ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
Данная заявка претендует на приоритет следующих приоритетных заявок: предварительная заявка США 62/656 163 (ссылка: D18040USP1), поданная 11 апреля 2018 г., и предварительная заявка США 62/755,957 (ссылка: D18040USP2), поданная 5 ноября 2018 г., которые включены в данную заявку посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к предоставлению устройства, системы и способа для рендеринга звука.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
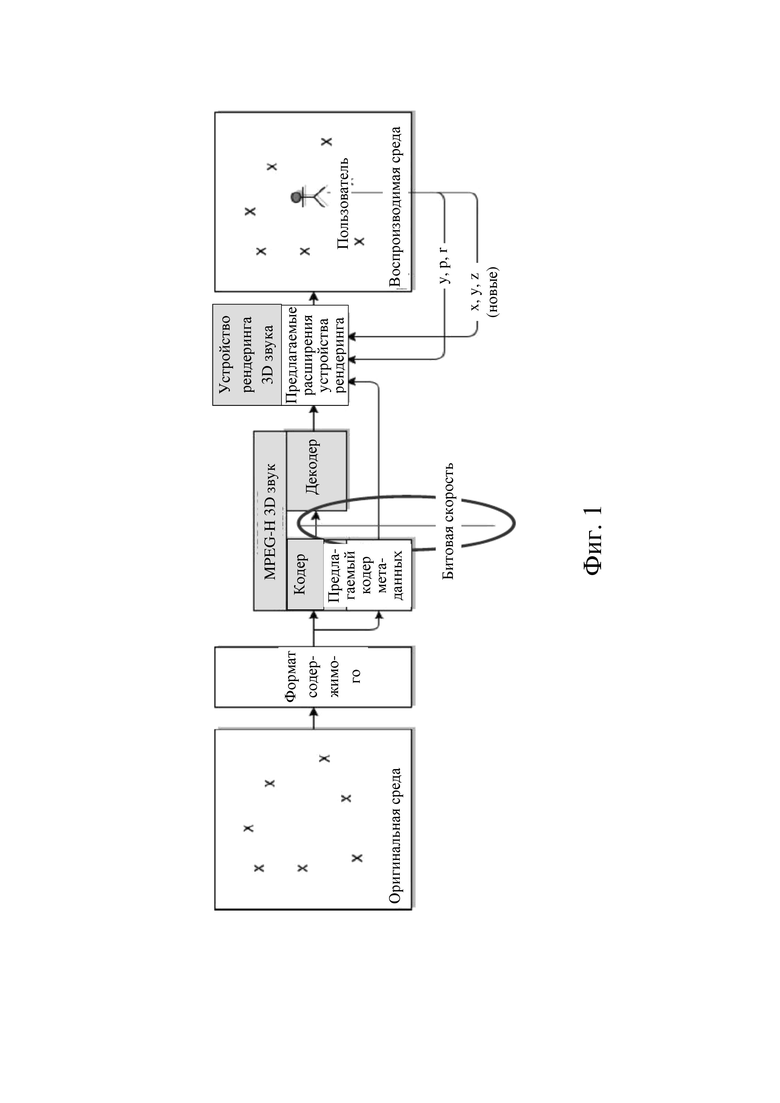
На фиг. 1 изображен пример кодера, который выполнен с возможностью обработки метаданных и расширений устройства рендеринга звука.
В некоторых случаях устройства рендеринга c 6DoF не могут воспроизвести желаемое создателем содержимого звуковое поле в некотором положении (положениях) (областях, траекториях) в пространстве виртуальной реальности / дополненной реальности / смешанной реальности (VR/AR/MR), по следующим причинам:
1. недостаточно метаданных, описывающих источники звука и среду VR/AR/MR; и
2. ограниченные возможности устройства рендеринга c 6DoF и ресурсы.
Определенные устройства рендеринга c 6DoF (создающие звуковые поля на основании только исходных сигналов источника звука и описания среды VR/AR/MR) могут оказаться не в состоянии воспроизвести задуманный сигнал в желаемом положении (положениях) по следующим причинам:
1.1) ограничения битовой скорости для параметризованной информации (метаданных), описывающей среду VR/AR/MR и соответствующие звуковые сигналы;
1.2) недоступность данных для обратного рендеринга c 6DoF (например, эталонные записи в одной или нескольких точках, представляющих интерес, доступны, но неизвестно, как воссоздать этот сигнал устройством рендеринга c 6DoF и какие для этого нужны входные данные);
2.1) художественный замысел, который может отличаться от выхода с параметрами по умолчанию (например, согласно законам физики) устройства рендеринга c 6DoF (например, подобно концепции «художественного понижающего микширования»); и
2.2) ограничения возможностей (например, битовой скорости, сложности, задержки и подобных ограничений) при реализации декодера (устройства рендеринга c 6DoF).
В то же время может требоваться, чтобы обеспечивалось высокое качество звука (и/или точность воспроизведения относительно предварительно заданного эталонного сигнала) для воспроизведения звука (то есть для выхода устройства рендеринга c 6DoF) для заданного положения (положений) в пространстве VR/AR/MR. Например, это может потребоваться для ограничения на совместимость c 3DoF/3DoF+ или для выполнения требований совместимости для разных режимов обработки (например, между режимом «Базовый вариант» и режимом «Малая мощность», которые не учитывают влияние геометрии VR/AR/MR) устройств рендеринга c 6DoF.
Таким образом, существует потребность в способах кодирования/декодирования и соответствующих кодерах/декодерах, которые усовершенствуют воспроизведение звукового поля, желаемого автором содержимого, в пространстве VR/AR/MR.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Один аспект настоящего изобретения относится к способу декодирования содержимого звуковой сцены из битового потока декодером, содержащим устройство рендеринга звука с одним или более средствами рендеринга. Способ может включать прием битового потока. Способ может дополнительно включать декодирование описания звуковой сцены из битового потока. Звуковая сцена может содержать акустическую среду, например такую, как акустическая среда VR/AR/MR. Способ может дополнительно включать определение одного или более эффективных звуковых элементов из описания звуковой сцены. Способ может дополнительно включать определение информации эффективных звуковых элементов, указывающей положения эффективных звуковых элементов одного или более эффективных звуковых элементов, из описания звуковой сцены. Способ может дополнительно включать декодирование указания режима рендеринга из битового потока. Указание режима рендеринга может указывать на то, представляют ли один или более эффективных звуковых элементов звуковое поле, полученное из подвергнутых предварительному рендерингу звуковых элементов, и следует ли выполнять их рендеринг с использованием предварительно заданного режима рендеринга. Способ может еще дополнительно включать, в ответ на указание режима рендеринга, указывающее, что один или более эффективных звуковых элементов представляют звуковое поле, полученное из подвергнутых предварительному рендерингу звуковых элементов, и что следует выполнять их рендеринг с использованием предварительно заданного режима рендеринга, выполнение рендеринга одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга. Рендеринг одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга может учитывать информацию эффективных звуковых элементов. Предварительно заданный режим рендеринга может определять предварительно заданную конфигурацию средств рендеринга для управления влиянием акустической среды звуковой сцены на выход рендеринга. Эффективные звуковые элементы могут быть подвергнуты рендерингу в эталонное положение, например. Предварительно заданный режим рендеринга может включать или отключать определенные средства рендеринга. Предварительно заданный режим рендеринга может также улучшать звуки для одного или более эффективных звуковых элементов (например добавлять искусственные звуки).
Один или более эффективных звуковых элементов, так сказать, инкапсулируют влияние звуковой среды, например эхо, реверберацию и акустическое преграждение. Это позволяет использовать в декодере особенно простой режим рендеринга (то есть предварительно заданный режим рендеринга). В то же время можно сохранить художественный замысел и пользователю (слушателю) можно обеспечить богатое восприятие звука с эффектом присутствия даже при маломощных декодерах. Более того, средства рендеринга декодера можно индивидуально настроить на основе указания режима рендеринга, которое обеспечивает дополнительное управление акустическими эффектами. Инкапсуляция влияния акустической среды в конечном итоге позволяет эффективно сжимать метаданные, указывающие акустическую среду.
В некоторых вариантах осуществления способ может дополнительно включать получение информации о положении слушателя, указывающей положение головы слушателя в акустической среде, и/или информации об ориентации слушателя, указывающей ориентацию головы слушателя в акустической среде. Соответствующий декодер может содержать интерфейс для приема информации о положении слушателя и/или информации об ориентации слушателя. Тогда рендеринг одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга может дополнительно учитывать информацию о положении слушателя и/или информацию об ориентации слушателя. При учете этой дополнительной информации можно сделать восприятие звука пользователем с еще большим эффектом присутствия и еще более выразительным.
В некоторых вариантах осуществления информация об эффективных звуковых элементах может содержать информацию, указывающую соответствующие схемы излучения звука одного или более эффективных звуковых элементов. Рендеринг одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга может затем дополнительно учитывать информацию, указывающую соответствующие схемы излучения звука одного или более эффективных звуковых элементов. Например, можно подсчитать коэффициент ослабления на основании схемы излучения звука соответствующего эффективного звукового элемента и относительного расположения между соответствующим эффективным звуковым элементом и положением слушателя. При учете схем излучения можно сделать восприятие звука пользователем с еще большим эффектом присутствия и еще более выразительным.
В некоторых вариантах осуществления в рендеринге одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга может применяться моделирование затухания звука в соответствии с относительными расстояниями между положением слушателя и положениями эффективных звуковых элементов одного или более эффективных звуковых элементов. То есть предварительно заданный режим рендеринга не может учитывать акустические элементы в акустической среде и применяет (только) моделирование затухания звука (в пустом пространстве). Это определяет простой режим рендеринга, который можно применять даже в маломощных декодерах. Кроме того, моделирование направленности звука можно применять, например, на основе схем излучения звука одного или более эффективных звуковых элементов.
В некоторых вариантах осуществления из описания звуковой сцены могут быть определены по меньшей мере два эффективных звуковых элемента. Тогда указание режима рендеринга может указывать соответствующий предварительно заданный режим рендеринга для каждого из по меньшей мере двух эффективных звуковых элементов. Кроме того, способ может включать рендеринг по меньшей мере двух эффективных звуковых элементов с использованием их соответствующих предварительно заданных режимов рендеринга. Рендеринг каждого эффективного звукового элемента с использованием его соответствующего предварительно заданного режима рендеринга может учитывать информацию эффективного звукового элемента для этого эффективного звукового элемента. Кроме того, предварительно заданный режим рендеринга для этого эффективного звукового элемента может определять соответствующую предварительно заданную конфигурацию средств рендеринга для управления влиянием акустической среды звуковой сцены на выход рендеринга для этого эффективного звукового элемента. Таким образом, для отдельных эффективных звуковых элементов можно обеспечить дополнительное управление акустическими эффектами, таким образом предоставляя возможность очень близкого соответствия художественному замыслу создателя содержимого.
В некоторых вариантах осуществления способ может дополнительно включать определение одного или более оригинальных звуковых элементов из описания звуковой сцены. Способ может дополнительно включать определение информации звуковых элементов, указывающей положения одного или более звуковых элементов, из описания звуковой сцены. Способ может еще дополнительно включать рендеринг одного или более звуковых элементов с использованием режима рендеринга для одного или более звуковых элементов, который отличается от предварительно заданного режима рендеринга, используемого для одного или более эффективных звуковых элементов. Рендеринг одного или более звуковых элементов с использованием режима рендеринга для одного или более звуковых элементов может учитывать информацию звуковых элементов. Указанный рендеринг может дополнительно учитывать влияние акустической среды на выход рендеринга. Соответственно, эффективные звуковые элементы, инкапсулирущие влияние акустической среды, могут быть подвергнуты рендерингу с использованием, например, простого режима рендеринга, тогда как (оригинальные) звуковые элементы могут быть подвергнуты рендерингу с использованием более сложного режима рендеринга, например эталонного.
В некоторых вариантах осуществления способ может дополнительно включать получение информации об области положения слушателя, указывающей область положения слушателя, для которой должен быть использован предварительно заданный режим рендеринга. Информация об области положения слушателя может быть, например, закодирована в битовом потоке. Таким образом, можно обеспечить использование предварительно заданного режима рендеринга только для тех областей положения слушателя, для которых эффективный звуковой элемент обеспечивает выразительное представление оригинальной звуковой сцены (например оригинальных звуковых элементов).
В некоторых вариантах осуществления предварительно заданный режим рендеринга, указанный указанием режима рендеринга, может зависеть от положения слушателя. Более того, способ может включать рендеринг одного или более эффективных звуковых элементов, с использованием того предварительно заданного режима рендеринга, который указан указанием режима рендеринга для области положения слушателя, указанной информацией об области положения слушателя. То есть указание режима рендеринга может указывать разные (предварительно заданные) режимы рендеринга для разных областей положения слушателя.
Другой аспект настоящего изобретения относится к способу генерирования содержимого звуковой сцены. Способ может включать получение одного или более звуковых элементов, представляющих захваченные сигналы, из звуковой сцены. Способ может дополнительно включать получение информации эффективных звуковых элементов, указывающей положения эффективных звуковых элементов одного или более эффективных звуковых элементов, которые нужно генерировать. Способ может еще дополнительно включать определение одного или более эффективных звуковых элементов из одного или более звуковых элементов, представляющих захваченные сигналы, путем применения моделирования затухания звука в соответствии с расстояниями между положением, в котором были захвачены захваченные сигналы, и положениями эффективных звуковых элементов одного или более эффективных звуковых элементов.
В соответствии с этим способом содержимое звуковой сцены может быть сгенерировано так, что при рендеринге в эталонное положение или положения захвата выдает близкую по восприятию аппроксимацию звукового поля, которое могло бы исходить из оригинальной звуковой сцены. В дополнение, однако, содержимое звуковой сцены может быть подвергнуто рендерингу в положения слушателя, которые отличаются от эталонного положения или положения захвата, таким образом обеспечивая восприятие звука с эффектом присутствия.
Другой аспект настоящего изобретения относится к способу кодирования содержимого звуковой сцены в битовый поток. Способ может включать прием описания звуковой сцены. Звуковая сцена может содержать акустическую среду и один или более звуковых элементов в соответствующих положениях звуковых элементов. Способ может дополнительно включать определение одного или более эффективных звуковых элементов в соответствующих положениях эффективных звуковых элементов из одного или более звуковых элементов. Это определение может быть выполнено таким способом, что рендеринг одного или более эффективных звуковых элементов в соответствующих положениях эффективных звуковых элементов в эталонное положение с использованием режима рендеринга, который не учитывает влияния акустической среды на выходе рендеринга (то есть применяет моделирование с ослаблением с увеличением дальности в пустом пространстве), дает психоакустическую аппроксимацию эталонного звукового поля в эталонном положении, которая могла бы быть результатом рендеринга одного или более звуковых элементов в их соответствующих положениях звуковых элементов в опорное положение с использованием эталонного режима рендеринга, который учитывает влияние акустической среды на выход рендеринга. Способ может дополнительно включать генерирование информации эффективных звуковых элементов, указывающей положения эффективных звуковых элементов одного или более эффективных звуковых элементов. Способ может дополнительно включать генерирование указания режима рендеринга, которое указывает, что один или более эффективных звуковых элементов представляют звуковое поле, полученное из подвергнутых предварительному рендерингу звуковых элементов, и что следует выполнять их рендеринг с использованием предварительно заданного режима рендеринга, который определяет предварительно заданную конфигурацию средств рендеринга декодера для управления влиянием акустической среды на выход рендеринга на декодере. Способ может еще дополнительно включать кодирование в битовый поток одного или более звуковых элементов, положений звуковых элементов, одного или более эффективных звуковых элементов, информации эффективных звуковых элементов и указания режима рендеринга.
