Область техники, к которой относится изобретение
[0001] Настоящее изобретение относится, в общем, к областям компьютерного зрения и компьютерной графики с использованием нейронных сетей, машинного обучения для интерактивной сегментации объектов на изображениях, и в частности, к способу интерактивной сегментации объекта на изображении и электронному вычислительному устройству для реализации данного способа.
Описание известного уровня техники
[0002] Разработка надежных моделей для визуального понимания тесно связана с аннотированием данных. Например, один беспилотный автомобиль может ежедневно создавать около 1 ТБ данных. Ввиду постоянных изменений в среде новые данные должны регулярно аннотироваться.
[0003] Сегментация объектов обеспечивает детальное представление сцены и может быть полезной во многих применениях, например, редактировании фотографий, автономном вождении, робототехнике, анализе медицинских изображений и т.д. Однако в настоящее время практическое использование сегментации объектов ограничено из-за чрезвычайно высоких затрат на аннотирование. В последнее время появились большие наборы данных для сегментации [3, 12], содержащие миллионы аннотированных экземпляров объектов. Аннотирование этих наборов данных стало возможным благодаря использованию автоматизированных интерактивных методов сегментации [1, 3].
[0004] Интерактивная сегментация является предметом исследований в течение длительного времени [26, 10, 11, 13, 2, 31, 18, 22, 15]. Основным сценарием, рассматриваемым в этих работах, является кликовая сегментация (сегментация на основе пользовательских вводов), при которой пользователь делает ввод в форме позитивных и негативных кликов (пользовательских вводов, указывающих объект или фон, соответственно). Классические подходы формулируют эту задачу как задачу оптимизации [4, 10, 11, 13, 2]. Эти методы имеют много встроенной эвристики и не используют в полной мере семантические априорные распределения, тем самым требуя большого объема ввода от пользователя. С другой стороны, основанные на глубоком обучении методы [31, 18, 22] имеют тенденцию к чрезмерному использованию семантики изображений. Показывая отличные результаты на объектах, присутствующих в обучающем наборе, они, как правило, плохо работают на классах объектов, неприсутствующих в обучающем наборе. В последних работах предлагаются различные решения этих проблем [19, 18, 21]. Тем не менее, современные сети для интерактивной сегментации либо способны точно сегментировать интересующий объект после нескольких кликов, либо не дают удовлетворительного результата после любого разумного количества кликов.
[0005] Предложенная недавно [15] схема уточнения путем обратных проходов (BRS) объединяет подходы к интерактивной сегментации, основанные на оптимизации и на глубоком обучении. BRS усиливает согласованность полученной маски объекта с кликами, сделанными пользователем. Эффект BRS основан на том факте, что небольшие отклонения вводов для глубокой сети могут вызывать массовые изменения в выходе сети [29]. Поэтому BRS требует многократных проходов вперед и назад по всей модели, что существенно повышает вычислительные затраты на один клик по сравнению с другими методами и непрактично для многих пользовательских сценариев.
[0006] Целью интерактивной сегментации изображения является получение точной маски объекта при использовании минимального пользовательского ввода. Большинство методов предполагают наличие интерфейса, в котором пользователь может несколько раз производить позитивные и негативные клики (начальные значения), пока не будет получена желаемая маска объекта.
Методы на основе оптимизации
[0007] До появления глубокого обучения интерактивную сегментацию обычно формулировали как задачу оптимизации. Li et al. [17] используют алгоритм разреза графа для отделения пикселей переднего плана от заднего плана, используя расстояния от каждого пикселя до затравок переднего плана и заднего плана в цветовом пространстве. Grady et al. [10] предложили метод, основанный на случайных блужданиях, где каждый пиксель маркируется в соответствии с меткой первой затравки, которой достигает блуждание. В более поздней работе [11] вычисляются геодезические расстояния от кликнутых точек до каждого пикселя изображения и используются для минимизации энергии. В [16] сначала генерируются несколько карт сегментации для изображения. Затем применяется алгоритм оптимизации, который принуждает пиксели одного и того же сегмента иметь одинаковую метку в полученной сегментационной маске.
[0008] Методы на основе оптимизации обычно демонстрируют предсказуемое поведение и позволяют получать детальные сегментационные маски при достаточном пользовательском вводе. Поскольку не требуется никакого обучения, требуемый от пользователя объем ввода не зависит от типа интересующего объекта. Основным недостатком этого подхода является недостаточное использование семантических априорных распределений. От пользователя требуются дополнительные усилия, чтобы получить точные маски объектов для известных объектов по сравнению с недавно предложенными методами на основе обучения.
Методы на основе обучения
[0009] Первый метод интерактивной сегментации на основе глубокого обучения был предложен в [31]. Согласно этому методу рассчитываются карты расстояний из позитивных и негативных кликов, эти карты складываются вместе с входным изображением и передаются в сеть, которая предсказывает маску объекта. Этот подход был использован позже в большинстве следующих работ. Liew et al. [19] предлагают комбинировать локальные предсказания на вставках, содержащих пользовательские клики, и тем самым уточнять вывод сети. Li et al. [18] заметили, что обученные модели имеют тенденцию к чрезвычайной уверенности в своих предсказаниях. Чтобы улучшить разнообразие выводов, они генерируют несколько масок и затем выбирают одну из них. В [28] пользовательские аннотации автоматически умножаются путем определения места кликов по переднему и заднему плану.
[0010] Общей проблемой всех основанных на глубоком обучении методов интерактивной сегментации является переоценка семантики и недостаточное использование пользовательских кликов. Это объясняется тем, что во время обучения пользовательские клики находятся во взаимно-однозначном соответствии с семантикой изображения и добавляют мало информации, и поэтому их можно легко недооценить в процессе обучения.
Оптимизация для активаций
[0011] Для различных задач [27, 32, 33, 8, 9] использовались схемы оптимизации, которые обновляют отклики активации, оставляя при этом неизменными веса нейросети. Szegedy et al. [29] формулируют задачу оптимизации для генерации состязательных примеров, т.е. изображений, которые визуально неотличимы от естественных, хотя и некорректно классифицируются сетью с высокой достоверностью. Они продемонстрировали, что в глубоких сетях небольшое отклонение входного сигнала может вызывать большие изменения в активациях последних слоев. В [15] авторы применяют эту идею к задаче интерактивной сегментации. Они находят минимальные правки для входных карт расстояний, получая в результате маску объекта, которая согласуется с предоставленной пользователем аннотацией.
[0012] Задачей настоящего изобретения является устранение по меньшей мере одного из вышеуказанных недостатков и обеспечение по меньшей мере одного из преимуществ, описанных ниже.
СПИСОК ЛИТЕРАТУРЫ
[1] Eirikur Agustsson, Jasper RR Uijlings, and Vittorio Ferrari. Interactive full image segmentation by considering all regions jointly. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11622-11631, 2019.
[2] Junjie Bai and Xiaodong Wu. Error-tolerant scribbles based interactive image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 392-399, 2014.
[3] Rodrigo Benenson, Stefan Popov, and Vittorio Ferrari. Large-scale interactive object segmentation with human annotators. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11700-11709, 2019.
[4] Yuri Y Boykov and M-P Jolly. Interactive graph cuts for optimal boundary & region segmentation of objects in nd images. In Proceedings eighth IEEE international conference on computer vision. ICCV 2001, volume 1, pages 105-112. IEEE, 2001.
[5] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), pages 801-818, 2018.
[6] Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv preprint arXiv:1512.01274, 2015.
[7] Mingfei Gao, Ruichi Yu, Ang Li, Vlad I Morariu, and Larry S Davis. Dynamic zoom-in network for fast object detection in large images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6926-6935, 2018.
[8] Leon Gatys, Alexander S Ecker, and Matthias Bethge. Texture synthesis using convolutional neural networks. In Advances in neural information processing systems, pages 262-270, 2015.
[9] Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2414-2423, 2016.
[10] Leo Grady. Random walks for image segmentation. IEEE Transactions on Pattern Analysis & Machine Intelligence, (11):1768-1783, 2006.
[11] Varun Gulshan, Carsten Rother, Antonio Criminisi, Andrew Blake, and Andrew Zisserman. Geodesic star convexity for interactive image segmentation. In 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 3129-3136. IEEE, 2010.
[12] Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5356-5364, 2019.
[13] Bharath Hariharan, Pablo Arbel´aez, Lubomir Bourdev, Subhransu Maji, and Jitendra Malik. Semantic contours from inverse detectors. In 2011 International Conference on Computer Vision, pages 991-998. IEEE, 2011.
[14] Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, and Mu Li. Bag of tricks for image classification with convolutional neural networks. arXiv preprint arXiv:1812.01187, 2018.
[15] Won-Dong Jang and Chang-Su Kim. Interactive image segmentation via backpropagating refinement scheme. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5297-5306, 2019.
[16] Tae Hoon Kim, Kyoung Mu Lee, and Sang Uk Lee. Nonparametric higher-order learning for interactive segmentation. In 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 3201-3208.IEEE, 2010.
[17] Yin Li, Jian Sun, Chi-Keung Tang, and Heung-Yeung Shum. Lazy snapping. ACM Transactions on Graphics (ToG), 23(3):303-308, 2004.
[18] Zhuwen Li, Qifeng Chen, and Vladlen Koltun. Interactive image segmentation with latent diversity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 577-585, 2018.
[19] JunHao Liew, YunchaoWei, Wei Xiong, Sim-Heng Ong, and Jiashi Feng. Regional interactive image segmentation networks. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 2746-2754. IEEE, 2017.
[20] Yongxi Lu, Tara Javidi, and Svetlana Lazebnik. Adaptive object detection using adjacency and zoom prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2351-2359, 2016.
[21] Soumajit Majumder and Angela Yao. Content-aware multilevel guidance for interactive instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11602-11611, 2019.
[22] Kevis-Kokitsi Maninis, Sergi Caelles, Jordi Pont-Tuset, and Luc Van Gool. Deep extreme cut: From extreme points to object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 616-625, 2018.
[23] David Martin, Charless Fowlkes, Doron Tal, Jitendra Malik, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. Iccv Vancouver, 2001.
[24] Kevin McGuinness and Noel E O’connor. A comparative evaluation of interactive segmentation algorithms. Pattern Recognition, 43(2):434-444, 2010.
[25] Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 724-732, 2016.
[26] Carsten Rother, Vladimir Kolmogorov, and Andrew Blake. Grabcut: Interactive foreground extraction using iterated graph cuts. In ACM transactions on graphics (TOG), volume 23, pages 309-314. ACM, 2004.
[27] Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013.
