Область техники, к которой относится изобретение
[0001] Настоящее изобретение относится к обучающему устройству и к способу обучения.
Уровень техники
[0002] В последние годы, попытка заменять функцию людей большим объемом данных предпринимается во многих областях техники посредством использования машинного обучения, которое является общеизвестным относительно искусственного интеллекта (AI). Эта область техники по-прежнему тщательно разрабатывается день за днем, но возникают определенные проблемы при текущих обстоятельствах. Их характерные примеры включают в себя предел точности, включающий в себя обобщающую способность для извлечения универсальных знаний из данных, и предел скорости обработки вследствие большой вычислительной нагрузки. В качестве известного алгоритма для высокопроизводительного машинного обучения, известны глубокое обучение (DL), сверточная нейронная сеть (CNN), в которой входной вектор ограничен периферией, и т.п. По сравнению с этими способами, при текущих обстоятельствах, известно, что градиентный бустинг (например, дерево решений на основе градиентного бустинга (GBDT)) имеет плохую точность для входных данных, таких как изображение, голос и язык, поскольку затруднительно извлекать набор признаков, но обеспечивает более высокую производительность для других структурированных данных. По существу, в Kaggle в качестве соревнований специалистов по обработке и анализу данных, GBDT представляет собой наиболее стандартный алгоритм. В реальном мире, считается, что 70% проблем, которые должны разрешаться посредством машинного обучения, представляют собой структурированные данные, отличные от изображения, голоса и языка, так что не подлежит сомнению, что GBDT представляет собой важный алгоритм для того, чтобы разрешать проблемы в реальном мире. Дополнительно, в последние годы, разработан способ извлечения признака из данных, таких как изображение и голос, с использованием дерева решений.
[0003] При градиентном бустинге, обработка обучения выполняется с более высокой скоростью, чем при глубоком обучении, таком как CCN. Тем не менее, фактически, обычная практика заключается в том, чтобы выполнять обучение несколько сотен раз или более для регулирования гиперпараметра и выбора признаков в качестве обязательной работы при практическом применении и для такой работы, как моделирование ансамбля и помещение в стек для повышения производительности, посредством комбинирования множества моделей для целей оценки обобщающей способности и повышения производительности. Таким образом, время вычисления становится проблемой даже при градиентном бустинге, обработка которого выполняется на относительно высокой скорости. Таким образом, в последние годы, сообщается о большом числе исследований для увеличения скорости обработки для обработки обучения посредством градиентного бустинга.
[0004] Чтобы увеличивать скорость обработки обучения посредством градиентного бустинга, обучающие данные должны разделяться на фрагменты, которые должны храниться посредством множества блоков памяти, и обработка обучения должна выполняться параллельно. При условии, что гистограмма информации градиентов и набор признаков обучающих данных, используемых при градиентном бустинге, вычисляются для сохранения, число блоков памяти, которые сохраняют гистограмму, просто увеличивается пропорционально числу разделений памяти, которая хранит обучающие данные, и размер схем также увеличивается.
[0005] Относительно гистограммы, описанной выше, чтобы увеличивать скорость гистограммы, раскрыта технология вычисления гистограммы для значений, которые вводятся параллельно (см. патентный документ 1). Чтобы вычислять набор признаков в форме гистограмм ориентированных градиентов (HOG) в качестве набора локальных признаков посредством программируемой пользователем вентильной матрицы (FPGA), раскрывается операция использования определенной переменной в качестве элемента разрешения гистограммы, чтобы интегрировать другие переменные (см. непатентный документ 1).
Сущность изобретения
Техническая задача
[0006] Хотя гистограмма параллельных вводов вычисляется в технологии, раскрытой в патентном документе 1, раскрывается только операция для гистограммы для одной переменной, т.е. гистограммы, которая подсчитывает значение переменной в качестве предварительно определенного элемента разрешения, так что технология не может применяться к созданию гистограммы информации градиентов и набора признаков, как описано выше. Дополнительно, с помощью технологии, раскрытой в непатентном документе 1, может создаваться гистограмма двух переменных, описанных выше, но две переменные не могут вводиться параллельно для того, чтобы создавать гистограмму.
[0007] Настоящее изобретение осуществлено с учетом такой ситуации и предлагает обучающее устройство и способ обучения для создания гистограммы набора признаков и информации градиентов, которые вводятся параллельно, и уменьшения размера схем памяти, которая хранит информацию гистограммы.
Решение задачи
[0008] Согласно аспекту настоящего изобретения, обучающее устройство выполнено с возможностью выполнять обучение посредством градиентного бустинга. Обучающее устройство включает в себя множество блоков памяти данных, множество блоков вывода градиентов, блок суммирования и блок памяти гистограмм. Множество блоков памяти данных выполнены с возможностью сохранять обучающие данные, включающие в себя, по меньшей мере, один тип набора признаков и информацию градиентов, соответствующую обучающим данным. Множество блоков вывода градиентов предусмотрены согласно множеству блоков памяти данных, и каждый из них выполнен с возможностью принимать ввод набора признаков и информации градиентов, соответствующей набору признаков, из соответствующего одного из множества блоков памяти данных и выводить информацию градиентов, соответствующую набору признаков, через порт вывода, соответствующий каждому значению входного набора признаков. Блок суммирования выполнен с возможностью суммировать один или более фрагментов информации градиентов, соответствующей идентичному значению набора признаков из числа фрагментов информации градиентов, выводимой из множества блоков вывода градиентов, и выводить суммированное значение информации градиентов, соответствующей каждому значению набора признаков. Блок памяти гистограмм выполнен с возможностью сохранять гистограмму, полученную посредством интегрирования суммированных значений информации градиентов, соответствующей каждому значению набора признаков, выводимого из блока суммирования, для каждого элемента разрешения в случае, в котором каждое значение задается в качестве элемента разрешения.
Преимущества изобретения
[0009] Согласно настоящему изобретению, можно создавать гистограмму набора признаков и информации градиентов, которые вводятся параллельно, и уменьшать размер схем памяти, которая хранит информацию гистограммы.
Краткое описание чертежей
[0010] Фиг. 1 является схемой, иллюстрирующей пример модели в виде дерева решений.
Фиг. 2 является схемой, иллюстрирующей пример модульной конфигурации обучающего и различающего устройства согласно первому варианту осуществления.
Фиг. 3 является схемой, иллюстрирующей пример конфигурации памяти указателей.
Фиг. 4 является схемой, иллюстрирующей пример модульной конфигурации обучающего модуля.
Фиг. 5 является схемой, иллюстрирующей работу модуля во время инициализации обучающего и различающего устройства согласно первому варианту осуществления.
Фиг. 6 является схемой, иллюстрирующей работу модуля в случае определения параметров узла на глубине 0, в узле 0 обучающего и различающего устройства согласно первому варианту осуществления.
Фиг. 7 является схемой, иллюстрирующей работу модуля во время ветвления на глубине 0, в узле 0 обучающего и различающего устройства согласно первому варианту осуществления.
Фиг. 8 является схемой, иллюстрирующей работу модуля в случае определения параметров узла на глубине 1, в узле 0 обучающего и различающего устройства согласно первому варианту осуществления.
Фиг. 9 является схемой, иллюстрирующей работу модуля во время ветвления на глубине 1, в узле 0 обучающего и различающего устройства согласно первому варианту осуществления.
Фиг. 10 является схемой, иллюстрирующей работу модуля в случае определения параметров узла на глубине 1, в узле 1 обучающего и различающего устройства согласно первому варианту осуществления.
Фиг. 11 является схемой, иллюстрирующей работу модуля во время ветвления на глубине 1, в узле 1 обучающего и различающего устройства согласно первому варианту осуществления.
Фиг. 12 является схемой, иллюстрирующей работу модуля в случае, в котором ветвление не выполняется в результате определения параметров узла на глубине 1, в узле 1 обучающего и различающего устройства согласно первому варианту осуществления.
Фиг. 13 является схемой, иллюстрирующей работу модуля во время обновления информации состояния всех фрагментов выборочных данных в случае, в котором обучение дерева решений завершается посредством обучающего и различающего устройства согласно первому варианту осуществления.
Фиг. 14 является схемой, иллюстрирующей пример конфигурации памяти моделей обучающего и различающего устройства согласно модификации первого варианта осуществления.
Фиг. 15 является схемой, иллюстрирующей пример конфигурации модуля классификации обучающего и различающего устройства согласно модификации первого варианта осуществления.
Фиг. 16 является схемой, иллюстрирующей пример модульной конфигурации обучающего и различающего устройства, к которому применяется параллелизм данных.
Фиг. 17 является схемой, иллюстрирующей пример конкретной модульной конфигурации обучающего модуля.
Фиг. 18 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления гистограмм градиентов обучающего модуля.
Фиг. 19 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления накопленных градиентов обучающего модуля.
Фиг. 20 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления гистограмм градиентов в случае, в котором реализуется параллелизм данных.
Фиг. 21 является схемой, иллюстрирующей пример модульной конфигурации обучающего модуля обучающего и различающего устройства согласно второму варианту осуществления.
Фиг. 22 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления гистограмм градиентов обучающего модуля согласно второму варианту осуществления.
Фиг. 23 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления гистограмм градиентов в случае, в котором число разделений предположительно равно 3 в обучающем модуле согласно второму варианту осуществления.
Фиг. 24 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления накопленных градиентов обучающего модуля согласно второму варианту осуществления.
Фиг. 25 является схемой, иллюстрирующей пример модульной конфигурации обучающего модуля в случае, в котором число типов наборов признаков предположительно равно 2 в обучающем и различающем устройстве согласно второму варианту осуществления.
Фиг. 26 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления гистограмм градиентов в случае, в котором число типов наборов признаков предположительно равно 2 в обучающем модуле согласно второму варианту осуществления.
Осуществление изобретения
[0011] Далее подробно описываются варианты осуществления обучающего устройства и способа обучения согласно настоящему изобретению со ссылкой на фиг. 1-26. Настоящее изобретение не ограничено нижеприведенными вариантами осуществления. Компоненты в нижеприведенных вариантах осуществления охватывают компонент, который легко предполагается специалистами в данной области техники, практически идентичный компонент и то, что называется "эквивалентом". Дополнительно, компоненты могут различными способами опускаться, заменяться, модифицироваться и комбинироваться без отступления от сущности вариантов осуществления, описанных ниже.
[0012] Первый вариант осуществления
Относительно логики GBDT
В DL, в качестве алгоритма высокопроизводительного машинного обучения, предпринимается попытка реализовывать различитель посредством различных видов жесткой логики, которая, как обнаружено, имеет более высокую эффективность по мощности по сравнению с обработкой с использованием графического процессора (GPU). Тем не менее архитектура GPU тесно совпадает, в частности, с CNN в области техники DL, так что, с учетом скорости, скорость различения, выполняемого посредством программируемой пользователем вентильной матрицы (FPGA), реализованной с помощью логики, не выше скорости GPU. С другой стороны, предпринимается попытка реализовывать жесткую логику FPGA в алгоритме на основе дерева решений, таком как GBDT, и получены сведения в отношении результата с более высокой скоростью, чем GPU. Это обусловлено тем, что, как описано ниже, алгоритм на основе дерева решений не подходит для архитектуры GPU с учетом его признака компоновки данных.
[0013] Анализ касательно обучения отстает от анализа касательно различения в мире. Фактически отсутствуют сообщения в отношении текущих обстоятельств DL, и число сообщений в отношении системы на основе дерева решений является небольшим. В частности, отсутствуют сообщения в отношении обучения посредством GBDT при текущих обстоятельствах, что в данный момент может считаться неразработанной областью техники. Чтобы получать точную модель различения, выбор и расчет набора признаков и выбор гиперпараметра обучающего алгоритма выполняются во время обучения, так что требуется огромное количество подборов. В частности, в случае, в котором имеется большой объем обучающих данных, скорость обработки обучения значительно влияет на точность конечной модели на практике. Дополнительно, в области техники, в которой требуется работа в реальном времени для обеспечения соответствия изменениям окружающей среды, к примеру, в робототехнике, высокочастотной торговле (HFT) и торгах в реальном времени (RTB), скорость непосредственно связана с производительностью. Таким образом, в случае, в котором высокоскоростная обработка обучения достигается посредством GBDT с высокой точностью, может рассматриваться возможность существенно повышать производительность системы с использованием GBDT в конечном счете.
[0014] Подобие GBDT для FPGA
Далее описывается, с учетом подобия GBDT для FPGA, то, почему скорость обработки дерева решений или GBDT посредством GPU не является высокой, и то, почему скорость его обработки посредством FPGA является высокой.
[0015] Во-первых, приводится описание с точки зрения того, что GBDT представляет собой алгоритм с использованием бустинга. В случае случайного леса (RF) с использованием ансамблевого обучения в области техники дерева решений, деревья не зависят друг от друга, так что параллелизация легко выполняется посредством GPU. Тем не менее, GBDT представляет собой способ соединения большого числа деревьев с использованием бустинга, так что обучение последующего дерева не может начинаться до тех пор, пока результат предыдущего дерева не получается. Таким образом, обработка представляет собой последовательную обработку, и важно обучать каждое дерево на высокой скорости в максимально возможной степени. С другой стороны, в RF, вариант увеличения общей скорости обучения может использоваться посредством увеличения скорости обучения для большого числа деревьев параллельно, даже если скорость обучения для каждого дерева является низкой. Таким образом, также в случае использования GPU, можно считать, что проблема задержки при доступе динамического оперативного запоминающего устройства (DRAM) (описывается ниже) может скрываться в определенной степени.
[0016] Далее приводится описание с точки зрения предела скорости доступа (в частности, при произвольном доступе) GPU-устройства к оперативному запоминающему устройству (RAM). Статическое оперативное запоминающее устройство (SRAM), встроенное в FPGA, может значительно увеличивать ширину шины RAM в FPGA, так что, например, 3,2 [ТБ/секунда] достигается следующим образом даже в случае использования XC7k325T, изготовленного компанией Xilinx Inc., в качестве FPGA со средними характеристиками. Емкость встроенного RAM составляет 16 [Мбит].
[0017] 445 BRAM * 36 битов * 100 МГц * 2 порта=445 * 36 * 2 * 100 * 10^6/10^12=3,2 ТБ/секунда
[0018] В случае использования VU9P, изготовленного компанией Xilinx Inc., в качестве высокопроизводительной FPGA, 6,9 [ТБ/секунда] достигается. Емкость встроенного RAM 270 составляет [Мбит].
[0019] 960 URAM * 36 битов * 100 МГц * 2 порта=960 * 36 * 2 * 100 * 10^6/10^12=6,9 ТБ/секунда
[0020] Эти значения получаются в случае инструктирования тактовой частоте составлять 100 [МГц], но фактически, операция может выполняться приблизительно при 200-500 [МГц] посредством создания схемной конфигурации, и предельная скорость передачи информации повышается в несколько раз. С другой стороны, RAM текущего поколения, соединенное с центральным процессором (CPU), представляет собой стандарт с удвоенной скоростью передачи данных версия 4 (DDR4), но скорость передачи информации, сформированная с одним запоминающим модулем с двухрядным расположением выводов (DIMM), остается равной 25,6 [ГБ/с], как описано ниже. Даже с чередующейся конфигурацией (256-битовая ширина) из четырех DIMM, скорость передачи информации достигает приблизительно 100 [ГБ/с]. В случае, в котором стандарт изготовления микросхем DDR4 представляет собой DDR4-3200 (ширина шины в 64 бита, 1 DIMM), следующее выражение удовлетворяется.
[0021] 200 МГц * 2 (DDR) * 64=200 * 10^6 * 2 * 64/10^9=25,6 ГБ/с
[0022] Скорость передачи информации стандарта с удвоенной скоростью передачи данных для графики версия 5 (GDDR5), смонтированного на GPU, приблизительно в четыре раза больше скорости передачи информации DDR4, но составляет приблизительно 400 [ГБ/с] максимум.
[0023] Таким образом, скорости передачи информации значительно отличаются друг от друга между RAM в FPGA и внешней памятью GPU и CPU. Хотя выше описывается случай последовательного доступа к адресу, время доступа во время произвольного доступа работает более существенно. Встроенное RAM FPGA представляет собой SRAM, так что задержка при доступе составляет 1 синхросигнал как при последовательном доступе, так и при произвольном доступе. Тем не менее каждое из DDR4 и GDDR5 представляет собой DRAM, так что задержка увеличивается в случае осуществления доступа к различным столбцам вследствие считывающего усилителя. Например, типичная задержка строба адреса столбца (CAS-задержка) составляет 16 синхросигналов в RAM DDR4, и вкратце, пропускная способность вычисляется как составляющая 1/16 от пропускной способности последовательного доступа.
[0024] В случае CNN, фрагменты данных смежных пикселов последовательно обрабатываются, так что задержка произвольного доступа не является существенной проблемой. Тем не менее, в случае дерева решений, адреса исходных данных соответствующих ветвей становятся прерывистыми по мере того, как ветвление продолжается, что по существу становится произвольным доступом. Таким образом, в случае сохранения данных в DRAM, его пропускная способность приводит к узкому месту, и скорость значительно понижается. GPU включает в себя кэш для того, чтобы подавлять снижение производительности в таком случае, но дерево решений по существу представляет собой алгоритм осуществления доступа ко всем данным, так что отсутствует локальность в доступе к данным, и эффект кэша практически на демонстрируется. В структуре GPU, GPU включает в себя совместно используемую память, включающее в себя SRAM, назначенную каждому арифметическому ядру (SM), и высокоскоростная обработка может выполняться посредством использования совместно используемой памяти в некоторых случаях. Тем не менее, в случае, в котором емкость каждого SM является небольшой, т.е. 16-48 [КБ], и доступ выполняется через SM, вызывается большая задержка. Далее представляется тестовое вычисление емкости совместно используемой памяти в случае Nvidia K80 в качестве дорогого крупномасштабного GPU в настоящее время.
[0025] K80=2 * 13 SMX=26 SMX=4 992 CUDA-ядра
26 * 48 * 8=9 Мбит
[0026] Как описано выше, даже в крупномасштабном GPU, который стоит сотни тысяч иен, емкость совместно используемой памяти составляет только 9 [Мбит], что является слишком небольшим. Дополнительно, в случае GPU, как описано выше, поскольку SM, которое выполняет обработку, не может непосредственно осуществлять доступ к совместно используемой памяти другого SM, имеется такое ограничение, что высокоскоростное кодирование затруднительно выполнять в случае использования для обучения дерева решений.
[0027] Как описано выше, при условии, что данные сохраняются в SRAM на FPGA, можно считать, что FPGA может реализовывать обучающий алгоритм GBDT с более высокой скоростью по сравнению с GPU.
[0028] Алгоритм GBDT
Фиг. 1 является схемой, иллюстрирующей пример модели в виде дерева решений. Далее описывается основная логика GBDT со ссылкой на выражения (1)-(22) и фиг. 1.
[0029] GBDT представляет собой способ контролируемого обучения, и контролируемое обучение представляет собой обработку оптимизации целевой функции obj(θ), включающей в себя функцию L(θ) потерь, представляющую степень подгонки относительно обучающих данных, и член Ω(θ) регуляризации, представляющий сложность обученной модели с использованием некоторой шкалы, как представлено посредством следующего выражения (1). Член Ω(θ) регуляризации имеет роль недопущения слишком сильного усложнения модели (дерева решений), т.е. повышения обобщающей способности.
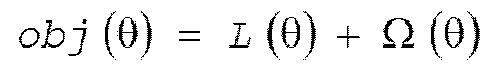 (1)
(1)
[0030] Функция потерь первого члена выражения (1), например, получается посредством суммирования потерь, вычисленных из l функции ошибок для соответствующих фрагментов выборочных данных (обучающих данных), как представлено посредством следующего выражения (2). В этом случае, n является числом фрагментов выборочных данных, i является номером выборки, γ является меткой, и γ (со шляпкой) модели является прогнозным значением.
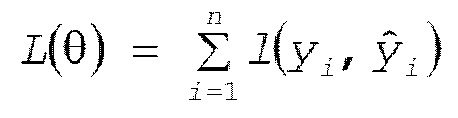 (2)
(2)
[0031] В этом случае, например, в качестве l функции ошибок используется квадратическая функция ошибок или логистическая функция потерь, как представлено посредством следующего выражения (3) и выражения (4).

[0032] В качестве члена Ω(θ) регуляризации второго члена выражения (1), например, используется возведенная в квадрат норма параметра θ, как представлено посредством следующего выражения (5). В этом случае, λ является гиперпараметром, представляющим весовой коэффициент регуляризации.
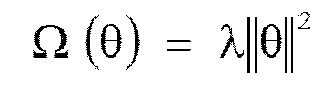 (5)
(5)
[0033] В данном документе рассматривается случай GBDT. Во-первых, прогнозное значение для i-х выборочных данных xi GBDT может представляться посредством следующего выражения (6).
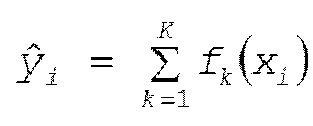 (6)
(6)
[0034] В этом случае, K является общим числом деревьев решений, k является номером дерева решений, fK() является выводом k-го дерева решений, и xi является значением набора признаков выборочных данных, которые должны вводиться. Соответственно, обнаружено, что конечный вывод получается посредством суммирования выводов соответствующих деревьев решений в GBDT, аналогично RF и т.п. Параметр θ представляется как θ = {f1, f2, ..., fK}. Согласно вышеприведенному описанию, целевая функция GBDT представляется посредством следующего выражения (7).
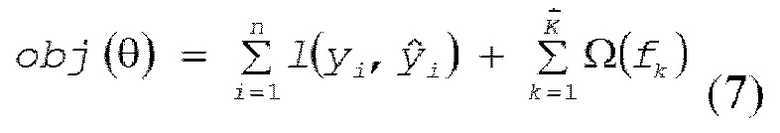
[0035] Обучение выполняется для целевой функции, описанной выше, но способ, такой как стохастический градиентный спуск (SGD), используемый для обучения нейронной сети и т.п., не может использоваться для модели в виде дерева решений. Таким образом, обучение выполняется посредством использования аддитивного обучения (бустинга). При аддитивном обучении, прогнозированное значение в определенном раунде t (число обучений, число моделей в виде дерева решений) представляется посредством следующего выражения (8).
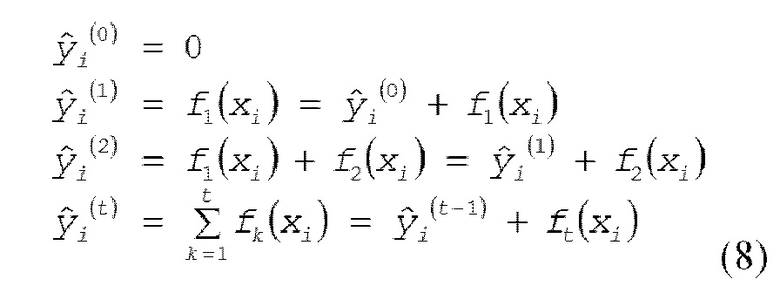
[0036] Из выражения (8) обнаружено, что (вывод) дерева ft(xi) решений должен получаться в определенном раунде t. С другой стороны, не требуется рассматривать другие раунды в определенном раунде t. Таким образом, нижеприведенное описание рассматривает раунд t. Целевая функция в раунде t представляется посредством следующего выражения (9).

[0037] В этом случае, разложение в ряд Тейлора (усеченное в члене второго порядка) целевой функции в раунде t представляется посредством следующего выражения (10).
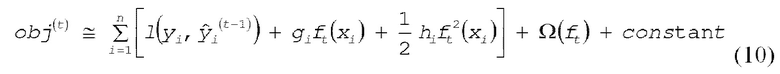
[0038] В этом случае, в выражении (10) фрагменты gi и hi информации градиентов представляются посредством следующего выражения (11).

