Настоящее изобретение относится к способу и системе для обеспечения закодированного кодовыми комбинациями словаря, предназначенного для использования в обработке языковых данных в компьютерных системах, таких как системы оптического распознавания символов (ОРС) или системы автоматического распознавания речи (АРР), и особенно к закодированному кодовыми комбинациями словарю, использующему по меньшей мере один классификатор кодовых комбинаций, связанный с кодовыми комбинациями символов или фонем, представляющих элементы языковых данных, выводимые из конкретного языкового словаря.
Существующие системы распознавания текста современного технического уровня, часто обозначаемые как системы оптического распознавания символов, обычно основаны на сопоставлении с известными установленными эталонами, посредством структурного сопоставления или посредством распознавания символов, основанного на наборе установленной совокупности правил распознавания, использующих набор вычисляемых особых признаков, извлекаемых из очертаний символов. Каждому символу назначается показатель или априорная расчетная вероятность для каждого класса или совокупности символов. Словарь используется для проверки того, что каждая цепочка предложенных символов может формировать слова, выбирая наиболее вероятное слово.
Системы распознавания текста современного технического уровня обычно терпят неудачу, когда они сталкиваются с текстовыми изображениями с ухудшением характеристик от умеренного до сильного. Такое ухудшение текстовых изображений может быть результатом фотокопирования исходного документа, машинописных документов, с которыми можно сталкиваться при сканировании более старого архивного материала, газет, которые обычно имеют плохую печать и качество бумаги, влияющие на качество текстовых изображений, факсов, которые обычно имеют плохую разрешающую способность в устройстве канала передачи и печати, и т.д. Эти и аналогичные проблемы описаны в книге Стефана Райса (Stephen Rice) и др. "Optical Character recognition - An illustrated Guide to the Frontier (Распознавание текста - иллюстрированное руководство для достижения предельной возможности)", Kluwer Academic Publishers 1999 г.
Современные системы распознавания текстов обеспечивают адаптацию только до ограниченной степени к конкретному шрифту или искажениям текста без фазы управляемого обучения, требующей взаимодействия с человеком в этом процессе, что значительно замедляет процесс. Обработка электронных документов, системы архивирования, электронное сохранение напечатанного материала и т.д. требуют сканирования неограниченного количества страниц, что делает невозможным использовать взаимодействие с человеком, чтобы добиться успеха при выполнении таких задач.
В этом отношении системы автоматического распознавания речи сталкиваются с проблемами, которые являются очень похожими на проблемы, с которыми сталкиваются при искаженных изображениях в обработке ОРС. Отправной точкой распознавания либо ввода ОРС, либо ввода АРР должно быть обеспечение возможности распознавания некоторых слов и/или символов, как надежно распознанных. Основанный на таких надежно идентифицированных элементах, процесс ОРС или АРР может продолжаться адаптивным способом или как система с перестраиваемой конфигурацией. Всякий раз, когда имеется искажение во вводе ОРС, или ввод АРР искажен, например, из-за различных образцов речи различных людей, способность распознавать некоторые символы или слова как надежные уменьшается. Однако, в соответствии с настоящим изобретением некоторые символы, слова могут быть надежно идентифицированы посредством обеспечения закодированного кодовыми комбинациями словаря, основанного по меньшей мере на одном идентифицируемом классификаторе кодовых комбинаций, связанном с кодовыми комбинациями, обнаруживаемыми в изображениях, содержащих текст, даже в изображениях, содержащих сильно искаженный текст, в системах ОРС, или в цифровых изображениях фонем в системах АРР.
Публикация к РСТ заявке WO 2005/050473 А2 раскрывает способ семантического группирования текстовых сегментов в системе обработки языковых данных, основанный на их семантическом значении. Группы относятся к одному или нескольким семантическим разделам и используются для обучения языковых моделей. Семантическое группирование раскрытия основано на модели выделения текста и модели передачи группы, обеспечивающих вероятностную оценку того, что текст относится к конкретному семантическому разделу.
Настоящее изобретение, при его осуществлении, направлено на достижение технического результата, который заключается в улучшении автоматического распознавания текста и речи.
Цель настоящего изобретения состоит в том, чтобы группировать слова, основываясь на физическом, геометрическом и структурном подобии элементов языковых данных, таких как буквы, слоги или фонемы, когда они представлены в компьютерной системе. Эта цель достигнута с помощью применения классификатора кодовых комбинаций для группирования слов, основываясь на их подобии. Посредством группирования всех слов с подобными кодовыми комбинациями в словаре можно выполнять просмотр в закодированном классификатором кодовых комбинаций словаре, основываясь на конкретной кодовой комбинации, и словарь выведет перечень всех слов в соответствующей группе. Семантическое значение или раздел не относятся к классификатору кодовых комбинаций по настоящему изобретению.
