ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в целом относится к вычислительным устройствам для обработки электронных документов, а в частности - к сравнению и повышению качества документов.
УРОВЕНЬ ТЕХНИКИ
[0002] В документообороте, делопроизводстве и во многих аспектах ведения бизнеса встречается задача сравнения двух или нескольких документов, содержащих текст или другую информацию с целью определения их идентичности или поиска различий между анализируемыми документами. Решение этой задачи часто предполагает продуцирование электронного документа путем сканирования или получение изображения бумажного документа иным образом, а также выполнение оптического распознавания символов (OCR) для получения текста документа. При сравнении документов часто возникают ложные различия, связанные не с фактическим отличием между документами, а с неточностями процедуры распознавания символов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0003] Настоящее изобретение иллюстрируется с помощью примеров, а не методом ограничения. Для его полного понимания приведенное ниже описание предпочтительных вариантов реализации следует рассматривать в сочетании с чертежами, на которых:
[0004] На Фиг. 1 представлена блок-схема одного из вариантов реализации вычислительного устройства, работающего в соответствии с одним или более аспектами настоящего изобретения;
[0005] Фиг. 2 иллюстрирует пример эталонного документа и сравниваемого с ним документа в соответствии с одним или более аспектами настоящего изобретения;
[0006] Фиг. 3 иллюстрирует примеры повышения качества документов в соответствии с одним или более аспектами настоящего изобретения.
[0007] На Фиг. 4 изображена блок-схема примера, иллюстрирующего способ 400 повышения качества и сравнения документов в соответствии с одним или более аспектами настоящего изобретения;
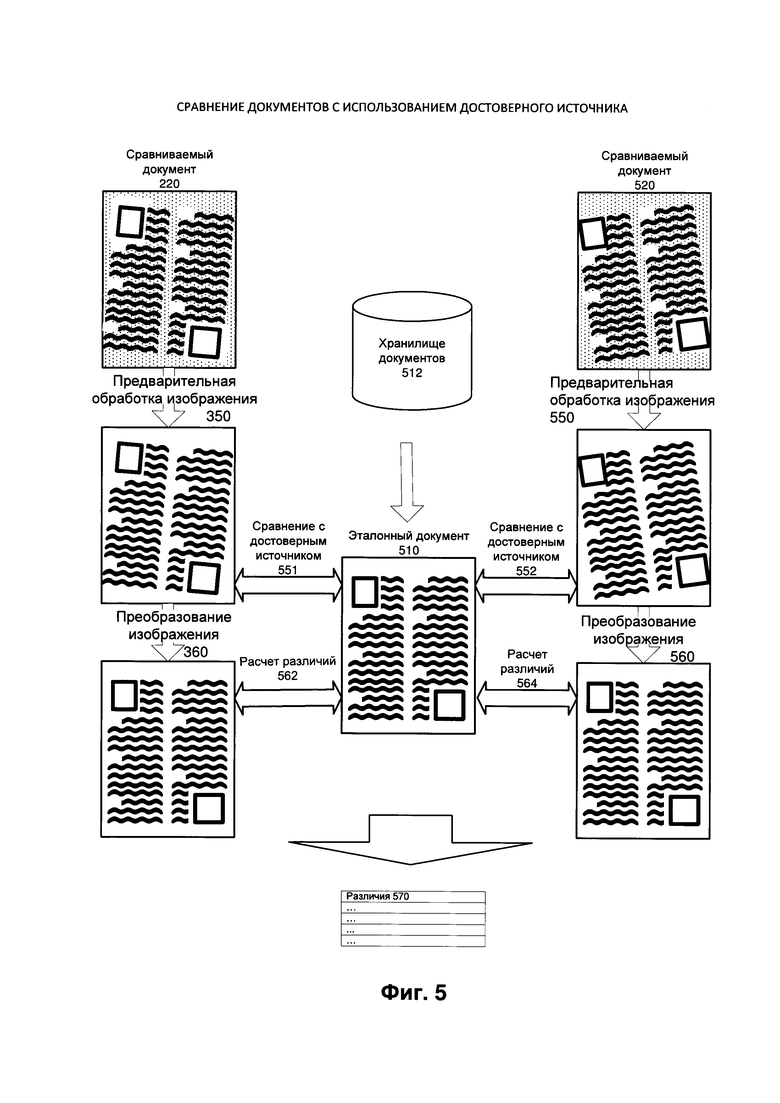
[0008] На Фиг. 5 иллюстрируется пример повышения качества и сравнения трех документов в соответствии с одним или более аспектами настоящего изобретения;
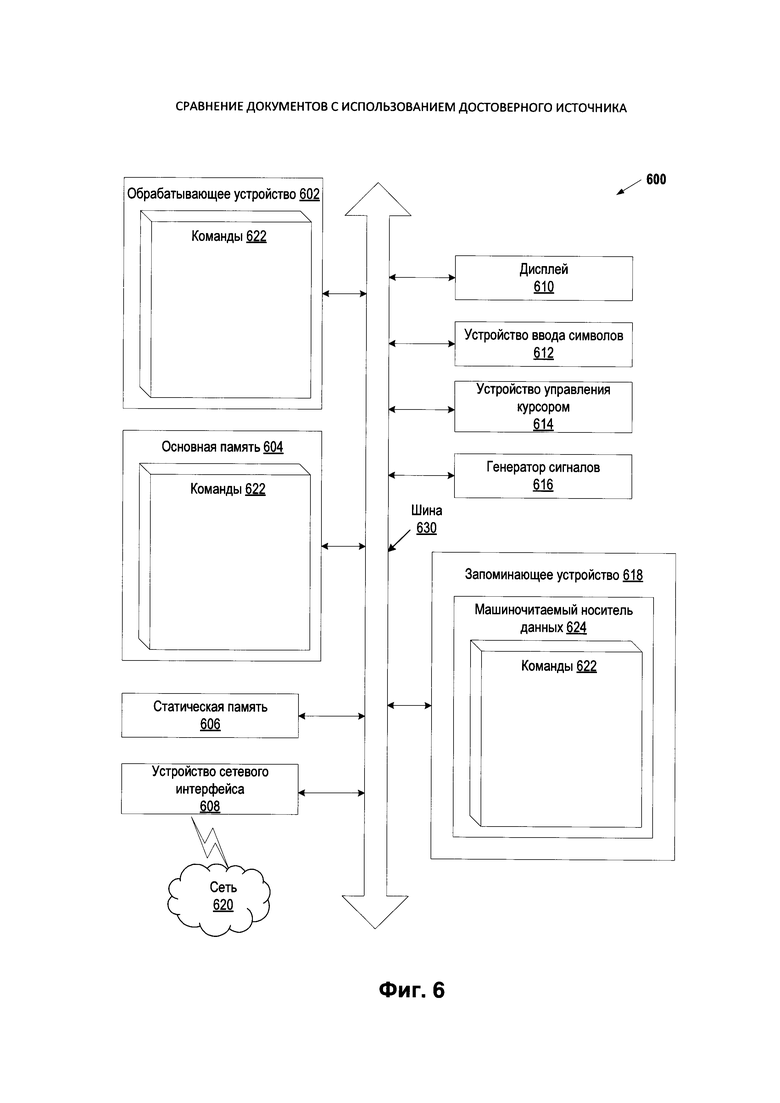
[0009] На Фиг. 6 изображена более подробная схема иллюстративного примера вычислительного устройства, реализующего методы настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00010] Настоящее изобретение относится к способам и системам сравнения документов с использованием эталонного документа. Дальнейшее упоминание термина «документ» в настоящем описании изобретения относится к электронному документу, который можно получить, например, путем оцифровывания бумажного документа, и который содержит электронное изображение бумажного документа. Описанная ниже обработка документов относится к обработке изображений документов. Эталонный документ может представлять собой первоначальную или более раннюю версию документа, и он может считаться достоверным источником, поскольку может содержать высококачественный текстовый слой, практически не имеющий визуальных артефактов, которые негативно влияют на распознавание символов (OCR). Система сравнения документов может использовать эталонный документ для создания специальных словарей и преобразования разметки связанного с ним документа. Каждый эталонный словарь содержит список слов из определенной части документа (например, фрагмента текста или страницы). Для повышения качества процедуры распознавания символов могут использоваться эталонные словари и преобразования разметки. Это может привести к уменьшению количества ложных различий, которые могут возникнуть из-за неточности при распознавании символов, а не из-за фактических различий между документами.
[00011] Система сравнения документов может преобразовать разметку сравниваемого документа, соотнеся ее с разметкой эталонного документа. Сравнение компоновок может включать в себя выбор в каждом документе реперных точек на основе реперов в изображении (например, слов или объектов) и обработку реперных точек для определения преобразования изображения. Затем система сравнения документов может преобразовать (например, с помощью линейного преобразования) соответствующий документ, чтобы исправить искажения и восстановить его разметку.
