Подробное описание изобретения
Настоящее изобретение относится к аудиообработке и, в частности, к аудиообработке относительно звуковых полей, которые задаются относительно опорного местоположения, такого как местоположение микрофона или виртуального микрофона.
Амбиофонические сигналы содержат усеченное сферическое гармоническое разложение звукового поля. Амбиофония имеет различные варианты. Предусмотрена "традиционная" амбиофония [31], которая сегодня известна как "амбиофония первого порядка (FOA)" и содержит четыре сигнала (т.е. один всенаправленный сигнал и вплоть до трех направленных сигналов в виде восьмерки). Более свежие варианты амбиофонии известны как "амбиофония высшего порядка (HOA)" и предоставляют улучшенное пространственное разрешение и большую зону наилучшего восприятия слушателя за счет переноса большего числа сигналов. В общем, полностью заданное HOA-представление N-ого порядка состоит из (N+1)2 сигналов.
В связи с идеей амбиофонии, представление на основе направленного кодирования аудио (DirAC) задумано, чтобы представлять звуковую FOA- или HOA-сцену в более компактном, параметрическом стиле. Более конкретно, пространственная звуковая сцена представляется посредством одного (или более) передаваемых аудиоканалов, которые представляют понижающее сведение акустической сцены и ассоциированную вспомогательную информацию направления и степени рассеяния в каждом частотно-временном (TF) бине (элементе разрешения). Дополнительная информация относительно DirAC содержится в [32, 33].
DirAC [32] может использоваться с различными микрофонными системами и с произвольными компоновками громкоговорителей. Цель DirAC-системы состоит в том, чтобы воспроизводить пространственное впечатление существующего акустического окружения максимально возможно точно с использованием многоканальной/трехмерной системы громкоговорителей. В выбранном окружении, отклики (непрерывные звуковые или импульсные отклики) измеряются с помощью всенаправленного микрофона (W) и с помощью набора микрофонов, который позволяет измерять направление поступления звука и степень рассеяния звука. Общепринятый способ заключается в том, чтобы применять три микрофона (X, Y, Z) в виде восьмерки, совмещенные с соответствующими декартовыми осями координат [34]. Способ для этого заключается в том, чтобы использовать микрофон на основе звукового поля, который непосредственно дает в результате все требуемые отклики. W-, X-, Y- и Z-сигналы также могут вычисляться из набора дискретных всенаправленных микрофонов.
В DirAC, звуковой сигнал сначала разделяется на частотные каналы. Направление и степень рассеяния звука измеряется в зависимости от времени в каждом частотном канале. В передаче, один или более аудиоканалов отправляются, вместе с проанализированными данными направления и степени рассеяния. В синтезе, аудио, которое применяется к громкоговорителям, например, может представлять собой всенаправленный канал W, либо звук для каждого громкоговорителя может вычисляться в качестве взвешенной суммы W, X, Y и Z, которая формирует сигнал, который имеет определенные направленные характеристики для каждого громкоговорителя. Каждый аудиоканал разделяется на частотные каналы, которые затем разделяются опционально на рассеянные и на нерассеянные потоки в зависимости от проанализированной степени рассеяния. Рассеянный поток воспроизводится с помощью технологии, которая формирует рассеянное восприятие звуковой сцены, например, с помощью технологий декорреляции, используемых в бинауральном кодировании по сигнальным меткам [35-37]. Нерассеянный звук воспроизводится с помощью технологии, которая имеет целью формировать точечный виртуальный источник согласно данным направления (например, VBAP [38]).
Три технологии для навигации в 6DoF с ограниченной степенью свободы предлагаются в [39]. С учетом одного амбиофонического сигнала, один амбиофонический сигнал вычисляется с использованием: 1) моделирования HOA-воспроизведения и перемещения слушателя в массиве виртуальных громкоговорителей, 2) вычисления и перемещения вдоль плоских волн и 3) повторного расширения звукового поля вокруг слушателя.
Кроме того, следует обратиться к DirAC-технологии, как описано, например, в публикации "Directional Audio Coding - Perception-Based Reproduction of Spatial Sound", V. Pulkki et al, International Workshop on the Principles and Applications of Spatial Hearing, 11-13 ноября 2009 года, Zao, Miyagi, Japan. Этот ссылочный документ описывает направленное кодирование аудио в качестве примера для связанной с опорным местоположением обработки звуковых полей, в частности, в качестве перцепционно обусловленной технологии для пространственной аудиообработки. Оно имеет применение в захвате, кодировании и повторном синтезе пространственного звука, в телеконференц-связи, в направленной фильтрации и в виртуальных слуховых окружениях.
Воспроизведение звуковых сцен зачастую акцентирует внимание на компоновках громкоговорителей, в поскольку они представляют собой типичное воспроизведение частном (например, в гостиной) и в профессиональном контексте (т.е. в кинотеатрах). Здесь, взаимосвязь сцены с геометрией воспроизведения является статической, поскольку она сопровождает двумерное изображение, которое вынуждает слушателя смотреть в направлении вперед. Затем, пространственная взаимосвязь звуковых и визуальных объектов задается и фиксируется во время производства.
В виртуальной реальности (VR), погружение явно достигается посредством предоставления возможности пользователю свободно перемещаться в сцене. Следовательно, необходимо отслеживать перемещение пользователя и регулировать визуальное и слуховое воспроизведение согласно позиции пользователя. Типично, пользователь носит наголовный дисплей (HMD) и наушники. Для восприятия на основе погружения с наушниками, аудио должно бинаурализироваться. Бинаурализация представляет собой моделирование того, как человеческая голова, уши и верхняя часть торса изменяют звук источника в зависимости от его направления и расстояния. Это достигается посредством свертки сигналов с передаточными функциями восприятия звука человеком (HRTF) для их относительного направления [1, 2]. Бинаурализация также заставляет звук казаться исходящим из сцены, а не из головы [3]. Общий сценарий, который уже успешно разрешен, представляет собой воспроизведение видео на 360º [4, 5]. Здесь, пользователь либо носит HMD, либо держит планшетный компьютер или телефон в руках. Посредством перемещения своей головы или устройства, пользователь может оглядываться в любом направлении. Он представляет собой сценарий с тремя степенями свободы (3DoF), поскольку пользователь имеет три степени перемещения (наклон в продольном направлении, наклон относительно вертикальной оси, наклон в поперечном направлении). Визуально, это реализуется посредством проецирования видео на сфере вокруг пользователя. Аудио зачастую записывается с помощью пространственного микрофона [6], например, амбиофонии первого порядка (FOA), рядом с видеокамерой. В амбиофонической области, вращение головы пользователя адаптируется простым способом [7]. Аудио затем, например, подготавливается посредством рендеринга в виртуальные громкоговорители, размещенные вокруг пользователя. Эти сигналы виртуальных громкоговорителей далее бинаурализируются.
Современные VR-варианты применения предоставляют возможность шести степеней свободы (6DoF). Помимо вращения головы, пользователь может перемещаться вокруг, что в результате приводит к перемещению его позиции в трех пространственных размерностях. 6DoF-воспроизведение ограничено посредством полного размера зоны ходьбы. Во многих случаях, эта зона является довольно небольшой, например, традиционная гостиная. 6DoF обычно встречается в VR-играх. Здесь, полная сцена является синтетической за счет формирования машиногенерируемых изображений (CGI). Аудио зачастую формируется с использованием объектно-ориентированного рендеринга, при котором каждый аудиообъект подготавливается посредством рендеринга с зависимым от расстояния усилением и относительным направлением от пользователя на основе данных отслеживания. Реализм может повышаться посредством искусственной реверберации и дифракции [8, 9, 10].
Относительно записанного контента, имеются некоторые отличительные сложности для принудительного аудиовизуального 6DoF-воспроизведения. Ранний пример пространственного звукового манипулирования в области перемещения в пространстве представляет собой пример технологий "акустического масштабирования"[11, 12]. Здесь, позиция слушателя фактически перемещается в записанную визуальную сцену, аналогично изменению масштаба в изображении. Пользователь выбирает одно направление или часть изображения и затем может прослушивать его из перемещенной точки. Это предусматривает то, что все направления поступления (DoA) изменяются относительно исходного, немасштабируемого воспроизведения.
Предложены способы для 6DoF-воспроизведения записанного контента, которые используют пространственно распределенные позиции записи. Для видео, массивы камер могут использоваться для того, чтобы формировать рендеринг на основе принципа светового поля [13]. Для аудио, аналогичная компоновка использует распределенные массивы микрофонов или амбиофонические микрофоны. Показано, что можно формировать сигнал "виртуального микрофона", размещенного в произвольной позиции, из таких записей [14].
Чтобы реализовывать такие пространственные звуковые модификации технически удобным способом, могут использоваться технологии параметрической звуковой обработки или кодирования (см. [15] на предмет общего представления). Направленное кодирование аудио (DirAC) [16] представляет собой популярный способ для того, чтобы преобразовывать запись в представление, которое состоит из аудиоспектра и параметрической вспомогательной информации относительно направления и степени рассеяния звука. Оно используется для вариантов применения на основе акустического масштабирования [11] и виртуальных микрофонов [14].
Способ, предложенный здесь, предоставляет 6DoF-воспроизведение из записи одного FOA-микрофона. Записи из одной пространственной позиции использованы для 3DoF-воспроизведения или акустического масштабирования. Но, согласно знаниям авторов изобретения, способ для интерактивного, полностью 6DoF-воспроизведения из таких данных не предложен к настоящему моменту. 6DoF-воспроизведение реализуется посредством интегрирования информации относительно расстояния источников звука в записи. Эта информация расстояния включается в параметрическое представление DirAC таким образом, что измененная перспектива слушателя корректно преобразуется.
Ни одно из амбиофонических представлений звукового поля (независимо от того, представляет оно собой регулярную FOA- или HOA-амбиофонию или DirAC-ориентированное параметрическое представление звукового поля) не предоставляет достаточную информацию, чтобы обеспечивать возможность сдвига с перемещением позиции слушателя, что требуется для 6DoF-вариантов применения, поскольку ни расстояние до объекта, ни абсолютные позиции объекта в звуковой сцене не определяются в этих форматах. Следует отметить, что сдвиг в позиции слушателя может перемещаться в эквивалентный сдвиг звуковой сцены в противоположном направлении.
Типичная проблема при перемещении в 6DoF проиллюстрирована на фиг. 1b. Допустим, что звуковая сцена описывается в позиции A с использованием амбиофонии. В этом случае, звуки из источника A и источника B поступают из идентичного направления, т.е. они имеют идентичное направление поступления (DoA). В случае перемещения в позицию B, DoA источника A и источника B отличаются. С использованием стандартного описания на основе амбиофонии звукового поля, т.е. без дополнительной информации, невозможно вычислять амбиофонические сигналы в позиции B, с учетом амбиофонических сигналов в позиции A.
Цель настоящего изобретения заключается в том, чтобы предоставлять улучшенное описание звукового поля, с одной стороны, или формирование модифицированного описания звукового поля, с другой стороны, которые обеспечивают улучшенную или гибкую, или эффективную обработку.
Эта цель достигается посредством устройства для формирования улучшенного описания звукового поля по п. 1, устройства для формирования модифицированного описания звукового поля по п. 8, способа формирования улучшенного описания звукового поля по п. 46, способа формирования модифицированного описания звукового поля по п. 47, компьютерной программы по п. 48 или улучшенного описания звукового поля по п. 49.
Настоящее изобретение основано на таких выявленных сведениях, что типичные описания звукового поля, которые связаны с опорным местоположением, требуют дополнительной информации таким образом, что эти описания звукового поля могут обрабатываться, так что может вычисляться модифицированное описание звукового поля, которое связано не с исходным опорным местоположением, а с другим опорным местоположением. С этой целью, формируются метаданные, связанные с пространственной информацией этого звукового поля, и метаданные вместе с описанием звукового поля соответствуют улучшенному описанию звукового поля, которое, например, может передаваться или сохраняться. Чтобы формировать модифицированное описание звукового поля из описания звукового поля и метаданных, и, в частности, метаданных, связанных с пространственной информацией описания звукового поля, модифицированное звуковое поле вычисляется с использованием этой пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение из опорного местоположения в другое опорное местоположение. Таким образом, улучшенное описание звукового поля, состоящее из описания звукового поля и метаданных, связанных с пространственной информацией этого звукового поля, лежащего в основе описания звукового поля, обрабатывается, чтобы получать модифицированное описание звукового поля, которое связано с другим опорным местоположением, заданным посредством дополнительной информации перемещения, которая, например, может предоставляться или использоваться на стороне декодера.
Тем не менее, настоящее изобретение не только связывается со сценарием кодера/декодера, но также может применяться в варианте применения, в котором формирование улучшенного описания звукового поля и формирование модифицированного описания звукового поля осуществляются по существу в одном и том же местоположении. Модифицированное описание звукового поля, например, может представлять собой описание непосредственно модифицированного звукового поля или фактически модифицированное звуковое поле в канальных сигналах, бинауральных сигналах или, кроме того, связанное с опорным местоположением звуковое поле, которое, тем не менее, теперь связывается с новым или другим опорным местоположением, а не с исходным опорным местоположением. Такой вариант применения, например, должен представлять собой сценарий виртуальной реальности, в котором существует описание звукового поля вместе с метаданными, и в котором слушатель перемещается из опорного местоположения, для которого предоставляется звуковое поле, и перемещается в другое опорное местоположение, и в котором после этого звуковое поле для слушателя, перемещающегося в виртуальной зоне, вычисляется таким образом, что оно соответствует звуковому полю, но теперь в другом опорном местоположении, в которое перемещен пользователь.
В конкретном варианте осуществления, улучшенное описание звукового поля имеет первое описание звукового поля, связанное с (первым) опорным местоположением, и второе описание звукового поля, связанное с дополнительным (вторым) опорным местоположением, которое отличается от (первого) опорного местоположения, и метаданные имеют информацию относительно опорного местоположения и дополнительного опорного местоположения, такую как векторы, указывающие из предварительно определенного начала координат в эти опорные местоположения. Альтернативно, метаданные могут представлять собой один вектор, указывающий либо в опорное местоположение, либо в дополнительное опорное местоположение, и вектор, тянущийся между двумя опорными местоположениями, с которыми связаны два различных описания звукового поля.
Описания звукового поля могут представлять собой непараметрические описания звукового поля, к примеру, описания на основе амбиофонии первого порядка или амбиофонии высшего порядка. Альтернативно или дополнительно, описания звукового поля могут представлять собой DirAC-описания или другие параметрические описания звукового поля, либо одно описание звукового поля, например, может представлять собой параметрическое описание звукового поля, а другое описание звукового поля, например, может представлять собой непараметрическое описание звукового поля.
Следовательно, описание звукового поля может формировать, для каждого описания звукового поля, DirAC-описание звукового поля, имеющее один или более сигналов понижающего сведения и отдельные данные направления и опционально данные степени рассеяния для различных частотно-временных бинов. В этом контексте, формирователь метаданных выполнен с возможностью формировать геометрические метаданные для обоих описаний звукового поля таким образом, что опорное местоположение и дополнительное опорное местоположение могут идентифицироваться из метаданных. Затем можно извлекать отдельные источники из обоих описаний звукового поля и выполнять дополнительную обработку для целей формирования улучшенного или модифицированного описания звукового поля.
Амбиофония становится одним из наиболее часто используемых форматов для трехмерного аудио в контексте вариантов применения в стиле виртуальной, дополненной и смешанной реальности. Разработан широкий спектр инструментальных средств получения и формирования аудио, которые формируют выходной сигнал в формате амбиофонии. Чтобы представлять амбиофонический кодированный контент в интерактивных вариантах применения в стиле виртуальной реальности (VR), формат амбиофонии преобразуется в бинауральный сигнал или каналы для воспроизведения. В вышеуказанных вариантах применения, слушатель обычно имеет возможность интерактивно изменять свою ориентацию в представленной сцене до такой степени, что он может поворачивать свою голову в звуковой сцене, что обеспечивает три степени свободы (3DoF, т.е. наклон в продольном направлении, наклон относительно вертикальной оси и наклон в поперечном направлении), и при этом подвергаться соответствующему качеству звука. Это реализуется посредством вращения звуковой сцены перед рендерингом согласно ориентации головы, которое может реализовываться с низкой вычислительной сложностью и является преимуществом амбиофонического представления. Тем не менее, в новых вариантах применения, таких как VR, требуется обеспечивать возможность свободного перемещения пользователя в звуковой сцене, а не только изменений ориентации (так называемых "шести степеней свободы", или 6DoF). Как следствие, обработка сигналов требуется для того, чтобы изменять перспективу звуковой сцены (т.е. чтобы фактически перемещаться в звуковой сцене вдоль осей X, Y или Z). Тем не менее, главный недостаток амбиофонии заключается в том, что процедура описывает звуковое поле из одной перспективы в звуковой сцене. В частности, она не содержит информацию относительно фактического местоположения источников звука в звуковой сцене, которая позволяет сдвигать звуковую сцену (выполнять "перемещение"), что требуется для 6DoF. Это описание изобретения предоставляет несколько расширений амбиофонии для того, чтобы преодолевать эту проблему, а также упрощать перемещение и в силу этого обеспечивать истинную 6DoF.
Записи на основе амбиофонии первого порядка (FOA) могут обрабатываться и воспроизводиться в наушниках. Они могут вращаться для того, чтобы учитывать ориентацию головы слушателей. Тем не менее, системы виртуальной реальности (VR) обеспечивают возможность слушателю перемещаться в шести степенях свободы (6DoF), т.е. в трех вращательных плюс в трех переходных степенях свободы. Здесь, явные углы и расстояния источников звука зависят от позиции слушателя. Описывается технология для того, чтобы упрощать 6DoF. В частности, FOA-запись описывается с использованием параметрической модели, которая модифицируется на основе позиции слушателя и информации относительно расстояний до источников. Способ оценивается посредством теста на основе прослушивания, сравнивающего различные бинауральные рендеринги синтетической звуковой сцены, в которой слушатель может свободно перемещаться.
