Область техники
Настоящее изобретение в целом относится к способам хранения данных и, в частности, к сбору и извлечению данных, полученных от различных источников данных.
Технологический процесс производства все больше зависит от систем сбора данных и использования их с целью повышения эффективности технологического процесса и уменьшения затрат на его обслуживание.
Большинство технологических процессов автоматизированы и работу оборудования отслеживают датчики, информация с которых поступает в систему хранения и обработки данных.
Важным аспектом сбора данных с датчиков является скорость записи данных, без потерь, и архивирование данных таким образом, чтобы получить данные из архива также с высокой скоростью для выработки оперативного решения.
Уровень техники
Специалисту данной области техники известны такие системы архивации данных, как SQL Server (Microsoft), системы архивирования, разработанные компанией Wonderware (https://www.wonderware.com), SIEMENS
(https://new.siemens.com/ru/nVprodukty/avtomatizacia/raspredelerm upravleniya/simatic-pcs-7/arhivaciya-dannyh-processa-i-otchetnost.html) и др.
Однако указанные системы (архивы) являются сложными и ресурсоемкими, имеют определенную скорость получения данных из архива, которая не всегда отвечает задачам предприятия и, кроме того, они являются дорогостоящими продуктами и не каждое предприятие может позволить себе установить указанные системы хранения данных.
Наиболее близким аналогом способа сбора и извлечения данных является способ, описанный в патенте US6651030, кл. G06F 15/177, опубликованном 18.11.2003. Запатентованный способ сбора данных включает прием данных от источников данных, сохранение данных в виде записей в файл данных с отметкой времени создания данных и запись файла заголовка, который связывает интервал времени с теми записями в файлах данных, временные метки которых попадают в интервал времени. Способ извлечения записей данных включает выбор интересующего временного интервала, доступ к файлу заголовка, который связывает интересующий временной интервал с записями данных, временные метки которых попадают в интересующий интервал, извлечение записей данных на основе меток времени записей данных.
Недостатком указанных способов является запись собранных данных в файл данных без разделения данных по параметрам, что увеличивает время записи данных и время извлечения данных по определенному параметру.
Сущность изобретения
Заявляемое техническое решение устраняет указанные недостатки аналога.
Технический результат, который может быть получен при реализации заявляемого решения, заключается в увеличении скорости записи данных без потерь и сокращении времени извлечения необходимых данных.
Указанный технический результат получают за счет создания способа хранения данных, включающего прием данных от источника данных, сохранение данных в виде записей данных в памяти компьютера, при этом каждая запись данных содержит метку времени, связанную с моментом создания данных, и значение параметра, формирование в памяти компьютера из записей данных блоков записей одинакового размера, при этом в одном блоке записей могут находиться записи данных только одного параметра, присвоение блоку записей заголовка, включающего идентификатор параметра и адрес, и сохранение сформированного блока записей в базу данных на машиночитаемый носитель, формирование и сохранение в базе данных списка адресов блоков записей для каждого параметра.
Причем заголовок блока записей включает адрес последующего блока записей или заголовок блока записей включает адрес предыдущего блока записей, еще в одном частном случае выполнения заголовок блока записей включает адрес предыдущего и последующего блока записей.
Заголовок блока записей может включать метку времени первой записи данных в блоке записей и/или метку времени последней записи данных в блоке записей и другую служебную информацию.
Сохраняют записи данных в блоке записей в порядке возрастания меток времени. Запись данных содержит дополнительную информацию.
Список адресов блоков записей содержит метки времени. При этом для каждого адреса из списка хранится метка времени первой записи данных и/или метка времени последней записи данных блока записей по данному адресу.
В качестве машиночитаемого носителя может быть использована память компьютера.
Указанный технический результат получают так же за счет способа извлечения данных, включающего введение поискового запроса для заданного параметра и заданного временного интервала, поиск в списке адресов блоков записей и адресов из заголовков блоков записей адреса блока записей, содержащего первую по времени запись данных параметра из заданного временного интервала, считывание записей данных из найденного блока записей, начиная с первой записи данных, метка времени которой больше времени начала заданного интервала времени, с переходом к последующим блокам записей по адресам из заголовков блоков записей, до блока записей, в котором содержится запись данных, метка времени которой превосходит время конца заданного интервала, извлечение записей данных с метками времени, которые попали в заданный интервал времени.
В частном случае выполнения способа извлечения данных по списку адресов и адресам из заголовков блоков записей находят блок записей, содержащий последнюю запись данных, метка времени которой не превосходит времени конца интервала, и считывают записи данных с переходом к предыдущим блокам записей по адресам из заголовков блоков записей, до блока записей, в котором содержится первая запись данных, метка времени которой меньше времени начала заданного временного интервала, извлечение записей данных с метками времени, которые попали в заданный интервал времени.
Указанные формы представления записей данных, формирование из них блоков записей, сохранения блоков записей в базу данных, позволяет быстро и надежно отыскать все записи по нужному параметру за заданный интервал времени, не перебирая все блоки записей данных, записанных в базу данных, а по поисковому запросу выявить нужный блок записей и из него получить запись о запрашиваемом параметре. Это значительно увеличивает скорость сохранения записей в базу данных и сокращает время поиска нужного параметра и надежность поиска без пропусков искомых данных.
Следует отметить, что термин «параметр» означает здесь значение какой-либо физической величины (например, давление или температура в реакторе, уровень жидкости в емкости, концентрация СО2 и пр.), измеренной и представленной в цифровом виде или полученной на основе значений других параметров.
Термин «запись данных» означает здесь конечную форму представления информации о значении параметра с меткой времени его получения.
