Область техники, к которой относится изобретение
[01] Настоящая технология в целом относится к машинному обучению и, в частности, к способу и серверу для обработки текстовой последовательности в задаче машинной обработки.
Уровень техники
[02] С увеличением количества пользователей, имеющих доступ к сети Интернет, возникло огромное число интернет-сервисов. Например, к таким сервисам относятся поисковые системы (такие как поисковые системы Yandex™ и Google™), позволяющие пользователям получать информацию путем отправки запросов поисковой системе. Кроме того, благодаря социальным сетям и мультимедийным сервисам множество пользователей с различным социальным уровнем и культурными традициями могут общаться друг с другом на унифицированных платформах для обмена контентом и информацией. Цифровой контент и другие данные, которыми обмениваются пользователи, могут быть представлены на множестве языков. Поэтому вследствие постоянно растущего объема информации, обмен которой возможен в сети Интернет, часто используются сервисы перевода, такие как Yandex.Translate™.
[03] Последний сервис особенно полезен, поскольку позволяет пользователям легко переводить текст (или даже устную речь) с одного языка, непонятного пользователю, на другой, понятный ему язык. Это означает, что сервисы перевода обычно разрабатываются для предоставления переведенного варианта контента на понятном пользователю языке, чтобы сделать этот контент доступным для пользователя.
[04] Несмотря на прогресс в последние годы, традиционные компьютерные системы, предоставляющие сервисы перевода, по-прежнему имеют много недостатков. Например, типичные машинные переводы плохо справляются с выбором правильного перевода слова в конкретном контексте или с конкретным значением.
[05] В результате этой неспособности обеспечивать правильный или лучший перевод предлагаемые пользователям сервисы перевода оказываются менее желательными или полезными, что может влиять на удержание пользователей интернет-компаниями, предлагающими эти сервисы перевода.
Раскрытие изобретения
[06] Разработчики настоящей технологии обнаружили определенные технические недостатки, связанные с имеющимися сервисами перевода. Традиционные системы часто предоставляют переводы текста пользователям. Тем не менее, эти переводы могут не быть правильными или лучшими переводами. В основном это связано с тем, что слово на первом языке может использоваться во множестве контекстов и поэтому может иметь множество значений. В результате для перевода этого слова потенциально может использоваться множество параллельных слов на втором языке.
[07] Традиционные системы используют способы сегментации на подслова для формирования обучающих данных, используемых для обучения системы перевода. Один из способов сегментации на подслова заключается в использовании алгоритма кодирования пар байтов (BPE, Byte Pair Encoding) при подготовке обучающих данных. Алгоритм BPE сохраняет часто встречающиеся слова без изменений и разделяет редкие или неизвестные слова на последовательность подслов. Благодаря применению подслов при обучении модель перевода может использовать морфологию, композицию слова и транслитерацию слов, чтобы лучше выполнять задачи перевода.
[08] Разработчики настоящей технологии установили, что алгоритм BPE имеет ряд недостатков вследствие его детерминированного характера - он обеспечивает разделение слов на однозначно определяемые последовательности подслов, т.е. для каждого слова модель формирует только один вариант сегментации. Разработчики настоящей технологии разработали способ и систему, которые улучшают традиционные системы перевода на основе алгоритма BPE и (а) лучше используют морфологию, (б) более эффективны при обучении с учетом композиционности слов и (в) более устойчивы к ошибкам сегментации.
[09] В по меньшей мере некоторых вариантах осуществления настоящей технологии разработчики настоящей технологии разработали способ и систему, позволяющие формировать несколько альтернативных вариантов сегментации слова. В частности, разработчики настоящей технологии разработали способ и систему, позволяющие формировать несколько альтернативных вариантов сегментации слова с использованием фреймворка BPE. Также можно сказать, что разработчики настоящей технологии разработали модифицированный фреймворк BPE для формирования нескольких альтернативных вариантов сегментации слова.
[10] Например, с применением традиционного фреймворка BPE система способна строить словарь подслов и таблицу слияний, указывающую на то, какие подслова должны сливаться в большее подслово (а также приоритеты соответствующих слияний). При сегментации сначала слова разделяются на последовательности символов, затем выученные операции сливания применяются для сливания этих символов в бо́льшие известные токены до тех пор, пока возможны дальнейшие сливания (на основе словаря подслов и таблицы слияний). В отличие от такого подхода, модифицированный фреймворк BPE использует способ регуляризации, совместимый с традиционным алгоритмом BPE. В модифицированном фреймворке BPE используются словарь и таблица слияний, которая может формироваться с помощью алгоритма BPE, но на каждом шаге сливания некоторые слияния пропускаются случайным образом (запрещаются для текущего шага сливания). В результате появляются альтернативные варианты сегментации, если этот процесс выполняется несколько раз для одного и того же слова.
[11] Согласно первому аспекту настоящей технологии реализован компьютерный способ обработки текстовой последовательности в задаче машинной обработки, подлежащей выполнению алгоритмом машинного обучения (MLA, Machine Learning Algorithm). Способ выполняется сервером. Способ включает в себя получение сервером словаря токенов. В словаре токенов хранится набор токенов из заранее заданного корпуса текстов. Токен из набора токенов представляет собой один символ или слитый набор токенов. Способ включает в себя получение сервером таблицы слияний. Таблица слияний указывает на возможные слияния пар токенов из набора токенов. Токен из возможного слияния связан с соответствующей частотой появления этого токена в заранее заданном корпусе текстов. Способ включает в себя получение сервером текстовой последовательности, указывающей на по меньшей мере одно слово. Для слова из текстовой последовательности способ включает в себя использование сервером словаря токенов для разделения этого слова на первоначальную последовательность токенов. Первоначальная последовательность токенов представляет собой отдельные символы этого слова. Для слова из текстовой последовательности способ включает в себя итеративное сливание сервером токенов из первоначальной последовательности токенов с целью формирования окончательной последовательности токенов для этого слова. Для слова из текстовой последовательности итеративное сливание включает в себя использование сервером на итерации сливания таблицы слияний для определения набора возможных слияний пар соседних токенов из текущей последовательности токенов для этой итерации сливания. Для слова из текстовой последовательности итеративное сливание включает в себя исключение сервером на итерации сливания по меньшей мере одного слияния из набора возможных слияний на основе заранее заданной вероятности исключения и формирование таким образом сокращенного набора возможных слияний для этой итерации сливания. Сокращенный набор возможных слияний меньше набора возможных слияний. Для слова из текстовой последовательности итеративное сливание включает в себя использование сервером на итерации сливания сокращенного набора возможных слияний для формирования новой последовательности токенов путем выполнения по меньшей мере одного слияния из сокращенного набора возможных слияний в текущей последовательности токенов. Новая последовательность токенов подлежит использованию сервером в качестве текущей последовательности токенов на следующей итерации сливания. Для слова из текстовой последовательности итеративное сливание на другой итерации сливания после текущей итерации сливания включает в себя определение сервером текущей последовательности токенов для другой итерации сливания в качестве подлежащей использованию в задаче машинной обработки окончательной последовательности токенов, если отсутствуют возможные слияния в текущей последовательности токенов для другой операции сливания.
[12] В некоторых вариантах осуществления способа использование сокращенного набора возможных слияний включает в себя выбор сервером по меньшей мере одного подлежащего выполнению слияния из сокращенного набора возможных слияний на основе соответствующей частоты появления для сокращенного набора возможных слияний.
[13] В некоторых вариантах осуществления способа он дополнительно включает в себя получение указания на заранее заданную вероятность исключения.
[14] В некоторых вариантах осуществления способа алгоритм MLA представляет собой алгоритм MLA для нейронного машинного перевода.
[15] В некоторых вариантах осуществления способа алгоритм MLA предназначен для использования с приложением поисковой системы.
[16] В некоторых вариантах осуществления способа алгоритм MLA предназначен для использования с приложением выбора целевой рекламы.
[17]. В некоторых вариантах осуществления способа он до получения словаря токенов и получения таблицы слияний включает в себя формирование словаря токенов и таблицы слияний на основе заранее заданного корпуса текстов.
[18] В некоторых вариантах осуществления способа корпус текстов не содержит упомянутой текстовой последовательности.
[19] В некоторых вариантах осуществления способа формирование словаря токенов включает в себя процедуру инициализации, основанную на словаре символов.
[20] В некоторых вариантах осуществления способа формирование таблицы слияний включает в себя процедуру инициализации с пустой таблицей.
[21] В некоторых вариантах осуществления способа текстовая последовательность представляет собой первую текстовую последовательность, содержащую слово. Способ включает в себя обработку второй текстовой последовательности, содержащей это слово, а первая окончательная последовательность токенов слова, связанного с первой текстовой последовательностью, отличается от второй окончательной последовательности токенов этого слова, связанного со второй текстовой последовательностью.
[22] В некоторых вариантах осуществления способа различие между первой окончательной последовательностью токенов и второй окончательной последовательностью токенов связано с различными использованными сокращенными наборами возможных слияний.
[23] В некоторых вариантах осуществления способа это различие также связано с различными использованными вероятностями исключения.
[24] Согласно второму аспекту настоящей технологии реализован компьютерный способ обработки текстовой последовательности в задаче машинной обработки, подлежащей выполнению алгоритмом MLA. Способ выполняется сервером. Способ включает в себя получение сервером словаря токенов. В словаре токенов хранится набор токенов из заранее заданного корпуса текстов. Токен из набора токенов представляет собой один символ или слитый набор токенов. Способ включает в себя получение сервером таблицы слияний. Таблица слияний указывает на возможные слияния пар токенов из набора токенов. Токен из возможного слияния связан с соответствующей частотой появления этого токена в заранее заданном корпусе текстов. Способ включает в себя получение сервером текстовой последовательности, указывающей на по меньшей мере одно слово. Для слова из текстовой последовательности способ включает в себя использование сервером словаря токенов для разделения этого слова на первоначальную последовательность токенов. Первоначальная последовательность токенов представляет собой отдельные символы этого слова. Для слова из текстовой последовательности способ включает в себя итеративное сливание сервером токенов из первоначальной последовательности токенов с целью формирования окончательной последовательности токенов для этого слова. Итеративное сливание включает в себя использование сервером на итерации сливания таблицы слияний для определения набора возможных слияний пар соседних токенов из текущей последовательности токенов для этой итерации сливания. Итеративное сливание включает в себя использование сервером на итерации сливания заранее заданной вероятности для выборочного включения возможных слияний из набора возможных слияний в дополненный набор возможных слияний для этой итерации сливания. Итеративное сливание включает в себя использование сервером на итерации сливания дополненного набора возможных слияний для формирования новой последовательности токенов путем выполнения по меньшей мере одного слияния из дополненного набора возможных слияний в текущей последовательности токенов. Новая последовательность токенов подлежит использованию сервером в качестве текущей последовательности токенов на следующей итерации сливания. Итеративное сливание на другой итерации сливания после текущей итерации сливания включает в себя определение сервером текущей последовательности токенов для другой итерации сливания в качестве подлежащей использованию в задаче машинной обработки окончательной последовательности токенов, если отсутствуют возможные слияния в текущей последовательности токенов для другой итерации сливания.
[25] В некоторых вариантах осуществления способа дополненный набор возможных слияний меньше набора возможных слияний.
[26] В некоторых вариантах осуществления способа дополненный набор возможных слияний идентичен набору возможных слияний.