[0039] Когда постоянный член игнорируется в выражении (10), целевая функция в раунде t представляется посредством следующего выражения (12).

[0040] В выражении (12) целевая функция в раунде t представляется посредством члена регуляризации и значения, полученного посредством выполнения дифференцирования первого порядка и дифференцирования второго порядка для функции ошибок посредством прогнозированного значения в предыдущем раунде, так что обнаружено, что может применяться функция ошибок, для которой могут выполняться дифференцирование первого порядка и дифференцирование второго порядка.
[0041] Далее рассматривается модель в виде дерева решений. Фиг. 1 иллюстрирует пример модели в виде дерева решений. Модель в виде дерева решений включает в себя узлы и листья. В узле, ввод вводится в следующий узел или лист при определенном условии ветвления, и лист имеет весовой коэффициент листа, который становится выводом, соответствующим вводу. Например, фиг. 1 иллюстрирует тот факт, что весовой коэффициент W2 листа для "листа 2" составляет "-1".
[0042] Модель в виде дерева решений формулируется так, как представлено посредством следующего выражения (13).
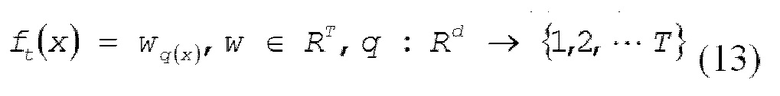
[0043] В выражении (13) w представляет весовой коэффициент листа, и q представляет структуру дерева. Таким образом, ввод (выборочные данные x) назначается любому из листьев в зависимости от структуры q дерева, и весовой коэффициент листа для листа выводится.
[0044] В этом случае, сложность модели в виде дерева решений задается так, как представлено посредством следующего выражения (14).
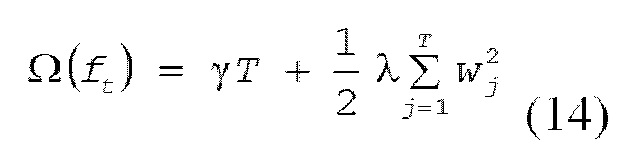
[0045] В выражении (14), первый член представляет сложность вследствие числа листьев, и второй член представляет возведенную в квадрат норму весового коэффициента листа; γ является гиперпараметром для управления важностью члена регуляризации. На основе вышеприведенного описания, целевая функция в раунде t организуется так, как представлено посредством следующего выражения (15).

[0046] Тем не менее в выражении (15), Ij, Gj и Hj представляются посредством следующего выражения (16).

[0047] Из выражения (15), целевая функция в определенном раунде t является квадратической функцией, связанной с весовым коэффициентом w листа, и минимальное значение квадратической функции и ее условие типично представляются посредством следующего выражения (17).

[0048] Таким образом, когда структура q дерева решений в определенном раунде t определяется, его целевая функция и весовой коэффициент листа представляются посредством следующего выражения (18).
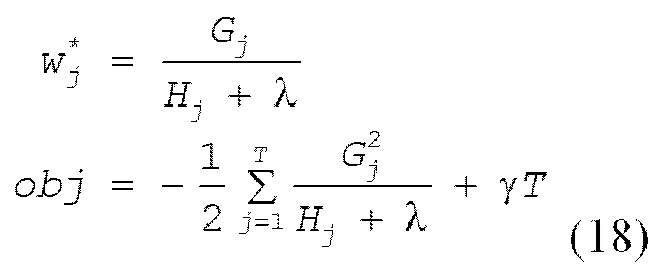
[0049] В этот момент, весовой коэффициент листа может вычисляться в то время, когда структура дерева решений определяется в определенном раунде. Далее описывается процедура обучения структуры дерева решений.
[0050] Способы обучения структуры дерева решений включают в себя жадный метод (жадный алгоритм). Жадный метод представляют собой алгоритм начала древовидной структуры с глубины 0 и обучения структуры дерева решений посредством вычисления количественного показателя ветвления (усиления) в каждом узле, чтобы определять то, следует или нет ветвиться. Количественный показатель ветвления получается посредством следующего выражения (19).

[0051] В этом случае, каждое из GL и HL является суммой информации градиентов выборки, ответвляющейся в левый узел, каждое из GR и HR является суммой информации градиентов выборки, ответвляющейся в правый узел, и γ является членом регуляризации. Первый член в [] выражения (19) представляет собой количественный показатель (целевую функцию) выборочных данных, ответвляющихся в левый узел, второй член представляет собой количественный показатель выборочных данных, ответвляющихся в правый узел, и третий член представляет собой количественный показатель в случае, в котором выборочные данные не ветвятся, что представляет степень улучшения целевой функции вследствие ветвления.
[0052] Количественный показатель ветвления, представленный посредством выражения (19), описанного выше, представляет добротность во время ветвления с определенным пороговым значением определенного набора признаков, но оптимальное условие не может определяться на основе одного количественного показателя ветвления. Таким образом, в жадном методе, количественный показатель ветвления получается для всех возможных вариантов пороговых значений всех наборов признаков, чтобы находить условие, при котором количественный показатель ветвления является наибольшим. Жадный метод представляет собой очень простой алгоритм, как описано выше, но его затраты на вычисление являются высокими, поскольку количественный показатель ветвления получается для всех возможных вариантов пороговых значений всех наборов признаков. Таким образом, для библиотеки, такой как XGBoost (описывается ниже), создается способ уменьшения затрат на вычисление при поддержании производительности.
[0053] Относительно XGBoost
Далее описывается XGBoost, который известен в качестве библиотеки GBDT. В обучающем алгоритме XGBoost, создаются два аспекта, т.е. уменьшение возможных вариантов пороговых значений и обработка отсутствующего значения.
[0054] Во-первых, далее описывается уменьшение возможных вариантов пороговых значений. Жадный метод, описанный выше, имеет такую проблему, что затраты на вычисление являются высокими. В XGBoost, число возможных вариантов пороговых значений уменьшается за счет способа эскиза взвешенных квантилей. В этом способе, сумма информации градиентов выборочных данных, ответвляющихся влево и вправо, является важной при вычислении количественного показателя ветвления (усиления), и только пороговое значение, при котором сумма информации градиентов варьируется с постоянным отношением, принудительно задается в качестве возможного варианта, поиск которого должен выполняться. В частности, используется градиент h второго порядка выборки. При условии, что число размерностей набора признаков составляет f, совокупность набор набора признаков и градиента h второго порядка выборочных данных представляются посредством следующего выражения (20).

