Область техники, к которой относится изобретение
[001] Настоящая технология относится к способам машинного обучения и, в частности, к способам и системам для обучения и использования моделей машинного обучения для ранжирования результатов поиска.
Уровень техники
[002] Веб-поиск представляет собой важную задачу, связанную с ежедневной обработкой миллиардов пользовательских запросов. Современные системы веб-поиска обычно ранжируют результаты поиска согласно их релевантности поисковому запросу и другим критериям. Определение релевантности результатов поиска запросу часто предусматривает использование алгоритмов машинного обучения (MLA, Machine Learning Algorithm), обученных применению нескольких определенных вручную признаков для оценивания различных показателей релевантности. Такое определение релевантности можно рассматривать, по меньшей мере частично, как проблему понимания языка, поскольку релевантность документа поисковому запросу имеет по меньшей мере некоторое отношение к семантическому пониманию запроса и результатов поиска, даже в случаях, когда запрос и результаты не содержат общих слов или когда результаты представляют собой изображения, музыку или другие нетекстовые результаты.
[003] Последние разработки в области нейронной обработки естественного языка включают в себя использование трансформерных моделей машинного обучения, как описано в статье Vaswani et al. "Attention Is All You Need", Advances in neural information processing systems, 2017, pages 5998-6008. Трансформер представляет собой модель глубокого обучения (т.е. искусственную нейронную сеть или другую модель машинного обучения, содержащую несколько слоев), в которой для назначения некоторым частям входных данных большей значимости, чем другим, используется механизм внимания. При обработке естественного языка механизм внимания используется с целью определения контекста для слов из входных данных, поскольку одно и то же слово в разных контекстах может иметь различные значения. Трансформеры способны параллельно обрабатывать множество слов или токенов естественного языка, что позволяет использовать параллелизм при обучении.
[004] На трансформерах основаны и другие достижения в области обработки естественного языка, включая "предобучаемые" системы, которые могут быть заранее обучены с использованием большого набора данных, а затем точно настроены для использования в конкретных целях. Примеры таких систем включают в себя модель "представления двунаправленного кодера из трансформеров" (BERT, Bidirectional Encoder Representations from Transformers), описанную в работе Devlin et al. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding", Proceedings of NAACL-HLT 2019, 2019, pages 4171-4186, и предобучаемый генеративный трансформер (GPT, Generative Pre-trained Transformer), описанный в работе Radford et al. "Improving Language Understanding by Generative Pre-Training", 2018.
[005] В общем случае для задач ранжирования результатов поиска трансформеры могут быть обучены определению параметров релевантности результатов поиска, предоставленных пользователю цифровой платформой (например, поисковой системой). В частности, такие параметры релевантности могут быть представлены значениями вероятности пользовательского действия (такого как "клик") с результатами поиска. В частности, в ответ на отправку пользователем поискового запроса цифровая платформа может определять набор цифровых документов (таких как веб-документы), соответствующих поисковому запросу. Кроме того, поисковый запрос и набор цифровых документов могут с целью ранжирования подаваться в модель машинного обучения (ML, Machine-Learning) на основе трансформера, обученную на особым образом организованных обучающих данных.
[006] Тем не менее, вследствие растущей потребности в более точном ранжировании результатов поиска может возникать необходимость в предоставлении ML-модели на основе трансформера дополнительных данных наряду с поисковым запросом и соответствующим набором документов, в результате чего могут возникать проблемы с эффективностью работы ML-модели на основе трансформера в реальном времени.
[007] Для решения описанной выше технической проблемы предложены некоторые известные подходы.
[008] В статье Rahimi et al. "Explaining documents' relevance to search queries" описана порождающая модель GenEx для объяснения результатов поиска пользователям. Модель GenEx поясняет результаты поиска путем предоставления краткого описания для аспекта запроса, соответствующего конкретному результату. Модель GenEx предложена в качестве новой модели на основе трансформерной архитектуры. Чтобы представлять документы для запросов и не использовать сами запросы в качестве объяснений, в трансформерную архитектуру добавляются два слоя внимания для запроса и вводится декодирование с маскированием запроса. Модель обучается без использования сформированных человеком объяснений. Вместо этого обучающие данные формируются автоматически, обеспечивая допустимый уровень шумов и обобщаемую обучающуюся модель.
Раскрытие изобретения
[009] Разработчики настоящей технологии установили, что точность ранжирования результатов поиска для пользователя может быть повышена, если при определении параметра релевантности для набора цифровых документов ML-модель на основе трансформера в дополнение к текущей паре "запрос - набор цифровых документов" также учитывает текущую и более общую заинтересованность пользователя в цифровых документах.
[010] Исходя из этого, разработчики разработали архитектуру алгоритма MLA, способного учитывать (а) свежие данные предыстории, связанные с пользователем, такие как прошлые пользовательские действия с другими результатами поиска в текущем пользовательском сеансе на цифровой платформе, и (б) большое количество данных предыстории, накопленных в течение более длительного периода времени, чем свежие данные предыстории. В частности, согласно по меньшей мере некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, алгоритм MLA содержит две ML-модели на основе трансформера: (а) первую модель, способную формировать векторное представление большого количества данных предыстории, и (б) вторую модель, способную использовать свежие данные предыстории вместе с векторным представлением большого количества данных предыстории для определения параметров релевантности результатов поиска.
[011] Соответственно, такая архитектура алгоритма MLA позволяет обрабатывать большое количество данных предыстории в автономном режиме и за счет этого при онлайн-расчетах экономить ресурсы сервера, выполняющего алгоритм MLA. Это дает возможность повышения точности и эффективности определения параметров релевантности результатов поиски в реальном времени.
[012] В частности, согласно первому аспекту настоящей технологии реализован компьютерный способ обучения алгоритма MLA ранжированию цифровых документов этапа использования на цифровой платформе. Алгоритм MLA содержит первую ML-модель и вторую ML-модель. Способ выполняется процессором. Способ включает в себя: получение процессором первых данных предыстории, содержащих (а) первое множество обучающих запросов, отправленных пользователем цифровой платформе в течение прошлого периода времени, и (б) наборы обучающих цифровых документов, сформированные цифровой платформой в течение прошлого периода времени в ответ на отправку ей каждого запроса из первого множества обучающих запросов; получение процессором вторых данных предыстории, часть которых содержит (а) второе множество обучающих запросов, отправленных пользователем цифровой платформе в течение прошлого обучающего пользовательского сеанса, который был короче и осуществлялся позднее прошлого периода времени, и (б) наборы обучающих цифровых документов, сформированные цифровой платформой в течение прошлого обучающего пользовательского сеанса в ответ на отправку ей каждого запроса из второго множества обучающих запросов, при этом обучающий цифровой документ, сформированный в течение прошлого периода времени или прошлого обучающего пользовательского сеанса, содержит указание на пользовательское действие пользователя с обучающим цифровым документом; и совместное обучение процессором первой и второй ML-моделей ранжированию цифровых документов этапа использования, включающее в себя: компоновку процессором первых данных предыстории в первое множество обучающих цифровых объектов, каждый из которых содержит (а) запрос из первого множества обучающих запросов и (б) набор обучающих цифровых документов, сформированный в ответ на запрос из первого множества обучающих запросов в течение прошлого периода времени; ввод процессором первого множества обучающих цифровых объектов в первую ML-модель для обучения первой ML-модели формированию векторного представления первых данных предыстории; формирование процессором на основе вторых данных предыстории второго множества обучающих цифровых объектов, каждый из которых содержит (а) запрос из второго множества обучающих запросов, (б) набор обучающих цифровых документов, сформированный в ответ на запрос из второго множества обучающих запросов в течение обучающего пользовательского сеанса, и (в) векторное представление первых данных предыстории; и ввод процессором второго множества обучающих цифровых объектов во вторую ML-модель для обучения второй ML-модели определению значения вероятности действия пользователя с цифровым документом этапа использования.
[013] В некоторых вариантах осуществления способа количество членов первого множества обучающих цифровых объектов больше количества членов второго множества обучающих цифровых объектов.
[014] В некоторых вариантах осуществления способа пользовательское действие пользователя с обучающим цифровым документом включает в себя по меньшей мере одно из следующего: (а) выбор обучающего цифрового документа из набора обучающих цифровых документов; (б) остановка на цифровом документе; (в) добавление обучающего цифрового документа в список избранного; (г) контакт с обучающим цифровым документом дольше порогового времени контакта; и (д) сохранение по меньшей мере части контента обучающего цифрового документа.
[015] В некоторых вариантах осуществления способа он дополнительно включает в себя: получение процессором запроса этапа использования, отправленного пользователем цифровой платформе в течение текущего пользовательского сеанса этапа использования; получение процессором набора цифровых документов этапа использования, соответствующих запросу этапа использования; получение процессором данных предыстории этапа использования, содержащих (а) множество прошлых запросов этапа использования, отправленных пользователем цифровой платформе в течение текущего пользовательского сеанса этапа использования до отправки запроса этапа использования, и (б) наборы прошлых цифровых документов этапа использования (Здесь и далее в аналогичных выделенных местах: в исходнике есть слово training, видимо, ошибочное. В переводе оно исключено.), сформированные цифровой платформой в ответ на отправку ей каждого запроса из множества прошлых запросов этапа использования, при этом прошлый цифровой документ этапа использования из наборов прошлых цифровых документов этапа использования содержит указание на пользовательское действие пользователя с прошлым цифровым документом этапа использования; формирование процессором цифрового объекта этапа использования, содержащего (а) запрос этапа использования, (б) набор цифровых документов этапа использования, (в) множество прошлых запросов этапа использования, (г) наборы прошлых цифровых документов этапа использования и (д) векторное представление первых данных предыстории; ввод процессором цифрового объекта этапа использования во вторую ML-модель алгоритма MLA с целью определения для каждого документа из набора цифровых документов этапа использования значения вероятности действия с ним пользователя; и ранжирование процессором документов из набора цифровых документов этапа использования согласно связанным с ними значениям вероятности.
[016] В некоторых вариантах осуществления способа он перед получением векторного представления первых данных предыстории дополнительно включает в себя обновление процессором первых данных предыстории.
[017] В некоторых вариантах осуществления способа обновление включает в себя сдвиг и/или расширение прошлого периода времени в направлении момента времени отправки запроса этапа использования.
[018] В некоторых вариантах осуществления способа обновление выполняется с заранее заданной частотой.
[019] В некоторых вариантах осуществления способа каждая из первой и второй ML-моделей представляет собой нейронную сеть с архитектурой кодер-декодер.
[020] В некоторых вариантах осуществления способа нейронная сеть представляет собой нейронную сеть на основе трансформера.
[021] Согласно второму аспекту настоящей технологии реализован сервер для обучения алгоритма MLA ранжированию цифровых документов этапа использования на цифровой платформе. Алгоритм MLA содержит первую ML-модель и вторую ML-модель. Сервер содержит машиночитаемую физическую память, хранящую команды, и процессор, который при исполнении команд способен: получать первые данные предыстории, содержащие (а) первое множество обучающих запросов, отправленных пользователем цифровой платформе в течение прошлого периода времени, и (б) наборы обучающих цифровых документов, сформированные цифровой платформой в течение прошлого периода времени в ответ на отправку ей каждого запроса из первого множества обучающих запросов; получать вторые данные предыстории, часть которых содержит (а) второе множество обучающих запросов, отправленных пользователем цифровой платформе в течение прошлого обучающего пользовательского сеанса, который был короче и осуществлялся позднее прошлого периода времени, и (б) наборы обучающих цифровых документов, сформированные цифровой платформой в течение прошлого обучающего пользовательского сеанса в ответ на отправку ей каждого запроса из второго множества обучающих запросов, при этом обучающий цифровой документ, сформированный в течение прошлого периода времени или прошлого обучающего пользовательского сеанса, содержит указание на пользовательское действие пользователя с обучающим цифровым документом; и совместно обучать первую и вторую ML-модели ранжированию цифровых документов этапа использования путем: компоновки первых данных предыстории в первое множество обучающих цифровых объектов, каждый из которых содержит (а) запрос из первого множества обучающих запросов и (б) набор обучающих цифровых документов, сформированный в ответ на запрос из первого множества обучающих запросов в течение прошлого периода времени; ввода первого множества обучающих цифровых объектов в первую ML-модель для обучения первой ML-модели формированию векторного представления первых данных предыстории; формирования на основе вторых данных предыстории второго множества обучающих цифровых объектов, каждый из которых содержит (а) запрос из второго множества обучающих запросов, (б) набор обучающих цифровых документов, сформированный в ответ на запрос из второго множества обучающих запросов в течение обучающего пользовательского сеанса, и (в) векторное представление первых данных предыстории; и ввода второго множества обучающих цифровых объектов во вторую ML-модель для обучения второй ML-модели определению значения вероятности действия пользователя с цифровым документом этапа использования.
[022] В некоторых вариантах осуществления сервера количество членов первого множества обучающих цифровых объектов больше количества членов второго множества обучающих цифровых объектов.
[023] В некоторых вариантах осуществления сервера пользовательское действие пользователя с обучающим цифровым документом включает в себя по меньшей мере одно из следующего: (а) выбор обучающего цифрового документа из набора обучающих цифровых документов; (б) остановка на цифровом документе; (в) добавление обучающего цифрового документа в список избранного; (г) контакт с обучающим цифровым документом дольше порогового времени контакта; и (д) сохранение по меньшей мере части контента обучающего цифрового документа.
