Область техники, к которой относится изобретение
[01] Настоящая технология относится к обработке аудиоданных и текста, в частности, к способам и серверам для обучения модели обнаружению смены диктора.
Уровень техники
[02] Перевод речи в видеозаписи с первоначально записанного языка на другой язык может быть сопряжен с большими трудозатратами на голосовое озвучивание (дубляж) переводимых аудиофрагментов исходной видеозаписи. Технологии озвучивания играют важную роль в обеспечении доступности контента для глобальной аудитории, поскольку они помогают представлять контент на разных языках. В общем случае под голосовым озвучиванием подразумевается объединение дополнительных или вспомогательных записей (дублированной речи) с первоначально записанной речью с целью формирования готовой звуковой дорожки для видеозаписи.
[03] Традиционное озвучивание реализуется на базе нейронных сетей, способных распознавать речь, преобразовывать речь в текст, разделять распознанный текст на отдельные фрагменты, назначать фразы соответствующим дикторам, переводить фрагменты на целевой язык и формировать дублированный звук, который затем накладывается на исходный видеоматериал.
[04] При этом дублированная речь может отличаться от первоначально записанной речи в том смысле, что моменты ее начала и окончания могут не совпадать с моментами начала и окончания первоначально записанной речи. В результате переведенный звук оказывается рассинхронизированным и непривлекательным для зрителей. Качество синхронизации дублированной речи также снижается из-за смены дикторов в первоначально записанной речи.
[05] Обнаружение смены диктора (SCD, Speaker Change Detection) в озвучивании представляет собой технологически ориентированный процесс, включающий в себя определение и маркировку смены дикторов или актеров в аудио- и/или видеозаписи. Решения для обнаружения смены диктора помогают синхронизировать дублированные голоса с исходным видеоматериалом и/или поддерживать точность синхронизации звука с движением губ путем распознавания моментов окончания речи одних персонажей и начала речи других персонажей.
[06] В известных технических решениях был предложен ряд способов для обнаружения смены диктора.
[07] В патентной заявке US 20220254351 A1 «Method and system for correcting speaker diarization using speaker change detection based on text» («Способ и система для уточнения диаризации диктора за счет обнаружения смены диктора на основе текста»), опубл. 11 августа 2022 года и принадлежащей компании Works Mobile Japan Corp, раскрыты способ и система для уточнения диаризации диктора за счет обнаружения смены диктора на основе текста. Способ уточнения диаризации диктора может предусматривать диаризацию диктора для входного аудиопотока, распознавание речи, содержащейся во входном аудиопотоке, преобразование речи в текст, обнаружение смены диктора на основе полученного текста и уточнение диаризации диктора с учетом обнаруженной смены диктора.
[08] В статье Mao et al. «Speech Recognition and Multi-Speaker Diarization of Long Conversations» («Распознавание речи и диаризация длительных разговоров с участием нескольких дикторов»), опубл. на веб-сайте arxiv.org 5 ноября 2020 года, раскрыт способ раздельного обучения моделей автоматического распознавания речи (ASR, Automatic Speech Recognition) и диаризации диктора (SD, Speaker Diarization) при известных границах фрагментов речи. Кроме того, в этой статье представлены алгоритм декодирования со сдвигом внимания и методы дополнения данных, которые в сочетании с предварительным обучением моделей, как утверждается, повышают эффективность автоматического распознавания речи и диаризации диктора.
Раскрытие изобретения
[09] Разработчики настоящей технологии выявили ряд технических недостатков, характерных для существующих услуг озвучивания. Целью настоящей технологии является устранение по меньшей мере части недостатков известных технических решений.
[10] В по меньшей мере некоторых вариантах осуществления реализованы способы и система для обеспечения работы механизма озвучивания. В общем случае механизм озвучивания представляет собой компьютерный модуль, используемый в процессе озвучивания, в ходе которого формируются синхронизированные аудиодорожки на целевом языке, отличающемся от исходного языка. Например, целевая аудиодорожка может быть синхронизирована с движением губ и метками времени исходного звука на исходном языке. В некоторых вариантах осуществления механизм озвучивания может производить морфинг голоса для изменения высоты, тембра и ритма дублированного звука в соответствии с исходным звуком. Механизм озвучивания может использоваться в режиме реального времени, например, в прямых трансляциях и на видеоконференциях, где требуется мгновенное озвучивание, а также может применяться на этапе постпроизводства для предварительно записанного контента.
[11] В частности, в соответствии с первым широким аспектом настоящей технологии реализован способ обучения модели. Способ реализуется на сервере. Способ предусматривает получение набора данных для обучения пунктуации, содержащего первые входные данные, включающие в себя аудиоданные и текстовые данные, представляющие речь диктора, и первую метку, включающую в себя последовательность контрольных токенов, которая содержит (1) контрольный текстовый токен, указывающий на слово, и (2) контрольный пунктуационный токен, указывающий на знак пунктуации и следующий за контрольным текстовым токеном, обучение модели, с использованием набора данных для обучения пунктуации, формированию рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования обученной пунктуации модели, получение набора данных для обучения смене диктора, содержащего вторые входные данные, включающие в себя вторые аудиоданные и вторые текстовые данные, представляющие речь нескольких дикторов, и вторую метку, включающую в себя вторую последовательность контрольных токенов, которая содержит (1) второй контрольный текстовый токен, указывающий на второе слово, (2) второй контрольный пунктуационный токен, указывающий на второй знак пунктуации, и (3) контрольный токен смены диктора, указывающий на смену диктора и следующий за вторым контрольным пунктуационным токеном, дообучение обученной пунктуации модели, с использованием набора данных для обучения смене диктора, формированию второй рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования модели смены диктора, получение рабочего набора данных, содержащего рабочие текстовые данные и рабочие аудиоданные, формирование, с использованием модели смены диктора, второй рабочей последовательности токенов, содержащей рабочий текстовый токен, рабочий пунктуационный токен, следующий за рабочим текстовым токеном, и рабочий токен смены диктора, следующий за рабочим пунктуационным токеном, на основе комбинации рабочих аудиоданных и рабочих текстовых данных, и формирование синтезированного аудиоконтента на основе второй рабочей последовательности токенов.
[12] В некоторых вариантах реализации способа модель смены диктора содержит подмодель для аудиоданных, подмодель для текста и третью подмодель, а формирование второй рабочей последовательности токенов предусматривает формирование, с использованием подмодели для аудиоданных, рабочей последовательности векторных представлений аудиоданных на основе рабочих аудиоданных, формирование, с использованием подмодели для текста, рабочей последовательности векторных представлений текста на основе рабочих текстовых данных, формирование конкатенированных промежуточных выходных данных с использованием рабочей последовательности векторных представлений аудиоданных и рабочей последовательности векторных представлений текста, и формирование, с использованием третьей подмодели, второй рабочей последовательности токенов с использованием конкатенированных промежуточных выходных данных.
[13] В некоторых вариантах реализации способа подмодель для аудиоданных представляет собой модель WavLM.
[14] В некоторых вариантах реализации способа подмодель для текста представляет собой модель mT5.
[15] В некоторых вариантах реализации способа третья подмодель представляет собой модель трансформера.
[16] В некоторых вариантах реализации способа он дополнительно предусматривает формирование, с использованием модели преобразования речи в текст, текстовых данных на основе аудиоданных, формирование, с использованием модели преобразования речи в текст, вторых текстовых данных на основе вторых аудиоданных и формирование, с использованием модели преобразования речи в текст, рабочих текстовых данных на основе рабочих аудиоданных.
[17] В некоторых вариантах реализации способа контрольный пунктуационный токен следует непосредственно за контрольным текстовым токеном, контрольный токен смены диктора - непосредственно за вторым контрольным пунктуационным токеном, рабочий пунктуационный токен - непосредственно за рабочим текстовым токеном, а рабочий токен смены диктора - непосредственно за рабочим пунктуационным токеном.
[18] В соответствии со вторым широким аспектом настоящей технологии реализован способ дообучения предварительно обученной модели. Способ реализуется на сервере. Способ предусматривает получение набора данных для обучения смене диктора, содержащего вторые входные данные, включающие в себя вторые аудиоданные и вторые текстовые данные, представляющие речь нескольких дикторов, и вторую метку, включающую в себя вторую последовательность контрольных токенов, которая содержит (1) второй контрольный текстовый токен, указывающий на второе слово, (2) второй контрольный пунктуационный токен, указывающий на второй знак пунктуации, и (3) контрольный токен смены диктора, указывающий на смену диктора и следующий за вторым контрольным пунктуационным токеном во второй последовательности контрольных токенов, дообучение предварительно обученной модели, с использованием набора данных для обучения смене диктора, формированию второй рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования модели смены диктора, при этом с целью формирования рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных предварительно обученная модель обучалась на основе набора данных для обучения пунктуации, содержащего первые входные данные, включающие в себя аудиоданные и текстовые данные, представляющие речь диктора, и первую метку, включающую в себя последовательность контрольных токенов, которая содержит (1) контрольный текстовый токен, указывающий на слово, и (2) контрольный пунктуационный токен, указывающий на знак пунктуации и следующий за контрольным текстовым токеном, получение рабочего набора данных, содержащего рабочие текстовые данные и рабочие аудиоданные, формирование, с использованием модели смены диктора, второй рабочей последовательности токенов, содержащей рабочий текстовый токен, рабочий пунктуационный токен, следующий за рабочим текстовым токеном, и рабочий токен смены диктора, следующий за рабочим пунктуационным токеном, на основе комбинации рабочих аудиоданных и рабочих текстовых данных, и формирование синтезированного аудиоконтента на основе второй рабочей последовательности токенов.
[19] В некоторых вариантах реализации способа контрольный пунктуационный токен следует непосредственно за контрольным текстовым токеном, контрольный токен смены диктора - непосредственно за вторым контрольным пунктуационным токеном, рабочий пунктуационный токен - непосредственно за рабочим текстовым токеном, а рабочий токен смены диктора - непосредственно за рабочим пунктуационным токеном.
[20] В соответствии с третьим широким аспектом настоящей технологии реализован сервер для обучения модели. Сервер содержит по меньшей мере один процессор и по меньшей мере одну физическую машиночитаемую память, хранящую исполняемые команды, при исполнении которых по меньшей мере одним процессором на сервере обеспечивается получение набора данных для обучения пунктуации, содержащего первые входные данные, включающие в себя аудиоданные и текстовые данные, представляющие речь диктора, и первую метку, включающую в себя последовательность контрольных токенов, которая содержит (1) контрольный текстовый токен, указывающий на слово, и (2) контрольный пунктуационный токен, указывающий на знак пунктуации и следующий за контрольным текстовым токеном, обучение модели, с использованием набора данных для обучения пунктуации, формированию рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования обученной пунктуации модели, получение набора данных для обучения смене диктора, содержащего вторые входные данные, включающие в себя вторые аудиоданные и вторые текстовые данные, представляющие речь нескольких дикторов, и вторую метку, включающую в себя вторую последовательность контрольных токенов, которая содержит (1) второй контрольный текстовый токен, указывающий на второе слово, (2) второй контрольный пунктуационный токен, указывающий на второй знак пунктуации, и (3) контрольный токен смены диктора, указывающий на смену диктора и следующий за вторым контрольным пунктуационным токеном, дообучение обученной пунктуации модели, с использованием набора данных для обучения смене диктора, формированию второй рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования модели смены диктора, получение рабочего набора данных, содержащего рабочие текстовые данные и рабочие аудиоданные, формирование, с использованием модели смены диктора, второй рабочей последовательности токенов, содержащей рабочий текстовый токен, рабочий пунктуационный токен, следующий за рабочим текстовым токеном, и рабочий токен смены диктора, следующий за рабочим пунктуационным токеном, на основе комбинации рабочих аудиоданных и рабочих текстовых данных, и формирование синтезированного аудиоконтента на основе второй рабочей последовательности токенов.
[21] В некоторых вариантах реализации сервера модель смены диктора содержит подмодель для аудиоданных, подмодель для текста и третью подмодель, а формирование второй рабочей последовательности токенов предусматривает формирование, с использованием подмодели для аудиоданных, рабочей последовательности векторных представлений аудиоданных на основе рабочих аудиоданных, формирование, с использованием подмодели для текста, рабочей последовательности векторных представлений текста на основе рабочих текстовых данных, формирование конкатенированных промежуточных выходных данных с использованием рабочей последовательности векторных представлений аудиоданных и рабочей последовательности векторных представлений текста, и формирование, с использованием третьей подмодели, второй рабочей последовательности токенов с использованием конкатенированных промежуточных выходных данных.
