Область техники
Изобретение относится к области «Компьютерные системы, основанные на специфических вычислительных моделях - использующие модели нейронных сетей с использованием электронных средств» и может быть использовано для энергоэффективного исполнения нейросетевых моделей.
Предшествующий уровень техники
Из существующего уровня техники известен ряд примеров создания специализированных массивно-параллельных вычислительных систем, предназначенных для решения задач вывода в глубоких нейросетевых моделей.
Патент США № US 2016/0342889 A1 описывает специализированный векторный вычислитель, основанный на систолическом матричном умножителе, поддерживающий специализированную систему команд и предназначенный для выполнения матрично-векторных умножений для решения задач вычисления сверточных слоев в нейросетевых моделях. Устройство снабжено специальным буфером для промежуточного хранения как исходных данных, так и результатов вычислений, а также модулем прямого доступа к памяти, позволяющим осуществлять автономный обмен информацией с внешней памятью. Устройство снабжено двумя основными вычислительными модулями - матричным блоком, выполняющим, собственно, операции свертки, и векторным блоком, выполняющим поточечные операции над результатом, в частности, применение активационных функций и сдвиг. Ограничением данного устройства является его специализация для работы со сверточными слоями определенных размеров.
Патент № WO 2020/044152 A1 описывает массивно-параллельную вычислительную систему, основанную на наборе простых вычислителей, связанных общей сетью межсоединений в прямоугольную сетку, при этом, каждый вычислитель снабжен небольшим объемом локальной памяти, а также опционально контроллером широкополосной памяти. Для ввода-вывода система использует несколько программируемых логических интегральных схем, реализующих интерфейсную логику. В патенте предлагается две реализации системы - с использованием всей кремниевой пластины, на которой изготавливаются чипы в качестве одного большого чипа, используя, при этом, специализированные методики для решения проблем, связанных с ограниченным выходом годных в микроэлектронных процессах, а также с использованием части такой системы с использованием 3D интеграции с памятью и управляющими программируемыми логическими схемами. Назначением данной системы является использование в датацентрах для обеспечения высокопроизводительной обработки данных с использованием нейросетевых алгоритмов.
В патенте США № US 9,886,377 B2 описывается подход к построению устройств для выполнения нейросетевых алгоритмов, основанных на параллельной вычислительной архитектуре, в которой большое количество векторных вычислительных модулей объединено в однородную сетку, объединенную общим адресным интерконнектом. Каждый вычислительный модуль снабжен набором арифметико-логических блоков, управляющей системой и локальной памятью. Кроме того, патент описывает выполнение алгоритмов нейросетевой свертки такой системой. Одним из существенных отличий от заявляемого изобретения является то, что блоки памяти локальны по отношению к вычислительным модулям, при этом взаимодействие может осуществляться только через общую адресную шину. Такой подход к построению влечет за собой сниженную энергоэффективность из-за необходимости использовать маршрутизацию при любом обмене данными между модулями.
Наиболее близким по технической сущности к заявляемому изобретению является патент США № US 10,282,659 B2 описывает специализированную вычислительную систему, содержащую в себе массив специализированных вычислительных ядер, каждое из которых является специализированным процессором с простой системой команд, но, при этом, имеющим набор исполнительных модулей, которые могут использоваться одновременно, что реализуется с помощью подхода VLIW (от анг. Очень длинная машинная команда). Каждое вычислительное ядро включает в себя конволюционный модуль, предназначенный для выполнения векторно-векторных и векторно-матричных операций, а также скалярный арифметико-логический модуль и контроллеры передачи данных. Вычислительные ядра объединены общей шиной межсоединений, которая также присоединяется к контроллерам внешней памяти. Основным отличием данного изобретения от заявляемой системы является обеспечение прямого доступа к памяти каждого вычислительного ядра соседними вычислительными ядрами, а также наличие специализированных подсистем, обеспечивающих синхронизацию между процессорами.
Раскрытие изобретения
Техническим результатом является создание вычислительной системы для выполнения нейросетевых алгоритмов.
Технической задачей, решаемой данным изобретением, является решение вычислительных задач, использующих нейросетевые модели за счет построения специализированных вычислительных систем, основанных на нейросетевых потоковых процессорах.