[024] В некоторых вариантах осуществления сервера процессор дополнительно способен: получать запрос этапа использования, отправленный пользователем цифровой платформе в течение текущего пользовательского сеанса этапа использования; получать набор цифровых документов этапа использования, соответствующих запросу этапа использования; получать данные предыстории этапа использования, содержащие (а) множество прошлых запросов этапа использования, отправленных пользователем цифровой платформе в течение текущего пользовательского сеанса этапа использования до отправки запроса этапа использования, и (б) наборы прошлых цифровых документов этапа использования, сформированные цифровой платформой в ответ на отправку ей каждого запроса из множества прошлых запросов этапа использования, при этом прошлый цифровой документ этапа использования из наборов прошлых цифровых документов этапа использования содержит указание на пользовательское действие пользователя с прошлым цифровым документом этапа использования; формировать цифровой объект этапа использования, содержащий (а) запрос этапа использования, (б) набор цифровых документов этапа использования, (в) множество прошлых запросов этапа использования, (г) наборы прошлых цифровых документов этапа использования и (д) векторное представление первых данных предыстории; вводить цифровой объект этапа использования во вторую ML-модель алгоритма MLA с целью определения для каждого документа из набора цифровых документов этапа использования значения вероятности действия с ним пользователя; и ранжировать документы из набора цифровых документов этапа использования согласно связанным с ними значениям вероятности.
[025] В некоторых вариантах осуществления сервера перед получением векторного представления первых данных предыстории процессор дополнительно способен обновлять первые данные предыстории.
[026] В некоторых вариантах осуществления сервера процессор способен обновлять первые данные предыстории путем сдвига и/или расширения прошлого периода времени в направлении момента времени отправки запроса этапа использования.
[027] В некоторых вариантах осуществления сервера процессор способен обновлять первые данные предыстории с заранее заданной частотой.
[028] В некоторых вариантах осуществления сервера каждая из первой и второй ML-моделей представляет собой нейронную сеть с архитектурой кодер-декодер.
[029] В некоторых вариантах осуществления сервера нейронная сеть представляет собой нейронную сеть на основе трансформера.
[030] В контексте настоящего описания термин "сервер" означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение "сервер" не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении "по меньшей мере один сервер".
[031] В контексте настоящего описания термин "клиентское устройство" означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения "клиентское устройство" не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
[032] В контексте настоящего описания термин "база данных" означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[033] В контексте настоящего описания выражение "информация" включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[034] В контексте настоящего описания выражение "компонент" включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[035] В контексте настоящего описания выражение "пригодный для использования в компьютере носитель информации" относится к носителям любого рода и вида, включая оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[036] В контексте настоящего описания числительные "первый", "второй", "третий" и т.д. используются лишь для указания на различие между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие "второго сервера" в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на "первый" элемент и "второй" элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях "первый" сервер и "второй" сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - разные программные и/или аппаратные средства.
[037] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или к одному из вышеупомянутых аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[038] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, на приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[039] Эти и другие признаки, аспекты и преимущества настоящей технологии поясняются в дальнейшем описании, в приложенной формуле изобретения и на следующих чертежах.
[040] На фиг. 1 представлена схема примера компьютерной системы для реализации некоторых не имеющих ограничительного характера вариантов осуществления систем и/или способов согласно настоящей технологии.
[041] На фиг. 2 представлена сетевая вычислительная среда, подходящая для обучения алгоритма MLA определению значений вероятности действия пользователя с цифровыми документами цифровой платформы, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[042] На фиг. 3 приведена блок-схема архитектуры ML-модели, выполняемой сервером из сетевой вычислительной среды, представленной на фиг. 2, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[043] На фиг. 4 приведено схематическое изображение сервера из сетевой вычислительной среды, представленной на фиг. 2, обучающего алгоритм MLA, содержащий две связанные ML-модели, каждая из которых реализована на основе архитектуре ML-модели, представленной на фиг. 3, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[044] На фиг. 5 приведена временная диаграмма получения сервером из сетевой вычислительной среды, представленной на фиг. 2, данных предыстории для обучения алгоритма MLA, представленного на фиг. 4, согласно с некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[045] На фиг. 6 приведено схематическое изображение сервера из сетевой вычислительной среды, представленной на фиг. 2, использующего алгоритм MLA, представленный на фиг. 4, для определения значений вероятности действия пользователя с цифровыми документами цифровой платформы, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[046] На фиг. 7 приведена блок-схема способа обучения алгоритма MLA, представленного на фиг. 4, определению значений вероятности действия пользователя с цифровыми документами согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
Осуществление изобретения
[047] Представленные здесь примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но реализуют принципы настоящей технологии в пределах ее существа и объема.
[048] Чтобы способствовать лучшему пониманию, последующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалистам в данной области техники должно быть понятно, что другие варианты осуществления настоящей технологии могут быть значительно сложнее.
[049] В некоторых случаях приводятся полезные примеры модификаций настоящей технологии. Они способствуют пониманию, но также не определяют объема или границ настоящей технологии. Представленный перечень модификаций не является исчерпывающим и специалист в данной области техники может разработать другие модификации в пределах объема настоящей технологии. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии.
[050] Описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть понятно, что любые описанные здесь структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих основы настоящей технологии. Также должно быть понятно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены на машиночитаемом физическом носителе информации и могут выполняться компьютером или процессором, независимо от того, показан такой компьютер или процессор явно или нет.
[051] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как "процессор" или "графический процессор", могут быть реализованы с использованием специализированных аппаратных средств, а также с использованием аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, эти функции могут выполняться одним выделенным процессором, одним совместно используемым процессором и/или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина "процессор" или "контроллер" не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может подразумевать, помимо прочего, аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и/или энергонезависимое запоминающее устройство. Также могут подразумеваться другие аппаратные средства, общего назначения и/или заказные.
[052] Программные модули или просто модули, реализация которых предполагается в виде программных средств, могут быть представлены здесь как любое сочетание элементов блок-схемы или других элементов, указывающих на выполнение шагов процесса и/или содержащих текстовое описание. Такие модули могут выполняться аппаратными средствами, показанными явно или подразумеваемыми.
[053] Далее с учетом вышеизложенных принципов рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
Компьютерная система
[054] На фиг. 1 представлена компьютерная система 100, пригодная для использования в некоторых вариантах осуществления настоящей технологии. Компьютерная система 100 содержит различные аппаратные элементы, включая один или несколько одноядерных или многоядерных процессоров, обобщенно представленных процессором 110, графический процессор 111 (GPU), твердотельный накопитель 120, ОЗУ 130, интерфейс 140 дисплея и интерфейс 150 ввода-вывода.
[055] Связь между различными элементами компьютерной системы 100 может осуществляться через одну или несколько внутренних и/или внешних шин 160 (таких как шина PCI, шина USB, шина FireWire стандарта IEEE 1394, шина SCSI, шина Serial-ATA и т.д.), с которыми различные аппаратные элементы соединены электронным образом.
[056] Интерфейс 150 ввода-вывода может соединяться с сенсорным экраном 190 и/или с одной или несколькими внутренними и/или внешними шинами 160. Сенсорный экран 190 может входить в состав дисплея. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сенсорный экран 190 представляет собой дисплей. Сенсорный экран 190 может также называться экраном 190. В представленных на фиг. 1 вариантах осуществления изобретения сенсорный экран 190 содержит сенсорные средства 194 (например, чувствительные к нажатию ячейки, встроенные в слой дисплея и позволяющие обнаруживать физическое взаимодействие между пользователем и дисплеем) и контроллер 192 сенсорных средств ввода-вывода, который обеспечивает связь с интерфейсом 140 дисплея и/или с одной или несколькими внутренними и/или внешними шинами 160. В некоторых вариантах осуществления изобретения интерфейс 150 ввода-вывода может соединяться с клавиатурой (не показана), мышью (не показана) или сенсорной площадкой (не показана), которые обеспечивают действие пользователя с компьютерной системой 100 в дополнение к сенсорному экрану 190 или вместо него.
[057] Следует отметить, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии некоторые элементы компьютерной системы 100 могут отсутствовать. Например, может отсутствовать сенсорный экран 190, в частности, если компьютерная система реализована в виде сервера (не ограничиваясь этим).
[058] Согласно вариантам осуществления настоящей технологии, твердотельный накопитель 120 хранит программные команды, пригодные для загрузки в ОЗУ 130 и исполнения процессором 110 и/или графическим процессором 111. Программные команды могут, например, входить в состав библиотеки или приложения.
Сетевая вычислительная среда
[059] На фиг. 2 представлена схема сетевой вычислительной среды 200, пригодной для использования с некоторыми не имеющими ограничительного характера вариантами осуществления систем и/или способов согласно настоящей технологии. Сетевая вычислительная среда 200 содержит сервер 202, соединенный через сеть 208 связи с электронным устройством 204. В не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 204 может быть связано с пользователем 216.
[060] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 204 может представлять собой любые компьютерные аппаратные средства, способные выполнять программы, подходящие для решения поставленной задачи. Таким образом, в качестве некоторых не имеющих ограничительного характера примеров электронного устройства 204 можно привести персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты. Должно быть понятно, что в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 204 может быть не единственным электронным устройством, связанным с пользователем 216, который может быть связан с другими электронными устройствами (не показаны на фиг. 2), которым через сеть 208 связи доступна цифровая платформа 210, без выхода за границы настоящей технологии.
[061] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 реализован в виде традиционного компьютерного сервера и может содержать некоторые или все элементы компьютерной системы 100, представленной на фиг. 1. В конкретном не имеющем ограничительного характера примере сервер 202 реализован в виде сервера Dell(tm) PowerEdge(tm), работающего под управлением операционной системы Microsoft(tm) Windows Server(tm), но он также может быть реализован с использованием любых других подходящих аппаратных средств, прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии (не показаны) функции сервера 202 могут быть распределены между несколькими серверами.
[062] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может содержать цифровую платформу 210. В общем случае цифровая платформа 210 представляет собой веб-ресурс, способный обеспечивать доступ ко множеству различных цифровых документов, размещенных на цифровой платформе 210, управление ими, их представление и взаимодействие с ними. Обычно виды цифровых документов, размещенных на цифровой платформе 210, зависят от ее реализации. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии цифровая платформа 210 представляет собой платформу потокового аудио, такую как платформа потокового аудио Spotify(tm), платформа потокового аудио Yandex.Music(tm) и т.п., а множество цифровых документов может содержать различные цифровые аудиодокументы, такие как фонограммы, аудиокниги, подкасты и т.п. В другом примере, где цифровая платформа 210 представляет собой платформу видеохостинга или платформу потокового видео, такую как платформа видеохостинга YouTube(tm), или платформа потокового видео Netflix(tm), множество цифровых документов может содержать различные цифровые видеодокументы, такие как видеоклипы, фильмы, новостные видеоматериалы и т.п. В другом примере, где цифровая платформа реализована в виде платформы онлайн-списков, такой как платформа онлайн-списков Yandex.Market(tm), платформа онлайн-списков Avito(tm) и т.п., множество цифровых документов может содержать рекламу различных элементов, предлагаемых для продажи, таких как товары и услуги. В другом примере цифровая платформа 210 может быть реализована в виде поисковой системы, такой как поисковая система Google(tm), поисковая система Yandex(tm) и т.п., а множество цифровых документов может содержать веб-документ, включающий в себя цифровые документы всех указанных выше видов. Должно быть понятно, что также возможны другие варианты реализации цифровой платформы 210 и другие виды размещенных на ней цифровых документов.
[063] Соответственно, для предоставления доступа ко множеству цифровых документов пользователям цифровой платформы 210, таким как пользователь 216, цифровая платформа 210 может поддерживать средства поиска, позволяющие пользователю 216 отправлять на цифровую платформу 210 поисковые запросы (например, через специальный пользовательский интерфейс), в ответ на которые цифровая платформа 210 может определять соответствующие наборы цифровых документов.
[064] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, для хранения множества цифровых документов, потенциально доступных через сеть 208 связи, сервер 202 может быть связан с базой 206 данных. В этой связи в тех вариантах изобретения, где цифровая платформа 210 содержит платформу потоковой передачи данных или платформу онлайн-списков, поставщики цифровых документов, такие как музыканты, студии и продавцы, могут предварительно наполнять базу 206 данных указаниями на множество цифровых документов. В тех вариантах осуществления изобретения, где цифровая платформа 210 реализована в виде поисковой системы, база 206 данных может быть предварительно наполнена указаниями на множество цифровых документов с использованием процесса обхода, который в некоторых не имеющих ограничительного характера вариантах осуществления изобретения может, например, быть реализован сервером 202. Кроме того, несмотря на то, что в представленных на фиг. 2 вариантах осуществления изобретения база 206 данных показана в виде одного элемента, должно быть понятно, что в других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции базы 206 данных могут быть распределены между несколькими базами данных. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии база 206 данных может быть доступна серверу 202 через сеть 208 связи, а не через прямую линию связи (отдельно не обозначена), как показано на фиг. 2.
[065] Как описано ниже, в дополнительных не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может хранить в базе 206 данных (а) данные, указывающие на пользователей цифровой платформы 210, таких как пользователь 216, включая некоторые их пользовательские признаки, и/или (б) данные предыстории относительно поисков, выполненных пользователем 216 на цифровой платформе 210. Например, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, пользовательские признаки пользователя 216 могут, в числе прочего, содержать социально-демографические характеристики пользователя 216, которые могут включать в себя возраст пользователя 216, пол пользователя 216, статус занятости пользователя 216, средний доход пользователя 216 и т.п. Данные, полученные в результате поисков, выполненных пользователем на цифровой платформе 210, могут содержать (а) поисковые запросы, отправленные пользователем 216 на цифровую платформу 210, и/или (б) наборы цифровых документов, определенные в ответ на поисковые запросы, и/или (в) пользовательские действия пользователя 216 с каждым ранее полученным набором цифровых документов.
[066] Таким образом, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, пользователь 216 с использованием электронного устройства 204 может отправлять запрос 212 на цифровую платформу 210, которая может определять в базе 206 данных набор 214 цифровых документов, соответствующих запросу 212. Кроме того, чтобы способствовать навигации пользователя 216 в наборе 214 цифровых документов, цифровая платформа 210 может ранжировать цифровые документы из набора 214 цифровых документов, например, согласно их степени релевантности для пользователя 216.
