ОБЛАСТЬ ТЕХНИКИ
[01] Настоящая технология относится к электронным устройствам и способам создания прогностической модели. Конкретнее, настоящая технология относится к способу и системе для преобразования значения категориальной фактора в его числовое представление для использования прогностической моделью.
УРОВЕНЬ ТЕХНИКИ
[02] Алгоритмы машинного обучения (MLA) используются для различных задач в компьютерных технологиях. Обычно, MLA используются для создания прогнозов, связанных с пользовательским взаимодействием с компьютерным устройством. Примером сферы использования MLA является пользовательское взаимодействие с содержимым, доступным, например, в сети Интернет.
[03] Объем доступной информации на различных интернет-ресурсах экспоненциально вырос за последние несколько лет. Были разработаны различные решения, которые позволяют обычному пользователю находить информацию, которую он(а) ищет. Примером такого решения является поисковая система. Примеры поисковых систем включают в себя такие поисковые системы как GOOGLE™, YANDEX™, YAHOO!™ и другие. Пользователь может получить доступ к интерфейсу поисковой системы и подтвердить поисковый запрос, связанный с информацией, которую пользователь хочет найти в Интернете. В ответ на поисковый запрос поисковые системы предоставляют ранжированный список результатов поиска. Ранжированный список результатов поиска создается на основе различных алгоритмов ранжирования, которые реализованы в конкретной поисковой системе, и которые используются пользователем, производящим поиск. Общей целью таких алгоритмов ранжирования является представление наиболее релевантных результатов вверху ранжированного списка, а менее релевантных результатов - на менее высоких позициях ранжированного списка результатов поиска (а наименее релевантные результаты поиска будут расположены внизу ранжированного списка результатов поиска).
[04] Поисковые системы обычно являются хорошим поисковым инструментом в том случае, когда пользователю заранее известно, что именно он(а) хочет найти. Другими словами, если пользователь заинтересован в получении информации о наиболее популярных местах в Италии (т.е. поисковая тема известна), пользователь может ввести поисковый запрос: «Наиболее популярные места в Италии». Поисковая система предоставит ранжированный список интернет-ресурсов, которые потенциально являются релевантными по отношению к поисковому запросу. Пользователь далее может просматривать ранжированный список результатов поиска для того, чтобы получить информацию, в которой он заинтересован, в данном случае - о посещаемых местах в Италии. Если пользователь по какой-либо причине не удовлетворен представленными результатами, пользователь может произвести вторичный поиск, уточнив запрос, например «наиболее популярные места в Италии летом», «наиболее популярные места на юге Италии», «Наиболее популярные места в Италии для романтичного отдыха».
[05] В примере поисковой системы, алгоритм машинного обучения (MLA) используется для создания ранжированных поисковых результатов. Когда пользователь вводит поисковый запрос, поисковая система создает список релевантных веб-ресурсов (на основе анализа просмотренных веб-ресурсов, указание на которые хранится в базе данных поискового робота в форме списков словопозиций или тому подобного). Далее поисковая система выполняет MLA для ранжирования таким образом созданного списка поисковых результатов. MLA ранжирует список поисковых результатов на основе их релевантности для поискового запроса. Подобный MLA "обучается" для прогнозирования релевантности данного поискового результата для поискового запроса на основе множества "факторов", связанных с данным поисковым результатом, а также указаний на взаимодействия прошлых пользователей с поисковыми результатами, когда они вводили аналогичные поисковые запросы в прошлом.
[06] Как было упомянуто ранее, поисковые системы полезны в случаях когда пользователь знает, что именно он(а) ищет (т.е. обладает конкретным поисковым намерением). Существует и другой подход, в котором пользователю предоставляется возможность обнаруживать содержимое и, конкретнее, позволяется отображать и/или рекомендовать содержимое, в поиске которого пользователь не был явно заинтересован. В некоторым смысле, подобные системы рекомендуют пользователю содержимое без отдельного поискового запроса, на основе явных или неявных интересов пользователя.
[07] Примерами таких систем являются система рекомендаций FLIPBOARD™, которая агрегирует и рекомендует содержимое из различных социальных сетей. Система рекомендаций FLIPBOARD предоставляет содержимое в «журнальном формате», где пользователь может «пролистывать» страницы с рекомендуемым/агрегированным содержимым. Системы рекомендаций собирают содержимое из социальных медиа и других веб-сайтах, представляет его в журнальном формате, и позволяют пользователям «пролистывать» ленты социальных новостей и ленты веб-сайтов, которые поддерживают партнерские отношения с компанией, что позволяет эффективно «рекомендовать» содержимое пользователю, даже если пользователь явно не выражал свой интерес в конкретном содержимом. Другим примером системы рекомендаций является система рекомендаций YANDEX.ZEN™, которая создает и представляет персонализированный контент пользователю, когда пользователь запускает приложение, связанное с Yandex.Zen, которым может быть специальное приложение или соответствующая страница браузерного приложения.
[08] Для создания ранжированных результатов поиска в поисковой системе или списка рекомендуемых ресурсов в обычной системе рекомендаций, соответствующие системы используют алгоритм машинного обучения рекомендуемый контент из различных источников, доступных в Интернете.
[09] Обзор алгоритмов машинного обучения
[10] Существует множество типов MLA, известных в данной области техники. В широком смысле, можно выделить три типа MLA: алгоритм машинного обучения на основе обучения с учителем, алгоритм машинного обучения на основе обучения без учителя и алгоритм машинного обучения на основе обучения с подкреплением.
[11] Процесс MLA с учителем основан на целевом значении - итоговой переменной (или зависимой переменной), которая будет прогнозироваться из заданного набора предикторов (независимых переменных). Используя набор переменных, MLA (во время обучения) создает функцию, которая сопоставляет исходные данные с желаемыми результатами. Процесс обучения продолжается до тех пор пока MLA не достигнет желаемого уровня точности проверки данных. Примеры MLA на основе обучения с учителем включают в себя: Регрессию, Дерево решений, Случайный Лес, Логистическую Регрессию и т.д.
[12] MLA без учителя не использует для прогнозирования целевое значение или итоговую переменную как таковые. Подобные MLA используются для кластеризации множества значений в различные группы, которые широко используются для сегментирования клиентов в различные группы для конкретных целей. Примеры MLA без учителя включают в себя: Алгоритм Apriori, метод K-средних.
[13] MLA с подкреплением обучается принятию конкретных решений. Во время обучения, MLA находится обучающей среде, где он обучает сам себя постоянно используя систему проб и ошибок. MLA обучается на основе предыдущего опыта и пытается усвоить максимально качественные знания для принятия точных решений. Примером MLA с подкреплением может быть Марковский процесс.
[14] MLA на основе деревьев решений является примером MLA с учителем. Этот тип MLA использует дерево решений (как прогностическую модель) для перехода от наблюдений за элементом (представлены в виде ветвей) к выводам о целевом значении элемента (представлены в виде листьев). Древовидные модели, в которых итоговая переменная может принимать дискретный набор значений, называются деревьями классификации; в этих древовидных структурах, листья представляют собой отметки класса, а ветви представляют собой сочетание факторов, которое приводит к этим отметкам класса. Деревья решений, в которых итоговая переменная может принимать непрерывные значения (как правило, вещественные числа), называются регрессионными деревьями.
[15] Для того чтобы MLA на основе деревьев решений работали, необходимо "создать" или обучить их с помощью обучающего набора объектов, содержащего множество обучающих объектов (например, документы, события и тому подобное). Эти обучающие объекты были "размечены" людьми-асессорами. Например, человек-асессор может ранжировать данный обучающий объект как "неинтересный", "интересный" или "очень интересный".
[16] Градиентный бустинг
[17] Градиентный бустинг - один из подходов к созданию MLA на основе деревьев решений, в котором создается прогностическая модель в форме ансамбля деревьев. Ансамбль деревьев создается ступенчатым способом. Каждое последующее дерево решений в ансамбле деревьев решений сосредоточено на обучении на основе тех итераций в предыдущем дереве решений, которые были "слабыми моделями" в предыдущей(их) итерации(ях) в ансамбле деревьев решений (т.е. теми, которые связаны с маловероятным прогнозом / высокой вероятностью ошибки).
[18] В общем случае, бустинг представляет собой способ, нацеленный на улучшение качества прогнозирования MLA. В этом сценарии, вместо того, чтобы полагаться на прогноз одного обученного алгоритма (например, одного дерева решений) система использует несколько обученных алгоритмов (т.е. ансамбль деревьев решений) и принимает окончательное решение на основе множества прогнозируемых результатов этих алгоритмов.
[19] В бустинге деревьев решений, MLA сначала создает первое дерево, затем второе, что улучшает прогноз результата, полученного от первого дерева, а затем третье дерево, которое улучшает прогноз результата, полученного от первых двух деревьев, и так далее. Таким образом, MLA в некотором смысле создает ансамбль деревьев решений, где каждое последующее дерево становится лучше предыдущего, конкретно сосредотачиваясь на слабых моделях из предыдущих итераций деревьев решений. Другими словами, каждое дерево создается на одном и том же обучающем наборе обучающих объектов, и, тем не менее, обучающие объекты, в которых первое дерево совершает "ошибки" в прогнозировании, являются приоритетными для второго дерева и т.д. Эти "сильные" обучающие объекты (те, которые на предыдущих итерациях деревьев решений были спрогнозированы менее точно), получают более высокие весовые коэффициенты, чем те, для которых были получены удовлетворительные прогнозы.
[20] Жадные алгоритмы
[21] При создании деревьев решений (например, с помощью градиентного бустинга), широко используются жадные алгоритмы. Жадный алгоритм - это алгоритмическая парадигма, которая связана с решением задач эвристическим путем принятия локально оптимального решения на каждом этапе (например, на каждом уровне дерева решений) с предположением о том, что таким образом будет найдено глобальное оптимальное значение. При создании деревьев решений использование жадного алгоритма может быть сведено к следующему: для каждого уровня дерева решений, алгоритм машинного обучения пытается найти наиболее оптимальное значение (фактора и/или разделения) - оно будет являться локально оптимальным решением. Когда определено оптимальное значение для данного узла, MLA переходит к созданию более низкого уровня дерева решений, ранее определенные значения для более высоких узлов являются "зафиксированными" - т.е. учитываются "без изменений" для данной итерации дерева решений в ансамбле дерева решений.
[22] Как и в случае с одним деревом, каждое дерево в ансамбле деревьев создается с помощью жадного алгоритма, что означает то, что когда MLA выбирает фактор и разделяющее значение для каждого узла дерева, MLA осуществляет выбор, который является локально оптимальным, например, для конкретного узла, а не для всего дерева в целом.
[23] Забывчивые деревья решений
[24] После того как были выбраны лучшие фактор и разделение для данного узла, алгоритм переходит к дочернему узлу данного узла и выполняет жадный выбор фактора и разделения для этого дочернего узла. В некоторых вариантах осуществления технологии, при выборе фактора для данного узла, алгоритм машинного обучения не может использовать факторы, использованные в узлах на более глубинных уровнях дерева. В других вариантах осуществления технологии, каждый глубинный уровень MLA анализирует все возможные факторы, вне зависимости от того, были ли они использованы на предыдущих уровнях. Подобные деревья называются "забывчивыми" деревьями, поскольку на каждом уровне дерево "забывает" о том, что оно использовало конкретный фактор на предыдущем уровне и снова учитывает этот фактор. Для выбора наилучшего фактора и разделителя для узла, для каждого возможного варианта вычисляется функция усиления). Выбирается опция (фактор или разделяющее значение) с наибольшим усилением.
[25] Параметр Качества Прогноза
[26] Когда создается данное дерево, для определения качества прогноза данного дерева (или данного уровня данного дерева при создании данного дерева), MLA вычисляет метрику (т.е. "оценку"), которая означает, насколько близко текущая итерация модели, которая включает в себя данное дерево (или данный уровень данного дерева) и предыдущие деревья, подходит к прогнозу правильного ответа (целевого значения). Оценка модели вычисляется на основе сделанных прогнозов и фактических целевых значений (правильных значений) обучающих объектов, использованных для обучения.
[27] Когда создается первое дерево, MLA выбирает значения для первого фактора и первого разделяющего значения для корневого узла первого дерева и оценивает качество подобной модели. Для этого, MLA "скармливает" обучающие объекты первому дереву в том смысле, что он спускает обучающие объекты по ветвям дерева решений, и эти "скормленные" обучающие объекты разделяются на два (или более) различных листа первого дерева на разделении первого узла (т.е. они "категоризируются" деревом решений или, конкретнее, модель дерева решений пытается спрогнозировать целевое значение обучающего объекта, который проходит через модель дерева решений). После того, как все обучающие объекты были категоризированы, вычисляется параметр качества прогноза - определяется то, насколько близка категоризация объектов к фактическим значениям целевых объектов.
[28] Конкретнее, зная целевые значения обучающих объектов, MLA вычисляет параметр качества прогноза (например, усиление информации и тому подобное) для этого первого фактора - первого разделения узла, и далее выбирает второй фактор со вторым разделением для корневого узла. Для этого второго варианта фактора и разделения корневого узла, MLA осуществляет те же этапы, что и в первом варианте (MLA "скармливает" обучающие объекты дереву и вычисляет результирующую метрику с помощью второго варианта комбинации фактора и разделения для корневого узла).
[29] MLA далее повторяет тот же процесс с третьим, четвертым, пятым и т.д. вариантам фактора и разделениям для корневого узла до тех пор пока MLA не проверит все возможные варианты фактора и разделяющего значения, и далее MLA выбирает тот вариант фактора и разделяющего значения для корневого узла, который дает наилучший результат прогноза (т.е. обладает самой высокой метрикой).
[30] После того как были выбраны фактор и разделяющее значение для корневого узла, MLA переходит к дочерним узлам корневого узла и выбирает свойства и разделяющие значения для дочерних узлов тем же способом, что и для корневого узла. Этот процесс далее повторяется для дочерних узлов первого дерева до тех пор пока дерево решений не будет создано.
[31] Далее, в соответствии с методом применения бустинга, MLA переходит к созданию второго дерева. Второе дерево нацелено на улучшение результатов прогнозирования, созданных первым деревом. Оно должно "исправлять" ошибки в прогнозировании, которые допущены первым деревом. Для этого второе дерево создается на обучающем объекте, и примеры, в которых были допущены ошибки первым деревом, обладают более высоким весовым коэффициентом, чем примеры, для которых первое дерево выдало правильный прогноз. Второе дерево создается аналогично тому как создавалось первое дерево.
[32] Этот подход позволяет последовательно создавать, десятки, сотни и даже тысячи деревьев. Каждое последующее дереве в ансамбле деревьев улучшает качество прогноза предыдущего дерева.
[33] Числовые и Категориальные Факторы
[34] В широком смысле, деревья решений могут использовать два типа факторов для анализа - числовые факторы и категориальные факторы.
[35] Примерами числовых факторов могут быть: возраст, число хитов для документов, число раз, когда данный поисковый запрос появлялся в документе и т.д. В широком смысле, числовые факторы могут быть бинарными (т.е. 0 или 1) или непрерывными (например, вес, высота и т.д.).
[36] Числовые факторы могут легко сравниваться друг с другом. Например, когда числовые факторы представляют то, насколько высоким является пользователь, их легко можно сравнить друг с другом, чтобы сделать вывод о том, что Пользователь А выше пользователя В.
[37] Числовые факторы анализируются деревом путем сравнения числового фактора с заранее определенным значением на каждом из разделений дерева. Например, числовой фактор "число кликов" может сравниваться на каждом разделении: "выше 10000?" В зависимости от значения числового фактора, спуск по дереву на каждом разделении может идти в "левую" или "правую" сторону.
[38] MLA может быть обучен на числовых факторах для прогноза числового целевого значения. Например, MLA может быть обучен прогнозировать "КЛИК" или "ОТСУТСТВИЕ КЛИКА" для конкретного документа/веб-ресурса (т.е. 1 для клика и 0 для отсутствия клика).
[39] Категориальные факторы могут быть как непрерывно-дискретными (например, породы собак) так и бинарными (например, самец/самка).
[40] Обычным подходом в данной области техники является преобразование категориального фактора в его числовое представление и обработка числового представления категориального фактора. Существуют различные подходы к преобразованию категориальных факторов в их числовое представление: категориальное кодирование, числовое кодирование, унитарное кодирование, бинарное кодирование и т.д.
[41] Американская патентная заявка 8,572,071 (Опубликованная 29 октября 2013 года, под авторством Поттера и др., и выданная Ратгерскому университету в Нью-Джерси) описывает способ и устройство преобразования данных в векторную форму. Каждый вектор состоит из набора свойств, которые либо являются логическими, либо представлены в логической (булевой) форме. Векторы могу попадать или не попадать в категории, размеченные предметными экспертами (SME). Если категории существуют, метки категорий разделяют вектора на подмножества. Первое преобразование вычисляет предварительную вероятность для каждого свойства на основе связей между свойствами в каждом подмножестве векторов. Второе преобразование вычисляет новое числовое значение для каждого свойства на основе связей между свойствами в каждом подмножестве векторов. Третье преобразование работает с категоризованными векторами. На основе автоматического выбора категорий из свойств, это преобразование вычисляет новое числовое значение для каждого свойства на основе связей между свойствами в каждом подмножестве векторов.
[42] Американская патентная заявка US 7,113,932 (опубликованная 26 сентября 2006 под авторством Тайбнеджад и др., и выданная "MCI" LLC) описывает системную программу обработки данных для разработки, обучения и реализации нейронной сети, которая может идентифицировать покупателей с риском безнадежного долга. Вектор фактора применяется к нейронной сети для создания выводов, которые выдают примерное значение относительной вероятности того, что для клиентов, которые упоминаются в записях, используемых для создания вектора фактора, существует риск безнадежного долга. Статистические значения, относящиеся к категориальным свойствам клиентов в отношении вероятности того, что существует риск безнадежного долга, заменяются на категориальные свойства, и свойства нормализуются до того как вектор фактора применяется к сети. В одном варианте осуществления технологии, клиенты являются клиентами удаленного поставщика услуг.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[43] Варианты осуществления настоящей технологии были разработаны с учетом определения разработчиками по меньшей мере одной технической проблемы, связанной с известными подходами к использованию категориальных факторов в деревьях решений.
[44] Для целей иллюстрации предположим, что фактор, который необходимо обработать алгоритму машинного обучения, представляет собой "музыкальный жанр", и целью прогнозирования функции для MLA является способность прогнозировать "прослушано" или "не послушно" на основе музыкального жанра. Фактор "музыкальный жанр" является категориальным или, иным словами, может принимать множество значений - например: джаз, классика, регги, фолк, хип-хоп, поп, панк, опера, кантри, хеви-метал, рок и т.д.
[45] Для того, чтобы MLA мог обработать категориальный фактор, этот фактор необходимо преобразовать в числовое значение. Конкретнее, значение данного категориального фактора (т.е. одного из вариантов джаз, классика, регги, фолк, хип-хоп, поп, панк, опера, кантри, хеви-метал, рок) необходимо преобразовать в его числовое значение).
[46] В соответствии с неограничивающими вариантами осуществления настоящей технологии, MLA сначала создает упорядоченный список всех обучающих объектов, обладающих категориальными факторами, которые будут обработаны во время этапа обучения MLA.
[47] В случае если обучающие объекты с категориальными факторами обладают присущими им временными связями (например, месяцы года, года и т.д.), алгоритм машинного обучения организует обучающие объекты, обладающие категориальными факторами, в соответствии с этими временными связями. В случае если обучающие объекты с категориальными факторами не обладают присущими временными связями, алгоритм машинного обучения создает упорядоченный список обучающих объектов, обладающих категориальными факторами, на основе правила. Например, MLA может создавать случайный порядок обучающих объектов, обладающих категориальными факторами. Случайный порядок становится основой для временного порядка обучающих объектов, обладающих категориальными факторами, которые, в ином случае, не обладают никакими присущими временными связями.
[48] В вышеприведенном примере, где категориальные факторы представляют собой музыкальные жанры - эти обучающие объекты, обладающие категориальными факторами, могут быть связаны или не связаны с присущими им временными связями. Например, в тех сценариях, где обучающие объекты, которые обладают категориальными факторами, связаны с аудиотреками, воспроизводимыми на музыкальном он-лайн хранилище или загруженными с него, обучающие объекты, которые обладают категориальными факторами, могут быть обладать присущими им временными связями на основе времени воспроизведения/загрузки.
[49] Вне зависимости от того, как создается порядок, MLA далее "замораживает" обучающие объекты, обладающие категориальными факторами, в таким образом организованном порядке. Таким образом организованный порядок, в некотором роде, может указывать для каждого обучающего объекта, обладающего категориальным фактором, на то, какие другие обучающие объекты, обладающие категориальными факторами, находятся "до" и какие находятся "после" (даже если обучающие объекты, обладающие категориальными факторами, не связаны с присущими временными связями).
[50] На Фиг. 1 представлен неограничивающий пример упорядоченного списка обучающих объектов 102, обучающие объекты связаны с категориальными факторами (продолжая пример, в котором категориальные факторы представляют собой музыкальные жанры - джаз, классика, регги, фолк, хип-хоп, поп, панк, опера, кантри, хеви-метал, рок и т.д.).
[51] Упорядоченный список обучающих объектов 102 обладает множеством обучающих объектов 104. Исключительно в целях иллюстрации, множество обучающих объектов 104 включает в себя первый обучающий объект 106, второй обучающий объект 108, третий обучающий объект 110, четвертый обучающий объект 112, пятый обучающий объект 114, шестой обучающий объект 116, седьмой обучающий объект 118 и восьмой обучающий объект 120. Естественно, множество обучающих объектов 104 может содержать меньшее или большее количество обучающих объектов. Каждый из обучающих объектов из множества обучающих объектов 104 обладает категориальным фактором 122, связанным с ним, а также значением 124 события. Используя в качестве примера первый обучающий объект 106, его категориальный фактор 112 связан с жанром "поп", а значение 124 события равно "0" (что указывает, например, на отсутствие клика во время взаимодействия с первым обучающим объектом 106 предыдущим пользователем или асессором).
[52] Продолжая описание примера, представленного на Фиг. 1:
- для второго обучающего объекта 108, категориальный фактор 112 связан с жанром "рок", а значение 124 события равно "1" (что указывает, например, на наличие клика);
- для третьего обучающего объекта 110, категориальный фактор 112 связан с жанром "диско", а значение 124 события равно "1" (что указывает, например, на наличие клика);
- для четвертого обучающего объекта 112, категориальный фактор 112 связан с жанром "поп", а значение 124 события равно "0" (что указывает, например, на отсутствие клика);
- для пятого обучающего объекта 114, категориальный фактор 112 связан с жанром "поп", а значение 124 события равно "1" (что указывает, например, на наличие клика);
- для пятого обучающего объекта 116, категориальный фактор 112 связан с жанром "джаз", а значение 124 события равно "0" (что указывает, например, на отсутствие клика);
- для шестого обучающего объекта 118, категориальный фактор 112 связан с жанром "классика", а значение 124 события равно "1" (что указывает, например, на наличие клика);
- для седьмого обучающего объекта 120, категориальный фактор 112 связан с жанром "регги", а значение 124 события равно "1" (что указывает, например, на наличие клика).
[53] Порядок упорядоченного списка обучающих объектов 102 показан на Фиг. 1 указан под номером 126. В соответствии с неограничивающими вариантами осуществления настоящей технологии, в соответствии с порядком 126 упорядоченного списка обучающих объектов 102, данный обучающий объект в упорядоченном списке обучающих объектов 102 может находиться до или после другого обучающего объекта в упорядоченном списке обучающих объектов 102. Например, первый обучающий объект 106, можно сказать, находится до любого другого обучающего объекта из множества обучающих объектов 104. В качестве другого примера, четвертый обучающий объект 112 может находиться (i) после первого обучающего объекта 106, второго обучающего объекта 108, третьего обучающего объекта 110 и (ii) до пятого обучающего объекта 114, шестого обучающего объекта 116, седьмого обучающего объекта 118 и восьмого обучающего объекта 120. В качестве последнего примера, восьмой обучающий объект 120 находится после всех других обучающих объектов из множества обучающих объектов 104.
[54] В соответствии с неограничивающими вариантами осуществления настоящей технологии, когда алгоритму машинного обучения необходимо преобразовать категориальный фактор в его числовое представление, алгоритм высчитывает число вхождений данного категориального фактора по отношению к другим категориальным факторам, связанным с обучающими объектами, которые находятся до данного категориального фактора в упорядоченном списке обучающих объектов 102.
[55] Другими словами, в широком смысле, MLA создает указание на "счетчик" данного категориального фактора, как будет более подробно описано далее. Для создания временной аналогии, MLA использует только те категориальные факторы, которые произошли "раньше" по отношению к данному категориальному фактору. Таким образом, при преобразовании категориального фактора в его числовое представление, MLA не "заглядывает" в будущее данного категориального фактора (т.е. целевые значения этих категориальных факторов, которые случились "в будущем" в отношении данного категориального фактора). Таким образом, по меньшей мере в некоторых вариантах осуществления настоящей технологии возможно по меньшей мере снизить существующую проблему переобучения MLA.
[56] В конкретном варианте осуществления из неограничивающих вариантов осуществления настоящей технологии, MLA вычисляет функцию на основе значений срабатывания (WIN) и несрабатывания (LOSS), связанных с категориальным фактором и его "прошлым".
[57] В качестве иллюстрации рассмотрим пятый обучающий объект 114 (обладающий значением категориального фактора 112 "поп" и связанный со значением 124 события, которое равно "1"). MLA переводит значение категориального фактора 112 (т.е. "поп") в числовой фактор с помощью формулы:

[58] Где счетчик - это числовое представление значения категориального фактора для данного объекта, NumberWINs - число событий для данного значения категориального фактора, которые считаются связанными со срабатываниями, а NumberOCCURENCEs - число вхождений одинакового значения обрабатываемого категориального фактора, причем, как число событий, которые считаются срабатываниями, так и число вхождений значения категориального фактора, находятся по порядку 126 до данного обрабатываемого категориального фактора.
[59] В качестве примера, числом событий, которые считаются срабатываниями, может быть успешное событие, которое связано с данным объектом, связанным с данным значением категориального фактора (т.е. песня конкретного жанра, связанного с данным объектом, которая проигрывалась или была загружена или была отмечена как "понравившееся"), т.е. значение 124 события равно "1", а не "0". Число вхождений представляет собой общее число вхождений значения данного категориального фактора в упорядоченный список обучающих объектов 102, которые "находятся" до текущего вхождения (т.е. до категориального фактора, счетчик для которого обрабатывается алгоритмом машинного обучения). Другими словами, система вычисляет счетчик для данного фактора путем просмотра "снизу вверх" упорядоченного списка обучающих объектов 102. В качестве примера, для данного значения фактора (рок) данного объекта, число событий, которые считаются срабатываниями, может являться числом вхождений объектов с конкретном типом события (например, песня, связанная с обучающим объектом, была воспроизведена или загружена или отмечена как "понравившееся", т.е. значение 124 события равно "1", а не "0"), и число вхождений может представлять собой общее число вхождений того же значения фактора (рок), что и данный объект.
[60] В альтернативных вариантах осуществления настоящей технологии, формула 1 может быть модифицирована таким образом, что вместо NumberOCCURENCEs для данного объекта, что является числом вхождений объектов с тем же значением категориального фактора в упорядоченном списке до данного объекта, NumberOCCURENCEs может представлять собой число всех объектов в упорядоченном списке до данного объекта, вне зависимости от их значений категориального фактора.
[61] В некоторых вариантах осуществления настоящей технологии, Формула 1 может быть модифицирована с помощью константы.
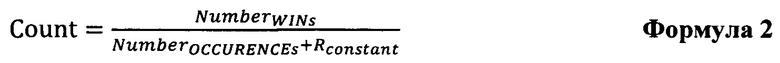
[62] В которой Rconstant может являться заранее определенным значением.
[63] Формула 2 может быть особенно полезной для избежания ошибок при вычислениях, в которых данный категориальный фактор появляется в первый раз (т.е. в которых существует ноль предыдущих вхождений и ноль предыдущих срабатываний, и Rconstant позволяет избежать ошибки при попытке деления на ноль).
[64] В широком смысле, неограничивающие варианты осуществления настоящей технологии могут использовать любую формулу, в которой используются "прошлые" появления ситуаций срабатывания и общее число вхождений текущего обрабатываемого категориального фактора.
