ОБЛАСТЬ ТЕХНИКИ
[0001] Реализация процессов раскрытия информации, как правило, относится к компьютерным системам и, в частности, к системам и способам анализа документов.
УРОВЕНЬ ТЕХНИКИ
[0002] Одной из основополагающих задач при обработке и хранении документов, а также при создании ссылок на них, является группировка документов по разным категориям. Традиционные методы группировки документов могут предусматривать использование большого числа предварительно заданных категорий и/или правил классификации. Такие способы группировки документов требуют множества ручных операций и им не хватает функциональной гибкости.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] Варианты осуществления изобретения описывают механизмы кластеризации документов, включающие в себя: получение входного документа; определение путем оценки функции сходства документов множества показателей сходства, где каждый показатель сходства соответствующего множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером документов из множества кластеров документов; определение на основе множества показателей сходства, что входной документ не относится ни к одному из кластеров документов из множества кластеров документов; создание нового кластера документов; и создание связи входного документа с новым кластером документов. В некоторых вариантах осуществления изобретения функция сходства базируется на одном или более типах вычисленных атрибутов первого документа, выбранных из группы, состоящей из атрибута типа GRID, атрибута типа SVD, атрибута типа «Изображение», причем использование функции сходства подразумевает использование первой нейронной сети, в которой входной документ представляет собой текстовый документ, при этом функция сходства определяет показатель сходства первого документа и первого кластера документов из множества кластеров путем расчета уровня сходства между первым документом и центроидом первого кластера документов, а также функция сходства определяет показатель сходства первого документа и первого кластера документов из множества кластеров путем расчета соответствующих уровней сходства между первым документом и одним или более документами из первого кластера документов. В некоторых вариантах осуществления изобретения наблюдается реагирование на определение того, что первый кластер документов из множества кластеров связан с первым документом, имеющим первое значение свойства документа, а второй кластер документов множества кластеров связан со вторым документом, имеющим первое значение свойства документа, объединяющее первый и второй кластеры документов.
[0004] Постоянный машиночитаемый носитель данных содержит команды, которые, при доступе к ним обрабатывающего устройства, инициируют получение этим устройством входного документа; определение, путем оценки функции сходства документов, множества показателей сходства, причем каждый показатель сходства из множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером из множества кластеров документов; определение на основе множества показателей сходства того, что входной документ не относится ни к одному из кластеров документов из множества кластеров документов; создание нового кластера документов; и создание связи входного документа с новым кластером документов. В некоторых вариантах осуществления изобретения функция сходства базируется на одном или более типах вычисленных атрибутов первого документа, выбранных из группы, состоящей из атрибута типа GRID, атрибута типа SVD, атрибута типа «Изображение», причем использование функции сходства подразумевает использование первой нейронной сети, в которой входной документ представляет собой текстовый документ, при этом функция сходства определяет показатель сходства первого документа и первого кластера документов из множества кластеров путем расчета уровня сходства между первым документом и центроидом первого кластера документов, а также функция сходства определяет меру подобия первого документа и первого кластера документов из множества кластеров путем расчета соответствующих уровней сходства между первым документом и одним или более документами из первого кластера документов. В некоторых вариантах осуществления изобретения в ответ на определение того, что первый кластер документов множества кластеров связан с первым документом, имеющим первое значение свойства документа, а второй кластер документов множества кластеров связан со вторым документом, имеющим первое значение свойства документа, осуществляется слияние первого и второго кластеров документов.
[0005] Система раскрытия предмета изобретения включает в себя запоминающее устройство и вычислительное устройство, которое оперативно связано с запоминающим устройством. Вычислительное устройство обеспечивает: получение входного документа; определение путем оценки функции сходства документов множества показателей сходства, при этом каждый показатель сходства множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером из множества кластеров документов; определение на основе множества показателей сходства, что входной документ не относится ни к одному из кластеров из множества кластеров документов; создание нового кластера документов; и создание связи входного документа с новым кластером документов. В некоторых вариантах осуществления изобретения функция сходства базируется на одном или более типах вычисленных атрибутов первого документа, выбранных из группы, состоящей из атрибута типа GRID, атрибута типа SVD, атрибута типа «Изображение», причем использование функции сходства подразумевает использование первой нейронной сети, в которой входной документ представляет собой текстовый документ, при этом функция сходства определяет показатель сходства первого документа и первого кластера документов из множества кластеров путем расчета уровня сходства между первым документом и центроидом первого кластера документов, а также функция сходства определяет показатель сходства первого документа и первого кластера документов из множества кластеров путем расчета соответствующих уровней сходства между первым документом и одним или более документами из первого кластера документов. В некоторых вариантах осуществления изобретения в ответ на определение того, что первый кластер документов из множества кластеров связан с первым документом, имеющим первое значение свойства документа, а второй кластер документов из множества кластеров связан со вторым документом, имеющим первое значение свойства документа, осуществляется объединение первого и второго кластеров документов.
[0006] В некоторых вариантах осуществления настоящего изобретения также описываются механизмы кластеризации документов, включающие в себя: получение входного документа; определение на основе оценки первой функции сходства документа первого множества показателей сходства, причем каждый показатель сходства первого множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером из множества кластеров документов; определение на основе множества показателей сходства, что входной документ относится к первому кластеру из множества кластеров документов, когда максимальная разница между центроидом первого кластера документов и ответными центроидами подмножества из множества кластеров документов опускается ниже заданного порогового значения; определение, путем оценки второй функции сходства документа, второго множества показателей сходства, при этом каждый показатель сходства второго множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером документов подмножества, принадлежащего множеству кластеров документов; создание ассоциативной связи входного документа с кластером документов, связанным с максимальным показателем сходства второго множества показателей сходства.
[0007] В некоторых вариантах осуществления настоящего изобретения также описываются механизмы кластеризации документов, включающие в себя: получение входного документа; идентификацию путем оценки функции ранжирования для входного документа первого кластера из множества кластеров документов, когда входной документ относится к идентифицированному кластеру документов, а максимальная разница между центроидом первого кластера документов и ответными центроидами подмножества из множества кластеров документов опускается ниже заданного порогового значения; определение путем оценки функции сходства документов множества показателей сходства, где каждый показатель сходства из множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером из подмножества кластеров документов; создание связи входного документа с кластером документов, связанным с максимальным показателем сходства, что зависит от определения того, что максимальный показатель сходства опускается ниже порогового значения измерения сходства, что приводит к созданию нового кластера документов; и создание связи входного документа с новым кластером документов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0008] Сущность изобретения будет более понятна на основе подробного описания, приведенного ниже, и из приложенных чертежей различных вариантов осуществления изобретения. Однако не следует считать, что чертежи ограничивают сущность изобретения конкретными вариантами осуществления; они предназначены только для пояснения и улучшения понимания сущности изобретения.
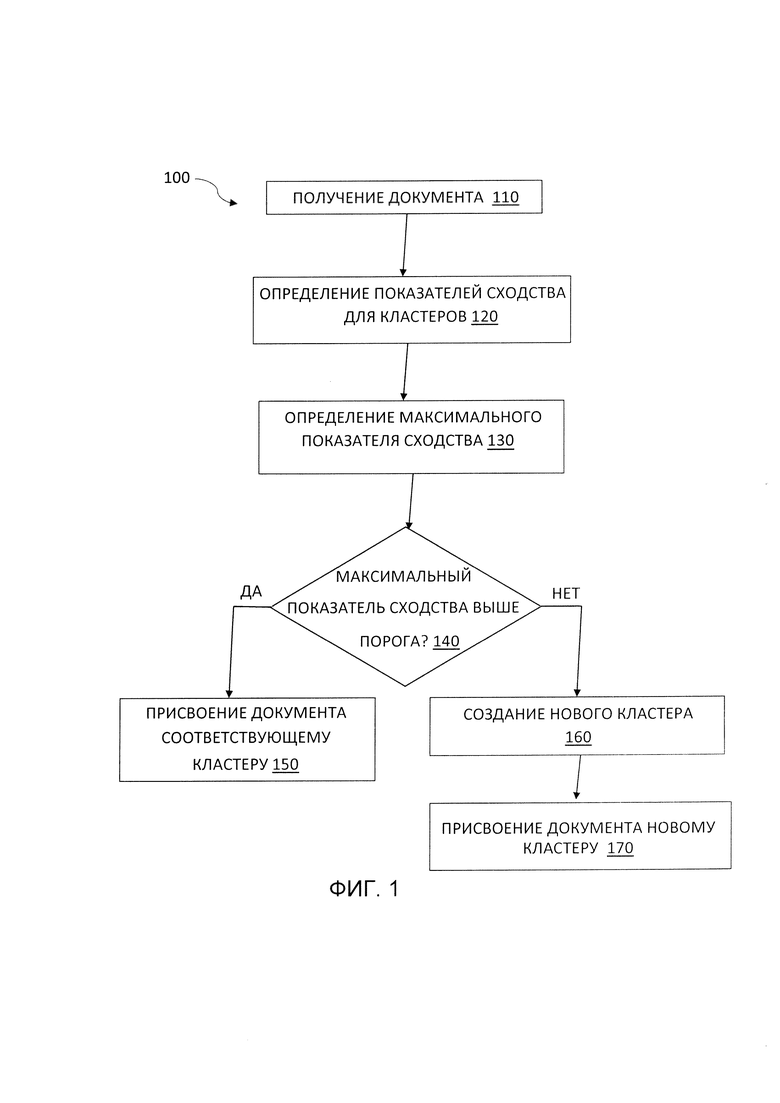
[0009] На Фиг. 1 представлена функциональная блок-схема, иллюстрирующая способ кластеризации документов в соответствии с некоторыми вариантами осуществления настоящего изобретения.