[0055] Функция rf ранга задается так, как представлено посредством следующего выражения (21).
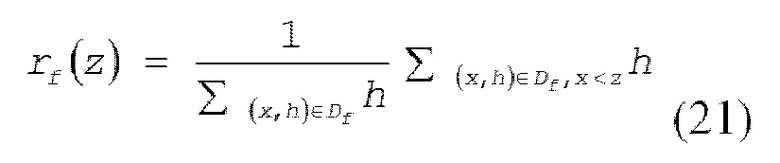
[0056] В этом случае, z является возможным вариантом порогового значения. Функция rf ранга в выражении (21) представляет отношение суммы градиентов второго порядка выборочных данных, меньшей определенного возможного варианта порогового значения, к сумме градиентов второго порядка всех фрагментов выборочных данных. В конечном счете, совокупность определенных возможных вариантов {sf1, sf2,…, SfL} пороговых значений должен получаться для набора признаков, представленного посредством размерности f, которая получается посредством следующего выражения (22).
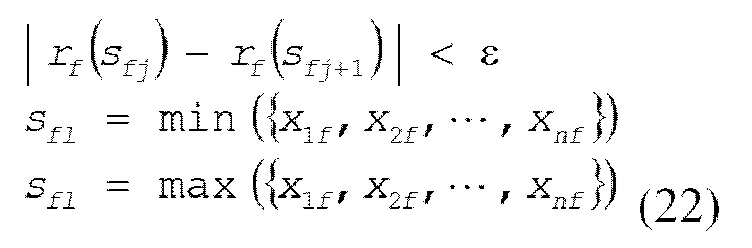
[0057] В этом случае, ε представляет собой параметр для определения степени уменьшения возможных вариантов пороговых значений, и может получаться примерно 1/ε возможных вариантов пороговых значений.
[0058] В качестве эскиза взвешенных квантилей, могут рассматриваться два шаблона, т.е. глобальный шаблон, в котором эскиз взвешенных квантилей выполняется в первом узле дерева решений (совместно выполняется для всех фрагментов выборочных данных), и локальный шаблон, в котором эскиз взвешенных квантилей выполняется в каждом узле (выполняется каждый раз для выборки, назначенной соответствующему узлу). Обнаружено, что локальный шаблон является соответствующим с учетом обобщающей способности, так что локальный шаблон используется в XGBoost.
[0059] Далее описывается обработка отсутствующего значения. Типично отсутствует эффективный способ обработки отсутствующего значения выборочных данных, который должен вводиться в области техники машинного обучения, независимо от GBDT и дерева решений. Предусмотрен способ дополнения отсутствующего значения со средним значением, медианой, совместным фильтром и т.п., и способ исключения набора признаков, включающего в себя большое число отсутствующих значений, например, но эти способы успешно реализуются не в очень большом числе случаев с учетом производительности. Тем не менее, структурированные данные зачастую включают в себя отсутствующее значение, так что некоторый показатель требуется при практическом применении.
[0060] В XGBoost, обучающий алгоритм создается для того, чтобы непосредственно обрабатывать выборочные данные, включающие в себя отсутствующее значение. Он представляет собой способ получения количественного показателя в то время, когда все фрагменты данных отсутствующего значения назначаются любому из левого и правого узлов при получении количественного показателя ветвления в узле. В случае выполнения эскиза взвешенных квантилей, описанного выше, возможный вариант порогового значения может получаться для набора, за исключением выборочных данных, включающих в себя отсутствующее значение.
[0061] Относительно LightGBM
Далее описывается LightGBM в качестве библиотеки GBDT. LightGBM использует быстрый алгоритм с использованием квантования набора признаков, что называется "группированием в элементы разрешения", для предварительной обработки и использования GPU для вычисления количественного показателя ветвления. Производительность LightGBM является практически идентичной производительности XGBoost, а скорость обучения LightGBM в несколько раз превышает скорость обучения XGBoost. В последние годы, число пользователей LightGBM растет.
[0062] Во-первых, далее описывается квантование набора признаков. Когда набор данных является крупномасштабным, количественный показатель ветвления должен вычисляться для большого числа возможных вариантов пороговых значений. В LightGBM, число возможных вариантов пороговых значений уменьшается посредством квантования набора признаков в качестве предварительной обработки обучения. Дополнительно, вследствие квантования, значения и число возможных вариантов пороговых значений не варьируются для каждого узла, как в XGBoost, так что LightGBM представляет собой обязательную обработку в случае использования GPU.
[0063] Различные исследования проведены для квантования набора признаков с названием "группирование в элементы разрешения". В LightGBM, набор признаков разделяется на k элементов разрешения, и только k возможных вариантов пороговых значений присутствуют; k равно 255, 63 и 15, например, и производительность или скорость обучения варьируется в зависимости от набора данных.
[0064] Вычисление количественного показателя ветвления упрощается вследствие квантования набора признаков. В частности, возможный вариант порогового значения становится простым квантованным значением. Таким образом, достаточно создавать гистограмму градиента первого порядка и градиента второго порядка для каждого набора признаков и получать количественный показатель ветвления для каждого элемента разрешения (квантованного значения). Это называется "гистограммой набора признаков".
[0065] Далее описывается вычисление количественного показателя ветвления с использованием GPU. Шаблонов вычисления количественного показателя ветвления имеется 256 максимум, поскольку набор признаков квантуется, но число фрагментов выборочных данных может превышать десятки тысяч в зависимости от набора данных, так что создание гистограммы преобладает над временем обучения. Как описано выше, гистограмма набора признаков должна получаться при вычислении количественного показателя ветвления. В случае использования GPU, множество подпроцессов должны обновлять идентичную гистограмму, но идентичный элемент разрешения может обновляться в этот момент. Таким образом, должна использоваться атомарная операция, и производительность снижается, когда отношение обновления идентичного элемента разрешения является высоким. Таким образом, в LightGBM, то, какая из гистограмм градиента первого порядка и градиента второго порядка используется для обновления значения, определяется для каждого подпроцесса при создании гистограммы, что понижает частоту обновления идентичного элемента разрешения.
[0066] Конфигурация обучающего и различающего устройства
Фиг. 2 является схемой, иллюстрирующей пример модульной конфигурации обучающего и различающего устройства согласно варианту осуществления. Фиг. 3 является схемой, иллюстрирующей пример конфигурации памяти указателей. Фиг. 4 является схемой, иллюстрирующей пример модульной конфигурации обучающего модуля. Далее описывается модульная конфигурация обучающего и различающего устройства 1 согласно настоящему варианту осуществления со ссылкой на фиг. 2-4.
[0067] Как проиллюстрировано на фиг. 2, обучающее и различающее устройство 1 согласно настоящему варианту осуществления включает в себя CPU 10, обучающий модуль 20 (обучающий блок), память 30 данных, память 40 моделей и модуль 50 классификации (различающий блок). Из них, обучающий модуль 20, память 30 данных, память 40 моделей и модуль 50 классификации сконфигурированы посредством FPGA. CPU 10 может выполнять обмен данными с FPGA через шину. В дополнение к компонентам, проиллюстрированным на фиг. 2, обучающее и различающее устройство 1 может включать в себя другие компоненты, такие как, например, RAM, служащее в качестве рабочей области CPU 10, постоянное запоминающее устройство (ROM,) сохраняющее компьютерную программу и т.п., выполняемую посредством CPU 10, вспомогательное устройство хранения данных, сохраняющее различные виды данных (компьютерную программу и т.п.), и интерфейс связи для обмена данными с внешним устройством.
[0068] CPU 10 представляет собой арифметическое устройство, которое управляет обучением GBDT в целом. CPU 10 включает в себя блок 11 управления. Блок 11 управления управляет соответствующими модулями, включающими в себя обучающий модуль 20, память 30 данных, память 40 моделей и модуль 50 классификации. Блок 11 управления реализуется посредством компьютерной программы, выполняемой посредством CPU 10.
[0069] Обучающий модуль 20 представляет собой аппаратный модуль, который вычисляет номер оптимального набора признаков (в дальнейшем в этом документе также называемое "номером набора признаков" в некоторых случаях) для каждого узла, составляющего дерево решений, и порогового значения, и в случае, в котором узел представляет собой лист, вычисляет весовой коэффициент листа, который должен записываться в память 40 моделей. Как проиллюстрировано на фиг. 4, обучающий модуль 20 также включает в себя модули 21_1, 21_2, ..., и 21_n вычисления усиления (блоки вычисления усиления) и модуль 22 извлечения оптимальных условий (блок извлечения). В этом случае, n является числом, по меньшей мере, равным или большим числа наборов признаков выборочных данных (включающих в себя как обучающие данные, так и различающие данные). В случае указания необязательного модуля вычисления усиления из числа модулей 21_1, 21_2, …, и 21_n вычисления усиления, либо в случае, в котором модули 21_1, 21_2, ..., и 21_n вычисления усиления совместно называются, они упоминаются просто как "модуль 21 вычисления усиления".
[0070] Модуль 21 вычисления усиления представляет собой модуль, который вычисляет количественный показатель ветвления при каждом пороговом значении с использованием выражения (19), описанного выше, для соответствующего набора признаков из числа наборов признаков, включенных в выборочные данные, которые должны вводиться. В этом случае, обучающие данные выборочных данных включают в себя метку (истинное значение) в дополнение к набору признаков, и различающие данные выборочных данных включают в себя набор признаков и не включают в себя метку. Каждый модуль 21 вычисления усиления включает в себя память, которая выполняет операцию для соответствующих гистограмм всех наборов признаков, вводимых за один раз (в 1 синхросигнале), и сохраняет гистограммы и выполняет операцию для всех наборов признаков параллельно. На основе результатов гистограмм, усиления соответствующих наборов признаков вычисляются параллельно. Вследствие этого, обработка может выполняться для всех наборов признаков за один раз или одновременно, так что скорость обработки обучения может значительно повышаться. Этот способ параллельного считывания и обработки всех наборов признаков называется "параллелизмом признаков". Чтобы реализовывать этот способ, память данных должна иметь возможность считывать все набора признаков за один раз (в 1 синхросигнале). Таким образом, этот способ не может реализовываться с памятью, имеющей нормальную ширину данных, такую как 32-битовая или 256-битовая ширина. При использовании программного обеспечения, число битов данных, которые могут обрабатываться посредством CPU за один раз, типично составляет 64 бита максимум, и даже когда число в отношении наборов признаков равно 100, и число битов каждого набора признаков составляет 8 битов, 8000 битов требуются, так что способ вообще не может реализовываться. Таким образом, в предшествующем уровне техники, используется способ сохранения различного набора признаков для каждого адреса памяти (например, 64-битовой ширины, которая может обрабатываться посредством CPU) и сохранения наборов признаков в целом для множества адресов. С другой стороны, настоящий способ включает в себя новый технический контент таким образом, что все набора признаков сохраняются в одном адресе памяти, и все набора признаков считываются посредством одного доступа.
[0071] Как описано выше, в GBDT, обучение дерева решений не может быть параллелизованным. Таким образом, то, как быстро каждое дерево решений обучается, преобладает над скоростью обработки обучения. С другой стороны, в RF для выполнения ансамблевого обучения, отсутствует зависимость между деревьями решений во время обучения, так что обработка обучения для каждого дерева решений может быть легко параллелизована, но ее точность типично меньше точности GBDT. Как описано выше, посредством применения параллелизма признаков, как описано выше, к обучению GBDT, имеющего большую точность, чем точность RF, скорость обработки обучения дерева решений может повышаться.
[0072] Модуль 21 вычисления усиления выводит вычисленный количественный показатель ветвления в модуль 22 извлечения оптимальных условий.
[0073] Модуль 22 извлечения оптимальных условий представляет собой модуль, который принимает ввод каждого количественного показателя ветвления, соответствующего набору признаков, выводимому из каждого модуля 21 вычисления усиления, и извлекает пороговое значение и число набора признаков (номер набора признаков), количественный показатель ветвления которого является наибольшим. Модуль 22 извлечения оптимальных условий записывает извлеченное номер набора признаков и пороговое значение в память 40 моделей в качестве данных условий ветвления соответствующего узла (примера данных узла).
[0074] Память 30 данных представляет собой SRAM, которое сохраняет различные виды данных. Память 30 данных включает в себя память 31 указателей, память 32 признаков и память 33 состояний.
[0075] Память 31 указателей представляет собой память, которая сохраняет адрес назначения хранения выборочных данных, сохраненных в памяти 32 признаков. Как проиллюстрировано на фиг. 3, память 31 указателей включает в себя банк A (область банка) и банк B (область банка). Ниже подробнее поясняется операция разделения области на два банка, включающие в себя банк A и банк B, и сохранения адреса назначения хранения выборочных данных со ссылкой на фиг. 5-13. Память 31 указателей может иметь три или более банков.
[0076] Память 32 признаков представляет собой память, которая сохраняет выборочные данные (включающие в себя обучающие данные и различающие данные).
[0077] Память 33 состояний представляет собой память, которая сохраняет информацию состояния (w, g и h, описанные выше) и информацию метки.
[0078] Память 40 моделей представляет собой SRAM, которое сохраняет данные условий ветвления (номер набора признаков и пороговое значение) для каждого узла дерева решений, флаг листа (информацию флага, пример данных узла), указывающий то, представляет узел собой лист или нет, и весовой коэффициент листа в случае, в котором узел представляет собой лист.
[0079] Модуль 50 классификации представляет собой аппаратный модуль, который распределяет фрагменты выборочных данных для каждого узла и каждого дерева решений. Модуль 50 классификации вычисляет информацию (w, g, h) состояния, которая должна записываться в память 33 состояний.
[0080] Не только при различении (ветвлении) выборочных данных (обучающих данных) при обработке обучения, описанной выше, но также и при обработке различения для выборочных данных (различающих данных), модуль 50 классификации может различать различающие данные с идентичной модульной конфигурацией. Во время обработки различения, обработка, выполняемая посредством модуля 50 классификации, может быть конвейерной за счет совместного считывания всех наборов признаков, и скорость обработки может увеличиваться таким образом, что один фрагмент выборочных данных различается для каждого синхросигнала. С другой стороны, в случае, в котором набора признаков не могут совместно считываться, как описано выше, то, какое из наборов признаков требуется, не может обнаруживаться, если не ветвление в соответствующий узел, так что обработка не может быть конвейерной в форме осуществления доступа к адресу соответствующего набора признаков каждый раз.
[0081] При условии, что предусмотрено множество модулей 50 классификации, описанных выше, множество фрагментов различающих данных могут разделяться (параллелизм данных) для распределения в соответствующие модули 50 классификации, и каждому из модулей 50 классификации может инструктироваться выполнять обработку различения для того, чтобы увеличивать скорость обработки различения.
[0082] Обработка обучения обучающего и различающего устройства
Далее конкретно описывается обработка обучения обучающего и различающего устройства 1 со ссылкой на фиг. 5-13.
[0083] Инициализация
Фиг. 5 является схемой, иллюстрирующей работу модуля во время инициализации обучающего и различающего устройства согласно варианту осуществления. Как проиллюстрировано на фиг. 5, во-первых, блок 11 управления инициализирует память 31 указателей. Например, как проиллюстрировано на фиг. 5, блок 11 управления записывает, в банк A памяти 31 указателей, адреса фрагментов выборочных данных (обучающих данных) в памяти 32 признаков, соответствующих числу фрагментов обучающих данных в порядке (например, в порядке возрастания адреса).
[0084] Все фрагменты обучающих данных не обязательно используются (все адреса не обязательно записываются), и может быть возможным использовать фрагменты обучающих данных, которые случайно выбираются (записывать адреса выбранных фрагментов обучающих данных) на основе вероятности, соответствующей предварительно определенному случайному числу, посредством того, что называется "субдискретизацией данных". Например, в случае, в котором результат субдискретизации данных равен 0,5, половина всех адресов фрагментов обучающих данных может записываться в память 31 указателей (в этом случае, банк A) с половиной вероятности, соответствующей случайному числу. Чтобы формировать случайное число, может использоваться псевдослучайное число, созданное посредством сдвигового регистра с линейной обратной связью (LFSR).
[0085] Все набора признаков фрагментов обучающих данных, используемых для обучения, не обязательно используются, и может быть возможным использовать только набора признаков, которые случайно выбираются (например, выбранную половину этого) на основе вероятности, соответствующей случайному числу аналогично вышеприведенному описанию посредством того, что называется "субдискретизацией признаков". В этом случае, например, в качестве данных наборов признаков, отличных от наборов признаков, выбранных посредством субдискретизации признаков, константы могут выводиться из памяти 32 признаков. Вследствие этого, демонстрируется такой эффект, что обобщающая способность для неизвестных данных (различающих данных) улучшается.
[0086] Определение данных условий ветвления на глубине 0, в узле 0
Фиг. 6 является схемой, иллюстрирующей работу модуля в случае определения параметров узла на глубине 0, в узле 0 обучающего и различающего устройства согласно варианту осуществления. Предполагается, что вершина иерархии дерева решений представляет собой "глубину 0", иерархические уровни ниже вершины упоминаются как "глубина 1", "глубина 2", ..., по порядку, самый левый узел в конкретном иерархическом уровне упоминается как "узел 0", и узлы справа от него упоминаются как "узел 1", "узел 2", ..., по порядку.
[0087] Как проиллюстрировано на фиг. 6, во-первых, блок 11 управления передает начальный адрес и конечный адрес в обучающий модуль 20 и инструктирует обучающему модулю 20 начинать обработку посредством триггера. Обучающий модуль 20 указывает адрес целевого фрагмента обучающих данных из памяти 31 указателей (банка A) на основе начального адреса и конечного адреса, считывает обучающие данные (набор признаков) из памяти 32 признаков и считывает информацию (w, g, h) состояния из памяти 33 состояний на основе адреса.
[0088] В этом случае, как описано выше, каждый модуль 21 вычисления усиления обучающего модуля 20 вычисляет гистограмму соответствующего набора признаков, сохраняет гистограмму в своем SRAM и вычисляет количественный показатель ветвления при каждом пороговом значении на основе результата гистограммы. Модуль 22 извлечения оптимальных условий обучающего модуля 20 принимает ввод количественного показателя ветвления, соответствующего каждому набору признаков, выводимому из модуля 21 вычисления усиления, и извлекает пороговое значение и число набора признаков (номер набора признаков), количественный показатель ветвления которого является наибольшим. Модуль 22 извлечения оптимальных условий затем записывает извлеченный номер набора признаков и пороговое значение в память 40 моделей в качестве данных условий ветвления соответствующего узла (глубины 0, узла 0). В этот момент, модуль 22 извлечения оптимальных условий задает флаг листа равным "0", чтобы указывать то, что ветвление дополнительно выполняется из узла (глубины 0, узла 0), и записывает данные узла (они могут представлять собой часть данных условий ветвления) в память 40 моделей.
[0089] Обучающий модуль 20 выполняет операцию, описанную выше, посредством указания адресов фрагментов обучающих данных, записываемых в банк A по порядку, и считывания соответствующих фрагментов обучающих данных из памяти 32 признаков на основе адресов.
[0090] Обработка ветвления данных на глубине 0, в узле 0
Фиг. 7 является схемой, иллюстрирующей работу модуля во время ветвления на глубине 0, в узле 0 обучающего и различающего устройства согласно варианту осуществления.
[0091] Как проиллюстрировано на фиг. 7, блок 11 управления передает начальный адрес и конечный адрес в модуль 50 классификации и инструктирует модулю 50 классификации начинать обработку посредством триггера. Модуль 50 классификации указывает адрес целевых обучающих данных из памяти 31 указателей (банка A) на основе начального адреса и конечного адреса и считывает обучающие данные (набор признаков) из памяти 32 признаков на основе адреса. Модуль 50 классификации также считывает данные условий ветвления (номер набора признаков, пороговое значение) соответствующего узла (глубины 0, узла 0) из памяти 40 моделей. Модуль 50 классификации определяет то, следует инструктировать считываемым выборочным данным ветвиться в левую сторону или в правую сторону узла (глубины 0, узла 0), в соответствии с данными условий ветвления, и на основе результата определения, модуль 50 классификации записывает адрес обучающих данных в памяти 32 признаков в другой банк (записывающий банк) (в этом случае, банк B) (область банка для записи), отличающийся от считывающего банка (в этом случае, банка A) (области банка для считывания) памяти 31 указателей.
[0092] В этот момент, если определяется то, что ветвление выполняется в левую сторону узла, модуль 50 классификации записывает адрес обучающих данных в порядке возрастания адреса в банке B, как проиллюстрировано на фиг. 7. Если определяется то, что ветвление выполняется в правую сторону узла, модуль 50 классификации записывает адрес обучающих данных в порядке убывания адреса в банке B. Вследствие этого, в записывающем банке (в банке B), адрес обучающих данных, ответвляющихся в левую сторону узла, записывается в качестве младшего адреса, и адрес обучающих данных, ответвляющихся в правую сторону узла, записывается в качестве старшего адреса, с четким разделением. Альтернативно, в записывающем банке, адрес обучающих данных, ответвляющихся в левую сторону узла, может записываться в качестве старшего адреса, и адрес обучающих данных, ответвляющихся в правую сторону узла, может записываться в качестве младшего адреса, с разделением.
[0093] Таким образом, два банка, т.е. банк A и банк B сконфигурированы в памяти 31 указателей, как описано выше, и память может эффективно использоваться посредством попеременного выполнения считывания и записи в нем, хотя емкость SRAM в FPGA ограничена. В качестве упрощенного способа, предусмотрен собой способ конфигурирования каждой из памяти 32 признаков и памяти 33 состояний таким образом, что они имеют два банка. Тем не менее, данные, указывающие адрес в памяти 32 признаков, типично меньше выборочных данных, так что использование памяти может дополнительно снижаться посредством способа подготовки памяти 31 указателей таким образом, чтобы косвенно указывать адрес, аналогично настоящему варианту осуществления.
[0094] В качестве операции, описанной выше, модуль 50 классификации выполняет обработку ветвления для всех фрагментов обучающих данных. Тем не менее после того, как обработка ветвления завершается, соответствующие числа фрагментов обучающих данных, разделяемых в левую сторону и правую сторону узла (глубины 0, узла 0), не являются идентичными, так что модуль 50 классификации возвращает, в блок 11 управления, адрес (промежуточный адрес) в записывающем банке (в банке B), соответствующий границе между адресами обучающих данных, ответвляющихся в левую сторону, и адреса обучающих данных, ответвляющихся в правую сторону. Промежуточный адрес используется в следующей обработке ветвления.
[0095] Определение данных условий ветвления на глубине 1, в узле 0
Фиг. 8 является схемой, иллюстрирующей работу модуля в случае определения параметров узла на глубине 1, в узле 0 обучающего и различающего устройства согласно варианту осуществления. Работа является по существу идентичной работе при обработке определения данных условий ветвления на глубине 0, в узле 0, проиллюстрированной на фиг. 6, но иерархический уровень целевого узла изменяется (с глубины 0 на глубину 1), так что роли банка A и банка B в памяти 31 указателей изменяются на противоположные. В частности, банк B служит в качестве считывающего банка, и банк A служит в качестве записывающего банка (см. фиг. 9).
[0096] Как проиллюстрировано на фиг. 8, блок 11 управления передает начальный адрес и конечный адрес в обучающий модуль 20 на основе промежуточного адреса, принимаемого из модуля 50 классификации через обработку на глубине 0, и инструктирует обучающему модулю 20 начинать обработку посредством триггера. Обучающий модуль 20 указывает адрес целевых обучающих данных из памяти 31 указателей (банка B) на основе начального адреса и конечного адреса, считывает обучающие данные (набор признаков) из памяти 32 признаков на основе адреса и считывает информацию (w, g, h) состояния из памяти 33 состояний. В частности, как проиллюстрировано на фиг. 8, обучающий модуль 20 указывает адреса в порядке с левой стороны (с младшего адреса) до промежуточного адреса в банке B.
[0097] В этом случае, как описано выше, каждый модуль 21 вычисления усиления обучающего модуля 20 сохраняет набор признаков считываемых обучающих данных в своем SRAM и вычисляет количественный показатель ветвления при каждом пороговом значении. Модуль 22 извлечения оптимальных условий обучающего модуля 20 принимает ввод количественного показателя ветвления, соответствующего каждому набору признаков, выводимому из модуля 21 вычисления усиления, и извлекает пороговое значение и число набора признаков (номер набора признаков), количественный показатель ветвления которого является наибольшим. Модуль 22 извлечения оптимальных условий затем записывает извлеченное номер набора признаков и пороговое значение в память 40 моделей в качестве данных условий ветвления соответствующего узла (глубины 1, узла 0). В этот момент, модуль 22 извлечения оптимальных условий задает флаг листа равным "0", чтобы указывать то, что ветвление дополнительно выполняется из узла (глубины 1, узла 0), и записывает данные узла (они могут представлять собой часть данных условий ветвления) в память 40 моделей.
[0098] Обучающий модуль 20 выполняет операцию, описанную выше, посредством указания адресов в порядке с левой стороны (с младшего адреса) до промежуточного адреса в банке B и считывания каждого фрагмента обучающих данных из памяти 32 признаков на основе адресов.
[0099] Обработка ветвления данных на глубине 1, в узле 0
Фиг. 9 является схемой, иллюстрирующей работу модуля во время ветвления на глубине 1, в узле 0 обучающего и различающего устройства согласно варианту осуществления.
[0100] Как проиллюстрировано на фиг. 9, блок 11 управления передает начальный адрес и конечный адрес в модуль 50 классификации на основе промежуточного адреса, принимаемого из модуля 50 классификации через обработку на глубине 0, и инструктирует модулю 50 классификации начинать обработку посредством триггера. Модуль 50 классификации указывает адрес целевых обучающих данных с левой стороны памяти 31 указателей (банка B) на основе начального адреса и конечного адреса и считывает обучающие данные (набор признаков) из памяти 32 признаков на основе адреса. Модуль 50 классификации также считывает данные условий ветвления (номер набора признаков, пороговое значение) соответствующего узла (глубины 1, узла 0) из памяти 40 моделей. Модуль 50 классификации определяет то, следует инструктировать считываемым выборочным данным ветвиться в левую сторону или в правую сторону узла (глубины 1, узла 0), в соответствии с данными условий ветвления, и на основе результата определения, модуль 50 классификации записывает адрес обучающих данных в памяти 32 признаков в другой банк (записывающий банк) (в этом случае, банк A) (область банка для записи), отличающийся от считывающего банка (в этом случае, банка B) (области банка для считывания) памяти 31 указателей.
[0101] В этот момент, если определяется то, что ветвление выполняется в левую сторону узла, модуль 50 классификации записывает адрес обучающих данных в порядке возрастания адреса в банке A, как проиллюстрировано на фиг. 9. Если определяется то, что ветвление выполняется в правую сторону узла, модуль 50 классификации записывает адрес обучающих данных в порядке убывания адреса в банке A. Вследствие этого, в записывающем банке (в банке A), адрес обучающих данных, ответвляющихся в левую сторону узла, записывается в качестве младшего адреса, и адрес обучающих данных, ответвляющихся в правую сторону узла, записывается в качестве старшего адреса, с четким разделением. Альтернативно, в записывающем банке, адрес обучающих данных, ответвляющихся в левую сторону узла, может записываться в качестве старшего адреса, и адрес обучающих данных, ответвляющихся в правую сторону узла, может записываться в качестве младшего адреса, с разделением.
[0102] В качестве операции, описанной выше, модуль 50 классификации выполняет обработку ветвления для фрагмента обучающих данных, указанного посредством адреса, записываемого слева от промежуточного адреса в банке B из всех фрагментов обучающих данных. Тем не менее после того, как обработка ветвления завершается, соответствующие числа фрагментов обучающих данных, разделяемых в левую сторону и правую сторону узла (глубины 1, узла 0), не являются идентичными, так что модуль 50 классификации возвращает, в блок 11 управления, адрес (промежуточный адрес) в записывающем банке (в банке A), соответствующий середине адресов обучающих данных, ответвляющихся в левую сторону, и адреса обучающих данных, ответвляющихся в правую сторону. Промежуточный адрес используется в следующей обработке ветвления.
[0103] Определение данных условий ветвления на глубине 1, в узле 1
Фиг. 10 является схемой, иллюстрирующей работу модуля в случае определения параметров узла на глубине 1, в узле 1 обучающего и различающего устройства согласно варианту осуществления. Аналогично случаю по фиг. 8, иерархический уровень является идентичным иерархическому уровню узла на глубине 1, в узле 0, так что банк B служит в качестве считывающего банка, и банк A служит в качестве записывающего банка (см. фиг. 11).
[0104] Как проиллюстрировано на фиг. 10, блок 11 управления передает начальный адрес и конечный адрес в обучающий модуль 20 на основе промежуточного адреса, принимаемого из модуля 50 классификации через обработку на глубине 0, и инструктирует обучающему модулю 20 начинать обработку посредством триггера. Обучающий модуль 20 указывает адрес целевых обучающих данных из памяти 31 указателей (банка B) на основе начального адреса и конечного адреса, считывает обучающие данные (набор признаков) из памяти 32 признаков на основе адреса и считывает информацию (w, g, h) состояния из памяти 33 состояний. В частности, как проиллюстрировано на фиг. 10, обучающий модуль 20 указывает адреса в порядке с правой стороны (со старшего адреса) до промежуточного адреса в банке B.
[0105] В этом случае, как описано выше, каждый модуль 21 вычисления усиления обучающего модуля 20 сохраняет каждое набор признаков считываемых обучающих данных в своем SRAM и вычисляет количественный показатель ветвления при каждом пороговом значении. Модуль 22 извлечения оптимальных условий обучающего модуля 20 принимает ввод количественного показателя ветвления, соответствующего каждому набору признаков, выводимому из модуля 21 вычисления усиления, и извлекает пороговое значение и число набора признаков (номер набора признаков), количественный показатель ветвления которого является наибольшим. Модуль 22 извлечения оптимальных условий затем записывает извлеченное номер набора признаков и пороговое значение в память 40 моделей в качестве данных условий ветвления соответствующего узла (глубины 1, узла 1). В этот момент, модуль 22 извлечения оптимальных условий задает флаг листа равным "0", чтобы указывать то, что ветвление дополнительно выполняется из узла (глубины 1, узла 1), и записывает данные узла (они могут представлять собой часть данных условий ветвления) в память 40 моделей.
[0106] Обучающий модуль 20 выполняет операцию, описанную выше, посредством указания адресов в порядке с правой стороны (со старшего адреса) до промежуточного адреса в банке B и считывания каждого фрагмента обучающих данных из памяти 32 признаков на основе адресов.
[0107] Обработка ветвления данных на глубине 1, в узле 1
Фиг. 11 является схемой, иллюстрирующей работу модуля во время ветвления на глубине 1, в узле 1 обучающего и различающего устройства согласно варианту осуществления.
[0108] Как проиллюстрировано на фиг. 11, блок 11 управления передает начальный адрес и конечный адрес в модуль 50 классификации на основе промежуточного адреса, принимаемого из модуля 50 классификации через обработку на глубине 0, и инструктирует модулю 50 классификации начинать обработку посредством триггера. Модуль 50 классификации указывает адрес целевых обучающих данных с правой стороны памяти 31 указателей (банка B) на основе начального адреса и конечного адреса и считывает обучающие данные (набор признаков) из памяти 32 признаков на основе адреса. Модуль 50 классификации считывает данные условий ветвления (номер набора признаков, пороговое значение) соответствующего узла (глубины 1, узла 1) из памяти 40 моделей. Модуль 50 классификации затем определяет то, следует инструктировать считываемым выборочным данным ветвиться в левую сторону или в правую сторону узла (глубины 1, узла 1), в соответствии с данными условий ветвления, и на основе результата определения, модуль 50 классификации записывает адрес обучающих данных в памяти 32 признаков в другой банк (записывающий банк) (в этом случае, банк A) (область банка для записи), отличающийся от считывающего банка (в этом случае, банка B) (области банка для считывания) памяти 31 указателей.
[0109] В этот момент, если определяется то, что ветвление выполняется в левую сторону узла, модуль 50 классификации записывает адрес обучающих данных в порядке возрастания адреса в банке A, как проиллюстрировано на фиг. 11. Если определяется то, что ветвление выполняется в правую сторону узла, модуль 50 классификации записывает адрес обучающих данных в порядке убывания адреса в банке A. Вследствие этого, в записывающем банке (в банке A), адрес обучающих данных, ответвляющихся в левую сторону узла, записывается в качестве младшего адреса, и адрес обучающих данных, ответвляющихся в правую сторону узла, записывается в качестве старшего адреса, с четким разделением. Альтернативно, в записывающем банке, адрес обучающих данных, ответвляющихся в левую сторону узла, может записываться в качестве старшего адреса, и адрес обучающих данных, ответвляющихся в правую сторону узла, может записываться в качестве младшего адреса, с разделением. В таком случае, операция на фиг. 9 должна выполняться одновременно.
[0110] В качестве операции, описанной выше, модуль 50 классификации выполняет обработку ветвления для фрагмента обучающих данных, указанного посредством адреса, записываемого справа от промежуточного адреса в банке B из всех фрагментов обучающих данных. Тем не менее, после того, как обработка ветвления завершается, соответствующие числа фрагментов обучающих данных, разделяемых в левую сторону и правую сторону узла (глубины 1, узла 1), не являются идентичными, так что модуль 50 классификации возвращает, в блок 11 управления, адрес (промежуточный адрес) в записывающем банке (в банке A), соответствующий середине адресов обучающих данных, ответвляющихся в левую сторону, и адреса обучающих данных, ответвляющихся в правую сторону. Промежуточный адрес используется в следующей обработке ветвления.
[0111] Случай, в котором ветвление не выполняется во время определения данных условий ветвления на глубине 1, в узле 1
Фиг. 12 является схемой, иллюстрирующей работу модуля в случае, в котором ветвление не выполняется в результате определения параметров узла на глубине 1, в узле 1 обучающего и различающего устройства согласно варианту осуществления. Аналогично случаю по фиг. 8, иерархический уровень является идентичным иерархическому уровню узла на глубине 1, в узле 0, так что банк B служит в качестве считывающего банка.
[0112] Как проиллюстрировано на фиг. 12, блок 11 управления передает начальный адрес и конечный адрес в обучающий модуль 20 на основе промежуточного адреса, принимаемого из модуля 50 классификации через обработку на глубине 0, и инструктирует обучающему модулю 20 начинать обработку посредством триггера. Обучающий модуль 20 указывает адрес целевых обучающих данных из памяти 31 указателей (банка B) на основе начального адреса и конечного адреса, считывает обучающие данные (набор признаков) из памяти 32 признаков на основе адреса и считывает информацию (w, g, h) состояния из памяти 33 состояний. В частности, как проиллюстрировано на фиг. 12, обучающий модуль 20 указывает адреса в порядке с правой стороны (со старшего адреса) до промежуточного адреса в банке B.
[0113] Если определяется то, что ветвление не должно дополнительно выполняться из узла (глубины 1, узла 1) на основе вычисленного количественного показателя ветвления и т.п., обучающий модуль 20 задает флаг листа равным "1", записывает данные узла (они могут представлять собой часть данных условий ветвления) в память 40 моделей и передает, в блок 11 управления, тот факт, что флаг листа узла равен "1". Вследствие этого, следует признавать то, что ветвление не выполняется до более низкого иерархического уровня, чем узел (глубина 1, узел 1). В случае, в котором флаг листа узла (глубины 1, узла 1) равен "1", обучающий модуль 20 записывает весовой коэффициент (w) листа (он может представлять собой часть данных условий ветвления) в память 40 моделей вместо численного набора признаков и порогового значения. Вследствие этого, емкость памяти 40 моделей может уменьшаться по сравнению со случаем, в котором емкости обеспечиваются в памяти 40 моделей отдельно.
[0114] Посредством продолжения вышеуказанной обработки, проиллюстрированной на фиг. 6-12, для каждого иерархического уровня (глубины), все дерево решений завершается (дерево решений обучается).
[0115] Случай, в котором обучение дерева решений завершается
Фиг. 13 является схемой, иллюстрирующей работу модуля во время обновления информации состояния всех фрагментов выборочных данных в случае, в котором обучение дерева решений завершается посредством обучающего и различающего устройства согласно варианту осуществления.
[0116] В случае, в котором обучение одного дерева решений, составляющего GBDT, завершается, градиент g первого порядка и градиент h второго порядка, соответствующие функции ошибок каждого фрагмента обучающих данных, и весовой коэффициент w листа для каждого фрагмента обучающих данных должны вычисляться для использования при бустинге (в этом случае, градиентном бустинге) в следующее дерево решений. Как проиллюстрировано на фиг. 13, блок 11 управления инструктирует модулю 50 классификации начинать вычисление, описанное выше, посредством триггера. Модуль 50 классификации выполняет обработку определения ветвления для узлов на всех глубинах (иерархических уровнях) для всех фрагментов обучающих данных и вычисляет весовой коэффициент листа, соответствующий каждому фрагменту обучающих данных. Модуль 50 классификации затем вычисляет информацию (w, g, h) состояния для вычисленного весового коэффициента листа на основе информации метки и записывает информацию (w, g, h) состояния обратно в исходный адрес памяти 33 состояний. Таким образом, обучение следующего дерева решений выполняется посредством использования обновленной информации состояния.
[0117] Как описано выше, в обучающем и различающем устройстве 1 согласно настоящему варианту осуществления, обучающий модуль 20 включает в себя памяти (например, SRAM) для считывания соответствующих наборов признаков входных выборочных данных. Вследствие этого, все набора признаков выборочных данных могут считываться посредством одного доступа, и каждый модуль 21 вычисления усиления может выполнять обработку для всех наборов признаков за один раз, так что скорость обработки обучения для дерева решений может значительно повышаться.
[0118] В обучающем и различающем устройстве 1 согласно настоящему варианту осуществления, два банка, т.е. банк A и банк B сконфигурированы в памяти 31 указателей, и считывание и запись выполняются попеременно. Вследствие этого, память может эффективно использоваться. В качестве упрощенного способа, предусмотрен собой способ конфигурирования каждой из памяти 32 признаков и памяти 33 состояний таким образом, что они имеют два банка. Тем не менее, данные, указывающие адрес в памяти 32 признаков, типично меньше выборочных данных, так что емкость памяти может дополнительно сокращаться посредством способа подготовки памяти 31 указателей таким образом, чтобы косвенно указывать адрес, аналогично настоящему варианту осуществления. Если определяется то, что ветвление выполняется в левую сторону узла, модуль 50 классификации записывает адрес обучающих данных в порядке от младшего адреса в записывающем банке двух банков, и если определяется то, что ветвление выполняется в правую сторону узла, модуль 50 классификации записывает адрес обучающих данных в порядке от старшего адреса в записывающем банке. Вследствие этого, в записывающем банке, адрес обучающих данных, ответвляющихся в левую сторону узла, записывается в качестве младшего адреса, и адрес обучающих данных, ответвляющихся в правую сторону узла, записывается в качестве старшего адреса, с четким разделением.
[0119] Модификация
Фиг. 14 является схемой, иллюстрирующей пример конфигурации памяти моделей обучающего и различающего устройства согласно модификации. Со ссылкой на фиг. 14, далее описывается конфигурация, в которой память предоставляется для каждой глубины (иерархического уровня) дерева решений в памяти 40 моделей обучающего и различающего устройства 1 согласно настоящей модификации.
[0120] Как проиллюстрировано на фиг. 14, память 40 моделей обучающего и различающего устройства 1 согласно настоящей модификации включает в себя память 41_1 для глубины 0, память 41_2 для глубины 1, …, и память 41_m для глубины (m-1) для сохранения данных (в частности, данных условий ветвления) для каждой глубины (иерархического уровня) модельных данных обученного дерева решений. В этом случае, m является числом, по меньшей мере, равным или большим числа глубины (иерархического уровня) модели дерева решений. Таким образом, память 40 моделей включает в себя независимый порт для извлечения данных (данных узла на глубине 0, данных узла на глубине 1…, данных узла на глубине (m-1)) одновременно для каждой глубины (иерархического уровня) модельных данных обученного дерева решений. Вследствие этого, модуль 50 классификации может считывать данные (данные условий ветвления), соответствующие следующему узлу на всех глубинах (иерархических уровнях), параллельно на основе результата ветвления в первом узле дерева решений, и может выполнять обработку ветвления на соответствующих глубинах (иерархических уровнях) одновременно в 1 синхросигнале (конвейерную обработку) для фрагмента выборочных данных (различающих данных) без использования памяти. Вследствие этого, обработка различения, выполняемая посредством модуля 50 классификации, занимает только время, соответствующее числу фрагментов выборочных данных, и скорость обработки различения может значительно повышаться. С другой стороны, в предшествующем уровне техники, выборочные данные копируются в новую область памяти для каждого узла, что влияет на скорость вследствие времени для считывания и записи, выполняемого посредством памяти, и время, требуемое для обработки различения равно (число фрагментов выборочных данных * номер глубины (иерархического уровня)), так что обработка различения согласно настоящей модификации имеет большое преимущество, как описано выше.
[0121] Фиг. 15 является схемой, иллюстрирующей пример конфигурации модуля классификации обучающего и различающего устройства согласно модификации. Как проиллюстрировано на фиг. 15, модуль 50 классификации включает в себя различитель 51_1 узла 0, различитель 51_2 узла 1, различитель 51_3 узла 2, ... Фрагмент выборочных данных для каждого синхросигнала подается из памяти 32 признаков в качестве набора признаков. Как проиллюстрировано на фиг. 15, набор признаков вводится в различитель 51_1 узла 0 сначала, и различитель 51_1 узла 0 принимает данные узла (данные узла на глубине 0) (условие того, следует ветвиться вправо или влево либо нет, и номер набора признаков, которое должно использоваться) из соответствующей памяти 41_1 для глубины 0 памяти 40 моделей. Различитель 51_1 узла 0 различает то, ветвятся либо нет соответствующие выборочные данные вправо или влево, в соответствии с условием. В этом случае, задержка каждой памяти для глубины (памяти 41_1 для глубины 0, памяти 41_2 для глубины 1, памяти 41_3 для глубины 2, ...,) предположительно составляет 1 синхросигнал. На основе результата, полученного посредством различителя 51_1 узла 0, то, ветвятся или нет выборочные данные и в какой номер узла, указывается посредством адреса в следующей памяти 41_2 для глубины 1, и данные соответствующего узла (данные узла на глубине 1) извлекаются и вводятся в различитель 51_2 узла 1.
[0122] Задержка памяти 41_1 для глубины 0 составляет 1 синхросигнал, так что набор признаков аналогично вводится в различитель 51_2 узла 1 с задержкой в 1 синхросигнал. Набор признаков следующих выборочных данных вводится в различитель 51_1 узла 0 с идентичным синхросигналом. Таким образом, посредством выполнения различения через конвейерную обработку, одно дерево решений в целом может различать один фрагмент выборочных данных с 1 синхросигналом при таком предварительном условии, что памяти выполняют вывод одновременно для каждой глубины. Только один адрес требуется для памяти 41_1 для глубины 0, поскольку предусмотрен один узел на глубине 0, два адреса требуются для памяти 41_2 для глубины 1, поскольку предусмотрено два узла на глубине 1, аналогично, четыре адреса требуются для памяти 41_3 для глубины 2, и восемь адресов требуются для памяти для глубины 3 (не проиллюстрировано). Хотя модуль 50 классификации различает все дерево, обучение может выполняться только с использованием различителя 51_1 узла 0 во время обучения узла, чтобы уменьшать размер схем посредством использования идентичной схемы.
[0123] Второй вариант осуществления
Далее описывается обучающее и различающее устройство согласно второму варианту осуществления, главным образом в отношении отличий от обучающего и различающего устройства 1 согласно первому варианту осуществления. Первый вариант осуществления описывает обработку обучения и обработку различения посредством GBDT при условии, что предусмотрено одна память 30 данных, в которой сохраняются выборочные данные. Настоящий вариант осуществления описывает операцию выполнения обработки обучения посредством разделения памяти данных на множество частей для того, чтобы реализовывать параллелизм данных для обработки множества фрагментов выборочных данных параллельно.
[0124] Относительно параллелизма данных
Фиг. 16 является схемой, иллюстрирующей пример модульной конфигурации обучающего и различающего устройства, к которому применяется параллелизм данных. Со ссылкой на фиг. 16, далее описывается конфигурация обучающего и различающего устройства 1a в качестве примера конфигурации для реализации параллелизма данных.
[0125] Чтобы реализовывать параллелизм данных для выборочных данных (обучающих данных или различающих данных), во-первых, память данных может разделяться на два блока памяти 30a и 30b данных, чтобы хранить разделенные фрагменты выборочных данных, как проиллюстрировано на фиг. 16. Хотя не проиллюстрировано в памяти 30b данных по фиг. 16, память 30b данных также включает в себя память 31 указателей, память 32 признаков и память 33 состояний, аналогично памяти 30a данных. Тем не менее, недостаточно просто разделять память, которая хранит выборочные данные, и требуется механизм для выполнения обработки (обработки обучения, обработки различения и т.п.) для разделенных фрагментов выборочных данных параллельно. В примере конфигурации, проиллюстрированном на фиг. 16, число скомпонованных модулей, которые выполняют обработку различения, является идентичным числу разделенных блоков памяти данных. Таким образом, обучающее и различающее устройство 1a включает в себя модули классификации 50a и 50b для выполнения обработки различения для соответствующих фрагментов выборочных данных, сохраненных в двух блоках памяти 30a и 30b данных, параллельно. Если акцентировать внимание на каждом отдельном модуле, при условии, что обработка выполняется посредством параллелизма признаков, конфигурация модуля изменяется незначительно для реализации параллелизма данных, как описано выше, так что ее реализация упрощается.
[0126] Параллелизм данных для увеличения скорости обработки обучения, т.е. обработки, выполняемой посредством обучающего модуля 20, имеет такую проблему, что размер схем увеличивается, поскольку память данных разделяется на две памяти 30a и 30b данных для хранения разделенных фрагментов выборочных данных, и память, которая хранит гистограмму (в дальнейшем в этом документе также называемую "гистограммой градиентов" в некоторых случаях) набора признаков, вычисленного в процессе обработки обучения, и информацию градиентов (см. выражение (11), описанное выше), увеличивается пропорционально числу разделений памяти данных, как описано выше.
[0127] Способ вычисления количественного показателя ветвления с использованием гистограммы градиентов
Во-первых, далее описывается способ вычисления количественного показателя ветвления посредством обучающего модуля 20. В этом случае, набор признаков выборочных данных (в этом случае, обучающих данных) предположительно квантуется таким образом, что оно имеет определенную битовую ширину. Например, в случае, в котором набор признаков составляет 8 битов (значения 256 шаблонов), и число размерностей набора признаков равно 100, обучающий модуль 20 вычисляет количественные показатели ветвления в 256 * 100=25600 шаблонов. В этом случае, число возможных вариантов порогового значения равно 256.
[0128] Чтобы вычислять количественный показатель ветвления, соответствующий определенному условию ветвления (одно пороговое значение, соответствующее одному набору признаков), требуется получать сумму информации градиентов обучающих данных, имеющих набор признаков, равный или больший порогового значения (соответствующего GR и HR в выражении (19), описанном выше), и сумму информации градиентов обучающих данных, имеющих набор признаков, меньший порогового значения (соответствующего GL и HL в выражении (19), описанном выше), из обучающих данных в настоящем узле. В этом случае, как представлено посредством нижеприведенной таблицы 1, далее конкретно описывается случай, в котором число фрагментов обучающих данных равно 4, число размерностей набора признаков равно 1, и его значения составляют 3 шаблона, и информация градиентов представляет собой градиент g первого порядка.
[0129] Как представлено посредством таблицы 1, предусмотрено 3 шаблона наборов признаков, т.е. 0, 1 и 2, так что пороговые значения также равны 0, 1 и 2, сумма информации градиентов при каждом пороговом значении является значением, представленным посредством нижеприведенной таблицы 2, и количественный показатель ветвления, соответствующий каждому из пороговых значений 3 шаблонов, вычисляется.
[0130] Чтобы получать сумму информации градиентов для конкретного порогового значения, требуется обращаться ко всем фрагментам обучающих данных в настоящем узле. Если эта обработка должна выполняться для всех пороговых значений каждый раз, требуется очень большое время обработки. Например, в случае, в котором набор признаков составляет 8 битов (256 шаблонов), также предусмотрено 256 шаблонов пороговых значений, так что сумма информации градиентов должна получаться (число фрагментов обучающих данных в настоящем узле * 256) раз. Требуется очень большое время обработки, так что обработка вычисления количественного показателя ветвления упрощается посредством получения суммы информации градиентов для каждого значения набора признаков (гистограммы градиентов) и общей суммы информации градиентов заранее и приема кумулятивной суммы гистограммы градиентов.
[0131] В случае выборочных данных, представленных посредством таблицы 1, описанной выше, сумма информации градиентов для каждого значения набора признаков (гистограммы градиентов) становится значением, представленным посредством нижеприведенной таблицы 3.
[0132] Общая сумма информации градиентов для каждого значения набора признаков составляет 0,1+0,2+0,1-0,3=0,1. В этом случае, сумма GL информации градиентов получается посредством получения кумулятивной суммы гистограммы градиентов, GR информации градиентов получается посредством вычитания суммы GL информации градиентов из общей суммы информации градиентов, и суммы GL и GR информации градиентов для каждого порогового значения становятся значениями, представленными посредством нижеприведенной таблицы 4.
[0133] При таком способе, достаточно обращаться к обучающим данным в настоящем узле один раз, и после этого, количественные показатели ветвления для всех условий ветвления могут получаться посредством обращения к гистограммам градиентов, соответствующим числу пороговых значений. В случае, в котором набор признаков составляет 8 битов (256 шаблонов), достаточно выполнять обработку (число фрагментов обучающих данных в настоящем узле+256) раз. Вышеописанный случай представляет собой случай, в котором набор признаков имеет одну размерность, но даже когда набор признаков имеет две или более размерностей, идентичная обработка может вычисляться параллельно посредством гистограммы получения градиента для каждой размерности набора признаков. Далее описывается конфигурация и работа для вычисления гистограммы градиентов и получения данных условий ветвления посредством обучающего модуля 20, проиллюстрированного на фиг. 17, конфигурация которого подробнее проиллюстрирована на основе фиг. 4, иллюстрирующего конфигурацию обучающего модуля 20, который выполняет обучение посредством параллелизма признаков в первом варианте осуществления, и дополнительно описывается конфигурация и работа в случае использования конфигурации с параллелизмом данных.