[65] Таким образом, в широком смысле, формула может выглядеть следующим образом:

[66] В некоторых вариантах осуществления настоящей технологии, MLA может вычислять, для значения данного категориального фактора для данного объекта, множество счетчиков. Например, каждый счетчик из множества счетчиков может быть вычислен с помощью Формулы 2 с другим Rconstant. Конкретнее, первый счетчик из множества счетчиков может быть вычислен с помощью Формулы 2 с первым Rconstant, а второй счетчик из множества счетчиков может быть вычислен с помощью Формулы 2 со вторым Rconstant- Альтернативно, первый счетчик из множества счетчиков может быть вычислен с помощью Формулы 1 с NumberOCCURENCEs, что представляет все предыдущие вхождения того же категориального фактора, а второй счетчик из множества счетчиков может быть вычислен с помощью Формулы 1 с NumberOCCURENCEs, что представляет собой все предыдущие вхождения всех категориальных факторов.
[67] В альтернативных вариантах осуществления технологии, любая из формул 1, 2 или 3 может быть модифицирована для анализа группы факторов, а не одного фактора.
[68] Например, вместо жанра песни формула может анализировать совместное вхождение жанра и данного исполнителя (в качестве примеров двух категориальных факторов или группы категориальных факторов, которые могут быть связаны с одним обучающим объектом). При анализе групп категориальных факторов MLA применяет способ "динамического бустинга". Как и в случае обработки одного категориального фактора, когда MLA обрабатывает группу факторов, MLA анализирует совместное вхождение группы факторов, которые находятся до текущего вхождения группы анализируемых категориальных факторов (т.е. MLA не "смотрит вперед" в упорядоченном списке факторов).
[69] Формула может быть модифицирована следующим образом:
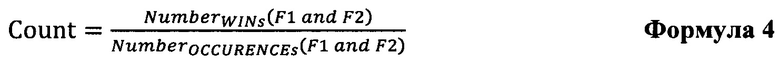
[70] Где оба NumberWINs(F1 and F2) и NumberOCCURENCEs(F1 and F2) учитывают срабатывания и совместные вхождения группы значений факторов (F1 и F2), которые находятся выше текущего вхождения группы факторов в упорядоченном списке обучающих объектов 102.
[71] По мере того как растет число факторов (например, для обучающих объектов, которые являются песнями, категориальные факторы могут включать в себя: жанр, исполнитель, альбом и т.д.), растет и число возможных комбинаций в группах значений факторов, которые обрабатываются MLA с целью обучения, и, в конечном итоге, применения формулы обученного MLA.
[72] В зависимости от типа обучающих объектов, число комбинаций может возрастать экспоненциально. Следовательно, с точки зрения затрачиваемых ресурсов, может не быть оправдано вычисление счетчиков для всех возможных комбинаций категориальных факторов и/или значений категориальных факторов. Вместо предварительного вычисления, для данного объекта, всех возможных комбинаций значений категориальных факторов, в неограничивающих вариантах осуществления настоящей технологии предусмотрено создание счетчиков комбинаций факторов "внутри" алгоритма машинного обучения, по мере того как алгоритм проходит по всем значениям категориальных факторов (т.е. "на ходу", когда MLA создает дерево решений (и его конкретную итерацию), а не заранее вычисляя все возможные счетчики для всех возможных комбинаций категориальных факторов). Основным техническим преимуществом этого подхода является то, что MLA необходимо вычислять только те комбинации, которые фактически возникают, а не каждую возможную комбинацию категориальных факторов и/или значений категориальных факторов.
[73] Например, вместо вычисления счетчиков (т.е. числового представления) для каждого возможной комбинации жанра и исполнителя, MLA может вычислять счетчики (т.е. числовое представление) только для тех комбинаций значений категориальных факторов, которые MLA находит в упорядоченном списке обучающих объектов 102, что позволяет значительно сократить вычислительные мощности и ресурсы памяти, которые требуются для хранения информации о каждой возможной комбинации категориальных факторов.
[74] В широком смысле, когда MLA создает конкретную итерацию модели дерева решений (например, конкретное дерево решений в ансамбле деревьев решений, которые обучаются в случае использования градиентного бустинга). Для каждого узла дерева решений, MLA преобразовывает категориальные факторы (или группу категориальных факторов, в зависимости от ситуации) в их числовое представление, как было описано ранее.
[75] После того как для данного узла или данного уровня был выбран лучший из таких образом преобразованных категориальных факторов (а также любые другие числовые факторы, которые могут быть обработаны данным узлом) - они "замораживаются" для этого узла/этого уровня дерева решений на данной итерации бустинга дерева решений. В некоторых вариантах осуществления настоящей технологии, когда MLA спускается к более низкоуровневым узлам, он вычисляет только счетчики для тех комбинаций категориальных факторов, которые он встречает для текущей вариации дерева решений (т.е. учитывает категориальные факторы, которые были выбраны как лучшие, и были "заморожены" на более высоких уровнях деревьев решений).
[76] В альтернативных вариантах осуществления настоящей технологии, когда MLA спускается к более низкоуровневым узлам, он вычисляет только счетчики для тех комбинаций категориальных факторов, которые он встречает для текущей вариации дерева решений (т.е. учитывает категориальные факторы, которые были выбраны как лучшие, и были "заморожены" на более высоких уровнях деревьев решений), а также предыдущие вариации деревьев решений, которые создаются во время предыдущей итерации бустинга деревьев решений как части процесса создания ансамбля деревьев решений.
[77] Используя в качестве примера текущий уровень дерева решения - третий уровень (т.е. третий уровень, которому предшествуют корневой узел, первый уровень и второй уровень дерева решений), когда MLA вычисляет числовое представление категориальных факторов для третьего уровня, MLA вычисляет все возможные комбинации категориальных факторов для третьего уровня в комбинации с "замороженными" категориальными факторами, которые были выбраны как лучшие и которые были "заморожены" для корневого узла, узла первого уровня и узла второго уровня.
[78] Другими словами, можно сказать, что для данного узла на данном уровне дерева решений, MLA вычисляет "счетчики" возможных категориальных факторов для данного узла данного уровня дерева решений путем добавления всех возможных категориальных факторов к уже выбранным лучшим категориальным факторам, которые были "заморожены" на предыдущих уровнях, в отношении данного уровня дерева решений.
[79] Далее рассмотрим разделения, которые выбраны в связи с данным категориальным фактором (или, конкретнее, его счетчиком) на данном уровне дерева решений. Разделения также вычисляются "внутри" алгоритма MLA, т.е. "на ходу", когда MLA создает дерево решений (на данной его итерации) вместо предварительного вычисления всех возможных разделений для всех возможных счетчиков.
[80] В одном конкретном варианте осуществления технологии, MLA создает разделения путем создания диапазона всех возможных значений для разделений (для данного счетчика, который был создан на основе данного категориального фактора) и применения заранее определенной сетки. В некоторых вариантах осуществления настоящей технологии, диапазон может находиться между значениями 0 и 1. В других вариантах осуществления настоящей технологии, в которых важно применение коэффициента (Rconstant) при вычислении значений счетчиков, диапазон может находиться в следующих пределах: (i) значение коэффициента (ii) значение коэффициента плюс единица.
[81] В некоторых вариантах осуществления настоящей технологии, заранее определенная сетка представляет собой сетку с постоянным интервалом, которая разделяет диапазон на постоянные интервалы. В других вариантах осуществления настоящей технологии, заранее определенная сетка представляет собой сетку с непостоянным интервалом, которая разделяет диапазон на непостоянные интервалы.
[82] В результате отсутствия предварительной обработки всех возможных комбинаций категориальных факторов и обработки счетчиков "внутри" алгоритма машинного обучения, возможно обрабатывать разделения для узлов "внутри" MLA, который создает дерево решений. В соответствии с неограничивающими вариантами осуществления технологии, MLA определяет разделения для узлов деревьев, не зная все возможные значения для счетчиков на основе вышеописанного подхода с использованием сеток. MLA создает диапазон комбинации факторов и разделяет его на равные "области", границы которых становятся значениями для разделений. В фазе использования, MLA необходимо определить, в какую область "попадает" данный счетчик - это и становится значением разделения.
[83] В некоторых вариантах осуществления настоящей технологии, MLA вычисляет разделения для каждого уровня дерева решений и, после того как данный уровень дерева решений оптимизирован (т.е. после того как MLA выбрал "лучший" фактор и разделение для данного уровня дерева решений), MLA стирает вычисленные разделения. Когда MLA переходит на следующий уровень, MLA заново вычисляет разделения. В других вариантах осуществления настоящей технологии, разделения вычисляются и "забываются" при переходе от дерева к дереву, а не от уровня к уровню.
[84] Когда MLA создает дерево решений на конкретной итерации создания модели дерева решений, для каждого уровня, MLA проверяет и оптимизирует лучшее из: какой фактор расположить на узле уровня, и какое разделяющее значение (из всех возможных заранее определенных значений) расположить на узле.
[85] Первым объектом настоящей технологии является способ преобразования значения категориального фактора в его числовое представление, категориальный фактор связан с обучающим объектом, используемым для обучения алгоритма машинного обучения (MLA). MLA выполняется системой машинного обучения для прогнозирования целевого значения объекта фазы использования. Способ включает в себя: получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения, к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором; создание набора моделей для MLA, причем каждая модель из набора моделей основана на ансамбле деревьев решений; для каждой модели из набора моделей: организация набора обучающих объектов в соответствующий упорядоченный список обучающих объектов, причем соответствующий упорядоченный список обучающих объектов организован таким образом, что для каждого обучающего объекта в соответствующем упорядоченном списке обучающих объектов существует по меньшей мере одно из: (i) предыдущий обучающий объект, который находится до данного обучающего объекта и (ii) последующий обучающий объект, который находится после данного обучающего объекта; при создании данной итерации дерева решений в данном ансамбле деревьев решений: выбор одной из набора моделей и соответствующего упорядоченного списка; создание структуры дерева решений с помощью одной модели из набора моделей; при обработке данного категориального фактора с помощью структуры дерева решений данный категориальный фактор связан с данным обучающим объектом; причем данный обучающий объект обладает по меньшей мере одним предыдущим обучающим объектом в упорядоченном списке обучающих объектов, создание его числового представления, которое основано на: (i) числе общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же значением категориального фактора в соответствующем упорядоченном списке (ii) числе заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора в соответствующем упорядоченном списке.
[86] В некоторых вариантах осуществления способа, создание включает в себя применение формулы:

[87] где:
[88] NumberOCCURENCEs число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора; и
[89] NumberWINs число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора.
[90] В некоторых вариантах осуществления способа, создание включает в себя применение формулы:

[91] где:
[92] NumberOCCURENCEs число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым категориальным фактором; и
[93] NumberWINs число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым категориальным фактором; и
[94] Rconstant является заранее определенным значением.
[95] В некоторых вариантах осуществления способа, данный категориальный фактор является набором категориальных факторов, который включает в себя по меньшей мере первый категориальный фактор и второй категориальный фактор, причем создание их числового представления включает в себя: (i) использование в качестве числа общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора: числа общих вхождений по меньшей мере одного предыдущего обучающего объекта, обладающего как значением первого категориального фактора, так и значением второго категориального фактора; и (ii) использование в качестве числа заранее определенных результатов событий, связанных с по меньшей мере одним обучающим объектом, обладающим тем же значением категориального фактора: числа заранее определенных результатов событий, связанных с по меньшей мере одним обучающим объектом, обладающим как как значением первого категориального фактора, так и значением второго категориального фактора.
[96] В некоторых вариантах осуществления способа, создание числового представления включает в себя применение формулы:
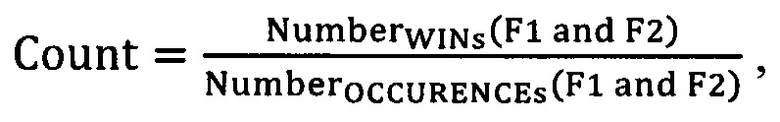
[97] где
[98] (i) NumberWINs(F1 and F2) is - число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым набором значений категориальных факторов; и
[99] (ii) NumberOCCURENCEs(F1 and F2)is the - число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым набором значений категориальных факторов.
[100] В некоторых вариантах осуществления способа, индикатор события обладает заранее определенным значением, и это заранее определенное значение является одним из положительного результата или отрицательного результата.
[101] В некоторых вариантах осуществления способа, организация набора обучающих объектов в упорядоченный список обучающих объектов выполняется в момент времени до создания числового значения.
[102] В некоторых вариантах осуществления способа, обучающие объекты связаны с присущим им временным порядком, и причем организация набора обучающих объектов в упорядоченный список, и причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя организацию обучающих объектов в соответствии с временным порядком.
[103] В некоторых вариантах осуществления способа, обучающие объекты не связаны с присущим им временным порядком, и причем организация набора обучающих объектов в упорядоченный список, и причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя организацию обучающих объектов в соответствии заранее определенным правилом.
[104] В некоторых вариантах осуществления способа, обучающие объекты не связаны с присущим им временным порядком, и причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя создание случайного порядка обучающих объектов, который будет использован как упорядоченный список.
[105] В некоторых вариантах осуществления способа, способ далее включает в себя использование структуры дерева решений для других моделей из набора моделей для данной итерации дерева решений.
[106] В некоторых вариантах осуществления способа, способ далее включает в себя заполнение каждой из набора моделей с помощью набора обучающих объектов, причем значения категориальных факторов документов преобразованы в свои числовые представления с помощью соответствующего упорядоченного списка обучающих объектов.
[107] В некоторых вариантах осуществления способа, набор моделей включает в себя набора протомоделей, и причем набор моделей далее включает в себя итоговую модель, и причем способ далее включает в себя: на каждой итерации обучения, выбор наилучшей работающей из набора протомоделей, и использование наилучшей работающей из набора протомоделей для создания дерева решений итоговой модели для итерации обучения.
[108] В некоторых вариантах осуществления способа, способ далее включает в себя определение наилучшей работающей из набора протомоделей путем применения алгоритма проверки.
[109] В некоторых вариантах осуществления способа, алгоритм проверки учитывает работу данной итерации каждой из набора моделей и предыдущих деревьев решений в соответствующей модели из набора моделей.
[110] В некоторых вариантах осуществления способа, использование различных соответствующих упорядоченных наборов приводит к тому, что значения в листьях разных моделей из набора моделей по меньшей мере частично отличаются.
[111] В некоторых вариантах осуществления способа, использование набора других моделей со связанными соответствующими упорядоченными списками приводит к снижению эффекта переобучения во время обучения.
[112] В некоторых вариантах осуществления способа, любой из упорядоченных списков отличается от других из упорядоченных списков.
[113] Другим объектом настоящей технологии является способ преобразования значения категориального фактора в его числовое представление, категориальный фактор связан с обучающим объектом, используемым для обучения алгоритма машинного обучения (MLA). Алгоритм машинного обучения выполняется электронным устройством для прогнозирования объекта фазы использования. Способ включает в себя: получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения, к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором; создание набора моделей для MLA, причем каждая модель из набора моделей основана на ансамбле деревьев решений; для каждой модели из набора моделей: организация набора обучающих объектов в соответствующий упорядоченный список обучающих объектов, причем соответствующий упорядоченный список обучающих объектов организован таким образом, что для каждого обучающего объекта в соответствующем упорядоченном списке обучающих объектов существует по меньшей мере одно из: (i) предыдущий обучающий объект, который находится до данного обучающего объекта и (ii) последующий обучающий объект, который находится после данного обучающего объекта; при создании данной итерации дерева решений в данном ансамбле деревьев решений: выбор одной из набора моделей и соответствующего упорядоченного списка; создание структуры дерева решений с помощью одной модели из набора моделей; при обработке данного категориального фактора с помощью структуры дерева решений, для данного категориального фактора, связанного с данным обучающим объектом, данный обучающий объект обладает по меньшей мере одним предыдущим обучающим объектом в соответствующем упорядоченном списке обучающих объектов, создание включает в себя вычисление функции с помощью формулы:
f (Number_WINs_PAST, Number_Occurence_PAST),
[114] где:
[115] Number_WINs_PAST - число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает теми же самыми значениями категориального фактора в соответствующем упорядоченном списке; и
[116] Number_Occurence_PAST - число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора в соответствующем упорядоченном списке.
[117] Еще одним объектом настоящей технологии является сервер, выполненный с возможностью выполнять алгоритм машинного обучения, который основан на прогностической модели дерева решений на основе дерева решений, причем дерево решений предназначено для обработки значения категориального фактора путем преобразования его в его числовое представление, причем категориальный фактор связан с обучающим объектом, используемым для обучения MLA. MLA используется сервером для прогнозирования целевого значения объекта фазы использования. Сервер включает в себя: постоянный машиночитаемый носитель; процессор, связанный с постоянным машиночитаемым носителем, причем процессор выполнен с дополнительной возможностью осуществлять: получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения, к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором; создание набора моделей для MLA, причем каждая модель из набора моделей основана на ансамбле деревьев решений; для создания, процессор далее выполнен с возможностью, для каждой модели из набора моделей осуществлять: организацию набора обучающих объектов в соответствующий упорядоченный список обучающих объектов, причем соответствующий упорядоченный список обучающих объектов организован таким образом, что для каждого обучающего объекта в соответствующем упорядоченном списке обучающих объектов существует по меньшей мере одно из: (i) предыдущий обучающий объект, который находится до данного обучающего объекта и (ii) последующий обучающий объект, который находится после данного обучающего объекта; при создании данной итерации дерева решений в данном ансамбле деревьев решений, процессор далее выполнен с возможностью осуществлять: выбор одной из набора моделей и соответствующего упорядоченного списка; создание структуры дерева решений с помощью одной модели из набора моделей; при обработке данного категориального фактора с помощью структуры дерева решений, для данного категориального фактора, который фактор связан с данным обучающим объектом, причем данный обучающий объект обладает по меньшей мере одним предыдущим обучающим объектом в упорядоченном списке обучающих объектов, создание его числового представления, которое основано на: (i) числе общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же значением категориального фактора (ii) числе заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора.
[118] Еще одним объектом настоящей технологии является способ преобразования в числовое представление значения категориального фактора, который связан с обучающим объектом для обучения алгоритма машинного обучения (MLA), причем MLA использует модель, основанную на дерева решений, обладающую деревом решений, причем обучающий объект обрабатывается на узле данного уровня дерева решений, причем дерево решений обладает по меньшей мере одним предыдущим уровнем дерева решений, причем на по меньшей мере одном предыдущем уровне значение по меньшей мере одного категориального фактора преобразовано в свое предыдущее числовое представление для по меньшей мере одного предыдущего уровня дерева решений. Алгоритм машинного обучения выполняется электронным устройством для прогнозирования объекта фазы использования. Способ включает в себя: получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения, к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором; создание числового представления значения категориального фактора путем: извлечения предыдущего числового представления по меньшей мере одного значения категориального фактора для данного объекта из набора обучающих объектов на по меньшей мере одном предыдущем уровне дерева решений; создание, для каждой комбинации из по меньшей мере одного предыдущего значения категориального фактора на по меньшей мере одном предыдущем уровне дерева решений и по меньшей мере некоторых значений категориальных факторов из набора обучающих объектов, текущего числового представления для данного уровня дерева решений, причем создание осуществляется в процессе создания дерева решений.
[119] В некоторых вариантах осуществления способа, набор обучающих объектов организован в упорядоченный список таким образом, что: для каждого данного обучающего объекта в упорядоченном списке обучающих объектов существует по меньшей мере один из: (i) предыдущий обучающий объект, который находится до данного обучающего объекта и (ii) последующий обучающий объект, который находится после данного обучающего объекта, и при этом по меньшей мере некоторые из значений категориальных факторов являются значениями категориальных факторов, которые связаны с обучающими объектами, находящимися раньше в упорядоченном списке обучающих объектов.
[120] В некоторых вариантах осуществления способа, создание выполняется только для тех предыдущих значений категориальных факторов, которые были созданы по меньшей мере на один уровень раньше в дереве решений.
[121] В некоторых вариантах осуществления способа, создание выполняется только для тех предыдущих значений категориальных факторов, которые были созданы по меньшей мере на один уровень раньше в дереве решений и по меньшей мере на предыдущей итерации дерева решений.
[122] В некоторых вариантах осуществления способа, индикатор события обладает заранее определенным значением, и это заранее определенное значение является одним из положительного результата или отрицательного результата.
[123] В некоторых вариантах осуществления способа, способ далее включает в себя организацию набора обучающих объектов в упорядоченный список обучающих объектов.
[124] В некоторых вариантах осуществления способа, организация обучающих объектов в упорядоченный список обучающих объектов выполняется в момент времени до создания числового значения.
[125] В некоторых вариантах осуществления способа, организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя организацию множества наборов упорядоченных списков, и в котором способ далее включает в себя, до этапа создания числового значения, выбор одного из множества наборов из упорядоченных списков.
[126] В некоторых вариантах осуществления способа, обучающие объекты связаны с присущим им временным порядком, и причем организация набора обучающих объектов в упорядоченный список, и причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя организацию обучающих объектов в соответствии с временным порядком.
[127] В некоторых вариантах осуществления способа, обучающие объекты не связаны с присущим им временным порядком, и причем организация набора обучающих объектов в упорядоченный список, и причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя организацию обучающих объектов в соответствии заранее определенным правилом.
[128] В некоторых вариантах осуществления способа, обучающие объекты не связаны с присущим им временным порядком, и причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя создание случайного порядка обучающих объектов, который будет использован как упорядоченный список.
[129] Еще одним объектом настоящей технологии является сервер, который выполнен с возможностью выполнять алгоритм машинного обучения, который основан на прогностической модели дерева решений на основе дерева решений, дерево решений выполнено с возможностью обрабатывать значение категориального фактора путем преобразования его в его числовое представление, категориальный фактор связан с обучающим объектом, используемым для обучения алгоритма машинного обучения, обучающий объект обрабатывается в узле данного уровня дерева решений, дерево решений обладает по меньшей мере одним предыдущим уровнем дерева решений, по меньшей мере один предыдущий уровень обладает по меньшей мере одним предыдущим обучающим объектом, который обладает по меньшей мере одним значением категориального фактора, которое было преобразовано в свое предыдущее числовое представление по меньшей мере для одного предыдущего уровня дерева решений. Сервер включает в себя: постоянный машиночитаемый носитель; процессор, соединенный с постоянным машиночитаемым носителем, причем процессор выполнен с возможностью осуществлять: получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения, к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором; создание числового представления значения категориального фактора путем: извлечения предыдущего числового представления по меньшей мере одного значения категориального фактора для данного объекта из набора обучающих объектов на по меньшей мере одном предыдущем уровне дерева решений; создание, для каждой комбинации из по меньшей мере одного предыдущего значения категориального фактора на по меньшей мере одном предыдущем уровне дерева решений и по меньшей мере некоторых значений категориальных факторов из набора обучающих объектов, текущего числового представления для данного уровня дерева решений, причем создание осуществляется в процессе создания дерева решений.
[130] В некоторых вариантах осуществления сервера, набор обучающих объектов организован в упорядоченный список таким образом, что: для каждого данного обучающего объекта в упорядоченном списке обучающих объектов существует по меньшей мере один из: (i) предыдущий обучающий объект, который находится до данного обучающего объекта и (ii) последующий обучающий объект, который находится после данного обучающего объекта, и при этом по меньшей мере некоторые из значений категориальных факторов являются значениями категориальных факторов, которые связаны с обучающими объектами, находящимися раньше в упорядоченном списке обучающих объектов.
[131] В некоторых вариантах осуществления сервера, для создания числового представления значений категориальных факторов, процессор выполнен с возможностью выполнять создание только для тех предыдущих значений категориальных факторов, которые были созданы по меньшей мере на один уровень раньше в дереве решений.
[132] В некоторых вариантах осуществления сервера, для создания числового представления значения категориальных факторов, процессор выполнен с возможностью выполнять создание только для тех предыдущих значений категориальных факторов, которые были созданы по меньшей мере на один уровень раньше в дереве решений и по меньшей мере на предыдущей итерации дерева решений.
[133] В некоторых вариантах осуществления сервера, индикатор события обладает заранее определенным значением, и это заранее определенное значение является одним из положительного результата или отрицательного результата.
[134] В некоторых вариантах осуществления сервера, процессор выполнен с возможностью организовать набор обучающих объектов в упорядоченный список обучающих объектов.
[135] В некоторых вариантах осуществления сервера, для организации обучающих объектов в упорядоченный список обучающих объектов, процессор выполнен с возможностью осуществлять организацию набора обучающих объектов в упорядоченный список обучающих объектов выполняется в момент времени до этапа создания числового значения.
[136] В некоторых вариантах осуществления сервера, для организации обучающих объектов в упорядоченный список обучающих объектов, процессор выполнен с возможностью осуществлять организацию множества из набора упорядоченным списков, и в котором способ далее включает в себя, до этапа создания числового значения, выбор данного одного из набора упорядоченного списка.
[137] В некоторых вариантах осуществления сервера, обучающие объекты связаны с присущим им временным порядком, и причем для организации набора обучающих объектов в упорядоченный список, процессор выполнен с возможностью осуществлять организацию набора обучающих объектов в упорядоченный список обучающих объектов для организации обучающих объектов в соответствии с временным порядком.
[138] В некоторых вариантах осуществления сервера, обучающие объекты связаны с присущим им временным порядком, и причем для организации набора обучающих объектов в упорядоченный список, процессор выполнен с возможностью осуществлять организацию набора обучающих объектов в упорядоченный список обучающих объектов для организации обучающих объектов в соответствии с заранее определенным правилом.
[139] В некоторых вариантах осуществления сервера, обучающие объекты не связаны с присущим им временным порядком, и причем для организации набора обучающих объектов в упорядоченный список обучающих объектов процессор выполнен с возможностью осуществлять создание случайного порядка обучающих объектов, который будет использован как упорядоченный список.
[140] Еще одним объектом настоящей технологии является способ создания разделяющего значения для узла дерева решений в модели дерева решений, используемой алгоритмом машинного обучения (MLA), разделяющее значение относится к узлу на конкретном уровне дерева решений, узел для классификации объекта, обладающего значением категориального фактора, которое будет преобразовано в свое числовое представление, разделение инициирует классификацию объекта в один из дочерних узлов на основе числового значения и разделяющего значения, алгоритм машинного обучения выполняется электронным устройством для прогнозирования значения для объекта фазы использования. Способ включает в себя: создание диапазона всех возможных значений категориальных факторов; применение сетки к диапазону для разделения диапазона на области, причем каждая область обладает границами; использование границ в качестве разделяющего значения; создание и применение осуществляются до того как значение категориального фактора преобразуется в его числовое представление.
[141] В некоторых вариантах осуществления способа, сетка обладает заранее определенным форматом.
[142] В некоторых вариантах осуществления способа, сетка является сеткой с постоянным интервалом.
[143] В некоторых вариантах осуществления способа, сетка является сеткой с непостоянным интервалом.
[144] В некоторых вариантах осуществления способа, диапазон находится между нулем и единицей.
[145] В некоторых вариантах осуществления способа, числовые представления значений категориальных факторов вычисляются с помощью Rconstant, и в котором диапазон находится между Rconstant и 1+(Rconstant).
[146] В некоторых вариантах осуществления способа, способ далее включает в себя, во время фазы использования, для данного значения счетчика, представляющего собой категориальный фактор, определение того, в какую часть, определенную сеткой, попадает данное значение счетчика, и использование соответствующих границ как значений для разделения.
[147] В некоторых вариантах осуществления способа, использование границы как разделяющего значения выполняется для каждого уровня дерева решений и причем способ далее включает в себя, после обучения данного уровня дерева решений, новое вычисление разделяющего значения.
[148] В некоторых вариантах осуществления способа, использование границы как разделяющего значения выполняется для каждого дерева решений и причем способ далее включает в себя, после обучения данного дерева решений, новое вычисление разделяющего значения.
[149] В некоторых вариантах осуществления способа, использование границы как разделяющего значения выполняется во время этапа обучения MLA, и в котором обучение MLA во время текущей итерации одного из: (i) данного уровня дерева решений и (ii) данной итерации дерева решений, включает в себя: выбор лучшего значения фактора, которое будет находиться на данной итерации, и лучшего значения разделения, связанного с ним.