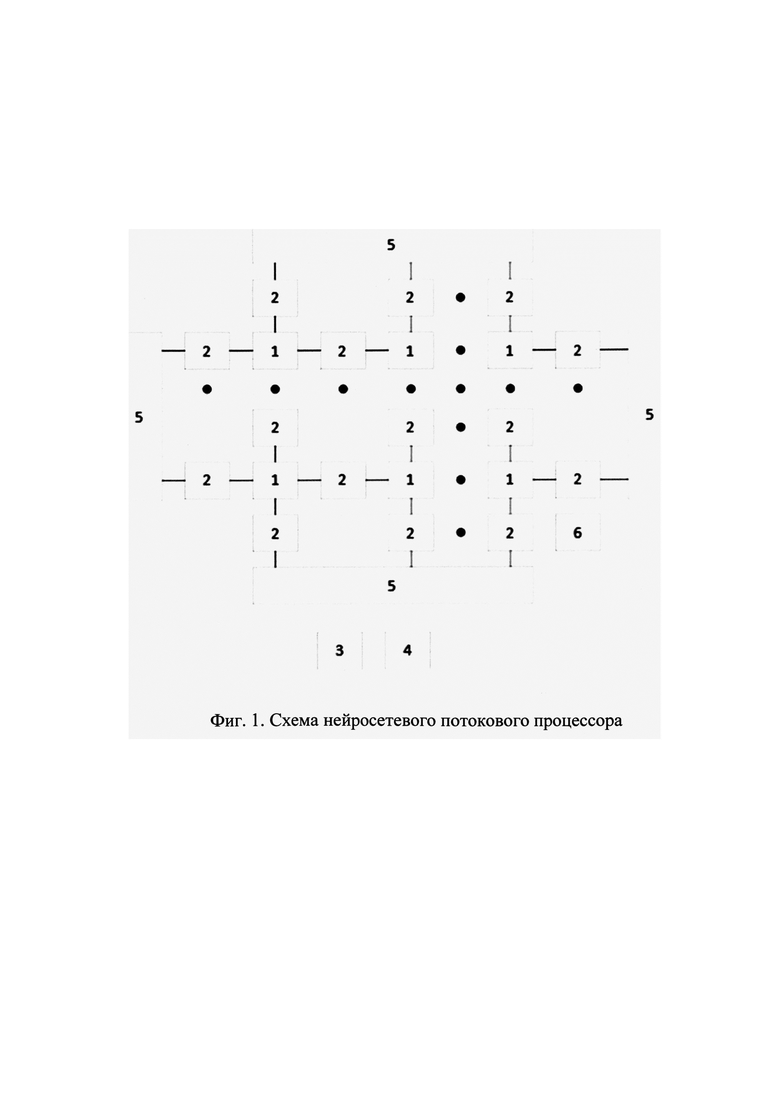
Основой специализированной вычислительной системы является один или несколько нейросетевых потоковых процессоров, каждый из которых выполняет вычисления с помощью массива вычислительных ядер, при этом каждое из вычислительных ядер имеет возможность выполнения специализированного программного кода и снабжено несколькими вычислительными блоками - в частности, блоком векторно-матричных операций, блоком скалярных операций и блоком операций с памятью. Вычислительные ядра объединены в общую вычислительную сеть, в которой также присутствуют блоки локальной памяти, к которым вычислительные ядра осуществляют доступ. Вариант реализации такого нейросетевого потокового процессора приведен на фиг. 1. В таком варианте вычислительные ядра 1 чередуются с блоками локальной памяти 2, при этом каждый блок локальной памяти (за исключением краевых) разделяется двумя соседними вычислительными ядрами. Это обеспечивает эффективную передачу данных между вычислительными ядрами в задачах потоковой обработки данных, примером которых являются глубокие нейронные сети. Нейросетевой потоковый процессор снабжен также блоком синхронизации 3, предоставляющим настраиваемые барьеры исполнения для задаваемого набора вычислительных ядер и служащий для согласования потоков исполнения каждого вычислительного ядра и блоком диагностики 4, выполняющим функции сбора метрик исполнения каждого вычислительного ядра (количество прошедших тактов и количество выполненных инструкций каждым ядром), а также функции сигнализирования об исключительных ситуациях, таких, как конфликты доступа к локальной памяти и ошибки декодирования инструкций. Нейросетевой потоковый процессор также снабжен вспомогательным процессорным ядром 6, выполняющим функции сбора диагностической информации и управления конфигурацией всего нейросетевого потокового процессора. Соединения позиций 3, 4, 6 с другими блоками на фиг. 1 не приведены для упрощения восприятия, так как эти блоки выполняют по сути служебные функции (см выше: диагностики, синхронизации и т.п.). Ввод и вывод информации осуществляется с помощью специализированных краевых интерфейсных блоков 5, обеспечивающих передачу данных из блоков локальной памяти 2, присоединенных к краевым интерфейсным блокам 5, другим нейросетевым потоковым процессорам или внешним устройствам.
