Область техники, к которой относится изобретение
[01] Настоящая технология в целом относится к машинному переводу и, в частности, к способу и серверу для выполнения контекстно-зависимого перевода.
Уровень техники
[02] По мере увеличения количества пользователей, имеющих доступ к сети Интернет, возникает огромное число интернет-сервисов. Такие сервисы, например, включают в себя поисковые системы (в том числе, такие как поисковые системы Yandex™ и Google™), позволяющие пользователям получать информацию путем отправки запросов поисковой системе. Кроме того, благодаря социальным сетям и мультимедийным сервисам множество пользователей с различным социальным и культурным опытом могут общаться на унифицированных платформах с целью обмена контентом и информацией. Цифровой контент и другие данные, которыми обмениваются пользователи, могут быть представлены на множестве языков. Поэтому постоянно растущий объем информации, обмен которой происходит в сети Интернет, приводит к частому использованию сервисов перевода, например, таких как Yandex.Translate™.
[03] Последний сервис особенно полезен, поскольку с его помощью пользователи могут легко переводить текст (или даже устную речь) с одного языка, непонятного данному пользователю, на другой понятный ему язык. Это означает, что сервисы перевода обычно разрабатываются для предоставления переведенного варианта контента на понятном пользователю языке, чтобы сделать контент доступным для пользователя.
[04] Системы перевода обучаются на основе большого количества примеров параллельных предложений на исходном языке и языке перевода. Тем не менее, традиционные компьютерные системы, предоставляющие услуги перевода, по-прежнему имеют много недостатков, например, неправильно переводят редкие слова или слова, специфичные для конкретной области.
[05] В патентной заявке US20170323203 описаны системы и способы для нейронного машинного перевода.
Раскрытие изобретения
[06] Разработчики настоящей технологии выявили определенные технические недостатки, связанные с имеющимися сервисами перевода. Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений. Разработчики настоящей технологии установили, что модели перевода могут быть усовершенствованы для реализации лучшего контекстно-зависимого перевода предложений.
Нейронный машинный перевод (NMT, Neural Machine Translation)
[07] Нейронные сети (NN, Neural Network) обеспечили значительный прогресс в обработке естественного языка и в машинном переводе. В моделях перевода могут использоваться сети NN с трансформерной архитектурой. Это по меньшей мере частично объясняется способностью трансформерных архитектур учитывать широкий контекст, предоставляемый сетями с долгой краткосрочной памятью (LSTM, Long Short-Term Memory), а затем и механизмом внимания.
[08] В общем случае модель NMT во время обучения просматривает предложение 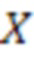 , состоящее из входных слов
, состоящее из входных слов 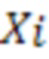 (каждое представлено в виде одного или нескольких входных токенов) на исходном языке и формирует его перевод
(каждое представлено в виде одного или нескольких входных токенов) на исходном языке и формирует его перевод 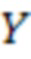 , состоящий из выходных слов
, состоящий из выходных слов  (каждое представлено одним или несколькими выходными токенами). Для обучения модели NMT требуются предложения из корпуса параллельных текстов, т.е. из набора данных, содержащего предложения на исходном языке и соответствующие им предложения на языке перевода. Модель NMT обычно обучается оцениванию вероятности
(каждое представлено одним или несколькими выходными токенами). Для обучения модели NMT требуются предложения из корпуса параллельных текстов, т.е. из набора данных, содержащего предложения на исходном языке и соответствующие им предложения на языке перевода. Модель NMT обычно обучается оцениванию вероятности  наблюдения выходного слова при заданном входном предложении и всех предыдущих словах
наблюдения выходного слова при заданном входном предложении и всех предыдущих словах 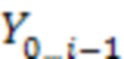 , например, с применением метода максимального правдоподобия.
, например, с применением метода максимального правдоподобия.
[09] Переводы формируются в процессе, называемом декодированием. Цель процесса декодирования для модели NMT заключается в поиске наиболее вероятного перевода , который описывается следующим образом:
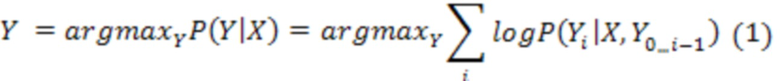
для исходного предложения , оцениваемого моделью NMT. Тем не менее, точное нахождение этого перевода может быть трудновыполнимым с вычислительной точки зрения, поэтому вместо него может использоваться аппроксимация в виде лучевого поиска. В общем случае в компьютерных науках лучевой поиск соответствует эвристическому алгоритму поиска, который исследует граф, разворачивая наиболее перспективный узел из ограниченного набора, при этом в качестве кандидатов сохраняется лишь заранее заданное количество лучших частных решений.
[10] Перевод может формироваться итеративно по одному слову. В начале каждой итерации имеется k префиксов перевода, также называемых гипотезами. Затем из всех состоящих из одного токена продолжений предыдущих k префиксов выбираются k новых лучших гипотез, ранжированных по соответствующей вероятности. Если одно из выбранных продолжений состоит из специального токена конца последовательности (EOS, End-Of-Sequence), то оно считается завершенным и исключается из текущих k лучших. Процесс может быть остановлен, когда максимальная вероятность текущих незавершенных гипотез меньше вероятности текущей наилучшей завершенной гипотезы, и/или по достижении заранее заданного максимального количества итераций.
[11] Разработчики настоящей технологии обнаружили, что некоторые традиционные модели NMT некачественно переводят контекстно-зависимый контент. Разработчики разработали способы и системы, в которых контекстная информация об одном или нескольких словах из предложения вносится особым образом в процессе перевода. В частности, в контексте настоящей технологии контекстная строка вставляется в исходное предложение и содержит контекстную информацию об одном или нескольких словах из исходного предложения. Таким образом, контекстная информация может использоваться моделью NMT при формировании переводов одного или нескольких слов.
[12] В некоторых вариантах осуществления настоящей технологии контекстная строка может использоваться для уточнения темы, связанной с исходным предложением. Например, пусть имеется исходное предложение на английском языке «The game is tomorrow». Следует отметить, что правильный перевод слова «game» на русский язык может представлять собой слова «игра» или «матч», что зависит от контекста, в котором используется исходное предложение. В этом примере модель перевода может вставить контекстную строку «Soccer -» в исходное предложение, в результате чего получается следующее дополненное исходное предложение: «Soccer - The game is tomorrow». В результате модель перевода может сформировать перевод на русский язык «Футбол - Матч завтра» вместо перевода «Футбол - Игра завтра». В этом примере контекстная строка, вставленная в исходное предложение, содержит контекстную информацию в виде зависящего от темы термина, используемого моделью перевода при переводе слова «game».
[13] В других вариантах осуществления настоящей технологии контекстная строка может использоваться для уточнения пола объекта в исходном предложении. Например, пусть имеется исходное предложение на английском языке «The cat is hungry». Следует отметить, что правильный перевод слова «cat» на русский язык может представлять собой слова «кошка» (женского рода) или «кот» (мужского рода), а правильный перевод слова «hungry» на русский язык может представлять собой слова «голодна» (женского рода) или «голоден» (мужского рода) в зависимости от того, является конкретное животное, упомянутое в исходном предложении, самкой или самцом. Структура английского языка вследствие своих особенностей не обеспечивает информацию о поле объекта. В этом примере модель перевода может вставить контекстную строку «She -» в исходное предложение, в результате чего получается следующее дополненное исходное предложение: «She - The cat is hungry». В результате модель перевода может сформировать перевод на русский язык «Она - кошка голодна» вместо перевода «Он - кот голоден». В этом примере контекстная строка, вставленная в исходное предложение, содержит контекстную информацию в виде зависящего от рода термина, который используется моделью перевода при переводе слов «cat» и «hungry».
[14] Контекстная строка может быть предоставлена модели перевода различными способами. В некоторых вариантах осуществления изобретения сервер может анализировать одно или несколько других предложений из абзаца, в котором обнаружено исходное предложение. В других вариантах осуществления изобретения сервер может получать информацию об одном или нескольких словах из репозитория. В других вариантах осуществления изобретения множество контекстных строк-кандидатов может заранее сохраняться, доступ к ним может осуществляться сервером и конкретный кандидат может выбираться сервером для вставки в исходное предложение. Конкретный кандидат может выбираться на основе информации, полученной сервером и/или извлеченной из первоисточника исходного предложения, без выхода за границы настоящей технологии.
[15] Разработчики настоящей технологии также установили, что вставка контекстной строки в начало предложения может быть полезной при обработке выходных данных из модели перевода. Следует отметить, что благодаря вставке контекстной строки в такую заранее заданную позицию, модель перевода способна идентифицировать, какая часть выходного предложения соответствует переводу вставленной контекстной строки и/или какая другая часть выходного предложения соответствует переводу исходного предложения (не дополненного). В результате часть выходного предложения, соответствующая переводу вставленной контекстной строки, может быть точно удалена из целевого предложения, которое должно быть предоставлено в качестве перевода исходного предложения (не дополненного).
