ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее техническое решение, в общем, относится к области вычислительной техники, а в частности к способам и системам поиска и коррекции ошибок в текстах на естественном языке.
УРОВЕНЬ ТЕХНИКИ
[002] В настоящее время выявление и исправление в текстах нетривиальных ошибок (англ. «Grammatical Error Correction», GEC) - бурно развивающаяся область научных и прикладных исследований на стыке лингвистики и компьютерных наук (англ. «computer science»), в которой, однако, в отличие от смежных областей, таких, как машинный перевод, автоматическое порождение и распознавание звучащей речи и т.п., пока мало заметных достижений. Если задача поиска в текстах орфографических ошибок в целом решена еще в XX веке, через выявление в тексте «несуществующих» слов, неизвестных морфологическому анализатору, то эффективные решения по выявлению более сложных языковых ошибок, связанных с неправильным употреблением, заменой, перестановкой, пропуском и т.п. существующих слов, находятся только в процессе разработки.
[003] Традиционные решения основаны на лингвистических алгоритмах, в том числе применяющих правила, шаблоны и словари. Такой подход можно назвать эвристическим. Например, грамматический корректор ОРФО 2016 (https://www.orfo.ru/products) а) ищет в предложениях текста фрагменты, соответствующие правилам (шаблонам), написанным на специальном языке описания грамматических конструкций, и для фрагментов, соответствующих тому и или иному шаблону, выдает информационные пояснения (описание ошибки) и вариант или варианты исправления; б) применяет к предложениям лингвистические алгоритмы, такие, например, как проверка парности скобок.
[004] Похожий подход, целиком основанный на правилах, применяется в проекте LanguageTool (https://lanquaqetool.org).
[005] Недостаток таких подходов состоит в том, что они позволяют эффективно выявлять только некоторые типы ошибок. С их помощью, например, трудно или невозможно с достаточной полнотой и точностью распознавать такие ошибки, как: ошибки на слитное или раздельное написание «не» с русскими существительными, прилагательными, наречиями и причастиями; написание одной или двух букв «н» в русских словах; различение форм инфинитива на -ться и личных форм на -тся; различение паронимов (зрительский/зрительный; эффективный/эффектный; осветить/освятить и т.п.); случайные замены одного слова на другое при пропуске букв («брызги шаманского», «стеная антилопа»); некоторые типы ошибок на артикль в английском языке, и многое другое.
[006] В последнее время развивается подход к GEC, основанный на машинном обучении, в том числе с использованием предобученных нейросетевых платформ (Google BERT, RoBERTa, GPT-2 и др.). Такой подход можно назвать нейросетевым. Так, в ряде работ развивается подход к исправлению грамматических и речевых ошибок как к переводу с «неграмотного» на «грамотный» английский (русский и т.п.) язык, ср., например, в источнике информации [1]. В некоторых работах последних лет предложен альтернативный подход - нейронная сеть учится тегировать ошибки в предложениях, причем первоначальное обучение нейросети проводится с использованием искусственно порожденных корпусов предложений с ошибками, ср., например, две следующие работы: [2], [3].
[007] При несомненных достоинствах нейросетевого подхода, ему (в известных нам реализациях) свойственны следующие недостатки:
 недостаточная (менее 80%) точность обнаружения ошибок: значительный уровень «шума», когда правильные предложения опознаются как ошибочные;
недостаточная (менее 80%) точность обнаружения ошибок: значительный уровень «шума», когда правильные предложения опознаются как ошибочные;
 отличие «профиля» порождаемых ошибок от естественных ошибок, допускаемых реальными носителями языка и иностранцами;
отличие «профиля» порождаемых ошибок от естественных ошибок, допускаемых реальными носителями языка и иностранцами;
 неприменимость к некоторым типам ошибок - например, ко многим стилистическим ошибкам.
неприменимость к некоторым типам ошибок - например, ко многим стилистическим ошибкам.
[008] Передовые коммерческие сервисы проверки правильности текстов, такие как Gram marly (https://www.qrammarly.com) или Outwrite (https://www.outwrite.com), по-видимому, в той или иной пропорции совмещают эвристический и нейросетевой подходы, однако о принципах их работы никаких подробностей не сообщается.
СУЩНОСТЬ ТЕХНИЧЕСКОГО РЕШЕНИЯ
[009] Технической проблемой или технической задачей, решаемой в данном техническом решении, является осуществление способа и системы для автоматического поиска и коррекции ошибок в текстах на естественном языке посредством эффективного соединения эвристического и нейросетевого подхода.
[0010] Техническим результатом, достигаемым при решении вышеуказанной технической проблемы, является выявление грамматических, речевых, стилистических ошибок с более высокой точностью и полнотой.
[0011] Дополнительными достигаемыми техническими результатами является преодоление ограничений, присущих эвристическому и нейросетевому подходам по отдельности; возможность параллельного независимого развития различных модулей, входящих в систему.
[0012] Данное решение может применяться также для задач исправления ошибок после распознавания речи и для предобработки запросов к виртуальным ассистентам.
[0013] Указанный технический результат достигается благодаря:
 модульной организации системы: независимому подключению к ней модулей поиска и исправления ошибок различной природы (эвристических и нейросетевых); возможности подключения факультативных модулей для исправления конкретных типов ошибок;
модульной организации системы: независимому подключению к ней модулей поиска и исправления ошибок различной природы (эвристических и нейросетевых); возможности подключения факультативных модулей для исправления конкретных типов ошибок;
 усовершенствования обоих подходов к GEC по сравнению с имеющимися образцами - в частности, применению эвристического подхода при подготовке данных для обучения нейросетевого модуля и подхода, основанного на машинном обучении, при сборе данных для эвристического модуля;
усовершенствования обоих подходов к GEC по сравнению с имеющимися образцами - в частности, применению эвристического подхода при подготовке данных для обучения нейросетевого модуля и подхода, основанного на машинном обучении, при сборе данных для эвристического модуля;
 итеративному дообучению нейросетевой модели с учетом экспертной разметки;
итеративному дообучению нейросетевой модели с учетом экспертной разметки;
 эффективному сведению результатов (найденных ошибок), полученных от различных модулей, управляющим модулем системы, с разрешением возможных конфликтов между ними.
эффективному сведению результатов (найденных ошибок), полученных от различных модулей, управляющим модулем системы, с разрешением возможных конфликтов между ними.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0014] Признаки и преимущества настоящего технического решения станут очевидными из приведенного ниже подробного описания и прилагаемых чертежей, на которых:
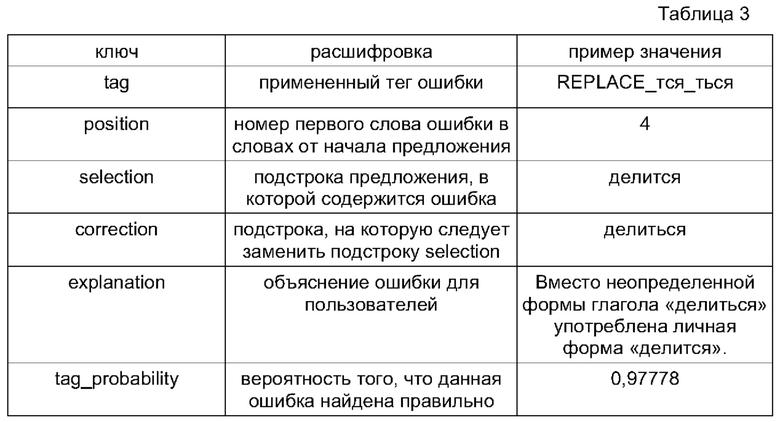
[0015] На Фиг. 1 показан пример реализации системы автоматического поиска и коррекции ошибок в текстах на естественном языке в виде блок-схемы.
[0016] На Фиг. 2 показан вариант реализации модулей исполнительного комплекса.
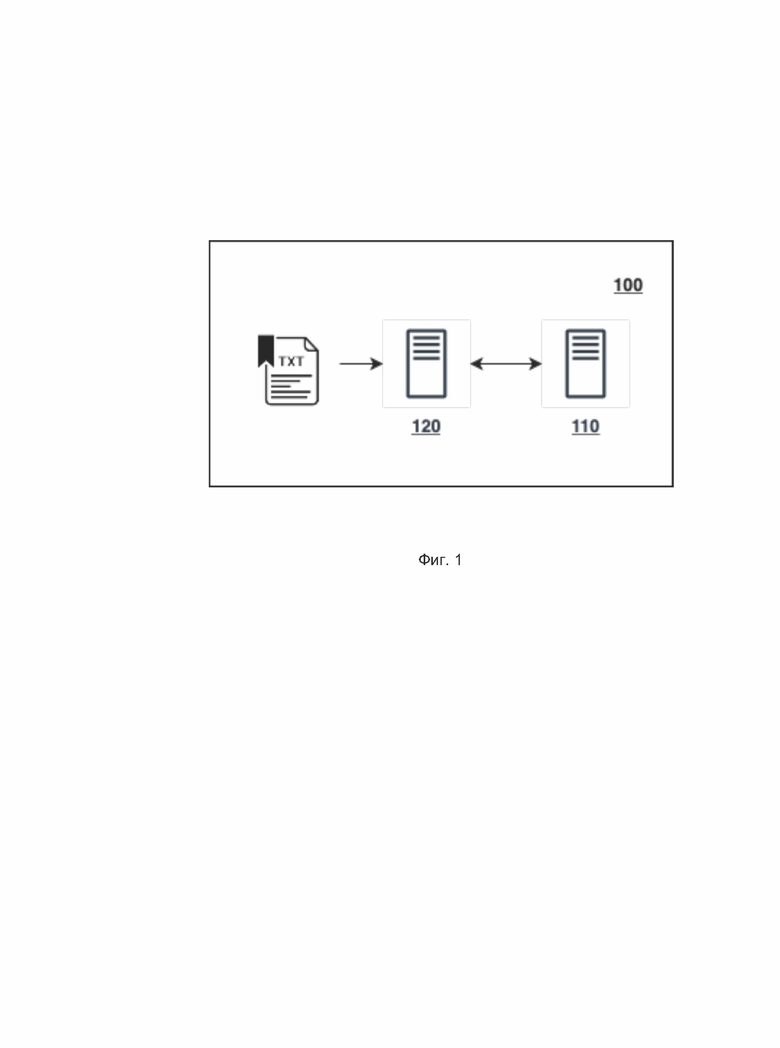
[0017] На Фиг. 3 показан пример реализации центрального управляющего модуля.