Термин «блок записей» означает здесь набор записей одного и того же параметра, отсортированных по времени в их временных метках, причем набор записей имеет фиксированный размер, одинаковый для всех параметров.
Термин «база данных» означает здесь набор блоков записей разных параметров и списки адресов блоков записей каждого параметра, которые могут содержать метки времени первой и/или последней записи блока записей, сохраненных на машиночитаемый носитель и/или память компьютера.
Краткое описание чертежей
Заявляемое техническое решение может быть проиллюстрировано следующими фигурами чертежей, где
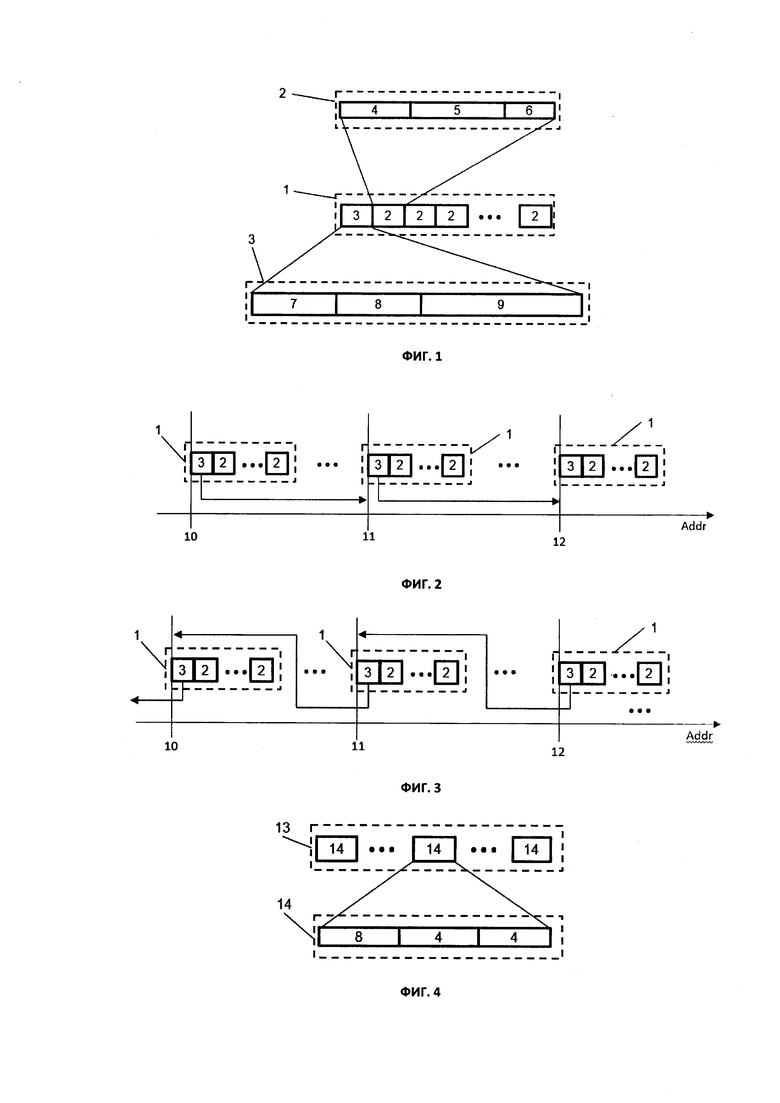
на фиг. 1 схематически показана форма представления сохраняемой информации. Так блок записей 1 включает записи данных 2 и заголовок 3 блока записей. Запись данных 2 содержит метку времени 4, значение параметра 5 и может факультативно содержать дополнительные данные 6 записи данных, такие как, например, признак качества данных в соответствии со стандартом ОРС Foundation. Важной составляющей блока записей 1 является его заголовок 3, который в свою очередь включает идентификатор параметра 7, адрес 8 предыдущего или последующего блока записей этого параметра и может содержать дополнительную информацию 9. Такой дополнительной информацией может быть, например, метки времени 4 первой и/или последней записи данных 2 в блоке записей 1, адрес предыдущего или последующего блока записей, дополняющий адрес 8, чтобы хранить в заголовке 3 адреса, как предыдущего, так и последующего блока записей. Такая форма представления сохраняемой информации позволяет быстро, без перебора всех сохраненных блоков записей, по заголовку блока записей выделить нужный блок и найти в нем запись данных искомого параметра.
На фиг. 2 представлен частный случай системы сохранения блоков записей одного параметра, где отображено размещение в адресном пространстве базы данных трех следующих подряд по времени блоков записей 1. На фиг. 2 показано, что каждый блок записей 1, помимо записей данных 2 содержит заголовок 3, в котором хранится адрес последующего по времени блока записей. Так первый по времени блок записей 1 размещен по адресу 10, второй блок записей - по адресу 11, а третий - по адресу 12. Из фиг. 2 видно, что заголовок 3 первого блока записей 1 хранит адрес 11 второго (последующего по времени) блока записей 1, а второй блок записей 1 в своем заголовке 3 хранит адрес 12 третьего блока записей 1.
На фиг. 3 представлен еще один частный случай системы сохранения блоков записей 1 одного параметра, когда заголовок 3 блока записей 1 содержит адрес предыдущего по времени блока записей. Здесь, так же, как и на фиг. 2, представлены три следующих подряд по времени блока записей 1. Из фиг. 3 видно, что заголовок 3 последнего блока записей 1 хранит адрес 11 второго блока записей 1 (предыдущего по времени), который в своем заголовке 3 хранит адрес 10 первого по времени из представленных на фиг. 3 блока записей 1. Такая структура взаимосвязи блоков записей позволяет максимально быстро извлечь все данные по параметру за любой интервал времени.
