Область техники, к которой относится изобретение
Варианты осуществления изобретения, в общем, относятся к устройствам обработки и, более конкретно, относятся к неограниченной транзакционной памяти с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку.
Уровень техники
Для улучшения рабочих характеристик, некоторые компьютерные системы могут выполнять множество потоков обработки одновременно. В общем, перед тем, как поток получит доступ к совместно используемому ресурсу, он может получить блокировку совместно используемого ресурса. В ситуациях, когда совместно используемый ресурс представляет собой структуру данных, сохраненную в памяти, все потоки, которые пытаются получить доступ к одному и тому же ресурсу, могут установить последовательность исполнения своих операций с учетом взаимной исключительности, предоставляемой механизмом блокировки. Это может отрицательно сказываться на рабочих характеристиках системы и может привести к отказам программы, например, из-за ошибок, ограниченных с зависанием блокировки.
Для уменьшения потерь производительности, возникающих в результате использования механизмов блокировки, в некоторых компьютерных системах может использоваться транзакционная память. Транзакционная память, в общем, относится к модели синхронизации, которая позволяет множеству потоков одновременно получать доступ к совместно используемому ресурсу, без использования механизма блокировки. Однако исполнение транзакционной памяти в процессорах может повысить сложность конструкции, например, из-за ошибок прогнозирования, возникающих в результате упреждающего исполнения.
Краткое описание чертежей. Изобретение будет более полно понято из подробного описания изобретения, представленного ниже, и из приложенных чертежей различных вариантов осуществления раскрытия. Чертежи, однако, не следует рассматривать как ограничение для раскрытия конкретных вариантов осуществления, поскольку они предназначены только для пояснения и понимания.
На фиг. 1 иллюстрируется блок-схема вычислительной системы, в соответствии с вариантом осуществления раскрытия.
На фиг. 2 показана блок-схема потока, иллюстрирующая блок-схему ядра процессора, в соответствии с вариантом осуществления раскрытия.
На фиг. 3А показан пример листинга псевдокода, иллюстрирующий синтаксис транзакции, в соответствии с вариантом осуществления раскрытия.
На фиг. 3В показан пример листинга псевдокода аппаратных инструкций, ассоциированных со ограниченной транзакцией, в соответствии с вариантом осуществления раскрытия.
На фиг. 3С показан пример листинга псевдокода аппаратных инструкций, ассоциированных с неограниченной транзакцией, в соответствии с вариантом осуществления раскрытия.
На фиг. 4А показан пример листинга псевдокода исполнения оптимизированной ограниченной транзакции, в соответствии с вариантом осуществления раскрытия.
На фиг. 4В и 4С показаны блок-схемы, концептуально иллюстрирующие примерные сценарии глобальной аппаратной блокировки, считываемой как в неоптимизированной, так и в оптимизированной форме, в соответствии с вариантом осуществления раскрытия.
На фиг. 5А и 5В показаны блок-схемы последовательности операций, иллюстрирующие способ для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, использующей аппаратную глобальную блокировку, в соответствии с воплощением раскрытия
На фиг. 6А показана блок-схема, иллюстрирующая микроархитектуру для процессора, в котором воплощена неограниченная транзакционная память с гарантиями продвижения при пересылке, с использованием аппаратной глобальной блокировки, в которой может использоваться один вариант осуществления раскрытия.
На фиг. 6В показана блок-схема, иллюстрирующая магистраль, работающую не по порядку, и каскад переименования регистра, магистраль выработки/исполнения, работающую по порядку, воплощенную в соответствии с, по меньшей мере, одним вариантом осуществления раскрытия.
На фиг. 7 иллюстрируется блок-схема микроархитектуры для процессора, который включает в себя логические схемы, для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, с использованием аппаратной глобальной блокировки, в соответствии с одним вариантом осуществления раскрытия.
На фиг. 8 показана блок-схема, иллюстрирующая систему, в которой может использоваться вариант осуществления раскрытия.
На фиг. 9 показана блок-схема системы, в которой может работать вариант осуществления раскрытия.
На фиг. 10 показана блок-схема системы, в которой может работать вариант осуществления раскрытия.
На фиг. 11 показана блок-схема системы на кристалле (SoC), в соответствии с вариантом осуществления настоящего раскрытия
На фиг. 12 показана блок-схема варианта осуществления конструкции SoC, в соответствии с настоящим раскрытием.
На фиг. 13 иллюстрируется блок-схема одного варианта осуществления компьютерной системы.
Подробное описание изобретения
Варианты осуществления изобретения воплощают технологии для неограниченной транзакционной памяти с гарантиями продвижения при пересылке, в которых используется аппаратная глобальная блокировка в устройстве обработки. Традиционно, синхронизация между потоками, которые обращаются к общей памяти, была реализована с использованием блокировки для защиты совместно используемых данных от одновременного доступа. Однако блокировка может привести к ненужной последовательной обработке в системе или может быть чрезмерно сложной для программистов для правильного выполнения. Транзакционная память была предложена, как альтернативное решение для блокировки, и обеспечивает возможность параллельного упреждающего исполнения потоками критических участков, называемых транзакциями. Если возникает конфликт во время исполнения, тогда потоки останавливают или выполняют возврат своих транзакций и исполняют их снова для разрешения конфликта. Один тип ТМ представляет собой программную транзакционную память (STM), где транзакции воплощены полностью в виде программных средств для синхронизации совместно используемой памяти в многопотоковых программах. Однако STM потребовать использования большого количества служебных данных, что не позволяет использовать STM в качестве общего решения.
В последнее время поставщики аппаратных средств предоставили аппаратную транзакционную память (НТМ), работающую на принципе наилучших усилий в устройствах обработки. НТМ на принципе наилучших усилий может обеспечить лучшие характеристики, чем STM, но не выполняет гарантии продвижения при пересылке; то есть, настоящие варианты осуществления НТМ не могут гарантировать, что транзакция будет выполнена, независимо от того, какое количество раз она будет повторно исполнена. ("Наилучшие усилия" относится к концепции, когда система НТМ выполняет все от нее зависящее, но не может гарантировать, что транзакция будет выполнена). Например, транзакция Т1 может быть отклонена транзакцией Т2, которая может быть затем отменена перезапущенной транзакцией Т1, и так далее. Без гарантий продвижения при пересылке НТМ, работающая на принципе наилучших усилий, может деградировать до динамической взаимной блокировки. Кроме того, транзакции аппаратных средств, в общем, могут быть отклонены по множеству причин: истинные или ложные конфликты, переполнения, нелегальные инструкции и т.д.
В результате, современные НТМ, работающие по принципу наилучших усилий, обычно обеспечивают программный путь отхода для решения проблемы отсутствия гарантий продвижения при пересылке и обеспечивают то, что аппаратные транзакции, которые не могут быть выполнены в аппаратных средствах, в конечном итоге, будут выполнены, используя программное обеспечение. Такие системы называются гибридными ТМ (НуТМ), в которых используются, как аппаратные, так и программные транзакции. Было предложено множество алгоритмов НуТМ, но они проявляют тенденцию иметь недостаток существенного усложнения пространства ТМ и введения служебных издержек из-за необходимости использования синхронизирующих аппаратных и программных транзакций.
Предыдущие предложения неограниченных (то есть, без ограничений по размеру транзакции) НТМ, которые не основаны на опции программного отхода, воплощают изменения в протокол когерентности кэш и/или сложных метаданных, таким образом, что они не являются практическими решениями. В отличие от этого, варианты осуществления раскрытия обеспечивают неограниченную НТМ с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку в устройстве обработки. В частности, варианты осуществления раскрытия исполняют одну неограниченную транзакцию в аппаратных средствах, без маркировки битов транзакции в кэш, параллельно с множеством неограниченных транзакций (которые выполняют с упреждающим исполнением). Одна глобальная аппаратная блокировка достигается неограниченной транзакцией и должна быть считана ограниченными транзакциями перед тем, как они будут считаны ограниченными транзакциями, прежде чем они детектируют потенциальные конфликты между неограниченной транзакцией и ограниченными транзакциями. Неограниченная НТМ, в соответствии с вариантами осуществления раскрытия может быть воплощена в существующих системах НТМ с минимальными изменениями и без изменений протокола когерентности кэш этих систем (которые используются для детектирования конфликтов и обеспечивают когерентность памяти).
Хотя следующие варианты осуществления могут быть описаны со ссылкой на конкретные интегральные схемы, такие как вычислительные платформы или микропроцессоры, другие варианты осуществления применимы для других типов интегральных схем и логических устройств. Аналогичные технологии и описания представленных здесь вариантов осуществления, могут применяться для других типов схем или полупроводниковых устройств. Например, раскрытые варианты осуществления не ограничены настольными компьютерными системами или Ultrabooks™ и также могут использоваться в других устройствах, таких как портативные устройства, планшеты, другие тонкие ноутбуки, устройства типа системы на кристалле (SOC) и встроенные приложения. Некоторые примеры портативных устройств включают в себя сотовые телефоны, устройства, работающие с протоколом Интернет, цифровые камеры, карманные персональные компьютеры (PDA) и переносные ПК. Встроенные приложения обычно включают в себя микроконтроллер, цифровой сигнальный процессор (DSP), систему на кристалле, сетевые компьютеры (NetPC), телевизионные приставки, сетевые концентраторы, коммутаторы глобальной вычислительной сети (WAN) или любую другую систему, которая может выполнять функции и операции, описанные ниже.
Хотя следующие варианты осуществления описаны со ссылкой на процессор, другие варианты осуществления применимы для других типов интегральных схем и логических устройств. Аналогичные технологии и описания вариантов осуществления раскрытия могут применяться для других типов схем или полупроводниковых устройств, которые могут получить пользу, благодаря более высокой пропускной способности магистрали и улучшенным рабочим характеристикам. Описания вариантов осуществления раскрытия применимы к любому процессору или устройству, в котором выполняются манипуляции с данными. Однако настоящее раскрытие не ограничено процессорами или устройствами, которые выполняют операции с данными размером 512 битов, 256 битов, 128 битов, 64 бита, 32 бита или 16 битов, и может применяться к любому процессору и устройству, в котором выполняются манипуляции для управления данными. Кроме того, в следующем описании представлены примеры, и на приложенных чертежах показаны различные примеры с целью иллюстрации. Однако эти примеры не следует рассматривать в ограничительном смысле, поскольку они предназначены просто для использования в качестве примеров вариантов осуществления настоящего раскрытия, а не для предоставления исчерпывающего списка всех возможных вариантов осуществления настоящего раскрытия.
Поскольку все больше компьютерных систем используют в приложениях для Интернет, редактирования текста и в мультимедийных приложениях, дополнительная поддержка процессора была введена с течением времени. В одном варианте осуществления набор инструкций может быть ассоциирован с одной или больше компьютерными архитектурами, включающими в себя типы данных, инструкции, архитектуру регистра, режимы адресации, архитектуру памяти, обработку прерываний и исключений и внешний ввод и вывод (I/O).
В одном варианте осуществления архитектура набора инструкций (ISA) может быть воплощена с помощью одной или больше микроархитектур, которые включают в себя логические и электрические схемы процессора, используемые для воплощения одного или больше наборов инструкций. В соответствии с этим, процессоры с разными микроархитектурами могут совместно использовать, по меньшей мере, часть общего набора инструкций. Например, процессор Intel® Pentium 4, процессоры Intel® Core™ и процессоры компании Advanced Micro Devices, Inc. of Sunnyvale CA воплощают практически идентичные версии набора инструкций х86 (с некоторыми расширениями, которые были добавлены в более новых версиях), но имеют разные внутренние конструкции. Аналогично, процессоры, разработанные другими компаниями разработчиками процессоров, такие как ARM Holdings, Ltd., MIPS, или их лицензеобладатели или последователи, могут совместно использовать, по меньшей мере, часть общего набора инструкций, но могут включать в себя различные конструкции процессора. Например, одна и та же архитектура регистра в ISA может быть воплощена по-разному в разных микроархитектурах, используя новые или хорошо известные технологии, включающие в себя специализированные физические регистры, один или больше динамически выделенных физических регистров, использующих механизм переименования регистра (например, использование таблицы псевдонима регистров (RAT), буфер изменения порядка (ROB) и файл изъятия регистров. В одном варианте осуществления регистры могут включать в себя один или больше регистров, архитектуру регистров, файлы регистров или другие наборы регистров, которые могут быть адресуемыми или могут не быть адресуемыми программистом, работающим с программными средствами.
В одном варианте осуществления инструкция может включать в себя один или больше форматов инструкции. В одном варианте осуществления формат инструкции может обозначать различные поля (количество битов, места расположения битов и т.д.), для установления, помимо прочего, операции, которая должна быть выполнена, и операнда (операндов), для которого должна быть выполнена эта операция. Некоторые форматы инструкции могут быть дополнительно разделены в соответствии с определением по шаблонам инструкций (или подформатами). Например, шаблоны инструкции заданного формата инструкции могут быть определены так, чтобы они имели разные поднаборы полей формата инструкций и/или были определены так, чтобы они имели заданное поле, интерпретируемое по-разному. В одном варианте осуществления инструкция выражена с использованием формата инструкций (и, если он определен, в заданном одном из шаблонов инструкций этого формата инструкций) и устанавливает или обозначает операцию и операнды, по которым будет работать операция.
На фиг. 1 иллюстрируется блок-схема вычислительной системы 100, в соответствии с вариантом осуществления раскрытия. Система 100 может включать в себя одно или больше вычислительных устройств 102-1 через 102-N (в общем, называемых "процессорами 102" или процессорными устройствами 102"). Процессоры 102 могут связываться через взаимное соединение или шину 104. Каждый процессор 102 может включать в себя различные компоненты, некоторые из которых для ясности описаны со ссылкой на процессор 102-1. В соответствии с этим, каждый из остальных процессоров 102-2-102-N может включать в себя некоторые или аналогичные компоненты, описанные со ссылкой на процессор 102-1.
В одном варианте осуществления процессор 102-1 может включать в себя одно или больше процессорных ядер 106-1-106-М (называются здесь "ядрами 106", или в более общем случае, "ядром 106"), кэш 108 (который может включать в себя один или больше частных или совместно используемых кэш) и/или маршрутизатор 110. Процессорные ядра 106 могут быть воплощены на одном кристалле интегральной схемы (IC). Кроме того, IC может включать в себя один или больше совместно используемых и/или частных кэш (таких как кэш 108), шин или взаимных соединений (таких как шина или взаимное соединение 112), контроллеров памяти или других компонентов.
Маршрутизатор 110 может использоваться для обмена данными между различными компонентами процессоров 102-1 и/или системой 100. Кроме того, процессоры 102-1 могут включать в себя больше чем один маршрутизатор 110. Кроме того, множество маршрутизаторов 110 могут связываться друг с другом для обеспечения передачи данных между различными компонентами внутри или за пределами процессора 102-1.
Кэш 108 может содержать данные (например, включающие в себя инструкции), которые используются одним или больше компонентами процессора 102-1, такими как ядра 106. Например, кэш 108 может локально содержать данные, сохраняемые в памяти 114 для более быстрого доступа компонентами процессора 102. Как показано на фиг. 1, память 114 может сообщаться процессорами 102 через взаимное соединение 104. В одном варианте осуществления кэш 108 может представлять собой, по меньшей мере, кэш последнего уровня (LLC). Кроме того, каждое из ядер 106 может включать в себя кэш 116 уровня 1 (L1) (в общем, называется здесь "кэш 116 L1"). Кроме того, процессор 102-1 также может включать в себя кэш среднего уровня, который совместно используется несколькими ядрами 106. Различные компоненты процессора 102-1 могут связываться с кэш 108 непосредственно, через шину (например, шину 112), и/или контроллер памяти, или концентратор.
В одном варианте осуществления, устройство 102-1 обработки воплощает неограниченную НТМ. Как описано выше, НТМ воплощена в виде аппаратных средств и обеспечивает для потов возможность параллельного упреждающего исполнения критических участков, называемых транзакциями. Если возникает конфликт во время исполнения, тогда потоки останавливают или выполняют возврат их транзакций и снова исполняют для разрешения конфликта. Неограниченная НТМ в вариантах осуществления использует традиционную, ограниченную конструкцию НТМ и затем встраивает в нее преобразованные в последовательную форму неограниченные аппаратные транзакции. Ограниченность относится к пределу (скрытому или явно выраженному), установленному в отношении размера (например, количество операций и т.д.) транзакций, исполняемых в соответствии с конструкцией НТМ. Например, из-за ограничения размера кэш, существует предел для набора записей (доступа к сохранению в памяти, выполняемому транзакцией) для транзакции, которая может отслеживаться с помощью аппаратных средств (например, кэш, таких как кэш 116 L1, в некоторых воплощениях НТМ). После достижения этого предела, транзакция должна быть отменена, поскольку аппаратные средства больше не отслеживают точно доступ к памяти транзакции, исключая, таким образом, точный возврат транзакции, если возникает конфликт. Как описано выше, предыдущие решения НТМ обеспечивают возможность работы программного обеспечения возврата в связи с этой проблемой ограниченности. Неограниченная транзакция включает в себя транзакцию, которая может исполняться без каких-либо пределов в отношении размера транзакции.
В одном варианте осуществления неограниченные НТМ, в соответствии с вариантами осуществления раскрытия используют дополнительные неограниченные компоненты 118 (UB) НТМ для выполнения одной неограниченной транзакции в аппаратных средствах без упреждающего исполнения (например, без пометки битов транзакции в кэш 116 L1), параллельно с множеством ограниченных транзакций. Компоненты 118 UB НТМ могут включать в себя счетчик и логическую схему повторной попытки для воплощения аппаратного менеджера разногласий, как описано дополнительно ниже со ссылкой на фиг. 2. Глобальная аппаратная блокировка (GHWL) 120 в памяти 114 получается в результате неограниченной транзакции, и она должна быть считана всеми ограниченными транзакциями прежде, чем они будут выполнены. Для исключения состязания между ограниченными транзакциями и неограниченной транзакцией, ограниченные транзакции при выполнении транзакций считывают GHWL 120, чтобы проверить, поддерживается ли она. Если GHWL 120 выполняется, что обозначает, что исполняется неограниченная транзакция, ограниченные транзакции должны быть отменены для исключения недетектированных конфликтов. В некоторых вариантах осуществления CPU ID 125 также ассоциирован с GHWL 120, и может использоваться для идентификации ядра 106, которое исполняет свои операции в неограниченном режиме, с целью определения, когда поток должен выпустить GHWL 120, как дополнительно описано ниже. Поскольку в неограниченной транзакции не используется упреждающее исполнение, она всегда исполняется, в результате чего, обеспечивается гарантия продвижения при пересылке. При таком подходе ограниченные аппаратные транзакции все еще выполняются параллельно, как и в оригинальных конструкциях НТМ, поэтому, параллельная обработка не теряется при исполнении только этих типов транзакций.
На фиг. 2 иллюстрируется блок-схема ядра 106 процессора, в соответствии с вариантом осуществления раскрытия. В одном варианте осуществления ядро 106 процессора является таким же, как и ядро 106 процессора, описанное со ссылкой на фиг. 1. Стрелки, показанные на фиг. 2, могут иллюстрировать поток инструкций через ядро 106. Одно или больше ядер процессора (таких как ядро 106 процессора) могут быть воплощены на одном кристалле IC (или на одной подложке), как описано со ссылкой на фиг. 1. Кроме того, кристалл может включать в себя один или больше совместно используемых и/или частных кэш (например, кэш 108 на фиг. 1), взаимных соединений (например, взаимных соединений 104 и/или 112 по фиг. 1), контроллеров памяти или других компонентов. В одном варианте осуществления ядро 106 процессора, показанное на фиг. 2, может использоваться для обеспечения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку.
Как показано на фиг. 2, ядро 106 процессора может включать в себя модуль 202 выборки, предназначенный для выборки инструкций для исполнения ядром 106. Инструкции могут быть выбраны из любого устройства сохранения, такого как память 114 на фиг. 1 и/или другие устройства памяти. Ядро также может включать в себя модуль 204 декодирования, предназначенный для декодирования выбранных инструкций. Например, модуль 204 декодирования может декодировать выбранную инструкцию во множество микроопераций (uops).