Один или более эффективных звуковых элементов, так сказать, инкапсулируют влияние звуковой среды, например эхо, реверберацию и акустическое преграждение. Это позволяет использовать в декодере особенно простой режим рендеринга (то есть предварительно заданный режим рендеринга). В то же время можно сохранить художественный замысел и пользователю (слушателю) можно обеспечить богатое восприятие звука с эффектом присутствия даже при маломощных декодерах. Более того, средства рендеринга декодера можно индивидуально настроить на основе указания режима рендеринга, которое обеспечивает дополнительное управление акустическими эффектами. Инкапсуляция влияния акустической среды в конечном итоге позволяет эффективно сжимать метаданные, указывающие акустическую среду.
В некоторых вариантах осуществления способ может дополнительно включать получение информации о положении слушателя, указывающей положение головы слушателя в акустической среде, и/или информации об ориентации слушателя, указывающей ориентацию головы слушателя в акустической среде. Способ может еще дополнительно включать кодирование в битовый поток информации о положении слушателя и/или информации об ориентации слушателя.
В некоторых вариантах осуществления информация эффективных звуковых элементов может быть сгенерирована так, чтобы содержать информацию, указывающую соответствующие схемы излучения звука одного или более эффективных звуковых элементов.
В некоторых вариантах осуществления по меньшей мере два эффективных звуковых элемента могут быть сгенерированы и закодированы в битовый поток. Тогда указание режима рендеринга может указывать соответствующий предварительно заданный режим рендеринга для каждого из по меньшей мере двух эффективных звуковых элементов.
В некоторых вариантах осуществления способ может дополнительно включать получение информации об области положения слушателя, указывающей область положения слушателя, для которой должен быть использован предварительно заданный режим рендеринга. Способ может также дополнительно включать кодирование информации об области положения слушателя в битовый поток.
В некоторых вариантах осуществления предварительно заданный режим рендеринга, указанный указанием режима рендеринга, может зависеть от положения слушателя, так что указание режима рендеринга указывает соответствующий предварительно заданный режим рендеринга для каждого из множества положений слушателя.
Другой аспект настоящего изобретения относится к декодеру звука, содержащему процессор, подключенный к памяти, в которой хранятся команды для процессора. Процессор может быть приспособлен выполнять способ согласно соответствующим из представленных выше аспектов или вариантов осуществления.
Другой аспект настоящего изобретения относится к кодеру звука, содержащему процессор, подключенный к памяти, в которой хранятся команды для процессора. Процессор может быть приспособлен выполнять способ согласно соответствующим из представленных выше аспектов или вариантов осуществления.
Дополнительные аспекты настоящего изобретения относятся к соответствующим компьютерным программам и машиночитаемым носителям данных.
Будет понятно, что этапы способа и характерные признаки устройств можно взаимно заменять различными способами. В частности, детали раскрытого способа могут быть реализованы в виде устройства, приспособленного для выполнения некоторых или всех этапов способа, и наоборот, как будет понятно специалисту. В частности, понятно, что соответствующие утверждения, сделанные в отношении способов, аналогично применимы и к соответствующим устройствам, и наоборот.
Краткое описание графических материалов
Иллюстративные варианты осуществления настоящего изобретения описаны ниже со ссылкой на сопроводительные графические материалы, на которых одинаковые ссылочные номера обозначают одинаковые или подобные элементы, и на которых
на фиг. 1 схематически показан пример системы кодер / декодер,
на фиг. 2 схематически показан пример звуковой сцены,
на фиг. 3 схематически показан пример положений в акустической среде звуковой сцены,
на фиг. 4 схематически показан пример системы кодер / декодер согласно вариантам осуществления настоящего изобретения,
на фиг. 5 схематически показан другой пример системы кодер / декодер согласно вариантам осуществления настоящего изобретения,
на фиг. 6 показана блок-схема, схематически иллюстрирующая пример способа кодирования содержимого звуковой сцены согласно вариантам осуществления настоящего изобретения,
на фиг. 7 показана блок-схема, схематически иллюстрирующая пример способа декодирования содержимого звуковой сцены согласно вариантам осуществления настоящего изобретения,
на фиг. 8 показана блок-схема, схематически иллюстрирующая пример способа генерирования содержимого звуковой сцены согласно вариантам осуществления настоящего изобретения,
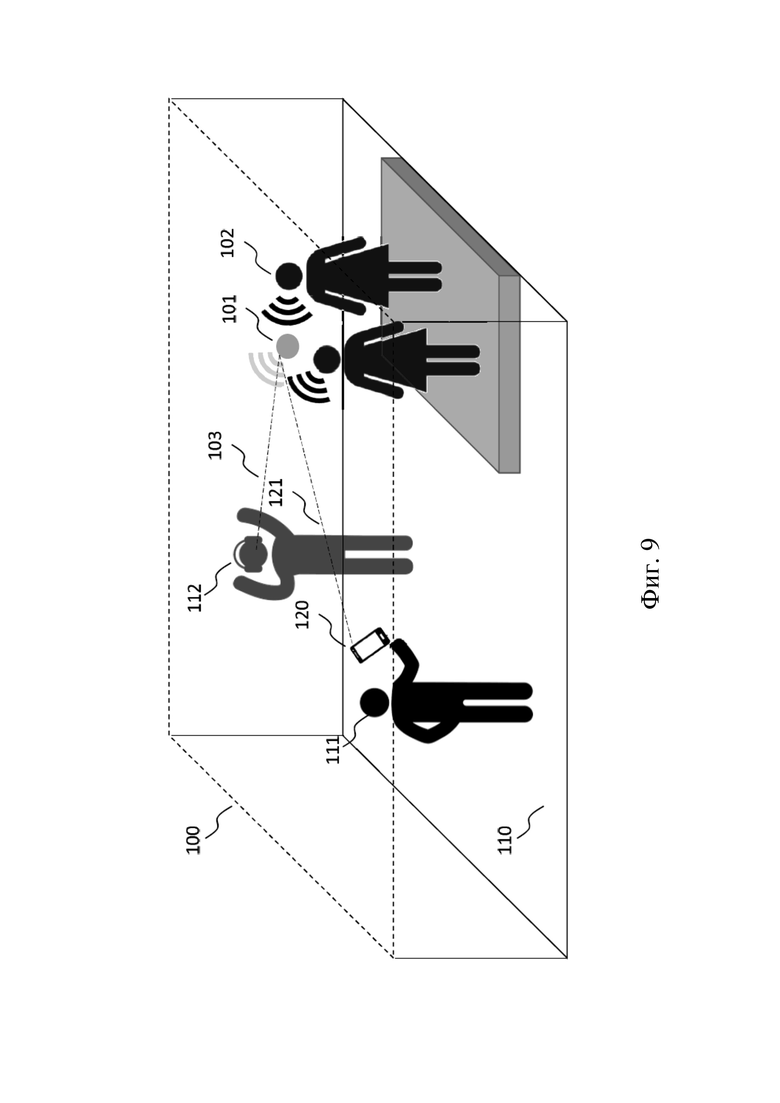
на фиг. 9 схематически показан пример среды, в которой может быть выполнен способ по фиг. 8,
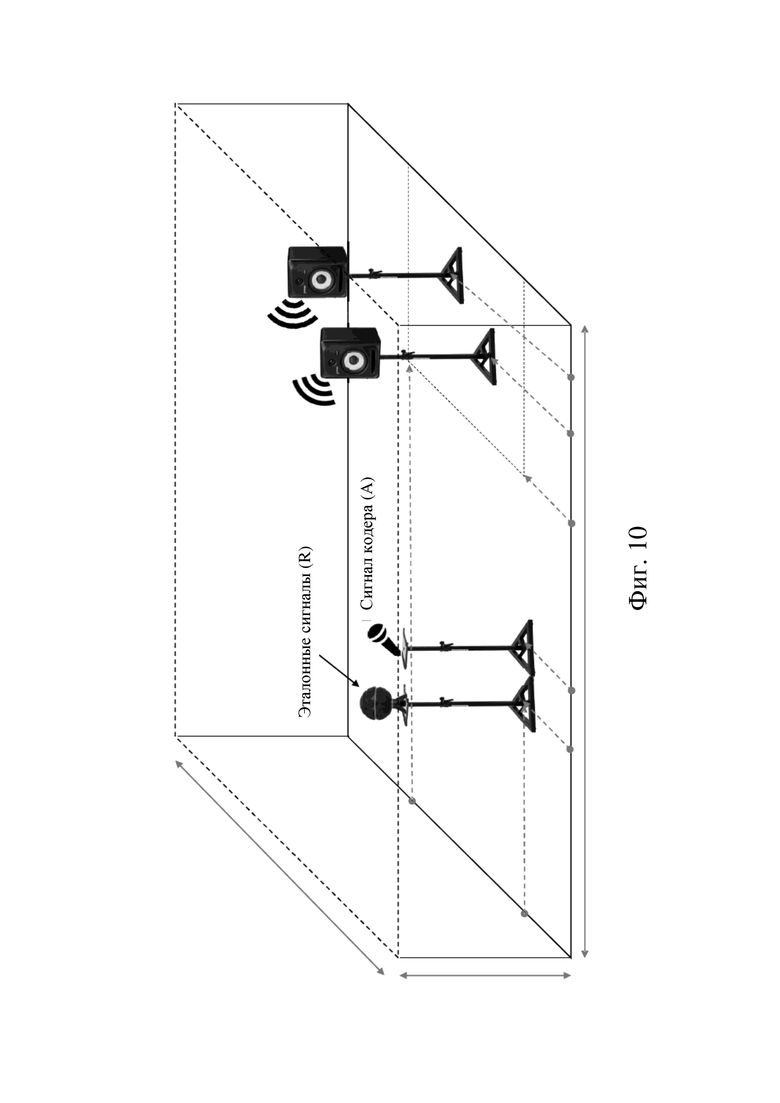
на фиг. 10 схематически показан пример среды для испытания выхода декодера согласно вариантам осуществления настоящего изобретения,
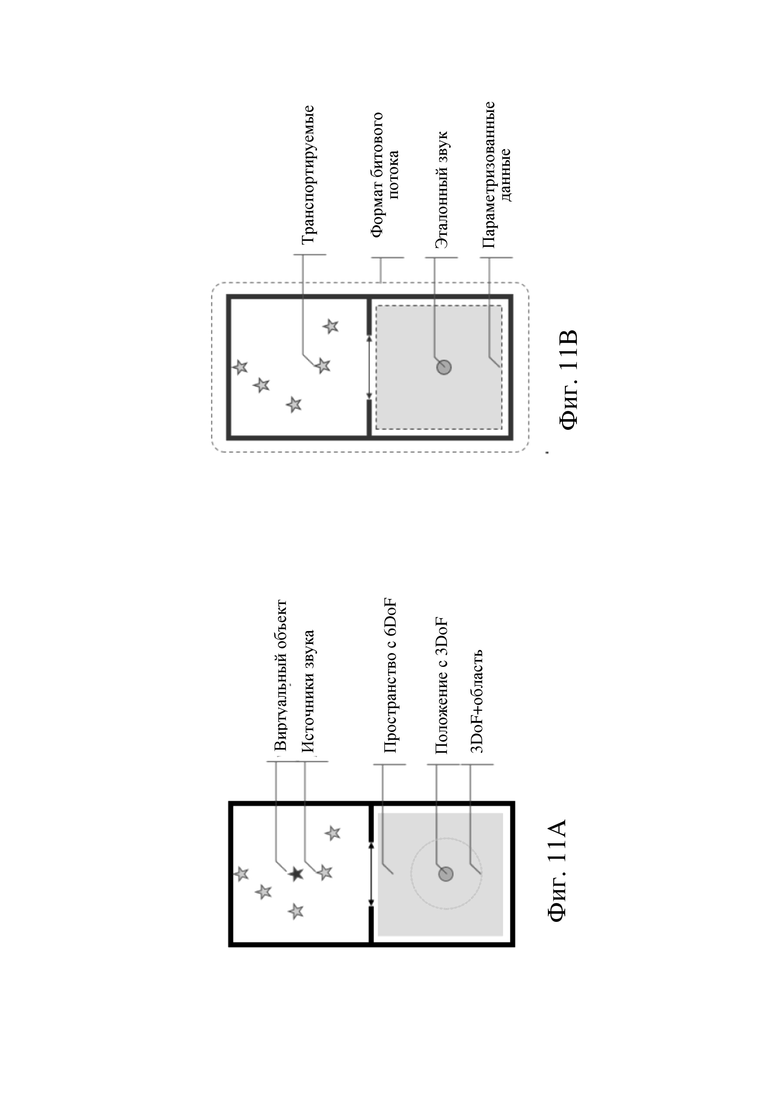
на фиг. 11 схематически показан пример элементов данных, транспортируемых в битовом потоке, согласно вариантам осуществления настоящего изобретения,
на фиг. 12 схематически показаны примеры разных режимов рендеринга со ссылкой на звуковую сцену,
на фиг. 13 схематически показаны примеры кодера и декодера, выполняющих обработку согласно вариантам осуществления настоящего изобретения со ссылкой на звуковую сцену,
на фиг. 14 схематически показаны примеры рендеринга эффективного звукового элемента в разные положения слушателя согласно вариантам осуществления настоящего изобретения и
на фиг. 15 схематически показан пример звуковых элементов, эффективных звуковых элементов и положений слушателя в акустической среде согласно вариантам осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Как указано выше, одинаковые или подобные ссылочные номера в описании обозначают одинаковые или подобные элементы, а повторное описание таких элементов может быть пропущено для краткости.
Настоящее изобретение относится к устройству рендеринга VR/AR/MR или устройству рендеринга звука (например, устройству рендеринга звука, рендеринг которого совместим со стандартом звука MPEG). Настоящее изобретение дополнительно относится к концепциям художественного предварительного рендеринга, которые с высоким качеством и эффективной битовой скоростью обеспечивают представления звукового поля в предварительно заданной кодером области (областях) c 3DoF+.
