Настоящее изобретение относится к аудиообработке и, в частности, к аудиообработке относительно звуковых полей, которые задаются относительно опорного местоположения, такого как местоположение микрофона или виртуального микрофона.
Амбиофонические сигналы содержат усеченное сферическое гармоническое разложение звукового поля. Амбиофония имеет различные варианты. Предусмотрена "традиционная" амбиофония [31], которая сегодня известна как "амбиофония первого порядка (FOA)" и содержит четыре сигнала (т.е. один всенаправленный сигнал и вплоть до трех направленных сигналов в виде восьмерки). Более свежие варианты амбиофонии известны как "амбиофония высшего порядка (HOA)" и предоставляют улучшенное пространственное разрешение и большую зону наилучшего восприятия слушателя за счет переноса большего числа сигналов. В общем, полностью заданное HOA-представление N-ого порядка состоит из (N+1)2 сигналов.
В связи с идеей амбиофонии, представление на основе направленного кодирования аудио (DirAC) задумано, чтобы представлять звуковую FOA- или HOA-сцену в более компактном, параметрическом стиле. Более конкретно, пространственная звуковая сцена представляется посредством одного (или более) передаваемых аудиоканалов, которые представляют понижающее микширование акустической сцены и ассоциированную вспомогательную информацию направления и степени рассеяния в каждом частотно-временном (TF) бине. Дополнительная информация относительно DirAC содержится в [32, 33].
DirAC [32] может использоваться с различными микрофонными системами и с произвольными компоновками громкоговорителей. Цель DirAC-системы состоит в том, чтобы воспроизводить пространственное впечатление существующего акустического окружения максимально возможно точно с использованием многоканальной/трехмерной системы громкоговорителей. В выбранном окружении, отклики (непрерывные звуковые или импульсные отклики) измеряются с помощью всенаправленного микрофона (W) и с помощью набора микрофонов, который позволяет измерять направление поступления звука и степень рассеяния звука. Общепринятый способ заключается в том, чтобы применять три микрофона (X, Y, Z) в виде восьмерки, совмещенные с соответствующими декартовыми осями координат [34]. Способ для этого заключается в том, чтобы использовать микрофон на основе звукового поля, который непосредственно дает в результате все требуемые отклики. W-, X-, Y- и Z-сигналы также могут вычисляться из набора дискретных всенаправленных микрофонов.
В DirAC, звуковой сигнал сначала разделяется на частотные каналы согласно частотной избирательности слуховой системы человека. Направление и степень рассеяния звука измеряется в зависимости от времени в каждом частотном канале. В передаче, один или более аудиоканалов отправляются, вместе с проанализированными данными направления и степени рассеяния. В синтезе, аудио, которое применяется к громкоговорителям, например, может представлять собой всенаправленный канал W, либо звук для каждого громкоговорителя может вычисляться в качестве взвешенной суммы W, X, Y и Z, которая формирует сигнал, который имеет определенные направленные характеристики для каждого громкоговорителя. Каждый аудиоканал разделяется на частотные каналы, которые затем разделяются опционально на рассеянные и на нерассеянные потоки в зависимости от проанализированной степени рассеяния. Рассеянный поток воспроизводится с помощью технологии, которая формирует рассеянное восприятие звуковой сцены, например, с помощью технологий декорреляции, используемых в бинауральном кодировании по сигнальным меткам [35-37]. Нерассеянный звук воспроизводится с помощью технологии, которая имеет целью формировать точечный виртуальный источник согласно данным направления (например, VBAP [38]).
Три технологии для навигации в 6DoF с ограниченной степенью свободы предлагаются в [39]. С учетом одного амбиофонического сигнала, один амбиофонический сигнал вычисляется с использованием: 1) моделирования HOA-воспроизведения и перемещения слушателя в массиве виртуальных громкоговорителей, 2) вычисления и перемещения вдоль плоских волн и 3) повторного расширения звукового поля вокруг слушателя.
Кроме того, следует обратиться к DirAC-технологии, как описано, например, в публикации "Directional Audio Coding - Perception-Based Reproduction of Spatial Sound", V. Pulkki et al, International Workshop on the Principles and Applications of Spatial Hearing, 11-13 ноября 2009 года, Zao, Miyagi, Japan. Этот ссылочный документ описывает направленное кодирование аудио в качестве примера для связанной с опорным местоположением обработки звуковых полей, в частности, в качестве перцепционно обусловленной технологии для пространственной аудиообработки.
Воспроизведение звуковых сцен зачастую акцентирует внимание на компоновках громкоговорителей, поскольку они представляют собой типичное воспроизведение в частном (например, в гостиной) и в профессиональном контексте (т.е. в кинотеатрах). Здесь, взаимосвязь сцены с геометрией воспроизведения является статической, поскольку она сопровождает двумерное изображение, которое вынуждает слушателя смотреть в направлении вперед. Затем, пространственная взаимосвязь звуковых и визуальных объектов задается и фиксируется во время производства.
В виртуальной реальности (VR), погружение явно достигается посредством предоставления возможности пользователю свободно перемещаться в сцене. Следовательно, необходимо отслеживать перемещение пользователя и регулировать визуальное и слуховое воспроизведение согласно позиции пользователя. Типично, пользователь носит наголовный дисплей (HMD) и наушники. Для восприятия на основе погружения с наушниками, аудио должно бинаурализироваться. Бинаурализация представляет собой моделирование того, как человеческая голова, уши и верхняя часть торса изменяют звук источника в зависимости от его направления и расстояния. Это достигается посредством свертки сигналов с передаточными функциями восприятия звука человеком (HRTF) для их относительного направления [1, 2]. Бинаурализация также заставляет звук казаться исходящим из сцены, а не из головы [3]. Общий сценарий, который уже успешно разрешен, представляет собой воспроизведение видео на 360º [4, 5]. Здесь, пользователь либо носит HMD, либо держит планшетный компьютер или телефон в руках. Посредством перемещения своей головы или устройства, пользователь может оглядываться в любом направлении. Он представляет собой сценарий с тремя степенями свободы (3DoF), поскольку пользователь имеет три степени перемещения (наклон в продольном направлении, наклон относительно вертикальной оси, наклон в поперечном направлении). Визуально, это реализуется посредством проецирования видео на сфере вокруг пользователя. Аудио зачастую записывается с помощью пространственного микрофона [6], например, амбиофонии первого порядка (FOA), рядом с видеокамерой. В амбиофонической области, вращение головы пользователя адаптируется простым способом [7]. Аудио затем, например, подготавливается посредством рендеринга в виртуальные громкоговорители, размещенные вокруг пользователя. Эти сигналы виртуальных громкоговорителей далее бинаурализируются.
Современные VR-варианты применения предоставляют возможность шести степеней свободы (6DoF). Помимо вращения головы, пользователь может перемещаться вокруг, что в результате приводит к перемещению его позиции в трех пространственных размерностях. 6DoF-воспроизведение ограничено посредством полного размера зоны ходьбы. Во многих случаях, эта зона является довольно небольшой, например, традиционная гостиная. 6DoF обычно встречается в VR-играх. Здесь, полная сцена является синтетической за счет формирования машиногенерируемых изображений (CGI). Аудио зачастую формируется с использованием объектно-ориентированного рендеринга, при котором каждый аудиообъект подготавливается посредством рендеринга с зависимым от расстояния усилением и относительным направлением от пользователя на основе данных отслеживания. Реализм может повышаться посредством искусственной реверберации и дифракции [8, 9, 10].
Относительно записанного контента, имеются некоторые отличительные сложности для принудительного аудиовизуального 6DoF-воспроизведения. Ранний пример пространственного звукового манипулирования в области перемещения в пространстве представляет собой пример технологий "акустического масштабирования" [11, 12]. Здесь, позиция слушателя фактически перемещается в записанную визуальную сцену, аналогично изменению масштаба в изображении. Пользователь выбирает одно направление или часть изображения и затем может прослушивать его из перемещенной точки. Это предусматривает то, что все направления поступления (DoA) изменяются относительно исходного, немасштабируемого воспроизведения.
Предложены способы для 6DoF-воспроизведения записанного контента, которые используют пространственно распределенные позиции записи. Для видео, массивы камер могут использоваться для того, чтобы формировать рендеринг на основе принципа светового поля [13]. Для аудио, аналогичная компоновка использует распределенные массивы микрофонов или амбиофонические микрофоны. Показано, что можно формировать сигнал "виртуального микрофона", размещенного в произвольной позиции, из таких записей [14].
Чтобы реализовывать такие пространственные звуковые модификации технически удобным способом, могут использоваться технологии параметрической звуковой обработки или кодирования (см. [15] на предмет общего представления). Направленное кодирование аудио (DirAC) [16] представляет собой популярный способ для того, чтобы преобразовывать запись в представление, которое состоит из аудиоспектра и параметрической вспомогательной информации относительно направления и степени рассеяния звука. Оно используется для вариантов применения на основе акустического масштабирования [11] и виртуальных микрофонов [14].
Способ, предложенный здесь, предоставляет 6DoF-воспроизведение из записи одного FOA-микрофона. Записи из одной пространственной позиции использованы для 3DoF-воспроизведения или акустического масштабирования. Но, согласно знаниям авторов изобретения, способ для интерактивного, полностью 6DoF-воспроизведения из таких данных не предложен к настоящему моменту. 6DoF-воспроизведение реализуется посредством интегрирования информации относительно расстояния источников звука в записи. Эта информация расстояния включается в параметрическое представление DirAC таким образом, что измененная перспектива слушателя корректно преобразуется. Для оценки с помощью теста на основе прослушивания, парадигма множественных управляющих воздействий со скрытой ссылкой и привязкой (MUSHRA) [17] адаптируется для VR. Посредством использования CGI и синтетически сформированного звука, можно создавать объектно-ориентированную ссылку для сравнения. Виртуальная FOA-запись осуществляется в отслеживаемой позиции пользователя, подготавливая посредством рендеринга 6DoF-отрегулированные сигналы. Помимо предложенного способа, воспроизведение без информации расстояния и перемещения представлено в качестве условий в тесте на основе прослушивания.
Ни одно из амбиофонических представлений звукового поля (независимо от того, представляет оно собой регулярную FOA- или HOA-амбиофонию или DirAC-ориентированное параметрическое представление звукового поля) не предоставляет достаточную информацию, чтобы обеспечивать возможность сдвига с перемещением позиции слушателя, что требуется для 6DoF-вариантов применения, поскольку ни расстояние до объекта, ни абсолютные позиции объекта в звуковой сцене не определяются в этих форматах. Следует отметить, что сдвиг в позиции слушателя может перемещаться в эквивалентный сдвиг звуковой сцены в противоположном направлении.
Типичная проблема при перемещении в 6DoF проиллюстрирована на фиг. 1b. Допустим, что звуковая сцена описывается в позиции A с использованием амбиофонии. В этом случае, звуки из источника A и источника B поступают из идентичного направления, т.е. они имеют идентичное направление поступления (DoA). В случае перемещения в позицию B, DoA источника A и источника B отличаются. С использованием стандартного описания на основе амбиофонии звукового поля, т.е. без дополнительной информации, невозможно вычислять амбиофонические сигналы в позиции B, с учетом амбиофонических сигналов в позиции A.
Цель настоящего изобретения заключается в том, чтобы предоставлять улучшенное описание звукового поля, с одной стороны, или формирование модифицированного описания звукового поля, с другой стороны, которые обеспечивают улучшенную или гибкую, или эффективную обработку.
Эта цель достигается посредством устройства для формирования улучшенного описания звукового поля по п. 1, устройства для формирования модифицированного описания звукового поля по п. 10, способа формирования улучшенного описания звукового поля по п. 27, способа формирования модифицированного описания звукового поля по п. 28, компьютерной программы по п. 29 или улучшенного описания звукового поля по п. 30.
Настоящее изобретение основано на таких выявленных сведениях, что типичные описания звукового поля, которые связаны с опорным местоположением, требуют дополнительной информации таким образом, что эти описания звукового поля могут обрабатываться, так что может вычисляться модифицированное описание звукового поля, которое связано не с исходным опорным местоположением, а с другим опорным местоположением. С этой целью, формируются метаданные, связанные с пространственной информацией этого звукового поля, и метаданные вместе с описанием звукового поля соответствуют улучшенному описанию звукового поля, которое, например, может передаваться или сохраняться. Чтобы формировать модифицированное описание звукового поля из описания звукового поля и метаданных, и, в частности, метаданных, связанных с пространственной информацией описания звукового поля, модифицированное звуковое поле вычисляется с использованием этой пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение из опорного местоположения в другое опорное местоположение. Таким образом, улучшенное описание звукового поля, состоящее из описания звукового поля и метаданных, связанных с пространственной информацией этого звукового поля, лежащей в основе описания звукового поля, обрабатывается, чтобы получать модифицированное описание звукового поля, которое связано с другим опорным местоположением, заданным посредством дополнительной информации перемещения, которая, например, может предоставляться или использоваться на стороне декодера.
Тем не менее, настоящее изобретение не только связано со сценарием кодера/декодера, но также может применяться в варианте применения, в котором формирование улучшенного описания звукового поля и формирование модифицированного описания звукового поля осуществляются по существу в одном и том же местоположении. Модифицированное описание звукового поля, например, может представлять собой описание непосредственно модифицированного звукового поля или фактически модифицированное звуковое поле в канальных сигналах, бинауральных сигналах или, кроме того, связанное с опорным местоположением звуковое поле, которое, тем не менее, теперь связывается с новым или другим опорным местоположением, а не с исходным опорным местоположением. Такой вариант применения, например, должен представлять собой сценарий виртуальной реальности, в котором существует описание звукового поля вместе с метаданными, и в котором слушатель перемещается из опорного местоположения, для которого предоставляется звуковое поле, и перемещается в другое опорное местоположение, и в котором после этого звуковое поле для слушателя, перемещающегося в виртуальной зоне, вычисляется таким образом, что оно соответствует звуковому полю, но теперь в другом опорном местоположении, в которое перемещен пользователь.
В предпочтительном варианте осуществления, формирователь звуковых полей формирует DirAC-описание звукового поля, имеющее один или более сигналов понижающего микширования и отдельные данные направления и опционально данные степени рассеяния для различных частотно-временных бинов. В этом контексте, формирователь метаданных выполнен с возможностью формировать дополнительную отдельную информацию расстояния или глубины для различных частотно-временных бинов в качестве метаданных. В частности, и в предпочтительном варианте осуществления, метаданные, связанные с пространственной информацией, должны представлять собой карту глубины, ассоциирующую определенное расстояние с определенной информацией позиции, такой как информация направления поступления.
В вариантах осуществления, направление поступления задается посредством только угла высоты (elevation) или только азимутального угла либо обоих углов, и карта глубины затем должна ассоциировать с каждой информацией позиции или информацией направления поступления (DoA-информацией) определенную информацию расстояния, такую как расстояние в метрах и т.п. или относительное расстояние, или квантованное абсолютное, или относительное расстояние, или любая другая информация расстояния, из которой, в завершение, может извлекаться расстояние относительно опорного местоположения, с которым связано звуковое поле.
Далее приводятся другие предпочтительные реализации.
Амбиофония становится одним из наиболее часто используемых форматов для трехмерного аудио в контексте вариантов применения в стиле виртуальной, дополненной и смешанной реальности. Разработан широкий спектр инструментальных средств получения и формирования аудио, которые формируют выходной сигнал в формате амбиофонии. Чтобы представлять амбиофонический кодированный контент в интерактивных вариантах применения в стиле виртуальной реальности (VR), формат амбиофонии преобразуется в бинауральный сигнал или каналы для воспроизведения. В вышеуказанных вариантах применения, слушатель обычно имеет возможность интерактивно изменять свою ориентацию в представленной сцене до такой степени, что он может поворачивать свою голову в звуковой сцене, что обеспечивает три степени свободы (3DoF, т.е. наклон в продольном направлении, наклон относительно вертикальной оси и наклон в поперечном направлении), и при этом подвергаться соответствующему качеству звука. Это реализуется посредством вращения звуковой сцены перед рендерингом согласно ориентации головы, которое может реализовываться с низкой вычислительной сложностью и является преимуществом амбиофонического представления. Тем не менее, в новых вариантах применения, таких как VR, требуется обеспечивать возможность свободного перемещения пользователя в звуковой сцене, а не только изменений ориентации (так называемых "шести степеней свободы", или 6DoF). Как следствие, обработка сигналов требуется для того, чтобы изменять перспективу звуковой сцены (т.е. чтобы фактически перемещаться в звуковой сцене вдоль осей X, Y или Z). Тем не менее, главный недостаток амбиофонии заключается в том, что формат описывает звуковое поле из одной перспективы в звуковой сцене. В частности, она не содержит информацию относительно фактического местоположения источников звука в звуковой сцене, которая позволяет сдвигать звуковую сцену (выполнять "перемещение"), что требуется для 6DoF. Это описание изобретения предоставляет несколько расширений амбиофонии для того, чтобы преодолевать эту проблему, а также упрощать перемещение и в силу этого обеспечивать истинную 6DoF.
Записи на основе амбиофонии первого порядка (FOA) могут обрабатываться и воспроизводиться в наушниках. Они могут вращаться для того, чтобы учитывать ориентацию головы слушателей. Тем не менее, системы виртуальной реальности (VR) обеспечивают возможность слушателю перемещаться в шести степенях свободы (6DoF), т.е. в трех вращательных плюс в трех переходных степенях свободы. Здесь, явные углы и расстояния источников звука зависят от позиции слушателя. Описывается технология для того, чтобы упрощать 6DoF. В частности, FOA-запись описывается с использованием параметрической модели, которая модифицируется на основе позиции слушателя и информации относительно расстояний до источников. Способ оценивается посредством теста на основе прослушивания, сравнивающего различные бинауральные рендеринги синтетической звуковой сцены, в которой слушатель может свободно перемещаться.
В дополнительных предпочтительных вариантах осуществления, улучшенное описание звукового поля выводится посредством выходного интерфейса для формирования выходного сигнала для передачи или хранения, при этом выходной сигнал содержит, для временного кадра, один или более аудиосигналов, извлекаемых из звукового поля, и пространственную информацию для временного кадра. В частности, формирователь звуковых полей, в дополнительных вариантах осуществления, является адаптивным с возможностью извлекать данные направления из звукового поля, причем данные направления означают направление поступления звука за период времени или частотный бин, и формирователь метаданных выполнен с возможностью извлекать пространственную информацию в качестве элементов данных, ассоциирующих информацию расстояния с данными направления.
В частности, в таком варианте осуществления, выходной интерфейс выполнен с возможностью формировать выходные сигналы таким образом, что элементы данных для временного кадра связываются с данными направления для различных частотных бинов.
В дополнительном варианте осуществления, формирователь звуковых полей также выполнен с возможностью формировать информацию степени рассеяния для множества частотных бинов временного кадра звукового поля, при этом формирователь метаданных выполнен с возможностью формировать информацию расстояния только для частотного бина, отличающегося от предварительно определенного значения или отличающегося от бесконечности, либо формировать значение расстояния для частотного бина вообще, когда значение степени рассеяния ниже предварительно определенного или адаптивного порогового значения. Таким образом, для частотно-временных бинов, которые имеют высокую степень рассеяния, значения расстояния не формируются вообще, либо формируется предварительно определенное значение расстояния, которое интерпретируется посредством декодера определенным способом. Таким образом, необходимо удостоверяться в том, что для частотно-временных бинов, имеющих высокую степень рассеяния, любой связанный с расстоянием рендеринг не выполняется, поскольку высокая степень рассеяния указывает то, что для такого частотно-временного бина звук исходит не из определенного локализованного источника, а исходит из любого направления и в силу этого является идентичным независимо от того, воспринимается звуковое поле в исходном опорном местоположении либо в другом или новом опорном местоположении.
