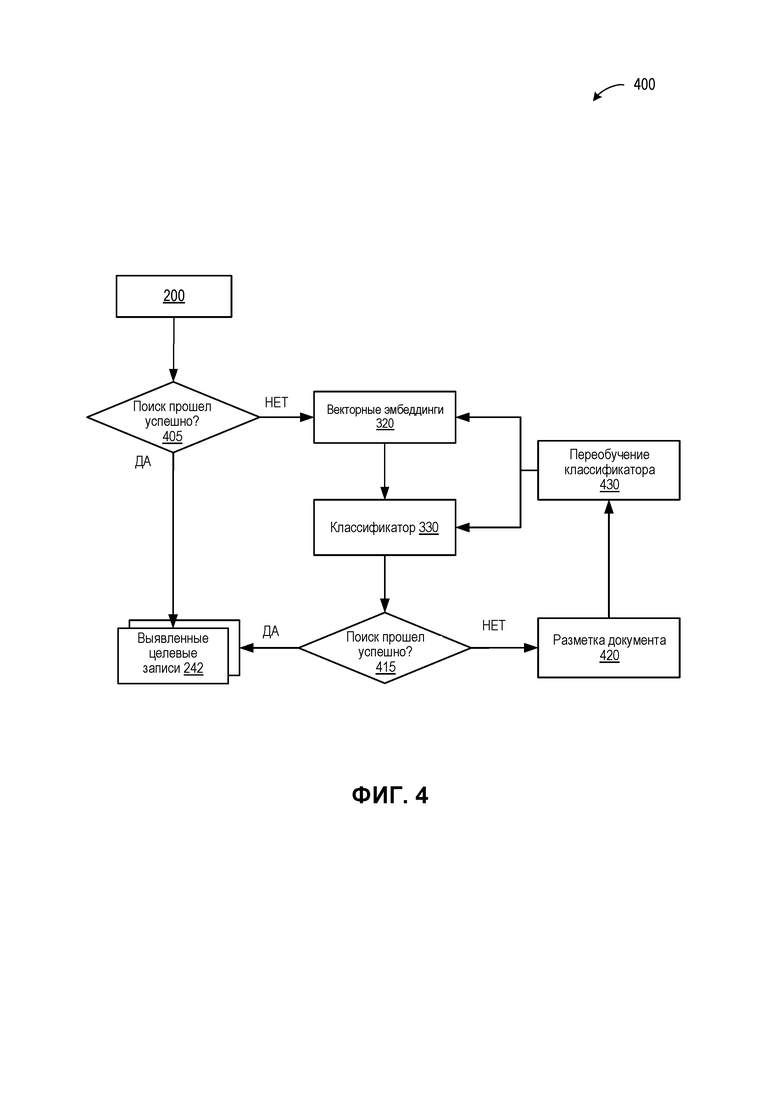


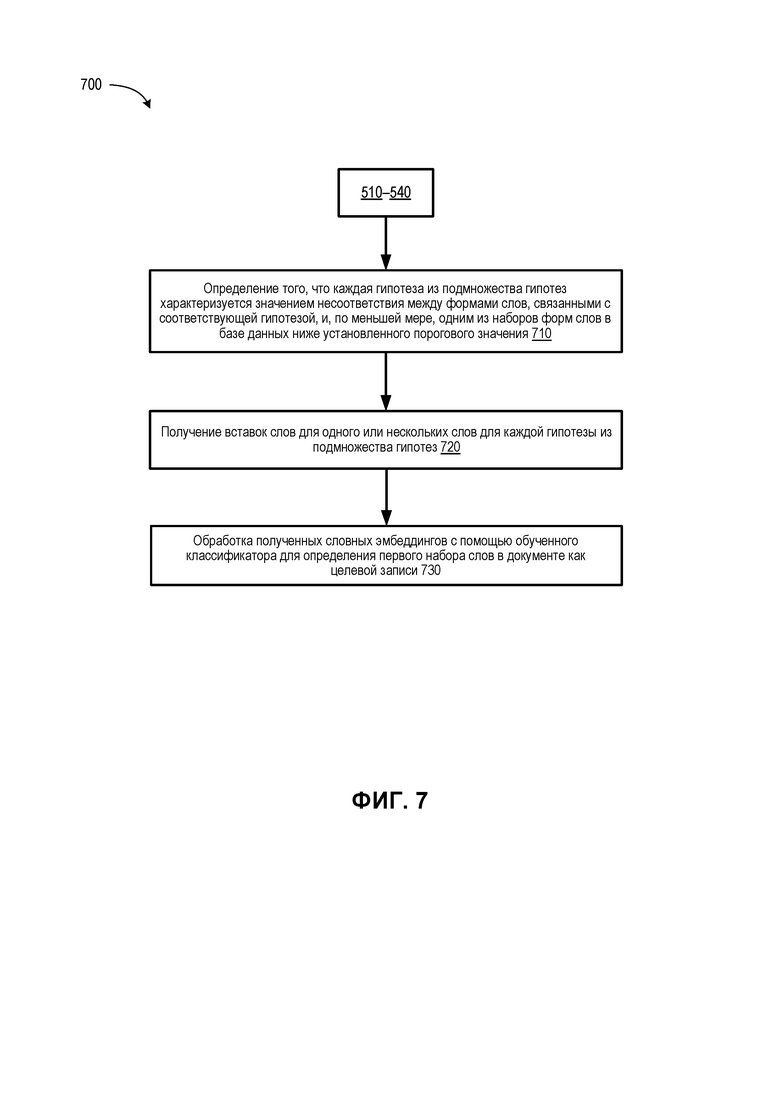
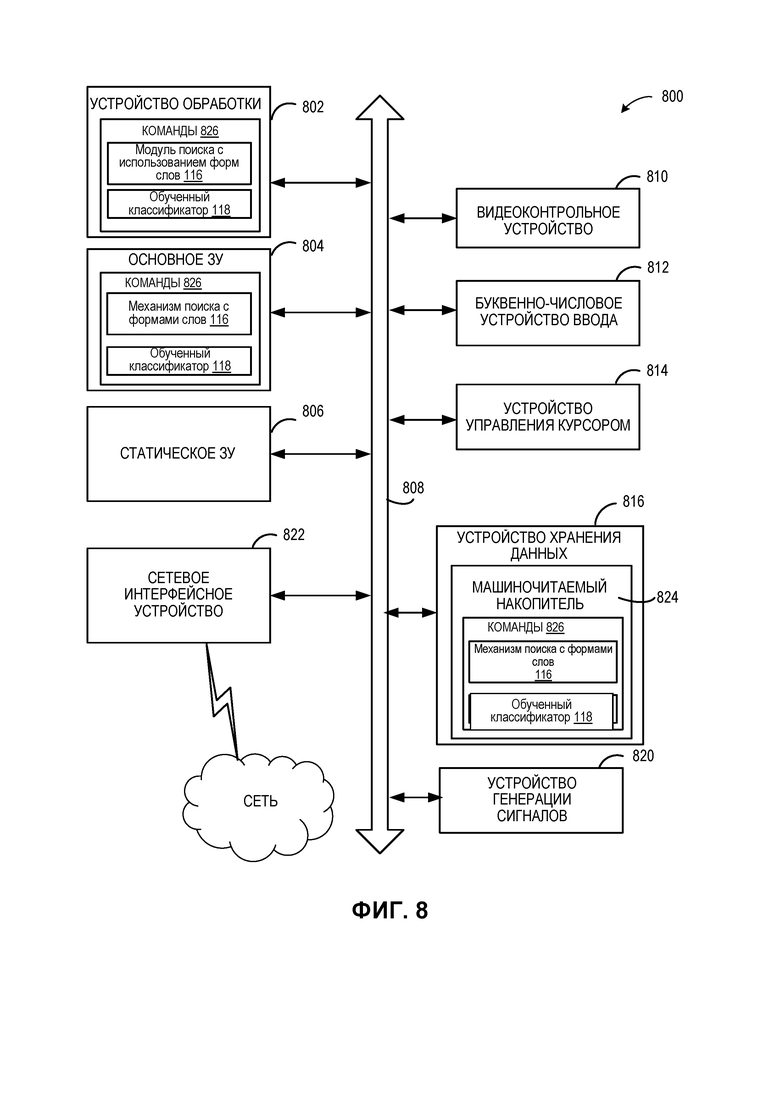
Изобретение относится к области вычислительной техники для обработки текстовых данных. Технический результат заключается в повышении точности обнаружения текстовых полей и значений этих полей в цифровых документах с помощью поиска с использованием форм слов. Технический результат достигается за счет определения схемы маппинга, в которой слова представлены посредством форм слов, при этом одна и та же форма слова может соответствовать различным словам; определения базы данных, содержащей множество записей базы данных; и множества наборов форм слов в базе данных; формирования множества гипотез, включающих: первую гипотезу, проекционно ассоциирующую с целевой записью (i) первый набор слов в документе и (ii) соответствующий первый набор форм слов; и вторую гипотезу, проекционно ассоциирующую с целевой записью (i) второй набор слов в документе и (ii) соответствующий второй набор форм слов; исключения второй гипотезы на основе несоответствия между вторым набором форм слов и каждым из множества наборов форм слов в базе данных; и определения первого набора слов в документе в качестве целевой записи посредством подтверждения первой гипотезы. 3 н. и 17 з.п. ф-лы, 10 ил.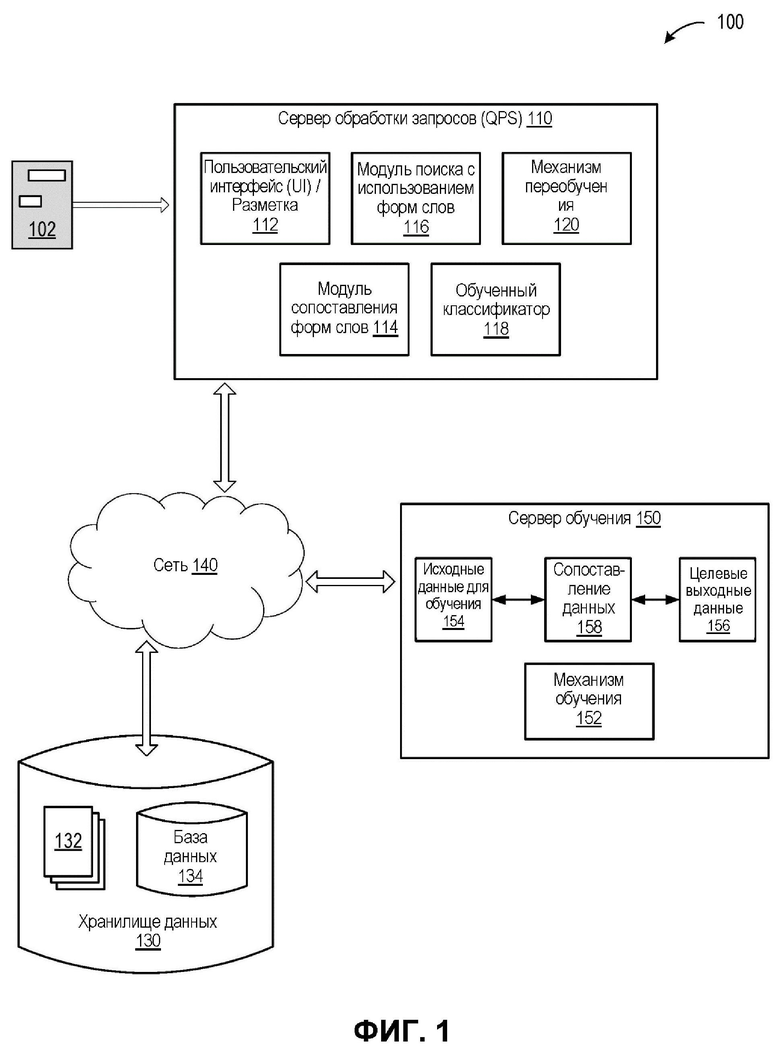
1. Способ выявления целевой записи в документе, включающий:
определение схемы маппинга, в которой слова представлены посредством форм слов, при этом одна и та же форма слова может соответствовать различным словам; определение:
базы данных, содержащей множество записей базы данных; и
множества наборов форм слов в базе данных, где каждый набор форм слов в базе данных из множества таких наборов соответствует одному или более словам соответствующей записи в базе данных;
формирование множества гипотез, включающее:
первую гипотезу, проекционно ассоциирующую с целевой записью (i) первый набор слов в документе и (ii) соответствующий первый набор форм слов; и
вторую гипотезу, проекционно ассоциирующую с целевой записью (i) второй набор слов в документе и (ii) соответствующий второй набор форм слов;
исключение второй гипотезы на основе несоответствия между вторым набором форм слов и каждым из множества наборов форм слов в базе данных; и
определение первого набора слов в документе в качестве целевой записи посредством подтверждения первой гипотезы.
