Изобретение относится к области микропроцессоров, а именно к скалярно-векторным процессорам, и может быть использовано при построении архитектуры процессорных IP-ядер, ориентированных на решение задач цифровой обработки сигналов, включая приложения искусственного интеллекта и нейронных сетей.
Постоянное повышение сложности решаемых задач в области цифровой обработки сигналов и увеличение объемов обрабатываемых данных приводят к непрерывному росту требований к вычислительной производительности выполняющих эти задачи микропроцессорных систем. Основным методом повышения производительности вычислений является их распараллеливание. Возможность распараллеливания обеспечивают тем, что во многих задачах обработки сигналов требуется, как правило, выполнение большого объема одинаковых вычислительных процедур по отношению к большим массивам обрабатываемых данных. Массивы однотипных данных векторизуют, и дальнейшую высокопроизводительную обработку проводитят уже не над отдельными элементами, а над векторами. Архитектуры микропроцессоров, выполняющих подобную обработку, известны под названием SIMD-архитектур (SIMD - Single Instruction, Multiple Data).
Сложность, однако, заключается в том, что ни в одном реальном приложении не удается достичь стопроцентной векторизации. Известен закон Амдала, согласно которому общее ускорение, полученное в результате векторизации на векторном процессоре с Р элементами обработки, в зависимости от доли кода f, которая может быть векторизована, равно 1/(1-f+f/P). Таким образом, в реальных прикладных задачах, наряду с векторной обработкой, всегда присутствует и скалярная часть вычислений.
На практике применяют различные подходы к организации такого рода смешанных вычислений. Например, для реализации нейронных сетей широко используют гетерогенные вычислительные системы, содержащие в своем составе центральный процессор (CPU), выполняющий верхний уровень задачи и связанные с этим скалярные вычисления, и графический процессор (GPU), функцией которого является выполнение массивно-параллельной обработки данных. Недостатком такого подхода является то, что передача данных от одного процессора другому связана со значительными временными задержками, что сказывается отрицательным образом на реально достигаемой производительности.
Это привело к появлению архитектур, в которых некоторое количество скалярных и векторных вычислительных секций (ядер) объединяют в составе одного микропроцессора. Одной из главных проблем таких архитектур является организация эффективного взаимодействия между скалярным и векторным каналами микропроцессора. Дело в том, что во многих прикладных задачах, связанных с обработкой векторных данных, возникает потребность в выполнении операций, в которых скалярный канал формирует и/или потребляет скаляр, требуемый и/или формируемый векторным каналом микропроцессора. Таким образом, скалярный канал процессора может подготовить или дополнительно обработать скаляры, необходимые для векторного канала или созданные векторным каналом, гарантируя, что векторный канал может продолжать потоковую обработку векторов без лишних торможений.
Примером операций, в которые вовлечены и скалярный и векторный каналы процессора, являются операции редукции - к ним относятся, в частности, определение и вывод минимального или максимального значения вектора, сумма или произведение элементов вектора и т.п.
В задачах обработки изображений широко применяют и другие операции, выполняемые над вектором в целом - операции перестановок (shuffle), вычисление гистограмм, табличные преобразования (LUT, Look-Up Table). Известные способы реализации таких процедур имеют свои достоинства и недостатки. Программная реализация на основе стандартного набора команд не позволяет достичь высокой производительности, а аппаратная реализация в виде ускорителей требует дополнительных аппаратурных затрат и обладает ограниченной гибкостью. По указанным причинам поиск эффективных способов выполнения такого рода вычислительных процедур остается по-прежнему актуальным.
Известно решение (патент US 5659706), в котором описывается скалярно-векторный процессор с отдельной скалярным и векторным каналами. Каждый из каналов процессора разделен на функциональные блоки. Недостатком этого решения является то, что между функциональными блоками скалярного и векторного канала процессора нет тесного взаимодействия. Оба канала работают полностью независимо, и это приводит к дополнительным временным потерям при передаче данных от одной части процессора к другой, соответственно, к ухудшению быстродействия процессора.
Известно другое решение (патент US 5822606 А), в котором описана одна из первых архитектур сигнальных процессоров, содержащая одновременно функционирующие скалярное и векторные вычислительные ядра. Недостатком этой архитектуры является то, что, как и в предыдущем случае, скалярное и векторные вычислительные ядра непосредственно между собой не взаимодействуют, обмены данными между ними выполняются через внешнюю память, что связано со значительными задержками, соответственно, к ухудшению быстродействия процессора.
В патенте US 2004015677 А1 описана архитектура скалярно-векторного процессора цифровой обработки сигналов, в которой предусматривается выполнение некоторых операций редукции в последовательном стиле, путем передачи данных от одной SIMD-секции к другой. Недостатком данной архитектуры является невысокая производительность, достигаемая при последовательной организации вычислений.
Известна архитектура (патент US 2005/0240644 А1) скалярно-векторного процессора, который включает в себя набор функциональных (вычислительных) блоков, содержащих взаимодействующие между собой векторный и скалярный каналы. Недостатком этой архитектуры является то, что взаимодействие между векторным и скалярным каналами процессора ограничено рамками конкретного функционального блока. Кроме того, данное решение не предусматривает поддержку операций редукции.
В патенте US 2020/142704 А1 описана архитектура скалярно-векторного процессора, в которой наряду с SIMD-распараллеливанием, используется также параллелизм на уровне команд по принципу VLIW (Very Long Instruction Word) как в скалярном, так и в векторном канале процессора, что повышает общую производительность. Однако никаких механизмов взаимодействия между скалярным и векторным каналами процессора не предусмотрено.
Наиболее близким к заявленному изобретению является архитектурный подход, описанный в патенте US 2021/0216318 А1. В данном патенте предложено целое семейство вариантов архитектур скалярно-векторного процессора, в том числе такие, в которых поддерживается взаимодействие скалярного и векторного каналов процессора и предусмотрено выполнение операций редукции. Данные архитектуры скалярно-векторного процессора выбраны в качестве прототипов заявленного изобретения. Однако операции редукции в данном патенте реализуют на базе векторных вычислительных секций за счет дополнительных связей между секциями. Это ухудшает масштабируемость архитектуры и делает невозможным одновременное выполнение операций редукции и других векторных вычислений. Кроме того, предложенный подход не предусматривает поддержку выполнения других операций над вектором в целом - перестановки, вычисление гистограмм, табличные преобразования (LUT).
Техническим результатом изобретения является создание скалярно-векторного процессора, который обладает повышенной эффективностью, скоростью работы, функциональностью и универсальностью за счет того, что: в его составе содержится блок редукции, соединенный со скалярным и векторным каналами процессора и реализующий функции их взаимодействия в разнообразных операциях, в которых скалярный канал формирует и/или потребляет скаляр, требуемый и/или формируемый векторным каналом процессора; блок редукции выполняет, кроме того, различные операции над вектором в целом - операции перестановок (shuffle), LUT-преобразования, вычисления гистограмм; скалярный и векторный каналы процессора объединены дополнительно кольцеобразной шиной, позволяющей производить по ней обмен данными одновременно с выполнением вычислительных операций в скалярном и векторном каналах процессора и в блоке редукции.
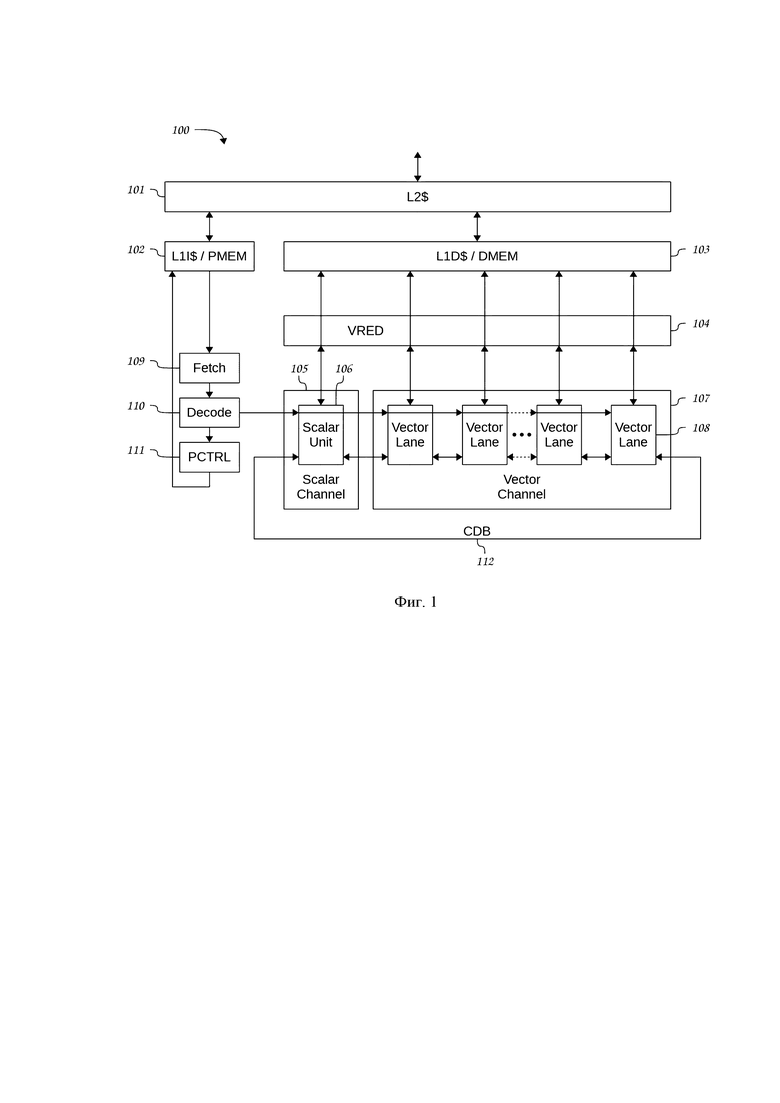
Поставленный технический результат достигнут путем создания скалярно-векторного процессора 100, содержащего соединенные кольцевой шиной CDB 112 скалярный и векторный каналы 105 и 107 обработки данных, которые соединены с блоком редукции VRED 104, а также с памятью данных первого уровня DMEM/L1D$ 103, которая соединена с кэш-памятью второго уровня L2$ 101, которая соединена с внешним интерфейсом процессора, который имеет доступ к внешней памяти вычислительной системы, а также соединена с памятью программ первого уровня РМЕМ/L1I$ 102, выход которой соединен с входом блока выборки команд FETCH 109, выход которого соединен с входом блока декодирования команд DECODE 110, первый выход которого соединен с входами скалярного и векторного каналов, а второй выход соединен с блоком программного управления PCTRL 111, выход которого соединен с входом памяти программ первого уровня РМЕМ/L1I$ 102, причем
- память программ первого уровня РМЕМ/L1I$ 102 и память данных первого уровня DMEM/L1D$ 103 выполнены с возможностью формирования обращений и передачи их в
- кэш-память второго уровня L2$ 101, которая выполнена с возможностью обслуживания обращений из памяти программ первого уровня PMEM/L1I$ 102 и памяти данных первого уровня DMEM/L1D$ 103, а также загрузки данных через внешний интерфейс из внешней памяти вычислительной системы и передачи данных в память данных первого уровня DMEM/L1D$ 103 и память программ первого уровня РМЕМ/L1I$ 102;
- блок выборки команд FETCH 109 выполнен с возможностью выборки команд из памяти программ РМЕМ/L1I$ 102 и передачи их в
- блок декодирования команд DECODE ПО, выполненный с возможностью декодирования команд и формирования команд программного управления для исполнительных устройств процессора и передачи их в
- блок PCTRL, который выполнен с возможностью выполнения команд программного управления.
В предпочтительном варианте осуществления процессора память данных первого уровня DMEM/L1D$ 103 выполнена в виде кэш-памяти первого уровня L1D$ или в виде тесно связанной ТСМ (Tightly-Coupled Memory) статической памяти DMEM.
В предпочтительном варианте осуществления процессора память программ первого уровня PMEM/L1I$ 102 выполнена в виде кэш-памяти первого уровня L1I$ или в виде тесно связанной ТСМ (Tightly-Coupled Memory) статической памяти РМЕМ.
В предпочтительном варианте осуществления процессора на уровне вычислительного ядра имеет гарвардскую архитектуру с возможностью одновременного доступа к памяти программ первого уровня PMEM/L1I$ 102 и памяти данных первого уровня DMEM/L1D$ 103 по отдельным шинам.
В предпочтительном варианте осуществления процессора кэш-память второго уровня L2$ 101 имеет фон-неймановскую архитектуру.
В предпочтительном варианте осуществления процессора команды программного управления выбраны из набора команд, содержащего команды программных переходов и команды программных циклов.
В предпочтительном варианте осуществления процессора команды объединены в инструкции, которые организованы в виде VLIW-пакета 201 (VLIW - Very Long Instruction Word).
В предпочтительном варианте осуществления процессора VLIW-пакет 201 содержит до восьми команд, из которых до четырех команд предназначены для исполнительных устройств скалярного канала обработки данных и до четырех команд предназначены для исполнительных устройств векторного канала обработки данных.
В предпочтительном варианте осуществления процессора VLIW-пакет 201 содержит до двух команд скалярных обменов данными и до двух векторных команд обмена данными с памятью данных DMEM/L1D$ 103.
В предпочтительном варианте осуществления процессор имеет систему команд, состоящую из команд программного управления, команд исполнительных устройств скалярного канала обработки данных и векторного канала обработки данных, а также команд блока редукции VRED 104.
В предпочтительном варианте осуществления процессора скалярный канал 105 содержит одну скалярную вычислительную секцию 106.
В предпочтительном варианте осуществления процессора скалярная вычислительная секция 106 содержит скалярный регистровый файл RF 301, который является многопортовым и в котором хранятся обрабатываемые скалярные данные.
В предпочтительном варианте осуществления процессора скалярный регистровый файл RF 301 содержит порты, связанные со скалярным каналом 105 обработки данных и выполненные с возможностью обмена данными с памятью данных DMEM/L1D$ 103.
