РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Настоящая заявка испрашивает приоритет согласно предварительной заявке США №62/405824, поданной 7 октября 2016 г; содержание которой полностью включено в настоящее описание посредством ссылки.
УРОВЕНЬ ТЕХНИКИ
Область техники
[0002] Настоящее изобретение в целом относится к области секвенирования ДНК и, в частности, относится к системам и способам проведения в режиме реального времени вторичного анализа для применения секвенирования следующего поколения.
Описание предшествующего уровня техники
[0003] Генетическую мутацию можно идентифицировать путем идентификации вариантов - относительно референсных последовательностей - в прочтениях последовательности. Чтобы идентифицировать вариант, образец от субъекта можно полностью секвенировать с применением инструмента секвенирования для получения прочтений последовательности. После получения прочтений последовательности перед определением варианта прочтения последовательности могут быть собраны или выровнены. Таким образом, идентификация вариантов включает различные этапы, которые после завершения процесса секвенирования выполняют последовательно, и выполнение которых может занимать много времени.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0004] В настоящей заявке описаны системы и способы секвенирования полинуклеотидов. В одном варианте реализации система содержит: память, содержащую референсную нуклеотидную последовательность; процессор, выполненный с возможностью исполнения инструкций для осуществления способа, который включает: получение первой нуклеотидной подпоследовательности прочтения из системы секвенирования; обработку первой нуклеотидной подпоследовательности с применением первого способа выравнивания для определения первого множества вероятных местоположений прочтения на референсной последовательности; определение того, совпадает ли первая нуклеотидная подпоследовательность с референсной последовательностью, на основании определенных вероятных местоположений; получение второй нуклеотидной подпоследовательности из системы секвенирования; обработку второй нуклеотидной подпоследовательности для определения второго множества вероятных местоположений прочтения, которые совпадают с референсной последовательностью с применением: второго способа выравнивания последовательностей, если прочтение совпадает с референсной последовательностью, и первого способа выравнивания последовательностей в противном случае, где второй способ выравнивания последовательностей более эффективен в отношении вычислений, чем первый способ выравнивания последовательностей, для определения второго множества вероятных местоположений прочтения.
[0005] В одном варианте реализации способ включает: получение первой нуклеотидной подпоследовательности из системы секвенирования во время цикла секвенирования; и проведение вторичного анализа первой нуклеотидной подпоследовательности прочтения на основе референсной последовательности с применением первого способа анализа или второго способа анализа, где второй способ анализа является более эффективным в отношении вычисления, чем первый способ обработки, при проведении вторичного анализа.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] На ФИГ. 1 представлена схематичная иллюстрация, показывающая пример системы секвенирования для проведения вторичного анализа в режиме реального времени.
[0007] На ФИГ. 2 показана функциональная блок-схема примера компьютерной системы для проведения анализов в режиме реального времени.
[0008] На ФИГ. 3 представлена блок-схема примера способа для секвенирования путем синтеза.
[0009] На ФИГ. 4 представлена блок-схема примера способа для проведения вызова оснований.
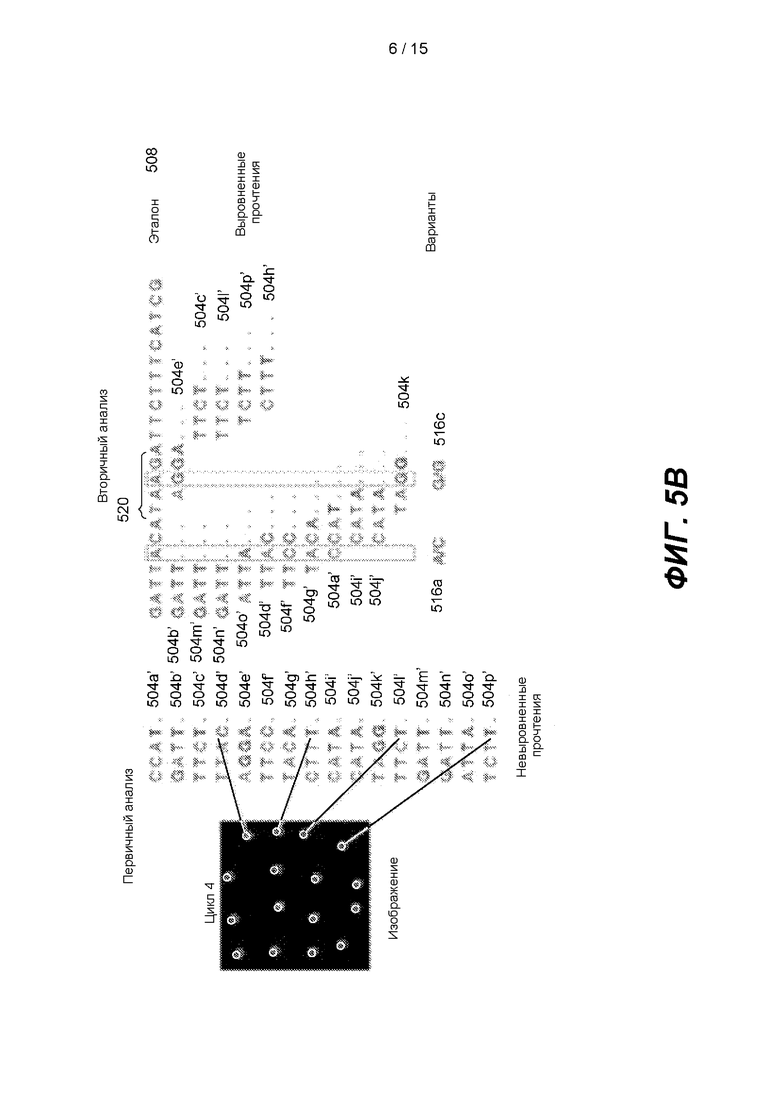
[0010] На ФИГ. 5А и 5В показан пример итерационного выравнивания и вызова варианта.
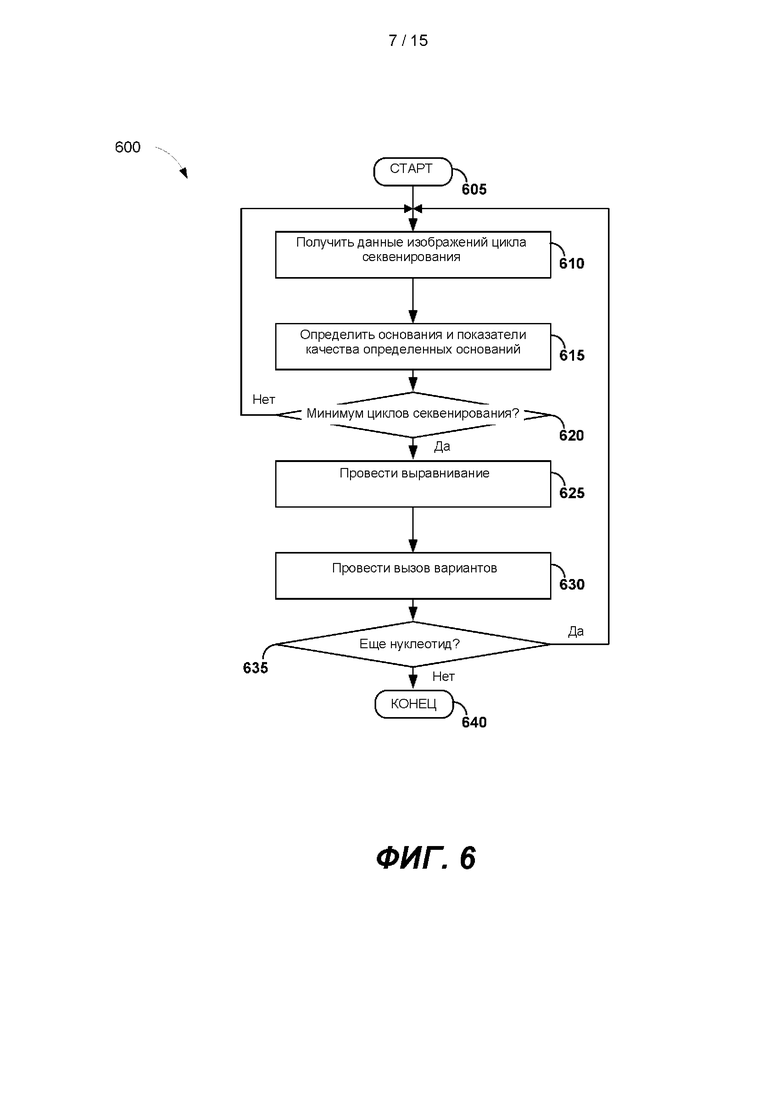
[0011] На ФИГ. 6 представлена блок-схема примера способа для проведения вторичного анализа последовательности в режиме реального времени.
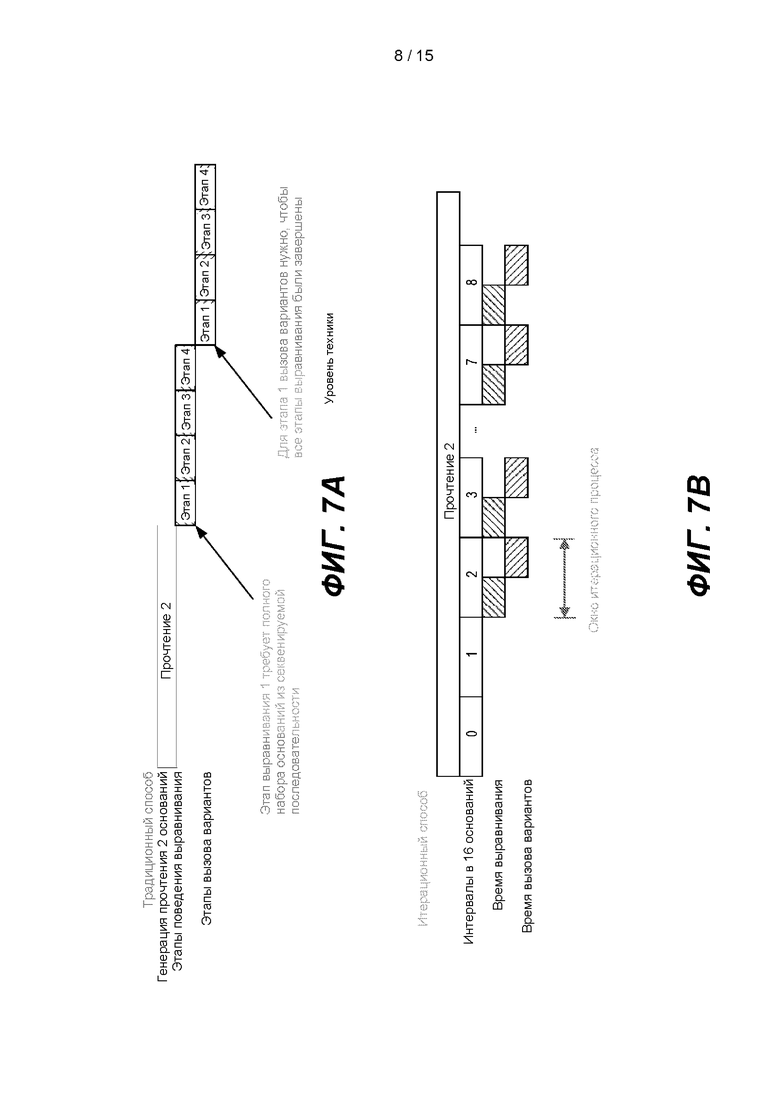
[0012] На ФИГ. 7А и 7В представлены схематичные иллюстрации, сравнивающие традиционный способ вторичного анализа (ФИГ. 7А) с итерационным способом вторичного анализа (ФИГ. 7В).
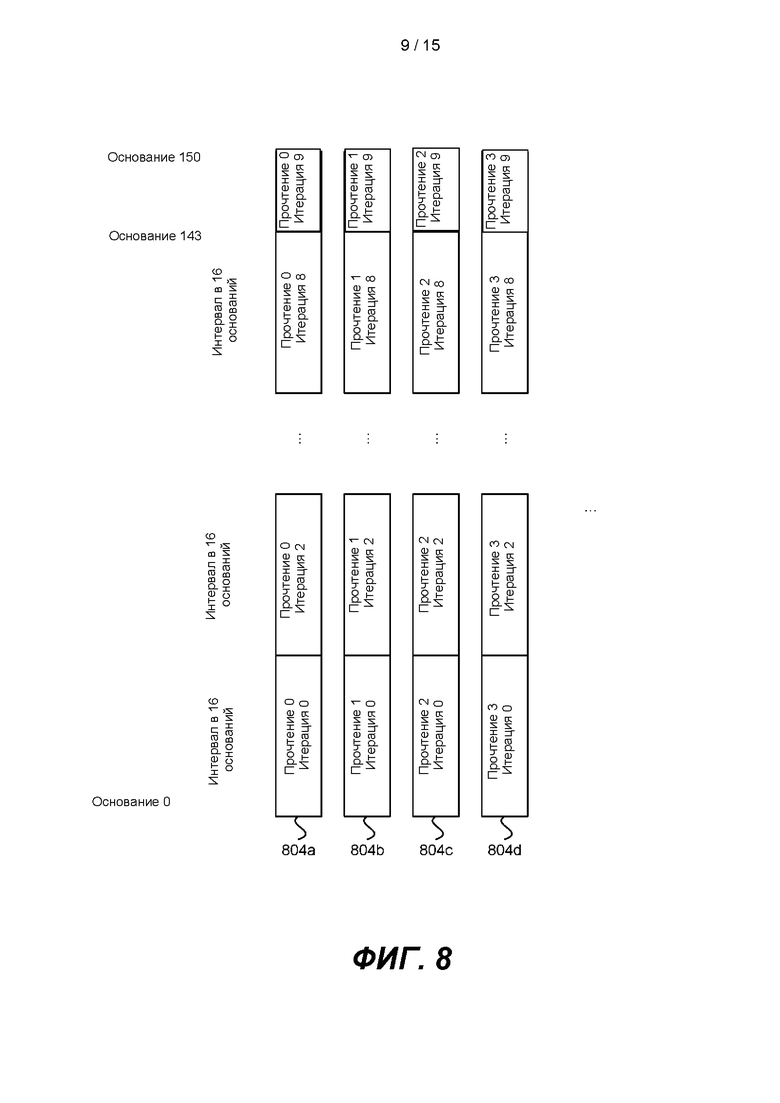
[0013] На ФИГ. 8 представлена схематичная иллюстрация генерации прочтения с интервалом в 16 оснований.