[150] Еще одним объектом настоящей технологии является сервер, который выполнен с возможностью выполнять MLA, MLA основан на дереве решений, относящегося к модели дерева решений, дерево решений обладает узлом, узел обладает разделяющим значением, узел представляет собой данный уровень дерева решений, узел используется для классификации объекта, обладающего категориальным фактором, которые будет преобразован в свое числовое представление значения, разделение используется для инициирования классификации объекта в один из дочерних узлов данного узла на основе числового значения и разделяющего значения. Сервер включает в себя: постоянный машиночитаемый носитель; процессор, соединенный с постоянным машиночитаемым носителем, причем процессор выполнен с возможностью осуществлять: создание диапазона всех возможных значений категориальных факторов; применение сетки к диапазону для разделения диапазона на области, причем каждая область обладает границами; использование границ в качестве разделяющего значения; создание и применение осуществляются до того как категориальный фактор преобразуется в его числовое представление.
[151] В некоторых вариантах осуществления сервера, сетка обладает заранее определенным форматом.
[152] В некоторых вариантах осуществления сервера, сетка является сеткой с постоянным интервалом.
[153] В некоторых вариантах осуществления сервера, сетка является сеткой с непостоянным интервалом.
[154] В некоторых вариантах осуществления сервера, диапазон находится между нулем и единицей.
[155] В некоторых вариантах осуществления сервера, числовое представление значения категориального фактора вычисляется с помощью Rconstant, и в котором диапазон находится между Rconstant и 1+(Rconstant).
[156] В некоторых вариантах осуществления сервера, процессор далее выполнен с возможностью, во время фазы использования, для данного значения счетчика, представляющего собой категориальный фактор, осуществлять определение того, в какую часть, определенную сеткой, попадает данное значение счетчика, и использование соответствующих границ как значений для разделения.
[157] В некоторых вариантах осуществления сервера, для использования границы как разделяющего значения, процессор выполнен с возможностью использовать границу как разделяющее значение для каждого уровня дерева решений, и причем процессор далее выполнен с возможностью, после обучения данного уровня дерева решений, осуществлять новое вычисление разделяющего значения.
[158] В некоторых вариантах осуществления сервера, для использования границы как разделяющего значения, процессор выполнен с возможностью использовать границу как разделяющее значение для каждой итерации дерева решений, и причем процессор далее выполнен с возможностью, после обучения данной итерации дерева решений, осуществлять новое вычисление разделяющего значения.
[159] В некоторых вариантах осуществления сервера, для использования границы как разделяющего значения, процессор выполнен с возможностью осуществлять использование границы как разделяющего значения во время этапа обучения MLA, и в котором обучение MLA во время текущей итерации одного из: (i) данного уровня дерева решений и (ii) данной итерации дерева решений, процессор дополнительно выполнен с возможностью осуществлять: выбор лучшего значения фактора, которое будет находиться на данной итерации, и лучшего значения разделения, связанного с ним.
[160] В контексте настоящего описания, если четко не указано иное, "электронное устройство", "пользовательское устройство", "сервер", "удаленный сервер" и "компьютерная система" подразумевают под собой аппаратное и/или системное обеспечение, подходящее к решению соответствующей задачи. Таким образом, некоторые неограничивающие примеры аппаратного и/или программного обеспечения включают в себя компьютеры (серверы, настольные компьютеры, ноутбуки, нетбуки и так далее), смартфоны, планшеты, сетевое оборудование (маршрутизаторы, коммутаторы, шлюзы и так далее) и/или их комбинацию.
[161] В контексте настоящего описания, если четко не указано иное, «машиночитаемый носитель» и «память» подразумевает под собой носитель абсолютно любого типа и характера, и примеры, не ограничивающие настоящую технологию, включают в себя ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB-ключи, флеш-карты, твердотельные накопители и накопители на магнитной ленте.
[162] В контексте настоящего описания, если четко не указано иное, «указание» информационного элемента может представлять собой сам информационный элемент или указатель, отсылку, ссылку или другой косвенный способ, позволяющий получателю указания найти сеть, память, базу данных или другой машиночитаемый носитель, из которого может быть извлечен информационный элемент. Например, указание на документ может включать в себя сам документ (т.е. его содержимое), или же оно может являться уникальным дескриптором документа, идентифицирующим файл по отношению к конкретной файловой системе, или каким-то другими средствами передавать получателю указание на сетевую папку, адрес памяти, таблицу в базе данных или другое место, в котором можно получить доступ к файлу. Как будет понятно специалистам в данной области техники, степень точности, необходимая для такого указания, зависит от степени первичного понимания того, как должна быть интерпретирована информация, которой обмениваются получатель и отправитель указателя. Например, если до установления связи между отправителем и получателем понятно, что признак информационного элемента принимает вид ключа базы данных для записи в конкретной таблице заранее установленной базы данных, содержащей информационный элемент, то передача ключа базы данных - это все, что необходимо для эффективной передачи информационного элемента получателю, несмотря на то, что сам по себе информационный элемент не передавался между отправителем и получателем указания.
[163] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[164] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь. Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[165] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт, сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[166] На Фиг. 1 представлен неограничивающий пример упорядоченного списка обучающих объектов, причем обучающие объекты связаны с категориальными факторами, упорядоченный список обучающих объектов осуществлен в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[167] На Фиг. 2 представлен диапазон всех возможных значений для разделений (для данного счетчика, который был создан на основе данного категориального фактора), и заранее определенная сетка применяется к диапазону, причем и диапазон и применяемая сетка реализованы в соответствии с неограничивающими вариантами осуществления настоящей технологии.
[168] На Фиг. 3 представлена схема части прото-дерева с одним узлом первого уровня и двумя узлами второго уровня, созданными в соответствии с другими вариантами осуществления настоящей технологии.
[169] На Фиг. 4 представлена диаграмма компьютерной системы, которая подходит для реализации настоящей технологии, и/или которая используется в сочетании с вариантами осуществления настоящей технологи.
[170] На Фиг. 5 представлена схема сетевой вычислительной среды в соответствии с вариантом осуществления настоящей технологии;
[171] На Фиг. 6 представлена схема, показывающая древовидную модель частично, и два примера векторов признаков в соответствии с вариантом осуществления настоящей технологии.
[172] На Фиг. 7 представлена схема полной древовидной модели в соответствии с вариантом осуществления настоящей технологии.
[173] На Фиг. 8 представлена схема, показывающая части предварительной древовидной модели и полную предварительную древовидную модель в соответствии с вариантом осуществления настоящей технологии.
[174] На Фиг. 9 представлена схема, показывающая части предварительной древовидной модели в соответствии с другим вариантом осуществления настоящей технологии.
[175] На Фиг. 10 представлена схема полной предварительной древовидной модели в соответствии с другим вариантом осуществления настоящей технологии.
[176] На Фиг. 11 представлена схема части прото-дерева с одним узлом первого уровня и двумя узлами второго уровня, а также упорядоченный список обучающих объектов, созданные в соответствии с другими вариантами осуществления настоящей технологии.
[177] На Фиг. 12 представлена схема, показывающая первый компьютерный способ, являющийся вариантом осуществления настоящей технологии;
[178] На Фиг. 13 представлена схема, показывающая второй компьютерный способ, являющийся вариантом осуществления настоящей технологии.
[179] На Фиг. 14 представлена схема набора моделей и связанных соответствующих упорядоченных наборов обучающих объектов, используемых для обучения алгоритма машинного обучения в соответствии с некоторыми неограничивающими вариантами осуществления настоящей технологии.
[180] Также следует отметить, что чертежи выполнены не в масштабе, если не специально указано иное.
[181] В конце настоящего описания предусмотрено приложение А. Приложение А включает в себя копию еще не опубликованной статьи под заголовком "CatBoost: градиентный бустинг с использованием категориальных факторов". Статья предоставляет дополнительную информацию об известном уровне техники, описание реализации неограничивающих вариантов осуществления настоящей технологии, а также некоторые дополнительные примеры. Эта статья включена здесь в полном объеме посредством ссылки для всех юрисдикции, допускающих включение в описание сведений посредством ссылки.
ОСУЩЕСТВЛЕНИЕ
[182] Все примеры и используемые здесь условные конструкции предназначены, главным образом, для того, чтобы помочь читателю понять принципы настоящей технологии, а не для установления границ ее объема. Следует также отметить, что специалисты в данной области техники могут разработать различные схемы, отдельно не описанные и не показанные здесь, но которые, тем не менее, воплощают собой принципы настоящей технологии и находятся в границах ее объема.
[183] Кроме того, для ясности в понимании, следующее описание касается достаточно упрощенных вариантов осуществления настоящей технологии. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[184] Некоторые полезные примеры модификаций настоящей технологии также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающего списка, и специалисты в данной области техники могут создавать другие модификации, остающиеся в границах объема настоящей технологии. Кроме того, те случаи, где не были представлены примеры модификаций, не должны интерпретироваться как то, что никакие модификации невозможны, и/или что то, что было описано, является единственным вариантом осуществления этого элемента настоящей технологии.
[185] Более того, все заявленные здесь принципы, аспекты и варианты осуществления настоящей технологии, равно как и конкретные их примеры, предназначены для обозначения их структурных и функциональных основ, вне зависимости от того, известны ли они на данный момент или будут разработаны в будущем. Таким образом, например, специалистами в данной области техники будет очевидно, что представленные здесь блок-схемы представляют собой концептуальные иллюстративные схемы, отражающие принципы настоящей технологии. Аналогично, любые блок-схемы, диаграммы, псевдокоды и т.п. представляют собой различные процессы, которые могут быть представлены на машиночитаемом носителе и, таким образом, использоваться компьютером или процессором, вне зависимости от того, показан явно подобный компьютер или процессор, или нет.
[186] Функции различных элементов, показанных на чертежах, включая функциональный блок, обозначенный как «процессор» или «графический процессор», могут быть обеспечены с помощью специализированного аппаратного обеспечения или же аппаратного обеспечения, способного использовать подходящее программное обеспечение. Когда речь идет о процессоре, функции могут обеспечиваться одним специализированным процессором, одним общим процессором или множеством индивидуальных процессоров, причем некоторые из них могут являться общими. В некоторых вариантах осуществления настоящей технологии, процессор может являться универсальным процессором, например, центральным процессором (CPU) или специализированным для конкретной цели процессором, например, графическим процессором (GPU). Более того, использование термина «процессор» или «контроллер» не должно подразумевать исключительно аппаратное обеспечение, способное поддерживать работу программного обеспечения, и может включать в себя, без установления ограничений, цифровой сигнальный процессор (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянное запоминающее устройство (ПЗУ) для хранения программного обеспечения, оперативное запоминающее устройство (ОЗУ) и энергонезависимое запоминающее устройство. Также в это может быть включено другое аппаратное обеспечение, обычное и/или специальное.
[187] Программные модули или простые модули, представляющие собой программное обеспечение, могут быть использованы здесь в комбинации с элементами блок-схемы или другими элементами, которые указывают на выполнение этапов процесса и/или текстовое описание. Подобные модели могут быть выполнены на аппаратном обеспечении, показанном напрямую или косвенно.
[188] С учетом этих примечаний, далее будут рассмотрены некоторые не ограничивающие варианты осуществления аспектов настоящей технологии. Следует отметить, что по меньшей мере некоторые варианты осуществления настоящей технологии могут способствовать снижению эффекта переобучения или, по меньшей мере, отсрочить момент наступления переобучения.
[189] На Фиг. 4 представлена схема компьютерной системы 400, которая подходит для некоторых вариантов осуществления настоящей технологии, причем компьютерная система 400 включает в себя различные аппаратные компоненты, включая один или несколько одно- или многоядерных процессоров, которые представлены процессором 410, графическим процессором (GPU) 411, твердотельным накопителем 420, ОЗУ 430, интерфейсом 440 монитора, и интерфейсом 450 ввода/вывода.
[190] Связь между различными компонентами компьютерной системы 400 может осуществляться с помощью одной или нескольких внутренних и/или внешних шин 460 (например, шины PCI, универсальной последовательной шины, высокоскоростной шины IEEE 1394, шины SCSI, шины Serial ATA и так далее), с которыми электронными средствами соединены различные аппаратные компоненты. Интерфейс 440 монитора может быть соединен с монитором 442 (например, через HDMI-кабель 144), видимым пользователю 470, интерфейс 450 ввода/вывода может быть соединен с сенсорным экраном (не изображен), клавиатурой 451 (например, через USB-кабель 453) и мышью 452 (например, через USB-кабель 454), причем как клавиатура 451, так и мышь 452 используются пользователем 470.
[191] В соответствии с вариантами осуществления настоящей технологии твердотельный накопитель 420 хранит программные инструкции, подходящие для загрузки в ОЗУ 130, и использующиеся процессором 410 и/или графическим процессором GPU 411 для обработки показателей активности, связанных с пользователем. Например, программные команды могут представлять собой часть библиотеки или приложение.
[192] На Фиг. 5 показана сетевая компьютерная среда 500, подходящая для использования с некоторыми вариантами осуществления настоящей технологии, причем сетевая компьютерная среда 500 включает в себя ведущий сервер 510, обменивающийся данными с первым ведомым сервером 520, вторым ведомым сервером 522 и третьим ведомым сервером 524 (также здесь и далее упоминаемыми как ведомые серверы 520, 522, 524) по сети (не изображена), предоставляя этим системам возможность обмениваться данными. В некоторых вариантах осуществления настоящей технологии, не ограничивающих ее объем, сеть может представлять собой интернет. В других вариантах осуществления настоящей технологии сеть может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
[193] Сетевая компьютерная среда 500 может включать в себя большее или меньшее количество ведомых серверов, что не выходит за границы настоящей технологии. В некоторых вариантах осуществления настоящей технологии конфигурация "ведущий сервер - ведомый сервер" может не быть необходима, может быть достаточно одиночного сервера. Следовательно, число серверов и тип архитектуры не является ограничением объема настоящей технологии. Архитектура ведущий сервер - ведомый сервер, которая представлена на Фиг. 5, является частично полезной (но не ограничивающей) в тех случаях, когда желательна параллельная обработка всех или некоторых процедур, которые будут описаны далее.
[194] В одном варианте осуществления настоящей технологии между ведущим сервером 510 и/или ведомыми серверами 520, 522, 524 может быть установлен канал передачи данных (не показан), чтобы обеспечить возможность обмена данными. Такой обмен данными может происходить на постоянной основе или же, альтернативно, при наступлении конкретных событий. Например, в контексте сбора данных с веб-страниц и/или обработки поисковых запросов обмен данными может возникнуть в результате контроля ведущим сервером 510 обучения моделей машинного обучения, осуществляемого сетевой компьютерной средой.
[195] В некоторых вариантах осуществления настоящей технологии ведущий сервер 510 может получить набор обучающих объектов и/или набор тестирующих объектов и/или набор факторов от внешнего сервера поисковой системы (не изображен) и отправить набор обучающих объектов и/или набор тестирующих объектов и/или набор факторов одному или нескольким ведомым серверам 520, 522, 524. После получения от ведущего сервера 510, один или несколько ведомых серверов 520, 522, 524 могут обработать набор обучающих объектов и/или набор тестирующих объектов и/или набор факторов в соответствии с неограничивающими вариантами осуществления настоящей технологией для создания одной или нескольких моделей машинного обучения, причем каждая модель машинного обучения включает в себя в некоторых случаях одну или несколько древовидных моделей. В некоторых вариантах осуществления настоящей технологии одна или несколько древовидных моделей моделируют связь между документом и целевым значением (им может быть параметр интереса, оценка релевантности и т.д.).
[196] Созданная модель машинного обучения может быть передана ведущему серверу 510 и, таким образом, ведущий сервер 510 может создать прогноз, например, в контексте поискового запроса, полученного от внешнего сервера поисковой системы, на основе поискового запроса, полученного от электронного устройства, связанного с пользователем, который хочет использовать компьютерный поиск. После применения созданной модели машинного обучения к поисковому запросу, ведущий сервер 510 может передать один или несколько соответствующих результатов внешнему серверу поисковой системы. В некоторых альтернативных вариантах осуществления настоящей технологии один или несколько ведомых серверов 520, 522, 524 могут напрямую сохранять созданную модель машинного обучения и обрабатывать поисковый запрос, полученный от внешнего сервера поисковой системы через ведущий сервер 510 или напрямую от внешней поисковой системы.
[197] Ведущий сервер 510 может быть выполнен как обычный компьютерный сервер и может включать в себя некоторые или все характеристики компьютерной системы 400, изображенной на Фиг. 4. В примере варианта осуществления настоящей технологии ведущий сервер 510 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что ведущий сервер 510 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, ведущий сервер 510 является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность ведущего сервера 210 может быть разделена, и может выполняться с помощью нескольких серверов.
[198] Варианты осуществления ведущего сервера 510 широко известны среди специалистов в данной области техники. Тем не менее, для краткой справки: ведущий сервер 510 включает в себя интерфейс передачи данных (не показан), который настроен и выполнен с возможностью устанавливать соединение с различными элементами (например, с внешним сервером поисковой системы и/или ведомыми серверами 520, 522, 524 и другими устройствами, потенциально соединенными с сетью) по сети. Ведущий сервер 510 дополнительно включает в себя по меньшей мере один компьютерный процессор (например, процессор 410 ведущего сервера 510), функционально соединенный с интерфейсом передачи данных и настроенный и выполненный с возможностью выполнять различные процессы, описанные здесь.
[199] Основной задачей ведущего сервера 510 является координация создания моделей машинного обучения ведомыми серверами 520, 522, 524. Как было описано ранее, в одном варианте осуществления настоящей технологии набор обучающих объектов и/или набор тестирующих объектов и/или набор факторов может быть передан некоторым или всем ведомым серверам 520, 522, 524, и таким образом, ведомые серверы 520, 522, 524 могут создавать одну или несколько моделей машинного обучения на основе набора обучающих объектов и/или набора тестирующих объектов и/или набора факторов. В некоторых вариантах осуществления настоящей технологии, модель машинного обучения может включать в себя одну или несколько древовидных моделей. Каждая из древовидных моделей может быть сохранена на одном или нескольких ведомых серверах 520, 522, 524. В некоторых альтернативных вариантах осуществления настоящей технологии древовидные модели могут быть сохранены по меньшей мере на двух серверах из ведомых серверов 520, 522, 524. Как будет понятно специалистам в данной области техники, то, где сохраняются модель машинного обучения и/или древовидные модели, формирующие модель машинного обучения, не является важным для настоящей технологии, и может быть предусмотрено множество вариантов без отклонения от объема настоящей технологии.
[200] В некоторых вариантах осуществления настоящей технологии после того, как ведомые серверы 520, 522, 224 сохранили одну или несколько моделей машинного обучения, ведомые серверы 520, 522, 524 могут получить инструкции на проведение связей между документом и целевым значением, причем документ отличается от обучающих объектов из набора обучающих объектов и включает в себя набор факторов, соответствующих значениям, связанным с некоторыми факторами, выбранными из набора факторов, определяющих структуру по меньшей мере одной древовидной модели.
[201] Как только связывание между документом и целевым значением было завершено ведомыми серверами 520, 522, 524, ведущий сервер 510 может получить от ведомых серверов 520, 522, 524 целевое значение, которое должно быть связано с документом. В некоторых других вариантах осуществления настоящей технологии ведущий сервер 510 может отправлять документ и/или набор факторов, связанный с документом, не получая целевого значения в ответ. Этот сценарий может возникнуть после определения одним или несколькими ведомыми серверами 520, 522, 524 того, что документ и/или набор факторов, связанный с документом, приводят к модификации одной из древовидных моделей, хранящихся на ведомых серверах 520, 522, 524.
[202] В некоторых вариантах осуществления настоящей технологии ведущий сервер 510 может включать в себя алгоритм, который может создавать инструкции для модификации одной или нескольких моделей, хранящихся на ведомых серверах 520, 522, 524, с целевым значением для связи с документом. В таких примерах одна из древовидных моделей, хранящаяся на ведомых серверах 520, 522, 524, может быть модифицирована таким образом, что документ может быть связан с целевым значением в древовидной модели. В некоторых вариантах осуществления настоящей технологии после того, как одна из древовидных моделей, хранящаяся на ведомых серверах 520, 522, 524, была модифицирована, ведомые серверы 520, 522, 524 могут передать сообщение ведущему серверу 510, причем сообщение указывает на модификацию, осуществленную в одной из древовидных моделей. Могут быть предусмотрены другие варианты того, как ведущий сервер 510 взаимодействует с ведомыми серверами 520, 522, 524 что не выходит за границы настоящей технологии и может быть очевидным специалисту в данной области техники. Кроме того, важно иметь в виду, что для упрощения вышеприведенного описания конфигурация ведущего сервера 510 была сильно упрощена. Считается, что специалисты в данной области техники смогут понять подробности реализации ведущего сервера 510 и его компонентов, которые могли быть опущены в описании с целью упрощения.
[203] Ведомые серверы 520, 522, 524 могут быть выполнены как обычные компьютерные серверы и могут включать в себя некоторые или все характеристики компьютерной системы 400, изображенной на Фиг. 4. В примере варианта осуществления настоящей технологии ведомые серверы 520, 522, 524 могут представлять собой серверы Dell™ PowerEdge™, на которых используется операционная система Microsoft™ Windows Server™. Излишне говорить, что ведомые серверы 520, 522, 524 могут представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, ведомые серверы 520, 522, 524 функционируют на основе распределенной архитектуры. В альтернативных вариантах настоящей технологии, не ограничивающих ее объем, настоящую технологию может выполнять единственный ведомый сервер.
[204] Варианты осуществления ведомых серверов 520, 522, 524 широко известны среди специалистов в данной области техники. Тем не менее, для краткой справки: каждый из ведомых серверов 520, 522, 524 может включать в себя интерфейс передачи данных (не показан), который настроен и выполнен с возможностью устанавливать соединение с различными элементами (например, в внешним сервером поисковой системы и/или ведущим сервером 510 и другими устройствами, потенциально соединенные с сетью) по сети. Каждый из ведомых серверов 520, 522, 524 дополнительно включает в себя один или несколько пунктов из следующего: компьютерный процессор (например, аналогично процессору 410 на Фиг. 4), функционально соединенный с интерфейсом связи и настроенный и выполненный с возможностью выполнять различные процессы, описанные здесь. Каждый из ведомых серверов 520, 522, 524 дополнительно может включать в себя одно или несколько устройств памяти (например, аналогичных твердотельному накопителю 420, и/или ОЗУ 430, изображенным на Фиг. 4).
[205] Общей задачей ведомых серверов 520, 522, 524 является создание одной или нескольких моделей машинного обучения. Как было описано ранее, в одном варианте осуществления настоящей технологии, модель машинного обучения может включать в себя одну или несколько древовидных моделей. Каждая из древовидных моделей включает в себя набор факторов (которые также могут упоминаться как подгруппа факторов, если факторы, образующие подгруппу, были выбраны из набора факторов). Каждый фактор из набора факторов соответствует одному или нескольким узлам соответствующей древовидной модели.
[206] Во время создания одной или нескольких моделей машинного обучения для выбора и упорядочивания факторов таким образом, чтобы создать древовидную модель, ведомые серверы 520, 522, 524 могут исходить из набора обучающих объектов и/или набора тестирующих объектов. Этот процесс выбора и упорядочивания факторов может быть повторен с помощью многочисленных итераций таким образом, что ведомые серверы 520, 522, 524 создают множество древовидных моделей, причем каждая из древовидных моделей соответствует различным выборам и/или порядкам (после упорядочивания) факторов. В некоторых вариантах осуществления настоящей технологии набор обучающих объектов и/или набор тестирующих объектов и/или набор факторов может быть получен от ведущего сервера 510 и/или внешнего сервера. После создания моделей машинного обучения ведомые серверы 520, 522, 524 могут передать ведомому серверу 510 указание на то, что модели машинного обучения были созданы и могут использоваться для создания прогнозов, например (но не вводя ограничений) в контексте классификации документов во время процесса сбора данных в сети («веб-кроулинга») и/или после обработки поискового запроса, полученного от внешнего сервера поисковой системы и/или для создания персонализированных рекомендаций содержимого.
[207] В некоторых вариантах осуществления настоящей технологии ведомые серверы 520, 522, 524 могут также получать документ и набор факторов, связанных с документом, вместе с целевым значением, которое надлежит связать с документом. В некоторых других вариантах осуществления настоящей технологии ведомые серверы 520, 522, 524 могут не передавать никакого целевого значения ведущему серверу 510. Этот сценарий может возникнуть после определения ведомыми серверами 520, 522, 524 того, что целевое значение, которое надлежит связать с документом, что приводит к модификации одной из древовидных моделей, хранящихся на этих серверах.
[208] В некоторых вариантах осуществления настоящей технологии после того, как одна из древовидных моделей, хранящаяся на ведомых серверах 520, 522, 524, была модифицирована, ведомые серверы 520, 522, 524 могут передать сообщение ведущему серверу 510, причем сообщение указывает на модификацию, осуществленную в одной из древовидных моделей. Могут быть предусмотрены другие варианты того, как ведомые серверы 520, 522, 524 взаимодействует с ведущим сервером 510, что не выходит за границы настоящей технологии и может быть очевидным специалисту в данной области техники. Кроме того, важно иметь в виду, что для упрощения вышеприведенного описания конфигурация ведомых серверов 520, 522, 524 была сильно упрощена. Считается, что специалисты в данной области техники смогут понять подробности реализации ведомых серверов 520, 522, 524 и его компонентов, которые могли быть опущены в описании с целью упрощения.
[209] На Фиг. 5 показано, что ведомые серверы 520, 522, 524 могут быть функционально соединены соответственно с базой данных 530 «хэш-таблицы 1», базой данных 532 «хэш-таблицы 2» и базой данных 534 «хэш-таблицы n» (здесь и далее упоминаемых как «базы данных 530, 532, 534»). Базы данных 530, 532, 534 могут быть частью ведомых серверов 520, 522, 524 (например, они могут быть сохранены в устройствах памяти ведомых серверов 520, 522, 524, таких как твердотельный накопитель 420 и/или ОЗУ 430) или могут быть сохранены на отдельных серверах баз данных. В некоторых вариантах осуществления настоящей технологии может быть достаточно единственной базы данных, доступной ведомым серверам 520, 522, 524. Следовательно, число баз данных и организация баз данных 530, 532, 534 не является ограничением объема настоящей технологии. Базы данных 530, 532, 534 могут быть использованы для доступа и/или хранения данных, относящихся к одной или нескольким хэш-таблицам, представляющим модели машинного обучения, например (но без введения ограничений) древовидные модели, созданные в соответствии с настоящей технологией.
[210] В некоторых вариантах осуществления настоящей технологии, каждая из баз 530, 532, 534 данных хранит тот же набор информации (т.е. ту же информацию, которая хранится во всех базах 530, 532, 534 данных). Например, каждая из баз 530, 532, 534 данных может хранить один и тот же набор обучающих объектов. Это особенно полезно (без установления ограничений) в тех вариантах осуществления настоящей технологии, где структура ведущего сервера 510 и/или ведомых серверов 520, 522, 524 используется для параллельной обработки и создания деревьев решений. В данном случае, каждая из баз 520, 522, 524 данных обладает доступом к одному и тому же набору обучающих объектов.
[211] В некоторых вариантах осуществления настоящей технологии ведомые серверы 520, 522, 524 могут получить доступ к базам данных 530, 532, 534, чтобы идентифицировать целевое значение, которое надлежит связать с документом, и далее обработать набор факторов, связанный с документом, с помощью ведомых серверов 520, 522, 524 в соответствии с настоящей технологией. В некоторых других вариантах осуществления настоящей технологии ведомые серверы 520, 522, 524 могут получить доступ к базам данных 530, 532, 534, чтобы сохранить новую запись (здесь и далее также упоминаемую как «хэшированный комплексный вектор» и/или «ключ») в одной или нескольких хэш-таблицах, причем новая запись была создана после обработки набора факторов, связанных с документом; она представляет целевое значение, которое надлежит связать с документом. В таких вариантах осуществления настоящей технологии новая запись может представлять модификацию древовидных моделей, представленных хэш-таблицей. Несмотря на то, что на Фиг. 5 представлен варианта осуществления настоящей технологии, в котором базы данных 530, 532, 534 включают в себя хэш-таблицы, следует понимать, что могут быть предусмотрены альтернативные варианты сохранения моделей машинного обучения без отклонения от объема настоящей технологии.
[212] Подробности того, как обрабатываются древовидные модели, формирующие модель машинного обучения, будут предоставлены в описаниях к Фиг. 6-8.
[213] На Фиг. 6 изображены часть древовидной модели 600, первый набор 630 факторов и второй набор 640 факторов. Первый набор 630 факторов и второй набор 640 факторов могут также упоминаться как векторы признаков. Часть древовидной модели 600 могла быть создана в соответствии с настоящей технологией и может представлять связь между документом и целевым значением. Древовидная модель 600 может быть упомянута как модель машинного обучения или часть модели машинного обучения (например, для вариантов осуществления настоящей технологии, в которых модель машинного обучения опирается на множество древовидных моделей). В некоторых случаях древовидная модель 600 может быть упомянута как модель прогнозирования или часть модели прогнозирования (например, для вариантов осуществления настоящей технологии, в которых модель прогнозирования опирается на множество древовидных моделей).