В одном примере устройство рендеринга звука c 6DoF может выводить соответствие с эталонным сигналом (звуковым полем) в конкретном положении (положениях). Устройство рендеринга звука c 6DoF может расширять преобразование метаданных, относящихся к VR/AR/MR, в собственный формат, такой как входной формат устройства рендеринга звука MPEG-H 3D.
Целью является предложить устройство рендеринга звука, совместимое со стандартами (например, совместимое со стандартом MPEG или совместимое с любым из будущих стандартов MPEG) для создания звукового выхода в виде предварительно заданного эталонного сигнала (сигналов) в положении (положениях) c 3DoF.
Прямолинейным подходом, поддерживающим такие требования, могло бы быть транспортирование предварительно заданного (подвергнутого предварительному рендерингу) сигнала (сигналов) непосредственно на сторону декодера / устройства рендеринга. Этот подход обладает следующими очевидными недостатками:
1. увеличение битовой скорости (т. е. подвергнутый предварительному рендерингу сигнал (сигналы) отправляют в дополнение к исходным сигналам источника звука); и
2. ограниченная действительность (т. е. подвергнутый предварительному рендерингу сигнал (сигналы) является действительным только для положения (положений) c 3DoF).
В целом, настоящем изобретение относится к эффективному генерированию, кодированию, декодированию и рендерингу такого сигнала (сигналов) для обеспечения функциональности рендеринга c 6DoF. Соответственно в настоящем описании описаны способы преодоления упомянутых выше недостатков, включая:
1. использование подвергнутого предварительному рендерингу сигнала (сигналов) вместо исходных сигналов источника звука (или как вспомогательного дополнения к ним); и
2. увеличение диапазона применимости (использования для рендеринга c 6DoF) от положения (положений) c 3DoF до области c 3DoF+ для подвергнутого предварительному рендерингу сигнала (сигналов) посредством сохранения высокого уровня аппроксимации звукового поля.
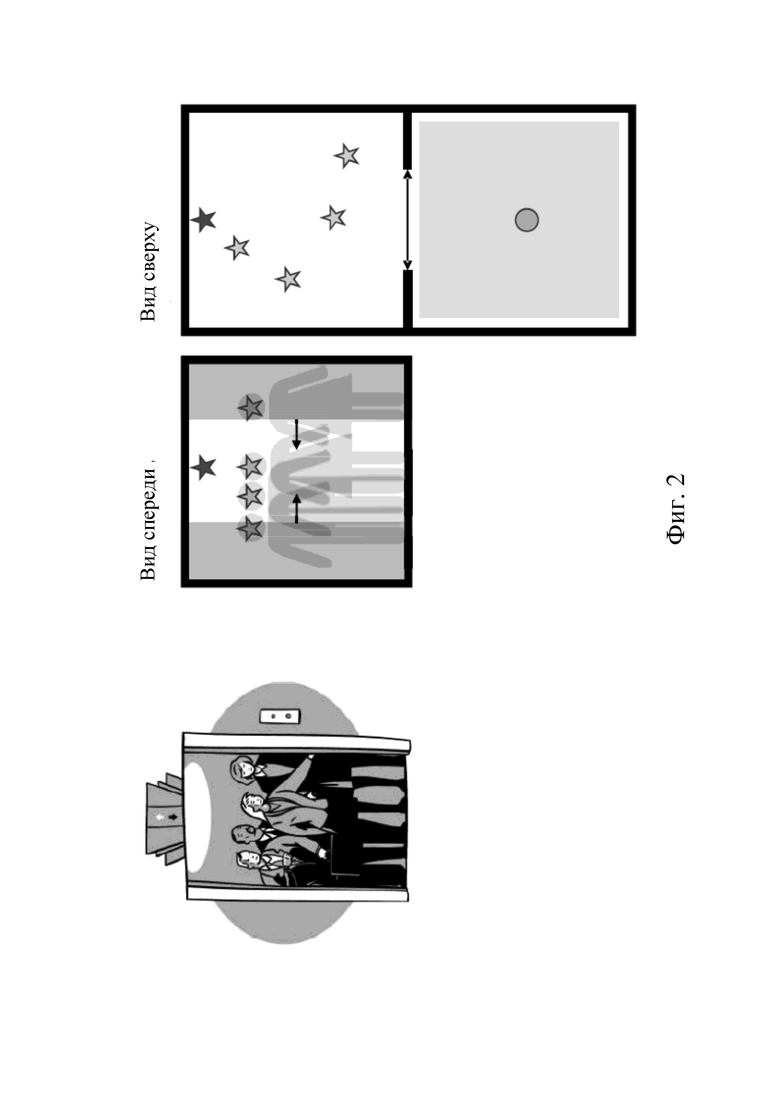
Пример сценария, к которому применимо настоящее изобретение, проиллюстрирован на фиг. 2. На фиг. 2 изображено иллюстративное пространство, например лифт и слушатель. В одном примере слушатель может стоять перед лифтом, двери которого открываются и закрываются. Внутри лифта есть несколько людей, которые разговаривают, и звучит окружающая музыка. Слушатель может перемещаться рядом, но не может войти в кабину лифта. На фиг. 2 изображены вид сверху и вид спереди системы лифта.
Собственно, можно сказать, что лифт и источники звука (разговаривающие люди, окружающая музыка) на фиг. 2 задают звуковую сцену.
В общем, в контексте настоящего изобретения под звуковой сценой понимают все звуковые элементы, акустические элементы и акустическую среду, которые нужны для рендеринга звука в сцене, то есть входные данные, необходимые для устройства рендеринга звука (например, устройства рендеринга звука MPEG-I). В контексте настоящего изобретения под звуковым элементом понимают один или более звуковых сигналов и связанные метаданные. Звуковые элементы могут быть, например, звуковыми объектами, каналами или сигналами HOA. Под звуковым объектом понимают звуковой сигнал со связанными статическими / динамическими метаданными (например, информацией о положении), в которых содержится информация, необходимая для воспроизведения звука источника звука. Под акустическим элементом понимают физический объект в пространстве, который взаимодействует со звуковыми элементами и оказывает влияние на рендеринг звуковых элементов на основании положения и ориентации пользователя. Акустический элемент может разделять метаданные со звуковым объектом (например положение и ориентацию). Под акустической средой понимают метаданные, описывающие звуковые свойства виртуальной сцены, для которой нужно выполнить рендеринг, например комнаты или местности.
Для такого сценария (или фактически любой другой звуковой сцены) было бы желательно задействовать устройство рендеринга звука для рендеринга представления звукового поля звуковой сцены, которое является достоверным представлением оригинального звукового поля по меньшей мере в эталонном положении, которое соответствует художественному замыслу и/или рендеринг которого можно выполнить устройством рендеринга звука с определенными (ограниченными) возможностями рендеринга. Дополнительно желательно соблюдать любые ограничения битовой скорости при передаче звукового содержимого от кодера на декодер.
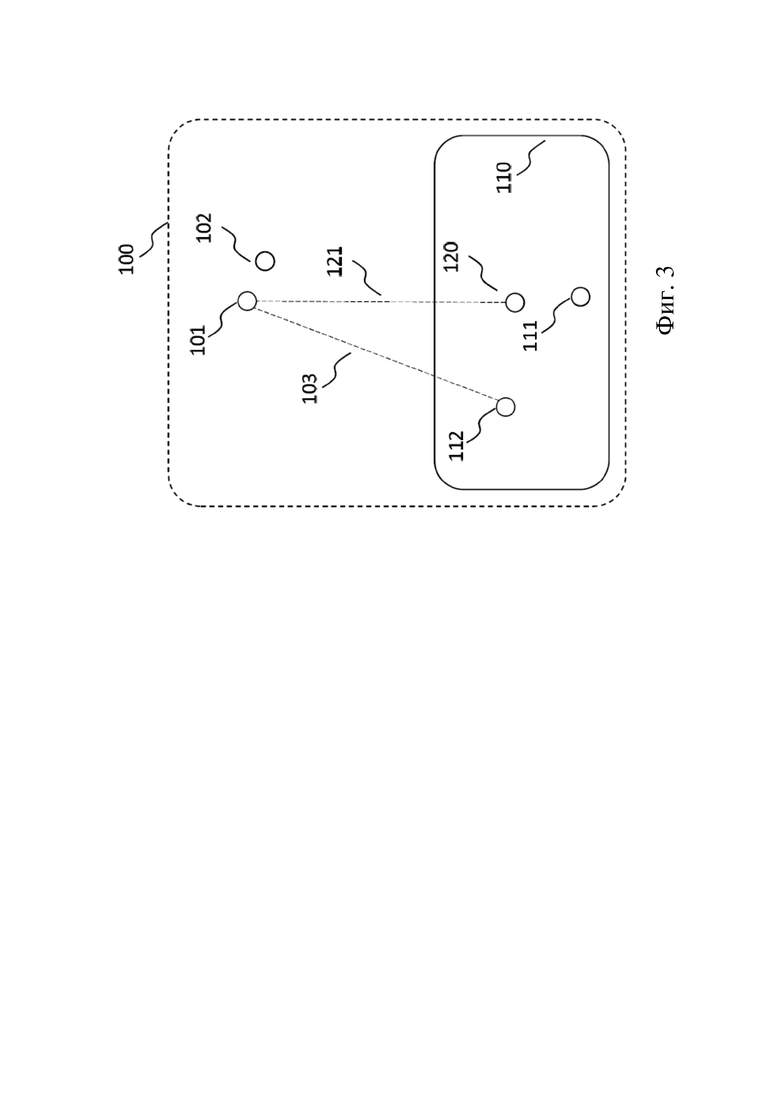
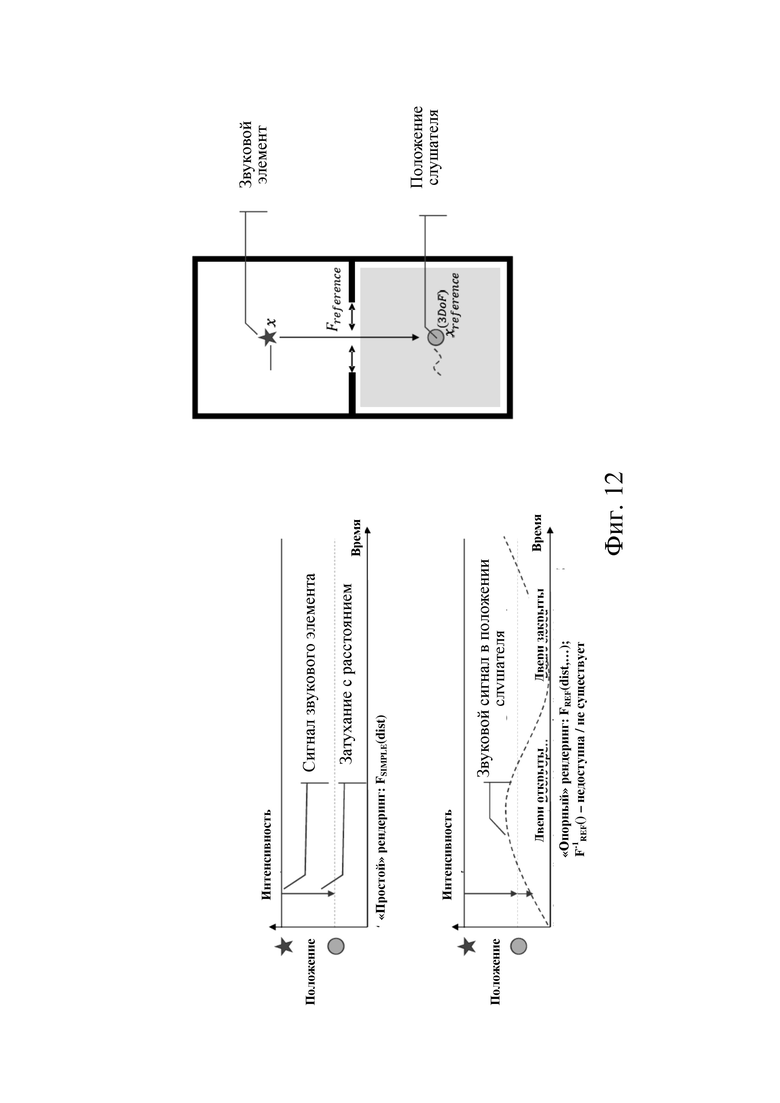
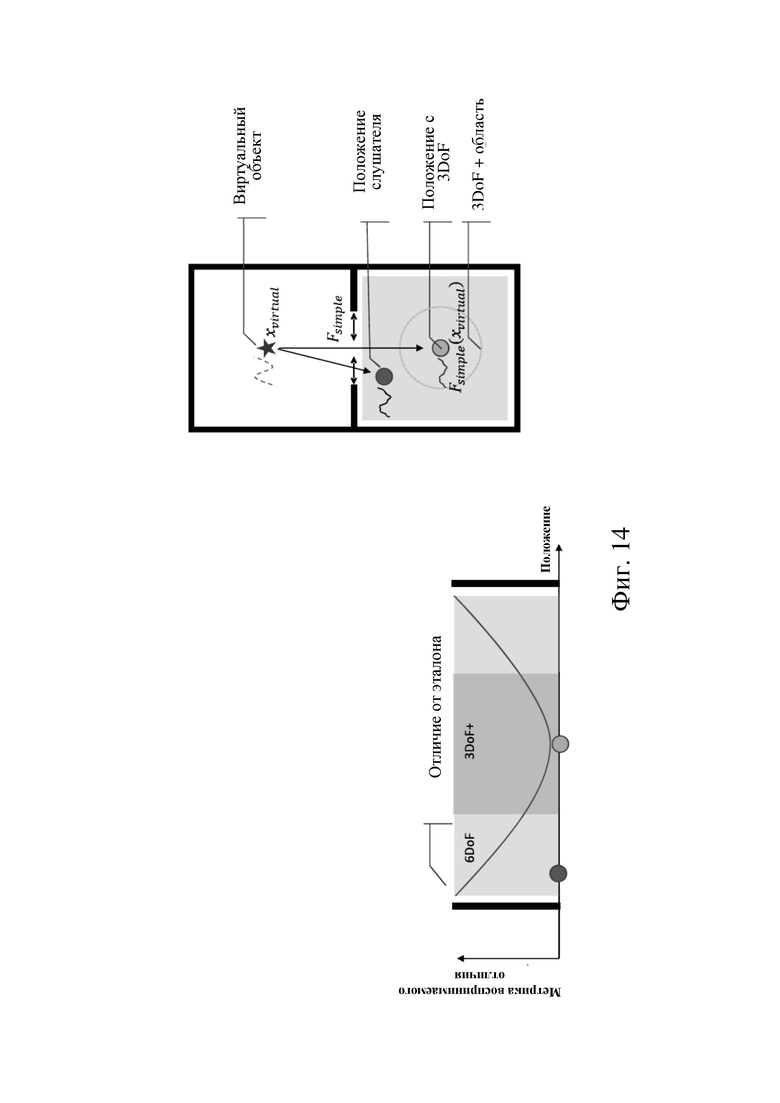
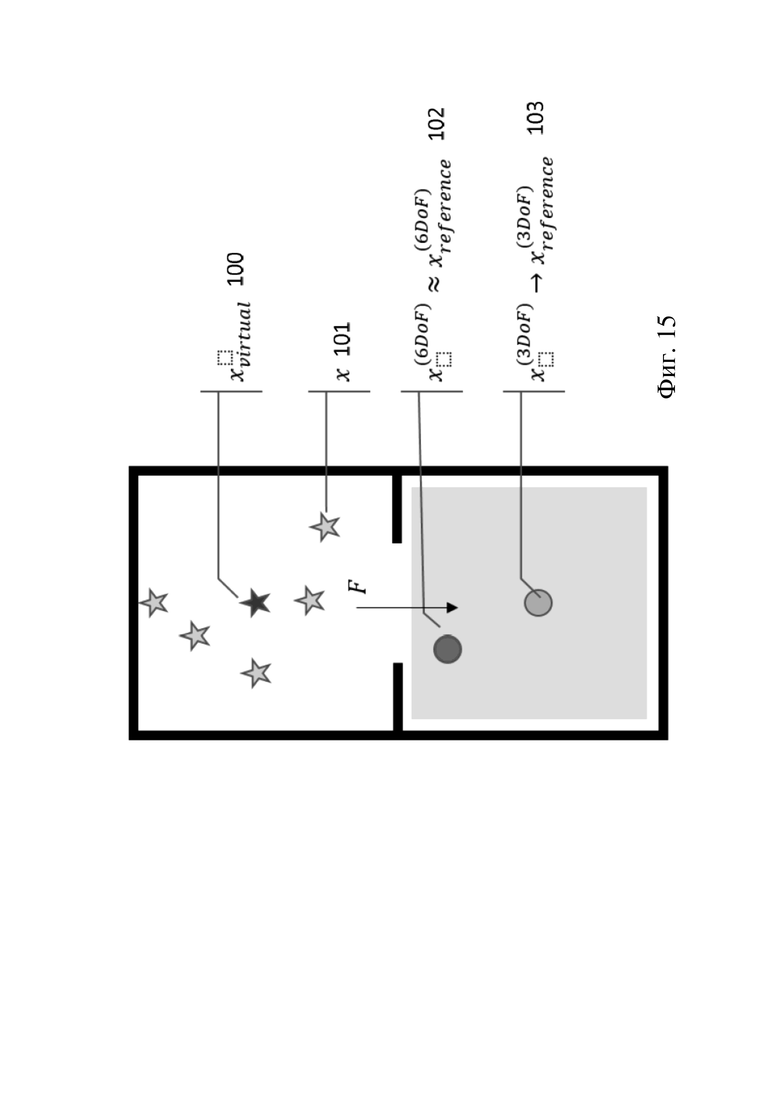
На фиг. 3 схематически показан план звуковой сцены относительно среды прослушивания. Звуковая сцена содержит акустическую среду 100. Акустическая среда 100 в свою очередь содержит один или более звуковых элементов 102 в соответствующих положениях. Один или более звуковых элементов можно использовать для генерирования одного или более эффективных звуковых элементов 101 в соответствующих положениях, которые не обязательно совпадают с положением (положениями) одного или более звуковых элементов. Например, для данного набора звуковых элементов положение эффективного звукового элемента можно задать в центре (например, в центре тяжести) положений звуковых элементов. Генерируемый эффективный звуковой элемент может иметь такое свойство, что рендеринг эффективного звукового элемента в эталонное положение 111 в области 110 положения слушателя предварительно заданной функцией рендеринга (например, простой функцией рендеринга, которая только применяет ослабление с увеличением дальности в пустом пространстве) формирует звуковое поле, которое (по существу) по восприятию эквивалентно звуковому полю в эталонном положении 111, которое могло бы быть результатом рендеринга звуковых элементов 102 эталонной функцией рендеринга (например, функцией рендеринга, учитывающей характеристики (например влияние) акустической среды, включая звуковые элементы (например эхо, реверберацию, преграждение и т. п.). Естественно, однажды сгенерированные эффективные звуковые элементы 101 также могут быть подвергнуты рендерингу с использованием предварительно заданной функции рендеринга в положение 112 слушателя в области 110 положения слушателя, которая отличается от эталонного положения 111. Положение слушателя может быть на расстоянии 103 от положения эффективного звукового элемента 101. Один пример генерирования эффективного звукового элемента 101 из звуковых элементов 102 будет более подробно описан ниже.
