Область техники, к которой относится изобретение
[1] Настоящая технология относится в целом к машинному обучению и, в частности, к способу и серверу для обучения алгоритма машинного обучения переводу.
Уровень техники
[2] С увеличением количества пользователей, имеющих доступ к сети Интернет, значительно выросло число различных сервисов Интернета. К таким сервисам относятся, например, поисковые системы (в частности, Yandex™ и Google™), позволяющие пользователям получать информацию, отправляя поисковые запросы. Кроме того, сервисы социальных сетей и мультимедийные сервисы позволяют большому количеству пользователей с различным социальным и культурным опытом взаимодействовать друг с другом на унифицированных платформах для обмена контентом и информацией. Цифровой контент и другая информация, которыми обмениваются пользователи, могут быть на разных языках. По этой причине при постоянно растущем объеме информации, которой обмениваются люди в Интернете, часто используются сервисы перевода, такие как Yandex.Translate™.
[3] Последний сервис оказался особенно полезным, позволяя пользователям легко переводить текст (или даже устную речь) с одного языка, который пользователь не понимает, на другой язык, который пользователь понимает. Это означает, что сервисы перевода, в целом, предназначены для обеспечения перевода контента на понятный пользователю язык, чтобы сделать контент доступным для понимания пользователем.
[4] Несмотря на значительный прогресс, достигнутый в последнее время, обычные компьютерные системы, обеспечивающие сервисы перевода, все еще имеют много недостатков. Например, типичные машинные переводы имеют проблемы с выбором точного перевода слова в определенном контексте или с определенным значением.
[5] Неспособность обеспечивать точный или лучший перевод делает сервисы перевода, предлагаемые пользователям, менее востребованными, что может влиять на показатели удержания пользователей интернет-компаниями, предоставляющими эти сервисы перевода.
Раскрытие изобретения
[6] Разработчики настоящей технологии обнаружили определенные технические недостатки, связанные с существующими сервисами перевода. Обычные системы часто предоставляют пользователям перевод текста. Тем не менее, эти переводы могут быть не точными или не качественными. В основном это связано с тем, что конкретное слово на исходном языке может использоваться в различных контекстах и, таким образом, может иметь множество значений. В результате в качестве перевода одного слова потенциально может использоваться множество параллельных слов на втором языке.
[7] Обычные системы хорошо справляются с выбором параллельного слова на втором языке в качестве перевода заданного слова на первом языке (таким образом обеспечивая потенциально приемлемый перевод), но плохо подбирают правильное или лучшее параллельное слово на втором языке с учетом контекста, в котором использовано заданное слово на первом языке.
[8] Разработчики настоящей технологии обнаружили, что многие традиционные системы перевода игнорируют контекст. Другими словами, традиционные системы перевода способны формировать перевод слова без учета контекста, в котором это слово используется. При этом перевод часто не дает пользователям желаемого результата, поскольку во многих случаях перевод слова без учета контекста, в котором оно использовано, может быть неадекватным и/или может дезориентировать пользователя, пытающегося понять текст на иностранном языке.
[9] Разработчики настоящей технологии создали способы повторного обучения алгоритма машинного обучения (MLA, Machine Learning Algorithm) переводу контента с первого языка на второй язык. Разработчики настоящей технологии обнаружили, что некоторые алгоритмы MLA обучаются на ряде примеров, большинство из которых взято из основного контекста. В результате возникает смещение алгоритмов MLA, приводящее к формированию перевода контента, соответствующего основному контексту.
[10] Поэтому в соответствии с некоторыми вариантами осуществления настоящей технологии алгоритмы MLA повторно обучаются на основе другого набора обучающих примеров, имеющего контролируемую пропорцию примеров, встречающихся в соответствующих контекстах. Кроме того, каждый обучающий пример может быть размечен указанием на соответствующий контекст, в котором он встречается, что позволяет алгоритму MLA «учиться» связывать текст с соответствующим контекстом. В результате реализации настоящей технологии такое повторное обучение позволяет исправлять или по меньшей мере уменьшать смещение алгоритма MLA, возникшее при первоначальном обучении.
[11] Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений.
[12] В первом аспекте настоящей технологии реализован способ обучения алгоритма MLA переводу текстовой строки на первом языке параллельной текстовой строкой на втором языке. Способ выполняется на сервере, реализующем алгоритм MLA. Сервер имеет доступ к парам обучающих строк, при этом каждая пара содержит (1) текстовую строку на первом языке и (2) параллельную текстовую строку на втором языке. Пары обучающих строк встречаются в соответствующем реальном контексте. Контекст включает в себя основной контекст и по меньшей мере один вспомогательный контекст. Алгоритм MLA обучается с использованием первого набора пар обучающих строк определению параллельной текстовой строки на втором языке в ответ на текстовую строку на первом языке. Первый набор пар обучающих строк имеет естественную пропорцию пар строк каждого контекста. Алгоритм MLA оказывается смещенным к формированию параллельной текстовой строки в качестве перевода соответствующей текстовой строки, встречающейся в основном контексте. Способ включает в себя определение сервером второго набора пар обучающих строк для обучения алгоритма MLA. Второй набор пар обучающих строк имеет контролируемую пропорцию пар строк каждого контекста. Пары обучающих строк во втором наборе пар обучающих строк связаны с метками, указывающими на контекст соответствующих пар строк. Способ включает в себя повторное обучение сервером алгоритма MLA с использованием второго набора пар обучающих строк и соответствующих меток. Алгоритм MLA повторно обучается определению контекста этапа использования для текстовой строки этапа использования и формированию соответствующей параллельной текстовой строки этапа использования в качестве перевода строки текста этапа использования с учетом контекста этапа использования.
[13] В некоторых вариантах осуществления способа естественная пропорция пар строк каждого контекста соответствует пропорции пар строк каждого контекста, который может быть получен из множества сетевых ресурсов, доступных через сеть связи.
[14] В некоторых вариантах осуществления способа обучающая текстовая строка из основного контекста содержит основной контент сетевого ресурса. Другая обучающая текстовая строка, встречающаяся в по меньшей мере одном вспомогательном контексте, содержит по меньшей мере одно из следующего:
- контент нижнего колонтитула (footer) сетевого ресурса;
- контент верхнего колонтитула (header) сетевого ресурса;
- контент заголовка (title) сетевого ресурса; и
- контент управления навигацией сетевого ресурса.
[15] В некоторых вариантах осуществления способа естественная пропорция относится к большинству пар обучающих строк в первом наборе пар обучающих строк основного контекста.
[16] В некоторых вариантах осуществления способа контролируемая пропорция содержит по существу равные пропорции пар обучающих строк, встречающихся в основном контексте и в по меньшей мере одном вспомогательном контексте.
[17] В некоторых вариантах осуществления способа алгоритм MLA содержит кодирующую часть (кодер), предназначенную для текстовых строк на первом языке, и декодирующую часть (декодер), предназначенную для текстовых строк на втором языке. Повторное обучение алгоритма MLA включает в себя обучение сервером кодера формированию выходных данных кодера для (1) обучающей текстовой строки на первом языке из пары обучающих строк во втором наборе пар обучающих строк и (2) соответствующей метки. Повторное обучение алгоритма MLA включает в себя обучение сервером декодера формированию выходных данных декодера для (1) обучающей параллельной текстовой строки на втором языке из пары обучающих строк во втором наборе пар обучающих строк и (2) соответствующей метки. Повторное обучение алгоритма MLA выполняется таким образом, чтобы обеспечить максимальное сходство между выходными данными кодера и выходными данными декодера.
[18] В некоторых вариантах осуществления способа он дополнительно включает в себя прием сервером первой текстовой строки этапа использования на первом языке, содержащей заданное слово. Способ включает в себя получение сервером второй текстовой строки этапа использования на первом языке, содержащей заданное слово. Способ включает в себя выполнение сервером алгоритма MLA для формирования первой параллельной текстовой строки этапа использования на втором языке на основе первой текстовой строки этапа использования, при этом заданное слово переводится первым параллельным словом из первой параллельной текстовой строки этапа использования. Способ также включает в себя выполнение сервером алгоритма MLA для создания второй параллельной текстовой строки этапа использования на втором языке на основе второй текстовой строки этапа использования, при этом заданное слово переводится вторым параллельным словом из второй параллельной текстовой строки этапа использования. Если алгоритм MLA определяет, что контекст первой текстовой строки этапа использования отличается от контекста второй текстовой строки этапа использования, то первое параллельное слово и второе параллельное слово являются разными переводами заданного слова.
[19] В некоторых вариантах осуществления способа повторное обучение алгоритма MLA включает в себя использование сервером для повторного обучения алгоритма MLA функции потерь, ограничивающей адаптацию. Функция потерь, ограничивающая адаптацию, позволяет после обучения алгоритма MLA ограничивать адаптацию алгоритма MLA, обученного на основе первого набора пар обучающих строк.
[20] В некоторых вариантах осуществления способа ограничение адаптации алгоритма MLA включает в себя ограничение ухудшения качества перевода текстовой строки этапа использования из основного контекста.
[21] В некоторых вариантах осуществления способа использование функции потерь, ограничивающей адаптацию, на итерации в ходе повторного обучения алгоритма MLA включает в себя следующее:
- вычисление сервером распределения «учителей» для заданного слова при переводе алгоритмом MLA, обученным до повторного обучения, при этом распределение «учителей» указывает на вероятность того, что соответствующие потенциальные слова являются переводом заданного слова, определенным алгоритмом MLA, обученным до повторного обучения;
- вычисление сервером распределения «учеников» для заданного слова при переводе повторно обученным алгоритмом MLA, при этом распределение «учеников» указывает на вероятность того, что соответствующие потенциальные слова являются переводом заданного слова, определенным повторно обученным алгоритмом MLA на данной итерации;
- вычисление сервером значения кросс-энтропии, являющегося первым типом меры сходства между распределением «учеников» и фактическим распределением, при этом фактическое распределение указывает на правильный перевод заданного слова, встречающегося в соответствующем контексте;
- вычисление сервером значения расхождения, являющегося вторым типом меры сходства между распределением «учителей» и распределением «учеников»; и
- вычисление сервером взвешенной суммы значения кросс-энтропии и значения расхождения, которая является значением функции потерь, ограничивающей адаптацию, для заданного слова на данной итерации.
[22] Во втором аспекте настоящей технологии реализован сервер для обучения алгоритма MLA переводу текстовой строки на первом языке параллельной текстовой строкой на втором языке. Алгоритм MLA реализуется сервером. Сервер имеет доступ к парам обучающих строк, при этом каждая пара содержит (1) текстовую строку на первом языке и (2) параллельную текстовую строку на втором языке. Пары обучающих строк встречаются в соответствующем реальном контексте. Контекст включает в себя основной контекст и по меньшей мере один вспомогательный контекст. Алгоритм MLA обучен с использованием первого набора пар обучающих строк определению параллельной текстовой строки на втором языке в ответ на текстовую строку на первом языке. Первый набор пар обучающих строк имеет естественную пропорцию пар строк каждого контекста. Алгоритм MLA оказывается смещенным к формированию параллельной текстовой строки в качестве перевода соответствующей текстовой строки, встречающейся в основном контексте. Сервер способен определять второй набор пар обучающих строк, используемый для обучения алгоритма MLA. Второй набор пар обучающих строк имеет контролируемую пропорцию пар строк каждого контекста. Пары обучающих строк во втором наборе пар обучающих строк связаны с метками, указывающими на контекст соответствующих пар строк. Сервер способен повторно обучать алгоритм MLA с использованием второго набора пар обучающих строк и соответствующих меток, при этом алгоритм MLA повторно обучается определению контекста этапа использования для текстовой строки этапа использования и формированию соответствующей параллельной текстовой строки этапа использования в качестве перевода строки текста этапа использования с учетом контекста этапа использования.
[23] В некоторых вариантах осуществления сервера естественная пропорция пар строк каждого контекста соответствует пропорции пар строк каждого контекста, который может быть получен из множества сетевых ресурсов, доступных через сеть связи.
[24] В некоторых вариантах осуществления сервера обучающая текстовая строка, встречающаяся в основном контексте, содержит основной контент сетевого ресурса, а другая обучающая текстовая строка, встречающаяся в по меньшей мере одном вспомогательном контексте, содержит по меньшей мере одно из следующего:
- контент нижнего колонтитула сетевого ресурса;
- контент верхнего колонтитула сетевого ресурса;
- контент заголовка сетевого ресурса; и
- контент управления навигацией сетевого ресурса.
[25] В некоторых вариантах осуществления сервера естественная пропорция относится к большинству пар обучающих строк в первом наборе пар обучающих строк, встречающихся в основном контексте.
[26] В некоторых вариантах осуществления сервера контролируемая пропорция содержит по существу равные пропорции пар обучающих строк, встречающихся в основном контексте и в по меньшей мере одном вспомогательном контексте.
[27] В некоторых вариантах осуществления сервера алгоритм MLA содержит кодер, предназначенный для текстовых строк на первом языке, и декодер, предназначенный для текстовых строк на втором языке. Для повторного обучения алгоритма MLA сервер способен обучать кодер формированию выходных данных кодера для (1) обучающей текстовой строки на первом языке из пары обучающих строк во втором наборе пар обучающих строк и (2) соответствующей метки. Для повторного обучения алгоритма MLA сервер способен обучать декодер формированию выходных данных декодера для (1) обучающей параллельной текстовой строки на втором языке из пары обучающих строк во втором наборе пар обучающих строк и (2) соответствующей метки. Кодер и декодер обучаются таким образом, чтобы обеспечить максимальное сходство между выходными данными кодера и выходными данными декодера.
[28] В некоторых вариантах осуществления сервера он дополнительно способен принимать первую текстовую строку этапа использования на первом языке, содержащую заданное слово. Сервер способен принимать вторую текстовую строку этапа использования на первом языке, содержащую заданное слово. Сервер способен выполнять алгоритм MLA для формирования первой параллельной текстовой строки этапа использования на втором языке на основе первой текстовой строки этапа использования, при этом заданное слово переводится первым параллельным словом из первой параллельной текстовой строки этапа использования. Сервер способен выполнять алгоритм MLA для формирования второй параллельной текстовой строки этапа использования на втором языке на основе второй текстовой строки этапа использования, при этом заданное слово переводится вторым параллельным словом из второй параллельной текстовой строки этапа использования. Если алгоритм MLA определяет, что контекст первой текстовой строки этапа использования отличается от контекста второй текстовой строки этапа использования, то первое параллельное слово и второе параллельное слово являются разными переводами заданного слова.
[29] В некоторых вариантах осуществления сервера он при повторном обучении алгоритма MLA способен использовать функцию потерь, ограничивающую адаптацию, для повторного обучения алгоритма MLA. Функция потерь, ограничивающая адаптацию, после обучения алгоритма MLA позволяет ограничивать адаптацию алгоритма MLA, обученного на основе первого набора пар обучающих строк.
[30] В некоторых вариантах осуществления сервера ограничение адаптации алгоритма MLA включает в себя ограничение ухудшения качества перевода текстовой строки этапа использования из основного контекста.