[22] В некоторых вариантах реализации сервера подмодель для аудиоданных представляет собой модель WavLM.
[23] В некоторых вариантах реализации сервера подмодель для текста представляет собой модель mT5.
[24] В некоторых вариантах реализации сервера третья подмодель представляет собой модель трансформера.
[25] В некоторых вариантах реализации сервера по меньшей мере один процессор дополнительно обеспечивает на севере формирование, с использованием модели преобразования речи в текст, текстовых данных на основе аудиоданных, формирование, с использованием модели преобразования речи в текст, вторых текстовых данных на основе вторых аудиоданных и формирование, с использованием модели преобразования речи в текст, рабочих текстовых данных на основе рабочих аудиоданных.
[26] В некоторых вариантах реализации сервера контрольный пунктуационный токен следует непосредственно за контрольным текстовым токеном, контрольный токен смены диктора - непосредственно за вторым контрольным пунктуационным токеном, рабочий пунктуационный токен - непосредственно за рабочим текстовым токеном, а рабочий токен смены диктора - непосредственно за рабочим пунктуационным токеном.
[27] В контексте настоящего описания «сервер» представляет собой компьютерную программу, выполняемую на соответствующих аппаратных средствах и способную принимать по сети запросы (например, от клиентских устройств), а также выполнять эти запросы или инициировать их выполнение. Такие аппаратные средства могут быть реализованы в виде одного физического компьютера или одной физической компьютерной системы, что не имеет существенного значения для настоящей технологии. В данном контексте при употреблении выражения «сервер» не подразумевается, что какая-либо конкретная задача или все задачи (например, принятые команды или запросы) принимаются, выполняются или запускаются на одном и том же сервере (т.е. одними и теми же программными и/или аппаратными средствами), а имеется в виду, что участвовать в приеме, передаче, выполнении или инициировании выполнения каких-либо задач или запросов либо результатов каких-либо задач или запросов может любое количество программных или аппаратных средств, и что все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем выражение «по меньшей мере один сервер» охватывает оба этих случая.
[28] В контексте настоящего описания «клиентское устройство» представляет собой любые компьютерные аппаратные средства, способные обеспечивать работу программного обеспечения, подходящего для выполнения поставленной задачи. Таким образом, примерами (не имеющими ограничительного характера) клиентских устройств являются персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, например, маршрутизаторы, коммутаторы и шлюзы. При этом следует отметить, что устройство, действующее в данном контексте в качестве клиентского, не лишается возможности действовать в качестве сервера для других клиентских устройств. Употребление выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, передачи, выполнения или инициирования выполнения каких-либо задач или запросов, результатов каких-либо задач или запросов либо шагов какого-либо метода, описанного в настоящем документе.
[29] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных и компьютерных аппаратных средств для хранения таких данных, их применения или обеспечения их использования иным способом. База данных может размещаться в тех же аппаратных средствах, в которых реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо в отдельных аппаратных средствах, таких как специализированный сервер или группа серверов.
[30] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (отзывы, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничиваясь ими.
[31] В контексте настоящего описания выражение «компонент» означает программное обеспечение (в контексте конкретных аппаратных средств), необходимое и достаточное для выполнения конкретных упоминаемых функций.
[32] В контексте настоящего описания выражение «компьютерный носитель информации» предназначено для обозначения носителей любого рода и вида, включая ОЗУ, ПЗУ, диски (CD-ROM, DVD, дискеты, жесткие диски и т.п.), USB-накопители, твердотельные накопители, ленточные накопители и т.д.
[33] В контексте настоящего описания числительные «первый», «второй», «третий» и т.д. служат лишь для указания на различия между существительными, к которым они относятся, а не для описания каких-либо определенных взаимосвязей между этими существительными. Таким образом, следует понимать, что, например, термины «первый сервер» и «третий сервер» не предполагают существования каких-либо определенных порядка, типов, хронологии, иерархии или ранжирования серверов, а употребление этих терминов (само по себе) не подразумевает обязательного наличия какого-либо «второго сервера» в той или иной конкретной ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылки на «первый» элемент и «второй» элемент не исключают того, что эти два элемента в действительности могут быть одним и тем же элементом. Так, например, в одних случаях «первый» и «второй» серверы могут представлять собой одни и те же программные и/или аппаратные средства, а в других случаях - разные программные и/или аппаратные средства.
[34] Каждый вариант осуществления настоящей технологии относится по меньшей мере к одной из вышеупомянутых целей и/или к одному из вышеупомянутых аспектов, но не обязательно ко всем ним. Следует понимать, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, не упомянутым здесь явным образом.
[35] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, на приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[36] Для более полного понимания настоящей технологии, а также ее аспектов и дополнительных признаков следует обратиться к следующему описанию, которое должно использоваться в сочетании с сопроводительными чертежами.
[37] На фиг. 1 представлена система, пригодная для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологии.
[38] На фиг. 2 представлен конвейер обработки, реализуемый сервером, показанным на фиг. 1, для формирования модифицированного звука на основе исходного звука из видеофайла, в соответствии с по меньшей мере некоторыми вариантами осуществления настоящей технологии.
[39] На фиг. 3 схематически представлена архитектура модели обнаружения смены диктора, реализуемой сервером, показанным на фиг. 1.
[40] На фиг. 4 представлены первая итерация обучения, выполняемая в процессе обучения пунктуации модели обнаружения смены диктора, показанной на фиг. 3, и вторая итерация обучения, выполняемая на сервере, показанном на фиг. 1, в процессе дообучения модели обнаружения смены диктора, показанной на фиг. 3.
[41] На фиг. 5 представлена рабочая итерация обучения, выполняемая на сервере, показанном на фиг. 1, на этапе работы модели обнаружения смены диктора, показанной на фиг. 3.
[42] На фиг. 6 представлена блок-схема способа, реализуемого на сервере, показанном на фиг. 1, в по меньшей мере некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии.
Осуществление изобретения
[43] На фиг. 1 схематически представлена система 100, пригодная для реализации не имеющих ограничительного характера вариантов осуществления настоящей технологией. Следует понимать, что изображенная система 100 является иллюстративным вариантом реализации настоящей технологии. Соответственно, приведенное ниже описание системы представляет собой лишь описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях ниже приводятся предположительно полезные примеры модификаций системы 100. Они призваны способствовать пониманию и также не определяют объема или границ настоящей технологии. Представленный перечень модификаций не является исчерпывающим и специалисту в данной области должно быть понятно, что возможны и другие модификации. Кроме того, отсутствие конкретных примеров модификаций не означает, что модификации невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области должно быть понятно, что это не обязательно. Также следует понимать, что в некоторых случаях система 100 предусматривает простые варианты реализации настоящей технологии и что такие варианты представлены для облегчения ее понимания. Специалисты в данной области должны понимать, что различные варианты осуществления настоящей технологии могут быть значительно сложнее.
[44] В общем случае система 100 способна предоставлять электронные услуги озвучивания пользователю 102 электронного устройства 104. Например, система 100 способна получать видеофайл со звуком на первом языке, формировать звук на втором языке и предоставлять пользователю видеофайл со звуком на втором языке. Ниже приводится описание по меньшей мере некоторых элементов системы 100, при этом следует понимать, что без отступления от существа и объема настоящей технологии в состав системы 100 могут входить элементы, не показанные на фиг. 1.
Сеть связи
[45] Электронное устройство 104 соединено с сетью 110 связи для обеспечения связи с сервером 112. В частности, электронное устройство 104 может быть соединено с сервером 112 через сеть 110 связи для предоставления пользователю 102 онлайн-услуг, например, на базе механизмов трансляции потокового видео. Сеть 110 связи обеспечивает, среди прочего, обмен данными между электронным устройством 104 и сервером 112 в виде одного или нескольких пакетов данных.
[46] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 110 связи реализована как сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 110 связи может быть реализована иначе, например, как любая глобальная сеть связи, локальная сеть связи, частная сеть связи и т.п. Способ реализации канала связи (отдельно не обозначен) между электронным устройством 104 и сетью 110 связи зависит, среди прочего, от способа реализации электронного устройства 104.
[47] Для примера можно отметить, что в тех вариантах осуществления настоящей технологии, где электронное устройство 104 реализовано в виде устройства беспроводной связи (такого как смартфон), канал связи может быть реализован в виде беспроводного канала связи (такого как, среди прочего, канал сети связи 3G, канал сети связи 4G, канал Wi-Fi® (Wireless Fidelity), канал Bluetooth® и т.п.), но не ограничиваясь этим. В тех примерах, где электронное устройство 104 реализовано в виде ноутбука, канал связи может быть как беспроводным (например, Wi-Fi®, Bluetooth® и т.п.), так и проводным (например, на основе Ethernet-соединения).
Электронное устройство
[48] Система 100 содержит электронное устройство 104, связанное с пользователем 102. Соответственно, электронное устройство 104 в некоторых случаях называется «клиентским устройством», «устройством конечного пользователя», «клиентским электронным устройством» или просто «устройством». Следует отметить, что для электронного устройства 104, связанного с пользователем 102, не предлагается и не предусматривается какого-либо конкретного режима работы, например, необходимости входа в систему, необходимости регистрации и т.п.
[49] На реализацию электронного устройства 104 не накладывается особых ограничений, а примерами реализации электронного устройства 104 могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (смартфоны, сотовые телефоны, планшеты и т.п.) и сетевое оборудование (например, маршрутизаторы, коммутаторы и шлюзы). Электронное устройство 104 содержит аппаратные средства, программное обеспечение и/или микропрограммное обеспечение (либо их сочетание), которые известны в данной области техники и обеспечивают выполнение приложения браузера.
[50] В общем случае приложение браузера призвано предоставлять пользователю 102 доступ к одному или нескольким сетевым ресурсам, таким как веб-страницы. При этом на реализацию приложения браузера не накладывается особых ограничений. Одним из примеров приложения браузера может служить браузер Yandex™.
[51] Пользователь 102 может использовать приложение браузера для получения доступа к платформе потокового видео, осуществляющей трансляцию видеоконтента. Например, электронное устройство 104 может формировать запрос с указанием видеоконтента, который требуется просмотреть пользователю 102. В некоторых вариантах осуществления в запросе от электронного устройства 104 также может указываться необходимый язык звука, сопровождающего видеоконтент. Кроме того, электронное устройство 104 может получать ответ (не показан) на запрос воспроизведения видеоконтента и звука на выбранном языке для пользователя 102. Как правило, передача запроса и получение ответа электронным устройством 104 могут осуществляться через сеть 110 связи. Содержимое запроса и ответа может зависеть, среди прочего, от того, передается ли видео- и аудиоконтент в режиме прямой трансляции.
База данных
[52] Система 100 также содержит базу 150 данных, которая соединена с сервером 112 и способна хранить данные, извлеченные или иным способом полученные или сформированные сервером 112. В общем случае база 150 данных может получать от сервера 112 данные, которые были извлечены, получены или сформированы иным способом сервером 112 в процессе обработки, для их временного и/или постоянного хранения, а также передавать сохраненные данные на сервер 112 для их использования. Предполагается, что без отступления от существа и объема настоящей технологии база 150 данных может быть разделена на несколько распределенных баз данных.
[53] База 150 данных способна хранить данные для обеспечения работы механизмов трансляции потокового видео сервера 112. В связи с этим база 150 данных может хранить множество элементов цифрового контента, в том числе видео- и аудиофайлы, представляющие мультимедийный контент, потребляемый пользователем 102, но не ограничиваясь этим. Примерами элементов цифрового контента могут служить, в частности, цифровые видеозаписи, цифровые фильмы, цифровое аудиозаписи, цифровая музыка, материалы веб-сайтов, материалы социальных сетей и т.п.
[54] Согласно приведенному ниже описанию, база 150 данных способна хранить данные для обучения и дообучения (т.е. тонкой настройки) одной или нескольких моделей машинного обучения с целью формирования последовательностей выходных токенов, в частности, текстовых токенов, пунктуационных токенов и токенов смены диктора.