В некоторых вариантах осуществления эффективные звуковые элементы 102 можно альтернативно определить на основании одного или более захваченных сигналов 120, захват которых осуществляется в положении захвата в области 110 положения слушателя. Например, пользователь в аудитории, в которой исполняют музыку, может выполнить захват звука, испускаемого из звукового элемента (например музыкантом) на сцене. Затем для заданного желаемого положения эффективного звукового элемента (например, относительно положения захвата, например путем указания расстояния 121 между эффективным звуковым элементом 101 и положением захвата, возможно в сочетании с углами, указывающими направление вектора расстояния между эффективным звуковым элементом 101 и положением захвата) эффективный звуковой элемент 101 можно сгенерировать на основании захваченного сигнала 120. Сгенерированный эффективный звуковой элемент 101 может иметь такое свойство, что рендеринг эффективного звукового элемента 101 в эталонное положение 111 (которое не обязательно совпадает с положением захвата) предварительно заданной функцией рендеринга (например простой функцией рендеринга, которая только применяет ослабление с увеличением дальности в пустом пространстве) формирует звуковое поле, которое (по существу) по восприятию эквивалентно звуковому полю в эталонном положении 111, которое было порождено из оригинального звукового элемента 102 (например музыкантом). Пример случая такого использования будет более подробно описан ниже.
Следует отметить, что эталонное положение 111 может в некоторых случаях быть тем же, что и положение захвата, и эталонный сигнал (то есть сигнал в эталонном положении 111) может быть равным захваченному сигналу 120. Это может быть обоснованным предположением для применения VR/AR/MR, где пользователь может использовать вариант с записью с применением муляжа головы. В практических ситуациях это предположение может не быть обоснованным, поскольку эталонными приемниками являются уши пользователя, а устройство захвата сигнала (например, мобильный телефон или микрофон) может располагаться скорее всего далеко от ушей пользователя.
Ниже будут более подробно описаны способы и устройства для удовлетворения потребностей, описанных вначале.
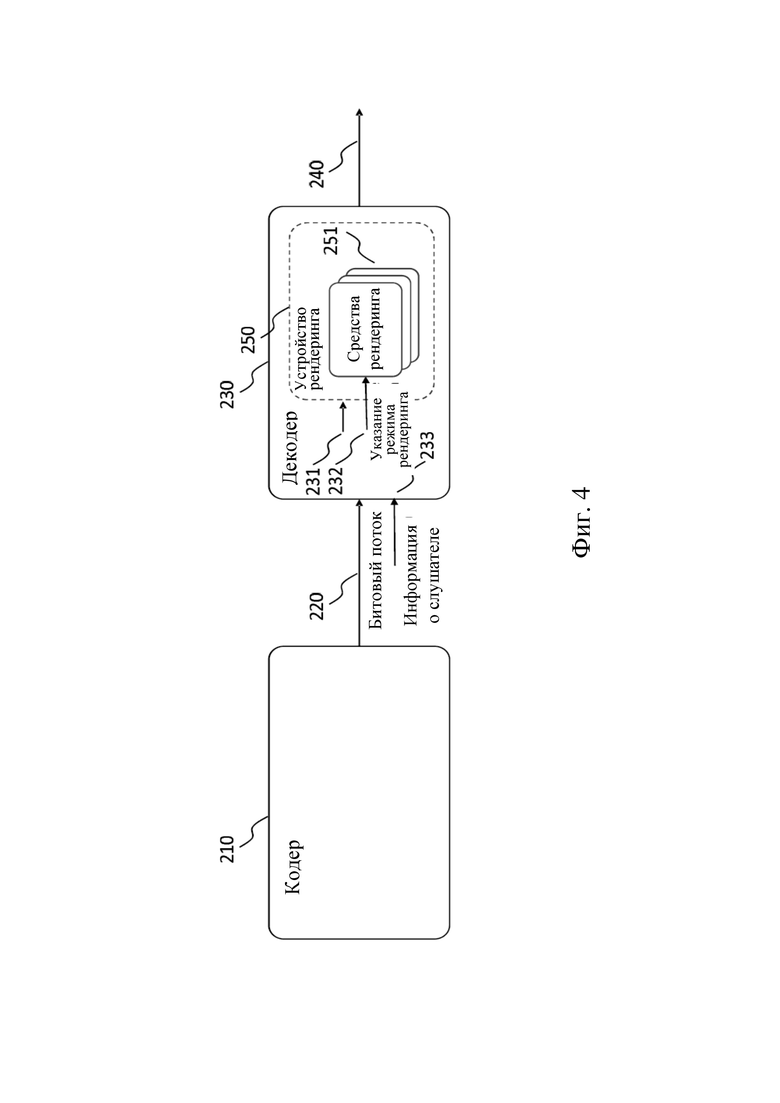
На фиг. 4 показан пример системы кодер / декодер согласно вариантам осуществления настоящего изобретения. Кодер 210 (например кодер MPEG-I) выдает битовый поток 220, который может быть использован декодером 230 (например декодером MPEG-I) для генерирования выхода 240 звука. Декодер 230 может дополнительно получать информацию 233 о слушателе. Информация 233 о слушателе не обязательно включена в битовый поток 220, но может происходить из любого источника. Например, информация о слушателе может генерироваться и выдаваться устройством слежения за положением головы пользователя и подавать на вход (специального) интерфейса декодера 230.
Декодер 230 содержит устройство 250 рендеринга звука, которое в свою очередь содержит одно или более средств 251 рендеринга. В контексте настоящего изобретения под устройством рендеринга звука понимают нормативный модуль рендеринга звука, например MPEG-I, содержащий средства рендеринга, интерфейсы для внешних средств рендеринга и интерфейсы для системного уровня для внешних ресурсов. Под средствами рендеринга понимают компоненты устройства рендеринга звука, которые выполняют аспекты рендеринга, например параметризацию модели помещения, преграждение, реверберацию, бинауральный рендеринг и т. п.
Устройство 250 рендеринга снабжается в качестве вводов одним или более эффективными звуковыми элементами, информацией 231 эффективных звуковых элементов и указанием 232 режима рендеринга. Эффективные звуковые элементы, информация эффективных звуковых элементов и указание 232 режима рендеринга будут более подробно описаны ниже. Информацию 231 эффективных звуковых элементов и указание 232 режима рендеринга можно получать (например, определять / декодировать) из битового потока 220. Устройство 250 рендеринга выполняет рендеринг представления звуковой сцены на основании эффективных звуковых элементов и информации эффективных звуковых элементов, используя одно или более средств 251 рендеринга. Здесь указание 232 режима рендеринга указывает режим рендеринга, в котором работают одно или более средств 251 рендеринга. Например, определенные средства 251 рендеринга могут быть активированы или деактивированы в соответствии с указанием 232 режима рендеринга. Более того, определенные средства 251 рендеринга можно сконфигурировать в соответствии с указанием 232 режима рендеринга. Например, можно выбрать (например, установить) параметры управления определенных средств 251 рендеринга в соответствии с указанием 232 режима рендеринга.
В контексте настоящего изобретения задачами кодера (например кодера MPEG-I) являются определение метаданных 6DoF и данных управления, определение эффективных звуковых элементов (например, включая монофонический звуковой сигнал для каждого эффективного звукового элемента), определение положений для эффективных звуковых элементов (например x, y, z) и определение данных для управления средствами рендеринга (например флагов включения / выключения и конфигурационных данных). Данные для управления средствами рендеринга могут соответствовать упомянутому выше указанию режима рендеринга, содержать его или содержаться в нем.
В дополнение к указанному выше, кодер согласно вариантам осуществления настоящего изобретения может сводить к минимуму воспринимаемое отличие выходного сигнала 240 относительно эталонного сигнала R (если существует) для эталонного положения 111. То есть для средства рендеринга / функции F() рендеринга, которые должны использоваться декодером, обрабатываемого сигнала A и положения (x, y, z) эффективного звукового элемента кодер может реализовать следующую оптимизацию:
{x,y,z; F}: ||Выход(эталонное положение)(F(x,y,z)(A)) - R||воспринимаемое -> min
Более того, кодер согласно вариантам осуществления настоящего изобретения может назначать «прямые» части обрабатываемого сигнала A оцениваемым положениям оригинальных объектов 102. Для декодера это может, например, означать, что он будет иметь возможность воссоздавать некоторые эффективные звуковые элементы 101 из одного захваченного сигнала 120.
В некоторых вариантах осуществления можно использовать устройство рендеринга звука MPEG-H 3D, расширенное простым моделированием расстояния для 6DoF, где положение эффективного звукового элемента выражается через азимут, подъем, радиус, а средство F() рендеринга относится к простому мультипликативному изменению коэффициента усиления объекта. Положение звукового объекта и коэффициент усиления можно получить вручную (например, путем настройки кодера) или автоматически (например, путем оптимизации методом последовательного перебора).