[00012] В одном из примеров реализации эталонный документ может представлять собой имеющий юридическую силу договор, который был составлен в электронном формате и впоследствии преобразован в формат Portable Document Format (PDF). Сравниваемый документ может представлять собой версию имеющего юридическую силу договора, которая была изменена, напечатана, подписана и отсканирована. Сканирование документа может изменить документ путем введения, например, искажения перспективы. Это искажение может негативно повлиять на распознавание символов и может привести к ошибкам распознавания. Метод настоящего изобретения вводит итеративное сравнение, которое может включать в себя несколько операций распознавания символов и преобразование документа для уменьшения количества ложных различий.
[00013] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, а не для ограничения.
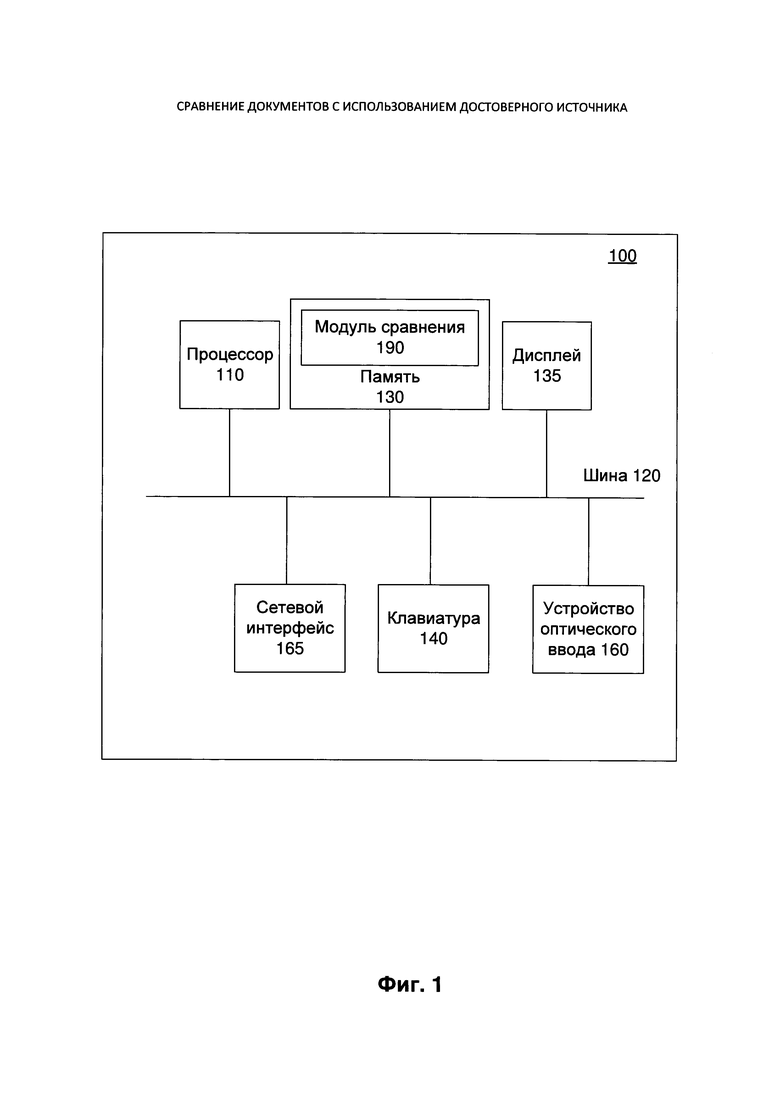
[00014] На Фиг. 1 изображена блок-схема одного иллюстративного примера вычислительного устройства 100, работающего в соответствии с одним или более аспектами настоящего изобретения. В иллюстративных примерах вычислительное устройство 100 может быть представлено различными вычислительными устройствами, включая планшетный компьютер, смартфон, ноутбук или настольный компьютер.
[00015] Вычислительное устройство 100 может содержать процессор 110, соединенный с системной шиной 120. Другие устройства, подключенные к системной шине 120, могут включать в себя память 130, дисплей 135, клавиатуру 140, оптическое устройство ввода 160 и один или более сетевых интерфейсов 165. Термин «подключенный» в этом документе означает электрическое соединение и/или обмен данными через одно или более интерфейсных устройств, адаптеров и т.п.
[00016] В различных иллюстративных примерах процессор 110 может быть представлен одним или более устройствами обработки, такими как универсальные и/или специализированные процессоры. Память 130 может представлять собой одно или более энергозависимых устройств памяти (например, микросхемы ОЗУ), одно или более энергонезависимых устройств памяти (например, микросхемы ПЗУ или ЭППЗУ) и/или одно или более устройств памяти (например, оптические или магнитные диски). Оптическое устройство ввода 160 может представлять собой сканер или фотокамеру, предназначенную для улавливания света, отраженного от объектов, расположенных в ее поле зрения. Пример вычислительного устройства, в котором реализованы аспекты настоящего изобретения, будет рассмотрен более подробно ниже в описании Фиг. 6.
[00017] В памяти 130 могут храниться команды модуля сравнения 190 для выполнения оптического распознавания символов. В некоторых реализациях изобретения модуль сравнения 190 может выполнять методы сравнения и преобразования документов в соответствии с одним или более аспектами настоящего изобретения. В качестве иллюстративного примера модуль сравнения 190 может быть реализован в виде функции, которая вызывается с помощью пользовательского интерфейса другого приложения. Кроме того, модуль сравнения 190 может быть реализован в виде отдельного приложения. В одном из примеров реализации память 130 может хранить несколько отдельных документов, которые затем сравниваются.
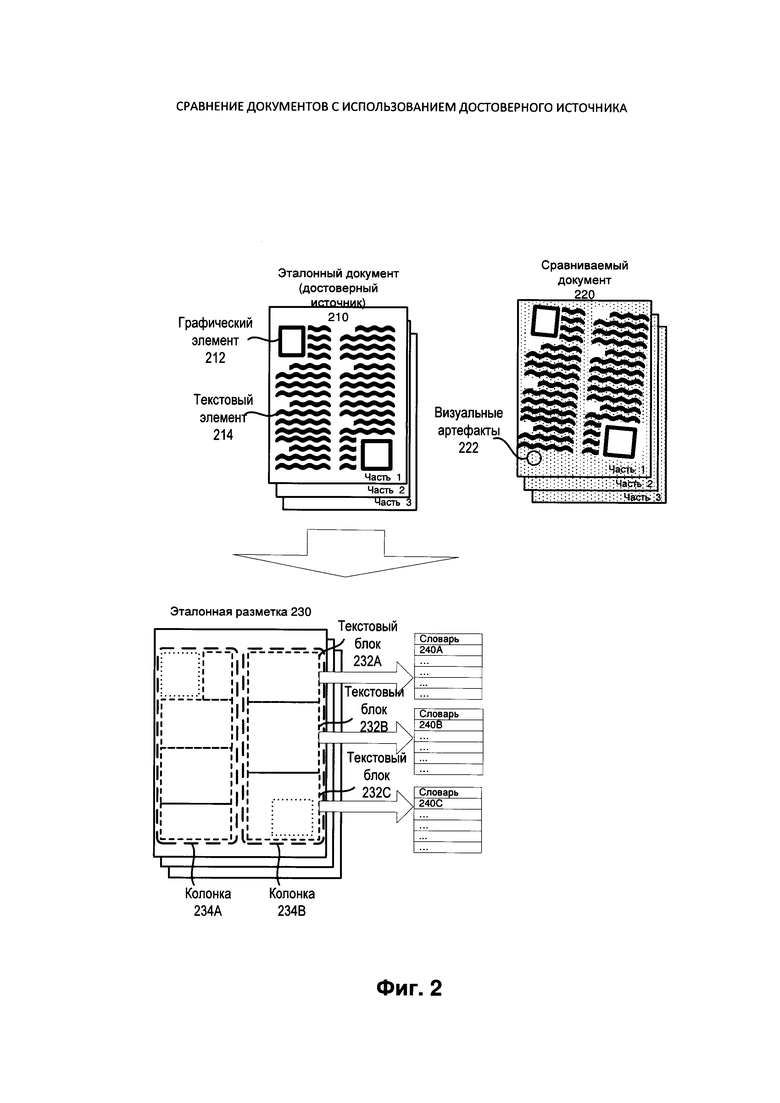
[00018] На Фиг. 2 иллюстрируется пример эталонного документа 210 и сравниваемого документа 220, которые могут сравниваться друг с другом с помощью модуля сравнения 190, работающего в вычислительном устройстве 100 в соответствии с одним или более аспектами настоящего изобретения. Эталонный документ 210 может содержать графический элемент 212 и текстовый элемент 214, а сравниваемый документ может содержать аналогичные графические и текстовые элементы, которые могли быть искажены при оцифровке документа (например, при сканировании или получении изображения). Эти искажения могут, в частности, представлять собой сдвиг или поворот и/или визуальные артефакты 222: например, редкие черно-белые искажения (такие как т.н. «шум типа salt-and-pepper» или Гауссов шум).