[067] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии такие степени релевантности каждого документа из набора 214 цифровых документов для пользователя 216 могут быть представлены значениями вероятности действия пользователя 216 с каждым документом из набора 214 цифровых документов. Например, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, действие с цифровым документом может включать в себя по меньшей мере одно из следующего: (а) выбор пользователем 216 цифрового документа из набора 214 цифровых документов путем выполнения по меньшей мере одного "клика" на цифровом документе; (б) выполнение пользователем 216 "длинного клика" на цифровом документе, например, когда пользователь 216 остается в цифровом документе более заранее заданного периода времени (например, более 120 секунд); (в) остановка пользователя 216 на цифровом документе из набора 214 цифровых документов в течение заранее заданного периода времени; (г) контакт пользователя 216 с цифровым документом дольше заранее заданного порогового периода контакта, например, такого как 2, 5 или 10 минут; (д) сохранение пользователем 216 по меньшей мере части цифрового документа, например, путем сохранения веб-страницы в формате HTML или добавления фонограммы в список избранных фонограмм. Должно быть понятно, что без выхода за границы настоящей технологии возможны и другие виды пользовательских действий пользователя 216 с цифровыми документами.
[068] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии для определения значений вероятности для каждого цифрового документа из набора 214 цифровых документов сервер 202 может обучать и затем применять алгоритм 218 MLA.
[069] Разработчики настоящей технологии установили, что для более точного определения значения вероятности действия пользователя 216 с каждым документом из набора 214 цифровых документов алгоритму 218 MLA следует учитывать (1) более общие зависимости в пользовательских действиях пользователя 216 с цифровыми документами, которые, например, могут быть определены путем анализа большего количества данных предыстории, связанных с пользователем 216, например, накопленных в течение одной или нескольких недель, одного или нескольких месяцев, одного года или нескольких лет и т.п., и (2) более поздние зависимости в пользовательских действиях пользователя 216 с цифровыми элементами, которые, например, могут быть определены путем анализа меньшего количества более свежих данных предыстории, связанных с пользователем 216, например, накопленных в течение текущего пользовательского сеанса пользователя 216 на цифровой платформе 210 до отправки запроса 212.
[070] При этом анализ такого объема данных в реальном времени может требовать очень большого количества ресурсов процессора 110 сервера 202, в результате чего может возникать воспринимаемая пользователем задержка при предоставлении набора 214 цифровых документов, что может негативно влиять на удовлетворенность пользователя от цифровой платформы 210. Исходя из этого разработчики разработали архитектуру алгоритма 218 MLA, содержащую две связанные ML-модели, при этом первая ML-модель способна (а) получать большое количество данных предыстории и (б) формировать их векторное представление, а вторая ML-модель способна (а) получать более свежие данные предыстории, (б) получать векторное представление большого количества данных предыстории от первой ML-модели и (в) на основе векторного представления большого количества данных предыстории и более свежих данных предыстории определять значение вероятности действия пользователя 216 с каждым документом из набора 214 цифровых документов.
[071] Как описано ниже, такая архитектура алгоритма 218 MLA позволяет обрабатывать большое количество данных предыстории с целью формирования их векторного представления в автономном режиме и в результате экономить ресурсы сервера 202 при онлайн-расчетах. Таким образом, настоящие способы и системы способны обеспечивать повышение точности ранжирования набора 214 цифровых документов при ограниченных ресурсах сервера 202, что позволяет повышать удовлетворенность пользователя 216 от цифровой платформы 210.
[072] На реализацию первой и второй ML-моделей алгоритма 218 MLA не накладывается ограничений. В различных не имеющих ограничительного характера вариантах осуществления настоящей технологии ML-модель может основываться на нейронных сетях (NN, Neural Network), на алгоритме MLA на основе деревьев решений, на алгоритме MLA на основе деревьев решений с градиентным бустингом, на алгоритме MLA на основе обучения правилам ассоциации, на алгоритме MLA на основе глубокого обучения, на алгоритме MLA на основе индуктивного логического программирования, на алгоритме MLA на основе метода опорных векторов, на алгоритме MLA на основе кластеризации, на байесовских сетях, на алгоритме MLA на основе обучения с подкреплением, на алгоритме MLA на основе обучения представлению, на алгоритме MLA на основе обучения сходству и метрикам, на алгоритме MLA на основе обучения на скудном словаре, на алгоритм MLA на основе генетических алгоритмов и т.п. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии ML-модель может содержать сеть NN с архитектурой кодер-декодер, такую как рекуррентная сеть NN, сеть NN с долгой краткосрочной памятью (LSTM, Long Short-Term Memory) и т.д. Следует отметить, что также возможны варианты осуществления изобретения, где первая и вторая ML-модели алгоритма MLA реализованы по-разному.
[073] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первая и вторая ML-модели алгоритма 218 MLA могут быть реализованы в виде сети NN на основе трансформера, такой как сеть NN на основе технологии BERT. В этих вариантах осуществления изобретения ML-модель алгоритма 218 MLA может быть обучена подобно алгоритмам MLA для обработки естественного языка, способным определять отсутствующие токены (такие как слова, фонемы, слоги и т.п.) в тексте на основе контекста, предоставленного соседними токенами.
[074] В общем случае можно сказать, что сервер 202 должен выполнять два процесса в отношении алгоритма 218 MLA. Первый из этих двух процессов представляет собой процесс обучения, где сервер 202 способен обучать алгоритм 218 MLA на основе обучающего набора данных определению значений вероятности действия пользователя 216 с цифровыми документами из набора 214 цифровых документов. Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, второй процесс представляет собой процесс этапа использования, где сервер 202 выполняет обученный таким образом алгоритм 218 MLA для определения значений вероятности (как описано ниже).
[075] Архитектура алгоритма 218 MLA, содержащего первую и вторую ML-модели, основанные на сетях NN на основе трансформера, и процессы этапа использования такого алгоритма MLA согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии описаны ниже со ссылкой на фиг. 4-6.
Сеть связи
[076] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 208 связи представляет собой сеть Интернет. В альтернативных не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 208 связи может быть реализована в виде любой подходящей локальной сети (LAN, Local Area Network), глобальной сети (WAN, Wide Area Network), частной сети связи и т.п. Очевидно, что варианты осуществления сети связи приведены лишь в иллюстративных целях. Реализация линий связи (отдельно не обозначены) между сервером 202 и электронным устройством 204 с одной стороны и сетью 208 связи с другой стороны зависит, среди прочего, от реализации сервера 202 и электронного устройства 204. В качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где электронное устройство 204 реализовано в виде устройства беспроводной связи, такого как смартфон, линия связи может быть реализована в виде беспроводной линии связи. Примеры беспроводных линий связи включают в себя канал сети связи 3G, канал сети связи 4G и т.д. В сети 208 связи также может использоваться беспроводное соединение с сервером 202.
Архитектура модели машинного обучения
[077] На фиг. 3 представлена блок-схема архитектуры 300 ML-модели, используемой для реализации алгоритма 218 MLA, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии. Как отмечено выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии архитектура 300 ML-модели может основываться на модели машинного обучения BERT, как описано, например, в указанной выше работе (Devlin et al.). Подобно модели BERT, архитектура 300 ML-модели содержит стек 302 трансформеров из трансформерных блоков, содержащий, например, трансформерные блоки 304, 306 и 308.
[078] Каждый из трансформерных блоков 304, 306 и 308 содержит блок трансформерного кодера, например, как описано в указанной выше работе (Vaswani et al.). Каждый из трансформерных блоков 304, 306 и 308 содержит слой 320 многоголового внимания (показан для иллюстрации только в трансформерном блоке 304) и слой 322 нейронной сети прямого распространения (также для иллюстрации показан только в трансформерном блоке 304). Трансформерные блоки 304, 306 и 308 обычно имеют одинаковую структуру, но имеют различные веса (после обучения). В слое 320 многоголового внимания реализованы зависимости между входными данными трансформерного блока, которые, например, могут использоваться с целью предоставления контекстной информации для каждого элемента входных данных на основе каждого другого элемента входных данных трансформерного блока. В слое 322 нейронной сети прямого распространения обычно эти зависимости отсутствуют, поэтому входные данные слоя 322 нейронной сети прямого распространения могут обрабатываться параллельно. Должно быть понятно, что несмотря на то, что на фиг. 3 показано только три трансформерных блока (трансформерные блоки 304, 306 и 308), в фактических вариантах реализации настоящей технологии стек 302 трансформеров может содержать намного больше таких трансформерных блоков. Например, в некоторых вариантах реализации изобретения в стеке 302 трансформеров может использоваться 12 трансформерных блоков.
[079] Входные данные 330 стека 302 трансформеров содержат токены, такие как токен 332 [CLS] и токены 334. Токены 334 могут, например, представлять слова или части слов. Токен 332 [CLS] используется в качестве представления для классификации всего набора токенов 334. Каждый токен 334 и токен 332 [CLS] представлены вектором. В некоторых вариантах осуществления изобретения длина каждого из этих векторов может, например, соответствовать 768 значениям с плавающей запятой. Должно быть понятно, что для эффективного уменьшения размеров (размерности) векторов может использоваться множество способов сжатия. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии токен 332 [CLS] может содержать множество входных токенов [CLS], например, 2, 3, 6 или 10, каждый из которых является векторным представлением для классификации различных аспектов токенов 334.
[080] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве входных данных 330 стека 302 трансформеров может использоваться фиксированное количество токенов 334. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии могут использоваться 1024 токена, а в других вариантах осуществления изобретения стек 302 трансформеров может получать 512 токенов (помимо токена 332 [CLS]). Входные данные 330 короче этого фиксированного количества токенов 334 могут быть расширены до фиксированной длины, например, путем добавления дополнительных токенов.
[081] В некоторых вариантах осуществления изобретения входные данные 330 могут быть сформированы из обучающего цифрового объекта 336, такого как по меньшей мере один прошлый цифровой документ и связанный с ним прошлый запрос, с использованием токенизатора 338, как описано ниже. Архитектура токенизатора 338 обычно зависит от обучающего цифрового объекта 336, используемого в качестве входных данных токенизатора 338. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии для формирования входных данных 330 в токенизаторе 338 могут использоваться известные способы кодирования, такие как кодирование пар байтов, а также могут использоваться предобучаемые нейронные сети.
[082] В других не имеющих ограничительного характера вариантах осуществления настоящей технологии токенизатор 338 может быть реализован на основе схемы кодирования пар байтов WordPiece, в частности, используемой в моделях обучения BERT, с достаточно большим размером словаря. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии размер словаря может соответствовать приблизительно 120 000 токенов. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии входные данные 330, сформированные токенизатором 338, могут быть заранее обработаны перед применением. Например, все слова входных данных 330 могут быть преобразованы в строчные буквы, а также может быть выполнена нормализация Unicode NFC. Схема кодирования пар байтов WordPiece, которая может быть использована в некоторых вариантах осуществления изобретения для построения словаря токенов, описана, например, в работе Rico Sennrich et al. "Neural Machine Translation of Rare Words with Subword Units", Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016, pages 1715-1725.
[083] В дополнительных не имеющих ограничительного характера вариантах осуществления настоящей технологии формирование входных данных 330 после использования токенизатора 338 может дополнительно включать в себя применение сервером 202 позиционного алгоритма векторизации (не показан), способного регистрировать позиционные данные в частях входного обучающего цифрового объекта 336. Например, если входной обучающий цифровой объект 336 содержит текстовое предложение, то позиционный алгоритм векторизации может формировать вектор, указывающий на позиционные данные слов в этом текстовом предложении. На реализацию позиционного алгоритма векторизации не накладывается ограничений. Например, он, в числе прочего, может содержать позиционный алгоритм синусоидальной векторизации, позиционный алгоритм векторизации с объединением кадров или позиционный алгоритм сверточной векторизации.
[084] Выходные данные 350 стека 302 трансформеров содержат выходные данные 352 [CLS] и вектор выходных данных 354, включая выходное значение для каждого токена 334 из входных данных 330 стека 302 трансформеров. Выходные данные 350 могут быть отправлены модулю 370 задачи. Как показано на фиг. 3, в некоторых вариантах осуществления изобретения модуль 370 задачи использует только выходные данные 352 [CLS], представляющие весь вектор выходных данных 354. Это может быть наиболее полезно, когда модуль 370 задачи используется в качестве классификатора либо для определения метки или значения, характеризующего весь входной обучающий цифровой объект 336, например, для формирования оценки релевантности, такой как значение вероятности действия пользователя 216 с цифровым документом, как описано выше.
[085] Как описано ниже, в тех вариантах осуществления изобретения, где токен 332 [CLS] входных данных 330 архитектуры 300 ML-модели содержит множество входных токенов [CLS], выходные данные 352 [CLS] могут содержать множество выходных токенов [CLS], количество которых соответствует количеству токенов во множестве входных токенов [CLS] из входных данных 330. Таким образом, множество выходных токенов [CLS] задает векторное представление всех входных данных 330.
[086] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии (не показаны на фиг. 3) все или некоторые значения вектора выходных данных 354 и, возможно, выходные данные 352 [CLS] могут использоваться в качестве входных данных модуля 370 задачи. Это может быть наиболее полезно, когда модуль 370 задачи используется с целью формирования меток или значений для каждого токена 334 из входных данных 330, например, для прогнозирования замаскированного или отсутствующего токена либо для распознавания именованного объекта. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии модуль 370 задачи может содержать нейронную сеть прямого распространения (не показана), формирующую зависящий от задачи результат 380, такой как оценка релевантности или вероятность "клика". Другие модели также могут использоваться в модуле 370 задачи. Например, модуль 370 задачи может представлять собой трансформер или нейронную сеть другого вида. Кроме того, зависящий от задачи результат 380 может использоваться в качестве входных данных других моделей, таких как модель CatBoost, как описано в работе Dorogush et al. "CatBoost: gradient boosting with categorical features support", NIPS 2017.
[087] Должно быть понятно, что архитектура 300 ML-модели, описанная выше со ссылкой на фиг. 3, упрощена для ясности и лучшего понимания некоторых не имеющих ограничительного характера вариантов осуществления настоящей технологии. Например, в практических вариантах реализации архитектуры 300 ML-модели каждый из трансформерных блоков 304, 306 и 308 может включать в себя операции нормализации слоя, модуль 370 задачи может содержать функцию нормализации softmax и т.д. Специалистам в данной области должно быть понятно, что эти операции широко используются в нейронных сетях и моделях глубокого обучения, таких как архитектура 300 ML-модели.
