Область техники, к которой относится изобретение
[01] Настоящая технология в целом относится к машинному переводу и, в частности, к способу и серверу для выполнения проблемно-ориентированного перевода.
Уровень техники
[02] По мере увеличения количества пользователей, имеющих доступ к сети Интернет, возникает огромное число интернет-сервисов. Такие сервисы, например, включают в себя поисковые системы (в том числе, такие как поисковые системы Yandex™ и Google™), позволяющие пользователям получать информацию путем отправки запросов поисковой системе. Кроме того, благодаря социальным сетям и мультимедийным сервисам множество пользователей с различным социальным и культурным опытом могут общаться на унифицированных платформах с целью обмена контентом и информацией. Цифровой контент и другие данные, которыми обмениваются пользователи, могут быть представлены на множестве языков. Поэтому вследствие постоянно растущего объема информации, обмен которой происходит в сети Интернет, часто используются сервисы перевода, например, такие как Yandex.Translate™.
[03] Последний сервис особенно полезен, поскольку с его помощью пользователи могут легко переводить текст (или даже устную речь) с одного языка, непонятного данному пользователю, на другой понятный ему язык. Это означает, что сервисы перевода обычно разрабатываются для предоставления переведенного варианта контента на понятном пользователю языке, чтобы сделать контент доступным для пользователя.
[04] Системы перевода обучаются на основе большого количества примеров параллельных предложений на исходном языке и языке перевода. Тем не менее, традиционные компьютерные системы, предоставляющие услуги перевода, по-прежнему имеют много недостатков, например, неправильно переводят редкие слова или слова, специфичные для конкретной области.
[05] В патенте US9311299 описаны способ и система для маркировщика частей речи, который может быть особенно полезен для языков с ограниченными ресурсами.
Раскрытие изобретения
[06] Разработчики настоящей технологии выявили определенные технические недостатки, связанные с имеющимися сервисами перевода. Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений. Разработчики настоящей технологии установили, что модели перевода могут быть усовершенствованы для предоставления лучшего проблемно-ориентированного перевода предложений.
Нейронный машинный перевод (NMT, Neural Machine Translation)
[07] Нейронные сети (NN, Neural Networks) обеспечили значительный прогресс в обработке естественного языка и в машинном переводе. В моделях перевода часто используются сети NN с трансформерной архитектурой. Это по меньшей мере частично объясняется способностью механизма внимания трансформерных архитектур учитывать широкий контекст, предоставляемый в сетях с долгой краткосрочной памятью (LSTM, Long Short-Term Memory) и более поздних разработках.
[08] В общем случае модель NMT во время обучения просматривает предложение 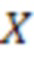 из входных слов
из входных слов 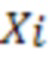 (каждое представлено в виде одного или нескольких входных токенов) на исходном языке и формирует его перевод
(каждое представлено в виде одного или нескольких входных токенов) на исходном языке и формирует его перевод  , состоящий из выходных слов
, состоящий из выходных слов 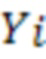 (каждое представлено одним или несколькими выходными токенами). Для обучения модели NMT требуются предложения из корпуса параллельных текстов, т.е. из набора данных, содержащего предложения на исходном языке и соответствующие им предложения на языке перевода. Модель NMT обычно обучается оцениванию вероятности
(каждое представлено одним или несколькими выходными токенами). Для обучения модели NMT требуются предложения из корпуса параллельных текстов, т.е. из набора данных, содержащего предложения на исходном языке и соответствующие им предложения на языке перевода. Модель NMT обычно обучается оцениванию вероятности 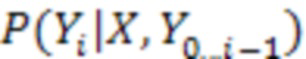 наблюдения выходного слова при заданном входном предложении и всех предыдущих словах
наблюдения выходного слова при заданном входном предложении и всех предыдущих словах 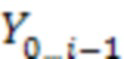 , например, с применением метода максимального правдоподобия.
, например, с применением метода максимального правдоподобия.
[09] Переводы формируются в процессе, называемом декодированием. Цель процесса декодирования для модели NMT заключается в поиске наиболее вероятного перевода , который описывается следующим образом:
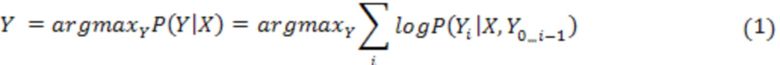
для исходного предложения , оцениваемого моделью NMT. Тем не менее, точное определение этого перевода может быть трудновыполнимым с вычислительной точки зрения, поэтому вместо этого часто используется аппроксимация в виде лучевого поиска. В общем случае в компьютерных науках лучевой поиск соответствует эвристическому алгоритму поиска, который исследует граф, разворачивая наиболее перспективный узел из ограниченного набора, при этом в качестве кандидатов сохраняется лишь заранее заданное количество лучших частных решений.
[10] Перевод может формироваться итеративно по одному слову. В начале каждой итерации имеется k префиксов перевода, также называемых гипотезами. Затем из всех состоящих из одного токена продолжений предыдущих k префиксов выбираются k новых лучших гипотез, ранжированных по соответствующей вероятности. Если одно из выбранных продолжений состоит из специального токена конца последовательности (EOS, End-Of-Sequence), то оно считается завершенным и исключается из текущих k лучших. Процесс может быть остановлен, когда максимальная вероятность текущих незавершенных гипотез меньше вероятности текущей наилучшей завершенной гипотезы и/или по достижении заранее заданного максимального количества итераций.
[11] На фиг. 8 представлен пример графа 800 лучевого поиска для модели NMT, переводящей входное предложение «a cat sat on a mat» («на циновке сидела кошка»). В этом примере модель NMT обучается переводить с английского языка на русский язык и использует лучевой поиск с размером луча k = 2.
[12] Граф 800 лучевого поиска содержит токены-кандидаты 801-809 и 821-828, а также соответствующие вероятности. Последовательность 850 выходных токенов выбирается из графа 800 лучевого поиска на основе соответствующих логарифмических вероятностей, нормализованных по длине. Как показано, последовательность 850 выходных токенов содержит токены 801-809. Токен 801 является токеном начала последовательности (BOS, Beginning-Of-Sequence), токен 802 представляет слово «на», токены 803, 804 и 805 представляют слово «циновке», токены 806 и 807 представляют слово «сидела», токен 808 представляет слово «кошка», токен 809 является токеном EOS.
[13] Разработчики настоящей технологии установили, что такая модель NMT некачественно переводит входные предложения в особых областях и/или неспособна правильно переводить некоторые редкие слова. Например, проблемно-ориентированному переводу слова «mat» на русский язык вместо слова «циновка» может соответствовать слово «матрас». Кроме того, следует отметить, что для повторного обучения модели NMT для каждой области требуется большое количество вычислений и что для такого обучения может быть доступно лишь небольшое количество проблемно-зависимых данных.
Управляемая модель NMT
[14] Некоторые модели NMT называются управляемыми моделями NMT, поскольку они могут использовать некоторые дополнительные «знания» о выходном предложении для управления формируемыми переводами. Управлять формируемыми переводами можно различными способами.
[15] В некоторых случаях управление выходным предложением может обеспечиваться путем выполнения ограниченного лучевого поиска. В общем случае при ограниченном лучевом поиске для каждого возможного состояния гипотезы выделяются дополнительные лучи. Например, могут использоваться 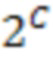 состояний, представляющие все возможные сочетания ограничений количеством
состояний, представляющие все возможные сочетания ограничений количеством 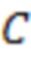 , которые могут удовлетворяться или не удовлетворяться. В другом примере могут использоваться
, которые могут удовлетворяться или не удовлетворяться. В другом примере могут использоваться 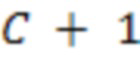 состояний, представляющих количество удовлетворенных ограничений. В каждом выделенном луче могут быть независимо рассчитаны и сохранены для последующих итераций k лучших гипотез. Если состояние гипотезы изменилось после добавления в конец нового токена, то эта гипотеза будет конкурировать только за место в луче, соответствующем новому состоянию. Условие завершения выполняется лишь для луча, соответствующего наиболее удовлетворенным ограничениям, и окончательный перевод берется из этого луча.
состояний, представляющих количество удовлетворенных ограничений. В каждом выделенном луче могут быть независимо рассчитаны и сохранены для последующих итераций k лучших гипотез. Если состояние гипотезы изменилось после добавления в конец нового токена, то эта гипотеза будет конкурировать только за место в луче, соответствующем новому состоянию. Условие завершения выполняется лишь для луча, соответствующего наиболее удовлетворенным ограничениям, и окончательный перевод берется из этого луча.
[16] В других случаях управление выходным предложением может обеспечиваться путем выполнения динамического выделения лучей (DBA, Dynamic Beam Allocation). В общем случае метод DBA предусматривает разделение одного луча на сегменты (buckets) для каждого состояния и динамическую корректировку размера каждого сегмента. Первоначально размеры сегментов могут быть распределены равномерно. Если сегмент содержит меньше гипотез, чем первоначально, то его размер распределяется между другими сегментами, при этом предпочтение отдается сегментам с наиболее удовлетворенными ограничениями (если у них достаточно гипотез для заполнения этого размера).
[17] Разработчики настоящей технологии установили, что несмотря на способность метода ограниченного лучевого поиска и метода DBA обеспечивать некоторое управление формируемым текстом, эти методы приводят к значительному увеличению вычислительной сложности модели и часто не справляются со своей задачей, применяя ограничения в отношении неправильных слов. Подобные ошибки могут возникать вследствие того, что управляемые таким образом модели NMT в известном смысле «не знают» о том, в отношении каких слов должны применяться ограничения.
[18] В других случаях управление выходным предложением может обеспечиваться путем применения управляемого словарем лучевого поиска. В общем случае такие методы могут использоваться для выделения обрабатываемых моделью входных слов при формировании текущего выходного слова и применении необходимых ограничений, если эти слова входят в состав рекомендации. Для реализации этого способа перед формированием следующего слова необходимо предсказывать сопоставление следующего формируемого слова и входного слова.
[19] Разработчики настоящей технологии установили, что надлежащее прогнозирование следующего сопоставления представляет собой сложную задачу, поскольку эталонных данных для сопоставления обычно имеется мало, а сама задача является мультимодальной. Иными словами, для различных продолжений гипотезы правильными могут быть различные сопоставления. Можно сказать, что такая модель может иметь тенденцию к повторению перевода несколько раз, поскольку она не распознает предыдущие переводы в сформированном префиксе. Разработчики также установили, что вследствие сложности получения правильных сопоставлений методы на основе сопоставления имеют те же недостатки, что и описанные выше ограниченный лучевой поиск и метод DBA, когда терминологические рекомендации применяются не полностью и/или в неправильном месте предложения. Кроме того, поскольку управляемая таким образом модель NMT в известном смысле «не знает» о том, какие исходные слова использованы в рекомендациях, модель стремится их переводить, поскольку не «видит» их переводы в сформированном префиксе.
[20] В других случаях управление выходным предложением может быть обеспечено путем использования дополнительных данных в качестве входной информации для модели (метод на основе входных данных). Таким моделям NMT известно, что перевод соответствует рекомендациям, и они менее подвержены недостаткам, подобным тем, что присущи описанным выше подходам. Эти подходы полагаются на саму модель NMT для получения корректных выходных данных. Разработчики настоящей технологии установили, что такие модели стремятся игнорировать эти входные данные, поскольку в них не предусмотрены выходные ограничения. Это особенно заметно в тех случаях, когда рекомендуемый перевод отклоняется от обучающего распределения.
Фреймворк «Рекомендации из двуязычных словарей» (HBD, Hints from Bilingual Dictionaries) для управляемой модели NMT
[21] Разработчики настоящей технологии разработали фреймворк для внедрения рекомендаций во входные предложения с целью обеспечения управления выходными предложениями, формируемыми моделью NMT. В общем случае этот фреймворк содержит три основных шага: (а) формирование обучающих примеров, (б) обучение модели NMT определению того, когда должны применяться ограничения на основе рекомендаций, и (в) применение ограничений при переводе.
[22] На первом шаге формируются обучающие данные, при этом система определяет соответствие между входными словами и эталонными выходными словами, представляющими их возможные переводы, чтобы сформировать контрольные переводы-рекомендации. Например, для сопоставления слов с целью получения контрольных сопоставлений может использоваться готовое инструментальное средство. Тем не менее, в некоторых вариантах осуществления настоящей для поиска возможных переводов входных слов в каждом обучающем примере из корпуса параллельных предложений технологии может использоваться двуязычный словарь.
[23] Входное предложение может быть дополнено путем в известном смысле «обертывания» исходного слова рекомендацией в следующем формате: <HINT_START> исходные_слова <HINT_SEPARATOR> слова_рекомендуемого_перевода <HINT_END>”. В этом не имеющем ограничительного характера примере соответствующая последовательность токенов, среди прочего, содержит специальный начальный токен <HINT_START>, специальный токен - разделитель перевода и рекомендации <HINT_SEPARATOR> и специальный конечный токен <HINT_END>. Специальный начальный токен может выбираться произвольным образом из заранее заданных начальных токенов, при этом значение 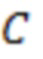 соответствует максимально возможному количеству рекомендаций в одном переведенном предложении. В некоторых вариантах осуществления изобретения для модели NMT может быть полезной рандомизация, чтобы выучивать надлежащие внутренние представления для всех специальных токенов. Следует отметить, что рекомендуемые переводы слов (проблемно-ориентированные переводы) могут вставляться в форме, представленной в словаре, а модель NMT впоследствии может выбирать их подходящую форму при формировании выходных данных.
соответствует максимально возможному количеству рекомендаций в одном переведенном предложении. В некоторых вариантах осуществления изобретения для модели NMT может быть полезной рандомизация, чтобы выучивать надлежащие внутренние представления для всех специальных токенов. Следует отметить, что рекомендуемые переводы слов (проблемно-ориентированные переводы) могут вставляться в форме, представленной в словаре, а модель NMT впоследствии может выбирать их подходящую форму при формировании выходных данных.
[24] Выходные слова, соответствующие исходным словам с рекомендациями, также «обернуты» подобным образом: <HINT_START> слова_перевода <HINT_END>. Следовательно, можно сказать, что обучающий пример может быть дополнен путем вставки рекомендации в соответствующие предложения, а соответствующие последовательности токенов, сформированные на основе дополненных предложений, содержат специальные токены, представляющие эту рекомендацию.
[25] На втором шаге модель NMT обучается. Этот шаг предназначен для обучения модели NMT использованию переводов-рекомендаций для определения того, когда в отношении выходных данных должны применяться ограничения.