[28] Gwangmo Song, Heesoo Myeong, and Kyoung Mu Lee. Seednet: Automatic seed generation with deep reinforcement learning for robust interactive segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1760-1768, 2018.
[29] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
[30] Vladimir Vezhnevets and Vadim Konouchine. Growcut: Interactive multi-label nd image segmentation by cellular automata. In proc. of Graphicon, volume 1, pages 150-156. Citeseer, 2005.
[31] Ning Xu, Brian Price, Scott Cohen, Jimei Yang, and Thomas S Huang. Deep interactive object selection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 373-381, 2016.
[32] Qiong Yan, Li Xu, Jianping Shi, and Jiaya Jia. Hierarchical saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1155-1162, 2013.
[33] Jianming Zhang, Sarah Adel Bargal, Zhe Lin, Jonathan Brandt, Xiaohui Shen, and Stan Sclaroff. Top-down neural attention by excitation backprop. International Journal of Computer Vision, 126(10):1084-1102, 2018.
[34] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep High-Resolution Representation Learning for Human Pose Estimation. IEEE Conference on Computer Vision and Pattern Recognition, pages 5686-5696, 2019.
[35] Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, Wenyu Liu, and Bin Xiao. Deep high-resolution representation learning for visual recognition. IEEE transactions on pattern analysis and machine intelligence, 2020.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0013] Предложена схема уточнения признаков путем обратных проходов (f-BRS), которая решает задачу оптимизации в отношении вспомогательных переменных вместо сетевых вводов и требует выполнения прямого и обратного прохода только для небольшой части сети. Эксперименты на базах данных GrabCut, Berkeley, DAVIS и SBD установили новый современный уровень, требующий на порядок меньше времени на клик, чем исходная схема BRS [15].
[0014] В настоящем изобретении предложена схема f-BRS (схема уточнения признаков путем обратных проходов), которая репараметризует задачу оптимизации и поэтому требует проходов вперед/назад только через небольшую часть сети (т.е. несколько последних слоев). Простейшая оптимизация для активации в небольшой подсети не привела бы к желаемому эффекту, так как рецептивное поле сверток в последних слоях слишком мало относительно выхода. Поэтому для оптимизации вводится набор вспомогательных параметров, которые инвариантны к положению на изображении. Оптимизация в отношении этих параметров приводит к аналогичному эффекту, как в исходной BRS, без необходимости вычисления обратного прохода через всю сеть.
[0015] Эксперименты согласно настоящему изобретению, выполненные на стандартных базах данных: GrabCut [26], Berkeley [23], DAVIS [25] и SBD [13], показали улучшение по сравнению с существующими подходами с точки зрения скорости и точности.
[0016] Согласно одному аспекту настоящего изобретения предложен способ интерактивной сегментации объекта на изображении, заключающийся в том, что: вводят (S101) изображение и пользовательские вводы, причем каждый пользовательский ввод указывает либо объект, либо фон на изображении и задан координатами; преобразуют (S102) каждый пользовательский ввод в карту расстояний и тензорное представление, включающее в себя координаты и указатель того, что пользовательский ввод указывает либо объект, либо фон; объединяют (S103) с помощью обученного средства искусственного интеллекта карты расстояний с изображением в промежуточное представление; извлекают (S104) с помощью обученного средства искусственного интеллекта признаки изображения из промежуточного представления; корректируют (S105) с помощью обученного средства искусственного интеллекта масштаб на 1 и смещение на 0; перемасштабируют (S106) с помощью обученного средства искусственного интеллекта извлеченные признаки, используя скорректированный масштаб и скорректированное смещение; предсказывают (S107) с помощью обученного средства искусственного интеллекта сегментационную маску, сегментирующую объект на изображении, посредством предсказания того, что перемасштабированные признаки принадлежат объекту или фону, на основе промежуточного представления; оценивают (S108) с помощью обученного средства искусственного интеллекта, соответствует ли расхождение между предсказанной сегментационной маской и тензорным представлением минимальному пороговому значению, предварительно установленному пользователем; и корректируют (S109) с помощью обученного средства искусственного интеллекта масштаб и смещение, используя итерационную процедуру оптимизации, чтобы минимизировать расхождение между предсказанной сегментационной маской и тензорным представлением, причем этапы (S106) - (S109) повторяют до тех пор, пока на этапе (S107) не будет предсказана такая сегментационная маска, при которой расхождение между предсказанной сегментационной маской и тензорным представлением будет соответствовать минимальному пороговому значению или количество повторений достигнет максимального количества, предварительно установленного пользователем.
[0017] В дополнительном аспекте обученное средство искусственного интеллекта содержит три части, причем первая часть обученного средства искусственного интеллекта выполняет этап (S103), вторая часть обученного средства искусственного интеллекта выполняет этап (S104) и третья часть обученного средства искусственного интеллекта выполняет этапы (S105)-(S109).
[0018] В еще одном аспекте, первая часть обученного средства искусственного интеллекта представляет собой сверточную нейронную сеть, вторая часть обученного средства искусственного интеллекта представляет собой сверточную нейронную сеть, такую как одна из Resnet-34, ResNet-50, ResNet-101, HRNetV2-W18, HRNetV2-W32, HRNetV2-W48, и третья часть обученного средства искусственного интеллекта представляет собой сверточную нейронную сеть, при этом все упомянутые сверточные нейронные сети состоят из сверточных слоев, функций активации, соединений перехода и слоев нормализации.
[0019] В еще одном дополнительном аспекте при обучении средства искусственного интеллекта: вводят (S201) набор изображений и истинные сегментационные маски, причем каждая истинная сегментационная маска соответствует связанному с ней изображению, содержащемуся в наборе изображений; моделируют (S202) пользовательские вводы путем генерации набора пользовательских вводов для изображения, выбранного из набора изображений, причем каждый пользовательский ввод указывает либо объект, либо фон на выбранном изображении и задан координатами; преобразуют (S203) каждый сгенерированный пользовательский ввод в карту расстояний; объединяют (S204) с помощью средства искусственного интеллекта карты расстояний с выбранным изображением в промежуточное представление; извлекают (S205) с помощью средства искусственного интеллекта признаки выбранного изображения из промежуточного представления; предсказывают (S206) с помощью средства искусственного интеллекта сегментационную маску, сегментирующую объект на выбранном изображении, путем предсказания того, что извлеченные признаки принадлежат объекту или фону, на основе промежуточного представления; обновляют (S207) числовые параметры средства искусственного интеллекта, используя итерационную процедуру оптимизации, чтобы минимизировать расхождение между предсказанной сегментационной маской и истинной сегментационной маской, соответствующей выбранному изображению, при этом этапы (S202) - (S207) повторяют для каждого изображения в наборе изображений до тех пор, пока число повторений не достигнет максимального числа, предварительно установленного пользователем.
[0020] В еще одном аспекте способ дополнительно включает в себя следующие этапы: обрезают (S110) изображение по расширенной ограничивающей рамке объекта на основании сегментационной маски, предсказанной на этапе (S107), причем ограничивающую рамку объекта расширяют на соответствующую величину, чтобы сохранить мелкие детали на ограничивающей рамке, при этом после этапа (S110) повторно выполняют этапы (S103)-(S105) на обрезанном изображении и повторно выполняют этапы (S106) - (S109) после того, как этапы (S103) - (S105) были повторно выполнены на обрезанном изображении.
[0021] Согласно другому аспекту настоящего изобретения предложено электронное вычислительное устройство, содержащее: по меньшей мере один процессор и память, хранящую числовые параметры обученного средства искусственного интеллекта и инструкции, которые при их исполнении по меньшей мере одним процессором побуждают по меньшей мере один процессор выполнять способ интерактивной сегментации объекта на изображении по любому из пп.1-5
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0022] Представленные выше и другие аспекты, признаки и преимущества настоящего изобретения будут более очевидны из следующего подробного описания в совокупности с прилагаемыми чертежами, на которых изображено следующее:
[0023] Фиг.1 - результаты интерактивной сегментации на изображении из базы данных DAVIS.
[0024] Фиг. 2a - блок-схема, иллюстрирующая операции обученного средства искусственного интеллекта.
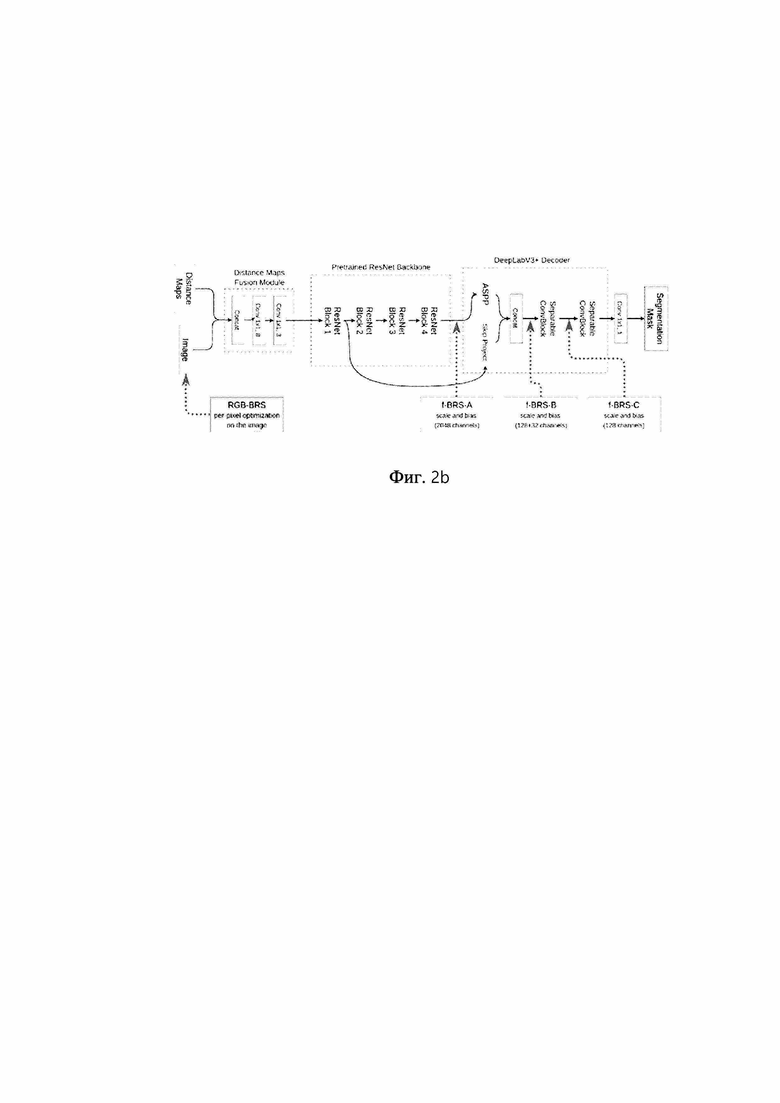
[0025] Фиг. 2b - вариант осуществления процесса, показанного на фиг. 2а.
