Система визуального поиска относится к области информационного поиска и предназначена для обнаружения по заданному изображению схожих по содержанию графических файлов в коллекции изображений. Поиск основан на алгоритмах компьютерного зрения и позволяет анализировать объекты на изображении. Система визуального поиска позволяет без использования концепции индексирования, метода полного перебора или просмотра миниатюр, осуществлять обнаружение схожих по содержанию изображений (поиск по образцу) на персональном компьютере или переносном устройстве. Предложенное изобретение позволяет повысить вероятность нахождения за счет хэширования каждого изображения из коллекции с использованием сверточных нейронных сетей. Данная система может быть использована при решении задач визуального поиска; классификации; а также в качестве программного обеспечения систем для поиска достопримечательностей по фотографиям в туристических фирмах; в системах поиска текстов и изображений, в электронных каталогах открытого доступа (краеведческие музеи, кадастровые карты); в качестве подсистемы для электронной торговли, в которых веб-интерфейс пользователя включает возможность поиска схожих по содержанию товаров не только по категориям, но и по цветовой составляющей или другим визуальным признакам.
Известен патент РФ «Поиск изображений на естественном языке» №2688271 С2, G06F 17/20, опубл. 21.05.2019, авторами которого являются Эль-Сабан Мотаз Ахмад, Тавфик Ахмед Иассин, Чалаби Ачраф Абдел Монейм Тавфик, Сайед Сайед Хассан. Данное изобретение может быть использовано в системе поиска изображений.
Сущность изобретения №2688271 С2 заключается в том, что поиск изображений осуществляется на естественном языке с использованием концепции онтологии. Изображения автоматически помечается тегами, авторами разработан способ соотнесения термина запроса на естественном языке с одним или более тегами, которые описывают содержание изображения. Запрос на естественном языке соотносится путем вычисления одной или более мер расстояния между запросом и тегами изображений, что избавляет пользователей от необходимости вручную прокручивать списки изображений и просматривать метаданные. Данный подход не учитывает цветовую составляющую, таким образом абсолютные разные по архитектуре и стилю здания могут иметь низкую меру близости.
В патенте «Способ индексации и поиска цифровых изображений» №2510935 С2, G06F 17/30, опубл. 10.04.2014, автором которого является Игнатов Артем Константинович, поиск цифровых изображений осуществляется на локальном компьютере, в том числе в глобальной сети Интернет. Технический результат данного изобретения заключается в уменьшении времени автоматической и полуавтоматической индексации изображений и в повышении быстродействия процедуры поиска изображений, содержащих схожие преобладающие цвета, в базе данных. Находится цвет, который имеет наименьшее расстояние Манхэттен от найденного преобладающего цвета в выбранной цветовой системе координат, который используют в качестве идентификатора для организации процедуры поиска. Недостатком данного способа поиска цифровых изображений является учет исключительно цветовой составляющей. В результате не оцениваются изображенные на фотографии объекты.
Наиболее близким аналогом предложенного изобретения является патент «Поиск изображений на естественном языке» №2688271 С2, G06F 17/20, опубл. 21.05.2019, авторами которого являются Эль-Сабан Мотаз Ахмад (US), Тавфик Ахмед Иассин (US), Чалаби Ачраф Абдел Монейм Тавфик (US), Сайед Сайед Хассан (US). Технический результат данного изобретения достигается за счет того, что в способе предусмотрена возможность принимать запрос на естественном языке, вычислять расстояние между запросами и выбирать тег изображения на основе вычислений, при этом онтология представляет собой лексическую базу данных слов, сгруппированных в когнитивные синонимы. Данный патент преимущественно применяется в глобальных информационных сетях и не подходит для поиска изображения на локальных устройствах.
