ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННУЮ ЗАЯВКУ
[0001] Данная заявка представляет собой международную заявку PCT/CN2019/128573 на RU национальной фазе, поданную 26 декабря 2019, которая притязает на приоритет заявки на патент КНР 201811648151.2, поданной в Национальное ведомство по интеллектуальной собственности КНР 29 декабря 2018, которая полностью приведена здесь для ссылки.
ОБЛАСТЬ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] Варианты осуществления настоящего изобретения относятся к области технологий компьютерного зрения, таким как способ и аппарат для обработки изображений, устройство и носитель данных.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
[0003] Компьютерное зрение представляет собой науку, которая изучает способы использования машин для симулирования функций визуальной обработки человека и других живых организмов. Компьютерное зрение подразумевает замену глаз человека камерой для получения визуальной информации и замену мозга компьютером для обработки и анализа информации и, таким образом, выполнения таких задач как классификация изображений, сегментирование изображений, распознавание объектов, определение координат ключевых точек, распознавание позы, и распознавание человеческих лиц.
[0004] С повышением производительности компьютерного аппаратного обеспечения и формированием крупных объемов визуальных данных в сфере компьютерного зрения стало широко использоваться глубокое обучение. Глубокое обучение, основанное на исследованиях искусственных нейронных сетей, является важным ответвлением машинного обучения, которое образует новую сквозную методику. Основой глубокого обучения является симулирования способа обучения мозга человека и построение глубокой сверточной нейронной сети с последующим пониманием данных. Глубокое обучение относится к глубокой сверточной нейронной сети. Способ распознавания в рамках компьютерного зрения предусматривает выделение отдельных признаков на основе восприятия различных цветов, текстур и границ на изображениях. Глубокая сверточная нейронная сеть представляет собой глубокую сетевую структуру, составленную из множества различных линейных слоев и нелинейных слоев, которая может выделять признаки от поверхностных до глубоких и от конкретных до абстрактных. Данные высокоуровневые признаки автоматически выделяются с помощью сети, которая обладает сильной способностью в плане определения признаков и может обеспечивать выделение многих абстрактных концепций и семантической информации из изображений, например целевых объектов на изображениях и координат целевых объектов.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0005] В соответствии с одним вариантом осуществления настоящего изобретения предусмотрен способ обработки изображений. Способ включает:
[0006] получение исходного изображения и вспомогательной информации исходного изображения;
[0007] получение карты признаков объекта путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач и получение вспомогательной карты признаков путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач; и
[0008] получение карты ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач.
[0009] В соответствии с одним вариантом осуществления настоящего изобретения предусмотрен аппарат для обработки изображений. Аппарат включает:
[0010] модуль для получения исходного изображения и вспомогательной информации, выполненный с возможностью получать исходное изображение и вспомогательную информацию исходного изображения;
[0011] модуль для получения карты признаков, выполненный с возможностью получать карту признаков объекта путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач и получать вспомогательную карту признаков путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач; и
[0012] модуль для получения карты ответов исходного изображения, выполненный с возможностью получать карту ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач.
[0013] В соответствии с одним вариантом осуществления настоящего изобретения предусмотрено устройство. Устройство включает:
[0014] один или несколько процессоров; и
[0015] память, выполненную с возможностью хранить одну или несколько программ,
[0016] при этом одна или несколько программ выполняются одним или несколькими процессорами для побуждения одного или нескольких процессоров выполнять способ в соответствии с вариантами осуществления настоящего изобретения.
[0017] В соответствии с одним вариантом осуществления настоящего изобретения предусмотрен машиночитаемый носитель данных, на котором хранится компьютерная программа. При выполнении компьютерной программы процессором осуществляется реализация способа в соответствии с вариантами осуществления настоящего изобретения.
ОПИСАНИЕ ФИГУР
[0018] Фиг. 1 представляет собой блок-схему способа обработки изображений в соответствии с одним вариантом осуществления настоящего изобретения;
[0019] Фиг. 2 представляет собой блок-схему другого способа обработки изображений в соответствии с одним вариантом осуществления настоящего изобретения;
[0020] Фиг. 3 представляет собой схематическую диаграмму варианта использования способа обработки изображений в соответствии с одним вариантом осуществления настоящего изобретения;
[0021] Фиг. 4 представляет собой блок-схему еще одного способа обработки изображений в соответствии с одним вариантом осуществления настоящего изобретения;
[0022] Фиг. 5 представляет собой схематическую диаграмму варианта использования другого способа обработки изображений в соответствии с одним вариантом осуществления настоящего изобретения;
[0023] Фиг. 6 представляет собой схематическую структурную диаграмму аппарата для обработки изображений в соответствии с одним вариантом осуществления настоящего изобретения; а
[0024] Фиг. 7 представляет собой схематическую структурную диаграмму устройства в соответствии с одним вариантом осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0025] Настоящее изобретение будет дополнительно описано далее в комбинации с фигурами и вариантами осуществления. Описанные здесь варианты осуществления используются лишь для объяснения настоящего изобретения, но не ограничивают настоящее изобретение. Прилагаемые фигуры иллюстрируют лишь части, связанные с настоящим изобретением, но не все структуры.
[0026] В данной области существуют, по меньшей мере, следующие проблемы: несмотря на широкое использование глубокого обучения для классификации изображений, сегментирования изображений, распознавания объектов, определения координат ключевых точек, распознавания позы, распознавания человеческих лиц и так далее, вследствие ситуаций, таких как сложные или изменчивые сцены и/или трудности при идентификации объектов, модель для обработки визуальных задач, сгенерированная на основе обучения в рамках глубокого обучения, не имеет высокой точности предсказания при обработке визуальных задач.
[0027] Варианты осуществления настоящего изобретения предусматривают способ и аппарат для обработки изображений, устройство и носитель данных для повышения точности предсказания модели для обработки визуальных задач.
[0028] Варианты осуществления
[0029] Для решения описанной выше технической проблемы, заключающейся в том, что модель для визуальной обработки, сгенерированная на основе глубокого обучения, не обладает высокой точностью предсказания при обработке визуальных задач, могут быть добавлены предварительные данные. Так называемые предварительные данные могут пониматься как вспомогательная информация, связанная с исходным изображением. Указанное ниже будет описано ниже в комбинации с вариантами осуществления.
[0030] Фиг. 1 представляет собой блок-схему способа обработки изображений в соответствии с одним вариантом осуществления настоящего изобретения. Настоящий вариант осуществления подходит для обработки визуальных задач. Способ может быть реализован с помощью любого аппарата для обработки изображений, при этом аппарат может быть реализован в виде программного обеспечения и/или аппаратного обеспечения и может быть выполнен в виде устройства, например компьютера или мобильного терминала. Как показано на Фиг. 1, способ включает этапы с 110 по 130.
[0031] На этапе 110 осуществляется получение исходного изображения и вспомогательной информации исходного изображения.
[0032] В рамках вариантов осуществления настоящего изобретения для повышения точности предсказания модели для обработки визуальных задач получают исходное изображение, при этом также получают вспомогательную информацию, связанную с исходным изображением. Вспомогательная информация, связанная с исходным изображением, может использоваться в качестве предварительных данных.
[0033] Исходное изображение может пониматься как изображение, в отношении которого следует реализовать визуальные задачи. Визуальные задачи могут включать классификацию изображений, сегментирование изображений, распознавание объектов, определение координат ключевых точек, распознавание позы, и им подобные. В некоторых вариантах осуществления исходное изображение может представлять собой одиночное изображение или кадр видео.
[0034] Если исходное изображение представляет собой одиночное изображение, то вспомогательная информация исходного изображения может включать фоновое изображение, соответствующее исходному изображению, при этом фоновое изображение, соответствующее исходному изображению, может пониматься следующим образом: исходное изображение включает целевой объект, в то время как фоновое изображение представляет собой изображение, которое не включает целевой объект. В некоторых вариантах осуществления фоновое изображение представляет собой изображение, полученное путем удаления целевого объекта с исходного изображения. В рамках примера варианта осуществления, например, изображение, полученное с помощью камеры для съемки спящего котенка в углу комнаты, представляет собой исходное изображение, в то время как изображение, полученное с помощью камеры для съемки данного угла комнаты, представляет собой фоновое изображение, при этом целевой объект представляет собой спящего котенка.
[0035] Если исходное изображение представляет собой кадр видео и кадр видео используется в качестве текущего кадра видео, который не является первым кадром видео, то вспомогательная информация исходного изображения может включать предыдущий кадр видео текущего кадра видео и карту ответов предыдущего кадра видео.
[0036] На этапе 120 осуществляется получение карты признаков объекта путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач и осуществляется получение вспомогательной карты признаков путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач.
[0037] На этапе 130 осуществляется получение карты ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач.
[0038] В рамках вариантов осуществления настоящего изобретения карта ответов исходного изображения может пониматься как результат, полученный путем выполнения визуальной задачи соответствующего типа в отношении исходного изображения. Форма карты ответов исходного изображения определяется в соответствии с типом визуальной задачи. Например, если визуальная задача представляет собой сегментирование изображений (сегментирование изображений заключается в классификации каждого пиксела изображения в соответствии с его категорией), то карта ответов исходного изображения может представлять собой карту вероятностей категории каждого пиксела на исходном изображении или может представлять собой карту для семантического сегментирования изображения, полученную с помощью конвертации из карты вероятностей путем установки порогового значения вероятности; если визуальная задача представляет собой распознавание объектов, то карта ответов исходного изображения может представлять собой карту, включающую рамку выделения, при этом целевой объект располагается в рамке выделения; и если визуальная задача представляет собой определение координат ключевых точек, то карта ответов исходного изображения может представлять собой тепловую карту, сгенерированную на основе координат ключевой точки.