[0026] Фиг. 3 - пример применения метода увеличения (Zoom-In).
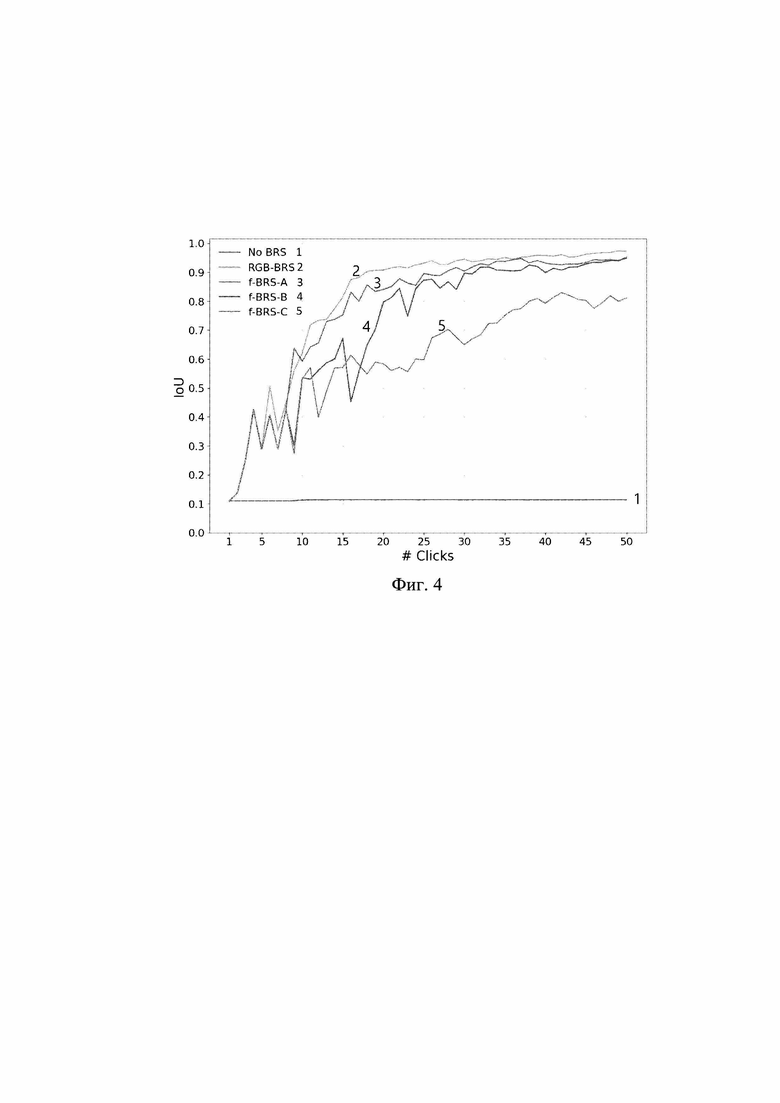
[0027] Фиг.4 - IoU в отношении количества кликов, добавленных пользователем для одного из наиболее сложных изображений из базы данных GrabCut (вырезки).
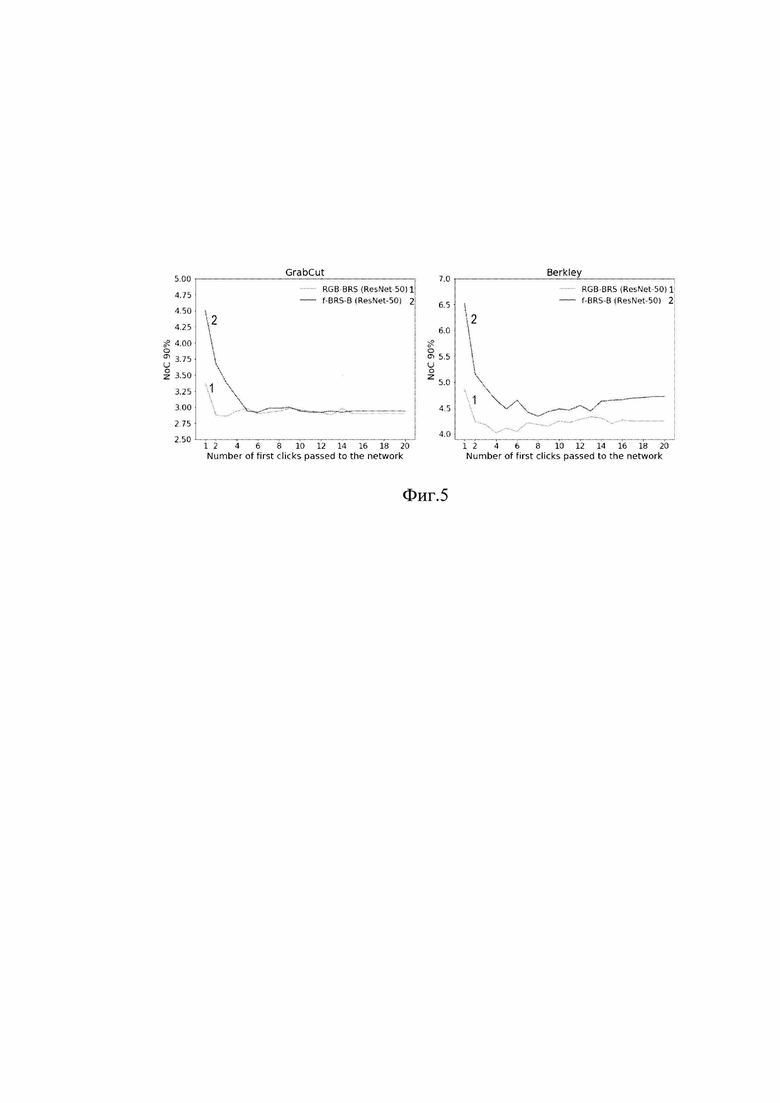
[0028] Фиг.5 - оценка различных стратегий обработки кликов на базах данных GrabCut и Berkeley.
[0029] Фиг.6 - блок-схема последовательности операций, иллюстрирующая предпочтительный вариант осуществления способа интерактивной сегментации объекта на изображении.
[0030] Фиг. 7 - блок-схема, иллюстрирующая процесс обучения средства искусственного интеллекта в соответствии с настоящим изобретением.
[0031] Фиг. 8 - блок-схема, иллюстрирующая электронное вычислительное устройство согласно настоящему изобретению.
[003] В дальнейшем описании, если не указано иное, одни и те же ссылочные позиции используются для одинаковых элементов, изображенных на разных чертежах, и их параллельное описание не приводится.
ПОДРОБНОЕ ОПИСАНИЕ
[0033] Следующее описание со ссылками на прилагаемые чертежи предоставлено для того, чтобы облегчить полное понимание различных вариантов осуществления настоящего изобретения, охарактеризованных формулой изобретения и ее эквивалентами. Для облегчения такого понимания описание содержит различные конкретные детали, однако эти детали следует рассматривать только как примерные. Соответственно, специалисты в данной области техники поймут, что можно разработать различные изменения и модификации различных вариантов осуществления, описанных в данном документе, не выходя за рамки объема настоящего изобретения. Кроме того, описания известных функций и структур могут быть опущены для ясности и краткости.
[0034] Термины и формулировки, используемые в следующем описании и формуле изобретения, не ограничиваются их библиографическими значениями, а просто используются автором для обеспечения ясного и последовательного понимания настоящего изобретения. Соответственно, для специалистов в данной области техники должно быть очевидным, что последующее описание различных вариантов осуществления настоящего изобретения дано только для иллюстрации.
[0035] Следует понимать, что формы единственного числа включают в себя множественное число, если в контексте явно не указано иное.
[0036] Следует понимать, что хотя термины "первый", "второй" и т.д. могут использоваться в данном документе со ссылкой на элементы настоящего раскрытия, не следует истолковывать такие элементы как ограниченные этими терминами. Эти термины используются только для отличия одного элемента от других элементов.
[0037] Кроме того, следует понимать, что термины "содержит", "содержащий", "включает" и/или "включающий", используемые в данном документе, означают наличие упомянутых признаков, значений, операций, элементов и/или компонентов, но не исключают наличия или добавления одного или более других признаков, значений, операций, элементов, компонентов и/или их групп.
[0038] В различных вариантах осуществления настоящего раскрытия "модуль" или "блок" может выполнять по меньшей мере одну функцию или операцию и может быть реализован аппаратным средством, программным средством или их комбинацией. "Множество модулей" или "множество блоков" может быть реализовано по меньшей мере одним процессором (не показан) посредством его интеграции с по меньшей мере одним модулем, отличным от "модуля" или "блока", который должен быть реализован с помощью конкретного аппаратного средства.
[0039] Далее более подробно описываются различные варианты осуществления настоящего изобретения со ссылками на прилагаемые чертежи.
[0040] Предложенное изобретение может быть использовано в фоторедакторах для создания визуальных эффектов, в интерактивных средствах для аннотирования наборов данных для сегментации. Изобретение может быть использовано в любых электронных вычислительных устройствах, например, компьютерах, смартфонах с сенсорным вводом и т.д.
[0041] По сравнению с существующими аналогами предлагаемый способ обеспечивает сходимость к желаемому результату при увеличении размера интерактивного ввода (например, количества кликов), и он более эффективен в отношении вычислений. По сравнению с ближайшим аналогом предложенный способ может использовать промежуточные признаки в любой позиции в сети в качестве целевой переменной для оптимизации. Это свойство позволяет найти баланс между скоростью и качеством исполнения.
[0042] Целью изобретения является получение сегментации одного или более объектов на изображении, выбранных пользователем в интерактивном режиме. Предложенный способ уточняет полученные предсказания путем минимизации функции потерь, целевой переменной для которой являются значения масштабов и смещений для объектов в любой позиции в нейронной сети.
[0043] Признаки, отличающие изобретение от аналогов:
1. В отличие от большинства аналогичных способов предлагаемый алгоритм гарантирует сходимость к желаемому результату с увеличением размера интерактивного ввода (например, количества кликов).
2. В отличие от ближайшего аналога, уточнение предсказания имеет значительно меньшую вычислительную сложность.
3. Предложенную схему для уточнения предсказаний можно адаптировать к произвольной архитектуре нейронной сети. Можно выбрать целевую переменную для оптимизации, позволяющую минимизировать вычислительную сложность без значительной потери точности.