На основе такого нейросетевого потокового процессора строится специализированная вычислительная система, присоединяющаяся к внешней компьютерной системе с помощью стандартного внешнего интерфейса, такого, как PCI-Express. Специализированная вычислительная система (вычислительный модуль), включает в себя один или несколько нейросетевых потоковых процессоров, а также оперативную память, внешний интерфейс и вспомогательные устройства, размещенные на общей печатной плате.
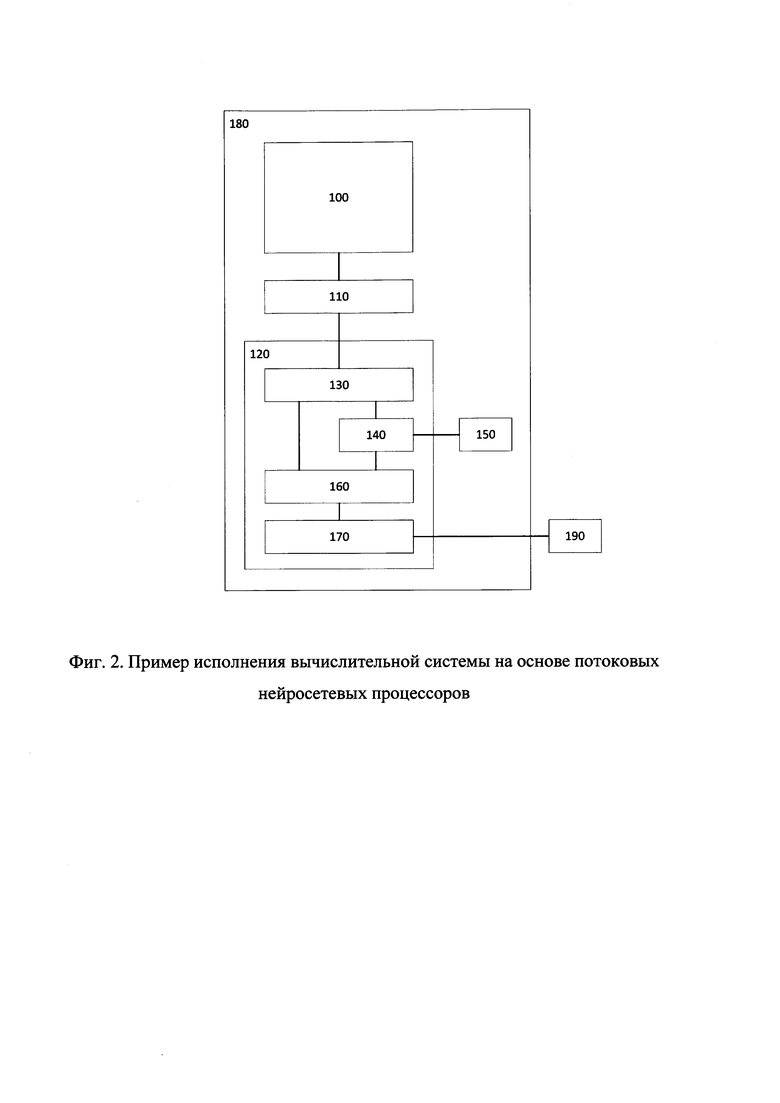
Пример конкретного исполнения специализированной вычислительной системы приведен на фиг. 2 (Здесь для примера показан вариант с одним нейросетевым потоковым процессором). В данной реализации специализированная вычислительная система 180 использует внешнюю программируемую логическую интегральную схему (ПЛИС) 120, обеспечивающую взаимодействие с динамической оперативной памятью 150 и внешней компьютерной системой 190. Нейросетевой потоковый процессор 100 подключается с помощью интерфейса, физический уровень которого представляет собой коммуникационную шину 110, размещенную на одной печатной плате с нейросетевым потоковым процессором 100 и ПЛИС 120. Для обеспечения взаимодействия с нейросетевым потоковым процессором на ПЛИС реализуется блок физического интерфейса 130, выполняющий функции сериализации и десериализации данных, а также выравнивания физических задержек, неизбежно вносимых коммуникационной шиной 110 на печатной плате. Для передачи данных между нейросетевым потоковым процессором и ПЛИС в качестве коммуникационной шины может использоваться как параллельная шина с выделенной линией синхросигнала, так и последовательная шина, реализованная в виде набора высокоскоростных последовательных каналов, использующих низковольтный дифференциальный интерфейс. В этом случае используется процедура восстановления синхросигнала из данных, а в ПЛИС и нейросетевом потоковом процессоре реализованы специальные блоки сериализации и десериализации, обеспечивающие передачу данных через последовательный интерфейс, при этом в нейросетевом потоковом процессоре такие блоки подключаются к краевым интерфейсным блокам.
Для обеспечения возможности горизонтального масштабирования вычислительной мощности системы, краевые интерфейсные блоки нейросетевого потокового процессора выполняются с возможностью обеспечения обмена данными не только с ПЛИС, но так же и с другими нейросетевыми процессорами. В этом случае, интерфейс обеспечивает возможность прозрачной передачи данных между блоками локальной памяти нейросетевых потоковых процессоров, присоединенных к краевым интерфейсным блокам. В таком случае в вычислительной системе устанавливается несколько нейросетевых потоковых процессоров, соединенных с помощью своих краевых интерфейсных блоков друг с другом. Нейросетевые потоковые процессоры могут быть установлены как на общей печатной плате, так и на специальной общей подложке-интерпозере с целью уменьшения задержек, возникающих в коммуникационных шинах.