[16] Согласно первому аспекту настоящей технологии реализован способ выполнения контекстно-зависимого перевода предложений с первого языка на второй язык. Способ реализуется сервером. На сервере работает сеть NN и ему доступен контекстно-зависимый словарь, содержащий контекстные слова на первом языке и соответствующие переводы на втором языке. Способ включает в себя формирование сервером дополненной последовательности входных токенов на основе входного предложения на первом языке и контекстного слова на первом языке, вставленного во входное предложение. Контекстное слово связано с соответствующим контекстным словом на втором языке. Входное предложение содержит слово. Слово представлено в дополненной последовательности входных токенов в виде первого входного токена. Контекстное слово представлено в дополненной последовательности входных токенов в виде второго входного токена. Второй входной токен размещен в дополненной последовательности входных токенов в заранее заданной позиции и содержит контекстную информацию о первом входном токене. Способ включает в себя итеративное формирование сервером с использованием сети NN последовательности выходных токенов на основе дополненной последовательности входных токенов. Последовательность выходных токенов содержит первый выходной токен и второй выходной токен. Второй выходной токен размещен в последовательности выходных токенов в заранее заданной позиции и представляет соответствующее контекстное слово на втором языке. Первый выходной токен представляет контекстно-зависимый перевод слова.
[17] В некоторых вариантах осуществления способа первый входной токен представляет собой подпоследовательность входных токенов. Слово представлено в дополненной последовательности входных токенов в виде этой подпоследовательности входных токенов.
[18] В некоторых вариантах осуществления способа первый выходной токен представляет собой другую подпоследовательность выходных токенов. Контекстно-зависимый перевод слова представлен этой другой подпоследовательностью выходных токенов.
[19] В некоторых вариантах осуществления способа входное предложение представляет собой предложение из множества предложений в цифровом документе. Способ дополнительно включает в себя определение сервером контекстного слова на основе другого предложения из этого множества предложений.
[20] В некоторых вариантах осуществления способа он дополнительно включает в себя определение сервером контекстного слова на основе данных, заранее сохраненных применительно к одному или нескольким словам из входного предложения.
[21] В некоторых вариантах осуществления способа он включает в себя обращение сервера к контекстно-зависимому словарю для определения контекстного слова на первом языке и соответствующего контекстного слова на втором языке.
[22] В некоторых вариантах осуществления способа он дополнительно включает в себя формирование сервером выходного предложения на втором языке с использованием последовательности выходных токенов.
[23] В некоторых вариантах осуществления способа формирование выходного предложения включает в себя удаление соответствующего контекстного слова.
[24] В некоторых вариантах осуществления способа заранее заданная позиция в дополненной последовательности входных токенов соответствует позиции, предшествующей входным токенам, представляющим входное предложение.
[25] В некоторых вариантах осуществления способа заранее заданная позиция в дополненной последовательности входных токенов соответствует началу дополненной последовательности входных токенов.
[26] В некоторых вариантах осуществления способа заранее заданная позиция в последовательности выходных токенов соответствует началу последовательности выходных токенов.
[27] В некоторых вариантах осуществления способа сеть NN представляет собой трансформерную модель. Трансформерная модель содержит кодирующую часть, предназначенную для первого языка, и декодирующую часть, предназначенную для второго языка.
[28] В некоторых вариантах осуществления способа контекстная информация представляет род входного слова.
[29] В некоторых вариантах осуществления способа контекстная информация представляет тему входного предложения, содержащего входное слово.
[30] Согласно второму аспекту настоящей технологии реализован сервер для выполнения контекстно-зависимого перевода предложений с первого языка на второй язык. На сервере работает сеть NN и ему доступен контекстно-зависимый словарь, содержащий контекстные слова на первом языке и соответствующие переводы на втором языке. Сервер способен формировать дополненную последовательность входных токенов на основе входного предложения на первом языке и контекстного слова на первом языке, вставленного во входное предложение. Контекстное слово связано с соответствующим контекстным словом на втором языке. Входное предложение содержит слово. Слово представлено в дополненной последовательности входных токенов в виде первого входного токена. Контекстное слово представлено в дополненной последовательности входных токенов в виде второго входного токена. Второй входной токен размещен в дополненной последовательности входных токенов в заранее заданной позиции и содержит контекстную информацию о первом входном токене. Сервер способен итеративно формировать с использованием сети NN последовательность выходных токенов на основе дополненной последовательности входных токенов. Последовательность выходных токенов содержит первый выходной токен и второй выходной токен. Второй выходной токен размещен в последовательности выходных токенов в заранее заданной позиции и представляет соответствующее контекстное слово на втором языке. Первый выходной токен представляет контекстно-зависимый перевод слова.
[31] В некоторых вариантах осуществления сервера первый входной токен представляет собой подпоследовательность входных токенов. Слово представлено в дополненной последовательности входных токенов в виде этой подпоследовательности входных токенов.
[32] В некоторых вариантах осуществления сервера первый выходной токен представляет собой другую подпоследовательность выходных токенов. Контекстно-зависимый перевод слова представлен этой другой подпоследовательностью выходных токенов.
[33] В некоторых вариантах осуществления сервера входное предложение представляет собой предложение из множества предложений в цифровом документе. Сервер дополнительно способен определять контекстное слово на основе другого предложения из этого множества предложений.
[34] В некоторых вариантах осуществления сервер дополнительно способен определять контекстное слово на основе данных, заранее сохраненных применительно к одному или нескольким словам из входного предложения.
[35] В некоторых вариантах осуществления сервер способен обращаться к контекстно-зависимому словарю для определения контекстного слова на первом языке и соответствующего контекстного слова на втором языке.
[36] В некоторых вариантах осуществления сервер дополнительно способен формировать выходное предложение на втором языке с использованием последовательности выходных токенов.
[37] В некоторых вариантах осуществления сервера формирование выходного предложения включает в себя удаление соответствующего контекстного слова.
[38] В некоторых вариантах осуществления сервера заранее заданная позиция в дополненной последовательности входных токенов соответствует позиции, предшествующей входным токенам, представляющим входное предложение.
[39] В некоторых вариантах осуществления сервера заранее заданная позиция в дополненной последовательности входных токенов соответствует началу дополненной последовательности входных токенов.
[40] В некоторых вариантах осуществления сервера заранее заданная позиция в последовательности выходных токенов соответствует началу последовательности выходных токенов.
[41] В некоторых вариантах осуществления сервера сеть NN представляет собой трансформерную модель, содержащую кодирующую часть, предназначенную для первого языка, и декодирующую часть, предназначенную для второго языка.
[42] В некоторых вариантах осуществления сервера контекстная информация представляет род входного слова.
[43] В некоторых вариантах осуществления сервера контекстная информация представляет тему входного предложения, содержащего входное слово.
[44] В контексте данного описания трансформерная модель представляет собой модель с архитектурой вида «кодер-декодер», в которой используются механизмы внимания. Механизмы внимания могут применяться во время обработки данных кодером, при обработке данных декодером и при взаимодействиях кодер-декодер. В трансформерной модели может использоваться множество механизмов внимания.
[45] Один из компонентов трансформерной модели может представлять собой механизм самовнимания. Различие между механизмом внимания и механизмом самовнимания заключается в том, что механизм самовнимания работает между схожими представлениями, например, между всеми состояниями кодера в одном слое. Механизм самовнимания входит в состав трансформерной модели, в которой токены взаимодействуют друг с другом. Каждый токен в известном смысле «наблюдает» за другими токенами в предложении с помощью механизма внимания, собирает контекст и обновляет свое предыдущее представление. Каждый входной токен в механизме самовнимания получает три представления: (а) запрос, (б) ключ и (в) значение. Запрос используется, когда токен наблюдает за другими токенами - он ищет информацию, чтобы лучше «понимать» себя. Ключ реагирует на запрос - он используется для расчета весов внимания. Значение используется для расчета результата внимания - оно предоставляет информацию о токенах, которые сообщают, что им требуется внимание (т.е. таким токенам присваиваются большие веса).
[46] Другой компонент трансформерной модели может представлять собой механизм замаскированного самовнимания. Декодер обычно содержит этот особый механизм самовнимания, который отличается от механизма самовнимания в кодере. Кодер получает все токены одновременно и токены могут наблюдать за всеми токенами во входном предложении, а в декодере токены формируются поодиночке, т.е. при формировании модели не известно, какие токены будут сформированы в будущем. Чтобы запретить декодеру «просмотр вперед», в трансформерной модели используется механизм замаскированного самовнимания, т.е. будущие токены маскируются.