[214] Документ может быть различных форм, форматов и может иметь разную природу, например, без введения ограничений, документ может быть текстовым файлом, текстовым документом, веб-страницей, аудио файлом, видео файлом и так далее. Документ может также упоминаться как файл, что не выходит за границы настоящей технологии. В одном варианте осуществления настоящей технологии файл может быть документом, который может быть найден поисковой системой. Однако, могут быть предусмотрены другие варианты осуществления технологии, что не выходит за границы настоящей технологии и может быть очевидным специалисту в данной области техники.
[215] Как было упомянуто ранее, целевое значение может быть разных форм и форматов, например (без введения ограничений), он представляет указание на порядок ранжирования документа, такое как отношение количества щелчков мышью к количеству показов ("click-through rate (CTR)"). В некоторых вариантах осуществления настоящей технологии целевое значение может упоминаться как метка и/или ранжирование, в частности, в контексте поисковых систем. В некоторых вариантах осуществления настоящей технологии, целевое значение может быть создано алгоритмом машинного обучения с использованием документа обучения. В некоторых альтернативных вариантах осуществления настоящей технологии могут быть использованы другие способы, например (без введения ограничений), определение целевого значения вручную. Следовательно, то, как создается целевое значение, никак не ограничивается, и могут быть предусмотрены другие варианты осуществления технологии, что не выходит за границы настоящей технологии и может быть очевидным специалисту в данной области техники.
[216] Путь в части древовидной модели 600 может быть определен первым набором 630 факторов и/или вторым набором 640 факторов. Первый набор 630 факторов и второй набор 640 факторов могут также быть связаны с тем же самым документом или с различными документами. Часть древовидной модели 600 включает в себя множество узлов, каждый из которых соединен с одной или несколькими ветвями. В варианте осуществления на Фиг. 6, присутствуют первый узел 602, второй узел 604, третий узел 606, четвертый узел 608 и пятый узел 610.
[217] Каждый узел (первый узел 602, второй узел 604, третий узел 606, четвертый узел 608 и пятый узел 610) связан с условием, таким образом определяя так называемое разделение.
[218] Первый узел 602 связан с условием "if Page_rank<3" (значение ранжирования страницы), связанным с двумя ветками (т.е. значение «истина» представлено бинарным числом «1», а значение «ложь» представлено бинарным числом «0»); второй узел 604 связан с условием "Is main page?" («Главная страница?»), связанным с двумя ветками (т.е. Значение «истина» представлено бинарным числом «1», а значение «ложь» представлено бинарным числом "0"); третий узел 606 связан с условием "if Number_clicks < 5,000" (число щелчков), связанным с двумя ветками (т.е. значение «истина» представлено бинарным числом «1», а значение «ложь» представлено бинарным числом «0»); четвертый узел 608 связан с условием "which URL?" («Какой URL?»), которое связано более чем с двумя ветками (т.е. каждая ветка связана со своим URL, например, с URL "yandex.ru"); и пятый узел 610 связан с условием "which Search query?" («Какой поисковый запрос?»), которое связано более чем с двумя ветками (т.е. каждая ветка связана со своим поисковым запросом, например, поисковый запрос «посмотреть Эйфелеву башню»).
[219] В одном варианте осуществления технологии каждое из условий, установленной выше, может определять отдельный фактор (т.е. первый узел 602 определяется условием "if Page_rank < 3 "(значение ранжирования страницы), второй узел 604 определяется условием "Is main page?" («Главная страница?»), третий узел 606 определяется условием "if Number_clicks < 5,000" (число щелчков), четвертый узел 608 определяется условием "which URL?" («Какой URL?»), пятый узел 610 определяется условием "which Search query?" («Какой поисковый запрос?»). Кроме того, пятый узел 610 по ветке «посмотреть Эйфелеву башню» связан с листом 612. В некоторых вариантах осуществления настоящей технологии лист 612 может указывать на целевое значение.
[220] Согласно описанной выше конфигурации, древовидная модель 600, определенная конкретным выбором и порядком первого узла 602, второго узла 604, третьего узла 606, четвертого узла 608 и пятого узла 610, может связывать документ (например, без введения ограничений, веб-страницу в формате html) с целевым значением, связанным с листом 612, причем связь определяется путем в части древовидной модели 300 на основе первого набора 630 факторов и/или второго набора 640 факторов.
[221] Следует учитывать, что с целью упрощения понимания приведена только часть древовидной модели 600. Специалисту в области настоящей технологии может быть очевидно, что число узлов, ветвей и листов фактически не ограничено и зависит исключительно от сложности построения древовидной модели. Кроме того в некоторых вариантах осуществления настоящей технологии древовидная модель может бинарной - включающей в себя набор узлов, каждый из которых содержит только две ветви (т.е. значение «истина» представлено бинарным числом «1», а значение «ложь» представлено бинарным числом "0").
[222] Однако настоящая технология не ограничивается подобными древовидными моделями, и может быть предусмотрено множество вариаций, что может быть очевидно специалисту в области настоящей технологии: например, древовидная модель, состоящая из первой части, определяющей бинарную древовидную модель, и второй части, определяющей древовидную модель, которая определяет категориальную модель дерева, что проиллюстрировано на древовидной модели 600 (первая часть определяется первым узлом 602, вторым узлом 604, третьим узлом 606, а вторая часть определяется четвертым узлом 608 и пятым узлом 610).
[223] Первый набор 630 факторов является примером факторов, определяющих путь, проиллюстрированный на древовидной модели 600. Набор 630 факторов может быть связан с документом и может предоставить возможность определить путь в древовидной модели 600, описанной выше. По меньшей мере один факторов из набора факторов может быть бинарного типа и/или типа вещественных чисел (например, типа целых чисел, типа чисел с плавающей запятой).
[224] На Фиг. 6 представлен набор факторов включает в себя первый компонент 632, связанный со значением «01» и второй компонент 634, связанный со значением «3500». Хотя в настоящем описании используется термин «компонент», следует иметь в виду, что можно с равным успехом использовать термин «переменная», который можно рассматривать как эквивалент слова «компонент». Первый компонент 632 включает в себя бинарную последовательность «01», которая при переводе на древовидную модель 600 представляет первую часть пути. В примере, представленном на Фиг. 6, первая часть пути представлена с помощью применения первой двоичной цифры "0" из последовательности "01" к первому узлу 602, а затем второй цифры "1" последовательности "01" ко второму узлу 604. Второй компонент 634 при переводе на древовидную модель 600 представляет вторую часть пути. На Фиг. 6, вторая часть пути представлена с помощью применения числа "3500" к третьему узлу 606.
[225] Несмотря на то, что на Фиг. 6 приведена первая часть данных как включающая в себя первый компонент 632 и второй компонент 634, число компонентов и число цифр, включенное в один из компонентов, не ограничено и может быть предусмотрено множество вариантов, что не выходит за границы настоящей технологии.
[226] На Фиг. 6 представлен первый набор факторов, который также включает в себя третий компонент 636, связанный со значением "yandex.ru" и четвертый компонент 638, связанный со значением «посмотреть Эйфелеву башню». Третий компонент 636 и четвертый компонент 638 могут быть категориального типа. В некоторых вариантах осуществления настоящей технологии третий компонент 636 и четвертый компонент 638 также могут упоминаться как категориальные факторы и могут включать в себя, например (без введения ограничений), хост, URL, доменное имя, IP-адрес, поисковой запрос и/или ключевое слово.
[227] В некоторых вариантах осуществления настоящей технологии третий компонент 636 и четвертый компонент 638 могут быть в общем охарактеризованы как включающие в себя значение фактора, которое предоставляет возможность категоризировать информацию. В некоторых вариантах осуществления настоящей технологии третий компонент 636 и четвертый компонент 638 могут принимать форму последовательности и/или строки символов и/или цифр. В других вариантах осуществления настоящей технологии, третий компонент 636 и четвертый компонент 638 могут содержать параметр, который принимает больше двух значений, как пример на Фиг. 6, что приводит к тому, что древовидная модель 600 обладает множеством ветвей, соединенных с данным узлом, как множеством возможных значений параметра.
[228] Может быть предусмотрено множество других вариантов того, что включают в себя третий компонент 636 и четвертый компонент 638, что не выходит за границы настоящей технологии. В некоторых вариантах осуществления настоящей технологии третий компонент 636 и четвертый компонент 638 могут представлять путь в части древовидной модели, причем эта часть является не-бинарной, как в случае, изображенном на Фиг. 6. В пределах объема настоящей технологии могут быть возможны другие варианты.
[229] Третий компонент 636 включает в себя строку символов "yandex.ru", которая, при переводе на древовидную модель 600 представляет четвертую часть пути. На Фиг. 6, четвертая часть пути представлена с помощью применения строки символов "yandex.ru" к четвертому узлу 608. Четвертый компонент 638 при переводе на древовидную модель 600 представляет пятую часть пути. На Фиг. 6, пятая часть пути представлена с помощью применения строки символов «посмотреть Эйфелеву башню» к пятому узлу 610, приводя к узлу 612 и целевому значению, связанному с ним. Несмотря на то, что на Фиг. 6 приведены третий компонент 636 и четвертый компонент 638, число компонентов и число цифр и/или символов, включенное в один из компонентов, не ограничено и может быть предусмотрено множество вариантов, что не выходит за границы настоящей технологии.
[230] Обратимся ко второму набору 640 факторов, который представляет собой другой пример факторов, определяющих путь, проиллюстрированный древовидной моделью 600. Как и в случае первого набора 630 факторов, второй набор 335 факторов может быть связан с документом и может предоставить возможность определить путь в древовидной модели 600, описанной выше. Второй набор 640 факторов аналогичен по всем аспектам первому набору 630 факторов за исключением того, что второй набор 640 факторов включает в себя первый компонент 642, а не первый компонент 632, и второй компонент 634 из первого набора 630 факторов.
[231] Первый компонент 642 включает в себя последовательность цифр «010», причем первый компонент 632 связан со значением «01» и второй компонент 634 связан со значением «3500». Как будет понятно специалисту в области настоящей технологии в первом компоненте 642 значение «3500» представлено бинарной цифрой «0», которая является результатом значения «3500», примененного к условию, связанному с третьим узлом 606 (т.е. "Number_clicks < 5,000", число щелчков мышью). В итоге первый компонент 642 может быть рассмотрен как альтернативное представление первого компонента 632 и второго компонента 634 того же пути в древовидной модели 600.
[232] В итоге в некоторых вариантах осуществления настоящей технологи значение вещественного числа может быть переведено в бинарное значение, в частности, в случаях, в которых узел древовидной модели, к которому нужно применить целочисленное значение, соответствует бинарной части древовидной модели. Также возможны другие варианты; примеры второго набора 640 факторов не должны рассматриваться как ограничивающие объем настоящей технологии. Второй набор 640 факторов также включает в себя второй компонент 644 и третий компонент 646, которые идентичны третьему компоненту 636 и четвертому компоненту 638 первого набора 630 факторов.
[233] На Фиг. 7 приведен пример полной древовидной модели 700. Задачей древовидной модели 700 является иллюстрация типовой древовидной модели, которая может быть модифицирована таким образом, чтобы отвечать требованиям конкретной модели прогнозирования. Такие модификации могут включать в себя, например (но без введения ограничений), добавление или удаление одного или нескольких уровней дерева, добавление или удаление узлов (т.е. факторов и соответствующих разделений), добавление или удаление ветвей, соединяющих узлы, и/или листов дерева.
[234] Древовидная модель 700 может быть частью модели машинного обучения или моделью машинного обучения. Древовидная модель 700 может быть предварительной древовидной моделью или обученной древовидной моделью. В некоторых вариантах осуществления настоящей технологии, древовидная модель 700, после ее создания, может быть обновлена и/или модифицирована, например, для повышения уровня точности модели машинного обучения и/или расширения объема применения модели машинного обучения. В некоторых вариантах осуществления настоящей технологии древовидная модель 700 может исходить из обработки, например (но без установления ограничений), поисковых запросов или персонализированных рекомендаций содержимого. Без отклонения от объема настоящей технологии могут быть предусмотрены другие области, которые берет за основу древовидная модель 700.
[235] Древовидная модель 700 включает в себя первый узел 702, связанный с первым фактором "f1". Первый узел 702 определяет первый уровень древовидной модели 700. Первый узел 702 соединен ветвями со вторым узлом 704 и третьим узлом 706. Второй узел 704 и третий узел 706 связаны со вторым фактором "f2". Второй узел 704 и третий узел 706 определяют второй уровень древовидной модели 700. В одном варианте осуществления технологии, первый фактор "f1" и разделение для первого фактора "f1" были выбраны в наборе факторов для размещения на первом уровне древовидной модели 700 на основе набора обучающих объектов. Более подробное описание того, как осуществляется выбор факторов из набора факторов и соответствующих разделений, будет приведено ниже.
[236] Первый фактор "f1" определен таким образом, что, для данного объекта, значение параметра, связанного с первым фактором "f1" определяет то, связан ли объект со вторым узлом 704 или третьим узлом 706. В качестве примера, если значение меньше, чем значение "f1", то объект связан со вторым узлом 704. В другом примере, если значение больше, чем значение "f1", то объект связан с третьим узлом 706.
[237] В свою очередь, второй узел 704 связан с четвертым узлом 708, связанным с третьим фактором "f3", и четвертый узел 710 связан с третьим фактором "f3". Третий узел 706 связан с шестым узлом 712, связанным с третьим фактором "f3", и седьмой узел 714 связан с третьим фактором "f3". Четвертый узел 708, пятый узел 710, шестой узел 712 и седьмой узел 714 определяют третий уровень древовидной модели 700. Как было описано ранее по отношению к первому узлу 702, для данного объекта, значение параметра, связанного со вторым фактором "f2" определяет то, будет ли связан объект с четвертым узлом 708, или с пятым узлом 710 (если объект связан со вторым узлом 704), или с шестым узлом 712 или седьмым узлом 714 (если объект связан с третьим узлом 706).
[238] В свою очередь, каждый узел из узлов: четвертого узла 708, пятого узла 710, и шестого узла 712 и седьмого узла 714 связан с наборами прогнозированных параметров. На Фиг. 7 наборы прогнозированных параметров включают в себя первый набор 720, второй набор 722, третий набор 724 и четвертый набор 726. Каждый из наборов прогнозированных параметров включает в себя три целевых значения, а именно "C1", "С2" и "С3".
[239] Как будет понятно специалистам в данной области техники, древовидная модель 700 иллюстрирует вариант осуществления настоящей технологии, в котором конкретный уровень древовидной модели 700 связан с одним фактором. На Фиг. 7, первый уровень включает в себя первый узел 702 и связан с первым фактором "f1"; второй уровень включает в себя второй узел 704 и третий узел 706, и связан со вторым фактором "f2"; а третий уровень включает в себя четвертый узел 708, пятый узел 710, шестой узел 712 и седьмой узел 714, и связан с третьим фактором "f3".
[240] Другими словами, в представленном на Фиг. 7 варианте осуществления технологии, первый уровень связан с первым фактором "f1", второй уровень связан со вторым фактором "f2", и третий уровень связан с третьим фактором "f3". Могут быть, однако, предусмотрены другие варианты осуществления технологии. В частности, в альтернативном варианте осуществления технологии созданная древовидная модель может включать в себя различные факторы для данного уровня древовидной модели. Например, первый уровень такой древовидной модели может включать в себя первый узел, связанный с первым фактором "f1", второй уровень может включать в себя второй узел, связанный со вторым фактором "f2" и третий узел, связанный с третьим фактором "f3". Как будет понятно специалистам в области настоящей технологии, можно предусмотреть множество вариантов того, какие факторы могут быть связаны с данным уровнем, не выходя за границы настоящей технологии.
[241] Релевантные этапы создания варианта модели прогнозирования в виде дерева решений (также упоминаемой как «обученное дерево решений», «древовидная модель», и/или «модель дерева решений») будут описаны с учетом Фиг. 8, 9 и 10.
[242] На Фиг. 8 представлены этапы создания варианты модели прогнозирования в виде дерева решений. На Фиг. 9 и 10 представлены наборы прото-деревьев (также упоминаемых как «предварительные древовидные модели» или «предварительные модели прогнозирования в виде деревьев решений», используемые для выбора первого фактора и второго факторов, которые используются в варианте осуществления прогностической модели обученного дерева решений.
[243] Следует отметить, что термин "протодерево" широко используется в настоящем описании. В некоторых вариантах осуществления настоящей технологии, термин "протодерево" используется для описания частично построенного / частично обученного дерева решений, например, когда дерево решений создается "уровень за уровнем". В других вариантах осуществления настоящей технологии, термин "протодерево" использован для описания обученного дерева решений в ансамбле деревьев решений, когда ансамбль деревьев решений создается в соответствии, например, с методами градиентного бустинга.
[244] На Фиг. 8 представлен процесс создания прогностической модели обученного дерева решений на основе набора объектов. Следует отметить, что нижеследующее описание прогностической модели обученного дерева решений, показанного на Фиг. 8, является только одним неограничивающим вариантом осуществления прогностической модели обученного дерева решений, и предусматривается, что другие неограничивающие варианты осуществления могут иметь больше или меньше узлов, факторов, уровней и листов.
[245] Как проиллюстрировано первым деревом 810 решений, создание прогностической модели обученного дерева решений начинается с выбора первого фактора, связанного здесь с первым узлом 811. Способ, с помощью которого выбираются факторы на каждом уровне, будет описан подробнее ниже.
[246] На окончании путей от первого узла 811 по ветви первого дерева решений 810 есть два листа 812 и 813. Каждый из листов 812 и 813 обладает "значением листа", которые связаны с заранее определенным целевым значением на данном уровне создания дерева решений. В некоторых вариантах осуществления технологии первый фактор "f1" был выбран для узла 811 первого уровня древовидной модели 810 на основе набора обучающих объектов и/или параметра точности дерева 810 решений. Параметр точности листа и/или параметр точности дерева 810 решений вычисляются посредством определения параметра качества прогнозирования, как будет более подробно описано далее.
[247] Конкретнее, первый фактор "f1" и соответствующее разделение были выбраны из всех возможных факторов и всех возможных разделений на основе таким образом созданного параметра качества прогнозирования.
[248] Второй фактор "f2" выбирается следующим и добавляется к дереву 810 решений, что создает дерево 820 решений. Второй узел 822 и третий узел 823, связанные со вторым фактором, добавляются к двум ветвям, исходящим из первого узла 811. В альтернативном варианте осуществления настоящей технологии второй узел 822 и третий узел 823 могут быть связаны с различными факторами.
[249] В вариантах осуществления, представленных на Фиг. 8, первый узел 811 дерева 820 решений остается таким же, как и в дереве 810 решений, потому что первый фактор был выбран и назначен на первый уровень, и связан с первым узлом 811 (на основе метода градиентного бустинга).
[250] Листы 824-828 теперь связаны с окончаниями путей в дереве 820 решений. Второй узел 822 имеет два листа, лист 824 и лист 825, исходящие из второго узла 822. Третий узел 823 имеет три листа, лист 826, лист 827 и лист 828, исходящие из третьего узла 823. Число листов, исходящих из любого данного узла, может зависеть, например, от факторов, выбранных в любом данном узле, и признаков обучающих объектов, с помощью которых была создана древовидная модель.
[251] Также как и в случае с первым фактором "f1", параметр качества прогнозирования используется для выбора второго фактора "f2" и соответствующих разделений для второго узла 822 и третьего узла 823.
[252] Также на Фиг. 8, показано, что затем выбирается фактор "0" третьего уровня и добавляется к дереву 820 решений, что создает дерево 830 решений. Первый узел 811, второй узел 822 и третий узел 823 остаются теми же самыми, что и в дереве 810 решений и в дереве 820 решений. Первый фактор и второй фактор (и связанные с ними разделения) также остаются теми же самыми факторами (и узлами), выбранными и назначенными ранее.
[253] Новые узлы 834-838 добавляются к ветвям, исходящим из второго узла 822 и третьего узла 823. Новые листы 840-851, связанные с окончаниями путей дерева 830 принятия решения, исходят из новых узлов 834-838. Каждый лист из новых листов 840-851 имеет соответствующее значение листа, связанное с одним или несколькими прогнозированными значениями. В этом примере варианта осуществления настоящей технологии во время создания прогностической модели обученного дерева решений было выбрано три фактора. Предусматривается, что в различных вариантах осуществления прогностической модели обученного дерева решений может быть больше или меньше трех факторов. Следует отметить, что создаваемая древовидная модель может обладать числом уровней, созданных так, как описано выше, которое больше или меньше трех.
[254] То, как именно выбираются факторы для прогностической модели обученного дерева решений, как показано на Фиг. 7 и 8, будет описано в отношении Фиг. 9 и 10.
[255] Для выбора в качестве первого фактора «наилучшего» фактора создается набор «протодеревьев» («протодеревьев») с первым узлом. На Фиг. 9 показаны три протодерева 910, 920 и 930 как типичная выборка из набора протодеревьев. В каждом отдельном протодереве 910, 920 и 930 первый узел связан с отдельным фактором из набора доступных факторов. Например, узел 911 протодерева 910 связан с одним из факторов, "fa", а узел 921 протодерева 920 связан с фактором "fb", а в протодереве 930 узел 931 связан с фактором "fn". В некоторых вариантах осуществления настоящей технологии для каждого из факторов, из которых должен быть выбран первый фактор, создается одно протодерево. Все протодеревья отличаются друг от друга, и они могут не учитываться после выбора наилучшего фактора для использования в качестве узла первого уровня.
[256] В некоторых вариантах осуществления настоящей технологии такие факторы как, например, "fa", "fb" и "fn", будут связаны с признаками, которые являются численными или категориальными. Например, возможно не только наличие двух листов на узел (как в случае с использованием только бинарных данных), но и наличие большего количества листов (и ветвей, к которым могут быть добавлены дополнительные узлы). Как показано на Фиг. 9, протодерево 910, включающее в себя узел 911, имеет ветви, идущие в три листа 912-914, а протодерево 920 и протодерево 930 имеет два (922, 923) листа и четыре листа (932-935), соответственно.
[257] Этот набор протодеревьев, показанный на Фиг. 9, далее используется для выбора «наилучшего» первого фактора для добавления к создаваемой прогностической модели обученного дерева решений. Для каждого дерева из протодеревьев, параметр качества прогнозирования вычисляется по меньшей мере для некоторых листов, исходящих из одного или нескольких узлов.
[258] Например, параметр качества прогнозирования определяется для протодеревьев 910, 920 и 930. В некоторых вариантах осуществления настоящей технологии факторы точности листа определяются по меньшей мере для некоторых листов, например, для листов 912, 913, и 914 протодерева 910. В некоторых вариантах осуществления настоящей технологии факторы точности листа могут быть комбинированы для определения параметра точности. То, как именно определяется параметр качества прогнозирования, будет определено далее более подробно.
[259] Первый фактор для использования при создании древовидной модели затем может быть выбран путем выбора протодерева «наилучшего качества» на основе параметра качества прогнозирования для каждого протодерева. Фактор, связанный с протодеревом «наилучшего качества» затем выбирается как первый фактор для создания прогностической модели обученного дерева решений.
[260] С целью иллюстрации выберем протодерево 920 как «наилучшее» протодерево, например, на основе определения того, что протодерево 920 связано с наивысшим параметром точности. На Фиг. 10 показан созданный второй набор протодеревьев для выбора «наилучшего» фактора второго фактора для добавления к создаваемой прогностической модели обученного дерева решений. Узел 921 и его соответствующие ветви сохраняются от протодерева 920. Остальное протодерево 920 и первый набор протодеревьев может не учитываться.
[261] Те же самые обучающие объекты затем используются для тестирования второго набора протодеревьев, включающих в себя узел 921, связанный с «наилучшим» первым фактором (назначенным с помощью описанного выше процесса) и двух узлов, связанных со вторым фактором, причем второй фактор из набора факторов для каждого протодерева свой.
[262] В этом примере присутствуют два узла второго уровня, потому что с узлом 921 связаны две ветви. Если бы «наилучшим» протодеревом было протодерево 830, присутствовало бы четыре узла, связанных с четырьмя ветвями, исходящими из узла 831.
[263] Как показано на трех примерах протодеревьев 940, 960 и 980 из второго набора протодеревьев, который показан на Фиг. 10, первый узел каждого протодерева - это узел 921 от наилучшего первого протодерева, и в деревьях присутствуют, добавленные к двум ветвям, исходящим от узла 921, два узла 942, 943 (для протодерева 940), два узла 962, 963 (для протодерева 960) и два узла 982, 983 (для протодерева 980). Каждое из окончаний протодеревьев 940, 960 и 980 связано с листами 944-647; 964-968 и 984-988, соответственно.
[264] «Наилучший» второй фактор теперь выбирается таким же образом, как описано выше для «наилучшего» первого фактора, причем протодерево, состоящее из первого фактора и второго фактора, будет обладать «более высоким качеством» (обладая более высоким параметром точности), чем другие протодеревья, которые не были выбраны. Затем второй фактор, связанный со вторыми узлами протодерева, обладающими наиболее высоким параметром качества прогнозирования, выбирается как второй фактор для того, чтобы быть присвоенным создающейся прогностической модели обученного дерева решений. Например, если протодерево 960 определяется как протодерево с наивысшим параметром качества прогнозирования, узел 962 и узел 963 будут добавлены к создающейся прогностической модели обученного дерева решений.
[265] Аналогично, если добавляются последующие факторы и уровни, будет создаваться новый набор протодеревьев с использованием узла 921, узла 962, и узла 963, с новыми узлами, добавленным к пяти ветвям, исходящим из узла 962 и узла 963. Способ будет проводиться для какого угодно количества уровней и связанных факторов при создании прогностической модели обученного дерева решений. Следует отметить, что прогностическая модель обученного дерева решений может обладать числом уровней, созданных так, как описано выше, которое больше или меньше трех.
[266] Когда создание прогностической модели обученного дерева решений завершено, для законченной модели прогнозирования может быть осуществлено определение параметра качества прогнозирования. В некоторых вариантах осуществления настоящей технологии определение модели прогнозирования может основываться на наборе прогностических моделей обученного дерева решений, а не на единственной прогностической модели обученного дерева решений, причем каждая прогностическая модель обученного дерева решений из набора может быть создана в соответствии со способом, описанным выше. В некоторых вариантах осуществления настоящей технологии факторы могут быть выбраны из того же самого набора факторов, и может быть использован тот же самый набор обучающих объектов.
[267] Общее описание обработки категориальных факторов в их числовые представления
[268] В соответствии с неограничивающими вариантами осуществления настоящей технологии, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 выполнены с возможностью обрабатывать категориальные факторы. Конкретнее, в соответствии с неограничивающими вариантами осуществления настоящей технологии, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 выполнены с возможностью обрабатывать категориальные факторы в их числовые представления. Конкретнее, в соответствии с неограничивающими вариантами осуществления настоящей технологии, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 выполнены с возможностью обрабатывать категориальные факторы в их числовые представления с помощью "парадигмы динамического бустинга". В некоторых неограничивающих вариантах осуществления настоящей технологии, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 выполнены с возможностью обрабатывать группу категориальных факторов в их числовые представления, группа категориальных факторов включает в себя по меньшей мере первый категориальный фактор и второй категориальный фактор.
[269] Для целей иллюстрации предположим, что фактор, который необходимо обработать ведущему серверу 510 и/или ведомым серверам 520, 522, 524, представляет собой "музыкальный жанр", и целью прогнозирования функции для MLA является способность прогнозировать "прослушано" или "не послушно" на основе музыкального жанра. Фактор "музыкальный жанр" является категориальным или, иным словами, может принимать множество (конечное) значений - например: джаз, классика, регги, фолк, хип-хоп, поп, панк, опера, кантри, хеви-метал, рок и т.д.
[270] Для обработки категориального фактора ведущим сервером 510 и/или ведомыми серверами 520, 522, 524, этот категориальный фактор необходимо преобразовать в числовое значение. Конкретнее, значение данного категориального фактора (т.е. одного из варианта джаз, классика, регги, фолк, хип-хоп, поп, панк, опера, кантри, хеви-метал, рок) необходимо преобразовать в его числовое значение).
[271] В соответствии с неограничивающими вариантами осуществления настоящей технологии, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 сначала создают упорядоченный список всех обучающих объектов, обладающих категориальными факторами, которые будут обработаны во время этапа обучения MLA.