[0039] Первая модель для обработки визуальных задач может быть сгенерирована на основе обучения сверточной нейронной сети. Первая модель для обработки визуальных задач может включать основной путь и ответвленный путь. Сверточная нейронная сеть представляет собой многослойную нейронную сеть и может включать сверточный слой, слой объединения, слой нелинейной активации и полностью связанный слой. Каждый слой составлен из нескольких карт признаков, при этом пиксел в рамках каждой карты признаков соответствует нейрону. Карта признаков может быть представлена как W×H×K, при этом W обозначает ширину карты признаков, H обозначает длину карты признаков, K обозначает количество каналов, а W×H соответствует размеру карты признаков. В рамках сверточной нейронной сети количество каналов указывает на количество сверточных ядер в каждом сверточном слое. Указанные выше сверточный слой, слой объединения, слой нелинейной активации и полностью связанный слой образуют сетевую структуру сверточной нейронной сети. Указанная выше сеть имеет относительно сложную структуру и относительно большое количество параметров. В целях упрощения структуры сети и снижения количества параметров могут использоваться легковесные сверточные нейронные сети, например полностью сверточная нейронная сеть. Так называемая полностью сверточная нейронная сеть представляет собой сверточную нейронную сеть, которая не включает полностью связанный слой. Структура первой модели для обработки визуальных задач будет описана далее на основе первой модели для обработки визуальных задач, сгенерированной путем обучения полностью сверточной нейронной сети. В некоторых вариантах осуществления основной путь первой модели для обработки визуальных задач включает первый модуль понижающей дискретизации и модуль повышающей дискретизации. Выход первого модуля понижающей дискретизации соединен с модулем повышающей дискретизации. Ответвленный путь первой модели для обработки визуальных задач включает второй модуль понижающей дискретизации, при этом первый модуль понижающей дискретизации соединен параллельно со вторым модулем понижающей дискретизации. Каждый модуль понижающей дискретизации может включать M сверточных слоев, при этом каждый модуль повышающей дискретизации может включать M транспонированных сверточных слоев. Слой пакетной нормализации и слой нелинейной активации могут быть присоединены после каждого сверточного слоя. После прохождения изображения через первый модуль понижающей дискретизации и второй модуль понижающей дискретизации получают карту признаков понижающей дискретизации. Карта признаков понижающей дискретизации содержит связанную с признаками изображения информацию. Кроме того, поскольку размер карты признаков понижающей дискретизации является уменьшенным по сравнению с размером поданного на изображения, карта признаков понижающей дискретизации имеет большее принимающее поле и может обеспечивать получение большего количества связанной с контекстом информации. Карту признаков повышающей дискретизации получают путем подачи карты признаков понижающей дискретизации на модуля повышающей дискретизации, при этом карта признаков повышающей дискретизации имеет тот же размер, что и исходное изображение. В некоторых вариантах осуществления конкретная форма структуры первой модели для обработки визуальных задач может быть составлена в соответствии с фактическими обстоятельствами.
[0040] Карту признаков объекта получают путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач. Здесь карта признаков объекта может представлять собой карту признаков понижающей дискретизации, полученную с помощью первого модуля понижающей дискретизации, как описано выше. Карта признаков объекта включает связанную с признаками информацию исходного изображения. Вспомогательную карту признаков получают путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач. Здесь вспомогательная карта признаков может представлять собой карту признаков понижающей дискретизации, полученную с помощью второго модуля понижающей дискретизации, как описано выше. Вспомогательная карта признаков включает связанную с признаками информацию из вспомогательной информации исходного изображения.
[0041] Карту ответов исходного изображения получают путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач. Здесь карта ответов исходного изображения может представлять собой карту признаков повышающей дискретизации, полученную с помощью модуля повышающей дискретизации, как описано выше. В некоторых вариантах осуществления, поскольку вспомогательная информация исходного изображения также участвует в процессе генерирования карты ответов исходного изображения, то предварительные данные также участвуют в процессе генерирования карты ответов исходного изображения. Другими словами, вспомогательная информация исходного изображения в качестве предварительных данных играет роль в плане улучшения точности предсказания модели в процессе генерирования карты ответов исходного изображения, при этом карта ответов исходного изображения, которая генерируется при участии вспомогательной информации исходного изображения, является более точной, чем карта ответов исходного изображения, сгенерированная лишь при участии исходной карты без вспомогательной информации исходного изображения.
[0042] В некоторых вариантах осуществления карта признаков объекта имеет тот же размер, что и вспомогательная карта признаков, при этом карта признаков объекта имеет то же количество каналов, что и вспомогательная карта признаков. В целях достижения того, что карта признаков объекта имеет тот же размер, что и вспомогательная карта признаков, первый модуль понижающей дискретизации и второй модуль понижающей дискретизации, как описано выше, могут иметь одинаковую структуру и одинаковое количество сверточных ядер, то есть первый модуль понижающей дискретизации и второй модуль понижающей дискретизации могут иметь одинаковое количество сверточных слоев и одинаковое количество сверточных ядер. Могут использоваться следующие два способа объединения карты признаков объекта и вспомогательной карты признаков, включающие: первый способ, при котором карта признаков объекта и вспомогательная карта признаков объединяются путем добавления без переноса, и второй способ, при котором карта признаков объекта и вспомогательная карта признаков объединяются путем взаимодействия каналов. Конкретный используемый способ для их объединения может быть установлен в соответствии с фактическими обстоятельствами.
[0043] В некоторых вариантах осуществления, когда исходное изображение представляет собой кадр видео, вспомогательная информация исходного изображения включает предыдущий кадр видео и карту ответов предыдущего кадра видео, при этом карта ответов предыдущего кадра видео может представлять собой карту, полученную путем подачи предыдущего кадра видео в качестве входной переменной на первую модель для обработки визуальных задач. Кроме того, с учетом того, что вспомогательная информация исходного изображения должна использоваться в качестве предварительных данных для повышения точности предсказания модели, то, таким образом, необходимо обеспечить точность карты ответов предыдущего кадра видео в рамках вспомогательной информации исходного изображения в качестве предварительных данных, при этом чем выше точность, тем лучше. Для повышения точности карты ответов предыдущего кадра видео в рамках вспомогательной информации исходного изображения может быть выбрана модель для визуальной обработки с более высокой точностью предсказания, то есть предыдущий кадр видео, который удовлетворяет предварительно определенным условиям и используется в качестве входной переменной, не подается на первую модель для обработки визуальных задач, а подается на модель для визуальной обработки, которая имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач. Как правило, чем выше точность предсказания модели, тем более сложной является структура модели и тем более высоким является количество параметров. В данном случае вычислительная стоимость является большей, и, соответственно, эффективность предсказания является более низкой. Как описано выше, для получения карты ответов предыдущего кадра видео с более высокой точностью выбирают визуальную модель с точностью предсказания, которая обеспечивает повышение точности карты ответов предыдущего кадра видео одновременно со снижением эффективности предсказания модели. На основе указанного выше, необходимость подачи предыдущего кадра видео в качестве входной переменной на первую модель для обработки визуальных задач для получения карты ответов предыдущего кадра видео или подачи предыдущего кадра видео в качестве входной переменной на модель с более высокой точностью предсказания, чем у первой модели для обработки визуальных задач, для получения карты ответов предыдущего кадра видео, может быть определена в соответствии с фактическими обстоятельствами, при этом она включает следующие два способа:
[0044] Первый способ. Если предыдущий кадр видео принадлежит к одному из первых N кадров видео, то карту ответов предыдущего кадра видео получают путем подачи предыдущего кадра видео в качестве входной переменной на модель с более высокой точностью предсказания, чем у первой модели для обработки визуальных задач. Если предыдущий кадр видео не принадлежит к одному из первых N кадров видео, то карту ответов предыдущего кадра видео получают путем подачи предыдущего кадра видео в качестве входной переменной на первую модель для обработки визуальных задач, при этом N представляет собой положительное целое число. Причина, по которой может быть выполнена указанная выше обработка, заключается в том, что: несколько кадров видео в рамках видео обычно имеют связь друг с другом, и, таким образом, карты ответов первых N кадров видео получают путем подачи нескольких кадров видео в качестве входных переменных на модели с более высокой точностью предсказания, чем у первой модели для обработки визуальных задач, и, таким образом, это может обеспечивать точность карты ответов предыдущего кадра видео в рамках вспомогательной информации исходного изображения в качестве предварительных данных. В некоторых вариантах осуществления указанный выше первый способ предусматривает использование в качестве единицы видео для определения способа получения карты ответов предыдущего кадра видео.