[27] Согласно третьему аспекту настоящей технологии реализован сервер для обработки текстовой последовательности в задаче машинной обработки, подлежащей выполнению алгоритмом MLA. Сервер имеет доступ к алгоритму MLA. Сервер способен получать словарь токенов. В словаре токенов хранится набор токенов из заранее заданного корпуса текстов. Токен из набора токенов представляет собой один символ или слитый набор токенов. Сервер способен получать таблицу слияний. Таблица слияний указывает на возможные слияния пар токенов из набора токенов. Токен из возможного слияния связан с соответствующей частотой появления этого токена в заранее заданном корпусе текстов. Сервер способен получать текстовую последовательность, указывающую на по меньшей мере одно слово. Для слова из текстовой последовательности сервер способен использовать словарь токенов для разделения этого слова на первоначальную последовательность токенов. Первоначальная последовательность токенов представляет собой отдельные символы этого слова. Для слова из текстовой последовательности сервер способен итеративно сливать токены из первоначальной последовательности токенов с целью формирования окончательной последовательности токенов для этого слова. Способность сервера к итеративному сливанию включает в себя способность сервера к использованию на итерации сливания таблицы слияний для определения набора возможных слияний пар соседних токенов из текущей последовательности токенов для этой итерации сливания. Способность сервера к итеративному сливанию включает в себя способность сервера к исключению сервером на итерации сливания по меньшей мере одного слияния из набора возможных слияний на основе заранее заданной вероятности исключения и формирования таким образом сокращенного набора возможных слияний для этой итерации сливания. Сокращенный набор возможных слияний меньше набора возможных слияний. Способность сервера к итеративному сливанию включает в себя способность сервера к использованию на итерации сливания сокращенного набора возможных слияний для формирования новой последовательности токенов путем выполнения по меньшей мере одного слияния из сокращенного набора возможных слияний в текущей последовательности токенов. Новая последовательность токенов подлежит использованию сервером в качестве текущей последовательности токенов на следующей итерации сливания. Способность сервера к итеративному сливанию включает в себя способность сервера к определению на другой итерации сливания после текущей итерации сливания текущей последовательности токенов для другой итерации сливания в качестве подлежащей использованию в задаче машинной обработки окончательной последовательности токенов, если отсутствуют возможные слияния в текущей последовательности токенов для другой итерации сливания.
[28] В некоторых вариантах осуществления сервера способность сервера к использованию сокращенного набора возможных слияний включает в себя способность сервера к выбору по меньшей мере одного подлежащего выполнению слияния из сокращенного набора возможных слияний на основе соответствующей частоты появления сокращенного набора возможных слияний.
[29] В некоторых вариантах осуществления сервер дополнительно способен получать указание на заранее заданную вероятность исключения.
[30] В некоторых вариантах осуществления сервера алгоритм MLA представляет собой алгоритм MLA для нейронного машинного перевода.
[31] В некоторых вариантах осуществления сервера алгоритм MLA предназначен для использования с приложением поисковой системы.
[32] В некоторых вариантах осуществления сервера алгоритм MLA предназначен для использования с приложением выбора целевой рекламы.
[33] В некоторых вариантах осуществления сервера он до получения словаря токенов и получения таблицы слияний способен формировать словарь токенов и таблицу слияний на основе заранее заданного корпуса текстов.
[34] В некоторых вариантах осуществления сервера корпус текстов не содержит упомянутой текстовой последовательности.
[35] В некоторых вариантах осуществления сервера формирование словаря токенов включает в себя процедуру инициализации, основанную на словаре символов.
[36] В некоторых вариантах осуществления сервера формирование таблицы слияний включает в себя процедуру инициализации с пустой таблицей.
[37] В некоторых вариантах осуществления сервера текстовая последовательность представляет собой первую текстовую последовательность, содержащую слово, а сервер дополнительно способен обрабатывать вторую текстовую последовательность, содержащую это слово. Первая окончательная последовательность токенов слова, связанного с первой текстовой последовательностью, отличается от второй окончательной последовательности токенов этого слова, связанного со второй текстовой последовательностью.
[38] В некоторых вариантах осуществления сервера различие между первой окончательной последовательностью токенов и второй окончательной последовательностью токенов связано с различными использованными сокращенными наборами возможных слияний.
[39] В некоторых вариантах осуществления сервера это различие дополнительно связано с различными использованными вероятностями исключения.
[40] Согласно еще одному аспекту настоящей технологии реализован компьютерный способ обработки текстовой последовательности в задаче машинной обработки, подлежащей выполнению алгоритмом MLA. Способ выполняется сервером. Способ включает в себя получение сервером словаря токенов. В словаре токенов хранится набор токенов из заранее заданного корпуса текстов. Токен из набора токенов представляет собой один символ или слитый набор токенов. Способ включает в себя получение сервером таблицы слияний. Таблица слияний указывает на возможные слияния пар токенов из набора токенов. Токен из возможного слияния связан с соответствующей частотой появления этого токена в заранее заданном корпусе текстов. Способ включает в себя получение сервером текстовой последовательности, указывающей на по меньшей мере одно слово. Для слова из текстовой последовательности способ включает в себя использование сервером словаря токенов для разделения этого слова на первоначальную последовательность токенов. Первоначальная последовательность токенов представляет собой отдельные символы этого слова. Для слова из текстовой последовательности способ включает в себя итеративное сливание сервером токенов из первоначальной последовательности токенов с целью формирования окончательной последовательности токенов для этого слова. Итеративное сливание включает в себя использование сервером на итерации сливания таблицы слияний для определения набора возможных слияний пар соседних токенов из текущей последовательности токенов для этой итерации сливания. Итеративное сливание включает в себя использование сервером на итерации сливания стохастического алгоритма для исключения по меньшей мере одного слияния из набора возможных слияний и формирование таким образом сокращенного набора слияний для этой итерации сливания. Сокращенный набор возможных слияний меньше набора возможных слияний. Итеративное сливание включает в себя использование сервером на итерации сливания сокращенного набора возможных слияний для формирования новой последовательности токенов путем выполнения по меньшей мере одного слияния из сокращенного набора возможных слияний в текущей последовательности токенов. Новая последовательность токенов подлежит использованию сервером в качестве текущей последовательности токенов на следующей итерации сливания. Итеративное сливание на другой итерации сливания после текущей итерации сливания включает в себя определение сервером текущей последовательности токенов для другой итерации сливания в качестве подлежащей использованию в задаче машинной обработки окончательной последовательности токенов, если отсутствуют возможные слияния в текущей последовательности токенов для другой итерации сливания.
[41] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[42] В контексте настоящего описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов либо шагов любого описанного здесь способа.
[43] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[44] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[45] В контексте настоящего описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[46] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[47] В контексте настоящего описания числительные «первый» «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - разные программные и/или аппаратные средства.
[48] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[49] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[50] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[51] На фиг. 1 представлена схема системы, пригодной для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии.
[52] На фиг. 2 представлены данные, хранящиеся в запоминающем устройстве, показанном на фиг. 1, согласно по меньшей мере некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[53] На фиг. 3 представлен пример традиционного процесса сегментации на подслова и примеры модифицированного процесса сегментации на подслова, выполняемого сервером, показанным на фиг. 1, согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[54] На фиг. 4 представлена блок-схема способа обработки текстовой последовательности в задаче машинной обработки согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[55] Кроме того, после описания осуществления изобретения приведено Приложение А, содержащее статью «BPE-dropout: простая и эффективная регуляризация подслов» с информацией относительно некоторых описанных здесь аспектов настоящей технологии и/или дополнительных аспектов настоящей технологии. Приложение A и содержащаяся в ней информация приведены для справки и должны быть удалены из заявки до публикации описания к патенту.
Осуществление изобретения
[56] На фиг. 1 представлена схема системы 100, пригодной для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии. Очевидно, что система 100 приведена лишь для демонстрации варианта реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях приводятся полезные примеры модификаций системы 100. Они способствуют пониманию, но также не определяют объема или границ настоящей технологии. Эти модификации не составляют исчерпывающего перечня. Как должно быть понятно специалисту в данной области, возможны и другие модификации. Кроме того, если в некоторых случаях модификации не описаны (т.е. примеры модификаций отсутствуют), это не означает, что они невозможны и/или что описание содержит единственный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области должно быть понятно, что это может быть не так. Кроме того, следует понимать, что система 100 в некоторых случаях может представлять собой упрощенную реализацию настоящей технологии и что такие варианты представлены, чтобы способствовать лучшему ее пониманию. Специалистам в данной области должно быть понятно, что другие варианты осуществления настоящей технологии могут быть значительно сложнее.
[57] В целом, система 100 способна предоставлять сервисы электронного перевода для пользователя 102 электронного устройства 104. Например, система 100 может предоставлять переведенный вариант по меньшей мере части сетевого ресурса, такого как веб-страница (или ее часть), в частности, электронному устройству для его отображения пользователю 102.
[58] Например, пользователю 102 может потребоваться оценить контент веб-страницы. При этом в некоторых случаях контент веб-страницы может быть представлен на иностранном (непонятном) пользователю 102 языке. Во многих таких ситуациях может быть желательно предоставлять пользователю 102 сервисы перевода, способствующие пониманию пользователем 102 отображаемого контента.
[59] В некоторых вариантах осуществления настоящей технологии сервисы перевода системы 100 могут предназначаться для предоставления переведенного варианта контента на понятном пользователю 102 языке электронному устройству 104 для отображения пользователю 102. Иными словами, сервисы перевода системы 100 могут быть предназначены для предоставления переведенного варианта контента, доступного для понимания пользователем 102.
[60] В других вариантах осуществления изобретения пользователь 102 может использовать электронное устройство 104 для доступа к сервисам перевода, размещенным на удаленном устройстве, таком как сервер 106. В таких случаях пользователь 102 может использовать электронное устройство 104 для предоставления подлежащего переводу контента серверу 106. В ответ сервер 106 может использовать один или несколько компьютерных алгоритмов для формирования переведенного контента (на требуемом языке) и предоставления этого переведенного контента электронному устройству 104 для отображения пользователю 102.
[61] Ниже описаны по меньшей мере некоторые элементы системы 100. Тем не менее, должно быть понятно, что без выхода за границы настоящей технологии в состав системы 100 могут входить элементы, отличные от представленных на фиг. 1.
Электронное устройство
[62] Система 100 содержит электронное устройство 104, связанное с пользователем 102. Электронное устройство 104 иногда может называться клиентским устройством, оконечным устройством, клиентским электронным устройством или просто устройством. Следует отметить, что связь электронного устройства 104 с пользователем 102 не означает необходимости предлагать или подразумевать какой-либо режим работы, например, вход в систему, регистрацию и т.п.
[63] На реализацию устройства 104 не накладывается особых ограничений. Например, устройство 104 может быть реализовано как персональный компьютер (настольный, ноутбук, нетбук и т.д.), беспроводное устройство связи (смартфон, сотовый телефон, планшет и т.д.) или как сетевое оборудование (маршрутизатор, коммутатор, шлюз и т.д.). Устройство 104 содержит известные в данной области техники аппаратные средства и/или прикладное программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для выполнения браузерного приложения 105.
[64] Браузерное приложение 105 обеспечивает пользователю 102 доступ к одному или нескольким сетевым ресурсам, таким как веб-страницы. На реализацию браузерного приложения 105 не накладывается особых ограничений. Например, браузерное приложение 105 может быть реализовано в виде браузера Yandex™. Браузерное приложение 105 электронного устройства 104 может обеспечивать пользователю возможность навигации по множеству сетевых ресурсов 112. В не имеющем ограничительного характера примере множество сетевых ресурсов 112 может соответствовать веб-страницам, размещенным на одном или нескольких сетевых серверах 113.
[65] Например, после предоставления пользователем 102 указания на адрес ресурса из множества сетевых ресурсов 112 браузерное приложение 105 может инициировать формирование электронным устройством 104 запроса 150 ресурса, предназначенного для сетевого сервера 113, на котором размещен этот ресурс из множества сетевых ресурсов 112. Запрос 150 ресурса может быть представлен в виде пакета данных, содержащего машиночитаемые команды, способные запрашивать информацию с сетевого сервера 113, на котором размещен ресурс из множества сетевых ресурсов 112.