Относительно модуля вычисления звуковых полей, предпочтительные варианты осуществления содержат интерфейс перемещения для предоставления информации перемещения или информации вращения, указывающей вращение предназначенного слушателя в модифицированное звуковое поле, модуль подачи метаданных для подачи метаданных в модуль вычисления звуковых полей и модуль подачи звуковых полей для подачи описания звукового поля в модуль вычисления звуковых полей и, дополнительно, выходной интерфейс для вывода модифицированного звукового поля, содержащего модифицированное описание звукового поля и модифицированные метаданные, причем модифицированные метаданные извлекаются из метаданных с использованием информации перемещения, либо выходной интерфейс выводит множество каналов громкоговорителей, причем каждый канал громкоговорителя связан с предварительно заданной позицией громкоговорителя, либо выходной интерфейс выводит бинауральное представление модифицированного звукового поля.
В варианте осуществления, описание звукового поля содержит множество компонентов звукового поля. Множество компонентов звукового поля содержат всенаправленный компонент и, по меньшей мере, один направленный компонент. Такое описание звукового поля, например, представляет собой амбиофоническое описание звукового поля первого порядка, имеющее всенаправленный компонент и три направленных компонента X, Y, Z, либо такое звуковое поле представляет собой амбиофоническое описание высшего порядка, содержащее всенаправленный компонент, три направленных компонента относительно направлений по оси X, Y и Z и, дополнительно, дополнительные направленные компоненты, которые связаны с направлениями, отличными от направлений по оси X, Y, Z.
В варианте осуществления, устройство содержит анализатор для анализа компонентов звукового поля, чтобы извлекать, для различных временных или частотных бинов, информацию направления поступления. Устройство дополнительно имеет модуль преобразования с перемещением для вычисления модифицированной DoA-информации на каждый частотный или временной бин с использованием DoA-информации и метаданных, причем метаданные связаны с картой глубины, ассоциирующей расстояние с DoA-информацией для временного или частотного бина.
Кроме того, модуль вычисления звуковых полей имеет модуль компенсации расстояния для вычисления модифицированного звукового поля с использованием компенсационной информации расстояния в зависимости от расстояния, предоставленного из карты глубины для частотного или временного бина, и от нового расстояния, ассоциированного с временным или частотным бином, причем новое расстояние связано с модифицированной DoA-информацией.
В варианте осуществления, модуль вычисления звуковых полей вычисляет первый вектор, указывающий из опорного местоположения в источник звука, полученный посредством анализа звукового поля. Кроме того, модуль вычисления звуковых полей вычисляет второй вектор, указывающий из другого опорного местоположения в источник звука, и это вычисление проводится с использованием первого вектора и информации перемещения, причем информация перемещения задает вектор перемещения из опорного местоположения в другое опорное местоположение. Так же, в таком случае расстояние от другого опорного местоположения до источника звука вычисляется с использованием второго вектора.
Кроме того, модуль вычисления звуковых полей выполнен с возможностью принимать, в дополнение к информации перемещения, информацию вращения, указывающую вращение головы слушателя в одном из трех направлений вращения, предоставленных посредством наклона в продольном направлении, наклона относительно вертикальной оси и наклона в поперечном направлении. Модуль вычисления звуковых полей затем выполнен с возможностью выполнять преобразование с вращением, чтобы вращать модифицированные данные направления поступления для звукового поля с использованием информации вращения, при этом модифицированные данные направления поступления извлекаются из данных направления поступления, полученных посредством анализа звука описания звукового поля, и информации перемещения.
В варианте осуществления, модуль вычисления звуковых полей выполнен с возможностью определять сигналы источников из описания звукового поля и направлений сигналов источников, связанных с опорным местоположением, посредством анализа звука.
После этого вычисляются новые направления источников звука, которые связаны с другим опорным местоположением, и это выполняется с использованием метаданных, а затем вычисляется информация расстояния источников звука, связанных с другим опорным местоположением, и после этого модифицированное звуковое поле синтезируется с использованием информации расстояния и новых направлений источников звука.
В варианте осуществления, синтез звукового поля выполняется посредством панорамирования сигналов источников звука в направление, предоставленное посредством новой информации направления относительно компоновки для воспроизведения, и масштабирование сигналов источников звука выполняется с использованием информации расстояния перед выполнением операции панорамирования или после выполнения операции панорамирования.
В дополнительном варианте осуществления, рассеянная часть сигнала источника звука суммируется с прямой частью сигнала источника звука, причем прямая часть модифицируется посредством информации расстояния перед суммированием с рассеянной частью.
В частности, предпочтительно выполнять синтез источников звука в спектральном представлении, в котором новая информация направления вычисляется для каждого частотного бина, в котором информация расстояния вычисляется для каждого частотного бина, и в котором прямой синтез для каждого частотного бина с использованием аудиосигнала для частотного бина выполняется с использованием аудиосигнала для частотного бина, панорамирующего усиления для частотного бина, извлекаемого из новой информации направления, и коэффициента масштабирования для частотного бина, извлекаемого из информации расстояния для частотного бина, выполняется.
Кроме того, синтез рассеянных сигналов выполняется с использованием рассеянного аудиосигнала, извлекаемого из аудиосигнала из частотного бина, и с использованием параметра степени рассеяния, извлекаемого посредством анализа сигналов для частотного бина, и после этого прямой сигнал и рассеянный сигнал комбинируются, чтобы получать синтезированный аудиосигнал для временного или частотного бина, и после этого частотно-временное преобразование выполняется с использованием аудиосигналов для других частотно-временных бинов, чтобы получать синтезированный аудиосигнал временной области в качестве модифицированного звукового поля.
Следовательно, в общем, модуль вычисления звуковых полей выполнен с возможностью синтезировать, для каждого источника звука, звуковое поле, связанное с другим опорным местоположением, например, посредством обработки, для каждого источника, сигнала источника с использованием нового направления для сигнала источника, чтобы получать описание звукового поля сигнала источника, связанного с другим/новым опорным местоположением. Кроме того, сигнал источника модифицируется перед обработкой сигнала источника или после обработки сигнала источника с использованием информации направления. Так же, в завершение, описания звукового поля для источников суммируются между собой, чтобы получать модифицированное звуковое поле, связанное с другим опорным местоположением.
В дополнительном варианте осуществления, модуль вычисления звуковых полей выполняет, альтернативно DirAC-анализу или любому другому анализу источников звука, алгоритм разделения источников. Алгоритм разделения источников, в конечном счете, выдает сигналы источников звука, например, во временной области или в частотной области. Рассеянный сигнал затем вычисляется посредством вычитания сигналов источников звука из исходного звукового поля таким образом, что исходное звуковое поле разлагается на рассеянный сигнал и несколько сигналов источников звука, причем каждый сигнал источника звука имеет ассоциированное определенное направление.
Далее поясняются предпочтительные варианты осуществления настоящего изобретения со ссылками на прилагаемые чертежи, на которых:
Фиг. 1a является предпочтительным вариантом осуществления устройства для формирования улучшенного описания звукового поля;
Фиг. 1b является иллюстрацией, поясняющей примерную проблему, лежащую в основе настоящего изобретения;
Фиг. 2 является предпочтительной реализацией устройства для формирования улучшенного описания звукового поля;
Фиг. 3a иллюстрирует улучшенное описание звукового поля, содержащее аудиоданные и вспомогательную информацию для аудиоданных;
Фиг. 3b иллюстрирует дополнительную иллюстрацию улучшенного звукового поля, содержащего аудиоданные и метаданные, связанные с пространственной информацией, такой как карта глубины;
Фиг. 3c иллюстрирует другой формат для ассоциирования метаданных с описанием звукового поля;
Фиг. 3d иллюстрирует дополнительный формат для ассоциирования метаданных с описанием звукового поля;
Фиг. 4a иллюстрирует реализацию устройства для формирования модифицированного описания звукового поля;
Фиг. 4b иллюстрирует дополнительную реализацию устройства для формирования модифицированного описания звукового поля;
Фиг. 4c иллюстрирует дополнительный вариант осуществления устройства для формирования модифицированного описания звукового поля;
Фиг. 4d иллюстрирует примерное устройство для формирования описания звукового поля из аудиосигнала, такого как моносигнал, и данных направления поступления;
Фиг. 5 иллюстрирует воспроизведение с шестью DoF пространственного аудио;
Фиг. 6 иллюстрирует предпочтительный вариант осуществления воспроизведения с шестью DoF, содержащий устройство для формирования улучшенного описания звукового поля и устройство для формирования модифицированного описания звукового поля;
Фиг. 7 иллюстрирует представление сцены в стиле виртуальной реальности;
Фиг. 8 иллюстрирует MUSHRA-панель в виртуальной реальности;
Фиг. 9 иллюстрирует MUSHRA-рейтинги в качестве коробчатых диаграмм;
Фиг. 10 иллюстрирует тракты передачи сигналов для опорного рендеринга и DirAC;
Фиг. 11a иллюстрирует предпочтительную реализацию устройства для формирования модифицированного описания звукового поля;
Фиг. 11b иллюстрирует предпочтительную реализацию для вычисления нового DoA и нового расстояния источника звука относительно нового/другого опорного местоположения;
Фиг. 12 иллюстрирует дополнительную предпочтительную реализацию устройства для формирования модифицированного описания звукового поля;
Фиг. 13a иллюстрирует реализацию на основе DirAC-анализа предшествующего уровня техники; и
Фиг. 13b иллюстрирует реализацию на основе DirAC-синтеза предшествующего уровня техники.
Чтобы обеспечивать 6DoF-варианты применения для упомянутых амбиофонических/DirAC-представлений, необходимо расширять эти представления таким способом, который предоставляет отсутствующую информацию для обработки перемещения. Следует отметить, что это расширение, например, может 1) добавлять расстояние или позиции объектов в существующее представление сцены и/или 2) добавлять информацию, которая должна упрощать процесс разделения отдельных объектов.
Кроме того, цель вариантов осуществления заключается в том, чтобы сохранять/многократно использовать структуру существующих (непараметрических или параметрических) амбиофонических систем, чтобы предоставлять обратную совместимость с этими представлениями/системами в том смысле, что:
- расширенные представления могут преобразовываться в существующие нерасширенные представления (например, для рендеринга), и
- чтобы обеспечивать возможность многократного использования существующих программных и аппаратных реализаций при работе с расширенным представлением.
Далее описываются несколько подходов, а именно, один ограниченный (но очень простой) подход и три различных расширенных формата амбиофонии, чтобы обеспечивать 6DoF.
Как описано в разделе предшествующего уровня техники, традиционное DirAC переносит параметрическую вспомогательную информацию, которая характеризует направление и степень рассеяния для каждого TF (частотно-временного) бина. Расширение существующего DirAC-формата дополнительно предоставляет информацию глубины для каждого или нескольких, но не всех TF-бинов. Аналогично информации направления, релевантность информации глубины зависит от фактической степени рассеяния. Высокая степень рассеяния означает, что как направление, так и глубина не являются релевантными (и могут фактически опускаться для очень высоких значений степени рассеяния).
Следует отметить, что DirAC с расширением глубины не предоставляет полное решение 6DoF, поскольку оно позволяет переносить только информацию направления и глубины для одного объекта на каждый TF-бин.
Следует отметить, что информация глубины либо может оцениваться из аудиосигналов или из видеосигналов (например, карты глубины, наиболее часто используемой при формировании стереоскопических (трехмерных) изображений/видео или в технологии на основе принципа светового поля), либо может добавляться вручную или автоматически конкретно, когда звуковое поле формируется посредством синтеза звука с помощью локализованных источников звука.
Фиг. 1a иллюстрирует устройство для формирования улучшенного описания звукового поля, содержащего формирователь 100 (описаний) звуковых полей для формирования, по меньшей мере, одного описания звукового поля, указывающего звуковое поле относительно, по меньшей мере, одного опорного местоположения. Кроме того, устройство содержит формирователь 110 метаданных для формирования метаданных, связанных с пространственной информацией звукового поля. Метаданные принимают, в качестве ввода, звуковое поле либо, альтернативно или дополнительно, отдельную информацию относительно источников звука.
Вывод формирователя 100 описаний звуковых полей и формирователя 110 метаданных составляют улучшенное описание звукового поля. В варианте осуществления, вывод формирователя 100 описаний звуковых полей и формирователя 110 метаданных может комбинироваться в модуле 120 комбинирования или выходном интерфейсе 120, чтобы получать улучшенное описание звукового поля, которое включает в себя пространственные метаданные или пространственную информацию звукового поля, сформированную посредством формирователя 110 метаданных.
Фиг. 1b иллюстрирует ситуацию, которая разрешается посредством настоящего изобретения. Позиция A, например, представляет собой, по меньшей мере, одно опорное местоположение, и звуковое поле формируется посредством источника A и источника B, и определенный фактический или, например, виртуальный микрофон, расположенный в позиции A, обнаруживает звук из источника A и источника B. Звук представляет собой наложение звука, исходящего из источников исходящего звука. Это представляет описание звукового поля, сформированное посредством формирователя описаний звуковых полей.
Дополнительно, формирователь метаданных должен, посредством определенных реализаций, извлекать пространственную информацию относительно источника A и другую пространственную информацию относительно источника B, такую как расстояния этих источников до опорной позиции, такой как позиция A.
Естественно, опорная позиция, альтернативно, может представлять собой позицию B. Затем фактический или виртуальный микрофон должен быть размещен в позиции B, и описание звукового поля представляет собой звуковое поле, например, представленное посредством амбиофонических компонентов первого порядка или амбиофонических компонентов высшего порядка либо любых других звуковых компонентов, имеющих потенциал для того, чтобы описывать звуковое поле относительно, по меньшей мере, одного опорного местоположения, т.е. позиции B.
Формирователь метаданных после этого может формировать, в качестве информации относительно источников звука, расстояние источника A звука до позиции B или расстояние источника B до позиции B. Альтернативная информация относительно источников звука, конечно, может представлять собой абсолютную или относительную позицию относительно опорной позиции. Опорная позиция может представлять собой начало общей системы координат или может быть расположена в заданной взаимосвязи с началом общей системы координат.
Другие метаданные могут представлять собой абсолютную позицию одного источника звука и относительную позицию другого источника звука относительно первого источника звука и т.д.
Фиг. 2 иллюстрирует предпочтительную реализацию формирователя описаний звуковых полей. Формирователь описаний звуковых полей, например, может состоять из реального или виртуального микрофона 200, который формирует, из входного звукового поля, компоненты звукового поля, такие как амбиофоническое представление первого порядка, проиллюстрированное на фиг. 2 в качестве всенаправленного компонента w и трех компонентов x, y, z направления.
На основе этого описания звукового поля, анализатор 210 звуковых полей, который может, дополнительно, содержать понижающий микшер, должен формировать параметрическое описание звукового поля, состоящее из понижающего моно- или стереомикширования и дополнительных параметров, таких как DoA-параметры направления поступления, например, на каждый временной кадр или частотный бин или, в общем, частотно-временной бин, и, дополнительно, информация степени рассеяния для идентичного или меньшего числа частотно-временных бинов.
Кроме того, формирователь 110 метаданных, например, должен реализовываться как формирователь карт глубины, который формирует карту глубины, которая ассоциирует, с каждым направлением поступления или DoA-информацией, определенное расстояние в абсолютных или относительных величинах. Кроме того, формирователь 110 метаданных, в предпочтительном варианте осуществления, также управляется посредством параметра степени рассеяния для частотно-временного бина. В этой реализации, формирователь 110 метаданных должен реализовываться с возможностью не формировать информацию расстояния для временного и/или частотного бина, который имеет значение степени рассеяния, превышающее определенное предварительно определенное или адаптивное пороговое значение. Это обусловлено тем фактом, что когда определенный временной или частотный бин показывает высокую степень рассеяния, в таком случае можно приходить к заключению, что в этом временном или частотном бине, не существуют локализованные источники звука, а существует только рассеянный звук, исходящий из всех направлений. Таким образом, для такого временного или частотного бина, формирователь метаданных должен формировать, в карте глубины, вообще не значение, как указано посредством "Н.д." на фиг. 2, или альтернативно, формирователь метаданных должен вводить значение расстояния, имеющее предварительно определенное значение, такое как код для высокого, бесконечного или любого другого значения, которое должно подтверждаться посредством декодера в качестве такого значения, указывающего на нелокализованный источник звука для частотно-временного бина.
Карта глубины и описание звукового поля, сформированные посредством анализатора 210 звуковых полей согласно представлению понижающего моно/стереомикширования вместе с пространственными параметрами, которые связаны с опорным местоположением, затем комбинируются в модуле 120 комбинирования, чтобы формировать улучшенное описание звукового поля.
Фиг. 3a иллюстрирует пример потока битов или общего потока данных, содержащего улучшенное описание звукового поля. Поток данных должен содержать временные кадры i, i+1 и т.д., как указано посредством ссылок с номерами 302, 304, 306, и связанную вспомогательную информацию для соответствующего временного кадра, как проиллюстрировано посредством блоков 310, 312. В варианте осуществления, вспомогательная информация должна включать в себя информацию направления поступления на каждый частотно-временной бин, как указано в 314, и, опционально, значение степени рассеяния на каждый частотно-временной бин, как проиллюстрировано посредством элемента 316, и, дополнительно, для кадра i, карту 320 глубины. Примерная карта глубины также проиллюстрирована на фиг. 3a, как указано посредством элемента 322 и 324. Элемент 322 иллюстрирует другую DoA-информацию, протягивающуюся, например, между 0° и 350° в азимутальном направлении с примерным приращением в 10°. Дополнительно, элемент 324 иллюстрирует соответствующее значение расстояния, ассоциированное с определенным DoA-значением. Такая карта глубины должна формироваться для каждого приращения высоты таким образом, что, в конечном счете, карта глубины ассоциирует, с каждой комбинацией азимутального угла и угла высоты, т.е. с каждой DoA-информацией, определенное значение расстояния.
Естественно, могут выполняться другие, вероятно, более эффективные способы для формирования и передачи карты глубины, при которых, типично, для каждого DoA-значения, возникающего для частотного бина в определенном временном кадре, который имеет значение степени рассеяния, ниже определенного порогового значения, должно присутствовать расстояние.
Фиг. 3b иллюстрирует другую реализацию, в которой анализатор 210 звуковых полей на фиг. 2 фактически не формирует понижающее микширование, а формирует полное представление в B-формате, A-формате либо любое другое, такое как представление высшего порядка в течение определенного периода времени. В таком случае, карта 320a глубины и другая карта 320b глубины должны быть ассоциированы с представлением аудиосигналов, указываемым в 326 на фиг. 3b. Когда, например, период времени, с которым ассоциировано представление в B-формате или высшего порядка, содержит несколько отдельных периодов времени, и когда изменение местоположения источников возникает в эти периоды времени, в таком случае карта 320a глубины для первого периода i времени, и другая карта глубины для периода i+1 времени, указываемая в элементе 320b, должны быть ассоциированы с представлением 326 аудиосигналов. Как указано, представление аудиосигналов на фиг. 3b отличается от представления на фиг. 3a, поскольку фиг. 3a имеет только представление компонента понижающего микширования или w и, дополнительно, представление в различных временных кадрах, при этом фиг. 3b имеет другое представление аудиосигналов с полным направленным компонентным представлением с тремя или более направленных компонентов и не разделяется на отдельные временные кадры, а ассоциируется с картами глубины для меньших временных приращений по сравнению с периодами времени, для которых предоставляется элемент 326. Хотя проиллюстрировано на фиг. 3b в качестве последовательного формата, следует отметить, что может использоваться параллельный формат или смешение между параллельным и последовательным либо определенным другим форматом, таким как формат MP4-контейнера.
Фиг. 3c и 3d иллюстрируют другие форматы для ассоциирования метаданных с описанием звукового поля в форме представления в B-формате или высшего порядка. Индекс i, i+1 означает время, и индекс (1), (2), (Ni) означает направление.
Фиг. 4a иллюстрирует предпочтительную реализацию устройства для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля. В частности, устройство содержит модуль 420 вычисления звуковых полей, который формирует модифицированное звуковое поле с использованием метаданных, описания звукового поля и информации перемещения, указывающей перемещение из опорного местоположения в другое опорное местоположение.
Когда, например, звуковое поле предоставляется относительно позиции A на фиг. 1b, в таком случае другое опорное местоположение может представлять собой позицию B, и информация перемещения, например, должна представлять собой вектор, указывающий перемещение позиции A в позицию B. Модуль 420 вычисления звуковых полей далее должен вычислять модифицированное звуковое поле, как если оно должно восприниматься посредством слушателя, расположенного в позиции B, и для этого вычисления, модуль вычисления звуковых полей имеет описание звукового поля, связанное с позицией A и информацией перемещения, и, дополнительно, метаданные, связывающие пространственную позицию источника A и источника B.
