ОБЛАСТЬ ТЕХНИКИ
[0001] Заявленное решение относится к области защиты информации, в частности к решениям для предотвращения утечки информации при печати документов.
УРОВЕНЬ ТЕХНИКИ
[0002] Технологии предотвращения утечек (англ. Data Leak Prevention, DLP) представляют собой технологии предотвращения утечек конфиденциальной информации из информационной системы вовне, а также технические устройства (программные или программно-аппаратные) для такого предотвращения утечек.
[0003] Из патентной заявки US 20080091954 A1 (Morris et al., 17.04.2008) известно решение для проверки целостности данных, представленных на печатных документах. Решение базируется на применении уникального идентификатора, с помощью которого осуществляется анализ содержимого документа. Каждому сегменту документа присваивается цифра или группа цифр, и каждой странице или сегменту документа может быть присвоена одна цифра в общем идентификаторе. Совокупность цифр, связанных с документом, объединяется в строку аутентификации. При получении запроса на последующую обработку документа выполняется аутентификация и проверка целостности документа путем считывания представленного документа для получения строки аутентификации, и последующего сравнения новой строки с ранее сохраненной строкой. После успешного сопоставления документ считается действительным, аутентифицированным и неизмененным.
[0004] Недостатком данного решения является невозможность его использования для предотвращения утечек с целью идентификацию сотрудника, допустившего факт утечки при печати документов. Также, другим недостатком является недостаточная эффективность защиты документов, что обусловлено применением кода для сравнения аутентичности документа, что позволяет только установить факт неизменности и подлинности документа, но не предотвратить утечку информации.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0005] Заявленное изобретение направлено на решение технической проблемы, заключающейся в создании эффективного средства для защиты цифровой информации от утечки при ее печати.
[0006] Технический результат заключается в повышении эффективности защиты данных от утечки, за счет внедрения цифровых меток в документ, кодирующих уникальный идентификатор пользователя, для последующей его идентификации при анализе распечатанных документах.
[0007] Заявленный результат достигается за счет способа кодирования информации для защиты от ее утечек при печати документов, выполняемого с помощью процессора компьютерного устройства, при этом способ содержит этапы, на которых:
получают на компьютерном устройстве пользователя информацию о печати по меньшей мере одного цифрового документа, содержащего по меньшей мере текст, при этом компьютерное устройство связано с уникальным идентификатором (УИД) пользователя;
осуществляют до момента передачи цифрового документа на печать его обработку, в ходе которой
распознают буквы, содержащиеся в цифровом документе;
кодируют УИД пользователя в набор цифровых меток, которые располагаются на контурах букв и/или вблизи контуров букв цифрового документа;
передают цифровой документ на печать с закодированным УИД пользователя.
[0008] В одном из частных примеров реализации способа распознавание цифрового документа выполняется с помощью оптического распознавания символов (OCR).
[0009] В другом частном примере реализации способа распознаются все символы на каждой странице цифрового документа.
[0010] В другом частном примере реализации способа каждый символ УИД пользователя кодируется в двоичный код.
[0011] В другом частном примере реализации способа на основании разряда двоичного кода определяется область размещения цифровых меток.
[0012] Заявленный технический результат также достигается за счет осуществления способа защиты информации от утечек на печатных документах, выполняемого с помощью процессора компьютерного устройства, при этом способ содержит этапы, на которых:
получают по меньшей мере часть изображения печатного документа с закодированным УИД пользователя вышеуказанным способом;
выполняют распознавание полученного изображения;
определяют буквы, содержащие цифровые метки в своей окрестности;
выполняют определение и извлечение закодированного УИД.
[0013] В одном из частных примеров выполнения способа распознавание цифрового документа выполняется с помощью OCR.
[0014] Заявленное решение также осуществляется с помощью соответствующих систем, содержащих процессор и память, которые хранят машиночитаемые инструкции для реализации каждого из вышеописанных способов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0015] Фиг. 1 иллюстрирует блок-схему способа кодирования цифровой метки.
[0016] Фиг. 2А-2В иллюстрируют примеры размещения цифровых меток в цифровом документе.
[0017] Фиг. 3 иллюстрирует блок-схему декодирования цифровых меток.
[0018] Фиг. 4 иллюстрирует диаграмму час раскрытия позиций УИД.