[47] Еще один компонент трансформерной модели может представлять собой механизм многоголового внимания. Следует отметить, что для понимания роли слова в предложении требуется понимание того, как оно связано с другими частями предложения. Это важно не только при обработке исходного предложения, но и при формировании целевых объектов. В результате благодаря механизму внимания этого вида трансформерная модель может «концентрироваться на различных вещах». Механизм многоголового внимания вместо одного механизма внимания содержит несколько независимо работающих «голов». Он может быть реализован в виде нескольких механизмов внимания, результаты которых объединяются.
[48] Кодер трансформерной модели может содержать механизм самовнимания кодера и блок сети прямого распространения. Механизм самовнимания кодера может представлять собой механизм многоголового внимания, используемый для наблюдения токенами друг за другом. Запросы, ключи и значения рассчитываются на основе состояний кодера. Блок сети прямого распространения получает информацию из токенов и обрабатывает эту информацию.
[49] Декодер трансформерной модели может содержать механизм (замаскированного) самовнимания декодера, механизм внимания декодер-кодер и сеть прямого распространения. Механизм замаскированного самовнимания декодера может представлять собой механизм замаскированного многоголового внимания, используемый для наблюдения токенами за предыдущими токенами. Запросы, ключи и значения рассчитываются на основе состояний декодера. Механизм внимания декодер-кодер может представлять собой механизм многоголового внимания, используемый для просмотра целевыми токенами исходной информации. Запросы рассчитываются на основе состояний декодера, а ключи и значения рассчитываются на основе состояний кодера. Блок сети прямого распространения получает информацию из токенов и обрабатывает эту информацию.
[50] Можно сказать, что токены в кодере поддерживают связь друг с другом и обновляют свои представления. Также можно сказать, что в декодере целевой токен сначала просматривает ранее сформированные целевые токены, затем источник и, наконец, обновляет свои представления. Это может повторяться в нескольких слоях. В одном не имеющем ограничительного характера варианте реализации это может повторяться шесть раз.
[51] Как описано выше, в дополнение к механизму внимания слой содержит блок сети прямого распространения. Например, блок сети прямого распространения может быть представлен двумя линейными слоями с нелинейной связью вида «усеченное линейное преобразование» (ReLU, Rectifier Linear Unit) между ними. После просмотра других токенов с помощью механизма внимания блок сети прямого распространения используется в модели для обработки новой информации. Трансформерная модель может дополнительно содержать остаточные связи для добавления входных данных блока к его выходным данным. Остаточные связи могут использоваться для объединения слоев. В трансформерной модели остаточные связи могут использоваться после соответствующего механизма внимания и блока сети прямого распространения. Например, слою «Add & Norm» (суммирование и нормализация) могут предоставляться (а) входные данные механизма внимания через остаточную связь и (б) выходные данные механизма внимания. Затем результат слоя «Add & Norm» может предоставляться блоку сети прямого распространения или другому механизму внимания. В другом примере слою «Add & Norm» могут предоставляться (а) входные данные блока сети прямого распространения через остаточную связь и (б) выходные данные блока сети прямого распространения. Как описано выше, трансформерная модель может содержать слои «Add & Norm». В общем случае такой слой может независимо нормализовывать векторное представление каждого примера в пакете. Это делается для управления «потоком» в следующий слой. Нормализация слоя позволяет повышать устойчивость схождения и в некоторых случаях даже качество.
[52] В контексте данного описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В данном контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[53] В контексте данного описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает применения нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
[54] В контексте данного описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[55] В контексте данного описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[56] В контексте данного описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[57] В контексте данного описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[58] В контексте данного описания числительные «первый», «второй», «третий» и т.д. используются лишь для указания на различие между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
[59] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[60] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[61] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[62] На фиг. 1 представлена схема системы, пригодной для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии.
[63] На фиг. 2 представлена традиционная модель перевода для формирования последовательности выходных токенов.
[64] На фиг. 3 представлена структура данных, хранящихся в базе данных системы, представленной на фиг. 1, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[65] На фиг. 4 представлен дополненный обучающий пример, сформированный сервером из системы, представленной на фиг. 1, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[66] На фиг. 5 представлена итерация обучения модели перевода из системы, представленной на фиг. 1, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[67] На фиг. 6 представлена итерация этапа использования модели перевода, представленной на фиг. 5, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[68] На фиг. 7 представлена блок-схема способа, выполняемого согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
Осуществление изобретения
[69] На фиг. 1 представлена схема системы 100, пригодной для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии. Должно быть понятно, что система 100 приведена лишь для демонстрации варианта реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях приводятся полезные примеры модификаций системы 100. Они способствуют пониманию, но также не определяют объема или границ настоящей технологии. Эти модификации не составляют исчерпывающего перечня. Как должно быть понятно специалисту в данной области, возможны и другие модификации. Кроме того, если в некоторых случаях модификации не описаны (т.е. примеры модификаций отсутствуют), это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области должно быть понятно, что это не обязательно так. Кроме того, следует понимать, что система 100 в некоторых случаях может представлять собой упрощенную реализацию настоящей технологии и что такие варианты представлены, чтобы способствовать лучшему ее пониманию. Специалистам в данной области должно быть понятно, что другие варианты осуществления настоящей технологии могут быть значительно сложнее.
[70] В целом, система 100 способна предоставлять сервисы электронного перевода для пользователя 102 электронного устройства 104. Например, система 100 может получать предложение на исходном языке и предоставлять переведенный вариант этого предложения на языке перевода. Ниже описаны по меньшей мере некоторые элементы системы 100. Тем не менее, должно быть понятно, что в состав системы 100 могут входить элементы, отличные от представленных на фиг. 1, без выхода за границы настоящей технологии.
Сеть связи
[71] Электронное устройство 104 подключено к сети 110 связи для обмена данными с сервером 112. Например, электронное устройство 104 может быть связано с сервером 112 через сеть 110 связи для предоставления сервисов перевода пользователю 102. Сеть 110 связи, среди прочего, способна передавать запросы и ответы между электронным устройством 104 и сервером 112 в виде одного или нескольких пакетов данных, содержащих передаваемые данные.
[72] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 110 связи может использоваться сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления данной технологии сеть 110 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п. Реализация линии связи (отдельно не обозначена) между электронным устройством 104 и сетью 110 связи зависит, среди прочего, от реализации электронного устройства 104.
[73] Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где электронное устройство 104 реализовано в виде беспроводного устройства связи (такого как смартфон), линия связи может быть реализована в виде беспроводной линии связи (такой как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где электронное устройство 104 реализовано в виде ноутбука, линия связи может быть беспроводной (такой как Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.д.) или проводной (такой как соединение на основе Ethernet).
Электронное устройство
[74] Система 100 содержит электронное устройство 104, связанное с пользователем 102. Электронное устройство 104 иногда может называться клиентским устройством, оконечным устройством, клиентским электронным устройством или просто устройством. Следует отметить, что связь электронного устройства 104 с пользователем 102 не означает необходимости предлагать или подразумевать какой-либо режим работы, например, вход в систему, регистрацию и т.п.
[75] На реализацию электронного устройства 104 не накладывается каких-либо особых ограничений. Например, электронное устройство 104 может быть реализовано в виде персонального компьютера (настольного, ноутбука, нетбука и т.д.), беспроводного устройства связи (смартфона, сотового телефона, планшета и т.д.) или сетевого оборудования (маршрутизатора, коммутатора, шлюза и т.д.). Электронное устройство 104 содержит известные в данной области техники аппаратные средства и/или прикладное программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для выполнения браузерного приложения.
[76] В общем случае браузерное приложение обеспечивает пользователю 102 доступ к одному или нескольким сетевым ресурсам, например, к веб-страницам. На реализацию браузерного приложения не накладывается каких-либо особых ограничений. Например, браузерное приложение может быть реализовано в виде браузера Yandex™.
[77] Пользователь 102 может использовать браузерное приложение для доступа к системе перевода с целью перевода одного или нескольких предложений с исходного языка на язык перевода. Например, электронное устройство 104 может формировать запрос, указывающий на одно или несколько предложений, которые желает перевести пользователь 102. Электронное устройство 104 также может получать ответ (не показан) для отображения пользователю 102 переведенного варианта одного или нескольких предложений на языке перевода. Обычно запрос и ответ могут передаваться электронному устройству 104 и от него через сеть 110 связи.