Общим недостатком рассмотренных изобретений является субъективность оценки, так как пользователи могут по-разному задавать различные ключевые слова для одного и того же образа. В некоторых случаях невозможно составить словесное описание изображения (например, абстрактные картины). Использование преобладающего цвета позволяет обнаруживать объекты, которые могут не совпадать по смысловой составляющей, то есть отсутствует содержательный анализ изображений. Алгоритм поиска должен анализировать содержание, например, форму объектов, их текстуру. Для эффективной индексации и быстрого поиска по коллекциям необходима разработка специальных алгоритмов и программных средств, позволяющих за несколько секунд отвечать на пользовательские запросы [1-3].
Известна Система визуального поиска графических файлов в коллекции изображений, описанная в статье Isuru Suranga Wijesinghe, Chathurika Gamage, Charith Chitraranjan «Deep Supervised Hashing through Ensemble CNN Feature Extraction and Low-Rank Matrix Factorization for Retinal Image Retrieval of Diabetic Retinopathy», опубликованная 2019 году на 8 листах в интернет-источнике URL: https://www.researchgate.net/publication/338441571_Deep_Supervised_Hashing_through_Ensemble_CNN_Feature_Extraction_and_Low-Rank_Matrix_Factorization_for_Retinal_Image_Retrieval_of_Diabetic Retinopathy
Данная система отличается от представленной тем, что в блоке формирования метрической оценки сходства применяются следующие методы: метод кластеризации k-средних, гистограмма цветов, ключевые точки, операции свертки и подвыборки, то есть используются четыре метода для оценки. С использованием методы k-средних определяется количество классов на изображении, для каждого класса определяются ключевые точки с использованием детектора SURF (Speeded up Robust Features). После разделения изображения на n классов для каждой выделенной области необходимо выполнить свертку и сформировать хэш. Для n классов на изображении будет сформировано n хэшей. Численная мера сходства двух изображений рассчитывается как разность по модулю между хэшами изображений, в статье «Deep Supervised Hashing through Ensemble CNN Feature Extraction and Low-Rank Matrix Factorization for Retinal Image Retrieval of Diabetic Retinopathy» используется расстояние хэмминга.
Система Deep Supervised Hashing through Ensemble CNN Feature Extraction and Low-Rank Matrix Factorization for Retinal Image Retrieval of Diabetic Retinopathy используется для поиска медицинских снимков и установки предположительного диагноза, разработанная нами система применима для изображений, хранящихся на персональных компьютерах или полученная с камеры, которые могут быть подвержены различного рода искажениям, рассовмещениям, шуму соль-перец, и могут быть представлены рисунком пользователя выполненного с различной степенью сложности.
В разработанной системе поисковая коллекция представляет собой 2 файла: в первом хранится полный путь к файлу за исключением имени, во втором - ссылка на первый файл, непосредственно имя файла и вычисленная метрика (метрическая оценка сходства двух изображений). В системе Deep Supervised Hashing through Ensemble CNN Feature Extraction and Low-Rank Matrix Factorization for Retinal Image Retrieval of Diabetic Retinopathy применяется база данных медицинских снимков.
Цель предложенного изобретения - повышение точности поиска изображений по содержанию на компьютере или переносном устройстве за счет хэширования каждого изображения из коллекции с использованием операций сверточных нейронных сетей, учитывающих только пиксели изображения.
