Область техники, к которой относится изобретение
[01] Настоящая технология в целом относится к обработке естественной речи и, в частности, к способам и системам для распознавания устной человеческой речи.
Уровень техники
[02] Системы преобразования речи в текст (STT, Speech-To-Text) позволяют обрабатывать устную человеческую речь с целью определения в ней отдельных слов и преобразования таким образом фрагментов человеческой речи в текст. Например, такие системы могут использоваться в сочетании с так называемыми приложениями виртуального помощника и обеспечивать улучшенное взаимодействие между пользователем и некоторыми онлайн-сервисами (например, платформами интернет-покупок, системами интернет-бронирования и т.п.) и/или его электронным устройством. Это особенно важно для начинающих пользователей и/или для пользователей с ограниченными возможностями, которые в определенный момент времени не могут использовать интерфейсы пользователь-машина таких онлайн-сервисов и/или электронного устройства для эффективного взаимодействия с ними. Например, пользователь, управляющий транспортным средством или пользователь с нарушениями зрения может не иметь возможности использовать клавиатуру на сенсорном экране, связанную с его электронным устройством, для навигации на веб-сайте врача, чтобы записаться на прием, или на веб-сайте платформы интернет-покупок с целью формирования заказа. В то же время персонал службы работы с клиентами этих онлайн-сервисов может быть не состоянии быстро помочь таким пользователям, например, из-за большого количества запросов от других пользователей.
[03] Таким образом, для навигации пользователя на соответствующем онлайн-сервисе и для формирования запросов может использоваться приложение виртуального помощника с поддержкой функции виртуального собеседника (также известное как чатбот). В частности, приложение виртуального помощника может инициировать диалог с пользователем в текстовом или звуковом формате, получать запрос в виде речевого фрагмента пользователя и использовать распознанный системой STT полученный речевой фрагмент для формирования дополнительных уточняющих вопросов. Можно сказать, что таким образом приложение виртуального помощника имитирует человека, помогающего пользователю, поддерживая диалог с ним.
[04] Например, когда приложение виртуального помощника используется для планирования приема пациентов врачом, оно может быть активировано пользователем, обращающимся к врачу, например, по телефону, или начинающим диалог на его веб-сайте, и может приветствовать пользователя и определять его потребности с помощью фразы «Hello, you have reached the office of Doctor House. How can I be of service to you today?» («Здравствуйте, вы обратились в офис врача Хауса. Чем я могу быть Вам полезен сегодня?»). В ответ пользователь может произнести следующую фразу: «I’d like to make an appointment with the doctor» («Я хотел бы записаться на прием к врачу»). Кроме того, приложение виртуального помощника может получать звуковое представление этого запроса пользователя, формировать с использованием системы STT его текстовое представление для дальнейшей обработки и предоставления следующего уточняющего вопроса, такого как запрос информации профиля конкретного пользователя, доступности пользователя, срочности встречи и т.п., соответствующий ответ на который приложение виртуального помощника способно таким же образом обрабатывать с использованием системы STT. Наконец, на основе распознанных таким образом речевых ответов пользователя и, например, доступности врача, приложение виртуального помощника может выполнять запрос пользователя путем назначения для него приема и сохранения данных, указывающих на него, в расписании врача, что может подтверждаться приложением виртуального помощника, формирующим другой ответ, указывающий на следующую фразу: «Your appointment with Doctor House has been scheduled for December 20, 2021 at 11 AM» («Ваша встреча с врачом Хаусом назначена на 20 декабря 2021 года в 11:00».
[05] Тем не менее, один из недостатков таких приложений может заключаться в неспособности используемой с ними системы STT определять контекст для слов из полученных звуковых представлений речевых фрагментов пользователя. В частности, без выявления контекста фразы система STT может оказаться неспособной надлежащим образом определять семантические связи между словами и поэтому может формировать их неправильные текстовые представления. В описанном выше примере планирования приема система STT может быть заранее настроена на ожидание полной формы обращения «the Doctor House» («врач Хаус»), и поэтому может быть неспособной понять слово «the doctor» («врач») в ответе пользователя, что может привести к дополнительным ненужным вопросам к пользователю. В другом примере, получив звуковое представление имени и фамилии пользователя «Neville Longbottom» («Невиль Лонгботтом»), система STT может формировать текстовое представление «Neville long bottom» («длинное дно Невиля»), не соответствующее данным профиля пользователя. Это может привести к тому, что приложение виртуального помощника с худшим качеством будет поддерживать диалоги с пользователем во время реализации его запроса и, таким образом, негативно влиять на впечатление пользователя от взаимодействия с приложением виртуального помощника.
[06] Для решения описанной выше технической проблемы были предложены некоторые известные подходы.
[07] В патентной заявке US20190005138A1 «Obtaining responsive information from multiple corpora» (Google LLC, опубликована 3 января 2019 г.) описаны способы для автоматизированных помощников, выполняющих поиск информации в различных альтернативных корпусах.
[08] В патентной заявке US20210166678A1 «Electronic device and controlling the electronic device» (Samsung Electronics Co Ltd, опубликована 3 июня 2021 г.) описано электронное устройство, содержащее процессор, способный определять, требуется ли передавать серверу, хранящему первую диалоговую систему, речь пользователя, вводимую через микрофон, при этом на основе определения того, что речь пользователя передается серверу, осуществляется управление коммуникатором для передачи серверу речи пользователя и по меньшей мере части сохраненной информации истории диалогов.
[09] В патентной заявке US2020382448A1 «Contextual feedback to a natural understanding system in a chat bot» (Microsoft Technology Licensing LLC, опубликована 21 июля 2020 г.) описана вычислительная система чатбота, содержащая контроллер программы-робота и процессор естественной речи.
Раскрытие изобретения
[010] Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений.
[011] Разработчики настоящей технологии установили, что качество распознавания речи, обеспечиваемое системой STT, может быть повышено, если система STT способна учитывать последнюю сформированную для пользователя фразу приложения виртуального помощника в качестве контекста для ответа. В частности, разработчики реализовали систему STT на основе способов машинного обучения (таких как нейронные сети), предусматривающих обучение распознаванию речевых фрагментов пользователя на основе не только соответствующих текстовых представлений, но и фраз, в ответ на которые пользователь предоставляет эти речевые фрагменты.
[012] Обученная таким образом система STT может преобразовывать каждое слово из речевого фрагмента в текст в рамках конкретного связанного с ним контекста, в результате чего предполагается повышение качества распознавания речи и общей удовлетворенности пользователей, использующих приложения виртуального помощника.
[013] Согласно первому аспекту настоящей технологии реализован способ формирования текстовых представлений речевого фрагмента пользователя. Речевой фрагмент пользователя получается электронным устройством, связанным с пользователем. Речевой фрагмент пользователя предоставляется в ответ на формируемые компьютером речевые фрагменты, выданные электронным устройством. Электронное устройство способно связываться с сервером. Сервер предназначен для формирования формируемых компьютером речевых фрагментов. Способ выполняется сервером. Способ включает в себя: получение сервером от электронного устройства аудиосигнала, являющегося звуковым представлением речевого фрагмента пользователя, представляющего собой ответ на формируемый компьютером речевой фрагмент, ранее выданный электронным устройством пользователю; получение сервером формируемой компьютером текстовой строки, являющейся текстовым представлением формируемого компьютером речевого фрагмента; и формирование сервером с использованием модели STT другой текстовой строки, являющейся текстовым представлением речевого фрагмента пользователя, на основе аудиосигнала и формируемой компьютером текстовой строки, учитываемой в качестве контекста речевого фрагмента пользователя.
[014] В некоторых вариантах осуществления способа он дополнительно включает в себя: формирование сервером с использованием модели STT первой текстовой строки, являющейся текстовым представлением первого речевого фрагмента пользователя, на основе первого аудиосигнала, являющегося звуковым представлением первого речевого фрагмента пользователя; формирование сервером с использованием другой модели формируемой компьютером текстовой строки на основе первой текстовой строки; формирование сервером с использованием модели преобразования текста в речь (TTS, Text-To-Speech) формируемого компьютером аудиосигнала, являющегося звуковым представлением формируемого компьютером речевого фрагмента, на основе формируемой компьютером текстовой строки.
[015] В некоторых вариантах осуществления способа модель STT представляет собой нейронную сеть (NN, Neural Network) с архитектурой кодер-декодер, содержащую стек слоев кодера и стек слоев декодера, а формирование другой текстовой строки включает в себя: формирование сервером звукового вектора, представляющего аудиосигнал, с использованием алгоритма векторизации звука; ввод сервером звукового вектора в стек кодера сети NN; формирование сервером с использованием алгоритма векторизации текста текстового вектора, представляющего формируемую компьютером текстовую строку; и ввод сервером текстового вектора в стек декодера сети NN.
[016] В некоторых вариантах осуществления способа сеть NN представляет собой сеть NN на основе трансформера.
[017] В некоторых вариантах осуществления способа он дополнительно включает в себя обучение модели STT на этапе обучения на основе обучающего набора данных, содержащего множество обучающих объектов, при этом обучающий объект содержит: (а) указание на обучающий аудиосигнал, сформированный на основе обучающего речевого фрагмента пользователя, произнесенного обучающим пользователем; (б) первую обучающую текстовую строку, являющуюся текстовым представлением обучающего речевого фрагмента пользователя; и (в) вторую обучающую текстовую строку, используемую для предоставления контекста для первой текстовой строки и являющуюся текстовым представлением соответствующего формируемого компьютером речевого фрагмента, в ответ на который обучающий пользователь произнес обучающий речевой фрагмент пользователя.
[018] В некоторых вариантах осуществления способа он дополнительно включает в себя получение сервером первого аудиосигнала от электронного устройства.
[019] В некоторых вариантах осуществления способа он дополнительно включает в себя отправку сервером формируемого компьютером аудиосигнала электронному устройству.
[020] В некоторых вариантах осуществления способа другая модель содержит модель обработки естественной речи (NLP, Natural Language Processing).
[021] В некоторых вариантах осуществления способа одна или несколько моделей размещены на другом сервере.
[022] В некоторых вариантах осуществления способа модель NLP представляет собой модель NN на основе трансформера.
[023] В некоторых вариантах осуществления способа модель TTS представляет собой модель NN на основе трансформера.
[024] В некоторых вариантах осуществления способа он дополнительно включает в себя: формирование сервером с использованием модели STT второй текстовой строки на основе второго аудиосигнала, являющегося звуковым представлением второго речевого фрагмента пользователя, соответствующего запросу, следующему за формируемым компьютером речевым фрагментом; формирование сервером на основе второй текстовой строки с использованием другой модели другой формируемой компьютером текстовой строки, являющейся текстовым представлением другого формируемого компьютером речевого фрагмента, подлежащего предоставлению пользователю; формирование сервером на основе другой формируемой компьютером текстовой строки с использованием модели TTS другого формируемого компьютером аудиосигнала, являющегося звуковым представлением другого формируемого компьютером речевого фрагмента, подлежащего предоставлению пользователю в ответ на второй речевой фрагмент пользователя; получение сервером от электронного устройства третьего аудиосигнала, являющегося звуковым представлением третьего речевого фрагмента пользователя, соответствующего другому запросу, следующему за другим формируемым компьютером речевым фрагментом; и формирование сервером с использованием модели STT на основе третьего аудиосигнала, формируемой компьютером текстовой строки и другой формируемой компьютером текстовой строки третьей текстовой строки, являющейся текстовым представлением третьего речевого фрагмента пользователя, с учетом формируемой компьютером текстовой строки и другой формируемой компьютером текстовой строки в качестве контекста другого следующего запроса.
[025] В некоторых вариантах осуществления способа он дополнительно включает в себя отправку сервером другого формируемого компьютером аудиосигнала электронному устройству.
[026] Согласно второму аспекту настоящей технологии реализован сервер для формирования текстовых представлений речевого фрагмента пользователя. Речевой фрагмент пользователя получается электронным устройством, связанным с пользователем и способным связываться с сервером. Речевой фрагмент пользователя предоставляется в ответ на формируемые компьютером речевые фрагменты, выданные электронным устройством. Сервер содержит процессор и машиночитаемый физический носитель информации, хранящий команды. Процессор при исполнении команд способен: получать от электронного устройства аудиосигнал, являющийся звуковым представлением речевого фрагмента пользователя, представляющего собой ответ на формируемый компьютером речевой фрагмент, ранее выданный электронным устройством пользователю; получать формируемую компьютером текстовую строку, являющимся текстовым представлением формируемого компьютером речевого фрагмента; и формировать с использованием модели STT другую текстовую строку, являющуюся текстовым представлением речевого фрагмента пользователя, на основе аудиосигнала и формируемой компьютером текстовой строки, учитываемой в качестве контекста речевого фрагмента пользователя.
[027] В некоторых вариантах осуществления сервера процессор дополнительно способен: формировать с использованием модели STT первую текстовую строку, являющуюся текстовым представлением первого речевого фрагмента пользователя, на основе первого аудиосигнала, являющегося звуковым представлением первого речевого фрагмента пользователя; формировать с использованием другой модели формируемую компьютером текстовую строку на основе первой текстовой строки; и формировать с использованием модели TTS формируемый компьютером аудиосигнал, являющийся звуковым представлением формируемого компьютером речевого фрагмента, на основе формируемой компьютером текстовой строки.
[028] В некоторых вариантах осуществления сервера модель STT представляет собой сеть NN с архитектурой кодер-декодер, содержащую стек слоев кодера и стек слоев декодера, а процессор способен формировать другую текстовую строку путем: формирования звукового вектора, представляющего аудиосигнал, с использованием алгоритма векторизации звука; ввода звукового вектора в стек кодера сети NN; формирования с использованием алгоритма векторизации текста текстового вектора, представляющего формируемую компьютером текстовую строку; и ввода текстового вектора в стек декодера сети NN.
[029] В некоторых вариантах осуществления сервера сеть NN представляет собой сеть NN на основе трансформера.
[030] В некоторых вариантах осуществления сервера процессор дополнительно способен обучать модель STT на этапе обучения на основе обучающего набора данных, содержащего множество обучающих объектов, при этом обучающий объект содержит: (а) указание на обучающий аудиосигнал, сформированный на основе обучающего речевого фрагмента пользователя, произнесенного обучающим пользователем; (б) первую обучающую текстовую строку, являющуюся текстовым представлением обучающего речевого фрагмента пользователя; и (в) вторую обучающую текстовую строку, используемую для предоставления контекста для первой текстовой строки и являющуюся текстовым представлением соответствующего формируемого компьютером речевого фрагмента, в ответ на который обучающий пользователь произнес обучающий речевой фрагмент пользователя.
[031] В некоторых вариантах осуществления сервера другая модель содержит модель NLP.