В соответствии с аспектом настоящего изобретения слова формируют повторяющиеся кодовые комбинации вследствие повторяющейся природы букв, составляющих слова. В предшествующем уровне техники это явление используется, например, в криптографическом анализе. В соответствии с настоящим изобретением по меньшей мере один классификатор кодовых комбинаций, связанный с такими аспектами повторения букв, составляющих слова, обеспечиваемые на конкретном языке, подлежащем обработке в программе OCR или в системе АРР, используется для кодирования словаря кодовых комбинаций, связывающего упомянутый по меньшей мере один классификатор кодовых комбинаций с упомянутыми словами, таким образом обеспечивая возможность распознавания слов текстового ввода в упомянутой системе ОРС или АРР, посредством идентифицирования упомянутого по меньшей мере одного классификатора кодовых комбинаций из любого ввода ОРС (цифрового изображения отсканированного или сфотографированного в цифровой форме ввода документа), или любого ввода, представляющего кодовые комбинации речи в цифровой форме (представленного в цифровой форме микрофонного ввода, файла и т.д.), и использования упомянутого закодированного кодовыми комбинациями словаря для распознавания упомянутого ввода ОРС или АРР.
В соответствии с другим аспектом настоящего изобретения несколько различных аспектов кодирования различных закодированных кодовыми комбинациями словарей упомянутых классификаторов кодовых комбинаций или те, что обеспечивают кодирование различных классификаторов кодовых комбинаций, могут использоваться на одном и том же вводе ОРС или АРР, чтобы увеличить объем распознанного текста из упомянутого ввода.
Фиг. 1 схематично иллюстрирует пример варианта осуществления настоящего изобретения.
Фиг. 2 иллюстрирует использование опорных линий в соответствии с примером варианта осуществления настоящего изобретения.
Фиг. 3 - другой пример кодирования в соответствии с примером варианта осуществления настоящего изобретения.
Фиг. 4 - другой пример кодирования в соответствии с примером варианта осуществления настоящего изобретения.
Фиг. 5 - другой пример кодирования в соответствии с примером варианта осуществления настоящего изобретения.
Фиг. 6 - пример непериодического звука (буквы [f] в слове [first] (первый)) в соответствии с примером варианта осуществления настоящего изобретения.
Фиг. 7 - пример периодического звука (буквы [m] в слове [met] (встреченный)) в соответствии с примером варианта осуществления настоящего изобретения.
Фиг. 8 - пример переходного взрывного звука (буквы [t] в словах [first met] (встреченный в первый раз)) в соответствии с примером варианта осуществления настоящего изобретения.
Фиг. 9 - схематичная блок-схема алгоритма предпочтительного варианта осуществления настоящего изобретения.
В последующих разделах будет обеспечено подробное описание предпочтительного варианта осуществления настоящего изобретения, во-первых, с помощью описания некоторых примеров классификаторов кодовых комбинаций, связанных с кодовыми комбинациями, обнаруживаемыми в области ОРС и области АРР, соответственно, сопровождаемых описанием примера предпочтительного способа и системы, использующей упомянутый способ, обеспечивающий закодированный кодовыми комбинациями словарь.
Фиг. 1 иллюстрирует пример варианта осуществления настоящего изобретения. Существующий словарь 10 для конкретного языка, например английского, используемого в ОРС или АРР, анализируется в секции 11, для обеспечения по меньшей мере одного классификатора кодовых комбинаций, относящегося к кодовым комбинациям, связанным с упомянутыми словами, содержащимися в упомянутом словаре 10. Затем используется по меньшей мере один классификатор кодовых комбинаций, идентифицированный в секции 11, чтобы образовать взаимосвязь 12 между кодовыми комбинациями и словами, проанализированными в 11, для обеспечения упомянутых слов, связанных с кодовыми комбинациями, из словаря 10 в перечне 13. Затем двоичный растровый ввод 14 от ввода ОРС (сканера, фотокамеры и т.д.) или ввода АРР (вывода цифрового микрофона, компьютерного файла и т.д.) анализируется в секции 15, которая является анализирующим элементом, подобным секции 11, обеспечивающей кодовые комбинации, основанные на упомянутом по меньшей мере одном классификаторе кодовых комбинаций. После этого кодовые комбинации 16 используются для адресации перечня 13, обеспечивая вывод 17 слов, связанных с упомянутой кодовой комбинацией. Если кодовая комбинация однозначно идентифицирует единственное слово, это единственное слово выводится из перечня 13. Если кодовая комбинация связана с множеством слов, из перечня 13 выводится множество слов. Вывод 17 из перечня 13 затем сообщается, например, в адаптивный раздел в системе ОРС или АРР, или используется для того, чтобы конфигурировать (вручную или автоматически) систему ОРС или АРР для дальнейшего распознавания символов и/или слов из ввода 14.
