ОБЛАСТЬ ТЕХНИКИ
[1] Настоящее техническое решение, в общем, относится к способам обработки данных и подготовки структур данных для просмотра и визуализации, а именно к способу формирования партиционированных витрин данных, содержащих геоданные, и их использования в процессе эксплуатации хранилища данных.
УРОВЕНЬ ТЕХНИКИ
[2] В настоящее время известен способ обработки данных в хранилищах данных, при котором логически выделяются три стандартных слоя данных:
• Исходный (stage);
• Нормализованный (детальный);
• Адаптированный для просмотра (витрины).
[3] Как правило для обработки каждого из слоев применяются отдельные технические решения. Витрины часто партиционируются (шардируются, например, на различных инстансах баз данных) по каким-то признакам, например, периоду, id клиента, и в общем, по любому другому атрибуту.
[4] В любых витринах данных, когда речь идет о больших данных, как правило применяется партиционирование. В частности, в геовитринах партиционируются данные путем отнесения данных к одному или другому географическому объекту.
[5] Из уровня техники известно техническое решение, описанное в RU 2681361 «СИСТЕМА ФОРМИРОВАНИЯ ПОЛЬЗОВАТЕЛЬСКОГО ИНТЕРФЕЙСА ДЛЯ ВВОДА, ОТОБРАЖЕНИЯ И МОДИФИКАЦИИ ВЕКТОРНЫХ ПРОСТРАНСТВЕННЫХ ДАННЫХ», 18.04.2018, Федеральное государственное казенное военное образовательное учреэкдение высшего образования Академия Федеральной службы охраны Российской Федерации (RU): «система формирования пользовательского интерфейса для ввода, отображения и модификации векторных пространственных данных дополнительно содержит блок управления обработкой набора исходных векторных пространственных данных, блок генерации программного кода функциональных частей пользовательского интерфейса, блок хранения метаданных об исходных векторных пространственных данных, блок хранения промежуточных данных, блок хранения метаданных о выходных векторных пространственных данных».
[6] Из уровня техники известно техническое решение, описанное в US11036752B2 «Optimizing incremental loading of warehouse data», 08.08.2016, Oracle International Corp. (US): представлена оптимизация инкрементальной загрузки данных в базу данных путем выявления затрагиваемых партиций и отключения на время загрузки данных только этих партиций, также описана загрузкуа и хранение данных».
[7] Недостатками известных решений являются то обстоятельство, что при обработке данных и их партиционировании, каждая партиция имеет формат, с которой может работать только конкретная система управления базами данных, в которой был проведен процесс партиционирования, что налагает существенные ограничения при их использовании.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[8] Данное техническое решение направлено на устранение недостатков, присущих существующим решениям, известным из уровня техники.
[9] Решаемой технической проблемой в данном техническом решении является то, что при обработке данных и их партиционировании, каждая партиция имеет формат, с которой может работать только конкретная система управления базами данных, в которой был проведен процесс партиционирования, что налагает существенные ограничения при их использовании.
[10] Основным техническим результатом, проявляющимся при решении вышеуказанной проблемы, является расширение арсенала технических средств путем обеспечения возможности создавать и использовать партиционированные данные в виде статичных и готовых к передаче файлов.
[11] Дополнительными техническими результатами, проявляющимся при решении вышеуказанной проблемы, являются ускорение обработки данных, ускорение интеграции модулей хранилищ данных и ускорение кэширования данных на различных уровнях их обработки при работе с партиционированными данными.
[12] Указанные технические результаты достигаются благодаря осуществлению способа формирования партиционированных витрин данных, содержащих геоданные, и их использования в процессе эксплуатации хранилища данных, реализуемого с помощью процессора и устройства хранения данных, включающего следующие шаги:
• получают на вход данные, включающие в себя: геоданные, список числовых значений от минимального до максимального значения уровня масштаба формируемых витрин данных и датасет с произвольными атрибутами, для формирования витрины данных;
• проводят объединение полученных геоданных и датасета;
• на основе результата проведенного на предыдущем шаге объединения формируют тайлы и их идентификаторы для всех уровней масштаба формируемых витрин данных следующим образом:
 для текущего уровня масштаба в цикле по идентификаторам тайлов получают все имеющиеся для этого тайла данные в объединенном датасете;
для текущего уровня масштаба в цикле по идентификаторам тайлов получают все имеющиеся для этого тайла данные в объединенном датасете;
преобразуют тайлы в формат для обработки витриной данных и сохраняют в памяти устройства хранения данных.
• используют полученные тайлы в процессе эксплуатации хранилища данных для формирования партиционированных витрин данных, содержащих геоданные, следующим способом:
выбирают необходимый уровень масштаба;
автоматически определяют все идентификаторы тайлов на текущем уровне масштаба;
запрашивают тайлы согласно определенным идентификаторам, создают и визуализируют соответствующие витрины данных.
[13] В одном из частных примеров осуществления способа при формировании тайлов и их идентификаторов производят дополнительные вычисления над данными, позволяющие изменять атрибуты.