[31] В некоторых вариантах осуществления сервера для использования функции потерь, ограничивающей адаптацию, на итерации в ходе повторного обучения алгоритма MLA сервер способен:
- вычислять распределение «учителей» для заданного слова при переводе алгоритмом MLA, обученным до повторного обучения, при этом распределение «учителей» указывает на вероятность того, что соответствующие потенциальные слова являются переводом заданного слова, определенным алгоритмом MLA, обученным до повторного обучения;
- вычислять распределение «учеников» для данного слова при переводе повторно обученным алгоритмом MLA, при этом распределение «учеников» указывает на вероятность того, что соответствующие потенциальные слова являются переводом заданного слова, определенным повторно обученным алгоритмом MLA на данной итерации;
- вычислять значение кросс-энтропии, являющегося первым типом меры сходства между распределением «учеников» и фактическим распределением, при этом фактическое распределение указывает на правильный перевод заданного слова, встречающегося в соответствующем контексте;
- вычислять значение расхождения, являющееся вторым типом меры подобия между распределением «учителей» и распределением «учеников»; и
- вычислять взвешенную сумму значения кросс-энтропии и значения расхождения, которая является значением функции потерь, ограничивающей адаптацию, для заданного слова на данной итерации.
[32] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, при этом оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[33] В контексте настоящего описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов либо шагов любого описанного здесь способа.
[34] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, что и процесс, обеспечивающий хранение или использование информации, хранящейся в этой базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[35] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[36] В контексте настоящего описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[37] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[38] В контексте настоящего описания числительные «первый» «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается здесь в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
[39] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[40] Дополнительные и/или альтернативные признаки, аспекты и преимущества реализаций настоящей технологии поясняются в следующем описании, приложенных чертежах и формуле изобретения.
Краткое описание чертежей
[41] Для лучшего понимания настоящей технологии, а также ее других аспектов и дополнительных особенностей последующее описание следует использовать совместно с приложенными чертежами.
[42] На фиг. 1 представлена система, подходящая для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии.
[43] На фиг. 2 представлена веб-страница в том виде, как она может отображаться приложением браузера с фиг. 1, в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[44] На фиг. 3 представлен корпус пар текстовых строк для определенной пары языков в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[45] На фиг. 4 приведен пример алгоритма MLA, обученного переводу текстовых строк с первого языка на второй язык в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[46] На фиг. 5 приведены различные окна браузера приложения браузера с фиг. 1 в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[47] На фиг. 6 представлена блок-схема последовательности действий способа обучения алгоритма MLA с фиг. 4 в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
Осуществление изобретения
[48] На фиг. 1 представлена схема системы 100, пригодной для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии. Очевидно, что система 100 приведена лишь в качестве иллюстрации варианта реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях приводятся полезные примеры модификаций системы 100. Они способствуют пониманию, но также не определяют объем или границы настоящей технологии. Эти модификации не составляют исчерпывающего перечня. Как должно быть понятно специалисту в данной области, возможны и другие модификации. Кроме того, если в некоторых случаях модификации не описаны (т.е. примеры модификаций отсутствуют), это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области должно быть понятно, что это может быть не так. Кроме того, следует понимать, что система 100 в некоторых случаях может представлять собой упрощенную реализацию настоящей технологии и что такие варианты представлены для того, чтобы способствовать лучшему ее пониманию. Специалистам в данной области должно быть понятно, что различные варианты осуществления настоящей технологии могут быть значительно сложнее.
[49] В общем случае система 100 способна предоставлять пользователю 102 электронного устройства 104 сервис электронного перевода. Например, система 100 может предоставлять переводную версию по меньшей мере части сетевого ресурса, такого как веб-страница (или ее часть), например, на электронном устройстве 104 для отображения пользователю 102.
[50] Например, пользователь 102 желает ознакомиться с контентом веб-страницы. В некоторых случаях контент на этой веб-странице может быть на иностранном (непонятном) для пользователя 102 языке. Во многих таких ситуациях может быть желательно предоставить пользователю 102 сервисы перевода, помогающие пользователю 102 понимать отображаемый контент.
[51] В некоторых вариантах осуществления настоящей технологии сервисы перевода системы 100 могут быть предназначены для предоставления переводной версии контента электронному устройству 104 с целью отображения пользователю 102, при этом переводная версия предоставляется на языке, понятном для пользователя 102. Другими словами, сервисы перевода системы 100 могут быть предназначены для предоставления переводной версии контента, понятной пользователю 102.
[52] В некоторых вариантах осуществления предполагается, что переводная версия контента может отображаться пользователю 102 путем замены контента, отображаемого пользователю 102, переводной версией этого контента. Другими словами, контент, отображаемый пользователю на иностранном языке, может быть заменен его переводной версией.
[53] Следует отметить, что в некоторых случаях система 100 может предоставлять электронному устройству 104 переводную версию лишь того контента, который в данное время отображается пользователю 102. Например, электронное устройство 104 может в данное время отображать пользователю 102 только часть веб-страницы. В другом случае только часть контента веб-страницы может в данное время отображаться пользователю 102.
[54] Другими словами, в некоторых вариантах осуществления настоящей технологии система 100 способна предоставлять переводную версию лишь того контента, который в данное время отображается пользователю 102, в отличие от предоставления переводной версии всего контента веб-страницы (включая не отображаемую в данный момент часть веб-страницы).
[55] В некоторых вариантах осуществления предоставление перевода лишь для отображаемой в данный момент части веб-страницы может обеспечивать повышение производительности сервисов перевода, поскольку это снижает нагрузку при обработке данных и/или сетевую нагрузку по меньшей мере на некоторые компоненты системы 100, как это описано ниже более подробно.
[56] В некоторых случаях предоставление перевода лишь для отображаемой в данный момент части веб-страницы может быть приемлемым для пользователя, использующего сервисы перевода системы 100. Действительно, в некоторых случаях пользователь 102 может быть удовлетворен переводом отображаемой в данный момент части веб-страницы и может решить не анализировать не отображаемую в данный момент часть веб-страницы.
[57] В этих случаях возможность предоставления перевода только для отображаемой в данный момент части веб-страницы позволяет избегать ненужного использования вычислительной мощности системы 100 для перевода того контента веб-страницы, который не просматривается пользователем 102.
[58] других случаях пользователь 102 может решить проанализировать не отображаемую в данный момент часть веб-страницы. Из приведенного ниже описания ясно, что пользователь 102 может решить «прокрутить» данную веб-страницу, например, таким образом вызывая отображение электронным устройством 104 другой части веб-страницы. В этот момент времени пользователю 102 отображается другая часть веб-страницы. Отображаемая в данный момент часть является другой частью веб-страницы и сервисы перевода системы 100 могут обеспечить перевод этой другой части веб-страницы.
[59] Таким образом, можно сказать, что в некоторых вариантах осуществления настоящей технологии система 100 может предоставлять «динамические» сервисы перевода для пользователя 102, в том смысле, что система 100 может предоставлять переводную версию контента, отображаемого в данный момент пользователю 102, во время просмотра или прокрутки контента пользователем 102.
[60] Следует отметить, что некоторые неограничивающие примеры настоящей технологии описаны здесь применительно к переводу контента веб-страницы, тем не менее, следует понимать, что сервисы перевода системы 100 могут использоваться в различных других случаях, где контент, отображаемый пользователю 102 электронным устройством 104, поступает не с веб-страницы, а с других видов сетевых ресурсов.
[61] Далее описаны по меньшей мере некоторые элементы системы 100, при этом следует понимать, что частью системы 100 могут быть и другие элементы, отличные от показанных на фиг. 1, без выхода за пределы настоящей технологии.
Электронное устройство
[62] Система 100 содержит электронное устройство 104, связанное с пользователем 102. Электронное устройство 104 иногда может называться «клиентским устройством», «устройством конечного пользователя», «клиентским электронным устройством» или просто «устройством». Следует отметить, что связь устройства 104 с пользователем 102 не означает необходимости предлагать или подразумевать какой-либо режим работы, например, необходимость входа в систему, необходимость регистрации и т.п.
[63] На реализацию устройства 104 не накладывается особых ограничений. В качестве примера, устройство 104 может быть реализовано в виде персонального компьютера (настольного компьютера, ноутбука, нетбука и т.д.), устройства беспроводной связи (например, смартфона, сотового телефона, планшета и т.п.), а также сетевого оборудования (например, маршрутизатора, коммутатора и шлюза). Устройство 104 содержит известные в данной области техники аппаратные средства и/или программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для выполнения приложения 105 браузера.
[64] В общем случае цель приложения 105 браузера состоит в том, чтобы обеспечить пользователю 102 доступ к одному или нескольким сетевым ресурсам, например, к веб-страницам. На реализацию приложения 105 браузера не накладывается каких-либо особых ограничений. Примером реализации приложения 105 браузера может быть браузер Yandex™.
[65] В верхней части фиг. 5 показан не имеющий ограничительного характера пример представления 500 окна 502 браузера приложения 105 браузера, отображаемого пользователю 102 устройством 104. Например, пользователь 102 может инициировать запуск устройством 104 приложения 105 браузера, таким образом инициируя отображение пользователю 102 окна 500 браузера устройством 104.
[66] Окно 500 браузера включает в себя полосу 504 просмотра, панель 506 отображения и полосу 508 прокрутки. Панель 504 просмотра включает в себя адресную строку или инструмент Omnibar 510, кнопку 512 перехода и кнопку 514 перевода. Адресная строка 510 может использоваться пользователем 102 для ввода адреса желаемого сетевого ресурса в адресной строке 510. Например, желаемый сетевой ресурс может быть новостной веб-страницей, содержащей интересующий пользователя 102 контент. В проиллюстрированном не имеющем ограничительного характера примере адресом является «www.example.com».
[67] Затем пользователь 102 может активировать кнопку 512 перехода, которая запускает приложение 105 браузера для перехода к желаемому сетевому ресурсу и отображения на панели 506 отображения окна 502 браузера части или всего контента желаемого сетевого ресурса. Например, панель 506 отображения отображает контент, часть которого соответствует новостному сообщению о текущем состоянии рынке жилья.
[68] Пользователь 102 может использовать полосу 508 прокрутки окна 502 браузера для прокрутки контента желаемого сетевого ресурса, что приводит к отображению панелью 506 отображения пользователю 102 дополнительного контента, когда пользователь 102 прокручивает страницу. Например, пользователь 102 может выполнить действие «прокрутка вниз», используя полосу 508 прокрутки, в результате чего на панели 506 отображения отображается дополнительный контент из новостной статьи.
[69] Следует отметить, что окно 502 браузера, показанное на фиг. 5, является упрощенной версией окна браузера, которое может отображаться электронным устройством 104 пользователю 102. Другими словами, другие или дополнительные полосы, панели и/или кнопки могут быть реализованы как часть окна 502 браузера, отображаемого пользователю 102 электронным устройством 104, без выхода за пределы настоящей технологии.
[70] Как упоминалось ранее, в этом не имеющем ограничительного характера примере окно 502 браузера также содержит кнопку 514 перевода. После нажатия кнопки 514 перевода приложение 105 браузера может получить явное указание от пользователя 102 использовать сервисы перевода системы 100. Например, приложение 105 браузера может использовать сервисы перевода системы 100 для перевода информации, отображаемой в текущий момент на панели 506 отображения окна 502 браузера.
[71] В некоторых вариантах осуществления приложение 105 браузера может продолжать использовать сервисы перевода системы 100 до тех пор, пока не получит явное указание от пользователя 102 прекратить использование сервисов перевода системы 100. Например, пользователь 102 может нажать кнопку 514 перевода второй раз, явно указывая приложению 105 браузера прекратить использование сервисов перевода системы 100. Другими словами, кнопка 514 перевода может быть реализована для предоставления функциональных возможностей «режим перевода включен» и «режим перевода выключен» в приложении 105 браузера.
[72] В других вариантах осуществления приложение 105 браузера может использовать сервисы перевода системы 100 до тех пор, пока весь отображаемый в данный момент контент на панели 506 дисплея не будет переведен или заменен его переводной версией. Другими словами, кнопка 514 перевода может быть реализована для предоставления функциональности «перевод при действии» в приложении 105 браузера, при этом пользователю 102 не нужно давать явное указание приложению 105 браузера для прекращения использования сервисов перевода системы 100.
[73] В качестве альтернативы, кнопка 514 перевода может отсутствовать, а приложение 105 браузера может позволять пользователю 102 явно указывать, какая из функций «режим перевода включен», «режим перевода выключен» и/или «перевод при действии» желательна, с помощью других средств, например, путем настройки, в частности, приложения 105 браузера.
[74] Кроме того, приложение 105 браузера может запускать и останавливать использование сервисов перевода системы 100 без явных указаний от пользователя 102. Например, приложение 105 браузера может позволять пользователю 102 выбирать нужный язык для перевода и если язык контента, отображаемого пользователю 102, не соответствует языку перевода, приложение 105 браузера может начинать использование сервисов перевода системы 100 без явных указаний от пользователя 102. Кроме того, если язык контента, отображаемого пользователю 102, совпадает с указанным языком перевода, приложение 105 браузера может прекращать использование сервисов перевода системы 100 без явных указаний от пользователя 102.
[75] В некоторых вариантах осуществления пользователь 102 может вручную выбирать язык перевода (например, в настройках). В качестве альтернативы, приложение 105 браузера может «распознавать» предпочтительный язык перевода для пользователя 102 на основе истории просмотра пользователем 102 и автоматически выбирать предпочтительный язык в качестве языка перевода. Например, если история просмотра пользователя 102 указывает на то, что пользователь 102 переходит в основном на сетевые ресурсы с информацией на русском языке, приложение 105 браузера может (1) определять, что русский язык является предпочтительным языком пользователя 102, и (2) автоматически выбирать русский язык в качестве языка перевода.
[76] Как показано на фиг. 1, приложение 105 браузера электронного устройства 104 позволяет пользователю 102 перемещаться по множеству 112 сетевых ресурсов. В одном не имеющем ограничительного характера примере множество 112 сетевых ресурсов может соответствовать веб-страницам, размещенным на одном или нескольких сетевых серверах 113.
[77] Например, после того, как пользователь 102 ввел адрес одного ресурса из множества 112 сетевых ресурсов, приложение 105 браузера может инициировать на электронном устройстве 104 формирование запроса 150 ресурсов, отправляемого сетевому серверу 113, на котором размещен данный ресурс из множества 112 сетевых ресурсов. Запрос 150 ресурсов может иметь вид пакета данных, который содержит машиночитаемые команды для запроса информации от сетевого сервера 113, на котором размещен данный ресурс из множества 112 сетевых ресурсов.
[78] Кроме того, электронное устройство 112 может принимать ответ 155 ресурса от сетевого сервера 113, на котором размещен данный ресурс из множества 112 сетевых ресурсов. Ответ 155 ресурса может иметь вид другого пакета данных, который содержит машиночитаемые команды, позволяющие приложению 105 браузера отображать контент данного ресурса из множества 112 сетевых ресурсов.
[79] Передача запросов 150 ресурсов и ответов 155 ресурсов между электронным устройством 104 и одним или несколькими сетевыми серверами 113, реализация множества 112 сетевых ресурсов и вид информации, передаваемой в ответах 155 ресурсов в ответ на запросы 150 ресурсов, описаны ниже.
Сеть связи
[80] Устройство 104 подключено к сети 110 связи для получения доступа к одному или нескольким сетевым серверам 113, на которых размещено множество 112 сетевых ресурсов. Например, устройство 104 может быть подключено к одному или нескольким сетевым серверам 113 через сеть 110 связи для предоставления пользователю 102 контента множества 112 сетевых ресурсов.
[81] Предполагается, что устройство 104 также подключено к сети 110 связи для получения доступа к серверу 106. Например, устройство 104 может быть подключено к серверу 106 через сеть 110 связи для предоставления пользователю 102 упомянутых выше сервисов перевода.