[66] Электронное устройство 104 также способно получать ответ 155 ресурса от сетевого сервера 113, на котором размещен ресурс из множества сетевых ресурсов 112. Ответ 155 ресурса может быть представлен в виде другого пакета данных, содержащего машиночитаемые команды, способные обеспечивать браузерному приложению 105 возможность отображения контента ресурса из множества сетевых ресурсов 112.
[67] На передачу запросов 150 ресурса и ответов 155 ресурса между электронным устройством 104 и одним или несколькими сетевыми серверами 113 не накладывается особых ограничений. Тем не менее, следует отметить, что по меньшей мере одно браузерное приложение 105 и по меньшей мере один ресурс из множества сетевых ресурсов 112 могут обеспечивать предоставление сервисов перевода пользователю 102. Например, браузерное приложение 105 и/или один или несколько ресурсов из множества сетевых ресурсов 112 могут быть реализованы с использованием системы перевода (состоящей из одного или нескольких компьютерных алгоритмов, предназначенных для перевода контента), способной обеспечивать возможность перевода контента для пользователя 102 с одного языка на другой. Как более подробно описано ниже, для предоставления сервисов перевода пользователю 102 браузерное приложение 105 может быть связано с сервером 106.
Сеть связи
[68] Устройство 104 соединено с сетью 110 связи для доступа к одному или нескольким сетевым серверам 113, на которых размещено множество сетевых ресурсов 112. Например, устройство 104 может быть соединено с одним или несколькими сетевыми серверами 113 через сеть 110 связи для предоставления пользователю 102 контента множества сетевых ресурсов 112.
[69] Предполагается, что устройство 104 также соединено с сетью 110 связи для доступа к серверу 106. Например, устройство 104 может быть соединено с сервером 106 через сеть 110 связи для предоставления пользователю 102 вышеупомянутых сервисов перевода.
[70] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 110 связи может использоваться сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления данной технологии сеть 110 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п. Реализация линии связи (отдельно не обозначена) между устройством 104 и сетью 110 связи зависит, среди прочего, от реализации устройства 104.
[71] Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, в которых устройство 104 реализовано как беспроводное устройство связи (такое как смартфон), линия связи может быть реализована как беспроводная линия связи (такая как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где устройство 104 реализовано как ноутбук, линия связи может быть беспроводной (такой как Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.д.) или проводной (такой как соединение на основе Ethernet).
[72] Сеть 110 связи способна, среди прочего, передавать запросы 150 ресурса от устройства 104 к одному или нескольким сетевым серверам 113 и ответы 155 ресурса от одного или нескольких сетевых серверов 113 к устройству 104.
[73] Также предполагается, что сеть 110 связи способна передавать, среди прочего, запросы 160 сервера от устройства 104 к серверу 106 и ответы 165 сервера от сервера 106 к устройству 104. На реализацию запросов 160 сервера и ответов 165 сервера не накладывается особых ограничений. Тем не менее, в общем случае запросы 160 сервера и ответы 165 сервера могут быть использованы для обеспечения работы сервисов перевода сервера 106.
[74] Сетевой сервер из числа сетевых серверов 113 может быть реализован в виде традиционного компьютерного сервера. В примере осуществления настоящей технологии сетевой сервер может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сетевой сервер может быть реализован с использованием любых других подходящих аппаратных средств, прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания.
Множество сетевых ресурсов
[75] В общем случае на одном или нескольких сетевых серверах 113 может быть размещено множество сетевых ресурсов 112. В некоторых вариантах осуществления настоящей технологии каждый ресурс из множества сетевых ресурсов 112 может быть реализован в виде соответствующей веб-страницы, размещенной на соответствующем сервере из числа сетевых серверов 113. На сервере из числа сетевых серверов 113 также может быть размещен один или несколько ресурсов из множества сетевых ресурсов 112. Например, на сервере из числа сетевых серверов 113 может быть размещен веб-сайт, содержащий несколько ресурсов из множества сетевых ресурсов 112.
[76] Когда пользователь 102 с помощью браузерного приложения 105 предоставляет адрес требуемого сетевого ресурса, электронное устройство 104 отправляет соответствующий запрос 150 ресурса соответствующему сетевому серверу 113, на котором размещен требуемый сетевой ресурс (например, из множества сетевых ресурсов 112). Запрос 150 ресурса содержит машиночитаемые команды для получения с соответствующего сетевого сервера 113 электронного документа, содержащего контент для отображения пользователю 102 с помощью браузерного приложения 105.
[77] На характер электронного документа не накладывается особых ограничений. В качестве иллюстрации, электронный документ может представлять собой веб-страницу (например, требуемый сетевой ресурс), размещенную на соответствующем сетевом сервере 113. Например, электронный документ может быть сформирован на языке разметки, таком как HTML, XML и т.п.
[78] Таким образом, можно сказать, что запрос 150 ресурса предназначен для выдачи указания сетевому серверу о предоставлении электронному устройству 104 электронного документа, содержащего контент для отображения пользователю 102 с помощью браузерного приложения 105.
[79] В ответ на запрос 150 ресурса соответствующий сетевой сервер 113 отправляет ответ 155 ресурса электронному устройству 104. Ответ 155 ресурса содержит электронный документ. Таким образом, можно сказать, что ответ 155 ресурса предназначен для передачи электронному устройству 104 данных, представляющих собой электронный документ.
[80] В общем случае электронный документ представляет собой веб-страницу (например, требуемый сетевой ресурс), указывающую (а) какой контент должен отображаться браузерным приложением 105 пользователю 102 и (б) как этот контент должен отображаться браузерным приложением 105 пользователю 102. Иными словами, электронный документ указывает (а) на контент веб-страницы, подлежащий отображению пользователю 102 браузерным приложением 105, и (б) на команды визуализации для указания браузерному приложению 105 того, как контент веб-страницы должен отображаться на электронном устройстве 104.
[81] В по меньшей мере некоторых вариантах осуществления настоящей технологии предполагается, что пользователь 102 может выбирать по меньшей мере некоторый контент сетевого ресурса, отображаемый ему с помощью электронного устройства 104, и может использовать электронное устройство 104 для доступа к сервисам перевода сервера 106. Реализация сервером 106 сервисов перевода более подробно описана ниже.
Сервер
[82] Система 100 также содержит сервер 106, который может быть реализован в виде традиционного компьютерного сервера (см. фиг. 1). Предполагается, что сервер 106 может быть реализован подобно сетевому серверу из числа сетевых серверов 113 без выхода за границы настоящей технологии.
[83] В представленных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 106 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 106 могут быть распределены между несколькими серверами. Сервер 106 может содержать один или несколько процессоров, одно или несколько устройств долговременной памяти, машиночитаемые команды и/или дополнительные аппаратные средства, дополнительные компоненты программных средств и/или их сочетание для реализации различных функций сервера 106 без выхода за границы настоящей технологии.
[84] В целом, сервер 106 может управляться и/или администрироваться поставщиком сервиса перевода (не показан), таким как оператор сервисов перевода Yandex™. Предполагается, что поставщик сервисов перевода и поставщик браузерного приложения 105 могут представлять собой одного и того же поставщика. Например, браузерное приложение 105 (в частности, браузер Yandex™) и сервисы перевода (например, сервисы перевода Yandex™) могут предоставляться, управляться и/или администрироваться одним и тем же оператором или организацией.
[85] Можно сказать, что сервер 106 может выполнять один или несколько компьютерных алгоритмов для (а) получения контента, подлежащего переводу, (б) обработки или подготовки этого контента для перевода, (в) формирования на его основе переведенного контента и (г) предоставления переведенного контента пользователю 102 электронного устройства 104.
[86] В по меньшей мере некоторых вариантах осуществления настоящей технологии сервер 106 может реализовывать алгоритм 124 MLA или иметь доступ к нему. В общем случае алгоритмы MLA могут обучаться на обучающих выборках и осуществлять прогнозирование на основе новых (неизвестных) данных. Алгоритмы MLA обычно используются для первоначального построения модели на основе обучающих входных данных, чтобы затем на основе данных осуществлять прогнозы или принимать решения, выраженные в виде выходных данных, вместо исполнения статических машиночитаемых команд.
[87] Алгоритмы MLA обычно используются в качестве моделей оценивания, моделей ранжирования, моделей классификации и т.п. Должно быть понятно, что для различных задач могут использоваться алгоритмы MLA различных видов с различными структурами или топологиями.
[88] Алгоритмы MLA определенного вида включают в себя нейронные сети (NN, Neural Networks). В общем случае сеть NN состоит из взаимосвязанных групп искусственных «нейронов», обрабатывающих информацию с использованием коннекционного подхода. Сети NN используются для моделирования сложных взаимосвязей между входными и выходными данными (без фактической информации об этих взаимосвязях) или для поиска закономерностей в данных. Сети NN сначала адаптируются на этапе обучения, когда они обеспечиваются известным набором входных данных и информацией для адаптации сети NN с целью формирования соответствующих выходных данных (для ситуации, в отношении которой выполняется попытка моделирования). На этом этапе обучения сеть NN адаптируется к изучаемой ситуации и изменяет свою структуру так, чтобы сеть NN была способна обеспечить адекватное предсказание выходных данных для входных данных в новой ситуации (на основе того, что было выучено). Таким образом, вместо попытки определения сложных статистических распределений или математических алгоритмов для ситуации, сеть NN пытается предоставить «интуитивный» ответ на основе «восприятия» ситуации.
[89] Сети NN широко используются во многих случаях, когда важно получить выходные данные на основе входных данных и менее важно или вовсе неважно то, как получаются эти выходные данные. Например, сети NN широко используются для оптимизации распределения веб-трафика между серверами, автоматического перевода текста на различные языки, а также при обработке данных, включая фильтрацию, кластеризацию, векторизацию и т.п.
[90] Вкратце, можно сказать, что реализация алгоритма 124 MLA сервером 106 может быть разделена на два основных этапа: этап обучения и этап использования. Сначала алгоритм MLA обучается на этапе обучения. Затем, когда алгоритму MLA известно, какие входные данные можно ожидать и какие выходные данные должны выдаваться, алгоритм MLA выполняется с реальными данными на этапе использования.
[91] Разработчики настоящей технологии установили, что обработка и/или подготовка данных для обучения алгоритма 124 MLA формированию переведенного контента может, в известном смысле, обеспечить алгоритму 124 MLA возможность «научиться» лучше переводить контент. Например, разработчики настоящей технологии установили, что сегментация на подслова в отношении текстовых последовательностей, подлежащих использованию в качестве части обучающих данных, может быть полезной для обучения алгоритма 124 MLA.
[92] Один из способов сегментации на подслова заключается в использовании алгоритма BPE при подготовке обучающих данных. В общем случае алгоритм BPE сохраняет часто встречающиеся слова без изменений и разделяет редкие или неизвестные слова на последовательность подслов. Благодаря применению подслов при обучении модель перевода (например, алгоритм 124 MLA) может использовать морфологию, композицию слова и транслитерацию слов, чтобы лучше выполнять задачи перевода.
[93] Разработчики настоящей технологии установили, что традиционный алгоритм BPE имеет ряд недостатков вследствие его детерминированного характера - он предполагает разделение слов на однозначно определяемые последовательности подслов, т.е. для каждого слова модель формирует лишь один вариант сегментации. Разработчики настоящей технологии разработали способ и систему, которые улучшают традиционные системы перевода на основе алгоритма BPE и (а) лучше используют морфологию, (б) более эффективны при обучении учету композиционности слов и (в) более устойчивы к ошибкам сегментации.
[94] Несмотря на то, что здесь представлены варианты осуществления изобретения, предназначенные для обработки данных с целью формирования обучающих данных для обучения алгоритма 124 MLA выполнению задачи перевода, в других вариантах осуществления настоящей технологии описанные здесь способы и системы могут способствовать обработке данных с целью формирования обучающих данных для обучения алгоритма 124 MLA выполнению других задач. Например, алгоритм 124 MLA может использоваться сервером 106 в качестве части приложения поисковой системы для предоставления лучших результатов поиска пользователям приложения поисковой системы. В другом примере алгоритм 124 MLA может использоваться сервером 106 в качестве части приложения выбора целевой рекламы для предоставления целевых рекламных объявлений пользователям приложения целевой рекламы. В еще одном примере алгоритм 124 MLA может использоваться сервером 106 в качестве части рекомендательного приложения для предоставления лучших рекомендаций контента пользователям рекомендательного приложения.
