ными и информационным входами памяти результата, с первым входом коммутатора и с пятым входом блока обработки команд и адресов, первый выход которого соединен с адресным и информационным входом памяти заявок, а второй выход - с третьим входом блока распределения команд и данных, четвертый вход которого и второй вход коммутатора соединены с третьим входом скалярного процессора, выход блока распределения команд и данных подключен к входу блока обработки данных и третьему входу коммутатора, четвертый и пятый входы которого соединены соответственно с выходом памяти векторных данных и первым входом скалярного процессора, первый, второй и третий выходы коммутатора подключены соответственно к первому и третьему выходам скалярного процессора и к вторым адресному и информационному входам памяти результата, выход которого объединен с выходом памяти заявок и подключен к второму выходу скалярного процессора, третий выход блока обработки команд и адресов соединен с вторым входом блока управления памятями, причем блок управления памятями содержит два счетчика записи, два счетчика считывания, два элемента И и узел формирования режимов, причем первый вход блока управления памятями соединен с управляющими входами первого и второго счетчиков записи, информационные выходы которых соответственно подключены к первому и третьему выходам блока управления памятями, выходы переполнения первого и второго счетчиков записи и первого и второго счетчиков считывания подключены соответственно к первому, второму, третьему и четвертому входам узла формирования режимов, первый и второй выходы которого объединены и подключены к пятому выходу блока управления памяти, второй вход которого соединен с первыми входами первого и второго элементов И, вторые входы которых подключены соответственно к первому и второму выходам узла формирования режимов, выходы первого и второго элементов И подключены соответственно к счетным входам первого и второго счетчиков считывания, информационные выходы которых соответственно подключены к второму и четвертому выходам блока управления памятями, первый и второй выходы узла формирования режимов подключены соответственно к счетным входам первого и второго счетчиков записи, блок обработки команд и адресов содержит коммутатор направлений, регистр команд, счетчик адреса команды, счетчик номера команды, дешифратор кода операций, регистр адреса микрокоманды, узел памяти микрокоманд, регистр микрокоманды, дешифратор управления, узел программных регистров, буферный регистр.
регистр результата, счетчик номера операнда, накапливающий сумматор, причем первый и второй входы блока обработки команд и адресов соединены с первым и вторым информационным входами коммутатора направлений, управляюший вход которого соединен с третьим входом блока обработки команд и адресов, а выход - с информационным входом регистра команд, первые адресный и информационный входы узла программных регистров, информационный вход счетчика номера команды, вход сброса регистра команды объединены и подключены к пятому входу блока обработки команд и адресов, адресный выход регистра команды подключен к информационному входу счетчика адреса, счетный вход которого подключен к третьему выходу блока обработки команд и адресов, к счетному входу счетчика номера команды и к выходу признака наличия команды регистра команды, выход кода операций которого соединен с входом дешифратора кода операций, выход которого соединен с управляющим входом счетчика адреса команды, объединен с адресным выходом регистра микрокоманды и подключен к входу регистра адреса микрокоманды, выход которого соединен с адресным входом узла памяти микрокоманд, выход которого соединен с входом регистра микрокоманды, выход числа операндов в команде регистра команды объединен с выходом счетчика номера команды и подключен к информационному входу счетчика номера операнда, счетный вход которого соединен с выходом типа адресации регистра команды и с входом дешифратора управления, выход которого соединен с управляюшими входами накапливающего сумматора и узла программных регистров, второй адресный вход которого подключен к выходу адреса операнда регистра команды и к первому информационному входу накапливающего сумматора, четвертый вход блока обработки команд и адресов соединен с вторым информационным входом узла программных регистров, выход которого соединен с вторым информационным входом накапливающего сумматора, третий информационный вход которого соединен с выходом буферного регистра, вход которого соединен с выходом накапливающего сумматора, выход счетчика номера операнда объединен с выходом накапливающего сумматора и подключен к входу регистра результата, выход операнда которого объединен с выходом кода микрокоманды регистра микрокоманды, с выходом счетчика номера команды и подключен к второму выходу блока обработки команд и адресов, выход счетчика адреса команды и выход адреса регистра результата объединены и подключены к первому выходу блока обработки команд и адресов, причем блок распределения команд и данных содержит память кодов операций и адресов результатов, первую и вторую памяти операндов, кольцевой регистр и узел анализа готовности команды, причем первые адресные и информационные входы памяти кодов операций и адресов результатов и первой и второй памяти операндов подключены к третьему входу блока распределения команд и данных, вторые адресные и информационные входы первой и второй памятей операндов соединены с первым входом блока распределения команд и данных, вторые адресные и информационные входы памяти кодов операций и адресов результатов соединены с четвертым входом блока распределения команд и данных, третий адресный вход памяти кодов операции и адресов результатов соединен с третьими адресными входами первой и второй памятей операндов и подключен к второму входу блока распределения команд и данных, вход сброса памяти кодов операций и адресов результатов соединен с входами сброса первой и второй памятей операндов и подключен к второму входу блока распределения команд и данных, выход кольцевого регистра соединен с управляющими входами памяти кода операций и адресов результатов и первой и второй памятей операндов, выходы готовности памяти кодов операций и адресов результатов и первой и второй памятей операндов подключены соответственно к первому, второму и третьему входам узла анализа готовности команды, четвертый вход которого соединен с выходом типа команды памяти кодов операций и адресов результатов, а выход - с управляющим входом кольцевого регистра, информационные выходы памяти кодов операций и адресов результатов, первой и второй памятей операндов объединены и подключены к выходу блока распределения команд и данных, причем -векторный процессор содержит группу п элементов И, блок элементов ИЛИ, коммутатор операндов,п памятей команд, узел анализа приоритета, информационный регистр, регистр векторной команды, К операционных блоков и п памятей результатов, 1-й (,..., К) операционный блок содержит блок элементов, ИЛИ, память входных операндов, п узлов векторных регистров, дешифратор направления, п узлов анализа готовности векторных операндов, узел обработки векторных данных, регистр векторной операции, регистр векторного результата, выход которого соединен с первым информационным входом i-ro (i l,..., п) узла векторных регистров, второй информационный вход которого соединен с выходом памяти входных операндов, адресный и информационный входы которого соединены с выходом информационного регистра, вход которого соединен с выходом коммутатора операн/1,0В, i-e информационный и управляющий
входы которого соединены соответственно с i-M входом векторного процессора и i-м выходом узла анализа приоритета, i-й вход которого объединен с информационным и адресным входом i-й памяти команд и подключен к i-му входу векторного процессора, i-й выход узла анализа приоритета подключен к управляющему входу 1-й памяти команд, выход которой подключен к i-му входу блока элементов ИЛИ, выход которого соединен с входом регистра векторной команды, выход кода операции которого подключен к входам регистров векторной операции К операционных блоков, выход регистра векторной операции -го операционного блока подключен к первому входу узла обработки векторных данных, выход которого соединен с входом регистра векторного результата, выход номера регистра векторной команды соединен с адресными входами п узлов векторных регистров Е-го операционного блока, выход номера узла векторных регистров регистра векторной команды соединен с входом дешифратора направлений Е-го операционного блока, выход которого подключен к управляющим входам п узлов анализа готовности векторных операндов, информационные входы которых подключены соответственно к выходам п узлов векторных регистров, выходы векторных операндов п узлов анализа готовности векторных операндов подключены соответственно к входам блока элементов ИЛИ 1-го операционного блока, выход которого соединен с вторым входом узла обработки векторных данных, выход бита готовности -го узла анализа готовности векторных операндов 2-го операционного блока подключен соответственно к -му входу i-ro элемента И группы, выход которого подключен к (п+1)-му входу узла анализа приоритета, выходы i-x узлов векторных регистров К операционных блоков соединены соответственно с &ми входами i-й памяти результатов, выход которой подключен к i-му выходу векторного процессора.