[088] Кроме того, как описано выше, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, алгоритм 218 MLA, выполняемый сервером 202 для ранжирования наборов цифровых документов, определенных цифровой платформой 210, таких как набор 214 цифровых документов, соответствующий запросу 212, может содержать две связанные ML-модели, реализованные на основе архитектуры 300 ML-модели.
[089] На фиг. 4 представлена архитектура алгоритма 218 MLA, реализованного на основе архитектуры 300 ML-модели согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[090] Предполагается, что архитектура алгоритма 218 MLA содержит первую ML-модель 402 и вторую ML-модель 404, каждая из которых в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии может быть реализована подобно описанной выше архитектуре 300 ML-модели. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии первая и вторая ML-модели 402, 404 могут быть реализованы по-разному. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первая ML-модель 402 может быть реализована подобно архитектуре 300 ML-модели, а вторая ML-модель 404 может быть реализована в виде ML-модели на основе деревьев решений, такой как вышеупомянутая модель CatBoost. В другом примере первая ML-модель 402 может быть реализована подобно архитектуре 300 ML-модели, а вторая ML-модель 404 может быть реализована в виде другой сети NN с архитектурой кодер-декодер, такой как рекуррентная сеть NN или сеть NN вида LSTM.
[091] Как описано ниже, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии первая и вторая ML-модели 402, 404 могут быть связаны друг с другом так, чтобы первые выходные данные 410 первой ML-модели 402 предоставлялись в качестве части вторых входных данных 418 второй ML-модели 404.
Процесс обучения
[092] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может получать обучающие данные и на их основе обучать алгоритм 218 MLA определению значений вероятности действия пользователя 216 с каждым документом из набора 214 цифровых документов.
[093] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии для обучения алгоритма 218 MLA сервер 202 может получать два отдельных обучающих набора данных с целью обучения первой и второй моделей 402, 404 (см. фиг. 4). В частности, сервер 202 может получать данные предыстории, связанные с каждым пользователем цифровой платформы 210, и на основе этих данных предыстории формировать первое множество 405 обучающих цифровых объектов для обучения первой ML-модели 402 и второе множество 407 обучающих цифровых объектов для обучения второй ML-модели 404.
[094] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии данные предыстории содержат данные прошлых поисков, выполненных пользователями цифровой платформы 210. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может получать данные предыстории непосредственно от электронных устройств пользователей цифровой платформы 210, таких как электронное устройство 204 пользователя 216. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может получать данные предыстории для прошлых поисков из базы 206 данных. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии для формирования первого и второго множеств 405, 407 обучающих цифровых объектов сервер 202 может получать данные предыстории для прошлых поисков, выполненных пользователями цифровой платформы 210 в течение заранее заданного периода времени, такого как одна или несколько недель, один или несколько месяцев, один год или несколько лет и т.п.
[095] В частности, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии данные предыстории для прошлых поисков, выполненных пользователем цифровой платформы 210, таким как пользователь 216, содержат множество прошлых запросов, отправленных пользователем 216 цифровой платформе 210, таких как прошлый запрос 412. Кроме того, для прошлого запроса 412 сервер 202 может получать набор прошлых цифровых документов 414, определенных как соответствующие прошлому запросу 412. Прошлый цифровой документ из набора прошлых цифровых документов 414 содержит соответствующее значение метки 415, указывающей на прошлое пользовательское действие пользователя 216 с прошлым цифровым документом после получения набора прошлых цифровых документов 414.
[096] Как описано выше, прошлый цифровой документ из набора прошлых цифровых документов 414 может содержать элементы электронного медиаконтента различных форматов и видов, которые пригодны для передачи, получения, хранения и представления на пользовательском электронном устройстве, таком как электронное устройство 204 пользователя 216, с использованием подходящего программного обеспечения, например, такого как браузер или другое веб-приложение.
[097] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, прошлое пользовательское действие пользователя 216 с прошлым цифровым документом из набора прошлых цифровых документов 414 может включать в себя по меньшей мере одно из следующего: (а) "клик" пользователя 216 на прошлом цифровом документе; (б) "длинный клик" на прошлом цифровом документе, когда пользователь после выполнения на нем "клика" остается в прошлом цифровом документе в течение заранее заданного периода времени (например, 2, 5 или 10 минут); (в) остановка на прошлом цифровом документе, например, в течение заранее заданного периода времени (такого как 10 секунд); (г) добавление прошлого цифрового документа в список избранных цифровых документов, например, в закладки браузерного приложения; (д) копирование части прошлого цифрового документа, такой как часть текста или изображения из него; и (е) сохранение по меньшей мере части прошлого цифрового документа во внутренней памяти электронного устройства 204. Следует отметить, что возможны и другие пользовательские действия, указывающие на заинтересованность пользователя 216 в прошлом цифровом документе.
[098] Таким образом, метка 415 прошлого цифрового документа может представлять собой двоичное значение, такое как "1" (или "положительное"), если пользователь 216 взаимодействовал с прошлым цифровым документом (например, выполнил "клик"), либо "0" (или "отрицательное"), если пользователь 216 не взаимодействовал с прошлым цифровым документом после получения соответствующего набора прошлых цифровых документов 414.
[099] В дополнительных не имеющих ограничительного характера вариантах осуществления настоящей технологии прошлый запрос 412 может дополнительно содержать метаданные запроса (не показаны), такие как географический регион, из которого пользователь 216 отправил прошлый запрос 412, и т.п. Подобным образом, прошлый цифровой документ из набора прошлых цифровых документов 414 может дополнительно содержать метаданные документа (не показаны), такие как его заголовок и его веб-адрес (например, в виде универсального указателя ресурсов (URL, Universal Resource Locator)).
[0100] Кроме того, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, на основе различных частей данных предыстории, связанных с пользователем 216, (как описано выше) сервер 202 способен (а) формировать набор обучающих цифровых объектов из первого множества 405 обучающих цифровых объектов для обучения первой ML-модели 402 и (б) формировать набор обучающих цифровых объектов из второго множества 407 обучающих цифровых объектов для обучения второй ML-модели 404.
[0101] На фиг. 5 представлена временная диаграмма получения сервером 202 различных частей данных предыстории, связанных с пользователем 216, для формирования наборов обучающих цифровых объектов из первого и второго множеств 405, 407 обучающих цифровых объектов (см. фиг. 4) согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии. В частности, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может формировать данные предыстории, связанные с пользователем 216, в виде двух частей: (а) первые данные 505 предыстории, содержащие данные прошлых поисков, выполненных пользователем 216 в течение первого периода 502 времени, и (б) вторые данные 507 предыстории, часть которых содержит данные прошлых поисков, выполненных пользователем 216 в течение второго периода 504 времени. Как показано на фиг. 5, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, второй период 504 времени короче первого периода 502 времени. Например, может быть выбран сравнительно большой первый период 502 времени, такой как несколько недель или месяцев, а второй период 504 времени может быть заранее задан сравнительно коротким, например, равным нескольким часам (1, 2, 5 или 7), суткам или неделе. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии второй период 504 времени может не иметь фиксированной продолжительности и может выбираться равным всему прошлому пользовательскому сеансу пользователя 216 на цифровой платформе 210. Таким образом, в этих вариантах осуществления изобретения сервер 202 может формировать вторые данные 507 предыстории так, чтобы каждая часть вторых данных 507 предыстории соответствовала данным предыстории, связанным с пользователем 216 и накопленным в течение прошлого пользовательского сеанса пользователя 216.
[0102] Кроме того, в некоторых не имеющих ограничительных характера вариантах осуществления настоящей технологии сервер 202 может формировать данные предыстории, связанные с пользователем 216, так, чтобы каждая часть вторых данных 507 предыстории была более свежей, чем первые данные 505 предыстории. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии по меньшей мере часть вторых данных 507 предыстории может перекрываться с первыми данными 505 предыстории. Таким образом сервер 202 может определять наборы обучающих цифровых объектов из первых и вторых данных 505, 507 предыстории для каждого пользователя цифровой платформы 210.
[0103] На основе первых данных 505 предыстории сервер 202 может формировать набор обучающих цифровых объектов из первого множества 405 обучающих цифровых объектов, связанных с пользователем 216, так, что обучающий цифровой объект содержит (а) прошлый запрос 412, отправленный пользователем 216 в течение первого периода 502 времени, (б) набор прошлых цифровых документов 414 и (в) значения метки 415, указывающей на прошлое пользовательское действие пользователя 216 с каждым прошлым цифровым документом, как описано выше.
[0104] Кроме того, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии с использованием токенизатора 338, описанного выше применительно к архитектуре 300 ML-модели, сервер 202 может на основе цифрового объекта из первого множества 405 обучающих цифровых объектов формировать значения первых входных данных 408 для первой ML-модели 402. Кроме того, сервер 202 может подавать первые входные данные 408 в первую ML-модель 402 и обучать таким образом первую ML-модель 402 определению значений вероятности действия пользователя 216 с цифровыми документами этапа использования, такими как цифровые документы из набора 214 цифровых документов. При этом в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может (а) инициализировать веса трансформерных блоков 304, 306, 308 первой ML-модели 402, например, случайным образом, и (б) корректировать их значения путем минимизации различия или расстояния между прогнозируемыми и фактическими значениями меток, связанных с каждым прошлым цифровым документом из первого множества 405 обучающих цифровых объектов. Например, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может определять такое различие с использованием функции потерь, такой как функция потери кросс-энтропии, и дополнительно корректировать веса трансформерных блоков 304, 306 и 308 путем минимизации различия между прогнозируемыми и фактическими значениями меток, связанных с прошлыми цифровыми документами.
[0105] Должно быть понятно, что в не имеющих ограничительного характера вариантах осуществления настоящей технологии возможны и другие варианты реализации функции потерь, например, функция потерь среднеквадратичной ошибки, функция потерь по Губеру, кусочно-линейная функция потерь и т.д. На способ минимизации функции потерь сервером 202 не накладывается ограничений. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии он обычно зависит от дифференцируемости функции потерь. Например, если функция потерь является непрерывно дифференцируемой, то подходы к ее минимизации могут включать в себя алгоритм градиентного спуска, алгоритм оптимизации на основе метода Ньютона и т.д. В тех вариантах осуществления изобретения, где функция потерь не является дифференцируемой, для ее минимизации сервер 202 может, например, применять прямые алгоритмы, стохастические алгоритмы и/или популяционные алгоритмы.
[0106] Таким образом, обучив первую ML-модель 402 на основе набора обучающих цифровых объектов из первого множества 405 обучающих цифровых объектов, связанных с пользователем 216, сервер 202 может определять значения первых выходных данных 410, содержащих первые выходные данные [CLS] (отдельно не обозначены). Как описано выше применительно к архитектуре 300 ML-модели, первые выходные данные [CLS] из первых выходных данных 410 задают для каждого пользователя цифровой платформы 210 векторное представление всего первого множества 405 обучающих цифровых объектов. В частности, можно сказать, что первые выходные данные [CLS] из числа значений первых выходных данных 410 указывают на взаимосвязи между (а) пользовательскими признаками пользователя 216, (б) прошлым запросом 412, (в) признаками прошлых цифровых документов из набора прошлых цифровых документов 414, такими как их заголовки и URL-адреса, и (г) значениями метки 415, указывающими на прошлые пользовательские действия пользователя 216 с каждым прошлым цифровым документом из набора прошлых цифровых документов 414. Поскольку сервер 202 формирует эти значения из первого множества 405 обучающих цифровых объектов на основе первых данных 505 предыстории, накопленных для пользователя 216 в течение первого периода 502 времени, как описано выше, то можно сказать, что первые выходные данные [CLS] первой ML-модели 402 являются векторным представлением всех первых данных 505 предыстории, связанных с пользователем 216.
[0107] Кроме того, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может хранить первые выходные данные 410, связанные с пользователем 216 и содержащие первые выходные данные [CLS], во внутренней памяти сервера 202, такой как его твердотельный накопитель 120, с целью последующего использования первых выходных данных 410 для обучения второй ML-модели 404 и для использования алгоритма 218 MLA в целом, как описано ниже.
[0108] Подобным образом сервер 202 может формировать значения первых выходных данных 410 для всех других пользователей цифровой платформы 210. С этой целью сервер 202 может (а) получать первые данные 505 предыстории, связанные с другим пользователем цифровой платформы 210, (б) формировать на основе первых данных 505 предыстории, связанных с другим пользователем, набор обучающих цифровых объектов из первого множества 405 обучающих цифровых объектов, (в) вводить набор обучающих цифровых объектов из первого множества 405 обучающих цифровых объектов в первую ML-модель 402 для определения значений первых выходных данных 410, связанных с другим пользователем цифровой платформы 210, и (г) сохранять значения первых выходных данных 410 для последующего использования, как описано ниже.
[0109] Кроме того, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии с использованием значений первых выходных данных 410, определенных с применением обучения первой ML-модели 402, и части связанных с пользователем 216 вторых данных 507 предыстории, полученных как описано выше, сервер 202 может формировать набор обучающих цифровых объектов из второго множества 407 обучающих цифровых объектов, связанных с пользователем 216, для обучения второй ML-модели 404. В частности, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, обучающий цифровой объект из второго множества 407 обучающих цифровых объектов содержит (а) прошлый запрос (отдельно не обозначен), отправленный пользователем 216 в течение второго периода 504 времени, (б) другой набор прошлых цифровых документов, определенных цифровой платформой 210 как соответствующие прошлому запросу, отправленному в течение второго периода 504 времени, и (в) первые выходные данные [CLS] из значений первых выходных данных 410 первой ML-модели 402, представляющие первые данные 505 предыстории, связанные с пользователем 216. Как и в случае набора прошлых цифровых документов, сформированного в течение первого периода 502 времени, прошлый цифровой документ из другого набора прошлых цифровых документов также содержит значение метки 415, указывающей на прошлое пользовательское действие пользователя 216 с прошлым цифровым документом.