На фиг. 4 схематично представлен частный случай выполнения списка 13, который содержит структуры 14, где каждая структура 14 состоит из адреса 8 блока записей 1 и меток времени 4 первой и последней по времени записи данных 2 в данном блоке записей 1. Наличие такого списка 13 позволяет очень быстро находить блок записей 1, хранящий записи данных 2, на заданный момент времени без сканирования всех блоков записей базы данных.
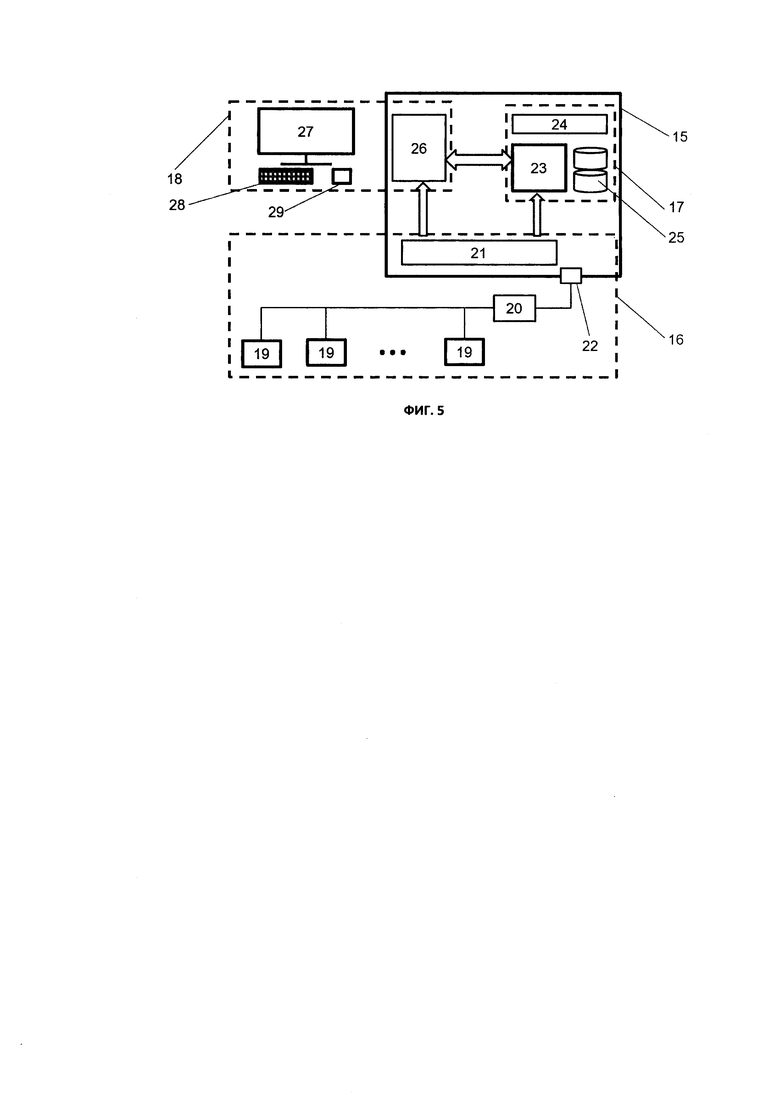
На фиг. 5 схематично представлена система контроля за технологическим процессом. Она включает в себя три подсистемы: подсистему 16 сбора и обработки данных, подсистему HMI (человеко-машинный интерфейс) 18 и подсистему архивирования 17. Программные компоненты 21, 23 и 26 указанных подсистем функционируют на одном компьютере 15. Все приведенные ниже примеры выполнения способа сохранения и извлечения данных рассматриваются для системы, отображенной на фиг. 5.
Подробное раскрытие изобретения
Информация о состоянии функционирования различных устройств производства представляет собой огромный объем данных. Такие большие объемы данных должны быть сохранены в хронологическом порядке и возникают проблемы в хранении данных реального времени. Временный выход из строя отдельных устройств вносит свои неудобства, т.к. часть информации может быть пропущена в таком потоке сохранения данных. Возникает необходимость в надежном и скоростном способе архивирования и извлечения данных, который позволит быстро принять верное решение и, таким образом, увеличить производительность работы оборудования предприятия или подготовить отчет с актуальной информацией.
Заявляемое техническое решение может применяться в системах промышленной автоматизации (АСУТП, АСУЭ, и др.), системах коммерческого и технического учета (АСКУЭ, АСТУЭ, и др.), а также в системах диспетчеризации промышленных объектов, объектов ЖКХ и в автоматизации зданий.
История изменения во времени каждого параметра сохраняется в виде записей данных 2 (фиг. 1), содержащих значение параметра 5, метку времени 4 (реального времени), связанную с моментом получения значения параметра 5 и может содержать набор дополнительной (служебной) информации 6, если таковая требуется. Например, запись может содержать метку времени размером 8 байт (64-битное Unix-время), значение параметра 5 в формате числа с плавающей точкой - 4 байта, а в качестве дополнительной (служебной) информации 6 может быть использован, например, признак качества в соответствии со стандартом ОРС Fondation. Такое построение записи данных 2 позволяет выстраивать записи данных в последовательности по их меткам времени 4. Дополнительные данные 6 позволяют в дальнейшем при анализе данных учитывать их достоверность.