В дополнительных предпочтительных вариантах осуществления, улучшенное описание звукового поля выводится посредством выходного интерфейса для формирования выходного сигнала для передачи или хранения, при этом выходной сигнал содержит, для временного кадра, один или более аудиосигналов, извлекаемых из звукового поля, и пространственную информацию для временного кадра. В частности, формирователь звуковых полей, в дополнительных вариантах осуществления, является адаптивным с возможностью извлекать данные направления из звукового поля, причем данные направления означают направление поступления звука за период времени или частотный бин, и формирователь метаданных выполнен с возможностью извлекать пространственную информацию в качестве элементов данных, ассоциирующих информацию расстояния с данными направления.
В частности, в таком варианте осуществления, выходной интерфейс выполнен с возможностью формировать выходные сигналы таким образом, что элементы данных для временного кадра связываются с данными направления для различных частотных бинов.
В дополнительном варианте осуществления, формирователь звуковых полей также выполнен с возможностью формировать информацию степени рассеяния для множества частотных бинов временного кадра звукового поля, при этом формирователь метаданных выполнен с возможностью формировать информацию расстояния только для частотного бина, отличающегося от предварительно определенного значения или отличающегося от бесконечности, либо формировать значение расстояния для частотного бина вообще, когда значение степени рассеяния ниже предварительно определенного или адаптивного порогового значения. Таким образом, для частотно-временных бинов, которые имеют высокую степень рассеяния, значения расстояния не формируются вообще, либо формируется предварительно определенное значение расстояния, которое интерпретируется посредством декодера определенным способом. Таким образом, необходимо удостоверяться в том, что для частотно-временных бинов, имеющих высокую степень рассеяния, любой связанный с расстоянием рендеринг не выполняется, поскольку высокая степень рассеяния указывает то, что для такого частотно-временного бина звук исходит не из определенного локализованного источника, а исходит из любого направления и в силу этого является идентичным независимо от того, воспринимается звуковое поле в исходном опорном местоположении либо в другом или новом опорном местоположении.
Относительно модуля вычисления звуковых полей, предпочтительные варианты осуществления содержат интерфейс перемещения для предоставления информации перемещения или информации вращения, указывающей вращение предназначенного слушателя в модифицированное звуковое поле, модуль подачи метаданных для подачи метаданных в модуль вычисления звуковых полей и модуль подачи звуковых полей для подачи описания звукового поля в модуль вычисления звуковых полей и, дополнительно, выходной интерфейс для вывода модифицированного звукового поля, содержащего модифицированное описание звукового поля и модифицированные метаданные, причем модифицированные метаданные извлекаются из метаданных с использованием информации перемещения, либо выходной интерфейс выводит множество каналов громкоговорителей, причем каждый канал громкоговорителя связан с предварительно заданной позицией громкоговорителя, либо выходной интерфейс выводит бинауральное представление модифицированного звукового поля.
В варианте осуществления, описание звукового поля содержит множество компонентов звукового поля. Множество компонентов звукового поля содержат всенаправленный компонент и, по меньшей мере, один направленный компонент. Такое описание звукового поля, например, представляет собой амбиофоническое описание звукового поля первого порядка, имеющее всенаправленный компонент и три направленных компонента X, Y, Z, либо такое звуковое поле представляет собой амбиофоническое описание высшего порядка, содержащее всенаправленный компонент, три направленных компонента относительно направлений по оси X, Y и Z и, дополнительно, дополнительные направленные компоненты, которые связаны с направлениями, отличными от направлений по оси X, Y, Z.
В варианте осуществления, устройство содержит анализатор для анализа компонентов звукового поля, чтобы извлекать, для различных временных или частотных бинов, информацию направления поступления. Устройство дополнительно имеет модуль преобразования с перемещением для вычисления модифицированной DoA-информации в расчете на частотный или временной бин с использованием DoA-информации и метаданных, причем метаданные связаны с картой глубины, ассоциирующей расстояние с источником, включенным в оба описания звукового поля, полученные, например, посредством обработки триангуляции с использованием двух углов относительно двух других опорных местоположений и расстояния/позиций или опорных местоположений. Это может применяться к полнополосному представлению или к различным частотным бинам временного кадра.
Кроме того, модуль вычисления звуковых полей имеет модуль компенсации расстояния для вычисления модифицированного звукового поля с использованием компенсационной информации расстояния в зависимости от расстояния, вычисленного с использованием метаданных, идентичных для каждого частотного или временного бина или отличающихся для каждого или некоторых частотно-временных бинов, и от нового расстояния, ассоциированного с временным или частотным бином, причем новое расстояние связано с модифицированной DoA-информацией.
В варианте осуществления, модуль вычисления звуковых полей вычисляет первый вектор, указывающий из опорного местоположения в источник звука, полученный посредством анализа звукового поля. Кроме того, модуль вычисления звуковых полей вычисляет второй вектор, указывающий из другого опорного местоположения в источник звука, и это вычисление проводится с использованием первого вектора и информации перемещения, причем информация перемещения задает вектор перемещения из опорного местоположения в другое опорное местоположение. Так же, в таком случае расстояние от другого опорного местоположения до источника звука вычисляется с использованием второго вектора.
Кроме того, модуль вычисления звуковых полей выполнен с возможностью принимать, в дополнение к информации перемещения, информацию вращения, указывающую вращение головы слушателя в одном из трех направлений вращения, предоставленных посредством наклона в продольном направлении, наклона относительно вертикальной оси и наклона в поперечном направлении. Модуль вычисления звуковых полей затем выполнен с возможностью выполнять преобразование с вращением, чтобы вращать модифицированные данные направления поступления для звукового поля с использованием информации вращения, при этом модифицированные данные направления поступления извлекаются из данных направления поступления, полученных посредством анализа звука описания звукового поля, и информации перемещения.
В варианте осуществления, модуль вычисления звуковых полей выполнен с возможностью определять сигналы источников из описания звукового поля и направлений сигналов источников, связанных с опорным местоположением, посредством анализа звука.
После этого вычисляются новые направления источников звука, которые связаны с другим опорным местоположением, и это выполняется с использованием метаданных, а затем вычисляется информация расстояния источников звука, связанных с другим опорным местоположением, и после этого модифицированное звуковое поле синтезируется с использованием информации расстояния и новых направлений источников звука.
В варианте осуществления, синтез звукового поля выполняется посредством панорамирования сигналов источников звука в направление, предоставленное посредством новой информации направления относительно компоновки для воспроизведения, и масштабирование сигналов источников звука выполняется с использованием информации расстояния перед выполнением операции панорамирования или после выполнения операции панорамирования.
В дополнительном варианте осуществления, рассеянная часть сигнала источника звука суммируется с прямой частью сигнала источника звука, причем прямая часть модифицируется посредством информации расстояния перед суммированием с рассеянной частью.
В частности, предпочтительно выполнять синтез источников звука в спектральном представлении, в котором новая информация направления вычисляется для каждого частотного бина, в котором информация расстояния вычисляется для каждого частотного бина, и в котором прямой синтез для каждого частотного бина с использованием аудиосигнала для частотного бина выполняется с использованием аудиосигнала для частотного бина, панорамирующего усиления для частотного бина, извлекаемого из новой информации направления, и коэффициента масштабирования для частотного бина, извлекаемого из информации расстояния для частотного бина, выполняется.
Кроме того, синтез рассеянных сигналов выполняется с использованием рассеянного аудиосигнала, извлекаемого из аудиосигнала из частотного бина, и с использованием параметра степени рассеяния, извлекаемого посредством анализа сигналов для частотного бина, и после этого прямой сигнал и рассеянный сигнал комбинируются, чтобы получать синтезированный аудиосигнал для временного или частотного бина, и после этого частотно-временное преобразование выполняется с использованием аудиосигналов для других частотно-временных бинов, чтобы получать синтезированный аудиосигнал временной области в качестве модифицированного звукового поля.
Следовательно, в общем, модуль вычисления звуковых полей выполнен с возможностью синтезировать, для каждого источника звука, звуковое поле, связанное с другим опорным местоположением, например, посредством обработки, для каждого источника, сигнала источника с использованием нового направления для сигнала источника, чтобы получать описание звукового поля сигнала источника, связанного с другим/новым опорным местоположением. Кроме того, сигнал источника модифицируется перед обработкой сигнала источника или после обработки сигнала источника с использованием информации направления. Так же, в завершение, описания звукового поля для источников суммируются между собой, чтобы получать модифицированное звуковое поле, связанное с другим опорным местоположением.
В дополнительных вариантах осуществления и, в частности, для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, модуль вычисления звуковых полей вычисляет модифицированное звуковое поле с использованием пространственной информации относительно первого описания звукового поля, с использованием пространственной информации относительно второго описания звукового поля и с использованием информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение. В частности, метаданные, например, могут представлять собой вектор, направленный в опорное местоположение описания звукового поля, и другой вектор, направленный из идентичного начала координат в дополнительное опорное местоположение второго описания звукового поля.
Чтобы разрешать информацию перемещения, объекты формируются посредством применения разделения источников или формирования диаграммы направленности, или, в общем, любого вида анализа источника звука к первому и второму описанию звукового поля. После этого вычисляется информация направления поступления всех объектов независимо от того, представляют эти объекты собой широкополосные объекты или объекты для отдельных частотно-временных бинов. Затем объекты, извлеченные из различных описаний звукового поля, сопоставляются друг с другом, чтобы находить, по меньшей мере, один совпадающий объект, т.е. объект, возникающий в первом и втором описаниях звукового поля. Это сопоставление выполняется, например, посредством вычисления корреляции или когерентности с использованием объектных сигналов и/или информации направления поступления или другой информации.
Таким образом, результат процедуры заключается в том, что существует, для совпадающего объекта, первая DoA-информация, связанная с опорным местоположением, и вторая DoA-информация, связанная с дополнительным опорным местоположением. Далее, позиции совпадающих объектов и, в частности, расстояние совпадающего объекта до опорного местоположения или дополнительного опорного местоположения вычисляется на основе триангуляции с использованием информации относительно опорного местоположения или опорного местоположения, включенной в ассоциированные метаданные.
Эта информация и, в частности, информация позиции для совпадающего объекта затем используется для модификации каждого совпадающего объекта на основе оцененной позиции и требуемой позиции, т.е. после перемещения, с использованием обработки компенсации расстояния. Чтобы вычислять новую DoA-информацию для новой позиции слушателя, используется старая DoA-информация из обоих опорных местоположений и информация перемещения. По существу, эта обработка может выполняться для обоих отдельных описаний звукового поля, поскольку каждый совпадающий объект возникает в обоих описаниях звукового поля. Тем не менее, в соответствии с предпочтительными вариантами осуществления, используется описание звукового поля, имеющее опорное местоположение, ближайшее к новой позиции слушателя после перемещения.
Затем новое DoA используется для вычисления нового описания звукового поля для совпадающего объекта, связанного с другим опорным местоположением, т.е. в которое перемещен пользователь. После этого и для того, чтобы также включать несовпадающие объекты, описания звукового поля для этих объектов вычисляются также, но с использованием старой DoA-информации. Так же, в завершение, модифицированное звуковое поле формируется посредством суммирования всех отдельных описаний звукового поля между собой.
Изменения в ориентации могут быть реализованы посредством применения одного вращения к виртуальному амбиофоническому сигналу.
Таким образом, метаданные не используются для непосредственного предоставления расстояния объекта до опорного местоположения. Вместо этого, метаданные предоставляются для идентификации опорного местоположения каждого из двух или более описаний звукового поля, и расстояние между опорным местоположением и определенным совпадающим объектом вычисляется, например, на основе этапов обработки триангуляции.
Далее поясняются предпочтительные варианты осуществления настоящего изобретения со ссылками на прилагаемые чертежи, на которых:
Фиг. 1a является предпочтительным вариантом осуществления устройства для формирования улучшенного описания звукового поля;
Фиг. 1b является иллюстрацией, поясняющей примерную проблему, лежащую в основе настоящего изобретения;
Фиг. 2 является предпочтительной реализацией устройства для формирования улучшенного описания звукового поля;
Фиг. 3a иллюстрирует улучшенное описание звукового поля, содержащее аудиоданные и вспомогательную информацию для аудиоданных;
Фиг. 3b иллюстрирует дополнительную иллюстрацию улучшенного звукового поля, содержащего аудиоданные и метаданные, связанные с пространственной информацией, такой как геометрическая информация для каждого описания звукового поля;
Фиг. 4a иллюстрирует реализацию устройства для формирования модифицированного описания звукового поля;
Фиг. 4b иллюстрирует дополнительную реализацию устройства для формирования модифицированного описания звукового поля;
Фиг. 4c иллюстрирует сценарий с опорной позицией/местоположением A, дополнительной опорной позицией/местоположением B и другим опорным местоположением вследствие перемещения;
Фиг. 5 иллюстрирует 6DoF-воспроизведение пространственного аудио в общем смысле;
Фиг. 6a иллюстрирует предпочтительный вариант осуществления для реализации модуля вычисления звуковых полей;
Фиг. 6b иллюстрирует предпочтительную реализацию для вычисления нового DoA и нового расстояния источника звука относительно нового/другого опорного местоположения;
Фиг. 6c иллюстрирует предпочтительный вариант осуществления 6DoF-воспроизведения, содержащий устройство для формирования улучшенного описания звукового поля, например, для каждого отдельного описания звукового поля и устройство для формирования модифицированного описания звукового поля для совпадающих источников;
Фиг. 7 иллюстрирует предпочтительный вариант осуществления для выбора одного из первого и второго описаний звукового поля для вычисления модифицированного звукового поля для широкополосного или узкополосного объекта;
Фиг. 8 иллюстрирует примерное устройство для формирования описания звукового поля из аудиосигнала, такого как моносигнал, и данных направления поступления;
Фиг. 9 иллюстрирует дополнительный предпочтительный вариант осуществления для модуля вычисления звуковых полей;
Фиг. 10 иллюстрирует предпочтительную реализацию устройства для формирования модифицированного описания звукового поля;
Фиг. 11 иллюстрирует дополнительную предпочтительную реализацию устройства для формирования модифицированного описания звукового поля;
Фиг. 12a иллюстрирует реализацию на основе DirAC-анализа предшествующего уровня техники; и
Фиг. 12b иллюстрирует реализацию на основе DirAC-синтеза предшествующего уровня техники.
Чтобы обеспечивать 6DoF-варианты применения для упомянутых амбиофонических/DirAC-представлений, необходимо расширять эти представления таким способом, который предоставляет отсутствующую информацию для обработки перемещения. Следует отметить, что это расширение, например, может 1) добавлять расстояние или позиции объектов в существующее представление сцены и/или 2) добавлять информацию, которая должна упрощать процесс разделения отдельных объектов.
Кроме того, цель вариантов осуществления заключается в том, чтобы сохранять/многократно использовать структуру существующих (непараметрических или параметрических) амбиофонических систем, чтобы предоставлять обратную совместимость с этими представлениями/системами в том смысле, что:
- расширенные представления могут преобразовываться в существующие нерасширенные представления (например, для рендеринга), и
- чтобы обеспечивать возможность многократного использования существующих программных и аппаратных реализаций при работе с расширенным представлением.
Далее описываются несколько подходов, а именно, один ограниченный (но очень простой) подход и три различных расширенных формата амбиофонии, чтобы обеспечивать 6DoF.
Звуковая сцена описывается с использованием двух или более амбиофонических сигналов, каждый из которых описывает звуковую сцену в различной позиции либо, другими словами, из другой перспективы. Предполагается, что относительные позиции известны. Модифицированный амбиофонический сигнал в требуемой позиции в звуковой сцене формируется из входных амбиофонических сигналов. Сигнально-ориентированный или параметрический подход может использоваться для того, чтобы формировать виртуальный амбиофонический сигнал в требуемой позиции.
Принцип многоточечного амбиофонического представления является применимым как для традиционной, так и для параметрической (DirAC-ориентированной) амбиофонии.
Виртуальный амбиофонический сигнал в требуемой позиции (т.е. после перемещения) вычисляется с использованием следующих этапов в сигнально-ориентированном варианте осуществления на основе перемещения:
1. Объекты формируются посредством применения разделения источников к каждому традиционному амбиофоническому сигналу.
2. DoA всех объектов вычисляются для каждого традиционного амбиофонического сигнала.
3. Объекты, извлеченные из одного традиционного амбиофонического сигнала, сопоставляются с объектами, извлеченными из других традиционных амбиофонических сигналов. Сопоставление выполняется на основе соответствующих DoA и/или сигналов (например, посредством корреляции/когерентности).
4. Позиции совпадающих объектов оцениваются на основе триангуляции.
5. Каждый совпадающий объект (одноканальный ввод) модифицируется на основе оцененной позиции и требуемой позиции (т.е. после перемещения) с использованием компенсационного фильтра расстояния.
6. DoA в требуемой позиции (т.е. после перемещения) вычисляется для каждого совпадающего объекта. Это DoA представляется посредством DoA'.
7. Амбиофонический объектный сигнал вычисляется для каждого совпадающего объекта. Амбиофонический объектный сигнал формируется таким образом, что совпадающий объект имеет направление DoA' поступления.
8. Амбиофонический объектный сигнал вычисляется для каждого несовпадающего объекта. Амбиофонический объектный сигнал формируется таким образом, что несовпадающий объект имеет направление DoA поступления.
9. Виртуальный амбиофонический сигнал получается посредством суммирования всех амбиофонических объектных сигналов между собой.