[032] В некоторых вариантах осуществления сервера одна или несколько моделей размещены на другом сервере, связанном с сервером.
[033] В контексте настоящего описания трансформерная модель представляет собой модель с архитектурой вида «кодер-декодер», в которой используются механизмы внимания. Механизмы внимания могут применяться при обработке данных кодером, при обработке данных декодером и при взаимодействиях кодер-декодер. В трансформерной модели может использоваться множество механизмов внимания.
[034] Один из компонентов трансформерной модели может представлять собой механизм самовнимания. Различие между механизмом внимания и механизмом самовнимания заключается в том, что механизм самовнимания работает со схожими представлениями, например, со всеми состояниями кодера в одном слое. Механизм самовнимания входит в состав трансформерной модели, в которой токены взаимодействуют друг с другом. Каждый токен, в известном смысле, «наблюдает» за другими токенами в предложении с помощью механизма внимания, собирает контекст и обновляет свое предыдущее представление. Каждый входной токен в механизме самовнимания получает три представления: (а) запрос, (б) ключ и (в) значение. Запрос используется, когда токен наблюдает за другими токенами: он ищет информацию, чтобы лучше «понимать» себя. Ключ реагирует на появление запроса - он используется для расчета весов внимания. Значение используется для расчета результата внимания: оно предоставляет информацию о токенах, которые сообщают, что им это требуется (т.е. таким токенам присваиваются большие веса).
[035] Другой компонент трансформерной модели может представлять собой механизм маскированного самовнимания. Декодер обычно содержит этот особый механизм самовнимания, отличающийся от механизма самовнимания в кодере. Кодер получает все токены одновременно, при этом токены могут наблюдать за всеми токенами во входном предложении, а в декодере токены формируются поодиночке, т.е. во время формирования модели неизвестно, какие токены будут сформированы в будущем. Чтобы запретить декодеру «просмотр вперед», в трансформерной модели используется механизм маскированного самовнимания, т.е. будущие токены маскируются.
[036] Еще один компонент трансформерной модели может представлять собой механизм многоголового внимания. Следует отметить, что для понимания роли слова в предложении требуется понимание того, как оно связано с различными частями предложения. Это важно не только при обработке исходного предложения, но и при формировании целей. В результате благодаря механизму внимания этого вида трансформерная модель может «концентрироваться» на различных вещах. Механизм многоголового внимания вместо одного механизма внимания содержит несколько независимо работающих голов. Он может быть реализован в виде нескольких механизмов внимания, результаты которых объединяются.
[037] Кодер трансформерной модели может содержать механизм самовнимания кодера и блок сети прямого распространения. Механизм самовнимания кодера может представлять собой механизм многоголового внимания, используемый для наблюдения токенами друг за другом. Запросы, ключи и значения рассчитываются на основе состояний кодера. Блок сети прямого распространения получает информацию из токенов и обрабатывает эту информацию.
[038] Декодер трансформерной модели может содержать механизм (маскированного) самовнимания декодера, механизм внимания декодер-кодер и сеть прямого распространения. Механизм маскированного самовнимания декодера может представлять собой механизм маскированного многоголового внимания, используемый для наблюдения со стороны токенов за предыдущими токенами. Запросы, ключи и значения рассчитываются на основе состояний декодера. Механизм внимания декодер-кодер может представлять собой механизм многоголового внимания, используемый для просмотра исходной информации целевыми токенами. Запросы рассчитываются на основе состояний декодера, а ключи и значения рассчитываются на основе состояний кодера. Блок сети прямого распространения получает информацию из токенов и обрабатывает эту информацию.
[039] Можно сказать, что токены в кодере поддерживают связь друг с другом и обновляют свои представления. Также можно сказать, что в декодере целевой токен сначала просматривает ранее сформированные целевые токены, затем источник и, наконец, обновляет свои представления. Это может повторяться в нескольких слоях. В одном не имеющем ограничительного характера варианте реализации это может повторяться шесть раз.
[040] Как описано выше, в дополнение к механизму внимания слой содержит блок сети прямого распространения. Например, блок сети прямого распространения может быть представлен двумя линейными слоями с нелинейной связью вида «усеченное линейное преобразование» (ReLU, Rectifier Linear Unit) между ними. После просмотра других токенов с помощью механизма внимания в модели для обработки этой новой информации используется блок сети прямого распространения. Трансформерная модель может дополнительно содержать остаточные связи для добавления входных данных блока к его выходным данным. Остаточные связи могут использоваться для объединения слоев. В трансформерной модели остаточные связи могут использоваться после соответствующего механизма внимания и блока сети прямого распространения. Например, слою «Add & Norm» (суммирование и нормализация) могут предоставляться (а) входные данные механизма внимания через остаточную связь и (б) выходные данные механизма внимания. Затем результат слоя «Add & Norm» может предоставляться блоку сети прямого распространения или другому механизму внимания. В другом примере слою «Add & Norm» могут предоставляться (а) входные данные блока сети прямого распространения через остаточную связь и (б) выходные блока сети прямого распространения. Как описано выше, трансформерная модель может содержать слои «Add & Norm». В общем случае такой слой может независимо нормализовывать векторное представление каждого примера в пакете. Это выполняется для управления «потоком» в следующий слой. Нормализация слоя позволяет повышать устойчивость схождения и в некоторых случаях даже качество.
[041] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результаты любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[042] В контексте настоящего описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
[043] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[044] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[045] В контексте настоящего описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[046] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[047] В контексте настоящего описания числительные «первый», «второй», «третий» и т.д. используются лишь для указания на различие между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
[048] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[049] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[050] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[051] На фиг. 1 представлена схема примера компьютерной системы для реализации некоторых вариантов осуществления систем и/или способов согласно настоящей технологии.
[052] На фиг. 2 представлена сетевая вычислительная среда, пригодная для некоторых вариантов осуществления настоящей технологии.
[053] На фиг. 3 представлена схема процесса формирования приложением виртуального помощника, размещенным на сервере из сетевой вычислительной среды, представленной на фиг. 2, соответствующего речевого ответа на речевой фрагмент согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[054] На фиг. 4 представлена схема архитектуры модели машинного обучения, пригодной для использования в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии.
[055] На фиг. 5 представлена схема модели TTS для формирования соответствующего речевого ответа на речевой фрагмент пользователя, реализованной на основе архитектуры модели машинного обучения, представленной на фиг. 4, и размещенной на сервере из сетевой вычислительной среды, представленной на фиг. 2, согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[056] На фиг. 6 представлена схема модели STT, реализованной на основе архитектуры модели машинного обучения, представленной на фиг. 4, в ходе ее обучения сервером из сетевой вычислительной среды, представленной на фиг. 2, формированию текстового представления речевого фрагмента пользователя для формирования моделью TTS соответствующего речевого ответа на него согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[057] На фиг. 7 представлена схема модели STT, представленной на фиг. 6, в ходе ее применения на этапе использования согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[058] На фиг. 8 представлена блок-схема способа формирования сервером из сетевой вычислительной среды, представленной на фиг. 2, текстового представления речевого фрагмента пользователя согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
Осуществление изобретения
[059] Представленные здесь примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но реализуют принципы настоящей технологии в пределах ее существа и объема.
[060] Кроме того, чтобы способствовать лучшему пониманию, последующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалистам в данной области техники должно быть понятно, что другие варианты осуществления настоящей технологии могут быть значительно сложнее.
[061] В некоторых случаях приводятся полезные примеры модификаций настоящей технологии. Они способствуют пониманию, но также не определяют объема или границ настоящей технологии. Представленный перечень модификаций не является исчерпывающим и специалист в данной области техники может разработать другие модификации в пределах объема настоящей технологии. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии.
[062] Более того, описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть понятно, что любые описанные здесь структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих основы настоящей технологии. Также должно быть понятно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены на машиночитаемом физическом носителе информации и могут выполняться компьютером или процессором, независимо от того, показан такой компьютер или процессор явно или нет.
[063] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как «процессор» или «графический процессор», могут быть реализованы с использованием специализированных аппаратных средств, а также с использованием аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, эти функции могут выполняться одним выделенным процессором, одним совместно используемым процессором и/или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может подразумевать, помимо прочего, аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и/или энергонезависимое запоминающее устройство. Также могут подразумеваться другие аппаратные средства, общего назначения и/или заказные.
[064] Программные модули или просто модули, реализация которых предполагается в виде программных средств, могут быть представлены здесь как любое сочетание элементов блок-схемы или других элементов, указывающих на выполнение шагов процесса и/или содержащих текстовое описание. Такие модули могут выполняться аппаратными средствами, показанными явно или подразумеваемыми.
[065] Далее с учетом вышеизложенных принципов рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
Компьютерная система
[066] На фиг. 1 представлена компьютерная система 100, пригодная для использования в некоторых вариантах осуществления настоящей технологии. Компьютерная система 100 содержит различные аппаратные элементы, включая один или несколько одноядерных или многоядерных процессоров, обобщенно представленных процессором 110, графический процессор 111 (GPU, Graphics Processing Unit), твердотельный накопитель 120, ОЗУ 130, интерфейс 140 дисплея и интерфейс 150 ввода-вывода.
[067] Связь между различными элементами компьютерной системы 100 может осуществляться через одну или несколько внутренних и/или внешних шин 160 (таких как шина PCI, шина USB, шина FireWire стандарта IEEE 1394, шина SCSI, шина Serial-ATA и т.д.), с которыми различные аппаратные элементы соединены электронными средствами.
[068] Интерфейс 150 ввода-вывода может соединяться с сенсорным экраном 190 и/или с одной или несколькими внутренними и/или внешними шинами 160. Сенсорный экран 190 может входить в состав дисплея. В некоторых вариантах реализации сенсорный экран 190 представляет собой дисплей. Сенсорный экран 190 может также называться экраном 190. В представленных на фиг. 1 вариантах осуществления изобретения сенсорный экран 190 содержит сенсорные аппаратные средства 194 (например, чувствительные к нажатию ячейки, встроенные в слой дисплея и позволяющие фиксировать физическое взаимодействие между пользователем и дисплеем) и контроллер 192 ввода-вывода для сенсорных устройств, который обеспечивает связь с интерфейсом 140 дисплея и/или с одной или несколькими внутренними и/или внешними шинами 160. В некоторых вариантах осуществления изобретения интерфейс 150 ввода-вывода может соединяться с клавиатурой (не показана), мышью (не показана) или сенсорной площадкой (не показана), которые обеспечивают взаимодействие пользователя с компьютерной системой 100 в дополнение к сенсорному экрану 190 или вместо него. В некоторых вариантах осуществления изобретения компьютерная система 100 может содержать один или несколько микрофонов (не показаны). Микрофоны могут записывать аудиосигнал, такой как речевые фрагменты пользователя. Речевые фрагменты пользователя могут преобразовываться в команды для управления компьютерной системой 100.
[069] Следует отметить, что в некоторых не имеющих ограничительного характера вариантах осуществления изобретения некоторые элементы компьютерной системы 100 могут отсутствовать. Например, может отсутствовать сенсорный экран 190, в частности, если компьютерная система реализована в виде интеллектуального акустического устройства (но не ограничиваясь этим).
[070] Согласно вариантам осуществления настоящей технологии, твердотельный накопитель 120 хранит программные команды, пригодные для загрузки в ОЗУ 130 и исполнения процессором 110 и/или процессором 111 GPU. Программные команды могут, например, входить в состав библиотеки или приложения.
Сетевая вычислительная среда
[071] На фиг. 2 представлена схема сетевой вычислительной среды 200, пригодной для использования с некоторыми вариантами осуществления систем и/или способов согласно настоящей технологии. Сетевая вычислительная среда 200 содержит сервер 250, связанный через сеть 240 связи с электронным устройством 210. В не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 210 может быть связано с пользователем 230.
[072] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 250 реализован в виде традиционного компьютерного сервера и может содержать некоторые или все элементы компьютерной системы 100, представленной на фиг. 1. В одном не имеющем ограничительного характера примере сервер 250 реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™, но он также может быть реализован с использованием любых других подходящих аппаратных средств, прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 250 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии (не показаны) функции сервера 250 могут быть распределены между несколькими серверами.
[073] Кроме того, электронное устройство 210 может представлять собой любые компьютерные аппаратные средства, способные выполнять программы, подходящие для решения поставленной задачи. Таким образом, в качестве некоторых не имеющих ограничительного характера примеров электронного устройства 210 можно привести персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 210 также может содержать некоторые или все элементы компьютерной системы 100, представленной на фиг. 1. Следует отметить, что электронное устройство 210 может содержать дополнительные элементы, такие как микрофон (отдельно не показан) для преобразования полученных звуков, зафиксированных вблизи электронного устройства 210, таких как речевые фрагменты пользователя 230, в машиночитаемый формат, такой как цифровой звуковой формат, включая, например, MP3, Ogg и т.п., и громкоговоритель (также отдельно не показан) для воспроизведения поступающих звуковых сигналов вблизи электронного устройства 210, как описано ниже.
[074] Кроме того, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сетевая вычислительная среда 200 может содержать второй сервер 260, связанный через сеть 240 связи с электронным устройством 210 и с сервером 250. Предполагается, что второй сервер 260 может быть реализован подобно серверу 250.
[075] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сетевая вычислительная среда 200 может обеспечивать и/или поддерживать автоматическую связь с пользователем 230, как описано ниже.
[076] Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии второй сервер 260 может быть связан с поставщиком услуг, предоставляющим услуги пользователям, таким как пользователь 230, для помощи в получении которых второй сервер 260 может содержать приложение 265 виртуального помощника. Соответственно, второй сервер 260 может обеспечивать доступ к приложению 265 виртуального помощника электронному устройству, связанному с сетью 240 связи, такому как электронное устройство 210.
[077] В общем случае приложение 265 виртуального помощника, которое здесь также называется приложением чатбота, может инициировать, а затем поддерживать автоматическую связь с пользователем 230 и способствовать в получении им услуг от поставщика услуг, связанного со вторым сервером 260. Например, приложение 265 виртуального помощника может быть задействовано путем активации соответствующего элемента управления пользователем 230, обращающимся к поставщику услуг с использованием электронного устройства 210, например, путем набора соответствующего телефонного номера или запуска приложения 265 виртуального помощника на веб-сайте, связанном с поставщиком услуг. Кроме того, в процессе поддержания автоматической связи с пользователем 230 приложение 265 виртуального помощника может получать речевой фрагмент 235 пользователя, содержащий пользовательский запрос пользователя 230, и предоставлять ему формируемый компьютером речевой фрагмент 270, который может содержать дополнительные вопросы, уточняющие данные пользователя 230, обращающегося к поставщику услуг.