[0019] Фиг. 5 иллюстрирует общий вид вычислительного устройства.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0020] На Фиг. 1 представлен способ (100) защиты информации в цифровых документах от утечки с помощью кодирования УИД пользователя в виде цифровых меток в документ. На первом этапе (101) получается информация о печати цифрового документа. Выполнение способа (100) осуществляется на компьютерном устройстве пользователя, например, сотрудника, при этом к устройству привязан УИД пользователя, позволяющий его идентифицировать. Исполнение этапа (101) одушевляется с помощью программной логики, исполняемой компьютерным устройством и может быть реализовано, например, в виде программного агента или модуля, обеспечивающего получение сигналов от процессора, свидетельствующих об отправке цифрового документа на печать. Цифровой документ представляет собой, как правило, файл и может содержать текст, графику или их сочетания.
[0021] После получения на устройстве команды на перехват и анализ документа до его отправки на принтер на этапе (102) выполняется распознавание упомянутого цифрового документа. Обработка документа выполняется с помощью технологии OCR для обеспечения распознавания букв и символов в цифровом документе.
[0022] После этапа распознавания цифрового документа на этапе (103) осуществляется процесс кодирования УИД. УИД представляет собой, например, числовой табельный номер сотрудника - цифровой код TAB, состоящий, например, из 8-ми цифр. Данный код можно представить как массив цифр ТАВ8={n1, n2, …nm}, ТАВ8 ∈ [0…9], m=8. Схематичный вид кода представлен в таблице.

[0023] Каждый элемент табельного номера представляет собой число от 0 до 9, соответственно, каждый элемент табельного номера можно отобразить в двоичном виде размерностью в 4 бит, т.е. он будет представлять собой двоичное число от 1 до 1100, являющееся гомоморфизмом со сдвигом, представленным в таблице 2.

[0024] Отображение 0 в 0001 необходимо для того, чтобы фиксировать наличие 0 в табельном номере. Для кодирования элемента табельного номера в двоичном коде 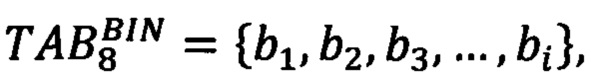 i=8, необходимо 4 разряда bi={с1, с2, с3, с4}, пример которых представлен в Таблице 3.
i=8, необходимо 4 разряда bi={с1, с2, с3, с4}, пример которых представлен в Таблице 3.

[0025] Таким образом, возможно кодировать любое число в букву посредством двоичного кодирования. Пример такого разделения для последующего кодирования представлено на Фиг. 2А - Фиг. 2В. Каждая распознанная буква (20) делится на 4 четверти в плоскости по часовой стрелке, начиная с левого нижнего угла.
[0026] При наличии 1-цы в I разряде двоичного представления цифры табельного номера с1 метка размещается в I четверти. Аналогичные операции проводятся со всеми разрядами двоичного представления цифры.
[0027] Метод нанесения метки в пространство возле буквы заключается в том, что как по казано на Фиг. 2Б-2В наносится цифровая метка в виде линии (21) на поверхности буквы или точки (22) в окрестности буквы в заданной четверти.
[0028] Пример кодирования меток в буквы представлен в Таблице 4.