[0044] На фиг.1 представлены результаты интерактивной сегментации на изображении из базы данных DAVIS. Первый ряд: входное изображение и результаты сегментации после 1, 2, 10, 15, 20 кликов, соответственно, с использованием предложенной схемы f-BRS-B. Второй ряд: истинная сегментационная маска и результаты сегментации после 1, 2, 10, 15, 20 кликов, соответственно, без BRS. Зеленые (светлые) точки обозначают позитивные клики, красные (темные) точки - негативные клики.
[0045] В настоящем изобретении сформулирована задача оптимизации для интерактивной сегментации. В отличие от [15], здесь не выполняется оптимизация на вводах в сеть, а вводится вспомогательный набор параметров для оптимизации. После такой репараметризации нет необходимости запускать обратный проход через всю сеть во время процедуры оптимизации. Оцениваются различные репараметризации, а также оцениваются скорость и точность полученных методов. Полученный алгоритм оптимизации f-BRS на порядок быстрее, чем BRS из [15].
[0046] Ниже используется унифицированная запись. Пространство входных изображений обозначается как  , а функция, которую выполняет глубокая нейронная сеть в качестве средства искусственного интеллекта, обозначается как
, а функция, которую выполняет глубокая нейронная сеть в качестве средства искусственного интеллекта, обозначается как 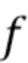 .
.
Генерация состязательных примеров
[0047] Szegedy et al. В [29] сформулировали задачу оптимизации для генерации состязательных примеров для задачи классификации изображений. Они находят изображения, которые визуально неотличимы от естественных и которые некорректно классифицируются сетью. Непрерывная функция потерь, обозначенная как 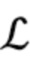 , вычисляет значение штрафа за некорректную классификацию изображения. Для данного изображения
, вычисляет значение штрафа за некорректную классификацию изображения. Для данного изображения 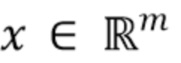 и целевой метки
и целевой метки 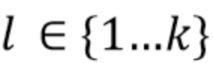 они ставят цель найти
они ставят цель найти 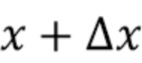 , которое является ближайшим изображением к
, которое является ближайшим изображением к  , классифицированным как
, классифицированным как 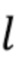 . Для этого они решают следующую задачу оптимизации:
. Для этого они решают следующую задачу оптимизации:
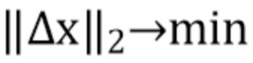 при условии, что
при условии, что
1. 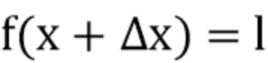 (1)
(1)
2. 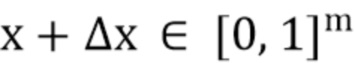
[0048] Эта задача сводится к минимизации следующей функции энергии:
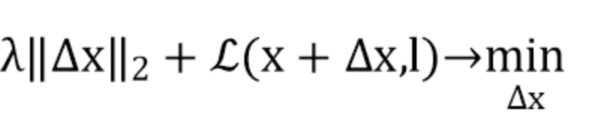 (2)
(2)
[0049] Переменная 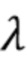 в более поздних работах обычно считается постоянной и служит компромиссом между двумя слагаемыми энергии.
в более поздних работах обычно считается постоянной и служит компромиссом между двумя слагаемыми энергии.
Схема уточнения путем обратных проходов для интерактивной сегментации
[0050] Jang et al. [15] предлагают схему уточнения путем обратных проходов, которая применяет подобный метод оптимизации к задаче интерактивной сегментации изображения. В их работе сеть принимает на вход изображение, объединенное в пакет вместе с картами расстояний для пользовательских кликов. Они находят минимальные правки в картах расстояний, которые приводят к согласованию маски объекта с предоставленной пользователем аннотацией. Для этого они минимизируют сумму двух функций энергии, т.е. корректирующей энергии и инерционной энергии. Функция корректирующей энергии обеспечивает согласованность полученной маски с предоставленной пользователем аннотацией, а инерционная энергия предотвращает чрезмерные отклонения на входах сети.
[0051] Координаты пользовательского клика обозначаются как 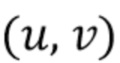 , а его метка (позитивная или негативная) - как
, а его метка (позитивная или негативная) - как 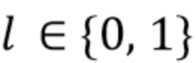 . Вывод сети для изображения в позиции обозначается как
. Вывод сети для изображения в позиции обозначается как 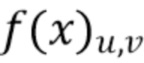 , а набор всех пользовательских кликов обозначается как
, а набор всех пользовательских кликов обозначается как 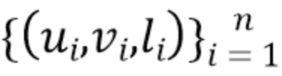 . Задача оптимизации в [15] формулируется следующим образом:
. Задача оптимизации в [15] формулируется следующим образом:
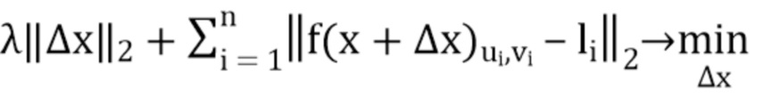 (3)
(3)
где первый член представляет инерционную энергию, а второй - корректирующую энергию, и является константой, которая регулирует компромисс между двумя членами энергии. Эта задача оптимизации напоминает задачу из (2), когда потеря классификации для одной конкретной метки заменяется суммой потерь для меток всех пользовательских кликов. В данном случае от авторов не требуется гарантии, что результатом оптимизации является действительное изображение, поэтому энергию (3) можно минимизировать с помощью L-BFGS без ограничений.
[0052] Основным недостатком этого подхода является то, что L-BFGS требует вычисления градиентов относительно вводов сети, т.е. обратных проходов через всю сеть. Это трудоемко в вычислительном отношении и приводит к значительным вычислительным затратам.
[0053] Так как первый слой сети является сверткой, т.е. линейной комбинацией вводов, можно минимизировать энергию (3) относительно входного изображения вместо карт расстояний и получить эквивалентное решение. Кроме того, если она минимизирована относительно изображения RGB, которое инвариантно к интерактивному вводу, результат используется в качестве инициализации для оптимизации (3) с новыми кликами. Поэтому в наших экспериментах BRS устанавливается в качестве базовой схемы относительно входного изображения и обозначается как RGB-BRS.
Уточнение признаков путем обратных проходов
[0054] Для ускорения процесса оптимизации необходимо вычислить обратное распространение не для всей сети, а только для некоторой ее части. Этого можно достичь путем оптимизации некоторых промежуточных параметров в сети вместо ввода. Примитивным подходом было бы просто оптимизировать выводы некоторых из последних слоев и, таким образом, вычислить обратное распространение только через головную часть сети. Однако такой примитивный подход не привел бы к желаемому результату. Свертки в последних слоях имеют очень маленькое рецептивное поле по отношению к выходам сети. Следовательно, цели оптимизации можно легко достичь путем изменения всего лишь нескольких компонентов тензора признака, что вызовет лишь незначительные локализованные изменения вокруг кликнутых точек в полученной маске объекта.
[0055] Функция репараметризуется и вводятся вспомогательные переменные для оптимизации. 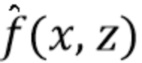 обозначает функцию, которая зависит как от входа , так и от введенных переменных
обозначает функцию, которая зависит как от входа , так и от введенных переменных 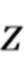 . При фиксированных вспомогательных параметрах
. При фиксированных вспомогательных параметрах 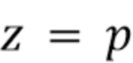 репараметризованная функция эквивалентна исходной функции
репараметризованная функция эквивалентна исходной функции 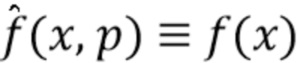 . Следовательно, требуется найти небольшое значение
. Следовательно, требуется найти небольшое значение 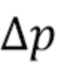 , которое бы приблизило значения
, которое бы приблизило значения  в кликнутых точках к меткам, предоставленным пользователем. Задача оптимизации формулируется следующим образом:
в кликнутых точках к меткам, предоставленным пользователем. Задача оптимизации формулируется следующим образом:
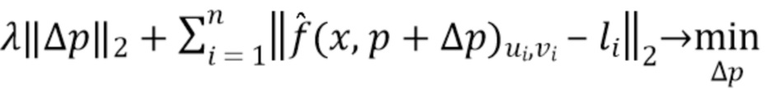 (4)
(4)
[0056] Это задача оптимизации f-BRS (уточнения признаков путем обратных проходов). Чтобы f-BRS была эффективной, необходимо выбрать репараметризацию, которая а) не оказывает локализованного влияния на выходы; б) не требует обратного прохода через всю сеть для оптимизации.
[0057] Одним из вариантов такой репараметризации может быть поканальное масштабирование и смещение для активаций последних слоев в сети. Масштаб и смещение инвариантны к положению на изображении, поэтому изменения этих параметров могут повлиять на результаты глобально. По сравнению с оптимизацией в отношении активаций оптимизация в отношении масштаба и смещения не может привести к вырожденным решениям (т.е. незначительным локальным изменениям вокруг кликнутых точек).
[0058] Вывод некоторого промежуточного слоя сети для изображения обозначается 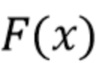 , а количество его каналов обозначается
, а количество его каналов обозначается 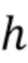 . Тогда
. Тогда 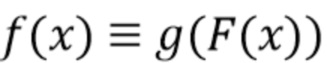 , где
, где  - функция, которую реализует головная часть сети. При этом репараметризованная функция
- функция, которую реализует головная часть сети. При этом репараметризованная функция 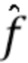 выглядит следующим образом:
выглядит следующим образом:
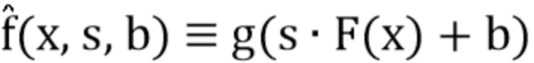 (5)
(5)
где 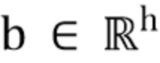 - вектор смещений,
- вектор смещений, 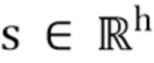 - вектор коэффициентов масштабирования и означает поканальное умножение.
- вектор коэффициентов масштабирования и означает поканальное умножение.  для
для 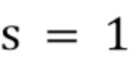 и
и  , следовательно, эти значения берутся в качестве исходных значений для оптимизации.
, следовательно, эти значения берутся в качестве исходных значений для оптимизации.
[0059] Путем изменения части сети, к которой применяются вспомогательные масштаб и смещение, достигается естественный компромисс между точностью и скоростью.