На печатной плате также размещена динамическая оперативная память 150, выполняющая функцию хранения основного объема данных, включающих в себя данные о нейросетевой модели, входные векторы и промежуточные результаты вычислений. Взаимодействие с динамической оперативной памятью также осуществляет специализированный блок (контроллер динамической оперативной памяти 140), реализованный на ПЛИС, включающий в себя контроллер памяти и блок прямого доступа к памяти (ПДП), обеспечивающий потоковую передачу данных в блок физического интерфейса нейросетевого потокового процессора.
Реализация также может использовать контроллер памяти и блок ПДП, размещенные непосредственно на чипе нейросетевого потокового процессора. В этом случае, взаимодействие с динамической оперативной памятью осуществляется непосредственно нейросетевым потоковым процессором.
Общее управление системой осуществляется процессором общего назначения 160, который выполняет также функции взаимодействия, в том числе управляет автономным обменом данными, с внешней компьютерной системой 190 через внешний интерфейс PCI-Express, реализуемый с использованием контроллера интерфейса 170. Взаимодействие с внешней компьютерной системой также может реализовываться с помощью внешнего интерфейса 1000Base-T. При этом, процессор общего назначения также реализует TCP/IP стек, обеспечивающий возможность удаленного вызова функций специализированной вычислительной системы внешней компьютерной системой. Процессор общего назначения и контроллер интерфейса может быть также реализован на чипе нейросетевого потокового процессора. Поскольку в этом случае нейросетевому потоковому процессору необходим доступ в динамическую оперативную память для осуществления взаимодействия с внешней компьютерной системой, такой вариант реализации возможен в том случае, когда контроллер памяти и блок ПДП также размещены на чипе нейросетевого потокового процессора. В таком варианте реализации ПЛИС не требуется, поскольку все выполняемые ей функции переложены на нейросетевой потоковый процессор, что позволяет уменьшить сложность специализированной вычислительной системы и количество компонентов, необходимых для ее реализации. В таком варианте реализации коммуникационная шина 110 и блок физического интерфейса 130 отсутствуют, поскольку все компоненты специализированной вычислительной системы размещены на одном чипе.