Кроме того, ядро 106 может включать в себя модуль 206 планирования. Модуль 206 планирования может выполнять различные операции, ассоциированные с сохранением декодированных инструкций (например, принятых из модуля 204 декодирования), до тех пор, пока инструкции не будут готовы к отправке, например, до тех пор, пока все значения источника декодированных инструкций не станут доступными. В одном варианте осуществления модуль 206 планирования может планировать и/или вырабатывать (или пересылать) декодированные инструкции в исполнительный модуль 208, для исполнения. Исполнительный модуль 208 может исполнять пересылаемые инструкции после их декодирования (например, модулем 204 декодирования) и пересылки (например, модулем 206 планирования). В варианте осуществления исполнительный модуль 208 может включать в себя больше, чем один исполнительный модуль, такой как исполнительный модуль памяти, исполнительный модуль целых чисел, исполнительный модуль для работы с плавающей точкой или другие исполнительные модули. Кроме того, исполнительный модуль 208 может исполнять инструкции не по порядку. Следовательно, ядро 106 процессора может представлять собой ядро процессора, работающие не по порядку в одном варианте осуществления.
Ядро 106 также может включать в себя модуль 210 изъятия инструкции. Модуль 210 изъятия инструкции может изымать исполненные инструкции после их выполнения. В варианте осуществления изъятие выполненных инструкций может привести к тому, что состояние процессора будет фиксировано без исполнения инструкций, физические регистры, используемые инструкциями, будут откреплены и т.д.
Как показано на фиг. 2, ядро 106 может включать в себя буфер 212 изменения порядка (ROB), предназначенный для сохранения информации об инструкциях, запущенных на исполнение (или uops) для доступа различными компонентами ядра 106. Ядро 106 может дополнительно включать в себя таблицу псевдонима регистра (RAT) 214 для поддержания отображения логических (или архитектурных) регистров (таких как регистры, идентифицированные операндами программных инструкций) для соответствующих физических регистров. В одном варианте осуществления каждый вход в RAT 214 может включать в себя идентификатор ROB, назначенный для каждого физического регистра. Кроме того, буфер порядка памяти (MOB), который может включать в себя буфер нагрузки или буфер сохранения, может сохранять находящиеся на исполнении операции в памяти, которые не были загружены или записаны обратно в память (например, память, которая является внешней для ядра 106, такая как память 114). Кроме того, ядро 106 может включать в себя модуль 220 шины, который обеспечивает возможность обмена данными между компонентами ядра 106 и другим компонентом (такими как компоненты, описанные со ссылкой на фиг. 1) через одну или больше шин (например, шины 104 и/или 112) из памяти 114, перед сохранением принятых данных в кэш 116.
Кэш 116 L1 может включать в себя одну или больше линий 224 кэш (например, линии 0-N кэш). В одном варианте осуществления каждая линия 224 кэш может включать в себя бит 226 упреждающего исполнения для каждого потока, исполняемого в ядре 106. Бит 226 упреждающего исполнения может быть установлен или сброшен для обозначения доступа (загрузки и/или исполнения) в соответствующей линии кэш по запросу на доступ к транзакционной памяти. Даже при том, что линии 224 кэш показаны, как имеющие соответствующий бит 226 упреждающего исполнения, также возможны другие конфигурации. Например, линия 224 кэш может иметь бит считывания транзакции и бит записи транзакции. В качестве другого примера, бит 226 упреждающего исполнения может соответствовать выбранному участку кэш 116, такому как блок данных кэш, или другому участку кэш 116. Кроме того, бит 226 упреждающего исполнения может быть сохранен в других местах, кроме кэш 116, таких как, например, кэш 108 на фиг. 1, память 114 или кэш "жертвенных" данных.
Ядро 106 также может воплощать НТМ на основе кэш для вариантов осуществления ограниченных транзакций. Транзакционные операции помечены путем установки транзакционных битов, таких как бит 226 упреждающего исполнения, ассоциированный с линиями 224 кэш. В некоторых вариантах осуществления конфликты могут быть детектированы при гранулярности линии кэш, используя протокол когерентности кэш. Если линия 224 кэш, доступ к которой осуществляется через транзакции, становится опустошенной, транзакция затем отменяется. Вместо использования возврата программными средствами при отмене транзакции в вариантах осуществления раскрытия, вводится компонент 230 аппаратного менеджера исполнения НТМ, и счетчик 235 повторной попытки НТМ для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку (GHWL), такую как GHWL 120 на фиг. 1. Компонент 230 аппаратного менеджера исполнения НТМ рассматривают причину отмены, в некоторых случаях, и принимает решение, следует ли использовать политику повторной попытки, отслеживаемой счетчиком 235 повторной попытки НТМ (например, в случае конфликта) или начать неограниченную транзакцию. GHWL 120 также должен быть считан при выполнении транзакции всеми ограниченными транзакциями, для правильной синхронизации с неограниченными транзакциями.
На фиг. 3А показан пример листинга псевдокода, иллюстрирующего синтаксис транзакции. Как показано, в листинге 300 кода представлен пример программного кода, который исполняет транзакцию, и листинг 310 кода обеспечивает соответствующую аппаратную транзакцию листинга 300 программных средств с помощью устройства обработки, такого как ядро 106. Варианты осуществления раскрытия не ограничены конкретными формулировками инструкций и/или терминологией, представленной в листингах 300, 310, и могут воплощать другие вариации этих инструкций. Как представлено в программном листинге 300, критический участок инициируется TX_BEGIN для обозначения начала транзакции, и заканчивается TX_END, для обозначения конца транзакции.
Аппаратный листинг 310 показывает, что после первого исполнения, эти инструкции (например, TX_BEGIN) инициируют ограниченную аппаратную транзакцию. На фиг. 3В показан пример листинга псевдокода аппаратных инструкций, ассоциированных со ограниченной транзакцией. Поток, исполняющий ограниченную аппаратную транзакцию может начать упреждающее исполнение, когда GHWL 120 является свободным. В одном варианте осуществления, в качестве части критического участка упреждающего исполнения, исполняется инструкция, обеспечивающая упреждающее исполнение (например, такая как "enable_spec_writes") ядром 116, что приводит к отслеживанию транзакционных операций, путем установки транзакционных битов, таких как бит 226 упреждающего исполнения, ассоциированный с линиями 224 кэш для кэш 116 L1 (или любого другого кэш и/или памяти, используемой для воплощения НТМ), доступ к которой осуществляется соответствующими транзакционными операциями.
Если транзакция не исполняется, и ее отменяют из-за конфликта (как обозначено аппаратным статусом отмены, который может быть сохранен в специализированном регистре 240 ядра 106), тогда счетчик 235 повторной попытки НТМ может быть последовательно увеличен. Счетчик 235 повторной попытки НТМ может представлять собой накопитель, который отслеживает отмены для каждой транзакции. Политика повторной попытки, которая может быть воплощена аппаратным компонентом 230 управления разногласиями НТМ, определяет, следует ли выполнить повторную попытку транзакции, как ограниченной аппаратной транзакции или следует ли ее повторно назначать, как неограниченную аппаратную транзакцию. В некоторых вариантах осуществления к считчику 235 повторной попытки НТМ можно обращаться для определения, было ли достигнуто пороговое число повторных попыток транзакции. Если это так, тогда ограниченная транзакция может быть преобразована в неограниченную транзакцию с гарантией продвижения при пересылке и со сбросом счетчика 235 повторной попытки НТМ.
В других вариантах осуществления, если причина отмены представляет собой неподдерживаемую инструкцию или переполнение, транзакцию повторно запускают непосредственно, как неограниченную аппаратную транзакцию, и выполняют сброс счетчика 235 повторных попыток НТМ. Такие преобразования ограниченных и неограниченных транзакций являются прозрачными для программиста, и ими могут управлять аппаратные средства НТМ ядра 106, такие как аппаратный компонент 230 менеджера содержания НТМ.
Варианты осуществления раскрытия поддерживают одновременное исполнение одной неограниченной транзакции с любым количеством ограниченных транзакций. Процесс, который исполняет неограниченную транзакцию, должен получать GHWL 120 для обеспечения того, что больше нет других неограниченных транзакций, работающих одновременно, как показано в примерном листинге 330 псевдокода аппаратных инструкций, ассоциированных с неограниченной транзакцией на фиг. 3С. Неограниченная транзакция выполняет все записи на месте (то есть, без упреждающего исполнения), делая их видимыми для параллельных считывателей (например, других потоков). По этой причине неограниченные транзакции не могут быть отменены в вариантах осуществления раскрытия.
Кроме того, неограниченные транзакции не помечают биты транзакции, такие как биты 226 упреждающего исполнения, в линиях 224 кэш, к которым они обращаются. В одном варианте осуществления это ограничено с тем, что НТМ не исполняет инструкцию для обеспечения записей упреждающего исполнения (например, "enable_spec_writes"), при начале неограниченной транзакции. Поэтому, линии 224 кэш, доступ к которым выполняют неограниченные транзакции, могут быть удалены из кэш 116 без последствий.
В некоторых вариантах осуществления, когда транзакция заканчивается (например, как часть процедуры TX_END, предоставляемой аппаратными средствами ядра 106), транзакция может проверять, была ли выполнена GHWL 120, и также может сравнивать CPU ID ядра 106 с CPU ID 125, сохраненным с GHWL 120. Если присутствует соответствие, тогда поток мог быть знать, что он является неограниченным и мог бы очистить CPU ID 125 и снять GHWL 120. Если соответствие отсутствует или если CPU ID весь занят нулями, тогда поток мог быть знать, что он находится в ограниченном режиме и может выполнять изменения в кэш 116, которые помечены, как предназначенные для упреждающего исполнения в памяти, среди других задач, выполняемых, как часть окончания транзакции.
В результате описанных выше вариантов осуществления, неограниченные транзакции не отменяют в кэш и при ассоциативных переполнениях. Поскольку неограниченные транзакции не могут быть отменены, они также поддерживают инструкции, которые являются нелегальными в ограниченных транзакциях, такие как системные вызовы и I/O. В конечном итоге, ограниченная транзакция, которая постоянно отменяется из-за конфликтов, может быть повторно запущена, как неограниченная транзакция (например, используя политику повторной попытки и счетчик повторной попытки, описанный выше), что гарантирует, что она будет успешной; и это свойство обеспечивает продвижение при пересылке.
При наивном подходе, используя такую конструкцию, состязания должны быть исключены между неограниченной транзакцией и ограниченными транзакциями. Это может быть обработано, благодаря чтению GHWL 120 неограниченными транзакциями (при выполнении транзакции), как описано выше, предотвращая, таким образом, исполнение ограниченных транзакций параллельно с неограниченной транзакцией. Когда ограниченная транзакция считывает GHWL 120 в начале исполнения, GHWL 120 добавляют в считанный набор транзакций. Если ограниченная транзакция начинает исполнение, в то время как GHWL 120 не поддерживается, и впоследствии ее получают (то есть, начинается неограниченная транзакция), ограниченная транзакция, вследствие этого, отменяется из-за конфликта транзакций, идентифицированного в НТМ, в результате конфликта по адресу GHWL 120 в считанном наборе ограниченных транзакций. Этот конфликт автоматически определяется по протоколу когерентности, используемому ядром 106 и воплощением НТМ.
В некоторых вариантах осуществления считывание GHWL 120 может быть оптимизировано, для поддержки параллельного исполнения ограниченных транзакций вместе с одиночной неограниченной транзакцией. Вместо регулярной отмены таких транзакций, в результате требования считывания ограниченными транзакциями GHWL 120 в момент начала транзакции, варианты осуществления раскрытия следят за тем, чтобы правильность была обеспечена, если GHWL 120 считывают во время исполнения ограниченной транзакции. В результате, НТМ может запускать любое количество ограниченных транзакций одновременно с одной неограниченной транзакцией.
В частности, как показано в листинге 400 псевдокода на фиг. 4А, если ограниченные транзакции считывают GHWL 120 во время исполнения транзакции, после исполнения критического участка, а не перед этим, возможна определенная конкуренция между разными типами транзакций. При таких установках неограниченная транзакция должна сделать свои изменения видимыми для ограниченной транзакции, для поддержания возможности последовательного представления; и, поэтому, упреждающее исполнение неограниченной транзакции становится невозможным. На фиг. 4В и 4С показаны блок-схемы, концептуально иллюстрирующие примерные сценарии, в которых такая оптимизация со считыванием GHWL обеспечивает возможность большей степени конкуренции.
На фиг. 4В показан пример 410 считывания неоптимизированной GHWL, которая иллюстрирует возможные накладки между одной неограниченной транзакцией 412 и множеством ограниченных транзакций 414a-d. В одном варианте осуществления каждая транзакция исполняется разным ядром одного или больше устройств обработки. Пример 410 иллюстрирует, что все ограниченные транзакции 414a-d, которые начали исполнение перед получением GHWL 120, возвращают обратно, как только ограниченной транзакцией 412 будет получена GHWL 120. Кроме того, в то время как получают GHWL 120, ни один из потоков не может начать исполнение в упреждающем режиме (ограниченном режиме).
На фиг. 4С, пример 420 считываемого оптимизированного GHWL иллюстрирует ту же ограниченную транзакцию 412 и неограниченную транзакцию из примера 410 по фиг. 4В, но ограниченные транзакции 414a-d в этом примере 420 считывают GHWL 120 после исполнения критической части. Как показано, ограниченные транзакции 414а, b, которые начинают перед блокировкой 120 GHWL 120 получают возврат только, если критический участок заканчивается перед тем, как блокировка будет снята. Работающие ограниченные транзакции 414с, d других потоков все еще могут начать упреждающее исполнение и успешно выполнить его, если только их критический участок заканчивается после высвобождения блокировки.
На фиг. 5А и 5В показаны схемы потоков, иллюстрирующие способ 500, для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, с использованием аппаратной глобальной блокировки в соответствии с воплощением раскрытия. Способ 500 может быть выполнен с использованием логики обработки, которая может содержать аппаратные средства (например, схему, специализированную логику, программируемую логику, микрокод и т.д.), программное обеспечение (такое как инструкции, работающее в устройстве обработки), встроенное программное обеспечение или их комбинация. В одном варианте осуществления способ 500 выполняется ядром 106 по фиг. 1 и 2.
Способ 500 начинается в блоке 505, где транзакция начинает исполнение в ядре. В одном варианте осуществления инструкция TXBEGIN инициирует исполнение транзакции, используя НТМ ядра 106. В блоке 510 критическая часть транзакции исполняется с упреждающим исполнением. В одном варианте осуществления инструкция для обеспечения упреждающей записи вырабатывается, как часть упреждающего исполнения критического участка транзакции. Упреждающая запись обеспечивает установку бита упреждающего исполнения в линии кэш, ассоциированной с записью транзакции, который обозначает линию кэш, которая должна быть очищена при отказе в транзакции или при ее исполнении (переданной в основную память) после исполнения транзакции.
В блоке 515 принятия решения определяют, возникли ли какие-либо условия отклонения во время упреждающего исполнения критического участка. Условия отклонения могут включать в себя конфликты при доступе к памяти, неподдерживаемые (нелегальные) инструкции, состояния переполнения и так далее. Если какие-либо состояния отклонения возникают в блоке 515 решения, тогда способ 500 переходит к блоку 520 для отмены транзакции. В блоке 525, счетчик повторной попытки для транзакции последовательно увеличивают. В одном варианте осуществления счетчик повторной попытки может представлять собой накопитель, воплощенный в ядре 106. В блоке 525 решения определяют, превысил ли счетчик повторной попытки пороговое значение повторной попытки. Такое пороговое значение повторной попытки может быть запрограммировано в ядре 106, или может представлять собой максимальную величину, которую может содержать накопитель. Если счетчик повторной попытки не превысил пороговое значение, тогда способ 500 возвращается к блоку 510 для повторной попытки упреждающего исполнения критического участка транзакции. Если счетчик повторной попытки превысил пороговое значение повторной попытки, способ 500 может перейти в блок 550 для исполнения транзакции в неограниченном режиме, как дополнительно будет описано ниже.
В некоторых вариантах осуществления определенные типы состояний отказа могут привести к обходу счетчика повторной попытки и вызвать непосредственное преобразование транзакции в неограниченный режим. Например, исполнение неподдерживаемых инструкций или состояний переполнения может привести к пропуску транзакцией политики повторной попытки и немедленному преобразованию в неограниченную транзакцию. Это может быть ограничено с тем, что никакое количество повторных попыток для этих типов состояний отказа не приводит к улучшению состояния отмены для транзакции. В некоторых вариантах осуществления код, представляющий состояние отмены для транзакции, сохраняют в специализированном регистре ядра 106.
Возвращаясь снова в блок 515 решения, если состояние отказа не возникает во время упреждающего исполнения критического участка, способ 500 переходит в блок 535 для считывания глобальной аппаратной блокировки (GHWL). В одном варианте осуществления GHWL поддерживается в основной памяти устройства обработки. В другом варианте осуществления глобальная аппаратная блокировка поддерживается в местоположении, доступ к которому осуществляется для множества потоков устройства обработки. В блоке 540 решения определяют, была ли выполнена GHWL. Если это так, тогда возникает состояние отмены, и способ 500 возвращается в блок 520 для отмены транзакции. С другой стороны, если GHWL не была принята в блоке 540 решения, тогда способ 500 переходит в блок 545 для выполнения транзакции. В одном варианте осуществления, выполнение транзакции включает в себя выполнение упреждающего исполнения линий кэш в памяти и очистку битов упреждающего исполнения в кэш. В некоторых вариантах осуществления, даже при том, что это, в частности, не представлено, считывание GHWL может возникнуть, как часть начала транзакции, перед упреждающим исполнением критического участка. В этом случае, если GHWL будет установлена, транзакция будет отклонена перед упреждающим исполнением критического участка. Если GHWL не будет установлена, тогда GHWL добавляют к набору считывания транзакции для использования протокола когерентности кэш-памяти, для идентификации конфликтов (например, если GHWL будет получена во время исполнения транзакции, транзакция должна быть отменена).
Возвращаясь обратно в блок 525, если счетчик повторных попыток не превышает пороговое значение повторных попыток (или если состояние отмены приводит к непосредственному преобразованию в неограниченной транзакции), тогда способ 500 переходит в блок 550 для начала исполнения транзакции в неограниченном режиме. В блоке 550 ограниченная транзакция преобразуется в неограниченную транзакцию. В одном варианте осуществления, как часть неограниченного режима, транзакция исполняется без выработки инструкции записей обеспечения возможности упреждающего исполнения, таким образом, что запросы на доступ к памяти, ассоциированные с транзакцией, передают в память, без пометки каких-либо битов упреждающего исполнения в кэш. В блоке 555, транзакция получает GHWL. В одном варианте осуществления, если GHWL уже была получена другим потоком, тогда поток запрашивающей транзакции ожидает (например, вращается на блокировке, его добавляют в очередь ожидания и т.д.), пока не будет установлена GHWL.
В блоке 560, критический участок транзакции исполняется без упреждения. Как описано выше, транзакция исполняется без вырабатывания разрешающих упреждающих записей инструкций, обеспечивая, таким образом, исполнение транзакции без упреждения, и запросы доступа к памяти передают в память без какой-либо возможности возврата или отмены. В блоке 565, транзакция устанавливает GHWL. В одном варианте осуществления, как часть процедуры окончания транзакции, все исполняющиеся транзакции сравнивают с CPU ID ядра, исполняющего транзакцию, с CPU ID, ассоциированным с GHWL. Если эти CPU ID соответствуют друг другу, поток тогда знает, что он должен установить GHWL, как часть процедуры окончания транзакции. Если CPU ID не соответствуют или CPU ID, ассоциированный с GHWL, равен нулям, тогда поток не устанавливает блокировку GHWL (поскольку блокировка не принадлежит ему).