[078] На реализацию приложения 265 виртуального помощника не накладывается каких-либо ограничений, она может зависеть от услуг, предоставляемых поставщиком услуг, связанным со вторым сервером 260. Например, если поставщик услуг представляет собой врача или медицинскую клинику, то приложение 265 виртуального помощника может управлять приемом пациентов (например, планировать, изменять или отменять его). В другом примере поставщик услуг может представлять собой платформу интернет-покупок, продающую различные продукты, такие как товары и услуги, а приложение 265 виртуального помощника может принимать и отправлять онлайн-заказы пользователя 230. В еще одном примере поставщик услуг может представлять собой обычный (не онлайн) продовольственный магазин или обычный ресторан, а приложение 265 виртуального помощника может принимать и отправлять заказы продуктов для пользователя 230. Также возможны другие варианты поставщиков услуг и соответствующих пользователей приложения 265 виртуального помощника без выхода за границы настоящей технологии.
[079] В конкретном не имеющем ограничительного характера примере приложение 265 виртуального помощника может быть реализовано в виде приложения виртуального помощника ALISA™, предоставляемого компанией ООО Яндекс (ул. Льва Толстого, 16, Москва, 119021, Россия). Тем не менее, следует отметить, что приложение 265 виртуального помощника может быть реализовано в виде любого другого коммерчески доступного или проприетарного приложения виртуального помощника.
[080] В частности, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, для формирования соответствующего формируемого компьютером речевого фрагмента 270 для речевого фрагмента 235 пользователя приложение 265 виртуального помощника может: (1) инициировать получение с использованием микрофона электронного устройства 210 речевого фрагмента 235 пользователя для формирования на его основе звукового представления 245, представляющего речевой фрагмент 235 пользователя; (2) инициировать передачу звукового представления 245 речевого фрагмента серверу 250 для формирования текстового представления 255 речевого фрагмента; (3) инициировать передачу текстового представления 255 речевого фрагмента второму серверу 260 для формирования на основе текстового представления 255 речевого фрагмента формируемого компьютером речевого фрагмента 270; и (4) инициировать передачу данных, указывающих на соответствующий формируемый компьютером речевой фрагмент 270, электронному устройству 210 для его воспроизведения пользователю 230.
[081] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии звуковое представление 245 речевого фрагмента может соответствовать амплитудно-временному представлению речевого фрагмента 235 пользователя, такому как представление оцифрованного соответствующего аудиосигнала в одном из вышеупомянутых форматов. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии звуковое представление речевого фрагмента может соответствовать частотно-временному представлению речевого фрагмента 235 пользователя. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии частотно-временное представление может представлять собой соответствующую спектрограмму, связанную с речевым фрагментом 235 пользователя. Формирование спектрограмм не входит в задачу настоящей технологии. Тем не менее, вкратце, сервер 250 может формировать соответствующую спектрограмму речевого фрагмента 235 пользователя путем применения преобразования Фурье в отношении частей амплитудно-временного представления речевого фрагмента 235 пользователя, последовательно определяемых на основе заранее заданного временного окна. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии соответствующая спектрограмма может быть преобразована с использованием мел-шкалы. Например, соответствующая спектрограмма может быть сформирована, как описано в патентной заявке того же заявителя US17408958 «Method and system for classifying a user of an electronic device» (подана 23 августа 2021 г.), содержание которой полностью включено в настоящий документ посредством ссылки.
[082] Кроме того, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, текстовое представление 255 речевого фрагмента соответствует текстовой строке, представляющей речевой фрагмент 235 пользователя, который может быть сохранен и отправлен сервером 250 в одном из текстовых форматов, например, в виде обычного текста.
[083] Ниже с ссылкой на фиг. 3-7 описано формирование сервером 250 и вторым сервером 260 соответствующего формируемого компьютером речевого фрагмента 270 для речевого фрагмента 235 пользователя. Следует отметить, что сервер 250 и второй сервер 260 могут выполняться одним и тем же элементом или различными элементами без выхода за границы настоящей технологии.
[084] На фиг. 3 представлена схема процесса формирования сетевой вычислительной средой 200 соответствующего формируемого компьютером речевого фрагмента 270 в ответ на получение речевого фрагмента 235 пользователя согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[085] Сначала, как описано выше, приложение 265 виртуального помощника может (а) инициировать получение речевого фрагмента 235 пользователя электронным устройством 210, формирующим в связи с этим соответствующее звуковое представление 245 речевого фрагмента, и (б) инициировать передачу электронным устройством 210 звукового представления 245 речевого фрагмента серверу 250 для распознавания речи в речевом фрагменте 235 пользователя и формирования текстового представления 255 речевого фрагмента.
[086] Для формирования текстового представления 255 речевого фрагмента из звукового представления 245 речевого фрагмента сервер 250 может содержать модель 302 STT (или осуществлять доступ к ней иным образом). Архитектура и конфигурация модели 302 STT для распознавания речи более подробно описаны ниже со ссылкой на фиг. 6 и 7. Тем не менее, в общем случае модель 302 STT способна обрабатывать устную естественную речь, например, речевой фрагмент 235 пользователя 230, с целью распознавания в нем отдельных слов и таким образом формировать текстовое представление 255 речевого фрагмента, например, текстовую строку, такую как «Hello, it’s John Smith, I want to make an appointment with my family doctor» («Здравствуйте, это Джон Смит, я хочу записаться на прием к своему семейному врачу») или «Hi, I’d like to order a pizza» («Привет, я хотел бы заказать пиццу») и т.п.
[087] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии, сформировав текстовое представление 255 речевого фрагмента, сервер 250 может отправлять его второму серверу 260 для дальнейшей обработки естественной речи в текстовом представлении 255 речевого фрагмента.
[088] С этой целью, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, второй сервер 260 может содержать модель 304 NLP (или осуществлять доступ к ней иным образом), которая может (1) понимать язык в текстовом представлении 255 речевого фрагмента, т.е. определять контекстные и грамматические взаимосвязи между словами в нем, и (2) формировать на основе текстового представления 255 речевого фрагмента формируемую компьютером текстовую строку 370, представляющую собой текстовое представление соответствующего формируемого компьютером речевого фрагмента 270, который должен выдаваться пользователю 230. Архитектура и конфигурация модели 304 NLP описаны ниже.
[089] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии с целью формирования соответствующего формируемого компьютером речевого фрагмента 270 для пользователя 230 приложение 265 виртуального помощника может инициировать передачу формируемой компьютером текстовой строки 370 модели 306 TTS, которая может преобразовывать формируемую компьютером текстовую строку 370 в элемент речи на естественном языке и далее передавать его данные электронному устройству 210 для воспроизведения пользователю 230. Архитектура и конфигурация модели 306 TTS описаны ниже.
[090] Должно быть понятно, что, несмотря на то, что в представленных на фиг. 3 вариантах осуществления изобретения модель 304 NLP и модель 306 TTS размещены на втором сервере 260, в других не имеющих ограничительного характера вариантах осуществления настоящей технологии каждую из этих моделей может содержать и, следовательно, обучать и использовать сервер 250. Иными словами, сервер 250 и второй сервер 260 могут быть реализованы в виде одного сервера. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 304 NLP и модель 306 TTS могут быть размещены на отдельных сторонних серверах (не показаны), подключенных к сети 240 связи.
Сеть связи
[091] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 240 связи представляет собой сеть Интернет. В альтернативных не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 240 связи может быть реализована в виде любой подходящей локальной сети (LAN, Local Area Network), глобальной сети (WAN, Wide Area Network), частной сети связи и т.п. Очевидно, что варианты осуществления сети связи приведены лишь в иллюстративных целях. Реализация соответствующих линий связи (отдельно не обозначены) между сервером 250, вторым сервером 260 и электронным устройством 210 с одной стороны и сетью 240 связи с другой стороны зависит, среди прочего, от реализации сервера 250, второго сервера 260 и электронного устройства 210. Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где электронное устройство 210 реализовано в виде устройства беспроводной связи, такого как смартфон, линия связи может быть реализована в виде беспроводной линии связи. Примеры беспроводных линий связи включают в себя канал сети связи 3G, канал сети связи 4G и т.д. В сети 240 связи также может использоваться беспроводное соединение с сервером 250 и со вторым сервером 260.
Архитектура модели машинного обучения
[092] На фиг. 4 представлена архитектура 400 модели машинного обучения, пригодная для использования в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии. Архитектура 400 модели машинного обучения основана на архитектуре модели нейронной сети на основе трансформера, как описано, например, в работе Vaswani et al. «Attention Is All You Need», Proceedings of 31st Conference on Neural Information Processing Systems (NIPS, 2017), содержание которой полностью включено в настоящий документ посредством ссылки.
[093] Таким образом, архитектура 400 модели машинного обучения может содержать стек 402 слоев кодера и стек 403 слоев декодера, которые способны обрабатывать входные данные 412 и целевые данные 417 архитектуры 400 модели машинного обучения, соответственно.
[094] Кроме того, блок 404 кодера стека 402 слоев кодера содержит слой 406 многоголового внимания (MHA, Multi-Head Attention) кодера и слой 408 сети NN прямого распространения кодера. Слой 406 MHA кодера содержит зависимости между частями предоставленных ему входных данных 412. Например, если входные данные 412 содержат текстовые данные, такие как текстовое предложение, слой 406 MHA кодера может содержать зависимости между словами предложения. В другом примере, где входные данные 412 стека 402 слоев кодера содержат аудиосигнал, например, представляющий фрагмент человеческой речи (такой как речевой фрагмент 235 пользователя, описанный выше), слой 406 MHA кодера может содержать зависимости между конкретными звуками и/или акустическими признаками фрагмента человеческой речи. Такие зависимости могут использоваться слоем 406 MHA кодера для определения контекстной информации части входных данных 412 стека 402 слоев кодера (например, представляющей слово из предложения или акустический признак речевого фрагмента 235 пользователя), связанной с другой частью входных данных 412.
[095] Кроме того, слой 408 сети NN прямого распространения способен преобразовывать его входные данные из слоя 406 MHA кодера в формат, принимаемый одним или несколькими следующими слоями архитектуры 400 модели машинного обучения, такими как слой 409 MHA кодера-декодера (описано ниже). Слой 408 сети NN прямого распространения кодера обычно не содержит зависимости слоя 406 MHA кодера, поэтому входные данные слоя 408 сети NN прямого распространения кодера могут обрабатываться параллельно.
[096] Кроме того, входные данные 412 стека 402 слоев кодера могут быть представлены множеством 414 входных векторов, формируемых алгоритмом 410 векторизации входных данных. В общем случае алгоритм 410 векторизации входных данных способен формировать векторные представления фиксированной размерности входных данных 412 в соответствующем пространстве векторных представлений. Иными словами, если входные данные 412 содержат данные, указывающие на речевой фрагмент 235 пользователя, такие как звуковое представление 245 речевого фрагмента, то алгоритм 410 векторизации входных данных может формировать множество 414 входных векторов, в котором координаты векторов, представляющих схожие акустические признаки звукового представления 245 речевого фрагмента (например, представляющих части со схожим звучанием из речевого фрагмента 235 пользователя), располагаются ближе друг к другу в соответствующем пространстве векторных представлений.
[097] В общем случае реализация алгоритма 410 векторизации входных данных зависит от формата предоставляемых ему входных данных 412. Если входные данные 412 содержат фрагменты человеческой речи, как в представленном выше примере, то алгоритм 410 векторизации входных данных может быть реализован в виде алгоритма векторизации звука, включая, среди прочего, алгоритм векторизации звука вида кодировщика Seq2Seq (Sequence-to-Sequence Autoencoder), алгоритм векторизации звука вида «сверточная векторная регрессия», алгоритм векторизации звука вида «основанная на буквах n-грамма», алгоритм векторизации звука на основе модели LSTM (Long Short-Term Memory) и т.п.
[098] Вектор из множества 414 векторов может содержать числовые значения, например, 468 значений с плавающей запятой, представляющие соответствующую часть входных данных 412, такую как слово, часть речевого фрагмента 235 пользователя и т.п.
[099] Формирование множества 414 входных векторов может также включать в себя применение позиционного алгоритма векторизации (не показан), способного регистрировать позиционные данные в частях входных данных 412. Например, если входные данные 412 содержат текстовое предложение, то позиционный алгоритм векторизации может формировать вектор, указывающий на позиционные данные слов в этом текстовом предложении. В другом примере, где входные данные 412 представляют речевой фрагмент 235 пользователя, позиционный алгоритм векторизации может регистрировать позиционные данные акустических признаков, связанных с этим фрагментом. Иными словами, позиционный алгоритм векторизации может формировать вектор, содержащий контекстную информацию из входных данных 412, который может быть добавлен к множеству 414 входных векторов. На реализацию позиционного алгоритма векторизации не накладывается каких-либо ограничений. Например, он (в числе прочего) может содержать позиционный алгоритм синусоидальной векторизации, позиционный алгоритм векторизации с наложением кадров и позиционный алгоритм сверточной векторизации.
[0100] Следует отметить, что стек 402 слоев кодера может содержать несколько блоков кодера, например, 6 или 12, реализованных подобно блоку 404 кодера.
[0101] Блок 405 декодера стека 403 слоев декодера архитектуры 400 модели машинного обучения содержит (а) слой 407 MHA декодера и (б) слой 411 сети NN прямого распространения декодера, которые обычно могут быть реализованы подобно слою 406 MHA кодера и слою 408 сети NN прямого распространения кодера, соответственно. Тем не менее, архитектура блока 405 декодера отличается от архитектуры блока 404 кодера тем, что блок 405 декодера дополнительно содержит слой 409 MHA кодера-декодера. Слой 409 MHA кодера-декодера способен (а) получать входные векторы от стека 402 слоев кодера и от слоя 407 MHA декодера и, следовательно, (б) определять в ходе обучения, как описано ниже, зависимости между входными данными 412 и целевыми данными 417 (такими, как текстовые данные) архитектуры 400 модели машинного обучения, введенным в стек 403 слоев декодера. Иными словами, выходные данные слоя 409 MHA кодера-декодера представляют собой векторы внимания, содержащие данные, указывающие на взаимосвязи между соответствующими частями входных данных 412 и целевых данных 417.
[0102] Как и в случае входных данных 412, с целью подачи целевых данных 417 в блок 405 декодера алгоритм 415 векторизации целевых данных может применяться в отношении целевых данных 417 для формирования множества 419 целевых векторов, содержащих числовые представления соответствующих частей целевых данных 417. Подобно алгоритму векторизации входных данных, алгоритм 415 векторизации целевых данных может формировать отображения целевых данных 417 в соответствующее пространство векторных представлений. Например, если целевые данные 417 содержат текстовые данные, такие как текстовое предложение, алгоритм 415 векторизации целевых данных может формировать множество 419 целевых векторов, в котором координаты векторов, представляющих слова текстового предложения со схожим значением, располагаются ближе друг к другу в соответствующем пространстве векторных представлений. Таким образом, алгоритм 415 векторизации целевых данных может быть реализован в виде алгоритма векторизации текста, включая, среди прочего, алгоритм векторизации текста вида Word2Vec (Word to Vector), алгоритм векторизации текста вида GloVe (Global Vectors for Word Representation) и т.п.
