ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное техническое решение в общем относится к области микропроцессоров, а в частности к векторному вычислительному устройству.
УРОВЕНЬ ТЕХНИКИ
[0002] В настоящий момент в современном мире выполняется большое количество операций с данными. С развитием и внедрением нейронных сетей во все сферы жизнедеятельности, появилась необходимость в устройствах, способных эффективно работать с нейронными сетями. Так, процессоры общего назначения, ввиду своей архитектуры, не приспособлены для выполнения процессов машинного обучения, таких как обучение нейронных сетей и т.д., с высокой скоростью. В связи с этим, в последние годы, особую важность получило направление развития векторных процессоров.
[0003] Векторный процессор - это тип процессора, который может обрабатывать несколько элементов данных одновременно, что обеспечивает более высокую производительность, чем скалярные процессоры для ряда операций. Такой процессор способен выполнять операции над вектором элементов данных параллельно. Векторные процессоры особенно полезны для таких задач, как вычисление нейронных сетей, обработка изображений и т.д., т.е. для вычислений где необходимо обрабатывать параллельно большие объемы данных.
[0004] Так, из уровня техники известно векторное вычислительное устройство (см. Интернет: https://cloud.google.com/tpu/docs/system-architecture-tpu-vm). Указанный векторный процессор, разработанный компанией Google™, предназначен для повышения пропускной способности данных (повышение производительности вычислений) для процессов машинного обучения.
[0005] Элементы векторного процессора расположены на кристалле интегральной схемы. Для ускорения вычислений, вычислительные блоки сегментированы на несколько дорожек, каждая из которых предназначена для осуществления вычислительной операции с элементом вектора, что обеспечивает распараллеливание операций. Внутри каждой дорожки расположена векторная память, которая может включать в себя несколько банков памяти, каждый из которых имеет несколько ячеек адреса памяти. Более подробно, каждая дорожка (линия) включает в себя многомерный регистр данных/файлов, сконфигурированный для хранения множества векторных элементов, и арифметико-логический блок (ALU), сконфигурированный для выполнения арифметических операций над векторными элементами, доступными из регистра данных и хранящимися в нем. Все элементы процессора конфигурируются посредством VLIW инструкций.
[0006] Недостатками указанного решения являются низкая производительность ввиду архитектурных особенностей, связанных с организацией дорожек, а также способ конфигурирования элементов при выполнении арифметических операций. Кроме того, за счет предлагаемого распараллеливания операций на множество линий, некоторые вычислительные операции, требующие получения промежуточных результатов, исполняются в несколько тактов (проходов) процессора, что, соответственно увеличивает время исполнения операции, и, как следствие, снижает производительность. Также, представленное решение не подразумевает возможность конфигурирования вычислительных блоков посредством потока команд (Dataflow). Еще одним недостатком является низкая пропускная способность векторной памяти, из-за необходимости соединения линий с вычислительными блоками между собой посредством шин данных.
[0007] Соответственно, целью настоящего технического решения является создание векторного вычислительного устройства, обладающего высокой производительностью. Кроме того, данное решение должно обеспечить возможность потоковой конфигурации вычислительных элементов процессора, в том числе и векторной памяти, а также обеспечить уменьшение площади кристалла и улучшение энергоэффективности, за счет особенностей заявленной архитектуры процессора.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0008] В заявленном техническом решении предлагается новый подход к архитектуре векторного процессора, обеспечивающего высокую производительность.
[0009] Решается техническая проблема повышения эффективности и скорости работы векторного процессора за счет увеличения количества операций за один такт процессора.
[0010] Техническим результатом, достигающимся при решении данной проблемы, является повышение скорости работы векторного процессора.
[0011] Дополнительным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является уменьшение площади кристалла векторного процессора.
[0012] Указанные технические результаты достигаются благодаря осуществлению векторного процессора, размещенного на кристалле, содержащего:
• скалярные устройства, каждое из которых выполнено с возможностью получения элемента вектора из устройства умножения матриц и состоит из:
 по меньшей мере двух скалярных модулей, образующих по меньшей мере одну скалярную линию, выполненных с возможностью осуществления арифметических операций над элементом вектора;
по меньшей мере двух скалярных модулей, образующих по меньшей мере одну скалярную линию, выполненных с возможностью осуществления арифметических операций над элементом вектора;
по меньшей мере одного первого демультиплексора, выполненного с возможностью перенаправления данных от первого скалярного модуля в линии, в многопортовую общую память или второй скалярный модуль в линии;
блока сложных арифметических операций, соединенного по меньшей мере с одним скалярным модулем в линии, и выполненного с возможностью исполнения математических функций над элементом вектора;
по меньшей мере одного второго демультиплексора, выполненного с возможностью перенаправления данных из многопортовой памяти в скалярный модуль или устройство умножения матриц;
• многопортовая общая память, соединенная по меньшей мере с внешней памятью, вторым демультиплексором каждого скалярного устройства и устройством умножения матриц, выполненная с возможностью буферизации и хранения результатов промежуточных вычислений над элементами вектора каждого скалярного устройства;
• блок горизонтальных операций, связанный со скалярными устройствами, выполненный с возможностью:
исполнения арифметических операций с объединенными элементами вектора;
трансляции результата исполнения арифметической операции с объединенными элементами вектора в скалярные устройства.
[0013] В одном из частных вариантов реализации скалярные устройства располагаются на кристалле в виде плитки.
[0014] В другом частном варианте реализации каждое скалярное устройство содержит по меньшей мере четыре скалярных модуля.
[0015] В другом частном варианте реализации по меньшей мере четыре скалярных модуля образуют по меньшей мере две скалярные линии.
[0016] В другом частном варианте реализации скалярная линия представляет собой последовательно соединенные по меньшей мере два скалярных модуля.
[0017] В другом частном варианте реализации каждый из по меньшей мере двух скалярных модулей, представляет собой конфигурируемый потоковый процессор содержащий: блок суммирования, блок произведения, модуль вычисления функций и локальную память.
[0018] В другом частном варианте реализации коммутация данных, осуществляемая каждым первым демультиплексором в каждом скалярном устройстве, от первого скалярного модуля в линии, зависит от исполняемой операции процессора.
[0019] В другом частном варианте реализации элементы процессора соединены между собой посредством AXI4-Stream интерфейса.
[0020] В другом частном варианте реализации математические функции над элементом вектора представляют собой, по меньшей мере:
• экспонента;
• натуральный логарифм;
• обратное число;
• обратный квадратный корень;
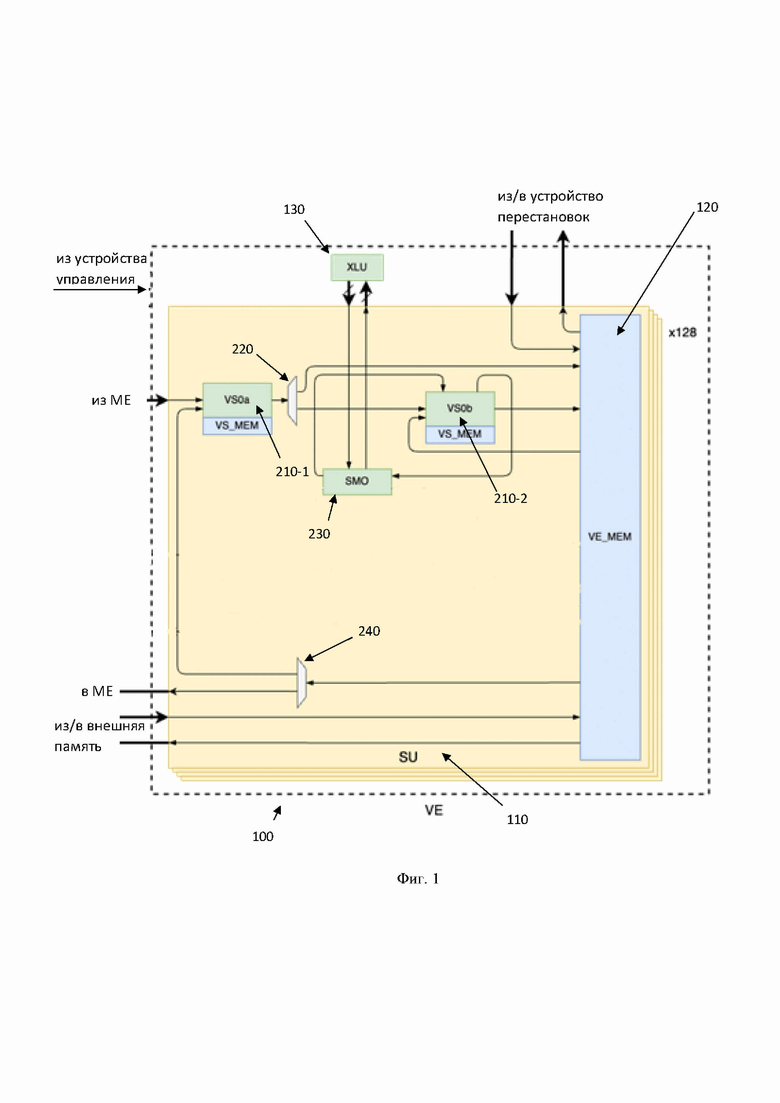
• математические функции с использованием LUT таблиц.
[0021] В другом частном варианте реализации арифметические операции, исполняемые блоком горизонтальных операций, представляют собой, по меньшей мере:
• сложение элементов вектора, полученных от скалярных устройств;
• нахождение максимального элемента среди полученных скалярных элементов;
• нахождение минимального элемента среди полученных скалярных элементов;
• нахождение обратного значения скалярных элементов;
• нахождение обратного квадратного корня скалярных элементов.
[0022] В другом частном варианте реализации исполняемая операция, осуществляемая процессором, задается по меньшей мере одним потоком конфигураций.
[0023] В другом частном варианте реализации каждая конфигурация определяет параметры и тип обработки вектора.
[0024] В другом частном варианте реализации одна конфигурация распараллеливается на каждое из скалярных устройств.
[0025] В другом частном варианте реализации элементы процессора соединены между собой шиной (interconnect).
[0026] В другом частном варианте реализации шина выполнена с возможностью обеспечения связи между устройствами векторного процессора и распространения конфигураций и данных.
[0027] В другом частном варианте реализации многопортовая общая память содержит:
• порт записи для каждого скалярного модуля;
• порт чтения для каждого скалярного модуля;
• порты для связи с внешней памятью;
• порты для связи с устройством перестановок.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0028] Признаки заявленного технического решения и подробное описание приведено ниже в виде прилагаемых чертежей.
[0029] Фиг. 1 иллюстрирует пример структурной схемы векторного процессора с одной скалярной линией.
[0030] Фиг. 2 иллюстрирует пример структурной схемы векторного процессора с двумя скалярной линией.
[0031] Фиг. 3 иллюстрирует структурную схему одной скалярной линии.
[0032] Фиг. 4 иллюстрирует пример размещения элементов на кристалле.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0033] Ниже будут описаны понятия и термины, необходимые для понимания данного технического решения.
[0034] Векторный процессор - это процессор, в котором операндами некоторых команд могут выступать упорядоченные массивы данных - векторы. Отличается от скалярных процессоров, которые могут работать только с одним операндом в единицу времени.
[0035] Заявленное техническое решение предлагает новый подход в создании векторного процессора, обладающего высокой производительностью. Кроме того, заявленное решение обеспечивает возможность потоковой конфигурации вычислительных элементов процессора, что дополнительно повышает скорость работы процессора, ввиду исключения необходимости отправки набора инструкций на каждую исполняемую однотипную команду. Так, за счет предлагаемой архитектуры заявленного решения обеспечивается возможность исполнения потоковых операций над данными, без необходимости переконфигурирования элементов процессора после каждой операции, что дополнительно повышает быстродействие процессора.
[0036] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, конфигурирование вычислительных элементов векторного процессора на исполнение операции с вектором и т.п.Инструкции могут быть осуществлены множеством способов, включающих в себя, например, потоковую конфигурацию машинных команд, объектно-ориентированные методы и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться по проводным каналам от устройств управления.
[0037] На Фиг. 1 представлена блок схема векторного процессора 100. Указанный процессор 100 включает в себя множество скалярных устройств 110, каждое из которых состоит из скалярных модулей 210-1 и 210-2, первого демультиплексора 220, блока сложных арифметических операций 230, второго демультиплексора 240, многопортовой общей памяти 120, блока горизонтальных операций 130.
[0038] Архитектура заявленного векторного процессора, преимущественно, направлена на решение массивно-параллельных вычислений, включая задачи вычисления нейронных сетей и искусственного интеллекта, обработку видеопотоков и т.д. Однако, стоит отметить, что заявленный векторный процессор не должен ограничиваться задачами машинного обучения или вычислениями на основе нейронных сетей, а может также применяться для вычислений, связанных с различными областями технологий, для которых требуются такие процессоры, например, обработка изображений и т.д.
[0039] Как указывалось, выше, заявленный векторный процессор 100 (Vector Engine (VE)), предназначен для выполнения ряда математических операций над векторами, например, длиной 128 слов формата FP24, с возможностью буферизации входных и промежуточных значений. Основное применение процессора 100 - исполнение вычислений сверточных слоев нейронных сетей после умножения матриц фичей и весов в устройстве умножения матриц (Matrix Engine (ME)). Векторный процессор, преимущественно, является частью ускорителя нейросетей, и предназначен для завершения вычисления слоев нейросети. Векторный процессор 100 управляется посредством потоков конфигураций, получаемых из устройства управления (внешнее по отношению к процессору). Также, векторный процессор 100 имеет соединение с внешней памятью для получения/отправки данных в/из нее. В еще одном частном варианте осуществления векторный процессор 100 выполнен с возможностью взаимодействия с устройством перестановок (является внешним по отношению к процессору 100).
[0040] Элементы векторного процессора 100 расположены на кристалле интегральной схемы (ИС). В одном частном варианте осуществления кристалл ИС может являться частью другого кристалла ИС, например, ускорителя нейросетей, который также содержит другие компоненты, связанные с процессором 100 (устройство умножения матриц ME, устройство управления CU, устройство перестановок и т.д.).
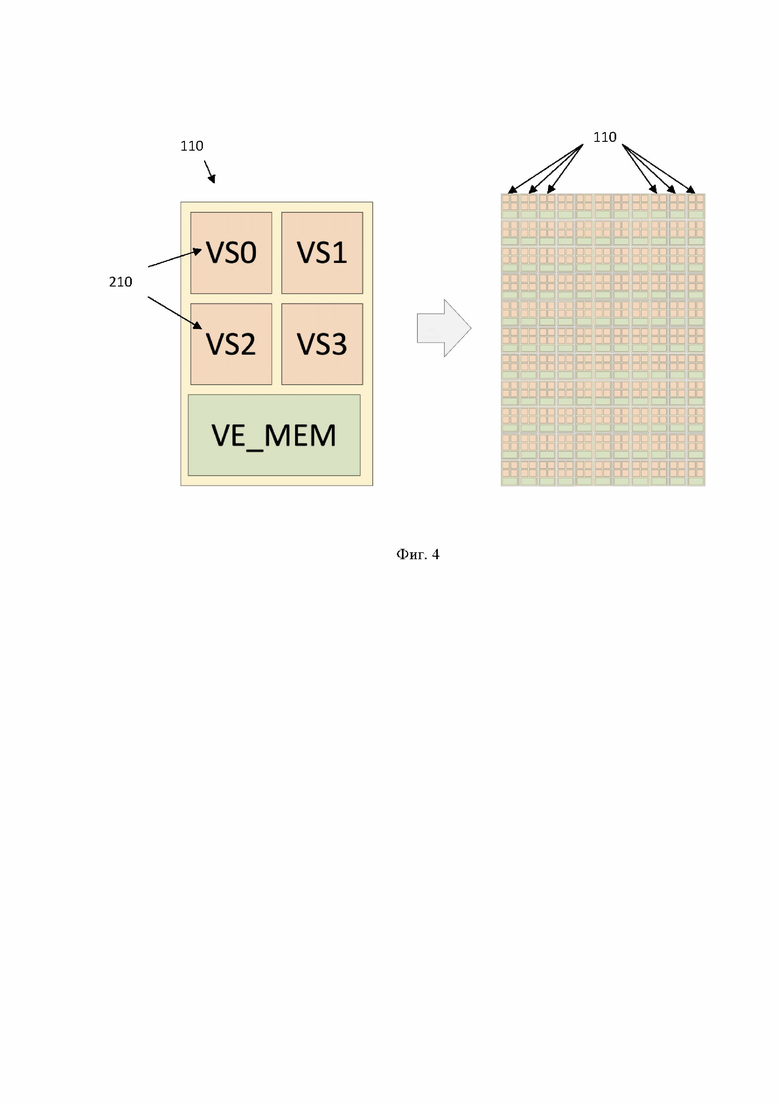
[0041] Скалярные устройства (Scalar Unit, (SU)) 110 представляют собой скалярные вычислительные блоки, каждый из которых выполнен с возможностью обработки одного 24-битного слова (скаляр) из общего количества слов вектора. Так, количество устройств 110 определяет длину вектора, которую способен обработать процессор 100 за один проход. В одном частном варианте осуществления процессор 100 разбит на 128 скалярных устройств 110 каждое из которых обрабатывает одно 24-битное слово (скаляр) из 128 слов вектора. Соответственно, в других частных вариантах осуществления процессор 100 может содержать большее или меньшее количество устройств 110, из которые являются частью процессора 100.
[0042] Устройства 110 выложены на кристалле в виде плитки («тайлов»). Пример расположения устройств 110 в виде плитки представлен на Фиг. 4. Слева показано одно устройство 110, содержащее четыре устройства 210, справа - 128 устройств 110. Каждое из устройств 110 является независимым. В одном частном варианте осуществления устройства 110 могут быть объединены в кластера, например, по 16, 8 устройств 110 и т.д. Устройства 110 связаны с общей шиной данных (interconnect). Устройства 110 являются независимыми и работают параллельно. Т.е. в соответствии с конфигурацией, подаваемой на шину от устройства управления, указанная конфигурация распараллеливается на каждое устройство 110, например, на 128 устройств 110, и каждое устройство 110 выполняет операцию независимо с каждым элементов вектора (скаляром). Также, по указанной шине осуществляется взаимодействие с внешними элементами процессора 100.
[0043] В свою очередь, для выполнения арифметических операций над элементом вектора, каждое устройство 110 состоит из по меньшей мере двух скалярных модулей 210 (Vector Subunit (VS)), образующих по меньшей мере одну скалярную линию (210-1-210-2), выполненных с возможностью осуществления арифметических операций над элементом вектора; по меньшей мере одного первого демультиплексора 220, выполненного с возможностью перенаправления данных от первого скалярного модуля 210-1 (VS) в линии, в многопортовую общую память 120 или второй скалярный модуль в линии 210-2; блока сложных арифметических операций 230 (Special Math Operations (SMO)), соединенного по меньшей мере с одним скалярным модулем в линии, например, модулем 210-2, и выполненного с возможностью исполнения математических функций над элементом вектора; по меньшей мере одного второго демультиплексора, выполненного с возможностью перенаправления данных из многопортовой памяти 120 в скалярный модуль, например, модуль 210-1 или устройство умножения матриц (ME).