[26] Следует отметить, что на этапе использования входные предложения могут быть дополнены тем же образом, что и на этапе обучения. Ограничения при формировании выходных данных не применяются, пока модель не выдаст первый специальный начальный токен <HINT_START>, обнаруженный в дополненном входном предложении. После выдачи такого специального начального токена в модели NMT применяются ограничения в отношении формирования только форм проблемно-ориентированного перевода, за которым следует специальный конечный токен <HINT_END>. В некоторых вариантах осуществления изобретения для получения допустимых форм проблемно-ориентированного перевода может быть использовано готовое инструментальное средство для лемматизации. Затем все ограничения могут быть сняты до тех пор, пока модель не выдаст следующий специальный начальный токен, и т.д. После завершения формирования моделью выходных данных специальные токены могут быть удалены для получения окончательного перевода.
[27] Разработчики настоящей технологии установили, что благодаря использованию таких специальных начальных токенов и специальных конечных токенов модель NMT получает позиционные данные. Например, специальный начальный токен используется для определения того, какие токены должны быть сформированы после него, поэтому модель NMT может назначать высокую вероятность правильному токену. В том же примере специальный конечный токен используется для определения того, что проблемно-ориентированный перевод слова уже сформирован.
[28] Следует отметить, что в некоторых вариантах осуществления настоящей технологии модель NMT сама по себе не может иметь ограничений или требований, касающихся формирования специального начального токена. Таким образом, ограничения применяются лишь в случае появления специальных начальных токенов в луче поиска «естественным образом». Разработчики установили, что отсутствие ограничений в модели NMT, касающихся формирования специальных начальных токенов, позволяет уменьшать отклонение для более раннего формирования проблемно-ориентированных переводов при декодировании.
[29] В некоторых вариантах осуществления изобретения метод DBA может применяться при декодировании в отношении ограничений без увеличения размера луча перевода. Дополнительно или в качестве альтернативы, вероятности правильных продолжений проблемно-ориентированных переводов могут увеличиваться. Разработчики установили, что параметр такого увеличения может быть настроен или скорректирован, поскольку величина корректировки вероятностей может быть слишком большой для одних предложений и слишком малой для других предложений.
[30] На фиг. 9 представлен пример графа 900 лучевого поиска для модели NMT, переводящей входное предложение «a cat sat on a mat» («на циновке сидела кошка»). В этом примере модель NMT обучается согласно фреймворку HBD переводу с английского языка на русский язык и использует лучевой поиск с размером луча k = 2, а также рекомендацию для слова «mat», при этом проблемно-ориентированному переводу слова «mat» соответствует слово «матрас».
[31] Граф 900 лучевого поиска содержит токены-кандидаты 901-910 и 921-929, а также соответствующие вероятности. Последовательность 950 выходных токенов выбирается из графа 900 лучевого поиска на основе соответствующих вероятностей. Как показано, последовательность 950 выходных токенов содержит токены 901-910. Токен 901 является токеном BOS, токен 902 представляет слово «на», токен 903 представляет специальный начальный токен, токены 904 и 905 представляют соответствующую ограничениям часть последовательности 950 выходных токенов и представляют слово «матрасе», токен 906 представляет специальный конечный токен, токены 907 и 908 представляют слово «сидела», токен 909 представляет слово «кошка», а токен 910 является токеном EOS.
[32] Следует отметить, что представленном примере после токена 903 в модели NMT применяется ограничение при формировании формы проблемно-ориентированного перевода слова «mat». По этой причине в графе 900 лучевого поиска токены 904, 905 и токены 904, 924 представляют соответствующие формы проблемно-ориентированного перевода слова «mat»: «матрасе» и «матрас», соответственно.
[33] Предполагается, что использование фреймворка HBD для управления выходными данными, формируемыми моделью NMT, может быть полезнее использования ограниченного лучевого поиска, поскольку последний требует увеличения вычислительной сложности модели.
[34] Предполагается, что использование фреймворка HBD для управления выходными данными, формируемыми моделью NMT, может быть полезнее использования традиционного метода DBA, поскольку качество перевода с использованием метода DBA снижается, когда количество ограничений превышает размер луча k. Основная причина этого заключается в том, что в методе DBA ограничения не зависят от того, какая часть входного предложения переводится, и все ограничения могут выполняться в начале перевода. В результате в луче не остается места для гипотез без выполненных ограничений и формируются неудовлетворительные переводы, где рекомендуемые переводы расположены в неправильном месте выходных данных. Более того, даже когда в методе DBA соблюдены все ограничения, ничто не мешает модели формировать нежелательные переводы слов с рекомендациями, если она не считает, что рекомендуемые переводы соответствуют этим словам с рекомендациями. В отличие от этого, фреймворк HBD позволяет применять ограничения в конкретных позициях формируемых выходных данных.
[35] Предполагается, что использование фреймворка HBD для управления выходными данными, формируемыми моделью NMT, может быть полезнее использования подходов на основе сопоставления вследствие неудовлетворительного качества предсказания сопоставлений, что приводит к ошибкам в формируемом тексте. В отличие от этого, фреймворк HBD обеспечивает механизм для модели NMT, позволяющий в известном смысле «оповещать» лучевой поиск о необходимости начать применять ограничения путем вставки токенов сопоставления как части декодирования. В некоторых вариантах осуществления изобретения можно сказать, что модель может выучивать правило, согласно которому эти токены должны появляться в выходных данных в случае их обнаружения во входных данных, а также она выучивает их наиболее вероятную позицию, которая затем выбирается при лучевом поиске. Таким образом, модель может сообщать о необходимости применения ограничений путем назначения высокой вероятности специальным начальным токенам. В других вариантах осуществления изобретения модель также может зависеть от начального токена <HINT_START> и обладать информацией о проблемно-ориентированных переводах, подлежащих формированию.
[36] В некоторых вариантах осуществления изобретения предполагается, что благодаря использованию разреженных ссылок для токенов сопоставления и выполнению сопоставления в качестве части декодирования модель может получать высокоточные сопоставления во время перевода и применять ограничения только в правильных позициях. Следует отметить, что высокоточное сопоставление не может приводить к низкой полноте (recall), поскольку модели NMT известно, что она должна формировать токен сопоставления и переводы, не допуская их низкой вероятности.
[37] Предполагается, что использование фреймворка HBD для управления выходными данными, формируемыми моделью NMT, может быть полезнее использования подходов на основе входных данных. Как описано выше, попытки внедрения дополнительных входных данных в модель NMT часто приводят к тому, что модель игнорирует эти входные данные. Во фреймворке HBD модель не только получает дополнительные входные данные для ее оптимизации, но и учитывает ограничения, чтобы гарантировать использование правильных переводов.
[38] В некоторых вариантах осуществления изобретения можно сказать, что при использовании большого количества терминологических рекомендаций фреймворк HBD не увеличивает вычислительных затрат и не теряет качества перевода, как в других подходах, использующих ограниченный лучевой поиск. В других вариантах осуществления изобретения можно сказать, что благодаря использованию фреймворка HBD модели NMT известно, когда и какие рекомендации переводятся, в отличие от метода ограниченного лучевого поиска и метода на основе сопоставления. В других вариантах осуществления изобретения можно сказать, что за счет использования фреймворка HBD сохраняются строгие гарантии ограничений в отличие от подходов, использующих только дополнительные входные данные. В дополнительных вариантах осуществления изобретения можно сказать, что фреймворк HBD может быть реализован независимо от базовой архитектуры модели NMT, что может быть полезно, поскольку современные программные архитектуры часто изменяются.
[39] Согласно первому аспекту настоящей технологии реализован способ выполнения проблемно-ориентированного перевода предложений с первого языка на второй язык. На сервере работает сеть NN и серверу доступен проблемно-ориентированный словарь, содержащий проблемно-ориентированные переводы слов с первого языка на второй язык. Способ выполняется сервером. Способ включает в себя формирование сервером дополненной последовательности входных токенов на основе входного предложения на первом языке и рекомендации, вставленной во входное предложение. Входное предложение содержит слово. Слово представлено в дополненной последовательности входных токенов в виде данного входного токена. Слово имеет проблемно-ориентированный перевод, представленный в виде другого токена. Рекомендация представлена в дополненной последовательности входных токенов в виде входного начального токена и входного конечного токена. Входной начальный токен вставлен в позицию, предшествующую данному входному токену, а входной конечный токен вставлен в позицию, следующую за данным входным токеном, для идентификации входного токена из дополненной последовательности входных токенов как данного входного токена. Способ включает в себя итеративное формирование сервером с применением сети NN последовательности выходных токенов на основе дополненной последовательности входных токенов. Способ при итеративном формировании включает в себя в ответ на формирование на данной итерации выходного начального токена в последовательности выходных токенов применение ограничивающего условия в отношении следующего выходного токена, который должен быть сформирован сетью NN для последовательности выходных токенов, таким образом, чтобы следующий выходной токен представлял собой другой токен. Способ при итеративном формировании включает в себя в ответ на формирование на другой итерации выходного конечного токена прекращение применения ограничивающего условия в отношении следующего токена, который должен быть сформирован сетью NN. Способ включает в себя формирование сервером второго предложения на втором языке, содержащего проблемно-ориентированный перевод входного слова, с использованием последовательности выходных токенов.
[40] В некоторых вариантах осуществления способа данный входной токен представляет собой подпоследовательность входных токенов и входное слово представлено этой подпоследовательностью входных токенов в дополненной последовательности входных токенов.
[41] В некоторых вариантах осуществления способа другой токен представляет собой другую подпоследовательность токенов и проблемно-ориентированный перевод слова представлен этой другой подпоследовательностью токенов.
[42] В некоторых вариантах осуществления способа проблемно-ориентированный словарь содержит множество проблемно-ориентированных переводов входного слова. Множество проблемно-ориентированных переводов представлено соответствующими подпоследовательностями из множества других подпоследовательностей токенов. Применение ограничивающего условия включает в себя применение ограничивающего условия в отношении следующей подпоследовательности выходных токенов, которые должны быть сформированы сетью NN для последовательности выходных токенов, таким образом, чтобы следующая подпоследовательность выходных токенов представляла собой подпоследовательность из множества других подпоследовательностей токенов.
[43] В некоторых вариантах осуществления способа следующая подпоследовательность выходных токенов завершается выходным конечным токеном.
[44] В некоторых вариантах осуществления способа множество проблемно-ориентированных переводов входного слова содержит грамматические варианты входного слова.
[45] В некоторых вариантах осуществления способа сеть NN представляет собой трансформерную модель, содержащую кодер и декодер. Способ дополнительно включает в себя формирование сервером на этапе обучения дополненной последовательности первых токенов на основе первого предложения на первом языке и первой рекомендации, вставленной в первое предложение. Первое предложение содержит первое слово. Первое слово представлено в дополненной последовательности первых токенов в виде данного первого токена. Первая рекомендация представлена в дополненной последовательности первых токенов в виде первого начального токена и первого конечного токена. Первый начальный токен вставлен в позицию, предшествующую данному первому токену, а первый конечный токен вставлен в позицию, следующую за данным первым токеном, для идентификации первого токена из дополненной последовательности первых токенов как данного первого токена. Способ дополнительно включает в себя формирование сервером на этапе обучения дополненной последовательности вторых токенов на основе второго предложения на втором языке и второй рекомендации, вставленной во второе предложение. Второе предложение представляет собой перевод первого предложения. Второе предложение содержит второе слово. Второе слово представляет собой проблемно-ориентированный перевод первого слова. Второе слово представлено в дополненной последовательности вторых токенов в виде данного второго токена. Вторая рекомендация представлена в дополненной последовательности вторых токенов в виде второго начального токена и второго конечного токена. Второй начальный токен вставлен в позицию, предшествующую данному второму токену, а второй конечный токен вставлен в позицию, следующую за данным вторым токеном, для идентификации второго токена из дополненной последовательности вторых токенов как данного второго токена. Способ на этапе обучения дополнительно включает в себя обучение сервером трансформерной модели путем предоставления дополненной последовательности первых токенов кодеру и дополненной последовательности вторых токенов декодеру таким образом, чтобы обучить декодер формированию выходного начального токена и выходного конечного токена в правильных позициях в последовательности выходных токенов.
[46] В некоторых вариантах осуществления способа рекомендация дополнительно представлена в дополненной последовательности входных токенов в виде специального токена перевода-рекомендации и другого токена, вставленных после данного входного токена и перед входным конечным токеном.
[47] В некоторых вариантах осуществления способа применение ограничивающего условия включает в себя обращение сервера к подпоследовательности токенов из «белого списка», содержащей другой токен и специальный конечный токен, и применение сервером ограничений для модели перевода при формировании подпоследовательности токенов из «белого списка» в качестве следующего выходного токена.
[48] Согласно второму аспекту настоящей технологии реализован способ обучения трансформерной модели выполнению перевода с первого языка на второй язык. Трансформерная модель содержит кодер и декодер. Сервер выполняет трансформерную модель. Способ включает в себя формирование сервером на этапе обучения дополненной последовательности первых токенов на основе первого предложения на первом языке и первой рекомендации, вставленной в первое предложение. Первое предложение содержит первое слово. Первое слово представлено в дополненной последовательности первых токенов в виде данного первого токена. Первая рекомендация представлена в дополненной последовательности первых токенов в виде первого начального токена и первого конечного токена. Первый начальный токен вставлен в позицию, предшествующую данному первому токену, а первый конечный токен вставлен в позицию, следующую за данным первым токеном, для идентификации первого токена из дополненной последовательности первых токенов как данного первого токена. Способ включает в себя формирование сервером на этапе обучения дополненной последовательности вторых токенов на основе второго предложения на втором языке и второй рекомендации, вставленной во второе предложение. Второе предложение представляет собой перевод первого предложения. Второе предложение содержит второе слово. Второе слово представляет собой проблемно-ориентированный перевод первого слова. Второе слово представлено в дополненной последовательности вторых токенов в виде данного второго токена. Вторая рекомендация представлена в дополненной последовательности вторых токенов в виде второго начального токена и второго конечного токена. Второй начальный токен вставлен в позицию, предшествующую данному второму токену, а второй конечный токен вставлен в позицию, следующую за данным вторым токеном, для идентификации второго токена из дополненной последовательности вторых токенов как данного второго токена. Способ на этапе обучения включает в себя обучение сервером трансформерной модели путем предоставления дополненной последовательности первых токенов кодеру и дополненной последовательности вторых токенов декодеру таким образом, чтобы обучить декодер формированию выходного начального токена и выходного конечного токена в правильных позициях в последовательности выходных токенов.
[49] В некоторых вариантах осуществления способ на этапе использования сети NN дополнительно включает в себя итеративное формирование сервером с применением сети NN дополненной последовательности выходных токенов на основе дополненной последовательности входных токенов. При итеративном формировании в ответ на формирование на данной итерации выходного начального токена в последовательности выходных токенов способ включает в себя применение ограничивающего условия в отношении следующего выходного токена, который должен быть сформирован сетью NN для дополненной последовательности выходных токенов, таким образом, чтобы следующий выходной токен представлял собой другой токен. При итеративном формировании в ответ на формирование выходного конечного токена на другой итерации способ включает в себя прекращение применения ограничивающего условия в отношении следующего выходного токена, который должен быть сформирован сетью NN. Способ на этапе использования сети NN дополнительно включает в себя формирование сервером второго предложения на втором языке с использованием дополненной последовательности выходных токенов.