2. Способ по п. 1, отличающийся тем, что схема маппинга включает один или более уровней промежуточных форм слов, причем:
первый промежуточный уровень форм слов одного или более промежуточных уровней форм слов представляет различные слова посредством одной промежуточной формы слова первого уровня, и
последний уровень промежуточных форм слов одного или более уровней промежуточных форм слов представляет различные промежуточные формы слова последнего уровня с помощью одной формы слова.
3. Способ по п. 2, отличающийся тем, что первый уровень промежуточных форм слова выполняет маппинг:
различных букв с одним первым буквенно-цифровым символом и различных цифр с одним вторым буквенно-цифровым символом.
4. Способ по п. 2, отличающийся тем, что множество гипотез дополнительно включает третью гипотезу, проекционно ассоциирующую набор слов в документе с целевой записью, при этом способ дополнительно включает:
исключение третьей гипотезы на основе несоответствия между (i) набором промежуточных форм слов первого уровня, представляющих третий набор слов в документе, и (ii) каждым из множества промежуточных наборов первого уровня форм слов в базе данных, которые представляют соответствующую запись в базе данных.
5. Способ по п. 4, отличающийся тем, что исключение третьей гипотезы происходит при определении того, что несоответствие между набором промежуточных форм слов первого уровня и каждым из множества промежуточных наборов форм слов в базе данных первого уровня превышает пороговое значение.
6. Способ по п. 1, отличающийся тем, что подтверждение первой гипотезы включает:
получение сокращенного множества записей в базе данных за счет исключения одной или более записей в базе данных из множества записей в базе данных на основе несоответствия между каждым набором форм слов, связанным с соответствующей гипотезой из множества гипотез, и одной или несколькими исключаемыми записями в базе данных;
определение значения несоответствия, характеризующего степень схожести между (i) первым набором слов в документе и (ii) первой записью в базе данных из сокращенного множества записей в базе данных; и
при определении того, что значение несоответствия ниже порогового значения несоответствия - определение первой записи в базе данных как целевой записи.
7. Способ по п. 1, отличающийся тем, что исключение второй гипотезы включает:
определение множества значений несоответствия, каждое из которых характеризует степень схожести между (i) вторым набором форм слов в документе и (ii) каждым набором форм слов в базе данных из множества таких наборов форм слов в базе данных; и
определение того, что каждое значение несоответствия из множества таких значений превышает пороговое значение несоответствия.
8. Способ по п. 1, отличающийся тем, что первый набор слов в документе и второй набор слов в документе имеют заданное количество слов, которое зависит от типа целевой записи.
9. Способ по п. 1, отличающийся тем, что подтверждение первой гипотезы включает:
множество гипотез характеризуется дополнительным пороговым значением несоответствия между одним или несколькими формами слов и по меньшей мере одним набором форм слов в базе данных из множества таких представлений, при этом подмножество гипотез включает первую гипотезу;
получение словных эмбеддингов для одного или нескольких слов для каждой гипотезы из подмножества гипотез; и
обработку полученных словных эмбеддингов с помощью обученного классификатора для определения первого набора слов в документе как целевой записи.
10. Способ по п. 9, отличающийся тем, что обученный классификатор проходит обучение с использованием множества обучающих документов, при этом каждый из обучающих документов из множества таких документов содержит указания на одну или несколько обучающих записей.
11. Способ по п. 1, отличающийся тем, что по меньшей мере некоторые гипотезы из множества гипотез формируются по меньшей мере частично на основе форм слов, выбранных для соответствующей гипотезы.
12. Энергонезависимый машиночитаемый носитель данных, содержащий инструкции, которые при обращении к ним устройства обработки данных побуждают его исполнять:
определение схемы маппинга, в которой слова представлены посредством форм слов, при этом одна и та же форма слова может соответствовать различным словам;
определение базы данных, содержащей множество записей базы данных; и
множества наборов форм слов в базе данных, где каждый набор форм слов в базе данных из множества таких наборов соответствует одному или более словам соответствующей записи в базе данных;
формирование множества гипотез, включающее:
первую гипотезу, проекционно ассоциирующую с целевой записью (i) первый набор слов в документе и (ii) соответствующий первый набор форм слов; и
вторую гипотезу, проекционно ассоциирующую с целевой записью (i) второй набор слов в документе и (ii) соответствующий второй набор форм слов;
исключение второй гипотезы на основе несоответствия между вторым набором форм слов и каждым из множества наборов форм слов в базе данных; и
определение первого набора слов документа в качестве целевой записи посредством подтверждения первой гипотезы.