[00019] Эталонный документ 210 и сравниваемый документ 220 могут быть похожи друг на друга. Например, сравниваемый документ 220 может быть другой версией (например, более ранней или более поздней версией) эталонного документа 210. Эталонный документ 210 может быть достоверным источником с текстовым слоем и разметкой более высокого качества и с меньшим числом визуальных артефактов 222, чем в сравниваемом документе 210. Визуальные артефакты 222 могут представлять собой шумы (например, «шум типа salt-and-pepper»), искажения, расфокусировку, блики и/или смазы. В одном примере реализации эталонный документ 210 может быть оцифрованным документом с высоким качеством и точностью изображения при минимальном количестве визуальных артефактов. В другом примере реализации эталонный документ 210 может представлять собой документ с фиксированной разметкой (например, в формате PDF или TIFF), преобразованный электронным образом из документа с редактируемой разметкой (например, DOC, ODF, RTF или ТХТ) без оцифровки. Электронная конвертация может включать в себя преобразование векторной графики в растровое изображение (например, пиксели или точки) для последующей цифровой обработки изображений, например, аналогично растеризации или трассировке лучей.
[00020] Как показано на Фиг. 2, модуль сравнения может проводить анализ документов и процедур OCR для оценки эталонного документа 210 и определения эталонной разметки 230 и эталонных словарей 240А-С. Анализ документа может определить эталонную разметку 230, которая может включать в себя местоположения (например, координаты), параметры и структуру элементов документа, таких как графический элемент 212 и текстовый элемент 214. В структуру элементов могут входить текстовые блоки 232А-С, колонки 234А-В, а также таблицы, верхние и нижние колонтитулы и другие элементы разметки. В одном примере эталонная разметка 230 и эталонные словари 240А-С строятся для каждого изображения документа (например, для каждой страницы эталонного документа).
[00021] Эталонные словари 240А-С могут строиться на базе процедуры OCR и/или анализа документа. Эталонные словари 240А-С могут включать в себя список слов, содержащихся в одной или более частях эталонного документа 210, и могут использоваться для повышения качества и/или проверки достоверности результатов оптического распознавания символов в сравниваемом документе 220. Каждый словарь может содержать список слов, который включает слова только из определенной части (например, страницы, фрагмента текста) эталонного документа. Как показано на Фиг. 2, эталонные словари 240А-С могут содержать списки слов из текстовых блоков 232А-С, соответственно. В другом примере реализации эталонный словарь может создаваться для конкретной страницы, колонки, таблицы, абзаца, ячейки или иной части документа.
[00022] В качестве альтернативы эталонные словари 240А-С могут включать набор символов (например, алфавит, цифры и символы). Набор символов можно получить в результате осуществления процедур OCR и/или анализа документов. Набор символов может быть ограничен только символами, присутствующими в определенной части эталонного документа 210. Это ограничение можно использовать для второй процедуры оптического распознавания изображений документов, которые содержат, например, китайские, японские и/или корейские символы (CJK-символы), потому что ограниченный набор символов может включать только подмножество всех символов, например 200 символов из 40 ООО имеющихся символов. Символы, включенные в ограниченный набор символов, можно закодировать с помощью любой стандартной кодировки текста, такой как Unicode (например, UTF-8, UTF-16), ASCII, японской кодировки Shift-JIS или другой подобной кодировки текста.
[00023] В одном примере реализации эталонные словари 240А-С могут включать в себя ограниченный список слов и ограниченный набор символов, каждый из которых может быть сформирован на основе определенной части изображения эталонного документа. Их можно использовать для повышения качества последующей (например, второй) процедуры распознавания символов в сравниваемом документе 220.
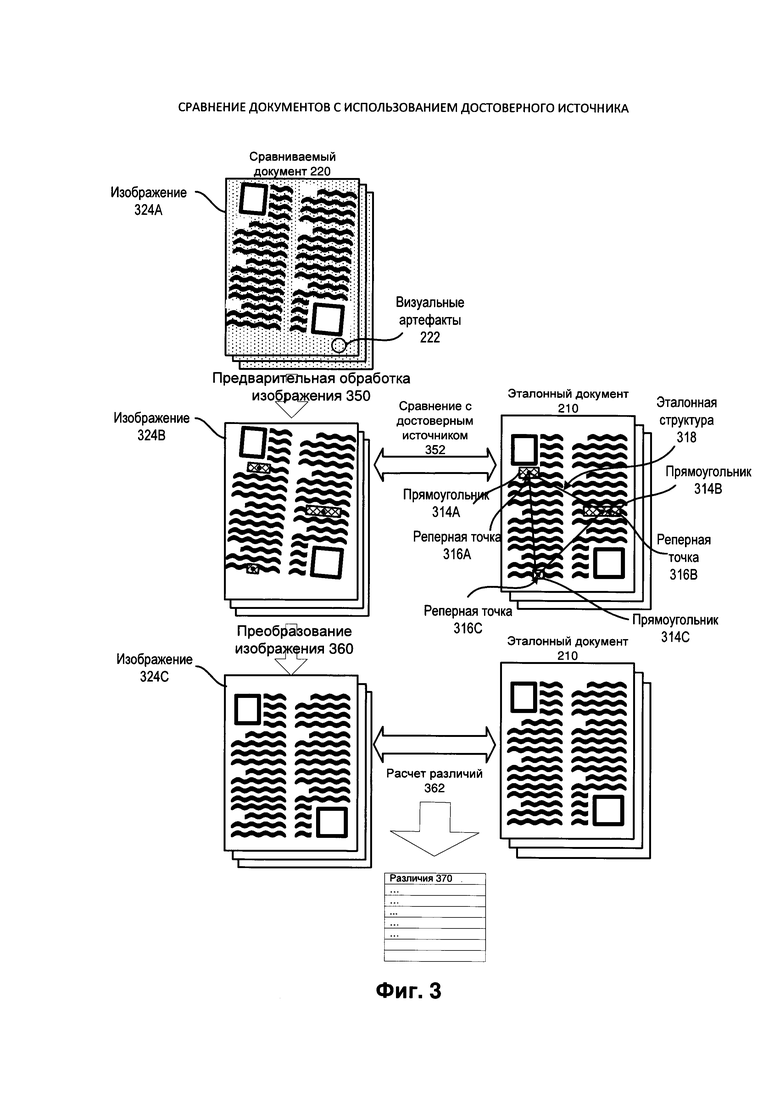
[00024] На Фиг. 3 приведен пример, иллюстрирующий процедуры повышения качества и сравнения. Пример содержит сравниваемый документ 220, который представлен изображениями 324А-С на различных этапах повышения качества. Процедура повышения качества может предполагать предварительную обработку изображения 350, сравнение 352, преобразование изображения 360 и расчет различия 362.
[00025] Предварительная обработка изображения 350 может изменить изображение 324А для получения изображения 324В, выполняя один или более этапов цифровой обработки изображения для повышения качества изображения. Она может включать бинаризацию, подавление шумов и/или другие аналогичные методы обработки изображения. Бинаризация может изменить изображение и преобразовать его в бинаризованное изображение (например, двухуровневое изображение), в котором для каждого пикселя, используются только два значения цвета, как правило, черный и белый цвета. Бинаризация изображения может быть произведена для полутоновых изображений или цветных изображений, с использованием определенного алгоритма, например, пороговой бинаризации изображения.
[00026] Пороговая бинаризация изображения может включать установку пороговых значений для пикселя или группы пикселей и оценку значений пикселей, чтобы определить, какое из двух значений будет назначено этому пикселю. В одном примере реализации для пороговой бинаризации изображения на основе кластеризации можно использовать метод Оцу. Этот алгоритм может вычислить оптимальное пороговое значение, разделяющее несколько классов так, чтобы их совместный разброс (дисперсия внутри класса) был минимальным. Его также можно использовать для выполнения многоуровневого разделения по порогу с использованием метода мульти-Оцу.
[00027] Предварительная обработка изображения 350 также может включать снижение уровня шумов, которое может включать в себя удаление и/или уменьшение визуальных артефактов 222. Снижение уровня шумов может быть выполнено с использованием технологии снижения уровня шумов, такой как линейные или нелинейные сглаживающие фильтры и/или анизотропная диффузия. Некоторые другие методы предварительной обработки изображения могут включать удаление пятен из изображения, фильтрацию текстур, кадрирование полей страницы, выравнивание, изменение ориентации страницы, выпрямление линий, исправление перспективы, удаление смаза от движения, разделение по горизонтали расположенных рядом изображений, разделение отсканированной страницы с несколькими слайдами или визитными карточками на отдельные изображения и/или другие подобные методы.