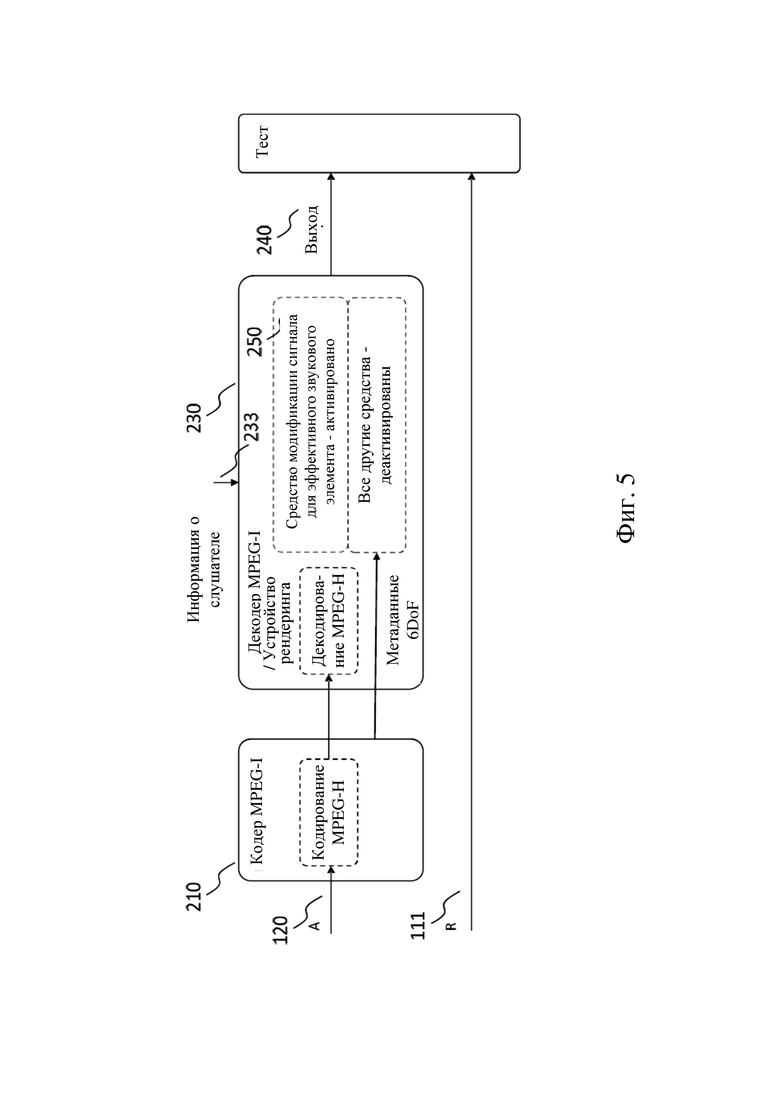
На фиг. 5 схематически показан другой пример системы кодер / декодер согласно вариантам осуществления настоящего изобретения.
Кодер 210 принимает указание звуковой сцены A (обрабатываемый сигнал), которое затем подвергается кодированию способом, описанным в настоящем изобретении (например, кодированием MPEG-H). Дополнительно кодер 210 может генерировать метаданные (например метаданные 6DoF), включающие информацию об акустической среде. Кодер может также генерировать, возможно как часть метаданных, указание режима рендеринга для конфигурирования средств рендеринга устройства 250 рендеринга звука декодера 230. Средства рендеринга могут включать, например, средство модификации сигнала для эффективных звуковых элементов. В зависимости от указания режима рендеринга конкретные средства рендеринга устройства рендеринга звука могут быть активированы или деактивированы. Например, если указание режима рендеринга указывает, что нужно выполнять рендеринг эффективного звукового элемента, может активироваться средство модификации сигнала, тогда как все другие средства рендеринга деактивируются. Декодер 230 выдает выход 240 звука, который можно сравнить с эталонным сигналом R, который может быть результатом рендеринга оригинальных звуковых элементов в эталонное положение 111 с использованием эталонной функции рендеринга. Пример схемы расположения для сравнения выхода 240 звука с эталонным сигналом R схематически показан на фиг. 10.
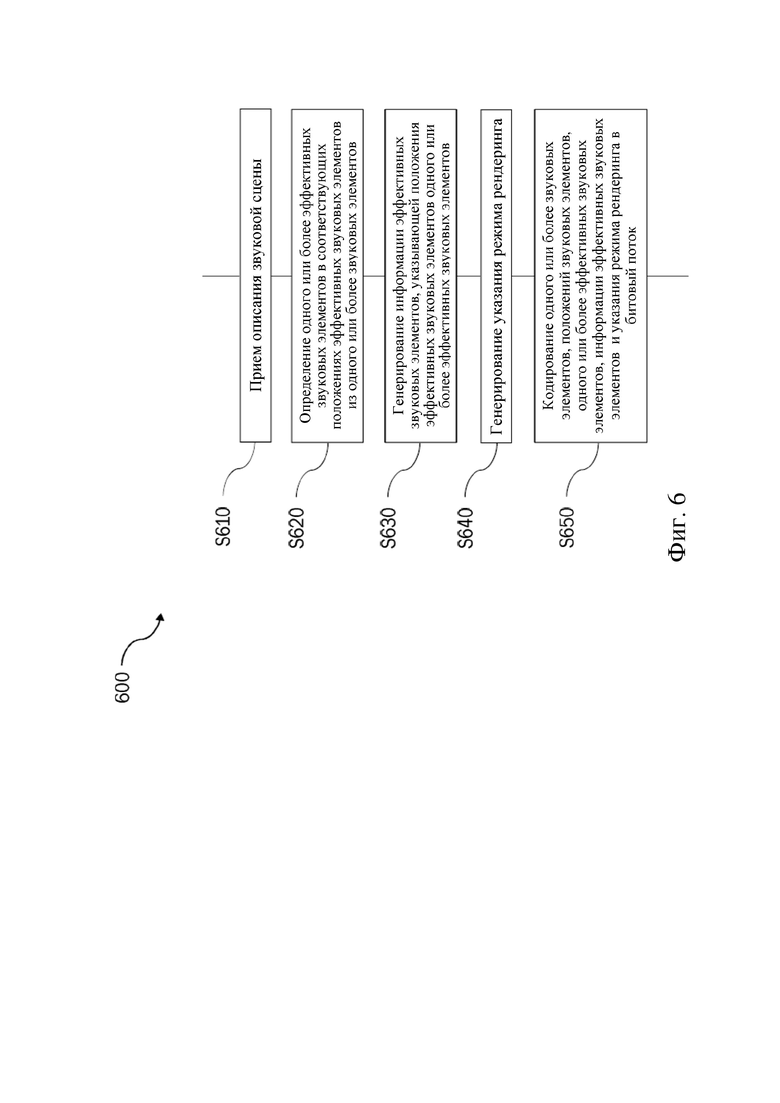
На фиг. 6 показана блок-схема, иллюстрирующая пример способа 600 кодирования содержимого звуковой сцены в битовый поток согласно вариантам осуществления настоящего изобретения.
На этапе S610 принимают описание звуковой сцены. Звуковая сцена содержит акустическую среду и один или более звуковых элементов в соответствующих положениях звуковых элементов.
На этапе S620 из одного или более звуковых элементов определяют один или более эффективных звуковых элементов в соответствующих положениях эффективных звуковых элементов. Для одного или более эффективных звуковых элементов определение производят так, что рендеринг одного или более эффективных звуковых элементов в их соответствующих положениях эффективных звуковых элементов в эталонное положение с использованием режима рендеринга, который не учитывает влияния акустической среды на выход рендеринга, дает психоакустическую аппроксимацию эталонного звукового поля в эталонном положении, которая могла бы быть результатом рендеринга одного или более (оригинальных) звуковых элементов в их соответствующих положениях звуковых элементов в эталонное положение с использованием эталонного режима рендеринга, который учитывает влияние акустической среды на выход рендеринга. Влияние акустической среды может включать эхо, реверберацию, отражение и т. п. В режиме рендеринга, который не учитывает влияния акустической среды на выход рендеринга, может применяться моделирование с ослаблением с увеличением дальности (в пустом пространстве). Неограничивающий пример способа определения таких эффективных звуковых элементов будет описан более подробно ниже.
На этапе S630 генерируют информацию эффективных звуковых элементов, указывающую положения эффективных звуковых элементов одного или более эффективных звуковых элементов.
На этапе S640 генерируют указание режима рендеринга, указывающее на то, что один или более эффективных звуковых элементов представляют звуковое поле, полученное из подвергнутых предварительному рендерингу звуковых элементов, и что следует выполнять их рендеринг с использованием предварительно заданного режима рендеринга, который определяет предварительно заданную конфигурацию средств рендеринга декодера для управления влиянием акустической среды на выход рендеринга в декодере.
На этапе S650 выполняют кодирование в битовый поток одного или более звуковых элементов, положений звуковых элементов, одного или более эффективных звуковых элементов, информации эффективных звуковых элементов и указания режима рендеринга.
В простейшем случае указание режима рендеринга может быть флагом, указывающим, что вся акустика (т. е. влияние акустической среды) включена (т. е. инкапсулирована) в один или более эффективных звуковых элементов. Соответственно, указание режима рендеринга может быть указанием для декодера (или устройства рендеринга звука декодера) использовать простой режим рендеринга, в котором применяется только ослабление с увеличением дальности (например, путем умножения с зависимым от расстояния коэффициентом усиления), а все другие средства рендеринга деактивированы. В более сложных случаях указание режима рендеринга может включать одно или более управляющих значений для конфигурирования средств рендеринга. Это может включать активацию и деактивацию отдельных средств рендеринга, а также более точное управление средствами рендеринга. Например, средства рендеринга можно конфигурировать посредством указания режима рендеринга, чтобы улучшать акустику при выполнении рендеринга одного или более эффективных звуковых элементов. Это можно использовать для добавления (искусственных) звуков, например эха, реверберации, отражения и т. п., например в соответствии с художественным замыслом (например создателя содержимого).
Иными словами, способ 600 может относиться к способу кодирования звуковых данных, при этом звуковые данные представляют один или более звуковых элементов в соответствующих положениях звуковых элементов в акустической среде, содержащей один или более звуковых элементов (например представлений физических объектов). Этот способ может включать определение эффективного звукового элемента в положении эффективного звукового элемента в акустической среде, таким образом, что рендеринг эффективного звукового элемента в эталонное положение при использовании функции рендеринга, которая учитывает ослабление с увеличением дальности между положением эффективного звукового элемента и эталонным положением, но не учитывает акустические элементы в акустической среде, аппроксимирует эталонное звуковое поле в эталонном положении, которое могло бы быть результатом эталонного рендеринга одного или более звуковых элементов в их соответствующих положениях звуковых элементов в эталонное положение. Затем эффективный звуковой элемент и положение эффективного звукового элемента можно кодировать в битовый поток.
В рассмотренной выше ситуации определение эффективного звукового элемента в положении эффективного звукового элемента может включать рендеринг одного или более звуковых элементов в эталонное положение в акустической среде с использованием первой функции рендеринга и тем самым получение опорного звукового поля в эталонном положении, где первая функция рендеринга учитывает акустические элементы в акустической среде, а также ослабление с увеличением дальности между положениями звуковых элементов и эталонным положением, и определение, на основании эталонного звукового поля в эталонном положении, эффективного звукового элемента в положении эффективного звукового элемента в акустической среде, таким образом, что рендеринг эффективного звукового элемента в эталонное положение с использованием второй функции рендеринга дало бы звуковое поле в эталонном положении, которое аппроксимирует эталонное звуковое поле, где вторая функция рендеринга учитывает ослабление с увеличением дальности между положением эффективного звукового элемента и эталонным положением, но не учитывает акустические элементы в акустической среде.
Способ 600, описанный выше, может относиться к случаю использования 0DoF без данных слушателя. В общем, способ 600 поддерживает концепцию «интеллектуального» кодера и «простого» декодера.
Что касается данных слушателя, способ 600 в некоторых реализациях может включать получение информации о положении слушателя, указывающей положение головы слушателя в акустической среде (например, в области положения слушателя). Дополнительно или альтернативно способ 600 может включать получение информации об ориентации слушателя, указывающей ориентацию головы слушателя в акустической среде (например, в области положения слушателя). Затем информацию о положении слушателя и/или информацию об ориентации слушателя можно кодировать в битовый поток. Информацию о положении слушателя и/или информацию об ориентации слушателя может использовать декодер для соответствующего рендеринга одного или более эффективных звуковых элементов. Например, декодер может подвергать рендерингу один или более эффективных звуковых элементов в фактическое положение слушателя (в отличие от эталонного положения). Подобным образом, особенно для случаев применения наушников, декодер может выполнять вращение подвергнутого рендерингу звукового поля в соответствии с ориентацией головы слушателя.
В некоторых реализациях способ 600 может генерировать информацию эффективных звуковых элементов, содержащую информацию, которая указывает соответствующие схемы излучения звука одного или более эффективных звуковых элементов. Эту информацию затем может использовать декодер для соответствующего рендеринга одного или более эффективных звуковых элементов. Например, при рендеринге одного или более эффективных звуковых элементов декодер может применять соответствующий коэффициент усиления к каждому из одного или более эффективных звуковых элементов. Эти коэффициенты усиления можно определить на основании соответствующих схем излучения. Каждый коэффициент усиления можно определить на основании угла между вектором расстояния между соответствующим эффективным звуковым элементом и положением слушателя (или эталонным положением, если выполняется рендеринг в эталонное положение) и вектором направления излучения, указывающим направление излучения соответствующего звукового элемента. Для более сложных схем излучения со многими векторами направления излучения и соответствующими весовыми коэффициентами коэффициент усиления можно определить на основании взвешенной суммы коэффициентов усиления, где каждый коэффициент усиления определяется на основании угла между вектором расстояния и соответствующим вектором направления излучения. Значения веса в сумме могут соответствовать весовым коэффициентам. Коэффициент усиления, определенный на основании схемы излучения, можно суммировать с коэффициентом усиления ослабления с увеличением дальности, применяемым в предварительно заданном режиме рендеринга.
В некоторых реализациях по меньшей мере два эффективных звуковых элемента могут быть сгенерированы и закодированы в битовый поток. Тогда указание режима рендеринга может указывать соответствующий предварительно заданный режим рендеринга для каждого из по меньшей мере двух эффективных звуковых элементов. По меньшей мере два предварительно заданных режима рендеринга могут быть различными. Поэтому для разных эффективных звуковых элементов можно указывать разные объемы акустических эффектов, например в соответствии с художественным замыслом создателя содержимого.
В некоторых реализациях способ 600 может дополнительно включать получение информации об области положения слушателя, указывающей область положения слушателя, для которой должен быть использован предварительно заданный режим рендеринга. Эта информация об области положения слушателя затем может быть закодирована в битовый поток. В декодере следует использовать предварительно заданный режим рендеринга, если положение слушателя, в которое нужно выполнить рендеринг, находится в пределах области положения слушателя, указанной информацией об области положения слушателя. В иных случаях декодер может применять режим рендеринга по своему выбору, например режим рендеринга по умолчанию.
Дополнительно могут быть предусмотрены разные предварительно заданные режимы рендеринга, в зависимости от положения слушателя, в которое нужно выполнить рендеринг. Таким образом, предварительно заданный режим рендеринга, указанный указанием режима рендеринга, может зависеть от положения слушателя, так что указание режима рендеринга указывает соответствующий предварительно заданный режим рендеринга для каждого из множества положений слушателя. Аналогично можно предусмотреть разные предварительно заданные режимы рендеринга в зависимости от области положения слушателя, в которую нужно выполнить рендеринг. Следует отметить, что для разных положений слушателя (или областей положения слушателя) могут быть разные эффективные звуковые элементы. Предоставление такого указания режима рендеринга позволяет управлять (искусственными) звуками, например (искусственными) эхо, реверберацией, отражением и т. п., которые применяются для каждого положения слушателя (или области положения слушателя).
На фиг. 7 показана блок-схема, иллюстрирующая пример соответствующего способа 700 декодирования содержимого звуковой сцены из битового потока декодером согласно вариантам осуществления настоящего изобретения. Декодер может содержать устройство рендеринга звука с одним или более средствами рендеринга.