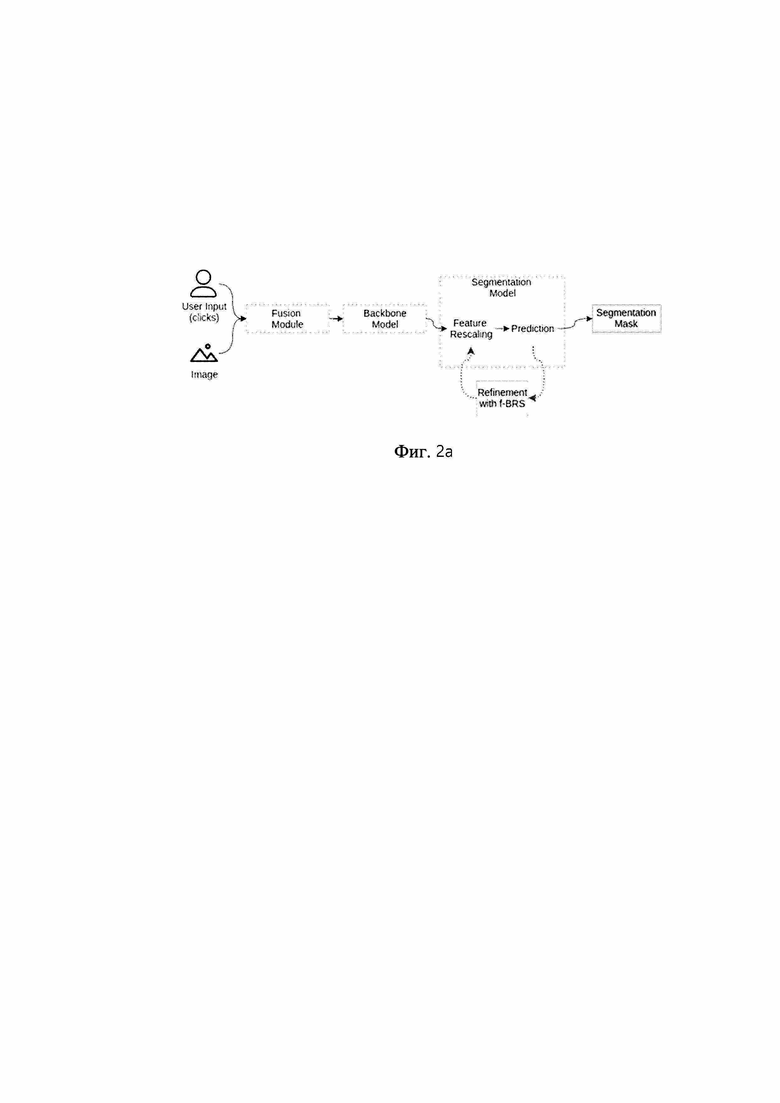
[0060] На фиг. 2a проиллюстрирован предложенный способ. Изображение и предоставленные пользователем аннотации подаются на вход в качестве ввода.
[0061] Например, пользовательская аннотация может быть представлена в форме позитивных и негативных кликов, т.е. пользователь кликает по точкам, принадлежащим интересующему объекту, и точкам, принадлежащим фону. Такой пользовательский ввод сначала преобразуется в тензорное представление. Например, можно использовать карты расстояний (т.е. изображения, которые содержат значения расстояний от кликов пользователя до каждой точки на изображении).
[0062] Изображение и тензорное представление пользовательского ввода передаются в модуль слияния (фиг. 2a). Цель модуля слияния - преобразовать их в промежуточное представление, которое можно передать в магистральную модель на фиг. 2а. Функции извлекаются с помощью прямого прохода через магистральную модель.
[0063] Результирующую сегментационную маску получают из извлеченных признаков, используя процедуру оптимизации (перемасштабирование, предсказание, уточнение признаков с помощью f-BRS на фиг. 2a). Нейронная сеть принимает извлеченные признаки и вспомогательные переменные и предсказывает сегментационную маску (блок предсказания, фиг. 2a). Вспомогательные переменные могут, например, содержать масштабы и смещения для введенных объектов (блок перемасштабирования признаков на фиг. 2a). Целью оптимизации является нахождение таких вспомогательных параметров, которые обеспечивают наиболее точную сегментацию по отношению к пользовательскому вводу. Одной из функций потерь для оптимизации может быть L2-расстояние между выводом сети и унитарно-кодированными метками пользовательских кликов. Оптимизацию можно выполнять, например, используя метод L-BFGS (уточнение с помощью f-BRS на фиг. 2a).
[0064] На фиг. 2b представлен вариант осуществления процесса, показанного на фиг. 2а. f-BRS-A оптимизирует масштаб и смещение для признаков после предобученной магистральной модели, f-BRS-B оптимизирует масштаб и смещение для признаков после ASPP, f-BRS-C оптимизирует масштаб и смещение для признаков после первого отделимого блока свертки. Количество каналов приведено для магистральной модели ResNet-50. На фиг. 2b показана архитектура сети, используемой в данной работе, а также различные варианты оптимизации. Оказалось, что применение f-BRS к нескольким последним слоям приводит к небольшому падению точности по сравнению с полносетевой схемой BRS, что позволяет достичь значительного ускорения.
Увеличение (Zoom-In) для интерактивной сегментации
[0065] В предыдущих работах по интерактивной сегментации часто использовался логический вывод на обрезанных изображениях для достижения ускорения и сохранения мелких деталей в сегментационной маске. Обрезка помогает выводить маски мелких предметов, но она также может ухудшить результаты в тех случаях, когда интересующий объект слишком велик, чтобы поместиться в одно обрезанное изображение.
[0066] В данной работе используется альтернативный метод увеличения (Zoom-In), который довольно прост, но улучшает как качество, так и скорость интерактивной сегментации. Он основан на идеях, взятых из обнаружения объектов [20, 7].
[0067] Первых 1-3 кликов достаточно для того, чтобы в большинстве случаев сеть достигла около 80% IoU с истинной маской. Это позволяет делать грубую обрезку вокруг интересующего региона. Таким образом, начиная с третьего клика, изображение обрезается в соответствии с ограничивающей рамкой выведенной маски объекта, и интерактивная сегментация применяется только к этой области увеличения. Ограничивающую рамку расширяют по сторонам, например, на 40%, чтобы сохранить контекст и не пропустить мелкие детали на границе. Однако расширение ограничивающей рамки не ограничено этими 40% и может осуществляться на любую подходящую величину. Если пользователь делает клик за пределами ограничивающей рамки, область увеличения расширяется. Затем размер ограничивающей рамки изменяется таким образом, чтобы его самая длинная сторона соответствовала 400 пикселям. На фиг. 3 показан пример увеличения (Zoom-In). На фиг. 3 видно, как обрезка изображения позволяет восстановить мелкие детали в сегментационной маске. Такой метод помогает сети предсказывать более точные маски для небольших объектов. В наших экспериментах увеличение постоянно улучшало результаты, поэтому оно используется по умолчанию во всех экспериментах данной работы. В таблице 1 представлено количественное сравнение результатов с увеличением Zoom-In и без него на базах данных GrabCut и Berkeley.
Эксперименты
[0068] Предложенный метод оценивается с использованием стандартного экспериментального протокола для следующих баз данных: SBD [13], GrabCut [26], Berkeley [23] и DAVIS [25].
[0069] База данных SBD впервые использовался для оценки методов сегментации объектов в [31]. Эта база данных содержит 8498 обучающих изображений и 2820 тестовых изображений. Как и в предыдущих работах, модели обучались на обучающей части, и для оценки производительности использовалась контрольная выборка, содержащая 6671 масок объекта уровня экземпляра.
[0070] База данных GrabCut содержит 50 изображений с одной маской объекта для каждого изображения.
[0071] Для базы данных Berkeley используется тот же тестовый набор, что и в [24], который содержит 96 изображений с 100 масками объектов для тестирования.
[0072] База данных DAVIS используется для оценки алгоритмов сегментации видео. Для оценки алгоритмов интерактивной сегментации можно выбирать произвольные кадры из видео. Для оценки используются те же 345 отдельных кадров из видео последовательностей, что и в [15]. Маски объектов уровня экземпляра объединяются в одну семантическую сегментационную маску для каждого изображения в соответствии с протоколом оценки.
[0073] В таблице 1 представлена оценка предложенных способов с магистральной моделью ResNet-50 с увеличением Zoom-In (ZI) и без него для баз данных GrabCut и Berkeley с использованием NoC@90.
Таблица 1
[0074] В таблице 2 представлен анализ сходимости на базах данных Berkeley, SBD и DAVIS. Показаны количество изображений, некорректно сегментированных после 20 и 100 кликов, и показатель производительности NoC100@90.
Таблица 2
Протокол оценки
[0075] Указан показатель количества кликов NoC (Number of Clicks,), который подсчитывает среднее количество кликов, необходимое для достижения целевого пересечения между двумя ограничивающими рамками IoU (intersection over union) с истинной маской. Целевой показатель IoU устанавливается на 85% или 90% для разных баз данных с обозначением соответствующего показателя как NoC@85 и NoC@90 соответственно. Для объективного сравнения используется та же стратегия генерации кликов, что и в [18, 31], которая работает следующим образом. Находится доминирующий тип ошибок предсказания (ложно-позитивные или ложно-негативные) и генерируется следующий негативный или позитивный клик, соответственно, в точке, наиболее удаленной от границ соответствующей области ошибки.
Архитектура сети
[0076] В этой работе во всех экспериментах используется стандартная современная модель DeepLabV3+ [5] для семантической сегментации. Эта архитектура сети в одном из вариантов осуществления показана на фиг. 2b.
[0077] Модель содержит блок слияния с картами расстояний DMF (Distance Maps Fusion) для адаптивного слияния изображений RGB и карт расстояний. В качестве ввода принимается изображение RGB, объединенное с двумя картами расстояний (одна для позитивных и одна для негативных кликов). Блок DMF обрабатывает 5-канальный ввод с 1×1 свертками, за которым следует LeakyReLU, и выдает 3-канальный тензор, который можно передать в магистраль, предобученную на изображениях RGB.
Детали реализации
[0078] Задача обучения формулируется как задача бинарной сегментации, и для обучения используется двоичная кросс-энтропийная потеря. Все модели обучаются на обрезанных изображениях размером 320×480 с горизонтальными и вертикальными транспонированиями, используемыми в качестве дополнений. Размер изображений произвольно изменяется от 0,75 до 1,25 относительно исходного размера перед обрезкой.
[0079] Клики отбираются во время обучения в соответствии со стандартной процедурой, впервые предложенной в [31]. Максимальное количество позитивных и негативных кликов установлено на 10, что дает максим 20 кликов на одно изображение.