[50] Согласно третьему аспекту настоящей технологии реализован сервер для выполнения проблемно-ориентированного перевода предложений с первого языка на второй язык. На сервере работает сеть NN и серверу доступен к проблемно-ориентированный словарь, содержащий проблемно-ориентированные переводы слов с первого языка на второй язык. Сервер способен формировать дополненную последовательность входных токенов на основе входного предложения на первом языке и рекомендации, вставленной во входное предложение. Входное предложение содержит слово. Слово представлено в дополненной последовательности входных токенов в виде данного входного токена. Слово имеет проблемно-ориентированный перевод, представленный в виде другого токена. Рекомендация представлена в дополненной последовательности входных токенов в виде входного начального токена и входного конечного токена. Входной начальный токен вставлен в позицию, предшествующую данному входному токену, а входной конечный токен вставлен в позицию, следующую за данным входным токеном, для идентификации входного токена из дополненной последовательности входных токенов как данного входного токена. Сервер способен итеративно формировать с применением сети NN последовательность выходных токенов на основе дополненной последовательности входных токенов. При итеративном формировании в ответ на формирование на данной итерации выходного начального токена в последовательности выходных токенов сервер способен применять ограничивающее условие в отношении следующего выходного токена, который должен быть сформирован сетью NN для последовательности выходных токенов, таким образом, чтобы следующий выходной токен представлял собой другой токен. При итеративном формировании в ответ на формирование выходного конечного токена на другой итерации сервер способен прекращать применение ограничивающего условия в отношении следующего токена, который должен быть сформирован сетью NN. Сервер способен формировать второе предложение на втором языке, содержащее проблемно-ориентированный перевод входного слова, с использованием последовательности выходных токенов.
[51] В некоторых вариантах осуществления сервера данный входной токен представляет собой подпоследовательность входных токенов и входное слово представлено этой подпоследовательностью входных токенов в дополненной последовательности входных токенов.
[52] В некоторых вариантах осуществления сервера другой токен представляет собой другую подпоследовательность токенов и проблемно-ориентированный перевод слова представлен этой другой подпоследовательностью токенов.
[53] В некоторых вариантах осуществления сервера проблемно-ориентированный словарь содержит множество проблемно-ориентированных переводов входного слова. Множество проблемно-ориентированных переводов представлено соответствующими подпоследовательностями из множества других подпоследовательностей токенов. Для применения ограничивающего условия сервер способен применять ограничивающее условие в отношении следующей подпоследовательности выходных токенов, которые должны быть сформированы сетью NN для последовательности выходных токенов, таким образом, чтобы следующая подпоследовательность выходных токенов представляла собой подпоследовательность из множества других подпоследовательностей токенов.
[54] В некоторых вариантах осуществления сервера следующая подпоследовательность выходных токенов завершается выходным конечным токеном.
[55] В некоторых вариантах осуществления сервера множество проблемно-ориентированных переводов входного слова содержит грамматические варианты входного слова.
[56] В некоторых вариантах осуществления сервера сеть NN представляет собой трансформерную модель, содержащую кодер и декодер, а сервер дополнительно способен формировать на этапе обучения дополненную последовательность первых токенов на основе первого предложения на первом языке и первой рекомендации, вставленной в первое предложение. Первое предложение содержит первое слово. Первое слово представлено в дополненной последовательности первых токенов в виде данного первого токена. Первая рекомендация представлена в дополненной последовательности первых токенов в виде первого начального токена и первого конечного токена. Первый начальный токен вставлен в позицию, предшествующую данному первому токену, а первый конечный токен вставлен в позицию, следующую за данным первым токеном, для идентификации первого токена из дополненной последовательности первых токенов как данного первого токена. Сервер дополнительно способен формировать на этапе обучения дополненную последовательность вторых токенов на основе второго предложения на втором языке и второй рекомендации, вставленной во второе предложение. Второе предложение представляет собой перевод первого предложения. Второе предложение содержит второе слово. Второе слово представляет собой проблемно-ориентированный перевод первого слова. Второе слово представлено в дополненной последовательности вторых токенов в виде данного второго токена. Вторая рекомендация представлена в дополненной последовательности вторых токенов в виде второго начального токена и второго конечного токена. Второй начальный токен вставлен в позицию, предшествующую данному второму токену, а второй конечный токен вставлен в позицию, следующую за данным вторым токеном, для идентификации второго токена из дополненной последовательности вторых токенов как данного второго токена. Сервер на этапе обучения дополнительно способен обучать трансформерную модель путем предоставления дополненной последовательности первых токенов кодеру и дополненной последовательности вторых токенов декодеру таким образом, чтобы обучить декодер формированию выходного начального токена и выходного конечного токена в правильных позициях в последовательности выходных токенов.
[57] В некоторых вариантах осуществления сервера рекомендация дополнительно представлена в дополненной последовательности входных токенов в виде специального токена перевода-рекомендации и другого токена, вставленных после данного входного токена и перед входным конечным токеном.
[58] В некоторых вариантах осуществления сервера для применения ограничивающего условия сервер способен обращаться к подпоследовательности токенов из «белого списка», содержащей другой токен и специальный конечный токен, и применять ограничения для модели перевода при формировании подпоследовательности токенов из «белого списка» в качестве следующего выходного токена.
[59] Согласно четвертому аспекту настоящей технологии реализован сервер для обучения трансформерной модели выполнению перевода с первого языка на второй язык. Трансформерная модель содержит кодер и декодер. Сервер выполняет трансформерную модель. Сервер способен формировать на этапе обучения дополненную последовательность первых токенов на основе первого предложения на первом языке и первой рекомендации, вставленной в первое предложение. Первое предложение содержит первое слово. Первое слово представлено в дополненной последовательности первых токенов в виде данного первого токена. Первая рекомендация представлена в дополненной последовательности первых токенов в виде первого начального токена и первого конечного токена. Первый начальный токен вставлен в позицию, предшествующую данному первому токену, а первый конечный токен вставлен в позицию, следующую за данным первым токеном, для идентификации первого токена из дополненной последовательности первых токенов как данного первого токена. Сервер способен формировать на этапе обучения дополненную последовательность вторых токенов на основе второго предложения на втором языке и второй рекомендации, вставленной во второе предложение. Второе предложение представляет собой перевод первого предложения. Второе предложение содержит второе слово. Второе слово представляет собой проблемно-ориентированный перевод первого слова. Второе слово представлено в дополненной последовательности вторых токенов в виде данного второго токена. Вторая рекомендация представлена в дополненной последовательности вторых токенов в виде второго начального токена и второго конечного токена. Второй начальный токен вставлен в позицию, предшествующую данному второму токену, а второй конечный токен вставлен в позицию, следующую за данным вторым токеном, для идентификации второго токена из дополненной последовательности вторых токенов как данного второго токена. Сервер на этапе обучения способен обучать трансформерную модель путем предоставления дополненной последовательности первых токенов кодеру и дополненной последовательности вторых токенов декодеру таким образом, чтобы обучить декодер формированию выходного начального токена и выходного конечного токена в правильных позициях в последовательности выходных токенов.
[60] В некоторых вариантах осуществления сервер на этапе использования сети NN дополнительно способен итеративно формировать с применением сети NN дополненную последовательность выходных токенов на основе дополненной последовательности входных токенов. При итеративном формировании в ответ на формирование на данной итерации выходного начального токена в последовательности выходных токенов сервер способен применять ограничивающее условие в отношении следующего выходного токена, который должен быть сформирован сетью NN для дополненной последовательности выходных токенов, таким образом, чтобы следующий выходной токен представлял собой другой токен. При итеративном формировании в ответ на формирование выходного конечного токена на другой итерации сервер способен прекращать применение ограничивающего условия в отношении следующего выходного токена, который должен быть сформирован сетью NN. Сервер на этапе использования сети NN дополнительно способен формировать второе предложение на втором языке с использованием дополненной последовательности выходных токенов.
[61] В контексте данного описания трансформерная модель представляет собой модель с архитектурой вида «кодер-декодер», в которой используются механизмы внимания. Механизмы внимания могут применяться во время обработки данных кодером, при обработке данных декодером и при взаимодействиях кодер-декодер. В трансформерной модели может использоваться множество механизмов внимания.
[62] Один из компонентов трансформерной модели может представлять собой механизм самовнимания. Различие между механизмом внимания и механизмом самовнимания заключается в том, что механизм самовнимания работает между схожими представлениями, например, между всеми состояниями кодера в одном слое. Механизм самовнимания входит в состав трансформерной модели, в которой токены взаимодействуют друг с другом. Каждый токен в известном смысле «наблюдает» за другими токенами в предложении с помощью механизма внимания, собирает контекст и обновляет свое предыдущее представление. Каждый входной токен в механизме самовнимания получает три представления: (а) запрос, (б) ключ и (в) значение. Запрос используется, когда токен наблюдает за другими токенами - он ищет информацию, чтобы лучше «понимать» себя. Ключ реагирует на запрос - он используется для расчета весов внимания. Значение используется для расчета результата внимания - оно предоставляет информацию о токенах, которые сообщают, что им требуется внимание (т.е. таким токенам присваиваются большие веса).
[63] Другой компонент трансформерной модели может представлять собой механизм замаскированного самовнимания. Декодер обычно содержит этот особый механизм самовнимания, который отличается от механизма самовнимания в кодере. Кодер получает все токены одновременно и токены могут наблюдать за всеми токенами во входном предложении, а в декодере токены формируются поодиночке, т.е. при формировании модели не известно, какие токены будут сформированы в будущем. Чтобы запретить декодеру «просмотр вперед», в трансформерной модели используется механизм замаскированного самовнимания, т.е. будущие токены маскируются.
[64] Еще один компонент трансформерной модели может представлять собой механизм многоголового внимания. Следует отметить, что для понимания роли слова в предложении требуется понимание того, как оно связано с другими частями предложения. Это важно не только при обработке исходного предложения, но и при формировании целевых объектов. В результате благодаря механизму внимания этого вида трансформерная модель может «концентрироваться на различных вещах». Механизм многоголового внимания вместо одного механизма внимания содержит несколько независимо работающих «голов». Он может быть реализован в виде нескольких механизмов внимания, результаты которых объединяются.
[65] Кодер трансформерной модели может содержать механизм самовнимания кодера и блок сети прямого распространения. Механизм самовнимания кодера может представлять собой механизм многоголового внимания, используемый для наблюдения токенами друг за другом. Запросы, ключи и значения рассчитываются на основе состояний кодера. Блок сети прямого распространения получает информацию из токенов и обрабатывает эту информацию.
[66] Декодер трансформерной модели может содержать механизм (замаскированного) самовнимания декодера, механизм внимания декодер-кодер и сеть прямого распространения. Механизм замаскированного самовнимания декодера может представлять собой механизм замаскированного многоголового внимания, используемый для наблюдения токенами за предыдущими токенами. Запросы, ключи и значения рассчитываются на основе состояний декодера. Механизм внимания декодер-кодер может представлять собой механизм многоголового внимания, используемый для просмотра целевыми токенами исходной информации. Запросы рассчитываются на основе состояний декодера, а ключи и значения рассчитываются на основе состояний кодера. Блок сети прямого распространения получает информацию из токенов и обрабатывает эту информацию.
[67] Можно сказать, что токены в кодере поддерживают связь друг с другом и обновляют свои представления. Также можно сказать, что в декодере целевой токен сначала просматривает ранее сформированные целевые токены, затем источник и, наконец, обновляет свои представления. Это может повторяться в нескольких слоях. В одном не имеющем ограничительного характера варианте реализации это может повторяться шесть раз.
[68] Как описано выше, в дополнение к механизму внимания слой содержит блок сети прямого распространения. Например, блок сети прямого распространения может быть представлен двумя линейными слоями с нелинейной связью вида «усеченное линейное преобразование» (ReLU, Rectifier Linear Unit) между ними. После просмотра других токенов с помощью механизма внимания блок сети прямого распространения используется в модели для обработки этой новой информации. Трансформерная модель может дополнительно содержать остаточные связи для добавления входных данных блока к его выходным данным. Остаточные связи могут использоваться для объединения слоев. В трансформерной модели остаточные связи могут использоваться после соответствующего механизма внимания и блока сети прямого распространения. Например, слою «Add & Norm» (суммирование и нормализация) могут предоставляться (а) входные данные механизма внимания через остаточную связь и (б) выходные данные механизма внимания. Затем результат слоя «Add & Norm» может предоставляться блоку сети прямого распространения или другому механизму внимания. В другом примере слою «Add & Norm» могут предоставляться (а) входные данные блока сети прямого распространения через остаточную связь и (б) выходные данные блока сети прямого распространения. Как описано выше, трансформерная модель может содержать слои «Add & Norm». В общем случае такой слой может независимо нормализовывать векторное представление каждого примера в пакете. Это выполняется для управления «потоком» в следующий слой. Нормализация слоя позволяет повышать устойчивость схождения и в некоторых случаях даже качество.
[69] В контексте данного описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В данном контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[70] В контексте данного описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает применения нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
[71] В контексте данного описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[72] В контексте данного описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[73] В контексте данного описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[74] В контексте данного описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[75] В контексте данного описания числительные «первый», «второй», «третий» и т.д. используются лишь для указания на различие между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
[76] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[77] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[78] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[79] На фиг. 1 представлена схема системы, пригодной для реализации вариантов осуществления настоящей технологии, не имеющих ограничительного характера.
[80] На фиг. 2 представлена традиционная модель перевода для формирования последовательности выходных токенов.
[81] На фиг. 3 представлена структура данных, хранящихся в базе данных системы, представленной на фиг. 1, согласно некоторым вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[82] На фиг. 4 представлен дополненный обучающий пример, сформированный сервером из системы, представленной на фиг. 1, согласно некоторым вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[83] На фиг. 5 представлена итерация обучения модели перевода из системы, представленной на фиг. 1, согласно некоторым вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[84] На фиг. 6 представлена итерация этапа использования модели перевода, представленной на фиг. 5, согласно некоторым вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[85] На фиг. 7 представлено декодирование, выполняемое моделью перевода, представленной на фиг. 5, на итерации этапа использования, представленной на фиг. 6, согласно некоторым вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[86] На фиг. 8 представлен пример графа лучевого поиска для модели NMT, переводящей входное предложение, обученной согласно традиционным способам и использующей лучевой поиск.
