ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится, в общем, к вычислительной технике и, более конкретно, к системе обеспечения катастрофоустойчивости информационной инфраструктуры работающего приложения, а также к способам ее развертывания и функционирования.
УРОВЕНЬ ТЕХНИКИ
Повсеместная цифровизация производственных процессов привела к тому, что способность предприятия осуществлять свою деятельность напрямую зависит от работоспособности информационных систем и сервисов. Как следствие, задача обеспечения доступности соответствующих программных процессов и используемых ими данных становится критически важной, особенно для сценариев, когда инфраструктура информационных систем оказывается непригодной для дальнейшего использования, а сроки ее возврата к нормальному функционированию невозможно прогнозировать (например, вследствие стихийного бедствия, техногенной катастрофы или каких-либо иных факторов, имеющих масштабное влияние).
Традиционно вопросы готовности к такого рода ситуациям относят к сфере обеспечения катастрофоустойчивости информационных сервисов, понимая под этим комплекс технических и организационных мер, направленных на минимизацию влияния масштабных отказов инфраструктуры на деятельность предприятия и на контролируемое восстановление средств автоматизации. При этом подразумевается, что в силу масштабности отказов обеспечить полностью непрерывное функционирование приложений или технически невозможно, или экономически нецелесообразно, и, как следствие, допускаются некоторый простой приложения в течение заранее оговоренных временных рамок, которые могут быть охарактеризованы параметром RTO (Recovery Time Objective, целевое время восстановления), и частичная потеря данных, которая может быть охарактеризована параметром RPO (Recovery Point Objective, допустимый диапазон потери данных). Дополнительные пояснения касаемо целевых параметров катастрофоустойчивости RTO и RPO и их использования будут даны ниже.
Общепринятым подходом для решения задачи обеспечения катастрофоустойчивости приложения(й) является заблаговременная подготовка резервной инфраструктуры (в первую очередь, серверов и хранилищ данных) для исходной, основной инфраструктуры приложения и настройка механизма переноса данных с основной инфраструктуры на резервную. В зависимости от применяемых технических решений достигается различная степень синхронности основной и резервных инфраструктур, что непосредственно влияет на сроки готовности резервной инфраструктуры к активации и на ее пригодность к поддержанию деятельности предприятия в соответствии с целевыми характеристиками обеспечения катастрофоустойчивости (RTO и RPO). Однако, сложность решения связана с тем фактом, что современные приложения представляют собой многокомпонентные программно-аппаратные ландшафты, использующие различные технологические решения, для которых не существует единого способа создания резервных компонентов, поддержания их в актуальном состоянии в процессе нормального функционирования приложения на основной инфраструктуре и активации приложения на резервной инфраструктуре при отказе основной.
Конкретными практическими примерами подобных прикладных ландшафтов могут служить интернет-магазин, новостной портал-агрегатор, система обеспечения совместной работы пользователей, система комплексной автоматизации службы поддержки.
В соответствии с обобщенным иллюстративным примером, в состав информационной инфраструктуры приложения могут входить следующие компоненты:
подсистемы долговременного хранения и управления информацией в виде структурированных данных, включающие в себя одну или более баз данных, использующих в качестве базовой технологии некоторую реляционную СУБД (например, такую как PostgreSQL или Oracle DB) или no-SQL СУБД (например, такую как MongoDB или CouchDB);
подсистемы долговременного хранения информации в виде файлов, использующие в качестве базовой технологии файловые серверы или сервисы по управлению документами (например, такие как Microsoft SharePoint или NextCloud);
подсистемы накопления и аналитической обработки информации, использующие в качестве базовой технологии набор решений по консолидации, преобразованию и анализу данных из множества источников (например, такие как Hadoop, Informatica, Oralce BI);
подсистемы промежуточного кеширования данных, использующие некоторые in-memory хранилища данных (например, такие как Kafka, Redis или Tarantool);
разнообразные прикладные сервисы (например, программные компоненты, реализующие отдельные функции в составе сквозного бизнес-сервиса и в процессе своей работы могущие обращаться к другим подсистемам и/или прикладным сервисам), в том числе базирующиеся на микросервисных архитектурах;
подсистемы обеспечения взаимодействия конечных пользователей с приложением (например, Web-сервисы или сервисы приема и обработки вызовов API);
инфраструктурные сервисы (например, сервисные шины, подсистемы управления микросервисами, сервисы аутентификации и авторизации пользователей, службы каталогов, proxy-серверы, сервисы обеспечения информационной безопасности, сервисы мониторинга и т.п.).
Продолжая рассматриваемый обобщенный иллюстративный пример, информационно-технологическая инфраструктура, лежащая в основе такого многокомпонентного ландшафта приложения, может включать в себя:
платформы виртуализации и облачные платформы (например, такие как VMware ESXi, KVM, OpenStack, OpenNebula, Basis.Dynamix, AstraLinux Брест), предоставляющие вычислительные ресурсы для работы вышеперечисленных подсистем и программных компонентов;
физические серверы различных аппаратных архитектур, предоставляющие вычислительные ресурсы для работы вышеперечисленных подсистем и программных компонентов;
системы хранения данных (например, специализированные аппаратные системы хранения данных или программно-определяемые системы хранения данных), предоставляющие ресурсы хранения для вышеперечисленных подсистем и программных компонентов.
Для создания и поддержания актуальности резервных инфраструктурных компонентов в уровне техники предложен ряд технологических решений, применяемых в целях обеспечения катастрофоустойчивости приложений.
Так, репликация данных средствами специализированных систем хранения данных в определенных сценариях позволяет достичь почти идентичного состояния основной и резервной инфраструктур, однако не автоматизирует ни процедуры анализа и первичного создания резервной инфраструктуры, ни процесс переключения приложения как целостного информационного сервиса на резервную инфраструктуру, так как ограничена исключительно уровнем ресурсов хранения и не учитывает вышележащих слоев. Кроме того, такой подход требует идентичности аппаратных решений, применяемых в основной и резервных инфраструктурах, что не всегда приемлемо с технической или экономической точек зрения. Примерами подобного рода решений являются HPE StorageWorks Continuous Access, DELL VMAX SRDF.
Далее, решения, встроенные непосредственно в некоторый программный компонент ландшафта приложения, также способны обеспечивать почти идентичное состояние между такими компонентами в исходной и резервной инфраструктурах, частично автоматизируют как создание, так и переключение на резервный компонент, однако, ограничены только данным компонентом и сами по себе не обеспечивают согласованную защиту всего приложения, которое, как правило, состоит из множества разнообразных компонентов, некоторые из которых могут не иметь таких встроенных средств. Такие подходы, например, реализованы в Oracle DataGuard.
Решения на базе систем резервного копирования обеспечивают актуальность резервных копий только на некоторый момент времени в прошлом и характеризуются большей продолжительностью процесса активации резервной инфраструктуры по сравнению с другими решениями, что ограничивает их применимость для наиболее критичных с точки зрения производственного процесса приложений. Кроме того, они не автоматизируют ни анализ исходной инфраструктуры, ни создание резервной инфраструктуры, ни процедуры ее активации. В качестве примеров решений данного вида можно привести Veritas Netbackup, Veeam Backup & Replicator.
Затем, решения, встроенные в облачные платформы, способны обеспечивать почти идентичное состояние между исходной и резервной инфраструктурами и частично автоматизировать процедуру активации резервной инфраструктуры, однако существующие реализации ограничены платформой одного типа и не способны управлять гетерогенными конфигурациями, когда исходная и резервная инфраструктуры развернуты на разных платформах или используют разные технологии виртуализации. Подобного рода решения реализованы, в частности, в VMware Site Recovery Manager (SRM).
Наконец, решения для обеспечения мобильности серверов/прикладных сред позволяют достичь идентичности между исходной и резервной инфраструктурами на определенный момент во времени и в некоторых своих реализациях способны работать в гетерогенных конфигурациях, но не приспособлены для постоянного поддержания актуальности резервной инфраструктуры на протяжении длительного времени, что является неотъемлемым требованием обеспечения катастрофоустойчивости. Примерами таких решений могут служить Zerto или Double-Take Replication.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Задачей настоящего изобретения является создание технологий развертывания и соответствующего функционирования системы обеспечения катастрофоустойчивости работающего приложения, которые бы позволили избежать недостатков предшествующего уровня техники, обсужденных выше.
В контексте решения данной задачи, согласно первому аспекту настоящего изобретения предложен способ развертывания системы обеспечения катастрофоустойчивости в распределенной сетевой среде. Распределенная сетевая среда содержит по меньшей мере одну основную инфраструктуру приложения, реализованную на одном или более серверах основной инфраструктуры, при этом в каждой основной инфраструктуре приложения из по меньшей мере одной основной инфраструктуры приложения работает приложение, катастрофоустойчивость которого требуется обеспечить. Распределенная сетевая среда содержит мастер-контроллер системы обеспечения катастрофоустойчивости, реализованный на одном или более вычислительных устройствах. Предложенный способ содержит следующие этапы, выполняемые для каждой основной инфраструктуры приложения из по меньшей мере одной основной инфраструктуры приложения.
Конфигурируют в распределенной сетевой среде по меньшей мере одну резервную инфраструктуру для основной инфраструктуры приложения, причем резервная инфраструктура реализована на одном или более серверах резервной инфраструктуры.
В основной инфраструктуре приложения устанавливают и запускают подсистему системы обеспечения катастрофоустойчивости для основной инфраструктуры приложения (подсистему-источник) и в каждой резервной инфраструктуре из по меньшей мере одной резервной инфраструктуры устанавливают и запускают подсистему системы обеспечения катастрофоустойчивости для резервной инфраструктуры (подсистему-приемник).
Нижеследующие этапы предложенного способа осуществляются для каждой резервной инфраструктуры из по меньшей мере одной резервной инфраструктуры.
Посредством мастер-контроллера определяют один или более ресурсов хранения в основной инфраструктуре приложения, которые задействуются для работы приложения, для репликации в резервную инфраструктуру и, для каждого из определенных одного или более ресурсов хранения (ресурса-источника), выбирают в резервной инфраструктуре по меньшей мере один соответствующий ресурс хранения (ресурс-приемник), образуя репликационную пару из ресурса-источника и ресурса-приемника.
Для каждой репликационной пары, не останавливая работу приложения, выполняют предварительную репликацию данных с ресурса-источника на ресурс-приемник, при этом предварительная репликация данных содержит этапы, на которых: выполняют первичное копирование блоков данных ресурса-источника на ресурс-приемник; посредством подсистемы-источника выполняют регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала первичного копирования, и, по завершении первичного копирования, формируют массив информации регистрации изменений в отношении зарегистрированных блоков данных и передают сформированный массив информации регистрации изменений в резервную инфраструктуру; и посредством подсистемы-приемника осуществляют запись на ресурс-приемник блоков данных с использованием принятого массива информации регистрации изменений.
Для каждой репликационной пары, не останавливая работу приложения, выполняют циклы синхронизации, при этом каждый цикл синхронизации содержит этапы, на которых: в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, посредством подсистемы-источника выполняют регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формируют массив информации регистрации изменений в отношении зарегистрированных блоков данных; передают сформированные один или более массивов информации регистрации изменений в резервную инфраструктуру и сохраняют один или более массивов информации регистрации изменений в резервной инфраструктуре; и посредством подсистемы-приемника осуществляют запись на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных в резервной инфраструктуре.
В соответствии с вариантом осуществления, предложенный способ дополнительно содержит, перед конфигурированием по меньшей мере одной резервной инфраструктуры, этапы, на которых, с использованием мастер-контроллера: получают информацию о технических характеристиках и настройках одного или более серверов основной инфраструктуры посредством установки и запуска специализированных служебных утилит на каждом из одного или более серверов основной инфраструктуры; и определяют параметры, характеризующие ресурсные потребности основной инфраструктуры приложения, с использованием полученной информации о технических характеристиках и настройках одного или более серверов основной инфраструктуры.
Упомянутые один или более серверов основной инфраструктуры могут представлять собой множество серверов основной инфраструктуры, и один или более из множества серверов основной инфраструктуры могут быть виртуальными серверами, реализованными посредством виртуальных машин, при этом получение информации о технических характеристиках и настройках серверов основной инфраструктуры согласно данному варианту осуществления осуществляется посредством обращения к API гипервизоров, обеспечивающих работу виртуальных машин.
Согласно одному варианту осуществления, конфигурирование по меньшей мере одной резервной инфраструктуры содержит этапы, на которых: получают информацию о технических характеристиках и настройках каждого из совокупности серверов в распределенной сетевой среде, которые могут быть использованы для по меньшей мере одной резервной инфраструктуры, посредством установки и запуска специализированных служебных утилит на каждом из совокупности серверов; и выполняют исходное конфигурирование одного или более из совокупности серверов для по меньшей мере одной резервной инфраструктуры на основе анализа, по меньшей мере, упомянутых параметров ресурсных потребностей основной инфраструктуры приложения и полученной информации о технических характеристиках и настройках совокупности серверов.
Согласно другому варианту осуществления, исходное конфигурирование одного или более серверов резервной инфраструктуры для основной инфраструктуры приложения выполнено заблаговременно, и при упомянутом конфигурировании по меньшей мере одной резервной инфраструктуры получают информацию о технических характеристиках и настройках одного или более серверов резервной инфраструктуры посредством установки и запуска специализированных служебных утилит на каждом из одного или более серверов резервной инфраструктуры.
Каждый из одного или более серверов резервной инфраструктуры до активации резервной инфраструктуры в качестве основной инфраструктуры приложения предпочтительно функционирует под управлением временной операционной системы, запущенной в режиме boot-to-RAM.
В соответствии с вариантом осуществления, предложенный способ дополнительно содержит этапы, на которых, перед упомянутыми установкой и запуском подсистемы-источника и подсистемы-приемника: выполняют оценку достижимости целевых характеристик обеспечения катастрофоустойчивости, предварительно заданных в мастер-контроллере, на основе упомянутой информации о технических характеристиках и настройках одного или более серверов основной инфраструктуры, упомянутых параметров ресурсных потребностей основной инфраструктуры приложения и информации о технических характеристиках и настройках одного или более серверов резервной инфраструктуры; и выполняют корректировку по меньшей мере одной из целевых характеристик обеспечения катастрофоустойчивости, если в результате оценки установлена недостижимость этой по меньшей мере одной целевой характеристики обеспечения катастрофоустойчивости, при этом целевые характеристики обеспечения катастрофоустойчивости содержат параметр RTO и параметр RPO, причем по меньшей мере один из параметра RTO и параметра RPO является индивидуальным для каждого сочетания «основная инфраструктура приложения - резервная инфраструктура».
Согласно варианту осуществления, конфигурирование по меньшей мере одной резервной инфраструктуры содержит этапы, на которых: конфигурируют правила автоматического преобразования настроек сетевых интерфейсов на одном или более серверах резервной инфраструктуры на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения; и/или конфигурируют правила автоматического изменения системных настроек операционной системы каждого из одного или более серверов резервной инфраструктуры на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения; и/или конфигурируют зависящие от приложения правила, причем данное конфигурирование содержит задание одной или более контрольных точек для приложения, в каждой из которых в резервной инфраструктуре может быть запущен соответствующий пользовательский исполняемый сценарий для выполнения действий, специфических для приложения, в целях дополнительного обеспечения целостности данных приложения на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения.
В соответствии с предпочтительным вариантом осуществления, для выполнения регистрации блоков данных ресурса-источника, подвергшихся изменению, при выполнении предварительной репликации и выполнении циклов синхронизации используются CBT-журналы и COW-журналы, а каждый массив информации регистрации изменений содержит stash-файл.
Согласно предпочтительному варианту осуществления, предварительная репликация дополнительно содержит этап, на котором, перед выполнением первичного копирования данных, в подсистеме-источнике открывают первый CBT-журнал, при этом, при выполнении предварительной репликации, выполняются следующие действия. Упомянутое выполнение регистрации содержит этапы, на которых: регистрируют информацию о блоках данных ресурса-источника, подвергшихся изменению во время первичного копирования, в первом CBT-журнале; в момент завершения первичного копирования, закрывают первый CBT-журнал и открывают второй COW-журнал и второй CBT-журнал; регистрируют блоки данных ресурса-источника, подвергшиеся изменению, во втором COW-журнале и втором CBT-журнале. Упомянутое формирование массива информации регистрации изменений содержит этапы, на которых: создают stash-файл и для каждого блока данных ресурса-источника, который в закрытом первом CBT-журнале помечен как подвергшийся изменению: проверяют, помечен ли блок данных как подвергшийся изменению во втором CBT-журнале; если это так, соответственно записывают в созданный stash-файл содержимое блока данных из второго COW-журнала, в противном случае соответственно записывают в созданный stash-файл текущее содержимое блока данных с ресурса-источника. При упомянутом осуществлении записи на ресурс-приемник применяют принятый stash-файл к ресурсу-приемнику.
Согласно предпочтительному варианту осуществления, при выполнении циклов синхронизации, для каждого текущего интервала регистрации изменений, выполняются следующие действия. Упомянутое выполнение регистрации содержит этапы, на которых: открывают текущий COW-журнал и текущий CBT-журнал; регистрируют блоки данных ресурса-источника, подвергшиеся изменению после начала текущего интервала регистрации изменений, в текущем COW-журнале и текущем CBT-журнале. Упомянутое формирование массива информации регистрации содержит этапы, на которых: создают stash-файл и для каждого блока данных ресурса-источника, который помечен в CBT-журнале, закрытом по истечении предыдущего интервала регистрации изменений, как подвергшийся изменению: проверяют, помечен ли блок данных как подвергшийся изменению в текущем CBT-журнале; если это так, соответственно записывают в созданный stash-файл содержимое блока данных из текущего COW-журнала, в противном случае соответственно записывают в созданный stash-файл текущее содержимое блока данных с ресурса-источника. Упомянутое выполнение регистрации дополнительно содержит этап, на котором, по истечении текущего интервала регистрации изменений, закрывают текущий COW-журнал и текущий CBT-журнал. При упомянутом осуществлении записи на ресурс-приемник последовательно применяют stash-файлы, сохраненные в резервной инфраструктуре, к ресурсу-приемнику. Длительность интервала регистрации изменений предпочтительно определяется параметром RPO. Упомянутое осуществление записи на ресурс-приемник блоков данных с использованием сохраненных массивов информации регистрации изменений предпочтительно выполняется с задержкой после упомянутого сохранения одного или более массивов информации регистрации изменений в резервной инфраструктуре, причем задержка является заранее заданной в мастер-контроллере.
Согласно варианту осуществления, при выполнении циклов синхронизации, анализируют достижимость параметра RPO на основе темпа передачи сформированных массивов информации регистрации изменений из основной инфраструктуры приложения в резервную инфраструктуру и, в случае обнаружения недостижимости параметра RPO, выдают в мастер-контроллер сообщение о недостижимости RPO; и анализируют достижимость параметра RTO на основе упомянутой задержки и темпа применения сохраненных массивов информации регистрации к ресурсу-приемнику и, в случае обнаружения недостижимости параметра RTO, выдают в мастер-контроллер сообщение о недостижимости RTO.
В соответствии со вторым аспектом настоящего изобретения, предложена система обеспечения катастрофоустойчивости, развернутая в распределенной сетевой среде, содержащей основную инфраструктуру приложения, реализованную на одном или более серверах основной инфраструктуры, причем в основной инфраструктуре приложения работает приложение, катастрофоустойчивость которого требуется обеспечить. Для основной инфраструктуры приложения сконфигурирована резервная инфраструктура, реализованная на одном или более серверах резервной инфраструктуры в распределенной сетевой среде. Каждый из одного или более серверов резервной инфраструктуры предпочтительно функционирует под управлением временной операционной системы, запущенной в режиме boot-to-RAM.
Предложенная система обеспечения катастрофоустойчивости содержит: мастер-контроллер, реализованный на одном или более вычислительных устройствах распределенной сетевой среды; подсистему для основной инфраструктуры приложения (подсистему-источник), функционирующую в основной инфраструктуре приложения; и подсистему для резервной инфраструктуры (подсистему-приемник), функционирующую в резервной инфраструктуре.
Мастер-контроллер выполнен с возможностью определять один или более ресурсов хранения в основной инфраструктуре приложения, которые задействуются для работы приложения, для репликации в резервную инфраструктуру и, для каждого из определенных одного или более ресурсов хранения (ресурса-источника), выбирать в резервной инфраструктуре по меньшей мере один соответствующий ресурс хранения (ресурс-приемник), образуя репликационную пару из ресурса-источника и ресурса-приемника.
Подсистема-источник содержит: хост-контроллер подсистемы-источника, выполненный с возможностью взаимодействия с мастер-контроллером, диспетчер репликационной пары подсистемы-источника и компоненты репликации подсистемы-источника под управлением диспетчера репликационной пары подсистемы-источника. На каждом из одного или более серверов основной инфраструктуры, который содержит один или более ресурсов-источников соответствующих репликационных пар, запущен экземпляр хост-контроллера подсистемы-источника, для каждой из этих соответствующих репликационных пар запущен экземпляр диспетчера репликационной пары подсистемы-источника, который находится на связи с экземпляром хост-контроллера подсистемы-источника, и для каждого экземпляра диспетчера репликационной пары подсистемы-источника запущен соответствующий экземпляр компонентов репликации подсистемы-источника.
Подсистема-приемник содержит: хост-контроллер подсистемы-приемника, выполненный с возможностью взаимодействия с мастер-контроллером, диспетчер репликационной пары подсистемы-приемника и компоненты репликации подсистемы-приемника под управлением диспетчера репликационной пары подсистемы-приемника. На каждом из одного или более серверов резервной инфраструктуры, который содержит один или более ресурсов-приемников соответствующих репликационных пар, запущен экземпляр хост-контроллера подсистемы-приемника, для каждой из этих соответствующих репликационных пар запущен экземпляр диспетчера репликационной пары подсистемы-приемника, который находится на связи с экземпляром хост-контроллера подсистемы-приемника, и для каждого экземпляра диспетчера репликационной пары подсистемы-приемника запущен соответствующий экземпляр компонентов репликации подсистемы-приемника.
Экземпляр диспетчера репликационной пары подсистемы-источника, соответствующий экземпляр компонентов репликации подсистемы-источника, экземпляр диспетчера репликационной пары подсистемы-приемника и соответствующий экземпляр компонентов репликации подсистемы-приемника, запущенные для каждой репликационной пары, выполнены с возможностью осуществлять, не останавливая работу приложения, следующие операции.
Выполняется предварительная репликация данных с ресурса-источника на ресурс-приемник, содержащая: первичное копирование блоков данных ресурса-источника на ресурс-приемник; регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала первичного копирования, и, по завершении первичного копирования, формирование массива информации регистрации изменений в отношении зарегистрированных блоков данных и передачу сформированного массива информации регистрации изменений в резервную инфраструктуру; и запись на ресурс-приемник блоков данных с использованием принятого массива информации регистрации изменений.
Выполняются циклы синхронизации, при этом каждый цикл синхронизации содержит: в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формирование массива информации регистрации изменений в отношении зарегистрированных блоков данных; передачу сформированных одного или более массивов информации регистрации изменений в резервную инфраструктуру и сохранение одного или более массивов информации регистрации изменений в резервной инфраструктуре; и запись на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных в резервной инфраструктуре.
Согласно предпочтительному варианту осуществления, для каждой репликационной пары экземпляр диспетчера репликационной пары подсистемы-источника и экземпляр диспетчера репликационной пары подсистемы-приемника выполнены с возможностью непосредственного взаимодействия друг с другом.
Согласно варианту осуществления, компоненты репликации подсистемы-источника содержат, по меньшей мере: средство обнаружения изменений, средство формирования истории изменений и средство передачи. Для каждой репликационной пары: соответствующий экземпляр средства обнаружения изменений выполнен с возможностью отслеживать операции ввода-вывода на ресурсе-источнике и выполнять регистрацию происходящих изменений блоков данных; соответствующий экземпляр средства формирования истории изменений выполнен с возможностью формировать массивы информации регистрации изменений на основе регистрации, выполненной экземпляром средства обнаружения изменений; и соответствующий экземпляр средства передачи выполнен с возможностью осуществлять передачу массивов информации регистрации изменений в резервную инфраструктуру.
В соответствии с вариантом осуществления, компоненты репликации подсистемы-приемника содержат, по меньшей мере: средство приема и средство применения изменений. Для каждой репликационной пары: соответствующий экземпляр средства приема выполнен с возможностью осуществлять прием массивов информации регистрации изменений от средства приема подсистемы-источника и обеспечивать сохранение принятых массивов информации регистрации изменений в резервной инфраструктуре; и соответствующий экземпляр средства применения изменений выполнен с возможностью обрабатывать массивы информации регистрации изменений и применять их к ресурсу-приемнику для записи соответствующих блоков данных на ресурс-приемник.
Согласно варианту осуществления, подсистема-источник дополнительно содержит хранилище истории изменений подсистемы-источника для сохранения массивов информации регистрации изменений перед их передачей, и/или подсистема-приемник дополнительно содержит хранилище истории изменений подсистемы-приемника для сохранения принимаемых массивов информации регистрации изменений перед их применением.
Согласно одному варианту осуществления, экземпляры хост-контроллера подсистемы-источника, диспетчера репликационной пары подсистемы-источника и компонентов репликации подсистемы-источника, установленные на соответствующем сервере основной инфраструктуры, реализованы посредством машиноисполняемых процессов, функционирующих на уровне операционной системы этого сервера, и/или экземпляры хост-контроллера подсистемы-приемника, диспетчера репликационной пары подсистемы-приемника и компонентов репликации подсистемы-приемника, установленные на соответствующем сервере резервной инфраструктуры, реализованы посредством машиноисполняемых процессов, функционирующих на уровне операционной системы этого сервера.
В соответствии с другим вариантом осуществления, экземпляры хост-контроллера подсистемы-источника, диспетчера репликационной пары подсистемы-источника и компонентов репликации подсистемы-источника реализованы посредством машиноисполняемых процессов, функционирующих в специализированной аппаратной плате, устанавливаемой в соответствующий сервер основной инфраструктуры, изолированно от операционной системы этого сервера, причем машиноисполняемые процессы выполнены с возможностью перехватывать обращения к ресурсам-источникам, инициируемые на уровне процессов операционной системы, и/или экземпляры хост-контроллера подсистемы-приемника, диспетчера репликационной пары подсистемы-приемника и компонентов репликации подсистемы-приемника реализованы посредством машиноисполняемых процессов, функционирующих в специализированной аппаратной плате, устанавливаемой в соответствующий сервер резервной инфраструктуры, изолированно от операционной системы этого сервера, причем машиноисполняемые процессы выполнены с возможностью перехватывать обращения к ресурсам-приемникам, инициируемые на уровне процессов операционной системы. Согласно данному варианту осуществления, хранилище истории изменений подсистемы-источника может быть реализовано на специализированной аппаратной плате, устанавливаемой в соответствующий сервер основной инфраструктуры, и/или хранилище истории изменений подсистемы-приемника может быть реализовано на специализированной аппаратной плате, устанавливаемой в соответствующий сервер резервной инфраструктуры.