[0080] Во всех экспериментах используется Adam с 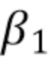 =0,9,
=0,9,  =0,999, и сети обучаются в течение 120 эпох (100 эпох со скоростью обучения 5×10-4, последние 20 эпох со скоростью обучения 5×10-5). Размер пакета установлен на 28, и для всех экспериментов используется синхронный BatchNorm. ResNet-34 и ResNet-50 обучаются на 2 графических процессорах (Tesla P40), а ResNet-101 обучается на 4 графических процессорах (Tesla P40). Скорость обучения для предобученной магистральной модели ResNet была в 10 раз ниже, чем скорость обучения для остальной части сети. Значение установлено на 10-3 для RGB-BRS и на 10-4 для всех вариантов f-BRS.
=0,999, и сети обучаются в течение 120 эпох (100 эпох со скоростью обучения 5×10-4, последние 20 эпох со скоростью обучения 5×10-5). Размер пакета установлен на 28, и для всех экспериментов используется синхронный BatchNorm. ResNet-34 и ResNet-50 обучаются на 2 графических процессорах (Tesla P40), а ResNet-101 обучается на 4 графических процессорах (Tesla P40). Скорость обучения для предобученной магистральной модели ResNet была в 10 раз ниже, чем скорость обучения для остальной части сети. Значение установлено на 10-3 для RGB-BRS и на 10-4 для всех вариантов f-BRS.
[0081] Для обучения и вывода наших моделей используется фреймворк MXNet Gluon [6] с GluonCV [14]. Предобученные модели для ResNet-34, ResNet-50 и ResNet-101 взяты из GluonCV Model Zoo. Эксперименты также проводятся с использованием недавно предложенных магистральных сетей HRNetV2 [34, 35].
Анализ сходимости
[0082] Идеальный метод интерактивной сегментации должен демонстрировать предсказуемую производительность даже для категорий невидимых объектов или необычного спроса от пользователя. Более того, наиболее интересными в сценарии аннотирования данных являются сложные сценарии, которые требуют значительного объема пользовательского ввода. Таким образом, желаемым свойством способа интерактивной сегментации является сходимость, т.е. ожидание того, что с добавлением большего числа кликов результат улучшится и, наконец, достигнет удовлетворительной точности.
[0083] Однако, ни процедура обучения, ни логический вывод в сетях прямого распространения для интерактивной сегментации не гарантируют сходимости. Так, при использовании сетей прямого распространения результат не сходится для значительного количества изображений, т.е. дополнительные клики пользователя не улучшают результирующую сегментационную маску. Пример такого поведения можно найти на фиг. 4. На фиг. 4 показан IoU относительно количества кликов, добавленных пользователем для одного из самых сложных изображений из базы данных GrabCut (вырезки). Кривая 1 соответствует схеме без BRS, кривая 2 - RGB-BRS, кривая 3 - f-BRS-A, кривая 4 - f-BRS-B, кривая 5 - f-BRS-C. Все результаты получены с использованием одной и той же модели с ResNet-50. Можно заметить, что без BRS модель не сходится к корректным результатам. Очень похожее поведение наблюдается с различными сетевыми архитектурами, а именно с архитектурой [15] и с DeepLabV3+. Далее описываются эксперименты.
Мотивация использования метрики NoC100
[0084] В предыдущих работах обычно сообщалось о NoC с максимальным числом сгенерированных кликов, ограниченным 20 (этот показатель называется NoC). Однако этот предел превышен для большой части изображений в стандартных базах данных. С точки зрения NoC, изображения, требующие 20 кликов и 2000 кликов для получения точных масок, понесут одинаковые потери производительности. Поэтому NoC не проводит различия между случаями, когда метод интерактивной сегментации требует несколько большего пользовательского ввода для сходимости, и случаями, когда он вообще не в состоянии сходиться (не способен достичь удовлетворительных результатов после любого разумного количества кликов пользователя).
[0085] В приведенных ниже экспериментах анализируется NoC с максимальным количеством кликов, ограниченным 100 (этот показатель обозначается как NoC100). NoC100 лучше подходит для анализа сходимости и позволяет идентифицировать изображения, в которых интерактивная сегментация не состоялась. NoC100 значительно больше подходит для сравнения методов интерактивной сегментации, чем NoC.
Эксперименты и обсуждение
[0086] В таблице 2 представлено количество изображений, которые не были корректно сегментированы даже после 20 и 100 кликов, и NoC100 для целевого IoU=90% (NoC100@90).
[0087] Можно заметить, что как DeepLabV3+, так и архитектура сети из [15] без BRS не смогли получить точные результаты сегментации относительно большой части изображений из всех баз данных даже при наличии 100 пользовательских кликов.
[0088] Интересно отметить, что этот процент также высок для базы данных SBD, имеющего наиболее близкое распределение к обучающему набору. Изображения, которые не могли бы быть сегментированы с 100 пользовательскими кликами, являются очевидными случаями отказа метода. Использование как исходной схемы BRS, так и предлагаемой схемы f-BRS позволяет сократить количество таких случаев в несколько раз и приводит к значительному улучшению в условиях NoC100.
[0089] Следовательно, использование основанного на оптимизации уточнения путем обратных проходов приводит не только к улучшению метрик, но, что важно отметить, меняет поведение интерактивной системы сегментации и ее свойства сходимости.
[0090] В таблице 3 представлены результаты оценки баз данных GrabCut, Berkeley, SBD и DAVIS. Лучшие и вторые среди лучших результаты выделены жирным шрифтом и подчеркнуты, соответственно.
Таблица 3
[0091] В таблице 4 представлено сравнение результатов схемы без BRS и схемы с f-BRS типа A, B и C с магистральной моделью ResNet-50.
Таблица 4
≥20
≥20
Оценка важности кликов, поданных в сеть
[0092] Увеличение количества кликов, поданных в сеть, не всегда приводит к улучшению результатов. Более того, слишком большое количество кликов может привести к непредсказуемому поведению сети. С другой стороны, формулировка задачи оптимизации для уточнения путем обратных проходов обеспечивает согласованность полученной маски с предоставленной пользователем аннотацией.
[0093] Можно заметить, что пользовательские клики могут обрабатываться только в качестве цели для функции потерь BRS без передачи их в сеть через карты расстояний. Состояние сети инициализируется путем выполнения предсказания с первыми несколькими кликами. Затем полученная сегментационная маска итеративно уточняется только с помощью BRS в соответствии с новыми кликами.
[0094] Исследуется взаимосвязь между количеством первых кликов, переданных в сеть, и полученным NoC@90 на базах данных GrabCut и Berkeley. Результаты этого исследования для RGB-BRS и f-BRS-B показаны на фиг. 5. На фиг. 5 представлена оценка различных стратегий обработки кликов для баз данных GrabCut и Berkeley. Графики показывают NoC@90 относительно количества кликов, переданных в сеть, при этом кривая 1 соответствует RGB-BRS (ResNet-50), кривая 2 - f-BRS-B (ResNet-50). Результаты показывают, что подача всех кликов в сеть не является оптимальной стратегией. Понятно, что для RGB-BRS оптимум достигается при ограничении количества кликов до 4, а для f-BRS-B - 8 кликов. Это иллюстрирует, что как BRS, так и f-BRS могут самостоятельно адаптировать вывод сети к пользовательскому вводу.
[0095] Во всех других экспериментах количество переданных в сеть кликов было ограничено до 8 для алгоритмов f-BRS и до 4 для RGB-BRS.
Сравнение с предыдущими работами
Сравнение с использованием стандартного протокола
[0096] В таблице 3 представлено сравнение с предыдущими работами по стандартному протоколу и показано среднее значение NoC с двумя порогами IoU: 85% и 90%.
[0097] Предложенный алгоритм f-BRS требует меньшего числа кликов, чем традиционные алгоритмы, свидетельствуя о том, что предложенный алгоритм дает точные маски объектов при меньших усилиях пользователя.
[0098] Испытаны три магистральные модели на всех базах данных. Удивительно, но между этими моделями нет существенной разницы в производительности. Самая маленькая модель ResNet-34 показывает лучшее качество на базе данных GrabCut, превосходя намного более тяжелые модели, такие как ResNet-101. Тем не менее, во время обучения была значительная разница между этими моделями в значениях целевой функции потерь на контрольной выборке.
[0099] Это показывает, что целевая функция потерь плохо коррелирует с метрикой NoC.
Анализ времени выполнения
[0100] Измеряется среднее время выполнения предложенного алгоритма в секундах на клик SPC (seconds per click) и общее время работы для обработки базы данных. Первая метрика показывает задержку после того, как пользователь сделал клик, прежде чем он увидит обновленный результат. Вторая метрика указывает общее время, которое пользователь должен потратить для получения удовлетворительной аннотации изображения. В этих экспериментах порог количества кликов на одно изображение устанавливается равным 20. Тестирование выполняется на базах данных Berkeley и DAVIS с использованием ПК с процессором AMD Ryzen Threadripper 1900X и графическим процессором GTX 1080 Ti.
[0101] В таблице 4 показаны результаты для различных версий предложенного способа и для его реализованных базовых схем: без BRS и с RGB-BRS. Время выполнения f-BRS на порядок ниже по сравнению с RGB-BRS и добавляет лишь небольшие затраты ресурсов по сравнению с чистой моделью прямого распространения.
Сравнение разных версий f-BRS
[0102] Выбор слоя, в который вводятся вспомогательные переменные, обеспечивает компромисс между скоростью и точностью f-BRS. Сравниваются три варианта: f-BRS-A относится к введению масштаба и смещения после магистральной модели, f-BRS-B относится к введению масштаба и смещения до первого отделимого блока свертки в DeepLabV3+, и f-BRS-C относится к введению масштаба и смещения перед вторым отделимым блоком свертки в DeepLabV3+. В качестве базовой схемы для наших экспериментов сообщаются результаты для сети прямого распространения без BRS. Реализованы RGB-BRS с применением оптимизации по отношению к входному изображению. В этих экспериментах используется магистральная модель ResNet-50.
[0103] В данном эксперименте сообщаются NoC@90 и количество изображений, для которых удовлетворительный результат не был получен после 20 пользовательских кликов. Также измеряются SPC (количество секунд на клик) и время (общее время обработки набора данных). Следует отметить, что прямое сравнение затрачиваемого времени с числовыми значениями, сообщенными в предыдущих работах, недопустимо из-за различий в используемых платформах и оборудовании, поэтому имеет смысл только относительное сравнение.
[0104] В таблице 4 показаны результаты оценки для баз данных Berkeley и DAVIS. Можно заметить, что все версии f-BRS работают лучше, чем базовая схема без BRS. f-BRS-B приблизительно в 8 раз быстрее, чем RGB-BRS, и при этом показывает очень близкие результаты по NoC. Поэтому эта версия выбрана для сравнительных экспериментов.
