ОБЛАСТЬ ТЕХНИКИ
[1] Настоящее техническое решение, в общем, относится к способам обработки данных и подготовки структур данных для просмотра и визуализации, а именно к способу объединения данных информационных систем для их последующей визуализации.
УРОВЕНЬ ТЕХНИКИ
[2] Существующие информационные системы позволяют графически визуализировать показатели, уже находящиеся в базе данных, другими словами, только те данные, что ранее были загружены в базу данных. Это вызывает сложности при необходимости проведения совместного анализа (в одном элементе визуализации) данных из разных информационных систем, например - из разных BI-систем. В известных способах объединения данных для дальнейшего анализа, эти данные в общем случае должны быть извлечены из одной базы данных и загружены в другую, что может быть запрещено или ограничено политикой безопасности какой-либо из взаимодействующих систем.
[3] Например, при анализе показателей эффективности сайта, как правило, используются внешние BI-системы (Яндекс. Метрика, Google Analytics), а для анализа эффективности других бизнес-показателей используются другие BI-системы. Автоматически установить однозначное соответствие между событиями основных бизнес-процессов и событиях на сайте при этом зачастую невозможно.
[4] Необходим способ установления соответствия показателей для построения единой отчетности. Например, шкала времени может иметь разные единицы измерения (часы, дни), разный формат записи (ГГГГ-ММ-ДД, ДД.ММ.ГГГГ, ДД.ММ.ГГ и т.д.). Например, денежные единицы могут иметь различное обозначение («руб.», «т.р.», «тыс.р.»,  ).
).
[5] Из уровня техники известны решения компании ООО «Полиматика рус»: например, Polymatica Dashboards, однако в данных продуктах процесс объединения данных представляет собой выполнение группы запросов JOIN на языке SQL на уровне баз данных, то есть создается некий виртуальный датасет, который получается в процессе работы системы путем направления SQL-запроса к нескольким источникам. Но если источники данных разнородные (например, названия полей сделаны в совершенно разных системах именования), то написать такой запрос с JOIN может быть очень сложным, так как неизвестно, по каким полям объединять таблицы. Для решения описанной проблемы необходим алгоритм, позволяющий автоматически определить поля, по котором нужно сделать запрос на JOIN, для корректного объединения данных.
[6] Кроме того, данный способ может быть полезен, например, в случае, когда один из источников содержит данные, которые не могут или не должны быть выгружены из него. В этом случае становится актуальным способ, позволяющий выполнять обработку общих данных в дополнительном слое абстракции, например, в оперативной памяти клиентского ЭВМ использующего доверенные и разрешенные коннекторы к источникам данных.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[7] Данное техническое решение направлено на устранение недостатков, присущих существующим решениям, известным из уровня техники.
[8] Решаемой технической проблемой в данном техническом решении является сложность объединения данных из разнородных источников данных при совместной работе нескольких информационных систем в процессе решения какой-либо задачи, требующей данные от всех участников процесса.
[9] Основным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является обеспечение возможности работы с разнородными источниками данных без необходимости предварительного объединения исходных данных в базы данных.
[10] Дополнительными техническими результатами, проявляющимся при решении вышеуказанной проблемы, являются повышение производительности и улучшение безопасности при обработке данных.
[11] Указанные технические результаты достигаются благодаря осуществлению способа объединения данных информационных систем для их последующей визуализации, реализуемый с помощью процессора и устройства хранения данных, включающий следующие шаги:
• определяют источники данных в каждой из информационных систем, данные которых предполагается объединять;
• получают параметры доступа для каждого определенного на предыдущем шаге источника данных и осуществляют их проверку доступности;
• составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных;
• на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления;
• учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных;
• на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных;
• на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных;
• осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности.
[12] В одном из частных примеров осуществления способа в случае выявления значимых изменений при проверке актуальности, повторно составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных; на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления; учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных; на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных; на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных; осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности.
[13] В другом частном примере осуществления способа в случае выявления незначимых изменений при проверке актуальности, выявленные изменения отражаются при визуализации данных.