[14] В другом частном примере осуществления способа выбор уровня масштаба осуществляется через предустановленные значения.
[15] В другом частном примере осуществления способа выбор уровня масштаба осуществляется динамически.
[16] Кроме того, заявленный технический результат достигается за счет системы формирования партиционированных витрин данных, содержащих геоданные, и их использования в процессе эксплуатации хранилища данных, содержащей:
по меньшей мере одно устройство обработки данных;
по меньшей мере одно устройство хранения данных;
по меньшей мере одну программу, где одна или более программ хранятся на одном или более устройствах хранения данных и исполняются на одном и более устройствах обработки данных, причем одна или более программ обеспечивает выполнение следующих шагов:
• получают на вход данные, включающие в себя: геоданные, список числовых значений от минимального до максимального значения уровня масштаба формируемых витрин данных и датасет с произвольными атрибутами, для формирования витрины данных;
• проводят объединение полученных геоданных и датасета;
• на основе результата проведенного на предыдущем шаге объединения формируют тайлы и их идентификаторы для всех уровней масштаба формируемых витрин данных следующим образом:
для текущего уровня масштаба в цикле по идентификаторам тайлов получают все имеющиеся для этого тайла данные в объединенном датасете;
преобразуют тайлы в формат для обработки витриной данных и сохраняют в памяти устройства хранения данных.
• используют полученные тайлы в процессе эксплуатации хранилища данных для формирования партиционированных витрин данных, содержащих геоданные, следующим способом:
выбирают необходимый уровень масштаба;
автоматически определяют все идентификаторы тайлов на текущем уровне масштаба;
запрашивают тайлы согласно определенным идентификаторам, создают и визуализируют соответствующие витрины данных.
[17] В одном из частных примеров осуществления способа при формировании тайлов и их идентификаторов производят дополнительные вычисления над данными, позволяющие изменять атрибуты.
[18] В другом частном примере осуществления способа выбор уровня масштаба осуществляется через предустановленные значения.
[19] В другом частном примере осуществления способа выбор уровня масштаба осуществляется динамически.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[20] Признаки и преимущества настоящего технического решения станут очевидными из приводимого ниже подробного описания и прилагаемых чертежей, на которых:
[21] Фиг. 1 иллюстрирует блок-схему выполнения заявленного способа.
[22] Фиг. 2 иллюстрирует пример работы описываемого технического решения при уровне масштаба от 0 до 1.
[23] Фиг. 3 иллюстрирует пример работы описываемого технического решения при уровне масштаба 2.
[24] Фиг. 4 иллюстрирует пример работы описываемого технического решения при уровне масштаба 13.
[25] Фиг. 5 иллюстрирует систему для реализации заявленного способа.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[26] Ниже будут описаны термины и понятия, необходимые для реализации настоящего технического решения.
[27] Партиционирование или секционирование (англ. partitioning) - разделение хранимых объектов баз данных (таких как таблиц, индексов, материализованных представлений) на отдельные части с раздельными параметрами физического хранения. Используется в целях повышения управляемости, производительности и доступности для больших баз данных. Возможные критерии разделения данных, используемые при секционировании - по предопределенным диапазонам значений, по спискам значений, при помощи значений хеш-функций; в некоторых случаях используются другие варианты. Под композитными (составными) критериями разделения понимают последовательно примененные критерии разных типов. В отличие от сегментирования, где каждый сегмент управляется отдельным экземпляром СУБД, и используются средства координации между ними (что позволяет распределить базу данных на несколько вычислительных узлов), при секционировании доступ ко всем секциям осуществляется из единого экземпляра СУБД (или симметрично из любого экземпляра кластерной СУБД, такого, как Oracle RAC).
[28] Тайловая, плиточная или знакоместная графика (от англ. tile - плитка) - метод создания больших изображений (как правило, уровней в компьютерных играх) из маленьких фрагментов одинаковых размеров. Тайлы - небольшие изображения одинаковых размеров, служащие фрагментами большой картины. Количество тайлов на один «мир» может достигать нескольких сотен. Матрица клеток при этом хранит только номера тайлов, за счет чего достигается экономия памяти при построении огромных двухмерных пространств.
[29] Датасет или набор данных (data set или dataset) - это коллекция данных. В случае с табличными данными, набор данных соответствует одной или нескольким таблицам баз данных, где каждый столбец таблицы соответствует отдельной переменной, и каждая строка соответствует записи в наборе данных. Наборы данных хранят значения для каждой переменной, например высота и вес объекта, для каждого члена набора данных. Наборы данных могут также состоять из коллекции документов или файлов.
[30] Уровень масштаба - согласованный заранее между конечным пользователем и системой формирования геовитрин список числовых значений от минимального до максимального значения. Просмотр данных витрин возможен только на одном из уровней масштаба, определенных в этом списке. Способ подходит для различных геодезических проекций, но используемая в конкретной реализации способа проекция геообъектов на плоскость также должна быть согласована заранее.