[272] В случае если обучающие объекты с категориальными факторами обладают присущими временными связями (например, месяцы года, года и т.д.), фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 организует обучающие объекты, обладающие категориальными факторами, в соответствии с этими временными связями. В случае если обучающие объекты с категориальными факторами не обладают присущими временными связями, фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создает упорядоченный список обучающих объектов, обладающих категориальными факторами, на основе правила.
[273] Например, фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 может создавать случайный порядок обучающих объектов, обладающих категориальными факторами. Случайный порядок становится основой для временного порядка обучающих объектов, обладающих категориальными факторами, которые, в ином случае, не обладают никакими присущими временными связями.
[274] В вышеприведенном примере, где категориальные факторы представляют собой музыкальные жанры - эти обучающие объекты, обладающие категориальными факторами, могут быть связаны или не связаны с присущими им временными связями. Например, в тех сценариях, где обучающие объекты, которые обладают категориальными факторами, связаны с аудиотреками, воспроизводимыми на музыкальном он-лайн хранилище или загруженными с него, обучающие объекты, которые обладают категориальными факторами, могут быть обладать присущими временными связями на основе времени воспроизведения/загрузки.
[275] Вне зависимости от того, как создается порядок, фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 далее "замораживают" обучающие объекты, обладающие категориальными факторами, в таким образом организованном порядке. Таким образом организованный порядок, в некотором роде, может указывать для каждого обучающего объекта, обладающего категориальным фактором, на то, какие другие обучающие объекты, обладающие категориальными факторами, находятся "до" и какие находятся "после" (даже если обучающие объекты, обладающие категориальными факторами, не связаны с присущими временными связями).
[276] На Фиг. 1 представлен неограничивающий пример упорядоченного списка обучающих объектов 102, обучающие объекты связаны с категориальными факторами (продолжая пример, в котором категориальные факторы представляют собой музыкальные жанры - джаз, классика, регги, фолк, хип-хоп, поп, панк, опера, кантри, хеви-метал, рок и т.д.).
[277] Упорядоченный список обучающих объектов 102 обладает множеством обучающих объектов 104. Исключительно в целях иллюстрации, множество обучающих объектов 104 включает в себя первый обучающий объект 106, второй обучающий объект 108, третий обучающий объект 110, четвертый обучающий объект 112, пятый обучающий объект 114, шестой обучающий объект 116, седьмой обучающий объект 118 и восьмой обучающий объект 120. Естественно, множество обучающих объектов 104 может содержать меньшее или большее количество обучающих объектов. Каждый из обучающих объектов из множества обучающих объектов 104 обладает категориальным фактором 122, связанным с ним, а также значением 124 события. Используя в качестве примера первый обучающий объект 106, его категориальный фактор 112 связан с жанром "поп", а значение 124 события равно "0" (что указывает, например, на отсутствие клика во время взаимодействия с первым обучающим объектом 106 предыдущим пользователем или асессором).
[278] Продолжая описание примера, представленного на Фиг. 1:
- для второго обучающего объекта 108, категориальный фактор 112 связан с жанром "рок", а значение 124 события равно "1" (что указывает, например, на значение фактора наличия клика);
- для третьего обучающего объекта 110, категориальный фактор 112 связан с жанром "диско", а значение 124 события равно "1" (что указывает, например, на наличие клика);
- для четвертого обучающего объекта 112, категориальный фактор 112 связан с жанром "поп", а значение 124 события равно "0" (что указывает, например, на отсутствие клика);
- для пятого обучающего объекта 114, категориальный фактор 112 связан с жанром "поп", а значение 124 события равно "1" (что указывает, например, на наличие клика);
- для пятого обучающего объекта 116, категориальный фактор 112 связан с жанром "джаз", а значение 124 события равно "0" (что указывает, например, на отсутствие клика);
- для шестого обучающего объекта 118, категориальный фактор 112 связан с жанром "классика", а значение 124 события равно "1" (что указывает, например, на наличие клика);
- для седьмого обучающего объекта 120, категориальный фактор 112 связан с жанром "регги", а значение 124 события равно "1" (что указывает, например, на наличие клика).
[279] Порядок упорядоченного списка обучающих объектов 102 показан на Фиг. 1 указан под номером 126. В соответствии с неограничивающими вариантами осуществления настоящей технологии, в соответствии с порядком 126 упорядоченного списка обучающих объектов 102, данный обучающий объект в упорядоченном списке обучающих объектов 102 может находиться до или после другого обучающего объекта в упорядоченном списке обучающих объектов 102. Например, первый обучающий объект 106, можно сказать, находится до любого другого обучающего объекта из множества обучающих объектов 104. В качестве другого примера, четвертый обучающий объект 112 может находиться (i) после первого обучающего объекта 106, второго обучающего объекта 108, третьего обучающего объекта 110 и (ii) до пятого обучающего объекта 114, шестого обучающего объекта 116, седьмого обучающего объекта 118 и восьмого обучающего объекта 120. В качестве последнего примера, восьмой обучающий объект 120 находится после всех других обучающих объектов из множества обучающих объектов 104.
[280] В соответствии с неограничивающими вариантами осуществления настоящей технологии, фактор, что ведущему серверу 510 и/или ведомым серверам 520, 522, 524 необходимо преобразовать категориальный фактор в его числовое представление, фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 высчитывают число вхождений данного категориального фактора по отношению к другим категориальным факторам, связанным с обучающими объектами, которые находятся до данного категориального фактора в упорядоченном списке обучающих объектов 102.
[281] Другими словами, в широком смысле, фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают указание на "счетчик" данного категориального фактора, как будет более подробно описано далее. Для предоставления временной аналогии, фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 используют только те категориальные факторы, которые происходили в "прошлом" по отношению к данному категориальному фактору. Таким образом, при преобразовании категориального фактора в его числовое представление, фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 не "заглядывают" в будущее данного категориального фактора (т.е. целевые значения этих категориальных факторов, которые случились "в будущем" в отношении данного категориального фактора).
[282] В конкретном варианте осуществления из неограничивающих вариантов осуществления настоящей технологии, фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 вычисляют функцию на основе значений срабатывания и несрабатывания, связанных с категориальным фактором и его "прошлым".
[283] В качестве иллюстрации рассмотрим пятый обучающий объект 114 (обладающий значением категориального фактора 112 "поп" и связанный со значением 124 события, которое равно "1"). Фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 преобразуют значение категориального фактора 122 (т.е. "поп") в числовой фактор с помощью формулы:

[284] Где счетчик - это числовое представление значения категориального фактора для данного объекта, NumberWINs - число событий для данного значения категориального фактора, которые считаются связанными со срабатываниями, а NumberOCCURENCEs - число вхождений одинакового значения обрабатываемого категориального фактора, причем, как число событий, которые считаются срабатываниями, так и число вхождений значения категориального фактора, находящихся по порядку 126 до данного обрабатываемого категориального фактора.
[285] В качестве примера, числом событий, которые считаются срабатываниями, может быть успешное событие, которое связано с данным объектом, связанным с данным значением категориального фактора (т.е. песня конкретного жанра, связанного с данным объектом, которая проигрывалась или была загружена или была отмечена как "понравившееся"), т.е. значение 124 события равно "1", а не "0". Число вхождений представляет собой общее число вхождений значения данного категориального фактора в упорядоченный список обучающих объектов 102, которые "находятся" до текущего вхождения (т.е. до категориального фактора, счетчик для которого обрабатывается алгоритмом машинного обучения). Другими словами, система вычисляет счетчик для данного фактора путем просмотра "снизу вверх" упорядоченного списка обучающих объектов 102. В качестве примера, для данного значения фактора (рок) данного объекта, число событий, которые считаются срабатываниями, может являться числом вхождений объектов с конкретном типом события (например, песня, связанная с обучающим объектом, была воспроизведена или загружена или отмечена как "понравившееся", т.е. значение 124 события равно "1", а не "0"), и число вхождений может представлять собой общее число вхождений того же значения фактора (рок), что и данный объект.
[286] В некоторых вариантах осуществления настоящей технологии, Формула 1 может быть модифицирована с помощью константы.
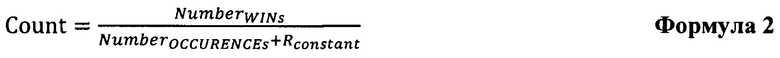
[287] В которой R_constant может являться заранее определенным значением.
[288] В широком смысле, неограничивающие варианты осуществления настоящей технологии могут использовать любую формулу, в которой используются "прошлые" появления ситуаций срабатывания и общее число вхождений текущего обрабатываемого категориального фактора.
[289] Таким образом, в широком смысле, формула может выглядеть следующим образом:
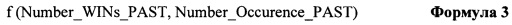
[290] В альтернативных вариантах осуществления технологии, любая из формул 1, 2 или 3 может быть модифицирована для анализа группы факторов, а не одного фактора.
[291] Например, вместо того, чтобы просто просматривать жанр песни, формула может анализировать совместное вхождение данного жанра и данного исполнителя. При анализе групп категориальных факторов, фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 применяют ту же самую парадигму "динамического бустинга". Как и в случае с обработкой одного категориального фактора, когда фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 обрабатывают группу факторов, фактор, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 только анализируют совместные вхождения группы факторов, которые находятся до текущего вхождения группы анализируемых категориальных факторов.
[292] Формула может быть модифицирована следующим образом:
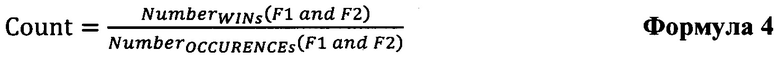
[293] Где оба NumberWINs(F1 and F2) и NumberOCCURENCEs(F1 and F2) учитывают срабатывания и совместные вхождения группы значений факторов (F1 и F2), которые находятся выше текущего вхождения группы факторов в упорядоченном списке обучающих объектов 102.
[294] По мере того как растет число факторов (например, для обучающих объектов, которые являются песнями, категориальные факторы могут включать в себя: жанр, исполнитель, альбом и т.д.), растет и число возможных комбинаций в группах факторов, которые обрабатываются фактором, что ведущий сервер 510 и/или ведомые серверы 520, 522, 524 с целью обучения, и, в конечном итоге, применения формулы обученного MLA.
[295] Вместо предварительного вычисления всех возможных комбинаций категориальных факторов, в неограничивающих вариантах осуществления настоящей технологии предусмотрено создание счетчиков комбинаций факторов "внутри" алгоритма машинного обучения, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 проходят по всем категориальным факторам (т.е. "на ходу", когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают дерево решений (и его конкретную итерацию), а не заранее вычисляя все возможные счетчики для всех возможных комбинаций категориальных факторов). Основным техническим преимуществом данного подхода является то, что ведущему серверу 510 и/или ведомым серверам 520, 522, 524 необходимо вычислять только те комбинации, которые фактически возникают, а не каждую возможную комбинацию категориальных факторов.
[296] Например, вместо вычисления счетчиков (т.е. числового представления) для каждого возможной комбинации жанра и исполнителя, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 могут вычислять счетчики (т.е. числовое представление) только для тех комбинаций значений категориальных факторов, которые ведущий сервер 510 и/или ведомые серверы 520, 522, 524 находят в упорядоченном списке обучающих объектов 102, что позволяет значительно сократить вычислительные мощности и ресурсы памяти, которые требуются для хранения информации о каждой возможной комбинации значений категориальных факторов.
[297] В широком смысле, когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают конкретную итерацию модели дерева решений (например, конкретное дерево решений в ансамбле деревьев решений, которые обучаются в случае использования градиентного бустинга). Для каждого узла дерева решений, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 преобразовывают значения категориальных факторов (или группу значений категориальных факторов, в зависимости от ситуации) в их числовое представление, как было описано ранее.
[298] После того как для данного узла или данного уровня был выбран лучший из таких образом преобразованных категориальных факторов (а также любые другие числовые факторы, которые могут быть обработаны данным узлом) - они "замораживаются" для этого узла/этого уровня дерева решений на данной итерации бустинга дерева решений. В некоторых вариантах осуществления настоящей технологии, когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 спускаются на более низкоуровневые узлы, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 только вычисляют счетчики для тех комбинаций категориальных факторов, которые были встречены ведущим сервером 510 и/или ведомыми серверами 520, 522, 524 для текущей вариации дерева решений (т.е. учитывать категориальные факторы, которые были выбраны как лучшие, и были "заморожены" на более высоких уровнях деревьев решений). В альтернативных вариантах осуществления настоящей технологии, когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 спускаются на более низкоуровневые узлы, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 только вычисляют счетчики для тех комбинаций значений категориальных факторов, которые были встречены ведущим сервером 510 и/или ведомыми серверами 520, 522, 524 для текущей вариации дерева решений (т.е. учитывать категориальные факторы, которые были выбраны как лучшие, и были "заморожены" на более высоких уровнях деревьев решений), а также предыдущие вариации деревьев решений, которые были построены во время предыдущей итерации бустинга деревьев решений, как часть создания ансамбля деревьев решений.
[299] Используя в качестве примера текущий уровень дерева решения - третий уровень (т.е. третий уровень, которому предшествуют корневой узел, первый уровень и второй уровень дерева решений), когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 вычисляют числовое представление категориальных факторов для третьего уровня, MLA вычисляет все возможные комбинации категориальных факторов для третьего уровня в комбинации с "замороженными" категориальными факторами, которые были выбраны как лучшие и которые были "заморожены" для корневого узла, узла первого уровня и узла второго уровня.
[300] Другими словами, можно сказать, что для данного узла на данном уровне дерева решений, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 вычисляет "счетчики" возможных категориальных факторов для данного узла данного уровня дерева решений путем добавления всех возможных категориальных факторов к уже выбранным лучшим категориальным факторам, которые были "заморожены" на предыдущих уровнях, в отношении данного уровня дерева решений.
[301] Далее рассмотрим разделения, которые выбраны в связи с данным категориальным фактором (или, конкретнее, его счетчиком) на данном уровне дерева решений. Разделения также вычисляются "внутри" алгоритма MLA, т.е. "на ходу", когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают дерево решений (на данной его итерации) вместо предварительного вычисления всех возможных разделений для всех возможных счетчиков.
[302] На Фиг. 2, в одном конкретном варианте осуществления технологии, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают разделения путем создания диапазона всех возможных значений для разделений (для данного счетчика, который был создан на основе данного категориального фактора) и применения заранее определенной сетки. В некоторых вариантах осуществления настоящей технологии, диапазон 202 может находиться между значениями 0 и 1. В других вариантах осуществления настоящей технологии, в которых важно применение коэффициента (Rconstant) при вычислении значений счетчиков, диапазон 202 может находиться в следующих пределах: (i) значение коэффициента (ii) значение коэффициента плюс единица.
[303] В некоторых вариантах осуществления настоящей технологии, заранее определенная сетка представляет собой сетку 204 с постоянным интервалом, которая разделяет диапазон 202 на постоянные интервалы 206. В других вариантах осуществления настоящей технологии, заранее определенная сетка 204 представляет собой сетку с непостоянным интервалом, которая разделяет диапазон на непостоянные интервалы.
[304] В результате отсутствия предварительной обработки всех возможных комбинаций категориальных факторов и обработки счетчиков "внутри" алгоритма машинного обучения, возможно обрабатывать разделения для узлов "внутри" MLA, который создает дерево решений. В соответствии с неограничивающими вариантами осуществления технологии, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 определяют разделения для узлов деревьев, не зная все возможные значения для счетчиков на основе вышеописанного подхода с использованием сеток. Ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают диапазон 202 разделений и организуют его в виде "областей" 206, и границы областей 206 (например, границы 208 и 210) становятся значениями для разделений. В фазе использования, ведущему серверу 510 и/или ведомым серверам 520, 522, 524 необходимо определять, в какую область 206 "попадает" данный счетчик - и она становится значением разделения.
[305] В некоторых вариантах осуществления настоящей технологии, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 вычисляют разделения для каждого уровня дерева решений и, после того как данный уровень дерева решений оптимизирован (т.е. после того как ведущий сервер 510 и/или ведомые серверы 520, 522, 524 выбирает "лучший" фактор и разделение для данного уровня дерева решений), MLA может стереть вычисленные разделения. Когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 переходят к следующему уровню, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 заново рассчитывают разделения. В других вариантах осуществления настоящей технологии, разделения вычисляются и "забываются" при переходе от дерева к дереву, а не от уровня к уровню.
[306] Когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают дерево решений на конкретной итерации создания модели дерева решений, для каждого уровня, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 проверяют и оптимизируют лучшее из: какой фактор расположить на узле уровня, и какое разделяющее значение (из всех возможных заранее определенных значений) расположить на узле.
[307] Для иллюстрации вышесказанного на Фиг. 3 представлена часть протодерева 300 с одним узлом первого уровня (первым узлом 302), который также может считаться "корневым узлом", и двумя узлами второго уровня (вторым узлом 304 и третьим узлом 306). Для целей иллюстрации предположим, что значение фактора и разделения для первого узла 302 были выбраны (f1/s1). Когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают дерево решений на конкретной итерации создания модели дерева решений, уровне второго узла 304 и третьего узла 306, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 проверяют и оптимизируют лучшее из: какой фактор расположить на узле уровня, и какое разделяющее значение (из всех возможных заранее определенных значений) расположить на узле. Конкретнее, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 выбрали fn/sn как фактор и разделения для второго узла 304 и fm/sm как фактор для разделения для третьего узла 306.
[308] С учетом описанной выше архитектуры, возможно выполнить способ преобразования значения категориального фактора в его числовое представление, категориальный фактор связан с обучающим объектом, используемым для обучения алгоритма машинного обучения (MLA). На Фиг. 11 представлена блок-схема способа 1100, который выполняется в соответствии с неограничивающими вариантами осуществления настоящей технологии. Способ 1100 может выполняться ведущим сервером 510 и/или ведомыми серверами 520, 522, 524.
[309] Этап 1102 - получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором
[310] На этапе 1102, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором и соответствующим значением категориального фактора.
[311] Этап 1104 - организация набора обучающих объектов в упорядоченный список обучающих объектов, причем упорядоченный список обучающих объектов организован таким образом, что для каждого обучающего объекта в упорядоченном списке обучающих объектов существует по меньшей мере один из: (i) предыдущий обучающий объект, который находится до данного обучающего объекта и (ii) последующий обучающий объект, который находится после данного обучающего объекта
[312] На этапе 1104 ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют организацию набора обучающих объектов в упорядоченный список обучающих объектов, причем упорядоченный список обучающих объектов организован таким образом, что для каждого обучающего объекта в упорядоченном списке обучающих объектов существует по меньшей мере один из: (i) предыдущий обучающий объект, который находится до данного обучающего объекта и (ii) последующий обучающий объект, который находится после данного обучающего объекта
[313] Этап 1106 - для данного категориального фактора, связанного с данным обучающим объектом, причем данный обучающий объект обладает по меньшей мере одним предыдущим обучающим объектом в соответствующем упорядоченном списке обучающих объектов, создание его числового представления, причем создание основывается на: (i) числе общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же значением категориального фактора (ii) числе заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора
[314] На этапе 1106 ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют, для данного категориального фактора, связанного с данным обучающим объектом, причем данный обучающий объект обладает по меньшей мере одним предыдущим обучающим объектом в соответствующем упорядоченном списке обучающих объектов, создание его числового представления, причем создание основывается на: (i) числе общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же значением категориального фактора (ii) числе заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора
[315] В некоторых вариантах осуществления способа 1100, создание включает в себя применение формулы:

[316] где:
[317] NumberOCCURENCEs число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора; и
[318] NumberWINs число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора.
[319] В некоторых вариантах осуществления способа 1100, создание включает в себя применение формулы:
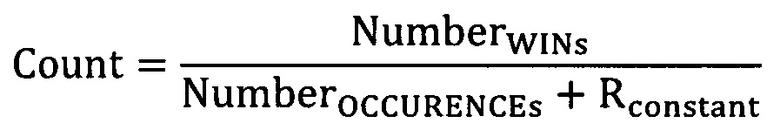
[320] где:
[321] NumberOCCURENCEs число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора;
[322] NumberWINs число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора; и
[323] Rconstant является заранее определенным значением.
[324] В некоторых вариантах осуществления способа 1100, данный категориальный фактор является набором категориальных факторов, который включает в себя по меньшей мере первый категориальный фактор и второй категориальный фактор, причем создание их числового представления включает в себя: (i) использование числа общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора: числа общих вхождений по меньшей мере одного предыдущего обучающего объекта, обладающего как значением первого категориального фактора, так и значением второго категориального фактора; и (ii) использование в качестве числа заранее определенных результатов событий, связанных с по меньшей мере одним обучающим объектом, обладающим тем же значением категориального фактора: числа заранее определенных результатов событий, связанных с по меньшей мере одним обучающим объектом, обладающим как как значением первого категориального фактора, так и значением второго категориального фактора.
[325] В некоторых вариантах осуществления способа 1100, создание числового представления включает в себя применение формулы:
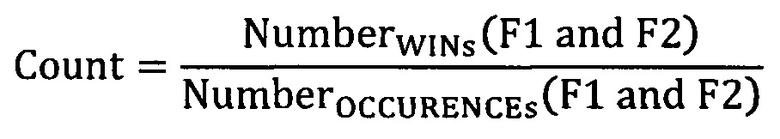
[326] где
[327] (i) NumberWINs(F1 and F2) is - число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым набором значений категориальных факторов; и
[328] (ii) NumberOCCURENCEs(F1 and F2) is the - число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым набором значений категориальных факторов.
[329] В некоторых вариантах осуществления способа 1100, индикатор события обладает заранее определенным значением, и это заранее определенное значение является одним из положительного результата или отрицательного результата.
[330] В некоторых вариантах осуществления способа 1100, организация набора обучающих объектов в упорядоченный список обучающих объектов выполняется в момент времени до создания числового значения.
[331] В некоторых вариантах осуществления способа 1100, организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя организацию множества наборов упорядоченных списков, и в котором способ далее включает в себя, до этапа создания числового значения, выбор одного из множества наборов из упорядоченных списков.
[332] В некоторых вариантах осуществления способа 1100, обучающие объекты связаны с присущим им временным порядком, и причем организация набора обучающих объектов в упорядоченный список, и причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя организацию обучающих объектов в соответствии с временным порядком.
[333] В некоторых вариантах осуществления способа 1100, обучающие объекты не связаны с присущим им временным порядком, и причем организация набора обучающих объектов в упорядоченный список, и причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя организацию обучающих объектов в соответствии заранее определенным правилом.
[334] В некоторых вариантах осуществления способа 1100, обучающие объекты не связаны с присущим им временным порядком, и причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя создание случайного порядка обучающих объектов, который будет использован как упорядоченный список.
[335] Учитывая описанную выше архитектуру, возможно осуществить способ преобразования значения категориального фактора в его числовую форму, категориальный фактор связан с обучающим объектом для обучения алгоритма машинного обучения (MLA), MLA использует модель дерева решений, обладающую деревом решений, обучающий объект обрабатывается на узле данного уровня дерева решений, дерево решений обладает по меньшей мере одним предыдущим уровнем дерева решений, по меньшей мере один предыдущий уровень обладает по меньшей мере одним обучающим объектом, который обладает по меньшей мере одним категориальным фактором, который было преобразован в свое предыдущее числовое представление по меньшей мере для одного предыдущего уровня дерева решений.
[336] На Фиг. 12 представлена блок-схема способа 1200, который выполняется в соответствии с не ограничивающими вариантами осуществления настоящей технологии. Способ 1200 может выполняться ведущим сервером 510 и/или ведомыми серверами 520, 522, 524.
[337] Этап 1202 - получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором
[338] На этапе 1202, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором и значением категориального фактора.
[339] Этап 1204 - создание числового представления значения категориального фактора (создание осуществляется в процессе создания дерева решений), причем создание осуществляется путем осуществления этапов 1206 и 1208
[340] На этапе 1204, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют создание числового представления значения категориального фактора (создание осуществляется в процессе создания дерева решений), причем создание осуществляется путем осуществления этапов 1206 и 1208.
[341] Этап 1206 - извлечение предыдущего числового представления по меньшей мере одного значения категориального фактора для данного объекта из набора обучающих объектов по меньшей на одном предыдущем уровне дерева решений
[342] На этапе 1206, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют извлечение предыдущего числового представления по меньшей мере одного значения категориального фактора для данного объекта из набора обучающих объектов по меньшей на одном предыдущем уровне дерева решений.
[343] Этап 1208 - создание, для каждой комбинации из по мере одного предыдущего значения категориального фактора на по меньшей мере одном предыдущем уровне дерева решений и по меньшей мере некоторых значений категориальных факторов из набора обучающих объектов, текущего числового представления для данного уровня дерева решений
[344] На этапе 1208, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют создание, для каждой комбинации из по мере одного предыдущего значения категориального фактора на по меньшей мере одном предыдущем уровне дерева решений и по меньшей мере некоторых значений категориальных факторов из набора обучающих объектов, текущего числового представления для данного уровня дерева решений.
[345] В некоторых вариантах осуществления способа 1200, создание выполняется только для тех предыдущих значений категориальных факторов, которые были созданы по меньшей мере на один уровень раньше в дереве решений. В других неограничивающих вариантах осуществления способа 1200, создание выполняется только для тех предыдущих значений категориальных факторов, которые были созданы по меньшей мере на один уровень раньше в дереве решений и по меньшей мере на предыдущей итерации дерева решений.
[346] В некоторых неограничивающих вариантах осуществления способа 1200, способ 1200 далее включает в себя организацию набора обучающих объектов в упорядоченный список обучающих объектов. Организация обучающих объектов в упорядоченный список обучающих объектов выполняется в момент времени до создания числового значения.
[347] В некоторых неограничивающих вариантах осуществления способа 1200, организация набора обучающих объектов в упорядоченный список обучающих объектов может включать в себя организацию множества наборов упорядоченных списков, и в котором способ 1200 далее включает в себя, до этапа создания числового значения, выбор одного из множества наборов из упорядоченных списков.
[348] Способ создания разделяющего значения для узла дерева решений в модели дерева решений, используемой алгоритмом машинного обучения (MLA), разделяющее значение относится к узлу на конкретном уровне дерева решений, узел для классификации объекта, обладающего значением категориального фактора, которое будет преобразовано в свое числовое представление, разделение инициирует классификацию объекта в один из дочерних узлов на основе числового значения и разделяющего значения, алгоритм машинного обучения выполняется электронным устройством для прогнозирования значения для объекта фазы использования, способ включает в себя:
[349] На Фиг. 13 представлена блок-схема способа 1300, который выполняется в соответствии с неограничивающими вариантами осуществления настоящей технологии. Способ 1300 может выполняться ведущим сервером 510 и/или ведомыми серверами 520, 522, 524.
[350] Этап 1302 - создание диапазона всех возможных значений категориальных факторов
[351] На этапе 1302 ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют создание диапазона 202 всех возможных значений категориальных факторов.
[352] Этап 1304 - применение сетки к диапазону для разделения диапазона на области, причем каждая область обладает границей
[353] На этапе 1304, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют применение сетки 204 к диапазону для разделения диапазона 202 на области, причем каждая область обладает границей.
[354] Этап 1306 - использование границы как разделяющего значения;
[355] На этапе 1306 ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют использование границы как разделяющего значения.
[356] Этап 1308 - создания и применения, которые выполняются до того, как категориальный фактор был преобразован в его числовое представление
[357] На этапе 1308, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 осуществляют этапы создания и применения до того, как категориальный фактор был преобразован в его числовое представление.
[358] В некоторых вариантах осуществления способа 1300, сетка 204 обладает заранее определенным форматом.
[359] В некоторых вариантах осуществления способа 1300, сетка 204 является сеткой с постоянным интервалом.
[360] В некоторых вариантах осуществления способа 1300, сетка 204 является сеткой с непостоянным интервалом.
[361] В некоторых вариантах осуществления способа 1300, диапазон 202 находится между нулем и единицей.
[362] В некоторых вариантах осуществления способа 1300, числовые значения категориальных факторов вычисляются с помощью Rconstant, и в котором диапазон 202
находится Между Rconstant и 1+(Rconstant).
[363] В некоторых вариантах осуществления способа 1300, способ 1300 далее включает в себя, во время фазы использования, для данного значения счетчика, представляющего собой категориальный фактор, определение того, в какую часть, определенную сеткой, попадает данное значение счетчика, и использование соответствующих границ как значений для разделения.