[82] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 110 связи может использоваться сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 110 связи может быть реализована иначе, например, как любая глобальная сеть связи, локальная сеть связи, частная сеть связи и т.п. Реализация канала связи (отдельно не обозначен) между устройством 104 и сетью 110 связи зависит, среди прочего, от реализации устройства 104.
[83] Исключительно в качестве примера, а не ограничения, в тех вариантах осуществления настоящей технологии, где устройство 104 реализовано как устройство беспроводной связи (например, смартфон), канал связи может быть реализован как канал беспроводной связи (например, канал связи 3G, канал связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п., но не ограничиваясь ими). В тех примерах, где устройство 104 реализовано как портативный компьютер, канал связи может быть беспроводным (например, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.) или проводным (например, соединение на основе Ethernet).
[84] Сеть 110 может передавать, среди прочего, запросы 150 ресурсов от устройства 104 к соответствующим одному или нескольким сетевым серверам 113 и ответы 155 ресурсов от соответствующих одного или нескольких сетевых серверов 113 к устройству 104.
[85] Также предполагается, что сеть 110 связи может передавать, среди прочего, запросы 160 сервера от устройства 104 к серверу 106 и ответов 165 от сервера 106 к устройству 104. Цель и содержание запросов 160 сервера и ответов 165 сервера описаны более подробно ниже, но в общем случае запросы 160 сервера и ответы 165 сервера могут использоваться для включения упомянутых выше сервисов перевода.
Множество сетевых ресурсов
[86] Сетевой сервер, как и другие сетевые серверы 113, может быть реализован в виде обычного компьютерного сервера. В примере варианта осуществления настоящей технологии сетевой сервер может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сетевой сервер может быть реализован на любом другом подходящем аппаратном обеспечении, программном обеспечении и/или встроенном программном обеспечении или их комбинации.
[87] В общем случае в одном или нескольких сетевых серверах 113 может размещаться множество 112 сетевых ресурсов. В некоторых вариантах осуществления настоящей технологии каждый из множества 112 сетевых ресурсов может быть реализован как соответствующая веб-страница, размещенная на соответствующем одном или нескольких сетевых серверах 113. Кроме того, в одном или нескольких сетевых серверах 113 может размещаться один или несколько ресурсов из множества 112 сетевых ресурсов. Например, в одном или нескольких сетевых серверах 113 может размещаться веб-сайт, содержащий более одного ресурса из множества 112 сетевых ресурсов.
[88] Когда пользователь 102 указывает адрес желаемого сетевого ресурса через приложение 105 браузера, электронное устройство 104 передает соответствующий запрос 150 ресурса на соответствующий сетевой сервер 113, на котором размещен желаемый сетевой ресурс (например, находящийся среди множества 112 сетевых ресурсов). Запрос 150 ресурса содержит машиночитаемые команды для получения электронного документа от соответствующего сетевого сервера 113 и этот электронный документ содержит контент, который должен отображаться пользователю 102 через приложение 105 браузера.
[89] На природу электронного документа не накладывается особых ограничений. В качестве иллюстрации, электронный документ может представлять собой веб-страницу (например, желаемый сетевой ресурс), размещенную на соответствующем сетевом сервере 113. В частности, электронный документ может быть составлен на языке разметки, таком как HTML, XML и т.п.
[90] Следовательно, можно сказать, что цель запроса 150 ресурса состоит в том, чтобы дать сетевому серверу команду на предоставление электронному устройству 104 электронного документа, содержащего контент, отображаемый пользователю 102 через приложение 105 браузера.
[91] В ответ на запрос 150 ресурса сетевой сервер 113 передает ответ 155 ресурса на электронное устройство 104. Ответ 155 ресурса содержит электронный документ. Следовательно, можно сказать, что цель ответа 155 ресурса состоит в передаче данных, представляющих собой электронный документ, электронному устройству 104.
[92] В общем случае электронный документ, представляющий собой веб-страницу (например, требуемый сетевой ресурс), указывает на то, (1) какой контент должен отображаться приложением 105 браузера пользователю 102, и (2) каким образом этот контент должен отображаться приложением 105 браузера пользователю 102. Другими словами, электронный документ (1) указывает на контент веб-страницы, отображаемый приложением 105 браузера пользователю 102, и (2) содержит команды визуализации для указания приложению 105 браузера, каким образом контент веб-страницы должен отображаться на электронном устройстве 104.
[93] На фиг. 2 показано представление 200 веб-страницы (например, ресурса из множества 112 сетевых ресурсов), как оно может отображаться приложением 105 браузера в соответствии с соответствующими командами визуализации. Представление 200 включает в себя визуализируемую версию 202 веб-страницы.
[94] Визуализируемая версия 202 содержит (1) раздел 204 верхнего колонтитула, (2) раздел 205 заголовка, (3) раздел 206 нижнего колонтитула, (4) основной раздел 207 и (5) раздел 208 управления навигацией. Следует отметить, что визуализируемая версия веб-страницы может иметь меньшее количество разделов или может иметь дополнительные разделы по сравнению с теми, что в качестве примера изображены здесь как часть визуализируемой версии 202, без выхода за пределы настоящей технологии.
[95] Следует отметить, что каждый из (1) раздела 204 верхнего колонтитула, (2) раздела 205 заголовка, (3) раздела 206 нижнего колонтитула, (4) основного раздела 207 и (5) раздела 208 управления навигацией отображает соответствующий контент веб-страницы. Информация о том, какой контент и в каком разделе визуализируемой версии 202 должен отображаться, включена в электронный документ, представляющий собой веб-страницу. Эта информация может обрабатываться приложением 105 браузера в процессе визуализации веб-страницы.
[96] Например, (1) контент 214 верхнего колонтитула веб-страницы отображается в разделе 204 верхнего колонтитула, (2) контент 215 заголовка веб-страницы отображается в разделе 205 заголовка, (3) контент 216 нижнего колонтитула веб-страницы отображается в разделе 206 нижнего колонтитула, (4) основной контент 217 веб-страницы отображается в основном разделе 207, а (5) контент 218 управления навигацией веб-страницы отображается в разделе 208 управления навигацией.
[97] В частности, контент 214 верхнего колонтитула обычно включает в себя контент из верхней части веб-страницы, такой как логотипы, слоганы организации, управляющей этой веб-страницей, и т.п. В некоторых реализациях веб-страницы контент 214 верхнего колонтитула может содержать файлы изображений.
[98] Контент 215 заголовка обычно включает в себя фрагмент, обычно описывающий предмет, к которому относится веб-страница. Например, если веб-страница относится к новостному материалу, контент 215 заголовка может включать в себя фрагмент (сниппет), который обычно описывает эту новость. Например, сниппет, содержащийся в контенте 215 заголовка, может быть текстовой строкой, в которой в некоторых случаях не соблюдаются грамматические правила или могут содержаться исключительно заглавные буквы.
[99] Контент 216 нижнего колонтитула обычно включает в себя контент, расположенный внизу веб-страницы, такой как информация, касающаяся условий использования, обратной связи, пользовательских соглашений, служб поддержки и т.п. Например, контент 216 нижнего колонтитула может содержать юридические формулировки и/или гиперссылки, содержащие юридические формулировки.
[100] Контент 218 управления навигацией обычно включает в себя ряд кнопок и гиперссылок навигации, которые отображаются пользователю 102 с целью помочь пользователю 102 в навигации по веб-сайту, связанному с данной веб-страницей, и/или по дополнительным веб-сайтам и/или дополнительным веб-страницам, связанным с данной веб-страницей. Например, в некоторых случаях гиперссылки, отображаемые пользователю 102 как часть контента 218 управления навигацией, могут быть связаны с адресом, который по меньшей мере частично совпадает с адресом веб-страницы. Это особенно актуально, когда эти гиперссылки отображаются с целью перенаправления пользователя 102 с данной веб-страницы веб-сайта на другие веб-страницы этого веб-сайта.
[101] Основной контент 217 обычно включает в себя основной контент веб-страницы, с которым пользователь 102 может пожелать ознакомиться. Например, если веб-страница относится к новостному материалу, основной контент 217 может включать в себя текст, подробно излагающий новость. Основной текст обычно содержит множество предложений, которые, как правило, соответствуют грамматическим правилам, и состоит из логически организованных полных предложений. В большинстве случаев основной текст гораздо более точно следует грамматическим правилам по сравнению с заголовком или со сниппетом веб-сайта. Основной контент может также содержать изображения или другой тип контента, помимо текстовых строк.
[102] Следует также отметить, что основной контент 217 обычно представляет собой большую часть контента веб-страницы. Другими словами, доля основного контента 217 в общем контенте веб-страницы обычно больше, чем доля любого из контента 214 верхнего колонтитула, контента 215 заголовка, контента 216 нижнего колонтитула и контента элемента управления навигацией 218 в общем контенте веб-страницы.
[103] Из вышеизложенного следует понимать, что в зависимости от раздела веб-страницы, в котором содержится контент, этот контент может иметь различное значение. Для лучшей иллюстрации этого можно предположить, что основной контент 217 и контент 218 управления навигацией содержат слово «Home». Другими словами, можно предположить, что слово «Home» отображается (1) в основном разделе 207 веб-страницы и (2) в разделе 208 управления навигацией веб-страницы.
[104] В этом примере слово «Home», используемое в контексте основного раздела 207, потенциально может иметь другое значение, чем слово «Home», используемое в контексте раздела 208 управления навигацией. Например, слово «Home», используемое в основном контексте (размещенном в основном разделе 207), может относиться к жилым помещениям, а слово «Home», используемое в контексте управления навигацией (встречается в разделе 208 управления навигацией) может относиться к домашней странице или к главной странице веб-сайта.
[105] Таким образом, можно сказать, что значение слова (или фразы) зависит от контекста, в котором оно используется или встречается. В результате слово (или фраза), используемое в первом контексте (встречающееся в первом разделе веб-страницы), может иметь значение, отличное от значения того же слова (или фразы), используемого во втором контексте (встречающегося во втором разделе веб-страницы). Другими словами, слово (или фраза) может использоваться в разных контекстах, специфичных для соответствующих разделов веб-страницы, а следовательно, такое слово (или фраза) может иметь разные значения в зависимости от того, в каком разделе содержится данное слово (или фраза).
[106] В приведенном выше примере на английском языке (1) главная страница веб-сайта и (2) жилые помещения могут обозначаться словом «Home», тем не менее, в других языках, например, в русском языке, это может быть иначе. Например, в русском языке слово, обозначающее главную страницу сайта, и слово, обозначающее жилое помещение, являются совершенно разными словами. В результате (1) выбор правильного или лучшего слова на русском языке для перевода слова «Home» при использовании в контексте управления навигацией и одновременно (2) выбор правильного или лучшего слова на русском языке для перевода слова «Home» при использовании в основном контексте представляет собой сложную задачу.
[107] Как более подробно описано ниже, разработчики настоящей технологии разработали системы и методы, позволяющие сервисам перевода, предоставляемым пользователю 102, правильно или лучше выбирать переводную версию контента (например, текста, слова (слов), фразы (фраз), предложения (предложений) и т.п.) с учетом контекста, в котором контент используется на веб-странице. Применительно к приведенному выше примеру, это означает, что сервисы перевода, понимаемые в контексте настоящей технологии, позволяют (1) выбирать правильное или лучшее слово на русском языке для перевода слова «Home» при использовании в контексте управления навигацией и одновременно (2) выбирать правильное или лучшее слово на русском языке для перевода слова «Home» при использовании в основном контексте.
Сервер и база данных
[108] Как показано на фиг. 1, система 100 также содержит сервер 106, который может быть реализован как обычный компьютерный сервер. Предполагается, что сервер 106 может быть реализован подобно сетевому серверу из числа одного или нескольких сетевых серверов 113 без выхода за пределы настоящей технологии.
[109] В показанных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 106 представляет собой одиночный сервер. В альтернативных не имеющих ограничительного характера вариантах осуществления настоящей технологии функциональные возможности сервера 106 могут быть распределены и могут быть реализованы в нескольких серверах. Сервер 106 может содержать один или несколько процессоров, одно или несколько устройств энергонезависимой памяти, машиночитаемые команды и/или дополнительные аппаратные средства, дополнительные программные компоненты и/или их комбинацию для реализации различных функций сервера 106 без выхода за пределы настоящей технологии.
[110] Система 100 также содержит базу 108 данных, подключенную к серверу 106 и способную хранить информацию, извлеченную или иным образом определенную или сформированную сервером 106. В общем случае база 108 данных может принимать данные от сервера 106, которые были извлечены или иным образом определены или сформированы в ходе обработки сервером 108 для их временного или постоянного хранения, и может предоставлять сохраненные данные серверу 106 для их использования. Предполагается, что база 108 данных может быть разделена на несколько распределенных баз данных без выхода за пределы настоящей технологии. Данные, получаемые базой 108 данных от сервера 106 или предоставляемые ему, описаны далее.
[111] В общем случае сервер 106 может находиться под контролем или управлением поставщика сервисов перевода (не показан), такого как оператор сервисов перевода Yandex™. Предполагается, что поставщик сервисов перевода и поставщик приложения 105 браузера могут быть одним и тем же поставщиком. Так, приложение 105 браузера (например, браузер Yandex™) и сервисы перевода (например, сервисы перевода Yandex™) могут предоставляться, контролироваться или управляться одним и тем же оператором или организацией.
[112] Сервер 106 может выполнять приложение 120 обходчика. В общем случае приложение 120 обходчика способно «посещать» сетевые ресурсы, доступные по сети 110 связи (такие как множество 112 сетевых ресурсов или других потенциальных сетевых ресурсов), и загружать их для дальнейшей обработки. Например, приложение 120 обходчика может обращаться к различным сетевым серверам (например, к одному или нескольким сетевым серверам 113 или к другим потенциальным сетевым серверам) и получать электронные документы, представляющие собой веб-страницы (например, сетевые ресурсы), размещенные на различных сетевых серверах.
[113] Предполагается, что в некоторых вариантах осуществления настоящей технологии приложение 120 обходчика может загружать электронные документы, соответствующие различным версиям веб-страницы. В частности, каждая версия веб-страницы может содержать контент веб-страницы на соответствующем языке. Многие веб-страницы, доступные сегодня в Интернете, имеют версии для пользователей, говорящих на разных языках.
[114] Например, банковские учреждения обычно предоставляют несколько версий своих веб-страниц, где контент каждой версии демонстрируется на соответствующем языке. Например, первая версия веб-страницы, предоставляемая банковским учреждением, может содержать контент на английском языке для англоговорящих клиентов, а вторая версия веб-страницы, предоставляемая банковским учреждением, может содержать контент на русском языке для русскоязычных клиентов. Следовательно, в этом случае приложение 120 обходчика может загружать электронный документ, представляющий собой английскую версию веб-страницы, и электронный документ, представляющий собой русскую версию веб-страницы.
[115] В качестве другого примера, правительственное учреждение может предоставлять несколько версий веб-страницы, где контент каждой версии демонстрируется на соответствующем языке. Это особенно характерно для правительственных учреждений стран, имеющих более одного официального языка, например, Канады. В частности, первая версия веб-страницы, предоставляемая правительственным учреждением Канады, может содержать контент на английском языке для англоговорящих жителей, а вторая версия веб-страницы, предоставляемая правительственным учреждением Канады, может содержать контент на французском языке для франкоговорящих жителей. Следовательно, в этом случае приложение 120 обходчика может загружать электронный документ, представляющий собой английскую версию веб-страницы, и электронный документ, представляющий собой французскую версию веб-страницы.