[95] В по меньшей мере некоторых вариантах осуществления настоящей технологии разработчики настоящей технологии разработали способ и систему, позволяющие формировать несколько альтернативных вариантов сегментации слова. В частности, разработчики настоящей технологии разработали способ и систему, позволяющие формировать несколько альтернативных вариантов сегментации слова с использованием фреймворка BPE. Также можно сказать, что разработчики настоящей технологии разработали модифицированный фреймворк BPE для формирования нескольких альтернативных вариантов сегментации слова путем добавления в него стохастической составляющей.
[96] Например, в традиционном фреймворке BPE система способна строить словарь подслов и таблицу слияний, указывающую на то, какие подслова должны сливаться в большее подслово (а также приоритеты соответствующих слияний). Во время сегментации слова сначала разделяются на последовательности символов, затем выученные итерации сливания применяются для сливания этих символов в бо́льшие известные подслова до тех пор, пока это возможно. В отличие от этого подхода, предложенный разработчиками настоящей технологии модифицированный фреймворк BPE использует способ регуляризации, совместимый с традиционным алгоритмом BPE. Модифицированный фреймворк BPE использует словарь и таблицу слияний, которая может быть построена с помощью алгоритма BPE, но на каждом шаге сливания некоторые слияния пропускаются случайным образом (запрещаются для текущего шага сливания). Таким образом в результате получаются различные альтернативные варианты сегментации для одного и того же слова.
[97] Ниже со ссылками на фиг. 3 более подробно описано выполнение традиционной сегментации на подслова с использованием традиционного фреймворка BPE и возможный вариант использования сервером 106 модифицированного фреймворка BPE.
База данных
[98] Система 100 также содержит базу 108 данных, связанную с сервером 106 и способную хранить информацию, извлеченную либо иным образом определенную или сформированную сервером 106 (см. фиг. 1 и 2). В целом, база 108 данных способна получать с сервера 106 данные, которые были извлечены либо иным образом определены или сформированы сервером 112 во время обработки, для временного и/или постоянного хранения и выдавать сохраненные данные серверу 106 для их использования. Предполагается, что база 108 данных может быть разделена на несколько распределенных баз данных без выхода за границы настоящей технологии. Ниже описано, какие данные база 108 данных может получать с сервера 108 и/или предоставлять ему.
[99] На фиг. 2 приведено представление 200 базы 108 данных, хранящей данные, согласно по меньшей мере некоторым вариантам осуществления настоящей технологии. В по меньшей мере некоторых вариантах осуществления изобретения предполагается, что в базе 108 данных могут храниться данные 210 словаря токенов и данные 230 слияний.
[100] Данные 210 словаря токенов (здесь также называются словарем токенов) могут содержать набор 220 токенов. Например, токен из набора 220 токенов может представлять собой один символ, такой как «a», «b», «c» и т.д. Другой токен из набора токенов может представлять собой многосимвольный токен, такой как «ab», «abc», «re», «un» и т.д. Предполагается, что многосимвольный токен может быть составлен из по меньшей мере двух односимвольных токенов. Также можно сказать, что многосимвольный токен может соответствовать токену, полученному в результате слияния по меньшей мере двух односимвольных токенов.
[101] В некоторых вариантах осуществления настоящей технологии сервер 106 может получать и сохранять в базе 108 данных данные 210 словаря токенов. В других вариантах осуществления сервер 106 может формировать и сохранять в базе 108 данных данные 210 словаря токенов. Предполагается, что в по меньшей мере одном не имеющем ограничительного характера варианте осуществления изобретения данные 210 словаря могут формироваться с применением традиционного фреймворка BPE.
[102] Независимо от того, получены или сформированы сервером данные 210 словаря токенов, они формируются на основе заранее заданного корпуса текстов. Например, сервер 106 может анализировать заранее заданный корпус текстов, определять в нем множество отдельных символов и множество многосимвольных последовательностей и идентифицировать их как соответствующие токены из набора 220 токенов. Можно сказать, что в некоторых вариантах осуществления изобретения с целью формирования словаря 210 токенов сервер 106 может выполнять процедуру инициализации для словаря символов на основе слов, обнаруженных в заранее заданном корпусе текстов. В некоторых вариантах осуществления изобретения этот заранее заданный корпус текстов может быть получен сервером 106 из одного или нескольких ресурсов из множества сетевых ресурсов 112.
[103] Предполагается, что в некоторых вариантах осуществления настоящей технологии данные 210 словаря токенов кроме набора 220 токенов могут содержать дополнительные данные о наборе 220 токенов из заранее заданного корпуса текстов.
[104] В еще одном варианте осуществления изобретения набор 220 токенов из словаря 210 токенов может содержать токен «UNK». Как описано ниже, сервер 106 может использовать токен «UNK», когда один или несколько символов подлежащего сегментации слова (из текстовой последовательности) неизвестны или не могут быть опознаны сервером 106. Кроме того, сервер 106 может заменять неизвестный или неподдающийся опознанию токен в окончательной последовательности сегментации токеном «UNK» из словаря 210 токенов (в некоторых вариантах осуществления изобретения это может быть полезно при обработке соответствующей текстовой последовательности для использования соответствующей текстовой последовательности в качестве обучающих данных при обучении алгоритма 124 MLA).
[105] Данные 230 слияний могут храниться в базе 108 данных в виде таблицы, которая здесь также называется таблицей слияний. Таблица 230 слияний указывает на множество 240 возможных слияний пар токенов из набора 220 токенов из словаря 210 токенов. Например, таблица 230 слияний может указывать на возможность слияния токенов «a» и «b» (из набора 220 токенов) и на невозможность слияния токенов «x» и «z» (из набора 220 токенов).
[106] Предполагается, что в некоторых вариантах осуществления изобретения сервер 106 может получать таблицу 230 слияний, а в других вариантах осуществления изобретения сервер 106 может формировать таблицу 230 слияний. Предполагается, что в по меньшей мере одном не имеющем ограничительного характера варианте осуществления изобретения таблица 230 слияний может формироваться с применением традиционного фреймворка BPE. В других вариантах осуществления изобретения сервер 106 может формировать таблицу 230 слияний путем выполнения процедуры инициализации на структуре пустой таблицы.
[107] Предполагается, что в некоторых вариантах осуществления настоящей технологии таблица 230 слияний кроме множества 240 возможных слияний может содержать дополнительные данные о токенах, связанных с соответствующими слияниями из множества 240 возможных слияний. Например, таблица 230 слияний может содержать данные, указывающие на частоту появления соответствующих токенов, связанных с соответствующими слияниями из множества 240 слияний и обнаруженных в заранее заданном корпусе текстов.
[108] Ниже со ссылками на фиг. 3 описано применение традиционного фреймворка BPE для сегментации на подслова и применение модифицированного фреймворка BPE, предложенного разработчиками настоящей технологии, для сегментации на подслова.
[109] На фиг. 3 представлена текстовая последовательность 300, содержащая, среди прочего, слово 302 «unrelated». Как описано выше, сервер 106 может получать текстовую последовательность 300 для ее подготовки к решению задачи машинной обработки алгоритмом 124 MLA. Следует отметить, что в некоторых вариантах осуществления настоящей технологии заранее заданный корпус текстов, используемый для формирования словаря 210 токенов, может не содержать текстовую последовательность 300. Например, сервер 106 может получать текстовую последовательность 300 для обработки и/или для подготовки текстовой последовательности 300 к использованию в качестве обучающих данных при обучении алгоритма 124 MLA.
Традиционный процесс сегментации на подслова
[110] На фиг. 3 представлен традиционный процесс 310 сегментации слова 302 на подслова (с применением традиционного фреймворка BPE). Как показано, традиционный процесс 310 сегментации на подслова включает в себя множество 312 итераций, на которых формируются различные последовательности токенов (на основе слова 302). Например, традиционный процесс 310 сегментации на подслова может начинаться с разделения слова 302 на первоначальную последовательность 314 токенов, представляющую собой отдельные символы слова 302, т.е. слово 302 разделяется на первоначальную последовательность 314 токенов «u» «n» «r» «e» «l» «a» «t» «e» «d».
[111] Следует отметить, что в традиционном процессе 310 сегментации на подслова может использоваться словарь 210 токенов и таблица 230 слияний. Например, словарь 210 токенов может быть доступен для формирования первоначальной последовательности 314 токенов. В том же примере на начальной итерации может быть доступна таблица 230 слияний и она может использоваться для определения набора возможных слияний пар соседних токенов из первоначальной последовательности 314 токенов. Можно предположить, что набор возможных слияний из множества 240 возможных слияний содержит возможное слияние соседних токенов «r» и «e» в слитый токен «re» и другие возможные слияния.
[112] Таблица 230 слияний также может быть доступна для определения частоты появления соответствующих слитых токенов из набора возможных слияний в первоначальной последовательности 314 токенов. Пусть слитый токен «re» связан с наибольшей частотой появления в таблице 230 слияний по сравнению с любым другим слитым токеном, который может быть получен путем применения других возможных слияний из набора возможных слияний. Тогда на начальной итерации первоначальная последовательность 314 токенов может подвергаться сливанию так, чтобы выполнялось потенциальное слияние из набора возможных слияний, обеспечивающее слитый токен, частота появления которого больше, чем у всех остальных слитых токенов из набора возможных слияний, которые могут быть получены. Таким образом, в этом случае первоначальная последовательность токенов объединяется так, так чтобы сформировать новую последовательность 316 токенов «u» «n» «re» «l» «a» «t» «e» «d». Затем эта новая последовательность 316 токенов используется в качестве текущей последовательности токенов на следующей итерации и, соответственно, следующая итерация выполняется на новой последовательности 316 токенов с необходимыми изменениями.
[113] Как показано на фиг. 3, после нескольких итераций, выполненных подобно начальной итерации, традиционный процесс 310 сегментации на подслова выдает окончательную последовательность токенов «unrelated», которая в этом случае представляет собой само слово 302. Важно отметить, что этот результат процесса 310 сегментации на подслова является детерминированным по своей природе, т.е. если такой же словарь токенов и такая же таблица слияний используются процессом 310 сегментации на подслова во время отдельных попыток сегментации слова 302, то окончательные последовательности токенов, сформированные традиционным процессом 310 сегментации на подслова при этих попытках, будут идентичными.
[114] Как описано выше, традиционный фреймворк BPE используется для разделения слов на однозначно определяемые последовательности подслов, т.е. при обработке каждого слова получается лишь один вариант сегментации. Это может быть нежелательно, поскольку такой подход может (а) создавать препятствия для учета морфологии слова, (б) затруднять обучение на основе композиции слова и (в) усугублять ошибки сегментации.
Модифицированный процесс сегментации на подслова
[115] В связи с этим в по меньшей мере некоторых вариантах осуществления настоящей технологии реализованы способ и система, способные выполнять модифицированный фреймворк BPE, являющийся стохастическим по своему характеру, т.е. при выполнении модифицированного процесса 320 сегментации слова на подслова окончательные последовательности токенов, полученные в результате соответствующих попыток сегментации этого слова, могут отличаться друг от друга.
[116] На фиг. 3 представлены три отдельные попытки сегментации слова 302 «unrelated». Например, сервер 106 может выполнить первую попытку сегментации в момент времени t1, вторую попытку сегментации в момент времени t2 и третью попытку сегментации в момент времени t3. Как показано, первая попытка сегментации включает в себя множество 322 итераций, вторая попытка сегментации включает в себя множество 332 итераций, а третья попытка сегментации включает в себя множество 342 итераций. Ниже более подробно описано выполнение сервером 106 первой попытки сегментации.