13. Носитель данных по п. 12, отличающийся тем, что схема маппинга включает один или более уровней промежуточных форм слов, при этом:
первый промежуточный уровень форм слов одного или более промежуточных уровней форм слов представляет различные слова с помощью одной промежуточной формы слова первого уровня, и
последний уровень промежуточных форм слов одного или более уровней промежуточных форм слов представляет различные промежуточные формы слова последнего уровня посредством одной формы слова.
14. Носитель данных по п. 13, отличающийся тем, что на первом уровне промежуточных форм слов происходит маппинг:
различных букв с одним первым буквенно-цифровым символом и различных цифр с одним вторым буквенно-цифровым символом.
15. Носитель данных по п. 13, отличающийся тем, что множество гипотез дополнительно включает третью гипотезу, при проверке которой происходит постепенная проекционная ассоциация третьего набора слов в документе с целевой записью, при этом инструкции дополнительно побуждают устройство обработки данных выполнять:
исключение третьей гипотезы на основе несоответствия между (i) набором промежуточных форм слов первого уровня, представляющих третий набор слов в документе, и (ii) каждым из множества промежуточных наборов форм слов в базе данных первого уровня, которые представляют соответствующую запись в базе данных.
16. Носитель данных по п. 12, отличающийся тем, что для подтверждения первой гипотезы устройство обработки данных побуждается выполнять:
получение сокращенного множества записей в базе данных за счет исключения одной или нескольких записей в базе данных из множества на основе несоответствия между каждым набором форм слов, связанным с соответствующей гипотезой из множества гипотез и одной или несколькими исключаемыми записями в базе данных;
определение значения несоответствия, характеризующего степень схожести между (i) первым набором слов в документе и (ii) первой записью в базе данных из сокращенного множества записей в базе данных; и
при определении того, что значение несоответствия ниже порогового значения несоответствия - определение первой записи в базе данных в качестве целевой записи.
17. Носитель данных по п. 12, отличающийся тем, что для исключения второй гипотезы устройство обработки данных побуждается выполнять:
определение множества значений несоответствия, каждое из которых характеризует степень схожести между (i) вторым набором форм слов в документе и (ii) каждым набором форм слов из множества в базе данных; и
определение того, что каждое значение несоответствия из множества таких значений превышает пороговое значение несоответствия.
18. Носитель данных по п. 12, отличающийся тем, что первый набор слов в документе и второй набор слов в документе имеют заданное количество слов, которое зависит от типа целевой записи.
19. Носитель данных по п. 12, отличающийся тем, что для подтверждения первой гипотезы устройство обработки данных побуждается выполнять:
определение того, что каждая гипотеза, входящая в подмножество, включенное во множество гипотез, характеризуется дополнительным пороговым значением несоответствия между одной или несколькими формами слов и по меньшей мере одним набором форм слов в базе данных из множества таких представлений, при этом подмножество гипотез включает первую гипотезу;
получение словных эмбеддингов для одного или нескольких слов для каждой гипотезы из подмножества гипотез; и
обработку полученных словных эмбеддингов с помощью обученного классификатора для определения первого набора слов в документе как целевой записи.
20. Система для выявления целевой записи в документе, включающая:
запоминающее устройство; и
устройство обработки данных, функционально связанное с запоминающим устройством и выполняющее:
определение схемы маппинга, в которой слова представлены посредством форм слов, при этом одна и та же форма слова может соответствовать различным словам;
определение базы данных, содержащей множество записей базы данных; и
множества наборов форм слов в базе данных, где каждый набор форм слов в базе данных из множества таких наборов соответствует одному или более словам соответствующей записи в базе данных;
формирование множества гипотез, включающее:
первую гипотезу, проекционно ассоциирующую с целевой записью (i) первый набор слов в документе и (ii) соответствующий первый набор форм слов; и
вторую гипотезу, проекционно ассоциирующую с целевой записью (i) второй набор слов в документе и (ii) соответствующий второй набор форм слов;
исключение второй гипотезы на основе несоответствия между вторым набором форм слов и каждым из множества наборов форм слов в базе данных; и
определение первого набора слов документа в качестве целевой записи посредством подтверждения первой гипотезы.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| US 9645993 B2, 09.05.2017 | |||
| СИСТЕМА И СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ ПОЛЬЗОВАТЕЛЬСКИХ СЕМАНТИЧЕСКИХ СЛОВАРЕЙ ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2584457C1 |