Виртуальный амбиофонический сигнал в требуемой позиции (т.е. после перемещения) вычисляется с использованием следующих этапов в параметрическом варианте осуществления на основе перемещения в соответствии с дополнительным вариантом осуществления:
1. Модель звукового поля предполагается. Звуковое поле может разлагаться на один или более прямых звуковых компонентов и рассеянных звуковых компонентов. Прямые звуковые компоненты состоят из сигнала и информации позиции (например, в полярных или декартовых координатах). Альтернативно, звуковое поле может разлагаться на один или более прямых/главных звуковых компонентов и остаточный звуковой компонент (одно- или многоканальный).
2. Компоненты и параметры сигналов предполагаемой модели звукового поля оцениваются с использованием входных амбиофонических сигналов.
3. Компоненты и/или параметры сигналов модифицируются в зависимости от требуемого перемещения или требуемой позиции, в звуковой сцене.
4. Виртуальный амбиофонический сигнал формируется с использованием модифицированных сигнальных компонентов и модифицированных параметров.
Формирование многоточечных амбиофонических сигналов является простым для машиногенерируемого и произведенного контента, а также в контексте естественной записи через массивы микрофонов или пространственные микрофоны (например, через микрофон в B-формате). В варианте осуществления, предпочтительно выполнять сопоставление источников после этапа 2 или вычисление с триангуляцией перед этапом 3. Кроме того, один или более этапов обоих вариантов осуществления также могут использоваться в соответствующих других вариантах осуществления.
Изменение ориентации может быть реализовано посредством применения одного вращения к виртуальному амбиофоническому сигналу.
Фиг. 1a иллюстрирует устройство для формирования улучшенного описания звукового поля, содержащего формирователь 100 (описаний) звуковых полей для формирования, по меньшей мере, одного описания звукового поля, указывающего звуковое поле относительно, по меньшей мере, одного опорного местоположения. Кроме того, устройство содержит формирователь 110 метаданных для формирования метаданных, связанных с пространственной информацией звукового поля. Метаданные принимают, в качестве ввода, звукового поля либо, альтернативно или дополнительно, отдельную информацию относительно источников звука.
Вывод формирователя 100 описаний звуковых полей и формирователя 110 метаданных составляют улучшенное описание звукового поля. В варианте осуществления, вывод формирователя 100 описаний звуковых полей и формирователя 110 метаданных может комбинироваться в модуле 120 комбинирования или выходном интерфейсе 120, чтобы получать улучшенное описание звукового поля, которое включает в себя пространственные метаданные или пространственную информацию звукового поля, сформированную посредством формирователя 110 метаданных.
Фиг. 1b иллюстрирует ситуацию, которая разрешается посредством настоящего изобретения. Позиция A, например, представляет собой, по меньшей мере, одно опорное местоположение, и звуковое поле формируется посредством источника A и источника B, и определенный фактический или, например, виртуальный микрофон, расположенный в позиции A, обнаруживает звук из источника A и источника B. Звук представляет собой наложение звука, исходящего из источников исходящего звука. Это представляет описание звукового поля, сформированное посредством формирователя описаний звуковых полей.
Дополнительно, формирователь метаданных должен, посредством определенных реализаций, извлекать пространственную информацию относительно источника A и другую пространственную информацию относительно источника B, такую как расстояния этих источников до опорной позиции, такой как позиция A.
Естественно, опорная позиция, альтернативно, может представлять собой позицию B. Затем фактический или виртуальный микрофон должен быть размещен в позиции B, и описание звукового поля представляет собой звуковое поле, например, представленное посредством амбиофонических компонентов первого порядка или амбиофонических компонентов высшего порядка либо любых других звуковых компонентов, имеющих потенциал для того, чтобы описывать звуковое поле относительно, по меньшей мере, одного опорного местоположения, т.е. позиции B.
Формирователь метаданных после этого может формировать, в качестве информации относительно источников звука, расстояние источника A звука до позиции B или расстояние источника B до позиции B. Альтернативная информация относительно источников звука, конечно, может представлять собой абсолютную или относительную позицию относительно опорной позиции. Опорная позиция может представлять собой начало общей системы координат или может быть расположена в заданной взаимосвязи с началом общей системы координат.
Другие метаданные могут представлять собой абсолютную позицию одного источника звука и относительную позицию другого источника звука относительно первого источника звука и т.д.
Фиг. 2 иллюстрирует устройство для формирования улучшенного описания звукового поля, в котором формирователь звуковых полей содержит формирователь 250 звуковых полей для первого звукового поля, формирователь 260 звуковых полей для второго звукового поля и произвольное число формирователей звуковых полей для одного или более звуковых полей, таких как третье, четвертое и т.д. звуковое поле. Дополнительно, метаданные выполнены с возможностью вычислять и перенаправлять в модуль 120 комбинирования информацию относительно первого звукового поля и второго звукового поля. Вся эта информация используется посредством модуля 120 комбинирования, чтобы формировать улучшенное описание звукового поля. Таким образом, модуль 120 комбинирования также конфигурируется как выходной интерфейс с возможностью формировать улучшенное описание звукового поля.
Фиг. 3a иллюстрирует улучшенное описание звукового поля в качестве потока данных, содержащего первое описание 330 звукового поля, второе описание 340 звукового поля и ассоциированные с ними метаданные 350, содержащие информацию относительно первого описания звукового поля и второго описания звукового поля. Первое описание звукового поля, например, может представлять собой описание в B-формате или описание высшего порядка либо любое другое описание, которое обеспечивает возможность определять направленное распределение источников звука в полнополосном представлении или в частотно-избирательном представлении. Таким образом, первое описание 330 звукового поля и второе описание 340 звукового поля, например, также могут представлять собой параметрические описания звукового поля для других опорных местоположений, имеющих, например, сигнал понижающего сведения и данные направления поступления для различных частотно-временных бинов.
Тем не менее, геометрическая информация 350 для первого и второго описаний звукового поля является идентичной для всех источников, включенных в первое описание 330 звукового поля, либо для источников во втором описании 340 звукового поля, соответственно. Таким образом, когда, в качестве примера, существуют три источника в первом описании 330 звукового поля и геометрическая информация относительно первого описания звукового поля, в таком случае эта геометрическая информация является идентичной для трех источников в первом описании звукового поля. Аналогично, когда, например, существуют пять источников во втором описании звукового поля, в таком случае геометрическая информация для второго звукового поля, включенная в метаданные 350, является идентичной для всех источников во втором описании звукового поля.
Фиг. 3b иллюстрирует примерное составление метаданных 350 по фиг. 3a. В варианте осуществления, опорное местоположение 351 может быть включено в метаданные. Тем не менее, это не обязательно имеет место, информация 351 опорного местоположения также может опускаться.
Для первого звукового поля, предоставляется первая геометрическая информация, которая, например, может представлять собой информацию относительно вектора A, проиллюстрированного на фиг. 4c, указывающего из начала координат в опорную позицию/местоположение A, с которой связано первое звуковое поле.
Вторая геометрическая информация, например, может представлять собой информацию относительно вектора B, указывающего из начала координат во вторую опорную позицию/местоположению B, с которой связано второе описание звукового поля.
A и B представляют собой опорные местоположения или позиции записи для обоих описаний звукового поля.
Альтернативная геометрическая информация, например, может представлять собой информацию относительно вектора d, тянущегося между опорным местоположением A и дополнительным опорным местоположением B, и/или начала координат и вектора, указывающего из начала координат в одну из обеих точек. Таким образом, геометрическая информация, включенная в метаданные, может содержать вектор A и вектор D либо может содержать вектор B и вектор D, либо может содержать вектор A и вектор B без вектора D, либо может содержать другую информацию, из которой опорное местоположение A и опорное местоположение B могут идентифицироваться в определенной трехмерной системе координат. Тем не менее, идентичное соображение дополнительно применяется также для двумерного звукового описания, как конкретно проиллюстрировано на фиг. 4c, который показывает только двумерный случай.
Фиг. 4a иллюстрирует предпочтительную реализацию устройства для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля. В частности, устройство содержит модуль 420 вычисления звуковых полей, который формирует модифицированное звуковое поле с использованием метаданных, описания звукового поля и информации перемещения, указывающей перемещение из опорного местоположения в другое опорное местоположение.
В варианте осуществления, модуль 420 вычисления звуковых полей соединяется с входным интерфейсом 400 для приема улучшенного описания звукового поля, например, как поясняется относительно фиг. 1a или 2, и входной интерфейс 400 затем разделяет описание звукового поля, с одной стороны, т.е. что сформировано посредством блока 100 по фиг. 1a или блока 210 по фиг. 2. Кроме того, входной интерфейс 400 отделяет метаданные от улучшенного описания звукового поля, т.е. элемента 350 по фиг. 3a или опциональные 351 и 352-354 по фиг. 3b.
Кроме того, интерфейс 410 перемещения получает информацию перемещения и/или дополнительную или отдельную информацию вращения от слушателя. Реализация интерфейса 410 перемещения может представлять собой модуль слежения за положением головы, который отслеживает не только вращение головы в окружении в стиле виртуальной реальности, но также и перемещение головы из одной позиции, т.е. из позиции A на фиг. 1b, в другую позицию, т.е. в позицию B на фиг. 1b.
Фиг. 4b иллюстрирует другую реализацию, аналогичную фиг. 1a, но связанную не со сценарием кодера/декодера, а связанную с общим сценарием, в котором подача метаданных, указываемая посредством модуля 402 подачи метаданных, подача звуковых полей, указываемая посредством модуля 404 подачи звуковых полей, выполняются без определенного входного интерфейса, разделяющего кодированное или улучшенное описание звукового поля, но все выполняются, например, в фактическом существующем сценарии, например, в варианте применения в стиле виртуальной реальности. Тем не менее, настоящее изобретение не ограничено вариантами применения в стиле виртуальной реальности и также может реализовываться в любых других вариантах применения, в которых пространственная аудиообработка звуковых полей, которые связаны с опорным местоположением, является полезной для того, чтобы преобразовывать звуковое поле, связанное с первым опорным местоположением, в другое звуковое поле, связанное с другим вторым опорным местоположением.
Модуль 420 вычисления звуковых полей затем формирует модифицированное описание звукового поля или, альтернативно, формирует представление (виртуальных) громкоговорителей, или формирует бинауральное представление, такое как двухканальное представление для воспроизведения в наушниках. Таким образом, модуль 420 вычисления звуковых полей может формировать, в качестве модифицированного звукового поля, модифицированное описание звукового поля, по существу идентичное описанию исходного звукового поля, но теперь относительно новой опорной позиции. В альтернативном варианте осуществления, представление виртуальных или фактических громкоговорителей может формироваться для предварительно определенной компоновки громкоговорителей, такой как схема 5.1, или компоновки громкоговорителей, имеющей большее число громкоговорителей и, в частности, имеющей трехмерную компоновку громкоговорителей, а не только двумерную компоновку, т.е. компоновку громкоговорителей, имеющую громкоговорители, приподнятые относительно позиции пользователя. Другие варианты применения, которые являются конкретно полезными для вариантов применения в стиле виртуальной реальности, представляют собой варианты применения для бинаурального воспроизведения, т.е. для наушника, который может применяться к голове пользователя виртуальной реальности.
В качестве примера, нижеописанный фиг. 6 иллюстрирует ситуацию, в которой DirAC-синтезатор работает только с компонентом понижающего сведения, таким как всенаправленный компонент или компонент давления, тогда как, в дополнительном альтернативном варианте осуществления, проиллюстрированном относительно фиг. 12b, DirAC-синтезатор работает с общими данными звукового поля, т.е. с полным компонентным представлением, имеющим, в этом варианте осуществления на фиг. 12b, описание полей со всенаправленным компонентом w и тремя направленными компонентами x, y, z.
Фиг. 4c иллюстрирует сценарий, лежащий в основе предпочтительных вариантов осуществления настоящего изобретения. Чертеж иллюстрирует первую опорную позицию/местоположение A, вторую опорную позицию/местоположение B и два различных источника A и B звука и вектор l перемещения.
Оба источника A и B звука включаются в описание звукового поля, связанное с опорным местоположением A, и второе описание звукового поля, связанное с опорной позицией B.
Чтобы вычислять расстояние источника A, например, до первой опорной позиции или до второй опорной позиции, различные описания звукового поля, связанные с A и B, подвергаются процедуре разделения источников, и после этого получается сопоставление источников, полученных посредством этих различных процедур разделения звука. Это, например, должно приводить к источнику A. Источник A находится в алгоритме разделения источников для первого описания звукового поля, а также для второго описания звукового поля. Информация направления поступления для источника A должна представлять собой, при получении из первого описания звукового поля, связанного с опорной позицией A, угол α. Дополнительно, информация направления поступления для идентичного источника A, но теперь полученная из второго описания звукового поля, связанного с дополнительной опорной позицией B, представляет собой угол β.
Теперь, на основе известного или вычисляемого расстояния D, т.е., например, получаемого или вычисляемого из метаданных для описаний звукового поля и на основе двух углов α и β, треугольник, заданный посредством источника A, опорной позиции A и опорной позиции B, полностью задается. Таким образом, расстояние от источника A до опорной позиции A или расстояние от источника A до опорной позиции B или общей позиции источника A, т.е. вектор, указывающий из начала координат в фактическую позицию источника A, может вычисляться, например, посредством операций обработки триангуляции. Позиция или расстояние представляют информацию относительно расстояния или относительно позиции.
Идентичная процедура затем может выполняться для каждого совпадающего источника, т.е. также для источника B.
Таким образом, информация расстояния/позиции для каждого совпадающего источника вычисляется, и после этого каждый совпадающий источник может обрабатываться, как если расстояние/позиция полностью известно либо, например, предоставляется посредством дополнительных метаданных. Тем не менее, только геометрическая информация для первого описания звукового поля и второго описания звукового поля требуется вместо любой информации расстояния/глубины для каждого отдельного источника.
Фиг. 8 иллюстрирует другую реализацию для выполнения синтеза, отличающуюся от DirAC-синтезатора. Когда, например, анализатор звуковых полей формирует, для каждого сигнала источника, отдельный моносигнал S и первоначальное направление поступления, и когда, в зависимости от информации перемещения, вычисляется новое направление поступления, в таком случае формирователь 430 амбиофонических сигналов по фиг. 8, например, должен использоваться для того, чтобы формировать описание звукового поля для сигнала источника звука, т.е. моносигнала S, но для новых данных направления поступления (DoA), состоящих из горизонтального угла θ или угла θ подъема и азимутального угла φ. Далее, процедура, выполняемая посредством модуля 420 вычисления звуковых полей по фиг. 4b, заключается в том, чтобы формировать, например, представление звукового поля на основе амбиофонии первого порядка для каждого источника звука с новым направлением поступления, и после этого дополнительная модификация в расчете на источник звука может выполняться с использованием коэффициента масштабирования в зависимости от расстояния звукового поля до нового опорного местоположения, и после этого все звуковые поля из отдельных источников могут накладываться друг на друга, чтобы в итоге получать модифицированное звуковое поле, снова, например, в амбиофоническом представлении, связанном с определенным новым опорным местоположением.
Когда интерпретируется то, что каждый частотно-временной бин, обработанный посредством DirAC-анализатора 422, 422a, 422b по фиг. 6, представляет определенный источник звука (с ограниченной полосой пропускания), в таком случае формирователь 430 амбиофонических сигналов может использоваться, вместо DirAC-синтезатора 425, 425a, 425b, для того чтобы формировать, для каждого частотно-временного бина, полное амбиофоническое представление с использованием сигнала понижающего сведения или сигнала давления либо всенаправленного компонента для этого частотно-временного бина в качестве "моносигнала S" по фиг. 8. Затем отдельное частотно-временное преобразование в частотно-временном преобразователе для каждого W-, X-, Y-, Z-компонента в таком случае должно приводить к описанию звукового поля, отличающемуся от того, что проиллюстрировано на фиг. 4c.
Сцена записывается из точки обзора (PoV) микрофона, причем эта позиция используется в качестве начала опорной системы координат. Сцена должна воспроизводиться из PoV слушателя, который отслеживается в 6DoF, см. фиг. 5. Один источник звука показывается здесь для иллюстрации, взаимосвязь применима для каждого частотно-временного бина.
Фиг. 5 иллюстрирует 6DoF-воспроизведение пространственного аудио. Источник звука записывается посредством микрофона с DoA rr на расстоянии dr относительно позиции и ориентации микрофонов (черная линия и дуга). Оно должно воспроизводиться относительно перемещающегося слушателя с DoA rl и расстоянием dl (штриховая линия). Это должно учитывать перемещение l в пространстве и вращение o слушателей (точечная линия). DoA представляется как вектор с единичной длиной, указывающей на источник.
Источник звука в координатах dr ∈ ℝ3 записывается из направления поступления (DoA), выражаемого посредством единичного вектора  . Это DoA может оцениваться из анализа записи. Оно исходит из расстояния
. Это DoA может оцениваться из анализа записи. Оно исходит из расстояния  . Предполагается, что эта информация может извлекаться из метаданных для каждого источника или, в общем, из элемента 352, 353, 354 по фиг. 3b и может представляться как описание расстояния, имеющее любое направление r от позиции записи к расстоянию (например, представленному в метрах и т.п.), полученному, например, посредством обработки триангуляции с использованием двух углов относительно двух других опорных местоположений и расстояния/позиций или опорных местоположений.
. Предполагается, что эта информация может извлекаться из метаданных для каждого источника или, в общем, из элемента 352, 353, 354 по фиг. 3b и может представляться как описание расстояния, имеющее любое направление r от позиции записи к расстоянию (например, представленному в метрах и т.п.), полученному, например, посредством обработки триангуляции с использованием двух углов относительно двух других опорных местоположений и расстояния/позиций или опорных местоположений.
Слушатель отслеживается в 6DoF. В данное время, он находится в позиции l ∈ ℝ3 относительно микрофона и имеет вращение o ∈ ℝ3 относительно системы координат микрофонов. Позиция записи выбирается в качестве начала системы координат, чтобы упрощать систему обозначений.
Таким образом, звук должен воспроизводиться с другим расстоянием d1, приводящим к измененной громкости и другому DoA r1, которое представляет собой результат как перемещения, так и последующего вращения.