[0103] Предполагается, что алгоритм 415 векторизации целевых данных может быть реализован подобно алгоритму 410 векторизации входных данных. Кроме того, позиционный алгоритм может применяться в отношении множества 419 целевых векторов для фиксации позиционных данных из частей целевых данных 417, как описано выше применительно к множеству 414 входных векторов.
[0104] Как описано ниже, архитектура 400 модели машинного обучения может получать входные данные 412 и целевые данные 417 из цифрового объекта, например, такого как обучающий цифровой объект 640 STT, как описано со ссылкой на фиг. 6.
[0105] Следует отметить, что стек 403 слоев декодера может содержать несколько блоков декодера, например, 6 или 12, реализованных подобно блоку 405 декодера. Предполагается, что после обучения архитектуры 400 модели машинного обучения все блоки стека 402 слоев кодера и стека 403 слоев декодера имеют различные веса, используемые при формировании выходных данных 425. Для корректировки весов в ходе обучения в отношении архитектуры 400 модели машинного обучения может применяться алгоритм обратного распространения и могут определяться и минимизироваться различия между входными данными 415 и выходными данными 425. Такие различия могут выражаться функцией потерь, такой как функция потерь кросс-энтропии.
[0106] Должно быть понятно, что в не имеющих ограничительного характера вариантах осуществления настоящей технологии также возможны другие варианты реализации функции потерь, например, функция потерь среднеквадратичной ошибки, функция потерь по Губеру, кусочно-линейная функция потерь и т.д.
[0107] Выходные данные 425 архитектуры 400 модели машинного обучения могут содержать выходной вектор, соответствующий вектору из множества 414 входных векторов. Например, как описано ниже, в тех вариантах осуществления изобретения, где входные данные 412 архитектуры 400 модели машинного обучения содержат звуковое представление 245 речевого фрагмента для речевого фрагмента 235 пользователя, выходной вектор может содержать вероятности, указывающие на соответствующую часть текстового представления 255 речевого фрагмента.
[0108] Должно быть понятно, что архитектура 400 модели машинного обучения, описанная со ссылкой на фиг. 4, упрощена для лучшего понимания и что фактический вариант реализации архитектуры 400 модели машинного обучения может содержать дополнительные слои и/или блоки, например, как описано в вышеупомянутой работе Vaswani et al. В частности, в некоторых вариантах реализации архитектуры 400 модели машинного обучения каждый блок 404 кодера и каждый блок 405 декодера может также содержать слой операций нормализации. Кроме того, формирование выходных данных 425 может включать в себя применение функции нормализации softmax на выходе стека 403 слоев декодера и т.д. Специалистам в данной области техники должно быть понятно, что эти операции широко используются в нейронных сетях и моделях глубокого обучения, таких как архитектура 400 модели машинного обучения.
Модель NLP
[0109] В контексте настоящего описания модель NLP, такая как описанная ниже модель 304 NLP, представляет собой модель машинного обучения, обученную чтению, пониманию и формированию фрагментов естественной речи. Иными словами, можно сказать, что модель 304 NLP может выполнять два различных процесса: (а) процесс понимания естественной речи (NLU, Natural Language Understanding), например, для понимания текстового представления 255 речевого фрагмента, сформированного моделью 302 STT, преобразующий текстовое представление 255 речевого фрагмента в структурированные данные, и (б) процесс формирования естественной речи (NLG, Natural Language Generation) для формирования на основе структурированных данных формируемой компьютером текстовой строки 370.
[0110] Таким образом, формируемая компьютером текстовая строка 370 может, например, указывать на следующую строку диалога приложения виртуального помощника, соответствующую речевому фрагменту 235 пользователя. В частности, в случае речевого фрагмента 235 пользователя «Hello, it’s John Smith, I want to make an appointment with my family doctor» («Здравствуйте, это Джон Смит, я хочу записаться на прием к своему семейному врачу») формируемая компьютером текстовая строка 370 может указывать на следующую фразу: «Sure! Can I have your medical insurance card number?» («Конечно! Могу я узнать номер Вашей карты медицинского страхования?»).
[0111] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 304 NLP может быть реализована на основе сети NN, такой как сеть NN вида LSTM или рекуррентная сеть NN. Тем не менее, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, модель 304 NLP может быть реализована в виде модели NN на основе трансформера. При этом модель 304 NLP может содержать некоторые или все элементы архитектуры 400 модели машинного обучения, описанной выше.
[0112] В частности, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 304 NLP также может содержать стек 402 слоев кодера и стек 403 слоев декодера, включая несколько блоков кодера и декодера. Тем не менее, соответствующие количества таких блоков в стеке 402 слоев кодера и в стеке 403 слоев декодера могут отличаться от их количества в архитектуре 400 модели машинного обучения.
[0113] Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 304 NLP может содержать один блок кодера и тринадцать блоков декодера, реализованных подобно блоку 404 кодера и блоку 405 декодера, соответственно, как описано выше. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 304 NLP может не содержать блоков кодера и содержать несколько блоков декодера, например, 6, 12 или 96 (в этом случае модель 304 может называться предварительно обученным генеративным трансформером (GPT, Generative Pre-trained Transformer)). При этом в других не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 304 NLP может содержать только блоки кодера, например, 12, 24 или 36, и не содержать блоков декодера (в этом случае модель 304 может называться «Представлениями двунаправленного кодера из трансформеров» (BERT, Bidirectional Encoder Representations from Transformers)).
[0114] Также возможны и другие конфигурации стека 402 слоев кодера и стека 403 слоев декодера для реализации модели 304 NLP без выхода за границы настоящей технологии.
[0115] Кроме того, для обучения модели 304 NLP формированию формируемых компьютером текстовых строк в ответ на текстовые представления речевых фрагментов, формируемые моделью 302 STT, например, формируемой компьютером текстовой строки 370 для текстового представления 255 речевого фрагмента для речевого фрагмента 235 пользователя, второй сервер 260 может подавать в модель 304 NLP обучающий набор данных NLP, содержащий множество обучающих цифровых объектов NLP.
[0116] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, обучающий цифровой объект NLP из множества обучающих цифровых объектов NLP может содержать (а) первую формируемую пользователем текстовую строку и (б) вторую формируемую пользователем текстовую строку, соответствующую первой формируемой пользователем строке. Например, с этой целью обучающий цифровой объект NLP может быть получен в сети Интернет из общедоступных диалогов в социальных медиа, таких как комментарии или сообщения на веб-сайте социальной сети либо обсуждения на веб-сайте форума. В другом примере первая формируемая пользователем текстовая строка и вторая формируемая пользователем текстовая строка могут быть сформированы на основе диалогов между различными сервисами технической поддержки, например, между сервисами поставщика услуг (описано выше) и их клиентами.
[0117] Кроме того, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, второй сервер 260 может подавать (а) первую формируемую пользователем текстовую строку в стек 402 слоев кодера и (б) вторую формируемую пользователем текстовую строку в стек 403 слоев декодера, как описано выше. Таким образом, второй сервер 260 может подавать множество обучающих цифровых объектов NLP, содержащее, например, тысячи или сотни тысяч схожих обучающих цифровых объектов NLP, в модель 304 NLP и обучать таким образом модель 304 NLP формированию выходных данных 425, содержащих векторы распределения вероятностей для слов формируемой компьютером текстовой строки этапа использования, являющейся текстовым представлением речевого фрагмента пользователя этапа использования.
[0118] Кроме того, может быть определена функция потерь, представляющая различия между входными данными 412 и выходными данными 425, и путем минимизации такой функции потерь второй сервер 260 может определять веса для узлов модели 304 NLP с использованием алгоритма обратного распространения. Дополнительная информация об обучении модели 304 NLP содержится, например, в статье «Towards a Human-like Open-Domain Chatbot» (Adiwardana et al., Google Research), содержание которой полностью включено в настоящий документ посредством ссылки.
[0119] В тех вариантах осуществления изобретения, где модель 304 NLP содержит только стек 402 слоев кодера или только стек 403 слоев декодера, модель 304 NLP сначала может быть предварительно обучена на основе более общего обучающего набора данных, а затем точно настроена на основе обучающего набора данных NLP, описанного выше, как подробно описано, например, в статье «Language Models are Few-Shot Learners» (Brown et al., OpenAI), содержание которой полностью включено в настоящий документ посредством ссылки.
[0120] Таким образом, второй сервер 260 может обучать модель 304 NLP формированию формируемой компьютером текстовой строки 370 в ответ на текстовое представление 255 речевого фрагмента для речевого фрагмента 235 пользователя.
Модель TTS
[0121] Как описано выше со ссылкой на фиг. 3, после получения от модели 304 NLP формируемой компьютером текстовой строки 370 приложение 265 виртуального помощника может отправлять формируемую компьютером текстовую строку 370 модели 306 TTS для формирования формируемого компьютером аудиосигнала, указывающего на соответствующий формируемый компьютером речевой фрагмент 270 для речевого фрагмента 235 пользователя.
[0122] В общем случае в контексте данного документа модель 306 TTS представляет собой модель машинного обучения, способную преобразовывать элементы естественной речи в виде текста, например, в устную речь. На реализацию модели 306 TTS не накладывается каких-либо ограничений. В числе прочего, она может содержать модель TTS WaveNet, модель TTS Deep Voice, модель TTS Tacotron и т.п.
[0123] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, модель 306 TTS может быть реализована в виде модели NN на основе трансформера и, таким образом, может содержать некоторые или все элементы архитектуры 400 модели машинного обучения, описанной выше со ссылкой на фиг. 4.
[0124] На фиг. 5 представлена схема модели 306 TTS на основе архитектуры 400 модели машинного обучения, представленной на фиг. 4, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии. Таким образом, как описано ниже, входные данные 412 модели 306 TTS могут содержать текстовые строки, а целевые данные 417 могут содержать звуковые представления речевых фрагментов пользователя, соответствующие текстовым строкам входных данных 412.
[0125] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 306 TTS может содержать дополнительные элементы для обработки входных данных 412 и целевых данных 417. В частности, для ввода входных данных 412 модель 306 TTS может содержать алгоритм 502 преобразования текста в фонемы, способный формировать фонетическое представление входной строки, такой как слова или предложения. Например, фонетическое представление слова может содержать соответствующую фонетическую транскрипцию согласно международному фонетическому алфавиту (IPA, International Phonetic Alphabet).
[0126] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, для формирования множества 414 входных векторов, соответствующих векторным представлениям фонетического представления входной текстовой строки в соответствующем пространстве векторных представлений, как описано выше, модель 306 TTS содержит дополнительную сеть NN - предварительную сеть 504 кодера. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии предварительная сеть 504 кодера может быть реализована в виде сверточной сети NN (CNN, Convolutional NN), содержащей заранее заданное количество слоев, например, три.
[0127] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии звуковое представление речевого фрагмента пользователя, вводимое в модель 306 TTS в качестве части целевых данных 417, может быть сформировано подобно звуковому представлению 245 речевого фрагмента, как описано выше со ссылкой на фиг. 2. С этой целью в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии звуковое представление для модели 306 TTS может, например, содержать соответствующую мел-спектрограмму, связанную с речевым фрагментом пользователя.
[0128] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии для получения звукового представления стеком 403 слоев декодера модель 306 TTS может дополнительно содержать еще одну дополнительную сеть NN, способную формировать множество 419 целевых векторов на основе звуковых представлений речевого фрагмента пользователя. В частности, эта сеть NN может содержать заранее заданное количество полносвязных слоев (например, два), каждый из которых содержит, в частности, 256 скрытых узлов с функцией активации вида ReLU.
[0129] Кроме того, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, модель 306 TTS может быть обучена, например, вторым сервером 260, определению соответствий между фонемами слов или фраз из входных данных 412 и звуковыми представлениями речевых фрагментов пользователя из целевых данных 417. Таким образом, второй сервер 260 может обучать модель 306 TTS формированию формируемых компьютером звуковых сигналов, указывающих на формируемые компьютером речевые фрагменты, которые должны быть предоставлены в ответ на получение соответствующей текстовой строки, такой как формируемая компьютером текстовая строка 370.
[0130] С этой целью второй сервер 260 может обучать модель 306 TTS на основе обучающего набора данных TTS, содержащего множество обучающих цифровых объектов TTS. В частности, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, обучающий цифровой объект TTS из множества обучающих цифровых объектов TTS может содержать (1) обучающую текстовую строку и (2) соответствующее обучающее звуковое представление, такое как мел-спектрограмма (описано выше), речевого фрагмента пользователя, сформированного обучающим пользователем, произносящим обучающую текстовую строку.
[0131] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии обучающая текстовая строка может быть заранее подготовлена для произнесения обучающим пользователем с целью формирования связанного с ней соответствующего звукового представления. Например, может использоваться обучающая текстовая строка «Hello! You have reached the office of Doctor House. How can we help you today?» («Здравствуйте, Вы обратились в офис врача Хауса. Чем мы можем быть Вам полезны сегодня?»), и обучающий пользователь может произнести эту обучающую текстовую строку и записать свой речевой фрагмент с помощью электронного устройства, подобного электронному устройству 210, описанному выше. На основе записи речевого фрагмента пользователя второй сервер 260 может сформировать соответствующее обучающее звуковое представление, связанное с обучающей текстовой строкой.
[0132] Тем не менее, в других не имеющих ограничительного характера вариантах осуществления настоящей технологии второй сервер 260 может получать (1) обучающий аудиосигнал TTS, например, представляющий заранее записанную речь относительно большой продолжительности, равной, например, 25 часам, и (2) соответствующее обучающее текстовое представление TTS этой заранее записанной речи, представленной обучающим аудиосигналом TTS. Кроме того, второй сервер 260 может (1) разделять обучающий аудиосигнал TTS на множество частей, например, равной длины, такой как 10 секунд, (2) формировать для части обучающего сигнала TTS соответствующее обучающее звуковое представление, (3) определять соответствующие части в обучающем текстовом представлении TTS заранее записанной речи, соответствующие множеству частей обучающего аудиосигнала TTS, и (4) формировать обучающий цифровой объект TTS, содержащий обучающую текстовую строку, соответствующую части обучающего текстового представления TTS заранее записанной речи, и соответствующее обучающее звуковое представление.