[0134] Пример конфигурации обучающего модуля для получения данных условий ветвления с использованием гистограммы градиентов
Фиг. 17 является схемой, иллюстрирующей пример конкретной модульной конфигурации обучающего модуля. Со ссылкой на фиг. 17, далее описывается конфигурация и работа обучающего модуля 20, представляющего конфигурацию, проиллюстрированную на фиг. 4, подробнее описанном выше.
[0135] Обучающий модуль 20, проиллюстрированный на фиг. 17, включает в себя модули 21_1, 21_2, ..., и 21_n вычисления усиления и модуль 22 извлечения оптимальных условий. В этом случае, n является числом, по меньшей мере, равным или большим числа типов наборов признаков выборочных данных (в этом случае, обучающих данных). В случае указания необязательного модуля вычисления усиления из числа модулей 21_1, 21_2, …, и 21_n вычисления усиления, либо в случае, в котором модули 21_1, 21_2, …, и 21_n вычисления усиления совместно называются, они упоминаются просто как "модуль 21 вычисления усиления".
[0136] Каждый из модулей 21_1-21_1n вычисления усиления представляет собой модуль, который вычисляет количественный показатель ветвления при каждом пороговом значении с использованием выражения (19), описанного выше, для соответствующего набора признаков из числа наборов признаков, включенных в выборочные данные, которые должны вводиться. Модуль 21_1 вычисления усиления включает в себя модуль 61_1 вычисления гистограмм градиентов, модуль 62_1 вычисления накопленных градиентов и модуль 63_1 вычисления.
[0137] Модуль 61_1 вычисления гистограмм градиентов представляет собой модуль, который вычисляет, с использованием каждого значения набора признаков входных выборочных данных в качестве элемента разрешения гистограммы, гистограмму градиентов посредством интегрирования значений информации градиентов, соответствующей выборочным данным.
[0138] Модуль 62_1 вычисления накопленных градиентов представляет собой модуль, который вычисляет суммы информации градиентов (GL, GR, HL, HR) посредством получения кумулятивной суммы гистограммы градиентов для каждого порогового значения набора признаков.
[0139] Модуль 63_1 вычисления представляет собой модуль, который вычисляет количественный показатель ветвления при каждом пороговом значении с использованием выражения (19), описанного выше, и с использованием суммы информации градиентов, вычисленной посредством модуля 62_1 вычисления накопленных градиентов.
[0140] Аналогично, модуль 21_2 вычисления усиления включает в себя модуль 61_2 вычисления гистограмм градиентов, модуль 62_2 вычисления накопленных градиентов и модуль 63_2 вычисления, и это применимо и к модулю 21_n вычисления усиления. В случае указания необязательного модуля вычисления гистограмм градиентов из числа модулей 61_1, 61_2, …, и 61_n вычисления гистограмм градиентов, либо в случае, в котором модули 61_1, 61_2, …, и 61_n вычисления гистограмм градиентов совместно называются, они упоминаются просто как "модуль 61 вычисления гистограмм градиентов". В случае указания необязательного модуля вычисления накопленных градиентов из числа модулей 62_1, 62_2, …, и 62_n вычисления накопленных градиентов, либо в случае, в котором модули 62_1, 62_2, …, и 62_n вычисления накопленных градиентов совместно называются, они упоминаются просто как "модуль 62 вычисления накопленных градиент". В случае указания необязательного модуля вычисления из числа модулей 63_1, 63_2, …, и 63_n вычисления, либо в случае, в котором модули 63_1, 63_2, …, и 63_n вычисления совместно называются, они упоминаются просто как "модуль 63 вычисления".
[0141] Модуль 22 извлечения оптимальных условий представляет собой модуль, который принимает ввод количественного показателя ветвления, соответствующего каждому пороговому значению и каждому набору признаков, выводимому из соответствующих модулей 21 вычисления усиления, и извлекает пороговое значение и число набора признаков (номер набора признаков), количественный показатель ветвления которого является наибольшим. Модуль 22 извлечения оптимальных условий записывает извлеченное номер набора признаков и пороговое значение в память 40 моделей в качестве данных условий ветвления (примера данных узла) соответствующего узла.
[0142] Конфигурация и работа модуля вычисления гистограмм градиентов
Фиг. 18 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления гистограмм градиентов обучающего модуля. Со ссылкой на фиг. 18, далее описывается конфигурация и работа модуля 61 вычисления гистограмм градиентов в обучающем модуле 20. Фиг. 18 иллюстрирует случай, в котором набор признаков предположительно имеет одну размерность, и информация градиентов предположительно включает в себя градиент g первого порядка и градиент h второго порядка, что может называться просто "информацией g градиентов" и "информацией h градиентов" в некоторых случаях.
[0143] Как проиллюстрировано на фиг. 18, модуль 61 вычисления гистограмм градиентов включает в себя счетчик 201 данных, сумматор 202, задержку 203, память 204 гистограмм градиентов, память 205 для хранения общих сумм, сумматор 206, задержку 207, память 208 гистограмм градиентов и память 209 для хранения общих сумм.
[0144] Счетчик 201 данных выводит адрес для считывания, из памяти 30 данных, выборочных данных (набора признаков), которые должны подвергаться обработке обучения, и соответствующих фрагментов информации g и h градиентов.
[0145] Сумматор 202 суммирует суммированную информацию g градиентов, считываемую из памяти 204 гистограмм градиентов, с информацией g градиентов, которая заново считывается из памяти 30 данных.
[0146] Задержка 203 выводит набор признаков, считываемое из памяти 30 данных с задержкой, которая должна согласовываться со временем записи информации g градиентов, суммированной посредством сумматора 202, в память 204 гистограмм градиентов.
[0147] Память 204 гистограмм градиентов представляет собой память, которая последовательно сохраняет суммированную информацию g градиентов с использованием значения набора признаков в качестве адреса и сохраняет гистограмму градиентов для каждого значения (элемента разрешения) набора признаков в конце.
[0148] Память 205 для хранения общих сумм представляет собой память, которая сохраняет общую сумму информации g градиентов, считываемой из памяти 30 данных.
[0149] Сумматор 206 суммирует суммированную информацию h градиентов, считываемую из памяти 208 гистограмм градиентов, с информацией h градиентов, которая заново считывается из памяти 30 данных.
[0150] Задержка 207 выводит набор признаков, считываемое из памяти 30 данных с задержкой, которая должна согласовываться со временем записи информации h градиентов, суммированной посредством сумматора 206, в память 208 гистограмм градиентов.
[0151] Память 208 гистограмм градиентов представляет собой память, которая последовательно сохраняет суммированную информацию h градиентов с использованием значения набора признаков в качестве адреса и сохраняет гистограмму градиентов для каждого значения (элемента разрешения) набора признаков в конце.
[0152] Память 209 для хранения общих сумм представляет собой память, которая сохраняет общую сумму информации h градиентов, считываемой из памяти 30 данных.
[0153] Далее просто описывается рабочая процедура для вычисления гистограммы градиентов модуля 61 вычисления гистограмм градиентов. Во-первых, модуль 61 вычисления гистограмм градиентов считывает фрагмент обучающих данных (набор признаков, информацию градиентов) настоящего узла, сохраненную в памяти 30 данных, с использованием адреса, выводимого из счетчика 201 данных. Сумматор 202 считывает информацию g градиентов (суммированную информацию g градиентов) из памяти 204 гистограмм градиентов с использованием набора признаков, считываемого из памяти 30 данных, в качестве адреса. Сумматор 202 затем суммирует информацию g градиентов (суммированную информацию g градиентов), считываемую из памяти 204 гистограмм градиентов, с информацией g градиентов, считываемой из памяти 30 данных, и записывает (обновляет) суммированную информацию g градиентов в память 204 гистограмм градиентов с использованием набора признаков, считываемого из памяти 30 данных, в качестве адреса. Память 205 для хранения общих сумм суммирует фрагменты информации g градиентов каждый раз, когда информация g градиентов считывается из памяти 30 данных, и сохраняет общую сумму информации g градиентов. То же применимо к обработке для получения информации h градиентов, выполняемой посредством сумматора 206, задержки 207, памяти 208 гистограмм градиентов и памяти 209 для хранения общих сумм. Вышеуказанная операция многократно выполняется для всех фрагментов обучающих данных в настоящем узле.
[0154] Конфигурация и работа модуля вычисления накопленных градиентов
Фиг. 19 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления накопленных градиентов обучающего модуля. Со ссылкой на фиг. 19, далее описывается конфигурация и работа модуля 62 вычисления накопленных градиентов в обучающем модуле 20. Фиг. 19 иллюстрирует случай, в котором набор признаков предположительно имеет одну размерность, и информация градиентов предположительно включает в себя градиент g первого порядка и градиент h второго порядка.
[0155] Как проиллюстрировано на фиг. 19, модуль 62 вычисления накопленных градиентов включает в себя счетчик 210 пороговых значений, блок 211 накопления, задержку 212, блок 213 вычисления разностей, блок 214 накопления, задержку 215 и блок 216 вычисления разностей.
[0156] Счетчик 210 пороговых значений выводит пороговое значение в качестве адреса для считывания, из памяти 204 и 208 гистограмм градиентов, информации (g, h) градиентов, суммированной для каждого значения набора признаков, т.е. гистограммы градиентов каждого значения набора признаков.
[0157] Блок 211 накопления считывает, из памяти 204 гистограмм градиентов, гистограмму градиентов информации g градиентов, соответствующую пороговому значению (адресу), выводимому из счетчика 210 пороговых значений, дополнительно накапливает гистограмму градиентов в кумулятивной сумме гистограммы градиентов, которая в настоящее время сохраняется, и хранит ее в качестве новой кумулятивной суммы гистограммы градиентов.
[0158] Задержка 212 выводит, в качестве суммы GL информации g градиентов, кумулятивную сумму гистограммы градиентов информации g градиентов, считываемой из блока 211 накопления с задержкой, которая должна согласовываться со временем, когда сумма GR информации g градиентов выводится из блока 213 вычисления разностей.
[0159] Блок 213 вычисления разностей вычисляет сумму GR информации g градиентов посредством вычитания, из общей суммы информации g градиентов, считываемой из памяти 205 для хранения общих сумм, кумулятивной суммы гистограммы градиентов информации g градиентов (т.е. суммы GL информации g градиентов), считываемой из блока 211 накопления.
[0160] Блок 214 накопления считывает, из памяти 208 гистограмм градиентов, гистограмму градиентов информации h градиентов, соответствующей пороговому значению (адресу), выводимому из счетчика 210 пороговых значений, дополнительно накапливает гистограмму градиентов в кумулятивной сумме гистограммы градиентов, которая в настоящее время сохраняется, и хранит ее в качестве новой кумулятивной суммы гистограммы градиентов.
[0161] Задержка 215 выводит, в качестве суммы HL информации h градиентов, кумулятивную сумму гистограммы градиентов информации h градиентов, считываемой из блока 214 накопления с задержкой, которая должна согласовываться со временем, когда сумма HR информации h градиентов выводится из блока 216 вычисления разностей.
[0162] Блок 216 вычисления разностей вычисляет сумму HR информации h градиентов посредством вычитания, из общей суммы информации h градиентов, считываемой из памяти 209 для хранения общих сумм, кумулятивной суммы гистограммы градиентов информации h градиентов (т.е. суммы HL информации h градиентов), считываемой из блока 214 накопления.
[0163] Далее просто описывается рабочая процедура для вычисления сумм (GL, GR, HL, HR) информации градиентов, выполняемая посредством модуля 62 вычисления накопленных градиентов. Модуль 62 вычисления накопленных градиентов начинает обработку вычисления после того, как модуль 61 вычисления гистограмм градиентов завершает операцию обработки вычисления и хранения для гистограммы градиентов информации градиентов. Таким образом, после того, как модуль 61 вычисления гистограмм градиентов завершает обработку вычисления, каждая из памяти 204 и 208 гистограмм градиентов хранит гистограммы градиентов фрагментов информации g и h градиентов, вычисленных из всех фрагментов обучающих данных в настоящем узле.
[0164] Во-первых, модуль 62 вычисления накопленных градиентов считывает гистограмму градиентов информации g градиентов, сохраненную в памяти 204 гистограмм градиентов, с использованием порогового значения в качестве адреса, выводимого из счетчика 210 пороговых значений. Блок 211 накопления считывает, из памяти 204 гистограмм градиентов, гистограмму градиентов информации g градиентов, соответствующую пороговому значению, выводимому из счетчика 210 пороговых значений, накапливает гистограмму градиентов в кумулятивной сумме гистограммы градиентов, которая в настоящее время сохраняется, и хранит ее в качестве новой кумулятивной суммы гистограммы градиентов. Блок 213 вычисления разностей вычисляет сумму GR информации g градиентов посредством вычитания, из общей суммы информации g градиентов, считываемой из памяти 205 для хранения общих сумм, кумулятивной суммы гистограммы градиентов информации g градиентов (т.е. суммы GL информации g градиентов), считываемой из блока 211 накопления, и выводит сумму GR в модуль 63 вычисления. Задержка 212 выводит, в модуль 63 вычисления, кумулятивную сумму гистограммы градиентов информации g градиентов (т.е. сумму GL информации g градиентов), считываемой из блока 211 накопления во время вывода посредством блока 213 вычисления разностей. То же применимо к обработке для получения информации h градиентов (обработке вычисления сумм HL и HR информации h градиентов), выполняемой посредством блока 214 накопления, задержки 215 и блока 216 вычисления разностей. Вышеуказанная операция многократно выполняется для всех пороговых значений, и она реализуется, когда счетчик 210 пороговых значений последовательно подсчитывает пороговые значения, которые должны выводиться в раунде.
[0165] Модуль вычисления гистограмм градиентов в случае, в котором реализуется параллелизм данных
Фиг. 20 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления гистограмм градиентов в случае, в котором реализуется параллелизм данных. Со ссылкой на фиг. 20, далее описывается конфигурация и работа модуля 61 вычисления гистограмм градиентов в случае, в котором реализуется параллелизм данных. Фиг. 20 иллюстрирует случай, в котором число разделений для параллелизма данных предположительно равно 2, набор признаков предположительно имеет одну размерность, и информация градиентов предположительно включает в себя только градиент g первого порядка.
[0166] Как проиллюстрировано на фиг. 20, для того, чтобы реализовывать параллелизм данных, число разделений которого равно 2, памяти 30a и 30b данных в качестве разделенных блоков памяти сконфигурированы вместо памяти 30 данных, проиллюстрированной на фиг. 18, и модули 61a и 61b вычисления гистограмм градиентов сконфигурированы вместо модуля 61 вычисления гистограмм градиентов.
[0167] Как проиллюстрировано на фиг. 20, модуль 61a вычисления гистограмм градиентов включает в себя счетчик 201a данных, сумматор 202a, задержку 203a, память 204a гистограмм градиентов и память 205a для хранения общих сумм. Модуль 61b вычисления гистограмм градиентов включает в себя счетчик 201b данных, сумматор 202b, задержку 203b, память 204b гистограмм градиентов и память 205b для хранения общих сумм. Функции счетчиков 201a и 201b данных, сумматоров 202a и 202b, задержек 203a и 203b, памяти 204a и 204b гистограмм градиентов и памяти 205a и 205b для хранения общих сумм являются идентичными соответствующим функциям, описанным выше со ссылкой на фиг. 18.
[0168] В случае простого конфигурирования параллелизма данных, как проиллюстрировано на фиг. 20, число модулей 61 вычисления гистограмм градиентов, которые должны размещаться, может быть идентичным числу разделений, аналогично блокам памяти 30 данных. В этом случае, число блоков памяти гистограмм градиентов равно (размерности набора признаков * число разделений). В примере, проиллюстрированном на фиг. 20, набор признаков имеет одну размерность, и число разделений равно 2, так что два блока памяти 204a и 204b гистограмм градиентов размещаются. Дополнительно, в случае рассмотрения соответствующих блоков памяти гистограмм градиентов для градиента g первого порядка и градиента h второго порядка в качестве информации градиентов, требуемая общая емкость памяти гистограмм градиентов равна (емкость одной памяти в (число элементов разрешения * битовая ширина) * 2 (градиент g первого порядка, градиент h второго порядка) * размерности набора признаков * число разделений). В крупномасштабном наборе данных, число размерностей набора признаков может составлять от нескольких сотен до нескольких тысяч во многих случаях, и большое число блоков памяти требуются, когда увеличивается число разделений. Соответственно, емкость блоков памяти становится узким местом, и размер схем увеличивается. Например, в случае, в котором набор признаков составляет 8 битов (256 шаблонов) и имеет 2000 размерностей, информация градиентов включает в себя два градиента, т.е. градиент g первого порядка и градиент h второго порядка, и битовая ширина гистограммы градиентов составляет 12 битов, 12 [биты] * 256=3072 [биты] устанавливается, так что емкость памяти для одной памяти гистограмм градиентов должна удовлетворять 3072 битам. Память типично подготавливается на основе степени 2, так что в этом случае, емкость памяти составляет 4096 битов (4 Кбита). Таким образом, в случае одного разделения (отсутствия разделения), общая емкость памяти гистограмм градиентов представляется следующим образом.
[0169] 4 [Кбит] * 2 (градиент g первого порядка, градиент h второго порядка) * 2000 [размерности] = 16 [Мегабит]
[0170] Таким образом, емкость памяти в 16 Мегабит требуется в расчете на одно разделение (отсутствие разделения), и в случае разделения памяти, емкость памяти в (число разделений * 16 Мегабит) требуется.
[0171] Например, далее рассматривается случай микросхемы под названием "виртекс", UltrScale+VU9P, изготовленной компанией Xilinx Inc., в качестве высокопроизводительной FPGA. Схемы, которые могут использоваться для памяти гистограмм градиентов, включают в себя распределенное RAM и блочное RAM. В VU9P распределенное RAM составляет 36,1 Мегабит максимум, и блочное RAM составляет 75,9 Мегабит максимум. Таким образом, два разделения представляют собой предел в случае использования распределенного RAM в качестве памяти гистограмм градиентов, и четыре разделения представляют собой предел в случае использования блочного RAM. Распределенное RAM и блочное RAM должны использоваться для целей, отличных от цели хранения гистограммы градиентов, так что верхний предел числа разделений меньше числа, описанного выше. Соответственно, в случае, в котором совокупность набора признаков и информации градиентов вводится параллельно, конфигурация, которая может вычислять и сохранять гистограмму градиентов с менее крупномасштабной схемой, требуется по сравнению с конфигурацией обучающего модуля 20, описанной выше со ссылкой на фиг. 17-20. Далее описывается конфигурация и работа обучающего модуля согласно настоящему варианту осуществления со ссылкой на фиг. 21-26.
[0172] Конфигурация обучающего модуля согласно второму варианту осуществления
Фиг. 21 является схемой, иллюстрирующей пример модульной конфигурации обучающего модуля обучающего и различающего устройства согласно второму варианту осуществления. Со ссылкой на фиг. 21, далее описывается конфигурация и работа обучающего модуля 20a обучающего и различающего устройства (примера обучающего устройства) согласно настоящему варианту осуществления. На фиг. 21, число разделений для параллелизма данных предположительно равно 2, и набор признаков предположительно имеет одну размерность.
[0173] Как проиллюстрировано на фиг. 21, обучающий модуль 20a согласно настоящему варианту осуществления включает в себя модуль 71 вычисления гистограмм градиентов, модуль 72 вычисления накопленных градиентов (блок вычисления накопленных градиентов), модуль 73 вычисления (блок вычисления количественных показателей) и модуль 22 извлечения оптимальных условий.
[0174] Модуль 71 вычисления гистограмм градиентов представляет собой модуль, который вычисляет, с использованием каждого значения набора признаков входных выборочных данных в качестве элемента разрешения гистограммы, гистограмму градиентов (пример гистограммы) посредством интегрирования значений информации градиентов, соответствующей выборочным данным. Модуль 71 вычисления гистограмм градиентов включает в себя модули 301a и 301b вывода градиентов (блок вывода градиентов), модуль 302 суммирования (блок суммирования), модуль 303 накопления (блок памяти гистограмм) и память 304 для хранения общих сумм.
[0175] Каждый из модулей 301a и 301b вывода градиентов представляет собой модуль, который включает в себя порт вывода, соответствующий каждому значению набора признаков, принимает ввод набора признаков и информации градиентов из памяти 30a и 30b данных (блока памяти данных) и выводит информацию градиентов через порт вывода, соответствующий значению входного набора признаков.
[0176] Модуль 302 суммирования представляет собой модуль, который суммирует соответствующие фрагменты информации градиентов, которые должны выводиться для каждого значения (элемента разрешения) набора признаков.
[0177] Модуль 303 накопления представляет собой модуль, который суммирует суммированную информацию градиентов, вводимую из модуля 302 суммирования, с суммированной информацией градиентов, которая в настоящее время хранится для каждого значения (элемента разрешения) набора признаков, и хранит гистограмму градиентов информации градиентов для каждого элемента разрешения в конце.
[0178] Память 304 для хранения общих сумм представляет собой память, которая сохраняет общую сумму информации градиентов, вычисленную посредством модуля 302 суммирования.
[0179] Модуль 72 вычисления накопленных градиентов представляет собой модуль, который вычисляет суммы (GL, GR, HL, HR) информации градиентов посредством получения кумулятивной суммы гистограммы градиентов для каждого порогового значения набора признаков.
[0180] Модуль 73 вычисления представляет собой модуль, который вычисляет количественный показатель ветвления при каждом пороговом значении с использованием выражения (19), описанного выше, и с использованием суммы информации градиентов, вычисленной посредством модуля 72 вычисления накопленных градиентов.
[0181] Модуль 22 извлечения оптимальных условий представляет собой модуль, который принимает ввод количественного показателя ветвления, соответствующего каждому набору признаков (на фиг. 21, одному набору признаков) и каждому пороговому значению, выводимому из модуля 73 вычисления, и извлекает пороговое значение и число набора признаков (номер набора признаков), количественный показатель ветвления которого является наибольшим. Модуль 22 извлечения оптимальных условий записывает извлеченное номер набора признаков и пороговое значение в память 40 моделей в качестве данных условий ветвления соответствующего узла (примера данных узла).
[0182] Как проиллюстрировано на фиг. 21, для того, чтобы реализовывать параллелизм данных в случае, в котором число разделений равно 2, память разделяется на две памяти, т.е. память 30a и 30b данных, и модуль 71 вычисления гистограмм градиентов разделяется на два модуля, т.е. модули 301a и 301b вывода градиентов на предыдущей стадии. На фиг. 21, блок физического разделения представляется как "разделение 1" и "разделение 2".
[0183] Конфигурация и работа модуля вычисления гистограмм градиентов
Фиг. 22 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления гистограмм градиентов обучающего модуля согласно второму варианту осуществления. Со ссылкой на фиг. 22, далее описывается конфигурация и работа модуля 71 вычисления гистограмм градиентов в обучающем модуле 20a согласно настоящему варианту осуществления. Фиг. 21 иллюстрирует случай, в котором число разделений для параллелизма данных предположительно равно 2, набор признаков предположительно имеет одну размерность, и информация градиентов предположительно включает в себя только один фрагмент информации (например, градиент g первого порядка).
[0184] Как проиллюстрировано на фиг. 21, модуль 71 вычисления гистограмм градиентов включает в себя счетчик 311a и 311b данных в дополнение к конфигурации, описанной выше со ссылкой на фиг. 20.
[0185] Счетчик 311a данных выводит адрес для считывания выборочных данных (набора признаков), которые должны подвергаться обработке обучения, и соответствующей информации градиентов из памяти 30a данных.
[0186] Как проиллюстрировано на фиг. 22, модуль 301a вывода градиентов включает в себя блоки 312_1, 312_2, ..., и 312_N сравнения (блоки определения) и мультиплексоры 313_1, 313_2, ..., и 313_N (блоки выбора). В этом случае, N является числом значений, которое может приниматься посредством набора признаков, и является числом элементов разрешения в гистограмме градиентов. В случае указания необязательного блока сравнения из числа блоков 312_1, 312_2, ..., и 312_N сравнения, либо в случае, в котором блоки 312_1, 312_2, ..., и 312_N сравнения совместно называются, они упоминаются просто как "блок 312 сравнения" (блок определения). В случае указания необязательного мультиплексора из числа мультиплексоров 313_1, 313_2, ..., и 313_N, либо в случае, в котором мультиплексоры 313_1, 313_2, ..., и 313_N совместно называются, они упоминаются просто как "мультиплексор 313" (блок выбора).
[0187] Блок 312 сравнения принимает ввод значений набора признаков, считываемого из памяти 30a данных, и набора признаков конкретного элемента разрешения и сравнивает значения друг с другом. Если значения являются идентичными друг другу, блок 312 сравнения выводит тот факт, что значения являются идентичными друг другу (например, вывод включения уровня напряжения), в мультиплексор 313. Например, в случае, в котором набор признаков, считываемое из памяти 30a данных, является идентичным значению набора признаков элемента 1 разрешения, блок 312_1 сравнения выводит тот факт, что значения являются идентичными друг другу, в мультиплексор 313_1.
[0188] Мультиплексор 313 принимает ввод 0 и информации градиентов, соответствующей набору признаков (обучающим данным), которое считывается из памяти 30a данных посредством блока 312 сравнения, и выводит входную информацию градиентов или 0 в соответствии с результатом сравнения, выводимым из блока 312 сравнения. Например, мультиплексор 313_1 принимает ввод 0 и информацию градиентов, соответствующую набору признаков, которое считывается из памяти 30a данных посредством блока 312_1 сравнения, выводит входную информацию градиентов в качестве информации градиентов, соответствующей элементу 1 разрешения в случае, в котором вывод результата сравнения из блока 312_1 сравнения указывает то, что значения являются идентичными друг другу, и выводит 0 в случае, в котором результат сравнения указывает то, что значения не являются идентичными друг другу. Таким образом, в этом механизме информация градиентов, соответствующая набору признаков, выводится из мультиплексора 313, соответствующего значению набора признаков, считываемого из памяти 30a данных, и 0 выводится из другого мультиплексора 313.
[0189] Функции памяти 30b данных, счетчика 311b данных и модуля 301b вывода градиентов являются идентичными функциям памяти 30a данных, счетчика 311a данных и модуля 301a вывода градиентов, описанных выше, соответственно.
[0190] Модуль 302 суммирования суммирует информацию градиентов, вводимую из мультиплексора 313 для каждого значения набора признаков, т.е. для каждого элемента разрешения, и выводит суммированную информацию градиентов в модуль 303 накопления. Модуль 302 суммирования включает в себя сумматоры 321_1, 321_2, ..., и 321_N и сумматор 322.
[0191] Каждый из сумматоров 321_1, 321_2, ..., и 321_N суммирует информацию градиентов, вводимую из мультиплексора 313 для каждого из элементов 1, 2, ..., и N разрешения, и выводит суммированную информацию градиентов в модуль 303 накопления. Например, сумматор 321_1 суммирует информацию градиентов в качестве вывода из мультиплексора 313_1, соответствующего элементу 1 разрешения в модуле 301a вывода градиентов, с информацией градиентов в качестве вывода из мультиплексора 313_1, соответствующего элементу 1 разрешения в модуле 301b вывода градиентов, и выводит суммированную информацию градиентов в модуль 303 накопления (в этом случае, в блок 331_1 накопления элемента 1 разрешения, описанный ниже).
[0192] Сумматор 322 принимает ввод фрагментов информации градиентов, которая должна суммироваться, причем фрагменты информации градиентов считываются из памяти 30a и 30b данных посредством модуля 301a вывода градиентов и модуля 301b вывода градиентов, соответственно. Сумматор 322 затем выводит суммированную информацию градиентов в память 304 для хранения общих сумм.
[0193] Модуль 303 накопления суммирует суммированную информацию градиентов, вводимую из модуля 302 суммирования, с суммированной информацией градиентов, которая в настоящее время хранится для каждого значения (элемента разрешения) набора признаков, и хранит гистограмму градиентов информации градиентов для каждого элемента разрешения в конце. Модуль 303 накопления включает в себя блок 331_1 накопления элемента 1 разрешения, блок 331_2 накопления элемента 2 разрешения, ..., и блок 331_N накопления элемента N разрешения.
[0194] Блок 331_1 накопления элемента 1 разрешения, блок 331_2 накопления элемента 2 разрешения, ..., и блок 331_N накопления элемента N разрешения суммируют суммированную информацию градиентов, вводимую из соответствующих сумматоров 321_1, 321_2, ..., и 321_N, с суммированной информацией градиентов, которая в настоящее время хранится для каждого из элементов 1, 2, ..., и N разрешения. Например, блок 331_1 накопления элемента 1 разрешения суммирует суммированную информацию градиентов, вводимую из сумматора 321_1, с суммированной информацией градиентов, которая в настоящее время хранится, и хранит гистограмму градиентов информации градиентов элемента 1 разрешения.
[0195] Память 304 для хранения общих сумм суммирует суммированную информацию градиентов, выводимую из сумматора 322, с суммированной информацией градиентов, которая в настоящее время хранится. Таким образом, память 304 для хранения общих сумм сохраняет общую сумму информации градиентов, соответствующую всем фрагментам обучающих данных.
[0196] Далее просто описывается рабочая процедура для вычисления гистограммы градиентов, выполняемая посредством модуля 71 вычисления гистограмм градиентов согласно настоящему варианту осуществления. Счетчик 311a (311b) данных выводит адрес для считывания выборочных данных (набора признаков), которые должны подвергаться обработке обучения, и соответствующей информации градиентов из памяти 30a данных. Блок 312 сравнения модуля 301a (301b) вывода градиентов принимает ввод значений набора признаков, считываемого из памяти 30a (30b) данных, и набора признаков конкретного элемента разрешения и сравнивает значения друг с другом. Если значения являются идентичными друг другу, блок 312 сравнения выводит тот факт, что значения являются идентичными друг другу, в мультиплексор 313. Мультиплексор 313 принимает ввод 0 и информацию градиентов, соответствующую набору признаков (обучающим данным), которое считывается из памяти 30a (30b) данных посредством блока 312 сравнения, и выводит 0 или входную информацию градиентов в соответствии с результатом сравнения, выводимым из блока 312 сравнения. Соответствующие сумматоры 321_1, 321_2, ..., и 321_N модуля 302 суммирования суммируют информацию градиентов, вводимую из мультиплексора 313 для каждого из элементов 1, 2, ..., и N разрешения, и выводят суммированную информацию градиентов в модуль 303 накопления. Блок 331_1 накопления элемента 1 разрешения, блок 331_2 накопления элемента 2 разрешения, ..., и блок 331_N накопления элемента N разрешения модуля 303 накопления суммируют суммированную информацию градиентов, вводимую из соответствующих сумматоров 321_1, 321_2, ..., и 321_N, с суммированной информацией градиентов, которая в настоящее время хранится для каждого из элементов 1, 2, ..., и N разрешения, и хранят гистограмму градиентов информации градиентов для каждого элемента разрешения в конце. Вышеуказанная операция многократно выполняется для всех фрагментов обучающих данных в настоящем узле.
[0197] В конфигурации модуля 71 вычисления гистограмм градиентов согласно настоящему варианту осуществления, как описано выше, гистограмма градиентов сохраняется в соответствующем регистре (блоке накопления) для каждого элемента разрешения набора признаков вместо сохранения в памяти, аналогично традиционной конфигурации, проиллюстрированной на фиг. 20. Конфигурация модуля 71 вычисления гистограмм градиентов, проиллюстрированного на фиг. 22, может реализовываться с регистрами, число которых равно (число элементов разрешения набора признаков * размерности набора признаков (на фиг. 22, число размерностей предположительно равно одной)). Таким образом, общая емкость, требуемая для сохранения гистограммы градиентов, представляется как (число элементов разрешения * битовая ширина * 2 (градиент g первого порядка, градиент h второго порядка) * размерности набора признаков), что не зависит от числа разделений. Таким образом, по сравнению с традиционной конфигурацией, проиллюстрированной на фиг. 20, нагрузочная способность схемы для сохранения гистограммы градиентов может значительно уменьшаться. Дополнительно, в конфигурации модуля 71 вычисления гистограмм градиентов согласно настоящему варианту осуществления, размер схем не зависит от числа разделений, так что число разделений для параллелизма данных может увеличиваться до тех пор, пока позволяет размер схем других модулей, и скорость обработки обучения может повышаться.
[0198] Например, в случае, в котором набор признаков составляет 8 битов (256 шаблонов) и имеет 2000 размерностей, и информация градиентов включает в себя два градиента, т.е. градиент g первого порядка и градиент h второго порядка, число требуемых регистров представляется следующим образом.
[0199] 256 (число элементов разрешения) * 2 (градиент g первого порядка, градиент h второго порядка) * 2000 [размерности] = 1024000 [регистры]
[0200] В случае микросхемы под названием VU9P, описанной выше, максимальное число регистров составляет 2364000, так что число регистров, требуемых для хранения гистограммы градиентов, может подавляться таким образом, что оно составляет практически половину от максимального числа регистров в конфигурации модуля 71 вычисления гистограмм градиентов согласно настоящему варианту осуществления.
[0201] Фиг. 23 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления гистограмм градиентов в случае, в котором число разделений предположительно равно 3 в обучающем модуле согласно второму варианту осуществления. Со ссылкой на фиг. 23, далее описывается конфигурация пример модуля 71 вычисления гистограмм градиентов в случае, в котором число разделений для параллелизма данных предположительно равно 3. Фиг. 23 иллюстрирует случай, в котором набор признаков предположительно имеет одну размерность, и информация градиентов предположительно включает в себя только один фрагмент информации (например, градиент g первого порядка).
[0202] Например, на фиг. 23, модуль 302 суммирования включает в себя сумматоры 321_1_1, ..., и 321_N_1, сумматоры 321_1_2, ..., и 321_N_2 и сумматоры 322_1 и 322_2. Аналогично модулю 71 вычисления гистограмм градиентов, проиллюстрированному на фиг. 23, модуль 302 суммирования может интегрировать (суммировать) фрагменты информации градиентов пошагово. Например, относительно элемента 1 разрешения, сумматор 321_1_1 суммирует информацию градиентов, выводимую из "разделения 1", с информацией градиентов, выводимой из "разделения 2", для вывода в сумматор 321_1_2. Сумматор 321_1_2 суммирует суммированное значение, выводимое из сумматора 321_1_1, с информацией градиентов, выводимой из "разделения 3", для вывода в блок 331_1 накопления элемента 1 разрешения модуля 303 накопления.
[0203] Конфигурация и работа модуля вычисления накопленных градиентов
Фиг. 24 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления накопленных градиентов обучающего модуля согласно второму варианту осуществления. Со ссылкой на фиг. 24, далее описывается конфигурация и работа модуля 72 вычисления накопленных градиентов в обучающем модуле 20a согласно настоящему варианту осуществления. Фиг. 24 иллюстрирует случай, в котором число разделений для параллелизма данных предположительно равно 1, набор признаков предположительно имеет одну размерность, и информация градиентов предположительно включает в себя два фрагмента информации (например, градиент g первого порядка и градиент h второго порядка).
[0204] Традиционный модуль 62 вычисления накопленных градиент, проиллюстрированный на фиг. 19, осуществляет доступ к памяти 204 (208) гистограмм градиентов с использованием вывода (порогового значения) из счетчика 210 пороговых значений в качестве адреса. На фиг. 24, гистограмма градиентов хранится посредством регистра (блока накопления) для каждого элемента разрешения, так что только значение, соответствующее пороговому значению счетчика пороговых значений, извлекается из каждого элемента разрешения через мультиплексор.
[0205] Как проиллюстрировано на фиг. 24, модуль 72 вычисления накопленных градиентов включает в себя счетчик 340 пороговых значений, блок 341 накопления, задержку 342, блок 343 вычисления разностей, блок 344 накопления, задержку 345, блок 346 вычисления разностей и мультиплексоры 347 и 348. На фиг. 24, модуль 303 накопления и память 304 для хранения общих сумм, соответствующие градиенту g первого порядка, предположительно представляют собой модуль 303g накопления и память 304g для хранения общих сумм, соответственно. Модуль 303 накопления и память 304 для хранения общих сумм, соответствующие градиенту h второго порядка, предположительно представляют собой модуль 303h накопления и память 304h для хранения общих сумм, соответственно.
[0206] Счетчик 340 пороговых значений выводит пороговое значение для считывания, из модулей 303g и 303h накопления, информации (g, h) градиентов, суммированной для каждого значения (элемента разрешения) набора признаков, т.е. гистограммы градиентов каждого элемента разрешения набора признаков.
[0207] Мультиплексор 347 принимает ввод порогового значения из счетчика 340 пороговых значений и ввод значения для хранения (гистограммы градиентов) каждого блока накопления (блока 331_1 накопления элемента 1 разрешения, блока 331_2 накопления элемента 2 разрешения, ..., и блока 331_N накопления элемента N разрешения) модуля 303g накопления. Мультиплексор 347 затем выводит, в блок 341 накопления, гистограмму градиентов, соответствующую элементу разрешения, соответствующему пороговому значению, из счетчика 340 пороговых значений из числа входных гистограмм градиентов соответствующих элементов разрешения.
[0208] Мультиплексор 348 принимает ввод порогового значения из счетчика 340 пороговых значений и ввод значения для хранения (гистограммы градиентов) каждого блока накопления (блока 331_1 накопления элемента 1 разрешения, блока 331_2 накопления элемента 2 разрешения, ..., и блока 331_N накопления элемента N разрешения) модуля 303h накопления. Мультиплексор 348 затем выводит, в блок 344 накопления, гистограмму градиентов, соответствующую элементу разрешения, соответствующему пороговому значению, из счетчика 340 пороговых значений из числа входных гистограмм градиентов соответствующих элементов разрешения.
[0209] Блок 341 накопления принимает, из мультиплексора 347, ввод гистограммы градиентов информации g градиентов, соответствующей пороговому значению, выводимому из счетчика 340 пороговых значений, накапливает входную гистограмму градиентов в кумулятивной сумме гистограммы градиентов, которая в настоящее время сохраняется, и хранит ее в качестве новой кумулятивной суммы гистограммы градиентов.
[0210] Задержка 342 выводит, в качестве суммы GL информации g градиентов, кумулятивную сумму гистограммы градиентов информации g градиентов, считываемой из блока 341 накопления с задержкой, которая должна согласовываться со временем, когда сумма GR информации g градиентов выводится из блока 343 вычисления разностей.
[0211] Блок 343 вычисления разностей вычисляет сумму GR информации g градиентов посредством вычитания кумулятивной суммы гистограммы градиентов информации g градиентов, считываемой из блока 341 накопления (т.е. суммы GL информации g градиентов), из общей суммы информации g градиентов, считываемой из памяти 304g для хранения общих сумм.
[0212] Блок 344 накопления принимает, из мультиплексора 348, ввод гистограммы градиентов информации h градиентов, соответствующей пороговому значению, выводимому из счетчика 340 пороговых значений, накапливает входную гистограмму градиентов в кумулятивной сумме гистограммы градиентов, которая в настоящее время сохраняется, и хранит ее в качестве новой кумулятивной суммы гистограммы градиентов.
[0213] Задержка 345 выводит, в качестве суммы HL информации h градиентов, кумулятивную сумму гистограммы градиентов информации h градиентов, считываемой из блока 344 накопления с задержкой, которая должна согласовываться со временем, когда сумма HR информации h градиентов выводится из блока 346 вычисления разностей.
[0214] Блок 346 вычисления разностей вычисляет сумму HR информации h градиентов посредством вычитания кумулятивной суммы гистограммы градиентов информации h градиентов, считываемой из блока 344 накопления (т.е. суммы HL информации h градиентов), из общей суммы информации h градиентов, считываемой из памяти 304h для хранения общих сумм.
[0215] Далее просто описывается рабочая процедура для вычисления сумм (GL, GR, HL, HR) информации градиентов, выполняемая посредством модуля 72 вычисления накопленных градиентов. Модуль 72 вычисления накопленных градиентов начинает обработку вычисления после того, как модуль 71 вычисления гистограмм градиентов завершает операцию обработки вычисления и хранения для гистограммы градиентов информации градиентов. Таким образом, после того, как модуль 71 вычисления гистограмм градиентов завершает обработку вычисления, модули 303g и 303h накопления хранят гистограммы градиентов соответствующих фрагментов информации g и h градиентов, вычисленных из всех фрагментов обучающих данных настоящего узла.
[0216] Во-первых, мультиплексор 347 принимает ввод порогового значения из счетчика 340 пороговых значений и ввод значения для хранения (гистограммы градиентов) каждого блока накопления (блока 331_1 накопления элемента 1 разрешения, блока 331_2 накопления элемента 2 разрешения, ..., и блока 331_N накопления элемента N разрешения) модуля 303g накопления. Мультиплексор 347 выводит, в блок 341 накопления, гистограмму градиентов, соответствующую элементу разрешения, соответствующему пороговому значению, из счетчика 340 пороговых значений из числа входных гистограмм градиентов соответствующих элементов разрешения. Блок 341 накопления затем принимает, из мультиплексора 347, ввод гистограммы градиентов информации g градиентов, соответствующей пороговому значению, выводимому из счетчика 340 пороговых значений, накапливает входную гистограмму градиентов в кумулятивной сумме гистограммы градиентов, которая в настоящее время сохраняется, и хранит ее в качестве новой кумулятивной суммы гистограммы градиентов. Задержка 342 выводит, в модуль 73 вычисления, кумулятивную сумму гистограммы градиентов информации g градиентов, считываемой из блока 341 накопления с задержкой, которая должна согласовываться со временем, когда сумма GR информации g градиентов выводится из блока 343 вычисления разностей, в качестве суммы GL информации g градиентов. Блок 343 вычисления разностей вычисляет сумму GR информации g градиентов посредством вычитания кумулятивной суммы гистограммы градиентов информации g градиентов, считываемой из блока 341 накопления (т.е. суммы GL информации g градиентов), из общей суммы информации g градиентов, считываемой из памяти 304g для хранения общих сумм, и выводит сумму GR в модуль 73 вычисления. То же применимо к обработке для получения информации h градиентов (к обработке вычисления для суммы HL и HR информации h градиентов), выполняемой посредством мультиплексора 348, блока 344 накопления, задержки 345 и блока 346 вычисления разностей. Вышеуказанная операция многократно выполняется для всех пороговых значений, и она реализуется, когда счетчик 340 пороговых значений последовательно подсчитывает пороговые значения, которые должны выводиться в раунде.
[0217] Таким образом, модуль 72 вычисления накопленных градиентов и модуль 73 вычисления выполняют обработку после того, как модуль 71 вычисления гистограмм градиентов выполняет операцию обработки вычисления и хранения для гистограммы градиентов информации градиентов заранее. Вследствие этого, скорость обработки вычисления для количественного показателя ветвления (усиления), выполняемой посредством обучающего модуля 20a, может увеличиваться.
[0218] Конфигурация обучающего модуля в случае, в котором число размерностей равно 2
Фиг. 25 является схемой, иллюстрирующей пример модульной конфигурации обучающего модуля в случае, в котором число типов наборов признаков предположительно равно 2 в обучающем и различающем устройстве согласно второму варианту осуществления. Фиг. 26 является схемой, иллюстрирующей пример модульной конфигурации модуля вычисления гистограмм градиентов в случае, в котором число типов наборов признаков предположительно равно 2 в обучающем модуле согласно второму варианту осуществления. Со ссылкой на фиг. 25 и фиг. 26, далее описывается конфигурация и работа обучающего модуля 20b обучающего и различающего устройства (примера обучающего устройства) согласно настоящему варианту осуществления. Фиг. 25 иллюстрирует случай, в котором число разделений для параллелизма данных предположительно равно 2, и набор признаков предположительно имеет две размерности.
[0219] Как проиллюстрировано на фиг. 25, обучающий модуль 20b включает в себя модуль 71 вычисления гистограмм градиентов, модули 72_1 и 72_2 вычисления накопленных градиентов, модули 73_1 и 73_2 вычисления и модуль 22 извлечения оптимальных условий. Модуль 71 вычисления гистограмм градиентов включает в себя модули 301a_1, 301a_2, 301b_1 и 301b_2 вывода градиентов, модули 302_1 и 302_2 суммирования, модули 303_1 и 303_2 накопления и памяти 304_1 и 304_2 для хранения общих сумм. Как проиллюстрировано на фиг. 26, модуль 71 вычисления гистограмм градиентов включает в себя счетчики 311a и 311b данных в дополнение к конфигурации, проиллюстрированной на фиг. 25.
[0220] Как проиллюстрировано на фиг. 26, каждый из модулей 301a_1, 301a_2, 301b_1 и 301b_2 вывода градиентов включает в себя блоки 312_1, 312_2, ..., и 312_N сравнения и мультиплексоры 313_1, 313_2, ..., и 313_N. Каждый из модулей 302_1 и 302_2 суммирования включает в себя сумматоры 321_1, 321_2, ..., и 321_N и сумматор 322. Каждый из модулей 303_1 и 303_2 накопления включает в себя блок 331_1 накопления элемента 1 разрешения, блок 331_2 накопления элемента 2 разрешения, ..., и блок 331_N накопления элемента N разрешения.
[0221] В конфигурации, проиллюстрированной на фиг. 25 и фиг. 26, модули 301a_1 и 301b_1 вывода градиентов, модуль 302_1 суммирования, модуль 303_1 накопления, память 304_1 для хранения общих сумм, модуль 72_1 вычисления накопленных градиентов и модуль 73_1 вычисления используются для обработки, соответствующей "набору 1 признаков". С другой стороны, модули 301a_2 и 301b_2 вывода градиентов, модуль 302_2 суммирования, модуль 303_2 накопления, память 304_2 для хранения общих сумм, модуль 72_2 вычисления накопленных градиентов и модуль 73_2 вычисления используются для обработки, соответствующей "набору 2 признаков". Работа каждого из модулей является идентичной работе, описанной выше со ссылкой на фиг. 22 и фиг. 24.
[0222] Как описано выше, емкость, требуемая для сохранения гистограммы градиентов, представляется как (число элементов разрешения * битовая ширина * 2 (градиент g первого порядка, градиент h второго порядка) * размерности набора признаков), так что модули 303 накопления, число которых соответствует размерностям набора признаков, требуются (на фиг. 25, модули 303_1 и 303_2 накопления). Тем не менее, емкость не зависит от числа разделений, так что, хотя фиг. 25 и фиг. 26 примерно иллюстрируют случай, в котором число разделений равно 2, достаточно размещать два модуля 303 накопления до тех пор, пока размерности набора признаков равны двум, даже когда число разделений становится равным или превышающим 3.
[0223] Как описано выше, в обучающем модуле 20a (20b) обучающего и различающего устройства согласно настоящему варианту осуществления, модуль 71 вычисления гистограмм градиентов сохраняет гистограмму градиентов в соответствующем регистре (блоке накопления) для каждого элемента разрешения набора признаков вместо сохранения гистограммы градиентов в памяти, аналогично традиционной конфигурации, проиллюстрированной на фиг. 20. Конфигурация модуля 71 вычисления гистограмм градиентов может реализовываться с регистрами, число которых равно (число элементов разрешения набора признаков * размерности набора признаков). Таким образом, общая емкость, требуемая для сохранения гистограммы градиентов, представляется как (число элементов разрешения * битовая ширина * 2 (градиент g первого порядка, градиент h второго порядка) * размерности набора признаков), что не зависит от числа разделений. Таким образом, по сравнению с традиционной конфигурацией, проиллюстрированной на фиг. 20, можно значительно уменьшать размер схем памяти (блока накопления, регистра), которое хранит информацию гистограммы градиентов, созданной для набора признаков, и информацию градиентов, которые вводятся параллельно. Дополнительно, в конфигурации модуля 71 вычисления гистограмм градиентов согласно настоящему варианту осуществления, размер схем не зависит от числа разделений, так что число разделений для параллелизма данных может увеличиваться до тех пор, пока позволяет размер схем других модулей, и скорость обработки обучения может повышаться.
[0224] Примеры
Далее описывается результат прогнозирования скорости обработки обучения, выполняемой посредством обучающего и различающего устройства 1 согласно варианту осуществления, описанному выше.
[0225] Во-первых, скорость обучения XGBoost и LightGBM, описанных выше в качестве характерной библиотеки GBDT, оценена для сравнения. В декабре 2017 года, скорость обучения LightGBM с использованием GPU была высокой, и эта скорость измерена.
[0226] Время обработки вычислено из синхросигнала аппаратной конфигурации. В логике аппаратных средств, которые реализуются в этом случае, обработка главным образом включает в себя три фрагмента обработки, т.е. обработку обучения, выполняемую посредством обучающего модуля 20, обработку различения, выполняемую посредством модуля 50 классификации (в единицах узлов), и обработку различения, выполняемую посредством модуля 50 классификации (в единицах деревьев).
[0227] Относительно обработки, выполняемой посредством обучающего модуля
В этом случае, преобладающая обработка заключается в том, чтобы вычислять количественный показатель ветвления и создавать гистограмму градиентов из каждого набора признаков выборочных данных. При создании гистограммы градиентов из каждого набора признаков выборочных данных, все фрагменты выборочных данных должны считываться для каждой глубины (иерархического уровня). Обучение для некоторых фрагментов выборочных данных заканчивается на небольшой глубине дерева, так что эта оценка составляет максимальное значение. Чтобы вычислять количественный показатель ветвления, обращаются ко всем элементам разрешения гистограммы градиентов, так что требуются синхросигналы, соответствующие числу элементов разрешения (размерностям набора признаков). Соответственно, число Clearning синхросигналов обработки, выполняемой посредством обучающего модуля 20, представляется посредством следующего выражения (23).
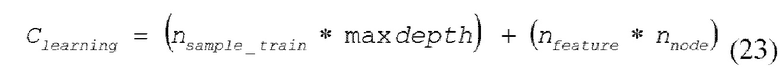
[0228] В этом случае, nsample_train является числом фрагментов выборочных данных, используемых для обучения дерева решений, которое типично представляет собой набор, субвыборочный из всех фрагментов выборочных данных. Дополнительно, maxdepth является максимальной глубиной дерева решений, nfeature является числом элементов разрешения (размерностей набора признаков), и nnode является числом узлов.
[0229] Относительно обработки, выполняемой посредством модуля классификации (в единицах узлов)
В этом случае, обработка выполняется для того, чтобы определять то, назначаются или нет выборочные данные нижнему узлу слева или справа, с использованием результата обученного узла. Общее число фрагментов выборочных данных, обрабатываемых для каждой глубины, является постоянным, так что число CClassification_node синхросигналов представляется посредством следующего выражения (24). Фактически, обучение некоторых узлов завершается в середине обработки, так что следующая оценка составляет максимальное значение.
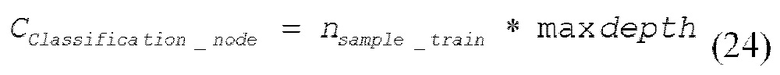
[0230] Относительно обработки, выполняемой посредством модуля классификации (в единицах деревьев)
В этом случае, после того, как обучение одного дерева решений завершается, информация градиентов обновляется для каждого фрагмента выборочных данных для обучения следующего дерева решений. Таким образом, прогнозирование должно проводиться для всех фрагментов выборочных данных с использованием обученного дерева решений. При обработке в единицах деревьев, вызывается задержка, соответствующая глубине. В этом случае, число CClassification_tree синхросигналов представляется посредством следующего выражения (25).