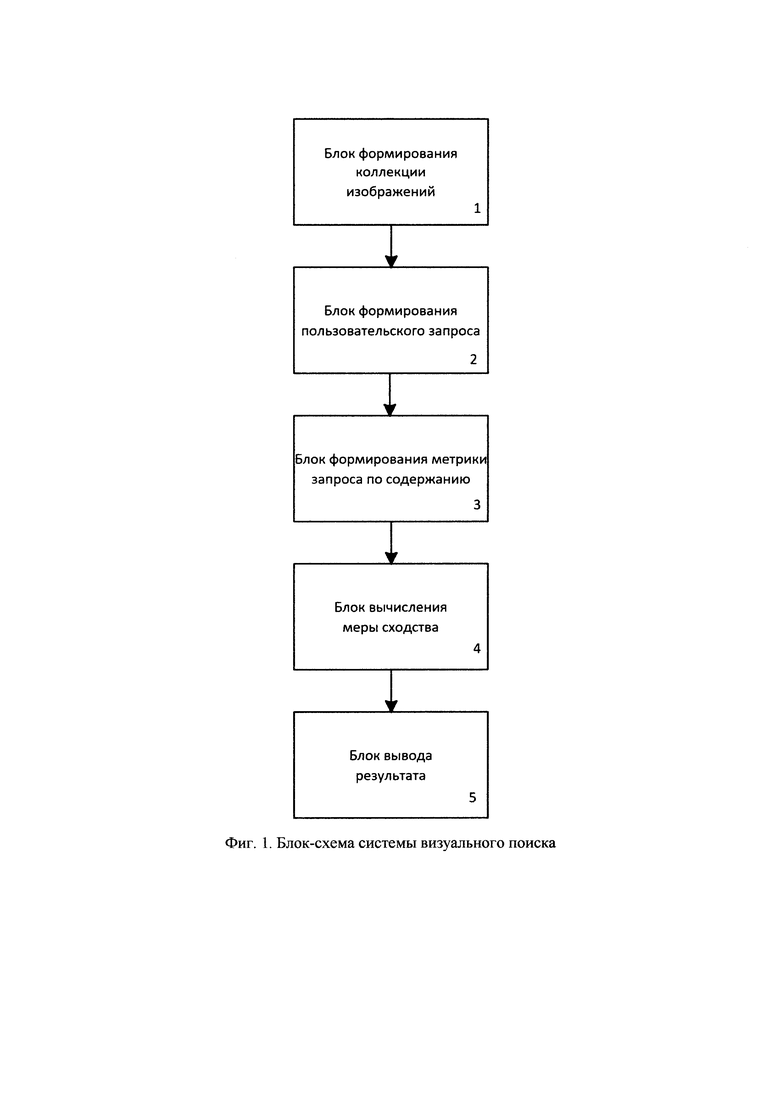
Система визуального поиска в коллекции изображений состоит из следующих блоков: блок формирования поисковой коллекции, блок формирования пользовательского запроса, блок формирования метрической оценки сходства двух изображений, блок вычисления меры сходства, блока вывода результата поиска. Данные блоки являются аппаратно-техническими средствами.
На фиг. 1 изображена блок-схема системы визуального поиска, состоящая из: 1 - блока формирования коллекции изображения, 2 - блока формирования пользовательского запроса, 3 - блока формирования метрики запроса по содержанию, 4 - блока вычисления меры сходства, 5 - блока вывода результата.
Блок 1 реализован при помощи пользовательского графического интерфейса (ГПИ). ГПИ реализует возможность выбора изображения (изображения-запроса), на основании которого необходимо провести поиск по содержанию (поиск по образцу), возможность сканировать диски и переносные устройства, с сохранением даты и времени последнего сканирования. Под сканированием понимают обнаружение графических файлов следующих форматов: JPG, BMP, PNG и добавление этих файлов в поисковую коллекцию, а также вычисление метрики запроса по содержанию, которое рассмотрено в блоке 3.
Коллекция представляет собой 2 файла: в первом хранится полный путь к файлу за исключением имени, во втором - ссылка на первый файл, непосредственно имя файла и вычисленная метрика (метрическая оценка сходства двух изображений). Данная структура была разработана для уменьшения размера поисковой коллекции. Подобная оптимизация позволила сократить размер поисковой коллекции в 10 раз. Каждое изображение из поисковой коллекции преобразуют в уменьшенную копию, за счет чего избавляются от высокочастотной составляющей и получают метрику, инвариантную пропорциям изображения.
Основным ограничивающим фактором при формировании поисковой коллекции является считывание изображений с переносных устройств, сканирование дисков занимает большую часть времени работы приложения. Но так как сканирование в программе выполняется однократно, то в качестве времени работы будет учитываться непосредственно поиск в коллекции изображений.