Записи данных 2 об истории изменения одного параметра во времени сохраняются в виде блоков записей 1, которые имеют одинаковый размер. Количество записей данных 2 в одном блоке записей 1 ограничивается его размером, причем все они относятся только к одному параметру. Каждый блок записей 1 имеет заголовок 3, который в свою очередь включает идентификатор параметра 7. Это позволяет сократить размер записи, поскольку идентификатор параметра 7 присутствует только в заголовке 3 блока записей 1 и распространяется на все записи данных 2 в нем, что также приводит к сокращению времени сохранения и чтения данных за счет уменьшения объема сохраняемой и считываемой информации, а также за счет использования блочных операций.
Указанная структура блока записей 1 приводит к тому, что при поиске нужной информации о параметре просматриваются блоки с идентификатором только данного параметра. Это приводит к снижению времени поиска.
Заголовок 3 блока записей 1, помимо идентификатора параметра 7 содержит адрес 8 другого блока записей 1, хранящего записи данных 2 того же параметра. Это может быть адрес последующего по времени блока записей 1 или предыдущего. На фиг. 2 представлен частный случай выполнения системы хранения данных одного параметра, когда каждый блок записей 1 в заголовке 3 хранит адрес 8 последующего блока записей 1 этого параметра. Причем блоки записей 1 с адресами 10, 11 и 12 записаны последовательно по времени: блок записей 1 с адресом 10 - первых по времени записей, а с адресом 12 - последних. На фиг. 3 показан другой частный случай выполнения системы хранения данных одного параметра, где показаны те же блоки записей 1, но в их заголовках 3 хранится адрес 8 не последующего, а предыдущего блока записей 1. Наличие адресов 8 последующего или предыдущего блока записей 1 в заголовке 3 позволяет быстро находить следующий для считывания блок записей 1, если запрос данных по времени выходит за диапазон времени хранимых записей данных 2 в данном блоке записей 1. Это позволяет существенно сократить время извлечения данных.
Внутри каждого блока 1 все записи данных 2 о параметре отсортированы по времени.
Заголовок 3 блока записей 1 содержит метку времени 4 первой записи в блоке записей и/или метку времени последней записи в этом блоке записей. Это позволяет быстрее искать нужный блок записей 1 при извлечении данных за заданный временной интервал, поскольку для анализа соответствия данного блока записей 1 требованиям запроса достаточно считать только его заголовок 3, а не весь блок записей 1. Если метки времени 4 записей данных 2 данного блока записей 1 не попадают в заданный интервал времени, то выполняется переход к другому блоку записей 1 искомого параметра, адрес 8 которого записан в заголовке 3 данного блока 1.
Из блоков записей 1 формируется база данных. При этом в базу данных поступают блоки записей 1, содержащие историю изменения различных параметров. Они последовательно записываются по свободным адресам на машиночитаемом носителе (в базе) не зависимо от параметра. При этом формируют список 13 адресов 8 блоков записей 1 для каждого параметра, который тоже сохраняется в базу данных. Список 13 адресов 8 блоков записей 1 схематично представлен на фиг. 4. На фиг. 4 показано, что информация об адресах 8 блоков записей 1, содержащих историю изменения одного параметра, сохраняется в виде структур 14, содержащих адреса 8 блоков записей 1. В частном случае выполнения, указанные структуры 14 кроме адресов 8 содержат метки времени 4 первой и последней записи данных 2 в данном блоке записей 1. При сохранении каждого нового блока записей 1 в базу данных в список 13 добавляется следующая структура 14. В частном случае выполнения структуры 14 она может содержать только одну метку времени 4 - первой или последней записи данных 2 в блоке записей 1.
В еще одном частном случае выполнения структуры 14 она может не содержать временную метку 4. В этом случае добавление новой структуры 14 в список 13 выполняется не при сохранении блока записей 1 в базу данных, а с заданным временным интервалом (например, раз в сутки). Блоки записей 1 формируются с разным временным промежутком, поэтому за время формирования одного из таких блоков записей 1 в список 13 может быть сохранено несколько структур 14 (по фиксированным временным интервалам) с адресом 8 формируемого блока записей 1. В другом частном случае за указанный интервал времени может быть сохранено несколько блоков записей 1. При этом число структур 14 с адресами 8 блоков записей 1 в списке 13 не будет соответствовать числу блоков записей 1, хранящих историю данного параметра.
Еще в одном частном случае число структур 14 может быть меньше числа блоков записей 1, хранящих историю одного параметра, когда в целях сокращения размера списка 13 в него сохраняют структуры 14 не для каждого блока записей 1, а, например, каждый третий или каждый десятый, или используется другой принцип сокращения размера списка 13.
База данных хранится в виде одного или нескольких файлов на машиночитаемом носителе информации (HDD, SSD, SD и др.) и/или в оперативной памяти компьютера.
Предлагаемый способ сохранения данных позволяет максимально быстро, без потерь получать из базы данных сведения о параметре, т.е. извлечь все данные по параметру за любой интервал времени, за счет того, что не требуется сканировать все блоки записей 1, сохраненные в базе данных, а для поиска блока записей 1 искомого параметра выбирают из списка 13 адресов блоков записей 1 адрес 8 блока, содержащего первую по времени запись, метка времени 4 которой превосходит время начала заданного интервала времени. Если в списке 13 нет структуры 14 с адресом 8 такого блока записей 1 (в результате сокращения размера списка 13 или записи структур 14 по фиксированным временным интервалам), то выполняется поиск последнего блока записей 1, метка времени 4 последней записи данных 2 которого меньше времени начала заданного временного интервала и далее выполняется поиск с переходом по адресам 8 в заголовках 3 блоков записей 1 с анализом меток 4 первой и последней записи данных до выявления блока записей 1, содержащего первую запись данных 2, временная метка 4 которой больше времени начала заданного временного интервала. Осуществляют, считывание записей из найденного блока записей 1, начиная с первой записи данных 2, метка времени 4 которой больше времени начала заданного интервала времени до блока записей 1, в котором содержится первая запись данных 2, метка времени 4 которой превосходит время конца заданного интервала времени, извлечение записей данных 2 с метками времени 4, которые попали в заданный интервал времени. Все считанные записи от первой, попадающей в заданный временной интервал, до последней являются результатом извлечения данных.