На фиг. 6А показана блок-схема, иллюстрирующая микроархитектуру для процессора 600, в которой воплощена неограниченная транзакционная память с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, в соответствии с одним вариантом осуществления раскрытия. В частности, процессор 600 представляет ядро с упорядоченной архитектурой и логикой переименования регистров, логикой выработки/исполнения не по порядку, которая должна быть включена в процессор, в соответствии, по меньшей мере, с одним вариантом осуществления раскрытия.
Процессор 600 включает в себя внешний модуль 630, соединенный с модулем 650 исполнительного механизма, и оба они соединены с модулем 670 памяти. Процессор 600 может включать в себя ядро с архитектурой с сокращенным набором команд (RISC), ядро с архитектурой с командными словами (CISC) большой длины (VLIW) или гибридный, или альтернативный тип ядра. В качестве еще одной другой опции процессор 600 может включать в себя ядро специального назначения, такое как, например, сеть или ядро передачи данных, механизм сжатия, графическое ядро и т.п. В одном варианте осуществления процессор 600 может представлять собой многоядерный процессор или может представлять собой часть многопроцессорной системы.
Внешний модуль 630 включает в себя модуль 632 прогнозирования ответвления, соединенный с модулем 634 кэш-инструкции, который соединен с буфером 636 хранения инструкции трансляции (TLB), который соединен с модулем 638 выборки инструкции, который соединен с модулем 640 декодирования. Модуль 640 декодирования (также известный, как декодер) может декодировать инструкции, и генерировать в качестве выхода одну или больше микроопераций, точек входа микрокода, микроинструкций, других инструкций или других сигналов управления, которые декодируют или которые по-другому отражают, или выводят из оригинальных инструкций. Декодер 640 может быть воплощен с использованием разных механизмов. Примеры соответствующих механизмов включают в себя, но не ограничены этим, справочные таблицы, воплощения в виде аппаратных средств, программируемые логические матрицы (PLA), постоянные запоминающие устройства для микрокода (ROM) и т.д. Модуль 634 кэш инструкции дополнительно соединен с модулем 670 памяти. Модуль 640 декодирования соединен с модулем 652 переименования/выделения в модуле 650 исполнительного механизма.
Модуль 650 исполнительного механизма включает в себя модуль 652 переименования/выделения, соединенный с модулем 654 изъятия и с набором из одного или больше модуля (модулей) 656 планировщика. Модуль (модули) 656 планировщика представляют собой любое количество разных планировщиков, включающих в себя станции резервирования (RS), окно центральной инструкции и т.д. Модуль (модули) 656 планировщика соединен с модулем (модулями) 658 файла (файлами) физического регистра. Каждый из модулей 658 файла (файлов) физического регистра представляет один или больше файлов физического регистра, разные из которых содержат один или больше разных типов данных, таких как скалярное целое число, скалярное число в плавающей точкой, упакованное целое число, упакованное число с плавающей точкой, векторное целое число, векторное число с плавающей точкой и т.д., статус (например, указатель инструкций, который представляет собой адрес следующей инструкции, предназначенной для исполнения) и т.д. На модуль (модули) 658 файла (файлов) наложен модуль 654 изъятия для иллюстрации различных способов, в соответствии с которым может быть воплощено переименование регистра и исполнение по порядку (например, используя буфер (буферы) изменения порядка и файл (файлы) регистра изъятия, используя будущий файл (файлы), буфер (буферы) предыстории и файл (файлы) регистра устранения; используя карты регистра и набор регистров; и т.д.).
В одном варианте осуществления ядро 690 может быть таким же, как и ядра 106 процессора, описанные со ссылкой на фиг. 1 и 2. В частности, ядро 690 может включать в себя неограниченные компоненты НТМ, описанные со ссылкой на фиг. 1 и 2, для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, описанную со ссылкой на варианты осуществления раскрытия.
В общем случае, архитектурные регистры видны снаружи процессора или из перспективы программиста. Регистры не ограничены каким-либо известным конкретным типом цепей. Всевозможные типы регистров пригодны, если только они позволяют сохранять и предоставлять данные, как описано здесь. Примеры соответствующих регистров включают в себя, но не ограничены этим, специализированные физические регистры, динамически выделяемые физические регистры, используя переименование регистра, комбинации специализированных и динамически выделяемых физических регистров и т.д. Модуль 654 отстранения и модуль (модули) файла (файлов) 658 физического регистра соединены с исполнительным кластером (кластерами) 660. Исполнительный кластер (кластеры) 660 включает в себя набор из одного или больше исполнительных модулей 662 и набор из одного или больше модулей 664 доступа к памяти. Исполнительные модули 662 могут выполнять различные операции (например, сдвиг, суммирование, вычитание, умножение) и работают с различными типами данных (например, скалярными данными с плавающей точкой, упакованными целыми числами, упакованными данными с плавающей точкой, векторным целым числом, векторным числом с плавающей точкой).
В то время как некоторые варианты осуществления могут включать в себя множество исполнительных модулей, специализированных для конкретных функций или наборов функций, другие варианты осуществления могут включать в себя только один исполнительный модуль или множество исполнительных модулей, которые выполняют все функции. Модуль (модули) 656 планировщика, модуль (модули) 658 файла (файлов) физического регистра и исполнительный кластер (кластеры) 660 показаны, как присутствующие, возможно, во множественном числе, поскольку некоторые варианты осуществления создают отдельные магистрали для определенных типов данных/операций (например, магистраль скалярного целого числа, магистраль скалярного числа с плавающей точкой/ упакованного целого числа/упакованного числа с плавающей точкой/ векторного целого числа/векторного числа с плавающей точкой, и/или магистраль доступа к памяти, таким образом, что каждая из них имеет свой собственный модуль планировщика, модуль файла (файлов) физического регистра и/или исполнительный кластер - и в случае отдельной магистрали доступа к памяти будут воплощены определенные варианты осуществления, в которых только исполнительный кластер такой магистрали имеет модуль (модули) 664 доступа к памяти). Следует также понимать, что в случае, когда используются отдельные магистрали, одна или больше из этих магистралей может выпускать/может исполняться не по порядку, а остальные по порядку.
Набор модулей 664 доступа к памяти соединен с модулем 670 памяти, который может включать в себя модуль 680 предварительной выборки данных, модуль 672 данных TLB, модуль 674 кэш-данных (DCU), и модуль 676 кэш уровня 2 (L2), помимо прочих. В некоторых вариантах осуществления DCU 674 также известен, как кэш данных первого уровня (кэш LI). DCU 674 может обрабатывать множество отдельных потерь кэш и может продолжить обслуживать поступающие сохранения и загрузки. Он также обеспечивает поддержание когерентности кэш. Модуль 672 данных TLB представляет собой кэш, используемый для улучшения скорости транзакции виртуальных адресов путем отображения пространства виртуального и физического адреса. В одном примерном варианте осуществления модули 664 доступа к памяти могут включать в себя модуль загрузки, модуль адреса сохранения и модуль данных сохранения, каждый из которых сохранен с модулем 672 TLB данных в модуле 670 памяти. Модуль 676 кэш L2 может быть соединен с одним или другими уровнями кэш и, в конечном итоге, с основной памятью.
В одном варианте осуществления модуль 680 предварительной выборки данных выполняет упреждающую загрузку/предварительную выборку данных в DCU 674, путем автоматического прогнозирования, какие данные программа будет употреблять в ближайшее время. Упреждающая выборка может относиться к передаче данных, сохраненных в одном месте в памяти, в соответствии с иерархией памяти (например, в кэш памяти низкого уровня) до места расположения памяти высокого уровня, которое близко (например, приводит к меньшей задержке при доступе) для процессора, прежде, чем данные будут фактически запрошены процессором. Более конкретно, упреждающая выборка может относиться к раннему получению данных из одного из кэш/памяти низкого уровня в кэш данных и/или буфер предварительной выборки прежде, чем процессор выработает требование в отношении возврата конкретных данных.
Процессор 600 может поддерживать один или больше из набора инструкций (например, набор инструкций х86 (с некоторыми расширениями, которые были добавлены в более новых версиях); набор инструкций MIPS компании MIPS Technologies of Sunnyvale, CA; набор инструкций ARM (с дополнительными расширениями, такими как НЕОН) производства ARM Holdings of Sunnyvale, CA).
Следует понимать, что ядро может поддерживать многопоточную обработку (исполнение двух или больше параллельных наборов операций или потоков), и может выполнять их различными способами, включая в себя многопоточную обработку со срезом времени, одновременную многопроцессорную обработку (в случае, когда одно физического ядро обеспечивает логическое ядро для каждого из потоков, и это физическое ядро одновременно выполняет многопоточную обработку), или их комбинацию (например, выборку по срезу времени и декодирование и одновременную многопроцессорную обработку после этого, таким же образом, как в технологии Intel® Hyperthreading).
В то время как переименование регистра описано в контексте исполнения не по порядку, следует понимать, что переименование регистра может использоваться в архитектуре исполнения по порядку. В то время как иллюстрируемый вариант осуществления процессора также включает в себя отдельные инструкции и модули кэш данных, и совместно используемый модуль кэш L2, альтернативные варианты осуществления могут иметь одиночный внутренний кэш, как для инструкций, так и для данных, такой как, например, внутренний кэш Уровня 1 (L1), или множество уровней внутреннего кэш. В некоторых вариантах осуществления система может включать в себя комбинацию внутреннего кэш и внешнего кэш, который является внешним для ядра и/или процессора. В качестве альтернативы, все кэш могут быть внешними для ядра и/или процессора.
На фиг. 6В показана блок-схема, иллюстрирующая магистраль, работающую по порядку, и каскад переименования регистра, магистраль выработки/исполнения не по порядку воплощена процессорным устройством 600 на фиг. 6А, в соответствии с некоторыми вариантами осуществления раскрытия. Прямоугольники, представленные сплошными линиями на фиг. 6В, иллюстрируют магистраль, работающую по порядку, в то время как прямоугольники, показанные пунктирными линиями, иллюстрируют переименование регистров, магистраль выработки/исполнения не по порядку. На фиг. 6В магистраль 600 процессора включает в себя каскад 602 выборки, каскад 604 декодирования длины, каскад 606 декодирования, каскад 608 выделения, каскад 610 переименования, каскад 612 планирования (также известный, как каскад отправки или выработки), каскад 614 считывания регистра/считывания памяти, исполнительный каскад 616, каскад 618 обратной записи/записи в память, каскад 622 обработки исключений и каскад 624 передачи. В некоторых вариантах осуществления порядок каскадов 602-624 может отличаться от представленных и не ограничивается конкретным порядком, показанным на фиг. 6В.
На фиг. 7 иллюстрируется блок-схема микроархитектуры для процессора 700, который включает в себя логические схемы, для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, в соответствии с одним вариантом осуществления раскрытия. В некоторых вариантах осуществления инструкция, в соответствии с одним вариантом осуществления, может быть воплощена так, чтобы она могла работать с элементами данных, имеющими размеры байта, слова, двойного слова, учетверенного слова и т.д., а также с такими типами данных, как целое число одной и двойной точности и типами данных с плавающей точкой. В одном варианте осуществления, внешний модуль 701, работающий по порядку, представляет собой часть процессора 700, который выполняет выборку инструкций для исполнения, и подготавливает их для использования в последующем в магистрали процессора.
Внешний модуль 701 может включать в себя несколько модулей. В одном варианте осуществления предварительный модуль 726 выборки инструкции выполняет выборку инструкций из памяти и подает их в декодер 728 инструкции, который, в свою очередь, декодирует или интерпретирует их. Например, в одном варианте осуществления, декодер декодирует принятую инструкцию в одну или больше операций, называемых "микроинструкциями" или "микрооперациями" (также называемыми микро op или uops), которые может исполнять устройство. В других вариантах осуществления декодер анализирует инструкцию в коде операций и соответствующие данные, и управляет полями, которые используются микроархитектурой, для выполнения операций в соответствии с одним вариантом осуществления. В одном варианте осуществления кэш 730 отслеживания отбирает декодируемые микрооперации и собирает их в программу упорядоченной последовательности или среды в очереди 734 микроопераций для выполнения. Когда кэш 730 отслеживания сталкивается со сложной инструкцией, ROM 732 микрокода предоставляет микрооперации, необходимые для завершения операции.
Некоторые инструкции преобразуют в одну микрооперацию, тогда как другие требуют нескольких микроопераций для завершения всей операции. В одном варианте осуществления, если больше чем четыре микрооперации требуются для завершения инструкции, декодер 728 обращается к ROM 732 микрокода для выполнения инструкции. Для одного варианта осуществления инструкция может быть декодирована в малое количество микроопераций, для обработки в декодере 728 инструкций. В другом варианте осуществления инструкция может быть сохранена в пределах ROM 732 микрокода, в случае, когда множество микроопераций требуется для выполнения операции. Кэш 730 отслеживания обращается к программируемой логической матрице (PLA) точки входа для определения правильного указателя микроинструкций, для считывания последовательности микрокода, для завершения одного или больше инструкций, в соответствии с одним вариантом осуществления из ROM 732 микрокода. После того, как ROM 732 микрокода закончит установление порядка следования микроопераций для инструкции, внешний модуль 701 устройства возобновляет выборку микроопераций из кэш 730 отслеживания.
Механизм исполнения 703 не по порядку используется в случае, когда инструкции подготавливают к исполнению. Логика исполнения не по порядку имеет множество буферов для сглаживания и изменения порядка потока инструкций, для оптимизации рабочей характеристики, по мере их поступления по магистрали и планирования для исполнения. Логика распределения выделяет машинные буфера и ресурсы, требуемые для каждой микрооперации для исполнения. Логика изменения наименования регистра изменяет логические регистры по входам в файл регистра. Логика распределителя также выделяет вход для каждой микрооперации в одной из двух очередей микроопераций, одной для операций с памятью и другой для операций не с памятью, перед планировщиками инструкции: планировщика памяти, быстрым планировщиком 702, медленным/общим планировщиком 704 с плавающей точкой и простым планировщиком 706 с плавающей точкой. Планировщики 702, 704, 706 микроопераций определяют, когда микрооперации готовы для исполнения на основе готовности их ресурсов, зависящих от входного операнда регистра и доступности исполнительных ресурсов, которые необходимы для микроопераций для выполнения их операции. Быстрый планировщик 702 по одному варианту осуществления может планировать для каждой половины основного цикла тактовой частоты, в то время как другие планировщики могут планировать только один раз основной цикл тактовой частоты процессора. Планировщики выносят решение, какие следует использовать порты отправки для планирования микрооперации для ее исполнения.
Файлы 708, 710 регистров, расположены между планировщиками 702, 704, 706, и исполнительные модули 712, 714, 716, 718, 720, 722, 724 в исполнительном блоке 711. Существует отдельный файл 708, 710 регистра, для операций с целыми числами и с плавающей точкой, соответственно. Каждый файл 708, 710 регистра, в одном варианте осуществления также включает в себя обходную сеть, которая может обходить или передавать только что выполненные результаты, которые еще не были записаны, в файл регистра для новых зависимых микроопераций. Файл 708 регистра целых чисел и файл 710 регистра с плавающей точкой также позволяет выполнять обмен данными друг с другом. Для одного варианта осуществления файл 708 регистра целых чисел разделен на два отдельных файла регистра, один файл регистра для 32 битов данных низкого порядка и второй файл регистра для 32 битов данных высокого порядка. Файл 710 регистра с плавающей точкой, в соответствии с одним вариантом осуществления имеет входы шириной 128 битов, поскольку инструкции с плавающей точкой обычно имеют операнды от 64 до 128 битов шириной.
Исполнительный блок 711 содержит исполнительные модули 712, 714, 716, 718, 720, 722, 724, в которых фактически исполняются инструкции. Данный блок включает в себя файлы 708, 710 регистра, которые содержат значения операнда данных с целыми числами и плавающей точкой, которые должны исполнять микроинструкции. Процессор 700 в одном варианте осуществления состоит из множества исполнительных модулей: модуля генерирования адресов (AGU) 712, AGU 714, быстрого ALU 716, быстрого ALU 718, медленного ALU 720, ALU 722 с плавающей точкой, модуля 724 перемещения с плавающей точкой. Для одного варианта осуществления исполнительные блоки 722, 724 с плавающей точкой исполняют ММХ, SIMD и SSE с плавающей точкой или другие операции. ALU 722 с плавающей точкой по одному варианту осуществления включают в себя делитель с плавающей точкой 64 бита на 64 бита для исполнения деления, квадратного корня и остальных микроопераций. Для вариантов осуществления настоящего раскрытия инструкции, использующие значение с плавающей точкой, могут обрабатываться в аппаратных средствах для вычислений с плавающей точкой.
В одном варианте осуществления операции ALU переходят к исполнительным модулям 716, 718 высокоскоростного ALU. Скоростные ALU 716, 718 в одном варианте осуществления могут исполнять быстрые операции с эффективной задержкой на полцикла тактовой частоты. Для одного варианта осуществления самые сложные операции с целыми числами отправляют в медленный ALU 720, поскольку медленный ALU 720 включает в себя исполнительные аппаратные средства для работы с целыми числами для операций с большой задержкой, таких как умножитель, сдвиги, логика флагов и обработка разветвления. Операции загрузки/сохранения в памяти исполняются AGU 712, 714. В одном варианте осуществления ALU 716, 718, 720 для работы с целыми числами описаны в контексте исполнения операций с целыми числами для операндов данных 64 бита. В альтернативных вариантах осуществления ALU 716, 718, 720 могут быть воплощены для поддержки различных битов данных, включающих в себя 16, 32, 128, 256 битов и т.д. Аналогично, модули 722, 724 с плавающей точкой могут быть воплощены для поддержания определенного диапазона операндов, имеющих биты разной ширины. В одном варианте осуществления модули 722, 724 с плавающей точкой могут работать с операндами пакетных данных шириной 128 битов совместно с SIMD и мультимедийными инструкциями.
В одном варианте осуществления планировщики 702, 704, 706 микроопераций отправляют зависимые операции перед тем, как закончится исполнение родительской нагрузки. Поскольку микрооперации запланированы для упреждающего исполнения и исполняются в процессоре 700, процессор 700 также включает в себя логику для обработки потерь в памяти. Если загрузка данных теряется в кэш данных, могут выполняться зависимые операции на ходу в магистрали, которые оставили планировщик с временно неправильными данными. Механизм повторной обработки отслеживает и повторно исполняет инструкции, которые используют некорректные данные. Только зависимые операции требуется повторно исполнять, и независимые операции разрешается закончить. Планировщики и механизм повторной обработки в одном варианте осуществления процессора также могут быть разработаны для захвата последовательности инструкций для операций сравнения текстовых строк.
Процессор 700 также включает в себя логику для воплощения сохранения прогнозирования адреса, для устранения противоречий памяти в соответствии с вариантами осуществления раскрытия. В одном варианте осуществления исполнительный блок 711 процессора 700 может включать в себя модуль прогнозирования адреса сохранения (не показан) для воплощения прогнозирования адреса сохранения для устранения противоречий в памяти.
Термин "регистры" может относиться к местам сохранения на борту процессора, которые используются, как часть инструкций, для идентификации операндов. Другими словами, регистры могут представлять собой устройство, которое можно использовать из-за пределов процессора (из перспективы программиста). Однако регистры в варианте осуществления могут не быть ограничены значением определенного типа цепи. Скорее, регистр варианта осуществления может быть выполнен с возможностью сохранения и предоставления данных, и выполнения описанных здесь функций. Регистры, описанные здесь, могут быть воплощены с помощью схемы в процессоре, используя любое количество различных технологий, таких как специализированные физические регистры, динамически выделенные физические регистры, используя переименование регистра, комбинации специализированных и динамически выделенных физических регистров и т.д. В одном варианте осуществления регистры целых чисел содержат данные целых чисел размером тридцать два бита. Файл регистра в одном варианте осуществления также содержит восемь мультимедийных регистров SIMD для упакованных данных.