Согласно еще одному варианту осуществления, упомянутые один или более серверов основной инфраструктуры представляют собой множество серверов основной инфраструктуры, причем один или более из множества серверов основной инфраструктуры являются виртуальными серверами, реализованными посредством виртуальных машин, при этом соответствующие экземпляры хост-контроллера подсистемы-источника, диспетчера репликационной пары подсистемы-источника и компонентов репликации подсистемы-источника реализованы посредством машиноисполняемых процессов, функционирующих на уровне гипервизоров, обеспечивающих работу виртуальных машин; и/или упомянутые один или более серверов резервной инфраструктуры представляют собой множество серверов резервной инфраструктуры, причем один или более из множества серверов резервной инфраструктуры являются виртуальными серверами, реализованными посредством виртуальных машин, при этом соответствующие экземпляры хост-контроллера подсистемы-приемника, диспетчера репликационной пары подсистемы-приемника и компонентов репликации подсистемы-приемника реализованы посредством машиноисполняемых процессов, функционирующих на уровне гипервизоров, обеспечивающих работу виртуальных машин.
Резервная инфраструктура может быть активирована в качестве основной инфраструктуры приложения по приему в подсистеме-приемнике соответствующей команды от мастер-контроллера. Согласно возможной реализации, перед указанной активацией резервной инфраструктуры приостанавливается выполнение циклов синхронизации в основной инфраструктуре приложения и в резервной инфраструктуре и останавливается работа приложения в основной инфраструктуре приложения.
Согласно третьему аспекту настоящего изобретения, предложен способ функционирования системы обеспечения катастрофоустойчивости, развернутой в распределенной сетевой среде. Распределенная сетевая среда содержит основную инфраструктуру приложения, реализованную на одном или более серверах основной инфраструктуры, причем в основой инфраструктуре приложения работает приложение, катастрофоустойчивость которого требуется обеспечить. Для основной инфраструктуры приложения сконфигурирована резервная инфраструктура, реализованная на одном или более серверах резервной инфраструктуры в распределенной сетевой среде. Система обеспечения катастрофоустойчивости содержит: мастер-контроллер, реализованный на одном или более вычислительных устройствах распределенной сетевой среды; подсистему для основной инфраструктуры приложения (подсистему-источник), функционирующую в первой инфраструктуре; и подсистему для резервной инфраструктуры (подсистему-приемник), функционирующую в резервной инфраструктуре. Посредством мастер-контроллера в основной инфраструктуре приложения и резервной инфраструктуре определены репликационные пары путем выбора, для каждого из одного или более ресурсов хранения, которые задействуются для работы приложения в основной инфраструктуре приложения (ресурса-источника), соответствующего ресурса хранения в резервной инфраструктуре (ресурса-приемника), с образованием репликационной пары из ресурса-источника и ресурса-приемника, причем для каждой репликационной пары выполнена предварительная репликация данных с ресурса-источника на ресурс-приемник.
Предложенный способ содержит следующие этапы, выполняемые для каждой репликационной пары, не останавливая работу приложения.
Выполняют частичную ресинхронизацию данных ресурса-источника и ресурса-приемника. Частичная ресинхронизация содержит этапы, на которых: посредством подсистемы-приемника генерируют карту текущего содержимого ресурса-приемника и передают карту текущего содержимого ресурса-приемника в подсистему-источник; по приему карты текущего содержимого ресурса-приемника, посредством подсистемы-источника выполняют регистрацию блоков данных ресурса-источника, подвергшихся изменению, формируют массив информации регистрации изменений на основе карты текущего содержимого ресурса-приемника и зарегистрированных блоков данных и передают сформированный массив информации регистрации изменений в резервную инфраструктуру; сохраняют массив информации регистрации изменений в резервной инфраструктуре; и посредством подсистемы-приемника осуществляют запись на ресурс-приемник блоков данных с использованием сохраненного массива информации регистрации изменений.
Выполняют циклы синхронизации, при этом каждый цикл синхронизации содержит этапы, на которых: по завершении упомянутой передачи массива информации регистрации изменений, сформированного при частичной ресинхронизации, в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, посредством подсистемы-источника выполняют регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формируют массив информации регистрации изменений в отношении зарегистрированных блоков данных; передают сформированные один или более массивов информации регистрации изменений в резервную инфраструктуру и сохраняют один или более массивов информации регистрации изменений в резервной инфраструктуре; и после завершения упомянутой записи блоков данных при частичной ресинхронизации, посредством подсистемы-приемника осуществляют запись на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных в резервной инфраструктуре.
Согласно варианту осуществления, формирование карты текущего содержимого ресурса-приемника содержит этапы, на которых в системе-приемнике: для каждого блока данных ресурса-приемника в соответствии с заранее заданным алгоритмом вычисляют уникальный идентификатор на основе содержимого этого блока данных и записывают результаты вычислений в файл, причем данный файл представляет карту текущего содержимого ресурса-приемника. При передаче карты текущего содержимого ресурса-приемника в подсистему-источник передают упомянутый файл. В качестве упомянутого заранее заданного алгоритма может использоваться алгоритм вычисления хеш-суммы содержимого блока данных.
В соответствии с предпочтительным вариантом осуществления, для выполнения регистрации блоков данных ресурса-источника, подвергшихся изменению, при выполнении частичной ресинхронизации и выполнении циклов синхронизации используются CBT-журналы и COW-журналы, а каждый массив информации регистрации изменений содержит stash-файл.
Согласно предпочтительному варианту осуществления, при выполнении частичной ресинхронизации выполняются следующие действия. Упомянутое выполнение регистрации содержит этапы, на которых: открывают COW-журнал и CBT-журнал и регистрируют блоки данных ресурса-источника, подвергшиеся изменению, в COW-журнале и CBT-журнале. Упомянутое формирование массива информации регистрации изменений содержит этапы, на которых: создают stash-файл; и, для каждого блока данных ресурса-источника, проверяют, помечен ли блок данных ресурса-источника как подвергшийся изменению в CBT-журнале, если это так, берут содержимое блока данных ресурса-источника из COW-журнала, в противном случае берут содержимое блока данных ресурса-источника с ресурса-источника, в соответствии с упомянутым заранее заданным алгоритмом вычисляют уникальный идентификатор блока данных ресурса-источника на основе содержимого этого блока данных, если вычисленный уникальный идентификатор блока данных ресурса-источника отличается от уникального идентификатора соответствующего блока данных ресурса-приемника согласно принятому файлу карты текущего содержимого ресурса-приемника, соответственно записывают содержимое блока данных ресурса-источника в stash-файл.
В соответствии с предпочтительным вариантом осуществления, при выполнении циклов синхронизации выполняются следующие действия, для каждого текущего интервала регистрации изменений. Упомянутое выполнение регистрации содержит этапы, на которых: открывают текущий COW-журнал и текущий CBT-журнал; регистрируют блоки данных ресурса-источника, подвергшиеся изменению после начала текущего интервала регистрации изменений, в текущем COW-журнале и текущем CBT-журнале. Упомянутое формирование массива информации регистрации содержит этапы, на которых: создают stash-файл; и для каждого блока данных ресурса-источника, который помечен в CBT-журнале, закрытом по истечении предыдущего интервала регистрации изменений, как подвергшийся изменению: проверяют, помечен ли блок данных как подвергшийся изменению в текущем CBT-журнале, если это так, соответственно записывают в созданный stash-файл содержимое блока данных из текущего COW-журнала, в противном случае соответственно записывают в созданный stash-файл текущее содержимое блока данных с ресурса-источника Упомянутое выполнение регистрации дополнительно содержит этап, на котором, по истечении текущего интервала регистрации изменений, закрывают текущий COW-журнал и текущий CBT-журнал. При упомянутом осуществлении записи на ресурс-приемник последовательно применяют stash-файлы, сохраненные в резервной инфраструктуре, к ресурсу-приемнику.
В соответствии с четвертым аспектом настоящего изобретения, предложена система обеспечения катастрофоустойчивости, развернутая в распределенной сетевой среде, содержащей основную инфраструктуру приложения, реализованную на одном или более серверах основной инфраструктуры, причем в основной инфраструктуре приложения работает приложение, катастрофоустойчивость которого требуется обеспечить. Для основной инфраструктуры приложения сконфигурирована резервная инфраструктура, реализованная на одном или более серверах резервной инфраструктуры в распределенной сетевой среде.
Предложенная система обеспечения катастрофоустойчивости содержит: мастер-контроллер, реализованный на одном или более вычислительных устройствах распределенной сетевой среды; подсистему для основной инфраструктуры приложения (подсистему-источник), функционирующую в основной инфраструктуре приложения; и подсистему для резервной инфраструктуры (подсистему-приемник), функционирующую в резервной инфраструктуре. Посредством мастер-контроллера в основной инфраструктуре приложения и резервной инфраструктуре определены репликационные пары путем выбора, для каждого из одного или более ресурсов хранения, которые задействуются для работы приложения в основной инфраструктуре приложения (ресурса-источника), соответствующего ресурса хранения в резервной инфраструктуре (ресурса-приемника), с образованием репликационной пары из ресурса-источника и ресурса-приемника, причем для каждой репликационной пары выполнена предварительная репликация данных с ресурса-источника на ресурс-приемник.
Подсистема-источник содержит: хост-контроллер подсистемы-источника, выполненный с возможностью взаимодействия с мастер-контроллером; диспетчер репликационной пары подсистемы-источника; и компоненты репликации подсистемы-источника под управлением диспетчера репликационной пары подсистемы-источника. На каждом из одного или более серверов основной инфраструктуры, который содержит один или более ресурсов-источников соответствующих репликационных пар, запущен экземпляр хост-контроллера подсистемы-источника, для каждой из этих соответствующих репликационных пар запущен экземпляр диспетчера репликационной пары подсистемы-источника, который находится на связи с экземпляром хост-контроллера подсистемы-источника, и для каждого экземпляра диспетчера репликационной пары подсистемы-источника запущен соответствующий экземпляр компонентов репликации подсистемы-источника.
Подсистема-приемник содержит: хост-контроллер подсистемы-приемника, выполненный с возможностью взаимодействия с мастер-контроллером; диспетчер репликационной пары подсистемы-приемника; и компоненты репликации подсистемы-приемника под управлением диспетчера репликационной пары подсистемы-приемника. На каждом из одного или более серверов резервной инфраструктуры, который содержит один или более ресурсов-приемников соответствующих репликационных пар, запущен экземпляр хост-контроллера подсистемы-приемника, для каждой из этих соответствующих репликационных пар запущен экземпляр диспетчера репликационной пары подсистемы-приемника, который находится на связи с экземпляром хост-контроллера подсистемы-приемника, и для каждого экземпляра диспетчера репликационной пары подсистемы-приемника запущен соответствующий экземпляр компонентов репликации подсистемы-приемника.
Экземпляр диспетчера репликационной пары подсистемы-источника, соответствующий экземпляр компонентов репликации подсистемы-источника, экземпляр диспетчера репликационной пары подсистемы-приемника и соответствующий экземпляр компонентов репликации подсистемы-приемника, запущенные для каждой репликационной пары, выполнены с возможностью осуществлять, не останавливая работу приложения, следующие операции.
Выполняется частичная ресинхронизация данных ресурса-источника и ресурса-приемника, содержащая: генерирование карты текущего содержимого ресурса-приемника и передачу карты текущего содержимого ресурса-приемника в подсистему-источник; по приему карты текущего содержимого ресурса-приемника, регистрацию блоков данных ресурса-источника, подвергшихся изменению, формирование массива информации регистрации изменений на основе карты текущего содержимого ресурса-приемника и зарегистрированных блоков данных и передачу сформированного массива информации регистрации изменений в резервную инфраструктуру; сохранение массива информации регистрации изменений в резервной инфраструктуре; и осуществление записи на ресурс-приемник блоков данных с использованием сохраненного массива информации регистрации изменений.
Выполняются циклы синхронизации, при этом каждый цикл синхронизации содержит: по завершении упомянутой передачи массива информации регистрации изменений, сформированного при частичной ресинхронизации, в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, выполнение регистрации блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формирование массива информации регистрации изменений в отношении зарегистрированных блоков данных; передачу сформированных одного или более массивов информации регистрации изменений в резервную инфраструктуру и сохранение одного или более массивов информации регистрации изменений в резервной инфраструктуре; и после завершения упомянутой записи блоков данных при частичной ресинхронизации, осуществление записи на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных в резервной инфраструктуре.
Согласно пятому аспекту настоящего изобретения, предложен способ функционирования системы обеспечения катастрофоустойчивости, развернутой в распределенной сетевой среде согласно в соответствии со способом согласно любому из вариантов осуществления первого аспекта. Предложенный способ функционирования содержит этапы, на которых: обнаруживают событие, идентифицируемое как отказ основной инфраструктуры приложения; и по приему, в подсистеме-приемнике в резервной инфраструктуре для основной инфраструктуры приложения, команды активации от мастер-контроллера, выданной вследствие данного обнаружения, активируют резервную инфраструктуру в качестве основной инфраструктуры приложения.
В соответствии с вариантом осуществления, предложенный способ дополнительно содержит, после упомянутого обнаружения, этап, на котором выполняют оценку обнаруженного события, при этом команда активации выдается из мастер-контроллера на основе выполненной оценки.
Согласно варианту осуществления, предложенный способ дополнительно содержит, перед упомянутой активацией, этап, на котором в резервной инфраструктуре: для ресурса-приемника каждой репликационной пары, посредством подсистемы-приемника осуществляют запись блоков данных на ресурс-приемник на основе, по меньшей мере, некоторых из массивов информации регистрации изменений, которые были сохранены в резервной инфраструктуре и которые еще не были использованы для осуществления записи блоков данных на ресурс-приемник.
Согласно шестому аспекту настоящего изобретения, предложен способ функционирования системы обеспечения катастрофоустойчивости, развернутой в распределенной сетевой среде согласно в соответствии со способом согласно любому из вариантов осуществления первого аспекта. Предложенный способ функционирования содержит этапы, на которых, по приему в подсистеме-источнике в основной инфраструктуре приложения и в подсистеме-приемнике в резервной инфраструктуре для основной инфраструктуры приложения команды активации от мастер-контроллера: останавливают выполнение циклов синхронизации в основной инфраструктуре приложения и в резервной инфраструктуре и останавливают работу приложения в основной инфраструктуре приложения; и активируют резервную инфраструктуру в качестве основной инфраструктуры приложения, при этом, по меньшей мере, некоторые из одного или более серверов основной инфраструктуры могут быть выключены.
В соответствии с вариантом осуществления, предложенный способ дополнительно содержит, перед упомянутой активацией, этапы, на которых, для каждой репликационной пары: посредством подсистемы-источника в основной инфраструктуре приложения передают в резервную инфраструктуру все из массивов информации регистрации изменений, которые еще не были переданы в резервную инфраструктуру, и сохраняют эти массивы информации регистрации изменений в резервной инфраструктуре; и/или посредством подсистемы-приемника в резервной инфраструктуре осуществляют запись блоков данных на ресурс-приемник на основе, по меньшей мере, некоторых из массивов информации регистрации изменений, которые были сохранены в резервной инфраструктуре и которые еще не были использованы для осуществления записи.
Согласно варианту осуществления пятого или шестого аспекта настоящего изобретения, на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения: на одном или более серверах резервной инфраструктуры преконфигурированы правила автоматического преобразования настроек сетевых интерфейсов; преконфигурированы правила автоматического изменения системных настроек операционной системы каждого из одного или более серверов резервной инфраструктуры; преконфигурированы зависящие от приложения правила посредством задания одной или более контрольных точек для приложения, в каждой из которых в резервной инфраструктуре может быть запущен соответствующий пользовательский исполняемый сценарий для выполнения действий, специфических для приложения, в целях дополнительного обеспечения целостности данных приложения; каждый из одного или более серверов резервной инфраструктуры до активации резервной инфраструктуры в качестве основной инфраструктуры приложения функционирует под управлением временной операционной системы, запущенной в режиме boot-to-RAM. В рассматриваемом варианте осуществления активация резервной инфраструктуры содержит этапы, на которых: согласно преконфигурированным правилам автоматического преобразования, преобразуют настройки сетевых интерфейсов на, по меньшей мере, некоторых из одного или более серверов резервной инфраструктуры, и/или согласно преконфигурированным правилам автоматического изменения, изменяют системные настройки операционной системы, по меньшей мере, некоторых из одного или более серверов резервной инфраструктуры, и/или согласно преконфигурированным зависящим от приложения правилам, в резервной инфраструктуре для требующейся контрольной точки запускают соответствующий пользовательский исполняемый сценарий; перезагружают один или более серверов резервной инфраструктуры для обеспечения работы приложения в резервной инфраструктуре и запускают приложение в резервной инфраструктуре, причем после перезагрузки один или более серверов резервной инфраструктуры функционируют под управлением основной операционной системы.
В соответствии с седьмым аспектом настоящего изобретения, предложен способ функционирования системы обеспечения катастрофоустойчивости, развернутой в распределенной сетевой среде. Распределенная сетевая среда содержит: первую инфраструктуру, реализованную на одном или более первых серверах в распределенной сетевой среде, причем в первой инфраструктуре, в первом режиме, работает приложение, катастрофоустойчивость которого требуется обеспечить, и вторую инфраструктуру, реализованную на одном или более вторых серверах в распределенной сетевой среде, при этом первая инфраструктура и вторая инфраструктура коммуникационно связаны друг с другом, причем вторая инфраструктура выполнена с возможностью исполнения упомянутого приложения. Система обеспечения катастрофоустойчивости содержит: мастер-контроллер, реализованный на одном или более вычислительных устройствах распределенной сетевой среды, подсистему для первой инфраструктуры (первую подсистему), функционирующую в первой инфраструктуре, и подсистему для второй инфраструктуры (вторую подсистему), функционирующую во второй инфраструктуре. Посредством мастер-контроллера в первой инфраструктуре и второй инфраструктуре определены репликационные пары путем выбора, для каждого из одного или более ресурсов хранения, которые задействуются для работы приложения в первой инфраструктуре (ресурса-источника), соответствующего ресурса хранения во второй инфраструктуре (ресурса-приемника), с образованием репликационной пары из ресурса-источника и ресурса-приемника. Для каждой репликационной пары выполнена предварительная репликация данных с ресурса-источника на ресурс-приемник.
Предложенный способ содержит следующие этапы, выполняемые для каждой репликационной пары, не останавливая работу приложения.
Выполняют циклы синхронизации, причем каждый цикл синхронизации содержит этапы, на которых: в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, посредством первой подсистемы выполняют регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формируют массив информации регистрации изменений в отношении зарегистрированных блоков данных; передают сформированные один или более массивов информации регистрации изменений во вторую инфраструктуру и сохраняют один или более массивов информации регистрации изменений во второй инфраструктуре, и посредством второй подсистемы осуществляют запись на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных во второй инфраструктуре.
При переходе из первого режима во второй режим: приостанавливают выполнение циклов синхронизации в первой инфраструктуре и во второй инфраструктуре и останавливают работу приложения в первой инфраструктуре; активируют вторую инфраструктуру в качестве первой инфраструктуры и запускают приложение во второй инфраструктуре, функционирующей в качестве первой инфраструктуры; активируют первую инфраструктуру в качестве второй инфраструктуры; и возобновляют выполнение циклов синхронизации во второй инфраструктуре, функционирующей в качестве первой инфраструктуры, и в первой инфраструктуре, функционирующей в качестве второй инфраструктуры.
Согласно варианту осуществления, на случай перехода из первого режима во второй режим: на одном или более серверах второй инфраструктуры преконфигурированы правила автоматического преобразования настроек сетевых интерфейсов; для каждого из одного или более серверов второй инфраструктуры преконфигурированы правила автоматического изменения системных настроек операционной системы; преконфигурированы зависящие от приложения правила посредством задания одной или более контрольных точек для приложения, в каждой из которых во второй инфраструктуре может быть запущен соответствующий пользовательский исполняемый сценарий для выполнения действий, специфических для приложения, в целях дополнительного обеспечения целостности данных приложения. В соответствии с рассматриваемым вариантом осуществления, активация второй инфраструктуры в качестве первой инфраструктуры при переходе из первого режима во второй режим дополнительно содержит этапы, на которых, перед упомянутым запуском приложения: согласно преконфигурированным правилам автоматического преобразования, преобразуют настройки сетевых интерфейсов на, по меньшей мере, некоторых из одного или более серверов второй инфраструктуры; и/или согласно преконфигурированным правилам автоматического изменения, изменяют системные настройки операционной системы, по меньшей мере, некоторых из одного или более серверов второй инфраструктуры; и/или согласно преконфигурированным зависящим от приложения правилам, во второй инфраструктуре для требующейся контрольной точки запускают соответствующий пользовательский исполняемый сценарий; перезагружают один или более серверов второй инфраструктуры для обеспечения работы приложения во второй резервной инфраструктуре.
Согласно одному варианту осуществления, первым режимом является штатный режим работы приложения, при этом первой инфраструктурой является основная инфраструктура приложения, а второй инфраструктурой является резервная инфраструктура, сконфигурированная для основной инфраструктуры приложения, при этом вторым режимом является режим, отличающийся от штатного режима. В частности, вторым режимом может быть режим реверса репликации, при этом переход во второй режим происходит по команде реверса репликации от мастер-контроллера.
Согласно другому варианту осуществления, первым режимом является режим реверса репликации, при этом второй инфраструктурой является инфраструктура, которая изначально была основной инфраструктурой приложения и временно функционирует в качестве резервной инфраструктуры, а первой инфраструктурой является резервная инфраструктура, временно функционирующая в качестве основной инфраструктуры приложения, причем вторым режимом является штатный режим работы приложения, при этом переход во второй режим осуществляется по команде реверса репликации от мастер-контроллера.
В соответствии с восьмым аспектом настоящего изобретения, предложена система обеспечения катастрофоустойчивости, развернутая в распределенной сетевой среде, содержащей первую инфраструктуру, реализованную на одном или более первых серверах в распределенной сетевой среде, причем в первой инфраструктуре, в первом режиме, работает приложение, катастрофоустойчивость которого требуется обеспечить, и вторую инфраструктуру, реализованную на одном или более вторых серверах в распределенной сетевой среде, при этом первая инфраструктура и вторая инфраструктура коммуникационно связаны друг с другом, причем вторая инфраструктура выполнена с возможностью исполнения упомянутого приложения.
Предложенная система обеспечения катастрофоустойчивости содержит: мастер-контроллер, реализованный на одном или более вычислительных устройствах распределенной сетевой среды; подсистему для первой инфраструктуры (первую подсистему), функционирующую в первой инфраструктуре; и подсистему для второй инфраструктуры (вторую подсистему), функционирующую во второй инфраструктуре. Посредством мастер-контроллера в первой инфраструктуре и второй инфраструктуре определены репликационные пары путем выбора, для каждого из одного или более ресурсов хранения, которые задействуются для работы приложения в первой инфраструктуре (ресурса-источника), соответствующего ресурса хранения во второй инфраструктуре (ресурса-приемника), с образованием репликационной пары из ресурса-источника и ресурса-приемника.
Первая подсистема содержит: первый хост-контроллер, выполненный с возможностью взаимодействия с мастер-контроллером; первый диспетчер репликационной пары; и первые компоненты репликации под управлением первого диспетчера репликационной пары. На каждом из одного или более первых серверов, который содержит один или более ресурсов-источников соответствующих репликационных пар, запущен экземпляр первого хост-контроллера, для каждой из этих соответствующих репликационных пар запущен экземпляр первого диспетчера репликационной пары, который находится на связи с экземпляром первого хост-контроллера, и для каждого экземпляра первого диспетчера репликационной пары запущен соответствующий экземпляр первых компонентов репликации.
Вторая подсистема содержит: второй хост-контроллер, выполненный с возможностью взаимодействия с мастер-контроллером; второй диспетчер репликационной пары; и вторые компоненты репликации под управлением второго диспетчера репликационной пары. На каждом из одного или более вторых серверов, который содержит один или более ресурсов-приемников соответствующих репликационных пар, запущен экземпляр второго хост-контроллера, для каждой из этих соответствующих репликационных пар запущен экземпляр второго диспетчера репликационной пары, который находится на связи с экземпляром второго хост-контроллера, и для каждого экземпляра второго диспетчера репликационной пары запущен соответствующий экземпляр вторых компонентов репликации.
Экземпляр первого диспетчера репликационной пары, соответствующий экземпляр первых компонентов репликации, экземпляр второго диспетчера репликационной пары и соответствующий экземпляр вторых компонентов репликации, запущенные для каждой репликационной пары, выполнены с возможностью осуществлять, не останавливая работу приложения, циклы синхронизации. Каждый цикл синхронизации содержит: в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формирование массива информации регистрации изменений в отношении зарегистрированных блоков данных; передачу сформированных одного или более массивов информации регистрации изменений во вторую инфраструктуру и сохранение одного или более массивов информации регистрации изменений во второй инфраструктуре; и запись на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных во второй инфраструктуре. При переходе из первого режима во второй режим: приостанавливается выполнение циклов синхронизации в первой инфраструктуре и во второй инфраструктуре и останавливается работа приложения в первой инфраструктуре; и выполняется активация второй инфраструктуры в качестве первой инфраструктуры и первой инфраструктуры в качестве второй инфраструктуры, при этом активация содержит: запуск приложения во второй инфраструктуре, функционирующей в качестве первой инфраструктуры, и возобновление выполнения циклов синхронизации во второй инфраструктуре, функционирующей в качестве первой инфраструктуры, и в первой инфраструктуре, функционирующей в качестве второй инфраструктуры.
Достигаемый настоящим изобретением технический результат заключается в предоставлении системы обеспечения катастрофоустойчивости работающего приложения и соответствующих способов ее развертывания и функционирования, которыми обеспечивается: по меньшей мере, частичная автоматизация конфигурирования, для основной инфраструктуры приложения, одной или нескольких резервных инфраструктур, которые могут быть гетерогенными по отношению к основной инфраструктуре приложения; постоянная и согласованная синхронизация состояния резервной инфраструктур(ы) с изменениями, происходящими в основной инфраструктуре приложения, в соответствии с заранее заданными целевыми характеристиками обеспечения катастрофоустойчивости; поддержание постоянной готовности к активации приложения на резервной инфраструктуре(ах) и автоматизация технологических операций по такой активации, а также мониторинг достижимости целевых параметров обеспечения защиты приложения и информирование оператора об их потенциальном нарушении, в общем, минимизируя человеческое участие и сокращая длительность и обеспечивая должную надежность восстановления работы приложения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг.1 - иллюстративная схема компонентов системы обеспечения катастрофоустойчивости согласно варианту осуществления настоящего изобретения;
Фиг.2 - блок-схема способа 200 развертывания и запуска системы обеспечения катастрофоустойчивости согласно варианту осуществления настоящего изобретения;
Фиг.3 - блок-схема выполнения этапа 280 предварительной репликации способа 200 согласно варианту осуществления настоящего изобретения;
Фиг.4 - блок-схема осуществления этапа 290 выполнения циклов синхронизации способа 200 согласно варианту осуществления настоящего изобретения;
Фиг.5 - блок-схема выполнения этапа 285 частичной ресинхронизации способа 200 согласно варианту осуществления настоящего изобретения;
Фиг.6 - блок-схема способа функционирования системы обеспечения катастрофоустойчивости согласно одному варианту осуществления настоящего изобретения;
Фиг.7 - блок-схема способа функционирования системы обеспечения катастрофоустойчивости согласно другому варианту осуществления настоящего изобретения;
Фиг.8 - блок-схема способа функционирования системы обеспечения катастрофоустойчивости согласно еще одному варианту осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Далее делается отсылка к примерным вариантам осуществления настоящего изобретения, которые иллюстрируются на сопровождающих чертежах, где одинаковые ссылочные номера обозначают аналогичные элементы. Следует при этом понимать, что варианты осуществления изобретения могут принимать различные формы и не должны рассматриваться как ограниченные приведенными здесь описаниями. Соответственно, иллюстративные варианты осуществления описываются ниже со ссылкой на фигуры чертежей для пояснения существа аспектов настоящего изобретения.