На этапе S710 принимают битовый поток. На этапе S720 из битового потока декодируют описание звуковой сцены. На этапе S730 из описания звуковой сцены определяют один или более эффективных звуковых элементов.
На этапе S740 из описания звуковой сцены определяют информацию эффективных звуковых элементов, указывающую положения эффективных звуковых элементов одного или более эффективных звуковых элементов.
На этапе S750 из битового потока декодируют указание режима рендеринга. Указание режима рендеринга указывает, представляют ли один или более эффективных звуковых элементов звуковое поле, полученное из подвергнутых предварительному рендерингу звуковых элементов, и следует ли выполнять их рендеринг с использованием предварительно заданного режима рендеринга.
На этапе S760 в ответ на указание режима рендеринга, указывающее, что один или более эффективных звуковых элементов представляют звуковое поле, полученное из подвергнутых предварительному рендерингу звуковых элементов, и что следует выполнять их рендеринг с использованием предварительно заданного режима рендеринга, выполняют рендеринг одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга. При рендеринге одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга учитывают информацию эффективных звуковых элементов. Более того, предварительно заданный режим рендеринга определяет предварительно заданную конфигурацию средств рендеринга для управления влиянием акустической среды звуковой сцены на выход рендеринга.
В некоторых реализациях способ 700 может включать получение информации о положении слушателя, указывающей положение головы слушателя в акустической среде (например в области положения слушателя) и/или информации об ориентации слушателя, указывающей ориентацию головы слушателя в акустической среде (например в области положения слушателя). Затем, рендеринг одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга может дополнительно учитывать информацию о положении слушателя и/или информацию об ориентации слушателя, например согласно тому, как указано выше со ссылкой на способ 600. Соответствующий декодер может содержать интерфейс для приема информации о положении слушателя и/или информации об ориентации слушателя.
В некоторых реализациях способа 700 информация эффективных звуковых элементов может содержать информацию, которая указывает соответствующие схемы излучения звука одного или более эффективных звуковых элементов. Рендеринг одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга может затем дополнительно учитывать информацию, указывающую соответствующие схемы излучения звука одного или более эффективных звуковых элементов, например согласно тому, как указано выше со ссылкой на способ 600.
В некоторых реализациях способа 700 в рендеринге одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга может применяться моделирование затухания звука (в пустом пространстве) в соответствии с относительными расстояниями между положением слушателя и положениями эффективных звуковых элементов одного или более эффективных звуковых элементов. Такой предварительно заданный режим рендеринга можно назвать простым режимом рендеринга. Применение простого режим рендеринга (то есть только ослабления с увеличением дальности в пустом пространстве) является возможным, поскольку влияние акустической среды «инкапсулировано» в одном или более эффективных звуковых элементах. При этом часть вычислительной нагрузки декодера можно делегировать кодеру, что позволяет выполнять рендеринг звукового поля с эффектом присутствия в соответствии с художественным замыслом даже маломощными декодерами.
В некоторых реализациях способа 700 из описания звуковой сцены можно определить по меньшей мере два эффективных звуковых элемента. Тогда указание режима рендеринга может указывать соответствующий предварительно заданный режим рендеринга для каждого из по меньшей мере двух эффективных звуковых элементов. В такой ситуации способ 700 может дополнительно включать рендеринг по меньшей мере двух эффективных звуковых элементов с использованием их соответствующих предварительно заданных режимов рендеринга. Рендеринг каждого эффективного звукового элемента с использованием его соответствующего предварительно заданного режима рендеринга может учитывать информацию эффективного звукового элемента для этого эффективного звукового элемента, и режим рендеринга для этого эффективного звукового элемента может определять соответствующую предварительно заданную конфигурацию средств рендеринга для управления влиянием акустической среды звуковой сцены на выход рендеринга для этого эффективного звукового элемента. По меньшей мере два предварительно заданных режима рендеринга могут быть различными. Поэтому для разных эффективных звуковых элементов можно указывать разные объемы акустических эффектов, например в соответствии с художественным замыслом создателя содержимого.
В некоторых реализациях как эффективные звуковые элементы, так и (фактические / оригинальные) звуковые элементы могут быть закодированы в предназначенном для декодирования битовом потоке. Тогда способ 700 может включать определение одного или более звуковых элементов из описания звуковой сцены и определение информации звуковых элементов, указывающей положения звуковых элементов одного или более звуковых элементов, из описания звуковой сцены. Затем выполняется рендеринг одного или более звуковых элементов с использованием режима рендеринга для одного или более звуковых элементов, который отличается от предварительно заданного режима рендеринга, используемого для одного или более эффективных звуковых элементов. Рендеринг одного или более звуковых элементов с использованием режима рендеринга для одного или более звуковых элементов может учитывать информацию звуковых элементов. Это позволяет выполнять рендеринг эффективных звуковых элементов с использованием, например, простого режима рендеринга, и вместе с тем выполнять рендеринг (фактических / оригинальных) звуковых элементов с использованием, например, эталонного режима рендеринга. Также предварительно заданный режим рендеринга можно сконфигурировать отдельно от режима рендеринга, используемого для звуковых элементов. В общем в режимах рендеринга для звуковых элементов и эффективных звуковых элементов могут быть задействованы разные конфигурации вовлеченных в работу средств рендеринга. Акустический рендеринг (учитывающий влияние акустической среды) можно применять к звуковым элементам, тогда как моделирование с ослаблением с увеличением дальности (в пустом пространстве) можно применять к эффективным звуковым элементам, возможно вместе с искусственными звуками (которые не обязательно определены акустической средой, принимаемой для кодирования).
В некоторых реализациях способ 700 может дополнительно включать получение информации об области положения слушателя, указывающей область положения слушателя, для которой должен быть использован предварительно заданный режим рендеринга. Для рендеринга в положение прослушивания, указанное информацией об области положения слушателя, в пределах области положения слушателя, следует использовать предварительно заданный режим рендеринга. Иначе декодер может применять режим рендеринга по своему выбору (который может зависеть от варианта реализации), например режим рендеринга по умолчанию.
В некоторых реализациях способа 700 предварительно заданный режим рендеринга, указанный указанием режима рендеринга, может зависеть от положения слушателя (или области положения слушателя). Тогда декодер может выполнять рендеринг одного или более эффективных звуковых элементов с использованием того предварительно заданного режима рендеринга, который указан указанием режима рендеринга для области положения слушателя, указанной информацией об области положения слушателя.
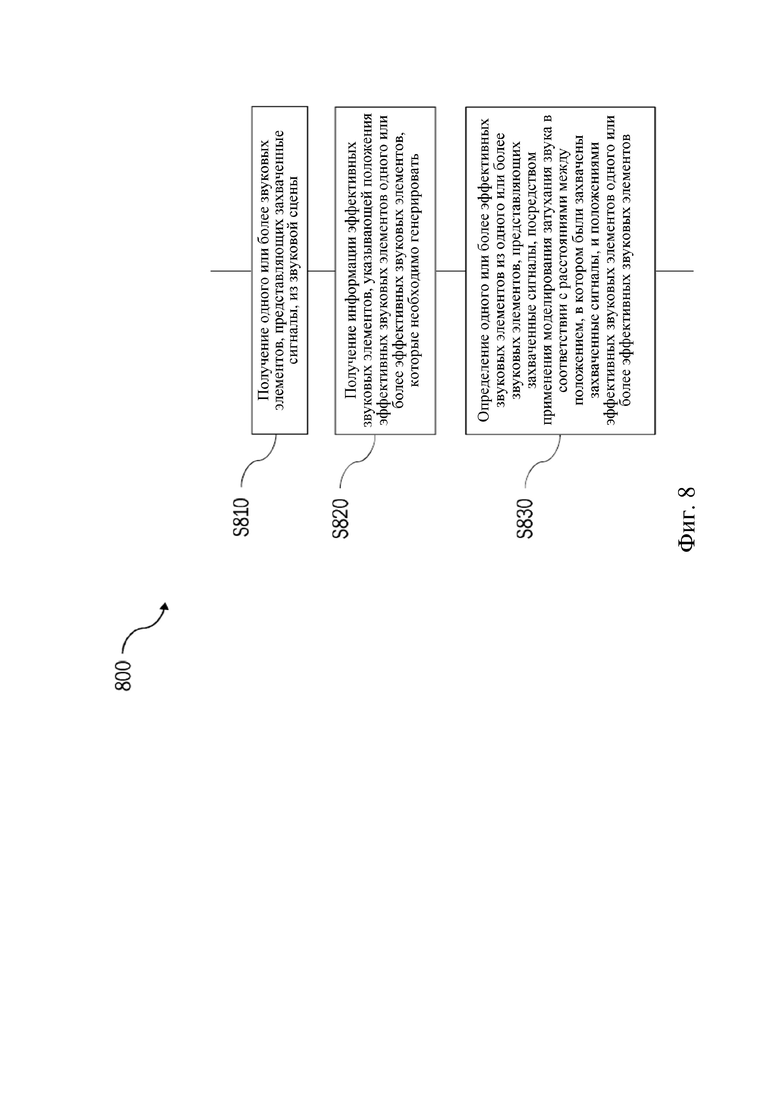
На фиг. 8 показана блок-схема, иллюстрирующая пример способа 800 генерирования содержимого звуковой сцены.
На этапе S810 получают один или более звуковых элементов, представляющих захваченные сигналы, из звуковой сцены. Это можно сделать, например, путем захвата звука, например, с использованием микрофона или мобильного устройства, обладающего возможностью записи.
На этапе S820 получают информацию эффективных звуковых элементов, указывающую положения эффективных звуковых элементов одного или более эффективных звуковых элементов, которые нужно сгенерировать. Положения эффективных звуковых элементов можно оценить или можно получить в виде пользовательского ввода.
На этапе S830 один или более эффективных звуковых элементов определяют из одного или более звуковых элементов, представляющих захваченные сигналы, путем применения моделирования затухания звука в соответствии с расстояниями между положением, в котором были захвачены захваченные сигналы, и положениями эффективных звуковых элементов одного или более эффективных звуковых элементов.
Способ 800 позволяет выполнять практическую А(/В) запись захваченных звуковых сигналов 120, представляющих звуковые элементы 102, из дискретного положения захвата (см. фиг. 3). Способы и устройства в соответствии с настоящим изобретением должны обеспечить возможность восприятия этого материала из эталонного положения 111 или других положений 112 и ориентаций (то есть в структуре c 6DoF) в пределах области 110 положения слушателя (например, с как можно более выразительным пользовательским восприятием, с использованием, например, платформ c 3DoF+, 3DoF, 0DoF). Это схематически показано на фиг. 9.
Далее будет более подробно описан один неограничивающий пример определения эффективных звуковых элементов из (фактических / оригинальных) звуковых элементов в звуковой сцене.
Как было указано выше, варианты осуществления настоящего изобретения относятся к воссозданию звукового поля в «положении c 3DoF» способом, который соответствует предварительно заданному эталонному сигналу (который может согласоваться или может не согласоваться с физическими законами распространения звука). Это звуковое поле должно основываться на всех оригинальных «источниках звука» (звуковых элементах) и отражать влияние сложных (и возможно динамически изменяющихся) геометрических свойств соответствующей акустической среды (например среды VR/AR/MR, т. е. «дверей», «стен» и т. п.). Например, со ссылкой на пример на фиг. 2, звуковое поле может относиться ко всем источникам звука (звуковым элементам) внутри лифта.
Более того, выходное звуковое поле соответствующего устройства рендеринга (например устройства рендеринга c 6DoF) нужно воссоздать достаточно хорошо, чтобы обеспечить высокий уровень погружения VR/AR/MR для «пространства c 6DoF».
Соответственно, варианты осуществления настоящего изобретения относятся к тому, что вместо рендеринга нескольких оригинальных звуковых объектов (звуковых элементов) и учета влияния сложной акустической среды вводится виртуальный звуковой объект (объекты) (эффективные звуковые элементы), который подвергнут предварительному рендерингу в кодере, представляя всю звуковую сцену (то есть учитывая влияние акустической среды звуковой сцены). Все эффекты акустической среды (например акустическое преграждение, реверберация, прямое отражение, эхо и т. п.) захватываются непосредственно в сигнале виртуального объекта (эффективного звукового элемента), который кодируется и передается на устройство рендеринга (например устройство рендеринга c 6DoF).
Соответствующее устройство рендеринга на стороне декодера (например устройство рендеринга c 6DoF) может работать в «простом режиме рендеринга» (не учитывающем среду VR/AR/MR) во всем пространстве c 6DoF для объектов таких типов (типов элементов). Простой режим рендеринга (как пример упомянутого выше предварительно заданного режима рендеринга) может учитывать только ослабление с увеличением дальности (в пустом пространстве), но не может учитывать эффекты акустической среды (например акустического элемента в акустической среде), такие как реверберация, эхо, прямое отражение, акустическое преграждение и т. п.
Для расширения диапазона применимости предварительно заданного эталонного сигнала виртуальный объект (объекты) (эффективные звуковые элементы) могут быть расположены в определенных положениях в акустической среде (пространстве VR/AR/MR) (например, в центре интенсивности звука оригинальной звуковой сцены или оригинальных звуковых элементов). Это положение может определяться в кодере автоматически путем обратного рендеринга звука или вручную по указанию поставщика контента. В таком случае кодер транспортирует только:
1.b) флаг, сигнализирующий «тип c предварительным рендерингом» виртуального звукового объекта (или в общем указание режима рендеринга);
2.b) сигнал виртуального звукового объекта (эффективный звуковой элемент), полученный из по меньшей мере подвергнутого предварительному рендерингу эталона (например, монофонический объект); и
3.b) координаты «положения c 3DoF» и описание «пространства c 6DoF» (например, информация эффективных звуковых элементов, включая положения эффективных звуковых элементов)
Предварительно заданный эталонный сигнал для обычного подхода не является тем же, что сигнал (2.b) виртуального звукового объекта для предложенного подхода. А именно, «простой» рендеринг c 6DoF сигнала (2.b) виртуального звукового объекта должен аппроксимировать предварительно заданный эталонный сигнал как можно лучше для заданного «положения (положений) c 3DoF».
В одном примере кодер звука может выполнять следующий способ кодирования:
1. определение требуемого «положения (положений) c 3DoF» и соответствующей «области (областей) c 3DoF+» (например, положений слушателя и/или областей положения слушателя, в которые нужно выполнить рендеринг)
2. эталонный рендеринг (или прямая запись) для этих «положений (положения) c 3DoF»
3. обратный рендеринг звука, определение сигнала (сигналов) и положения (положений) виртуального звукового объекта (объектов) (эффективных звуковых элементов), которые обеспечивают наилучшую возможную аппроксимацию полученного эталонного сигнала (сигналов) в «положении (положениях) c 3DoF»
4. кодирование результирующих виртуального звукового объекта (объектов) (эффективных звуковых элементов) и его/их положения (положений) вместе с сигналами соответствующего пространства c 6DoF (акустической среды) и атрибутами «объекта, подвергнутого предварительному рендерингу», делающими возможным «простой режим рендеринга» устройства рендеринга c 6DoF (например, указание режима рендеринга)
Сложность обратного рендеринга звука (см. пункт 3 выше) непосредственно коррелирует со сложностью обработки 6DoF «простого режима рендеринга» устройства рендеринга c 6DoF. Более того, эта обработка производится на стороне кодера, который, как полагается, имеет меньше ограничений относительно вычислительной мощностьи.