[0110] Предполагается, что, поскольку второе множество 407 обучающих цифровых объектов основано на части вторых данных 507 предыстории, соответствующих второму периоду 504 времени, который в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии короче первого периода 502 времени, то в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии общее количество членов во втором множестве 407 обучающих цифровых объектов оказывается меньшим, чем в первом множестве 405 обучающих цифровых объектов.
[0111] Кроме того, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может (а) формировать вторые входные данные 418 путем применения токенизатора 338 в отношении набора обучающих цифровых объектов из второго множества 407 обучающих цифровых объектов, связанных с пользователем 216, и (б) вводить вторые входные данные 418 во вторую ML-модель 404 и обучать таким образом вторую ML-модель 404 определению значений вероятности действия пользователя 216 с цифровыми документами этапа использования подобно тому, как это описано выше применительно к обучению первой ML-модели 402. В частности, в результате на основе набора обучающих цифровых объектов из второго множества 407 обучающих цифровых объектов, связанных с пользователем 216, сервер 202 может обучать вторую ML-модель 404 и, следовательно, алгоритм 218 MLA так, чтобы в ответ на применение алгоритма 218 MLA в отношении цифровых документов этапа использования вторая ML-модель 404 могла формировать значения вторых выходных данных 420, содержащих вторые выходные данные [CLS] (отдельно не обозначены), включая вектор, значения которого содержат значения вероятности действия пользователя 216 с каждым цифровым документом этапа использования.
[0112] Кроме того, с использованием подхода, подобного описанному выше, сервер 202 может обучать алгоритм 218 MLA определению значений вторых выходных данных 420, связанных с каждым другим пользователем цифровой платформы 210. В частности, в этой связи сервер 202 может (а) формировать (или получать иным образом) значения первых выходных данных 410, связанных с другим пользователем цифровой платформы 210, как описано выше, (б) на основе первых выходных данных [CLS] из значений первых выходных данных 410, представляющих первые данные 505 предыстории, связанные с другим пользователем, формировать набор обучающих цифровых объектов из второго множества 407 обучающих цифровых объектов и (в) на основе набора обучающих цифровых объектов из второго множества 407 обучающих цифровых объектов обучать вторую ML-модель 404 определению значений вероятности действия другого пользователя с документами этапа использования.
[0113] Таким образом, путем ввода в первую и вторую ML-модели 402, 404 наборов обучающих цифровых объектов, связанных с каждым пользователем цифровой платформы, сервер 202 способен совместно обучать первую и вторую ML-модели 402, 404 и, следовательно, обучать алгоритм 218 MLA. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может совместно обучать первую и вторую ML-модели 402, 404 формированию значений первых и вторых выходных данных 410, 420, соответственно, поочередно для каждого пользователя цифровой платформы 210. В этих вариантах осуществления изобретения сервер 202 может рассматривать первую и вторую ML-модели 402, 404 как единую ML-модель и вводить в нее различные значения первых и вторых входных данных 408, 418 поочередно для каждого пользователя цифровой платформы 210 с целью определения значений вторых выходных данных 420, указывающих на значения вероятности действия пользователей с цифровыми документами этапа использования. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может совместно обучать первую и вторую ML-модели 402, 404 путем (а) обучения первой ML-модели 402 предварительному формированию значений первых выходных данных 410 для всех пользователей цифровой платформы 210, (б) сохранения значений первых выходных данных 410, например, в твердотельном накопителе 120 сервера 202, и (в) получения для пользователя цифровой платформы 210 значений первых выходных данных 410 для последующего обучения второй ML-модели 404 формированию значений вторых выходных данных 420.
[0114] В результате сервер 202 может обучать алгоритм 218 MLA определению значений вероятности действия каждого пользователя цифровой платформы 210 с цифровыми документами этапа использования, такими как набор 214 цифровых документов. Ниже описано применение сервером 202 обученного таким образом алгоритма 218 MLA.
Процесс этапа использования
[0115] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, в ходе процесса этапа использования сервер 202 может применять обученный, как описано выше, алгоритм 218 MLA для ранжирования цифровых документов этапа использования, таких как набор 214 цифровых документов, определенных цифровой платформой 210 в ответ на запрос 212, отправленный ей пользователем 216. С этой целью сервер 202 может на основе набора 214 цифровых документов формировать и вводить в алгоритм 218 MLA цифровой объект этапа использования.
[0116] На фиг. 6 представлено схематическое изображение сервера 202, применяющего обученный, как описано выше, алгоритм MLA, в отношении цифрового объекта 602 этапа использования, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[0117] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, для формирования цифрового объекта 602 этапа использования сервер 202 в дополнение к запросу 212 и связанному с ним набору 214 цифровых документов может получать данные 604 предыстории этапа использования, связанные с пользователем 216. Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, данные 604 предыстории этапа использования представляют собой часть самых свежих данных предыстории, накопленных до момента времени отправки запроса 212 цифровой платформе 210 в течение второго периода 504 времени, как описано выше применительно ко вторым данным 507 предыстории. Таким образом, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии данные 604 предыстории этапа использования содержат связанные с пользователем 216 данные предыстории, накопленные до момента времени отправки запроса 212 в течение второго периода 504 времени с фиксированной длительностью, такой как 2-3 часа, одни сутки и т.п. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии данные 604 предыстории этапа использования содержат связанные с пользователем 216 данные предыстории, накопленные до момента времени отправки запроса 212 в течение второго периода 504 времени, продолжительность которого соответствует текущему пользовательскому сеансу пользователя 216 на цифровой платформе 210.
[0118] Подобно любым другим данным предыстории, описанным выше, данные 604 предыстории этапа использования содержат (а) множество прошлых запросов этапа использования, отправленных пользователем 216 в течение второго периода 504 времени до момента времени отправки запроса 212, таких как прошлый запрос 612 этапа использования, (б) множество прошлых цифровых документов 614 этапа использования, соответствующих прошлому запросу 612 этапа использования, и (в) значения метки 415, указывающей на пользовательские действия пользователя 216 с каждым документом из множества прошлых цифровых документов 614 этапа использования.
[0119] Кроме того, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может получать значения первых выходных данных 410 первой ML-модели 402, связанных с пользователем 216 и сформированных, как это описано выше применительно к обучению алгоритма 218 MLA.
[0120] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может обновлять значения первых выходных данных 410, связанных с каждым пользователем цифровой платформы 210, путем обновления первых данных 505 предыстории, связанных с пользователем, таким как пользователь 216, на основе которых сервер 202 инициирует формирование первой ML-моделью 402 набора обучающих цифровых объектов для первых выходных данных 410, связанных с пользователем 216. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может обновлять первые данные 505 предыстории, связанные с пользователем 216, путем расширения первого периода 502 времени, в течение которого должны накапливаться первые данные 505 предыстории, в направлении момента времени отправки запроса 212. Например, сервер 202 может расширять первый период 502 времени в направлении момента времени начала получения данных 604 предыстории этапа использования. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 вместо изменения продолжительности первого периода 502 времени может сдвигать первый период 502 времени в направлении момента времени отправки запроса 212. В результате в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может периодически обновлять первые данные 505 предыстории, связанные с пользователем 216, в частности, регулярно - заранее заданное количество раз (например, один, два и т.п.) в сутки, в неделю или в месяц. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может обновлять первые данные 505 предыстории перед формированием каждого цифрового объекта этапа использования.
[0121] Таким образом, сервер 202 может формировать цифровой объект 602 этапа использования, содержащий (а) запрос 212, (б) набор 214 цифровых документов, (в) множество прошлых запросов этапа использования; (г) множества прошлых цифровых документов этапа использования, такие как множество прошлых цифровых документов 614 этапа использования, соответствующих прошлому запросу 612 этапа использования и содержащих значения метки 415, и (д) значения первых выходных данных 410, содержащих первые выходные данные [CLS], представляющие первые данные 505 предыстории, связанные с пользователем 216, как описано выше. В дополнительных не имеющих ограничительного характера вариантах осуществления настоящей технологии цифровой объект 602 этапа использования может также содержать метаданные, связанные с запросами и цифровыми документами, как описано выше.
[0122] Кроме того, как описано выше применительно к обучению второй ML-модели 404, с использованием токенизатора 338 сервер 202 способен токенизировать цифровой объект 602 этапа использования с целью формирования вторых входных данных 418 для ввода во вторую ML-модель 404. В ответ вторая ML-модель 404 способна формировать значения этапа использования для вторых выходных данных 420, где вторые выходные данные [CLS] содержат вектор, значение которого представляет собой значение вероятности действия пользователя 216 с цифровым документом из набора 214 цифровых документов.
[0123] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии (не показаны) сервер 202 может формировать цифровой объект 602 этапа использования без добавления в него набора 214 цифровых документов. В этих вариантах осуществления изобретения сервер 202 может (а) отдельно формировать векторное представление набора 214 цифровых документов, например, с использованием алгоритма векторизации, и (б) конкатенировать векторное представление набора 214 цифровых документов и вторые выходные данные [CLS] второй ML-модели 404, сформированные в ответ на ввод в нее цифрового объекта 602 этапа использования, и определять таким образом значение вероятности действия пользователя 216 с каждым документом из набора 214 цифровых документов.
[0124] На реализацию алгоритма векторизации не накладывается ограничений, обычно он зависит от вида цифрового объекта. Например, если цифровой документ представляет собой текстовый веб-документ, то алгоритм векторизации может включать в себя алгоритм векторизации текста Word2Vec или алгоритм векторизации текста GloVe и т.п. В другом примере, где цифровой документ представляет собой аудиопоток, алгоритм векторизации может содержать алгоритм векторизации звука, включая, среди прочего, алгоритм векторизации звука вида "автокодировщик из последовательности в последовательность" (Seq2Seq (Sequence-to-Sequence) Autoencoder), алгоритм векторизации звука вида "сверточная векторная регрессия", алгоритм векторизации звука вида "основанная на буквах n-грамма", алгоритм векторизации звука на основе модели LSTM и т.п. Также не накладывается ограничений на способ конкатенации сервером 202 векторного представления набора 214 цифровых документов и вторых выходных данных [CLS]. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии он может, например, включать в себя скалярное умножение векторов.
[0125] Кроме того, сервер 202 может ранжировать набор 214 цифровых документов согласно определенным таким образом значениям вероятности и представлять набор 214 цифровых документов пользователю 216 в ответ на запрос 212.
[0126] Таким образом, архитектура алгоритма 218 MLA, содержащего две связанные ML-модели, такие как первая и вторая ML-модели 402, 404, позволяет учитывать большее количество данных предыстории действий пользователя с прошлыми цифровыми документами и, следовательно, способна повышать точность определения значений вероятности действия пользователей с цифровыми документами этапа использования. В то же время эта архитектура обеспечивает возможность автономной обработки сервером 202 большей части данных предыстории, накопленных в течение более длительного периода времени, таких как первые данные 505 предыстории, что способствует экономии ресурсов сервера 202 при расчетах в реальном времени и, следовательно, позволяет повышать эффективность предоставления ранжированных результатов поиска пользователям. Оба этих преимущества способствуют повышению удовлетворенности пользователя от взаимодействия с цифровой платформой 210.
Способ
[0127] Описанные выше архитектура и примеры позволяют выполнять способ обучения алгоритма MLA ранжированию цифровых документов, такого как описанный выше алгоритм 218 MLA. На фиг. 7 представлена блок-схема способа 700 согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии. Способ 700 может выполняться сервером 202.
[0128] Как описано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии алгоритм 218 MLA может содержать две связанные ML-модели. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии каждая из этих двух ML-моделей может содержать ML-модель, основанную на сети NN на основе трансформера, такую как первая и вторая ML-модели 402, 404, описанные выше со ссылкой на фиг. 3 и 4.
Шаг 702: получение процессором первых данных предыстории, содержащих (а) первое множество обучающих запросов, отправленных пользователем цифровой платформе в течение прошлого периода времени, и (б) наборы обучающих цифровых документов, сформированные цифровой платформой в течение прошлого периода времени в ответ на отправку ей каждого запроса из первого множества обучающих запросов.
[0129] Способ 700 начинается с шага 702, на котором сервер 202 способен получать, например, от электронных устройств пользователей цифровой платформы 210, первые данные 505 предыстории, связанные с каждым пользователем цифровой платформы 210, таким как пользователь 216. Как описано выше со ссылкой на фиг. 5, первые данные 505 предыстории, связанные с пользователем 216, могут накапливаться в течение первого периода 502 времени, который может быть сравнительно длительным, таким как одна или несколько недель, месяцев или даже лет.
[0130] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, первые данные 505 предыстории, связанные с пользователем 216, содержат данные прошлых поисков пользователя 216 на цифровой платформе 210 и, таким образом, могут включать в себя (а) множество прошлых запросов, отправленных пользователем 216 цифровой платформе 210 в течение первого периода 502 времени, таких как прошлый запрос 412, (б) наборы прошлых цифровых документов, определенных цифровой платформой 210 как соответствующие каждому запросу из множества прошлых запросов, отправленных в течение первого периода 502 времени, такие как набор прошлых цифровых документов 414, соответствующих прошлому запросу 412, и (в) значения метки 415, указывающей на прошлые пользовательские действия с каждым прошлым цифровым документом в течение первого периода 502 времени.
[0131] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, прошлое пользовательское действие пользователя 216 с прошлым цифровым документом из набора прошлых цифровых документов 414 может включать в себя по меньшей мере одно из следующего: (а) "клик" пользователя 216 на прошлом цифровом документе; (б) "длинный клик" на прошлом цифровом документе, когда пользователь после выполнения на нем "клика" остается в прошлом цифровом документе в течение заранее заданного периода времени (например, 2, 5 или 10 минут); (в) остановка на прошлом цифровом документе, например, в течение заранее заданного периода времени (такого как 10 секунд); (г) добавление прошлого цифрового документа в список избранных цифровых документов, например, в закладки браузерного приложения; (д) копирование части прошлого цифрового документа, такой как часть текста или изображения из него; и (е) сохранение по меньшей мере части прошлого цифрового документа во внутренней памяти электронного устройства 204.