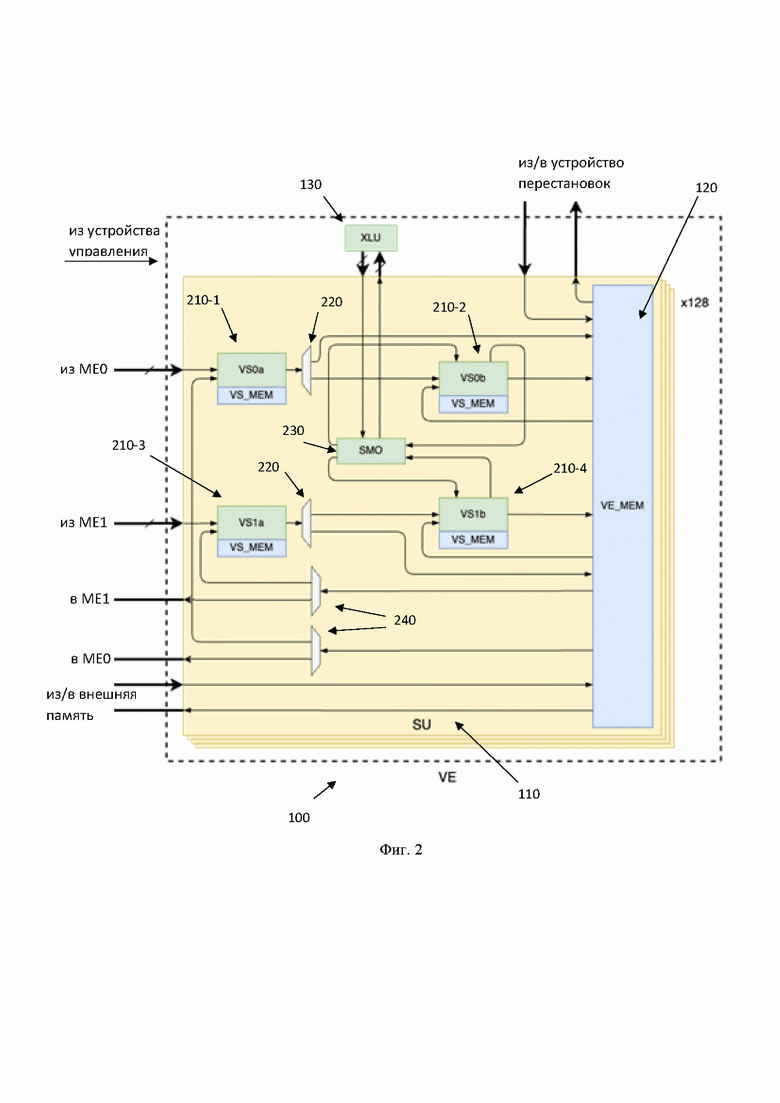
[0044] Стоит отметить, что под линией понимается группа последовательно соединенных модулей 210 в составе каждого устройства 110. Так, в одном частном варианте осуществления, количество линий в составе каждого устройства 110 зависит от количества блоков матричного умножения, содержащихся в устройстве более высокого уровня (например, ускорителя нейросетей). Так, в еще одном частном варианте осуществления каждое устройство 110 может содержать две линии, образованные четырьмя модулями 210, как это показано на Фиг. 2: Линия 0: (МЕ0→) модуль 210-1→ модуль 210-2→ память 120. Линия 1: (МЕ1→) модуль 210-3→ модуль 210-4→ память 120. В еще одном частном варианте осуществления линия может содержать только один модуль 210. Такой вариант осуществления возможен при исполнении математического аппарата, не требующего сложных вычислений.
[0045] Устройства 210 в разных линиях работают независимо и связаны друг с другом только через память 120. Т.е. линии между собой являются идентичными и модули 210 имеющие одинаковую позицию в линии обладают одинаковыми функциональными возможностями. Так, например, вторые в линии модули 210 (210-2 и 210-4) подключены к блоку 230, и, посредством его, к блоку горизонтальных операций 130.
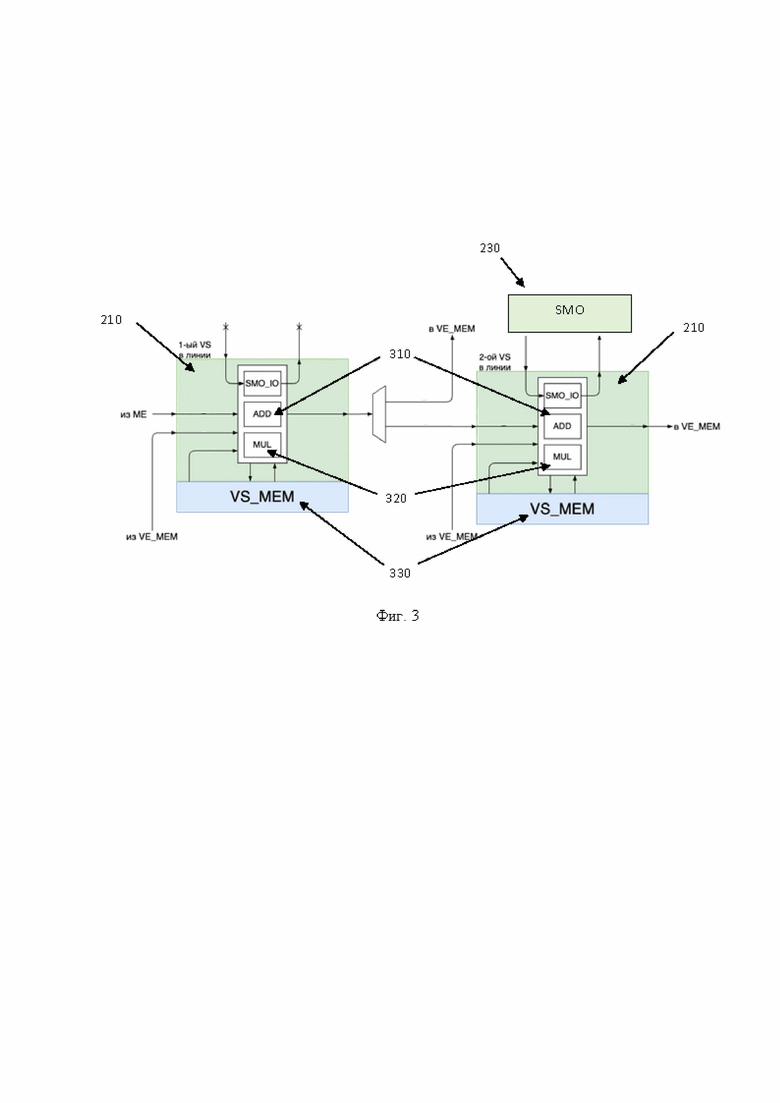
[0046] Возвращаясь к Фиг. 1, скалярные модули 210 обеспечивают исполнение арифметических операций над данными из устройства матричного умножения (ME) или памяти 120. Оба модуля 210-1 и 210-2 в линии идентичны, каждый состоит из следующих элементов, показанных на Фиг. 3: блок суммирования 310, блок произведения 320, локальной памяти 330, а также блока интерфейса для связи с блоком сложных математических операций 230. На Фиг. 3 показан пример одной линии, состоящей из двух скалярных модулей 210, например, таких как модули 210-1 и 210-2. Модули 210 имеют два входа (первый из устройства матричных умножений (ME), второй из памяти векторного процессора) и два выхода (в память векторного процессора). Выход первого модуля 210 в линии подается на демультиплексор, такой как демультиплексор 220 управляемый инструкцией этого модуля. Так, если в инструкции указана операция OUTPUT_VM (запись в память векторного процессора) - данные из модуля 210-1 перенаправляются на запись в память 120, если операция OUTPUT_VS - данные подаются на вход следующего модуля 210 в линии, например, модуля 210-2.
[0047] Такой принцип организации архитектуры процессора 100 обеспечивает сокращение количества инструкций, требуемых для исполнения операции в процессоре 100 и обеспечивает возможность потокового исполнения операций. Так, такой принцип также позволяет достичь повышения производительности процессора 100 за счет сокращения количества обращений к процессору 100 для его конфигурирования. Т.е. последовательный способ соединения модулей 210 в линии позволяет сократить количество операций, требуемых процессору для выполнения вычисления, требующего промежуточный результат. Так, в качестве примера рассмотрим операцию (А+В)*С.При параллельной обработки такой операции потребуется конфигурировать модуль на исполнение первой операции, а именно выполнение операции (А+В), сохранение этого результата в память, чтение результата из памяти для умножения на С.Соответственно, в заявленном решении, за счет наличия последовательной линии арифметических блоков (модули 210), модуль 210-1 выполнит операцию А+В и передаст результат в модуль 210-2 для умножения. Т.е. такая архитектура позволяет выполнять операции последовательно, находясь в вычислительном конвейере. При этом, поддержка потоковой конфигурации процессора (DataFlow), дополнительно повышает скорость работы процессора 100 ввиду исключения необходимости многократной конфигурации вычислительных элементов на выполнение однотипных операций. Так, при потоковой конфигурации исполняемая операция задается один раз и выполняется для всего входящего пакета данных. Данный пример приведен для более точного отражения сути заявленного технического решения и не должен ограничивать сложность исполняемых операций. Так, посредством модулей 210-1 и 210-2 могут быть исполнены более сложные операции, например, exp[([(A+B)*C]+D)*E], где, соответственно, [(А+В)*С] будет выполняться первым модулем в линии, а остальная часть во втором.
[0048] Соответственно, аналогичная ситуация будет и для модулей 210-3 и 210-4, показанных на Фиг. 2, образующих вторую линию. Как указывалось, выше, линии между собой идентичны. Выход последнего из модулей 210 в линии всегда подается на запись в память 120(в VE_MEM). У каждого модуля 210 также есть доступ на чтение памяти 120.. Стоит отметить, что наличие второй и последующих линий (третья, четвертая и т.д.) обеспечивает повышение параллельных вычислений, однако увеличивает площадь и энергопотребление процессора 100.
[0049] Каждое из арифметических устройств, составляющих модуль 210, может представлять собой конфигурируемый потоковый процессор и поддерживает свой уникальный набор команд. Для блока суммирования 310 это в первую очередь сложение и вычитание, для блока произведения 320 произведение. Кроме того, как указывалось выше, для исполнения функций над операндами последний модуль в линии соединен с блоком 230 через блок интерфейса связи с блоком выполнения сложных математических операций. Более подробно, блок суммирования 310 выполнен с возможностью исполнения простых арифметических операций, таких как суммирование, нахождения минимального, максимального числа, операция аккумуляции, операции сравнения (больше/меньше, равенство) и т.д. Блок 320 выполнен с возможностью выполнения таких операций как умножение, возведение в степень и т.д.
[0050] Соответственно, как видно из схемы, второй модуль 210 в линии соединен, посредством блока интерфейса (SMO_IO) с блоком сложных математических операций 230 (Special Math Operations, SMO), который является общим для линий. Указанный блок 230 предназначен для исполнения редких и сложных арифметических операций, в соответствии с задаваемой конфигурацией 230.
[0051] Указанный блок 230 позволяет исполнять редкие и сложные арифметические операции. Поскольку блок 230 не имеет своих инструкций, SMO_IO (блок интерфейса последнего модуля 210 в линии, отображенного на Фиг. 3) добавляет номер исполняемой операции в USER биты AXI пакета перед его отправкой в блок 230. Только последние (например, вторые) модули 210 в линии имеют подключение к блоку 230. Соответственно, первые модули 210 в линии не имеют внешних подключений и не могут быть настроены на исполнение операций. Более подробно указанный блок 230 описывается ниже.
[0052] Кроме того, стоит отметить, что, хотя и в данном решении описываются примеры для одной и двух линий, состоящих из двух и четырех модулей 210, количество линий может быть большим или меньшим. Количество модулей 210 в каждой линии также может отличаться и зависит от степени сложности исполняемой операции. Так, в одном частном варианте осуществления в каждой линии может быть расположено три и более модулей 210. Соответственно при таком исполнении линии, первый и последний модуль будут иметь соединения, идентичные первому и второму модулю в вышеописанной линии, а остальные модули в линии будут являться промежуточными и обеспечивать требуемую вычислительную мощность.
[0053] Продолжая раскрытие модулей 210, каждое арифметическое устройство может быть одновременно настроено на исполнение только одной из своих операций. Текущая операция каждого устройства задается инструкцией для модуля 210. Арифметические устройства могут быть соединены в цепь, состав и порядок которой задается динамически с помощью инструкции модуля 210. Цепь задает только источник первого операнда для каждого арифметического устройства. Однако, блок сложения 310 и умножения 320 для своих бинарных операций также используют второй операнд, который может браться либо из VS_MEM (памяти 330) или читаться из памяти 120 (VE_MEM).. Кроме того, наличие локальной памяти 330 позволяет сохранять промежуточный результат вычисления непосредственно внутри модуля 210 если результат вычисления не превышает размерлокальной памяти 330. Такой подход также позволяет использовать результат для последующих вычислений без обращения к общей памяти 120.
[0054] Возвращаясь к блоку 230 (Special Math Operations (SMO)) обеспечивает исполнение сложных редких арифметических операций, которые не исполняются в арифметических устройствах модулей 210, а именно: экспонента ЕХР; натуральный логарифм LN; обратное число 1/×(RCP); обратный квадратный корень 1/√×(RSQRT); математические функции с использованием LUT таблиц, ReLU и другие произвольные активации; горизонтальные операции через устройство XLU.
[0055] Один блок 230 обслуживает обе линии из модулей 210, принимая данные от последних модулей 210 в линиях, например, модулей 210-2 и 210-4. Блок 230 имеет отдельную 24-битную входную AXI шину для каждого из модулей 210. Данные для обработки с помощью блока 230 формируются и отправляются посредством устройства SMO_IO внутри модулей 210. Путь данных в блок 230 зависит от того, какая из операций должна быть исполнена. Блок 230 не имеет собственных инструкций, поэтому исполняемая операция задается ее номером в USER битах входящего AXI пакета. Номер операции блока 230 добавляется в AXI пакет устройством SMO_IO на основе текущей инструкции модуля 210. Блок 230 соединен с блоком горизонтальных операций 130. Стоит отметить, что в одном частном варианте осуществления, блок 230 выполнен с возможностью, например, посредством планировщика задач, поочередной отправки операций, требуемых исполнения в блоке 130, в соответствии с их приоритетностью. Т.е. блок 230 поочередно отправляет некоторые операции, которые независимо поступают от модулей 210, в блоке 130.
[0056] Блок горизонтальных операций 130 (Cross-Lane Unit (XLU)), связан со скалярными устройствами 110, через блоки 230 каждого скалярного устройства, и выполнен с возможностью: исполнения арифметических операций с объединенными элементами вектора; трансляции результата исполнения арифметической операции с объединенными элементами вектора в скалярные устройства.
[0057] Все горизонтальные операции, исполняемые блоком 130, принимают целый вектор, например, из 128 24-битных слов. Каждый 24-битных скаляр отправляется из блока 230 одного из, например, 128 скалярных модулей 210. Блок 130 исполняет операцию только после поступления всех 128 скаляров. Данные подаются в блок 130 от независимых устройств 110, например, от 128 устройств 110, посредством шины данных (interconnect). Т.е. все устройства 110 независимо отправляют результаты своих вычислений в блок 130 через шину данных.
[0058] Блок 130 поддерживает такие операции, как: ADD_TREE; ADD_TREE+RCP; ADD_TREE+RSQRT; MAX_TREE; MAX_TREE+RCP; MAX_TREE+RSQRT; MIN_TREE; MIN_TREE+RCP; MIN_TREE+RSQRT. Где: ADD_TREE - сложить 128 чисел, MAX_TREE - найти максимальное из 128 чисел, MIN_TREE - найти минимальное из 128 чисел, RCP=1/×, RSQRT=1/√×.
[0059] Результатом операций блока 130 является один 24-битный скаляр. Копия итогового 24-битного числа отправляется в блок 230 каждого из 128 устройств 110.
[0060] Многопортовая общая память 120 (VMEM) представляет собой основную память для буферизации промежуточных результатов вычисления нейронной сети. Стоит отметить, что под термином общая память подразумевается память, к которой у всех элементов имеется доступ. Физически же, память 120 разбита на множество «кусков» в соответствии с количеством устройств 110. В памяти могут храниться данные в разных форматах используемые для конфигурации различных узлов, например, целочисленные индексы перестановок для устройства перестановок и таблицы для вычисления активационных функций. В памяти 120 сохраняются результаты работы модулей 210, откуда они поступают либо снова в модули 210, либо в матричные умножители в качестве входных данных (фичи), либо в устройство перестановок, либо во внешнюю память, например, память типа НВМ. Так, память 120 соединена по меньшей мере с внешней памятью (НВМ), вторым демультиплексором каждого скалярного устройства и устройством умножения матриц и выполнена с возможностью буферизации и хранения результатов промежуточных вычислений над элементами вектора каждого скалярного устройства.
[0061] В одном частном варианте осуществления память 120 имеет следующие порты: порт записи для каждого скалярного модуля 210; порт чтения для каждого скалярного модуля 210; порты для связи с внешней памятью (НВМ); порты для связи с устройством перестановок (Shuffler).
[0062] В еще одном частном варианте осуществления память 120 может представлять собой разделяемую память с 6 портами для чтения и 6 портами для записи. Всего, таким образом, память 120 может иметь 12 портов: четыре порта для записи из каждого модуля 210; четыре порта для чтения в каждый модуль 210, причем порты для чтения в первые модули 210 в линии делятся через вторые демультиплексоры 240 с подачей данных в устройства ME в той же линии; два порта (чтение и запись) для устройств контроллеров памяти (DMA); два порта (чтение и запись) для устройства перестановок shuffler. Соответственно, для организации памяти 120 при другом количестве линий (одна, три и т.д.), количество портов для записи из каждого модуля 210 и для чтения в каждый модуль 210 может быть изменено (уменьшено/увеличено) в соответствии с количеством модулей.
[0063] Все порты памяти 120 являются конфигурируемыми. Конфигурация портов, кроме портов для shuffler, задает последовательность адресов доступа; адреса доступа на портах для shuffler генерируются самим модулем shuffler.
[0064] Все элементы внутри процессора 100 (VE) используют AXI4-Stream интерфейс для обмена данными друг с другом и с внешними устройствами, а также для приема инструкций из устройства управления (Control Unit, (CU)). AXI позволяет автоматически управлять передачей данных в сколь угодно длинной цепи устройств без искажения и потерь. Например, если устройство в цепи не может принять новые данные, оно уведомляет об этом отправляющее устройство, сбрасывая сигнал ready. В свою очередь отправляющее устройство не может отправить данные без сигнала ready от получателя, а значит, не может само принять новые данные на место отправленных и останавливает подачу сигнала ready своему отправителю. Так, передача останавливается по всей цепи вплоть до источника данных (например, порта чтения SHMEM) до тех пор, пока не разрешится причина остановки самого первого устройства.
[0065] Длина входной последовательности скаляров не указывается и может быть произвольно длинной. Окончание последовательности обозначается сигналом last=1: сигнал приходит в начало цепи устройств вместе с последним пакетом данных последовательности и передается через всю цепь.
[0066] Процессор 100 выполнен с возможностью обмена данными с устройствами, работающими с векторными данными: матричным умножителем (ME), устройством перестановок (Shuffler). Так, в рамках работы устройства, такого как ускоритель нейросетей, векторный процессор 100, который может являться частью указанного ускорителя, получает вектор, состоящий из 128 скаляров в формате FP24. Как указывалось выше, вектор может поступать, например, от устройства матричных умножений. Каждый скаляр передается в свое устройство 110. Индекс устройства 110 равен индексу скаляра в векторе. Передача осуществляется по независимой 24-битной AXI шине (шина interconnect). При получении всех 128 скаляров на принимающей стороне формируется вектор (индекс скаляра в векторе равен индексу передавшего устройства 110).
[0067] Память 120 обменивается данными с внешней памятью (НВМ - High Bandwidth Memory). Для этого выделена пара устройств контроллеров памяти (DMA - Direct Memory Access) для записи в НВМ и пара DMA для чтения из НВМ.
[0068] Работа векторного процессора 100 управляется набором потоков конфигураций (инструкций) каждого элемента в его составе. Каждая конфигурация определяет параметры обработки некоторого количества векторов на одном элементе, например, устройстве 110. В процессе работы конфигурации сменяются по мере завершения их обработки. Работа каждого устройства 110 в общем случае является независимой, синхронизация осуществляется посредством зависимости по данным. Внутренние связи между устройствами реализуются на основе протокола AXI4-Stream.
[0069] Для конфигурации устройств, входящих в состав процессора 100, устройство управления (CU) может иметь несколько очередей инструкций (две и более). Так, каждая очередь инструкций может передаваться по собственной шине. Рассмотрим вариант с четырьмя очередями инструкций (Threads). Соответственно устройство управления будет соединено с процессором 100 посредством 4 шин для передачи инструкций в векторный процессор 100. Каждая шина имеет ширину 64 бита. Все инструкции разбиты на слова по 32 бита. Например, инструкция модуля 210 состоит из 20 слов (640 бит). Передача слов одной инструкции происходит последовательно по одной из 4 шин. Конфигурация устройства 110 происходит после получения последнего слова текущей инструкции.
[0070] Так, рассмотрим в качестве примера процессор 100 с двумя линиями. Инструкции разных элементов процессора 100 будут распределены по 4 очередям CU (устройство управления) следующим образом: Thread_0 (очередь_0): модули 210-1 и 210-2, порты памяти 120 для чтения в модуль 210-1/210-2 и записи из модуля 210-2, демультиплексора 240 (в инструкции порта памяти 120), демультиплексора 220 (в инструкции модуля 210-1).
[0071] Thread_1 (очередь_1): модули 210-3 и 210-4, порты памяти 120 для чтения в модуль 210-3/210-4 и записи из модуля 210-4, второго демультиплексора 240 (в инструкции порта памяти 120), второго демультиплексора 220 (в инструкции модуля 210-4).
[0072] Thread_2 (очередь_2): порты памяти 120 для чтения/записи в/из внешней памяти (НВМ).
[0073] Thread_3 (очередь_3): порты памяти 120 для чтения/записи в устройство перестановок (Shuffler).
[0074] Все инструкции записываются в свои очереди в программном порядке (в порядке расположения инструкций в НВМ).
[0075] 128 одинаковых устройств 110 (скалярные устройства) конфигурируются одной инструкцией, раздублированной 128 раз. Например, 128 модулей 210-1 принимают одну и ту же инструкцию. Тоже и для инструкций портов памяти 120, например, первый порт записи памяти 120 в каждом устройстве 110 конфигурируется одной и той же инструкцией. Инструкция распространяется во все устройства 110 параллельно по дереву устройств Broadcast, однако из-за сильной рассеяности устройств 110 по кристаллу ядра одна инструкция доходит до разных устройств 110 за разное число тактов. После исполнения инструкции из каждого устройства 110 передается сигнал "done": сначала "done" собирается от каждого из 128 устройств 110 и только потом один общий "done" отправляется в CU.
[0076] Инструкция модуля 210-1 также конфигурирует демультиплексор 220, чтобы выбрать, куда передаются данные из модуля 210-1: на вход модуля 210-2 или на запись в память 120. Аналогично, инструкция модуля 210-3 конфигурирует второй демультиплексор 220. Демультиплексоры 240 (каждый для своей линии) конфигурируются инструкциями портов чтения памяти 120. Каждое из двух состояний демультиплексоров 240 соответствует отдельной инструкции порта памяти 120: одна для чтения в модули 210, другая для чтения в ME.
[0077] В еще одном частном варианте осуществления также предусмотрена поддержка зацикливания операций модулей 210 посредством специального поля конфигурации. Блоки 230 (SMO) и 130 (XLU) не имеют собственных конфигураций.
[0078] Рассмотрим один из сценариев работы процессора 100. На вход процессора 100 поступает вектор, например, длиной 128 чисел. Указанный вектор поступает от устройства матричного умножения (ME), которое может быть реализовано, например, в виде систолического массива. Далее, все 128 чисел по шине данных (interconnect) распределяются по 128 устройствам 110 в соответствии с их индексом в векторе. В каждом устройстве 110, в зависимости от конфигурации, выполняется арифметическая операция над элементом вектора. Стоит отметить, что в зависимости от сложности операции, а, следовательно, и конфигурации, в линии устройства 110 может быть задействован или не задействован блок 230 а также второй модуль в линии 210-2. В соответствии с исполняемой конфигурацией результат вычисления из модуля 210-1, посредством демультиплексора 220, либо передается в память 120, либо передается в следующий модуль 210 в линии/ блок 230/ блок 130 и т.д. Кроме того, в одном частном варианте осуществления, при необходимости изначальной работы с модулем 230, конфигурация может содержать инструкции, транслирующие число вектора из ME через модуль 210-1 в модуль 210-2 для последующего исполнения операции в блоке 230 и/или в блоке 130. После исполнения арифметических операций каждым из устройств 110, результаты передаются в память 120. Как указывалось выше, память 120 выступает синхронизирующим устройством для 128 асинхронных устройств 110, и хранит результаты исполнения, например, в виде вектора. Далее, при необходимости дальнейших операций с вычисленным вектором, посредством демультиплексора 240, указанный результат может поступать либо в матричный умножитель (в форме вектора), либо в каждое из устройств 110 (в форме скаляров в соответствии с индексом в векторе).
[0079] Таким образом, в представленных материалах заявки были описаны различные варианты исполнения векторного процессора, обеспечивающего высокую скорость работы за счет организации вычислительных элементов в виде скалярных устройств 110 с линиями, которые в свою очередь содержат последовательные арифметические блоки (модули 210), что, соответственно, позволяет исполнять операции с элементами вектора, где требуются действия с промежуточным результатом, т.е. обеспечивают выполнение операций по конвейерному типу. Кроме того, заявленное решение обеспечивает возможность потоковой конфигурации вычислительных элементов процессора, в том числе и векторной памяти, что дополнительно повышает быстродействие процессора из-за исключения необходимости отправки команд на каждую однотипную операцию всем элементам процессора.
[0080] Конкретный выбор элементов процессора 100 для реализации различных программно-аппаратных и/или архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала.
[0081] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы.
| название | год | авторы | номер документа |
|---|---|---|---|
| МАТРИЧНО-ВЕКТОРНЫЙ УМНОЖИТЕЛЬ С НАБОРОМ РЕГИСТРОВ ДЛЯ ХРАНЕНИЯ ВЕКТОРОВ, СОДЕРЖАЩИМ МНОГОПОРТОВУЮ ПАМЯТЬ | 2019 |
|
RU2795887C2 |
| УСТРОЙСТВО МАТРИЧНЫХ ВЫЧИСЛЕНИЙ | 2025 |
|
RU2838831C1 |
| СКАЛЯРНО-ВЕКТОРНЫЙ ПРОЦЕССОР | 2021 |
|
RU2781355C1 |
| Управляющая векторная вычислительная система | 1982 |
|
SU1120340A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОМПИЛЯЦИИ НЕЙРОННЫХ СЕТЕЙ | 2024 |
|
RU2835757C1 |
| ВЕКТОРНОЕ ВЫЧИСЛИТЕЛЬНОЕ ЯДРО | 2023 |
|
RU2819403C1 |
| КОНВЕЙЕРНЫЙ ПРОЦЕССОР | 1992 |
|
RU2032215C1 |
| УСТРОЙСТВО УПРАВЛЕНИЯ ВЫЧИСЛИТЕЛЬНЫМИ УСТРОЙСТВАМИ УСКОРИТЕЛЯ ВЫВОДА НЕЙРОННЫХ СЕТЕЙ | 2024 |
|
RU2832408C1 |
| Метод построения процессоров для вывода в сверточных нейронных сетях, основанный на потоковых вычислениях | 2020 |
|
RU2732201C1 |
| СИСТЕМЫ И СПОСОБЫ ПРЕДОТВРАЩЕНИЯ НЕСАНКЦИОНИРОВАННОГО ПЕРЕМЕЩЕНИЯ СТЕКА | 2014 |
|
RU2629442C2 |
Изобретение относится к области микропроцессоров, а в частности к векторному вычислительному устройству. Техническим результатом является повышение скорости работы векторного процессора. Устройство размещено на кристалле и содержит: скалярные устройства, каждое из которых состоит из по меньшей мере двух скалярных модулей, образующих по меньшей мере одну скалярную линию, по меньшей мере одного первого демультиплексора, блока сложных арифметических операций, по меньшей мере одного второго демультиплексора; многопортовую общую память; блок горизонтальных операций. 14 з.п. ф-лы, 4 ил.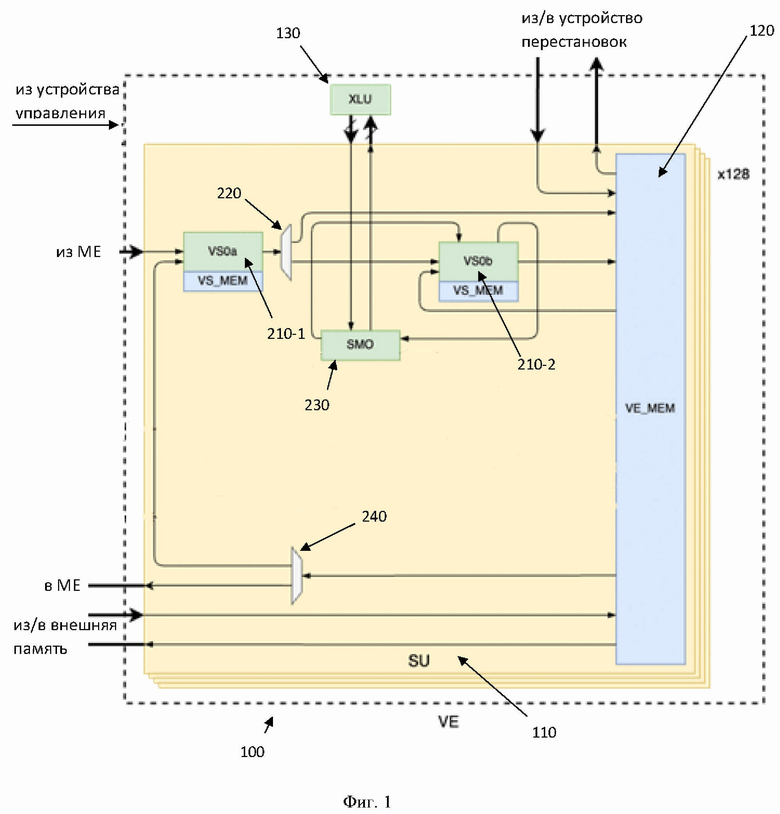
1. Векторный процессор, размещенный на кристалле, содержащий:
• скалярные устройства, каждое из которых выполнено с возможностью получения элемента вектора из устройства умножения матриц и состоит из:
 по меньшей мере двух скалярных модулей, образующих по меньшей мере одну скалярную линию, выполненных с возможностью осуществления арифметических операций над элементом вектора;
по меньшей мере двух скалярных модулей, образующих по меньшей мере одну скалярную линию, выполненных с возможностью осуществления арифметических операций над элементом вектора;
 по меньшей мере одного первого демультиплексора, выполненного с возможностью перенаправления данных от первого скалярного модуля в линии в многопортовую общую память или второй скалярный модуль в линии;
по меньшей мере одного первого демультиплексора, выполненного с возможностью перенаправления данных от первого скалярного модуля в линии в многопортовую общую память или второй скалярный модуль в линии;
 блока сложных арифметических операций, соединенного по меньшей мере с одним скалярным модулем в линии и выполненного с возможностью исполнения математических функций над элементом вектора;
блока сложных арифметических операций, соединенного по меньшей мере с одним скалярным модулем в линии и выполненного с возможностью исполнения математических функций над элементом вектора;
 по меньшей мере одного второго демультиплексора, выполненного с возможностью перенаправления данных из многопортовой памяти в скалярный модуль или устройство умножения матриц;
по меньшей мере одного второго демультиплексора, выполненного с возможностью перенаправления данных из многопортовой памяти в скалярный модуль или устройство умножения матриц;
• многопортовая общая память, соединенная по меньшей мере с внешней памятью, вторым демультиплексором каждого скалярного устройства и устройством умножения матриц, выполненная с возможностью буферизации и хранения результатов промежуточных вычислений над элементами вектора каждого скалярного устройства;
• блок горизонтальных операций, связанный со скалярными устройствами, выполненный с возможностью:
 исполнения арифметических операций с объединенными элементами вектора;
исполнения арифметических операций с объединенными элементами вектора;
 трансляции результата исполнения арифметической операции с объединенными элементами вектора в скалярные устройства.
трансляции результата исполнения арифметической операции с объединенными элементами вектора в скалярные устройства.
2. Векторный процессор по п. 1, характеризующийся тем, что скалярные устройства располагаются на кристалле в виде плитки.
3. Векторный процессор по п. 1, характеризующийся тем, что каждое скалярное устройство содержит по меньшей мере четыре скалярных модуля.
4. Векторный процессор по п. 3, характеризующийся тем, что по меньшей мере четыре скалярных модуля образуют по меньшей мере две скалярные линии.
5. Векторный процессор по п. 1, характеризующийся тем, что скалярная линия представляет собой последовательно соединенные по меньшей мере два скалярных модуля.
6. Векторный процессор по п. 1, характеризующийся тем, что каждый из по меньшей мере двух скалярных модулей представляет собой конфигурируемый потоковый процессор, содержащий: блок суммирования, блок произведения, модуль вычисления функций и локальную память.
7. Векторный процессор по п. 1, характеризующийся тем, что коммутация данных, осуществляемая каждым первым демультиплексором в каждом скалярном устройстве от первого скалярного модуля в линии, зависит от исполняемой операции процессора.
8. Векторный процессор по п. 1, характеризующийся тем, что математические функции над элементом вектора представляют собой по меньшей мере:
• экспоненту;
• натуральный логарифм;
• обратное число;
• обратный квадратный корень;
• математические функции с использованием LUT таблиц.
9. Векторный процессор по п. 1, характеризующийся тем, что арифметические операции, исполняемые блоком горизонтальных операций, представляют собой по меньшей мере:
• сложение элементов вектора, полученных от скалярных устройств;
• нахождение максимального элемента среди полученных скалярных элементов;
• нахождение минимального элемента среди полученных скалярных элементов;
• нахождение обратного значения скалярных элементов;
• нахождение обратного квадратного корня скалярных элементов.
10. Векторный процессор по п. 1, характеризующийся тем, что исполняемая операция, осуществляемая процессором, задается по меньшей мере одним потоком конфигураций.
11. Векторный процессор по п. 10, характеризующийся тем, что каждая конфигурация определяет параметры и тип обработки вектора.
12. Векторный процессор по п. 10, характеризующийся тем, что одна конфигурация распараллеливается на каждое из скалярных устройств.
13. Векторный процессор по п. 1, характеризующийся тем, что элементы процессора соединены между собой шиной.
14. Векторный процессор по п. 13, характеризующийся тем, что шина выполнена с возможностью обеспечения связи между устройствами векторного процессора и распространения конфигураций и данных.
15. Векторный процессор по п. 1, характеризующийся тем, что многопортовая общая память содержит:
• порт записи для каждого скалярного модуля;
• порт чтения для каждого скалярного модуля;
• порты для связи с внешней памятью;
• порты для связи с устройством перестановок.
| CN 118276937 A, 02.07.2024 | |||
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| EP 4116819 A1, 11.01.2023 | |||
| СКАЛЯРНО-ВЕКТОРНЫЙ ПРОЦЕССОР | 2021 |
|
RU2781355C1 |