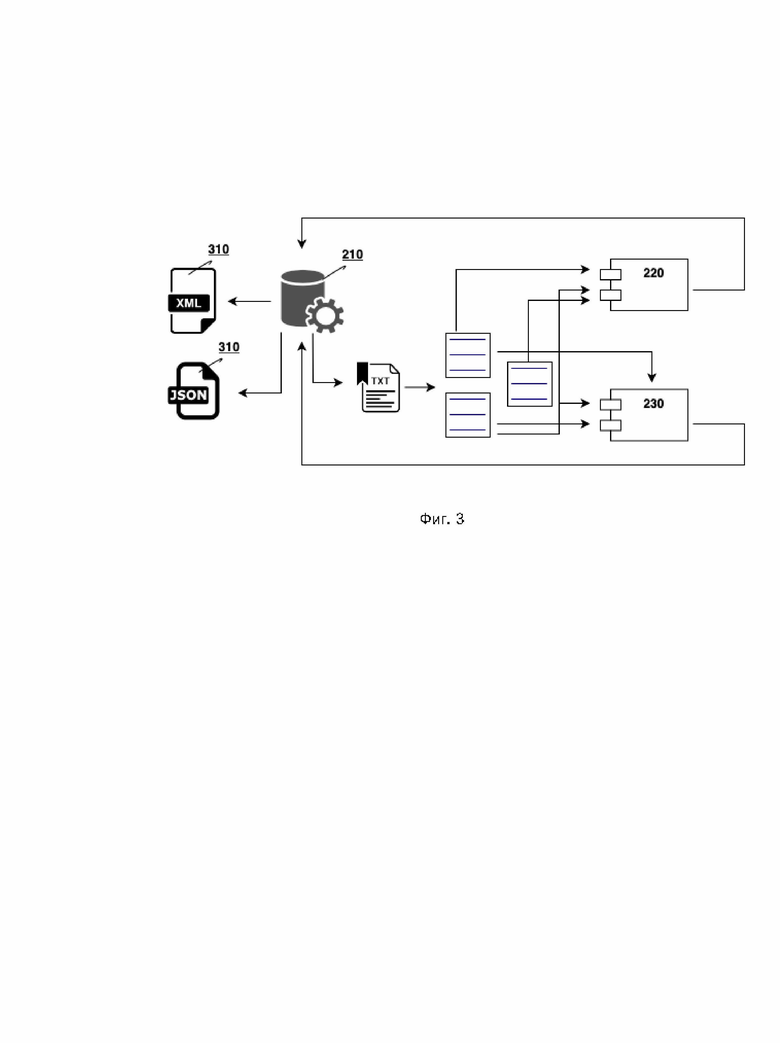
[0018] На Фиг. 4 показан вариант реализации эвристического модуля.
[0019] На Фиг. 5 показан пример реализации структуры эвристического модуля проверки грамматической правильности.
[0020] На Фиг. 6 показан вариант реализации нейросетевого модуля.
[0021] На Фиг. 7 показан пример реализации модулей вспомогательного комплекса.
ПОДРОБНОЕ ОПИСАНИЕ ТЕХНИЧЕСКОГО РЕШЕНИЯ
[0022] Ниже будут подробно рассмотрены термины и их определения, используемые в описании технического решения.
[0023] В данном изобретении под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[0024] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы) или подобное. Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных. В роли устройства хранения данных могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, ПЗУ (постоянное запоминающее устройство), твердотельные накопители (SSD), оптические приводы.
[0025] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[0026] JSON (англ. «JavaScript Object Notation») - текстовый формат обмена данными, представляющий собой набор пар ключ: значение (или упорядоченный набор значений).
[0027] XML (англ. «eXtensible Markup Language)) - расширяемый язык разметки) - текстовый формат, предназначенный для хранения и обмена структурированными данными.
[0028] Правило - описанная специальным языком разметки сущность, содержащая шаблон последовательности грамматических, синтаксических, лексических вхождений. Правило срабатывает при успешном наложении данного шаблона на анализируемый текст. Правила вырабатываются вручную на основе анализа большого количества проблемных текстов.
[0029] Искусственная нейронная сеть (иногда «нейронная сеть» или «нейросеть») - математическая модель (а также ее программное воплощение), построенная по принципу организации и функционирования сетей нервных клеток живого организма. При обучении нейросети вычисляется набор коэффициентов (весов), который затем используется при решении практических задач - таких, как распознавание образов или поиск грамматических ошибок.
[0030] Набор тегов - список строк вида REPLACE_x_y, INSERT_x или DELETE_x, который определяет действия, необходимые для того, чтобы породить или исправить ошибку (замена у на х: порождение ошибки, замена х на у: исправление ошибки). Например, тег REPLACE_предать_придать позволяет породить ошибку в предложении «Он не придал этому значения» → «Он не предал этому значения».
[0031] Словари ошибок - составленные лингвистами файлы, состоящие из пар «слово/словосочетание, которое нужно найти в правильном предложении» - «слово/словосочетание, на которое его нужно заменить, чтобы внести ошибку» и сопутствующей информации в виде тега, который будет приписан этой ошибке, и типа генерации: односторонняя замена (генерировать ошибку нужно только х→у), двусторонняя замена (генерировать нужно и ошибку х→у, и ошибку у→х), вставка (т.е. внесенной ошибкой является вставка лишнего слова/словосочетания в правильное предложение).
[0032] Описанное техническое решение, показанное на Фиг. 1, в принципе применимо к любому естественному языку, не ограничиваясь. В конкретном примере реализации решения применяется к русскому и английскому языкам.
[0033] Решение 100 представляет собой технический комплекс компонентов, состоящий из исполнительного комплекса 120, работающего в режиме реального времени, обеспечивающего поиск и коррекцию ошибок, и вспомогательного комплекса 110, обеспечивающего подготовку данных для исполнительного комплекса.
[0034] Исполнительный комплекс 120 состоит из центрального управляющего модуля (иначе - «сервер проверки текста») и ряда подключаемых к нему модулей, представляющих собой автономные единицы, работающие независимо друг от друга. Разные модули могут реализовывать разные подходы к обнаружению ошибок, ориентированы на поиск разных типов ошибок, и т.п.
[0035] Вспомогательный комплекс 110 обеспечивает подготовку данных для модулей исполнительного комплекса 120 и состоит из модулей, обеспечивающих подготовку данных для соответствующих им модулей исполнительного комплекса.
[0036] Далее будет описан исполнительный комплекс 120, обеспечивающий проверку ошибок в режиме реального времени и показанный подробно на Фиг. 2.
[0037] В число модулей исполнительного комплекса 120 входят следующие основные модули:
 центральный управляющий модуль 210;
центральный управляющий модуль 210;
 эвристический модуль 220 проверки грамматической правильности, основанный на правилах;
эвристический модуль 220 проверки грамматической правильности, основанный на правилах;
 нейросетевой модуль 230, отвечающий за обнаружение сложных ошибок, для которых эвристические решения неэффективны, и работающий на принципах машинного обучения;
нейросетевой модуль 230, отвечающий за обнаружение сложных ошибок, для которых эвристические решения неэффективны, и работающий на принципах машинного обучения;
[0038] Данные три модуля составляют основу исполнительного комплекса 120 описываемой системы 100 и решения, именно в них, и особенно в способе их взаимодействия, сосредоточена ее новизна.
[0039] Среди дополнительных модулей исполнительного комплекса 120 в некоторых примерах реализации могут быть:
 спелл-чекер (англ. spelling checker) (не показан на фигуре) - модуль проверки орфографии по словарю с моделью словоизменения для каждого слова (лексемы); спелл-чекер для каждой встретившейся в тексте словоформы определяет, входит ли она в число известных ему (описываемых им) словоформ, и если не входит, то предлагает для нее варианты замен на известные ему слова;
спелл-чекер (англ. spelling checker) (не показан на фигуре) - модуль проверки орфографии по словарю с моделью словоизменения для каждого слова (лексемы); спелл-чекер для каждой встретившейся в тексте словоформы определяет, входит ли она в число известных ему (описываемых им) словоформ, и если не входит, то предлагает для нее варианты замен на известные ему слова;
 дополнительные специальные модули (не показаны на фигуре), обеспечивающие поиск таких типов ошибок, которые по разным причинам плохо поддаются обнаружению двумя основными модулями, - например, дополнительный эвристический модуль, обеспечивающий поиск повторов одинаковых или родственных слов (включающий: словарь родственных слов; словарь служебных слов, повторы которых не проверяются; словарь допустимых сочетаний, включающих повторы; эвристические алгоритмы оценки степени неудачности повтора, и др.);
дополнительные специальные модули (не показаны на фигуре), обеспечивающие поиск таких типов ошибок, которые по разным причинам плохо поддаются обнаружению двумя основными модулями, - например, дополнительный эвристический модуль, обеспечивающий поиск повторов одинаковых или родственных слов (включающий: словарь родственных слов; словарь служебных слов, повторы которых не проверяются; словарь допустимых сочетаний, включающих повторы; эвристические алгоритмы оценки степени неудачности повтора, и др.);
 факультативные модули (не показаны на фигуре), направленные на решение специальных задач проверки текста, для которых может быть использовано решение, - например, для включения описываемой системы в контур системы автоматической проверки эссе для единого государственного экзамена могут быть добавлены модули (не входящие в основное решение, описываемое в данной заявке), проверяющие соответствие структуры текста предъявляемым к ней требованиям; соответствие текста специальным требованиям к его оформлению; поиск фактических ошибок, и т.п.