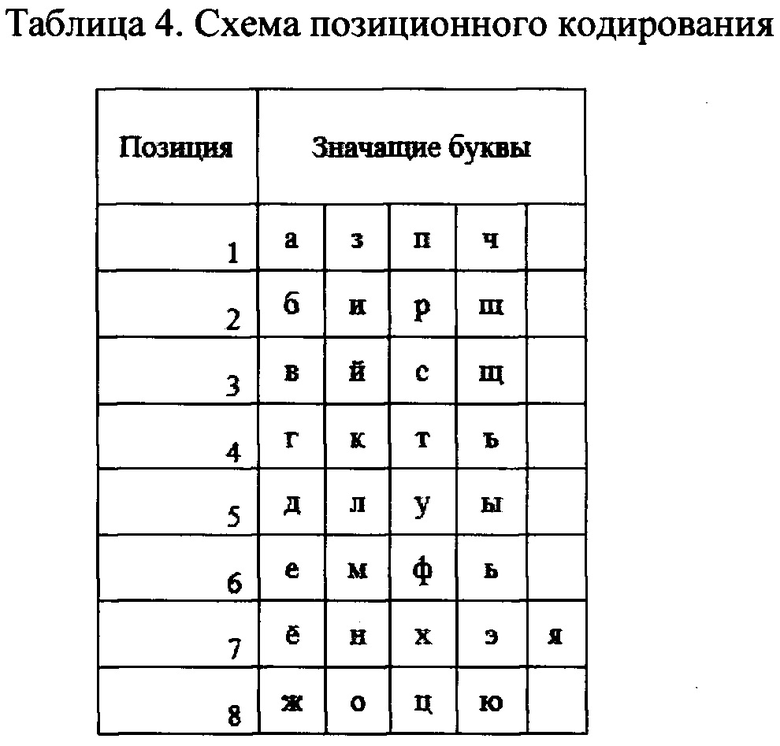
[0029] Выше представленная таблица 4 означает, что каждую позицию числа в табельном номере возможно кодировать на любую из 4-х букв. Выбор букв для нанесения метки осуществляется постранично. Пусть документ D содержит  страниц, тогда документ D - есть массив страниц,
страниц, тогда документ D - есть массив страниц, 
[0030] На каждой странице pi, 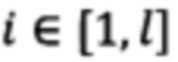 считывается посимвольно текст и записывается в массив символов
считывается посимвольно текст и записывается в массив символов  где
где  - количество символов на странице pi, из них выявляются русские буквы
- количество символов на странице pi, из них выявляются русские буквы 
[0031] Далее создаются 8 массивов Pos1, Pos2…Pos8, каждый из которых соответствует каждой позиции табельного номера. Каждый массивов Pos заполняется теми символами из  которые соответствуют позиции из таблицы 4. Например, Pos1, заполняется всеми символами из
которые соответствуют позиции из таблицы 4. Например, Pos1, заполняется всеми символами из  которые имеют значения {а, з, п, ч}, вне зависимости от регистра.
которые имеют значения {а, з, п, ч}, вне зависимости от регистра.
[0032] Массивы Pos1, Pos2…Pos8 перемешиваются, к примеру, тасованием Кнута. Пусть 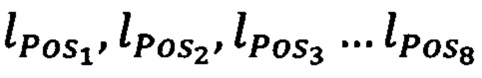 - размерности полученных массивов, Р - процент символов на внедрение метки Р∈[0,3…0,7], тогда каждый массив из Pos1, Pos2…Pos8 обрезается с конца до размерности
- размерности полученных массивов, Р - процент символов на внедрение метки Р∈[0,3…0,7], тогда каждый массив из Pos1, Pos2…Pos8 обрезается с конца до размерности 
[0033] Полученные массивы  используются для нанесения цифровых меток вышеописанным способом. Внесение цифровых меток осуществляется с помощью вырезания букв с помощью OCR, внесения меток в пиксельные координаты и внесение букв с цифровыми метками обратно в документ, направляемый на печать. После внедрения всех меток (21, 22) на искомой странице pi тоже самое выполняется для следующей страницы pi+1 и так далее до конца документа
используются для нанесения цифровых меток вышеописанным способом. Внесение цифровых меток осуществляется с помощью вырезания букв с помощью OCR, внесения меток в пиксельные координаты и внесение букв с цифровыми метками обратно в документ, направляемый на печать. После внедрения всех меток (21, 22) на искомой странице pi тоже самое выполняется для следующей страницы pi+1 и так далее до конца документа 
[0034] В Таблице 5 приведен пример кодирования меток для УИД пользователя - 00013400.

[0035] После внесения в документ, направленный на печать цифровых меток, кодирующих УИД, на этапе (104) выполняется его направление на печать. Распечатанный документ будет содержать закодированный УИД неразличимый для человеческого глаза. Размер цифровых меток может выбираться произвольно (например, метки радиусом от 1-2 пикселей).
[0036] На Фиг. 3 приведена последовательность этапов, выполняемых при выполнении способа (300) распознавании УИД на распечатанных документах. На этапе (301) вычислительное устройство, используемое для определения УИД в распечатанном документе, получает изображение такого документа. Изображение может содержать полностью или частично текст, с закодированном УИД, полученный, например, с помощью фотографирования внешним устройством (смартфон, камера и т.п.) или при помощи сканирования с помощью OCR распечатанного документа.