База данных
[78] Система 100 также содержит базу 150 данных, связанную с сервером 112 и способную хранить информацию, полученную либо иным образом определенную или сформированную сервером 112. В целом, база 150 данных способна получать с сервера 112 данные, которые были извлечены либо иным образом определены или сформированы сервером 112 во время обработки, для временного и/или постоянного хранения и способна выдавать сохраненные данные серверу 112 для их использования. Предполагается, что база 150 данных может быть разделена на несколько распределенных баз данных без выхода за границы настоящей технологии.
[79] База 150 данных способна хранить данные для поддержки сервисов переводов, предоставляемых системой перевода сервера 112. С этой целью база 150 данных может, среди прочего, хранить контекстно-зависимый словарь 140 и множество обучающих примеров 130, как показано на фиг. 3.
[80] В общем случае контекстно-зависимый словарь 140 представляет собой структуру данных, содержащую контекстные строки 310 на первом языке и соответствующие контекстные строки 320 на втором языке. В представленном не имеющем ограничительного характера примере контекстные строки 310 на первом языке содержат контекстную строку 302 и контекстную строку 304, а контекстные строки 320 на втором языке содержат контекстную строку 312 и контекстную строку 314. Контекстная строка 312 представляет собой перевод контекстной строки 302 на второй язык. Контекстная строка 314 представляет собой перевод контекстной строки 304 на второй язык.
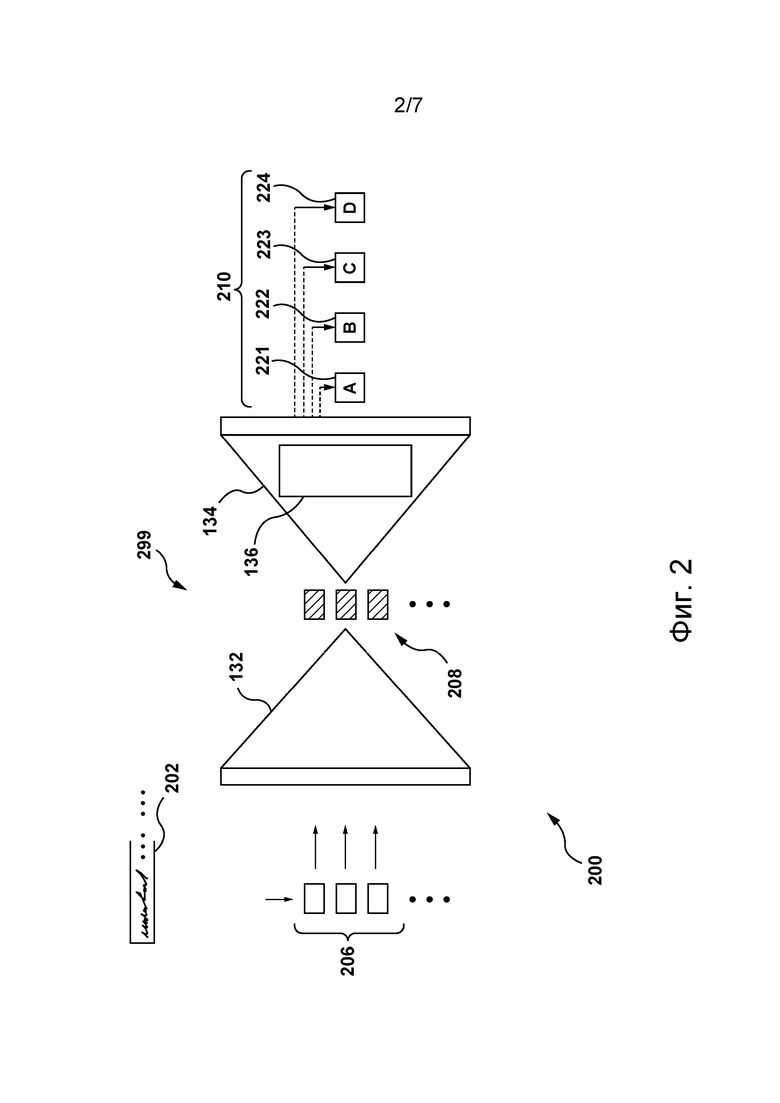
[81] В одном варианте осуществления настоящей технологии контекстно-зависимый словарь 140 может содержать одну или несколько следующих пар контекстных строк для языковой пары английский-русский:
«She -» и «Она -»;
«He -» и «Он -»;
«She:» и «Она:»;
«She said /» и «Она сказала /»;
«Weather -» и «Погода -»;
«Soccer -» и «Футбол -».
[82] В некоторых вариантах осуществления настоящей технологии предполагается, что контекстно-зависимый словарь может содержать переводы контекстной строки на несколько вторых языков без выхода за границы настоящей технологии. Можно сказать, что структура данных может быть двуязычной, трехъязычной и т.д. В других вариантах осуществления настоящей технологии предполагается, что контекстная строка может содержать одно слово, а другая контекстная строка может содержать два или более слов. В некоторых случаях контекстная строка может содержать сочетание слов и других специальных символов, таких как «-», «;», «:», «/», «#», «@», «*», «&» и т.п.
[83] Дополнительно или в качестве альтернативы, база 150 данных может хранить множество контекстно-зависимых словарей, подобных контекстно-зависимому словарю 140, каждый из которых связан с соответствующим видом контента. Например, контекстно-зависимый словарь 140 может содержать пары зависящих от рода контекстных строк, а другой контекстно-зависимый словарь может содержать пары зависящих от темы контекстных строк.
[84] Как описано выше, база 150 данных может дополнительно содержать множество обучающих примеров 130 для обучения одного или нескольких алгоритмов машинного обучения (MLA, Machine Learning Algorithm), содержащихся в системе перевода сервера 112. Множество обучающих примеров 130 может содержать большое количество параллельных предложений, при этом каждая пара предложений содержит первое предложение на первом языке и второе предложение на втором языке. Также предполагается, что соответствующее множество обучающих примеров может быть сохранено для соответствующей пары исходного и целевого языков без выхода за границы настоящей технологии. Параллельные предложения могут быть определены в одном или нескольких текстовых источниках и на их определение не накладывается каких-либо особых ограничений. Возможное использование множества обучающих примеров 130 сервером 112 при обучении одного или нескольких алгоритмов MLA более подробно описано ниже.
Сервер
[85] Система 100 также содержит сервер 112, который может быть реализован в виде традиционного компьютерного сервера. В представленных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 112 представляет собой один сервер. В альтернативных не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 112 могут быть распределены между несколькими серверами. Сервер 112 может содержать один или несколько процессоров, одно или несколько устройств физической памяти, машиночитаемые команды и/или дополнительные аппаратные элементы, дополнительные компоненты программных средств и/или их сочетание для реализации различных функций сервера 112 без выхода за границы настоящей технологии.
[86] В целом, сервер 112 может управляться и/или администрироваться поставщиком сервиса перевода (не показан), таким как оператор сервисов перевода Yandex™. Предполагается, что поставщик сервисов перевода и поставщик браузерного приложения могут представлять собой одного и того же поставщика. В частности, браузерное приложение (например, браузер Yandex™) и сервисы перевода (например, сервисы перевода Yandex™) могут предоставляться, управляться и/или администрироваться одним и тем же оператором или субъектом.
[87] Как описано выше, на сервере 112 размещена система перевода (не показана). В общем случае система перевода реализована в виде множества компьютерных процедур, используемых для перевода одного или нескольких предложений с исходного языка на язык перевода и для предоставления таких переводов пользователям системы перевода. С этой целью сервер 112 может выполнять модель 120 перевода.