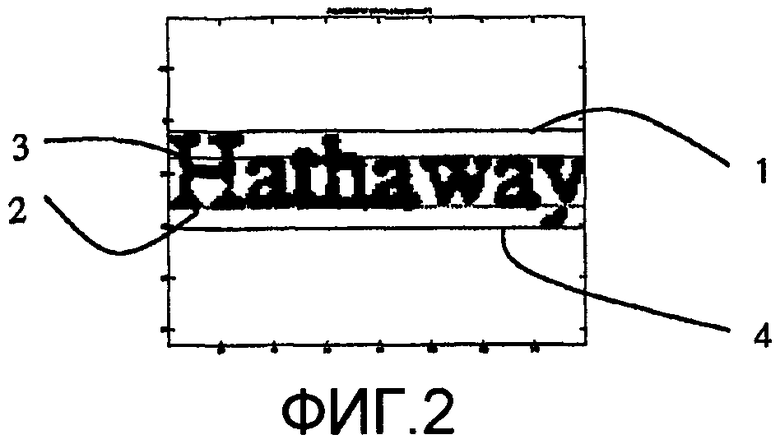
В качестве примера классификаторов кодовых комбинаций, связанных с кодовыми комбинациями в изображениях в системах ОРС, Фиг. 2 иллюстрирует пример использования опорных линий. Со ссылкой на Фиг. 2 отметим, что текстовая строка отличается своими опорными линиями, называемыми линией 4 нижних выносных элементов, линией 1 верхних выносных элементов, линией 2 шрифта и верхней линией 3 строчных букв. В соответствии с аспектом настоящего изобретения такие опорные линии могут использоваться для кодирования кодовых комбинаций, связанных с тем, как символы позиционированы относительно таких опорных линий.
В соответствии с примером варианта осуществления настоящего изобретения буквы, продолжающиеся выше верхней линии 3 строчных букв, как показано на Фиг. 2, кодируются буквой O (выше), буквы, продолжающиеся ниже линии 2 шрифта, кодируются буквой U (ниже), а остающиеся буквы кодируются буквой M (средние). Например, слово "funny" (забавный) теперь кодируется как OMMMU, а слово "instruments" (инструменты) - как OMMOMMMMMOM, тип кодирования, который ограничивает количество возможных комбинаций букв. В соответствии с примером варианта осуществления настоящего изобретения английский словарь, содержащий приблизительно 125 000 слов, кодируется, как изображено на Фиг. 1, обеспечивая закодированный кодовыми комбинациями словарь в соответствии с настоящим изобретением.
В соответствии с другим примером варианта осуществления настоящего изобретения кодирование слов расширено на символы, которые не являются сегментированными символами, где каждый фрагмент символа закодирован способом, подобным описанному выше. В качестве примера, фрагментированное слово "funny" (забавный) можно закодировать как OMMMMMMUM, где 'u' и 'n' закодированы, как ММ из-за двойных ножек, а 'y' закодирована как UM. Благодаря такому подходу закодированный классификатором кодовых комбинаций словарь может использоваться, как инструмент для решения проблем сегментации в распознавании текстов, если могут быть идентифицированы однозначные кодовые комбинации.
Фиг. 3 иллюстрирует пример необычного шрифта (Harpoon) с очень короткой фразой, которая может быть распознана исключительно при использовании закодированного кодовыми комбинациями словаря, в соответствии с настоящим изобретением. Даже при том, что люди легко читают этот текст, никакое коммерческое программное обеспечение ОРС, такое как Scansofts OmniPage или ABBYYs FineReader, не способно распознать этот пример текста, поскольку там не имеется эталонов шрифта Harpoon в какой-либо из программ, и структура символов этого шрифта слегка отличаются от обычной структуры символов, имеющейся во многих других шрифтах.
Примером кодовой комбинации, которая может использоваться, является кодовая комбинация верхних выносных элементов/нижних выносных элементов этих двух слов, которая представляет собой OMMMMMMMOOM MOUMMMOOMM. В упомянутом примере английского словаря, содержащего приблизительно 125 000 слов, слово 'cigarettes' (сигареты) является единственным словом в этом словаре, которое имеет кодовую комбинацию верхних выносных элементов/нижних выносных элементов, представляющую собой MOUMMMOOMM. Без какой-либо другой информации, чем сегментация символов и кодовая комбинация верхних выносных элементов/нижних выносных элементов, способ в соответствии с настоящим изобретением способен распознать это слово как 'cigarettes' (сигареты), используя этот конкретный словарь и упомянутое кодирование верхних выносных элементов/нижних выносных элементов.