[364] В некоторых вариантах осуществления способа 1300, использование границы как разделяющего значения выполняется для каждого уровня дерева решений и причем способ далее включает в себя, после обучения данного уровня дерева решений, новое вычисление разделяющего значения.
[365] В некоторых вариантах осуществления способа 1300, использование границы как разделяющего значения выполняется для каждого дерева решений и причем способ далее включает в себя, после обучения данного дерева решений, новое вычисление разделяющего значения.
[366] В некоторых вариантах осуществления способа 1300, использование границы как разделяющего значения выполняется во время этапа обучения MLA, и в котором обучение MLA во время текущей итерации одного из: (i) данного уровня дерева решений и (ii) данной итерации дерева решений, включает в себя: выбор лучшего значения фактора, которое будет находиться на данной итерации, и лучшего значения разделения, связанного с ним.
[367] В соответствии с некоторыми неограничивающими вариантами осуществления настоящей технологии, когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают модель на основе дерева решений для алгоритма машинного обучения, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают набор моделей, причем каждая модель является отдельным ансамблем деревьев решений.
[368] На Фиг. 14 представлен набор моделей 1400. На этой конкретной иллюстрации набор моделей 1400 содержит четыре модели - три протомодели 1402 и итоговую модель 1404. Три протомодели 1402 включают в себя первую протомодель 1406, вторую протомодель 1408 и третью протомодель 1410. Первая протомодель 1406, вторая протомодель 1408 и третья протомодель 1410 являются рабочими моделями и используются для оптимизации итоговую модель 1404.
[369] Каждая из первой протомодели 1406, второй протомодели 1408 и третьей протомодели 1410 включает в себя отдельный ансамбль деревьев (каждый ансамбль деревьев обладает несколькими итерациями или вариантами деревьев решений), только один ансамбль деревьев пронумерован числом 1411 на Фиг. 14.
[370] Дополнительно, каждая из первой протомодели 1406, второй протомодели 1408 и третьей протомодели 1410 связана со своим собственным упорядоченным списком обучающих объектов. То есть, первая протомодель 1406 связана с первым упорядоченным списком объектов 1412, вторая протомодель 1408 связана с первым упорядоченным списком объектов 1414 и третья протомодель 1410 связана с первым упорядоченным списком объектов 1416. Первый упорядоченный список объектов 1412, второй упорядоченный список объектов 1414 и третий упорядоченный список объектов 1416 могут быть созданы так, как это описано в отношении упорядоченного списка обучающих объектов 102.
[371] Таким образом, можно сказать, что каждая итерация первой протомодели 1406, второй протомодели 1408, третьей протомодели 1410 и итоговой модели 1404 связаны с той же самой структурой древовидной модули, но, поскольку используется другая версия упорядоченного списка обучающих объектов (и, следовательно, некоторые или все уровни данного дерева решений будут обладать другими выбранными факторами и разделениями), листья на данной итерации первой протомодели 1406, второй протомодели 1408, третьей протомодели 1410 и итоговой модели 1404 связаны с другими значениями (по меньшей мере в отношении категориальных факторов, которые преобразованы в их числовые представления, как было описано выше). Данная итерация создания деревьев решений схематически представлена на Фиг. 14 под номером 1421.
[372] Когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают данную итерацию дерева решений в данном ансамбле деревьев решений, ведущий сервер 510 и/или ведомые серверы 520, 522, 524 выполняют: выбор одной из набора моделей и соответствующего упорядоченного списка; создание структуры дерева решений с помощью одной модели из набора моделей; при обработке данного категориального фактора с помощью структуры дерева решений данный категориальный фактор связан с данным обучающим объектом; причем данный обучающий объект обладает по меньшей мере одним предыдущим обучающим объектом в упорядоченном списке обучающих объектов, создание его числового представления, которое основано на: (i) числе общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же значением категориального фактора в соответствующем упорядоченном списке (ii) числе заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора в соответствующем упорядоченном списке.
[373] Другими словами, для каждой итерации создания деревьев решений (например, данной итерации 1421), ведущий сервер 510 и/или ведомые серверы 520, 522, 524 выбирают конкретную модель из трех протомоделей 1402 и используют ее для создания древовидной структуры, которая далее изменяется для других из трех протомоделей 1402. Выбор может быть произведен случайным образов или с использованием заранее определенного алгоритма. Для каждой итерации создания дерева решений, показанного на Фиг. 14, модель, которая была использована для создания структуры дерева решений, отмечена звездочкой (*). Варианты таким образом выбранной модели показаны стрелками только для данной итерации 1421. Тем не менее, они работают по существу таким же образом для других итераций создания деревьев решений.
[374] Поскольку каждая из трех протомоделей 1402 связана с своим вариантом упорядоченного списка обучающих объектов, значения в листах будут отличаться в трех протомоделях 1402 на данной итерации создания модели дерева решений (например, на данной итерации 1421). На Фиг. 14 схематически показано как значения в листьях 1430 по меньшей мере частично отличаются от значений в листьях 1432. В данном подходе, где присутствует несколько моделей (т.е. три протомодели 1402), каждая модель обладает своим вариантом упорядоченного списка обучающих объектов (т.е. первым упорядоченным список объектов 1412, вторым упорядоченным список объектов 1414 и третьим упорядоченным список объектов 1416), что позволяет снизить эффект или отсрочить момент наступления переобучения.
[375] Когда ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают новую итерацию 1440 дерева решений в данном ансамбле деревьев решений (в представленном варианте осуществления, вторая модель, т.е. вторая протомодель 1408, была выбрана как основа для создания структуры деревьев решений), ведущий сервер 510 и/или ведомые серверы 520, 522, 524 создают структуру дерева решений с помощью выбранной модели и далее "проецируют" таким образом созданную структуру на остальные модели деревьев решений (показано на Фиг. 14 с помощью стрелок 1442. Каждая из протомоделей 1402 далее заполняется обучающими объектами (в которых категориальные факторы преобразуются с помощью соответствующих упорядоченных списков, т.е. первого упорядоченного списка объектов 1412, второго упорядоченного списка объектов 1414 и третьего упорядоченного списка объектов 1416).
[376] Ведущий сервер 510 и/или ведомые серверы 520, 522, 524 далее выбирают "лучшую модель". Выбор лучей модели может осуществлять с помощью одного из известных способов проверки. Следует отметить, что когда применяются способы проверки, они используют значения листов на данной итерации данного дерева решений, а также предыдущих деревьев решений в той же самой модели. С учетом того, что каждая модель обладает своим упорядоченным списком обучающих объектов, на каждой итерации создания дерева решений лучшие результаты будут, вероятно, выдавать разные модели. Таким образом выбранная лучшая модель далее используется для создания дерева решений на текущей итерации итоговой модели 1404.
[377] Конкретные варианты осуществления настоящей технологии могут быть реализованы с помощью различных математических принципов, закодированных в соответствующие исполняемые на компьютере инструкции для выполнения различных описанных здесь способов и процедур. Примером подобных принципов может быть статья, озаглавленная "Борьба искажениями при динамическом бустинге" под авторством Дорогуш и др., поданная в Библиотеку Корнеллского Университета 28 января 2017 года, и доступная по следующей ссылке: https://arxiv.org/abs/1706.09516; содержимое этой статьи в полном объеме включено в настоящее описание).
[378] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом варианте осуществления настоящей технологии. Например, варианты осуществления настоящей технологии могут быть выполнены без проявления некоторых технических результатов, другие могут быть выполнены с проявлением других технических результатов или вовсе без них.
[379] Некоторые из этих этапов, а также процессы передачи-получения сигнала являются хорошо известными в данной области техники и поэтому для упрощения были опущены в некоторых частях данного описания. Сигналы могут быть переданы-получены с помощью оптических средств (например, оптоволоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[380] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
Приложение А
РЕФЕРАТ
В данной статье описывается CatBoost - новая библиотека градиентного бустинга с открытым исходным кодом, которая успешно обрабатывает категориальные факторы и превосходит по качеству существующие общедоступные варианты осуществления градиентного бустинга на наборе популярных публично доступных наборов данных. Библиотека обладает вариантом графического процессора, который обучает алгоритм, и вариантом центрального процессора, который применяет алгоритм, которые работают существенно быстрее, чем другие библиотеки градиентного бустинга на ансамблях аналогичных размеров.
1. Введение
Градиентный бустинг является важной методикой машинного обучения, которая достигает самых передовых результатов во множестве практических задач. Вот уже многие годы он остается основным способом, применяемым в задачах обучения с гетерогенными факторами, зашумленными данными и сложными зависимостями: веб-поиск, системы рекомендаций, прогноз погоды и многие другие [2, 15, 17, 18]. Он опирается на сильные теоретические результаты, которые объясняют, как сильные предикторы могут быть построены путем итеративного объединения более слабых моделей (базовых предикторов) с помощью жадной процедуры, которая соответствует градиентному спуску в функциональном пространстве.
Наиболее популярные способы градиентного бустинга используют деревья решений в качестве базовых предикторов. Для числовых объектов удобно использовать деревья решений, но на практике многие наборы данных содержат категориальные факторы, которые также важны для прогнозирования. Категориальный фактор - это фактора, обладающий дискретным набором значений, которые необязательно сопоставимы друг с другом (например, ID пользователя или название города). Наиболее часто используемая практика работы с категориальными факторами в градиентном бустинге - преобразование их в числа до обучения.
В этой статье мы представляем новый алгоритм градиентного бустинга, который успешно обрабатывает категориальные факторы и использует их в процессе обучения, а не во время предварительной обработки. Еще одно преимущество алгоритма заключается в том, что он использует новую схему вычисления значений в листах при выборе древовидной структуры, что помогает снизить переобучение.
В результате, новый алгоритм превосходит существующие современные реализации градиентно ускоренных деревьев решений (GBDTs) XGBoost [4], LightGBM1 (1https://github.com/Microsoft/LightGBM) и H2O2 (2http://docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science/gbm.html), на разнообразном наборе популярных задач (раздел 6). Алгоритм называется CatBoost (от англ. "categorical boosting" - "категориальный бустинг") и выпущен в открытом исходном коде.3 (3https://github.com/catboost/catboost)
CatBoost имеет варианты осуществления с CPU и с GPU. Вариант осуществления с GPU обеспечивает гораздо более быстрое обучение и работает быстрее, чем оба современных вариантов осуществления градиентного бустинга деревьев решений с GPU с открытым исходным кодом, XGBoost и LightGBM, на ансамблях аналогичных размеров.
Предложенный алгоритм также обладает более быстрым вариантом осуществления с CPU с применением модели, которая превосходит варианты осуществления XGBoost и LightGBM на ансамблях аналогичных размеров.
2. Категориальные факторы
Категориальный факторы обладают дискретным набором значений, называемых категориями, которые не обязательно могут быть сравнимы друг с другом; поэтому подобные факторы не могут быть использованы напрямую в бинарном дереве решений. Обычной практикой работы с категориальными факторами является преобразование их в числа на этапе предварительной обработки, т.е. каждая категория для каждого примера заменяется одним или несколькими числовыми значениями.
Наиболее широко используемым методом, который обычно применяется к категориальным признакам низкой мощности, является one-hot encoding: исходный фактор удаляется, и для каждой категории добавляется новая двоичная переменная [14]. One-hot encoding может выполняться во время фазы предварительной подготовки или во время обучения, последнее может быть реализовано более эффективно с точки зрения времени обучения и реализовано в CatBoost.
Другим способом работы с категориальными факторами является вычисление некоторых статистических данных с использованием значений меток имеющихся примеров. Конкретнее, предположим, что нам дан набор данных наблюдений: D={(Xi, Yi)i=1…n, где Xi=(xi,1, …, xi,m) является вектором m факторов, некоторые числовые, некоторые категориальные, и Yi ∈ R является значением метки. проще всего заменить категорию средним значением метки
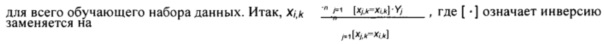 кавычек, т.е., [xj,k=xi,k] равно 1, если xj,k=xi,k и 0 в противном случае. Это процедура, очевидно, приводит к переобучению. Например, если есть единственный пример из категории xi,k i во всем наборе данных, то новое числовое значение фактора будет равно значению метки этого примера. Простым способом решения этой проблемы будет разбиение набора данных на две части и использование одной части только для вычисления статистики, а второй - для осуществления обучения. Это снижает переобучение, но также снижает и объем данных, используемых для обучения модели и расчета статистики.
кавычек, т.е., [xj,k=xi,k] равно 1, если xj,k=xi,k и 0 в противном случае. Это процедура, очевидно, приводит к переобучению. Например, если есть единственный пример из категории xi,k i во всем наборе данных, то новое числовое значение фактора будет равно значению метки этого примера. Простым способом решения этой проблемы будет разбиение набора данных на две части и использование одной части только для вычисления статистики, а второй - для осуществления обучения. Это снижает переобучение, но также снижает и объем данных, используемых для обучения модели и расчета статистики.
CatBoost использует более эффективную стратегию, которая снижает переобучение и позволяет использовать весь набор данных для обучения. А именно, мы выполняем случайную перестановку набора данных и для каждого примера вычисляем среднее значение метки для примера с тем же категориальным значением, расположенным до рассматриваемого в перестановке. Пусть σ=(σ1, …, σn) будет перестановкой, тогда 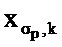
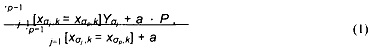 ,
,
куда также добавляется предыдущее значение Р и параметр а>0, который является весовым коэффициентом предыдущего. Добавление предыдущих является распространенной практикой, которая помогает снижать шум, получаемый от низкочастотных категорий [3]. Для регрессионных задач стандартной методикой расчета до является получение среднего значения метки в наборе данных, а для бинарной классификации-априорная вероятность встречи с положительным классом [14].
Также полезно использовать несколько перестановок. Тем не менее, видно, что прямое использование статистики, вычисленной для нескольких перестановок, приведет к переобучению. Как будет описано в следующем разделе, CatBoost использует новую схему для вычисления значений листов, которая позволяет использовать несколько перестановок без возникновения этой проблемы.
Комбинации факторов
Обратите внимание, что любая комбинация нескольких категориальных факторов может рассматриваться как новая. Например, предположим, что задача представляет собой музыкальную рекомендацию, и у нас есть два категориальных фактора: ID пользователя и музыкальный жанр. Некоторые пользователи, например, предпочитают, рок-музыку. Когда мы преобразуем ID пользователя и музыкальный Жанр в числовые факторы в соответствии с (1), мы теряем эту информацию. Комбинация из двух факторов и разрешает эту проблему и дает новый мощный фактор. Однако число комбинаций растет экспоненциально с числом категориальных факторов в наборе данных, а также учесть их все в алгоритме невозможно. При создании нового разделения на текущем дереве, CatBoost считает комбинации жадным образом. Для первого разделения в дереве не учитываются никакие комбинации. Для следующих разделений, CatBoost объединяет все комбинации и категориальные факторы, присутствующие в текущем дереве, со всеми категориальными объектами в dataset. Комбинированные значения преобразуются в числа на лету. CatBoost также создает комбинации числовых и категориальных факторов следующим образом: все разделения, выбранные в дереве, считаются категориальными с двумя значениями, и используются в комбинациях так же, как и категориальные.
Важные подробности реализации
Еще одним способом замены категории числом является вычисление числа вхождений этой категории в наборе данных. Это простая, но мощная техника, реализованная в CatBoost. Этот тип статистических данных также вычисляется для комбинаций факторов.
Для того чтобы подходить оптимальному предшествующему значению на каждом шаге алгоритма CatBoost, мы рассмотрим несколько предыдущих значений и построим для каждого из них фактор, который является более эффективным с точки зрения качества, чем стандартные методы, упомянутые выше.
3. Борьба с градиентным искажением
CatBoost, как и все стандартные варианты осуществления градиентного бустинга, строит каждое новое дерево для уточнения градиентов текущей модели. Однако все классические алгоритмы бустинга страдают от переобучения, вызванного проблемой искаженных точечных оценок градиента. Градиенты, используемые на каждом шаге, оцениваются с использованием тех же точек данных, на которых построена текущая модель. Это приводит к сдвигу распределения оцененных градиентов в любой области пространства факторов по сравнению с истинным распределением градиентов в этой области, что приводит к переобучению. Идея искаженных градиентов описана в известной в данной области техники литературе [1] [9]. Мы предоставили формальный анализ этой проблемы в работе [5]. В работе также содержатся модификации классического алгоритма градиентного бустинга, которые пытаются решить эту проблему. CatBoost реализует одну из этих модификаций, кратко описанных ниже.
Во многих алгоритмах градиентного бустинга (например, XGBoost, LightGBM) построение следующего дерева состоит из двух шагов: выбор древовидной структуры и установка значений в листьях после фиксирования древовидной структуры. Чтобы выбрать наилучшую древовидную структуру, алгоритм перечисляет различные разделения, строит деревья с этими разделениями, устанавливает значения в полученных листах, оценивает деревья и выбирает наилучшее разделение. Значения листьев в обеих фазах рассчитываются как приближения для градиентов [8] или для шагов по методу Ньютона. В CatBoost вторая фаза осуществляется с помощью традиционной схемы GBDT, и для первой фазы мы используем модифицированную версию.
Согласно интуиции, полученной из эмпирических результатов и теоретического анализа в [5], крайне желательно использовать неискаженные оценки шага градиента. Допустим Fi является моделью, созданной после создания первых i деревьев, gi(Xk, Yk) является градиентным значением на k-том обучающем образце после создания i деревьев. Чтобы градиент gi(Xk, Yk) был неискаженным по отношению к модели Fi, необходимо иметь Fi обученных без наблюдения Xk. Поскольку нам нужны неискаженные градиенты для всех тренировочных примеров, никакие наблюдения не могут быть использованы для обучения Fi, что на первый взгляд делает тренировочный процесс невозможным. Мы предлагаем следующий "трюк" для решения этой проблемы: для каждого примера Xk, мы обучаем отдельную модель Mk, которая никогда не обновляется с использованием оценки градиента для этого примера. С помощью Mk мы оцениваем градиент на Xk и используем эту оценку для оценки получившегося дерева. Представим псевдо-код, объясняющий, как можно выполнить этот "трюк". Пусть Loss (у, а) - оптимизирующая функция потерь, где у - значение метки, а a - значение формулы.

Обратим внимание, что Mi обучается без использования примера Xi. Реализация CatBoost использует следующую релаксацию этой идеи: все Mi обладают одинаковыми древовидными структурами.
В CatBoost мы создаем s случайных перестановок нашего учебного набора данных. Мы используем несколько перестановок для повышения надежности алгоритма: мы выбираем случайную перестановку и получаем градиенты на ее основе. Это те же самые перестановки, что и при вычислении статистических данных для категориальных факторов. Мы используем различные перестановки для обучения различных моделей, таким образом, использование нескольких перестановок не приводит к переобучению. Для каждой перестановки σ мы обучаем n различных моделей Mi, как показано выше. Это означает, что для построения одного дерева нам нужно сохранить и пересчитать O(n2) приближений для каждой перестановки σ: для каждой модели Mi мы должны обновить Mi(X1), …, Mi(Xi). Таким образом, результирующая сложность этой операции - O(s n2). В нашем практическом варианте осуществления мы используем один важный "трюк", который сводит сложность построения одного дерева к O(s n): для каждой перестановки вместо сохранения и обновления O(n2) значений Mi(Xj), мы сохраняем значения Mr(Xj), i=1, …, [log (n)], j<2i+1, где Mr(Xj)i приближение для примера j, основанного на первых 2i примерах. Далее, число прогнозов Mr(Xj) не превышает  Градиент на примере Xk, который используется для выбора древовидной структуры, оценивается на основе приближения
Градиент на примере Xk, который используется для выбора древовидной структуры, оценивается на основе приближения
Mri(Xk), где i=[log2(k)].
4. Быстрое применение модели
CatBoost использует забывчивые деревья в качестве базовых предикторов. В таких деревьях используется один и тот же критерий разделения по всему уровню дерева [12, 13]. Такие деревья сбалансированы и менее склонны к переобучению. Забывчивые деревья с градиентным бустингом успешно использовались в различных учебных задачах [7, 10]. В забывчивых деревьях индекс каждого листа может быть закодирован как двоичный вектор с длиной, равной глубине дерева. Этот факт широко используется в оценке модели CatBoost: сначала мы бинаризуем все используемые плавающие факторы, статистические данные и one-hot закодированные факторы, а затем используем бинарные факторы для вычисления прогнозов модели.
Все значения бинарных факторов для всех примеров хранятся в непрерывном векторе В. Конечные значения хранятся в векторах с плавающей точкой размера 2d, где d - глубина дерева. Для расчета индекса листа для t-го дерева и
, например, х мы построили двоичный вектор 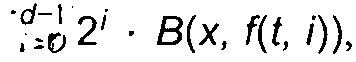 где В(х, f) является значением двоичный фактор f на примере x, который мы считываем из вектора В и f(t, i), является числом бинарного фактора из t-го дерева на глубине i.
где В(х, f) является значением двоичный фактор f на примере x, который мы считываем из вектора В и f(t, i), является числом бинарного фактора из t-го дерева на глубине i.
Эти векторы могут быть построены параллельно данным с помощью встроенных SSE, которые развить скорость для трехкратного ускорения. Это приводит к гораздо более быстрому применению, чем какое-либо из существующих, что показано в наших экспериментах.
5. Быстрое обучение на GPU
Плотные числовые факторы Одним из наиболее важных этапов создания для любой реализации GBDT является поиск наилучшего разделения. Этот этап является основной вычислительной нагрузкой для построения дерева решений на плотных числовых наборах данных. CatBoost использует забывчивые деревья решений в качестве базовых обучающихся моделей и выполняет дискретизацию факторов в фиксированное количество интервалов для уменьшения нагрузки на памяти [10]. Число интервалов является параметром алгоритма. В результате мы могли бы использовать гистограммный подход для поиска лучших разделений. Наш подход к построению деревьев решений на GPU по существу похож на описанное в [11]. Мы группируем несколько числовых факторов в одно 32-разрядное целое число и в текущее время используем:
- 1 бит для бинарных факторов и группируем 32 фактора на целое число.
- 4 бита для факторов с не более чем 15 ячейками, 8 факторов на целое число.
- 8 битов для других факторов (максимальная дискретизация фактора - 255), 4 фактора на целое число.
С точки зрения использования памяти GPU, CatBoost по меньшей мере настолько же эффективен, как и LightGBM [11]. Основным отличием является другой способ расчета гистограммы. Алгоритмы в LightGBM и XGBoost4 (4https://devblogs.nvidia.com/parallelforall/gradient-boosting-(lecision-trees-xgboost-cuda/) имеют существенный недостаток: они полагаются на атомарные операции. Такой метод очень легко использовать с параллельным доступом к памяти, но он также является относительно медленным даже на современном поколении GPU. На самом деле, гистограммы могут быть вычислены более эффективно без каких-либо атомарных операций. Мы опишем здесь только основную идею нашего подхода на упрощенном примере: одновременное вычисление четырех 32-интервальных гистограмм с одним плавающим аддитивным статистическим значением для одной точки. Эта идея может быть эффективно обобщена для случаев с несколькими статистическими данными и несколькими гистограммами.
Мы обладаем значениями метки y[i] и группами факторовв (f1, f2, f3, f4)[i]. Необходимо высчитать 4 гистограммы: 
каждого варпа5 (5 групп из 32 потоков, работающих параллельно на нынешней видеокарте NVIDIA) гистограмм вместо 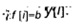 CatBoost строит частичную гистограмму для гистограмм на блок потоков Опишем работу, выполняемую одним варпом на первых 32 образцах. Поток с индексом i обрабатывает образец i. Поскольку мы строим 4 гистограммы сразу, нам нужно 32*32*4 байта общей памяти на один варп. Для обновления гистограмм, все 32 потока загружают метки образцов и сгруппированных факторов регистры. Затем варп выполняет обновление гистограммы общей памяти одновременно в 4 итерациях: на I-ой (I=0…3) поток итерации с индексом i работает с фактором f(I+i) mod 4 и добавляет y[i] для hist[(I+i) mod 4][f(I+i) mod 4]. При правильной компоновке гистограммы, эта операция позволит избежать каких-либо конфликтов банков и параллельно добавить статистические данные по всем 32 параллельным потокам.
CatBoost строит частичную гистограмму для гистограмм на блок потоков Опишем работу, выполняемую одним варпом на первых 32 образцах. Поток с индексом i обрабатывает образец i. Поскольку мы строим 4 гистограммы сразу, нам нужно 32*32*4 байта общей памяти на один варп. Для обновления гистограмм, все 32 потока загружают метки образцов и сгруппированных факторов регистры. Затем варп выполняет обновление гистограммы общей памяти одновременно в 4 итерациях: на I-ой (I=0…3) поток итерации с индексом i работает с фактором f(I+i) mod 4 и добавляет y[i] для hist[(I+i) mod 4][f(I+i) mod 4]. При правильной компоновке гистограммы, эта операция позволит избежать каких-либо конфликтов банков и параллельно добавить статистические данные по всем 32 параллельным потокам.
Реализация CatBoost создает гистограммы для 8 факторов на группу и 2 статистических значений; для 32 бинарных факторов на группу и 2 статистических значений; для 4 факторов на группу и 2 статистических данных с счетчиками интервалов 32, 64, 128 и 255. Для быстрого вычисления всех этих гистограмм мы должны использовать всю доступную общую память. В результате наш код не может достичь 100% занятости. Таким образом, мы осуществляем развертывание цикла, чтобы использовать параллелизм на уровне инструкций. Этот метод позволяет достичь высокой эффективности даже на при более низкой занятости6 (6http://www.nvidia.com/content/GTC-2010/pdfs/2238_GTC2010.pdf)
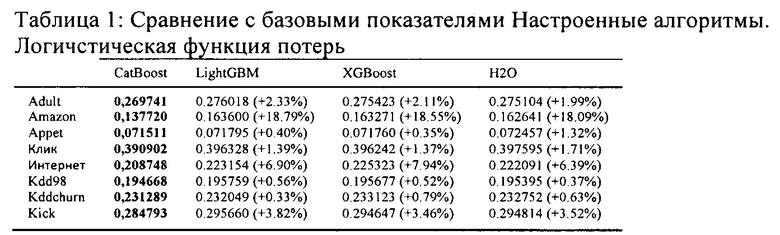
Категориальные факторы CatBoost реализует несколько способов работы с категориальными факторами. Для one-hot закодированных факторов не требуется никакой специальной обработки - основанный на гистограмме подход для поиска разделения можно легко использовать в подобном случае. Вычисление статистических данных для одиночных категориальных факторов также может быть сделано на фазе предварительной обработки. CatBoost также использует статистические данные для комбинаций факторов. Работа с ними - самая медленная и самая затратная в плане потребления памяти часть алгоритма.
Мы используем идеальный хэш для хранения значений категориальных факторов, чтобы уменьшить использование памяти. Из-за ограничений памяти на GPU, мы сохраняем сжатые по числу бит идеальные хэши в оперативной памяти процессора и передаем необходимые данные по требованию, перекрывая вычисления и операции с памятью. Построение комбинаций факторов "на лету" требует динамического построения (совершенных) хэш-функций для этих новых факторов и вычисления статистических данных относительно некоторой перестановки (через 1) яля каждого уникального значения хэша. Мы используем поразрядную сортировку для построения совершенных хэшей и группируем наблюдения за хэшем. В каждой группе нам необходимо вычислить префиксные суммы некоторой статистических данных. Расчет этих статистических данных производится с помощью процедуры GPU сегментированного сканирования (сегментированное сканирование CatBoost осуществляется с помощью преобразования операторов [16] и основывается на высоко-эффективной реализации процедуры сканирования CUB [6]).
Поддержка нескольких GPU Вариант осуществления CatBoost GPU поддерживает несколько GPU. Распределенное обучение дерева может быть распараллелено по образцам или факторам. CatBoost использует сложную схему вычислений с несколькими перестановками обучающего набора данных 3 и вычисляет статистические данные для категориальных факторов во время обучения 5. Поэтому нам нужно использовать параллельное обучение факторов.
6. Эксперименты
Качество: сравнение с базовыми показателями Мы сравниваем наш алгоритм с XGBoost, LightGBM и Н20. Результаты сравнения представлены в Таблице 1. Подробное описание экспериментальной установки, а также описания наборов данных опубликованы на нашем github вместе с кодом эксперимента и набором всех использованных библиотек, поэтому результат может быть воспроизведен. В этом сравнении выполнена предварительная обработка категориальных факторов с использованием статистических данных на случайной перестановке данных. Настройка параметров и обучение проводились на 4/5 данных, а тестирование выполнялось на оставшейся 1/5. Обучение с выбранными параметрами проводилось 5 раз с разными случайными исходниками, в результате имеется средняя логистическая функция потерь на 5 прогонах.