[87] На фиг. 9 представлен пример графа лучевого поиска для модели NMT, переводящей входное предложение, обученной согласно фреймворку HBD и использующей лучевой поиск и рекомендацию, согласно некоторым вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[88] На фиг. 10 представлена блок-схема способа, выполняемого согласно некоторым вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
Осуществление изобретения
[89] На фиг. 1 представлена схема системы 100, пригодной для реализации вариантов осуществления настоящей технологии, не имеющих ограничительного характера. Очевидно, что система 100 приведена лишь для демонстрации варианта реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях приводятся полезные примеры модификаций системы 100. Они способствуют пониманию, но также не определяют объема или границ настоящей технологии. Эти модификации не составляют исчерпывающего перечня. Как должно быть понятно специалисту в данной области, могут быть возможными и другие модификации. Кроме того, если в некоторых случаях модификации не описаны (т.е. примеры модификаций отсутствуют), это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области должно быть понятно, что это может быть не так. Кроме того, следует понимать, что система 100 в некоторых случаях может представлять собой упрощенную реализацию настоящей технологии и что такие варианты представлены, чтобы способствовать лучшему ее пониманию. Специалистам в данной области должно быть понятно, что другие варианты осуществления настоящей технологии могут быть значительно сложнее.
[90] В целом, система 100 способна предоставлять сервисы электронного перевода для пользователя 102 электронного устройства 104. Например, система 100 может получать предложение на исходном языке и предоставлять переведенный вариант этого предложения на языке перевода. Ниже описаны по меньшей мере некоторые элементы системы 100. При этом должно быть понятно, что элементы, отличные от представленных на фиг. 1, могут входить в состав системы 100 без выхода за границы настоящей технологии.
Сеть связи
[91] Электронное устройство 104 подключено к сети 110 связи для обмена данными с сервером 112. Например, электронное устройство 104 может быть связано с сервером 112 через сеть 110 связи для предоставления сервисов перевода пользователю 102. Сеть 110 связи, среди прочего, способна передавать запросы и ответы между электронным устройством 104 и сервером 112 в виде одного или нескольких пакетов данных, содержащих передаваемые данные.
[92] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 110 связи может использоваться сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления данной технологии сеть 110 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п. Реализация линии связи (отдельно не обозначена) между электронным устройством 104 и сетью 110 связи зависит, среди прочего, от реализации электронного устройства 104.
[93] Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где электронное устройство 104 реализовано в виде беспроводного устройства связи (такого как смартфон), линия связи может быть реализована в виде беспроводной линии связи (такой как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где электронное устройство 104 реализовано в виде ноутбука, линия связи может быть беспроводной (такой как Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.д.) или проводной (такой как соединение на основе Ethernet).
Электронное устройство
[94] Система 100 содержит электронное устройство 104, связанное с пользователем 102. Электронное устройство 104 иногда может называться клиентским устройством, оконечным устройством, клиентским электронным устройством или просто устройством. Следует отметить, что связь электронного устройства 104 с пользователем 102 не означает необходимости предлагать или подразумевать какой-либо режим работы, например, вход в систему, регистрацию и т.п.
[95] На реализацию электронного устройства 104 не накладывается каких-либо особых ограничений. Например, электронное устройство 104 может быть реализовано в виде персонального компьютера (настольного, ноутбука, нетбука и т.д.), беспроводного устройства связи (смартфона, сотового телефона, планшета и т.д.) или сетевого оборудования (маршрутизатора, коммутатора, шлюза и т.д.). Электронное устройство 104 содержит известные в данной области техники аппаратные средства и/или прикладное программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для выполнения браузерного приложения.
[96] В общем случае браузерное приложение обеспечивает пользователю 102 доступ к одному или нескольким сетевым ресурсам, например, к веб-страницам. На реализацию браузерного приложения не накладывается каких-либо особых ограничений. Например, браузерное приложение может быть реализовано в виде браузера Yandex™.
[97] Пользователь 102 может использовать браузерное приложение для доступа к системе перевода с целью перевода одного или нескольких предложений с исходного языка на язык перевода. Например, электронное устройство 104 может формировать запрос, указывающий на одно или несколько предложений, которые желает перевести пользователь 102. Электронное устройство 104 также может получать ответ (не показан) для отображения пользователю 102 переведенного варианта одного или нескольких предложений на языке перевода. Обычно запрос и ответ могут передаваться электронному устройству 104 и от него через сеть 110 связи.
База данных
[98] Система 100 также содержит базу 150 данных, связанную с сервером 112 и способную хранить информацию, полученную либо иным образом определенную или сформированную сервером 112. В целом, база 150 данных способна получать с сервера 112 данные, которые были извлечены либо иным образом определены или сформированы сервером 112 во время обработки, для временного и/или постоянного хранения и способна выдавать сохраненные данные серверу 112 для их использования. Предполагается, что база 150 данных может быть разделена на несколько распределенных баз данных без выхода за границы настоящей технологии.
[99] База 150 данных способна хранить данные для поддержки сервисов переводов, которые может предоставлять система перевода сервера 112. С этой целью база 150 данных может, среди прочего, хранить проблемно-ориентированный словарь 140 и множество обучающих примеров 130 (см. фиг. 3).
[100] В общем случае проблемно-ориентированный словарь 140 представляет собой структуру данных, содержащую большое количество слов 310 на первом языке (т.е. на исходном языке) и их соответствующие проблемно-ориентированные переводы 320 на втором языке (т.е. на языке перевода). Структура данных доступна серверу 112 для получения из нее информации.
[101] В одном не имеющем ограничительного характера варианте осуществления изобретения проблемно-ориентированный словарь 140 может быть сформирован оператором сервера 112 на основе сторонних запросов. В одном примере на основе сторонних запросов оператор может включить в проблемно-ориентированный словарь 140 слово «Microsoft» на английском языке и его проблемно-ориентированный перевод «Майкрософт» на русском языке.
[102] В представленном не имеющем ограничительного характера примере слова 310 на первом языке содержат первое слово 302, второе слово 304 и третье слово 306. Проблемно-ориентированный словарь 140 содержит проблемно-ориентированный перевод 312 первого слова 302. Проблемно-ориентированный перевод 312 представляет собой одно слово. Проблемно-ориентированный словарь 140 также содержит проблемно-ориентированный перевод 314 второго слова 304. Проблемно-ориентированный перевод 314 состоит из двух слов. Проблемно-ориентированный словарь 140 содержит множество проблемно-ориентированных переводов (без числового обозначения), содержащее первый проблемно-ориентированный перевод 316 и второй проблемно-ориентированный перевод 318 третьего слова 306. Предполагается, что первый проблемно-ориентированный перевод 316 и второй проблемно-ориентированный перевод 318 могут представлять соответствующие грамматические варианты или формы проблемно-ориентированного перевода третьего слова 306.
[103] В некоторых вариантах осуществления настоящей технологии предполагается, что проблемно-ориентированный словарь может содержать проблемно-ориентированные переводы на несколько вторых языков без выхода за границы настоящей технологии. Можно сказать, что структура данных может быть двуязычной, трехъязычной и т.д.
[104] Дополнительно или в качестве альтернативы база 150 данных может хранить множество проблемно-ориентированных словарей, подобных проблемно-ориентированному словарю 140, каждый из которых связан с соответствующей областью. Например, проблемно-ориентированный словарь 140 может быть предназначен для переводов слов, используемых в медицине, а другие проблемно-ориентированные словари могут быть предназначены для переводов слов, используемых, соответственно, в аэрокосмической области, юриспруденции, торговле, спорте и т.п.
[105] Следует отметить, что переводы слова могут отличаться в зависимости от конкретной области, к которой относится перевод предложения или слова. В результате предоставления проблемно-ориентированного перевода слова вместо его произвольного перевода возможно повышение качества перевода системы перевода. Как более подробно описано ниже, проблемно-ориентированный словарь 140 может использоваться электронным устройством 104 на этапах обучения и использования по меньшей мере некоторых алгоритмов машинного обучения (MLA, Machine Learning Algorithm), содержащихся в системе перевода сервера 112.
[106] Как описано выше, база 150 данных может дополнительно содержать множество обучающих примеров 130 для обучения одного или нескольких алгоритмов MLA, имеющихся в системе перевода сервера 112. Множество обучающих примеров 130 может содержать большое количество параллельных предложений, при этом каждая пара предложений содержит первое предложение на первом языке и второе предложение на втором языке. Также предполагается, что соответствующее множество обучающих примеров может быть сохранено для соответствующей пары исходного и целевого языков без выхода за границы настоящей технологии. Возможное использование множества обучающих примеров 130 сервером 112 при обучении одного или нескольких алгоритмов MLA более подробно описано ниже.
Сервер
[107] Система 100 также содержит сервер 112, который может быть реализован в виде традиционного компьютерного сервера. В представленных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 112 представляет собой один сервер. В альтернативных не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 112 могут быть распределены между несколькими серверами. Сервер 112 может содержать один или несколько процессоров, одно или несколько устройств физической памяти, машиночитаемые команды и/или дополнительные аппаратные элементы, дополнительные компоненты программных средств и/или их сочетание для реализации различных функций сервера 112 без выхода за границы настоящей технологии.
[108] В целом, сервер 112 может управляться и/или администрироваться поставщиком сервиса перевода (не показан), таким как оператор сервисов перевода Yandex™. Предполагается, что поставщик сервисов перевода и поставщик браузерного приложения могут представлять собой одного и того же поставщика. В частности, браузерное приложение (например, браузер Yandex™) и сервисы перевода (например, сервисы перевода Yandex™) могут предоставляться, управляться и/или администрироваться одним и тем же оператором или субъектом.
[109] Как описано выше, на сервере 112 размещена система перевода (не показана). В общем случае система перевода реализована в виде множества компьютерных процедур, используемых для перевода одного или нескольких предложений с исходного языка на язык перевода и для предоставления таких переводов пользователям системы перевода. С этой целью сервер 112 способен выполнять модель 120 перевода.
Алгоритмы машинного обучения
[110] В общем случае алгоритмы MLA способны обучаться на обучающих выборках и осуществлять прогнозирование на основе новых (ранее не известных) данных. Алгоритмы MLA обычно используются для первоначального построения модели на основе обучающих входных данных, чтобы затем на основе данных выполнять прогнозирование или принимать решения, выраженные в виде выходных данных, вместо исполнения статических машиночитаемых команд.
[111] Алгоритмы MLA обычно используются в качестве моделей оценивания, моделей перевода, моделей классификации и т.п. Должно быть понятно, что для различных задач могут использоваться алгоритмы MLA различных видов с различными структурами или топологиями.
[112] Алгоритмы MLA одного конкретного вида включают в себя сети NN. В общем случае сеть NN состоит из взаимосвязанных групп искусственных нейронов, обрабатывающих информацию с использованием коннекционного подхода к вычислениям. Сети NN используются для моделирования сложных взаимосвязей между входными и выходными данными (без фактической информации об этих взаимосвязях) или для поиска закономерностей в данных. Сети NN сначала адаптируются на этапе обучения, когда они обеспечиваются известным набором входных данных и информацией для адаптации сети NN с целью формирования правильных выходных данных (для ситуации, в отношении которой выполняется попытка моделирования). На этапе обучения сеть NN адаптируется к изучаемой ситуации и изменяет свою структуру таким образом, чтобы быть способной обеспечивать адекватное предсказание выходных данных для входных данных в новой ситуации (на основе того, что было выучено). Таким образом, вместо попытки определения сложных статистических распределений или математических алгоритмов для ситуации сеть NN пытается предоставить «интуитивный» ответ на основе «восприятия» этой ситуации.
[113] Сети NN широко используются во многих таких ситуациях, где важно лишь получение выходных данных на основе входных данных и менее важна или вовсе не важна информация о том, как получены эти выходные данные. Например, сети NN широко используются для оптимизации распределения веб-трафика между серверами, автоматического перевода текста на различные языки, а также при обработке данных, включая фильтрацию, кластеризацию, векторизацию и т.п.
[114] Реализация алгоритма MLA может быть разделена на два основных этапа: этап обучения и этап использования. Сначала алгоритм MLA обучается на этапе обучения. Затем, когда алгоритму MLA известно, какие предполагаются входные данные и какие должны выдаваться выходные данные, алгоритм MLA выполняется с реальными данными на этапе использования.
[115] Предполагается, что модель 120 перевода может представлять собой модель NMT с трансформерной архитектурой. В общем случае трансформерная модель или просто трансформер представляет собой модель глубокого обучения, которая использует механизм внимания и может по-разному оценивать значение каждой части входных данных.
[116] Подобно некоторым другим моделям, в трансформере применяется архитектура вида «кодер-декодер». Кодер состоит из кодирующих слоев, которые поочередно итеративно обрабатывают входные данные, а декодер состоит из декодирующих слоев, которые поочередно итеративно обрабатывают выходные данные кодера. Функция каждого слоя кодера заключается в формировании кодировок, содержащих информацию о взаимной релевантности частей входных данных. Кодировки передаются следующему слою кодера в качестве входных данных. Можно сказать, что каждый слой декодера выполняет «противоположную» операцию: использует вложенную контекстную информацию из всех кодировок для формирования выходной последовательности. Для достижения этой цели слои кодера и декодера используют механизм внимания.
[117] В общем случае для части входных данных механизм внимания определяет веса релевантности других частей входных данных и использует их для формирования выходных данных. Каждый слой декодера также может содержать дополнительный механизм внимания, получающий информацию из выходных данных предыдущих декодеров до получения информации слоем декодера из кодировок. Предполагается, что слои кодера и декодера могут содержать сеть NN прямого распространения для дополнительной обработки выходных данных, а также содержат остаточные связи и шаги нормализации слоя.
[118] На фиг. 2 представлены кодирующая часть 132 (или просто кодер) и декодирующая часть 134 (или просто декодер) традиционной трансформерной модели 299. В общем случае кодер 132 получает последовательность входных токенов, сформированных на основе текста на исходном языке, и выдает компактное представление этой входной последовательности, пытаясь обобщить или сжать всю информацию из последовательности. Эти компактные представления получает декодирующая часть 134, которая также может получать другие внешние входные данные. На каждом шаге декодирующая часть 134 формирует элемент своей выходной последовательности (выходной токен) на основе полученных входных данных и может обновлять свое состояние для следующего шага, на котором формируется другой элемент выходной последовательности (следующий выходной токен).
[119] Декодирующая часть 134 может быть реализована с использованием механизма 136 внимания. Механизм 136 внимания может быть реализован с помощью слоя внимания, который позволяет декодирующей части 134 в известном смысле «принимать во внимание» конкретную информацию при формировании выходных данных, как описано ниже.