В частном случае выполнения способа извлечения данных, когда в заголовках 3 блоков записей 1 сохраняют адрес 8 не последующего блока записей, а предыдущего, выполняется поиск посредством списка 13 адресов 8 блоков записей 1 и адресов 8 из заголовков 3 блоков записей 1 того блока записей 1, который содержит первую запись данных 2, метка времени 4 которой превосходит время конца заданного временного интервала. Осуществляют, считывание записей из найденного блока записей 1, начиная с первой записи данных 2, метка времени 4 которой меньше времени конца заданного интервала времени в обратном по времени направлении до блока записей 1, в котором содержится последняя запись данных 2, метка времени 4 которой превосходит время начала заданного интервала, извлечение записей с метками времени, которые попали в заданный интервал времени. Все считанные записи от первой попадающей в заданный временной интервал до последней являются результатом извлечения данных.
Частные случаи выполнения способа сохранения и извлечения данных могут быть проиллюстрированы приведенными неисчерпывающими примерами, которые проиллюстрированы фиг. 5.
На фиг. 5 схематично представлена система контроля за технологическим процессом. Она включает в себя три подсистемы: подсистему 16 сбора и обработки данных, подсистему HMI (человеко-машинный интерфейс) 18 и подсистему архивирования 17. Программные компоненты 21, 23 и 26 указанных подсистем функционируют на одном компьютере 15.
Подсистема 16 сбора и обработки данных включает в себя модули ввода/вывода 19, к которым подключены датчики, контролирующие технологические параметры, и которые опрашиваются по интерфейсу RS-485, подключенному к USB-порту 22 компьютера 15 через конвертер интерфейсов RS-485/USB 20, а так же программный компонент 21, который по протоколу MODBUS с заданной частотой опрашивает модули ввода/вывода 19, обрабатывает полученные данные, переводя их в значения физических величин в формате float, присваивает им временные метки, соответствующие моменту получения этих данных по протоколу, и признак качества в соответствии со стандартом ОРС Foundation. Далее подсистема 16 сбора и обработки данных передает значения контролируемых технологических параметров вместе с метками времени и признаками качества в подсистему HMI 18 и подсистему архивирования 17. Передача значений осуществляется только для тех параметров, значения которых изменились по сравнению с предыдущим переданным значением на величину превышающую 0,2% от их возможного диапазона изменения.
Подсистема HMI 18 состоит из средств взаимодействия с оператором (монитор 27, клавиатура 28 и манипулятор типа мышь 29) и программного компонента 26, который обрабатывает команды оператора, поданные посредством клавиатуры 28 и манипулятора типа мышь 29, посылает запросы и получает данные от подсистемы 16 сбора и обработки данных и подсистемы архивирования 17, формирует визуальное изображение на основе полученных данных и выводит его на монитор 27.
Подсистема архивирования 17 состоит из двух зеркалированных жестких дисков 25, закрепленной области оперативной памяти 24 компьютера и программного компонента архивирования 23, который принимает данные от подсистемы 16 сбора и обработки данных, формирует из принятых данных записи данных 2, из которых в оперативной памяти 24 формирует блоки записей 1, например, по 200 записей данных 2 одного параметра в каждом блоке записей 1 и сохраняет блоки записей 1 по мере их заполнения записями данных 2 в базу данных на диски 25. Причем для каждого параметра в оперативной памяти 24 выделяется место для формирования одного блока записей 1. После заполнения этого блока записей 1 записями данных 2 и сохранения его в базу данных на диски 25 занимаемое им место в памяти 24 освобождается и используется для формирования следующего блока записей 1 данного параметра. Причем запись данных 2 состоит из метки времени 4 в формате 64-битное Unix-время (8 байт), значения параметра 5 в формате float (4 байта) и дополнительной информации 6 в виде признака качества данных в соответствии со стандартом ОРС Foundation (1 байт). Кроме того, подсистема архивирования 17 формирует в оперативной памяти 24 для каждого параметра списки 13 адресов размещения блоков записей 1, хранящих записи данных 2 со значениями данного параметра. Эти списки 13 по мере дополнения в них новой информации также сохраняются в базу данных на диски 25. Кроме того, подсистема архивирования 17 принимает запросы на поиск данных от подсистемы HMI 18, выполняет выборку запрошенных данных и передает их в подсистему HMI 18.
Пример 1.
Сохраняют в заголовок 3 блока записей 1 метку времени 4 последней записи данных 2 и адрес 8 последующего блока записей 1, а в списке 13 для каждого параметра сохраняют структуры 14, содержащие адрес 8 и метку времени 4 последней записи данных 2, для каждого десятого блока записей 1 данного параметра в базе данных.