Для представленной ниже дискуссии, под термином регистры понимают, как регистры данных, разработанные для содержания пакетных данных, такие как регистры ММХТМ 64 шириной бита (также в некоторых случаях называются регистрами ′mm′) в микропроцессорах, в которых используется технология ММХ Intel Corporation Santa Clara, California. Эти регистры ММХ, доступные, как для работы с целыми числами, так и с числами с плавающей точкой, могут работать с элементами пакетных данных, которые сопровождают инструкции SIMD и SSE. Аналогично, регистры ХММ шириной 128 битов, относящиеся к SSE2, SSE3, SSE4, или за пределами этой технологии (в общем, называются "SSEx"), также могут использоваться для содержания таких операндов пакетных данных. В одном варианте осуществления, при сохранении пакетных данных и данных целого числа, регистры не требуется дифференцировать между двумя типами данных. В одном варианте осуществления целое число и плавающая точка могут содержаться в одном и том же файле регистра или в разных файлах регистра. Кроме того, в одном варианте осуществления, данные с плавающей точкой и целочисленные данные могут быть сохранены в разных регистрах или в одних и тех же регистрах.
Рассмотрим теперь фиг. 8, на которой показана блок-схема, иллюстрирующая систему 800, в которой может использоваться вариант осуществления раскрытия. Как показано на фиг. 8, многопроцессорная система 800 представляет собой систему взаимного соединения из точки в точку, и включает в себя первый процессор 870 и второй процессор 880, соединенные через взаимное соединение 850 из точки в точку. Хотя здесь показаны только два процессорами 870, 880, следует понимать, что объем вариантов осуществления раскрытия не ограничен этим. В других вариантах осуществления один или больше дополнительных процессоров могут присутствовать в данном процессоре. В одном варианте осуществления многопроцессорная система 800 может воплощать неограниченную транзакционную память с гарантиями продвижения при пересылке, использующую аппаратную глобальную блокировку, как описано здесь.
Процессоры 870 и 880 показаны, как включающие в себя интегрированные модули 872 и 882 контроллера памяти, соответственно. Процессор 870 также включает в себя, как часть его модулей, контроллер шины интерфейсы 876 и 878 "из точки в точку" (Р-Р); аналогично, второй процессор 880 включает в себя интерфейсы 886 и 888 Р-Р. Процессоры 870, 880 могут выполнять обмен информацией через интерфейс 850 "из точки в точку" (Р-Р), используя схемы 878, 888 интерфейса Р-Р. Как показано на фиг. 8, IMC 872 и 882 соединяют процессоры с соответствующими запоминающими устройствами, а именно, с памятью 832 и памятью 834, которые могут представлять собой часть основной памяти, локально соединенной с соответствующими процессорами.
Процессоры 870, 880 каждый может выполнять обмен информацией с набором 890 микросхем через индивидуальные интерфейсы 852, 854 Р-Р, используя схемы 876, 894, 886, 898 интерфейса из точки в точку. Набор 890 микросхем может также выполнять обмен информацией с высокоэффективной графической схемой 838 через высокоэффективный графический интерфейс 839.
Совместно используемый кэш (не показан) может быть включен либо в процессор, или может быть расположен за пределами обоих процессоров, но соединен с процессорами через взаимное соединение Р-Р, таким образом, что информация локального кэш одного или обоих процессоров может быть сохранена в совместно используемом кэш, если процессор переведен в режим малого потребления энергии.
Набор 890 микросхем может быть соединен с первой шиной 816 через интерфейс 896. В одном варианте осуществления, первая шина 816 может представлять собой шину подключения периферийных компонентов (PCI) или шину, такую как шина PCI Express или другую шину взаимного соединения третьего поколения I/O, хотя объем настоящего раскрытия не ограничен этим.
Как показано на фиг. 8, различные устройства 814 I/O могут быть соединены с первой шиной 816, вместе с межшинным мостом 818, который соединяет первую шину 816 со второй шиной 820. В одном варианте осуществления вторая шина 820 может представлять собой шину с малым количеством выводов (LPC). Различные устройства могут быть соединены со второй шиной 820, включая в себя, например, клавиатуру и/или мышь 822, устройство 827 передачи данных и модуль 828 сохранения, такой как привод диска или другое устройство массового сохранения информации, которое может включать в себя инструкции/код и данные 830, в одном варианте осуществления. Кроме того, I/O 824 может быть соединен со второй шиной 820. Следует отметить, что возможны другие архитектуры. Например, вместо архитектуры "из точки в точку", показанной на фиг. 8, система может воплощать многоточечную шину или другую подобную архитектуру.
Обращаясь теперь к фиг. 9, можно видеть, что здесь показана блок-схема системы 900, в которой может работать вариант осуществления раскрытия. Система 900 может включать в себя один или больше процессоров 910, 915, которые соединены с концентратором 920 контроллера графической памяти (GMCH). Необязательное свойство дополнительных процессоров 915 обозначено на фиг. 9 пунктирными линиями. В одном варианте осуществления процессоры 910, 915 воплощают неограниченную транзакционную память с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, в соответствии с вариантами осуществления раскрытия.
Каждый процессор 910, 915 может представлять собой определенную версию схемы, интегральной схемы, процессора и/или кремниевой интегральной схемы, как описано выше. Однако следует отметить, что маловероятно, что интегрированная графическая логика и интегрированные модули управления памятью будут присутствовать в процессорах 910, 915. На фиг. 9 иллюстрируется, что GMCH 920 может быть соединен с памятью 940, которая может представлять собой, например, динамическое оперативное запоминающее устройство (DRAM). DRAM может, по меньшей мере, для одного варианта осуществления, быть ассоциировано с энергонезависимым кэш.
GMCH 920 может представлять собой набор микросхем или часть набора микросхем. GMCH 920 может связываться с процессором (процессорами) 910, 915 и управлять взаимодействием между процессором (процессорами) 910, 915 и памятью 940. GMCH 920 также может действовать, как ускоренный интерфейс шины между процессором (процессорами) 910, 915 и другими элементами системы 900. Для, по меньшей мере, одного варианта осуществления GMCH 920 связывается с процессором (процессорами) 910, 915 через многоточечную шину, такую как системная шина (FSB) 995.
Кроме того, GMCH 920 соединен с дисплеем 945 (таким как дисплей с плоской панелью или с сенсорным экраном). GMCH 920 может включать в себя интегрированный графический ускоритель. GMCH 920 дополнительно соединен с концентратором 950 контроллера (ICH) ввода-вывода (I/O), который может использоваться для соединения различных периферийных устройств с системой 900. В качестве примера, в варианте осуществления, показанном на фиг. 9, представлено внешнее графическое устройство 960, которое может представлять собой дискретное графическое устройство, соединенное с ICH 950, вместе с другим периферийным устройством 970.
В качестве альтернативы, дополнительные или другие процессоры могут также присутствовать в системе 900. Например, дополнительный процессор (процессоры) 915 может включать в себя дополнительные процессоры (процессор), которые являются такими же, как и процессор 910, дополнительный процессор (процессоры), которые являются гетерогенными или асимметричными для процессора 910, ускорители (такие как, например, графические ускорители или модули цифровой сигнальной обработки (DSP)), программируемые пользователем вентильной матрицы, или любой другой процессор. Возможны различия между процессором (процессорами) 910, 915 с точки зрения спектра результатов измерений качества, включая в себя архитектурные, микроархитектурные, тепловые характеристики потребления энергии и т.п. Такие различия могут эффективно проявляться сами по себе, как асимметрия и гетерогенность среди процессоров 910, 915. По меньшей мере, для одного варианта осуществления различные процессоры 910, 915 могут находиться в том же пакете подложек.
Обращаясь теперь к фиг. 10, здесь показана блок-схема системы 1000, в которой может работать вариант осуществления настоящего раскрытия. На фиг. 10 иллюстрируются процессоры 1070, 1080. В одном варианте осуществления процессоры 1070, 1080 могут воплощать неограниченную транзакционную память с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, как описано выше. Процессоры 1070, 1080 могут включать в себя интегрированную память и логику ("CL") 1072 и 1082 управления I/O, соответственно, и могут выполнять обмен данными друг с другом через взаимное соединение 1050 из точки в точку между интерфейсами 1078 и 1088 "из точки в точку" (Р-Р), соответственно. Процессоры 1070, 1080 каждый связывается с набором микросхем 1090 через взаимные соединения 1052 и 1054 из точки в точку, через соответствующие интерфейсы 1076-1094 и 1086-1098 Р-Р, как показано. Для, по меньшей мере, одного варианта осуществления CL 1072, 1082 может включать в себя интегрированные модули управления памятью. CL 1072, 1082 может включать в себя логику управления I/O. Как показано на чертеже, запоминающее устройство 1032, 1034 соединено с CL 1072, 1082, и устройства 1014 I/O также соединены с логикой 1072, 1082 управления. Традиционные устройства 1015 I/O соединены с набором 1090 микросхем через интерфейс 1096.
Варианты осуществления могут быть воплощены во множестве систем разных типов. На фиг. 11 показана блок-схема SoC 1100, в соответствии с вариантом осуществления настоящего раскрытия. Прямоугольники из пунктирных линий представляют собой необязательные свойства для более усовершенствованных SoC. На фиг. 11, модуль (модули) 1112 взаимного соединения соединены с: процессором 1120 приложения, который включает в себя набор из одного или больше ядер 1102A-N и модулем (модулями) 1106 совместно используемого кэш; модулем 1112 системного агента; модулем (модулями) 1116 контроллера шины; модулем (модулями) 1114 контроллера интегрированный памяти; набором из одного или больше мультимедийных процессоров 1120, которые могут включать в себя интегрированную графическую логику 1122, процессор 1124 изображения для предоставления функции неподвижной фото- и/или видеокамеры, аудиопроцессор 1126 для предоставления аппаратного ускорения для обработки аудиоданных, и видеопроцессор 1128 для предоставления ускорения при обработке кодирования/декодирования видеоданных; модуль 1130 статической оперативной памяти (SRAM); модуль 1132 прямого доступа к памяти (DMA); и модуль 1140 дисплея, предназначенный для соединения с одним или больше внешними дисплеями. В одном варианте осуществления модуль памяти может быть включен в интегрированный модуль (модули) 1114 контроллера памяти. В другом варианте осуществления модуль памяти может быть включен в один или больше из других компонентов SoC 1100, которые могут использоваться для доступа и/или управления памятью. Процессор 1110 приложения может включать в себя неограниченные компоненты НТМ для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, как описано здесь в вариантах осуществления.
Иерархия памяти включает в себя один или больше уровней кэш в пределах ядер, набор из одного или больше совместно используемых модулей 1106 кэш и внешнюю память (не показана), соединенную с набором из интегрированных модулей 1114 контроллера памяти. Набор совместно используемых модулей 1106 кэш может включать в себя один или больше кэши среднего уровня, таких как уровень 2 (L2), уровень 3 (L3), уровень 4 (L4) или кэш других уровней, кэш последнего уровня (LLC) и/или их комбинации.
В некоторых вариантах осуществления одно или больше из ядер 1102A-N выполнены с возможностью многопроцессорной обработки. Системный агент 1112 включает в себя компоненты, координирующие и обеспечивающие управление ядрами 1102A-N. Модуль 1112 системного агента может включать в себя, например, модуль (PCU) управления питанием и модуль дисплея. PCU может представлять собой логику или может включать логику и компоненты, необходимые для регулирования состояния питания ядер 1102A-N и интегрированной графической логики 1108. Модуль дисплея предназначен для управления одним или больше внешними подключенными дисплеями.
Ядра 1102A-N могут быть гомогенными или гетерогенными с точки зрения архитектуры и/или набора инструкций. Например, некоторые из ядер 1102A-N могут работать по порядку, в то время как другие могут работать не по порядку. В качестве другого примера, два или больше из ядер 1102A-N могут быть выполнены с возможностью исполнения такого же набора инструкций, в то время как другие могут быть выполнены с возможностью исполнения только поднабора этого набора инструкций или другого набора инструкций.
Процессор 1110 приложения может представлять собой процессор общего назначения, такой как процессор Core™ i3, i5, i7, 2 Duo и Quad, Xeon™, Itanium™, Atom™ или Quark™, которые поставляет компания Intel™ Corporation, of Santa Clara, Calif. В качестве альтернативы, процессор 1110 приложения может поставляться другой компанией, такой как ARM Holdings™, Ltd, MIPS™, и т.д. Процессор 1110 приложения может представлять собой процессор специального назначения, такой как, например, сетевой процессор или процессор обмена данными, механизм сжатия, графический процессор, сопроцессор, встроенный процессор и т.п. Процессор 1110 приложения может быть воплощен в одной или больше микросхемах. Процессор 1110 приложения может представлять собой часть и/или может быть воплощен на одной или больше подложках, использующих одну из множества технологий обработки, таких как, например, BiCMOS, CMOS или NMOS.
На фиг. 12 показана блок-схема варианта осуществления конструкции системы на кристалле (SoC) в соответствии с настоящим раскрытием. В качестве конкретного иллюстративного примера SoC 1200 включена в оборудование пользователя (UE). В одном варианте осуществления UE относится к любому устройству, предназначенному для использования конечным пользователем для обмена данными, такому как портативный телефон, смартфон, планшетный компьютер, ультратонкий ноутбук с широкополосным адаптером, или любое другое аналогичное устройство передачи данных. Часто UE соединяется с базовой станцией или узлом, который потенциально соответствует по своей сути мобильной станции (MS) в сети GSM.
Здесь SOC 1200 включает в себя 2 ядра 1206 и 1207. Ядра 1206 и 1207 могут соответствовать архитектуре набора инструкций, такой как процессор Core™ на основе архитектуры компании Intel®, процессор компании Advanced Micro Devices, Inc. (AMD), процессор на основе MIPS, конструкция процессора на основе ARM, или их специальная версия, а также их лицензедержателей или правопреемников. Ядра 1206 и 1207 соединены с управлением 1208 кэш, который ассоциирован с модулем 1209 интерфейса шины, и кэш 1210 L2, для сообщения с другими частями системы 1200. Взаимное соединение 1210 включает в себя взаимные соединения на кристалле, такие как IOSF, АМВА или другие взаимные соединения, описанные выше, которые потенциально воплощают один или больше аспектов описанного раскрытия. В одном варианте осуществления ядра 1206, 1207 могут воплощать неограниченную транзакционную память с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, как описано здесь в вариантах осуществления.
Взаимное соединение 1210 обеспечивает канал передачи данных с другими компонентами, таким как модуль 1230 идентичности абонента (SIM) для формирования интерфейса с SIM-картой, ROM 1235 начальной загрузки, для считывания кода начальной загрузки для исполнения ядрами 1206 и 1207, для инициализации и загрузки SoC 1200, контроллер 1240 SDRAM для формирования интерфейса с внешней памятью (например, DRAM 1260), 1245 контроллер флэш для формирования интерфейса с энергонезависимой памятью (например, памятью флэш 1265), периферийный контроллер 1250 (например, последовательный периферийный интерфейс) для формирования интерфейса с периферийными устройствами, видео кодеки 1220 и видеоинтерфейс 1225 для отображения и приема входных данных (например, ввод данных через сенсорный экран), GPU 1215 для выполнения расчетов, ограниченных с графикой, и т.д. В любой из этих интерфейсов могут быть встроены аспекты описанного здесь раскрытия. Кроме того, система 1200 иллюстрирует периферийные устройства для обмена данными, такие как модуль 1270 Bluetooth, модем 12753G, GPS 1280 и Wi-Fi 1285.
На фиг. 13 иллюстрируется схематическое представление устройства в форме примера вычислительной системы 1300, в которой может быть выполнен набор инструкций для обеспечения исполнения устройством любой одной или больше из методологий, описанных здесь. В альтернативных вариантах осуществления устройство может быть соединено (например, по сети) с другими устройствами в LAN, интранет, экстранет или Интернет. Устройство может работать в качестве сервера или устройства-клиента в сетевой среде клиент-сервер, или как устройство одного уровня в пиринговой (или распределенной) сетевой среде. Устройство может представлять собой персональный компьютер (PC), планшетный PC, телевизионную приставку (STB), карманный персональный компьютер (PDA), сотовый телефон, сетевое оборудование, сервер, сетевой маршрутизатор, переключатель или мост, или любое устройство, выполненное с возможностью исполнения набора инструкций (последовательно или в другом порядке), которые устанавливают действия, предпринимаемые этим устройством. Кроме того, в то время как представлено только одно устройство, термин "устройство" также следует рассматривать, как включающее в себя любой набор устройств, которые по-отдельности или совместно исполняют набор (или множеств наборов) инструкций, для выполнения любой одной или больше из методик, описанных здесь.
Компьютерная система 1300 включает в себя устройство 1302 обработки, основную память 1304 (например, постоянное запоминающее устройство (ROM), память типа флэш, динамическое оперативное запоминающее устройство (DRAM) (такое как синхронное DRAM (SDRAM) или DRAM (RDRAM) и т.д.), статическое запоминающее устройство 1306 (например, память типа флэш, статическая оперативное запоминающее устройство (SRAM) и т.д.), и устройство 1318 сохранения данных, которые сообщаются друг с другом через шину 1330.
Устройство 1302 обработки представляет одно или больше из устройств обработки общего назначения, таких как микропроцессор, центральное процессорное устройство и т.п. Более конкретно, устройство обработки может представлять собой микропроцессор для расчета сложного набора команд, (CISC), микропроцессор с архитектурой сокращенного набора команд (RISC), микропроцессор с архитектурой с командными словами сверхбольшой длины (VLIW), или процессор, воплощающий другие наборы инструкций, или процессоры, воплощающие комбинацию набора инструкций. Устройство 1302 обработки также может представлять собой одно или больше устройств обработки специального назначения, таких как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), цифровой сигнальный процессор (DSP), сетевой процессор и т.п. В одном варианте осуществления процессорное устройство 1302 обработки может включать в себя одно или больше ядер обработки. Процессорное устройство 1302 выполнено с возможностью исполнения логики 1326 обработки для выполнения операций и этапов, описанных здесь. В одном варианте осуществления процессорное устройство 1302 является таким же, как и процессорная архитектура 100, описанная со ссылкой на фиг. 1, в которой воплощается неограниченная транзакционная память с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, как описано здесь с вариантами осуществления раскрытия.
Компьютерная система 1300 может дополнительно включать в себя устройство 1308 сетевого интерфейса, которое соединено с возможностью обмена данными с сетью 1320. Компьютерная система 1300 также может включать в себя модуль 1310 отображения видеоизображения (например, жидкокристаллический дисплей (LCD) или электроннолучевую трубку (CRT)), устройство 1312 цифро-буквенного ввода данных (например, клавиатуру), устройство 1314 управления курсором (например, мышь), и устройство 1316 генерирования сигнала (например, громкоговоритель). Кроме того, компьютерная система 1300 может включать в себя модуль 1322 графической обработки, модуль 1328 обработки видеоданных и модуль 1332 обработки аудиоданных.
Устройство 1318 сохранения данных может включать в себя носитель 1324 информации с машинным доступом, на котором содержится программное обеспечение 1326, воплощающее в себя одну или больше методологий или функций, описанных здесь, таких как воплощение прогнозирования адреса сохранения для устранения противоречий в памяти, как описано выше. Программное обеспечение 1326 также может содержаться, полностью или, по меньшей мере, частично, в основной памяти 1304 в виде инструкции 1326 и/или в устройстве 1302 обработки, как логика 1326 обработки во время исполнения компьютерной системой 1300; основная память 1304 и устройство 1302 обработки также составляют носитель информации с машинным доступом.