Блок 2 формирует пользовательский запрос. Пользователем выбирается изображение, на основании которого будет осуществлен поиск. Изображение-запрос может быть представлено изображением из памяти локального компьютера, картой местности, нарисованным пользователем с различной степенью точности, отсканированным файлом с возможными рассовмещениями. Поиск осуществляется без использования дополнительной информации о нем (дата, название, ключевые слова, местоположение), то есть недоступна никакая другая информация кроме пикселей изображений.
Блок 3 - это блок формирования метрики запроса по содержанию. В последнее время было предложено несколько методов для обнаружения схожих по содержанию изображений с использованием метрической и неметрической оценки сходства [4]. Применение метрической оценки сходства рассмотрено в статьях [5-7]. В данных работах изображения описаны векторами признаков и визуальное сходства между ними вычисляется, не принимая во внимание возможную взаимосвязь в наборе данных. Поэтому при сильной нелинейной зависимости в наборе данных, оценка схожести может пропустить одинаковые по содержанию изображения. Однако, согласно исследованиям авторов [8, 9], метрическая оценка сходства не действительна для восприятия человеком визуального сходства, и, следовательно, функции визуального сходства необязательно должны удовлетворять условиям метрик расстояния [4]. В разработанной системе предлагается использование метрической оценки сходства на основе Евклидова расстояния, однако хэш, по которому осуществляется сопоставление, формируется на основе нейросетевого подхода, с применением операций свертки и подвыборки [10].
Метрики для корректного поиска должны быть инвариантны к углам поворота, изменению масштаба и угла зрения [11]. Для вычисления метрики использовались:
- метод кластеризации k-средних;
- гистограмма цветов;
- ключевые точки;
- операции свертки и подвыборки.
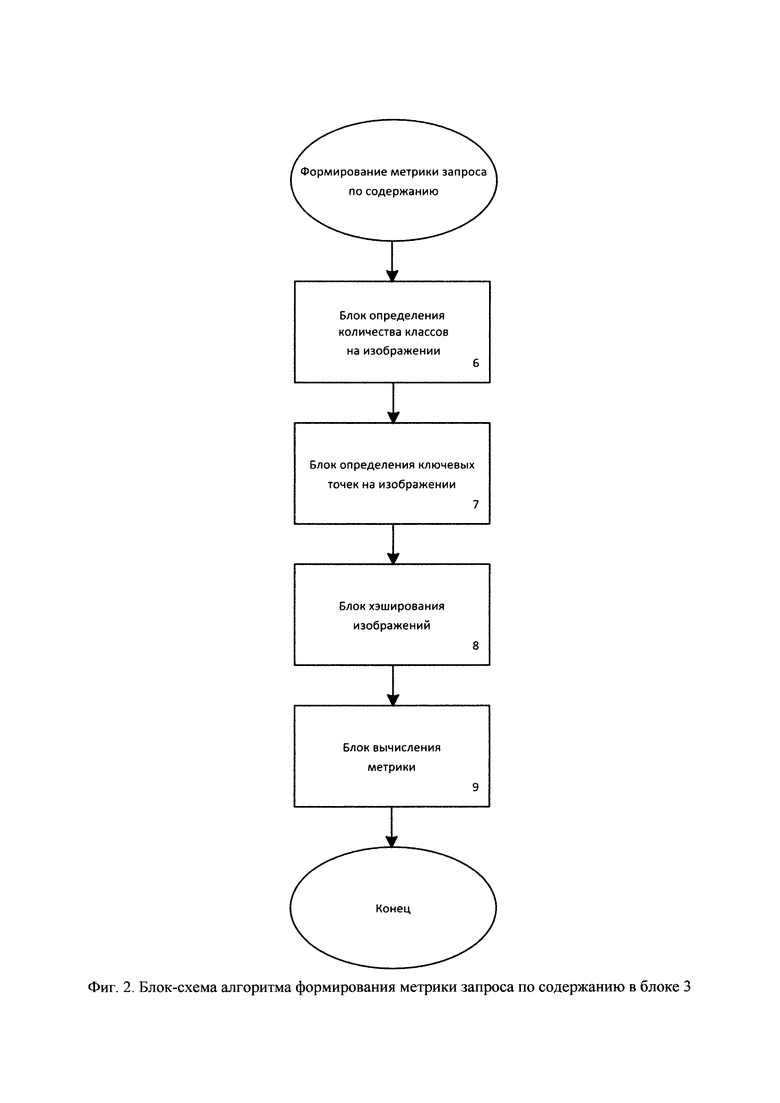
Блок-схема алгоритма формирования метрики запроса по содержанию представлена на фиг. 2.