[0037] Далее на этапе (302) также при помощи технологии OCR выполняется распознавание букв в документе, при этом если страниц в документе несколько, то распознается каждая страница документа. На этапе (303) выполняется считывание цифровых меток в окрестностях распознанных букв. Пример анализа цифровых меток может осуществляться по примеру, приведенному в Таблице 5, которая может применяться как таблица для сопоставления меток соответствующей цифре УИД пользователя.
[0038] После этого выполняется декодирование УИД на этапе (304) и установление по нему табельного номера сотрудника и соответствующего пользователя, с компьютерного устройства которого была осуществлена печать документа.
[0039] Математическое обоснование метода
[0040] Для этого убедимся, что частоты раскрытия позиций ТАВ8={n1, n2, … nm}, m=8 равномерно распределены для всех m, что позволяет показать вероятность извлечения табельного номера (УИД) из текста страницы.
[0041] Для математического обоснования было проведено исследование по частоте встречающихся букв в тексте с разным содержанием, к примеру, рассмотрим, такое распределение характерное для литературных произведений. Список литературных произведений, участвующих в эксперименте: Сильмариллион. Дж.Р.Р. Толкин, Двадцать тысяч лье под водой. Жюль Г.Верн, Двадцать лет спустя. Александр Дюма, Три мушкетера. Александр Дюма, Унесенные ветром. Маргарет Митчелл, Айвенго. Вальтер Скотт, Герой нашего времени. Н.В. Гоголь, Война и мир. Л.Н. Толстой, Обитаемый остров. Борис и Аркадий Стругацкие, Преступление и наказание. Ф.М. Достоевский, Живые и мертвые. К.М. Симонов, всего 8366594 символов, 3919 страниц. Математическая лингвистика показала следующие вероятности частоты встречи букв русского алфавита в текстах (Таблица 6).
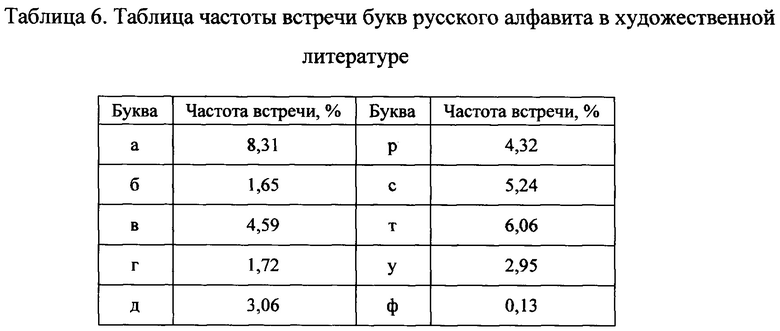
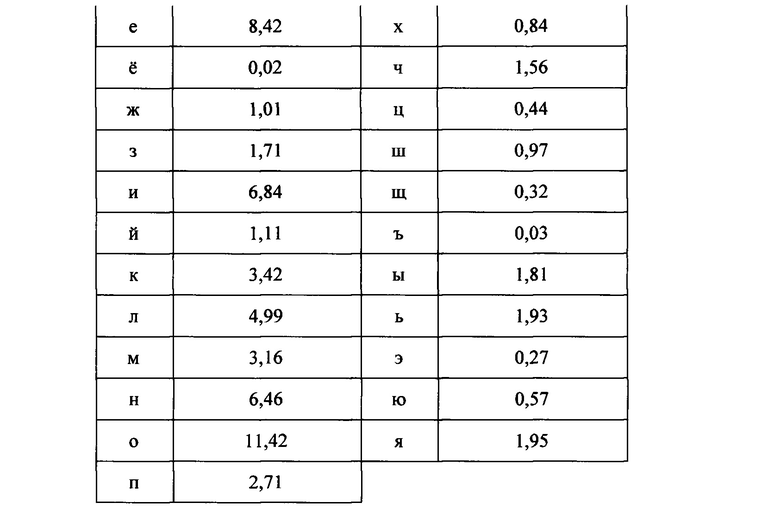
[0042] Для получения значения частоты раскрытия позиций ТАВ8={n1, n2, … nm} выполняются следующие действия. Из таблиц 4 и 5 известны буквы, в которые кодируются разряды. Для получения частоты раскрытия разрядов для алгоритма нанесения метки в пространстве возле буквы, частоты букв, в которые кодируются метки, складываются, т.к. позиция выкрывается при обнаружении метки хотя бы в одной из них. В результате вышеописанных действий получается таблица 7.