Носитель 1324 информации с машинным доступом также может использоваться для сохранения инструкции 1326, воплощая неограниченную транзакционную память с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, такую как описано со ссылкой на ядра 106 обработки на фиг. 1 и 2, и/или программную библиотеку, содержащую способы, которые вызывают описанные выше приложения. В то время как носитель 1324 информации с машинным доступом показан в примерном варианте осуществления, как один носитель, термин "носитель информации с машинным доступом" следует рассматривать, как включающий в себя одиночный носитель или множество носителей информации (например, централизованную или распределенную базу данных, и/или ассоциированные кэш и серверы), которые содержат один или больше наборов инструкций. Термин "носитель информации с машинным доступом" также следует рассматривать, как включающий в себя любой носитель информации, который выполнен с возможностью сохранения, кодирования или переноса набора инструкций для исполнения устройством и который обеспечивает выполнение устройством одной или больше из методологий настоящего раскрытия. Термин "носитель информации с машинным доступом", соответственно, следует рассматривать, как включающий в себя, но не ограниченный этим, твердотельное запоминающее устройство и оптические и магнитные носители информации.
Следующие примеры относятся к дополнительным вариантам осуществления. Пример 1 представляет устройство обработки для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, использующей аппаратную глобальную блокировку. В дополнение к Примеру 1, устройство обработки содержит аппаратную транзакционную память (НТМ), аппаратный менеджер разногласий, который обеспечивает перевод ограниченных транзакций в неограниченные транзакции, неограниченная транзакция получает глобальную аппаратную блокировку для неограниченной транзакции, глобальная аппаратная блокировка считывается ограниченными транзакциями, которые отменяют, когда применяют глобальную аппаратную блокировку. Устройство обработки дополнительно содержит исполнительный модуль, соединенный с возможностью обмена данными с аппаратным менеджером разногласий НТМ для исполнения инструкций неограниченной транзакции без упреждающего исполнения, неограниченная транзакция вырабатывает глобальную аппаратную блокировку после завершение исполнения инструкций.
В Примере 2 предмет изобретения по Примеру 1, в случае необходимости, может включать в себя, в котором аппаратный менеджер разногласий НТМ для обращения к политике повторной попытки для определения, когда следует выполнять перевод ограниченной транзакции в неограниченную транзакцию. В Примере 3 предмет изобретения по одному из Примеров 1-2, в случае необходимости может включать в себя, дополнительно содержащий счетчик повторных попыток НТМ, к которому обращается аппаратный менеджер разногласий НТМ, как часть политики повторных попыток, в котором когда счетчик повторных попыток НТМ, ассоциированный со ограниченной транзакцией, превышает пороговое значение повторных попыток, менеджер разногласий аппаратных средств НТМ обеспечивает перевод ограниченной транзакции в неограниченную транзакцию. В Примере 4 предмет изобретения по одному из Примеров 1-3, в случае необходимости, может включать в себя, в котором ограниченную транзакцию переводят в неограниченную транзакцию при возникновении состояния отмены, вызванного конфликтом, и при превышении счетчиком повторных попыток НТМ порогового значения повторных попыток.
В Примере 5 предмет изобретения по любому одному из Примеров 1-4, в случае необходимости, может включать в себя, в котором ограниченную транзакцию переводят в неограниченную транзакцию при возникновении состояния отмены, содержащего, по меньшей мере, одну неподдерживаемую инструкцию или состояние переполнения. В Примере 6 предмет изобретения по любому одному из Примеров 1-5, в случае необходимости, может включать в себя, в котором ограниченные транзакции считывают глобальную аппаратную блокировку перед упреждающим исполнением инструкций ограниченных транзакций. В Примере 7 предмет изобретения по любому одному из Примеров 1-6, в случае необходимости, может включать в себя, в котором ограниченные транзакции считывают глобальную аппаратную блокировку, как часть процедуры передачи, следующей после упреждающего исполнения блоков инструкций ограниченных транзакций.
В Примере 8, предмет изобретения по любому из Примеров 1-7, в случае необходимости, может включать в себя, в котором глобальную аппаратную блокировку поддерживают в основной памяти, ассоциированной с устройством обработки. В Примере 9, предмет изобретения по любому одному из Примеров 1-8, в случае необходимости, может включать в себя, в котором накопитель для идентификатора (ID) CPU ассоциирован с глобальной аппаратной блокировкой и содержит ID CPU, соответствующий CPU потока, исполняющего неограниченную транзакцию, которая получает глобальную аппаратную блокировку. В Примере 10 предмет изобретения по любому одному из Примеров 1-9, в случае необходимости, может включать в себя, в котором исполнение инструкций неограниченных транзакций, гарантирующих продвижение при пересылке устройства обработки, в качестве неограниченных транзакций, не может быть отменено и, по мере того, как ограниченные транзакции становятся неограниченными транзакциями, по меньшей мере, после того, как их отменят заданное количество раз. Все необязательные свойства устройства, описанного выше, также могут быть воплощены в отношении способа или потока, описанных здесь.
Пример 11 представляет собой способ для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, содержащий: выполняют перевод ограниченной транзакции в неограниченную транзакцию, получают глобальную аппаратную блокировку для неограниченной транзакции, глобальную аппаратную блокировку считывают ограниченные транзакции, которые отменяют, когда глобальная аппаратная блокировка установлена, исполняют инструкции неограниченной транзакции без упреждающего исполнения и устраняют глобальную аппаратную блокировку. В Примере 12 предмет изобретения по любому одному из Примера 11, в случае необходимости, может включать в себя дополнительную ссылку на политику повторной попытки, для определения, когда следует перевести ограниченную транзакцию в неограниченную транзакцию.
В Примере 13, предмет изобретения по любому одному из Примеров 11-12, в случае необходимости, может включать в себя, в котором счетчик повторной попытки НТМ, на который ссылаются, как на часть политики повторной попытки, в котором когда счетчик повторной попытки НТМ, ассоциированный со ограниченной транзакцией, превышает пороговое значение повторной попытки, ограниченную транзакцию преобразуют в неограниченную транзакцию. В Примере 14, предмет изобретения по любому одному из Примеров 11-13, в случае необходимости, может включать в себя, в котором ограниченную транзакцию переводят в неограниченную транзакцию при возникновении состояния отмены, вызванного конфликтом, и при превышении счетчиком повторных попыток НТМ порогового значения повторных попыток.
В Примере 15, предмет изобретения по любому одному из Примеров 11-14, в случае необходимости, может включать в себя, в котором перевод ограниченной транзакции в неограниченную транзакцию после возникновения состояния отмены, содержащего, по меньшей мере, одну из неподдерживаемой инструкции или состояния переполнения. В Примере 16, предмет изобретения по любому из Примеров 11-15, в случае необходимости, может включать в себя, в котором ограниченные транзакции считывают глобальную аппаратную блокировку перед упреждающим исполнением инструкций ограниченных транзакций. В Примере 17, предмет изобретения по любому одному из Примеров 11-16, в случае необходимости, может включать в себя, в котором ограниченные транзакции, считывают глобальную аппаратную блокировку, как часть процедуры передачи, следующей после упреждающего исполнения инструкций ограниченных транзакций.
В Примере 18, предмет изобретения по любому из Примеров 11-17, в случае необходимости, может включать в себя, в котором глобальную аппаратную блокировку поддерживают в основной памяти, ассоциированной с устройством обработки. В Примере 19, предмет изобретения по любому из Примеров 11-18, в случае необходимости, может включать в себя, в котором накопитель для идентификатора (ID) CPU ассоциирован с глобальной аппаратной блокировкой и содержит CPU ID, соответствующий CPU потока, исполняющего неограниченную транзакцию, которая получает глобальную аппаратную блокировку. В Примере 20, предмет изобретения по любому одному из Примеров 11-19, в случае необходимости, может включать в себя, в котором исполнение инструкций неограниченной транзакции гарантирует продвижение при пересылке устройства обработки, поскольку неограниченные транзакции не могут быть отменены, и ограниченные транзакции становятся неограниченными транзакциями, по меньшей мере, при отмене заданное количество раз.
Пример 21 направлен на систему для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку. В Примере 21 система включает в себя память для сохранения глобальной аппаратной блокировки, и устройство обработки соединено с памятью с возможностью передачи данных. В дополнение к Примеру 21, устройство обработки предназначено для перевода ограниченной транзакции в неограниченную транзакцию, получения глобальной аппаратной блокировки для неограниченной транзакции, глобальную аппаратную блокировку считывают ограниченные транзакции, которые отменяют, когда глобальная аппаратная блокировка установлена, исполнения инструкций неограниченной транзакции без упреждающего исполнения, и устранения глобальной аппаратной блокировки.
В Примере 22, предмет изобретения по Примеру 21, в случае необходимости, может включать в себя, дополнительно содержащий: обращаются к политике повторной попытки для определения, когда следует перевести ограниченную транзакцию в неограниченную транзакцию. В Примере 23, предмет изобретения по любому одному из Примеров 21-22, в случае необходимости, может включать в себя, в котором к счетчику повторных попыток НТМ обращаются, как к части политики повторных попыток, в котором когда счетчик повторных попыток НТМ, ассоциированный со ограниченной транзакцией, превышает пороговое значение повторных попыток, ограниченную транзакцию преобразуют в неограниченную транзакцию.
В Примере 24, предмет изобретения по любому одному из Примеров 20-22, в случае необходимости, может включать в себя, в котором ограниченную транзакцию переводят в неограниченную транзакцию при возникновении состояния отмены, вызванного конфликтом, и при превышении счетчиком повторных попыток НТМ, порогового значения повторных попыток. В Примере 25, предмет изобретения по любому одному из Примеров 20-23, в случае необходимости, может включать в себя, в котором ограниченную транзакцию переводят в неограниченную транзакцию при возникновении состояния отмены, содержащего, по меньшей мере, одну из неподдерживаемых инструкций или состояния переполнения.
В Примере 26, предмет изобретения по любому одному из Примеров 20-24, в случае необходимости, может включать в себя, в котором ограниченные транзакции, считывают глобальную аппаратную блокировку перед упреждающим исполнением инструкций ограниченных транзакций. В Примере 27, предмет изобретения по любому одному из Примеров 20-25, в случае необходимости, может включать в себя, в котором ограниченные транзакции, считывают глобальную аппаратную блокировку, как часть процедуры передачи, следующей после упреждающего исполнения инструкций ограниченных транзакций. В Примере 28, предмет изобретения по любому одному из Примеров 20-26, в случае необходимости, может включать в себя, в котором глобальную аппаратную блокировку поддерживают в основной памяти, ассоциированной с устройством обработки.
В Примере 29, предмет изобретения по любому одному из Примеров 20-27, в случае необходимости, может включать в себя, в котором накопитель для идентификатора (ID) CPU ассоциирован с глобальной аппаратной блокировкой и содержит CPU ID, соответствующий CPU потока, исполняющего неограниченную транзакцию, которая получает глобальную аппаратную блокировку. В Примере 30, предмет изобретения по любому одному из Примеров 20-28, в случае необходимости, может включать в себя, в котором исполнение инструкций неограниченной транзакции, гарантирует продвижение при пересылке устройства обработки, поскольку неограниченные транзакции не могут быть отменены, и, по мере того, как ограниченная транзакция становится неограниченной транзакцией, по меньшей мере, после отмены заданное количество раз. Все дополнительные свойства системы, описанные выше, также могут быть воплощены в отношении способа или потока, описанных здесь.
Пример 31 представляет собой энергонезависимый считываемый компьютером носитель информации, предназначенный для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку. В Примере 31, энергонезависимый считываемый компьютером носитель информации включает в себя данные, которые при доступе к ним устройства обработки, обеспечивают исполнение устройством обработки операций, содержащих: переводят ограниченную транзакцию в неограниченную транзакцию, получают глобальную аппаратную блокировку для неограниченной транзакции, глобальную аппаратную блокировку считывают неограниченные транзакции, которые отклоняют, когда установлена глобальная аппаратная блокировка, исполняют инструкции неограниченной транзакции без упреждающего исполнения, и устраняют глобальную аппаратную блокировку.
В Примере 32, предмет изобретения по Примеру 30, в случае необходимости, может включать в себя: дополнительно содержащий обращение к политике повторной попытки для определения, когда следует выполнить перевод ограниченной транзакции в неограниченную транзакцию. В Примере 33, предмет изобретения по Примерам 30-31, в случае необходимости, может включать в себя, в котором обращаются к счетчику повторной попытки НТМ, как к части политики повторной попытки, в котором когда счетчик повторной попытки НТМ, ассоциированный со ограниченной транзакцией, превышает пороговое значение повторной попытки, ограниченную транзакцию преобразуют в неограниченную транзакцию.
В Примере 34, предмет изобретения по Примерам 30-32, в случае необходимости, может включать в себя, в котором ограниченную транзакцию переводят в неограниченную транзакцию при возникновении состояния отмены, вызванного конфликтом, и при превышении счетчиком повторных попыток НТМ порогового значения повторных попыток. В Примере 35, предмет изобретения по Примерам 30-33, в случае необходимости, может включать в себя: ограниченную транзакцию переводят в неограниченную транзакцию при возникновении состоянии отмены, содержащего, по меньшей мере, одну из неподдерживаемых инструкций или состояние переполнения.
В Примере 36, предмет изобретения по Примерам 30-34, в случае необходимости, может включать в себя, в котором ограниченные транзакции, считывают глобальную аппаратную блокировку перед упреждающим исполнением инструкций ограниченных транзакций. В Примере 37, предмет изобретения по Примерам 30-35, в случае необходимости, может включать в себя, в котором ограниченные транзакции считывают глобальную аппаратную блокировку, как часть процедуры передачи, следующей после упреждающего исполнения инструкций ограниченных транзакций. В Примере 38 предмет изобретения по Примерам 30-36, в случае необходимости, может включать в себя, в котором глобальную аппаратную блокировку поддерживают в основной памяти, ассоциированной с устройством обработки.
В Примере 39, предмет изобретения по Примерам 30-37, в случае необходимости, может включать в себя, в котором накопитель для идентификатора (ID) CPU ассоциирован с глобальной аппаратной блокировкой и содержит ID CPU, соответствующий CPU потока, исполняющего неограниченную транзакцию, которая получает глобальную аппаратную блокировку. В Примере 40 предмет изобретения по Примерам 30-38, в случае необходимости, может включать в себя, в котором исполняют инструкции неограниченных транзакций, гарантирующих продвижение при пересылке устройства обработки, поскольку неограниченные транзакции не могут быть отменены и по мере того, как ограниченные транзакции становятся неограниченными транзакциями, по меньшей мере, при отмене заданное количество раз.
Пример 41 направлен на устройство для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, использующей аппаратную глобальную блокировку, содержащую средство для перевода ограниченной транзакции в неограниченную транзакцию, средство для получения глобальной аппаратной блокировки для неограниченной транзакции, глобальную аппаратную блокировку считывают ограниченные транзакции, которые отменяют, когда установлена глобальная аппаратная блокировка, средство для исполнения инструкций неограниченной транзакции без упреждающего исполнения, и средство для устранения глобальной аппаратной блокировки. В Примере 42, предмет изобретения по Примеру 41, в случае необходимости, может включать в себя устройство, дополнительно выполненное с возможностью исполнения способа по любому одному из Примеров 12-20.
Пример 43 представляет собой, по меньшей мере, один считываемый устройством носитель, содержащий множество инструкций, которые, в ответ на их исполнение в компьютерном устройстве, обеспечивают исполнение компьютерным устройством способа в соответствии с любым одним из Примеров 11-20. Пример 44 представляет собой устройство для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, использующее аппаратную глобальную блокировку, выполненное с возможностью исполнения способа по любому одному из Примеров 11-20. Пример 45 направлен на устройство для воплощения неограниченной транзакционной памяти с гарантиями продвижения при пересылке, используя аппаратную глобальную блокировку, содержащее средство для исполнения способа по любому одному из пп. 11-20. Конкретные детали в Примерах могут использоваться везде в одном или больше вариантах осуществления.
В то время как раскрытие было представлено в отношении ограниченного количества вариантов осуществления, для специалистов в данной области техники будут понятны множество их модификаций и вариантов. Предполагается, что приложенная формула изобретения охватывает все такие модификации и модификации, которые попадают в пределы истинной сущности и объема данного раскрытия.
Конструкция может проходить через различные этапы, от формирования для моделирования до изготовления. Данные, представляющие конструкцию, могут представлять конструкцию с множеством подходов. Во-первых, что полезно при моделировании, аппаратные средства могут быть представлены, используя описательный язык аппаратных средств или другой язык функционального описания. Кроме того, модель уровня цепи с логикой и/или транзисторными вентилями может быть сформирована на некоторых этапах процесса конструирования. Кроме того, большинство конструкций, на определенном этапе, достигают уровня представления данными физического размещения различных устройств в аппаратной модели. В случае, когда используют обычные технологии изготовления полупроводников, данные, представляющие модель аппаратных средств, могут представлять собой данные, определяющие присутствие или отсутствие различных элементов на разных уровнях маски для масок, используемых для получения интегральной схемы. При любом представлении конструкции данные могут быть сохранены в любой форме считываемого устройством носителя информации. Память или магнитный, или оптический накопитель, такой как диск, может представлять собой считываемый компьютером носитель информации, предназначенный для сохранения информации, передаваемой через оптические или электрические волны, модулированные или по-другому генерируемые для передачи такой информации. Когда передают электрическую несущую волну, обозначающую или несущую код, или конструкцию, в той степени, что выполняется копирование, размещение в буфере или повторная передача электрического сигнала, получают новую копию. Таким образом, провайдер передачи данных или сетевой провайдер может сохранять на материальном, считываемом устройством носителе информации, по меньшей мере, временно, изделие, такое как информация, кодированная на несущей волне, воплощающая технологии вариантов осуществления настоящего раскрытия.
Модуль, используемый здесь, относится к любой комбинации аппаратных средств, программных средств и/или встроенного программного обеспечения. В качестве примера, модуль включает в себя аппаратное средство, такое как микроконтроллер, ассоциированный с энергонезависимым носителем информации, для сохранения кода, выполненного с возможностью его исполнения микроконтроллером. Поэтому, ссылка на модуль, в одном варианте осуществления, относится к аппаратным средствам, которые, в частности, выполнены с возможностью распознавания и/или исполнения кода, предназначенного для содержания на энергонезависимом носителе информации. Кроме того, в другом варианте осуществления, использование модуля относится к энергонезависимому носителю информации, включающему в себя код, который, в частности, выполнен с возможностью его исполнения микроконтроллером, для выполнения заданных операций. И как можно предположить, в еще одном, другом варианте осуществления, термин модуль (в этом примере) может относиться к комбинации микроконтроллера и энергонезависимого носителя информации. Часто границы модуля, которые иллюстрируются, как отдельные, как правило, изменяются и потенциально могут быть наложены друг на друга. Например, первый и второй модуль могут совместно использовать аппаратные средства, программное средство, встроенное программное обеспечение или их комбинацию, в то время, как они потенциально содержат некоторые независимые аппаратные средства, программное средство или встроенное программное обеспечение. В одном варианте осуществления использование термина логика включает в себя аппаратные средства, такие как транзисторы, регистры или другие аппаратные средства, такие как программируемые логические устройства.
Использование фразы "выполненный с возможностью", в одном варианте осуществления, относится к размещению, соединению вместе, изготовлению, предложению для продажи, импорту и/или конструированию устройства, аппаратного средства, логической схемы или элемента для выполнения назначенной или заданной задачи. В этом примере устройство или его элемент, который не работает, все еще "выполнен с возможностью" исполнения назначенной задачи, если он разработан, соединен и/или взаимно соединен для выполнения упомянутой назначенной задачи. В качестве просто иллюстративного примера, логический вентиль может представлять 0 или 1 во время работы. Но логический вентиль "выполненный с возможностью" предоставления разрешающего сигнала для тактовой частоты, не включает в себя каждый потенциальный логический вентиль, который может представлять 1 или 0. Вместо этого, логический вентиль представляет собой вентиль, соединенный определенным образом, в котором во время работы выход в виде 1 или 0 предназначен для включения тактовой частоты. Следует еще раз отметить, что использование термина "выполненный с возможностью" не требует операции, но, вместо этого, фокусируется на латентном состоянии устройства, аппаратных средств и/или элемента, где в латентном состоянии устройство, аппаратное средство и/или элемент разработан для выполнения определенной задачи, когда устройство, аппаратное средство и/или элемент работают.