Блок 4 осуществляет вычисление меры сходства между изображения. Численная мера сходства двух изображений рассчитывается как разность по модулю между хэшами этих изображений. Чем численная мера меньше, тем наиболее близкими по содержанию являются фотографии. Расчет численной меры сходства вычисляется следующим образом:
list_Scorei=|scoreimg - scorei, (1)
здесь list_Scorei - вычисленная мера сходства для i-го изображения из поисковой коллекции, scoreimg - хэш, описывающий изображение-запрос (метрика), scorei - хэш, описывающий изображение из поисковой коллекции (метрика), i - порядковый номер изображения в поисковой коллекции.
Блок 5 - блок вывода результата. В качестве результата выдается список изображений в определенной последовательности с одинаковым для запроса содержанием и их расположение. После вычисления меры сходства между изображением из поисковой коллекции и загруженным пользователем запросом, формируется список с названием графического файла и численной оценкой сходства. На фиг. 5 приведен результат выполнения поиска. Время выполнения поиска среди коллекции, в которой содержится более 50 тысяч изображений составляет, 12 миллисекунд.
На фиг. 2 приведена блок-схема алгоритма формирования метрики запроса по содержанию, состоящая из: 6 - блок определения количества классов на изображении, 7 - блок определения ключевых точек на изображении, 8 - блок хэширования изображений, 9 - блок вычисления метрики.
Количество классов на изображении (6) оценивается следующим образом:
- применение медианной фильтрации для уменьшения влияния шумовой составляющей;
- получение первой производной по отфильтрованной гистограмме изображения;
- квантование (близких к нулю значений) первой производной гистограммы изображения;
- определение количества пиков на гистограмме при помощи анализа первой производной.
Далее на изображении определяются ключевые точки (7). Исходный графический файл заменяется некоторой математической моделью - набором ее ключевых (особых) точек. Особой называется такая точка изображенного объекта, которая с большой долей вероятности будет найдена на другом изображении этого же объекта [12]. Детектором называется метод извлечения ключевых точек на изображении. В предложенной системе использовался детектор SURF, так как он обладает наилучшей точностью при масштабировании, высокой точностью при изменении яркости.
Для каждого класса обнаруживаются ключевые точки, соответствующие этому классу. Исходя из проведенных исследований, в рассмотрении остаются ключевые точки, характеристики которых соответствуют множеству KeyPoints и определяются по следующему условию:
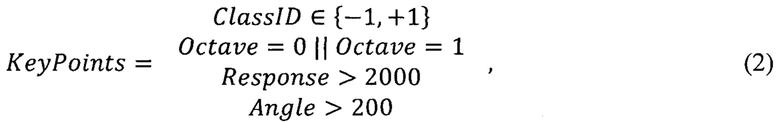
здесь ClassID - класс принадлежности ключевой точки, Octave - уровень пирамиды, на которой была отмечена эта точка, Response - отзывчивость этой точки, Angle - угол направления ключевой точки. Все характеристики получены SURF детектором.
Каждой выделенной области на изображении однозначно соответствуют ключевые точки. Сравнение ключевых точек происходит для каждого выделенного класса, полученного в (6).