Кодовая комбинация верхних выносных элементов/нижних выносных элементов для слова 'innumerable' (неисчислимые) на Фиг. 3 обеспечивает 14 возможных слов из упомянутого английского словаря (denumerable (вычисляемый), foreseeable (обозримый), hermeneutic (интерпретационный), increasable (увеличиваемый), inenarrable (неописуемый), inexcusable (непростительный), innumerable (неисчислимый), irrecusable (неоспоримый), irremovable (неустранимый), irrevocable (безвозвратный), leucocratic (лейкократовый), traversable (оспоримый), treasonable (изменнический) и treasurable (сберегаемый)), имеющих одинаковую кодовую комбинацию верхних выносных элементов/нижних выносных элементов. Поскольку способ в соответствии с настоящим изобретением распознал единственное слово "cigarettes" (сигареты), восемь знаков 'acegirst', встречающихся в слове "cigarettes", могут использоваться для обеспечения либо эталонов, либо основанного на классификаторе кодовых комбинаций распознавания слова 'innumerable' (неисчислимые). Частично распознанная кодовая комбинация верхних выносных элементов/нижних выносных элементов для 'innumerable' становится iMMMMeraOOe, и в словаре имеется только один подходящий вариант, 'innumerable'. Используя только два слова и их кодовую комбинацию верхних выносных элементов/нижних выносных элементов, способ в соответствии с настоящим изобретением способен распознать эти тринадцать знаков 'abcegilmnrstu' такого неизвестного шрифта.
Фиг. 4 представляет пример архивного материала низкого качества с шрифтом пишущей машинки очень короткой фразы, которая может быть частично распознана с использованием закодированного кодовыми комбинациями словаря в соответствии с настоящим изобретением. Снова никакое обыкновенное ОРС не может даже приблизиться к распознаванию примера из-за уровня помех. Текст является моноширинным, и поэтому символьная сегментация тривиальна.
В соответствии с аспектом настоящего изобретения кодовая комбинация верхних выносных элементов/нижних выносных элементов этих трех слов на Фиг. 4, которые представляют собой MMU MMOMOMMM OMMMUMMOOMOMO, может быть использована в закодированном кодовыми комбинациями словаре. Быстрая проверка в таком закодированном кодовыми комбинациями словаре, таком как использованный выше английский словарь, обеспечивает 'incapacitated' (нетрудоспособный), как однозначную кодовую комбинацию, и она может быть прямо распознана, в то время как 'any' (любой) имеет 52 альтернативных слова с той же самой кодовой комбинацией верхних выносных элементов/нижних выносных элементов, а 'reindeer' (северный олень) имеет 60 альтернативных слов с той же самой кодовой комбинацией верхних выносных элементов/нижних выносных элементов. Чтобы распознать два первых слова 'any reindeer' (любой северный олень), пример варианта осуществления настоящего изобретения дополнительно сужает варианты. И символ 'i', и символ 'd' имеют вполне явные внешние контуры (формы) в слове 'incapacitated', и для этих двух букв могут использоваться устойчивые правила распознавания, основанные на внешних контурах. В примере варианта осуществления кодовая комбинация снижается до MMiMdMMM, и эта кодовая комбинация является однозначной для слова 'reindeer' (северный олень).
В соответствии с другим аспектом настоящего изобретения для цели распознавания может использоваться более сложное кодирование кодовой комбинации, чем кодирование верхних выносных элементов/нижних выносных элементов, используемое в предыдущих примерах. Пример варианта осуществления настоящего изобретения состоит в использовании кодирования дуг и ножек, как иллюстрируется в таблице 1 ниже.
Пример кодирования дуг и ножек
При применении кодирования дуг/ножек, обеспеченного в таблице 1, кодовая комбинация FHE GFBHAFFG BHFFEFFBBFBFA представит предложение 'any incapacitated reindeer' (любой нетрудоспособный северный олень), иллюстрируемое на Фиг. 4. При использовании английского словаря, содержащего 125 000 слов, закодированных с помощью кодовых комбинаций из таблицы 1, слово 'incapacitated' представляет однозначную кодовую комбинацию, слово 'reindeer' представляет также однозначную кодовую комбинацию, в то время как в словаре имеется четыре альтернативных слова (amp (усилитель), any (любой), cup (чаша), sup (глоток)) с такой же кодовой комбинацией, как слово 'any'.
В соответствии с еще одним аспектом настоящего изобретения в обеспечении закодированного кодовыми комбинациями словаря могут использоваться топологические свойства символа, выраженные, например, в математических терминах, таких как количество элементов и отверстий, которые составляют символ. Пример обеспечен в таблице 2 ниже. В примере, представленном в таблице 2, мы использовали дополнительную информацию о положении отверстий в символе.