[00028] Когда предварительная обработка изображения 350 завершена, вычислительное устройство 100 может произвести анализ для определения разметки и/или текста сравниваемого документа 220. Анализ может быть выполнен в несколько этапов, один этап может включать в себя анализ документа для определения разметки, тогда как другой этап может включать в себя выполнение OCR. На этапе OCR для распознавания текста может использоваться разметка, определенная при анализе документа. В одном примере реализации сначала может быть выполнен анализ документа, а после завершения анализа документа может быть выполнен этап OCR, а в другом примере реализации они могут выполняться параллельно.
[00029] Анализ может производиться с помощью любого инструмента анализа документов или методов распознавания символов. В одном из примеров реализации при анализе документов могут выдвигаться гипотезы в отношении разметки исходного документа. Такие гипотезы могут включать одну или более гипотез в отношении классификации и/или атрибутов различных элементов документа, находящихся в одной или более областях документа (например, в прямоугольных блоках). Например, по отношению к определенной области в документе система OCR проверяет следующие гипотезы: область содержит текст; область содержит рисунок; область содержит таблицу; область содержит схему; и область содержит изображение снимка экрана. Далее для получения разметки документа могут использоваться инструменты анализа документов и методы OCR.
[00030] Вычислительное устройство 100 также может выполнить сравнение 352 сравниваемого документа 220 и эталонного документа 210 (т.е. достоверного источника), чтобы определить соответствующие друг другу изображения (например, соответствующие страницы). Такое сравнение может представлять собой итеративное сравнение, при котором сравниваются разметки и/или текст документов. Сравнение разметок может включать в себя анализ сходства и различий в отношении количества, положения, параметров и/или расположения частей. Например, как показано на Фиг. 3, при сравнении сравниваемого документа 220 и эталонного документа 210 вычислительное устройство может определить, что изображения имеют одинаковое количество графических элементов и текстовых элементов, и что эти элементы имеют схожие параметры и расположение (местонахождение). Оно также может проанализировать расположение и определить, что графические элементы находятся в том же положении по отношению к абзацам, а именно, что они встроены в первый и последний абзацы страницы.
[00031] Сравнение 352 также может проанализировать текст, полученный после распознавании символов, которое обсуждалось выше, чтобы обнаружить соответствующие изображения документов. Анализ текста может быть основан на методике, определяющей степень сходства между строками символов для каждого изображения документа, например, путем определения количества совпавших строк символов (например, слов), и/или количества строк, которые не совпадают. Термин «соответствующие изображения» может означать, что изображения документа примерно соответствуют без точного совпадения. В одном примере реализации соответствующие изображения могут иметь одинаковое или близкое количество элементов. Эти элементы могут включать слова, текстовые блоки, блоки иллюстраций и т.д. В другом примере реализации соответствующие изображения могут быть представлены изображениями, в которых коэффициент совпадающих (например, соответствующих или связанных) слов превышает определенное значение. Методика определения совпадающих слов может включать расчет и сравнение расстояния редактирования для пар слов, и позволяет определять, например, приближенное соответствие строк или нечеткое соответствие строк.
[00032] Значение расстояния редактирования может быть целым числом, которое количественно определяет различие между двумя строками. Значение расстояния редактирования может быть получено путем подсчета минимального количества операций, необходимых для преобразования одной строки символов в другую строку символов. Расстояние редактирования можно рассчитать с использованием любого метода, например, метрики Левенштейна. Метрика Левенштейна позволяет вычислить расстояние редактирования путем измерения количества случаев редактирования одиночных символов, необходимых для изменения одного слова в другое слово. В одном примере реализации метрика Левенштейна может измерять только следующие операции: удаление одного символа, вставку одного символа и замену одного символа на другой символ без учета других операций, таких как перестановка двух соседних символов.
[00033] Пару слов можно рассматривать как совпадение, если расстояние редактирования меньше порогового значения, которое может быть определено на основе относительного предела, абсолютного предела или комбинации первого и второго. Относительный предел может быть основан на длине слова поиска, и может быть представлен как отношение расстояния редактирования к длине строки, например, 1:N, где N представляет собой количество символов в слове (например, 2, 3, 4, 5). В одном примере относительным пределом может быть соотношение 1:3 от длины слова поиска, при этом слово с девятью символами может содержать три ошибки и считаться приближенным соответствием. В дополнение к относительному пределу или в качестве альтернативы ему можно использовать абсолютный предел различий независимо от длины строки. Например, если имеется более X различий, то пара слов не может рассматриваться как совпадение. В этом случае X может иметь значение между 1 и 10, например 3. Это значение выбирается на основании эмпирического анализа.
[00034] Вычислительное устройство может использовать приблизительное сопоставление строк, которое обсуждалось выше, при выдвижении гипотезы похожести о том, что изображения отдельных документов являются соответствующими, например, являются ли они связанными или похожими друг на друга (например, если один документ является более поздней версией другого документа, или если оба документа имеют общий исходный документ). Гипотеза похожести может быть основана на количестве совпадающих слов и/или на количестве слов, которые не совпадают согласно описанным выше расчетам. Аналогично случаю совпадения слов соответствие изображений (уровень соответствия) может также иметь пороговое значение. Порог может установить предельное значение, выраженное в виде количества или процентного отношения совпадающих слов, используемых для определения того, что изображения документов совпадают (соответствуют). В одном примере реализации гипотеза может быть основана только на части слов в изображении, например, только на длинных словах, а не на каждом слове изображения. Длинными словами могут быть слова с количеством символов, превосходящим заданное значение (например, 3, 4, 5 символов). Используя сравнение длинных слов, можно исключить многочисленные ложные различия, которые чаще происходят в коротких словах.
[00035] После того как вычислительное устройство 100 обнаруживает соответствующие изображения в эталонном документе, оно может перейти к вычислению функции преобразования разметки путем определения реперных точек внутри каждого из соответствующих изображений. В одном примере реализации вычислительное устройство может определить реперные точки во время выполнения путем идентификации реперов в изображении, таких как определенное слово или словосочетание. Слова или словосочетание могут быть уникальными, поскольку они появляются один раз на каждом из соответствующих изображений и, следовательно, могут оказаться полезными для сопоставления соответствующих изображений.
[00036] При использовании слов как реперов изображения реперные точки могут находиться в центрах слов. Вычислительное устройство может аппроксимировать центр слова, определяя прямоугольные размеры слова и используя центр прямоугольных размеров в качестве реперной точки. В одном примере реализации процедура OCR может предоставить вычислительному устройству координаты прямоугольников, которые включают (например, охватывают) слова. Как показано на Фиг. 3, вычислительное устройство 100 может анализировать эталонный документ 210 и определить три уникальных (или самых длинных) слова, которые будут играть роль реперов изображения, представленных в виде прямоугольников 314А-С. В центрах прямоугольников находятся реперные точки 316А-С, соответственно.
[00037] Вычислительное устройство может определить, что пара соответствующих изображений может иметь несколько уникальных реперов изображений и таким образом несколько вариантов реперных точек. Реперные точки можно определить, используя абсолютные или относительные координаты, и определить двумерную плоскость по трем точкам, не лежащим на одной прямой. Эти точки могут определить треугольник с эталонной структурой, например, эталонную структуру 318, определяемую реперными точками 316А-С.
[00038] При выборе между несколькими возможными реперными точками вычислительное устройство может выбрать реперные точки, максимально удаленные друг от друга. Использование удаленных друг от друга точек позволяет повысить устойчивость преобразования к ошибкам, которые возникают из-за зернистости системы координат, поэтому удаленные точки могут повысить точность преобразования. Определение наиболее удаленных точек может быть основано на выборе набора реперных точек из числа нескольких кандидатов на реперные точки, которые определяют эталонную структуру 318, имеющую максимальный размер (например, наибольшую площадь и/или наибольший периметр).
[00039] Множество реперных точек 316А-С в эталонном документе 210 может иметь соответствующий набор реперных точек в сравниваемом документе 220. Два набора реперных точек можно сравнивать, чтобы определить линейную или геометрическую функцию преобразования. Функция преобразования может содержать систему линейных и/или геометрических уравнений, которые можно суммировать с помощью матрицы преобразования (например, матрицы 2×2).