В варианте осуществления, модуль 420 вычисления звуковых полей соединяется с входным интерфейсом 400 для приема улучшенного описания звукового поля, например, как поясняется относительно фиг. 1a или 2, и входной интерфейс 400 затем разделяет описание звукового поля, с одной стороны, т.е. что сформировано посредством блока 100 по фиг. 1a или блока 210 по фиг. 2. Кроме того, входной интерфейс 400 отделяет метаданные от улучшенного описания звукового поля, т.е. элемента 310, 312 по фиг. 3a или 320a, 320b по фиг. 3b.
Кроме того, интерфейс 410 перемещения получает информацию перемещения и/или дополнительную или отдельную информацию вращения от слушателя. Реализация интерфейса 410 перемещения может представлять собой модуль слежения за положением головы, который отслеживает не только вращение головы в окружении в стиле виртуальной реальности, но также и перемещение головы из одной позиции, т.е. из позиции A на фиг. 1b, в другую позицию, т.е. в позицию B на фиг. 1b.
Фиг. 4b иллюстрирует другую реализацию, аналогичную фиг. 1a, но связанную не со сценарием кодера/декодера, а связанную с общим сценарием, в котором подача метаданных, указываемая посредством модуля 402 подачи метаданных, подача звуковых полей, указываемая посредством модуля 404 подачи звуковых полей, выполняются без определенного входного интерфейса, разделяющего кодированное или улучшенное описание звукового поля, но все выполняются, например, в фактическом существующем сценарии, например, в варианте применения в стиле виртуальной реальности. Тем не менее, настоящее изобретение не ограничено вариантами применения в стиле виртуальной реальности и также может реализовываться в любых других вариантах применения, в которых пространственная аудиообработка звуковых полей, которые связаны с опорным местоположением, является полезной для того, чтобы преобразовывать звуковое поле, связанное с первым опорным местоположением, в другое звуковое поле, связанное с другим вторым опорным местоположением.
Модуль 420 вычисления звуковых полей затем формирует модифицированное описание звукового поля или, альтернативно, формирует представление (виртуальных) громкоговорителей, или формирует бинауральное представление, такое как двухканальное представление для воспроизведения в наушниках. Таким образом, модуль 420 вычисления звуковых полей может формировать, в качестве модифицированного звукового поля, модифицированное описание звукового поля, по существу идентичное описанию исходного звукового поля, но теперь относительно новой опорной позиции. В альтернативном варианте осуществления, представление виртуальных или фактических громкоговорителей может формироваться для предварительно определенной компоновки громкоговорителей, такой как схема 5.1, или компоновки громкоговорителей, имеющей большее число громкоговорителей и, в частности, имеющей трехмерную компоновку громкоговорителей, а не только двумерную компоновку, т.е. компоновку громкоговорителей, имеющую громкоговорители, приподнятые относительно позиции пользователя. Другие варианты применения, которые являются конкретно полезными для вариантов применения в стиле виртуальной реальности, представляют собой варианты применения для бинаурального воспроизведения, т.е. для наушника, который может применяться к голове пользователя виртуальной реальности.
Фиг. 4c иллюстрирует предпочтительную реализацию настоящего изобретения в контексте DirAC-анализа/синтеза. С этой целью, описание звукового поля, фактически снимаемое посредством реальных микрофонов или первоначально сформированное посредством виртуальных микрофонов, или синтезированное ранее и теперь используемое в варианте применения в стиле виртуальной реальности либо в любом другом варианте применения, вводится в частотно-временной преобразователь 421.
Далее, DirAC-анализатор 422 выполнен с возможностью формирования, для каждого частотно-временного бина, элемента данных направления поступления и элемента данных степени рассеяния.
С использованием информации пространственного звукового поля, к примеру, предоставляемой посредством карты глубины, например, выполнения, посредством блока 423, преобразования с перемещением, и, опционально, информации масштабирования объема, вычисляется значение нового направления поступления. Предпочтительно, также выполняется преобразование 424 с вращением, и, конечно, информация отслеживания, связанная с информацией перемещения, с одной стороны, и информацией вращения, с другой стороны, используется в блоках 423-424 для того, чтобы формировать данные нового направления поступления в качестве ввода в блок 425 DirAC-синтезатора. После этого, дополнительно, информация масштабирования в зависимости от нового расстояния между источником звука и новой опорной позицией, указываемой посредством отслеживания информации, также формируется в блоке 423 и используется в DirAC-синтезаторе 425 для того, чтобы в завершение выполнять DirAC-синтез для каждого частотно-временного бина. Далее, в блоке 426, выполняется частотно-временное преобразование, предпочтительно, относительно определенной предварительно определенной компоновки виртуальных громкоговорителей, и после этого в блоке 427, выполняется бинауральный рендеринг для бинаурального представления наушников.
В дополнительном варианте осуществления, DirAC-синтезатор непосредственно предоставляет бинауральные сигналы в TF-области.
В зависимости от реализации DirAC-анализатора и, конечно, в зависимости от реализации DirAC-синтезатора 425, исходное звуковое поле во вводе в блок 421 или в выводе блока 421 может перенаправляться в DirAC-синтезатор 425, либо альтернативно, сигнал понижающего микширования, сформированный посредством DirAC-анализатора 422, перенаправляется в DirAC-синтезатор.
В качестве примера, нижеописанный фиг. 6 иллюстрирует ситуацию, в которой DirAC-синтезатор работает только с компонентом понижающего микширования, таким как всенаправленный компонент или компонент давления, тогда как, в дополнительном альтернативном варианте осуществления, проиллюстрированном относительно фиг. 12b, DirAC-синтезатор работает с общими данными звукового поля, т.е. с полным компонентным представлением, имеющим, в этом варианте осуществления на фиг. 12b, описание полей со всенаправленным компонентом w и тремя направленными компонентами x, y, z.
Фиг. 4d иллюстрирует другую реализацию для выполнения синтеза, отличающуюся от DirAC-синтезатора. Когда, например, анализатор звуковых полей формирует, для каждого сигнала источника, отдельный моносигнал S и исходное направление поступления, и когда, в зависимости от информации перемещения, новое направление поступления вычисляется, в таком случае формирователь 430 амбиофонических сигналов по фиг. 4d, например, должен использоваться для того, чтобы формировать описание звукового поля для сигнала источника звука, т.е. моносигнала S, но для новых данных направления поступления (DoA), состоящих из горизонтального угла θ или угла θ высоты и азимутального угла φ. Далее, процедура, выполняемая посредством модуля 420 вычисления звуковых полей по фиг. 4b, должна формировать, например, представление звукового поля на основе амбиофонии первого порядка для каждого источника звука с новым направлением поступления, и после этого дополнительная модификация на каждый источник звука может выполняться с использованием коэффициента масштабирования в зависимости от расстояния звукового поля до нового опорного местоположения, и после этого все звуковые поля из отдельных источников могут накладываться друг на друга, чтобы в завершение получать модифицированное звуковое поле, снова, например, в амбиофоническом представлении, связанном с определенным новым опорным местоположением.
Когда интерпретируется то, что каждый частотно-временной бин, обработанный посредством DirAC-анализатора 422, представляет определенный источник звука (с ограниченной полосой пропускания), в таком случае формирователь 430 амбиофонических сигналов может использоваться, вместо DirAC-синтезатора 425, для того чтобы формировать, для каждого частотно-временного бина, полное амбиофоническое представление с использованием сигнала понижающего микширования или сигнала давления или всенаправленного компонента для этого частотно-временного бина в качестве "моносигнала S" по фиг. 4d. Далее, отдельное частотно-временное преобразование в частотно-временном преобразователе 426 для каждого из W-, X-, Y-, Z-компонента в таком случае должно приводить к описанию звукового поля, отличающемуся от того, что проиллюстрировано на фиг. 4c.
Далее приводятся дополнительные варианты осуществления. Цель состоит в том, чтобы получать виртуальный бинауральный сигнал в позиции слушателя с учетом сигнала в исходной позиции записи и информации относительно расстояний источников звука от позиции записи. Физические источники предположительно должны быть разделимыми посредством своего угла относительно позиции записи.
Сцена записывается из точки обзора (PoV) микрофона, причем эта позиция используется в качестве начала опорной системы координат. Сцена должна воспроизводиться из PoV слушателя, который отслеживается в 6DoF, см. фиг. 5. Один источник звука показывается здесь для иллюстрации, взаимосвязь является применимой для каждого частотно-временного бина.
Фиг. 5 иллюстрирует 6DoF-воспроизведение пространственного аудио. Источник звука записывается посредством микрофона с DoA rr на расстоянии dr относительно позиции и ориентации микрофонов (черная линия и дуга). Оно должно воспроизводиться относительно перемещающегося слушателя с DoA rl и расстоянием dl (штриховая линия). Это должно учитывать перемещение l в пространстве и вращение o слушателя (точечная линия).
Источник звука в координатах dr∈ℝ3 записывается из направления поступления (DoA), выражаемого посредством единичного вектора 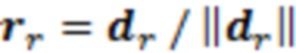 . Это DoA может оцениваться из анализа записи. Оно исходит из расстояния
. Это DoA может оцениваться из анализа записи. Оно исходит из расстояния 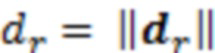 . Предполагается, что эта информация может оцениваться автоматически, например, с использованием времяпролетной камеры, чтобы получать информацию расстояния в форме карты m(r) глубины, преобразующей каждое направление r из позиции записи в расстояние ближайшего источника звука в метрах.
. Предполагается, что эта информация может оцениваться автоматически, например, с использованием времяпролетной камеры, чтобы получать информацию расстояния в форме карты m(r) глубины, преобразующей каждое направление r из позиции записи в расстояние ближайшего источника звука в метрах.
Слушатель отслеживается в 6DoF. В данное время, он находится в позиции l ∈ ℝ3 относительно микрофона и имеет вращение o ∈ ℝ3 относительно системы координат микрофонов. Позиция записи выбирается в качестве начала системы координат, чтобы упрощать систему обозначений.
Таким образом, звук должен воспроизводиться с другим расстоянием d1, приводящим к измененной громкости и другому DoA r1, которое представляет собой результат как перемещения, так и последующего вращения.
Ниже приводится способ для получения виртуального сигнала из перспективы слушателей посредством выделенных преобразований на основе параметрического представления, как пояснено в следующем разделе.
Предложенный способ основан на базовом DirAC-подходе для параметрического пространственного кодирования звука (см. [16]). Предполагается, что предусмотрен один доминирующий прямой источник на каждый частотно-временной экземпляр проанализированного спектра, и они могут обрабатываться независимо. Запись преобразуется в частотно-временное представление с использованием кратковременного преобразования Фурье (STFT). Индекс временного кадра обозначается с помощью n, а частотный индекс - с помощью k. Преобразованная запись затем анализируется, оценивая направления rr(k, n) и степень рассеяния ψ(k, n) для каждого частотно-временного бина комплексного спектра P(k, n). В синтезе, сигнал разделяется на прямую и рассеянную часть. Здесь, сигналы громкоговорителей вычисляются посредством панорамирования прямой части в зависимости от позиций динамиков и суммирования рассеянной части.
Способ для преобразования FOA-сигнала согласно перспективе слушателей в 6DoF может разделяться на пять этапов, см. фиг. 6.
Фиг. 6 иллюстрирует способ 6DoF-воспроизведения. Записанный FOA-сигнал в B-формате обрабатывается посредством DirAC-кодера, который вычисляет значения направления и степени рассеяния для каждого частотно-временного бина комплексного спектра. Вектор направления затем преобразуется посредством отслеживаемой позиции слушателя, и согласно информации расстояния, приведенной на карте расстояний. Результирующий вектор направления затем вращается согласно вращению головы. В завершение, сигналы для каналов 8+4 виртуальных громкоговорителей синтезируются в DirAC-декодере. Они затем бинаурализируются.
В варианте осуществления, входной сигнал анализируется в DirAC-кодере 422, информация расстояния добавляется из карты m(r) расстояний, после чего отслеживаемое перемещение и вращение слушателя применяются в новых преобразованиях 423 и 424. DirAC-декодер 425 синтезирует сигналы для 8+4 виртуальных громкоговорителей, которые в свою очередь бинаурализируются 427 для воспроизведения в наушниках. Следует отметить, что поскольку вращение звуковой сцены после перемещения является независимой операцией, оно альтернативно может применяться в модуле бинаурального рендеринга. Единственный параметр, преобразованный для 6DoF, представляет собой вектор направления. Посредством определения модели, рассеянная часть предположительно является изотропной и гомогенной и в силу этого оставляется без изменений.
Ввод в DirAC-кодер представляет собой звуковой FOA-сигнал в представлении в B-формате. Он состоит из четырех каналов, т.е. всенаправленного звукового давления и трех пространственных градиентов первого порядка, которые при определенных допущениях являются пропорциональными скорости частиц. Этот сигнал кодируется параметрическим способом, см. [18]. Параметры извлекаются из комплексного звукового давления P(k, n), которое представляет собой преобразованный всенаправленный сигнал, и комплексного вектора скорости частиц [UX(k, n), UY(k, n), UZ(k, n)]T, соответствующего преобразованным сигналам градиента.
DirAC-представление состоит из сигнала P(k, n), степени рассеяния ψ(k, n) и направления r(k, n) звуковой волны в каждом частотно-временном бине. Чтобы извлекать последнее из означенного, во-первых, активный вектор Ia(k, n) интенсивности звука вычисляется в качестве действительной части (обозначаемой посредством Re(·)) произведения вектора давления с комплексно-сопряженным числом (обозначаемым посредством (·)*) вектора скорости [18]:
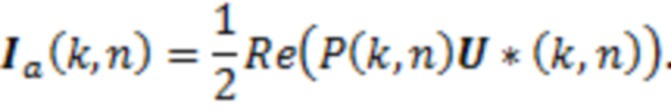
(1)
Степень рассеяния оценивается из коэффициента варьирования этого вектора [18].
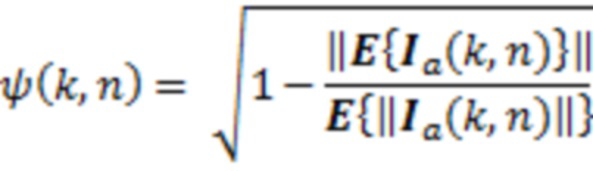 , (2)
, (2)
где 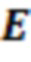 обозначает оператор математического ожидания вдоль временных кадров, реализованный в качестве скользящего среднего.
обозначает оператор математического ожидания вдоль временных кадров, реализованный в качестве скользящего среднего.
Поскольку есть намерение манипулировать звуком с использованием основанной на направлении карты расстояний, дисперсия оценок направлений должна быть низкой. Поскольку кадры типично являются короткими, это не всегда имеет место. Следовательно, в опциональном варианте осуществления, скользящее среднее применяется, чтобы получать сглаженную оценку 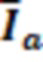 (k, n) направления. DoA прямой части сигнала затем вычисляется в качестве вектора единичной длины в противоположном направлении:
(k, n) направления. DoA прямой части сигнала затем вычисляется в качестве вектора единичной длины в противоположном направлении:
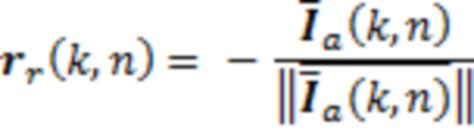
(3)
Поскольку направление кодируется как трехмерный вектор единичной длины для каждого частотно-временного бина, проще всего интегрировать информацию расстояния. Векторы направления умножаются на свою соответствующую запись карты таким образом, что длина вектора представляет расстояние dr(k, n) соответствующего источника звука:
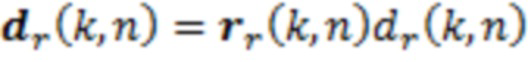 =
= 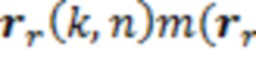 (k, n)), (4)
(k, n)), (4)
где dr(k, n) является вектором, указывающим из позиции записи микрофона в источник звука, активный во временном n и частотном k бине.
Позиция слушателя задается посредством системы отслеживания для текущего кадра обработки в качестве l(n). В силу векторного представления позиций источников, можно вычитать позиционный вектор l(n) отслеживания, чтобы давать в результате новый, перемещенный вектор d1(k, n) направления с длиной 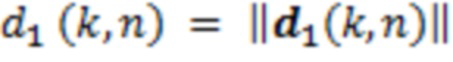 , см. фиг. 10. Расстояния от PoV слушателя до источников звука извлекаются, и DoA адаптируются за один этап:
, см. фиг. 10. Расстояния от PoV слушателя до источников звука извлекаются, и DoA адаптируются за один этап:
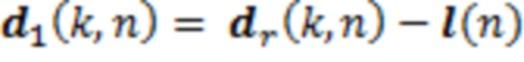
(5)
Важный аспект реалистичного воспроизведения представляет собой ослабление расстояния. Ослабление предположительно представляет собой функцию расстояния между источником звука и слушателем [19]. Длина векторов направления должна кодировать ослабление или усиление для воспроизведения. Расстояние до позиции записи кодируется в dr(k, n) согласно карте расстояний, и расстояние, которое должно воспроизводиться, кодируется в d1(k, n). Если векторы нормализуются в единичную длину, а затем выполняется умножение на отношение старого и нового расстояния, видно, что требуемая длина задается посредством деления d1(k, n) на длину исходного вектора:
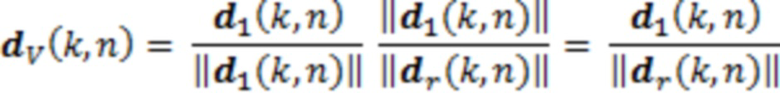
(6)
Изменения ориентации слушателя применяются на следующем этапе. Ориентация, предоставленная посредством отслеживания, может записываться в качестве вектора, состоящего из наклона в продольном направлении, наклона относительно вертикальной оси и наклона в поперечном направлении 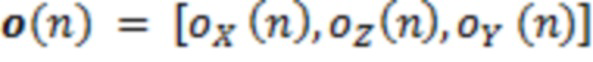 T относительно позиции записи в качестве начала координат. Направление источника вращается согласно ориентации слушателя, которая реализуется с использованием двумерных матриц вращения:
T относительно позиции записи в качестве начала координат. Направление источника вращается согласно ориентации слушателя, которая реализуется с использованием двумерных матриц вращения:
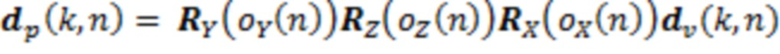
(7)
Результирующее DoA для слушателя затем предоставляется посредством вектора, нормализованного в единичную длину:
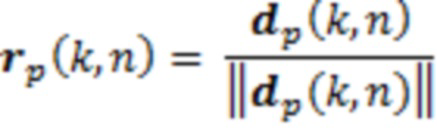
(8)
Преобразованный вектор направления, степень рассеяния и комплексный спектр используются для того, чтобы синтезировать сигналы для равномерно распределенной компоновки 8+4 виртуальных громкоговорителей. Восемь виртуальных динамиков расположены в азимутальных шагах на 45° на плоскости слушателя (с высотой 0°), а четыре - в перекрестном формировании на 90° выше при высоте в 45°. Синтез разбивается на прямую и рассеянную часть для каждого канала  громкоговорителя, где
громкоговорителя, где 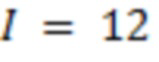 является числом громкоговорителей [16]:
является числом громкоговорителей [16]:
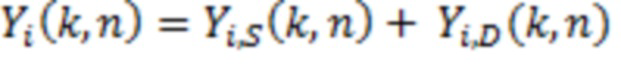
(9)
Для прямой части, амплитудное панорамирование на основе краевого затухания (EFAP) применяется, чтобы воспроизводить звук из направления вправо, с учетом геометрии виртуальных громкоговорителей [20]. С учетом DoA-вектора rp(k, n), это предоставляет панорамирующее усиление Gi(r) для каждого канала i виртуального громкоговорителя. Зависимое от расстояния усиление для каждого DoA извлекается из результирующей длины вектора направления, dp(k, n). Прямой синтез для канала i становится следующим:
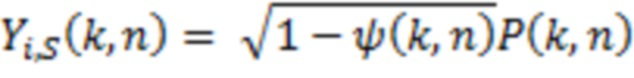
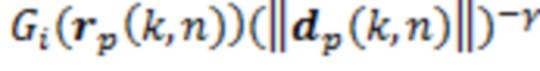 ,
,
(10)
где экспонента γ является коэффициентом настройки, который типично задается равным приблизительно 1 [19]. Следует отметить, что при γ=0 зависимое от расстояния усиление выключается.