факультативные модули (не показаны на фигуре), направленные на решение специальных задач проверки текста, для которых может быть использовано решение, - например, для включения описываемой системы в контур системы автоматической проверки эссе для единого государственного экзамена могут быть добавлены модули (не входящие в основное решение, описываемое в данной заявке), проверяющие соответствие структуры текста предъявляемым к ней требованиям; соответствие текста специальным требованиям к его оформлению; поиск фактических ошибок, и т.п.
[0040] Далее будет описан центральный управляющий модуль 210 исполнительного комплекса 120, который показан на Фиг. 3.
[0041] Центральный управляющий модуль 210 делит проверяемый текст на предложения; передает части текста на проверку подключенным модулям; получает от подключенных модулей результаты проверки; обеспечивает объединение результатов разных модулей в общую разметку текста, осуществляемую по единым принципам - например, в виде JSON-разметки, включающей а) выделяемый фрагмент текста; б) пояснение, описывающее ошибку, и в) вариант (или варианты) ее исправления.
[0042] При этом центральный управляющий модуль 210 может получать исходные данные от модулей асинхронно и в разных (их собственных) форматах, основанных на XML или JSON и содержащих (показано на Фиг. 3), например, теги ошибок (нейромодуль 230), имена правил (эвристический модуль 220), переменные, соответствующие выделенным правилом фрагментам текста (эвристический модуль 220), и т.п.
[0043] Центральный управляющий модуль 210 также осуществляет фильтрацию результатов, приходящих от модулей (например, модуля 220 и/или 230). Можно выключить тот или иной тип ошибок, если их распознавание не требуется, точность их обнаружения недостаточна или выделение ошибок такого типа обеспечивается другим модулем, входящим в систему 100. Например, если в ходе разработки нейросетевого модуля 230 для того или иного тега (типа ошибок) еще не достигнута требуемая точность распознавания, этот тег может быть просто выключен управляющим модулем 210 из общих результатов. Фильтрация результатов позволяет также включать и выключать показ тех или иных типов ошибок в зависимости от параметров, заданных пользователем системы, типов текстов и т.п.: так, выделение в тексте разговорной лексики, осуществляемое эвристическим модулем 220, может быть включено (для деловых писем и других формальных текстов) или выключено (для частной переписки).
[0044] Центральный управляющий модуль 210 осуществляет также разрешение возможных конфликтов между результатами, полученными от разных модулей (а при необходимости - и от одного модуля). Если два модуля находят ошибки, затрагивающие одни и те же слова (например, слово спиться разговорное и инфинитив спиться употреблен вместо личной формы спится) управляющий модуль 210 решает, должны ли быть предъявлены пользователю обе ошибки или только одна, в каком порядке, следует ли предъявлять вторую ошибку в случае исправления или отказа от исправления первой, и т.п.
[0045] Ниже будет подробно описан и показан на Фиг. 4 эвристический модуль 220 проверки грамматической правильности, основанный на правилах, входящий в состав исполнительного комплекса 120.
[0046] Данный модуль 220 представляет из себя программную библиотеку, которая получает на вход проверяемый текст, применяет к нему правила поиска грамматических и других ошибок, а на выходе в соответствии с программным интерфейсом, понимаемым управляющим модулем 210 исполнительного комплекса 120, передает последнему информацию о сработавших правилах, в том числе:
 имя сработавшего правила;
имя сработавшего правила;
 позиции фрагмента текста, к которому оно было применено;
позиции фрагмента текста, к которому оно было применено;
 позиции фрагмента текста, который должен быть выделен при показе правила (по умолчанию совпадает с предыдущим);
позиции фрагмента текста, который должен быть выделен при показе правила (по умолчанию совпадает с предыдущим);
 позиции заменяемого фрагмента текста (по умолчанию совпадает с предыдущим);
позиции заменяемого фрагмента текста (по умолчанию совпадает с предыдущим);
 варианты замены (исправления ошибки);
варианты замены (исправления ошибки);
 пояснение, объясняющее суть найденной ошибки.
пояснение, объясняющее суть найденной ошибки.
[0047] Возможна также интеграция модуля 220 в сторонние продукты (например, в текстовые редакторы, такие как Microsoft Word, LibreOffice Writer и так далее, не ограничиваясь) при помощи библиотек-прослоек (англ. wrapper) для адаптации программного интерфейса (API) к потребностям целевого клиентского программного обеспечения.
[0048] Данный модуль 220 работает с правилами, описывающими ошибки, которые составляются лингвистами для каждого языка в отдельности. Правила собраны в словари правил, в которых, кроме непосредственно правил, могут быть описаны элементы, применяемые к правилам словаря по умолчанию; например, в словаре может быть приведено пояснение, которое используется при срабатывании любого правила из словаря, если в нем нет собственного пояснения, заменяющего пояснение по умолчанию.
[0049] Каждое правило описывает конкретную ошибку и описывает условия (контекст) при которых данная ошибка детектируется, а также возможные исключения - контексты, при которых ошибка детектироваться не должна. В связи со сложностью естественного языка правила имеют эвристический характер: они не претендуют на то, чтобы описать все потенциально возможные контексты, в которых ошибка должна быть детектирована или все возможные исключения, а покрывают большинство наиболее распространенных случаев. При этом точность срабатывания (исключение ложных срабатываний, т.е. контекстов, где ошибки на самом деле нет) приоритетнее, чем полнота (учет всех контекстов, где ошибка есть). Одной из задач лингвистов при разработке словарей правил является их уточнение с целью увеличения точности срабатывания.
[0050] Исходные тексты словарей правил реализованы на оригинальном языке описания правил, как показано на примере в Таблице 1.
[0051]


[0052] Ниже будет коротко описан язык описания правил для эвристического модуля 220 проверки грамматической правильности.
[0053] Основной элемент правила - шаблон поиска вхождения, описывающий контексты (фрагменты текста), к которым правило должно быть применено. Например, правило, приведенное в Таблице 1, должно срабатывать, если в предложении на английском языке встречается глагол «accustom» (в произвольной форме, например, «is accustomed»), после него следует предлог «with», а далее - вопросительное слово (например, «why»), причастие настоящего времени (например, «handling») или именная группа (например, «those rules»).
[0054] Среди элементов шаблона поиска вхождения могут быть задействованы следующие:
 непосредственные лексические вхождения (слова), рассчитанные на строгий и нестрогий (с учетом формообразования) поиск в тексте;
непосредственные лексические вхождения (слова), рассчитанные на строгий и нестрогий (с учетом формообразования) поиск в тексте;
 обобщенные описатели (кванторы) частей речи, членов предложения, членов словарей специальных слов;
обобщенные описатели (кванторы) частей речи, членов предложения, членов словарей специальных слов;
 служебные элементы, ограничивающие область применения правила или уточняющие его поведение (такие, как маркер начала или конца предложения, маркер подсветки, инвертор правила и т.п.);
служебные элементы, ограничивающие область применения правила или уточняющие его поведение (такие, как маркер начала или конца предложения, маркер подсветки, инвертор правила и т.п.);
 элементы группировки (списки, последовательности, опциональные элементы, условия), в их число также входят маркеры заменяемого фрагмента;
элементы группировки (списки, последовательности, опциональные элементы, условия), в их число также входят маркеры заменяемого фрагмента;
 постфиксные элементы-ограничители, уточняющие поведение элемента и не имеющие самостоятельного смысла;
постфиксные элементы-ограничители, уточняющие поведение элемента и не имеющие самостоятельного смысла;
 маркеры синтаксических конструкций.
маркеры синтаксических конструкций.
[0055] В целом язык описания правил достаточно развит, чтобы описать вхождения большинства лексических, стилистических, грамматических и синтаксических ошибок. Сложные лексические, синтаксические и смысловые ошибки могут быть обнаружены при помощи других модулей, использующих нечеткую логику, в частности, основным нейросетевым модулем 230.