[00040] Ниже приведен пример уравнения линейного преобразования:
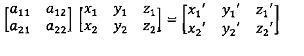
Уравнение линейного преобразования
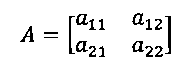 matrix of linear transformation;
matrix of linear transformation;
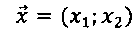 - координаты реперной точки X в изображении эталонного документа;
- координаты реперной точки X в изображении эталонного документа;
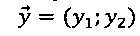 - координаты реперной точки Y в изображении эталонного документа;
- координаты реперной точки Y в изображении эталонного документа;
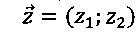 - координаты реперной точки Z в изображении эталонного документа;
- координаты реперной точки Z в изображении эталонного документа;
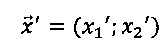 - координаты реперной точки X′ в сравниваемом изображении;
- координаты реперной точки X′ в сравниваемом изображении;
 - координаты реперной точки Y′ в сравниваемом изображении;
- координаты реперной точки Y′ в сравниваемом изображении;
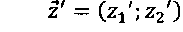 - координаты реперной точки Z′ в сравниваемом изображении;
- координаты реперной точки Z′ в сравниваемом изображении;
[00041] Оно состоит из двух наборов реперных точек, причем каждый набор включает по меньшей мере три точки. Каждая реперная точка может содержать по меньшей мере две координаты, например, 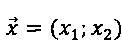 . Координаты могут измеряться в любой системе координат, которая может использоваться для идентификации точки в двумерном пространстве, например, в декартовой системе координат или в полярной системе координат.
. Координаты могут измеряться в любой системе координат, которая может использоваться для идентификации точки в двумерном пространстве, например, в декартовой системе координат или в полярной системе координат.
[00042] После определения функции преобразования вычислительное устройство 100 может выполнять преобразование изображения 360, при котором может применяться функция преобразования изображений для изменения разметки, текста и/или графических элементов сравниваемого документа 220 в соответствии с разметкой изображения эталонного документа. Как показано на Фиг. 3, преобразование изображения 360 может изменить изображение 324b путем поворота текста и графики на 5 градусов против часовой стрелки и сдвига их вниз, в результате получается изображение 324С.
[00043] После применения функции преобразования вычислительное устройство 100 может выполнить проверку качества результатов преобразования изображения. Проверка может включать выбор дополнительного набора реперных точек в эталонном документе 210, которые отличаются от первого набора реперных точек. На основе этих новых точек вычислительное устройство 100 может выбирать соответствующие точки в сравниваемом документе 220 и преобразовать изображение, используя предыдущую функцию преобразования. Если результирующие точки в связанном изображении находятся в пределах порогового расстояния от соответствующего репера в изображении, например, внутри охватывающего слово прямоугольника или в непосредственной близости от прямоугольника, то функция может определить, что функция преобразования является правильной. В противном случае вычислительное устройство может определить, что функция преобразования является неправильной.
[00044] Если определено, что функция преобразования является некорректной, то можно выбрать новый набор реперов изображения. Описанные выше процедуры могут быть повторены с использованием нового набора реперных точек, полученных из новых реперов. Они могут включать определение, применение и проверку нескольких новых функций преобразования, пока не будет найдена правильная функция преобразования или пока число неудачных попыток не достигнет порога (например, 2, 3, 4, 5 или больше попыток).
[00045] После определения того, что результаты преобразования изображения являются корректными, вычислительное устройство 100 может повторно запустить процедуру распознавания символов (например, OCR) в преобразованной версии сравниваемого документа 220. Вторая процедура распознавания символов может дать результаты текста, который имеют меньшую погрешность распознавания. Эти результаты могут заместить результаты первой процедуры распознавания символов, и их можно использовать для последующего расчета различия 362.
[00046] Процесс с этапами сравнения и преобразования может быть итеративным. В одном примере реализации вычислительное устройство может выполнять итерации в состоящем из нескольких частей документе, последовательно обрабатывая изображение за изображением (страницу за страницей), при этом возможен выбор изображения из каждого документа и их сравнение, а затем переход к другому изображению в каждом документе и их сравнение. Если изображения совпадают (при этом говорят о соответствующих изображениях), то можно приступить к преобразованию изображения и повторно распознать символы, если они не совпадают (не имеют соответствия), то можно пропустить этапы преобразования и второго распознавания символов и начать вычисление, фильтрацию и классификацию различий (на основе результата распознавания символов на первом этапе), что описано более подробно ниже. В другом примере реализации итерационное сравнение может включать выбор изображения (например, страницы) из сравниваемого документа 220 или из эталонного документа 210, и последующее сравнение его с несколькими изображениями (например, страницами) из другого документа, пока не будет обнаружено соответствие, либо изображения (например, страницы) другого документа будут исчерпаны, и в этот момент итерационное сравнение перейдет к следующей части и выполнит аналогичную серию сравнений.
[00047] На Фиг. 4 приведена блок-схема одного иллюстративного примера способа 400 обработки электронных документов в соответствии с одним или более аспектами настоящего изобретения. Способ 400 и/или каждая из его отдельных функций, процедур, подпрограмм или операций может выполняться одним или более процессорами компьютерного устройства (например, вычислительного устройства 100 на Фиг. 1) и/или каждая из его отдельных функций, программ, подпрограмм или операций может выполняться одним или более процессорами компьютерного устройства (например, вычислительного устройства 100 на Фиг. 1), на котором выполняется этот способ. В некоторых реализациях изобретения способ 400 может выполняться с помощью одного потока обработки. При альтернативном подходе способ 400 может выполняться с помощью двух или более потоков обработки, причем каждый поток обработки выполняет одну или более отдельных функций, процедур, подпрограмм или операций способа. В одном из примеров рабочие процессы или потоки обработки способа 400 могут быть синхронизированы (например, с использованием семафоров, критических секций и/или других механизмов синхронизации потоков).
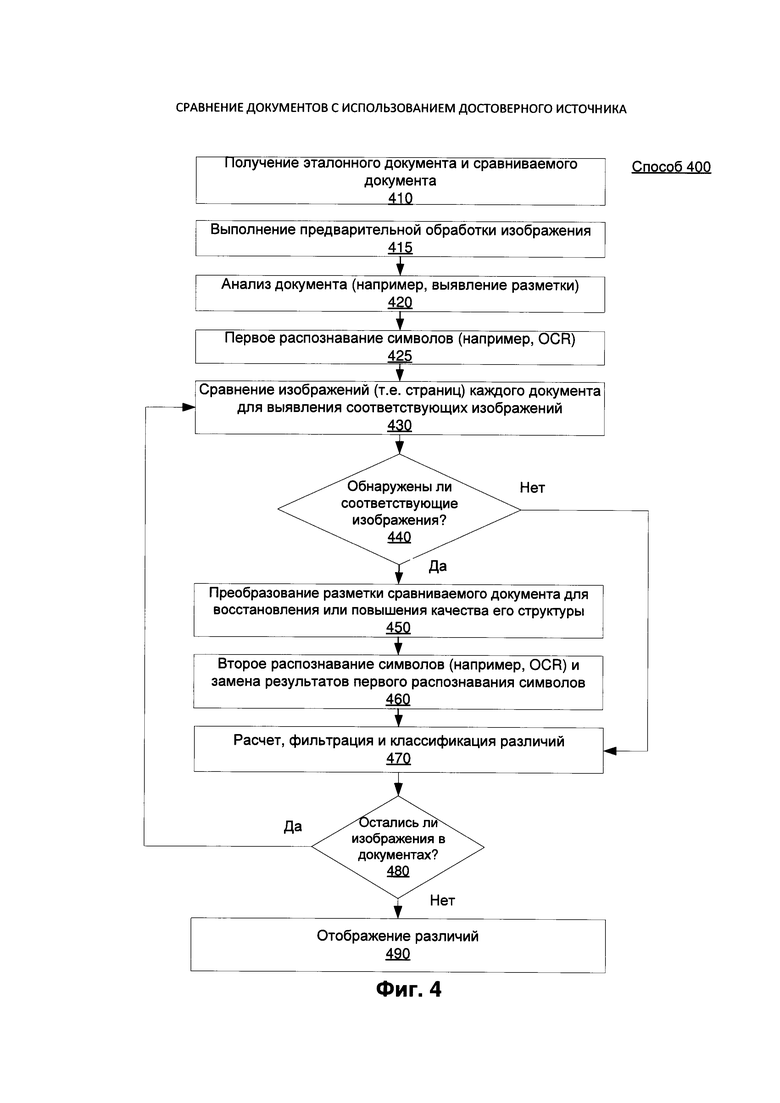
[00048] В блоке 410 вычислительное устройство 100 может принимать несколько электронных документов, например, эталонных документов 210 и сравниваемых документов 220. Документы 210 и 220 могут поступать из разных источников и храниться в разных местах. В одном примере реализации пользователь может вручную выбирать документы 210 и 220, предоставляя информацию о их местоположении вычислительному устройству 100. В другом примере реализации вычислительное устройство 100 может автоматически получать сравниваемый документ от устройства оцифровывания (например, сканера), при этом пользователь не предоставляет информацию о местоположении, а впоследствии может забрать соответствующий эталонный документ из хранилища документов автоматически, используя любой известный метод классификации. Хранилище документов может быть доступно вычислительному устройству, оно может находиться в вычислительном устройстве или в удаленном устройстве (например, на сервере компании, стороннем сервере).