Работа специализированной вычислительной системы состоит из трех этапов - начальная инициализация, загрузка нейросетевой модели и исполнение модели. В начале процесса инициализации производится загрузка операционной системы процессора общего назначения 160, конфигурирование ПЛИС и инициализация драйвера конечной точки PCI-Express, или TCP/IP стека при наличии интерфейса 1000Base-T, что позволяет внешней системе 190 опознать устройство и загрузить соответствующий драйвер. После завершения этого этапа выполняется сброс нейросетевого потокового процессора и блока физического интерфейса 130. После этого производится калибровка блока физического интерфейса 130 с целью определения задержек, возникающих при передаче данных по коммуникационной шине 110. Для выполнения калибровки в нейросетевой потоковый процессор загружается специальная калибровочная программа, генерирующая псевдослучайный поток данных, проходящий через внешний интерфейс, после чего блок физического интерфейса 130 настраивает физический интерфейс ввода-вывода таким образом, чтобы минимизировать ошибки передачи. Кроме того, выполняется инициализация динамической оперативной памяти 150. После окончания этого процесса, процессор общего назначения 160 посылает сигнал внешней компьютерной системе 190 об окончании процедуры инициализации, что позволяет внешней компьютерной системе 190 начать использование специализированной вычислительной системы. В случае, если контроллер интерфейса реализован непосредственно на нейросетевом потоковом процессоре, калибровка блока физического интерфейса 130 не производится ввиду его отсутствия.
Для выполнения вычислений необходимо загрузить нейросетевую модель. Для этого внешняя компьютерная система 190 посылает запрос специализированной вычислительной системе на выделение области памяти, достаточной для хранения модели, а также входных и выходных буферов, через которые, в дальнейшем, будут передаваться данные. После успешного выделения памяти, процессор общего назначения 160 настраивает контроллер интерфейса 170 для автономной передачи данных, описывающих нейросетевую модель из памяти внешней компьютерной системы в динамическую оперативную память. В случае использования интерфейса 1000Base-T, данные, описывающие нейросетевую модель, передаются внешней компьютерной системой.
После выполнения операции загрузки, модель может быть запущена на исполнение. Для этого, внешняя компьютерная система посылает запрос вычислительному модулю, после чего процессор общего назначения настраивает блок внешнего интерфейса на прием входного вектора признаков у внешней компьютерной системы и передает его в буфер в динамической оперативной памяти 150, выделенный при загрузке модели. После завершения передачи, процессор общего назначения конфигурирует нейросетевой потоковый процессор в соответствии с данными нейросетевой модели и запускает блок прямого доступа к памяти, включенный в контроллер динамической оперативной памяти 140, который передает в нейросетевой потоковый процессор поток данных в соответствии с загруженной нейросетевой моделью и принимает результаты промежуточных и конечных вычислений, передавая их в оперативную память. По окончанию исполнения, предварительно выделенный на этапе загрузки модели выходной буфер в оперативной памяти будет содержать результат исполнения нейросетевой модели, который затем передается во внешнюю систему с помощью блока внешнего интерфейса, используя шину PCI-Express или с использованием протокола TCP через интерфейс 1000Base-T.
Специализированная вычислительная система позволяет выделить несколько входных и выходных буферов для модели, что обеспечивает возможность осуществлять передачу входных данных и результатов параллельно с исполнением. Кроме того, при необходимости одновременно могут быть загружены несколько нейросетевых моделей.
Специализированная вычислительная система может также быть реализована таким образом, что программируемая логическая интегральная схема отсутствует, при этом, контроллер памяти, процессор общего назначения и внешний интерфейс реализован непосредственно в нейросетевом потоковом процессоре. В этом случае блок физического интерфейса к нейросетевому процессору отсутствует. Иллюстрация для такого варианта реализации специализированной вычислительной системы не приводится.