[117] Первая попытка сегментации может начинаться с использования сервером 106 словаря 210 токенов для разделения слова 302 на первоначальную последовательность 314 токенов «u» «n» «r» «e» «l» «a» «t» «e» «d». Следует отметить, что в некоторых вариантах осуществления изобретения это первоначальное разделение может быть выполнено подобно тому, как оно выполняется в традиционном процессе 310 сегментации на подслова. Определив первоначальную последовательность 314 токенов, сервер 106 может итеративно сливать (с использованием множества 322 итераций) токены из первоначальной последовательности 314 токенов для формирования окончательной последовательности 324 токенов.
Начальная итерация первой попытки сегментации
[118] На начальной итерации из множества 322 итераций сервер 106 может использовать таблицу 230 слияний для определения набора возможных слияний пар соседних токенов в текущей последовательности токенов для начальной итерации (на начальной итерации текущая последовательность токенов представляет собой первоначальную последовательность 314 токенов).
[119] Можно предположить, что сервер 106 с использованием таблицы 230 слияний определяет следующий набор возможных слияний:
«u» + «n», в результате которого получается «un»,
«n» + «r», в результате которого получается «nr»,
«r» + «e», в результате которого получается «re»,
«e» + «l», в результате которого получается «el»,
«l» + «a», в результате которого получается «la»,
«a» + «t», в результате которого получается «at»,
«t» + «e», в результате которого получается «te», и
«e» + «d», в результате которого получается «ed».
[120] При этом в отличие от традиционного процесса 310 сегментации, где слияние выбирается исключительно на основе того, какой получаемый при этом токен имеет наибольшую частоту появления в таблице 230 слияний, при выполнении процесса 320 сегментации на подслова сервер 106 может исключать по меньшей мере одно возможное слияние из набора возможных слияний. С этой целью сервер 106 может использовать вероятность такого исключения.
[121] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии вероятность исключения может быть задана заранее (например, оператором). Пусть заранее заданная вероятность исключения равна 0,1. Это означает, что сервер 106 может выполнять алгоритм исключения, способный исключать возможное слияние из набора возможных слияний с вероятностью 10%. Это может повторяться сервером 106 для каждого слияния из набора возможных слияний. Можно сказать, что сервер 106 может выполнять алгоритм исключения, способный выполнять стохастическое исключение по меньшей мере некоторых возможных слияний из набора возможных слияний.
[122] В других не имеющих ограничительного характера вариантах осуществления изобретения сервер 106 способен выполнять алгоритм исключения, способный назначать соответствующим слияниям из набора возможных слияний случайное значение в диапазоне от 0 до 1. В некоторых случаях алгоритм может случайным образом назначать случайные значения соответствующим слияниям из набора возможных слияний. После назначения случайных значений соответствующим слияниям из набора возможных слияний сервер 106 может сравнивать эти случайные значения с заранее заданным пороговым значением. Если случайное значение больше заранее заданного порогового значения, то соответствующее возможное слияние из набора возможных слияний включается в состав сокращенного набора возможных слияний. Если случайное значение меньше заранее заданного порогового значения, то соответствующее возможное слияние из набора возможных слияний исключается из сокращенного набора возможных слияний.
[123] Иными словами, сервер 106 может определять сокращенный набор возможных слияний из набора возможных слияний путем назначения соответствующим слияниям из набора возможных слияний случайных значений (например, случайных значений в диапазоне от 0 до 1) и проверки того, больше или меньше они заранее заданного порога. Эта проверка может использоваться сервером 106 в качестве критерия включения и/или исключения, определяющего, должно ли возможное слияние из набора возможных слияний входить в состав сокращенного набора возможных слияний. Также можно сказать, что в этом не имеющем ограничительного характера варианте осуществления изобретения сервер 106 может выполнять алгоритм, способный выполнять стохастическое исключение по меньшей мере некоторых возможных слияний из набора возможных слияний.
[124] В еще одном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 106 может исключать по меньшей мере одно слияние из набора возможных слияний путем использования алгоритма, способного выдавать случайное значение из диапазона от 0 до 1, указывающее на то, должно ли исключаться это по меньшей мере одно слияние из набора возможных слияний. Это случайное значение также может сравниваться с заранее заданным пороговым значением. Например, если случайное значение меньше заранее заданного порогового значения, то сервер 106 может определять, что по меньшей мере одно слияние из набора возможных слияний не должно исключаться. Если случайное значение больше заранее заданного порогового значения, то сервер 106 может определять, что по меньшей мере одно слияние из набора возможных слияний должно быть исключено (например, случайным образом). Также можно сказать, что в этом не имеющем ограничительного характера варианте осуществления изобретения сервер 106 может выполнять алгоритм, способный выполнять стохастическое исключение по меньшей мере некоторых возможных слияний из набора возможных слияний.
[125] В итоге предполагается, что в контексте настоящей технологии сервер 106 может использовать один или несколько стохастических процессов для исключения одного или нескольких слияний из набора возможных слияний. Предполагается, что с этой целью сервер 106 может использовать заранее заданную вероятность исключения, чтобы обеспечить стохастическое исключение по меньшей мере одного слияния из набора возможных слияний.
[126] Пусть на этой начальной итерации (см. фиг. 3) сервер 106 использует вероятность исключения для исключения из набора возможных слияний
«u» + «n», в результате которого получается «un»,
«n» + «r», в результате которого получается «nr»,
«r» + «e», в результате которого получается «re»,
«e» + «l», в результате которого получается «el»,
«l» + «a», в результате которого получается «la»,
«a» + «t», в результате которого получается «at»,
«t» + «e», в результате которого получается «te», и
«e» + «d», в результате которого получается «ed»,
следующих возможных слияний:
«n» + «r», в результате которого получается «nr»,
«a» + «t», в результате которого получается «at», и
«e» + «d», в результате которого получается «ed».
Тогда сервер 106 может сформировать следующий сокращенный набор возможных слияний для этой начальной итерации:
«u» + «n», в результате которого получается «un»,
«r» + «e», в результате которого получается «re»,
«e» + «l», в результате которого получается «el»,
«l» + «a», в результате которого получается «la», и
«t» + «e», в результате которого получается «te».
[127] Затем сервер 106 может обратиться к словарю 210 токенов для выбора подлежащего выполнению слияния из сокращенного набора возможных слияний начальной итерации. Например, сервер 106 может определить из таблицы 230 слияний, что слитый токен «re» имеет бо́льшую вероятность появления, чем любой другой слитый токен, который может быть получен с использованием сокращенного набора возможных слияний. Иными словами, сервер 106 может определить, что частота появления слитого токена «re» больше, чем любого из токенов «un», «el», «la» и «te».
[128] В результате сервер 106 может выполнить возможное слияние «r» + «e» из сокращенного набора возможных слияний и таким образом получить токен «re». Таким образом, сервер 106 может сформировать новую последовательность 326 токенов «u» «n» «re» «l» «a» «t» «e» «d». Затем сервер 106 может использовать новую последовательность 326 токенов в качестве текущей последовательности токенов для следующей итерации из множества 322 итераций.
[129] Следует отметить, что в этом конкретном примере начальной итерации процесса 320 сегментации на подслова сервер 106 может сформировать новую последовательность 326 токенов, идентичную новой последовательности 316 токенов, сформированной традиционным процессом 310 сегментации на подслова. Это объясняется тем, что в данном конкретном примере предполагалось, что сервер 106 выполнил стохастическое исключение возможных слияний, которые не включают в себя возможное слияние «r» + «e», связанное с наибольшей частотой появления.
[130] Тем не менее, как это показано ниже со ссылками на начальную итерацию третьей попытки сегментации, описанный выше конкретный пример, в котором получается новая последовательность 326 токенов, идентичная новой последовательности 316 токенов, сформированной традиционным процессом 310 сегментации на подслова, представляет собой случайное совпадение.
Начальная итерация третьей попытки сегментации
[131] Пусть, как и в предыдущем примере, текущая последовательность токенов на этой начальной итерации представляет собой первоначальную последовательность 314 токенов и что сервер 106 определяет тот же набор возможных слияний для этой начальной итерации:
«u» + «n», в результате которого получается «un»,
«n» + «r», в результате которого получается «nr»,
«r» + «e», в результате которого получается «re»,
«e» + «l», в результате которого получается «el»,
«l» + «a», в результате которого получается «la»,
«a» + «t», в результате которого получается «at»,
«t» + «e», в результате которого получается «te», и
«e» + «d», в результате которого получается «ed»,
[132] При этом пусть, в отличие от предыдущего примера, на этой начальной итерации сервер 106 использует заранее заданную вероятность исключения для исключения из набора возможных слияний
«u» + «n», в результате которого получается «un»,
«n» + «r», в результате которого получается «nr»,
«r» + «e», в результате которого получается «re»,
«e» + «l», в результате которого получается «el»,
«l» + «a», в результате которого получается «la»,
«a» + «t», в результате которого получается «at»,
«t» + «e», в результате которого получается «te», и
«e» + «d», в результате которого получается «ed»,
следующих возможных слияний:
«n» + «r», в результате которого получается «nr»,
«r» + «e», в результате которого получается «re», и
«e» + «l», в результате которого получается «el».
Тогда сервер 106 может сформировать следующий сокращенный набор возможных слияний для этой начальной итерации:
«u» + «n», в результате которого получается «un»,
«l» + «a», в результате которого получается «la»,
«a» + «t», в результате которого получается «at»,
«t» + «e», в результате которого получается «te», и
«e» + «d», в результате которого получается «ed».
[133] Затем сервер 106 может обратиться к словарю 210 токенов для выбора подлежащего выполнению слияния из сокращенного набора возможных слияний для этой начальной итерации. Например, сервер 106 может определить из таблицы 230 слияний, что слитый токен «at» имеет бо́льшую вероятность появления, чем любой другой слитый токен, который может быть получен с использованием сокращенного набора возможных слияний. Иными словами, сервер 106 может определить, что частота появления слитого токена «at» больше, чем любого из токенов «un», «la», «te» и «ed».
[134] В результате сервер 106 может выполнить возможное слияние «a» + «t» из сокращенного набора возможных слияний и таким образом получить токен «at». Таким образом, сервер 106 способен сформировать новую последовательность 346 токенов «u» «n» «r» «e» «l» «at» «e» «d». Затем сервер 106 может использовать новую последовательность 346 токенов в качестве текущей последовательности токенов для следующей итерации из множества 342 итераций.
[135] Как показано, в этом конкретном примере сервер 106, выполняющий стохастическое исключение по меньшей мере некоторых слияний из набора возможных слияний, способен обеспечивать формирование новой последовательности 346 токенов, которая отличается от новой последовательности 316 токенов, сформированной во время выполнения традиционного процесса 310 сегментации на подслова. При этом сервер 106, выполняющий один и тот же процесс во время начальной итерации первой попытки сегментации и во время начальной итерации третьей попытки сегментации, сформировал две отличающихся последовательности токенов. Иными словами, во время начальной итерации первой попытки сегментации сервер 106 сформировал новую последовательность 326 токенов, а во время начальной итерации третьей попытки сегментации сервер 106 сформировал новую последовательность 346 токенов. Различие между новыми последовательностями токенов, сформированными для одной и той же текущей последовательности токенов, возникает вследствие стохастического исключения некоторого возможного слияния (или нескольких слияний) из набора возможных слияний.