На Фиг.1 в общем виде проиллюстрированы компоненты системы обеспечения катастрофоустойчивости, развертываемой в распределенной сетевой среде 1000, согласно варианту осуществления настоящего изобретения.
Под распределенной сетевой средой 1000 в настоящей заявке понятным для специалиста образом, в общем, подразумевается совокупность распределенных специализированных сетевых устройств и систем (таких как различного рода серверные устройства, облачные хранилища, интерфейсные и защитные сетевые устройства и т.п.) и оконечных устройств (таких как пользовательские компьютеры, смартфоны, телеметрическое оборудование и т.п.), между которыми обеспечена проводная и/или беспроводная связность и на которых установлено или прошито соответствующее программное обеспечение.
На по меньшей мере одном сервере 1100 распределенной сетевой среды 1000 реализована инфраструктура рабочего приложения, катастрофоустойчивость которого требуется обеспечить (далее по тексту настоящей заявки и на чертежах такое приложение без ограничения общности может именоваться как «защищаемое приложение»). Примеры таких инфраструктур приложений приведены в разделе “Уровень техники“ настоящей заявки, и для реализации самой рассматриваемой инфраструктуры приложения на сервере(ах) 1100 в данном варианте осуществления могут использоваться аналогичные известные подходы. Далее по тексту настоящей заявки и на чертежах такая инфраструктура приложения, в которой в штатном режиме работает защищаемое приложение, без ограничения общности может именоваться как «основная инфраструктура приложения», а любой из по меньшей мере одного сервера 1100, на котором реализована основная инфраструктура приложения, может именоваться как «сервер основной инфраструктуры». При этом понятие «сервер основной инфраструктуры» может понятным для специалиста образом относиться как к физическому серверу, так и к виртуальному серверу, реализованному на основе соответствующей технологии виртуализации посредством виртуальной машины на физическом вычислительном устройстве. Иными словами, часть серверов основной инфраструктуры могут быть физическими серверами, часть - виртуальными, причем некоторые из виртуальных серверов могут быть реализованы на этих физических серверах. Помимо этого, без ограничения общности рассматриваемый по меньшей мере один сервер основной инфраструктуры может упоминаться в тексте настоящей заявки как «серверы основной инфраструктуры» или как «сервер основной инфраструктуры», в зависимости от контекста.
Также в распределенной сетевой среде 1000 на по меньшей мере одном сервере 1200 распределенной сетевой среды 1000 должна быть предусмотрена резервная инфраструктура для основной инфраструктуры приложения. В соответствии с заранее заданным планом обеспечения катастрофоустойчивости, защищаемое приложение, в случае возникновения нештатной ситуации в основной инфраструктуре приложения, должно продолжить работу в резервной инфраструктуре. Далее по тексту настоящей заявки и на чертежах такая инфраструктура без ограничения общности может именоваться как «резервная инфраструктура», а любой из по меньшей мере одного сервера 1200, на котором реализована резервная инфраструктура, может именоваться как «сервер резервной инфраструктуры». Аналогично, понятие «сервер резервной инфраструктуры» может понятным для специалиста образом относиться как к физическому серверу, так и к виртуальному серверу, т.е. часть серверов резервной инфраструктуры могут быть физическими серверами, часть - виртуальными, причем некоторые из виртуальных серверов могут быть реализованы на этих физических серверах. Также без ограничения общности по меньшей мере один сервер резервной инфраструктуры может упоминаться в настоящей заявке как «серверы резервной инфраструктуры» или как «сервер резервной инфраструктуры», в зависимости от контекста.
Для возможных вариантов воплощения физических серверов основной и резервной инфраструктур с точки зрения компонентной структуры базовых аппаратных средств и программного обеспечения, а также возможных технологий виртуализации могут использоваться известные, в том числе коммерчески доступные, технические решения (см., в частности, раздел “Уровень техники“ настоящей заявки). При этом, для серверов основной и резервной инфраструктур могут использоваться схожие или отличающиеся программно-аппаратные платформы и/или технологии виртуализации.
Одним из основных компонентов системы обеспечения катастрофоустойчивости согласно настоящему изобретению является мастер-контроллер 1010, который в типичном случае реализуется на одном или более вычислительных устройствах распределенной сетевой среды 1000. Мастер-контроллер 1010, с одной стороны, реализует пользовательский интерфейс для предоставления возможности взаимодействия с системой обеспечения катастрофоустойчивости, а, с другой стороны, взаимодействует с основной инфраструктурой приложения и резервной инфраструктурой, в том числе - с другими компонентами системы обеспечения катастрофоустойчивости, для управления и контроля выполнения ими соответствующих действий и для получения информации о статусе и результатах выполнения. Также мастер-контроллер 1010 хранит необходимую для работы системы обеспечения катастрофоустойчивости информацию, для чего может быть предусмотрена база 1011 данных мастер-контроллера. База 1011 данных мастер-контроллера может быть известным для специалиста образом реализована на упомянутых вычислительных устройствах, на которых функционирует мастер-контроллер 1010, либо отдельно от них.
Ниже со ссылкой на блок-схему по Фиг.2 описывается способ 200 развертывания и запуска системы обеспечения катастрофоустойчивости согласно варианту осуществления настоящего изобретения.
На этапе 210 выполняется предварительная настройка параметров. На данном этапе пользователь, обладающий достаточными полномочиями (к примеру, администратор основной инфраструктуры приложения или администратор системы обеспечения катастрофоустойчивости), взаимодействует с мастер-контроллером 1010 системы обеспечения катастрофоустойчивости и задает, по меньшей мере, следующие параметры:
параметры доступа к, по меньшей мере, серверам 1100 основной инфраструктуры;
первичные требования к целевым характеристикам обеспечения катастрофоустойчивости;
прочие параметры функционирования системы обеспечения катастрофоустойчивости.
Такой пользователь по тексту настоящей заявки может без ограничения общности именоваться как «оператор».
К упомянутым параметрам доступа могут относится, к примеру, сетевые адреса серверов 1100 основной инфраструктуры, протокол доступа в их операционную систему (ОС), авторизационная информация и т.п. Целевыми характеристикам обеспечения катастрофоустойчивости являются, как минимум, параметры RTO и RPO, описанные выше. Примеры упомянутых прочих параметров, которые требуются для функционирования системы обеспечения катастрофоустойчивости согласно настоящему изобретению, будут указаны ниже.
Взаимодействие оператора с мастер-контроллером 1010 на этапе 210 может быть известным для специалиста образом реализовано через графический пользовательский интерфейс (GUI) или через интерфейс прикладного программирования (API). Следует понимать, что указанные параметры могут быть сообщены в мастер-контроллер 1010 и иным известным для специалиста образом.
Введенная информация запоминается, например, в базе 1011 данных мастер-контроллера и может использоваться в дальнейшем мастер-контроллером 1010, в частности, для управления процессом обеспечения катастрофоустойчивости и отслеживания текущего статуса, информирования пользователя о выполненных действиях и результатах.
На этапе 220 выполняют автоматический опрос и анализ в отношении, по меньшей мере, основной инфраструктуры приложения в целях получения детальной информации о ее конфигурации и технических характеристиках. На этом этапе мастер-контроллер 1010 осуществляет доступ в операционную систему каждого из, по меньшей мере, некоторых из серверов 1100 основной инфраструктуры. Данный доступ может быть осуществлен посредством авторизации по одному из общепринятых протоколов, к примеру, в соответствии с параметрами доступа, заданными на этапе 210. Далее, на этапе 220 на соответствующих серверах 1100 основной инфраструктуры устанавливаются и запускаются специализированные утилиты, опрашивающие различные подсистемы сервера и анализирующие их конфигурационные файлы. Упомянутые установка и запуск могут быть осуществлены посредством мастер-контроллера 1010; в то же время, для специалиста должно быть понятно, что данные операции могут быть выполнены и иным образом, не задействуя мастер-контроллер 1010. Результатом работы этих специализированных утилит является структурированный набор данных о настройках и конфигурации основной инфраструктуры приложения, включая, для каждого из упомянутых соответствующих серверов 1100 основной инфраструктуры, в частности:
тип, производитель, версия ОС;
версии ядра ОС и системных библиотек;
количество процессоров (ЦПУ) и объем оперативной памяти (ОЗУ);
тип сервера, а именно является ли данный сервер физическим сервером или соответствует использованию некоторой технологии серверной виртуализации, включая облачные платформы;
конфигурация ресурсов хранения и используемый на данном сервере механизм управления разметкой дисков (например, sfdisk или Windows diskpart), а также наличие логических структур поверх базовых ресурсов хранения (например, программные RAID-массивы по типу mdraid, логические менеджеры томов по типу LVM);
конфигурация сетевых ресурсов и используемый на данном сервере механизм управления ими (например, network manager, netplan, network-scripts или Windows netsh);
конфигурация и состояние системных сервисов и используемый на данном сервере механизм управления ими (к примеру, systemctl или Windows services);
конфигурация активных сетевых соединений;
конфигурация специальных утилит, например, обеспечивающих интеграцию ОС с платформой виртуализации, на которой функционирует данный сервер (примером таких специальных утилит является VMware Tools);
статистика использования ресурсов данного сервера (загрузка ЦПУ, использование ОЗУ, занятый объем на ресурсах хранения, использование полосы пропускания сетей и т.п.).
Если какой-либо из соответствующих серверов основной инфраструктуры является виртуальным сервером, реализованным посредством виртуальной машины, то набор данных о настройках и конфигурации основной инфраструктуры приложения, подобный указанному выше, может быть получен, по меньшей мере отчасти, посредством обращения со стороны упомянутых специализированных утилит к API гипервизора, обеспечивающего работу виртуальной машины.
Затем, на этапе 220 мастер-контроллер сохраняет набор данных о настройках и конфигурации основной инфраструктуры приложения, полученный в результате исполнения специализированных утилит, например, в базе 1011 данных мастер-контроллера. Следует отметить, что специализированные утилиты, используемые на этапе 220, могут устанавливаться на временной основе, т.е. они могут быть удалены с соответствующих серверов 1100 основной инфраструктуры после завершения их работы по сбору требующейся информации.
На этапе 230 выполняется обработка по анализу набора данных о настройках и конфигурации основной инфраструктуры приложения, полученного на этапе 220, для определения параметров, характеризующих ресурсные потребности основной инфраструктуры приложения. В частности, исходя из полученного набора данных может оцениваться достаточность фактических ресурсов основной инфраструктуры приложения путем сравнения наблюдаемой нагрузки на ЦПУ/ОЗУ/ресурсы хранения данных с заранее заданными пороговыми величинами (к примеру, известными из практики эксплуатации подобных инфраструктур приложений), по достижении которых происходит деградация производительности. Соответственно, определяемые параметры потребностей могут превышать фактические ресурсные показатели основной инфраструктуры приложения. Обработка по этапу 230 может выполняться мастер-контроллером 1010.
В соответствии с одной возможной реализацией, выполняется этап 240, на котором в распределенной сетевой среде 1000 создается экземпляр резервной инфраструктуры для основной инфраструктуры приложения. Для этого, используя подход согласно этапу 220, на этапе 240 выполняется получение информации о технических характеристиках и настройках каждого из некоей совокупности серверов в распределенной сетевой среде 1000, которые могут быть использованы для создаваемого экземпляра резервной инфраструктуры; более конкретно, на каждом из этих серверов могут быть аналогичным образом установлены и запущены специализированные утилиты, в результате работы которых могут быть получены параметры, соответственно перечисленные при описании этапа 220. Затем, на основе анализа, по меньшей мере, параметров ресурсных потребностей основной инфраструктуры приложения, определенных на этапе 230, и полученной информации о технических характеристиках и настройках совокупности серверов выполняется исходное конфигурирование одного или более из совокупности серверов в качестве серверов 1200 резервной инфраструктуры для создаваемого экземпляра резервной инфраструктуры. Для исходного конфигурирования по этапу 240 могут применяться, в частности, автоматизированные средства управления конфигурациями вычислительных ресурсов и ресурсов хранения, аналогичные таким, как Ansible вкупе с соответствующим модулями, Terraform вкупе с соответствующими плагинами. Наконец, на этапе 240 устанавливается высокоскоростная сетевая линия связи между основной инфраструктурой приложения и резервной инфраструктурой. Данное установление линии связи может быть реализовано понятным для специалиста образом: например, с помощью специальных программных утилит, запускаемых в основной инфраструктуре приложения и резервной инфраструктуре, устанавливаются сетевые соединения между соответствующими серверами основной и резервной инфраструктур и осуществляется мониторинг состояния этих соединений (в частности, осуществляется выбор протокола TCP/UDP, построение оптимального point-to-point маршрута, отслеживание наличия связи и фактической полосы пропускания).
Следует отметить, что хотя, в соответствии с вышеприведенным описанием, на этапе 240 создан один экземпляр резервной инфраструктуры, на данном этапе аналогичным образом может быть создано более одного экземпляра резервной инфраструктуры, если это предусмотрено планом обеспечения катастрофоустойчивости; то есть, в данном случае обеспечивается дополнительная избыточность по резервной инфраструктуре. Серверы резервной инфраструктуры, соответственно используемые в разных экземплярах резервной инфраструктуры, могут отличаться друг от друга как в аппаратном, так и в программном плане; тем не менее, серверы резервной инфраструктуры каждого из экземпляров резервной инфраструктуры отвечают, по меньшей мере, ресурсным потребностям основной инфраструктуры приложения. Сетевые линии связи при этом соответственно устанавливаются между основной инфраструктурой приложения и каждым из экземпляров резервной инфраструктуры.
Согласно другой возможной реализации, одна или более инфраструктур, отвечающих ресурсным потребностям основной инфраструктуры приложения, могут быть изначально доступны в распределенной сетевой среде 1000 (т.е. заблаговременно выполнено исходное конфигурирование в терминологии раскрытия этапа 240) для их последующей подготовки в качестве резервных для основной инфраструктуры приложения. При этом, для такого заблаговременного создания экземпляров резервной инфраструктуры могли использоваться подходы, отличные от подхода, задействованного на этапе 240. В случае рассматриваемой другой реализации, на этапе 210, наряду с заданием параметров доступа к серверам 1100 основной инфраструктуры, посредством мастер-контроллера 1010 могут аналогичным образом задаваться параметры доступа к серверам каждого из экземпляров резервной инфраструктуры; помимо этого, на этапе 220 упомянутый автоматический опрос и анализ может аналогичным образом выполняться и в отношении каждого из экземпляров резервной инфраструктуры, с получением параметров, соответственно приведенных при раскрытии этапа 220, в качестве детальной информации о конфигурации и технических характеристиках соответствующего экземпляра резервной инфраструктуры.
Иными словами, этап 240 является опциональным для настоящего изобретения; в виду этого, он показан пунктирным блоком на Фиг.2.
В соответствии с предпочтительным вариантом осуществления, охватывающим оба из вариантов реализации, рассмотренных выше, при упомянутом исходном конфигурировании на каждый из серверов резервной инфраструктуры устанавливают временную ОС, под управлением которой данный сервер будет функционировать на всем протяжении работы системы обеспечения катастрофоустойчивости согласно настоящему изобретению до момента, когда защищаемое приложение запускается на резервной инфраструктуре. Потребность в использовании временной ОС обуславливается двумя факторами: во-первых, необходимостью гарантировать стабильность работы сервера резервной инфраструктуры в процессе приема и обработки данных от основной инфраструктуры приложения, что достигается использованием специально подготовленного и протестированного системного образа, который может поставляться с системой обеспечения катастрофоустойчивости; во-вторых, невозможностью запуска сервера резервной инфраструктуры с копии загрузочного диска соответствующего сервера основной инфраструктуры до завершения процесса репликации данных, так как на активном загрузочном диске сервера основной инфраструктуры также могут регистрироваться изменения, возникающие в результате нормального функционирования его ОС или работы защищаемого приложения, а попытка применять их к активному загрузочному диску сервера резервной инфраструктуры неминуемо приведет к нарушению целостности данных, сбою в работе сервера резервной инфраструктуры и прерыванию процесса репликации. Поэтому согласно настоящей заявке предпочтительно задействуется подход, основывающийся на запуске сервера резервной инфраструктуры в режиме boot-to-RAM, когда его загрузочный диск эмулируется на ресурсах оперативной памяти.
Далее по тексту описания изобретения при обсуждении какого-либо аспекта взаимодействия между основной инфраструктурой приложения и (одной) резервной инфраструктурой подразумевается, что аналогичное взаимодействие может иметь место между основной инфраструктурой приложения и каждым из нескольких экземпляров резервной инфраструктуры.
На этапе 250 выполняется анализ информации, полученной на этапах 220-240, для предварительной верификации технической возможности репликации данных из основной инфраструктуры приложения в резервную инфраструктуру. На этом этапе, в частности, может проверяться наличие сетевой связности между основной инфраструктурой приложения и резервной инфраструктурой. Данная проверка предпочтительно осуществляется для вышеописанного варианта реализации, связанного с невыполнением этапа 240, и может основываться, к примеру, на результатах работы специализированных утилит по этапу 220. На этапе 250 также может проверяться пригодность линии связи между основной инфраструктурой приложения и резервной инфраструктурой; например, данная проверка может осуществляться путем соотнесения подлежащих репликации объемов дисковых ресурсов и полученных сведений о пропускной способности линии связи. Затем, на данном этапе может проверяться пригодность серверов резервной инфраструктуры к приему реплицируемых данных; эта проверка предпочтительно осуществляется для упомянутого варианта реализации, связанного с невыполнением этапа 240, и может осуществляться, например, путем сравнения количества и объема дисковых ресурсов в основной инфраструктуре приложения и резервной инфраструктуре. Помимо этого, на этапе 250 может проверяться достижимость целевого допустимого диапазона потери данных, например, путем соотнесения RPO, заданного на этапе 210, с пропускной способностью канала связи и наблюдаемым объемом изменений на ресурсах хранения, возникающим в результате работы защищаемого приложения, а также достижимость целевого времени восстановления, к примеру, путем соотнесения RTO, заданного на этапе 210, с параметрами производительности дисковой подсистемы сервера(ов) основной инфраструктуры и ожидаемым объемом изменений, накапливаемых на сервер(ах) резервной инфраструктуры до момента их записи на соответствующие ресурсы хранения резервной инфраструктуры. Наконец, на этапе 250 пользователю предоставляются, по меньшей мере частично: сведения, полученные на этапах 220-240, результаты анализа, проведенного на этапе 250, а также, при необходимости, рекомендации по корректировке целевых характеристик обеспечения катастрофоустойчивости. Этап 250 может выполняться посредством мастер-контроллера 1010.
На этапе 260, по результатам этапов 220-250, выполняется окончательная настройка параметров репликации. Этап 260 может выполняться посредством мастер-контроллера 1010, в частности, путем взаимодействия пользователя с мастер-контроллером 1010.
Прежде всего, на этапе 260 определяются один или более ресурсов хранения в основной инфраструктуре приложения, которые задействуются для работы защищаемого приложения, для репликации в резервную инфраструктуру и, для каждого из определенных одного или более ресурсов хранения, в резервной инфраструктуре выбирается по меньшей мере один соответствующий ресурс хранения для приема реплицируемых данных, образуя таким образом репликационную пару. Далее по тексту описания изобретения и на чертежах, в любой репликационной паре, ресурс хранения основной инфраструктуры приложения может именоваться как «ресурс-источник», а соответствующий ресурс хранения резервной инфраструктуры может именоваться как «ресурс-приемник»; соответствующий сервер основной инфраструктуры, где находится ресурс-источник, может именоваться как «начало репликационной пары», а соответствующий сервер резервной инфраструктуры, где находится ресурс-приемник, может именоваться как «окончание репликационной пары». Иными словами, посредством конфигурирования таким образом репликационных пары задается соответствие между ресурсами хранения в основной инфраструктуре приложения и резервной инфраструктуре, тем самым, в частности, определяя, какой из дисков на сервере резервной инфраструктуры должен стать репликой для конкретного диска на сервере основной инфраструктуры.
При этом, не все ресурсы хранения в основной инфраструктуре приложения обязательно должны быть сконфигурированы в репликационные пары: например, диски, непосредственно не участвующие в работе защищаемого приложения, могут быть исключены из данного конфигурирования. Как следствие, экономится ресурс линии связи между основной инфраструктурой приложения и резервной инфраструктурой, что в конечном счете положительно влияет на достижимость целевых характеристик обеспечения катастрофоустойчивости.
Однако, если, к примеру, в основной инфраструктуре приложения используется программный RAID-массив или другой вариант программного объединения физических носителей в единую логическую структуру (например, LVM), то для репликации такой структуры будут создаваться репликационные пары для каждого физического устройства хранения данных в ее составе.
Далее, на этапе 260 конфигурируются правила автоматического преобразования настроек сетевых интерфейсов на одном или более серверах резервной инфраструктуры на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения. Зачастую, сетевые настройки между основной инфраструктурой приложения и резервной инфраструктурой не совпадают - в частности, могут различаться диапазоны IP-адресов, параметры маршрутизации и т.п. Как следствие, возможная попытка активировать резервную инфраструктуру с теми же сетевыми настройками, с которыми работала основная инфраструктура приложения, приведет к конфликтам на сетевом уровне, что сделает приложение недоступным для использования. Поэтому в большинстве случаев перед активацией резервной инфраструктуры требуется выполнить дополнительные действия по преобразованию сетевых настроек на серверах резервной инфраструктуры в соответствии с задаваемыми правилами: например, преобразовать один диапазон статических IP-адресов в другой; изменить принцип назначения IP-адреса со статического на динамический или наоборот; отключить указанный сетевой интерфейс; не вносить изменений и т.п. Конспективно говоря, правилами автоматического преобразования, задаваемыми на этапе 260, учитывается различие в сетевых конфигурациях между основной инфраструктурой приложения и резервной инфраструктурой.
Затем, на этапе 260 конфигурируются правила автоматического изменения системных настроек операционной системы каждого из серверов резервной инфраструктуры на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения. Важным свойством технического решения, предложенного в настоящей заявке, является его пригодность для работы в том числе и в так называемых гетерогенных средах, то есть когда основная инфраструктура приложения и резервная инфраструктура могут использовать разные технологии предоставления серверных ресурсов, например, «две разных платформы виртуализации» или «физические серверы и некоторая платформа виртуализации». При этом совокупность и содержание системных настроек, выполняемых на уровне ОС сервера и требующихся для нормального функционирования как самой ОС, так и работающего на ней защищаемого приложения, а также набор системных драйверов или специальных утилит, обеспечивающих интеграцию системного слоя сервера с подлежащей аппаратной платформой (по типу VMware tools или KVM tools) зачастую варьируются в зависимости от типа аппаратной платформы. Как следствие, попытка активации резервной инфраструктуры с теми же системными настройками и/или набором драйверов или утилит, с которыми работала основная инфраструктура приложения, особенно если типы инфраструктур отличаются в вышеуказанном смысле, с высокой вероятностью приведет к невозможности запуска ОС, нестабильности ее работы или деградации ряда функций, что может сделать защищаемое приложение непригодным для использования. Поэтому в большинстве случаев заблаговременно перед активацией резервной инфраструктуры требуется выполнить дополнительные действия на серверах резервной инфраструктуры по преобразованию системных настроек в соответствии с заданными правилами: например, преобразовать структуру дисковых разделов из MBR в GPT; изменить первичный загрузчик; проинсталлировать и/или активировать драйверы ОС, специфичные для резервной инфраструктуры; заменить утилиты, специфичные для резервной инфраструктуры. Конспективно говоря, правилами автоматического изменения, задаваемыми на этапе 260, учитываются технологические различия между основной инфраструктурой приложения и резервной инфраструктурой.
На этапе 260 также конфигурируются зависящие от защищаемого приложения правила, тем самым конфигурируя дополнительные последующие действия, отражающие специфику защищаемого приложения. Обобщенно говоря, данное конфигурирование может содержать задание одной или более контрольных точек для приложения, в каждой из которых в резервной инфраструктуре может быть запущен соответствующий пользовательский исполняемый сценарий для выполнения действий, специфических для приложения, в целях дополнительного обеспечения целостности данных приложения на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения.
Так, важным условием достижения катастрофоустойчивости приложения в соответствии с заданными целевыми параметрами обеспечения катастрофоустойчивости (см. этап 210) является целостность прикладных данных на резервной инфраструктуре на четко определенные моменты времени. В противном случае при попытке активации приложения на резервной инфраструктуре ему на вход могут быть поданы испорченные данные, что может препятствовать его запуску или привести к непредсказуемым результатам в работе. Некоторые компоненты прикладного ландшафта, например, базы данных или подсистемы, в которых логически единый массив информации распределяется между несколькими независимыми ресурсами хранения (например, каталог хранится на одном сервере, а данные, на которые ссылается этот каталог, - на другом), предъявляют особые требования к поддержанию такой целостности. В подобных случаях может потребоваться дополнительный механизм взаимодействия между системой обеспечения катастрофоустойчивости согласно настоящему изобретению и защищаемым приложением, чтобы, например, синхронизировать момент достижения приложением, работающим в основной инфраструктуре приложения, некоторого консистентного состояния и момент создания системой обеспечения катастрофоустойчивости консистентной копии изменений, произошедших на ресурсах хранения основной инфраструктуры приложения, для ее передачи в резервную инфраструктуру. Поэтому в системе обеспечения катастрофоустойчивости реализована возможность задания правил для запуска предоставленных пользователем сценариев на разных этапах ее работы для достижения такой синхронизации там, где этого требуют специфика или архитектура защищаемого приложения.
Так как специфика приложений, влияющая на обеспечение консистентности данных, хранящихся и обрабатываемых в разных подсистемах, сильно варьируется от приложения к приложению даже в случае, когда эти приложения функционально подобны, универсального способа фиксации консистентного состояния в общем случае не существует. Поэтому в системе обеспечения катастрофоустойчивости, предложенной в настоящей заявке, может быть реализована возможность вызова файлов-сценариев, подготовленных, к примеру, оператором, в которых и выполняются заданные оператором специфические для конкретного защищаемого приложения действия (например, временный перевод СУБД в режим работы на файлах транзакций, сброс программного кэша на диски и временная работа с данными в оперативной памяти и т.п.). В соответствии с вариантом осуществления предложенной системы, в контексте алгоритма репликации данных, предусмотрен ряд контрольных точек, в которых могут быть вызваны такие сценарии. Оператор при необходимости, к примеру, используя мастер-контроллер 1010, загружает сценарии в систему обеспечения катастрофоустойчивости и указывает, в какой контрольной точке выполнить тот или иной сценарий и как реагировать на штатное или нештатное завершение сценария.