[31] Заявленное техническое решение может выполняться, например системой, машиночитаемым носителем, сервером и т.д. В данном техническом решении под системой подразумевается, в том числе компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
[32] Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
[33] Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных, например таких устройств, как оперативно запоминающие устройства (ОЗУ) и/или постоянные запоминающие устройства (ПЗУ). В качестве ПЗУ могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, твердотельные накопители (SSD), оптические носители данных (CD, DVD, BD, MD и т.п.) и др.
[34] Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
[35] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, получение и обработка данных, формирование профиля пользователя, прием и передача сигналов, анализ принятых данных, идентификация пользователя и т.п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, объектно-ориентированные методы. Например, инструкции могут быть реализованы, посредством языка программирования С++, Java, Python, различных библиотек (например, Microsoft Foundation Classes) и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться как по проводным, так и по беспроводным каналам передачи данных, например, Wi-Fi, Bluetooth, USB, WLAN, LAN и т.п.
[36] Представленный способ формирования партиционированных витрин данных, содержащих геоданные, и их использования в процессе эксплуатации хранилища данных (на Фиг. 1 представлена схема способа) решает задачи обеспечения возможности создавать и использовать партиционированные данные в виде статичных и готовых к передаче файлов, а также ускорения обработки данных, ускорения интеграции модулей хранилищ данных и ускорения кэширования данных на различных уровнях их обработки при работе с партиционированными данными за счет последовательного выполнения следующих шагов:
• получают на вход данные, включающие в себя: геоданные, список числовых значений от минимального до максимального значения уровня масштаба формируемых витрин данных и датасет с произвольными атрибутами, для формирования витрины данных;
• проводят объединение полученных геоданных и датасета;
• на основе результата проведенного на предыдущем шаге объединения формируют тайлы и их идентификаторы для всех уровней масштаба формируемых витрин данных следующим образом:
 для текущего уровня масштаба в цикле по идентификаторам тайлов получают все имеющиеся для этого тайла данные в объединенном датасете;
для текущего уровня масштаба в цикле по идентификаторам тайлов получают все имеющиеся для этого тайла данные в объединенном датасете;
преобразуют тайлы в формат для обработки витриной данных и сохраняют в памяти устройства хранения данных.
• используют полученные тайлы в процессе эксплуатации хранилища данных для формирования партиционированных витрин данных, содержащих геоданные, следующим способом:
выбирают необходимый уровень масштаба;
автоматически определяют все идентификаторы тайлов на текущем уровне масштаба;
запрашивают тайлы согласно определенным идентификаторам, создают и визуализируют соответствующие витрины данных.
[37] В примере реализации способа ниже (функции на языке JS с указанием инструментария и примерами исходных и результирующих данных) в качестве геоданных использовалась GeoJSON с системой координат wgs84. Но возможно использовать любой формат (kml, csv, avro, parquet, …) с любой системой координат.






И т.д. с дальнейшими гео-координатами.


И т.д. с дальнейшими партицированными данными (тайлами) в виде отдельных файлов.
[38] В описываемом техническом решении предлагается хранить и использовать партиционированные данные в виде статичных и готовых к передаче пользователю файлов.
Преимущества использования файлов:
1. Обработка файлов является одним из базовых инструментов большинства ОС, и поддерживается ядром. Не требуется разработка дополнительных инструментов
2. Легко осуществляется кэширование данных на различных уровнях (сервер, CDN-сеть, прокси-сервер, клиентское устройство)
3. Легко интегрировать различные модули хранилища данных, так как осуществляется простое перемещение файлов, и существует широкий спектр базовых инструментов для этого.
[39] В отличие от известных в уровне техники решений, где каждая партиция имеет формат, понятный только конкретной СУБД, в данном решении каждая партиция хранится в виде отдельного файла. Также в этом решении предлагается объединять в каждом файле по выбранной географической области как сами меры, которые интересуют пользователя, так и вспомогательную информацию (контуры областей, точки, другие картографические слои).
[40] Рассмотрим традиционный способ хранения партиционированных данных, например, в СУБД PostgreSQL: традиционно файлы конфигурации и файлы данных, используемые кластером базы данных, хранятся вместе в каталоге данных кластера, обычно называемом PGDATA (по имени переменной среды, которая может использоваться для ее определения). Обычное место для PGDATA - /var/lib/pgsql/data. На одном компьютере может существовать несколько кластеров, управляемых разными экземплярами сервера. Каталог PGDATA содержит несколько подкаталогов и управляющих файлов, как показано в списке ниже. В дополнение к этим обязательным элементам файлы конфигурации кластера postgresql.conf, pg_hba.conf и pg_ident.conf традиционно хранятся в PGDATA, хотя их можно разместить в другом месте.