Давление 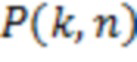 используется для того, чтобы формировать I декоррелированных сигналов
используется для того, чтобы формировать I декоррелированных сигналов 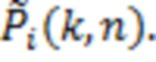 Эти декоррелированные сигналы суммируются с отдельными каналами громкоговорителей в качестве рассеянного компонента. Это придерживается стандартного способа [16]:
Эти декоррелированные сигналы суммируются с отдельными каналами громкоговорителей в качестве рассеянного компонента. Это придерживается стандартного способа [16]:
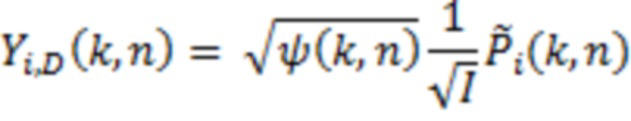
(11)
Рассеянная и прямая часть каждого канала суммируются между собой, и сигналы преобразуются обратно во временную область посредством обратного STFT. Эти канальные сигналы временной области свертываются с HRTF для левого и правого уха в зависимости от позиции громкоговорителя, чтобы создавать бинаурализированные сигналы.
Для оценки, воспроизводится одна сцена в виртуальной гостиной. Различные условия рендеринга используются для того, чтобы воспроизводить три одновременно активных источника звука. Новая MUSHRA-VR-технология использована для того, чтобы оценивать качество с помощью тестируемых исследуемых объектов.
Виртуальное окружение в эксперименте представляет собой внутреннее помещение с тремя источниками звука на различных расстояниях от позиции записи. На уровне приблизительно 50 см находится говорящий человек, на уровне 1 м - радиостанция, и на уровне 2 м - открытое окно, см. фиг. 7. Фиг. 7 иллюстрирует VR-сцену, в которой звук исходит из/от пользователя, радиостанции и открытого окна, причем каждый источник помечается с помощью окружности. Пользователь может ходить в зоне, помеченной посредством пунктирного прямоугольника вокруг пользователя к окну.
Визуальный рендеринг проводится с использованием Unity и HTC VIVE. Аудиообработка реализуется с помощью подключаемых модулей по технологии виртуальной студии (VST) и Max/MSP. Обмен данными отслеживания и условиями проводится через сообщения на основе открытого звукового управления (OSC). Зона ходьбы составляет приблизительно 2×2 м.
Хотя устанавливаются стандарты для оценки статического воспроизведения аудио, они обычно не являются непосредственно применимым для VR. В частности, для 6DoF должны быть разработаны новые подходы для оценки качества звука, поскольку восприятие является более сложным, чем только при аудиооценке, и представленный контент зависит от уникального тракта движения каждого слушателя. Новые способы, такие как ориентирование в VR [21] или физиологические реакции на восприятие на основе погружения [22], активно исследуются, но традиционные хорошо протестированные способы также могут быть адаптированы к VR-окружению, чтобы поддерживать исследовательскую работу, проводимую сегодня.
MUSHRA представляет собой широко приспосабливаемый способ оценки качества звука, применяемый к широкому диапазону вариантов использования от оценки качества речи до многоканальных пространственных аудиокомпоновок [17]. Это обеспечивает возможность параллельного сравнения ссылки с несколькими рендерингами идентичного аудиоконтента и предоставляет абсолютную шкалу оценки качества с помощью тестовых элементов скрытой ссылки и привязки. В этом тесте, MUSHRA-технология приспосабливается в VR-компоновке, и в силу этого требуются некоторые отступления от рекомендуемой реализации. В частности, версия, реализованная здесь, не обеспечивает возможность цикличного выполнения аудиоконтента, и привязочный элемент представляет собой 3DoF-рендеринг.
Различные условия случайно присваиваются тестовым условиям в каждой серии. Каждый участник запрашивается на предмет того, чтобы оценивать качество звука каждого условия и выдавать количественный показатель по шкале от 0 до 100. Они знают, что одно из условий фактически является идентичным ссылке и, по сути, должно количественно оцениваться в 100 баллов. Худшее "привязочное" условие должно количественно оцениваться в 20 (плохое) или ниже; все другие условия должны количественно оцениваться как промежуточные.
MUSHRA-панель в VR проиллюстрирована на фиг. 8. Ползунки на фиг. 8 для присваивания рейтинга четырем условиям могут окрашиваться, ниже них содержатся числовое значение и кнопка для выбора условия. Панель спроектирована таким образом, что рейтинги тестируемых систем могут присваиваться в любое время при наличии незаметного интерфейса в виртуальном окружении. Посредством нажатия кнопки на карманном контроллере, полупрозрачный интерфейс подвергается созданию экземпляра на уровне глаз в поле зрения (FoV) пользователя на расстоянии, подходящем для естественного просмотра. Присутствует лазерный указатель, который реплицирует состояния наведения мыши (неактивное, активное, нажатое, выделенное) для кнопок, чтобы помогать со взаимодействием. Нажатие идентичной кнопки на карманном контроллере удаляет панель, но поддерживает все номинальные токи и воспроизведение на основе выбора условий. Все рейтинги регистрируются в реальном времени в файле, включающем в себя легенду для рандомизации условий.
Всего четыре различных условия реализованы для эксперимента.
REF: Объектно-ориентированный рендеринг. Он представляет собой опорное условие. B-формат формируется на лету для текущей позиции слушателя и затем подготавливается посредством рендеринга через виртуальные динамики.
C1: 3DoF-воспроизведение. Позиция слушателя игнорируется, т.е. 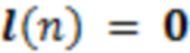 , но по-прежнему применяется его вращение
, но по-прежнему применяется его вращение 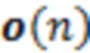 головы. Усиление задается равным усилению источников на расстоянии 2 м от слушателя. Это условие используется в качестве привязки.
головы. Усиление задается равным усилению источников на расстоянии 2 м от слушателя. Это условие используется в качестве привязки.
C2: Предложенный способ для 6DoF-воспроизведения без информации расстояния. Позиция слушателя используется для того, чтобы изменять вектор направления. Все источники расположены на сфере за пределами зоны ходьбы. Радиус сферы является фиксированно равным 2 м, т.е. 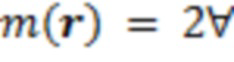 , и зависимое от расстояния усиление применяется (γ=1).
, и зависимое от расстояния усиление применяется (γ=1).
C3: Предложенный способ 6DoF-воспроизведения с информацией расстояния. Позиция 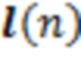 слушателя используется для того, чтобы изменять вектор направления. Информация m(r) расстояния используется для того, чтобы вычислять корректное DoA в позиции слушателя (5), и зависимое от расстояния усиление (6) применяется (γ=1).
слушателя используется для того, чтобы изменять вектор направления. Информация m(r) расстояния используется для того, чтобы вычислять корректное DoA в позиции слушателя (5), и зависимое от расстояния усиление (6) применяется (γ=1).
Идентичный конвейер обработки сигналов используется для всех условий. Это обусловлено необходимостью обеспечивать то, что сравнение фокусируется только на пространственном воспроизведении, и результат не затрагивается посредством окрашивания или других эффектов. Конвейер показывается на фиг. 10. Фиг. 10 иллюстрирует тракты передачи сигналов для опорного рендеринга и DirAC. В опорном случае, данные отслеживания используются для того, чтобы изменять позиционирование и вращение объектно-ориентированного синтеза в B-формате (левая верхняя часть). В других условиях C1-C3, данные отслеживания применяются в DirAC-области (правая часть).
Два сигнала в B-формате вычисляются из трех исходных моносигналов. Прямой (сухой) сигнал вычисляется онлайн. Реверберационный (мокрый) сигнал предварительно вычисляется оффлайн. Они суммируются между собой и обрабатываются посредством DirAC, которое подготавливает посредством рендеринга в виртуальные громкоговорители, которые затем бинаурализируются. Отличие заключается в применении данных отслеживания. В опорном случае, они применяются перед синтезом сигнала в B-формате таким образом, что они фактически записываются в позиции слушателя. В других случаях, они применяются в DirAC-области.
Объектно-ориентированный рендеринг используется в качестве опорного сценария. Фактически, слушатель оснащается микрофоном в B-формате на своей голове и формирует запись согласно своей позиции и вращению головы. Это реализуется просто: Объекты размещаются относительно отслеживаемой позиции слушателя. FOA-сигнал формируется из каждого источника с ослаблением расстояния. Синтетический прямой сигнал  в B-формате для сигнала
в B-формате для сигнала 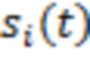 источника на расстоянии
источника на расстоянии 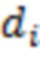 , в направлении с азимутом θ и высотой ψ является следующим:
, в направлении с азимутом θ и высотой ψ является следующим:
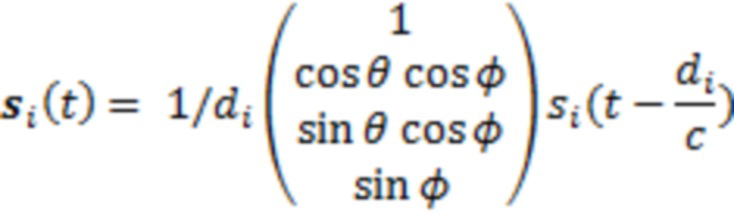 ,
,
(12)
где c является скоростью звука в м/с. После этого, отслеживаемое вращение применяется в FOA-области [7].
Искусственная реверберация суммируется с сигналом источника время-независимым способом, чтобы повышать реализм подготовленной посредством рендеринга звуковой сцены в помещениях. Ранние отражения от границ помещения в форме скворечника суммируются с точной задержкой, направлением и ослаблением. Поздняя реверберация формируется с пространственной сетью задержки обратной связи (FDN), которая распределяет многоканальный вывод в компоновку виртуальных громкоговорителей [23]. Время T60 частотно-зависимой реверберации составляет 90-150 мс со средним значением в 110 мс. После этого применяется тональный корректирующий фильтр с характеристикой нижних частот.
Реверберированный сигнал затем преобразуется из компоновки 8+4 виртуальных динамиков в B-формат посредством умножения каждого из сигналов виртуальных динамиков на шаблон в B-формате их DoA, как указано в (12). Реверберирующий сигнал в B-формате суммируется с прямым сигналом.
Суммированный B-формат обрабатывается в DirAC-области. Кодирование осуществляется с использованием гребенки фильтров квадратурного зеркального фильтра (QMF) с 128 полосами частот, выбранной в силу ее высокого временного разрешения и низкого временного наложения спектров. Направление и степень рассеяния оцениваются со сглаживанием на основе скользящего среднего в 42 мс. Декодирование представляет собой формирование сигналов 8+4 виртуальных громкоговорителей. Эти 8+4 сигнала затем свертываются с помощью HRTF для бинаурального воспроизведения.
Всего 19 исследуемых объектов присваивают рейтинг сцене. Им 23-41 год, трое из них являются женщинами, ни один не сообщает о нарушениях слуха. Большинству участников требуется менее десяти минут для присваивания рейтинга. Исследуемые объекты, которые требуют больше времени, являются вообще незнакомыми с оценкой аудио в стиле виртуальной реальности, при которой звук и видео не всегда совпадают.
Фиг. 6 показывает результирующие количественные показатели в качестве коробчатых диаграмм, т.е. MUSHRA-рейтинги (N=19) в качестве коробчатых диаграмм. пунктирная линия представляет медианный количественный показатель, коробки -первый-третий квартиль, отводы имеют межквартильный размах (IQR) в +/-1,5.
Можно видеть, что все исследуемые объекты корректно идентифицируют ссылку в качестве наилучшей, хотя 4 из них присваивают ей рейтинг ниже 100. Хотя она звучит идентично в позиции записи, отличия касательно других условий являются очевидными для всех участников. Предложенное 6DoF-воспроизведение в DirAC-области с информацией (C3) расстояния получает второй наибольший общий количественный показатель. Воспроизведение без информации (C2) расстояния или даже без отслеживания (C1) позиции количественно оценивается как более низкое почти каждым участником. Можно видеть, что участники не соглашаются со значением, присвоенным привязочному (C1) условию. Хотя 13 из количественно оценивают его ниже 30, другие шесть не так уверены и выбирают значения вплоть то 70.
Значительный основной эффект условия выявлен (p<0,001, F=43,75) согласно одностороннему дисперсионному анализу повторных показателей (ANOVA). В качестве апостериорного анализа, выполнены несколько сравнений Тьюки средних с 95%-м семейным доверительным уровнем. Все пары условий выявлены как существенно отличающиеся, наиболее сильно так, что (p<0,001), только C2-C3 не являются настолько очевидными (p<0,04).
Даже если выявлено, что условия существенно отличаются, дисперсия в ответах является относительно большой. Одной причиной этого могут быть различные уровни восприятия тестируемых исследуемых объектов с VR. Может быть желательным иметь ознакомительный предварительный тест или группировать исследуемые объекты посредством восприятия. Тем не менее, использование диапазона от новичка до эксперта в VR и тестах на основе прослушивания при одновременном формировании значительных эффектов показывает то, что результаты являются применимыми для этих факторов.
Некоторые участники испытывают затруднение при определении 3DoF-условия в качестве привязки. Это также может отражать неопытность в VR-аудио. Тем не менее, это может упрощать процедуру и способствовать согласованности, чтобы предоставлять дополнительную непространственную привязку, такую как мономикширование источников звука.
Относительно предложенного способа воспроизведения, видно, что он предоставляет возможность воспроизведения FOA-контента, записываемого в одной точке в пространстве, в 6DoF. Хотя большинство участников теста присваивают более высокий рейтинг идеальной ссылке в форме сигнала в B-формате, предложенный способ достигает наибольшего среднего количественного показателя для воспроизведения из других условий. Предложенный способ работает, даже когда источники звука в записи расположены на различных расстояниях от микрофонов. В этом случае, расстояния должны записываться в качестве метаданных, которые должны воспроизводиться. Результаты показывают то, что, воспроизведение расстояния повышает реализм восприятия. Эффект может быть более сильным, если зона ходьбы предоставляет возможность пользователям обходить вокруг всех источников звука.
Предложен новый способ воспроизведения аудио при шести степенях свободы (6DoF). Аудио записывается в качестве амбиофонии первого порядка (FOA) в одной позиции, и данные расстояния для источников звука получаются в качестве вспомогательной информации. С использованием этой информации, аудио воспроизводится относительно живого отслеживания слушателя в параметрической области направленного кодирования аудио (DirAC).
Субъективный тест показывает то, что предложенный способ ранжируется близко с объектно-ориентированным рендерингом. Это подразумевает то, что предложенный способ воспроизведения может успешно предоставлять виртуальное воспроизведение за рамками трех степеней свободы, когда учитывается информация расстояния.
Фиг. 11a иллюстрирует дополнительную предпочтительную реализацию модуля 420 вычисления звуковых полей.
На основе описания звукового поля, полнополосное направление поступления или направление поступления на каждую полосу частот определяется на 1100. Эта информация направления поступления представляет данные направления поступления звукового поля. На основе этих данных направления поступления, преобразование с перемещением выполняется на этапе 1110. С этой целью, используется карта 1120 глубины, включенная в качестве метаданных для описания звукового поля. На основе карты 1120 глубины, этап 1110 формирует данные нового направлении поступления для звукового поля, которые, в этой реализации, зависят только от перемещения из опорного местоположения в другое опорное местоположение. С этой целью, этап 1110 принимает сформированную информацию перемещения, например, посредством отслеживания в контексте реализации в стиле виртуальной реальности.
Предпочтительно или альтернативно, также используются данные вращения. С этой целью, этап 1130 выполняет преобразование с вращением с использованием информации вращения. Когда выполняется как перемещение, так и вращение, в таком случае предпочтительно выполнять преобразование с вращением после вычисления новых DoA звукового поля, которые уже включают в себя информацию из перемещения и карты 1120 глубины.
Затем, на этапе 1140 формируется новое описание звукового поля. С этой целью, может использоваться описание исходного звукового поля, либо, альтернативно, могут использоваться сигналы источников, которые разделены от описания звукового поля посредством алгоритма разделения источников, либо могут использоваться любые другие варианты применения. По существу, новое описание звукового поля, например, может представлять собой направленное описание звукового поля, полученное посредством амбиофонического формирователя 430 или сформированное посредством DirAC-синтезатора 425, либо может представлять собой бинауральное представление, сформированное из представления виртуальных динамиков в последующем бинауральном рендеринге.
Предпочтительно, как проиллюстрировано на фиг. 11a, расстояние согласно направлению поступления также используется в формировании нового описания звукового поля, чтобы адаптировать громкость или уровень громкости определенного источника звука к новому местоположению, т.е. к новому или другому опорному местоположению.
Хотя фиг. 11a иллюстрирует ситуацию, в которой преобразование с вращением выполняется после преобразования с перемещением, следует отметить, что порядок может отличаться. В частности, преобразование с вращением может применяться к DoA звукового поля, сформированным посредством этапа 1100, и после этого применяется дополнительное преобразование с перемещением, которое обусловлено перемещением исследуемого объекта из опорного местоположения в другое опорное местоположение.
Тем не менее, следует отметить, что DoA звукового поля должны использоваться для того, чтобы находить соответствующую информацию расстояния из карты 1120 глубины, а не вращаемых DoA. Таким образом, осле того, как DoA звукового поля определены посредством этапа 1100, информация расстояния получается посредством использования карты 1120 глубины, и эта информация расстояния затем используется посредством формирования нового описания звукового поля на этапе 1140 для учета измененного расстояния и в силу этого измененного уровня громкости определенного источника относительно определенного опорного местоположения. По существу, можно сказать, что в случае, если расстояние становится большим, в таком случае конкретный сигнал источника звука ослабляется, в то время как, когда расстояние становится короче, таком случае сигнал источника звука усиливается. Естественно, ослабление или усиление определенного источника звука в зависимости от расстояния осуществляется пропорционально изменению расстояния, но, в других вариантах осуществления, менее комплексные операции могут применяться к этому усилению или ослаблению сигналов источников звука в достаточно приблизительных приращениях. Даже такая менее комплексная реализация предоставляет превосходные результаты по сравнению с ситуацией, когда любое изменение расстояния полностью игнорируется.
Фиг. 11b иллюстрирует предпочтительную реализацию модуля 420 вычисления звуковых полей. На этапе 1102, выполняется вычисление разделения источников и направления поступления или, в общем, информации направления для каждого источника. Затем, на этапе 1104, вектор направления поступления, например, умножается на вектор информации расстояния, т.е. вектор из исходного опорного местоположения в источник звука, т.е. вектор из элемента 520 в элемент 510 по фиг. 5. Затем, на этапе 1106, информация перемещения, т.е. вектор из элемента 520 в элемент 500 по фиг. 5 учитывается, чтобы вычислять новый перемещенный вектор направления, который представляет собой вектор из позиции 500 слушателя в позицию 510 источника звука. Затем вектор нового направления поступления с корректной длиной, указываемой посредством dv, вычисляется на этапе 1108. Этот вектор направляется в направлении, идентичном направлению dr, но имеет другую длину, поскольку длина этого вектора отражает тот факт, что источник 510 звука записывается в исходном звуковом поле с определенной громкостью, и в силу этого длина dv более или менее указывает изменение уровня громкости. Это получается посредством деления вектора dl на расстояние dr до плоскости записи, т.е. на длину вектора dr из микрофона 520 в источник 510 звука.
Когда, как показано на фиг. 5, воспроизведенное расстояние превышает записанное расстояние, в таком случае длина dv ниже единичной. Это должно приводить к ослаблению источника 510 звука для воспроизведения в новой позиции слушателя. Тем не менее, когда воспроизведенное расстояние dl меньше записанного расстояния, в таком случае длина dv, вычисленная посредством этапа 1108, больше 1, и соответствующий коэффициент масштабирования должен приводить к усилению источника звука.