[00049] В блоке 415 вычислительное устройство 100 также может выполнять предварительную обработку изображения для одного или более документов с целью повышения качества изображения. Затем вычислительное устройство может проанализировать документы, как показано в блоке 420, для определения разметки изображения документа, например, расположения текстовых блоков.
[00050] В блоке 425 вычислительное устройство 100 также может выполнять первую процедуру распознавания символов. Процедура первого распознавания символов может выполняться после завершения анализа документа, и использовать результаты анализа документа, чтобы определить местонахождение частей документа, которые могут включать текст. Затем процедура первого распознавания символов может проанализировать эти части, чтобы получить результаты в виде текста.
[00051] В блоке 430 вычислительное устройство 100 может итеративно сравнивать изображения документа (например, страницы), чтобы выявить соответствующие изображения (например, страницы). Такой результат может достигать путем выбора изображения (например, страницы или части страницы) из каждого документа и сравнения их, например, исходя из результатов определения разметки и текста для фрагментов текста 420 и 425. Такое сравнение может включать сравнение текстов, которое вычисляет расстояние редактирования для нескольких пар слов. Такое сравнение может учитывать только длинные слова, имеющие количество символов, превышающее заранее заданное число, и игнорировать более короткие слова.
[00052] В блоке 440 вычислительное устройство 100 может определить, соответствует ли изображение эталонного документа (например, страниц) изображению сравниваемого документа (например, страниц). Поскольку эта процедура предназначена для определения различий, изображения документов могут соответствовать приблизительно в отличие от точного совпадения, как описано выше. Если изображения не совпадают, то способ переходит к блоку 470 и проверяет наличие дополнительных изображений для сравнения. В противном случае способ переходит к блоку 450.
[00053] В блоке 450 вычислительное устройство 100 может преобразовывать изображения (например, страницы) сравниваемого документа, чтобы устранить искажения, которые могли быть введены во время оцифровки. Такое преобразование может включать анализ реперных точек в обоих документах для расчета функции преобразования, а затем применение этой функции преобразования к части документа (например, к странице).
[00054] В блоке 460 вычислительное устройство может выполнить вторую процедуру распознавания символов (например, повторно запустить распознавание символов) в сравниваемом документе с использованием специальных словарей, полученных из эталонного документа (например, словаря для фрагмента текста или словаря для страницы). Второе распознавание символов может быть выполнено после преобразования сравниваемого документа 220 в отличие от первого распознавания символов, которое выполняется до преобразования. Результаты второго распознавания символов могут иметь меньше неточностей по сравнению с первым распознаванием символов, поскольку преобразованный документ может иметь меньше искажений. Вычислительное устройство может заменить результаты первой процедуры распознавания символов изображения сравниваемого документа результатами второй процедуры распознавания символов. Поэтому использование этих результатов может приводить к меньшему количеству ложных различий.
[00055] В блоке 470 вычислительное устройство может вычислять различия и устранить, отфильтровать и классифицировать остающиеся различия. Вычислительное устройство 100 может рассчитать различия, используя метод сравнения, такой как метод, используемый в утилите diff для среды Unix или программа WinMerge для среды Microsoft. Эти различия не являются окончательными, они могут также включать одну или более дополнительных итераций проверки, сортировки и удаления незначительных расхождений. Часть различий может быть вызвана расхождениями OCR из-за неточностей в подсистеме OCR, а не фактическими различиями между документами. Расхождения OCR могут быть вызваны дефектами в сравниваемых документах, например, в виде смаза, расфокусировки текста, блика или чрезмерных шумов. В некоторых вариантах реализации изобретения эти дефекты могут быть вызваны сканированием или фотографированием текста. В одном примере реализации расхождения OCR можно уменьшить путем сравнения строк (например, слов), которые различаются в сравниваемых документах. Если различающиеся символы графически похожи, то весьма вероятно, что эти расхождения были вызваны особенностями распознания. Если несоответствие состоит из визуально похожих символов, имеющих разные коды Unicode, то такое несоответствие также считается незначительным и может не показываться пользователю. Ниже приведены примеры различий, вызванных визуальным сходством символов: буква «О» и цифра ноль «0»; различия в алфавитах, такие как буквы «АВС» в кириллице и подобные буквы «АВС» в латинице; различия, вызванные разной шириной символов, такие как тире и дефисы различной длины; фиксированный интервал и обычные иероглифы; доли в виде ¾ и 3/4 и т.д.
[00056] После устранения расхождений вычислительное устройство может фильтровать и классифицировать остающиеся различия. Фильтрация различий предназначена для удаления ложных или незначительных различий, а классификация используется для определения категории и уточнения типов изменений. Классификация различий может включать, например, выявление или кластеризацию типов существенных изменений, таких как «вставка», «удаление», «изменение текста» и т.д. Они могут отображаться пользователю, чтобы позволить пользователю быстро определить визуально, какие типы получаемых несоответствий имеют значение для него, и какие являются несущественными. Например, несоответствие типа «символ X изменяется на символ Y» может быть незначительным для пользователя, в то время как несоответствие типа «слово А изменено на слово В» может быть значительным. В некоторых вариантах реализации изобретения список различий, которые были определены как незначительные, может отображаться пользователю. Такой список может представляться иным образом (например, отображаться только после выбора пользователем, отображаться ниже в интерфейсе, и т.д.), чем в списке существенных различий. В одном примере расчет различий и устранение, фильтрация и классификация оставшихся разногласий может использовать метод, описанный в российской заявке на патент 2013156257 с названием «Устройство и способ поиска различий в документах», содержание которой включено в настоящее описание посредством ссылки.
[00057] В блоке 480 вычислительное устройство 100 может анализировать документ, чтобы определить, имеют ли документы дополнительные части (например, изображения/страницы), которые еще не были проанализированы. При наличии дополнительных изображений вычислительное устройство 100 может перейти в блок 430, чтобы сравнить другой набор страниц. При отсутствии дополнительных изображений оно может перейти к блоку 490.
[00058] В блоке 490 остающиеся различия могут быть представлены пользователю в виде измененного изображения с наложенными аннотациями, и/или в виде текстового списка различий. Например, система может быть настроена на определение режима отображения пользователю результатов проведенного сравнения. Отображение результатов сравнения может также предоставляться по умолчанию в настройках. Согласно некоторым вариантам реализации изобретения функция отображения пользователю может быть выбрана для настроек, чтобы обеспечить как можно больше точных деталей о результатах проведенного анализа, содержащего все найденные различия, включая различия, вызванные неточными результатами OCR. Кроме того, пользователь может вручную выбрать типы существенных расхождений, которые должны включаться в окончательный список расхождений, и тех расхождений, которые могут быть удалены из этого списка. В некоторых вариантах реализации могут быть установлены различные вариации найденных расхождений.
[00059] Результаты сравнения документа могут отображаться, например, путем отображения областей различий на экране или распечатки. При обнаружении расхождений в документах та конкретная область (текст), где расположены эти различия, выделяется цветом. Тип обнаруженных различий может сообщаться пользователю определенным цветом области. В некоторых вариантах реализации цвет области может предоставляться пользователю заранее в заданных параметрах. Например, желтый цвет может быть сигналом того, что в этой области были обнаружены различия типа «удаление», в то время как красный цвет может указывать на «вставки» и т.д. В некоторых примерах реализации изобретения, если изменение обнаружено внутри одного слова, все слово выделяется желтым цветом, а измененный символ в нем выделяется красным цветом. В различных вариантах реализации изобретения могут использоваться различные другие способы представления различия (например, визуальное представление).
[00060] На Фиг. 5 показан пример, иллюстрирующий процедуру повышения качества документа и сравнения для трех или более документов. В этом случае можно сравнить первый сравниваемый документ 220, второй сравниваемый документ 520 и эталонный документ 510, чтобы определить различия 570. Вычислительное устройство 100 может динамически выбрать эталонный документ 510 из хранилища документов 512 во время выполнения. Динамический выбор может быть основан на классификации одного или более сравниваемых документов 220 и 520. Как уже говорилось выше, эталонный документ 510 может быть более ранней версией документа, в этом случае классификацию можно использовать для определения исходного документа и/или наиболее похожей версии (например, самой последней). В другом примере вычислительное устройство может не иметь доступа к исходному документу или более ранней версии, и оно может использовать классификацию для выявления общего эталонного документа (например, шаблона). Общий эталонный документ может быть слабо связан со сравниваемым документом в том отношении, что сравниваемый документ не может быть получен из общего эталонного документа. Несмотря на это, общий эталонный документ может иметь разметку, аналогичную разметке сравниваемых документов 220 и 520, например, общий эталонный документ может быть изображением стандартного договора, паспорта, визитной карточки, слайда из презентации, документа Word или другого аналогичного документа. Классификация сравниваемого документа (сравниваемых документов) может быть основана на любой известной методике, например, на морфологическом анализе изображений.