[120] В некоторых случаях декодирующая часть 134 может представлять собой «жадный» декодер. Например, декодирующая часть 134 может формировать выходную последовательность, представляющую слово на языке перевода, которое с наибольшей вероятностью представляет собой перевод соответствующего слова на исходном языке. Предполагается, что в процессе декодирования может использоваться алгоритм лучевого поиска.
[121] Исходное предложение 202 может быть разделено на последовательность 206 входных токенов. Входные токены могут быть предоставлены кодирующей части 132. Кодирующая часть 132 способна формировать скрытые векторные представления на основе введенных токенов. Например, электронное устройство 104, использующее кодирующую часть 132, может формировать векторные представления 208 для последовательности 206 входных токенов.
[122] Векторные представления могут быть предоставлены декодирующей части 134. Декодирующая часть 134 способна формировать выходные токены на основе, среди прочего, векторных представлений, сформированных кодирующей частью 132, и других входных данных, например, таких как ранее сформированные выходные токены. Выходные токены, сформированные декодирующей частью 134, могут быть использованы для предоставления перевода исходного предложения 202 (т.е. целевого предложения) пользователю 202.
[123] Декодирующая часть 134 способна использовать последовательность векторных представлений 208 для формирования первого выходного токена 221. На следующем шаге декодирующая часть 134 способна дополнительно использовать первый выходной токен 221 (дополнительные входные данные) для формирования второго выходного токена 222. На следующем шаге декодирующая часть 134 способна дополнительно использовать второй выходной токен 222 (дополнительные входные данные) для формирования третьего выходного токена 223. На следующем шаге декодирующая часть 134 способна дополнительно использовать третий выходной токен 223 (дополнительные входные данные) для формирования четвертого выходного токена 224 и т.д.
[124] Как описано выше, электронное устройство 104 может использовать механизм 136 внимания, чтобы учитывать предыдущие выходные токены, сформированные декодирующей частью 134, при формировании текущего выходного токена в последовательности выходных токенов. В некоторых вариантах осуществления изобретения декодирующая часть 134 может использовать один или несколько выходных токенов, сформированных декодирующей частью 134 и связанных с текущим словом и/или с предыдущим словом, сформированными декодирующей частью 134.
[125] Декодирующая часть 134 формирует последовательность 210 выходных токенов на основе, среди прочего, векторных представлений 208 и предыдущих выходных токенов из последовательности 210 выходных токенов для формирования текущего выходного токена в последовательности 210 выходных токенов.
[126] Разработчики настоящей технологии установили, что традиционная модель 299 перевода некачественно переводит входные предложения в особых областях и/или неспособна правильно переводить некоторые редкие слова. Кроме того, следует отметить, что для повторного обучения модели NMT для каждой области требуется большое количество вычислений, при этом для такого обучения может быть доступно лишь небольшое количество проблемно-зависимых данных.
[127] В некоторых вариантах осуществления настоящей технологии разработчики реализовали фреймворк для вставки рекомендаций во входные предложения для обеспечения управления выходными предложениями, формируемыми моделью NMT. Формирование обучающих примеров для обучения такой модели NMT описано ниже.
[128] На фиг. 4 представлена пара 400 параллельных предложений, доступных серверу 112 в базе 150 данных. Пара 400 параллельных предложений содержит первое предложение 410 на первом языке и второе (параллельное) предложение 420 на втором языке.
[129] Сервер 112 может выполнять сопоставление слов в паре 400 параллельных предложений. В некоторых вариантах осуществления изобретения сервер 112 может использовать проблемно-ориентированный словарь 140 для определения слова 415 в первом предложении 410 и слова 425 (сопоставленного) во втором предложении 420. Можно сказать, что слово 425 представляет собой проблемно-ориентированный перевод слова 415, определенный на основе информации, доступной в проблемно-ориентированном словаре 410.
[130] В контексте настоящей технологии сервер 112 способен дополнять первое предложение 410 и второе предложение 420 рекомендациями. Иными словами, сервер 112 может формировать пару 450 дополненных предложений путем вставки рекомендаций в пару 400 параллельных предложений.
[131] Сервер 112 вставляет рекомендацию в первое предложение 410 в виде текстовых входных данных 431 <HINT_START> и текстовых входных данных 432 <HINT_END>. Текстовые входные данные 431 вставляются в первое предложение 410 в позицию, предшествующую позиции слова 415, а текстовые входные данные 432 вставляются в первое предложение 410 в позицию, следующую за позицией слова 415. В некоторых вариантах осуществления изобретения предполагается, что сервер 112 может вставлять текстовые входные данные 431 в позицию, непосредственно предшествующую позиции слова 415, а тестовые входные данные 432 - в позицию, непосредственно следующую за позицией слова 415, «обертывая» таким образом слово 415 текстовыми входными данными 431 и текстовыми входными данными 432 в первом дополненном предложении 430. Как описано ниже, вставка текстовых входных данных 431 и текстовых входных данных 432 в первое предложение 410 может выполняться для предоставления модели 120 перевода позиционных данных о слове 415 в первом дополненном предложении 430 (и в соответствующей дополненной последовательности токенов).
[132] В представленном не имеющем ограничительного характера варианте осуществления изобретения рекомендация, вставленная сервером 112, дополнительно содержит текстовые входные данные 433 <HINT_SEP> и слово 425. Сервер 112 вставляет текстовые входные данные 433 и слово 425 в позицию между словом 415 и текстовыми входными данными 432. Вставка текстовых входных данных 433 и слова 425 может выполняться для предоставления модели 120 перевода дополнительной информации о проблемно-ориентированном переводе слова 415 (т.е. о слове 425).
[133] Сервер 112 вставляет рекомендацию во второе предложение 420 в виде текстовых входных данных 441 <HINT_START> и текстовых входных данных 442 <HINT_END>. Текстовые входные данные 441 вставляются во второе предложение 420 в позицию, предшествующую позиции слова 425, а текстовые входные данные 442 вставляются во второе предложение 420 в позицию, следующую за позицией слова 425. В некоторых вариантах осуществления изобретения предполагается, что сервер 112 может вставлять текстовые входные данные 441 в позицию, непосредственно предшествующую позиции слова 425, а тестовые входные данные 442 - в позицию, непосредственно следующую за позицией слова 425, «обертывая» таким образом слово 425 текстовыми входными данными 441 и текстовыми входными данными 442 во втором дополненном предложении 440. Как описано ниже, вставка текстовых входных данных 441 и текстовых входных данных 442 во второе предложение 420 может выполняться для предоставления модели 120 перевода позиционных данных о слове 425 во втором дополненном предложении 440 (и в соответствующей дополненной последовательности токенов).
[134] В некоторых вариантах осуществления настоящей технологии можно сказать, что сервер 112 может использовать обучающий пример, содержащий пару параллельных предложений, для формирования дополненного обучающего примера, содержащего пару параллельных дополненных предложений. Процесс дополнения обучающего примера включает в себя вставку соответствующих рекомендаций в первое предложение и во второе предложение обучающего примера. Первая рекомендация вставляется в виде по меньшей мере двух элементов текстовых входных данных, «обертывающих» слово в первом предложении. Вторая рекомендация вставляется в виде по меньшей мере двух элементов текстовых входных данных, «обертывающих» соответствующее слово (проблемно-ориентированный перевод) во втором предложении. В дополнительных вариантах осуществления изобретения первая рекомендация может дополнительно содержать другие текстовые входные данные, представляющие информацию о проблемно-ориентированном переводе в первом предложении.
[135] В контексте настоящей технологии сервер 112 способен обучать модель 120 перевода на паре 450 дополненных предложений вместо пары 400 предложений. На фиг. 5 показано, как сервер 112 может использовать пару 450 дополненных предложений для обучения модели 120 перевода. Сервер 112 способен предоставлять первое дополненное предложение 430 кодирующей части модели 120 перевода и второе дополненное предложение 440 декодирующей части модели 120 перевода.
[136] Следует отметить, что модель 120 перевода может выполнять токенизацию первого дополненного предложения 430. В общем случае токенизация представляет собой процесс разделения части текста, такой как предложение, на меньшие фрагменты, называемые токенами. Токен может представлять собой слово, часть слова и/или символ, например, знак препинания. В результате сервер 112 может формировать первую дополненную последовательность 530 токенов на основе первого дополненного предложения 430 и вторую дополненную последовательность 540 токенов на основе второго дополненного предложения 440.
[137] Первая дополненная последовательность 530 токенов содержит подпоследовательность токенов, содержащую токены 531, 515, 533, 525 и 532. Токен 531 является специальным начальным токеном, представляющим текстовые входные данные 431. Токен 515 представляет слово 415. Токен 533 является специальным токеном перевода-рекомендации, представляющим текстовые входные данные 433. Токен 525 представляет слово 425 (проблемно-ориентированный перевод слова 415). Токен 532 является специальным конечным токеном, представляющим текстовые входные данные 432.
[138] Предполагается, что в некоторых вариантах осуществления изобретения токены 533 и 525 могут отсутствовать в первой дополненной последовательности 530 токенов без выхода за границы настоящей технологии. В других вариантах осуществления изобретения первая дополненная последовательность 530 токенов может содержать в дополнение к токенам, представляющим слова из первого предложения 410, специальные токены, представляющие вставленную рекомендацию, т.е. по меньшей мере специальный начальный токен и специальный конечный токен в позициях, «обертывающих» токен 515.
[139] Вторая дополненная последовательность 540 токенов содержит подпоследовательность токенов, содержащую токены 541, 525 и 542. Токен 541 является специальным начальным токеном, представляющим текстовые входные данные 441. Токен 525 представляет слово 425. Токен 542 является специальным конечным токеном, представляющим текстовые входные данные 442.
[140] В некоторых вариантах осуществления изобретения вторая дополненная последовательность 540 токенов может содержать в дополнение к токенам, представляющим слова из второго предложения 420, специальные токены, представляющие вставленную рекомендацию, т.е. по меньшей мере специальный начальный токен и специальный конечный токен в позициях, «обертывающих» токен 525.
[141] Предполагается, что первую дополненную последовательность 530 токенов и вторую дополненную последовательность 540 токенов можно назвать дополненными по сравнению с последовательностями токенов, которые сервер 112 сформировал бы на основе первого предложения 410 и второго предложения 420, соответственно. Иными словами, можно сказать, что первая дополненная последовательность 530 токенов и вторая дополненная последовательность 540 токенов являются дополненными вследствие наличия специальных токенов в первой дополненной последовательности 530 токенов и во второй дополненной последовательности 540 токенов.
[142] На итерации обучения первая дополненная последовательность 530 токенов может быть обработана кодирующей частью модели 120 перевода, а вторая дополненная последовательность 540 токенов может быть обработана декодирующей частью модели 120 перевода.
[143] При обучении модели 120 перевода в нее вводится большое количество дополненных обучающих примеров, сформированных подобно тому, как описано со ссылкой на фиг. 4. Можно сказать, что модель 120 перевода выучивает, где формировать выходной специальный начальный токен в последовательности выходных токенов.
[144] Разработчики настоящей технологии установили, что при обработке могут использоваться позиционные данные, предоставляемые выходным специальным начальным токеном. Как более подробно описано ниже, после формирования выходного специального начального токена моделью 120 перевода на этапе использования сервер 112 может применять ограничение (например, при обработке) таким образом, чтобы следующий токен (или токены), формируемый моделью перевода, представлял проблемно-ориентированный перевод, за которым следует выходной специальный конечный токен.
[145] Разработчики настоящей технологии установили, что при обработке также могут использоваться позиционные данные, предоставляемые выходным специальным конечным токеном. Как более подробно описано ниже, после формирования выходного специального конечного токена моделью 120 перевода на этапе использования сервер 112 способен отменять ограничение таким образом, чтобы следующий токен формировался без ограничений.
[146] В некоторых вариантах осуществления настоящей технологии можно сказать, что модель 120 перевода может быть обучена не только формированию специального начального токена, но и формированию специального конечного токена на основе входных токенов. В других вариантах осуществления изобретения также можно сказать, что модель перевода может быть обучена учитывать слово перевода-рекомендации, которое может быть вставлено во входное предложение, при выполнении перевода.
[147] На фиг. 6 представлена итерация этапа использования модели 120 перевода. В ходе итерации этапа использования сервер 112 способен получать для перевода входное предложение 610 на первом языке. Сервер 112 может сравнивать слова из входного предложения 610 и определять, соответствует ли по меньшей мере одно слово из входного предложения 610 слову из проблемно-ориентированного словаря 140. В ответ сервер 112 может определять наличие слова 615 во входном предложении. Предполагается, что сервер 112 может определять один или несколько проблемно-ориентированных переводов слова 615 в проблемно-ориентированном словаре 140.
[148] Сервер 112 способен дополнять входное предложение 610 рекомендацией. Сервер 112 вставляет рекомендацию во входное предложение 610 в виде текстовых входных данных 621 <HINT_START> и текстовых входных данных 622 <HINT_END>. Текстовые входные данные 621 вставляются во входное предложение 610 в позицию, предшествующую позиции слова 615, а текстовые входные данные 622 вставляются во входное предложение 610 в позицию, следующую за позицией слова 615. В некоторых вариантах осуществления изобретения предполагается, что сервер 112 может вставлять текстовые входные данные 621 в позицию, непосредственно предшествующую позиции слова 615, а тестовые входные данные 622 в позицию, непосредственно следующую за позицией слова 615, «обертывая» таким образом слово 615 текстовыми входными данными 621 и текстовыми входными данными 622 в дополненном входном предложении 620. Вставка текстовых входных данных 621 и текстовых входных данных 622 во входное предложение 610 может выполняться для предоставления модели 120 перевода позиционных данных о слове 615 в дополненном входном предложении 620 (и в соответствующей дополненной последовательности токенов).
[149] В представленном не имеющем ограничительного характера варианте осуществления изобретения рекомендация, вставленная сервером 112, дополнительно содержит текстовые входные данные 623 <HINT_SEP> и слово 625. Сервер 112 вставляет текстовые входные данные 623 и слово 625 в позицию между словом 615 и текстовыми входными данными 622. Вставка текстовых входных данных 623 и слова 625 может выполняться для предоставления модели 120 перевода дополнительной информации о проблемно-ориентированном переводе слова 615 (т.е. о слове 625).
[150] Сервер 112 способен выполнять токенизацию дополненного входного предложения 620, формируя таким образом дополненную последовательность 630 входных токенов. Дополненная последовательность 630 входных токенов содержит подпоследовательность токенов, содержащую токены 631, 635, 633, 645 и 632. Токен 631 является специальным начальным токеном, представляющим текстовые входные данные 621. Токен 635 представляет слово 615. Токен 633 является специальным токеном перевода-рекомендации, представляющим текстовые входные данные 623. Токен 645 представляет слово 625 (проблемно-ориентированный перевод слова 615). Токен 632 является специальным конечным токеном, представляющим текстовые входные данные 622.