PG_VERSION Файл, содержащий номер основной версии PostgreSQL.
base Подкаталог, содержащий подкаталоги для каждой базы данных
global Подкаталог, содержащий общие для кластера таблицы, такие как pg_database
pg_commit_ts Подкаталог, содержащий данные временной метки фиксации транзакции.
pg_clog Подкаталог, содержащий данные о статусе фиксации транзакции.
pg_dynshmem Подкаталог, содержащий файлы, используемые подсистемой динамической разделяемой памяти.
pg_logical Подкаталог, содержащий данные о состоянии для логического декодирования.
pg_multixact Подкаталог, содержащий данные о состоянии нескольких транзакций (используется для общих блокировок строк)
pg_notify Подкаталог, содержащий данные о статусе LISTEN/NOTIFY.
pg_replslot Подкаталог, содержащий данные слота репликации.
pg_serial Подкаталог, содержащий информацию о совершенных сериализуемых транзакциях.
pg_snapshots Подкаталог, содержащий экспортированные снимки.
pg_stat Подкаталог, содержащий постоянные файлы для подсистемы статистики.
pg_stat_tmp Подкаталог, содержащий временные файлы для подсистемы статистики.
pg_subtrans Подкаталог, содержащий данные о статусе подтранзакции.
pg_tblspc Подкаталог, содержащий символические ссылки на табличные пространства.
pg_twophase Подкаталог, содержащий файлы состояния для подготовленных транзакций.
pg_xlog Подкаталог, содержащий файлы WAL (Write Ahead Log).
postgresql.auto.conf Файл, используемый для хранения параметров конфигурации, установленных ALTER SYSTEM.
postmaster.opts Файл, в котором записаны параметры командной строки, с которыми последний раз запускался сервер.
postmaster.pid Файл блокировки, записывающий текущий идентификатор процесса postmaster (PID), путь к каталогу данных кластера, отметку времени запуска postmaster, номер порта, путь к каталогу сокета домена Unix (пустой в Windows), первый допустимый listen_address (IP-адрес или *, или пустой, если TCP не прослушивается) и идентификатор сегмента общей памяти (этот файл отсутствует после выключения сервера)
[41] Для каждой базы данных в кластере есть подкаталог в PGDATA/base, названный в честь OID базы данных в pg database. Этот подкаталог является расположением по умолчанию для файлов базы данных; в частности, там хранятся его системные каталоги.
[42] Каждая таблица и индекс хранятся в отдельном файле. Для обычных отношений эти файлы называются по номеру файлового узла таблицы или индекса, который можно найти в pg_class.relfilenode. Но для временных отношений имя файла имеет форму tBBBFFF, где ВВВ - это идентификатор серверной части, создавшей файл, a FFF - номер файлового узла. В любом случае в дополнение к основному файлу (a/k/a main fork) каждая таблица и индекс имеют карту свободного пространства, в которой хранится информация о свободном пространстве, доступном в отношении. Карта свободного пространства хранится в файле с именем, состоящим из номера файлового узла и суффикса _fsm. Таблицы также имеют карту видимости, хранящуюся в ответвлении с суффиксом _vm, чтобы отслеживать, какие страницы, как известно, не имеют мертвых кортежей. Незарегистрированные таблицы и индексы имеют третью ветку, известную как вилка инициализации, которая хранится в вилке с суффиксом _init.
[43] Рассмотрим структуру данных из описываемого решения: максимально простая структура из простых файлов с одинаковым предназначением. Каждый файл содержит как геометрию, которая попала в этот тайл, так и измерения и меры. Атрибуты партиционирования, их количество и последовательность выбираются в зависимости от решаемой задачи.
[44] Ниже приведен пример партиционирование по дате (у_2021-01-01) слою (fields или adm) и сетке XYZ (Leaflet). В качастве формата файлов используется protobuf (pbf):


[45] Преимущества объединения данных и геометрии в одном файле:
1. Минимизация клиент-серверных взаимодействий
2. Легко осуществляется дополнение нового уровня гранулярности данных
3. Сложность и трудоемкость операция запросов данных не зависит от количества объектов, измерений и мер в одном запросе
Пример 1: Пользователь хочет получить экономические показатели Самарской области за несколько последних лет.
В этом случае данные могут быть партиционироеаны следующим образом:
• Файл 1: "Самарская область, 2020, экономические показатели»
• Файл 2: "Самарская область, 2021, экономические показатели»
• Файл 3: "Самарская область, 2022, экономические показатели»
Пример 2: Пользователь хочет получить экономические показатели одного района Самарской области за несколько последних лет.
В этом случае данные могут быть партиционироеаны следующим образом:
• Файл 1: "Самарская область, Волжский район, 2020, экономические показатели»
• Файл 2: "Самарская область, Волжский район, 2021, экономические показатели»
• Файл 3: "Самарская область, Волжский район, 2022, экономические показатели»
Как видно из примеров выше, не потребуется пересчет ранее рассчитанных данных, а только расчет нового «масштаба» данных.