[0045] Второй способ. Если продолжительность видео превышает или равна пороговому значению продолжительности, то точность предыдущего кадра видео, полученного с помощью первого способа, может не удовлетворять фактическим требованиям. На основе указанного выше, несколько кадров видео в рамках видео могут быть разделены на две или более последовательности кадров видео в соответствии с порядком по времени, при этом данные несколько последовательностей кадров видео не накладываются друг на друга, а количество кадров видео, включенных в последовательности кадров видео, может являться одинаковым или различаться, при этом оно может быть определено в соответствии с фактическими требованиями. В некоторых вариантах осуществления каждая последовательность кадров видео может быть разделена на первый кадр видео, второй кадр видео, … и P-й кадр видео в соответствии с порядком по времени. В некоторых вариантах осуществления предыдущий кадр видео будет принадлежать к одной последовательности кадров видео в рамках нескольких последовательностей кадров видео. После указанной выше обработки видео и получения нескольких последовательностей кадров видео, способ получения карты ответов предыдущего кадра видео будет изменен с использования в качестве единицы видео в рамках первого способа на использование в качестве единицы последовательности кадров видео. В некоторых вариантах осуществления, если предыдущий кадр видео принадлежит к одному из первых T кадров видео в рамках последовательности кадров видео, соответствующей предыдущему кадру видео, то предыдущий кадр видео подается в качестве входной переменной на модели с более высокой точностью предсказания, чем у первой модели для обработки визуальных задач, для получения карты ответов предыдущего кадра видео; а если предыдущий кадр видео не принадлежит к одному из первых T кадров видео в рамках последовательности кадров видео, соответствующей предыдущему кадру видео, то предыдущий кадр видео подается в качестве входной переменной на первую модель для обработки визуальных задач для получения карты ответов предыдущего кадра видео, при этом T представляет собой положительное целое число. Причина, по которой может быть выполнена указанная выше обработка, заключается в том, что: несколько кадров видео в рамках последовательности видео обычно имеют связь друг с другом, и, таким образом, карты ответов первых N кадров видео в каждой последовательности видео получают путем подачи нескольких кадров видео в качестве входных переменных на модели с более высокой точностью предсказания, чем у первой модели для обработки визуальных задач, и, таким образом, это может обеспечивать точность карты ответов предыдущего кадра видео в рамках вспомогательной информации исходного изображения в качестве предварительных данных. В то же время, способ получения карты ответов предыдущего кадра видео определяют путем использования в качестве единицы последовательности кадров видео, а не видео, тем самым повышая точность карты ответов предыдущего кадра видео в рамках вспомогательной информации исходного изображения.
[0046] В некоторых вариантах осуществления, если исходное изображение представляет собой кадр видео, который не является первым кадром видео, то вспомогательная информация исходного изображения включает предыдущий кадр видео текущего кадра видео и карту ответов предыдущего кадра видео, при этом необходимость корректирования формы презентирования карты ответов предыдущего кадра видео определяется в соответствии с типами визуальных задач. Например, если визуальная задача представляет собой сегментирование изображений, то карта ответов предыдущего кадра видео представляет собой карту вероятностей категории каждого пиксела на предыдущем кадре видео или карта ответов предыдущего кадра видео представляет собой карту для семантического сегментирования изображения, полученную с помощью конвертации из карты вероятностей путем установки порогового значения вероятности, при этом форма презентирования карты ответов предыдущего кадра видео при сегментировании изображений может напрямую использоваться в качестве входной переменной и подаваться на ответвленный путь первой модели для обработки визуальных задач, при этом корректирование не требуется. Если визуальная задача представляет собой распознавание объектов, то карта ответов предыдущего кадра видео представляет собой карту, включающую рамку выделения, при этом карта, включающая рамку выделения, подвергается корректированию; значение пиксела в рамке выделения может быть избирательно установлено как 1, при этом значение пиксела за пределами рамки выделения может быть избирательно установлено как 0, при этом скорректированная карта ответов предыдущего кадра видео подается в качестве входной переменной на ответвленный путь первой модели для обработки визуальных задач. В некоторых вариантах осуществления значение пиксела за пределами рамки выделения может быть установлено в соответствии с фактическими требованиями. Если визуальная задача представляет собой определение координат ключевых точек, то карта ответов предыдущего кадра видео представляет собой тепловую карту, сгенерированную на основе координат ключевой точки, при этом карта ответов предыдущего кадра видео может быть напрямую подана в качестве входной переменной на ответвленный путь первой модели для обработки визуальных задач, при этом форма презентирования карты ответов предыдущего кадра видео не требует корректирования.
[0047] В соответствии с техническим решением в рамках настоящего варианта осуществления, карту признаков объекта получают путем получения исходного изображения и вспомогательной информации исходного изображения и подачи исходного изображения на основной путь первой модели для обработки визуальных задач, при этом вспомогательную карту признаков получают путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач; при этом карту ответов исходного изображения получают путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач. В рамках описанного выше процесса генерирования карты ответов исходного изображения с участием вспомогательной информации исходного изображения, поскольку вспомогательная информация исходного изображения может обеспечивать относительно сильные предварительные данные, которые помогают решать проблемы, затрагивающие точность предсказания модели для обработки визуальных задач, такие как сложные и изменчивые сцены и/или трудности при идентификации объектов, то, таким образом, точность предсказания модели для обработки визуальных задач повышается.
[0048] Необязательно, на основе указанного выше технического решения вспомогательная информация исходного изображения включает фоновое изображение, соответствующее исходному изображению.
[0049] В некоторых вариантах осуществления настоящего изобретения вспомогательная информация исходного изображения может включать фоновое изображение, соответствующее исходному изображению. Как описано выше, фоновое изображение исходного изображения может пониматься следующим образом: исходное изображение включает целевой объект, в то время как фоновое изображение представляет собой изображение, которое не включает целевой объект. Другими словами, фоновое изображение представляет собой изображение, полученное путем удаления целевого объекта с исходного изображения. Смысл указанного выше понимания фонового изображения будет описан далее.
[0050] В некоторых вариантах осуществления в рамках процесса обработки визуальных задач могут возникнуть следующие ситуации: если визуальная задача представляет собой сегментирование изображений, то передний план и фон могут быть перепутаны или края карты ответов исходного изображения могут быть неровными, при этом в данном случае карта ответов исходного изображения может представлять собой карту для семантического сегментирования изображения; если визуальная задача представляет собой распознавание объектов, то может возникнуть ситуация, при которой сгенерированная рамка выделения сильно дрожит; если визуальная задача представляет собой определение координат ключевых точек, то может возникнуть ситуация, при которой ключевая точка не может быть идентифицирована или ключевая точка дрожит. В некоторых вариантах осуществления указанные выше ситуации показывают, что точность предсказания модели является недостаточно высокой и причина, по которой точность предсказания модели является недостаточно высокой, заключается в сложной и изменчивой сцене, а не в том, что сам целевой объект является сложным в плане распознавания. По сравнению с целевым объектом, сложная и изменчивая сцена может пониматься как связанная с фоновыми помехами информация. На основе указанного выше, поскольку фоновое изображение представляет собой изображение, с которого удален целевой объект, и которое сравнивается с исходным изображением, то фоновое изображение включает лишь связанную с фоновыми помехами информацию. Вспомогательную карту признаков получают путем подачи фонового изображения в качестве входной переменной ответвленный путь первой модели для обработки визуальных задач, при этом вспомогательная карта признаков будет выделять признак связанной с фоновыми помехами информации, при этом вспомогательная карта признаков участвует в процессе генерирования карты ответов исходного изображения, так что сгенерированная карта ответов исходного изображения представляет собой карту ответов для подавления фоновых помех. В некоторых вариантах осуществления, если фоновое изображение представляет собой изображение, на котором целевой объект удален с исходного изображения, то фоновое изображение в качестве предварительных данных обладает функцией подавления фоновых помех и, таким образом, точность предсказания модели повышается.
[0051] Необязательно, на основе описанного выше технического решения, если исходное изображение представляет собой текущий кадр видео и текущий кадр видео не является первым кадром видео, то вспомогательная информация исходного изображения включает предыдущий кадр видео текущего кадра видео и карту ответов предыдущего кадра видео.
[0052] В некоторых вариантах осуществления настоящего изобретения в ситуации, при которой исходное изображение представляет собой текущий кадр видео в рамках видео, вспомогательная информация исходного изображения включает предыдущий кадр видео текущего кадра видео и карту ответов предыдущего кадра видео. В рамках процесса обработки визуальных задач могут возникнуть следующие ситуации: если визуальная задача представляет собой сегментирование изображений, может возникнуть сильное мерцание масок сегментирования между различными кадрами видео; если визуальная задача представляет собой распознавание объектов, то может возникнуть сильное дрожание рамок выделения, сгенерированных в нескольких последовательных кадрах видео; если визуальная задача представляет собой определение координат ключевых точек, то ключевые точки на смежных кадрах видео могут дрожать. В некоторых вариантах осуществления указанные выше ситуации показывают, что точность предсказания модели является невысокой и причина, по которой точность предсказания модели является невысокой, заключается в том, что объект и/или сцена являются сложными в плане распознавания. На основе указанного выше, поскольку два смежных кадра видео имеют определенную связь, карты ответов двух смежных кадров видео также имеют определенную связь, другими словами, карта ответов предыдущего кадра видео имеет относительно высокую связь с генерируемой картой ответов текущего кадра видео, то есть карта ответов предыдущего кадра видео может использоваться в качестве предварительных данных для участия в процессе генерирования карты ответов текущего кадра видео. В некоторых вариантах осуществления указанный выше процесс может заключаться в том, что вспомогательную карту признаков получают путем подачи карты ответов предыдущего кадра видео в качестве входной переменной на ответвленный путь первой модели для обработки визуальных задач, при этом вспомогательная карта признаков будет выделять признак предыдущего кадра видео и участвовать в процессе генерирования карты ответов текущего кадра видео. Карта ответов предыдущего кадра видео в качестве предварительных данных обладает функцией повышения связности между кадрами и дополнительно повышает точность предсказания модели. В некоторых вариантах осуществления, поскольку предыдущее видео и карта ответов предыдущего видео предоставляют относительно сильные предварительные данные, структура первой модели обработки визуальных данных, сгенерированной на основе обучения сверточной нейронной сети, может быть максимально упрощена для повышения эффективности предсказания модели.