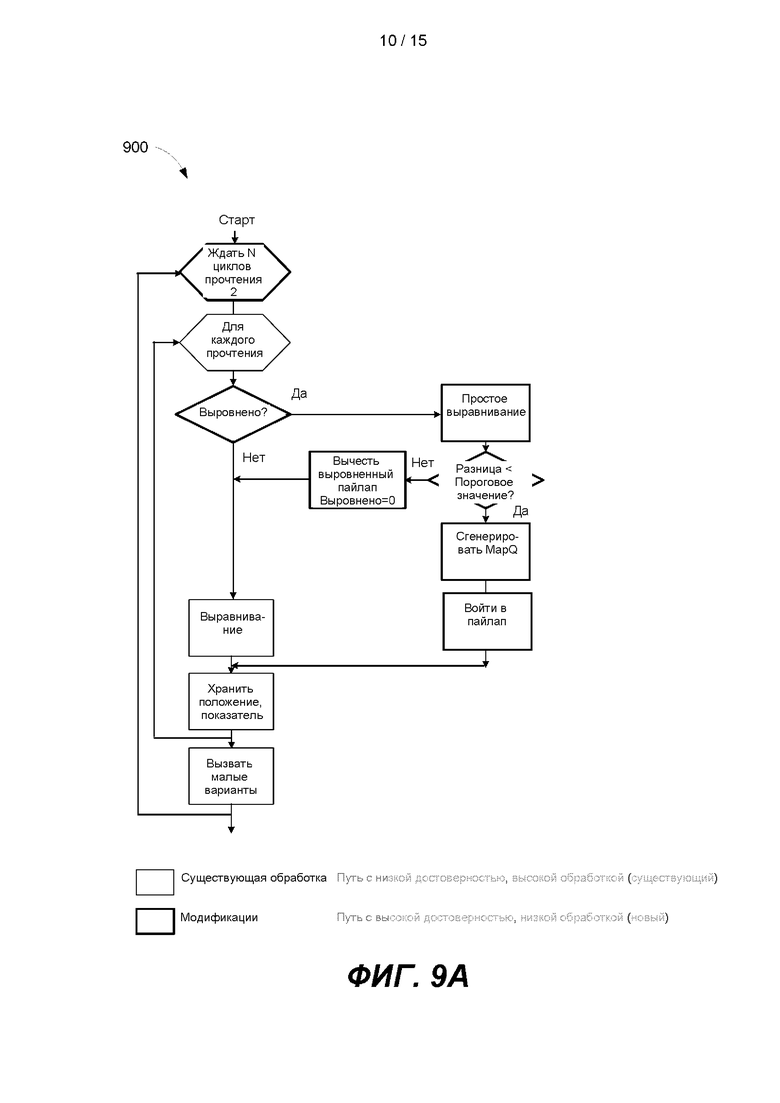
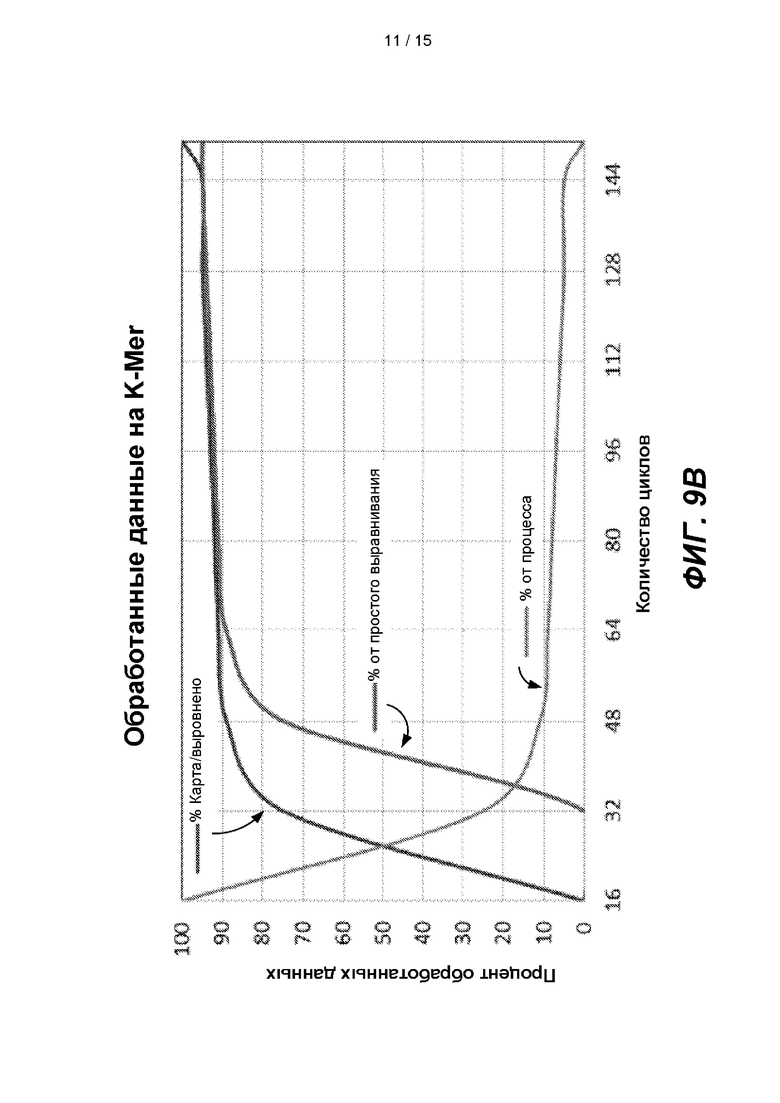
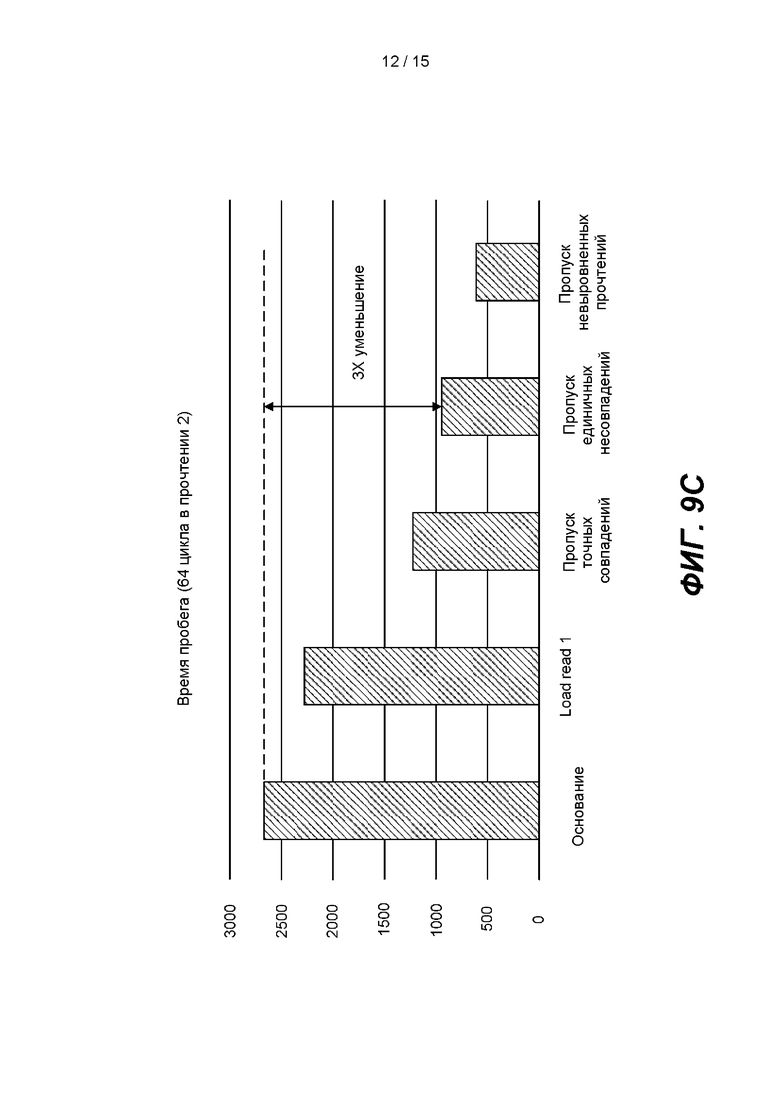
[0014] На ФИГ. 9А представлена блок-схема примера способа для проведения вторичного анализа в режиме реального времени. На ФИГ. 9В представлен прогнозируемый линейный график, показывающий данные, обработанные по K-Mer. На ФИГ. 9С представлена гистограмма, показывающая время цикла.
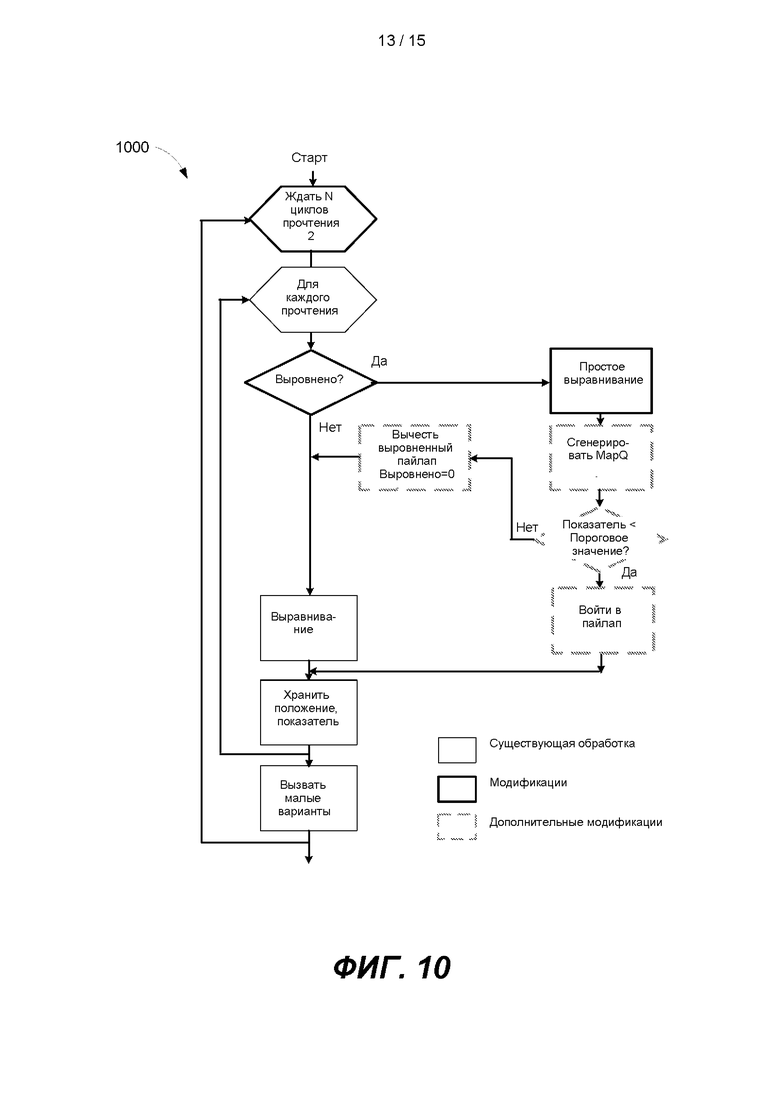
[0015] На ФИГ. 10 представлена другая блок-схема примера способа для проведения вторичного анализа в режиме реального времени.
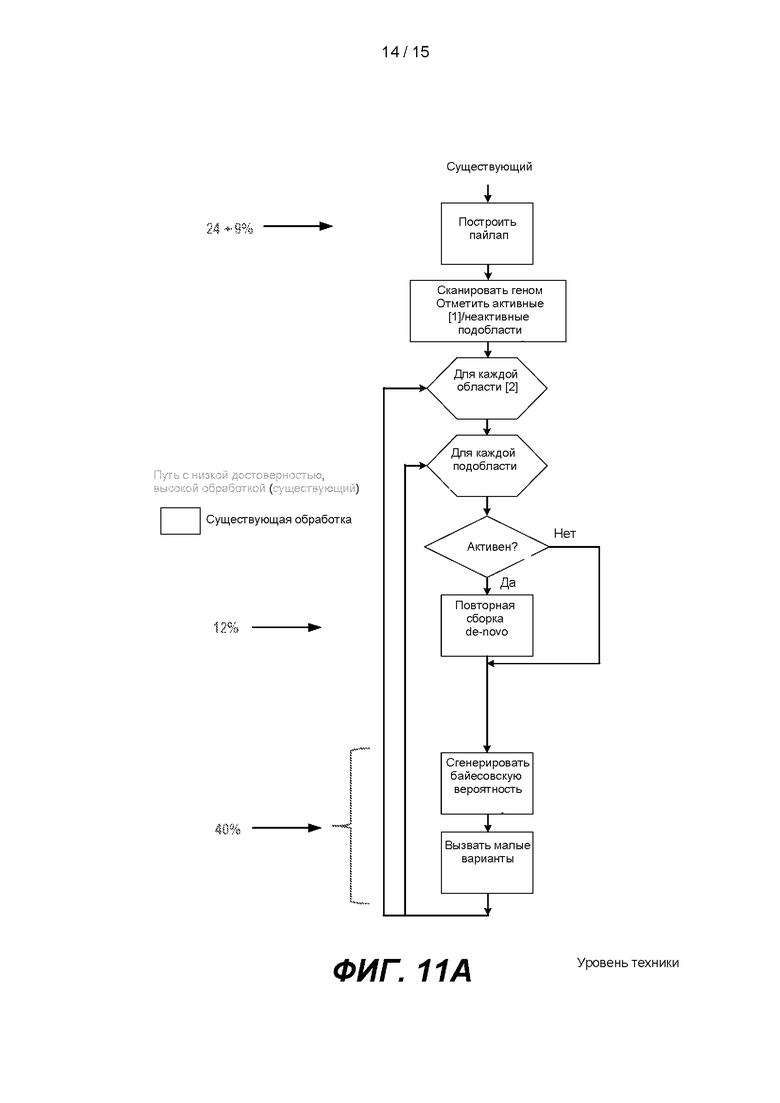
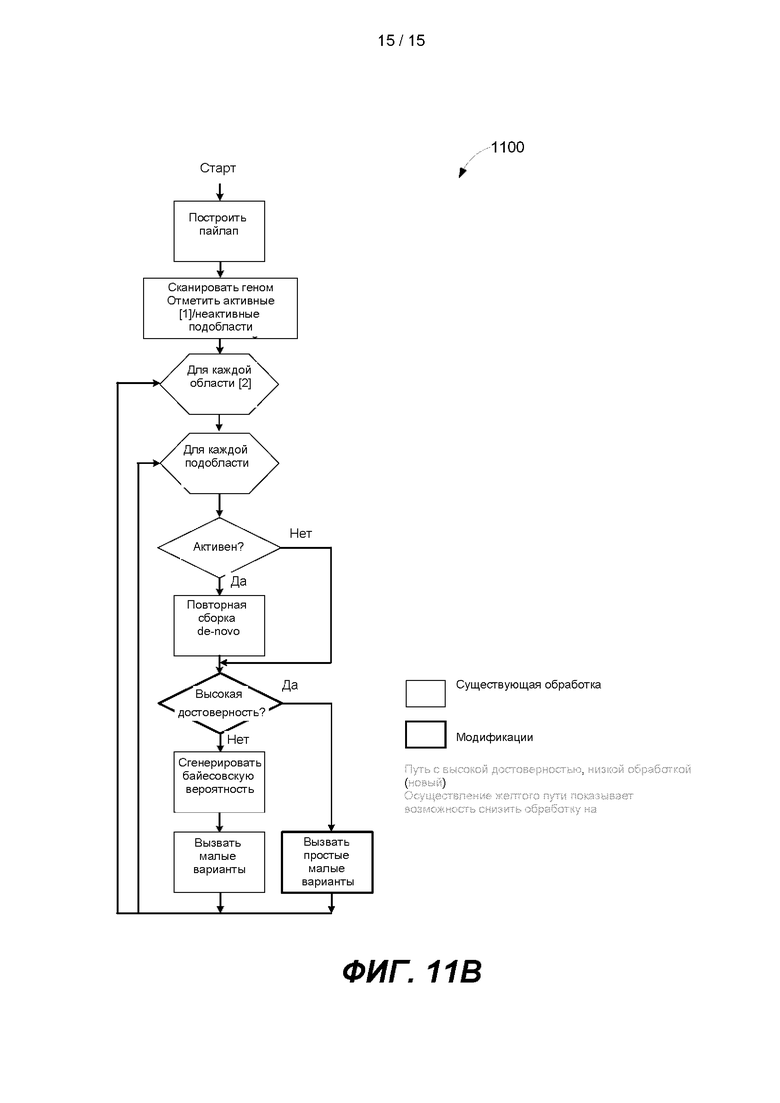
[0016] На ФИГ. 11А и 11В сравниваются существующий определитель вариантов (ФИГ. 11А) с определителем вариантов, который использует способ с высокой достоверностью, низкой обработкой, как описано в настоящей заявке (ФИГ. 11В).