Ниже приводится способ для получения виртуального сигнала из перспективы слушателей посредством выделенных преобразований на основе параметрического представления, как пояснено в следующем разделе.
Предложенный способ основан на базовом DirAC-подходе для параметрического пространственного кодирования звука (см. [16]). Предполагается, что предусмотрен один доминирующий прямой источник в расчете на частотно-временной экземпляр проанализированного спектра, и они могут обрабатываться независимо. Запись преобразуется в частотно-временное представление с использованием кратковременного преобразования Фурье (STFT). Индекс временного кадра обозначается с помощью n, а частотный индекс - с помощью k. Преобразованная запись затем анализируется, оценивая направления rr(k, n) и степень рассеяния ψ(k, n) для каждого частотно-временного бина комплексного спектра P(k, n). В синтезе, сигнал разделяется на прямую и рассеянную часть. Здесь, сигналы громкоговорителей вычисляются посредством панорамирования прямой части в зависимости от позиций динамиков и суммирования рассеянной части.
Способ для преобразования FOA-сигнала согласно перспективе слушателей в 6DoF может разделяться на пять этапов, см. фиг. 6c.
Фиг. 6c иллюстрирует способ 6DoF-воспроизведения. Записанный FOA-сигнал в B-формате обрабатывается посредством DirAC-кодера, который вычисляет значения направления и степени рассеяния для каждого частотно-временного бина комплексного спектра. Вектор направления затем преобразуется посредством отслеживаемой позиции слушателя, и согласно информации расстояния, приведенной в карте расстояний для каждого источника, извлекаемой, например, посредством вычислений с триангуляцией. Результирующий вектор направления затем вращается согласно вращению головы. В завершение, сигналы для каналов 8+4 виртуальных громкоговорителей синтезируются в DirAC-декодере. Они затем бинаурализируются.
В варианте осуществления, входной сигнал анализируется в DirAC-кодере 422, информация расстояния добавляется из карты m(r) расстояний, предоставляющей расстояние для каждого (совпадающего) источника, после чего отслеживаемое перемещение и вращение слушателя применяются в новых преобразованиях 423 и 424. DirAC-декодер 425 синтезирует сигналы для 8+4 виртуальных громкоговорителей, которые в свою очередь бинаурализируются 427 для воспроизведения в наушниках. Следует отметить, что поскольку вращение звуковой сцены после перемещения является независимой операцией, оно альтернативно может применяться в модуле бинаурального рендеринга. Единственный параметр, преобразованный для 6DoF, представляет собой вектор направления. Посредством определения модели, рассеянная часть предположительно является изотропной и гомогенной и в силу этого оставляется без изменений.
Ввод в DirAC-кодер представляет собой звуковой FOA-сигнал в представлении в B-формате. Он состоит из четырех каналов, т.е. всенаправленного звукового давления и трех пространственных градиентов первого порядка, которые при определенных допущениях являются пропорциональными скорости частиц. Этот сигнал кодируется параметрическим способом, см. [18]. Параметры извлекаются из комплексного звукового давления P(k, n), которое представляет собой преобразованный всенаправленный сигнал, и комплексного вектора скорости частиц [UX(k, n), UY(k, n), UZ(k, n)]T, соответствующего преобразованным сигналам градиента.
DirAC-представление состоит из сигнала P(k, n), степени рассеяния ψ(k, n) и направления r(k, n) звуковой волны в каждом частотно-временном бине. Чтобы извлекать последнее из означенного, во-первых, активный вектор Ia(k, n) интенсивности звука вычисляется в качестве действительной части (обозначаемой посредством Re(·)) произведения вектора давления с комплексно-сопряженным числом (обозначаемым посредством (·)*) вектора скорости [18]:
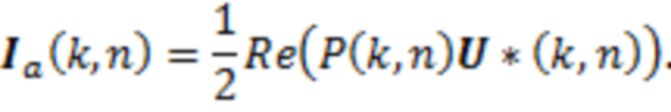
(1)
Степень рассеяния оценивается из коэффициента варьирования этого вектора [18].
 , (2)
, (2)
где 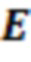 обозначает оператор математического ожидания вдоль временных кадров, реализованный в качестве скользящего среднего.
обозначает оператор математического ожидания вдоль временных кадров, реализованный в качестве скользящего среднего.
Поскольку он предназначен для того, чтобы манипулировать звуком с использованием карты расстояний на основе направления, имеющей расстояние для каждого (совпадающего) источника до опорного местоположения, дисперсия оценок направлений должна быть низкой в опциональном варианте осуществления. Поскольку кадры типично являются короткими, это не всегда имеет место. Следовательно, скользящее среднее применяется, чтобы получать сглаженную оценку  (k, n) направления. Далее, DoA прямой части сигнала, в варианте осуществления, вычисляется в качестве вектора единичной длины в противоположном направлении:
(k, n) направления. Далее, DoA прямой части сигнала, в варианте осуществления, вычисляется в качестве вектора единичной длины в противоположном направлении:

(3)
Поскольку направление кодируется как трехмерный вектор единичной длины для каждого частотно-временного бина, проще всего интегрировать информацию расстояния. Векторы направления умножаются на свою соответствующую запись карты таким образом, что длина вектора представляет расстояние dr(k, n) соответствующего источника звука:
 =
=  (k, n)), (4)
(k, n)), (4)
где dr(k, n) является вектором, указывающим из позиции записи микрофона в источник звука, активный во временном n и частотном k бине.
Позиция слушателя задается посредством системы отслеживания для текущего кадра обработки в качестве l(n). В силу векторного представления позиций источников, можно вычитать позиционный вектор l(n) отслеживания, чтобы давать в результате новый, перемещенный вектор d1(k, n) направления с длиной 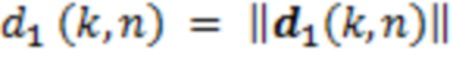 , см. фиг. 6b. Расстояния от PoV слушателя до источников звука извлекаются, и DoA адаптируются за один этап:
, см. фиг. 6b. Расстояния от PoV слушателя до источников звука извлекаются, и DoA адаптируются за один этап:
 (5)
(5)
Важный аспект реалистичного воспроизведения представляет собой ослабление расстояния. Ослабление предположительно представляет собой функцию расстояния между источником звука и слушателем [19]. Длина векторов направления должна кодировать ослабление или усиление для воспроизведения. Расстояние до позиции записи кодируется в dr(k, n) согласно карте расстояний, и расстояние, которое должно воспроизводиться, кодируется в d1(k, n). Если векторы в единичную длину нормализуются, а затем выполняется умножение на отношение старого и нового расстояния, видно, что требуемая длина задается посредством деления d1(k, n) на длину исходного вектора:
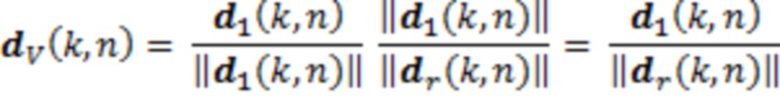
(6)
Изменения ориентации слушателя применяются на следующем этапе. Ориентация, предоставленная посредством отслеживания, может записываться в качестве вектора, состоящего из наклона в продольном направлении, наклона относительно вертикальной оси и наклона в поперечном направлении 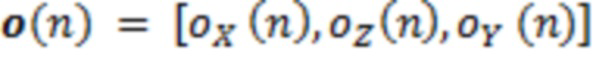 T относительно позиции записи в качестве начала координат. Направление источника вращается согласно ориентации слушателя, которая реализуется с использованием двумерных матриц вращения:
T относительно позиции записи в качестве начала координат. Направление источника вращается согласно ориентации слушателя, которая реализуется с использованием двумерных матриц вращения:

(7)
Результирующее DoA для слушателя затем предоставляется посредством вектора, нормализованного в единичную длину:

(8)
Преобразованный вектор направления, степень рассеяния и комплексный спектр используются для того, чтобы синтезировать сигналы для равномерно распределенной компоновки 8+4 виртуальных громкоговорителей. Восемь виртуальных динамиков расположены в азимутальных шагах на 45° на плоскости слушателя (с подъемом 0°), а четыре - в перекрестном формировании на 90° выше при подъеме в 45°. Синтез разбивается на прямую и рассеянную часть для каждого канала  громкоговорителя, где
громкоговорителя, где  является числом громкоговорителей [16]:
является числом громкоговорителей [16]:

(9)
Для прямой части, амплитудное панорамирование на основе краевого затухания (EFAP) применяется, чтобы воспроизводить звук из направления вправо, с учетом геометрии виртуальных громкоговорителей [20]. С учетом DoA-вектора rp(k, n), это предоставляет панорамирующее усиление Gi(r) для каждого канала i виртуального громкоговорителя. Зависимое от расстояния усиление для каждого DoA извлекается из результирующей длины вектора направления, dp(k, n). Прямой синтез для канала i становится следующим:

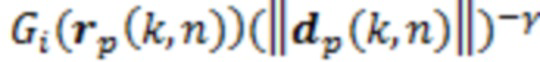 ,
,
(10)
где экспонента γ является коэффициентом настройки, который типично задается равным приблизительно 1 [19]. Следует отметить, что при γ=0 зависимое от расстояния усиление выключается.
Давление  используется для того, чтобы формировать I декоррелированных сигналов
используется для того, чтобы формировать I декоррелированных сигналов 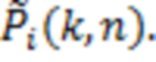 , Эти декоррелированные сигналы суммируются с отдельными каналами громкоговорителей в качестве рассеянного компонента. Это придерживается стандартного способа [16]:
, Эти декоррелированные сигналы суммируются с отдельными каналами громкоговорителей в качестве рассеянного компонента. Это придерживается стандартного способа [16]:

(11)
Рассеянная и прямая часть каждого канала суммируются между собой, и сигналы преобразуются обратно во временную область посредством обратного STFT. Эти канальные сигналы временной области свертываются с HRTF для левого и правого уха в зависимости от позиции громкоговорителя, чтобы создавать бинаурализированные сигналы.
Фиг. 6a иллюстрирует дополнительный предпочтительный вариант осуществления для вычисления модифицированного звукового поля с использованием пространственной информации и первого и второго описаний звукового поля и информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение, например, как поясняется относительно вектора l на фиг. 4c или фиг. 5.
Фиг. 6a иллюстрирует этап 700, указывающий применение процедуры разделения звука или, в общем, анализа звука к первому описанию звукового поля, связанному с опорной позицией A по фиг. 4c, и ко второму описанию звукового поля, связанному с опорной позицией B по фиг. 4c.
Эта процедура должна давать в результате первую группу из одного или более извлеченных объектов и, дополнительно, вторую группу из одного или более извлеченных объектов.
Эти группы используются на этапе 702 для вычисления информации направления поступления для всех разделенных источников, т.е. для первой группы извлеченных источников и второй группы из одного или более извлеченных источников.
В других вариантах осуществления, этапы 700 и 702 реализуются в пределах одной процедуры, предоставляющей, с одной стороны, сигнал для источника и, с другой стороны, DoA-информацию для источника. Это также относится к параметрическим процедурам, таким как временно/частотно-избирательные процедуры, к примеру, DirAC, в которых сигнал источника представляет собой сигнал представления в B-формате в частотно-временном бине либо сигнал давления или всенаправленный сигнал частотно-временного бина и DoA-информацию в качестве DoA-параметра для этого конкретного бина.
Затем, на этапе 704, сопоставление источников выполняется между источниками первой группы и источниками второй группы, и результат сопоставления источников представляет собой совпадающие источники.
Эти совпадающие источники используются для вычисления звукового поля для каждого совпадающего объекта с использованием нового DoA и нового расстояния, как проиллюстрировано на этапе 710. Кроме того, информация направления поступления совпадающих объектов, т.е. два на каждый объект, к примеру, α и β по фиг. 4c для источника A, используется на этапе 706 для того, чтобы вычислять позиции совпадающих объектов либо, альтернативно или дополнительно, расстояния совпадающих объектов с использованием, например, операций триангуляции.
Результат этапа 706 представляет собой позицию каждого совпадающего объекта или, альтернативно или дополнительно, расстояние совпадающего объекта до одного из первого или второго опорного местоположения A, B, проиллюстрированных, например, на фиг. 4c.
Дополнительно, предпочтительно использовать не только информацию перемещения на этапе 708, но также и информацию вращения для вычисления новой информации направления поступления и новых расстояний для совпадающих объектов.
Хотя указано то, что позиции совпадающих объектов вводятся на этапе 708, следует подчеркнуть, что только для вычисления новой информация направления поступления для совпадающего объекта, фактическая позиция совпадающего объекта или, другими словами, расстояние совпадающего объекта не требуется для вычисления нового направления поступления относительно нового (другого) опорного местоположения, в которое перемещен слушатель, например, расстояние не требуется.
Тем не менее, расстояние в дальнейшем требуется для того, чтобы адаптировать сигнал источника к новой ситуации. Таким образом, когда расстояние источника или звукового объекта до новой опорной позиции становится короче, в таком случае должен вычисляться коэффициент масштабирования, который ниже единицы. Тем не менее, когда расстояние становится более высоким, в таком случае коэффициент масштабирования вычисляется таким образом, что он выше единицы, например, как поясняется относительно фиг. 6b. Следовательно, хотя проиллюстрировано на фиг. 6a для варианта осуществления, не обязательно имеет место то, что явные позиции совпадающих объектов и после этого расстояния совпадающих объектов вычисляются, и далее звуковое поле вычисляется для каждого совпадающего объекта с использованием нового направления поступления и нового расстояния. Вместо этого, только расстояние совпадающего объекта до одного опорного местоположения из двух опорных местоположений является, в общем, достаточным, и после этого звуковое поле для каждого совпадающего объекта вычисляется с использованием нового DoA и нового расстояния.
Дополнительно, этап 714 иллюстрирует вычисление звуковых полей для несовпадающих объектов с использованием старой DoA-информации, полученной посредством этапа 702. Кроме того, звуковые поля для совпадающих объектов, полученные на этапах 710, и несовпадающих объектов, полученные посредством этапа 714, комбинируются на этапе 712, чтобы получать модифицированное описание звукового поля, которое, например, может представлять собой описание на основе амбиофонии, к примеру, описание на основе амбиофонии первого порядка, описание на основе амбиофонии высшего порядка или, альтернативно, описание каналов громкоговорителей, связанное с определенной компоновкой громкоговорителей, которое, конечно, является идентичным для этапа 710 и этапа 714, так что простое поканальное суммирование может выполняться на этапе 712.
Фиг. 6b иллюстрирует предпочтительную реализацию модуля 420 вычисления звуковых полей. На этапе 1102, выполняется вычисление разделения источников и направления поступления или, в общем, информации направления для каждого источника. Затем, на этапе 1104, вектор направления поступления, например, умножается на вектор информации расстояния, т.е. вектор из исходного опорного местоположения в источник звука, т.е. вектор из элемента 520 в элемент 510 по фиг. 5. Затем, на этапе 1106, информация перемещения, т.е. вектор из элемента 520 в элемент 500 по фиг. 5 принимается во внимание, чтобы вычислять новый перемещенный вектор направления, который представляет собой вектор из позиции 500 слушателя в позицию 510 источника звука. Затем вектор нового направления поступления с корректной длиной, указываемой посредством dv, вычисляется на этапе 1108. Этот вектор направляется в направлении, идентичном направлению dr, но имеет другую длину, поскольку длина этого вектора отражает тот факт, что источник 510 звука записывается в исходном звуковом поле с определенной громкостью, и в силу этого длина dv более или менее указывает изменение уровня громкости. Она получается посредством деления вектора dl на расстояние dr до плоскости записи, т.е. на длину вектора dr из микрофона 520 в источник 510 звука. Как указано, длина вектора dr из микрофона 520 в источник 510 звука может извлекаться посредством вычисления с триангуляцией. Когда микрофон находится в опорном местоположении первого описания звукового поля, в таком случае используется расстояние от опорного местоположения первого описания звукового поля до источника звука. Тем не менее, когда микрофон находится в дополнительном опорном местоположении второго описания звукового поля, в таком случае используется расстояние от дополнительного опорного местоположения второго описания звукового поля до источника звука.
Когда, как показано на фиг. 5, воспроизведенное расстояние превышает записанное расстояние, в таком случае длина dv ниже единичной. Это должно приводить к ослаблению источника 510 звука для воспроизведения в новой позиции слушателя. Тем не менее, когда воспроизведенное расстояние dl меньше записанного расстояния, в таком случае длина dv, вычисленная посредством этапа 1108, больше 1, и соответствующий коэффициент масштабирования должен приводить к усилению источника звука.
На фиг. 6a, элемент 710 указывает то, что звуковое поле для каждого совпадающего объекта вычисляется с использованием новой информации направления поступления и нового расстояния. Тем не менее, по существу, для вычисления звукового поля для каждого совпадающего объекта, в общем, могут использоваться объектные сигналы, полученные либо из первой группы из одного или более извлеченных источников, либо из второй группы из одного или более извлеченных источников. Тем не менее, в варианте осуществления, конкретный выбор, проиллюстрированный на фиг. 7, выполняется для того, чтобы определять то, какое описание звукового поля используется для выполнения вычисления звуковых полей на этапе 710. На этапе 720, определяется первое расстояние новой позиции слушателя до первого опорного местоположения первого описания звукового поля. Относительно фиг. 4c, оно представляет собой расстояние между разностным опорным местоположением и опорной позицией A.
Кроме того, на этапе 722, определяется второе расстояние новой позиции слушателя до второго опорного местоположения второго описания звукового поля. В этом варианте осуществления по фиг. 4c, оно представляет собой расстояние между другим опорным местоположением (вследствие перемещения) и опорной позицией B.