[46] Витрины данных в хранилищах данных содержат часть предрассчитанных данных (слоев данных). В описываемом решении данная концепция полностью реализуется, и более того, предрассчитаны не только данные, но и заранее подготовлен ответ сервера клиенту в виде готового файла. Преимущества такого подхода заключается в том, что расчет может осуществляться в периоды минимальной загрузки сервера. Предрасчитываются все воможные варианты запросов пользователя, но фактически заменяются только изменившиеся файлы. Однако если при этом серверная часть реализации способа может определить набор файлов, которые затрагиваются перерасчетом, то перерасчитаны и заменены могут быть только эти файлы. Например, если изменились экономические показатели одного региона РФ, то будут перерасчитаны только файлы, затрагивающие этот регион, а также все файлы более высокого уровня иерархии (агрегаты по всей РФ). При этом файлы, относящиеся к другим регионам, пересчитаны и затронуты не будут.
[47] При этом способ не исключает параллельного использования традиционных СУБД для хранения предрасчитанных данных на сервере на основе идентификаторов тайлов, в частности, для партиционирования, хранения вспомогательной информации, расчета агрегатов. Существенным в данном способе является оптимизация основной пользовательской функции - просмотра данных.
[48] Идентификаторы тайлов могут быть получены: либо из входных требований для расчета; либо исходя из полученных геоданных, либо изначально берутся вообще все возможные значения.
[49] Система кодирования идентификатора файла известна как серверу, так и клиенту, и позволяет легко получить идентификатор запрашиваемого объекта данных.
[50] Система кодирования может быть как одной из стандартных, так и проприетарной для каждого клиента.
В качестве примера рассмотрим:
• Сетку XYZ из Leaflet
Например, для визуализации карты нашей планеты можно использовать цилиндрическую проекцию (если искажения этой проекции допустимы) и нарезку на тайлы одного размера (в пикселях).
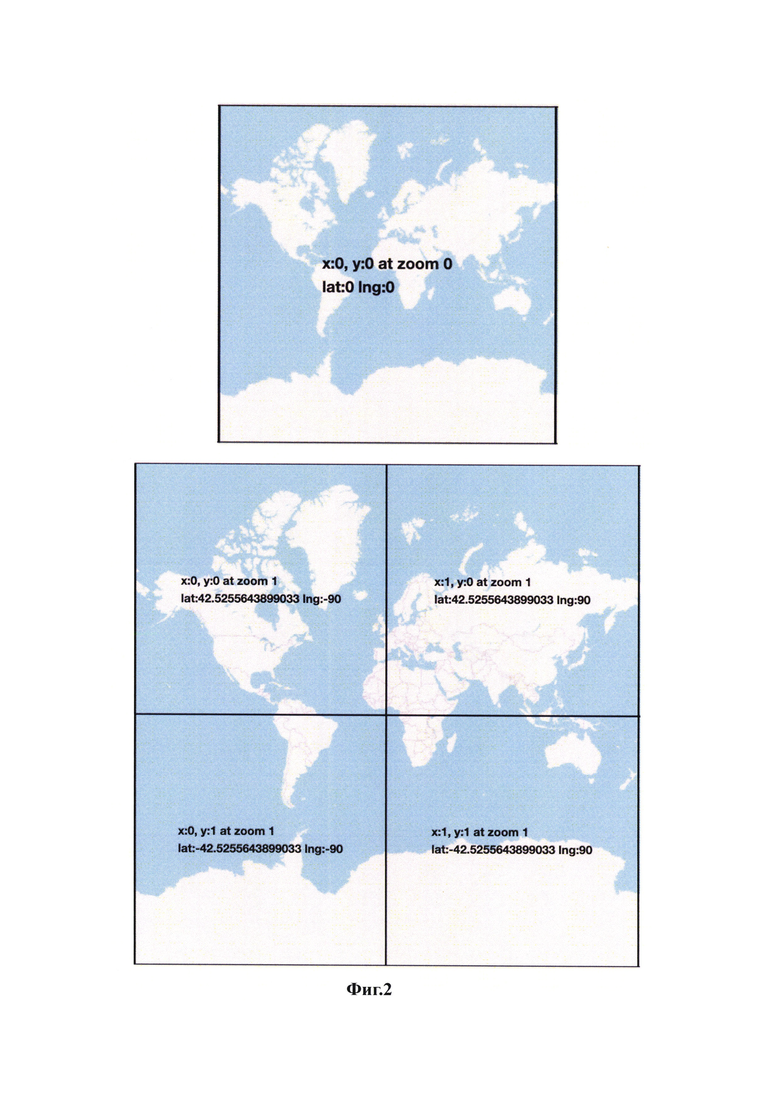
На максимальном отдалении (Zoom=0) вся карта вписывается в один тайл: на Фиг. 2.
При каждом последующем уровне масштабирования количество тайлов увеличивается в 2 раза (по отношению к предыдущему) по осям х и у.
Zoom=1: на Фиг. 2;
Zoom=2: на Фиг. 3;
Zoom=13: на Фиг. 4.
[51] В частном варианте реализации пользователь выбирает ту географическую область, которая ему нужна, путем формирования идентификатора нужного файла по заранее известной формуле. Затем пользователь обращается к конкретному файлу.