[0053] В некоторых вариантах осуществления, в соответствии с указанным выше, необходимость подачи предыдущего кадра видео в качестве входной переменной на первую модель для обработки визуальных задач для получения карты ответов предыдущего кадра видео или подачи предыдущего кадра видео в качестве входной переменной на модель с более высокой точностью предсказания, чем у первой модели для обработки визуальных задач, для получения карты ответов предыдущего кадра видео, может быть определена в соответствии с фактическими обстоятельствами.
[0054] Необязательно, на основе указанного выше технического решения, для получения карты ответов предыдущего кадра видео могут использоваться следующие способы: если предыдущий кадр видео принадлежит к одному из первых N кадров видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на вторую модель для обработки визуальных задач; а если предыдущий кадр видео не принадлежит к одному из первых N кадров видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на первую модель для обработки визуальных задач. Вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем точность первой модели для обработки визуальных задач, при этом N представляет собой положительное целое число.
[0055] В некоторых вариантах осуществления настоящего изобретения с учетом того, что вспомогательная информация исходного изображения используется в качестве предварительных данных для повышения точности предсказания модели, то, таким образом, она должна обеспечивать точность карты ответов предыдущего кадра видео в рамках вспомогательной информации исходного изображения в качестве предварительных данных, при этом чем выше точность, тем лучше. Для повышения точности карты ответов предыдущего кадра видео в рамках вспомогательной информации исходного изображения может быть рассмотрена и выбрана модель для визуальной обработки с более высокой точностью предсказания, то есть предыдущий кадр видео в качестве входной переменной не выбирается для подачи на первую модель для обработки визуальных задач, а выбирается для подачи на модель для визуальной обработки, которая имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач. Как правило, чем выше точность предсказания модели, тем более сложной является структура модели и тем более высоким является количество параметров. В данном случае вычислительная стоимость является большей, и, соответственно, эффективность предсказания модели является более низкой. Как описано выше, для получения карты ответов предыдущего кадра видео с более высокой точностью выбирают визуальную модель с точностью предсказания, которая обеспечивает повышение точности карты ответов предыдущего кадра видео одновременно со снижением эффективности предсказания модели. На основе указанного выше, необходимость подачи предыдущего кадра видео в качестве входной переменной на первую модель для обработки визуальных задач для получения карты ответов предыдущего кадра видео или подачи предыдущего кадра видео в качестве входной переменной на модель с более высокой точностью предсказания, чем у первой модели для обработки визуальных задач, для получения карты ответов предыдущего кадра видео, может быть определена в соответствии с фактическими обстоятельствами.
[0056] Может быть принято, что если предыдущий кадр видео принадлежит к одному из первых N кадров видео, то предыдущий кадр видео используется в качестве входной переменной и подается на вторую модель для обработки визуальных задач для получения карты ответов предыдущего кадра видео; если предыдущий кадр видео не принадлежит к одному из первых N кадров видео, то предыдущий кадр видео используется в качестве входной переменной и подается на первую модель для обработки визуальных задач для получения карты ответов предыдущего кадра видео, при этом вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач, при этом N представляет собой положительное целое число. В некоторых вариантах осуществления указанный выше первый способ представляет собой способ, предусматривающий использование в качестве единицы видео для определения карты ответов предыдущего кадра видео.
[0057] Причина, по которой может быть выполнена указанная выше обработка, заключается в том, что: поскольку два смежных кадра видео в рамках видео обычно связаны друг с другом, то карту ответов первых N кадров видео получают путем подачи первых N кадров видео в качестве входных переменных на вторую модель для обработки визуальных задач, при этом затем это может обеспечивать точность карты ответов кадра видео в качестве предварительных данных, то есть обеспечивается точность предсказания модели. Кроме того, вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач, и, таким образом, вторая модель для обработки визуальных задач имеет более сложную структуру, чем первая модель для обработки визуальных задач. В некоторых вариантах осуществления вторая модель для обработки визуальных задач имеет большее количество параметров, чем первая модель для обработки визуальных задач. Вычислительная стоимость будет повышаться при повышении сложности структуры модели и увеличении количества параметров. Повышение вычислительной стоимости означает снижение эффективности предсказания модели. На основе указанного выше, описанный выше способ обеспечивает поддержание относительно высокого уровня вычислительной эффективности модели одновременно с обеспечением точности карты ответов предыдущего кадра видео в качестве предварительных данных, то есть в рамках описанного выше способа учитывается как точность предсказания модели, так и эффективность предсказания модели.
[0058] В некоторых вариантах осуществления, если объект визуальной задачи представляет собой видео, то после обработки видео в соответствии с описанным выше способом описанный выше способ будет обеспечивать повышение связности между кадрами в рамках визуальных эффектов. Другими словами, после обработки видео в соответствии с описанным выше способом, поскольку точность предсказания модели повышается, то достигается некоторая степень связности между кадрами.
[0059] Необязательно, на основе указанного выше технического решения, карта ответов предыдущего кадра видео может быть получена в соответствии со следующими способами: если предыдущий кадр видео принадлежит к одному из первых T кадров видео последовательности кадров видео, соответствующей предыдущему кадру видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на вторую модель для обработки визуальных задач; а если предыдущий кадр видео не принадлежит к одному из первых T кадров видео последовательности кадров видео, соответствующей предыдущему кадру видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на первую модель для обработки визуальных задач. Последовательность кадров видео представляет собой одну из нескольких последовательностей кадров видео, полученных путем разделения нескольких кадров видео, при этом вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач, а T представляет собой положительное целое число.
[0060] В некоторых вариантах осуществления настоящего изобретения, если длительность видео превышает или равна пороговому значению длительности, то способ использования видео в качестве единицы для определения способа получения карты ответов предыдущего кадра видео может не удовлетворять фактическим требованиям. На основе указанного выше несколько кадров видео в рамках видео могут быть разделены на две или более последовательности кадров видео в соответствии с порядком по времени, при этом данные несколько последовательностей кадров видео не накладываются друг на друга, а количество кадров видео, включенных в последовательности кадров видео, может являться одинаковым или различаться, при этом оно может быть определено в соответствии с фактическими требованиями. В некоторых вариантах осуществления каждая последовательность кадров видео может быть разделена на первый кадр видео, второй кадр видео, … и P-й кадр видео в соответствии с порядком по времени. В некоторых вариантах осуществления предыдущий кадр видео будет принадлежать к одной последовательности кадров видео в рамках нескольких последовательностей кадров видео. После указанной выше обработки видео способ получения карты ответов предыдущего кадра видео будет изменен с использования в качестве единицы видео на использование в качестве единицы последовательности кадров видео. В некоторых вариантах осуществления, если предыдущий кадр видео принадлежит к одному из первых T кадров видео последовательности кадров видео, соответствующей предыдущему кадру видео, то карту ответов предыдущего кадра видео получают путем подачи предыдущего кадра видео в качестве входной переменной на вторую модель для обработки визуальных задач; если предыдущий кадр видео не принадлежит к одному из первых T кадров видео последовательности кадров видео, соответствующей предыдущему кадру видео, то карту ответов предыдущего кадра видео получают путем подачи предыдущего кадра видео в качестве входной переменной на первую модель для обработки визуальных задач. Вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем точность первой модели для обработки визуальных задач, при этом T представляет собой положительное целое число.
[0061] Причина, по которой может быть выполнена указанная выше обработка, заключается в том, что: несколько кадров видео в рамках последовательности видео обычно имеют связь друг с другом, и, таким образом, карты ответов первых T кадров видео в каждой последовательности видео получают путем подачи нескольких кадров видео в качестве входных переменных на вторую модель для обработки визуальных задач и затем это может обеспечивать точность карты ответов предыдущего кадра видео в рамках вспомогательной информации исходного изображения в качестве предварительных данных. В некоторых вариантах осуществления способ получения карты ответов предыдущего кадра видео определяют путем использования в качестве единицы последовательности кадров видео, а не видео, тем самым повышая точность карты ответов предыдущего кадра видео в рамках вспомогательной информации исходного изображения. Кроме того, поскольку вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач, то вторая модель для обработки визуальных задач имеет более сложную структуру, чем первая модель для обработки визуальных задач, при этом вторая модель для обработки визуальных задач имеет большее количество параметров, чем первая модель для обработки визуальных задач. Вычислительная стоимость будет повышаться при повышении сложности структуры модели и увеличении количества параметров. Повышение вычислительной стоимости означает снижение эффективности предсказания модели. На основе указанного выше, описанный выше способ обеспечивает поддержание относительно высокого уровня вычислительной эффективности модели одновременно с обеспечением точности карты ответов предыдущего кадра видео в качестве предварительных данных, то есть в рамках описанного выше способа учитывается как точность предсказания модели, так и эффективность предсказания модели.