Пример топологического кодирования символов в словах словаря
Текст на Фиг. 5 получен с помощью цифровой фотокамеры, и геометрическое искажение делает трудным распознавание текста, поскольку размер и перекос символов изменяются по строке текста. Однако топологические свойства могут легко быть вычислены для каждого отдельного символа, как известно специалистам в данной области техники.
Применение топологического кодирования кодовых комбинаций из таблицы 2 и кодирование текста на Фиг. 5 обеспечивают следующую кодовую комбинацию: IC CCE DECCECC CIDCIBCC CDCC. Слово 'midnight' (полночь) имеет однозначную кодовую комбинацию и прямо распознается в словаре, содержащем 125 000 слов, закодированных с помощью этого примера кодовой комбинации, в то время как слово 'darkest' (самый темный) имеет 72 варианта, а 'hour' (час) имеет 152 варианта с тем же самым кодированием кодовой комбинации. Слово 'in' (в) имеет только шесть вариантов (if, in, is, it, iv, ix) (если, в, является, это, iv, ix), все из которых начинаются с буквы 'i', а последние два являются римскими цифрами.
При объединении топологических свойств из таблицы 2 с кодированием верхних выносных элементов/нижних выносных элементов, описанным выше, среди 125 000 слов в упомянутом словаре обеспечивается однозначная кодовая комбинация для слова 'darkest' (самый темный).
Системы автоматического распознавания речи (АРР) сталкиваются с тем же самым типом проблем, какие обнаруживаются в ОРС, в том смысле, что некоторые кодовые комбинации, представляющие элементы (буквы, слова и т.д.), должны быть надежно распознаны, чтобы обеспечивать возможность адаптации или конфигурации системы АРР. В соответствии с аспектом настоящего изобретения, кодирование кодовой комбинации звука может быть основано на типах фонем. Например, речь может быть разделена на гласные [звуковые кодовые комбинации, связанные с буквами aeiouy], назальные [nm], боковые [l], вибрирующие [r], фрикативные [fsvz] и взрывные [ptkbdg] звуки, с различием между звонкими и глухими звуками или без него.
Например, слово 'instruments' (инструменты) тогда кодируется как VNFTVNVNPF, где V представляет гласные, N - назальные, F - фрикативные, T - вибрирующие и P - взрывные звуки. Это является только примером кодирования, и можно использовать различные звуковые комбинации. Некоторые звуки могут представлять несколько символов в речи, а также можно использовать другие классификации звуков, в соответствии с настоящим изобретением.
Согласно еще одному аспекту настоящего изобретения звук также может быть закодирован с использованием схемы кодирования, основанной на кодовых комбинациях, обнаруживаемых в изображениях звуковых кодовых комбинаций, например, на изменении амплитуды звукового выходного сигнала от микрофона относительно времени. Фиг. 6 иллюстрирует такую взаимосвязь для буквы f в слове first (первый). Этот тип кодовой комбинации отличается стационарным непериодическим звуком, содержащим сигналы со случайным поведением и большой степенью высокочастотного содержания во временном звуковом сигнале. Стационарные непериодические звуки легко отличаются от других звуковых типов, например, с помощью преобразования Фурье, как известно специалистам в данной области техники.
В соответствии с другим аспектом настоящего изобретения все гласные звуки и некоторые звонкие и вибрирующие согласные представляют собой квазистационарные периодические звуки, отличающиеся повторяющейся звуковой кодовой комбинацией с небольшим количеством частот, называемых формантными частотами. Это представляет собой вокальный аккорд, который делает выбор основной частоты, и положение подвижных элементов речевого трактата, которое делает выбор формантных частот. Эти звонкие звуки часто дополнительно классифицируются на основании количества формант и относительных частот формант в системах автоматического распознавания речи. Большим источником для погрешностей являются большие различия от одного говорящего к другому. Однако бывает просто отличать квазистационарные периодические звуки от других звуковых типов, например, с помощью преобразования Фурье для звукового сигнала, как известно специалистам в данной области техники. Фиг. 7 иллюстрирует пример периодического звука для буквы m в слове met (встреченный).
В соответствии с еще одним аспектом настоящего изобретения взрывные звуки отличаются их неустановившимся переходным звуковым сигналом, поскольку речевой тракт закрывается и открывается снова во время речи. Взрывные звуки могут содержать переходную фазу закрывания, фазу подавления (приглушенную или звонкую) и переходную фазу открывания. Даже при том, что каждый из взрывных звуков имеет отчетливо отличающийся звуковой сигнал, они легко отличаются от других звуковых типов, например, с помощью преобразования Фурье, как известно специалистам в данной области техники. Фиг. 8 иллюстрирует пример переходного взрывного звука для буквы t в слове met (встреченный).