[151] Предполагается, что в некоторых вариантах осуществления изобретения токены 633 и 645 могут отсутствовать в дополненной последовательности 630 входных токенов без выхода за границы настоящей технологии. В других вариантах осуществления изобретения дополненная последовательность 630 входных токенов может содержать в дополнение к токенам, представляющим слова из первого предложения 610, специальные токены, представляющие вставленную рекомендацию, т.е. по меньшей мере специальный начальный токен и специальный конечный токен в позициях, «обертывающих» токен 635.
[152] Сервер 112 способен использовать модель 120 перевода для итеративного формирования последовательности 640 выходных токенов на основе дополненной последовательности 630 входных токенов. Последовательность 640 выходных токенов, среди прочего, содержит выходной начальный токен 641, выходной токен 645 и выходной конечный токен 642. Модель 120 перевода итеративно формирует выходные токены в последовательности 640 выходных токенов.
[153] На фиг. 7 представлено несколько итераций процесса итеративного формирования последовательности 640 выходных токенов. В ходе итерации 701 декодирующая часть модели 120 перевода формирует выходной токен (без числового обозначения). На итерации 702 (следующая итерация) модель 120 перевода формирует выходной начальный токен 641. Определив, что сформированный на итерации 702 выходной токен представляет собой специальный начальный токен, сервер 112 способен применять ограничивающее условие в отношении следующего выходного токена (или токенов), который должен быть сформирован моделью 120 перевода для последовательности 640 выходных токенов, таким образом, чтобы следующий выходной токен (или токены) соответствовал (или соответствовали) токену, представляющему проблемно-ориентированный перевод слова.
[154] В некоторых вариантах осуществления настоящей технологии можно сказать, что сервер 112 может применять ограничение при обработке. Например, сервер 112 может формировать «белый список» подпоследовательностей токенов, соответствующих одному или нескольким проблемно-ориентированным переводам слова 615. «Белый список» может быть сформирован на основе одной или нескольких форм проблемно-ориентированного перевода из проблемно-ориентированного словаря 140. Предполагается, что количество подпоследовательностей токенов в «белом списке» может соответствовать количеству форм проблемно-ориентированного перевода. В других вариантах осуществления изобретения предполагается, что подпоследовательности из «белого списка» могут содержать представляющие проблемно-ориентированный перевод токены, за которыми следует специальный конечный токен.
[155] Таким образом, в некоторых вариантах осуществления изобретения, определив, что сформирован специальный начальный токен, сервер 112 может применять ограничения для модели 120 перевода при формировании по меньшей мере одной подпоследовательности токенов из «белого списка». В результате в этих вариантах осуществления изобретения модель 120 перевода формирует один или несколько токенов, представляющих проблемно-ориентированный перевод слова 615, за которыми следует специальный конечный токен.
[156] В представленном не имеющем ограничительного характера варианте осуществления изобретения на итерации 703 (следующей за итерацией 702) ограничения применяются для декодирующей части модели 120 перевода при формировании выходного токена 645. В некоторых вариантах осуществления изобретения токен 633 перевода-рекомендации может содержать информацию, указывающую на выходной токен 645. В других вариантах осуществления изобретения информация о выходном токене 645 может быть предоставлена сервером 112 (например, «белый список»). Таким образом, после итерации 703 следующий выходной токен в последовательности 640 выходных токенов соответствует выходному токену 645, представляющему проблемно-ориентированный перевод слова (представленного входным токеном 635).
[157] В некоторых вариантах осуществления изобретения модель 120 перевода может выполнять несколько ограниченных таким образом итераций для формирования набора выходных токенов, представляющих проблемно-ориентированный перевод слова из предложения. В одном не имеющем ограничительного характера примере, если «белый список» содержит одну подпоследовательность токенов, содержащую пять токенов, то для модели 120 перевода могут применяться ограничения при формировании четырех токенов, представляющих проблемно-ориентированный перевод, и следующего за ними пятого токена, представляющего специальный конечный токен.
[158] Следует отметить, что в тех вариантах осуществления изобретения, где имеется несколько форм проблемно-ориентированного перевода и поэтому «белый список» содержит несколько подпоследовательностей токенов, модель 120 перевода может формировать одну из подпоследовательностей токенов из «белого списка» в последовательности выходных токенов на основе соответствующих вероятностей соответствия наилучшему продолжению текущей сформированной последовательности выходных токенов. Например, алгоритм лучевого поиска может применяться для определения того, формирование какой подпоследовательности токенов из «белого списка» в последовательности выходных токенов обеспечит лучший перевод.
[159] В представленном не имеющем ограничительного характера варианте осуществления изобретения на итерации 704 декодирующая часть модели 120 перевода способна формировать выходной конечный токен 642. Определив, что сформированный на итерации 704 выходной токен представляет собой специальный конечный токен, сервер 112 может прекращать применение ограничивающего условия в отношении следующего выходного токена, который должен быть сформирован моделью 120 перевода. Можно сказать, что появление специального конечного токена в последовательности выходных токенов указывает на то, что проблемно-ориентированный перевод слова завершен и, следовательно, модель 120 перевода может возобновить формирование выходных токенов без ограничивающего условия.
[160] На итерации 705 (следующей за итерацией 704) декодирующая часть модели 120 перевода формирует другой выходной токен (без числового обозначения) без применения ограничения. Таким образом, после итерации 704 в отношении следующего выходного токена больше не применяется ограничение, согласно которому токен должен представлять проблемно-ориентированный перевод.
[161] После формирования декодирующей частью модели 120 перевода токена EOS, обозначающего конец последовательности 640 выходных токенов, сервер 112 может использовать последовательность 640 выходных токенов для формирования второго предложения на втором языке (т.е. на языке перевода). Например, сервер 112 может удалять один или несколько специальных токенов из последовательности 640 выходных токенов и использовать остаток для формирования второго предложения. Сервер 112 может удалять из последовательности 640 выходных токенов специальный токен BOS, выходной начальный токен 641, выходной конечный токен 642 и специальный токен EOS. Сервер 112 может использовать оставшиеся выходные токены (включая выходной токен 645) из последовательности 640 выходных токенов для формирования второго предложения, содержащего проблемно-ориентированный перевод слова из входного предложения.
[162] В некоторых вариантах осуществления настоящей технологии предполагается, что в исходном предложении могут быть определены несколько слов для предоставления соответствующих проблемно-ориентированных переводов. В этих вариантах осуществления изобретения входные токены каждого такого слова могут быть «обернуты» специальными токенами. В этих вариантах осуществления изобретения предполагается, что декодирующая часть модели 120 перевода может формировать несколько выходных начальных токенов и несколько выходных конечных токенов в последовательности выходных токенов для применения ограничений в отношении соответствующих частей последовательности выходных токенов.
[163] В некоторых вариантах осуществления настоящей технологии сервер 112 способен выполнять способ 1000, представленный на фиг. 10. Далее более подробно описаны различные шаги способа 1000.
Шаг 1002: формирование дополненной последовательности входных токенов на основе входного предложения на первом языке и рекомендации, вставленной во входное предложение.
[164] Способ 1000 начинается с шага 1002, на котором сервер 112 может формировать дополненную последовательность входных токенов на основе входного предложения на первом языке и рекомендации, вставленной во входное предложение.
[165] Например, входное предложение 610 содержит слово 615, представленное входным токеном 635 в дополненной последовательности 630 входных токенов. Рекомендация представлена в дополненной последовательности 630 входных токенов в виде входного начального токена 631 и входного конечного токена 632. Входной начальный токен 631 вставлен в позицию, предшествующую входному токену 635, а входной конечный токен 632 вставлен в позицию, следующую за входным токеном 635, для идентификации входного токена из дополненной последовательности входных токенов как входного токена 635.
[166] В некоторых вариантах осуществления изобретения рекомендация дополнительно представлена в дополненной последовательности 630 входных токенов в виде специального токена 633 перевода-рекомендации и другого токена 645. В этих вариантах осуществления изобретения специальный токен 633 перевода-рекомендации и другой токен 645 вставлены после входного токена 635 и перед входным конечным токеном 632.
[167] В других вариантах осуществления изобретения входной токен 635 может представлять собой подпоследовательность входных токенов и входное слово 615 может быть представлено такой подпоследовательностью входных токенов в дополненной последовательности 630 входных токенов. В других вариантах осуществления изобретения другой токен 645 представляет собой другую подпоследовательность токенов и проблемно-ориентированный перевод 625 представлен этой другой подпоследовательностью токенов. Предполагается, что множество проблемно-ориентированных переводов входного слова может содержать грамматические варианты входного слова.
Шаг 1004: итеративное формирование с применением сети NN последовательности выходных токенов на основе дополненной последовательности входных токенов.
[168] Способ 1000 продолжается на шаге 1004, на котором сервер 112 может формировать с применением сети NN последовательность выходных токенов на основе дополненной последовательности входных токенов.
[169] Например, сервер 112 может использовать модель 120 перевода для формирования последовательности 640 выходных токенов на основе дополненной последовательности 630 входных токенов. В некоторых вариантах осуществления изобретения последовательность 640 выходных токенов может дополнительно основываться на подпоследовательности токенов из «белого списка».
[170] В ходе процесса итеративного формирования в ответ на формирование выходного начального токена 641 сервер 112 может применять ограничивающее условие в отношении следующего выходного токена, который должен быть сформирован сетью NN, таким образом, чтобы следующий выходной токен представлял собой другой токен 645. В ходе процесса итеративного формирования в ответ на формирование выходного конечного токена 642 сервер 112 может прекращать применение ограничивающего условия в отношении следующего токена, который должен быть сформирован сетью NN.
[171] В некоторых случаях проблемно-ориентированный словарь содержит множество проблемно-ориентированных переводов входного слова. В этих случаях сервер 112 может применять ограничивающее условие в отношении следующей подпоследовательности выходных токенов, формируемых сетью NN, таким образом, чтобы следующая подпоследовательность выходных токенов представляла собой подпоследовательность из множества других подпоследовательностей токенов, представляющих множество проблемно-ориентированных переводов.
[172] В других вариантах осуществления изобретения применение ограничивающего условия включает в себя обращение сервера 112 к подпоследовательности токенов из «белого списка», содержащей другой токен и специальный конечный токен, и применение сервером 112 ограничений для модели 120 перевода при формировании подпоследовательности токенов из «белого списка» в качестве следующего выходного токена.
Шаг 1006: формирование второго предложения на втором языке с использованием последовательности выходных токенов.
[173] Способ 1000 продолжается на шаге 1006, на котором сервер 112 формирует второе предложение на втором языке с использованием последовательности выходных токенов. Второе предложение содержит проблемно-ориентированный перевод входного слова 615. Например, сервер 112 может отфильтровывать из последовательности 640 выходных токенов один или несколько токенов, соответствующих специальным токенам.