[0062] Необязательно, на основе указанного выше технического решения для обучения первой модели для обработки визуальных задач может быть принят следующий способ: получают исходное изображение для обучения, сопроводительную информацию исходного изображения для обучения и вспомогательную информацию для обучения исходного изображения для обучения. Карту признаков объекта для обучения получают путем подачи исходного изображения для обучения на основной путь сверточной нейронной сети, при этом вспомогательную карту признаков для обучения получают путем подачи вспомогательной информации для обучения на ответвленный путь сверточной нейронной сети. Карту ответов исходного изображения для обучения получают путем объединения карты признаков объекта для обучения и вспомогательной карты признаков для обучения и подачи объединенной карты признаков объекта для обучения и вспомогательной карты признаков для обучения на основной путь сверточной нейронной сети. Функцию потерь сверточной нейронной сети получают в соответствии с сопроводительной информацией исходного изображения для обучения и картой ответов исходного изображения для обучения. Параметр сети сверточной нейронной сети корректируют в соответствии с функцией потерь до тех пор, пока выходное значение функции потерь не будет меньше или равно предварительно установленному пороговому значению, при этом сверточная нейронная сети используется в качестве первой модели для обработки визуальных задач.
[0063] В некоторых вариантах осуществления настоящего изобретения для повышения точности предсказания первой модели для обработки визуальных задач в качестве входной переменной первой модели для обработки визуальных задач рассматривается вспомогательная информация для обучения, которая может служить в качестве предварительных данных и одновременно участвует в процессе обучения первой модели для обработки визуальных задач, а также рассматривается в качестве входной переменной ответвленного пути первой модели для обработки визуальных задач. В некоторых вариантах осуществления ответвленный путь, на который поступает исходное изображение для обучения в качестве входной переменной, обозначается как основной путь первой модели для обработки визуальных задач, при этом ответвленный путь, на который поступает вспомогательная информация для обучения в качестве входной переменной, обозначается как ответвленный путь первой модели для обработки визуальных задач. В некоторых вариантах осуществления, поскольку первая модель для обработки визуальных задач генерируется на основе обучения сверточной нейронной сети то, таким образом, ответвленный путь, на которой подается исходное изображение для обучения в качестве входной переменной в рамках процесса обучения, представляет собой основной путь сверточной нейронной сети, а ответвленный путь, на которую подается вспомогательная информация для обучения в качестве входной переменной, представляет собой ответвленный путь сверточной нейронной сети.
[0064] Сопроводительная информация исходного изображения будет отличаться в соответствии с различными типами визуальных задач. Например, если визуальная задача представляет собой сегментирование изображений, то сопроводительная информация исходного изображения представляет собой фактическую метку каждого пиксела исходного изображения, при этом фактическая метка обозначает категорию пиксела; если визуальная задача представляет собой распознавание объектов, то сопроводительная информация исходного изображения представляет собой рамку выделения, при этом рамка выделения включает целевой объект; а если визуальная задача представляет собой определение координат ключевых точек, то сопроводительная информация исходного изображения представляет собой информацию о координатах ключевой точки.
[0065] Карту признаков объекта для обучения получают путем подачи исходного изображения для обучения на основной путь сверточной нейронной сети, при этом вспомогательную карту признаков для обучения получают путем подачи вспомогательной информации для обучения на ответвленный путь сверточной нейронной сети. В некоторых вариантах осуществления, если исходное изображение для обучения представляет собой кадр видео для обучения, то вспомогательная информация для обучения исходного изображения для обучения может включать предыдущий кадр видео для обучения и карту ответов предыдущего кадра видео для обучения; если исходное изображение для обучения представляет собой одиночное изображение, то вспомогательная информация для обучения исходного изображения для обучения может включать фоновое изображение для обучения. Когда исходное изображение для обучения представляет собой кадр видео для обучения и вспомогательная информация для обучения исходного изображения для обучения включает предыдущий кадр видео для обучения и карта ответов предыдущего кадра видео для обучения, то вспомогательная карта признаков для обучения может быть получена путем подачи карты ответов предыдущего кадра видео для обучения в качестве входной переменной на вторую модель для обработки визуальных задач.
[0066] Карту ответов исходного изображения для обучения получают путем объединения карты признаков объекта для обучения и вспомогательной карты признаков для обучения и подачи карты признаков объекта для обучения и вспомогательной карты признаков для обучения на основной путь сверточной нейронной сети. Функцию потерь сверточной нейронной сети получают (например, получают с помощью вычислений) в соответствии с сопроводительной информацией исходного изображения для обучения и картой ответов исходного изображения для обучения, при этом функция потерь может представлять собой функцию перекрестных энтропийных потерь, функцию потерь 0-1, функцию квадратичных потерь, функцию абсолютных потерь, логарифмическую функцию потерь и им подобную, что может быть определено в соответствии с фактическими условиями.
[0067] Процесс обучения сверточной нейронной сети заключается в вычислении функции потерь сверточной нейронной сети с помощью прямого распространения и вычисления частного производного функции потерь с учетом параметра сети и использования обратного градиентного распространения для корректировки параметров сверточной нейронной сети, пока выходное значение функции потерь сверточной нейронной сети не будет меньшим или равным предварительно определенному пороговому значению. Когда выходное значение функции потерь модели на основе сверточной нейронной сети является меньшим или равным предварительно определенному пороговому значению, это указывает на то, что обучение сверточной нейронной сети завершено, при этом также определен параметр сверточной нейронной сети. На основе указанного выше, сверточная нейронная сеть, чье обучение было окончено, может использоваться в качестве первой модели для обработки визуальных задач.
[0068] В некоторых вариантах осуществления сверточная нейронная сеть, описанная в рамках вариантов осуществления настоящего изобретения, может представлять собой полностью сверточную нейронную сеть, то есть полностью сверточную нейронную сеть, как описано выше, при этом форма структуры полностью сверточной нейронной сети может быть образована в соответствии с фактическими условиями.
[0069] В некоторых вариантах осуществления в зависимости от различных форм исходного изображения для обучения, содержание вспомогательной информации для обучения исходного изображения для обучения также будет различаться, при этом на основе этого первая модель для обработки визуальных задач, полученная путем обучения в соответствии с описанным выше способом, также будет отличаться, при этом упомянутое здесь различие может быть связано с различающимися параметрами сети первой модели для обработки визуальных задач.
[0070] В некоторых вариантах осуществления, поскольку вспомогательная информация для обучения исходного изображения для обучения также участвует в процессе обучения модели и вспомогательная информация для обучения исходного изображения для обучения в качестве исходных данных играет роль в плане получения более высокой точности предсказания первой модели для обработки визуальных задач, полученной путем обучения в рамках процесса обучения, то первая модель для обработки визуальных задач, которая генерируется при участии вспомогательной информации для обучения исходного изображения для обучения, имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач, сгенерированная лишь при участии исходного изображения для обучения без участия вспомогательной информации для обучения исходного изображения для обучения.
[0071] Кроме того, вторая модель для обработки визуальных задач, как описано в некоторых вариантах осуществления настоящего изобретения, представляет собой модель, обучение которой было завершено, при этом вторая модель для обработки визуальных задач может быть выполнена с возможностью генерировать карту ответов предыдущего кадра видео для обучения и карты ответов предыдущего кадра видео.
[0072] Необязательно, на основе указанного выше технического решения вспомогательная информация для обучения представляет собой вспомогательную информацию для обучения, полученную с помощью обработки приращения данных.
[0073] В некоторых вариантах осуществления настоящего изобретения модель для обработки визуальных задач генерируют на основе обучения сверточной нейронной сети. Одним из главных преимуществ сверточной нейронной сети является способность вбирать и преобразовывать их в непрерывное обучение и обновление параметров для получения модели, имеющей хорошую эффективность в плане предсказания и хорошую способность в плане обобщения. Для получения модели с хорошей эффективностью в плане предсказания и хорошей способностью в плане обобщения сверточная нейронная сеть имеет требования как в плане количества, так и качества образцов для обучения, другими словами, как количество, так и качество образов для обучения имеет важное влияние на эффективность в плане предсказания и способность в плане обобщения модели. На основе указанного выше, может быть проведена обработка образца для обучения путем использования способа пририщения для повышения количества образцов для обучения и повышения качества образцов для обучения, для повышения эффективности в плане предсказания и улучшения способности в плане обобщения модели.
[0074] В одном варианте осуществления настоящего изобретения, поскольку вспомогательная информация для обучения используется в качестве предварительных данных для повышения эффективности модели в плане предсказания, указанные здесь образцы для обучения относятся к вспомогательной информации для обучения. То есть вариант осуществления настоящего изобретения предусматривает использование способа приращения для обработки вспомогательной информации для обучения, другими словами, вспомогательная информация для обучения представляет собой вспомогательную информацию для обучения, полученную после обработки приращения данных.
[0075] То, что используется способ приращения данных для обработки вспомогательной информации для обучения и, таким образом, может быть повышено качество вспомогательной информации для обучения, может быть понято следующим образом: в рамках практических вариантов использования, поскольку камера в большинстве случаев не является зафиксированной и исходные изображения для обучения и фоновые изображения для обучения в рамках вспомогательной информации для обучения получают по отдельности, но не одновременно, то, таким образом, угол съемки, яркость, искажение, цветность и им подобные параметры исходного изображения для обучения и фонового изображения для обучения в рамках вспомогательной информации для обучения могут не являться одинаковыми, при этом степень их различий может быть различной при различных ситуациях. Для учета данных различий и их максимального сглаживания в реальных ситуациях вышеуказанные различия указываются на фоновом изображении в рамках вспомогательной информации для обучения. Способ приращения данных представляет собой способ, в рамках которого может быть реализовано указание указанных выше различий. То есть фоновое изображение для обучения в рамках вспомогательной информации для обучения, подвергнутое обработке приращения данных, может отражать различия относительно исходного изображения для обучения в плане угла съемки, яркости, искажения, и цветности при различных ситуациях, так что степень различий между ними является минимально возможной в рамках фактических условий. Кроме того, если исходное изображение для обучения представляет собой текущий кадр видео для обучения и вспомогательная информация для обучения исходного изображения для обучения включает предыдущий кадр видео для обучения и карту ответов предыдущего кадра видео для обучения, то обработка приращения данных также выполняется в отношении карты ответов предыдущего кадра видео для обучения, так что карта ответов предыдущего кадра видео для обучения остается соответствующей предыдущему кадру видео для обучения.