[0133] Таким образом, сформировав (или получив иным образом) обучающий набор данных TTS, как описано выше, второй сервер 260 может обучать модель 306 TTS основанному на формируемой компьютером текстовой строке 370 формированию формируемого компьютером аудиосигнала, указывающего на формируемый компьютером речевой фрагмент 270. В частности, как описано выше, во-первых, второй сервер 260 может подавать обучающую текстовую строку с использованием алгоритма 502 преобразования текста в фонемы и предварительной сети 504 кодера, как описано выше, в стек 402 слоев кодера. Во-вторых, второй сервер 260 может подавать соответствующее обучающее звуковое представление, связанное с текстовой строкой, через предварительную сеть 505 декодера, как описано выше, в стек 403 слоев декодера. Таким образом, второй сервер 260 может вводить каждый объект из множества обучающих цифровых объектов TTS.
[0134] Затем, как описано выше, с использованием алгоритма обратного распространения и минимизации функции потерь, указывающей на различия между входными данными 412 и выходными данными 425, второй сервер 260 может обучать модель 306 TTS формированию в ответ на текстовую строку этапа использования, такую как формируемая компьютером текстовая строка 370, выходных данных 425, содержащих векторы распределения вероятностей для частей формируемого компьютером аудиосигнала, соответствующего формируемой компьютером текстовой строке 370. Затем на основе соответствующего звукового представления этапа использования второй сервер 260 может формировать формируемый компьютером аудиосигнал, представляющий соответствующий формируемый компьютером речевой фрагмент 270 приложения 265 виртуального помощника для речевого фрагмента 235 пользователя.
[0135] Дополнительные сведения о реализации модели 306 TTS согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии приведены в статье «Close to Human Quality TTS with Transformer» (Li et al., University of Electronic Science and Technology of China), содержание которой полностью включено в настоящий документ посредством ссылки. Кроме того, дополнительные сведения о модели 306 TTS, которая может быть использована для реализации некоторых не имеющих ограничительного характера вариантов осуществления настоящей технологии, приведены в статье «FastSpeech 2: Fast and High-Quality End-to-End Text to Speech (Yi Ren et al., Zhejiang University, Microsoft Research Asia and Microsoft Azure Speech), содержание которой полностью включено в настоящий документ посредством ссылки. Дополнительные сведения о модели 306 TTS, которая может быть использована для реализации некоторых не имеющих ограничительного характера вариантов осуществления настоящей технологии, также приведены в статье «Fastpitch: parallel text-to-speech with pitch prediction» (Adrian Lancuck, NVIDIA Corporation), содержание которой полностью включено в настоящий документ посредством ссылки.
[0136] Таким образом, сетевая вычислительная среда 200 может формировать соответствующий формируемый компьютером речевой фрагмент 270 для передачи его электронному устройству 210 в ответ на получение речевого фрагмента 235 пользователя (см. фиг. 3).
[0137] При этом разработчики настоящей технологии установили, что качество и релевантность соответствующего формируемого компьютером речевого фрагмента 270 приложения 265 виртуального помощника могут быть повышены путем повышения точности формирования моделью 302 STT текстового представления 255 речевого фрагмента. Следует отметить, что второй сервер 260 использует выходные данные модели 302 STT при обработке, выполняемой моделью 304 NLP и моделью 306 TTS. В результате повышения качества выходных данных, формируемых моделью 302 STT, также возможно повышение эффективности других расположенных в нисходящем направлении элементов сетевой вычислительной среды 200, используемой приложением 265 виртуального помощника для формирования формируемых компьютером речевых фрагментов для пользователя 230.
[0138] В связи с этим разработчики установили, что модель 302 STT может точнее формировать текстовое представление 255 речевого фрагмента, если она способна учитывать предыдущую формируемую компьютером текстовую строку 360 модели 304 NLP в качестве контекста звукового представления 245 речевого фрагмента для речевого фрагмента 235 пользователя. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии предыдущая формируемая компьютером текстовая строка 360 может быть сформирована моделью 304 NLP для предыдущего соответствующего формируемого компьютером речевого фрагмента, сформированного моделью 306 TTS, как описано выше, в ответ на который пользователь 230 предоставил речевой фрагмент 235 пользователя.
[0139] Таким образом, разработчики реализовали описанные здесь способы и системы, позволяющие модели 302 TTS учитывать предыдущую формируемую компьютером текстовую строку 360 в качестве контекста для речевого фрагмента 235 пользователя с целью формирования соответствующего текстового представления 255 речевого фрагмента, далее используемого для формирования формируемого компьютером речевого фрагмента 270. В результате, благодаря настоящим способам и системам, возможно повышение точности модели 302 STT, например, путем устранения проблемы лексической неоднозначности при обработке звукового представления 245 речевого фрагмента для речевого фрагмента 235 пользователя.
[0140] Например, если в речевом фрагменте 235 пользователя пользователь 230 сообщает свою фамилию, например, «It’s Wordsworth» («Это Вордсворт»), то без контекстной информации модель 302 STT может сформировать текстовое представление 255 речевого фрагмента «It’s words worth» («Это стоит слов»), поскольку у нее отсутствует информация о том, что это фамилия, которая должна быть представлена в виде одного слова. При этом благодаря подаче в модель 302 STT в качестве данных обратной связи предыдущей формируемой компьютером текстовой строки 360, которая использовалась при формировании предыдущего соответствующего формируемого компьютером речевого фрагмента для пользователя 230, такой как «Can I have your last name, please?» («Могу я узнать Вашу фамилию?»), можно обеспечить надлежащий контекст для речевого фрагмента 235 пользователя, позволяющий модели 302 STT распознать известную фамилию «Wordsworth» («Вордсворт»). В другом примере модель 302 STT, которой не был предоставлен надлежащий контекст, может на основе речевого фрагмента 235 пользователя, содержащего указание на адрес пользователя 230, такого как «4245, Bellechasse» («4245, Бельшасс»), сформировать текстовое представление 255 речевого фрагмента «4245 belle chasse» («4245, красивая охота»), не распознав известный французский топоним «Bellechasse» («Бельшасс»), который в данном примере соответствует названию улицы.
[0141] Таким образом, благодаря описанным в данном документе способам и системам, возможно повышение точности распознавания речи моделью 302 STT, что, в свою очередь, позволяет формировать для пользователя 230 более релевантные речевые ответы на его речевые фрагменты, предоставляемые приложению 265 виртуального помощника, что в результате позволяет обеспечивать лучшее взаимодействие пользователя 230 с приложением 265 виртуального помощника.
[0142] Ниже со ссылкой на фиг. 6 и 7 описаны архитектура и конфигурация модели 302 STT согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
Модель STT
[0143] Как описано выше, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, модель 302 STT может быть реализована в виде модели машинного обучения. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель машинного обучения содержит модель на основе сети NN. В качестве не имеющих ограничительного характера примеров моделей на основе сети NN, которые можно использовать для реализации настоящей технологии, можно привести модель на основе рекуррентной сети NN (RNN, Recurrent NN) или модель на основе сети NN вида LSTM.
[0144] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модель 302 STT может быть реализована в виде модели NN на основе трансформера. С этой целью модель 302 STT может содержать некоторые или все компоненты архитектуры 400 модели машинного обучения, описанной выше со ссылкой на фиг. 4.
[0145] При этом согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, модель 302 STT может содержать дополнительные компоненты. На фиг. 6 представлена схема модели 302 STT, реализованной согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[0146] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, модель 302 STT может содержать стек 603 слоев декодера STT, в котором архитектура блока 605 декодера STT отличается от архитектуры блока 405 декодера в архитектуре 400 модели машинного обучения. В частности, помимо компонентов блока 405 декодера, описанного выше, блок 605 декодера STT может содержать дополнительный слой 607 MHA для получения дополнительных входных данных 621. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии дополнительные входные данные 621 могут использоваться для предоставления дополнительного контекста для входных данных 412 и целевых данных 417, как более подробно описано ниже. Таким образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии дополнительный слой 607 MHA может определять зависимости между соответствующими частями входных данных 412, целевых данных 417 и дополнительных входных данных 621.
[0147] Предполагается, что для ввода дополнительных входных данных 621 в блок 605 декодера STT сервер 250 может применять второй алгоритм 610 векторизации входных данных, реализованный подобно алгоритму 410 векторизации входных данных или алгоритму 415 векторизации целевых данных. Кроме того, как описано выше применительно к входным данным 412 и целевым данным 417, сервер 250 может применять в отношении дополнительных входных данных 621 позиционный алгоритм векторизации (не показан), способный формировать вектор, указывающий на позиционные данные в частях предоставленных данных.
[0148] Как и в представленных выше примерах, касающихся обучения модели 304 NLP и модели 306 TTS, сервер 250 может получать входные данные 412, целевые данные 417 и дополнительные входные данные 621 для их ввода в модель 302 STT из соответствующего цифрового объекта, такого как обучающий цифровой объект 640 STT, как описано ниже.
[0149] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, для использования модели 302 STT с целью формирования текстовых представлений речевых фрагментов для входных звуковых представлений фрагментов человеческой речи, таких как текстовое представление 255 речевого фрагмента, сервер 250 может выполнять два соответствующих процесса в отношении модели 302 STT. Первый процесс из числа двух процессов представляет собой процесс обучения, где сервер 250 способен на основе обучающего набора данных обучать модель 302 STT формированию текстового представления 255 речевого фрагмента, как описано ниже. Второй процесс представляет собой процесс этапа использования, где сервер 250 способен применять обученную таким образом модель 302 STT в отношении входных звуковых представлений согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, как описано ниже.
Процесс обучения
[0150] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 250 может обучать модель 302 STT на основе обучающего набора данных STT, содержащего множество обучающих цифровых объектов STT, формируемых сервером 250 с использованием обучающих речевых фрагментов обучающих пользователей.
[0151] В частности, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии обучающий цифровой объект 640 STT из множества обучающих цифровых объектов STT может содержать (а) обучающее звуковое представление 642 речевого фрагмента, сформированное на основе обучающего речевого фрагмента обучающего пользователя подобно тому, как описано выше применительно к формированию звукового представления 245 речевого фрагмента, и (б) обучающее текстовое представление 644, например, сформированное вручную (например, введенное с клавиатуры) обучающим пользователем во время формирования обучающего цифрового объекта 640 STT (см. фиг. 6). В дополнительных не имеющих ограничительного характера вариантах осуществления настоящей технологии обучающее текстовое представление 644 речевого фрагмента может быть заранее сформировано для дальнейшего его предоставления обучающему пользователю, который затем формирует обучающий речевой фрагмент на основе обучающего текстового представления 644 речевого фрагмента.
[0152] В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 250 может формировать обучающий цифровой объект 640 STT на основе заранее записанной речи, как описано выше применительно к обучению модели 306 TTS.
[0153] Кроме того, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, обучающий цифровой объект 640 STT также может содержать (в) обучающую формируемую компьютером текстовую строку 646, в ответ на получение которой были сформированы обучающее звуковое представление 642 речевого фрагмента и/или обучающее текстовое представление 644 речевого фрагмента. Если обучающее звуковое представление 642 речевого фрагмента указывает на обучающий речевой фрагмент пользователя «4245, Bellechasse» («4245, Бельшасс») (см. один из представленных выше примеров лексической неоднозначности), который дополнительно отражается в обучающем текстовом представлении 644 речевого фрагмента, то обучающая формируемая компьютером тестовая строка 646 может указывать на вопрос «Can I have your address?» («Могу я узнать Ваш адрес?»). Таким образом, обучающая формируемая компьютером текстовая строка 646 может быть использована с целью предоставления контекста для обучающего речевого фрагмента пользователя, представленного обучающим звуковым представлением 642 речевого фрагмента и обучающим текстовым представлением 644 речевого фрагмента. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии обучающая формируемая компьютером текстовая строка 646 может быть сформирована, например, моделью 304 NLP (или другой подобной ей моделью) в ответ на получение предыдущего обучающего речевого фрагмента пользователя, как описано выше.
[0154] Кроме того, как описано выше, для подачи обучающего цифрового объекта 640 STT в модель 302 STT сервер 250 может преобразовывать обучающее звуковое представление 642 речевого фрагмента, обучающее текстовое представление 644 речевого фрагмента и обучающую формируемую компьютером текстовую строку 646 в их соответствующие векторные представления. В частности, сервер 250 может применять алгоритм 410 векторизации входных данных в отношении обучающего звукового представления 642 речевого фрагмента для формирования множества 414 входных векторов, как описано выше. Подобным образом сервер 250 может применять алгоритм 415 векторизации целевых данных в отношении обучающего текстового представления 644 речевого фрагмента для формирования множества целевых векторов. И наконец, сервер 250 может применять второй алгоритм 610 векторизации входных данных в отношении обучающей формируемой компьютером текстовой строки 646 для формирования множества 627 дополнительных входных векторов.
[0155] Кроме того, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 250 может подавать (а) множество 414 входных векторов, представляющих обучающее звуковое представление 642 речевого фрагмента, в стек 402 слоев кодера модели 302 STT, например, в блок 404 кодера, (б) множество 419 целевых векторов, представляющих обучающее текстовое представление 644 речевого фрагмента, в стек 603 слоев декодера STT модели 302 STT, например, в блок 605 декодера STT, и (в) множество 627 дополнительных входных векторов, представляющих обучающую формируемую компьютером текстовую строку 646, также в блок 605 декодера STT. Как описано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 250 может подавать множество 419 целевых векторов и множество 627 дополнительных входных векторов в различные слои MHA блока 605 декодера STT, т.е. в слой 407 MHA декодера и в дополнительный слой 607 MHA, соответственно.
[0156] Таким образом, сервер 250 может предоставлять модели 302 STT множество обучающих цифровых объектов STT, например, содержащее тысячи или сотни тысяч обучающих цифровых объектов STT, подобных обучающему цифровому объекту 640 STT. Кроме того, как описано выше, сервер 250 может корректировать первоначальные веса узлов каждого слоя из стека 402 слоев кодера и из стека 603 слоев декодера STT путем использования алгоритма обратного распространения и минимизации функции потерь.
[0157] Таким образом, сервер 250 может обучать модель 302 STT формированию текстовых представлений речевых фрагментов, таких как текстовое представление 255 речевого фрагмента, для фрагментов человеческой речи на основе их соответствующих звуковых представлений речевых фрагментов.
Процесс этапа использования
[0158] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, в ходе этапа использования сервер 250 может использовать обученную таким образом модель 302 STT для распознавания фрагментов человеческой речи. На фиг. 7 представлена схема модели 302 STT, представленной на фиг. 6, которая выполняется сервером 250 в ходе этапа использования, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[0159] В частности, сервер 250 может получать звуковое представление 245 речевого фрагмента для речевого фрагмента 235 пользователя, полученного от пользователя 230. Кроме того, сервер 250 может применять алгоритм 410 векторизации входных данных в отношении звукового представления 245 речевого фрагмента с целью формирования представляющего его множества 414 входных векторов для подачи в стек 402 слоев кодера модели 302 STT. Сервер 250 также может получать от модели 304 NLP предыдущую формируемую компьютером текстовую строку 360, которая использовалась для формирования моделью 306 TTS предыдущего соответствующего формируемого компьютером речевого фрагмента, в ответ на который пользователь 230 предоставил речевой фрагмент 235 пользователя. Таким образом, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 250 может применять второй алгоритм 610 векторизации входных данных в отношении предыдущей формируемой компьютером текстовой строки 360 для формирования множества 627 дополнительных входных векторов. Затем сервер 250 может подавать сформированное таким образом множество 627 дополнительных входных векторов, представляющих предыдущую формируемую компьютером текстовую строку 360, в дополнительный слой 607 MHA блока 605 декодера STT модели 302 STT.
[0160] Таким образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в ответ на получение множества 414 входных векторов и множества 627 дополнительных входных векторов модель 302 STT может формировать выходные данные 425, содержащие векторы распределения вероятностей, указывающие на текстовое представление 255 речевого фрагмента для речевого фрагмента 235 пользователя.
[0161] В результате путем выполнения обученной таким образом модели 302 STT и предоставления ей предыдущей формируемой компьютером текстовой строки, использованной для формирования моделью 306 TTS соответствующих предыдущих речевых ответов приложения 265 виртуального помощника, сервер 250 может предоставлять контекст для каждого речевого фрагмента пользователя для пользователя 230, что позволяет повысить качество формирования моделью 302 STT соответствующих текстовых представлений речевых фрагментов, например, путем устранения описанных выше проблем с лексической неоднозначностью.
[0162] Например, для каждого следующего экземпляра речевого фрагмента 235 пользователя сервер 250 может предоставлять модели 302 STT соответствующую предыдущую формируемую компьютером текстовую строку, ранее выданную моделью 304 NLP модели 306 TTS для формирования соответствующего предыдущего речевого ответа для приложения 265 виртуального помощника, в качестве контекста для следующего речевого фрагмента пользователя. Таким образом, сервер 250 может повышать точность распознавания речи моделью 302 STT, за счет чего приложение 265 виртуального помощника способно предоставлять более ожидаемые и релевантные речевые ответы пользователю 230, улучшая таким образом впечатление пользователя от взаимодействия с приложением 265 виртуального помощника.
Способ
[0163] Описанные выше архитектура и примеры позволяют выполнять способ формирования текстового представления речевого фрагмента пользователя, например, текстового представления 255 речевого фрагмента для речевого фрагмента 235 пользователя. На фиг. 8 представлена блок-схема способа 800 согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии. Способ 800 может выполняться сервером 250.
Шаг 802: получение сервером от электронного устройства аудиосигнала, являющегося звуковым представлением речевого фрагмента пользователя, представляющего собой ответ на формируемый компьютером речевой фрагмент, ранее выданный электронным устройством пользователю.
[0164] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, способ 800 начинается с шага 802, на котором сервер 250 может получать звуковое представление речевого фрагмента 235 пользователя 230, такое как звуковое представление 245 речевого фрагмента, как описано выше со ссылкой на фиг. 3.
[0165] Как описано выше, пользователь 230 может предоставлять речевой фрагмент 235 пользователя во время своего взаимодействия с приложением 265 виртуального помощника, выполняемого вторым сервером 260, в ответ на предыдущий соответствующий формируемый компьютером речевой фрагмент, сформированный для него моделью 306 TTS.
[0166] Способ 800 продолжается на шаге 804.
Шаг 804: получение сервером формируемой компьютером текстовой строки, являющейся текстовым представлением формируемого компьютером речевого фрагмента.
[0167] На шаге 804 сервер 250 может получать через сеть 240 связи от модели 304 NLP, размещенной на втором сервере 260, предыдущую формируемую компьютером текстовую строку 360, использованную для формирования предыдущего соответствующего формируемого компьютером речевого фрагмента, в ответ на который пользователь 230 предоставил речевой фрагмент 235 пользователя, как описано со ссылкой на фиг. 7.
[0168] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 250 может использовать предыдущую формируемую компьютером текстовую строку 360 в качестве контекста для речевого фрагмента 235 пользователя при формировании с использованием модели 302 STT текстового представления 255 речевого фрагмента для речевого фрагмента 235 пользователя, как описано выше со ссылкой на фиг. 7.
[0169] Далее способ 800 переходит к шагу 806.
Шаг 806: формирование сервером с использованием модели STT другой текстовой строки, являющейся текстовым представлением речевого фрагмента пользователя, на основе аудиосигнала и формируемой компьютером текстовой строки, учитываемой в качестве контекста речевого фрагмента пользователя.
[0170] На шаге 806 сервер 250 может формировать с использованием модели 302 STT текстовое представление 255 речевого фрагмента для речевого фрагмента 235 пользователя с учетом в качестве контекста для него предыдущей формируемой компьютером текстовой строки 360. Как описано выше, предыдущая формируемая компьютером текстовая строка 360 использована для формирования предыдущего соответствующего формируемого компьютером речевого фрагмента, в ответ на который пользователь 230 предоставил речевой фрагмент 235 пользователя.
[0171] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, модель 302 STT может быть реализована в виде модели машинного обучения. Например, как описано выше со ссылкой на фиг. 6, модель 302 STT может быть реализована в виде модели NN на основе трансформера с архитектурой кодер-декодер, такой как архитектура 400 модели машинного обучения, описанная выше со ссылкой на фиг. 4. Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, модель 302 STT может содержать некоторые дополнительные компоненты, помимо предусмотренных в архитектуре 400 модели машинного обучения.
[0172] В частности, вместо стека 403 слоев декодера модель 302 STT может содержать стек 603 слоев декодера STT, в котором архитектура блока 605 декодера STT отличается от архитектуры блока 405 декодера тем, что после слоя 409 MHA кодера-декодера предусмотрен дополнительный слой 607 MHA.
[0173] Сервер 250 может на основе обучающего набора данных STT обучать модель 302 STT формированию текстового представления 255 речевого фрагмента с учетом в качестве контекста для него предыдущей формируемой компьютером текстовой строки 360, как описано выше со ссылкой на фиг. 6. В частности, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, обучающий набор данных STT может содержать множество обучающих цифровых объектов STT, при этом обучающий цифровой объект 640 STT из их числа может содержать (а) обучающее звуковое представление 642 речевого фрагмента, сформированное на основе обучающего речевого фрагмента обучающего пользователя подобно тому, как описано выше применительно к формированию звукового представления 245 речевого фрагмента, (б) обучающее текстовое представление 644 речевого фрагмента и (в) обучающую формируемую компьютером текстовую строку 646, в ответ на получение которой были сформированы обучающее звуковое представление 642 речевого фрагмента и/или обучающее текстовое представление 644 речевого фрагмента.
[0174] Таким образом, для обучения модели 302 STT формированию текстового представления 255 речевого фрагмента сервер 250 может подавать в нее множество обучающих цифровых объектов STT, при этом подача обучающего цифрового объекта 640 STT включает в себя (а) ввод с применением алгоритма 410 векторизации входных данных обучающего звукового представления 642 речевого фрагмента в стек 402 слоев кодера, например, в блок 404 кодера, (б) ввод с применением алгоритма 415 векторизации целевых данных обучающего текстового представления 644 речевого фрагмента в стек 603 слоев декодера STT и, в частности, в слой 409 MHA кодера-декодера блока 605 декодера STT, и (в) ввод с применением второго алгоритма 610 векторизации входных данных обучающей формируемой компьютером текстовой строки 646 в дополнительный слой 607 MHA блока 605 декодера STT.
[0175] Кроме того, сервер 250 может использовать обученную таким образом модель 302 STT для формирования текстового представления 255 речевого фрагмента. В частности, как описано выше со ссылкой на фиг. 7, для формирования текстового представления 255 речевого фрагмента сервер 250 может (а) вводить с применением алгоритма 410 векторизации входных данных звуковое представление 245 речевого фрагмента в стек 402 слоев кодера модели 302 STT и (б) вводить с применением второго алгоритма 610 векторизации входных данных предыдущую формируемую компьютером текстовую строку 360 в стек 603 слоев декодера STT и, в частности, в дополнительный слой 607 MHA блока 605 декодера STT, как описано выше со ссылкой на фиг. 7.
[0176] Затем сервер 250 может отправлять через сеть 240 связи текстовое представление 255 речевого фрагмента второму серверу 260, содержащему модель 304 NLP и модель 306 TTS. Таким образом, во-первых, с использованием модели 304 NLP второй сервер 260 может формировать формируемую компьютером текстовую строку 370 на основе текстового представления 255 речевого фрагмента. Во-вторых, с использованием модели 306 TTS на основе формируемой компьютером текстовой строки 370 второй сервер 260 может формировать соответствующий формируемый компьютером речевой фрагмент 270 для его отправки электронному устройству 210 в ответ на речевой фрагмент 235 пользователя, как описано выше со ссылкой на фиг. 4 и 5.
[0177] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, модель 304 NLP и модель 306 TTS могут быть реализованы в виде модели NN на основе трансформера и обучены, как описано выше со ссылкой на фиг. 4 и 5.
[0178] Таким образом, сервер 250 с использованием модели 302 STT может формировать текстовые представления речевых фрагментов для следующих речевых фрагментов пользователя 230 для приложения 265 виртуального помощника. Например, с целью формирования соответствующего текстового представления речевого фрагмента для следующего речевого фрагмента пользователя, предоставленного пользователем 230 в ответ на формируемый компьютером речевой фрагмент 270, сервер 250 может использовать формируемую компьютером текстовую строку 370 из модели 304 NLP в качестве контекста для следующего речевого фрагмента пользователя, как описано выше применительно к речевому фрагменту 235 пользователя.
[0179] Таким образом, некоторые варианты осуществления способа 800 позволяют повысить точность распознавания речи моделью 302 STT в речевых фрагментах пользователя, что, в свою очередь, обеспечивает повышение эффективности модели 304 NLP и модели 306 TTS при предоставлении формируемых компьютером речевых фрагментов в ответ на речевые фрагменты пользователя. В результате возможно улучшение впечатления пользователя от взаимодействия с приложениями виртуального помощника.
[0180] На этом выполнение способа 800 завершается.
[0181] Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте осуществления настоящей технологии.