[174] Для специалиста в данной области могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ и сервер для выполнения контекстно-зависимого перевода | 2021 |
|
RU2812301C2 |
| СПОСОБЫ И СЕРВЕРЫ ДЛЯ ОБУЧЕНИЯ МОДЕЛИ ОБНАРУЖЕНИЮ СМЕНЫ ДИКТОРА | 2024 |
|
RU2841235C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБУЧЕНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПЕРЕВОДА | 2023 |
|
RU2835121C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБРАБОТКИ ТЕКСТОВОЙ ПОСЛЕДОВАТЕЛЬНОСТИ В ЗАДАЧЕ МАШИННОЙ ОБРАБОТКИ | 2020 |
|
RU2775820C2 |
| Способ и сервер для обучения алгоритму машинного обучения для выполнения перевода | 2020 |
|
RU2789796C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ РЕЧЕВОГО ФРАГМЕНТА ПОЛЬЗОВАТЕЛЯ | 2021 |
|
RU2808582C2 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2021 |
|
RU2824338C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| СПОСОБЫ И ЭЛЕКТРОННЫЕ УСТРОЙСТВА ДЛЯ ПАКЕТИРОВАНИЯ ЗАПРОСОВ, ПРЕДНАЗНАЧЕННЫХ ДЛЯ ОБРАБОТКИ ОБРАБАТЫВАЮЩИМ БЛОКОМ | 2021 |
|
RU2810916C2 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |

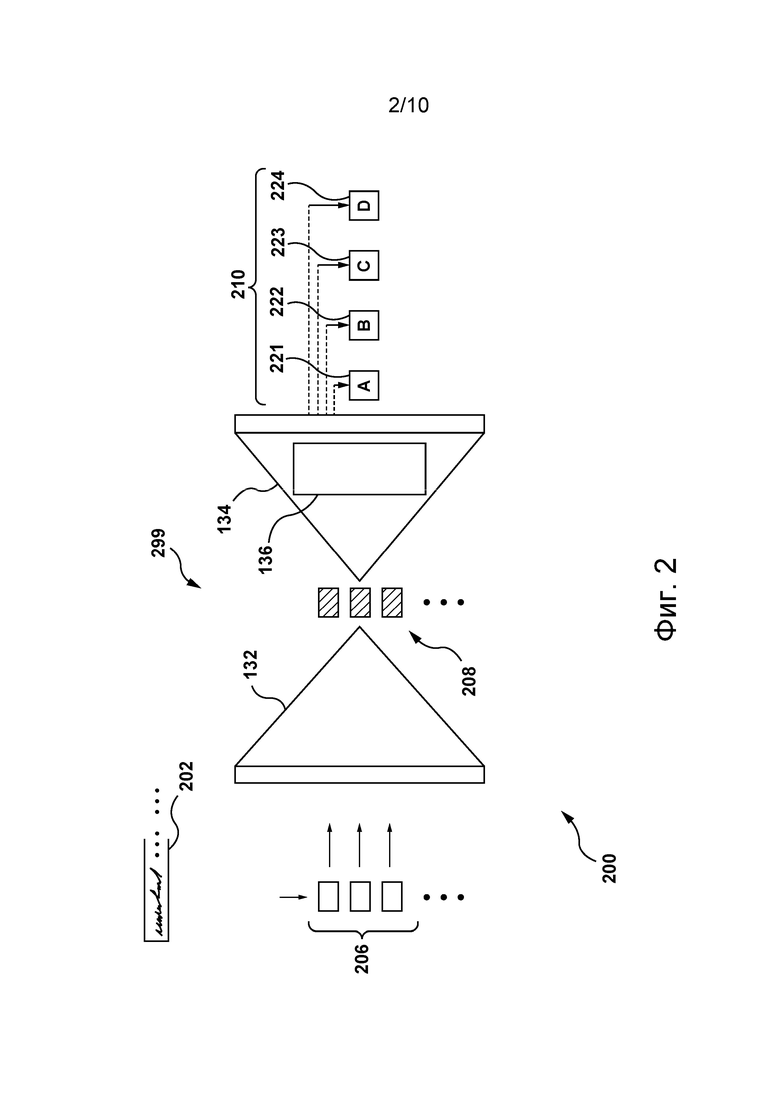
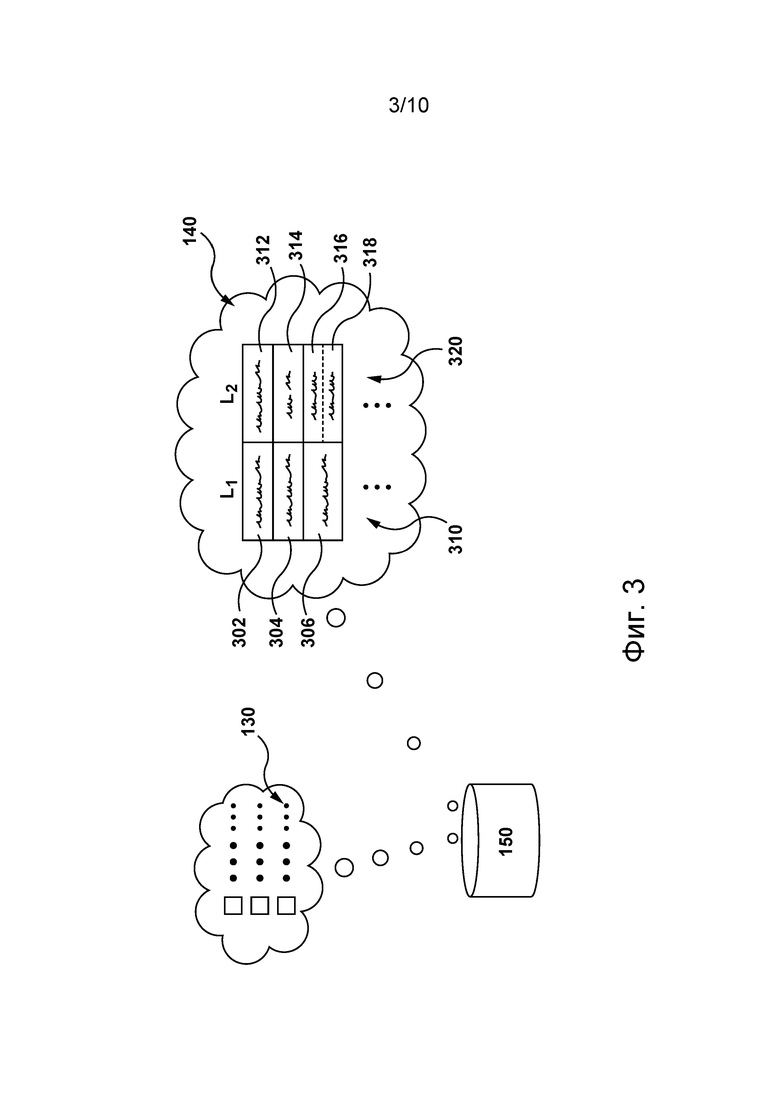
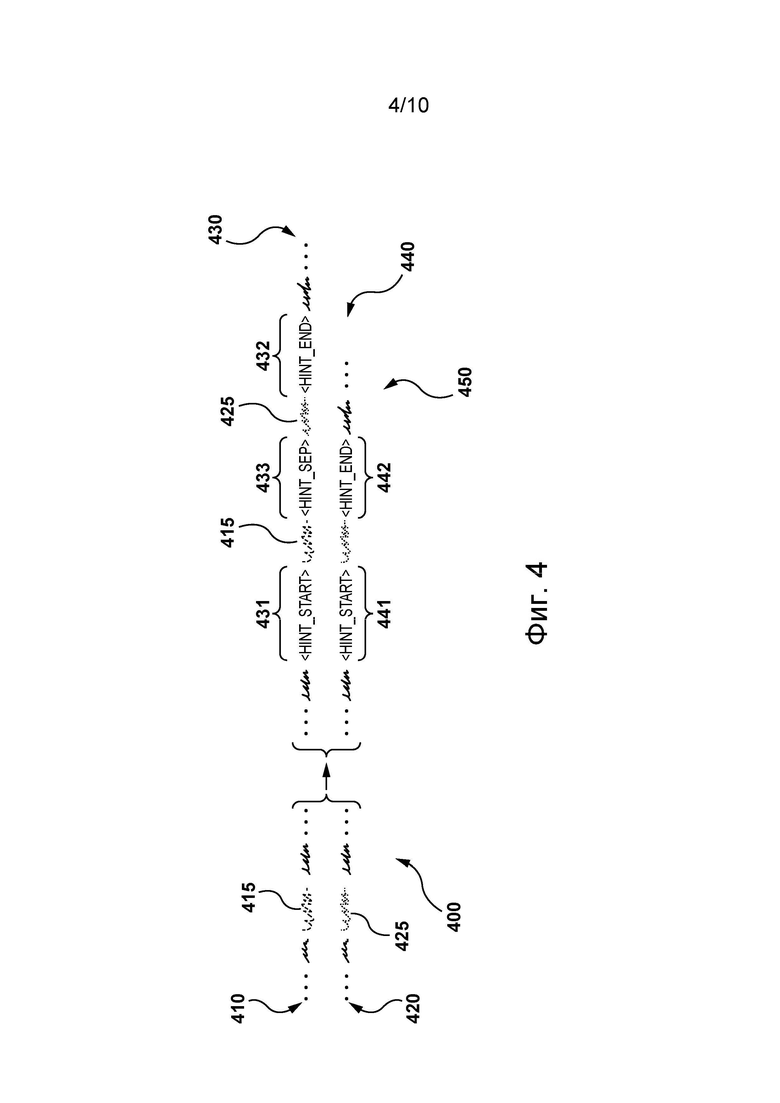
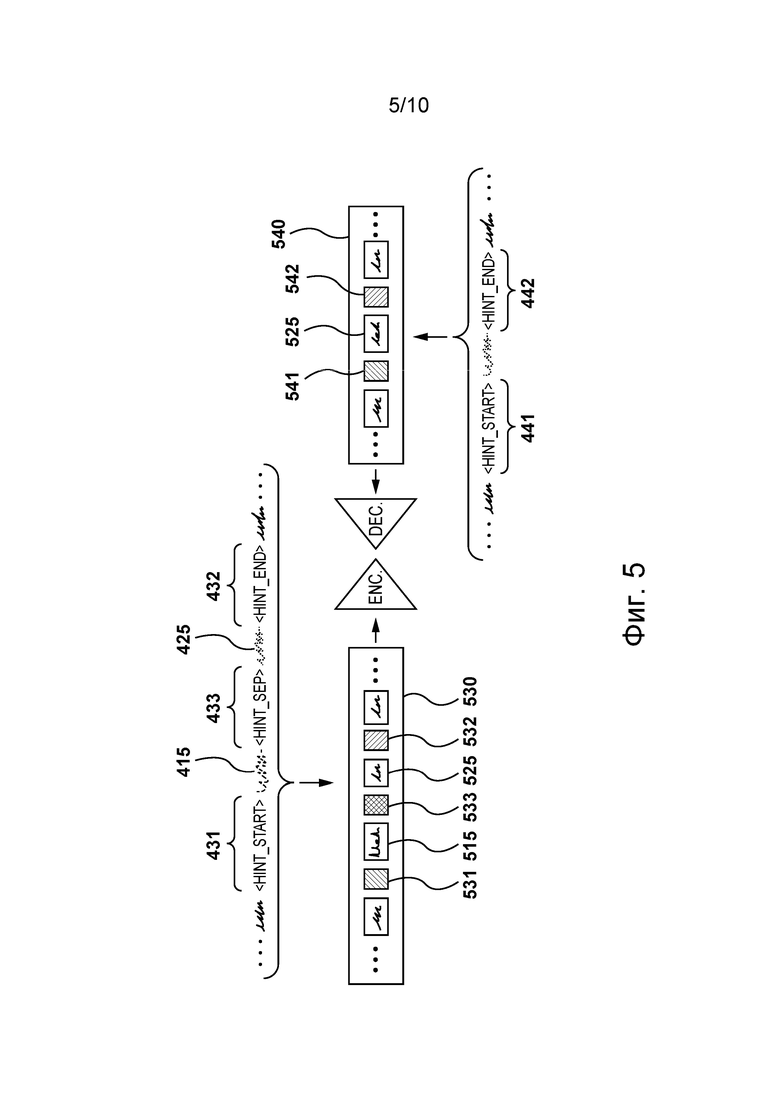
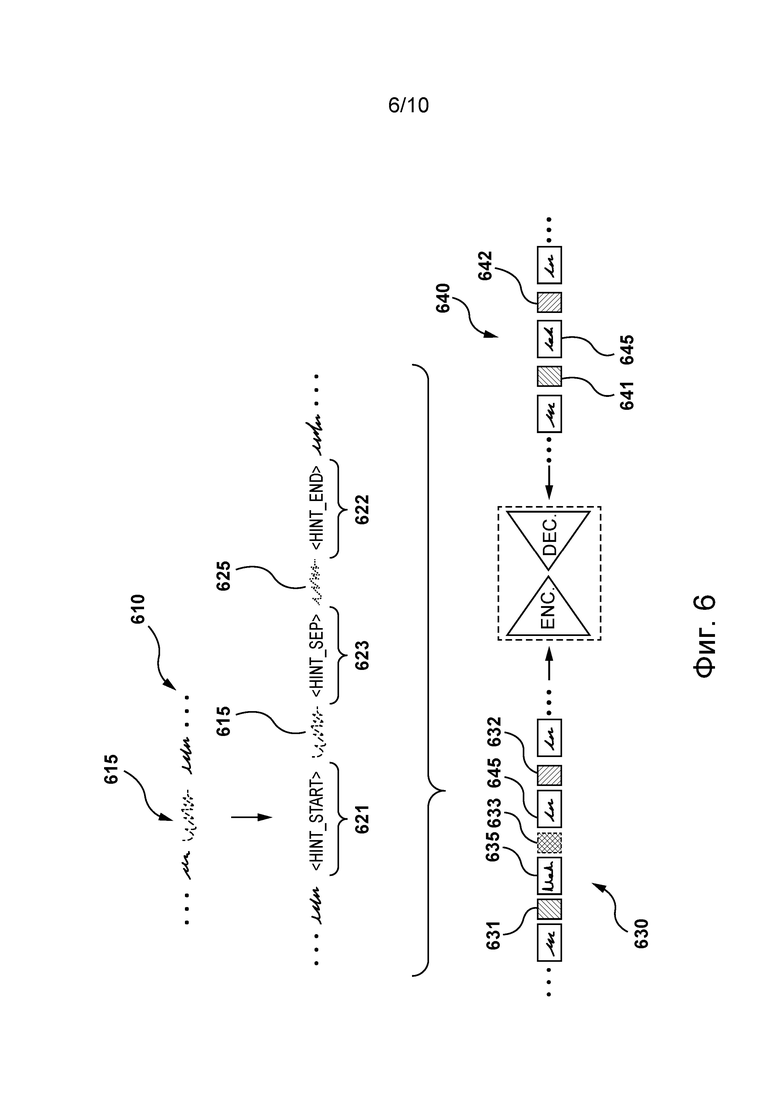
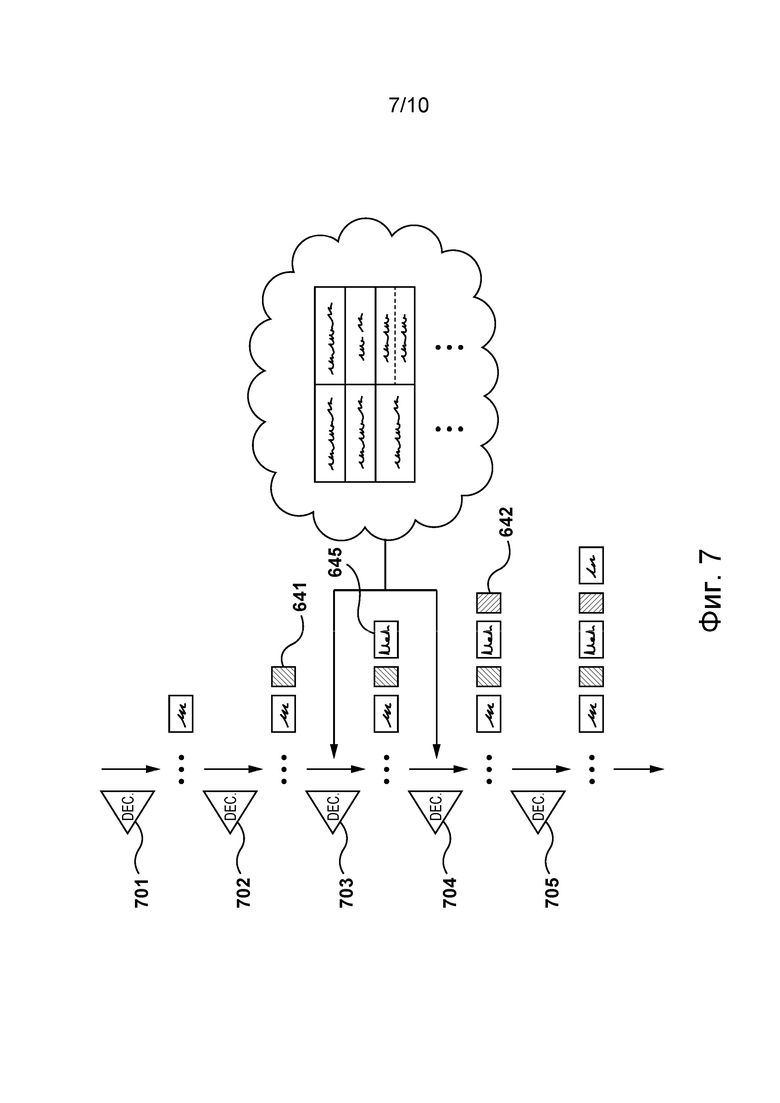
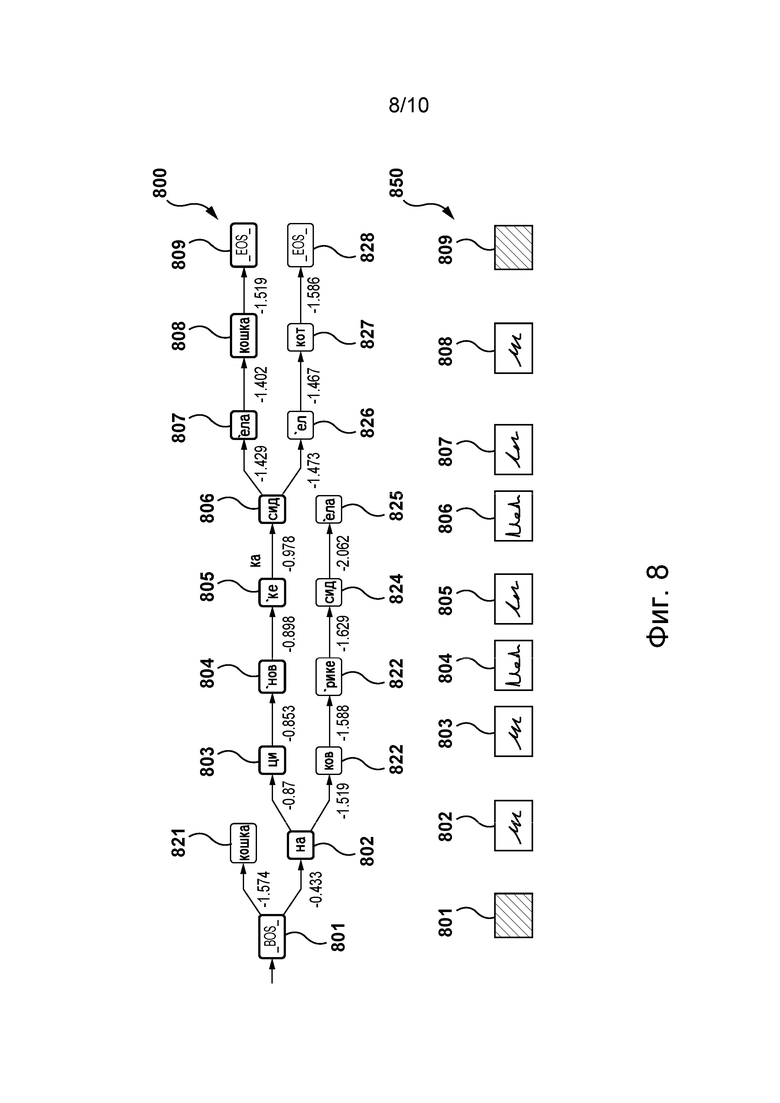

Изобретение относится к машинному переводу, в частности к способу и серверу для выполнения проблемно-ориентированного перевода. Технический результат заключается в обеспечении выполнения проблемно-ориентированного машинного перевода с должным качеством и снижением затрат вычислительных ресурсов. Способ выполнения машинного проблемно-ориентированного перевода предложений с первого языка на второй язык, выполняемый сервером с работающей на нем нейронной сетью (NN), причем серверу доступен проблемно-ориентированный словарь, содержащий проблемно-ориентированные переводы слов с первого языка на второй язык. Способ включает в себя формирование сервером дополненной последовательности входных токенов на основе входного предложения на первом языке и рекомендации, вставленной во входное предложение; итеративное формирование с использованием нейронной сети последовательности выходных токенов на основе дополненной последовательности входных токенов; формирование второго предложения на втором языке, содержащего проблемно-ориентированный перевод входного слова, с использованием последовательности выходных токенов. 2 н. и 16 з.п. ф-лы, 10 ил.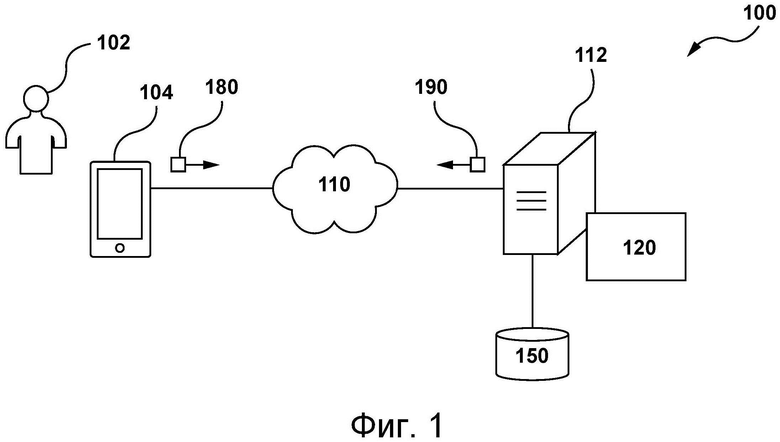
1. Способ выполнения машинного проблемно-ориентированного перевода предложений с первого языка на второй язык, выполняемый сервером с работающей на нем нейронной сетью (NN), причем серверу доступен проблемно-ориентированный словарь, содержащий проблемно-ориентированные переводы слов с первого языка на второй язык, при этом способ содержит этапы, на которых:
формируют дополненную последовательность входных токенов на основе входного предложения на первом языке и рекомендации, вставленной во входное предложение, при этом входное предложение содержит слово, представленное в дополненной последовательности входных токенов в виде заданного входного токена и имеющее проблемно-ориентированный перевод, представленный в виде другого токена, а рекомендация представлена в дополненной последовательности входных токенов посредством, по меньшей мере, входного начального токена и входного конечного токена, при этом, для идентификации входного токена в дополненной последовательности входных токенов в качестве заданного входного токена, входной начальный токен вставлен в позицию, предшествующую заданному входному токену, а входной конечный токен вставлен в позицию, следующую за заданным входным токеном;
итеративно формируют, посредством применения нейронной сети, последовательность выходных токенов на основе дополненной последовательности входных токенов, причем итеративное формирование последовательности выходных токенов содержит этапы, на которых:
- в ответ на формирование на одной из итераций выходного начального токена в последовательности выходных токенов применяют ограничивающее условие в отношении следующего выходного токена, который должен быть сформирован нейронной сетью для последовательности выходных токенов, так чтобы следующий выходной токен представлял собой упомянутый другой токен, и
- в ответ на формирование на другой из итераций выходного конечного токена прекращают применение ограничивающего условия в отношении следующего выходного токена, который должен быть сформирован нейронной сетью; и
формируют выходное предложение на втором языке на основе последовательности выходных токенов.
2. Способ по п.1, в котором заданный входной токен представляет собой подпоследовательность входных токенов, и входное слово представлено этой подпоследовательностью входных токенов в дополненной последовательности входных токенов.
3. Способ по п.2, в котором упомянутый другой токен представляет собой другую подпоследовательность токенов, и упомянутый проблемно-ориентированный перевод слова представлен этой другой подпоследовательностью токенов.
4. Способ по п.2 или 3, в котором проблемно-ориентированный словарь содержит множество проблемно-ориентированных переводов входного слова, представленных соответствующими подпоследовательностями из множества других подпоследовательностей токенов, при этом упомянутое применение ограничивающего условия включает в себя применение ограничивающего условия в отношении следующей подпоследовательности выходных токенов, которые должны быть сформированы нейронной сетью для последовательности выходных токенов, так чтобы следующая подпоследовательность выходных токенов представляла собой подпоследовательность из упомянутого множества других подпоследовательностей токенов.
5. Способ по п.4, в котором следующая подпоследовательность выходных токенов завершается выходным конечным токеном.
6. Способ по п.4, в котором упомянутое множество проблемно-ориентированных переводов входного слова содержит грамматические варианты входного слова.
7. Способ по п.1, при этом нейронная сеть представляет собой трансформерную модель, содержащую кодер и декодер, причем способ дополнительно содержит, до упомянутого итеративного формирования последовательности выходных токенов, этап обучения, на котором:
формируют дополненную последовательность первых токенов на основе первого предложения на первом языке и первой рекомендации, вставленной в первое предложение, при этом первое предложение содержит первое слово, представленное в дополненной последовательности первых токенов в виде заданного первого токена, а первая рекомендация представлена в дополненной последовательности первых токенов посредством первого начального токена и первого конечного токена, причем, для идентификации первого токена в последовательности первых токенов в качестве заданного первого токена, первый начальный токен вставлен в позицию, предшествующую заданному первому токену, а первый конечный токен вставлен в позицию, следующую за заданным первым токеном;
формируют дополненную последовательность вторых токенов на основе второго предложения на втором языке и второй рекомендации, вставленной во второе предложение, которое представляет собой перевод первого предложения и содержит второе слово, представляющее собой проблемно-ориентированный перевод первого слова и представленное в дополненной последовательности вторых токенов в виде заданного второго токена, при этом вторая рекомендация представлена в дополненной последовательности вторых токенов посредством второго начального токена и второго конечного токена, причем, для идентификации второго токена в последовательности вторых токенов в качестве заданного второго токена, второй начальный токен вставлен в позицию, предшествующую заданному второму токену, а второй конечный токен вставлен в позицию, следующую за заданным вторым токеном;