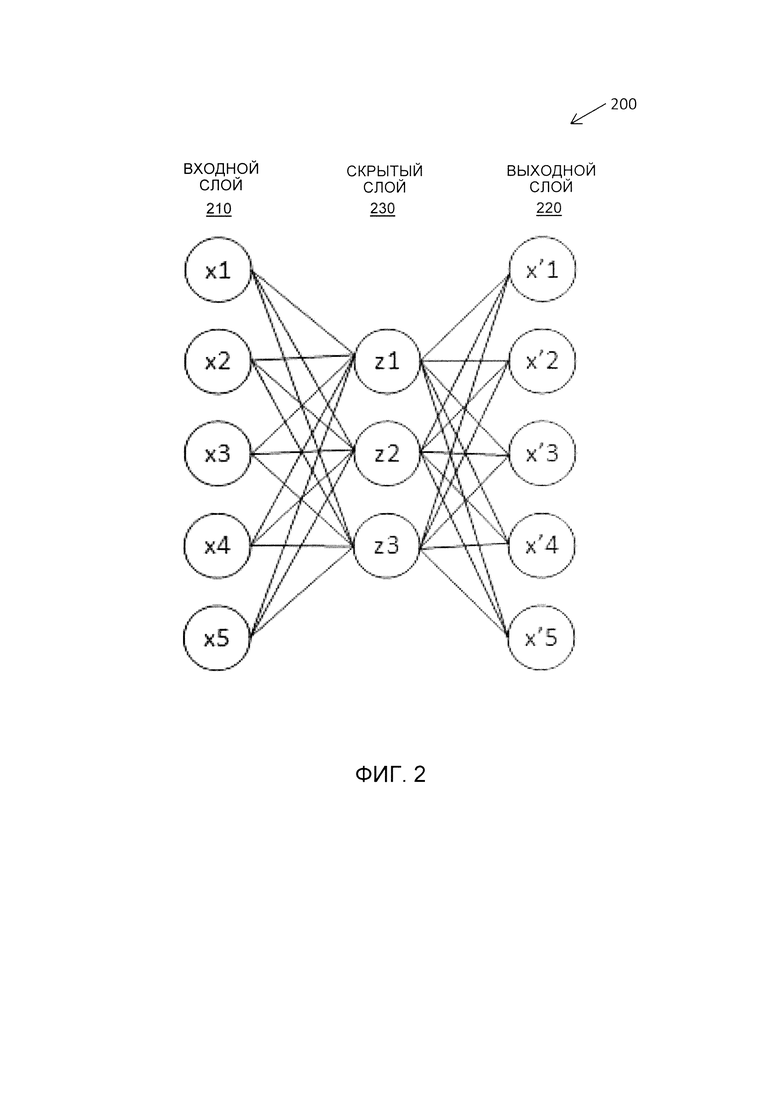
[0010] На Фиг. 2 представлена схематическая иллюстрация структуры нейронной сети в соответствии с одним или более вариантами реализации настоящего изобретения.
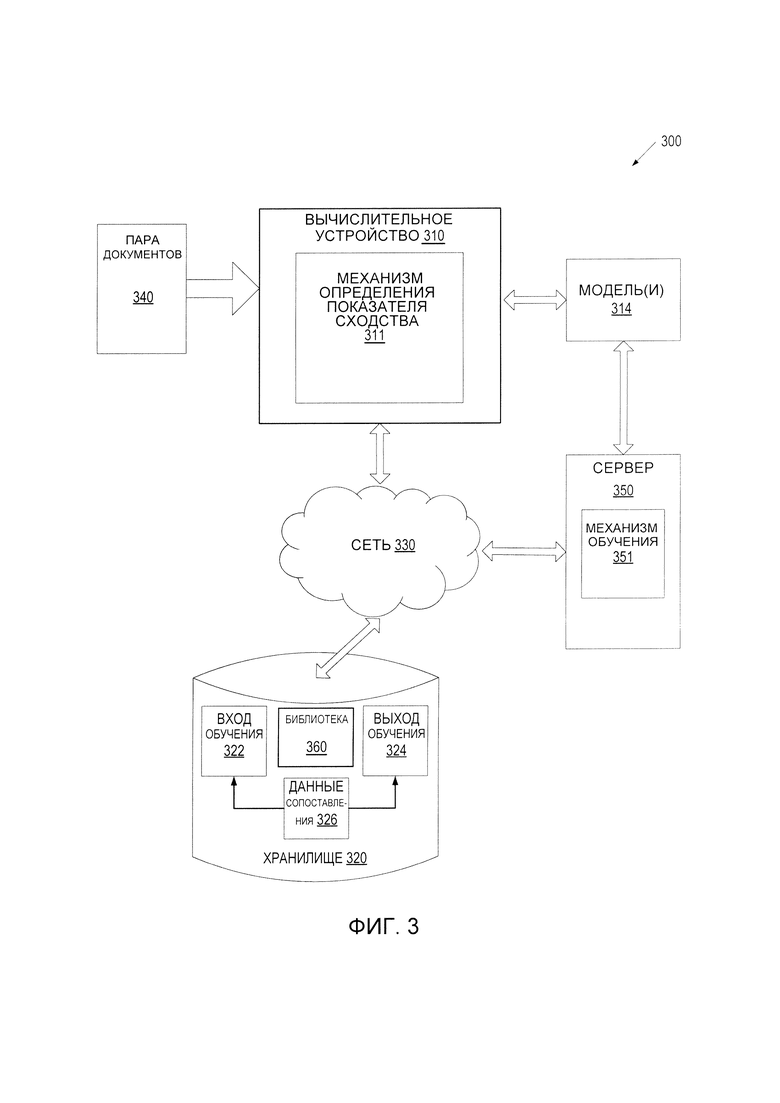
[0011] На Фиг. 3 представлена блок-схема примера компьютерной системы, в которой могут работать варианты осуществления настоящего изобретения.
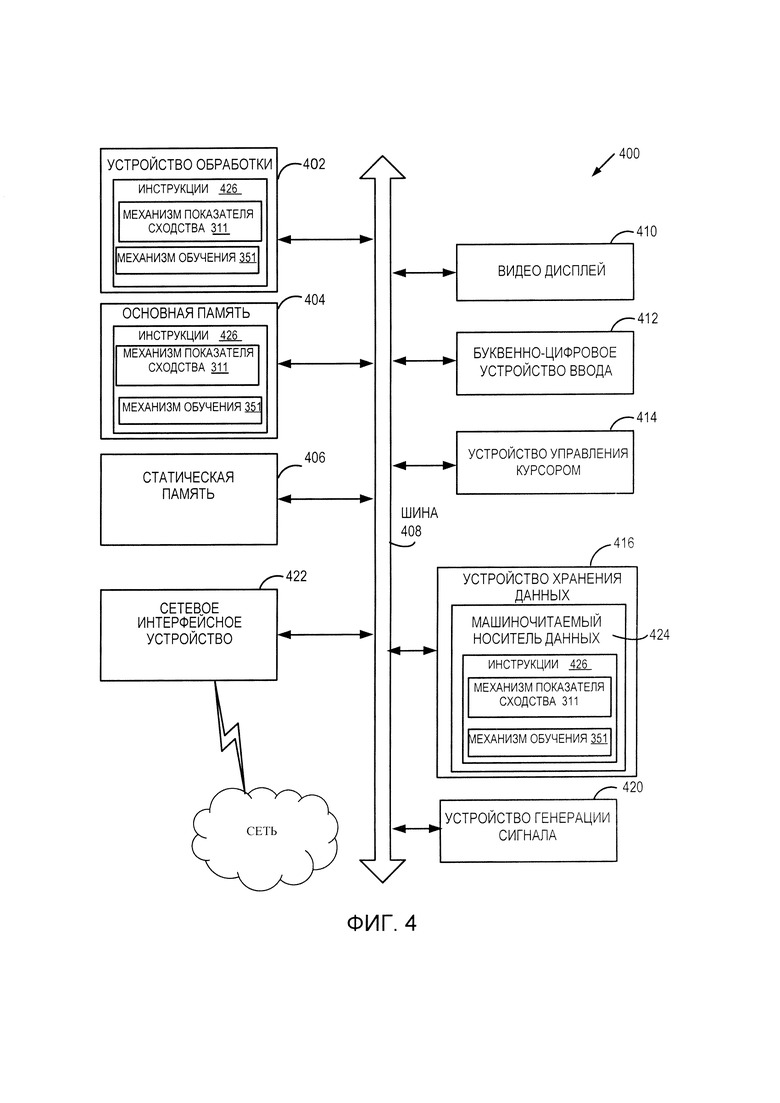
[0012] На Фиг. 4 представлена иллюстрация блок-схемы компьютерной системы в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0013] На Фиг. 5 представлена функциональная блок-схема, иллюстрирующая пример способа кластеризации документов в соответствии с некоторыми вариантами осуществления настоящего изобретения.