В варианте реализации специализированной вычислительной системы, когда блок контроллер динамической оперативной памяти, процессор общего назначения и контроллер интерфейса размещены непосредственно на чипе нейросетевого потокового процессора, также может быть установлено несколько нейросетевых потоковых процессоров, соединенных друг с другом с помощью своих краевых интерфейсных блоков. В этом случае функции коммуникации с внешней компьютерной системой берет на себя один из нейросетевых потоковых процессоров, при этом блоки других нейросетевых потоковых процессоров, ответственные за это отключаются. В такой конфигурации нейросетевые процессоры могут быть установлены не на печатной плате, а на общей подложке-интерпозере, снижающей задержки передачи данных между нейросетевыми потоковыми процессорами. Кроме того, в качестве динамической оперативной памяти может быть использована НВМ (high bandwidth memory) память, доступ к которой осуществляется с помощью специализированных контроллеров, встроенных в нейросетевые потоковые процессоры, при этом такая динамическая оперативная память устанавливается на общей подложке-интерпозере с нейросетевыми потоковыми процессорами.
Краткий перечень чертежей
На фиг. 1 представлена схема нейросетевого потокового процессора, содержащая вычислительные ядра 1, разделяемые блоки памяти 2, блок синхронизации 3, блок диагностики 4, краевые интерфейсные блоки 5 и вспомогательное процессорное ядро 6.
На фиг. 2 представлен пример исполнения вычислительной системы на основе нейросетевых потоковых процессоров, включающей в себя нейросетевой потоковый процессор 100, коммуникационную шину 110, программируемую логическую интегральную схему 120 и динамическую оперативную память 150. Программируемая логическая интегральная схема содержит в себе блок физического интерфейса 130 к нейросетевому потоковому процессору, контроллер динамической оперативной памяти 140, процессор общего назначения 160 и контроллер интерфейса 170, через который специализированная вычислительная система 180 подключается к внешней компьютерной системе 190.
Промышленная применимость
Устройство - специализированная вычислительная система, основанная на нейросетевых потоковых процессорах, может быть использовано в различных встраиваемых применениях, критичных к энергопотреблению и требующих высокой производительности для выполнения различных алгоритмов машинного обучения, основанных на глубоких нейронных сетях, таких, как робототехнические платформы, автономные камеры и различные устройства, использующие граничные вычисления.
Выводы
Описанная специализированная вычислительная система строится на основе специализированных нейросетевых потоковых процессоров и обеспечивает выполнение нейросетевых алгоритмов и решение вычислительных задач, основанных на использовании нейросетевых алгоритмов машинного обучения. Вычислительная система подключается к внешней компьютерной системе с помощью стандартных интерфейсов PCI-Express или 1000Base-T и обеспечивает горизонтальное масштабирование производительности путем установки нескольких нейросетевых потоковых процессоров, соединенных друг с другом.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ ДЛЯ МНОГОПОТОКОВОЙ ОБРАБОТКИ ЦИФРОВЫХ ДАННЫХ И СПОСОБ ОБРАБОТКИ С ИСПОЛЬЗОВАНИЕМ ДАННОГО МОДУЛЯ | 2018 |
|
RU2708794C2 |
| ВИРТУАЛИЗАЦИЯ МАССОВОГО ЗАПОМИНАЮЩЕГО УСТРОЙСТВА ДЛЯ ОБЛАЧНЫХ ВЫЧИСЛЕНИЙ | 2014 |
|
RU2649771C2 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ | 2017 |
|
RU2643622C1 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ С ДИНАМИЧЕСКИМ ПЕРЕРАСПРЕДЕЛЕНИЕМ ВЫЧИСЛИТЕЛЬНЫХ РЕСУРСОВ | 2023 |
|
RU2823113C1 |
| РЕКОНФИГУРИРУЕМАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2022 |
|
RU2798443C1 |
| РЕКОНФИГУРИРУЕМАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2017 |
|
RU2677363C1 |
| КОМПЬЮТЕРНАЯ СИСТЕМА | 2014 |
|
RU2579949C2 |
| РЕКОНФИГУРИРУЕМАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2019 |
|
RU2713757C1 |
| АВТОНОМНЫЙ ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ | 2019 |
|
RU2720556C1 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ ДЛЯ МНОГОЗАДАЧНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ | 2021 |
|
RU2780169C1 |
Изобретение относится к вычислительной технике. Техническим результатом является создание вычислительной системы для выполнения нейросетевых алгоритмов. Вычислительная система содержит массив вычислительных ядер, чередующихся с блоками локальной памяти, блок синхронизации, блок диагностики, краевые интерфейсные блоки, вспомогательное процессорное ядро, процессор общего назначения, динамическую оперативную память, контроллер динамической оперативной памяти, контроллер интерфейса, использующийся для подключения к внешней компьютерной системе. 9 з.п. ф-лы, 2 ил.