[0231] В этом случае, все фрагменты выборочных данных означают общее число всех фрагментов обучающих выборочных данных до субдискретизации и всех фрагментов выборочных данных проверки достоверности.
[0232] Соответственно, число Ctree синхросигналов (максимальное значение) для обработки обучения для одного дерева решений представляется посредством следующего выражения (26).

[0233] GBDT включает в себя большое число деревьев решений, так что при условии, что число деревьев решений составляет ntree, число Cgbdt синхросигналов всей GBDT-модели представляется посредством следующего выражения (27).
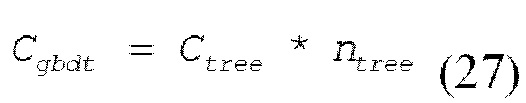
[0234] Выше описывается тестовое вычисление в случае параллелизма признаков, описанного выше. В том, что называется "параллелизмом данных" в случае параллельного размещения большого числа модулей и разделения модулей для каждого фрагмента данных, скорость может по существу увеличиваться согласно числу модулей в случае, в котором число фрагментов данных в каждом узле балансируется для каждого модуля. Степень дисбаланса зависит от выборочных данных и способа разделения выборочных данных для каждого модуля, так что этот объем служебной информации анализируется с использованием реальных данных в дальнейшем. Согласно прогнозированию, эффективность оценивается как повышенная на 50% или более, даже если этот объем служебной информации учитывается.
[0235] Относительно используемых данных
В качестве выборочных данных для тестирования, обучающие данные и различающие данные (данные для оценки) случайно выбираются примерно из ста тысяч фрагментов данных. Далее представляется общий обзор набора данных.
[0236] Число классов: 2
Размерности набора признаков: 129
Число фрагментов обучающих данных: 63415
Число фрагментов данных для оценки: 31707
[0237] Условие измерения для скорости представляется посредством нижеприведенной таблицы 5. Тактовая частота работающей FPGA предположительно составляет 100 [МГц] (фактически, тактовая частота может иметь более высокое значение с высокой вероятностью).
[0238] Тестовое вычисление аппаратной логики
Нижеприведенная таблица 6 представляет тестовое вычисление скорости обучения с архитектурой, описанной выше, с использованием выражения для вычисления скорости, описанного выше. Тем не менее, это тестовое вычисление представляет собой тестовое вычисление в случае, в котором все фрагменты выборочных данных достигают ветви в конце, и представляет худшее значение.
[0239] Результат сравнения, включающий в себя фактическое измерение посредством CPU и GPU
Нижеприведенная таблица 7 представляет результат фактического измерения посредством CPU и GPU. Для сравнения, в нее также включается результат тестового вычисления жесткой логики. Вплоть до этого момента, тестовое вычисление выполняется только с использованием параллелизма признаков, так что результат тестового вычисления в случае использования параллелизма данных одновременно добавляется для ссылки.
*2 GPU GTX1080Ti /CPU Core i7 Intel Core i7 7700 (4C8T 3,6 ГГц);
*3 тестовое вычисление выполняется при условии, что параллелизм данных составляет 15 параллелей, и эффективность параллелизма данных составляет 75% (предполагается подложка KC705);
*4 тестовое вычисление выполняется при условии, что параллелизм данных составляет 240 параллелей, и эффективность параллелизма данных составляет 50% (предполагается крупный экземпляр AWS f1.16 x).
[0240] Обнаружено, что скорость обучения текущих данных уменьшается даже в случае использования GPU по сравнению со случаем использования CPU. Microsoft Corporation в качестве разработчика LightGBM заявляет то, что скорость обучения увеличивается приблизительно в 3-10 раз в случае использования GPU, но скорость обучения сильно зависит от данных. Обнаружено, что скорость обучения для настоящих данных не может успешно увеличиваться посредством GPU. Этот результат также представляет то, что скорость обучения посредством GPU не увеличивается легко при использовании алгоритма GBDT по сравнению с CNN. В результате использования CPU, скорость обучения при использовании LightGBM в качестве одного из последних алгоритмов увеличивается приблизительно в 10 раз по сравнению с XGBoost в качестве наиболее базовой библиотеки. При использовании жесткой логики только с использованием параллелизма признаков, скорость обучения увеличивается приблизительно в 2,3 раза по сравнению с CPU (LightGBM), что является самым быстрым для персонального компьютера (PC). На основе тестового вычисления, в случае использования также параллелизма данных с 15 параллелями, скорость обучения увеличивается в 25 раз или более, даже если эффективность параллелизма данных предположительно составляет 75%, и увеличивается в 275 раз или более, если эффективность предположительно составляет 50% в случае 240 параллелей и с учетом крупного экземпляра AWS f1.16x. Тем не менее, это тестовое вычисление представляет собой тестовое вычисление в случае, в котором скорость передачи информации памяти достигает предела.
[0241] С точки зрения того, что потребление мощности прогнозируемо составляет несколько [Вт] для FPGA и равно или выше 100 [Вт] для CPU и GPU, потребление мощности отличается между ними на две цифры в дополнение к скорости, так что эффективность по мощности может отличаться между ними на три или более цифр.
Список номеров ссылок
[0242] 1 и 1a - обучающее и различающее устройство
10 - CPU
11 - блок управления
20, 20a и 20b - обучающий модуль
21, 21_1 и 21_2 - модуль вычисления усиления
22 - модуль извлечения оптимальных условий
30, 30a, 30b - память данных
POINTER MEMORY - Память указателей
FEATURE MEMORY - Память признаков
STATE MEMORY - Память состояний
MODEL MEMORY - Память моделей
41_1 - память для глубины 0
41_2 - память для глубины 1
41_3 - память для глубины 2
50, 50a и 50b - модуль классификации
51_1 - различитель узла 0
51_2 - различитель узла 1
51_3 - различитель узла 2
61, 61_1 и 61_2 - модуль вычисления гистограмм градиентов
61a и 61b - модуль вычисления гистограмм градиентов
62, 62_1 и 62_2 - модуль вычисления накопленных градиентов
63, 63_1 и 63_2 - модуль вычисления
71 - модуль вычисления гистограмм градиентов
72, 72_1 и 72_2 - модуль вычисления накопленных градиентов
73, 73_1 и 73_2 - модуль вычисления
201, 201a и 201b - счетчик данных
202, 202a и 202b - сумматор
203, 203a и 203b - задержка
204, 204a и 204b - память гистограмм градиентов
205, 205a и 205b - память для хранения общих сумм
206 - сумматор
207 - задержка
208 - память гистограмм градиентов
209 - память для хранения общих сумм
210 - счетчик пороговых значений
211 - блок накопления
212 - задержка
213 - блок вычисления разностей
214 - блок накопления
215 - задержка
216 - блок вычисления разностей
301a, 301a_1 и 301a_2 - модуль вывода градиентов
301b, 301b_1 и 301b_2 - модуль вывода градиентов
302, 302_1 и 302_2 - модуль суммирования
303, 303_1 и 303_2 - модуль накопления
303g и 303h - модуль накопления
304, 304_1 и 304_2 - память для хранения общих сумм
304g и 304h - память для хранения общих сумм
311a и 311b - счетчик данных
312, 312_1 и 312_2 - блок сравнения
313, 313_1 и 313_2 - мультиплексор
321_1 и 321_2 - сумматор
321_1_1 и 321_1_2 - сумматор
322, 322_1 и 322_2 - сумматор
331_1 - блок накопления элемента 1 разрешения
331_2 - блок накопления элемента 2 разрешения
340 - счетчик пороговых значений
341 - блок накопления
342 - задержка
343 - блок вычисления разностей
344 - блок накопления
345 - задержка
346 - блок вычисления разностей
347 и 348 – мультиплексор.
Список библиографических ссылок
Патентные документы
[0243] PTL 1
Выложенная патентная публикация (Япония) номер 2013-8270
Непатентные документы
[0244] NPL 1
Michal Drozdz и Tomasz Kryjak, "FPGA Implementation of Multi-scale Face Detection Using HOG Features and SVM Classifier". Image Processing and Communications 21.3 (2016 год): 27-44.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВЫДЕЛЕНИЕ РЕСУРСОВ ДЛЯ МАШИННОГО ОБУЧЕНИЯ | 2013 |
|
RU2648573C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ФОРМИРОВАНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ | 2022 |
|
RU2828354C2 |
| СПОСОБ И СИСТЕМА МАШИННОГО ОБУЧЕНИЯ ИЕРАРХИЧЕСКИ ОРГАНИЗОВАННОМУ ЦЕЛЕНАПРАВЛЕННОМУ ПОВЕДЕНИЮ | 2019 |
|
RU2755935C2 |
| Способ автоматической сегментации флюорограмм грудной клетки больных пневмонией | 2016 |
|
RU2629629C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБУЧЕНИЯ ИЗОЛИРУЮЩЕГО ЛЕСА, А ТАКЖЕ СПОСОБ И УСТРОЙСТВО ДЛЯ РАСПОЗНАВАНИЯ ПОИСКОВОГО РОБОТА | 2021 |
|
RU2826553C1 |
| ВЫБОРКА КОМАНД ПО УКАЗАНИЮ В СРЕДСТВЕ СБОРА СВЕДЕНИЙ О ХОДЕ ВЫЧИСЛЕНИЙ | 2013 |
|
RU2585982C2 |
| УПРАВЛЕНИЕ В РЕЖИМЕ НИЗКИХ ПРИВИЛЕГИЙ РАБОТОЙ СРЕДСТВА СБОРА СВЕДЕНИЙ О ХОДЕ ВЫЧИСЛЕНИЙ | 2013 |
|
RU2585969C2 |
| СПОСОБЫ И СИСТЕМЫ ИДЕНТИФИКАЦИИ ПОЛЕЙ В ДОКУМЕНТЕ | 2020 |
|
RU2760471C1 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СЕРВЕР ПРЕОБРАЗОВАНИЯ ЗНАЧЕНИЯ КАТЕГОРИАЛЬНОГО ФАКТОРА В ЕГО ЧИСЛОВОЕ ПРЕДСТАВЛЕНИЕ | 2017 |
|
RU2693324C2 |