[52] В пользовательском приложении, например, браузере, по известной из предыдущего пункта системе кодирования и текущих действий пользователя, например выбранной области для отображения, производится определение необходимых для загрузки идентификаторов файлов. Преимущество: формула известна заранее, она простая, поэтому данная операция не требует больших вычислительных мощностей.
[53] Пользовательское устройство на основе полученного списка идентификаторов файлов загружает их стандартным для пользовательской ОС способом. Преимущества:
• не требуется реализация загрузки файлов - этот функционал стандартный и уже реализован в ОС пользователя;
• возможно применение распараллеливания при наличии поддержки на уровне ОС и протокола, использование различных протоколов (HTTP, FTP, S3);
• возможно применение кэширование на различных уровнях (пользовательское устройство, локальная сеть (прокси-сервер), сервер);
• легко реализуется локальное кэширование данных на стороне пользователя, например, при реализации мобильного приложения, так как требуется сохранять файлы.
[54] При использовании основной пользовательской функции системы (просмотр данных) при изменении в ней данных пользовательское устройство загружает только изменения, а не все данные. Существует несколько известных способов реализации данного шага, например, использование заголовка E-Tag протокола HTTP, параметризация правил определения идентификаторов файлов. Преимущества:
• минимизация объема передаваемых данных;
• наличие существующих реализаций данного шага;
• неограниченное горизонтальное масштабирование системы, например можно просто копировать одинаковые файлы на N серверов и осуществлять балансировку методом round robin, что убирает необходимость в сложном управлении контейнерной архитектурой;
• высокая скорость работы серверной части, так как отсутствуют серверные вычисления во время обращения пользователя (все данные заранее предрасчитаны);
• высокая скорость работы серверной части, так как пользователь загружает в основном необходимые данные;
• удообное управление гранулярностью данных.
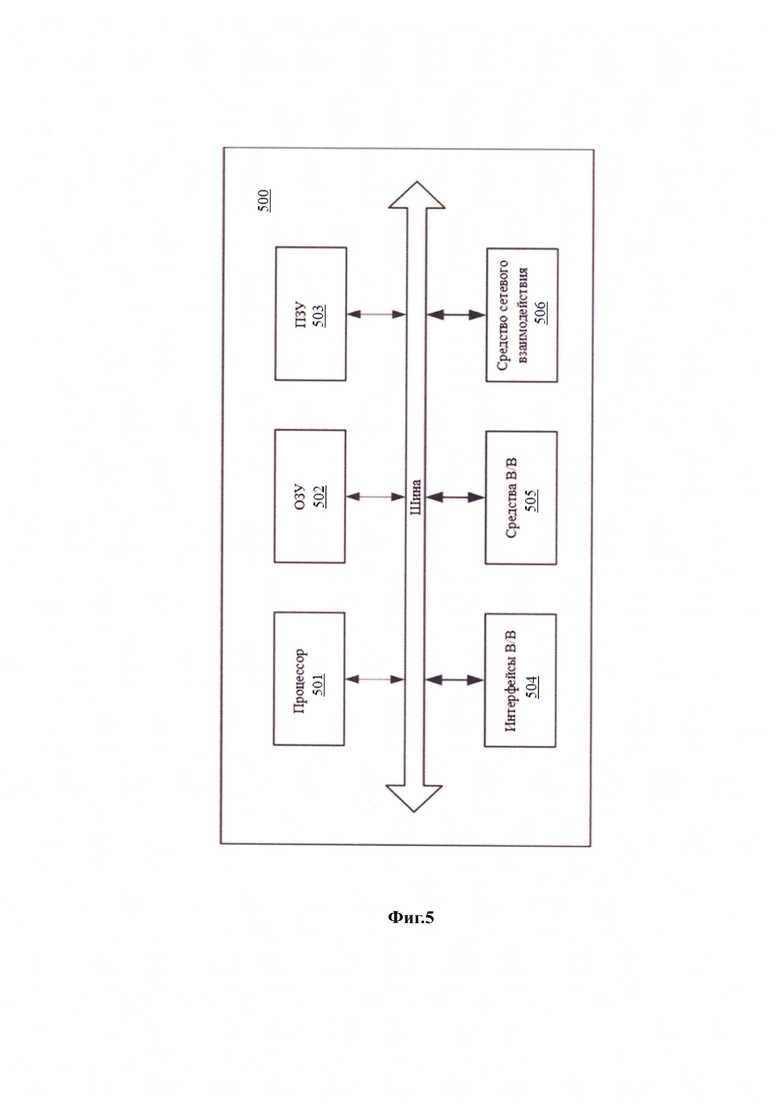
[55] В общем виде (см. Фиг. 5) система формирования партиционированных витрин данных, содержащих геоданные, и их использования в процессе эксплуатации хранилища данных (500) содержит объединенные общей шиной информационного обмена один или несколько процессоров (501), средства памяти, такие как ОЗУ (502) и ПЗУ (503) и интерфейсы ввода/вывода (504).