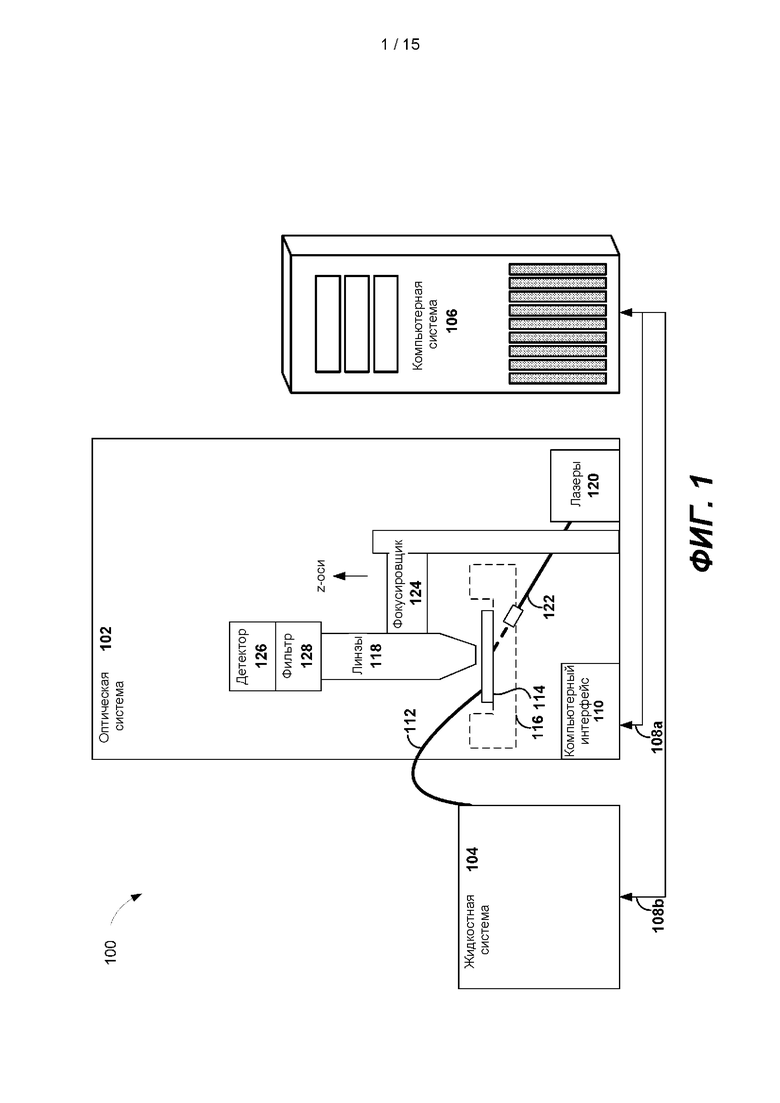
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0017] В следующем подробном описании представлена ссылка на прилагаемые чертежи, которые составляют его часть. В чертежах одинаковые символы, как правило, определяют одни и те же компоненты, если контекстом не определено иное. Иллюстративные варианты реализации, описанные в подробном описании, чертежах и формуле изобретения, не должны считаться ограничивающими. Можно использовать другие варианты реализации и вносить другие изменения, не отклоняясь от сущности или объема объекта изобретения, представленного в настоящей заявке. Нетрудно понять, что аспекты настоящего изобретения, как в целом описано в настоящей заявке и проиллюстрировано на Фигурах, могут быть составлены, заменены, скомбинированы, разделены и спроектированы с самыми различными конфигурациями, все из которых явным образом составляют часть данного описания.
[0018] В настоящей заявке описаны системы и способы проведения вторичного анализа данных секвенирования нуклеотидов времясберегающим образом. В некоторых вариантах реализации способ включает проведение вторичного анализа несколько раз, пока система секвенирования генерирует прочтения последовательности. Вторичный анализ может охватывать как выравнивание прочтений последовательности с референсной последовательностью (например, референсной последовательностью генома человека), так и применение этого выравнивания для выявления различий между образцом и референсом. Вторичный анализ может дать возможность обнаружения генетических различий, обнаружения и генотипирования вариантов, идентификации однонуклеотидных полиморфизмов (SNP), небольших вставок и делеций (инсерционно-делеционные мутации) и структурных изменений в ДНК, таких как варианты числа копий (CNV) и хромосомные перестройки.
[0019] При проведении вторичного анализа во время генерации прочтений последовательности с помощью системы и способа можно несколько раз определять предварительные вызовы вариантов в режиме реального времени (или с нулевой или низкой задержкой). Конечные результаты определений вариантов могут быть доступны вскоре после (или сразу после) окончания цикла секвенирования. Альтернативным образом, цикл секвенирования может быть прекращен досрочно, если во время цикла вызовы вариантов доступны с достаточной достоверностью. В некоторых вариантах реализации из системы секвенирования передается только информация, связанная с определениями вариантов (например, вызовами вариантов). Это может уменьшить или минимизировать необходимую передачу данных по сравнению с проведением определений вариантов в системе, которая является внешней. Кроме того, в вычислительную систему (например, облачную компьютерную систему) для дальнейшей обработки можно послать только информацию о варианте. В этом варианте реализации циклы секвенирования можно остановить до завершения полного процесса секвенирования. Например, если идентичность представляющего интерес патогена определяют после ряда запусков секвенирования в цикле секвенирования, цикл секвенирования можно остановить. Таким образом можно уменьшить время конкретного ответа (например, идентификации патогена). В одном варианте исходы и промежуточные результаты системы могут включать гистограммы дубликатов, точных совпадений, одиночных и двойных SNP, а также одиночных и двойных инсерционно-делеционных мутаций.
Определения
[0020] Если не указано иное, технические и научные термины, используемые в настоящей заявке, имеют то же значение, под которым их обычно понимают средние специалисты в области техники, к которой относится настоящее изобретение. См., например, Singleton et al., Dictionary of Microbiology and Molecular Biology 2nd ed., J. Wiley & Sons (New York, NY 1994); Sambrook et al., Molecular Cloning, A Laboratory Manual, Cold Springs Harbor Press (Cold Springs Harbor, NY 1989). В целях настоящего изобретения ниже определены следующие термины.
Секвенатор для выполнения вторичного анализа в реальном времени
[0021] В настоящей заявке описаны системы и способы для неоднократного проведения вторичного анализа, эффективного в отношении временных и/или вычислительных ресурсов. Вторичный анализ может охватывать как выравнивание прочтений последовательности с референсной последовательностью (например, референсной последовательностью генома человека), так и применение этого выравнивания для выявления различий между образцом и референсом. Вторичный анализ может дать возможность обнаружения генетических различий, обнаружения и генотипирования вариантов, идентификации однонуклеотидных полиморфизмов (SNP), небольших вставок и делеций (инсерционно-делеционные мутации) и структурных изменений в ДНК, таких как варианты числа копий (CNV) и хромосомные перестройки. Вторичный анализ можно проводить в ходе одного цикла секвенирования, пока генерируются данные секвенирования для следующего цикла секвенирования.
[0022] На ФИГ. 1 представлена схематичная иллюстрация, показывающая примерную систему секвенирования 100 для проведения вторичного анализа в режиме реального времени. Неограничивающие примеры способа секвенирования, используемого системой секвенирования 100, могут включать секвенирование путем синтеза и секвенирование единичных молекул Heliscope. Система секвенирования 100 может содержать оптическую систему 102, выполненную с возможностью генерации необработанных данных секвенирования с использованием реактивов для секвенирования, поставляемых вместе с жидкостной системой 104, которая является частью системы секвенирования 100. Необработанные данные секвенирования могут включать флюоресцентные изображения, снятые оптической системой 102. Компьютерную систему 106, которая является частью системы секвенирования 100, можно выполнить с возможностью управления оптической системой 102 и жидкостной системой 104 через каналы связи 108а и 108b. Например, компьютерный интерфейс 110 оптической системы 102 можно выполнить с возможностью связи с компьютерной системой 106 через канал связи 108а.
[0023] Во время реакций секвенирования жидкостная система 104 может направлять поток реактивов через одну или несколько трубок для реактивов 112 в расположенную на монтажной площадке 116 проточную кювету 114 и из нее. Реактивами могут быть, например, флюоресцентно меченые нуклеотиды, буферы, ферменты и реактивы для расщепления. Проточная кювета 114 может содержать по меньшей мере один жидкостный канал. Проточная кювета 114 может быть расположена по шаблону или случайным образом. Проточная кювета 114 может содержать по меньшей мере в одном жидкостном канале несколько кластеров одноцепочечных полинуклеотидов для секвенирования. Длина полинуклеотидов может находиться в широком диапазоне, например, от 200 оснований до 1000 оснований. Полинуклеотиды могут быть присоединены к одному или более жидкостным каналам проточной кюветы 114. В некоторых вариантах реализации проточная кювета 114 может содержать множество гранул, при этом каждая гранула может содержать множество копий полинуклеотида для секвенирования. Монтажную площадку 116 можно выполнить с возможностью обеспечения правильного выравнивания и перемещения проточной кюветы 114 относительно других компонентов оптической системы 102. В одном варианте реализации монтажную площадку 116 можно использовать для выравнивания проточной кюветы 114 с линзой 118.
[0024] Оптическая система 102 может содержать несколько лазеров 120, выполненных с возможностью генерации света на заданных длинах волн. Свет, генерируемый лазерами 120, может проходить через оптоволоконный кабель 122 для возбуждения флюоресцентных меток в проточной кювете 114. Линза 118, установленная на фокусировщике 124, может перемещаться вдоль оси z. Сфокусированные флюоресцентные излучения могут быть обнаружены детектором 126, например, датчиком на приборе с зарядовой связью (CCD) или датчиком на металлооксидном полупроводнике (CMOS).
[0025] Фильтрующий узел 128 оптической системы 102 можно выполнить с возможностью фильтрации флюоресцентного излучения флюоресцентных меток в проточной кювете 114. Фильтрующий узел 128 может содержать первый фильтр и второй фильтр. Каждый фильтр может быть низкопроходным, высокопроходным или полосным, в зависимости от типов флюоресцентных молекул, используемых в системе. Первый фильтр можно выполнить с возможностью обнаружения флюоресцентного излучения первых флюоресцентных меток детектором 126. Второй фильтр можно выполнить с возможностью обнаружения флюоресцентного излучения вторых флюоресцентных меток детектором 126. С двумя фильтрами в фильтрующем узле 128 детектор 126 может определять две разные длины волны флюоресцентного излучения.
[0026] В некоторых вариантах реализации оптическая система 102 может содержать дихроматичный элемент, выполненный с возможностью разделения флюоресцентных излучений. Оптическая система 102 может содержать два детектора, первый детектор в сочетании с первым фильтром для определения флюоресцентных излучений с первой длиной волны и второй детектор в сочетании со вторым фильтром для определения флюоресцентных излучений со второй длиной волны.
[0027] При использовании образец, содержащий полинуклеотид для секвенирования, загружают в проточную кювету 114 и помещают на монтажную площадку 116. Компьютерная система 106 затем активирует жидкостную систему 104, чтобы начать цикл секвенирования. Во время реакций секвенирования компьютерная система 106 через интерфейс связи 108b дает команду жидкостной системе 104 подавать реактивы, например, нуклеотидные аналоги, в проточную кювету 114. Через интерфейс связи 108а и компьютерный интерфейс 110 компьютерная система 106 выполнена с возможностью управления лазерами 120 оптической системы 102 с целью генерации света с заданной длиной волны и излучения его на имеющие флюоресцентные метки нуклеотидные аналоги, инкорпорированные в растущие праймеры, которые гибридизованы с секвенируемыми полинуклеотидами. Компьютерная система 106 управляет детектором 126 оптической системы 102 с целью захвата эмиссионного спектров аналогов нуклеотидов в флюоресцентных изображениях. Компьютерная система 106 получает от детектора 126 флюоресцентные изображения и обрабатывает полученные флюоресцентные изображения, чтобы определить нуклеотидную последовательность в секвенируемых полинуклеотидах.
Компьютерная система
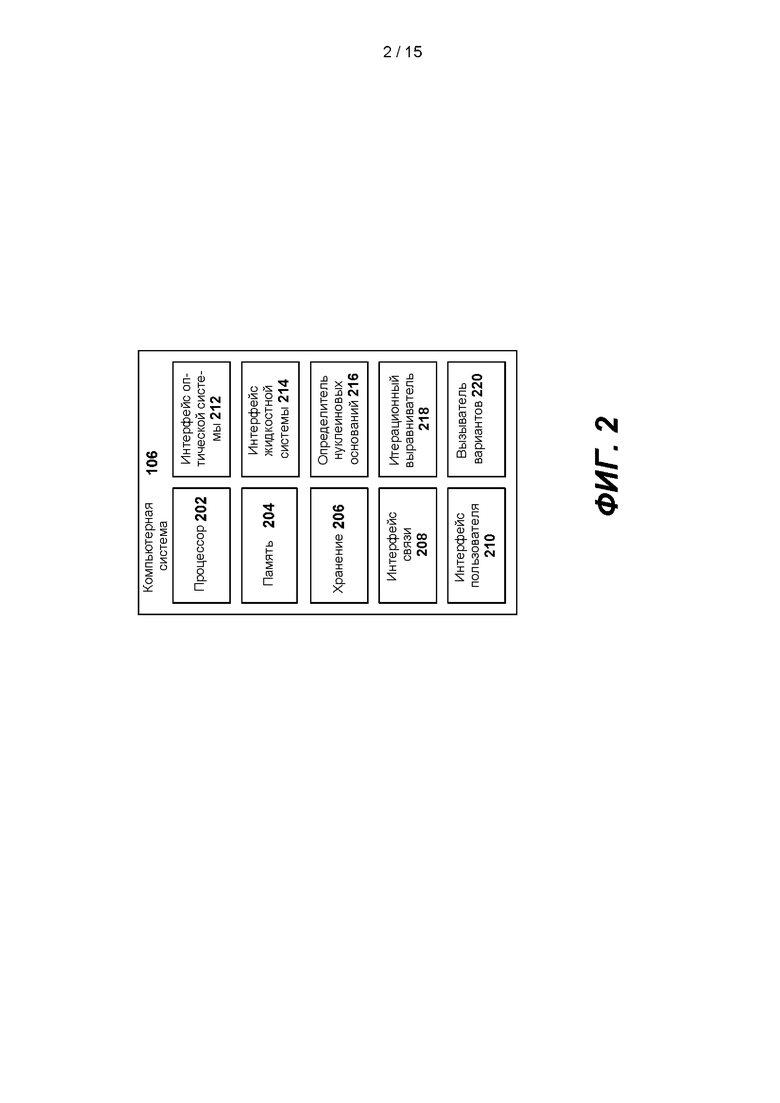
[0028] Компьютерную систему 106 системы секвенирования 100 можно выполнить с возможностью управления оптической системой 102 и жидкостной системой 104, как описано выше. При том что возможны различные конфигурации компьютерной системы 106, на ФИГ. 2 показан один вариант реализации. Как показано на ФИГ. 2, компьютерная система 106 может содержать процессор 202, который имеет электрическую связь с памятью 204, запоминающим устройством 206 и интерфейсом связи 208. В одном варианте реализации компьютерная система 106 содержит программируемую полем вентильную матрицу (ППВМ), графический процессор (ГП) и/или векторный центральный процессор (ЦП), служащие для выравнивания последовательности и генерации вызовов вариантов.
[0029] Процессор 202 можно выполнить с возможностью исполнения команд, в результате которых жидкостная система 104 подает реактивы в проточную кювету 114 во время реакций секвенирования. Процессор 202 может исполнять команды, которые управляют лазерами 120 оптической системы 102 с целью генерации света на заданных длинах волн. Процессор 202 может исполнять команды, которые управляют детектором 126 оптической системы 102, и принимать данные от детектора 126. Процессор 202 может исполнять команды для обработки данных, например флюоресцентных изображений, полученных от детектора 126, и для определения нуклеотидной последовательности полинуклеотидов на основе данных, полученных от детектора 126.
[0030] Память 204 можно выполнить с возможностью хранения команд конфигурирования процессора 202 с целью выполнения функций компьютерной системы 106, если система секвенирования 100 включена. Если система 100 секвенирования выключена, хранилище 206 может хранить инструкции для конфигурирования процессора 202 с целью выполнения функций компьютерной системы 106. Интерфейс связи 208 можно выполнить с возможностью улучшения связи между компьютерной системой 106, оптической системой 102 и жидкостной системой 104.
[0031] Компьютерная система 106 может содержать пользовательский интерфейс 210, выполненный с возможностью связи с устройством отображения (не показано) для отображения результатов секвенирования (включая результаты вторичных анализов, таких как определение вариантов) системы секвенирования 100. Пользовательский интерфейс 210 можно выполнить с возможностью приема входных данных от пользователей системы секвенирования 100. Интерфейс оптической системы 212 и интерфейс жидкостной системы 214 компьютерной системы 106 можно выполнить с возможностью управления оптической системой 102 и жидкостной системой 104 через линии связи 108а и 108b, проиллюстрированные на ФИГ. 1. Например, интерфейс оптической системы 212 может связываться с компьютерным интерфейсом 110 оптической системы 102 через линию связи 108а.
[0032] Компьютерная система 106 может содержать определитель нуклеиновых оснований 216, выполненный с возможностью определения нуклеотидной последовательности полинуклеотидов с использованием данных, полученных от детектора 126. Определитель нуклеиновых оснований 216 может генерировать матрицу местоположений кластеров полинуклеотидов в проточной кювете 114, используя флюоресцентные изображения, снятые детектором 126. На основе созданной матрицы местоположений определитель нуклеиновых оснований 216 может регистрировать местоположения полинуклеотидных кластеров в проточной кювете 114 на флюоресцентных изображениях, снятых детектором 126. Определитель нуклеиновых оснований 216 может извлекать по флюоресцентным изображениям интенсивность флюоресцентного излучения, чтобы генерировать извлеченную интенсивность. Определитель нуклеиновых оснований 216 может определять по извлеченным интенсивностям основания полинуклеотида. Определитель нуклеиновых оснований 216 может определять показатели качества оснований в определяемых полинуклеотидах.
[0033] Компьютерная система 106 может содержать итерационный выравниватель 218 и определитель вариантов 220, определитель вариантов Strelka (sites.google.com/site/strelkasomaticvariantcaller/home/faq). Во время цикла секвенирования итерационный выравниватель 218 может выравнивать прочтения последовательности, определенные определителем нуклеиновых оснований 216, с референсной последовательностью. Выровненные прочтения последовательности могут иметь связанные показатели. Показатели могут представлять собой вероятности (например, проценты несовпадения) того, что прочтения последовательности правильно выровнены с референсной последовательностью. В некоторых вариантах реализации компьютерная система 106 может содержать аппаратное обеспечение, такое как программируемая полем вентильная матрица (ППВМ) или графический процессор (ГП), для выравнивания прочтений последовательности с референсной последовательностью и для определения вызовов вариантов. В некоторых вариантах реализации итерационный выравниватель 218 и определитель вариантов 220 могут находить применение в компьютерной системе, отличной от компьютерной системы 106. В некоторых вариантах реализации компьютерная система 106 может представлять собой интегрированный компонент системы секвенирования 100. В некоторых вариантах реализации оптическая система 102, жидкостная система 104 и/или компьютерная система 106 могут быть объединены в один аппарат.
Секвенирование путем синтеза
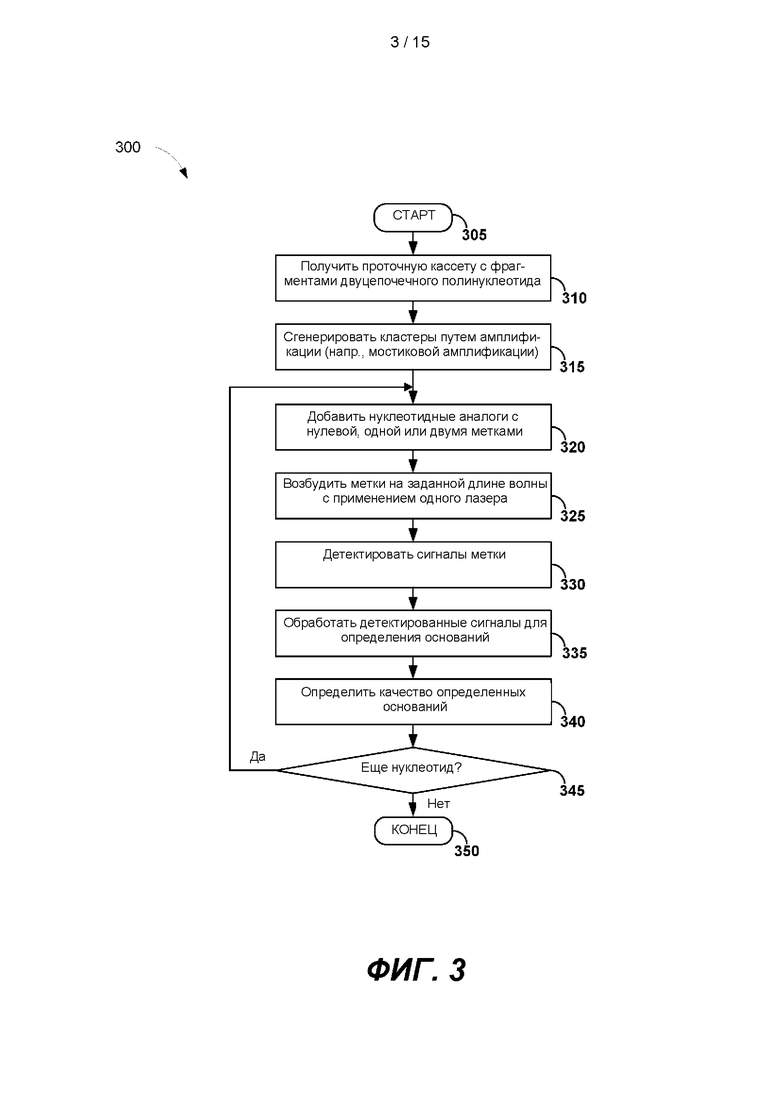
[0034] На ФИГ. 3 представлена блок-схема примера способа 300 для секвенирования путем синтеза с применением системы секвенирования 100. После запуска способа 300 на этапе 305 проточная кювета 114, содержащая фрагменты фрагментированного двухцепочечного полинуклеотида, переходит на этап 310. Фрагменты фрагментированного двухцепочечного полинуклеотида можно получить из образца дезоксирибонуклеиновой кислоты (ДНК). Образец ДНК может быть получен из различных источников, например, биологического образца, образца клетки, образца из окружающей среды или любой их комбинации. Образец ДНК может содержать одну или более биологических жидкостей, тканей и клеток пациента. Например, образец ДНК может содержать или быть взятым из крови, мочи, спинномозговой жидкости, плевральной жидкости, околоплодных вод, спермы, слюны, костного мозга, биоптата или любой их комбинации.
[0035] Образец ДНК может содержать ДНК из представляющих интерес клеток. Представляющие интерес клетки могут различаться и в некоторых вариантах реализации они экспрессируют злокачественный фенотип. В некоторых вариантах реализации представляющие интерес клетки могут включать опухолевые клетки, клетки костного мозга, раковые клетки, стволовые клетки, эндотелиальные клетки, инфицированные вирусом патогенные клетки, клетки паразитического организма или любую их комбинацию.
[0036] Длины фрагментов фрагментированных двухцепочечных полинуклеотидов могут составлять от 200 оснований до 1000 оснований. После того как проточная кювета 114, содержащая фрагменты фрагментированного двухцепочечного полинуклеотида, перешла на этап 310, способ 300 переходит к этапу 315, где происходит мостиковая амплификация фрагментов двухцепочечного полинуклеотида в кластеры полинуклеотидных фрагментов, прикрепленных к внутренней поверхности одного или более каналов проточной кюветы, например, проточной кюветы 114. Внутренняя поверхность одного или более каналов проточной кюветы может содержать два типа праймеров, например, праймер первого типа (Р1) и праймер второго типа (Р2), а фрагменты ДНК могут быть амплифицированы общеизвестными способами.
[0037] После генерации кластеров в проточной кювете 114 можно начать процесс секвенирования путем синтеза по способу 300. Процесс секвенирования путем синтеза может включать определение нуклеотидной последовательности кластеров одноцепочечных полинуклеотидных фрагментов. Чтобы определить последовательность кластера одноцепочечных полинуклеотидных фрагментов, имеющих последовательность 5'-Pl-F-A2R-3', праймеры с последовательностью A2F, которая комплементарна последовательности A2R, можно удлинить путем добавления на этапе 320 нуклеотидных аналогов с нулевой, одной или двумя метками ДНК-полимеразы, с целью образования растущих праймеров-полинуклеотидов.
[0038] В ходе каждого цикла секвенирования к растущим праймерам-полинуклеотидам можно добавить и инкорпорировать в них четыре типа нуклеотидных аналогов. Четыре типа нуклеотидных аналогов могут иметь различные модификации. Например, нуклеотид первого типа может быть аналогом дезоксигуанозин трифосфата (dGTP), не конъюгированным с какой-либо флюоресцентной меткой. Нуклеотид второго типа может быть аналогом дезокситимидин трифосфата (dTTP), конъюгированного с флюоресцентной меткой первого типа посредством линкера. Нуклеотид третьего типа может быть аналогом дезоксицитидин трифосфата (dCTP), конъюгированного с флюоресцентной меткой второго типа посредством линкера. Нуклеотид четвертого типа может быть аналогом дезоксиаденозин трифосфата (dATP), конъюгированного с флюоресцентной меткой первого типа и флюоресцентной меткой второго типа посредством одного или более линкеров. Линкеры могут содержать одну или более групп расщепления. Перед последующим циклом секвенирования флюоресцентные метки можно удалить из нуклеотидных аналогов. Например, линкер, присоединяющий флюоресцентную метку к нуклеотидному аналогу, может содержать азидную и/или алкоксильную группу, например, на одном и том же углероде, таким образом что линкер может быть отделен фосфиновым реактивом после каждого цикла включения, что приводит к удалению флюоресцентой метки из последующих циклов секвенирования.
[0039] Нуклеотидтрифосфаты могут быть обратимо заблокированы в 3' положении, так что секвенирование находится под контролем и в каждом цикле возможно добавить не более одного нуклеотидного аналога к каждому удлиняющемуся праймер-полинуклеотиду. Например, 3'-положение рибозы в нуклеотидном аналоге может содержать как алкоксильные, так и азидные функциональные группы, которые можно удалить расщеплением с помощью фосфинового реактива, в результате чего образуется нуклеотид, который в дальнейшем можно удлинить. После инкорпорации аналогов нуклеотидов жидкостная система 104 может промыть один или более каналов проточной кюветы 114, для того чтобы удалить все неинкорпорированные аналоги нуклеозидов и фермент. Перед последующим циклом секвенирования обратимые 3'-блоки можно удалить, чтобы в каждый удлиняющийся праймер-полинуклеотид можно было добавить другой нуклеотидный аналог.
[0040] На этапе 325 лазеры, такие как лазеры 120, могут возбуждать две флюоресцентные метки на заданных длинах волн. На этапе 330 можно обнаружить сигналы от флюоресцентных меток. Детектирование флюоресцентных меток может включать улавливание флюоресцентных излучений в двух флюоресцентных изображениях на первой длине волны и на второй длине волны, например, детектором 126 с применением двух фильтров. Флюресцентные излучения первой флюоресцентной метки могут быть на первой длине волны или около нее, а флюоресцентные излучения второй флюоресцентной метки могут быть на второй длине волны или около нее. Флюоресцентные изображения можно хранить для последующей обработки в автономном режиме. В некоторых вариантах реализации флюоресцентные изображения можно обрабатывать с целью определения последовательности растущих праймер-полинуклеотидов в каждом кластере в режиме реального времени.
[0041] При обработке флюоресцентных изображений в режиме реального времени он-лайн флюоресцентные изображения, содержащие обнаруженные флюоресцентные сигналы, можно обработать на этапе 335, и можно определить основания в инкорпорированных нуклеотидах. У каждого определенного нуклеотидного основания можно определить показатель качества на этапе 340. На этапе принятия решения 345 можно определить, детектировать ли большее количество нуклеотидов, на основании, например, качества сигнала или после заданного количества оснований. Если детектируют большее количество нуклеотидов, то определение нуклеотидов в следующем цикле секвенирования можно выполнить на этапе 320. В некоторых вариантах реализации к одному концу цепи ДНК в соответствии с кластером можно добавить меченые нуклеотиды. Меченые нуклеотиды также можно добавить к другому концу цепи ДНК в соответствии с кластером. Прочтения на одном конце цепи ДНК часто обозначают как набор прочтений 1, а соответствующие прочтения на другом конце цепи ДНК часто обозначают как набор прочтений 2. Техника секвенирования, которая позволяет определять два или более прочтения последовательности из двух участков на одном полинуклеотидном дуплексе, называется парно-концевым (РЕ) секвенированием. Два или более прочтений последовательностей из двух участков на одном полинуклеотидном дуплексе обозначают как набор прочтений 1, набор прочтений 2 и т.д. Парно-концевое секвенирование описано в заявке на патент США №14/683580, содержание которой включено в настоящую заявку во всей полноте посредством ссылки. Преимущество парно-концевого секвенирования состоит в том, что при секвенировании двух участков из одной матрицы получают значительно больше информации, чем при секвенировании каждой из двух независимых матриц случайным образом.
[0042] Перед следующим циклом секвенирования флюоресцентные метки можно удалить из нуклеотидных аналогов, и можно удалить обратимые 3'-блоки, чтобы в каждый удлиняющийся праймер-полинуклеотид можно было добавить другой нуклеотидный аналог. После обработки всех флюоресцентных изображений способ 300 можно закончить на этапе 350.
Определение оснований
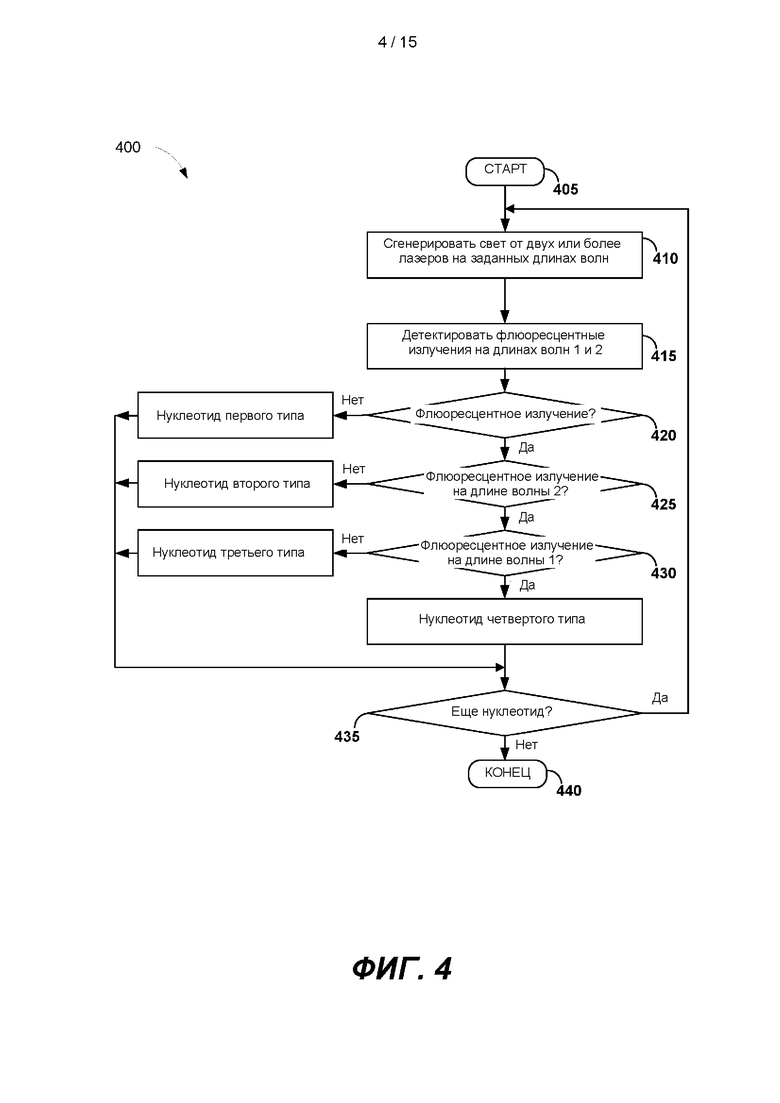
[0043] Определение оснований может означать процесс определения оснований нуклеотидов, инкорпорированных в кластеры растущих праймер-полинуклеотидов, в которых секвенируют гуанин (G), тимин (Т), цитозин (С) или аденин (А). На ФИГ. 4 представлена блок-схема примера способа 400 для проведения определения оснований с применением системы секвекнирования 100. Показанная на ФИГ. 3 обработка детектированных сигналов может включать проведение определения оснований по способу 400. После начала этапа 405 свет с заданными длинами волн можно генерировать с помощью лазеров. Генерируемый свет может излучаться на аналоги нуклеотидов на этапе 410. Например, компьютерная система 106 посредством интерфейса оптической системы 212 и канала связи 108а может дать команду лазерам 120 генерировать свет на заданной длине волны.
[0044] Генерируемый лазером свет может излучаться на нуклеотидные аналоги, инкорпорированные в растущие праймеры-полинуклеотиды, присоединенные к внутренней поверхности одного или нескольких каналов проточной кюветы, например проточной кюветы 114. Праймер-полинуклеотиды могут содержать кластеры одноцепочечных полинуклеотидных фрагментов, гибрид изо ванных с секвенирующими праймерами. Каждый из нуклеотидных аналогов может содержать нулевое количество, одну или две флюоресцентные метки. Две флюоресцентные метки могут представлять собой первую флюоресцентную метку и вторую флюоресцентную метку. Флюоресцентные метки после возбуждения сгенерированным лазером светом могут испускать флюоресцентное излучение. Например, первая флюоресцентная метка может испускать флюоресцентное излучение на первой длине волны, которое может быть снято, например, в первом флюоресцентном изображении. Вторая флюоресцентная метка может испускать флюоресцентное излучение на второй длине волны, которое может быть снято, например, во втором флюоресцентном изображении.
[0045] Нуклеотидные аналоги могут содержать нуклеотид первого типа, нуклеотид второго типа, нуклеотид третьего типа и нуклеотид четвертого типа. Нуклеотид первого типа, например аналог дезоксигуанозин трифосфата (dGTP), не конъюгирован с первой флюоресцентной меткой или со второй флюоресцентной меткой. Нуклеотид второго типа, например аналог дезокситимидин трифосфата (dTTP), может быть конъюгирован с флюоресцентной меткой первого типа, но не с флюоресцентной меткой второго типа. Нуклеотид третьего типа, например, аналог дезоксицитидин трифосфата (dCTP), может быть конъюгирован с флюоресцентной меткой второго типа, но не с флюоресцентной меткой первого типа. Нуклеотид четвертого типа, например аналог дезоксиаденозин трифосфата (dATP), может быть конъюгирован с флюоресцентной меткой первого типа и с флюоресцентной меткой второго типа.
[0046] На этапе 415 флюоресцентные излучения нуклеотидных аналогов на первой длине волны и на второй длине волны можно детектировать с применением по меньшей мере одного детектора. Например, детектор 126 может снять два флюоресцентных изображения, первое флюоресцентное изображение на первой длине волны, а второе флюоресцентное изображение на второй длине волны. После получения двух флюоресцентных изображений от оптической системы 102 определитель нуклеиновых оснований 216 может определить наличие или отсутствие флюоресцентных излучений на двух флюоресцентных изображениях.
[0047] Поскольку нуклеотид первого типа не конъюгирован с первой флюоресцентной меткой или второй флюоресцентной меткой, нуклеотид первого типа может не испускать или испускать минимальное флюоресцентное излучение на первой длине волны или второй длине волны. На этапе принятия решения 420, если флюоресцентное излучение не обнаружено, можно определить, что нуклеотид является нуклеотидом первого типа, например dGTP. Если обнаружено любое или более чем минимальное флюоресцентное излучение, способ 400 может перейти к этапу принятия решения 425.
[0048] Поскольку нуклеотид второго типа конъюгирован с флюоресцентной меткой первого типа, но не с флюоресцентной меткой второго типа, нуклеотид второго типа может испускать флюоресцентное излучение на первой длине волны и не испускать или испускать минимальное флюоресцентное излучение на второй длине волны. На этапе принятия решения 425, если во втором флюоресцентном изображении флюоресцентное излучение на второй длине волны не обнаружено, а на этапе принятия решения 420 на первом флюоресцентном изображении обнаружено флюоресцентное излучение на первой длине волны, можно определить, что нуклеотид является нуклеотидом второго типа, например dTTP. Если обнаружены флюоресцентные излучения на второй длине волны, способ 400 может перейти к этапу принятия решения 430.
[0049] Поскольку нуклеотид третьего типа конъюгирован с флюоресцентной меткой второго типа, но не с флюоресцентной меткой первого типа, нуклеотид третьего типа может испускать флюоресцентное излучение на второй длине волны и не испускать или испускать минимальное флюоресцентное излучение на первой длине волны. На этапе принятия решения 430, если в первом флюоресцентном изображении флюоресцентное излучение на первой длине волны не обнаружено, а на этапе принятия решения 425 на втором флюоресцентном изображении обнаружено флюоресцентное излучение на второй длине волны, можно определить, что нуклеотид является нуклеотидом третьего типа, например dCTP.
[0050] Поскольку нуклеотид четвертого типа конъюгирован как с флюоресцентной меткой первого типа, так и с флюоресцентной меткой второго типа, нуклеотид четвертого типа может испускать флюоресцентное излучение как на первой длине волны, так и на второй длине волны. На этапе принятия решения 430, если в первом флюоресцентном изображении обнаружено флюоресцентное излучение на первой длине волны, а на этапе принятия решения 425 на втором флюоресцентном изображении можно детектировать флюоресцентное излучение на второй длине волны, можно определить, что нуклеотид является нуклеотидом четвертого типа, например dATP.
[0051] Проточная кювета 114 может содержать кластеры растущих праймеров-полинуклеотидов для секвенирования. На этапе принятия решения 435, если есть по меньшей мере еще один кластер с флюоресцентным излучением, подлежащим обработке в данном цикле секвенирования, способ 400 может продолжаться до этапа 410. Если больше нет подлежащих обработке кластеров одноцепочечного полинуклеотида, способ 400 может закончиться на этапе 440.
Способы секвенирования
[0052] Описанные в настоящей заявке способы можно применять в сочетании с различными методами секвенирования нуклеиновых кислот. В частности, применимыми методами являются те, в которых нуклеиновые кислоты присоединены к матрице в определенных положениях, таким образом, что их относительные местоположения не изменяются, и при этом получают многократные изображения матрицы. В частности, применимы варианты реализации, в которых изображения получают в разных цветовых каналах, например, совпадающих с разными метками, используемыми для различения одного типа нуклеотидных оснований от другого. В некоторых вариантах реализации процесс определения нуклеотидной последовательности целевой нуклеиновой кислоты может быть автоматизированным процессом. Предпочтительные варианты реализации включают методы секвенирования путем синтеза («SBS»).
[0053] «Методы секвенирования путем синтеза («SBS»)» обычно включают ферментативное удлинение возникающей цепи нуклеиновой кислоты посредством итерационного добавления нуклеотидов к матричной цепи. В традиционных способах SBS при каждой доставке целевой нуклеотид может быть обеспечен одним нуклеотидным мономером в присутствии полимеразы. Однако в описанных в настоящей заявке способах при доставке целевой нуклеотид может быть обеспечен более чем одним нуклеотидным мономером в присутствии полимеразы.
Итерационное выравнивание и определение варианта
[0054] На ФИГ. 5А и 5В показан пример процесса итерационного выравнивания и определения варианта согласно одному варианту реализации. После получения изображений в определенном количестве минимальных циклов секвенирования можно выполнять первичный анализ в режиме реального времени, чтобы определить вызовы оснований и показатели качества для каждого невыровненного прочтения. На ФИГ. 5А показанное минимальное количество циклов секвенирования составляет три. В некоторых вариантах реализации минимальное количество циклов секвенирования может составлять 16, 32 или более циклов. Вызов оснований и определение показателя качества проиллюстрированы выше со ссылкой на ФИГ. 3. Каждое прочтение можно выровнять с референсной последовательностью с выбором наиболее вероятного выравнивания, и затем прочтения можно собрать в пайлап и можно выполнить определение варианта.
[0055] На ФИГ. 5А первичный анализ включает определение невыровненных прочтений последовательности, таких как CCA 504а, ТТА 504d и TAG 504k, из 16 кластеров, показанных на проточной кювете. Под заголовком Первичный анализ каждый кластер представлен в виде ряда букв, при этом каждая буква представляет секвенированный полинуклеотид. После того как прошло минимальное количество циклов секвенирования, например, 3 цикла, вторичный анализ может включать выравнивание 16 прочтений последовательности с референсной последовательностью (GATTACATAAGATTCTTTCATCG 508), показанной под заголовком Вторичный анализ на ФИГ. 5А. На диаграмме Вторичного анализа последовательности, выровненные с референсной последовательностью, составляют пайлап полинуклеотидов. Например, прочтения последовательности ССА 504а (строка 1 под заголовком «Первичный анализ»), ТТА 504d (строка 4) и TAG 504k (строка 11) могут быть выровнены с последовательностями АСА, ТТА и ТАС, соответственно, в пределах подпоследовательности ТТАСАТ 512 референсной последовательности 508 с одним, нулевым и одним несовпадением соответственно. Таким образом, третье положение подпоследовательности ТТАСАТ 512 можно определить так, чтобы оно стало С 516а вместо А в референсной последовательности 508 с некоторой вероятностью точности, а четвертое положение подпоследовательности ТТАСАТ 512 можно определить так, чтобы оно стало G 516b вместо С в референсной последовательности с некоторой вероятностью точности. Аналогичным образом можно определить другие варианты референсной последовательности.
[0056] По мере проведения новых циклов секвенирования и определения вызовов оснований вероятности выравнивания могут уточняться, и выравнивания прочтений могут сдвигаться к новому наиболее вероятному выравниванию. Этот сдвиг вызовет запуск нового определения вариантов в задействованных участках. На ФИГ. 5В после четвертого цикла секвенирования прочтения последовательностей ССА 504а, ТТА 504d и TAG 504k из третьего цикла секвенирования становятся ССАТ 504а '(строка 1 под заголовком «Первичный анализ»), ТТАС 504d' (строка 4) и TAGG 504k '(строка 11) соответственно. При этом прочтения последовательностей ССАТ 504а' и ТТАС 504d' еще можно выровнять с подпоследовательностью ТТАСАТ 512 референсной последовательности 508 с одним и нулевым несовпадением соответственно. Для прочтений последовательностей ССАТ 504а 'и ТТАС 504d' положение выравнивания не меняется между итерацией, показанной на ФИГ. 5А, и итерацией, показанной на ФИГ. 5В; третье положение подпоследовательности ТТАСАТ 512 можно определить как С 516а вместо А в референсной последовательности. Чтобы выровнять прочтение TAGG 504k ' с подпоследовательностью ТТАСАТ 512 необходимы два несовпадения. Однако прочтение последовательности TAGG 504K' можно выровнять с TAAG 520 референсной последовательности 508 с более высокой вероятностью, поскольку это выравнивание имеет только одно несовпадение. Примеры на ФИГ. 5а и ФИГ. 5В показывают, что по мере выполнения секвенирования положения выравнивания могут сдвигаться, и определение вариантов может улучшаться.
[0057] В некоторых вариантах реализации выравнивание прочтений последовательности с референсной последовательностью включает сохранение списка наиболее вероятных выравниваний в виде конечных элементов узла для каждого прочтения последовательности. Каждый конечный элемент может иметь соответствующую вероятность. Конечные элементы с вероятностями, которые попадают ниже определенного порога, можно откинуть.
Вторичный анализ в режиме реального времени
[0058] На ФИГ. 6 представлена блок-схема примера способа 600 для проведения вторичного анализа последовательности в режиме реального времени. После начала способа 600 на этапе 605 данные изображений цикла секвенирования можно получить на этапе 610. Например, компьютерная система 106 может получать данные изображений от детектора 126. На этапе 615 можно определить основания и можно определить показатели качества оснований. Генерирование данных изображения и определение оснований и качества определенных оснований проиллюстрированы выше со ссылкой на ФИГ. 3-4. После каждого цикла секвенирования длины прочтений последовательности становятся длиннее на один нуклеотид. Например, после 31-го цикла секвенирования прочтения последовательности имеют длину в 31 нуклеотид, а после 32-го цикла секвенирования прочтения последовательности становятся на 1 нуклеотид длиннее, достигая в длину 32 нуклеотидов.
[0059] На этапе принятия решения 620 можно определить, было ли выполнено определенное количество минимальных циклов секвенирования. Минимальное количество циклов секвенирования может составлять 16, 32 или более циклов. Если количество выполненных циклов секвенирования меньше, чем минимальное необходимое количество циклов секвенирования, способ 600 переходит к этапу 610. Если количество выполненных циклов секвенирования составляет, по меньшей мере, минимальное необходимое количество циклов секвенирования, способ 600 переходит к этапу 625.
[0060] На этапе 625 определенные прочтения последовательности можно выровнять с референсной последовательностью. В способе 600 можно применять различные методы выравнивания в разных исполнениях. Неограничивающие примеры методов выравнивания включают в себя глобальные выравнивания (например, алгоритм Нидлмана-Вунша), локальные выравнивания, динамическое программирование (например, алгоритм Смита-Ватермана), эвристические алгоритмы или вероятностные методы, прогрессивные методы, итерационные методы, поиск мотивов или анализ профиля, генетические алгоритмы, имитацию отжига, парные выравнивания, множественные выравнивания последовательностей.
[0061 На этапе 630 могут быть определены варианты. Начальный вариант можно определить только после достижения заданного порогового значения варианта. Пороговое значение варианта может быть важным из-за возможных ошибок ПЦР или секвенирования. Пороговое значение варианта может быть основано на выравнивании основания относительно положения в референсной последовательности, которое отличается от основания базы в соответствующем положении в референсной последовательности.
[0062] На ФИГ. 5А пороговым значением варианта является один результат измерения. Таким образом, третье положение подпоследовательности ТТАСАТ 512 можно определить как С 516а вместо А в референсной последовательности. Если пороговое значение варианта составляет два или более, вариант С не будет вызван на этапе 630 в конкретном цикле секвенирования. На ФИГ. 5В, третье положение ТТАСАТ можно определить как С вместо А в референсной последовательности, если пороговое значение варианта - более чем два результата измерения. В некоторых вариантах реализации пороговое значение варианта может представлять собой процент от всех оснований, выровненных по конкретному положению в контрольной последовательности, например 1%, 5%, 10%, 25%, 50% или более. Как описано более подробно ниже, наиболее вероятные выравнивания можно сохранить как конечные элементы узла для каждого прочтения последовательности. Каждый конечный элемент может иметь соответствующую вероятность. Конечные элементы с вероятностями, которые попадают ниже определенного порога, можно откинуть. Таким образом, варианты, вызванные для положения нуклеотида в референсной последовательности, можно уточнить или откинуть в ходе последующих циклов.
[0063] На этапе принятия решения 635 можно определить, следует ли прочесть дальнейшие нуклеотиды, или все циклы секвенирования завершены. Это можно определить на основании, например, качества сигнала или после заданного количества оснований. Если следует прочесть дальнейшие нуклеотиды и не все циклы секвенирования завершены, то способ 600 переходит на этап 610, в котором можно сгенерировать данные секвенирования для следующего цикла секвенирования. Если нуклеотидов для прочтения больше нет и все циклы секвенирования завершены, способ 600 заканчивают в блоке 650.
[0064] В некоторых вариантах реализации этапы 625 и 630 и этапы 610 и 615 можно выполнять параллельно после проведения минимального количества циклов секвенирования. Например, после проведения 32 циклов секвенирования способ может перейти на этап 625 для выполнения выравнивания прочтений последовательностей, длина которых составляет 32 нуклеотида. Если в способе 600 выполняют выравнивание на этапе 625 и вызов вариантов на этапе 630, можно проводить следующий цикл секвенирования (т.е. 33-й цикл секвенирования). Таким образом, варианты можно вызвать на этапе 630 до завершения 33-го цикла секвенирования. И способ 600 может сделать возможным выравнивание и определение варианта в режиме реального времени (или с нулевой или низкой задержкой), пока проводят циклы секвенирования. Кроме того, варианты, вызванные во время более ранних циклов секвенирования, можно уточнить в ходе последующих циклов. Таким образом, вызов варианта, показанный на ФИГ. 6, может быть итерационным процессом. Например, вариант, вызванный после 32-го цикла секвенирования или в ходе 33-го цикла секвенирования, может быть исходным вызванным вариантом. Во время последующих циклов секвенирования вызванный вариант можно уточнить (при этом тот вариант, который ранее был вызван для определенного положения нуклеотида, более не вызывают и отбрасывают). В качестве другого примера, как показано на ФИГ. 5А и 5В, вариант для четвертого положения ТТАСАТ был вызван как G после третьего цикла, при этом ни один вариант для положения не был вызван после четвертого положения.
[0065] В другом варианте реализации процесс секвенирования можно завершить до того времени, как будут завершены все циклы секвенирования. Например, если конкретный целевой вариант идентифицирован до завершения всех циклов секвенирования, процесс секвенирования можно остановить. Это позволяет системе снижать затраты на реактивы и обеспечивать желаемый результат раньше, чем в системах, которым необходимо завершить все циклы перед выполнением вызова целевого варианта.
[0066] В некоторых вариантах реализации выравнивание можно не выполнять на этапе 625, а варианты вызывают на этапе 630 в каждом цикле секвенирования. Например, можно выполнять выравнивания и вызывать варианты в каждом n-м цикле секвенирования, где n - 1, 2, 3, 4, 5, 10, 20 или более циклов секвенирования. В некоторых вариантах реализации частота выравнивания, выполняемого на этапе 625, и вариантов, вызываемых на этапе 630, может быть основана на количестве вариантов, вызванных в предыдущем цикле секвенирования. В качестве примера, если в одном цикле секвенирования вызвано большое количество вариантов, выравнивания и вызов вариантов можно проводить чаще (например, в следующем цикле) или реже. В качестве другого примера, если в одном цикле секвенирования не вызван вариант или не вызван новый вариант, выравнивания и вызов вариантов можно проводить чаще или реже (например, не в следующем цикле).
[0067] В некоторых вариантах реализации вызов вариантов на этапе 630 можно проводить выборочно для участка референсной последовательности. В разных вариантах реализации выравниваемая часть референсной последовательности может различаться. Например, вызов вариантов можно выполнять выборочно для участка референсной последовательности, где выравнивание прочтений последовательности с референсной последовательностью изменилось в ходе предыдущего цикла секвенирования (например, в непосредственно предшествовавшем цикле секвенирования). В качестве другого примера, участок выравниваемой референсной последовательности можно определить на основании известных локализаций одно нуклеотидного полиморфизма (SNP).
[0068] В некоторых вариантах реализации способ 600 для проведения вторичного анализа последовательности в режиме реального времени может быть основан на древовидной структуре для каждого прочтения. Корень древа может быть помечен знаком «$», обозначающим начало последовательности. Дочерние узлы корня соответствуют четырем возможным вызовам оснований: «А», «С», «G» и «Т». Каждый узел древа может иметь 3 переменные, связанные со следующим: с общим количеством различий последовательности текущей ветви, ведущей от корня к этому узлу (обозначена как последовательность S), с основаниями из текущего прочтения (обозначены как последовательность W), и затем со стартовыми и стоп-индексами в преобразовании Барроуза-Уиллера (BWT) референсной последовательности для всех положений в референсе, которые совпадают с последовательностью S. Важное свойство BWT состоит в том, что все ряды, которые имеют общую стартовую последовательность, гарантированно идут при трансформации последовательно, и поэтому вместо хранения списка отдельных индексов в референсе, совпадающем с последовательностью S, достаточно отследить стартовые индексы и стоп-индексы. Это имеет значение при картировании прочтений в референсном геноме человека, поскольку существует очень много повторяющихся участков.
[0069] Каждый дочерний узел корня тоже будет иметь 4 собственных дочерних узла, также соответствующих четырем возможным основаниям «А», «С», «G» и «Т». Опять же можно отслеживать количество отличий от последовательности текущего прочтения W. Например, если прочтение первых двух циклов было «С», а затем «Т», прочтение может проходить через древо, определяемое как Корень->С->Т. Таким образом, суммарные накопленные различия в последнем Т узле будут нулевыми. Напротив, для пути, определенного как Корень->А->G, суммарные накопленные различия в узле G будут равны 2, потому что ни А, ни G не имеют совпадений с соответствующим циклом в текущем прочтении.
[0070] В некоторых вариантах реализации можно определить ограничение на приемлемое количество отличий с референсом. Как только достигнуто ограничение, ветвь замирает и в последующих циклах ее анализ более проводить не будут. Преобразование BWT с соответствующими индексами можно применять для выполнения вычислений, необходимых в каждом узле в постоянном, О (1), времени. Объем памяти, необходимый для вычисления, и количество узлов в древе зависят от общего количества допустимых пороговых значений ошибок. В некоторых вариантах реализации можно поддерживать небольшие вставки и делеций.
[0071] В некоторых вариантах реализации по начальным данным можно создать более сложные перегруппировки. Так, если обнаружено, что определенное прочтение ни с чем не совпадает, процесс можно начать снова через несколько более поздних циклов, ожидая, что другая часть прочтения появится где-то на карте. Все эти прочтения можно отследить, и при наличии доступных вычислительных мощностей можно выполнить более сложный анализ (например, метод динамического программирования, такой как алгоритм Смита-Уотермана).
Альтернативный вариант реализации
[0072] Дополнительные варианты реализации представляют собой системы и способы для вторичного анализа, которые включают итерационную обработку прочтений последовательности. Вторичный анализ может охватывать как выравнивание прочтений последовательности с референсной последовательностью (например, референсной последовательностью генома человека), так и применение этого выравнивания для выявления различий между образцом и референсом, такое как детектирование и вызов варианта. В одном варианте реализации результаты выравнивания и вызова вариантов можно получить до завершения работы секвенатора. Например, эти результаты могут быть предоставлены через временные интервалы, зависящие от доступных вычислительных ресурсов. Этого можно достичь путем дополнения промежуточных результатов выравнивания из предыдущей итерации результатами выравнивания из текущей итерации. Результаты выравнивания из текущей итерации генерируют путем сравнения только что секвенированных оснований текущей итерации с основаниями референсной последовательности в ранее выровненном положении Результаты сравнения объединяют с результатами выравнивания из предыдущей итерации, и объединенный результат сохраняют для следующей итерации.
[0073] На ФИГ. 7А и 7В представлены схематичные иллюстрации, сравнивающие традиционный способ вторичного анализа (ФИГ. 7А) с вторичным анализом варианта реализации настоящего изобретения (ФИГ. 7В). На ФИГ. 7А показано, что в традиционном способе вторичного анализа выравнивание не продолжают до тех пор, пока не будет секвенирован полный набор оснований в прочтении. Процесс выравнивания может включать несколько стадий выравнивания. На первой стадии выравнивания ожидают, пока станет доступен полный набор секвенированных оснований в прочтении. После завершения процесса выравнивания можно начать процесс вызова вариантов, который включает несколько стадий вызова вариантов. На первой стадии вызова вариантов ожидают, пока станет доступен полный набор данных выравнивания.
[0074] На ФИГ. 7В показан итерационный способ вторичного анализа согласно одному варианту реализации настоящего изобретения. Как показано, выравнивание и вызов вариантов проходят в режиме реального времени и выдают промежуточные результаты. Обработку можно запланировать через фиксированные интервалы. Фиксированные интервалы могут включать получение подпоследовательности N оснований, где N - положительное целое число, например 16. Например, обработка может происходить с интервалом в 16 оснований. В качестве другого примера, обработка может происходить с интервалами 1, 2, 4, 8, 16, 32, 64, 128, 151 или более оснований. В одном варианте реализации обработка может происходить с интервалами, укладывающимися в любое число от 1 до 152, наиболее предпочтительно с интервалами 16 +/- 8. В одном варианте реализации интервалы можно изменять от одной итерации к другой итерации. Система секвенирования, такая как система секвенирования 100 на ФИГ. 1, может генерировать прочтения последовательности с интервалами в 16 оснований, как показано на ФИГ. 8. Альтернативным образом количество оснований в каждом интервале обработки может быть различным. Например, первый интервал можно обработать после секвенированных 16 оснований, а вторую итерацию можно обработать после 18 секвенированных оснований. Количество оснований в итерации может быть таким низким как 1, или таким высоким, как количество оснований в прочтении.
[0075] Процесс, описанный на ФИГ. 7В можно применить к набору Прочтение 1 или к набору Прочтение 2, когда используют метод парно-концевого секвенирования. Кроме того, информацию, полученную при обработке набора Прочтение 1, можно применить к набору Прочтение 2. Например, возможно выполнить этап выравнивания, используя обычные способы во время или после секвенирования набора Прочтение 1, и эту информацию можно использовать для обработки набора Прочтения 2 после секвенирования полинуклеотидов Прочтения 2.
[0076] Как показано на ФИГ. 8, многократные прочтения 804a-804d одноцепочечных полинуклеотидов можно генерировать из аппарата для секвенирования. Эти одноцепочечные полинуклеотиды могут иметь 151 основание в длину, которые обозначают от основания 0 до основания 150. Последовательности этих одноцепочечных полинуклеотидов можно определить с помощью секвенирования путем синтеза, описанного выше. После итерации 0 (первой итерации) из 16 циклов секвенирования система секвенирования определяет 16 оснований из прочтений последовательности. Например, для Прочтения 0 (804а) генерируют прочтения последовательности от Основания 0 до Основания 15, а прочтения последовательности от Основания 0 до Основания 15 определяют как Прочтение 1 (804b), и т.д. После итерации 1 (второй итерации) из дополнительных 16 циклов секвенирования определяют 16 дополнительных оснований последовательностей для каждого прочтения. Например, для Прочтения 0 (804а) генерируют прочтения от Основания 16 до Основания 31. Система секвенирования может продолжать генерировать прочтения с интервалом в 16 оснований до тех пор, пока на итерации 8 не будут сгенерированы прочтения последовательности от Основания 128 до Основания 143 каждого кластера. Система секвенирования может генерировать прочтения от Основания 144 до Основания 151 каждого кластера на итерации 9 (последняя итерация). В альтернативном варианте реализации количество оснований, генерируемых на каждой итерации, может быть различным, причем количество оснований на итерацию определяют по доступным вычислительным ресурсам. Например, первый интервал обработки может состоять из 16 оснований, тогда как второй интервал обработки может состоять из 18 оснований. Наименьшее количество оснований в интервале обработки составляет единицу, а наибольшее количество оснований в интервале обработки равно длине прочтения.
[0077] На ФИГ. 7В показано, что выравнивание может происходить с интервалами в 16 оснований. Вызов вариантов может происходить с интервалами 16 после завершения выравнивания. Например, система секвенирования для вторичного анализа в режиме реального времени может выдавать 16 оснований прочтений последовательности каждые 1,3 часа. Для вторичного анализа в режиме реального времени общее время, требуемое для выполнения выравнивания и вызова вариантов, должно быть в пределах 1,3 часа, чтобы пользователь мог иметь доступ к вызовам вариантов, сделанным до того как станут доступны следующие 16 оснований прочтений последовательности.
[0078] В одном варианте реализации обработка может происходить непрерывно настолько быстро, насколько возможно на доступных компьютерных ресурсах, без фиксированных этапов итерации. Анализ может настраиваться самостоятельно и будет максимально приближен к прогрессу секвенирования. Результаты выравнивания и вызова вариантов можно сгенерировать по требованию в любое время.
Альтернативный вариант реализации - выравнивание
[0079] На ФИГ. 9А представлена блок-схема примера способа 900 для проведения вторичного анализа последовательности в режиме реального времени. Способ 900 включает два пути: путь по способу традиционного вторичного анализа с низкой достоверностью, высоким уровнем вычислений и путь согласно одному варианту реализации настоящего изобретения с высокой достоверностью, низким уровнем вычислений. Путь с низкой достоверностью, высоким уровнем вычислений и путь с высокой достоверностью, низким уровнем вычислений обозначены в настоящей заявке как синий путь и желтый путь, соответственно.
[0080] Путь с низкой достоверностью, высоким уровнем вычислений может включать выравнивание последовательности каждого прочтения с референсной последовательностью. В этом пути все основания из доступных итераций прочтения используют для выравнивания прочтения с референсной последовательностью. Например, если как итерация 0, так и итерация 1 состоят из 16 оснований, то при выравнивании будут обработаны 32 основания. Один из ряда обычных методов выравнивания можно применять в пути с малой достоверностью и высоким уровнем вычислений. После завершения выравнивания последовательностей положения картирования и выравнивания можно сохранить и оценить. После выравнивания всех прочтений можно вызвать варианты.
[0081] Способ 900 улучшен по сравнению с традиционным способом вторичного анализа благодаря добавлению пути с высокой достоверностью и низким уровнем вычислений. На итерации 0 в способе 900 ждут завершения ряда циклов, чтобы сгенерировать ряд оснований в каждом прочтении. Например, в способе 900 можно ждать завершения 16 циклов секвенирования для генерации 16 оснований в каждом прочтении. Во время итерации 0 анализируют и обрабатывают 16 оснований в каждом прочтении по пути с низкой достоверностью и высоким уровнем вычислений. Традиционный метод обозначен в настоящей заявке как синий путь. Во время итерации 1 и любой последующей итерации анализируют и обрабатывают 16 оснований в каждом прочтении либо по пути с низкой достоверностью и высоким уровнем вычислений, либо по пути с высокой достоверностью и низким уровнем вычислений. Если прочтение было выровнено с достаточной степенью достоверности в непосредственно предшествовавшей итерации, 16 оснований текущей итерации анализируют по пути с высокой достоверностью и низким уровнем вычислений. В ином случае 16 оснований текущей итерации анализируют по пути с высокой достоверностью и низким уровнем вычислений.
[0082] Если прочтение выровняли с достаточной достоверностью в непосредственно предшествовавшей итерации, 16 оснований текущей итерации выравнивают по следующим 16 основаниям референсной последовательности. Это выравнивание обозначено в настоящей заявке как простое выравнивание, которое требует меньшей обработки по сравнению с обычным выравниванием последовательности. Вместо выравнивания последовательности по всей референсной последовательности можно определить количество несовпадений между 16 основаниями текущей итерации и следующими 16 основаниями референсной последовательности. Если количество несовпадений превышает пороговое значение, обработку 16 оснований можно вернуть к пути обработки с низкой достоверностью, высоким уровнем вычислений. При возврате к пути с низкой достоверностью, высоким уровнем вычислений выровненную несовпадающую переменную можно установить как 0 или ошибочную. Количество несовпадений можно определить в отношении 16 оснований текущей итерации или всех оснований текущей итерации и предыдущей(их) итерации(й).
[0083] Если количество несовпадений ниже порогового значения, обработку 16 оснований можно оставить на пути с высокой достоверностью и низким уровнем вычислений, и можно сохранить результат выравнивания конкретного прочтения. Можно задать альтернативные метрики, чтобы определить, установлена ли несовпадающая переменная как 0 или Ошибка. Например, если количество несовпадений ниже порогового значения, можно рассчитать показатель MapQ (качество MAPping). Показатель MapQ может быть равен 10 log10 Pr {неправильное положение картирования}, округленному до ближайшего целого числа. Таким образом, если вероятность правильного картирования некоторого случайного прочтения составила 0,99, тогда показатель MapQ должен составлять 20 (то есть log10 0,01 * -10). Если вероятность правильного совпадения увеличена до 0,999, показатель MapQ повысится до 30. И наоборот, если вероятность правильного совпадения стремится к нулю, показатель MapQ стремится к нулю тоже.
[0084] Если обработку 16 оснований оставляют на пути с высокой достоверностью, низким уровнем вычислений, то прочтение может войти в пайлап (когда множественные прочтения выровнены с теми же местоположениями в референсной последовательности, так что эти прочтения составляют "стопку" друг на друге на референсной последовательности). Если обработку 16 оснований вернуть на путь с низкой достоверностью, высоким уровнем вычислений, прочтение можно удалить из пайлапа. В одном варианте реализации прочтение обрабатывают по пути с низкой достоверностью, высоким уровнем вычислений, только если количество кандидатов, общее количество местоположений выравнивания в последовательности ниже порогового значения, например 1000. Если прочтение обработано, результат выравнивания сохраняют.
[0085] На ФИГ. 9В представлен концептуальный график количества данных, обработанных по двум путям обработки с применением способа 900, показанного на ФИГ. 9А. После 16 циклов секвенирования система секвенирования генерирует 16 оснований в каждом прочтении. Во время итерации 0 все прочтения обрабатывают с низкой достоверностью и высоким уровнем вычислений. После 32 циклов секвенирования около 75% кандидатов считают выровненными после итерации 1. Во время итерации 0 эти кандидаты обрабатывают с низкой достоверностью и высоким уровнем вычислений. После итерации 2 около 90% кандидатов считают выровненными и во время итерации 3 обрабатывают с высокой степенью достоверности и низким уровнем вычислений. Если прочтения обработаны с высокой степенью достоверности и низкой скоростью вычислений, требуется меньше вычислений и обработки, поскольку необходимы только простые выравнивания. Поскольку большую часть данных обрабатывают по пути с высокой степенью достоверности, с низким уровнем вычислений, и этот путь требует меньше обработки, общее требуемое время было ниже, чем в случае, если прочтения обрабатывают только по пути с низкой достоверностью, высоким уровнем вычислений. Таким образом, результаты выравнивания и вызова вариантов можно получить до завершения работы секвенатора. Эти результаты могут быть предоставлены пользователю через временные интервалы, зависящие от доступных вычислительных ресурсов. Соответственно, при способе 900 вторичный анализ можно проводить времяэффективным образом, чтобы сделать возможным вторичный анализ в режиме реального времени.
[0086] На ФИГ. 9С показано прогнозируемое улучшение времени выполнения выравнивания, описанного на ФИГ. 10. Данные «Основание» сгенерированы с применением только «Существующей обработки» (обычного или синего пути) на ФИГ. 10. Данные «Load Read 1» показывают сокращенные циклы обработки, если данные из набора Прочтение 1 выровнены, предварительно сохранены и затем использованы для ускорения обработки данных в наборе Прочтение 2. В способе 900 можно применять один из двух типов простых выравнивателей для пути обработки с высокой достоверностью и низким уровнем вычислений: простой выравниватель, который пропускает точные совпадения, или простой выравниватель, который пропускает одиночные несовпадения. Простой выравниватель, который пропускает одиночные совпадения, допускает нулевое или одно несовпадение. Данные «Пропуск точных совпадений» показывают сокращенные циклы обработки, когда обычный (синий) путь пропускают, если 16 оснований текущей итерации в точности соответствуют 16 основаниям референсной последовательности в предварительно заданном референсном положении. Данные «Пропуск одиночных несовпадений» показывают сокращенные циклы обработки, когда обычный (синий) путь пропускают, если 16 оснований текущей итерации выравнивают с 16 основаниями референсной последовательности в предварительно заданном референсном положении с по большей мере одним несовпадением. На ФИГ. 9С показано, что по сравнению с исходным уровнем, если способ 900 использует простой выравниватель, который пропустил обычную обработку в случае, когда на пути обработки с высокой достоверностью, низким уровнем вычислений были обнаружены одиночные несовпадения, время цикла снижено в три раза. Обратите внимание, что эти числа были сгенерированы прототипом процессора, который не включает в себя все этапы обработки и, следовательно, являются прогностическими.
[0087] На ФИГ. 10 представлена другая блок-схема примера способа 1000 для проведения вторичного анализа последовательности в режиме реального времени. Способ 1000 и способ 900, показанные на ФИГ. 9, можно проводить по тому же пути обработки с низкой достоверностью, высоким уровнем вычислений, и по другому пути обработки с высокой достоверностью, низким уровнем вычислений. Путь обработки способа 100 с высокой достоверностью, низким уровнем вычислений генерирует показатель MapQ после простого выравнивания и использует показатель MapQ для определения того, следует ли продолжать обработку по пути с высокой достоверностью, низким уровнем вычислением, или следует вернуться к пути с низкой достоверностью, высоким уровнем вычислений.
[0088] Высокий процент времени цикла связан с малым процентом прочтений. В некоторых вариантах реализации путь обработки способа 900 или 1000 с малой достоверностью и высоким уровнем вычислений может пропускать этапы выравнивания и сохранения, если достоверность успеха, определенная с применением метрики, является низкой. В одном варианте реализации можно сгенерировать метрику, которая указывает на количество вероятных местоположений, в которых подпоследовательность можно выровнять с референсной последовательностью. Достоверность успешного выравнивания будет низкой, если количество вероятных местоположений велико. Во втором варианте реализации достоверность успешного выравнивания будет низкой, если разнообразие оснований в последовательности является низким. Разнообразие оснований можно определить, например, путем подсчета количества уникальных n-меров в подпоследовательности, где n-мер представляет собой последовательность оснований в подпоследовательности, длина которой меньше или равна длине самой подпоследовательности.
Альтернативный вариант реализации - вызов вариантов
[0089] На ФИГ. 11А и 11В показана упрощенная блок-схема существующего способа вызова вариантов, малого определителя вариантов Strelka (ФИГ. 11А) и способа вызова вариантов настоящего изобретения (ФИГ. 11В). На ФИГ. 11А показано, что малый определитель вариантов в качестве входных данных использует информацию о пайлапе, сгенерированную из выравнивателя. Из пайлапа малый определитель вариантов идентифицирует участки изменения последовательности, известные как активные участки. Затем к активным участкам можно применить повторную сборку de novo. В каждой геномной позиции генерируются вероятности для определения того, насколько вероятно, что секвенированный полинуклеотид в геномной позиции представляет собой А, С, Т или G. Из этих вероятностей можно определить вариант.
[0090] На ФИГ. 11В показан вариант реализации вызова вариантов, описанный в настоящем изобретении. В этом варианте реализации метрика сгенерирована для определения того, можно ли определить с высокой достоверностью полинуклеотид в геномном положении. Например, можно сгенерировать решение с высокой степенью достоверности, если все полинуклеотиды в данной геномной позиции одинаковы. Альтернативным образом, решение с высокой степенью достоверности можно сгенерировать, если количество полинуклеотидов одного типа в геномном положении превышает пороговое значение. Можно также применять альтернативные метрики для определения высокой достоверности. Если можно определить полинуклеотид с высокой достоверностью, тогда выработку вероятностей можно пропустить и можно выполнить простой вызов вариантов. Например, простой определитель вариантов может вызвать любой вариант, который определен с высокой достоверностью.
[0091] Этап генерации вероятностей и этап вызова вариантов в существующем способе вызова вариантов могут комбинироваться, что требует до 40% вычислительной и обрабатывающей мощности определителя вариантов. На ФИГ. 11В показан способ вызова вариантов 1100, в котором применен как путь обработки по существующему способу вызова вариантов с низкой достоверностью, высоким уровнем вычислений, так и путь обработки с высокой достоверностью, низким уровнем вычислений. С добавлением высокой достоверности и низкого уровня вычислений определитель вариантов Strelka был оптимизирован, а обработка была снижена почти на 40%. К альтернативным определителям вариантов можно добавить путь обработки с высокой достоверностью, низким уровнем вычислений.
[0092] Как показано на ФИГ. 7В, определитель вариантов может работать в окне итерационной обработки. Определитель вариантов на ФИГ. 11А или ФИГ. 11В может работать в окне итерационной обработки. Кроме того, в окне итерационной обработки может работать более чем один тип определителя вариантов. Например, малый определитель вариантов, такой как Strelka, и альтернативный определитель вариантов, такой как структурный определитель вариантов или определитель вариантов с числом копий, могут работать в окне итерационной обработки.
[0093] По меньшей мере в некоторых из ранее описанных вариантов реализации один или несколько элементов, используемых в варианте реализации, можно взаимозаменяемо использовать в другом варианте реализации, если такая замена технически осуществима. Специалистам в данной области техники будет понятно, что в вышеописанных способах и структурах можно сделать различные другие опущения, дополнения и модификации, не отклоняясь от объема изобретения. Все такие модификации и изменения предназначены для попадания в объем изобретения, как определено в прилагаемой формуле изобретения.
[0094] Что касается использования по существу в настоящей заявке любых в единственном и/или множественном числе, специалисты в данной области техники могут переводить из множественного числа в единственное число и/или из единственного числа во множественное число, в зависимости от контекста и/или применения. Различные перестановки единственного/множественного числа могут быть очевидным образом изложены в настоящей заявке в целях ясности изложения.
[0095] Специалистам в данной области техники будет понятно, что в целом термины, используемые в настоящей заявке, и особенно в прилагаемой формуле изобретения (например, тексты прилагаемой формулы изобретения), обычно следует понимать как "открытые" термины (например, термин «включающий» следует интерпретировать как «включающий, но не ограничивающийся указанным», термин «имеющий» следует интерпретировать как «имеющий по меньшей мере», термин «включает» следует интерпретировать как «включает, но не ограничивается указанным» и т.д.). Кроме того, специалистам в данной области техники будет понятно, что, если в описании формулы предполагается конкретное количество, такое предположение будет явно указано в формуле изобретения, и в случае отсутствия такого указания такого предположения нет. Например, чтобы помочь пониманию, прилагаемая в дальнейшем формула может содержать использование вводных фраз «по меньшей мере, один» и «один или более» для введения описания формулы. Однако не следует считать, что использование таких фраз означает, что описание пунктов формулы с единственным числом ограничивает любой конкретный пункт, содержащий такое описание формулы, вариантами реализации, содержащими только одно такое описание, даже если тот же самый пункт включает вводные фразы «один или более» или «по меньшей мере один» и единственное число (например, единственное число следует истолковывать как «хотя бы один» или« один или более»). Кроме того, даже если в формуле изобретения явно перечислено конкретное количество, специалисты в данной области техники поймут, что такое перечисление следует интерпретировать как означающее по меньшей мере указанное количество (например, простое упоминание «двух повторений», без других объяснений означает не менее двух повторений или два или более повторения). Кроме того, в тех случаях, когда использовано выражение, аналогичное «по меньшей мере одно из А, В и С и т.д.» как правило, такая конструкция предназначена для того чтобы специалист в данной области техники понял выражение (например, «система, имеющая по меньшей мере один из А, В и С», будет включать, не ограничиваясь тем самым, системы, которые имеют один А, один В, один С, А и В совместно, А и С совместно, В и С совместно и/или А, В и С совместно и т.д.). В тех случаях, когда использовано выражение, аналогичное «по меньшей мере одно из А, В и С и т.д.», как правило, такая конструкция предназначена для того чтобы специалист в данной области техники понял выражение (например, «система, имеющая по меньшей мере один из А, В или С», будет включать, не ограничиваясь тем самым, системы, которые имеют один А, один В, один С, А и В совместно, А и С совместно, В и С совместно и/или А, В и С совместно и т.д.). Специалистам в данной области техники также будет понятно, что практически любое разделительное слово и/или выражение, представляющие два или более альтернативных термина, будь то в описании, формуле изобретения или чертежах, следует понимать как охватывающие возможность включения одного из терминов, любого из терминов или обоих терминов. Например, фразу «А или В» следует понимать как включающую возможности «А» или «В» или «А и В.»