Затем, на этапе 260 могут быть заданы дополнительные параметры, определяющие режимы работы системы обеспечения катастрофоустойчивости в процессе репликации. В частности, можно активировать следующие дополнительные функции:
компрессия данных, передаваемых между основной и резервной инфраструктурами; такая компрессия может быть осуществлена посредством сжатия данных перед или непосредственно в процессе передачи с использованием одного известных алгоритмов сжатия, например, LZW;
шифрование данных, передаваемых между основной и резервной инфраструктурами; такое шифрование может быть осуществлено посредством кодирования данных перед или непосредственно в процессе передачи с использованием одного из известных алгоритмов шифрования, например, TLS;
дедупликация данных, передаваемых между основной и резервной инфраструктурами, к примеру, посредством алгоритма OpenDedup.
Наконец, на этапе 260 может быть выполнена корректировка целевых значений RTO и RPO. Такая корректировка может быть выполнена, например, оператором посредством использования мастер-контроллера 1010, на основе рекомендации, выданной на этапе 250, если в результате проведенного анализа было установлено, что изначально заданные их значения технически недостижимы.
Следует подчеркнуть, что вышеперечисленный набор действий по этапу 260 не является исчерпывающим; более того, выполнение всех этих действий не является обязательным. В зависимости от намерений оператор(ов), результатов анализа по этапам 220-240, специфики используемых инфраструктур и особенностей защищаемого приложения некоторые из этих действий могут быть опущены или не требуются.
На этапе 270 в основной инфраструктуре приложения устанавливаются и запускаются компоненты системы обеспечения катастрофоустойчивости, которые в совокупности обозначены в настоящей заявке и на чертежах как подсистема системы обеспечения катастрофоустойчивости для основной инфраструктуры приложения или, для краткости, подсистема-источник. Подсистема-источник устанавливается на каждый из серверов основной инфраструктуры, которые задействуются в репликации данных, необходимых для работы защищаемого приложения, в резервную инфраструктуру. На Фиг.1 в качестве неограничивающей иллюстрации подсистема-источник 1110 показана установленной на сервере 1100 основной инфраструктуры.
Управляющим компонентом подсистемы-источника 1110 является хост-контроллер 1111 подсистемы-источника, и под его управлением функционируют другие компоненты подсистемы-источника 1110. Хост-контроллер 1111 непосредственно взаимодействует с мастер-контроллером 1010, и для этого на этапе 270 устанавливается сетевой канал 1012 управления «мастер-контроллер → подсистема-источник». В силу вышесказанного, сетевой канал 1012 будет соответственно создан между мастер-контроллером 1010 и каждым экземпляром хост-контроллера 1111, установленным и работающим на соответствующем сервере основной инфраструктуры.
Хост-контроллер 1111 подсистемы-источника получает команды от мастер-контроллера 1010 через сетевой канал 1012, инициирует выполнение упомянутыми другими компонентами соответствующих действий и сообщает о результатах, статусе и/или телеметрии в мастер-контроллер 1010. В основной инфраструктуре приложения может быть предусмотрен журнал 1112 состояний подсистемы-источника для хранения текущего состояния, истории команд, событий и прочих параметров хост-контроллера 1111, необходимых для управления процессом обеспечения катастрофоустойчивости приложения на стороне подсистемы-источника 1110. Журнал 1112 состояний в типичном случае может быть реализован как энергонезависимое хранилище, например, база данных. Журнал 1112 состояний может использоваться для восстановления процесса обеспечения катастрофоустойчивости приложения в случае сбоев, нарушения каналов связи, непредвиденных перезагрузок или остановок сервера(ов) основной инфраструктуры. Следует отметить, что журнал 1112 состояний может быть реализован как на сервере 1100, так и на другом вычислительном устройстве в распределенной сетевой среде 1000; такие возможные реализации должны быть ясны для специалиста.
Под непосредственным управлением хост-контроллера 1111 подсистемы-источника функционирует диспетчер 1114 репликационной пары подсистемы-источника, причем экземпляр данного компонента подсистемы-источника 1110 устанавливается и запускается на соответствующем сервере основной инфраструктуры для каждой из определенных на этапе 260 репликационных пар, для которых этот сервер является началом.
Помимо этого, на этапе 270 в подсистеме-источнике 1110 устанавливаются и запускаются компоненты 1115-1117 репликации подсистемы-источника, причем экземпляр компонентов репликации соответственно устанавливается и запускается для каждого экземпляра диспетчера репликационной пары подсистемы-источника.
Каждый экземпляр диспетчера 1114 репликационной пары управляет функционированием соответствующего экземпляра компонентов 1115-1117 репликации в основной инфраструктуре приложения, отслеживает их статус и сообщает о статусе в хост-контроллер 1111 основной инфраструктуры.
Описание варианта осуществления конкретных компонентов 1115-1117 репликации подсистемы-источника и их функций будет приведено ниже.
На этапе 270 в резервной инфраструктуре аналогичным образом устанавливаются и запускаются компоненты системы обеспечения катастрофоустойчивости, которые в совокупности обозначены в настоящей заявке и на чертежах как подсистема системы обеспечения катастрофоустойчивости для резервной инфраструктуры или, для краткости, подсистема-приемник. Подсистема-приемник устанавливается на каждый из серверов резервной инфраструктуры, которые соответственно задействуются в репликации данных с основной инфраструктуры приложения. На Фиг.1 в качестве неограничивающей иллюстрации подсистема-приемник 1210 показана установленной на сервере 1200 основной инфраструктуры.
Управляющим компонентом подсистемы-приемника 1210 является хост-контроллер 1211 подсистемы-приемника, и под его управлением функционируют другие компоненты подсистемы-приемника 1210. Хост-контроллер 1211 непосредственно взаимодействует с мастер-контроллером 1010, и для этого на этапе 270 устанавливается сетевой канал 1013 управления «мастер-контроллер → подсистема-приемник». В силу вышесказанного, сетевой канал 1013 будет соответственно создан между мастер-контроллером 1010 и каждым экземпляром хост-контроллера 1211, установленным и работающим на соответствующем сервере резервной инфраструктуры.
Хост-контроллер 1211 подсистемы-приемника получает команды от мастер-контроллера 1010 через сетевой канал 1013, инициирует выполнение упомянутыми другими компонентами соответствующих действий и сообщает о результатах, статусе и/или телеметрии в мастер-контроллер 1010. В резервной инфраструктуре может быть предусмотрен журнал 1212 состояний подсистемы-приемника для хранения текущего состояния, истории команд, событий и прочих параметров хост-контроллера 1211, необходимых для управления процессом обеспечения катастрофоустойчивости приложения на стороне подсистемы-приемника 1210. Журнал 1212 состояний в типичном случае может быть реализован как энергонезависимое хранилище, например, база данных. Журнал 1212 состояний может использоваться для восстановления процесса обеспечения катастрофоустойчивости приложения в случае сбоев, нарушения каналов связи, непредвиденных перезагрузок или остановок сервера(ов) резервной инфраструктуры. Следует отметить, что журнал 1212 состояний может быть реализован как на сервере 1200, так и на другом вычислительном устройстве в распределенной сетевой среде 1000; такие возможные реализации должны быть ясны для специалиста.
Под непосредственным управлением хост-контроллера 1211 подсистемы-приемника функционирует диспетчер 1214 репликационной пары подсистемы-приемника, причем экземпляр диспетчера репликационной пары устанавливается и запускается на соответствующем сервере резервной инфраструктуры для каждой из определенных на этапе 260 репликационных пар, для которой этот сервер является окончанием.
Помимо этого, на этапе 270 в подсистеме-приемнике 1210 устанавливаются и запускаются компоненты 1215, 1216 репликации подсистемы-приемника, причем экземпляр компонентов репликации соответственно устанавливается и запускается для каждого экземпляра диспетчера репликационной пары подсистемы-приемника.
Каждый экземпляр диспетчера 1214 репликационной пары управляет функционированием соответствующего экземпляра компонентов 1215, 1216 репликации в резервной инфраструктуре, отслеживает их статус и сообщает о статусе в хост-контроллер 1111 подсистемы-источника.
Описание варианта осуществления конкретных компонентов 1215, 1216 репликации подсистемы-источника и их функций будет приведено ниже.
В соответствии с предпочтительным вариантом осуществления настоящего изобретения, для каждой репликационной пары соответствующие экземпляр диспетчера репликационной пары подсистемы-источника и экземпляр диспетчера репликационной пары подсистемы-приемника выполнены с возможностью непосредственного взаимодействия друг с другом, и для этого на этапе 270 между этими соответствующими экземплярами диспетчеров репликационной пары устанавливается сетевой канал 1014 для передачи команд и обмена информацией. Для простоты и наглядности, на Фиг.1 неограничивающим образом показана одна пара диспетчера 1114 репликационной пары подсистемы-источника и диспетчера 1214 репликационной пары подсистемы-приемника и, соответственно, один сетевой канал 1014 между ними.
Здесь следует отметить, что благодаря тому, что каждый из серверов резервной инфраструктуры предпочтительно запускается в режиме boot-to-RAM, описанном выше, дисковый ресурс на сервере резервной инфраструктуры, составляющий репликационную пару с загрузочным диском соответствующего сервера основной инфраструктуры, высвобождается для записи на него изменений, поступающих от сервера основной инфраструктуры, без риска нарушения целостности данных или влияния на стабильность работы сервера резервной инфраструктуры и компонентов 1111, 1114-1117, 1211, 1214-1216, обеспечивающих репликацию. Кроме того на сервере резервной инфраструктуры отпадает необходимость в создании временного диска, который бы выполнял роль загрузочного в процессе работы системы обеспечения катастрофоустойчивости согласно настоящему изобретению, что упрощает подготовку инфраструктуры и экономит ресурсы.
Конкретные реализации компонентов 1111, 1114-1117, составляющих подсистему-источник 1110, и компонентов 1211, 1214-1216, составляющих подсистему-приемник 1210, будут раскрыты ниже.
Следует отметить, что для доступа к серверам основной и резервной инфраструктуры в целях выполнения соответствующих действий согласно этапам 220-270, описанным выше, может использоваться подключение к серверам по протоколу SSH и выполнение надлежащих команд в их операционных системах.
На этапе 280 для каждой репликационной пары, не останавливая работу защищаемого приложения, посредством системы обеспечения катастрофоустойчивости, развернутой на этапах 210-270, выполняется предварительная репликация данных с ресурса-источника на ресурс-приемник. Вариант осуществления этапа 280 описывается со ссылкой на Фиг.3 ниже.
Начиная с этапа 290 посредством развернутой системы обеспечения катастрофоустойчивости выполняются циклы синхронизации между основной инфраструктурой приложения и резервной инфраструктурой. По сути, c этапа 290 приложение, штатно работающее в основной инфраструктуре приложения, оказывается фактически защищенным посредством системы обеспечения катастрофоустойчивости согласно настоящему изобретению. Вариант осуществления этапа 290 описывается со ссылкой на Фиг.4 ниже.
Также посредством системы обеспечения катастрофоустойчивости может быть выполнен необязательный этап 285 частичной ресинхронизации. Этот этап может выполняться для ситуаций, когда система обеспечения катастрофоустойчивости успешно прошла этап предварительной репликации и, возможно, находилась в стадии выполнения циклов синхронизации, но дальнейшая синхронизация прерывалась по каким-либо причинам. Вариант осуществления этапа 285 способа 200 также описывается ниже, со ссылкой на Фиг.5.
Следует отметить, что хотя в вышеприведенном раскрытии по Фиг.1, 2 описывалось развертывание и функционирование, в распределенной сетевой среде 1000, одной основной инфраструктуры приложения и соответствующих одного или более экземпляров резервной инфраструктуры, для специалиста должно быть понятно, что аналогичным образом в распределенной сетевой среде 1000 могут быть развернуты более одной основной инфраструктуры приложения, в каждой из которых работает свое защищаемое приложение, и соответствующие один или более экземпляров резервной инфраструктуры для нее, под управлением мастер-контроллера 1010. При этом, RTO и/или RPO, а также другие параметры, задаваемые на этапах 210, 260, могут задаваться на индивидуальной основе для каждого сочетания «основная инфраструктура приложения - резервная инфраструктура».
Далее со ссылкой на блок-схему по Фиг.3 описывается выполнение этапа 280 первичной репликации способа 200 согласно варианту осуществления настоящего изобретения. Как было отмечено выше, этап 280 выполняется для каждой репликационной пары, не останавливая работу защищаемого приложения в основной инфраструктуре приложения.
На этапе 301 выполняется первичное копирование блоков данных ресурса-источника 1113 на ресурс-приемник 1213.
Здесь следует пояснить, что в контексте настоящей заявки любой ресурс хранения данных, более конкретно - диск, обычным образом для области техники, к которой относится настоящее изобретение, рассматривается как блочное устройство, и, соответственно, все данные, которые хранятся на диске, разбиты на блоки фиксированного размера. При этом, размер блока данных соответствует гранулярности записи на диск (иными словами, размер блока - это своего рода квант записи на диск) и, как следствие, определяет минимальный объем изменения. К примеру, если в блоке размером 4 КБ изменился один байт, весь блок считается изменившимся.
На этапе 301 выполняется последовательное копирование всех блоков данных ресурса-источника 1113 на ресурс-приемник 1213. Параллельно с выполнением последовательного копирования, в подсистеме-источнике 1110 на этапе 301 осуществляется регистрация блоков ресурса-источника 1113, подвергшихся изменению после начала данного копирования.
На этапе 302, по завершении первичного копирования согласно этапу 301, в подсистеме-источнике 1110 формируется массив информации регистрации изменений в отношении блоков, зарегистрированных на этапе 301.
Для выполнения вышеуказанных регистрации изменений на этапе 301 и формирования массива на этапе 302, в подсистеме-источнике 1110 соответственно предусмотрены детектор 1115 изменений и формирователь 1116 истории изменений, являющиеся компонентами из состава экземпляра компонентов репликации подсистемы-источника 1110, который был соответственно установлен и запущен на этапе 270 для соответствующего экземпляра диспетчера 1114 репликационной пары подсистемы-источника.
В соответствии с предпочтительным вариантом осуществления, реализация регистрации изменений по этапу 301 основывается на использовании известной технологии журналов регистрации COW и CBT.
В качестве пояснения, файл журнала COW (Copy-on-Write) используется для получения так называемого мгновенного снимка диска, и в COW-файл переносится первоначальное содержимое тех блоков на диске, которые подвергаются изменению после момента времени, фиксирующего создание мгновенного снимка диска. COW-файл, в общем, представляет собой последовательность пар {ключ : значение}, где ключ - адрес блока на диске, а значение - его первоначальное (т.е. до изменения) содержимое. Файл журнала CBT (Changed Block Tracking) также используется для получения мгновенного снимка диска, и в CBT-файле фиксируется сам факт изменений блоков на диске, произошедших с момента времени создания его мгновенного снимка. CBT-файл, в общем, представляет битовую карту диска, где каждому блоку поставлен в соответствие один бит: к примеру, установкой некоего бита в CBT-файле в 1 указывается, что соответствующий блок подвергся изменению (а первоначальное его содержимое можно получить из соответствующей записи в COW-файле).
Соответственно, на этапе 301 детектор 1115 изменений отслеживает операции ввода-вывода в отношении ресурса-источника 1113 и фиксирует происходящие изменения блоков данных в COW- и CBT-журналах. Более конкретно, на этапе 301, непосредственно перед началом первичного копирования, детектором 1115 изменений создается первый COW-файл, или, иными словами, открывается первый COW-журнал, и открывается первый CBT-журнал, после чего вышеописанным образом осуществляется регистрация сведений о блоках ресурса-источника 1113, подвергающихся изменению во время осуществления первичного копирования, в первом CBT-журнале. В момент завершения первичного копирования, то есть когда все блоки ресурса-источника 1113 окажутся скопированными на ресурс-приемник 1213, на этапе 301 первый CBT-журнал закрывается и открываются второй COW-журнал и второй CBT-журнал, после чего детектор 1115 изменений вышеописанным образом продолжает регистрацию блоков ресурса-источника 1113, подвергшихся изменению, во втором COW-журнале и втором CBT-журнале. В результате успешного завершения этапа 301 на ресурсе-приемнике 1213 получается набор данных, который в общем случае является неконсистентным по отношению к данным ресурса-источника 1113.
Из вышеприведенного описания видно, что первый COW-журнал не задействуется в регистрации изменений - по сути, он открывается в пару к первому CBT-журналу, что является особенностью данной технологии, используемой в рассматриваемом предпочтительном варианте осуществления настоящего изобретения. В качестве опции, на этапе 301 первый COW-журнал может быть деактивирован или, иными словами, закрыт сразу после его открытия.
В соответствии с предпочтительным вариантом осуществления, при формировании массива информации регистрации изменений на этапе 302 формируется stash-файл, который может составлять часть формируемого массива информации регистрации изменений (в каковом случае в данный массив может дополнительно включаться сопутствующая вспомогательная информация) или представлять собой массив информации регистрации изменений. При этом, stash-файл как таковой, по сути, соответствует расширению вышеописанной технологии регистрации изменений на диске на основе COW- и CBT-журналов: так, в stash-файле аккумулируются зарегистрированные в соответствующих COW- и CBT-журналах изменения, произошедшие на диске-источнике за определенный период времени, для их передачи на диск-приемник и применения к диску-приемнику. С точки зрения формата, stash-файл в общем виде представляет собой последовательность пар {ключ : значение}, где ключ - адрес блока на диске, а значение - его содержимое, полученное таким образом, чтобы после применения stash-файла к диску-приемнику обеспечить консистентность соответствующего содержимого диска-приемника на заданный момент времени.
На этапе 302 формирователь 1116 истории изменений обрабатывает сведения об изменениях на ресурсе-источнике 1113, накопленные в первом CBT-журнала и вторых COW- и CBT-журналах на этапе 301, и формирует соответствующий stash-файл. Более конкретно, формирователь 1116 истории изменений создает stash-файл и выполняет проверку первого CBT-журнала, закрытого на этапе 301. При осуществлении данной проверки формирователь 1116 истории изменений, последовательно для каждого блока данных ресурса-источника 1113, который в первом CBT-журнале помечен как подвергшийся изменению (к примеру, бит установлен в 1 для данного блока), проверяет, помечен ли блок данных как подвергшийся изменению во втором CBT-журнале. Если это так, в созданный stash-файл соответственно записывается содержимое этого блока из второго COW-журнала, в противном случае в stash-файл соответственно записывается текущее содержимое блока с ресурса-источника 1113.
На этапе 303 формирователь 1116 истории изменений перенаправляет массив информации регистрации изменений, сформированный на этапе 302, в передатчик 1117, который, наряду с детектором 1116 изменений и формирователем 1116 истории изменений, также является компонентом из состава экземпляра компонентов репликации подсистемы-источника, который был соответственно установлен и запущен на этапе 270 для соответствующего экземпляра диспетчера 1114 репликационной пары. Передатчик 1117 передает массив информации регистрации изменений на сервер 1200 резервной инфраструктуры, который, в соответствии с неограничивающей иллюстрацией по Фиг.1, является окончанием рассматриваемой репликационной пары.
На этапе 304 массив информации регистрации изменений, переданный на этапе 303, принимается в подсистеме-приемнике 1210, и на этапе 305, используя принятый массив информации регистрации изменений, осуществляется запись соответствующих блоков на ресурс-приемник 1213.
Для выполнения вышеуказанных приема на этапе 304 и записи на этапе 305, в подсистеме-приемнике 1210 соответственно предусмотрены приемник 1216 и актуализатор 1215 изменений, являющиеся компонентами из состава экземпляра компонентов репликации подсистемы-приемника, который был соответственно установлен и запущен на этапе 270 для соответствующего экземпляра диспетчера 1214 репликационной пары подсистемы-приемника.
Следует отметить, что для непосредственного сообщения между передатчиком 1117 и приемником 1216 по передаче массива(ов) информации регистрации изменений между соответствующими серверами 1100 и 1200, на этапе 270, аналогично каналу 1014, устанавливается сетевой канал 1015.
В соответствии с предпочтительным вариантом осуществления, на этапе 305 актуализатор 1215 изменений применяет полученный от приемника 1216 stash-файл к ресурсу-приемнику 1213. Более конкретно, актуализатор 1215 изменений последовательно берет пары {ключ : значение} из stash-файла и записывает содержимое (значение) по соответствующему адресу блока (ключ) в ресурсе-приемнике 1213.
В результате успешного завершения этапа 305 (и, соответственно, этапа 280) на ресурсе-приемнике 1213 получается набор данных, являющийся консистентным на момент окончания первичного копирования.
Далее со ссылкой на блок-схему по Фиг.4 описывается осуществление этапа 290 выполнения циклов синхронизации способа 200 согласно варианту осуществления настоящего изобретения. Как было отмечено выше, этап 290, аналогично этапу 280, выполняется для каждой репликационной пары, не останавливая работу защищаемого приложения в основной инфраструктуре приложения. Ниже приводится раскрытие этапов 401-405, выполняемых на каждом текущем цикле синхронизации.
На этапе 401 в течение каждого заданного интервала регистрации изменений из одного или более интервалов регистрации изменений, в подсистеме-источнике 1110 выполняется регистрация блоков ресурса-источника 1113, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формируется массив информации регистрации изменений в отношении зарегистрированных блоков.
В соответствии с предпочтительным вариантом осуществления, для реализации этапа 401 применяется вышеописанная технология, основывающаяся на COW-, CBT-, stash-файлах.
Более конкретно, для каждого текущего интервала регистрации изменений, на этапе 401, в момент начала 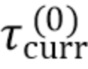 текущего интервала регистрации изменений, детектор 1115 изменений открывает COW-журнал и CBT-журнал, которые становятся текущими для данного интервала регистрации изменений, и регистрирует блоки ресурса-источника 1113, подвергшиеся изменению с момента , в текущем COW-журнале и текущем CBT-журнале. По истечении текущего интервала регистрации изменений, формирователь 1116 истории изменений создает stash-файл и, для каждого блока ресурса-источника 1113, который помечен в CBT-журнале, закрытом по истечении предыдущего интервала регистрации изменений, как подвергшийся изменению, формирователь 1116 истории изменений проверяет, помечен ли этот блок как подвергшийся изменению в текущем CBT-журнале. Если это так, формирователь 1116 истории изменений соответственно записывает в созданный stash-файл содержимое проверяемого блока из текущего COW-журнала, в противном случае формирователь 1116 истории изменений соответственно записывает в stash-файл текущее содержимое этого блока с ресурса-источника 1113. При этом, по истечении текущего интервала регистрации изменений текущий COW-журнал и текущий CBT-журнал закрываются. Длительность интервала регистрации изменений предпочтительно определяется параметром RPO, заданным на этапе 210. В силу вышесказанного, потенциальное применение созданного stash-файла к ресурсу-приемнику 1213 обеспечит консистентность его данных на момент .
текущего интервала регистрации изменений, детектор 1115 изменений открывает COW-журнал и CBT-журнал, которые становятся текущими для данного интервала регистрации изменений, и регистрирует блоки ресурса-источника 1113, подвергшиеся изменению с момента , в текущем COW-журнале и текущем CBT-журнале. По истечении текущего интервала регистрации изменений, формирователь 1116 истории изменений создает stash-файл и, для каждого блока ресурса-источника 1113, который помечен в CBT-журнале, закрытом по истечении предыдущего интервала регистрации изменений, как подвергшийся изменению, формирователь 1116 истории изменений проверяет, помечен ли этот блок как подвергшийся изменению в текущем CBT-журнале. Если это так, формирователь 1116 истории изменений соответственно записывает в созданный stash-файл содержимое проверяемого блока из текущего COW-журнала, в противном случае формирователь 1116 истории изменений соответственно записывает в stash-файл текущее содержимое этого блока с ресурса-источника 1113. При этом, по истечении текущего интервала регистрации изменений текущий COW-журнал и текущий CBT-журнал закрываются. Длительность интервала регистрации изменений предпочтительно определяется параметром RPO, заданным на этапе 210. В силу вышесказанного, потенциальное применение созданного stash-файла к ресурсу-приемнику 1213 обеспечит консистентность его данных на момент .
На этапе 402 формирователь 1116 истории изменений осуществляет сохранение созданного stash-файла. Согласно одному варианту реализации, для этой цели в основной инфраструктуре приложения (предпочтительно, непосредственно в составе сервера 1100) может быть предусмотрено отдельное запоминающее устройство - журнальный диск 1118, в котором сохраняются сформированные массивы информации регистрации изменений. Также в журнальном диске 1118 могут сохраняться (например, на временной основе) COW- и CBT-файлы, соответственно используемые согласно рассматриваемому предпочтительному варианту осуществления.
Использование журнального диска 1118 на сервере 1100 основной инфраструктуры источнике позволяет гарантировать наличие отдельного от ресурса-источника 1113 дискового пространства для накопления stash-, COW- и CBT-файлов исходя из настроек репликации и особенностей основной и резервной инфраструктур (например, пропускной способности каналов связи и темпа применения зарегистрированных изменений на ресурсе-источнике) и, таким образом, избежать конкуренции за ресурсы подсистемы хранения данных сервера 1110 основной инфраструктуры в процессе работы системы обеспечения катастрофоустойчивости согласно настоящему изобретению. Следует отметить, что журнальный диск 1118 может аналогичным образом задействоваться при осуществлении этапов 301, 302, описанных выше.
В то же время, использование журнального диска 1118 не является обязательным в контексте настоящего изобретения, и, согласно альтернативному варианту реализации, соответствующему неиспользованию журнального диска, накопление stash-, COW- и CBT-файлов может осуществляться на ресурсе-источнике 1113.
На этапе 403, по истечении текущего цикла синхронизации, массивы информации регистрации изменений, сохраненные по результату выполнения этапа 402, передаются, к примеру, с журнального диска 1118, на сервер 1200 резервной инфраструктуры по сетевому каналу 1015.
Следует отметить, что выполнение этапа 402 не является обязательным и массивы информации регистрации изменений могут сразу передаваться на сервер 1200 по мере их создания на этапе 401.
На этапе 404 приемник 1216 принимает массивы информации регистрации изменений, передаваемые с сервера 1100 основной инфраструктуры, и на сервере 1200 выполняется их сохранение. Аналогично серверу 1100, на сервере 1200 может быть предусмотрен журнальный диск 1217, в котором накапливаются принимаемые массивы информации регистрации изменений. Либо, альтернативно, принятые массивы информации регистрации изменений могут сохраняться непосредственно на ресурсе-приемнике 1213.
На этапе 405 на сервере 1200 резервной инфраструктуры осуществляется запись на ресурс-приемник 1213 блоков данных с использованием массивов информации регистрации изменений, сохраненных на этапе 404, например, на журнальном диске 1217. Более конкретно, актуализатор 1215 изменений последовательно, согласно времени их создания, извлекает с журнального диска 1217 stash-файлы и применяет каждый извлеченный stash-файл к ресурсу-приемнику 1213, аналогично тому, как это выполнялось на этапе 305.