Сервер
[55] Система 100 также содержит сервер 112, который может быть реализован в виде обычного компьютерного сервера. В представленных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 112 представляет собой одиночный сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 112 могут быть распределены между несколькими серверами. Без отступления от существа и объема настоящей технологии сервер 112 может содержать один или несколько процессоров, одно или несколько физических запоминающих устройств, машиночитаемые команды и/или дополнительные аппаратные элементы, дополнительные программные компоненты и/или их комбинации для реализации различных функций сервера 112.
[56] В общем случае сервер 112 может работать под контролем и/или управлением поставщика видеоуслуг (не показан), например, такого, как оператор платформы потокового видео Yandex™. Предполагается, что поставщиком услуг потокового видео и поставщиком приложения браузера может быть один и тот же поставщик. Например, приложение браузера (в частности, браузер Yandex™) и механизмы трансляции потокового видео (в частности, механизмы трансляции потокового видео Yandex™) могут предоставляться, контролироваться и/или управляться одним и тем же оператором или одной и той же организацией.
[57] Как указано выше, на сервере 112 размещен механизм трансляции потокового видео (не показан). В общем случае механизм трансляции потокового видео реализован в виде множества компьютерных процедур, которые используются для предоставления пользователю 102 видеоконтента с сопровождающим аудиоконтентом на одном или нескольких языках.
[58] Разработчики настоящей технологии учли, что большой объем мультимедийного контента, транслируемого в сети Интернет, первоначально создается на английском языке, тогда как многие пользователи не говорят по-английски или владеют английским языком не на том уровне, чтобы должным образом воспринимать контент на английском языке. Для обеспечения доступности такого мультимедийного контента широкому кругу пользователей в традиционных решениях либо предлагаются субтитры на разных языках, либо аудиоконтент дублируется на разных языках. Разработчиками были разработаны способы и системы, обеспечивающие услуги озвучивания видео, благодаря которым аудиоконтент на одном или нескольких языках формируется сервером 112 без участия человека.
[59] В некоторых вариантах осуществления сервер 112 способен предоставлять электронные услуги автоматического озвучивания в тех случаях, когда исходный аудиоконтент переводится на один или несколько языков, воспроизводится мужским или женским голосом и может быть наложен на исходный видеоконтент для воспроизведения пользователю 102.
[60] Как более подробно описано ниже, услуги автоматического озвучивания могут быть реализованы на базе нескольких нейронных сетей, которые способны (1) распознавать речь (преобразовывать звук в текст), разделять распознанный текст на отдельные фрагменты (например, на фразы), переводить фрагменты на целевой язык и формировать дублированный контент, который накладывается на исходный видеоконтент. Система может дополнительно определять пол диктора и синтезировать голос с соответствующими характеристиками.
[61] На фиг. 2 представлен конвейер 200 обработки, реализованный на сервере 112 в некоторых вариантах осуществления настоящей технологии. Первая процедура из конвейера 200 обработки выполняется модулем 202 распознавания речи в отношении исходного аудиоконтента. В общем случае первая процедура служит для получения исходного аудиоконтента 251 и формирования данных 252 распознавания речи.
[62] Данные 252 распознавания речи могут представлять собой результат автоматического распознавания речи или другого звука из элемента видеоконтента. Данные 252 распознавания речи могут включать в себя множество сформированных символьных строк, в котором каждая отдельная сформированная символьная строка представляет собой слово, фразу или набор символов, произносимых одним или несколькими дикторами в элементе видеоконтента. Каждая сформированная символьная строка в данных 252 распознавания речи может быть связана с информацией о времени, характеризующей конкретное время, когда на видео произносится сформированная символьная строка. Например, информация о времени для фразы «доброе утро» может включать в себя время, когда произносится слово «доброе», и время, когда произносится слово «утро». Информация о времени может относиться к моментам начала и окончания речи (как, например, метки времени) для каждой сформированной символьной строки или к моменту начала и продолжительности речи для каждой сформированной символьной строки.
[63] В некоторых вариантах осуществления модуль 202 распознавания речи способен дополнительно обрабатывать исходный аудиоконтент для удаления оттуда помех, не связанных с речью, таких как звуки музыки. В дополнительных вариантах осуществления модуль 202 распознавания речи способен вставлять знаки пунктуации и/или дополнительно разделять слова на фрагменты слов.
[64] В некоторых вариантах осуществления модуль 202 распознавания речи может включать в себя модель преобразования речи в текст (STT, Speech-To-Text). Модель преобразования речи в текст может представлять собой модель машинного обучения, например, модель нейронной сети (NN, Neural Network). Не имеющими ограничительного характера примерами моделей нейронных сетей, которые могут использоваться для реализации настоящей технологии, являются модель рекуррентной нейронной сети и модель нейронной сети с длинной краткосрочной памятью (LSTM, Long Short-Term Memory). В дополнительных вариантах осуществления модель машинного обучения может быть реализована в виде модели трансформера.
[65] В по меньшей мере некоторых вариантах осуществления реализована модель автоматического распознавания речи (ASR, Automatic Speech Recognition). Модель автоматического распознавания речи может быть выполнена в виде комбинации модели seq2seq и сверточной нейронной сети (CNN, Convolutional Neural Network). Модель seq2seq может быть реализована в виде модели трансформера VGG. Дополнительно или опционально для промежуточного распознавания (например, для распознавания фрагментов) также может использоваться трансформер коннекционистской временной классификации (CTC, Connectionist Temporal Classification). В по меньшей мере некоторых вариантах осуществления модель автоматического распознавания речи может быть реализована подобно модели автоматического распознавания речи, раскрытой в патенте US11145305 этого же заявителя, содержание которого полностью включено в настоящий документ посредством ссылки.
[66] Как более подробно описано ниже, модуль 202 распознавания речи способен обнаруживать смену диктора. Обнаружение смены диктора представляет собой технологически ориентированный процесс, предполагающий определение и маркировку смены дикторов или актеров в аудио- и/или видеозаписи. Распознавание моментов окончания речи одних персонажей и начала речи других персонажей позволяет модулю 202 распознавания речи предоставлять дополнительную информацию для других элементов конвейера 200 обработки и тем самым улучшать процесс формирования дублированного контента.
[67] Вторая процедура в конвейере 200 обработки предусматривает нахождение в данных 252 распознавания речи фраз, произносимых соответствующими дикторами в исходном аудиоконтенте 251. Иными словами, вторая процедура может включать в себя определение диктора, который сформировал соответствующую порцию данных 252 распознавания речи. В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, вторая процедура может выполняться моделью 301 диаризации. В общем случае модель 301 диаризации способна определять, когда две следующие друг за другом фразы в данных 252 распознавания речи произносятся одним и тем же диктором, а когда они произносятся разными дикторами. Для этого модель 301 диаризации способна учитывать токены смены диктора, сформированные модулем 202 распознавания речи.
[68] В частности, при получении двух фраз и токена смены диктора, указывающего на вероятность смены диктора, равную 0, модель 301 диаризации может определить, что обе фразы были произнесены одним и тем же диктором. И наоборот, если вероятность, указываемая токеном смены диктора между двумя фразами, превышает заданный порог вероятности (например, 0,75, 0,85 или 0,95), модель 301 диаризации может определить, что эти две фразы была произнесены разными дикторами.
[69] В различных не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 301 диаризации может быть реализована в виде нейронной сети с архитектурой нейронной сети с временной задержкой с акцентом на канальное внимание и распространение и агрегирование каналов (ECAPA-TDNN, Emphasized Channel Attention, Propagation and Aggregation in Time Delay Neural Network). В конкретном не имеющем ограничительного характера примере модель 301 диаризации может быть реализована, как описано на веб-ресурсе huggingface.co/speechbrain/spkrec-ecapa-voxceleb. Для обеспечения учета токенов смены диктора в модели 301 диаризации к выходным данным модели 301 диаризации может дополнительно применяться алгоритм кластеризации.
[70] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии после применения модели 301 диаризации, прежде чем приступать к переводу данных 252 распознавания речи, сервер 112 способен производить конкатенацию фраз, произносимых в исходном аудиоконтенте 251 каждым диктором, чтобы сгруппировать фразы в данных 252 распознавания речи по дикторам.
[71] После применения модели 301 диаризации и группирования фраз в данных 252 распознавания речи по дикторам модуль 204 перевода выполняет третью процедуру из конвейера 200 обработки в отношении данных 252 распознавания речи. В общем случае третья процедура служит для получения данных 252 распознавания речи и формирования данных 253 перевода.
[72] Данные 253 перевода представляют собой перевод символьных строк из данных 252 распознавания речи (представленных на исходном языке исходного аудиоконтента) на второй язык. Модуль 204 перевода также может получать информацию о гендерной принадлежности человека, произносящего речь в исходном аудиоконтенте. В некоторых случаях модуль 204 перевода может формировать различные данные 253 перевода, в частности, в зависимости от того, кем является говорящий - мужчиной или женщиной.
[73] Предполагается, что модуль 204 перевода способен применять множество моделей перевода для перевода символьных строк с исходного языка на один или несколько других языков.
[74] При этом на способ реализации той или иной модели перевода в модуле 204 перевода не накладывается особых ограничений. В одном из вариантов осуществления модель перевода может быть реализована в виде модели статистического машинного перевода (SMT, Statistical Machine Translation), обученной переводу фразы с первого языка на второй язык.
[75] В общем случае статистический машинный перевод связан с автоматическим преобразованием фраз на одном естественном языке (например, французском) на другой естественный язык (например, английский). Первый язык называется исходным, а второй - целевым. Этот процесс можно рассматривать как стохастический. Существует множество вариантов статистического машинного перевода, различающихся способом моделирования перевода. Одни решения основаны на преобразовании строк в строки, другие - на преобразовании деревьев в строки, а в третьих используются модели преобразования деревьев в деревья. Эффективность модели статистического машинного перевода оценивается с использованием двуязычных (параллельных) корпусов (пар «оригинал-перевод») и/или одноязычных корпусов (примеров целевых предложений). Предполагается, что сервер 112 способен формировать функцию перевода за счет обучения модели статистического машинного перевода на основе сопоставленных текстовых корпусов, представляющих соответствующую пару языков. Предполагается, что без отступления от существа и объема настоящей технологии модель перевода может быть реализована как модель типа «кодер-декодер».
[76] В некоторых вариантах осуществления модель перевода может быть представлена в виде нейронной сети с архитектурой трансформера. Способность архитектур трансформеров учитывать широкий контекст, вносимый сетями с длинной краткосрочной памятью, а затем и механизмом внимания, может оказаться практически значимой для модели перевода. Предполагается, что в модели перевода могут учитываться дополнительные признаки, например, пол диктора.
[77] Четвертая процедура из конвейера 200 обработки выполняется модулем 206 синтеза речи применительно к данным 253 перевода. В общем случае четвертая процедура служит для получения данных 253 перевода и формирования данных 254 синтеза речи.
[78] Данные 254 синтеза речи включают в себя переведенный аудиоконтент, сформированный, в частности, на основе данных 253 перевода, и представляющий собой фразы, произносимые на одном (или нескольких) других языках. Кроме того, на основе данных 254 синтеза речи сервер 112 способен формировать выходной аудиоконтент 208, содержащий озвученные переведенные символьные строки из данных 253 перевода. Также сервер 112 способен обеспечивать воспроизведение выходного аудиоконтента 208 на электронном устройстве 104 для его представления пользователю 102.
[79] В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, модуль 206 синтеза речи может включать в себя акустическую модель 214 и вокодер 212. В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, акустическая модель 214 и вокодер 212 могут быть реализованы в виде глубоких нейросетевых моделей. Следует отметить, что акустическая модель 214 может формировать мел-спектрограммы, например, на основе фонем, а вокодер 212 - синтезировать изменяющиеся во времени звуковые волны, в частности, на основе мел-спектрограмм из модели преобразования текста в спектрограмму.