Фиг. 12 иллюстрирует дополнительную предпочтительную реализацию модуля вычисления звуковых полей.
На этапе 1200, отдельные источники из звукового поля определяются, например, на каждую полосу частот или в полной полосе частот. Когда выполняется определение на каждый кадр и полосу частот, то это может осуществляться посредством DirAC-анализа. Если выполняется полнополосное или подполосное определение, то это может осуществляться посредством любого вида полнополосного или подполосного алгоритма разделения источников.
На этапе 1210, перемещение и/или вращение слушателя определяется, например, посредством слежения за положением головы.
На этапе 1220, старое расстояние для каждого источника определяется посредством использования метаданных и, например, посредством использования карты глубины в реализации DirAC-анализа. Таким образом, каждая полоса частот считается определенным источником (при условии, что степень рассеяния ниже определенного порогового значения), и после этого определяется определенное расстояние для каждого частотно-временного бина, имеющего низкое значение степени рассеяния.
Затем, на этапе 1230, новое расстояние на каждый источник получается, например, посредством векторного вычисления на каждую полосу частот, которое, например, поясняется в контексте фиг. 11b.
Кроме того, как проиллюстрировано на этапе 1240, старое направление на каждый источник определяется, например, посредством DoA-вычисления, полученного в DirAC-анализе, либо, например, посредством анализа информации направления поступления или направления в алгоритме разделения источников.
Затем, на этапе 1250, новое направление на каждый источник определяется, например, посредством выполнения векторного вычисления на каждую полосу частот или в полной полосе частот.
После этого, на этапе 1260, новое звуковое поле формируется для перемещенного и вращаемого слушателя. Это может осуществляться, например, посредством масштабирования прямой части на каждый один канал в DirAC-синтезе. В зависимости от конкретной реализации, модификация расстояния может выполняться на этапах 1270a, 1270b или 1270c, помимо или альтернативно выполнению модификации расстояния на этапе 1260.
Когда, например, определяется то, что звуковое поле имеет только один источник, в таком случае модификация расстояния может уже выполняться на этапе 1270a.
Альтернативно, когда отдельные сигналы источников вычисляются посредством этапа 1200, в таком случае модификация расстояния может выполняться для отдельных источников на этапе 1270b, до того, как фактическое новое звуковое поле формируется на этапе 1260.
Дополнительно, когда формирование звуковых полей на этапе 1260, например, подготавливает посредством рендеринга не сигнал компоновки громкоговорителей или бинауральный сигнал, а другое описание звукового поля, например, с использованием амбиофонического кодера или модуля 430 вычисления, в таком случае модификация расстояния также может выполняться после формирования на этапе 1260, что означает на этапе 1270c. В зависимости от реализации, модификация расстояния также может быть распределена в несколько модулей модификации, так что, в конечном счете, определенный источник звука имеет определенный уровень громкости, который направляется посредством разности между исходным расстоянием между источником звука и опорным местоположением и новым расстоянием между источником звука и другим опорным местоположением.
Фиг. 13a иллюстрирует DirAC-анализатор, как первоначально раскрыто, например, в более раннем противопоставленном материале "Directional Audio Coding" из IWPASH 2009 года.
DirAC-анализатор содержит гребенку 1310 полосовых фильтров, энергоанализатор 1320, анализатор 1330 интенсивности, блок 1340 временного усреднения и модуль 1350 вычисления степени рассеяния и модуль 1360 вычисления направления.
В DirAC, как анализ, так и синтез выполняется в частотной области. Предусмотрено несколько способов для разделения звука на полосы частот, каждая из которых имеет отличительные свойства. Наиболее часто используемые преобразования частоты включают в себя кратковременное преобразование Фурье (STFT) и гребенку квадратурных зеркальных фильтров (QMF). В дополнение к ним, имеется полная свобода в том, чтобы проектировать гребенку фильтров с произвольными фильтрами, которые оптимизируются под любые конкретные цели. Цель направленного анализа заключается в том, чтобы оценивать в каждой полосе частот направление поступления звука, вместе с оценкой того, поступает либо нет звук из одного или более направлений одновременно. В принципе, это может выполняться с помощью ряда технологий; тем не менее, выявлено, что энергетический анализ звукового поля является подходящим, что проиллюстрировано на фиг. 13a. Энергетический анализ может выполняться, когда сигнал давления и сигналы скорости в одной, двух или три размерностях захватываются из одной позиции. В сигналах в B-формате первого порядка, всенаправленный сигнал называется W-сигналом, который понижающе масштабирован посредством квадратного корня двух. Звуковое давление может оцениваться в качестве 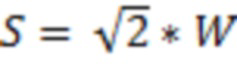 , выражаемого в STFT-области.
, выражаемого в STFT-области.
X-, Y- и Z-каналы имеют диаграмму направленности диполя, направленного вдоль декартовой оси, которые формируют вместе вектор u=[X, Y, Z]. Вектор оценивает вектор скорости звукового поля и также выражается в STFT-области. Энергия E звукового поля вычисляется. Захват сигналов в B-формате может получаться либо с совпадающим позиционированием направленных микрофонов, либо с близкорасположенным набором всенаправленных микрофонов. В некоторых вариантах применения, сигналы микрофонов могут формироваться в вычислительной области, т.е. моделироваться.
Направление звука задается в качестве противоположного направления вектора I интенсивности. Направление обозначается как соответствующие значения углового азимута и высоты в передаваемых метаданных. Степень рассеяния звукового поля также вычисляется с использованием оператора математического ожидания вектора интенсивности и энергии. Результат этого уравнения представляет собой действительнозначное число между нулем и единицей, отличающее то, поступает звуковая энергия из одного направления (степень рассеяния равна нулю) или из всех направлений (степень рассеяния равна единице). Эта процедура является надлежащей в случае, когда доступна полная трехмерная (или меньшей размерности) информация скорости.
Фиг. 13b иллюстрирует DirAC-синтез, снова имеющий гребенку 1370 полосовых фильтров, блок 1400 виртуальных микрофонов, блок 1450 прямого/синтезатора рассеянных сигналов и определенную компоновку громкоговорителей или виртуальную предназначенную компоновку 1460 громкоговорителей. Дополнительно, используются модуль 1380 преобразования степени рассеяния в усиление, блок 1390 обработки таблиц усилений на основе векторного амплитудного панорамирования (VBAP), компенсационный блок 1420 микрофонов, блок 1430 усреднения усиления громкоговорителей и модуль 1440 распределения для других каналов.
В этом DirAC-синтезе с громкоговорителями, высококачественная версия DirAC-синтеза, показанного на фиг. 13b, принимает все сигналы в B-формате, для которых сигнал виртуального микрофона вычисляется для каждого направления громкоговорителя из компоновки 1460 громкоговорителей. Используемая диаграмма направленности типично является диполем. Сигналы виртуальных микрофонов затем модифицируются нелинейным способом, в зависимости от метаданных. Версия с низкой скоростью передачи битов DirAC не показана на фиг. 13b; тем не менее, в этой ситуации, передается только один канал аудио, как проиллюстрировано на фиг. 6. Различие в обработке заключается в том, что все сигналы виртуальных микрофонов должны заменяться посредством одного принимаемого канала аудио. Сигналы виртуальных микрофонов разделяются на два потока: рассеянные и нерассеянные потоки, которые обрабатываются отдельно.
Нерассеянный звук воспроизводится в качестве точечных источников посредством использования векторного амплитудного панорамирования (VBAP). При панорамировании, монофонический звуковой сигнал применяется к поднабору громкоговорителей после умножения на конкретные для громкоговорителя коэффициенты усиления. Коэффициенты усиления вычисляются с использованием информации компоновки громкоговорителей и указываемого направления панорамирования. В версии с низкой скоростью передачи битов, входной сигнал просто панорамируется в направления, подразумеваемые посредством метаданных. В высококачественной версии, каждый сигнал виртуального микрофона умножается на соответствующий коэффициент усиления, что формирует идентичный эффект с панорамированием; тем не менее, он менее подвержен нелинейным артефактам.
Во многих случаях, направленные метаданные подвергаются резким временным изменениям. Чтобы не допускать артефактов, коэффициенты усиления для громкоговорителей, вычисленные с помощью VBAP, сглаживаются посредством временной интеграции с частотно-зависимыми постоянными времени, равными приблизительно 50 периодам цикла в каждой полосе частот. Это эффективно удаляет артефакты; тем не менее, изменения направления не воспринимаются как более медленные, чем без усреднения, в большинстве случаев.
Цель синтеза рассеянного звука состоит в том, чтобы создавать восприятие звука, который окружает слушателя. В версии с низкой скоростью передачи битов, рассеянный поток воспроизводится посредством декорреляции входного сигнала и его воспроизведения из каждого громкоговорителя. В высококачественной версии, сигналы виртуальных микрофонов рассеянного потока являются уже некогерентными в определенной степени, и они должны декоррелироваться только немного. Этот подход предоставляет лучшее пространственное качество для реверберации объемного звучания и окружающего звука, чем версия с низкой скоростью передачи битов.
Для DirAC-синтеза с наушниками, DirAC формулируется с определенным количеством виртуальных громкоговорителей вокруг слушателя для нерассеянного потока и определенным числом громкоговорителей для рассеянного потока. Виртуальные громкоговорители реализуются как свертка входных сигналов с измеренными передаточными функциями восприятия звука человеком (HRTF).
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
Изобретаемое улучшенное описание звукового поля может сохраняться на цифровом носителе хранения данных или энергонезависимом носителе хранения данных или может передаваться по передающей среде, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронночитаемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат энергонезависимый носитель хранения данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления изобретаемого способа в силу этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Литературные ссылки
[1] Liitola, T., Headphone sound externalization, Ph.D. thesis, Helsinki University of Technology. Department of Electrical and Communications Engineering Laboratory of Acoustics and Audio Signal Processing., 2006.
[2] Blauert, J., Spatial Hearing - Revised Edition: The Psychophysics of Human Sound Localization, The MIT Press, 1996, ISBN 0262024136.
[3] Zhang, W., Samarasinghe, P. N., Chen, H., and Abhayapala, T. D., “Surround by Sound: A Re-view of Spatial Audio Recording and Reproduction,” Applied Sciences, 7(5), стр. 532, 2017.
[4] Bates, E. and Boland, F., “Spatial Music, Virtual Reality, and 360 Media,” in Audio Eng. Soc. Int. Conf. on Audio for Virtual and Augmented Reality, Лос Анджелес, Калифорния, США, 2016.
[5] Anderson, R., Gallup, D., Barron, J. T., Kontkanen, J., Snavely, N., Esteban, C. H., Agarwal, S., and Seitz, S. M., “Jump: Virtual Reality Video,” ACM Transactions on Graphics, 35(6), стр. 198, 2016.
[6] Merimaa, J., Analysis, Synthesis, and Perception of Spatial Sound: Binaural Localization Modeling and Multichannel Loudspeaker Reproduction, Ph.D. thesis, Helsinki University of Technology, 2006.
[7] Kronlachner, M. and Zotter, F., “Spatial Transformations for the Enhancement of Ambisonics Recordings,” in 2nd International Conference on Spatial Audio, Эрланген, Германия, 2014.
[8] Tsingos, N., Gallo, E., and Drettakis, G., “Perceptual Audio Rendering of Complex Virtual Environments,” ACM Transactions on Graphics, 23(3), стр. 249-258, 2004.
[9] Taylor, M., Chandak, A., Mo, Q., Lauterbach, C., Schissler, C., and Manocha, D., “Guided multi-view ray tracing for fast auralization,” IEEE Trans. Visualization & Comp. Graphics, 18, стр. 1797- 1810, 2012.
[10] Rungta, A., Schissler, C., Rewkowski, N., Mehra, R., and Manocha, D., “Diffraction Kernels for Interactive Sound Propagation in Dynamic Environments,” IEEE Trans. Visualization & Comp. Graphics, 24(4), стр. 1613-1622, 2018.
[11] Thiergart, O., Kowalczyk, K., and Habets, E. A. P., “An Acoustical Zoom based on Informed Spatial Filtering,” in Int. Workshop on Acoustic Signal Enhancement, стр. 109-113, 2014.
[12] Khaddour, H., Schimmel, J., and Rund, F., “A Novel Combined System of Direction Estimation and Sound Zooming of Multiple Speakers,” Radioengineering, 24(2), 2015.
[13] Ziegler, M., Keinert, J., Holzer, N., Wolf, T., Jaschke, T., op het Veld, R., Zakeri, F. S., and Foessel, S., “Immersive Virtual Reality for Live-Action Video using Camera Arrays,” in IBC, Амстердам, Нидерланды, 2017.
[14] Thiergart, O., Galdo, G. D., Taseska, M., and Habets, E. A. P., “Geometry-Based Spatial Sound Acquisition using Distributed Microphone Arrays,” IEEE Trans. Audio, Speech, Language Process., 21(12), стр. 2583-2594, 2013.
[15] Kowalczyk, K., Thiergart, O., Taseska, M., Del Galdo, G., Pulkki, V., and Habets, E. A. P., “Parametric Spatial Sound Processing: A Flexible and Efficient Solution to Sound Scene Acquisition, Modification, and Reproduction,” IEEE Signal Process. Mag., 32(2), стр. 31-42, 2015.
[16] Pulkki, V., “Spatial Sound Reproduction with Directional Audio Coding,” J. Audio Eng. Soc., 55(6), стр. 503-516, 2007.
[17] International Telecommunication Union, “ITU-R BS.1534-3, Method for the subjective assessment of intermediate quality level of audio systems,” 2015.
[18] Thiergart, O., Del Galdo, G., Kuech, F., and Prus, M., “Three-Dimensional Sound Field Analysis with Directional Audio Coding Based on Signal Adaptive Parameter Estimators,” in Audio Eng. Soc. Conv. Spatial Audio: Sense the Sound of Space, 2010.
[19] Kuttruff, H., Room Acoustics, Taylor & Francis, 4 edition, 2000.
[20] Borß, C., “A polygon-based panning method for 3D loudspeaker setups,” in Audio Eng. Soc. Conv., стр. 343-352, Лос Анджелес, Калифорния, США, 2014.
[21] Rummukainen, O., Schlecht, S., Plinge, A., and Habets, E. A. P., “Evaluating Binaural Reproduction Systems from Behavioral Patterns in a Virtual Reality - A Case Study with Impaired Binaural Cues and Tracking Latency,” in Audio Eng. Soc. Conv. 143, Нью-Йорк, NY, США, 2017.
[22] Engelke, U., Darcy, D. P., Mulliken, G. H., Bosse, S., Martini, M. G., Arndt, S., Antons, J.-N., Chan, K. Y., Ramzan, N., and Brunnström, K., “Psychophysiology-Based QoE Assessment: A Survey,” IEEE Selected Topics in Signal Processing, 11(1), стр. 6-21, 2017.
[23] Schlecht, S. J. and Habets, E. A. P., “Sign-Agnostic Matrix Design for Spatial Artificial Reverberation with Feedback Delay Networks,” in Proc. Audio Eng. Soc. Conf., стр. 1-10- accepted, Tokyo, Japan, 2018
[31] M. A. Gerzon, "Periphony: With-height sound reproduction,'' J. Acoust. Soc. Am., том 21,110. 1, стр. 2-10, 1973.
[32] V. Pulkki, "Directional audio coding in spatial sound reproduction and stereo upmixing," in Proc. of the 28th AES International Conference, 2006.
[33] --, "Spatial sound reproduction with directional audio coding," Journal Audio Eng. Soc„ том 55, номер 6, стр. 503-516, июнь 2007.
[34] C. G. and G. M., "Coincident microphone simulation covering three dimensional space and yielding various directional outputs," патент США 4 042 779, 1977.
[35] C. Faller and F. Baumgarte, "Binaural cue coding - part ii: Schemes and applications, "IEEE Trans. Speech Audio Process„ том 11, номер 6, ноябрь 2003.
[36] C. Faller, "Parametric multichannel audio coding: Synthesis of coherence cues," IEEE Trans. Speech Audio Process., том 14, номер 1, январь 2006 .
[37] H. P. J. E. E. Schuijers, J. Breebaart, "Low complexity parametric stereo coding," in Proc. of the 116th A ES Convention, Берлин, Германия, 2004.
[38] V. Pulkki, "Virtual sound source positioning using vector base amplitude panning," J. Acoust. Soc. A m„ том 45, номер 6, стр. 456-466, июнь 1997.
[39] J. G. Tylka and E. Y. Choueiri, "Comparison of techniques for binaural navigation of higher order ambisonics sound fields," in Proc. of the AES International Conference on Audio for Virtual and Augmented Reality, Нью-Йорк, сентябрь 2016.