[0132] Далее способ 700 продолжается на шаге 704.
Шаг 704: получение процессором вторых данных предыстории, часть которых содержит (а) второе множество обучающих запросов, отправленных пользователем цифровой платформе в течение прошлого обучающего пользовательского сеанса, который был короче и осуществлялся позднее прошлого периода времени, и (б) наборы обучающих цифровых документов, сформированные цифровой платформой в течение прошлого обучающего пользовательского сеанса в ответ на отправку ей каждого запроса из второго множества обучающих запросов.
[0133] На шаге 704 сервер 202 может получать вторые данные 507 предыстории для каждого пользователя цифровой платформы 210, такого как пользователь 216. Как описано выше со ссылкой на фиг. 5, часть вторых данных 507 предыстории подобна данным прошлых поисков, выполненных пользователем 216, из первых данных 505 предыстории, но накоплена в течение второго периода 504 времени, который короче первого периода 502 времени и может, например, составлять несколько часов или суток. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии продолжительность второго периода 504 времени может соответствовать прошлому пользовательскому сеансу пользователя 216 на цифровой платформе 210.
[0134] Далее способ 700 продолжается на шаге 706.
Шаг 706: совместное обучение процессором первой и второй ML-моделей ранжированию цифровых документов этапа использования.
[0135] На шаге 706, получив первые и вторые данные 505, 507 предыстории для каждого пользователя цифровой платформы 210, сервер 202 может группировать их в обучающие цифровые объекты для совместного обучения первой и второй ML-моделей 402, 404 алгоритма 218 MLA определению значений вероятности действия пользователей с цифровыми документами этапа использования.
[0136] В частности, сервер 202 может на основе связанных с пользователем 216 первых данных 505 предыстории формировать набор обучающих цифровых объектов из первого множества 405 обучающих цифровых объектов для обучения первой ML-модели 402. Как описано выше со ссылкой на фиг. 4, обучающий цифровой объект из первого набора 405 обучающих цифровых объектов содержит (а) прошлый запрос 412, отправленный пользователем 216 в течение первого периода 502 времени, (б) набор прошлых цифровых документов 414 и (в) значения метки 415, указывающей на прошлое пользовательское действие пользователя 216 с каждым прошлым цифровым документом, как описано выше.
[0137] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 с использованием токенизатора 338 может на основе связанного с пользователем 216 цифрового объекта формировать значения первых входных данных 408 для первой ML-модели 402. Кроме того, сервер 202 может вводить значения первых входных данных 408 в первую ML-модель 402 и обучать таким образом первую ML-модель 402, как описано выше. В результате сервер 202 может определять значения первых выходных данных 410, содержащих первые выходные данные [CLS], которые являются векторным представлением всех первых данных 505 предыстории, связанных с пользователем 216.
[0138] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 также может сохранять определенные таким образом значения первых выходных данных 410, связанных с пользователем 216 и содержащих первые выходные данные [CLS], во внутренней памяти сервера 202, такой как твердотельный накопитель 120.
[0139] Кроме того, на основе определенных таким образом значений первых выходных данных 410, связанных с пользователем 216, и части вторых данных 507 предыстории сервер 202 может формировать набор обучающих цифровых объектов из второго множества 407 обучающих цифровых объектов для обучения второй ML-модели 404. В частности, обучающий цифровой объект из второго множества 407 обучающих цифровых объектов содержит (а) прошлый запрос, отправленный пользователем 216 в течение второго периода 504 времени, (б) другой набор прошлых цифровых документов, определенных цифровой платформой 210 как соответствующие прошлому запросу, отправленному в течение второго периода 504 времени, (в) значения метки 415, указывающей на прошлые пользовательские действия с каждым прошлым цифровым документом в течение второго периода 504 времени, и (г) первые выходные данные [CLS] из значений первых выходных данных 410 первой ML-модели 402, представляющие первые данные 505 предыстории, связанные с пользователем 216.
[0140] Кроме того, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 202 может (а) формировать вторые входные данные 418 путем применения токенизатора 338 в отношении набора обучающих цифровых объектов из второго множества 407 обучающих цифровых объектов, связанных с пользователем 216, и (б) вводить вторые входные данные 418 во вторую ML-модель 404 и обучать таким образом вторую ML-модель 404 определению значений вероятности действий пользователя 216 с цифровыми документами этапа использования подобно тому, как это описано выше применительно к обучению первой ML-модели 402.
[0141] Таким образом, путем (а) определения наборов из первого и второго множеств 405, 407 обучающих цифровых объектов для каждого пользователя цифровой платформы 210 и (б) ввода наборов в первую и вторую ML-модели 402, 404, как описано выше, сервер 202 способен совместно обучать первую и вторую ML-модели 402, 404 и, таким образом, обучать алгоритм 218 MLA. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может совместно обучать первую и вторую ML-модели 402, 404 формированию значений первых и вторых выходных данных 410, 420, соответственно, поочередно для каждого пользователя цифровой платформы 210. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может совместно обучать первую и вторую ML-модели 402, 404 путем (а) обучения первой ML-модели 402 предварительному формированию значений первых выходных данных 410 для всех пользователей цифровой платформы 210, (б) сохранения значений первых выходных данных 410, например, в твердотельном накопителе 120 сервера 202, и (в) получения для пользователя цифровой платформы 210 значений первых выходных данных 410 для последующего обучения второй ML-модели 404 формированию значений вторых выходных данных 420.
[0142] Кроме того, согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, после обучения алгоритма 218 MLA, как описано выше, сервер 202 может использовать его для ранжирования результатов поиска, таких как набор 214 цифровых документов, определенных цифровой платформой 210 в ответ на запрос 212, отправленный пользователем 216. С этой целью в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может (а) формировать на основе запроса 212, набора 214 цифровых документов и данных предыстории 604 этапа использования цифровой объект 602 этапа использования и (б) применять в отношении него алгоритм 218 MLA (как это описано выше со ссылкой на фиг. 6).
[0143] Согласно некоторым не имеющим ограничительного характера вариантам осуществления настоящей технологии, цифровой объект 602 этапа использования содержит (а) запрос 212, (б) набор 214 цифровых документов, (в) множество прошлых запросов этапа использования, (г) множества прошлых цифровых документов этапа использования, такие как множество прошлых цифровых документов 614 этапа использования, соответствующих прошлому запросу 612 этапа использования и содержащих значения метки 415, и (д) значения первых выходных данных 410, содержащих первые выходные данные [CLS], представляющие первые данные 505 предыстории, связанные с пользователем 216, как описано выше. В дополнительных не имеющих ограничительного характера вариантах осуществления настоящей технологии цифровой объект 602 этапа использования может дополнительно содержать метаданные, связанные с запросами и цифровыми документами, как это описано выше.
[0144] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может обновлять значения первых выходных данных 410, связанных с каждым пользователем цифровой платформы 210, путем обновления первых данных 505 предыстории, связанных с пользователем, таким как пользователь 216, на основе которых сервер 202 инициирует формирование первой ML-моделью 402 набора обучающих цифровых объектов для первых выходных данных 410, связанных с пользователем 216. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может обновлять первые данные 505 предыстории, связанные с пользователем 216, путем расширения первого периода 502 времени, в течение которого должны накапливаться первые данные 505 предыстории, в направлении момента времени отправки запроса 212. Например, сервер 202 может расширять первый период 502 времени в направлении момента времени начала получения данных 604 предыстории этапа использования. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 вместо изменения продолжительности первого периода 502 времени может сдвигать первый период 502 времени в направлении момента времени отправки запроса 212. В результате в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может периодически обновлять первые данные 505 предыстории, связанные с пользователем 216, в частности, регулярно - заранее заданное количество раз (например, один, два и т.п.) в сутки, в неделю или в месяц. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 202 может обновлять первые данные 505 предыстории перед формированием каждого цифрового объекта этапа использования.