1. Вычислительная система для выполнения нейросетевых алгоритмов, состоящая из одного или нескольких нейросетевых потоковых процессоров, содержащих в себе:
- массив вычислительных ядер, чередующихся с блоками локальной памяти;
- блок синхронизации;
- блок диагностики;
- краевые интерфейсные блоки;
- вспомогательное процессорное ядро;
кроме того, вычислительная система включает в себя:
- процессор общего назначения;
- динамическую оперативную память;
- контроллер динамической оперативной памяти;
- контроллер интерфейса, использующийся для подключения к внешней компьютерной системе.
2. Вычислительная система по п. 1, отличающаяся тем, что процессор общего назначения, контроллер динамической оперативной памяти и контроллер интерфейса размещены в программируемой логической интегральной схеме, установленной на одной печатной плате с нейросетевыми потоковыми процессорами, при этом программируемая логическая интегральная схема содержит интерфейс, физический уровень которого представляет собой коммуникационную шину к нейросетевому потоковому процессору.
3. Вычислительная система по п. 1, отличающаяся тем, что для взаимодействия с внешней компьютерной системой используется внешний интерфейс PCI-Express, а процессор общего назначения реализует драйвер конечной точки PCI-Express и управляет автономным обменом данными с внешней компьютерной системой.
4. Вычислительная система по п. 1, отличающаяся тем, что для подключения к внешней компьютерной системе используется интерфейс 1000Base-T, а процессор общего назначения реализует TCP/IP стек и обеспечивает интерфейс для удаленного вызова функций.
5. Вычислительная система по п. 1, отличающаяся тем, что передача данных между нейросетевым потоковым процессором и программируемой логической интегральной схемой реализована в виде набора высокоскоростных последовательных каналов, использующих восстановление синхросигнала из данных и низковольтный дифференциальный интерфейс.
6. Вычислительная система по п. 1, отличающаяся тем, что нейросетевой потоковый процессор снабжен собственным контроллером динамической оперативной памяти, который обеспечивает передачу данных между динамической оперативной памятью и блоками локальной памяти нейросетевых процессоров.
7. Вычислительная система по п. 6, отличающаяся тем, что контроллер интерфейса и процессор общего назначения размещены непосредственно на чипе нейросетевого потокового процессора.
8. Вычислительная система по п. 7, отличающаяся тем, что в качестве динамической оперативной памяти используется память НВМ (high bandwidth memory), размещенная на общей подложке-интерпозере с нейросетевым потоковым процессором.
9. Вычислительная система по п. 1, отличающаяся тем, что нейросетевые потоковые процессоры, соединенные своими внешними интерфейсами, расположены на общей подложке-интерпозере.
10. Вычислительная система по п. 9, отличающаяся тем, что на общей подложке-интерпозере также размещена оперативная НВМ память, доступ к которой осуществляется с помощью контроллеров динамической оперативной памяти, встроенных в нейросетевые потоковые процессоры.
| Метод построения процессоров для вывода в сверточных нейронных сетях, основанный на потоковых вычислениях | 2020 |
|
RU2732201C1 |
| ВЫСОКОПРОИЗВОДИТЕЛЬНАЯ КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ | 2017 |
|
RU2733058C1 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ ДЛЯ МНОГОПОТОКОВОЙ ОБРАБОТКИ ЦИФРОВЫХ ДАННЫХ И СПОСОБ ОБРАБОТКИ С ИСПОЛЬЗОВАНИЕМ ДАННОГО МОДУЛЯ | 2018 |
|
RU2708794C2 |
| Одновременно-последовательная система цветного телевидения | 1959 |
|
SU124002A1 |
| US 10282659 B2, 07.05.2019 | |||
| WO 2020044152 A1, 05.03.2020. | |||