[0182] Для специалиста в данной области техники могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ МЕДИАКОНТЕНТА | 2022 |
|
RU2815896C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБУЧЕНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПЕРЕВОДА | 2023 |
|
RU2835121C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ПРЕОБРАЗОВАНИЯ ТЕКСТА В РЕЧЬ | 2020 |
|
RU2775821C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ ПЕРЕВОДУ | 2020 |
|
RU2770569C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2832419C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ ВОСПРОИЗВЕДЕННОГО РЕЧЕВОГО ФРАГМЕНТА | 2020 |
|
RU2767962C2 |
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ ОБУЧАЮЩИХ ДАННЫХ ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2023 |
|
RU2831408C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО РАЗГОВОРНОГО РЕЧЕВОГО ФРАГМЕНТА | 2019 |
|
RU2757264C2 |
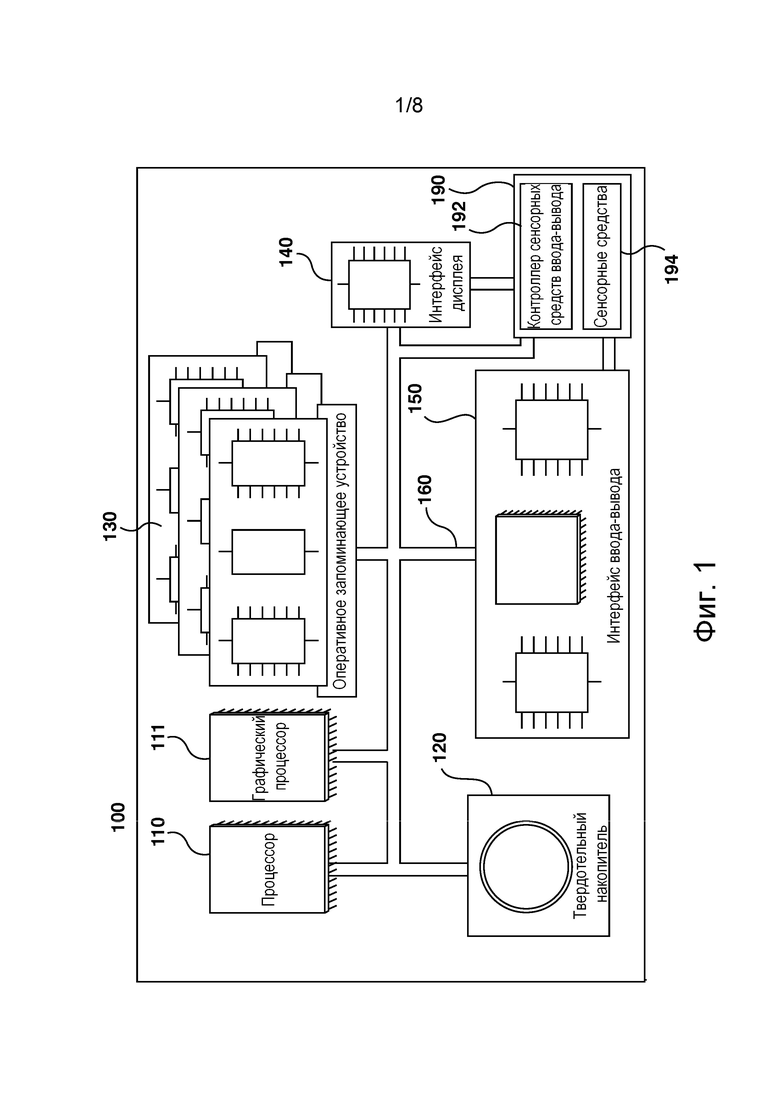
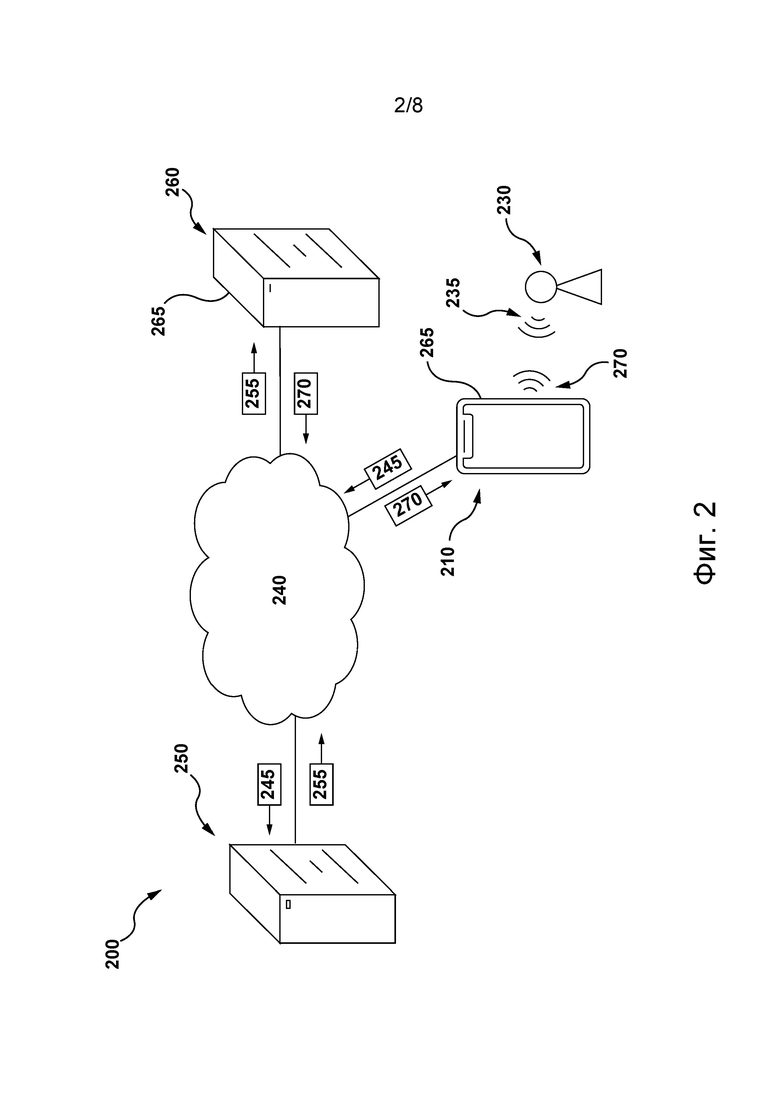
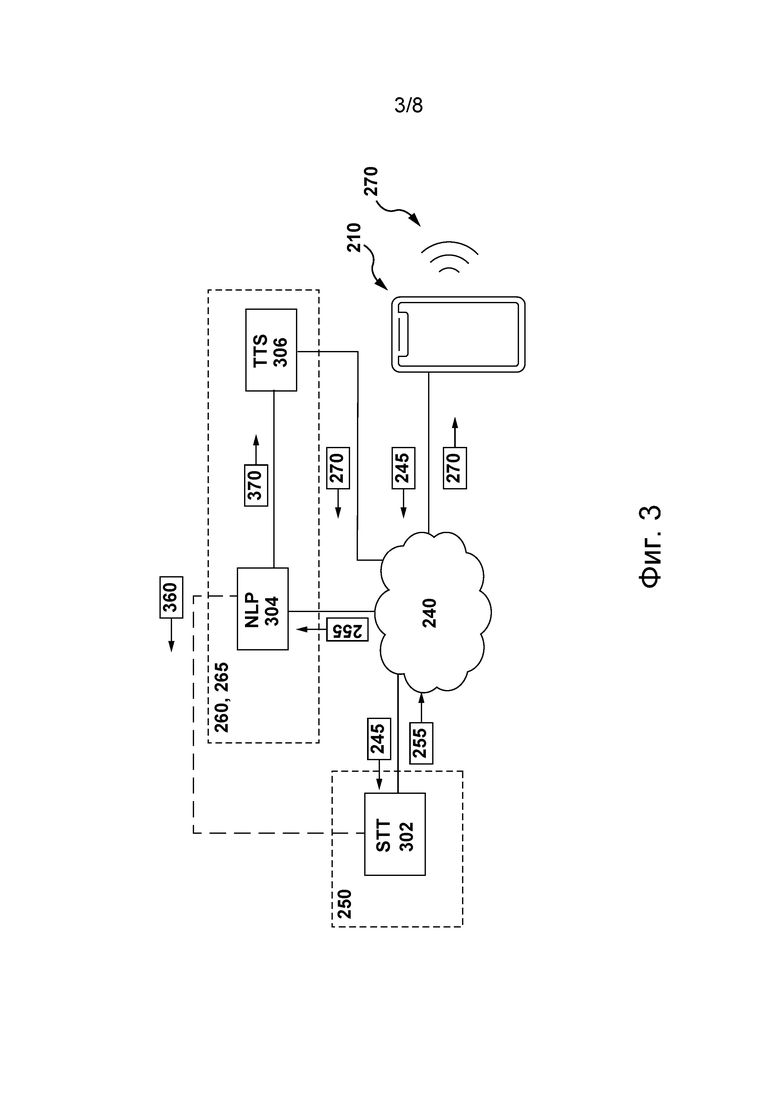
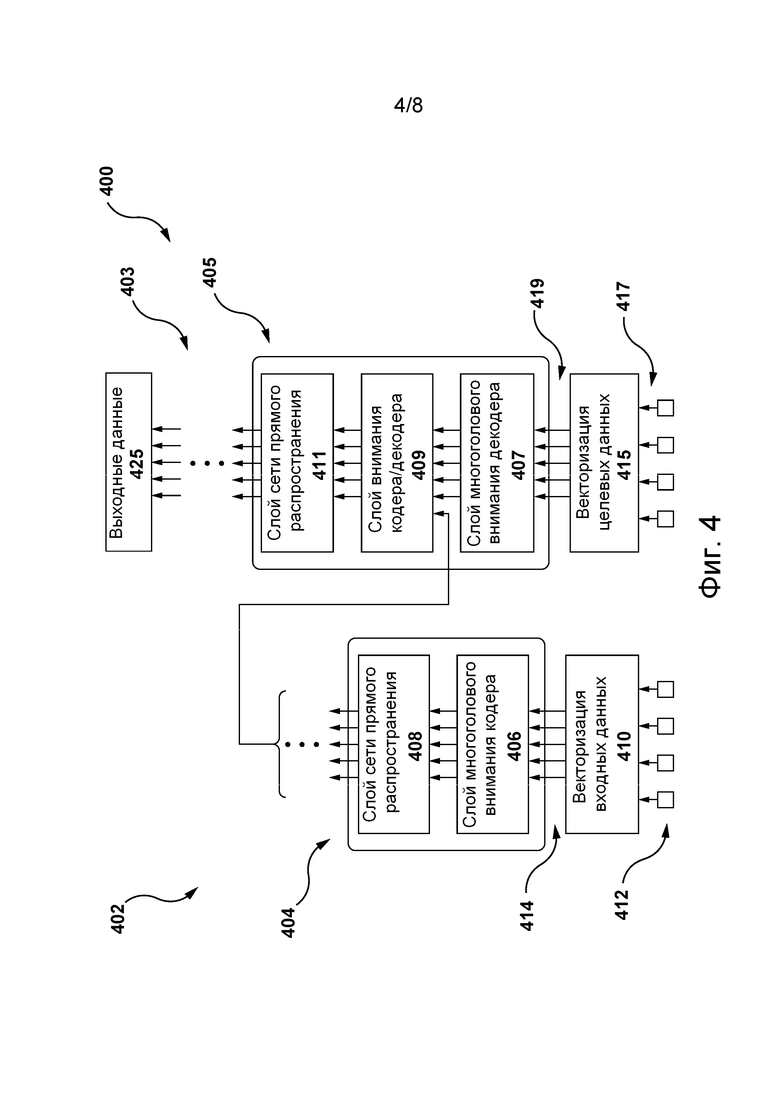
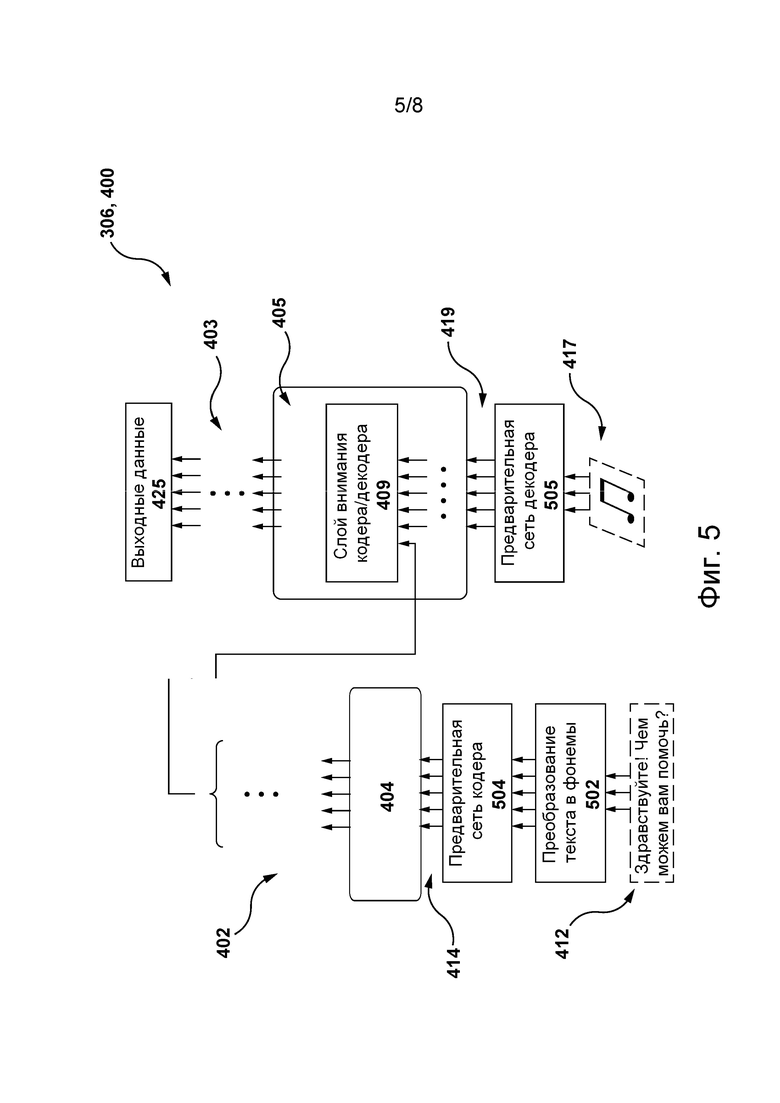
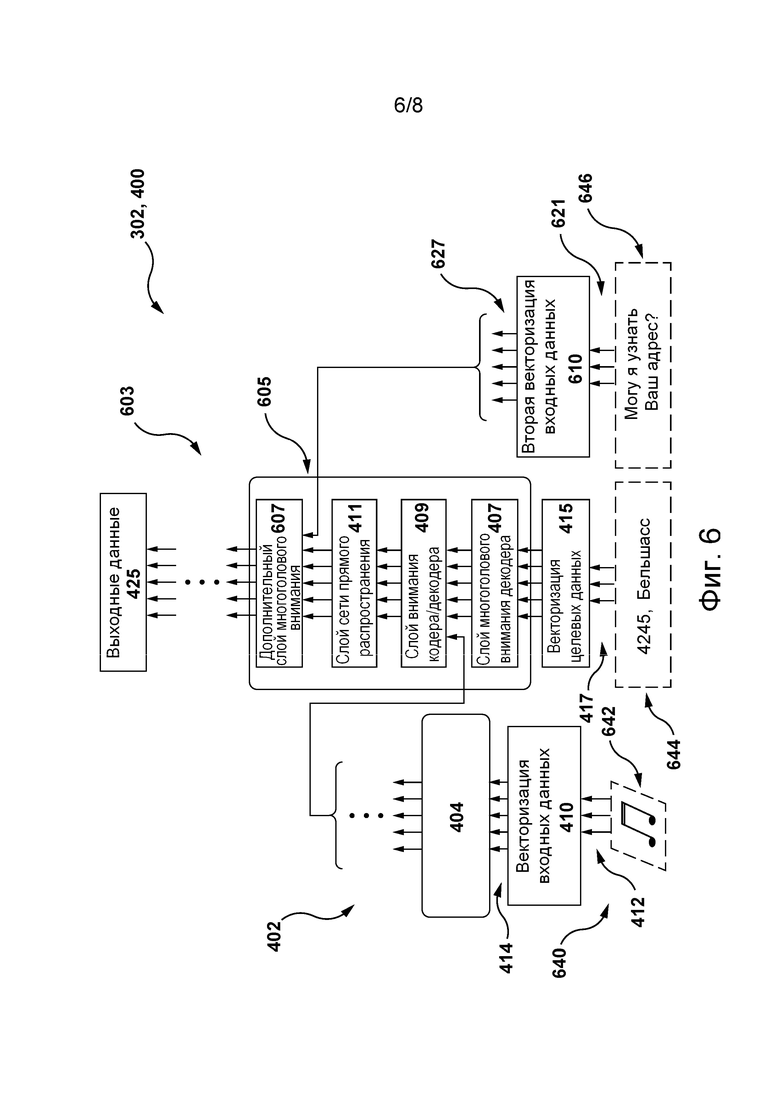
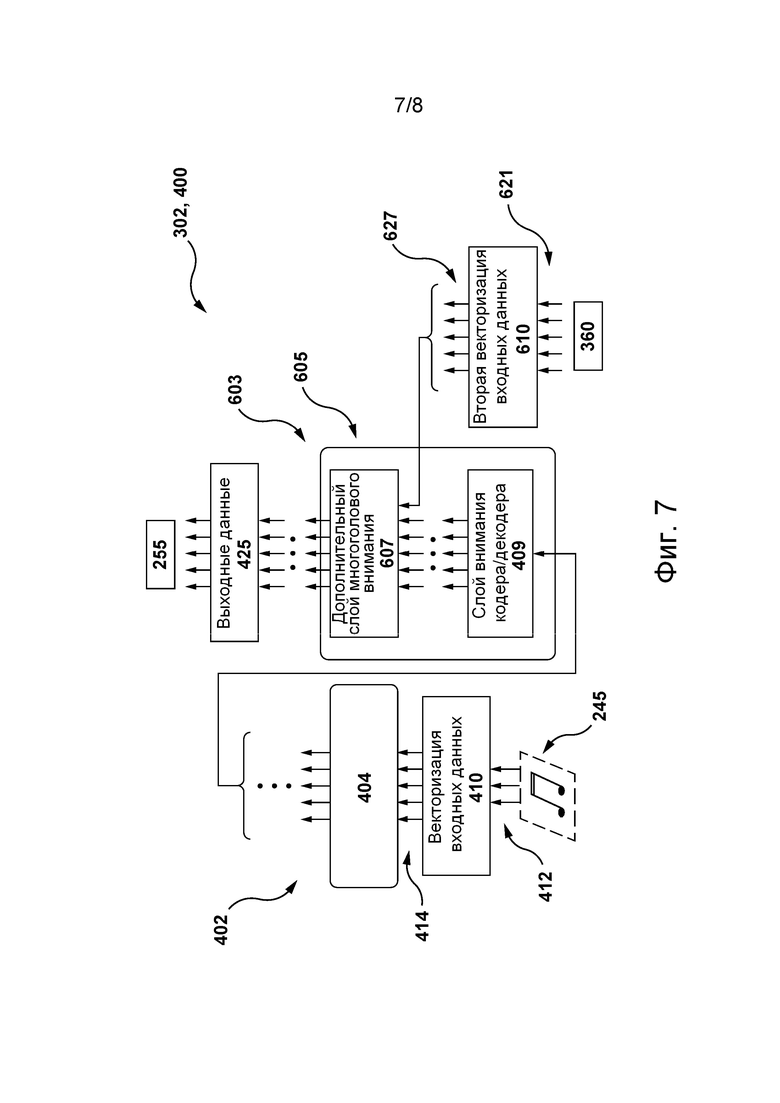
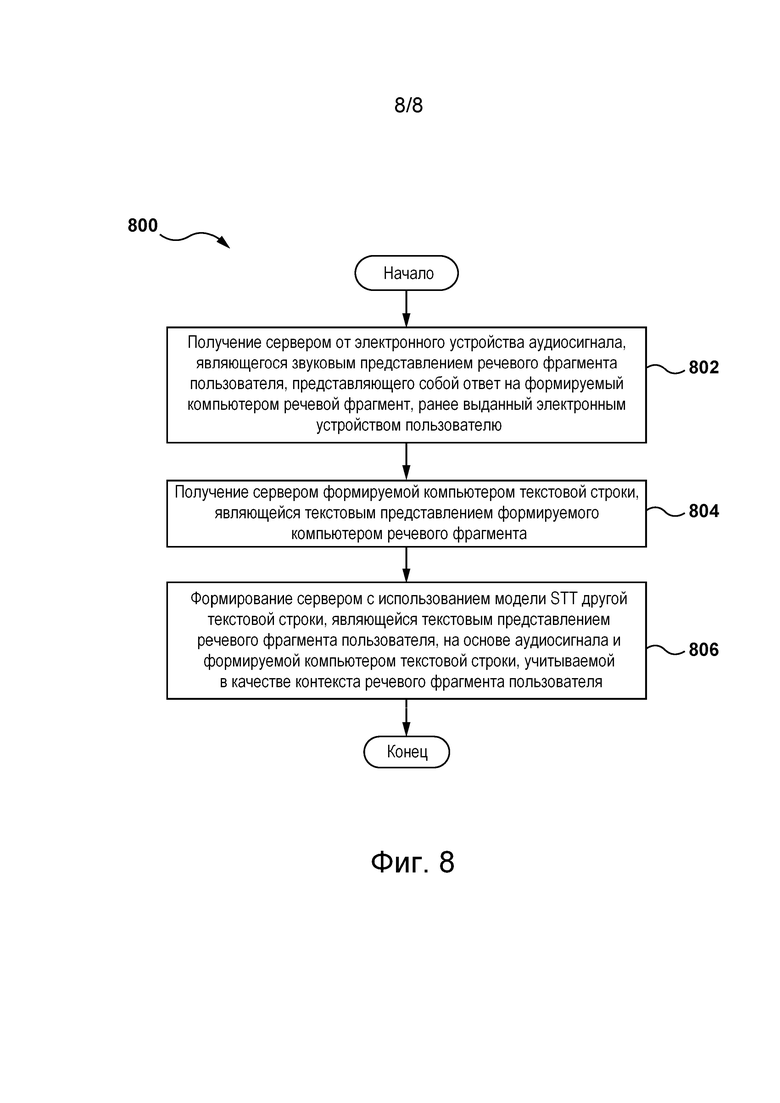
Настоящая технология относится к обработке естественной речи. Способ включает в себя: получение аудиосигнала, являющегося звуковым представлением речевого фрагмента пользователя, представляющего собой ответ на формируемый компьютером речевой фрагмент, ранее выданный электронным устройством пользователю; получение формируемой компьютером текстовой строки, являющейся текстовым представлением формируемого компьютером речевого фрагмента; и формирование с использованием модели преобразования речи в текст (STT) другой текстовой строки, являющейся текстовым представлением речевого фрагмента пользователя, на основе аудиосигнала и формируемой компьютером текстовой строки, учитываемой в качестве контекста речевого фрагмента пользователя. Таким образом достигается повышение качества распознавания речи и общей удовлетворенности пользователей, использующих приложения виртуального помощника. 2 н. и 18 з.п. ф-лы, 8 ил.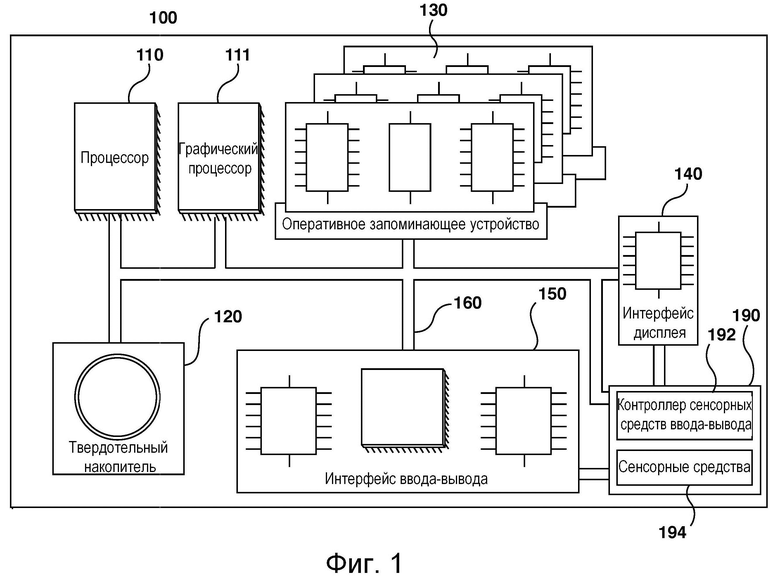
1. Способ формирования текстовых представлений речевого фрагмента пользователя, полученного связанным с пользователем электронным устройством и предоставленного в ответ на формируемые компьютером речевые фрагменты, выдаваемые электронным устройством, способным связываться с сервером, предназначенным для формирования формируемых компьютером речевых фрагментов, при этом способ выполняется сервером и включает в себя:
- получение сервером от электронного устройства аудиосигнала, являющегося звуковым представлением речевого фрагмента пользователя, представляющего собой ответ на формируемый компьютером речевой фрагмент, ранее выданный электронным устройством пользователю;
- получение сервером формируемой компьютером текстовой строки, являющейся текстовым представлением формируемого компьютером речевого фрагмента; и
- формирование сервером с использованием модели преобразования речи в текст (STT) другой текстовой строки, являющейся текстовым представлением речевого фрагмента пользователя, на основе аудиосигнала и формируемой компьютером текстовой строки, учитываемой в качестве контекста речевого фрагмента пользователя,
при этом модель преобразования речи в текст (STT) представляет собой нейронную сеть (NN).
2. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя:
- формирование сервером с использованием модели STT первой текстовой строки, являющейся текстовым представлением первого речевого фрагмента пользователя, на основе первого аудиосигнала, являющегося звуковым представлением первого речевого фрагмента пользователя;
- формирование сервером с использованием другой модели формируемой компьютером текстовой строки на основе первой текстовой строки; и
- формирование сервером с использованием модели преобразования текста в речь (TTS) формируемого компьютером аудиосигнала, являющегося звуковым представлением формируемого компьютером речевого фрагмента, на основе формируемой компьютером текстовой строки.
3. Способ по п. 1, где нейронная сеть (NN) имеет архитектуру кодер-декодер, содержащую стек слоев кодера и стек слоев декодера, а формирование другой текстовой строки включает в себя:
- формирование сервером звукового вектора, представляющего аудиосигнал, с использованием алгоритма векторизации звука;
- ввод сервером звукового вектора в стек кодера сети NN;
- формирование сервером с использованием алгоритма векторизации текста текстового вектора, представляющего формируемую компьютером текстовую строку; и
- ввод сервером текстового вектора в стек декодера сети NN.
4. Способ по п. 3, отличающийся тем, что сеть NN представляет собой сеть NN на основе трансформера.
5. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя обучение модели STT на этапе обучения на основе обучающего набора данных, содержащего множество обучающих объектов, при этом обучающий объект содержит (а) указание на обучающий аудиосигнал, сформированный на основе обучающего речевого фрагмента пользователя, произнесенного обучающим пользователем, (б) первую обучающую текстовую строку, являющуюся текстовым представлением обучающего речевого фрагмента пользователя, и (в) вторую обучающую текстовую строку, используемую для предоставления контекста для первой текстовой строки и являющуюся текстовым представлением соответствующего формируемого компьютером речевого фрагмента, в ответ на который обучающий пользователь произнес обучающий речевой фрагмент пользователя.
6. Способ по п. 2, отличающийся тем, что он дополнительно включает в себя получение сервером первого аудиосигнала от электронного устройства.
7. Способ по п. 2, отличающийся тем, что он дополнительно включает в себя отправку сервером формируемого компьютером аудиосигнала электронному устройству.
8. Способ по п. 2, отличающийся тем, что другая модель содержит модель обработки естественной речи (NLP).