[0096] Кроме того, если признаки или аспекты изобретения описаны в терминах групп Маркуша, специалисты в данной области техники поймут, что изобретение также тем самым описано в терминах любого отдельного члена или подгруппы членов группы Маркуша.
[0097] Как будет понятно специалисту в данной области техники, для любых и всех целей, таких как предоставление письменного описания, все описанные в настоящей заявке диапазоны также охватывают любые и все возможные поддиапазоны и комбинации поддиапазонов. Любой из перечисленных диапазонов легко можно распознать как в достаточной степени описывающий и позволяющий разбить тот же диапазон по меньшей мере на равные половины, трети, четверти, пятые, десятые доли и т.д. В качестве неограничивающего примера каждый диапазон, обсуждаемый в настоящей заявке, можно легко разбить на нижнюю треть, среднюю треть и верхнюю треть и т.д. Специалисту в данной области техники также будет понятно, что все выражения, такие как «до», «по меньшей мере», «более чем», «менее чем» и тому подобные включают перечисленное количество и относятся к диапазонам, которые можно впоследствии разбить на поддиапазоны, как обсуждалось выше. Наконец, как будет понятно специалисту в данной области техники, диапазон включает в себя каждый отдельный элемент. Так, например, группа, имеющая 1-3 пункта, относится к группам, имеющим 1, 2 или 3 пункты. Подобным образом группа, имеющая 1-5 пунктов, относится к группам, имеющим 1, 2, 3, 4 или 5 пунктов и так далее.
[0098] В то время как в настоящей заявке описаны различные аспекты и варианты реализации, специалистам в данной области техники будут очевидны другие аспекты и варианты реализации. Различные аспекты и варианты реализации, описанные в настоящей заявке, служат для иллюстративных целей и не являются ограничивающими, при этом истинный объем и сущность изобретения представлены в следующей формуле изобретения.

Группа изобретений относится к области биотехнологии. Предложена система и способ секвенирования полинуклеотидов. Система содержит устройство для секвенирования, память, содержащую референсную нуклеотидную последовательность, и процессор, выполненный с возможностью управления устройством для секвенирования и исполнения инструкций для осуществления способа. Способ включает получение первой нуклеотидной подпоследовательности прочтения, проведение вторичного анализа первой нуклеотидной подпоследовательности прочтения на основе референсной последовательности с применением первого или второго способов выравнивания последовательностей, определение необходимости генерирования дополнительных нуклеотидных прочтений устройством для секвенирования. При этом второй способ выравнивания последовательностей является более эффективным в отношении вычисления, чем первый способ выравнивания последовательностей, а вторичный анализ включает определение первой подпоследовательности референсной последовательности и определение различий между первой нуклеотидной подпоследовательностью и первой подпоследовательностью референсной последовательности. Изобретения обеспечивают проведение вторичного анализа данных секвенирования нуклеотидов времясберегающим образом. 2 н. и 25 з.п. ф-лы, 16 ил.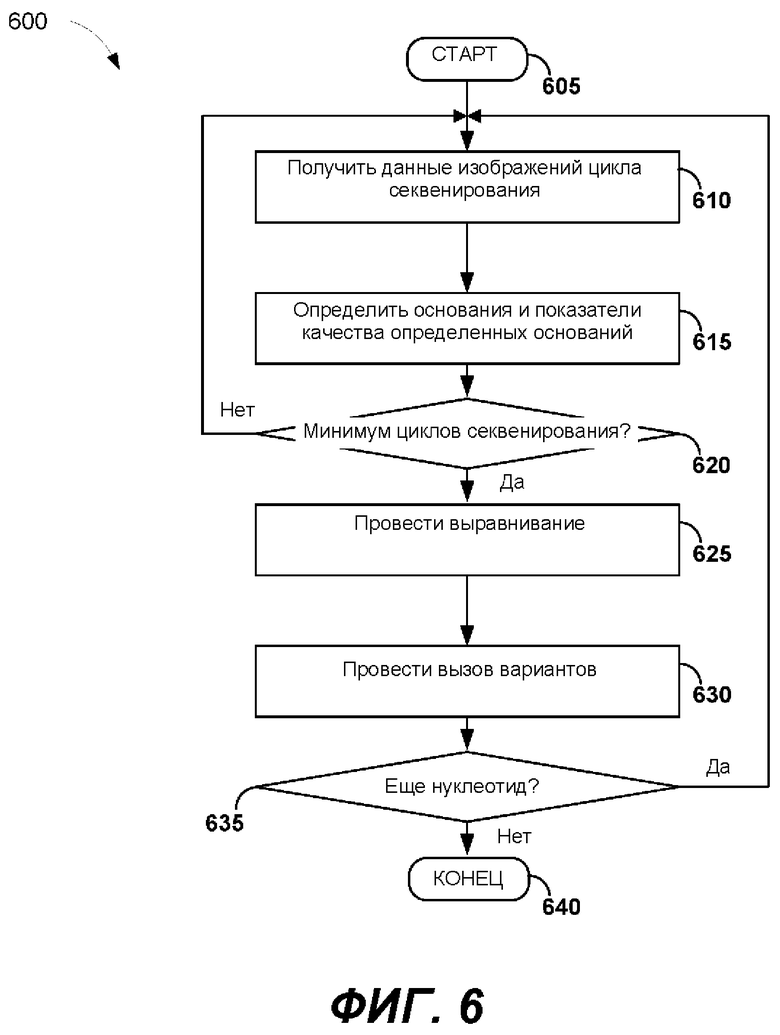
1. Система для секвенирования полинуклеотидов, содержащая:
устройство для секвенирования, выполненное с возможностью генерации необработанных данных секвенирования с использованием реактивов для секвенирования;
память, содержащую референсную нуклеотидную последовательность;
процессор, выполненный с возможностью управления устройством для секвенирования и исполнения инструкций для осуществления способа, который включает:
получение первой нуклеотидной подпоследовательности прочтения из устройства для секвенирования;
обработку первой нуклеотидной подпоследовательности для определения первого множества вероятных местоположений прочтения на референсной последовательности с использованием первого способа выравнивания последовательностей;
определение того, совпадает ли первая нуклеотидная подпоследовательность с референсной последовательностью с достоверным значением на основании определенных вероятных местоположений;
получение второй нуклеотидной подпоследовательности из устройства для секвенирования, причем указанная вторая нуклеотидная подпоследовательность содержит первую нуклеотидную подпоследовательность плюс один или более дополнительных нуклеотидов;
обработку второй нуклеотидной подпоследовательности для определения второго множества вероятных местоположений прочтения, которые выровнены с референсной последовательностью с применением:
второго способа выравнивания последовательностей, который выравнивает указанные один или более дополнительные нуклеотиды во второй нуклеотидной подпоследовательности со следующими частями референсной последовательности посредством простого выравнивания, если первая нуклеотидная подпоследовательность совпадает с референсной последовательностью с достоверным значением, или
повторения первого способа выравнивания последовательностей со второй нуклеотидной подпоследовательностью, если вторая нуклеотидная подпоследовательность не совпадает с референсной последовательностью с достоверным значением,
где второй способ выравнивания последовательностей более эффективен в отношении вычислений, чем первый способ выравнивания последовательностей.
2. Система по п. 1, отличающаяся тем, что вторую нуклеотидную подпоследовательность обрабатывают с применением либо первого способа выравнивания последовательностей, либо второго способа выравнивания последовательностей на основании количества несовпадений или вероятности точного совпадения.
3. Система по п. 1, отличающаяся тем, что длина первой нуклеотидной подпоследовательности составляет один или более нуклеотидов.
4. Система по п. 1, отличающаяся тем, что длина второй нуклеотидной подпоследовательности составляет один или более нуклеотидов.
5. Система по п. 1, отличающаяся тем, что второй способ выравнивания последовательностей более эффективен в отношении вычислений, чем первый способ выравнивания последовательностей, в том, что касается использования памяти или количества вычислительных операций.
6. Система по п. 1, отличающаяся тем, что процессор дополнительно выполнен с возможностью хранения данных, соответствующих по меньшей мере одному из первого множества вероятных местоположений, если первая нуклеотидная подпоследовательность выровнена с референсной последовательностью.
7. Система по п. 6, отличающаяся тем, что процессор дополнительно выполнен с возможностью хранения данных, соответствующих по меньшей мере одному из второго множества вероятных местоположений, если прочтение остается выровненным с референсной последовательностью.
8. Система по п. 1, отличающаяся тем, что обработка второй нуклеотидной подпоследовательности с применением второго способа выравнивания последовательностей включает проведение простого выравнивания для определения показателя простого выравнивания.
9. Система по п. 8, отличающаяся тем, что выполнение простого выравнивания включает сравнение второй нуклеотидной подпоследовательности с соответствующими последовательностями второй нуклеотидной подпоследовательности в референсной последовательности на основе первого множества вероятных местоположений.
10. Система по п. 8, отличающаяся тем, что обработка второй нуклеотидной подпоследовательности с применением указанного второго способа выравнивания последовательностей дополнительно включает определение показателя качества картирования (MapQ) для каждого из второго множества вероятных местоположений прочтения.
11. Система по п. 10, отличающаяся тем, что показатель простого выравнивания включает показатель MapQ.
12. Система по п. 1, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнения вызова вариантов по результату первого способа выравнивания последовательностей или второго способа выравнивания последовательностей, включающего по меньшей мере одно из первого множества вероятных местоположений или по меньшей мере одно из второго множества вероятных местоположений.
13. Система по п. 12, отличающаяся тем, что выполнение вызова вариантов по результату первого способа выравнивания последовательностей или второго способа выравнивания последовательностей включает:
выполнение вызова вариантов по результату первого способа выравнивания последовательностей или второго способа выравнивания последовательностей с применением первого способа вызова вариантов или второго способа вызова вариантов, при этом второй способ вызова вариантов более эффективен в отношении вычислений, чем первый способ вызова вариантов, в том, что касается вызова вариантов второй подпоследовательности.
14. Система по п. 12, отличающаяся тем, что вызов вариантов проводят с применением результатов первого способа выравнивания последовательностей или второго способа выравнивания последовательностей на основе метрики вызова вариантов.
15. Система по п. 14, отличающаяся тем, что метрику вызова вариантов определяют на основании ряда различных типов оснований, вызванных в положении референсной последовательности.
16. Система по п. 1, отличающаяся тем, что обработку первой нуклеотидной подпоследовательности завершают до того, как система определяет вторую нуклеотидную подпоследовательность во время цикла секвенирования.
17. Система по п. 1, отличающаяся тем, что в устройстве для секвенирования для определения первой подпоследовательности применяют способ секвенирования путем синтеза.
18. Компьютеризированный способ секвенирования полинуклеотидов, включающий:
получение первой нуклеотидной подпоследовательности прочтения из устройства для секвенирования во время цикла секвенирования; и
проведение вторичного анализа первой нуклеотидной подпоследовательности прочтения на основе референсной последовательности с применением первого способа выравнивания последовательностей или второго способа выравнивания последовательностей, где второй способ выравнивания последовательностей является более эффективным в отношении вычисления, чем первый способ выравнивания последовательностей, при проведении вторичного анализа, и при этом указанный вторичный анализ включает:
сравнение первой нуклеотидной подпоследовательности с референсной последовательностью для определения первой подпоследовательности референсной последовательности, обладающей высокой степенью сходства с первой нуклеотидной подпоследовательностью, и для определения различий между первой нуклеотидной подпоследовательностью и первой подпоследовательностью референсной последовательности; и
определение необходимости генерирования дополнительных нуклеотидных прочтений устройством для секвенирования.
19. Способ по п. 18, отличающийся тем, что проведение вторичного анализа включает обработку первой нуклеотидной подпоследовательности для определения первого множества вероятных местоположений прочтения, которые выровнены с референсной последовательностью, с применением:
первого способа выравнивания последовательностей, если прочтение не выровнено с референсной последовательностью на предыдущей итерации,
второго способа выравнивания последовательностей в противном случае,
при этом второй способ выравнивания последовательностей более эффективен в отношении вычислений, чем первый способ выравнивания последовательностей, при определении первого множества вероятных местоположений прочтения.
20. Способ по п. 19, отличающийся тем, что обработка второй нуклеотидной подпоследовательности с применением второго способа выравнивания последовательностей включает проведение простого выравнивания для определения показателя простого выравнивания.
21. Способ по п. 19, отличающийся тем, что результаты вторичного анализа включают результат первого способа выравнивания последовательностей, результат второго способа выравнивания последовательностей или любую их комбинацию.
22. Способ по п. 18, отличающийся тем, что проведение вторичного анализа включает выполнение вызова вариантов первой нуклеотидной подпоследовательности, включающее:
выполнение вызова вариантов по результату первого способа выравнивания последовательностей или второго способа выравнивания последовательностей с применением первого способа вызова вариантов или второго способа вызова вариантов, при этом второй способ вызова вариантов более эффективен в отношении вычислений, чем первый способ вызова вариантов, в том, что касается вызова вариантов первой подпоследовательности.
23. Способ по п. 22, отличающийся тем, что результаты вторичного анализа включают результат первого способа вызова вариантов, результат второго способа вызова вариантов или любую их комбинацию.
24. Способ по п. 18, дополнительно включающий обеспечение пользователя результатами вторичного анализа во время цикла секвенирования.
25. Способ по п. 24, отличающийся тем, что результаты вторичного анализа предоставляют пользователю через фиксированные интервалы.
26. Способ по п. 24, отличающийся тем, что результаты вторичного анализа предоставляют пользователю по запросу пользователя.
27. Способ по п. 18, отличающийся тем, что проведение вторичного анализа включает проведение вторичного анализа первой нуклеотидной подпоследовательности прочтения на основе результатов предыдущего интервала секвенирования в цикле секвенирования.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| MILLER J | |||
| R | |||
| Assembly algorithms for next-generation sequencing data // Genomics, Voд | |||
| Прибор для очистки паром от сажи дымогарных трубок в паровозных котлах | 1913 |
|
SU95A1 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| СПОСОБ СЕКВЕНИРОВАНИЯ ДНК И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ (ВАРИАНТЫ) | 2013 |
|
RU2539038C1 |