В этом случае, при сохранении каждого блока записей 1 в базу данных на диски 25 в ею заголовок 3 заносится в качестве дополнительной информации 9 метка времени 4 его последней записи данных 2, а в заголовок 3 предыдущего блока записей 1 заносится адрес 8, по которому записывается данный блок записей 1. Сохранение блока записей 1 в базу данных на диски 25 выполняется в случае его заполнения записями данных 2 до полною заданного объема. Кроме того, при сохранении в базу данных на диски 25 каждого десятого блока записей 1 данного параметра в список 13 добавляют структуру 14, содержащую адрес 8 сохраняемого блока записей 1 и метку времени 4 последней записи данных 2 этого блока записей 1.
Для просмотра архивных данных в подсистеме HMI 18, например, для отображения изменения параметра на тренде за предыдущую неделю, программный компонент 26 подсистемы HMI 18 формирует запрос в подсистему архивирования 17, в котором указывается идентификатор параметра 7, а также время начала и время конца временного интервала. В данном случае началом временного интервала будет время 00:00:00.000 предыдущего понедельника, а концом - 23:59:59.999 предыдущего воскресенья. Чтобы подготовить выборку записей в этом временном интервале сначала осуществляют поиск в базе данных блока записей 1, для которого время начала заданного временного диапазона (00:00:00.000 понедельника) находится между метками времени 4 первой и последней записи данных 2. Для этого обращаются к списку 13 для заданного параметра. В этом списке находят адрес 8 последнего блока записей 1, время последней записи которого меньше заданного времени начала временного интервала. Считывают заголовок 3 найденного блока записей 1 и переходят к следующему блоку записей 1 по адресу 8, записанному в найденном блоке записей 1. Считывают его заголовок 3. Если хранящаяся в нем временная метка 4 последней записи данных 2 меньше времени начала заданного временного интервала, то по адресу 8 из заголовка 3 данного блока записей 1 переходят к следующему блоку записей 1. И так далее пока метка времени 4 последней записи данных 2 в заголовке 3 очередного блока записей 1 не будет превосходить время начала заданного временного интервала. Такая запись данных 2 считается первой найденной искомого интервала. Далее считывают все записи данных 2 данного блока записей 1 и находят среди них первую запись данных 2, временная метка 4 которой будет больше времени начала заданного временного интервала. Все записи данных 2, начиная с первой найденной и до последней данного блока записей 1, сохраняют в выборку. Далее по адресу 8 из заголовка 3 данного блока записей 1 переходят к следующему блоку записей 1. Если временная метка 4 из заголовка 3 этого блока записей 1 меньше времени конца заданного временного интервала (23:59:59.999 воскресенья), то все записи данных 2 из данного блока записей 1 извлекают и добавляют в выборку. Если временная метка 4 из заголовка 3 данного блока записей 1 превосходит время конца заданного временного интервала, то считывают все записи данных 2 данного блока записей 1, но помещают в выборку только те записи данных 2, метки времени 4 которых меньше конца заданного временного интервала. На этом поиск записей заканчивают и все записи данных, помещенные в выборку, передаются в программный компонент 26 подсистемы HMI 18, которая по полученной выборке строит изображение тренда изменения значения заданного параметра, которое затем выводится на монитор 27. Причем при формировании изображения анализируется значение признака качества, являющегося дополнительным значением 6 каждой записи данных 2. Там, где величина этого признака не равна 192 (данные имеют качество GOOD) тренд отображается пунктирной линией.
Пример 2.
Сохраняют в заголовок 3 блока записей 1 метку времени 4 первой записи данных 2 данного блока записей 1 и адрес 8 предыдущего блока записей 1, а в список 13 добавляют структуру 14, содержащую только адрес 8 текущего заполняемого блока записей 1, один раз в сутки в момент наступления новых суток.
В этом случае при сохранении каждого блока записей 1 в базу данных на диски 25 его адрес 8 записывается в заголовок 3 вновь создаваемого блока записей 1. При добавлении во вновь создаваемый блок записей 1 первой записи данных 2 ее метка времени 4 записывается в заголовок 3 данного блока записей 1 в качестве дополнительной информации 9.
Так же, как и в Примере 1 для просмотра в подсистеме HMI 18 изменения параметра на тренде за предыдущую неделю, программный компонент 26 подсистемы HMI 18 формирует запрос в подсистему архивирования 17, в котором указан идентификатор параметра 7, а также время начала и время конца временного интервала: 00:00:00.000 предыдущего понедельника и 23:59:59.999 предыдущего воскресенья. В этом случае, чтобы подготовить выборку записей данных 2, сначала находят в базе данных блок записей 1, для которого время конца заданного временного диапазона (23:59:59.999 воскресенья) расположен между метками времени 4 первой и последней записи данных 2. Для этого применяют список 13 адресов 8 для заданного параметра. Поскольку записи в этот список 13 заносят раз в сутки, то порядковый номер каждой записи определяет время с точностью до суток при условии, что известна дата первой записи. Например, к началу заданного поискового временного интервала система работала уже 1 год и 2 недели. Тогда адрес 8 блока записей 1, который заполнялся на момент начала заданного временного интервала, находится в списке 13 адресов на 379 месте (365 - один год и 14 - две недели), а адрес 8 блока записей 1, который заполнялся в момент конца заданного временного интервала находится на 386 месте (на неделю позже). Поэтому считывают 386-й адрес в списке 13 адресов и переходят к блоку записей 1 по этому адресу 8. Считывают все записи данных 2 из данного блока записей 1. Все записи данных 2, метка времени 4 которых меньше времени конца заданного временного интервала, извлекают и помещают в выборку. Далее переходят по адресу 8 из заголовка 3 данного блока записей 1 к предыдущему блоку записей 1.