Кроме того, использование фраз "для", "в состоянии/для" и "работающий для", в одном варианте осуществления относятся к определенному устройству, логике, аппаратному средству и/или элементу, разработанному так, что обеспечивается возможность использования этого устройства, логики, аппаратного средства и/или элемента определенным образом. Как отмечено выше, использование фраз "в состоянии для" или "работающий для", в одном варианте осуществления, относятся к скрытому состоянию устройства, логики, аппаратного средства и/или элемента, где устройство, логика, аппаратное средство и/или элемент не работают, но разработаны таким образом, что обеспечивается возможность использования устройства определенным образом.
Значение, используемое здесь, включает в себя любое известное представление числа, состояния, логического состояния или двоичного логического состояния. Часто использование логических уровней, значений логики или логических значений также обозначают, как 1-цы и 0-ли, которые просто представляют состояния двоичной логики. Например, 1 относится к высокому логическому уровню, и 0 относится к низкому логическому уровню. В одном варианте осуществления элемент памяти, такой как транзистор или ячейка памяти флэш, могут быть выполнены с возможностью содержания одного логического значения или множества логических значений. Однако использовались другие представления значений в компьютерных системах. Например, десятичное число десять также может быть представлено, как двоичное значение 910 и шестнадцатеричная буква А. Поэтому, значение включает в себя любое представление информации, которая может содержаться в компьютерной системе.
Кроме того, состояния могут быть представлены значениями или частями значений. В качестве примера, первое значение, такое как логическая единица, может представлять принятое по умолчанию состояние или исходное состояние, в то время как второе значение, такое как логический ноль, может представлять собой не принятое по умолчанию состояние. Кроме того, термины сброс и установка, в одном варианте осуществления, относятся к значению по умолчанию и обновленному значению или состоянию, соответственно. Например, принятое по умолчанию значение потенциально включает в себя высокое логическое значение, то есть, сброс, в то время как обновленное значение потенциально включает в себя низкое логическое значение, то есть, установку. Следует отметить, что любая комбинация значений может использоваться для представления любого количества состояний.
Варианты осуществления способов, аппаратных средств, программного обеспечения, встроенного программного обеспечения или кода, представленные выше, могут быть воплощены через инструкции или код, сохраненные в носителе информации с машинным доступном, считываемым устройством, компьютерным доступом или считываемым компьютером, которые исполняют с помощью элемента обработки. Энергонезависимый с машинным доступом/считываемый устройством носитель информации включает в себя любой механизм, который обеспечивает (то есть, сохраняет и/или передает) информацию в форме, считываемой устройством, таким как компьютер или электронная система. Например, энергонезависимый носитель информации с машинным доступом включает в себя оперативное запоминающее устройство (RAM), такое как статическое RAM (SRAM) или динамическое RAM (DRAM); ROM; магнитный или оптический накопитель информации; запоминающее устройство флэш; электрические устройства накопители; оптические устройства накопители; акустические устройства накопители; другую форму устройств накопителей для содержания информации, принятой из энергозависимых (распространяющихся) сигналов (например, несущих волн, инфракрасных сигналов, цифровых сигналов); и т.д., которые требуется отличать от энергонезависимых носителей информации, которые могут принимать информацию от них.
Инструкции, используемые для программирования логики, для выполнения вариантов осуществления раскрытия, могут быть сохранены в памяти, в системе, такой как DRAM, кэш, память типа флэш или в другом накопителе. Кроме того, инструкции могут быть распределены через сеть или используя другие считываемые компьютером носители информации. Таким образом, считываемый устройством носитель информации может включать в себя любой механизм для сохранения или передачи информации в форме, считываемой устройством (например, компьютером), но не ограничен этим, гибкие дискеты, оптические диски, компакт-диск, постоянное запоминающее устройство (CD-ROM) и магнитооптические диски, постоянное запоминающее устройство (ROM), оперативное запоминающее устройство (RAM), стираемое программируемое постоянное запоминающее устройство (EPROM), электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), магнитные или оптические карты, память типа флэш или физический, считываемый устройством накопитель, используемый при передаче информации через Интернет, через электрические, оптические, акустические или другие формы распространяющихся сигналов (например, волны носителей, инфракрасные сигналы, цифровые сигналы и т.д.). В соответствии с этим, считываемый компьютером носитель информации включает в себя любой тип физического считываемого устройством носителя информации, пригодного для сохранения или передачи электронных инструкций или информации в форме, считываемой устройством (например, компьютером).
Ссылки в данном описании на "один вариант осуществления" или "вариант осуществления" означают, что конкретное свойство, структура или характеристика, описанная в связи с вариантом осуществления, включена, по меньшей мере, в один вариант осуществления настоящего раскрытия. Таким образом, появление фраз "в одном варианте осуществления" или "в варианте осуществления" в различных местах в данном описании не обязательно все относятся к одному и тому же варианту осуществления. Кроме того, конкретные свойства, структуры, или характеристики могут быть скомбинированы любым соответствующим образом в одном или больше вариантах осуществления.