[116] Предполагается, что сервер 106 может хранить электронные документы, загруженные приложением 120 обходчика, в базе 108 данных. В некоторых вариантах осуществления предполагается, что сервер 106 может хранить электронные документы групповым образом, т.е. электронные документы, хранящиеся в базе 108 данных, могут быть сгруппированы или иным образом идентифицированы в базе 108 данных для указания того, какие электронные документы связаны с соответствующими версиями одной веб-страницы.
[117] В некоторых вариантах осуществления настоящей технологии сервер 106 может также выполнять приложение 122 сопоставления строк. В общем случае приложение 122 сопоставления строк может использоваться сервером 106 для построения корпуса параллельных текстов с текстовыми строками на разных языках. Сервер 106 может выполнять приложение 122 сопоставления строк для сохраненных версий веб-страницы, чтобы идентифицировать и извлекать параллельные текстовые строки из контента различных версий веб-страницы.
[118] Например, если некоторая веб-страница доступна в английской версии и в русской версии, приложение 122 сопоставления строк может идентифицировать и извлекать (1) текстовые строки из контента английской версии веб-страницы и (2) параллельные текстовые строки из контента русской версии веб-страницы.
[119] В контексте настоящего описания текстовая строка на первом языке является текстовой строкой, параллельной другой текстовой строке на втором языке, если текстовая строка на первом языке является переводом другой текстовой строки на втором языке.
[120] Для иллюстрации на фиг. 3 изображен корпус 300. Предположим, что корпус 300 построен сервером 106 для англо-русских пар текстовых строк. Тем не менее, следует отметить, что сервер 106 может создавать корпусы пар строк для любой другой пары языков, отличной от пары английский-русский, подобно корпусу 300, без выхода за пределы настоящей технологии.
[121] Корпус 300 содержит множество 302 пар текстовых строк. Множество 302 пар текстовых строк содержит первый набор 304 текстовых строк на первом языке (в данном случае на английском языке) и второй набор 306 текстовых строк на втором языке (в данном случае на русском языке). Первый набор 304 текстовых строк и второй набор 306 текстовых строк образуют набор 302 пар текстовых строк, при этом каждая из множества 302 пар текстовых строк содержит текстовую строку из первого множества 304 текстовых строк и соответствующую параллельную текстовую строку из второго множества 306 текстовых строк.
[122] Например, набор 302 пар текстовых строк содержит пару 308 текстовых строк. В этом примере пара 308 текстовых строк содержит (1) первую текстовую строку 310 на первом языке (например, на английском языке) и (2) вторую текстовую строку 312 на втором языке (например, на русском языке). Первая текстовая строка 310 может быть идентифицирована и извлечена приложением 122 сопоставления строк из английской версии веб-страницы, а вторая текстовая строка 312 может быть идентифицирована и извлечена приложением 122 сопоставления строк из русской версии веб-страницы.
[123] Предполагается, что приложение 122 сопоставления строк также может определять, что вторая текстовая строка 312 является русским переводом первой текстовой строки 310 и/или наоборот. Следовательно, можно сказать, что приложение 122 сопоставления строк также может определять, что вторая текстовая строка 312 является текстовой строкой, параллельной первой текстовой строке 310 и/или наоборот. Другими словами, можно сказать, что пара 308 текстовых строк содержит первую текстовую строку 310 на первом языке и параллельную текстовую строку на втором языке, которая является второй текстовой строкой 312.
[124] В некоторых вариантах осуществления настоящей технологии приложение 122 сопоставления строк также может размечать каждую пару из набора 302 пар текстовых строк с использованием информации, указывающей на контекст, в котором текстовые строки встречаются в соответствующих версиях веб-страницы.
[125] В одном примере первая выборка 320 пар текстовых строк из набора 302 пар текстовых строк может быть размечена информацией, указывающей на то, что текстовые строки в этой выборке встречаются в первом контексте. Например, можно предположить, что первая выборка 320 пар текстовых строк извлечена из основного контента веб-страниц и, следовательно, она встречается в основном контексте.
[126] В другом примере вторая выборка 330 пар текстовых строк из набора 302 пар текстовых строк может быть размечена информацией, указывающей на то, что текстовые строки в этой выборке встречаются во втором контексте. Например, можно предположить, что вторая выборка 330 пар текстовых строк извлечена из контента заголовка веб-страниц и, следовательно, встречается в контексте заголовка (в отличие от первой выборки 320 пар текстовых строк из основного контекста).
[127] В еще одном примере третья выборка 340 пар текстовых строк из набора 302 пар текстовых строк может быть размечена информацией, указывающей на то, что текстовые строки в этой выборке встречаются в третьем контексте. Например, можно предположить, что третья выборка 340 пар текстовых строк извлечена из контента элемента управления навигацией веб-страниц и, следовательно, встречается в контексте элемента управления навигацией (в отличие от (1) первой выборки 320 пар текстовых строк, встречающейся в контексте основного раздела, и (2) второй выборки 330 пар текстовых строк, встречающейся в контексте заголовка).
[128] Как показано на фиг. 3, первая выборка 320 пар текстовых строк содержит большее количество пар текстовых строк, чем (1) вторая выборка 330 пар текстовых строк и (2) третья выборка 340 пар текстовых строк.
[129] Как упоминалось ранее, бо́льшая часть контента веб-страницы обычно находится в основном разделе веб-страницы. Следовательно, при обработке контента большого количества веб-страниц с помощью приложения 122 сопоставления строк естественным образом получается большее количество пар текстовых строк в наборе 302 пар текстовых строк, связанных с основным контекстом, по сравнению с количеством пар текстовых строк в наборе 302 пар текстовых строк, встречающихся в любом другом контексте, например, в контексте заголовка или в контексте управления навигацией.
[130] Следовательно, можно сказать, что каждая пара из набора 302 пар текстовых строк может быть связана с соответствующим контекстом из множества контекстов. Множество контекстов содержит (1) основной контекст и (2) по меньшей мере один вспомогательный контекст. В не имеющем ограничительного характера примере сетевых ресурсов, являющихся веб-страницами, основным контекстом является контекст основного раздела, а по меньшей мере один вспомогательный контекст является контекстом заголовка и контекстом управления навигацией (предполагается, что контекст нижнего колонтитула и контекст верхнего колонтитула могут быть частью по меньшей мере одного вспомогательного контекста).
[131] Кроме того, можно также сказать, что набор 302 пар текстовых строк содержит «естественную пропорцию» пар текстовых строк каждого контекста. В контексте настоящего описания термин «естественная пропорция» относится к пропорции пар текстовых строк каждого контекста, которые обычно встречаются в сетевых ресурсах. В не имеющем ограничительного характера примере сетевых ресурсов, являющихся веб-страницами, под «естественной пропорцией» пар текстовых строк каждого контекста подразумевается доля пар текстовых строк каждого контекста, которая обычно встречается на веб-страницах.
[132] Как объяснялось выше, значительная часть (если не большинство) контента веб-страницы обычно относится к контексту основного раздела. Следовательно, в некоторых вариантах осуществления естественная пропорция пар текстовых строк каждого контекста в наборе 302 пар текстовых строк означает, что набор 302 пар текстовых строк содержит значительную часть пар текстовых строк, встречающихся в основном контексте (например, в контексте основного раздела). В других вариантах осуществления естественная пропорция пар текстовых строк каждого контекста в наборе 302 пар текстовых строк означает, что набор 302 пар текстовых строк содержит большее количество пар текстовых строк, встречающихся в основном контексте (например, в контексте основного раздела) по сравнению с рядом пар текстовых строк, встречающихся в любом вспомогательном контексте (например, в контексте заголовка или в контексте управления навигацией).
[133] Предполагается, что в некоторых вариантах осуществления настоящей технологии сервер 106 может хранить корпус 300 в базе 108 данных. В качестве альтернативы, корпус 300 может непрерывно пополняться в заранее определенные периоды времени дополнительными парами текстовых строк, извлеченными приложением 122 сопоставления строк.
[134] Кроме того, сервер 106 может хранить корпусы для других языковых пар, кроме англо-русской пары, в дополнение к корпусу 300 в базе 108 данных. Например, если сервисы перевода системы 100 предназначены для предоставления сервисов перевода на 50 различных языков, база 108 данных может хранить ряд корпусов, соответствующих количеству всех возможных языковых пар среди 50 различных языков. Как указано выше, каждый корпус, хранящийся в базе 108 данных, может быть построен подобно корпусу 300.
Алгоритм машинного обучения
[135] Как показано на фиг. 1, сервер 106 также способен выполнять алгоритм 124 MLA. В общем случае алгоритмы MLA могут обучаться на обучающих выборках и делать прогнозы для новых (незнакомых) данных. Алгоритмы MLA обычно используются для первого построения модели на основе обучающих входных данных, чтобы затем делать прогнозы на основе данных или выдавать на выходе решения, вместо выполнения статических машиночитаемых команд.
[136] Алгоритмы MLA обычно используются в качестве моделей оценки, моделей ранжирования, моделей классификации и т.п. Следует понимать, что для различных задач могут использоваться разные виды алгоритмов MLA с разной структурой или топологией.
[137] Один вид алгоритмов MLA включает в себя нейронные сети (NN, Neural Networks). В общем случае сеть NN состоит из взаимосвязанной группы искусственных «нейронов», которые обрабатывают информацию, используя коннекционный подход к вычислениям. Сети NN используются для моделирования сложных отношений между входами и выходами (без фактического знания взаимосвязей) или для поиска закономерностей в данных. Сети NN сначала настраиваются на этапе обучения, на котором им предоставляется известный набор входных данных и информация для адаптации сети NN с целью формирования соответствующих выходных данных (для ситуации, которая подвергается моделированию). В ходе фазы обучения сеть NN адаптируется к изучаемой ситуации и изменяет свою структуру таким образом, чтобы обеспечить разумные прогнозируемые выходные данные для заданных входных данных в новой ситуации (на основе того, что было изучено). Таким образом, вместо того, чтобы пытаться определить сложные статистические механизмы или математические алгоритмы для ситуации, сеть NN пытается дать «интуитивный» ответ, основанный на «восприятии» ситуации.
[138] Сети NN обычно используются в тех случаях, когда важно знать лишь результат, основанный на входных данных, а то, как именно этот результат получен, менее важно или вовсе не важно. Например, сети NN часто используются для оптимизации распределения веб-трафика между серверами, автоматического перевода текста на разные языки, обработки данных, включая фильтрацию, кластеризацию, векторизацию и т.п.
[139] Вкратце, можно сказать, что реализация алгоритма 124 MLA сервером 112 может быть в общих чертах разделена на два этапа - этап обучения и этап использования. Сначала алгоритм MLA обучается на этапе обучения. Затем, когда алгоритм MLA знает, какие данные следует ожидать в качестве входных данных и какие данные предоставлять в качестве выходных данных, алгоритм MLA запускается в работу на этапе использования с применением данных этапа использования.
[140] Тем не менее, как очевидно из приведенного ниже описания, в некоторых вариантах осуществления настоящей технологии реализация алгоритма 124 MLA сервером 112 может быть в общих чертах разделена на три этапа: первая фаза обучения, вторая фаза обучения (или фаза повторного обучения) и этап использования.
[141] Как упоминалось ранее, алгоритм 124 MLA может быть реализован в виде сети NN. На фиг. 4 приведено схематическое представление 400 обучающей итерации сети 410 NN. Предполагается, что в некоторых вариантах осуществления настоящей технологии алгоритм 124 MLA может быть реализован в виде сети 410 NN.
[142] Следует понимать, что первая фаза обучения сети 410 NN может включать в себя очень большое количество итераций обучения, выполняемых подобно рассматриваемой итерации обучения сети 410 NN. Также следует отметить, что обучающая итерация сети 410 NN, описанная далее, является одной из многих итераций, выполняемых в ходе первой фазы обучения.
Итерация обучения в первой фазе обучения
[143] Сеть 410 NN содержит кодирующую часть (кодер) 420 и декодирующую часть (декодер) 430. Сети NN с архитектурой кодер-декодер могут использоваться для целей перевода. Например, каждый из кодера 420 и декодера 430 может быть рекуррентной сетью NN (RNN) или сверточной сетью NN (CNN). Также предполагается, что каждый из кодера 420 и декодера 430 может иметь иерархическую структуру или топологию без выхода за пределы настоящей технологии.
[144] Вкратце, обучающая итерация сети 410 NN в ходе первой фазы обучения проводится на основе пары обучающих текстовых строк. В не имеющем ограничительного характера примере на фиг. 4 пара обучающих текстовых строк может соответствовать паре 308 текстовых строк из корпуса 300, показанного на фиг. 3. Другие итерации обучения сети 410 NN могут проводиться на основе других пар текстовых строк из корпуса 300. Следовательно, можно сказать, что сеть 410 NN может быть обучена на основе набора пар текстовых строк из корпуса 300.
[145] В ходе обучающей итерации, показанной на фиг. 4, первая текстовая строка 310 (первая обучающая текстовая строка из пары обучающих строк) преобразуется в последовательность «токенов», которая вводится в кодер 420. Следовательно, можно сказать, что обучающие входные данные для кодера 420 основаны на первой текстовой строке 310.
[146] Кодер 420 способен обрабатывать данные, представляющие собой обучающие входные данные (например, последовательность «токенов», указывающих на первую текстовую строку 310), и таким образом формировать выходные данные 425 кодера. Выходные данные 425 кодера являются в определенном смысле «вектором мысли» кодера 420 для обучающих входных данных, представляющим собой скрытое представление обучающих входных данных, обработанных кодером 420.
[147] Кроме того, в ходе обучающей итерации, показанной на фиг. 4, вторая текстовая строка 312 (вторая обучающая текстовая строка пары обучающих строк) преобразуется в последовательность «токенов», которая вводится в декодер 430. Следовательно, можно сказать, что обучающие входные данные для декодера 430 основаны на второй текстовой строке 312 (текстовой строке, параллельной текстовой строке, используемой кодером 420 на обучающей итерации).
[148] Подобно тому, что было описано выше для кодера 420, декодер 430 способен обрабатывать данные, представляющие собой обучающие входные данные (например, последовательность «токенов», указывающих на вторую текстовую строку 312), и таким образом формировать выходные данные 435 декодера. Выходные данные 435 декодера являются в определенном смысле «вектором мысли» декодера 430 для обучающих входных данных, представляющим собой скрытое представление обучающих входных данных, обработанных декодером 430.
[149] Цель обучения сети 410 NN состоит в настройке для пары обучающих текстовых строк (параллельных обучающих строк) (1) кодера 420 для формирования выходных данных 425 кодера и (2) декодера 430 для формирования выходных данных 435 декодера таким образом, чтобы сходство между (1) выходными данными 425 кодера и (2) выходными данными 435 декодера было максимальным. Это может быть достигнуто, например, путем использования в ходе итераций обучения сети 410 NN различных известных технологий для настройки взаимосвязей между «нейронами» кодера 420 и декодера 430 на основе сравнения сходства между выходными данными кодера 425 и выходными данными 435 декодера. Другими словами, они настраиваются для формирования одинаковых «скрытых» результатов для одной и той же фразы на разных языках. Например, в отношении сети 410 NN могут применяться методы обратного распространения или различные штрафные функции для настройки взаимосвязей между «нейронами» кодера 420 и декодера 430 на основе сравнения сходства между выходными данными 425 кодера и выходными данными декодера 435.
[150] Следует понимать, что если выходные данные 425 кодера и выходные данные 435 декодера схожи, то это означает, что кодер 420 может (1) принимать входные данные на основе первой текстовой строки 310 и (2) формировать выходные данные кодера, что (3) выходные данные кодера могут подаваться в блок 430 декодера для декодирования входных данных кодера и (4) в результате кодер 420 может обеспечивать текстовую строку, схожую со второй текстовой строкой 312.