Алгоритмы машинного обучения
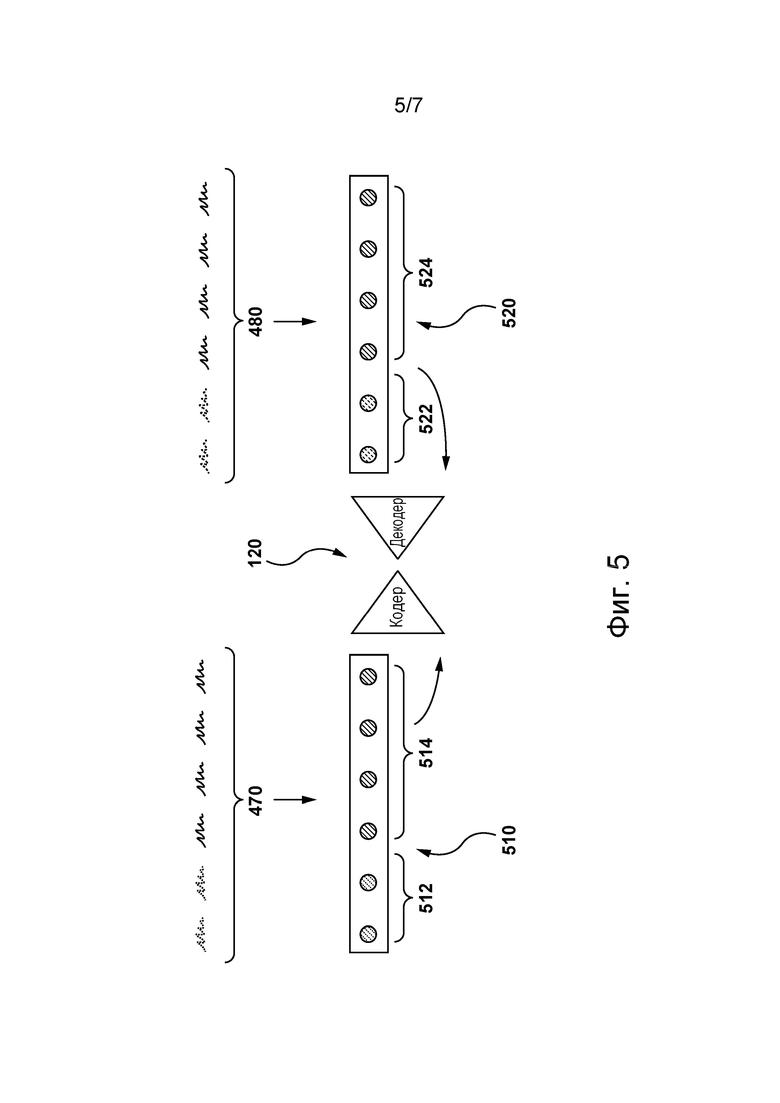
[88] В общем случае алгоритмы MLA способны обучаться на обучающих выборках и осуществлять прогнозирование на основе новых (ранее не известных) данных. Алгоритмы MLA обычно используются для первоначального построения модели на основе обучающих входных данных, чтобы затем на основе данных выполнять прогнозирование или принимать решения, выраженные в виде выходных данных, вместо исполнения статических машиночитаемых команд.
[89] Алгоритмы MLA обычно используются в качестве моделей оценивания, моделей перевода, моделей классификации и т.п. Должно быть понятно, что для различных задач могут использоваться алгоритмы MLA различных видов с различными структурами или топологиями.
[90] Алгоритмы MLA одного конкретного вида включают в себя сети NN. В общем случае сеть NN состоит из взаимосвязанных групп искусственных нейронов, обрабатывающих информацию с использованием коннекционного подхода к вычислениям. Сети NN используются для моделирования сложных взаимосвязей между входными и выходными данными (без фактической информации об этих взаимосвязях) или для поиска закономерностей в данных. Сети NN сначала адаптируются на этапе обучения, когда они обеспечиваются известным набором входных данных и информацией для адаптации сети NN с целью формирования правильных выходных данных (для ситуации, в отношении которой выполняется попытка моделирования). На этапе обучения сеть NN адаптируется к изучаемой ситуации и изменяет свою структуру таким образом, чтобы быть способной обеспечивать адекватное предсказание выходных данных для входных данных в новой ситуации (на основе того, что было выучено). Таким образом, вместо попытки определения сложных статистических распределений или математических алгоритмов для ситуации сеть NN пытается предоставить «интуитивный» ответ на основе «восприятия» этой ситуации.
[91] Сети NN широко используются во многих таких ситуациях, где важно лишь получение выходных данных на основе входных данных и менее важна или вовсе не важна информация о том, как получены эти выходные данные. Например, сети NN широко используются для оптимизации распределения веб-трафика между серверами, автоматического перевода текста на различные языки, а также при обработке данных, включая фильтрацию, кластеризацию, векторизацию и т.п.
[92] Реализация алгоритма MLA может быть разделена на два основных этапа: этап обучения и этап использования. Сначала алгоритм MLA обучается на этапе обучения. Затем, когда алгоритму MLA известно, какие предполагаются входные данные и какие должны выдаваться выходные данные, алгоритм MLA выполняется с реальными данными на этапе использования.
[93] Предполагается, что модель 120 перевода может представлять собой модель NMT с трансформерной архитектурой. В общем случае трансформерная модель или просто трансформер представляет собой модель глубокого обучения, которая использует механизм внимания и может по-разному оценивать значение каждой части входных данных.
[94] Подобно некоторым другим моделям, в трансформере применяется архитектура вида «кодер-декодер». Кодер состоит из кодирующих слоев, которые поочередно итеративно обрабатывают входные данные, а декодер состоит из декодирующих слоев, которые поочередно итеративно обрабатывают выходные данные кодера. Функция каждого слоя кодера заключается в формировании кодировок, содержащих информацию о взаимной релевантности частей входных данных. Кодировки передаются следующему слою кодера в качестве входных данных. Можно сказать, что каждый слой декодера выполняет «противоположную» операцию - использует вложенную контекстную информацию из всех кодировок для формирования выходной последовательности. Для достижения этой цели слои кодера и декодера используют механизмы внимания.
[95] В общем случае для части входных данных механизм внимания определяет веса релевантности других частей входных данных и использует их для формирования выходных данных. Каждый слой декодера также может содержать дополнительный механизм внимания, получающий информацию из выходных данных предыдущих декодеров до получения информации слоем декодера из кодировок. Предполагается, что слои кодера и декодера могут содержать сеть NN прямого распространения для дополнительной обработки выходных данных, а также содержат остаточные связи и шаги нормализации слоя.
[96] На фиг. 2 представлены кодирующая часть 132 (или просто кодер) и декодирующая часть 134 (или просто декодер) трансформерной модели 299. В общем случае кодер 132 получает последовательность входных токенов, сформированных на основе текста на исходном языке, и выдает компактное представление входной последовательности, пытаясь обобщить или сжать всю информацию из этой последовательности. Эти компактные представления получает декодирующая часть 134, которая также может получать другие внешние входные данные. На каждом шаге декодирующая часть 134 формирует элемент своей выходной последовательности (выходной токен) на основе полученных входных данных и может обновлять свое состояние для следующего шага, на котором формируется другой элемент выходной последовательности (следующий выходной токен).
[97] Декодирующая часть 134 может быть реализована с использованием механизма 136 внимания. Механизм 136 внимания может быть реализован с помощью слоя внимания, который позволяет декодирующей части 134 в известном смысле «принимать во внимание» конкретную информацию при формировании выходных данных, как описано ниже.
[98] В некоторых случаях декодирующая часть 134 может представлять собой «жадный» декодер. Например, декодирующая часть 134 может формировать выходную последовательность, представляющую слово на языке перевода, которое с наибольшей вероятностью представляет собой перевод соответствующего слова на исходном языке. Предполагается, что в процессе декодирования может использоваться алгоритм лучевого поиска.
[99] Исходное предложение 202 может быть разделено на последовательность 206 входных токенов. Входные токены могут быть предоставлены кодирующей части 132. Кодирующая часть 132 способна формировать скрытые векторные представления на основе введенных токенов. Например, электронное устройство 104, использующее кодирующую часть 132, может формировать векторные представления 208 для последовательности 206 входных токенов.
[100] Векторные представления могут быть предоставлены декодирующей части 134. Декодирующая часть 134 способна формировать выходные токены на основе, среди прочего, векторных представлений, сформированных кодирующей частью 132, и других входных данных, например, таких как ранее сформированные выходные токены. Выходные токены, сформированные декодирующей частью 134, могут быть использованы для предоставления перевода исходного предложения 202 (т.е. целевого предложения) пользователю 202.
[101] Декодирующая часть 134 способна использовать последовательность векторных представлений 208 для формирования первого выходного токена 221. На следующем шаге декодирующая часть 134 способна дополнительно использовать первый выходной токен 221 (дополнительные входные данные) для формирования второго выходного токена 222. На следующем шаге декодирующая часть 134 способна дополнительно использовать второй выходной токен 222 (дополнительные входные данные) для формирования третьего выходного токена 223. На следующем шаге декодирующая часть 134 способна дополнительно использовать третий выходной токен 223 (дополнительные входные данные) для формирования четвертого выходного токена 224 и т.д.
[102] Как описано выше, электронное устройство 104 может использовать механизм 136 внимания, чтобы учитывать предыдущие выходные токены, сформированные декодирующей частью 134, при формировании текущего выходного токена в последовательности выходных токенов. В некоторых вариантах осуществления изобретения декодирующая часть 134 может использовать один или несколько выходных токенов, сформированных декодирующей частью 134 и связанных с текущим словом и/или с предыдущим словом, сформированными декодирующей частью 134.