В соответствии с предпочтительным вариантом осуществления, запись по этапу 405 выполняется с задержкой 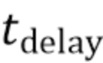 после сохранения массивов информации регистрации изменений на этапе 404. При этом, относится к упомянутым прочим параметрам, задаваемым на этапе 210 посредством мастер-контроллера 1010. Введение , в частности, позволяет дополнительно выполнять на этапе 405 проверку корректности извлекаемых stash-файлов перед непосредственным их применением, во избежание применения к ресурсу-приемнику 1213 ошибочных или поврежденных stash-файлов. Подобная проверка может быть реализована с использованием известных соответствующих технологий понятным для специалиста образом.
после сохранения массивов информации регистрации изменений на этапе 404. При этом, относится к упомянутым прочим параметрам, задаваемым на этапе 210 посредством мастер-контроллера 1010. Введение , в частности, позволяет дополнительно выполнять на этапе 405 проверку корректности извлекаемых stash-файлов перед непосредственным их применением, во избежание применения к ресурсу-приемнику 1213 ошибочных или поврежденных stash-файлов. Подобная проверка может быть реализована с использованием известных соответствующих технологий понятным для специалиста образом.
Согласно варианту осуществления, при выполнении этапов 401-405, в подсистеме-источнике 1110, посредством диспетчера 1114 репликационной пары под управлением хост-контроллера 1111, выполняется мониторинг достижимости параметра RPO на основе темпа передачи сформированных массивов информации регистрации изменений с сервера 1100 основной инфраструктуры на сервер 1200 резервной инфраструктуры. Если в результате такого мониторинга выясняется, что подсистема-источник 1110 не успевает передавать на сервер 1200 резервной инфраструктуры массивы информации регистрации изменений, т.е., по существу, консистентную историю изменений, в объеме, достаточном для достижения целевой точки восстановления (RPO), хост-контроллер 1111 выдает в мастер-контроллер 1010 сообщение о недостижимости RPO, причем данное сообщение может содержать технически достижимое или рекомендованное значение RPO.
Также согласно данному варианту осуществления, при выполнении этапов 401-405, в подсистеме-приемнике 1210, посредством диспетчера 1214 репликационной пары под управлением хост-контроллера 1211, выполняется анализ достижимости параметра RTO на основе и темпа применения сохраненных массивов информации регистрации изменений к ресурсу-приемнику 1213. Если в результате данного анализа выясняется, что подсистема-приемник 1210 не успевает применять полученные массивы информации регистрации изменений в темпе, достаточном для соблюдения целевого времени восстановления (RTO), хост-контроллер 1211 выдает в мастер-контроллер 1010 сообщение о недостижимости RTO, причем данное сообщение может содержать технически достижимое или рекомендованное значение RTO и/или рекомендацию по альтернативной настройке .
Мониторинг достижимости RPO и RTO может выполняться на постоянной или периодической основе.
Получив через мастер-контроллер 1010 сообщение о недостижимости заданных параметров RTO или RPO, оператор может, в частности, прекратить репликацию и/или соответственно изменить настройки RTO, RPO, .
Далее со ссылкой на блок-схему по Фиг.5 описывается осуществление этапа 285 частичной ресинхронизации способа 200 согласно варианту осуществления настоящего изобретения.
Частичная ресинхронизация применима для ситуаций, когда система обеспечения катастрофоустойчивости согласно настоящей заявке успешно прошла этап 280 предварительной репликации данных (см. раскрытие по Фиг.3 выше) и, возможно, находилась на стадии выполнения циклов синхронизации (этап 290, см. раскрытие по Фиг.4), но дальнейшая синхронизация прерывалась по каким-либо причинам: например, имел место перезапуск одного из программных компонентов в резервной инфраструктуре или имело место временное нарушение сетевой связности между основной и резервной инфраструктурами. В подобных ситуациях частичная ресинхронизация позволяет избежать необходимости заново передавать весь объем данных с ресурса-источника на ресурс-приемник за счет определения дельты между их содержимым и передачи только изменений, произошедших на ресурсе-источнике на момент восстановления нормального состояния соответствующей инфраструктуры, тем самым позволяя оптимизировать объем данных, передаваемых между основной инфраструктурой приложения и резервной инфраструктурой. Соответственно, изображение необязательного этапа 285 на Фиг.2 в качестве предшествующего этапу 290 является условным - в соответствии с вышесказанным, этап 285 может быть выполнен и после начала этапа 290.
На этапе 501 в подсистеме-приемнике 1210 генерируется карта текущего содержимого ресурса-приемника 1213. Согласно предпочтительному варианту осуществления, в целях генерирования карты текущего содержимого на этапе 501, для каждого блока ресурса-приемника 1213 в соответствии с заранее заданным алгоритмом вычисляется уникальный идентификатор на основе содержимого этого блока. В качестве такого алгоритма может использоваться какой-либо из известных алгоритмов вычисления хеш-суммы содержимого блока данных. Вычисленные идентификаторы соответственно записываются в файл, представляющий карту текущего содержимого ресурса-приемника.
На этапе 502 файл карты текущего содержимого ресурса-приемника передается на сервер 1100 основной инфраструктуры. На этапе 503 файл карты текущего содержимого ресурса-приемника принимается в подсистеме-источнике 1110, и принятый файл может быть сохранен, к примеру, на журнальном диске 1118.
На этапе 503, по окончании приема карты текущего содержимого ресурса-приемника, в подсистеме-источнике 1110 выполняется регистрация блоков данных ресурса-источника 1113, подвергшихся изменению, и формируется массив информации регистрации изменений на основе карты текущего содержимого ресурса-приемника и зарегистрированных блоков.
В соответствии с предпочтительным вариантом осуществления, как и в случае этапов 301, 401, для реализации этапа 503 применяется технология, основывающаяся на COW-, CBT-, stash-файлах.
Более конкретно, детектор 1115 изменений открывает COW-журнал и CBT-журнал и регистрирует блоки ресурса-источника 1113, подвергшиеся изменению, в этих COW-журнале и CBT-журнале. Формирователь 1116 истории изменений создает stash-файл и последовательно для каждого блока данных ресурса-источника 1113 выполняет следующие операции. А именно, формирователь 1116 истории изменений проверяет, помечен ли блок ресурса-источника 1113 в CBT-журнале как подвергшийся изменению, и, если это так, формирователь 1116 истории изменений берет для использования содержимое блока ресурса-источника 1113 из COW-журнала, в противном случае - непосредственно с ресурса-источника. Далее формирователь 1116 истории изменений в соответствии с тем же заданным алгоритмом (например, основывающимся на хеш-функции), что использовался на этапе 501, вычисляет уникальный идентификатор блока ресурса-источника 1113 на основе используемого его содержимого. Если вычисленный уникальный идентификатор блока ресурса-источника 1113 отличается от уникального идентификатора соответствующего блока ресурса-приемника 1213 согласно файлу карты текущего содержимого ресурса-приемника, принятому на этапе 502, то формирователь 1116 истории изменений соответственно записывает используемое содержимое блока ресурса-источника в stash-файл.
На этапе 504 сформированный массив информации регистрации изменений передается посредством передатчика 1117 на сервер 1200 резервной инфраструктуры. Как и в случае этапа 402, массив информации регистрации изменений перед передачей по этапу 504 может быть в необязательном порядке сохранен формирователем 1116 истории изменений на журнальном диске 1118.
На этапе 505 приемник 1216 принимает массив информации регистрации изменений, переданный с сервера 1100 основной инфраструктуры. Как и в случае этапа 404, принятый массив информации регистрации изменений может быть сохранен, к примеру, на журнальном диске 1217.
На этапе 506 на сервере 1200 резервной инфраструктуры осуществляется запись на ресурс-приемник 1213 блоков данных с использованием массива информации регистрации изменений, принятого на этапе 504. Более конкретно, актуализатор 1215 изменений применяет принятый stash-файл к ресурсу-приемнику 1213, аналогично тому, как это выполнялось на этапе 305.
В результате успешного завершения этапа 505 на ресурсе-приемнике 1213 получается набор данных, являющийся консистентным на момент открытия COW- и CBT-журналов на этапе 503.
На этапе 504, по завершении передачи массива информации регистрации изменений, запускается выполнение циклов синхронизации, отвечающее этапу 290 и раскрытию по Фиг.4.
Следует понимать, что подсистема-источник 1110 может включать в себя другие компоненты помимо компонентов 1111, 1114-1117, и подсистема-приемник 1210 может включать в себя другие компоненты помимо компонентов 1211, 1214-1216. Например, в дополнение к компонентам репликации 1215, 1216 в подсистеме-приемнике 1210 может быть предусмотрен отдельный компонент для создания карты текущего содержимого ресурса-приемника на этапе 501. Также следует понимать, что для создания массивов информации регистрации изменений, предназначенных для обеспечения консистентности между данными ресурса-источника и ресурса-приемника на заданные моменты времени, могут использоваться технологии, отличные от основывающейся на COW-, CBT-, stash-файлах, задействовавшейся в предпочтительном варианте осуществления настоящего изобретения, описанном выше.
Ниже речь пойдет о вариантах реализации компонентов системы обеспечения катастрофоустойчивости согласно настоящему изобретению, которые, в частности, показаны на Фиг.1.
Согласно варианту осуществления настоящего изобретения, в, по меньшей мере, некоторых из физических серверов основной инфраструктуры установленные на них экземпляры хост-контроллера, диспетчера репликационной пары и компонентов репликации подсистемы-источника могут быть реализованы посредством программных процессов, функционирующих на уровне операционной системы этих серверов. Соответственно, в, по меньшей мере, некоторых из физических серверов резервной инфраструктуры установленные на них экземпляры хост-контроллера, диспетчера репликационной пары и компонентов репликации подсистемы-приемника могут быть реализованы посредством программных процессов, функционирующих на уровне операционной системы этих серверов. Данный вариант осуществления является наиболее универсальным, так как не требует специализированного оборудования или получения привилегированного доступа к ресурсам гипервизора, однако обеспечивает минимальную изоляцию компонентов системы обеспечения катастрофоустойчивости от самих серверов.
Согласно варианту осуществления, вышеуказанные программные процессы, которыми реализуются соответствующие экземпляры хост-контроллера, диспетчера репликационной пары и компонентов репликации, могут функционировать в специализированной аппаратной плате, устанавливаемой в каждый из соответствующих физических серверов. Естественно, специализированная плата содержит аппаратные (в частности, процессор(ы) и оперативную память) и программные средства, необходимые для надлежащей работы соответствующих компонентов системы обеспечения катастрофоустойчивости. При такой реализации программные процессы оказываются изолированными от операционной системы сервера, в который установлена специализированная плата, и возможного влияния системных сбоев или вмешательства пользователя. Подобная специализированная плата может иметь интерфейсы для взаимодействия с ресурсами хранения данных (например, такие как, но не в ограничительном смысле, шины типа SAS, SATA, SCSI и т.п.), интерфейсы для передачи данных по каналам связи (например, такие как, но не в ограничительном смысле, Ethernet, FibreChannel, Infiniband и т.п.) и интерфейсы управления (например, такие как, но не в ограничительном смысле, Ethernet, I2C, SPI и т.п., причем такие интерфейсы могут быть как физически отделены от интерфейсов передачи данных, так и совпадать с ними). Также эта плата может реализовывать API управления функциями, служащие для настройки, управления и получения информации о текущем состоянии (например, такие как, но не в ограничительном смысле, CLI, RESTful API, SOAP и т.п.). С точки зрения операционной системы сервера, в который устанавливается такая плата, она выполняет функции типового контроллера подсистемы хранения данных или RAID-контроллера.
Будучи установленной в сервере(ах) основной инфраструктуры, рассматриваемая специализированная плата перехватывает инициируемые на уровне процессов операционной системой обращения к ресурсам хранения данных, отслеживает происходящие на ресурсах хранения изменения, формирует массивы информации регистрации изменений, после чего прозрачно для инициатора таких обращений пропускает их на ресурсы хранения данных; далее сформированные массивы информации регистрации изменений отправляются по внешним каналам связи на целевые серверы в составе резервной инфраструктуры, где осуществляется их прием и применение к ресурсам хранения резервной инфраструктуры в соответствии с заданными пользователем параметрами.
Будучи установленной в сервере(ах) резервной инфраструктуры, такая плата принимает массивы информации регистрации изменений по внешним каналам связи и согласно заданным пользователем настройкам применяет их к ресурсам хранения данных для поддержания актуальности резервной инфраструктуры.
Кроме того, если подобная специализированная плата оборудована собственными энергонезависимыми ресурсами хранения и/или перезаряжаемыми элементами питания, емкость которых достаточна для завершения текущих операций и сохранения полученной информации, то тем самым достигается дополнительная степень защиты компонентов системы обеспечения катастрофоустойчивости от возможных сбоев питания серверов. В частности, такие собственные энергонезависимые ресурсы хранения могут соответственно использоваться в качестве журнальных хранилищ 1118, 1217.
Согласно варианту осуществления настоящего изобретения, когда сервером основной или резервной инфраструктуры является виртуальный сервер, реализуемый посредством виртуальной машины (см., в частности, раздел “Уровень техники“ настоящей заявки), соответствующие экземпляры хост-контроллера, диспетчера репликационной пары и компонентов репликации могут быть реализованы посредством программных процессов, функционирующих на уровне гипервизора, обеспечивающего работу виртуальной машины соответственно в основной или резервной инфраструктуре.
Вышеописанные варианты осуществления на основе программных процессов могут использоваться на практике в различных сочетаниях. К примеру, на сервере основной инфраструктуры соответствующие компоненты системы обеспечения катастрофоустойчивости могут быть реализованы на уровне процессов его ОС, а в соответствующий сервер резервной инфраструктуры может быть установлена специализированная аппаратная плата.
Следует понимать, что помимо программных процессов, реализующих, на том или ином уровне, на сервере основной инфраструктуры функции хост-контроллера 1111 подсистемы-источника, диспетчера 1114 репликационной пары подсистемы-источника, детектора 1115 изменений, формирователя 1116 истории изменений и передатчика 1117, на этом же сервере может быть предусмотрено осуществление функций хост-контроллера 1211 подсистемы-приемника, диспетчера 1214 репликационной пары подсистемы-приемника, приемника 1216 и актуализатора 1215 изменений. Указанные предусмотренные функции могут быть отчасти реализованы программными процессами, дополнительными по отношению к процессам, реализующим подсистему-источник 1110 (что относится, например, к процессам, реализующим хост-контроллер 1211, диспетчер 1214 репликационной пары и актуализатор 1215 изменений), и эти программные процессы соответственно находятся в остановленном состоянии при штатном функционировании основной инфраструктуры приложения, так и отчасти реализованы программными процессами подсистемы-источника 1110 - например, помимо функции передатчика 1117, соответствующий процесс может реализовывать и функцию приемника 1216.
Аналогичным образом, помимо программных процессов, реализующих на сервере резервной инфраструктуры функции хост-контроллера 1211 подсистемы-приемника, диспетчера 1214 репликационной пары подсистемы-приемника, актуализатора 1215 изменений и приемника 1216 на этом же сервере может быть предусмотрено осуществление функций хост-контроллера 1111 подсистемы-источника, диспетчера 1114 репликационной пары подсистемы-источника, детектора 1115 изменений, формирователя 1116 истории изменений и передатчика 1117.
Как неоднократно отмечалось ранее, целью создания и поддержания актуальности резервной инфраструктуры является постоянная готовность к запуску в ней защищаемого приложения, каковой запуск может упоминаться по тексту настоящей заявки как «активация резервной инфраструктуры» или «активация резервной инфраструктуры в качестве основной инфраструктуры приложения».
Ниже неограничивающим образом перечислены основные случаи, в которых может быть активирована резервная инфраструктура:
Случай 1. Наступление события, идентифицируемого как катастрофический отказ основной инфраструктуры приложения.
Инициатором активации резервной инфраструктуры в Случае 1 может служить некоторая система мониторинга, которая, в общем случае, является внешней по отношению к системе обеспечения катастрофоустойчивости, предложенной в настоящей заявке, и которая обнаруживает подобные события на основе ряда заранее заданных критериев и отправляет в мастер-контроллер 1010 соответствующую команду, например, посредством вызова соответствующей функции API мастер-контроллера 1010. Неограничивающими примерами таких заранее заданных критериев являются: 1) проверка доступности сервера(ов) основной инфраструктуры, на котором работает защищаемое приложение, например, путем попытки сетевого подключения к его ОС и/или выполнения в ней типовой команды (к примеру, листинг системных процессов), 2) проверка работоспособности приложения путем подключения к сетевому сервису приложения и выполнения некоей типовой операции (например, запрос статистики приложения); при этом может быть предусмотрено несколько попыток выполнения проверки на некотором характерном промежутке времени, чтобы избежать ложных срабатываний вследствие временных (т.е. не имеющих катастрофического характера) неполадок в основной инфраструктуре приложения. В качестве возможных реализаций такой системы мониторинга могут использоваться Prometheus, HP OpenView, Zabbix. В зависимости от настроенных на мастер-контроллере правил (см. этап 260) дальнейшие действия по активации резервной инфраструктуры могут быть выполнены либо в полностью автоматическом режиме, либо с участием оператора, который, получив оповещение от мастер-контроллера 1010, может выполнить дополнительную оценку наступившего события и принять окончательное решение о целесообразности активации резервной инфраструктуры.
Дальнейшие действия выполняются на серверах резервной инфраструктуры (к примеру, на сервере 1200) автоматически под управлением установленных на этих серверах хост-контроллеров (например, хост-контроллера 1211) в соответствии с заложенным в них алгоритмом активации для сценария переключения на резервную инфраструктуру.
Случай 2. Получение команды оператора на перевод защищаемого приложения на резервную инфраструктуру.
Данное действие не обязательно связано с возникновением сбойных ситуаций в основной инфраструктуре приложения: например, причиной выдачи такой команды может быть вывод основной инфраструктуры приложения из эксплуатации или временный ее перевод в режим технического обслуживания. Инициатором активации резервной инфраструктуры в Случае 2 в типичном случае выступает оператор, который дает соответствующую команду в мастер-контроллер 1010 через его API или пользовательский интерфейс.
Дальнейшие действия выполняются на серверах резервной инфраструктуры (к примеру, на сервере 1200) автоматически под управлением установленных на этих серверах хост-контроллеров (например, хост-контроллера 1211) в соответствии с заложенным в них алгоритмом активации для сценария переключения на резервную инфраструктуру.
Случай 3. Получение команды на изменение направления (реверс) синхронизации.
По этой команде основная инфраструктура приложения и резервная инфраструктура меняются ролями, т.е., обобщенно говоря, защищаемое приложение начинает работать на бывшей резервной инфраструктуре, которая в этот момент начинает выполнять роль основной, а репликация данных осуществляется на бывшую основную инфраструктуру приложения, которая в этот момент становится резервной. Инициатором активации резервной инфраструктуры и подготовки основной инфраструктуры приложения для функционирования в качестве резервной в Случае 3 в типичном случае выступает опять же оператор, который дает соответствующую команду в мастер-контроллер 1010 через его API или пользовательский интерфейс.
Дальнейшие действия выполняются на серверах соответствующих инфраструктур под управлением установленных на них хост-контроллеров в соответствии с заложенным в них алгоритмом активации для сценария реверса синхронизации.
Далее со ссылкой на Фиг.6-8 будут соответственно описываться варианты осуществления, отвечающие реализациям согласно Случаям 1-3, обрисованным выше.
Так, со ссылкой на блок-схему по Фиг.6 дается описание варианта осуществления способа 600 функционирования системы обеспечения катастрофоустойчивости согласно настоящему изобретению для сценария активации резервной инфраструктуры, соответствующего Случаю 1.
На этапе 610 обнаруживается событие, идентифицируемое как отказ основной инфраструктуры приложения. Данное обнаружение может быть выполнено, например, внешней системой мониторинга, находящейся на связи с мастер-контроллером 1010, как отмечалось выше. В рассматриваемом варианте осуществления предполагается, что основная инфраструктура приложения становится неработоспособной в результате данного отказа.
На этапе 620 в соответствующем хост-контроллере(ах) подсистемы-приемника от мастер-контроллера 1010 принимается команда активации, выданная им вследствие обнаружения по этапу 610. В соответствии с одной возможной реализацией, выдача команды активации из мастер-контроллера предваряется выполнением оценки обнаруженного события. Более конкретно, оператор, получив от мастер-контроллера 1010 оповещение о потенциально катастрофическом событии, произошедшем в основной инфраструктуре приложения, выполнит дополнительную оценку наступившего события и примет окончательное решение о целесообразности активации резервной инфраструктуры, т.е. о необходимости выдачи в нее команды активации с мастер-контроллера.
На этапе 630 в резервной инфраструктуре, для ресурса-приемника (например, 1213) каждой репликационной пары, посредством соответствующего актуализатора изменений (например, 1215) из состава подсистемы-приемника (например, 1210) осуществляется запись блоков данных на этот ресурс-приемник на основе, по меньшей мере, некоторых из массивов информации регистрации изменений, которые были сохранены в резервной инфраструктуре (например, на журнальном диске 1217) и которые еще не были использованы для осуществления записи блоков данных на этот ресурс-приемник (см. этапы 404-405). Так, в качестве варианта, подразумевающего вмешательство оператора, предусмотрено выборочное применение сохраненных незадействованных массивов информации регистрации изменений, когда, например, оператором задается точка во времени, которой должно достичь (или, иными словами, до которой требуется «докатить») состояние ресурса(ов)-приемника(ов), в каковом случае все изменения, произошедшие после заданной точки, к ресурсу(ам)-приемнику(ам) не применяются. Запись по этапу 630 осуществляется немедленно, т.е. с игнорированием задержки применения, если таковая была задана. По сути, выполнением этапа 630 обеспечивается требующаяся консистентность ресурса(ов)-приемника(ов) перед активацией резервной инфраструктуры.
Для специалиста должно быть понятно, что при отсутствии в резервной инфраструктуре непримененных массивов информации регистрации изменений на момент приема команды активации этап 630 не выполняется.
На этапе 640 активируется резервная инфраструктура. При осуществлении активации по этапу 640 могут быть выполнены одно или более из действий, описанных ниже.
Так, согласно правилам автоматического преобразования, которые могли быть преконфигурированы на этапе 260, соответственно преобразуются настройки сетевых интерфейсов на, по меньшей мере, некоторых из серверов резервной инфраструктуры. Указанное преобразование может содержать изменение IP-адреса на конкретном интерфейсе, отключение конкретного интерфейса, использование DHCP для получения IP-адреса и т.п. В возможной реализации, подразумевающей непосредственное участие оператора, возможна корректировка соответствующих правил, ранее настроенных на этапе 260, перед выполнением преобразования на этапе 640.
Затем, на этапе активации резервной инфраструктуры, согласно правилам автоматического изменения, которые могли быть преконфигурированы на этапе 260, соответственно изменяются системные настройки операционной системы, по меньшей мере, некоторых из серверов резервной инфраструктуры. Указанное изменение может содержать замену драйверов в операционной системе и/или модификацию правил загрузки операционной системы на соответствующем сервере(ах) резервной инфраструктуры и т.п. В возможной реализации, подразумевающей участие оператора, опять же возможна корректировка соответствующих правил, ранее настроенных на этапе 260, перед выполнением изменения на этапе 640.
Далее, на этапе 640 согласно зависящим от приложения правилам, которые могли быть преконфигурированы на этапе 260, на соответствующем сервере(ах) резервной инфраструктуры для требующейся контрольной точки запускается соответственный пользовательский исполняемый сценарий, которым, как было отмечено ранее, учитывается специфика защищаемого приложения, а также могут учитываться возможные системные преобразования и изменения, ранее выполненные на рассматриваемом этапе способа 600. Результатом указанного запуска может быть, к примеру, модификация конфигурационных файлов приложения в резервной инфраструктуре, изменение UUID дисковых ресурсов и т.п.
Наконец, серверы резервной инфраструктуры перезагружаются для обеспечения работы защищаемого приложения в резервной инфраструктуре. Согласно предпочтительному варианту осуществления, соответствующему функционированию серверов резервной инфраструктуры, до ее активации, в режиме boot-to-RAM, при указанной перезагрузке каждый из серверов резервной инфраструктуры перезагружается с надлежащего дискового ресурса и начинает функционировать под управлением своей основной операционной системы. После этого в резервной инфраструктуре запускается защищаемое приложение, при этом приложение стартует в резервной инфраструктуре на базе того набора данных на ресурсах-приемниках, который соответствует моменту завершения репликации (см. этапы 290, 401-405), либо точке «докатки» по этапу 630.
Затем, со ссылкой на блок-схему по Фиг.7 дается описание варианта осуществления способа 700 функционирования системы обеспечения катастрофоустойчивости согласно настоящему изобретению для сценария активации резервной инфраструктуры, соответствующего Случаю 2. Как описывалось выше в отношении Случая 2, активация резервной инфраструктуры для данного сценария команды может иметь место по различным причинам; тем не менее, в рассматриваемом варианте осуществления без ограничения общности предполагается, что основная инфраструктура приложения сохраняет, по меньшей, частичную работоспособность.
На этапе 710 в соответствующем хост-контроллере(ах) подсистемы-приемника от мастер-контроллера 1010 принимается команда активации в отношении резервной инфраструктуры; в соответствующем хост-контроллере(ах) подсистемы-источника от мастер-контроллера 1010 может быть принята та же команда активации, либо может быть принято информационное сообщение о команде активации, выданной в резервную инфраструктуру. Команда активации может быть инициирована на этапе 710 оператором посредством соответствующего управления мастер-контроллером 1010.
На этапе 720, по приему команды активации от мастер-контроллера 1010, прекращается выполнение циклов синхронизации в основной инфраструктуре приложения и в резервной инфраструктуре и останавливается работа защищаемого приложения в основной инфраструктуре приложения.
При прекращении выполнения циклов синхронизации в основной инфраструктуре приложения прекращается любое отслеживание изменений на ресурсах-источниках, и из основной инфраструктуры приложения в резервную инфраструктуру передаются все из массивов информации регистрации изменений, которые еще не были переданы в резервную инфраструктуру (см. этап 403); эти массивы информации регистрации изменений сохраняются в резервной инфраструктуре (см. этап 404).
При прекращении выполнения циклов синхронизации в резервной инфраструктуре, на необязательном этапе 730, аналогично этапу 630, для ресурса-приемника каждой репликационной пары осуществляется запись блоков данных на этот ресурс-приемник на основе, по меньшей мере, некоторых из массивов информации регистрации изменений, которые были сохранены в резервной инфраструктуре и которые еще не были применены к этому ресурсу-приемнику.
На этапе 740 активируется резервная инфраструктура. Активация согласно этапу 740, в целом, аналогична таковой по этапу 640. Иными словами, на этапе 740 также могут быть выполнены, по меньшей мере, некоторые из действий, указанных при раскрытии этапа 640 выше.
По меньшей мере, некоторые серверов основной инфраструктуры могут быть выключены, например, после активации резервной инфраструктуры на этапе 740.
Наконец, со ссылкой на блок-схему по Фиг.8 дается описание варианта осуществления способа 800 функционирования системы обеспечения катастрофоустойчивости согласно настоящему изобретению для Случая 3, соответствующего реверсу репликации данных.