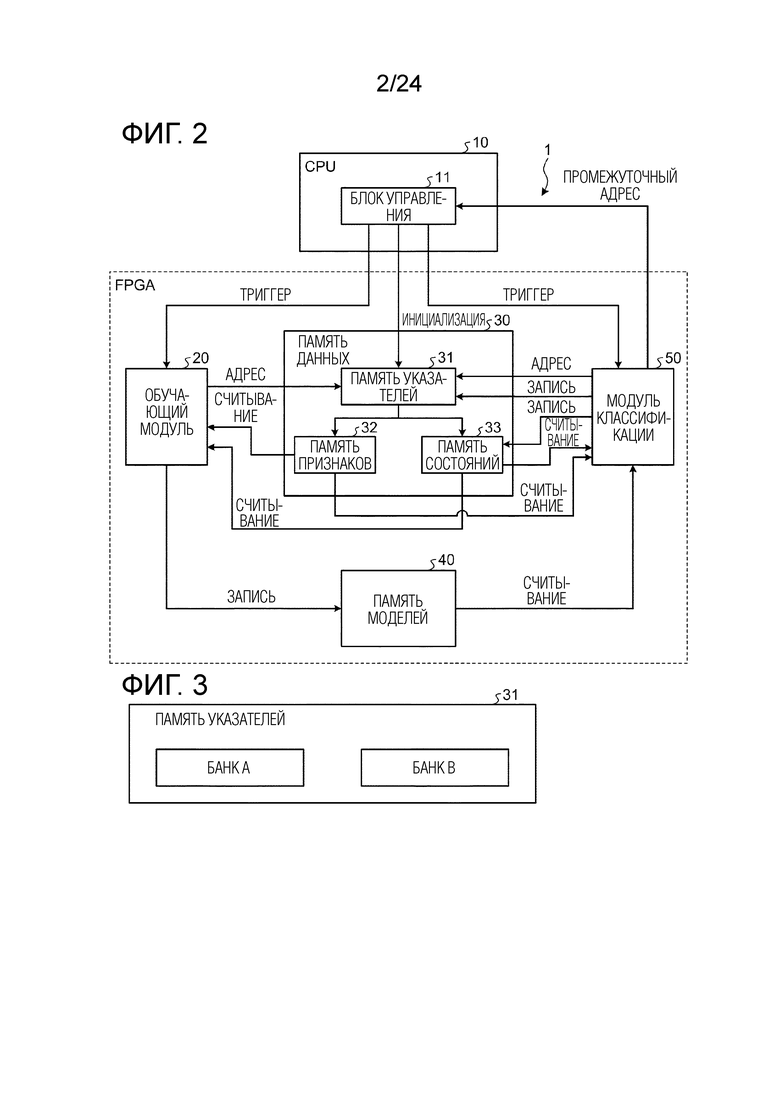
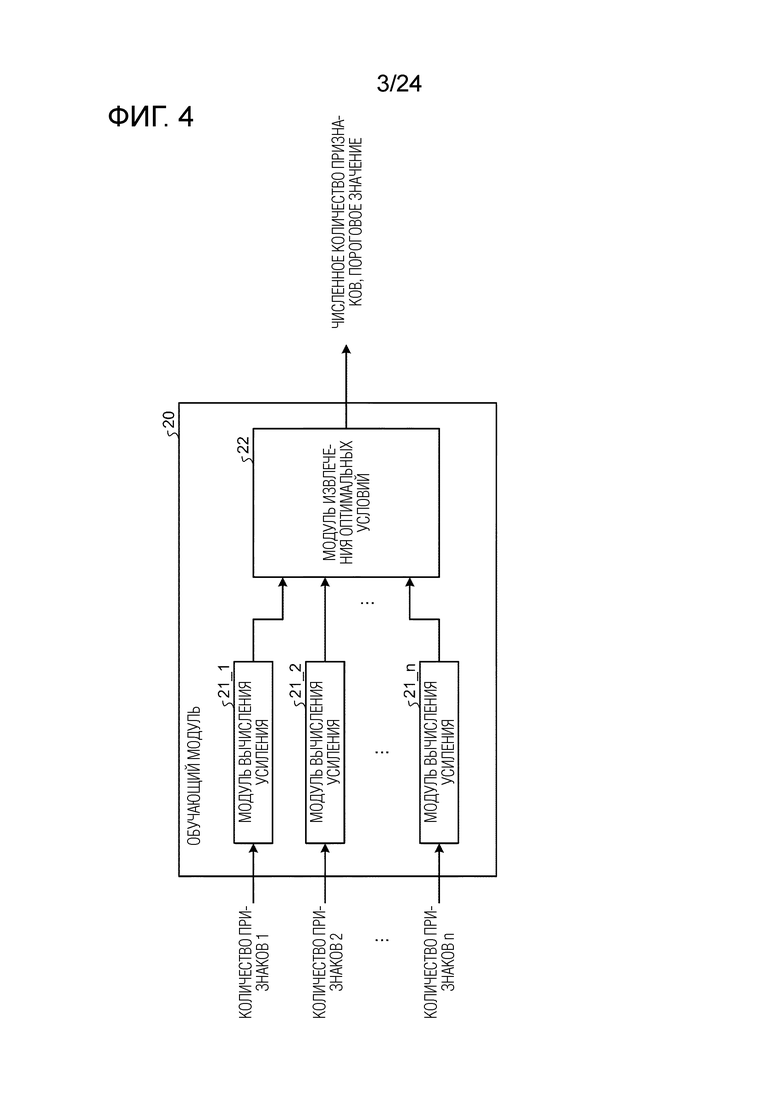