В соответствии с примером варианта осуществления настоящего изобретения схема кодирования, обеспечивающая N для стационарных непериодических звуков [fsvz], P для периодических звуков [aeiouynmlr] и T для переходных звуков [ptkbdg], может использоваться для кодирования закодированного кодовыми комбинациями словаря, например, для английского языка. В примере словаря, содержащего 125 000 слов, слово 'instruments' (инструменты) тогда кодируется как PPNTPPPPPTN. Имеется только 4 из 125 000 слов в упомянутом словаре, которые соответствуют этой кодовой комбинации кодирования на основании произношения. Эти 4 слова представляют собой instalments (фрагменты), instruments (инструменты), masterminds (вдохновители) и restaurants (рестораны). Благодаря независимому распознаванию, например, вибрирующего звука ('r') в слове 'instruments' (инструменты), обеспечивается однозначная кодовая комбинация. В соответствии с примером варианта осуществления настоящего изобретения, как изображено на Фиг. 1, английский словарь 10 может анализироваться в секции 11, чтобы обеспечивать такие кодовые комбинации 12, которые связывают звуки, представляющие слова, и буквы, обеспечиваемые в перечне 13. Всякий раз, когда звуковой ввод 14 анализируется в секции 15, может использоваться кодовая комбинация 16 для нахождения связанных слов и букв из перечня 13, а вывод 17 может использоваться для обеспечения адаптации или конфигурирования вручную или автоматически системы АРР.
Фиг. 9 изображает блок-схему алгоритма, иллюстрирующую предпочтительный вариант осуществления настоящего изобретения. Отправная точка для обеспечения закодированного кодовыми комбинациями словаря представляет собой анализирование существующего словаря, содержащего конкретный язык, например английский. На Фиг. 9, словарь 20 анализируется в секции 21. Система кодирования, подлежащая использованию, может быть сохранена в ячейке 25 памяти, которая может содержать схему кодирования, как иллюстрируется в приведенных выше таблице 1 и таблице 2, для использования в системе ОРС, или ячейка 25 памяти может содержать схемы кодирования фонем, как описано выше, когда она используется в системе АРР. В соответствии с аспектом настоящего изобретения ячейка 25 памяти может содержать несколько схем кодирования, например схемы, обеспечиваемые как таблицей 1, так и таблицей 2.
В дополнение к конкретным схемам кодирования, подлежащим использованию в анализирующей секции 11, ячейка 25 памяти может содержать схемы кодирования, включающие в себя результаты статистического анализа классификатора кодовых комбинаций, обеспечиваемого в секции 24, и/или априорное знание о конкретном языке, содержащемся в секции 26. В примере варианта осуществления секция 24 статистического анализа принимает текстовое изображение или речевые сигналы от секции 28 и анализирует входной сигнал, чтобы оценить, которые наборы классификаторов кодовых комбинаций лучше всего представлены во входном сигнале, обеспечивая возможность для анализирующей секции 21 обеспечивать кодовые комбинации 22 классификаторов кодовых комбинаций, которые являются существенными в фактическом текстовом изображении или речевом сигнале. Таким образом, закодированный кодовыми комбинациями словарь может обеспечиваться как "способ наилучшего приближения" для фактического входного сигнала 28. Когда упомянутые кодовые комбинации 22 классификаторов кодовых комбинаций проанализированы, в секцию 23 группирования сообщается выходной сигнал, обеспечивая перечни словаря, связывающие упомянутые кодовые комбинации со словами из словаря 20 в ячейке 27 памяти. Ввод текстового изображения или речевой сигнал 28 анализируются в секции 29 для обеспечения кодовых комбинаций 30 классификаторов кодовых комбинаций. Секция 29 принимает те же самые схемы кодирования, которые используются в секции 21, от ячейки 25 памяти. Выходной сигнал от секции 30 используется для выполнения процесса поиска в словаре в секции 31, адресуясь к перечню, обеспечиваемому в секции 27, с помощью кодовой комбинации классификатора кодовых комбинаций от секции 30. Выходной сигнал от секции 31 поиска в словаре приводит в результате либо к однозначному слову или звуковой идентификации 32, либо к перечню кандидатов 33. Выходной сигнал 32 и 33 используется для адаптации или конфигурации системы АРР или ОРС.