Считывают из предыдущего блока записей 1 записи данных 2. Если метка времени 4 в заголовке 3 данного блока записей 1 больше времени начала заданного временного интервала, то все записи данных 2 данного блока записей 1 извлекают и помещают в выборку. В противном случае, в выборку помещают только те записи данных 2, метка времени 4 которых больше времени начала заданного временного интервала. На этом формирование выборки заканчивается, и она передается программному компоненту 26 подсистемы HMI 18.
Пример 3.
Сохраняют в заголовок 3 блока записей 1 адрес 8 последующего блока записей 1, а также дополнительную информацию 9, включающую метки времени 4 первой и последней записей данных 2 данного блока записей 1 и адрес 8 предыдущего блока записей 1. При этом список 13 хранит структуры 14, включающие адрес 8 блока записей 1 и временные метки 4 его первой и последней записей данных 2.
В этом случае при сохранении блока записей 1 в базу данных на диски 25 в его заголовок 3 записывают адрес 8 вновь создаваемого (последующего для сохраняемого) блока записей 1 и метка времени 4 последней записи сохраняемого блока записей 1. При этом в заголовок 3 вновь созданного блока записей 1 записывается адрес 8 сохраняемого блока записей и метка времени 4 первой записи данных 2 при ее добавлении в новый блок записей 1.
Подсистема HMI 18 запрашивает данные по параметру за предыдущую неделю. Подсистеме HMI 18 была передана извлеченная выборка записей данных 2. Однако, после получения выборки записей данных 2 для отображения тренда, оператор изменил масштаб временной оси тренда, для чего потребовалось добавить данные еще за три дня до времени начала временного интервала предыдущего запроса и два дня после конца интервала предыдущего запроса. В этом случае требуется добавить данные в уже полученную выборку. Причем как после, так и до заданного временного интервала. Для этого выполняют две дополнительные выборки. Первая, для получения записей данных от времени конца начального интервала времени (23:59:59.999 предыдущего воскресенья) до 23:59:59.999 вторника текущей недели. Для этого используют механизм, описанный в Примере 1. Сначала посредством списка 13 находят адрес блока записей 1, соответствующего времени начала временного интервала данной выборки (23:59:59.999 предыдущего воскресенья). При этом используют временные метки 4 первой и последней записей данных 2 из структур 14 списка 13. Считывают, по найденному таким образом адресу 8, блок записей 1. Если метка времени 4 последней записи данных 2 в заголовке 3 меньше времени конца временного интервала (23:59:59.999 вторника текущей недели), то выбирают из считанного блока записей 1 все записи данных 2, метки времени 4 которых больше времени начала временного интервала, извлекают их в выборку и далее считывают блок записей 1, находящийся по адресу 8 последующего блока записей 1 из заголовка 3. Если метка времени 4 последней записи данных 2 в заголовке 3 данного (последующего) блока записей 1 меньше времени конца интервала времени, то все записи данных 2 этого блока записей 1 извлекают и сохраняют в выборку. Повторяют указанные операции до тех пор, пока метка времени 4 последней записи 2 очередного блока записей 1 не будет больше времени конца заданного интервала. В этом случае в выборку сохраняют только те записи данных 2 из последнего считанного блока записей 1, метка времени 4 которых меньше времени конца заданного интервала. На этом заполнение первой дополнительной выборки завершают. Если же значение метки времени 4 последней записи 2 первого считанного блока записей 1 превосходит время конца заданного временного интервала, то в выборку помещают записи данных 2 этого блока записей 1, временные метки 4 которых попадают в заданный интервал времени и перехода к другим блокам записей 1 не выполняют.
Для формирования второй дополнительной выборки применяют последовательность действий, описанную в Примере 2, когда выполняют переход по адресу 8 предыдущего блока записей 1 из заголовка 3 текущего блока записей 1, и сравнивают значение метки времени 4 первой записи данных 2 с временем начала заданного временного интервала для определения последнего считываемого блока записей 1 для формирования выборки. В данном случае делают выборку записей данных 2, временные метки 4 которых находятся в диапазоне от 00:00:00.000 пятницы предшествующей предыдущей недели до 00:00:00.000 предыдущего понедельника. Посредством списка 13 определяют адрес блока записей 1, соответствующего времени конца временного интервала второй выборки (00:00:00.000 предыдущего понедельника). Для этого используют временные метки 4 первой и последней записей данных 2 из структур 14 списка 13. Считывают по найденному таким образом адресу 8 блок записей 1. Если значение метки времени 4 первой записи данных этого блока записей 1 меньше времени начала заданного временного интервала, то выбирают из блока записей 1 записи данных 2, чьи временные метки 4 попадают в заданный временной интервал, извлекают и помещают их в выборку и завершают поиск. Если значение метки времени 4 первой записи данных 2 этого блока записей 1 больше времени начала заданного временного интервала 4, то помещают в выборку все записи данных 2, временные метки 4 которых меньше времени конца заданного временного интервала и считывают предыдущий блок записей 1 по адресу 8 из заголовка 3 данного блока записей 1. Если метка времени 4 первой записи данных 2 больше времени начала заданного временного интервала, то все записи данных 2 этого блока записей 1 извлекают и помещают в выборку и выполняют переход к считыванию предыдущего по времени блока записей 1. Выполняют данные операции до тех пор, пока метка времени 4 очередного считанного блока записей 1 не будет меньше времени начала заданного временного интервала. В этом случае в выборку сохраняют только те записи данных 2, метки времени 4 которых больше времени начала заданного интервала времени и формирование выборки на этом завершают.
Полученные две дополнительные выборки записей данных 2 передаются в подсистему HMI 18 для доработки недостающих фрагментов тренда.