[00061] После получения эталонного документа 510 вычислительное устройство может выполнять действия, подобные действиям, которые выполняются со сравниваемым документом 220 на Фиг. 3. Кроме того, оно может выполнять такие же этапы или этапы обработки, в основном аналогичные этапам для сравниваемого документа 520. Вычислительное устройство может выполнять описанные действия параллельно, например, предварительная обработка изображения 350 и преобразование изображения 360 могут быть аналогичны и осуществляться параллельно с предварительной обработкой изображения 550 и преобразованием изображения 560, соответственно. Аналогичным образом, сравнение 551 и расчет различий 562 могут выполняться параллельно со сравнением 552 и вычислением различий 564.
[00062] В другом примере реализации, который не показан, эталонный документ 510 может использоваться для преобразования сравниваемых документов 220 и 520 без использования расчета различий. Таким образом, различия 570 могут существовать между сравниваемыми документами, а не между сравниваемым документом и эталонным документом. В этом случае эталонный документ может использоваться для преобразования изображений и повторного запуска распознавания OCR, но он не требуется для любых последующих шагов сравнения.
[00063] На Фиг.6 показана более подробная схема примера вычислительного устройства 600, внутри которого имеется набор команд, который может заставить вычислительное устройство выполнить любой один или более методов, описанных в данном документе. Вычислительное устройство 600 может включать те же компоненты, что и вычислительное устройство 100 на Фиг. 1, а также некоторые дополнительные или другие компоненты, некоторые из которых могут быть необязательными для обеспечения аспектов настоящего изобретения. Вычислительное устройство может быть подключено к другому вычислительному устройству по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительное устройство может работать в качестве сервера или клиента в сетевой среде «клиент/сервер», или в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительное устройство может быть предоставлено в виде персонального компьютера (ПК), планшетного компьютера, приставки (STB), персонального цифрового помощника (PDA), сотового телефона или любого вычислительного устройства, способного выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этим вычислительным устройством. Кроме того, в то время как показано только одно вычислительное устройство, термин «вычислительное устройство» также включает в себя любую совокупность вычислительных устройств, которые по отдельности или совместно выполняют набор (или несколько наборов) команд для реализации любого метода или методов, приведенных в данном описании.
[00064] Пример вычислительного устройства 600 включает в себя процессор 602, оперативную память 604 (например, постоянное запоминающее устройство (ПЗУ) или динамическую оперативную память (DRAM)) и устройство хранения данных 618, которые взаимодействуют друг с другом через шину 630.
[00065] Процессор 602 может быть представлен одним или более универсальными устройствами обработки данных, такими как микропроцессор, центральный процессор и т.п. В частности, процессор 602 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW) или процессор, в котором реализованы другие наборов команд, или процессоры, в которых реализована комбинация наборов команд. Процессор 602 также может представлять собой одно или более устройств обработки специального назначения, такие как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровых сигналов (DSP), сетевой процессор или тому подобное. Процессор 602 настроен на выполнение команд 622 для выполнения операций и функций, описанных в этом описании изобретения.
[00066] Компьютерное устройство 600 может дополнительно включать устройство сетевого интерфейса 608, блок видеодисплея 610, устройство ввода символов 612 (например, клавиатуру), устройство управления курсором 614 и генератор сигналов.
[00067] Устройство хранения данных 618 может включать машиночитаемый носитель данных 624, в котором хранится один или более наборов команд 622, в котором реализован один или несколько методов или функций, описанных в данном описании изобретения. Команды 622 также могут находиться полностью или по меньшей мере частично в основной памяти 604 и/или в процессоре 602 при выполнении их вычислительным устройством 1000, причем оперативная память 604 и процессор 602 также составляют машиночитаемый носитель данных. Команды 622 могут дополнительно передаваться или приниматься по сети 620 через устройство сетевого интерфейса 608.
[00068] В некоторых реализациях изобретения команды 622 могут включать команды способа 400 для повышения качества и сравнения документов, причем они могут выполняться с помощью модуля сравнения 190, показанного на Фиг. 1. В то время как машиночитаемый носитель данных 624 показан в примере на Фиг. 4 как единый носитель, термин «машиночитаемый носитель данных» следует понимать как единый носитель либо множество таких носителей (например, централизованную или распределенную базу данных, и/или соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также относится к любым носителям, обеспечивающим хранение, кодирование или перенос набора исполняемых машиной команд при исполнении которых машиной реализуется один или более методов данного изобретения. Таким образом, термин «машиночитаемый носитель данных» относится также к твердотельной памяти, а также оптическим и магнитным носителям.
[00069] Способы, компоненты и функции, описанные в этом документе, могут быть реализованы с помощью дискретных компонентов оборудования, либо они могут быть встроены в функции других компонентов оборудования, таких как ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор) или аналогичных устройств. Кроме того, методы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональной схемы внутри устройства. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации вычислительных средств и программных компонентов, либо исключительно с помощью программного обеспечения.
[00070] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, очевидно, что настоящее изобретение может быть осуществлено практически без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схемы, а не детально, чтобы не усложнять описание настоящего изобретения.
[00071] Некоторые части описания предпочтительных вариантов реализации были представлены с помощью алгоритмов и символических представлений операций над битами данных в памяти компьютера. Эти алгоритмические описания и представления являются средствами, используемыми специалистами в области обработки данных, чтобы наиболее эффективно передать сущность своей работы другим специалистам в этой области техники. В настоящем документе и в целом алгоритмом называется самосогласованная последовательность операций, приводящих к требуемому результату. Операции требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и подвергать другим манипуляциям. Оказалось, что прежде всего для обычного использования удобно описывать эти сигналы в виде битов, значений, элементов, символов, членов, цифр и т.д.
[00072] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами, и что они представляют собой просто удобные метки, применяемые к этим величинам. Если специально не указано иное, что является очевидным из приведенного ниже обсуждения, следует понимать, что во всем описании все утверждения, в которых используются такие термины как «определение», «вычисление», «расчет», «получение», «определение», «изменение» и т.п., относятся к действиям и процессам в вычислительном устройстве или в аналогичном электронном вычислительном устройстве, которое манипулирует данными и преобразует данные, представленные в виде физических (например, электронных) величин в регистрах вычислительного устройства и в памяти в другие данные, аналогичным образом представленные в виде физических величин в памяти или регистрах вычислительного устройства или в других устройствах хранения и передачи информации или в устройствах отображения.
[00073] Настоящее изобретение также относится к устройству для выполнения операций, описанных в этом документе. Такое устройство может быть специально сконструировано для требуемых целей или оно может содержать универсальный компьютер, который избирательно активируется или реконфигурируется с помощью компьютерной программы, хранящейся в компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например (помимо прочего): диск любого типа, в том числе гибкий диск, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд.
[00074] Следует иметь в виду, что приведенное выше описание предназначено для иллюстрации, и что оно не носит ограничительный характер. Различные другие реализации станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому объем раскрытия должен определяться со ссылкой на прилагаемую формулу изобретения наряду с полным объемом эквивалентов, на которые такие требования предоставляют право.