Случай 3 соответствует комплексному сценарию, при котором, вслед за запуском в резервной инфраструктуре защищаемого приложения (к примеру, согласно любому из вышеописанных способов 600, 700, отвечающих Случаям 1, 2, соответственно) инициируется репликация данных в обратном направлении, что может иметь место, к примеру, в процессе возврата к нормальному, штатному функционированию защищаемого приложения на основной инфраструктуре приложения, например, восстановленной после катастрофического отказа, либо перезагрузки одного или более из серверов основной инфраструктуры или перезапуска одного или более из их программных компонентов. Предложенный здесь вариант осуществления позволяет минимизировать время готовности резервной инфраструктуры к очередному запуску в ней защищаемого приложения в случае повторных отказов основной инфраструктуры приложения. После указанного возврата направление репликации данных сменяется - репликация вновь осуществляется из основной инфраструктуры приложения в резервную инфраструктуру.
В целях простоты дальнейшего изложения, исключительно в рамках раскрытия по Фиг.8 будут использоваться термины «первая инфраструктура» и «вторая инфраструктура», а также «первый режим» и «второй режим». Когда первым режимом является штатный режим работы защищаемого приложения, первой инфраструктурой является основная инфраструктура приложения, а второй инфраструктурой - резервная инфраструктура; в этом случае вторым режимом, в общем, является режим, отличающийся от штатного. Когда первым режимом является режим реверса репликации, второй инфраструктурой является инфраструктура, которая изначально была основной инфраструктурой приложения и на текущий момент временно функционирует в качестве резервной инфраструктуры, а первой инфраструктурой является резервная инфраструктура, активированная и временно функционирующая в качестве основной инфраструктуры приложения; в этом случае вторым режимом является штатный режим работы приложения.
Возвращаясь к Фиг.8, далее со ссылкой на данную фигуру с учетом вышесказанного дается обобщенное раскрытие рассматриваемого варианта осуществления с реверсом репликации данных.
На этапе 810, в первом режиме, защищаемое приложение работает в первой инфраструктуре и выполняются циклы синхронизации между первой инфраструктурой и второй инфраструктурой.
На этапе 820 инициируется переход из первого режима во второй режим.
Вследствие инициирования по этапу 820, на этапе 830 приостанавливается выполнение циклов синхронизации в первой инфраструктуре и во второй инфраструктуре и останавливается работа защищаемого приложения в первой инфраструктуре.
Затем, на этапе 840 вторая инфраструктура активируется в качестве первой инфраструктуры, и защищаемое приложение запускается во второй инфраструктуре, которая теперь функционирует в качестве первой инфраструктуры.
На этапе 850 первая инфраструктура активируется в качестве второй инфраструктуры.
Наконец, на этапе 860 возобновляется выполнение циклов синхронизации во второй инфраструктуре, функционирующей в качестве первой инфраструктуры, и в первой инфраструктуре, функционирующей в качестве второй инфраструктуры.
Итак, когда первым режимом является штатный режим, защищаемое приложение работает в основной инфраструктуре приложения (соответственно первой инфраструктуре) и репликация данных выполняется в резервную инфраструктуру (соответственно вторую инфраструктуру) (см. этапы 290, 401-405). В случае, к примеру, возникновения катастрофического сбоя в основной инфраструктуре приложения, т.е. при переходе во второй режим, не являющийся штатным, выполняется активация резервной инфраструктуры (см. способ 600), т.е. в терминологии способа 800 вторая инфраструктура активируется в качестве первой инфраструктуры, и защищаемое приложение продолжит функционировать и, следовательно, изменять свои данные на ресурсах-приемниках резервной инфраструктуры, как минимум до тех пор пока сбой в основной инфраструктуре приложения не будет устранен и восстановительные работы не будут закончены. Следует понимать, что рассмотренный здесь переход из первого режима во второй режим может быть инициирован и вследствие ситуаций, не связанных с отказом основной инфраструктуры приложения (см. Случай 2, способ 700, описанные выше).
В некий момент, например, когда основная инфраструктура приложения восстановлена, возникает необходимость передачи изменений, произошедших за это время в резервной инфраструктуре, которая на текущий момент функционирует в качестве основной и таким образом является первой инфраструктурой в терминологии способа 800, обратно в восстановленную основную инфраструктуру приложения в целях надлежащего перезапуска в ней защищаемого приложения, для чего в системе обеспечения катастрофоустойчивости согласно настоящему изобретению предусмотрен режим реверса репликации.
Восстановленная основная инфраструктура приложения изначально запускается в качестве резервной инфраструктуры приложения, таким образом становясь на текущий момент второй инфраструктурой в терминологии способа 800. Для данного запуска могут аналогичным образом отчасти использоваться соответствующие действия, описанные выше при раскрытии способа 200.
После указанного запуска инициируется режим реверса репликации, в котором репликация данных осуществляется посредством выполнения циклов синхронизации из “временно основной“ резервной инфраструктуры во “временно резервную“ основную инфраструктуру. Репликация в режиме реверса репликации, в общем, осуществляется аналогично этапам 401-405 и, следовательно, для ее реализации могут быть задействованы компоненты системы обеспечения катастрофоустойчивости, соответственно описанные выше. При этом, как следует из указанного вышеприведенного раскрытия, репликация данных в режиме реверса репликации также выполняется без прекращения работы защищаемого приложения. Перед запуском циклов синхронизации в данном контексте может быть выполнена частичная ресинхронизация между рассматриваемыми двумя инфраструктурами аналогично этапам 285, 501-506, описанным выше.
Для специалиста должно быть понятно, что вышеописанное реверсирование направления репликации данных может быть схожим образом реализовано и для случая, не связанного с отказом или иным выведением из эксплуатации основной инфраструктуры приложения. Так, данное реверсирование может быть инициировано при штатном функционировании основной и резервной инфраструктур по команде реверса репликации, выдаваемой мастер-контроллером 1010 в эти инфраструктуры (этап 820), после чего выполняются этапы 830-860 аналогично вышеописанному.
В некое оптимальное время, например, в период минимальной нагрузки со стороны пользователей на защищаемое приложение, которое на текущий момент временно работает в резервной инфраструктуре (здесь первой инфраструктуре), может быть принято решение о перезапуске приложения в (восстановленной) основной инфраструктуре приложения (здесь второй инфраструктуре). Как отмечалось ранее, инициатором смены направления репликации данных может выступать оператор, который дает соответствующую команду в мастер-контроллер 1010 через его API или пользовательский интерфейс, тем самым, по существу, инициируя переход из режима реверса репликации (здесь первого режима) к функционированию защищаемого приложения в штатном режиме (здесь во втором режиме). Данное решение, в то же время, не отменяет потребности в сохранении возможности снова перевести защищаемое приложение в резервную инфраструктуру в случае, например, повторения сбоя в основной инфраструктуре приложения.
В соответствии со способом 800, по получении команды реверса репликации от мастер-контроллера 1010 в рассматриваемых двух инфраструктурах, приостанавливается текущее выполнение репликации данных между ними и останавливается работа защищаемого приложения во “временно основной“ резервной инфраструктуре, “временно резервная“ инфраструктура вновь активируется в качестве основной инфраструктуры приложения, с перезапуском в ней защищаемого приложения в штатном режиме, и “бывшая основная“ инфраструктура вновь запускается в качестве резервной инфраструктуры. После этого между основной инфраструктурой приложения и резервной инфраструктурой перезапускается выполнение циклов синхронизации, как описывалось выше (см. этапы 290, 401-405), т.е. репликация данных вновь меняет направление на противоположное. Опять же, перед перезапуском циклов синхронизации может быть выполнена частичная ресинхронизация между рассматриваемыми двумя инфраструктурами аналогично этапам 285, 501-506, раскрытым ранее.
Благодаря предусмотренному режиму реверса репликации, вариант осуществления которого описывался выше, необходимая последовательность действий на обеих инфраструктурах выполняется согласованно и автоматически, что минимизирует время переключения защищаемого приложения обратно на инфраструктуру, которая снова становится основной, и позволяет избежать достаточно длительной процедуры первичного копирования данных обратно на инфраструктуру, которая снова становится резервной.
Следует понимать, что раскрытые здесь варианты осуществления настоящего изобретения являются лишь иллюстративными, но не единственно возможными. Точнее, объем настоящего изобретения определяется нижеследующей формулой изобретения и ее эквивалентами.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРОГРАММНО-ОПРЕДЕЛЯЕМАЯ АВТОМАТИЗИРОВАННАЯ СИСТЕМА И АРХИТЕКТУРА | 2016 |
|
RU2729885C2 |
| ЦЕНТРАЛИЗОВАННОЕ УПРАВЛЕНИЕ ПРОГРАММНО-ОПРЕДЕЛЯЕМОЙ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ | 2016 |
|
RU2747966C2 |
| ПЛАТФОРМА СОСТАВНЫХ ПРИЛОЖЕНИЙ НА БАЗЕ МОДЕЛИ | 2008 |
|
RU2502127C2 |
| Интегрированный программно-аппаратный комплекс | 2016 |
|
RU2646312C1 |
| СПОСОБ ДЛЯ РАЗМЕЩЕНИЯ РАБОЧИХ НАГРУЗОК В ПРОГРАММНО-ОПРЕДЕЛЯЕМОЙ АВТОМАТИЗИРОВАННОЙ СИСТЕМЕ | 2016 |
|
RU2730534C2 |
| АППАРАТНАЯ ВИРТУАЛИЗИРОВАННАЯ ИЗОЛЯЦИЯ ДЛЯ ОБЕСПЕЧЕНИЯ БЕЗОПАСНОСТИ | 2017 |
|
RU2755880C2 |
| СИСТЕМА И СПОСОБ ДЛЯ СЕТИ АВТОМАТИЗИРОВАННОГО БУРЕНИЯ | 2018 |
|
RU2780964C2 |
| РАСЩЕПЛЕННАЯ ЗАГРУЗКА ДЛЯ ЭЛЕКТРОННЫХ ЗАГРУЗОК ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2006 |
|
RU2424552C2 |
| АРХИТЕКТУРА ОРГАНИЗАЦИИ ПРОМЫШЛЕННЫХ ПРОГРАММНО-ОПРЕДЕЛЯЕМЫХ СЕТЕЙ ДЛЯ РАЗВЕРТЫВАНИЯ В ПРОГРАММНО-ОПРЕДЕЛЯЕМОЙ АВТОМАТИЗИРОВАННОЙ СИСТЕМЕ | 2017 |
|
RU2737480C2 |
| СРЕДСТВА УПРАВЛЕНИЯ ДОСТУПОМ К ОНЛАЙНОВОЙ СЛУЖБЕ С ИСПОЛЬЗОВАНИЕМ ВНЕМАСШТАБНЫХ ПРИЗНАКОВ КАТАЛОГА | 2011 |
|
RU2598324C2 |
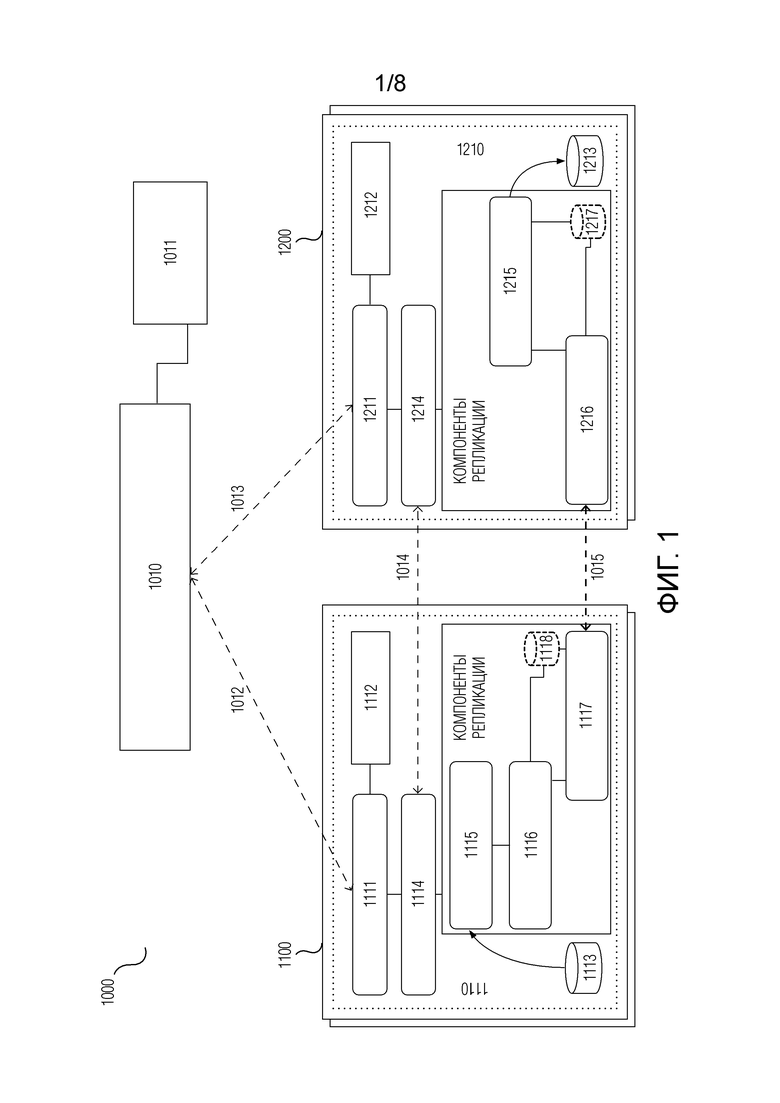
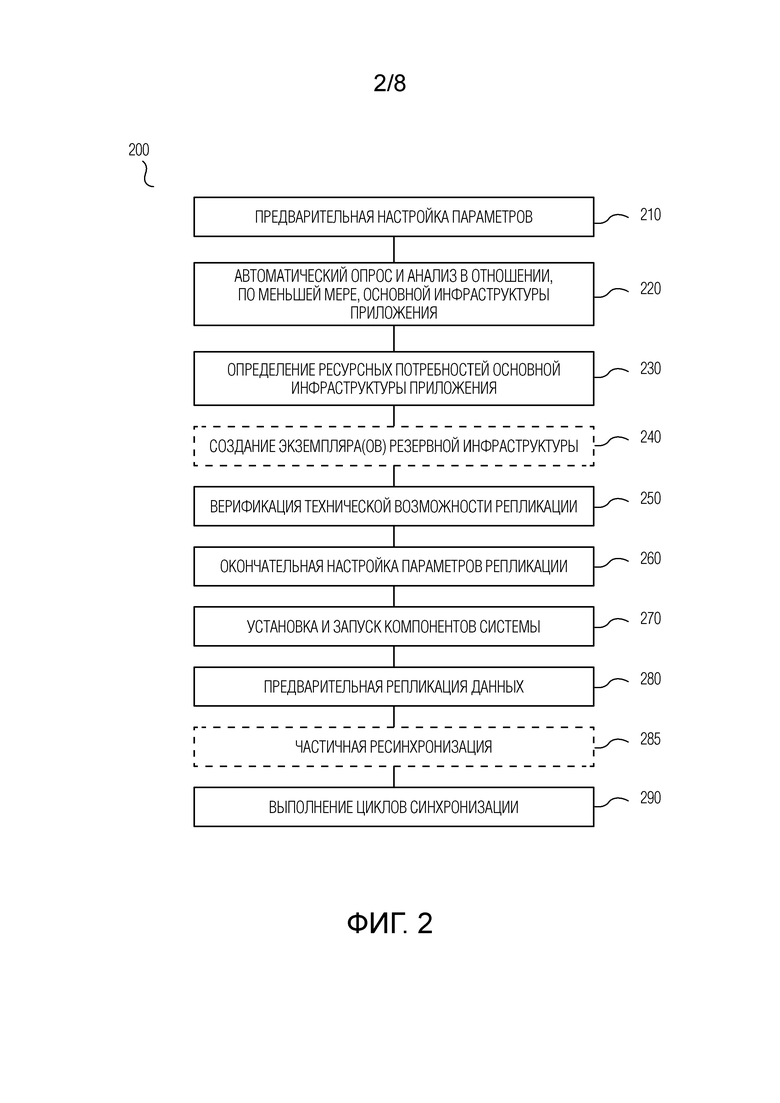
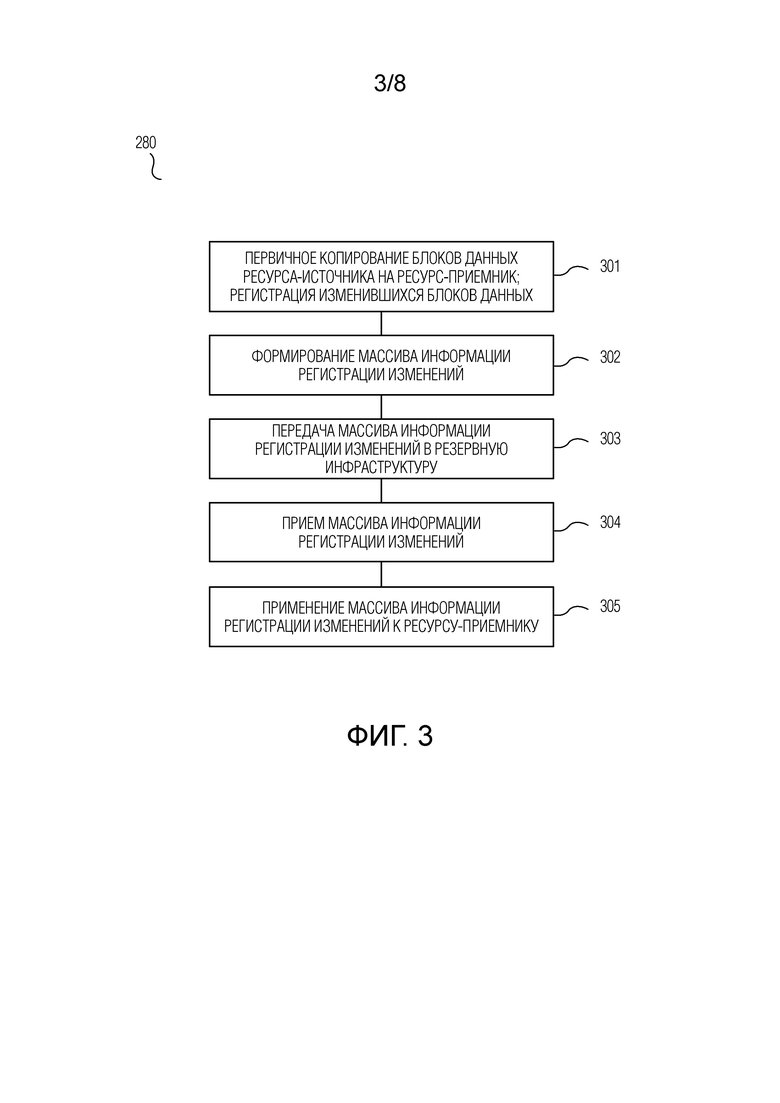
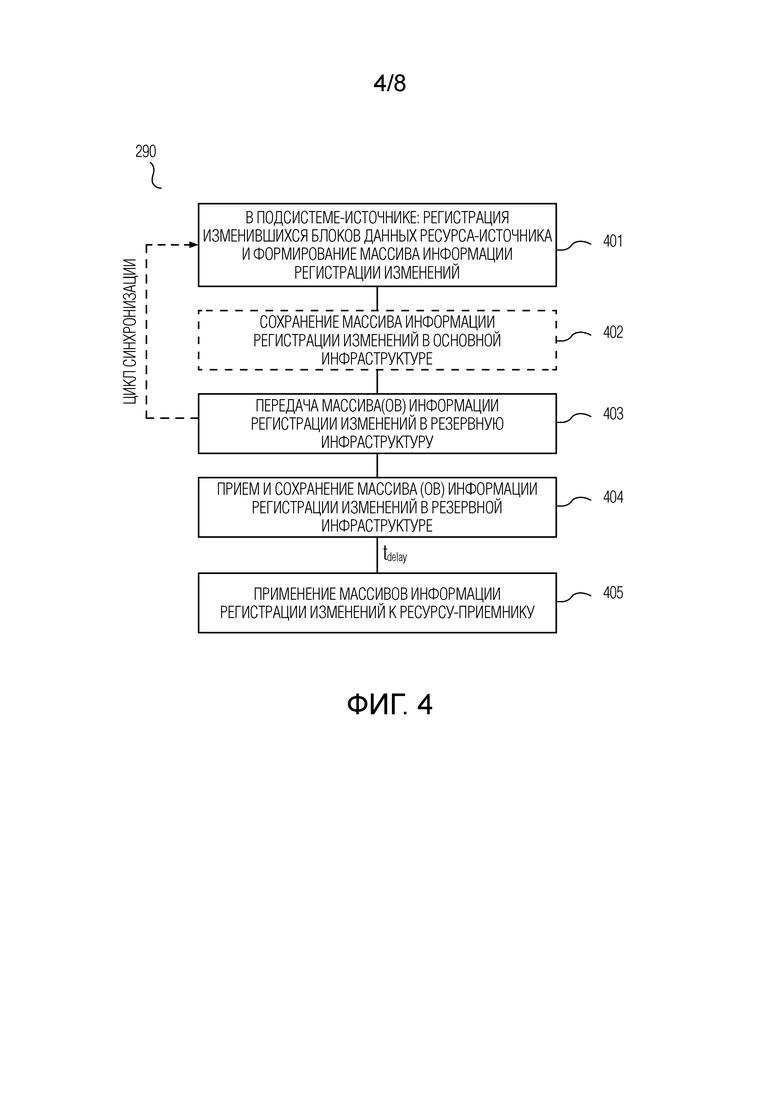
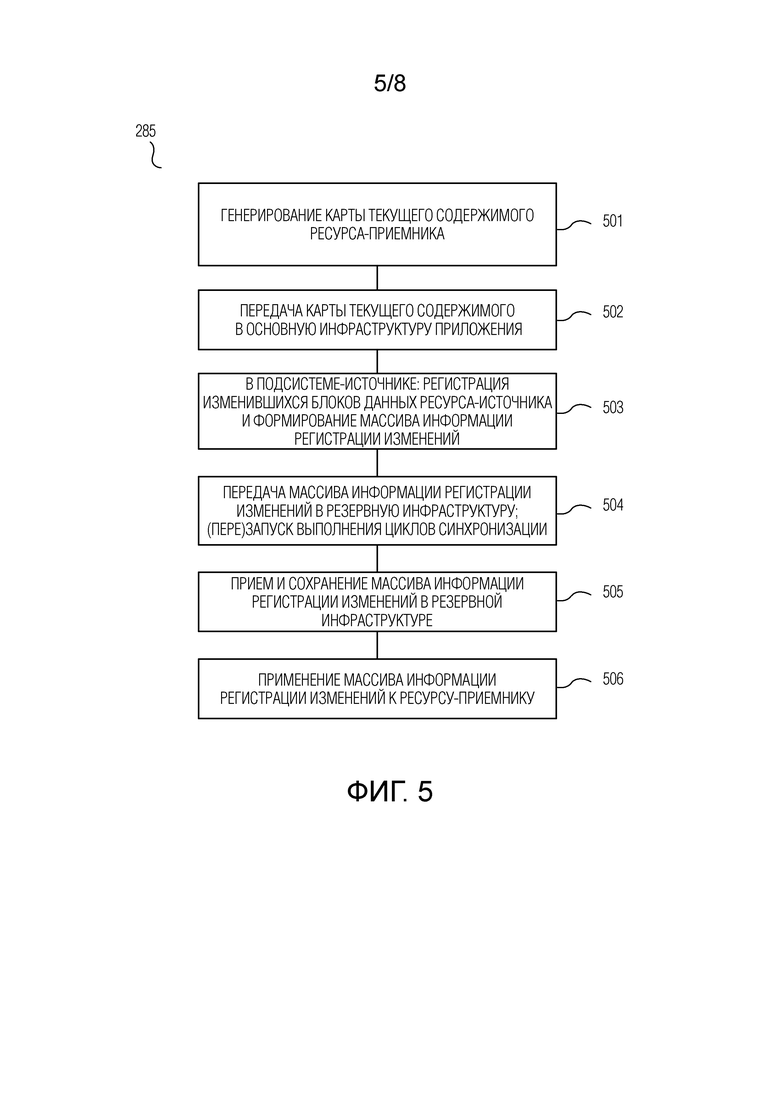
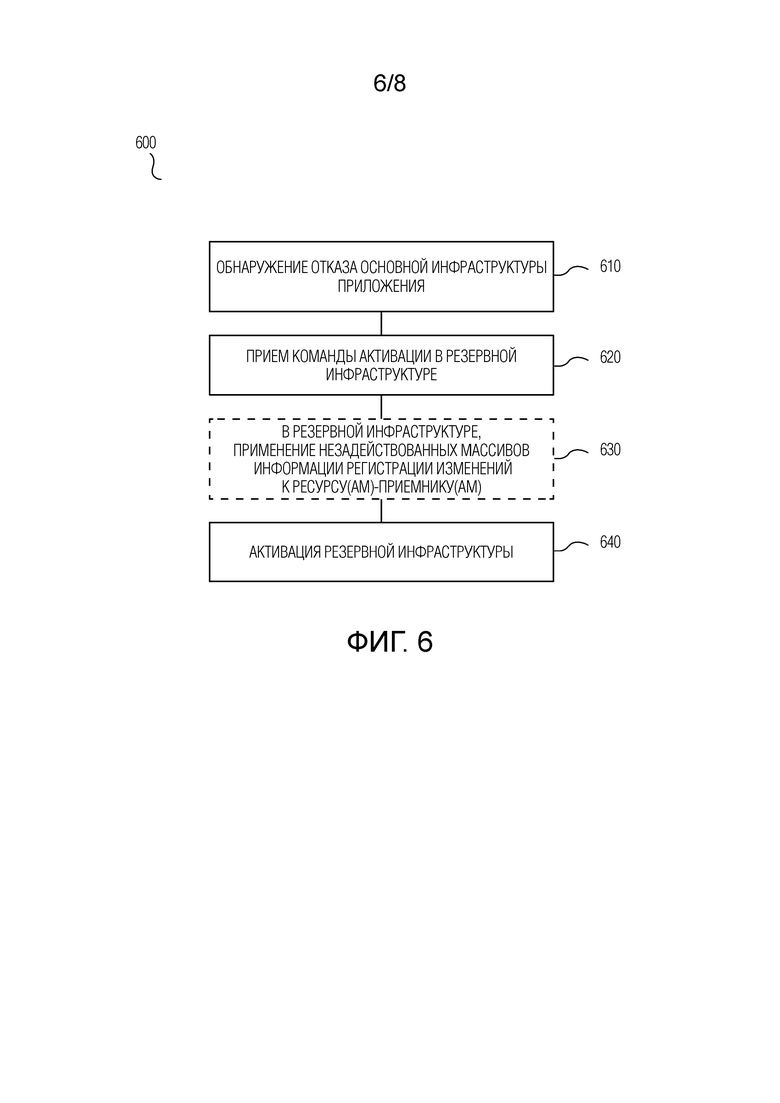
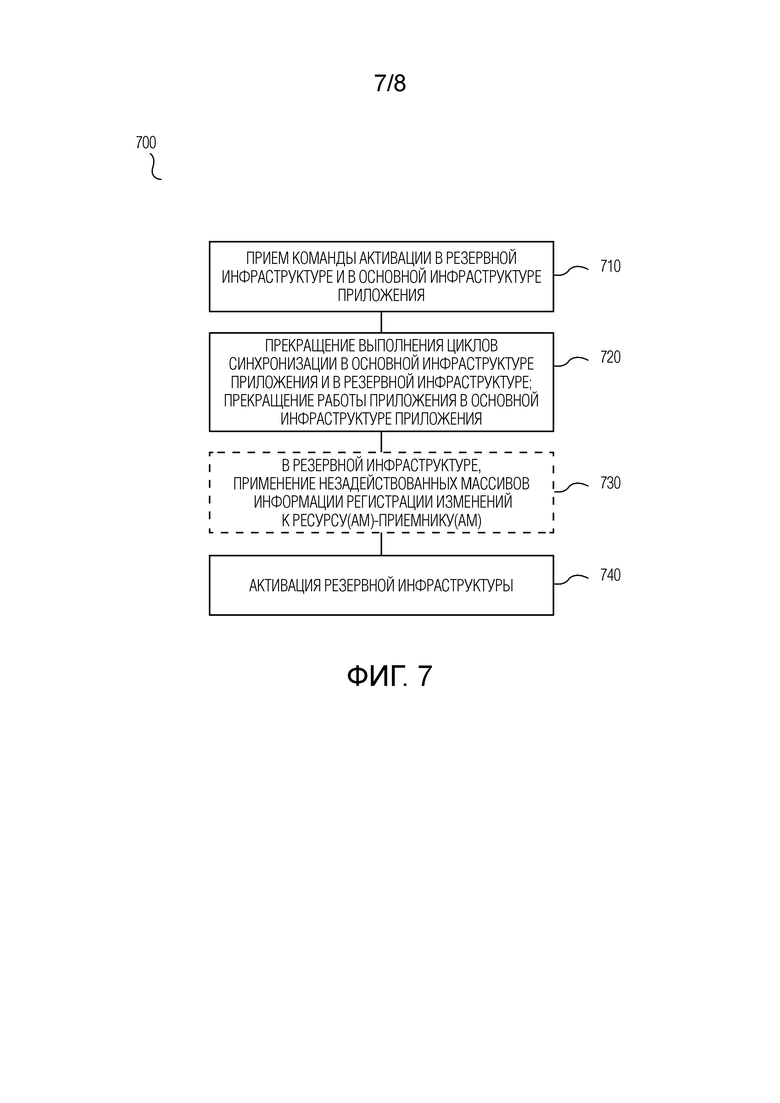
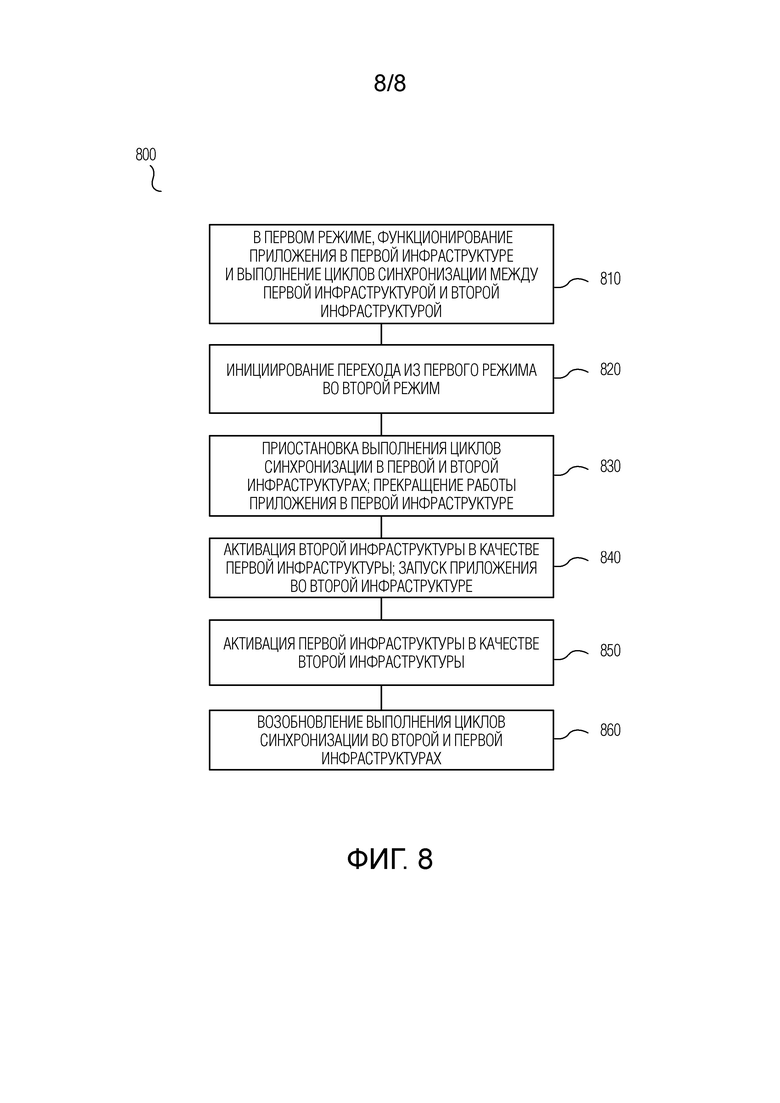
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении катастрофоустойчивости информационной инфраструктуры приложения. Технический результат достигается за счет системы, которая содержит мастер-контроллер, подсистему-источник, функционирующую в основной инфраструктуре приложения, и подсистему-приемник, функционирующую в резервной инфраструктуре. Мастер-контроллер выполнен с возможностью определять ресурсы хранения в основной инфраструктуре, которые задействуются для работы приложения, для репликации в резервную инфраструктуру и для каждого из определенных ресурсов хранения (ресурса-источника) выбирать в резервной инфраструктуре соответствующий ресурс хранения (ресурс-приемник), образуя репликационную пару из ресурса-источника и ресурса-приемника. Каждая из подсистемы-источника и подсистемы-приемника содержит: хост-контроллер, взаимодействующий с мастер-контроллером, диспетчер репликационной пары и компоненты репликации под управлением диспетчера репликационной пары. Между основной и резервной инфраструктурами выполняется синхронизация с консистентной репликацией данных между ними. 8 н. и 40 з.п. ф-лы, 8 ил.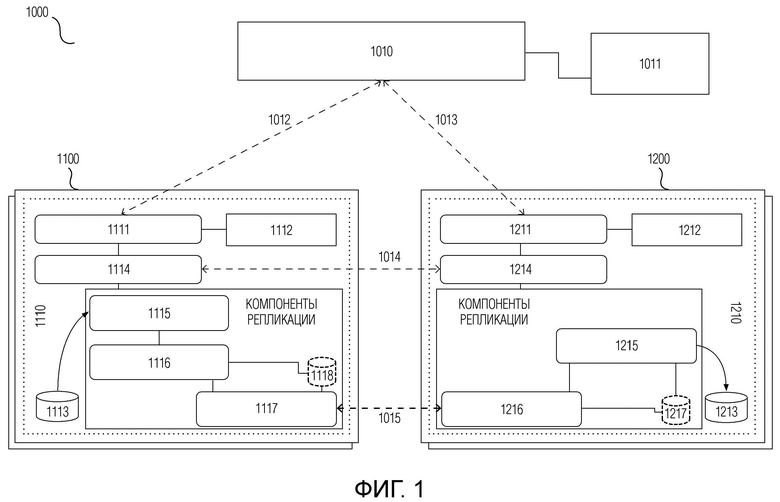
1. Способ развертывания системы обеспечения катастрофоустойчивости в распределенной сетевой среде, причем распределенная сетевая среда содержит по меньшей мере одну основную инфраструктуру приложения, реализованную на одном или более серверах основной инфраструктуры, при этом в каждой основной инфраструктуре приложения из по меньшей мере одной основной инфраструктуры приложения работает приложение, катастрофоустойчивость которого требуется обеспечить, причем распределенная сетевая среда содержит мастер-контроллер системы обеспечения катастрофоустойчивости, реализованный на одном или более вычислительных устройствах, при этом способ содержит этапы, на которых,
для каждой основной инфраструктуры приложения из по меньшей мере одной основной инфраструктуры приложения:
конфигурируют в распределенной сетевой среде по меньшей мере одну резервную инфраструктуру для основной инфраструктуры приложения, причем резервная инфраструктура реализована на одном или более серверах резервной инфраструктуры;
в основной инфраструктуре приложения устанавливают и запускают подсистему системы обеспечения катастрофоустойчивости для основной инфраструктуры приложения (подсистему-источник) и в каждой резервной инфраструктуре из по меньшей мере одной резервной инфраструктуры устанавливают и запускают подсистему системы обеспечения катастрофоустойчивости для резервной инфраструктуры (подсистему-приемник);
для каждой резервной инфраструктуры из по меньшей мере одной резервной инфраструктуры,
посредством мастер-контроллера,
определяют один или более ресурсов хранения в основной инфраструктуре приложения, которые задействуются для работы приложения, для репликации в резервную инфраструктуру и,
для каждого из определенных одного или более ресурсов хранения (ресурса-источника), выбирают в резервной инфраструктуре по меньшей мере один соответствующий ресурс хранения (ресурс-приемник), образуя репликационную пару из ресурса-источника и ресурса-приемника;
для каждой репликационной пары, не останавливая работу приложения,
выполняют предварительную репликацию данных с ресурса-источника на ресурс-приемник, при этом предварительная репликация данных содержит этапы, на которых:
выполняют первичное копирование блоков данных ресурса-источника на ресурс-приемник,
посредством подсистемы-источника выполняют регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала первичного копирования, и, по завершении первичного копирования, формируют массив информации регистрации изменений в отношении зарегистрированных блоков данных и передают сформированный массив информации регистрации изменений в резервную инфраструктуру и
посредством подсистемы-приемника осуществляют запись на ресурс-приемник блоков данных с использованием принятого массива информации регистрации изменений; и
для каждой репликационной пары, не останавливая работу приложения, выполняют циклы синхронизации, при этом каждый цикл синхронизации содержит этапы, на которых:
в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, посредством подсистемы-источника выполняют регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формируют массив информации регистрации изменений в отношении зарегистрированных блоков данных,
передают сформированные один или более массивов информации регистрации изменений в резервную инфраструктуру и сохраняют один или более массивов информации регистрации изменений в резервной инфраструктуре и
посредством подсистемы-приемника осуществляют запись на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных в резервной инфраструктуре.
2. Способ по п. 1, дополнительно содержащий, перед конфигурированием по меньшей мере одной резервной инфраструктуры, этапы, на которых, с использованием мастер-контроллера:
получают информацию о технических характеристиках и настройках одного или более серверов основной инфраструктуры посредством установки и запуска специализированных служебных утилит на каждом из одного или более серверов основной инфраструктуры;
определяют параметры, характеризующие ресурсные потребности основной инфраструктуры приложения, с использованием полученной информации о технических характеристиках и настройках одного или более серверов основной инфраструктуры.
3. Способ по п. 2, в котором упомянутые один или более серверов основной инфраструктуры представляют собой множество серверов основной инфраструктуры, причем один или более из множества серверов основной инфраструктуры являются виртуальными серверами, реализованными посредством виртуальных машин, при этом получение информации о технических характеристиках и настройках серверов основной инфраструктуры осуществляется посредством обращения к API гипервизоров, обеспечивающих работу виртуальных машин.
4. Способ по п. 2 или 3, в котором конфигурирование по меньшей мере одной резервной инфраструктуры содержит этапы, на которых:
получают информацию о технических характеристиках и настройках каждого из совокупности серверов в распределенной сетевой среде, которые могут быть использованы для по меньшей мере одной резервной инфраструктуры, посредством установки и запуска специализированных служебных утилит на каждом из совокупности серверов; и
выполняют исходное конфигурирование одного или более из совокупности серверов для по меньшей мере одной резервной инфраструктуры на основе анализа, по меньшей мере, упомянутых параметров ресурсных потребностей основной инфраструктуры приложения и полученной информации о технических характеристиках и настройках совокупности серверов.