В предпочтительном варианте осуществления процессора скалярный регистровый файл RF 301 содержит порты, связанные с исполнительными устройствами скалярной вычислительной секции 106 скалярного канала 105 обработки данных, выполненные с возможностью передачи исходных данных для выполнения вычислительных операций и записи результатов операций обратно в скалярный регистровый файл RF 301.
В предпочтительном варианте осуществления процессора скалярная вычислительная секция 106 содержит блоки обработки данных SLSE0 310, SLSE1 311, которые выполнены с возможностью обеспечения обмена данными между памятью данных DMEM/L1D$ 103 и скалярным регистровым файлом RF 301, в том числе выполнения команд пересылок данных между памятью данных DMEM/L1D$ 103 и скалярным регистровым файлом RF 301.
В предпочтительном варианте осуществления процессора скалярная вычислительная секция 106 содержит блоки обработки данных ALU0 302, ALU1 303, ALU2 304, ALU3 305, выполняющие арифметические и логические операции над числами с фиксированной запятой.
В предпочтительном варианте осуществления процессора скалярная вычислительная секция 106 содержит блоки обработки данных FALU0 306, FALU1 307, выполняющие арифметические и логические операции над числами с плавающей запятой.
В предпочтительном варианте осуществления процессора скалярная вычислительная секция 106 содержит блоки обработки данных SMU0 308, SMU1 309, выполняющие операции умножения над числами с фиксированной и плавающей запятой.
В предпочтительном варианте осуществления процессора скалярная вычислительная секция 106 содержит блок обработки данных SH 312, выполняющий операции логического и арифметического сдвига.
В предпочтительном варианте осуществления процессора скалярная вычислительная секция 106 содержит блок обработки данных CONV 315, выполняющий операции преобразования типов данных.
В предпочтительном варианте осуществления процессора скалярная вычислительная секция 106 содержит блок обработки данных DIV 313, выполняющий операции деления.
В предпочтительном варианте осуществления процессора скалярная вычислительная секция 106 содержит блок обработки данных MF 314, выполняющий операции вычисления трансцендентных математических функций. Базовый набор операций, выполняемых блоком MF 314, приведен в таблице 9.
В предпочтительном варианте осуществления процессора векторный канал 107 состоит из нескольких векторных вычислительных секций 108, количество которых соответствует разрядности обрабатываемого вектора.
В предпочтительном варианте осуществления процессора векторная вычислительная секция 108 содержит векторный регистровый файл VRF 401, который является многопортовым и мультиформатным, и в котором хранятся обрабатываемые векторные данные.
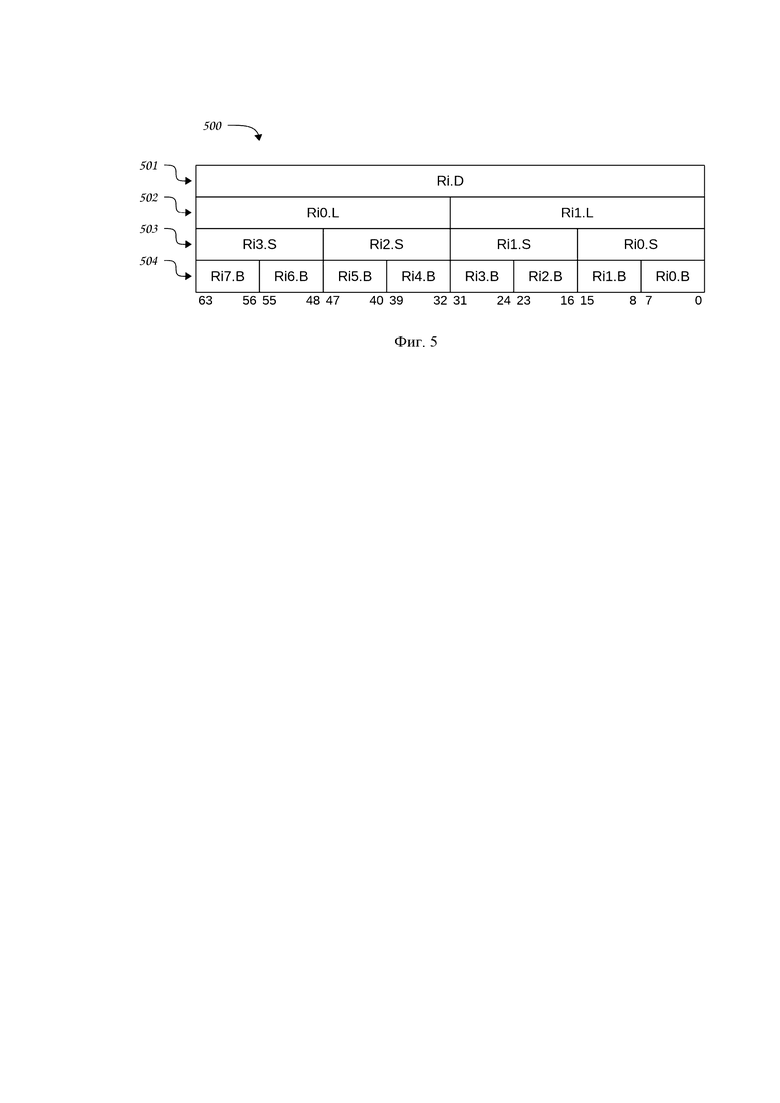
В предпочтительном варианте осуществления процессора векторный регистровый файл VRF 401 является мультиформатным, так что каждый 64-разрядный регистр 500 векторного регистрового файла VRF 401 может хранить либо одно 64-разрядное значение 501, либо два 32-разрядных значения 502, либо четыре 16-разрядных значения 503, либо восемь 8-разрядных значений 504.
В предпочтительном варианте осуществления процессора векторный регистровый файл VRF 401 содержит порты, связанные с внешним интерфейсом векторного канала 107 и выполненные с возможностью обмена данными с памятью данных DMEM/L1D$ 103.
В предпочтительном варианте осуществления процессора векторный регистровый файл VRF 401 содержит порты, связанные с исполнительными устройствами векторной вычислительной секции 108, выполненные с возможностью передачи исходных данных для выполнения вычислительных операций и записи результатов обратно.
В предпочтительном варианте осуществления процессора векторный регистровый файл VRF 401 выполнен с возможностью работы с различными форматами данных.
В предпочтительном варианте осуществления процессора векторная вычислительная секция 108 содержит блоки VLSE0 412, VLSE1 413, которые выполнены с возможностью обеспечения обмена данными между памятью данных DMEM/L1D$ 103 и векторным регистровым файлом VRF 401, в том числе и выполнения команд пересылок данных между памятью данных DMEM/L1D$ 103 и векторным регистровым файлом VRF 401.
В предпочтительном варианте осуществления процессора векторная вычислительная секция 108 содержит блоки VALU0 403, VALU1 404, VALU2 405, VALU3 406, выполненные с возможностью осуществления арифметических и логических операции над числами с фиксированной запятой.
В предпочтительном варианте осуществления процессора векторная вычислительная секция 108 содержит блоки VFALU0 407, VFALU1 408, выполненные с возможностью осуществления арифметических и логических операции над числами с плавающей запятой.
В предпочтительном варианте осуществления процессора векторная вычислительная секция 108 содержит блоки VMU0 409, VMU1 410, выполненные с возможностью осуществления операций умножения и умножения с накоплением над числами с фиксированной и плавающей запятой.
В предпочтительном варианте осуществления процессора векторная вычислительная секция 108 содержит векторный регистровый файл регистров-аккумуляторов VAC 402, выполненный с возможностью хранения данных, получаемых и используемых в результате выполнения операций умножения с накоплением, выполняемых блоками векторных умножителей VMU0 409, VMU1 410.
В предпочтительном варианте осуществления процессора векторная вычислительная секция 108 содержит блок VSH 411, выполненный с возможностью осуществления операции логического и арифметического сдвига над векторными операндами.
В предпочтительном варианте осуществления процессора векторная вычислительная секция 108 содержит блок VCONV 414, выполненный с возможностью осуществления операции преобразования типов данных над векторными операндами.
В предпочтительном варианте осуществления процессора блок редукции VRED 104 выполнен с возможностью вычисления функций редукции, и при этом обеспечения повышенной эффективности, скорости работы, функциональности и универсальности процессора.
В предпочтительном варианте осуществления процессора блок редукции VRED 104 выполнен с возможностью вычисления функций редукции, и при этом реализации функций взаимодействия скалярной и векторной частей процессора в разнообразных операциях, в которых скалярный канал 105 формирует и/или потребляет скаляр, требуемый и/или формируемый векторным каналом 107.
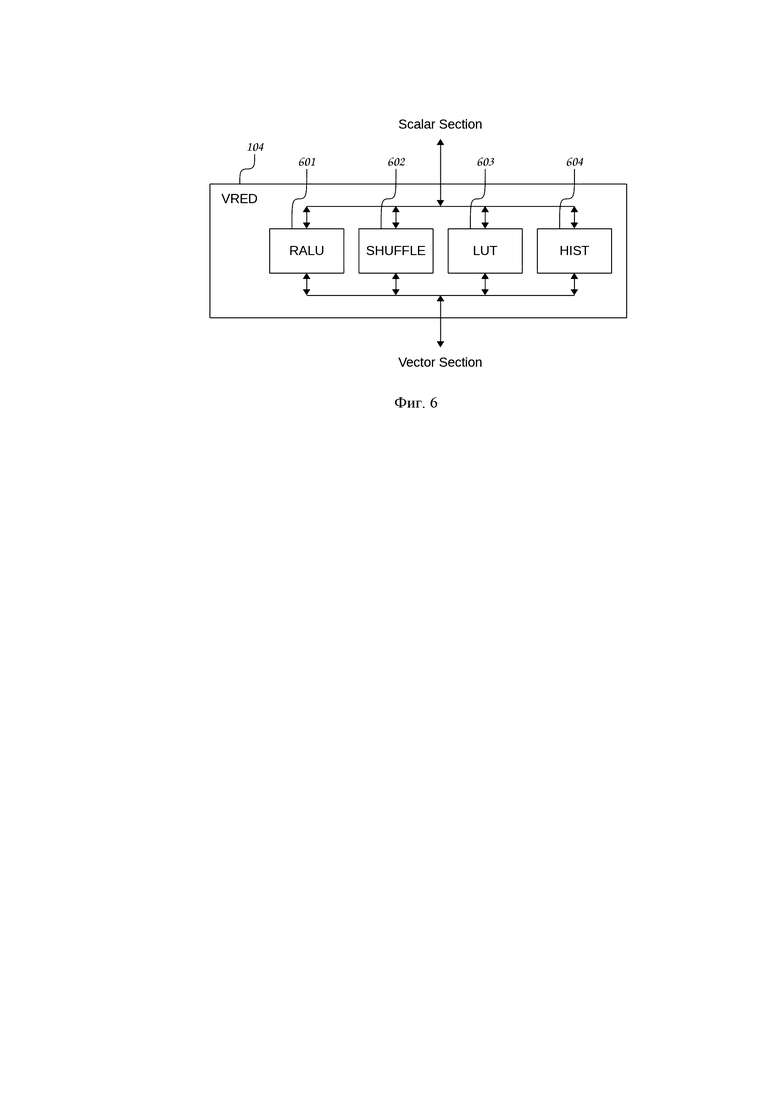
В предпочтительном варианте осуществления процессора блок редукции VRED 104 содержит блок RALU 601, выполненный с возможностью осуществления арифметико-логических межсекционных операций редукции.
В предпочтительном варианте осуществления процессора блок редукции VRED 104 содержит блок SHUFFLE 602, выполненный с возможностью осуществления операций межсекционных перестановок.
В предпочтительном варианте осуществления процессора блок редукции VRED 104 содержит блок LUT 603, выполненный с возможностью осуществления операций межсекционньгх табличных преобразований.
В предпочтительном варианте осуществления процессора блок редукции VRED 104 содержит блок HIST 604, выполненный с возможностью осуществления операций вычисления гистограмм.
В предпочтительном варианте осуществления процессора кольцевая шина CDB (Circular Data Bus) 112, выполнена с возможностью осуществления обмена данными одновременно с осуществлением вычислительных операций в скалярном и векторном каналах 105, 107 и в блоке редукции VRED 104.
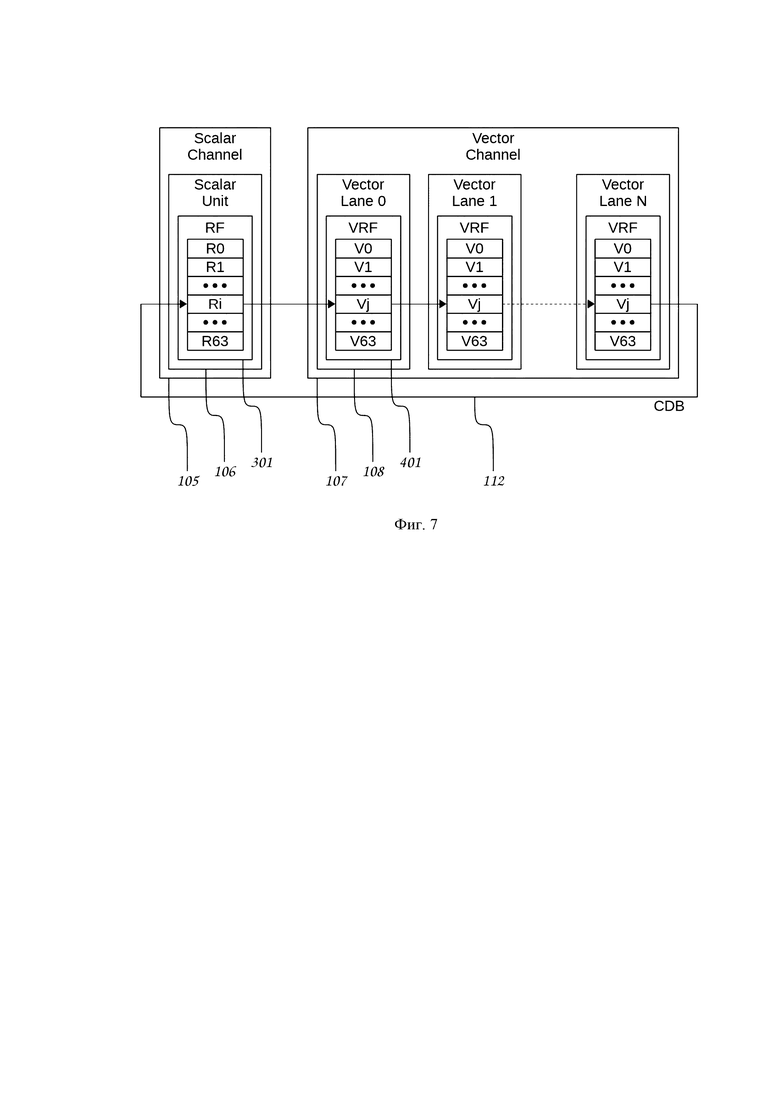
В предпочтительном варианте осуществления процессора кольцевая шина CDB 112, выполнена с возможностью осуществления команд циклического сдвига, в результате выполнения которых регистр Ri скалярного регистрового файла RF 301 смещается в регистр Vj векторного регистрового файла VRF 401 нулевой векторной вычислительной секции 108: Vj.0=Ri; регистр Vj векторного регистрового файла VRF 401 старшей (N-1) векторной вычислительной секции 108 смещается в регистр Ri скалярного регистрового файла RF 301: Ri=Vj.N-1; регистры Vj векторных регистровых файлов VRF 401 остальных векторных вычислительных секций 108 смещаются на одну секцию в сторону старших секций: Vj.k=Vj.k-1, k=1,2,…,N-1.