Очевидно, что расстояние от другого опорного местоположения до опорной позиции B ниже разности от другого опорного местоположения до опорной позиции A. Таким образом, оно должно определяться на этапе 724. Так же, на этапе 726, объектный сигнал выбирается из группы, извлекаемой из описания звукового поля с меньшим расстоянием. Таким образом, чтобы подготавливать посредством рендеринга источники A и B, которые соответствуют совпадающим источникам на иллюстрации по фиг. 4c, должны использоваться сигналы источников звука, извлекаемые из второго описания звукового поля, связанного с дополнительной опорной позицией B.
Тем не менее, в других вариантах осуществления, в которых перемещение указывает из начала координат в другое опорное местоположение, например, слева на иллюстрации по фиг. 4c, меньшее расстояние должно быть от этого другого опорного местоположения до опорной позиции A, и далее первое описание звукового поля используется для вычисления в завершение звукового поля для каждого совпадающего объекта на этапе 710 по фиг. 6b. С другой стороны, выбор должен выполняться посредством процедуры, проиллюстрированной на фиг. 7.
Фиг. 9 иллюстрирует дополнительный предпочтительный вариант осуществления. На этапе 740, выполняется анализ звукового поля для первого описания звукового поля, например, анализ параметрического звукового поля в форме DirAC-анализа, проиллюстрированного на этапе 422 по фиг. 6c.
Это дает в результате первый набор параметров, например, для каждого частотно-временного бина, при этом каждый набор параметров содержит DoA-параметр и, опционально, параметр степени рассеяния.
На этапе 741, анализ звукового поля выполняется для второго описания звукового поля и, снова, DirAC-анализ выполняется, как указано на этапе 740 и, например, как поясняется относительно этапа 422 по фиг. 6c.
Это дает в результате второй набор параметров, например, для частотно-временных бинов.
Затем, на этапе 746, позиция для каждой пары параметров может определяться с использованием соответствующего DoA-параметра из первого частотно-временного бина и DoA-параметра из идентичного частотно-временного бина из второго набора параметров. Это должно давать в результате позицию для каждой пары параметров. Тем не менее, позиция является тем более полезной, чем ниже степень рассеяния для соответствующего частотно-временного бина в первом наборе параметров и/или во втором наборе параметров.
Таким образом, предпочтительно в дальнейшем использовать только позиции из частотно-временных бинов, которые приводят к достаточно низкой степени рассеяния в первом и втором наборе параметров.
Дополнительно, предпочтительно также выполнять корреляцию для соответствующих сигналов в частотно-временном бине, которые также выводятся посредством этапа 740 и этапа 741.
Таким образом, "сопоставление источников" этапа 704 на фиг. 6a, например, может полностью не допускаться и заменяться посредством определения совпадающих источников/совпадающих частотно-временных бинов на основе параметров степени рассеяния, или сопоставление может выполняться дополнительно с использованием соответствующего сигнала в частотно-временном бине из компонентов в B-формате, например, либо из сигнала давления или объектного сигнала, выводимого посредством этапа 422 по фиг. 6c.
В любом случае, этап 46 должен давать в результате определенные позиции для определенных (выбранных) частотно-временных бинов, которые соответствуют "совпадающим объектам", найденным на этапе 704 по фиг. 6a.
Затем, на этапе 748, вычисляются модифицированные параметры и/или сигналы для позиций, полученных посредством этапа 746, и/или соответствующего перемещения/вращения, полученного, например, посредством этого модуля отслеживания, и вывод этапа 748 представляет модифицированные параметры и/или модифицированные сигналы для различных частотно-временных бинов.
Таким образом, этап 748 может соответствовать преобразованию 423 с перемещением и преобразованию с вращением этапа 424 для целей вычисления модифицированных параметров, и вычисление модифицированных сигналов, например, должно выполняться посредством этапа 425 по фиг. 6c, предпочтительно также с учетом определенного коэффициента масштабирования, извлекаемого из позиций для соответствующих частотно-временных бинов.
В завершение, синтез описания звукового поля выполняется на этапе 750 с использованием модифицированных данных. Он, например, может выполняться посредством DirAC-синтеза с использованием либо первого, либо второго описания звукового поля или может выполняться посредством формирователя амбиофонических сигналов, как проиллюстрировано на этапе 425, и результат должен представлять собой новое описание звукового поля для передачи/хранения/рендеринга.
Фиг. 10 иллюстрирует дополнительную предпочтительную реализацию модуля 420 вычисления звуковых полей. По меньшей мере, части процедуры, проиллюстрированной на фиг. 10, выполняются для каждого совпадающего источника отдельно. Этап 1120 определяет расстояние для совпадающего источника, например, посредством вычисления с триангуляцией.
На основе описания звукового поля, полнополосное направление поступления или направление поступления в расчете на полосу частот определяется на 1100. Эта информация направления поступления представляет данные направления поступления звукового поля. На основе этих данных направления поступления, преобразование с перемещением выполняется на этапе 1110. С этой целью, этап 1120 вычисляет расстояние для каждого совпадающего источника. На основе данных, этап 1110 формирует новые данные направлении поступления для звукового поля, которые, в этой реализации, зависят только от перемещения из опорного местоположения в другое опорное местоположение. С этой целью, этап 1110 принимает сформированную информацию перемещения, например, посредством отслеживания в контексте реализации в стиле виртуальной реальности.
Предпочтительно или альтернативно, также используются данные вращения. С этой целью, этап 1130 выполняет преобразование с вращением с использованием информации вращения. Когда выполняется как перемещение, так и вращение, в таком случае предпочтительно выполнять преобразование с вращением после вычисления новых DoA звукового поля, которые уже включают в себя информацию из перемещения и расстояния от источника из этапа 1120.
Затем, на этапе 1140 формируется новое описание звукового поля. С этой целью, может использоваться описание исходного звукового поля, либо, альтернативно, могут использоваться сигналы источников, которые разделены от описания звукового поля посредством алгоритма разделения источников, либо могут использоваться любые другие варианты применения. По существу, новое описание звукового поля, например, может представлять собой направленное описание звукового поля, полученное посредством амбиофонического формирователя 430 или сформированное посредством DirAC-синтезатора 425, либо может представлять собой бинауральное представление, сформированное из представления виртуальных динамиков в последующем бинауральном рендеринге.
Предпочтительно, как проиллюстрировано на фиг. 10, расстояние согласно направлению поступления также используется в формировании нового описания звукового поля, чтобы адаптировать громкость или уровень громкости определенного источника звука к новому местоположению, т.е. к новому или другому опорному местоположению.
Хотя фиг. 10 иллюстрирует ситуацию, в которой преобразование с вращением выполняется после преобразования с перемещением, следует отметить, что порядок может отличаться. В частности, преобразование с вращением может применяться к DoA звукового поля, сформированным посредством этапа 1100, и после этого применяется дополнительное преобразование с перемещением, которое обусловлено перемещением субъекта из опорного местоположения в другое опорное местоположение.
После того, как DoA звукового поля определены посредством этапа 1100, информация расстояния получается из метаданных с использованием этапа 1120, и эта информация расстояния затем используется посредством формирования нового описания звукового поля на этапе 1140 для учета измененного расстояния и в силу этого измененного уровня громкости определенного источника относительно определенного опорного местоположения. По существу, можно сказать, что в случае, если расстояние становится большим, в таком случае конкретный сигнал источника звука ослабляется, в то время как, когда расстояние становится короче, таком случае сигнал источника звука усиливается. Естественно, ослабление или усиление определенного источника звука в зависимости от расстояния осуществляется пропорционально изменению расстояния, но, в других вариантах осуществления, менее комплексные операции могут применяться к этому усилению или ослаблению сигналов источников звука в достаточно приблизительных приращениях. Даже такая менее комплексная реализация предоставляет превосходные результаты по сравнению с ситуацией, когда любое изменение расстояния полностью игнорируется.
Фиг. 11 иллюстрирует дополнительную предпочтительную реализацию модуля вычисления звуковых полей. На этапе 1200, отдельные источники из звукового поля определяются, например, в расчете на полосу частот или в полной полосе частот. Когда выполняется определение в расчете на кадр и полосу частот, то это может осуществляться посредством DirAC-анализа. Если выполняется полнополосное или подполосное определение, то это может осуществляться посредством какого-либо вида полнополосного или подполосного алгоритма разделения источников.
На этапе 1210, перемещение и/или вращение слушателя определяется, например, посредством расположения виртуальной камеры внутри сцены.
На этапе 1220, старое расстояние для каждого источника определяется посредством использования метаданных и, например, посредством использования метаданных для вычисления с триангуляцией. Таким образом, каждая полоса частот считается определенным источником (при условии, что степень рассеяния ниже определенного порогового значения), и после этого определяется определенное расстояние для каждого частотно-временного бина, имеющего низкое значение степени рассеяния.
Затем, на этапе 1230, новое расстояние в расчете на источник получается, например, посредством векторного вычисления в расчете на полосу частот, которое, например, поясняется в контексте фиг. 6b.
Кроме того, как проиллюстрировано на этапе 1240, старое направление в расчете на источник определяется, например, посредством DoA-вычисления, полученного в DirAC-анализе, либо, например, посредством анализа информации направления поступления или направления в алгоритме разделения источников.
Затем, на этапе 1250, новое направление в расчете на источник определяется, например, посредством выполнения векторного вычисления в расчете на полосу частот или в полной полосе частот.
После этого, на этапе 1260, новое звуковое поле формируется для перемещенного и вращаемого слушателя. Это может осуществляться, например, посредством масштабирования прямой части в расчете на один канал в DirAC-синтезе. В зависимости от конкретной реализации, модификация расстояния может выполняться на этапах 1270a, 1270b или 1270c, помимо или альтернативно выполнению модификации расстояния на этапе 1260.
Когда, например, определяется то, что звуковое поле имеет только один источник, в таком случае модификация расстояния может уже выполняться на этапе 1270a.
Альтернативно, когда отдельные сигналы источников вычисляются посредством этапа 1200, в таком случае модификация расстояния может выполняться для отдельных источников на этапе 1270b, до того, как фактическое новое звуковое поле формируется на этапе 1260.
Дополнительно, когда формирование звуковых полей на этапе 1260, например, подготавливает посредством рендеринга не сигнал компоновки громкоговорителей или бинауральный сигнал, а другое описание звукового поля, например, с использованием амбиофонического кодера или модуля 430 вычисления, в таком случае модификация расстояния также может выполняться после формирования на этапе 1260, что означает на этапе 1270c. В зависимости от реализации, модификация расстояния также может быть распределена в несколько модулей модификации, так что, в конечном счете, определенный источник звука имеет определенный уровень громкости, который направляется посредством разности между исходным расстоянием между источником звука и опорным местоположением и новым расстоянием между источником звука и другим опорным местоположением.
Фиг. 12a иллюстрирует DirAC-анализатор, как первоначально раскрыто, например, в более раннем противопоставленном материале "Directional Audio Coding" из IWPASH 2009 года.
DirAC-анализатор содержит гребенку 1310 полосовых фильтров, энергоанализатор 1320, анализатор 1330 интенсивности, блок 1340 временного усреднения и модуль 1350 вычисления степени рассеяния и модуль 1360 вычисления направления.
В DirAC, как анализ, так и синтез выполняется в частотной области. Предусмотрено несколько способов для разделения звука на полосы частот, каждая из которых имеет отличительные свойства. Наиболее часто используемые преобразования частоты включают в себя кратковременное преобразование Фурье (STFT) и гребенку квадратурных зеркальных фильтров (QMF). В дополнение к ним, имеется полная свобода в том, чтобы проектировать гребенку фильтров с произвольными фильтрами, которые оптимизируются под любые конкретные цели. Цель направленного анализа заключается в том, чтобы оценивать в каждой полосе частот направление поступления звука, вместе с оценкой того, поступает либо нет звук из одного или более направлений одновременно. В принципе, это может выполняться с помощью ряда технологий; тем не менее, выявлено, что энергетический анализ звукового поля является подходящим, что проиллюстрировано на фиг. 12a. Энергетический анализ может выполняться, когда сигнал давления и сигналы скорости в одном, двух или три измерениях захватываются из одной позиции. В сигналах в B-формате первого порядка, всенаправленный сигнал называется W-сигналом, который понижающе масштабирован посредством квадратного корня двух. Звуковое давление может оцениваться в качестве 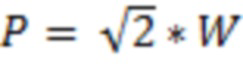 , выражаемого в STFT-области.
, выражаемого в STFT-области.
X-, Y- и Z-каналы имеют диаграмму направленности диполя, направленного вдоль декартовой оси, которые формируют вместе вектор u=[X, Y, Z]. Вектор оценивает вектор скорости звукового поля и также выражается в STFT-области. Энергия E звукового поля вычисляется. Захват сигналов в B-формате может получаться либо с совпадающим позиционированием направленных микрофонов, либо с близкорасположенным набором всенаправленных микрофонов. В некоторых вариантах применения, сигналы микрофонов могут формироваться в вычислительной области, т.е. моделироваться.
Направление звука задается в качестве противоположного направления вектора I интенсивности. Направление обозначается как соответствующие значения углового азимута и подъема в передаваемых метаданных. Степень рассеяния звукового поля также вычисляется с использованием оператора математического ожидания вектора интенсивности и энергии. Результат этого уравнения представляет собой действительнозначное число между нулем и единицей, отличающее то, поступает звуковая энергия из одного направления (степень рассеяния равна нулю) или из всех направлений (степень рассеяния равна единице). Эта процедура является надлежащей в случае, когда доступна полная трехмерная (или меньшей размерности) информация скорости.
Фиг. 12b иллюстрирует DirAC-синтез, снова имеющий гребенку 1370 полосовых фильтров, блок 1400 виртуальных микрофонов, блок 1450 прямого/синтезатора рассеянных сигналов и определенную компоновку громкоговорителей или виртуальную предназначенную компоновку 1460 громкоговорителей. Дополнительно, используются модуль 1380 преобразования степени рассеяния в усиление, блок 1390 обработки таблиц усилений на основе векторного амплитудного панорамирования (VBAP), компенсационный блок 1420 микрофонов, блок 1430 усреднения усиления громкоговорителей и модуль 1440 распределения для других каналов.
В этом DirAC-синтезе с громкоговорителями, высококачественная версия DirAC-синтеза, показанного на фиг. 12b принимает все сигналы в B-формате, для которых сигнал виртуального микрофона вычисляется для каждого направления громкоговорителя компоновки 1460 громкоговорителей. Используемая диаграмма направленности типично является диполем. Сигналы виртуальных микрофонов затем модифицируются нелинейным способом, в зависимости от метаданных. Версия с низкой скоростью передачи битов DirAC не показана на фиг. 12b; тем не менее, в этой ситуации, передается только один канал аудио, как проиллюстрировано на фиг. 6. Различие в обработке заключается в том, что все сигналы виртуальных микрофонов должны заменяться посредством одного принимаемого канала аудио. Сигналы виртуальных микрофонов разделяются на два потока: рассеянные и нерассеянные потоки, которые обрабатываются отдельно.
Нерассеянный звук воспроизводится в качестве точечных источников посредством использования векторного амплитудного панорамирования (VBAP). При панорамировании, монофонический звуковой сигнал применяется к поднабору громкоговорителей после умножения с конкретными для громкоговорителя коэффициентами усиления. Коэффициенты усиления вычисляются с использованием информации компоновки громкоговорителей и указываемого направления панорамирования. В версии с низкой скоростью передачи битов, входной сигнал просто панорамируется в направления, подразумеваемые посредством метаданных. В высококачественной версии, каждый сигнал виртуального микрофона умножается на соответствующий коэффициент усиления, что формирует идентичный эффект с панорамированием; тем не менее, он менее подвержен нелинейным артефактам.
Во многих случаях, направленные метаданные подвергаются резким временным изменениям. Чтобы не допускать артефактов, коэффициенты усиления для громкоговорителей, вычисленные с помощью VBAP, сглаживаются посредством временной интеграции с частотно-зависимыми постоянными времени, равными приблизительно 50 периодам цикла в каждой полосе частот. Это эффективно удаляет артефакты; тем не менее, изменения направления не воспринимаются как более медленные, чем без усреднения, в большинстве случаев.
Цель синтеза рассеянного звука состоит в том, чтобы создавать восприятие звука, который окружает слушателя. В версии с низкой скоростью передачи битов, рассеянный поток воспроизводится посредством декорреляции входного сигнала и его воспроизведения из каждого громкоговорителя. В высококачественной версии, сигналы виртуальных микрофонов рассеянного потока являются уже некогерентными в определенной степени, и они должны декоррелироваться только немного. Этот подход предоставляет лучшее пространственное качество для реверберации объемного звучания и окружающего звука, чем версия с низкой скоростью передачи битов.
Для DirAC-синтеза с наушниками, DirAC формулируется с определенным количеством виртуальных громкоговорителей вокруг слушателя для нерассеянного потока и определенным числом громкоговорителей для рассеянного потока. Виртуальные громкоговорители реализуются как свертка входных сигналов с измеренными передаточными функциями восприятия звука человеком (HRTF).
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
Изобретаемое улучшенное описание звукового поля может сохраняться на цифровом носителе хранения данных или энергонезависимом носителе хранения данных или может передаваться по передающей среде, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронночитаемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат энергонезависимый носитель хранения данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления изобретаемого способа в силу этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Литературные ссылки
[1] Liitola, T., Headphone sound externalization, Ph.D. thesis, Helsinki University of Technology. Department of Electrical and Communications Engineering Laboratory of Acoustics and Audio Signal Processing, 2006.
[2] Blauert, J., Spatial Hearing - Revised Edition: The Psychophysics of Human Sound Localization, The MIT Press, 1996, ISBN 0262024136.
[3] Zhang, W., Samarasinghe, P. N., Chen, H., and Abhayapala, T. D., “Surround by Sound: A Re-view of Spatial Audio Recording and Reproduction,” Applied Sciences, 7(5), стр. 532, 2017.