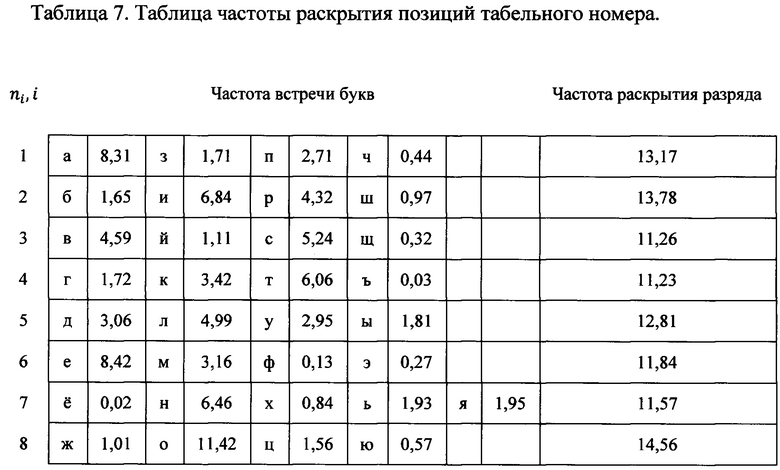
[0043] На основании таблицы 7 формируется диаграмма, представленная на Фиг. 4. Диаграмма показывает, что частота раскрытия всех позиций распределена относительно равномерно.
[0044] Вычислим количество каждой буквы русского алфавита экспериментальной выборки:
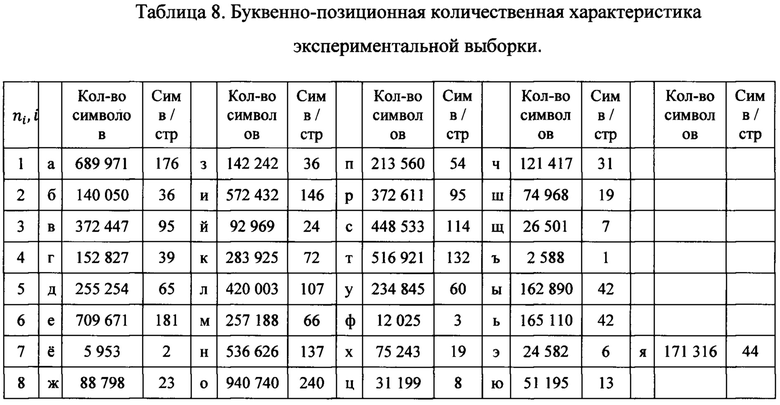
[0045] Для метода нанесения точки в пространство возле буквы принимается следующее допущение: процент Р символов на внедрение метки Р=0,3, при передаче через мессенджеры теряется определенный процент М=0,7 меток. На основании вышеописанного можно вычислить вероятность распознавания текста, если для дешифрования доступно:
целая страница;
 страницы;
страницы;
 страницы.
страницы.


[0046] Пример Экспериментального применения.
[0047] В ходе тестирования было распечатано и анализировано около 500 страниц разного содержания:
текст, разреженный текст, текст с таблицами, текст с графиками, текст с формулами;
с разными типами шрифтов: Arial, Calibri, Times New Roman;
разное оформление текста: обычный, курсив, полужирный, подчеркнутый;
разной размерности: 12рх, 14рх;
разным межстрочным интервалом: 0.5,1.15,1,5;
разным межзнаковым интервалом: обычный, разреженный, уплотненный;
[0048] В каждом случае рассматривалась возможность извлечения метки с:
распечатки напрямую;
с фотографии распечатки;
переданной по мессенджеру распечатки фотографии.
[0049] Печать проводилась на офисном черно белом лазерном принтере Lexmark MX711de на офисной бумаге «Снегурочка» с белизной CIE 146 по ISO 11475.
[0050] Фотографирование производилось на телефон Samsung А51 при офисном освещении, бумага лежит горизонтально на столе, фотографирование случайное под разными, незначительными углами, порядком 2-4% в 3-х измерениях.
[0051] При передаче фотографий использовался мессенджер Telegram со сжатием изображения при отправлении.