В предпочтительном варианте осуществления процессора кольцевая шина CDB 112, выполнена с возможностью последовательного перемещения данных из векторного канала 107 в скалярный канал 105 с целью выполнения операций, имеющихся только в скалярном канале 105, с последующим возвращением преобразованных данных в векторный канал 107.
Для лучшего понимания заявленного изобретения далее приводится его подробное описание с соответствующими графическими материалами.
Фиг. 1. Структурная схема скалярно-векторного процессора, выполненная согласно изобретению.
Фиг. 2. Структурная схема VLIW-инструкции скалярно-векторного процессора, выполненная согласно изобретению.
Фиг. 3. Структурная схема скалярной вычислительной секции скалярного канала скалярно-векторного процессора, выполненная согласно изобретению.
Фиг. 4. Структурная схема векторной вычислительной секции векторного канала скалярно-векторного процессора, выполненная согласно изобретению.
Фиг. 5. Структурная схема мультиформатного векторного регистрового файла в составе вычислительной секции векторного канала, выполненная согласно изобретению.
Фиг. 6. Структурная схема блока редукции, выполненная согласно изобретению.
Фиг. 7. Кольцевая шина для межсекционных скалярно-векторных обменов данными, выполненная согласно изобретению.
Табл. 1. Базовый набор команд устройства программного управления, выполненный согласно изобретению.
Табл. 2. Базовый набор команд блока обменов с памятью скалярного канала, выполненный согласно изобретению.
Табл. 3. Базовый набор команд блока арифметико-логических операций с фиксированной запятой скалярного канала, выполненный согласно изобретению.
Табл. 4. Базовый набор команд блока арифметико-логических операций с плавающей запятой скалярного канала, выполненный согласно изобретению.
Табл. 5. Базовый набор команд блока умножения с фиксированной и плавающей запятой скалярного канала, выполненный согласно изобретению.
Табл. 6. Базовый набор команд блока сдвига скалярного канала, выполненный согласно изобретению.
Табл. 7. Базовый набор команд блока преобразования типов скалярного канала, выполненный согласно изобретению.
Табл. 8. Базовый набор команд блока деления скалярного канала, выполненный согласно изобретению.
Табл. 9. Базовый набор команд блока вычисления трансцендентных функций скалярного канала, выполненный согласно изобретению.
Табл. 10. Базовый набор команд блока обменов с памятью векторного канала, выполненный согласно изобретению.
Табл. 11. Базовый набор команд блока арифметико-логических операций с фиксированной запятой векторного канала, выполненный согласно изобретению.
Табл. 12. Базовый набор команд блока арифметико-логических операций с плавающей запятой векторного канала, выполненный согласно изобретению.
Табл. 13. Базовый набор команд блока умножения с фиксированной и плавающей запятой векторного канала.
Табл. 14. Базовый набор команд блока сдвига векторного канала, выполненный согласно изобретению.
Табл. 15. Базовый набор команд блока преобразования типов векторного канала, выполненный согласно изобретению.
Табл. 16. Базовый набор команд арифметико-логического устройства межсекционной редукции.
Табл. 17. Базовый набор команд блока межсекционных перестановок, выполненный согласно изобретению.
Табл. 18. Базовый набор команд блока межсекционных табличных преобразований (LUT-преобразований), выполненный согласно изобретению.
Табл. 19. Базовый набор команд блока вычисления гистограмм, выполненный согласно изобретению.
Табл. 20. Базовый набор команд межсекционного скалярно-векторного сдвига, выполненный согласно изобретению.
Архитектура заявленного скалярно-векторного процессора ориентирована прежде всего на решение задач цифровой обработки сигналов, связанных с массивно-параллельными вычислениями, включая приложения искусственного интеллекта и нейронных сетей.
В состав процессора 100 (Фиг. 1) входит скалярный канал 105 (Scalar Channel) и векторный канал 107 (Vector Channel) обработки данных. Скалярный канал 105 включает в себя одну скалярную вычислительную секцию 106 (Scalar Unit), в то время как векторный канал включает несколько векторных вычислительных секций 108 (Vector Lane).
Взаимодействие процессора с памятью организовано традиционным способом. На уровне вычислительного ядра процессора реализуется гарвардская архитектура с возможностью одновременного доступа к памяти программ и данных по отдельным шинам. При этом память программ и данных может быть реализована как в виде кэш-памяти первого уровня (соответственно L1I$ 102 и L1D$ 103), так и в виде тесно связанной (Tightly-Coupled Memory, ТСМ) статической памяти (соответственно РМЕМ 102 и DMEM 103). На верхнем уровне реализуется фон-неймановская архитектура, в которой кэш-память второго уровня L2$ 101 обслуживает обращения кэш-памяти программ и данных первого уровня, и через внешний интерфейс имеет доступ к внешней памяти системы.
Инструкции, считываемые из программной памяти PMEM/L1I$ 102 при помощи устройства выборки FETCH 109, поступают в блок DECODE 110, который декодирует их и формирует сигналы управления для исполнительных устройств процессора.
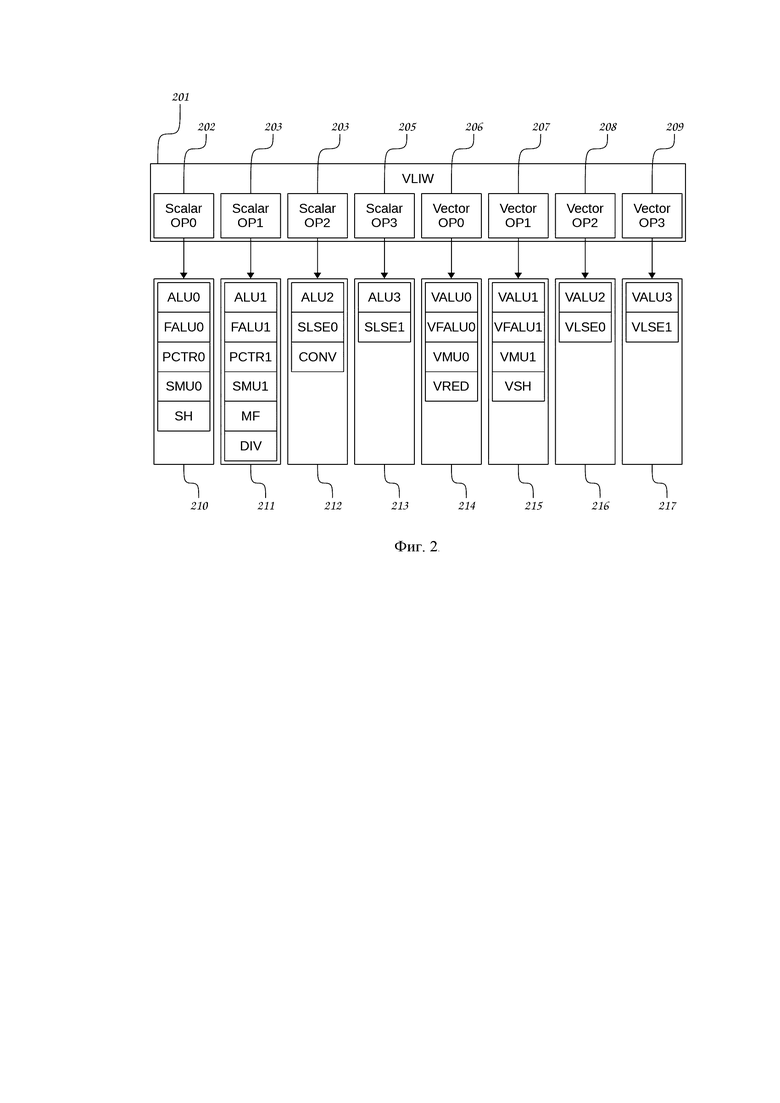
Инструкции организованы в виде VLIW-пакетов (VLIW - Very Long Instruction Word), содержащих несколько одновременно исполняемых команд как для скалярного, так и для векторного каналов 105, 107 процессора. На Фиг. 2 показана структура VLIW-пакета 201. Для каждой команды в VLIW-пакете 201 предусмотрено место, называемое слотом. Всего в VLIW-пакете имеется четыре слота 202-205 для команд скалярного канала 105 и четыре слота 206-209 для команд векторного канала 107. Таким образом, одновременно может выполняться до восьми команд. Каждый из восьми слотов 202-209 VLIW-пакета 201 может содержать команды определенного типа, предназначенные для соответствующего набора исполнительных устройств 210-217. Состав и общее количество команд для каждого VLIW-пакета могут быть различны.
Команды программного управления, в число которых входят команды программных переходов и команды программных циклов, выполняются с помощью блока программного управления PCTRL 111.
В таблице 1 приведен базовый набор команд программного управления, выполняемых с помощью блока PCTRL 111.
К командам скалярного канала 105 процессора относятся команды скалярных обращений к памяти данных (SLSE0 310, SLSE1 311) и команды на выполнение скалярных вычислительных операций - арифметико-логических операций с фиксированной запятой (ALU0 302, ALU1 303, ALU2 304, ALU3 305), арифметико-логических операций с плавающей запятой (FALU0 306, FALU1 307), умножения с фиксированной и плавающей запятой (SMU0 308, SMU1 309), сдвига (SH 312), преобразования типов (CONV 315), деления (DIV 313), вычисления трансцендентных математических функций (MF 314).
К командам векторного канала 107 процессора относятся команды векторных обращений к памяти данных (VLSE0 412, VLSE 413) и команды на выполнение векторных вычислительных операций - арифметико-логических операций с фиксированной запятой (VALU0 403, VALU1 404, VALU2 405, VALU3 406), арифметико-логических операций с плавающей запятой (VFALU0 407, VFALU1 408), умножения с фиксированной и плавающей запятой (VMU0 409, VMU1 410), сдвига (VSH 411), преобразования типов (VCONV 414), а также операций редукции (VRED 104).
В совокупности команды программного управления, команды исполнительных устройств скалярного и векторного каналов 105, 107 процессора, а также команды блока редукции 104 формируют полную систему команд процессора.
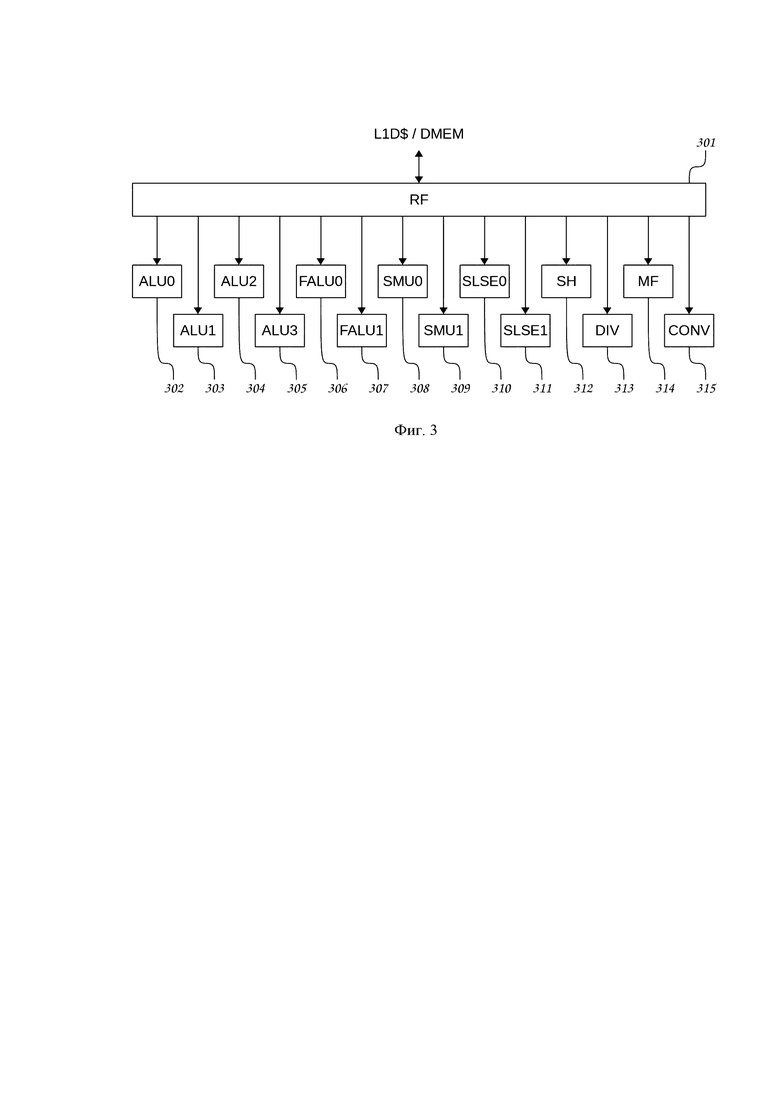
Структура скалярной вычислительной секции 106 скалярного канала 105 процессора приведена на Фиг. 3. Центральным элементом скалярной вычислительной секции 106 является многопортовый скалярный регистровый файл RF 301, в котором хранятся обрабатываемые скалярные данные. Через порты RF 301, связанные с внешним интерфейсом скалярного канала 105 процессора с помощью контроллеров скалярных обращений к памяти данных SLSE1 311, SLSE2 происходят обмены данными между памятью данных DMEM/L1D$ 103 и скалярным каналом 105 процессора. Через порты RF 301, связанные с исполнительными устройствами скалярной вычислительной секции 106 процессора, передают исходные данные для выполняемых вычислительных операций и записываются их результаты. К числу исполнительных устройств скалярной вычислительной секции 106 процессора относятся: четыре блока арифметико-логических устройств с фиксированной запятой ALU0 302, ALU1 303, ALU2 304, ALU3 305; два блока арифметико-логических устройств с плавающей запятой FALU0 306, FALU1 307; два блока умножителей с фиксированной и плавающей запятой SMU0 308, SMU1 309; блок сдвига SH 312; блок преобразователя типов CONV 315; блок делителя DIV 313; блок вычисления трансцендентных математических функций MF 314. Каждый из указанных блоков выполняет соответствующий набор скалярных вычислительных операций. Одновременно при указанной структуре VLIW-пакета может выполняться до четырех скалярных вычислительных операций, включая две операции скалярных обменов данными с памятью данных первого уровня DMEM/L1D$ 103.
В таблице 2 приведен базовый набор команд скалярных обращений к памяти данных 103, выполняемых блоками SLSE0 310, SLSE1 311.
В таблице 3 приведен базовый набор команд скалярных арифметико-логических операций с фиксированной запятой, выполняемых блоками ALU0 302, ALU1 303, ALU2 304, ALU3 305.
В таблице 4 приведен базовый набор команд скалярных арифметико-логических операций с плавающей запятой, выполняемых блоками FALU0 306, FALU1 307.
В таблице 5 приведен базовый набор скалярных команд умножения с фиксированной и плавающей запятой, выполняемых блоками SMU0 308, SMU1 309.
В таблице 6 приведен базовый набор скалярных команд сдвига, выполняемых с помощью блока SH 312.
В таблице 7 приведен базовый набор скалярных команд преобразования типов, выполняемых с помощью блока CONV 315.
В таблице 8 приведен базовый набор скалярных команд деления, выполняемых с помощью блока DIV 313.
В таблице 9 приведен базовый набор скалярных команд вычисления трансцендентных математических функций, выполняемых с помощью блока MF 314.
В таблицах 1-20 используются следующие обозначения:
R, Ri, Ra, Rt, Rs, Rd - скалярные регистры данных;
V, Vi, Va, Vt, Vs, Vd - векторные регистры данных;
VAi - векторные регистры-аккумуляторы;
.b, .h, .l, .d - спецификаторы формата данных:
.b - byte (8 разрядов);
.h - halfword (16 разрядов);
.l - long (32 разряда);
.d - double (64 разряда);
i8, i16, i32, i64 - целочисленные знаковые 8/16/32/64-разрядные форматы;
u8, u16, u32, u64 - целочисленные беззнаковые 8/16/32/64-разрядные форматы;
#imm - непосредственное значение;
#N - непосредственное N-разрядное значение;
trunkN - отсечение до N разрядов;
zextN→M - расширение числа с N до М разрядов путем заполнения недостающих старших разрядов нулями;
sextN→M - расширение числа с N до М разрядов путем заполнения недостающих старших разрядов знаковым разрядом;
{,} - конкатенация (объединение) нескольких операндов;
T[i], S[i], D[i], V[i] - элементы векторов.
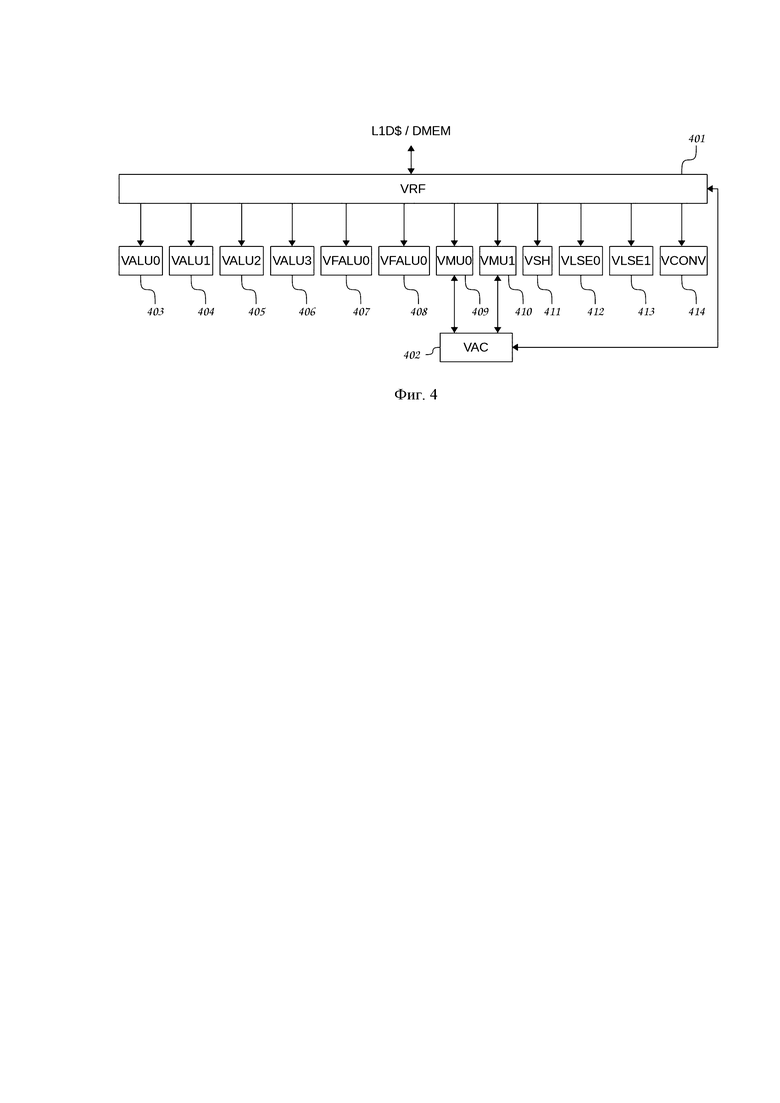
Векторный канал 107 процессора включает в себя несколько векторных вычислительных секций 108, общее количество которых определяется разрядностью обрабатываемого вектора. Структура векторной вычислительной секции 108 векторного канала 107 представлена на Фиг. 4. В ее состав входит многопортовый мультиформатный векторный регистровый файл VRF 401, предназначенный для хранения обрабатываемых векторных данных. Через порты VRF 401, связанные с внешним интерфейсом векторного канала 107 процессора с помощью контроллеров векторных обращений к памяти данных VLSE0 412, VLSE1 413 производится загрузка/выгрузка данных из/в память данных DMEM/L1D$ 103. Через порты VRF 401, связанные с исполнительными устройствами векторной вычислительной секции 108 процессора, векторные данные передают исполнительным устройствам, и полученные результаты снова записывают в векторный регистровый файл VRF 401.
Особенностью векторного регистрового файла VRF 401 является возможность работы с различными форматами данных, как это показано на Фиг. 5. Каждый 64-разрядный регистр 500 из векторного регистрового файла VRF 401 может хранить либо одно 64-разрядное значение 501, либо два 32-разрядных значения 502, либо четыре 16-разрядных значения 503, либо восемь 8-разрядных значений 504.
В состав векторной вычислительной секции 108 векторного канала 107 входит также векторный регистровый файл регистров-аккумуляторов VAC 402, предназначенный для хранения данных, получаемых и используемых в результате выполнения операций умножения с накоплением, выполняемых двумя блоками векторных умножителей VMU0 409, VMU1 410.
К числу исполнительных устройств вычислительной секции 108 векторного канала 107 процессора относятся также: четыре блока векторных арифметико-логических устройств с фиксированной запятой VALU0 403, VALU1 404, VALU2 405, VALU3 406; два блока векторных арифметико-логических устройств с плавающей запятой VFALU0 407, VFALU1 408; блок векторного сдвига VSH 411; блок преобразователя типов VCONV 414; блок вычисления функций редукции VRED 104. Каждый из указанных блоков выполняет соответствующий набор векторных вычислительных операций. Одновременно при указанной структуре VLIW-пакета выполняют до четырех векторных вычислительных операций, включая две операции векторных обменов данными с памятью DMEM/L1D$ 103.
В таблице 10 приведен базовый набор команд векторных обращений к памяти данных, выполняемых блоками VLSE0 412, VLSE1 413.
В таблице 11 приведен базовый набор команд векторных арифметико-логических операций с фиксированной запятой, выполняемых блоками VALU0 403, VALU1 404, VALU2 405, VALU3 406.
В таблице 12 приведен базовый набор команд векторных арифметико-логических операций с плавающей запятой, выполняемых блоками VFALU0 407, VFALU1 408.
В таблице 13 приведен базовый набор векторных команд умножения с фиксированной и плавающей запятой, выполняемых блоками VMU0 409, VMU1 410.
В таблице 14 приведен базовый набор векторных команд сдвига, выполняемых с помощью блока VSH 411.
В таблице 15 приведен базовый набор векторных команд преобразования типов, выполняемых с помощью блока VCONV 414.
Важнейшей особенностью рассматриваемой архитектуры скалярно-векторного процессора является наличие в ее составе блока редукции VRED 104, связывающего между собой скалярный и векторный каналы 105, 107 процессора, и предназначенную как для организации обменов между ними, так и для выполнения операций, использующих и/или формирующих одновременно и скалярные, и векторные данные. Структурная схема блока редукции VRED 104 представлена на Фиг. 6. В его состав входят следующие исполнительные устройства: блок арифметико-логических межсекционных операций редукции RALU 601, блок межсекционных перестановок SHUFFLE 602, блок межсекционных табличных преобразований LUT 603, блок вычисления гистограмм HIST 604.
В таблице 16 приведен базовый набор команд арифметико-логического устройства межсекционной редукции RALU 601, входящего в состав блока редукции VRED 104.
В таблице 17 приведен базовый набор команд блока межсекционных перестановок SHUFFLE 602, входящего в состав блока редукции VRED 104.
В таблице 18 приведен базовый набор команд блока межсекционных табличных преобразований LUT 603, входящего в состав блока редукции VRED 104.
В таблице 19 приведен базовый набор команд блока вычисления гистограмм HIST 604, входящего в состав блока редукции VRED 104.
Еще одним механизмом, объединяющим скалярный и векторный каналы процессора, является кольцевая шина CDB (Circular Data Bus) 112, изображенная на Фиг. 7.
Одной из команд, выполняемой с помощью кольцевой шины CDB 112, является команда циклического сдвига VPUSHRD Ri, Vj, в результате выполнения которой скалярный регистр Ri перемещается в векторный регистр Vj нулевой векторной вычислительной секции 108: Vj.0=Ri; векторный регистр Vj старшей векторной вычислительной секции 108 перемещается в скалярный регистр Ri: Ri=Vj.N; в остальных векторных вычислительных секциях 108 данные векторных регистров смещаются на одну секцию в сторону старших секций: Vj.k=Vj.k-1, k=1,2,…,N. Этот механизм может быть использован, например, для последовательного перемещения данных из векторного канала 107 процессора в скалярный канал 105 с целью выполнения специфических операций, имеющихся только в скалярном канале 105 (например, для вычисления трансцендентных математических функций), с последующим возвращением преобразованных данных в векторный канал 107 процессора.
В таблице 20 приведен базовый набор команд межсекционного скалярно-векторного сдвига, выполняемых с помощью кольцевой шины данных CDB 112.
Таким образом, рассматриваемая архитектура, по сравнению с ранее известными архитектурами скалярно-векторных процессоров, обладает значительно более широкими возможностями для организации эффективного взаимодействия между скалярным и векторным каналами 105, 107 процессора, тем самым обеспечивая более высокую производительность выполняемых скалярно-векторных вычислений.
Состав и функциональность исполнительных устройств скалярного и векторного каналов 105, 107 процессора могут быть дополнены или сокращены в зависимости от области применения процессора.
Хотя описанный выше вариант выполнения заявленного изобретения был изложен с целью иллюстрации заявленного изобретения, специалистам ясно, что возможны различные модификации, добавления и замены, не выходящие из объема и смысла заявленного изобретения, раскрытого в прилагаемой формуле изобретения.
B #32
B Ra.L
J #32
J Ra.L
BS #32, Ri.L
BS Ra.L, Ri.L
JS #32, Ri.L
JS Ra.L, Ri.L
DO #16, #32
DO R.L, #32
Табл. 1.
Табл. 2.
ADDD #imm, Rs, Rd
ADDD.SAT Rt, Rs, Rd
Rd.d = sat64(Rt.d + Rs.d)
ADDL #imm, Rs, Rd
ADDL.SAT Rt, Rs, Rd
Rd = sat32(Rt + Rd)
ADDL.SCL.RND Rt,Rs,Rd
Rd = (Rt + Rs + 1) >>1
Округляются младшие 16 бит.
SUBD #imm, Rs, Rd
SUBD.SAT Rt, Rs, Rd
Rd.d = sat64(Rs.d - Rt.d)
SUBL.SCL.RND Rt,Rs,Rd
Rd = (Rs - Rt - 1) >>1
Округляются младшие 16 бит.
NEGD.SAT Rs, Rd
Rd = sat32(-Rs)
NEGL.SAT Rs, Rd
Rd = sat32(-Rs)
ABSD.SAT Rs, Rd
Rd = sat64(|Rs|)
ABSL.SAT Rs, Rd
Rd = sat32(|Rs|)
Табл. 3.
Табл. 4.
MPYLLO #imm, Rs, Rd
Rd = trunk32(Rs * #imm)
MPYLULO #imm, Rs, Rd
Rd = trunk32(Rs * #imm)
MPYLHI #imm, Rs, Rd
MPYLHI.RND Rt, Rs, Rd
Rd = (Rs * #imm)>>32
Rd = (Rs * #imm + 0x8000_0000)>>32
MPYLUHI #imm, Rs, Rd
Rd = (Rs * #imm)>>32
MPYL #imm, Rs, Rdd
Rdd = Rs * #imm
MPYLU #imm, Rs, Rdd
Rdd = Rs * #imm
FMADD Rt, Rs, Rr, Rd
Rd = Rr + Rt*Rs
Табл. 5.
ASRD #5u, Rs, Rd
ASRD1 #5u, Rs, Rd
Rd.d = Rs.d >> #5u
Rd.d = Rs.d >> (#5u+32)
LSLD #5u,Rs, Rd
LSLD1 #5u,Rs, Rd
Rd.d = Rs.d <<< #5u
Rd.d = Rs.d <<< (#5u+32)
LSRD #u5,Rs, Rd
LSRD1 #u5,Rs, Rd
Rd.d = Rs.d >>> #5u
Rd.d = Rs.d >>> (#5u+32)
LSLD1.SAT #u5,Rs, Rd
Rd = sat64(Rs <<< (#5u+32))
Обычное поведение при #5 = 0: результат Rd = Rs.
Особое поведение при #5 = 0: результат Rd = {Rs.L[0], Rs.L[1]} (два слова 32-бит меняются местами).
ROLL #5u, Rs, Rd
RORL #5u, Rs, Rd
Табл. 6.
CVBL Rt, Rd
Rd.l = sext8→32(Rt.b)
CVHL Rt, Rd
Rd.l = sext16→32(Rt.h)
CVBD Rt, Rd
Rd.d = sext8→64(Rt.b)
CVHD Rt, Rd
Rd.d = sext16→64(Rt.h)
CVLD Rt, Rd
Rd.d = sext32→64(Rt.l)
CVLB.sat Rt, Rd
CVLBU.sat Rt, Rd
CVLH Rt, Rd
CVLH.sat Rt, Rd
CVLHU.sat Rt, Rd
CVDB Rt, Rd
CVDB.sat Rt, Rd
CVDBU.sat Rt, Rd
CVDH Rt, Rd
CVDH.sat Rt, Rd
CVDHU.sat Rt, Rd
CVDL Rt, Rd
CVDL.sat Rt, Rd
CVDLU.sat Rt, Rd
CVLB Rt, Rd Rd=sext8→32(trunk8(Rt))
CVLB.sat Rt, Rd
Rd=sext8→32 (sat8(Rt))
CVLBU.sat Rt, Rd
Rd=zext8→32 (usat8(Rt))
Усечение исходных данных (L) до запрашиваемой величины (B), с опциональной сатурацией. Полученное число (B) расширяется своим знаком (для знаковых расширений) или нулем (для беззнаковых расширений - с суффиксом U) до исходной величины (L)
Rd[1].h = 0
Старшие 16 бит регистра Rd заполняются нулем.
Rd[1].h = 0
Старшие 16 бит регистра Rd заполняются нулем.
FCVI.floor Rt, Rd
FCVI.round Rt, Rd
FCVI.ceil Rt, Rd
FCVI.trunc Rt, Rd
Опциональное округление
FCVIU.floor Rt, Rd
FCVIU.round Rt, Rd
FCVIU.ceil Rt, Rd
FCVIU.trunc Rt, Rd
Опциональное округление
DCVD.floor Rt, Rd
DCVD.round Rt, Rd
DCVD.ceil Rt, Rd
DCVD.trunc Rt, Rd
Опциональное округление
DCVDU.floor Rt, Rd
DCVDU.round Rt, Rd
DCVDU.ceil Rt, Rd
DCVDU.trunc Rt, Rd
Опциональное округление
Табл. 7.
if (Rs == 0)
REM = 0
DIV = (Rt >= 0)? 0x7FFFFFFF: 0x80000000
else
DIV = Rt / Rs
REM = Rt % Rs
Rd = DIV
if (Rs == 0)
REM = 0
DIV = (Rt >= 0)? 0x7FFFFFFF: 0x80000000
else
DIV = Rt / Rs
REM = Rt % Rs
Rd = REM
if (Rs == 0)
REM = 0
DIV = (Rt >= 0)? 0x7FFFFFFF: 0x80000000
else
DIV = Rt / Rs
REM = Rt % Rs
Rd = {REM, DIV}
if (Rs == 0)
DIV = 0xFFFFFFFF
REM = 0
else
DIV = Rt / Rs
REM = Rt % Rs
Rd = DIV
if (Rs == 0)
DIV = 0xFFFFFFFF
REM = 0
else
DIV = Rt / Rs
REM = Rt % Rs
Rd = REM
if (Rs == 0)
DIV = 0xFFFFFFFF
REM = 0
else
DIV = Rt / Rs
REM = Rt % Rs
Rd = {REM, DIV}
Табл. 8.
Вход (X) и выход (Z) имеют 32-разрядный формат плавающей точки: (float32)X, (float32)Z
Z=Ln X.
Вход (X) и выход (Z) имеют 32-разрядный формат плавающей точки: (float32)X, (float32)Z
Z=√X.
Вход (X) и выход (Z) имеют 32-разрядный формат плавающей точки:
(float32)X, (float32)Z.
Ограничения и особые случаи:
FSQRT(0) = 0
FSQRT(-0) = -0
FSQRT(A) = NaN, A < 0
Z=1./√X.
Вход (X) и выход (Z) имеют 32-разрядный формат плавающей точки: (float32)X, (float32)Z
Z=1./X.
Вход (X) и выход (Z) имеют 32-разрядный формат плавающей точки: (float32)X, (float32)Z
Табл. 9.
VLDBHU
VLDBLU
VLDHLU
VLDLDU
Табл. 10.
VADDD.SAT Vt, Vs, Vd
VADDDU.SAT Vt, Vs, Vd
D[i] = sat32(T[i] + S[i]),i=0
D[i] = usat32(T[i] + S[i]), i = 0, unsigned
Опциональная сатурация
VADDD.SCL.RND Vt, Vs, Vd
VADDDU.SCL Vt, Vs, Vd
VADDDU.SCL.RND Vt, Vs, Vd
D[i] = rnd(T[i] + S[i]) >> 1, i = 0
D[i] = (T[i] + S[i]) >> 1, i = 0, unsigned
D[i] = rnd(T[i] + S[i]) >> 1, i = 0, unsigned
Опциональное округление
VADDL #32, Vs, Vd
VADDL.SAT Vt, Vs, Vd
VADDLU.SAT Vt, Vs, Vd
D[i] = #I2 + S[i], i = 0:1
D[i] = sat32(T[i] + S[i]), i = 0:1
D[i] = usat32(T[i] + S[i]), i = 0:1, unsigned
Опциональная сатурация
VADDL.SCL.RND Vt, Vs, Vd
VADDLU.SCL Vt, Vs, Vd
VADDLU.SCL.RND Vt, Vs, Vd
D[i] = rnd(T[i] + S[i]) >> 1, i = 0:1
D[i] = (T[i] + S[i]) >> 1, i = 0:1, unsigned
D[i] = rnd(T[i] + S[i]) >> 1, i = 0:1, unsigned
Опциональное округление
VADDH #IMM16, Vs, Vd
VADDH.SAT Vt, Vs, Vd
VADDHU.SAT Vt, Vs, Vd
D[i] = #IMM16 + S[i], i = 0:3
D[i] = sat16(T[i] + S[i]), i = 0:3
D[i] = usat16(T[i] + S[i]), i = 0:3, unsigned
Опциональная сатурация
VADDH.SCL.RND Vt, Vs, Vd
VADDHU.SCL Vt, Vs, Vd
VADDHU.SCL.RND Vt, Vs, Vd
D[i] = rnd(T[i] + S[i]) >> 1, i = 0:3
D[i] = (T[i] + S[i]) >> 1, i = 0:3, unsigned
D[i] = rnd(T[i] + S[i]) >> 1, i = 0:3, unsigned
Опциональное округление
VADDB #IMM8, Vs, Vd
VADDB.SAT Vt, Vs, Vd
VADDBU.SAT Vt, Vs, Vd
D[i] = #IMM8 + S[i], i = 0:7
D[i] = sat8(T[i] + S[i]), i = 0:7
D[i] = usat8(T[i] + S[i]), i = 0:7, unsigned
Опциональная сатурация
VADDB.SCL.RND Vt, Vs, Vd
VADDBU.SCL Vt, Vs, Vd
VADDBU.SCL.RND Vt, Vs, Vd
D[i] = rnd(T[i] + S[i]) >> 1, i = 0:7
D[i] = (T[i] + S[i]) >> 1, i = 0:7, unsigned
D[i] = rnd(T[i] + S[i]) >> 1, i = 0:7, unsigned
Опциональное округление
VSUBD.SAT Vt, Vs, Vd
VSUBDU.SAT Vt, Vs, Vd
D[i] = sat64(S[i] - T[i]), i = 0
D[i] = usat64(S[i] - T[i]), i = 0, unsigned
Vt: = {T1, T0}, i64/u64, Vs = {S0, S0}, i64/u64
Vd = {D1, D0}, i64/u64
Опциональная сатурация
VSUBL #32, Vs, Vd
VSUBL.SAT Vt, Vs, Vd
VSUBLU.SAT Vt, Vs, Vd
D[i] = S[i] - #32, i = 0:1
D[i] = sat32(S[i] - T[i]), i = 0:1
D[i] = usat32(S[i] - T[i]), i = 0:1, unsigned
Опциональная сатурация
VSUBL.SCL.RND Vt, Vs, Vd
VSUBL.SCL.RND.SAT Vt, Vs, Vd
D[i] = rnd(S[i] - T[i] + 1) >> 1, i = 0:1
D[i] = sat32(rnd(S[i] - T[i]) >> 1), i = 0:1
Опциональное округление и сатурация
VSUBH #IMM16, Vs, Vd
VSUBH.SAT Vt, Vs, Vd
VSUBHU.SAT Vt, Vs, Vd
D[i] = S[i] - #IMM16, i = 0:1
D[i] = sat16(S[i] - T[i]), i = 0:1
D[i] = usat16(S[i] - T[i]), i = 0:3, unsigned
Опциональная сатурация
VSUBH.SCL.RND Vt, Vs, Vd
VSUBH.SCL.RND.SAT Vt, Vs, Vd
D[i] = rnd(S[i] - T[i]) >> 1, i = 0:1
D[i] = sat16(rnd(S[i] - T[i]) >> 1), i = 0:1
Опциональное округление и сатурация
VSUBB #IMM8, Vs, Vd
VSUBB.SAT Vt, Vs, Vd
VSUBBU.SAT Vt, Vs, Vd
D[i] = S[i] - #IMM8, i = 0:7
D[i] = sat8(S[i] - T[i]), i = 0:7
D[i] = usat8(S[i] - T[i]), i = 0:7, unsigned
Опциональная сатурация
VSUBB.SCL.RND Vt, Vs, Vd
VSUBB.SCL.RND.SAT Vt, Vs, Vd
D[i] = rnd(S[i] - T[i]) >> 1, i = 0:7
D[i] = sat8(rnd(S[i] - T[i]) >> 1), i = 0:7
Опциональное округление и сатурация
VABSD.SAT Vs, Vd
D[i] = sat64(abs(S[i])), i=0
VABSL.SAT Vs, Vd
D[i] = sat32(abs(S[i])), i=0:1
VABSH.SAT Vs, Vd
D[i] = sat16(abs(S[i])), i=0:3
VABSB.SAT Vs, Vd
D[i] = sat8(abs(S[i])), i=0:7
VMAXDU Vt, Vs, Vd
D[i] = umax(T[i], S[i]), i=0
VMAXLU Vt, Vs, Vd
D[i] = umax(T[i], S[i]), i=0:1
VMAXHU Vt, Vs, Vd
D[i] = umax(T[i], S[i]), i=0:3
VMAXBU Vt, Vs, Vd
D[i] = umax(T[i], S[i]), i=0:7
VMINDU Vt, Vs, Vd
D[i] = umin(T[i], S[i]), i=0
VMINLU Vt, Vs, Vd
D[i] = umin(T[i], S[i]), i=0:1
VMINHU Vt, Vs, Vd
D[i] = umin(T[i], S[i]), i=0:3
VMINBU Vt, Vs, Vd
D[i] = umin(T[i], S[i]), i=0:7
VMAX2LU Vt, Vs, Vd
D[0] = T[0]; then D[i] = maxu(D[0], S[i]), i=0, …, n-1
VMAX4HU Vt, Vs, Vd
D[0] = T[0]; then D[i] = maxu(D[0], S[i]), i=0, …, n-1
VMAX8BU Vt, Vs, Vd
D[0] = T[0]; then D[i] = maxu(D[0], S[i]), i=0, …, n-1
VMIN2LU Vt, Vs, Vd
D[0] = T[0]; then D[i] = minu(D[0], S[i]), i=0, …, n-1
VMIN4HU Vt, Vs, Vd
D[0] = T[0]; then D[i] = minu(D[0], S[i]), i=0, …, n-1
VMIN8BU Vt, Vs, Vd
D[0] = T[0]; then D[i] = minu(D[0], S[i]), i=0, …, n-1
VANDI Vt, Vs, Vd
D = ~ (T & S)
одного из операндов или результата, i8
VORI Vt, Vs, Vd
D = ~ (T | S)
одного из операндов или результата, i8
Табл. 11.
VS = {S3, S2, S1, S0}
VD = {S3 + T2, S2 + T3, S1 + T0, S0 + T1}
VS = {S1, S0}
Vd={S1 + T1, S0 + T0}
VS = {S0}
Vd = {S0 + T0}
VS = {S3, S2, S1, S0}
VD = {S3 - T2, S2 - T3, S1 - T0, S0 - T1}
VS = {S1, S0}
Vd = {S1 - T1, S0 - T0}
VS = {S0}
Vd = {S0 - T0}
D[i] = max(T[i], S[i])
D[i] = max(T[i], S[i])
D[i] = max(T[i], S[i])
D[i] = min(T[i], S[i])
D[i] = min(T[i], S[i])
D[i] = min(T[i], S[i])
Табл. 12.
S = {8{i8}} = {S7,…,S0};
D = {8{i16}} = {D7,…,D0} = {D1,D0};
Di = Ti ⋅ Si; i = 0:7;
[i16 = i8 ⋅ i8]
S = {8{u8}} = {S7,…,S0};
D = {8{u16}} = {D7,…,D0} = {D1,D0};
Di = Ti ⋅ Si; i = 0:7;
[u16 = u8 ⋅ u8]
S = {4{i16}} = {S3,…,S0};
D = {4{i32}} = {D3,…,D0} = {D1,D0};
Di = Ti ⋅ Si; i = 0:3;
[i32 = i16 ⋅ i16]
S = {4{u16}} = {S3,…,S0};
D = {4{u32}} = {D3,…,D0} = {D1,D0};
Di = Ti ⋅ Si; i = 0:3;
[u32 = u16 ⋅ u16]
S = {2{i32}} = {S1,S0};
D = {2{i64}} = {D1,D0} = {D1,D0};
Di = Ti ⋅ Si; i = 0,1;
[i64 = i32 ⋅ i32]
S = {2{u32}} = {S1,S0};
D = {2{u64}} = {D1,D0} = {D1,D0};
Di = Ti ⋅ Si; i = 0,1;
[u64 = u32 ⋅ u32]
S = {i64};
D = {i128} = {D1,D0};
D = T ⋅ S;
[i128 = i64 ⋅ i64]
S = {u64};
D = {u128} = {D1,D0};
D = T ⋅ S;
[u128 = u64 ⋅ u64]
VMPACBB T, S, VAd
S = {8{i8}} = {S7,…,S0};
AC = {8{i32}} = {AC7,…,AC0};
ACi += Ti ⋅ Si; i = 0:7;
В двухадресной форме неявно используется VA0.
[i32 += i8 ⋅ i8]
VMPACBB T, S, VAd
S = {8{i8}} = {S7,…,S0};
AC = {8{i32}} = {AC7,…,AC0};
ACi += Ti ⋅ Si; i = 0:7;
В двухадресной форме неявно используется VA0.
[i32 += u8 ⋅ i8]
VMPACBH T, S, VAd
S = {4{i16}} = {S3,…,S0};
AC = {4{i64}} = {AC3,…,AC0};
ACi += Ti ⋅ Si; i = 0:3;
В двухадресной форме неявно используется VA0.
[i64 += i8 ⋅ i16]
VMPACBUH T, S, VAd
S = {4{i16}} = {S3,…,S0};
AC = {4{i64}} = {AC3,…,AC0};
ACi += Ti ⋅ Si; i = 0:3;
В двухадресной форме неявно используется VA0.
[i64 += u8 ⋅ i16]
VMPACHH T, S, VAd
S = {4{i16}} = {S3,…,S0};
AC = {4{i64}} = {AC3,…,AC0};
ACi += Ti ⋅ Si; i = 0:3;
В двухадресной форме неявно используется VA0.
[i64 += i16 ⋅ i16]
VMPACHUH T, S, VAd
S = {4{i16}} = {S3,…,S0};
AC = {4{i64}} = {AC3,…,AC0};
ACi += Ti ⋅ Si; i = 0:3;
В двухадресной форме неявно используется VA0.
[i64 += u16 ⋅ i16]
VMPACLL T, S, VAd
S = {2{i32}} = {S1,S0};
AC = {4{i64}} = {AC3,…,AC0};
ACi += Ti ⋅ Si; i = 0,2;
В двухадресной форме неявно используется VA0.
[i64 += i32 ⋅ i32]
S = {4{f16}} = {S3,…,S0};
D = {4{f16}} = {D3,…,D0};
Di = Ti ⋅ Si; i = 0:3;
[f16 = f16 ⋅ f16]
S = {2{f32}} = {S1,S0};
D = {2{f32}} = {D1,D0};
Di = Ti ⋅ Si; i = 0,1;
[f32 = f32 ⋅ f32]
S = {f64};
D = {f64};
D = T ⋅ S;
[f64 = f64 ⋅ f64]
VHMPAC T, S, VAd
S = {4{f16}} = {S3,…,S0};
AC = {4{f32}} = {AC3,…,AC0};
ACi += Ti ⋅ Si; i = 0:3;
[f32 += f32(f16 ⋅ f16)]
В двухадресной форме неявно используется VA0.
VFMPAC T, S, VAd
S = {2{f32}} = {S1,S0};
AC = {2{f32}} = {AC1,AC0};
ACi += Ti ⋅ Si; i = 0,1;
В двухадресной форме неявно используется VA0.
[f32 += f32 ⋅ f32]
VFMPAC4 T, S, VAd
S = {S', S} = {4{f32}} = {S3,S2,S1,S0};
AC = {4{f32}} = {AC3,…,AC0};
ACi += Ti ⋅ Si; i = 0,3;
В двухадресной форме неявно используется VA0.
[f32 += f32 ⋅ f32]
Используются смежные входные регистры: R'[i] = R[i^1].
VDMPAC T, S, VAd
S = {1{f64}} = {S0};
AC = {1{f64}} = {AC0};
ACi += Ti ⋅ Si; i = 0;
В двухадресной форме неявно используется VA0.
[f64 += f64 ⋅ f64]
VDMPAC2 T, S, VAd
S = {S', S} = {2{f64}} = {S1, S0};
AC = {2{f64}} = {AC1,AC0};
ACi += Ti ⋅ Si; i = 0…1;
В двухадресной форме неявно используется VA0.
[f64 += f64 ⋅ f64]
Используются смежные входные регистры: R'[i] = R[i^1].
Табл. 13.
D[i] = S[i] >> #IMM5, i=0
D[i] = S[i] << #IMM5, i=0
D[i] = S[i] >>> #IMM5, i=0
Else D[i] = RND(S[i] >> T[i])
Else D[i] = RND(S[i] >>> T[i])
D[i] = S[i] >> #IMM5, i=0:1
D[i] = S[i] << #IMM5, i=0:1
D[i] = S[i] >>> #IMM5, i=0:1
Else D[i] = RND(S[i] >> T[i]), i=0…1
Else D[i] = RND(S[i] >>> T[i]), i=0…1
D[i] = S[i] >> #IMM5, i=0:3
D[i] = S[i] << #IMM5, i=0:3
D[i] = S[i] >>> #IMM5, i=0:3
Else D[i] = RND(S[i] >> T[i]), i=0:3
Else D[i] = RND(S[i] >>> T[i]), i=0:3
D[i] = S[i] >> #IMM5, i=0:7
D[i] = S[i] << #IMM5, i=0:7
D[i] = S[i] >>> #IMM5, i=0:7
Else D[i] = RND(D[i] >> T[i]), i=0:7
Else D[i] = RND(D[i] >>> T[i]), i=0:7
Табл. 14.
VCVBHOU Vs, Vd
VCVBHE Vs, Vd
VCVBHO Vs, Vd
Vd = {D3…D0}, i16
D[i]=zext8→16(S[2i+0]), i=0…3
D[i]=zext8→16(S[2i+1]), i=0…3
D[i] = sext8→16(S[2i+0]), i=0…3
D[i] = sext8→16(S[2i+1]), i=0…3
VCVHLOU Vs, Vd
VCVHLE Vs, Vd
VCVHLO Vs, Vd
Vd = {D1…D0}, i32
D[i]=zext16→32(S[2i+0]), i=0…1
D[i]=zext16→32(S[2i+1]), i=0…1
D[i]=sext16→32(S[2i+0]), i=0…1
D[i]=sext16→32(S[2i+1]), i=0…1
VCVLDOU Vs, Vd
VCVLDE Vs, Vd
VCVLDO Vs, Vd
Vd = {D0}, i64
D[i]=zext32→64(S[2i+0]), i=0…1
D[i]=zext32→64(S[2i+1]), i=0…1
D[i]=sext32→64(S[2i+0]), i=0…1
D[i]=sext32→64(S[2i+1]), i=0…1
Vs = {S0}, i64
Vd = {sat32(S0), sat32(T0)}, i32
Vs = {S0}, i64
Vd = {usat32(S0), usat32(T0)}, u32
Vs = {S1, S0}, i32
Vd = {sat16(S1), sat16(T1), sat16(S0), sat16(T0)}, i16
Vs = {S1, S0}, i32
Vd = {usat16(S1), usat16(T1), usat16(S0), usat16(T0)}, u16
Vs = {S3, S2, S1, S0}, i16
Vd = {sat8(S3), sat8(T3), …, sat8(S0), sat8(T0)}, i8
Vs = {S3, S2, S1, S0}, i16
Vd = {usat8(S3), usat8(T3), …,u sat8(S0), usat8(T0)},u8
VVd = {Vd’, Vd} = {{D1}, {D0}}, f64
Di = Ti, i = 0…1
Vs = {S0}, f64
Vd = {D1, D0}, f32
D1 = S0, D0 = T0
VVd = {Vd’, Vd} = {{D3, D1}, {D2, D0}}, f32
Di = Ti, i = 0…1
Vs = {S1, S0}, f64
Vd = {D3, D2, D1, D0}, f32
D3 = S1, D2 = T1, D1 = S0, D0 = T0
Vs = {S0}, i64
Vd = {D1, D0}, f32
D1 = S0, D0 = T0
Vs = {S0}, u64
Vd = {D1, D0}, f32
D1 = S0, D0 = T0
Vd = {D0}, f64
D0 = T0
Vd = {D0}, f64
D0 = T0
Vd = {D1, D0}, f32
D1 = T1, D0 = T0
Vd = {D1, D0}, f32
D1 = T1, D0 = T0
Vd = {Vd’, Vd] = {{D1}, {D0}}, f64
D1 = T1, D0 = T0
Vd = {Vd’, Vd] = {{D1}, {D0}}, f64
D1 = T1, D0 = T0
Vd = {Vd’, Vd] = {{D3, D1}, {D2, D0}}, f64
D3 = T3, D2 = T2, D1 = T1, D0 = T0
Vd = {Vd’, Vd} = {{D3, D1}, {D2, D0}}, f64
D3 = T3, D2 = T2, D1 = T1, D0 = T0
Vs = {S1, S0}, i32
Vd = {D3, D2, D1, D0}, f16
D3 = S1, D2 = T1, D1 = S0, D0 = T0
Vs = {S1, S0}, u32
Vd = {D3, D2, D1, D0}, f16
D3 = S1, D2 = T1, D1 = S0, D0 = T0
Vd = {Vd’, Vd] = {{D3, D2}, {D1, D0}}, f64
D3 = T3, D2 = T2, D1 = T1, D0 = T0
Vd = {Vd’, Vd} = {{D3, D2}, {D1, D0}}, f64
D3 = T3, D2 = T2, D1 = T1, D0 = T0
Vd = {D3, D2, D1, D0}, f16
D3 = T3, D2 = T2, D1 = T1, D0 = T0
Vd = {D3, D2, D1, D0}, f16
D3 = T3, D2 = T2, D1 = T1, D0 = T0
VHCVH.floor Vt, Vd
VHCVH.round Vt, Vd
VHCVH.ceil Vt, Vd
VHCVH.trunc Vt, Vd
Vd = {D3, D2, D1, D0}, i16
D3 = T3, D2 = T2, D1 = T1, D0 = T0
Опциональное округление, принудительная сатурация
VHCVHU.floor Vt, Vd
VHCVHU.round Vt, Vd
VHCVHU.ceil Vt, Vd
VHCVHU.trunc Vt, Vd
Vd = {D3, D2, D1, D0}, u16
D3 = T3, D2 = T2, D1 = T1, D0 = T0
Опциональное округление, принудительная сатурация
VVd = {Vd’, Vd} = {{D3, D1}, {D2, D0}}, i32
D3 = T3, D2 = T2, D1 = T1, D0 = T0
VVd = {Vd’, Vd} = {{D3, D1}, {D2, D0}}, u32
D3 = T3, D2 = T2, D1 = T1, D0 = T0
VVd = {Vd’, Vd} = {{D1}, {D0}}, i64
D1 = T1, D0 = T0
VVd = {Vd’, Vd} = {{D1}, {D0}}, u64
D1 = T1, D0 = T0
VFCVI.floor Vt, Vd
VFCVI.round Vt, Vd
VFCVI.ceil Vt, Vd
VFCVI.trunc Vt, Vd
VVd = {D1, D0}, i32
D1 = T1, D0 = T0
Опциональное округление, принудительная сатурация
VFCVIU.floor Vt, Vd
VFCVIU.round Vt, Vd
VFCVIU.ceil Vt, Vd
VFCVIU.trunc Vt, Vd
VVd = {D1, D0}, u32
D1 = T1, D0 = T0
Опциональное округление, принудительная сатурация
VDCVD.floor Vt, Vd
VDCVD.round Vt, Vd
VDCVD.ceil Vt, Vd
VDCVD.trunc Vt, Vd
VVd = {D0}, i64
D0 = T0
Опциональное округление, принудительная сатурация
VDCVDU.floor Vt, Vd
VDCVDU.round Vt, Vd
VDCVDU.ceil Vt, Vd
VDCVDU.trunc Vt, Vd
VVd = {D0}, u64
D0 = T0
Опциональное округление, принудительная сатурация
Vs = {S0}, f64
VVd = {D1, D0}, i32
D1 = S0, D0 = T0
Vs = {S0}, f64
VVd = {D1, D0}, u32
D1 = S0, D0 = T0
VFCVH.round Vt,Vs, Vd
VFCVH.trunc Vt, Vs, Vd
VFCVH.ceil Vt, Vs, Vd
VFCVH.floor Vt, Vs, Vd
Vs = {S1, S0}, f32
Vd = {D3, D2, D1, D0}, i16
D3 = S1, D2 = T1, D1 = S0, D0 = T0
Опциональное округление, принудительная сатурация
Табл. 15.
Vt = {T[i].D}, Vd = {D[i].D}
D[i].D = sum(T[0].D, …, T[i].D), i=0…7
Vt = {T[i].D}, i=0…7
Rd.D = SUM(T[i])
VANDREDRD Vt, Rd.D
Vt = {T[i].D}, i=0…7
R = AND(T[i])
Векторный вариант:
Vd = {D[i]}, D[i].D = R, i64, i=0…7
Скалярный вариант:
Rd.D = R
VORREDRD Vt, Rd.D
Vt = {T[i].D}, i=0…7
R = OR(T[i])
Векторный вариант:
Vd = {D[i]}, D[i].D = R, i64, i=0…7
Скалярный вариант:
Rd.D = R
VEORREDRD Vt, Rd.D
Vt = {T[i].D}, i=0…7
R = EOR(T[i])
Векторный вариант:
Vd = {D[i]}, D[i].D = R, i64, i=0…7
Скалярный вариант:
Rd.D = R
VADDREDRD Vt, Rd.D
Vt = {T[i].D}, i=0…7
R = SUM(T[i])
Векторный вариант:
Vd = {D[i]}, D[i].D = R, i64, i=0…7
Скалярный вариант:
Rd.D = R
VMAXREDRD Vt, Rd.D
Vt = {T[i].D}, i=0…7
R = MAX(T[i])
Векторный вариант:
Vd = {D[i]}, D[i].D = R, i64, i=0…7
Скалярный вариант:
Rd.D = R
VMINREDRD Vt, Rd.D
Vt = {T[i].D}, i=0…7
R = MIN(T[i])
Векторный вариант:
Vd = {D[i]}, D[i].D = R, i64, i=0…7
Скалярный вариант:
Rd.D = R
VMAXREDRDU Vt, Rd.D
Vt = {T[i].D}, i=0…7
R = MAX(T[i])
Векторный вариант:
Vd = {D[i]}, D[i].D = R, i64, i=0…7
Скалярный вариант:
Rd.D = R
VMINREDRDU Vt, Rd.D
Vt = {T[i].D}, i=0…7
R = MINU(T[i])
Векторный вариант:
Vd = {D[i]}, D[i].D = R, i64, i=0…7
Скалярный вариант:
Rd.D = R
VFADDREDR Vt, Rd.L
При условном исполнении на вход подаются только выделенные предикатом младшие элементы каждой векторной секции, записываются все подсвеченые выходные элемнеты (не только младшие). При нулевом условии скалярная команда исполняется, в результат записывается ноль.
Vt = {T[i].L}, i=0…15
R = FSUM(T[j*2]), j=0…7
Векторный вариант:
Vd = {D[i]}, D[i].L = R, f32, i=0…15
Скалярный вариант:
Rd.L = R
VFMAXREDR Vt, Rd.L
При условном исполнении на вход подаются только выделенные предикатом младшие элементы каждой векторной секции, записываются все подсвеченые выходные элемнеты (не только младшие). При нулевом условии скалярная команда исполняется, в результат записывается ноль.
Vt = {T[i].L}, i=0…15
R = FMAX(T[j*2]), j=0…7
Векторный вариант:
Vd = {D[i]}, D[i].L = R, f32, i=0…15
Скалярный вариант:
Rd.L = R
VFMINREDR Vt, Rd.L
При условном исполнении на вход подаются только выделенные предикатом младшие элементы каждой векторной секции, записываются все подсвеченые выходные элемнеты (не только младшие). При нулевом условии скалярная команда исполняется, в результат записывается ноль.
Vt = {T[i].L}, i=0…15
R = FMIN(T[j*2]), j=0…7
Векторный вариант:
Vd = {D[i]}, D[i].L = R, f32, i=0…15
Скалярный вариант:
Rd.L = R
Табл. 16.
Vs = {S63,…, S2, S1, S0}, i8
Vdi: = {R31,…, R2, R1, R0}, u16
Vdo: = {D31,…, D2, D1, D0}, i16
VV = {S63, …, S0, T63, …, T0}
Di = sext8→16(VV[R[i] & 0x7F]), i=0,1,…,31
Операция универсальной межсекционной выборки с расширением типа данных
Vs = {S63,…, S2, S1, S0}, i8
Vdi: = {R15,…, R2, R1, R0}, u32
Vdo: = {D15,…, D2, D1, D0}, i32
VV = {S63, …, S0, T63, …, T0}
Di = sext8→32(VV[R[i] & 0x7F]), i=0,1,…,31
Операция универсальной межсекционной выборки с расширением типа данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Vs = {S31,…, S2, S1, S0}, i16
Vdi: = {R15,…, R2, R1, R0}, u32
Vdo: = {D15,…, D2, D1, D0}, i32
VV = {S31, …, S0, T31, …, T0}
Di = sext16→32(VV[R[i] & 0x3F]), i=0,1,…,15
Операция универсальной межсекционной выборки с расширением типа данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Vs = {S63,…, S2, S1, S0}, u8
Vdi: = {R31,…, R2, R1, R0}, u16
Vdo: = {D31,…, D2, D1, D0}, u16
VV = {S63, …, S0, T63, …, T0}
Di = zext8→16(VV[R[i] & 0x7F]), i=0,1,…,31
Операция универсальной межсекционной выборки с расширением типа данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Vs = {S63,…, S2, S1, S0}, u8
Vdi: = {R15,…, R2, R1, R0}, u32
Vdo: = {D15,…, D2, D1, D0}, u32
VV = {S63, …, S0, T63, …, T0}
Di = zext8→32(VV[R[i] & 0x7F]), i=0,1,…,31
Операция универсальной межсекционной выборки с расширением типа данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Vs = {S31,…, S2, S1, S0}, u16
Vdi: = {R15,…, R2, R1, R0}, u32
Vdo: = {D15,…, D2, D1, D0}, u32
VV = {S31, …, S0, T31, …, T0}
Di = zext16→32(VV[R[i] & 0x3F]), i=0,1,…,15
Операция универсальной межсекционной выборки с расширением типа данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Vs = {S31…, S2, S1, S0}, i16
Vdi: = {R63…, R2, R1, R0}, u8
Vdo: = {D63…, D2, D1, D0}, i8
VV = {S31, …, S0, T31, …, T0}
Di = sati16→i8 (VV[R[i] & 0x3F]), i=0,1,…,63
Операция универсальной межсекционной выборки с принудительной сатурацией signed → signed в меньший тип данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Vs = {S15…, S2, S1, S0}, i31
Vdi: = {R63…, R2, R1, R0}, u8
Vdo: = {D63…, D2, D1, D0}, i8
VV = {S15, …, S0, T15, …, T0}
Di = sati32→u8 (VV[R[i] & 0x1F]), i=0,1,…,63
Операция универсальной межсекционной выборки с принудительной сатурацией signed → signed в меньший тип данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Vs = {S15…, S2, S1, S0}, i32
Vdi: = {R31…, R2, R1, R0}, u16
Vdo: = {D31…, D2, D1, D0}, i16
VV = {S15, …, S0, T15, …, T0}
Di = sati32→i16 (VV[R[i] & 0x1F]), i=0,1,…,31
Операция универсальной межсекционной выборки с принудительной сатурацией signed → signed в меньший тип данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Vs = {S31…, S2, S1, S0}, u16
Vdi: = {R63…, R2, R1, R0}, u8
Vdo: = {D63…, D2, D1, D0}, u8
VV = {S31, …, S0, T31, …, T0}
Di = sati16→u8 (VV[R[i] & 0x3F]), i=0,1,…,63
Операция универсальной межсекционной выборки с принудительной сатурацией signed → unsigned в меньший тип данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Vs = {S15…, S2, S1, S0}, u31
Vdi: = {R63…, R2, R1, R0}, u8
Vdo: = {D63…, D2, D1, D0}, u8
VV = {S15, …, S0, T15, …, T0}
Di = sati32→u8 (VV[R[i] & 0x1F]), i=0,1,…,63
Операция универсальной межсекционной выборки с принудительной сатурацией signed → unsigned в меньший тип данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Vs = {S15…, S2, S1, S0}, u32
Vdi: = {R31…, R2, R1, R0}, u16
Vdo: = {D31…, D2, D1, D0}, u16
VV = {S15, …, S0, T15, …, T0}
Di = sati32→u16 (VV[R[i] & 0x1F]), i=0,1,…,31
Операция универсальной межсекционной выборки с принудительной сатурацией signed → unsigned в меньший тип данных.
В качестве индексов берутся прежние значения регистра Vd, результат записывается в него же.
Табл. 17.
VLUT1 Vt, Vs, Vr, Vd
Vt = {T63…, T2, T1, T0}, u8
Vs = {S63…, S2, S1, S0}, u8
Vr = {R63…, R2, R1, R0}, u8
Vd = {D63…, D2, D1, D0}, u8
VV = {R63, …, R0, S63, …, S0}, u8
if (T[7] == a) then Di = VV[T[i] & 0x7F], i=0,1,…,63
a - целочисленный 1-битный параметр, который может принимать значения: 0, 1;
T, S, R - входные 512-разрядные вектора;
D - выходной 512-разрядный вектор.
Входные и выходные вектора разделены на 64 байта. Вектор VV: = {Vr, Vs} содержит таблицу преобразования, точнее - половину этой таблицы, полная таблица преобразования содержится в двух векторах VV, соответствующих двум значениям параметра a. Вектор S T содержит преобразуемые данные.
Выбор данных из таблицы для каждого байта ti вектора T (i = 0,1,…,63) определяется его младшими семью битами согласно формуле: di = SVV[ti[6:0]].
Особенностью команды VLUT является то, что кроме собственно выходного вектора она формирует также побайтовую маску записи для этого вектора согласно формуле: mi = (ti[7]== a). Таким образом, в выходной регистр D записываются данные только из нужной таблицы.
Табл. 18.
VHIST1 Vs, Vd
VHIST2 Vs, Vd
VHIST3 Vs, Vd
a - целочисленный 2-битный параметр, который может принимать значения: 0, 1, 2, 3;
S - входной 512-разрядный вектор;
D - выходной 512-разрядный вектор.
Входной и выходной вектор разделены на 64 байта. Для каждого i (i = 0,1,…,63) вычисляется количество байт, значение которых равно (64*a + i), и это количество записывается в i-й байт выходного вектора.
Для вычисления 256-уровневой гистограммы необходимо выполнить эту команду для всех четырех значений параметра a, затем преобразовать полученные 64-компонентные байтовые вектора с расширением до 16-разрядных или 32-разрядных беззнаковых целых, в зависимости от того, в каком формате будет производиться накопление бинов гистограммы, и произвести накопление.
Таким образом, для вычисления гистограмм потребуются также векторные команды расширения типа и целочисленного сложения. При компактном коде возможно вычисление 256-уровневой гистограммы для 64 пикселей примерно за 6 тактов.
Четыре значения параметра a могут быть реализованы в виде четырех различных команд.
VHISTC1 Vs, VAd
VHISTC2 Vs, VAd
VHISTC3 Vs, VAd
Табл. 19.
Vs = {S7…, S2, S1, S0}, u64
Vd = { S6, S5, S4, S3, S2, S1, S0, T7}
Операция кольцевого межсекционного сдвига на 8 байт. Извлекаемый элемент S7 теряется.
При условном исполнении команда исполняется в обычном режиме, но записываются только активные элементы согласно условию-предикату.
Vd = { S6, S5, S4, S3, S2, S1, S0, Rt}
Rt.D = S7.
Операция кольцевого межсекционного сдвига на 8 байт с пересылкой скалярного регистра в нулевую секцию. Извлекаемый элемент возвращается в Rt.D.
Табл. 20.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО ДЛЯ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ДАННЫХ | 1991 |
|
RU2028664C1 |
| РЕГУЛИРУЕМЫЙ СТАБИЛИЗАТОР ПЕРЕМЕННОГО НАПРЯЖЕНИЯ | 2013 |
|
RU2536875C2 |
| АДАПТИВНАЯ СИСТЕМА ТЕРМИНАЛЬНОГО УПРАВЛЕНИЯ | 2012 |
|
RU2500009C1 |
| Способ определения результатов векторно-матричных преобразований в параллельных акустооптических процессорах | 1989 |
|
SU1735836A1 |
| БОРТОВОЙ СПЕЦВЫЧИСЛИТЕЛЬ | 2013 |
|
RU2522852C1 |
| ВЕКТОРНОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО | 2024 |
|
RU2830044C1 |
| СПОСОБ НЕРАЗРУШАЮЩЕГО ОБЪЕМНОГО ИЗМЕРЕНИЯ ВЕКТОРНОЙ ФУНКЦИИ МАГНИТНОЙ ИНДУКЦИИ НЕОДНОРОДНО РАСПРЕДЕЛЕННОГО В ПРОСТРАНСТВЕ И ПЕРИОДИЧЕСКИ ИЗМЕНЯЮЩЕГОСЯ ВО ВРЕМЕНИ МАГНИТНОГО ПОЛЯ | 2012 |
|
RU2490659C1 |
| СИСТЕМА И СПОСОБЫ ОПРЕДЕЛЕНИЯ МЕСТОПОЛОЖЕНИЯ ВОЗДУШНОЙ ТУРБУЛЕНТНОСТИ | 2007 |
|
RU2470331C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРОСМОТРА ИНФОРМАЦИИ НА ДИСПЛЕЕ | 2002 |
|
RU2288512C2 |
| Многопроцессорная вычислительная система | 1982 |
|
SU1168960A1 |
Настоящее техническое решение относится к области микропроцессорной вычислительной техники. Технический результат заключается в повышении скорости работы и объема обрабатываемых данных за счёт параллельных скалярных и векторных вычислений. Технический результат достигается за счёт того, что скалярно-векторный процессор содержит блок редукции, соединенный со скалярным и векторным каналами процессора и реализующий функции их взаимодействия в операциях, где скалярный канал формирует и/или потребляет скаляр, требуемый и/или формируемый векторным каналом процессора; блок редукции выполняет, кроме того, операции над вектором в целом - операции перестановок (shuffle), LUT-преобразования, вычисления гистограмм; скалярный и векторный каналы процессора объединены дополнительно кольцеобразной шиной, позволяющей производить по ней обмен данными одновременно с выполнением вычислительных операций в скалярном и векторном каналах процессора и в блоке редукции. 43 з.п. ф-лы, 7 ил., 20 табл.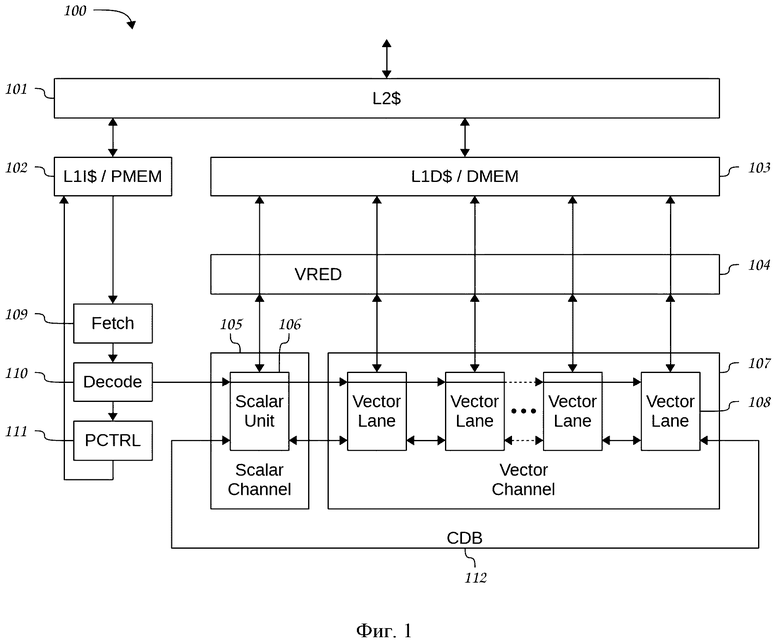
1. Скалярно-векторный процессор 100, содержащий соединенные кольцевой шиной CDB 112 скалярный и векторный каналы 105 и 107 обработки данных, которые соединены с блоком редукции VRED 104, а также с памятью данных первого уровня DMEM/L1D$ 103, которая соединена с кэш-памятью второго уровня L2$ 101, которая соединена с внешним интерфейсом процессора, который имеет доступ к внешней памяти вычислительной системы, а также соединена с памятью программ первого уровня PMEM/L1I$ 102, выход которой соединен с входом блока выборки команд FETCH 109, выход которого соединен с входом блока декодирования команд DECODE 110, первый выход которого соединен с входами скалярного и векторного каналов, а второй выход соединен с блоком программного управления PCTRL 111, выход которого соединен с входом памяти программ первого уровня PMEM/L1I$ 102, причем
- память программ первого уровня PMEM/L1I$ 102 и память данных первого уровня DMEM/L1D$ 103 выполнены с возможностью формирования обращений и передачи их в
- кэш-память второго уровня L2$ 101, которая выполнена с возможностью обслуживания обращений из памяти программ первого уровня РМЕМ/L1I$ 102 и памяти данных первого уровня DMEM/L1D$ 103, а также загрузки данных через внешний интерфейс из внешней памяти вычислительной системы и передачи данных в память данных первого уровня DMEM/L1D$ 103 и память программ первого уровня PMEM/L1I$ 102;
- блок выборки команд FETCH 109 выполнен с возможностью выборки команд из памяти программ PMEM/L1I$ 102 и передачи их в
- блок декодирования команд DECODE 110, выполненный с возможностью декодирования команд и формирования команд программного управления для исполнительных устройств процессора и передачи их в
- блок PCTRL, который выполнен с возможностью выполнения команд программного управления.
2. Процессор по п. 1, отличающийся тем, что память данных первого уровня DMEM/L1D$ 103 выполнена в виде кэш-памяти первого уровня L1D$ или в виде тесно связанной ТСМ (Tightly-Coupled Memory) статической памяти DMEM.
3. Процессор по п. 1, отличающийся тем, что память программ первого уровня РМЕМ/L1I$ 102 выполнена в виде кэш-памяти первого уровня L1I$ или в виде тесно связанной ТСМ (Tightly-Coupled Memory) статической памяти РМЕМ.
4. Процессор по п. 1, отличающийся тем, что на уровне вычислительного ядра имеет гарвардскую архитектуру с возможностью одновременного доступа к памяти программ первого уровня РМЕМ/L1$ 102 и памяти данных первого уровня DMEM/L1D$ 103 по отдельным шинам.
5. Процессор по п. 1, отличающийся тем, что кэш-память второго уровня L2$ 101 имеет фон-неймановскую архитектуру.
6. Процессор по п. 1, отличающийся тем, что команды программного управления выбраны из набора команд, содержащего команды программных переходов и команды программных циклов.
7. Процессор по п. 1, отличающийся тем, что команды объединены в инструкции, которые организованы в виде VLIW-пакета 201 (VLIW - Very Long Instruction Word).
8. Процессор по п. 7, отличающийся тем, что VLIW-пакет 201 содержит до восьми команд, из которых до четырех команд предназначены для исполнительных устройств скалярного канала обработки данных и до четырех команд предназначены для исполнительных устройств векторного канала обработки данных.
9. Процессор по п. 7, отличающийся тем, что VLIW-пакет 201 содержит до двух команд скалярных обменов данными и до двух векторных команд обмена данными с памятью данных DMEM/L1D$ 103.
10. Процессор по п. 1, отличающийся тем, что имеет систему команд, состоящую из команд программного управления, команд исполнительных устройств скалярного канала обработки данных и векторного канала обработки данных, а также команд блока редукции VRED 104.
11. Процессор по п. 1, отличающийся тем, что скалярный канал 105 содержит одну скалярную вычислительную секцию 106.
12. Процессор по п. 1, отличающийся тем, что скалярная вычислительная секция 106 содержит скалярный регистровый файл RF 301, который является многопортовым и в котором хранятся обрабатываемые скалярные данные.
13. Процессор по п. 12, отличающийся тем, что скалярный регистровый файл RF 301 содержит порты, связанные со скалярным каналом 105 обработки данных и выполненные с возможностью обмена данными с памятью данных DMEM/L1D$ 103.
14. Процессор по п. 12, отличающийся тем, что скалярный регистровый файл RF 301 содержит порты, связанные с исполнительными устройствами скалярной вычислительной секции 106 скалярного канала 105 обработки данных, выполненные с возможностью передачи исходных данных для выполнения вычислительных операций и записи результатов операций обратно в скалярный регистровый файл RF 301.
15. Процессор по п. 1, отличающийся тем, что скалярная вычислительная секция 106 содержит блоки обработки данных SLSE0 310, SLSE1 311, которые выполнены с возможностью обеспечения обмена данными между памятью данных DMEM/L1D$ 103 и скалярным регистровым файлом RF 301, в том числе выполнения команд пересылок данных между памятью данных DMEM/L1D$ 103 и скалярным регистровым файлом RF301.
16. Процессор по п. 1, отличающийся тем, что скалярная вычислительная секция 106 содержит блоки обработки данных ALU0 302, ALU1 303, ALU2 304, ALU3 305, выполняющие арифметические и логические операции над числами с фиксированной запятой.
17. Процессор по п. 1, отличающийся тем, что скалярная вычислительная секция 106 содержит блоки обработки данных FALU0 306, FALU1 307, выполняющие арифметические и логические операции над числами с плавающей запятой.
18. Процессор по п. 1, отличающийся тем, что скалярная вычислительная секция 106 содержит блоки обработки данных SMU0 308, SMU1 309, выполняющие операции умножения над числами с фиксированной и плавающей запятой.
19. Процессор по п. 1, отличающийся тем, что скалярная вычислительная секция 106 содержит блок обработки данных SH 312, выполняющий операции логического и арифметического сдвига.
20. Процессор по п. 1, отличающийся тем, что скалярная вычислительная секция 106 содержит блок обработки данных CONV 315, выполняющий операции преобразования типов данных.
21. Процессор по п. 1, отличающийся тем, что скалярная вычислительная секция 106 содержит блок обработки данных DIV 313, выполняющий операции деления.
22. Процессор по п. 1, отличающийся тем, что скалярная вычислительная секция 106 содержит блок обработки данных MF 314, выполняющий операции вычисления трансцендентных математических функций.
23. Процессор по п. 1, отличающийся тем, что векторный канал 107 состоит из нескольких векторных вычислительных секций 108, количество которых соответствует разрядности обрабатываемого вектора.
24. Процессор по п. 23, отличающийся тем, что векторная вычислительная секция 108 содержит векторный регистровый файл VRF 401, который является многопортовым и мультиформатным и в котором хранятся обрабатываемые векторные данные.
25. Процессор по п. 24, отличающийся тем, что векторный регистровый файл VRF 401 является мультиформатным, так что каждый 64-разрядный регистр 500 векторного регистрового файла VRF 401 может хранить либо одно 64-разрядное значение 501, либо два 32-разрядных значения 502, либо четыре 16-разрядных значения 503, либо восемь 8-разрядных значений 504.
26. Процессор по п. 24, отличающийся тем, что векторный регистровый файл VRF 401 содержит порты, связанные с внешним интерфейсом векторного канала 107 и выполненные с возможностью обмена данными с памятью данных DMEM/L1D$ 103.
27. Процессор по п. 24, отличающийся тем, что векторный регистровый файл VRF 401 содержит порты, связанные с исполнительными устройствами векторной вычислительной секции 108, выполненные с возможностью передачи исходных данных для выполнения вычислительных операций и записи результатов обратно.
28. Процессор по п. 24, отличающийся тем, что векторный регистровый файл VRF 401 выполнен с возможностью работы с различными форматами данных.
29. Процессор по п. 23, отличающийся тем, что векторная вычислительная секция 108 содержит блоки VLSE0 412, VLSE1 413, которые выполнены с возможностью обеспечения обмена данными между памятью данных DMEM/L1D$ 103 и векторным регистровым файлом VRF 401, в том числе и выполнения команд пересылок данных между памятью данных DMEM/L1D$ 103 и векторным регистровым файлом VRF 401.
30. Процессор по п. 23, отличающийся тем, что векторная вычислительная секция 108 содержит блоки VALU0 403, VALU1 404, VALU2 405, VALU3 406, выполненные с возможностью осуществления арифметических и логических операций над числами с фиксированной запятой.
31. Процессор по п. 23, отличающийся тем, что векторная вычислительная секция 108 содержит блоки VFALU0 407, VFALU1 408, выполненные с возможностью осуществления арифметических и логических операций над числами с плавающей запятой.
32. Процессор по п. 23, отличающийся тем, что векторная вычислительная секция 108 содержит блоки VMU0 409, VMU1 410, выполненные с возможностью осуществления операций умножения и умножения с накоплением над числами с фиксированной и плавающей запятой.
33. Процессор по п. 23, отличающийся тем, что векторная вычислительная секция 108 содержит векторный регистровый файл регистров-аккумуляторов VAC 402, выполненный с возможностью хранения данных, получаемых и используемых в результате выполнения операций умножения с накоплением, выполняемых блоками векторных умножителей VMU0 409, VMU1 410.
34. Процессор по п. 23, отличающийся тем, что векторная вычислительная секция 108 содержит блок VSH 411, выполненный с возможностью осуществления операций логического и арифметического сдвига над векторными операндами.
35. Процессор по п. 23, отличающийся тем, что векторная вычислительная секция 108 содержит блок VCONV 414, выполненный с возможностью осуществления операции преобразования типов данных над векторными операндами.
36. Процессор по п. 1, отличающийся тем, что блок редукции VRED 104 выполнен с возможностью вычисления функций редукции.
37. Процессор по п. 1, отличающийся тем, что блок редукции VRED 104 выполнен с возможностью вычисления функций редукции и при этом реализации функций взаимодействия скалярной и векторной частей процессора в разнообразных операциях, в которых скалярный канал 105 формирует и/или потребляет скаляр, требуемый и/или формируемый векторным каналом 107.
38. Процессор по п. 1, отличающийся тем, что блок редукции VRED 104 содержит блок RALU 601, выполненный с возможностью осуществления арифметико-логических межсекционных операций редукции.
39. Процессор по п. 1, отличающийся тем, что блок редукции VRED 104 содержит блок SHUFFLE 602, выполненный с возможностью осуществления операций межсекционных перестановок.
40. Процессор по п. 1, отличающийся тем, что блок редукции VRED 104 содержит блок LUT 603, выполненный с возможностью осуществления операций межсекционных табличных преобразований.
41. Процессор по п. 1, отличающийся тем, что блок редукции VRED 104 содержит блок HIST 604, выполненный с возможностью осуществления операций вычисления гистограмм.
42. Процессор по п. 1, отличающийся тем, что кольцевая шина CDB (Circular Data Bus) 112 выполнена с возможностью осуществления обмена данными одновременно с осуществлением вычислительных операций в скалярном и векторном каналах 105, 107 и в блоке редукции VRED 104.
43. Процессор по п. 1, отличающийся тем, что кольцевая шина CDB 112 выполнена с возможностью осуществления команд циклического сдвига, в результате выполнения которых регистр Ri скалярного регистрового файла RF 301 смещается в регистр Vj векторного регистрового файла VRF 401 нулевой векторной вычислительной секции 108: Vj.0=Ri; регистр Vj векторного регистрового файла VRF 401 старшей (N-1) векторной вычислительной секции 108 смещается в регистр Ri скалярного регистрового файла RF 301: Ri=Vj.N-1; регистры Vj векторных регистровых файлов VRF 401 остальных векторных вычислительных секций 108 смещаются на одну секцию в сторону старших секций: Vj.k=Vj.k-1, k=1,2,…,N-1.
44. Процессор по п. 1, отличающийся тем, что кольцевая шина CDB 112 выполнена с возможностью последовательного перемещения данных из векторного канала 107 в скалярный канал 105 с целью выполнения операций, имеющихся только в скалярном канале 105, с последующим возвращением преобразованных данных в векторный канал 107.
| US 8698817 B2, 15.04.2014 | |||
| КОНВЕЙЕРНЫЙ ПРОЦЕССОР | 1992 |
|
RU2032215C1 |
| US 5430884 A, 04.07.1995 | |||
| Ультразвуковой активатор жидких сред | 1989 |
|
SU1666174A1 |
| US 7334110 B1, 19.02.2008 | |||
| JP 5680697 B2, 05.09.2013. | |||