[151] Учитывая, что вторая текстовая строка 312 является текстовой строкой на русском языке, параллельной первой текстовой строке 310 на английском языке, это означает, что настройка кодера 420 и декодера 430 для формирования выходных данных 425 кодера и выходных данных 435 декодера, соответственно, так что их сходство становится максимальным, позволяет использовать обученную сеть 410 NN для перевода текстовых строк с первого языка на второй язык. Предполагается, что в ходе первой фазы обучения может выполняться большое количество обучающих итераций для настройки кодера 420 и декодера 430 аналогично тому, как выполняется обучающая итерация на основе пары 308 текстовых строк (данной пары обучающих текстовых строк).
[152] Следует понимать, что сеть 410 NN может быть обучена переводу текстовых строк в языковых парах, отличных от пары английский-русский. Это может быть достигнуто за счет использования другого корпуса, аналогичного корпусу 300, но содержащего пары текстовых строк для языковой пары, отличной от пары английский-русский. Также следует понимать, что для перевода текстовых строк сетью 410 NN могут использоваться дополнительные методы, например, такие как механизмы типа «внимание», без выхода за пределы настоящей технологии.
[153] Вкратце, алгоритм 124 MLA (например, сеть 410 NN) может быть обучен в ходе первой фазы обучения с использованием первого набора пар обучающих строк, например набора 302 пар строк из корпуса 300, определению параллельной текстовой строки на втором языке (например, на русском языке) в ответ на текстовую строку на первом языке (например, на английском языке).
[154] Следует напомнить, что набор 302 пар текстовых строк, которые могут использоваться в качестве первого набора пар обучающих строк в ходе первой фазы обучения, имеют естественную пропорцию пар текстовых строк каждого контекста (в частности, значительная часть обучающей пары текстовых строк встречается в основном контексте). Другими словами, первый набор пар обучающих строк, на основе которых алгоритм 124 MLA (например, сеть 410 NN) обучается в ходе первой фазы обучения, имеет естественную пропорцию пар обучающих строк каждого контекста.
[155] Предполагается, что обучение алгоритма 124 MLA (например, сети 410 NN) в ходе первой фазы обучения, как описано выше, может обеспечить формирование алгоритмом 124 MLA хорошего перевода с первого языка на второй язык. Действительно, алгоритм 124 MLA, обученный в ходе первой фазы обучения, как описано выше, может использоваться для реализации сервисов перевода системы 100 в некоторых вариантах осуществления настоящей технологии.
[156] Тем не менее, разработчики настоящей технологии обнаружили, что обучение алгоритма 124 MLA в ходе первой фазы обучения, как описано выше, может также приводить к смещению алгоритма 124 MLA к формированию параллельной текстовой строки в качестве перевода соответствующей текстовой строки, встречающейся в основном контексте (т.е. в основном контенте).
[157] В примере со словом «Home», приведенном выше, слово «Home», используемое в основном контексте (например, в основном контексте веб-страницы), может означать или относиться к жилым помещениям, а в контексте управления навигацией (например, во вспомогательном контексте веб-страницы) слово «Home» может означать или относиться к домашней странице или к главной странице веб-сайта. Следовательно, обучение алгоритма 124 MLA в ходе первой фазы обучения, как описано выше, может привести к тому, что алгоритм 124 MLA смещается к формированию параллельного слова в качестве перевода слова «Home», встречающегося в основном контексте, т.е. алгоритм 124 MLA может смещаться к переводу слова «Home» как означающего жилое помещение, независимо от того, используется или нет слово «Home» в другом контексте, отличном от основного контекста веб-страницы.
[158] Это проиллюстрировано на фиг. 1 и 5.
[159] Можно предположить, что электронное устройство 104 отображает окно 502 браузера приложения 105 браузера в соответствии с представлением 500. Как упомянуто выше, панель 506 отображения отображает пользователю 102 некоторый контент желаемого сетевого ресурса (например, желаемую веб-страницу). В частности, панель 506 управления навигацией отображает:
- контент 520 управления навигацией, содержащий страницы «Home», «Page 1» и «Page 2»;
- контент 530 заголовка, содержащий текст «HOUSING MARKET: OWNING A HOME MORE EXPENSIVE THAN EVER»; и
- по меньшей мере часть основного контента 540, содержащую текст «A family home is more than just a place to live in. It allows creating an atmosphere of comfort and love».
[160] Следует отметить, что в этом не имеющем ограничительного характера примере слово «Home» содержится в контенте 520 управления навигацией, в контенте 530 заголовка и в по меньшей мере части основного контента 540.
[161] Можно предположить, что в этом случае английский язык является иностранным языком для пользователя 102. Другими словами, пользователь 102 может быть не в состоянии понять контент 520 управления навигацией, контент 530 заголовка и по меньшей мере отображаемую часть основного контента 540. В этом случае пользователь 102 может активировать кнопку 514 перевода для перевода отображаемого контента.
[162] Предполагается, что в некоторых вариантах осуществления настоящей технологии приложение 105 браузера способно идентифицировать контент, отображаемый пользователю 102 в данное время. Например, приложение 105 браузера может идентифицировать текстовые строки, визуализируемые и отображаемые пользователю 102 в данное время в контенте 520 управления навигацией, контенте 530 заголовка и в по меньшей мере части основного контента 540.
[163] Это означает, что в этом не имеющем ограничительного характера примере приложение 105 браузера может идентифицировать текстовые строки «Home», «Page 1», «Page 2», «HOUSING MARKET: OWNING A HOME MORE EXPENSIVE THAN EVER» и «A family home is more than just a place to live in. It allows creating an atmosphere of comfort and love».
[164] Предполагается, что приложение 105 браузера может инициировать формирование запроса 160 сервера электронным устройством 104 (см. фиг. 1). Запрос 160 сервера может иметь форму одного или нескольких пакетов данных, которые содержат информацию, указывающую на идентифицированные текстовые строки (визуализируемые и отображаемые пользователю 102 в данное время). Электронное устройство 104 может передавать запрос 160 сервера на сервер 106 через сеть 110 связи.
[165] Сервер 106 может передавать идентифицированные текстовые строки, полученные в запросе 160 сервера, в алгоритм 124 MLA, обученный в ходе первой фазы обучения, как описано выше. Другими словами, сервер 106 может использовать алгоритм 124 MLA, обученный в ходе первой фазы обучения, описанной выше, на этапе использования для преобразования идентифицированных текстовых строк, полученных в запросе 160 сервера.
[166] В результате алгоритм 124 MLA, обученный в первой фазе обучения, как описано выше, может формировать:
- для слова «Home» параллельное слово «Дом»;
- для слова «Page 1» параллельное слово «Страница 1»;
- для слова «Page 2» параллельное слово «Страница 2»;
- для заголовка «HOUSING MARKET: OWNING A HOME MORE EXPENSIVE THAN EVER» параллельный заголовок «РЫНОК ЖИЛЬЯ: ВЛАДЕТЬ ДОМОМ ДОРОЖЕ, ЧЕМ КОГДА-ЛИБО»;
- для предложений «A family home is more than just a place to live in. It allows creating an atmosphere of comfort and love» параллельные предложения «Семейный дом - больше, чем просто место для проживания. Он позволяет создавать атмосферу комфорта и любви».
[167] Сервер 106 может получать вышеупомянутые параллельные текстовые строки, сформированные алгоритмом 124 MLA, и формировать ответ 165 сервера. Ответ 165 сервера может иметь форму одного или нескольких пакетов данных, которые содержат информацию, указывающую на сформированные параллельные текстовые строки, полученные от алгоритма 124 MLA. Сервер 106 может передавать ответ 165 сервера на электронное устройство 104 через сеть 110 связи.
[168] Электронное устройство 104 может передавать сформированные параллельные текстовые строки, полученные в ответе 165 сервера, в приложение 105 браузера. Приложение 105 браузера может заменять идентифицированные текстовые строки (визуализированные и отображенные пользователю 102) соответствующими сформированными параллельными текстовыми строками, полученными в ответе 165 сервера.
[169] После того как приложение 105 браузера заменило идентифицированные текстовые строки на соответствующие сформированные параллельные текстовые строки, электронное устройство 104 может отображать окно 502 браузера приложения 105 браузера в соответствии с представлением 590, показанным в средней части фиг. 5.
[170] В представленном примере приложение 105 браузера может отображать (1) переведенный контент 521 управления навигацией вместо контента 520 управления навигацией, (2) переведенный контент 531 заголовка вместо контента 530 заголовка и (3) переведенный контент 541 основного текста вместо по меньшей мере части основного контента 540.
[171] Как упомянуто выше, отображаемый переведенный контент в представлении 590 является хорошим переводом отображаемого контента в представлении 500. Такой перевод отображаемого контента в представлении 500 позволяет пользователю 102 понять большую часть отображаемого контента.
[172] Тем не менее, предполагается, что в некоторых вариантах осуществления настоящей технологии отображаемый переведенный контент в представлении 590 может не быть правильным или лучшим переводом отображаемого контента в представлении 500. В качестве примера, слово «Home», входящее (1) в контент 520 управления навигацией, (2) в контент 530 заголовка и (3) в основной контент 540, переводится как слово «Дом» во всех случаях: (1) в переведенном контенте 521 элемента управления навигацией, (2) в переведенном контенте 531 заголовка (фактически переведенного как «Домом», что является склонением (точнее, падежной формой) слова «Дом» на русском языке), и (3) в переведенном основном контенте 541.
[173] Следует отметить, что слово «Дом» в русском языке относится к жилым помещениям. Другими словами, слово «Дом» является правильным или лучшим переводом слова «Home» в основном контексте (то есть в контенте 540 основного раздела). Слово «Дом» не является правильным или лучшим переводом слова «Home» в контексте управления навигацией (то есть в контенте 520 управления навигацией). Слово «Дом» (фактически склонение «Домом») также не является правильным или лучшим переводом слова «Home» в контексте заголовка (то есть в контенте 530 заголовка).
[174] Как упоминалось ранее, в этом примере менее желательные переводы слова «Home» в переведенном контенте 521 управления навигацией и в переведенном контенте 531 заголовка могут быть вызваны тем, что алгоритм 124 MLA был обучен в ходе первой фазы обучения на основе первого набора пар обучающих текстовых строк, имеющих естественную пропорцию пар обучающих текстовых строк каждого контекста.
[175] Другими словами, из-за естественной пропорции обучающих текстовых строк каждого контекста, использованных для обучения алгоритма 124 MLA в ходе первой фазы обучения, алгоритм 124 MLA оказывается смещенным и формирует слово «Дом» в качестве перевода слова «Home», встречающегося в основном контексте (то есть как относящегося к жилым помещениям, а не как относящегося, например, к главной веб-странице). Действительно, значительная часть примеров обучения, предоставленных алгоритму 124 MLA на первом этапе обучения, указывает на то, что слово «Дом» является правильным или лучшим переводом слова «Home», и таким образом на этапе использования алгоритм 124 MLA оказывается смещенным, переводя слово «Home» словом «Дом».
[176] Можно сказать, что первая фаза обучения алгоритма 124 MLA не зависит от контекста, в том смысле, что контекст, в котором присутствуют обучающие примеры, не принимается во внимание или не рассматривается алгоритмом 124 MLA в ходе первой фазы обучения.
[177] Разработчики настоящей технологии разработали методы и системы, которые по меньшей мере уменьшают вышеупомянутое смещение алгоритма 124 MLA. Разработчики настоящей технологии понимают, что вышеупомянутое смещение алгоритма 124 MLA (например, сети 410 NN) может быть исправлено или по меньшей мере уменьшено путем дальнейшего обучения (или повторного обучения) алгоритма 124 MLA на основе второго набора обучающих пар текстовых строк, содержащих контролируемую пропорцию, а не естественную пропорцию пар текстовых строк каждого контекста.
[178] Предполагается, что в некоторых вариантах осуществления настоящей технологии вышеупомянутое смещение алгоритма 124 MLA (например, сети 410 NN) может быть исправлено или по меньшей мере уменьшено путем выполнения второй фазы обучения алгоритма 124 MLA, как упомянуто выше, с использованием второго набора пар обучающих текстовых строк, содержащего контролируемую пропорцию пар текстовых строк каждого контекста.
[179] Далее описано, как определяется второй набор пар обучающих текстовых строк и как может выполняться вторая фаза обучения алгоритма 124 MLA для исправления или по меньшей мере для уменьшения вышеупомянутого смещения алгоритма 124 MLA.
Вторая фаза обучения алгоритма MLA
[180] Как упомянуто выше, в ходе второй фазы обучения алгоритма 124 MLA используется второй набор пар обучающих текстовых строк вместо первого набора пар обучающих текстовых строк. Другими словами, в ходе второй фазы обучения используется набор пар текстовых строк, имеющих контролируемую пропорцию пар текстовых строк каждого контекста, вместо набора пар текстовых строк, имеющих естественную пропорцию пар текстовых строк каждого контекста.
[181] В ходе второй фазы обучения сервер 106 способен обучать алгоритм 124 MLA на основе близкого количества пар текстовых строк каждого контекста. Например, второй набор обучающих текстовых строк может содержать 1000 пар обучающих текстовых строк из основного контекста. При этом второй набор строк обучающего текста также может содержать приблизительно 1000 строк обучающего текста из по меньшей мере одного вспомогательного контекста.
[182] Следовательно, можно сказать, что сервер 106 может определять второй набор пар обучающих текстовых строк, управляя пропорцией пар текстовых строк каждого контекста, выбираемого из корпуса 300 для обучения (повторного обучения) алгоритма 124 MLA в ходе второй фазы обучения.
[183] Второй набор пар обучающих текстовых строк может быть определен сервером 106 на основе набора 302 пар текстовых строк. Тем не менее сервер 106 может управлять тем, какие из набора 302 пар текстовых строк должны быть включены во второй набор пар обучающих текстовых строк на основе их контекстов, так что второй набор пар обучающих текстовых строк имеет контролируемую пропорцию пар текстовых строк каждого контекста.
[184] Для лучшего понимания разницы между первой фазой обучения и второй фазой обучения алгоритма 124 MLA следует пояснить, что сервер 106 обучает алгоритм 124 MLA в ходе первой фазы обучения в определенном смысле «учиться», возможно, с нуля, преобразованию текстовой строки в параллельную текстовую строку. Это может быть трудной задачей, если используется лишь небольшое количество обучающих примеров.
[185] По этой причине в ходе первой фазы обучения алгоритма 124 MLA этот алгоритм должен получать большое количество обучающих примеров (первый набор пар обучающих текстовых строк может содержать весь набор 302 пар текстовых строк из корпуса 300), чтобы алгоритм 124 MLA мог «учится» переводить на основе большого количества обучающих примеров.
[186] К моменту начала второй фазы обучения алгоритма 124 MLA этот алгоритм уже достаточно обучен, чтобы формировать хорошие переводы. Таким образом, в ходе второй фазы обучения, в отличие от первой фазы обучения, цель состоит не в том, чтобы подавать большое количество обучающих примеров в алгоритм 124 MLA, а в том, чтобы контролировать, какие обучающие примеры подаются в алгоритм 124 MLA и иметь возможность исправлять некоторые смещения алгоритма 124 MLA, полученные в результате естественной пропорции обучающих примеров, использованных на первой фазе обучения.