[136] Таким образом, как показано на фиг. 3, несмотря на то, что первая попытка сегментации, вторая попытка сегментации и третья попытка сегментации начинаются с одной и той же последовательности токенов (с первоначальной последовательности 314 токенов), каждая попытка из числа первой попытки сегментации, второй попытки сегментации и третьей попытки сегментации завершается с разными окончательными последовательностями токенов. Иными словами, (а) сервер 106, выполняющий множество 322 итераций на основе первоначальной последовательности 314 токенов, формирует окончательную последовательность 324 токенов (в результате первой попытки сегментации), (б) сервер 106, выполняющий множество 332 итераций на основе первоначальной последовательности 314 токенов, формирует окончательную последовательность 334 токенов (в результате второй попытки сегментации) и (в) сервер 106, выполняющий множество 342 итераций на основе первоначальной последовательности 314 токенов, формирует окончательную последовательность 344 токенов (в результате третьей попытки сегментации), при этом окончательные последовательности 324, 334 и 344 отличаются друг от друга.
[137] Следует отметить, что способность сервера 106 формировать различные окончательные последовательности токенов с использованием процесса 320 сегментации на подслова может объясняться различными используемыми сокращенными наборами возможных слияний, при этом наличие различных используемых сокращенных наборов возможных слияний обусловлено стохастическим характером процесса 320 сегментации на подслова. В некоторых вариантах осуществления изобретения это различие может дополнительно объясняться использованием сервером 106 различных вероятностей исключения при соответствующих попытках сегментации.
[138] Вкратце, можно сказать, что в процессе 320 сегментации на подслова сервер 106 способен на итерации сливания (включая начальную итерацию сливания) использовать таблицу 230 слияний для определения набора возможных слияний пар соседних токенов в текущей последовательности токенов для текущей итерации сливания (если итерация сливания представляет собой начальную итерацию сливания, то текущая последовательность токенов представляет собой первоначальную последовательность токенов). Кроме того, в процессе 320 сегментации на подслова сервер 106 на итерации сливания способен исключать по меньшей мере одно слияние из набора возможных слияний на основе вероятности исключения и формировать таким образом сокращенный набор возможных слияний для этой итерации сливания. Реализация заранее заданной вероятности исключения может различаться, как описано выше, и может зависеть от конкретного варианта реализации настоящей технологии. При этом за счет использования сервером 106 вероятности исключения он может выполнять стохастическое исключение по меньшей мере одного слияния из набора возможных слияний с целью формирования соответствующего сокращенного набора возможных слияний для итерации сливания. Затем в процессе 320 сегментации на подслова сервер 106 способен на итерации сливания использовать сокращенный набор возможных слияний для формирования новой последовательности токенов путем выполнения по меньшей мере одного слияния из сокращенного набора возможных слияний в текущей последовательности токенов (например, выбор подлежащего выполнению слияния из сокращенного набора возможных слияний может основываться на частоте появления соответствующих слияний из сокращенного набора возможных слияний). Затем в процессе 320 сегментации на подслова сервер 106 способен использовать новую последовательность токенов в качестве текущей последовательности токенов для следующей итерации сливания.
[139] Следует отметить, что на другой итерации сливания после текущей итерации сливания сервер 106 может определять текущую последовательность токенов на другой итерации сливания в качестве подлежащей использованию в задаче машинной обработки окончательной последовательности токенов (например, такой как окончательные последовательности 324, 334 и 344 токенов), если отсутствуют возможные слияния в текущей последовательности токенов для другой итерации сливания.
[140] Следует отметить, что способ выполнения сервером 106 процесса 320 сегментации на подслова в по меньшей мере некоторых вариантах осуществления настоящей технологии более подробно описан в приложенной статье «BPE-dropout: простая и эффективная регуляризация подслов», содержание которой таким образом полностью включено в настоящий документ.
[141] В некоторых вариантах осуществления настоящей технологии сервер 106 может выполнять представленный на фиг. 4 способ 400 подготовки текстовой последовательности в задаче машинной обработки, подлежащей выполнению алгоритмом 124 MLA. Ниже более подробно описаны различные шаги способа 400.
Шаг 402: получение словаря токенов.
[142] Способ 400 начинается с шага 402, на котором сервер 106 получает словарь 210 токенов. Словарь 210 токенов содержит набор 220 токенов, как описано выше. Например, токен из набора 220 токенов может представлять собой один символ, такой как «a», «b», «c» и т.д. В другом примере другой токен из набора токенов может представлять собой многосимвольный токен, такой как «ab», «abc», «re», «un» и т.д. Предполагается, что многосимвольный токен может быть составлен из по меньшей мере двух односимвольных токенов. Также можно сказать, что многосимвольный токен может соответствовать токену, слитому из по меньшей мере двух односимвольных токенов.
[143] Следует отметить, что в некоторых вариантах осуществления настоящей технологии сервер 106 может формировать словарь 210 токенов. Например, сервер 106 может выполнять процедуру инициализации для словаря символов из заранее заданного корпуса текстов. В других вариантах осуществления изобретения словарь 210 токенов может быть построен сервером 106 с применением традиционного фреймворка BPE.
[144] В некоторых вариантах осуществления изобретения набор 220 токенов из словаря 210 токенов может содержать токен «UNK». Как описано выше, сервер 106 может использовать токен «UNK», когда один или несколько символов подлежащего сегментации слова (из текстовой последовательности) неизвестны или не могут быть опознаны сервером 106. Кроме того, сервер 106 может заменять неизвестный или неподдающийся опознанию токен в окончательной последовательности сегментации токеном «UNK» из словаря 210 токенов.
Шаг 404: получение таблицы слияний.
[145] Способ 400 продолжается на шаге 404, на котором сервер 106 получает таблицу 230 слияний, указывающую на возможные слияния пар токенов из набора 220 токенов или, иными словами, указывающую на множество 240 возможных слияний пар токенов из набора 220 токенов из словаря 210 токенов.
[146] Например, таблица 230 слияний может указывать на возможность слияния токенов «a» и «b» (из набора 220 токенов) и на невозможность слияния токенов «x» и «z» (из набора 220 токенов). Предполагается, что в некоторых вариантах осуществления изобретения таблица 230 слияний может быть получена сервером 106, а в других вариантах осуществления изобретения сервер 106 может сам формировать таблицу 230 слияний. Как описано выше, таблица 230 слияний может формироваться с применением традиционного фреймворка BPE. В дополнительных вариантах осуществления изобретения сервер 106 может формировать таблицу 230 слияний путем выполнения процедуры инициализации на структуре пустой таблицы.
[147] Следует отметить, что таблица 230 слияний может дополнительно содержать данные, указывающие на частоту появления токенов из соответствующих слияний из множества 240 возможных слияний. Например, частота появления токена в слиянии из множества 240 возможных слияний может соответствовать его частоте появления в заранее заданном корпусе текстов.
Шаг 406: получение текстовой последовательности, указывающей на по меньшей мере одно слово.
[148] Способ 400 продолжается на шаге 406, на котором сервер 106 получает текстовую последовательность 300, содержащую слово 302. Текстовая последовательность 300 может быть использована для обучения алгоритма 124 MLA. При этом сервер 106, выполняющий способ 400, способен обрабатывать текстовую последовательность 300 таким образом, чтобы она могла быть использована в качестве обучающих данных для алгоритма 124 MLA.
[149] Следует отметить, что в по меньшей мере некоторых вариантах осуществления изобретения заранее заданный корпус текстов может содержать или не содержать текстовую последовательность 300 без выхода за границы настоящей технологии.
Шаг 408: использование словаря токенов для слова из текстовой последовательности с целью разделения этого слова на первоначальную последовательность токенов.
[150] Способ 400 продолжается на шаге 408, на котором сервер 106 может использовать словарь 210 токенов для разделения слова 302 (или любого другого слова из текстовой последовательности 300) на первоначальную последовательность 314 токенов. Первоначальная последовательность 314 токенов представляет собой отдельные символы слова 302. Например, сервер 106 может обращаться к словарю токенов с целью получения токена для каждого соответствующего символа слова 302.
Шаг 410: итеративное сливание токенов из первоначальной последовательности токенов для слова из текстовой последовательности с целью формирования окончательной последовательности токенов для этого слова.
[151] Способ 400 продолжается на шаге 410, на котором сервер 106 итеративно сливает токены из первоначальной последовательности 314 токенов с целью формирования окончательной последовательности токенов для слова 302. Например, итеративное сливание, выполняемое сервером 106, может соответствовать выполнению сервером 106 множества 322 итераций для формирования окончательной последовательности 324 токенов. В другом примере итеративное сливание, выполняемое сервером 106, может соответствовать выполнению сервером 106 множества 332 итераций для формирования окончательной последовательности 334 токенов. В еще одном примере итеративное сливание, выполняемое сервером 106, может соответствовать выполнению сервером 106 множества 342 итераций для формирования окончательной последовательности 344 токенов.
[152] Следует отметить, что слово 302 может представлять собой часть текстовой последовательности 300 и часть другой текстовой последовательности, подлежащей обработке сервером 106 с использованием процесса 320 сегментации на подслова. Например, сервер 106 может выполнять первую попытку сегментации слова 302 при обработке текстовой последовательности 300 и выполнять вторую попытку сегментации слова 302 при обработке другой текстовой последовательности. Предполагается, что в результате сервер 106 способен формировать окончательную последовательность 324 токенов для слова 302 из текстовой последовательности 300 и формировать окончательную последовательность 334 токенов для слова 302 из другой текстовой последовательности. В некоторых вариантах осуществления изобретения различие между окончательной последовательностью 334 токенов и окончательной последовательностью 344 токенов может объясняться различием сокращенных наборов возможных слияний, использованных сервером 106 при соответствующих попытках сегментации слова 302, и может быть обусловлено стохастическим характером процесса 320 сегментации на подслова. Также предполагается, что это различие может объясняться различными вероятностями исключения, используемыми сервером 106 при первой попытке сегментации и при второй попытке сегментации.
[153] В некоторых вариантах осуществления настоящей технологии сервер 106 может использовать на итерации сливания заранее заданную вероятность и/или стохастический алгоритм для выборочного включения возможных слияний из набора возможных слияний в дополненный набор возможных слияний для этой итерации сливания. В некоторых случаях дополненный набор возможных слияний может быть тем же, что и набор возможных слияний, если сервер 106, использующий заранее заданную вероятность и/или стохастический алгоритм, выборочно не исключил никакое возможное слияние из набора возможных слияний. В некоторых случаях дополненный набор возможных слияний может быть меньше набора возможных слияний, если сервер 106, использующий заранее заданную вероятность и/или стохастический алгоритм, выборочно исключил какое-либо возможное слияние из набора возможных слияний. В этих вариантах осуществления изобретения сервер 106 может использовать дополненный набор возможных слияний для формирования новой последовательности токенов для итерации сливания путем выполнения по меньшей мере одного слияния из дополненного набора возможных слияний в текущей последовательности токенов подобно тому, как описано выше.