[0145] Кроме того, путем использования токенизатора 338 сервер 202 способен токенизировать цифровой объект 602 этапа использования с целью формирования значений вторых входных данных 418 для ввода во вторую ML-модель 404. В ответ вторая ML-модель 404 способна формировать значения этапа использования для вторых выходных данных 420, где вторые выходные данные [CLS] содержат вектор, значение которого представляет собой значение вероятности действия пользователя 216 с цифровым документом из набора 214 цифровых документов.
[0146] Тем не менее, как описано выше, в некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии (не показаны) сервер 202 может формировать цифровой объект 602 этапа использования без добавления в него набора 214 цифровых документов. В этих вариантах осуществления изобретения сервер 202 может (а) с использованием одного из вышеупомянутых вариантов реализации алгоритма векторизации отдельно формировать векторное представление набора 214 цифровых документов и (б) конкатенировать векторное представление набора 214 цифровых документов и вторые выходные данные [CLS] второй ML-модели 404, сформированные в ответ на ввод в нее цифрового объекта 602 этапа использования, и определять таким образом значения вероятности действия пользователя 216 с каждым документом из набора 214 цифровых документов.
[0147] Следовательно, некоторые варианты осуществления способа 700 позволяют учитывать большее количество данных предыстории для определения значений вероятности действия пользователей с цифровыми документами этапа использования цифровой платформы 210 при ограничении вычислительных ресурсов сервера 202. Это позволяет повышать точность и эффективность ранжирования результатов поиска.
[0148] На этом выполнение способа 700 завершается.
[0149] Должно быть понятно, что, несмотря на то, что представленные здесь варианты осуществления изобретения описаны со ссылками на конкретные особенности и структуры, их различные модификации и сочетания могут быть реализованы без выхода за границы таких раскрытий. Например, различные оптимизации, применяемые в нейронных сетях, включая трансформеры и/или модель BERT, могут подобным образом применяться и в настоящей технологии. Кроме того, могут применяться оптимизации, ускоряющие определение релевантности на этапе использования. Например, в некоторых вариантах осуществления изобретения трансформерная модель может быть разделена так, что некоторые трансформерные блоки распределены между обработкой запроса и обработкой документа, поэтому представления документов могут быть предварительно рассчитаны в автономном режиме и сохранены в индексе извлечения документов. Описание и чертежи следует рассматривать лишь как иллюстрацию обсуждаемых вариантов реализации или осуществления изобретения, принципы которого определенны приложенной формулой изобретения, которая охватывает все модификации, изменения, сочетания и эквиваленты в пределах объема настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ | 2021 |
|
RU2831678C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| СПОСОБ И СИСТЕМА ДЛЯ РАНЖИРОВАНИЯ ЦИФРОВЫХ ОБЪЕКТОВ НА ОСНОВЕ СВЯЗАННОЙ С НИМИ ЦЕЛЕВОЙ ХАРАКТЕРИСТИКИ | 2019 |
|
RU2757174C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ПОВТОРНОГО ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2019 |
|
RU2743932C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ОБУЧАЮЩИХ ДАННЫХ ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2021 |
|
RU2819647C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ МЕДИАКОНТЕНТА | 2022 |
|
RU2815896C2 |
| Система и способ для формирования обучающего набора для алгоритма машинного обучения | 2020 |
|
RU2790033C2 |
| Система и способ формирования обучающего набора для алгоритма машинного обучения | 2018 |
|
RU2744029C1 |
| СПОСОБ И СИСТЕМА ВЫБОРА ДЛЯ РАНЖИРОВАНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ С ПОМОЩЬЮ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2731658C2 |
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ ОБУЧАЮЩИХ ДАННЫХ ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2023 |
|
RU2831408C2 |
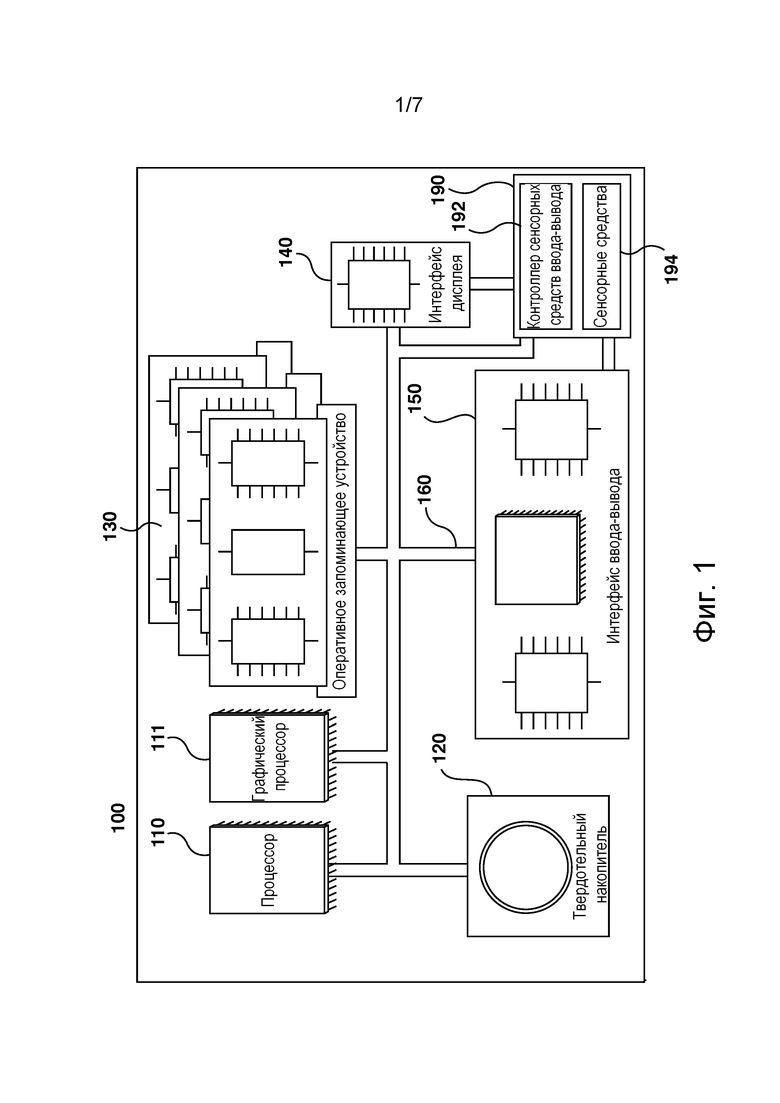
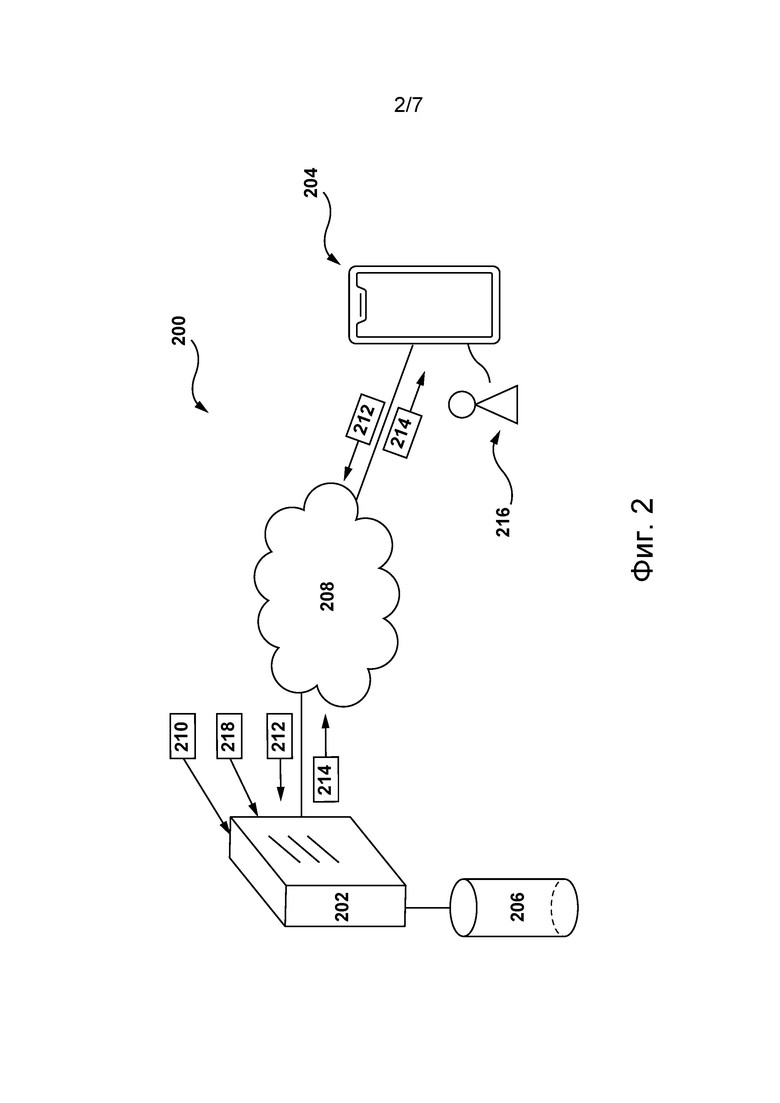
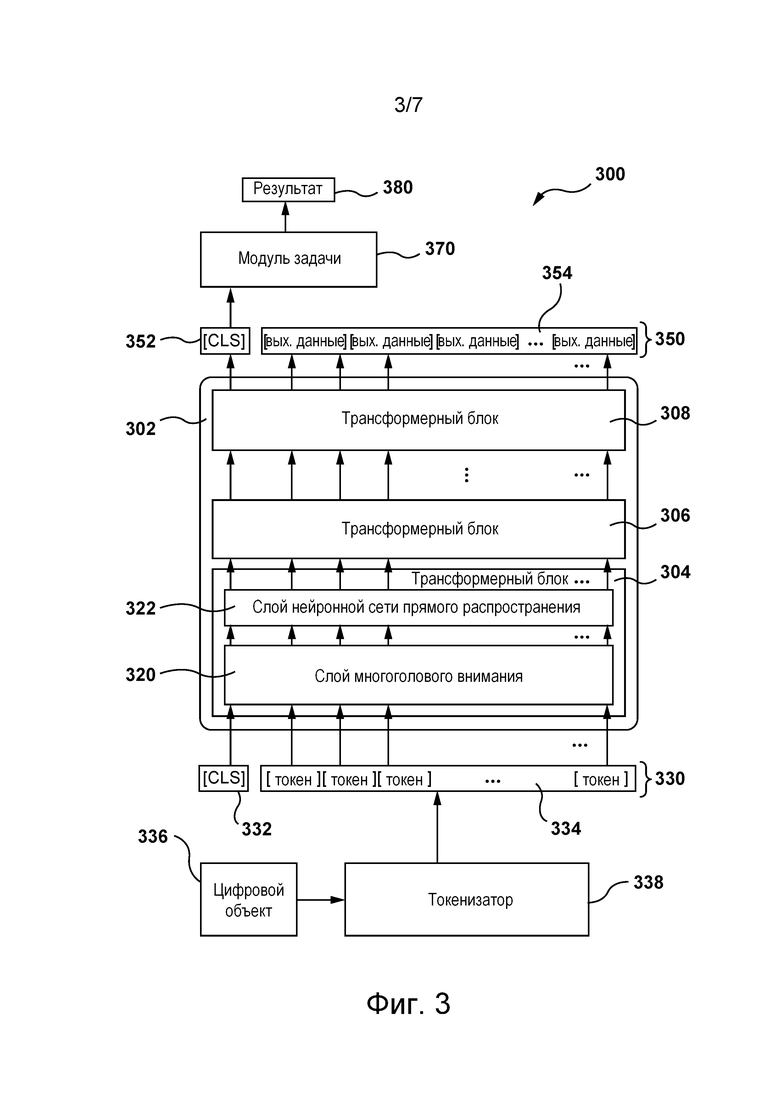
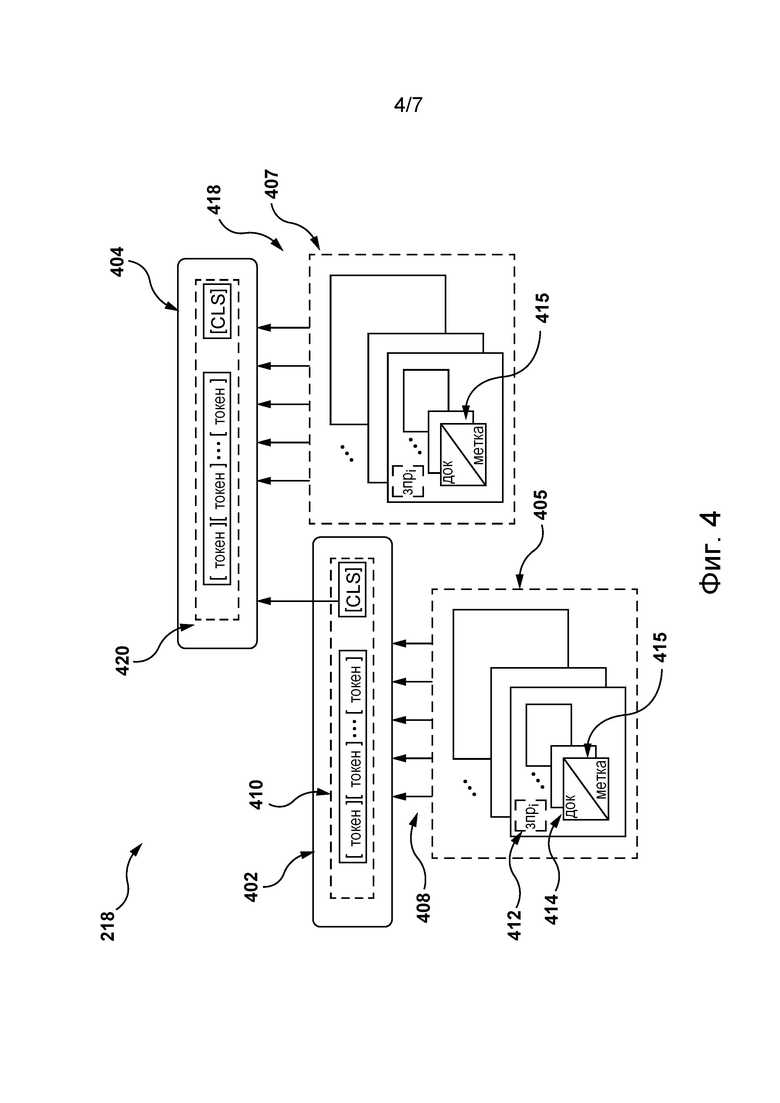
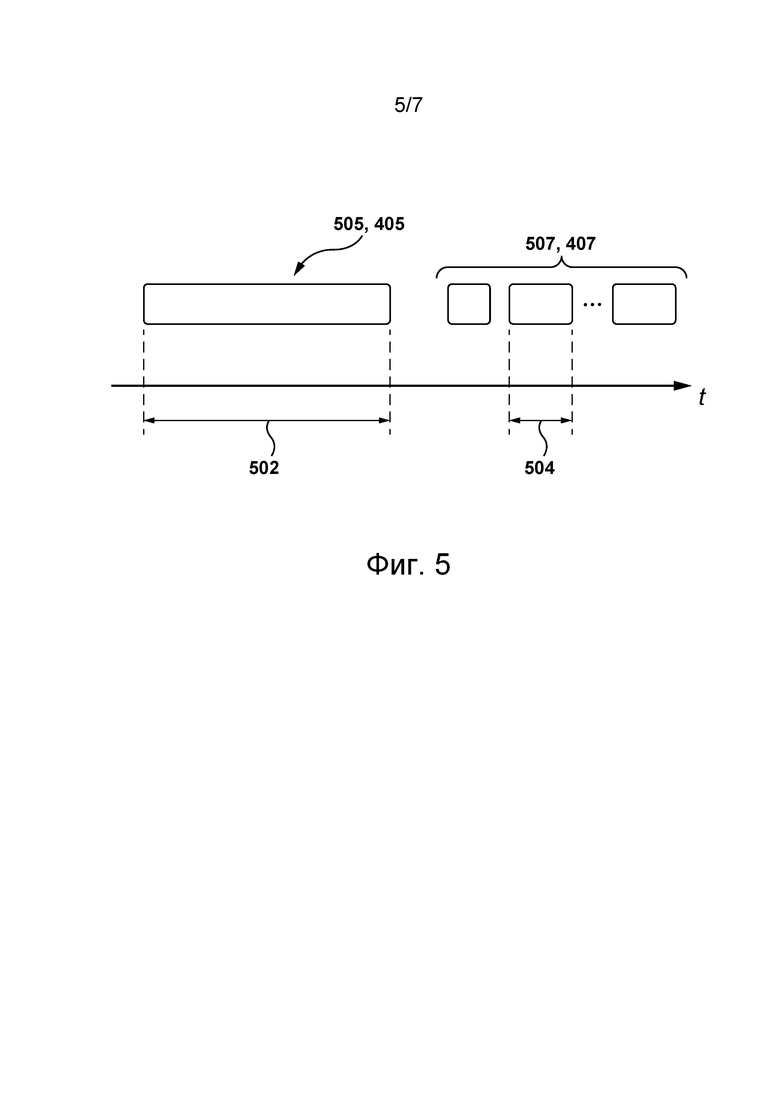
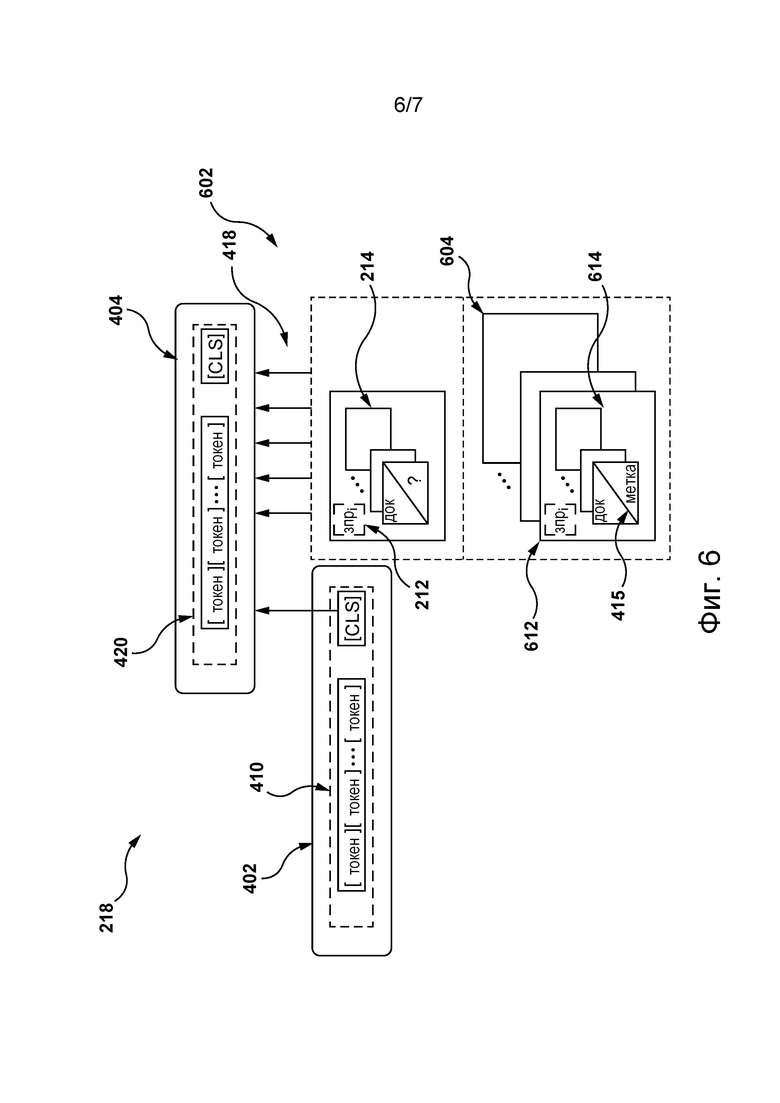
Изобретение относится к способам и системам для обучения и использования моделей машинного обучения для ранжирования результатов поиска. Технический результат заключается в повышении точности ранжирования набора цифровых документов при ограниченных ресурсах сервера. Способ включает: получение первых данных предыстории для прошлых поисков, выполненных пользователем в течение прошлого периода времени; получение вторых данных предыстории, часть которых содержит данные прошлых поисков, выполненных пользователем в течение прошлого пользовательского сеанса; совместное обучение первой и второй моделей машинного обучения ранжированию цифровых документов этапа использования, включающее в себя обучение на основе первых данных предыстории первой модели машинного обучения формированию векторного представления первых данных предыстории и обучение на основе векторного представления первых данных предыстории и вторых данных предыстории второй модели машинного обучения определению значения вероятности действия пользователя с цифровым документом этапа использования. 2 н. и 16 з.п. ф-лы, 7 ил.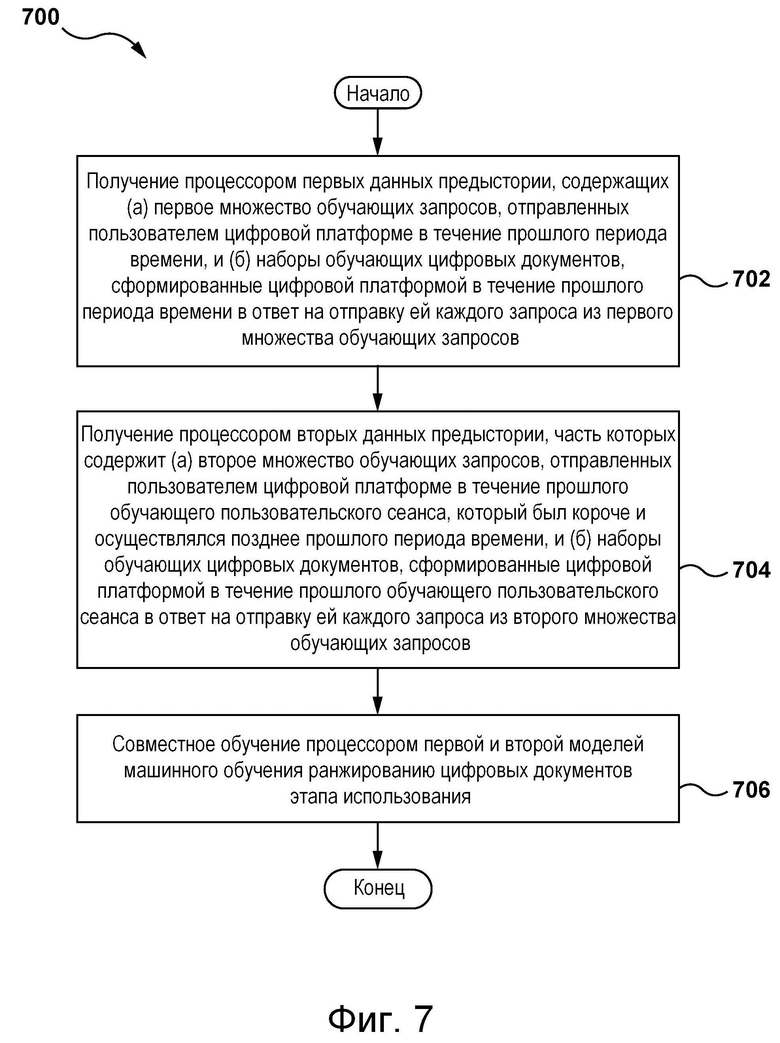
1. Компьютерный способ обучения алгоритма машинного обучения, содержащего первую модель машинного обучения и вторую модель машинного обучения, ранжированию цифровых документов этапа использования на цифровой платформе, выполняемый процессором и включающий в себя:
получение процессором первых данных предыстории, причём упомянутые первые данные предыстории получены от электронных устройств пользователей цифровой платформы посредством сети связи в течение первого периода времени, причём первые данные предыстории содержат (а) первое множество обучающих запросов, отправленных пользователем цифровой платформе в течение прошлого периода времени, и (б) наборы обучающих цифровых документов, сформированные цифровой платформой в течение прошлого периода времени в ответ на отправку ей каждого запроса из первого множества обучающих запросов;
получение процессором вторых данных предыстории, причём упомянутые вторые данные предыстории получены от электронных устройств пользователей цифровой платформы посредством сети связи в течение второго периода времени, причём часть вторых данных предыстории содержит (а) второе множество обучающих запросов, отправленных пользователем цифровой платформе в течение прошлого обучающего пользовательского сеанса, который был короче и осуществлялся позднее прошлого периода времени, и (б) наборы обучающих цифровых документов, сформированные цифровой платформой в течение прошлого обучающего пользовательского сеанса в ответ на отправку ей каждого запроса из второго множества обучающих запросов, при этом обучающий цифровой документ, сформированный в течение прошлого периода времени или прошлого обучающего пользовательского сеанса, содержит указание на пользовательское действие пользователя с обучающим цифровым документом; и
совместное обучение процессором первой и второй моделей машинного обучения ранжированию цифровых документов этапа использования, включающее в себя:
- компоновку процессором первых данных предыстории в первое множество обучающих цифровых объектов, каждый из которых содержит (а) запрос из первого множества обучающих запросов и (б) набор обучающих цифровых документов, сформированный в ответ на запрос из первого множества обучающих запросов в течение прошлого периода времени;
- ввод процессором первого множества обучающих цифровых объектов в первую модель машинного обучения для обучения первой модели машинного обучения формированию векторного представления первых данных предыстории;
- формирование процессором на основе вторых данных предыстории второго множества обучающих цифровых объектов, каждый из которых содержит (а) запрос из второго множества обучающих запросов, (б) набор обучающих цифровых документов, сформированный в ответ на запрос из второго множества обучающих запросов в течение обучающего пользовательского сеанса, и (в) векторное представление первых данных предыстории; и
- ввод процессором второго множества обучающих цифровых объектов во вторую модель машинного обучения для обучения второй модели машинного обучения определению значения вероятности действия пользователя с цифровым документом этапа использования.
2. Способ по п. 1, отличающийся тем, что количество членов первого множества обучающих цифровых объектов больше количества членов второго множества обучающих цифровых объектов.
3. Способ по п. 1, отличающийся тем, что пользовательское действие пользователя с обучающим цифровым документом включает в себя по меньшей мере одно из следующего:
- выбор обучающего цифрового документа из набора обучающих цифровых документов;
- остановка на цифровом документе;