обучают трансформерную модель путем предоставления дополненной последовательности первых токенов в кодер и дополненной последовательности вторых токенов в декодер, с тем чтобы обучить декодер формированию выходного начального токена и выходного конечного токена в правильных позициях в последовательности выходных токенов.
8. Способ по п.1, в котором рекомендация дополнительно представлена в дополненной последовательности входных токенов посредством специального токена перевода-рекомендации и упомянутого другого токена, вставленных после заданного входного токена и перед входным конечным токеном.
9. Способ по п.1, в котором упомянутое применение ограничивающего условия основывается на заранее определенной подпоследовательности токенов из «белого списка», содержащей упомянутый другой токен.
10. Сервер для выполнения проблемно-ориентированного машинного перевода предложений с первого языка на второй язык, содержащий:
по меньшей мере один процессор; и
по меньшей мере одно запоминающее устройство,
при этом в по меньшей мере одном запоминающем устройстве сохранены машиноисполняемые инструкции, которыми при их исполнении в по меньшей мере одном процессоре на сервере реализуется нейронная сеть (NN),
причем сервер имеет доступ к проблемно-ориентированному словарю, содержащему проблемно-ориентированные переводы слов с первого языка на второй язык, и
при этом в по меньшей мере одном запоминающем устройстве дополнительно сохранены машиноисполняемые инструкции, которые при их исполнении в по меньшей мере одном процессоре предписывают серверу:
формировать дополненную последовательность входных токенов на основе входного предложения на первом языке и рекомендации, вставленной во входное предложение, при этом входное предложение содержит слово, представленное в дополненной последовательности входных токенов в виде заданного входного токена и имеющее проблемно-ориентированный перевод, представленный в виде другого токена, а рекомендация представлена в дополненной последовательности входных токенов посредством, по меньшей мере, входного начального токена и входного конечного токена, при этом, для идентификации входного токена в дополненной последовательности входных токенов в качестве заданного входного токена, входной начальный токен вставлен в позицию, предшествующую заданному входному токену, а входной конечный токен вставлен в позицию, следующую за заданным входным токеном;
итеративно формировать, посредством применения нейронной сети, последовательность выходных токенов на основе дополненной последовательности входных токенов, при этом итеративное формирование последовательности выходных токенов содержит:
- в ответ на формирование на одной из итераций выходного начального токена в последовательности выходных токенов применение ограничивающего условия в отношении следующего выходного токена, который должен быть сформирован нейронной сетью для последовательности выходных токенов, так чтобы следующий выходной токен представлял собой упомянутый другой токен, и
- в ответ на формирование на другой из итераций выходного конечного токена прекращение применения ограничивающего условия в отношении следующего выходного токена, который должен быть сформирован нейронной сетью; и
формировать выходное предложение на втором языке на основе последовательности выходных токенов.
11. Сервер по п.10, при этом заданный входной токен представляет собой подпоследовательность входных токенов и входное слово представлено этой подпоследовательностью входных токенов в дополненной последовательности входных токенов.
12. Сервер по п.11, при этом упомянутый другой токен представляет собой другую подпоследовательность токенов, и упомянутый проблемно-ориентированный перевод слова представлен этой другой подпоследовательностью токенов.
13. Сервер по п.11 или 12, при этом проблемно-ориентированный словарь содержит множество проблемно-ориентированных переводов входного слова, представленных соответствующими подпоследовательностями из множества других подпоследовательностей токенов, причем при упомянутом применении ограничивающего условия машиноисполняемые инструкции дополнительно предписывают серверу применять ограничивающее условие в отношении следующей подпоследовательности выходных токенов, которые должны быть сформированы нейронной сетью для последовательности выходных токенов, так чтобы следующая подпоследовательность выходных токенов представляла собой подпоследовательность из упомянутого множества других подпоследовательностей токенов.
14. Сервер по п.13, при этом следующая подпоследовательность выходных токенов завершается выходным конечным токеном.
15. Сервер по п.13, при этом упомянутое множество проблемно-ориентированных переводов входного слова содержит грамматические варианты входного слова.
16. Сервер по п.10, в котором нейронная сеть представляет собой трансформерную модель, содержащую кодер и декодер, при этом машиноисполняемые инструкции дополнительно предписывают серверу выполнять, до упомянутого итеративного формирования последовательности выходных токенов, обучение посредством:
формирования дополненной последовательности первых токенов на основе первого предложения на первом языке и первой рекомендации, вставленной в первое предложение, при этом первое предложение содержит первое слово, представленное в дополненной последовательности первых токенов в виде заданного первого токена, а первая рекомендация представлена в дополненной последовательности первых токенов посредством первого начального токена и первого конечного токена, причем, для идентификации первого токена в последовательности первых токенов в качестве заданного первого токена, первый начальный токен вставлен в позицию, предшествующую заданному первому токену, а первый конечный токен вставлен в позицию, следующую за заданным первым токеном;
формирования дополненной последовательности вторых токенов на основе второго предложения на втором языке и второй рекомендации, вставленной во второе предложение, которое представляет собой перевод первого предложения и содержит второе слово, представляющее собой проблемно-ориентированный перевод первого слова и представленное в дополненной последовательности вторых токенов в виде заданного второго токена, при этом вторая рекомендация представлена в дополненной последовательности вторых токенов посредством второго начального токена и второго конечного токена, причем, для идентификации второго токена в последовательности вторых токенов в качестве заданного второго токена, второй начальный токен вставлен в позицию, предшествующую заданному второму токену, а второй конечный токен вставлен в позицию, следующую за заданным вторым токеном;
обучения трансформерной модели путем предоставления дополненной последовательности первых токенов в кодер и дополненной последовательности вторых токенов в декодер, с тем чтобы обучить декодер формированию выходного начального токена и выходного конечного токена в правильных позициях в последовательности выходных токенов.
17. Сервер по п.10, при этом рекомендация дополнительно представлена в дополненной последовательности входных токенов в виде специального токена перевода-рекомендации и упомянутого другого токена, вставленных после заданного входного токена и перед входным конечным токеном.
18. Сервер по п.10, в котором упомянутое применение ограничивающего условия основывается на заранее определенной подпоследовательности токенов из «белого списка», содержащей упомянутый другой токен.
| US 10133739 B2, 20.11.2018 | |||
| US 11017777 B2, 25.05.2021 | |||
| US 10747962 B1, 18.02.2020 | |||
| Способ и система перевода исходного предложения на первом языке целевым предложением на втором языке | 2017 |
|
RU2692049C1 |