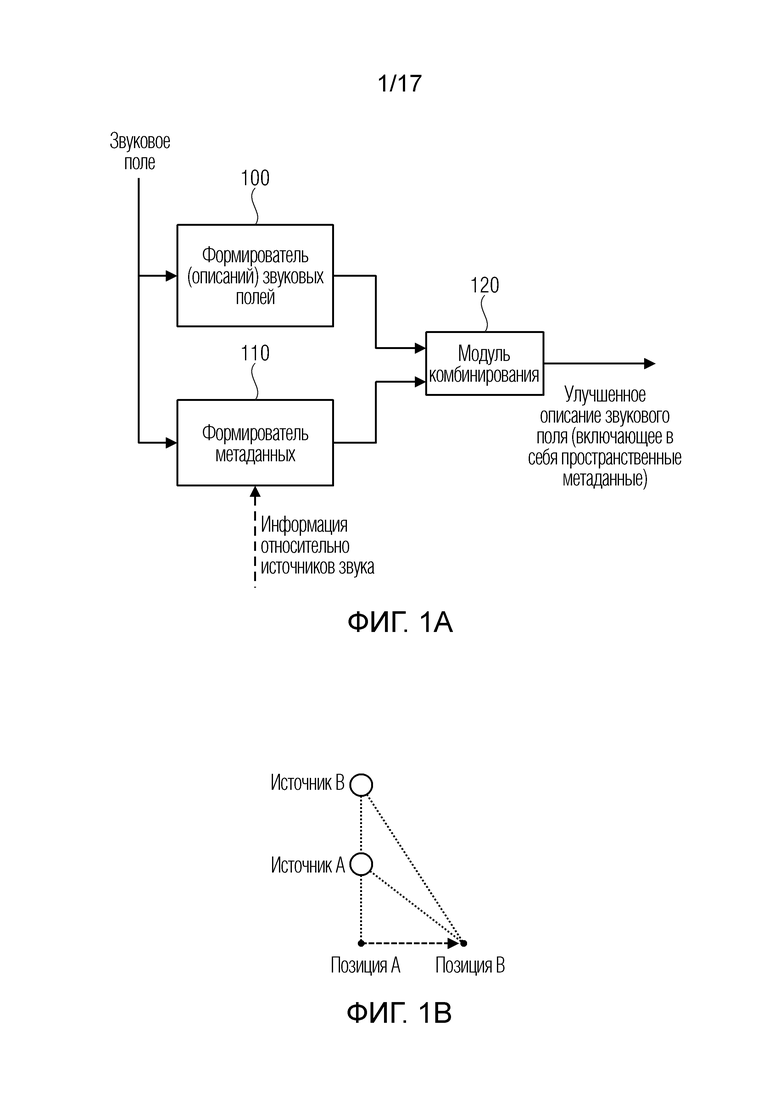
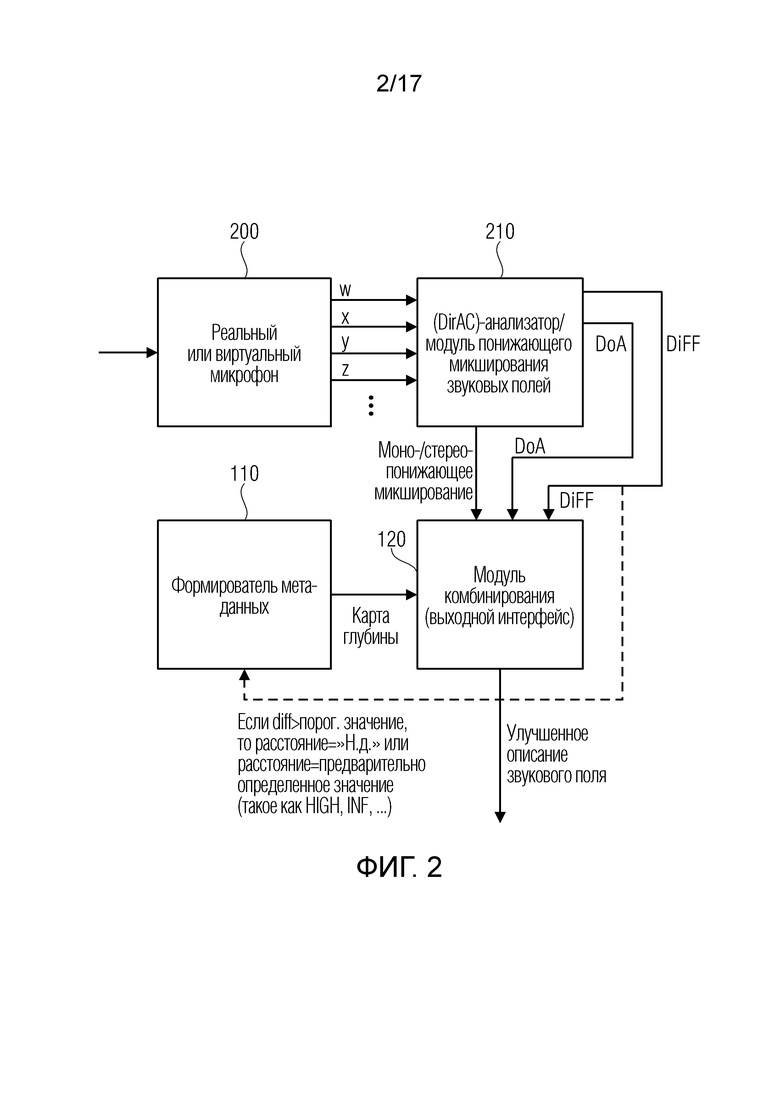
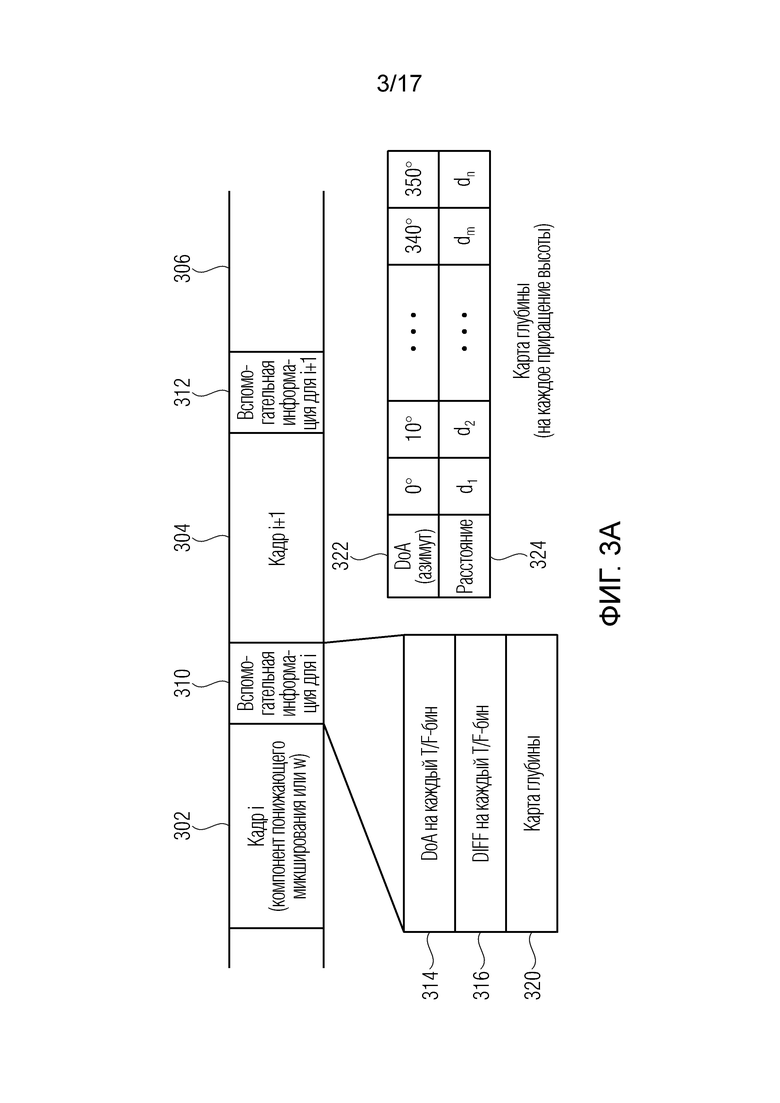

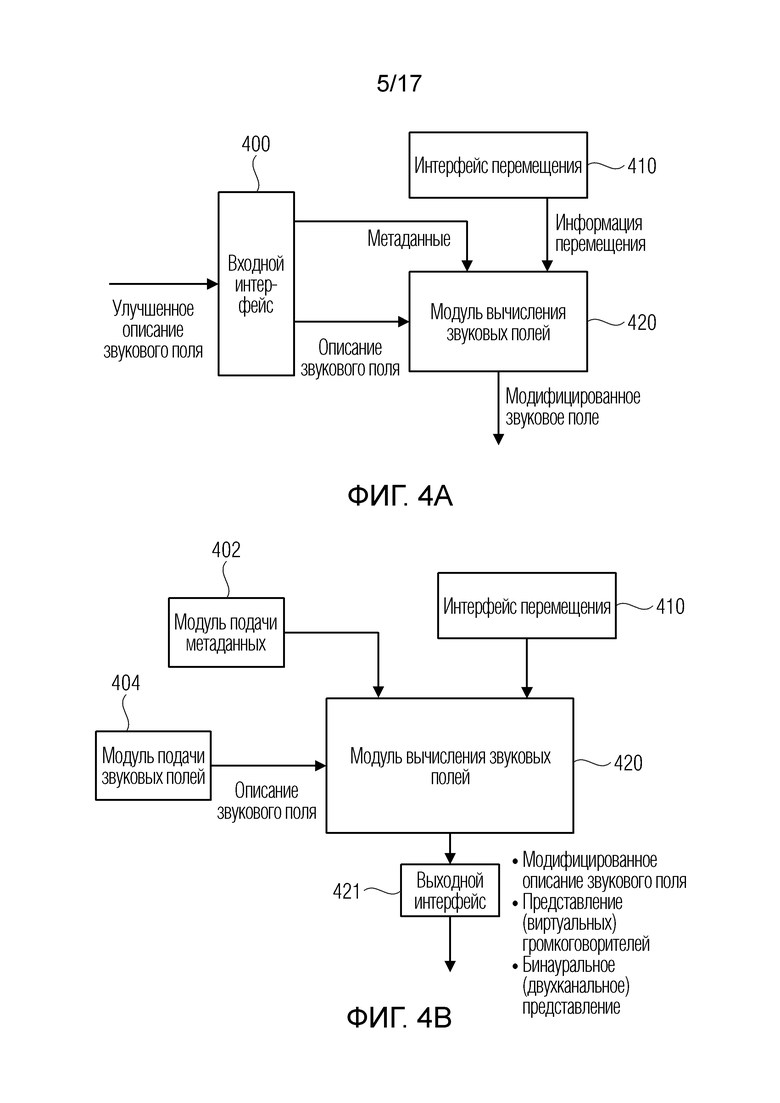
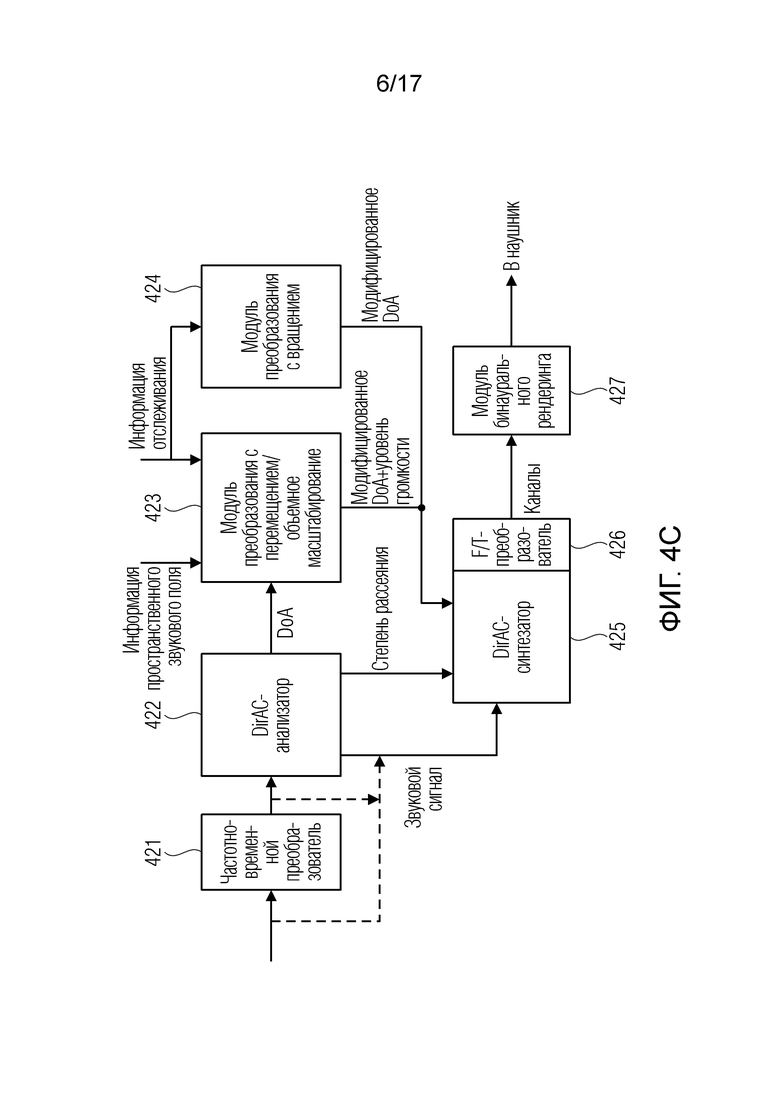
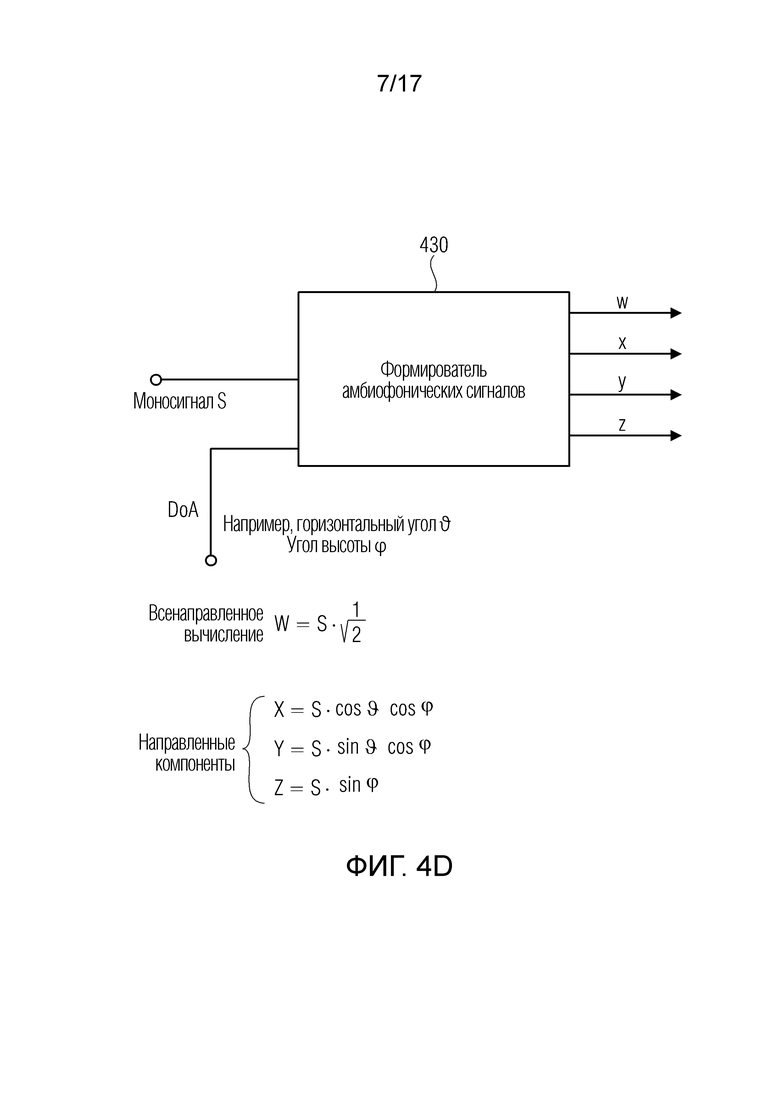
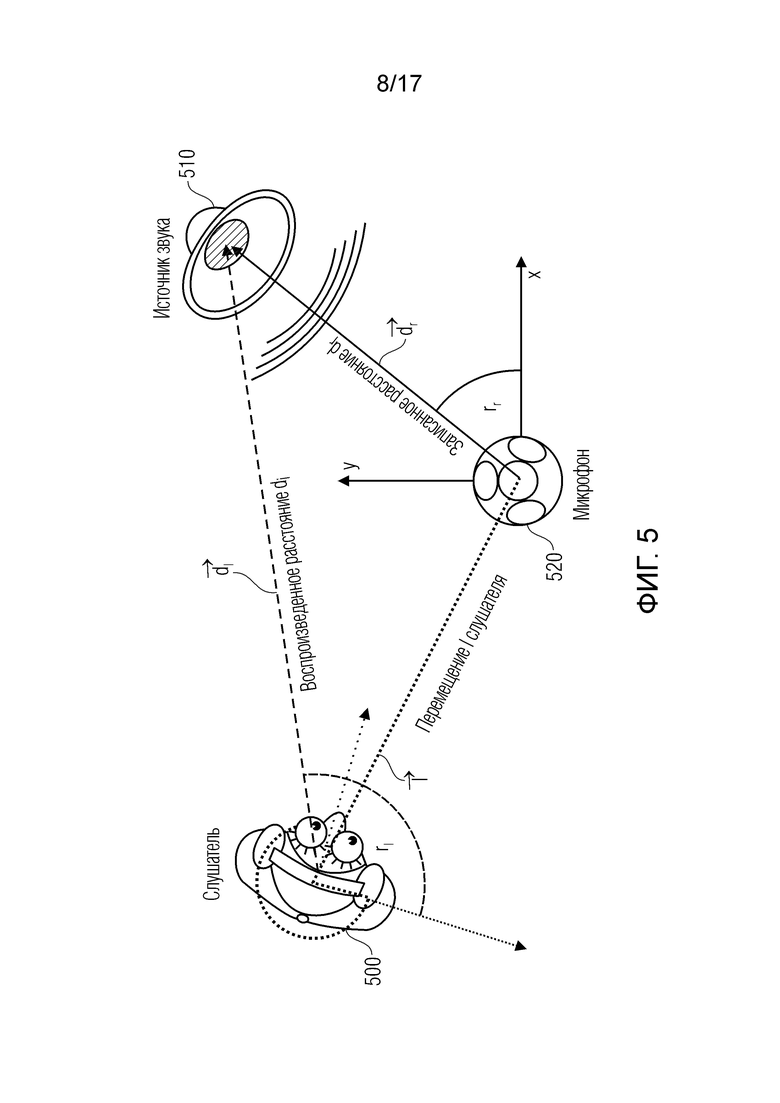
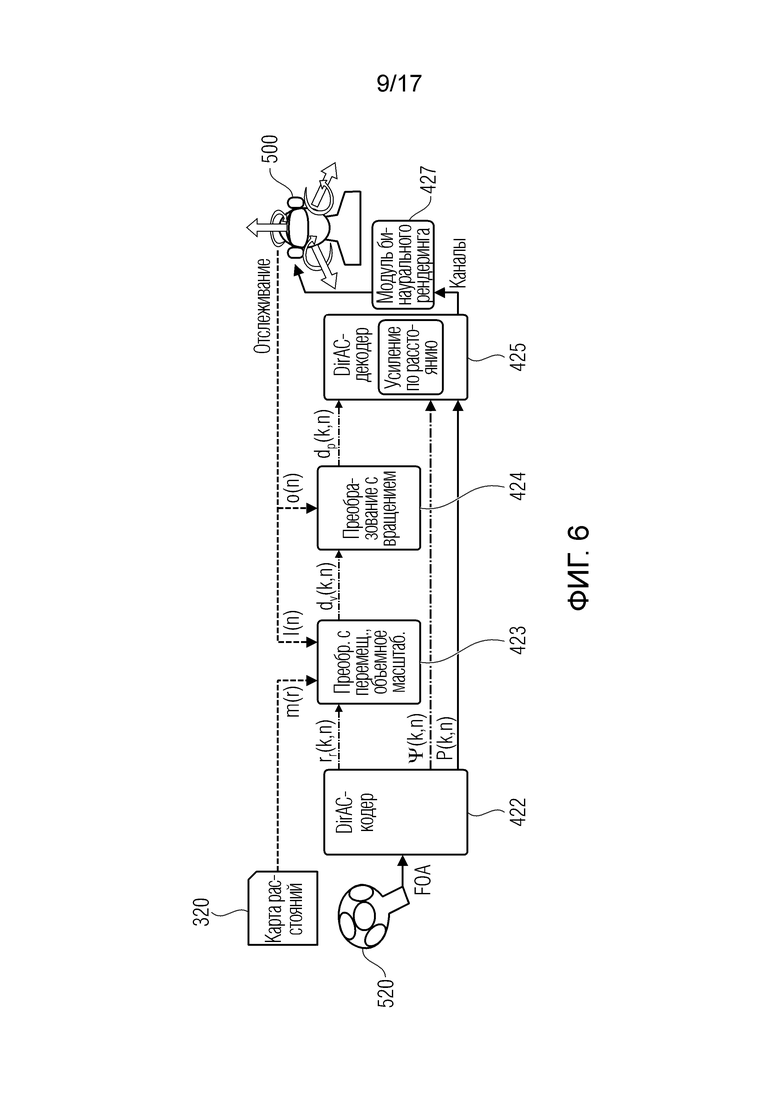
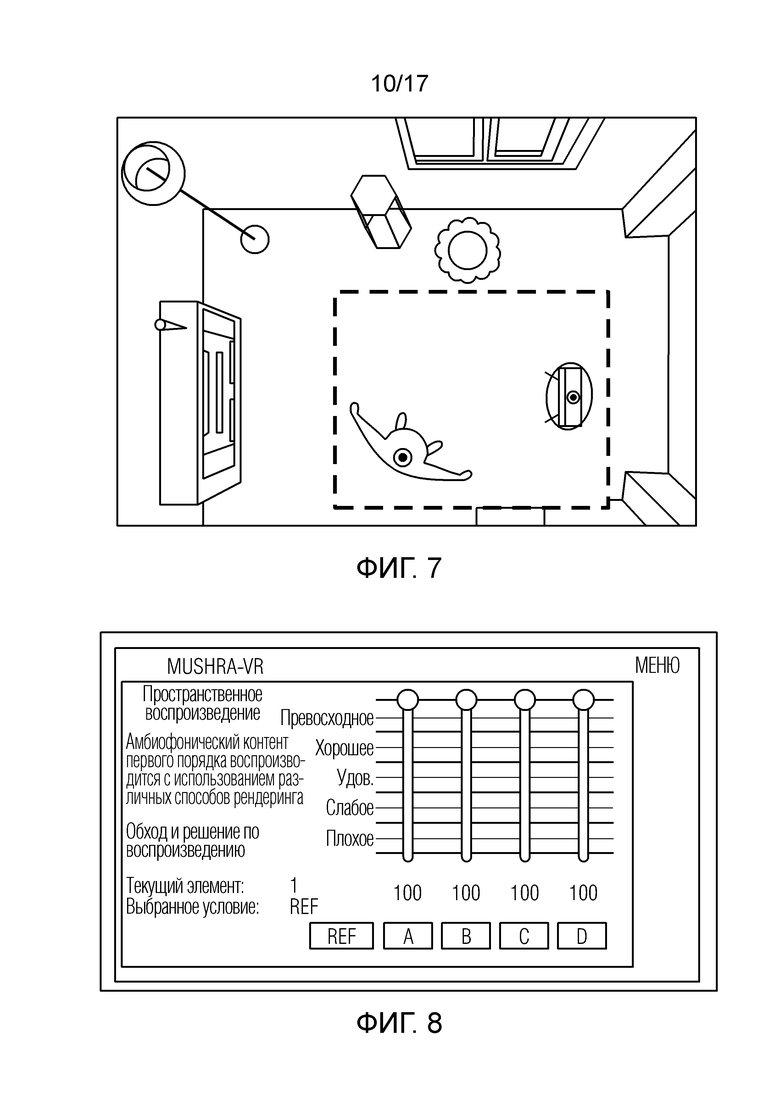
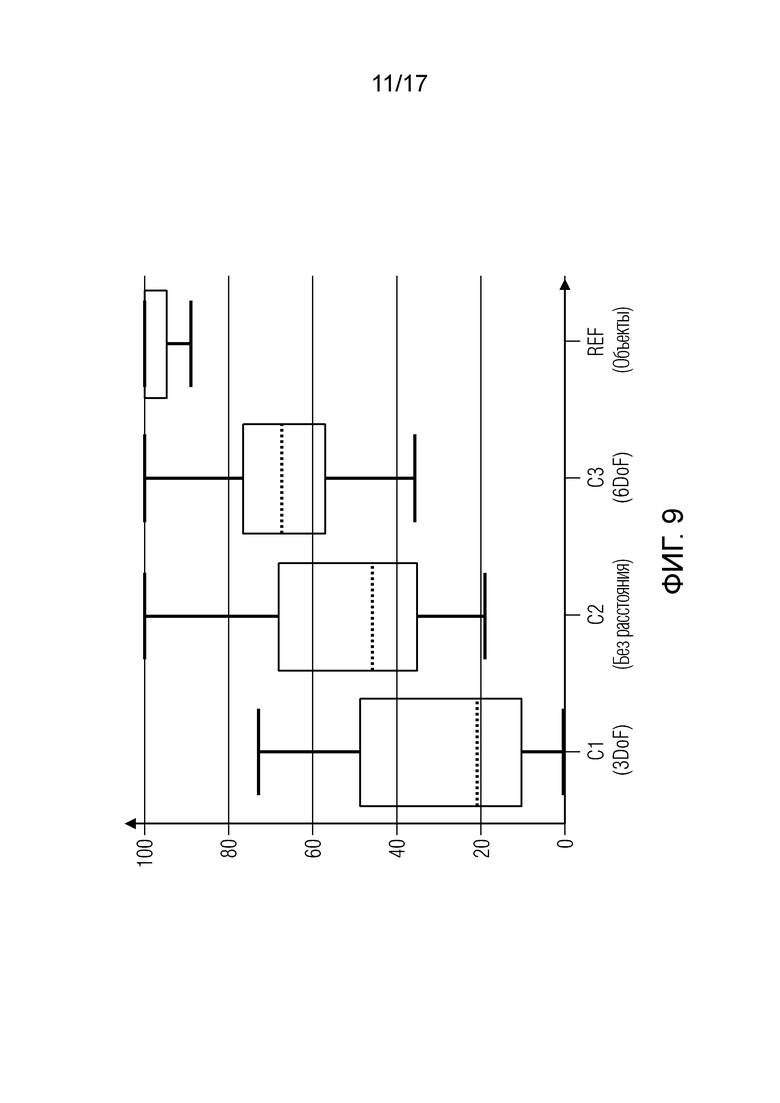
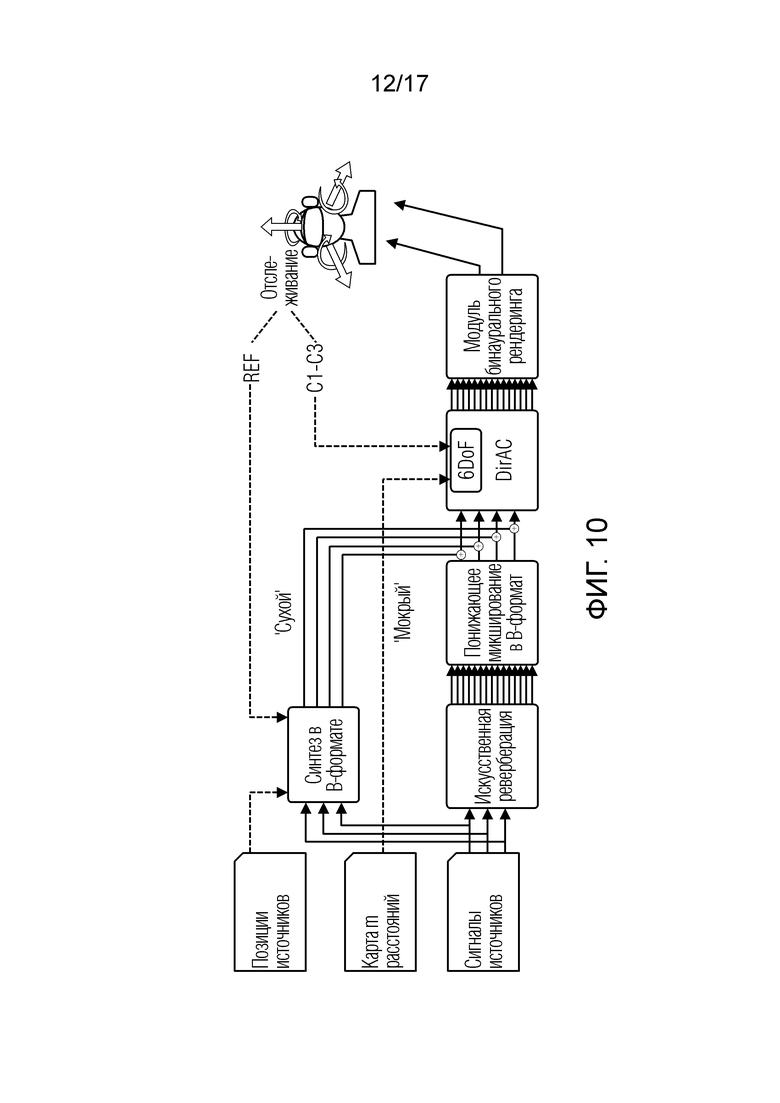
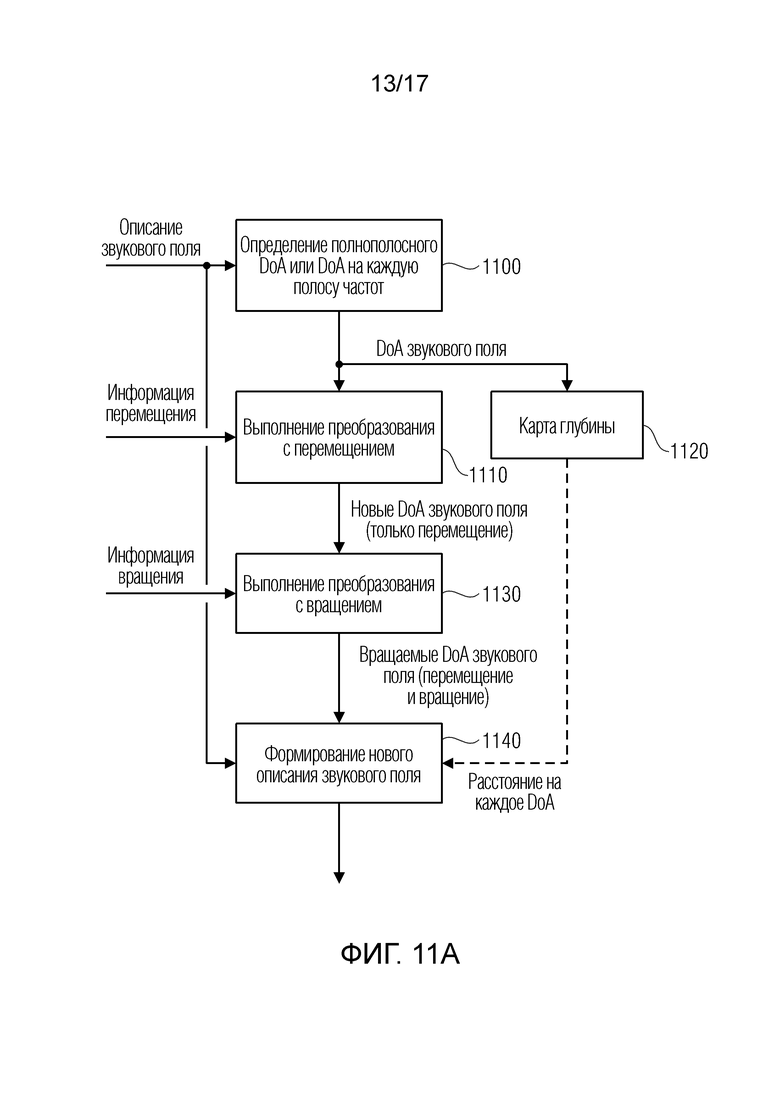
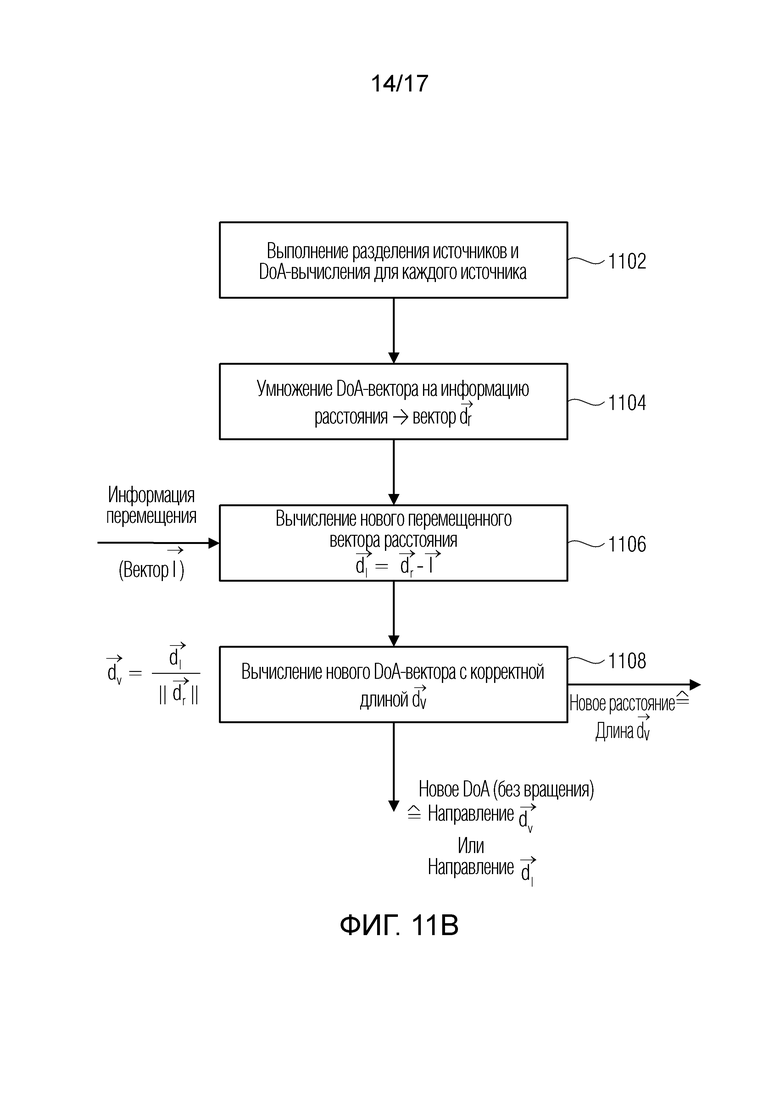
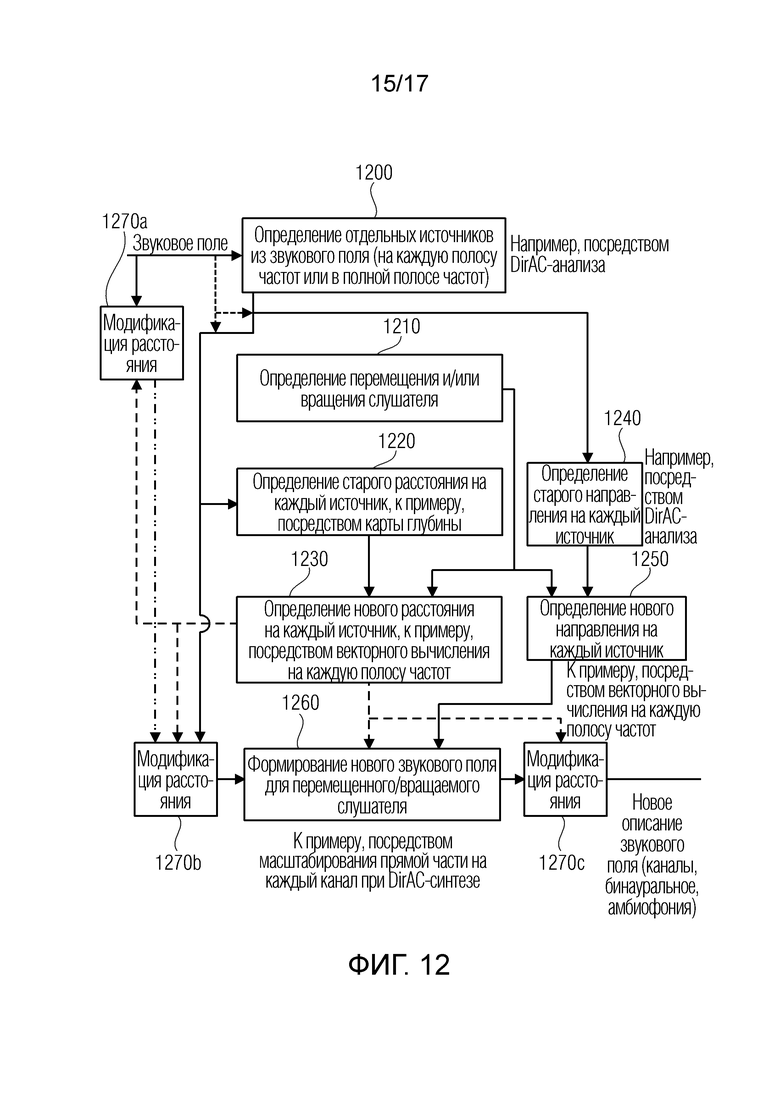
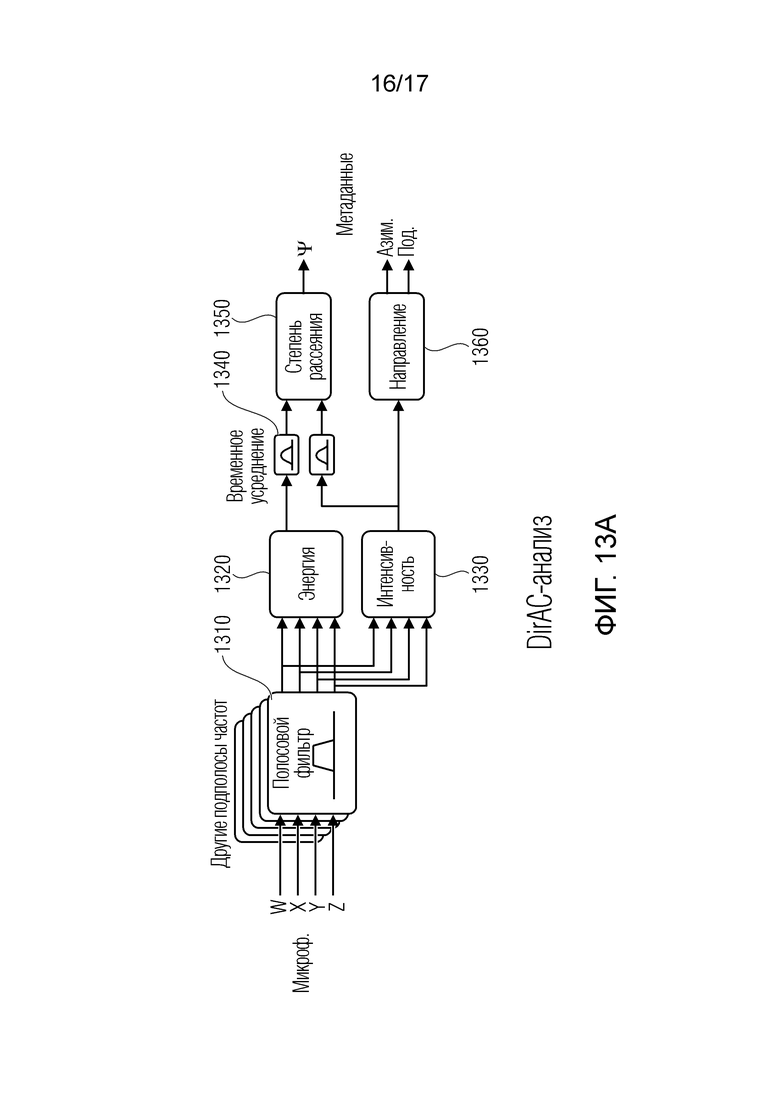
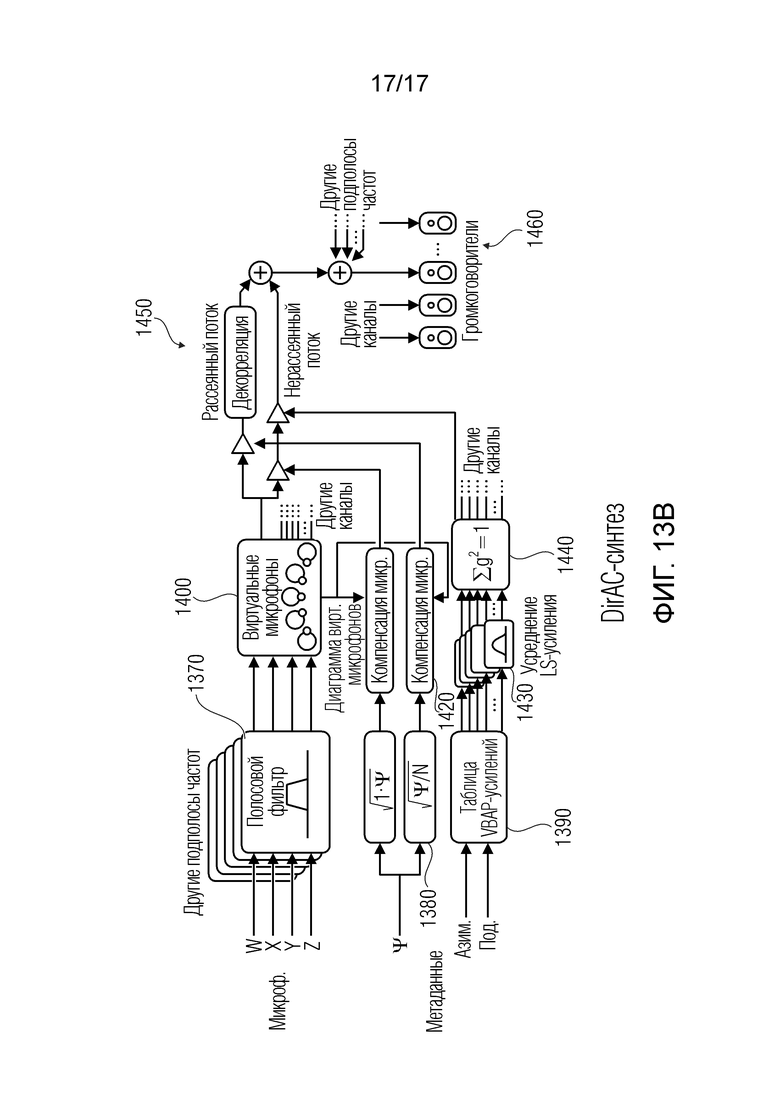
Изобретение относится к средствам для формирования описания звукового поля. Технический результат заключается в повышении качества формируемого звукового поля. Формируют по меньшей мере одно описание звукового поля, указывающее звуковое поле относительно по меньшей мере одного опорного местоположения. Формируют метаданные, связанные с пространственной информацией звукового поля. При этом упомянутое по меньшей мере одно описание звукового поля и метаданные составляют улучшенное описание звукового поля. Формирование упомянутого по меньшей мере одного описания звукового поля содержит этап, на котором формируют информацию степени рассеяния для множества частотных бинов временного кадра звукового поля, и при этом формирование метаданных содержит этап, на котором формируют информацию расстояния для частотного бина только тогда, когда значение степени рассеяния для частотного бина ниже порогового значения степени рассеяния, или при этом формирование метаданных содержит этап, на котором формируют метаданные расстояния, отличающиеся от предварительно определенного значения, только тогда, когда значение степени рассеяния для частотного бина ниже порогового значения степени рассеяния. 6 н. и 18 з.п. ф-лы, 22 ил.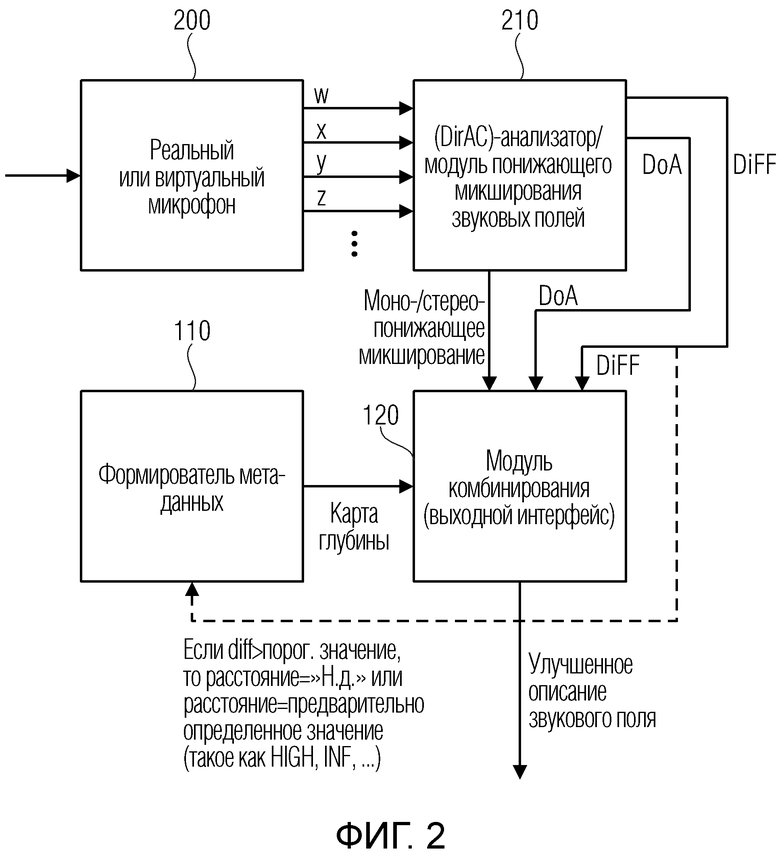