Благодаря наличию в заголовке 3 блока записей 1 адресов 8 как предыдущего, так и последующего блока записей 1, а также меток времени 4 как первой, так и последней записи данных 2 получена возможность делать выборки записей данных 2 как вперед, так и назад по времени, в зависимости от того, как удобнее в конкретном случае.
Группа изобретений относится к способам хранения и извлечению данных, полученных от различных источников данных. Техническим результатом является повышение скорости записи данных без потерь и сокращение времени извлечения необходимых данных. Способ хранения данных содержит: прием данных от источника данных, сохранение данных в виде записей данных в памяти компьютера, при этом каждая запись данных содержит метку времени, связанную с моментом создания данных, и значение параметра, формирование в памяти компьютера из записей данных блоков записей одинакового размера, при этом в одном блоке записей могут находиться записи данных только одного параметра, присвоение блоку записей заголовка, включающего идентификатор параметра и адрес, и сохранение сформированного блока записей в базу данных на машиночитаемый носитель, формирование и сохранение в базе данных списка адресов блоков записей для каждого параметра. 2 н. и 9 з.п. ф-лы, 5 ил., 3 пр.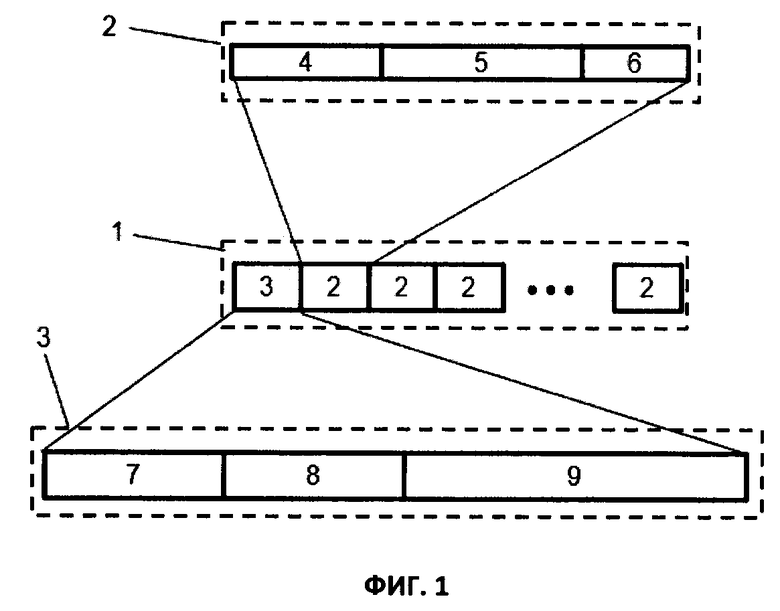
1. Способ хранения данных, включающий прием данных от источника данных, сохранение данных в виде записей данных в памяти компьютера, при этом каждая запись данных содержит метку времени, связанную с моментом создания данных, и значение параметра, формирование в памяти компьютера из записей данных блоков записей одинакового размера, при этом в одном блоке записей могут находиться записи данных только одного параметра, присвоение блоку записей заголовка, включающего идентификатор параметра и адрес, и сохранение сформированного блока записей в базу данных на машиночитаемый носитель, формирование и сохранение в базе данных списка адресов блоков записей для каждого параметра.
2. Способ по п. 1, в котором заголовок блока записей включает адрес последующего блока записей.
3. Способ по п. 1, в котором заголовок блока записей включает адрес предыдущего блока записей.
4. Способ по п. 1, в котором заголовок блока записей включает адрес предыдущего и последующего блока записей.
5. Способ по п. 1, в котором заголовок блока записей включает метку времени первой записи данных в блоке записей и/или последней записи данных в блоке записей.
6. Способ по п. 1, в котором сохраняют записи данных в блоке записей в порядке возрастания меток времени.
7. Способ по п. 1, в котором список адресов блоков записей содержит метки времени.
8. Способ по п. 7, в котором список содержит для каждого адреса метку времени первой записи данных и/или метку времени последней записи данных блока записей по данному адресу.
9. Способ по п. 1, в котором в качестве машиночитаемого носителя может быть использована оперативная память компьютера.
10. Способ извлечения данных, сохраненных способом по п. 1, включающий введение поискового запроса для заданного параметра и заданного временного интервала, поиск в списке адресов блоков записей и адресов из заголовков блоков записей адреса блока записей, содержащего первую по времени запись данных параметра из заданного временного интервала, считывание записей данных из найденного блока записей, начиная с первой записи данных, метка времени которой больше времени начала заданного интервала времени, с переходом к последующим блокам записей по адресам из заголовков блоков записей, до блока записей, в котором содержится запись данных, метка времени которой превосходит время конца заданного интервала, извлечение записей данных с метками времени, которые попали в заданный интервал времени.
11. Способ извлечения данных по п. 10, в котором по списку адресов и адресам из заголовков блоков записей находят блок записей, содержащий последнюю запись данных, метка времени которой не превосходит времени конца интервала, и считывают записи данных с переходом к предыдущим блокам записей по адресам из заголовков блоков записей, до блока записей, в котором содержится первая запись данных, метка времени которой меньше времени начала заданного временного интервала, извлечение записей данных с метками времени, которые попали в заданный интервал времени.
| US 20180067995 A1, 08.03.2018 | |||
| US 20200389626 A1, 10.12.2020 | |||
| СИСТЕМА И СПОСОБ ДЛЯ ЗАЩИТЫ ИНФОРМАЦИИ | 2018 |
|
RU2735439C2 |
| US 6651030 B2, 18.11.2003. | |||