[80] В некоторых вариантах осуществления настоящей технологии акустическая модель может быть реализована в виде известной модели Tacotron 2. В общем случае модель Tacotron 2 представляет собой рекуррентную сеть предсказания признаков типа «последовательность-последовательность» с одним или несколькими механизмами внимания, которая предсказывает последовательность кадров мел-спектрограммы по входной последовательности символов. В других вариантах осуществления вокодер может быть реализован в виде известной модели HiFi-GAN. В общем случае архитектура HiFi-GAN включает в себя один генератор и два дискриминатора: многомасштабный и многопериодный. Генератор представляет собой полносверточную нейронную сеть. Он использует мел-спектрограмму в качестве исходных данных и повышает ее разрешение, используя транспонированные свертки, до тех пор, пока не будет обеспечено соответствие между длиной выходной последовательности и временным разрешением необработанных звуковых сигналов. После каждой транспонированной свертки применяется модуль слияния мультирецептивных полей (MRF, Multi-Receptive Field Fusion). В других вариантах осуществления вокодер может быть реализован подобно модели, описанной в патентной заявке US 2022084499 «Method and server for a text-to-speech processing» («Способ и сервер для преобразования текста в речь») этого же заявителя, опубл. 17 марта 2022 года, содержание которой полностью включено в настоящий документ посредством ссылки.
[81] В некоторых вариантах осуществления настоящей технологии модуль 206 синтеза речи может быть реализован подобно модулю синтеза речи, описанному в патентной заявке RU 2022134630 («Способ и сервер для генерирования модифицированного аудио для видео») этого же заявителя, поданной 27 декабря 2022 года, содержание которой полностью включено в настоящий документ посредством ссылки.
[82] В некоторых вариантах осуществления модуль 206 синтеза речи также может получать информацию о гендерной принадлежности человека, произносящего речь в исходном аудиоконтенте. В некоторых случаях модуль 206 синтеза речи может формировать различные данные 254 синтеза речи, в частности, в зависимости от того, кем является говорящий - мужчиной или женщиной.
[83] Очевидно, что модуль 206 синтеза речи также может получать информацию о смене дикторов между разными фрагментами исходного аудиоконтента 251, выдаваемую моделью 301 диаризации до перевода данных 252 распознавания речи. Таким образом, в некоторых случаях модуль 204 перевода может формировать порции данных 254 синтеза речи, в частности, в зависимости от того, с кем связана эта речь - с первым (текущим) диктором или вторым (другим) диктором.
Модель обнаружения смены диктора
[84] На фиг. 3 представлен не имеющий ограничительного характера пример модели 300 обнаружения смены диктора, используемой на сервере 112 в составе модуля 202 распознавания речи в по меньшей мере одном из вариантов осуществления настоящей технологии.
[85] В общем случае модель 300 обнаружения смены диктора способна получать аудиоданные 350 и соответствующие текстовые данные 360 в качестве входных данных и формировать в ответ выходные данные в виде последовательности токенов 310, содержащих информацию, характеризующую смену дикторов в контенте, представленном аудиоданными 350 и соответствующими текстовыми данными 360.
[86] Модель 300 обнаружения смены диктора включает в себя подмодель 302 для аудиоданных и подмодель 304 для текста, куда передаются аудиоданные 350 и текстовые данные 360, соответственно. В частности, сервер 112 способен разделять аудиоданные 350 на последовательность фрагментов 355 аудиоданных и передавать эту последовательность в качестве входных данных в подмодель 302 для аудиоданных. Кроме того, сервер 112 способен разделять текстовые данные 360 на последовательность фрагментов 365 текстовых данных и передавать эту последовательность в качестве входных данных в подмодель 304 для текста.
[87] В варианте осуществления, показанном на фиг. 3, сервер 112 способен формировать последовательность 355, содержащую 6340 фрагментов аудиоданных, и последовательность 365, содержащую 512 фрагментов текстовых данных. Предполагается, что общее количество фрагментов в последовательности 355 и последовательности 365 может зависеть, среди прочего, от конкретного варианта реализации подмодели 302 для аудиоданных, конкретного варианта реализации подмодели 304 для текста, объема аудиоданных 350 и/или объема текстовых данных 360.
[88] В данном варианте осуществления архитектура подмодели 302 для аудиоданных может быть реализована подобно архитектуре модели WavLM, раскрытой в статье Sanyuan Chen et al. «WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing» («WavLM: крупномасштабное предварительное обучение с самоконтролем для полного цикла обработки речи»), опубл. в июле 2022 года, содержание которой полностью включено в настоящий документ посредством ссылки. Модель WavLM, основу которой составляет модель трансформера, содержит сверточный энкодер признаков и энкодер трансформера. Сверточный энкодер состоит из семи блоков временной свертки, за которыми следует слой нормализации и слой функции активации GELU. В одном из вариантов реализации временные свертки имеют 512 каналов с шагами (5, 2, 2, 2, 2, 2, 2) и значениями ширины ядра (10, 3, 3, 3, 3, 2, 2), вследствие чего выходные данные представляют фрагменты звука длительностью примерно 25 мс, следующие с шагом 20 мс. Выходные данные в сверточном представлении маскируются как входные данные трансформера. Трансформер имеет слой векторного представления относительного положения на основе свертки с размером ядра 128 и 16 группами в нижней части. Для улучшения модели может использоваться управляемое смещение относительного положения, которое кодируется в зависимости от смещения между «ключом» и «запросом» в механизме самовнимания трансформера.
[89] В данном варианте осуществления архитектура подмодели 304 для текста может быть реализована подобно архитектуре модели mT5, раскрытой в статье Linting Xue et al. «mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer» («mT5: трансформер для преобразования текста в текст, прошедший массовое многоязычное предварительное обучение»), опубл. в марте 2021 года, содержание которой полностью включено в настоящий документ посредством ссылки.
[90] Модель 300 обнаружения смены диктора способна производить конкатенацию векторных представлений выходных данных подмодели 302 для аудиоданных с векторными представлениями выходных данных подмодели 304 для текста с целью формирования конкатенированных промежуточных выходных данных 306 модели 300 обнаружения смены диктора. Можно утверждать, что модель 300 обнаружения смены диктора способна одновременно обрабатывать аудиоданные 350 и текстовые данные 360 и формировать конкатенированные промежуточные выходные данные 306 на основе как (1) векторных представлений аудиоданных, так и (2) векторных представлений текста.
[91] В варианте осуществления, показанном на фиг. 3, сервер 112 способен формировать конкатенированные промежуточные выходные данные 306 за счет конкатенации 6340 векторных представлений аудиоданных и 512 векторных представлений текста. Предполагается, что общее количество векторных представлений аудиоданных и теста, подлежащих конкатенации, может зависеть, среди прочего, от конкретного варианта реализации подмодели 302 для аудиоданных, конкретного варианта реализации подмодели 304 для текста, объема аудиоданных 350 и/или объема текстовых данных 360.
[92] Далее конкатенированные промежуточные выходные данные 306 передаются в третью подмодель 308, способную обрабатывать конкатенированные промежуточные выходные данные 306 и формировать в ответ последовательность токенов 310. В данном варианте осуществления архитектура третьей подмодели 308 реализована подобно архитектуре подмодели трансформера. Например, третья подмодель 308 может быть реализована в виде модели трансформера, способной принимать конкатенированные векторные представления аудиоданных и текста (например, конкатенированные промежуточные выходные данные 306) и формировать последовательность токенов (например, последовательность токенов 310).
[93] В контексте настоящей технологии модель 300 обнаружения смены диктора способна формировать последовательность токенов 310, содержащую по меньшей мере три типа токенов, а именно (1) словарные токены, (2) пунктуационные токены и (3) токены смены диктора. В примере, показанном на фиг. 3, последовательность токенов 310 содержит словарный токен 312, пунктуационный токен 320 и токен 330 смены диктора. Следует отметить, что подпоследовательность токенов, содержащая словарный токен 312, пунктуационный токен 320 и токен 330 смены диктора, может указывать на то, что слово, связанное со словарным токеном 312, произносится первым диктором и это слово является последним словом во фразе, поскольку пунктуационный токен 320 представляет точку, а следующее слово в записи произносится вторым (другим) диктором. Ниже со ссылкой на фиг. 4 и 5 описывается, как сервер 112 способен обучать и использовать модель 300 обнаружения смены диктора для формирования, соответственно, пунктуационных токенов и токенов смены диктора в составе последовательности токенов 310.
Обучение
[94] В некоторых вариантах осуществления настоящей технологии сервер 112 может реализовывать по меньшей мере два этапа обучения модели 300 обнаружения смены диктора. На первом этапе сервер 112 способен обучать алгоритм машинного обучения, используя большой объем данных. Затем, на втором этапе, сервер 112 способен дообучать предварительно обученный алгоритм машинного обучения, используя дополнительные данные для настройки алгоритма на конкретную задачу. В общем случае обучение алгоритма машинного обучения на первом этапе предусматривает формирование шаблонов алгоритма машинного обучения на основе данных, а на следующем этапе производится дообучение для оптимизации рабочих характеристик. Дообучение может использоваться в целях устранения эффекта переобучения, настройки модели на новые задачи и/или корректировки параметров модели для улучшения результатов. Это итеративный процесс, который может осуществляться сервером 112 для повышения точности и эффективности модели.
[95] В частности, начальное обучение обеспечивает построение модели машинного обучения. Этап начального обучения может начинаться со сбора и подготовки основного набора данных, содержащего входные данные (признаки) и соответствующие целевые выходные данные. Затем модель обучается сервером 112, который выявляет закономерности, взаимосвязи и статистические представления в этом наборе данных, составлению прогнозов или выполнению классификации.
[96] На этапе начального обучения сервер 112 способен разделять исходный набор данных на обучающий набор и проверочный набор. Также сервер 112 может выбирать архитектуру модели и инициализировать ее гиперпараметры (например, скорость обучения, размер партии и т.д.). Затем в модель с выбранной архитектурой передается обучающий набор данных, в результате чего за счет итеративной настройки внутренних параметров архитектуры модели расхождение между прогнозами модели и целевыми значениями (метками) сводится к минимуму. После этого сервер 112 может рассчитывать одну или несколько метрик эффективности для оценки работы модели на проверочном наборе данных.
[97] На этапе дообучения предварительно обученная модель настраивается на конкретную задачу или конкретные условия. Если предварительно обученная модель демонстрирует удовлетворительные результаты на обучающих данных, но не справляется с ранее неизвестными данными (эффект переобучения), то на этапе дообучения для улучшения обобщения могут применяться методы регуляризации и/или настройки гиперпараметров.
[98] При наличии, в частности, одной или нескольких предварительно обученных моделей дообучение может предусматривать обучение той или иной предварительно обученной модели, принимаемой в качестве базового варианта, на новой смежной задаче. Например, сервер 112 может получать предварительно обученную модель из базы 150 данных и реализовывать этап дообучения для настройки этой предварительно обученной модели на решение новой смежной задачи. Разработчики настоящей технологии установили, что применение принципов переноса обучения к предварительно обученной модели вместо реализации этапа начального обучения модели позволяет экономить время и вычислительные ресурсы.
[99] На фиг. 4 представлены первая итерация 400 обучения и вторая итерация 450 обучения, которые сервер 112 может выполнять, соответственно, на этапе начального обучения модели 300'' и этапе дообучения предварительно обученной модели 300'. Ниже приводится последовательное описание первой итерации 400 обучения и второй итерации 450 обучения.
Обучение пунктуации
[100] На первой итерации 400 обучения сервер 112 может получать первый обучающий набор 402 данных, содержащий обучающие входные данные 404 и метку 406. Обучающие входные данные 404 включают в себя входные аудиоданные 408 и входные текстовые данные 410. Входные аудиоданные 408 представляют собой запись речи диктора, а входные текстовые данные 410 - соответствующий текст, представляющий речь диктора. Следует отметить, что такой текст содержит слова, произносимые диктором, без каких-либо знаков пунктуации. Метка 406 содержит целевую последовательность токенов 420, которая содержит словарные токены, представляющие произносимые диктором слова, и пунктуационные токены, представляющие контрольные положения знаков пунктуации среди этих слов. В одном из вариантов осуществления положения пунктуационных токенов применительно к тексту могут задаваться людьми-оценщиками. В другом варианте осуществления текст может изначально содержать знаки пунктуации, но впоследствии, при формировании обучающих данных, они удаляются. В частности, целевая последовательность токенов 420 содержит словарный токен 422, за которым следует пунктуационный токен 424, который может указывать на то, что словарный токен 422 представляет последнее слово во фразе, произносимой диктором.