[0014] На Фиг. 6 представлена функциональная блок-схема, иллюстрирующая пример способа кластеризации документов в соответствии с некоторыми вариантами осуществления настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0015] Описывается реализация метода кластеризации документов. Различным способам группировки большого количества документов предшествует предварительное задание количества групп и конкретных параметров для каждой группы. Кроме того, для каждой группы должен быть создан набор атрибутов для идентификации документов, относящихся к этой группе. Это достаточно утомительные и трудоемкие задачи, требующие детального знания перед выполнением группировки типов документов, которые можно найти в хранилище документов. К тому же такой подход нелегко адаптировать к другому набору документов или изменению критериев группировки.
[0016] Например, при использовании такого подхода для настройки процесса группировки документов, связанных с поставщиками, необходимо будет создать подробное описание атрибутов документов для каждого известного поставщика. Затем необходимо разработать классификатор для сортировки документов на основе этих атрибутов. Однако при добавлении нового поставщика необходимо создать набор атрибутов, соответствующих новому поставщику, а также перенастроить классификатор документов, чтобы добавить новую категорию и новые критерии сортировки.
[0017] Варианты реализации изобретения учитывают вышеуказанные и другие недостатки путем предоставления механизмов кластеризации документов без предварительного знания типов документов, подлежащих сортировке, и независимо от количества существующих групп (кластеров) документов.
[0018] Используемый в настоящем документе термин «электронный документ» (а также просто «документ») может относиться к любому документу, изображение которого может быть доступно для вычислительной системы. Изображение может быть отсканированным, сфотографированным или любым другим представлением документа, которое можно преобразовать в форму данных, доступную для компьютера. Например, «электронный документ» может относиться к файлу, содержащему один или более элементов цифрового контента, который может быть визуализирован с целью наглядного представления электронного документа (например, на дисплее или на печатном носителе). В соответствии с различными вариантами осуществления настоящего изобретения документ может быть представлен в виде файла любого подходящего формата, например, PDF, DOC, ODT, JPEG и др.
[0019] «Документ» может представлять собой финансовый, юридический или любой другой документ, например документ, который составляется путем заполнения полей буквенно-цифровыми символами (например, буквы, слова, цифры) или изображениями. «Документ» может представлять собой любой документ, который печатается на принтере, набирается на клавиатуре или пишется от руки (например, путем заполнения стандартной формы). «Документом» может быть форма документа с различными полями - текстовыми полями (содержащими цифры, числа, буквы, слова, предложения), графическими полями (содержащими логотипы или любое другое изображение), таблицами (со строками, столбцами, ячейками) и так далее.
[0020] Используемый в настоящем документе термин «кластер документов» может относиться к одному или более документам, объединенным в группу на основе одной или более характеристик документов (атрибутов). Например, к этим характеристикам могут относиться тип документа (например, изображение, текстовый документ или таблица и т.д.), категория документа (например, соглашение, счет-фактура, визитные карточки или чеки) или поставщик, на которого имеется ссылка в документе.
[0021] Описанные здесь способы позволяют производить автоматическую кластеризацию документов с использованием искусственного интеллекта. К этим методам может относиться обучение нейронной сети кластеризации документов в неопределенные классы. Нейронная сеть может включать в себя несколько нейронов, которые связаны с весовыми коэффициентами и смещениями. Нейроны могут быть расположены слоями. Нейронная сеть может быть обучена на обучающей выборке документов, содержащей известные документы. Например, обучающая выборка может содержать примеры документов, принадлежащих к заранее определенным классам, в качестве обучающих входных данных и один или более показателей сходства, определяющих, насколько велико сходство документа с определенным классом, в качестве обучающих выходных данных.
[0022] Нейронная сеть может генерировать наблюдаемые выходные данные для каждого обучающего набора входных данных. Наблюдаемый результат на выходе нейронной сети можно сравнить с целевым выходом, который соответствует обучающим входным данным и указан в обучающем наборе данных, а ошибка может быть распространена в обратном направлении на предыдущие слои нейронной сети, параметры которой (например, весовые коэффициенты и смещения нейронов) могут быть соответствующим образом скорректированы. Во время обучения нейронной сети ее параметры можно скорректировать в целях получения оптимальной точности прогнозирования. После обучения нейронная сеть может использоваться для автоматической кластеризации документов с использованием показателей сходства между каким-либо документом и известными кластерами документов.
[0023] Фиг. 1 представляет собой функциональную блок-схему, иллюстрирующую пример способа 100 кластеризации документов в соответствии с некоторыми вариантами осуществления настоящего изобретения. Способ 100 может выполняться с помощью логических схем обработки данных, которые могут включать в себя аппаратное обеспечение (например, схемы, специальные логические устройства, программируемую логику, набор микрокоманд и т.д.), программное обеспечение (например, команды, исполняемые устройством обработки данных), прошивку или их комбинацию. В одном из вариантов осуществления способ 100 может выполняться устройством обработки данных (например, вычислительным устройством 310, показанном на Фиг. 3) вычислительного устройства 402, как описано в соответствии с Фиг. 4. В других вариантах осуществления способ 100 может выполняться в одном потоке обработки. Кроме того, способ 100 может выполняться в двух или более потоках обработки, при этом каждый поток выполняет одну или более отдельных функций, процедур, подпрограмм или операций способа. В пояснительном примере потоки обработки, применяющие способ 100, могут быть синхронизированы (например, с использованием семафоров, критических сегментов и/или других механизмов синхронизации потоков). Кроме того, потоки обработки, применяющие способ 100, могут выполняться асинхронно по отношению друг к другу. Поэтому, хотя на Фиг. 1 и в соответствующих описаниях способа 100 операции перечисляются в определенном порядке, в иных вариантах осуществления способов по меньшей мере некоторые из описанных операций могут выполняться параллельно и/или в произвольно выбранном порядке.
[0024] На шаге 110 устройство обработки данных, выполняющее способ 100, может получать один или более документов из хранилища документов.
[0025] В качестве хранилища документов может выступать электронное устройство, используемое для хранения данных. Это могут быть, без ограничений, внутренние и внешние жесткие диски, компакт-диски, DVD, дискеты, USB-накопители, ZIP-диски, магнитные ленты и SD-карты. Хранилище может содержать несколько каталогов и подкаталогов. Документом может быть текстовый документ, документ в формате PDF, документ с изображением, фотоизображение и т.д.
[0026] На шаге 120 устройство обработки данных, выполняющее способ 100, может определить для документа из хранилища показатель сходства для каждого единичного кластера или для нескольких существующих кластеров. Показатель сходства/подобия отражает степень сходства между документом и кластером документов (который может содержать один или несколько документов). Такой показатель сходства (мера сходства, мера подобия) может быть рассчитана с использованием функции сходства, которая при вводе двух документов формирует ряд показателей степени сходства между этими двумя документами. В некоторых вариантах осуществления настоящего изобретения выходное значение функции сходства - это число от 0 до 1.
[0027] В других вариантах осуществления функция сходства является аналитической функцией (т.е. может быть выражена математической формулой). В некоторых вариантах осуществления функция сходства может быть реализована в качестве алгоритма (например, описана как последовательность действий). Функция сходства может использовать один или более атрибутов документа для определения степени сходства между документами.
[0028] В некоторых вариантах осуществления для определения степени сходства используются атрибуты документов типа GRID. Атрибуты документа типа GRID рассчитываются путем разбиения документа на множество ячеек, которые формируют сетку, при этом атрибуты изображения рассчитываются для каждой ячейки. Для сравнения двух документов с использованием атрибутов типа GRID атрибуты ячейки первого документа сравниваются с атрибутами для соответствующей (т.е. аналогично позиционированной) ячейки второго документа. Для определения степени сходства всех документов используются результаты последовательного сопоставления соответствующих ячеек.
[0029] В некоторых вариантах осуществления для определения степени сходства используются атрибуты документов типа SVD. Атрибуты документа типа SVD (разложение по сингулярным значениям, singular value decomposition) определяются с использованием сингулярного разложения словесной матрицы с соответствующей частотой слов. Любой документ может характеризоваться набором слов, присутствующих в документе, и частотой их использования в документе. Возможно создать набор карт распределения, так чтобы каждая карта связывала слово с частотой его применения в документе. Например, карта распределения может быть представлена таблицей, в первой колонке которой перечислены слова (или их идентификаторы), а во второй - количество применений слова, присутствующего в документе. Такая матрица высокого ранга может быть преобразована в матрицу более низкого ранга, которая может быть использована в качестве атрибута типа SVD в документе.