Хэширование изображений (8) основано на операциях свертки и подвыборки. Основной идеей сверточной сети является то, что обработка участка изображения должна не зависеть от расположения этого участка на изображении. Каждое изображение разбивается на 3 цветовых канала: R, G, В. Входные данные каждого конкретного значения пикселя нормализуются в диапазоне [0; 1] по формуле:
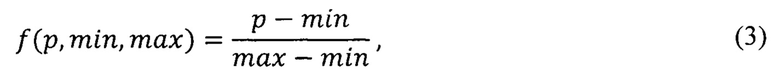
здесь ƒ - функция нормализации, р - значение конкретного цвета пикселя в диапазоне, min - минимальное значение пикселя, max - максимальное значение пикселя.
Свертка организована таким образом, что за 6 итераций можно преобразовать изображение в некоторый хэш, состоящий из 512 байт. Данный хэш позволяет получить характеристики изображений. Некоторое ядро свертки обрабатывает предыдущее ядро по фрагментам. На фиг. 3 представлена модель алгоритма свертки. Размер следующего слоя свертки рассчитывается по формуле:
(w, h)=(mW-kW+1, mH-kH+1), (4)
здесь (w, h) - вычисляемый размер следующего слоя свертки, mW - ширина предыдущего слоя, mH - высота предыдущего слоя, kW - ширина ядра, kH - высота ядра.
Ядро свертки представляет собой фильтр (скользящее окно), которое находит определенные признаки объектов. Ядро скользит по предыдущей итерации и производит операцию свертки. Операция ReLU - это активационная функции, которая обнуляет все отрицательные элементы [13, 14].
Подвыборка представляет собой нелинейное уплотнение карты признаков, при котором группа пикселей (2×2) уплотняется до 1 пикселя, проходя операцию подвыборки. Цель операции подвыборки - уменьшение размерности результата предыдущей операции (свертки).
Вычисление метрики (9) поясняется на фиг. 4. После разделения изображения на n классов для каждой выделенной области необходимо выполнить свертку и сформировать хэш. Для n классов на изображении будет сформировано n хэшей [15].
На фиг. 5 приведен результат выполнения поиска. Пользователь выбирает изображение, на основании которого необходимо осуществить поиск. Время выполнения поиска среди коллекции, в которой содержится более 50 тысяч изображений, составляет 12 миллисекунд. Из фиг. 5 видно, что все найденные изображения соответствуют пользовательскому запросу. Все изображения из поисковой выборки содержат деревья, которые изображены на запросе пользователя.
Список литературы
1. Бабенко А.В. Эффективные алгоритмы поиска по большим коллекциям изображений. Диссертация на соискание ученой степени кандидата физико-математических наук Москва 2017 [Электронный ресурс] http://www.keldysh.ru/council/1/2017-babenko/avtoref.pdf (дата обращения 01.12.18).
2. Eric J. Stollnitz, Tony D. DeRose, David H. Salesin Wavelets for Computer Graphics Theory and Applications перевод с английского Л.А. Кунгуровой под редакцией Е.В. Мищенко Москва Ижевск 2002.
3. А.А. Рогов, К.А. Рогова, К.Н. Спиридонов, М.Ю. Быстров Система поиска в электронной коллекции изображений петроглифов Карелии [Электронный ресурс] http://rcdl.ru/doc/2008/246_251_paper29.pdf (дата обращения 23.03.2019).
4. Noa Garcia, George Vogiatzis Learning Non-Metric Visual Similarity for Image Retrieval the IEEE International Conference on Computer Vision Workshops (ICCVW), 2017.
5. Venice Erin Liong, Jiwen Lu, Gang Wang, Pierre Moulin, and Jie Zhou. Deep hashing for compact binary codes learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015.
6. Albert Gordo, Jon Almazan, Jerome Revaud, and Diane Larlus. Deep image retrieval: Learning' global representations for image search. In Proceedings of the IEEE European Conference on Computer Vision, 2016.