[56] Процессор (501) (или несколько процессоров, многоядерный процессор и т.п.) может выбираться из ассортимента устройств, широко применяемых в настоящее время, например, таких производителей, как: Intel™, AMD™, Apple™, Samsung Exynos™, MediaTEK™, Qualcomm Snapdragon™ и т.п. Под процессором или одним из используемых процессоров в системе (500) также необходимо учитывать графический процессор, например, GPU NVIDIA с программной моделью, совместимой с CUDA, или Graphcore, тип которых также является пригодным для полного или частичного выполнения способа, а также может применяться для обучения и применения моделей машинного обучения в различных информационных системах.
[57] ОЗУ (502) представляет собой оперативную память и предназначено для хранения исполняемых процессором (501) машиночитаемых инструкций для выполнения необходимых операций по логической обработке данных. ОЗУ (502), как правило, содержит исполняемые инструкции операционной системы и соответствующих программных компонент (приложения, программные модули и т.п.). При этом, в качестве ОЗУ (502) может выступать доступный объем памяти графической карты или графического процессора.
[58] ПЗУ (503) представляет собой одно или более устройств постоянного хранения данных, например, жесткий диск (HDD), твердотельный накопитель данных (SSD), флэш-память (EEPROM, NAND и т.п.), оптические носители информации (CD-R/RW, DVD-R/RW, BlueRay Disc, MD) и др.
[59] Для организации работы компонентов устройства (500) и организации работы внешних подключаемых устройств применяются различные виды интерфейсов В/В (504). Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительного устройства, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB (2.0, 3.0, 3.1, micro, mini, type C), TRS/Audio jack (2.5, 3.5, 6.35), HDMI, DVI, VGA, Display Port, RJ45, RS232 и т.п.
[60] Для обеспечения взаимодействия пользователя с устройством (500) применяются различные средства (505) В/В информации, например, клавиатура, дисплей (монитор), сенсорный дисплей, тач-пад, джойстик, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации (сканер сетчатки глаза, сканер отпечатков пальцев, модуль распознавания голоса) и т.п.
[61] Средство сетевого взаимодействия (506) обеспечивает передачу данных посредством внутренней или внешней вычислительной сети, например, Интранет, Интернет, ЛВС и т.п. В качестве одного или более средств (506) может использоваться, но не ограничиваться: Ethernet карта, GSM модем, GPRS модем, LTE модем, 5G модем, модуль спутниковой связи, NFC модуль, Bluetooth и/или BLE модуль, Wi-Fi модуль и др.
[62] Конкретный выбор элементов устройства (500) для реализации различных программно-аппаратных архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала. В частности, подобная реализация может быть выполнена с помощью электронных компонент, используемых для создания цифровых интегральных схем. Не ограничиваясь, могут быть использоваться микросхемы, логика работы которых определяется при изготовлении, или программируемые логические интегральные схемы (ПЛИС), логика работы которых задается посредством программирования. Для программирования используются программаторы и отладочные среды, позволяющие задать желаемую структуру цифрового устройства в виде принципиальной электрической схемы или программы на специальных языках описания аппаратуры: Verilog, VHDL, AHDL и др. Альтернативой ПЛИС являются: программируемые логические контроллеры (ПЛК), базовые матричные кристаллы (БМК), требующие заводского производственного процесса для программирования; ASIC - специализированные заказные большие интегральные схемы (БИС), которые при мелкосерийном и единичном производстве существенно дороже. Таким образом, реализация может быть достигнута стандартными средствами, базирующимися на классических принципах реализации основ вычислительной техники.