[14] В другом частном примере осуществления способа в процессе определения общих для разных источников данных атрибутов данных, правил их сопоставления, основного источника данных, необходимых источников данных для построения визуализации и оптимального типа визуализации, возможна пользовательская корректировка.
[15] Кроме того, заявленный технический результат достигается за счет системы объединения данных информационных систем для их последующей визуализации объединения данных информационных систем для их последующей визуализации, содержащей:
- по меньшей мере одно устройство обработки данных;
- по меньшей мере одно устройство хранения данных;
- по меньшей мере одну программу, где одна или более программ хранятся на одном или более устройствах хранения данных и исполняются на одном и более устройствах обработки данных, причем одна или более программ обеспечивает выполнение следующих шагов:
• определяют источники данных в каждой из информационных систем, данные которых предполагается объединять;
• получают параметры доступа для каждого определенного на предыдущем шаге источника данных и осуществляют их проверку доступности;
• составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных;
• на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления;
• учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных;
• на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных;
• на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных;
• осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности.
[16] В одном из частных примеров реализации системы в случае выявления значимых изменений при проверке актуальности, повторно составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных; на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления; учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных; на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных; на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных; осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности.
[17] В другом частном примере реализации системы в случае выявления незначимых изменений при проверке актуальности, выявленные изменения отражаются при визуализации данных.
[18] В другом частном примере реализации системы в процессе определения общих для разных источников данных атрибутов данных, правил их сопоставления, основного источника данных, необходимых источников данных для построения визуализации и оптимального типа визуализации, возможна пользовательская корректировка.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[19] Признаки и преимущества настоящего технического решения станут очевидными из приводимого ниже подробного описания и прилагаемых чертежей, на которых:
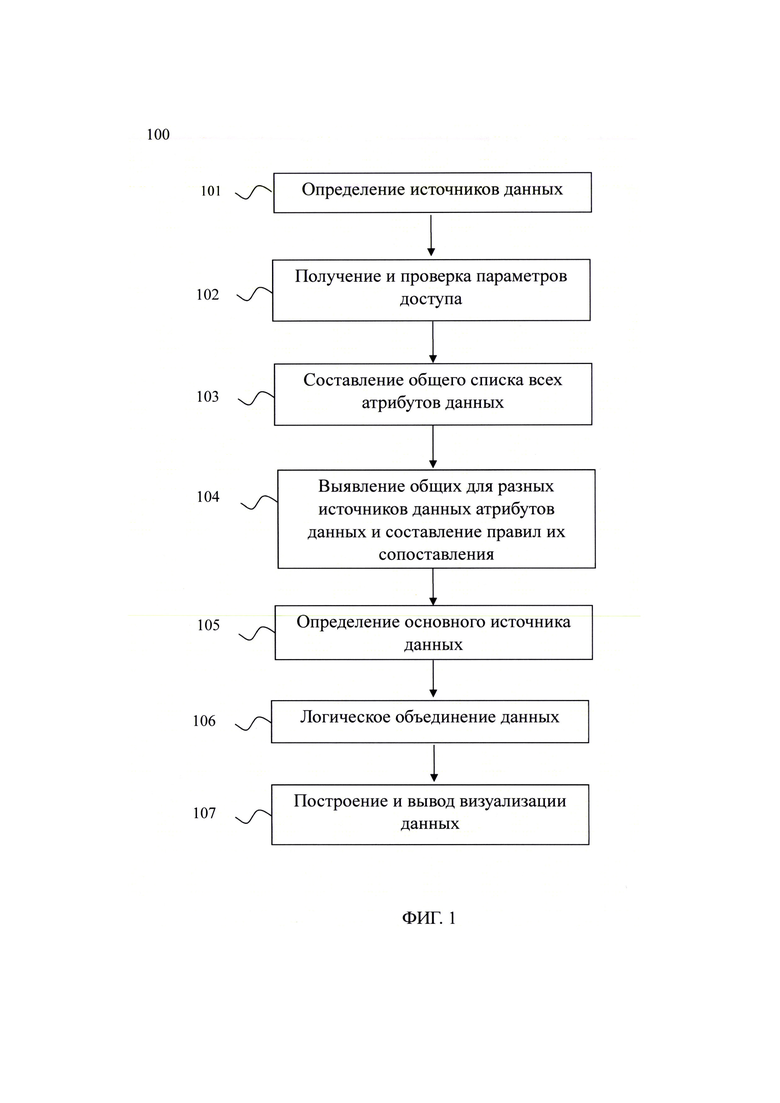
[20] Фиг. 1 иллюстрирует блок-схему выполнения заявленного способа.