[0076] На основе указанного выше, модель для обработки визуальных задач, полученная путем обучения и использования исходного изображение для обучения и вспомогательной информации для обучения, подвергнутых обработке приращения данных, в качестве входных переменных, имеет лучшую эффективность в плане предсказания и лучшую способность в плане обобщения, чем модель для обработки визуальных задач, полученная путем обучения и использования исходного изображения для обучения и вспомогательной информации для обучения, не подвергнутых обработке приращения данных, в качестве входных переменных. Таким образом, когда они используются для дальнейшей обработки визуальной задачи, то исходное изображение и вспомогательная информация исходного изображения могут иметь небольшое ограничение, при этом данное небольшое ограничение может указывать на то, что не является обязательным сохранять согласованность между ними двумя в плане яркости, искажения, цветности и так далее. В то же время, даже если они не имеют согласованности в плане указанных выше аспектов, то все равно может быть получен результат предсказания с относительно высокой точностью.
[0077] Необязательно, на основе указанного выше технического решения обработка приращения данных включает, по меньшей мере, одно из следующих преобразований: перенос, вращение, обрезание, нежесткое преобразование, шумовое преобразование и преобразование цвета.
[0078] В некоторых вариантах осуществления настоящего изобретения жесткое преобразование может указывать на преобразование, при котором изображение меняется лишь в плане координат и ориентации без изменения формы. Нежесткое преобразование представляет собой намного более сложное преобразование, чем жесткое преобразование, при этом нежесткое преобразование может включать сжимание, скручивание, перспективу и так далее. Шумовое преобразование может включать гауссов шум. Преобразование цвета может включать повышение насыщенности, повышение яркости, повышение контраста и им подобные. В некоторых вариантах осуществления способ приращения данных может быть выбран на основе фактических условий.
[0079] Фиг. 2 представляет собой блок-схему другого способа обработки изображений в соответствии с одним вариантом осуществления настоящего изобретения. Настоящее изобретения может являться подходящим для ситуации, при которой требуется обработка визуальной задачи. Способ может быть реализован с помощью аппарата для обработки изображений. Аппарат может быть реализован в виде программного обеспечения и/или аппаратного обеспечения. Аппарат может быть выполнен в виде устройства, такого как компьютер или мобильный терминал. Как показано на Фиг. 2, способ включает этапы с 210 по 230.
[0080] На этапе 210 осуществляется получение исходного изображения и фонового изображения исходного изображения.
[0081] На этапе 220 осуществляется получение карты признаков объекта путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач и осуществляется получение вспомогательной карты признаков путем подачи фонового изображения на ответвленный путь первой модели для обработки визуальных задач.
[0082] На этапе 230 осуществляется получение карты ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач.
[0083] В некоторых вариантах осуществления настоящего изобретения для понимания технического решения, предусмотренного в рамках варианта осуществления настоящего изобретения, будет приведено описание на основе примера, в рамках которого визуальная задача представляет собой сегментирование изображений.
[0084] На Фиг. 3 показана схематическая диаграмма варианта применения другого способа обработки изображений. В рамках Фиг. 3 осуществляется получение карты признаков объекта путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач и осуществляется получение вспомогательной карты признаков путем подачи фонового изображения на ответвленный путь первой модели для обработки визуальных задач. Осуществляется получение карты ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач, то есть получают изображение для семантического сегментирования изображения.
[0085] В рамках технического решения настоящего варианта осуществления осуществляется получение карты признаков объекта путем получения исходного изображения и фонового изображения и подачи исходного изображения на основной путь первой модели для обработки визуальных задач, и осуществляется получение вспомогательной карты признаков путем подачи фонового изображения на ответвленный путь первой модели для обработки визуальных задач. Осуществляется получение карты ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач. В рамках описанного выше процесса генерирования карты ответов исходного изображения с участием фонового изображения фоновое изображение может обеспечивать относительно сильные предварительные данные, которые помогают решать проблемы, затрагивающие точность предсказания модели для обработки визуальных задач, такие как сложные и изменчивые сцены и/или трудности при идентификации объектов, и, таким образом, точность предсказания модели для обработки визуальных задач повышается.
[0086] Фиг. 4 представляет собой блок-схему еще одного способа обработки изображений в соответствии с одним вариантом осуществления настоящего изобретения. Настоящий вариант осуществления может применяться в ситуации, при которой требуется обработка визуальной задачи. Способ может быть реализован с помощью аппарата для обработки изображений. Аппарат может быть реализован в виде программного обеспечения и/или аппаратного обеспечения. Аппарат может быть выполнен в виде устройства, такого как компьютер или мобильный терминал. Как показано на Фиг. 4, способ включает этапы с 310 по 330.
[0087] На этапе 310 получают текущий кадр видео, предыдущий кадр видео и карту ответов предыдущего кадра видео.
[0088] На этапе 320 осуществляется получение карты признаков объекта путем подачи текущего кадра видео на основной путь первой модели для обработки визуальных задач и осуществляется получение вспомогательной карты признаков путем подачи предыдущего кадра видео и карты ответов предыдущего кадра видео на ответвленный путь первой модели для обработки визуальных задач.
[0089] На этапе 330 осуществляется получение карты ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач.
[0090] В некоторых вариантах осуществления настоящего изобретения карта ответов предыдущего кадра видео может быть получена с помощью следующих двух способов.
[0091] Первый способ. Если предыдущий кадр видео принадлежит к одному из первых N кадров видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на вторую модель для обработки визуальных задач. Если предыдущий кадр видео не принадлежит к одному из первых N кадров видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на первую модель для обработки визуальных задач. Вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач, при этом N представляет собой положительное целое число.
[0092] Второй способ. Если предыдущий кадр видео принадлежит к одному из первых T кадров видео последовательности кадров видео, соответствующей предыдущему кадру видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на вторую модель для обработки визуальных задач. Если предыдущий кадр видео не принадлежит к одному из первых T кадров видео последовательности кадров видео, соответствующей предыдущему кадру видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на первую модель для обработки визуальных задач. Последовательность кадров видео представляет собой одну из нескольких последовательностей кадров видео, полученных путем разделения нескольких кадров видео, при этом вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач, а T представляет собой положительное целое число.
[0093] В некоторых вариантах осуществления способ получения карты ответов предыдущего кадра видео может быть выбран в соответствии с фактическими условиями.
[0094] Далее будет приведено описание на основе примера, в рамках которого визуальная задача представляет собой сегментирование изображений.
[0095] На Фиг. 5 показана схематическая диаграмма варианта применения другого способа обработки изображений. В рамках Фиг. 5 осуществляется получение карты признаков объекта путем подачи текущего кадра видео на основной путь первой модели для обработки визуальных задач и осуществляется получение вспомогательной карты признаков путем подачи предыдущего кадра видео и карты ответов предыдущего кадра видео на ответвленный путь первой модели для обработки визуальных задач. Карту ответов предыдущего кадра видео получают путем подачи предыдущего кадра видео на вторую модель для обработки визуальных задач. Осуществляется получение объединенной карты признаков путем объединения карты признаков объекта и вспомогательной карты признаков; при этом карту ответов исходного изображения получают путем подачи объединенной карты признаков на основной путь первой модели для обработки визуальных задач, то есть получают изображение для семантического сегментирования изображения.
[0096] В соответствии с техническим решением в рамках настоящего варианта осуществления, карту признаков объекта получают путем получения текущего кадра видео, предыдущего кадра видео и карты ответов предыдущего кадра видео и подачи текущего кадра видео на основной путь первой модели для обработки визуальных задач, при этом вспомогательную карту признаков получают путем подачи предыдущего кадра видео и карты ответов предыдущего кадра видео на ответвленный путь первой модели для обработки визуальных задач, при этом карту ответов исходного изображения получают путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач. В рамках описанного выше процесса генерирования карты ответов текущего кадра видео с участием предыдущего кадра видео и карты ответов предыдущего кадра видео, предыдущий кадр видео и карта ответов предыдущего кадра видео могут обеспечивать относительно сильные предварительные данные, которые помогают решать проблемы, затрагивающие точность предсказания модели для обработки визуальных задач, такие как сложные изменчивые сцены и/или трудности при идентификации объектов, и, таким образом, точность предсказания модели для обработки визуальных задач повышается.
[0097] Фиг. 6 представляет собой схематическую структурную диаграмму аппарата для обработки изображений в соответствии с одним вариантом осуществления настоящего изобретения. Настоящий вариант осуществления может применяться в ситуации, при которой требуется обработка визуальной задачи. Аппарат может быть реализован в виде программного обеспечения и/или аппаратного обеспечения. Аппарат может быть выполнен в виде устройства, обычно компьютера или мобильного терминала и так далее. Как показано на Фиг. 6, аппарат включает: модуль для получения исходного изображения и вспомогательной информации 410, модуль для получения карты признаков 420, и модуль для получения карты ответов исходного изображения 430.
[0098] Модуль для получения исходного изображения и вспомогательной информации 410 выполнен с возможностью получать исходное изображение и вспомогательную информацию исходного изображения.