[0052] В ходе эксперимента подбирались параметры, такие как размер меток, их оптимальные места и способы нанесения. Результаты последней фазы эксперимента показаны в таблице 10.


[0053] Вышеописанная таблица показывает хорошие результаты анализа переданных по мессенджеру фотографий распечаток на офисном черно-белом принтере. В результате эксперимента были подобраны оптимальные параметры для внедрения метки, которые с одной стороны, были бы заметны на распечатках как дефекты принтера, с другой стороны, хорошо извлекались из переданных фотографий по мессенджерам.
[0054] На Фиг. 5 представлен общий вид вычислительного устройства (500), пригодного для выполнения вышеуказанных способов. Устройство (500) может представлять собой, например, компьютер, сервер или иной тип пригодного вычислительного устройства.
[0055] В общем случае вычислительное устройство (500) содержит объединенные общей шиной информационного обмена один или несколько процессоров (501), средства памяти, такие как ОЗУ (502) и ПЗУ (503), интерфейсы ввода/вывода (504), устройства ввода/вывода (505), и устройство для сетевого взаимодействия (506).
[0056] Процессор (501) (или несколько процессоров, многоядерный процессор) могут выбираться из ассортимента устройств, широко применяемых в текущее время, например, компаний Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. В качестве процессора (501) может также применяться графический процессор, например, Nvidia, AMD, Graphcore и пр.
[0057] ОЗУ (502) представляет собой оперативную память и предназначено для хранения исполняемых процессором (501) машиночитаемых инструкций для выполнение необходимых операций по логической обработке данных. ОЗУ (502), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.).
[0058] ПЗУ (503) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[0059] Для организации работы компонентов устройства (500) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (504).
Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[0060] Для обеспечения взаимодействия пользователя с вычислительным устройством (500) применяются различные средства (505) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[0061] Средство сетевого взаимодействия (506) обеспечивает передачу данных устройством (500) посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (506) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[0062] Дополнительно могут применяться также средства спутниковой навигации в составе устройства (500), например, GPS, ГЛОНАСС, BeiDou, Galileo.
[0063] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ЗАЩИТЫ ЦИФРОВОЙ ИНФОРМАЦИИ, ОТОБРАЖАЕМОЙ НА ЭКРАНЕ ЭЛЕКТРОННЫХ УСТРОЙСТВ | 2021 |
|
RU2758668C1 |
| УСТРОЙСТВО И СПОСОБ ПОИСКА РАЗЛИЧИЙ В ДОКУМЕНТАХ | 2013 |
|
RU2571378C2 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ УСТРОЙСТВ, СВЯЗАННЫХ С МОШЕННИЧЕСКОЙ ФИШИНГОВОЙ АКТИВНОСТЬЮ | 2018 |
|
RU2705774C1 |
| Способ обеспечения безопасного использования электронного документа | 2018 |
|
RU2699234C1 |
| МЕТОДЫ ОБНАРУЖЕНИЯ ВВЕДЕННЫХ ПОЛЬЗОВАТЕЛЕМ КОНТРОЛЬНЫХ МЕТОК | 2014 |
|
RU2656573C2 |
| СПОСОБ И СИСТЕМА ЗАЩИТЫ ИНФОРМАЦИИ, ОТОБРАЖАЕМОЙ НА ЭКРАНЕ ЭЛЕКТРОННЫХ УСТРОЙСТВ, С ПОМОЩЬЮ АДАПТИВНЫХ ЦИФРОВЫХ МЕТОК | 2024 |
|
RU2838130C1 |
| СРАВНЕНИЕ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ ДОСТОВЕРНОГО ИСТОЧНИКА | 2014 |
|
RU2597163C2 |
| СПОСОБ ВНЕСЕНИЯ ЦИФРОВЫХ МЕТОК В ЦИФРОВОЕ ИЗОБРАЖЕНИЕ И УСТРОЙСТВО ДЛЯ ОСУЩЕСТВЛЕНИЯ СПОСОБА | 2019 |
|
RU2739936C1 |
| СПОСОБ КОДИРОВАНИЯ И ЗАПИСИ ДАННЫХ НА RFID-МЕТКУ | 2014 |
|
RU2592399C2 |
| ЗАКОДИРОВАННЫЕ КОДОВЫМИ КОМБИНАЦИЯМИ СЛОВАРИ | 2006 |
|
RU2421809C2 |




Изобретение относится к области защиты информации, в частности к решениям для предотвращения утечки информации при печати документов. Технический результат заключается в повышении эффективности защиты данных от утечки, за счет внедрения цифровых меток в документ, кодирующих уникальный идентификатор пользователя, для последующей его идентификации при анализе распечатанных документов, повышение надежности защиты информации. Результат достигается за счет способа кодирования информации для защиты от ее утечек при печати документов, в котором получают на компьютерном устройстве пользователя информацию о печати цифрового документа, содержащего текст, при этом компьютерное устройство связано с уникальным идентификатором (УИД) пользователя; осуществляют до момента передачи цифрового документа на печать распознавание букв, содержащихся в цифровом документе; кодирование УИД пользователя в набор цифровых меток, располагающихся в соответствующих окрестностях на контурах букв и/или вблизи контуров букв, кодирование УИД выполняется на каждой странице документа; передают цифровой документ на печать с закодированным УИД пользователя. 4 н. и 5 з.п. ф-лы, 7 ил., 10 табл.