[4] Bates, E. and Boland, F., “Spatial Music, Virtual Reality, and 360 Media,” in Audio Eng. Soc. Int. Conf. on Audio for Virtual and Augmented Reality, Лос Анджелес, Калифорния, США, 2016.
[5] Anderson, R., Gallup, D., Barron, J. T., Kontkanen, J., Snavely, N., Esteban, C. H., Agarwal, S., and Seitz, S. M., “Jump: Virtual Reality Video,” ACM Transactions on Graphics, 35(6), стр. 198, 2016.
[6] Merimaa, J., Analysis, Synthesis, and Perception of Spatial Sound: Binaural Localization Modeling and Multichannel Loudspeaker Reproduction, Ph.D. thesis, Helsinki University of Technology, 2006.
[7] Kronlachner, M. and Zotter, F., “Spatial Transformations for the Enhancement of Ambisonics Recordings,” in 2nd International Conference on Spatial Audio, Эрланген, Германия, 2014.
[8] Tsingos, N., Gallo, E., and Drettakis, G., “Perceptual Audio Rendering of Complex Virtual Environments,” ACM Transactions on Graphics, 23(3), стр. 249-258, 2004.
[9] Taylor, M., Chandak, A., Mo, Q., Lauterbach, C., Schissler, C., and Manocha, D., “Guided multi-view ray tracing for fast auralization,” IEEE Trans. Visualization & Comp. Graphics, 18, стр. 1797- 1810, 2012.
[10] Rungta, A., Schissler, C., Rewkowski, N., Mehra, R., and Manocha, D., “Diffraction Kernels for Interactive Sound Propagation in Dynamic Environments,” IEEE Trans. Visualization & Comp. Graphics, 24(4), стр. 1613-1622, 2018.
[11] Thiergart, O., Kowalczyk, K., and Habets, E. A. P., “An Acoustical Zoom based on Informed Spatial Filtering,” in Int. Workshop on Acoustic Signal Enhancement, стр. 109-113, 2014.
[12] Khaddour, H., Schimmel, J., and Rund, F., “A Novel Combined System of Direction Estimation and Sound Zooming of Multiple Speakers,” Radioengineering, 24(2), 2015.
[13] Ziegler, M., Keinert, J., Holzer, N., Wolf, T., Jaschke, T., op het Veld, R., Zakeri, F. S., and Foessel, S., “Immersive Virtual Reality for Live-Action Video using Camera Arrays,” in IBC, Амстердам, Нидерланды, 2017.
[14] Thiergart, O., Galdo, G. D., Taseska, M., and Habets, E. A. P., “Geometry-Based Spatial Sound Acquisition using Distributed Microphone Arrays,” IEEE Trans. Audio, Speech, Language Process., 21(12), стр. 2583-2594, 2013.
[15] Kowalczyk, K., Thiergart, O., Taseska, M., Del Galdo, G., Pulkki, V., and Habets, E. A. P., “Parametric Spatial Sound Processing: A Flexible and Efficient Solution to Sound Scene Acquisition, Modification, and Reproduction,” IEEE Signal Process. Mag., 32(2), стр. 31-42, 2015.
[16] Pulkki, V., “Spatial Sound Reproduction with Directional Audio Coding,” J. Audio Eng. Soc., 55(6), стр. 503-516, 2007.
[17] International Telecommunication Union, “ITU-R BS.1534-3, Method for the subjective assessment of intermediate quality level of audio systems,” 2015.
[18] Thiergart, O., Del Galdo, G., Kuech, F., and Prus, M., “Three-Dimensional Sound Field Analysis with Directional Audio Coding Based on Signal Adaptive Parameter Estimators,” in Audio Eng. Soc. Conv. Spatial Audio: Sense the Sound of Space, 2010.
[19] Kuttruff, H., Room Acoustics, Taylor & Francis, 4 edition, 2000.
[20] Borß, C., “A polygon-based panning method for 3D loudspeaker setups,” in Audio Eng. Soc. Conv., стр. 343-352, Лос Анджелес, Калифорния, США, 2014.
[21] Rummukainen, O., Schlecht, S., Plinge, A., and Habets, E. A. P., “Evaluating Binaural Reproduction Systems from Behavioral Patterns in a Virtual Reality - A Case Study with Impaired Binaural Cues and Tracking Latency,” in Audio Eng. Soc. Conv. 143, Нью-Йорк, NY, США, 2017.
[22] Engelke, U., Darcy, D. P., Mulliken, G. H., Bosse, S., Martini, M. G., Arndt, S., Antons, J.-N., Chan, K. Y., Ramzan, N., and Brunnström, K., “Psychophysiology-Based QoE Assessment: A Survey,” IEEE Selected Topics in Signal Processing, 11(1), стр. 6-21, 2017.
[23] Schlecht, S. J. and Habets, E. A. P., “Sign-Agnostic Matrix Design for Spatial Artificial Reverberation with Feedback Delay Networks,” in Proc. Audio Eng. Soc. Conf., стр. 1-10- accepted, Tokyo, Japan, 2018.
[31] M. A. Gerzon, "Periphony: With-height sound reproduction,'' J. Acoust. Soc. Am., том 21,110. 1, стр. 2-10, 1973.
[32] V. Pulkki, "Directional audio coding in spatial sound reproduction and stereo upmixing," in Proc. of the 28th AES International Conference, 2006.
[33] --, "Spatial sound reproduction with directional audio coding," Journal Audio Eng. Soc„ том 55, номер 6, стр. 503-516, июнь 2007.
[34] C. G. and G. M., "Coincident microphone simulation covering three dimensional space and yielding various directional outputs," патент США 4 042 779, 1977.
[35] C. Faller and F. Baumgarte, "Binaural cue coding - part ii: Schemes and applications, "IEEE Trans. Speech Audio Process„ том 11, номер 6, ноябрь 2003.
[36] C. Faller, "Parametric multichannel audio coding: Synthesis of coherence cues," IEEE Trans. Speech Audio Process., том 14, номер 1, январь 2006.
[37] H. P. J. E. E. Schuijers, J. Breebaart, "Low complexity parametric stereo coding," in Proc. of the 116th A ES Convention, Берлин, Германия, 2004.
[38] V. Pulkki, "Virtual sound source positioning using vector base amplitude panning," J. Acoust. Soc. A m„ том 45, номер 6, стр. 456-466, июнь 1997.
[39] J. G. Tylka and E. Y. Choueiri, "Comparison of techniques for binaural navigation of higher order ambisonics sound fields," in Proc. of the AES International Conference on Audio for Virtual and Augmented Reality, Нью-Йорк, сентябрь 2016.

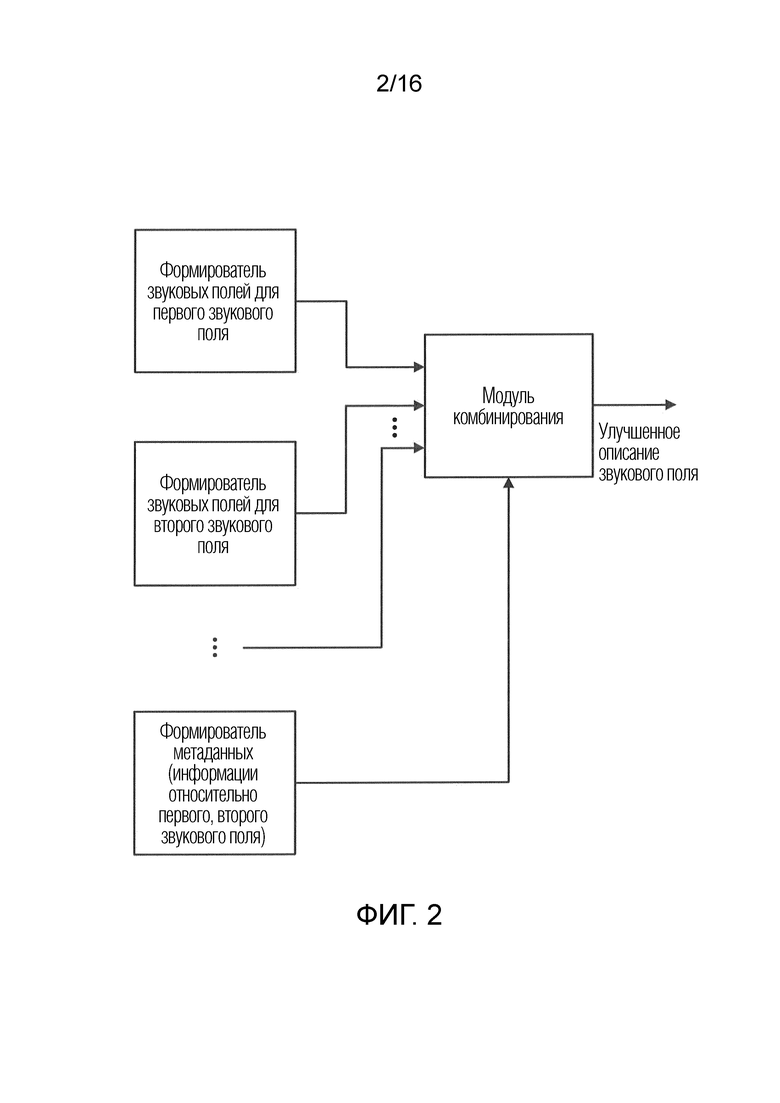


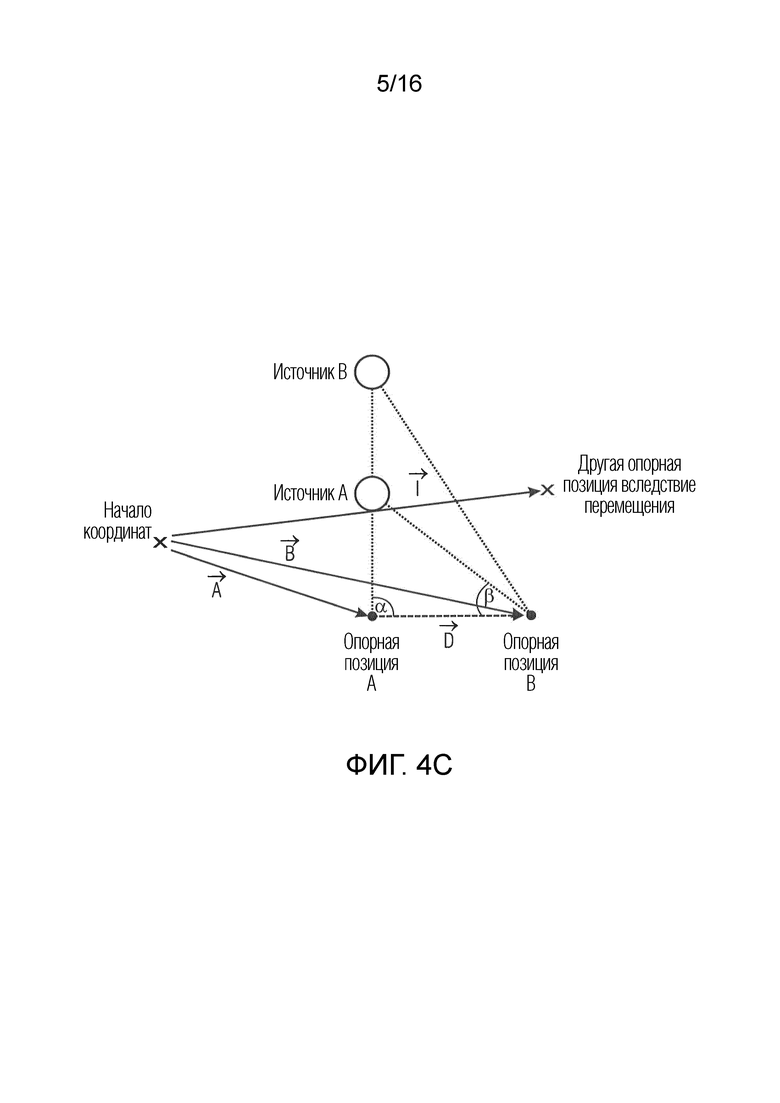
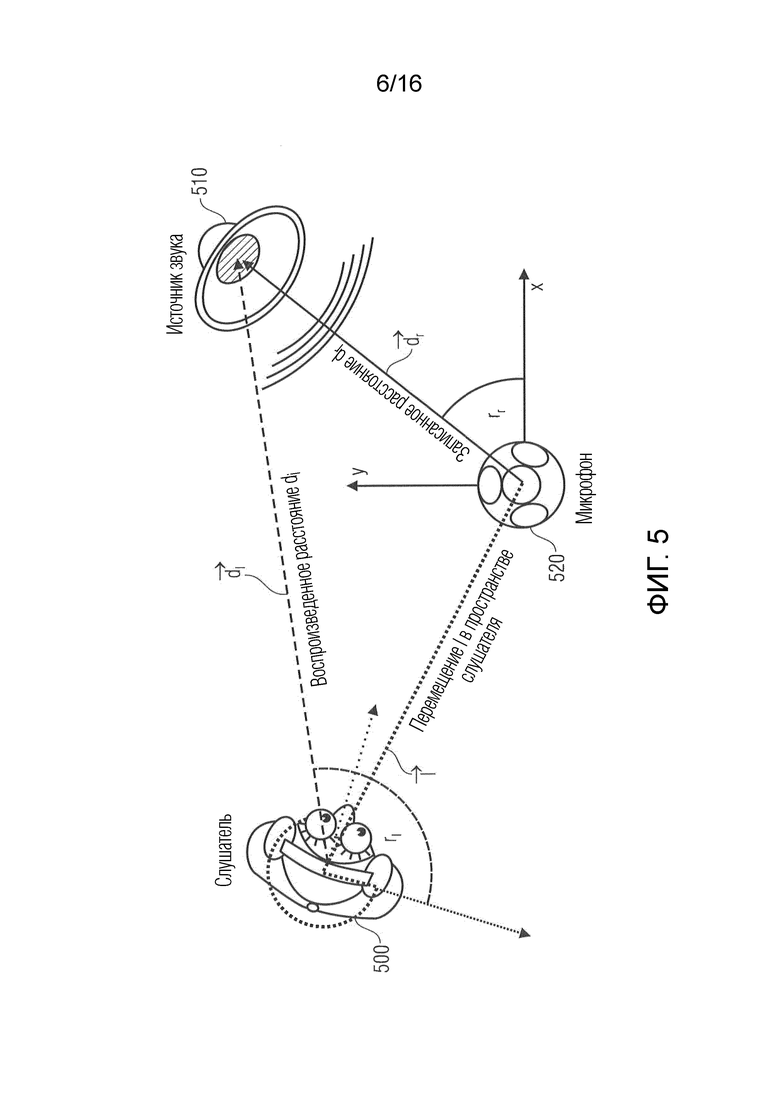



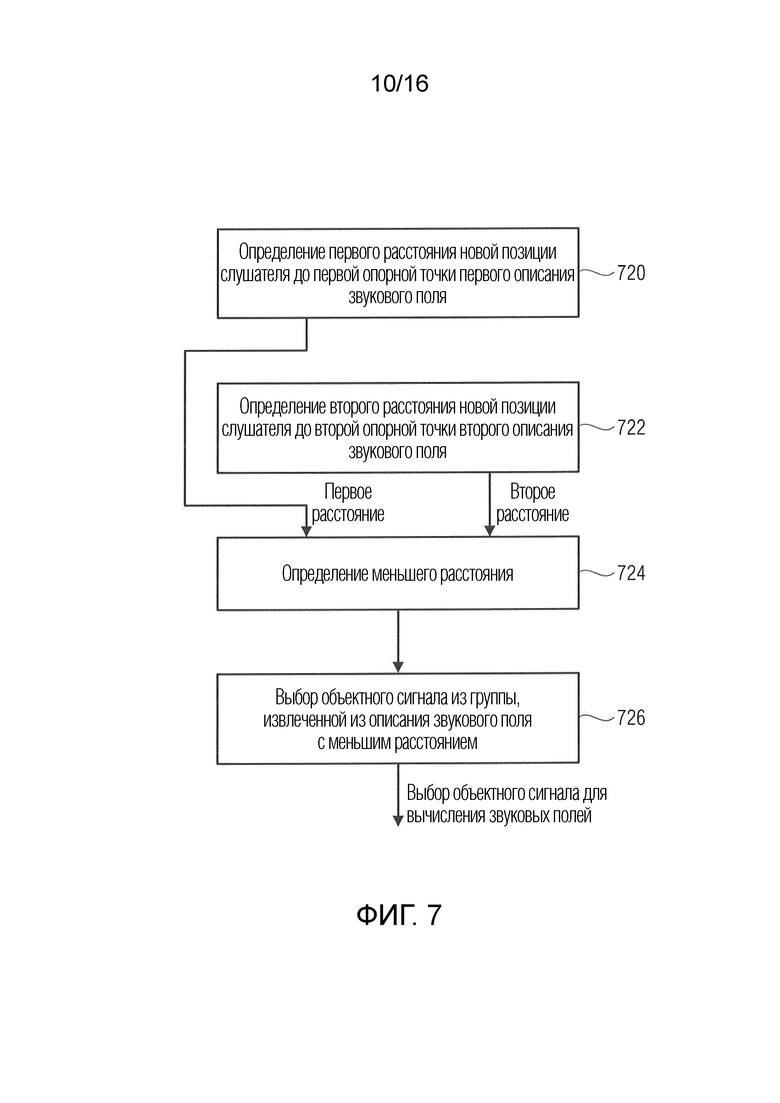
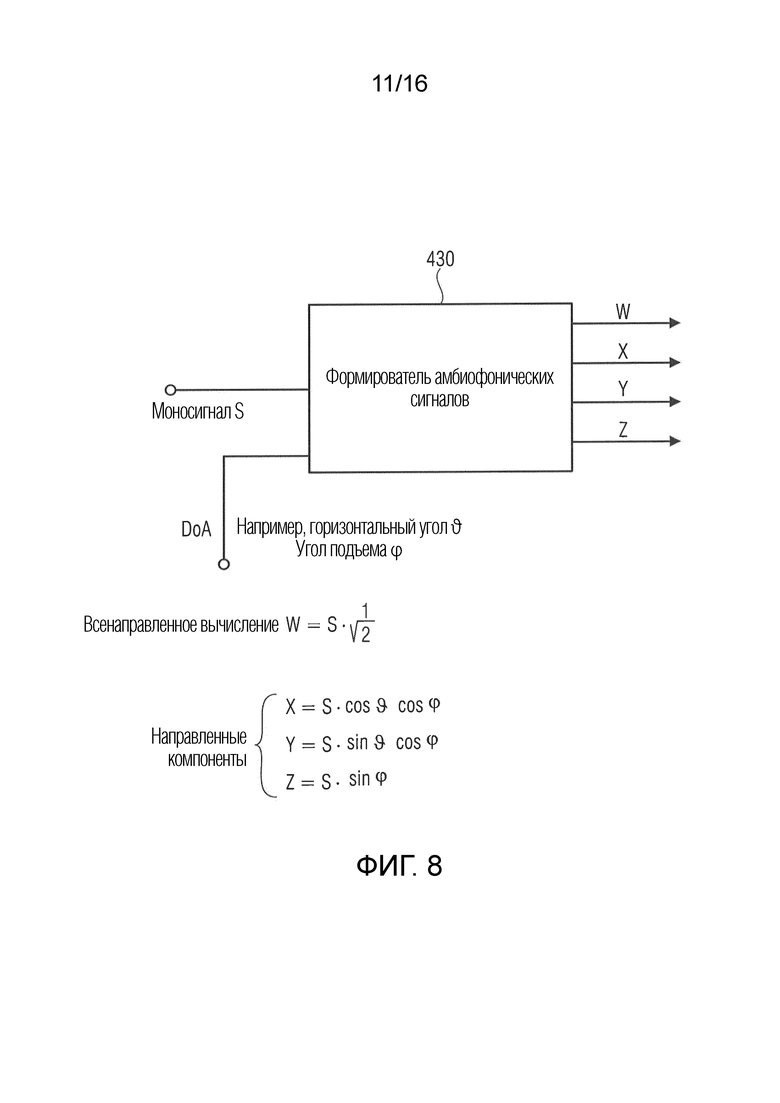
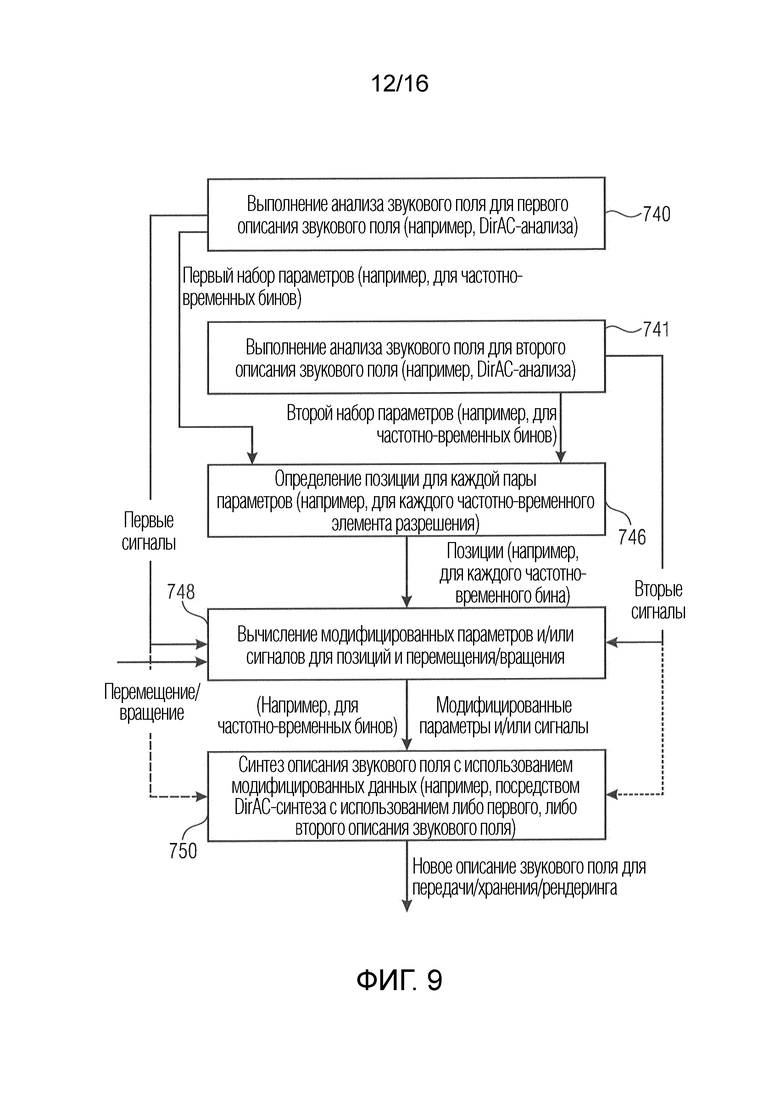




Изобретение относится к средствам для формирования описания звукового поля. Технический результат заключается в повышении эффективности формирования звукового поля. Формируют первое описание звукового поля, указывающее звуковое поле относительно первого опорного местоположения, и второе описание звукового поля, указывающее звуковое поле относительно второго опорного местоположения, причем второе опорное местоположение отличается от первого опорного местоположения. Формируют метаданные, связанные с пространственной информацией звукового поля. При этом формирование метаданных содержит определение по меньшей мере одного из первого геометрического описания для первого описания звукового поля и второго геометрического описания для второго описания звукового поля в качестве метаданных. При этом первое описание звукового поля, второе описание звукового поля и метаданные, содержащие по меньшей мере одно из первого геометрического описания и второго геометрического описания, составляют улучшенное описание звукового поля. 14 н. и 32 з.п. ф-лы, 19 ил.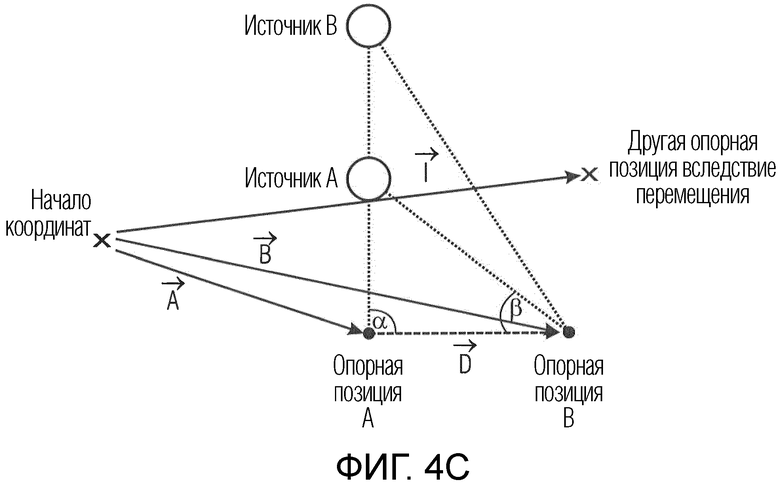
1. Устройство для формирования улучшенного описания звукового поля, причем устройство содержит:
- формирователь звуковых полей для формирования первого описания звукового поля, указывающего звуковое поле относительно первого опорного местоположения, и второго описания звукового поля, указывающего звуковое поле относительно второго опорного местоположения, причем второе опорное местоположение отличается от первого опорного местоположения; и
- формирователь метаданных для формирования метаданных, связанных с пространственной информацией звукового поля,
при этом формирователь звуковых полей выполнен с возможностью определять по меньшей мере одно из первого геометрического описания для первого описания звукового поля и второго геометрического описания для второго описания звукового поля в качестве метаданных, и
при этом первое описание звукового поля, второе описание звукового поля и метаданные, содержащие по меньшей мере одно из первого геометрического описания и второго геометрического описания, составляют улучшенное описание звукового поля.
2. Устройство по п. 1,
в котором формирователь метаданных выполнен с возможностью
определять, в качестве первого геометрического описания, одно из первого опорного местоположения и второго опорного местоположения и определять, в качестве второго геометрического описания, другое из первого опорного местоположения и второго опорного местоположения, либо расстояние между первым опорным местоположением и вторым опорным местоположением, либо вектор местоположения между первым опорным местоположением и вторым опорным местоположением в качестве метаданных.
3. Устройство по п. 1,
в котором первое описание звукового поля представляет собой первое описание на основе амбиофонии, и при этом второе описание звукового поля представляет собой второе описание на основе амбиофонии, или при этом первое описание звукового поля и второе описание звукового поля представляют собой одно из описания на основе амбиофонии или DirAC-описания.
4. Устройство по п. 1,
в котором первое геометрическое описание представляет собой информацию относительно первого вектора, направленного из предварительно определенного начала координат в первое опорное местоположение первого описания звукового поля, и
при этом второе геометрическое описание представляет собой информацию относительно второго вектора, направленного из предварительно определенного начала координат во второе опорное местоположение второго описания звукового поля.
5. Устройство по п. 1,
в котором первое геометрическое описание представляет собой информацию относительно одного из первого вектора, направленного из предварительно определенного начала координат в первое опорное местоположение первого описания звукового поля, и второго вектора, направленного из предварительно определенного начала координат во второе опорное местоположение второго описания звукового поля, и при этом второе геометрическое описание содержит информацию относительно вектора между первым опорным местоположением и вторым опорным местоположением.
6. Устройство по п. 1,
в котором одно из первого опорного местоположения и второго опорного местоположения представляет собой предварительно определенное начало координат, которое представляет собой первое геометрическое описание, и при этом второе геометрическое описание содержит информацию относительно вектора между предварительно определенным началом координат и другим из первого опорного местоположения и второго опорного местоположения.