2.Система по п. 1, отличающаяся тем, что узел анализа готовности команды содержит элемент ИЛИ и элемент И, причем первый, второй и третий входы элемента И соединены соответственно с первым и вторым входами узла и выходом элемента ИЛИ, первый и второй входы которого соединены с третьим и четвертым входами узла, выход элемента И подключен к выходу узла.
3.Система по п. 1, отличающаяся тем, что узел формирования режимов содержит два элемента И, два элемента НЕ и триггер, причем третий и четвертый входы узла соответственно через первый и второй элементы НЕ подключены к первым входам первого и второго элементов И, к вторым входам которых подключены соответственно второй и первый входы узла, выходы первого и второго элементов И подключены соответственно к единичному и нулевому входам триггера, прямой и инверсный выходы которого соединены соответственно с первым и вторым выходами узла.
4. Система по п. 1, отличающаяся тем, что i-й узел анализа готовности векторных операндов С-го операционного блока содержит триггер и элемент И, причем управляющий вход Е-го узла соединен с первым входом элемента И, второй вход которого соединен с выходом триггера и подключен к выходу бита готовности i-ro узла, третий вход элемента И объединен с единичным и нулевым входами триггера и подключен к информационному входу i-ro узла анализа готовности векторных операндов.
5. Система по п. 1, отличающаяся тем, что узел анализа приоритета векторного процессора содержит три группы элементов И, группу элементов НЕ, элемент ИЛИ, группу элементов ИЛИ, причем i-й вход узла подключен к первому входу i-ro элемента И первой группы (i l,..., п), второй вход которого соединен с (n + i)-M в.ходом узла и с входом i-ro эле.мента НЕ группы, выход которого соединен с р-м входом ( Р ,1,...,п-1) i-ro элемента И второй группы, выход которого подключен к i-му входу элемента ИЛИ, выход которого подключен к первому входу i-ro элемента И третьей группы, к второму входу которого подключен (n-fi)-й вход узла, выход i-ro элемента И третьей группы подключен к первому входу i-ro элемента ИЛИ группы, второй вход которого соединен с выходом i-ro элемента И первой группы, выход элемента ИЛИ груп пы подключен к i-му выходу узла.








| название | год | авторы | номер документа |
|---|---|---|---|
| Управляющая векторная вычислительная система | 1982 |
|
SU1120340A1 |
| Микропрограммируемый векторный процессор | 1987 |
|
SU1594557A1 |
| Адаптивная система обработки данных | 1984 |
|
SU1241250A1 |
| Устройство микропрограммного управления | 1987 |
|
SU1539776A1 |
| Процессор | 1984 |
|
SU1246108A1 |
| Устройство для сопряжения | 1980 |
|
SU926645A2 |
| КОНВЕЙЕРНЫЙ ПРОЦЕССОР | 1992 |
|
RU2032215C1 |
| Процессор | 1984 |
|
SU1247884A1 |
| Вычислительная система | 1989 |
|
SU1777148A1 |
| Процессор с микропрограммным управлением | 1983 |
|
SU1149273A1 |

1. МНОГОПРОЦЕССОРНАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА, содержащая группу центральных процессоров, группу блоков оперативной памяти и группу периферийных процессоров, соединенных соответственно с группой периферийных устройств, причем каждый центральный процессор группы содержит коммутаторы ввода-вывода и коммутаторы памяти, первые вход и выход каждого коммутатора памяти соединены с первыми выходом и входом коммутатора ввода-вывода соответственно, первая группа входов и выходов каждого коммутатора ввода вывода соединена с группой выходов и входов периферийных процессоров группы, вторая группа входов и выходов i-ro коммутатора ввода-вывода соединена с второй группой выходов и входов К-го коммутатора ввода-вывода (i K, i, ,.. .., М), f-e вход и выход каждого коммутатора памяти (f 2,..., M+l; М - число блоков оперативной памяти) соединены с


1
Изобретение относится к вычислительной технике и может быть использовано в автоматизированных системах обработки, требующих высокой производительности как на векторных, так и на скалярных вычислениях, а также требующих высокой живучести.
Цель изобретения - повыщение производительности и гибкости функционирования многопроцессорной вычислительной системы за счет перестраиваемости структуры системы, т. е. за счет динамического перераспределения ее вычислительных ресурсов по требованиям выполняемых программ.
На фиг. 1 изображена блок-схема многопроцессорной вычислительной системы (МВС); на фиг. 2 - блок-схема скалярного процессора; на фиг. 3 - блок-схема векторного процессора; на фиг. 4 - схема блока управления буферами; на фиг. 5 - схе.ма блока обработки команд и адресов; на фиг. 6 - схема блока распределения команд и данных; на фиг. 7 - схема узла анализа готовности команды; на фиг. 8 - схема узла формирования режимов; на фиг. 9 - схема узла анализа готовности векторных операндов; на фиг. 10 - схема узла анализа приоритета; на фиг. 11 - схема коммутатора на п входов и m выходов; на фиг. 12 - временная диаграмма совмещения выполнения команд в скалярных и векторных процессорах.
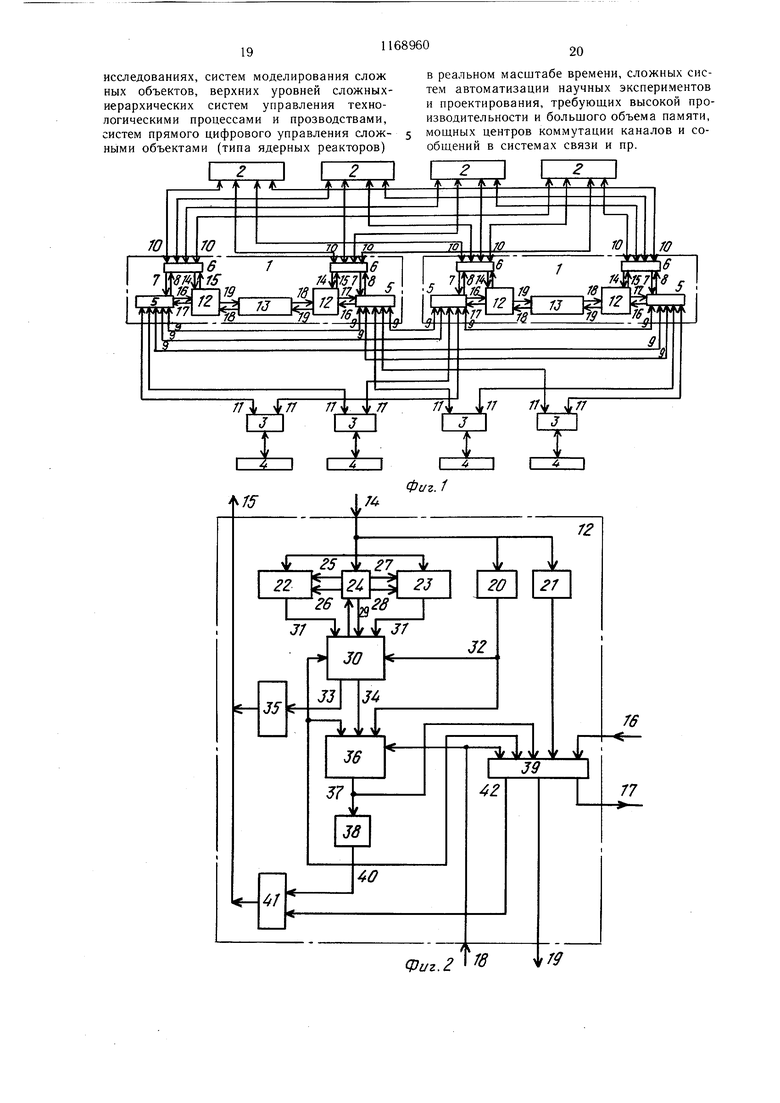
МВС (фиг. 1) содержит однотипные центральные процессоры 1, однотипные блоки 2 оперативной памяти (каждый из которых, в свою очередь, может состоять из нескольких параллельных однотипных модулей памяти), периферийные процессоры 3, подключенные к периферийны.м устройствам 4 (диски, магнитные ленты, пульт оператора и пр.) через двунаправленные линии связи.