1. Способ кодирования информации для защиты от ее утечек при печати документов, выполняемый с помощью процессора компьютерного устройства, при этом способ содержит этапы, на которых:
получают на компьютерном устройстве пользователя информацию о печати по меньшей мере одного цифрового документа, содержащего по меньшей мере текст, при этом компьютерное устройство связано с уникальным идентификатором (УИД) пользователя;
осуществляют до момента передачи цифрового документа на печать его обработку, в ходе которой
распознают буквы, содержащиеся в цифровом документе;
кодируют УИД пользователя в набор цифровых меток, при котором УИД переводится в двоичную форму;
выполняется разделение букв на четыре четверти, где каждая четверть содержит часть контура буквы и пространство вблизи контура;
вносят цифровые метки в виде точек в соответствующие окрестности вблизи контуров букв, при этом кодирование УИД выполняется на каждой странице документа;
передают цифровой документ на печать с закодированным УИД пользователя.
2. Способ по п. 1, характеризующийся тем, что распознавание цифрового документа выполняется с помощью оптического распознавания символов (OCR).
3. Способ по п. 2, характеризующийся тем, что распознаются все символы на каждой странице цифрового документа.
4. Способ по п. 1, характеризующийся тем, что каждый символ УИД пользователя кодируется в двоичный код.
5. Способ по п. 4, характеризующийся тем, что на основании разряда двоичного кода определяется область размещения цифровых меток.
6. Способ защиты информации от утечек на печатных документах, выполняемый с помощью процессора компьютерного устройства, при этом способ содержит этапы, на которых:
получают по меньшей мере часть изображения печатного документа с закодированным УИД пользователя способом по любому из пп. 1-5;
выполняют распознавание полученного изображения;
определяют буквы, содержащие цифровые метки в своей окрестности;
выполняют определение и извлечение закодированного УИД.
7. Способ по п. 6, характеризующийся тем, что распознавание цифрового документа выполняется с помощью OCR.
8. Система кодирования информации для защиты от ее утечек при печати документов, содержащая по меньшей мере один процессор, по меньшей мере одну память, связанную с процессором и содержащую машиночитаемые инструкции, которые при их исполнении процессором осуществляют способ по любому из пп. 1-5.
9. Система защиты информации от утечек на печатных документах, содержащая по меньшей мере один процессор, по меньшей мере одну память, связанную с процессором и содержащую машиночитаемые инструкции, которые при их исполнении процессором осуществляют способ по любому из пп. 6, 7.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| СПОСОБ И СИСТЕМА ВСТРАИВАНИЯ И ИЗВЛЕЧЕНИЯ СКРЫТЫХ ДАННЫХ В ПЕЧАТАЕМЫХ ДОКУМЕНТАХ | 2010 |
|
RU2446464C2 |
| СПОСОБ ВНЕДРЕНИЯ СКРЫТОГО ЦИФРОВОГО СООБЩЕНИЯ В ПЕЧАТАЕМЫЕ ДОКУМЕНТЫ И ИЗВЛЕЧЕНИЯ СООБЩЕНИЯ | 2010 |
|
RU2431192C1 |