Группа изобретений относится к технологиям распознавания электронных документов. Техническим результатом является повышение точности распознавания символов, за счет преобразования сравниваемого изображения документа на основе разметки изображения эталонного документа. Предложен способ для сравнения изображений документов, выполняемый посредством вычислительного устройства, содержащего процессор. Способ содержит этап, на котором получают изображение первого документа из эталонного документа и соответствующего изображения второго документа из сравниваемого документа. Далее согласно способу осуществляют определение разметки полученных изображений первого и второго документов. А также осуществляют первую процедуру оптического распознавания символов полученных изображений первого и второго документов и формирование эталонного словаря, причем эталонный словарь содержит слова из текстового блока из изображения первого документа. 3 н. и 18 з.п. ф-лы, 6 ил.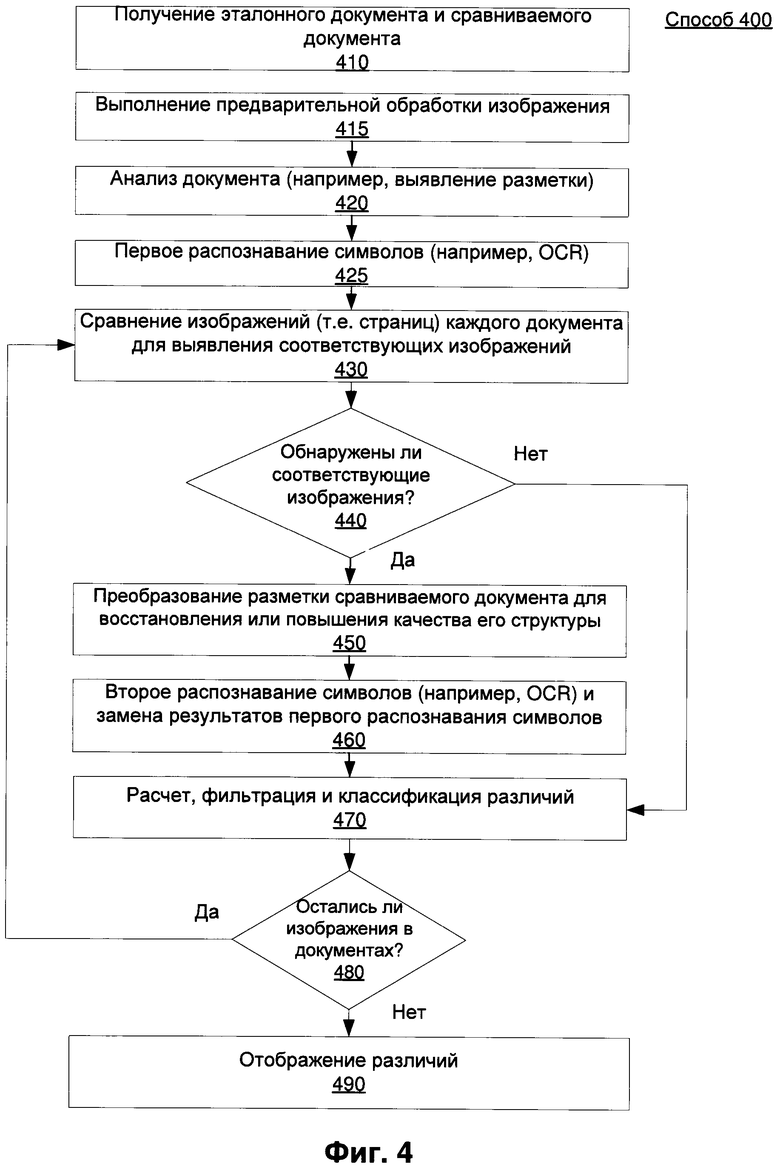
1. Способ для сравнения изображений документов, выполняемый посредством вычислительного устройства, содержащего процессор, заключающийся в:
получении изображения первого документа из эталонного документа и соответствующего изображения второго документа из сравниваемого документа;
определении разметки полученных изображений первого и второго документов;
выполнении первой процедуры оптического распознавания символов полученных изображений первого и второго документов и
формировании эталонного словаря, причем эталонный словарь содержит слова из текстового блока из изображения первого документа;
преобразовании изображения второго документа из сравниваемого документа на основе разметки изображения первого документа из эталонного документа;
выполнении повторного распознавания символов на полученном в результате преобразования изображения второго документа, причем повторное распознавание символов в сравниваемом документе включает использование сформированного эталонного словаря.
2. Способ по п. 1, дополнительно содержащий вычисление различия между сравниваемым документом и эталонным документом на основе результатов первичного распознавания символов первого документа из эталонного документа и повторного распознавания символов второго документа из сравниваемого документа.
3. Способ по п. 1, отличающийся тем, что сравнение изображений документов содержит сравнение по меньшей мере части первой разметки и части первого текста, полученного с помощью распознавания символов на первом изображении документа, и по меньшей мере части второй разметки и части второго текста, полученного путем распознавания символов на втором изображении документа.
4. Способ по п. 3, отличающийся тем, что часть первого текста и часть второго текста включают слова, содержащие по меньшей мере заранее выбранное количество символов, а сравнение изображений документов дополнительно содержит вычисление расстояния редактирования между соответствующими словами.
5. Способ по п. 1, отличающийся тем, что изображение первого документа состоит из изображения страницы первого документа.
6. Способ по п. 1, отличающийся тем, что преобразование включает линейное преобразование изображения второго документа на основе положений трех точек на изображении первого документа и на изображении второго документа.
7. Способ по п. 6, отличающийся тем, что положение трех точек на изображении первого документа и на изображении второго документа определяются на основе уникальных слов в результатах оптического распознавания символов на изображении первого документа и на изображении второго документа.
8. Способ по п. 1, дополнительно содержащий итеративное постраничное сравнение изображений документов на основе результатов оптического распознавания символов и выявленной разметки, представляющих собой эталонный документ и сравниваемый документ, для выявления изображения первого документа из эталонного документа, которое соответствует изображению второго документа из сравниваемого документа.
9. Компьютерно-реализуемая система для сравнения изображений документов, содержащая:
память;
процессор, работающий с этой памятью, причем этот процессор обеспечивает:
получение изображения первого документа из эталонного документа и соответствующего изображения второго документа из сравниваемого документа;
определение разметки полученных изображений первого и второго документов;
выполнение первой процедуры оптического распознавания символов полученных изображений первого и второго документов и
формирование эталонного словаря, причем эталонный словарь содержит слова из текстового блока из изображения первого документа;
преобразование изображения второго документа из сравниваемого документа на основе разметки изображения первого документа из эталонного документа;
выполнение повторного распознавания символов на полученном в результате преобразования изображения второго документа, причем повторное распознавание символов в сравниваемом документе включает использование сформированного эталонного словаря.
10. Компьютерно-реализуемая система по п. 9, отличающаяся тем, что процессор дополнительно обеспечивает: вычисление различий между сравниваемым документом и эталонным документом на основе результатов первичного распознавания символов первого документа из эталонного документа и повторного распознавания символов второго документа из сравниваемого документа.
11. Компьютерно-реализуемая система по п. 9, отличающаяся тем, что сравнение изображений документов содержит сравнение по меньшей мере части первой разметки и части первого текста, полученного с помощью распознавания символов на первом изображении документа, и по меньшей мере части второй разметки и части второго текста, полученного путем распознавания символов на втором изображении документа.
12. Компьютерно-реализуемая система по п. 11, отличающаяся тем, что часть первого текста и часть второго текста содержат слова, имеющие по меньшей мере заранее заданное количество символов, а сравнение изображений документов дополнительно содержит вычисление расстояния редактирования между соответствующими словами.
13. Компьютерно-реализуемая система по п. 9, отличающаяся тем, что изображение первого документа состоит из изображения страницы первого документа.
14. Компьютерно-реализуемая система по п. 9, отличающаяся тем, что преобразование включает в себя линейное преобразование изображения второго документа на основе положений трех точек на изображении первого документа и на изображении второго документа.
15. Компьютерно-реализуемая система по п. 9, отличающаяся тем, что положение трех точек на изображении первого документа и на изображении второго документа определяются на основе уникальных слов в результатах оптического распознавания символов на изображении первого документа и на изображении второго документа.
16. Постоянный машиночитаемый носитель данных, содержащий исполняемые команды для сравнения изображений документов, которые при исполнении их вычислительным устройством приводят к выполнению операций, включающих в себя:
получение изображения первого документа из эталонного документа и соответствующего изображения второго документа из сравниваемого документа;
определение разметки полученных изображений первого и второго документов;
выполнение первой процедуры оптического распознавания символов полученных изображений первого и второго документов и
формирование эталонного словаря, причем эталонный словарь содержит слова из текстового блока из изображения первого документа;
преобразование изображения второго документа из сравниваемого документа на основе разметки изображения первого документа из эталонного документа;
выполнение повторного распознавания символов на полученном в результате преобразования изображения второго документа, причем повторное распознавание символов в сравниваемом документе включает использование сформированного эталонного словаря.
17. Постоянный машиночитаемый носитель данных по п. 16, дополнительно обеспечивающий расчет различий между сравниваемым документом и эталонным документом на основе результатов первичного распознавания символов первого документа из эталонного документа и повторного распознавания символов второго документа из сравниваемого документа.
18. Постоянный машиночитаемый носитель данных по п. 16, отличающийся тем, что сравнение изображений документов содержит сравнение по меньшей мере части первой разметки и части первого текста, полученного с помощью распознавания символов на первом изображении документа, и по меньшей мере части второй разметки и части второго текста, полученного путем распознавания символов на втором изображении документа.
19. Постоянный машиночитаемый носитель данных по п. 18, отличающийся тем, что часть первого текста и часть второго текста содержат слова, имеющие по меньшей мере заранее заданное число символов, а сравнение изображений документов дополнительно предполагает вычисление расстояния редактирования между соответствующими словами.
20. Постоянный машиночитаемый носитель данных по п. 16, отличающийся тем, что преобразование включает в себя линейное преобразование изображения второго документа на основе положений трех точек на изображении первого документа и на изображении второго документа.
21. Постоянный машиночитаемый носитель данных по п. 20, отличающийся тем, что положение трех точек на изображении первого документа и на изображении второго документа определяются на основе уникальных слов в результатах оптического распознавания символов на изображении первого документа и на изображении второго документа.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| ГРАММАТИЧЕСКИЙ РАЗБОР ВИЗУАЛЬНЫХ СТРУКТУР ДОКУМЕНТА | 2006 |
|
RU2421810C2 |