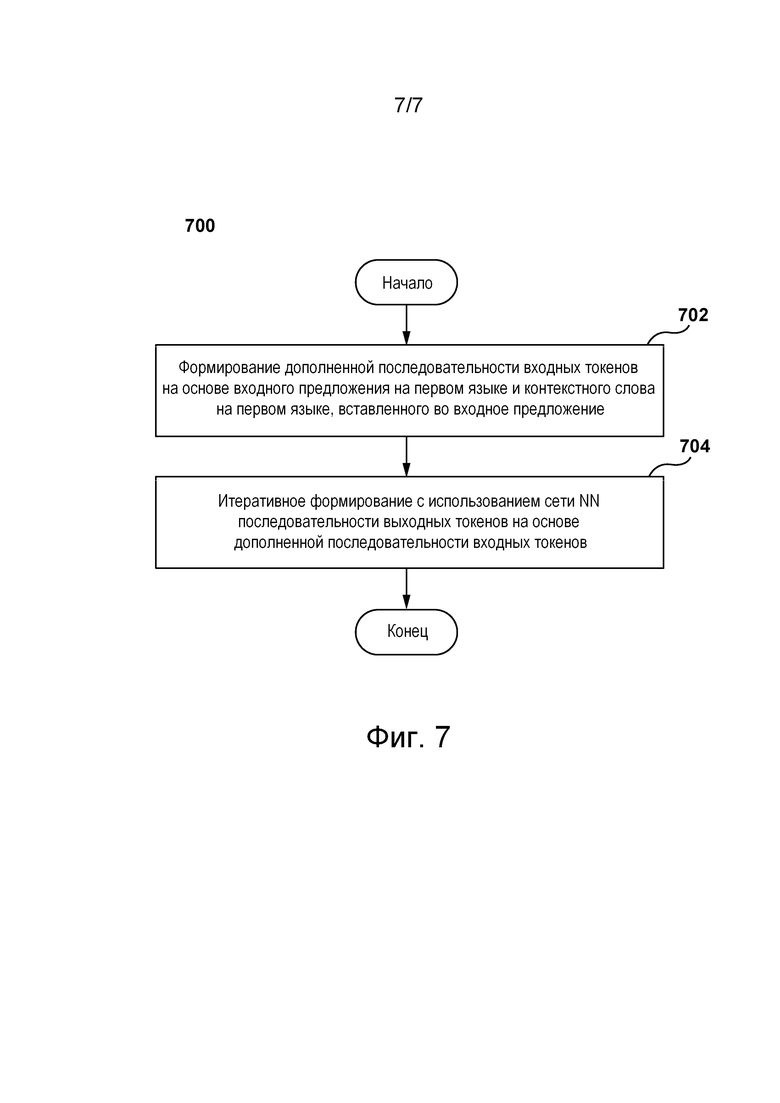
[103] Декодирующая часть 134 формирует последовательность 210 выходных токенов на основе, среди прочего, векторных представлений 208 и предыдущих выходных токенов из последовательности 210 выходных токенов для формирования текущего выходного токена в последовательности 210 выходных токенов.
[104] Разработчики настоящей технологии установили, что некоторые традиционные модели NMT некачественно переводят контекстно-зависимый контент. Разработчики разработали способы и системы, в которых контекстная информация об одном или нескольких словах из предложения вносится особым образом в процессе перевода. В частности, в контексте настоящей технологии контекстная строка вставляется в исходное предложение и содержит контекстную информацию об одном или нескольких словах из исходного предложения. Таким образом, контекстная информация может использоваться моделью NMT при формировании переводов одного или нескольких слов.
[105] В некоторых вариантах осуществления настоящей технологии контекстная строка может использоваться для уточнения темы, связанной с исходным предложением. Например, пусть имеется исходное предложение на английском языке «The game is tomorrow». Следует отметить, что правильный перевод слова «game» на русский язык может представлять собой слова «игра» или «матч» и зависит от контекста, в котором используется исходное предложение. В этом примере модель перевода может вставить контекстную строку «Soccer -» в исходное предложение, в результате чего получается следующее дополненное исходное предложение: «Soccer - The game is tomorrow». В результате модель перевода может сформировать перевод на русский язык «Футбол - Матч завтра» вместо перевода «Футбол - Игра завтра». В этом примере контекстная строка, вставленная в исходное предложение, содержит контекстную информацию в виде зависящего от темы термина, который используется моделью перевода при переводе слова «game».
[106] В других вариантах осуществления настоящей технологии контекстная строка может использоваться для уточнения пола объекта в исходном предложении. Например, пусть имеется исходное предложение на английском языке «The cat is hungry». Следует отметить, что что правильный перевод слова «cat» на русский язык может представлять собой слова «кошка» или «кот», а правильный перевод слова «hungry» на русский язык может представлять собой слова «голодна» или «голоден» в зависимости от того, является конкретное животное, упомянутое в исходном предложении, самкой или самцом. В этом примере модель перевода может вставить контекстную строку «She -» в исходное предложение, в результате чего получается следующее дополненное исходное предложение: «She - The cat is hungry». В результате модель перевода может сформировать перевод на русский язык «Она - кошка голодна» вместо перевода «Он - кот голоден». В этом примере контекстная строка, вставленная в исходное предложение, содержит контекстную информацию в виде зависящего от рода термина, который используется моделью перевода при переводе слов «cat» и «hungry».
[107] Контекстная строка может быть предоставлена моделям перевода различными способами. В некоторых вариантах осуществления изобретения сервер может анализировать одно или несколько других предложений из абзаца, в котором расположено исходное предложение. В других вариантах осуществления изобретения сервер может получать информацию об одном или нескольких словах из репозитория. В других вариантах осуществления изобретения множество контекстных строк-кандидатов может быть заранее сохранено, доступ к ним может осуществляться сервером и конкретный кандидат может быть выбран сервером для вставки в исходное предложение. Конкретный кандидат может выбираться на основе информации, полученной сервером и/или извлеченной из первоисточника исходного предложения. Каким образом контекстная строка может быть предоставлена серверу 112, более подробно описано ниже со ссылкой на фиг. 6.
[108] Разработчики настоящей технологии также установили, что вставка контекстной строки в начало предложения может быть полезной при обработке выходных данных из модели перевода. Следует отметить, что благодаря вставке контекстной строки в такую заранее заданную позицию модель перевода может идентифицировать, какая часть выходного предложения соответствует переводу вставленной контекстной строки. В результате часть выходного предложения, соответствующая переводу вставленной контекстной строки, может быть точно удалена из целевого предложения, которое должно быть предоставлено в качестве перевода исходного предложения (не дополненного).
[109] Обучение модели 120 перевода описано ниже со ссылкой на фиг. 4 и 5. На фиг. 4 представлена пара 400 параллельных предложений, которые сервер 112 может получать путем обращения к базе 150 данных. Пара 400 параллельных предложений содержит первое предложение 410 на первом языке и второе (параллельное) предложение 420 на втором языке. Также показана пара 430 контекстных строк, которые сервер 112 может получать путем обращения к базе 150 данных. Пара 430 контекстных строк содержит первую контекстную строку 440 и вторую контекстную строку 450.
[110] В этом примере сервер 112 может дополнять пару 400 предложений парой 430 контекстных строк и формировать таким образом пару 460 дополненных предложений. Сервер 112 способен вставлять первую контекстную строку 440 в начало первого предложения 410, вставлять вторую контекстную строку 450 в начало второго предложения 420 и формировать таким образом первое дополненное предложение 470 и второе дополненное предложение 480, соответственно. Следует отметить, что первая контекстная строка 440 из первого дополненного предложения 470 содержит контекстную информацию для одного или нескольких слов из первого предложения 410, а вторая контекстная строка 450 содержит контекстную информацию для одного или нескольких слов из второго предложения 420.
[111] На фиг. 5 представлена итерация обучения модели 120 перевода с использованием пары 460 дополненных предложений в качестве обучающего примера. Первое дополненное предложение 470 используется в качестве входных данных для кодирующей части модели 120 перевода, а второе дополненное предложение 480 используется в качестве входных данных для декодирующей части модели 120 перевода.
[112] Следует отметить, что первое дополненное предложение 470 и второе дополненное предложение 480 токенизируются при предоставлении модели 120 перевода. В общем случае токенизация представляет собой процесс разделения части текста, такой как предложение, на меньшие фрагменты, называемые токенами. Токен может представлять собой слово, часть слова и/или просто символ, например, знак препинания.
[113] В результате сервер 112 может формировать первую дополненную последовательность 510 токенов на основе первого дополненного предложения 470 и вторую дополненную последовательность 520 токенов на основе второго дополненного предложения 480. Первая дополненная последовательность 510 токенов содержит подпоследовательность 514 токенов, соответствующую первому предложению 410, и подпоследовательность 512 токенов, соответствующую первой контекстной строке 440. Вторая дополненная последовательность 520 токенов содержит подпоследовательность 524 токенов, соответствующую второму предложению 420, и подпоследовательность 522 токенов, соответствующую второй контекстной строке 450.