[154] Для специалиста в данной области могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
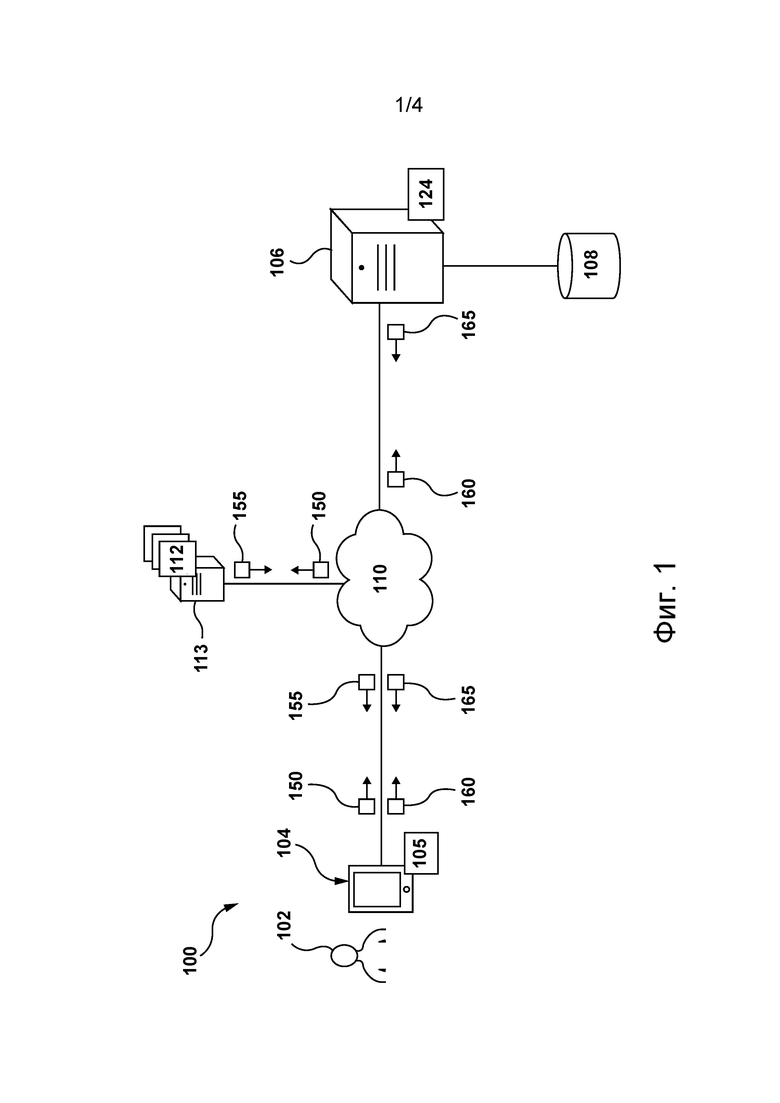
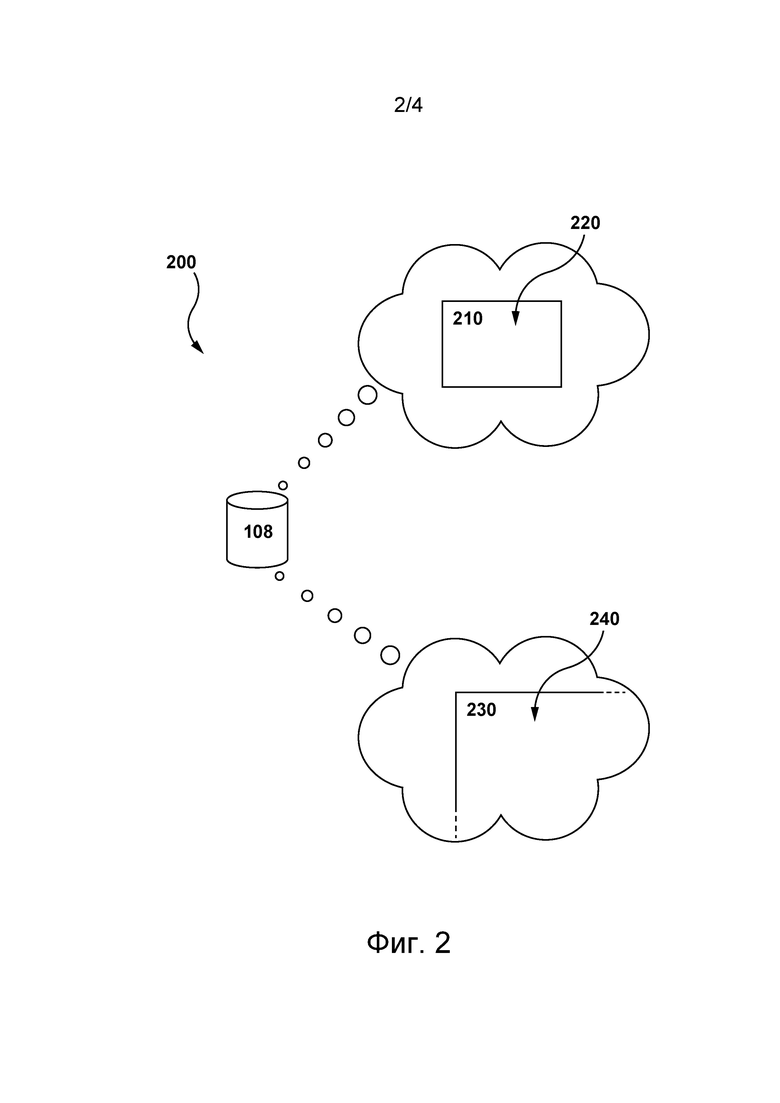
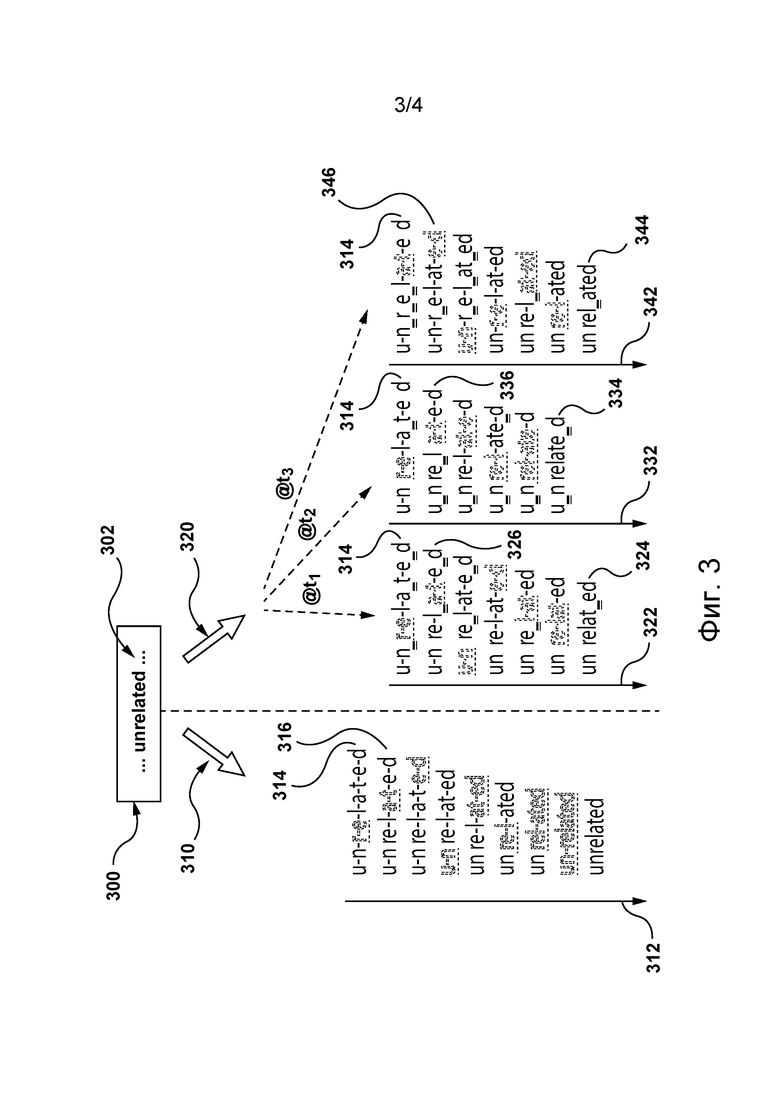
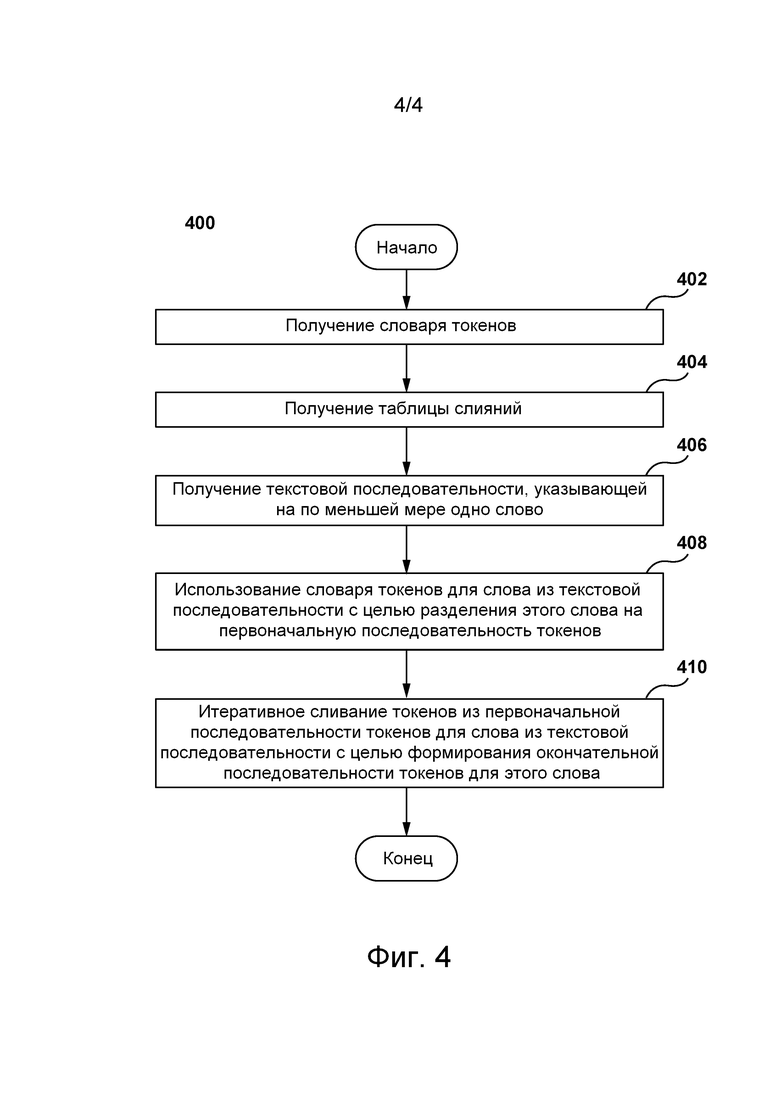
Изобретение относится к способам и серверу обработки текстовой последовательности в задаче машинной обработки. Технический результат заключается в повышении эффективности подготовки обучающих данных за счет получения нескольких вариантов сегментации слов. В способе выполняют получение сервером словаря токенов, в котором хранится набор токенов из заранее заданного корпуса текстов, при этом токен из набора токенов представляет собой один символ или слитый набор токенов; получение сервером таблицы слияний, указывающей на возможные слияния пар токенов из набора токенов, при этом токен из возможного слияния связан с частотой появления этого токена в заранее заданном корпусе текстов; получение сервером текстовой последовательности, указывающей на по меньшей мере одно слово; для слова из текстовой последовательности: использование сервером словаря токенов для разделения слова на первоначальную последовательность токенов, представляющую собой отдельные символы этого слова; итеративное сливание сервером токенов из первоначальной последовательности токенов с целью формирования окончательной последовательности токенов для этого слова, при этом итеративное сливание включает в себя: на текущей итерации сливания: использование сервером таблицы слияний для определения набора возможных слияний пар соседних токенов из текущей последовательности токенов для этой итерации сливания; исключение сервером по меньшей мере одного слияния из набора возможных слияний на основе вероятности исключения и формирование таким образом сокращенного набора возможных слияний для этой итерации сливания, при этом сокращенный набор возможных слияний меньше набора возможных слияний; использование сервером сокращенного набора возможных слияний для формирования новой последовательности токенов путем выполнения по меньшей мере одного слияния из сокращенного набора возможных слияний в текущей последовательности токенов, при этом новая последовательность токенов подлежит использованию сервером в качестве текущей последовательности токенов на следующей итерации сливания; на другой итерации сливания после текущей итерации сливания: определение сервером текущей последовательности токенов для другой итерации сливания в качестве окончательной последовательности токенов, подлежащей использованию в задаче машинной обработки, при отсутствии возможных слияний в текущей последовательности токенов для другой итерации сливания. 4 н. и 26 з.п. ф-лы, 4 ил.