Каждый центральный процессор 1 содержит коммутаторы 5 ввода вывода и коммутаторы 6 памяти, причем первые входы 7 и первые выходы 8 каждого коммутатора 5 ввода-вывода подключены к первым выходам и первым входам соответствующего
коммутатора 6 памяти того же центрального процессора, вторые входы и выходы 9 каждого коммутатора 5 ввода-вывода соединены двунаправленными линиями связи с вторыми выходами и входами всех остальных коммутаторов 5 ввода-вывода, вторые входы и выходы 10 каждого коммутатора 6 памяти соединены двунаправленными линиями связи с выходами и входами каждого блока 2 оперативной памяти, входы и выходы 11 каждого периферийного
процессора 3 соединены двунаправленными линиями связи с третьими выходами и входами одного из коммутаторов 5 ввода-вывода каждого центрального процессора 1. Каждый центральный процессор 1 содержит
однотипных скалярных процессоров 12 (на фиг. I приведена конфигурация МВС
с числом скалярных процессоров п 2 в каждом центральном процессоре; дальнейшее описание МВС приводится именно для такой ее конфигурации), а также общий для них векторный процессор 13. Первые входы 14 и первые входы 15 каждого скалярного процессора 12 соединены с третьими выходами и входами соответствующего коммутатора 6 памяти, вторые входы 16 и вторые выходы 17 каждого скалярного процессора 12 подключены к четвертым выходам и входам соответствующего коммутатора 5 ввода-вывода, третьи входы 18 и третьи выходы 19 каждого скалярного процессора 12 соединены с соответствующими выходами и -входами векторного процессора 13 того же центрального процессора 1.
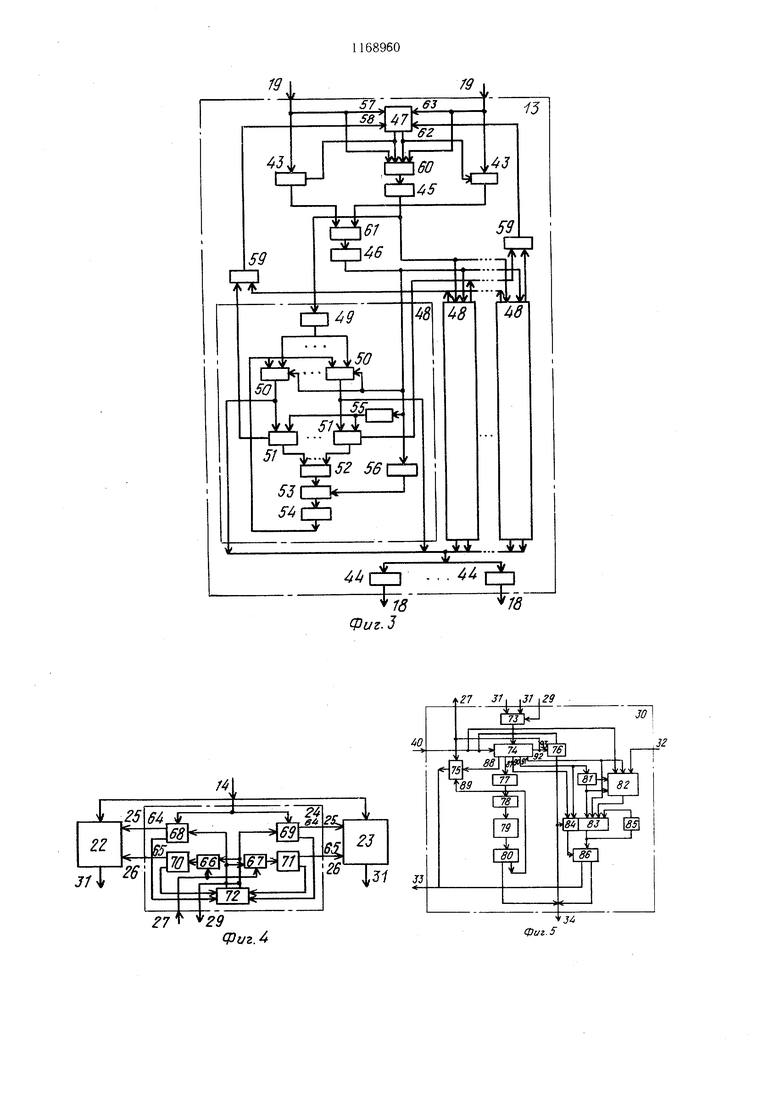
Каждый скалярный процессор 12 (фиг. 2) содержит память 20 скларных данных, память 21 векторных данных, первую 22 и вторую 23 памяти команд с блоком 24 управления памятями команд. Входы указанных памяти и блока управления памятями команд объединены и являются первыми входами 14 скалярного процессора 12, выходы блока 24 управления памятями команд соединены с управляющими входами 25-28 первой 22 и второй 23 памятей команд и с управляющим входом 29 блока 30 обработки команд и адресов, первые информационные входы 31 этого блока соединены с выходами обеих памятей 22 и 23 команд, а вторые информационные входы подключены к выходам 32 памяти 20 скалярных данных, выход блока 30 обработки команд и адресов подключен к второму входу блока 24 управления памятями команд, выходы 33 и 34 блока 30 обработки команд и адресов подключены соответственно к входам памяти 35 заявок и к первым входам блока 36 распределения команд и данных, вторые входы последнего соединены с выходами 32 памяти 20 скалярных данных, выходы 37 блока 36 распределения команд и данных соединены с входами блока 38 обработки данных и с первыми входами коммутатора 39, вторые и третьи входы которого соединены, соответственно с выходами памяти 21 векторных данных, и с выходами 40 блока 38 обработки данных, четвертые и пятые входы коммутатора 39 являются соответственно вторыми входами 16 и третьими входами 18 скалярного процессора 12: выходы блока 38 обработки данных подключены также к третьим информационным входам блока 30 обработки команд и адресов, к третьим входам блока 36 распределения команд и данных и к первым входам памяти 41 результатов, с вторыми входами которого соединены первые выходы 42 коммутатора 39, выходы памяти 35 заявок и памяти 41 результатов объединены и являются первыми выходами 15 скалярного процессора 12, вторые и третьи выходы коммутатора 39 являются, соответственно вторыми выходами 17 и третьими выходами 19 скалярного процессора 12.