5. Способ по п. 2 или 3, в котором конфигурирование по меньшей мере одной резервной инфраструктуры содержит этап, на котором получают информацию о технических характеристиках и настройках одного или более серверов резервной инфраструктуры посредством установки и запуска специализированных служебных утилит на каждом из одного или более серверов резервной инфраструктуры.
6. Способ по п. 4 или 5, дополнительно содержащий этапы, на которых, перед установкой и запуском подсистемы-источника и подсистемы-приемника:
выполняют оценку достижимости целевых характеристик обеспечения катастрофоустойчивости, предварительно заданных в мастер-контроллере, на основе упомянутой информации о технических характеристиках и настройках одного или более серверов основной инфраструктуры, упомянутых параметров ресурсных потребностей основной инфраструктуры приложения и информации о технических характеристиках и настройках одного или более серверов резервной инфраструктуры; и
выполняют корректировку по меньшей мере одной из целевых характеристик обеспечения катастрофоустойчивости, если в результате оценки установлена недостижимость этой по меньшей мере одной целевой характеристики обеспечения катастрофоустойчивости,
при этом целевые характеристики обеспечения катастрофоустойчивости содержат параметр RTO и параметр RPO, причем по меньшей мере один из параметра RTO и параметра RPO является индивидуальным для каждого сочетания «основная инфраструктура приложения - резервная инфраструктура».
7. Способ по п. 6, в котором конфигурирование по меньшей мере одной резервной инфраструктуры содержит этапы, на которых:
конфигурируют правила автоматического преобразования настроек сетевых интерфейсов на одном или более серверах резервной инфраструктуры на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения; и/или
конфигурируют правила автоматического изменения системных настроек операционной системы каждого из одного или более серверов резервной инфраструктуры на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения; и/или
конфигурируют зависящие от приложения правила, причем данное конфигурирование содержит задание одной или более контрольных точек для приложения, в каждой из которых в резервной инфраструктуре может быть запущен соответствующий пользовательский исполняемый сценарий для выполнения действий, специфических для приложения, в целях дополнительного обеспечения целостности данных приложения на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения.
8. Способ по п. 7, в котором для выполнения регистрации блоков данных ресурса-источника, подвергшихся изменению, при выполнении предварительной репликации и выполнении циклов синхронизации используются CBT-журналы и COW-журналы, а каждый массив информации регистрации изменений содержит stash-файл.
9. Способ по п. 8, в котором предварительная репликация дополнительно содержит этап, на котором, перед выполнением первичного копирования данных, в подсистеме-источнике открывают первый CBT-журнал,
при этом, при выполнении предварительной репликации,
упомянутое выполнение регистрации содержит этапы, на которых:
регистрируют информацию о блоках данных ресурса-источника, подвергшихся изменению во время первичного копирования, в первом CBT-журнале,
в момент завершения первичного копирования, закрывают первый CBT-журнал и открывают второй COW-журнал и второй CBT-журнал,
регистрируют блоки данных ресурса-источника, подвергшиеся изменению, во втором COW-журнале и втором CBT-журнале;
упомянутое формирование массива информации регистрации изменений содержит этапы, на которых:
создают stash-файл и
для каждого блока данных ресурса-источника, который в закрытом первом CBT-журнале помечен как подвергшийся изменению:
проверяют, помечен ли блок данных как подвергшийся изменению во втором CBT-журнале,
если это так, соответственно записывают в созданный stash-файл содержимое блока данных из второго COW-журнала, в противном случае соответственно записывают в созданный stash-файл текущее содержимое блока данных с ресурса-источника;
при упомянутом осуществлении записи на ресурс-приемник применяют принятый stash-файл к ресурсу-приемнику.
10. Способ по п. 9, в котором при выполнении циклов синхронизации,
для каждого текущего интервала регистрации изменений,
упомянутое выполнение регистрации содержит этапы, на которых:
открывают текущий COW-журнал и текущий CBT-журнал,
регистрируют блоки данных ресурса-источника, подвергшиеся изменению после начала текущего интервала регистрации изменений, в текущем COW-журнале и текущем CBT-журнале;
упомянутое формирование массива информации регистрации содержит этапы, на которых:
создают stash-файл и
для каждого блока данных ресурса-источника, который помечен в CBT-журнале, закрытом по истечении предыдущего интервала регистрации изменений, как подвергшийся изменению:
проверяют, помечен ли блок данных как подвергшийся изменению в текущем CBT-журнале,
если это так, соответственно записывают в созданный stash-файл содержимое блока данных из текущего COW-журнала, в противном случае соответственно записывают в созданный stash-файл текущее содержимое блока данных с ресурса-источника;
упомянутое выполнение регистрации дополнительно содержит этап, на котором, по истечении текущего интервала регистрации изменений, закрывают текущий COW-журнал и текущий CBT-журнал;
при упомянутом осуществлении записи на ресурс-приемник последовательно применяют stash-файлы, сохраненные в резервной инфраструктуре, к ресурсу-приемнику.
11. Способ по п. 10, в котором длительность интервала регистрации изменений определяется параметром RPO.
12. Способ по п. 10 или 11, в котором упомянутое осуществление записи на ресурс-приемник блоков данных с использованием сохраненных массивов информации регистрации изменений выполняют с задержкой после упомянутого сохранения одного или более массивов информации регистрации изменений в резервной инфраструктуре, причем задержка является заранее заданной в мастер-контроллере.
13. Способ по п. 12, в котором, при выполнении циклов синхронизации,
анализируют достижимость параметра RPO на основе темпа передачи сформированных массивов информации регистрации изменений из основной инфраструктуры приложения в резервную инфраструктуру и, в случае обнаружения недостижимости параметра RPO, выдают в мастер-контроллер сообщение о недостижимости RPO и
анализируют достижимость параметра RTO на основе упомянутой задержки и темпа применения сохраненных массивов информации регистрации к ресурсу-приемнику и, в случае обнаружения недостижимости параметра RTO, выдают в мастер-контроллер сообщение о недостижимости RTO.
14. Способ по любому одному из предшествующих пунктов, в котором каждый из одного или более серверов резервной инфраструктуры до активации резервной инфраструктуры в качестве основной инфраструктуры приложения функционирует под управлением временной операционной системы, запущенной в режиме boot-to-RAM.
15. Система обеспечения катастрофоустойчивости, развернутая в распределенной сетевой среде, содержащей основную инфраструктуру приложения, реализованную на одном или более серверах основной инфраструктуры, причем в основной инфраструктуре приложения работает приложение, катастрофоустойчивость которого требуется обеспечить, при этом для основной инфраструктуры приложения сконфигурирована резервная инфраструктура, реализованная на одном или более серверах резервной инфраструктуры в распределенной сетевой среде, причем система обеспечения катастрофоустойчивости содержит:
мастер-контроллер, реализованный на одном или более вычислительных устройствах распределенной сетевой среды;
подсистему для основной инфраструктуры приложения (подсистему-источник), функционирующую в основной инфраструктуре приложения; и
подсистему для резервной инфраструктуры (подсистему-приемник), функционирующую в резервной инфраструктуре, при этом
мастер-контроллер выполнен с возможностью
определять один или более ресурсов хранения в основной инфраструктуре приложения, которые задействуются для работы приложения, для репликации в резервную инфраструктуру и,
для каждого из определенных одного или более ресурсов хранения (ресурса-источника), выбирать в резервной инфраструктуре по меньшей мере один соответствующий ресурс хранения (ресурс-приемник), образуя репликационную пару из ресурса-источника и ресурса-приемника;
подсистема-источник содержит:
хост-контроллер подсистемы-источника, выполненный с возможностью взаимодействия с мастер-контроллером,
диспетчер репликационной пары подсистемы-источника и
компоненты репликации подсистемы-источника под управлением диспетчера репликационной пары подсистемы-источника, при этом
на каждом из одного или более серверов основной инфраструктуры, который содержит один или более ресурсов-источников соответствующих репликационных пар,
запущен экземпляр хост-контроллера подсистемы-источника,
для каждой из этих соответствующих репликационных пар запущен экземпляр диспетчера репликационной пары подсистемы-источника, который находится на связи с экземпляром хост-контроллера подсистемы-источника, и
для каждого экземпляра диспетчера репликационной пары подсистемы-источника запущен соответствующий экземпляр компонентов репликации подсистемы-источника;
подсистема-приемник содержит:
хост-контроллер подсистемы-приемника, выполненный с возможностью взаимодействия с мастер-контроллером,
диспетчер репликационной пары подсистемы-приемника и
компоненты репликации подсистемы-приемника под управлением диспетчера репликационной пары подсистемы-приемника, при этом
на каждом из одного или более серверов резервной инфраструктуры, который содержит один или более ресурсов-приемников соответствующих репликационных пар,
запущен экземпляр хост-контроллера подсистемы-приемника,
для каждой из этих соответствующих репликационных пар запущен экземпляр диспетчера репликационной пары подсистемы-приемника, который находится на связи с экземпляром хост-контроллера подсистемы-приемника, и
для каждого экземпляра диспетчера репликационной пары подсистемы-приемника запущен соответствующий экземпляр компонентов репликации подсистемы-приемника;
при этом экземпляр диспетчера репликационной пары подсистемы-источника, соответствующий экземпляр компонентов репликации подсистемы-источника, экземпляр диспетчера репликационной пары подсистемы-приемника и соответствующий экземпляр компонентов репликации подсистемы-приемника, запущенные для каждой репликационной пары, выполнены с возможностью осуществлять, не останавливая работу приложения, операции, содержащие:
предварительную репликацию данных с ресурса-источника на ресурс-приемник, при этом предварительная репликация данных содержит:
первичное копирование блоков данных ресурса-источника на ресурс-приемник,
регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала первичного копирования, и, по завершении первичного копирования, формирование массива информации регистрации изменений в отношении зарегистрированных блоков данных и передачу сформированного массива информации регистрации изменений в резервную инфраструктуру, и
запись на ресурс-приемник блоков данных с использованием принятого массива информации регистрации изменений; и
выполнение циклов синхронизации, при этом каждый цикл синхронизации содержит:
в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формирование массива информации регистрации изменений в отношении зарегистрированных блоков данных,
передачу сформированных одного или более массивов информации регистрации изменений в резервную инфраструктуру и сохранение одного или более массивов информации регистрации изменений в резервной инфраструктуре и
запись на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных в резервной инфраструктуре.
16. Система по п. 15, в которой для каждой репликационной пары экземпляр диспетчера репликационной пары подсистемы-источника и экземпляр диспетчера репликационной пары подсистемы-приемника выполнены с возможностью непосредственного взаимодействия друг с другом.
17. Система по п. 16, в которой
компоненты репликации подсистемы-источника содержат, по меньшей мере, средство обнаружения изменений, средство формирования истории изменений и средство передачи, при этом для каждой репликационной пары:
соответствующий экземпляр средства обнаружения изменений выполнен с возможностью отслеживать операции ввода-вывода на ресурсе-источнике и выполнять регистрацию происходящих изменений блоков данных,
соответствующий экземпляр средства формирования истории изменений выполнен с возможностью формировать массивы информации регистрации изменений на основе регистрации, выполненной экземпляром средства обнаружения изменений, и
соответствующий экземпляр средства передачи выполнен с возможностью осуществлять передачу массивов информации регистрации изменений в резервную инфраструктуру; и
компоненты репликации подсистемы-приемника содержат, по меньшей мере, средство приема и средство применения изменений, при этом для каждой репликационной пары:
соответствующий экземпляр средства приема выполнен с возможностью осуществлять прием массивов информации регистрации изменений от средства приема подсистемы-источника и обеспечивать сохранение принятых массивов информации регистрации изменений в резервной инфраструктуре и
соответствующий экземпляр средства применения изменений выполнен с возможностью обрабатывать массивы информации регистрации изменений и применять их к ресурсу-приемнику для записи соответствующих блоков данных на ресурс-приемник.
18. Система по п. 17, в которой
подсистема-источник дополнительно содержит хранилище истории изменений подсистемы-источника для сохранения массивов информации регистрации изменений перед их передачей и/или
подсистема-приемник дополнительно содержит хранилище истории изменений подсистемы-приемника для сохранения принимаемых массивов информации регистрации изменений перед их применением.
19. Система по п. 18, в которой
экземпляры хост-контроллера подсистемы-источника, диспетчера репликационной пары подсистемы-источника и компонентов репликации подсистемы-источника, установленные на соответствующем сервере основной инфраструктуры, реализованы посредством машиноисполняемых процессов, функционирующих на уровне операционной системы этого сервера, и/или
экземпляры хост-контроллера подсистемы-приемника, диспетчера репликационной пары подсистемы-приемника и компонентов репликации подсистемы-приемника, установленные на соответствующем сервере резервной инфраструктуры, реализованы посредством машиноисполняемых процессов, функционирующих на уровне операционной системы этого сервера.
20. Система по п. 18, в которой
экземпляры хост-контроллера подсистемы-источника, диспетчера репликационной пары подсистемы-источника и компонентов репликации подсистемы-источника реализованы посредством машиноисполняемых процессов, функционирующих в специализированной аппаратной плате, устанавливаемой в соответствующий сервер основной инфраструктуры, изолированно от операционной системы этого сервера, причем машиноисполняемые процессы выполнены с возможностью перехватывать обращения к ресурсам-источникам, инициируемые на уровне процессов операционной системы, и/или
экземпляры хост-контроллера подсистемы-приемника, диспетчера репликационной пары подсистемы-приемника и компонентов репликации подсистемы-приемника реализованы посредством машиноисполняемых процессов, функционирующих в специализированной аппаратной плате, устанавливаемой в соответствующий сервер резервной инфраструктуры, изолированно от операционной системы этого сервера, причем машиноисполняемые процессы выполнены с возможностью перехватывать обращения к ресурсам-приемникам, инициируемые на уровне процессов операционной системы.
21. Система по п. 20, в которой
хранилище истории изменений подсистемы-источника реализовано на специализированной аппаратной плате, устанавливаемой в соответствующий сервер основной инфраструктуры, и/или
хранилище истории изменений подсистемы-приемника реализовано на специализированной аппаратной плате, устанавливаемой в соответствующий сервер резервной инфраструктуры.
22. Система по п. 19, в которой
упомянутые один или более серверов основной инфраструктуры представляют собой множество серверов основной инфраструктуры, причем один или более из множества серверов основной инфраструктуры являются виртуальными серверами, реализованными посредством виртуальных машин, при этом соответствующие экземпляры хост-контроллера подсистемы-источника, диспетчера репликационной пары подсистемы-источника и компонентов репликации подсистемы-источника реализованы посредством машиноисполняемых процессов, функционирующих на уровне гипервизоров, обеспечивающих работу виртуальных машин, и/или
упомянутые один или более серверов резервной инфраструктуры представляют собой множество серверов резервной инфраструктуры, причем один или более из множества серверов резервной инфраструктуры являются виртуальными серверами, реализованными посредством виртуальных машин, при этом соответствующие экземпляры хост-контроллера подсистемы-приемника, диспетчера репликационной пары подсистемы-приемника и компонентов репликации подсистемы-приемника реализованы посредством машиноисполняемых процессов, функционирующих на уровне гипервизоров, обеспечивающих работу виртуальных машин.