- добавление обучающего цифрового документа в список избранного;
- контакт с обучающим цифровым документом дольше порогового времени контакта; и
- сохранение по меньшей мере части контента обучающего цифрового документа.
4. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя:
получение процессором запроса этапа использования, отправленного пользователем цифровой платформе в течение текущего пользовательского сеанса этапа использования;
получение процессором набора цифровых документов этапа использования, соответствующих запросу этапа использования;
получение процессором данных предыстории этапа использования, содержащих (а) множество прошлых запросов этапа использования, отправленных пользователем цифровой платформе в течение текущего пользовательского сеанса этапа использования до отправки запроса этапа использования, и (б) наборы прошлых цифровых документов этапа использования, сформированные цифровой платформой в ответ на отправку ей каждого запроса из множества прошлых запросов этапа использования, при этом прошлый цифровой документ этапа использования из наборов прошлых цифровых документов этапа использования содержит указание на пользовательское действие пользователя с прошлым цифровым документом этапа использования;
формирование процессором цифрового объекта этапа использования, содержащего:
- запрос этапа использования;
- набор цифровых документов этапа использования;
- множество прошлых запросов этапа использования;
- наборы прошлых цифровых документов этапа использования; и
- векторное представление первых данных предыстории;
ввод процессором цифрового объекта этапа использования во вторую модель машинного обучения алгоритма машинного обучения с целью определения для каждого документа из набора цифровых документов этапа использования значения вероятности действия с ним пользователя; и
ранжирование процессором документов из набора цифровых документов этапа использования согласно связанным с ними значениям вероятности.
5. Способ по п. 4, отличающийся тем, что перед получением векторного представления первых данных предыстории он дополнительно включает в себя обновление процессором первых данных предыстории.
6. Способ по п. 5, отличающийся тем, что обновление включает в себя сдвиг и/или расширение прошлого периода времени в направлении момента времени отправки запроса этапа использования.
7. Способ по п. 5, отличающийся тем, что обновление выполняется с заранее заданной частотой.
8. Способ по п. 1, отличающийся тем, что каждая из первой и второй моделей машинного обучения представляет собой нейронную сеть с архитектурой кодер-декодер.
9. Способ по п. 8, отличающийся тем, что нейронная сеть представляет собой нейронную сеть на основе трансформера.
10. Сервер для обучения алгоритма машинного обучения, содержащего первую модель машинного обучения и вторую модель машинного обучения, ранжированию цифровых документов этапа использования на цифровой платформе, содержащий машиночитаемую физическую память, хранящую команды, и процессор, способный при исполнении команд:
получать первые данные предыстории, причём упомянутые первые данные предыстории получены от электронных устройств пользователей цифровой платформы посредством сети связи в течение первого периода времени, причём первые данные предыстории содержат (а) первое множество обучающих запросов, отправленных пользователем цифровой платформе в течение прошлого периода времени, и (б) наборы обучающих цифровых документов, сформированные цифровой платформой в течение прошлого периода времени в ответ на отправку ей каждого запроса из первого множества обучающих запросов;
получать вторые данные предыстории, причём упомянутые вторые данные предыстории получены от электронных устройств пользователей цифровой платформы посредством сети связи в течение второго периода времени, причём часть вторых данных предыстории содержит (а) второе множество обучающих запросов, отправленных пользователем цифровой платформе в течение прошлого обучающего пользовательского сеанса, который был короче и осуществлялся позднее прошлого периода времени, и (б) наборы обучающих цифровых документов, сформированные цифровой платформой в течение прошлого обучающего пользовательского сеанса в ответ на отправку ей каждого запроса из второго множества обучающих запросов, при этом обучающий цифровой документ, сформированный в течение прошлого периода времени или прошлого обучающего пользовательского сеанса, содержит указание на пользовательское действие пользователя с обучающим цифровым документом; и
совместно обучать первую и вторую модели машинного обучения ранжированию цифровых документов этапа использования путем:
- компоновки процессором первых данных предыстории в первое множество обучающих цифровых объектов, каждый из которых содержит (а) запрос из первого множества обучающих запросов и (б) набор обучающих цифровых документов, сформированный в ответ на запрос из первого множества обучающих запросов в течение прошлого периода времени;
- ввода первого множества обучающих цифровых объектов в первую модель машинного обучения для обучения первой модели машинного обучения формированию векторного представления первых данных предыстории;
- формирования на основе вторых данных предыстории второго множества обучающих цифровых объектов, каждый из которых содержит (а) запрос из второго множества обучающих запросов, (б) набор обучающих цифровых документов, сформированный в ответ на запрос из второго множества обучающих запросов в течение обучающего пользовательского сеанса, и (в) векторное представление первых данных предыстории; и
- ввода второго множества обучающих цифровых объектов во вторую модель машинного обучения для обучения второй модели машинного обучения определению значения вероятности действия пользователя с цифровым документом этапа использования.
11. Сервер по п. 10, отличающийся тем, что количество членов первого множества обучающих цифровых объектов больше количества членов второго множества обучающих цифровых объектов.
12. Сервер по п. 10, отличающийся тем, что пользовательское действие пользователя с обучающим цифровым документом включает в себя по меньшей мере одно из следующего:
- выбор обучающего цифрового документа из набора обучающих цифровых документов;
- остановка на цифровом документе;
- добавление обучающего цифрового документа в список избранного;
- контакт с обучающим цифровым документом дольше порогового времени контакта; и
- сохранение по меньшей мере части контента обучающего цифрового документа.
13. Сервер по п. 10, отличающийся тем, что процессор дополнительно способен:
получать запрос этапа использования, отправленный пользователем цифровой платформе в течение текущего пользовательского сеанса этапа использования;
получать набор цифровых документов этапа использования, соответствующих запросу этапа использования;
получать данные предыстории этапа использования, содержащие (а) множество прошлых запросов этапа использования, отправленных пользователем цифровой платформе в течение текущего пользовательского сеанса этапа использования до отправки запроса этапа использования, и (б) наборы прошлых цифровых документов этапа использования, сформированные цифровой платформой в ответ на отправку ей каждого запроса из множества прошлых запросов этапа использования, при этом прошлый цифровой документ этапа использования из наборов прошлых цифровых документов этапа использования содержит указание на пользовательское действие пользователя с прошлым цифровым документом этапа использования;
формировать цифровой объект этапа использования, содержащий:
- запрос этапа использования;
- набор цифровых документов этапа использования;
- множество прошлых запросов этапа использования;
- наборы прошлых цифровых документов этапа использования; и
- векторное представление первых данных предыстории;
вводить цифровой объект этапа использования во вторую модель машинного обучения алгоритма машинного обучения с целью определения для каждого документа из набора цифровых документов этапа использования значения вероятности действия с ним пользователя; и
ранжировать документы из набора цифровых документов этапа использования согласно связанным с ними значениям вероятности.
14. Сервер по п. 13, отличающийся тем, что процессор дополнительно способен обновлять первые данные предыстории перед получением векторного представления первых данных предыстории.
15. Сервер по п. 14, отличающийся тем, что процессор способен обновлять первые данные предыстории путем сдвига и/или расширения прошлого периода времени в направлении момента времени отправки запроса этапа использования.
16. Сервер по п. 15, отличающийся тем, что процессор способен обновлять первые данные предыстории с заранее заданной частотой.
17. Сервер по п. 10, отличающийся тем, что каждая из первой и второй моделей машинного обучения представляет собой нейронную сеть с архитектурой кодер-декодер.
18. Сервер по п. 17, отличающийся тем, что нейронная сеть представляет собой нейронную сеть на основе трансформера.
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| CN 109857845 A, 07.06.2019 | |||
| US 10810193 B1, 20.10.2020 | |||
| US 11113289 B2, 07.09.2021. | |||