[187] В некоторых вариантах осуществления настоящей технологии также предполагается, что второй набор пар обучающих текстовых строк, используемых в ходе второй фазы обучения, может содержать по меньшей мере некоторые пары обучающих текстовых строк из числа первых пар обучающих текстовых строк.
[188] В других вариантах осуществления настоящей технологии пары обучающих текстовых строк могут подаваться в алгоритм 124 MLA в ходе второй фазы обучения сервером 106 управляемым образом. Другими словами, сервер 106 может подавать в алгоритм 124 MLA в ходе второй фазы обучения пары обучающих текстовых строк таким образом, чтобы сохранять контролируемую пропорцию пар текстовых строк каждого контекста.
[189] Предполагается, что в некоторых вариантах осуществления может быть полезно подавать в алгоритм 124 MLA в ходе второй фазы обучения пары обучающих текстовых строк в контролируемом порядке, поскольку это позволяет прервать, перезапустить или завершить вторую фазу обучения в любой момент времени. При этом сохраняется контролируемая пропорция пар текстовых строк каждого контекста, подаваемых в алгоритм 124 MLA в ходе второй фазы обучения.
[190] Следует напомнить, что в ходе построения корпуса 300 приложение 122 сопоставления строк может размечать каждую пару из набора 302 пар текстовых строк информацией, указывающей на контекст, в котором соответствующие текстовые строки встречаются в соответствующих версиях веб-страницы.
[191] Как уже упоминалось ранее:
- первая выборка 320 пар текстовых строк из набора 302 пар текстовых строк размечена информацией, указывающей на то, что текстовые строки в этой выборке встречаются в контексте основного раздела;
- вторая выборка 330 пар текстовых строк из набора 302 пар текстовых строк размечена информацией, указывающей на то, что текстовые строки в этой выборке встречаются в контексте заголовка; и
- третья выборка 340 пар текстовых строк из набора 302 пар текстовых строк размечена информацией, указывающей на то, что текстовые строки в этой выборке встречаются в контексте управления навигацией.
[192] В некоторых вариантах осуществления настоящей технологии предполагается, что сервер 106 способен подавать в алгоритм 124 MLA обучающие текстовые строки не только в контролируемой пропорции обучающих текстовых строк каждого контекста, но также в сочетании с соответствующими метками. Другими словами, сервер 106 может не только управлять на основе соответствующих контекстов пропорциями обучающих примеров, которые подаются в алгоритм 124 MLA в ходе второй фазы обучения, но сервер 106 также может подавать в алгоритм 124 MLA соответствующую метку для каждого обучающего примера, используемого в ходе второй фазы обучения.
[193] В некоторых вариантах осуществления настоящей технологии подача обучающих примеров в алгоритм 124 MLA в ходе второй фазы обучения в сочетании с соответствующими метками позволяет этому алгоритму в определенном смысле «учиться» соотносить некоторые текстовые особенности текстовой строки с контекстом, в котором встречается эта текстовая строка, для формирования правильной или лучшей параллельной текстовой строки. Другими словами, на этапе использования алгоритм 124 MLA может определять контекст этапа использования для текстовой строки этапа использования на основе текстовых признаков контекста этапа использования и формировать соответствующую параллельную текстовую строку этапа использования в качестве перевода текстовой строки этапа использования с учетом контекста этапа использования.
[194] Обучение алгоритма 124 MLA в ходе второй фазы обучения, как описано выше, позволяет исправлять или по меньшей мере уменьшать вышеупомянутое смещение алгоритма 124 MLA. Это проиллюстрировано на фиг. 1 и 5.
[195] Как упоминалось ранее, приложение 105 браузера может идентифицировать текстовые строки «Home», «Page 1», «Page 2», «HOUSING MARKET: OWNING A HOME MORE EXPENSIVE THAN EVER» и «A family home is more than just a place to live in. It allows creating an atmosphere of comfort and love» и передавать их в запросе 160 сервера. Сервер 106 позволяет передавать идентифицированные текстовые строки, полученные в запросе 160 сервера, в алгоритм 124 MLA.
[197] Тем не менее, в некоторых вариантах осуществления настоящей технологии к тому моменту времени, когда алгоритм 124 MLA принимает идентифицированные текстовые строки, алгоритм 124 MLA может быть обучен в ходе первой фазы обучения и во второй фазе обучения (повторно обучен), как описано выше. Другими словами, в этом примере этапа использования алгоритма 124 MLA, на котором алгоритм 124 MLA используется для перевода идентифицированных текстовых строк, сервер 106 уже мог завершить как первую, так и вторую фазы обучения алгоритм 124 MLA.
[197] В результате алгоритм 124 MLA, обученный в ходе первой фазы обучения и второй фазы обучения (повторного обучения), как описано выше, может формировать:
- для слова «Home» параллельное слово «Главная»;
- для слова «Page 1» параллельное слово «Страница 1»;
- для слова «Page 2» параллельное слово «Страница 2»;
- для заголовка «HOUSING MARKET: OWNING A HOME MORE EXPENSIVE THAN EVER» параллельный заголовок «РЫНОК ЖИЛЬЯ: ВЛАДЕТЬ ЖИЛЬЕМ ДОРОЖЕ, ЧЕМ КОГДА-ЛИБО»;
- для предложений «A family home is more than just a place to live in. It allows creating an atmosphere of comfort and love» параллельные предложения «Семейный дом - больше, чем просто место для проживания. Он позволяет создавать атмосферу комфорта и любви».
[198] Электронное устройство 104 способно отображать окно 502 браузера приложения 105 браузера в соответствии с представлением 595, показанным в нижней части фиг. 5, на основе параллельных текстовых строк, сформированных с помощью алгоритма 124 MLA, прошедшего повторное обучение, подобно тому, как электронное устройство 104 способно отображать окно 502 браузера приложения 105 браузера в соответствии с представлением 595, как описано выше.
[199] Как показано, приложение 105 браузера может отображать (1) переведенный контент 522 управления навигацией вместо контента 520 управления навигацией, (2) переведенный контент 532 заголовка вместо контента 530 заголовка и (3) переведенный основной контент 542 вместо по меньшей мере части основного контента 540.
[200] Следует отметить, что в отличие от переведенного контента в представлении 590, где слово «Home» было переведено словом «Дом» (1) в переведенном контенте 521 элемента управления навигацией, (2) в переведенном контенте 531 заголовка (фактически переведено словом «Домом») и (3) в переведенном контенте 541 основного раздела, в переведенном контенте представления 595 слово «Home» переводится разными параллельными словами (1) в переведенном контенте 522 управления навигацией, (2) в переведенном контенте 532 заголовка и (3) в переведенном основном контенте 542.
[201] Например, в переведенном контенте 522 управления навигацией словом, параллельным слову «Home», является слово «Главная». Следует понимать, что слово «Главная» на русском языке означает «Main», что является правильным или лучшим переводом слова «Home» в контексте управления навигацией.
[202] В другом примере в переведенном контенте 532 заголовка словом, параллельным слову «HOME», является слово «ЖИЛЬЕМ». Следует понимать, что слово «ЖИЛЬЕ» на русском языке означает «HOUSING», что является правильным или лучшим переводом слова «HOME» в контексте заголовка.
[203] В еще одном примере в переведенном основном контенте 542 словом, параллельным слову «home», является слово «дом». Следует понимать, что перевод слова «home» в основном контексте не изменился, несмотря на повторное обучение алгоритма 124 MLA в ходе второй фазы обучения.
[204] В некоторых вариантах осуществления настоящей технологии может быть желательно ограничить адаптацию алгоритма 124 MLA в ходе второй фазы обучения из его обученного состояния после первой фазы обучения. Первая фаза обучения позволяет алгоритму 124 MLA обеспечивать правильный или лучший перевод для контента в основном контексте (который, вероятно, является значительной частью контента данного сетевого ресурса) и хороший перевод для другого контента, присутствующего в по меньшей мере одном вспомогательном контексте. В результате цель второй фазы обучения состоит не в том, чтобы полностью повторно обучить алгоритма 124 MLA, а скорее в том, чтобы «настроить» алгоритм 124 MLA, обученный в ходе первой фазы обучения, для учета контекстов, в которых может использоваться контент.
[205] С этой целью в некоторых вариантах осуществления настоящей технологии могут быть предусмотрены различные методы ограничения адаптации для ограничения «регулировки» алгоритма 124 MLA в результате второй фазы обучения. Предполагается, что ограничение адаптации или настройки алгоритма 124 MLA в ходе фазы повторного обучения (второй фазы обучения) позволяет ограничивать ухудшение качества перевода текстовой строки этапа использования из основного контекста (например, в переведенном основном контенте 542 словом, параллельным слову «home», является «дом» и поэтому перевод слова «home» в основном контексте не изменился, несмотря на повторное обучение алгоритма 124 MLA в ходе второй фазы обучения).
[206] В некоторых вариантах осуществления сервер 104 может в ходе второй фазы обучения алгоритма 124 MLA использовать функцию потерь, ограничивающую адаптацию. Функция потерь, ограничивающая адаптацию, может ограничивать адаптацию обученного состояния алгоритма 124 MLA (полученного в результате первой фазы обучения) в ходе второй фазы обучения.
[207] Предполагается, что использование сервером 106 функции потерь, ограничивающей адаптацию, на итерации в ходе второй фазы обучения может включать в себя вычисление различных распределений и показателей подобия для текстовой строки или слова.
[208] Например, сервер 106 может вычислять распределение «учителей» для заданного слова в ходе его перевода алгоритмом 124 MLA, прошедшим только в первую фазу обучения. Распределение «учителей» может указывать на вероятность того, что соответствующие потенциальные параллельные слова являются переводом данного слова, определенного алгоритмом 124 MLA, прошедшим только первую фазу обучения.
[209] Например, сервер 106 может вычислять распределение «учеников» для заданного слова при его переводе алгоритмом 124 MLA согласно проведенному обучению (первой фазе обучения и потенциальной итерации обучения второй фазы обучения, выполненной к данному моменту). Распределение «учеников» может указывать на вероятность того, что соответствующие потенциальные параллельные слова являются переводом заданного слова, определенным алгоритмом 124 MLA согласно проведенному обучению (первой фазе обучения и потенциальной итерации обучения второй фазы обучения, выполненной к данному моменту).
[210] Кроме того, сервер 106 может вычислять значения перекрестной энтропии. Значение перекрестной энтропии может быть мерой сходства между распределением «учеников» и фактическим распределением для данного слова. Фактическое распределение может указывать на правильный или лучший перевод данного слова в соответствующем контексте.
[211] Кроме того, сервер 106 может вычислять значение расхождения. Значение расхождения может быть мерой сходства между распределением «учителей» и распределением «учеников».
[212] Кроме того, сервер 106 может вычислять взвешенную сумму значения перекрестной энтропии и значения расхождения. Взвешенная сумма может быть значением функции потерь, ограничивающей адаптацию, для слова на обучающей итерации второй фазы обучения алгоритма 124 MLA. Как упомянуто выше, функция потерь, ограничивающая адаптацию, может использоваться для ограничения адаптации обученного состояния алгоритма 124 MLA, возникшего в результате первой фазы обучения, на данной итерации обучения в ходе второй фазы обучения.
[213] В некоторых вариантах осуществления настоящей технологии сервер 106 может выполнять способ 600, представленный на фиг. 6, для обучения (повторного обучения) алгоритма 124 MLA переводу текстовой строки на первом языке параллельной текстовой строкой на втором языке. Далее описан способ 600.
Шаг 602: определение второго набора пар обучающих строк, имеющих контролируемую пропорцию пар строк каждого контекста.
[214] Способ 600 начинается с шага 602, на котором сервер 106 определяет второй набор пар обучающих строк, имеющих контролируемую пропорцию пар строк каждого контекста. Следует отметить, что второй набор пар обучающих строк, определенный на шаге 602, можно использовать в ходе второй фазы обучения (или фазы повторного обучения) алгоритма 124 MLA.
[215] Как упомянуто выше, в ходе второй фазы обучения алгоритма 124 MLA используется второй набор пар обучающих текстовых строк вместо первого набора пар обучающих текстовых строк. Другими словами, в ходе второй фазы обучения используется набор пар текстовых строк, имеющих контролируемую пропорцию пар текстовых строк каждого контекста, вместо набора пар текстовых строк, имеющих естественную пропорцию пар текстовых строк каждого контекста.
[216] В некоторых вариантах осуществления естественная пропорция пар строк каждого контекста соответствует пропорции пар строк каждого контекста, который может быть получен из набора 112 сетевых ресурсов, доступных через сеть 110 связи.
[217] В ходе второй фазы обучения сервер 106 может обучать алгоритм 124 MLA на основе близкого количества пар текстовых строк каждого контекста. Например, второй набор обучающих текстовых строк может содержать 1000 пар обучающих текстовых строк основного контекста. При этом второй набор строк обучающего текста также может содержать приблизительно 1000 обучающих текстовых строк по меньшей мере одного вспомогательного контекста.
[218] Следовательно, можно сказать, что сервер 106 может определять второй набор пар обучающих текстовых строк, управляя пропорцией пар текстовых строк каждого контекста, выбираемого из корпуса 300 для обучения (повторного обучения) алгоритма 124 MLA в ходе второй фазы обучения.
[219] Второй набор пар обучающих текстовых строк может быть определен сервером 106 на основе набора 302 пар текстовых строк. Тем не менее сервер 106 может управлять тем, какие из набора 302 пар текстовых строк должны быть включены во второй набор пар обучающих текстовых строк, на основе их соответствующих контекстов, чтобы второй набор пар обучающих текстовых строк имел контролируемую пропорцию пар текстовых строк каждого контекста.
[220] В некоторых вариантах осуществления настоящей технологии приложение 122 сопоставления строк на сервере 106 может размечать каждую пару из набора 302 пар текстовых строк информацией, указывающей на контекст, в котором эти текстовые строки встречаются в соответствующих версиях веб-страницы.
[221] В одном примере первая выборка 320 пар текстовых строк из набора 302 пар текстовых строк может быть размечена информацией, указывающей на то, что текстовые строки в этой выборке встречаются в первом контексте. Например, можно предположить, что первая выборка 320 пар текстовых строк извлечена из основного контента веб-страниц и, следовательно, встречается в основном контексте.
[222] В другом примере вторая выборка 330 пар текстовых строк из набора 302 пар текстовых строк может быть размечена информацией, указывающей на то, что текстовые строки в этой выборке встречаются во втором контексте. Например, можно предположить, что вторая выборка 330 пар текстовых строк извлечена из контента заголовка веб-страниц и, следовательно, встречается в контексте заголовка (в отличие от первой выборки 320 пар текстовых строк из основного контекста).
[223] Поэтому предполагается, что второй набор пар обучающих текстовых строк, используемых в ходе второй обучающей фазы (фазы повторного обучения), связан с соответствующими метками, указывающими на контекст соответствующих пар обучающих текстовых строк.
Шаг 604: повторное обучение алгоритма MLA с использованием второго набора пар обучающих строк и соответствующих меток.
[224] Способ 600 может заканчиваться на шаге 604, когда сервер 106 повторно обучает алгоритм 124 MLA с использованием второго набора пар обучающих строк и соответствующих меток. Алгоритм 124 MLA повторно обучается определению контекста этапа использования для текстовой строки этапа использования и созданию соответствующей параллельной текстовой строки этапа использования в качестве перевода текстовой строки этапа использования с учетом контекста этапа использования.
[225] Например, шаг 604 может соответствовать второй фазе обучения (или фазе повторного обучения) алгоритма 124 MLA, как описано выше. Повторное обучение алгоритма 124 MLA в ходе второй фазы обучения, как описано выше, позволяет исправлять или по меньшей мере уменьшать вышеупомянутое смещение алгоритма 124 MLA.