В соответствии с аспектом настоящего изобретения перечень кандидатов 33 должен быть минимальным. Идеальная ситуация состоит только в том, чтобы иметь однозначную идентификацию 32. Однако, в соответствии с примером варианта осуществления настоящего изобретения, количество кандидатов 33 можно снижать, повторяя, например, этапы предпочтительного варианта осуществления, как изображено на Фиг. 9. Однако выбор классификатора кодовых комбинаций, подлежащего использованию, должен отличаться от предварительно использованного. Таким образом, с используемым классификатором кодовых комбинаций могут быть связаны более надежно идентифицированные слова. В соответствии с еще одним примером варианта осуществления настоящего изобретения в создании словаря кодовых комбинаций может использоваться множество классификаторов кодовых комбинаций. Также может использоваться любая комбинация классификаторов кодовых комбинаций. Например, по меньшей мере первый классификатор кодовых комбинаций и по меньшей мере второй классификатор кодовых комбинаций могут использоваться в комбинации, как булево выражение, или в классификаторах кодовых комбинаций в соответствии с настоящим изобретением могут использоваться любое булево выражение или последовательность булевых выражений.







Изобретение относится к способу распознавания слов в компьютерных системах, таких как системы оптического распознавания символов (ОРС) или системы автоматического распознавания речи (АРР), и машиночитаемому носителю данных, содержащему команды для выполнения данного способа. Технический результат заключается в улучшении автоматического распознавания текста и речи за счет использования классификатора кодовых комбинаций. В способе выбирают классификатор кодовых комбинаций, связанный со словами определенного языка, на основании физического, геометрического или структурного подобия слов для осуществления распознавания слов. Извлекают слова из словаря, представляющего слова определенного языка, и используют классификатор кодовых комбинаций для группировки слов в различные группы в соответствии с одним классификатором кодовых комбинаций. Связывают каждую из групп слов и классификатор кодовых комбинаций в форме словаря, так что когда классификатор кодовых комбинаций используемого типа для группирования слов представляется словарю, то из словаря выводится перечень слов в соответствующей группе для дальнейшей обработки распознавания слов. 2 н. и 18 з.п. ф-лы, 9 ил., 2 табл.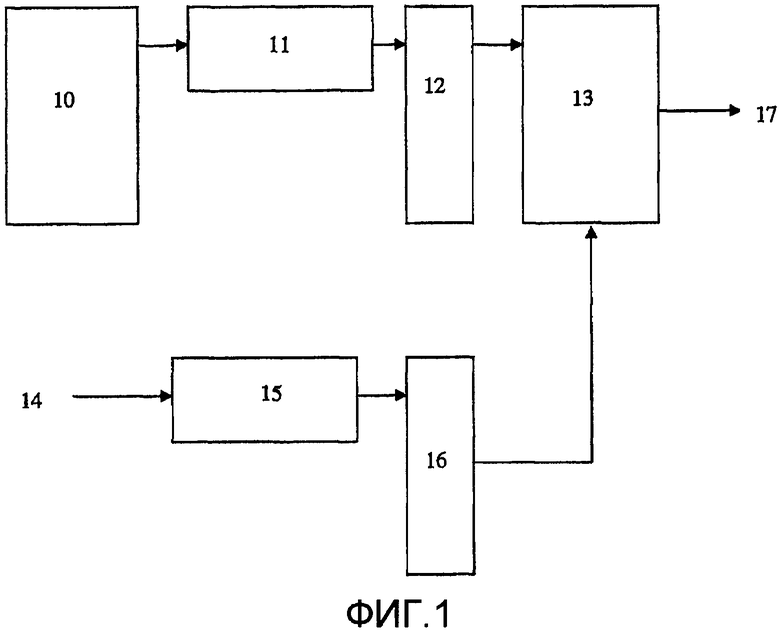
1. Способ распознавания слов в компьютерных системах, таких как системы оптического распознавания символов (ОРС) или системы автоматического распознавания речи (АРР), содержащий этапы, на которых
a) выбирают, по меньшей мере, один классификатор кодовых комбинаций, связанный со словами определенного языка, на основании физического, геометрического или структурного подобия слов для осуществления распознавания слов.
b) извлекают слова из словаря, представляющего слова определенного языка на этапе а), и затем используют, по меньшей мере, один классификатор кодовых комбинаций для группировки слов в различные группы в соответствии, по меньшей мере, с одним классификатором кодовых комбинаций,
c) связывают каждую из групп слов и, по меньшей мере, один классификатор кодовых комбинаций в форме словаря, так что, когда, по меньшей мере, один классификатор кодовых комбинаций используемого типа для группирования слов предоставляется словарю, то из словаря выводится перечень слов в соответствующей группе для дальнейшей обработки распознавания слов.
2. Способ по п.1, в котором упомянутые этапы а), b) и с) повторяют для минимизации количества слов при каждом группировании упомянутых слов на упомянутом этапе с), используя другой, по меньшей мере, один классификатор кодовых комбинаций на этапе а).