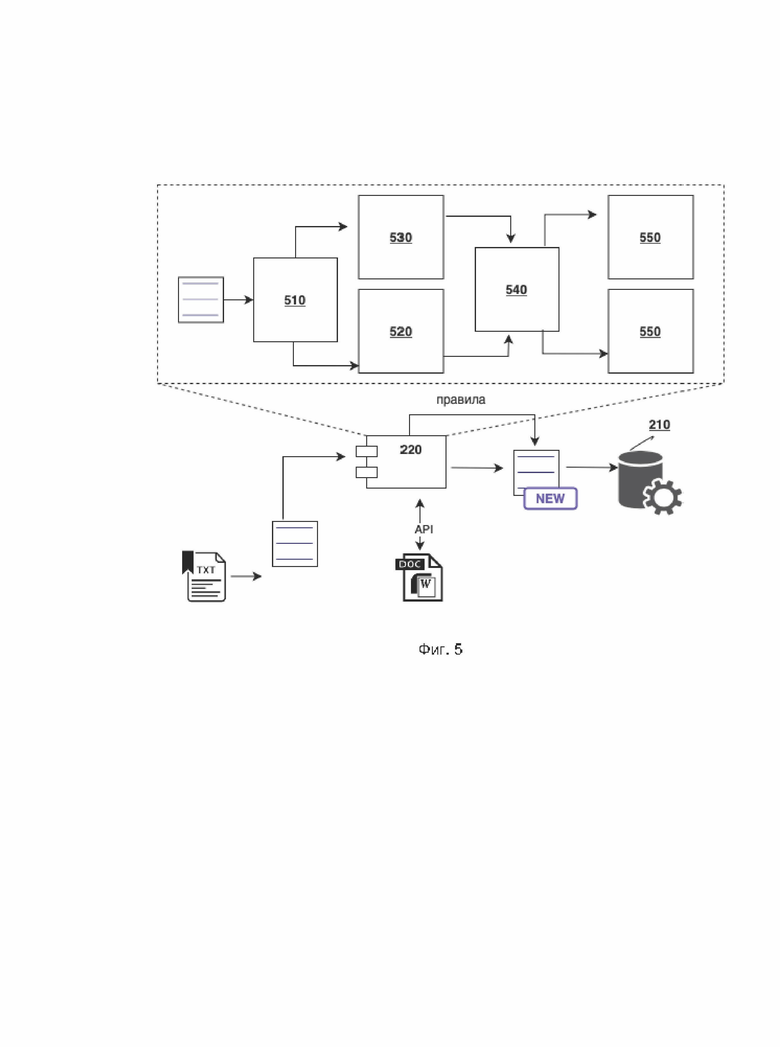
[0056] Ниже будет приведено описание структуры эвристического модуля 220 проверки грамматической правильности, как показано на Фиг. 5.
[0057] Модуль 220 внутренне разделен на следующие функциональные блоки, которые ниже будут подробно описаны.
[0058] Блок предварительной обработки текста 510 предназначен для формальной нормализации текста, поступающего на вход модуля 210, с целью облегчения применения к нему правил. Сюда входит работа с кодировками (перевод текста из произвольной кодировки, в которой он может быть, в такую, которая используется модулем); нормализация знаков препинания (например, сведение возможных вариантов тире и кавычек к стандартным для модуля), и т.п.
[0059] Блоки морфологического и синтаксического анализа приведены ниже. Для того, чтобы могли срабатывать элементы шаблона поиска вхождения, опирающиеся на морфологическую (например, глагол «accustom» в произвольной форме) или синтаксическую информацию (например, «именная группа»), необходимо найти соответствующие элементы в тексте.
[0060] Блок морфологического анализа 520 основан на внутренней морфологической базе и оригинальном блоке формообразования (порождения форм слова) и лемматизации (приведения слова к начальной форме). Для проверки условий, связанных с выбором формы слова, используются также данные блока синтаксического анализа 530 (см. ниже); они имеют более высокий приоритет, поскольку учитывают не только потенциальную возможность слова (например, «run») относиться к той или иной части речи (глагол, существительное, прилагательное и т.п.), но и конкретный контекст (например, в предолжении «The first run concluded on March 8» слово «run» выступает как существительное).
[0061] Блок синтаксического анализа 530 для английского языка может обращаться к стороннему программному комплексу, например, Link Grammar Parser (URL: https://www.link.cs.cmu.edu/link/), лицензия которого допускает такое использование. Данный программный комплекс предоставляет развитый API, с помощью которого можно получить большое количество грамматических данных для заданного текста.
[0062] Блок сопоставления правил 540 ищет в анализируемом тексте фрагменты, соответствующие шаблонам имеющихся правил для языка, по которому осуществляется проверка. В случае соответствия слов текста элементам шаблона проводится проверка всех условий и ограничений, описанных в шаблоне (с учетом результатов работы морфологического 520 и синтаксического 530 блоков), и, если они выполнены, правило считается сработавшим для данного фрагмента текста. Для одного текста возможно срабатывание нескольких правил, однако если правила отмечены как взаимоисключающие (внесены в одну группу взаимоисключающих правил), то сработавшим считается только одно из них, имеющее максимальный приоритет.
[0063] Блок исправления ошибок 550 для каждого из сработавших правил, определенных блоком сопоставления правил 540, вырабатывает вариант (или варианты) замены в соответствии с инструкциями, описанными в правиле, заменяя переменные в этих инструкциях конкретными словами из текста и при необходимости (с использованием морфологического и синтаксического блоков) приводя их в нужную грамматическую форму. Например, правило, описанное в Таблице 1, для предложения «I am accustomed with this» вырабатывает вариант замены «I am accustomed to this»; в данном случае исправление ошибки осуществляется через замену предлога «with» на «to».
[0064] Блок выработки толкования 560 для каждого из сработавших правил, определенных блоком сопоставления правил 540, формирует толкование на основе толкования, содержащегося в правиле, с заменой имеющихся в нем переменных (если они есть) словами из текста. Например, для правила из Таблицы 1 формируется толкование «Нарушение управления: в этом контексте нужно использовать предлог "to".» (в данном случае переменных в толковании нет).
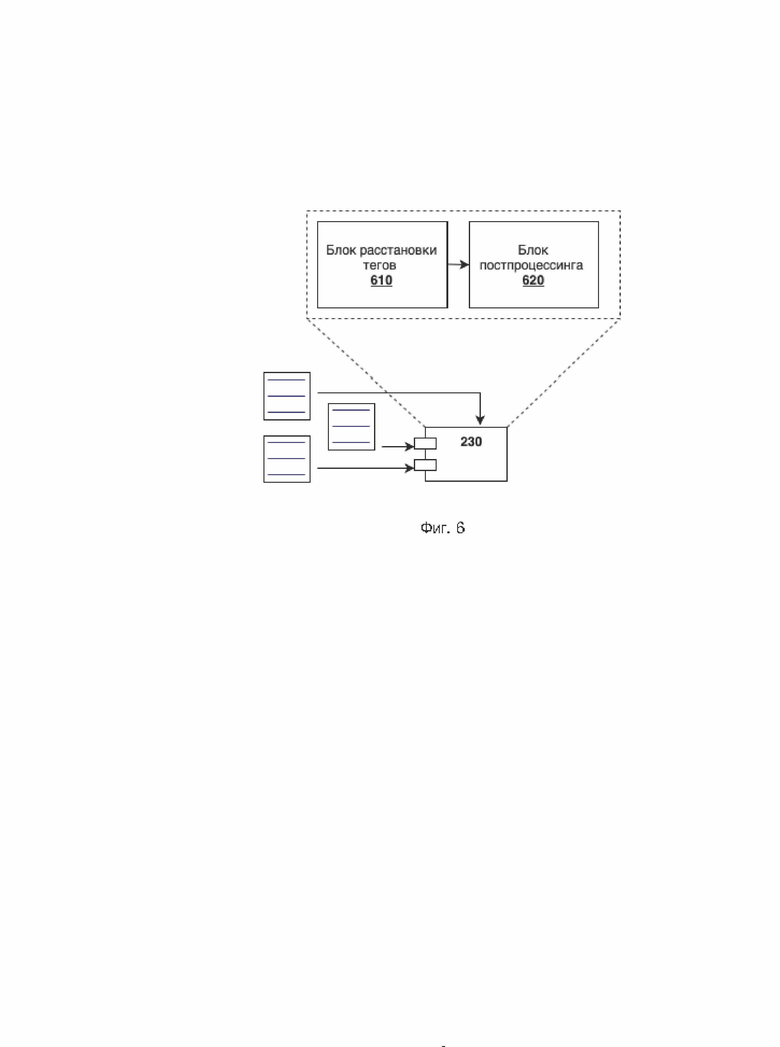
[0065] Далее будет подробно описан основной нейросетевой модуль 230, входящий в состав исполнительного комплекса 120, как показано на Фиг. 6.
[0066] Нейросетевой модуль 230 поиска ошибок предназначен для нахождения сложных грамматических и лексических ошибок в предложениях, которые приходят от пользователя. Он использует предварительно обученную модель машинного обучения, подготовленную при помощи нейросетевых модулей вспомогательного комплекса (будут подробно описаны ниже).
[0067] В отличие от эвристического модуля 220, нейросетевой модуль 230 не применяет для поиска ошибок никаких конкретных правил, а вместо этого оценивает вероятности наличия в тексте конкретной ошибки в конкретном месте на основе результатов предварительного проведенного обучения (с итеративным дообучением) на текстах с размеченными (тегированными) ошибками.
[0068] Нейросетевой модуль 230 включает блок расстановки тегов 610 и блок постпроцессинга 620.
[0069] Нейросетевой модуль 230 получает на вход предложение на естественном языке, в котором нужно найти ошибки. Деление проверяемого текста на предложения осуществляется главным управляющим модулем 210 исполнительного комплекса, что было описано ранее.
[0070] Блок расстановки тегов 610 применяет к проверяемому предложению обученную модель поиска сложных ошибок, заранее загруженную в память компьютера. На выходе из этого блока для каждого слова предложения вычисляются:
 наиболее вероятный для данного слова тег ошибки, либо тег О, обозначающий отсутствие ошибки;
наиболее вероятный для данного слова тег ошибки, либо тег О, обозначающий отсутствие ошибки;
 вероятность tag_probability наличия ошибки (приписывания тега ошибки) с точки зрения модели;
вероятность tag_probability наличия ошибки (приписывания тега ошибки) с точки зрения модели;
 вероятность отсутствия ошибки (приписывания тега О) с точки зрения модели.
вероятность отсутствия ошибки (приписывания тега О) с точки зрения модели.
[0071] Например, для предложения «Длинна реки - 100 км.» может быть получено распределение вероятностей наличия/отсутствия ошибок, показанное в Таблице 2; по горизонтали слова предложения; по вертикали - теги.