[226] Как упоминалось ранее, предполагается, что сервер 106 может подавать в алгоритм 124 MLA обучающие текстовые строки не только в контролируемой пропорции обучающих текстовых строк каждого контекста, но также в сочетании с соответствующими метками. Другими словами, сервер 106 может не только управлять пропорциями обучающих примеров, подаваемых в алгоритм 124 MLA в ходе второй фазы обучения (при повторном обучении), на основе соответствующих контекстов, но он также может подавать в алгоритм 124 MLA соответствующую метку каждого обучающего примера, используемого в ходе второй фазы обучения.
[227] В некоторых вариантах осуществления настоящей технологии подача обучающих примеров в алгоритм 124 MLA в ходе второй фазы обучения в сочетании с соответствующими метками позволяет этому алгоритму в определенном смысле «учиться» соотносить некоторые текстовые особенности текстовой строки с контекстом, в котором встречается эта текстовая строка, для формирования правильной или лучшей параллельной текстовой строки. Другими словами, на этапе использования алгоритм 124 MLA может определять контекст этапа использования для текстовой строки этапа использования, основанной на текстовых характеристиках контекста этапа использования, и формировать соответствующую параллельную текстовую строку этапа использования в качестве перевода текстовой строки этапа использования с учетом контекста этапа использования.
[228] Специалистам в данной области техники могут быть очевидными модификации и улучшения описанных выше вариантах реализации настоящей технологии. Предшествующее описание приведено лишь в качестве примера, но не для ограничения объема изобретения. Следовательно, объем настоящей технологии ограничен исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СЕРВЕР ДЛЯ ОБРАБОТКИ ТЕКСТОВОЙ ПОСЛЕДОВАТЕЛЬНОСТИ В ЗАДАЧЕ МАШИННОЙ ОБРАБОТКИ | 2020 |
|
RU2775820C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ПОВТОРНОГО ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2019 |
|
RU2743932C2 |
| Способ и сервер для определения обучающего набора для обучения алгоритма машинного обучения (MLA) | 2020 |
|
RU2817726C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ФОРМИРОВАНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ | 2022 |
|
RU2828354C2 |
| СПОСОБ И СИСТЕМА ДЛЯ КЛАССИФИКАЦИИ СЛОВА В КАЧЕСТВЕ НЕЦЕНЗУРНОГО СЛОВА | 2020 |
|
RU2803576C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ ПРОГНОЗИРОВАНАНИЮ ОЦЕНКИ ВИДИМОСТИ | 2022 |
|
RU2814079C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ ЭЛЕМЕНТОВ СИСТЕМОЙ РАНЖИРОВАНИЯ | 2020 |
|
RU2781621C2 |
| Способ и сервер для формирования расширенного запроса | 2021 |
|
RU2813582C2 |
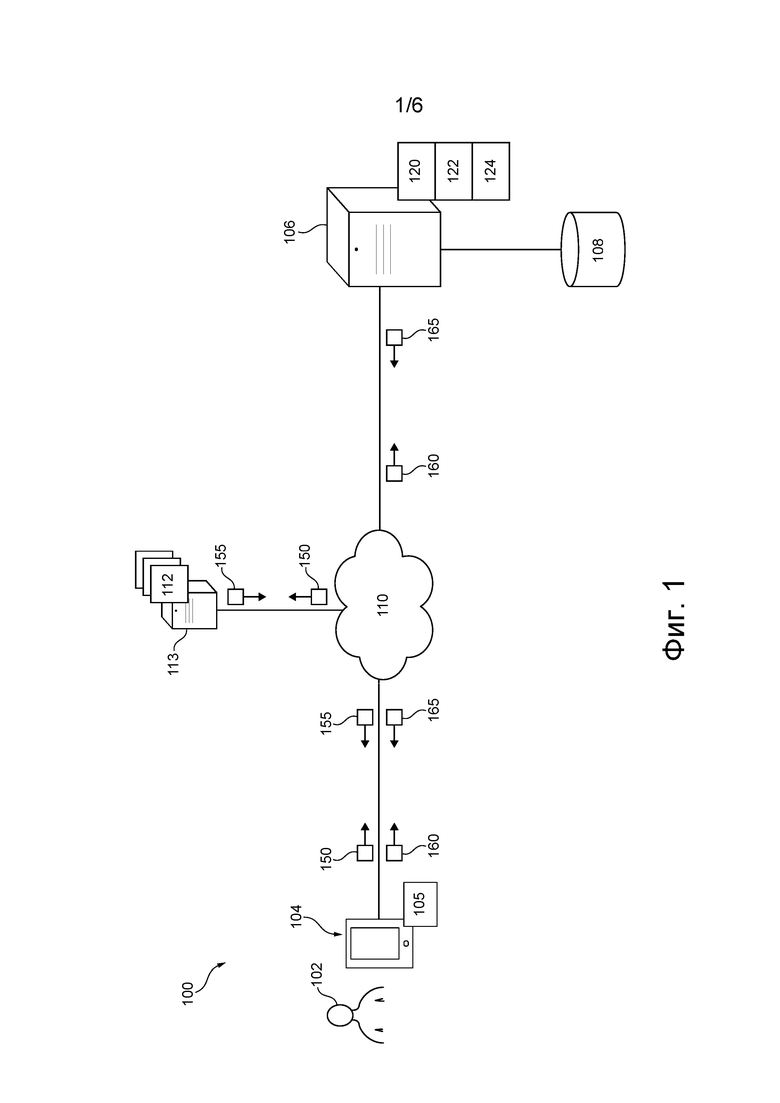
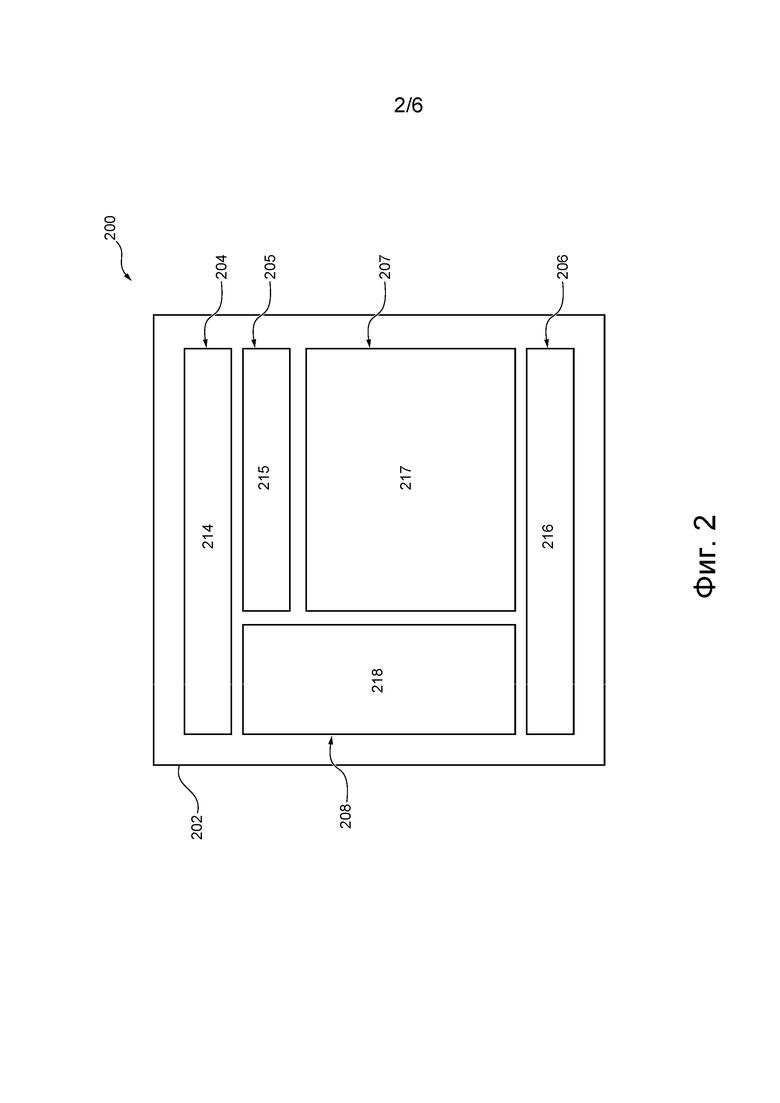
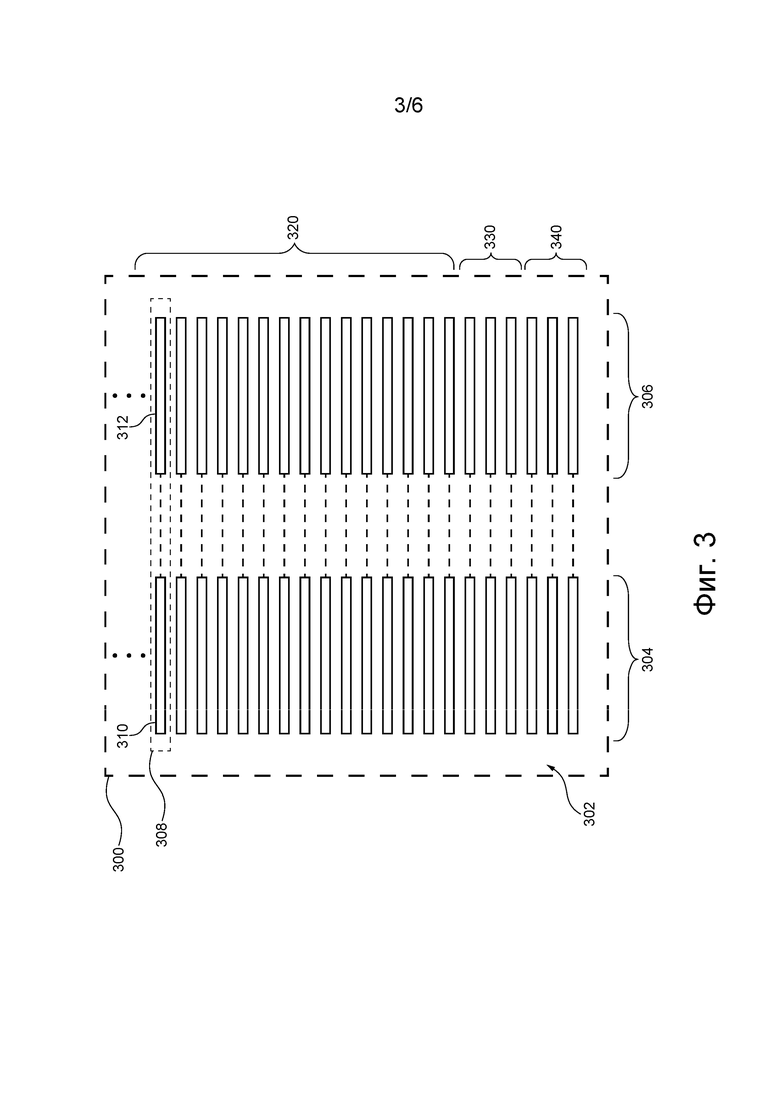
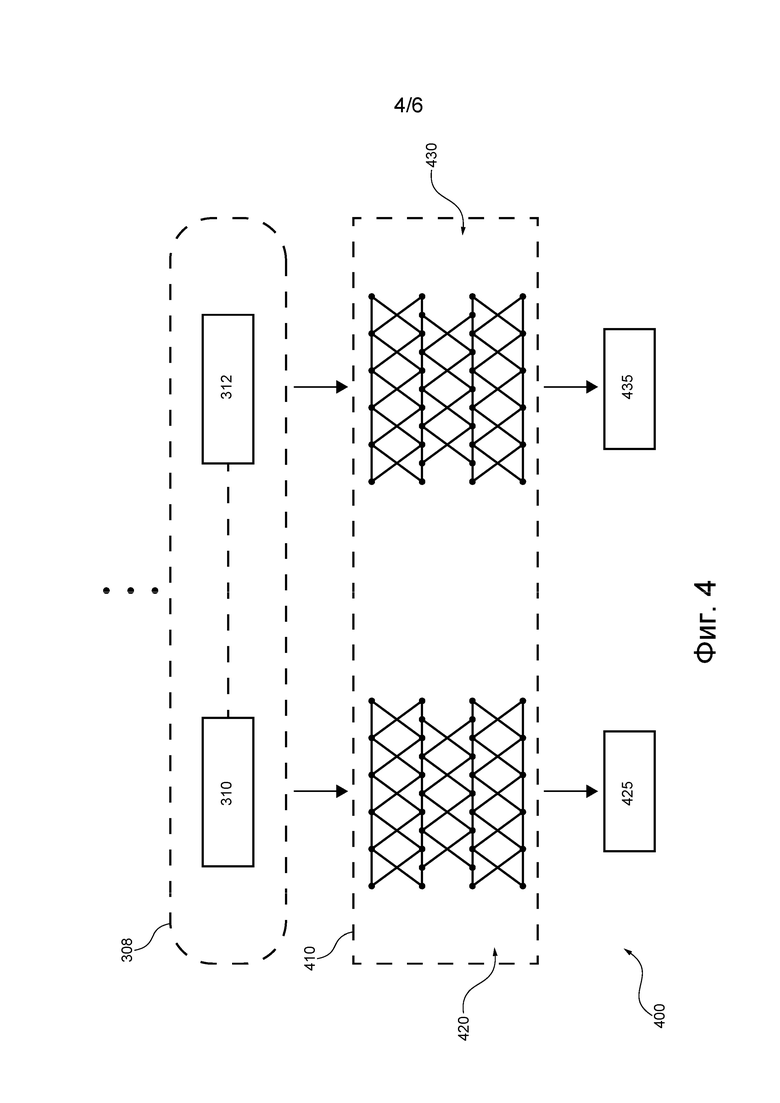
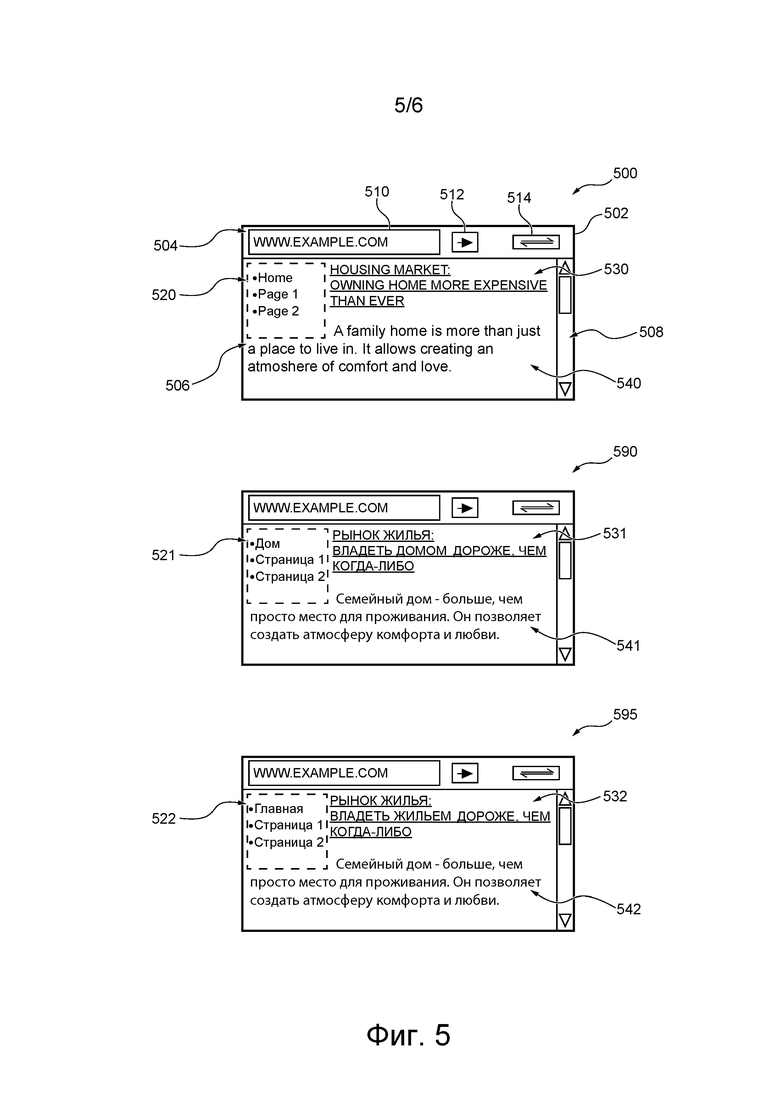
Изобретение относится к области вычислительной техники. Технический результат заключается в снижении смещения алгоритма MLA, возникшего при первоначальном обучении переводу текстовой строки на первом языке параллельной текстовой строкой на втором языке. Технический результат достигается за счет алгоритма MLA, который обучен с использованием первого набора пар строк. Первый набор пар строк имеет естественную пропорцию пар строк каждого контекста. Алгоритм MLA оказывается смещенным к формированию параллельной строки в качестве перевода соответствующей строки, встречающейся в основном контексте. Способ включает в себя определение второго набора пар строк, содержащих контролируемую пропорцию пар строк каждого контекста. Второй набор пар строк связан с метками, указывающими на соответствующие контексты. Способ включает в себя повторное обучение алгоритма MLA с использованием второго набора пар строк и соответствующих меток. Алгоритм MLA повторно обучается определению контекста строки и созданию соответствующей параллельной строки в качестве перевода с учетом контекста. 2 н. и 18 з.п. ф-лы, 6 ил.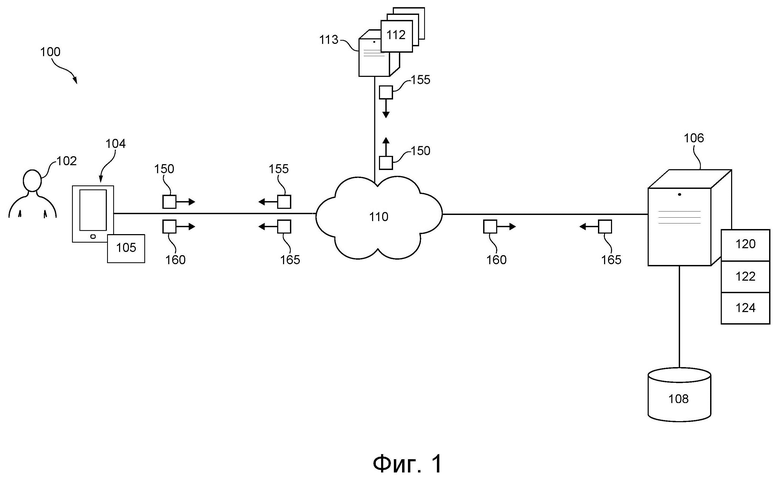
1. Способ обучения алгоритма машинного обучения (MLA) переводу текстовой строки на первом языке параллельной текстовой строкой на втором языке, выполняемый сервером, реализующим алгоритм MLA и имеющим доступ к парам обучающих строк, каждая из которых содержит (1) текстовую строку на первом языке и (2) параллельную текстовую строку на втором языке, при этом пары обучающих строк встречаются в соответствующих контекстах, включая основной контекст и по меньшей мере один вспомогательный контекст, алгоритм MLA обучен с использованием первого набора пар обучающих строк определению параллельной текстовой строки на втором языке в ответ на текстовую строку на первом языке, первый набор пар обучающих строк имеет естественную пропорцию пар строк каждого контекста, алгоритм MLA смещен к формированию параллельной текстовой строки в качестве перевода соответствующей текстовой строки, встречающейся в основном контексте, и способ включает в себя:
- определение сервером второго набора пар обучающих строк для обучения алгоритма MLA, при этом второй набор пар обучающих строк имеет контролируемую пропорцию пар строк каждого контекста, и пары обучающих строк во втором наборе пар обучающих строк связаны с метками, указывающими на контекст соответствующих пар обучающих строк; и
- повторное обучение сервером алгоритма MLA с использованием второго набора пар обучающих строк и соответствующих меток, при этом алгоритм MLA повторно обучается определению контекста этапа использования для текстовой строки этапа использования и формированию соответствующей параллельной текстовой строки этапа использования в качестве перевода текстовой строки этапа использования с учетом контекста этапа использования.
2. Способ по п. 1, в котором естественная пропорция пар строк каждого контекста соответствует пропорции пар строк каждого контекста, который может быть получен из множества сетевых ресурсов, доступных через сеть связи.
3. Способ по п. 1, в котором обучающая текстовая строка, встречающаяся в основном контексте, содержит основной контент сетевого ресурса, а другая обучающая текстовая строка, встречающаяся в по меньшей мере одном вспомогательном контексте, содержит по меньшей мере одно из следующего:
- контент нижнего колонтитула сетевого ресурса;
- контент верхнего колонтитула сетевого ресурса;
- контент заголовка сетевого ресурса; и
- контент управления навигацией сетевого ресурса.
4. Способ по п. 1, в котором естественная пропорция относится к большинству пар обучающих строк в первом наборе пар обучающих строк, встречающихся в основном контексте.
5. Способ по п. 1, в котором контролируемая пропорция содержит по существу равные пропорции пар обучающих строк, встречающихся в основном контексте и в по меньшей мере одном вспомогательном контексте.
6. Способ по п. 1, в котором алгоритм MLA содержит кодер, предназначенный для текстовых строк на первом языке, и декодер, предназначенный для текстовых строк на втором языке, при этом повторное обучение алгоритма MLA включает в себя обучение сервером кодера формированию выходных данных кодера для (1) обучающей текстовой строки на первом языке из пары обучающих строк во втором наборе пар строк и (2) соответствующей метки и обучение сервером декодера формированию выходных данных декодера для (1) обучающей параллельной текстовой строки на втором языке из пары обучающих строк во втором наборе пар строк и (2) соответствующей метки таким образом, чтобы максимально увеличить сходство между выходными данными кодера и выходными данными декодера.
7. Способ по п. 1, отличающийся тем, что включает в себя:
- получение сервером первой текстовой строки этапа использования на первом языке, содержащей заданное слово;
- получение сервером второй текстовой строки этапа использования на первом языке, содержащей заданное слово;
- выполнение сервером алгоритма MLA для формирования первой параллельной текстовой строки этапа использования на втором языке на основе первой текстовой строки этапа использования, при этом заданное слово переводится первым параллельным словом из первой параллельной текстовой строки этапа использования;
- выполнение сервером алгоритма MLA для формирования второй параллельной текстовой строки этапа использования на втором языке на основе второй текстовой строки этапа использования, при этом заданное слово переводится вторым параллельным словом из второй параллельной текстовой строки этапа использования,
при этом, если алгоритм MLA определяет, что контекст первой текстовой строки этапа использования отличается от контекста второй текстовой строки этапа использования, то первое параллельное слово и второе параллельное слово являются разными переводами заданного слова.