[114] Предполагается, что токены, соответствующие контекстной строке, могут содержать один или несколько токенов из дополненной последовательности токенов, при этом количество токенов, соответствующих контекстной строке, среди прочего, может зависеть от различных вариантов осуществления настоящей технологии. Соответствующие дополненные последовательности токенов могут содержать дополнительные токены, помимо представленных на фиг. 5, без выхода за границы настоящей технологии. Например, каждая дополненная последовательность токенов может начинаться и заканчиваться специальными токенами. В этом примере эти специальные токены могут включать в себя токен начала последовательности (BOS, Beginning-Of-Sequence) и токен EOS.
[115] Следует отметить, что токены, соответствующие контекстной строке в дополненной последовательности токенов, размещены в дополненной последовательности токенов в заранее заданной позиции. Как показано, подпоследовательность 512 токенов размещена в начале первой дополненной последовательности 510 токенов (например, сразу после токена BOS) и до подпоследовательности 514 токенов. Подпоследовательность 522 токенов размещена в начале второй дополненной последовательности 520 токенов (например, сразу после токена BOS) и до подпоследовательности 524 токенов.
[1] Как более подробно описано ниже для этапа использования модели 120 перевода, вставка контекстных строк в начало соответствующих предложений позволяет упростить идентификацию переведенной контекстной строки в входных данных модели 120 перевода так, чтобы ее можно было точно удалить из переведенного предложения.
[117] Во время итерации обучения, представленной на фиг. 5, первая дополненная последовательность 510 токенов обрабатывается кодирующей частью модели 120 перевода, а вторая дополненная последовательность 520 токенов обрабатывается декодирующей частью модели 120 перевода.
[118] Во время обучения в модель 120 перевода вводится большое количество дополненных обучающих примеров, сформированных подобно тому, как описано со ссылкой на фиг. 4. Можно сказать, что модель 120 перевода обучается использованию контекстной информации, содержащейся в токенах, соответствующих контекстным строкам в соответствующих дополненных последовательностях токенов, для выполнения контекстно-зависимого перевода с первого языка на второй язык.
[119] На фиг. 6 представлена итерация этапа использования модели 120 перевода. Сервер 112 может получать для перевода первое предложение 610 на первом языке. Сервер 112 также может получать первую контекстную строку 640.
[120] В некоторых вариантах осуществления изобретения первое предложение 610 может представлять собой предложение из множества предложений в цифровом документе. Например, первое предложение 610 может представлять собой предложение из тела веб-страницы. В другом примере первое предложение 610 может быть предоставлено серверу 112 электронным устройством 104, связанным с пользователем 102.
[121] В других вариантах осуществления изобретения сервер 112 может определять контекст, в котором используется первое предложение 610, на основе другого предложения из множества предложений. Например, пол объекта, упомянутого в первом предложении 610, может быть указан в другом предложении из множества предложений. В другом примере тема первого предложения 610 может быть указана в другом предложении из множества предложений. В других вариантах осуществления изобретения сервер 112 может определять контекст, в котором используется первое предложение, на основе данных, сохраненных применительно к одному или нескольким словам из первого предложения. В некоторых вариантах осуществления изобретения сервер 112 может обращаться к контекстно-зависимому словарю 140 для выбора контекстной строки, содержащей информацию, указывающую на определенный контекст.
[122] В одном примере, если определено, что пол объекта, упомянутого в первом предложении 610, является мужским, то сервер 112 может извлечь пару контекстных строк «He -» и «Он -». В этом примере сервер 112 вставляет контекстную строку 640 «He -» в начало первого предложения 610 и формирует таким образом первое дополненное предложение 670.
[123] Токенизация первого дополненного предложения 670 выполняется при предоставлении сервером 112 первого дополненного предложения модели 120 перевода. Как показано, первое дополненное предложение 670 токенизируется в дополненную последовательность 650 входных токенов. Модель 120 перевода способна формировать последовательность 660 выходных токенов на основе дополненной последовательности 650 входных токенов. Сервер 112 способен формировать дополненное выходное предложение 680 на основе последовательности 660 выходных токенов.
[124] Сервер 112 может определять часть дополненного выходного предложения 680, соответствующую переводу контекстной строки 640. Следует отметить, что серверу 112 доступна соответствующая контекстная строка 685, представляющая собой перевод контекстной строки 640. Поэтому сервер 112 может определять часть в начале дополненного выходного предложения 680, соответствующую контекстной строке 685. Сервер 112 способен удалять определенную таким образом часть из дополненного выходного предложения 680 и соответственно формировать выходное предложение 690.
[125] Следует отметить, что, несмотря на то, что выходное предложение 690 не содержит части, соответствующей контекстной строке 685, одно или несколько слов из выходного предложения 690 формируются, по меньшей мере частично, на основе контекстной информации, предоставленной контекстной строкой 685.
[126] В некоторых вариантах осуществления настоящей технологии сервер 112 способен выполнять способ 700, представленный на фиг. 7. Далее более подробно описаны различные шаги способа 700.
Шаг 702: формирование дополненной последовательности входных токенов на основе входного предложения на первом языке и контекстного слова на первом языке, вставленного во входное предложение.
[127] Способ 700 начинается с шага 702 на котором сервер 112 может формировать дополненную последовательность входных токенов на основе входного предложения на первом языке и контекстного слова на первом языке, вставленного во входное предложение. Контекстное слово связано с соответствующим контекстным словом на втором языке.
[128] Входное предложение содержит слово, представленное в дополненной последовательности входных токенов в виде первого входного токена. Контекстное слово представлено в дополненной последовательности входных токенов в виде второго входного токена. Второй входной токен размещен в дополненной последовательности входных токенов в заранее заданной позиции и содержит контекстную информацию о первом входном токене.
[129] Например, некоторое слово может быть представлено одним или несколькими входными токенами. Иными словами, предполагается, что первый входной токен может представлять собой подпоследовательность входных токенов и слово представлено этой подпоследовательностью входных токенов в дополненной последовательности входных токенов.
[130] Следует отметить, что входное предложение может быть получено от электронного устройства, связанного с пользователем, и/или может представлять собой предложение из множества предложений в цифровом документе. Предполагается, что сервер может определять контекстное слово на основе другого предложения из этого множества предложений.
[131] В других вариантах осуществления изобретения контекстное слово может быть определено на основе данных, заранее сохраненных применительно к одному или нескольким словам из входного предложения. Например, отдельные слова и/или сочетания слов могут быть сохранены в базе данных в сочетании с информацией, указывающей на контекстное слово, содержащее контекстную информацию об этих отдельных словах и/или сочетаниях слов. В других вариантах осуществления изобретения сервер может обращаться к контекстно-зависимому словарю для определения контекстного слова на первом языке и соответствующего контекстного слова на втором языке.
[132] В некоторых случаях контекстная информация может представлять род входного слова. В других случаях контекстная информация может представлять тему входного предложения, содержащего входное слово.
[133] Предполагается, что контекстное слово может быть вставлено в начало входного предложения, в результате чего соответствующие входные токены размещаются в начале дополненной последовательности входных токенов.
Шаг 704: итеративное формирование с использованием сети NN последовательности выходных токенов на основе дополненной последовательности входных токенов.
[134] Способ 700 продолжается на шаге 704, на котором сервер способен итеративно формировать с использованием сети NN последовательность выходных токенов на основе дополненной последовательности входных токенов. Последовательность выходных токенов содержит первый выходной токен и второй выходной токен. Второй выходной токен размещен в последовательности выходных токенов в заранее заданной позиции и представляет соответствующее контекстное слово на втором языке. Первый выходной токен представляет контекстно-зависимый перевод слова.
[135] Например, поскольку входные токены, представляющие контекстное слово, могут быть расположены в начале дополненной последовательности входных токенов, сеть NN может формировать выходные токены, представляющие переведенное контекстное слово, в начале выходной последовательности выходных токенов.
[136] Для специалиста в данной области могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.