[0099] Модуль для получения карты признаков 420 выполнен с возможностью подавать исходное изображение на основной путь первой модели для обработки визуальных задач для получения карты признаков объекта и подавать вспомогательную информацию на ответвленный путь первой модели для обработки визуальных задач для получения вспомогательной карты признаков.
[00100] Модуль для получения карты ответов исходного изображения 430 выполнен с возможностью объединять карту признаков объекта и вспомогательную карту признаков и подавать объединенную карту признаков объекта и вспомогательную карту признаков на основной путь первой модели для обработки визуальных задач для получения карты ответов исходного изображения.
[00101] В соответствии с техническим решением в рамках настоящего варианта осуществления, карту признаков объекта получают путем получения исходного изображения и вспомогательной информации исходного изображения и подачи исходного изображения на основной путь первой модели для обработки визуальных задач, при этом вспомогательную карту признаков получают путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач; при этом карту ответов исходного изображения получают путем объединения карты признаков объекта и вспомогательной карты признаков и подачи исходного изображения и вспомогательной информации исходного изображения на основной путь первой модели для обработки визуальных задач. В рамках описанного выше процесса генерирования карты ответов исходного изображения с участием вспомогательной информации исходного изображения вспомогательная информация исходного изображения может обеспечивать относительно сильные предварительные данные, которые помогают решать проблемы, затрагивающие точность предсказания модели для обработки визуальных задач, такие как сложные и изменчивые сцены и/или трудности при идентификации объектов, и, таким образом, точность предсказания модели для обработки визуальных задач повышается.
[00102] В некоторых вариантах осуществления настоящего изобретения аппарат для обработки изображений выполнен в виде устройства, которое может выполнять способ, описанный в рамках любого варианта осуществления настоящего изобретения, и имеет соответствующие функциональные модули и функции для выполнения способа.
[00103] Фиг. 7 представляет собой схематическую структурную диаграмму устройства в соответствии с одним вариантом осуществления настоящего изобретения. На Фиг. 7 показана блочная диаграмма примера устройства 512, подходящего для реализации вариантов осуществления настоящего изобретения. Устройство 512, показанное на Фиг. 7, является всего лишь примером.
[00104] Как показано на Фиг. 7, устройство 512 реализовано в виде вычислительного устройства общего назначения. Устройство 512 может включать следующие узлы: один или несколько процессоров 516, системную память 528 и шину 518, соединенные с различными системными узлами (включая системную память 528 и процессор 516).
[00105] Системная память 528 может включать машиночитаемый носитель данных в форме энергозависимой памяти, например памяти произвольного доступа (RAM) 530 и/или кэш-памяти 532. Система хранения данных 534 может быть выполнена с возможность чтения и записи на несъемный и энергонезависимый магнитный носитель данных. Системная память 528 может включать, по меньшей мере, один программный продукт, имеющий программных модулей группу (например, по меньшей мере, один), выполненных с возможностью выполнять функции в рамках различных вариантов осуществления настоящего изобретения.
[00106] Программа/утилита 540, имеющая группу программных модулей 542 (по меньшей мере, один), может храниться, например в памяти 528, при этом программные модули 542 в целом выполняют функции и/или способа в рамках вариантов осуществления, описанных в настоящем описании.
[00107] Устройство 512 также может связывать с одним или несколькими внешними устройствами 514 (например клавиатурой, указательным устройством, дисплеем 524 и им подобными). Такая связь может осуществляться через интерфейс ввода/вывода (I/O) 522. Более того, устройство 512 также может связываться с одной или несколькими сетями через сетевой адаптер 520.
[00108] Процессор 516 выполняет различные функции и обработку данных путем выполнения программ, хранящихся в системной памяти 528, например для реализации способа, предусмотренного в рамках варианта осуществления настоящего изобретения, при этом способ включает:
[00109] получение исходного изображения и вспомогательной информации исходного изображения;
[00110] получение карты признаков объекта путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач и получение вспомогательной карты признаков путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач; и
[00111] получение карты ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач.
[00112] Процессор может также реализовывать решение согласно способу обработки изображений в рамках устройства, предусмотренного любым вариантом осуществления настоящего изобретения. Аппаратная структура и функции устройства описаны в рамках соответствующего варианта осуществления.
[00113] В некоторых вариантах осуществления настоящего изобретения предусмотрен машиночитаемый носитель данных, на котором хранится компьютерная программа, при этом при выполнении компьютерной программы процессором программа реализует способ в соответствии с вариантом осуществления настоящего изобретения, при этом способ включает:
[00114] получение исходного изображения и вспомогательной информации исходного изображения;
[00115] получение карты признаков объекта путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач и получение вспомогательной карты признаков путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач; и
[00116] получение карты ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач.
[00117] В некоторых вариантах осуществления настоящего изобретения предусмотрен машиночитаемый носитель данных, при этом его машиночитаемые инструкции включают способ обработки, как описано выше, при этом они могут также обеспечивать выполнение соответствующих операций в соответствии со способом, предусмотренным в рамках любого из вариантов осуществления настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ ПОЗЫ ЧЕЛОВЕКА, УСТРОЙСТВО И НОСИТЕЛЬ ДАННЫХ | 2019 |
|
RU2773232C1 |
| СПОСОБ ИНТЕРАКТИВНОЙ СЕГМЕНТАЦИИ ОБЪЕКТА НА ИЗОБРАЖЕНИИ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2742701C1 |
| СПОСОБ ОЦЕНКИ КАЧЕСТВА ВИДЕО И АППАРАТ, УСТРОЙСТВО И НОСИТЕЛЬ ДАННЫХ | 2019 |
|
RU2764125C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ, УСТРОЙСТВО ОБРАБОТКИ ИЗОБРАЖЕНИЙ И НОСИТЕЛЬ ДАННЫХ | 2018 |
|
RU2709437C1 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| СПОСОБ, СИСТЕМА И МАШИНОЧИТАЕМЫЕ ЗАПОМИНАЮЩИЕ НОСИТЕЛИ ДЛЯ ВЫЯВЛЕНИЯ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ РЕКУРРЕНТНОЙ НЕЙРОННОЙ СЕТИ И СЦЕПЛЕННОЙ КАРТЫ ПРИЗНАКОВ | 2018 |
|
RU2701051C2 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОЙ ДИАГНОСТИКИ СОСУДИСТЫХ ПАТОЛОГИЙ НА ОСНОВАНИИ ИЗОБРАЖЕНИЯ | 2020 |
|
RU2741260C1 |
| ОБРАБОТКА ОККЛЮЗИЙ ДЛЯ FRC C ПОМОЩЬЮ ГЛУБОКОГО ОБУЧЕНИЯ | 2020 |
|
RU2747965C1 |
| СИСТЕМА И СПОСОБ ДЛЯ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ, ИНВАРИАНТНОЙ К СДВИГУ | 2017 |
|
RU2656990C1 |
| СПОСОБ АУДИОВИЗУАЛЬНОГО РАСПОЗНАВАНИЯ СРЕДСТВ ИНДИВИДУАЛЬНОЙ ЗАЩИТЫ НА ЛИЦЕ ЧЕЛОВЕКА | 2022 |
|
RU2791415C1 |

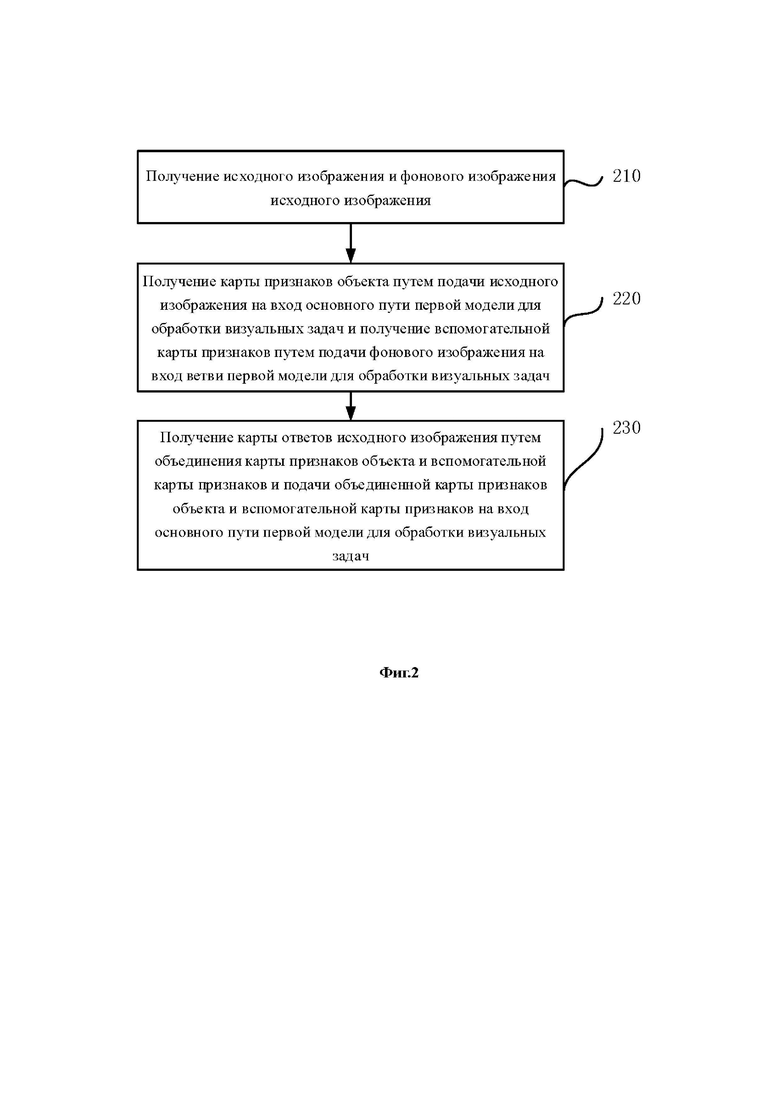


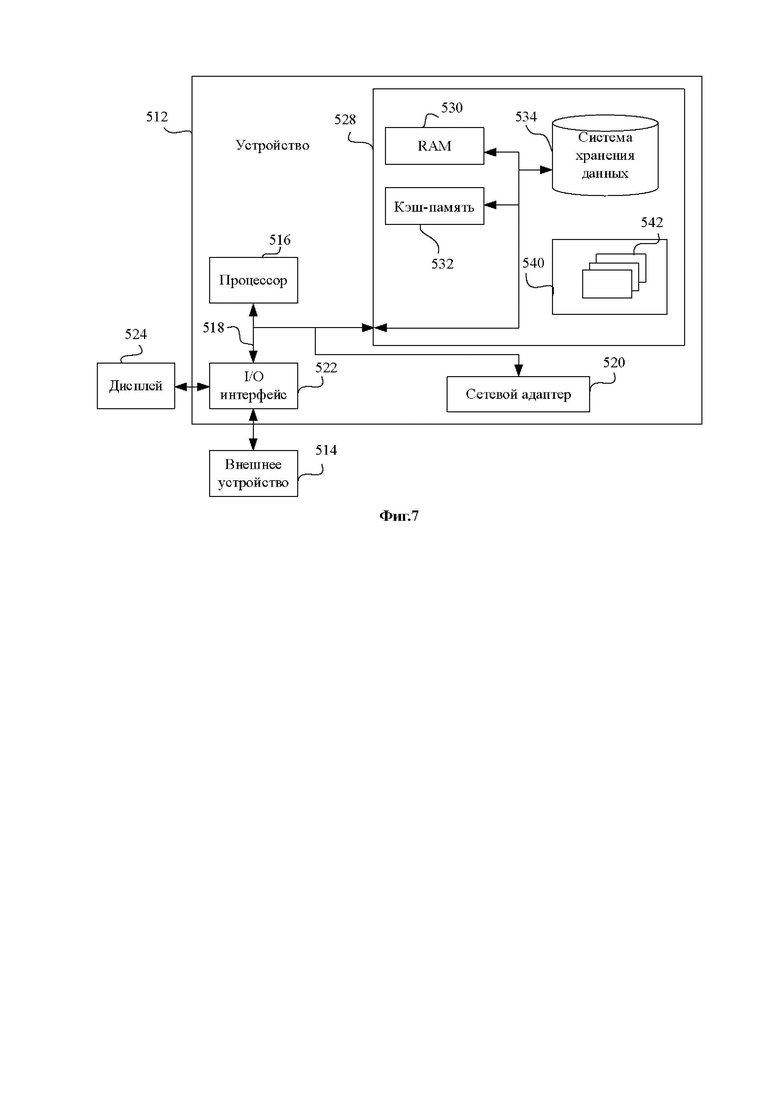