[63] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ (СУБД) | 2018 |
|
RU2704873C1 |
| СПОСОБ И СИСТЕМА КОМПЛЕКСНОГО УПРАВЛЕНИЯ БОЛЬШИМИ ДАННЫМИ | 2018 |
|
RU2690777C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОЙ ГЕНЕРАЦИИ И ЗАПОЛНЕНИЯ ВИТРИН ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ДЕКЛАРАТИВНОГО ОПИСАНИЯ | 2022 |
|
RU2795902C1 |
| СПОСОБ И СИСТЕМА ОБЪЕДИНЕНИЯ ДАННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ ДЛЯ ИХ ПОСЛЕДУЮЩЕЙ ВИЗУАЛИЗАЦИИ | 2023 |
|
RU2805382C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ВИЗУАЛИЗАЦИИ БОЛЬШИХ МАССИВОВ ДАННЫХ С ПОМОЩЬЮ ПОИСКА И ВЫДЕЛЕНИЯ ИХ ПАТТЕРНОВ ПОСТРОЕНИЯ | 2023 |
|
RU2813110C1 |
| СПОСОБ СОЗДАНИЯ ВИТРИНЫ ДАННЫХ | 2024 |
|
RU2840319C1 |
| Способ обработки данных в гибридном хранилище | 2023 |
|
RU2831216C1 |
| СПОСОБ ПОСТРОЕНИЯ РАСПРЕДЕЛЕННОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ | 2018 |
|
RU2699683C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЧЕСКОЙ ГЕНЕРАЦИИ ПРОГРАММНОГО КОДА ДЛЯ КОРПОРАТИВНОГО ХРАНИЛИЩА ДАННЫХ | 2017 |
|
RU2683690C1 |
| Способ сбора размеченного набора данных | 2020 |
|
RU2737600C1 |



Изобретение относится к способу и системе формирования партиционированных витрин данных, содержащих геоданные. Технический результат заключается в повышении эффективности идентификации тайлов. Способ содержит этапы, на которых получают на вход данные, включающие в себя: геоданные, список числовых значений от минимального до максимального значения уровня масштаба формируемых витрин данных и датасет с произвольными атрибутами, для формирования витрины данных; проводят объединение полученных геоданных и датасета; на основе результата проведенного на предыдущем шаге объединения формируют тайлы и их идентификаторы для всех уровней масштаба формируемых витрин данных следующим образом: для текущего уровня масштаба в цикле по идентификаторам тайлов получают все имеющиеся для этого тайла данные в объединенном датасете; преобразуют тайлы в формат для обработки витриной данных и сохраняют в памяти устройства хранения данных, используют полученные тайлы в процессе эксплуатации хранилища данных для формирования партиционированных витрин данных, содержащих геоданные, следующим способом: выбирают необходимый уровень масштаба; автоматически определяют все идентификаторы тайлов на текущем уровне масштаба; запрашивают тайлы согласно определенным идентификаторам, создают и визуализируют соответствующие витрины данных. 2 н. и 6 з.п. ф-лы, 5 ил.
1. Способ формирования партиционированных витрин данных, содержащих геоданные, реализуемый с помощью процессора и устройства хранения данных, включающий следующие шаги:
- получают на вход данные, включающие в себя: геоданные, список числовых значений от минимального до максимального значения уровня масштаба формируемых витрин данных и датасет с произвольными атрибутами, для формирования витрины данных;
- проводят объединение полученных геоданных и датасета;
- на основе результата проведенного на предыдущем шаге объединения формируют тайлы и их идентификаторы для всех уровней масштаба формируемых витрин данных следующим образом:
- для текущего уровня масштаба в цикле по идентификаторам тайлов получают все имеющиеся для этого тайла данные в объединенном датасете;
- преобразуют тайлы в формат для обработки витриной данных и сохраняют в памяти устройства хранения данных;
- используют полученные тайлы в процессе эксплуатации хранилища данных для формирования партиционированных витрин данных, содержащих геоданные, следующим способом:
- выбирают необходимый уровень масштаба;
- автоматически определяют все идентификаторы тайлов на текущем уровне масштаба;
- запрашивают тайлы согласно определенным идентификаторам, создают и визуализируют соответствующие витрины данных.
2. Способ по п. 1, характеризующийся тем, что при формировании тайлов и их идентификаторов производят дополнительные вычисления над данными, позволяющие изменять атрибуты.
3. Способ по п. 1, характеризующийся тем, что выбор уровня масштаба осуществляется через предустановленные значения.
4. Способ по п. 1, характеризующийся тем, что выбор уровня масштаба осуществляется динамически.
5. Система формирования партиционированных витрин данных, содержащих геоданные, содержащая:
- по меньшей мере одно устройство обработки данных;
- по меньшей мере одно устройство хранения данных;
- по меньшей мере одну программу, где одна или более программ хранятся на одном или более устройствах хранения данных и исполняются на одном и более устройствах обработки данных, причем одна или более программ обеспечивает выполнение следующих шагов:
- получают на вход данные, включающие в себя: геоданные, список числовых значений от минимального до максимального значения уровня масштаба формируемых витрин данных и датасет с произвольными атрибутами, для формирования витрины данных;
- проводят объединение полученных геоданных и датасета;
- на основе результата проведенного на предыдущем шаге объединения формируют тайлы и их идентификаторы для всех уровней масштаба формируемых витрин данных следующим образом:
- для текущего уровня масштаба в цикле по идентификаторам тайлов получают все имеющиеся для этого тайла данные в объединенном датасете;
- преобразуют тайлы в формат для обработки витриной данных и сохраняют в памяти устройства хранения данных;
- используют полученные тайлы в процессе эксплуатации хранилища данных для формирования партиционированных витрин данных, содержащих геоданные, следующим способом:
- выбирают необходимый уровень масштаба;
- автоматически определяют все идентификаторы тайлов на текущем уровне масштаба;
- запрашивают тайлы согласно определенным идентификаторам, создают и визуализируют соответствующие витрины данных.
6. Система по п. 5, характеризующаяся тем, что при формировании тайлов и их идентификаторов производят дополнительные вычисления над данными, позволяющие изменять атрибуты.
7. Система по п. 5, характеризующаяся тем, что выбор уровня масштаба осуществляется через предустановленные значения.
8. Система по п. 5, характеризующаяся тем, что выбор уровня масштаба осуществляется динамически.