Примеры элементов данных, которые нужно транспортировать в битовом потоке, схематически показаны на фиг. 11A. На фиг. 11B схематически показаны элементы данных, которые транспортировались бы в битовом потоке в обычных системах кодирования / декодирования.
На фиг. 12 показаны случаи использования прямого «простого» и «эталонного» режимов рендеринга. В левой части фиг. 12 показана работа упомянутых выше режимов рендеринга, а в правой части схематически показан рендеринг звукового объекта в положение слушателя с использованием любого из режимов рендеринга (на основе примера по фиг. 2).
• «Простой режим рендеринга» не может учитывать акустическую среду (например акустическую среду VR/AR/MR). То есть простой режим рендеринга может учитывать только ослабление с увеличением дальности (например в пустом пространстве). Например, как показано на верхней панели в левой части фиг. 12, простой режим Fsimple рендеринга учитывает только ослабление с увеличением дальности, но не может учитывать эффекты среды VR/AR/MR, например, открывание и закрывание двери (см., например, фиг. 2).
• «Эталонный рендеринг» (нижняя панель в левой части фиг. 12) может учитывать некоторые или все эффекты среды VR/AR/MR.
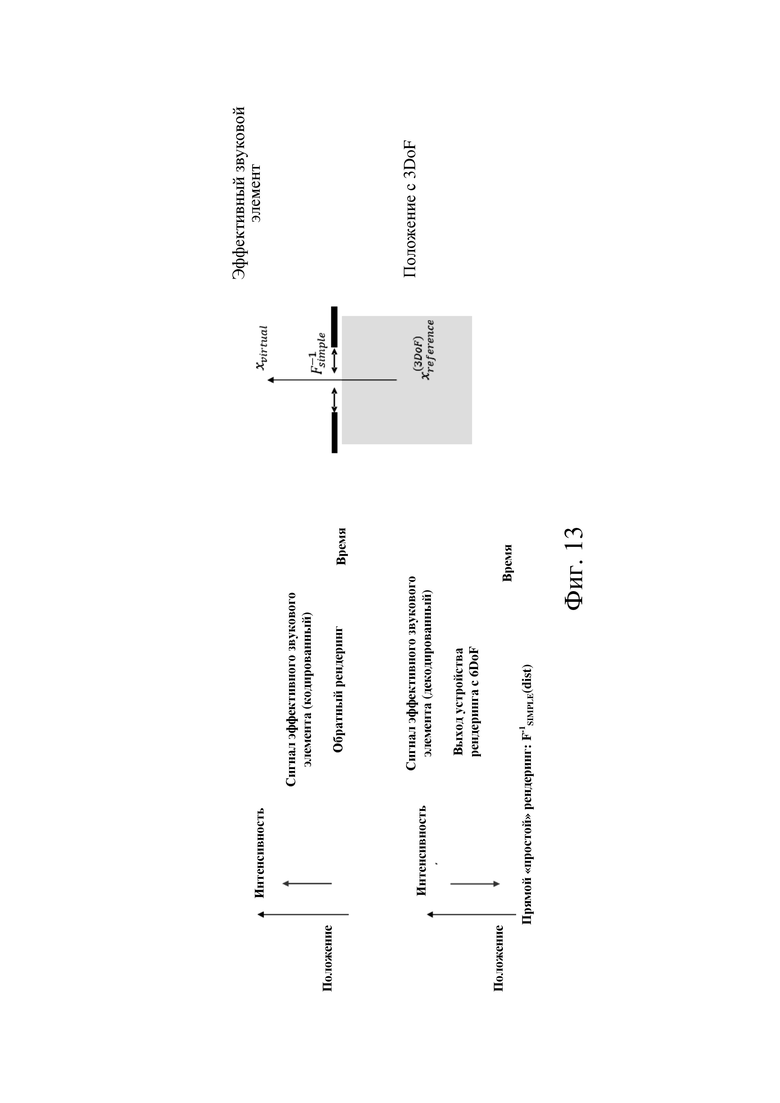
На фиг. 13 изображен пример обработки на стороне кодера / декодера для простого режима рендеринга. На верхней панели в левой части показана обработка в кодере, а на нижней панели в левой части показана обработка в декодере. В правой части схематически показан обратный рендеринг звукового сигнала в положении слушателя в положение эффективного звукового элемента.
Выход устройства рендеринга (например устройства рендеринга c 6DoF) может аппроксимировать эталонный звуковой сигнал в положении (положениях) c 3DoF. Эта аппроксимация может включать влияние ядро звука - кодер и эффекты агрегирования звукового объекта (то есть представление нескольких пространственно обособленных источников звука (звуковых элементов) через меньшее количество виртуальных объектов (эффективных звуковых элементов)). Например, аппроксимированный эталонный сигнал может учитывать положение слушателя, меняющееся в пространстве c 6DoF, и может подобным образом представлять несколько источников звука (звуковых элементов) на основании меньшего числа виртуальных объектов (эффективных звуковых элементов). Это схематически показано на фиг. 14.
В одном примере на фиг. 15 изображены сигналы (звуковые элементы) 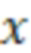 101 источников / объектов звука, сигналы (эффективные звуковые элементы)
101 источников / объектов звука, сигналы (эффективные звуковые элементы) 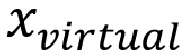 100 виртуальных звуковых объектов, требуемый выход рендеринга в 3DoF 102
100 виртуальных звуковых объектов, требуемый выход рендеринга в 3DoF 102 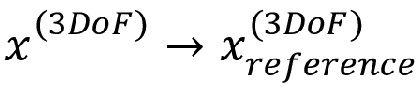 и аппроксимация требуемого рендеринга 103
и аппроксимация требуемого рендеринга 103 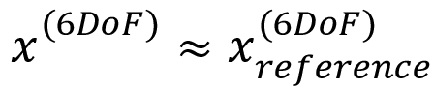 .
.
Далее используется следующая терминология:
- 3DoF - заданное эталонное положение (положения) совместимости  6DoF пространства
6DoF пространства
- 6DoF - произвольное разрешенное положение (положения) сцена VR/AR/MR
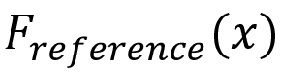 - - определенный кодером эталонный рендеринг
- - определенный кодером эталонный рендеринг
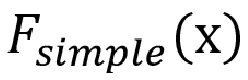 - - заданный декодером «простой режим рендеринга» c 6DoF
- - заданный декодером «простой режим рендеринга» c 6DoF
 - - представление звукового поля в положении c 3DoF / пространстве c 6DoF
- - представление звукового поля в положении c 3DoF / пространстве c 6DoF
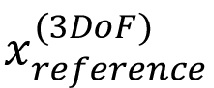 - - определенный кодером эталонный сигнал (сигналы) для положения (положений) c 3DoF:
- - определенный кодером эталонный сигнал (сигналы) для положения (положений) c 3DoF:
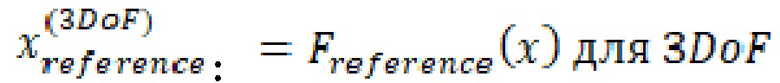 -
-
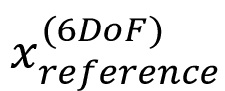 - - общий выход эталонного рендеринга
- - общий выход эталонного рендеринга
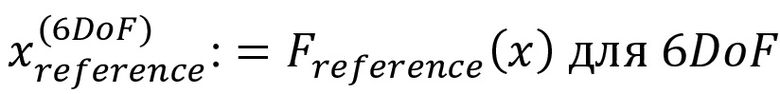 -
-
Дано (на стороне кодера):
• сигнал (сигналы) источника звука -
• эталонный сигнал (сигналы) для положения (положений) c 3DoF - 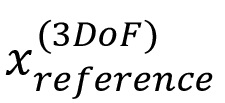
Доступно (в устройстве рендеринга):
• сигнал (сигналы) виртуальных объектов - 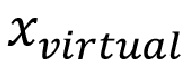
• «простой режим рендеринга» декодера c 6DoF - 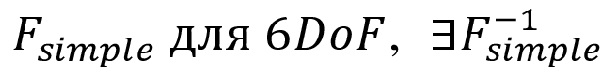
Задача: определить 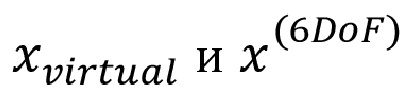 для обеспечения
для обеспечения
• требуемого выхода рендеринга в 3DoF - 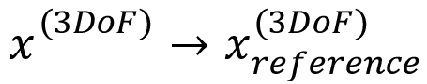
• аппроксимации требуемого рендеринга - 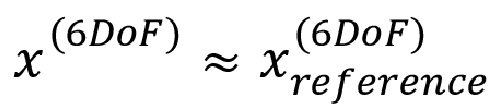
Решение:
• определение виртуального объекта (объектов) 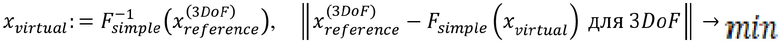
• рендеринг c 6DoF виртуального объекта (объектов) - 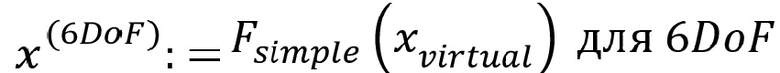
Можно выделить следующие основные преимущества предложенного подхода:
• Поддержка функции художественного рендеринга: выход устройства рендеринга c 6DoF может соответствовать произвольному (известному на стороне кодера) эталонному сигналу, подвергнутому художественному предварительному рендерингу.
• Сложность вычислений: устройство рендеринга звука c 6DoF (например, устройство рендеринга MPEG-I Audio) может работать в «простом режиме рендеринга» для сложных акустических сред VR/AR/MR.
• Эффективность кодирования: при этом подходе битовая скорость звука для сигнала (сигналов), подвергнутого предварительному рендерингу, пропорциональна количеству положений c 3DoF (точнее, количеству соответствующих виртуальных объектов), а не количеству оригинальных источников звука. Это может быть очень выгодно для случаев с большим количеством объектов и ограниченной свободой перемещения c 6DoF.
• Контроль качества звука в предварительно заданном положении (положениях): наилучшее воспринимаемое качество звука может быть точно обеспечено кодером для любого произвольного положения (положений) и соответствующей области (областей) c 3DoF+ в пространстве VR/AR/MR.
Настоящее изобретение поддерживает концепцию эталонных рендеринга / записи (то есть «художественного замысла»): эффекты любой сложной акустической среды (или эффекты художественного рендеринга) могут быть закодированы подвергнутым предварительному рендерингу звуковым сигналом (сигналами) (и переданы в нем).
Для обеспечения возможности эталонных рендеринга / записи в битовом потоке может быть передана сигналами следующая информация:
• Флаг (флаги) типа сигнала, подвергнутого предварительному рендерингу, который активирует «простой режим рендеринга», игнорирующий влияние акустической среды VR/AR/MR для соответствующего виртуального объекта (объектов).
• Параметризация, описывающая область применимости (то есть пространство c 6DoF) для рендеринга сигнала (сигналов) виртуальных объектов.
Во время обработки звука c 6DoF (например обработки звука MPEG-I) может быть указано следующее:
• Как устройство рендеринга c 6DoF микширует такие подвергнутые предварительному рендерингу сигналы между собой и с обычными сигналами.
Поэтому настоящее изобретение:
• обеспечивает традиционный подход к определению задаваемой декодером функции «простого режимп рендеринга» (т. е. 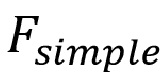 ); она может иметь произвольную сложность, но на стороне декодера должна существовать соответствующая аппроксимация (т. е.
); она может иметь произвольную сложность, но на стороне декодера должна существовать соответствующая аппроксимация (т. е. 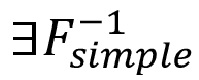 ); в идеале эта аппроксимация должна быть математически «четко определенной» (например алгоритмически стабильной и т. п.)
); в идеале эта аппроксимация должна быть математически «четко определенной» (например алгоритмически стабильной и т. п.)
• является расширяемым и применимым к традиционным представлениям звукового поля и источников звука (и их комбинаций): объектам, каналам, FOA, HOA
• может учитывать аспекты направленности источника звука (в дополнение к моделированию с ослаблением с увеличением дальности)
• является применимым ко множеству (даже перекрывающихся) положений c 3DoF для сигналов, подвергнутых предварительному рендерингу
• является применимым к сценариям, в которых сигнал (сигналы), подвергнутый предварительному рендерингу, микшируют с обычными сигналами (средой, объектами, FOA, HOA и т. п.)
• позволяет определять и получать эталонный сигнал (сигналы) 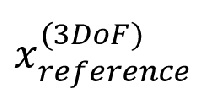 для положения (положений) c 3DoF в виде:
для положения (положений) c 3DoF в виде:
- выхода любого (произвольной сложности) «производственного устройства рендеринга», примененного на стороне создателя содержимого
- реальных звуковых записей сигналов / поля (и их художественной модификации)
Некоторые варианты осуществления настоящего изобретения могут быть направлены на определение положения c 3DoF на основании:
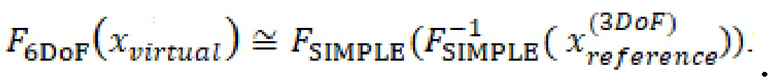
Способы и системы, описанные в настоящем документе, могут быть реализованы как программное обеспечение, аппаратно-программное обеспечение и/или аппаратное обеспечение. Некоторые компоненты могут быть реализованы в виде программного обеспечения, выполняемого процессором цифровой обработки сигналов или микропроцессором. Другие компоненты могут быть реализованы в виде аппаратного обеспечения или в виде специализированных интегральных микросхем. Сигналы, которые встречаются в описанных способах и системах, могут храниться на носителях, таких как оперативные запоминающие устройства или оптические носители информации. Они могут передаваться по сетям, таким как радиосети, спутниковые сети, беспроводные сети или проводные сети, например Интернет. Типичными устройствами, использующими способы и системы, описанные в настоящем документе, являются переносные электронные устройства или другая бытовая аппаратура, которая используется для хранения и/или рендеринга звуковых сигналов.
Примеры реализации способов и устройства согласно настоящему изобретению станут очевидными на основе следующих пронумерованных примеров вариантов осуществления (ППВО), которые не являются пунктами формулы изобретения.