Выводы
[0105] Предложена новая схема уточнения путем обратных проходов (f-BRS), которая работает на промежуточных признаках в сети и требует прохода вперед и назад только для небольшой части сети. Авторы оценили этот подход на четырех стандартных тестах интерактивной сегментации и установили новые современные результаты с точки зрения точности и скорости. Изобретение продемонстрировало лучшую сходимость схем уточнения путем обратных проходов по сравнению с методами чистого прямого распространения. Авторы оценили важность первых кликов, переданных в сеть, и показали, что и BRS, и f-BRS могут успешно адаптировать вывод сети к пользовательскому вводу.
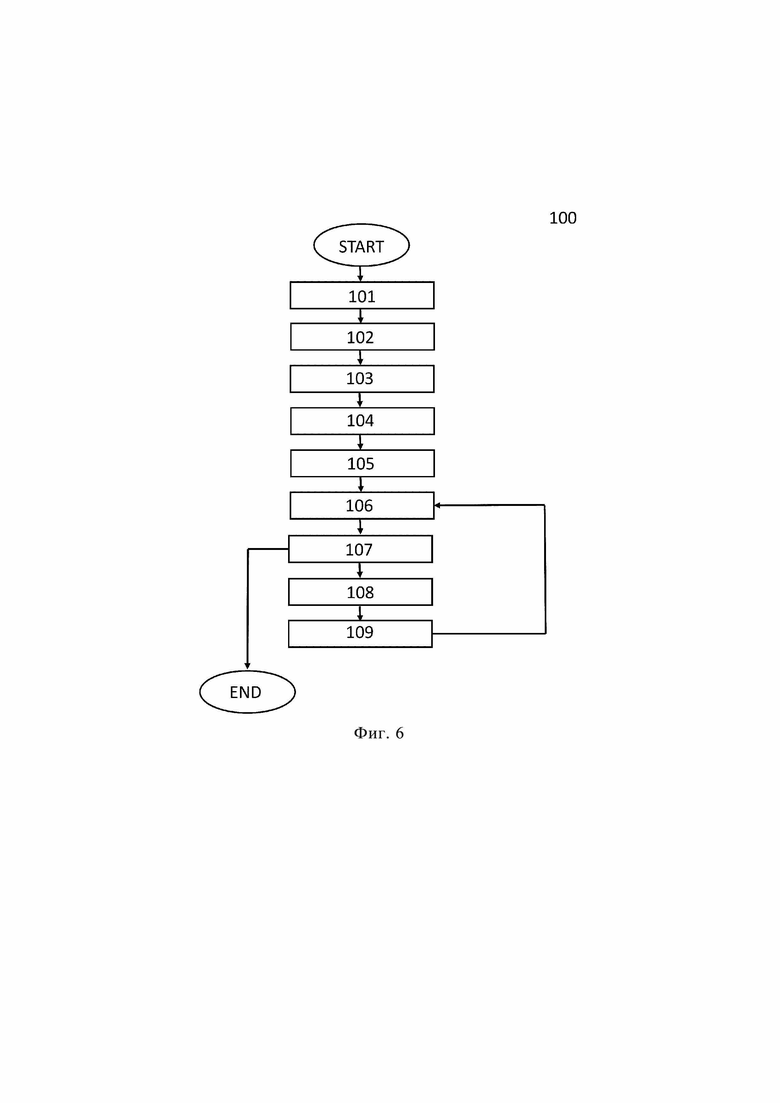
[0106] Один вариант осуществления способа 100 для интерактивной сегментации объекта на изображении будет описан более подробно со ссылками на фиг. 6. Способ 100 содержит этапы S101-S109. Способ 100 выполняется электронным вычислительным устройством 300.
[0107] На этапе S101 подлежащее сегментации изображение и пользовательские вводы подаются на вход электронного вычислительного устройства 300. Каждый пользовательский ввод указывает либо объект, либо фон на изображении и задан координатами. Пользовательский ввод может быть выполнен любым подходящим способом, например, с помощью мыши или сенсорной панели компьютера, посредством прикосновения пользователя к сенсорному экрану на устройстве, содержащем сенсорный экран, и т.д.
[0108] На этапе S102 каждый пользовательский ввод преобразуется в карту расстояний и тензорное представление, включающее в себя координаты и указание, что пользовательский ввод указывает либо объект, либо фон. Тензорное представление описано выше в разделе "Уточнение признаков путем обратных проходов", поэтому его подробное описание здесь опущено. Карта расстояний хорошо известна из уровня техники, поэтому ее подробное описание не требуется.
[0109] На этапе S103 обученное средство искусственного интеллекта, содержащийся в электронном вычислительном устройстве 300, объединяет карты расстояний с изображением в промежуточное представление.
[0110] На этапе S104 обученное средство искусственного интеллекта извлекает признаки изображения из промежуточного представления.
[0111] На этапе S105 обученное средство искусственного интеллекта корректирует масштаб на 1 и смещение на 0.
[0112] На этапе S106 обученное средство искусственного интеллекта перемасштабирует извлеченные признаки, используя скорректированный масштаб и скорректированное смещение.
[0113] На этапе S107 обученное средство искусственного интеллекта предсказывает сегментационную маску, сегментирующую объект на изображении, путем предсказания того, что перемасштабированные признаки принадлежат объекту или фону, на основе промежуточного представления.
[0114] На этапе S108 обученное средство искусственного интеллекта оценивает, соответствует ли расхождение между предсказанной сегментационной маской и тензорным представлением минимальному пороговому значению. Минимальное пороговое значение устанавливается пользователем предварительно.
[0115] На этапе S109 обученное средство искусственного интеллекта корректирует масштаб и смещение, используя процедуру итеративной оптимизации, чтобы минимизировать расхождение между предсказанной сегментационной маской и тензорным представлением.
[0116] Этапы с (S106) по (S109) повторяются до тех пор, пока на этапе (S107) не будет предсказана такая сегментационная маска, при которой расхождение между предсказанной сегментационной маской и тензорным представлением будет соответствовать минимальному пороговому значению или число повторений достигнет максимального значения. Максимальное количество повторений устанавливается пользователем предварительно.
[0117] Обученное средство искусственного интеллекта состоит из трех частей. Первая часть обученного средства искусственного интеллекта выполняет этап (S103). Вторая часть обученного средства искусственного интеллекта выполняет этап (S104). Третья часть обученного средства искусственного интеллекта выполняет этапы (S105) - (S109).
[0118] Первая часть обученного средства искусственного интеллекта представляет собой сверточную нейронную сеть. Вторая часть обученного средства искусственного интеллекта представляет собой сверточную нейронную сеть, такую как одна из Resnet-34, ResNet-50, ResNet-101, HRNetV2-W18, HRNetV2-W32, HRNetV2-W48. Третья часть обученного средства искусственного интеллекта представляет собой сверточную нейронную сеть. Все упомянутые сверточные нейронные сети состоят из сверточных слоев, функций активации, соединений перехода и слоев нормализации.
[0119] Способ 100 может дополнительно содержать этап (S110), на котором изображение обрезается по расширенной ограничивающей рамке объекта на основании сегментационной маски, предсказанной на этапе (S107). Ограничивающую рамку объекта можно расширить на соответствующую величину, чтобы сохранить мелкие детали на ограничивающей рамке. После этапа (S110) этапы (S103) - (S105) выполняются повторно на обрезанном изображении, а этапы (S106) - (S109) выполняются повторно после того, как этапы (S103) - (S105) были повторно выполнены на обрезанном изображении. Эта операция подробно описана в разделе "Увеличение (Zoom-in) для интерактивной сегментации", поэтому ее подробное описание здесь опущено.
[0120] На фиг.7 показан процесс 200 обучения средства искусственного интеллекта, содержащегося в электронном вычислительном устройстве 300. Процесс 200 обучения средства искусственного интеллекта содержит этапы S201-S207.
[0121] На этапе S201 в электронное вычислительное устройство 300 вводят набор изображений и истинные сегментационные маски. Каждая истинная сегментационная маска соответствует связанному с ней изображению, содержащемуся в наборе изображений.
[0122] На этапе S202 пользовательские вводы моделируются путем генерации набора пользовательских вводов для изображения, выбранного из набора изображений. Каждый пользовательский ввод указывает либо объект, либо фон на выбранном изображении и задан координатами.
[0123] На этапе S203 каждый сгенерированный пользовательский ввод преобразуется в карту расстояний.
[0124] На этапе S204 средство искусственного интеллекта объединяет карты расстояний с выбранным изображением в промежуточное представление.
[0125] На этапе S205 средство искусственного интеллекта извлекает признаки выбранного изображения из промежуточного представления.
[0126] На этапе S206 средство искусственного интеллекта предсказывает сегментационную маску, сегментирующую объект на выбранном изображении, посредством предсказания того, что извлеченные признаки принадлежат объекту или фону, на основе промежуточного представления.
[0127] На этапе S207 числовые параметры средства искусственного интеллекта обновляются посредством процедуры итеративной оптимизации, чтобы минимизировать расхождение между предсказанной сегментационной маской и истинной сегментационной маской, соответствующей выбранному изображению.
[0128] Этапы (S202) - (S207) повторяются для каждого изображения в наборе изображений, пока количество повторений не достигнет максимального числа. Максимальное число повторений устанавливается пользователем предварительно.
[0129] Способ, раскрытый в настоящем документе, может быть реализован электронным вычислительным устройством. По меньшей мере один из множества модулей может быть реализован через модель искусственного интеллекта (AI). Функция, связанная с AI, может выполняться через энергонезависимую память, энергозависимую память и процессор.
[0130] Процессор может включать в себя один или более процессоров. При этом один или более процессоров могут быть процессором общего назначения, таким как центральный процессор (CPU), процессором приложений (AP) или т.п., процессором только графики, таким как графический процессор (GPU), процессором машинного зрения (VPU) и/или специализированным процессором AI, таким как нейронный процессор (NPU).
[0131] Один или более процессоров управляют обработкой входных данных в соответствии с предопределенной моделью рабочего правила или (AI), хранящейся в энергонезависимой памяти и энергозависимой памяти. Предопределенная модель рабочего правила или искусственного интеллекта предоставляется посредством обучения или изучения.
[0132] В данном контексте предоставление посредством обучения означает, что при применении алгоритма обучения к множеству обучающих данных создается предопределенное рабочее правило или модель AI требуемой характеристики. Это обучение может выполняться в самом устройстве, в котором выполняется AI в соответствии с вариантом осуществления, и/или может быть реализовано через отдельный сервер/систему.
[0133] Модель AI может состоять из нескольких слоев нейронной сети. Каждый слой имеет множество весовых значений и выполняет операцию слоя посредством вычисления предыдущего слоя и операции с множеством весов. Примеры нейронных сетей включают в себя, без ограничения, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративные состязательные сети (GAN) и глубокие Q-сети.