Изобретение относится к области вычислительной техники для обработки изображений. Технический результат заключается в повышении точности предсказания модели для обработки визуальных задач. Технический результат достигается за счет способа обработки изображений, включающего: получение исходного изображения и вспомогательной информации исходного изображения; получение карты признаков объекта путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач и получение вспомогательной карты признаков путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач; и получение карты ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач. 4 н. и 4 з.п. ф-лы, 7 ил.
1. Способ обработки изображений, включающий:
получение исходного изображения и вспомогательной информации исходного изображения, причем исходное изображение представляет собой одиночное изображение или кадр видео, и когда исходное изображение представляет собой одиночное изображение, вспомогательная информация исходного изображения включает фоновое изображение, соответствующее исходному изображению, а когда исходное изображение представляет собой текущий кадр видео, то вспомогательная информация исходного изображения является предыдущим кадром видео и вспомогательной информацией карты ответов предыдущего кадра видео;
получение карты признаков объекта путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач и получение вспомогательной карты признаков путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач; и
получение карты ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели обработки визуальных задач; и
в котором, когда исходное изображение представляет собой текущий кадр видео, карту ответов предыдущего кадра видео получают следующим образом:
если предыдущий кадр видео принадлежит к одному из первых N кадров видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на вторую модель для обработки визуальных задач; и
если предыдущий кадр видео не принадлежит к одному из первых N кадров видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на первую модель для обработки визуальных задач,
при этом вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач, а N представляет собой положительное целое число.
2. Способ по п.1, отличающийся тем, что карту ответов предыдущего кадра видео получают следующим образом:
если предыдущий кадр видео принадлежит к одному из первых T кадров видео последовательности кадров видео, соответствующей предыдущему кадру видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на вторую модель для обработки визуальных задач; и
если предыдущий кадр видео не принадлежит к одному из первых T кадров видео последовательности кадров видео, соответствующей предыдущему кадру видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на первую модель для обработки визуальных задач,
при этом последовательность кадров видео представляет собой одну из нескольких последовательностей кадров видео, полученных путем разделения нескольких кадров видео, при этом вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач, а T представляет собой положительное целое число.
3. Способ по п.1, отличающийся тем, что первую модель для обработки визуальных задач обучают путем:
получения исходного изображения для обучения, сопроводительной информации исходного изображения для обучения и вспомогательной информации для обучения исходного изображения для обучения;
получения карты признаков объекта для обучения путем подачи исходного изображения для обучения на основной путь сверточной нейронной сети и получения вспомогательной карты признаков для обучения путем подачи вспомогательной информации для обучения на ответвленный путь сверточной нейронной сети;
получения карты ответов исходного изображения для обучения путем объединения карты признаков объекта для обучения и вспомогательной карты признаков для обучения и подачи объединенной карты признаков объекта для обучения и вспомогательной карты признаков для обучения на основной путь сверточной нейронной сети;
получения функции потерь сверточной нейронной сети в соответствии с сопроводительной информацией исходного изображения для обучения и картой ответов исходного изображения для обучения; и
корректировки параметра сети сверточной нейронной сети в соответствии с функцией потерь до тех пор, пока выходное значение функции потерь не будет меньше или равно предварительно установленному пороговому значению, при этом сверточная нейронная сеть используется в качестве первой модели для обработки визуальных задач.
4. Способ по п.3, отличающийся тем, что вспомогательная информация для обучения представляет собой вспомогательную информацию для обучения, полученную после обработки приращения данных.
5. Способ по п.4, отличающийся тем, что обработка приращения данных включает по меньшей мере одно из следующих преобразований: перенос, вращение, обрезание, нежесткое преобразование, шумовое преобразование и преобразование цвета.
6. Аппарат для обработки изображений, включающий:
модуль для получения исходного изображения и вспомогательной информации, выполненный с возможностью получать исходное изображение и вспомогательную информацию исходного изображения, причем исходное изображение представляет собой одиночное изображение или кадр видео, и когда исходное изображение представляет собой одиночное изображение, вспомогательная информация исходного изображения включает фоновое изображение, соответствующее исходному изображению, а когда исходное изображение представляет собой текущий кадр видео, то вспомогательная информация исходного изображения является предыдущим кадром видео и вспомогательной информацией карты ответов предыдущего кадра видео;
модуль для получения карты признаков, выполненный с возможностью получать карту признаков объекта путем подачи исходного изображения на основной путь первой модели для обработки визуальных задач и получать вспомогательную карту признаков путем подачи вспомогательной информации на ответвленный путь первой модели для обработки визуальных задач; и
модуль для получения карты ответов исходного изображения, выполненный с возможностью получать карту ответов исходного изображения путем объединения карты признаков объекта и вспомогательной карты признаков и подачи объединенной карты признаков объекта и вспомогательной карты признаков на основной путь первой модели для обработки визуальных задач; и
в котором, когда исходное изображение представляет собой текущий кадр видео, карту ответов предыдущего кадра видео получают следующим образом:
если предыдущий кадр видео принадлежит к одному из первых N кадров видео, то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на вторую модель для обработки визуальных задач; и
если предыдущий кадр видео не принадлежит к одному из первых N кадров видео,
то карта ответов предыдущего кадра видео представляет собой карту ответов, полученную путем подачи предыдущего кадра видео на первую модель для обработки визуальных задач,
при этом вторая модель для обработки визуальных задач имеет более высокую точность предсказания, чем первая модель для обработки визуальных задач, а N представляет собой положительное целое число.
7. Устройство для обработки изображений, включающее:
один или несколько процессоров и
память, выполненную с возможностью хранить одну или несколько программ,
при этом одна или несколько программ выполняются одним или несколькими процессорами для побуждения одного или нескольких процессоров выполнять способ по любому из пп.1-5.
8. Машиночитаемый носитель данных, на котором хранится компьютерная программа, при этом при выполнении компьютерной программы процессором реализуется способ по любому из пп.1-5.
| CN 108154518 A, 12.06.2018 | |||
| CN 108492319 A, 04.09.2018 | |||
| CN 108961220 A, 07.12.2018 | |||
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| УСТРОЙСТВО ОБРАБОТКИ ИЗОБРАЖЕНИЙ, СПОСОБ ОБРАБОТКИ ИЗОЬРАЖЕНИЙ И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ИНФОРМАЦИИ | 2011 |
|
RU2549169C2 |