[0030] В некоторых вариантах осуществления для определения степени сходства между двумя документами используются атрибуты типа «Изображения» документа. Атрибут типа изображения (атрибут тип Image) представляет собой набор параметров, создаваемых сверточной нейросетью, обрабатывающей изображение документа. Атрибут изображения обычно представляет собой набор чисел, кодирующих изображение документа.
[0031] В некоторых вариантах осуществления настоящего изобретения функция сходства использует один или более перечисленных выше атрибутов для определения показателя сходства между двумя документами. В других вариантах осуществления функция сходства использует другие типы атрибутов документов, не перечисленные выше, иногда в комбинации с вышеуказанными типами атрибутов.
[0032] В некоторых вариантах осуществления настоящего изобретения функция сходства может быть реализована с использованием градиентного бустинга (gradient boosting).
[0033] В некоторых случаях функция сходства реализуется как нейронная сеть.
[0034] В некоторых вариантах осуществления функция сходства может быть построена таким образом, что она может выдавать ложноотрицательные результаты (т.е. когда значение сходства, полученное функцией сходства для двух документов, принадлежащих к одному и тому же кластеру, опустится ниже заданного порогового значения сходства), при этом маловероятно, что она выдаст ложноположительные результаты (т.е. когда значение сходства, полученное функцией сходства для двух документов, принадлежащих к различным кластерам, превысит заданное пороговое значение сходства). Этого можно добиться за счет использования относительно большого числа атрибутов документов и/или обучения функции сходства на относительно большом количестве документов.
[0035] Фиг. 2 является схематической иллюстрацией структуры нейронной сети, работающей в соответствии с одним или более вариантами реализации настоящего изобретения. Как показано на Фиг. 2, нейронная сеть 200 может быть представлена в виде нерекуррентной нейронной сети с обратной связью, включая входной слой 210, выходной слой 220 и один или более скрытых слоев 230, соединяющих входной слой 210 и выходной слой 220. Выходной слой 220 может иметь такое же количество узлов, что и входной слой 210. Таким образом, сеть 200 можно обучать, используя неконтролируемый процесс обучения для восстановления ее собственных входных данных.
[0036] Нейронная сеть может включать в себя множество нейронов, которые ассоциированы с весовыми коэффициентами и отклонениями. Нейроны могут быть размещены послойно. Нейронная сеть может быть обучена на обучающей выборке данных из пар документов с известными показателями сходства.
[0037] Нейронная сеть может генерировать наблюдаемые выходные данные для каждого обучающего набора входных данных. Во время обучения нейронной сети ее параметры можно скорректировать в целях получения оптимальной точности прогнозирования. Обучение нейронной сети может включать в себя обработку нейронной сетью пар документов таким образом, чтобы сеть определяла показатель сходства (т.е. наблюдаемый выход) для этих пар документов, а также сравнение установленного показателя сходства с известным показателем сходства (т.е. с целевыми выходными данными, соответствующими обучающим входным данным, указанным в обучающей выборке данных). Наблюдаемые выходные данные нейронной сети можно сравнить с целевыми выходными данными, а ошибка может быть распространена в обратном направлении на предыдущие слои нейронной сети, параметры которых (например, весовые коэффициенты и смещения нейронов) могут быть соответствующим образом скорректированы, чтобы свести к минимуму функцию потерь (т.е. разницу между наблюдаемыми выходными данными и обучающими выходными данными).
[0038] После обучения нейронная сеть может быть использована для автоматического определения показателя сходства для пар документов. Механизмы, описанные в настоящем документе для определения показателей сходства, могут повысить качество процесса кластеризации документов путем определения показателя сходства с использованием обученной нейронной сети таким образом, чтобы учитывать наиболее релевантные атрибуты документа.
[0039] В некоторых вариантах осуществления для определения показателя сходства для документа 110 и кластера документов функция сходства рассчитывается для документа 110 и каждого документа подмножества из одного или нескольких документов кластера документов. В других вариантах осуществления для расчета показателя сходства подмножество документов из кластера документов выбирается случайным образом. В некоторых вариантах осуществления показатели сходства документов, выбранных из группы документов, и документа 110 усредняются для получения показателя сходства кластера документов и документа 110.
[0040] В некоторых вариантах осуществления для определения показателя сходства для документа 110 и кластера документов функция сходства рассчитывается для документа 110 и центроида кластера документов.
[0041] Центроид кластера документов - это документ, атрибуты которого равны или близки к средним значениям одного или более атрибутов одного или более документов в кластере.
[0042] На шаге 130 обрабатывающее устройство, выполняющее способ 100, может определить, какой из кластеров документов имеет самый высокий показатель сходства, как определено на этапе 120.
[0043] На шаге 140 обрабатывающее устройство, выполняющее способ 100, может сравнить самый высокий показатель сходства с предварительно заданным пороговым значением сходства. Если наивысший показатель сходства выше порогового значения, обрабатывающее устройство может причислить документ к кластеру, который соответствует показателю наибольшего сходства (шаг 150). В некоторых применениях настоящего изобретения после того, как документ добавляется в кластер, обрабатывающее устройство, выполняющее способ 110, пересчитывает центроид этого кластера.
[0044] Если обрабатывающее устройство, выполняющее способ 100, определяет, что самый высокий показатель сходства находится ниже порогового значения, устройство обработки данных может создать новый кластер документов (шаг 160). Затем обрабатывающее устройство может причислить документ к этому новому кластеру (шаг 170).
[0045] В некоторых вариантах осуществления пользователь может идентифицировать документы, которые были ошибочно причислены системой к неподходящему кластеру. В других вариантах осуществления пользователь может также определить правильный кластер для такого документа. В таких случаях ошибка может быть зафиксирована системой, и функция сходства может быть скорректирована, чтобы компенсировать ошибку.
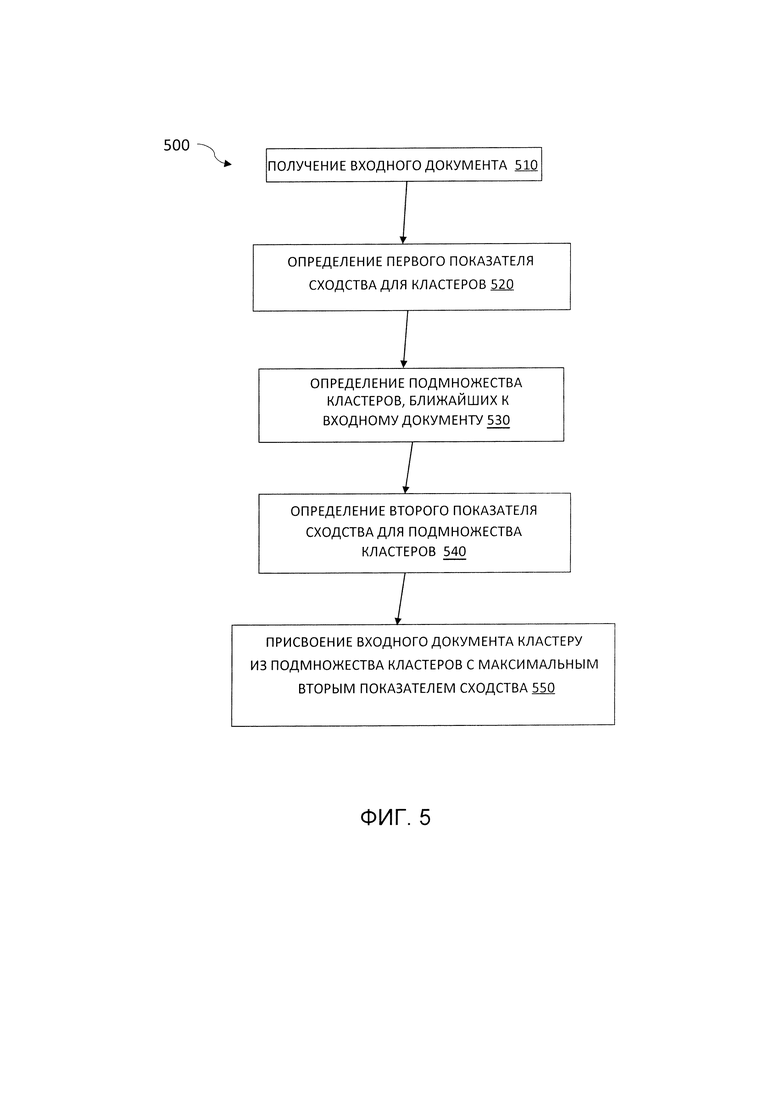
[0046] В некоторых вариантах осуществления настоящего изобретения способ 100 кластеризации документов включает в себя дифференциальную классификацию кластеров второго уровня, как показано на Фиг. 5. Обрабатывающее устройство, выполняющее способ 500, анализирует кластеры документов, используя первый показатель сходства для идентификации группы смежных кластеров.