[0134] Алгоритм обучения представляет собой способ обучения заданного целевого устройства (например, робота) с использованием множества обучающих данных для побуждения, разрешения или управления целевым устройством в целях выполнения определения или предсказания. Примеры алгоритмов обучения включают в себя, без ограничения, обучение с учителем, обучение без учителя, обучение с частичным привлечением учителя, или обучение с подкреплением
[0135] На фиг.8 показана блок-схема, иллюстрирующая электронное вычислительное устройство 300 согласно настоящему изобретению. Электронное вычислительное устройство 300 содержит по меньшей мере один процессор 301 и память 302.
[0136] Память 302 хранит числовые параметры обученного средства искусственного интеллекта и инструкции. По меньшей мере один процессор 301 выполняет инструкции, хранящиеся в памяти 302, для выполнения способа 100 интерактивной сегментации объекта на изображении.
[0137] Кроме того, раскрытый в данном документе способ может быть реализован на машиночитаемом носителе, который хранит числовые параметры обученного средства искусственного интеллекта и машиноисполняемые инструкции, которые при исполнении процессором компьютера побуждают компьютер выполнять предложенный способ. Обученное средство искусственного интеллекта и инструкции для реализации настоящего способа могут быть загружены в электронное вычислительное устройство через сеть или с носителя.
[0138] Приведенные выше описания вариантов осуществления изобретения являются иллюстративными, и модификации конфигурации и реализации не выходят за рамки настоящего описания. Например, хотя варианты осуществления изобретения описаны в целом со ссылкой на фиг. 1-8, представленные выше описания являются примерными. Хотя предмет изобретения описывается на языке, характеризующем конструктивные признаки или этапы способа, понятно, что предмет изобретения не обязательно ограничен описанными признаками или этапами. Кроме того, описанные выше конкретные признаки и этапы раскрыты как примерные формы реализации формулы изобретения. Изобретение не ограничивается проиллюстрированной последовательностью выполнения этапов способа, специалист сможет изменить эту последовательность без творческих усилий. Некоторые или все этапы способа могут выполняться последовательно или параллельно.
[0139] Соответственно, предполагается, что объем вариантов осуществления изобретения ограничен только следующей формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИНТЕРАКТИВНАЯ СЕГМЕНТАЦИЯ ИЗОБРАЖЕНИЙ | 2023 |
|
RU2833268C1 |
| ОБУЧЕНИЕ GAN (ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ) СОЗДАНИЮ ПОПИКСЕЛЬНОЙ АННОТАЦИИ | 2019 |
|
RU2735148C1 |
| Совместная неконтролируемая сегментация объектов и подрисовка | 2019 |
|
RU2710659C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| Способ обеспечения компьютерного зрения | 2022 |
|
RU2791587C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| СПОСОБ АУДИОВИЗУАЛЬНОГО РАСПОЗНАВАНИЯ СРЕДСТВ ИНДИВИДУАЛЬНОЙ ЗАЩИТЫ НА ЛИЦЕ ЧЕЛОВЕКА | 2022 |
|
RU2791415C1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| Система и способ для получения обработанного выходного изображения, имеющего выбираемый пользователем показатель качества | 2023 |
|
RU2823750C1 |



Изобретение относится к областям компьютерного зрения и компьютерной графики с использованием нейронных сетей, машинного обучения для интерактивной сегментации объектов на изображениях, и в частности к способу интерактивной сегментации объекта на изображении и электронному вычислительному устройству для реализации данного способа. Технический результат заключается в обеспечении сегментации одного или более объектов на изображении, выбранных пользователем в интерактивном режиме. Технический результат достигается за счет того, что реализована схема уточнения признаков путем обратных проходов (f-BRS), которая решает задачу оптимизации в отношении вспомогательных переменных вместо сетевых вводов и требует выполнения прямого и обратного прохода только для небольшой части сети (т.е. несколько последних слоев). Для оптимизации вводится набор вспомогательных параметров, которые инвариантны к положению на изображении. Оптимизация в отношении этих параметров приводит к аналогичному эффекту, как в исходной BRS, без необходимости вычисления обратного прохода через всю сеть. 2 н. и 4 з.п. ф-лы, 9 ил., 4 табл.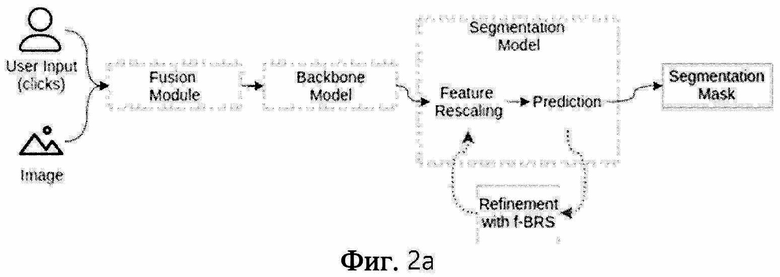
1. Способ интерактивной сегментации объекта на изображении, содержащий этапы, на которых:
вводят (S101) изображение и пользовательские вводы, причем каждый пользовательский ввод указывает либо объект, либо фон на изображении и задан координатами;
преобразуют (S102) каждый пользовательский ввод в карту расстояний и тензорное представление, включающее в себя координаты и указатель того, что пользовательский ввод указывает либо объект, либо фон;
объединяют (S103) с помощью обученного средства искусственного интеллекта карты расстояний с изображением в промежуточное представление;
извлекают (S104) с помощью обученного средства искусственного интеллекта признаки изображения из промежуточного представления;
корректируют (S105) с помощью обученного средства искусственного интеллекта масштаб на 1 и смещение на 0;
перемасштабируют (S106) с помощью обученного средства искусственного интеллекта извлеченные признаки, используя скорректированный масштаб и скорректированное смещение;
предсказывают (S107) с помощью обученного средства искусственного интеллекта сегментационную маску, сегментирующую объект на изображении, посредством предсказания того, что перемасштабированные признаки принадлежат объекту или фону, на основе промежуточного представления;
оценивают (S108) с помощью обученного средства искусственного интеллекта, соответствует ли расхождение между предсказанной сегментационной маской и тензорным представлением минимальному пороговому значению, предварительно установленному пользователем; и
корректируют (S109) с помощью обученного средства искусственного интеллекта масштаб и смещение, используя итерационную процедуру оптимизации, чтобы минимизировать расхождение между предсказанной сегментационной маской и тензорным представлением,
причем этапы (S106)-(S109) повторяют до тех пор, пока на этапе (S107) не будет предсказана такая сегментационная маска, при которой расхождение между предсказанной сегментационной маской и тензорным представлением будет соответствовать минимальному пороговому значению или количество повторений достигнет максимального количества, предварительно установленного пользователем.
2. Способ по п.1, в котором обученное средство искусственного интеллекта содержит три части, причем первая часть обученного средства искусственного интеллекта выполняет этап (S103), вторая часть обученного средства искусственного интеллекта выполняет этап (S104) и третья часть обученного средства искусственного интеллекта выполняет этапы (S105)-(S109).
3. Способ по п.2, в котором первая часть обученного средства искусственного интеллекта представляет собой сверточную нейронную сеть, вторая часть обученного средства искусственного интеллекта представляет собой сверточную нейронную сеть, такую как одна из Resnet-34, ResNet-50, ResNet-101, HRNetV2-W18, HRNetV2-W32, HRNetV2-W48, и третья часть обученного средства искусственного интеллекта представляет собой сверточную нейронную сеть, при этом все упомянутые сверточные нейронные сети состоят из сверточных слоев, функций активации, соединений перехода и слоев нормализации.
4. Способ по любому из пп.1-3, в котором обучение средства искусственного интеллекта содержит этапы, на которых:
вводят (S201) набор изображений и истинные сегментационные маски, причем каждая истинная сегментационная маска соответствует связанному с ней изображению, содержащемуся в наборе изображений;
моделируют (S202) пользовательские вводы путем генерации набора пользовательских вводов для изображения, выбранного из набора изображений, причем каждый пользовательский ввод указывает либо объект, либо фон на выбранном изображении и задан координатами;
преобразуют (S203) каждый сгенерированный пользовательский ввод в карту расстояний;
объединяют (S204) с помощью средства искусственного интеллекта карты расстояний с выбранным изображением в промежуточное представление;
извлекают (S205) с помощью средства искусственного интеллекта признаки выбранного изображения из промежуточного представления;
предсказывают (S206) с помощью средства искусственного интеллекта сегментационную маску, сегментирующую объект на выбранном изображении, путем предсказания того, что извлеченные признаки принадлежат объекту или фону, на основе промежуточного представления;
обновляют (S207) числовые параметры средства искусственного интеллекта, используя итерационную процедуру оптимизации, чтобы минимизировать расхождение между предсказанной сегментационной маской и истинной сегментационной маской, соответствующей выбранному изображению,
причем этапы (S202)-(S207) повторяют для каждого изображения в наборе изображений до тех пор, пока число повторений не достигнет максимального числа, предварительно установленного пользователем.
5. Способ по п.1, дополнительно содержащий этапы, на которых:
обрезают (S110) изображение по расширенной ограничивающей рамке объекта на основании сегментационной маски, предсказанной на этапе (S107), причем ограничивающую рамку объекта расширяют на соответствующую величину, чтобы сохранить мелкие детали на ограничивающей рамке,
при этом после этапа (S110) повторно выполняют этапы (S103)-(S105) на обрезанном изображении и повторно выполняют этапы (S106)-(S109) после того, как этапы (S103)-(S105) были повторно выполнены на обрезанном изображении.
6. Электронное вычислительное устройство, содержащее:
по меньшей мере один процессор и
память, хранящую числовые параметры обученного средства искусственного интеллекта и инструкции, которые при их исполнении по меньшей мере одним процессором побуждают по меньшей мере один процессор выполнять способ интерактивной сегментации объекта на изображении по любому из пп.1-5.
| US 20170140236 A1, 18.05.2017 | |||
| WO 2019066794 A1, 04.04.2019 | |||
| US 20190057507 A1, 21.02.2019 | |||
| СИСТЕМЫ И СПОСОБЫ СЕГМЕНТАЦИИ МЕДИЦИНСКИХ ИЗОБРАЖЕНИЙ НА ОСНОВАНИИ ПРИЗНАКОВ, ОСНОВАННЫХ НА АНАТОМИЧЕСКИХ ОРИЕНТИРАХ | 2015 |
|
RU2699499C2 |
| CN 110070107 A, 30.07.2019. | |||