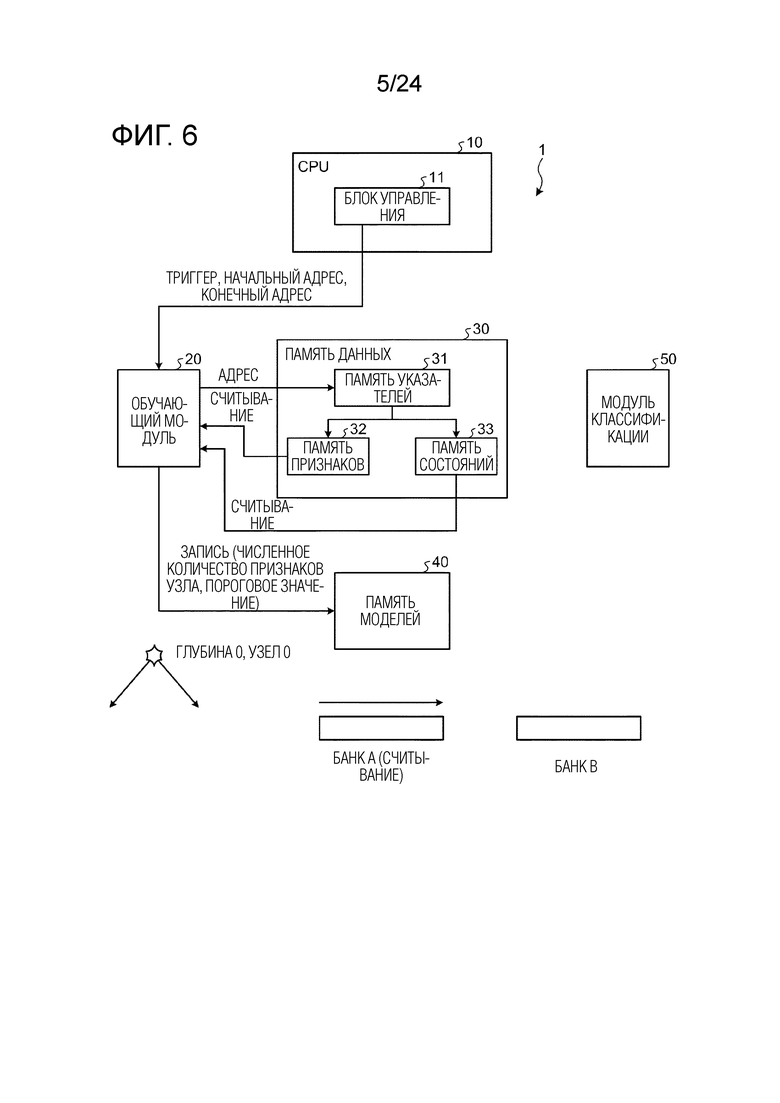


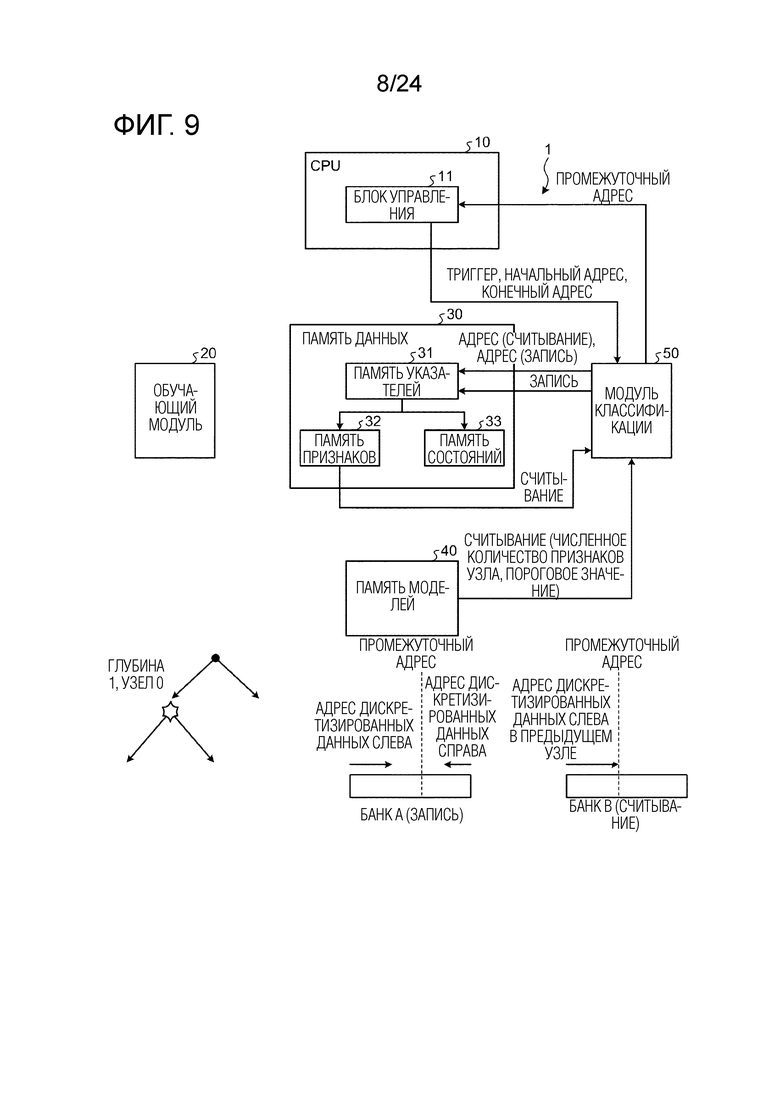
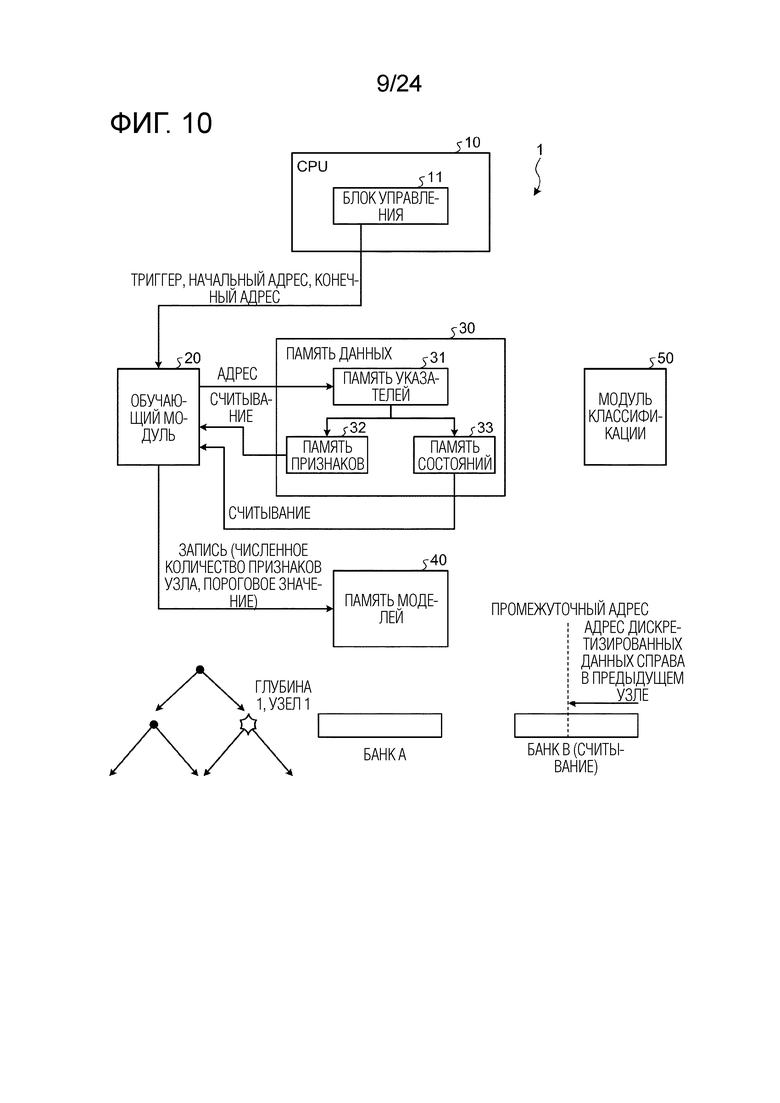
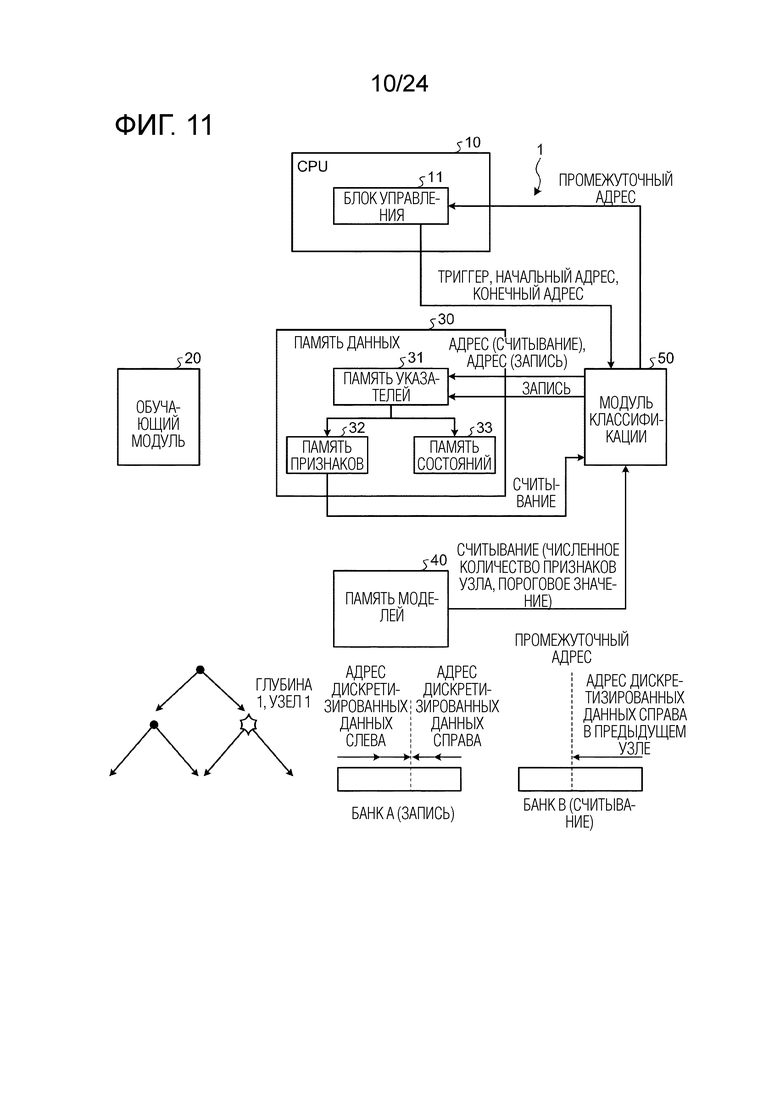

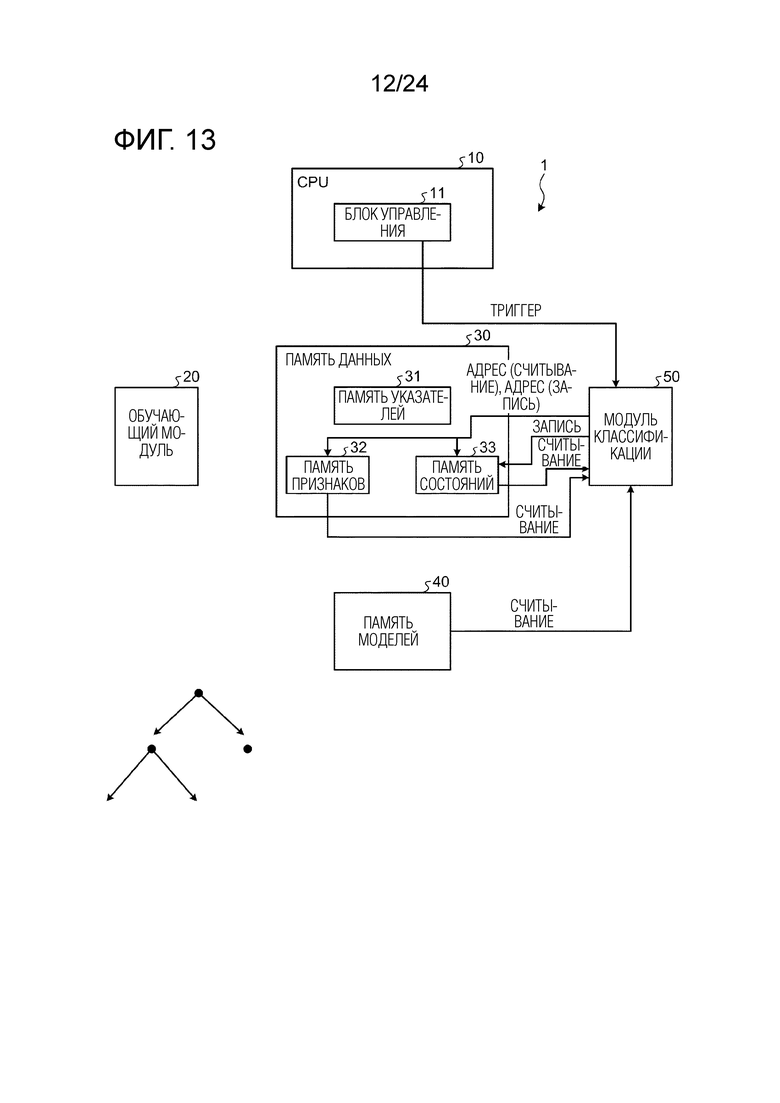
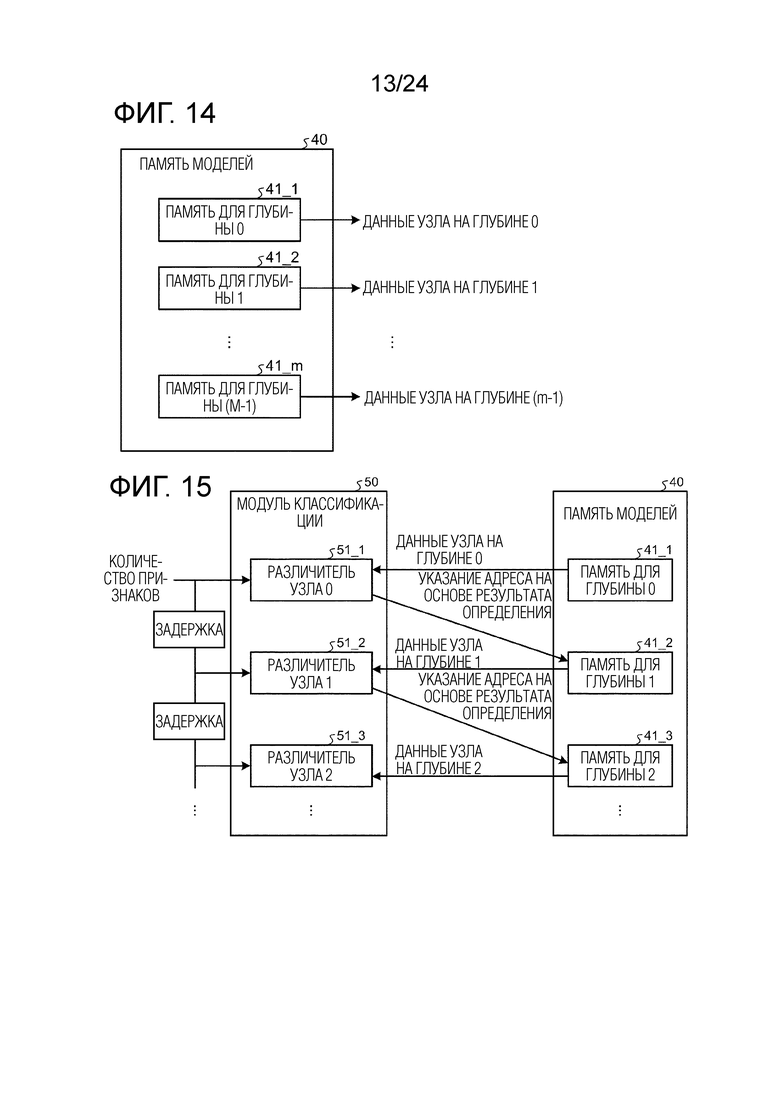
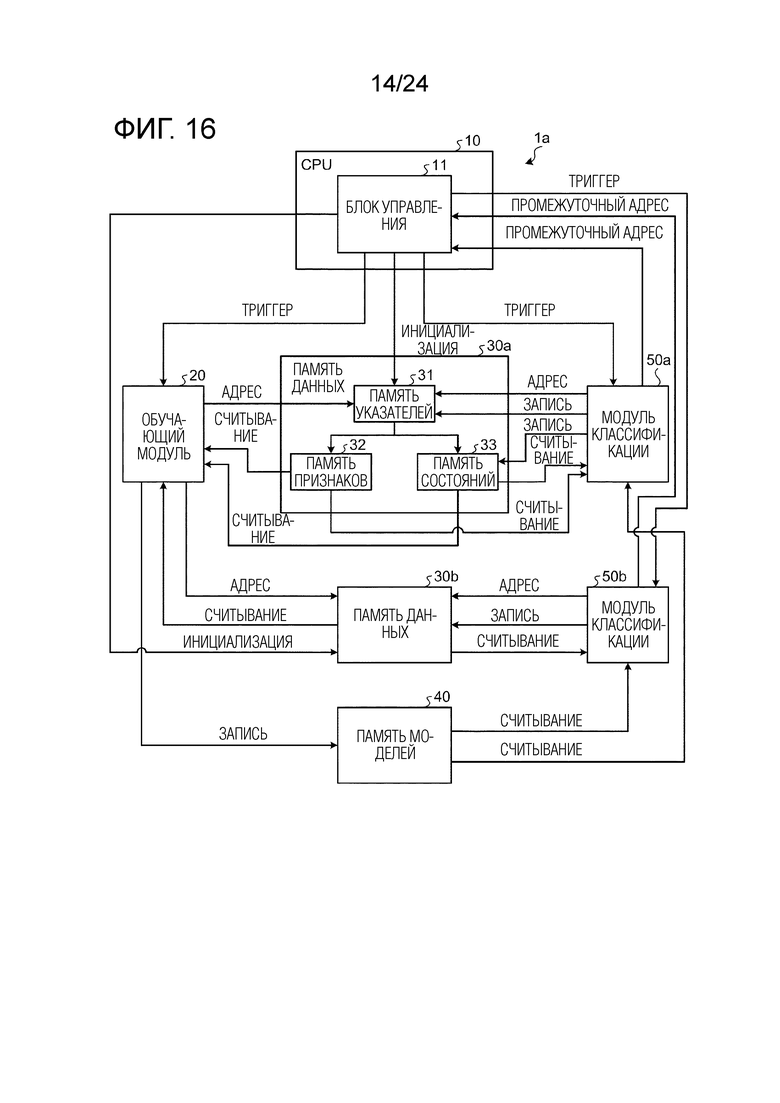