В предыдущем описании было представлено подробное описание изобретения со ссылкой на конкретные примерные варианты осуществления следует, однако, понимать, что различные модификации и изменения могут быть выполнены в его отношении без выхода за пределы широкой сущности и объема раскрытия, как представлено в приложенной формуле изобретения. Описание и чертежи, соответственно, следует рассматривать в иллюстративном смысле, а не в ограничительном смысле. Кроме того, представленное выше описание варианта осуществления и другие формулировки не обязательно относятся к одному и тому же варианту осуществления или одному примеру, но могут относиться к разным и отдельным вариантам осуществления, а также потенциально к одному и тому же варианту осуществления.
| название | год | авторы | номер документа |
|---|---|---|---|
| РАСШИРЕНИЕ СОГЛАСУЮЩЕГО ПРОТОКОЛА ДЛЯ ИНДИКАЦИИ СОСТОЯНИЯ ТРАНЗАКЦИИ | 2015 |
|
RU2665306C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ УСОВЕРШЕНСТВОВАННЫХ ТЕХНОЛОГИЙ ПРОПУСКА БЛОКИРОВКИ | 2014 |
|
RU2595925C2 |
| СПОСОБ И СИСТЕМА ДЛЯ УПРАВЛЕНИЯ ВЫПОЛНЕНИЕМ ВНУТРИ ВЫЧИСЛИТЕЛЬНОЙ СРЕДЫ | 2012 |
|
RU2577487C2 |
| МЕХАНИЗМ ЗАПРОСА ПОЗДНЕЙ БЛОКИРОВКИ ДЛЯ ПРОПУСКА АППАРАТНОЙ БЛОКИРОВКИ (HLE) | 2008 |
|
RU2501071C2 |
| ВЫПОЛНЕНИЕ ВЫНУЖДЕННОЙ ТРАНЗАКЦИИ | 2012 |
|
RU2549112C2 |
| ФИЛЬТРАЦИЯ ПРОГРАММНОГО ПРЕРЫВАНИЯ В ТРАНЗАКЦИОННОМ ВЫПОЛНЕНИИ | 2012 |
|
RU2568923C2 |
| СОХРАНЕНИЕ/ВОССТАНОВЛЕНИЕ ВЫБРАННЫХ РЕГИСТРОВ ПРИ ТРАНЗАКЦИОННОЙ ОБРАБОТКЕ | 2012 |
|
RU2562424C2 |
| БЛОК ДИАГНОСТИКИ ТРАНЗАКЦИЙ | 2012 |
|
RU2571397C2 |
| СПОСОБ, УСТРОЙСТВО И СИСТЕМА УМЕНЬШЕНИЯ ВРЕМЕНИ ВОЗОБНОВЛЕНИЯ РАБОТЫ ДЛЯ КОРНЕВЫХ ПОРТОВ И КОНЕЧНЫХ ТОЧЕК, ИНТЕГРИРОВАННЫХ В КОРНЕВЫЕ ПОРТЫ | 2014 |
|
RU2645596C1 |
| ОБРАБОТКА ТРАНЗАКЦИЙ | 2013 |
|
RU2606878C2 |
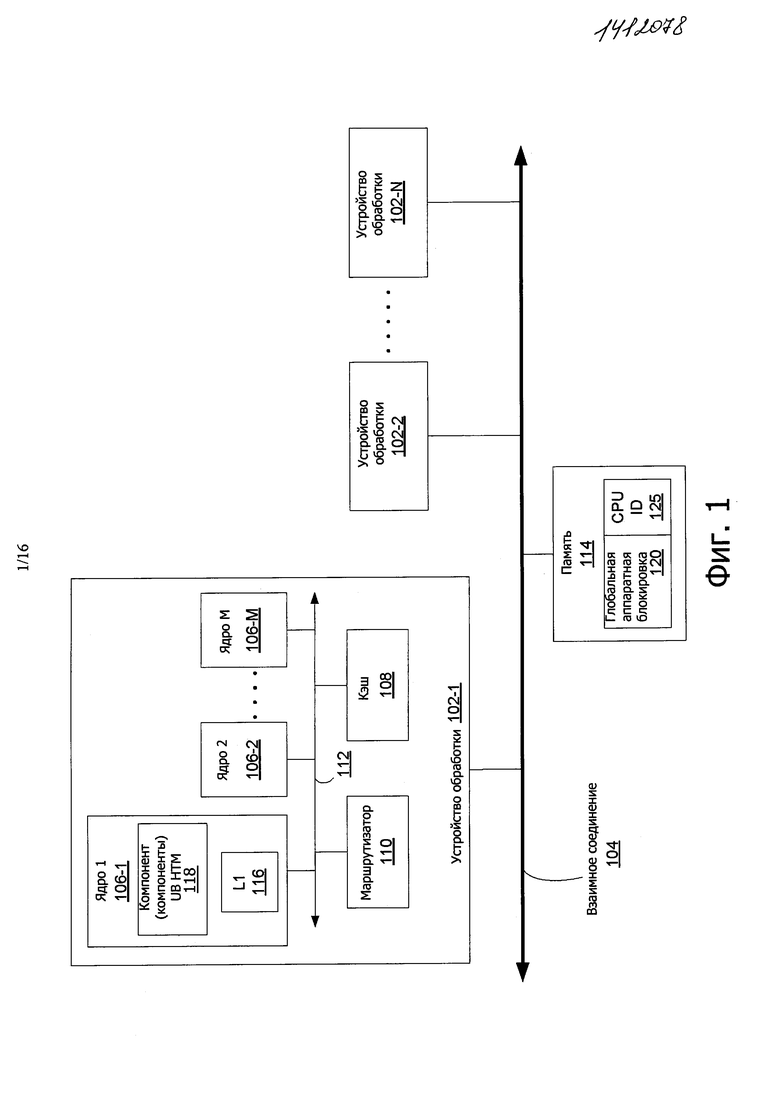
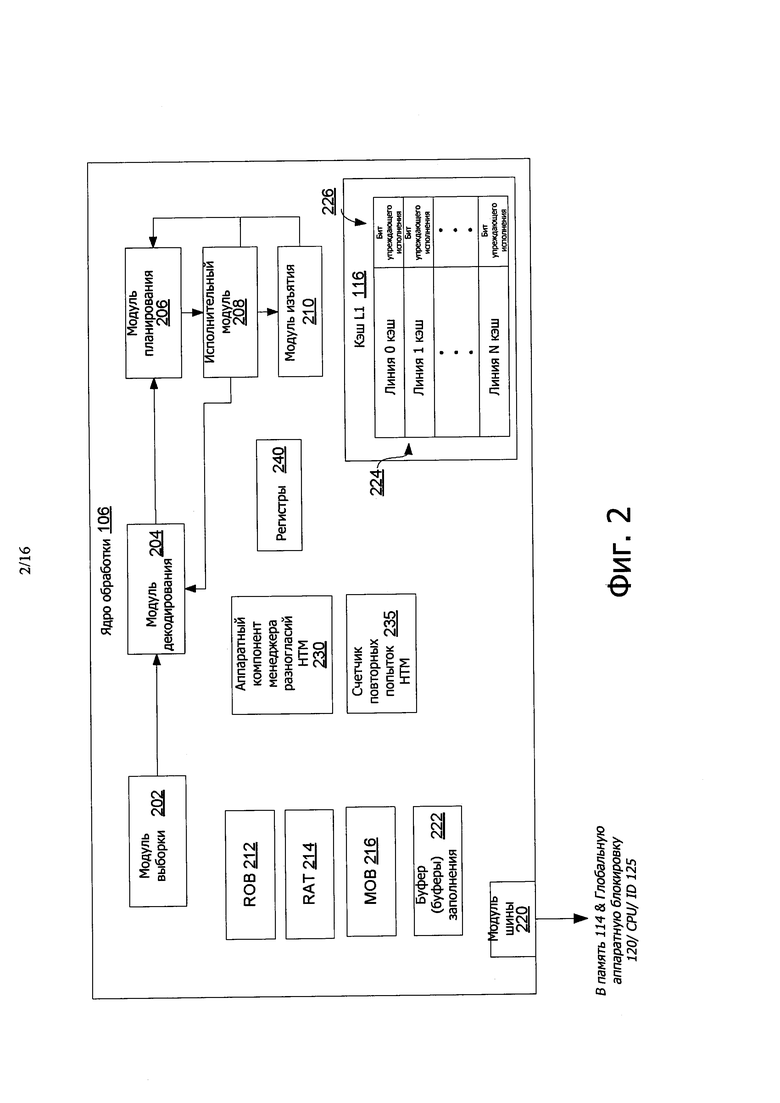
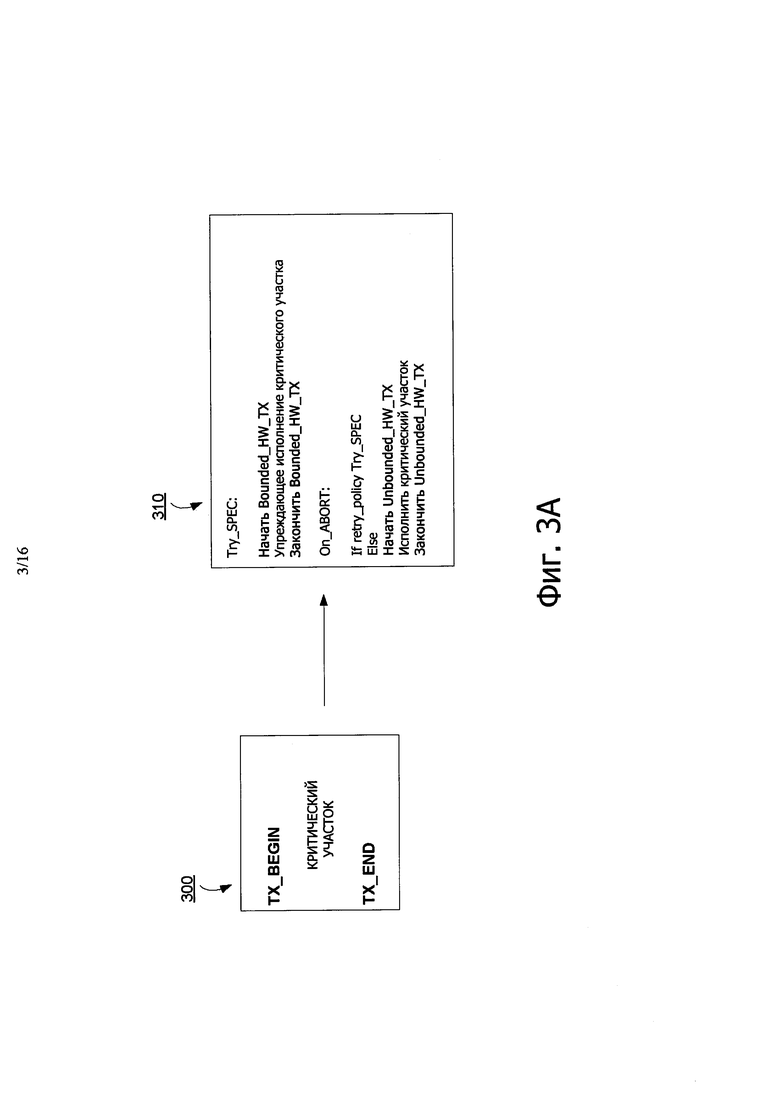
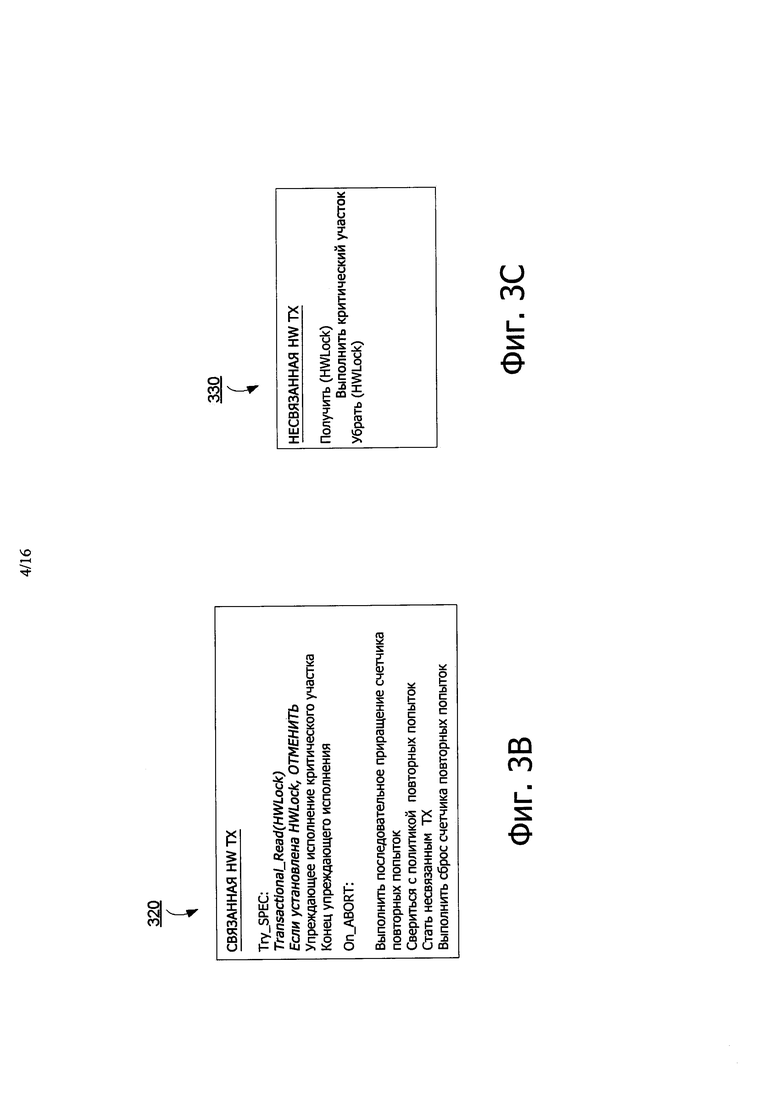

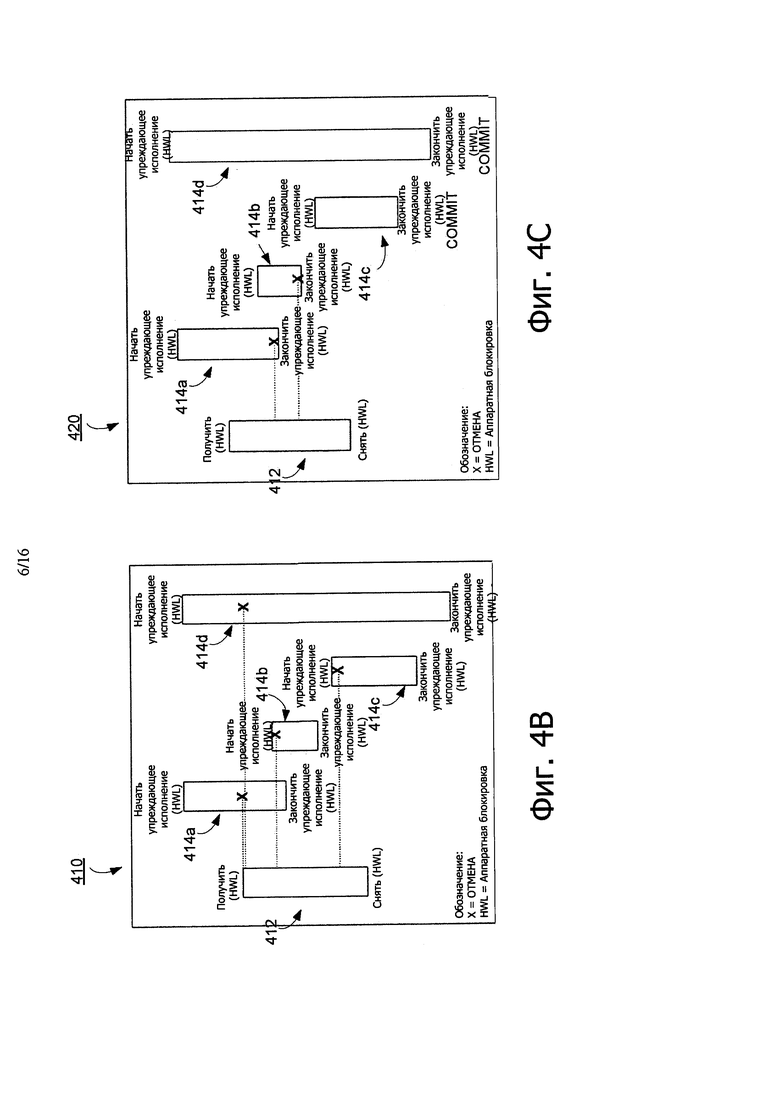
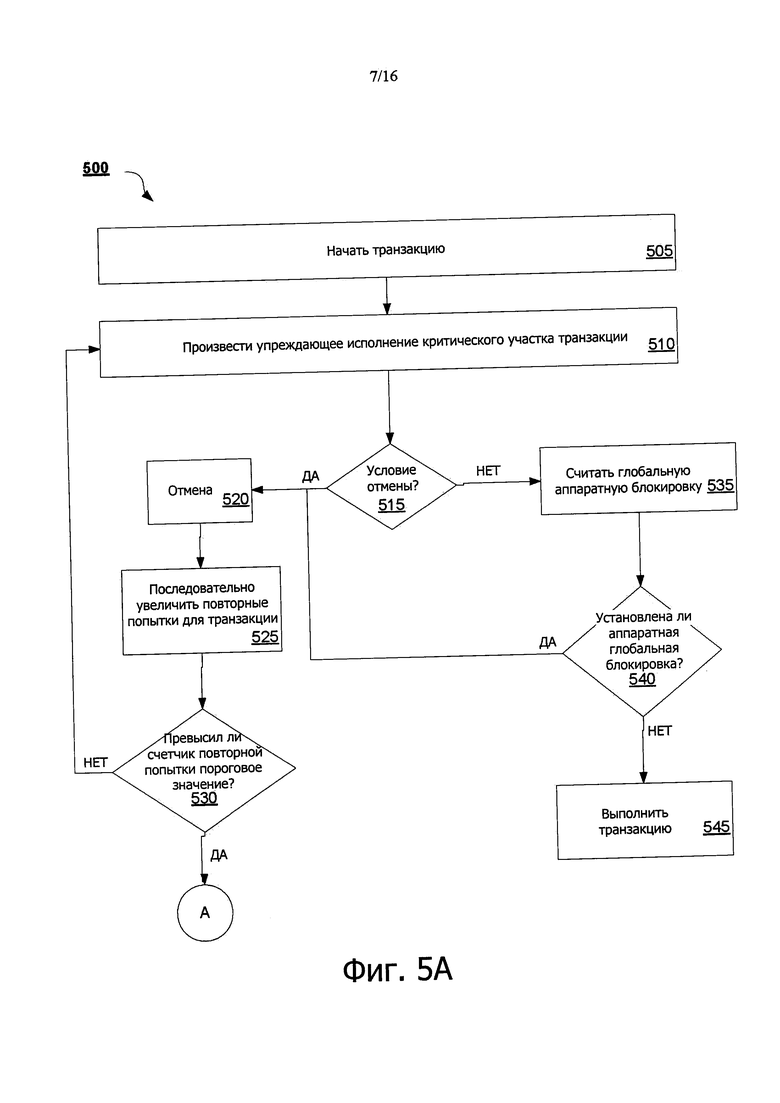
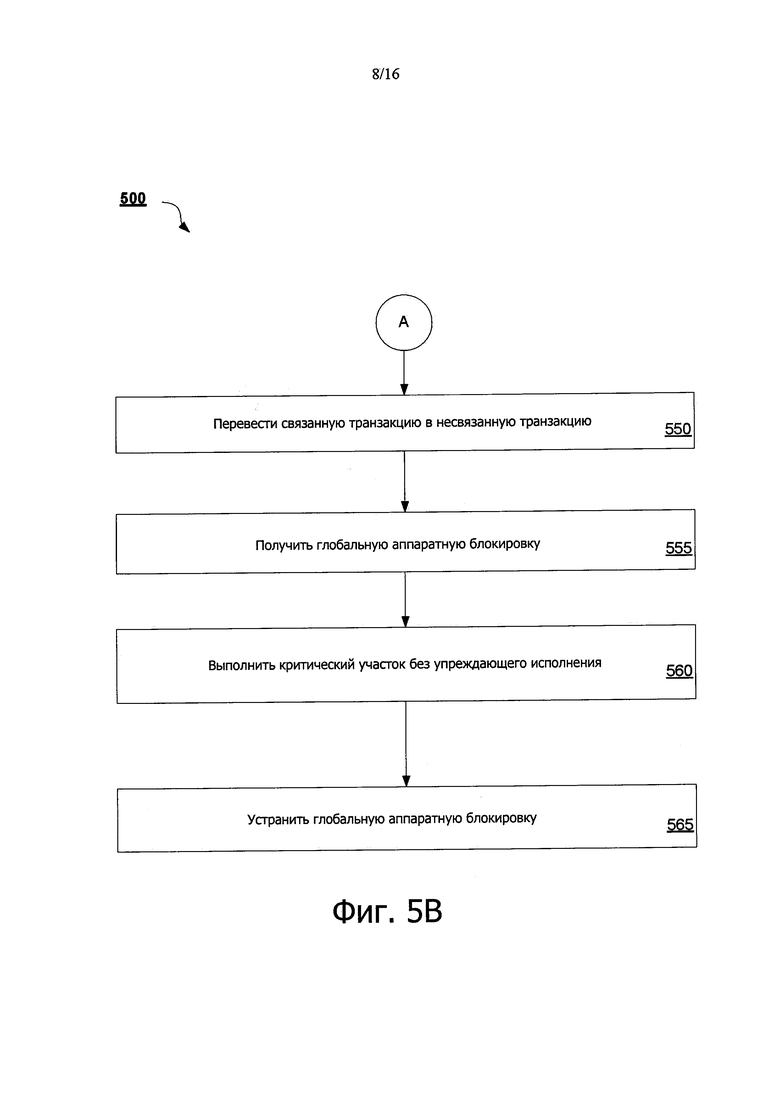
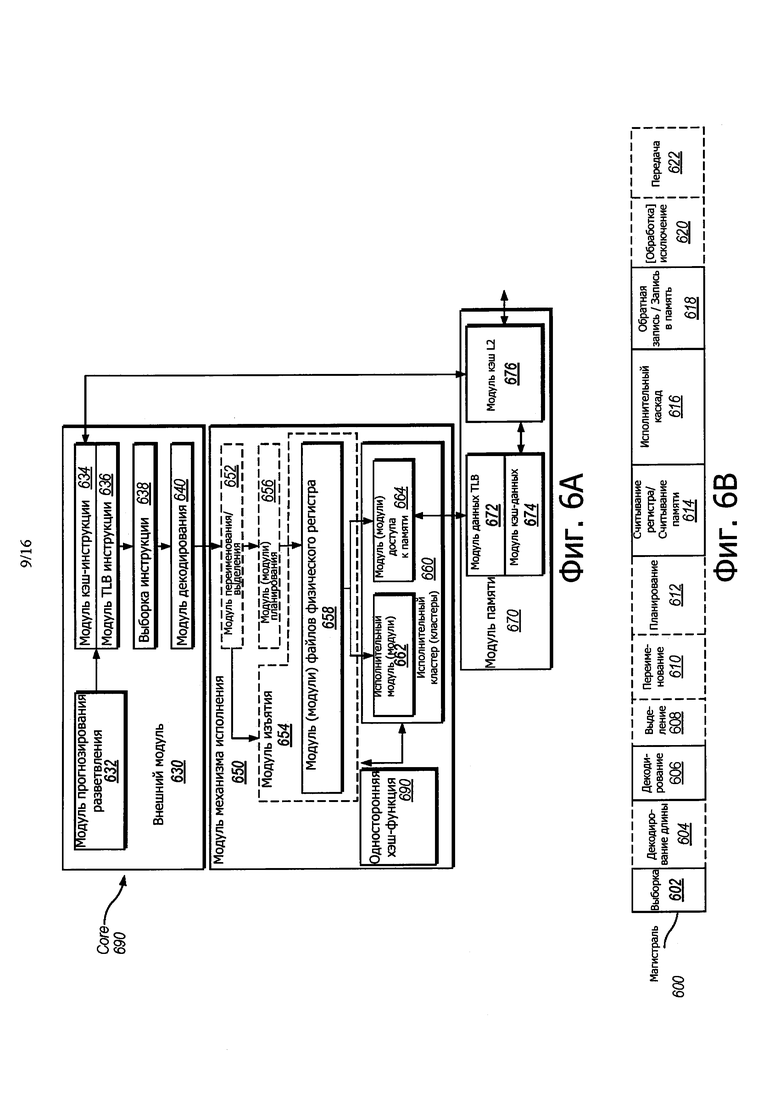
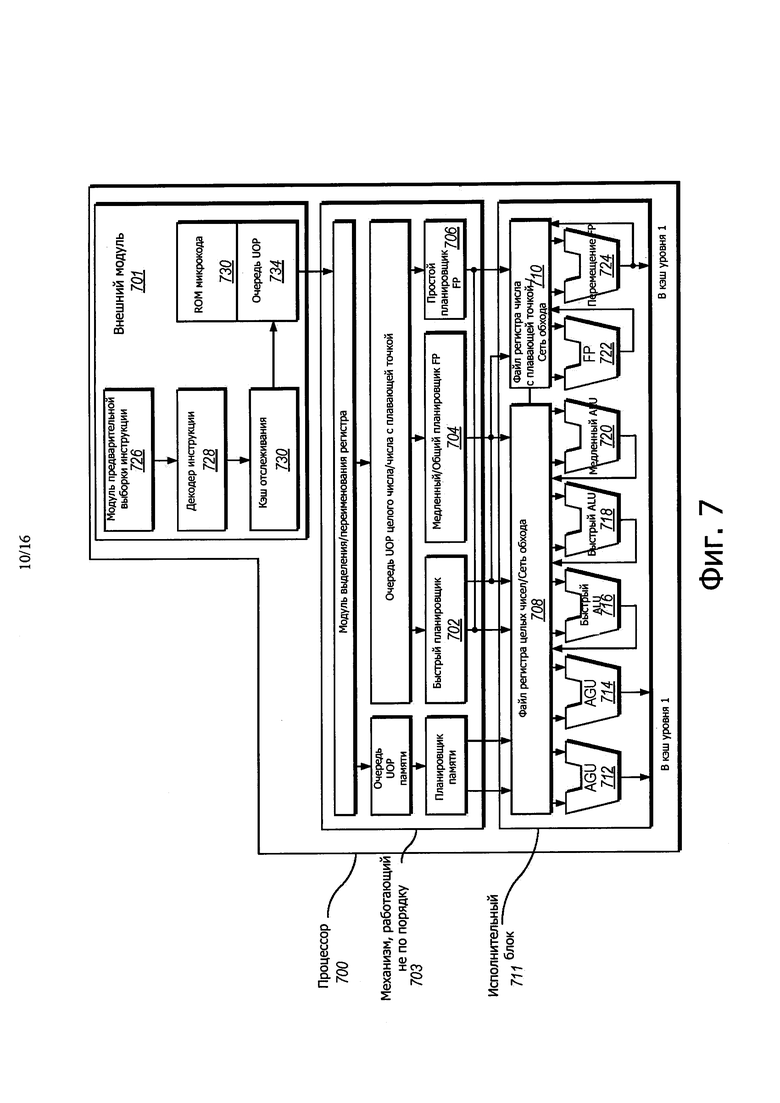
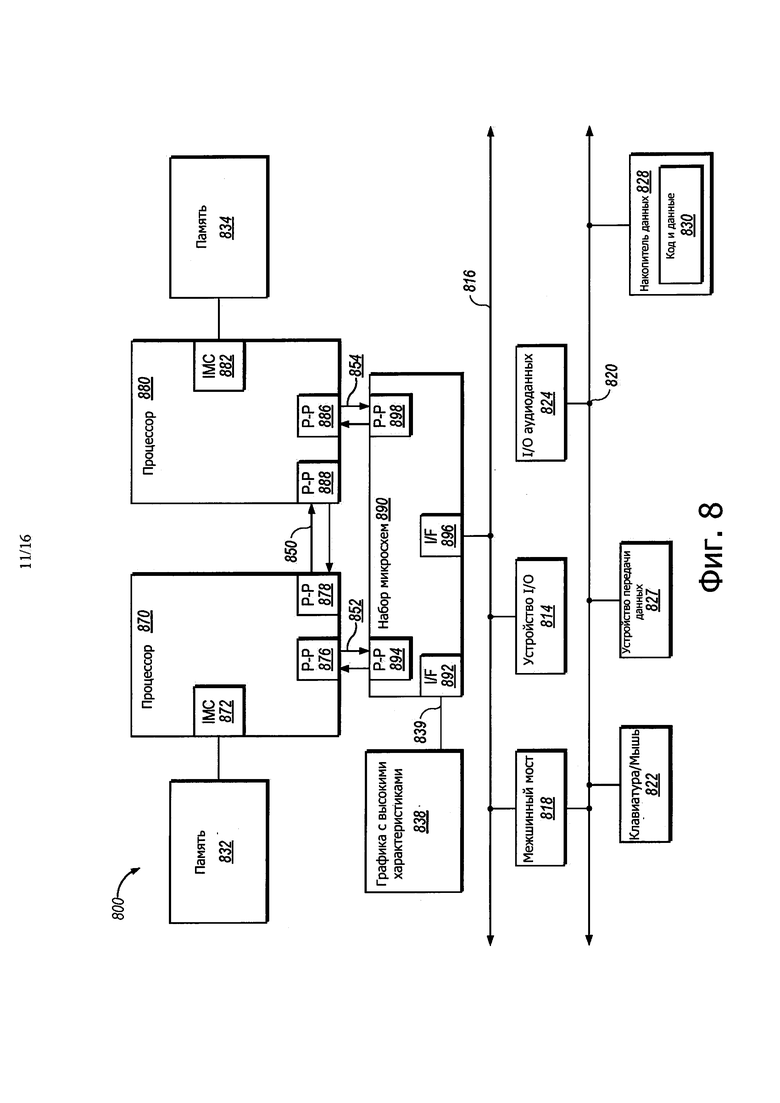
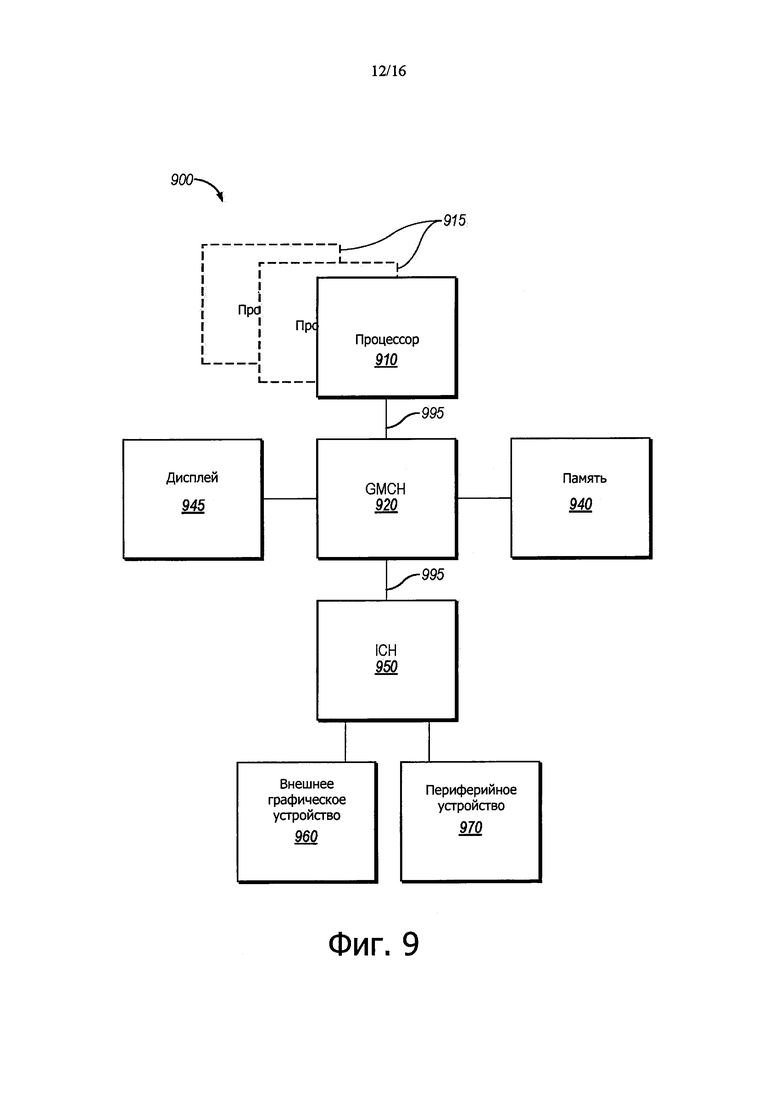
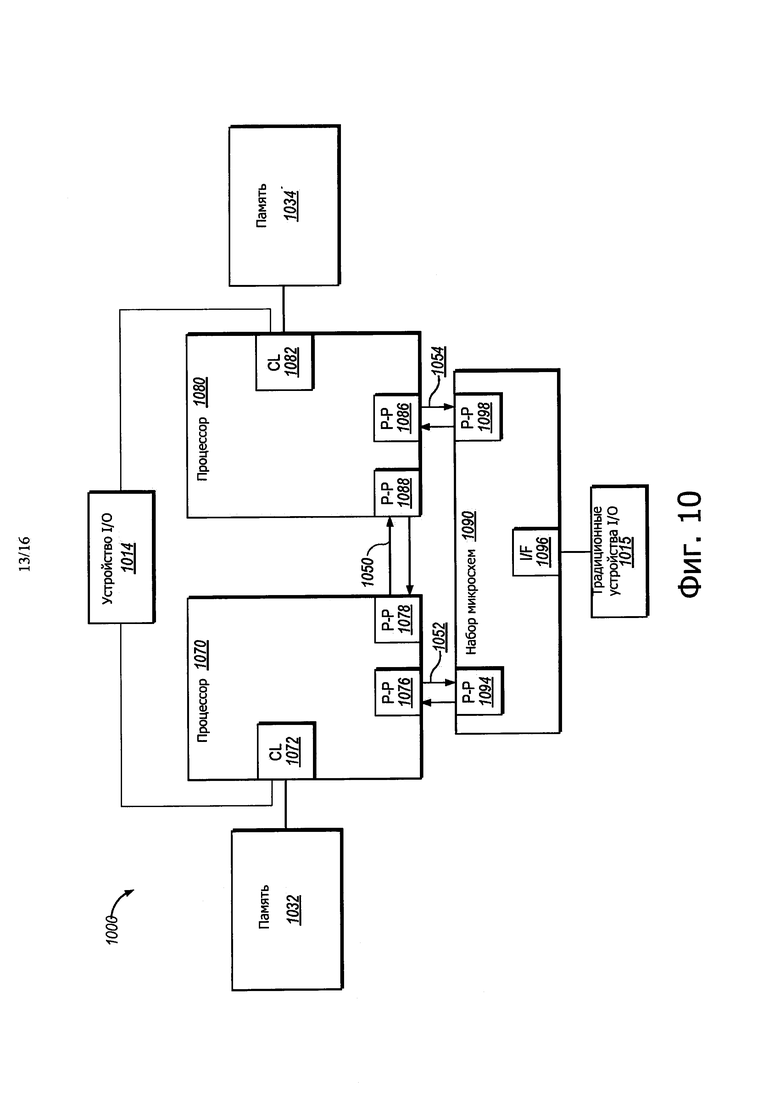
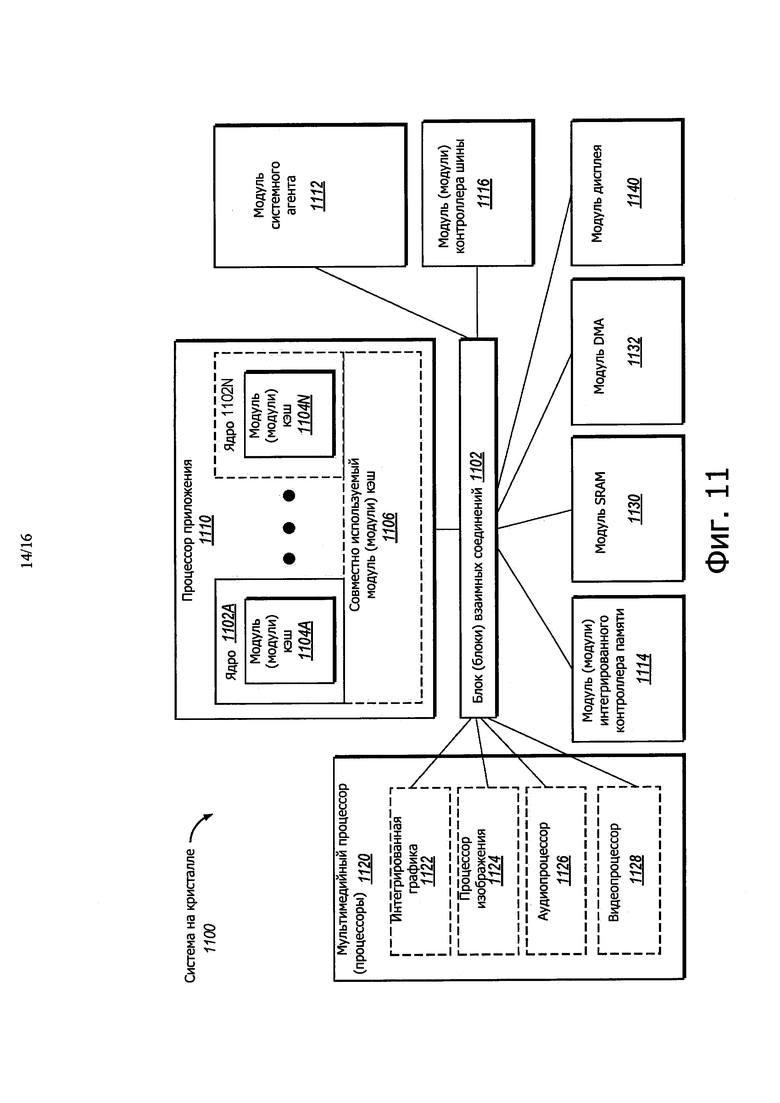
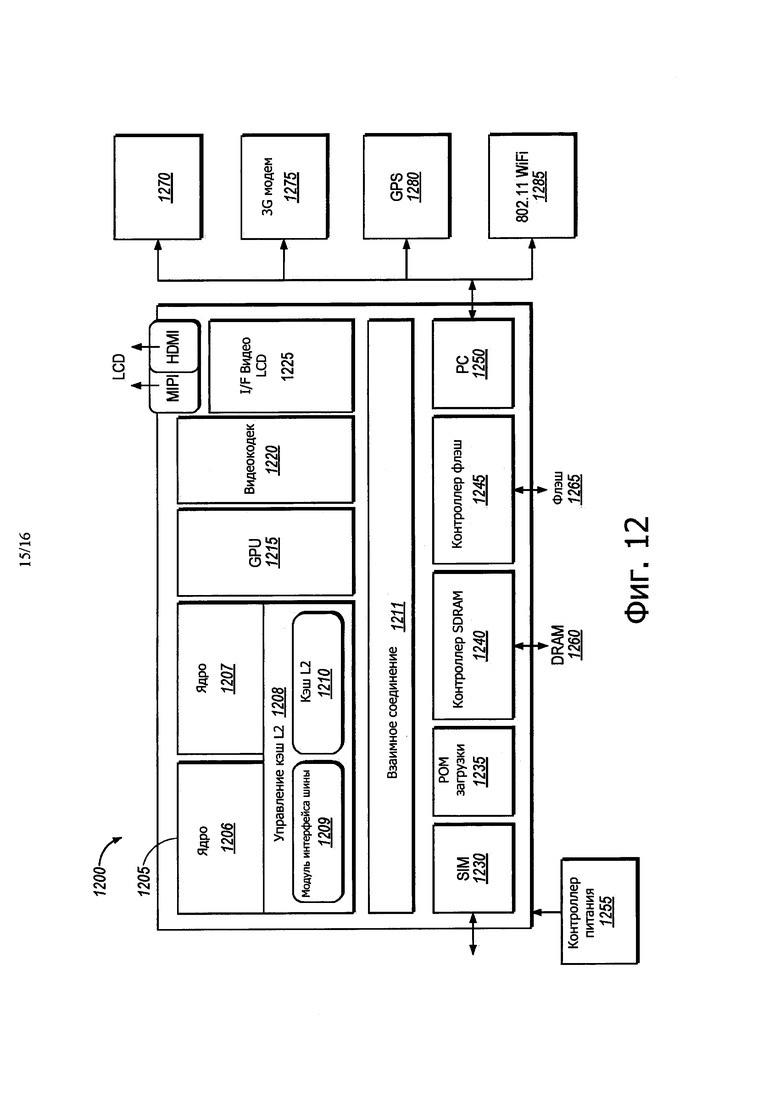
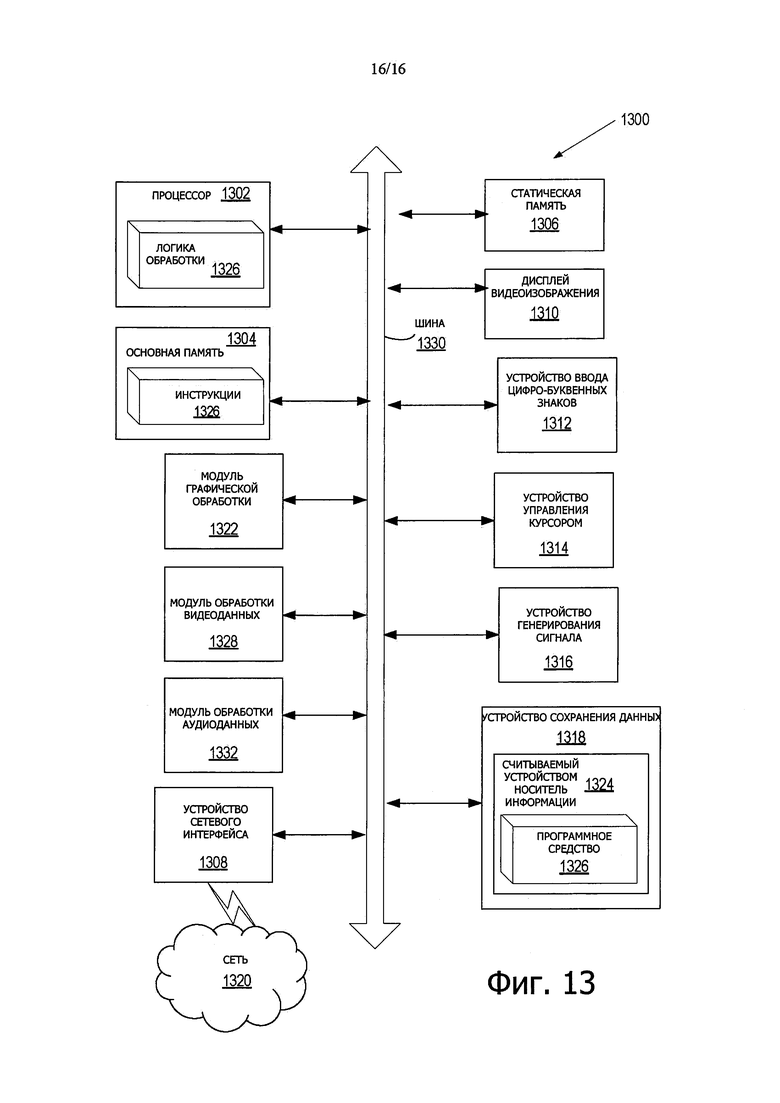
Изобретение относится к вычислительной технике. Технический результат заключается в гарантировании выполнения транзакции, используя аппаратную глобальную блокировку. Устройство обработки потоков содержит аппаратный менеджер разногласий аппаратной транзакционной памяти (НТМ), который обеспечивает перевод транзакции с упреждающим исполнением из множества транзакций с упреждающим исполнением в транзакцию без упреждающего исполнения, при этом транзакция без упреждающего исполнения предназначена для получения глобальной аппаратной блокировки для транзакции без упреждающего исполнения, а глобальная аппаратная блокировка считывается оставшимися транзакциями с упреждающим исполнением, которые отменяют, если глобальная аппаратная блокировка получена; и исполнительный модуль для исполнения инструкций транзакции без упреждающего исполнения без упреждения, в то время как глобальная аппаратная блокировка получена для транзакции без упреждающего исполнения, при этом транзакция без упреждающего исполнения предназначена для освобождения глобальной аппаратной блокировки после завершения исполнения инструкций транзакции без упреждающего исполнения. 3 н. и 22 з.п. ф-лы, 19 ил. 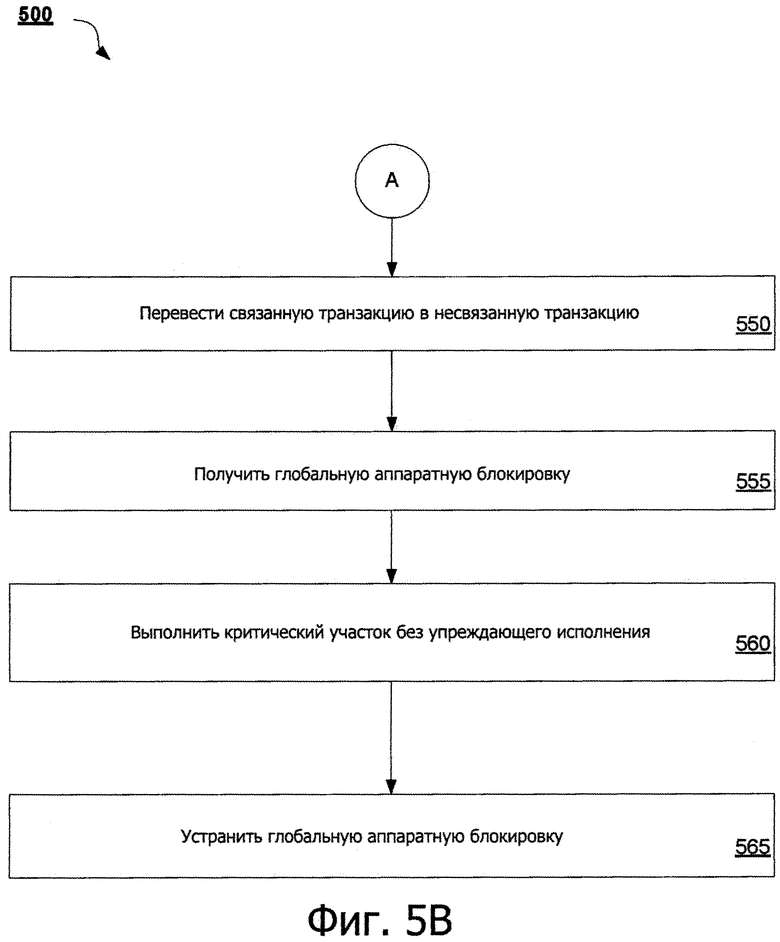
1. Устройство обработки, содержащее:
аппаратную транзакционную память (HTM), аппаратный менеджер разногласий, который обеспечивает перевод связанных транзакций в несвязанные транзакции, при этом несвязанная транзакция получает глобальную аппаратную блокировку для несвязанной транзакции, глобальная аппаратная блокировка считывается связанными транзакциями, которые отменяют, когда применяют глобальную аппаратную блокировку; и
исполнительный модуль, соединенный с возможностью обмена данными с аппаратным менеджером разногласий НТМ для исполнения инструкций несвязанной транзакции без упреждающего исполнения, несвязанная транзакция вырабатывает глобальную аппаратную блокировку после завершение исполнения инструкций.
2. Устройство обработки по п. 1, в котором аппаратный менеджер разногласий НТМ обеспечивает обращение к политике повторной попытки для определения, когда следует выполнять перевод связанной транзакции в несвязанную транзакцию.
3. Устройство обработки по п. 2, дополнительно содержащее счетчик повторных попыток НТМ, к которому обращается аппаратный менеджер разногласий НТМ, как часть политики повторных попыток, в котором когда счетчик повторных попыток НТМ, ассоциированный со связанной транзакцией, превышает пороговое значение повторных попыток, менеджер разногласий аппаратных средств НТМ обеспечивает перевод связанной транзакции в несвязанную транзакцию.
4. Устройство обработки по п. 3, в котором связанную транзакцию переводят в несвязанную транзакцию при возникновении состояния отмены, вызванного конфликтом, и при превышении счетчиком повторных попыток НТМ порогового значения повторных попыток.
5. Устройство обработки по п. 1, в котором связанную транзакцию переводят в несвязанную транзакцию при возникновении состояния отмены, содержащего, по меньшей мере, одну неподдерживаемую инструкцию или состояние переполнения.
6. Устройство обработки по п. 1, в котором связанные транзакции считывают глобальную аппаратную блокировку перед упреждающим исполнением инструкций связанных транзакций.
7. Устройство обработки по п. 1, в котором связанные транзакции считывают глобальную аппаратную блокировку перед упреждающим исполнением инструкций связанных транзакций..
8. Устройство обработки по п. 1, в котором глобальную аппаратную
блокировку поддерживают в основной памяти, ассоциированной с устройством обработки.
9. Устройство обработки по п. 8, в котором накопитель для идентификатора (ID) CPU ассоциирован с глобальной аппаратной блокировкой и содержит ID CPU, соответствующий CPU потока, исполняющего несвязанную транзакцию, которая получает глобальную аппаратную блокировку.
10. Устройство обработки по п. 1, в котором исполнение инструкций несвязанных транзакций, гарантирующих продвижение при пересылке устройства обработки, в качестве несвязанных транзакций, не может быть отменено и, по мере того, как связанные транзакции становятся несвязанными транзакциями, по меньшей мере, после того, как их отменят заданное количество раз.
11. Способ, содержащий:
выполняют перевод связанной транзакции в несвязанную транзакцию;
получают глобальную аппаратную блокировку для несвязанной транзакции, глобальную аппаратную блокировку считывают связанные транзакции, которые отменяют, когда глобальная аппаратная блокировка установлена;
исполняют инструкции несвязанной транзакции без упреждающего исполнения; и
устраняют глобальную аппаратную блокировку.
12. Способ по п. 11, дополнительно содержащий дополнительную ссылку на политику повторной попытки, для определения, когда следует перевести связанную транзакцию в несвязанную транзакцию, в котором счетчик повторной попытки НТМ, на который ссылаются, как на часть политики повторной попытки, в котором когда счетчик повторной попытки НТМ, ассоциированный со связанной транзакцией, превышает пороговое значение повторной попытки, связанную транзакцию преобразуют в несвязанную транзакцию.
13. Способ по п. 12, в котором связанную транзакцию переводят в несвязанную транзакцию при возникновении состояния отмены, вызванного конфликтом, и при превышении счетчиком повторных попыток НТМ порогового значения повторных попыток.
14. Способ по п. 11, в котором выполняют перевод связанной транзакции в несвязанную транзакцию после возникновения состояния отмены, содержащего, по меньшей мере, одну из неподдерживаемой инструкции или состояния переполнения.
15. Способ по п. 11, в котором связанные транзакции считывают глобальную аппаратную блокировку перед упреждающим исполнением инструкций связанных транзакций.
16. Способ по п. 11, в котором связанные транзакции, считывают глобальную аппаратную блокировку, как часть процедуры передачи, следующей после упреждающего исполнения инструкций связанных транзакций.
17. Способ по п. 11, в котором глобальную аппаратную блокировку поддерживают в основной памяти, ассоциированной с устройством обработки.
18. Способ по п. 17, в котором накопитель для идентификатора (ID) CPU ассоциирован с глобальной аппаратной блокировкой и содержит CPU ID, соответствующий CPU потока, исполняющего несвязанную транзакцию, которая получает глобальную аппаратную блокировку.
19. Система содержащая:
память для сохранения глобальной аппаратной блокировки; и
устройство обработки, соединенное с памятью с возможностью передачи данных для:
перевода связанной транзакции в несвязанную транзакцию;
получения глобальной аппаратной блокировки для несвязанной транзакции, глобальную аппаратную блокировку считывают связанные транзакции, которые отменяют, когда глобальная аппаратная блокировка установлена;
исполнения инструкций несвязанной транзакции без упреждающего исполнения;
и устранения глобальной аппаратной блокировки.
20. Система по п. 19, дополнительно содержащая: обращаются к политике повторной попытки для определения, когда следует перевести связанную транзакцию в несвязанную транзакцию, в которой к счетчику повторных попыток НТМ обращаются, как к части политики повторных попыток, в котором когда счетчик повторных попыток НТМ, ассоциированный со связанной транзакцией, превышает пороговое значение повторных попыток, связанную транзакцию преобразуют в несвязанную транзакцию.
21. Система по п. 20, в которой связанную транзакцию переводят в несвязанную транзакцию при возникновении состояния отмены, вызванного конфликтом, и при превышении счетчиком повторных попыток НТМ, порогового значения повторных попыток.
22. Система по п. 19, в которой связанную транзакцию переводят в несвязанную транзакцию при возникновении состояния отмены, содержащего, по меньшей мере, одну из неподдерживаемых инструкций или состояния переполнения.
23. Система по п. 19, в которой связанные транзакции, считывают глобальную аппаратную блокировку перед упреждающим исполнением инструкций связанных
транзакций.
24. Система по п. 19, в которой связанные транзакции, считывают глобальную аппаратную блокировку, как часть процедуры передачи, следующей после упреждающего исполнения инструкций связанных транзакций.
25. Система по п. 19, в которой глобальную аппаратную блокировку поддерживают в основной памяти, ассоциированной с устройством обработки, и в которой накопитель для идентификатора (ID) CPU ассоциирован с глобальной аппаратной блокировкой и содержит CPU ID, соответствующий CPU потока, исполняющего несвязанную транзакцию, которая получает глобальную аппаратную блокировку.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| ПОРЯДОК ФИКСАЦИИ ПРОГРАММНЫХ ТРАНЗАКЦИЙ И УПРАВЛЕНИЕ КОНФЛИКТАМИ | 2007 |
|
RU2439663C2 |
| ОПТИМИЗАЦИЯ ОПЕРАЦИЙ ПРОГРАММНОЙ ТРАНЗАКЦИОННОЙ ПАМЯТИ | 2006 |
|
RU2433453C2 |