[101] Сервер 112 способен передавать обучающие входные данные 404 в модель 300'' (например, входные аудиоданные 408 могут передаваться в подмодель для аудиоданных, а входные текстовые данные 410 - в подмодель для текста). Модель 300'' способна формировать прогнозную последовательность токенов, которая сравнивается с целевой последовательностью токенов 420 из метки 406. Затем производится настройка модели 300'', исходя из результатов сравнения прогнозной последовательности токенов и целевой последовательности токенов 420. После большого количества итераций обучения, выполненных подобно первой итерации 400 обучения, сервер 112 способен выполнять начальное обучение модели 300'' и получать в результате обученную модель 300'. Обученная модель 300' обучена прогнозированию положения пунктуационных токенов в выходной последовательности токенов с целью определения мест в текстовой версии речи диктора, куда должны быть вставлены знаки пунктуации, для дополнения текстовой версии речи диктора. Следует отметить, что дополненная таким способом текстовая версия речи диктора может способствовать повышению эффективности одного или нескольких элементов системы озвучивания.
[102] Разработчики настоящей технологии учли, что для обучения пунктуации существуют большие наборы данных. Наборы данных для обучения пунктуации могут включать в себя видео- и/или аудиофайлы с соответствующими субтитрами. В некоторых вариантах осуществления при формировании набора данных для обучения пунктуации сервер 112 способен выполнять одну или несколько операций фильтрации. Предполагается, что сервер 112 способен получать набор данных для обучения пунктуации из базы 150 данных. В одном из вариантов реализации набор данных для обучения пунктуации может включать в себя примерно миллион часов (фактических) аудиоданных с соответствующими текстовыми данными, содержащими знаки пунктуации. Можно утверждать, что в процессе обучения пунктуации модель обучается прогнозированию пунктуационных указателей после соответствующих слов.
Дообучение смене диктора
[103] На второй итерации 450 обучения сервер 112 может получать второй обучающий набор данных 452, содержащий обучающие входные данные 454 и метку 456. Обучающие входные данные 454 включают в себя входные аудиоданные 458 и входные текстовые данные 460. Входные аудиоданные 458 представляют собой запись речи одного или нескольких дикторов, а входные текстовые данные 460 - соответствующий текст, представляющий речь одного или нескольких дикторов. Следует отметить, что такой текст содержит слова, произносимые одним или несколькими дикторами, без каких-либо знаков пунктуации. Метка 456 содержит целевую последовательность токенов 470, которая содержит словарные токены, представляющие слова, произносимые одним или несколькими дикторами, пунктуационные токены, представляющие контрольные положения знаков пунктуации среди слов, и токены смены диктора, представляющие контрольные указания на места, в которых прекращает говорить текущий диктор и начинает говорить другой диктор. В частности, целевая последовательность токенов 470 содержит словарный токен 472, за которым сначала следует пунктуационный токен 474, который может указывать на то, что словарный токен 422 представляет последнее слово во фразе, произносимой диктором, а затем следует токен 476 смены диктора, который может указывать на то, что словарный токен 422 представляет последнее слово во фразе, произносимой текущим диктором до начала произнесения новой фразы другим диктором.
[104] Сервер 112 способен передавать обучающие входные данные 454 в предварительно обученную модель 300' (например, входные аудиоданные 458 могут передаваться в подмодель для аудиоданных, а входные текстовые данные 460 - в подмодель для текста). Предварительно обученная модель 300' способна формировать прогнозную последовательность токенов, которая сравнивается с целевой последовательностью токенов 470 из метки 456. Затем производится настройка предварительно обученной модели 300' по результатам сравнения прогнозной последовательности токенов и целевой последовательности токенов 470. После большого количества итераций обучения, выполненных подобно первой итерации 400 обучения, сервер 112 способен выполнять дообучение предварительно обученной модели 300' и получать в результате модель 300 обнаружения смены диктора. Модель 300 обнаружения смены диктора обучена прогнозированию положения пунктуационных токенов в выходной последовательности токенов с целью определения мест в текстовой версии речи диктора, куда должны быть вставлены знаки пунктуации, для дополнения текстовой версии речи диктора, а также прогнозированию положения токенов смены диктора в выходной последовательности токенов с целью определения мест в текстовой версии речи диктора, в которых происходит смена диктора, для дальнейшего дополнения текстовой версии речи диктора. Следует отметить, что дополненная таким способом текстовая версия речи диктора может способствовать повышению эффективности одного или нескольких элементов системы озвучивания.
[105] Разработчики настоящей технологии установили, что больших наборов данных для обучения смене диктора гораздо меньше, чем для обучения пунктуации. Наборы данных для обучения смене диктора также могут включать в себя видео- и/или аудиофайлы с соответствующими субтитрами. В некоторых вариантах осуществления при формировании набора данных для обучения смене диктора сервер 112 способен выполнять одну или несколько операций фильтрации. Предполагается, что сервер 112 способен получать набор данных для обучения смене диктора из базы 150 данных. В одном из вариантов реализации набор данных для обучения смене диктора может включать в себя примерно сто часов (фактических) аудиоданных с соответствующими текстовыми данными, содержащими знаки пунктуации. Можно утверждать, что в процессе обучения смене диктора модель обучается прогнозированию указаний на знаки пунктуации, а также указаний на смену диктора после соответствующих слов.
[106] Без привязки к какой-либо конкретной теории разработчики учли, что проведение дообучения на модели, предварительно обученной решению задачи обнаружения знаков пунктуации, позволяет этой модели использовать пунктуационные токены в качестве «подсказок» при решении задачи обнаружения смены диктора. Иными словами, модель 300 обнаружения смены диктора в некотором смысле «понимает», что смена диктора маловероятна в пределах фразы (то есть после словарного токена) и/или сравнительно более вероятна после окончания фразы (то есть после пунктуационного токена, представляющего точку). Также можно утверждать, что модель 300 обнаружения смены диктора обучена «пониманию», что вероятность того, что следующим токеном (который будет сформирован) окажется токен смены диктора, сравнительно выше, если последним токеном (который был сформирован) является пунктуационный токен, а не словарный токен.
Работа
[107] На фиг. 5 представлена рабочая итерация 500 модели 300 обнаружения смены диктора, выполняемая на сервере 112 для формирования последовательности токенов 310. Сервер 112 способен получать рабочий набор 502 данных. Рабочий набор 502 данных содержит аудиоданные 350 и соответствующие текстовые данные 360. В некоторых вариантах осуществления рабочий набор 502 данных может включать в себя предварительно записанные данные, полученные из базы 150 данных. В других вариантах осуществления рабочий набор 502 данных может представлять собой набор данных, получаемый сервером 112 в режиме реального времени, например, во время прямых трансляций и/или видеоконференций, где требуется мгновенный дубляж. В дополнительных вариантах осуществления вместе с аудиоданными 350 может приниматься видеофайл, а сервер 112 способен извлекать соответствующие текстовые данные 360 из аудиоданных 350 известными методами.
[108] Как упоминалось ранее, сервер 112 способен разделять аудиоданные 350 на последовательность фрагментов аудиоданных и передавать их в качестве входных данных в подмодель 302 для аудиоданных модели 300 обнаружения смены диктора. Кроме того, сервер 112 способен разделять текстовые данные 360 на последовательность фрагментов текстовых данных и передавать их в качестве входных данных в подмодель 304 для текста модели 300 обнаружения смены диктора. В ответ модель 300 обнаружения смены диктора может выполнять конкатенацию промежуточных векторных представлений, сформированных подмоделью 302 для аудиоданных и подмоделью 304 для текста, после чего конкатенированные промежуточные выходные данные модели 300 обнаружения смены диктора дополнительно обрабатываются выходной подмоделью 308 для формирования последовательности выходных токенов 310, содержащей словарный токен 312, за которым следуют сначала пунктуационный токен 320, а затем токен 330 смены диктора.
[109] Затем, как упоминалось выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 112 способен передавать последовательность выходных токенов 310, содержащую словарный токен 312, за которым следуют сначала пунктуационный токен 320, а затем токен 330 смены диктора, в модель 301 диаризации для выявления фраз, произносимых разными дикторами, в последовательности выходных токенов 310. Далее, используя выходные данные модели 301 диаризации, сервер 112 способен группировать фразы из данных 252 распознавания речи по дикторам, произносящим эти фразы. После этого, как подробно описано выше, сервер 112 способен (1) переводить сгруппированные таким способом фразы с помощью модуля 204 перевода, тем самым получая данные 253 перевода, и (2) формировать с помощью модуля 206 синтеза речи для каждой переведенной фразы из данных 253 перевода, связанной с текущим диктором, соответствующую порцию данных 254 синтеза речи, как указано выше.
[110] С учетом описанной выше архитектуры и приведенных примеров возможна реализация способа обучения такой модели, как модель 300 обнаружения смены диктора. На фиг. 6 представлена блок-схема способа 600 в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии. Способ 600 может быть реализован на сервере 112.
[111] Как указано выше, сервер 112 способен выполнять по меньшей мере два этапа обучения модели 300 обнаружения смены диктора. На первом этапе, который подробно описан выше со ссылкой на фиг. 4 применительно к первой итерации 400 обучения, сервер 112 способен обучать алгоритм машинного обучения на основе большого объема данных формированию прогнозных пунктуационных токенов для заданной последовательности текстовых токенов. Затем, на втором этапе, который подробно описан выше со ссылкой на фиг. 4 применительно ко второй итерации 450 обучения, сервер 112 способен дообучать предварительно обученный алгоритм машинного обучения на основе дополнительных данных с целью настройки этого алгоритма на прогнозирование положений токенов смены диктора в заданной последовательности текстовых токенов.
Шаг 602: получение набора данных для обучения пунктуации, содержащего первые входные данные, включающие в себя аудиоданные и текстовые данные, представляющие речь диктора, и первую метку, включающую в себя последовательность контрольных токенов.
[112] Способ 600 начинается с шага 602, на котором сервер 112 способен получать первый обучающий набор 402 данных для обучения модели 300'' определению положений пунктуационных токенов в заданной последовательности текстовых токенов. Как подробно описано выше со ссылкой на фиг. 4, первый обучающий набор данных 402 содержит обучающие входные данные 404 и метку 406. В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, обучающие входные данные 404 содержат входные аудиоданные 408 и входные текстовые данные 410. Входные аудиоданные 408 представляют собой запись речи диктора, а входные текстовые данные 410 - соответствующий текст, представляющий речь диктора.
[113] Метка 406 содержит целевую последовательность токенов 420, которая содержит словарные токены, представляющие произносимые диктором слова, и пунктуационные токены, представляющие контрольные положения знаков пунктуации среди слов. В одном из вариантов осуществления положения пунктуационных токенов применительно к тексту могут задаваться людьми-оценщиками.
[114] Следующим шагом в способе 600 является шаг 604.
Шаг 604: обучение модели с использованием набора данных для обучения пунктуации формированию рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования обученной пунктуации модели.
[115] На шаге 604, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 112 способен передавать обучающие входные данные 404 в модель 300'' (например, входные аудиоданные 408 могут передаваться в подмодель для аудиоданных, а входные текстовые данные 410 - в подмодель для текста). В ответ модель 300'' способна формировать прогнозную последовательность токенов, сравниваемую с целевой последовательностью токенов 420 из метки 406. Затем сервер 112 способен производить настройку модели 300'' путем оптимизации расхождения между прогнозной последовательностью токенов и целевой последовательностью токенов 420 (которое, например, может быть выражено функцией потерь). После большого количества итераций обучения, выполненных подобно итерации 400 обучения, сервер 112 способен выполнять начальное обучение модели 300'' и получать в результате обученную модель 300'.
[116] Таким образом, обученная модель 300' обучена прогнозированию положения пунктуационных токенов в выходной последовательности токенов с целью определения мест в текстовой версии речи диктора, куда должны быть вставлены знаки пунктуации, для дополнения текстовой версии речи диктора. Следует отметить, что дополненная таким способом текстовая версия речи диктора может способствовать повышению эффективности одного или нескольких элементов системы озвучивания.
[117] Следующим шагом в способе 600 является шаг 606.
Шаг 606: получение набора данных для обучения смене диктора, содержащего вторые входные данные, включающие в себя вторые аудиоданные и вторые текстовые данные, представляющие речь нескольких дикторов, и вторую метку, включающую в себя вторую последовательность контрольных токенов.
[118] На шаге 606, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 112 способен получать второй обучающий набор 452 данных для обучения обученной модели 300' прогнозированию положений токенов смены диктора в последовательности текстовых токенов. Как подробно описано выше со ссылкой на фиг. 4, второй обучающий набор данных 452 содержит обучающие входные данные 454 и метку 456. В соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, обучающие входные данные 454 содержат входные аудиоданные 458 и входные текстовые данные 460. Входные аудиоданные 458 представляют собой запись речи одного или нескольких дикторов, а входные текстовые данные 460 - соответствующий текст, представляющий речь одного или нескольких дикторов. Следует отметить, что такой текст содержит слова, произносимые одним или несколькими дикторами, без каких-либо знаков пунктуации. Метка 456 содержит целевую последовательность токенов 470, которая содержит (1) словарные токены, представляющие слова, произносимые одним или несколькими дикторами, (2) пунктуационные токены, представляющие контрольные положения знаков пунктуации среди слов, и (3) токены смены диктора, представляющие контрольные указания на места, в которых прекращает говорить текущий диктор и начинает говорить другой диктор.
[119] Следующим шагом в способе 600 является шаг 608.
Шаг 608: дообучение обученной пунктуации модели с использованием набора данных для обучения смене диктора формированию второй рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования модели смены диктора.
[120] На шаге 608, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 112 способен дообучать обученную модель 300' определению положений токенов смены диктора, используя второй обучающий набор данных, полученный на шаге 606.
[121] Для этого, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 112 способен передавать обучающие входные данные 454 в предварительно обученную модель 300' (например, входные аудиоданные 458 могут передаваться в подмодель 302 для аудиоданных, а входные текстовые данные 460 - в подмодель 304 для текста). В ответ предварительно обученная модель 300' может формировать прогнозную последовательность токенов, которую сервер 112 способен сравнивать с целевой последовательностью токенов 470 из метки 456. Затем сервер 113 способен производить настройку предварительно обученной модели 300' путем сведения к минимуму расхождения между прогнозной последовательностью токенов и целевой последовательностью токенов 470 (которое, например, может быть выражено соответствующим значением функции потерь).
[122] Таким образом, после большого количества итераций обучения, выполненных подобно итерации 400 обучения, сервер 112 способен выполнять дообучение предварительно обученной модели 300' и получать в результате модель 300 обнаружения смены диктора.
[123] Теперь модель 300 обнаружения смены диктора обучена прогнозированию положения пунктуационных токенов в выходной последовательности токенов с целью определения мест в текстовой версии речи диктора, куда должны быть вставлены знаки пунктуации, для дополнения текстовой версии речи диктора, а также прогнозированию положения токенов смены диктора в выходной последовательности токенов с целью определения мест в текстовой версии речи диктора, в которых происходит смена диктора, для дальнейшего дополнения текстовой версии речи диктора. Следует отметить, что дополненная таким способом текстовая версия речи диктора может способствовать повышению эффективности одного или нескольких элементов системы озвучивания.
[124] Следующим шагом в способе 600 является шаг 610.
Шаг 610: получение рабочего набора данных, содержащего рабочие текстовые данные и рабочие аудиоданные.
[125] На шаге 610, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 112 способен получать рабочий набор 502 данных. Как подробно описано выше со ссылкой на фиг. 5, рабочий набор 502 данных содержит аудиоданные 350 и соответствующие текстовые данные 360.
[126] Следующим шагом в способе 600 является шаг 612.
Шаг 612: формирование с использованием модели смены диктора второй рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных.
[127] Затем сервер 112 способен применять модель 300 обнаружения смены диктора к рабочему набору 502 данных. Для этого, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 112 способен разделять аудиоданные 350 на последовательность фрагментов аудиоданных и передавать их в качестве входных данных в подмодель 302 для аудиоданных модели 300 обнаружения смены диктора. Кроме того, сервер 112 способен разделять текстовые данные 360 на последовательность фрагментов текстовых данных и передавать их в качестве входных данных в подмодель 304 для текста модели 300 обнаружения смены диктора.
[128] В ответ модель 300 обнаружения смены диктора способна производить конкатенацию промежуточных векторных представлений, сформированных подмоделью 302 для аудиоданных и подмоделью 304 для текста, после чего конкатенированные промежуточные выходные данные модели 300 обнаружения смены диктора дополнительно обрабатываются выходной подмоделью 308 для формирования последовательности выходных токенов 310, содержащей словарный токен 312, за которым следуют сначала пунктуационный токен 320, а затем токен 330 смены диктора.
[129] Следующим шагом в способе 600 является шаг 614.
Шаг 614: определение с использованием модели диаризации рабочих текстовых токенов, связанных с соответствующими дикторами, во второй рабочей последовательности токенов для последующего осуществления перевода и синтеза речи.
[130] Далее, после определения положений пунктуационных токенов и токенов смены диктора в рабочем наборе 502 данных, сервер 112 способен определять принадлежность фраз дикторам в текстовых данных 360 из рабочего набора 502 данных. Иными словами, сервер 112 способен определять, когда две следующие друг за другом фразы из текстовых данных 360 произносятся одним и тем же диктором, а когда они произносятся разными дикторами. Для этого, в соответствии с некоторыми не имеющими ограничительного характера вариантами осуществления настоящей технологии, сервер 112 способен применять модель 301 диаризации к последовательности выходных токенов 310, как описано выше.
[131] После этого в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 112 способен (1) группировать (например, методом конкатенации) фразы, которые были определены моделью 301 диаризации как связанные с заданным диктором, и (2) передавать сгруппированные таким способом выходные токены модели 300 обнаружения смены диктора сначала в модуль 204 перевода для обеспечения перевода, а затем в модуль 206 синтеза речи для формирования соответствующих порций данных 254 синтеза речи.
[132] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модуль 204 перевода способен формировать порцию данных 253 перевода для каждой группы, определенной моделью 301 диаризации, из последовательности выходных токенов 310. Подобным образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модуль 206 синтеза речи способен формировать порцию данных 254 синтеза речи для каждой группы, связанной с соответствующим диктором, определенным моделью 301 диаризации, из последовательности выходных токенов 310, что может включать в себя, например, формирование порции данных 254 синтеза речи с использованием голоса, соответствующего голосу диктора, который произносит исходную фразу в аудиоданных 350 из рабочих данных 502. Иными словами, после группирования токенов из последовательности выходных токенов 310 моделью 301 диаризации сервер 112 способен выполнять перевод и синтезировать выходные токены 310, используя по группам, соответственно, модули 204, 206 перевода и синтеза речи.
[133] Таким образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модули 204, 206 перевода и синтеза речи могут использовать не собственно токены смены диктора, формируемые моделью 300 обнаружения смены диктора, такие как токен 330 смены диктора, а лишь фразы, сгруппированные по дикторам, определенным моделью 301 диаризации с помощью токенов смены диктора.
[134] На этом реализация способа 600 завершается.
[135] Для специалиста в данной области могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ПЕРЕФРАЗИРОВАНИЯ ТЕКСТА | 2023 |
|
RU2814808C1 |
| СПОСОБ И СИСТЕМА КЛАССИФИКАЦИИ ТЕКСТА | 2022 |
|
RU2818693C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |
| Способ и сервер для синтеза речи по тексту | 2015 |
|
RU2632424C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБРАБОТКИ ТЕКСТОВОЙ ПОСЛЕДОВАТЕЛЬНОСТИ В ЗАДАЧЕ МАШИННОЙ ОБРАБОТКИ | 2020 |
|
RU2775820C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ВЫПОЛНЕНИЯ ПРОБЛЕМНО-ОРИЕНТИРОВАННОГО ПЕРЕВОДА | 2021 |
|
RU2820953C2 |
| СИСТЕМА И МЕТОДИКА АВТОМАТИЧЕСКОГО ОБУЧЕНИЯ ЯЗЫКАМ НА ОСНОВЕ ЧАСТОТНОСТИ СИНТАКСИЧЕСКИХ МОДЕЛЕЙ | 2015 |
|
RU2632656C2 |
| СПОСОБ И СИСТЕМА ОПРЕДЕЛЕНИЯ МОШЕННИЧЕСКИХ ЗВОНКОВ И ОПОВЕЩЕНИЯ О НИХ АБОНЕНТОВ | 2022 |
|
RU2820329C2 |
| Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации | 2020 |
|
RU2750852C1 |
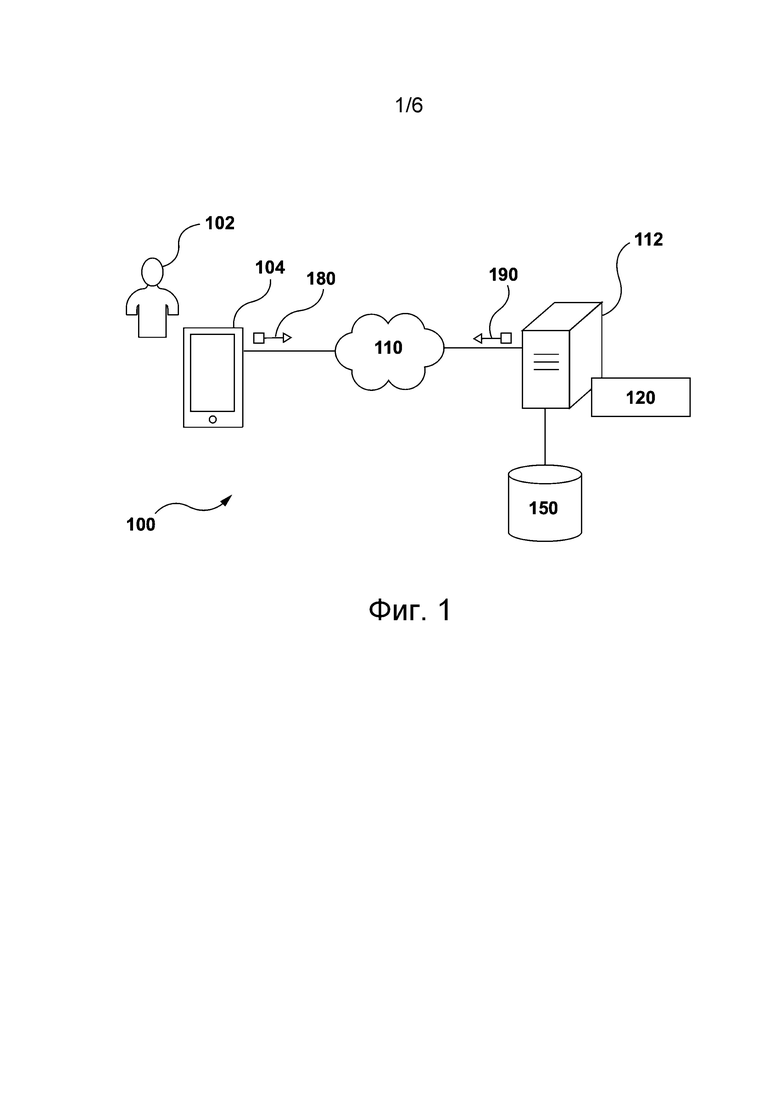
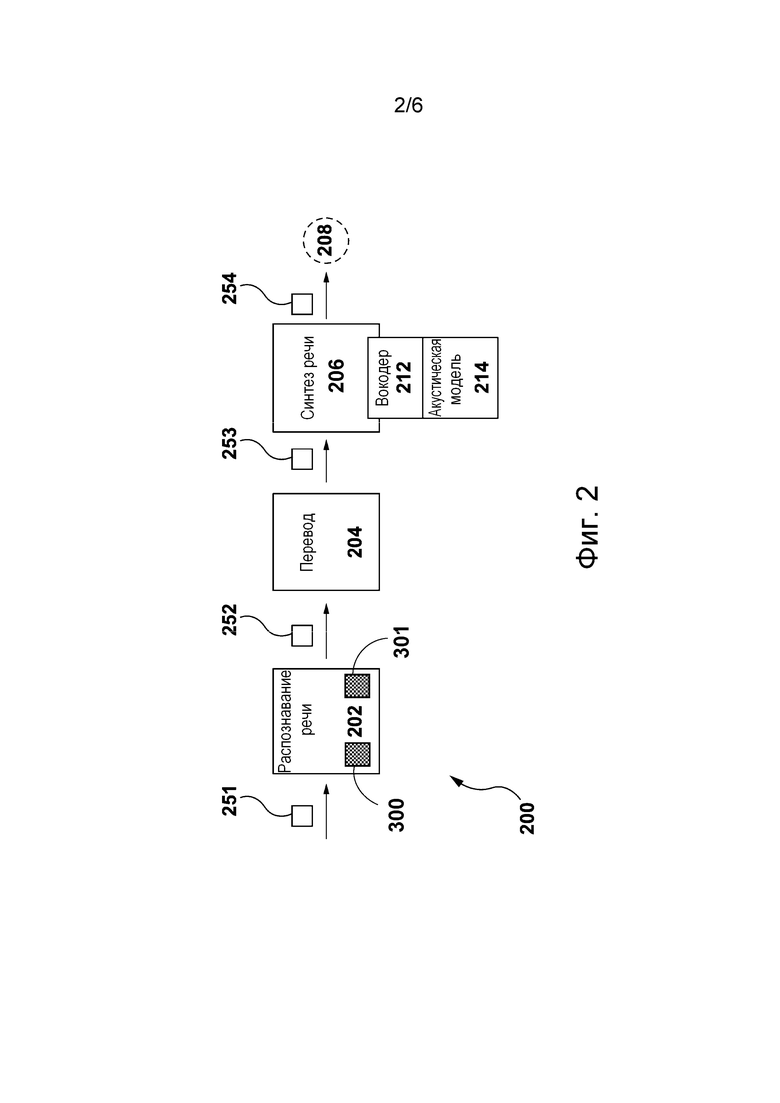
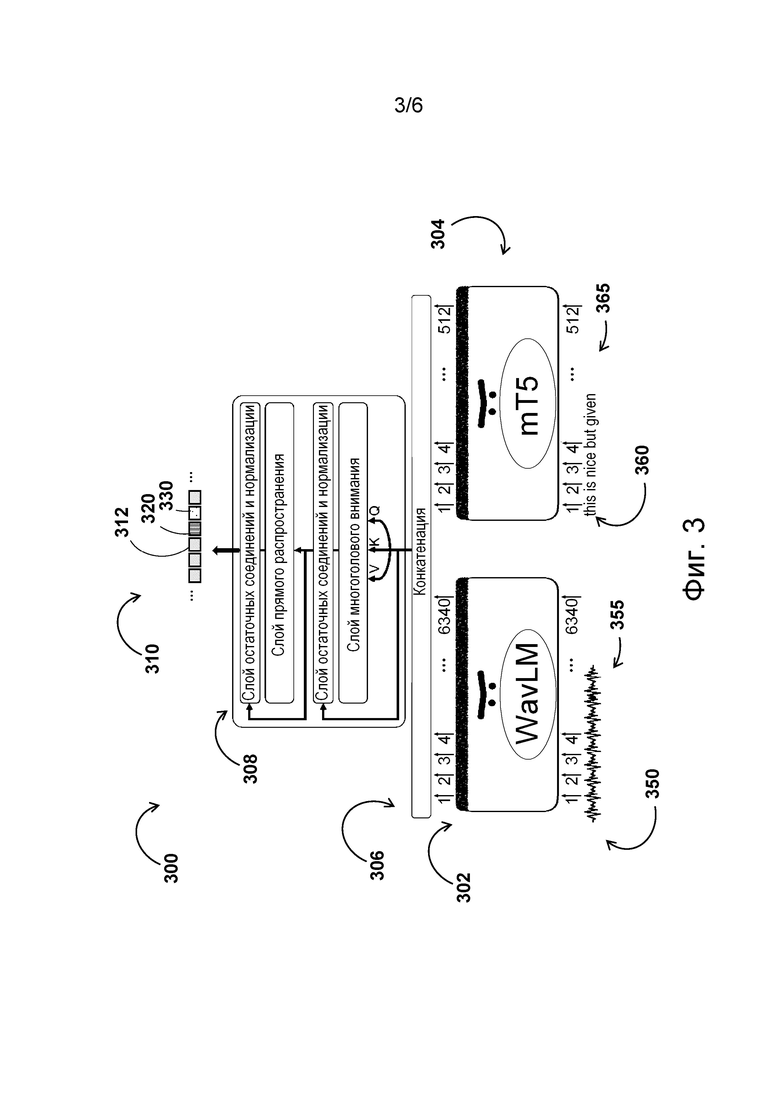
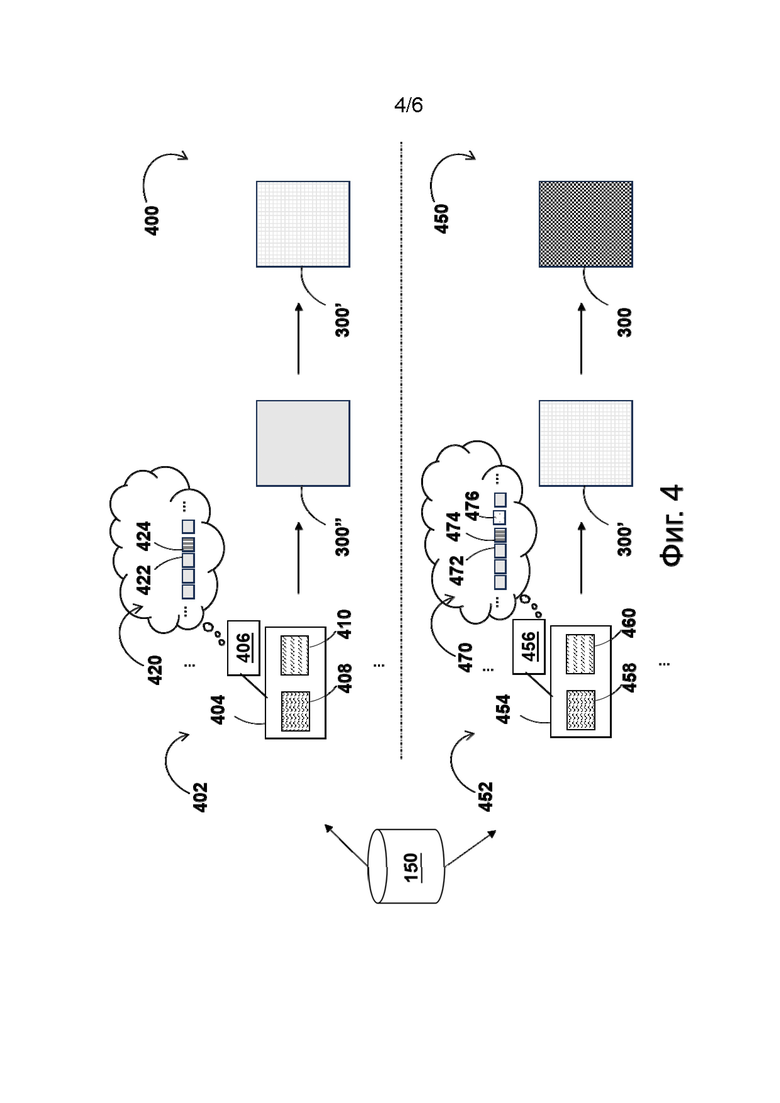
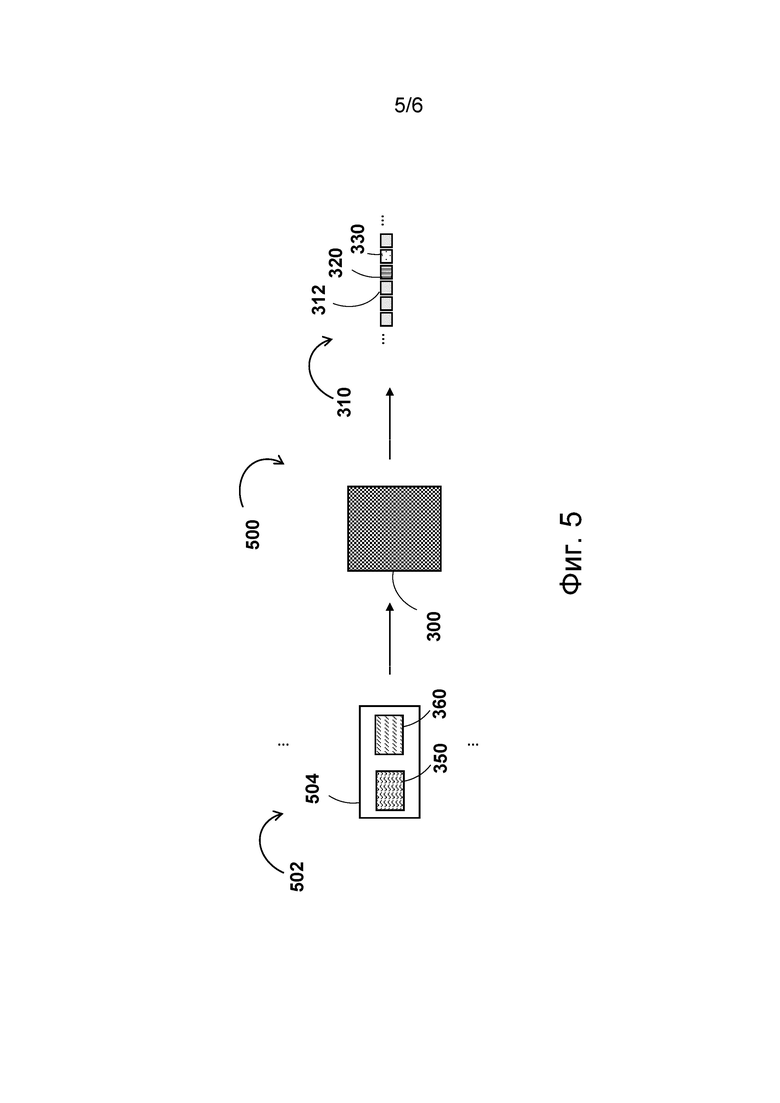
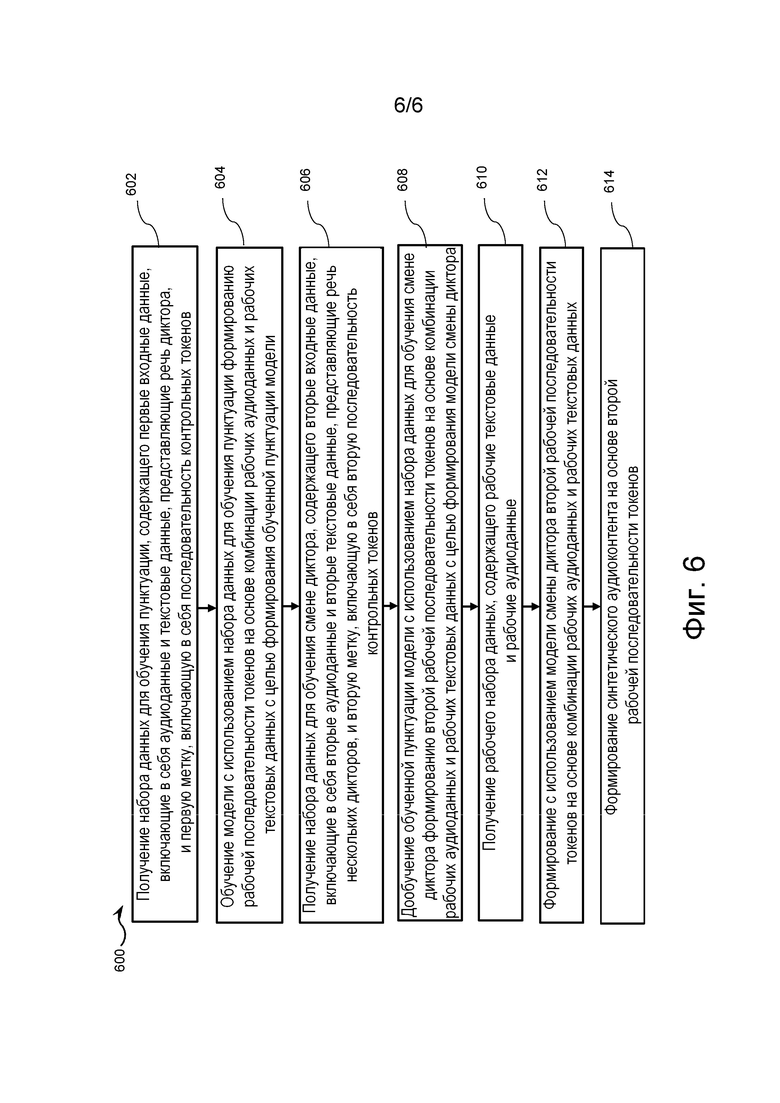
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении точности распознавания речи и диаризации диктора. Технический результат достигается за счет этапов, на которых выполняют: получение набора данных для обучения пунктуации, содержащего первые входные данные, включающие в себя аудиоданные и текстовые данные, представляющие речь, и первую метку, включающую в себя последовательность контрольных токенов, обучение модели с использованием набора данных для обучения пунктуации формированию обученной пунктуации модели, получение набора данных для обучения смене диктора, содержащего вторые входные данные, включающие в себя вторые аудиоданные и вторые текстовые данные, и вторую метку, включающую в себя вторую последовательность контрольных токенов, дообучение обученной пунктуации модели с использованием набора данных для обучения смене диктора формированию модели смены диктора, получение рабочих текстовых данных и соответствующих рабочих аудиоданных, и формирование второй рабочей последовательности токенов на основе рабочих аудиоданных и рабочих текстовых данных с использованием модели смены диктора. 3 н. и 13 з.п. ф-лы, 6 ил.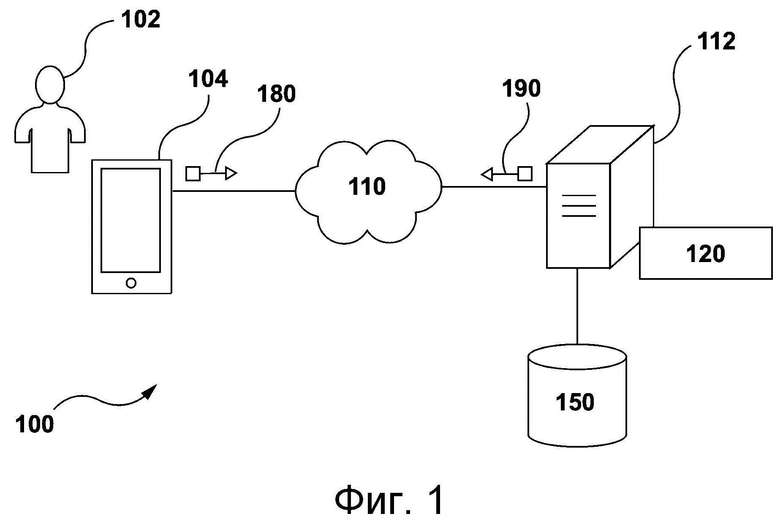
1. Способ обучения модели, реализуемый на сервере, предусматривающий:
- получение набора данных для обучения пунктуации, содержащего первые входные данные, включающие в себя аудиоданные и текстовые данные, представляющие речь диктора, и первую метку, включающую в себя последовательность контрольных токенов, содержащую контрольный текстовый токен, указывающий на слово, и контрольный пунктуационный токен, указывающий на знак пунктуации и следующий за контрольным текстовым токеном;
- обучение модели, с использованием набора данных для обучения пунктуации, формированию рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования обученной пунктуации модели;
- получение набора данных для обучения смене диктора, содержащего вторые входные данные, включающие в себя вторые аудиоданные и вторые текстовые данные, представляющие речь нескольких дикторов, и вторую метку, включающую в себя вторую последовательность контрольных токенов, содержащую второй контрольный текстовый токен, указывающий на второе слово, второй контрольный пунктуационный токен, указывающий на второй знак пунктуации, и контрольный токен смены диктора, указывающий на смену диктора и следующий за вторым контрольным пунктуационным токеном,
- дообучение обученной пунктуации модели, с использованием набора данных для обучения смене диктора, формированию второй рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования модели смены диктора;
- получение рабочего набора данных, содержащего рабочие текстовые данные и рабочие аудиоданные;
- формирование, с использованием модели смены диктора, второй рабочей последовательности токенов, содержащей рабочий текстовый токен, рабочий пунктуационный токен, следующий за рабочим текстовым токеном, и рабочий токен смены диктора, следующий за рабочим пунктуационным токеном, на основе комбинации рабочих аудиоданных и рабочих текстовых данных; и
- формирование синтезированного аудиоконтента на основе второй рабочей последовательности токенов.
2. Способ по п. 1, в котором модель смены диктора содержит подмодель для аудиоданных, подмодель для текста и третью подмодель, а формирование второй рабочей последовательности токенов предусматривает:
- формирование, с использованием подмодели для аудиоданных, рабочей последовательности векторных представлений аудиоданных на основе рабочих аудиоданных;
- формирование, с использованием подмодели для текста, рабочей последовательности векторных представлений текста на основе рабочих текстовых данных;
- формирование конкатенированных промежуточных выходных данных с использованием рабочей последовательности векторных представлений аудиоданных и рабочей последовательности векторных представлений текста; и
- формирование, с использованием третьей подмодели, второй рабочей последовательности токенов с использованием конкатенированных промежуточных выходных данных.
3. Способ по п. 2, в котором подмодель для аудиоданных представляет собой модель WavLM.
4. Способ по п. 2, в котором подмодель для текста представляет собой модель mT5.
5. Способ по п. 2, в котором третья подмодель представляет собой модель трансформера.
6. Способ по п. 1, дополнительно предусматривающий:
- формирование, с использованием модели преобразования речи в текст, текстовых данных на основе аудиоданных;
- формирование, с использованием модели преобразования речи в текст, вторых текстовых данных на основе вторых аудиоданных; и
- формирование, с использованием модели преобразования речи в текст, рабочих текстовых данных на основе рабочих аудиоданных.
7. Способ по п. 1, в котором контрольный пунктуационный токен следует непосредственно за контрольным текстовым токеном, контрольный токен смены диктора следует непосредственно за вторым контрольным пунктуационным токеном, рабочий пунктуационный токен следует непосредственно за рабочим текстовым токеном, а рабочий токен смены диктора следует непосредственно за рабочим пунктуационным токеном.
8. Способ дообучения предварительно обученной модели, реализуемый на сервере, предусматривающий:
- получение набора данных для обучения смене диктора, содержащего вторые входные данные, включающие в себя вторые аудиоданные и вторые текстовые данные, представляющие речь нескольких дикторов, и вторую метку, включающую в себя вторую последовательность контрольных токенов, содержащую второй контрольный текстовый токен, указывающий на второе слово, второй контрольный пунктуационный токен, указывающий на второй знак пунктуации, и контрольный токен смены диктора, указывающий на смену диктора и следующий за вторым контрольным пунктуационным токеном во второй последовательности контрольных токенов;
- дообучение предварительно обученной модели, с использованием набора данных для обучения смене диктора, формированию второй рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования модели смены диктора, при этом с целью формирования рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных предварительно обученная модель обучалась на основе набора данных для обучения пунктуации, содержащего первые входные данные, включающие в себя аудиоданные и текстовые данные, представляющие речь диктора, и первую метку, включающую в себя последовательность контрольных токенов, которая содержит контрольный текстовый токен, указывающий на слово, и контрольный пунктуационный токен, указывающий на знак пунктуации и следующий за контрольным текстовым токеном;
- получение рабочего набора данных, содержащего рабочие текстовые данные и рабочие аудиоданные;
- формирование, с использованием модели смены диктора, второй рабочей последовательности токенов, содержащей рабочий текстовый токен, рабочий пунктуационный токен, следующий за рабочим текстовым токеном, и рабочий токен смены диктора, следующий за рабочим пунктуационным токеном, на основе комбинации рабочих аудиоданных и рабочих текстовых данных; и
- формирование синтезированного аудиоконтента на основе второй рабочей последовательности токенов.
9. Способ по п. 8, в котором контрольный пунктуационный токен следует непосредственно за контрольным текстовым токеном, контрольный токен смены диктора следует непосредственно за вторым контрольным пунктуационным токеном, рабочий пунктуационный токен следует непосредственно за рабочим текстовым токеном, а рабочий токен смены диктора следует непосредственно за рабочим пунктуационным токеном.
10. Сервер для обучения модели, содержащий по меньшей мере один процессор и по меньшей мере одну физическую машиночитаемую память, хранящую исполняемые команды, при исполнении которых по меньшей мере одним процессором на сервере обеспечивается:
- получение набора данных для обучения пунктуации, содержащего первые входные данные, включающие в себя аудиоданные и текстовые данные, представляющие речь диктора, и первую метку, включающую в себя последовательность контрольных токенов, содержащую контрольный текстовый токен, указывающий на слово, и контрольный пунктуационный токен, указывающий на знак пунктуации и следующий за контрольным текстовым токеном;
- обучение модели, с использованием набора данных для обучения пунктуации, формированию рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования обученной пунктуации модели;
- получение набора данных для обучения смене диктора, содержащего вторые входные данные, включающие в себя вторые аудиоданные и вторые текстовые данные, представляющие речь нескольких дикторов, и вторую метку, включающую в себя вторую последовательность контрольных токенов, содержащую второй контрольный текстовый токен, указывающий на второе слово, второй контрольный пунктуационный токен, указывающий на второй знак пунктуации, и контрольный токен смены диктора, указывающий на смену диктора и следующий за вторым контрольным пунктуационным токеном;
- дообучение обученной пунктуации модели, с использованием набора данных для обучения смене диктора, формированию второй рабочей последовательности токенов на основе комбинации рабочих аудиоданных и рабочих текстовых данных с целью формирования модели смены диктора;
- получение рабочего набора данных, содержащего рабочие текстовые данные и рабочие аудиоданные;
- формирование, с использованием модели смены диктора, второй рабочей последовательности токенов, содержащей рабочий текстовый токен, рабочий пунктуационный токен, следующий за рабочим текстовым токеном, и рабочий токен смены диктора, следующий за рабочим пунктуационным токеном, на основе комбинации рабочих аудиоданных и рабочих текстовых данных; и
- формирование синтезированного аудиоконтента на основе второй рабочей последовательности токенов.
11. Сервер по п. 10, в котором модель смены диктора содержит подмодель для аудиоданных, подмодель для текста и третью подмодель, а формирование второй рабочей последовательности токенов предусматривает:
- формирование, с использованием подмодели для аудиоданных, рабочей последовательности векторных представлений аудиоданных на основе рабочих аудиоданных;
- формирование, с использованием подмодели для текста, рабочей последовательности векторных представлений текста на основе рабочих текстовых данных;
- формирование конкатенированных промежуточных выходных данных с использованием рабочей последовательности векторных представлений аудиоданных и рабочей последовательности векторных представлений текста; и
- формирование, с использованием третьей подмодели, второй рабочей последовательности токенов с использованием конкатенированных промежуточных выходных данных.
12. Сервер по п. 11, в котором подмодель для аудиоданных представляет собой модель WavLM.
13. Сервер по п. 11, в котором подмодель для текста представляет собой модель mT5.
14. Сервер по п. 11, в котором третья подмодель представляет собой модель трансформера.
15. Сервер по п. 10, в котором по меньшей мере один процессор дополнительно обеспечивает на сервере:
- формирование, с использованием модели преобразования речи в текст, текстовых данных на основе аудиоданных;
- формирование, с использованием модели преобразования речи в текст, вторых текстовых данных на основе вторых аудиоданных; и
- формирование, с использованием модели преобразования речи в текст, рабочих текстовых данных на основе рабочих аудиоданных.
16. Сервер по п. 10, в котором контрольный пунктуационный токен следует непосредственно за контрольным текстовым токеном, контрольный токен смены диктора следует непосредственно за вторым контрольным пунктуационным токеном, рабочий пунктуационный токен следует непосредственно за рабочим текстовым токеном, а рабочий токен смены диктора следует непосредственно за рабочим пунктуационным токеном.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| УСТРОЙСТВО АВТОМАТИЧЕСКОЙ ВЕРИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ | 2018 |
|
RU2704723C2 |