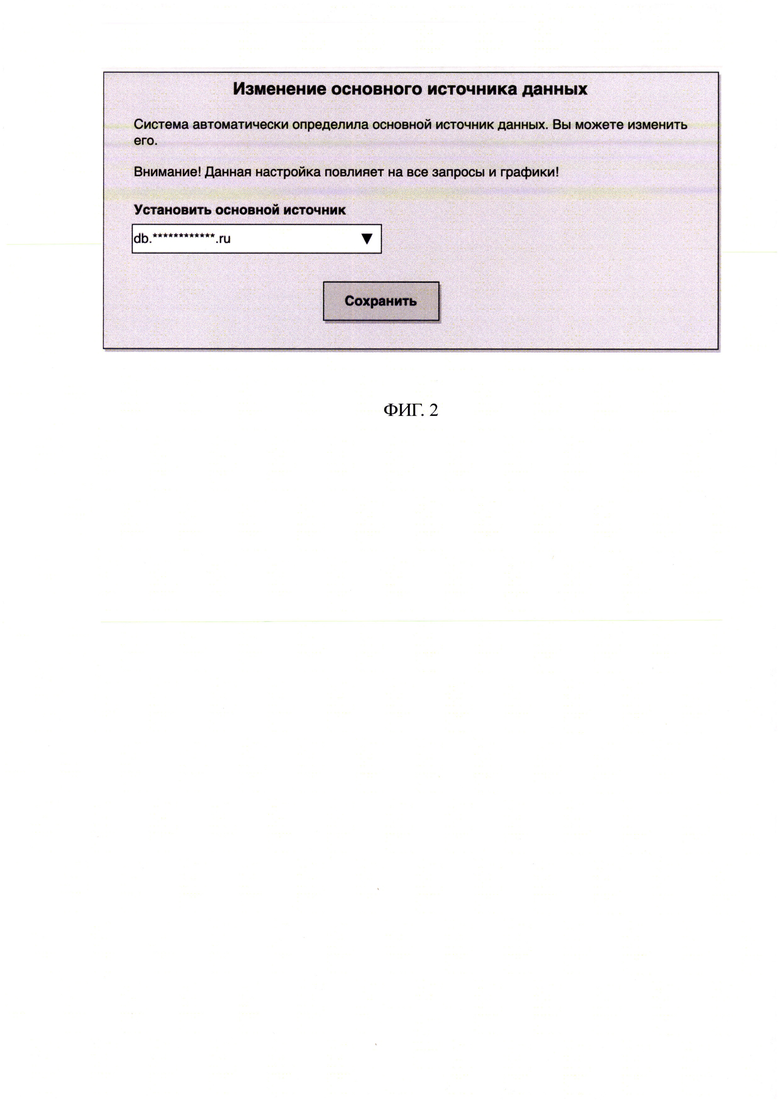
[21] Фиг. 2 пример сообщения об автоматическом нахождении источника данных.
[22] Фиг. 3 иллюстрирует пример единой схемы визуализации.
[23] Фиг. 4 иллюстрирует пример визуализации объединенных данных.