1. Устройство для формирования улучшенного описания звукового поля, содержащее:
формирователь (100) звуковых полей для формирования по меньшей мере одного описания звукового поля, указывающего звуковое поле относительно по меньшей мере одного опорного местоположения; и
формирователь (110) метаданных для формирования метаданных, связанных с пространственной информацией звукового поля,
при этом по меньшей мере одно описание звукового поля и метаданные составляют улучшенное описание звукового поля, и
при этом формирователь звуковых полей выполнен с возможностью формировать информацию (316) степени рассеяния для множества частотных бинов временного кадра звукового поля, и при этом формирователь (110) метаданных выполнен с возможностью формировать информацию расстояния для частотного бина только тогда, когда значение степени рассеяния для частотного бина ниже порогового значения степени рассеяния, или при этом формирователь (110) метаданных выполнен с возможностью формировать метаданные расстояния, отличающиеся от предварительно определенного значения, только тогда, когда значение степени рассеяния для частотного бина ниже порогового значения степени рассеяния, или
при этом формирователь (100) звуковых полей выполнен с возможностью формировать описание звукового поля по методу направленного кодирования аудио (DirAC), имеющее один или более сигналов понижающего микширования и отдельные данные направления и опционально данные степени рассеяния для различных частотно-временных бинов, и при этом формирователь (110) метаданных выполнен с возможностью формировать дополнительную отдельную информацию позиции или глубины для различных частотно-временных бинов в качестве метаданных.