9. Способ по п. 1 или 2, отличающийся тем, что одна или несколько моделей размещены на другом сервере.
10. Способ по п. 8, отличающийся тем, что модель NLP представляет собой модель NN на основе трансформера.
11. Способ по п. 2, отличающийся тем, что модель TTS представляет собой модель NN на основе трансформера.
12. Способ по п. 2, отличающийся тем, что он дополнительно включает в себя:
- формирование сервером с использованием модели STT второй текстовой строки на основе второго аудиосигнала, являющегося звуковым представлением второго речевого фрагмента пользователя, соответствующего запросу, следующему за формируемым компьютером речевым фрагментом;
- формирование сервером на основе второй текстовой строки с использованием другой модели другой формируемой компьютером текстовой строки, являющейся текстовым представлением другого формируемого компьютером речевого фрагмента, подлежащего предоставлению пользователю;
- формирование сервером с использованием модели TTS на основе другой формируемой компьютером текстовой строки другого формируемого компьютером аудиосигнала, являющегося звуковым представлением другого формируемого компьютером речевого фрагмента, подлежащего предоставлению пользователю в ответ на второй речевой фрагмент пользователя;
- получение сервером от электронного устройства третьего аудиосигнала, являющегося звуковым представлением третьего речевого фрагмента пользователя, соответствующего другому запросу, следующему за другим формируемым компьютером речевым фрагментом; и
- формирование сервером с использованием модели STT на основе третьего аудиосигнала, формируемой компьютером текстовой строки и другой формируемой компьютером текстовой строки третьей текстовой строки, являющейся текстовым представлением третьего речевого фрагмента пользователя, с учетом формируемой компьютером текстовой строки и другой формируемой компьютером текстовой строки в качестве контекста другого следующего запроса.
13. Способ по п. 12, отличающийся тем, что он дополнительно включает в себя отправку сервером другого формируемого компьютером аудиосигнала электронному устройству.
14. Сервер для формирования текстовых представлений речевого фрагмента пользователя, полученного электронным устройством, связанным с пользователем и способным связываться с сервером, и предоставленного в ответ на формируемые компьютером речевые фрагменты, выдаваемые электронным устройством, при этом сервер содержит процессор и машиночитаемый физический носитель информации, хранящий команды, и процессор выполнен с возможностью совершения следующих действий при исполнении команд:
- получение от электронного устройства аудиосигнала, являющегося звуковым представлением речевого фрагмента пользователя, представляющего собой ответ на формируемый компьютером речевой фрагмент, ранее выданный электронным устройством пользователю;
- получение формируемой компьютером текстовой строки, являющейся текстовым представлением формируемого компьютером речевого фрагмента; и
- формирование с использованием модели STT другой текстовой строки, являющейся текстовым представлением речевого фрагмента пользователя, на основе аудиосигнала и формируемой компьютером текстовой строки, учитываемой в качестве контекста речевого фрагмента пользователя,
при этом модель преобразования речи в текст (STT) представляет собой нейронную сеть (NN).
15. Сервер по п. 14, отличающийся тем, что процессор дополнительно выполнен с возможностью:
- формирования с использованием модели STT первой текстовой строки, являющейся текстовым представлением первого речевого фрагмента пользователя, на основе первого аудиосигнала, являющегося звуковым представлением первого речевого фрагмента пользователя;
- формирования с использованием другой модели формируемой компьютером текстовой строки на основе первой текстовой строки;
- формирования с использованием модели TTS формируемого компьютером аудиосигнала, являющегося звуковым представлением формируемого компьютером речевого фрагмента, на основе формируемой компьютером текстовой строки,
16. Сервер по п. 14, отличающийся тем, что нейронная сеть NN имеет архитектуру кодер-декодер, содержащую стек слоев кодера и стек слоев декодера, а процессор выполнен с возможностью формирования другой текстовой строки путем:
- формирования звукового вектора, представляющего аудиосигнал, с использованием алгоритма векторизации звука;
- ввода звукового вектора в стек кодера сети NN;
- формирования с использованием алгоритма векторизации текста текстового вектора, представляющего формируемую компьютером текстовую строку; и
- ввода текстового вектора в стек декодера сети NN.
17. Сервер по п. 16, отличающийся тем, что сеть NN представляет собой сеть NN на основе трансформера.
18. Сервер по п. 14, отличающийся тем, что процессор дополнительно выполнен с возможностью обучения модели STT на этапе обучения на основе обучающего набора данных, содержащего множество обучающих объектов, при этом обучающий объект содержит (а) указание на обучающий аудиосигнал, сформированный на основе обучающего речевого фрагмента пользователя, произнесенного обучающим пользователем, (б) первую обучающую текстовую строку, являющуюся текстовым представлением обучающего речевого фрагмента пользователя, и (в) вторую обучающую текстовую строку, используемую для предоставления контекста для первой текстовой строки и являющуюся текстовым представлением соответствующего формируемого компьютером речевого фрагмента, в ответ на который обучающий пользователь произнес обучающий речевой фрагмент пользователя.
19. Сервер по п. 15, отличающийся тем, что другая модель содержит модель NLP.
20. Сервер по п. 14 или 15, отличающийся тем, что одна или несколько моделей размещены на другом сервере, связанном с сервером.
| US 2015187359 A1, 02.07.2015 | |||
| US 20130110515 A1, 02.05.2013 | |||
| US 20120245944 A1, 27.09.2012 | |||
| US 2003182131 A1, 25.09.2003. |