3. Способ по пп.1 и 2, в котором упомянутый этап а) содержит этап, на котором выбирают множество классификаторов кодовых комбинаций.
4. Способ по пп.1 и 2, в котором упомянутый этап а) содержит выбор комбинации, по меньшей мере, из двух классификаторов кодовых комбинаций.
5. Способ по п.1, в котором упомянутые слова представляют собой буквы, а упомянутый, по меньшей мере, один классификатор кодовых комбинаций представляет собой горизонтальное положение верхних выносных элементов букв или нижних выносных элементов букв относительно опорных линий, содержащих упомянутые буквы.
6. Способ по п.1, в котором элементами, представляющими слова, являются буквы, а упомянутый, по меньшей мере, один классификатор кодовых комбинаций представляет собой дугу и ножку для упомянутых букв.
7. Способ по п.1, в котором элементами, представляющими слова, являются буквы, а упомянутый, по меньшей мере, один классификатор кодовых комбинаций представляет собой количество отверстий и элементов для упомянутых букв.
8. Способ по п.1, в котором элементами, представляющими слова, являются звуковые элементы, а упомянутый, по меньшей мере, один классификатор кодовых комбинаций представляет собой тип фонемы, связанный с упомянутыми звуковыми элементами.
9. Способ по п.8, в котором упомянутый тип фонемы представляет собой гласные, назальные, боковые, вибрирующие, фрикативные и взрывные звуки.
10. Способ по п.8, в котором упомянутые звуковые элементы представляют собой звонкие или глухие звуки.
11. Машиночитаемый носитель данных, содержащий команды, сохраненные на нем, причем команды при исполнении их процессором побуждают процессор выполнять способ по п.1, содержащий этапы
a) выбора, по меньшей мере, одного классификатора кодовых комбинаций, связанного со словами определенного языка, на основании физического, геометрического или структурного подобия слов для осуществления распознавания слов,
b) извлечения слов из словаря, представляющего слова определенного языка на этапе а), и затем использования, по меньшей мере, одного классификатора кодовых комбинаций для группировки слов в различные группы в соответствии, по меньшей мере, с одним классификатором кодовых комбинаций,
c) связывания каждой из групп слов и, по меньшей мере, одного классификатора кодовых комбинаций в форме словаря, так что, когда, по меньшей мере, один классификатор кодовых комбинаций используемого типа для группирования слов представляется словарю, то из словаря выводится перечень слов в соответствующей группе для дальнейшей обработки распознавания слов.
12. Машиночитаемый носитель данных по п.11, причем этапы а), b) и с) повторяются для минимизации количества слов в каждом упомянутом соединении слов в упомянутом перечне.
13. Машиночитаемый носитель данных по п.11 или 12, причем этап а) содержит определение множества классификаторов кодовых комбинаций.
14. Машиночитаемый носитель данных по п.11 и 12, причем этап а) содержит определение комбинации из, по меньшей мере, двух классификаторов кодовых комбинаций.
15. Машиночитаемый носитель данных по п.11, причем упомянутые слова являются буквами, а упомянутый, по меньшей мере, один классификатор кодовых комбинаций представляет собой горизонтальное положение верхних выносных элементов букв или нижних выносных элементов букв относительно опорных линий, содержащих упомянутые буквы.
16. Машиночитаемый носитель данных по п.11, причем элементами, представляющими слова, являются буквы, а упомянутый, по меньшей мере, один классификатор кодовых комбинаций представляет собой дугу и ножку для упомянутых букв.
17. Машиночитаемый носитель данных по п.11, причем элементами, представляющими слова, являются буквы, а упомянутый, по меньшей мере, один классификатор кодовых комбинаций представляет собой количество отверстий и элементов для упомянутых букв.
18. Машиночитаемый носитель данных по п.11, причем элементами, представляющими слова, являются звуковые элементы, а упомянутый, по меньшей мере, один классификатор кодовых комбинаций представляет собой тип фонемы, связанный с упомянутыми звуковыми элементами.
19. Машиночитаемый носитель данных по п.18, причем упомянутый тип фонемы представляет собой гласные, назальные, боковые, вибрирующие, фрикативные и взрывные звуки.
20. Машиночитаемый носитель данных по п.18, причем упомянутые звуковые элементы представляют собой звонкие или глухие звуки.
| US 5963666 А, 05.10.1999 | |||
| US 5745600 А, 28.04.1998 | |||
| US 5048113 А, 10.09.1991 | |||
| US 20040086179 A1, 06.05.2004 | |||
| US 6252988 B1, 26.06.2001 | |||
| КОРРЕКЦИЯ ОШИБОК ДЛЯ СИСТЕМ РАСПОЗНАВАНИЯ РЕЧИ | 2006 |
|
RU2379767C2 |