2. Устройство по п. 1,
в котором формирователь (100) звуковых полей выполнен с возможностью оценивать информацию глубины из аудиосигналов, используемых посредством формирователя (100) звуковых полей, или из видеосигналов, ассоциированных с аудиосигналами, или из карты глубины, используемой при формировании стереоскопических (трехмерных) изображений/видео или в технологии на основе принципа светового поля, или из геометрической информации компьютерной графической сцены.
3. Устройство по п. 1,
в котором формирователь (110) метаданных выполнен с возможностью формировать в качестве данных, связанных с пространственной информацией, карту (320) глубины, содержащую для различной информации (322) в виде данных направления, указывающей различные направления, соответствующую информацию (324) расстояния.
4. Устройство по п. 1, дополнительно содержащее выходной интерфейс (120) для формирования выходного сигнала для передачи или хранения, причем выходной сигнал содержит для временного кадра (302, 304, 306) один или более аудиосигнал, извлекаемый из звукового поля, и пространственную информацию (310, 320) для временного кадра (302, 304, 306).
5. Устройство по п. 1,
в котором формирователь звуковых полей выполнен с возможностью извлекать данные (314) направления из звукового поля, причем данные направления означают направление поступления звука за период времени или частотный бин, и при этом формирователь (110) метаданных выполнен с возможностью извлекать пространственную информацию в качестве элементов (324) данных, ассоциирующих информацию расстояния с данными направления.
6. Устройство по п. 5,
в котором формирователь звуковых полей выполнен с возможностью извлекать данные (322) направления для различных частотных бинов на каждый временной кадр описания звукового поля,
при этом формирователь метаданных выполнен с возможностью извлекать элементы (324) данных, ассоциирующие информацию расстояния с данными направления для временного кадра, и
при этом выходной интерфейс (120) выполнен с возможностью формировать выходные сигналы таким образом, что элементы (324) данных для временного кадра связываются с данными направления для различных частотных бинов.
7. Устройство по п. 1,
в котором пространственная информация представляет собой карту (320) глубины, содержащую множество элементов (322) данных направления поступления и множество ассоциированных расстояний (324) таким образом, что каждое направление поступления из множества данных элементов данных поступления имеет ассоциированное расстояние.
8. Устройство для формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, содержащее
модуль (420) вычисления звуковых полей для вычисления модифицированного звукового поля с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение из опорного местоположения в другое опорное местоположение,
при этом модуль (420) вычисления звуковых полей выполнен с возможностью определять, для частотно-временного бина, необходимость поддерживать данные направления или вычислять модифицированные данные направления на основе данных степени рассеяния для частотно-временного бина, при этом модифицированные данные направления вычисляются только для данных степени рассеяния, указывающих степень рассеяния ниже предварительно заданного или адаптивного уровня степени рассеяния, или
при этом модуль (420) вычисления звуковых полей выполнен с возможностью вычислять, для описания по методу направленного кодирования аудио (DirAC) в качестве описания звукового поля, модифицированные данные направления для различных частотно-временных бинов с использованием данных направления, информации глубины и информации перемещения и подготавливать посредством рендеринга DirAC-описание с использованием модифицированных данных направления в звуковое описание, содержащее множество аудиоканалов, либо передавать или сохранять DirAC-описание с использованием модифицированных данных направления вместо данных направления для частотно-временных бинов и опционально данных степени рассеяния, идентичных данным степени рассеяния, включенным в DirAC-описание, или
при этом описание звукового поля содержит множество компонентов звукового поля, причем множество компонентов звукового поля содержат всенаправленный компонент и по меньшей мере один направленный компонент, при этом модуль вычисления звуковых полей содержит: анализатор (422) звуковых полей для анализа компонентов звукового поля, чтобы извлекать, для различных частотных бинов, информацию направления поступления; модуль (423) преобразования с перемещением для вычисления модифицированной информации направления поступления на каждый частотный бин с использованием информации направления и метаданных, причем метаданные содержат карту (320) глубины, ассоциирующую информацию (324) расстояния с информацией (322) направления поступления для частотного бина; и модуль компенсации расстояния для вычисления модифицированного звукового поля с использованием компенсационной информации расстояния в зависимости от расстояния, предоставленного посредством карты (320) глубины для частотного бина, и нового расстояния, ассоциированного с частотным бином, связанным с модифицированной информацией направления поступления, или
при этом модуль (420) вычисления звуковых полей выполнен с возможностью: определять (1200) сигналы источников из описания звукового поля и направлений сигналов источников, связанных с опорным местоположением, посредством анализа звука; вычислять (1230) новые направления сигналов источников, связанных с другим опорным местоположением, с использованием информации перемещения; вычислять (1230) информацию расстояния для источников звука, связанных с другим опорным местоположением; и синтезировать (1260) модифицированное звуковое поле с использованием информации расстояния, сигналов источников и новых направлений.
9. Устройство по п. 8, дополнительно содержащее:
интерфейс (410) перемещения для предоставления информации перемещения или информации вращения, указывающей вращение предназначенного слушателя для модифицированного звукового поля;
модуль (402, 400) подачи метаданных для подачи метаданных в модуль (420) вычисления звуковых полей;
модуль (404, 400) подачи звуковых полей для подачи описания звукового поля в модуль (420) вычисления звуковых полей; и
выходной интерфейс (421) для вывода модифицированного звукового поля, содержащего модифицированное описание звукового поля и модифицированные метаданные, причем модифицированные метаданные извлекаются из метаданных с использованием информации перемещения, либо для вывода множества каналов громкоговорителей, причем каждый канал громкоговорителя связан с предварительно заданной позицией громкоговорителя, либо для вывода бинаурального представления модифицированного звукового поля.
10. Устройство по п. 8, в котором модуль (420) вычисления звуковых полей выполнен с возможностью:
вычисления (1104) первого вектора, указывающего из опорного местоположения в источник (510) звука, получаемый посредством анализа (1102) звукового поля;
вычисления (1106) второго вектора, указывающего из другого опорного местоположения (500) в источник (510) звука, с использованием первого вектора и информации перемещения, причем информация перемещения задает вектор перемещения из опорного местоположения (522) в другое опорное местоположение (500); и
вычисления (1106) значения модификации расстояния с использованием другого опорного местоположения (500), местоположения источника (510) звука и второго вектора либо с использованием расстояния от другого опорного местоположения (500) до местоположения источника (510) звука и второго вектора.
11. Устройство по п. 8,
в котором первый вектор вычисляется посредством умножения единичного вектора направления поступления на расстояние, включенное в метаданные, или
при этом второй вектор вычисляется посредством вычитания вектора перемещения из первого вектора, или
при этом значение модификации расстояния вычисляется посредством деления второго вектора на норму первого вектора.
12. Устройство по п. 8,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью принимать, в дополнение к информации перемещения, информацию вращения, и
при этом модуль (420) вычисления звуковых полей выполнен с возможностью выполнять преобразование (424) с вращением, чтобы вращать данные направления поступления для звукового поля с использованием информации вращения, при этом данные направления поступления извлекаются из данных направления поступления, полученных посредством анализа звукового поля описания звукового поля, и с использованием информации перемещения.
13. Устройство по п. 8, в котором модуль (420) вычисления звуковых полей выполнен с возможностью:
определять (1200, 1240) источники из описания звукового поля и направлений для источников посредством анализа звукового поля;
определять (1220), для каждого источника, расстояние источника от опорного местоположения с использованием метаданных;
определять (1250) новое направление источника, связанного с другим опорным местоположением, с использованием направления для источника и информации перемещения;
определять (1230) новую информацию расстояния для источника, связанного с другим опорным местоположением; и
формировать (1260) модифицированное звуковое поле с использованием нового направления источника, новой информации расстояния и описания звукового поля либо сигналов источников, соответствующих источникам, извлекаемым из описания звукового поля.
14. Устройство по п. 8, в котором модуль (420) вычисления звуковых полей выполнен с возможностью
синтезировать модифицированное звуковое поле посредством панорамирования сигнала источника звука в направление, предоставленное посредством нового направления относительно компоновки для воспроизведения и
посредством масштабирования сигнала источника звука с использованием информации расстояния перед выполнением панорамирования или после выполнения панорамирования.
15. Устройство по п. 8,
в котором модуль (420) вычисления звуковых полей выполнен с возможностью суммировать рассеянный сигнал с прямой частью сигнала источника звука, причем прямая часть модифицируется посредством информации расстояния перед суммированием с рассеянным сигналом.
16. Устройство по п. 8, в котором модуль (420) вычисления звуковых полей выполнен с возможностью:
выполнять (421) частотно-временное преобразование описания звукового поля и вычислять (422) направление поступления для множества частотных бинов временного кадра;
вычислять (423, 424) новое направление для каждого частотного бина,
вычислять информацию расстояния для каждого частотного бина и
выполнять прямой синтез для каждого частотного бина с использованием аудиосигнала для частотного бина, панорамирующего усиления для частотного бина, извлекаемого из нового направления для частотного бина, и вектора масштабирования для частотного бина, извлекаемого из информации расстояния для частотного бина.
17. Устройство по п. 16, в котором модуль (420) вычисления звуковых полей выполнен с возможностью:
выполнять синтез рассеянных сигналов с использованием рассеянного аудиосигнала, извлекаемого из аудиосигнала для частотного бина, и с использованием параметра степени рассеяния, извлекаемого посредством анализа звука для частотного бина, и комбинировать прямую часть и рассеянную часть, чтобы получать синтезированный аудиосигнал для частотного бина; и
выполнять (426) частотно-временное преобразование с использованием аудиосигналов для частотных бинов для временного кадра, чтобы получать синтезированный во временной области аудиосигнал в качестве модифицированного звукового поля.
18. Устройство по п. 8, в котором модуль (420) вычисления звуковых полей выполнен с возможностью синтезировать, для каждого источника звука, звуковое поле, связанное с другим опорным местоположением, причем синтез содержит:
для каждого источника, обработку (430) сигнала источника с использованием нового направления для сигнала источника, чтобы получать описание звукового поля сигнала источника, связанного с другим опорным местоположением;
модификацию сигнала источника перед обработкой сигнала источника или модификацию описания звукового поля с использованием информации направления; и
суммирование описаний звукового поля для источников, чтобы получать модифицированное звуковое поле, связанное с другим опорным местоположением.
19. Устройство по п. 8,
в котором анализ (1200) звука выполнен с возможностью получать, в дополнение к сигналу источника, рассеянный сигнал, и
при этом модуль (420) вычисления звуковых полей выполнен с возможностью суммировать рассеянный сигнал с прямой частью, вычисленной с использованием информации нового направления и расстояния.
20. Устройство по п. 19,
в котором анализ (1200) звука выполнен с возможностью определять сигналы источников посредством алгоритма разделения источников и вычитать по меньшей мере некоторые сигналы источников из описания звукового поля, чтобы получать рассеянный сигнал.
21. Способ формирования улучшенного описания звукового поля, содержащий этапы, на которых:
формируют по меньшей мере одно описание звукового поля, указывающее звуковое поле относительно по меньшей мере одного опорного местоположения; и
формируют метаданные, связанные с пространственной информацией звукового поля,
при этом упомянутое по меньшей мере одно описание звукового поля и метаданные составляют улучшенное описание звукового поля, и
при этом формирование упомянутого по меньшей мере одного описания звукового поля содержит этап, на котором формируют информацию (316) степени рассеяния для множества частотных бинов временного кадра звукового поля, и при этом формирование метаданных содержит этап, на котором формируют информацию расстояния для частотного бина только тогда, когда значение степени рассеяния для частотного бина ниже порогового значения степени рассеяния, или при этом формирование метаданных содержит этап, на котором формируют метаданные расстояния, отличающиеся от предварительно определенного значения, только тогда, когда значение степени рассеяния для частотного бина ниже порогового значения степени рассеяния, или
при этом формирование упомянутого по меньшей мере одного описания звукового поля содержит этап, на котором формируют описание звукового поля по методу направленного кодирования аудио (DirAC), имеющее один или более сигнал понижающего микширования и отдельные данные направления и опционально данные степени рассеяния для различных частотно-временных бинов, и при этом формирование метаданных содержит этап, на котором формируют дополнительную отдельную информацию позиции или глубины для различных частотно-временных бинов в качестве метаданных.
22. Способ формирования модифицированного описания звукового поля из описания звукового поля и метаданных, связанных с пространственной информацией описания звукового поля, при этом способ содержит этап, на котором
вычисляют модифицированное звуковое поле с использованием пространственной информации, описания звукового поля и информации перемещения, указывающей перемещение из опорного местоположения в другое опорное местоположение,
при этом вычисление звукового поля содержит этап, на котором определяют, для частотно-временного бина, необходимость поддерживать данные направления или вычисляют модифицированные данные направления на основе данных степени рассеяния для частотно-временного бина, при этом модифицированные данные направления вычисляются только для данных степени рассеяния, указывающих степень рассеяния ниже предварительно заданного или адаптивного уровня степени рассеяния, или
при этом вычисление звукового поля содержит этапы, на которых вычисляют, для описания по методу направленного кодирования аудио (DirAC) в качестве описания звукового поля, модифицированные данные направления для различных частотно-временных бинов с использованием данных направления, информации глубины и информации перемещения и подготавливают посредством рендеринга DirAC-описание с использованием модифицированных данных направления в звуковое описание, содержащее множество аудиоканалов, либо передают или сохраняют DirAC-описание с использованием модифицированных данных направления вместо данных направления для частотно-временных бинов и опционально данных степени рассеяния, идентичных данным степени рассеяния, включенным в DirAC-описание, или
при этом описание звукового поля содержит множество компонентов звукового поля, причем множество компонентов звукового поля содержат всенаправленный компонент и по меньшей мере один направленный компонент, при этом вычисление звукового поля содержит этапы, на которых: анализируют компоненты звукового поля, чтобы извлекать, для различных частотных бинов, информацию направления поступления; вычисляют модифицированную информацию направления поступления на каждый частотный бин с использованием информации направления и метаданных, причем метаданные содержат карту (320) глубины, ассоциирующую информацию (324) расстояния с информацией (322) направления поступления для частотного бина; и вычисляют модифицированное звуковое поле с использованием компенсационной информации расстояния в зависимости от расстояния, предоставленного посредством карты (320) глубины для частотного бина, и нового расстояния, ассоциированного с частотным бином, связанным с модифицированной информацией направления поступления, или
при этом вычисление звукового поля содержит этапы, на которых: определяют (1200) сигналы источников из описания звукового поля и направлений сигналов источников, связанных с опорным местоположением, посредством анализа звука; вычисляют (1230) новые направления сигналов источников, связанных с другим опорным местоположением, с использованием информации перемещения; вычисляют (1230) информацию расстояния для источников звука, связанных с другим опорным местоположением; и синтезируют (1260) модифицированное звуковое поле с использованием информации расстояния, сигналов источников и новых направлений.
23. Цифровой запоминающий носитель, содержащий сохраненную на нем компьютерную программу для осуществления, при выполнении на компьютере или в процессоре, способа по п. 21.
24. Цифровой запоминающий носитель, содержащий сохраненную на нем компьютерную программу для осуществления, при выполнении на компьютере или в процессоре, способа по п. 22.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 4042779 A1, 16.08.1977 | |||
| УСТРОЙСТВО И СПОСОБ ДЛЯ СОВМЕЩЕНИЯ ПОТОКОВ ПРОСТРАНСТВЕННОГО АУДИОКОДИРОВАНИЯ НА ОСНОВЕ ГЕОМЕТРИИ | 2012 |
|
RU2609102C2 |