ППВО1 относится к способу кодирования звуковых данных, включающему: кодирование сигнала виртуальных звуковых объектов, получаемого из по меньшей мере одного подвергнутого предварительному рендерингу эталонного сигнала; кодирование метаданных, указывающих положение c 3DoF и описание пространства c 6DoF; и передачу кодированного виртуального звукового сигнала и метаданных, указывающих положение c 3DoF и описание пространства c 6DoF.
ППВО2 относится к способу согласно ППВО1, дополнительно включающему передачу сигнала, который указывает наличие типа виртуального звукового объекта с предварительным рендерингом.
ППВО3 относится к способу согласно ППВО1 или ППВО2, где по меньшей мере один эталон, подвергнутый предварительному рендерингу, определяют на основании эталонного рендеринга положения c 3DoF и соответствующей области c 3DoF+.
ППВО4 относится к способу согласно любому из ППВО1 – ППВО3, дополнительно включающему определение положения виртуального звукового объекта относительно пространства c 6DoF.
ППВО5 относится к способу согласно любому из ППВО1 – ППВО4, где положение виртуального звукового объекта определяют на основании по меньшей мере одного из обратного рендеринга звука или задания вручную поставщиком содержимого.
ППВО6 относится к способу согласно любому из ППВО1 – ППВО5, где виртуальный звуковой объект аппроксимирует предварительно заданный эталонный сигнал для положения c 3DoF.
ППВО7 относится к способу согласно любому из ППВО1 – ППВО6, где виртуальный объект определяют на основании:
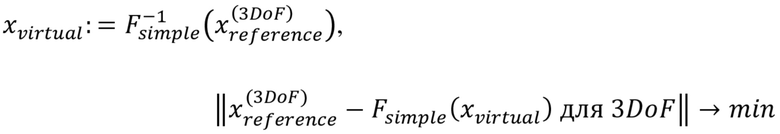 ,
,
где сигнал виртуального объекта 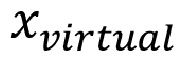 , «простой режим рендеринга» декодера c 6DoF
, «простой режим рендеринга» декодера c 6DoF
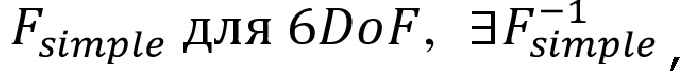
при этом виртуальный объект определяют так, чтобы минимизировать абсолютную разность между положением c 3DoF и определением простого режима рендеринга для виртуального объекта.
ППВО8 относится к способу рендеринга виртуального звукового объекта, причем этот способ включает рендеринг звуковой сцены c 6DoF на основании виртуального звукового объекта.
ППВО9 относится к способу согласно ППВО8, где рендеринг виртуального объекта выполняют на основании:
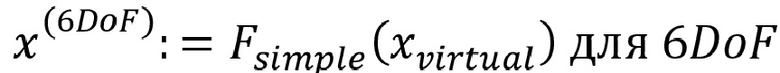
где 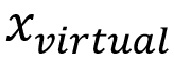 соответствует виртуальному объекту; где
соответствует виртуальному объекту; где 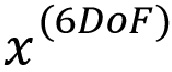 соответствует аппроксимированному подвергнутому рендерингу объекту в 6DoF; и
соответствует аппроксимированному подвергнутому рендерингу объекту в 6DoF; и 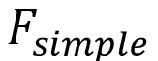 соответствует задаваемой декодером функции простого режима рендеринга.
соответствует задаваемой декодером функции простого режима рендеринга.
ППВО10 относится к способу согласно ППВО8 или ППВО9, где рендеринг виртуального объекта выполняют на основании сигнализации флагом типа виртуального звукового объекта с предварительным рендерингом.
ППВО11 относится к способу согласно любому из ППВО8 – ППВО10, дополнительно включающему прием метаданных, указывающих подвергнутое предварительному рендерингу положение c 3DoF и описание пространства c 6DoF, где рендеринг основан на положении c 3DoF и описании пространства c 6DoF.

Изобретение относится к средствам для рендеринга звука. Технический результат заключается в повышении эффективности рендеринга звука. Выполняют декодирование описания звуковой сцены из битового потока, где звуковая сцена содержит акустическую среду. Определяют эффективные звуковые элементы из описания звуковой сцены, где эффективные звуковые элементы инкапсулируют влияние акустической среды и соответствуют виртуальным звуковым объектам, представляющим звуковую сцену. Определяют информацию эффективных звуковых элементов, указывающую положения эффективных звуковых элементов, из описания звуковой сцены. Декодируют указание режима рендеринга из битового потока, указывающее на то, представляют ли эффективные звуковые элементы звуковое поле, полученное из подвергнутых предварительному рендерингу звуковых элементов, и следует ли выполнять их рендеринг с использованием предварительно заданного режима рендеринга. В ответ на указание режима рендеринга, указывающее, что эффективные звуковые элементы представляют звуковое поле и что следует выполнять их рендеринг с использованием предварительно заданного режима рендеринга, выполняют рендеринг эффективных звуковых элементов с использованием предварительно заданного режима рендеринга. 7 н. и 9 з.п. ф-лы, 16 ил.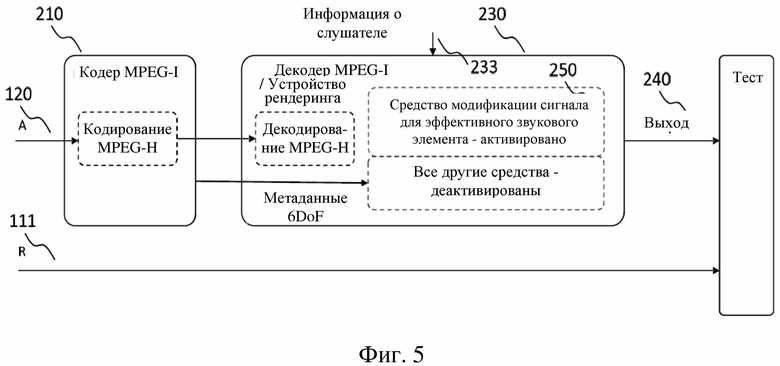
1. Способ декодирования содержимого звуковой сцены из битового потока декодером, который содержит устройство рендеринга звука с одним или более средствами рендеринга, указанный способ включает:
прием битового потока;
декодирование описания звуковой сцены из битового потока, где звуковая сцена содержит акустическую среду;
определение одного или более эффективных звуковых элементов из описания звуковой сцены, где один или более эффективных звуковых элементов инкапсулируют влияние акустической среды и соответствуют одному или более виртуальным звуковым объектам, представляющим звуковую сцену;
определение информации эффективных звуковых элементов, указывающей положения эффективных звуковых элементов одного или более эффективных звуковых элементов, из описания звуковой сцены, причем информация эффективных звуковых элементов содержит информацию, указывающую соответствующие схемы излучения звука одного или более эффективных звуковых элементов;
декодирование указания режима рендеринга из битового потока, где указание режима рендеринга указывает на то, представляют ли один или более эффективных звуковых элементов звуковое поле, полученное из подвергнутых предварительному рендерингу звуковых элементов, и следует ли выполнять их рендеринг с использованием предварительно заданного режима рендеринга; и
в ответ на указание режима рендеринга, указывающее, что один или более эффективных звуковых элементов представляют звуковое поле, полученное из подвергнутых предварительному рендерингу звуковых элементов, и что следует выполнять их рендеринг с использованием предварительно заданного режима рендеринга, выполнение рендеринга одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга,
при этом рендеринг одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга учитывает информацию эффективных звуковых элементов, и эта информация указывает соответствующие схемы излучения звука одного или более эффективных звуковых элементов, и при этом предварительно заданный режим рендеринга определяет предварительно заданную конфигурацию средств рендеринга для управления влиянием акустической среды звуковой сцены на выход рендеринга, и
в рендеринге одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга применяют моделирование затухания звука в соответствии с относительными расстояниями между положением слушателя и положениями эффективных звуковых элементов одного или более эффективных звуковых элементов.
2. Способ по п. 1, отличающийся тем, что дополнительно включает:
получение информации о положении слушателя, указывающей положение головы слушателя в акустической среде, и/или информации об ориентации слушателя, указывающей ориентацию головы слушателя в акустической среде,
при этом рендеринг одного или более эффективных звуковых элементов с использованием предварительно заданного режима рендеринга дополнительно учитывает информацию о положении слушателя и/или информацию об ориентации слушателя.
3. Способ по п. 1 или 2,
отличающийся тем, что из описания звуковой сцены определяют по меньшей мере два эффективных звуковых элемента;
при этом указание режима рендеринга указывает соответствующий предварительно заданный режим рендеринга для каждого из по меньшей мере двух эффективных звуковых элементов;
при этом способ включает рендеринг по меньшей мере двух эффективных звуковых элементов с использованием их соответствующих предварительно заданных режимов рендеринга; и
при этом рендеринг каждого эффективного звукового элемента с использованием его соответствующего предварительно заданного режима рендеринга учитывает информацию эффективного звукового элемента для этого эффективного звукового элемента, и причем режим рендеринга для этого эффективного звукового элемента определяет соответствующую предварительно заданную конфигурацию средств рендеринга для управления влиянием акустической среды звуковой сцены на выход рендеринга для этого эффективного звукового элемента.
4. Способ по любому из пп. 1-3, отличающийся тем, что дополнительно включает:
определение одного или более звуковых элементов из описания звуковой сцены;
определение информации звуковых элементов, указывающей положения звуковых элементов одного или более звуковых элементов, из описания звуковой сцены; и
рендеринг одного или более звуковых элементов с использованием режима рендеринга для одного или более звуковых элементов, отличающегося от предварительно заданного режима рендеринга, используемого для одного или более эффективных звуковых элементов,
при этом рендеринг одного или более звуковых элементов с использованием режима рендеринга для одного или более звуковых элементов учитывает информацию звуковых элементов.
5. Способ по любому из пп. 1-4, отличающийся тем, что дополнительно включает:
получение информации об области положения слушателя, указывающей область положения слушателя, для которой должен быть использован предварительно заданный режим рендеринга.
6. Способ по п. 5,
отличающийся тем, что предварительно заданный режим рендеринга, указанный указанием режима рендеринга, зависит от положения слушателя; и
при этом способ включает рендеринг одного или более эффективных звуковых элементов с использованием того предварительно заданного режима рендеринга, который указан указанием режима рендеринга для области положения слушателя, указанной информацией об области положения слушателя.
7. Способ генерирования содержимого звуковой сцены, включающий:
получение одного или более звуковых элементов, представляющих захваченные сигналы, из звуковой сцены, где звуковая сцена содержит акустическую среду;
получение информации эффективных звуковых элементов, указывающей положения эффективных звуковых элементов одного или более эффективных звуковых элементов, которые необходимо генерировать, причем один или более эффективных звуковых элементов инкапсулируют влияние акустической среды и соответствуют одному или более виртуальным звуковым объектам, представляющим звуковую сцену, и при этом информация эффективных звуковых элементов содержит информацию, указывающую соответствующие схемы излучения звука одного или более эффективных звуковых элементов; и
определение одного или более эффективных звуковых элементов из одного или более звуковых элементов, представляющих захваченные сигналы, посредством применения моделирования затухания звука в соответствии с расстояниями между положением, в котором были захвачены захваченные сигналы, и положениями эффективных звуковых элементов одного или более эффективных звуковых элементов.
8. Способ кодирования содержимого звуковой сцены в битовый поток, указанный способ включает:
прием описания звуковой сцены, причем звуковая сцена содержит акустическую среду и один или более звуковых элементов в соответствующих положениях звуковых элементов;
определение одного или более эффективных звуковых элементов в соответствующих положениях эффективных звуковых элементов из одного или более звуковых элементов, где один или более звуковых элементов соответствуют одному или более оригинальным звуковым объектам и где один или более эффективных звуковых элементов инкапсулируют влияние акустической среды и соответствуют одному или более виртуальным звуковым объектам, представляющим звуковую сцену;
генерирование информации эффективных звуковых элементов, указывающей положения эффективных звуковых элементов одного или более эффективных звуковых элементов, причем информацию эффективных звуковых элементов генерируют так, что она содержит информацию, указывающую соответствующие схемы излучения звука одного или более эффективных звуковых элементов;
генерирование указания режима рендеринга, которое указывает, что один или более эффективных звуковых элементов представляют звуковое поле, полученное из подвергнутых предварительному рендерингу звуковых элементов, и что следует выполнять их рендеринг с использованием предварительно заданного режима рендеринга, который определяет предварительно заданную конфигурацию средств рендеринга декодера для управления влиянием акустической среды на выход рендеринга на декодере; и
кодирование в битовый поток одного или более звуковых элементов, положений звуковых элементов, одного или более эффективных звуковых элементов, информации эффективных звуковых элементов и указания режима рендеринга.
9. Способ по п. 8, отличающийся тем, что дополнительно включает:
получение информации о положении слушателя, указывающей положение головы слушателя в акустической среде, и/или информации об ориентации слушателя, указывающей ориентацию головы слушателя в акустической среде; и
кодирование в битовый поток информации о положении слушателя и/или информации об ориентации слушателя.
10. Способ по п. 8 или 9,
отличающийся тем, что по меньшей мере два эффективных звуковых элемента генерируют и кодируют в битовый поток; и
при этом указание режима рендеринга указывает соответствующий предварительно заданный режим рендеринга для каждого из по меньшей мере двух эффективных звуковых элементов.
11. Способ по любому из пп. 8-10, отличающийся тем, что дополнительно включает:
получение информации об области положения слушателя, указывающей область положения слушателя, для которой должен быть использован предварительно заданный режим рендеринга; и
кодирование информации об области положения слушателя в битовый поток.
12. Способ по п. 11,
отличающийся тем, что предварительно заданный режим рендеринга, указанный указанием режима рендеринга, зависит от положения слушателя, так что указание режима рендеринга указывает соответствующий предварительно заданный режим рендеринга для каждого из множества положений слушателя.
13. Декодер звука, содержащий процессор, подключенный к памяти, в которой хранятся команды для процессора,
отличающийся тем, что процессор приспособлен выполнять способ по любому из пп. 1-6.
14. Машиночитаемый носитель данных, на котором хранится компьютерная программа, содержащая команды для обеспечения выполнения процессором, который исполняет команды, способа по любому из пп. 1-6.
15. Кодер звука, содержащий процессор, подключенный к памяти, в которой хранятся команды для процессора,
отличающийся тем, что процессор приспособлен выполнять способ по любому из пп. 7-12.
16. Машиночитаемый носитель данных, на котором хранится компьютерная программа, содержащая команды для обеспечения выполнения процессором, который исполняет команды, способа по любому из пп. 7-12.
| EP 2866227 A1, 29.04.2015 | |||
| EP 2930952 A1, 14.10.2015 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| RU 2015153540 A, 21.06.2017 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |