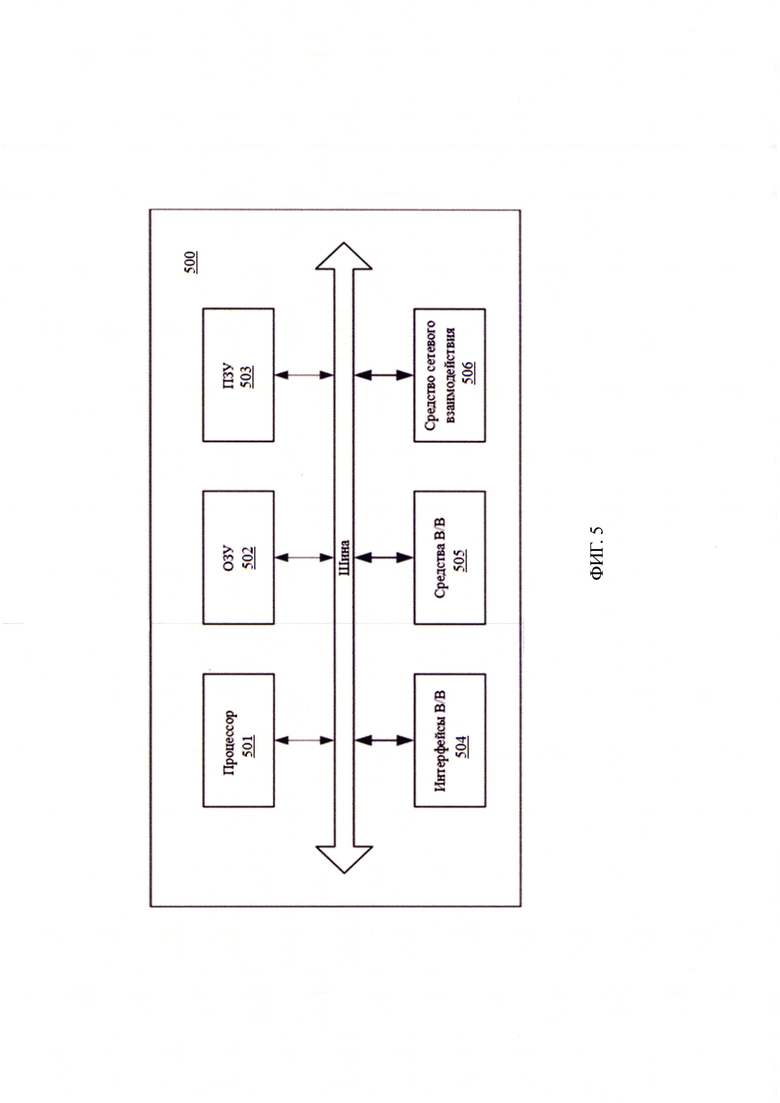
[24] Фиг. 5 иллюстрирует систему для реализации заявленного способа.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[25] Ниже будут описаны термины и понятия, необходимые для реализации настоящего технического решения.
[26] Атрибут данных - наименование столбца (колонки) в таблице
[27] Маппинг данных - представляет собой процесс генерации инструкций по объединению информации из нескольких наборов данных в единую схему, например конфигурацию таблицы.
[28] SQL-запросы - это наборы команд для работы с реляционными (табличными) базами данных. SQL (аббр. от англ. Structured Query Language - «язык структурированных запросов») - декларативный язык программирования, применяемый для создания, модификации и управления данными в реляционной базе данных, управляемой соответствующей системой управления базами данных.
[29] Абстрактный слой данных (слой абстракции базы данных - Database abstraction layer - DBAL) - это интерфейс прикладного программирования, который унифицирует связь между компьютерным приложением и системами управления базами данных (СУБД), такими как SQL Server, DB2, MySQL, PostgreSQL, Oracle или SQLite. Традиционно все поставщики СУБД предоставляют свой собственный интерфейс, адаптированный к их продуктам, что позволяет программисту реализовать код для всех интерфейсов баз данных, которые он или она хотел бы поддерживать. Уровни абстракции уменьшают объем работы, предоставляя последовательный API разработчику и максимально скрывая специфику базы данных за этим интерфейсом. Существует множество слоев абстракции с различными интерфейсами на многих языках программирования.
[30] Заявленное техническое решение может выполняться, например системой, машиночитаемым носителем, сервером и т.д. В данном техническом решении под системой подразумевается, в том числе компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[31] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[32] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[33] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[34] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, получение и обработка данных, формирование профиля пользователя, прием и передача сигналов, анализ принятых данных, идентификация пользователя и т.п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования С++, Java, Python, различных библиотек (например, Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например, Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
[35] Представленный способ объединения данных информационных систем для их последующей визуализации (на Фиг. 1 представлена схема способа) решает задачи обеспечения возможности работы с разнородными источниками данных без необходимости предварительного объединения исходных данных в базы данных, повышения производительности и улучшения безопасности при обработке данных за счет последовательного выполнения следующих шагов:
• определяют источники данных в каждой из информационных систем, данные которых предполагается объединять;
• получают параметры доступа для каждого определенного на предыдущем шаге источника данных и осуществляют их проверку доступности;
• составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных;
• на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления;
• учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных;
• на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных;
• на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных;
• осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности.
[36] На этапе получения и проверки параметров доступа для каждого источника данных информационная система, в которой авторизован пользователь, автоматически получает сохраненные заранее в конфигурационных файлах параметры доступа к каждому источнику данных, делает запрос во все указанные источники, считывает в свой дополнительный абстрактный слой данных (речь идет о логическом слое данных в информационной системе) структуру данных каждого источника и информацию об объеме данных. В случае отсутствие доступа к какому-либо источнику система запрашивает у пользователя дополнительные параметры для входа. Абстрактный слой данных в информационной системе, в которой авторизован пользователь, предназначен для временного хранения информации из других систем.
[37] Система на основе прочитанной структуры каждого источника составляет общий список всех атрибутов, а далее определяет их типы данных. Пример в Таблице 1:

[38] На основе общего списка атрибутов система автоматически определяет общие для разных источников атрибуты (совпадающие в разных источниках) и правила сопоставления. Данный шаг основан на:
1) справочниках типовых случаев сопоставления.
Например, для денежных шкал устанавливается, что «тыс.руб.»=1000 «руб.».
Например, для денежных шкал устанавливается, что значение в одном источнике может храниться в основных единицах валюты (рубли, доллары), а в другом - сразу в минимальных неделимых (копейки, центы).
2) полном или близком совпадении названий атрибутов.
Например, «USERID»=«user_id»=«UID» или «Объем продаж»=«объемы продаж»=«Продажи, объем».
3) Полном или близком совпадении форматов, а названия колонок могут быть разными, например в Таблице 2:

Или в Таблице 3:

В примере ниже (Таблица 4) в одной системе цена товара хранится в рублях и копейках (десятичная дробь, тип DECIMAL), а во второй системе - в копейках (целое число). Так как в системе существует правило, то система смогла сопоставить значения из одного источника со значениями из другого.

В частном варианте реализации система предлагает пользователю определить правила, по которым система определяет общие показатели и способ пересчета шкал / форматов.
Например, пользователь может указать, что атрибуты в разных системах «долгота» и «координата 1» следует считать одинаковыми.
Пример правила: если маска регулярного выражения «\d\d\s?\d\d\s?\d\d\d\d\d\d» применима сразу к двум атрибутам, то такие атрибуты считаются одинаковыми.
Данный опциональный шаг необходим для того, чтобы дать пользователю возможность сопоставить любые атрибуты, которые необходимо считать одинаковыми для целей их анализа.
[39] По критерию, учитывающему количество выявленных в источнике атрибутов, а также учитывающему объем данных в источнике, система определяет основной источник данных, т.е. источник, на базе которого будут строится запросы (в частном примере реализации - SQL-запросы) во все источники, то есть, сначала в запросе производится выборка данных из основного источника с необходимыми фильтрами, а затем к этой выборке осуществляется присоединение второстепенных источников.
Данный шаг необходим для оптимизации запросов (пример сообщения об автоматическом нахождении источника данных продемонстрирован на Фиг. 2).
[40] Система предлагает единую схему визуализации на базе основного и дополнительных источников данных, а именно необходимые источники данных для построения визуализации и тип визуализации (например, табличный). Например, пользователь хочет визуализировать сущность одного из источников данных, содержащую атрибут «product_id». В этом случае система на основе ранее созданных сопоставлений атрибутов предлагает использовать для построения визуализации все источники, связанные по атрибуту «product_id»: пример изображен на Фиг. 3.
[41] После этого система на основе типов атрибутов данных в источниках предлагает тип визуализации, например, табличный. Пользователь системы далее может настроить предложенную визуализацию как в части уточнения источников, так и в части настройки отображения. Важным на данном этапе является одновременное отображение на графике данных из всех доступных источников, объединенных по общим атрибутам. Пример визуализации изображен на Фиг. 4.