7. Wenjie Luo, Alexander G Schwing, and Raquel Urtasun. Efficient deep learning for stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016.
8. Laurens van der Maaten, Geoffrey Hinton Visualizing non-metric similarities in multiple maps. The Author(s) 2011. This article is published with open access at Springerlink.com DOI 10.1007/s10994-011-5273-4.
9. Tom'avs Skopal On Fast Non-metric Similarity Search by Metric Access Methods. (Eds.): EDBT 2006, LNCS 3896, pp. 718-736, 2006.
10. Valentina Potapova, Andrey Tarasov, Nataliya Grinchenko Image Search by Content System Development Published in: 2018 IEEE East-West Design & Test Symposium (EWDTS).
11. Bodrov O.A., Tarasov A.S., Tarasova V.Y., Bodrova I.V. IMAGE SEARCH ALGORITHM IN LOCAL DATA BASE 8th Mediterranean Conference on Embedded Computing, MECO 2019 - Proceedings. 8. 2019. C. 8759996.
12. Построение SIFT дескрипторов и задача сопоставления изображений [Электронный ресурс] https://habr.com/post/106302/ (дата обращения 18.12.18).
13. Николенко С, Кадурин А., Архангельская Е. Глубокое обучение погружение в мир нейронных сетей. - СПб.: Питер, 2019. - 480 с.
14. В. Ю. Тарасова, А.С.Тарасов, Н. Н. Гринченко Алгоритм обнаружения совпадений в коллекции изображений // в сборнике трудов Международного научно-технического форума СТНО-2019. Том 4. стр. 164-168.
15. Н.Н. Гринченко, В.Ю. Тарасова, А.С.Тарасов Разработка системы визуального поиска изображений // Известия ТулГУ. Технические науки 2019. Выпуск 2. стр 63-74.


Изобретение относится к области информационного поиска и предназначено для обнаружения по заданному изображению схожих по содержанию графических файлов в коллекции изображений. Техническим результатом является повышение точности поиска изображений по содержанию на компьютере или переносном устройстве. Технический результат достигается тем, что в заявленном решении предусмотрены: графический пользовательский интерфейс ввода данных, а также последовательно выполняющиеся взаимосвязанные блоки: блок формирования поисковой коллекции, блок формирования пользовательского запроса, блок формирования метрической оценки сходства двух изображений, в котором используется хэширование изображений с применением сверточных нейронных сетей, учитывающих только пиксели изображения, блок вычисления меры сходства изображения-запроса с каждым изображением из поисковой коллекции, блок вывода результата поиска, при этом в блоке формирования метрической оценки последовательно выполняются: блок определения количества классов на изображении, блок определения ключевых точек на изображении, блок хэширования изображений. 5 ил.
Система визуального поиска графических файлов в коллекции изображений, состоящая из графического пользовательского интерфейса ввода данных, а также последовательно выполняющихся взаимосвязанных блоков: блока формирования поисковой коллекции (1), блока формирования пользовательского запроса (2), блока формирования метрической оценки сходства двух изображений (3), в котором используется хэширование изображений с применением сверточных нейронных сетей, учитывающих только пиксели изображения, блока вычисления меры сходства изображения-запроса с каждым изображением из поисковой коллекции (4), блока вывода результата поиска (5), который реализован с помощью графического пользовательского интерфейса вывода информации, отличающаяся тем, что в блоке формирования метрической оценки (3) последовательно выполняются следующие блоки: блок определения количества классов на изображении (6), использующих гистограмму цветов и метод k-средних, блок определения ключевых точек на изображении (7), блок хэширования изображений (8), состоящий из вычисления операций свертки и подвыборки.
| ISURU WIJESINGHE et al.: "Deep Supervised Hashing through Ensemble CNN Feature Extraction and Low-rank Matrix Factorization for Retinal Image Retrieval of Diabetic Retinopathy", 2019, [найдено: 23.03.2023] Найдено в: |