23. Система по любому одному из пп. 15-22, в которой каждый из одного или более серверов резервной инфраструктуры функционирует под управлением временной операционной системы, запущенной в режиме boot-to-RAM.
24. Система по любому одному из пп. 15-23, в которой, по приему в подсистеме-приемнике от мастер-контроллера команды, резервная инфраструктура активируется в качестве основной инфраструктуры приложения.
25. Система по п. 24, в которой, перед активацией резервной инфраструктуры, приостанавливается выполнение циклов синхронизации в основной инфраструктуре приложения и в резервной инфраструктуре и останавливается работа приложения в основной инфраструктуре приложения.
26. Способ функционирования системы обеспечения катастрофоустойчивости, развернутой в распределенной сетевой среде,
при этом распределенная сетевая среда содержит основную инфраструктуру приложения, реализованную на одном или более серверах основной инфраструктуры, причем в основой инфраструктуре приложения работает приложение, катастрофоустойчивость которого требуется обеспечить, при этом для основной инфраструктуры приложения сконфигурирована резервная инфраструктура, реализованная на одном или более серверах резервной инфраструктуры в распределенной сетевой среде,
при этом система обеспечения катастрофоустойчивости содержит: мастер-контроллер, реализованный на одном или более вычислительных устройствах распределенной сетевой среды; подсистему для основной инфраструктуры приложения (подсистему-источник), функционирующую в первой инфраструктуре; и подсистему для резервной инфраструктуры (подсистему-приемник), функционирующую в резервной инфраструктуре,
при этом посредством мастер-контроллера в основной инфраструктуре приложения и резервной инфраструктуре определены репликационные пары путем выбора, для каждого из одного или более ресурсов хранения, которые задействуются для работы приложения в основной инфраструктуре приложения (ресурса-источника), соответствующего ресурса хранения в резервной инфраструктуре (ресурса-приемника) с образованием репликационной пары из ресурса-источника и ресурса-приемника, причем для каждой репликационной пары выполнена предварительная репликация данных с ресурса-источника на ресурс-приемник,
при этом способ содержит этапы, на которых:
для каждой репликационной пары, не останавливая работу приложения, выполняют частичную ресинхронизацию данных ресурса-источника и ресурса-приемника, при этом частичная ресинхронизация содержит этапы, на которых:
посредством подсистемы-приемника генерируют карту текущего содержимого ресурса-приемника и передают карту текущего содержимого ресурса-приемника в подсистему-источник,
по приему карты текущего содержимого ресурса-приемника, посредством подсистемы-источника выполняют регистрацию блоков данных ресурса-источника, подвергшихся изменению, формируют массив информации регистрации изменений на основе карты текущего содержимого ресурса-приемника и зарегистрированных блоков данных и передают сформированный массив информации регистрации изменений в резервную инфраструктуру,
сохраняют массив информации регистрации изменений в резервной инфраструктуре, и
посредством подсистемы-приемника осуществляют запись на ресурс-приемник блоков данных с использованием сохраненного массива информации регистрации изменений; и
для каждой репликационной пары, не останавливая работу приложения, выполняют циклы синхронизации, при этом каждый цикл синхронизации содержит этапы, на которых:
по завершении упомянутой передачи массива информации регистрации изменений, сформированного при частичной ресинхронизации, в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, посредством подсистемы-источника выполняют регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формируют массив информации регистрации изменений в отношении зарегистрированных блоков данных,
передают сформированные один или более массивов информации регистрации изменений в резервную инфраструктуру и сохраняют один или более массивов информации регистрации изменений в резервной инфраструктуре, и
после завершения упомянутой записи блоков данных при частичной ресинхронизации, посредством подсистемы-приемника осуществляют запись на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных в резервной инфраструктуре.
27. Способ по п. 26, в котором
формирование карты текущего содержимого ресурса-приемника содержит этапы, на которых в системе-приемнике:
для каждого блока данных ресурса-приемника в соответствии с заранее заданным алгоритмом вычисляют уникальный идентификатор на основе содержимого этого блока данных и
записывают результаты вычислений в файл, причем данный файл представляет карту текущего содержимого ресурса-приемника,
причем при передаче карты текущего содержимого ресурса-приемника в подсистему-источник передают упомянутый файл.
28. Способ по п. 26 или 27, в котором упомянутым заранее заданным алгоритмом является алгоритм вычисления хеш-суммы содержимого блока данных.
29. Способ по п. 27 или 28, в котором для выполнения регистрации блоков данных ресурса-источника, подвергшихся изменению, при выполнении частичной ресинхронизации и выполнении циклов синхронизации используются CBT-журналы и COW-журналы, а каждый массив информации регистрации изменений содержит stash-файл.
30. Способ по п. 29, в котором, при выполнении частичной ресинхронизации,
упомянутое выполнение регистрации содержит этапы, на которых:
открывают COW-журнал и CBT-журнал и
регистрируют блоки данных ресурса-источника, подвергшиеся изменению, в COW-журнале и CBT-журнале;
упомянутое формирование массива информации регистрации изменений содержит этапы, на которых:
создают stash-файл и,
для каждого блока данных ресурса-источника,
проверяют, помечен ли блок данных ресурса-источника как подвергшийся изменению в CBT-журнале,
если это так, берут содержимое блока данных ресурса-источника из COW-журнала, в противном случае берут содержимое блока данных ресурса-источника с ресурса-источника,
в соответствии с упомянутым заранее заданным алгоритмом вычисляют уникальный идентификатор блока данных ресурса-источника на основе содержимого этого блока данных,
если вычисленный уникальный идентификатор блока данных ресурса-источника отличается от уникального идентификатора соответствующего блока данных ресурса-приемника согласно принятому файлу карты текущего содержимого ресурса-приемника, соответственно записывают содержимое блока данных ресурса-источника в stash-файл.
31. Способ по п. 30, в котором, при выполнении циклов синхронизации,
для каждого текущего интервала регистрации изменений,
упомянутое выполнение регистрации содержит этапы, на которых:
открывают текущий COW-журнал и текущий CBT-журнал,
регистрируют блоки данных ресурса-источника, подвергшиеся изменению после начала текущего интервала регистрации изменений, в текущем COW-журнале и текущем CBT-журнале;
упомянутое формирование массива информации регистрации содержит этапы, на которых:
создают stash-файл и,
для каждого блока данных ресурса-источника, который помечен в CBT-журнале, закрытом по истечении предыдущего интервала регистрации изменений, как подвергшийся изменению:
проверяют, помечен ли блок данных как подвергшийся изменению в текущем CBT-журнале,
если это так, соответственно записывают в созданный stash-файл содержимое блока данных из текущего COW-журнала, в противном случае соответственно записывают в созданный stash-файл текущее содержимое блока данных с ресурса-источника;
упомянутое выполнение регистрации дополнительно содержит этап, на котором, по истечении текущего интервала регистрации изменений, закрывают текущий COW-журнал и текущий CBT-журнал;
при упомянутом осуществлении записи на ресурс-приемник последовательно применяют stash-файлы, сохраненные в резервной инфраструктуре, к ресурсу-приемнику.
32. Система обеспечения катастрофоустойчивости, развернутая в распределенной сетевой среде, содержащей основную инфраструктуру приложения, реализованную на одном или более серверах основной инфраструктуры, причем в основной инфраструктуре приложения работает приложение, катастрофоустойчивость которого требуется обеспечить, при этом для основной инфраструктуры приложения сконфигурирована резервная инфраструктура, реализованная на одном или более серверах резервной инфраструктуры в распределенной сетевой среде, причем система обеспечения катастрофоустойчивости содержит:
мастер-контроллер, реализованный на одном или более вычислительных устройствах распределенной сетевой среды;
подсистему для основной инфраструктуры приложения (подсистему-источник), функционирующую в основной инфраструктуре приложения; и
подсистему для резервной инфраструктуры (подсистему-приемник), функционирующую в резервной инфраструктуре, при этом
посредством мастер-контроллера в основной инфраструктуре приложения и резервной инфраструктуре определены репликационные пары путем выбора, для каждого из одного или более ресурсов хранения, которые задействуются для работы приложения в основной инфраструктуре приложения (ресурса-источника), соответствующего ресурса хранения в резервной инфраструктуре (ресурса-приемника) с образованием репликационной пары из ресурса-источника и ресурса-приемника, причем для каждой репликационной пары выполнена предварительная репликация данных с ресурса-источника на ресурс-приемник,
подсистема-источник содержит:
хост-контроллер подсистемы-источника, выполненный с возможностью взаимодействия с мастер-контроллером,
диспетчер репликационной пары подсистемы-источника и
компоненты репликации подсистемы-источника под управлением диспетчера репликационной пары подсистемы-источника, при этом
на каждом из одного или более серверов основной инфраструктуры, который содержит один или более ресурсов-источников соответствующих репликационных пар,
запущен экземпляр хост-контроллера подсистемы-источника,
для каждой из этих соответствующих репликационных пар запущен экземпляр диспетчера репликационной пары подсистемы-источника, который находится на связи с экземпляром хост-контроллера подсистемы-источника, и
для каждого экземпляра диспетчера репликационной пары подсистемы-источника запущен соответствующий экземпляр компонентов репликации подсистемы-источника;
подсистема-приемник содержит:
хост-контроллер подсистемы-приемника, выполненный с возможностью взаимодействия с мастер-контроллером,
диспетчер репликационной пары подсистемы-приемника и
компоненты репликации подсистемы-приемника под управлением диспетчера репликационной пары подсистемы-приемника, при этом
на каждом из одного или более серверов резервной инфраструктуры, который содержит один или более ресурсов-приемников соответствующих репликационных пар,
запущен экземпляр хост-контроллера подсистемы-приемника,
для каждой из этих соответствующих репликационных пар запущен экземпляр диспетчера репликационной пары подсистемы-приемника, который находится на связи с экземпляром хост-контроллера подсистемы-приемника, и
для каждого экземпляра диспетчера репликационной пары подсистемы-приемника запущен соответствующий экземпляр компонентов репликации подсистемы-приемника;
при этом экземпляр диспетчера репликационной пары подсистемы-источника, соответствующий экземпляр компонентов репликации подсистемы-источника, экземпляр диспетчера репликационной пары подсистемы-приемника и соответствующий экземпляр компонентов репликации подсистемы-приемника, запущенные для каждой репликационной пары, выполнены с возможностью осуществлять, не останавливая работу приложения, операции, содержащие:
частичную ресинхронизацию данных ресурса-источника и ресурса-приемника, при этом частичная ресинхронизация содержит:
генерирование карты текущего содержимого ресурса-приемника и передачу карты текущего содержимого ресурса-приемника в подсистему-источник,
по приему карты текущего содержимого ресурса-приемника, регистрацию блоков данных ресурса-источника, подвергшихся изменению, формирование массива информации регистрации изменений на основе карты текущего содержимого ресурса-приемника и зарегистрированных блоков данных и передачу сформированного массива информации регистрации изменений в резервную инфраструктуру,
сохранение массива информации регистрации изменений в резервной инфраструктуре и
осуществление записи на ресурс-приемник блоков данных с использованием сохраненного массива информации регистрации изменений; и
выполнение циклов синхронизации, при этом каждый цикл синхронизации содержит:
по завершении упомянутой передачи массива информации регистрации изменений, сформированного при частичной ресинхронизации, в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, выполнение регистрации блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формирование массива информации регистрации изменений в отношении зарегистрированных блоков данных,
передачу сформированных одного или более массивов информации регистрации изменений в резервную инфраструктуру и сохранение одного или более массивов информации регистрации изменений в резервной инфраструктуре и,
после завершения упомянутой записи блоков данных при частичной ресинхронизации, осуществление записи на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных в резервной инфраструктуре.
33. Система по п. 32, в которой для каждой репликационной пары экземпляр диспетчера репликационной пары подсистемы-источника и экземпляр диспетчера репликационной пары подсистемы-приемника выполнены с возможностью непосредственного взаимодействия друг с другом.
34. Способ функционирования системы обеспечения катастрофоустойчивости, развернутой в распределенной сетевой среде согласно способу по п. 1, при этом способ функционирования содержит этапы, на которых:
обнаруживают событие, идентифицируемое как отказ основной инфраструктуры приложения; и
по приему, в подсистеме-приемнике в резервной инфраструктуре для основной инфраструктуры приложения, команды активации от мастер-контроллера, выданной вследствие данного обнаружения, активируют резервную инфраструктуру в качестве основной инфраструктуры приложения.
35. Способ по п. 34, дополнительно содержащий, после упомянутого обнаружения, этап, на котором выполняют оценку обнаруженного события, при этом команда активации выдается из мастер-контроллера на основе выполненной оценки.
36. Способ по п. 34 или 35, дополнительно содержащий, перед упомянутой активацией, этап, на котором в резервной инфраструктуре: для ресурса-приемника каждой репликационной пары, посредством подсистемы-приемника осуществляют запись блоков данных на ресурс-приемник на основе, по меньшей мере, некоторых из массивов информации регистрации изменений, которые были сохранены в резервной инфраструктуре и которые еще не были использованы для осуществления записи блоков данных на ресурс-приемник.
37. Способ по п. 36, в котором,
на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения: на одном или более серверах резервной инфраструктуры преконфигурированы правила автоматического преобразования настроек сетевых интерфейсов; преконфигурированы правила автоматического изменения системных настроек операционной системы каждого из одного или более серверов резервной инфраструктуры; преконфигурированы зависящие от приложения правила посредством задания одной или более контрольных точек для приложения, в каждой из которых в резервной инфраструктуре может быть запущен соответствующий пользовательский исполняемый сценарий для выполнения действий, специфических для приложения, в целях дополнительного обеспечения целостности данных приложения,
каждый из одного или более серверов резервной инфраструктуры до активации резервной инфраструктуры в качестве основной инфраструктуры приложения функционирует под управлением временной операционной системы, запущенной в режиме boot-to-RAM,
активация резервной инфраструктуры содержит этапы, на которых:
согласно преконфигурированным правилам автоматического преобразования, преобразуют настройки сетевых интерфейсов на, по меньшей мере, некоторых из одного или более серверов резервной инфраструктуры, и/или,
согласно преконфигурированным правилам автоматического изменения, изменяют системные настройки операционной системы, по меньшей мере, некоторых из одного или более серверов резервной инфраструктуры, и/или,
согласно преконфигурированным зависящим от приложения правилам, в резервной инфраструктуре для требующейся контрольной точки запускают соответствующий пользовательский исполняемый сценарий;
перезагружают один или более серверов резервной инфраструктуры для обеспечения работы приложения в резервной инфраструктуре и запускают приложение в резервной инфраструктуре, причем после перезагрузки один или более серверов резервной инфраструктуры функционируют под управлением основной операционной системы.
38. Способ функционирования системы обеспечения катастрофоустойчивости, развернутой в распределенной сетевой среде согласно способу по п. 1, при этом способ функционирования содержит этапы, на которых, по приему в подсистеме-источнике в основной инфраструктуре приложения и в подсистеме-приемнике в резервной инфраструктуре для основной инфраструктуры приложения команды активации от мастер-контроллера:
останавливают выполнение циклов синхронизации в основной инфраструктуре приложения и в резервной инфраструктуре и останавливают работу приложения в основной инфраструктуре приложения; и
активируют резервную инфраструктуру в качестве основной инфраструктуры приложения.
39. Способ по п. 38, дополнительно содержащий, перед упомянутой активацией, этапы, на которых, для каждой репликационной пары:
посредством подсистемы-источника в основной инфраструктуре приложения передают в резервную инфраструктуру все из массивов информации регистрации изменений, которые еще не были переданы в резервную инфраструктуру, и сохраняют эти массивы информации регистрации изменений в резервной инфраструктуре и/или
посредством подсистемы-приемника в резервной инфраструктуре осуществляют запись блоков данных на ресурс-приемник на основе, по меньшей мере, некоторых из массивов информации регистрации изменений, которые были сохранены в резервной инфраструктуре и которые еще не были использованы для осуществления записи.
40. Способ по п. 39, в котором,
на случай активации резервной инфраструктуры в качестве основной инфраструктуры приложения: на одном или более серверах резервной инфраструктуры преконфигурированы правила автоматического преобразования настроек сетевых интерфейсов; преконфигурированы правила автоматического изменения системных настроек операционной системы каждого из одного или более серверов резервной инфраструктуры; преконфигурированы зависящие от приложения правила посредством задания одной или более контрольных точек для приложения, в каждой из которых в резервной инфраструктуре может быть запущен соответствующий пользовательский исполняемый сценарий для выполнения действий, специфических для приложения, в целях дополнительного обеспечения целостности данных приложения,
каждый из одного или более серверов резервной инфраструктуры до активации резервной инфраструктуры в качестве основной инфраструктуры приложения функционирует под управлением временной операционной системы, запущенной в режиме boot-to-RAM,
активация резервной инфраструктуры содержит этапы, на которых:
согласно преконфигурированным правилам автоматического преобразования, преобразуют настройки сетевых интерфейсов на, по меньшей мере, некоторых из одного или более серверов резервной инфраструктуры, и/или,
согласно преконфигурированным правилам автоматического изменения, изменяют системные настройки операционной системы, по меньшей мере, некоторых из одного или более серверов резервной инфраструктуры, и/или,
согласно преконфигурированным зависящим от приложения правилам, в резервной инфраструктуре для требующейся контрольной точки запускают соответствующий пользовательский исполняемый сценарий;
перезагружают один или более серверов резервной инфраструктуры для обеспечения работы приложения в резервной инфраструктуре и запускают приложение в резервной инфраструктуре, причем после перезагрузки один или более серверов резервной инфраструктуры функционируют под управлением основной операционной системы.
41. Способ по п. 40, дополнительно содержащий этап, на котором выключают, по меньшей мере, некоторые из одного или более серверов основной инфраструктуры.
42. Способ функционирования системы обеспечения катастрофоустойчивости, развернутой в распределенной сетевой среде,
причем распределенная сетевая среда содержит: первую инфраструктуру, реализованную на одном или более первых серверах в распределенной сетевой среде, причем в первой инфраструктуре, в первом режиме, работает приложение, катастрофоустойчивость которого требуется обеспечить, и вторую инфраструктуру, реализованную на одном или более вторых серверах в распределенной сетевой среде, при этом первая инфраструктура и вторая инфраструктура коммуникационно связаны друг с другом, причем вторая инфраструктура выполнена с возможностью исполнения упомянутого приложения,
при этом система обеспечения катастрофоустойчивости содержит: мастер-контроллер, реализованный на одном или более вычислительных устройствах распределенной сетевой среды, подсистему для первой инфраструктуры (первую подсистему), функционирующую в первой инфраструктуре, и подсистему для второй инфраструктуры (вторую подсистему), функционирующую во второй инфраструктуре,
при этом посредством мастер-контроллера в первой инфраструктуре и второй инфраструктуре определены репликационные пары путем выбора, для каждого из одного или более ресурсов хранения, которые задействуются для работы приложения в первой инфраструктуре (ресурса-источника), соответствующего ресурса хранения во второй инфраструктуре (ресурса-приемника) с образованием репликационной пары из ресурса-источника и ресурса-приемника, причем для каждой репликационной пары выполнена предварительная репликация данных с ресурса-источника на ресурс-приемник,
при этом способ содержит этапы, на которых:
для каждой репликационной пары, не останавливая работу приложения, выполняют циклы синхронизации, при этом каждый цикл синхронизации содержит этапы, на которых:
в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, посредством первой подсистемы выполняют регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формируют массив информации регистрации изменений в отношении зарегистрированных блоков данных,
передают сформированные один или более массивов информации регистрации изменений во вторую инфраструктуру и сохраняют один или более массивов информации регистрации изменений во второй инфраструктуре и
посредством второй подсистемы осуществляют запись на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных во второй инфраструктуре;
при переходе из первого режима во второй режим,
приостанавливают выполнение циклов синхронизации в первой инфраструктуре и во второй инфраструктуре и останавливают работу приложения в первой инфраструктуре,
активируют вторую инфраструктуру в качестве первой инфраструктуры и запускают приложение во второй инфраструктуре, функционирующей в качестве первой инфраструктуры,
активируют первую инфраструктуру в качестве второй инфраструктуры и
возобновляют выполнение циклов синхронизации во второй инфраструктуре, функционирующей в качестве первой инфраструктуры, и в первой инфраструктуре, функционирующей в качестве второй инфраструктуры.
43. Способ по п. 42, в котором,
на случай перехода из первого режима во второй режим: на одном или более серверах второй инфраструктуры преконфигурированы правила автоматического преобразования настроек сетевых интерфейсов; для каждого из одного или более серверов второй инфраструктуры преконфигурированы правила автоматического изменения системных настроек операционной системы; преконфигурированы зависящие от приложения правила посредством задания одной или более контрольных точек для приложения, в каждой из которых во второй инфраструктуре может быть запущен соответствующий пользовательский исполняемый сценарий для выполнения действий, специфических для приложения, в целях дополнительного обеспечения целостности данных приложения,
активация второй инфраструктуры в качестве первой инфраструктуры при переходе из первого режима во второй режим дополнительно содержит этапы, на которых, перед упомянутым запуском приложения:
согласно преконфигурированным правилам автоматического преобразования, преобразуют настройки сетевых интерфейсов на, по меньшей мере, некоторых из одного или более серверов второй инфраструктуры, и/или,
согласно преконфигурированным правилам автоматического изменения, изменяют системные настройки операционной системы, по меньшей мере, некоторых из одного или более серверов второй инфраструктуры, и/или,
согласно преконфигурированным зависящим от приложения правилам, во второй инфраструктуре для требующейся контрольной точки запускают соответствующий пользовательский исполняемый сценарий;
перезагружают один или более серверов второй инфраструктуры для обеспечения работы приложения во второй резервной инфраструктуре.
44. Способ по п. 43, в котором первым режимом является штатный режим работы приложения, при этом первой инфраструктурой является основная инфраструктура приложения, а второй инфраструктурой является резервная инфраструктура, сконфигурированная для основной инфраструктуры приложения, при этом вторым режимом является режим, отличающийся от штатного режима.
45. Способ по п. 44, в котором вторым режимом является режим реверса репликации, при этом переход во второй режим происходит по команде реверса репликации от мастер-контроллера.
46. Способ по п. 43, в котором первым режимом является режим реверса репликации, при этом второй инфраструктурой является инфраструктура, которая изначально была основной инфраструктурой приложения и временно функционирует в качестве резервной инфраструктуры, а первой инфраструктурой является резервная инфраструктура, временно функционирующая в качестве основной инфраструктуры приложения, причем вторым режимом является штатный режим работы приложения, при этом переход во второй режим осуществляется по команде реверса репликации от мастер-контроллера.
47. Система обеспечения катастрофоустойчивости, развернутая в распределенной сетевой среде, содержащей первую инфраструктуру, реализованную на одном или более первых серверах в распределенной сетевой среде, причем в первой инфраструктуре, в первом режиме, работает приложение, катастрофоустойчивость которого требуется обеспечить, и вторую инфраструктуру, реализованную на одном или более вторых серверах в распределенной сетевой среде, при этом первая инфраструктура и вторая инфраструктура коммуникационно связаны друг с другом, причем вторая инфраструктура выполнена с возможностью исполнения упомянутого приложения,
при этом система обеспечения катастрофоустойчивости содержит:
мастер-контроллер, реализованный на одном или более вычислительных устройствах распределенной сетевой среды;
подсистему для первой инфраструктуры (первую подсистему), функционирующую в первой инфраструктуре; и
подсистему для второй инфраструктуры (вторую подсистему), функционирующую во второй инфраструктуре,
при этом посредством мастер-контроллера в первой инфраструктуре и второй инфраструктуре определены репликационные пары путем выбора, для каждого из одного или более ресурсов хранения, которые задействуются для работы приложения в первой инфраструктуре (ресурса-источника), соответствующего ресурса хранения во второй инфраструктуре (ресурса-приемника) с образованием репликационной пары из ресурса-источника и ресурса-приемника,
при этом первая подсистема содержит:
первый хост-контроллер, выполненный с возможностью взаимодействия с мастер-контроллером,
первый диспетчер репликационной пары и
первые компоненты репликации под управлением первого диспетчера репликационной пары, причем
на каждом из одного или более первых серверов, который содержит один или более ресурсов-источников соответствующих репликационных пар,
запущен экземпляр первого хост-контроллера,
для каждой из этих соответствующих репликационных пар запущен экземпляр первого диспетчера репликационной пары, который находится на связи с экземпляром первого хост-контроллера, и
для каждого экземпляра первого диспетчера репликационной пары запущен соответствующий экземпляр первых компонентов репликации;
вторая подсистема содержит:
второй хост-контроллер, выполненный с возможностью взаимодействия с мастер-контроллером,
второй диспетчер репликационной пары и
вторые компоненты репликации под управлением второго диспетчера репликационной пары, причем
на каждом из одного или более вторых серверов, который содержит один или более ресурсов-приемников соответствующих репликационных пар,
запущен экземпляр второго хост-контроллера,
для каждой из этих соответствующих репликационных пар запущен экземпляр второго диспетчера репликационной пары, который находится на связи с экземпляром второго хост-контроллера, и
для каждого экземпляра второго диспетчера репликационной пары запущен соответствующий экземпляр вторых компонентов репликации;
при этом экземпляр первого диспетчера репликационной пары, соответствующий экземпляр первых компонентов репликации, экземпляр второго диспетчера репликационной пары и соответствующий экземпляр вторых компонентов репликации, запущенные для каждой репликационной пары, выполнены с возможностью осуществлять, не останавливая работу приложения, циклы синхронизации, при этом каждый цикл синхронизации содержит:
в течение каждого интервала регистрации изменений из одного или более интервалов регистрации изменений, регистрацию блоков данных ресурса-источника, подвергшихся изменению после начала интервала регистрации изменений, и, по истечении интервала регистрации изменений, формирование массива информации регистрации изменений в отношении зарегистрированных блоков данных,
передачу сформированных одного или более массивов информации регистрации изменений во вторую инфраструктуру и сохранение одного или более массивов информации регистрации изменений во второй инфраструктуре и
запись на ресурс-приемник блоков данных с использованием массивов информации регистрации изменений, сохраненных во второй инфраструктуре;
при этом, при переходе из первого режима во второй режим,
приостанавливается выполнение циклов синхронизации в первой инфраструктуре и во второй инфраструктуре и останавливается работа приложения в первой инфраструктуре и
выполняется активация второй инфраструктуры в качестве первой инфраструктуры и первой инфраструктуры в качестве второй инфраструктуры, при этом активация содержит:
запуск приложения во второй инфраструктуре, функционирующей в качестве первой инфраструктуры, и
возобновление выполнения циклов синхронизации во второй инфраструктуре, функционирующей в качестве первой инфраструктуры, и в первой инфраструктуре, функционирующей в качестве второй инфраструктуры.
48. Система по п. 47, в которой для каждой репликационной пары экземпляр первого диспетчера репликационной пары и экземпляр второго диспетчера репликационной пары выполнены с возможностью непосредственного взаимодействия друг с другом.
| Двухосный автомобиль | 1924 |
|
SU2024A1 |
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Способ саморегуляции сетевой инфраструктуры промышленных объектов при воздействии угроз безопасности | 2020 |
|
RU2753169C1 |