7. Устройство по п. 1, в котором формирователь звуковых полей выполнен с возможностью формирования первого описания звукового поля или второго описания звукового поля с использованием устройства реального микрофона или посредством синтеза звука с использованием технологии виртуального микрофона.
8. Устройство для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, причем устройство содержит
модуль (420) вычисления звуковых полей для вычисления модифицированного описания звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение,
при этом модуль (420) вычисления звуковых полей выполнен с возможностью:
- принимать первое описание звукового поля, связанное с первым опорным местоположением, и принимать второе описание звукового поля, связанное с дополнительным опорным местоположением, отличающимся от упомянутого опорного местоположения,
- выполнять разделение источников для первого описания звукового поля, чтобы получать первую группу из одного или более извлеченных объектов, и второго описания звукового поля, чтобы получать вторую группу из одного или более извлеченных объектов,
- вычислять данные направления поступления (DoA) для извлеченных объектов,
- сопоставлять первую группу извлеченных объектов первого описания звукового поля и вторую группу извлеченных объектов второго описания звукового поля, чтобы получать один или более сопоставленных объектов,
- оценивать позицию сопоставленного объекта из упомянутых одного или более сопоставленных объектов, и
- модифицировать сопоставленный объект из упомянутых одного или более сопоставленных объектов на основе оцененной позиции сопоставленного объекта из упомянутых одного или более сопоставленных объектов и другого опорного местоположения.
9. Устройство по п. 8, в котором модуль (420) вычисления звуковых полей выполнен с возможностью:
- вычислять данные направления поступления упомянутых одного или более сопоставленных объектов, и
- определять данные описания звукового поля для каждого сопоставленного объекта из упомянутых одного или более сопоставленных объектов с использованием вычисленных данных направления поступления для упомянутого другого опорного местоположения.
10. Устройство по п. 8,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью вычисления данных направления поступления упомянутых одного или более несопоставленных объектов и вычисления данных описания звукового поля для упомянутых одного или более несопоставленных объектов с использованием данных направления поступления для упомянутых одного или более несопоставленных объектов.
11. Устройство по п. 10,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью вычислять модифицированное описание звукового поля посредством комбинирования данных описания звукового поля для упомянутых одного или более сопоставленных объектов и данных описания звукового поля для упомянутых одного или более несопоставленных объектов.
12. Устройство для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, причем устройство содержит
модуль (420) вычисления звуковых полей для вычисления модифицированного описания звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение,
при этом модуль (420) вычисления звуковых полей выполнен с возможностью:
- предполагать модель звукового поля,
- оценивать компоненты и/или параметры сигналов предполагаемой модели звукового поля,
- модифицировать компоненты и/или параметры сигналов в зависимости от информации перемещения или в зависимости от упомянутого другого опорного местоположения и
- формировать модифицированное описание звукового поля с использованием модифицированных сигнальных компонентов и/или модифицированных параметров.
13. Устройство по п. 12,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью оценивать компоненты и/или параметры сигналов с использованием разложения предполагаемой модели звукового поля на один или более прямых звуковых компонентов и один или более рассеянных звуковых компонентов либо посредством использования разложения предполагаемой модели звукового поля на один или более прямых/основных звуковых компонентов и остаточный звуковой компонент, при этом остаточный звуковой компонент может представлять собой одноканальный сигнал или многоканальный сигнал.
14. Устройство по п. 8 или 12,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью применять вращение модифицированного описания звукового поля.
15. Устройство по п. 8 или 12,
в котором модифицированное описание звукового поля представляет собой амбиофоническое описание звукового поля.
16. Устройство для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, причем устройство содержит
модуль (420) вычисления звуковых полей для вычисления модифицированного описания звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение,
при этом модуль (420) вычисления звуковых полей выполнен с возможностью:
- принимать, в качестве описания звукового поля, первое описание звукового поля и второе описание звукового поля,
- выполнять разделение источников для первого описания звукового поля и второго описания звукового поля,
- извлекать источники первого описания звукового поля и второго описания звукового поля и данные направления поступления (DoA) для извлеченных источников,
- вычислять, для каждого извлеченного источника из упомянутых извлеченных источников, модифицированные DoA-данные относительно упомянутого другого опорного местоположения с использованием DoA-данных и информации перемещения и
- обрабатывать извлеченные источники и модифицированные DoA-данные, чтобы получать модифицированное описание звукового поля.
17. Устройство по п. 16,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью
отдельно выполнять разделение источников для каждого описания звукового поля и извлекать окружающий сигнал, или рассеянный сигнал, или остаточный сигнал для каждого описания звукового поля.
18. Устройство по п. 8, 12 или 16, дополнительно содержащее:
- интерфейс (410) перемещения для предоставления информации перемещения или информации вращения, указывающей вращение предназначенного слушателя для модифицированного описания звукового поля;
- модуль (402, 400) подачи метаданных для подачи метаданных в модуль (420) вычисления звуковых полей;
- модуль (404, 400) подачи звуковых полей для подачи описания звукового поля в модуль (420) вычисления звуковых полей; и
- выходной интерфейс (421) для вывода модифицированного звукового поля, содержащего модифицированное описание звукового поля и модифицированные метаданные, причем модифицированные метаданные извлекаются из метаданных с использованием информации перемещения, либо для вывода множества каналов громкоговорителей, причем каждый канал громкоговорителя связан с предварительно заданной позицией громкоговорителя, либо для вывода бинаурального представления модифицированного звукового поля.
19. Устройство для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, причем устройство содержит
модуль (420) вычисления звуковых полей для вычисления модифицированного описания звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение,
при этом описание звукового поля содержит множество компонентов звукового поля, причем множество компонентов звукового поля содержат всенаправленный компонент и по меньшей мере один направленный компонент,
при этом модуль (420) вычисления звуковых полей содержит:
- анализатор (422) звуковых полей для анализа компонентов звукового поля, чтобы извлекать, для различных частотных бинов, информацию направления поступления;
- модуль (423) преобразования с перемещением для вычисления модифицированной информации направления поступления в расчете на частотный бин с использованием информации направления поступления и метаданных, причем метаданные содержат карту глубины, ассоциирующую информацию расстояния с источником, представленным посредством частотного бина; и
- модуль компенсации расстояния для вычисления модифицированного описания звукового поля с использованием компенсационной информации расстояния в зависимости от расстояния, предоставленного посредством карты глубины для источника, и нового расстояния, ассоциированного с частотным бином, связанным с модифицированной информацией направления поступления.
20. Устройство для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, причем устройство содержит
модуль (420) вычисления звуковых полей для вычисления модифицированного описания звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение,
при этом модуль (420) вычисления звуковых полей выполнен с возможностью, для одного или более источников:
- вычисления (1104) первого вектора, указывающего из опорного местоположения в источник (510) звука, получаемый посредством анализа (1102) звукового поля, описанного с помощью описания звукового поля;
- вычисления (1106) второго вектора, указывающего из другого опорного местоположения (500) в источник (510) звука, с использованием первого вектора и информации перемещения, причем информация перемещения задает вектор перемещения из упомянутого опорного местоположения (522) в упомянутое другое опорное местоположение (500); и
- вычисления (1106) значения модификации расстояния с использованием упомянутого другого опорного местоположения (500), местоположения источника (510) звука и второго вектора либо с использованием расстояния от упомянутого другого опорного местоположения (500) до местоположения источника (510) звука и второго вектора.
21. Устройство по п. 8, 12, 16, 19, 20,
в котором первый вектор вычисляется посредством умножения единичного вектора направления поступления на расстояние, включенное в метаданные, или
в котором второй вектор вычисляется посредством вычитания вектора перемещения из первого вектора, причем информация перемещения задает вектор перемещения из упомянутого опорного местоположения (522) в упомянутое другое опорное местоположение (500), или
в котором значение модификации расстояния вычисляется посредством деления второго вектора на норму первого вектора.
22. Устройство по п. 8, 12, 16, 19, 20,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью принимать, в дополнение к информации перемещения, информацию вращения, и
при этом модуль (420) вычисления звуковых полей выполнен с возможностью выполнять преобразование (424) с вращением, чтобы вращать данные направления поступления для звукового поля, описанного с помощью описания звукового поля, с использованием информации вращения, при этом данные направления поступления извлекаются из данных направления поступления, полученных посредством анализа звукового поля из описания звукового поля, и с использованием информации перемещения.