[0047] Два или более кластеров считаются смежными, если расстояние между их центроидами меньше заданной степени разделения. Такие кластеры могут образовывать подмножество кластеров, состоящих из двух или более кластеров с существенно близкими показателями сходства.
[0048] В некоторых вариантах осуществления после получения документа 510 обрабатывающим устройством, реализующем способ 500 (см. шаг 510), используется первый показатель сходства для определения ближайшего к документу 510 подмножества кластеров (см. шаги 520, 530). Затем, как показано на шаге 540, для определения второго набора показателей сходства кластеров из подмножества кластеров, идентифицированных на шаге 530, используются вторые, более чувствительные функции сходства. На шаге 550, основывающемся на вторых показателях сходства, обрабатывающее устройство определяет кластер документов, ближайший к входному документу 510, и причисляет документ 510 к этому кластеру.
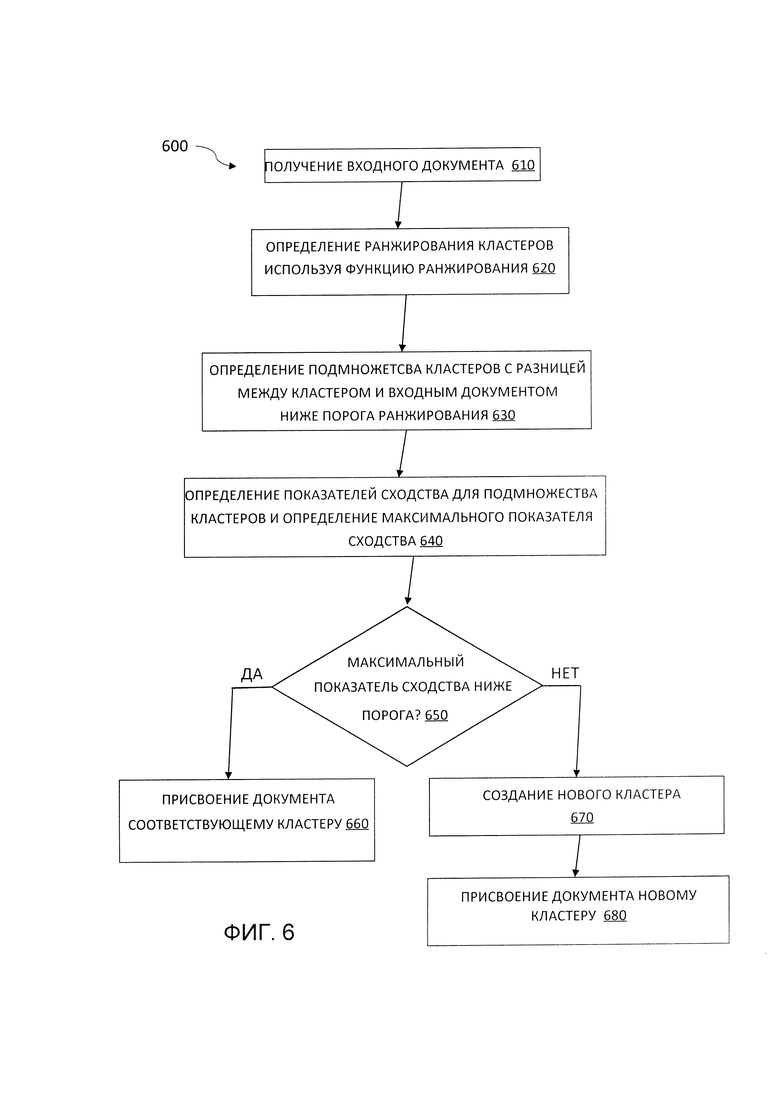
[0049] В некоторых вариантах осуществления настоящего изобретения, как показано на Фиг. 6, для определения наиболее перспективных кластеров для документа используется функция ранжирования, основанная на показателе сходства. Функция ранжирования вычисляет вероятность того, что входной документ будет в значительной степени сходен с данным кластером документов.
[0050] Как показано на Фиг. 6, на шаге 610 устройство обработки получает входной документ 610. Затем к кластерам документов применяется функция ранжирования для расчета вероятности принадлежности документа 610 к конкретному кластеру 620. На шаге 630 может быть идентифицировано/определено подмножество кластеров документов с высокой вероятностью сходства с документом. Иногда это подмножество включает в себя как минимум предварительно заданное количество кластеров документов с наибольшей вероятностью сходства. В других вариантах осуществления подмножество включает в себя все кластеры документов с вероятностью сходства с документом, превышающим заданное пороговое значение вероятности. На шаге 640 обрабатывающее устройство вычисляет для кластеров из подмножества кластеров документов более точные (и более ресурсоемкие) показатели сходства (например, показатели сходства, которые работают на большем количестве атрибутов документов). Из этих показателей сходства выявляется наивысший (максимальный) показатель сходства. На шаге 650 обрабатывающее устройство, выполняющее способ 600, может сравнить самый высокий показатель сходства с предварительно заданным пороговым значением сходства. Если максимальный показатель сходства превышает пороговый уровень, обрабатывающее устройство может причислить входной документ к кластеру, который соответствует самому высокому показателю сходства (шаг 660). Если обрабатывающее устройство, выполняющее способ 600, определяет, что самый высокий показатель сходства находится ниже порогового значения, устройство обработки данных может создать новый кластер документов (шаг 670). Затем обрабатывающее устройство может причислить документ 610 к этому новому кластеру (шаг 680).
[0051] В некоторых вариантах осуществления настоящего изобретения устройство обработки может выполнять операцию минимизации кластера. Кластеры, созданные по способу 100, а также ранее созданные кластеры, анализируются для определения атрибутов, удовлетворяющих одному или более критериям слияния кластеров. Два или более кластеров, в которых имеются документы с атрибутами, соответствующими этим критериям, могут объединяться в более крупные кластеры. В некоторых вариантах осуществления устройство обработки данных может пересчитывать центроиды вновь образованных кластеров.
[0052] Вышеупомянутый способ может быть использован для различных случаев применения. Как показано в пояснительном примере, этот способ может использоваться для группировки документов сторонами, упоминаемыми в документе. Входной поток документов может включать в себя такие документы, как заявки, счет-фактуры, коносаменты, заказы на покупку и т.д. Большинство этих документов берут начало в какой-то организации и включают название и адрес этой организации. Точного перечня этих организаций может и не быть. Кроме того, документы от новых организаций могут быть добавлены во входной поток в любое время.
[0053] Способ настоящего изобретения позволяет группировать эти документы по организациям. В других вариантах осуществления данный способ может допустить группировку таких документов по географическому местоположению, на которое имеется ссылка в этих документах (от этой организации или других организаций). В других вариантах осуществления документы могут быть сгруппированы по формату (например, все счета сгруппированы отдельно от заказов на покупку, квитанций, счет-фактур и т.д.). Документы могут быть сгруппированы по специфическим элементам (например, товарам или видам товаров), ссылкам в этих документах. Эти примеры являются иллюстративными и никак не ограничивают настоящее изобретение.
[0054] Фиг. 3 представляет собой блок-схему примерной компьютерной системы 300, в которой могут работать различные варианты осуществления изобретения. Как показано на примере, система 300 может включать в себя вычислительное устройство 310, хранилище 320 документов и сервер 350, подключенный к сети 330. Сеть 330 может быть публичной сетью (например, Интернетом), частной сетью (например, локальной сетью (LAN) или сетью широкого доступа (WAN)) или их комбинацией.
[0055] Вычислительным устройством 310 может быть настольный компьютер, портативный компьютер, смартфон, планшетный компьютер, сервер, сканер или любое подходящее вычислительное устройство, способное реализовать технические решения, описанные в настоящем документе. В некоторых вариантах осуществления вычислительным устройством 310 может быть (и/или включать в себя) одно или несколько вычислительных устройств системы 400 на Фиг. 4.
[0056] Пара документов 340 может быть получена вычислительным устройством 310. Пара документов 340 может быть получена любым подходящим способом. Кроме того, в тех случаях, когда вычислительное устройство 310 является сервером, клиентское устройство, подключенное к серверу через сеть 330, может загрузить пару документов 340 на сервер. В тех случаях, когда вычислительное устройство 310 является клиентским устройством, подключенным к серверу через сеть 330, клиентское устройство может загрузить пару документов 340 с сервера или из хранилища 320.
[0057] Пара документов 340 может использоваться для обучения набора моделей для машинного обучения или может быть новой парой документов, для которых необходимо определить показатель сходства.
[0058] В одном из вариантов осуществления вычислительное устройство 310 может включать в себя механизм/движок/средство 311 определения показателя сходства. В свою очередь, механизм 311 определения показателя сходства может содержать инструкции, хранящиеся на одном или более реальных, машиночитаемых носителях данных вычислительного устройства 310 и исполняемых одним или более обрабатывающими устройствами вычислительного устройства 310.
[0059] В одном из вариантов осуществления механизм 311 определения показателя сходства может использовать набор обученных моделей 314 машинного обучения для определения одного или более показателей сходства пар документов 340. Библиотека 360 пар документов может располагаться в хранилище 320. Для определения показателей сходства обучаются и используются модели 314 машинного обучения.
[0060] В качестве механизма 311 определения показателей сходства может выступать клиентское приложение или комбинация клиентского компонента и серверного компонента. В некоторых вариантах осуществления механизм 311 определения показателей сходства может работать полностью на клиентском вычислительном устройстве, таком как серверный компьютер, настольный компьютер, планшетный компьютер, смартфон, ноутбук, камера, видеокамера или тому подобное. В качестве альтернативы клиентский компонент механизма 311 определения показателя сходства, исполняемый на клиентском вычислительном устройстве, может принять пару документов и передать их на серверный компонент механизма 311 определения показателя сходства, исполняемый на серверном устройстве, которое выполняет определение показателя сходства. Серверный компонент механизма 311 определения показателя сходства может затем возвратить установленный показатель сходства для хранения на клиентский компонент механизма 311, исполняемый на клиентском вычислительном устройстве. В качестве альтернативы серверный компонент механизма 311 определения показателя сходства может передать результат идентификации другому приложению. В других вариантах осуществления механизм 311 определения показателя сходства может выполняться на серверном устройстве как приложение с выходом в Интернет, доступное через интерфейс браузера. Серверное устройство может быть представлено одной или несколькими компьютерными системами, такими как одна или более серверных машин, рабочих станций, мэйнфреймов, персональных компьютеров (ПК) и т.д.
[0061] Серверная машина 350 может представлять собой и/или включать в себя установленный в стойку сервер, маршрутизатор, персональный компьютер, портативный цифровой помощник, мобильный телефон, портативный компьютер, планшетный компьютер, камеру, видеокамеру, нетбук, настольный компьютер, медиацентр или любое сочетание вышеперечисленного. Серверная машина 350 может включать в себя механизм 351 обучения. Обучающий механизм 351 может создавать модель (модели) 314 машинного обучения для определения показателя сходства. Модель (модели) 314 машинного обучения, как показано на Фиг. 3, может обучаться с помощью обучающего механизма 351 с использованием обучающих данных, которые включают в себя обучающие входные и соответствующие выходные данные (правильные ответы для соответствующих обучающих входных данных). Обучающий механизм 35 1 может находить шаблоны в обучающих данных, которые преобразовывают обучающие входные данные в обучающие выходные данные (ответ, который нужно предсказать) и предоставляют модели 314 машинного обучения, которые фиксируют эти шаблоны. Набор моделей 314 машинного обучения может состоять, например, из одноуровневых линейных или нелинейных операций (например, машина опорных векторов (SVM)) или в виде глубокой нейронной сети, например модели машинного обучения, которая состоит из нескольких уровней нелинейных операций. Примерами глубоких нейронных сетей являются такие нейронные сети, как сверточные нейронные сети, рекуррентные нейронные сети (RNN) с одним или более скрытыми слоями и полносвязные нейронные сети. В некоторых вариантах осуществления модели 314 машинного обучения могут содержать одну или более нейронных сетей, как описано в связи с Фиг. 2.
[0062] Модели машинного обучения 314 можно обучать определению показателей сходства для пары документов 340. Обучающие данные могут содержаться в хранилище 320 и могут включать в себя один или более наборов 322 обучающих входных данных и один или более наборов 324 обучающих выходных данных. Обучающие данные могут также содержать данные 326 сопоставления (мапирования) информации, которые преобразовывают обучающие входные данные 322 в выходные данные 324. Во время процесса обучения обучающий механизм 351 может находить закономерности в обучающих данных 326 сопоставления, которые могут использоваться для преобразования обучающих входных данных в выходные данные. Эти закономерности могут впоследствии использоваться моделью (моделями) 314 машинного обучения для будущих прогнозов. Например, при получении на входе неизвестной пары документов обученная модель (модели) 314 машинного обучения может предсказать показатель сходства для этой пары документов и выдать такой показатель сходства в качестве результата на выходе.
[0063] Хранилище 320 может быть постоянным, и в нем могут храниться структуры для определения показателя сходства в соответствии с вариантами осуществления настоящего изобретения. Хранилище 320 может размещаться на одном или более устройствах хранения данных, таких как основное запоминающее устройство, магнитные или оптические диски хранения данных, ленты или жесткие диски, сетевое хранилище (NAS), системная сеть (SAN) и так далее. Несмотря на то, что хранилище 320 показано отдельно от вычислительного устройства 310, в конкретном варианте осуществления оно может быть частью вычислительного устройства 310. В некоторых вариантах осуществления хранилище 320 может быть подключенным к сети файловым сервером, в то время как в других случаях хранилище 320 может быть каким-то другим типом постоянного хранилища, например, объектно-ориентированной базой данных, реляционной базой данных и так далее, которые могут быть размещены на серверной машине (сервере) или одной или более машинах другого типа, подключенных к сети 330.
[0064] На Фиг. 4 изображен пример компьютерной системы 400, которая может выполнять любой из способов или несколько способов, описанных в настоящем документе. Компьютерная система (например, сетевая) может быть подключена к другим компьютерным системам в локальной сети (LAN), корпоративной сети типа Интранет, частной компьютерной сети типа Экстранет или к Интернету. Компьютерная система может работать в качестве сервера в сетевой среде клиент-сервер. Компьютерной системой может быть персональный компьютер (ПК), планшетный компьютер, ТВ-приставка, персональный цифровой помощник, мобильный телефон, камера, видеокамера или любое устройство, способное выполнить набор инструкций (последовательно или иным образом), определяющих действия, которые должны быть выполнены с помощью этого устройства. Кроме того, хотя на фигуре показана система только на базе одного компьютера, термин «компьютер» также должен подразумевать любую совокупность компьютеров, которые по отдельности или совместно выполняют набор (или несколько наборов) команд для выполнения любого из тех или иных способов, рассматриваемых в настоящем документе.
[0065] Компьютерная система 400, представленная в качестве примера, включает в себя вычислительное устройство 402, основное запоминающее устройство 404 (например, память только для чтения (ROM), флеш-память, динамическое запоминающее устройство с произвольным доступом (DRAM), такое как синхронная DRAM (SDRAM)), статическое запоминающее устройство 406 (например, флеш-память, статическое ЗУ с произвольной выборкой (SRAM)) и устройство 416 хранения данных, которые осуществляют коммуникацию через шину 408.
[0066] Устройство обработки 402 данных представляет собой одно или более устройств общего назначения, таких как микропроцессор, центральный процессор или тому подобное. В частности, обрабатывающее устройство 402 может быть вычислительным микропроцессором (CISC) со сложным набором инструкций, вычислительным микропроцессором с уменьшенным набором инструкций (RISC), микропроцессором с командными словами очень большой длины (VLIW) или процессором, реализующим другие наборы инструкций или комбинацию наборов инструкций. Устройство 402 обработки данных может также существовать в виде одного или более специальных обрабатывающих устройств, таких как специализированная интегральная микросхема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор обработки цифровых сигналов (DSP), сетевой процессор или тому подобное. Вычислительное устройство 402 настроено для исполнения инструкций 426 механизмом 311 определения показателей сходства и/или механизмом 351 обучения с Фиг. 3 и для выполнения операций и шагов, рассматриваемых в настоящем документе (например, способ 100 на Фиг. 1).
[0067] Компьютерная система 400 может также включать в себя устройство 422 сетевого интерфейса. В компьютерную систему 400 также может входить блок видеодисплея 410 (например, жидкокристаллический дисплей (LCD) или катодная лучевая трубка (CRT)), буквенно-цифровое устройство 412 ввода (например, клавиатура), устройство 414 управления курсором (например, мышь) и устройство 420 генерации сигнала (например, динамик). В одном иллюстративном примере показано, что видео дисплей 410, буквенно-цифровое устройство 412 ввода и устройство 414 управления курсором могут быть объединены в одном компоненте или устройстве (например, сенсорный ж/к экран).
[0068] Устройство 416 хранения данных может включать в себя машиночитаемый носитель 424 данных, на котором хранятся инструкции 426, реализующие одну или более методологий или функций, описанных в настоящем документе. Инструкции 426 могут также находиться полностью или, как минимум, частично в основном запоминающем устройстве 404 и/или в устройстве 402 обработки во время их исполнения компьютерной системой 400, основным запоминающим устройством 404 и устройством 402 обработки, которые также относятся к машиночитаемым носителям данных. В некоторых вариантах осуществления инструкции 426 могут далее быть переданы или получены через сеть посредством устройства 422 сетевого интерфейса.
[0069] Хотя машиночитаемый носитель 424 данных показан в иллюстративных примерах как одиночное устройство, термин «машиночитаемый носитель данных» должен подразумевать один или более носителей данных (например, централизованная или распределенная база данных и/или связанные с ней устройства кэш-памяти и серверы), на которых хранятся один или более наборов команд. Термин «машиночитаемый носитель данных» также должен подразумевать любую среду, способную хранить, кодировать или переносить набор инструкций для исполнения машиной, и которая вызывает выполнение машиной какой-либо или нескольких методик настоящего изобретения. Термин «машиночитаемый носитель данных» должен соответственно включать в себя, без ограничений, твердотельную память, оптические и магнитные носители информации.
[0070] Хотя операции в рамках способов, описанных в настоящем документе, отображаются и описываются в определенном порядке, порядок операций каждого способа может быть изменен таким образом, чтобы определенные операции выполнялись в обратном порядке или так, чтобы определенная операция могла выполняться, как минимум частично, одновременно с другими операциями. В отдельных вариантах осуществления инструкции или подоперации отдельных операций могут быть периодическими и/или чередующимися.
[0071] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Многие другие варианты осуществления станут очевидными для тех, кто обладает профессиональными навыками, после прочтения и понимания приведенного выше описания. Таким образом, область применения изобретения должна определяться в связи с прилагаемыми формулами изобретения, а также с полным перечнем их аналогов, на которые распространяется действие таких патентных формул.
[0072] В представленном выше описании изложены многочисленные детали. Однако для тех, кто обладает профессиональными навыками, будет очевидно, что аспекты настоящего изобретения могут применяться на практике без этих конкретных деталей. В некоторых случаях известные конструкции и устройства отображаются в виде блок-схем, без описания деталей, чтобы не загромождать излишними подробностями настоящего изобретения.
[0073] Некоторые части приведенных выше подробных описаний показаны с точки зрения алгоритмов и символических представлений операций на битах данных в компьютерной памяти. Эти алгоритмические описания и представления применяются как средство теми, кто компетентен в области обработки данных, чтобы наиболее эффективно донести суть своей работы до других квалифицированных в этой области специалистов. Приведенный в данном документе (и в целом) алгоритм сконструирован в общем как непротиворечивая последовательность шагов, ведущих к требуемому результату. Эти шаги требуют физических манипуляций с физическими количественными величинами. Обычно, хотя и не обязательно, эти количества принимают форму электрических или магнитных сигналов, которые могут храниться, передаваться, комбинироваться, сравниваться и подвергаться иным манипуляциям. Иногда, главным образом по причинам общего пользования, было удобно ссылаться на эти сигналы как на биты, значения, элементы, знаки, символы, термины, числа или тому подобное.
[0074] Вместе с тем следует иметь в виду, что все эти и аналогичные термины должны ассоциироваться с соответствующими физическими количествами и являются лишь удобными обозначениями, применяемыми к этим количествам. Если прямо не указано иное, как видно из последующего обсуждения, то следует понимать, что во всем описании такие термины, как «получение», «определение», «выбор», «хранение», «анализ» или тому подобное, относятся к действиям и процессам компьютерной системы или аналогичным электронным вычислительным устройствам, которые манипулируют данными, представленными в качестве физических (электронных) количественных величин в регистрах и в памяти компьютерной системы, а также преобразуют их в другие данные, аналогичным образом представленные в качестве физических количественных величин в рамках памяти или регистров компьютерной системы или другого такого устройства хранения, передачи или отображения информации.
[0075] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая вычислительная программа может храниться на машиночитаемом носителе данных, включая, среди прочего, диски любого типа, в том числе дискеты, оптические диски, компакт-диски и магнитно-оптические диски, ПЗУ (ROM), ОЗУ (RAM), ЭППЗУ (EPROM), ЭСППЗУ (EEPROM), магнитные или оптические карты или любой другой тип носителей данных, пригодный для хранения электронных команд, каждый из которых подключен к шине компьютерной системы.
[0076] Алгоритмы и изображения, приведенные в настоящем документе, не обязательно связаны с конкретными компьютерами или другими устройствами. С программами могут быть использованы различные системы общего назначения в соответствии с рекомендациями, предоставленными в настоящем документе, или может оказаться более удобным создать более специализированный аппарат для выполнения необходимых шагов в рамках способа. Необходимая конструкция для множества таких систем будет представлена ниже в описании. Кроме того, аспекты настоящего изобретения не описываются со ссылкой на какой-либо конкретный язык программирования. Следует принимать во внимание, что для реализации рекомендаций в рамках настоящего изобретения, как описано в настоящем документе, могут быть использованы различные языки программирования.
[0077] Аспекты настоящего изобретения могут быть предоставлены в качестве компьютерной программы или программного обеспечения, которое может включать в себя машиночитаемый носитель информации с хранящимися на нем командами, которые могут быть использованы для программирования компьютерной системы (или других электронных устройств) для выполнения процесса в соответствии с настоящим изобретением. Машиночитаемый носитель включает в себя любой механизм хранения или передачи информации в форме, читаемой машиной (например, компьютером). Например, к машиночитаемому (или читаемому компьютером) носителю относятся машиночитаемый (или читаемый компьютером) накопитель (например, ПЗУ (ROM), ОЗУ (RAM), средства хранения на магнитных дисках, оптические средства хранения данных, устройства флеш-памяти и т.д.).
[0078] Слова «пример» или «примерный» используются в настоящем документе для обозначения того, что служит примером или иллюстрацией. Любой аспект или конструкция, описанные в настоящем документе как «пример» или «примерный», не обязательно должны истолковываться как предпочтительные или выгодные по сравнению с другими аспектами или конструкциями. Слова «пример» или «примерный» лишь предполагают, что идея изобретения представлена конкретным образом. В данном применении союз «или» означает включающее, а не исключающее «или». То есть, если не указано иное, или не следует из контекста, «X включает в себя А или В» означает любую из естественных включающих перестановок. То есть, если X включает в себя А; X включает в себя В; или X включает в себя как А, так и В, то утверждение «X включает в себя А или В» удовлетворяет любому из предшествующих случаев. Кроме того, неопределенные артикли («а» и «an»), используемые в настоящей заявке и прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Кроме того, использование термина «применение» или «один случай применения» или «реализация» или «один случай реализации» по ходу изложения не означает одно и то же применение или реализацию, если они не описаны как таковые. Кроме того, термины «первый», «второй», «третий», «четвертый» и т.д., используемые в настоящем варианте, предназначены в качестве обозначений для разных элементов и не обязательно имеют смысл порядкового перечисления в зависимости от их численного обозначения.
[0079] Принимая во внимание множество вариантов и модификаций настоящего изобретения, которые, без сомнения, будут очевидны лицу со средним опытом в профессии после прочтения изложенного выше описания, следует понимать, что любой частный вариант осуществления изобретения, приведенный и описанный для иллюстрации, ни в коем случае не должен рассматриваться как ограничение. Поэтому ссылки на детали различных применений не направлены на ограничение сферы действия формул изобретения, которые сами по себе описывают только те свойства, которые рассматриваются в качестве изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| АВТОМАТИЧЕСКОЕ ОПРЕДЕЛЕНИЕ НАБОРА КАТЕГОРИЙ ДЛЯ КЛАССИФИКАЦИИ ДОКУМЕНТА | 2018 |
|
RU2701995C2 |
| СИСТЕМА И СПОСОБ ФОРМИРОВАНИЯ ОБУЧАЮЩЕГО НАБОРА ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2711125C2 |
| ИЗВЛЕЧЕНИЕ ПОЛЕЙ С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ БЕЗ ИСПОЛЬЗОВАНИЯ ШАБЛОНОВ | 2019 |
|
RU2737720C1 |
| ОДНОВРЕМЕННОЕ РАСПОЗНАВАНИЕ АТРИБУТОВ ЛИЦ И ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПРИ ОРГАНИЗАЦИИ ФОТОАЛЬБОМОВ | 2018 |
|
RU2710942C1 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2803399C2 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2772549C1 |
| МЕТОД ПОСТРОЕНИЯ И ОБНАРУЖЕНИЯ ТЕМАТИЧЕСКОЙ СТРУКТУРЫ КОРПУСА | 2013 |
|
RU2583716C2 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2778630C1 |
| СИСТЕМА АДМИНИСТРИРОВАНИЯ ТРАНЗАКЦИЙ С ИИ | 2020 |
|
RU2777958C2 |
| РАСПОЗНАВАНИЕ СИМВОЛОВ С ИСПОЛЬЗОВАНИЕМ ИЕРАРХИЧЕСКОЙ КЛАССИФИКАЦИИ | 2018 |
|
RU2693916C1 |
Изобретение относится к области вычислительной техники для анализа документов. Технический результат заключается в повышении точности кластеризации документов. Технический результат достигается за счет получения входного документа; определения, путем оценки функции сходства документов, использующей один или более вычисленных атрибутов входного документа, множества показателей сходства, где каждый показатель сходства из множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером документов из множества кластеров документов; определения максимального показателя сходства из множества показателей сходства; определения того, что входной документ не относится ни к одному из кластеров документов из множества кластеров документов, если максимальный показатель сходства ниже порогового значения; создания нового кластера документов; и присвоения входного документа новому кластеру документов. 5 н. и 15 з.п. ф-лы, 6 ил.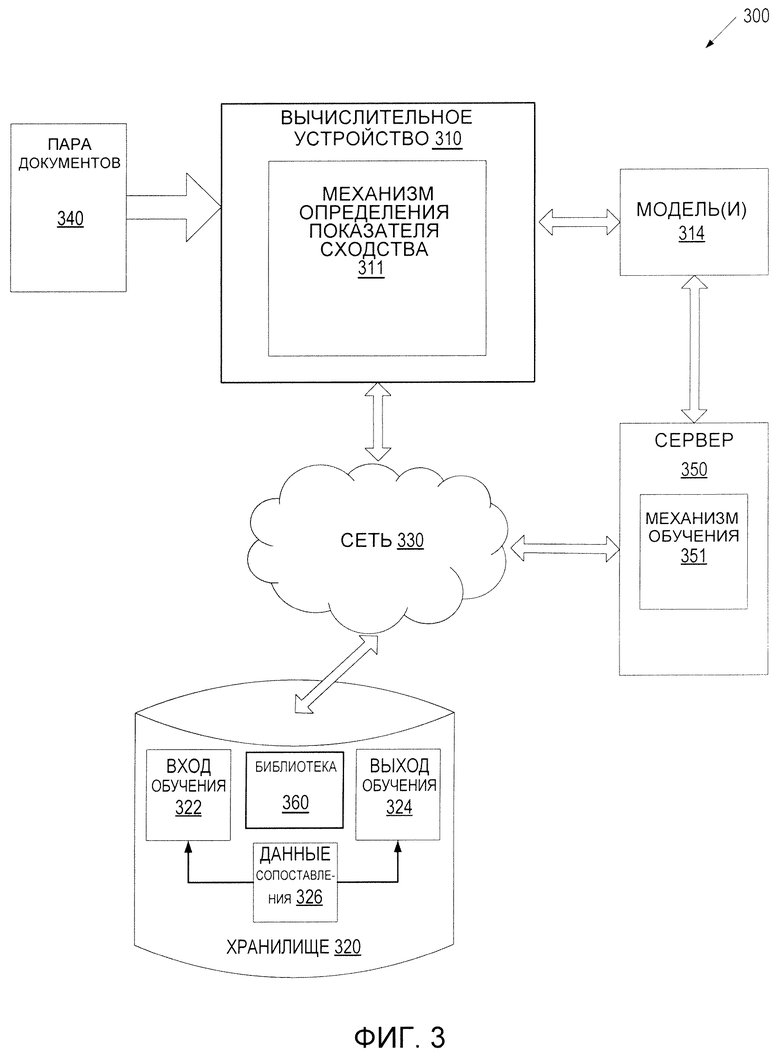
1. Способ кластеризации документов, исполняемый с помощью компьютерного устройства и включающий в себя:
получение входного документа;
определение, путем оценки функции сходства документов, использующей один или более вычисленных атрибутов входного документа, множества показателей сходства, где каждый показатель сходства из множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером документов из множества кластеров документов;
определение максимального показателя сходства из множества показателей сходства;
определение того, что входной документ не относится ни к одному из кластеров документов из множества кластеров документов, если максимальный показатель сходства ниже порогового значения;
создание нового кластера документов; и
присвоение входного документа новому кластеру документов.
2. Способ по п. 1, в котором типы вычисленных атрибутов первого документа выбираются из группы, состоящей из: атрибута типа GRID, атрибута типа SVD, атрибута типа Изображение.
3. Способ по п. 1, в котором использование функции сходства включает в себя применение первой нейронной сети.
4. Способ по п. 1, в котором входной документ является текстовым документом.
5. Способ по п. 1, в котором функция сходства определяет показатель сходства первого документа с первым кластером документов из множества кластеров путем расчета уровня сходства между первым документом и центроидом первого кластера документов.
6. Способ по п. 1, в котором функция сходства определяет показатель сходства первого документа с первым кластером документов из множества кластеров путем расчета соответствующих уровней сходства между первым документом и одним или более документами из первого кластера документов.
7. Способ по п. 1, дополнительно включающий: в ответ на определение того, что первый кластер документов из множества кластеров документов связан с первым документом, имеющим первое значение свойства документа, а второй кластер документов из множества кластеров документов связан со вторым документом, имеющим первое значение свойства документа, слияние первого кластера документов и второго кластера документов.
8. Способ кластеризации документов, исполняемый с помощью компьютерного устройства и включающий в себя:
получение входного документа;
определение, путем оценки первой функции сходства документов, первого множества показателей сходства, где каждый показатель сходства из первого множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером документов из множества кластеров документов;
определение, на основе множества показателей сходства, что входной документ относится к первому кластеру документов из множества кластеров документов, когда максимальная разница между центроидом первого кластера документов и ответными центроидами подмножества из данного множества кластеров документов опускается ниже предварительно заданного порога;
определение, путем оценки второй функции сходства документов, второго множества показателей сходства, где каждый показатель сходства из второго множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером документов из подмножества кластеров документов;
присвоение входного документа кластеру документов, ассоциированному с максимальным показателем сходства из второго множества показателей сходства.
9. Способ кластеризации документов, исполняемый с помощью компьютерного устройства и включающий в себя:
получение входного документа;
определение, путем оценки функции ранжирования для входного документа, первого кластера документов из множества кластеров документов, когда входной документ относится к идентифицированному кластеру документов, а максимальная разница между центроидом первого кластера документов и ответными центроидами подмножества кластеров документов опускается ниже заданного порога;
определение, путем оценки функции сходства документов, множества показателей сходства, где каждый показатель сходства из множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером документов из подмножества кластеров документов;
присвоение входного документа кластеру документов, ассоциированному с максимальным показателем сходства из множества показателей сходства.
10. Способ по п. 9, дополнительно включающий:
в ответ на определение того, что максимальный показатель сходства опускается ниже порогового значения сходства, создание нового кластера документов; и
создание связи входного документа с новым кластером документов.
11. Система для кластеризации документов, содержащая:
запоминающее устройство;
процессор, взаимосвязанный с запоминающим устройством, причем процессор сконфигурирован для:
получения входного документа;
определения, путем оценки функции сходства документов, множества показателей сходства, где каждый показатель сходства из множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером документов из множества кластеров документов;
определения максимального показателя сходства из множества показателей сходства;
определения того, что входной документ не относится ни к одному из кластеров документов из множества кластеров документов, если максимальный показатель сходства ниже порогового значения;
создания нового кластера документов; и
присвоения входного документа новому кластеру документов.
12. Система по п. 11, в которой функция сходства основана на одном или более типах вычисленных атрибутов первого документа, выбранных из группы, состоящей из: атрибута типа GRID, атрибута типа SVD и атрибута типа Изображение.
13. Система по п. 11, в которой использование функции сходства включает в себя применение первой нейронной сети.
14. Система по п. 11, в которой входной документ является текстовым документом.
15. Система по п. 11, в которой функция сходства определяет показатель сходства первого документа и первого кластера документов из множества кластеров путем расчета уровня сходства между первым документом и центроидом первого кластера документов.
16. Система по п. 11, в которой функция сходства определяет показатель сходства первого документа и первого кластера документов из множества кластеров путем расчета соответствующих уровней сходства между первым документом и одним или более документами из первого кластера документов.
17. Система по п. 11, дополнительно включающая: в ответ на определение того, что первый кластер документов из множества кластеров документов связан с первым документом, имеющим первое значение свойства документа, а второй кластер документов из множества кластеров документов связан со вторым документом, имеющим первое значение свойства документа, слияние первого кластера документов и второго кластера документов.
18. Постоянный машиночитаемый носитель данных, содержащий исполняемые команды, которые при обращении к ним компьютерной системы вынуждают ее:
получать входной документ;
определять, путем оценки функции сходства документов, множество показателей сходства, где каждый показатель сходства из множества показателей сходства отражает степень сходства между входным документом и соответствующим кластером документов из множества кластеров документов;
определять максимальный показатель сходства из множества показателей сходства;
определять, что входной документ не относится ни к одному из кластеров документов из множества кластеров документов, если максимальный показатель сходства ниже порогового значения;
создавать новый кластер документов; и
присваивать входной документ новому кластером документов.
19. Носитель данных по п. 18, в котором функция сходства основана на одном или более типах вычисленных атрибутов первого документа, выбранных из группы, состоящей из: атрибута типа GRID, атрибута типа SVD и атрибута типа Изображение.
20. Носитель данных по п. 18, в котором использование функции сходства включает в себя применение первой нейронной сети.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| CN 106649853 A, 10.05.2017 | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ ИТЕРАТИВНОЙ КЛАСТЕРИЗАЦИИ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ ПО СЕМАНТИЧЕСКОЙ БЛИЗОСТИ, СПОСОБ ПОИСКА В СОВОКУПНОСТИ КЛАСТЕРИЗОВАННЫХ ПО СЕМАНТИЧЕСКОЙ БЛИЗОСТИ ДОКУМЕНТОВ И МАШИНОЧИТАЕМЫЕ НОСИТЕЛИ | 2014 |
|
RU2556425C1 |