[42] На регулярной основе или по событиям (например, вход пользователя) система автоматически получает сохраненные заранее в конфигурационных файлах параметры доступа к каждому источнику данных, делает запрос во все указанные источники, считывает в свой дополнительный абстрактный слой структуру данных каждого источника и информацию об объеме данных, определяет, произошли ли изменения в используемых источниках.
[43] Автоматически на основе указанных ниже критериев определяет значимость изменений. Критерием существенности является влияние на произведенное ранее сопоставление атрибутов:
• в источнике исчезает атрибут, который был использован в установленной связи, или изменился формат атрибута таким образом, что система не может более сопоставить атрибуты до и после изменений;
• в источнике появляется новый атрибут, который система не может сопоставить;
• в источнике появляется новый атрибут, который система уже автоматически сопоставила с другим атрибутов по критерию не полного соответствия, а схожести.
Например, при изменении формата временной шкалы с одного известного системе на другой, известный системе, преобразование производится автоматически (ГГГГ-ММ-ДД-»ГГГГ-ММ-ДД ЧЧ:ММ).
Например, при использовании данных от иностранных поставщиков, температура может быть указана в градусах Фаренгейта, то делается автоматическое сопоставление в градусы Цельсия.
[44] В случае выявления значимых изменений при проверке актуальности, повторно составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных; на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления; учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных; на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных; на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных; осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности.
[45] В случае выявления незначимых изменений при проверке актуальности, выявленные изменения отражаются при визуализации данных.
[46] В процессе определения общих для разных источников данных атрибутов данных, правил их сопоставления, основного источника данных, необходимых источников данных для построения визуализации и оптимального типа визуализации, возможна пользовательская корректировка.
[47] В качестве примера результата работы описываемого способа можно привести объединение нескольких элементов визуализации данных (графиков, диаграмм, гистограмм и проч.) посредством ручного или автоматизированного нахождения общего атрибута, позволяющего совместный анализ исследуемого показателя, например: отображение нескольких графиков на объединенной шкале времени или объединение нескольких столбчатых диаграмм по уникальным идентификаторам.
[48] Основной особенностью, отличающей описываемый способ, является возможность работы с разнородными источниками данных без необходимости предварительного объединения исходных данных в базах данных источников. Указанный функционал достигается за счет программного создания в оперативной памяти клиентского ЭВМ дополнительного абстрактного слоя данных, в котором алгоритмизируется логика: поиска возможностей логического объединения данных, полученных из разных информационных систем; автоматического программного построения объединенного массива с общими данными нескольких информационных систем; визуализации объединенного массива.
[49] При этом дополнительно достигается:
• повышение производительности за счет возможности установки различного способа обработки данных из каждого источника, например времени кэширования, загрузки только части данных и т.д. Например, для источника, содержащего настолько большой объем данных, что прямые запросы к нему приводят к замедлению работы системы, в описываемом способе сразу предлагается создать ограниченную выборку данных по какому либо критерию, и все дальнейшие действия алгоритма проводить на этой выборке. При этом для источника, содержащего небольшой объем данных, будут обрабатываться все его данные. Т. е. влияние на производительность будет происходить прежде всего за счет снижения объема требуемой памяти и вычислительной мощности.
• возможность обрабатывать данные различных категорий критичности без их объединения в хранилище (исходные данные не покидают защищенного контура);
• приведение данных к единому стандарту отображения, например унификация единиц измерения, приведение к единым шкалам измерения и т.д.
[50] Указанные эффекты достигаются за счет маппинга данных в дополнительном абстрактном слое данных на стороне одной из объединяемых информационных систем.
[51] В общем виде (см. Фиг. 5) система объединения данных информационных систем для их последующей визуализации (500) содержит объединенные общей шиной информационного обмена один или несколько процессоров (501), средства памяти, такие как ОЗУ (502) и ПЗУ (503) и интерфейсы ввода/вывода (504).