23. Устройство для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, причем устройство содержит
модуль (420) вычисления звуковых полей для вычисления модифицированного описания звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение,
при этом модуль (420) вычисления звуковых полей выполнен с возможностью:
- определять (1200, 1240) источники из описания звукового поля и направлений для источников посредством анализа звукового поля;
- определять (1220), для источника, расстояние источника от опорного местоположения с использованием метаданных;
- определять (1250) новое направление источника, связанного с другим опорным местоположением, с использованием направления для источника и информации перемещения;
- определять (1230) новую информацию расстояния для источника, связанного с упомянутым другим опорным местоположением; и
- формировать (1260) модифицированное описание звукового поля с использованием нового направления источника, новой информации расстояния и описания звукового поля либо сигналов источников, соответствующих источникам, извлекаемым из описания звукового поля.
24. Устройство для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, причем устройство содержит
модуль (420) вычисления звуковых полей для вычисления модифицированного описания звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение,
при этом модуль (420) вычисления звуковых полей выполнен с возможностью:
- определять (1200) сигналы источников из описания звукового поля и направлений сигналов источников, связанных с опорным местоположением, посредством анализа (1200) звука;
- вычислять (1230) новые направления сигналов источников, связанных с другим опорным местоположением, с использованием информации перемещения;
- вычислять (1230) информацию расстояния для сигналов источников, связанных с упомянутым другим опорным местоположением; и
- синтезировать (1260) модифицированное описание звукового поля с использованием информации расстояния, сигналов источников и новых направлений.
25. Устройство по п. 24, в котором модуль (420) вычисления звуковых полей выполнен с возможностью
синтезировать (1260) модифицированное описание звукового поля посредством панорамирования сигнала источника из упомянутых сигналов источников в направление, предоставленное посредством нового направления относительно компоновки для воспроизведения, и
посредством масштабирования сигнала источника с использованием информации расстояния перед выполнением панорамирования или после выполнения панорамирования.
26. Устройство по п. 24,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью суммировать рассеянный сигнал с прямой частью сигнала источника, причем прямая часть модифицируется посредством информации расстояния перед суммированием с рассеянным сигналом.
27. Устройство по п. 24, в котором модуль (420) вычисления звуковых полей выполнен с возможностью:
- выполнять частотно-временное преобразование описания звукового поля и вычислять (422) направление поступления для множества частотных бинов временного кадра;
- вычислять (423, 424) новое направление для каждого частотного бина,
- вычислять информацию расстояния для каждого частотного бина, и
- выполнять прямой синтез для каждого частотного бина с использованием аудиосигнала для частотного бина, панорамирующего усиления для частотного бина, извлекаемого из нового направления для частотного бина, и коэффициента масштабирования для частотного бина, извлекаемого из информации расстояния для соответствующего сигнала источника, для получения прямой части.
28. Устройство по п. 27, в котором модуль (420) вычисления звуковых полей выполнен с возможностью:
- выполнять синтез рассеянных сигналов с использованием рассеянного аудиосигнала, извлекаемого из аудиосигнала для частотного бина, и с использованием параметра степени рассеяния, извлекаемого посредством анализа звука для частотного бина, для получения рассеянной части и комбинировать прямую часть и рассеянную часть, чтобы получать синтезированный аудиосигнал для частотного бина; и
- выполнять частотно-временное преобразование с использованием синтезированных аудиосигналов для частотных бинов для временного кадра, чтобы получать синтезированный во временной области аудиосигнал в качестве модифицированного описания звукового поля.
29. Устройство по п. 24, в котором модуль (420) вычисления звуковых полей выполнен с возможностью синтезировать, для каждого сигнала источника, звуковое поле, связанное с упомянутым другим опорным местоположением, причем синтез содержит:
- для каждого сигнала источника, обработку (430) сигнала источника с использованием нового направления для сигнала источника, чтобы получать описание звукового поля сигнала источника, связанного с упомянутым другим опорным местоположением;
- модификацию сигнала источника перед обработкой сигнала источника или модификацию описания звукового поля сигнала источника, связанного с упомянутым другим опорным местоположением, с использованием информации направления; и
- суммирование описаний звукового поля для сигналов источников, чтобы получать модифицированное описание звукового поля, связанное с упомянутым другим опорным местоположением.
30. Устройство по п. 24,
в котором анализ (1200) звука выполнен с возможностью определять сигналы источников посредством алгоритма разделения источников и вычитать по меньшей мере некоторые из сигналов источников из описания звукового поля, чтобы получать рассеянный сигнал.
31. Устройство для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, причем устройство содержит
модуль (420) вычисления звуковых полей для вычисления модифицированного описания звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение,
при этом модуль (420) вычисления звуковых полей выполнен с возможностью:
- сопоставлять первую группу источников первого описания звукового поля и вторую группу источников второго описания звукового поля, чтобы получать один или более сопоставленных источников,
- определять информацию направления поступления для каждого сопоставленного источника из упомянутых одного или более сопоставленных источников,
- определять расстояние источника до другого опорного местоположения с использованием информации направления поступления и метаданных для описания звукового поля, и
- определять коэффициент масштабирования с использованием расстояния источника до упомянутого другого опорного местоположения.
32. Устройство для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, причем устройство содержит
модуль (420) вычисления звуковых полей для вычисления модифицированного описания звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение опорного местоположения в другое опорное местоположение,
при этом модуль (420) вычисления звуковых полей выполнен с возможностью:
- выполнять анализ (700, 740, 741) звука для описания звукового поля, чтобы получать первую группу из одного или более извлеченных объектов или информацию направления поступления для одного или более извлеченных объектов, и для дополнительного описания звукового поля, связанного с дополнительным опорным местоположением, чтобы получать вторую группу из одного или более извлеченных объектов или информацию направления поступления для одного или более извлеченных объектов, с использованием метаданных;
- сопоставлять (704) первую группу и вторую группу с использованием сигналов объектов из этих групп или информации направления поступления для объектов из этих групп, чтобы находить по меньшей мере один сопоставленный объект;
- вычислять (706, 746) оцененную позицию сопоставленного объекта с использованием метаданных и первой информации направления поступления, полученной для сопоставленного объекта посредством выполнения анализа (700, 740, 741) звука, чтобы получать первую группу, и второй информации направления поступления, полученной для сопоставленного объекта посредством выполнения анализа (700, 740, 741) звука, чтобы получать вторую группу; и
- применять (710, 748) обработку компенсации расстояния к сопоставленному объекту на основе оцененной позиции и информации перемещения.
33. Устройство по п. 32,
в котором анализ (700, 740, 741) звука представляет собой DirAC-анализ, дающий в результате сигнал для каждого частотно-временного бина и значение направления поступления для каждого частотно-временного бина и опциональное значение степени рассеяния,
при этом сопоставление (704) выполняется для каждого отдельного частотно-временного бина, чтобы определять по меньшей мере один бин в качестве сопоставленного объекта, и
при этом оцененная позиция вычисляется (746) для этого по меньшей мере одного бина.
34. Устройство по п. 32,
в котором анализ (700, 740, 741) звука представляет собой анализ широкополосных источников, дающий в результате извлеченный широкополосный сигнал и информацию направления поступления для извлеченного широкополосного сигнала и, опционально, рассеянный сигнал,
при этом сопоставление (704) выполняется для извлеченных широкополосных сигналов с использованием показателя корреляции для каждой пары из извлеченного широкополосного сигнала из первой группы и извлеченного широкополосного сигнала из второй группы для получения по меньшей мере одного сопоставленного широкополосного объекта, и
при этом оцененная позиция вычисляется (706) для упомянутого по меньшей мере одного сопоставленного широкополосного объекта.
35. Устройство по п. 32,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью выполнять вычисление позиций упомянутого по меньшей мере одного сопоставленного объекта с использованием вычисления с триангуляцией, принимающего первую информацию направления поступления, извлекаемую из описания звукового поля, и вторую информацию направления поступления, извлекаемую из дополнительного описания звукового поля, и метаданные, содержащие информацию, из которой может извлекаться информация относительно вектора между опорным местоположением и дополнительным опорным местоположением.
36. Устройство по п. 8 или 35,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью выбирать, для вычисления описания звукового поля для сопоставленного объекта, связанного с упомянутым другим опорным местоположением, информацию, либо связанную с описанием звукового поля, либо связанную с дополнительным описанием звукового поля в зависимости от расстояния от опорного местоположения или дополнительного опорного местоположения до местоположения слушателя, определенного посредством информации перемещения.
37. Устройство по п. 36, в котором модуль (420) вычисления звуковых полей выполнен с возможностью:
- вычислять (720) первое расстояние между опорным местоположением и упомянутым другим опорным местоположением;
- вычислять (722) второе расстояние между дополнительным опорным местоположением и упомянутым другим опорным местоположением;
- выбирать (724) описание звукового поля, имеющее опорное местоположение, которое имеет меньшее расстояние из первого и второго расстояний.
38. Устройство по п. 32,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью вычислять, для каждого сопоставленного объекта, новую информацию направления поступления с использованием одного из информации направления поступления, извлекаемой из описания звукового поля, и дополнительного описания звукового поля.
39. Устройство по п. 37,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью вычислять, для каждого сопоставленного объекта, описание звукового поля с использованием новой информации направления поступления и масштабировать сигнал источника или описание звукового поля сигнала источника с использованием оцененной позиции сопоставленного объекта.
40. Устройство по п. 32,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью вычислять описание звукового поля для каждого несопоставленного объекта из первой группы и вычислять описание звукового поля для каждого несопоставленного объекта из второй группы с использованием соответствующей информации направления поступления.
41. Устройство по п. 40,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью вычислять модифицированное описание звукового поля посредством комбинирования (712) описания звукового поля сопоставленных объектов и описания звукового поля несопоставленных объектов.
42. Устройство по п. 32,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью определять информацию относительно рассеянного сигнала по меньшей мере для одной из первой группы и второй группы, и
при этом модуль (420) вычисления звуковых полей выполнен с возможностью суммировать рассеянный сигнал с описанием звукового поля сопоставленного объекта или описанием звукового поля несопоставленного объекта.
43. Способ формирования улучшенного описания звукового поля, содержащий этапы, на которых:
- формируют первое описание звукового поля, указывающее звуковое поле относительно первого опорного местоположения, и второе описание звукового поля, указывающее звуковое поле относительно второго опорного местоположения, причем второе опорное местоположение отличается от первого опорного местоположения; и
- формируют метаданные, связанные с пространственной информацией звукового поля,
при этом формирование метаданных содержит определение по меньшей мере одного из первого геометрического описания для первого описания звукового поля и второго геометрического описания для второго описания звукового поля в качестве метаданных, и
при этом первое описание звукового поля, второе описание звукового поля и метаданные, содержащие по меньшей мере одно из первого геометрического описания и второго геометрического описания, составляют улучшенное описание звукового поля.
44. Способ формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, при этом способ содержит этап, на котором
вычисляют модифицированное описание звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение из опорного местоположения в другое опорное местоположение,
при этом вычисление содержит этапы, на которых принимают первое описание звукового поля, связанное с первым опорным местоположением, и принимают второе описание звукового поля, связанное с дополнительным опорным местоположением, отличающимся от упомянутого опорного местоположения, выполняют разделение источников для первого описания звукового поля, чтобы получать первую группу из одного или более извлеченных объектов, и второго описания звукового поля, чтобы получать вторую группу из одного или более извлеченных объектов, вычисляют данные направления поступления (DoA) для извлеченных объектов, сопоставляют первую группу извлеченных объектов первого описания звукового поля и вторую группу извлеченных объектов второго описания звукового поля, чтобы получать один или более сопоставленных объектов, оценивают позицию сопоставленного объекта из упомянутых одного или более сопоставленных объектов, и модифицируют сопоставленный объект из упомянутых одного или более сопоставленных объектов на основе оцененной позиции сопоставленного объекта из упомянутых одного или более сопоставленных объектов и другого опорного местоположения, или
при этом вычисление содержит этапы, на которых предполагают модель звукового поля, оценивают компоненты и/или параметры сигналов предполагаемой модели звукового поля, модифицируют компоненты и/или параметры сигналов в зависимости от информации перемещения или в зависимости от упомянутого другого опорного местоположения, и формируют модифицированное описание звукового поля с использованием модифицированных сигнальных компонентов и/или модифицированных параметров, или
при этом вычисление содержит этапы, на которых принимают, в качестве описания звукового поля, первое описание звукового поля и второе описание звукового поля, выполняют разделение источников для первого описания звукового поля и второго описания звукового поля, извлекают источники первого описания звукового поля и второго описания звукового поля и данные направления поступления (DoA) для извлеченных источников, вычисляют, для каждого извлеченного источника из упомянутых извлеченных источников, модифицированные DoA-данные относительно упомянутого другого опорного местоположения с использованием DoA-данных и информации перемещения, и обрабатывают извлеченные источники и модифицированные DoA-данные, чтобы получать модифицированное описание звукового поля, или
при этом вычисление содержит этапы, на которых анализируют компоненты звукового поля, чтобы извлекать, для различных частотных бинов, информацию направления поступления; вычисляют модифицированную информацию направления поступления в расчете на частотный бин с использованием информации направления поступления и метаданных, причем метаданные содержат карту глубины, ассоциирующую информацию расстояния с источником, представленным посредством частотного бина; и вычисляют модифицированное описание звукового поля с использованием компенсационной информации расстояния в зависимости от расстояния, предоставленного посредством карты глубины для источника, и нового расстояния, ассоциированного с частотным бином, связанным с модифицированной информацией направления поступления, или
при этом вычисление содержит этапы, на которых, для одного или более источников, вычисляют (1104) первый вектор, указывающий из опорного местоположения в источник (510) звука, получаемый посредством анализа (1102) звукового поля, описанного с помощью описания звукового поля; вычисляют (1106) второй вектор, указывающий из другого опорного местоположения (500) в источник (510) звука, с использованием первого вектора и информации перемещения, причем информация перемещения задает вектор перемещения из упомянутого опорного местоположения (522) в упомянутое другое опорное местоположение (500); и вычисляют (1106) значение модификации расстояния с использованием упомянутого другого опорного местоположения (500), местоположения источника (510) звука и второго вектора либо с использованием расстояния от упомянутого другого опорного местоположения (500) до местоположения источника (510) звука и второго вектора, или
при этом вычисление содержит этапы, на которых определяют (1200, 1240) источники из описания звукового поля и направлений для источников посредством анализа звукового поля; определяют (1220), для источника, расстояние источника от опорного местоположения с использованием метаданных; определяют (1250) новое направление источника, связанного с другим опорным местоположением, с использованием направления для источника и информации перемещения; определяют (1230) новую информацию расстояния для источника, связанного с упомянутым другим опорным местоположением; и формируют (1260) модифицированное описание звукового поля с использованием нового направления источника, новой информации расстояния и описания звукового поля либо сигналов источников, соответствующих источникам, извлекаемым из описания звукового поля, или
при этом вычисление содержит этапы, на которых определяют (1200) сигналы источников из описания звукового поля и направлений сигналов источников, связанных с опорным местоположением, посредством анализа (1200) звука; вычисляют (1230) новые направления сигналов источников, связанных с другим опорным местоположением, с использованием информации перемещения; вычисляют (1230) информацию расстояния для сигналов источников, связанных с упомянутым другим опорным местоположением; и синтезируют (1260) модифицированное описание звукового поля с использованием информации расстояния, сигналов источников и новых направлений, или
при этом вычисление содержит этапы, на которых сопоставляют первую группу источников первого описания звукового поля и вторую группу источников второго описания звукового поля, чтобы получать один или более сопоставленных источников, определяют информацию направления поступления для каждого сопоставленного источника из упомянутых одного или более сопоставленных источников, определяют расстояние источника до другого опорного местоположения с использованием информации направления поступления и метаданных для описания звукового поля, и определяют коэффициент масштабирования с использованием расстояния источника до упомянутого другого опорного местоположения, или
при этом вычисление содержит этапы, на которых выполняют анализ (700, 740, 741) звука для описания звукового поля, чтобы получать первую группу из одного или более извлеченных объектов или информацию направления поступления для одного или более извлеченных объектов, и для дополнительного описания звукового поля, связанного с дополнительным опорным местоположением, чтобы получать вторую группу из одного или более извлеченных объектов или информацию направления поступления для одного или более извлеченных объектов, с использованием метаданных; сопоставляют (704) первую группу и вторую группу с использованием сигналов объектов из этих групп или информации направления поступления для объектов из этих групп, чтобы находить по меньшей мере один сопоставленный объект; вычисляют (706, 746) оцененную позицию сопоставленного объекта с использованием метаданных и первой информации направления поступления, полученной для сопоставленного объекта посредством выполнения анализа (700, 740, 741) звука, чтобы получать первую группу, и второй информации направления поступления, полученной для сопоставленного объекта посредством выполнения анализа (700, 740, 741) звука, чтобы получать вторую группу; и применяют (710, 748) обработку компенсации расстояния к сопоставленному объекту на основе оцененной позиции и информации перемещения.
45. Запоминающий носитель, содержащий сохраненную на нем компьютерную программу для осуществления, при выполнении на компьютере или в процессоре, способа по п. 43.
46. Запоминающий носитель, содержащий сохраненную на нем компьютерную программу для осуществления, при выполнении на компьютере или в процессоре, способа по п. 44.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| US 4042779 A1, 16.08.1977 | |||
| УСТРОЙСТВО И СПОСОБ ДЛЯ СОВМЕЩЕНИЯ ПОТОКОВ ПРОСТРАНСТВЕННОГО АУДИОКОДИРОВАНИЯ НА ОСНОВЕ ГЕОМЕТРИИ | 2012 |
|
RU2609102C2 |