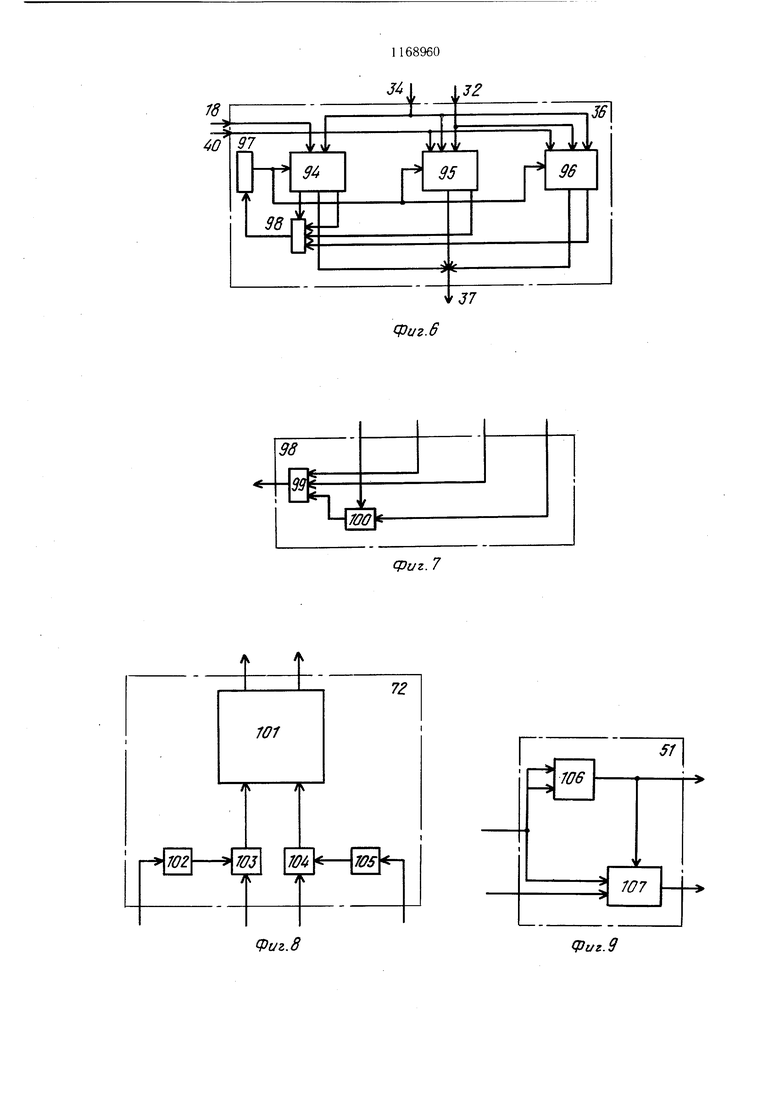
Каждый векторный процессор 13 (фиг.З) содержит п памятей 43 команд (по числу скалярных процессоров в центральном процессоре), п памятей 44 результатов, информационный регистр 45, регистр 46 векторной команды, узел 47 анализа приоритета, К операционных блоков 48. Каждый операционный блок 48 содержит память 49 входных операндов п узлов 50 векторных регистров, выходы которых соединены с информационными входами одноименных узлов 51 анализа готовности векторных операндов, а также с входами памяти 44 результатов, информационные выходы узлов 51 анализа готовности векторных операндов операционного блока 48 соединены с входами блока 52 элементов ИЛИ, выход которого подключен к информационному входу 53 обработки векторных данных, выход узла 53 подключен к входу регистра 54 векторного результата, выход которого соединен с первыми информационными входами узлов 50 векторных регистров, вторые информационные входы которых соединены с выходом памяти 49 входных операндов 49, управляющие входы узлов 51 анализа готовности векторных операндов, соединены с выходом дещифратора 55 направлений, вход которого объединен с адресными входами узлов 50 векторных регистров и соединен с выходом номера узла векторных регистров регистра 46 векторных команд, управляющий вход узла 53 обработки векторных данных соединен с выходом регистра 56 векторной операции, входы 57 и 58 яа,тяются входами узла 47: выходы битов готовности узлов 51 анализа готовности векторных операндов подключены к входам группы 59 элементов И, коммутатор 60 операндов, блок 61 элементов ИЛИ, входы 62 и 63 узла 47 анализа приоритета, выход 64 регистра 46, выход 65 регистра 46, выходы памятей 43 команд соединены с входами блока 61 элементов ИЛИ, выход которого соединен с входом регистра 46 векторной команды, выходы памятей 44 результатов соединены с выходами 18 векторного процессора 13.
Фиг. 4 иллюстрирует одну из возможных структурных реализаций блока 24 управления памятями команд и взаимодействие его с памятями 22 и 23 команд.
Блок 24 управления памятями команд содержит выходы 64 и 65, элементы И 66 и 67, счетчики 68 и 69 записи, счетчики 70 и 71 считывания, узел 72 формирования режимов.
На фиг. 5 приведена одна из возможных структурных схем блока 30 обработки команд и адресов скалярного процессора.
Блок 30 содержит коммутатора 73 направлений, регистр 74 команд, счетчик 75 адреса команды и счетчик 76 номера команды; дешифратор 77 кода операций, регистр 78 адреса микрокоманды, узел 79 памяти микрокоманд, регистр 80 микрокоманды дешифратор 81 управления, узел программных регистров, накапливающий сумматор 83, счетчик 84 номера операнда, буферный регистр 85 и регистр 86 результата, выходы 87 и 88 регистра 74, вход 89 счетчика 74, выходы 90-93 регистра 74.
Информационные входы коммутатора 73 направлений соединены с входами 31, управляющий вход коммутатора 73 - с входом 29 блока 30 обработки команд и адресов, выход коммутатора 73 направлений соединен с информационным входом регистра 74 команды, вход сброса регистра 74 команды объединен с информационным входом счетчика 76 номера команды, с адресным и информационным входом узла 82 программных регистров и подключен к входу 40 блока 30 обработки команд и адресов, адресный выход 88 регистра 74 команды соединен с входом счетчика 75 адреса команды, выход кода операций регистра 74 команды соединен с входом дещифратора кода 77 операций, выход которого соединен с входом регистра 78 адреса микрокоманды, суправляющим входом 89 счетчика адреса команды и с выходом регистра 80 микрокоманды, выход регистра 78 адреса микрокоманды соединен с входом узла 79 памяти микрокоманд, выход которого соединен с входом регистра 80 микрокоманды, выход 90 числа операндов в команде регистра команды соединен с информационным входом счетчика 84 номера операнда, выход 91 типа адресации регистра 74 команды соединен с счетчным входом счетчика 84 номера операнда и с входом дещифратора 81 управления, выход которого соединен с управляющими входами накапливающего сумматора 83 и узла 82 программных регистров, второй адресный вход которого подключен к выходу 92 адреса операнда регистра 74 команды и первому информационному входу накапливающего сумматора 83, вход 32 блока 30 обработки команд и адресов соединен с вторым информационным входом узла 82 программных регистров, выход которого соединен с вторым информационным входом накапливающего сумматора 83, третий информационный вход которого соединен с выходом буферного регистра 85, вход буферного регистра 85 соединен с выходом накапливающего сумматора 83 и подключен к входу регистра 86 результата, второй вход которого подключен к выходу счетчика 84 номера операнда, счетный вход счетчика адреса команды 75 соединен с выходом 27 блока 30 обработки команд и адресов и подключен к выходу 93 признака наличия команды регистра 74 команды и к счетному входу счетчика 76 номера команды, выход которого соединен с входом счетчика 84 номера операнда, объединен с выходом операнда регистра 86 результата и выходом кода микрокоманды регистра 80 микрокоманды и подключен к выходу 34 блока обработки команд и адресов, выход адреса регистра 86 результата объединен с выходом счетчика 75 адреса команды и подключен к выходу 33 блока обработки команд и адресов.
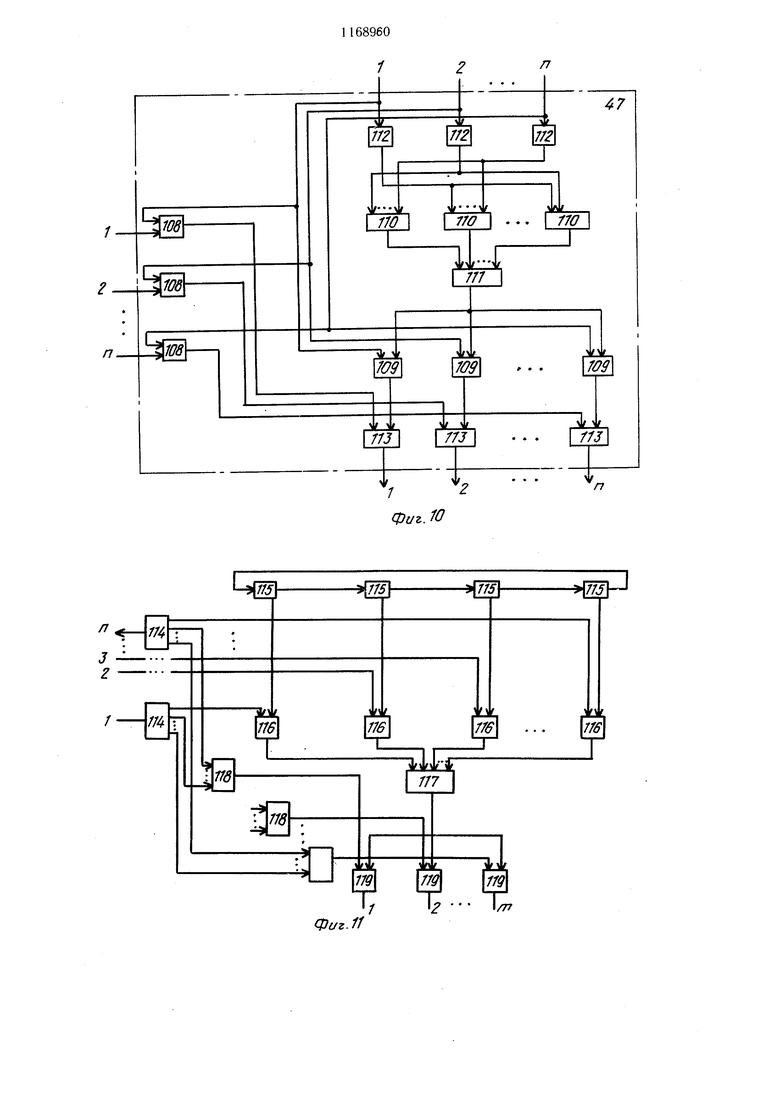
На фиг. 6 приведена одна из возможных структурных схем блока 36 распределения команд и данных.
Блок 36 содержит память 94 кодов операций и адресов результатов, памяти 95 и 96 операндов, кольцевой регистр 97 и узел 98 анализа готовности команды. Адресный и информационный входы памяти 94 кодов операций и адресов результатов объединены
5 с соответствующими входами памяти 95 и 96 операндов, и подключены к входу 34 блока 36 распределения команд и данных, вход 32 блока 36 подключен к вторым адресным и информационным входам памятей 95 и 96 операндов; входы 18 и 40 блока
распределения команд и данных объединены и подключены к входам сброса памятей 94 кодов операций и адресов результатов и памятей 95 и 96 операндов, выходы готовности памятей 94-96 и выход типа команды
, памяти 94 соединены с управляющими входами узла 98 анализа готовности команды, выход которого соединен с управляющим входом кольцевого регистра 97, выход которого подключен к управляющим входам памятей 94-96, информационные выходы памяти 94 кодов операций и адресов результатов и памятей 95 и 96 операндов объединены и подключены к выходу 37 блока 36 распределения команд и данных.
На фиг. 7 представлена возможная схема узла 98 анализа готовности команды.
Узел содержит элемент И 99 и элемент ИЛИ 100. Входами элемента И 99 явля-, ются выходы готовности памяти 94 кодов операций и адресов результатов и памяти
95 операндов и выход элемента 100, входами которого являются выход готовности памяти 96 операндов и выход типа команды памяти 94 кодов операций и адресов результатов, выход элемента 99 подключен к выходу узла 98 анализа готовности команды.
На фиг. 8 приведена возможная схема узла 72 формирования режимов. Узел содержит триггер 101, два элемента НЕ 102 и 105 и два элемента И 103 и 104. Входы элементов НЕ 102 и 105 и первые входы элементов И 103 и 104 подютючены к входам узла 72 формирования режимов 72, вторые входы элементов И 103 и 104 соединены соответственно с выходами элементов 102 и 105, выходы элементов И 103 и 104 подключены соответственно к единичному и нулевому входам триггера 101, прямой и инверсный выходы которого подключены к выходам узла 72 формирования режимов. На фиг. 9 приведена возможная схема узла 51 анализа готовности векторных операндов. Узел содержит триггер 106 и элемент И 107. Первый управляющий и информационный входы узла 51 анализа готовности векторных операндов подключены-к единичному и нулевому входам триггера 106 и к информационному входу элемента И 107, первый управляющий вход которого подключен к второму управляюцл,ему входу узла 51, второй управляющий вход элемента И 107 соединен с выходом триггера 106 и с управляющим выходом узла 51 анализа готовности векторных операндов, информационный выход которого соединен с выходом элемента И 107. На фиг. 10 представлена возможная схема узла 47 анализа приоритета векторного процессора 13. Узел содержит три группы по п элементов И 108-110, группу п элементов НЕ 111, элемент ИЛИ 112 и группу п элементов ИЛИ 113, Первые входы элементов И группы 108 подключены к входам 63 узла 47 анализа приоритета, вторые входы элементов И группы 108 объединены с входами 62 узла 47 анализа пpиopиJeтa, входами элементов НЕ группы 109 и подключены к первым входам элементов И группы 112, вторые входы которых объединены и подключены к выходу элемента ИЛИ 111, входы которого соединены с выходами элементов И группы ПО; входами каждого из п элементов И группы ПО являются выходы п-1 элемента НЕ группы 109; выходы элементов И группы 108 подключены к первым входам элементов ИЛИ группы 113, вторые входы которых подключены к выходам эле.ментов И группы 112, а выходы - к выходам узла 47 анализа приоритета. На фиг. 11 приведен пример схемы коммутатора с п входами и m выходами, которая может быть использована для реализации любого из коммутаторов, входящих в систему. Схема содержит п дещифраторов 114-, кольцевой распределитель 115, группу 116 элементов, элемент ИЛИ 117, группу 118 элементов ИЛИ и группу 119 элементов И, Выходы дещифраторов 114 подключены к первым входам группы 116 двухвходовых элементов И, вторыми входами которых являются выходы элементов 115 кольцевого распределителя. Информационные выходы дещифраторов 114 соединены с входами соответствующих элементов ИЛИ группы 118, выходы которых подключены к первым входам m элементов И группы 119. Вторые входы элементов И группы 119 соединены с выходом элемента ИЛИ 117, входы которого подключены к выходам элементов И группы 1 16. МВС функционируют следующим образом. Скалярные процессоры 12 центральных процессоров 1 (фиг. 1) независимо и асинхронно по отнощению один к другому считают и обрабатывают программы независимых задач (или программы параллельных фрагментов одной или нескольких задач). Для этого блок 30 обработки команд и адресов каждого скалярного процессора 12 формирует заявки (адреса) на считывание команд, которые поступают в память 35 заявок (фиг. 2), откуда эти заявки через выходы 15 скалярного процессора (фиг. 1 и 2) и через соответствующий коммутатор 6 памяти поступают но связям 10 на обслуживание в блоки 2 оперативной памяти. Считанные из оперативной памяти команды поступают через тот же коммутатор 6 памяти и входы 14 скалярного процессора 12 в одну из его памятей 22 или 23 команд. Эти памяти функционируют поочередно на запись и на считывание (режим «Пингпонг) по сигнала от блока управления памятями 24 команд 24: пока в одном из них накапливаются (записываются) команды считываемой программы, из другого накопленные команды считываются для обработки в блоке 30 обработки команд и адресов, а затем - наоборот. Пусть, например, узел 72 формирования режимов блока управления памятями 24 команд установлен в состояние, при котором разрещается счетчику 68 записи записывать команды в память 22 команд, а счетчику 71 считывания - считывать команды из памяти 23 команд. Сигнал поступления (из оперативной памяти) очередной команды по входам 14 увеличивает содержимое счетчика 68 записи на единицу, при этом указанный счетчик сигнало.м по входу 25 памяти 22 команд разрещает запись команды в указанную память. Запись команд в память 22 разрещается до переполнения счетчика 68 записи (это событие соответствует полному заполнению памяти 22 команд). В это же время счетчик 71 считывания подает сигналы на считывание команд из памяти 23 команд на его выходы 31 (в блок 30 обработки команд и адресов), при
считывании каждой команды содержимое счетчика считывания 71 уменьшается на единицу.
Сигнал переполнения счетчика 68 записи поступает на вход узла 72 формирования режимов и при условии, что счетчик
71считывания оказался к этому моменту обнуленным, узел 72 переводится в состояние, при котором разрешается счетчику 69 записи записывать команды в память 23 команд, а счетчику 70 считывания - считывать команды из памяти 22 команд. Узел
72подает сигналы о текуш,ем режиме обслуживания на выход 29 (в блок 30 обработки команд и адресов).
Возможны и иные структурные реализации блока 24 управления памятями, при которых обнуление счетчика считывания 70 или 71 приводит к изменению состояния узла 72, т. е. считыванию команд из еще не полностью заполненной памяти 22 или 23 команд.
Считываемые из памяти 22 или 23 команд команды поступают в блок 30 обработки команд и адресов, который декодирует команды и преобразует адреса команд и операндов в физические адреса в оперативной памяти МВС. Команды поступают в блок 30 обработки команд и адресов через его коммутатор 73 направлений (фиг. 5), который управляется сигналами (о номере считываемой памяти 22 или 23 команд с блока 24 управления памятями. Пришедшая команда фиксируется в регистре 74 команд, содержаш.ем разряды кода операции адресных частей команд и операндов. Значения тех разрядов регистра 74 команд, которые содержат код операций (выходы 87) поступают на дешифратор 77 кода операций который преобразует код операции в адрес соответствующей микрокоманды (или микропрограммы), поступающий через регистр 78 адреса микрокоманды и узел 79 памяти микрокоманд. Считанная из этого узла микрокоманда, соответствующая машинному коду выполняемой команды, фиксируется в регистре 80 микрокоманды. Адресная часть кода микрокоманды, зафиксированного в регистре 80, может использоваться для формирования адреса следующей микрокоманды в регистре 78 адреса микрокоманды.
Значения разрядов адресной части команды, зафиксированной в регистре 74 команд, подаются (адресный выход 88) в счетчик 75 адреса команды, который формирует адрес последующей команды «с опережением по отношению к адресу текущей команды (например, на целое число байтов, кратное степени числа «2).
Значения разрядов адресной части операндов, соответствующих типам адресации, подаются из регистра 74 команд (выход 91)
на дешифратор 81 управления, сигналы которого на узел 82 программных регистров 82 и накапливающий сумматор 83 задают соответствующую дисциплину обработки адресов операндов. Коды адресов операндов (выход 92 регистра команд 74) поступают либо в узел программных регистров 82 (если адрес соответствует номеру одного из программных регистров), либо на обработку в накапливающий сумматор 83.
Если операнд является векторным, то его адрес может описываться через адрес aj первого элемента вектора, шаг h и число s элементов вектора. Если, например. Низ предварительно записаны в некоторые регистры блока 82, то в адресе векторного операнда указаны номера программных регистров и адрес а, тогда дешифратор 81 задает циклическую процедуру расчета адресов элементов вектора: адрес второго элемента а вектора формируется путем сложения кода aj, поступающего с регистра 74 команд с содержимым соответствующего регистра (с кодом h) с выдачей кода аг в регистр 86 результата и запоминанием а на буферном регистре 85; при расчете адреса каждого последующего элемента вектора выполняется сложение содержимого буферного регистра 85 с кодом h. Одновременно счетчик адресов операндов подсчитывает число сформированных адресов. Например, в соответствующие его разряды перед первым сложением записывается число s, которое уменьшается при каждом сложении на единицу до обнуления всех разрядов, кроме младшего. Для каждой команды, поступающей в регистр 74 команд, формируется «внутренний номер команды, рассчитываемый счетчиком 76 номера команды, этот номер присваивается коду микрокоманды, зафиксированному в регистре 80 микрокоманд и вместе с кодом микрокоманды поступает на выходы 34 блока 30 обработки команд и адресов.
«Внутренний номер команды присваивается и всем адресам ее операндов, для каждого из которых счетчик 84 номера операнда формирует номер операнда в данной команде; номер команды и номер операнда являются «адресом возврата и передаются вместе с сформированным адресом операнда из регистра 86 результата на выходы 33 блока 30 обработки команд и адресов (на вход памяти 35 заявок к памяти, фиг. 2).
Аналогичным образом обрабатываются блоками 81-86 адреса результатов по их описанию в соответствующей части регистра 74 команд. Однако физические адреса результатов поступают не на выходы 33 (к памяти 35 заявок), а через выходы 34 вместе с соответствующими кодами операций (микрокомандами) - на блок 36 распределения команд и данных (фиг. 2), который определяет готовность скалярных команд к выполнению и распределяет команды по различным устройствам обработки: скалярные команды и команды управления направляются в блок 38 (обработки данных, векторные команды через коммутатор 39 - в векторный процессор 13.
Каждая команда, поступающая в блок 36 распределения команд и данных (фиг. 6), занимает одну строку в памяти 94 кодов операций и адресов результатов и соответствующие строки в памятях 95 и 96 операндов в соответствии с номером команды (строки), присвоенным, например, счетчиком 76 номера команды блока 30 обработки команд и адресов (фиг. 5). Каждая строка памяти 94, помимо разрядов для записи кода команды и адреса результата, содержит разряды типа команды (являющиеся частью кода команды) и разряд готовности команды. Каждая строка памятей 95 и 96 операндов также содержит разряды готовности. При записи команды в память 94 в разряд готовности команды устанавливается «1. Операнды, поступающие из оперативной памяти МВС в память 20 скалярных данных (фиг. 2) вместе с их «адресами возврата через выходы 32 этой памяти поступают в памяти 95 и 96 операндов (фиг. 6) . «Адрес возврата прищедшего операнда указывает номер строки и номер памяти 95 или
96операндов. При записи операнда в соответствующую строку памяти 95 и 96 в разряде готовности операнда устанавливается «1.
Кольцевой регистр 97 содержит количество разрядов, равное числу строк в памяти 94 кодов операций и адресов результатов; сигналы от кольцевого регистра 97 являются «указателями номера анализируемой строки памятей 94-96. В кольцевом регистре
97всегда присутствует код, содержащий «1 только в одном из разрядов и «О - во всех остальных разрядах.
Пусть, например, «1 содержится в некотором J-M разряде кольцевого регистра 97, при этом анализируется содержимое j-й строки памятей 94-96. Это означает, что значения разряда готовности j-й команды и разрядов готовности операндов подаются на узел 98 анализа готовности команд. Если j-я команда является, например, скалярной двуместной командой (т. е. для ее выполнения требуются два операнда). то узел 98 реализует логическую функцию «И на три входа от разрядов готовности. Если же j-я команда является скалярной одноместной командой, то узел 98 реализует эту же функцию с использованием разряда типа команды, разряда готовности j-й команды и разряда готовности ее единственного операнда.
Коды готовых к выполнению скалярных команд вместе с их операндами и адресами результатов поступают через выходы 37 блока 36 распределения команд и данных в блок 38 обработки данных (фиг. 2), который может быть реализован, например, на основе микропрограммной интерпретации команд. Результат выполнения млкропрограммы, обрабатывающей поступившую команду, подается на выходы 40 блока 38 обработки данных вместе с его адресом. Результат в соответствии с адресом может поступать в память 41 результатов скалярного процессора 12 для засылки в оперативную память (фиг. 2) в векторный процессор (через коммутатор 39) или в узел программных регистров (фиг. 5).
Векторные команды поступают из блока 36 распределения команд и данных через выходы 37 этого блока на коммутатор 39 скалярного процессора (фиг. 2), на который поступают из оперативной памяти МВС через память 21 векторных данных элементы обрабатываемых векторов. Коммутатор 39 подключен к векторному процессору 13 через выходы 19 скалярного процессора. По этим выходам векторные команды поступают в соответствующую память 43 команд векторного процессора, а векторные операнды через информационный регистр 45 - в памяти 49 входных операндов операционных блов 48 (фиг. 3). Элементы векторов распределяются по операционным блокам 48 следующим образом: если векторный процессор содержит К операционных блоков, то в первый из них направляются 1-й, (к-fl)-й, (2к +1)-й и т. д. Элементы вектора, во второй - 2-й, (К + 2)-й, (2к + 2)-й и т. д. элементы вектора, в К-й - К-й, (2к)-й, (Зк)-й и т. д. элементы вектора. Из памяти
49входных операндов элементы векторов поступают в один из п узлов 50 векторных регистров в зависимости от того, какой из п скалярных процессоров 12 направляет текущие векторные данные на обработку в векторный процессор. Каждый узел 50 векторных регистров снабжен узлом 51 анализа готовности векторных операндов. Когда в узле
50векторных регистров оказываются записанными элементы вектора, подлежащие обработке в данном операционном блоке 48 в со ответствии с текущей командой, узел 51 анализа готовности выдает сигнал готовности. Сигналы готовности всех операционных блоков 48 через соответствующие группы 59 элементов И поступают на соответствующие входы узла 47 анализа приоритета векторного процессора 13. Очередная векторная команда, код которой находится в памяти 43 команд, считается готовой к выполнению, если все операционные блоки 48 выдают сигнал готовности. Если в текущий момент времени оказалось, что сигналы готовности присутствуют на выходах нескольких элементов И 59, то узел 47 анализа приоритета выбирает скалярный процессор 12 с наивысшим приоритетом (наивысший приоритет кодируется «1, остальные «О). Коды приоритетов передаются от скалярных процессоров через линии 19 связи и управляющие входы 63 узла 47 анализа приоритета. В результата сравнения кодов приоритетов узел 47 анализа приоритета разрешает соответствующей памяти 43 команд считывать код текущей команды на регистр 46 векторной команды 46. Код текущей векторной команды из регистра 46 векторной команды записывается в регистр 56 векторной операции каждого из операционных блоков 48. В зависимости от того, из какой памяти 43 команд считана команда на регистр 46 векторной команды, дешифратор 55 направлений разрешает подключение информационных выходов соответствующего узла 50 векторных регистров через узел 51 анализа готовности векторных операндов и блок 52 элементов ИЛИ к узлу 53 обработки векторных данных. Узел обработки векторных данных 53 операционного блока 48 может быть реализован на основе микропрограммной интерпретации команд. Результаты выполнения операций над элементами векторов через регистр 54 векторного результата заносятся в соответствующий узел 50 векторных регистров.
Если результаты выполнения векторной команды адресованы в оперативную память, то из узла 50 векторных регистров эти результаты вместе с их адресами поступают в соответствующую память 44 результатов, откуда через выходы 18 векторного процессора 13, через коммутатор 39 и его выходы 42 поступают в память 41 результатов скалярного процессора 12 для передачи в оперативную память МВС.
Адрес последнего элемента вектора - результата выполнения векторной команды снабжается меткой, которая с выхода 18 векторного процессора поступает на вход сброса блока 36 распределения команд и данных скалярного процессора 12 (фиг. 2) для «затирания выполненной векторной команды в соответствующей строке памяти 94 кодов операций и адресов результатов.
Операционные блоки 48 векторного процессора 13 функционируют автономно по отношению один к другому. Это позволяет им выполнять действия над операндами асинхронно по отношению один к другому по реальным событиям завершения выполнения команд. Во время выполнения текущей команды в узле 53 обработки векторных данных операционных блоков 48 в регистр 46 векторной команды поступает очередная векторная команда, возможно, из
другого скалярного процессора 12, и тогда векторный процессор 13 работает в режиме разделения времени над командами различных скалярных процессоров 12. Во время выполнения векторной команды, поступившей от одного из скалярных процессоров 12, в другой узел 50 векторных регистров могут передаваться элементы векторов для векторных команд другого скалярного процессора 12.
Если программа, обрабатываемая в одном из скалярных процессоров 12, имеет высший приоритет по отношению к программе, обрабатываемой другим скалярным процессором, то первый скалярный процессор «мо5 нополизирует векторный процессор 13, тогда центральный процессор 1, функционирующий в общем случае в соответствии со структурным принципом МКМД (много потоков команд - много потоков данных), функционирует так, как если бы он имел струкутуру класса ОКМД) (один поток команд - много потоков данных). Это позволяет не только уменьшить время выполнения высокоприоритетных программ, но и расширить воз.можности проблемной ориен5 тации МВС в целом.
Аналогичный эффект обеспечивается и при отказе одного из скалярных процессоров 12 центрального процессора 1. В этом случае работоспособный процессор 12 также монополизирует векторный процессор 13.
Таким образом, может оказаться, в отличие от известных МВС, что отказ одного из «ведущих процессоров не приводит к уменьщению производительности МВС в целом (на векторых вычислениях).
Этот же эффект остается в силе в случаях, когда один из скалярных процессоров 12 занят выполнением скалярных команд, а также при перезагрузках скалярного процессора новыми программами и данными.
В целом, каждый центральный процес0 сор 1 функционирует по конвейерному принципу, при котором совмещаются во времени следующие операции: выборка команд из блоков оперативной памяти в памяти 22 и 23 команд скалярных процессоров 12; декодирование команд и формирование адресов (заявок к памяти) в блоках 30 обработки команд и адресов; подготовка команд к выполнению на различных исполнительных блоках с помощью блоков 36 распределения команд и данных; выполнение скалярных команд в блоках 38 обработки данных; выполнение векторных команд в операционных блоках 48 векторного процессора 13.
Для сглаживания возможных различий
J во времени обработки команд на различных этапах конвейерной обработки (а эти времена могут изменяться в зависимости от типов команд, используемых в них способов адресации, разрядности текущих данных, их конкретных численных значений и пр.) используется буферизация команд и данных между различными исполнительными блоками. Для этого служат памяти 22 и 23 команд, память 20 скалярных данных и память 21 векторных данных, память 35 заявок, память 41 результатов - в каждом скалярном процессоре 12, информационный регистр 45, память 44 результатов - в каждом векторном процессоре 13 и др.
Управление конвейерной обработкой в скалярном процессоре 12 осуществляется с помощью сигналов разрещения передачи информации, вырабатываемых последующими блоками при наличии в них свободных строк соответствующих буферов и передаваемых предыдущим блокам. Так, освобождение регистра 74 команд формирует сигнал разрещения считывания очередной команды из памяти 22 и 23 команд, который передается по связи 27 блоку 24 управления памятями команд.
Коммутаторы,5ввода-вывода и коммутаторы 6 памяти центральных процессоров 1, коммутаторы 39 скалярных процессоров 12 выполняют функции подключения источников заявок на обслуживание (команд, данных) к соответствующему блоку обработки. Подключение осуществляется в соответствии со значениями тех разрядов адресов (в частности «адресов возврата) команд и данных, которые соответствуют коду (номеру) блока их последующей обработки. Коммутаторы 5 ввода - вывода подключены по связям 11 к входам и выходам периферий-ных процессоров 3, по связям 7 и 8 - к коммутаторам 6 памяти, по связям 16 и 17 - к скалярному процессору 12. Кроме того, имеются щины 9 для объединения коммутаторов 5 обоих центральных процессеров 1.
Шина 11 связи коммутатора 5 с периферийным процессором 3 двунаправленная в случае считывания информация из периферийного процессора 3 ему передается заявка, содержащая начальный адрес и размер массива, а также адрес, по которому следует передать эту информацию, - «адрес возврата включающий номер центрального процессора 1, номера коммутаторов- 5 и 6, и адрес в оперативной памяти или номер скалярного процессора 12, а также номер регистра 49 памяти входных операндов и номер векторного процессора 13, куда должна быть передана информация.
Двунаправленные щины 9 коммутаторов 5 служат для расщирения связей центральных процессоров 1 с периферийными процессорами 3 и имеют тот же формат, что и шины 11.
Коммутаторы 6 памяти по двунаправленным связям 10 подключены по всем блокам
2памяти, по связям 7 и 8 - к соответствующим коммутаторам 5, по связям 14 и 15 - к соответствующим скалярным процессорам 12.
5 По связям 10 к блокам памяти передаются заявки, содержащие адрес в памяти, вид обращения к памяти - запись - чтение, а также адрес возврата, содержащий номер периферийного процессора и адрес в нем либо номера памятей 20-22 или 23
0 скалярного процессора 12.
По связям 7 передаются заявки к периферийным процессорам 3, содержащие номер процессора 3, начальный адрес и размер заявленного массива и адрес возврата
5 в атучае заявки на запись в оперативную память либо адрес и размер массива в случае заявки на чтение из оперативной памяти (запись в память периферийного процессора 3). По связям 8 передаются данные из процессоров 3 и заявки к ОП от процессоров
3в форматах, аналогичных предыдущим. По связям 14 из блока 2 памяти передаются команды и данные в скалярный процессор 12. Формат передачи включает адрес в памяти 200-22 или 23 процессора
5 12 и информацию. По связям 15 передаются заявки к ОП от скалярного процессора 12 и данные.
Формат заявки содержит номер блока 2 памяти, адрес в блоке памяти, вид обращения и адрес возврата - номер памятей
20-22 или 23 и номер регистра в памяти. Коммутаторы 39 скалярных процессоров 12 предназначены для связи скалярных процессоров 12 с векторным процессором 13 и коммутаторами ввода-вывода 5.
5 По щине 18 связи из векторного процессора 13 на второй вход коммутатора 39 передаются элементы вектора, расположенного в узле 50 векторных регистров, каждый из которых сопровождается адресом элемента вектора в оперативной памяти (при выполнении команды пересылки вектора). С третьего выхода коммутатора 39 по щине 42 они передаются в память 41 результатов. Формат передаваемого сообщения содержит номер регистра памяти 41, признак послед5 него элемента вектора, адрес и значение элемента вектора. Признак последнего элемента используется для затирания векторной ко манды в блоке 36 распределения команд и данных 36 скалярного процессора 12.
0 На первый вход коммутатора 39 по связи 40 подается результат выполнения скалярной команды, адресуемой к периферийному процессору 3. Третий вход коммутатора 39 используется для передачи векторной команды векторному процессору 13 через второй выход коммутатора 39, подключенный к выходам 19 скалярного процессора 12. Формат сообщения включает код
и «внутренний номер команды, номера векторных регистров и номера операндов и количество элементов вектора, обрабатываемых данной командой. Четвертый вход коммутатора 39 служит для передачи элементов векторных операндов из памяти 21 векторных операндов через второй выход коммутатора 39 и выход 19 скалярного процессора 12. Формат содержит адрес элемента вектора, включающий номер векторного регистра в узле 50 и номер операционного блока 48 в векторном процессоре 13, и значение элемента вектора.
Пятый вход коммутатора 39 подключен к входу 16 скалярного процессора 12, а первый выход коммутатора - к выходу 17 скалярного процессора 12 для осуществления связи скалярного процессора 12 с периферийными процессорами 3. Формат сообщения содержит тип сообщения, адрес и указание о количестве слов сообщения. Пример реализации коммутатора приведен на фиг. 11.
Периферийные процессоры 3 могут функционировать автономно и асинхронно по отнощению один к другому, выполняя функции связи центральных процессоров 1 и блоков 2 памяти с периферийными устройствами 4 (в частности, функции буферизации и предобработки программ и данных), а также выполняя программы операционной системы (в том числе - для организации ввода- вывода).
Периферийные процессоры 3 могут быть выполнены на основе процессоров стандартных микро- или мини-ЭВМ.
Таким образом, состав, конструктивные связи и функциональные свойства предложенной МВС позволяют за счет динамической перестраиваемости ее структуры (динамического перераспределения вычислительных ресурсов векторных процессоров) обеспечить значительно больщую производительность и живучесть по сравнению с МВС, содержащими неперераспределяемые вычислительные ресурсы (в том числе - по сравнению с известной МВС).
Временная диаграмма (фиг. 12) иллюстрирует совмещением выполнения команд в двух скалярных процессорах 12i и 12 и векторном процессоре 13 центрального процессора 1. Показаны интервалы занятости различных блоков скалярных процессоров: памятей 221 и 222 команд, регистров 74j и 74г команд, блоков 36 и Зба распределения команд и данных, блоков 38 и 38г обработки данных и векторного процессора 13,- при выполнении последовательности из двух скалярных команд (li и 2) в скалярном процессоре и следующих одна за другой векторной и скалярной команд ( 2j) в скалярном процессоре 12 и векторном процессоре 13.
Из диаграммы следует, что
tj - окончание заполнения памяти 22j команд скалярного процессора начало переписи первой команды в регистр 74 5 команд;
tj - начало заполнения строки в блоке 36 первой командой;
tj - окончание заполнения памяти 22i команд скалярного процессора 12 и начало переписи первой команды 1 , в регистр 74 команд;
t - начало заполнения строки в блоке Збг первой командой;
ts - освобождение регистра 74 команд
первой командой и начало переписи второй
5 команды из памяти 22i в регистр 741;
t {, - начало заполнения строки в блоке 36i второй командой (2);
tr - момент готовности первой команды 11 в блоке 361 и выдачи ее в блок 38l;
tg - освобождение регистра 74гкоманд первой командой и начало переписи второй команды из памяти 22г в регистр 74г;
tg - момент готовности первой команды 1а в блок Збг и выдача ее в процессор 13;
tjo- начало заполнения строки в блоке 5 Збг второй командой
t - освобождение регистра 74 команд второй командой;
ta - готовность второй команды 2 в блоке Зба и выдача ее в блок 38г;
113 - окончание выполнения команды li в 38i и освобождение строки в блоке 361;
11Л - освобождение регистра 74 команд второй командой 2i;
ti5 - готовность второй команды 2 в блоке 361 и выдача ее в блок 5 16- окончание выполнения команды 2з, в блоке 38г и освобожение строки в блоке Збг;
17 - окончание выполнения команды 2i в блоке 381 и освобождение строки в блоке 36i;
tj;g - окончание выполнения команды Ij, в процессоре 13 и освобождение строки в блоке
Из временной диаграммы видно, что в интервале совмещается выполнение 5 команд 1 и 1 в скалярном 12 и в векторном 13 процессорах, в интервале t -tjs команд Ij; и 2г в скалярных процессорах 12j и 122,, в интервале 1 5-iii - команд 2 и 22 вскалярных процессорах 12 и 12г и в интервале , - команд 1 0 и 2 в векторном 13 и в скалярном 122 процессорах.
Вычислительные комплексы с перестраиваемой структурой, построенные на базе 5 предлагаемой МВС, предназначаются для использования в качестве систем обработки данных в геофизие, метеорологии, аэросъемке, океанографических и другид
исследованиях, систем моделирования слож ных объектов, верхних уровней сложныхиерархических систем управления технологическими процессами и прозводствами, систем прямого цифрового управления сложными объектами (типа ядерных реакторов)
в реальном масштабе времени, сложных систем автоматизации научных экспериментов и проектирования, требующих высокой производительности и большого объема памяти, мошных центров коммутации каналов и сообщений в системах связи и пр.
Фиг. 1 Фиг. 4
Фиг.З г ЗГ. .
tJ:
Wf
i
U74k /
Фиг.З
Z
Г
51
706
(риг. 9
3 - 2
77д
4
Фиг.П
1168960 /
/7
п
Фиг. 0
Li
fVW
777
2 1/77
ii
1234 5678ЯЮ71Г213 74 75 76 7778
2i
Фаг. Г2
| Головня В | |||
| Н | |||
| Дадаева О | |||
| М | |||
| Планшайба для точной расточки лекал и выработок | 1922 |
|
SU1976A1 |
| М., ИТМ и ВТ АН СССР, 1977, с.65-135 | |||
| Северин Д | |||
| П | |||
| и др | |||
| Опыт обеспечения отказоустойчивости в мультипроцессорных системах | |||
| - Труды ИИЭР, т | |||
| Приспособление для соединения пучка кисти с трубкою или втулкою, служащей для прикрепления ручки | 1915 |
|
SU66A1 |
| Способ размножения копий рисунков, текста и т.п. | 1921 |
|
SU89A1 |