[52] Процессор (501) (или несколько процессоров, многоядерный процессор и т.п.) может выбираться из ассортимента устройств, широко применяемых в настоящее время, например, таких производителей, как: Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. Под процессором или одним из используемых процессоров в системе (500) также необходимо учитывать графический процессор, например, GPU NVIDIA с программной моделью, совместимой с CUDA, или Graphcore, тип которых также является пригодным для полного или частичного выполнения способа, а также может применяться для обучения и применения моделей машинного обучения в различных информационных системах.
[53] ОЗУ (502) представляет собой оперативную память и предназначено для хранения исполняемых процессором (501) машиночитаемых инструкций для выполнения необходимых операций по логической обработке данных. ОЗУ (502), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.). При этом, в качестве ОЗУ (502) может выступать доступный объем памяти графической карты или графического процессора.
[54] ПЗУ (503) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[55] Для организации работы компонентов устройства (500) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (504). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[56] Для обеспечения взаимодействия пользователя с устройством (500) применяются различные средства (505) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[57] Средство сетевого взаимодействия (506) обеспечивает передачу данных посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п.В качестве одного или более средств (506) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[58] Конкретный выбор элементов устройства (500) для реализации различных программно-аппаратных архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала. В частности, подобная реализация может быть выполнена с помощью электронных компонент, используемых для создания цифровых интегральных схем. Не ограничиваюсь, могут быть использоваться микросхемы, логика работы которых определяется при изготовлении, или программируемые логические интегральные схемы (ПЛИС), логика работы которых задается посредством программирования. Для программирования используются программаторы и отладочные среды, позволяющие задать желаемую структуру цифрового устройства в виде принципиальной электрической схемы или программы на специальных языках описания аппаратуры: Verilog, VHDL, AHDL и др. Альтернативой ПЛИС являются: программируемые логические контроллеры (ПЛК), базовые матричные кристаллы (БМК), требующие заводского производственного процесса для программирования; ASIC - специализированные заказные большие интегральные схемы (БИС), которые при мелкосерийном и единичном производстве существенно дороже. Таким образом, реализация может быть достигнута стандартными средствами, базирующимися на классических принципах реализации основ вычислительной техники.
[59] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ВИЗУАЛИЗАЦИИ БОЛЬШИХ МАССИВОВ ДАННЫХ С ПОМОЩЬЮ ПОИСКА И ВЫДЕЛЕНИЯ ИХ ПАТТЕРНОВ ПОСТРОЕНИЯ | 2023 |
|
RU2813110C1 |
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ ПАРТИЦИОНИРОВАННЫХ ВИТРИН ДАННЫХ, СОДЕРЖАЩИХ ГЕОДАННЫЕ, И ИХ ИСПОЛЬЗОВАНИЯ В ПРОЦЕССЕ ЭКСПЛУАТАЦИИ ХРАНИЛИЩА ДАННЫХ | 2023 |
|
RU2811359C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОЙ ГЕНЕРАЦИИ И ЗАПОЛНЕНИЯ ВИТРИН ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ДЕКЛАРАТИВНОГО ОПИСАНИЯ | 2022 |
|
RU2795902C1 |
| СИСТЕМА ИНТЕЛЛЕКТУАЛЬНОГО УПРАВЛЕНИЯ РИСКАМИ И УЯЗВИМОСТЯМИ ЭЛЕМЕНТОВ ИНФРАСТРУКТУРЫ | 2020 |
|
RU2747476C1 |
| Способ управления информационной системой предприятия | 2020 |
|
RU2736851C1 |
| СИСТЕМА ИНТЕЛЛЕКТУАЛЬНОГО УПРАВЛЕНИЯ КИБЕРУГРОЗАМИ | 2019 |
|
RU2702269C1 |
| СПОСОБ И СИСТЕМА МОНИТОРИНГА АВТОМАТИЗИРОВАННЫХ СИСТЕМ | 2023 |
|
RU2809254C1 |
| Система автоматического обновления и формирования техник реализации компьютерных атак для системы обеспечения информационной безопасности | 2023 |
|
RU2809929C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОГО ПРИНЯТИЯ ПРАВОВОГО РЕШЕНИЯ | 2019 |
|
RU2732071C1 |
| Способ обработки поисковых запросов для нескольких реляционных баз данных произвольной структуры | 2019 |
|
RU2730241C1 |


Изобретение относится к способу и системе объединения данных информационных систем для их последующей визуализации. Технический результат заключается в оптимизации запросов к различным источникам данных для объединения данных этих источников без необходимости предварительного объединения исходных данных в базы данных. Способ содержит этапы, на которых: определяют источники данных в каждой из информационных систем, данные которых предполагается объединять; получают параметры доступа для каждого определенного на предыдущем шаге источника данных и осуществляют их проверку доступности; составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных; на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления; учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных; на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных; на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных; осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности. 2 н. и 6 з.п. ф-лы, 5 ил.