Группа изобретений относится к области осуществления машинного перевода и может быть использована для выполнения контекстно-зависимого перевода. Техническим результатом является повышение точности перевода. Способ содержит формирование дополненной последовательности входных токенов на основе входного предложения на первом языке и контекстного слова на первом языке, вставленного во входное предложение. Контекстное слово представлено в виде входного токена в дополненной последовательности входных токенов, размещенного в заранее заданной позиции и содержащего контекстную информацию. Способ далее содержит итеративное формирование последовательности выходных токенов на основе дополненной последовательности входных токенов, при этом последовательность выходных токенов содержит выходной токен, размещенный в заранее заданной позиции и представляющий соответствующее контекстное слово на языке перевода, и другой выходной токен, представляющий контекстно-зависимый перевод слова из входной последовательности. 2 н. и 26 з.п. ф-лы, 7 ил.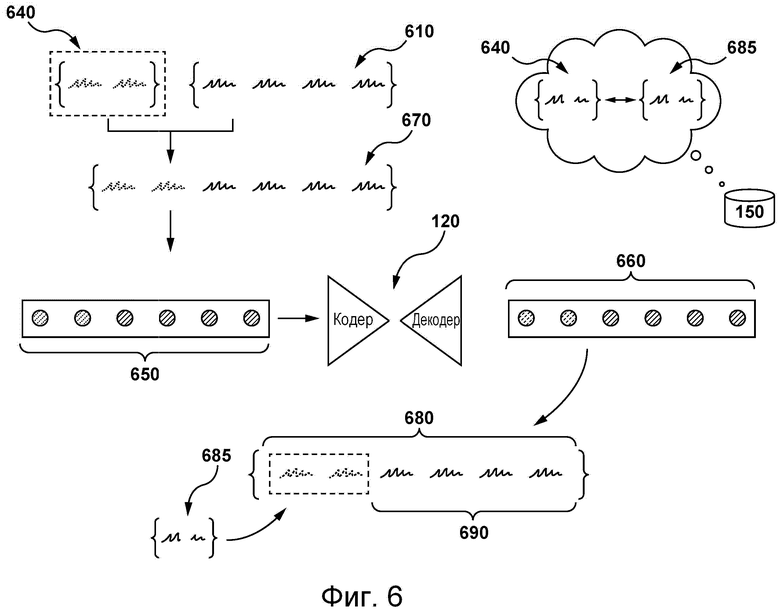
1. Способ выполнения контекстно-зависимого перевода предложений с первого языка на второй язык, осуществляемый сервером, на котором работает нейронная сеть (NN) и которому доступен контекстно-зависимый словарь, содержащий контекстные слова на первом языке и соответствующие переводы на второй язык, при этом способ включает в себя:
- формирование сервером дополненной последовательности входных токенов на основе входного предложения на первом языке и контекстного слова на первом языке, вставленного во входное предложение и связанного с соответствующим контекстным словом на втором языке, при этом входное предложение содержит слово, представленное в дополненной последовательности входных токенов в виде первого входного токена, а контекстное слово представлено в дополненной последовательности входных токенов в виде второго входного токена, размещенного в дополненной последовательности входных токенов в заранее заданной позиции и содержащего контекстную информацию о первом входном токене; и
- итеративное формирование сервером с использованием сети NN последовательности выходных токенов на основе дополненной последовательности входных токенов, при этом последовательность выходных токенов содержит первый выходной токен, представляющий контекстно-зависимый перевод слова, и второй выходной токен, размещенный в последовательности выходных токенов в заранее заданной позиции и представляющий соответствующее контекстное слово на втором языке.
2. Способ по п. 1, отличающийся тем, что первый входной токен представляет собой подпоследовательность входных токенов и слово представлено этой подпоследовательностью входных токенов в дополненной последовательности входных токенов.
3. Способ по п. 1, отличающийся тем, что первый выходной токен представляет собой другую подпоследовательность выходных токенов и контекстно-зависимый перевод слова представлен этой другой подпоследовательностью выходных токенов.
4. Способ по п. 1, отличающийся тем, что входное предложение представляет собой предложение из множества предложений в цифровом документе, а способ дополнительно включает в себя определение сервером контекстного слова на основе другого предложения из этого множества предложений.
5. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя определение сервером контекстного слова на основе данных, заранее сохраненных применительно к одному или нескольким словам из входного предложения.
6. Способ по п. 1, отличающийся тем, что он включает в себя обращение сервера к контекстно-зависимому словарю для определения контекстного слова на первом языке и соответствующего контекстного слова на втором языке.
7. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя формирование сервером выходного предложения на втором языке с использованием последовательности выходных токенов.
8. Способ по п. 7, отличающийся тем, что формирование выходного предложения включает в себя удаление соответствующего контекстного слова.
9. Способ по п. 1, отличающийся тем, что заранее заданная позиция в дополненной последовательности входных токенов соответствует позиции, предшествующей входным токенам, представляющим входное предложение.
10. Способ по п. 1, отличающийся тем, что заранее заданная позиция в дополненной последовательности входных токенов соответствует началу дополненной последовательности входных токенов.
11. Способ по п. 1, отличающийся тем, что заранее заданная позиция в последовательности выходных токенов соответствует началу последовательности выходных токенов.
12. Способ по п. 1, отличающийся тем, что сеть NN представляет собой трансформерную модель, содержащую кодирующую часть, предназначенную для первого языка, и декодирующую часть, предназначенную для второго языка.
13. Способ по п. 1, отличающийся тем, что контекстная информация представляет род входного слова.
14. Способ по п. 1, отличающийся тем, что контекстная информация представляет тему входного предложения, содержащего входное слово.
15. Сервер для выполнения контекстно-зависимого перевода предложений с первого языка на второй язык, на котором работает сеть NN и которому доступен контекстно-зависимый словарь, содержащий контекстные слова на первом языке и соответствующие переводы на второй язык, при этом сервер способен:
- формировать дополненную последовательность входных токенов на основе входного предложения на первом языке и контекстного слова на первом языке, вставленного во входное предложение и связанного с соответствующим контекстным словом на втором языке, при этом входное предложение содержит слово, представленное в дополненной последовательности входных токенов в виде первого входного токена, а контекстное слово представлено в дополненной последовательности входных токенов в виде второго входного токена, размещенного в дополненной последовательности входных токенов в заранее заданной позиции и содержащего контекстную информацию о первом входном токене; и
- итеративно формировать с использованием сети NN последовательность выходных токенов на основе дополненной последовательности входных токенов, при этом последовательность выходных токенов содержит первый выходной токен, представляющий контекстно-зависимый перевод слова, и второй выходной токен, размещенный в последовательности выходных токенов в заранее заданной позиции и представляющий соответствующее контекстное слово на втором языке.
16. Сервер по п. 15, отличающийся тем, что первый входной токен представляет собой подпоследовательность входных токенов и слово представлено этой подпоследовательностью входных токенов в дополненной последовательности входных токенов.
17. Сервер по п. 15, отличающийся тем, что первый выходной токен представляет собой другую подпоследовательность выходных токенов и контекстно-зависимый перевод слова представлен этой другой подпоследовательностью выходных токенов.
18. Сервер по п. 15, отличающийся тем, что входное предложение представляет собой предложение из множества предложений в цифровом документе и сервер дополнительно способен определять контекстное слово на основе другого предложения из этого множества предложений.
19. Сервер по п. 15, отличающийся тем, что он дополнительно способен определять контекстное слово на основе данных, заранее сохраненных применительно к одному или нескольким словам из входного предложения.
20. Сервер по п. 15, отличающийся тем, что он способен обращаться к контекстно-зависимому словарю для определения контекстного слова на первом языке и соответствующего контекстного слова на втором языке.
21. Сервер по п. 15, отличающийся тем, что он дополнительно способен формировать выходное предложение на втором языке с использованием последовательности выходных токенов.
22. Сервер по п. 21, отличающийся тем, что способность формировать выходное предложение включает в себя способность удалять соответствующее контекстное слово.
23. Сервер по п. 15, отличающийся тем, что заранее заданная позиция в дополненной последовательности входных токенов соответствует позиции, предшествующей входным токенам, представляющим входное предложение.
24. Сервер по п. 15, отличающийся тем, что заранее заданная позиция в дополненной последовательности входных токенов соответствует началу дополненной последовательности входных токенов.
25. Сервер по п. 15, отличающийся тем, что заранее заданная позиция в последовательности выходных токенов соответствует началу последовательности выходных токенов.
26. Сервер по п. 15, отличающийся тем, что сеть NN представляет собой трансформерную модель, содержащую кодирующую часть, предназначенную для первого языка, и декодирующую часть, предназначенную для второго языка.
27. Сервер по п. 15, отличающийся тем, что контекстная информация представляет род входного слова.
28. Сервер по п. 15, отличающийся тем, что контекстная информация представляет тему входного предложения, содержащего входное слово.
| US 20170323203 A1, 09.11.2017 | |||
| US 20210019373 A1, 21.01.2021 | |||
| US 20200117861 A1, 16.04.2020 | |||
| Способ и система перевода исходного предложения на первом языке целевым предложением на втором языке | 2017 |
|
RU2692049C1 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ПЕРЕВОДА С ОДНОГО ЯЗЫКА НА ДРУГОЙ | 2004 |
|
RU2357285C2 |