[0072] Блок постпроцессинга 620 переводит ответ модели в выходные данные нейросетевого модуля 230. Для каждого слова, помеченного тегом ошибки:
 сравнивает вероятность ошибки с пороговым значением, указанным в качестве параметра; если tag_probability меньше порогового значения (например, 0,7), ошибка отфильтровывается и в выдачу модуля не включается;
сравнивает вероятность ошибки с пороговым значением, указанным в качестве параметра; если tag_probability меньше порогового значения (например, 0,7), ошибка отфильтровывается и в выдачу модуля не включается;
 для остальных ошибок на основании словаря ошибок, использованного при обучении системы, и предсказанного моделью тега определяет фрагмент (подстроку) предложения, содержащий ошибку (это может быть одно слово или несколько слов, идущих друг за другом);
для остальных ошибок на основании словаря ошибок, использованного при обучении системы, и предсказанного моделью тега определяет фрагмент (подстроку) предложения, содержащий ошибку (это может быть одно слово или несколько слов, идущих друг за другом);
 также на основании словаря ошибок формирует вариант замены - слово или словосочетание, на которое надо заменить фрагмент, содержащий ошибку;
также на основании словаря ошибок формирует вариант замены - слово или словосочетание, на которое надо заменить фрагмент, содержащий ошибку;
 на основе конфигурационного файла, содержащего пояснения для тегов, формирует пояснения для каждой ошибки; при этом переменные могут заменяться словами, реально встретившимися в предложении.
на основе конфигурационного файла, содержащего пояснения для тегов, формирует пояснения для каждой ошибки; при этом переменные могут заменяться словами, реально встретившимися в предложении.
[0073] Выходные данные модуля 230 содержат список ошибок с их типом (тегом), начальной позицией в предложении, а также предлагаемые изменения этих фрагментов для получения правильного предложения, пояснение для пользователя и вероятность ошибки, как показано в Таблице 3.
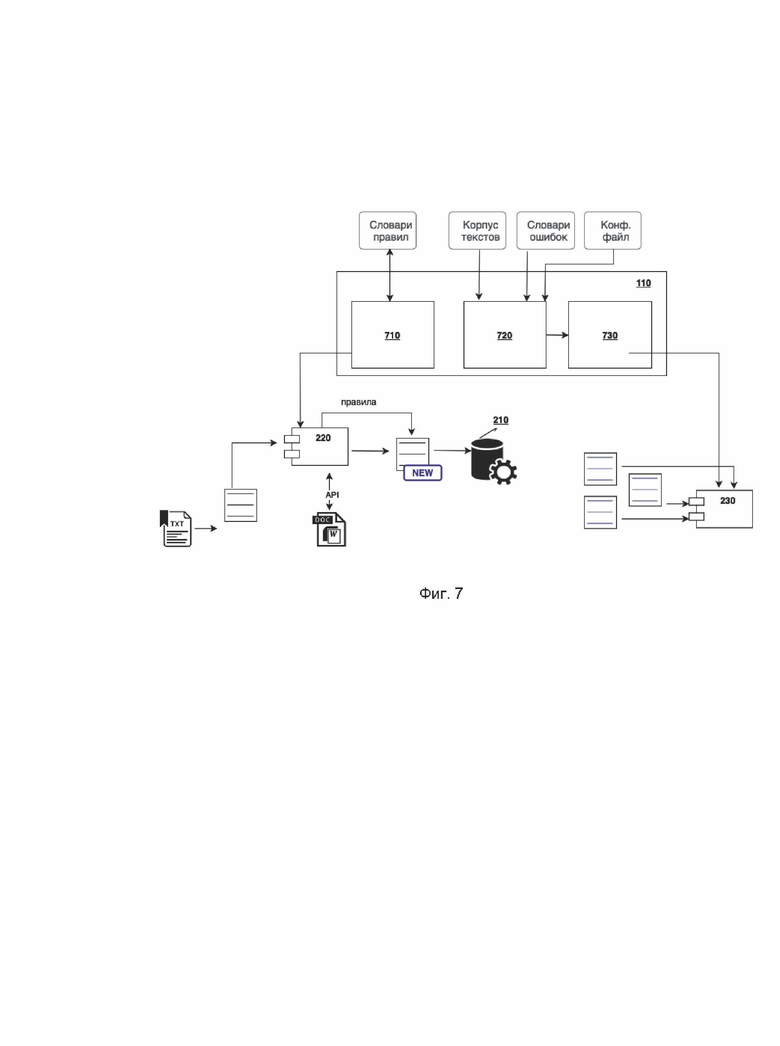
[0074] Далее будет описан вспомогательный комплекс 110, обеспечивающий подготовку данных для исполнительного комплекса 120, а именно входящие в него модули - обработки для эвристического модуля и обработки для нейросетевого модуля, как показано на Фиг. 7.
[0075] Вспомогательный эвристический модуль 710 (обработка для эвристического модуля) используется для подготовки и тестирования словарей эвристического модуля 220. Ниже будет приведено его описание.
[0076] Модуль 710 представляет из себя утилиту с пользовательским интерфейсом для разработчиков и лингвистов, включающую редактор, предназначенный для импорта исходных текстов словарей правил, их редактирования, верификации и компиляции во внутреннее бинарное представление, предназначенное для использования в исполнительном эвристическом модуле 220.
[0077] При компиляции словарей правил автоматически проверяется их срабатывание на примерах, входящих в специальные поля описания правил, - как «положительных» (ср. поле ЕХ в Таблице 1), так и «отрицательных». В случае, если какое-либо правило не срабатывает хотя бы для одного из положительных примеров, либо срабатывает хотя бы для одного из отрицательных, для этого правила генерируется предупреждение.
[0078] Далее приводится описание бинарного формата словарей, в который компилируются правила и который используется исполнительным эвристическим модулем 220.
[0079] Файлы бинарного представления имеют проприетарный формат, не содержат исходных служебных данных, не участвующих в интерпретации правил, в общем случае не поддаются реконструкции, и не предназначены для просмотра и редактирования.
[0080] Файл словаря правил состоит из заголовка с описанием словаря (сигнатура, версия, дата выпуска и т.п.) и последовательного набора секций произвольного размера и назначения, предваряемых собственными секционными заголовками.
[0081] Файл словаря правил скомпрессирован; для этого используются алгоритмы Лемпела-Зива (zlib, для секций с большим количеством текстовой информации) и Хаффмана (для секций с большим количеством бинарной информации с низкой энтропией); предусмотрена также возможность наложения слоя криптографии.
[0082] Во вспомогательный комплекс 110 также входят два вспомогательных нейросетевых модуля, которые в совокупности обеспечивают обработку для исполнительного нейросетевого модуля 230:
 модуль генерации обучающего набора данных 720;
модуль генерации обучающего набора данных 720;
 модуль обучения нейросетевой модели 730 (может работать в режиме обучения «с нуля» и в режиме дообучения с учетом имеющихся экспертных оценок).
модуль обучения нейросетевой модели 730 (может работать в режиме обучения «с нуля» и в режиме дообучения с учетом имеющихся экспертных оценок).
[0083] Далее будет подробно описан модуль генерации обучающего набора данных 720.
[0084] Данный модуль 720 предназначен для создания обучающего датасета (т.е. набора данных) - набора предложений, в которых алгоритмически порождены ошибки и помечены как ошибки разного типа с помощью тегов.
[0085] В качестве входных данных для модуля генерации обучающего набора данных 720 используются:
 исходный корпус текстов, которые можно рассматривать как корректные (хотя они и могут содержать некоторое количество ошибок) - например, статьи Википедии, тексты журналов, новостей, научных статей, книг и т.п.;
исходный корпус текстов, которые можно рассматривать как корректные (хотя они и могут содержать некоторое количество ошибок) - например, статьи Википедии, тексты журналов, новостей, научных статей, книг и т.п.;
 словари ошибок;
словари ошибок;
 конфигурационный файл.
конфигурационный файл.
[0086] Тексты, входящие в исходный корпус (файлы с отобранными для обучения корректными текстами), предварительно очищаются от ссылок и иной разметки и делятся на предложения.
[0087] Цель работы модуля генерации 720 - контролируемым образом внести в исходно корректные предложения ошибки, подобные тем, которые нейросетевой модуль 230 должен находить в текстах, и собрать из таких предложений сбалансированный датасет.
[0088] Ошибки могут вноситься в исходно правильные предложения двумя способами:
 эвристические алгоритмы, например: в произвольном слове, начинающемся с «недо-» отделить «не-» (то есть вставить после «не» пробел).
эвристические алгоритмы, например: в произвольном слове, начинающемся с «недо-» отделить «не-» (то есть вставить после «не» пробел).
 замены по словарю ошибок.
замены по словарю ошибок.
[0089] Поскольку первый способ в большинстве случаев может быть сведен ко второму (например, можно выбрать из исходного корпуса все слова, начинающиеся с «недо-», и внести их в словарь), ниже мы рассмотрим только его.
[0090] Модуль генерации 720 включает следующие блоки, работающие последовательно друг за другом:
1. Блок поиска кандидатов находит для каждого предложения из исходного корпуса все возможные для него места и типы ошибок, которые могут быть внесены в соответствии с используемым словарем ошибок (потенциальные ошибки).
2. Блок отбора выбирает из всех предложений, входящих в исходный датасет, и вариантов потенциальных ошибок некоторое подмножество (с повторениями) в соответствии с конфигурационным файлом, в котором задаются параметры обучающего датасета - например, распределение в нем предложений с одной или несколькими ошибками, минимальное и максимальное количество ошибок на тег, и т.п.
3. Блок применения ошибок вносит отобранные потенциальные ошибки в изначально правильные предложения, помечая их тегами, с которыми они были отобраны блоком отбора; кроме того, в датасет вносятся исходные корректные предложения, помеченные как безошибочные.
4. Блок дополнительных ошибок вносит в предложения, добавленные в обучающий корпус, дополнительные ошибки из числа потенциальных ошибок, найденных блоком поиска кандидатов, таким образом, чтобы распределение ошибок с 1, 2 и т.д. ошибками в обучающем корпусе соответствовало параметрам, заданным в конфигурационном файле.
[0091] На выходе блока обучения 730 формируется файл обучающего датасета, состоящий из предложений, где каждому слову сопоставлен тег ошибки или тег О, обозначающий отсутствие ошибки.
[0092] Далее будет описана работа блока поиска кандидатов (не показан).
[0093] Блок поиска кандидатов последовательно сканирует предложения исходного корпуса, проверяя:
 есть ли в них слова (словосочетания), соответствующие условиям какого-либо из используемых алгоритмов поиска ошибок;
есть ли в них слова (словосочетания), соответствующие условиям какого-либо из используемых алгоритмов поиска ошибок;
 есть ли в них слова (словосочетания), соответствующие входам словаря ошибок.
есть ли в них слова (словосочетания), соответствующие входам словаря ошибок.
[0094] Если такие слова (словосочетания) найдены, предложение вносится в список кандидатов на добавление в обучающий корпус для тега, который проставляется данным алгоритмом или содержится в данной записи в словаре ошибок. Поскольку в предложении может содержаться более одного места потенциальной ошибки, оно может быть добавлено в список кандидатов одновременно для нескольких разных тегов, и/или более одного раза для одного и того же тега.
[0095] Например, в предложении «Откуда начинать класть кафельную плитку, сверху или снизу?» присутствуют следующие входы словаря ошибок:
 «Откуда» - тег REPLACE_p+pron_adv, замена на «От куда»;
«Откуда» - тег REPLACE_p+pron_adv, замена на «От куда»;
 «сверху» - тег REPLACE_p+n_adv, замена на «с верху»;
«сверху» - тег REPLACE_p+n_adv, замена на «с верху»;
 «сверху» - тег REPLACE_c+верха_сверху, замена на «с верха»;
«сверху» - тег REPLACE_c+верха_сверху, замена на «с верха»;
 «снизу» - тег REPLACE_p+n_adv, замена на «с верху»;
«снизу» - тег REPLACE_p+n_adv, замена на «с верху»;
 «снизу» - тег REPLACE_c+верха_сверху, замена на «с низа».
«снизу» - тег REPLACE_c+верха_сверху, замена на «с низа».
[0096] Таким образом, это предложение входит в список кандидатов на добавление ошибки с тегом REPLACE_p+pron_adv, дважды - в список кандидатов на добавление ошибки с тегом REPLACE_p+n_adv, и дважды - с тегом REPLACE_c+верха_сверху, причем две пары потенциальных ошибок «конкурируют» за одну и ту же позицию: для каждого из слов «сверху» и «снизу» ошибки в предложение могут быть внесены двумя взаимоисключающими способами.
[0097] На выходе блока поиска кандидатов для каждого предложения исходного корпуса имеется сопоставленный ему список потенциальных ошибок с указанием для каждой ошибки тега и позиции (номера слова, к которому может быть применен данный тег).
[0098] Далее будет описана работа блока отбора.
[0099]Блок отбора предназначен для формирования сбалансированного обучающего датасета, в котором все типы ошибок (теги) представлены в достаточном для обучения модели количестве (минимальное количество предложений определяется параметром min_k), и при этом количество вхождения ошибки не превышает верхнего порога (определяется параметром max_k) во избежание явного предпочтения системой «частых» тегов по сравнению с «редкими».
[00100] При наличии в предложении нескольких потенциальных ошибок такое предложение рассматривается как несколько предложений-кандидатов на включение в обучающий корпус - по одному на каждую ошибку.
[00101] Так, если в предложении возможны 7 потенциальных ошибок с разными тегами, то для каждого тега вопрос о вхождении данного предложения в обучающий корпус решается отдельно - фактически, мы получаем 7 отдельных предложений-кандидатов.
[00102] При наличии в предложении двух (или более) потенциальных ошибок с одним и тем же тегом такое предложение рассматривается как два (или более) предложения-кандидата с этим тегом.
[00103] Для каждого тега, число предложений-кандидатов для которого меньше минимального min_k, в корпус включаются все предложения с этим тегом. Далее из их числа повторно берутся дополнительные предложения до тех пор, пока общее число предложений для тега не достигает min_k.
[00104] Например, если min_k равно 1000, а предложений с тегом REPLACE_отворот_ot+bopot в корпусе встретилось 412, то все 412 предложений, в которые может быть добавлена ошибка с этим тегом (т.е. предложения с сочетанием «от ворот») будут использованы дважды, и кроме этого из их числа будут случайным образом будет выбрано дополнительно 176 предложений, чтобы общее число отобранных предложений достигло 1000.
[00105] При этом все предложения с этим тегом окажутся «размножены»: они будут входить в корпус 2 или 3 раза.
[00106] Для каждого тега, число предложений-кандидатов для которого больше min_k, но не превышает max_k, берутся все предложения по одному разу.
[00107] Например, если min_k равно 1000, a max_k равно 5000, и тег REPLACE_равный_ровный входит в корпус 3158 раз, то все предложения с этим тегом (т.е. предложения, включающие слова «ровный», «выровнять» и т.п.в любой форме) включаются в корпус по одному разу без размножения.
[00108] Для каждого тега, число предложений-кандидатов для которого больше максимального max_k, из числа всех предложений-кандидатов случайным образом отбираются и включаются в обучающий корпус max_k предложений.
[00109] Например, если max_k равно 5000, и тег REPLACE_доить_для встречается 14857 раз (т.е. в исходном корпусе 14857 раз встречается предлог «для», в котором возможна опечатка «доя»), то из всех предложений, для которых возможна ошибка с этим тегом, случайным образом отбирается 5000 предложений-кандидатов.
[00110] На выходе из блока отбора формируется общий список предложений-кандидатов, представляющий собой объединение списков, полученных для отдельных тегов. Предложения в нем могут повторяться а) с одним и тем же тегом - для тегов, встречающихся в исходном корпусе менее min_k раз; б) с разными тегами - для любых тегов, при условии наличия в исходном предложении двух или более потенциальных ошибок.
[00111] Далее будет описана работа блока применения ошибок.
[00112] Блок применения ошибок получает на вход и обрабатывает сформированный блоком отбора общий список предложений-кандидатов, для каждого из которых известны тег и слово, к которому он должен быть применен.
[00113] Для каждого предложения-кандидата из исходного предложения и информации о теге и месте ошибки блок порождает предложение с ошибкой.
[00114] Так, для тегов вида REPLACE_… происходит замена исходного (правильного) слова или словосочетания на другое слово или словосочетание, предусмотренное словарем ошибок (или алгоритмом, связанным с тегом). Внесенное в предложение слово (или первое слово словосочетания) помечается данным тегом (как ошибочное), остальные слова - тегом О (как правильные), и предложение в таком виде добавляется в обучающий корпус.
[00115] Например, из предложения «Если нет оснований для задержания, то это похищение?», отобранного по тегу REPLACE_доить_для (для 4 слова в предложении), формируется предложение «Если нет оснований доя задержания, то это похищение?»; слово «доя» в нем помечается тегом REPLACE_доить_для, остальные слова - тегом О.
[00116] Для тегов вида INSERT_… аналогичным образом производится вставка слова (словосочетания) перед словом исходного предложения, с которым сопоставлен тег.
[00117] Для тегов вида DELETE_… производится удаление слова (словосочетания) из исходного предложения.
[00118] При этом во всех случаях в обучающий корпус добавляется также исходное предложение без изменений, в котором все слова помечены тегом О (как правильные).
[00119] На выходе блока применения ошибок получается предварительно сформированный обучающий датасет, в котором в каждом предложении имеется не более одной ошибки.
[00120] Блок дополнительных ошибок вносит в предложения с одной ошибкой, добавленные в обучающий датасет, дополнительные ошибки из числа потенциальных ошибок, отобранных блоком поиска ошибок.
[00121] Для этого из числа ранее добавленных в обучающий датасет предложений с одной ошибкой, для которых блоком поиска кандидатов найдены потенциальные ошибки в других позициях, случайным образом выбирается указанный в конфигурационном файле процент предложений, и в них случайным образом вносится одна из найденных для них потенциальных ошибок в другой позиции.
[00122] При этом слово, для которого внесена ошибка, помечается соответствующим данной потенциальной ошибке тегом; остальные слова (за исключением слова, уже помеченного ранее тегом ошибки) - тегом О; полученное предложение заменяет в обучающем корпусе предложение, отобранное для внесения дополнительной ошибки.
[00123] Например, для предложения «Откуда начинать класть кафельную плитку, с верху или снизу?» (полученное из исходного заменой «сверху» на «с верху» с приписыванием слову «с» тега REPLACE_p+n_adv), см. пример выше, может быть внесена одна из трех потенциальных ошибок, привязанных к другим словам:
 «Откуда» - тег REPLACE_p+pron_adv, замена на «От куда»;
«Откуда» - тег REPLACE_p+pron_adv, замена на «От куда»;
 «снизу» - тег REPLACE_p+n_adv, замена на «с верху»;
«снизу» - тег REPLACE_p+n_adv, замена на «с верху»;
 «снизу» - тег REPLACE_c+верха_сверху, замена на «с низа».
«снизу» - тег REPLACE_c+верха_сверху, замена на «с низа».
[00124] Если случайным образом выбрана третья из этих потенциальных ошибок, то данное предложение в обучающем корпусе заменяется на предложение «Откуда начинать класть кафельную плитку, с верху или с низа?», в котором первый предлог «с» по-прежнему помечен тегом REPLACE_p+n_adv, а второй предлог «с» помечен тегом REPLACE_c+верха_сверху; остальные слова предложения помечены тегом О.
[00125] Далее среди предложений с двумя ошибками, для которых блоком отбора были найдены потенциальные ошибки в других позициях, операция повторяется таким образом, чтобы процент предложений с тремя и более ошибками в обучающем датасете соответствовал параметру в конфигурационном файле, и так далее.
[00126] Например, в полученное на первом этапе работы блока дополнительных ошибок предложение «Откуда начинать класть кафельную плитку, с верху или с низа?» может быть внесена еще одна ошибка заменой слова «Откуда» на сочетание «От куда» с тегом REPLACE_p+pron_adv.
[00127] На выходе блока дополнительных ошибок (и модуля генерации в целом) получается сформированный обучающий датасет, который в дальнейшем используется модулем обучения.
[00128] Далее приводится описание модуля обучения 730, предназначенного для получения обученной модели, для использования нейросетевым модулем 230 исполнительного комплекса 120.
[00129] Входные данные для данного модуля 730 - обучающий датасет, полученный из модуля генерации 720 обучающего датасета.
[00130] Работа модуля 730 состоит из инициализации модели машинного обучения и применения к ней обучающего алгоритма.
[00131] В качестве модели может использоваться Google BERT из библиотеки transformers, поверх которого накладывается слой пословной классификации (Token Classification), в качестве оптимизатора в обучающем алгоритме - AdamW оттуда же.
[00132] Вместо Google BERT возможно использование других доступных нейросетей-трансформеров, обученных на данных того естественного языка, для которого проводится обучение, например, RoBERTa, GPT-2 и др.
[00133] В процессе обучения модель применяется к предложениям обучающего датасета и выдает распределение вероятностей ошибок из набора тегов для каждого слова.
[00134] Пример такого распределения вероятностей см. выше в Таблице 2.
[00135] После этого считается расхождение между максимумами распределения вероятностей и правильной разметкой тегов из обучающего датасета, и с помощью обычно применяемого для решения таких задач алгоритма градиентного спуска модель итеративно корректирует свои веса - коэффициенты, которые регулируют операции модели для получения наилучшего ответа.
[00136] В качестве выходных данных модуль обучения 730 порождает файл весов модели.
[00137] Далее описаны особенности работы модулей генерации 720 и обучения 730 в режиме дообучения.
[00138] Работа в режиме дообучения предназначена для коррекции обученной модели для улучшения точности ее предсказаний. Применяется несколько раз, пока не будет достигнуто желаемое качество.
[00139] В качестве исходных данных для модуля генерации 720 в режиме дообучения применяется специальный корпус, полученный описанным ниже образом.
[00140] Через исполнительный нейросетевой модуль 230 прогоняется набор предложений из корректного исходного корпуса, не пересекающегося с корректным исходным корпусом, использовавшимся для генерации обучающего корпуса.
[00141] Те предложения, в которых модуль выдачи ответа нашел ошибки, передаются лингвистам для ручной разметки.
[00142] Ручная разметка состоит в приписывания меток каждому из этих предложений, например: ошибка в исходном предложении действительно есть, и модель правильно ее исправила; ошибка в исходном предложении действительно есть, но модель ее исправила неправильно; ошибки в исходном предложении нет.
[00143] Кроме того, лингвисты формируют список тегов для автоматического добавления; предложения, в которых модель нашла ошибки с тегами, входящими в этот список, приравниваются к предложениям, которые размечены лингвистами как корректные (ошибки в исходном предложении нет).
[00144] Модуль генерации 720 принимает размеченные лингвистами предложения и совершает операции, порождающие дообучающий датасет аналогично тому, как формируется обучающий датасет на первом этапе.
[00145] Например, если модель исправила предложение «Он не придал этому значения.» на «Он не предал этому значения.», применив к слову «придал» тег REPLACE_предать_придать, в дообучающий датасет добавляется предложение «Он не предал этому значения.» с тегом REPLACE_предать_придать для третьего слова; кроме того, добавляется корректное предложение «Он не придал этому значения.», в котором все слова помечены тегом О, как правильные.
[00146] Дообучающий датасет объединяется с готовым обучающим датасетом, полученным на предыдущем этапе, после чего для объединенного обучающего датасета запускается модуль обучения 730.
[00147] Итогом работы модулей генерации 720 и обучения 730 в режиме дообучения является модель, которая делает меньше ошибок, поскольку учитывает ошибки, допущенные ей на предыдущем этапе обучения.
[00148] Элементы заявляемого технического решения находятся в функциональной взаимосвязи, а их совместное использование приводит к созданию нового и уникального технического решения. Таким образом, все блоки функционально связаны.
[00149] Все блоки, используемые в системе, могут быть реализованы с помощью электронных компонент, используемых для создания цифровых интегральных схем, что очевидно для специалиста в данном уровне техники. Не ограничиваясь, могут использоваться микросхемы, логика работы которых определяется при изготовлении, или программируемые логические интегральные схемы (ПЛИС), логика работы которых задается посредством программирования. Для программирования используются программаторы и отладочные среды, позволяющие задать желаемую структуру цифрового устройства в виде принципиальной электрической схемы или программы на специальных языках описания аппаратуры: Verilog, VHDL, AHDL и др. Альтернативой ПЛИС могут быть программируемые логические контроллеры (ПЛК), базовые матричные кристаллы (БМК), требующие заводского производственного процесса для программирования; ASIC - специализированные заказные большие интегральные схемы (БИС), которые при мелкосерийном и единичном производстве существенно дороже.
[00150] Обычно, сама микросхема ПЛИС состоит из следующих компонент:
конфигурируемых логических блоков, реализующих требуемую логическую функцию;
программируемых электронных связей между конфигурируемыми логическими блоками;
программируемых блоков ввода/вывода, обеспечивающих связь внешнего вывода микросхемы с внутренней логикой.
[00151] Также блоки могут быть реализованы с помощью постоянных запоминающих устройств.
[00152] Таким образом, реализация всех используемых блоков достигается стандартными средствами, базирующимися на классических принципах реализации основ вычислительной техники.
[00153] Как будет понятно специалисту в данной области техники, аспекты настоящего технического решения могут быть выполнены в виде системы, способа или компьютерного программного продукта. Соответственно, различные аспекты настоящего технического решения могут быть реализованы исключительно как аппаратное обеспечение, как программное обеспечение (включая прикладное программное обеспечение и так далее) или как вариант осуществления, сочетающий в себе программные и аппаратные аспекты, которые в общем случае могут упоминаться как «модуль», «система» или «архитектура». Кроме того, аспекты настоящего технического решения могут принимать форму компьютерного программного продукта, реализованного на одном или нескольких машиночитаемых носителях, имеющих машиночитаемый программный код, который на них реализован.
[00154] Также может быть использована любая комбинация одного или нескольких машиночитаемых носителей. Машиночитаемый носитель хранилища может представлять собой, без ограничений, электронную, магнитную, оптическую, электромагнитную, инфракрасную или полупроводниковую систему, аппарат, устройство или любую подходящую их комбинацию. Конкретнее, примеры (неисчерпывающий список) машиночитаемого носителя хранилища включают в себя: электрическое соединение с помощью одного или нескольких проводов, портативную компьютерную дискету; жесткий диск, оперативную память (ОЗУ), постоянную память (ПЗУ), стираемую программируемую постоянную память (EPROM или Flash-память), оптоволоконное соединение, постоянную память на компакт-диске (CD-ROM), оптическое устройство хранения, магнитное устройство хранения или любую комбинацию вышеперечисленного. В контексте настоящего описания, машиночитаемый носитель хранилища может представлять собой любой гибкий носитель данных, который может содержать или хранить программу для использования самой системой, устройством, аппаратом или в соединении с ними.
[00155] Программный код, встроенный в машиночитаемый носитель, может быть передан с помощью любого носителя, включая, без ограничений, беспроводную, проводную, оптоволоконную, инфракрасную и любую другую подходящую сеть или комбинацию вышеперечисленного.
[00156] Компьютерный программный код для выполнения операций для шагов настоящего технического решения может быть написан на любом языке программирования или комбинаций языков программирования, включая объектно-ориентированный язык программирования, например Python, R, Java, Smalltalk, С++ и так далее, и обычные процедурные языки программирования, например язык программирования «С» или аналогичные языки программирования. Программный код может выполняться на компьютере пользователя полностью, частично, или же как отдельный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере, или же полностью на удаленном компьютере. В последнем случае, удаленный компьютер может быть соединен с компьютером пользователя через сеть любого типа, включая локальную сеть (LAN), глобальную сеть (WAN) или соединение с внешним компьютером (например, через Интернете помощью интернет-провайдеров).
[00157] Аспекты настоящего технического решения были описаны подробно со ссылкой на блок-схемы, принципиальные схемы и/или диаграммы способов, устройств (систем) и компьютерных программных продуктов в соответствии с вариантами осуществления настоящего технического решения. Следует иметь в виду, что каждый блок из блок-схемы и/или диаграмм, а также комбинации блоков из блок-схемы и/или диаграмм, могут быть реализованы компьютерными программными инструкциями. Эти компьютерные программные инструкции могут быть предоставлены процессору компьютера общего назначения, компьютера специального назначения или другому устройству обработки данных для создания процедуры, таким образом, чтобы инструкции, выполняемые процессором компьютера или другим программируемым устройством обработки данных, создавали средства для реализации функций/действий, указанных в блоке или блоках блок-схемы и/или диаграммы.
[00158] Эти компьютерные программные инструкции также могут храниться на машиночитаемом носителе, который может управлять компьютером, отличным от программируемого устройства обработки данных или отличным от устройств, которые функционируют конкретным образом, таким образом, что инструкции, хранящиеся на машиночитаемом носителе, создают устройство, включающее инструкции, которые осуществляют функции/действия, указанные в блоке блок-схемы и/или диаграммы.
ИСПОЛЬЗУЕМЫЕ ИСТОЧНИКИ ИНФОРМАЦИИ
1. Wei Zhao, et al., 2019. Improving grammatical error correction via pre-training a copy-augmented architecture with unlabeled data. arXiv preprint arXiv: 1903.00138.
2. A. Awasthi, et al., 2019. Parallel iterative edit models for local sequence transduction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4260-4270, Hong Kong, China. Association for Computational Linguistics.
3. K. Omelianchuk et al., 2020. GECToR - Grammatical Error Correction: Tag, Not Rewrite. In Proceedings of the 15th Workshop on Innovative Use of NLP for Building Educational Applications, pages 163-170, Association for Computational Linguistics.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| Система и способ корректировки орфографических ошибок | 2020 |
|
RU2753183C1 |
| Система автоматического обновления и формирования техник реализации компьютерных атак для системы обеспечения информационной безопасности | 2023 |
|
RU2809929C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |
| СПОСОБ ДЛЯ ОТОБРАЖЕНИЯ СУБТИТРОВ В ПРОЦЕССЕ ВОСПРОИЗВЕДЕНИЯ МЕДИАКОНТЕНТА (ВАРИАНТЫ) | 2017 |
|
RU2668721C1 |
| МЕТОД И СИСТЕМА ДЛЯ ГЕНЕРАЦИИ СТАТЕЙ В СЛОВАРЕ ЕСТЕСТВЕННОГО ЯЗЫКА | 2014 |
|
RU2639280C2 |
| СПОСОБ УПРАВЛЕНИЯ ДИАЛОГОМ И СИСТЕМА ПОНИМАНИЯ ЕСТЕСТВЕННОГО ЯЗЫКА В ПЛАТФОРМЕ ВИРТУАЛЬНЫХ АССИСТЕНТОВ | 2020 |
|
RU2759090C1 |
| СПОСОБ И СИСТЕМА ПЕРЕФРАЗИРОВАНИЯ ТЕКСТА | 2023 |
|
RU2814808C1 |
| СПОСОБ ОБУЧЕНИЯ ИНОСТРАННОМУ ЯЗЫКУ | 2010 |
|
RU2422911C1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ КОМБИНАЦИИ КЛАССИФИКАТОРОВ, АНАЛИЗИРУЮЩИХ ЛОКАЛЬНЫЕ И НЕЛОКАЛЬНЫЕ ПРИЗНАКИ | 2018 |
|
RU2686000C1 |

Изобретение относится к области вычислительной техники для поиска и коррекции ошибок в текстах на естественном языке. Технический результат заключается в повышении точности и полноты выявления грамматических, речевых, стилистических ошибок. Технический результат достигается за счет модульной организации системы: независимому подключению к ней модулей поиска и исправления ошибок различной природы (эвристических и нейросетевых); возможности подключения факультативных модулей для исправления конкретных типов ошибок; усовершенствования обоих подходов к GEC по сравнению с имеющимися образцами - в частности, применению эвристического подхода при подготовке данных для обучения нейросетевого модуля и подхода, основанного на машинном обучении, при сборе данных для эвристического модуля; итеративному дообучению нейросетевой модели с учетом экспертной разметки; эффективному сведению результатов (найденных ошибок), полученных от различных модулей, управляющим модулем системы, с разрешением возможных конфликтов между ними. 12 з.п. ф-лы, 7 ил., 3 табл.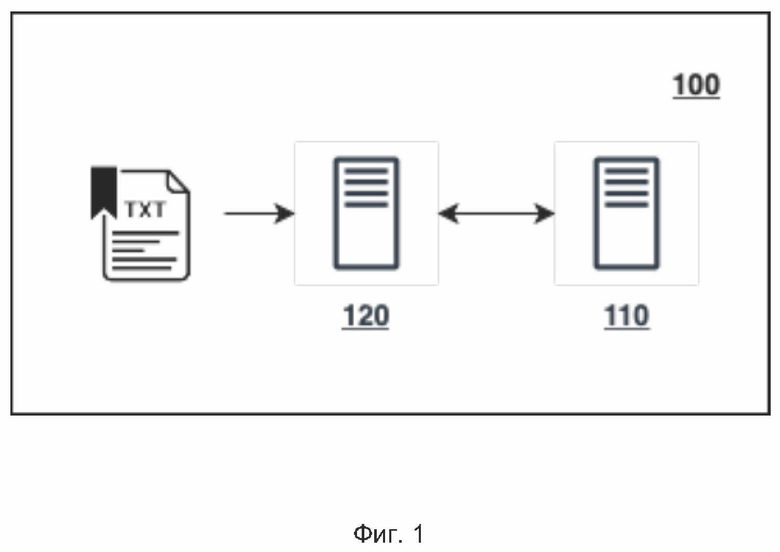
1. Система автоматического поиска и коррекции ошибок в текстах на естественном языке, содержащая:
• вспомогательный модуль, выполненный с возможностью редактирования словарей правил для эвристического модуля проверки грамматической правильности;
• модуль генерации обучающего набора данных, выполненный с возможностью создания обучающего набора предложений, в которых алгоритмически порождены ошибки и помечены как ошибки разного типа с помощью тегов;
• модуль обучения нейросетевой модели, выполненный с возможностью
- получения обучающего набора данных, полученного из модуля генерации обучающего набора данных,
- инициализации модели машинного обучения и ее применения в процессе обучения к предложениям обучающего набора данных и
- формирования распределения вероятностей ошибок из набора тегов для каждого слова в обучающем наборе предложений;
• центральный управляющий модуль, выполненный с возможностью
- получения исходных данных проверяемого текста от модулей системы,
- деления проверяемого текста на предложения,
- передачи фрагментов текста на проверку подключенным модулям,
- получения от подключенных модулей результатов проверки,
- объединения полученных на предыдущем шаге результатов проверки модулей в общую разметку текста, осуществляемую по единым принципам;
• эвристический модуль проверки грамматической правильности, выполненный с возможностью
- получения на вход проверяемого текста,
- применения к нему правил поиска грамматических и других ошибок,
- передачи управляющему модулю информации о сработавших правилах;
• нейросетевой модуль, выполненный с возможностью
- получения на вход предложения на естественном языке, в котором нужно найти ошибки,
- формирования списка ошибок с их типом (тегом), начальной позицией в предложении, а также предлагаемых изменений этих фрагментов для получения правильного предложения, пояснений для пользователя и вероятностью ошибки на основании предварительно обученной модели машинного обучения, подготовленной при помощи модуля генерации обучающего набора данных.
2. Система по п.1, характеризующаяся тем, что в качестве входных данных для модуля генерации обучающего набора данных используются исходный корпус текстов, которые можно рассматривать как корректные и/или словари ошибок, и/или конфигурационный файл.
3. Система по п.1, характеризующаяся тем, что модуль обучения нейросетевой модели работает в режиме обучения «с нуля» и/или в режиме дообучения с учетом ранее имеющихся экспертных оценок.
4. Система по п.1, характеризующаяся тем, что система дополнительно содержит модуль проверки орфографии по словарю с моделью словоизменения для каждого слова, который для каждой встретившейся в тексте словоформы определяет, входит ли она в число известных ему словоформ, и если не входит, то предлагает для нее варианты замен на известные ему слова.
5. Система по п.1, характеризующаяся тем, что управляющий модуль объединяет результаты проверки в виде JSON-разметки, включающей выделяемый фрагмент текста и пояснение, описывающее ошибку, и варианты ее исправления.
6. Система по п.1, характеризующаяся тем, что центральный управляющий модуль получает исходные данные от модулей асинхронно и в разных форматах, основанных на XML или JSON.
7. Система по п.1, характеризующаяся тем, что центральный управляющий модуль также осуществляет фильтрацию результатов, приходящих от модулей.
8. Система по п.1, характеризующаяся тем, что информация о сработавших правилах эвристического модуля содержит:
- имя сработавшего правила;
- позиции фрагмента текста, к которому оно было применено;
- позиции фрагмента текста, который должен быть выделен при показе правила;
- позиции заменяемого фрагмента текста;
- варианты замены или исправления ошибки;
- пояснение, объясняющее суть найденной ошибки.
9. Система по п.1, характеризующаяся тем, что эвристический модуль работает с правилами, описывающими ошибки, которые составляются лингвистами для каждого языка в отдельности.
10. Система по п.1, характеризующаяся тем, что каждое правило эвристического модуля описывает конкретную ошибку и описывает условия, при которых данная ошибка детектируется, а также исключения, при которых ошибка детектироваться не должна.
11. Система по п.1, характеризующаяся тем, что нейросетевой модуль оценивает вероятности наличия в тексте конкретной ошибки в конкретном месте на основе результатов предварительного проведенного обучения на текстах с размеченными ошибками.
12. Система по п.1, характеризующаяся тем, что моделью машинного обучения является BERT, или RoBERTa, или GPT-2.
13. Система по п.1, характеризующаяся тем, что в процессе обучения модель машинного обучения применяется к предложениям обучающего набора данных и выдаёт распределение вероятностей ошибок из набора тегов для каждого слова.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| US 11023766 B2, 01.06.2021 | |||
| Система и способ корректировки орфографических ошибок | 2020 |
|
RU2753183C1 |