1. Способ объединения данных информационных систем для их последующей визуализации, реализуемый с помощью процессора и устройства хранения данных, включающий следующие шаги:
• определяют источники данных в каждой из информационных систем, данные которых предполагается объединять;
• получают параметры доступа для каждого определенного на предыдущем шаге источника данных и осуществляют их проверку доступности;
• составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных;
• на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления;
• учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных;
• на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных;
• на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных;
• осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности.
2. Способ по п. 1, характеризующийся тем, что в случае выявления значимых изменений при проверке актуальности, повторно составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных; на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления; учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных; на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных; на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных; осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности.
3. Способ по п. 1, характеризующийся тем, что в случае выявления незначимых изменений при проверке актуальности, выявленные изменения отражаются при визуализации данных.
4. Способ по п. 1, характеризующийся тем, что в процессе определения общих для разных источников данных атрибутов данных, правил их сопоставления, основного источника данных, необходимых источников данных для построения визуализации и оптимального типа визуализации, возможна пользовательская корректировка.
5. Система объединения данных информационных систем для их последующей визуализации, содержащая:
 по меньшей мере одно устройство обработки данных;
по меньшей мере одно устройство обработки данных;
по меньшей мере одно устройство хранения данных;
по меньшей мере одну программу, где одна или более программ хранятся на одном или более устройствах хранения данных и исполняются на одном и более устройствах обработки данных, причем одна или более программ обеспечивает выполнение следующих шагов:
• определяют источники данных в каждой из информационных систем, данные которых предполагается объединять;
• получают параметры доступа для каждого определенного на предыдущем шаге источника данных и осуществляют их проверку доступности;
• составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных;
• на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления;
• учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных;
• на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных;
• на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных;
• осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности.
6. Система по п. 5, характеризующаяся тем, что в случае выявления значимых изменений при проверке актуальности, повторно составляют общий список всех атрибутов данных, определяя их типы и структуру данных в каждом из источников данных; на основе составленного на предыдущем шаге общего списка всех атрибутов данных выявляют общие для разных источников данных атрибуты данных и составляют правила их сопоставления; учитывая объем данных и количество выявленных в источниках данных атрибутов данных, определяют основной источник данных из имеющихся, на базе которого будут строиться запросы во все остальные источники данных для проведения объединения данных; на основе выявленных общих для разных источников данных атрибутов данных и составленных правил их сопоставления производят логическое объединение данных; на основе проведенного ранее логического объединения данных определяют оптимальный тип визуализации, при этом визуализируя все доступные источники данных, объединенные по общим атрибутам данных; осуществляют построение и вывод визуализации данных по ранее определенному типу визуализации, при этом осуществляя регулярную проверку доступности источников данных и их актуальности.
7. Система по п. 5, характеризующаяся тем, что в случае выявления незначимых изменений при проверке актуальности, выявленные изменения отражаются при визуализации данных.
8. Система по п. 5, характеризующаяся тем, что в процессе определения общих для разных источников данных атрибутов данных, правил их сопоставления, основного источника данных, необходимых источников данных для построения визуализации и оптимального типа визуализации, возможна пользовательская корректировка.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| US 8296360 B2, 23.10.2012 | |||
| ЩИТОВОЙ ДЛЯ ВОДОЕМОВ ЗАТВОР | 1922 |
|
SU2000A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| US 11392606 B2, 19.07.2022 | |||
| US 10803050 B1, 13.10.2020 | |||
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| US 9594805 B2, 14.03.2017 | |||
| US 7533107 B2, 12.05.2009. | |||