8. Способ по п. 1, в котором повторное обучение алгоритма MLA включает в себя использование сервером функции потерь, ограничивающей адаптацию, при повторном обучении алгоритма MLA, и функция потерь, ограничивающая адаптацию, способна после обучения алгоритма MLA ограничивать адаптацию алгоритма MLA, обученного на основе первого набора пар обучающих строк.
9. Способ по п. 8, в котором ограничение адаптации алгоритма MLA включает в себя ограничение ухудшения качества перевода текстовой строки этапа использования, встречающейся в основном контексте.
10. Способ по п. 8, в котором использование функции потерь, ограничивающей адаптацию, на итерации в ходе повторного обучения алгоритма MLA включает в себя следующее:
- вычисление сервером распределения «учителей» для заданного слова при переводе алгоритмом MLA согласно обучению до повторного обучения, при этом распределение «учителей» указывает на вероятность того, что соответствующие потенциальные слова являются переводом заданного слова, определенным алгоритмом MLA согласно обучению до повторного обучения;
- вычисление сервером распределения «учеников» для заданного слова при переводе повторно обученным алгоритмом MLA, при этом распределение «учеников» указывает на вероятность того, что соответствующие потенциальные слова являются переводом заданного слова, определенным повторно обученным алгоритмом MLA на данной итерации;
- вычисление сервером значения перекрестной энтропии, являющегося первым типом меры сходства между распределением «учеников» и фактическим распределением, указывающим на правильный перевод заданного слова, встречающегося в соответствующем контексте;
- вычисление сервером значения расхождения, являющегося вторым типом меры сходства между распределением «учителей» и распределением «учеников»; и
- вычисление сервером взвешенной суммы значения перекрестной энтропии и значения расхождения, являющейся значением функции потерь, ограничивающей адаптацию, для заданного слова на данной итерации.
11. Сервер для обучения алгоритма машинного обучения (MLA) переводу текстовой строки на первом языке параллельной текстовой строкой на втором языке, реализуемый сервером, имеющим доступ к парам обучающих строк, каждая из которых содержит (1) текстовую строку на первом языке и (2) параллельную текстовую строку на втором языке, при этом пары обучающих строк встречаются в соответствующих контекстах, включая основной контекст и по меньшей мере один вспомогательный контекст, алгоритм MLA обучен с использованием первого набора пар обучающих строк определению параллельной текстовой строки на втором языке в ответ на текстовую строку на первом языке, первый набор пар обучающих строк имеет естественную пропорцию пар строк каждого контекста, алгоритм MLA смещен к формированию параллельной текстовой строки в качестве перевода текстовой строки, встречающейся в основном контексте, а сервер выполнен с возможностью:
- определения второго набора пар обучающих строк для обучения алгоритма MLA, при этом второй набор пар обучающих строк имеет контролируемую пропорцию пар строк каждого контекста, и пары обучающих строк во втором наборе пар обучающих строк связаны с метками, указывающими на контекст соответствующих пар обучающих строк; и
- повторного обучения сервером алгоритма MLA с использованием второго набора пар обучающих строк и соответствующих меток, при этом алгоритм MLA повторно обучается определению контекста этапа использования для текстовой строки этапа использования и формированию соответствующей параллельной текстовой строки этапа использования в качестве перевода текстовой строки этапа использования с учетом соответствующего контекста этапа использования.
12. Сервер по п. 11, в котором естественная пропорция пар строк каждого контекста соответствует пропорции пар строк каждого контекста, который может быть получен из множества сетевых ресурсов, доступных через сеть связи.
13. Сервер по п. 11, в котором обучающая текстовая строка, встречающаяся в основном контексте, содержит основной контент сетевого ресурса, а другая обучающая текстовая строка, встречающаяся в по меньшей мере одном вспомогательном контексте, содержит по меньшей мере одно из следующего:
- контент нижнего колонтитула сетевого ресурса;
- контент верхнего колонтитула сетевого ресурса;
- контент заголовка сетевого ресурса; и
- контент управления навигацией сетевого ресурса.
14. Сервер по п. 11, в котором естественная пропорция относится к большинству пар обучающих строк в первом наборе пар обучающих строк, встречающихся в основном контексте.
15. Сервер по п. 11, в котором контролируемая пропорция содержит по существу равные пропорции пар обучающих строк, встречающихся в основном контексте и в по меньшей мере одном вспомогательном контексте.
16. Сервер по п. 11, в котором алгоритм MLA содержит кодер, предназначенный для текстовых строк на первом языке, и декодер, предназначенный для текстовых строк на втором языке, при этом для повторного обучения алгоритма MLA сервер выполнен с возможностью:
- обучения сервером кодера формированию выходных данных кодера для (1) обучающей текстовой строки на первом языке из пары обучающих строк во втором наборе пар строк и (2) соответствующей метки;
- обучения сервером декодера формированию выходных данных декодера для (1) обучающей параллельной текстовой строки на втором языке из пары обучающих строк во втором наборе пар строк и (2) соответствующей метки таким образом, чтобы максимально увеличить сходство между выходными данными кодера и выходными данными декодера.
17. Сервер по п. 11, дополнительно выполненный с возможностью:
- получения сервером первой текстовой строки этапа использования на первом языке, содержащей заданное слово;
- получения сервером второй текстовой строки этапа использования на первом языке, содержащей заданное слово;
- выполнения сервером алгоритма MLA для формирования первой параллельной текстовой строки этапа использования на втором языке на основе первой текстовой строки этапа использования, при этом заданное слово переводится первым параллельным словом из первой параллельной текстовой строки этапа использования;
- выполнения сервером алгоритма MLA для формирования второй параллельной текстовой строки этапа использования на втором языке на основе второй текстовой строки этапа использования, при этом заданное слово переводится вторым параллельным словом из второй параллельной текстовой строки этапа использования,
при этом, если алгоритм MLA определяет, что контекст первой текстовой строки этапа использования отличается от контекста второй текстовой строки этапа использования, то первое параллельное слово и второе параллельное слово являются разными переводами заданного слова.
18. Сервер по п. 11, отличающийся тем, что для повторного обучения алгоритма MLA сервер выполнен с возможностью использования сервером функции потерь, ограничивающей адаптацию, при повторном обучении алгоритма MLA, и функция потерь, ограничивающая адаптацию, способна после обучения алгоритма MLA ограничивать адаптацию алгоритма MLA, обученного на основе первого набора пар обучающих строк.
19. Сервер по п. 18, в котором ограничение адаптации алгоритма MLA включает в себя ограничение ухудшения качества перевода текстовой строки этапа использования, встречающейся в основном контексте.
20. Сервер по п. 18, отличающийся тем, что для использования функции потерь, ограничивающей адаптацию, на итерации в ходе повторного обучения алгоритма MLA сервер выполнен с возможностью:
- вычисления сервером распределения «учителей» для заданного слова при переводе алгоритмом MLA согласно обучению до повторного обучения, при этом распределение «учителей» указывает на вероятность того, что соответствующие потенциальные слова являются переводом заданного слова, определенным алгоритмом MLA согласно обучению до повторного обучения;
- вычисления сервером распределения «учеников» для заданного слова при переводе повторно обученным алгоритмом MLA, при этом распределение «учеников» указывает на вероятность того, что соответствующие потенциальные слова являются переводом заданного слова, определенным повторно обученным алгоритмом MLA на данной итерации;
- вычисления сервером значения перекрестной энтропии, являющегося первым типом меры сходства между распределением «учеников» и фактическим распределением, указывающим на правильный перевод заданного слова, встречающегося в соответствующем контексте;
- вычисления сервером значения расхождения, являющегося вторым типом меры сходства между распределением «учителей» и распределением «учеников»; и
- вычисления сервером взвешенной суммы значения перекрестной энтропии и значения расхождения, являющейся значением функции потерь, ограничивающей адаптацию, для заданного слова на данной итерации.
| Токарный резец | 1924 |
|
SU2016A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| АДАПТИВНЫЙ КОНТЕКСТНО-ТЕМАТИЧЕСКИЙ МАШИННЫЙ ПЕРЕВОД | 2016 |
|
RU2628202C1 |
| АДАПТИВНЫЙ МАШИННЫЙ ПЕРЕВОД | 2004 |
|
RU2382399C2 |