1. Компьютерный способ обработки текстовой последовательности в задаче машинной обработки, подлежащей выполнению алгоритмом машинного обучения (MLA), выполняемый сервером и включающий в себя:
- получение сервером словаря токенов, в котором хранится набор токенов из заранее заданного корпуса текстов, при этом токен из набора токенов представляет собой один символ или слитый набор токенов;
- получение сервером таблицы слияний, указывающей на возможные слияния пар токенов из набора токенов, при этом токен из возможного слияния связан с частотой появления этого токена в заранее заданном корпусе текстов;
- получение сервером текстовой последовательности, указывающей на по меньшей мере одно слово;
для слова из текстовой последовательности:
- использование сервером словаря токенов для разделения слова на первоначальную последовательность токенов, представляющую собой отдельные символы этого слова;
- итеративное сливание сервером токенов из первоначальной последовательности токенов с целью формирования окончательной последовательности токенов для этого слова, при этом итеративное сливание включает в себя:
на текущей итерации сливания:
- использование сервером таблицы слияний для определения набора возможных слияний пар соседних токенов из текущей последовательности токенов для этой итерации сливания;
- исключение сервером по меньшей мере одного слияния из набора возможных слияний на основе вероятности исключения и формирование таким образом сокращенного набора возможных слияний для этой итерации сливания, при этом сокращенный набор возможных слияний меньше набора возможных слияний;
- использование сервером сокращенного набора возможных слияний для формирования новой последовательности токенов путем выполнения по меньшей мере одного слияния из сокращенного набора возможных слияний в текущей последовательности токенов, при этом новая последовательность токенов подлежит использованию сервером в качестве текущей последовательности токенов на следующей итерации сливания;
на другой итерации сливания после текущей итерации сливания:
- определение сервером текущей последовательности токенов для другой итерации сливания в качестве окончательной последовательности токенов, подлежащей использованию в задаче машинной обработки, при отсутствии возможных слияний в текущей последовательности токенов для другой итерации сливания.
2. Способ по п. 1, отличающийся тем, что использование сокращенного набора возможных слияний включает в себя выбор сервером по меньшей мере одного подлежащего выполнению слияния из сокращенного набора возможных слияний на основе соответствующей частоты появления для сокращенного набора возможных слияний.
3. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя получение указания на заранее заданную вероятность исключения.
4. Способ по п. 1, отличающийся тем, что алгоритм MLA представляет собой алгоритм MLA для нейронного машинного перевода.
5. Способ по п. 1, отличающийся тем, что алгоритм MLA предназначен для использования с приложением поисковой системы.
6. Способ по п. 1, отличающийся тем, что алгоритм MLA предназначен для использования с приложением выбора целевой рекламы.
7. Способ по п. 1, отличающийся тем, что он до получения словаря токенов и получения таблицы слияний дополнительно включает в себя формирование словаря токенов и таблицы слияний на основе заранее заданного корпуса текстов.
8. Способ по п. 7, отличающийся тем, что корпус текстов не содержит упомянутой текстовой последовательности.
9. Способ по п. 7, отличающийся тем, что формирование словаря токенов включает в себя процедуру инициализации на основе словаря символов.
10. Способ по п. 7, отличающийся тем, что формирование таблицы слияний включает в себя процедуру инициализации с пустой таблицей.
11. Способ по п. 1, отличающийся тем, что текстовая последовательность представляет собой первую текстовую последовательность, содержащую слово, а способ дополнительно включает в себя обработку второй текстовой последовательности, содержащей это слово, при этом первая окончательная последовательность токенов слова, связанного с первой текстовой последовательностью, отличается от второй окончательной последовательности токенов этого слова, связанного со второй текстовой последовательностью.
12. Способ по п. 11, отличающийся тем, что различие между первой окончательной последовательностью токенов и второй окончательной последовательностью токенов связано с различными использованными сокращенными наборами возможных слияний.
13. Способ по п. 12, отличающийся тем, что упомянутое различие дополнительно связано с различными использованными вероятностями исключения.
14. Компьютерный способ подготовки текстовой последовательности в задаче машинной обработки, подлежащей выполнению алгоритмом MLA, выполняемый сервером и включающий в себя:
- получение сервером словаря токенов, в котором хранится набор токенов из заранее заданного корпуса текстов, при этом токен из набора токенов представляет собой один символ или слитый набор токенов;
- получение сервером таблицы слияний, указывающей на возможные слияния пар токенов из набора токенов, при этом токен из возможного слияния связан с соответствующей частотой появления этого токена в заранее заданном корпусе текстов;
- получение сервером текстовой последовательности, указывающей на по меньшей мере одно слово;
для слова из текстовой последовательности:
- использование сервером словаря токенов для разделения слова на первоначальную последовательность токенов, представляющую собой отдельные символы этого слова;
- итеративное сливание сервером токенов из первоначальной последовательности токенов с целью формирования окончательной последовательности токенов для этого слова, при этом итеративное сливание включает в себя:
на текущей итерации сливания:
- использование сервером таблицы слияний для определения набора возможных слияний пар соседних токенов из текущей последовательности токенов для этой итерации сливания;
- использование сервером заранее заданной вероятности для выборочного включения возможных слияний из набора возможных слияний в дополненный набор возможных слияний для этой итерации сливания;
- использование сервером дополненного набора возможных слияний для формирования новой последовательности токенов путем выполнения по меньшей мере одного слияния из дополненного набора возможных слияний в текущей последовательности токенов, при этом новая последовательность токенов подлежит использованию сервером в качестве текущей последовательности токенов на следующей итерации сливания;
на другой итерации сливания после текущей итерации сливания:
- определение сервером текущей последовательности токенов для другой итерации сливания в качестве окончательной последовательности токенов, подлежащей использованию в задаче машинной обработки, при отсутствии возможных слияний в текущей последовательности токенов для другой итерации сливания.
15. Способ по п. 14, отличающийся тем, что дополненный набор возможных слияний меньше набора возможных слияний.
16. Способ по п. 14, отличающийся тем, что дополненный набор возможных слияний идентичен набору возможных слияний.
17. Сервер для обработки текстовой последовательности в задаче машинной обработки, подлежащей выполнению алгоритмом MLA, имеющий доступ к алгоритму MLA и выполненный с возможностью:
- получения словаря токенов, в котором хранится набор токенов из заранее заданного корпуса текстов, при этом токен из набора токенов представляет собой один символ или слитый набор токенов;
- получения таблицы слияний, указывающей на возможные слияния пар токенов из набора токенов, при этом токен из возможного слияния связан с частотой появления этого токена в заранее заданном корпусе текстов;
- получения текстовой последовательности, указывающей на по меньшей мере одно слово;
для слова из текстовой последовательности:
- использования словаря токенов для разделения слова на первоначальную последовательность токенов, представляющую собой отдельные символы этого слова;
- итеративного сливания токенов из первоначальной последовательности токенов с целью формирования окончательной последовательности токенов для этого слова, при этом итеративное сливание включает в себя:
на текущей итерации сливания:
- использования таблицы слияний для определения набора возможных слияний пар соседних токенов из текущей последовательности токенов для этой итерации сливания;
- исключения по меньшей мере одного слияния из набора возможных слияний на основе заранее заданной вероятности исключения и формирования таким образом сокращенного набора возможных слияний для этой итерации сливания, при этом сокращенный набор возможных слияний меньше набора возможных слияний;
- использования сокращенного набора возможных слияний для формирования новой последовательности токенов путем выполнения по меньшей мере одного слияния из сокращенного набора возможных слияний в текущей последовательности токенов, при этом новая последовательность токенов подлежит использованию сервером в качестве текущей последовательности токенов на следующей итерации сливания;
на другой итерации сливания после текущей итерации сливания:
- определения текущей последовательности токенов для другой итерации сливания в качестве окончательной последовательности токенов, подлежащей использованию в задаче машинной обработки, при отсутствии возможных слияний в текущей последовательности токенов для другой итерации сливания.
18. Сервер по п. 17, отличающийся тем, что способность использования сервером сокращенного набора возможных слияний включает в себя способность сервера к выбору по меньшей мере одного подлежащего выполнению слияния из сокращенного набора возможных слияний на основе соответствующей частоты появления для сокращенного набора возможных слияний.
19. Сервер по п. 17, отличающийся тем, что он дополнительно способен получать указание на заранее заданную вероятность исключения.
20. Сервер по п. 17, отличающийся тем, что алгоритм MLA представляет собой алгоритм MLA для нейронного машинного перевода.
21. Сервер по п. 17, отличающийся тем, что алгоритм MLA предназначен для использования с приложением поисковой системы.
22. Сервер по п. 17, отличающийся тем, что алгоритм MLA предназначен для использования с приложением выбора целевой рекламы.
23. Сервер по п. 17, отличающийся тем, что до получения словаря токенов и получения таблицы слияний он дополнительно способен формировать словарь токенов и таблицу слияний на основе заранее заданного корпуса текстов.
24. Сервер по п. 23, отличающийся тем, что корпус текстов не содержит упомянутой текстовой последовательности.
25. Сервер по п. 23, отличающийся тем, что формирование словаря токенов включает в себя процедуру инициализации на основе словаря символов.
26. Сервер по п. 23, отличающийся тем, что формирование таблицы слияний включает в себя процедуру инициализации с пустой таблицей.
27. Сервер по п. 17, отличающийся тем, что текстовая последовательность представляет собой первую текстовую последовательность, содержащую слово, а сервер дополнительно способен обрабатывать вторую текстовую последовательность, содержащую это слово, при этом первая окончательная последовательность токенов слова, связанного с первой текстовой последовательностью, отличается от второй окончательной последовательности токенов этого слова, связанного со второй текстовой последовательностью.
28. Сервер по п. 27, отличающийся тем, что различие между первой окончательной последовательностью токенов и второй окончательной последовательностью токенов связано с различными использованными сокращенными наборами возможных слияний.
29. Сервер по п. 27, отличающийся тем, что упомянутое различие дополнительно связано с различными использованными вероятностями исключения.
30. Компьютерный способ обработки текстовой последовательности в задаче машинной обработки, подлежащей выполнению алгоритмом MLA, выполняемый сервером и включающий в себя:
- получение сервером словаря токенов, в котором хранится набор токенов из заранее заданного корпуса текстов, при этом токен из набора токенов представляет собой один символ или слитый набор токенов;
- получение сервером таблицы слияний, указывающей на возможные слияния пар токенов из набора токенов, при этом токен из возможного слияния связан с частотой появления этого токена в заранее заданном корпусе текстов;
- получение сервером текстовой последовательности, указывающей на по меньшей мере одно слово;
для слова из текстовой последовательности:
- использование сервером словаря токенов для разделения слова на первоначальную последовательность токенов, представляющую собой отдельные символы этого слова;
- итеративное сливание сервером токенов из первоначальной последовательности токенов с целью формирования окончательной последовательности токенов для этого слова, при этом итеративное сливание включает в себя:
на текущей итерации сливания:
- использование сервером таблицы слияний для определения набора возможных слияний пар соседних токенов из текущей последовательности токенов для этой итерации сливания;
- использование сервером стохастического алгоритма для исключения по меньшей мере одного слияния из набора возможных слияний и формирование таким образом сокращенного набора возможных слияний для этой итерации сливания, при этом сокращенный набор возможных слияний меньше набора возможных слияний;
- использование сервером сокращенного набора возможных слияний для формирования новой последовательности токенов путем выполнения по меньшей мере одного слияния из сокращенного набора возможных слияний в текущей последовательности токенов, при этом новая последовательность токенов подлежит использованию сервером в качестве текущей последовательности токенов на следующей итерации сливания;
на другой итерации сливания после текущей итерации сливания:
- определение сервером текущей последовательности токенов для другой итерации сливания в качестве окончательной последовательности токенов, подлежащей использованию в задаче машинной обработки, при отсутствии возможных слияний в текущей последовательности токенов для другой итерации сливания.
| Taku Kudo, "Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates", Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), DOI: 10.18653/v1/P18-1007, июль 2018, доступно" https://aclanthology.org/P18-1007.pdf | |||
| Tamali Banerjee и др., |