В таблице показано, что алгоритм CatBoost превосходит все другие алгоритмы для всех наборов данных в задаче классификации. В нашем репозитории на github также можно увидеть, что CatBoost с параметрами по умолчанию превосходит настроенные XGBoost и Н20 на всех наборах данных и LightGBM на всех наборах данных, за исключением одного.
GPU vs CPU обучение Скрипты для запуска экспериментов с GPU находятся в нашем репозитории github. В первом примере мы сравнили скорость обучения для наших вариантов осуществления с GPU и с CPU. Для версии CPU мы использовали dual-socket сервер с 2 процессорами Intel Xeon (E5-2650v2, 2.60 GHz) и 256 ГБ оперативной памяти, а также CatBoost в 32 потоках (равно количеству логических ядер). Вариант осуществления с GPU был запущен на нескольких серверах с различными типами GPU. Наш вариант осуществления с GPU не требует многоядерного сервера для высокой производительности, поэтому разные CPU и машины не должны существенно влиять на результаты эксперимента.
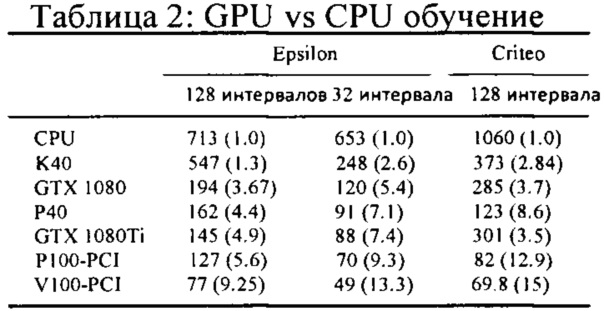
Результаты представлены в Таблице 2. Мы использовали набор данных Criteo (36*106 образцов, 26 категориальных, 13 числовых факторов) для оценки нашей поддержки категориальных факторов. Мы использовали 2 GTX1080, поскольку 1 не хватало памяти. Ясно видно, что версия с GPU значительно превосходит по времени обучения версию с CPU даже на старом поколении GPU (Tesla K40) и заметно ускоряется в 15 раз на карте NVIDIA V100.
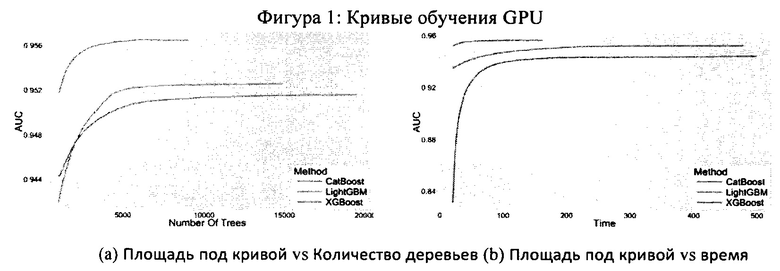
Мы использовали набор данных Epsilon (4*105 образцов, 2000 факторов) для оценки производительности на плотном числовом наборе данных. Для плотных числовых данных время обучения CatBoost с GPU зависит от уровня дискретизации факторов. В таблице мы указываем время для 128 интервалов по умолчанию и для 32 интервалов, поскольку этого часто бывает достаточно. Мы хотели бы отметить, что набор данных по Epsilon не обладает достаточным количеством образцов, чтобы полностью использовать GPU, и с еще большими наборами данных мы наблюдаем еще большие ускорения.
Производительность обучения GPU: сравнение с базовыми показателями Очень трудно сравнивать различные библиотеки бустинга по скорости обучения. Каждая библиотека имеет огромное количество параметров, которые влияют на скорость обучения, качество и размер модели неявным образом. Каждая библиотека имеет свое уникальное соотношение качества/скорости обучения и не может быть сравнена без знания предметной области (например, стоит ли 0.5% метрика качества того, чтобы обучать модель в 3-4 раза медленнее?). Кроме того, для каждой библиотеки возможно получить почти одинаковое качество с различными размерами и параметрами ансамбля. В результате, мы не можем сравнивать библиотеки по времени, которое необходимо для получения определенного уровня качества.
Таким образом, мы можем дать только некоторое представление о том, как быстро наш вариант осуществления с GPU может обучать модель фиксированного размера. Мы используем набор данных Epsilon (4*105 образцов для обучения, 105 образцов для тестирования). Для этого набора данных мы измеряем среднее время построения дерева, которое можно достичь, не используя субдискретизацию факторов и/или бэггинг CatBoost, и 2 варианта осуществления бустинга с GPU с открытым исходным кодом: XGBoost (мы используем версию на основе гистограммы, точная версия очень медленная) и LightGBM. Мы проводим все эксперименты на одних и тех же машинах с ускорителем NVIDIA P100, двухъядерным процессором Intel Xeon Е5-2660 и 128 ГБ оперативной памяти. Для XGBoost и CatBoost мы используем глубину дерева по умолчанию равную 6, для LightGBM мы установили счетчики листьев на 64, чтобы иметь более сопоставимые результаты. Мы установили количество интервалов 15 для всех 3 методов. Такое количество интервалов обеспечивает наилучшую производительность и наименьшее использование памяти для LightGBM и CatBoost (использование счетчика интервалов на 128-255 обычно приводит к тому, что оба алгоритма работают в 2-4 раза медленнее). Для XGBoost мы могли бы использовать еще меньшее количество интервалов, но прирост производительности по сравнению с 15 интервалами слишком мал, чтобы учитывать его. Все алгоритмы были запущены с 16 потоками, что равно количеству ядер оборудования. По умолчанию CatBoost использует схему борьбы с искажениями, описанную в разделе 3. Эта схема изначально в 2-3 раза медленнее, чем классический подход к бустингу. Вариант осуществления CatBoost с GPU Включает в себя режим, основанный на классической схеме, для тех случаев, когда необходима лучшая производительность обучения, в этом тесте мы использовали классическую схему.
Мы устанавливаем такую скорость обучения, что алгоритмы начинают переобучаться примерно после 8000 деревьев (кривые обучения показаны на Фигуре 1, качество полученных моделей отличается примерно на 0.5%). Мы измеряем время для обучения ансамблей из 8000 деревьев. Среднее время построения дерева для CatBoost составило 17,9 мс, для XGBoos - 488 мс, для LightGBM - 40 мс. Эти показатели времени очень грубо могут считаться сравнением скорости, потому что время обучения одной древовидной структуры зависит от распределения факторов и размера ансамбля. В то же время это показывает, что в случае ансамблей аналогичного размера, мы могли бы ожидать, что CatBoost и LightGBM смогут конкурировать по скорости, в то время как XGBoost значительно медленнее, чем любой из них.
Производительность
Применения Мы использовали модели LightGBM, XGBoost и CatBoost для набора данных Epsilon, обученного как описано выше. Для каждой модели мы ограничиваем число деревьев, используемых для оценки числом 8000, чтобы сделать результаты сопоставимыми - по причинам, которые были описаны выше. Следовательно, такое сравнение дает лишь некоторое представление о том, как быстро эти модели могут применяться. Для каждого алгоритма мы загрузили тестовый набор данных в python, преобразовали его во внутреннее представление алгоритма и измеряли время ожидания прогнозов модели предсказаний на процессоре Intel Xeon Е5-2660 с оперативной памятью 128 ГБ. Результаты приведены в Таблице (3). Можно видеть, что на ансамблях аналогичных размеров CatBoost может применяться примерно в 25 раз быстрее, чем XGBoost и примерно в 60 раз быстрее, чем LightGBM.

Список литературы
[1] L. Breiman. Out-of-bag estimation, 1996.
[2] R. Caruana and A. Niculescu-Mizil. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd international conference on Machine learning, pages 161-168. ACM, 2006.
[3] B. Cestnik et al. Estimating probabilities: a crucial task in machine learning. In ECAI, volume 90, pages 147-149, 1990.
[4] T. Chen and C. Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785-794. ACM, 2016.
[5] A.V. Dorogush, A. Gulin, G. Gusev, N. Kazeev, L. Ostroumova Prokhorenkova, and A. Vorobev. Fighting biases with dynamic boosting. arXiv preprint arXiv: 1706.09516, 2017.
[6] M.G. Duane Merrill NVIDIA Corporation. Single-pass parallel prefix scan with decoupled look-back. Technical report, NVIDIA, 2016.
[7] M. Ferov and M.  . Enhancing lambdamart using oblivious trees. arXiv preprint arXiv: 1609.05610, 2016.
. Enhancing lambdamart using oblivious trees. arXiv preprint arXiv: 1609.05610, 2016.
[8] J.H. Friedman. Greedy function approximation: a gradient boosting machine. Annals of statistics, pages 1189-1232, 2001.
[9] J.H. Friedman. Stochastic gradient boosting. Computational Statistics & Data Analysis, 38(4):367-378, 2002.
[10] A. Gulin, I. Kuralenok, and D. Pavlov. Winning the transfer learning track of yahool's learning to rank challenge with yetirank. In Yahoo! Learning to Rank Challenge, pages 63-76, 2011.
[11] C.-J. H. Huan Zhang, Si Si. Gpu-acceleration for large-scale tree boosting. arXiv: 1706.08359, 2017.
[12] R. Kohavi and C.-H. Li. Oblivious decision trees, graphs, and top-down pruning. In IJCAI, pages 1071-1079. Citeseer, 1995.
[13] P. Langley and S. Sage. Oblivious decision trees and abstract cases. In Working notes of the AAAI-94 workshop on case-based reasoning, pages 113-117. Seattle, WA, 1994.
[14] D. Micci-Barreca. A preprocessing scheme for high-cardinality categorical attributes in classifi- cation and prediction problems. ACM SIGKDD Explorations Newsletter, 3(1):27-32, 2001.
[15] B.P. Roe, H.-J. Yang, J. Zhu, Y. Liu, I. Stancu, and G. McGregor. Boosted decision trees as an alternative to artificial neural networks for particle identification. Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, 543(2):577-584, 2005.
[16] M.G. Shubhabrata Sengupta, Mark Harris. Efficient parallel scan algorithms for gpus. Technical report, NVIDIA, 2008.
[17] Q. Wu, C.J. Burges, K.M. Svore, and J. Gao. Adapting boosting for information retrieval measures. Information Retrieval, 13(3):254-270, 2010.
[18] Y. Zhang and A. Haghani. A gradient boosting method to improve travel time prediction. Transportation Research Part C: Emerging Technologies, 58:308-324, 2015.
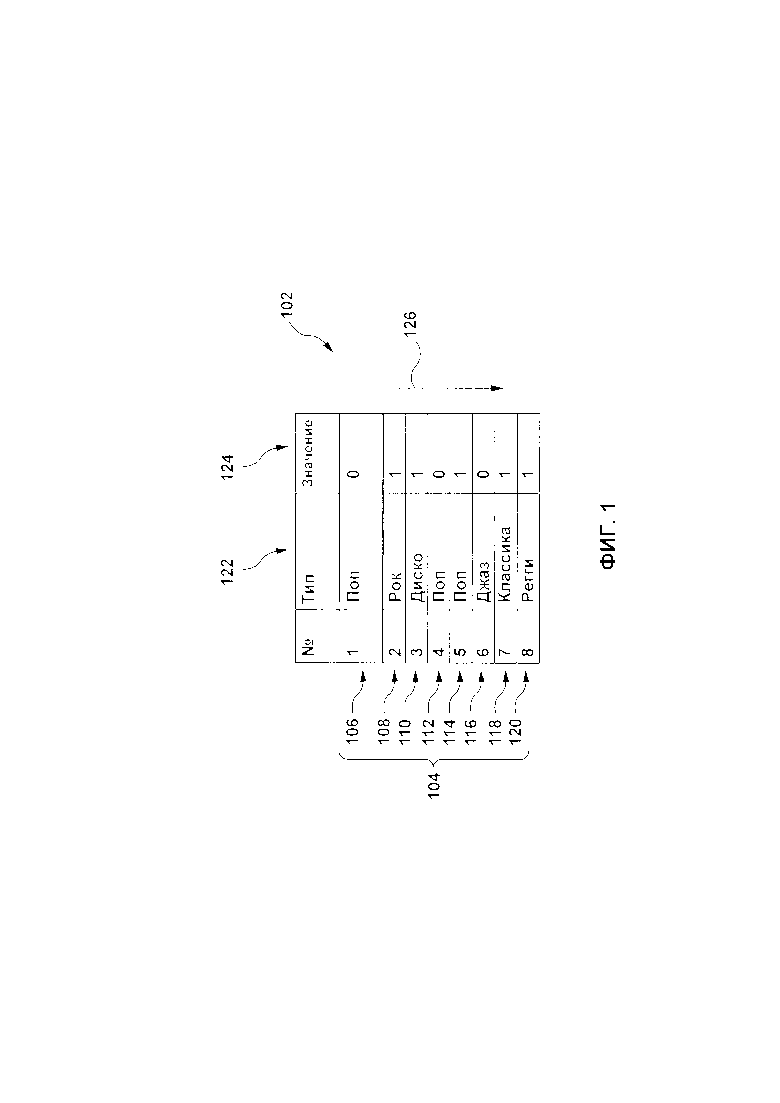
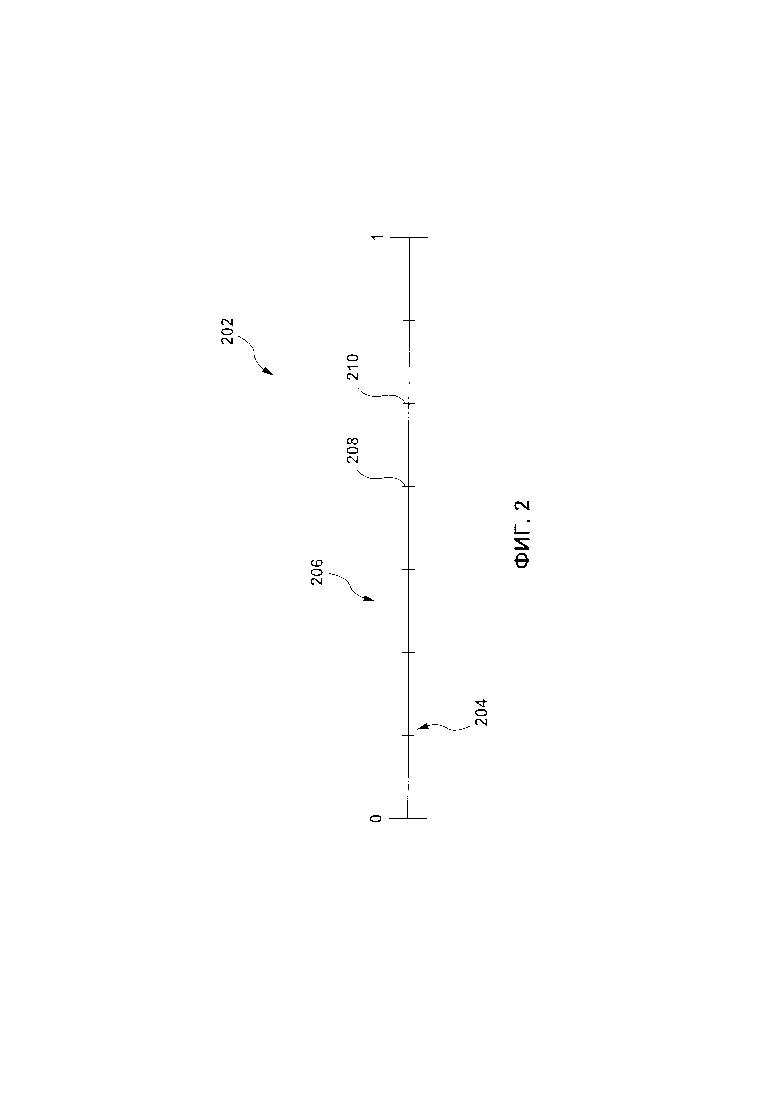
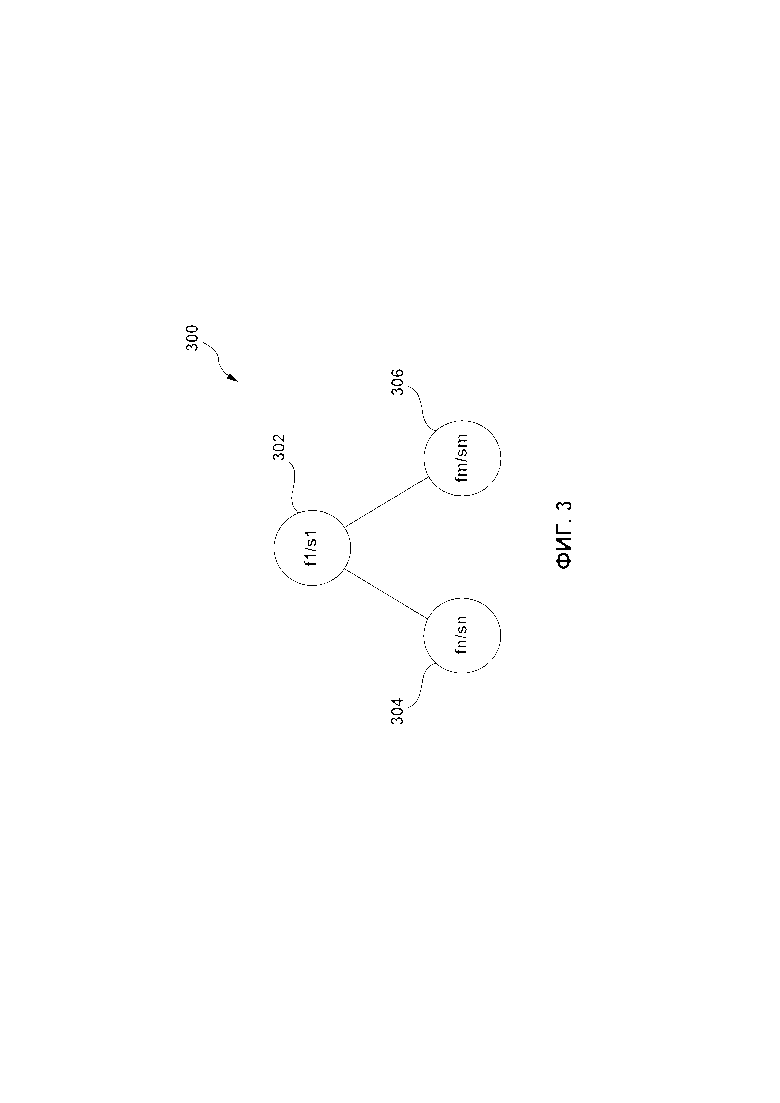
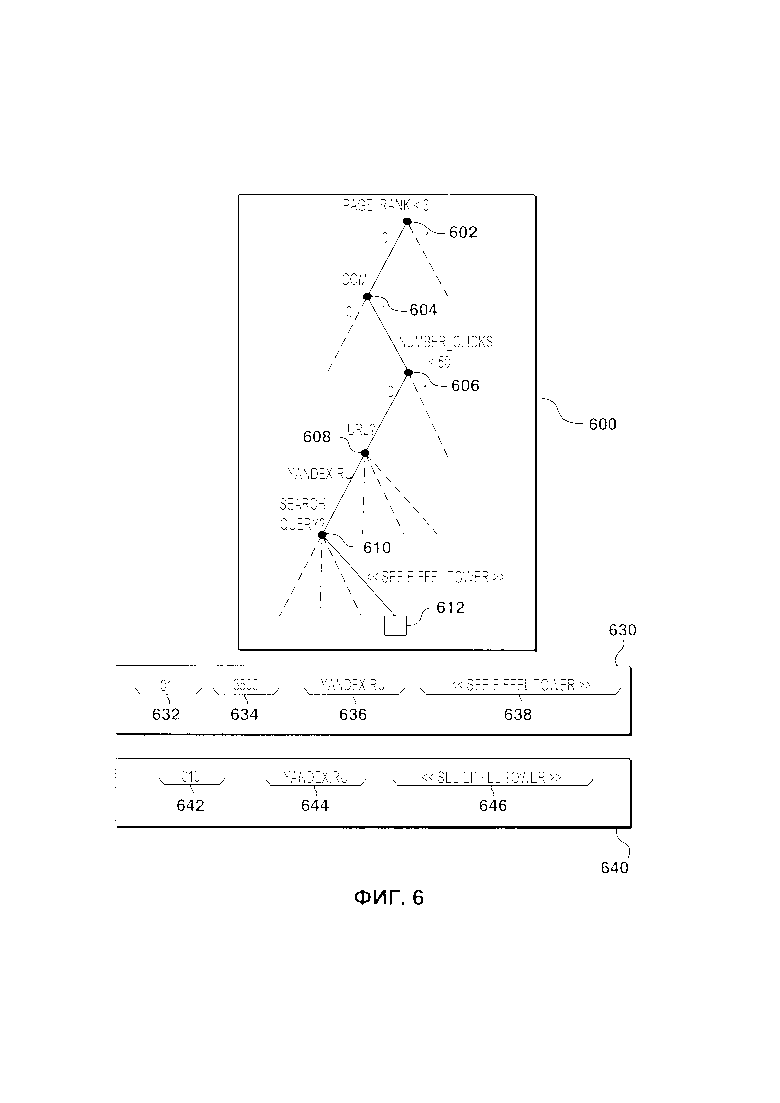
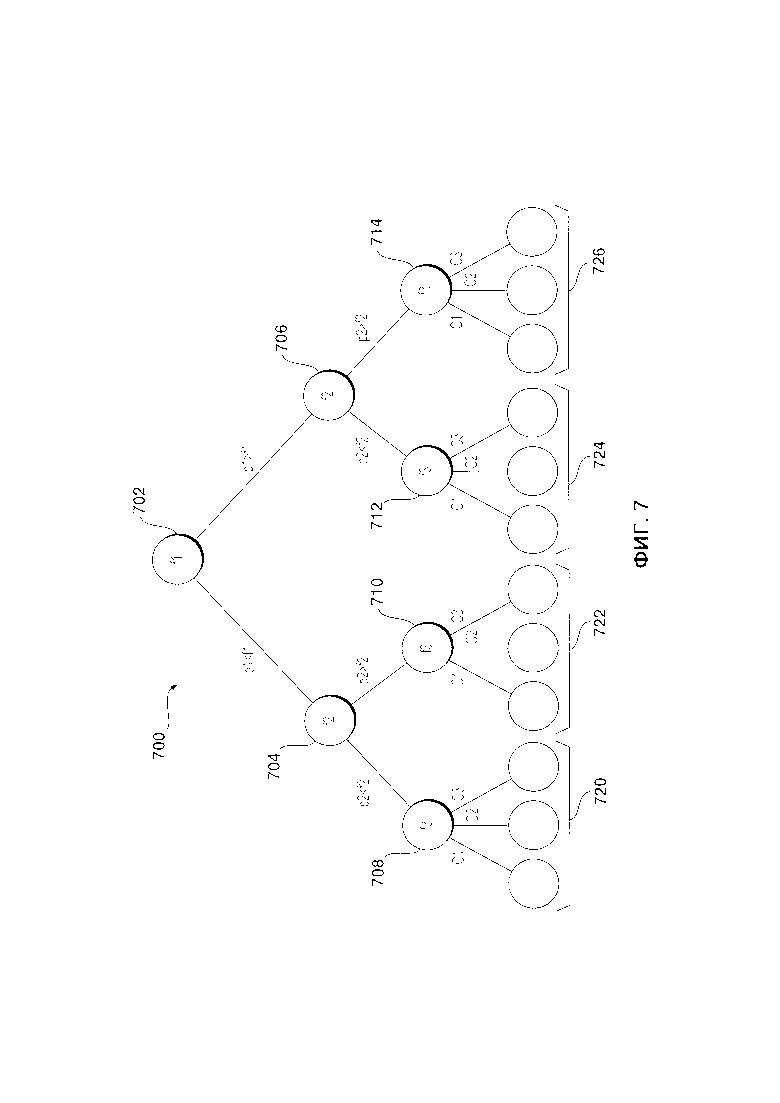
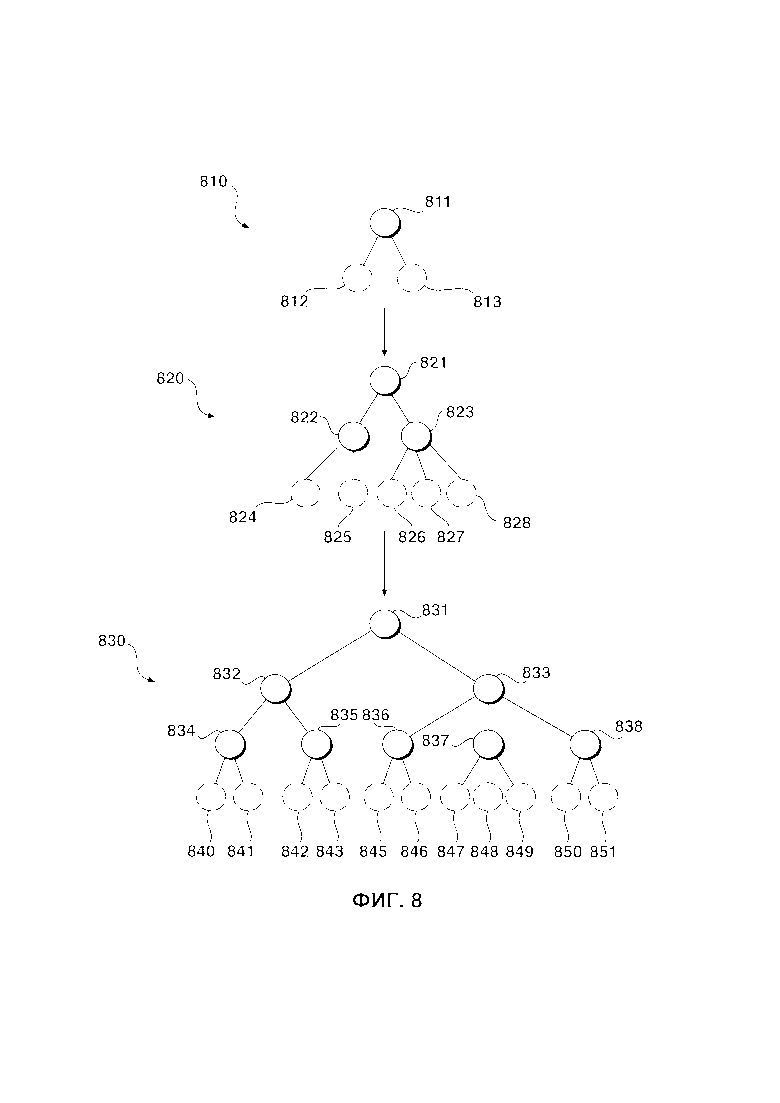
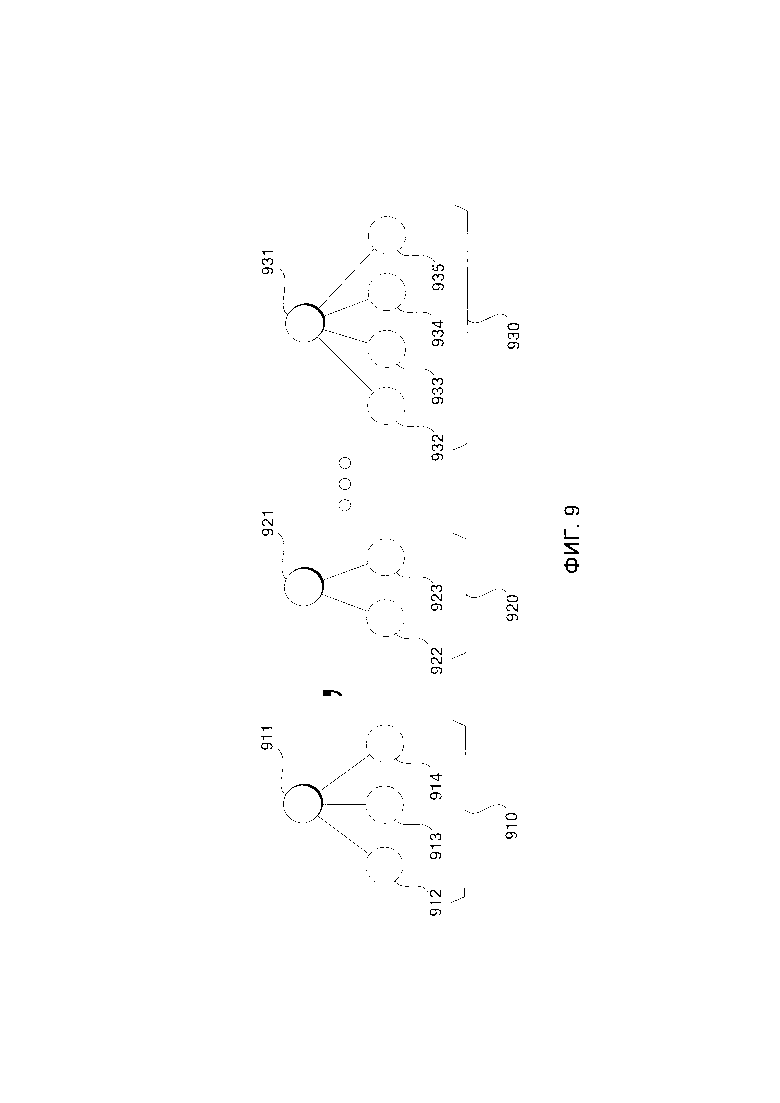
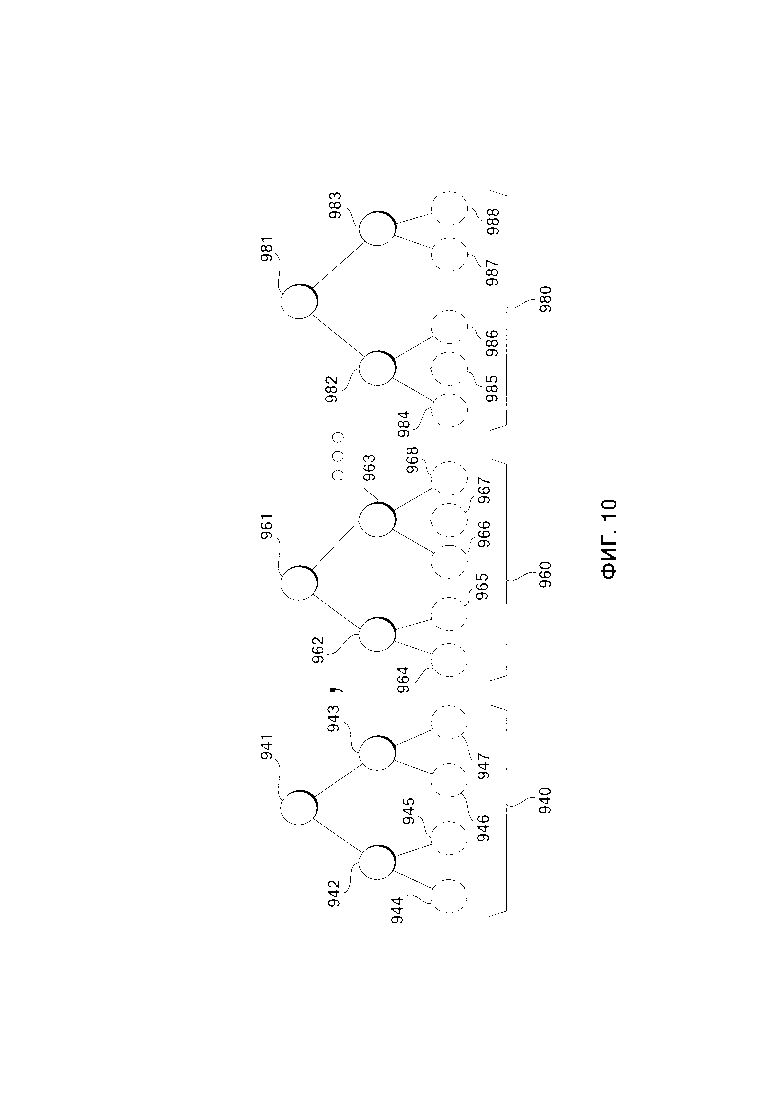
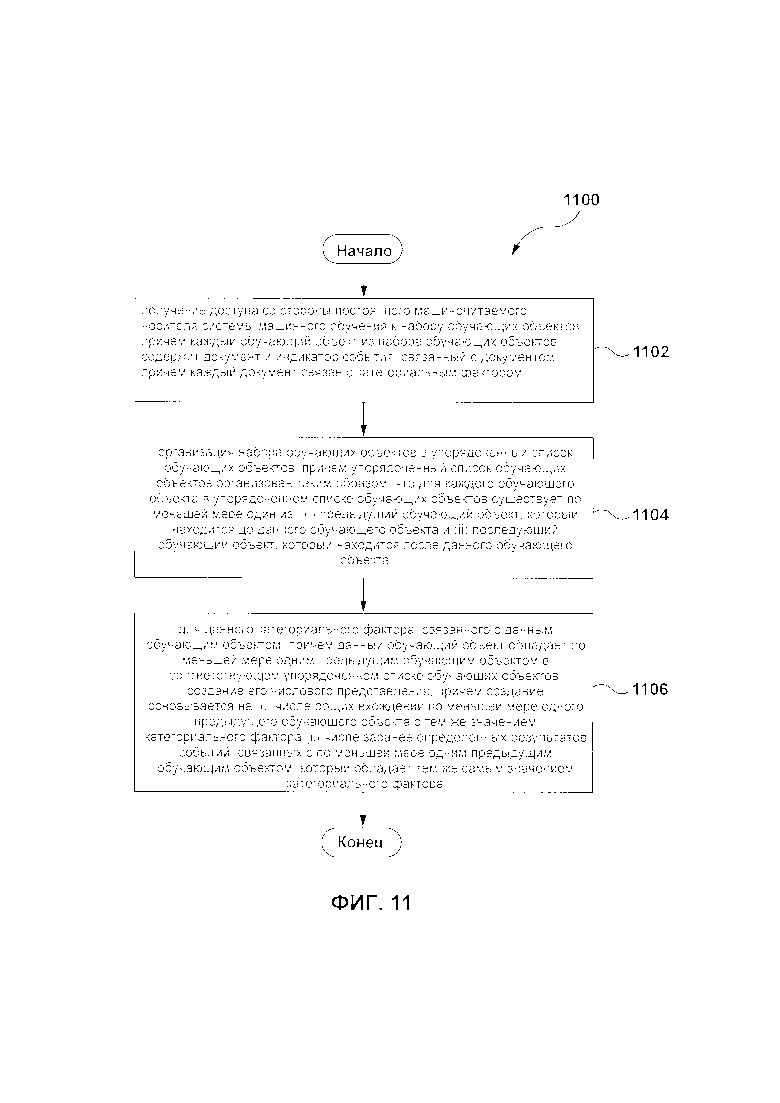
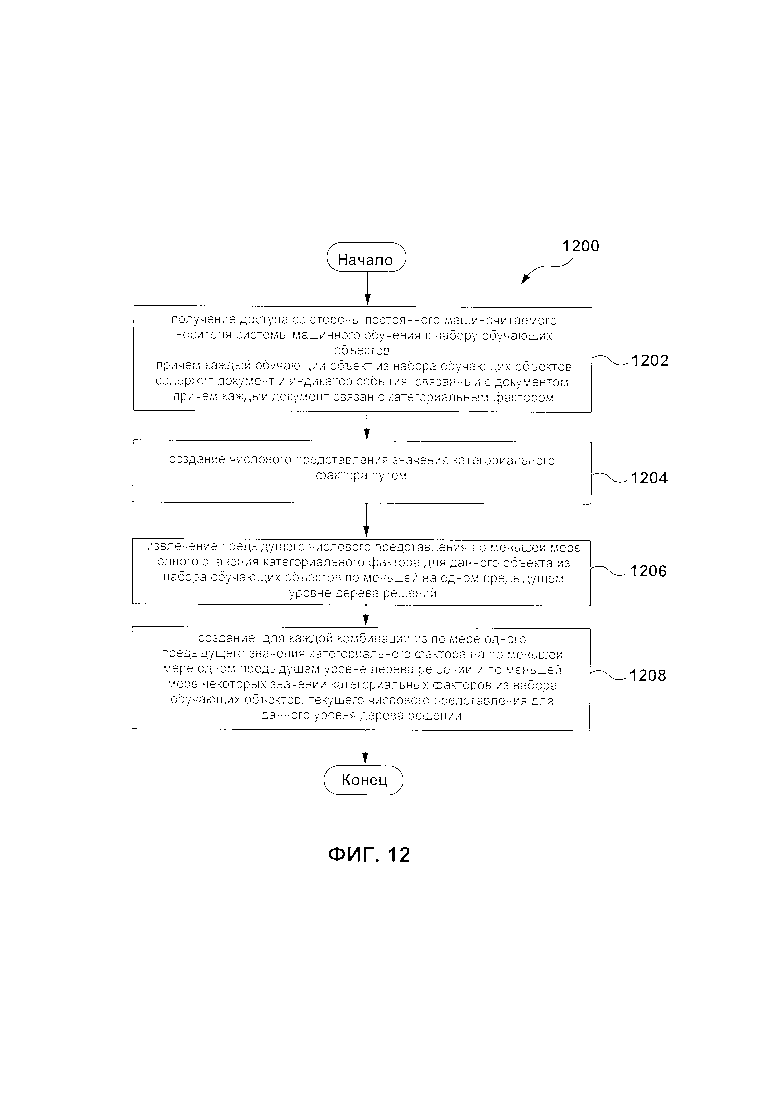
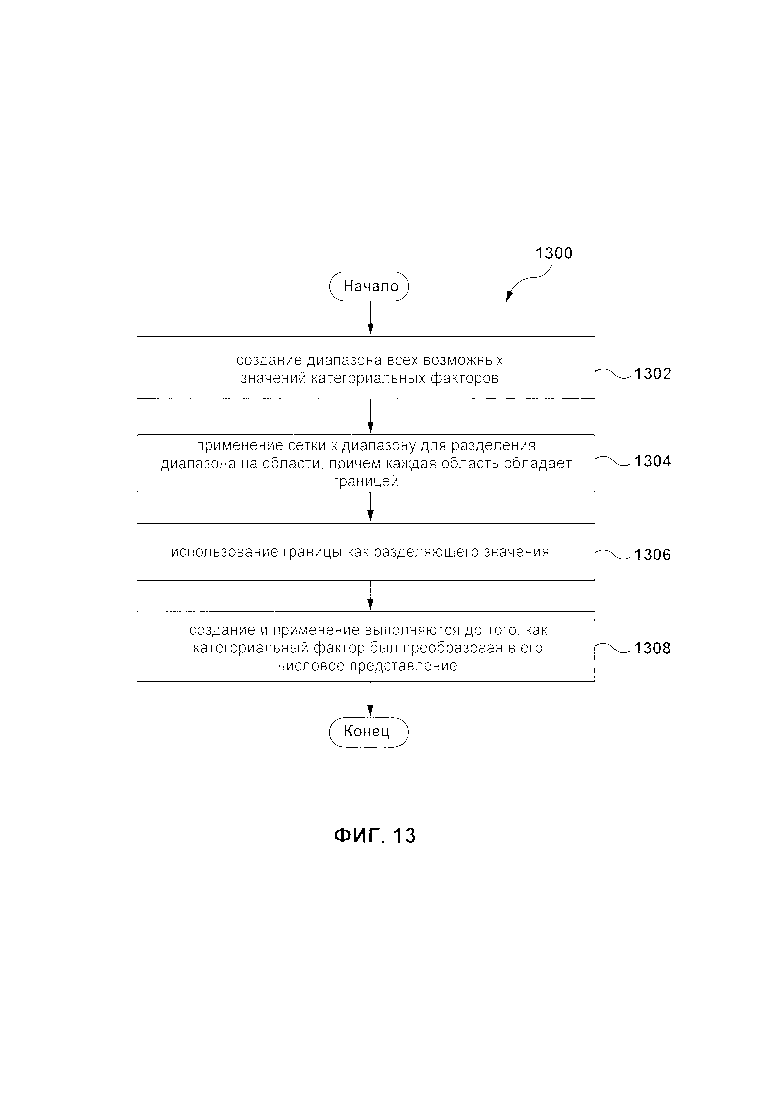
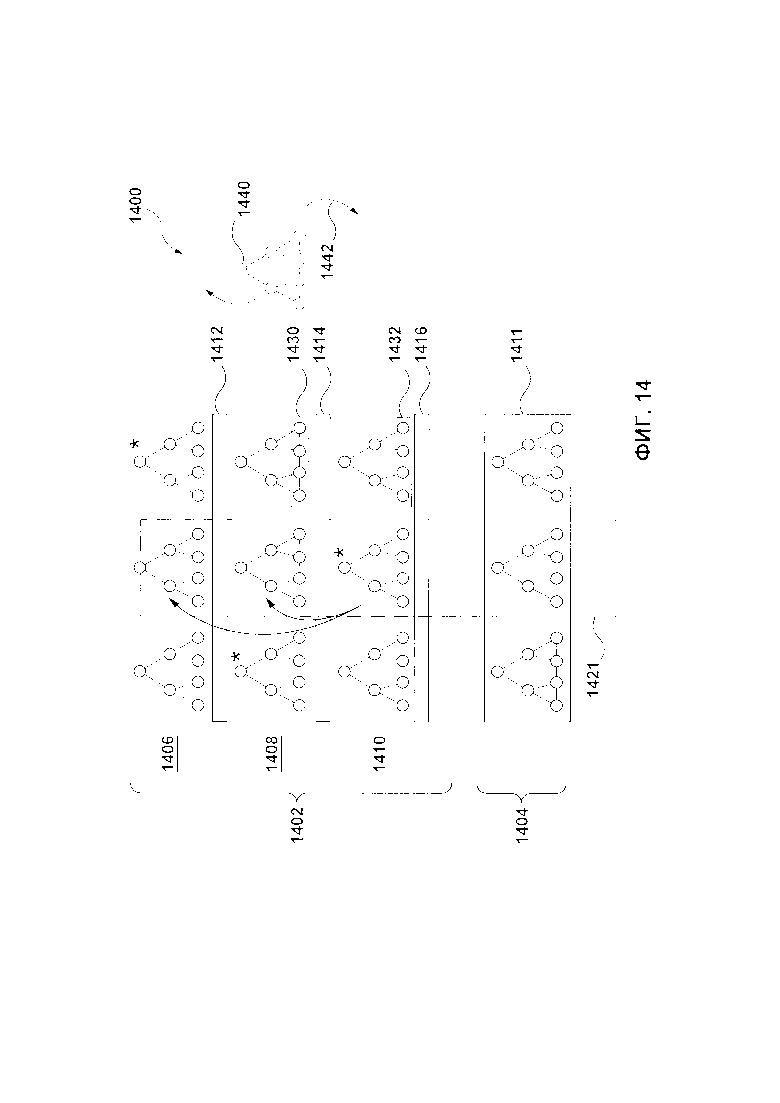
Группа изобретений относится к вычислительной технике и может быть использована для создания прогностической модели. Техническим результатом является обеспечение преобразования значения категориального фактора в его числовое представление. Категориальный фактор связан с обучающим объектом, используемым для обучения алгоритма машинного обучения (MLA). Способ содержит этапы, на которых MLA обучается с помощью нескольких моделей, причем каждая модель включает в себя множество деревьев решений (ансамбль деревьев решений), для каждой модели соответствующий набор обучающих объектов организуют в упорядоченный список обучающих объектов таким образом, что для каждого обучающего объекта существует по меньшей мере одно из: (i) предыдущий обучающий объект, который находится до данного обучающего объекта, и (ii) последующий обучающий объект, который находится после данного обучающего объекта, используют соответствующий упорядоченный список для данного категориального фактора, для создания числового представления значений данного категориального фактора. 3 н. и 17 з.п. ф-лы, 14 ил., 1 прилож.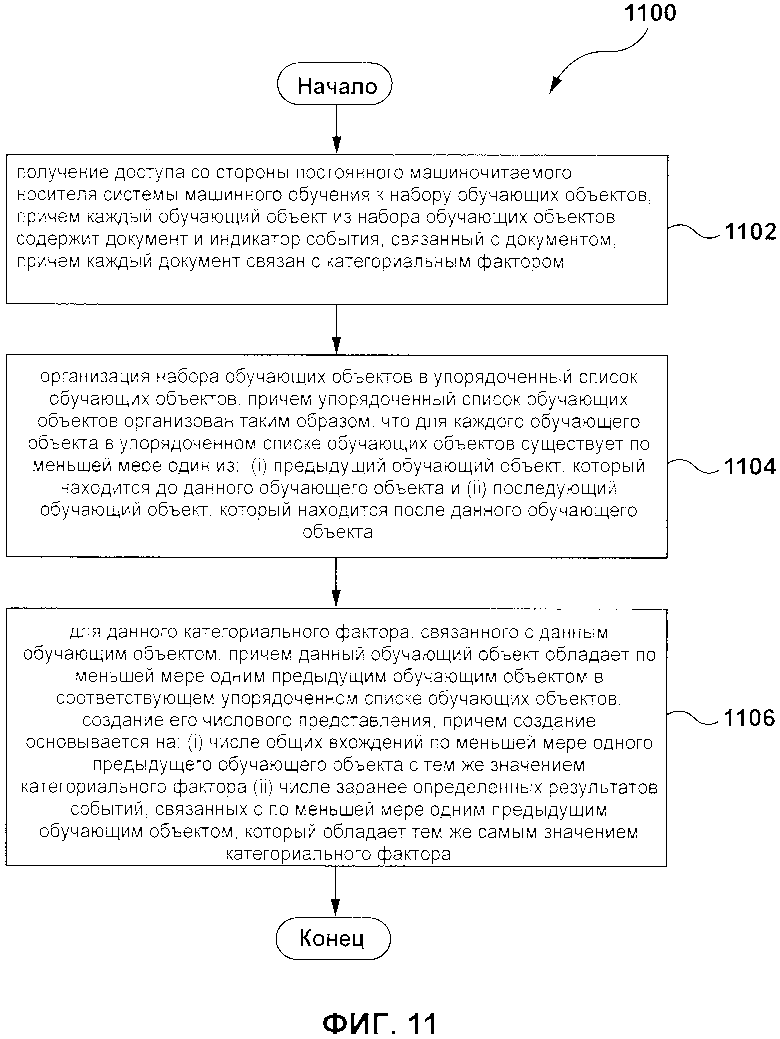
1. Способ преобразования значения категориального значения фактора в его числовое представление, категориальный фактор связан с обучающих объектом, который используется для обучения алгоритма машинного обучения, выполняемого системой машинного обучения, для прогнозирования целевого значения объекта фазы использования, способ включает в себя:
получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором;
создание набора моделей для MLA, причем каждая модель из набора моделей основана на ансамбле деревьев решений; для каждой модели из набора моделей:
организация набора обучающих объектов в соответствующий упорядоченный список обучающих объектов, причем соответствующий упорядоченный список обучающих объектов организован таким образом, что для каждого обучающего объекта в соответствующем упорядоченном списке обучающих объектов существует по меньшей мере один из:
(i) предыдущий обучающий объект, который находится до данного обучающего объекта, и
(ii) последующий обучающий объект, который находится после данного обучающего объекта;
при создании данной итерации дерева решений в данном ансамбле деревьев решений:
выбор одной модели из набора моделей и соответствующего упорядоченного списка;
создание структуры дерева решений с помощью одной модели из набора моделей;
при обработке данного категориального фактора с помощью структуры дерева решений, причем данный категориальный фактор связан с данным обучающим объектом, причем данный обучающий объект обладает по меньшей мере одним предыдущим обучающим объектом в соответствующем упорядоченном списке обучающих объектов, создание его числового представления, причем создание основывается на:
(i) числе общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора в соответствующем упорядоченном списке; и
(ii) числе заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора в соответствующем упорядоченном списке.
2. Способ по п. 1, в котором создание включает в себя применение формулы
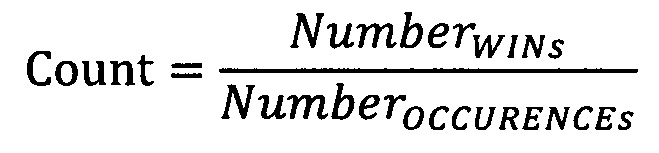
где NumberOCCURENCEs - число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора; и
NumberWINs - число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора.
3. Способ по п. 1, в котором создание включает в себя применение формулы
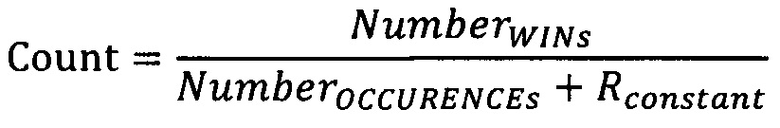
где NumberOCCURENCEs - число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым категориальным фактором; и
NumberWINs - число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым категориальным фактором; и
Rconstant является заранее определенным значением.
4. Способ по п. 1, в котором данный категориальный фактор является набором категориальных факторов, который включает в себя по меньшей мере первый категориальный фактор и второй категориальный фактор, причем создание их числового представления включает в себя:
(i) использование числа общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора:
числа общих вхождений по меньшей мере одного предыдущего обучающего объекта, обладающего как первым значением категориального фактора, так и вторым значением категориального фактора в соответствующем упорядоченном списке; и
(ii) использование в качестве числа заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора:
числа заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, обладающим как первым значением категориального фактора, так и вторым значением категориального фактора.
5. Способ по п. 4, создание числового представления включает в себя применение формулы
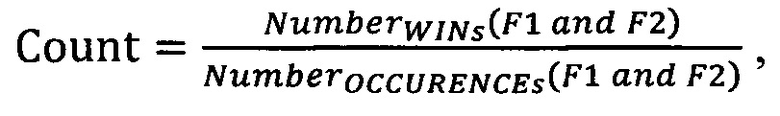
где (i) NumberWINs(F1 and F2) - число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым набором значений категориальных факторов; и
(ii) NumberOCCURENCEs(F1 and F2) - число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым набором значений категориальных факторов.
6. Способ по п. 1, в котором индикатор события обладает заранее определенным значением и это заранее определенное значение является одним из положительного результата или отрицательного результата.
7. Способ по п. 1, в котором организация набора обучающих объектов в упорядоченный список обучающих объектов выполняется в момент времени до создания числового значения.
8. Способ по п. 1, в котором обучающие объекты связаны с присущим им временным порядком, причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя организацию обучающих объектов в соответствии с временным порядком.
9. Способ по п. 1, в котором обучающие объекты не связаны с присущим им временным порядком, причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя организацию обучающих объектов в соответствии с заранее определенным правилом.
10. Способ по п. 1, в котором обучающие объекты не связаны с присущим им временным порядком, причем организация набора обучающих объектов в упорядоченный список обучающих объектов включает в себя создание случайного порядка обучающих объектов, который будет использован в качестве упорядоченного списка.
11. Способ по п. 1, который далее включает в себя использование структуры дерева решений для других моделей из набора моделей для данной итерации дерева решений.
12. Способ по п. 11, который далее включает в себя заполнение каждой из набора моделей с помощью набора обучающих объектов, причем значения категориальных факторов документов преобразованы в свои числовые представления с помощью соответствующего упорядоченного списка обучающих объектов.
13. Способ по п. 12, в котором набор моделей включает в себя набор протомоделей, и в котором набор моделей далее включает в себя итоговую модель, и в котором способ далее включает в себя:
на каждой итерации обучения, выбор наиболее хорошо работающей модели из набора протомоделей и
использование наиболее хорошо работающей модели из набора протомоделей для создания дерева решений итоговой модели для итерации обучения.
14. Способ по п. 13, способ далее включает в себя определение наилучшей работающей из набора протомоделей путем применения алгоритма проверки.
15. Способ по п. 14, в котором алгоритм проверки учитывает работу данной итерации каждой из набора моделей и предыдущих деревьев решений в соответствующей модели из набора моделей.
16. Способ по п. 12, в котором использование различных соответствующих упорядоченных наборов приводит к тому, что значения в листьях разных моделей из набора моделей по меньшей мере частично отличаются.
17. Способ по п. 16, в котором использование набора других моделей со связанными соответствующими упорядоченными списками приводит к снижению эффекта переобучения во время обучения.
18. Способ по п. 17, в котором любой из упорядоченных списков отличается от других из упорядоченных списков.
19. Способ преобразования значения категориального значения фактора в его числовое представление, причем категориальный фактор связан с обучающих объектом, который используется для обучения алгоритма машинного обучения, выполняемого электронным устройством, для прогнозирования целевого значения объекта фазы использования, способ включает в себя:
получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором;
создание набора моделей для MLA, причем каждая модель из набора моделей основана на ансамбле деревьев решений; для каждой модели из набора моделей:
организация набора обучающих объектов в соответствующий упорядоченный список обучающих объектов, причем соответствующий упорядоченный список обучающих объектов организован таким образом, что для каждого обучающего объекта в соответствующем упорядоченном списке обучающих объектов существует по меньшей мере один из:
(i) предыдущий обучающий объект, который находится до данного обучающего объекта, и
(ii) последующий обучающий объект, который находится после данного обучающего объекта;
при создании данной итерации дерева решений в данном ансамбле деревьев решений:
выбор одной модели из набора моделей и соответствующего упорядоченного списка;
создание структуры дерева решений с помощью одной модели из набора моделей;
при обработке данного категориального фактора с помощью структуры дерева решений, для данного категориального фактора, причем данный категориальный фактор связан с данным обучающим объектом, причем данный обучающий объект обладает по меньшей мере одним предыдущим обучающим объектом в соответствующем упорядоченном списке обучающих объектов, создание его числового представления, причем создание включает в себя вычисление функции с помощью формулы
f (Number_WINs_PAST, Number_Occurence_PAST),
где Number_WINs_PAST - число заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает теми же самыми значениями категориального фактора в соответствующем упорядоченном списке; и
Number_Occurence_PAST - число общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора в соответствующем упорядоченном списке.
20. Сервер, выполненный с возможностью осуществлять алгоритм машинного обучения (MLA), который основан на прогностической модели дерева решений, основанной на дереве решений, причем дерево решений предназначено для обработки значения категориального фактора путем преобразования его в его числовое представление, категориальный фактор связан с обучающим объектом, используемым для обучения MLA, причем MLA используется сервером для прогноза целевого значения объекта фазы использования, и сервер включает в себя:
постоянный носитель компьютерной информации;
процессор, связанный постоянным машиночитаемым носителем, процессор выполнен с возможностью осуществлять:
получение доступа со стороны постоянного машиночитаемого носителя системы машинного обучения к набору обучающих объектов, причем каждый обучающий объект из набора обучающих объектов содержит документ и индикатор события, связанный с документом, причем каждый документ связан с категориальным фактором;
создание набора моделей для MLA, причем каждая модель из набора моделей основана на ансамбле деревьев решений; для создания процессор далее выполнен с возможностью осуществлять для каждой модели из набора моделей:
организацию набора обучающих объектов в соответствующий упорядоченный список обучающих объектов, причем соответствующий упорядоченный список обучающих объектов организован таким образом, что для каждого обучающего объекта в соответствующем упорядоченном списке обучающих объектов существует по меньшей мере один из:
(i) предыдущий обучающий объект, который находится до данного обучающего объекта, и
(ii) последующий обучающий объект, который находится после данного обучающего объекта;
при создании данной итерации дерева решений в данном ансамбле деревьев решений, процессор выполнен с возможностью осуществлять:
выбор одной модели из набора моделей и соответствующего упорядоченного списка;
создание структуры дерева решений с помощью одной модели из набора моделей;
при обработке данного категориального фактора с помощью структуры дерева решений, для данного категориального фактора, причем данный категориальный фактор связан с данным обучающим объектом, причем данный обучающий объект обладает по меньшей мере одним предыдущим обучающим объектом в соответствующем упорядоченном списке обучающих объектов, создание его числового представления, причем создание основывается на:
(i) числе общих вхождений по меньшей мере одного предыдущего обучающего объекта с тем же самым значением категориального фактора; и
(ii) числе заранее определенных результатов событий, связанных с по меньшей мере одним предыдущим обучающим объектом, который обладает тем же самым значением категориального фактора.
| СПОСОБ (ВАРИАНТЫ) И СИСТЕМА (ВАРИАНТЫ) СОЗДАНИЯ МОДЕЛИ ПРОГНОЗИРОВАНИЯ И ОПРЕДЕЛЕНИЯ ТОЧНОСТИ МОДЕЛИ ПРОГНОЗИРОВАНИЯ | 2015 |
|
RU2632133C2 |
| СПОСОБ КЛАССИФИКАЦИИ ДОКУМЕНТОВ ПО КАТЕГОРИЯМ | 2012 |
|
RU2491622C1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |

