Уровень техники
Современные видеоредакторы с семантическим поиском упрощают работу с видеоматериалами и монтаж нужных фрагментов видео. Использование искусственного интеллекта и алгоритмов обработки естественного языка становится все более распространенным для улучшения пользовательского опыта. Технологии обработки видео и аудио с применением искусственного интеллекта включают более точное распознавание объектов и лиц, анализ эмоционального окраса и автоматическое извлечение смысла из мультимедийного контента. Подобные решения для видео также интегрируют облачные ресурсы для более мощных вычислений и хранения данных.
Общий вектор развития данной области указывает на более умные и адаптивные системы обработки видео и аудио, предоставляя пользователям широкий и продвинутый набор инструментов для творчества и редактирования мультимедийного контента. Несмотря на успехи в распознавании объектов, лиц и речи, точность этих технологий может не всегда соответсовавть, особенно при работе с сложным видео и аудио, например, в условиях низкого качества записи. Обработка в реальном времени видео и аудио также представляет технические сложности, требуя высокой производительности и эффективности алгоритмов. Существует необходимость в создании интуитивного и легкого в использовании решения для эффективной работы с функционалом семантического поиска и интеллектуальной обработки при работе с видео.
Известна Система и способ контекстуализации потока неструктурированного текста, представляющего устную речь (System and method for contextualising a stream of unstructured text representative of spoken word) по патенту US 20170011024 A1, включающая грамматический процессор, процессор предложений, частотный процессор, процессор агрегации и процессор эмоций. Неструктурированный поток текста обрабатывается и выводит общее количество аудиофайлов для каждой совпадающей фразы, слова и имени собственного, определенных из неструктурированного текста, в обработчик значимости данных. Обработчик значимости данных получает общее количество аудиофайлов для каждого имени, имени собственного и совпадающей реальной фразы, определенных из неструктурированного текста, и выводит список, включающий имена, имена собственные и совпадающие реальные фразы в порядке контекстуальной значимости.
Однако, данное решение в отличие от заявленного не может быть использовано для семантического поиска в видео и аудио, выделяя при этом ключевые смыслы, быструю обработку, а также отсутствует возможность создавать индивидуальные ролики и осуществлять онлайн-мониторинг и анализ, а также генерацию ключевых слов для SEO-оптимизации.
Раскрытие изобретения
Задачей изобретения является обеспечение пользователей более удобными и продвинутыми средствами обработки, анализа и управления видеоматериалами. Это включает в себя семантический поиск внутри видео, выделение ключевых смыслов, моментальное извлечение основного содержания, анализ контента, использование искусственного интеллекта для улучшения контента и анализа эмоционального контекста. Решение направлено на обеспечение пользователей более удобными и продвинутыми средствами обработки, анализа и управления видеоматериалами.
Основная цель состоит в предоставлении пользователям широкого набора инструментов для работы с видео, включая семантический поиск внутри видео, выделение ключевых смыслов, моментальное извлечение основного содержания, анализ контента, использование искусственного интеллекта для упрощения работы с контентом и анализом эмоционального контекста. Это также включает создание персонализированных видеороликов, проведение онлайн-мониторинга и анализа, а также оптимизацию контента для поисковых систем (SEO).
Существующие инструменты для обработки видеоматериалов обладают недостатками в эффективности, скорости и удобстве использования. При работе с выделением ключевой информации требуются значительные временные и трудовые затраты для анализа и управления контентом. Кроме того, известные решения не обеспечивают возможность персонализации контента или адаптации его для оптимизации веб-поиска.
Технический результат заключается в предоставлении пользователям удобных, быстрых инструментов для обработки, анализа и управления видеоматериалами, что содействует улучшению пользовательского опыта в создании и редактировании мультимедийного контента.
Пользователь может использовать настоящее решения для быстрого поиска конкретных сцен или ключевых моментов в больших видеоархивах, сокращая время, затраченное на поиск нужной информации. Также благодаря функциям семантического анализа и анализа эмоционального контекста, пользователь может быстро выявлять настроение или основные темы в видеоматериалах, что полезно для исследований и маркетинговых целей.
Осуществление изобретения
При реализации изобретения представлен компьютерно-реализуемый способ эффективной обработки видео для видеоаналитики и оптимизации поисковых систем, выполняемый с использованием процессора, который включает в себя следующие этапы:
a. семантический анализ внутри видео и аудио, осуществляемый за счет технологии для контекстного поиска в видео и аудио, основан на выделении ключевых смыслов и элементов контента в процессе поиска;
b. извлечение основного смысла из видео и аудио происходит за счет использования
специализированных алгоритмов обработки сигналов, машинного обучения и технологий обработки естественного языка;
c. покадровый анализ видео и системное вычисление пространственно-временной значимости каждого изображения лица для каждого объекта в рассматриваемом видео, при этом значимость определяется векторным представлением пространственной характеристики лица, которая отражает размер области лица относительно кадра, и векторным представлением временной характеристики изображения лица, описывающей длительность отображения анализируемого изображения лица в последовательных кадрах видео;
d. преобразование видео в отдельные ролики по смыслам проходит через автоматическое выделение смысловых фрагментов видео, реализованное через алгоритмы компьютерного зрения и технологии обработки сигналов, анализ аудиодорожки выделяет ключевые звуки речи или музыки, которые служат признаками смысловых фрагментов;
e. возможность работы с видео без перегрузки памяти системы и сохранение только необходимых роликов или их загрузка в социальные сети;
f. мгновенный анализ контента для быстрого ориентирования пользователя в видео с возможностью создания тайм-кодов для удобства навигации;
g. возможность использования искусственного интеллекта для выбора, редактирования и мгновенной загрузки роликов в социальные сети;
h. функционал анализа эмоционального окраса контента включает анализ изображений или видео для выделения лиц и определения эмоциональных выражений на них, а анализ аудиодорожки видео определяет интонации, тональность и эмоциональную окраску голоса в видео;
i. возможность создания и индивидуализии видео пользователями реализовано за счет использования алгоритмов машинного обучения для предложения пользователю индивидуальных идей и стилей редактирования на основе предыдущих предпочтений, включая возможность редактирования длину видео;
j. автоматическое выделение ключевых слов и фраз, наиболее релевантных содержанию видео за счет использования алгоритмов для определения наиболее эффективных ключевых слов, исходя из их популярности и использования в аналогичных контекстах.
При реализации использованы алгоритмы для проведения семантического анализа видео и аудио. В частности применяются такие алгоритмы, как “zero shot classification” и “sentence similarity”. Эти алгоритмы играют ключевую роль в процессе обработки медиа-контента, так как они способны проводить семантический анализ непосредственно после декодирования медиа в текст. Это позволяет быстро и эффективно извлекать основной смысл из видео и аудио.
Активация функционала, который выделяет ключевые смыслы и элементы контента в процессе поиска, осуществляется на основе данных, полученных от алгоритмов семантического анализа. Это позволяет системе точно определять и извлекать важную информацию из видео и аудио-материалов.
Преобразование видео в отдельные ролики по смыслам осуществляется путем автоматического выделения смысловых фрагментов видео с использованием алгоритмов компьютерного зрения и обработки сигналов. Это позволяет создавать более структурированные и информативные ролики, что улучшает их восприятие и удобство использования.
Алгоритм zero shot classification применяется для классификации объектов или данных на основе их характеристик. Этот способ позволяет системе обрабатывать новые классы без необходимости переобучения на новых данных, что значительно упрощает и ускоряет процесс обработки видео и аудио-контента.
Алгоритм sentence similarity используется для оценки семантической близости между предложениями или фразами. Это помогает системе определять степень схожести между текстовыми строками на основе их содержания и контекста, что является важным элементом в анализе и интерпретации контента.
Решение базируется на основах NLP (Natural language processing). Применяются модели машинного обучения, которые выстраивают контекстуальные отношения в тексте. Важно отметить, что такие модели позволяют получать численное или векторное представление некоторой формы данных в зависимости от контекста, который ее окружает. Так, например, Word2Vec не учитывают данного фактора, поэтому векторизация одного слова или предложения в разных текстах дает один и тот же результат. В данном решении же используются модели, которые подстраиваются под контекст и на выходе реализована возможность получать векторы фиксированной длины для дальнейшей обработки. Кроме того, скрытые состояния модели также хранят информацию, которая применяется в анализе.
Имея численное представление данных, имеется возможность выполнять разные задачи (при этом возможно их пересечение в итоговом результате):
1) извлекать главный смысл из видео - для этого необходимо разбить текст видео на предложения или группы предложений s_1,...s_n, называемыми ngram-ми. затем применяем алгоритм кластеризации, чтобы разделить s_i на группы связных текстов. Достигается это за счет минимизации расстояния (например, косинусного) между векторами или максимизации похожести (например, косинусного).
На рис. 1 представлена формула расчета косинусной схожести. Стоит отметить, что similarity=1-distance и поэтому оба эти алгоритма используются в данном решении.
Также необходимо выставить минимальный порог разности кластеров для их образования. Или необходимо выставить максимальный порог схожести. Эти понятия связаны и мы оперируем тем и другим.
На рис. 2 представлена формула формализации составления кластеров. C - кластеры, ε - максимальный порог схожести векторных представлений. В нашем случае представлений s_i.
Когда кластеры выстроены, мы берем максимальный из них по размеру и составляем из него итоговое видео. То есть мы находим argmax C_i по всем кластерам. Если задается ограничение на длительность видео, то мы находим центр масс векторов и ранжируем их по близости к этому центру.
2) извлекать смысл по запросу (q) - на данном этапе формируется всего один кластер или не формируется вовсе. Если кластер создается, то модель отвечает на вопрос вхождения каждого тестового s_i в кластер q, иначе используется вышеописанные алгоритмы поиска близости. Разница небольшая, но при необходимости используются оба подхода. Для этого выставляется некоторый порог вероятности p* и каждый s_i проверяется по условию: p(1 - dist(vectorized(s_i), vectorized(q))) >= p* или p(similarity(vectorized(s_i), vectorized(q))) >= p*. Также проверяется, насколько q может быть продолжением предыдущего контекста (то есть предложения или группы предложений или даже нескольких слов): p(is_next(q, s_i)) >= p*. Последний способ может как использовать векторизацию, так и использовать только скрытые состояния нейронной сети. Эти методы в частности имеют названия Sentence similarity и Zero Shot Classification. В общих чертах необходимо найти top n элементов функции argmax p(), убирая из выборки найденный элемент, пока p>=p*.
3) проводить мультимодальную обработку - разработанные модели могут получать на вход как текст, так и изображение и участок видео небольшой длины. После векторизации сопоставляются контексты разных видов друг с другом, то есть производится поиск значения функции argmax(p(q, x)), где q - входной вектор, а x пробегает некоторое множество векторизованных контекстов. Это множество может быть как списком текстов, видео так и изображений. Таким образом, добавляется эмоциональный окрас в видео, вставляя в некоторый его участок медиа, похожее на его контекст и иллюстрирующее суть.
4) проводить эффективный поиск - составляется упорядоченный набор векторизованных контекстов, благодаря этому проводится первичный поиск похожего контента с помощью классических алгоритмов поиска ближайших элементов в метрическом пространстве и при необходимости применяем модели машинного обучения для исходного контекста при необходимости конкретизации поиска.
5) выделять эмоциональный окрас. Составляем кластер с эмоциональными контекстами, далее обработка идет по пунктам 1) - 4). Такой кластер может содержать обобщение для эмоций или же только конкретный тип (например, негатив).
Пункты 4 и 5 представляют собой методы для эффективного поиска и выделения эмоционального окраса контента, они используют те же основные методы, что и представленные в пунктах 1-3.
Краткое описание чертежей
рис.1 - формула косинусная схожесть,
рис. 2 - формула формализации составления кластеров.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ДЛЯ ВЫБОРА ЗНАЧИМЫХ ЭЛЕМЕНТОВ СТРАНИЦЫ С НЕЯВНЫМ УКАЗАНИЕМ КООРДИНАТ ДЛЯ ИДЕНТИФИКАЦИИ И ПРОСМОТРА РЕЛЕВАНТНОЙ ИНФОРМАЦИИ | 2015 |
|
RU2708790C2 |
| Способ обработки видео для целей визуального поиска | 2018 |
|
RU2693994C1 |
| Алгоритм комплексного дистанционного бесконтактного мультиканального анализа психоэмоционального и физиологического состояния объекта по аудио- и видеоконтенту | 2017 |
|
RU2708807C2 |
| СПОСОБ И СИСТЕМА СЕГМЕНТАЦИИ СЦЕН ВИДЕОРЯДА | 2022 |
|
RU2783632C1 |
| МЕТОД ОТОБРАЖЕНИЯ РЕЛЕВАНТНОЙ КОНТЕКСТНО-ЗАВИСИМОЙ ИНФОРМАЦИИ | 2014 |
|
RU2683482C2 |
| ВИЗУАЛИЗАЦИЯ ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2011 |
|
RU2580022C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| СПОСОБ СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА С ИСПОЛЬЗОВАНИЕМ ГРАФИЧЕСКОГО ЯЗЫКА-ПОСРЕДНИКА | 2009 |
|
RU2509350C2 |
| СОЦИАЛЬНАЯ ГЛАВНАЯ СТРАНИЦА | 2011 |
|
RU2604436C2 |


Изобретение относится к области вычислительной техники для семантического анализа в видео и аудио. Технический результат заключается в повышении эффективности управления памятью устройства, предотвращая перегрузку вычислительного устройства. Технический результат достигается за счет способа программной обработки видео контента с применением семантического анализа, который использует технологии для семантического анализа в видео и аудио, выделяя ключевые смыслы. Способ выполняет покадровый анализ видео и системное вычисление пространственно-временной значимости каждого изображения лица для каждого объекта в рассматриваемом видео, при этом значимость определяется векторным представлением пространственной характеристики лица, которая отражает размер области лица относительно кадра, и векторным представлением временной характеристики изображения лица, описывающей длительность отображения анализируемого изображения лица в последовательных кадрах видео и автоматическое выделение ключевых слов и фраз, наиболее релевантных содержанию видео за счет использования алгоритмов для определения наиболее эффективных ключевых слов исходя из их популярности и использования в аналогичных контекстах. 2 з.п. ф-лы, 2 ил.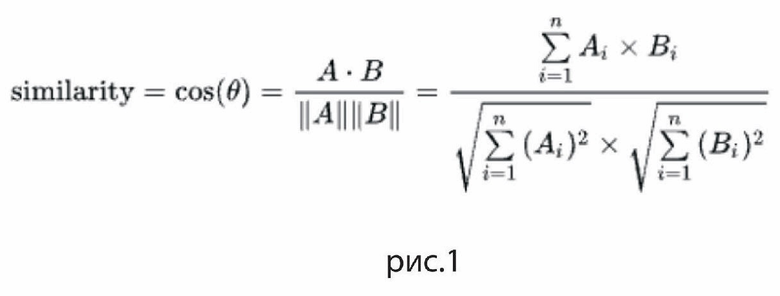
1. Компьютерно-реализуемый способ для работы с видео для видеоаналитики и поисковыми системами, осуществляемый с помощью процессора, включающий в себя:
a. семантический анализ внутри видео и аудио, осуществляемый за счет технологии для контекстного поиска в видео и аудио, основан на выделении ключевых смыслов и элементов контента в процессе поиска;
b. извлечение основного смысла из видео и аудио происходит за счет использования специализированных алгоритмов обработки сигналов, машинного обучения и технологий обработки естественного языка;
c. покадровый анализ видео и системное вычисление пространственно-временной значимости каждого изображения лица для каждого объекта в рассматриваемом видео, при этом значимость определяется векторным представлением пространственной характеристики лица, которая отражает размер области лица относительно кадра, и векторным представлением временной характеристики изображения лица, описывающей длительность отображения анализируемого изображения лица в последовательных кадрах видео;
d. преобразование видео в отдельные ролики по смыслам проходит через автоматическое выделение смысловых фрагментов видео, реализованное через алгоритмы компьютерного зрения и технологии обработки сигналов, анализ аудиодорожки выделяет ключевые звуки речи или музыки, которые служат признаками смысловых фрагментов;
e. возможность работы с видео без перегрузки памяти системы и сохранение только необходимых роликов или их загрузка в социальные сети;
f. мгновенный анализ контента для быстрого ориентирования пользователя в видео с возможностью создания тайм-кодов для удобства навигации;
g. возможность использования искусственного интеллекта для выбора, редактирования и мгновенной загрузки роликов в социальные сети;
h. функционал анализа эмоционального окраса контента включает анализ изображений или видео для выделения лиц и определения эмоциональных выражений на них, а анализ аудиодорожки видео определяет интонации, тональность и эмоциональную окраску голоса в видео;
i. возможность создания и индивидуализации видео пользователями реализована за счет использования алгоритмов машинного обучения для предложения пользователю индивидуальных идей и стилей редактирования на основе предыдущих предпочтений, включая возможность редактирования длины видео;
j. автоматическое выделение ключевых слов и фраз, наиболее релевантных содержанию видео, за счет использования алгоритмов для определения наиболее эффективных ключевых слов исходя из их популярности и использования в аналогичных контекстах.
2. Способ по п. 1, характеризующийся тем, что проведение анализа контента происходит непрерывно, в режиме реального времени, основываясь на ключевых характеристиках и особенностях контента с целью быстрого и точного выделения ключевых аспектов и изменений.
3. Способ по п. 1, характеризующийся тем, что модель машинного обучения состоит из группы моделей, каждая из которых обучена на выявление определенного алгоритма обработки контента, при этом каждая группа моделей специализируется на распознавании и анализе конкретных аспектов видеоматериала для выявления ключевых смыслов и элементов контента внутри видео и аудио, автоматически выделяющих смысловые фрагменты видео, для использования искусственного интеллекта в выборе готовых роликов, их редактирования и мгновенной загрузки в социальные сети.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| KR 101632689 B1, 25.03.2016 | |||
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| СИСТЕМА И СПОСОБ ДЛЯ ОБРАБОТКИ ВИДЕОДАННЫХ ИЗ АРХИВА | 2019 |
|
RU2710308C1 |