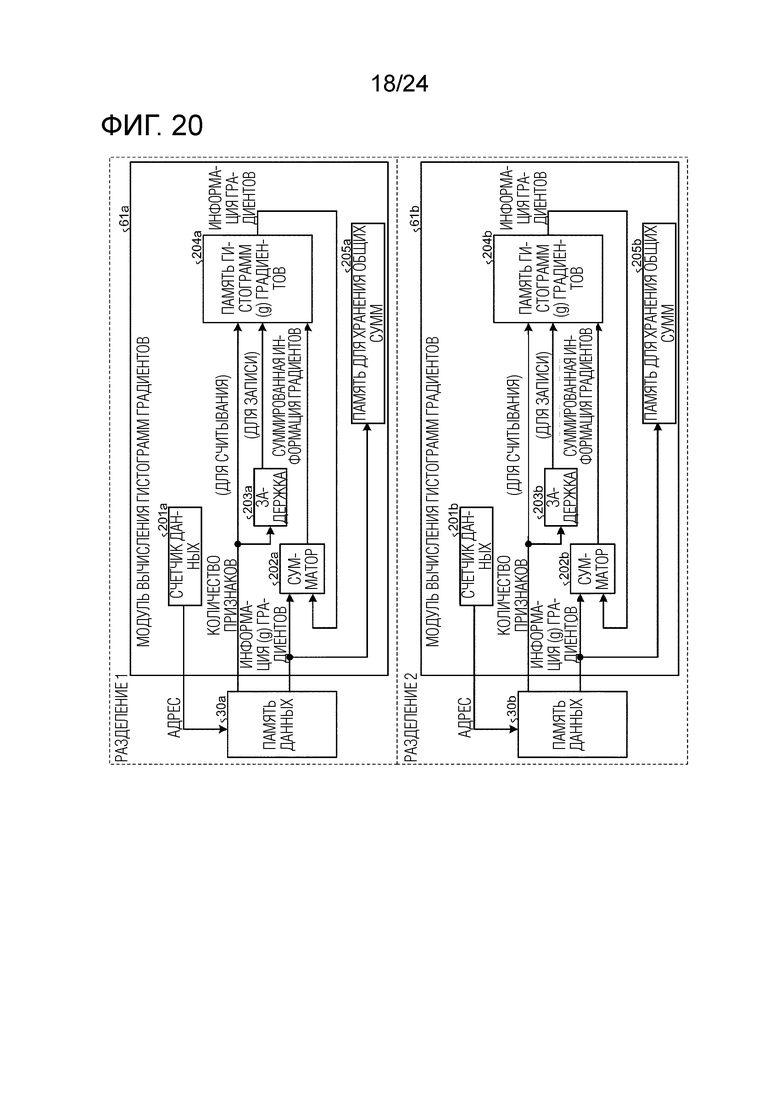
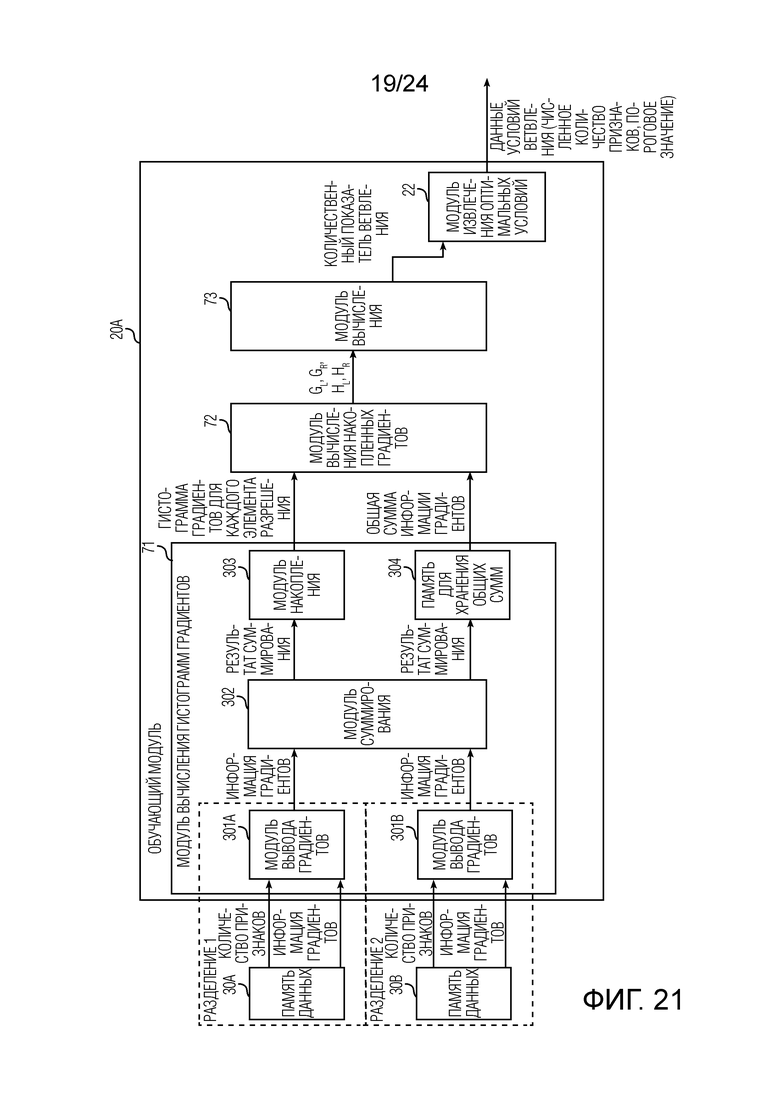
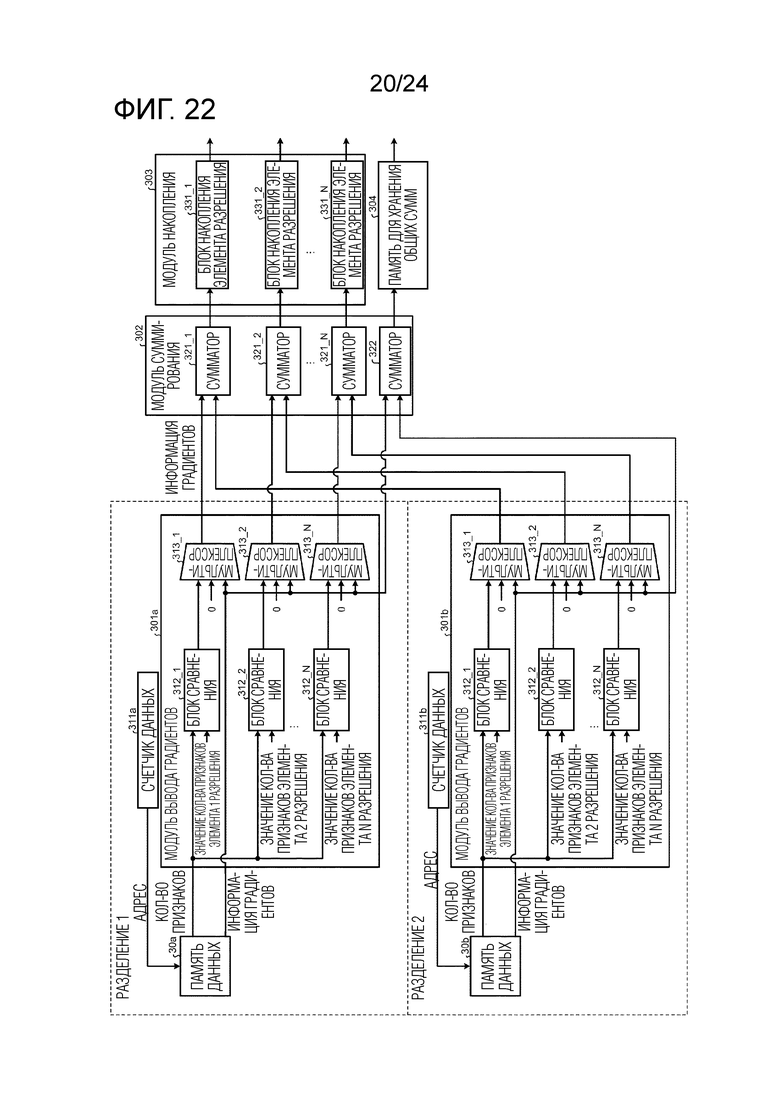
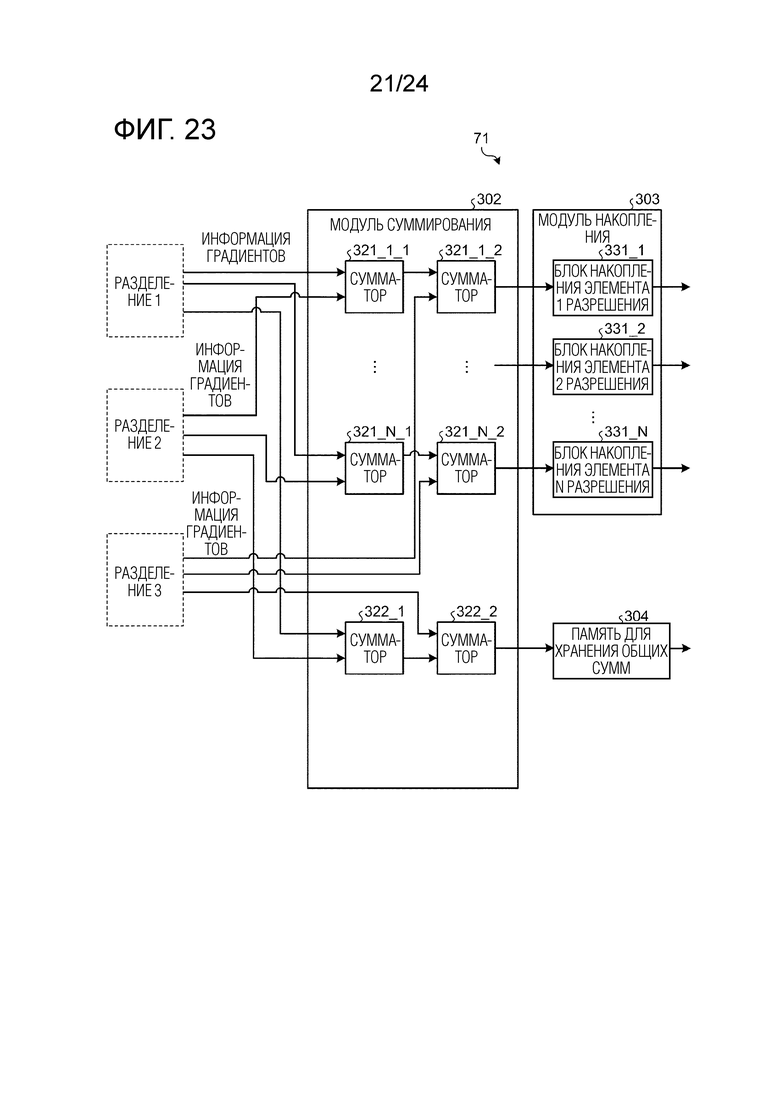

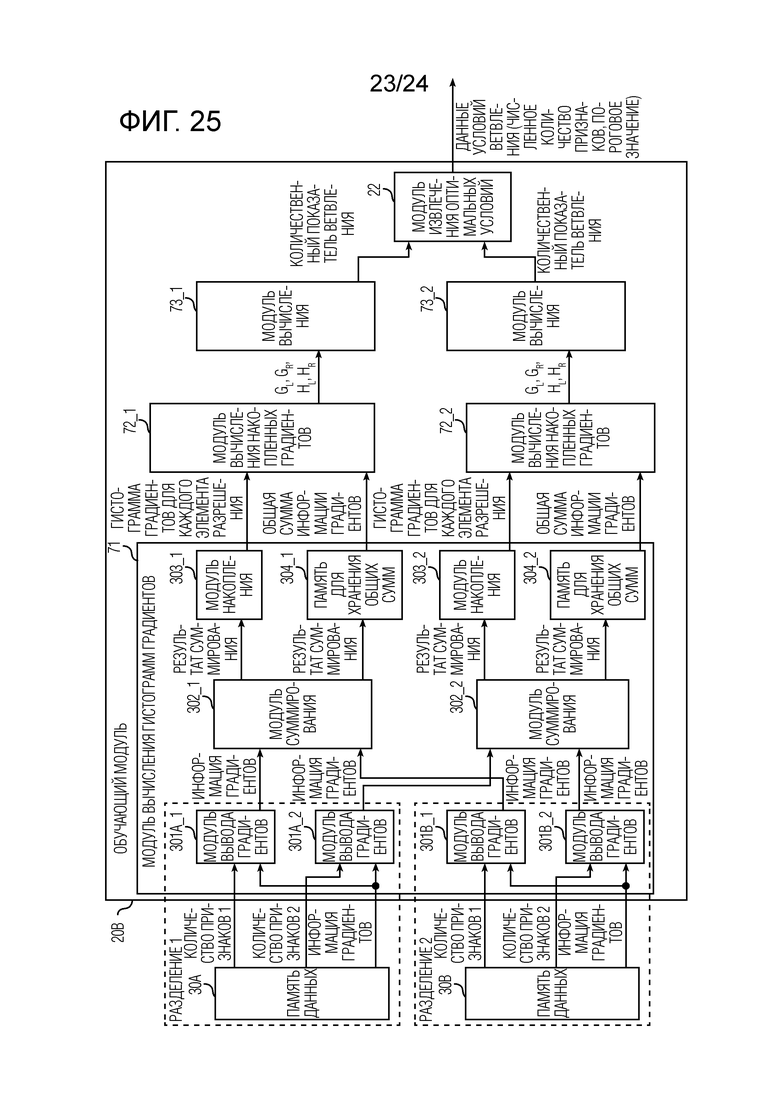
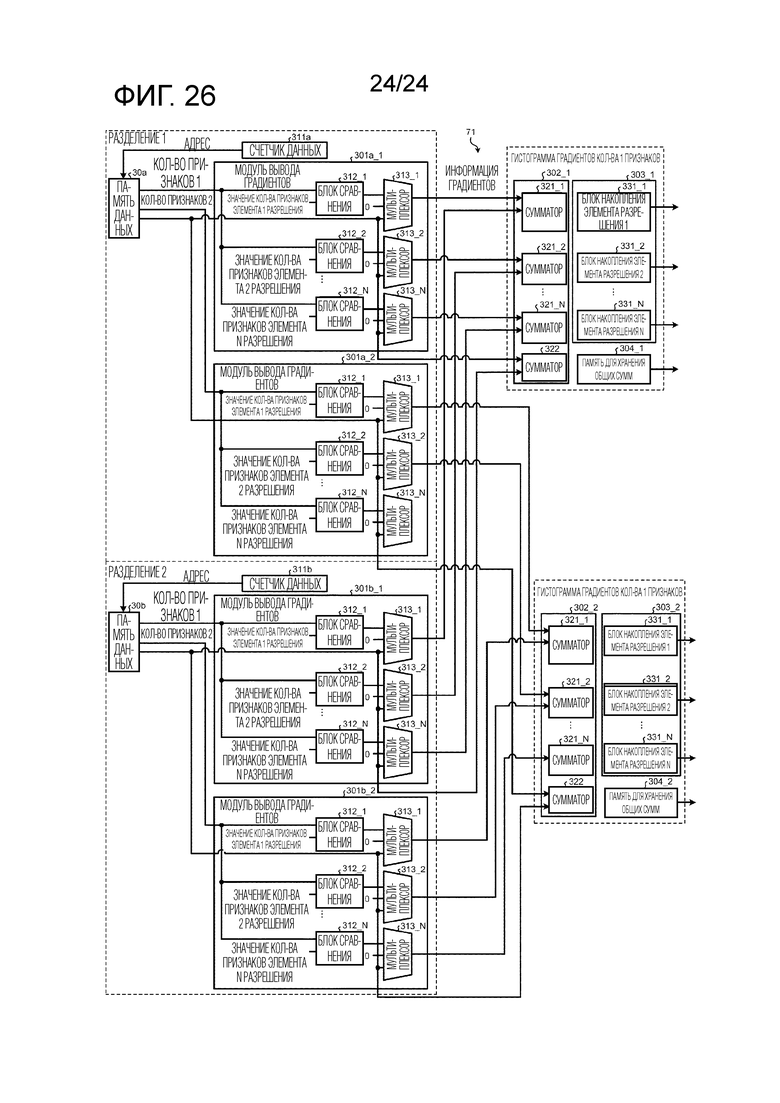
Группа изобретений относится к области машинного обучения. Техническим результатом является уменьшение размера схем памяти, которая хранит информацию гистограммы. Устройство содержит блоки памяти данных, выполненные с возможностью сохранять обучающие данные, включающие в себя тип количества признаков и соответствующую информацию градиентов; блоки вывода градиентов, каждый из которых выполнен с возможностью принимать ввод количества признаков и соответствующей информации градиентов из соответствующего одного из блоков памяти данных и выводить информацию градиентов через порт вывода, соответствующий каждому значению входного количества признаков; блок суммирования, выполненный с возможностью суммировать один или более фрагментов информации градиентов, соответствующей идентичному значению количества признаков, и выводить суммированное значение информации градиентов, соответствующей каждому значению количества признаков; и блок памяти гистограмм, выполненный с возможностью сохранять гистограмму, полученную посредством интегрирования суммированных значений информации градиентов, соответствующей каждому значению количества признаков, в качестве элемента разрешения. 2 н. и 8 з.п. ф-лы, 26 ил., 7 табл.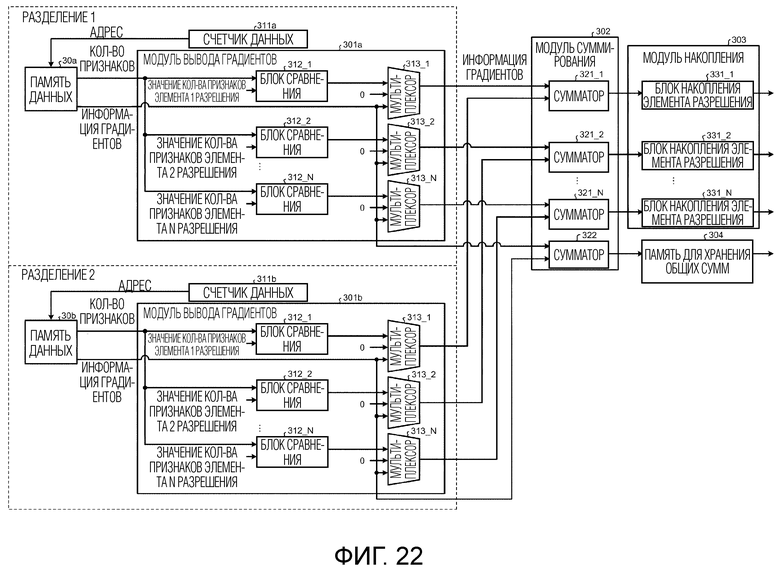
1. Вычислительное устройство, выполненное с возможностью осуществлять машинное обучение посредством градиентного бустинга, содержащее:
множество блоков памяти данных, приспособленных сохранять обучающие данные, включающие в себя по меньшей мере один тип набора признаков и информацию градиентов, соответствующую обучающим данным;
множество блоков вывода градиентов, которые предусмотрены согласно упомянутому множеству блоков памяти данных и каждый из которых выполнен с возможностью принимать ввод набора признаков и информации градиентов, соответствующей набору признаков, из соответствующего одного из множества блоков памяти данных и выводить информацию градиентов, соответствующую набору признаков, через порт вывода, соответствующий каждому значению входного набора признаков;
блок суммирования, выполненный с возможностью суммировать один или более фрагментов информации градиентов, соответствующих одному и тому же значению набора признаков, из числа фрагментов информации градиентов, выводимых из множества блоков вывода градиентов, и выводить суммированное значение информации градиентов, соответствующее каждому значению набора признаков; и
блок памяти гистограмм, выполненный с возможностью сохранять гистограмму, полученную посредством интегрирования выводимых из блока суммирования суммированных значений информации градиентов, соответствующих каждому значению набора признаков, для каждого элемента разрешения в случае, в котором это каждое значение задается в качестве элемента разрешения.
2. Вычислительное устройство по п.1, в котором блок памяти гистограмм содержит блок накопления, выполненный с возможностью сохранять гистограмму, полученную посредством интегрирования информации градиентов, соответствующей набору признаков для каждого элемента разрешения набора признаков.
3. Вычислительное устройство по п.1 или 2, в котором каждый из множества блоков вывода градиентов содержит:
блок определения, выполненный с возможностью определять, через какой порт вывода должна выводиться информация градиентов, соответствующая входному набору признаков, на основе набора признаков; и
блок выбора, выполненный с возможностью выбирать порт вывода, через который должна выводиться информация градиентов, на основе результата определения блока определения и выводить информацию градиентов в блок суммирования через выбранный порт вывода.
4. Вычислительное устройство по любому одному из пп.1-3, в котором:
множество блоков вывода градиентов предусмотрены для каждого типа набора признаков, считываемого из соответствующего одного из множества блоков памяти данных,
блок суммирования предусмотрен для каждого типа набора признаков, и
блок памяти гистограмм предусмотрен для каждого блока суммирования.
5. Вычислительное устройство по любому одному из пп.1-4, в котором:
информация градиентов содержит градиент первого порядка и градиент второго порядка при градиентном бустинге,
множество блоков вывода градиентов предусмотрены согласно каждому из градиента первого порядка и градиента второго порядка, считываемых из соответствующего одного из множества блоков памяти данных,
блок суммирования предусмотрен для каждого из градиента первого порядка и градиента второго порядка, и
блок памяти гистограмм предусмотрен для каждого блока суммирования.
6. Вычислительное устройство по любому одному из пп.1-5, в котором обучение выполняется для деревьев решений посредством градиентного бустинга.
7. Вычислительное устройство по любому одному из пп.1-5, в котором обучение выполняется для дерева решений, и обучение выполняется для следующего дерева решений посредством градиентного бустинга на основе результата обучения дерева решений, которое обучено.
8. Вычислительное устройство по п.6 или 7, дополнительно содержащее блок вычисления накопленных градиентов, выполненный с возможностью принимать ввод гистограммы для каждого элемента разрешения набора признаков, сохраненного в блоке памяти гистограмм, и вычислять, для каждого порогового значения набора признаков в узле дерева решений, кумулятивную сумму информации градиентов, соответствующей набору признаков, меньшему порогового значения, и кумулятивную сумму информации градиентов, соответствующей набору признаков, равного или большего порогового значения.
9. Вычислительное устройство по п.8, дополнительно содержащее блок вычисления количественных показателей, выполненный с возможностью вычислять количественный показатель ветвления для порогового значения, соответствующего каждой кумулятивной сумме, на основе кумулятивной суммы, вычисленной посредством блока вычисления накопленных градиентов.
10. Способ функционирования вычислительного устройства, выполненного с возможностью осуществлять машинное обучение посредством градиентного бустинга, при этом способ обучения содержит этапы, на которых:
принимают, для каждого из множества блоков памяти данных, приспособленных сохранять обучающие данные, включающие в себя по меньшей мере один тип набора признаков и информацию градиентов, соответствующую обучающим данным, ввод набора признаков и информации градиентов, соответствующей набору признаков, и выводят информацию градиентов, соответствующую набору признаков, через порт вывода, соответствующий каждому значению входного набора признаков;
суммируют один или более фрагментов информации градиентов, соответствующих одному и тому же значению набора признаков, из числа фрагментов выходной информации градиентов и выводят суммированное значение информации градиентов, соответствующее каждому значению набора признаков; и
сохраняют гистограмму, полученную посредством интегрирования выходных суммированных значений информации градиентов, соответствующих каждому значению набора признаков, для каждого элемента разрешения в случае, в котором это каждое значение задается в качестве элемента разрешения.
| US 20170372214 A1, 28.12.2017 | |||
| US 9269054 B1, 23.02.2016 | |||
| US 20120327260 A1, 27.12.2012 | |||
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2649792C2 |

